
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
195,719 | Extending Python with Rust | Introduction: Python is a great programming language but sometimes it can be a bit of sl... | 0 | 2019-10-26T17:00:21 | https://dev.to/p_chhetri/extending-python-with-rust-4pna | performance, python3, rust, python | ---
title: Extending Python with Rust
published: true
date: 2019-05-01 17:37:44 UTC
tags: performance,python3,rust,python
canonical_url:
---

### Introduction:
Python is a great programming language but sometimes it can be a bit of slowcoach when it comes to performing certain tasks. That’s why developers have been [building C/C++ extensions](https://docs.python.org/3/extending/building.html) and integrating them with Python to speed up the performance. However, writing these extensions is a bit difficult because these low-level languages are not type-safe, so doesn’t guarantee a defined behavior. This tends to introduce bugs with respect to memory management. Rust ensures memory safety and hence can easily prevent these kinds of bugs.
### Slow Python Scenario:
One of the many cases when Python is slow is building out large strings. In Python, the string object is immutable. Each time a string is assigned to a variable, a new object is created in memory to represent the new value. This contrasts with languages like Perl where a string variable can be modified in place. That’s why the common operation of constructing a long string out of several short segments is not very efficient in Python. Each time you append to the end of a string, the Python interpreter must allocate a new string object and copy the contents of both the existing string and the appended string into it. As the string under manipulation become large, this process can become increasingly slow.
Problem: Write a function which accepts a positive integer as argument and returns a string concatenating a series of integers from zero to that integer.
So let’s try solving the above problem in python and see if we can improve the performance by extending it via Rust.
### Python Implementations:
#### Method I: Naive appending
{% gist https://gist.github.com/chhetripradeep/fb1c2af57c7d3a65d9e2b0924defdcee %}
This is the most obvious approach. Using the concatenate operator (+=) to append each segment to the string.
#### Method II: Build a list of strings and then join them
{% gist https://gist.github.com/chhetripradeep/c2452b87b9df809a0c0ef5eec3222eb4 %}
This approach is commonly suggested as a very pythonic way to do string concatenation. First a list is built containing each of the component strings, then in a single join operation a string is constructed containing all of the list elements appended together.
#### Method III: List comprehensions
{% gist https://gist.github.com/chhetripradeep/4e1a604d225a75993802153485af8275 %}
This version is extremely compact and is also pretty understandable. Create a list of numbers using a list comprehension and then join them all together. This is just an abbreviated version of last approach and it consumes pretty much the same amount of memory.
Let’s measure the performance of each of these three approaches and see which one wins. We are going to do this using [pytest-benchmark](https://pypi.org/project/pytest-benchmark/) module.
{% gist https://gist.github.com/chhetripradeep/3b0cecfa5c7ead2a41bbf1d77e3d3e49 %}
Here is the result of the above benchmarks. Lower the value, better is the approach.
{% gist https://gist.github.com/chhetripradeep/e601bf2f4e06f625a8273d68d1124780 %}
Just by looking at the **Mean** column, one can easily justify that the list comprehension approach is definitely the winner among three approaches.
### Rust Implementations:
After trying out basic implementation of the above problem in Rust, and doing some rough benchmarking using [cargo-bench](https://github.com/rust-lang/cargo/blob/master/src/doc/man/cargo-bench.adoc), the result definitely looked promising. Hence, I decided to port the rust implementation as shared library using [rust-cpython](https://github.com/dgrunwald/rust-cpython) project and call it from python program.
To achieve this, I had create a rust crate with the following src/lib.rs.
{% gist https://gist.github.com/chhetripradeep/3c64187f83f598551b0bb05649553b91 %}
Building the above crate created a . **dylib** file which needs to be rename **.so**.
{% gist https://gist.github.com/chhetripradeep/6a0c2d1749f5ddf39de889bea664a12e %}
Then, we ran the same benchmark including the rust one as before.
{% gist https://gist.github.com/chhetripradeep/0243d40048dfd3b27a96470981cb1e33 %}
This time the result is more interesting.
{% gist https://gist.github.com/chhetripradeep/08cad5cbd4ff501011b002d33165b954 %}
The rust extension is definitely the winner. As you increase the number of iterations to even more, the result is even more promising.
Eg. for iterations = 1000, following are the benchmark results
{% gist https://gist.github.com/chhetripradeep/b2962ea087ce39fc06896d61307b0345 %}
### Code:
You can find the code used in the post:
- [https://github.com/chhetripradeep/rust-python-example](https://github.com/chhetripradeep/rust-python-example)
- [https://github.com/chhetripradeep/cargo-bench-example](https://github.com/chhetripradeep/cargo-bench-example)
### Conclusion:
I am very new to Rust but these results definitely inspires me to learn Rust more. If you know better implementation of above problem in Rust, do let me know.
[PyO3](https://github.com/PyO3/pyo3) started a fork of [rust-cpython](https://github.com/dgrunwald/rust-cpython) but definitely has lot more active development and hence on my todo-list of experimentation.
Distributing of your python module will demand the rust extension to be compiled on the target system because of the variation of architecture. [Milksnake](https://github.com/getsentry/milksnake) is a extension of [python-setuptools](https://pypi.org/project/setuptools/) that allows you to distribute dynamic linked libraries in Python wheels in the most portable way imaginable. | p_chhetri |
195,721 | A look at itertools chain method | The python itertools module is a collection of tools for handling iterators. I want to make an honest... | 0 | 2019-10-26T20:06:03 | https://dev.to/teaglebuilt/a-look-at-itertools-chain-method-4c13 | python |
The python itertools module is a collection of tools for handling iterators. I want to make an honest effort to break the habit of repetitive standard patterns of basic python functionality. For example...
We have a list of tuples.
```
a = [(1, 2, 3), (4, 5, 6)]
```
In order to iterate over the list and the tuples, we have a nested for loop.
```
for x in a:
for y in x:
print(y)
# output
1
2
3
4
5
6
```
I have decided to challenge myself to start using all that itertools has to offer in my every day solutions. Today lets take a look at the chain method!
This first approach will only return the two tuples as as index 0 and 1. Instead of nesting another loop, lets apply the chain method.
```]
from itertools import chain
a = [(1, 2, 3), (4, 5, 6)]
for _ in chain(a, b):
print(_)
# output
(1, 2, 3)
(4, 5, 6)
```
now we have access to iterate over the tuples without nesting another iteration with a for loop.
```
for _ in chain.from_iterable(a):
print(_)
# output
1
2
3
4
5
6
```
I think the chain method gives the flexibility to use this as a default choice for list iteration. | teaglebuilt |
195,733 | Wish you everyone a happy Diwali! | video demo of fireworks on html5 canvas | 0 | 2019-10-26T17:51:57 | https://dev.to/svijaykoushik/wish-you-everyone-a-happy-diwali-4mm6 | html, javascript, css, canvas | ---
title: Wish you everyone a happy Diwali!
published: true
description: video demo of fireworks on html5 canvas
tags: html, Javascript, CSS, canvas
---
Hello world,
I'm sorry, I couldn't publish a post this week. I wanted to write about particle physics with JavaScript and html5 canvas. But the demo took too long to make and I was busy with Diwali shopping. So I present to you the video of the demo this week and the actual post next week.
> Diwali, in the true sense, means ending all evils, cruelty and hatred > towards one another. Get together to celebrate the spirit of the festival.
Happy Diwali! ✨🎆🙌🏽 | svijaykoushik |
196,014 | Soldier to Software Engineer | As my 4 years in the U.S. Army came to an end, my Expiration - Term of Service date was approaching e... | 0 | 2019-10-27T04:53:08 | https://dev.to/arielb506/soldier-to-software-engineer-3dhd | career, advice, motivation, discuss | As my 4 years in the U.S. Army came to an end, my Expiration - Term of Service date was approaching extremely fast. As most veterans know, when you're approaching this, most people in your chain of command tell you that if you don't continue in the military, your life will fall apart and you will either end up being homeless or as a bus driver (no offense to bus drivers out there!)
## Backstory

When this date approached I was fortunate enough to be part of a great transitioning team, they were just rebranding to the "Soldier for Life" motto. But thanks to them, my eyes were opened about all the different routes I could take to become what I always wanted to be but always seemed far out of reach because of my lack of resources: a Software Engineer.
The doors that the G.I. Bill can open for you are endless, and it is sad to know that most of the transitioning veterans are not aware of them. Not only is the V.A. going to pay for your school, but also your housing, your medical insurance, and your books. They recommended me to start in a community college and then transition to a university from there.
In January 2016 I started my A.A. degree, the requirements to transition to the University of Florida were mostly math and physics requirements but thankfully I was able to learn in the environment that the Veteran's Success Center had in Santa Fe College, they provide tutors and they also recommended me to switch to Chapter 31, since I am a 50% disabled veteran. Here is my obtaining my A.A. with my lovely girlfriend:

##Outcome
Long story short, I was accepted into the University of Florida, where I will graduate with a degree in Computer Science. Besides all the coding, engineering, logical and analytical skills I have acquired in school, what I am most grateful for, is that my skills as a former soldier opened the doors to a lot of opportunities that I see my classmates miss out on for their lack of experience or discipline. When they mostly pass incredibly hard coding interviews in top companies around the country, they miss out on the opportunities because they fail the ability to be able to build rapport in the behavioral side of the interviews and leave a lasting impression.
I am happy and proud to announce, that even though I am already 28 years old, I have decided from several offers, to officially become a Software Engineer, where I'll be in this company's Engineering Leadership Development Program, where I will be able to obtain my Master's Degree absolutely free.
I wish I could motivate existing soldiers, veterans and all kinds of people, to never give up on your dreams, there are always paths to get there, no matter how difficult your path may seem, even if it's **O( n^2 ) time complexity.**
Never stop learning, go beyond school and in your free time, read books and take tutorials or extra classes and certification where you will be more valuable. When facing interviewers, never forget where you come from, be yourself, and remind yourself why you **want and need** that job, the combination of those things will give you the confidence needed to get that job you dreamed of! (Don't forget to answer any question in the STAR format!!)
Stay active, eat healthy foods, and you'll be a better developer, I promise. | arielb506 |
196,040 | [vim問題] iOSで利用できるVimは? | この記事では、iOS環境(iPhone/iPad)で利用できる「Vim」について、ご紹介します。 [解答] iVim オープンソースとして公開されている、iOS版Vimこと「iVim」です。2019年現... | 0 | 2019-10-27T05:30:37 | https://dev.to/vimtry/vim-ios-vim-egf | この記事では、iOS環境(iPhone/iPad)で利用できる「Vim」について、ご紹介します。 [解答] iVim オープンソースとして公開されている、iOS版Vimこと「iVim」です。2019年現在、唯一定期的に更
つづきは[こちら](https://vim.blue/vim-ios-ivim/)。
[https://vim.blue/vim-ios-ivim/](https://vim.blue/vim-ios-ivim/) | vimtry | |
196,072 | [Vim問題] ウインドウを水平分割する方法は何種類? | この記事では、Vimでプラグインを使わずに「ウインドウを水平分割する」ための方法について、ご紹介します。 [解答] コマンドもしくはキーバインドの2種類 Vimコマンド. 水平分割(上下の分割) :vs... | 0 | 2019-10-27T05:39:30 | https://dev.to/vimtry/vim-17ka | この記事では、Vimでプラグインを使わずに「ウインドウを水平分割する」ための方法について、ご紹介します。 [解答] コマンドもしくはキーバインドの2種類 Vimコマンド. 水平分割(上下の分割) :vsplit virt
つづきは[こちら](https://vim.blue/vim-window-vsplit/)。
[https://vim.blue/vim-window-vsplit/](https://vim.blue/vim-window-vsplit/) | vimtry | |
196,129 | Save forms temporary data | By now you should have come to a point were you already coded some forms. Used HTML to structure your... | 0 | 2019-10-27T10:29:05 | https://dev.to/jdsaraiva/save-forms-temporary-data-5e98 | javascript, php, html | By now you should have come to a point were you already coded some forms.
Used HTML to structure your form, JavaScript to get the data and PHP to save it, right ?
Maybe you have come to a point where you have a consistent form, with several inputs and options, however if this data isn’t validated on the server side the page will refresh and all the users inputs will be lost… obviously causing some frustration.
With this simple snippets my goal is to show you how to implement an almost generic form functions that will fetch the inputs values, save them on a temporary session variable and if something goes wrong the values are loaded again on the form.
This way you can have a safer server side validation and you visitors won’t have to refill the values if something goes wrong.
Let’s start with a really basic form (form.php);
```
<?php }
// check if data is valid
if (!filter_var($_POST["email"], FILTER_VALIDATE_EMAIL)) {
echo("e-mail is not valid");
// Something went wrong, load the user's data
loadSessionVariables();
} else {
echo "Welcome " . $_POST["name"] . ", you e-mail is: " . $_POST["email"];
}
}
?>
<form action="form.php" method="post">
First name:<br>
<input required type="text" name="name"><br>
E-mail:<br>
<input required type="text" name="email"><br><br>
<input onClick="saveData()" type="submit" value="Submit">
</form>
```
As you can see we have a basic form that gets the data and displays it.
Normally this data would be saved on a database of have further processing, although for the sake of simplicity we are just displaying it.
We will start by looping the form and save it’s input data, with this function:
```
function saveData(){
const forms = document.querySelectorAll('form');
const form = forms[0];
let array = [];
[...form.elements].forEach((input) => {
if ( input.type === "text" ) array.push(input.value);
});
sessionStorage.setItem("form-data", JSON.stringify(array ));
}
```
And if an error is detected we can load the data again with this one:
```
function loadSessionVariables(){ ?>
document.addEventListener("DOMContentLoaded",function(){
if (sessionStorage.getItem("form-data")) {
const forms = document.querySelectorAll('form');
const form = forms[0];
let retrievedData = sessionStorage.getItem("form-data");
retrievedData = JSON.parse(retrievedData);
let index = 0;
[...form.elements].forEach((input) => {
if ( input.type === "text") {
input.value = retrievedData[index];
index++;
}
});
sessionStorage.clear();
}
});
```
Overall you can find all the code here: https://github.com/jdsaraiva/Save-forms-temporary-data
Hope this simple code can help you to tackle this issue and make your website even more user friendly.
Let me know if it helped you out.
Best regards, João Dessain Saraiva. | jdsaraiva |
196,254 | What’s the biggest c*ck up you’ve made in an interview? | A few years ago now, I was interviewing for an internship as a Computational Biologist in my second y... | 0 | 2019-10-27T13:46:51 | https://dev.to/lukegarrigan/what-s-the-biggest-c-ck-up-you-ve-made-in-an-interview-4lnk | discuss, watercooler | A few years ago now, I was interviewing for an internship as a Computational Biologist in my second year of university. I had a pretty shoddy CV so I had a google and copied/pasted a Software Engineers template and put in my skills.
In the interview, everything was going perfect — I was interviewing well — I think — met the team, met the boss, text-book stuff.
Then LateX happened. One of the interviewers asked me about LateX — at the time I knew nothing about LateX so I was honest and said "I don’t really know much about it".
**”But you have it down as one of your skills”**
“Is it?” Was my reply.
SHIT, I’d copied and pasted this CV without removing all the skills they’d put. I panicked, I started to make up some nonsense about when I’d used it but didn’t feel very confident with it.
The whole interview was downhill from that point, I was shaking, embarrassed and just wanted to crawl in a hole.
So yeah, that’s my biggest cock up in an interview, I’d love to hear yours!
Oh yeah, I got the internship in the end, a bloody miracle if you ask me.
Thank you, if you like my rambling check out my personal blogging site at https://codeheir.com/
| lukegarrigan |
196,276 | angularJS + undefined SSR = SEO ⚡️ | [Story] How I made an angularJS SPA SEO friendly Introduction By reading the ti... | 0 | 2019-11-18T17:33:33 | https://dev.to/steeve/angularjs-undefined-ssr-seo-46lm | angular, php, writing | # [Story] How I made an angularJS SPA SEO friendly
## Introduction
By reading the title, you may have asked yourself:
`Sacrebleu! Are you still using angularJS? um.. 🤔`
This article is going against the flow by sharing to you outdated content through dying Framework _#AngularJS_. Some years ago, I used a lot of AngularJs and now I want to share the development of my first web project and solution I discovered when making an angularJS application SEO friendly.
AngularJS was created to make your website better by giving a better user experience. You wanted to make your app faster and you thought SPA was going to be awesome. You were right, but not totally...
## Table Of Contents
1. [Some context](#some-context)
2. [The problems](#the-problems)
3. [Solutions available](#solutions-available)
4. [My SSR solution](#my-ssr-solution)
## Some context
Back in time, I was a junior developer discovering web programming and I wanted to help a pom-pom girls organization managed by friends of mine. My goals were to:
- Create a (stunning) website from scratch
- Promote them on the internet
- Learn, learn, learn and learn
I heard about 3 emerging client-side frameworks to create SPA (Single page application): ember, Backbone.js, and AngularJS. As a beginner, I did not pay attention to SPA as I told myself "`A framework created by Google should be SEO friendly`" 😑 I chose AngularJS as front end, PHP as back end API with a MySQL database and handmade CSS design 👨🏻🎨. After some months of reading documentations, testing, designing, and programming during my spare time, the website was done: a fancy home page with a presentation, a team page, a blog page with articles and a contact page. An admin panel was available for the Pom Pom manager to edit the public pages (it's working like a CMS). After some months, I published the website. After following an SEO basis tutorial and creating a robots.txt and sitemap.xml, the website has been referenced on Google. 🎉

I was so proud to discover my first website on the google search list... <b>but</b> only one over 4 URL were referenced. At this moment begun a new adventure: How to make an angularJS SPA website optimized for search engine?
## The problems
Single-page applications are dynamically rewriting the current page rather than loading entire new pages from a server that makes the app faster and instantaneous for the user. However, when the crawlers are reading the template of your page, it sees:
```html
<h1>{{websiteName}}</h1>
```
instead of:
```html
<h1>Title of my website</h1>
```
Also, the head HTML tag was not filled with the right metadata on different pages. It was impossible to index the pages correctly,
resulting in bad organic search.
Before 2009, Google used to index only pure HTML without including dynamic Javascript content. The websites may receive an SEO penalty because Google considered the javascript content render as "Cloaking" and it was against the Webmaster Guidelines. However, since 2015, [Google announced](https://webmasters.googleblog.com/2015/10/deprecating-our-ajax-crawling-scheme.html) the ability to understand dynamic pages:
`Today, as long as you’re not blocking Googlebot from crawling your JavaScript or CSS files, we are generally able to render and understand your web pages like modern browsers.`
The other players like Bing were not able to render javascript. To be clear, you still needed to make your main content available through the server response to guarantee that search engines index it.

## Solutions available
First, enabled [html5mode API on your angular app](https://docs.angularjs.org/guide/$location#hashbang-and-html5-modes) but this requires server-side configuration to rewrite the URL (on the .htaccess in our case). It was not enough to make an SEO friendly website. Below is a list of available solutions at that time:
- Rewrite the codebase to the latest version of Angular (2) because it supports server-side rendering with the Universal module. I already passed to much time on this project.
- One alternative to avoid duplication was to parse the site with a browser executing javascript like PhantomJS to pre-render and save the result into a server and finally serve it to the crawlers. That's mean every change, I had to pre-render the page and push it to the production server? Mhh... it was not really exciting 🤔
- Use a pre-rendering platform or service to crawl the website, execute the javascript, create a cache from it and send the latter to the web crawlers. Sound like a good idea but it's not free.
## My SSR solution
First, enabling angularJS html5mode API is useful to remove the hashbang and get a regular URL.
Second, Here's my trick:
### Turn the main angularJS HTML template into PHP file.
I was able to:
- Edit the PHP template and fill the metadata tags according to the URL requested (title, description, etc...).
- Add some [structured data](https://developers.google.com/search/docs/guides/intro-structured-data) used by google crawlers to display rich results.
- Being SEO friendly through server-side rendering, here is an example of the index.php
```php
<?php
$path = $_SERVER['REQUEST_URI'];
$chunks = explode('/', $path);
$page = "";
$title = "";
$description = "";
$img = 'logo.jpg';
$alt = "";
?>
```
Then depending on the path, I was setting the metadata:
```php
if (in_array("contact", $chunks) == true) {
$title = "Contact";
$description = "Contact us to have more informations !";
$img = "/contact.jpg";
$alt = "contact picture";
} else if (in_array("team", $chunks) == true) {
$title = "Team";
$description = "Some description...";
$img = "/team.jpg";
$alt = "Some alt...";
}
// More else if
```
Next, I inserted the PHP variables into the HTML:
```php
<head>
<meta charset="utf-8" />
<title>
<?php echo $title; ?> - Cheery Dolls
</title>
<base href="/">
<meta name="description" content="<?php echo $description; ?>" />
<meta property="og:url" content="https://cheerydolls.fr<?php echo $path; ?>" />
<meta property="og:title" content="<?php echo $title; ?>" />
<meta property="og:description" content="<?php echo $desc; ?>" />
<!-- etc... -->
<head>
```
Every time a crawler was requesting a page, the server responded by the corresponding metadata that was making the page unique and indexable on the search page.
Also, I was able to print structured data on the index.php, for example, a blog breadcrumb:
```php
<?php
function display_breadcrumb ($article_title) {
$front = '<!-- breadcrumb -->
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [{
"@type": "ListItem",
"position": 1,
"name": "Blog",
"item": "https://cheerydolls.fr/blog"
}';
if (isset($article_title) && !empty($article_title)) {
$front .= ',{
"@type": "ListItem",
"position": 2,
"name": "Article",
"item": "https://cheerydolls.fr/blog/' . $article_title . '"
}';
}
$front .= ']}</script>';
return $front;
}
echo display_breadcrumb($article_name);
?>
```
It was not the best solution (also no the prettiest) to appear on the search page but it was doing the job. 🤷♂️ It leads to a hell of maintenance when I had to make important changes to the content, I had to change the rendering content every time...

## Conclusion
Build a website from scratch on your own is highly instructive in many aspects: server-side, API, client-side, SEO, security, design and more. I will advise you to do the same 😉 I spent so much energy on this project and I did think to give up sometimes because I was struggling so much in the beginning. It was also a project I was doing during my spare time and I was not paid for. By telling you this story, it makes me step back and revive the experience, choices I made and I learned a lot from it.
Nowadays a lot of wonderful frameworks are making our life easier like Nuxt, Next, Hugo and more! [AngularJS entered in long term support period](https://docs.angularjs.org/misc/version-support-status) and I advised you to migrate to the latest version of Angular or other frameworks.
I migrated the original Pom Pom girl's website to a modern stack: Nuxt + Vuetify + Express API. Check this out: [cheerydolls.fr](https://cheerydolls.fr).
If you want to learn more about Search Engine Optimization, I read recently a complete and interesting [cheat sheet](https://dev.to/pagely/seo-cheat-sheet-for-devs-5h1g) on dev.to.
Leave a like/comment to support my article or follow me to be notified of my next articles. 🔥
Thanks for reading!
### References in 2016
https://geoffkenyon.com/angularjs-seo-crawling/
https://stackoverflow.com/questions/41957366/angularjs-seo-once-and-for-all
https://www.verticalmeasures.com/blog/search-optimization/overcoming-angular-seo-issues-associated-with-angularjs-framework/
https://www.yearofmoo.com/2012/11/angularjs-and-seo.html | steeve |
196,312 | Do Design Systems prevent creativity? Let's Discuss about a question | What is a Design System? Design System is a comprehensive guide for project design – a col... | 0 | 2019-10-27T14:56:42 | https://justaashir.com/blog/design-systems-are-preventing-creativity/ | design, startup, discuss, codequality | ### What is a Design System?
Design System is a comprehensive guide for project design – a collection of rules, principles, constraints, and best practices. The core element of the Design System is often a Library of UI Components. These UI elements have also their representation implemented in code.
Design Systems are often called the single source of truth for the team involved in product creation. It allows the team to design, develop and maintain the quality of the product.
___
So I read this on Twitter :
{% twitter 1187438643763220480 %}
I was like how to answer this question? So Design Systems do prevent creativity because it's needed to generate more products than just making a perfect button. Every time you try to create a new button from scratch, your mind will generate a new type of button and you will find your previous work waste. It's much about solving the problems by designing not just designing for good looks.
this concept applies to the Frameworks too, Design Frameworks created by companies so their website looks the same to provide a better user experience but if you try to read the pros and cons of the Bootstrap and other Frameworks, You will find this point in cons that websites look same. Google Material Design is the hard work of many years by the creative team.
They simplify the design for us and what we are doing! We are marketing the Google Material Design by using it in our Web Apps.
The design System really provides consistency and unified design which attracts the user. I will follow-up more in upcoming posts.
{% twitter 1173988027795832832 %}
##### Don't Trust Blindly on the provided design systems by well-known companies
Almost Every Big company has a design system nowadays, I read about their design systems and they were like well-polished pixel-perfect. But Do the companies really follow their own design systems or this is just a myth or they are just doing it for marketing. I don't know! Design System is not everything, implementation of it matters most. I am not an expert at all, I am just writing my point of view.
`Design has always been largely about systems, and how to create products in a scalable and repeatable way… These systems enable us to manage the chaos and create better products… A unified design system is essential to building better and faster; better because a cohesive experience is more easily understood by our users, and faster because it gives us a common language to work with.`
___Airbnb
I'm [Aashir Aamir Khan](https://twitter.com/justaashir), Teenage Junior Web Developer, Looking for some Chocolates in the Chocolate Factory. Blogging to tell the community that I exist in this world.
___
- **Most Popular** : [Bulma - The Most Underrated Framework of the CSS Framework Era
](https://dev.to/justaashir/bulma-the-most-underrated-framework-of-the-css-framework-era-2gj8)
- **Most Popular** [Web Development Projects That can help You Get a Job in 2019-2020](https://dev.to/justaashir/web-development-projects-that-can-definitely-get-you-a-job-in-2019-2020-4c36)
- **My Study About Static Site Generators**
- [Static Site Generators are not for me! My Experience with Jekyll, Hugo, and NetlifyCMS
](https://dev.to/justaashir/static-site-generators-are-not-for-me-my-experience-with-jekyll-hugo-and-netlifycms-4mo5)
- [What is Going on With Static Site Generators? Why the numbers are increasing?
](https://dev.to/justaashir/what-is-going-on-with-static-site-generators-why-the-numbers-are-increasing-47fj)
| justaashir |
196,389 | Firefox (and other browsers) will be making better use of height and width attributes for modern sites | This video goes into it all... I'm excited about this because we deal with this problem on DEV.... | 0 | 2019-10-27T16:07:05 | https://dev.to/ben/firefox-and-other-browsers-will-be-making-better-use-of-height-and-width-attributes-for-modern-sites-4kpm | news, webdev, firefox, css | This video goes into it all...
{% youtube 4-d_SoCHeWE %}
I'm excited about this because we deal with this problem on DEV. Generating the proper height and width attributes on user generated content is not table stakes, but this change makes ultimately getting it right _way_ less hacky.
I've been really annoyed by this browser behavior and considered some unconventional ways to deal with this. I'm glad we didn't try to do something overly hacky.
This is a total aside to this feature in general, but in case you're curious, I made an issue about how we can implement this on DEV's user-generated content if anyone wants to take a hack at it...
{% github https://github.com/thepracticaldev/dev.to/issues/4616 %}
If anybody has more info about this in Chrome than is mentioned in the video, please drop a comment.
Happy coding ❤️ | ben |
196,442 | Overlay com cor sobre imagem no CSS: pseudo-element ou element? Analisando os métodos | Como fazer um overlay sobre uma imagem, mas por baixo de um texto, e que altere a opacidade no hover?... | 0 | 2019-10-27T21:07:56 | https://dev.to/quila/overlay-com-cor-sobre-imagem-no-css-pseudo-element-ou-element-analisando-os-metodos-41o3 | css, html | Como fazer um ***overlay sobre uma imagem, mas por baixo de um texto, e que altere a opacidade no hover***? Talvez com [pseudo-elements](https://developer.mozilla.org/pt-BR/docs/Web/CSS/Pseudo-elementos), se o HTML já estiver montado, sendo necessário apenas alterar o CSS ou usando elementos básicos.
A primeira vista, usar :pseudo-elements me parece mais prático, já que preciso mexer apenas no CSS do projeto, evitando qualquer modificação no HTML. Mas sabemos que é possível obter o mesmo resultado usando [elementos básicos](https://developer.mozilla.org/pt-BR/docs/Web/HTML/Element), e com o mesmo (quase o mesmo) CSS obter visualmente o mesmo resultado.
Mira:

Vale ressaltar que esse post não faz um comparativo de performance *(mas poderia)*, tão pouco irá apontar a melhor maneira ou a correta de resolver esse problema. Esse comparativo é apenas para fins didáticos.
---
## Ponto de partida
A partir de dois _cards_ idênticos, onde o _card_ recebe uma imagem de fundo e comporta apenas duas _[div](https://developer.mozilla.org/pt-BR/docs/Web/HTML/Element/div)_, sendo respectivamente título e subtitulo.
*O texto no rodapé do card com a cor branca é apenas para ficar elegante* :)
{% codepen https://codepen.io/quilamcz/pen/ExxXGXx ?default-tab=html,result %}
Veremos então como fazer um ***overlay sobre uma imagem, mas por baixo de um texto, e que altere a opacidade no hover...***
---
## Pseudo-element
O pseudo-element [:before](https://developer.mozilla.org/pt-BR/docs/Web/CSS/::before) e [:after](https://developer.mozilla.org/pt-BR/docs/Web/CSS/::after) para ser visível é necessário especificar um conteúdo, sendo essa a dificuldade mais corriqueira, já que é bem fácil esquece-lo.
Nesse caso, como não precisamos de conteúdo, adicionamos uma _string_ vazia apenas para o mesmo ser inserido no DOM:
```css
content: '';
```
Para estilizar e posicionar afim de obter o overlay, é necessário aplicar o pseudo-element no próprio card, além de alterar a posição do mesmo para *relative*, dessa maneira:
Acrescentei uma classe modificadora no primeiro card chamada **card--pseudo-elements**, para diferencia-lo do padrão.
```css
.card--pseudo-elements {
position: relative;
}
.card--pseudo-elements:before {
/* requerido */
content: '';
/* estilo de preto quase transparente */
background-color: black;
opacity: 0.5;
/* posiciona nos limites do elemento pai */
position: absolute;
top: 0;
right: 0;
bottom: 0;
left: 0;
/* suavização básica */
transition: 200ms all;
}
```
Feito isso, para fazer o efeito de escurecer o overlay, é necessário apenas aplicar o hover no card, e manipular o pseudo-element, assim:
```css
.card--pseudo-elements:hover:before {
opacity: 1;
}
```
Estaria pronto se não fosse por um problema: o overlay cobre todo o conteúdo do card. Isso ocorre por quê *(de modo resumido)* o elemento com posição absoluta fica numa camada superior [(z-index)](https://www.devmedia.com.br/css-z-index-entendendo-sobre-o-eixo-z-na-web/28698).

Contornamos isso apenas definindo o z-index dos elementos, dentro do card:
```css
.card--pseudo-elements .card__title,
.card--pseudo-elements .card__subtitle {
z-index: 1;
}
```
*Nesse estágio você pode ter se questionado ou tentado aplicar um z-index negativo para o seu :pseudo-element, afim de empurra-lo para trás do texto, mas isso não funciona. Veja mais sobre [z-index](https://www.google.com/search?q=z-index) para entender melhor.*
O resultado final com :pseudo-elements você confere abaixo:
{% codepen https://codepen.io/quilamcz/pen/MWWoxeE %}
---
## Elemento
Neste método, precisamos acrescentar um **elemento** no HTML. Além da classe módificadora *card--element* para diferenciar do outro método. O código fica assim:
```html
<div class="card">
<div class="card__title">
Maceió
</div>
<div class="card__subtitle">
Alagoas
</div>
<span class="card__overlay">
<!-- div overlay vazia -->
</span>
</div>
```
_Você pode inserir no início ou no final do card, **pessoalmente** prefiro inserir no final e como span visando reduzir o risco de interferência no layout atual._
No CSS o código é quase idêntico, mudando apenas os seletores, e a não obrigatoriedade do content. Veja:
```css
.card--element .card__overlay {
background-color: black;
opacity: 0.5;
position: absolute;
top: 0;
right: 0;
bottom: 0;
left: 0;
transition: 200ms all;
}
/* aplicando o hover */
.card--element:hover .card__overlay {
opacity: 0.9;
}
```
Aqui encontramos o mesmo problema do :pseudo-element, o overlay sobrepõe todo o conteúdo do card, sendo assim a solução é a mesma:
```css
.card--element .card__title,
.card--element .card__subtitle {
z-index: 1;
}
```
Abaixo você confere o resultado final com elemento básico:
{% codepen https://codepen.io/quilamcz/pen/YzzQgOP %}
## Conclusão
*Nota-se que a diferença entre os métodos é mínima, como o seletor diferente para o CSS e, de modo geral, uma linha a mais de código para ambos.*
Se com o :pseudo-element é necessário adicionar o content à sua regra de estilo e dispensa a marcação HTML, com elemento básico não precisamos do content, mas é necessário adicionar o elemento ao HTML. **O estilo e posicionamento do overlay é feito exatamente da mesma maneira.**
Abaixo deixo o resultado final com os dois métodos:
{% codepen https://codepen.io/quilamcz/pen/ExxXOme %}
---
**Não esqueça de comentar com suas dúvidas e/ou sugestões. Obrigado.**
*Talvez continue com a parte 2, abordando acessibilidade e performance.* | quila |
196,488 | Make Your Python Tests Run 10x Faster By using Heroku's CI | In this post, I'll show you how to deploy a very simple Python web app with very long tests. I'll also show you how to speed up those tests significantly using parallelism. | 0 | 2019-10-27T20:06:07 | https://www.daolf.com/posts/heroku-python-tests/ | python, devops, heroku | ---
title: Make Your Python Tests Run 10x Faster By using Heroku's CI
published: true
description: In this post, I'll show you how to deploy a very simple Python web app with very long tests. I'll also show you how to speed up those tests significantly using parallelism.
tags: ["python", "devops", "heroku"]
canonical_url: https://www.daolf.com/posts/heroku-python-tests/
cover_image: "https://thepracticaldev.s3.amazonaws.com/i/70gwdq9s9qt4aieg6k79.jpeg"
---
In this post, I'll show you how to deploy a very simple Python web app with very long tests. I'll also show you how to speed up those tests significantly using parallelism.
If you are already familiar with Heroku and just want to go straight to the point, go directly to [part 3](#parallel).
# It's testing time.
For my last project, ([a web scraping API](https://www.scrapingbee.com)) we decided to have part of our infrastructure on Heroku. The reason was simple: neither my co-founder nor I were very good at the ops side of dev, so we have chosen the simplest, most time-efficient way to deploy our app: Heroku. Prior to this we'd had middling experience with AWS, in particular [EBS](https://aws.amazon.com/elasticbeanstalk/).
Make no mistake – this simplicity comes at a price, and Heroku is crazy expensive. But their free plan is very good for side projects such as a [Twitch SMS notificator](https://www.freecodecamp.org/news/20-lines-of-python-code-get-notified-by-sms-when-your-favorite-team-scores-a-goal/) 😎.
So as I said, I've been using Heroku for quite a bit of time. And since the beginning we used the lightweight but simple CI integration that would automatically deploy our application every time we push, if and only if all our tests pass.
Nothing new under the sun here.
In this post you will see how to easily deploy a Heroku application and set up the continuous integration. But more importantly, you will see how to parallelize tests. Again, if you are already familiar with how to deploy a Heroku application and the continuous application, go directly here to learn about parallelising the test.
# First, deploy an app on Heroku:
If you don't already, you need to create a [Heroku account ](www.heroku.com). You also need to download and install the Heroku client.
I've provided a [test project](https://github.com/daolf/parallel-testing-heroku) on Github, so do not hesitate to check it out it you need help bootstrapping this tutorial.
You can pull this repo, `cd` into it and just do a `heroku create --app <app name>`. Then if you go onto your [app dashboard](https://dashboard.heroku.com/apps), you'll see your new app.
OK, now comes the interesting part – just go onto your dashboard and click on the name of your newly created app, then go to the "deploy" panel.
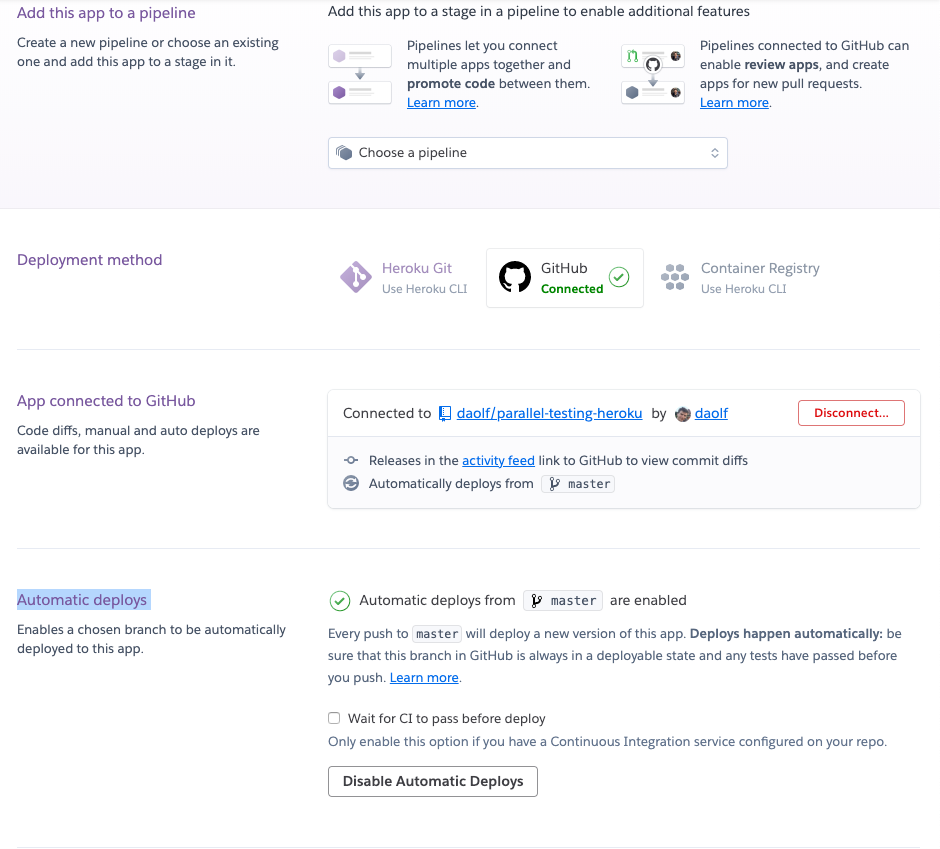
We will now link this Heroku app with your Github repo. This is rather easy: simply click on "Github" in the "Deployment method" section, add your repo in the "App connected to Github" section, and don't forget to click "Enable automatic deploys" in the "Automatic deploys" section.
Once everything is setup it should look a little bit like this:
If you go over "Settings -> Domains" you should see the domain where your app is live.
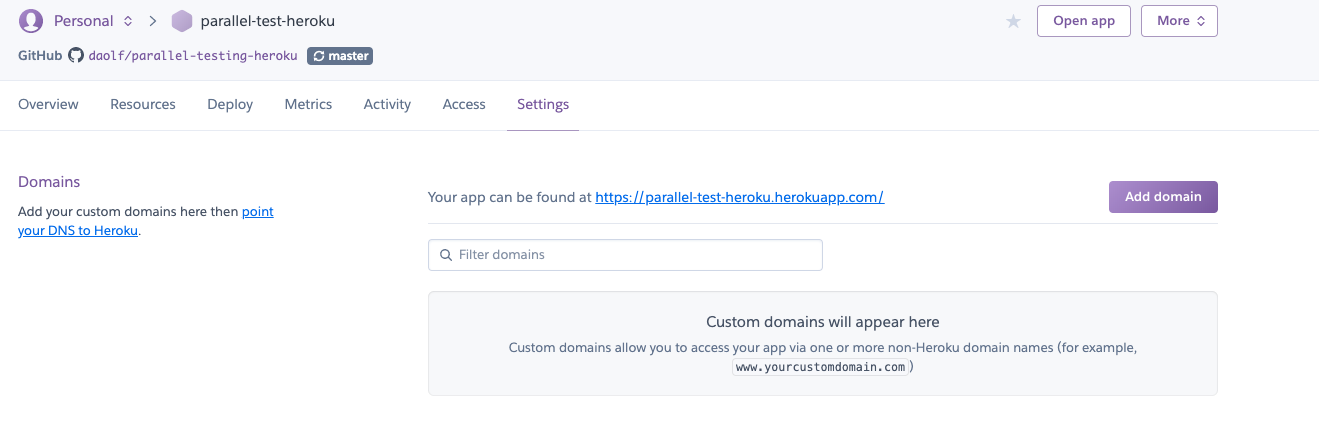
So now your app is live, and every-time you'll push to Github a new deploy will take place.
# Then add tests and CI:
In order to run tests on Heroku you have to do to is click on "Wait for CI to deploy" in the deploy section of your app.

You also need to add your application to a Heroku pipeline.
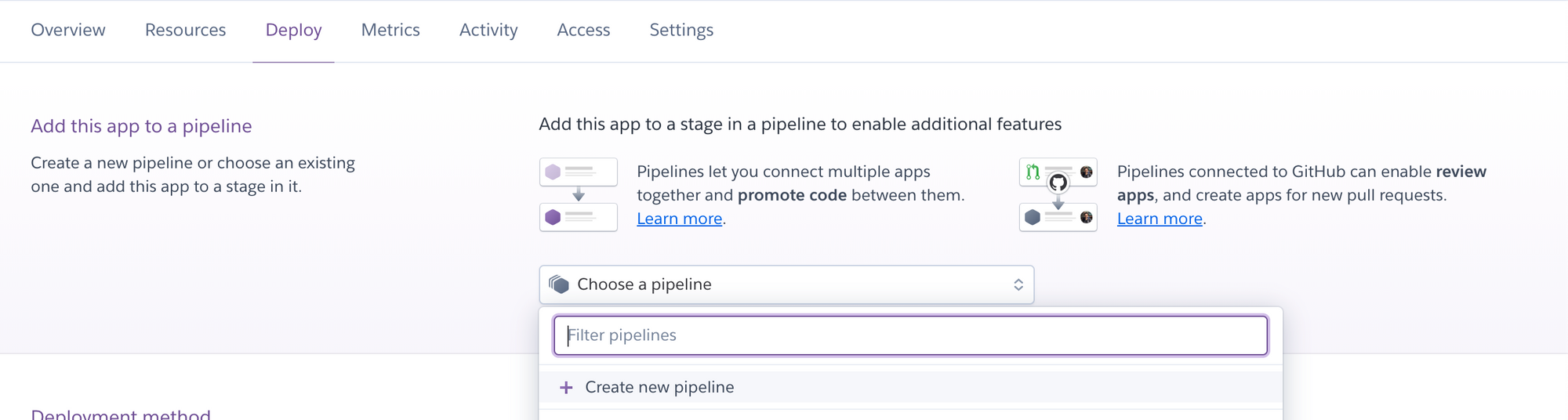
Doing this is really easy: just go on the Deploy tab of your application and create a new Pipeline with the name of your choice.
You have now access to the Pipeline view where you can click on your previously deployed app.

Go over to the Tests tab, link your Github repo, and click on "Enable Heroku CI". Be aware, this option costs **$10 a month**.
Let's go back to our code. The test file is already written, and now, all you have to do to trigger the magic is simply to push to master.
`git commit --allow-empty -m "Trigger heroku" && git push origin master`
And now, the app won't deploy right away – Heroku will wait for tests to pass before deploying. You can check what's going on behind the curtain on the Test tab.
The command that is run during the test is defined in the `app.json` file.
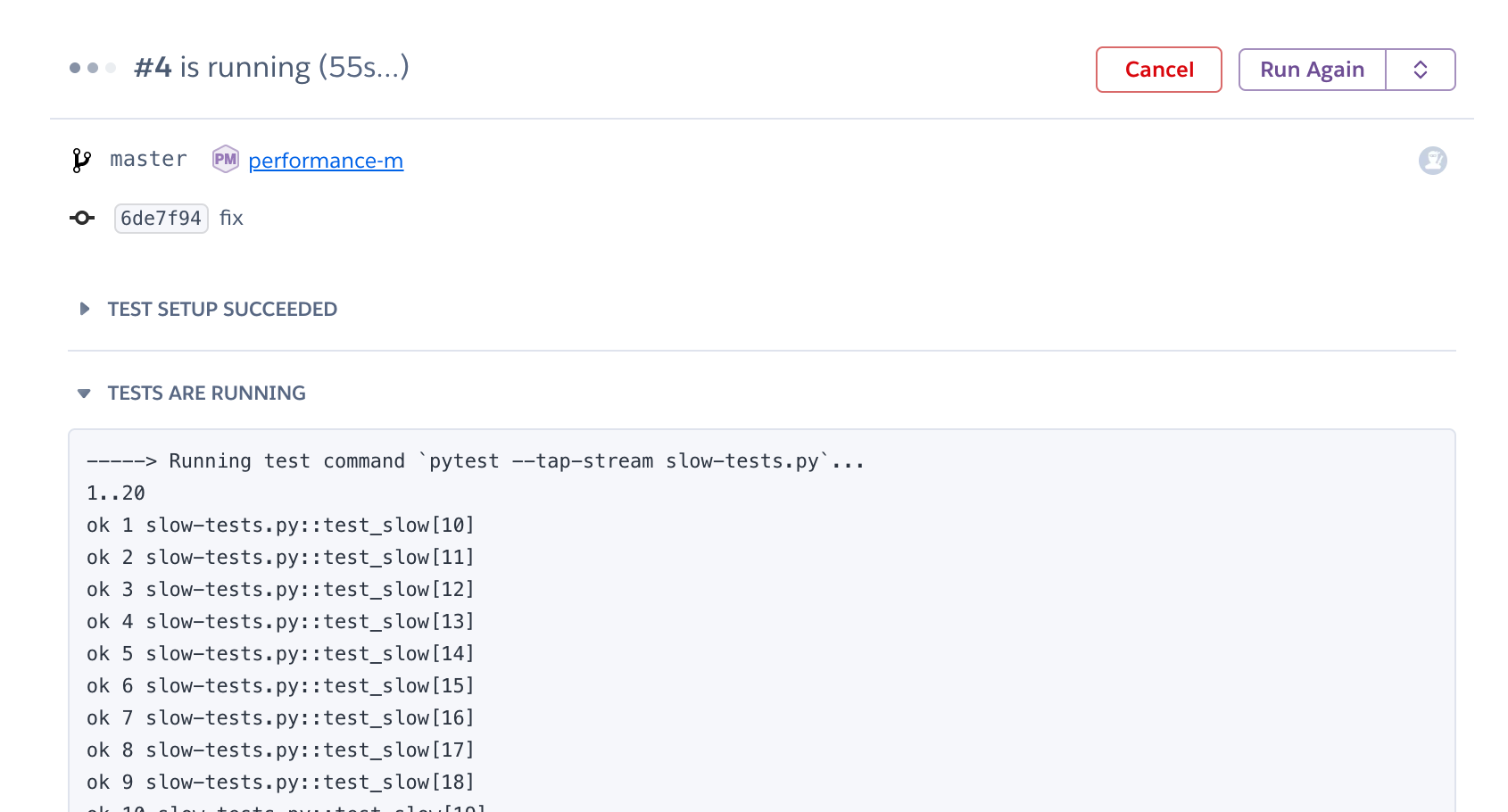
As you can see, tests are now being run sequentially on Heroku. If you look at the `slow-tests.py` file, you will see that I defined my tests using `pytest.mark.parametrize` that allows me to trigger multiple tests in one line:
```python
pytest.mark.parametrize("wait_time", [5] * 20)
def test_slow(wait_time):
time.sleep(wait_time)
assert True
```
This decorator means that the test will be run 20 times with `wait_time=5`.
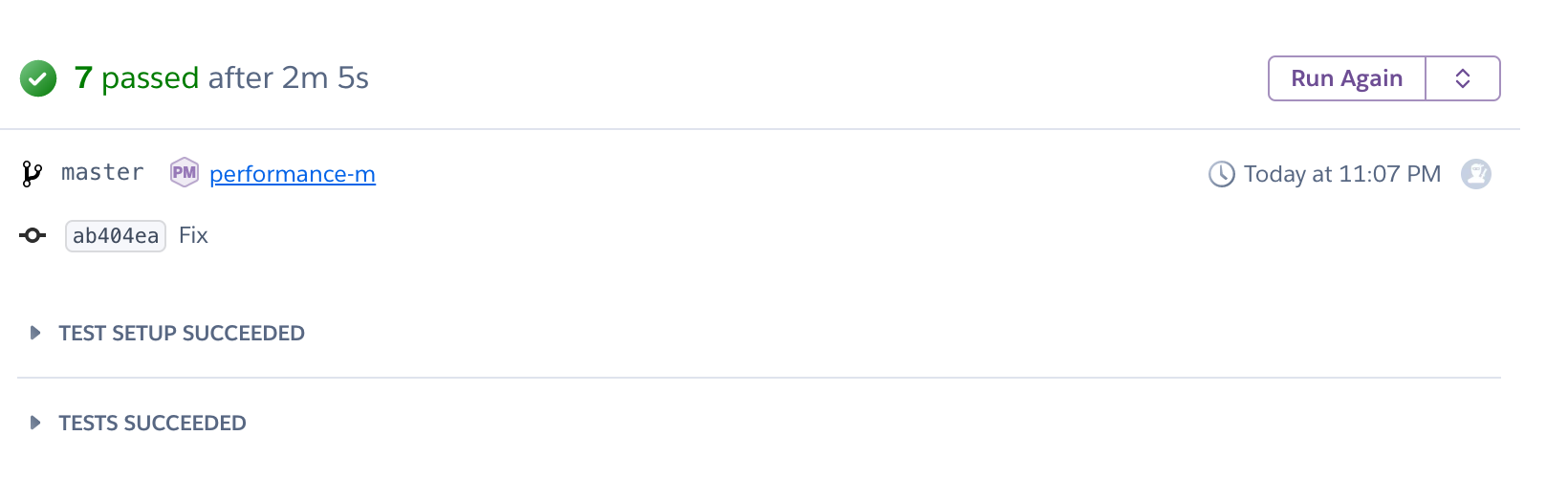
As you can see in Heroku, this test suite is (artificially) rather slow:
<h1 id="parallel"> Parallelising test on Heroku </h1>
As stated [here](https://devcenter.heroku.com/articles/heroku-ci-parallel-test-runs) in the doc, Heroku easily offers the ability to parallelise tests. In order to launch your tests on multiple dynos at the same time, you just have to tweak your `app.json` file a little bit.
```json
{
"environments": {
"test": {
"scripts": {
"test-setup": "pip install -r requirements.txt",
"test": "pytest --tap-stream slow-tests.py"
},
"formation": {
"test": {
"quantity": 12
}
}
}
},
"buildpacks": [{ "url": "heroku/python" }]
}
```
The `quantity` key will tell Heroku on how many dynos you want to run your test. From now on, pushing on master will launch the test on 12 dynos. But stopping here won't make your tests faster because the entire test suite will be run on 12 dynos. What we want is to run 1/12 of all tests on each of the 12 dynos.
It is actually easy to check:
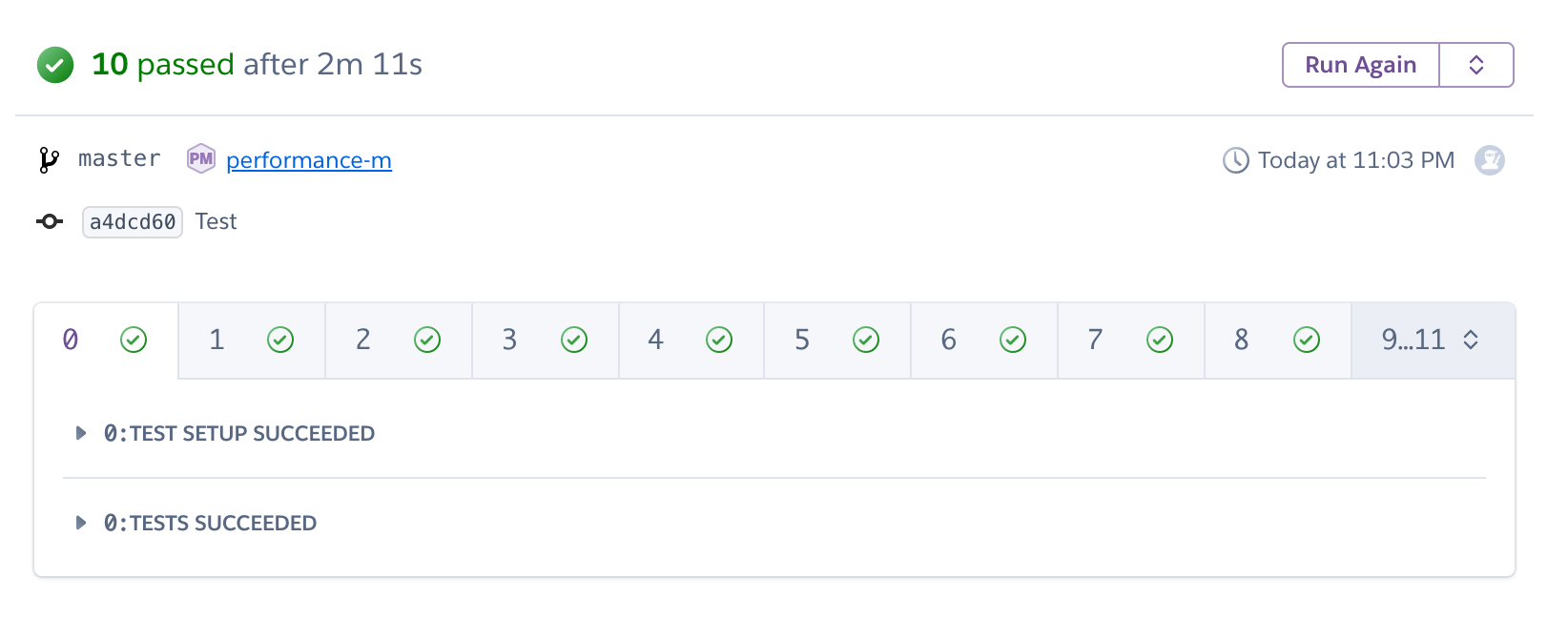
Tests were run on 12 dynos, but were not that much faster. So now comes the tricky and unfortunately not very well documented part: how do we tell Heroku to run 1/12 of the test suite on each of the 12 dynos?
# Splitting up tests
To do this we will use 2 environment variables set by Heroku and accessible on each dyno, `CI_NODE_TOTAL` and `CI_NODE_INDEX`. The first one indicates the total number of the dynos on which the tests are run, and the second one indicates the current dyno are you.
Let's see how to use them. pytest offers you the ability to overwrite the test items that are going to be executed during the test phase. To overwrite this function, just declare this snippet of code in `conftest.py` file:
```python
import os
def pytest_collection_modifyitems(items, config):
ci_node_total = int(os.getenv("CI_NODE_TOTAL", 1))
ci_node_index = int(os.getenv("CI_NODE_INDEX", 0))
items[:] = [
item
for index, item in enumerate(items)
if index % ci_node_total == ci_node_index
]
```
This method is used to modify test items that are going to be tested in place. This method does not return anything, which is why you have to update the array in place. This usually an example of what not to do, but that is not the subject of this post.
You have to keep in mind that this snippet is run on every test node. On every test node, `CI_NODE_TOTAL` is the same and `CI_NODE_INDEX` is different, so by only keeping tests whose index in items modulo `CI_NODE_TOTAL` equals `CI_NODE_INDEX` we ensure 2 things:
- every node runs 1 / `CI_NODE_TOTAL` number of tests
- every test originally in items ended up being run`
If it is not clear, imagine that I have 24 tests in items: `[t1, t2, ...., t24]`. This snippet of code, executed on the number 1, will update the items variable such that, at the end of `pytest_collection_modifyitems`, we have `items = [t1, t13]`. Then in dyno number 2 we have `items = [t2, t14]`, and so on.
And here is what happens on Heroku once we push:
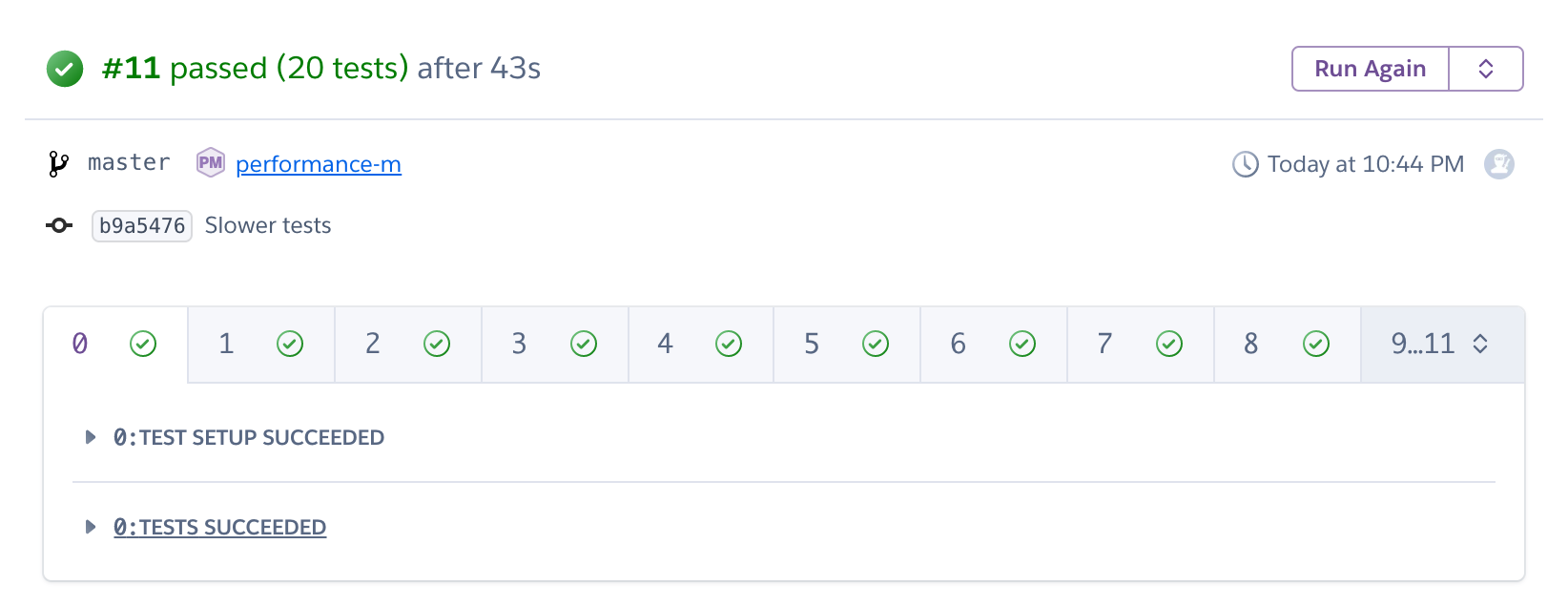
As you can see, we did not manage to divide the time by 12. The reason is simple: each dyno takes about 30 seconds to boot, and this time is incompressible. But we managed to divide time by 2, and more importantly, we can parallelize our tests to up to 32 dynos, so there is plenty of room for time improvement.
#Thank you for reading
I had trouble finding documentation about parallelising tests on Heroku in Python, and I really hope you liked this post and that it will speed up your deployment time on Heroku. All source code is freely available here on [Github](https://github.com/daolf/parallel-testing-heroku).
I frequently blog about Python and web scraping. Actually, I recently wrote a [Python web-scraping guide](https://www.scrapingbee.com/blog/web-scraping-without-getting-blocked) that got some nice attention from Reddit 😎, so don't hesitate to check it out.
You can follow me [here](https://twitter.com/PierreDeWulf) on Twitter so you don't miss any of my future blog posts.
| daolf |
196,521 | binary: what? why? how? | A quick guide to learn how to convert from decimal to binary and viceversa | 0 | 2019-10-28T14:32:39 | https://dev.to/wendisha/binary-what-why-how-3di7 | binary, computerscience, hardware, numericsystem | ---
title: binary: what? why? how?
published: true
description: A quick guide to learn how to convert from decimal to binary and viceversa
tags: binary,computerscience,hardware,numericsystem
---
In simple words, **binary** refers to something that is composed of or relates to two things; something that can be broken into two groups or categories. In the context of computing and mathematics, **binary** is a numeric system consisting of just 0's and 1's.
Everything needs to be translated into these 0's and 1's, so our computers get the appropiate signals to respond accordingly to the instructions and/or tasks we want them to perform. This translation is possible thanks to, among other components, the thousands, even billions of tiny transistors that when receiving voltage turn ON, representing 1's, and in the absence of said voltage turn OFF, representing 0's.
So now that we know what **binary** is, and why it is relevant to the computing world, let's look at how we can convert the numbers we are used to working with, to the Binary System.
These numbers that we use on a daily basis, are part of the Decimal System, based on powers of 10.
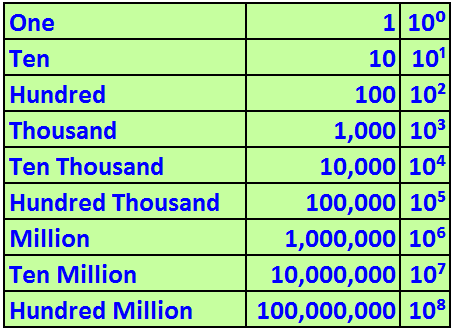
As per the previous image, we can see that if we have a number such as **532**, it is the result of the following operation:
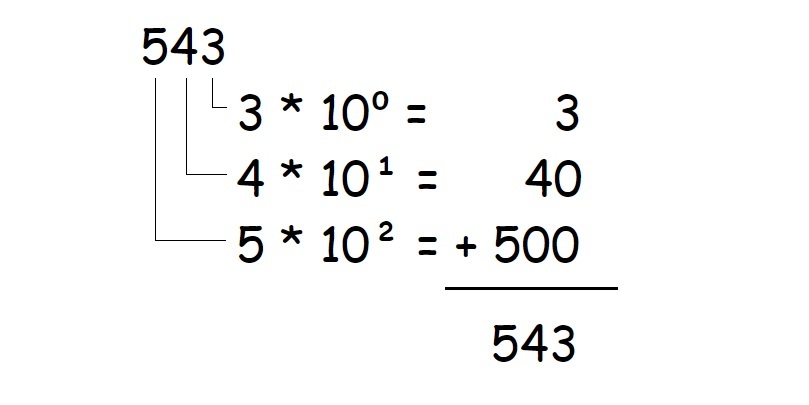
Now let's say we have a sequence of digits representing a binary number, such as **101**. How can we turn this number into our known "base ten" numbers? While the Decimal System uses powers of ten, the Binary System uses powers of two:
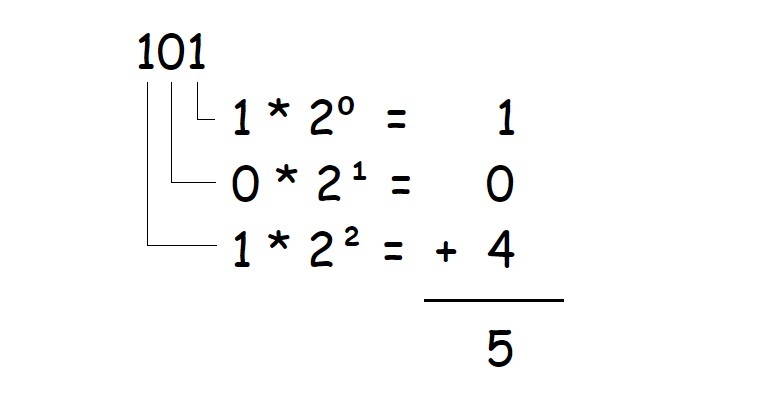
So knowing that the Binary System is "base two", we could convert numbers to "base ten" by considering their position from left to right, and summing up the values where a 1 is present.
Each of these binary digits are considered bits, and 8 bits conform a byte. Do these terms sound familiar? More on this on another post :)
| wendisha |
196,547 | Intro To HTML | Week three of coding school. Have you ever been internet surfing and never even looked at the website... | 0 | 2019-10-28T00:10:48 | https://dev.to/speerkrystal/intro-to-html-2i6h | codeschool, html |
Week three of coding school. Have you ever been internet surfing and never even looked at the websites you were going to? Or even noticed them? Well I haven’t until just recently. We are starting our first big project this week in class. Building our personal websites. I was like this is going to be easy I will just click here and copy paste there and done. Um…. Boy was I wrong. Till this week I never knew was HTML was or CSS. SO I have decided to share a few things about the first days of website development.
We are using HTML. HTML is a markup language which is used by the browser to manipulate text, images and other content to display it in required format. At first I was a little intimidated and then realized I had been using it all along. So below are the 5 points of our element.
1. Opening tag
2. Closing tag
3. The content
4. The element
By telling our compnter how to do this we are creating the format of how people will view your website. Now CSS ( Cascading style sheets)is what makes your website look awesome and also where you can add all your personal touches. I am looking forward to seeing my finished product. | speerkrystal |
196,618 | My first Java FX App | Hello fellow Devs, Have a look at my first Java FX Desktop Application with MySQL. Your feedback w... | 0 | 2019-10-28T03:48:36 | https://dev.to/ankitbeniwal/my-first-java-fx-app-3nb1 | javafx, java | Hello fellow Devs,
Have a look at my first Java FX Desktop Application with MySQL.
**Your feedback will be much appreciated.**
{% youtube ZVZwsPTVis4 %}
Thanks in anticipation! | ankitbeniwal |
196,743 | Benefits of Educational Management Software from Warals Technology? | The management system boosts the productivity of the institute. The reason of the increase in produc... | 0 | 2019-10-28T11:53:27 | http://warals.com/wims/ | javascript | The management system boosts the productivity of the institute. The reason of the increase in
productivity is decreased time to maintain the track records and increased accuracy in organizing the
data. We have developed all the required functions which can help to achieve the desired result with minimal effort and fewer resources and not to mention with easy to use interface.
WIMS is like a mini ERP for all kind of institute and training organization. Manage your operations like batch schedule, Student/Employee Management, Attendance and Course Tracker. We genuinely believe in customer success using our Products and Services.
Our Product WIMS is designed to reduce operational complexity and help to achieve the core goal of revenue generation of any Institutes/Training organizations. WIMS, as a specialized product is a result of collaborative efforts by our architects and end-users by getting the business requirements and aligning the flow according to them.
Our reporting Tool helps in informed decision making, and Informative Dashboard provides a quick snapshot of overall business for managers and owners. The IMS Business report is the annual leading industry study that provides vital journalistic reports.
Get a free online demo....
| waralst |
196,769 | 5 reasons to choose Open Source Parse Server and SashiDo for your Backend | We in SashiDo, strongly believe in the “no vendor lock-in” policy. We want our customers to stay with... | 0 | 2019-10-28T12:50:07 | https://blog.sashido.io/five-reasons-to-choose-open-source-parse-server-and-sashido-for-your-backend/ | backend, opensource, parseserver, mbaas | We in SashiDo, strongly believe in the “no vendor lock-in” policy. We want our customers to stay with us because they like the service we are providing, not because they are hostages of proprietary software. We are providing managed Mobile Backend as a Service using Parse Server (open-source backend engine) and our mission is to give to the mobile developers the easiest and cost-effective way to create functional and beautiful apps. We take care of apps’ infrastructure, scaling, security, database maintenance, backups, and Parse Server deployment to give the developers the time and energy to focus on their business idea.
We are really passionate about Parse Server, and we are here to give you 5 reasons why you should consider using Parse Server and SashiDo for your backend.
## 1. MBaaS providers retire or discontinue products, open-source Parse Server is here to stay.
Companies come and go. Just recently Telerik (a Progress company) decided to discontinue yet another MBaaS, forcing their clients to completely rewrite their code. And there’s absolutely no guarantee that this will not happen again. It’s not hard to imagine just how much additional expenses will occur to all Telerik Platform clients. Of course, they have their official alternative provided by Progress - Kinvey, but the new platform is so different that they will have to spend months in order to get their apps up and running in the new platform causing a huge delay in their current roadmap. And who will compensate them? No one.
Open Source Parse Server is a completely different story. It gives you vendor independence or how we like to call it “no vendor lock-in”. There are already several companies that offer Managed Parse Server hosting - SashiDo, Buddy, Back4App and more. Even if one of them decides to pivot or discontinue its offerings, the others will stay. And that’s not all - if you are unsatisfied with one company, you can always migrate to another (often free of charge) without rewriting your code. Or you can choose to host your app in your own Parse Server setup in Heroku or Digital Ocean. Basically, you have plenty of options none of which will drain your development budget which definitely makes the Open Source Parse Server more attractive than any proprietary MBaaS on the market.
##2. Using Open Source Parse Server will reduce your business risk.
Open Source Parse Server is the better choice if you planning long-term projects. Migration from one MBaaS to another will always come with additional expenses for development. And sometimes these expenses can go as much as the original development cost for your app.
Choosing Parse Server will guarantee you that you’ll never be forced to migrate to another backend solution. Even if one Parse Server hosting provider disappears you will always be able to move your app to another provider or get the public source code and host it on your own servers. Your app can live as long as you want without the need for unanticipated budget allocation for development.
##3. Parse Server community is independent of any financial decision.
Parse Server is maintained by developers with the common goal to make it better and feature-rich for other fellow app developers to use. Everybody can contribute to the open-source project and the decisions about what features to develop next are based solely on what the developers need.
On the other hand, companies that offer a proprietary backend solution often prioritize new features developed based on how much money they will be able to make out of them. And sometimes if a certain feature is not considered as profitable enough to make sane to be developed - it’s never started.
##4. Open Source projects have fewer prerequisites for hacker attacks and data leaks.
Cybersecurity is no joke these days. We witness major data breaches even from big companies too often to think there’s no way this can happen to us.
Companies that provide proprietary software often rely on [security through obscurity](https://en.wikipedia.org/wiki/Security_through_obscurity) principle, meaning that if no one outside the company know the exact implementation then the code is secure.
Almost every data breach is caused by human mistakes. Unfortunately, humans do make mistakes and security through obscurity principles may seems to cover up these mistakes nicely. The truth, however, is that nowadays hackers are capable of finding exploits even when the source code is not available for them to use.
No project is protected from human mistakes, not even the open-source one. But what makes open source more secure, is the way how open source communities work.
First, the project’s code is out there for everybody to see. Everybody who is interested can evaluate the code and if they see a vulnerability or just a small bug in the code they can suggest a fix. Instead of being automatically applied, this fix is to send as a suggestion for the people involved with the project. They review it and accept it only when they are sure the quality of the solution meets the project requirements. Finally, when a solution is accepted, it is merged with the master branch of the open-source project and the fix is available for everybody to use immediately. This makes the time between identifying a possible security breach and distributing a fix way shorter in the open-source projects than in the proprietary software.
Although we haven’t witnessed major data leak caused by an MBaaS provider yet, it’s not a guarantee that will not happen in the future. And if you are afraid that your data may go in the wrong hands, it’s better to trust what you can see for yourself, than what others claim, but no one can see for sure.
##5. Many hosting options for Parse Server create pricing competition.
If you are using a closed source MBaaS, provided by just one company, and you know that you’ll spend thousands of dollars for development to migrate to another MBaaS, you’ll accept some percentage of price increases as long as it’s not too drastic. It’s not exactly a monopoly, but the result is almost the same.
On the other hand, if you’re using Open Source Parse Server, you can switch providers at no development cost. When your provider increases its pricing, you have the power to decide whether this increase is reasonable or not and to take action to migrate elsewhere if necessary.
Open Source Parse Server is cool and the list with the benefits you will have with it does not end here. The truth is that it has something to offer to everyone. And we can all agree here, there’s nothing better than having provider alternatives because competition makes the world go round. | veselinastaneva |
196,783 | Bug tracking & new features development by mastering GitHub Issues | Content List Introduction Milestones, Labels & Assignees Notifications, @mentions, an... | 0 | 2019-10-28T13:15:03 | https://blog.sashido.io/bug-tracking-and-features-development-with-sashido-and-github-issues/ | github, debugging, tutorial, beginners | ## Content List ##
* [**Introduction**](#introduction)
* [**Milestones, Labels & Assignees**](#milestoneslabelsassignees)
* [**Notifications, @mentions, and References**](#notificationsmentionsandreferences)
* [**Search**](#search)
* [**Other Uses**](#otherusesforissues)
## Introduction ##
Each application you create on SashiDo has its own **Free Private** repository on GitHub.
Like any great project, yours will probably need to have a way to track its bugs, tasks, and improvements. Great news, as GitHub has just the right feature for the job. Its called **Issues** and it’s GitHub’s way of tracking and dealing with these sorts of things.

It’s really simple, as they function almost like an email, though the great part is that they can be shared and discussed with your team. Every repository comes with its own Issues section. So let's get straight to the point.
We can start by looking at [**Parse Server’s Issues section**](https://github.com/parse-community/parse-server/issues) for example:

GitHub's tracker is also quite special. It offers excellent formatting and focuses on collaboration and references. You can check out how a typical issue on GitHub looks in the image below:

* You can see that there is a **title** and a **description** which informs us what the issue is about.
* There are some neat color-coded **labels** which help you filter and organize your issue by category.
* **Milestones** are very useful for linking issues with specific feature or project phase (e.g Weekly Sprint 9/5-9/16 or Shipping 1.0). They are like a container for issues.
* Every issue can have an **assignee** which is responsible for moving the issue forward.
* And of course **comments** let anyone with access to the repository provide feedback and suggestions.
## Milestones, Labels & Assignees ##
At some point, you're going to have many issues and you may find it hard to find a specific one. Don't worry, because **labels**, **Milestones** & **assignees** are awesome features to help you filter and sort issues.
You can change and edit all of them by just clicking on their corresponding gears in the sidebar which is located on the right.

In case you do not see the edit button, that means that you do not have permission to edit the issue and you can ask the repository's owner to make you a collaborator, so you can get access.
### Milestones ###

Milestones are a great feature to group up your issues, for example by project, a feature or even a time period. They can be used in many different ways in software development. Here are some examples:
* **Beta Launch** - You can include any bugs that need to be fixed before you release the beta. By doing so you make sure that you don't miss anything along the way.
* **June Issues** - If you have many things to get done, you can specify a Milestone with the given issues you would like to work on during a specific period of time.
* **Redesign** - A great way to handle issues regarding the design of your project as well as collecting new ideas along the way.
### Labels ###

Labels are an exceptionally good way to organize your issues. There is no limit to how many labels you can have and you can even filter your issues by one or more labels at the same time.
### Assignees ###
Each issue may have an assignee which is responsible for pushing it forward. That's a great way to assign a particular person to track the issue and is familiar with it. That way he can easily track and push it forward.
## Notifications, @mentions, and References ##
Communication is the key to resolving any issue. By using GitHub's **@mention** system and references, you can link issues to the right people or teams so that the issues are resolved effectively. These features are really easy to learn and use and work in every text field as they're part of GitHub's text formatting syntax called [GitHub Flavored Markdown](https://help.github.com/articles/writing-on-github#name-and-team-mentions-autocomplete).

If you want to learn more about the syntax, you can check GitHub's official guide on [Mastering Markdown](http://guides.github.com/features/mastering-markdown/)
### Notifications ###
GitHub's way to keep you posted about your Issues is [Notifications](https://github.com/notifications). They can be utilized so you are up-to-date with new issues or to simply know if someone's waiting for your input so they can continue with their work.
You can receive notifications by two ways - either by email or via the web. To configure these settings navigate to your [notification settings](https://github.com/settings/notifications).
If you plan to receive many notifications, it's suggested that you configure to receive **Web** & **Email** notifications for **Participating** and **Web** for **Watching**.

Given that you're using this configuration, you'll receive emails when someone specifically mentions you and you can visit the web-based interface to keep in touch with repositories you have interest in.
You can easily view your notifications in the [Notifications Screen](https://github.com/notifications). It's located on the left of your avatar in the top-right corner of the page. There you can easily navigate through many notifications at the same time. You can mark them as **read** or you can **mute** a specific thread. You can speed up this process by using keyboard shortcuts. To check a list of available shortcuts press the `?` on the page.

There is a little difference between muting a thread and marking it as read. When you've marked a certain thread as read, you will not be notified until there has been a new comment, whereas if you mute it, you will not receive notifications until you are specifically @mentioned in the thread. That gives you the power to choose which threads are important to you and which you are not interested in.
GitHub comes with an awesome feature which syncs your notification statuses. Basically, if you read notification in your email, it will be marked as read in the web-based interface. Awesome, right. However, you should enable your email client to show images if you want this to work.
### @mentions ###
In order to reference other GitHub users in Issues, we use the @mention system. We can do so in both the description and the comment section of an issue by including the `@username` of the person. When we mention someone like that they'll receive a notification about it.
If you want to include people to a given issue you can use the `/cc` syntax. Here's an example:
> It looks like the images on our initial page are not loading.
>
> /cc @alexSmith
That's great, but only if you know who exactly to include. In most cases, we tend to work in teams and that way we may not know who exactly could be of help. Don't worry, because @mentions work with teams within organizations on GitHub. When you @mention a team it will send notifications to everyone who's part of it. Let's say for example you create an organization named @MySashiDoApp and under it, a team @javascrip-devs. An example @mention, in this case, would look like this:
> /cc @MySashiDoApp/javascript-devs
### References ###
Quite often different issues are intertwined or maybe you just want to reference one into the other. This can be done by using the hashtag `#` followed by the issue number.
> Hey @alexR, I think this issue may have something in common with #62
After you've done it, an event is created in issue #62 which looks something like this:

If you want to refer to an issue in an entirely different repo, just include the repository name like this `alex/example_project#62`
You can also reference issues directly in commits by including the issue number in the commit message.

If you preface the commit message with “Fixes”, “Fixed”, “Fix”, “Closes”, “Closed”, or “Close” and afterwards merge to master, the issue will automatically be closed.
All in all, references are great for adding visibility to the history of your project, as they profoundly link the work being done with the bug being tracked.
## Search ##
You can find the search box at the top of the page.

You can apply different filters to your search, for example:
* Keyword - e.g. [all issues mentioning the sidebar](https://github.com/twbs/bootstrap/issues?q=sidebar)
* State - [all issues mentioning the sidebar that are **closed**](https://github.com/twbs/bootstrap/issues?q=sidebar+is%3Aclosed)
* Assignee - [all issues mentioning the sidebar that were assigned to @mdo](https://github.com/twbs/bootstrap/issues?q=sidebar+is%3Aclosed+assignee%3Amdo)
If you'd like to read more about the search, you can do so in the official GitHub Article about [Using search to filter issues and pull requests](https://help.github.com/articles/using-search-to-filter-issues-and-pull-requests/)
## Other uses for Issues ##
Issues are not tied only for development purposes. In fact, they are quite useful to collaborate with your team on whatever issues you have. Here are some examples:
* [Bug tracker for your house](https://github.com/frabcus/house/issues?labels=building&state=open) including such gems as [the door being hung incorrectly](https://github.com/frabcus/house/issues/58)
* [Bug tracker for your open source projects](https://github.com/joyent/node/issues)
* [Request for recipes](https://github.com/newmerator/recipes/issues), maybe you have a good [gluten-free pizza dough recipe](https://github.com/newmerator/recipes/issues/3)?
* MostlyAdequate's [E-books](https://github.com/MostlyAdequate/mostly-adequate-guide/issues)
* [The French Civil Code](https://github.com/steeve/france.code-civil/issues), as unlikely as it may sound.
## Final ##
Whew! That was a long article, but you've learned how to manage and keep track of your issues. | veselinastaneva |
196,804 | It's the end of Python 2. Are we prepared? | In just a few short months, Python 2 will officially reach the end of its supported life. 💀 This mean... | 0 | 2019-10-28T13:45:35 | https://blog.tidelift.com/its-the-end-of-python-2.-are-we-prepared | opensource, python | In just a few short months, Python 2 will officially reach the end of its supported life. 💀 This means that anyone building applications in Python will need to have moved to Python 3 if they want to keep getting updates including, importantly, fixes for any security vulnerabilities in the core of Python or in the standard library. How did we get here?
Python 3 was initially released on December 3, 2008 and included a variety of major compatibility-breaking changes. Overall, these changes are welcomed by Pythonistas and remove a lot of hacks and workarounds that had evolved over time. One of my favorites is that things like *dict.items()* no longer return a list, so you don’t have to use *dict.iteritems()* to get a lower memory and more performant way to iterate over dictionary items.
Others, while still welcome, are more challenging from a compatibility perspective as they bring along syntax changes to the core language. This meant that many of the Python libraries that we use for building applications weren’t ready for Python 3. Django, Flask, urllib3, etc... none were ready for the initial release of Python 3. But they now are and have been for quite a while. The efforts to support multiple Python versions have been great but can’t continue forever.
This isn’t the first time this kind of event has happened in the Python world, though. Way back in October 2000, Python 2 came out. This major release of Python had a number of incompatible changes that impacted developers, especially surrounding how one worked with strings and Unicode.
At that time I was working for Red Hat and maintaining Anaconda, the installer for Red Hat Linux. We had decided that migrating all of the Python usage within Red Hat to Python 2 was a priority. There were many less Python modules back then and a small group of us (employed by Red Hat!) were able to do the work to update the modules we shipped to support Python 2. We sent patches upstream, in some cases taking over upstream maintenance of the module, and were able to help move the world forward to Python 2.
But today is different. There are now over 200,000 Python libraries. It’s not practical for one company to help drive all of the changes in the ecosystem to support this new and incompatible release. And the vast majority of the Python packages out there are maintained by volunteers—people who are doing this in their spare time and as a labor of love.
This challenge of how to migrate successfully from Python 2 to Python 3 is exactly the sort of situation where having an incentive for maintainers to support a new version and work with the incompatibilities would be so much better. It’s a perfect example of why we need to pay the maintainers of the open source libraries that all of our applications depend upon. With strong financial incentives in place, the speed and comprehensiveness of our preparation for Python 3 could have been accelerated.
For users, major incompatible changes like those involved in the migration to Python 3 are an important part of keeping software vibrant, alive, and performant. But without being a psychic, it is simply impossible to understand how the world will change and evolve and require modifications to our software.
| katzj |
196,831 | Need feedback for my personal portfolio | Hello, I'm Maksum Rifai from Indonesia. Please take time to see/test and feedback for my personal por... | 0 | 2019-10-28T14:21:53 | https://dev.to/maksumrifai/need-feedback-for-my-personal-portfolio-4o3h | webdev, portfolio, frontend, bootstrap | Hello, I'm Maksum Rifai from Indonesia.
Please take time to see/test and feedback for my personal portfolio. Thanks.
https://maksumrifai.github.com
https://maksumrifai.netlify.com | maksumrifai |
206,142 | What should a developer CV / resume look like? | There's no doubt in my mind, my CV (it's a resume in other countries) from school is nothing like my... | 0 | 2019-11-16T00:06:58 | https://dev.to/adam_cyclones/what-should-a-developer-cv-look-like-2f1g | discuss | There's no doubt in my mind, my CV (it's a resume in other countries) from school is nothing like my CV today, it's got a layout which is a little bit unusual for a CV but not mad as a box of frogs either. I like my CV like I like my tattoos, black and white. But never mind what I think, should a developer open InDesign and get to work building something that looks more like a magazine layout.
I am especially interested in hearing your thoughts! | adam_cyclones |
206,179 | Hover scroll portfolio, reCAPTCHA form | Module Monday 64 | Module Monday 64 | 0 | 2019-11-18T23:00:36 | https://guide.anymod.com/module-monday/64.html | showdev, githunt, webdev, javascript | ---
title: Hover scroll portfolio, reCAPTCHA form | Module Monday 64
published: true
description: Module Monday 64
tags: showdev, githunt, webdev, javascript
cover_image: https://res.cloudinary.com/component/image/upload/b_rgb:ffffff,c_lpad,h_350,w_800/v1573698448/screenshots/slide-cards.gif
canonical_url: https://guide.anymod.com/module-monday/64.html
---
## Open source modules
These modules can be used on any website, web app, or anywhere else. There are hundreds more like these built & shared on [AnyMod](https://anymod.com).
Click a mod to see it along with its source code.
## Hover scroll portfolio
Cards to display your work.
<a class="btn btn-sm" href="https://anymod.com/mod/portfolio-cards-with-auto-scroll-preview-balmna">View mod</a>
<a href="https://anymod.com/mod/portfolio-cards-with-auto-scroll-preview-balmna">
<img src="https://res.cloudinary.com/component/image/upload/v1573698448/screenshots/slide-cards.gif"/>
</a>
## Transitive intro
Simple hero unit that fades in on page load.
<a class="btn btn-sm" href="https://anymod.com/mod/hero-raodab?preview=true">View mod</a>
<a href="https://anymod.com/mod/hero-raodab?preview=true">
<img src="https://res.cloudinary.com/component/image/upload/v1573698447/screenshots/transitive-intro.gif"/>
</a>
## reCAPTCHA form
Contact form that prevents spam with a reCAPTCHA.
<a class="btn btn-sm" href="https://anymod.com/mod/contact-form-with-recaptcha-edlbn">View mod</a>
<a href="https://anymod.com/mod/contact-form-with-recaptcha-edlbn">
<img src="https://res.cloudinary.com/component/image/upload/v1573698441/screenshots/reCaptcha.gif"/>
</a>
## Image display
Show off your visuals with this responsive mod.
<a class="btn btn-sm" href="https://anymod.com/mod/caminar-image-display-alrrdn?preview=true">View mod</a>
<a href="https://anymod.com/mod/caminar-image-display-alrrdn?preview=true">
<img src="https://res.cloudinary.com/component/image/upload/v1573698442/screenshots/images.png"/>
</a>
## Footer with links
Reusable footer to add links anywhere you need them.
<a class="btn btn-sm" href="https://anymod.com/mod/footer-with-links-ordnll?preview=true">View mod</a>
<a href="https://anymod.com/mod/footer-with-links-ordnll?preview=true">
<img src="https://res.cloudinary.com/component/image/upload/v1573698440/screenshots/footer.png"/>
</a>
<hr>
I post new mods from the community [here](https://dev.to/tyrw) every (Module) Monday -- I hope you find them useful!
Happy coding ✌️
| tyrw |
206,225 | The Ember Times - Issue No. 124 | 👋 Emberistas! 🐹 This week: 400 Releases on the Ember.js Repo 🎉, share your thoughts for RFCs #549 an... | 2,173 | 2019-11-16T06:12:55 | https://blog.emberjs.com/2019/11/15/the-ember-times-issue-124.html | ember, javascript, webdev | 👋 Emberistas! 🐹
This week: 400 Releases on the Ember.js Repo 🎉, share your thoughts for RFCs #549 and #554 💬, learn how to use telemetry helpers to power up your codemods 📡, release of Octane Super Rentals Tutorial Part 2 🚀, enjoy the new and shiny Ember-powered Apple TV 🍏📺, and check out a new accessibility-focused ember-bootstrap release ✨!
---
## [400 Releases on the Ember.js Repo 🎉](https://github.com/emberjs/ember.js)
The [ember.js repo](https://github.com/emberjs/ember.js) hit 400 releases on GitHub this week! We’ve had over [770 contributors](https://github.com/emberjs/ember.js/graphs/contributors) between May 2011 to November 2019. A big thank you ❤️ to the numerous efforts of all all these community members!
---
## [RFC #549: Ember Dev for Other Platforms 💬](https://github.com/emberjs/rfcs/pull/549)
[Adam Baker (@bakerac4)](https://github.com/bakerac4) has proposed the need to better advertise Ember as a cross-platform solution: Use 1 framework to create web, mobile, *and* desktop apps! The possibility of marketing Ember as cross-platform exists already, thanks to projects like [Corber](http://corber.io/pages/frameworks/ember) and [Glimmer Native](https://github.com/bakerac4/glimmer-native).
How can we market Ember as cross-platform and support developing for other platforms? Be sure to [share your ideas with everyone](https://github.com/emberjs/rfcs/pull/549) today!
---
## [RFC #554: Deprecate `getWithDefault` 💬](https://github.com/emberjs/rfcs/pull/554)
[Chris Ng (@chrisng)](https://github.com/chrisrng) has proposed deprecating support for `getWithDefault`. This method, which has [existed since Ember 1.0](https://api.emberjs.com/ember/1.0/classes/Ember.Object/methods/getWithDefault?anchor=getWithDefault), is intended to help an Ember object return a default value.
The problem with `getWithDefault` lies in its behavior. It returns the default value *only* when the retrieved value of the property is `undefined`. Other falsey values, such as `null` or `''`, don't result in the default value. This behavior may or may not be what you intended.
To help you write code explicitly, TC39 has come up with the [nullish coalescing operator](https://github.com/tc39/proposal-nullish-coalescing), `??`, now in Stage 3 proposal. RFC 554 explains that it'd be better to rely on the native implementation.
What are your thoughts on deprecating `getWithDefault`? We encourage you to [read the RFC and participate](https://github.com/emberjs/rfcs/pull/554) today!
---
## [Creating Runtime Assisted Codemods Using Telemetry Helpers 📡](http://hangaroundtheweb.com/2019/10/creating-runtime-assisted-codemods-using-telemetry-helpers/)
Thanks to [Rajasegar Chandran (@rajasegar)](https://github.com/rajasegar) and [Ryan Mark (@tylerturdenpants)](https://github.com/tylerturdenpants), the [ember-codemods-telemetry-helpers](https://github.com/ember-codemods/ember-codemods-telemetry-helpers) addon features a [detailed readme](https://github.com/ember-codemods/ember-codemods-telemetry-helpers#ember-codemods-telemetry-helpers) and [companion blog post](http://hangaroundtheweb.com/2019/10/creating-runtime-assisted-codemods-using-telemetry-helpers/). 💞
Traditionally, Ember codemods have relied on **static code analysis** to help you (a codemod author) convert files from one version to the next. In contrast, telemetry-powered codemods can **run the app** to help you gather data on components, services, routes, controllers, etc.
To learn more about telemetry helpers, we encourage you to visit [Rajasegar's blog](http://hangaroundtheweb.com/2019/10/creating-runtime-assisted-codemods-using-telemetry-helpers/). You can also check out [ember-native-class-codemod](https://github.com/ember-codemods/ember-native-class-codemod) and [ember-no-implicit-this-codemod](https://github.com/ember-codemods/ember-no-implicit-this-codemod) to learn how codemods use telemetry helpers today!
---
## [Octane Super Rentals Tutorial Part 2 🚀](https://octane-guides-preview.emberjs.com/release/tutorial/10-part-2/)
[Godfrey Chan (@chancancode)](https://github.com/chancancode) and [Vaidehi Joshi (@vaidehijoshi)](https://github.com/vaidehijoshi) further expanded the Super Rentals Tutorial for Ember Octane by releasing part 2 of the tutorial!
This **automatically generated** tutorial now [supports decorators](https://github.com/cibernox/ember-cli-yuidoc/pull/52) thanks to [Chris Garrett (@pzuraq)](https://github.com/pzuraq) who had a fix to replace all `@` symbols within code blocks with a placeholder, processes them, and then switches them back after processing.
If you are looking to contribute check out the [super-rentals-tutorial repo on GitHub](https://github.com/ember-learn/super-rentals-tutorial)!
---
## [Brand-New Product Release Powered by Ember: Apple TV 🍏📺](https://twitter.com/mehulkar/status/1190318959955857408)
**Plenty of companies** and acclaimed brands **bet on Ember** when building digital products for thousands or even millions of users. Heroku, Netflix, TED, Tilde, Intercom and BetterUp are a few examples of [well-known businesses](https://emberjs.com/ember-users) who have benefitted from using Ember for years.
Did you also know that Apple's web platform **Apple TV** is [built with Ember](https://twitter.com/mehulkar/status/1190318959955857408)? Apple TV is now based on a modern 3.12 Ember tech stack which evolved its way up from a 3.4 app earlier this year. Furthermore, the app is increasingly adopting all the latest and sparkliest ✨ from the [new Ember Octane programming model](https://emberjs.com/editions/octane/), making it a great showcase for modern Ember apps in the wild!
Do you have any feedback? Feel free to reach out to [Mehul Kar (@mehulkar)](https://github.com/mehulkar) for any questions, suggestions or bug reports.
---
## [Accessibility-Focused Ember Bootstrap Release ✨](https://twitter.com/simonihmig/status/1190740590377472001)
A few weeks ago, [Simon Ihmig (@simonihmig)](https://github.com/simonihmig) and the folks at [kaliber5](https://github.com/kaliber5) released version 3.1.0 of the fantastic Ember addon [ember-bootstrap](https://github.com/kaliber5/ember-bootstrap).
This version focuses on **improving accessibility** by using [ember-focus-trap](https://github.com/josemarluedke/ember-focus-trap) to implement focus trap for modals and keyboard navigation of dropdowns. It also adds [ember a11y tests](https://github.com/ember-a11y/ember-a11y-testing) to the test suite! 🔥🔥🔥
Many thanks to all those that contributed to this release and the accessiblity concerns addressed by it 😄, including [Simon Ihmig (@simonihmig)](https://github.com/simonihmig), [Brad Overton (@techn1x)](https://github.com/Techn1x), [Ramiz Wachtler (@rwachtler)](https://github.com/rwachtler) and [Jeldrik Hanschke (@jelhan)](https://github.com/jelhan).
You can find the release notes on [GitHub](https://github.com/kaliber5/ember-bootstrap/blob/master/CHANGELOG.md#310-2019-11-02).
---
## [Contributors' Corner 👏](https://guides.emberjs.com/release/contributing/repositories/)
<p>This week we'd like to thank <a href="https://github.com/Gaurav0" target="gh-user">@Gaurav0</a>, <a href="https://github.com/pichfl" target="gh-user">@pichfl</a>, <a href="https://github.com/pzuraq" target="gh-user">@pzuraq</a>, <a href="https://github.com/kategengler" target="gh-user">@kategengler</a>, <a href="https://github.com/thejonrichmond" target="gh-user">@thejonrichmond</a>, <a href="https://github.com/rictic" target="gh-user">@rictic</a>, <a href="https://github.com/raycohen" target="gh-user">@raycohen</a>, <a href="https://github.com/lolmaus" target="gh-user">@lolmaus</a>, <a href="https://github.com/vladucu" target="gh-user">@vladucu</a>, <a href="https://github.com/kennethlarsen" target="gh-user">@kennethlarsen</a>, <a href="https://github.com/kellyselden" target="gh-user">@kellyselden</a>, <a href="https://github.com/rwjblue" target="gh-user">@rwjblue</a>, <a href="https://github.com/bertdeblock" target="gh-user">@bertdeblock</a>, <a href="https://github.com/Turbo87" target="gh-user">@Turbo87</a>, <a href="https://github.com/igorT" target="gh-user">@igorT</a>, <a href="https://github.com/ursm" target="gh-user">@ursm</a>, <a href="https://github.com/Mikek2252" target="gh-user">@Mikek2252</a>, <a href="https://github.com/runspired" target="gh-user">@runspired</a>, <a href="https://github.com/dmuneras" target="gh-user">@dmuneras</a>, <a href="https://github.com/chancancode" target="gh-user">@chancancode</a>, <a href="https://github.com/bendemboski" target="gh-user">@bendemboski</a> and <a href="https://github.com/patricklx" target="gh-user">@patricklx</a> for their contributions to Ember and related repositories! 💖</p>
---

## [Got a Question? Ask Readers' Questions! 🤓](https://docs.google.com/forms/d/e/1FAIpQLScqu7Lw_9cIkRtAiXKitgkAo4xX_pV1pdCfMJgIr6Py1V-9Og/viewform)
<p>Wondering about something related to Ember, Ember Data, Glimmer, or addons in the Ember ecosystem, but don't know where to ask? Readers’ Questions are just for you!</p>
<p><strong>Submit your own</strong> short and sweet <strong>question</strong> under <a href="https://bit.ly/ask-ember-core" target="rq">bit.ly/ask-ember-core</a>. And don’t worry, there are no silly questions, we appreciate them all - promise! 🤞</p>
</div>
---
## [#embertimes 📰](https://blog.emberjs.com/tags/newsletter.html)
Want to write for the Ember Times? Have a suggestion for next week's issue? Join us at [#support-ember-times](https://discordapp.com/channels/480462759797063690/485450546887786506) on the [Ember Community Discord](https://discordapp.com/invite/zT3asNS) or ping us [@embertimes](https://twitter.com/embertimes) on Twitter.
Keep on top of what's been going on in Emberland this week by subscribing to our [e-mail newsletter](https://the-emberjs-times.ongoodbits.com/)! You can also find our posts on the [Ember blog](https://emberjs.com/blog/tags/newsletter.html).
---
That's another wrap! ✨
Be kind,
Chris Ng, Isaac Lee, Jessica Jordan, Jared Galanis, Amy Lam and the Learning Team | embertimes |
206,315 | Accessible and adaptive select-menu's using react-laag and downshift | Creating a select menu that is both responsive and accessible can be really hard. The menu itself may... | 0 | 2019-11-17T13:23:37 | https://dev.to/everweij/accessible-and-adaptive-select-menu-s-using-react-laag-and-downshift-abn | react, menu, responsive, a11y | Creating a select menu that is both responsive and accessible can be really hard. The menu itself may look nice on a desktop where there's plenty of space, but unfortunately most mobile devices lack the space to show the menu properly. For that reason some people believe it's best to avoid the idea of a menu popping up all together, or at least create separate designs for both mobile and desktop. While this is a legit solution, it introduces the burden of having to maintain two designs.
Another approach is to create an _adaptive_ select menu. What I mean with _adaptive_ in this case, is a single select-menu that looks and behaves differently based on the context it is used in. So instead of creating two different components, you'll end up with one component that implements different contexts (desktop / mobile in our case).
In this post I'd like to show you how to build a component like that. This is a preview of what we're about to build:
(tip: open the sandbox in a [separate tab](https://vi96m.csb.app/) and resize the screen)
{% codesandbox accessible-responsive-select-menu-vi96m %}
# What do want to build?
So, we want to build an accessible select menu that works great on both desktop and mobile. Our select menu has two key components at play:
- a _trigger_ - a button in our example
- a _layer_ - the menu in our example
Let's describe how we want our component to look and behave:
**Desktop and Mobile**
- We want a component that takes a list of options
- We want a component that notifies us when an option was selected
- We want to tell the component which option is currently selected
- Our component should work on screen-readers
- We should interact with the component by only using the keyboard
- We want to close the menu when an option was selected or when the menu looses focus ('Escape' key / mouse-click elsewhere in the document)
**Desktop**
- The menu should be 'tied' to the button.
- Ideally, we want to position the menu on the left side of the button, and reposition it when there's not enough space left (when to user scrolls the page for instance).
- We want a smooth fade transition
**Mobile**
- The menu should be 'tied' to the bottom of the screen
- The menu should have the full width of the screen
- The menu should close when the trigger button is getting 'off-screen'
- We want a smooth slide transition
That is quite a list! Fortunately there are two libraries which will do a lot of hard work for us :)
# Tools
In order to build this select menu, we're going to use two libraries:
- [downshift](https://github.com/downshift-js/downshift), a set of tools which help you to make accessible autocomplete / select / dropdown experiences. Basically, downshift takes care of things like keyboard navigation and aria-props, and serves you a bundle of props for you to place on the relevant elements (trigger / menu / menu-item / etc )
- [react-laag](https://www.react-laag.com/), a set of tools which takes care of _positioning_ your layers, like tooltips and menu's. You could see react-laag as the React version of Popper.js + a couple of extra tools. You will see that both libraries complement each other really well. (disclaimer: I'm the author of react-laag)
# Let's get started!
Ok, let's start off by defining how we would like to use the component:
```jsx
function Example() {
const [selectedItem, setSelectedItem] = React.useState(null);
return (
<SelectMenu
items={["My Profile", "Settings", "Billing", "Notifications", "Logout"]}
selectedItem={selectedItem}
onSelect={setSelectedItem}
/>
);
}
```
Next, we should create the actual `<SelectMenu />`:
```jsx
function SelectMenu({ items, selectedItem, onSelect }) {
return null;
}
```
# Toggleable layers
We don't want to show the menu (layer) right away. Instead, we want to show the menu when, when the user toggles it with help of the trigger-element (Button is our case). react-laag provides a `<ToggleLayer />` component for this, since this pattern is so common:
```jsx
import * as React from 'react';
import { ToggleLayer } from 'react-laag';
function SelectMenu({ items, selectedItem, onSelect }) {
return (
<ToggleLayer
// we'll add this in a minute
isOpen={false}
// render our menu
renderLayer={({ isOpen, layerProps }) => {
// don't render if the menu isn't open
if (!isOpen) {
return null;
}
return (
<DesktopMenu {...layerProps}>
{items.map((option) => (
<DesktopMenuItem key={option}>
{option}
</DesktopMenuItem>
))}
</DesktopMenu>
);
}}
// provide placement configuration
placement={{
// ideally, we want the menu on the left side of the button
anchor: "LEFT_CENTER",
// we want to reposition the menu when the menu doesn't
// fit the screen anymore
autoAdjust: true,
// we want some spacing between the menu and the button
triggerOffset: 12,
// we want some spacing between the menu and the screen
scrollOffset: 16
}}
>
{({ isOpen, triggerRef }) => (
<Button ref={triggerRef}>{isOpen ? "Hide" : "Show"}</Button>
)}
</ToggleLayer>
);
}
```
Basically, we're rendering the `<Button />` inside of `children`, and our menu inside of the `renderLayer` prop. We also provide some configuration regarding positioning inside the `placement` prop.
>You may have noticed the `<Button />` and `<Menu />` components. These are just presentational components, and contain no additional logic.
# Detecting the viewport size
We want to style the menu differenly based in the viewport size of the user. Luckily, react-laag has a tool for that: `useBreakpoint()`
```jsx
import { ToggleLayer, useBreakpoint } from "react-laag";
function SelectMenu({ items, selectedItem, onSelect }) {
// detect whether we are on a mobile device
const isMobile = useBreakpoint(480);
return (
<ToggleLayer
isOpen={false}
renderLayer={({ isOpen, layerProps }) => {
if (!isOpen) {
return null;
}
// Assign the right components based on `isMobile`
const Menu = isMobile ? MobileMenu : DesktopMenu;
const MenuItem = isMobile ? MobileMenuItem : DesktopMenuItem;
// Ignore `layerProps.style` on mobile, because
// we want it to be positioned `fixed` on the bottom
// of the screen
const style = isMobile ? {} : layerProps.style;
return (
<Menu ref={layerProps.ref} style={style}>
{items.map(option => (
<MenuItem key={option}>{option}</MenuItem>
))}
</Menu>
);
}}
// rest of props skipped for brevity...
/>
);
}
```
# Adding some logic
Now that the essential components are in the correct place, we should add some logic. When should we show the menu? What happens when an user selects an option? etc...
This is where downshift comes in! We're going to use downshift's `useSelect`:
```jsx
import * as React from "react";
import { ToggleLayer, useBreakpoint } from "react-laag";
import { useSelect } from 'downshift';
function SelectMenu({ items, selectedItem, onSelect }) {
// detect whether we are on a mobile device
const isMobile = useBreakpoint(480);
const {
// tells us whether we should show the layer
isOpen,
// a couple of prop-getters which provides us
// with props that we should inject into our
// components
getToggleButtonProps,
getMenuProps,
getItemProps,
// which item is currently hightlighted?
highlightedIndex,
// action which sets `isOpen` to false
closeMenu
} = useSelect({
// pass in the props we defined earlier...
items,
selectedItem,
onSelectedItemChange: ({ selectedItem }) => {
if (selectedItem !== undefined) {
onSelect(selectedItem);
}
}
});
return (
<ToggleLayer
// we now know when the menu is open / closed :)
isOpen={isOpen}
renderLayer={({ isOpen, layerProps }) => {
if (!isOpen) {
return null;
}
// Assign the right components based on `isMobile`
const Menu = isMobile ? MobileMenu : DesktopMenu;
const MenuItem = isMobile ? MobileMenuItem : DesktopMenuItem;
// Ignore `layerProps.style` on mobile, because
// we want it to be positioned `fixed` on the bottom
// of the screen
const style = isMobile ? {} : layerProps.style;
return (
<Menu
// inject downshift's props and 'merge' them
// with our `layerProps.ref`
{...getMenuProps({ ref: layerProps.ref })}
style={style}
>
{items.map((item, index) => (
<MenuItem
style={
highlightedIndex === index
? { backgroundColor: "#eaf3f9" }
: {}
}
key={item}
// inject downshift's props
{...getItemProps({ item, index })}
>
{item}
</MenuItem>
))}
</Menu>
);
}}
// rest of props skipped for brevity...
>
{({ isOpen, triggerRef }) => (
<Button
// inject downshift's props and 'merge' them
// with our `triggerRef`
{...getToggleButtonProps({ ref: triggerRef })}
>
{isOpen ? "Hide" : "Show"}
</Button>
)}
</ToggleLayer>
);
}
```
# Adding an arrow for desktop
It's pretty common for a menu on desktop to place a small arrow on the menu that points to the trigger element. react-laag provides us a small utility component for just that. Let's implement it:
```jsx
import { ToggleLayer, useBreakpoint, Arrow } from "react-laag";
<ToggleLayer
renderLayer={({
isOpen,
layerProps,
// determines on which side the menu currently is
layerSide,
// the style we should pass to the <Arrow /> component
arrowStyle
}) => {
if (!isOpen) {
return null;
}
const Menu = isMobile ? MobileMenu : DesktopMenu;
const MenuItem = isMobile ? MobileMenuItem : DesktopMenuItem;
const style = isMobile ? {} : layerProps.style;
return (
<Menu
{...getMenuProps({ ref: layerProps.ref })}
style={style}
>
{!isMobile && (
// only render the arrow when on desktop
<Arrow
backgroundColor="white"
borderWidth={1}
borderColor={"#your-border-color"}
style={arrowStyle}
layerSide={layerSide}
/>
)}
{items.map((item, index) => (
<MenuItem
style={
highlightedIndex === index ? { backgroundColor: "#eaf3f9" } : {}
}
key={item}
{...getItemProps({ item, index })}
>
{item}
</MenuItem>
))}
</Menu>
);
}}
// rest of props skipped for brevity...
/>
```
# Adding transitions
It's entirely up to you how to implement the transitions. You could use a library like react-spring or framer-motion for example. To keep things simple we are gonna use plain css-transitions and a little utility component from react-laag: `<Transition />`.
```jsx
import { ToggleLayer, useBreakpoint, Arrow, Transition } from "react-laag";
<ToggleLayer
renderLayer={({ isOpen, layerProps, layerSide, arrowStyle }) => {
const Menu = isMobile ? MobileMenu : DesktopMenu;
const MenuItem = isMobile ? MobileMenuItem : DesktopMenuItem;
// Wrap our <Menu /> component in <Transition />
// Apply styles / transitions based on:
// - isOpen
// - isMobile
return (
<Transition isOpen={isOpen}>
{(isOpen, onTransitionEnd) => (
<Menu
{...getMenuProps({ ref: layerProps.ref })}
// Inform <Transition /> that a transition has ended
onTransitionEnd={onTransitionEnd}
style={
isMobile
? {
transform: `translateY(${isOpen ? 0 : 100}%)`,
transition: "transform 0.2s"
}
: {
...layerProps.style,
opacity: isOpen ? 1 : 0,
transition: "opacity 0.2s"
}
}
>
{!isMobile && (
<Arrow
backgroundColor="white"
borderWidth={1}
borderColor={"#your-border-color"}
style={arrowStyle}
layerSide={layerSide}
/>
)}
{items.map((item, index) => (
<MenuItem
style={
highlightedIndex === index
? { backgroundColor: "#eaf3f9" }
: {}
}
key={item}
{...getItemProps({ item, index })}
>
{item}
</MenuItem>
))}
</Menu>
)}
</Transition>
);
}}
// rest of props skipped for brevity...
/>;
```
# Close the menu when the button leaves the screen
Downshift already detects in various ways when the menu should be closed. There is, however, one thing that's missing, and that is when the user starts scrolling on mobile. By scrolling the button offscreen, is very well could be the user's intention to close the menu and move on. Fortunately there's an relatively easy way to detect this:
```jsx
function Select({ selectedItem, onSelect, items }) {
const {
isOpen,
getToggleButtonProps,
getMenuProps,
highlightedIndex,
getItemProps,
// this one's important
closeMenu
} = useSelect({
items,
selectedItem,
onSelectedItemChange: ({ selectedItem }) => {
if (selectedItem !== undefined) {
onSelect(selectedItem);
}
}
});
return (
<ToggleLayer
isOpen={isOpen}
renderLayer={}
// we want out menu to behave as a
// 'fixed'-styled layer on mobile
fixed={isMobile}
// when the button disappears (offscreen),
// close the menu on mobile
onDisappear={() => {
if (isMobile) {
closeMenu();
}
}}
/>
);
}
```
# Conclusion
I wanted to show you an example of how you could create an accessible select menu that works well on both desktop and mobile, with help of tools like downshift and react-laag. As you might have noticed, we didn't have to do any calculations or manual event-handling. All we did was connecting the right components together, and describe how we wanted certain things to behave. We also didn't really cover styling, because that's not where this post is about. The cool thing though, is that you could style this example however you like!
Check out the [sandbox](https://codesandbox.io/s/accessible-responsive-select-menu-vi96m) for the entire code if your interested.
For more information about downshift, check out their excellent [docs](https://github.com/downshift-js/downshift).
Please visit react-laag's [website](https://www.react-laag.com/) for more information and use-cases, or star it on [github](https://github.com/everweij/react-laag) ✨
Thanks for reading!
| everweij |
206,436 | Tic-Tac-Toe with a Neural Network | Let's train a Tic-Tac-Toe player with a neural network via reinforcement learning using PyTorch | 1,544 | 2019-12-27T05:15:18 | https://nestedsoftware.com/2019/12/27/tic-tac-toe-with-a-neural-network-1fjn.206436.html | tictactoe, neuralnetworks, pytorch, python | ---
title: Tic-Tac-Toe with a Neural Network
published: true
cover_image: https://thepracticaldev.s3.amazonaws.com/i/00vqwtc9m84gjs3lmrc8.jpg
description: Let's train a Tic-Tac-Toe player with a neural network via reinforcement learning using PyTorch
series: Tic-Tac-Toe
canonical_url: https://nestedsoftware.com/2019/12/27/tic-tac-toe-with-a-neural-network-1fjn.206436.html
tags: tic-tac-toe, neuralnetworks, pytorch, python
---
In [Tic-Tac-Toe with Tabular Q-learning](https://dev.to/nestedsoftware/tic-tac-toe-with-tabular-q-learning-1kdn), we developed a tic-tac-toe agent using reinforcement learning. We used a table to assign a Q-value to each move from a given position. Training games were used to gradually nudge these Q-values in a direction that produced better results: Good results pulled the Q-values for the actions that led to those results higher, while poor results pushed them lower. In this article, instead of using tables, we'll apply the same idea of reinforcement learning to neural networks.
## Neural Network as a Function
We can think of the Q-table as a multivariable function: The input is a given tic-tac-toe position, and the output is a list of Q-values corresponding to each move from that position. We will endeavour to teach a neural network to approximate this function.
For the input into our network, we'll flatten out the board position into an array of _9_ values: _1_ represents an _X_, _-1_ represents an _O_, and _0_ is an empty cell. The output layer will be an array of _9_ values representing the Q-value for each possible move: A low value closer to _0_ is bad, and a higher value closer to _1_ is good. After training, the network will choose the move corresponding to the highest output value from this model.
The diagram below shows the input and output for the given position after training (initially all of the values hover around _0.5_):
As we can see, the winning move for _X_, _A2_, has the highest Q-value, _0.998_, and the illegal moves have very low Q-values. The Q-values for the other legal moves are greater than the illegal ones, but less than the winning move. That's what we want.
## Model
The network (using PyTorch) has the following structure:
```python
class TicTacNet(nn.Module):
def __init__(self):
super().__init__()
self.dl1 = nn.Linear(9, 36)
self.dl2 = nn.Linear(36, 36)
self.output_layer = nn.Linear(36, 9)
def forward(self, x):
x = self.dl1(x)
x = torch.relu(x)
x = self.dl2(x)
x = torch.relu(x)
x = self.output_layer(x)
x = torch.sigmoid(x)
return x
```
The _9_ input values that represent the current board position are passed through two dense hidden layers of _36_ neurons each, then to the output layer, which consists of _9_ values, each corresponding to the Q-value for a given move
## Training
Most of the training logic for this agent is the same as for the Q-table implementation discussed earlier in this series. However, in that implementation, we prevented illegal moves. For the neural network, I decided to _teach_ it not to make illegal moves, so as to have a more realistic set of output values for any given position.
The code below, from [qneural.py](https://github.com/nestedsoftware/tictac/blob/master/tictac/qneural.py), shows how the parameters of the network are updated for a single training game:
```python
def update_training_gameover(net_context, move_history, q_learning_player,
final_board, discount_factor):
game_result_reward = get_game_result_value(q_learning_player, final_board)
# move history is in reverse-chronological order - last to first
next_position, move_index = move_history[0]
backpropagate(net_context, next_position, move_index, game_result_reward)
for (position, move_index) in list(move_history)[1:]:
next_q_values = get_q_values(next_position, net_context.target_net)
qv = torch.max(next_q_values).item()
backpropagate(net_context, position, move_index, discount_factor * qv)
next_position = position
net_context.target_net.load_state_dict(net_context.policy_net.state_dict())
def backpropagate(net_context, position, move_index, target_value):
net_context.optimizer.zero_grad()
output = net_context.policy_net(convert_to_tensor(position))
target = output.clone().detach()
target[move_index] = target_value
illegal_move_indexes = position.get_illegal_move_indexes()
for mi in illegal_move_indexes:
target[mi] = LOSS_VALUE
loss = net_context.loss_function(output, target)
loss.backward()
net_context.optimizer.step()
```
We maintain two networks, the policy network (`policy_net`) and the target network (`target_net`). We perform backpropagation on the policy network, but we obtain the maximum Q-value for the next state from the target network. That way, the Q-values obtained from the target network aren't changing during the course of training for a single game. Once we complete training for a game, we update the target network with the parameters of the policy network (`load_state_dict`).
`move_history` contains the Q-learning agent's moves for a single training game at a time. For the last move played by the Q-learning agent, we update its chosen move with the reward value for that game - _0_ for a loss, and _1_ for a win or a draw. Then we go through the remaining moves in the game history in reverse-chronological order. We tug the Q-value for the move that was played in the direction of the maximum Q-value from the next state (the next state is the state that results from the action taken in the current state).
This is analogous to the exponential moving average used in the tabular Q-learning approach: In both cases, we are pulling the current value in the direction of the maximum Q-value available from the next state. For any illegal move from a given game position, we also provide negative feedback for that move as part of the backpropagation. That way, our network will hopefully learn not to make illegal moves.
## Results
The results are comparable to the tabular Q-learning agent. The following table (based on _1,000_ games in each case) is representative of the results obtained after a typical training run:
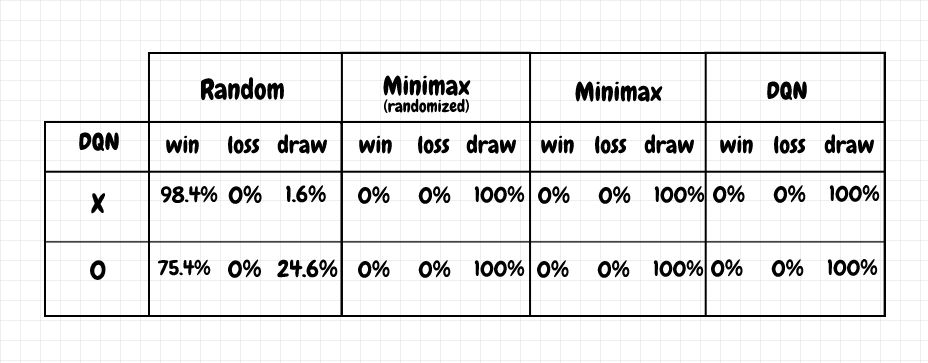
These results were obtained from a model that learned from _2 million_ training games for each of _X_ and _O_ (against an agent making random moves). It takes over an hour to train this model on my PC. That's a huge increase over the number of games needed to train the tabular agent.
I think this shows how essential large amounts of high-quality data are for deep learning, especially when we go from a toy example like this one to real-world problems. Of course the advantage of the neural network is that it can generalize - that is, it can handle inputs it has not seen during training (at least to some extent).
With the tabular approach, there is no interpolation: The best we can do if we encounter a position we haven't seen before is to apply a heuristic. In games like go and chess, the number of positions is so huge that we can't even begin to store them all. We need an approach which can generalize, and that's where neural networks can really shine compared to prior techniques.
Our network offers the same reward for a win as for a draw. I tried giving a smaller reward for a draw than a win, but even lowering the value for a draw to something like _0.95_ seems to reduce the stability of the network. In particular, playing as _X_, the network can end up losing a significant number of games against the randomized minimax agent. Making the reward for a win and a draw the same seems to resolve this problem.
Even though we give the same reward for a win and a draw, the agent seems to do a good job of winning games. I believe this is because winning a game usually ends it early, before all _9_ cells on the board have been filled. This means there is less dilution of the reward going back through each move of the game history (the same idea applies for losses and illegal moves). On the other hand, a draw requires (by definition) all _9_ moves to be played, which means that the rewards for the moves in a given game leading to a draw are more diluted as we go from one move to the previous one played by the Q-learning agent. Therefore, if a given move consistently leads to a win sooner, it will still have an advantage over a move that eventually leads to a draw.
## Network Topology and Hyperparameters
As mentioned earlier, this model has two hidden dense layers of _36_ neurons each. `MSELoss` is used as the loss function and the learning rate is _0.1_. `relu` is used as the activation function for the hidden layers. `sigmoid` is used as the activation for the output layer, to squeeze the results into a range between _0_ and _1_.
Given the simplicity of the network, this design may seem self-evident. However, even for this simple case study, tuning this network was rather time consuming. At first, I tried using `tanh` (hyperbolic tangent) for the output layer - it made sense to me to set _-1_ as the value for a loss and _1_ as the value for a win. However, I was unable to get stable results with this activation function. Eventually, after trying several other ideas, I replaced it with `sigmoid`, which produced much better results. Similarly, replacing `relu` with something else in the hidden layers made the results worse.
I also tried several different network topologies, with combinations of one, two, or three hidden layers, and using combinations of _9_, _18_, _27_, and _36_ neurons per hidden layer. Lastly, I experimented with the number of training games, starting at _100,000_ and gradually increasing that number to _2,000,000_, which seems to produce the most stable results.
## DQN
This implementation is inspired by DeepMind's DQN architecture (see [Human-level control through deep reinforcement learning](https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf)), but it's not exactly the same. DeepMind used a convolutional network that took direct screen images as input. Here, I felt that the goal was to teach the network the core logic of tic-tac-toe, so I decided that simplifying the representation made sense. Removing the need to process the input as an image also meant fewer layers were needed (no layers to identify the visual features of the board), which sped up training.
DeepMind's implementation also used _experience replay_, which applies random fragments of experiences as input to the network during training. My feeling was that generating fresh random games was simpler in this case.
Can we call this tic-tac-toe implementation "deep" learning? I think this term is usually reserved for networks with at least three hidden layers, so probably not. I believe that increasing the number of layers tends to be more valuable with convolutional networks, where we can more clearly understand this as a process where each layer further abstracts the features identified in the previous layer, and where the number of parameters is reduced compared to dense layers. In any case, adding layers is something we should only do if it produces better results.
## Code
The full code is available on github ([qneural.py](https://github.com/nestedsoftware/tictac/blob/master/tictac/qneural.py) and [main_qneural.py](https://github.com/nestedsoftware/tictac/blob/master/tictac/main_qneural.py)):
{% github nestedsoftware/tictac %}
## Related
* [Tic-Tac-Toe with Tabular Q-Learning](https://dev.to/nestedsoftware/tic-tac-toe-with-tabular-q-learning-1kdn)
* [Neural Networks Primer](https://dev.to/nestedsoftware/neural-networks-primer-374i)
* [PyTorch Image Recognition with Dense Network](https://dev.to/nestedsoftware/pytorch-image-recognition-dense-network-3nbd)
## References
* [Human-level control through deep reinforcement learning](https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf)
| nestedsoftware |
206,443 | Arcology Roguelike Lifestream E1 | Episode 1: Planning Here I introduce the game I want to build, the tools I want to use and... | 3,288 | 2019-11-16T21:23:29 | https://dev.to/pieterjoubert/arcology-roguelike-lifestream-e1-26jp | unity3d, roguelike, livestream, gamedev | # Episode 1: Planning
Here I introduce the game I want to build, the tools I want to use and the process I'm going to follow as well as doing some basic planning.
{% youtube bdwgC2cEZf0 %} | pieterjoubert |
207,027 | Multiple Authentication in laravel 6x | i have installed laravel default authentication system (using php artisan ui react --auth) which is b... | 0 | 2019-11-18T07:24:24 | https://dev.to/ksaroz/multiple-authentication-in-laravel-6x-ok6 | laravel, php | i have installed laravel default authentication system (using php artisan ui react --auth) which is best for me but i have created different table for user role and make relationship between user and role table and create new table called role_user but i am unable to redirect a different page based on user role in roles table. So, my question is how to redirect pages for different user based on role? I couldn't change the default /home page, in my condition all user role redirected to same /home page. | ksaroz |
208,694 | Improving our periodic code scheduler | Previously, we constructed a pretty simple and naive system that periodically runs a function. Not gr... | 3,336 | 2019-11-20T16:05:40 | https://dev.to/apisurfer/improving-our-periodic-code-runner-832 | javascript, scheduler, async | [Previously](https://dev.to/lvidakovic/run-code-periodically-using-promises-j09), we constructed a pretty simple and naive system that periodically runs a function. Not great, not terrible. Let's try to make it better one step at a time. Main drawback was that there was no way to stop it, but we'll get there. First, we are going to move some logic to an [async generator](https://dev.to/jfet97/javascript-iterators-and-generators-asynchronous-generators-2n4e). They work great with infinite streams. Our driving logic is basically an infinite stream of events that happen at a specified amount of time. We'll move the part that generates pause events to an async generator, while the loop will slightly change it's face and become a bit slicker to use, even though it might also need a refactor in the future.
From previous code:
```javascript
const pause = time => new Promise(resolve => setTimeout(resolve, time))
async function runPeriodically(callback, time) {
while (true) {
await callback()
await pause(time)
}
}
```
And it's usage:
```javascript
function logTime() {
const time = new Date()
console.log(time.toLocaleTimeString())
}
runPeriodically(logTime, 2000)
```
We move pause generation to an async generator and tweak the iterating loop:
```javascript
async function* cycle(time) {
while(true) {
yield pause(time)
}
}
async function runPeriodically(callback, time) {
for await (let tick of cycle(time)) {
await callback()
}
}
```
*runPeriodically* function can still be used exactly the same and is still with the fundamental problem of not being able stop the loop once it's been started. But the loop now only worries about the actual code that runs on every iteration, while async generator implements rudimental logic to yield pause events. Generators offer some unique set of features that allow them to communicate back and forth with the rest of the code and that's something we'll use to construct a more robust mechanism. Upcoming posts will provide several tweaks and fixes that give greater control over this kind of code runner. | apisurfer |
210,907 | Streaming on the Road – Building a Studio Edition | Last week, I had the pleasure of producing the Twitch stream for the DEVintersection conference in... | 0 | 2019-11-25T13:52:47 | https://jeffreyfritz.com/2019/11/streaming-on-the-road-building-a-studio-edition/ | streaming, hardware, setup | ---
title: Streaming on the Road – Building a Studio Edition
published: true
date: 2019-11-24 22:36:22 UTC
tags: streaming, hardware, setup
canonical_url: https://jeffreyfritz.com/2019/11/streaming-on-the-road-building-a-studio-edition/
---
Last week, I had the pleasure of producing the Twitch stream for the [DEVintersection conference](https://devintersection.com) in Las Vegas. This is a tremendous event that the Microsoft .NET, Visual Studio, and Azure teams as well as the Google Angular team speak at. I brought my travel streaming rig to the MGM Grand and built a studio with a backdrop, lighting, and some extra large monitors. In this post, I’ll walk you through the preparation of that physical space in a series of photos.
<figcaption>The empty conference room 253 when I arrived at the venue. Let’s start pulling together those long tables.</figcaption>
<figcaption>The table backed up against the curtains will be our on-stage set, the left-table will hold our confidence monitor and camera, and the right table with my bags, tripod, and GFUEL will be our director’s station.</figcaption>
<figcaption>Unpacked and preparing to build the director’s station. From right: power bar, network router, Elgato HD60s capture card, Zoom H6 in case, microphones in soft case, Live Coders bluetooth keyboard, stream decks, Intel Hades Canyon NUC, XLR extension cables, Sony A6000 camera, portable display, bluetooth mouse and keyboard, Microsoft Surface Headphones, Airpods, and GFUEL.</figcaption>
<figcaption>Devices connected and configured. The director has a Lepow portable display connected by HDMI to the Intel NUC with 2 stream decks, a bluetooth keyboard and mouse. The Zoom H6 is used as a portable audio mixer with the microphones plugged in. Camera is mounted on a tripod with an Elgato CamLink connecting it to the Intel NUC</figcaption>
<figcaption>Wiring of the Intel NUC’s 6 USBs:<br>3 streamdecks (1 on-set), Zoom H6 audio capture, <br>Elgato HD60s for on-set video capture from guest’s laptop, <br>Elgato CamLink for video from camera</figcaption>
<figcaption>Backdrop in place</figcaption>
<figcaption>Final view with lighting in place and the down-stage confidence monitor for the hosts.</figcaption>
I also put together a brief tour of the space from before the lighting was installed. This was my first time using a hand-held gimbal, so the editing was a little tricky as I got rid of some of the awkward angles.
{% youtube KGVmxa93wbk %}
Hardware used to build this studio includes (affiliate links):
StreamDeck ► https://amzn.to/2OD3k3w
Zoom H6 audio device ► https://amzn.to/37vDNBT
Lepow Portable Display ► https://amzn.to/2KMZJ1N
Intel Hades Canyon NUC: ► https://amzn.to/2KOTgDz
Sony a6000 Camera ► https://amzn.to/2XIn4a3
Elgato Camlink ► https://amzn.to/2QKJrdt | csharpfritz |
209,010 | doing more faster... | What is the best way to run a program in parallel? Just run two copies of it at the same time.... | 0 | 2019-11-21T03:18:14 | https://dev.to/tonetheman/doing-more-faster-54n8 | ---
title: doing more faster...
published: true
description:
tags:
---
What is the best way to run a program in parallel?
Just run two copies of it at the same time. :)
But that works.
And more often than not it is the easiest and most useful form of doing twice the work for the least cost. If you wrote your program that it takes input from a file or from the command line then running it twice will only cost you the time to write the bash script that runs it that way. | tonetheman | |
209,801 | Seeking Advice: Experiencing Hiring Fatigue | Seeking advice on how to best overcome hiring fatigue. | 0 | 2019-11-22T18:02:46 | https://dev.to/dyland/seeking-advice-experiencing-hiring-fatigue-4089 | discuss, career, productivity | ---
title: Seeking Advice: Experiencing Hiring Fatigue
published: true
description: Seeking advice on how to best overcome hiring fatigue.
tags: discuss,career,productivity
---
Greetings fellow Dev community! This is my first post so please forgive any faux pas regarding subject matter or formatting. I'm hoping to get some advice from folks with more experience in developer world regarding the hiring process and experiencing hiring fatigue.
###Background
I've been a self taught Front End Developer since around the end of 2015. I worked the first year or 2 just learning the basics (HTML, CSS & JS). Once I felt slightly confident I started making my own projects and then managed to pick up some freelance gigs from friends and people in my community. I also managed to get a few Open Source contributions under my belt and build a portfolio site with some projects https://www.dylandavenport.com/
I got my first full-time job as a developer almost 2 years ago at a non-profit. I love the work that I do and the people I work with are fantastic! With that being said those of you who know the non-profit world, the salary is usually lower if not much lower than average. That coupled with the fact that since my company is not very "tech focused" I guess you could say, it leaves very little room for me to be able to use things like Vue, React, SASS, etc. Which means I'm not learning as much as I would like.
I started looking at other positions about 8 months ago and have been getting interviews and have received positive feedback in those interviews. I have also gotten far enough in interviews to receive the coding challenge or technical assessments but that's where my confusion lies.
###The Problem At Hand
Once I get the coding challenges from employers I find that the majority of them are totally unrealistic. For example, one I have currently worked on has a simple form with some buttons and asks for some simple form validation using JavaScript. No sweat. Check if this input is filled in, add the result to the document as innerHTML in this DOM element, then create a button with a click event to remove the item. But then comes the parts that I feel are unrealistic. I can't touch the HTML file AT ALL, can't use for or while loops, etc.
While this in itself is not a problem in the sense that it's "too difficult", I can do it and have done it, I just don't see how this is an adequate way to test how I handle code in the real world. I can't imagine having to work on a project and have these types of restrictions. Which makes me feel like I'm kind of wasting my time working on problems that aren't real world problems.
I've spent countless nights staying up till the crack of dawn getting no sleep and then going into my day job just to complete these challenges and not get the position or even a call back. I'm just exhausted and I feel as though these types of expectations cause people like me to feel burnt out and jaded.
By no means am I complaining or lazy, I'm just not sure if this is a situation where I just haven't found the "right" position for me or if I am lacking in some way or just not seeing the "bigger picture". I'm sure it's a test of my problem solving skills but in situations like this my first thought is "Let me edit the HTML file like I would in the real world. Problem solved..." I want to solve REAL problems. Not manufactured problems with crazy conditions.
###Conclusion
I'm mostly looking for some guidance on how to proceed here. Should I keep doing what I'm doing and keep applying and wait for the perfect position to come up? Should I keep working on these assignments even if I feel the conditions aren't very realistic? I really love being a developer but as I'm sure you all know job hunting and the hiring process in general is somewhat broken and it's exhausting. Thanks for listening to my rant and please feel free to provide any honest feedback. | dyland |
210,172 | Take a Ten Minute Walk | Task description You live in the city of Cartesia where all roads are laid out in a perfe... | 3,404 | 2019-12-02T19:17:15 | https://dev.to/jamesrweb/kata-take-a-ten-minute-walk-14e6 | kata, challenge, codewars, javascript | ## Task description
> You live in the city of Cartesia where all roads are laid out in a perfect grid. You arrived ten minutes too early to an appointment, so you decided to take the opportunity to go for a short walk. The city provides its citizens with a Walk Generating App on their phones -- everytime you press the button it sends you an array of one-letter strings representing directions to walk (eg. ['n', 's', 'w', 'e']). You always walk only a single block in a direction and you know it takes you one minute to traverse one city block, so create a function that will return true if the walk the app gives you will take you exactly ten minutes (you don't want to be early or late!) and will, of course, return you to your starting point. Return false otherwise.
>
> Note: you will always receive a valid array containing a random assortment of direction letters ('n', 's', 'e', or 'w' only). It will never give you an empty array (that's not a walk, that's standing still!).
## Task solution
### Tests
```javascript
describe("walk validator", () => {
it("Throws when invalid input is provided", () => {
expect(() => isValidWalk("w")).toThrow(/InvalidArgumentException/);
expect(() => isValidWalk(["w", 2])).toThrow(/InvalidArgumentException/);
expect(() => isValidWalk(["w", "test"])).toThrow(/InvalidArgumentException/);
expect(() => isValidWalk(["w"], ["2", 2])).toThrow(/InvalidArgumentException/);
expect(() => isValidWalk(["w"], 1)).toThrow(/InvalidArgumentException/);
expect(() => isValidWalk(["w"], [1, 1, 1])).toThrow(/InvalidArgumentException/);
expect(() => isValidWalk(["w"], [0, 0], "ten")).toThrow(/InvalidArgumentException/);
});
it("Should correctly identify walkable directions", () => {
expect(isValidWalk(["n", "s", "n", "s", "n", "s", "n", "s", "n", "s"])).toBe(true);
expect(isValidWalk(["w", "e", "w"])).toBe(false);
expect(isValidWalk(["w"])).toBe(false);
expect(isValidWalk(["w", "e"], [1, 1], 2)).toBe(true);
});
});
```
Using Jest for our tests, we begin by defining our failing input cases as usual. In our case these are:
1. Are the directions not an array?
2. Are the instructions all strings?
3. Are the instructions expected strings ("n", "s", "e" or "w")?
4. Are the starting points (if defined) integers?
5. Are the starting points matching the expected `[x1, y1]` shape?
6. Are we able to use this function for any amount of time depending on user case?
Then we test the happy paths to be sure that our function can correctly identify valid pathways which bring us back to our starting point after the final direction is executed.
### Implementation
```javascript
function isValidWalk(walk, startingPosition = [0, 0], timeAvailableMinutes = 10) {
if (!Array.isArray(walk)) {
throw new Error(`InvalidArgumentException: Parameter 1 must be an array. Received: ${typeof walk}`);
} else if (!walk.every(item => typeof item === "string")) {
throw new Error("InvalidArgumentException: Parameter 1 must be an array of strings, atleast one element within the array provided is not a string");
} else if(!walk.every(item => ["n", "s", "e", "w"].includes(item))) {
throw new Error("InvalidArgumentException: Parameter 1 must be an array of strings. Each string must correspond to a compass direction, valid directions are: 'n', 's', 'e' and 'w'");
} else if (!Array.isArray(startingPosition)) {
throw new Error(`InvalidArgumentException: Parameter 2 must be an array. Received: ${typeof startingPosition}`);
} else if(startingPosition.length !== 2) {
throw new Error(`InvalidArgumentException: Parameter 2 must have 2 items representing the starting position of the user. Received: ${startingPosition} with a length of ${startingPosition.length}`);
} else if(!startingPosition.every(item => Number.isInteger(item))) {
throw new Error(`InvalidArgumentException: Parameter 2 must be an array of numbers and have a length of 2 items. This is to match the schema requirement of [x1: number, y1: number]. Received: ${startingPosition}`);
} else if(!Number.isInteger(timeAvailableMinutes)) {
throw new Error(`InvalidArgumentException: Parameter 3 must be an integer. Received: ${typeof timeAvailableMinutes}`);
}
const [x1, y1] = startingPosition;
const [x2, y2] = walk.reduce(([x, y], direction) => {
switch (direction) {
case 'n': return [x, y + 1];
case 's': return [x, y - 1];
case 'e': return [x + 1, y];
case 'w': return [x - 1, y];
}
}, [x1, y1]);
return walk.length === timeAvailableMinutes && x1 === x2 && y1 === y2;
}
```
We run our input checks and then begin to reason our coordinates. Firstly we strip the starting `x` and `y` positions of the user and name these `x1` and `y1`.
Next, we take the `walk` array of directions and reduce it to an array of `x2` and `y2` positions. To achieve this, the initial "accumulator" of the reducer is set to `x1` and `y1` and on each iteration of the reducer, based on the current direction, we either increment or decrement `x` or `y`. Upon the reducers final iteration, these values will now be our `x2` and `y2` coordinates.
Finally we check if the `walk` had the same amount of items as the minutes it takes per direction (as outlined in the task description) and from there we check if the start and end `x` and `y` values match. If all of these criteria match, we know the walk is valid since the walk time matches the available time and the end positions match the starting ones.
## Conclusions
This challenge was a good use case for reducers and the only change I would probably make to the implementation is to return early if the walk and time available don't match, like so:
```javascript
// code removed for reading ease
if(walk.length !== timeAvailableMinutes) return false;
const [x1, y1] = startingPosition;
const [x2, y2] = walk.reduce(([x, y], direction) => {
switch (direction) {
case 'n': return [x, y + 1];
case 's': return [x, y - 1];
case 'e': return [x + 1, y];
case 'w': return [x - 1, y];
}
}, [x1, y1]);
return x1 === x2 && y1 === y2;
// code removed for reading ease
``` | jamesrweb |
210,745 | 📷 More on Screenshots with JavaScript in Node.js (creating PDFs) | In the previous example we created a png screenshot. But we can also generate PDFs in various formats... | 3,417 | 2019-11-25T07:40:01 | https://dev.to/benjaminmock/more-on-screenshots-with-javascript-in-node-js-creating-pdfs-2b33 | javascript, webdev, puppeteer |
In the [previous example](https://dev.to/benjaminmock/how-to-take-a-screenshot-of-a-page-with-javascript-1e7c) we created a png screenshot. But we can also generate PDFs in various formats!
```js
// instead of calling await page.screenshot we now call
await page.pdf({
path: 'codesnacks.pdf',
format: 'A4'
})
```
For completeness, here's the full code to generate a PDF of a webpage in the A4 format:
```js
// npm i puppeteer
const puppeteer = require('puppeteer');
// we're using async/await - so we need an async function, that we can run
const run = async () => {
// open the browser and prepare a page
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://codesnacks.net/');
await page.pdf({
path: 'codesnacks.pdf',
format: 'A4',
});
// close the browser
await browser.close();
};
// run the async function
run();
```
| benjaminmock |
210,766 | How to get a part-time job as python/data developer | where to get a part-time remote job in HongKong as a python developer, Django, redis, mysql, Crypto-c... | 0 | 2019-11-25T08:56:09 | https://dev.to/xiandong79/how-to-get-a-part-time-job-as-python-data-developer-2n9 | career, remote | where to get a part-time remote job in HongKong as a python developer, Django, redis, mysql, Crypto-currency trading quant developer, data engineer, data analyst | xiandong79 |
210,971 | Life At A New Job: Contributing | One of the most important things about starting a new job is being aware of the expectations of your... | 0 | 2019-11-26T03:11:07 | https://dev.to/sarahscode/life-at-a-new-job-contributing-436e | career | ---
title: Life At A New Job: Contributing
published: true
date: 2019-11-25 00:00:00 UTC
tags: career
canonical_url:
---
One of the most important things about starting a new job is being aware of the expectations of your early days in the job. During my first week at work, I had a 1:1 meeting with my manager, and we discussed the expectations and goals for my first 30, 60, and 90 days. One of the goals of my first 30 days was to have my first PR merged by the end of my second week. At our next sprint planning (which is where we plan out our work for the next two weeks), I was assigned two "tickets", and by the end of my second week, I had completed one of the tickets and had my pull request (PR) merged into our repository.
As exciting as it was to have my first PR merged (and it was very exciting), I'm actually a little bit more excited about my second PR. My second PR, which was completed and merged in my third week, started off as something that I thought would involve deleting a few lines of code, but turned into an opportunity to change how we approached a particular component in our code in a way that I feel is more maintainable for the future.
Here is that story:
At my new company (as at many other companies, I'm sure), when we introduce new features, we don't immediately remove old functionality from the app - we add the new functionality, and use a feature flag in the code to indicate that it was turned on. As part of the feature development lifecycle, we eventually deprecate the old code and remove it and the feature flag from the codebase (which we call "sunsetting"). My second ticket involved sunsetting two feature flags, both of which had been used to change the functionality of buttons on a particular page of the app.
At first, it seemed like a pretty easy task. I was able to easily remove most of the references to the feature flag and the old code, but there was one area where the code got a little bit complicated. I was able to remove what I thought were all of the references to old code, but I was left with one piece of code that seemed like it did nothing. I checked with one of the more senior engineers, and he agreed that the code seemed unnecessary and could be deleted.
And so, with all the references to the old code gone and the new functionality working, I committed my code, put in a PR, and asked one of my teammates (the senior engineer who I had asked about deleting the unnecessary code) to review it. My teammate reviewed the PR and mentioned that the functionality of a certain component on the page was not working as expected, but offered to pair with me to figure out exactly what was going wrong.
My teammate suggested a method to fix the functionality that had broken with my PR, and while it fixed the broken functionality, it also broke the functionality that had been introduced with the feature flags I was sunsetting. After a little further exploration, we realized that the "unnecessary" code that I had deleted had actually been part of what made these buttons function properly. As it was currently designed, the code that generated these buttons with the new functionality could generate any one of four buttons. Only two of the buttons had the new functionality, and the code that I had thought was not necessary differentiated between the two buttons that had the new functionality and the two that did not. In deleting that code, I had deleted that separation and was trying to generate the same functionality for all four buttons, which did not work with how the rest of the app was set up.
In looking at the original code, I hadn't understand what was going on, which is why I deleted code that was actually necessary. To me, this was a sign that the original code was just not well written. Working with my teammate, we realized that this was an opportunity to make the code more understandable, and I tried to figure out the best way to re-enable the functionality I had unknowingly disabled in a way that future readers of the code would know exactly what my code was doing.
After trying a few things, I ultimately decided to write four separate blocks of code to generate the four separate buttons. It wasn't exactly DRY, but this way each button was handled independently and we could make changes to one button's code or functionality without affecting the other three buttons. I felt that the extra code was a fair exchange for the ability to easily see how each button is generated, and that while it added lines of code, it also added understandability and maintainability, which feels like a better choice in the long run.
Once I had added in this new code, I resubmitted my pull request, and (after one additional small change) it was approved and merged into the codebase. And so I had added my first lines of code to our codebase (my previous work had just been deleting).
As exciting as my first contribution was, it was my second contribution that I felt really improved me as a developer. We write code in a way that makes sense to us - and we don't always think about how another person may read that code in the future. With this work, I was reminded to always make sure your code makes sense, and that sometimes it's work a little extra work (or extra code) to ensure that things are sustainable for the future. | sarahscode |
210,995 | Build a Serverless Status Page with Azure Functions, SignalR, and Static HTML | 25 Days of Serverless Challenge 8 - Santa and his team need a status page solution to communicate issues to a broader audience. | 0 | 2019-12-09T15:21:46 | https://dev.to/azure/build-a-serverless-status-page-with-azure-functions-signalr-and-static-html-5106 | azure, serverless, webdev, node | ---
title: Build a Serverless Status Page with Azure Functions, SignalR, and Static HTML
published: true
description: 25 Days of Serverless Challenge 8 - Santa and his team need a status page solution to communicate issues to a broader audience.
cover_image: https://jhandcdn.blob.core.windows.net/blob/osman-rana-u5m61CHska4-unsplash.jpg
tags: #azure, #serverless, #webdev, #node
---
This article is part of [#25DaysOfServerless](http://aka.ms/25daysofserverless). New challenges will be published every day from Microsoft Cloud Advocates throughout the month of December. Find out more about how Microsoft Azure enables your [Serverless functions](https://docs.microsoft.com/azure/azure-functions/?WT.mc_id=25days_devto-blog-cxa).
---
### Day 8 of the #25DaysOfServerless Challenge
An evil grinch has stolen all the servers in the world and we have to visit many countries and situations to set things right!
...
Today we find ourselves visiting the North Pole at the head of global gift giving operations, Santa's workshop!
Tech doesn't always work perfect. Incidents and outages happen - even for Santa Claus. If something is wrong, we need a method to communicate the current status of service disruptions to a global audience. A "Status Page" solution.
Santa and his team need a way to report the status of service disruptions to everyone involved in a successful Christmas morning. A simplified version behind what you'll see at [status.azure.com](https://status.azure.com) where the status of many services are broadcast.
For simplicity, we want to be able to inform others by setting (and broadcasting) the current "Status" of a system (Reindeer Guidance & Delivery) to any one of the following information updates:
* **We have a problem** (Service Disruption / Offline)
* **Our problem is resolved** (Service Restored / Online)
* **Still investigating** (Standby for more updates)
We'll also display a log of all updates as they came through. That way people can easily catch up on what has transpired.

>Image credit: [Caro Ramsey](https://twitter.com/caroramsey)
---
## Solution
We can solve this with an [Azure Function](https://azure.microsoft.com/services/functions/?WT.mc_id=25daysofserverless-devto-cxa), combined with a [static HTML website](https://azure.microsoft.com/services/storage/?WT.mc_id=25daysofserverless-devto-cxa), an outgoing webhook, and [SignalR](https://azure.microsoft.com/services/signalr-service/?WT.mc_id=25daysofserverless-github-cxa) to automatically refresh/reload the browser.
### Tech Used
The brains behind this solution is an [Azure Function (running Node.js)](https://github.com/jasonhand/teams-incident-status-page-bot/tree/master/src/functions-javascript) that is triggered via [outgoing webhook (from Microsoft Teams)](https://docs.microsoft.com/en-us/microsoftteams/platform/webhooks-and-connectors/how-to/add-outgoing-webhook/?WT.mc_id=25daysofserverless-devto-cxa).
The function modifies an index.html file stored in a "web server" served from a serverless SMB file share in Azure Storage.
Users can `open`, `update`, and `close` "status updates" by invoking them from within a chat channel.
In addition to the website files, an [Azure Table](https://docs.microsoft.com/en-us/azure/cosmos-db/table-storage-overview/?WT.mc_id=25daysofserverless-devto-cxa) will be used for storing the history of each status update.
[SignalR](https://docs.microsoft.com/azure/azure-signalr/signalr-overview/?WT.mc_id=25daysofserverless-devto-cxa) manages refreshing the client so that changes made to the HTML are immediately visible without any end user interaction.
Application Insights is used to provide observability on the operation, behavior, and usage of the solution and is "best practice" for building highly available and reliable system... which we expect from any Status Page solution.


>Image credit: [Caro Ramsey](https://twitter.com/caroramsey)
([Click here to see it in action](https://jhandcdn.blob.core.windows.net/blob/UpdateFromTeams.gif))
### Prerequisites
You will need an account with the following services:
- [Microsoft Azure](https://azure.microsoft.com/?WT.mc_id=25daysofserverless-devto-cxa)
- [Microsoft Teams](https://docs.microsoft.com/en-us/MicrosoftTeams/teams-overview/?WT.mc_id=25daysofserverless-devto-cxa)
---
### Deployment Instructions
**1.** [Check out my solution on Github](https://github.com/jasonhand/teams-incident-status-page-bot), including a "Deploy to Azure" button so you can immediately dive in with a working deployment. All you need is a free Azure account.
The blue button deploys all resources needed for this solution in to the Resource Group and Azure region of your choice. The name you choose also determines the URL used to view the Status Page as well as the incoming URL used to trigger updates. Once the deployment is complete, continue with step 2.
---
**2.** In the Azure portal, open the Storage account and add a table named `statuses`. You do not need to set any properties or add records.

---
**3.** Navigate to the function app, and open the `teams-webhook` function. Click "Get Function URL" and copy the URL.
**4.**Open the URL of the Function in a new tab. This is "Status Page" that will change automatically when updated. It is NOT the same as the "Get Function URL" used in the next step.

---
**5.** Open Microsoft Teams and navigate to the "Apps" page of the team in which you want to create the bot. Click "Create outgoing webhook".
- Use `StatusPage` as the bot name (this is hardcoded, for now).
- Paste in the function URL, and enter a description and press the create button.
> You will be prompted with a secret code for validating webhook calls from Teams. We currently do not use this. Close the dialog box.
[](https://jhandcdn.blob.core.windows.net/blob/Webhook.gif)
**6.** In Microsoft Teams, update the status page by typing `@StatusPage` to summon the bot followed by `open We are experiencing a problem. Standby for more information`
Available commands are:
```bot
@StatusPage open [message]
@StatusPage update [message]
@StatusPage close [message]
@StatusPage help`
```
---
This solution is based on the on-stage demonstrations built for Microsoft Ignite The Tour.
To learn more about the full demonstration, view the repo for "[OPS20 - Responding To Incidents](https://myignite.techcommunity.microsoft.com/sessions/82997/?WT.mc_id=25daysofserverless-devto-cxa)". Huge Thanks to [Anthony Chu](https://github.com/anthonychu) in bringing this to life.

>Image credit: [Caro Ramsey](https://twitter.com/caroramsey)
What other ways could you solve this? Add your solutions in the comments below!
Want to submit your own solution to this challenge?
Once you have a solution [submit it as an issue](https://github.com/microsoft/25-days-of-serverless/issues/new?assignees=&labels=challenge-submission&template=challenge-solution-submission.md&title=%5BCHALLENGE+SUBMISSION%5D+).
If your solution doesn't involve code or repository to review, please record a short video and submit it as a link in the issue description. Make sure to tell us which challenge the solution is for.
We're excited to see what you build! Do you have comments or questions? Add them to the comments area below.
Watch for surprises all during December as we celebrate 25 Days of Serverless. Stay tuned here on dev.to as we feature challenges and solutions! [Sign up for a free account on Azure](https://azure.microsoft.com/free/?WT.mc_id=25days_devto-blog-cxa) to get ready for the challenges!
| jasonhand |
210,999 | Open / Closed Principle | The open closed principle is the O in the SOLID principles. It was created by Bertrand Meyer and... | 0 | 2019-11-26T15:19:36 | https://dev.to/naomidennis/open-closed-principle-nbb | solid, java, ocp | ---
title: Open / Closed Principle
published: true
description:
tags: solid, Java, ocp
---
The open closed principle is the **O** in the SOLID principles. It was created by Bertrand Meyer and states:
> Software entities should be open for extension, but closed for modification
Let's dive deeper with an example.
We've been tasked with creating a platform that merges all video streaming sites. The platform will be able to add a platform to its list of platforms, search for a video on all platforms and play a video from the search results. The class can look like so:
{% gist https://gist.github.com/Naomi-Dennis/4be0394ca15f33f4a37c881af0761a2c %}
`CentralVideoStreamingPlatform` covers most mainstream video streaming platforms. However, if we were to add another platform, say `DisneyPlus`, another `#add()` would be created. This directly violates the open for extension aspect of OCP.`CentralVideoStreamingPlatform` must be open to accept different details without needing to change code that's already written. By overloading `#add()` _again_, we are needlessly changing `CentralVideoStreamingPlatform`. Who's to say how many `#add()` `CentralVideoStreamingPlatform` would have as more streaming platforms are added?
To ensure `CentralVideoStreamingPlatform`'s extensibility, we can refactor the video streaming classes to implement a `VideoStreamingPlatform` interface and use one `#add()`.
{% gist https://gist.github.com/Naomi-Dennis/aa110c6258887f0209bf9c7ebe250be5 %}
### In Conclusion
The open closed principle is a great principle to keep in mind when writing classes.
| naomidennis |
211,055 | Docker and Docker Compose for PHP Development with GitHub and Digital Ocean Deployment | I have always missed some easy to follow tutorials on Docker, so I have decided to create it myself.... | 0 | 2019-11-25T17:43:59 | https://dev.to/zavrelj/docker-and-docker-compose-for-php-development-with-github-and-digital-ocean-deployment-52k9 | docker, php, github, digitalocean | I have always missed some easy to follow tutorials on Docker, so I have decided to create it myself. I hope it will help you understand why Docker is such a popular tool and why more and more developers are choosing Docker over Vagrant and other solutions.
When it comes to PHP development, you have basically three options on how to approach the problem of preparing a development environment for your project. The oldest way is to install individual services on your development machine manually. With different versions of these services on staging and production environments, you can get into dependencies problems rather quickly. Also, it’s quite a challenge to manage different projects with different requirements on a single computer.

You can solve this problem with virtual machines. Download VirtualBox and set up your environment individually for every project so they won’t interfere because they will be totally separated. When you need to deploy your work along with your environment to the remote server, you will just provision the whole virtual machine. Vagrant can help you with this process because it allows you to deploy your project directly. For example to a DigitalOcean Droplet. But the problem is that you are working with the full-blown operating systems even though they are virtualized.

What if there is another way? What if you don’t need full operating system encapsulated in virtual machines to keep your projects separated and yet you would be able to have the same development environment everywhere, on your local machine, on the testing server and even on the production server. Welcome to the world of Docker!

To better understand the difference between Docker and VM-based solution, take a look at the image below:

Docker can help you as a developer in three areas by:
1. eliminating the “it works on my machine” problem once and for all because it will package dependencies with your apps in the container for portability and predictability during development, testing, and deployment,
2. allowing you to deploy both microservices and traditional apps anywhere without costly rewrites by isolating apps in containers; this will eliminate conflicts and enhance security,
3. streamlining collaboration with system operators and getting updates into production faster.
Interested? Great! Let’s give it a try.
### I will make you a full-stack web developer in just 12 hours!
This tutorial is a part of a much larger and far more detailed online course available for free on <a href="https://skl.sh/3eP78uy" target="_blank">Skillshare</a>. If you're new to Skillshare, you'll get premium access not only to this course for free but to **all of my other courses as well and for a good measure, to over 22.000 courses** currently hosted on Skillshare.
You won't be charged anything for your first 2 months and you can cancel your membership whenever you want within that period. Consider it a 2 months worth of premium education for free. It's like Netflix, only for life-long learners :-)
<a href="https://skl.sh/3eP78uy" target="_blank"></a>
### Docker Installation
This one is easy, all you need is download a package for your operating system. In my case, I downloaded Docker for Mac. You will install Docker as any other application. Once you see the Docker happily humming in your top bar, you can start building awesomeness with me!

I will use Atom (www.atom.io) editor along with the terminal-plus package. If you want to follow my setup, be aware that you need to tweak the terminal-plus a bit to work. There is some minor issue, but it can be easily fixed like this:
1. Go to **~/.atom/packages/terminal-plus/package.json** and locate the dependencies section.
2. Remove the commit id (#……) at the end of the pty.js entry:
“pty.js”: “git+https://github.com/jeremyramin/pty.js.git**#28f2667**”
becomes
“pty.js”: “git+https://github.com/jeremyramin/pty.js.git”
3. Go to terminal and run these commands:
```
cd ~/.atom/packages/terminal-plus/
npm install
apm rebuild
```
Restart the Atom editor and terminal-plus should work now! Of course, you can choose your own text editor and terminal client. Everything will work the same.
### Create your first Docker image
The easiest way to create a Docker image is with the **Dockerfile** which is something like a recipe for building an **image**.
*NOTE: Image is something like a blueprint. You can use one blueprint to create many objects like cars or houses. Similarly, you can use one image to create many containers.*
Let’s take a look at how easy it is to create a development environment based on PHP 5 and Apache webserver.
Create a new folder on your Desktop and name it **docker-apache-php5**.

Inside **docker-apache-php5** folder, create new folder called **src** where we will add a new file called *phpinfo.php*
Create this file and put this code inside:
```php
<?php phpinfo(); ?>
```
This is a very simple php code that will call just one simple function, but this function will output a nice table with a detailed configuration of our development environment we are just creating.
Create another file, this time directly inside **docker-apache-php5** folder and call it **Dockerfile** (just like this, no extension). Inside this file, we will write some directives for Docker.
Your directory structure should look like this now:

We want to build our development environment on PHP 5 and Apache webserver. The best way is to start with the image already available. In the case of PHP, there is probably no better source than the official image.
Docker images are available on Docker Hub. Sign up for a free account and once you are in, you can search for images.
Go ahead and type **php** in the search box.

Select **php official** image and let’s take a look at the details:

We want to use **5.6-apache**, version which is PHP 5.6 including the Apache webserver. This is convenient because we don’t need to install Apache separately.

Go ahead and click on the link [(*5.6/apache/Dockerfile*)](https://github.com/docker-library/php/blob/e573f8f7fda5d7378bae9c6a936a298b850c4076/5.6/apache/Dockerfile) which will get you to GitHub Repository of this image. Just take a look at the Dockerfile.

Don’t panic, our Dockerfile will have just a couple of lines because we will take advantage of the hard work of the PHP team and use their image. This doesn’t mean that you can’t just sit down and write your own image based on Debian Linux, but why would you want to waste your time, when you can just use what’s already done?
In order to use this image, go to your Dockerfile and write this line of code:
```
FROM php:5.6-apache
```
This says that our own image will be based on the **5.6-apache** image created and maintained by the PHP team. Sweet.
Type this line below:
```
COPY src/ /var/www/html/
```
Make sure there is a space between **src/** and **/var**. It’s very important! Now, this line says that we want the content of the **src** folder we have created a few minutes ago, to be copied to **/var/www/html/** but you might wonder why and where it is located.
This is the folder structure that will be created while our image will be built or more specifically while we will create a container from that image. I showed you the Dockerfile for **5.6-apache** image on purpose. Remember the line **FROM debian:jessie**?

Our image will be based on a **5.6-apache** image, but even this image is based on another image. It this case, it is **debian:jessie** image. So basically, the PHP team grabbed **debian:jessie** image and added their own modifications with their Dockerfile, like we are adding our own modifications to **5.6-apache** image with our Dockerfile.
The point is that we are all adding layers to the basic **debian:jessie** image which is a Linux distribution and as you probably know, the Linux file system starts with root (**/**) followed by specific subfolders. Mac OS is based on UNIX and it works similarly. Your Desktop is actually located in **/Users/your-name/Desktop**. In my case, it is **/Users/zavrelj/Desktop**.
Now, for web content, Apache web server uses a directory called **html** which is stored inside **www** directory inside **var** directory. That’s how it is and because we know it, we can say that once our image with Apache web server is initialized or spun up to create a container, we can safely copy the content of our **src** folder to **/var/www/html** folder on Debian because it will be there since the Apache web server will create it during its own installation.
Give yourself a pause and let this all sink. It’s a really important concept.
Ok, the last line we will add to our Dockerfile looks like this:
```
EXPOSE 80
```
It says that we want the port 80 to be available for incoming requests.
Your Dockerfile should look like this now:

Once you have this, save the changes, open your favorite terminal app. In the terminal, set your **docker-apache-php5** folder as a working directory. I expect you to know how to work with the command line.
If you don’t just open terminal and type
```
pwd
```
It will show you your current working directory. If have you followed me step by step so far and you are on Mac computer, this command should get you to the right directory:
```
cd ~/Desktop/docker-apache-php5
```
Copy this code and paste it into the terminal, then hit Enter. To make sure, you are in the right directory, type **ls** in the terminal and hit Enter. If you see something like this, you’re good to go:

It’s important to be in the right directory, where the Dockerfile is saved. We will now build our image from the Dockerfile.
Type this line in terminal:
```
docker build -t php-image .
```
This command will build our image, **\-t** option lets you give the image a custom name, in our case, it will be **php-image** because I want you from the very beginning to be able to make a distinction between images and containers. Finally, the dot at the end of this command means that the Dockerfile is located in the current directory. That’s why we wanted to get there!
If everything went right, you should see something similar in your terminal:

Docker has just created an image and assigned it an ID, in my case **576a14c36bc9**. To see the list of all your images, just type this command in your terminal:
```
docker image ls
```
As you can see, there are two images, and they are sorted by the date of creation. The first one is our image we have just built, the second one is the image Docker pulled from Docker Hub. As you can see, its name is **php** and the tag is **5.6-apache**, together it makes **php:5.6-apache** which is exactly what we wrote in the first line of our Dockerfile! Docker needed to pull this image first in order to create our own image. That’s why we have two images even though we have created only one.

Now we need to create a container from our **php-image**. Our image is just like a snapshot. To be able to actually work with your services like PHP, you need to spin up the container from that image.
Type this in your terminal:
```
docker run -p 80:80 -d --name php-container php-image
```
This will create a container from our **php-image**.
**\-p 80:80** is port mapping, remember how we exposed 80 in the Dockerfile? Well, now we need to tell the container to use the exposed port 80 and deliver its content to the port 80 of our localhost,
**\-d** stands for a detached mode which will bring the process to the background so you can still use the same terminal window,
**\--name** allows us to give our container name of choice, otherwise, Docker would pick one for us randomly.
And finally, at the end of this command is the name of the image from which we want to create our container.
Remember that the name must be put only after all options! To make sure that your new container is up and running, type this command in terminal:
```
docker ps
```
You should see this:

You can see the container’s name, the image it was created from, ports, ID and status.
Since our container is waiting for some work, let’s make it do its job! Open your web browser and type **localhost/phpinfo.php**
You should get this:

It means that everything works and we are running PHP 5.6.30 on our local webserver! Great work!
### Adding database
Unfortunately, this container won’t work with a database because all we have is PHP and Apache webserver. To add a database server to our development environment, like MySQL for example, we would have to create a container for a database and connect it to our **php-container**, thus those two containers or rather services inside those containers could talk to each other.
Let’s take a look at how this can be done. We will start again in Docker Hub and search for mysql:

And sure enough, there is an official repository maintained by MySQL team. Let’s create our own **mysql-container** by running this code:
```
docker run --name mysql-container -e MYSQL_ROOT_PASSWORD=secret -d mysql:latest
```
When you run this code, Docker will first look for **mysql:latest** image on your computer. If it’s not available, it will pull it from Docker Hub first and then spin up the container from it. This is very important because Docker is trying to save your disk space. If **mysql:latest** image is already on your computer, Docker will use it instead of downloading yet another copy.
Remember this, we will come back to this concept later.

Type **docker ps** again. You should now see two containers and both are running.

This demonstrates, that you can immediately spin up a container from an already existing image. Only if you want to create your own image, you need to actually build it first and run it later to spin up a container from it.
Let’s create some mysql code to see if mysql is working. Since we run PHP 5.6, we can use **mysql\_connect** function. Even though it’s deprecated in PHP 5 and completely removed from PHP 7, for our testing purposes, it will be just fine.
In **src** directory, create a new file named **mysql.php** and place this content in it:
```php
<?php
$database = "users";
$user = "root";
$password = "secret";
$host = "mysql";
$db = mysql_connect("$host","$user","$password");
if (!$db) {
echo "Cannot connect to the database server";
}elseif ($db && !(mysql_select_db($SQL_DBASE, $db))) {
echo "Sucessfully connected to the database server! Database Users selected!";
}
?>
```
This is a very simple php code. It tries to connect to the database server with the credentials we provided. If the connection cannot be established, it will display an error. If the connection is successful and the database **users** exists, it will display a success message.
Now, try to go to **localhost/mysql.php** in your web browser. You should get this message:

Our **mysql.php** file can not be found, even though it is in the same directory as **phpinfo.php** file and this one can be found just fine.
The problem is that even though we added a new file and thus changed the content of our project, we are still running the old **php-container** based on the original **php-image** which has no clue about the changes we have just made.
To fix this, we need to rebuild our **php-image** and spin up a new container from this updated image. If you think now that this is a lot of hassle, it is, but just for now. You will truly appreciate a feature called **volumes** I will introduce later, once you go with me through this hell.
Stop the **php-container** we have created from **php-image** by running this command:
```
docker stop php-container
```
To list all containers, even those that are not running, use **docker ps -a** command. You can see that **php-container** has exited:

Once the container is stopped, we can remove it with this command:
```
docker rm php-container
```
You can remove the container even while it is running, in that case, you need to add **\-f** option to the end of the command above. Once the **php-container** is removed, you can remove the **php-image** as well. If you tried to remove **php-image** while the **php-container** still existed, Docker would protest.
```
docker rmi php-image
```
Ok, now we can rebuild our **php-image** again and the only reason for that is to copy our new **mysql.php** file into **/var/www/html** folder. Remember the instruction from Dockerfile? Here it is again: **COPY src/ /var/www/html/**
This is why we did all of this, to get our new **mysql.php** copied from **src** folder to **/var/www/html** folder. There is another, way better solution, though, and we will get to it soon. Let’s build our image again:
```
docker build -t php-image .
```
and spin up the updated container from it:
```
docker run -p 80:80 -d --name php-container php-image
```
Now, navigate to **localhost/mysql.php** from your web browser. The file apparently exists, but we have another problem:

PHP image is very lightweight, it doesn’t usually include PHP extensions and mysql is one of those missing. That means that PHP doesn’t know about any function called **mysql\_connect()**. To fix this, we need to add **mysql** extension to our **php-image** first. But don’t be scared, we won’t undergo the same painful process again.
You can directly rebuild the image and then run the container without the painful process of stopping the container, removing the container and rebuilding the image. But I didn’t tell you sooner because I wanted you to try all these commands so you know how to manage containers and images. I hope you will forgive me this pesky move 🙂
Go to your Dockerfile and add this line at the bottom:
```
RUN docker-php-ext-install mysql
```
This will add mysql extension to our PHP image. Now just run this command in terminal:
```
docker build -t php-image .
```
You can see that in Step 4/4, a mysql extension has been added to our image:

If you list all images with **docker image ls**, you can see that **php-image** has been created only a few seconds ago. This means that if you build the image with the same name, the original image is overwritten with the new one.

The same can’t be done with the container, though. If you try and run this command now while the original container is still running…
```
docker run -p 80:80 -d --name php-container php-image
```
…you will get this error message:

You need to stop and remove the currently running **php-container** first. As I mentioned already, you can do this at the same time by using -f option:
```
docker rm php-container -f
```
Now you can spin up the **php-container** again, but this time the updated **php-image** will be used.
```
docker run -p 80:80 -d --name php-container php-image
```
*NOTE: You might wonder if you could just spin up a container with a different name and kept the original one running.
You could do that! The problem is that you would have to map a different port as well because* ***port 80*** *would be still taken by the original* ***php-container****, thus unavailable for new mapping.
This could be of course solved by using for example* ***\-p 81:80*** *instead of* ***\-p 80:80****. Finally, you would have to explicitly type the port to the web browser like this:* ***localhost:81/mysql.php****.*
***Port 80*** *is the default one, that’s why it doesn’t have to be written explicitly, unlike other ports.*
OK, navigate to **localhost/mysql.php** from your web browser again. Even though we get another warning now, we are getting closer because the new error message comes directly from **mysql\_connect()** function. That means that it exists and PHP knows about it. But it seems like there is a problem with a network address:

The reason for this error is the fact that we have two separate containers. One for PHP (**php-container**) and one for MySQL (**mysql-container**). And they don’t know about each other, they don’t talk to each other. Let’s fix this. Stop **php-container** once again and remove it at the same time:
```
docker rm php-container -f
```
Run this code:
```
docker run -p 80:80 -d --name php-container --link mysql-container:mysql php-image
```
You are already familiar with this code except for the link part. This says that we want to link our **php-container** with **mysql-container**. Now, navigate to **localhost/mysql.php** from your web browser, this time you should see this:

Perfect! Now, in order to be able to modify the content of our **src** folder without the need to rebuild images all the time, we will add **\-v** option to our docker run command. So for the last time, stop and remove php-container:
```
docker rm php-container -f
```
Run it again with this new option:
```
docker run -p 80:80 -d -v ~/Desktop/docker-apache-php5/src/:/var/www/html/ --name php-container --link mysql-container:mysql php-image
```
This option should be quite familiar. We used something similar in our Dockerfile to tell our image to copy the content of our **src** folder to the Apache webserver default directory inside the container.
Well, this time, we will create the volume, which means that those two locations will be in sync. Actually, we will mount our folder saved in Desktop to the location inside the container. Once you make any kind of change in **src** folder, it will be automatically available in **/var/www/html** folder in Apache webserver.
Let’s test this! Go to your **mysql.php** file and add “AMAZING!” at the end of the echo like this:
```php
echo “Successfully connected to the database server! Database Users selected! **AMAZING!**“;
```
Save the file and refresh the browser! Isn’t that amazing? 🙂
### Docker Compose

So far, we did it all manually. We configured and created images, we created containers and link them together. If you work with two or three containers, it is doable, even though we have spent quite some time with this. However, if you need to set up the environment with many more containers, it will become very tedious to go through all those steps manually every time.
Luckily, there is a better way. Docker Compose is a tool for defining and running multi-container Docker applications. It allows you to create a YAML configuration file where you will configure your application’s services, and define all the steps necessary to build images, spin up containers and link them together. Finally, once all this is done, you will just set it all in motion with a single command.
Let’s take a look at how this works. This time, we will create the LEMP stack which will consist of Linux, PHP 7, Ngnix, and MySQL. It is generally recommended to have one process, or microservice per container, so we will separate things here. We will create six containers and orchestrate them with Docker Compose.
As we already did in the previous section, we will again use official images and extend them with our Dockerfiles. First, let’s delete all containers and images, so we can start with a clean slate.
To list all containers:
```
docker ps -a
```
To delete containers:
```
docker rm php-container -f
docker rm mysql-container -f
```
To list all images:
```
docker image ls
```
To delete images:
```
docker rmi php-image:latest -f
docker rmi php:5.6-apache -f
docker rmi mysql:latest -f
```
**\-f** option will force deletion even if the container is running or the image is in use.
If by any chance you won’t be able to delete container or image by its name, use its ID instead. This is actually the only viable alternative if you happen to have an image with no name: <none>

List all containers with:
```
docker ps -a
```
and all images with:
```
docker image ls
```
All clear? Great! Let’s begin! Go to your Desktop and create a new folder called **docker-ngnix-php7**.
### Nginx
Let’s start with a web server. Instead of Apache, we will use Nginx this time. First, we will check if there is any official image on Docker Hub. And sure enough, here it is:

We will choose the tag **latest**, so I hope you remember, that the name of the image and the tag go together like this: **nginx:latest**
Now, create a new file in your **docker-nginx-php7** directory and save it as **docker-compose.yml**
Inside, write this:
```
nginx:
image: nginx:latest
container_name: nginx-container
ports:
- 80:80
```
This should be somewhat familiar. Remember when we ran mysql image? We used this command in the terminal: **docker run -p 80:80 -d --name php-container php-image**.
Now, instead of running this command, we will take the options and save them in a configuration file. Then, we will let Docker Compose run commands for us by following the instructions in this file. Save the file. This is what it should look like:

Go to the **docker-nginx-php7** directory in your terminal and run this command:
```
docker-compose up -d
```
**\-d** option still means detached, nothing new here.
Docker Compose will pull Nginx image from Docker Hub, create a container and give it a name we specified. Then, it will start the container for us. Docker Compose will do all of these steps automatically.

I gave the container a specific name just for educational purposes here, so we can easily identify it. But it’s not a good practice in general because container names must be unique. If you specify a custom name, you won’t be able to scale that service beyond one container, so it’s probably better to let Docker assign automatically generated names instead. But, in our case, I want you to understand how things are working.
Use the familiar **docker ps** command to see the list of running containers. Write down the IP address assigned to **ngnix-container** and navigate to this address with your web browser. You don’t have to write the port number since 80 is a default value.

You should see your Nginx web server running:

That was easy, right?
### PHP
Let’s say that we want to add the PHP to the mix and we want it to be automatically downloaded, configured and started. We also want to modify our Nginx web server a bit. You know the drill. If you want to modify the official image and add your own changes, you need to use Dockerfile as we already did in the previous section.
Let’s do this again. First, we will create a new directory inside our **docker-ngnix-php7** folder and name it **nginx**. In this directory, we will save a new **Dockerfile**. Next, we will create a new **index.php** file which will be saved in **www/html** directory inside **docker-ngnix-php7** folder with this content:
```html
<!DOCTYPE html>
<head>
<title>Hello World!</title>
</head>
<body>
<h1>Hello World!</h1>
<p><?php echo 'We are running PHP, version: ' . phpversion(); ?></p>
</body>
```
This simple page will help us test if PHP is running.
*NOTE: If you use Atom editor, you can create* ***new*** *file and the whole new directory structure at the same time! Just click with the right mouse button on the name of* ***docker-nginx-php7*** *folder in left pane in Atom, choose* ***New File*** *and instead of typing just the name of the file, type the whole path* ***www/html/index.php****. Atom will create the file for you and both directories as well!*

Your folder structure should look like this now:

To configure our Nginx web server, we will use **default.conf**, so create this file and save it in **nginx** folder. Now add this content inside **default.conf** and save it:
```
server {
listen 80 default_server;
root /var/www/html;
index index.html index.php;
charset utf-8;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location = /favicon.ico { access_log off; log_not_found off; }
location = /robots.txt { access_log off; log_not_found off; }
access_log off;
error_log /var/log/nginx/error.log error;
sendfile off;
client_max_body_size 100m;
location ~ .php$ {
fastcgi_split_path_info ^(.+.php)(/.+)$;
fastcgi_pass php:9000;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_intercept_errors off;
fastcgi_buffer_size 16k;
fastcgi_buffers 4 16k;
}
location ~ /.ht {
deny all;
}
}
```
Now back to Dockerfile for Nginx. Write these two lines in it and save the changes:
```
FROM nginx:latest
COPY ./default.conf /etc/nginx/conf.d/default.conf
```
This means that we will start with the default nginx image (**nginx:latest**), but then, we will use our own configuration we have just saved in **default.conf** and copy it to the location of the original configuration. Now we need to tell Docker to use our own Dockerfile instead of downloading the original image and since Dockerfile is inside the nginx directory, we need to point to that directory. So instead of using **image: nginx:latest**, we will use **build: ./nginx/**
We will also create volumes so the Nginx web server and PHP as well can see the content of our **www/html/** directory we have created earlier, namely our **index.php** file which sits inside. This content will be in sync with the container’s directory **/var/www/html/** and what’s more important, it will be persistent even when we decide to destroy containers.
Next, we will create a new **php-container** using original PHP image, this time PHP 7 FPM version. We need to expose **port 9000** we set in **default.conf** file because the original image doesn’t expose it by default. And finally, we need to link our **nginx-container** to **php-container**. After implementing all those changes, our modified **docker-compose.yml** will look like this:
```
nginx:
build: ./nginx/
container_name: nginx-container
ports:
- 80:80
links:
- php
volumes:
- ./www/html/:/var/www/html/
php:
image: php:7.0-fpm
container_name: php-container
expose:
- 9000
volumes:
- ./www/html/:/var/www/html/
```
*NOTE: You might wonder what is the difference between* ***ports*** *and* ***expose****. Exposed ports are accessible only by the container to which they were exposed, in our case* ***php-container*** *will expose port 9000 only to the linked container which happens to be* ***nginx-container****. Ports defined just as ports are accessible by* ***the host machine****, so in my case, it would be my MacBook or rather the web browser I will use to access those ports.*
Even though our **nginx-container** is still running, we can run this command:
```
docker-compose up -d
```
This time, Docker will pull **php:7.0-fpm** image from Docker Hub and create a new image based on the instructions in our Dockerfile.

As you can see, Docker is warning us that it built the image for nginx service only because it didn’t exist. This means that if this image already existed, Docker wouldn’t build it and it would use the existing image instead. This is very important because even though you will change Dockerfile in the future, Docker will ignore those changes unless you specifically say that you want to rebuild the existing image by using the command **docker-compose build**.
Go ahead and take a look at the list of all images:
```
docker image ls
```
You should see the official nginx image, official php image that has just been pulled and finally, our modified version of the official nginx image which name is **dockernginxphp7\_nginx**. This name is based on the name of the directory where our **docker-compose.yml** file is saved. The last part of its name comes from the name of the image from which our image is derived, in our case **\_nginx**.

**docker ps** will show you two containers running:

*NOTE: If your* ***nginx-container*** *is not running, use* ***docker logs nginx-container*** *command to see what is the problem. Very probably, it will be some kind of typo in* ***default.conf*** *file.*
Even though we didn’t stop the original **nginx-container** based on the official nginx image, it’s not only stopped, it’s completely gone. Instead, we have our new modified nginx-container running, but this one is spun up from **dockernginxphp7\_nginx** image. If you go back to your web browser and refresh the page, you should see this:

Let’s see if the mounted directory works as expected. Go to your **index.php** file and write **AMAZING!** inside the h1 tag like this:

When you refresh the page, **AMAZING!** will appear:

One last thing before we move to the database. As you might have noticed, we have mounted the same directory **www/html/** to both our containers, **nginx-container** and **php-container**. While this is perfectly legit, it is a common practice to have a special data container for this purpose. Data container holds data and all other containers are connected or linked to it.
In order to set this up, we need to change our **docker-compose.yml** file once again:
```
nginx:
build: ./nginx/
container_name: nginx-container
ports:
- 80:80
links:
- php
volumes_from:
- app-data
php:
image: php:7.0-fpm
container_name: php-container
expose:
- 9000
volumes_from:
- app-data
app-data:
image: php:7.0-fpm
container_name: app-data-container
volumes:
- ./www/html/:/var/www/html/
command: “true”
```
As you can see, we added a new container, **app-data-container**, which uses the parameters of the same volumes we used for **php-container** and **nginx-container** so far. This data container will hold the application code, so it doesn’t need to run. It only needs to exist to be accessible, but since it won’t serve any other purpose, there is no need to keep it running and thus wasting resources.
We use the same official image we already have pulled previously. Again, this is to save some disk space. We don’t need to pull any new image for this purpose, the php image will work just fine. Also, we told Docker to mount volumes from **app-data** for **nginx-container** and **php-container**, so we won’t need volumes options for those anymore and we can delete it.
Finally, we say that both **nginx-container** and **php-container** will use volumes from **app-data-container**. Run **docker-compose up -d** once again. As you can see in the terminal, Docker has just created a new **app-data-container** and re-created **php-container** and **nginx-container**.

Now, let’s see the list of containers, but this time, let’s display all containers, not just the those that are running:
```
docker ps -a
```

As you can see, the **app-data-container** has been created but it’s not running because there is no reason for it to run. It only holds data. And it has been created from the same image as **php-container**, so we saved hundreds of megabytes we would otherwise need if we pulled data-only container.
### MySQL
We need to modify our php image because we need to install the extension that will allow php to connect to mysql. To do so, we will create a new folder named **php** and inside we will create a new Dockerfile with this content:
```
FROM php:7.0-fpm
RUN docker-php-ext-install pdo_mysql
```
Your folder structure should look like this now:

Next, we need to change our **docker-compose.yml** file again. We will change the way the **php-container** is built, next we will add **mysql-container** and **mysql-data-container** and finally, we will link **php-container** to **mysql-container**.
We will also define some environment variables for **mysql-container**. **MYSQL\_ROOT\_PASSWORD** and **MYSQL\_DATABASE** variables will be applied only if a volume doesn’t contain any data. Otherwise, these will be ignored. It makes sense because otherwise, we would create a new database with the same name and root password each time we would spin up a container, thus overwriting our database content. Not the behavior we want. I will name my database **zavrel\_db** but go ahead and change the name if you feel like it!
As with **app-data-container**, **mysql-data-container** will just hold the data, this time not our application code, though, but database data like tables with rows and their content. Since we won’t access this data directly, we don’t really care where they will be located on our host machine, so we don’t need to mount them to our directory structure.
```
nginx:
build: ./nginx/
container_name: nginx-container
ports:
- 80:80
links:
- php
volumes_from:
- app-data
php:
build: ./php/
container_name: php-container
expose:
- 9000
links:
- mysql
volumes_from:
- app-data
app-data:
image: php:7.0-fpm
container_name: app-data-container
volumes:
- ./www/html/:/var/www/html/
command: “true”
mysql:
image: mysql:latest
container_name: mysql-container
volumes_from:
- mysql-data
environment:
MYSQL_ROOT_PASSWORD: secret
MYSQL_DATABASE: zavrel_db
MYSQL_USER: user
MYSQL_PASSWORD: password
mysql-data:
image: mysql:latest
container_name: mysql-data-container
volumes:
- /var/lib/mysql
command: "true"
```
To test our MySQL setup, we will modify our **index.php** as well, so we can try to access our database:
```html
<!DOCTYPE html>
<head>
<title>Hello World!</title>
</head>
<body>
<h1>Hello World!</h1>
<p><?php echo 'We are running PHP, version: ' . phpversion(); ?></p>
<?
$database ="zavrel_db";
$user = "user";
$password = "password";
$host = "mysql";
$connection = new PDO("mysql:host={$host};dbname={$database};charset=utf8", $user, $password);
$query = $connection->query("SELECT TABLE_NAME FROM information_schema.TABLES WHERE TABLE_TYPE='BASE TABLE'");
$tables = $query->fetchAll(PDO::FETCH_COLUMN);
if (empty($tables)) {
echo "<p>There are no tables in database "{$database}".</p>";
} else {
echo "<p>Database "{$database}" has the following tables:</p>";
echo "<ul>";
foreach ($tables as $table) {
echo "<li>{$table}</li>";
}
echo "</ul>";
}
?>
</body>
```
This new script will take values we defined for the database, user, and password (notice that these are the same as environment values we set for our **mysql-container**) and try to establish the database connection. Once the connection is established, the script will try to select all tables from **INFORMATION\_SCHEMA** where table type is **BASE TABLE**. Now, if you’re not familiar with MySQL, this might be a bit confusing for you.
*NOTE: Basically, every MySQL instance has a special database that stores information about all the other databases that the MySQL server maintains. This special database is called* ***INFORMATION\_SCHEMA****.* ***INFORMATION\_SCHEMA*** *database contains several read-only tables. They are actually views, not databases. Databases are of* ***BASE TABLE*** *type.*
So when we try to select the table of type **BASE TABLE** we are actually looking for a database only and it is the database we will yet have to create. If it’s too much for you, don’t worry, it will all make sense soon.
Anyway, once you have **Dockerfile** and **index.php** updated, run **docker-compose up -d** again. Docker will pull mysql image, next, it will download and install a php extension for connection to the database.
Finally, it will start **app-data-container**, create **mysql-data-container** and **mysql-container** and recreate **php-container** and **nginx-container**.

Check with **docker ps -a** that you have five containers now, 2 of them exited (**mysql-data-container** and **app-data-container**).

Refresh **index.php** in your web browser. You should see this line at the bottom: **There are no tables in the database “zavrel\_db”.**

Which is perfectly fine because we haven’t created any tables in our database yet. However, there are already some tables, but those are not visible by a regular user. If you want to see them, change **$user** to “root” and **$password** to “secret” in **index.php**. This way, you will get access to everything!

Refresh the browser once more:

What a list! Right? Ok, let’s put back our regular user who can see only what he should see:

### Deep down the rabbit hole
So far, containers were like black boxes for us. We ran them, we listed them, but we never saw what is inside. That’s about to change now. I will show you how you can get right inside **mysql-container** and work with mysql server from within.
Run this command from your terminal:
```
docker exec -it mysql-container /bin/bash
```
Now you are inside the container! You can tell by the new prompt in your terminal:

It consists now of **root@** followed by the ID of the **mysql-container**. In my case, it’s **root@8a56e15cdd4d**, in your case the ID would be different, but it is the same ID your **mysql-container** has assigned. Want to check? List all running containers by **docker ps** and look for the **CONTAINER ID** in the list, it’s the first column.
You can now take a look around as you would in any other Linux system:
* **ls** command will show you the list of files and directories,
* **pwd** command will print the current directory, which is root directory (/),
* **uname -or** command will show you the kernel release and that this is actually a Linux operating system.
Remember, how we defined the volume for **mysql-container** in **docker-compose.yml** file?
```
volumes:
- /var/lib/mysql
```
Let’s take a look at this directory:
```
cd /var/lib/mysql
```
**ls** command will show you its content:

All right, let’s end this quick trip by going back to the root directory:
```
cd /
```
Now, we will run **mysql command-line interface** (MySQL CLI) inside our **mysql-container** that will allow us to work with the database server.
*NOTE: I want you to stop now for a while to let this sink and appreciate. You are working on your physical computer. This computer is running an operating system, Windows or Mac (if you’re on Linux, it’s a bit different). Inside your operating system, you are running a Docker container which is basically a Linux machine.
Now, we will go even deeper and run another command-line interface to work with the database server. Can you see how we go deeper and deeper, layer after layer, down the rabbit hole?* 🙂
Ok, let’s go back to work! To get access to MySQL CLI, we need a username and password. Luckily for us, we already created both user and password when we set up environment variables for our **mysql-container** in **docker-compose.yml** file. I hope you noticed that we also set up the root password as an environment variable. Remember this line?
```
MYSQL_ROOT_PASSWORD: secret
```
You might ask, how do we know that there is a user named root. Well, there is always this user. That’s why we were able to set the password for him with MYSQL\_ROOT\_PASSWORD variable without even questioning his existence.
To sign in mysql server, though, we won’t use root access because that would give us too many results as root can see everything.
Sign in with a regular user instead: **mysql -uuser -ppassword**
**\-uuser** means **user is “user”**
**\-ppassword** means **password is “password”**
Run the command and you will be taken deeper, inside the world mysql server. Again, you can tell by the prompt which changed now from **root@8a56e15cdd4d** (different ID in your case) to **mysql>** that we are somewhere else.
Inside mysql, there are different rules and different commands. Start with the command **show databases;** Don’t forget the semicolon! I told you, there are different rules in this world.

You will see the nice table with the list of all databases available. One of them is our own database with **zavrel\_db**. Remember when we created it? Again, we defined it while preparing our **mysql-container** in **docker-compose.yml** file: **MYSQL\_DATABASE: zavrel\_db**
Let’s create a new table in our database. First, we need to select it, so mysql knows which database we want to work with:
```
use zavrel_db
```
You will get the information that the database has been changed. Now, we can create a new table:
```
CREATE TABLE users (id int);
```
Go to your web browser and refresh the page, you will see this table in the list:

Ok. We are done here, let’s get all the way back to the familiar terminal of our computer. First, we need to leave MySQL CLI. This can be done by command **q**
Go ahead and run it! MySQL will say **Bye** and you are back inside your **mysql-container**. Again, you can tell by the prompt **root@8a56e15cdd4d**. Let’s go one layer up. To leave **mysql-container**, just use the shortcut **CTRL + D** or type **exit** and hit enter. See? We are finally back to our computer terminal! How was it? Did you like the trip? I hope you did!

I wanted to show you this rather complicated way of working with databases and tables so you can truly appreciate the web client we will learn about in a minute, but first, I want to go back to volumes once again, because we need to address few more things about them.
### Inspecting containers
Remember how I told you that we don’t really care about where Docker stores volumes of **mysql-data-container** on our computer (host machine) because we won’t access them directly anyway? Well, if you are curious where they are nevertheless, there is a way how to find out.
Run this command:
```
docker inspect mysql-data-container
```
Look for the **Mounts** section in the output you will get. Next to **Source** attribute is the location of database data on our host machine. It should be something like **/var/lib/docker/volumes/** and so on provided you are on Mac.

### Dangling volumes
When you create a container with mounted volumes and later destroy the container, mounted volumes won’t be destroyed with it unless you specifically say you want to destroy them as well. Such orphan volumes are called dangling volumes.
So far we used a command **docker rm container-name -f** to remove containers, but if you want to destroy volumes as well, you need to add another option, **\-v**. So it will look like this: **docker rm -v container-name -f**.
But what about containers we already destroyed so far without destroying their volumes as well? Let’s check out if there are any such volumes. First, let’s list all the volumes we have created so far:
```
docker volume ls
```
Now let’s narrow our list by adding the filter for dangling volumes only:
```
docker volume ls -qf dangling=true
```
**\-q** stand for quiet which only displays volume names
**\-f** stands for filter
It seems like we have some:

To delete them, we will combine two commands here:
```
docker volume rm $(docker volume ls -qf dangling=true)
```
This will remove all dangling volumes for us. Since Docker 1.13 you can use an easier command instead:
```
docker volume prune
```
This will remove all volumes not used by at least one container. Now if you check volumes again, you should have only one volume left:
```
docker volume ls
```

We reclaimed almost 500 MB of space!
### phpMyAdmin
Ok, let’s move on and spin up our last container. phpMyAdmin is a great tool for managing mysql databases directly from the web browser. No one will force you to stop your trips deep inside MySQL CLI if that’s what you like, but a web interface is way more convenient in my opinion. Add the following lines at the end of your **docker-compose.yml** file:
```
phpmyadmin:
image: phpmyadmin/phpmyadmin
container_name: phpmyadmin-container
ports:
- 8080:80
links:
- mysql
environment:
PMA_HOST: mysql
```
By now, everything should be fairly clear. We start with the official docker image, publish container’s port 80 to port 8080 of our host machine, so we can access phpMyAdmin from the web browser. We need to use a different port, though, because port 80 is already taken by the Nginx web server. Finally, we will link this container to our **mysql-container** and set an environment variable.
Go ahead and run this command once again:
```
docker-compose up -d
```
Docker will pull the phpMyAdmin image and create **phpmyadmin-container**.
Go to your web browser and type **:8080** behind the IP address your Nginx is working on. In my case, it looks like this **0.0.0.0:8080**, but **localhost:8080** works as well.
You should be presented with this login screen:

Now, log in as a regular user (user/password). You’re in mysql server! Check the list of databases on the left pane and click on **zavrel\_db**. Can you see the table **users** we have recently created inside MySQL CLI?

Give yourself a little break, maybe a cup of coffee, and let it all digest a bit. We will continue with more exciting stuff. But since now you have learned a lot! Pat yourself on your back for this!
### GitHub Volume
Mounting a local directory to make it accessible for **nginx-container** and **php-container** is fine until you want to deploy your application to some remote VPS (virtual private server). In such a case, it would be great to have your code copied to a remote volume automatically. In this section, I will show you how to use GitHub for this.
Let’s make a copy of our **docker-compose.yml** file and save it as **docker-compose-github.yml**. We will make some changes to our **app-data-container** so it won’t mount a local directory but rather get a repository from GitHub. In case you have your code on GitHub in a public repository, this will make it very easy to spin up your development environment on a remote server with the code cloned from your repository.
First, we need to create a Dockerfile for **app-data** image. Create a new folder called **app-data** and save the Dockerfile there with this content:
```
FROM php:7.0-fpm
RUN apt-get update && apt-get install -y git
RUN git clone [https://github.com/zavrelj/docker-tutorial/](https://github.com/zavrelj/docker-tutorial/) /var/www/html/
VOLUME ["/var/www/html/"]
```
Your folder structure should look like this now:

Again, we are using already pulled official php image, but on top of that, we will update the underlying **debian:jessie** Linux distro and then install **git**. Next, we will clone my public repository I have created for this purpose and save it inside **/var/www/html** directory inside our container. Finally, we will create a volume from this directory, so other containers, namely **nginx-container** and **php-container** can access it.
Now, we need to change **app-data** image instructions in our **docker-compose-github.yml** file like this:
```
app-data:
build: ./app-data/
container_name: app-data-container
command: “true”
```
Ok, let’s clean up everything, so we can start with a clean slate.
Stop all containers created with a **docker-compose** command:
```
docker-compose stop
```
Remove all those stopped containers including volumes that were attached to them:
```
docker-compose rm -v
```
Clean dangling volumes:
```
docker volume prune
```
In order to use our new **docker-compose-github.yml** file, we need to tell **docker-compose** about it, otherwise, it would use the default docker-compose.yml as always.
Rebuild the images with the new configuration file:
```
docker-compose -f docker-compose-github.yml build
```
and spin up containers again:
```
docker-compose -f docker-compose-github.yml up -d
```
Navigate to your page in the web browser and you should see this:

### Digital Ocean
Let’s provision our development environment to a remote server. Digital Ocean is a great service. If you don’t have an account yet, sign up with [***my referral link***](https://m.do.co/c/e1324db90e6f) and you will get $10 in credit!
Once you’re in, create a new Droplet:

and choose Docker from **One-click apps**:

Pick the smallest size available, it’s more than enough for our purposes:

Since I want you to use SSH for the remote access to your Droplet, you need to set it up, unless you already have it. The whole process is quite easy. Open new terminal window and type:
```
ssh-keygen -t rsa
```

When you’re asked where to save the key, just hit Enter.

If some other key is already there, it will be overwritten.

Enter the password for the newly generated key (twice).

Once you see this, your key is ready:

Run this command to display the public key, select it and use CMD + C shortcut to copy it to the clipboard:
```
cat ~/.ssh/id_rsa.pub
```

Go back to Droplet setup and hit **New SSH Key** button:

Paste your copied public key to the from and fill the name of your computer:

Make sure, your computer is selected for SSH access and choose a hostname. Finally, hit that green button **Create**.

Once your Droplet is created, write down its IP address.
### Transferring the project folder
If you have followed me step by step, you should have your **docker-nginx-php7** folder on your Desktop.
We will copy this folder to our Droplet so we can run Docker Compose with our YML configuration file remotely from the Droplet.
To copy the folder, we will use **rsync** command. Make sure you write this down exactly as it is. Instead of **IP**, use the actual IP address of your Droplet. We want to transfer the actual directory, not just the content inside it, so we need to omit the trailing slash:
```
rsync -r -e ssh ~/Desktop/docker-nginx-php7 root@IP:~/
```
This command will ask for your SSH key password and then create a copy of **docker-nginx-php7** folder inside the home folder of the user root (**/root**).

Now, let’s check if everything has been transferred. SSH into your remote server (your actual IP address instead of **IP**):
```
ssh root@IP
cd docker-nginx-php7
ls
```
Can you see your familiar directory structure including two configuration files?
Nice! Everything seems to be in place!

There’s no Docker Compose on this particular Droplet, but it’s fairly easy to install it. First, we need to install **python-pip**:
```
apt-get update
apt-get -y install python-pip
```
Next, we can install Docker Compose via pip:
```
pip install docker-compose
```
We are ready now to let Docker Compose do its magic. Let’s run our familiar command that will automate the whole process of pulling and building images, getting the code from GitHub and spinning up all containers. Since there are no images to rebuild, we can use the **up** command directly:
```
docker-compose -f docker-compose-github.yml up -d
```

Once everything is done and all containers are running, you can navigate to IP address of your Droplet ([**http://104.236.209.37/**](http://104.236.209.37/) in my case). Octocat should be waiting for you:

And if you add port 8080 behind the IP address, you will get phpMyAdmin welcome screen:

Go ahead and login with user / password or root / secret, both will work. Make sure that our **zavrel\_db** database is there:

**One last thing. Once you’re done with Digital Ocean, make sure to destroy your running Droplet so you won’t be billed. Or in case you used my referral link and received those $10 in credit, to not waste it all by running the Droplet you don’t need after you finish this tutorial.**
Alright! That’s all. I hope you have learned something useful today. If you liked this article, consider by complete web development course where I will show you how to use Docker in the development process of the whole discussion server based on PHP and MySQL. Learn more at [www.twdc.online](https://www.twdc.online).
## Want to learn more?
The rest of this tutorial is available for free on <a href="https://skl.sh/3eP78uy" target="_blank">Skillshare</a> as a part of the much larger and far more detailed video course. Again, if you're new to Skillshare, you'll also get premium access to more than 22.000 courses. Remember, that you won't be charged anything for your first 2 months and you can cancel your membership whenever you want within that period. Skillshare is Netflix for life-long learners.
<a href="https://skl.sh/3eP78uy" target="_blank"></a>
| zavrelj |
211,065 | Caching GraphQL Responses with TrunQ | TrunQ A lightweight NPM library for GraphQL response caching in its beta release. Landing... | 0 | 2019-11-25T18:08:43 | https://dev.to/brianjhaller/caching-grapql-responses-with-trunq-2dk8 | graphql, javascript, npm | # TrunQ
A lightweight NPM library for GraphQL response caching in its beta release. [Landing Page](www.trunq.io) and [GitHub](https://github.com/oslabs-beta/TrunQ)
## A Universal Problem
In a world where over 50% of web traffic is from mobile devices, load time optimization becomes more important than ever. In a world where developers rent compute power, client-server data optimization is king. In a world where...well, you get it. Every millisecond of load time, every byte of data saved translates to sales and savings for your project.
## GraphQL Gets You Halfway There...
GraphQL boasts improvements over RESTful APIs in one of those optimization categories. Properly implemented, GraphQL always fetches the exact response needed for a data-hungry client. However, GraphQL fails in some other areas of optimization. The fetching still takes time, especially to remote or external servers and APIs. GraphQL’s singular employment of the POST method forfeits native HTTP caching, reopening the danger of potential over-fetching by re-running queries and bogging down load times.
## ...But It Falls Short
One of the easiest ways to reduce load times and minimize data fetching is caching. However, because GraphQL’s architecture does not allow for HTTP caching via GET, there is not an easy and native way to implement this basic optimization. Developers are left to their own devices to implement their own caching solutions if they desire any sort of performant response. This has resulted in many unique, custom-tailored systems but no wide catch-all. The leading option on the market right now is Apollo, but this option requires the developer to use Apollo as their GraphQL server and takes a decent amount of code and effort to implement. Many times, small applications running GraphQL do not need the heavy and complex Apollo InMemoryCache but would greatly benefit from a small and easy way of stashing query responses.
## Our Solution
Enter TrunQ, our lightweight solution. Our team just released a beta version on NPM broken into two packages: client-side caching in local memory and server-side caching leveraging a Redis database (`npm i trunq` and `npm i trunq-server`, respectively). Perfect for small applications that use query as a way to access a third-party or remotely hosted GraphQL server, we simplify caching down to a few couple parameters and then do all fetching, caching, and parsing on behalf of the developer.
### A Very Simple Implementation
Take a simple GraphQL request:
```
const myGraphQLQuery = query {
artist (id: 'mark-rothko') {
name artworks (paintingId: 'chapel' size: 1) {
name imgUrl
}
}
}
```
After requiring it in, all the client side implementation takes is turning your code from:
```
function fetchThis (myGraphQLQuery) {
let results
fetch('/graphQL', {
method: "POST"
body: JSON.stringify(myGraphQLQuery)
})
.then(res => res.json)
.then(parsedRes => results = parsedRes)
...(rest of code)
}
```
Into:
```
async function fetchThis (myGraphQLQuery) {
let results = await trunq.trunQify(myGraphQLQUery, ['id', 'paintingId'], '/graphQL', 'client')
...(rest of code)
}
```
And voila, you can now cache things in client-side! We've saved you lines of code and the heartache of resolving asynchronous operations between a cache and a fetch, and instead presented a response in the same format you would expect from a regular GraphQL response.
Our server-side implementation is just as easy and out-of-the-box.
After requiring it in and spinning up a Redis database, all that is needed is specifying an endpoint for your 3rd party or remote API and an optional Redis port. Then just add our middleware in and it will return right back to our client-side package!
```
const trunQ = new TrunQServer(graphQL_API_URL, [redisPort], [cacheExpire]);
app.use('/graphql', trunQ.getAllData, (req, res, next) => {
res.status(200).json(trunQ.data);
})
```
### Fun Features
- Server and client side caching specified by developer
- No need to tag queries with keys, we do that for you
- Partial field matching means only missing fields will be fetched
- Superset and subset matching prevents refetching any data previously fetched
- Nested queries in one body of a fetch request will be parsed and cached separately, subsequent independent calls to each query will return from cache.
Visit our [GitHub](https://github.com/oslabs-beta/TrunQ) for detailed step-by-step instructions for our packages and Redis, and leave stars or feedback for improvement!
| brianjhaller |
211,088 | My Career Morph into a Swamp Community Tradition | I must confess that when I first heard about the Meetup Event Manager position at JFrog my first... | 0 | 2019-11-25T18:47:41 | https://jfrog.com/community/devops/my-career-morph-into-a-swamp-community-tradition | career, community, jfrog, containerregistry | I must confess that when I first heard about the Meetup Event Manager position at JFrog my first thought was…“OMG! T-Shirts!” Having worked with technology professionals all of my career, I have seen some nice swag, but I have always considered JFrog T-Shirts as an elite-class unto themselves. People even list them on eBay and yes I bought one!
OK, cool swag aside, joining a software company with a technical meetup focus requires there to truly be an ongoing commitment to open-source and free community software offerings. Was JFrog that kind of company?
So let’s rewind a little. I started my career in the technical recruiting industry. I learned early on that keeping up with technology trends, and translating these into career satisfaction for a "happy life" was a passion of mine.
While working with technologists looking for their next position was something I excelled in, engaging with the technical community had its challenges. Sure, I placed technology professionals for a living, but that does not mean everyone I meet is in my crosshairs. I get it though...when you receive 50+ recruiting emails per week and your voicemail is full every day about "jobs", the response is warranted. What could I do to try and lower some of these defenses?
About 5 years ago it hit me… I’ll offer technically specific career guidance at meetups based on current IT career and salary trends in the market. I wanted a platform to be authentically transparent, and become an “open source” confidant for those who wanted career guidance. I could make placements, and provide expertise to the community!
So for the past few years, I would speak quarterly within the PHP, Java, Python, Angular, .Net, Business Analysts technical meetup and “boot camp” communities. I found a new level of professional satisfaction in the reciprocity of honest career-oriented dialogue in a non-intimidating setting.
Fast forward to a few months ago when I began to look for a new position. I initially focused on different technical recruiting leadership roles as one would expect. That was until a friend in the meetup community told me about JFrog’s Meetup Event Manager position. As I learned more about it, a metamorphosis of sorts took place within me. I was more excited about this than anything else I was working towards. Applying my background and experience in the community was not only "an option", but my new desire. I have had the luxury my entire career of waking up and loving my job. For me to continue that path, I knew this was something I had to explore further.
When I researched JFrog, I learned that the technical community was a priority for JFrog starting from the first Artifactory OSS version in 2006. Since then they have added other open source tools and free resources to make the work lives of Software Engineers and DevOps professionals happier and more productive. That’s a mission I can get behind if they will give me the opportunity!
I was humbled and ecstatic to have been offered the position. The icing on the cake for me was when I learned on my first day that we were releasing the free to use JFrog Container Registry, a cloud-native, hybrid software download for Docker and Helm. I joined a company that regularly invests in its community roots. For me, this was a satisfying confirmation that I was in the right place. That, and those amazing T-Shirts! | ariwaller |
211,185 | Hyper.js for Windows 10 | Hyper is a HTML/CSS/JS terminal with awesome and extensible interface I like to use. The goal of th... | 0 | 2019-11-25T23:03:01 | https://dev.to/amaltapalov/hyper-js-for-windows-4m85 | webdev, devops, cli |
Hyper is a HTML/CSS/JS terminal with awesome and extensible interface I like to use.
> _The goal of the project is to create a beautiful and extensible experience for command-line interface users, built on open web standards. In the beginning, our focus will be primarily around speed, stability and the development of the correct API for extension authors._
In this post I will describe how to install Hyper for Windows OS.
### 1 step:
Download Hyper from official [Website](https://hyper.is/)
### 2 step:
Assuming you have [git-bash](https://gitforwindows.org/) installed hit up `ctrl + ,` and you are inside the .hyper.js (probably it is in `C:\Users\YOURUSERNAME`):
### 3 step:
Find these lines:
```
// the shell to run when spawning a new session
// if left empty, your system's login shell will be used by default
shell: '',
// for setting shell arguments
// by default ['--login'] will be used
shellArgs: ['--login'],
```
Then change above code to:
```
// the shell to run when spawning a new session
// if left empty, your system's login shell will be used by default
shell: 'C:\Program Files\Git\usr\bin\bash.exe',
// for setting shell arguments
// by default ['--login'] will be used
shellArgs: ['-i'],
```
### 4 step:
We are still in hyper.js config file and let's add another code (you can add this code just below 3 step):
```
// for environment variables
env: { TERM: 'cygwin' },
```
### 5 step:
Add if hyper is in _user variables_:
**Computer -> Properties -> Advanced -> Environment variables**
To add path you need to click on `New...` button. Then in appeared windows set following data:
```
variable name: Path
Variable value: C:\User\your_user_name\AppData\Local\hyper\app-2.1.2\resources\bin
```
### 6 step:
First you need to create a .bashrc file in your user folder.
- First variant: simply type: `cd ~ && touch .bashrc`
- Second variant: you can go to `C:\Users\YOURUSERNAME` and create this file by right click
### 7 step:
Check if version is corresponding in `.bashrc` file (probably it is in `C:\Users\YOURUSERNAME)`.
Should be something like that:
```
export PATH=\$PATH:~/AppData/Local/hyper/app-2.1.2/resources/bin
```
> _Please pay attention to version. You can control version you downloaded in AppData folder. But usually on computer this folder in hidden. So that to open it you can type in folder address bar:_
>
```
C:\Users\YOURUSERNAME\AppData\Local\hyper
```
>
### 8 step:
- Lets install Hyper type plugin (after installing - restart Hyper):
in Hyper type:
```
hyper install hyperborder
```
- Install theme:
```
hyper install hyper-snazzy
```
Link to dive deeper:
[Official website of Hyper](https://hyper.is)
That's it!
Congratulations! You have a Hyper CLI on your computer.
| amaltapalov |
211,240 | Install Vue JS with Laravel 6 | HiIf you are dont know how to install vue js in laravel 6 then i will help you to laravel install vue... | 0 | 2019-12-02T04:05:01 | https://www.itsolutionstuff.com/post/laravel-6-install-vue-js-exampleexample.html | ---
title: Install Vue JS with Laravel 6
published: true
date: 2019-11-26 04:02:18 UTC
tags:
canonical_url: https://www.itsolutionstuff.com/post/laravel-6-install-vue-js-exampleexample.html
---
HiIf you are dont know how to install vue js in laravel 6 then i will help you to laravel install vue js using laravel ui we will also install vue with laravel and also laravel 6 vue auth using laravel uiIf you are beginner with laravel 6 then i am sure i can help you to install vue in larav | savanihd | |
211,276 | GraphQL Mutations Tutorial - Building Comments Platform Using GraphQL and React | We'll build a commentary platform using GraphQL and React. | 0 | 2019-11-26T08:57:10 | https://dev.to/satansdeer/graphql-mutations-tutorial-building-comments-platform-using-graphql-and-react-2971 | graphql, react | ---
title: GraphQL Mutations Tutorial - Building Comments Platform Using GraphQL and React
published: true
description: We'll build a commentary platform using GraphQL and React.
tags: graphql, react
---
{% youtube UaUMYJ8Mq4Q %} | satansdeer |
211,300 | n gram highlighting in contenteditable div | n gram highlighting in contenteditabl... | 0 | 2019-11-26T10:20:54 | https://dev.to/nagaraju291990/n-gram-highlighting-in-contenteditable-div-4cm0 | {% stackoverflow 59045210 %} | nagaraju291990 | |
211,620 | Multi-Arch Container Images | Normally when building containers the target hardware is not even a consideration, a dockerfile is bu... | 0 | 2019-11-26T22:10:43 | https://bashton.io/posts/multi-arch-images/ | docker | Normally when building containers the target hardware is not even a consideration, a dockerfile is built and the images are pushed to a registry somewhere. The reality is all of these images are specific to a platform consisting of both an OS and an architecture. Even in the V1 Image [specification](https://github.com/moby/moby/blob/master/image/spec/v1.md) both of these fields are defined. With this specification you are able to at least know if the image would run on a target, but each reference was specific to an image for a specific platform, so you might have `busybox:1-arm64` and `busybox:1-ppc64le`. This is not ideal if you want to have a single canonical reference that is platform agnostic.
In 2016 Version 2 Schema 2 Image Manifest [specification](https://github.com/docker/distribution/blob/master/docs/spec/manifest-v2-2.md) was released giving us _Image Manifest Lists_ allowing to specify a group of manifests for all of the supported architectures. With this the client could pull `busybox:latest` and immediately know which image to pull for a given platform. Now all of your users whether they are running Linux on aarch64, Windows on x86_64, or z/Linux on an IBM mainframe could all expect to find your release in one place.
Using the `docker manifest` command we can see what this looks like for the `alpine:latest` image on docker hub.
```
❯ docker manifest inspect alpine:latest
```
```json
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"manifests": [
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 528,
"digest": "sha256:e4355b66995c96b4b468159fc5c7e3540fcef961189ca13fee877798649f531a",
"platform": {
"architecture": "amd64",
"os": "linux"
}
},
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 528,
"digest": "sha256:29a82d50bdb8dd7814009852c1773fb9bb300d2f655bd1cd9e764e7bb1412be3",
"platform": {
"architecture": "arm",
"os": "linux",
"variant": "v6"
}
}
]
}
```
At this point if you just want to be building these images, but really do not want to get into the details about how this all works, skip to the [last section](#a-simpler-path-with-buildx) on buildx. For the rest of you, I hope you enjoy our short journey.
## Assembling the Manifest List
Now that we have a way to represent these images how are these manifest lists assembled? The through the docker cli we can create and push using the same manifest utility we used to inspect.
```
❯ docker manifest create MANIFEST_LIST MANIFEST [MANIFEST...]
❯ docker manifest push [OPTIONS] MANIFEST_LIST
```
It is important to call out here that these commands only push the manifest list and not the references, so the container registry must already have the layers. It actively works with the registry and not local images, so if the references do not exist in the registry it will not allow them to be used.
If images are already being built for multiple architectures this is a simple addition to the CI process that greatly simplifies the distribution of images. What this has not solved is the generation of the images themselves. In some cases it might be possible to run docker build jobs directly on all of the architectures you support, but in many cases this is not feasible.
## Building the Images
One way to build these images is to cross compile to generate the binary artifacts and then add those artifacts to and existing base image for the architecture, this process is hardly clean, and unless performance is a serious concern I would suggest an alternative. What if we used emulation to drive the build process in the container?
Usually when people think of emulation they think of emulating a full VM using something like [QEMU](https://qemu.org) which can be very heavy, especially if we are just compiling a small C library. This mode of operation is system emulation where everything from the hardware to user space is full emulated. There is another mode of operation for QEMU called user-mode emulation where the system calls from the emulated user-mode are captured and passed to the host kernel.
To play with the concept a little, let's take this c program. This will print the architecture it was compiled for.
```c
#include <stdio.h>
#ifndef ARCH
#if defined(__x86_64__)
#define ARCH "x86_64"
#elif defined(__aarch64__)
#define ARCH "aarch64"
#elif defined(__arm__)
#define ARCH "arm"
#else
#define ARCH "Unknown"
#endif
#endif
int main() {
printf("Hello, looks like I am running on %s\n", ARCH);
}
```
Let's compile this application for both x86-64 and Arm, note that for Arm we are doing a static build.
```
❯ gcc hello.c -o hello-x86_64
❯ arm-linux-gnu-gcc hello.c -o hello-arm --static
```
Now execute them, in the case of Arm we are able to use the QEMU user-mode emulation to intercept the write system call and have the kernel process it rather than emulating all the way down to the serial driver.
```
❯ ./hello-x86_64
Hello, looks like I am running on x86_64
❯ ./hello-arm
bash: ./hello-arm: cannot execute binary file: Exec format error
❯ qemu-arm hello-arm
Hello, looks like I am running on arm
```
What would be really useful is if we could automatically call qemu-arm when we try to execute `hello-arm`. This is where a Linux Kernel feature comes a long that I had not been exposed to before `binfmt_misc`. To quote the Linux [docs](https://www.kernel.org/doc/html/latest/admin-guide/binfmt-misc.html):
This Kernel feature allows you to invoke almost (for restrictions see below) every program by simply typing its name in the shell. This includes for example compiled Java(TM), Python or Emacs programs.
The powerful thing here is we can have the kernel identify when an ELF file is being executed for a specific architecture that is not native and then pass that to an "interpreter" in this case that could by `qemu-arm`.
The registration looks like this:
```
❯ echo ':qemu-arm:M:0:\x7f\x45\x4c\x46\x01\x01\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x02\x00\x28\x00:\xff\xff\xff\xff\xff\xff\xff\x00\xff\xff\xff\xff\xff\xff\xff\xff\xfe\xff\xff\xff:/usr/bin/qemu-arm:CF' > /proc/sys/fs/binfmt_misc/register
❯ cat /proc/sys/fs/binfmt_misc/qemu-arm
enabled
interpreter /usr/bin/qemu-arm
flags: OCF
offset 0
magic 7f454c4601010100000000000000000002002800
mask ffffffffffffff00fffffffffffffffffeffffff
```
Now we can just run the Arm version of the program without explicitly calling QEMU.
```
❯ ./hello-arm
Hello, looks like I am running on arm
```
What this has really done it set us up to be able to run a container with an Arm image without the container having to be aware that any emulation is taking place. We can actually do this by forcing docker to run the Arm alpine container from the manifest list at the beginning of the article:
```
docker run --rm alpine:latest@sha256:29a82d50bdb8dd7814009852c1773fb9bb300d2f655bd1cd9e764e7bb1412be3 uname -a
Linux 4003fb15be7a 5.3.7-200.fc30.x86_64 #1 SMP Fri Oct 18 20:13:59 UTC 2019 armv7l Linux
```
The fact that we were able to run an Arm docker container on our x86_64 hardware really unlocks the original goal which was to be able to create cross platform images. Let's take a simple dockerfile for building our c program. Note that we are calling out the digest for the Arm alpine images.
```dockerfile
FROM alpine:latest@sha256:29a82d50bdb8dd7814009852c1773fb9bb300d2f655bd1cd9e764e7bb1412be3 AS builder
RUN apk add build-base
WORKDIR /home
COPY hello.c .
RUN gcc hello.c -o hello
FROM alpine:latest@sha256:29a82d50bdb8dd7814009852c1773fb9bb300d2f655bd1cd9e764e7bb1412be3
WORKDIR /home
COPY --from=builder /home/hello .
ENTRYPOINT ["./hello"]
```
```
❯ docker build -t hello-arm .
<...>
Successfully built 77154bf3d6c9
Successfully tagged hello-arm:latest
❯ docker run --rm hello-arm
Hello, looks like I am running on arm
```
It is worth pointing out here that the docker cli, if experimental features are turned on, provides the `--platform` flag which saves you from having to specify the digest for the Arm image. It is important to note though that this only impacts the pull, so if you have alpine:latest already for Arm and you switch platform flags to x86_64, you risk using the wrong image. This can be worked around by forcing the pull with `--pull`.
## Putting it Together
Using this and the image manifest command we can now build everything we need.
This will require using a docker registry, it is very simple to spin up the [JFrog Container Registry](https://jfrog.com/container-registry/) locally which is what I will be using for the rest of this. Make sure you have created a docker repository called `docker-local` and have authenticated with it.
The whole flow now looks like this:
```
❯ docker build --platform linux/amd64 -t localhost:8081/docker-local/hello-amd64 --pull .
❯ docker build --platform linux/arm/v7 -t localhost:8081/docker-local/hello-armv7 --pull .
❯ docker push localhost:8081/docker-local/hello-amd64
❯ docker push localhost:8081/docker-local/hello-armv7
❯ docker manifest create --insecure \
localhost:8081/docker-local/hello-multi:latest \
localhost:8081/docker-local/hello-amd64 \
localhost:8081/docker-local/hello-armv7
❯ docker manifest push localhost:8081/docker-local/hello-multi:latest
```
Using the manifest inspect we can now see the manifest list as we did with alpine from Docker Hub
```
❯ docker manifest inspect --insecure localhost:8081/docker-local/hello-multi:latest
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"manifests": [
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 736,
"digest": "sha256:ea1515064cdd83def95d992c7a22f22240930db16f656e0c40213e05a3a650e9",
"platform": {
"architecture": "amd64",
"os": "linux"
}
},
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 736,
"digest": "sha256:ecc5df1ebd48983a52f7cd570cb88c92ada135718a4cc2e0730259d6af052599",
"platform": {
"architecture": "arm",
"os": "linux"
}
}
]
}
```
## A Simpler Path with buildx
If that all seemed like a lot of extra bits to wire together just to build for two architectures and might break if you look at it wrong, you are not wrong. Also doing this on Windows or macOS is likely going to require running this all in a virtual machine. This is why there is a Docker CLI plugin that leverages BuildKit to make this all so much easier. The cool thing is under the hood it is basically doing all of the same things. It also provides helpful tools for including native workers in cases where you might have them to improve performance over QEMU.
There are more details at https://github.com/docker/buildx, but the short of it is if you are using Docker CE, make sure you are running edge and you have the experimental flags turned on. If you are using Docker Desktop you do not have to worry about including `qemu-user` for Arm as that is already handled, but if you are on Linux you will want to use your distributions package for this or register the qemu binaries using this docker iamge:
```
docker run --rm --privileged docker/binfmt:66f9012c56a8316f9244ffd7622d7c21c1f6f28d
```
If you use the docker command, the settings in to `/proc/sys/fs/binfmt_misc` are lost on reboot, so make sure they are registered before trying any builds.
```
❯ ls /proc/sys/fs/binfmt_misc
qemu-aarch64 qemu-arm qemu-ppc64le qemu-s390x register status
```
At this point you should see a new docker command `docker buildx`.
```
❯ docker buildx
Usage: docker buildx COMMAND
Build with BuildKit
Management Commands:
imagetools Commands to work on images in registry
Commands:
bake Build from a file
build Start a build
create Create a new builder instance
inspect Inspect current builder instance
ls List builder instances
rm Remove a builder instance
stop Stop builder instance
use Set the current builder instance
version Show buildx version information
```
We first need to register a new builder and then inspect what we can build with it.
```
❯ docker buildx create --use
strange_williamson
❯ docker buildx inspect --bootstrap
[+] Building 2.2s (1/1) FINISHED
=> [internal] booting buildkit 2.2s
=> => pulling image moby/buildkit:buildx-stable-1 1.4s
=> => creating container buildx_buildkit_strange_williamson0 0.7s
Name: strange_williamson
Driver: docker-container
Nodes:
Name: strange_williamson0
Endpoint: unix:///var/run/docker.sock
Status: running
Platforms: linux/amd64, linux/arm64, linux/ppc64le, linux/s390x, linux/386, linux/arm/v7, linux/arm/v6
```
We can use buildx in mostly the same way that we used it before to build our images, the difference being this time we supply all of the platforms that we are targeting and it will be using BuildKit.
```
❯ docker buildx build --platform linux/amd64,linux/arm64,linux/ppc64le .
WARN[0000] No output specified for docker-container driver. Build result will only remain in the build cache. To push result image into registry use --push or to load image into docker use --load
[+] Building 15.3s (28/28) FINISHED
=> [internal] booting buildkit 0.2s
=> => starting container buildx_buildkit_strange_williamson0 0.2s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 91B 0.0s
=> [linux/amd64 internal] load metadata for docker.io/library/alpine:latest 2.4s
=> [linux/ppc64le internal] load metadata for docker.io/library/alpine:latest 2.4s
=> [linux/arm64 internal] load metadata for docker.io/library/alpine:latest 2.4s
=> [internal] load build context 0.0s
=> => transferring context: 384B 0.0s
=> [linux/arm64 builder 1/5] FROM docker.io/library/alpine@sha256:c19173c5ada6 0.7s
=> => resolve docker.io/library/alpine@sha256:c19173c5ada610a5989151111163d28a 0.0s
=> => sha256:8bfa913040406727f36faa9b69d0b96e071b13792a83ad69c 2.72MB / 2.72MB 0.4s
=> => sha256:61ebf0b9b18f3d296e53e536deec7714410b7ea47e4d0ae3c 1.51kB / 1.51kB 0.0s
=> => sha256:c19173c5ada610a5989151111163d28a67368362762534d8a 1.64kB / 1.64kB 0.0s
=> => sha256:1827be57ca85c28287d18349bbfdb3870419692656cb67c4cd0f5 528B / 528B 0.0s
=> => unpacking docker.io/library/alpine@sha256:c19173c5ada610a5989151111163d2 0.1s
=> [linux/amd64 builder 1/5] FROM docker.io/library/alpine@sha256:c19173c5ada6 0.9s
=> => resolve docker.io/library/alpine@sha256:c19173c5ada610a5989151111163d28a 0.0s
=> => sha256:965ea09ff2ebd2b9eeec88cd822ce156f6674c7e99be082c7 1.51kB / 1.51kB 0.0s
=> => sha256:c19173c5ada610a5989151111163d28a67368362762534d8a 1.64kB / 1.64kB 0.0s
=> => sha256:e4355b66995c96b4b468159fc5c7e3540fcef961189ca13fee877 528B / 528B 0.0s
=> => sha256:89d9c30c1d48bac627e5c6cb0d1ed1eec28e7dbdfbcc04712 2.79MB / 2.79MB 0.5s
=> => unpacking docker.io/library/alpine@sha256:c19173c5ada610a5989151111163d2 0.2s
=> [linux/ppc64le builder 1/5] FROM docker.io/library/alpine@sha256:c19173c5ad 0.7s
=> => resolve docker.io/library/alpine@sha256:c19173c5ada610a5989151111163d28a 0.0s
=> => sha256:cd18d16ea896a0f0eb99be52a9722ffae9a5ac35cf28cb8b9 2.81MB / 2.81MB 0.4s
=> => sha256:803924e7a6c178a7b4c466cf6a70c9463e9192ef439063e6f 1.51kB / 1.51kB 0.0s
=> => sha256:c19173c5ada610a5989151111163d28a67368362762534d8a 1.64kB / 1.64kB 0.0s
=> => sha256:6dff84dbd39db7cb0fc928291e220b3cff846e59334fd66f27ace 528B / 528B 0.0s
=> => unpacking docker.io/library/alpine@sha256:c19173c5ada610a5989151111163d2 0.1s
=> [linux/arm64 stage-1 2/3] WORKDIR /home 0.1s
=> [linux/arm64 builder 2/5] RUN apk add build-base 6.5s
=> [linux/ppc64le stage-1 2/3] WORKDIR /home 0.1s
=> [linux/ppc64le builder 2/5] RUN apk add build-base 9.0s
=> [linux/amd64 builder 2/5] RUN apk add build-base 6.4s
=> [linux/amd64 stage-1 2/3] WORKDIR /home 0.0s
=> [linux/amd64 builder 3/5] WORKDIR /home 0.0s
=> [linux/arm64 builder 3/5] WORKDIR /home 0.1s
=> [linux/amd64 builder 4/5] COPY hello.c . 0.0s
=> [linux/arm64 builder 4/5] COPY hello.c . 0.0s
=> [linux/amd64 builder 5/5] RUN gcc hello.c -o hello 0.1s
=> [linux/arm64 builder 5/5] RUN gcc hello.c -o hello 2.6s
=> [linux/amd64 stage-1 3/3] COPY --from=builder /home/hello . 0.0s
=> [linux/ppc64le builder 3/5] WORKDIR /home 0.7s
=> [linux/arm64 stage-1 3/3] COPY --from=builder /home/hello . 0.7s
=> [linux/ppc64le builder 4/5] COPY hello.c . 0.5s
=> [linux/ppc64le builder 5/5] RUN gcc hello.c -o hello 1.0s
=> [linux/ppc64le stage-1 3/3] COPY --from=builder /home/hello . 0.4s
```
Since we are using a docker-container to do the building, the images by default will be isolated from the usual image storage. We are warned of this and need to provide a way to export them. One way of doing this is to have it export the oci-archive of the build, there are issues exporting multi-arch images to the docker daemon currently (docker target only supports v1s2 specification), which leaves the OCI target a reasonable choice for local inspection.
```
docker buildx build --platform linux/amd64,linux/arm64,linux/ppc64le -o type=oci,dest=- . > myimage-oci.tar
```
One very convenient tool for inspecting container images and image repositories is [skopeo](https://github.com/containers/skopeo). Make sure you are using a latest version of this as there have been recent changes in _v0.1.40_ around better supporting OCI as well as the `--all` parameter to copy which is needed for manifest lists. Using it we can convert the oci-archive to a docker archive and then inspect it to see the three images listed in the Image List Manifest as we would expect.
```
❯ skopeo copy oci-archive:../myimage-oci.tar docker-archive:../myimage-docker.tar -f v2s2
Getting image source signatures
Copying blob 89d9c30c1d48 done
Copying blob e9edb727823b done
Copying blob 9fbf10e0f163 done
Copying config 2c3d27a535 done
Writing manifest to image destination
Storing signatures
❯ skopeo inspect docker-archive:../myimage-docker.tar --raw | python3 -m json.tool
```
```json
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"config": {
"mediaType": "application/vnd.docker.container.image.v1+json",
"size": 1168,
"digest": "sha256:2c3d27a535333188b64165c72740387e62f79f836c2407e8f8d2b679b165b2b9"
},
"layers": [
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"size": 5814784,
"digest": "sha256:77cae8ab23bf486355d1b3191259705374f4a11d483b24964d2f729dd8c076a0"
},
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"size": 3072,
"digest": "sha256:11d5c669f7975adad168faa01b6c54aeea9622c9fcb294396431ee1dd73d012f"
},
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"size": 24064,
"digest": "sha256:5f985e16416a55b548f80ebd937b3f4f1e77b2967ab0577e1eb0b4c07a408343"
}
]
}
```
We can also use skopeo to upload the images and the image manifest to our [JFrog Container Registry](https://jfrog.com/container-registry/).
```
❯ skopeo copy --dest-tls-verify=false --dest-creds=user:pass \
oci-archive:myimage-oci.tar \
docker://localhost:8081/docker-local/hello-buildx \
-f v2s2 --all
Getting image list signatures
Copying 3 of 3 images in list
Copying image sha256:75f9363c559cb785c748e6ce22d9e371e1a71de776970a00a9b550386c73f76e (1/3)
Getting image source signatures
Copying blob 89d9c30c1d48 skipped: already exists
Copying blob e9edb727823b skipped: already exists
Copying blob 9fbf10e0f163 skipped: already exists
Copying config 2c3d27a535 done
Writing manifest to image destination
Storing signatures
Copying image sha256:9bd94cb2701dead0366850493f9220d74e3d271ee64d5ce9ddc40747d8d15004 (2/3)
Getting image source signatures
Copying blob 8bfa91304040 skipped: already exists
Copying blob 7dff5f8d776f skipped: already exists
Copying blob d53560c61a67 done
Copying config 551e2ac7ec done
Writing manifest to image destination
Storing signatures
Copying image sha256:6db849e4705f7f10621841084f9ac34e295e841521d264567cd2dcba9094c4d8 (3/3)
Getting image source signatures
Copying blob cd18d16ea896 skipped: already exists
Copying blob 0b02afc5b3b5 skipped: already exists
Copying blob 999706aeff73 done
Copying config b4592c67c0 done
Writing manifest to image destination
Storing signatures
Writing manifest list to image destination
Storing list signatures
```
## Image Distribution
The multi-arch images that we generated using both the manual flow of composing and the buildx managed flow are accessible through the registry as any container user would expect. The only difference is we have now enabled users from the IoT and enterprise spaces to consume our application without having to worry about the hardware they are running on. I hope that you will consider leveraging some of these methods to distribute your software to a broader audience.
 | btashton |
211,301 | Hacktoberfest - Opensource worldwide and local | I am working at KNP Labs as people manager and project facilitator. We create and contribute to sever... | 0 | 2019-11-26T12:27:46 | https://dev.to/eveyonline/hacktoberfest-opensource-worldwide-and-local-idf |
I am working at KNP Labs as people manager and project facilitator. We create and contribute to several **F**ree and **O**pen **S**ource **S**oftware projects, like [Bundles for Symfony](http://knpbundles.com/) and latest, some js/react libs.
Even if I do not code anymore, I still care a lot for open source projects and it's a strong value for me, that the company for which I am working, is contributing and sharing with the community.
This is a translation into English of my blog post of our company website : [KNPLabs.com](https://knplabs.com/en/blog/hacktoberfest-opensource-mondial-et-local)
Here we go !
As part of the [TURFU festival](https://turfu-festival.fr/agenda/) at ["Le Dôme"](http://ledome.info/), we organized a Hacktoberfest evening with our local dev association the ["Caen Camps"](https://www.caen.camp/).
## Worldwide
The [Hacktoberfest](https://hacktoberfest.digitalocean.com/) is a worldwide day to promote open source projects on github. The participation is impressive: 92,132 participants registered, with 482,182 participating in the open source projects. The companies Digtial Ocean and the Dev.to website sponsor worldwide stickers and T-Shirts for all those who make at least 4 PRs [pull request - what is a PR?](https://dev.to/kulkarniankita9/the-art-of-humanizing-pull-requests-prs-2238).

## Local
KNP Labs already contributes to open source projects and we wanted to introduce the open source community to developers at Caen (Normandy, France) and also propose to make common projects for those who are already experienced contributors.

"Le Dôme" welcomed us during the fabulous TURFU festival and the CaenCamps were co-organizers with us. We were about 20 attendees, with 8 people who never contributed.

KNP Labs sponsored the local brewery La Caenette ;-) and some pizzas were also on hand.

To learn more, [Digital Oceans Hacktoberfest](https://hacktoberfest.digitalocean.com/faq) website is really great !
See you next year !
Thanks to all the participants, [Lena](https://github.com/lcouellan), [Antoine](https://github.com/AntoineLelaisant) and [Eve](https://github.com/eveyonline) for co-organizing the event. Want to help with contributions? Send us a [hello on twitter](https://twitter.com/KNPLabs).
| eveyonline | |
211,310 | 4 Ways Of Accessing HTML Elements In The DOM | In this article we will go over the 4 ways of accessing elements in the DOM. | 0 | 2019-11-26T11:18:01 | https://dev.to/zaiste/4-ways-of-accessing-html-elements-in-the-dom-1jgf | beginners, webdev, javascript, tutorial | ---
title: 4 Ways Of Accessing HTML Elements In The DOM
published: true
description: In this article we will go over the 4 ways of accessing elements in the DOM.
tags: #beginners #webdev #javascript #tutorial
cover_image: https://thepracticaldev.s3.amazonaws.com/i/lh04yamv9sai8u9ey8ly.png
---
The [DOM](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Introduction) (Document Object Model) is a representation of a web page. It is a combination of elements that form a HTML document. Thanks to the DOM, programs can change the structure and content of a web document.
You can access HTML elements in a document **by type**, **their attributes** or **using a unique identifier**. In this article we will go over the 4 ways of accessing elements in the DOM.
## Accessing Elements by Unique Identifier (ID)
The most direct way of accessing an element is by using a unique identifier. Since the identifier is unique, this approach will always return a single element.
Let's consider the following snippet of HTML:
```html
<h1 id="title">This is a uniquely identified title</h1>
<div id="content">
...
</div>
```
We can access each of these elements by using the `getElementById` of the `document` object, e.g.
```js
const title = document.getElementById('title');
console.log(title);
```
Once you display that element it will return back the corresponding HTML tag content.
It is important to remember that HTML elements cannot use the same ID twice on the web page.
## Accessing Elements by Class
Another way of accessing elements on a web page is by identifying them via the values of the `class` attribute. Since the `class` values don't have to be unique, this approach allows targeting more than one element at once.
Let's consider the following snippet of HTML:
```html
<ul>
<li class="person">J. C. R. Licklider</li>
<li class="person">Claude Shannon</li>
...
</ul>
```
We can access all the `li` elements at once using the `getElementsByClassName` of the `document` object, e.g.
```js
const pioneers = document.getElementsByClassName('person');
```
The `pioneers` variable is a collection (an array) of HTML elements. Also, note that the `getElementsByClassName` name uses the the plural form (`Elements`). The `getElementById`, however, uses the singular form (`Element` ).
## Accessing Elements by Tag
There is also a way to access elements on a web page by the tag name. This approach is less specific and rarely used in practice as a result.
Let's consider the same snippet of HTML:
```html
<ul>
<li class="person">J. C. R. Licklider</li>
<li class="person">Claude Shannon</li>
...
</ul>
```
We can access all the `li` elements at once using the `getElementsByTagName` of the document object, e.g.
```js
const pioneersAndMore = document.getElementsByTagName('li');
```
This approach will also return a collection (an array) of elements. On top of that it will return each and every `li` tag in the document. If we happen to have another list on that page, but with different classes, this will also return them.
## Accessing Elements by CSS Selector
A [CSS selector](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Selectors) is a codified way to identify various HTML elements on a web page. The IDs must be prefixed with the `#` sign while classes with the `.` sign, e.g. `#title` and `.person` to identify the title and the pioneers from the previous examples. These are the most basic ways for element identification. CSS Selectors are much more powerful than that.
Let's consider the following snippet of HTML:
```html
<h1 id="title">Internet Pioneers</h1>
<ul>
<li class="person">J. C. R. Licklider</li>
<li class="person">Claude Shannon</li>
...
</ul>
```
We can now access both the title and the list elements using the query methods of the `document` object. There is the `querySelector` method to access a single element and `querySelectorAll` to access more than one element:
```js
const title = document.querySelector('#title');
const pioneers = document.querySelectorAll('.person');
```
Also, the `querySelectorAll` returns a **static collection** while all the `getElements*` methods return **live collections**. A live collection will auto-update once there are some changes on the web page (e.g. in response to another JavaScript program adding new elements that match the criteria of those methods).
---
This is a concise introduction to working with HTML using JavaScript. We went over some essential ways of accessing HTML elements on a web page. This should provide a good base and a staring point to the further explore the wonderful world of the web browser.
If you liked this article, consider subscribing to [my YouTube channel](https://www.youtube.com/zaiste). I produce free videos teaching programming in JavaScript, Dart and Flutter. Also, if you'd like to see my new content right away, consider following me [on Twitter](https://twitter.com/zaiste). Till the next time! | zaiste |
211,330 | Trigger local jobs for testing in Jenkins with github | 0.Expose local jenkins to the internet by ngrok Currently in our Jenkins setup, we're deploying and... | 0 | 2019-11-26T11:36:41 | https://dev.to/cuongld2/trigger-local-jobs-for-testing-in-jenkins-with-github-570a | local, jenkins, github, automation | ---
title: Trigger local jobs for testing in Jenkins with github
published: true
description:
tags: #local #jenkins #github #automation
---
0.Expose local jenkins to the internet by ngrok
Currently in our Jenkins setup, we're deploying and working in local machine and not expose this to the internet.
So in order for github can access to the local Jenkins, we would need some tool to expose Jenkins to the outside world.
Here is how it works with ngrok tool.
You can download ngrok tool from the official site: [ngrok site](https://ngrok.com/download)
After download and install, if you want to expose some local site to the outside, you need to specify the port and run the following command:
As in Windows : ngrok.exe http 8080 (example for port 8080 which is default port of Jenkins)
After that, you can use the following example address for working with github: https://27698b0d.ngrok.io
1.Setup webhooks
In order for Jenkins to know when there is any code change in github, you need to set the webhook.
Following is how to do it with github.
First, go to your dev repository → Choose webhooks
Click on Add webhook button, setup as the following:
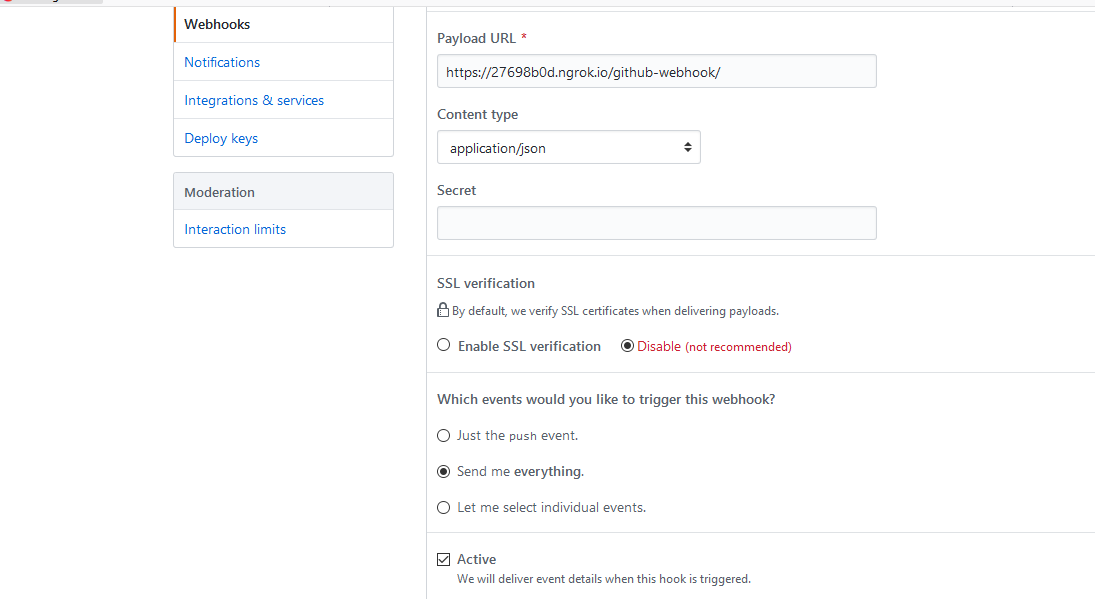
Then choose Add→ If the icon is set to green, you're good to go (big grin)
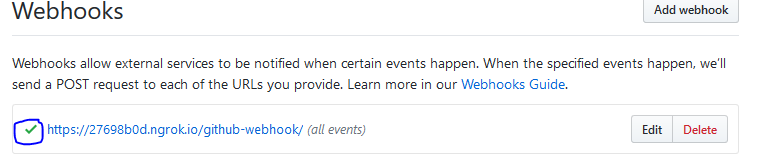
2.Setup job build in Jenkins
Now it comes to Jenkins part.
First, you need to add Jenkins Job → Choose Configure
Set the source code management for git repository like below:
In the build trigger, set github poll for activate job when there is code changed in the repository:
That's it.
Thanks for reading.
Hope this helps. | cuongld2 |
211,362 | Using CSS custom properties to reduce the size of your CSS | Unlike SASS variables, CSS Custom Properties can be modified in class selectors, allowing you to crea... | 0 | 2019-11-26T13:08:52 | https://dev.to/codyhouse/using-css-custom-properties-to-reduce-the-size-of-your-css-4npc | css, tutorial, beginners, webdev | Unlike SASS variables, CSS Custom Properties can be modified in class selectors, allowing you to create abstractions and reduce the size of your CSS.
Let me show you an example!
Here's a quick video tutorial. Jump this section if you prefer to read the article.
{% youtube fQ7ILuIw1z0 %}
In the [CodyHouse Framework](https://codyhouse.co/ds/components), we use the `.grid-gap-{size}` utility classes to set the spacing among grid items:
```scss
.grid {
display: flex;
flex-wrap: wrap;
> * {
flex-basis: 100%;
}
}
.grid-gap-xxxs {
margin-bottom: calc(-1 * var(--space-xxxs));
margin-left: calc(-1 * var(--space-xxxs));
> * {
margin-bottom: var(--space-xxxs);
margin-left: calc(var(--space-xxxs));
}
}
.grid-gap-xxs {
margin-bottom: calc(-1 * var(--space-xxs));
margin-left: calc(-1 * var(--space-xxs));
> * {
margin-bottom: var(--space-xxs);
margin-left: calc(var(--space-xxs));
}
}
.grid-gap-xs {
margin-bottom: calc(-1 * var(--space-xs));
margin-left: calc(-1 * var(--space-xs));
> * {
margin-bottom: var(--space-xs);
margin-left: calc(var(--space-xs));
}
}
.grid-gap-sm {
margin-bottom: calc(-1 * var(--space-sm));
margin-left: calc(-1 * var(--space-sm));
> * {
margin-bottom: var(--space-sm);
margin-left: calc(var(--space-sm));
}
}
.grid-gap-md {
margin-bottom: calc(-1 * var(--space-md));
margin-left: calc(-1 * var(--space-md));
> * {
margin-bottom: var(--space-md);
margin-left: calc(var(--space-md));
}
}
.grid-gap-lg {
margin-bottom: calc(-1 * var(--space-lg));
margin-left: calc(-1 * var(--space-lg));
> * {
margin-bottom: var(--space-lg);
margin-left: calc(var(--space-lg));
}
}
.grid-gap-xl {
margin-bottom: calc(-1 * var(--space-xl));
margin-left: calc(-1 * var(--space-xl));
> * {
margin-bottom: var(--space-xl);
margin-left: calc(var(--space-xl));
}
}
.grid-gap-xxl {
margin-bottom: calc(-1 * var(--space-xxl));
margin-left: calc(-1 * var(--space-xxl));
> * {
margin-bottom: var(--space-xxl);
margin-left: calc(var(--space-xxl));
}
}
.grid-gap-xxxl {
margin-bottom: calc(-1 * var(--space-xxxl));
margin-left: calc(-1 * var(--space-xxxl));
> * {
margin-bottom: var(--space-xxxl);
margin-left: calc(var(--space-xxxl));
}
}
```
Because there's a lot of repetition, a few weeks ago, we've decided to use CSS custom properties to simplify these classes.
The first step was creating an abstraction that contains the code we repeat for each utility class:
```scss
[class*="grid-gap"] {
margin-bottom: calc(-1 * var(--grid-gap, 1em));
margin-left: calc(-1 * var(--grid-gap, 1em));
> * {
margin-bottom: var(--grid-gap, 1em);
margin-left: var(--grid-gap, 1em);
}
}
```
This attribute selector looks for classes that contain the "grid-gap" string (all the grid-gap utility classes). Note that we've replaced the `--space-unit` variables with a new `--grid-gap` variable.
In our `.grid` class, we set the `--grid-gap` variable equal to 0 (default value).
```scss
.grid {
--grid-gap: 0px;
display: flex;
flex-wrap: wrap;
> * {
flex-basis: 100%;
}
}
```
Now we can modify, for example, the `.grid-gap-xxxxs` class as the following:
```scss
.grid-gap-xxxxs { --grid-gap: var(--space-xxxxs); }
```
We no longer need all the chunk of code about margins; we can just modify the value of the `--grid-gap` variable.
If we do the same for all the utility classes, we end up with the following:
```scss
.grid {
--grid-gap: 0px;
display: flex;
flex-wrap: wrap;
> * {
flex-basis: 100%;
}
}
[class*="grid-gap"] {
margin-bottom: calc(-1 * var(--grid-gap, 1em));
margin-left: calc(-1 * var(--grid-gap, 1em));
> * {
margin-bottom: var(--grid-gap, 1em);
margin-left: var(--grid-gap, 1em);
}
}
.grid-gap-xxxxs { --grid-gap: var(--space-xxxxs); }
.grid-gap-xxxs { --grid-gap: var(--space-xxxs); }
.grid-gap-xxs { --grid-gap: var(--space-xxs); }
.grid-gap-xs { --grid-gap: var(--space-xs); }
.grid-gap-sm { --grid-gap: var(--space-sm); }
.grid-gap-md { --grid-gap: var(--space-md); }
.grid-gap-lg { --grid-gap: var(--space-lg); }
.grid-gap-xl { --grid-gap: var(--space-xl); }
.grid-gap-xxl { --grid-gap: var(--space-xxl); }
.grid-gap-xxxl { --grid-gap: var(--space-xxxl); }
.grid-gap-xxxxl { --grid-gap: var(--space-xxxxl); }
```
This optimization reduces the CSS size of this example by more than half! Obviously, you can apply this technique only when it's possible to abstract some rules (I'm not suggesting that CSS custom properties will reduce by half the size of your CSS). But still, this tutorial is just an example of code optimization made possible by using CSS variables.
ps: CSS Variables are supported in [all modern browsers](https://caniuse.com/#feat=css-variables).
Originally published at [CodyHouse.co](https://codyhouse.co/blog/post/using-css-custom-properties-to-reduce-the-size-of-your-css) | guerriero_se |
211,367 | Promise flow: An in-depth look at then and catch | Promises are one way in which you can handle asynchronous operations in JavaScript. Today we are goin... | 0 | 2019-11-26T13:54:42 | https://dev.to/savagepixie/promise-flow-an-in-depth-look-at-then-and-catch-4gpf | javascript, promises, asynchronous | Promises are one way in which you can handle asynchronous operations in JavaScript. Today we are going to look at how the promise methods `then` and `catch` behave and how the information flows from one another in a chain.
I think one of the strengths of promise syntax is that it is very intuitive. This is a slightly modified version of a function I wrote to retrieve, modify and re-store information using [React Native's community Async Storage](https://github.com/react-native-community/async-storage):
```javascript
const findAndRemoveOutdated = (key) => AsyncStorage.getItem(key)
.then(data => data != null ? JSON.parse(data).items : [])
.then(items => items.filter(x => new Date(x.date) >= Date.now()))
.then(items => ({ items }))
.then(JSON.stringify)
.then(items => AsyncStorage.setItem(key, items))
```
Even if you don't know how Async Storage works, it's reasonably easy to see how the data flows from one `then` to the next one. Here's what's happening:
1. `AsyncStorage.getItem()` is fetching the value associated to `key`, which is a stringified JSON. (The data stored has this shape: `{ items: [{ date, ... }, { ... }, ... ]}`)
2. If the query doesn't return `null`, we parse the JSON and return it as an array. Otherwise we return an empty array.
3. We filter the returned array and keep only the items whose `date` is greater than or equal to now.
4. We create an object and assign the filtered array to its `items` property.
5. We stringify the object.
6. We save the new object in place of the old one.
So it is pretty intuitive. It reads like a list of steps manage the data, which it's what it is really. But while a bunch of `then`s is relatively easy to follow, it might get a bit more complicated when `catch` is involved, especially if said `catch` isn't at the end of the chain.
## An example of promise
For the rest of the article, we are going to work with an asynchronous function that simulates a call to an API. Said API fetches ninja students and sends their id, name and grade (we will set an object with a few students to use). If there are no students found, it sends `null`. Also, it's not a very reliable API, it fails around 15% of the time.
```javascript
const dataToReturn = [{ //Our ninja students are stored here.
id: 1,
name: 'John Spencer',
grade: 6,
},{
id: 2,
name: 'Tanaka Ike',
grade: 9,
},{
id: 3,
name: 'Ha Jihye',
grade: 10,
}]
const asyncFunction = () => new Promise((resolve, reject) => {
setTimeout(() => {
const random = Math.random()
return random > 0.4 //Simulates different possible responses
? resolve(dataToReturn) //Returns array
: random > 0.15
? resolve(null) //Returns null
: reject(new Error('Something went wrong')) //Throws error
}, Math.random() * 600 + 400)
})
```
If you want to get a hang of what it does, just copy it and run it a few times. Most often it should return `dataToReturn`, some other times it should return `null` and on a few occasions it should throw an error. Ideally, the API's we work in real life should be less error prone, but this'll be useful for our analysis.
## The basic stuff
Now we can simply chain `then` and `catch` to do something with the result.
```javascript
asyncFunction()
.then(console.log)
.catch(console.warn)
```
Easy peasy. We retrieve data and log it into the console. If the promise rejects, we log the error as a warning instead. Because `then` can accept two parameters (`onResolve` and `onReject`), we could also write the following with the same result:
```javascript
asyncFunction()
.then(console.log, console.warn)
```
## Promise state and `then`/`catch` statements
I wrote in a previous article that [a promise will have one of three different states](https://dev.to/savagepixie/promises-in-javascript-3j60#how-to-create-a-promise). It can be `pending` if it is still waiting to be resolved, it can be `fulfilled` if it has resolved correctly or it can be `rejected` if something has gone wrong.
When a promise is `fulfilled`, the program goes onto the next `then` and passes the returned value as an argument for `onResolve`. Then `then` calls its callback and returns a new promise that will also take one of the three possible states.
When a promise is `rejected`, on the other hand, it'll skip to the next `catch` or will be passed to the `then` with the `onReject` parameter and pass the returned value as the callback's argument. So all the operations defined between the rejected promise and the next `catch`<sup>[1](#myfootnote1)</sup> will be skipped.
### A closer look at `catch`
As mentioned above, `catch` catches any error that may occur in the execution of the code above it. So it can control more than one statement. If we were to use our `asyncFunction` to execute the following, we could see three different things in our console.
```javascript
asyncFunction()
//We only want students whose grade is 7 or above
.then(data => data.filter(x => x.grade >= 7))
.then(console.log)
.catch(console.warn)
```
- If everything goes all right, we will see the following array:
```
{
id: 2,
name: 'Tanaka Ike',
grade: 9,
},{
id: 3,
name: 'Ha Jihye',
grade: 10,
}
```
- If `asyncFunction` rejects and throws an error, we'll see `Error: "Something went wrong"`, which is the error we defined in the function's body.
- If `asyncFunction` returns `null`, the promise will be `fulfilled`, but the next `then` cannot iterate over it, so it will reject and throw an error. This error will be caught by our `catch` and we'll see a warning saying `TypeError: "data is null"`.
But there's more to it. Once it has dealt with the rejection, `catch` returns a new promise with the state of `fulfilled`. So if we were to write another `then` statement after the `catch`, the `then` statement would execute after the `catch`. So, if we were to change our code to the following:
```javascript
asyncFunction()
//We want to deal with the error first
.catch(console.warn)
//We still only want students whose grade is 7 or above
.then(data => data.filter(x => x.grade >= 7))
.then(console.log)
```
Then we could still see three different things in our console, but two would be slightly different:
- If `asyncFunction` returns `null`, we will still see the message `TypeError: "data is null"`, but this time it will be logged as an error instead of a warning, because it fired after the `catch` statement and there was nothing else to control it.
- If `asyncFunction` returns an error, `catch` will still handle it and log it as a warning, but right below it we'll see an error: `TypeError: "data is undefined"`. This happens because after it deals with the error, `catch` returns `undefined` (because we haven't told it to return anything else) as the value of a `fulfilled` promise.
Since the previous promise is `fulfilled`, `then` tries to execute its `onResolve` callback using the data returned. Since this data is `undefined`, it cannot iterate over it with filter and throws a new error, which isn't handled anywhere.
Let's now try to make our `catch` return something. If `asyncFunction` fails, we'll use an empty array instead.
```javascript
asyncFunction()
.catch(error => {
console.warn(error)
return []
})
.then(data => data.filter(x => x.grade >= 7))
.then(console.log)
```
Now, if the call to `asyncFunction` rejects, we will still see the warning in our console, but it'll be followed by an empty array instead of a type error. The empty array that it returns becomes the `data` that the following `then` filters. Since it is an array, the `filter` method works and returns something.
We still have the possible error if `asyncFunction` returns `null`, though. So let's deal with it:
```javascript
asyncFunction()
.catch(error => {
console.warn(error)
return []
})
.then(data => data.filter(x => x.grade >= 7))
.catch(error => {
console.warn(error)
return []
})
.then(console.log)
```
We've just copied the same `catch` statement and pasted it after the filtering `then`. Now, if an error occurs on either promise, we will see it logged as a warning (either as a type error or as our custom error) and an empty array logged under it. That is because our `catch` statements have dealt with all errors and returned `fulfilled` promises, so the `then` chain continues until it's time to log it in the console.
In fact, while we're at it, we might realise that the first `catch` is superfluous. It's doing the exact same thing as the second one and the result of filtering an empty array is always an empty array, so it doesn't really matter if the empty array returned by it gets filtered or not. So we can just dispose of it.
```javascript
asyncFunction()
.then(data => data.filter(x => x.grade >= 7))
.catch(error => {
console.warn(error)
return []
})
.then(console.log)
```
If we wanted, instead we could do some different error handling. We could feed it fake data (not advisable in real production), try fetching data from another API, or whatever our system requires.
## Conclusion
Whenever a promise is resolved, the runtime will execute the following `then` and `catch` statements depending on the promise's state.
- A `fulfilled` promise will trigger the next `then(onResolve)`. This `then` will return a new promise that will either be `fulfilled` or `rejected`.
- A `rejected` promise will jump straight to the next `catch` or `then(..., onReject)` statement. In turn, it will return a new promise. Unless the code in `catch` causes it to reject, the newly returned promise will allow any `then` statements below it to be executed normally.
---
<a name="myfootnote1">1</a>: From now on, I will only refer to `catch` as a method to handle errors, because it is more common. Know that anything that I say about `catch` also works for `then` when an `onReject` callback is passed to it. | savagepixie |
211,398 | Launching - Tech Video Podcast 🎤 🎧 📹 ! Made with ❤️ in Berlin, Germany 🇩🇪 | Hello world and Hello Everyone 👋 Wow, I am super excited to announce this 😱 Winter is coming with... | 0 | 2019-11-26T14:02:27 | https://dev.to/destrodevshow/launching-tech-vidoe-podcast-made-with-in-berlin-germany-1j05 | javascript, react, podcast, csharp | Hello world and Hello Everyone :wave:
<h4>Wow, I am super excited to announce this 😱 </h4>
Winter is coming with Darkness and sadness 😰
And in this Winter, I am planning to start a Podcast 🎤 to make the Winter a bit better :heart:
We will go LIVE on Youtube so that every one of you can interact in realtime and ask questions on the go.
[<h3>Please SUBSCRIBE to the Youtube Channel here :point_right:</h3>](https://www.youtube.com/channel/UCy5EgfydCQlVv_AM-FZyYcg)
{% youtube PtaziLK3xZE %}
[<h3>Please also LIKE the Facebook Page here :point_right:</h3>](https://www.facebook.com/the.destro.dev.show/)
| destro_mas |
211,427 | On.NET Episode: Exploring the new Azure .NET SDKs for .NET | In this episode, we're joined by Adrian and Alex from the Azure SDK team who have come to talk to us... | 0 | 2019-11-26T15:49:10 | https://dev.to/dotnet/on-net-episode-exploring-the-new-azure-net-sdks-for-net-30c5 | dotnet, azure, cloud, programming | In this episode, we're joined by Adrian and Alex from the Azure SDK team who have come to talk to us about the new iteration of Azure SDKs they've been working on. They'll discuss things like what's different with this batch of SDKs, support for distributed tracing, and even give us a demo of what the .NET SDK looks like.
{% youtube Hxne-iM1CtI %}
If you liked this video and would like to see some more of our .NET content, please subscribe to our [.NET Developers YouTube Channel](https://www.youtube.com/channel/UCvtT19MZW8dq5Wwfu6B0oxw).
## Useful Links
* [Azure SDK Releases](https://azure.github.io/azure-sdk/index.html?WT.mc_id=ondotnet-c9-cephilli)
* [Previewing Azure SDKs following new Azure SDK API Standards](https://azure.microsoft.com/blog/previewing-azure-sdks-following-new-azure-sdk-api-standards/?WT.mc_id=ondotnet-c9-cephilli)
* [OpenTelemetry](https://opentelemetry.io/)
* [Azure Monitor Docs](https://docs.microsoft.com/azure/azure-monitor/overview?WT.mc_id=ondotnet-c9-cephilli) | cecilphillip |
211,459 | Do you need GraphQL with Django? | Written by Tigran Bayburtsyan✏️ For the past 5 years, Django has been the most effective framework... | 0 | 2019-12-01T19:42:39 | https://blog.logrocket.com/do-you-need-graphql-with-django/ | graphql, javascript, django, productivity | ---
title: Do you need GraphQL with Django?
published: true
date: 2019-11-26 17:00:41 UTC
tags: graphql,javascript,django,productivity
canonical_url: https://blog.logrocket.com/do-you-need-graphql-with-django/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/f89t5ufu9brp45703r8a.png
---
**Written by [Tigran Bayburtsyan](https://blog.logrocket.com/author/tigran-bayburtsyan/)**✏️
For the past 5 years, Django has been the most effective framework for making quick web applications, API Endpoints, or Admin panels for other applications.
One of the biggest advantages of Django is its ability to enable users to write less code and get started quicker, especially if you’re including an admin panel and a fully-manageable database migration process as base functionality.
Django Rest Framework—an external toolkit—makes it easy to build API endpoints. It basically wraps full CRUD API around the Django Model with just a few lines of code.
This means that building any basic CRUD API with Django helps to keep more of a development focus on UI parts, which are key elements of all software products.
Similarly, GraphQL aims to automate backend APIs by providing type strict query language and a single API Endpoint where you can query all information that you need from UI and trigger actions (mutations) to send data to the backend.
My journey with GraphQL started with Facebook’s API, where GraphQL comes from.
Naturally, GraphQL is considered to be very close to the JavaScript world, mostly because browser-based apps are the first adopters of that technology.
That’s why my first GraphQL server+client was done in Node.js and React.js. After having the first app built on top of GraphQL API, I started to use it exclusively for my Web-based projects.
[](https://logrocket.com/signup/)
### Advantages of GraphQL
As you may have guessed, there is a library for Django to support GraphQL called Graphene Django, which is very similar to the Django Rest Framework.
However, there are significant differences between Django Rest and Django with GraphQL.
The key difference lies in UI usability: with Rest API, you’re getting endless URLs with specific parameter names where you have to check types and specific values.
Meanwhile, with GraphQL you’re defining mutation similar to the code below and getting strictly defined variable names and types, which become part of an automatic GraphQL type validation.
```jsx
type Mutation {
userLogin(email: String!, password: String!): UserLoginResponse
}
type UserLoginResponse {
token: String
error: Boolean
message: String
}
```
GraphQL also comes with another bonus packaged inside its type system. It automatically generates documentation where you can get available queries and mutations with their parameters/return types.
Django Rest also generates some form of documentation, but it is not as usable as the GraphQL Playground displayed below.
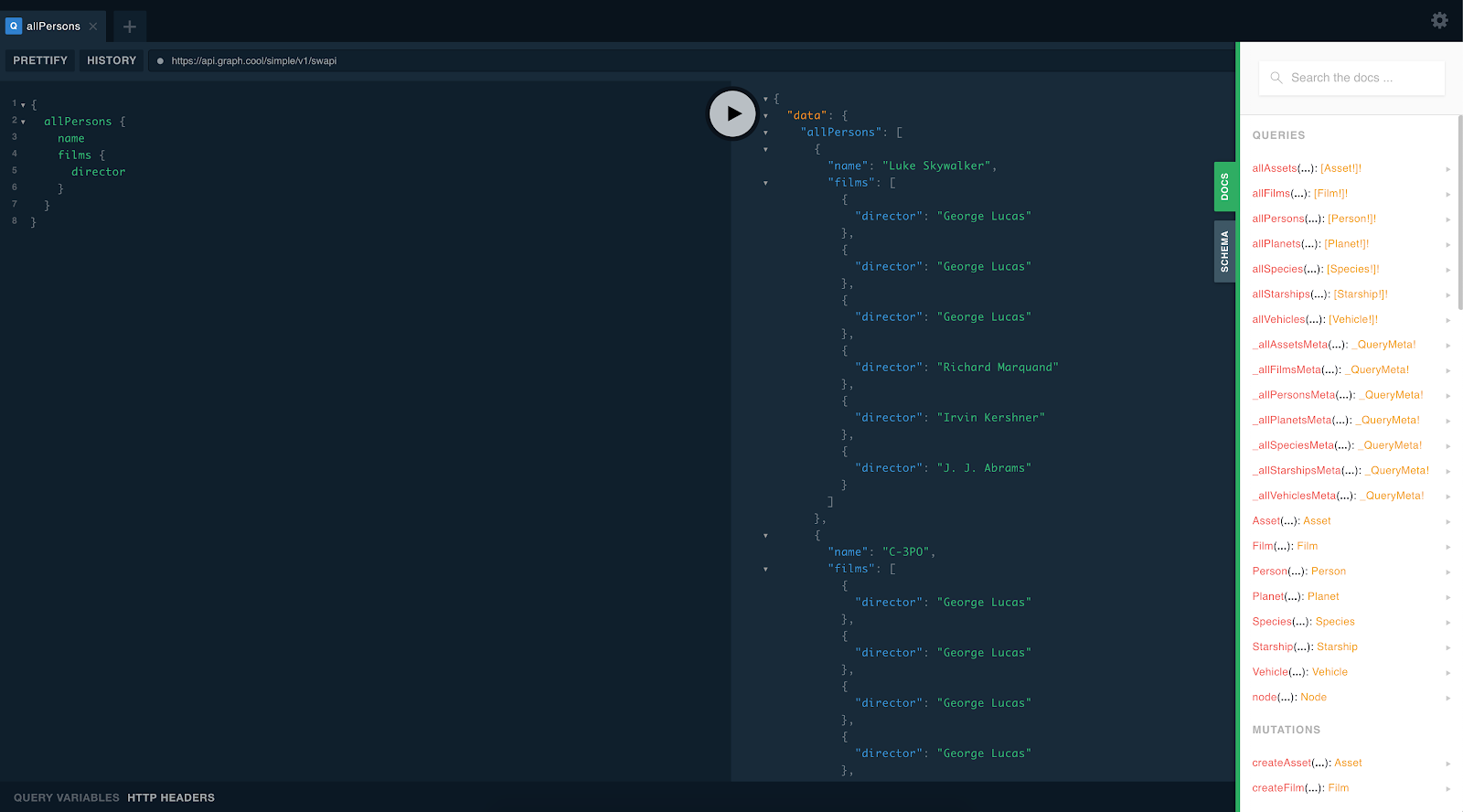
If you think this type of interface is available for all kinds of GraphQL endpoints, you’re wrong — this is only available in development mode servers.
In terms of security, having one API Endpoint is naturally more manageable than having hundreds of them—especially when you consider the fact that GraphQL automatically keeps specific type rules and won’t allow requests with incorrect parameter names or values.
### Django [❤](https://s.w.org/images/core/emoji/12.0.0-1/72x72/2764.png) GraphQL
Let’s make a basic setup with Django and GraphQL just to demonstrate how powerful this setup can be. On one hand, you’re getting easy CRUD management with database. On the other hand, you’re getting a very powerful API query language with a single endpoint.
Installation should be very easy. Just follow the steps defined here: [https://github.com/graphql-python/graphene-django](https://github.com/graphql-python/graphene-django)
The interesting parts are defining GraphQL types and queries in Python. It’s actually based on your database models, but you can also define custom queries without using Django Models.
```jsx
# schema.py
from graphene_django import DjangoObjectType
import graphene
from .models import Post as PostModel
from .models import User as UserModel
class Post(DjangoObjectType):
class Meta:
model = PostModel
interfaces = (relay.Node,)
@classmethod
def get_node(cls, info, id):
return Post.objects.get(id=id)
class User(DjangoObjectType):
class Meta:
model = UserModel
interfaces = (relay.Node,)
posts = graphene.List(Post)
def resolve_users(self, info):
return Post.objects.filter(user=self)
@classmethod
def get_node(cls, info, id):
return User.objects.get(id=id)
class Query(graphene.ObjectType):
users = graphene.List(User)
def resolve_users(self, info):
return UserModel.objects.all()
schema = graphene.Schema(query=Query)
```
Now you can very easily query all users with their posts.
The most important thing to remember is that you can query fields you want, which will affect the overall load time and traffic usage on the UI side.
For larger user bases, it’s important to keep traffic low and only query the fields you need. In the case of Rest API, you will get all fields anyway.
```jsx
query {
users {
name
posts {
id
title
content
}
}
}
```
This is the basic query outcome from the Python definition, which is pretty simple and — compared to Rest API — more expressive than you may think.
### What about GraphQL Subscriptions?
GraphQL Subscriptions function as a way to tell the server to retrieve data based on a specific query whenever the data is available.
It all works with WebSockets in near-real time, which means we have to somehow include Django Websockets and configure our backend server for accepting WebSockets.
Basically, GraphQL is just an API query language interpretation that works with any kind of network transportation when handling client and server-side GraphQL language interpretation.
It may seem difficult at first, but there’s an open-source library and Django GraphQL Subscriptions over at the [Django Websockets module](https://github.com/eamigo86/graphene-django-subscriptions).
```jsx
# settings.py
GRAPHENE = {
'SCHEMA_INDENT': 4,
'MIDDLEWARE': [
# Others middlewares
'graphene_django_subscriptions.depromise_subscription',
]
}
```
This will be enough to handle the subscription schema later on as a Subscription query.
A quick aside: Pinterist actually works entirely on GraphQL Subscriptions, which is all built on top of Django Backend (but probably modified a lot.)
### Conclusion
In my opinion, Django with GraphQL is more powerful and extensible than Django with Rest API.
However, it isn’t battle-tested and large companies are still in the process of adopting this kind of combination, but based on what you can get out of this simple configuration, imagine how much more comfortable web development will be when you use Django with GraphQL with modern technologies.
* * *
**Editor's note:** Seeing something wrong with this post? You can find the correct version [here](https://blog.logrocket.com/do-you-need-graphql-with-django/).
## Plug: [LogRocket](https://logrocket.com/signup/), a DVR for web apps

[LogRocket](https://logrocket.com/signup/) is a frontend logging tool that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
[Try it for free](https://logrocket.com/signup/).
* * *
The post [Do you need GraphQL with Django?](https://blog.logrocket.com/do-you-need-graphql-with-django/) appeared first on [LogRocket Blog](https://blog.logrocket.com). | bnevilleoneill |
211,541 | Making Fetch Happen: Replacing Native Plugins with Web APIs | Whenever I need to add a native device feature to an Ionic app, my first instinct is to reach for a n... | 0 | 2019-12-20T16:07:06 | https://ionicframework.com/blog/replacing-native-plugins-with-web-apis/ | webdev, javascript, pwa, cordova | ---
title: Making Fetch Happen: Replacing Native Plugins with Web APIs
published: true
date: 2019-11-26 18:42:17 UTC
tags: webdev, javascript, pwa, Cordova,
canonical_url: https://ionicframework.com/blog/replacing-native-plugins-with-web-apis/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/t79qnu47nys237444w4d.png
---
Whenever I need to add a native device feature to an Ionic app, my first instinct is to reach for a native plugin first. However, a built-in browser [Web API](https://developer.mozilla.org/en-US/docs/Web/API) could be the better alternative, offering the same feature set as well as improved performance and reduced maintenance cost.
## Web API Benefits
There are several benefits to using a Web API over a native plugin, including:
* <strong>Reduce app bloat:</strong> By design, native plugins bring in additional code to a project, increasing app download size for your users. A Web API, however, is already available.
* <strong>Increase app performance:</strong> Less plugin code leads to better overall performance. This is especially a factor in app startup timing, where most plugins are initialized and loaded into memory.
* <strong>Reduce app maintenance:</strong> Web APIs are less likely to degrade over time as new mobile operating system updates are released. Browser vendors regularly ship critical security updates as well - no action required by you or your app users.
* <strong>Faster development cycles:</strong> Less reliance on native plugins decreases the need to test on device hardware, which slows down development. That’s what makes `ionic serve` so powerful - build your entire app locally in the browser, then test on a device towards the end of the development cycle.
* <strong>Better cross-platform support:</strong> Web APIs make it easier to bring your app to more platforms. For example, the ability to deploy an iOS or Android app as a PWA.
<!--more-->
## A Real World Example: Switching from File Plugin to Fetch API
There’s an easier way to read a file on a device, which potentially replaces the need for the [Cordova File plugin](https://ionicframework.com/docs/native/file) entirely, by using the [Fetch Web API](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API).
<a href="https://blog.ionicframework.com/wp-content/uploads/2019/11/mean-girls-fetch-happen.png"><img src="https://blog.ionicframework.com/wp-content/uploads/2019/11/mean-girls-fetch-happen.png" alt="" class="aligncenter size-full wp-image-3027" /></a>
This is particularly useful when paired with the Cordova Camera plugin:
```typescript
// Capture photo using the device camera
const tempPhoto = await this.camera.getPicture(options);
// Convert from file:// protocol to WebView safe one (avoid CORS)
const webSafePhoto = this.webview.convertFileSrc(tempPhoto);
// Retrieve the photo image data
const response = await fetch(webSafePhoto);
```
I discovered this while building an encrypted image [demo app](https://github.com/ionic-team/demo-encrypted-image-storage). The demo’s main goal was to save an image captured from the device camera into [Ionic Offline Storage](https://ionicframework.com/docs/enterprise/offline-storage). The challenge was that Offline Storage required the image data to be stored as an array buffer, a data format that the Camera plugin didn’t provide.
One solution was to use the Cordova File plugin. This felt clunky and confusing to understand. To make it work, I had to use the File plugin to read the photo file into a `FileEntry` object, then convert it into a `Blob`, then into an `ArrayBuffer`:
```typescript
import { File } from '@ionic-native/file/ngx';
public async saveCameraPhoto() {
const options: CameraOptions = {
quality: 100,
destinationType: this.camera.DestinationType.FILE_URI,
encodingType: this.camera.EncodingType.JPEG,
mediaType: this.camera.MediaType.PICTURE
}
const tempPhoto = await this.camera.getPicture(options);
let fileEntry = await this.file.resolveLocalFilesystemUrl(tempPhoto) as any;
fileEntry.file((file) => {
const fileReader = new FileReader();
fileReader.onloadend = () => {
let blob = new Blob("image/jpeg", fileReader.result as ArrayBuffer);
const imageDoc = new MutableDocument(“doc”);
imageDoc.setBlob(“blob”, blob);
await this.database.save(imageDoc);
}
fileReader.readAsArrayBuffer(file);
});
}
```
In contrast, using the Fetch API only required a couple of lines of code.
```typescript
const response = await fetch(webSafePhoto);
const photoArrayBuffer = await response.arraybuffer();
```
The complete example:
```typescript
public async takePicture() {
const options: CameraOptions = {
quality: 100,
destinationType: this.camera.DestinationType.FILE_URI,
encodingType: this.camera.EncodingType.JPEG,
mediaType: this.camera.MediaType.PICTURE
}
const tempPhoto = await this.camera.getPicture(options);
const webSafePhoto = this.webview.convertFileSrc(tempPhoto);
const response = await fetch(webSafePhoto);
// Different data response options:
const photoBlob = await response.blob();
const photoArrayBuffer = await response.arraybuffer();
}
```
Cleaner, simpler code that accomplished exactly what I needed. 🤓
## Is a Web API the Right Choice for My App?
While there are many benefits to using a Web API over a native plugin, take some time to evaluate the situation based on your app’s needs. Considerations include:
* <strong>Functionality:</strong> Chances are high that the Web API’s features will differ from the plugin’s. If requirements change in the future, will the Web API be able to cover them? In my Fetch API example, it only retrieves data, so it’s not a complete replacement for the File plugin. If I needed to write a File, I’d go back to using the plugin.
* <strong>Performance:</strong> Web APIs are generally very performant given they are built into the browser. It still makes sense to test as needed, though.
* <strong>Platform Support:</strong> Is the Web API available to my users today, as well as any additional platforms I may support in the future?
Fortunately, checking platform support is easy thanks to two sites:
* [WhatWebCanDo.Today](https://whatwebcando.today/) describes the features of all APIs available.
* [CanIUse.com](https://caniuse.com) covers browser support for each API.
I recommend beginning your search on `WhatWebCanDo.Today` to determine exactly which APIs you might leverage, then do more research on `CanIUse.com` to ensure the API will be available and fully supported on all of the platforms you’re interested in.
Using Fetch as an example, we can see that [it has wide support](https://caniuse.com/#feat=fetch) across all browsers. As Ionic developers targeting iOS and Android, pay close attention to both iOS Safari and Android Browser support:
<a href="https://blog.ionicframework.com/wp-content/uploads/2019/11/real-world-debug-caniusefetch.png"><img src="https://blog.ionicframework.com/wp-content/uploads/2019/11/real-world-debug-caniusefetch.png" alt="caniuse.com - fetch" class="aligncenter size-full wp-image-3024" /></a>
In this case, support began in iOS 10 (10.3) and Android 5 (Chromium 76), so should be safe to use in an Ionic app.
## Web API First
The uniquely powerful benefit of web-based hybrid apps is the ability to leverage both web and native technology as needed.
While every app’s needs are different, explore Web API options first before reaching for a plugin. Though not for everyone, you might be pleasantly surprised at how far they can get you. For more interesting Web API examples, check out my Ionic Native [encrypted storage demo app](https://github.com/ionic-team/demo-encrypted-image-storage).
What are some creative ways you’ve used native web APIs recently? Or plugins you’ve replaced in favor of a web API? Share your insights below.
| dotnetkow |
211,575 | My reflections on Andela’s EPIC values | For the first time I heard Andela’s EPIC values (Excellence Passion Integrity and Collaboration), I w... | 0 | 2019-11-26T21:11:55 | https://dev.to/christelleter24/my-reflections-on-andela-s-epic-values-1b7g | For the first time I heard Andela’s EPIC values (Excellence Passion Integrity and Collaboration), I was just understanding them as they are. In the first two weeks of home study, I started to realize how Andela’s EPIC works, and how they should be implemented. Most of the time many people finish and submit works because it has to be completed. This is also true, but the key points to keep in mind is that what will be the output or result of the work, how long will it be used?
The way I take Andela excellence in the EPIC values is the mindset of having the big image of the work that you are working on and implement it by thinking about the final result. That time the quality of your work will meet the standards needed for your deliverable. Again this EPIC means that you are identifying the areas that you are good at, which shows you where you could be improved for the next iteration of the work. If you allow yourself to just do what is on your to-do list, it will be harder to find the time to think and have the big picture of your work.
Passion, passion could be defined as sacrificing your time and leave your comfort zone, and do what you are passioning about. If you are doing that, it’s your real passion, and if not, probably it’s not your real passion. You need to start making changes in your passion. I do believe that you can have passion to do something that you have never tried to do, but that belief will help you to make it the time that you will be having access to materials or resources in those particular areas you are passionate about. And it is normal that someone can fail for the first time while trying to do something, but that will be a part of learning.
Integrity means doing the right things in a good way, not because somebody is watching you, just because it’s how things are supposed to be. It's a personality that needed by everyone to deliver complete work with all requirements for it to be perfect. This is also another important thing that I found at Andela, where they set requirements for you, and then you do your best to include some additional functionality that did not capture on the to-do list. This is the best practice to make culture so that anyone who works with you will wish again to come back.
Collaboration is another key to deliver a good quality of the work, it is not just a simple work or event that happens and reaches to the end. Collaboration is a process that continues over time. The more team collaborate, the more quality of quality will be increased. A team that works hard it also motivates each member of the team. This helps everyone in a team to learn from each other, relationships become more comfortable, where everyone will be able to share and discuss ideas. At this point, results will be increasingly successful.
To sum up, if every person tries to follow the above Andela’s EPIC values, she/he will a better candidate that can work with any kind of diversity and also be productive.
| christelleter24 | |
211,684 | How And When To Use Git Reset | Most of us avoid dreaded git reset command — but actually it can be really useful, as long a... | 0 | 2019-11-26T23:19:58 | https://dev.to/char_bone/how-and-when-to-use-git-reset-2om6 | git, github, tutorial, webdev | #### Most of us avoid dreaded git reset command — but actually it can be really useful, as long as you know how it works!
### What does git reset do?
To put it simply, git reset will take your branch back to a certain point in the commit history, but there are 3 different levels to this:
* **soft**: Moves the **head** back to the commit specified but leaves all the updated files in the index and working directory —*all of the files after the commit that you’ve moved to have been tracked (like doing git add) and are ready to be committed as a new commit.*
* **mixed**: Moves the **head** and **index** back to the commit specified but leaves the files in the working directory — *all of the files after the commit are in your working directory as untracked files. If you add them all now, you’ll be at the same stage as a soft reset above.*
* **hard**: Moves the **head, index and working** directory back to the commit specified — *all of the updated files after the commit specified are now ***GONE***!!! (uncommitted files are unrecoverable at this point)*
### Why would you need this?
Here are a few examples so that you will have a better idea of when to use each. You should only ever do this on your own branch, or when you're sure no one has already pulled any of the commits that you will be removing.
#### Soft
Let’s say you have done a few tiny commits and you want them to all be put into 1 more descriptive commit.
A -> B -> C -> D
``` git reset — soft A```
Your branch head is now pointing at A
``` git commit -m “my new merged commit”
git push origin branch --force-with-lease```
We now have a new commit, E but it contains all of the files that were committed in B, C, D. Note: the force-with-lease flag is because otherwise git will complain that your local branch is behind the remote. (This is a safer version of force)
A->E
#### Mixed
You’ve just pushed a few commits, but you want to go back and remove a couple of files in a previous commit.
A->B->C
``` git reset --mixed A```
Your branch head and index is pointing at A
``` git status```
This will show that all of your changes in B and C are there, but are untracked
Now you are free to add the files that you wish to add into a new commit
``` git add <files> git commit -m "updated commit"
git push origin branch --force-with-lease```
A->D
Your head is now at the new commit D, and any files that you’ve not staged will still be in your working tree, ready to add into another commit or to do what you want with.
#### Hard
When would you possibly want this? Usually when things have gone wrong because it’s VERY RISKY. I’ll talk you through a scenario where I’ve needed it.
I’ve been working on my own branch, testing out a feature and I’ve changed many files, but it’s been a fail and I want to go back a few commits and get rid of every change I’ve made since.
If I’ve not made any commits or pushed any commits. I can just reset back to commit A and my working directory is now clear, all of my updated files are gone from history.
``` git reset --hard A```
If I’ve actually pushed these commits to my remote branch, then, before doing this, you need to **make sure that no one is working from those commits** because they will be orphaned. But if you know that it’s safe to do, then run the command above. The only difference here is that you will need to do a FORCED push afterwards to push the remote branch to that state, otherwise it will tell you that your local branch is behind.
``` git reset --hard A
git push origin branchname --force-with-lease```
This will delete your commits from the remote branch history, so you can see it could be very dangerous.
I have used this to get me out of reverted merge commit hell recently. I did a pull request to merge a branch into another branch, it had merge conflicts and the conflicts were not resolved correctly, so I reverted the merge. This however meant I couldn’t do the pull request again because it saw no updates, so I tried to revert that and it ended up in a bit of a mess. I then used git reset --hard to take the branches back to before this situation and get rid of these ugly reverts in the history!
#### Hopefully now you will see that git reset is very powerful and can help you in some situations, used with care!
[Originally posted on Medium](https://medium.com/charlottes-digital-web/how-and-when-to-use-git-reset-ec8088e0c811) | char_bone |
211,715 | On Substitution | I just wanted to share with you a cool tip I discovered along my journey to cut meat from my diet. T... | 0 | 2019-11-27T01:42:24 | https://dev.to/danieljaouen/on-substitution-5868 | productivity | I just wanted to share with you a cool tip I discovered along my journey to cut meat from my diet. That tip is called "substitution". It goes like this:
1. What I *think* I want is X.
2. What I *really* want is Y.
3. Therefore, substitute Z for X.
A few examples:
1. What I *think* I want is meat.
2. What I *really* want is protein.
3. Therefore, substitute Beyond Burgers for meat.
Or:
1. What I *think* I want is soda.
2. What I *really* want is hydration.
3. Therefore, substitute tea for soda.
That's it. Enjoy! | danieljaouen |
211,741 | A coding interview question asked at Google | Hey everyone! Hope you enjoyed solving last week’s challenge. In case you haven’t seen it, I’ll link... | 3,430 | 2019-12-02T04:50:36 | https://dev.to/coderbyte/a-google-coding-interview-question-4h0f | career, codenewbie, javascript, challenge | Hey everyone! Hope you enjoyed solving last week’s challenge. In case you haven’t seen it, I’ll link last week’s article so you can go check it out.
[The article](https://dev.to/coderbyte/a-common-coding-interview-question-461f)
[The challenge on Coderbyte](https://coderbyte.com/editor/Find%20Intersection:JavaScript?utm_source=Dev.to&utm_medium=Article&utm_campaign=CodeReview&utm_term=2%20-%20Common%20coding%20interview&utm_content=Intro%20paragraph)
Here's a popular way to solve last week's challenge:
## Two index approach:
A more optimized solution (one that is possible because the strings of numbers are sorted) involves initializing two indexes at the start of both strings. Check to see if the element at the index in the first string is equal to, less than, or greater than the element at the index in the second string. If they are equal, push the value to the result array. Because the strings are sorted, if the element in the first string is less than the element in the second string, you can be sure the first element doesn’t exist in the second string. Therefore, you can increment the first index to look at the next value. If the element in the first string is greater than the element in the second string, you can be sure that the value in the second string doesn’t exist in the first string and can increment the second index to look at the next value. This might be clearer to see in code!
```javascript
function intersection (arr) {
const inBothArrays = []
const [arr1, arr2] = arr.map((str) => str.split(', ').map((e) => parseInt(e)))
let index1 = 0
let index2 = 0
while (index1 < arr1.length && index2 < arr2.length) {
const elem1 = arr1[index1]
const elem2 = arr2[index2]
if (elem1 === elem2) {
inBothArrays.push(elem1)
index1++
index2++
} else if (elem1 > elem2) {
index2++
} else if (elem1 < elem2) {
index1++
}
}
return inBothArrays.join(',')
}
```
So for the example:
Calling `intersection([“3, 4, 7, 11, 15”, “1, 3, 5, 8, 11”]);` your function should return `“3,11”`.
Here is an illustration that might make this a little clearer.

Remember, this solution only works because the arrays are sorted. The time complexity of this solution is `O(n+m)`.
##This week's challenge:
For this week, we'll be solving a coding problem that was given in an actual Google phone screen interview. Remember to head over to [Coderbyte](https://coderbyte.com/editor/Equivalent%20Keypresses:JavaScript?utm_source=Dev.to&utm_medium=Article&utm_campaign=CodeReview&utm_term=3%20-%20Google%20interview%20question&utm_content=Intro%20paragraph) to submit your code!
Write a function that takes an array containing two strings where each string represents keypresses separated by commas. For this problem, a keypress can be either a printable character or a backspace (represented by `-B`). Your function should determine if the two strings of keypresses are equivalent.
You can produce a printable string from such a string of keypresses by having backspaces erase one preceding character. Consider two strings of keypresses equivalent if they produce the same printable string. For example:
```javascript
checkEquivalentKeypresses(["a,b,c,d", "a,b,c,c,-B,d"]) // true
checkEquivalentKeypresses(["-B,-B,-B,c,c", "c,c"]) // true
checkEquivalentKeypresses(["", "a,-B,-B,a,-B,a,b,c,c,c,d"]) // false
```
Have fun and you got this!!
##Our newsletter 📫
We’re going to be sending out a small, feature reveal snippet every time we release something big, so our community is the first to know when we break out something new. [Give us your email here] (https://coderbyte.typeform.com/to/fb7Yk8) and we'll add you to our "first to know" list :)
| elisabethgross |
211,863 | performance testing with locust - 03 - setup your system | In the last part of this series we created multiple tasks to be able to simulate more realistically u... | 3,319 | 2019-11-27T08:43:24 | https://dev.to/jankaritech/performance-testing-with-locust-03-setup-your-system-3ai7 | qa, performance, python, testautomation |
In the [last part of this series](https://dev.to/jankaritech/performance-testing-with-locust-02-multiple-tasks-4ckn) we created multiple tasks to be able to simulate more realistically uploading and downloading files.
Now we want to go the next step and use multiple ownCloud users.
I will use the term "ownCloud user" for users that are set-up in the ownCloud system, have a username and password and can be used to login into the system. When I'm using the term "locust user" I'm talking about simulated users that hammer the server with requests. So far we used only one ownCloud user "admin" and multiple locust users. All locust users used that one ownCloud user to access the ownCloud server.
In this part of the series we want to have one ownCloud user for every locust user, so every `TaskSet` will be connecting with an own ownCloud user to the ownCloud server.
## setup and teardown
This situation is pretty common in any kind of automated testing, before starting the tests often you have to set your system up and bring it into a "testable" state, or simply into the state you want to test.
Basically all test frameworks will have some kind of `setup` and `teardown` methods or hooks. [Same applies to locust, you even can have a separate `setup` and `teardown` method in your Locust class and your TaskSet class.](https://docs.locust.io/en/stable/writing-a-locustfile.html#setups-and-teardowns)
consider this simple locust script
```
from locust import HttpLocust, TaskSet, task, constant
class UserBehaviour(TaskSet):
def setup(self):
print ("setup of TaskSet")
def teardown(self):
print ("teardown of TaskSet")
@task(2)
def one_task(self):
print ("running one task")
@task(1)
def an_other_task(self):
print ("running another task")
class User(HttpLocust):
def setup(self):
print ("setup of Locust class")
def teardown(self):
print ("teardown of Locust class")
task_set = UserBehaviour
wait_time = constant(1)
```
We have two tasks and a `setup` and a `teardown`, one in the `User` class and one in the `UserBehavior` class
Now lets see what happens.
1. Starting locust from the CLI:
```
[2019-11-29 08:55:19,213] artur-OptiPlex-3050/INFO/locust.main: Starting web monitor at *:8089
[2019-11-29 08:55:19,213] artur-OptiPlex-3050/INFO/locust.main: Starting Locust 0.13.2
```
2. Starting the test from the webUI with 2 users
```
[2019-11-29 08:55:22,932] artur-OptiPlex-3050/INFO/locust.runners: Hatching and swarming 2 clients at the rate 1 clients/s...
[2019-11-29 08:55:22,932] artur-OptiPlex-3050/INFO/stdout: setup of Locust class
[2019-11-29 08:55:22,932] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:22,933] artur-OptiPlex-3050/INFO/stdout: setup of TaskSet
[2019-11-29 08:55:22,933] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:22,933] artur-OptiPlex-3050/INFO/stdout: running one task
[2019-11-29 08:55:22,933] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:23,933] artur-OptiPlex-3050/INFO/stdout: running another task
[2019-11-29 08:55:23,933] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:23,934] artur-OptiPlex-3050/INFO/stdout: running one task
[2019-11-29 08:55:23,934] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:24,934] artur-OptiPlex-3050/INFO/locust.runners: All locusts hatched: User: 2
[2019-11-29 08:55:24,934] artur-OptiPlex-3050/INFO/stdout: running one task
[2019-11-29 08:55:24,934] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:24,934] artur-OptiPlex-3050/INFO/stdout: running another task
[2019-11-29 08:55:24,935] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:25,935] artur-OptiPlex-3050/INFO/stdout: running one task
[2019-11-29 08:55:25,935] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:25,935] artur-OptiPlex-3050/INFO/stdout: running one task
[2019-11-29 08:55:25,935] artur-OptiPlex-3050/INFO/stdout:
...
[2019-11-29 08:55:31,939] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:32,939] artur-OptiPlex-3050/INFO/stdout: running another task
[2019-11-29 08:55:32,939] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:32,939] artur-OptiPlex-3050/INFO/stdout: running one task
[2019-11-29 08:55:32,939] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:33,940] artur-OptiPlex-3050/INFO/stdout: running one task
[2019-11-29 08:55:33,940] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:33,940] artur-OptiPlex-3050/INFO/stdout: running another task
[2019-11-29 08:55:33,940] artur-OptiPlex-3050/INFO/stdout:
```
3. Stopping the tests on the webUI
4. pressing `Ctrl+C` on the CLI
```
^C[2019-11-29 08:55:57,191] artur-OptiPlex-3050/ERROR/stderr: KeyboardInterrupt
[2019-11-29 08:55:57,191] artur-OptiPlex-3050/ERROR/stderr: 2019-11-29T03:10:57Z
[2019-11-29 08:55:57,191] artur-OptiPlex-3050/ERROR/stderr:
[2019-11-29 08:55:57,191] artur-OptiPlex-3050/INFO/locust.main: Shutting down (exit code 0), bye.
[2019-11-29 08:55:57,191] artur-OptiPlex-3050/INFO/locust.main: Cleaning up runner...
[2019-11-29 08:55:57,191] artur-OptiPlex-3050/INFO/locust.main: Running teardowns...
[2019-11-29 08:55:57,191] artur-OptiPlex-3050/INFO/stdout: teardown of TaskSet
[2019-11-29 08:55:57,191] artur-OptiPlex-3050/INFO/stdout:
[2019-11-29 08:55:57,191] artur-OptiPlex-3050/INFO/stdout: teardown of Locust class
[2019-11-29 08:55:57,191] artur-OptiPlex-3050/INFO/stdout:
```
Did you expect that? `teardown` only runs after locust is completely stopped, not when the test is stopped.
Makes sense, but does not help us with our issue, we want to create users before running the actual test and delete them afterwards. We might start and stop the test, without stopping locust and we can increase the locust users during the test and in that case we want to create more ownCloud users on the fly.
Luckily we have also `on_start` and `on_stop` methods
## create users with on_start
`on_start` is called when the locust user starts to run the TaskSet
Starting from the last script let's add an `on_start` method to create users
```
from locust import HttpLocust, TaskSet, task, constant
import uuid
userNo = 0
class UserBehaviour(TaskSet):
adminUserName = 'admin'
davEndpoint = "/remote.php/dav/files/"
fileName = ''
userName = ''
def on_start(self):
#create user
global userNo
self.userName = "locust" + str(userNo)
userNo = userNo + 1
self.client.post(
"/ocs/v2.php/cloud/users",
{"userid": self.userName, "password": self.userName},
auth=(self.adminUserName, self.adminUserName)
)
@task(3)
def downloadFile(self):
self.client.get(
self.davEndpoint + self.userName + "/ownCloud%20Manual.pdf",
auth=(self.userName, self.userName)
)
@task(1)
def uploadFile(self):
if self.fileName == '':
self.fileName = "/locust-perfomance-test-file" + str(uuid.uuid4()) + ".txt"
self.client.put(
self.davEndpoint + self.userName + self.fileName,
"my data",
auth=(self.userName, self.userName)
)
class User(HttpLocust):
task_set = UserBehaviour
wait_time = constant(1)
```
So what is new here?
The `on_start` method first constructs a ownCloud username out of "locust" & a number. The `userNo` variable has to be defined globally, so that it survives when locust initialize the next instance of the `User` class. Remember: the `Locust` class (`HttpLocust` inherits from `Locust`) represents one simulated user that accesses your application.
Next a `POST` request is send with the username as userid and password. That requests needs to be authenticated as the admin-user. ([Check the ownCloud docu if you are interested to learn more about those requests.](https://doc.owncloud.com/server/10.0/admin_manual/configuration/user/user_provisioning_api.html))
At last there is the `davEndpoint`, now it needs the specific username, so that information has been moved into the specific `GET` and `PUT` method.
If you run that script now with locust and start a test with, lets say 3 users, you should see something like that:
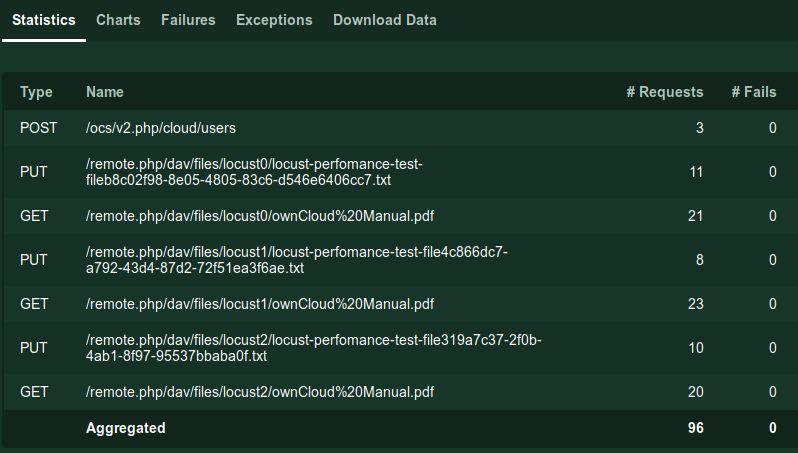
The first line tells us that 3 `POST` requests have been sent to `/ocs/v2.php/cloud/users`, that looks promising.
And in the `PUT` ans `GET` requests, the usernames "locust0" till "locust2" are mentioned, very good!
Now lets look into the users list of ownCloud. For that login with "admin" / "admin" to http://localhost:8080/ and in the top right corner click on "admin" and then on "Users".
Those three users were created and used. If you want to double check use them to login to ownCloud, you should see the uploaded file.
## delete users with on_stop
The only thing left is to clean up after us. Obviously we can simply kill the docker container, delete it and start it fresh with no users, but wouldn't it be nice to delete the users after stopping the test?
Let's use `on_stop` to clean up! It is run when the TaskSet is stopped.
Just add a simple small method to the `UserBehaviour` class:
```
def on_stop(self):
self.client.delete(
"/ocs/v2.php/cloud/users/" + self.userName,
auth=(self.adminUserName, self.adminUserName)
)
```
Remember to delete the users from ownCloud before rerunning the script (or just do `docker kill owncloud; docker rm owncloud` and start it again)
Now when you start the test and stop it again, you will see `DELETE` requests in the list, one per hatched locust user.
But what's that? The `DELETE` requests fail with `HTTPError('401 Client Error: Unauthorized for url: http://localhost:8080/ocs/v2.php/cloud/users/locust0',)`
Digging deeper (e.g. with WireShark) shows that the requests not only had the correct Authorization header sent, but also some cookies.
```
DELETE /ocs/v2.php/cloud/users/locust0 HTTP/1.1
Host: localhost:8080
User-Agent: python-requests/2.22.0
Accept-Encoding: gzip, deflate
Accept: */*
Connection: keep-alive
Cookie: cookie_test=test; oc1j5vb7hdm0=q2mv4lb5f2b37ti3etn8s1e0f1; oc_sessionPassphrase=y2u2sfTFfk8xx4cyIQZbycNvit4q0ZcKr4nHiiA7vSrGN%2BOZI30Ruvf3B5NyZrAxwtDNGz1wI7F6Yb2gjGsn%2FCnZ8Xpw3U8qRur1NrNcpJv%2Bm9egvmUiflwp3j7Rd3IG
Content-Length: 0
Authorization: Basic YWRtaW46YWRtaW4=
```
locust got those cookies from the first `GET` request we have sent as the specific ownCloud user, and it has kept them for all future requests. Generally that is a good thing, but ownCloud now ignores the Authorization header and uses the cookies to authenticate. So we effectively authenticate as the specific ownCloud user e.g. `locust0` and that user has no privilege to delete itself.
I could not find a way to clear the session, so we need a new one.
For that change the `on_stop` function to:
```
def on_stop(self):
from locust.clients import HttpSession
self.admin_client = HttpSession(base_url=self.client.base_url)
self.admin_client.delete(
"/ocs/v2.php/cloud/users/" + self.userName,
auth=(self.adminUserName, self.adminUserName)
)
```
Here we import the locust `HttpSession` class and use it to create a new session, with no cookies in our way.
And here we go, when starting and stopping the tests we have successful `DELETE` requests. One per hatched locust user.
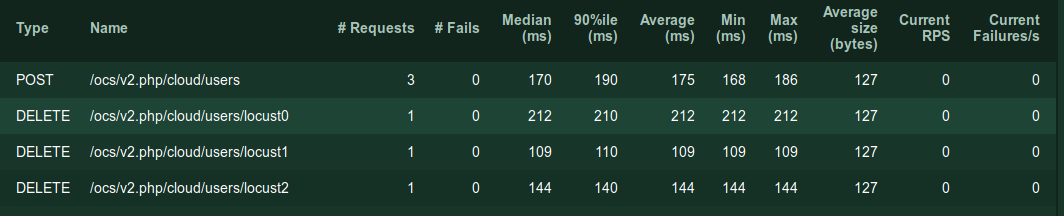
## what's next?
We have now some basic tests, now it's time to look closer into the metrics and try to understand the meaning of all the numbers locust throws at us.
| individualit |
211,906 | Creating a TS-written NPM package for use in Node-JS or Browser. | In this guide, I'll explain how to create an NPM package for NodeJS or the browser using Typescript without leaving built artifacts in your repository. | 0 | 2019-11-27T10:48:37 | https://dev.to/charperbonaroo/creating-a-ts-written-npm-package-for-use-in-node-js-or-browser-5gm3 | ts, typescript, npm, node | ---
title: Creating a TS-written NPM package for use in Node-JS or Browser.
published: true
description: In this guide, I'll explain how to create an NPM package for NodeJS or the browser using Typescript without leaving built artifacts in your repository.
tags: TS, Typescript, NPM, Node, NodeJS
---
# Creating a TS-written NPM package for use in Node-JS or Browser: The Long Guide
In this guide, I'll explain how to create an NPM package for NodeJS or the browser using Typescript without leaving built artifacts in your repository. At the end, my example library will be able to be included in any Javascript or Typescript project, including:
- Imported as a script in a `<script>` tag, using either direct download or a free CDN service.
- Installed in a client-side application using `npm` and a bundler like `webpack`.
- Installed in a server-side NodeJS application using `npm`.
Furthermore, the whole build and publish process will be automated as much as possible, while keeping the repository free from builds.
For this post, I'll be using a tiny library I wrote as an example. The library itself is meaningless and not very useful, which makes it a fine distraction-free example for this guide.
## The example library
The example library will be called `bonaroo-able`, only exporting a namespace called `Able`.
`Able` contains a small set of functions for managing a list of strings that act as abilities (permissions) for some user. This example library is written in Typescript and it has no browser- or NodeJS specific dependencies (EG it doesn't rely on the DOM or filesystem). More about this library later. For now, let's start with creating some config files.
## The NPM package
First, we need a `package.json`. The `package.json` file contains details about your Javascript package, including the name, author and dependencies. You can read about `package.json` files in the [npm docs](https://docs.npmjs.com/creating-a-package-json-file).
To create a `package.json` file, we use **npm**. In your library folder, run `npm init` and follow the instructions. For this guide, I'll be using jest to test my library. We can just use `jest` as a **test command**: We'll be installing this dependency later.
The **entry point** is the file that will be included when our package is included in another project. To allow our package to be used in non-Typescript projects, this entry point must be a regular Javascript file.
This Javascript file must include all of our library. I like to have an `index.js` file that requires all our of library. Because this is a Typescript project, we will have separate Typescript and Javascript files. We keep these in `src` (written source) and `dist` (distributed files) folders.
We'll be writing a `src/index.ts` file importing all of our library, and use the Typescript compiler to generate a Javascript variant in `dist/index.js`. This `dist/index.js` will be our package's entry point. We'll configure the Typescript compiler later.
```sh
$ npm init
This utility will walk you through creating a package.json file.
It only covers the most common items, and tries to guess sensible defaults.
See `npm help json` for definitive documentation on these fields
and exactly what they do.
Use `npm install <pkg>` afterwards to install a package and
save it as a dependency in the package.json file.
Press ^C at any time to quit.
package name: (bonaroo-able)
version: (1.0.0)
description: A tiny library handling abilities
entry point: (index.js) dist/index.js
test command: jest
git repository: https://github.com/tobyhinloopen/bonaroo-able
keywords: Abilities, Permissions
author: Charper Bonaroo BV
license: (ISC) UNLICENSED
About to write to /home/toby/bonaroo-able//package.json:
{
"name": "bonaroo-able",
"version": "1.0.0",
"description": "A tiny library handling abilities",
"main": "dist/index.js",
"scripts": {
"test": "jest"
},
"repository": {
"type": "git",
"url": "git+https://github.com/tobyhinloopen/bonaroo-able.git"
},
"keywords": [
"Abilities",
"Permissions"
],
"author": "Charper Bonaroo BV",
"license": "UNLICENSED",
"bugs": {
"url": "https://github.com/tobyhinloopen/bonaroo-able/issues"
},
"homepage": "https://github.com/tobyhinloopen/bonaroo-able#readme"
}
Is this OK? (yes)
$
```
Next, we'll be needing some dependencies. Obviously you'll be needing Typescript. We'll also be installing `jest`, `ts-jest` and `@types/jest`.
```sh
npm i -D typescript jest ts-jest @types/jest
```
## Configuring Typescript
Next, we need to configure Typescript. Let's create a minimal `tsconfig.json` file.
#### tsconfig.json
```json
{
"compilerOptions": {
"outDir": "dist",
"lib": ["es2016"],
"sourceMap": true
},
"include": [
"src/**/*.ts"
]
}
```
> ### About these options
> - **compilerOptions.outDir**: Generate JS files in this directory.
> - **compilerOptions.lib**: Tell the Typescript compiler the es2016 standard functions are available, like `Array.prototype.includes`.
> - **include**: Ensure only the Typescript in `src` is compiled & ignore all other source files (like the tests)
Since you cannot invoke Node binaries directly in all environments, I like to add all my commonly used commands to npm scripts. Add `"build": "tsc"` to the `scripts` section in your package.json
#### package.json (partial)
```json
"scripts": {
"build": "tsc",
"test": "jest"
},
```
To test whether everything is setup correctly, I like to create an entry point with a dummy function.
#### src/index.ts
```Typescript
export function hello(name: string): string {
return `Hello ${name}`;
}
```
Let's attempt to built this:
```sh
$ npm run build
> bonaroo-able@1.0.0 build /home/toby/bonaroo-able
> tsc
$
```
No errors. That's great. Also, note that Typescript has created some Javascript files for us! If you take a look at `dist/index.js`, you'll see a Javascript variant of our Typescript file. My generated file looks like this:
#### dist/index.js (generated)
```Javascript
"use strict";
exports.__esModule = true;
function hello(name) {
return "Hello " + name;
}
exports.hello = hello;
```
Note that all type information has been stripped, and the file has been changed to be compatible with older Javascript runtimes by changing the template string to a regular string with concat operator: `"Hello " + name`.
## Writing a test
Now test our "library": Let's write a test!
I like to create tests in a `test` directory, with a filenames matching the src files. For example, to test `src/Foo.ts`, I put my tests in `test/Foo.spec.ts`.
#### test/index.spec.ts
```Typescript
import { hello } from "../src";
test("hello", () => {
expect(hello("foo")).toEqual("Hello foo");
});
```
To be able to write our tests in Typescript, we need to configure jest first. We can [generate a config file with `ts-jest config:init`](https://kulshekhar.github.io/ts-jest/user/install).
```sh
$ node_modules/.bin/ts-jest config:init
Jest configuration written to "/home/toby/bonaroo-able/jest.config.js".
$
```
Now we're ready to confirm our test suite is working:
```sh
$ npm t
> bonaroo-able@1.0.0 test /home/toby/bonaroo-able
> jest
PASS test/index.spec.ts
✓ hello (2ms)
Test Suites: 1 passed, 1 total
Tests: 1 passed, 1 total
Snapshots: 0 total
Time: 1.267s, estimated 2s
Ran all test suites.
$
```
## Configuring GIT
Before we continue, let's configure source control to persist our working setup.
To keep our git repository clean, we omit `node_modules` and `dist` from the git repository.
#### .gitignore
```
dist/
node_modules/
```
Now let's create a git repository. Replace the remote with your git repo.
```sh
git init
git add --all
git commit -m "Initial commit"
git remote add origin git@github.com:tobyhinloopen/bonaroo-able.git
git push -u origin master
```
## Writing our Library
Now let's write the code for our library. Writing code is outside the scope of this guide. Here's an overview of my Able library. The filename points to the current version of the complete file on github.
#### [src/Able.ts](https://github.com/tobyhinloopen/bonaroo-able/blob/master/src/Able.ts) (overview, no function bodies)
```Typescript
export namespace Able {
export type AbilitySet = string[];
export interface GroupDefinition { [key: string]: AbilitySet; }
export interface ValueMap { [key: string]: string|string[]; }
export function flatten(definition: GroupDefinition, abilities: AbilitySet): AbilitySet;
export function extractValues(abilities: AbilitySet): [ValueMap, AbilitySet];
export function applyValues(abilities: AbilitySet, values: ValueMap): AbilitySet;
export function resolve(definition: GroupDefinition, abilities: AbilitySet): AbilitySet;
export function getMissingAbilities(abilities: AbilitySet, requiredAbilities: AbilitySet): AbilitySet;
export function canAccess(appliedAbilities: AbilitySet, requiredAbilities: AbilitySet): boolean;
}
```
#### [src/index.ts](https://github.com/tobyhinloopen/bonaroo-able/blob/master/src/index.ts)
```Typescript
import { Able } from "./Able";
export default Able;
Object.assign(module.exports, Able);
```
#### [test/index.spec.ts](https://github.com/tobyhinloopen/bonaroo-able/blob/master/test/index.spec.ts) (snippet, remaining tests removed)
```Typescript
import { Able } from "../src/Able";
describe("Able", () => {
it("flatten() includes own name", () => {
expect(Able.flatten({}, ["foo"])).toContain("foo");
});
// ...remaining tests...
});
```
#### [test/Able.spec.ts](https://github.com/tobyhinloopen/bonaroo-able/blob/master/test/Able.spec.ts)
```Typescript
import Able from "../src";
test("Able is exported", () => {
expect(Able).toBeInstanceOf(Object);
});
```
## Testing our build
In some cases, our tests might succeed while our build fails, or the build is
somehow invalid. To ensure the build is working, I like to add a very crude test to confirm the build is working and the exports are in-place.
This test will build the code, and run a simple JS file using the build to confirm the build is working.
In this build test, we copy one of our test suite's tests. I think it is safe to assume that if one test actually using the library succeeds, the library is built and exported correctly.
**test-build.js**
```js
const assert = require("assert");
const Able = require("./dist");
const definition = { foo: ["bar"] };
const abilities = ["foo", "bam"];
const result = Able.flatten(definition, abilities).sort();
assert.deepStrictEqual(result, ["foo", "bar", "bam"].sort());
```
Note that we're importing `./dist` here: We are explicitly importing `dist/index.js` that way. We need to build our code before we can import `dist/index.js`.
To build the code & run `test-build.js`, we'll add a script to `package.json`, called `test-build`.
**package.json** (partial)
```json
"scripts": {
"build": "tsc",
"test": "jest",
"test-build": "npm run build && node test-build.js"
},
```
I like to run all automated checks, currently `npm t` and `npm run test-build`, from a single script called `ci`. This script will run all automated checks and only pass when all automated checks passed.
Let's add `ci` to the scripts as well:
**package.json** (partial)
```json
"scripts": {
"build": "tsc",
"ci": "npm run test-build & npm t & wait",
"test": "jest",
"test-build": "npm run build && node test-build.js"
},
```
This `ci` script will be used to verify our build every release. Let's try it!
```sh
$ npm run ci
> bonaroo-able@1.0.0 ci /home/toby/bonaroo-able/
> npm run test-build & npm t & wait
> bonaroo-able@1.0.0 test-build /home/toby/bonaroo-able/
> npm run build && node test-build.js
> bonaroo-able@1.0.0 test /home/toby/bonaroo-able/
> jest
> bonaroo-able@1.0.0 build /home/toby/bonaroo-able/
> tsc
PASS test/Able.spec.ts
PASS test/index.spec.ts
Test Suites: 2 passed, 2 total
Tests: 11 passed, 11 total
Snapshots: 0 total
Time: 1.816s
Ran all test suites.
```
Later we'll make sure to only accept changes in the `master` branch that have passed this `npm run ci` call. That way, we'll make sure the `master` branch always features a valid build.
Let's commit all of our changes to git and start deploying our library.
## NPM release
The first and most useful release is the npm release. This allows our library users to `npm i` our library in most projects.
Both server-side projects and client-side projects that use a bundler like `webpack` can use an npm release without any changes.
Let's prepare our library for publication to NPM.
### Preparing our package for release
Let's first define what files we actually want to include in our package. You can peek the contents of your package-to-be using `npm publish --dry-run`:
```sh
$ npm publish --dry-run
npm notice
npm notice 📦 bonaroo-able@1.0.0
npm notice === Tarball Contents ===
npm notice 862B package.json
npm notice 56B .git
npm notice 69B jest.config.js
npm notice 284B test-build.js
npm notice 114B tsconfig.json
npm notice 3.9kB dist/Able.d.ts
npm notice 6.1kB dist/Able.js
npm notice 3.4kB dist/Able.js.map
npm notice 52B dist/index.d.ts
npm notice 184B dist/index.js
npm notice 198B dist/index.js.map
npm notice 6.0kB src/Able.ts
npm notice 24B src/index.ts
npm notice 3.4kB test/Able.spec.ts
npm notice 108B test/index.spec.ts
npm notice === Tarball Details ===
...
+ bonaroo-able@1.0.0
```
This built includes all kinds of things the user wouldn't care about. With `package.json`'s `files` property you can whitelist the files you want to include.
Only the built files are required to use our library: Let's add only the `dist` folder to the package:
**package.json** (partial)
```js
{
"main": "dist/index.js",
"files": ["dist"],
// ...
}
```
Now let's peek at our package's contents again:
```sh
$ npm publish --dry-run
npm notice
npm notice 📦 bonaroo-able@1.0.0
npm notice === Tarball Contents ===
npm notice 1.3kB package.json
npm notice 3.9kB dist/Able.d.ts
npm notice 6.1kB dist/Able.js
npm notice 3.4kB dist/Able.js.map
npm notice 52B dist/index.d.ts
npm notice 184B dist/index.js
npm notice 198B dist/index.js.map
npm notice === Tarball Details ===
npm notice name: bonaroo-able
...
+ bonaroo-able@1.0.0
```
That seems about right to me. Let's publish it!
### Publishing to NPM
Either sign-in `npm login` or sign-up `npm adduser`. After that, we're ready to publish our package.
**npm publish**
```sh
$ npm publish
npm notice
npm notice 📦 bonaroo-able@1.0.0
npm notice === Tarball Contents ===
npm notice 883B package.json
npm notice 3.9kB dist/Able.d.ts
npm notice 6.1kB dist/Able.js
npm notice 3.4kB dist/Able.js.map
npm notice 52B dist/index.d.ts
npm notice 184B dist/index.js
npm notice 198B dist/index.js.map
npm notice === Tarball Details ===
npm notice name: bonaroo-able
npm notice version: 1.0.0
npm notice package size: 2.3 kB
npm notice unpacked size: 7.1 kB
npm notice shasum: 4b25f5d01b4ef46259d947d0c0ce1455b92b8433
npm notice integrity: sha512-mX7RA0CS8hprb[...]lFsx3AGk5XIeA==
npm notice total files: 7
npm notice
+ bonaroo-able@1.0.0
```
Nice!
### Testing our release in Node
Now we can use our package in Node projects! Let's create a temporary Node project to test our package.
```sh
mkdir /tmp/node-test
cd $_
npm i bonaroo-able
node
```
```js
> const Able = require("bonaroo-able");
undefined
> const definition = { foo: ["bar"] };
undefined
> const abilities = ["foo", "bam"];
undefined
> result = Able.flatten(definition, abilities).sort();
[ 'bam', 'bar', 'foo' ]
```
### Testing our release in a webpack project
To use our package in the brower, the package user might be using webpack. Let's try our package in webpack!
```sh
mkdir /tmp/webpack-test
cd $_
npm init -y
npm i bonaroo-able
npm i -D webpack webpack-cli html-webpack-plugin webpack-dev-server clean-webpack-plugin
```
#### webpack.config.js
```js
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const { CleanWebpackPlugin } = require('clean-webpack-plugin');
module.exports = {
entry: {
app: './src/index.js',
},
plugins: [
new CleanWebpackPlugin(),
new HtmlWebpackPlugin({ title: "Titled Document" }),
],
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist'),
},
};
```
#### src/index.js
```js
const Able = require("bonaroo-able");
document.addEventListener("DOMContentLoaded", () => {
const definition = { foo: ["bar"] };
const abilities = ["foo", "bam"];
const result = Able.flatten(definition, abilities);
const code = document.createElement("code");
code.textContent = result.join(", ");
document.body.appendChild(code);
});
```
#### package.json (partial)
```json
"scripts": {
"build": "webpack",
"start": "webpack-dev-server --open"
},
```
Let's start the webpack dev server:
```sh
npm start
```
We are greeted with `foo, bam, bar` in our browser: Webpack build works!
## Building our library for usage in browser
One cannot use the `dist/*` files in the browser directly - we must combine these files somehow to create a single bundle for the browser.
Bundling libraries for use in the browser is a hairy subject. There are many solutions, none of them are perfect. In this guide, I'll cover only one solution: We'll be creating something called an **IIFE build** using [rollup.js](https://rollupjs.org/guide/en/).
An IIFE build looks something like this:
```js
var Able = (function() {
var Able = {};
var otherVars = 1;
Able.flatten = /* ... */
return Able;
})();
```
Because the library is defined inside a function expression that is invoked immediately using `(function() {})()`, all definitions inside the function are hidden, and only the return value is exposed to the global scoped.
Since the Function Expression is Immediately Invoked, it is called an IIFE.
Let's install **rollup**, add a build command to our package.json, and add a config file for rollup. Also, let's also add a reference to our browser bundle in the package.json's **browser** property.
```sh
npm i -D rollup rollup-plugin-commonjs rollup-plugin-node-resolve rollup-plugin-babel-minify
```
#### package.json (partial)
```js
{
"browser": "dist/bonaroo-able.min.js",
"scripts": {
// ...
"rollup": "rollup -c"
// ...
}
}
```
#### rollup.config.js
```js
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
import minify from 'rollup-plugin-babel-minify';
import pkg from './package.json';
export default [{
input: 'dist/index.js',
output: {
name: "Able",
file: pkg.browser,
format: 'iife',
sourcemap: true,
},
plugins: [
resolve(),
commonjs(),
minify({ comments: false }),
],
}];
```
Let's test or browser build:
#### example.html
```html
<!DOCTYPE html>
<title>bonaroo-able test</title>
<script src="./dist/bonaroo-able.min.js"></script>
<script>
document.addEventListener("DOMContentLoaded", function() {
const definition = { foo: ["bar"] };
const abilities = ["foo", "bam"];
const result = Able.flatten(definition, abilities);
const code = document.createElement("code");
code.textContent = result.join(", ");
document.body.appendChild(code);
});
</script>
```
You should see `foo, bam, bar` again in your browser when opening `example.html`.
---
## Build before publish
You can configure NPM to build automatically before publishing by adding a `prepublish` script to your package.json. Because `npm publish` publishes the built files, we want to make sure the files are built and tested before every publish.
We already have `npm run ci` to both build & test our build. Let's add `rollup` to `ci`, and add `npm run ci` to `prepublishOnly`:
#### package.json (partial)
```js
"scripts": {
// ...
"ci": "(npm run test-build && npm run rollup) & npm t & wait",
"prepublishOnly": "npm run ci && npm run rollup",
// ...
}
```
Let's publish our new build. NPM uses [semantic versioning](https://docs.npmjs.com/about-semantic-versioning). Every release, you must update your version number. Since we introduced a new feature (browser build) without breaking changes, we can release a new minor version. You can increment your build number with `npm version minor`, push our new version to git with `git push`, and finish with `npm publish` to publish our new version.
```sh
npm version minor
git push
npm publish
```
## Including our library in a browser directly from a CDN
> [**unpkg**](https://unpkg.com/) is a fast, global content delivery network for everything on npm. Use it to quickly and easily load any file from any package using a URL like:
>
> ```
> unpkg.com/:package@:version/:file
> ```
Thanks unpkg - I couldn't have explained it better myself. Let's try this!
- **package**: Our package name, `bonaroo-able`.
- **version**: We just minor-bumped our version to `1.1.0`.
- **file**: The browser file: `dist/bonaroo-able.min.js`.
That makes `https://unpkg.com/bonaroo-able@1.1.0/dist/bonaroo-able.min.js`. Let's grab our example.html again, and change the script source to this URL:
#### example.html
```html
<!DOCTYPE html>
<title>bonaroo-able test</title>
<script src="https://unpkg.com/bonaroo-able@1.1.0/dist/bonaroo-able.min.js"></script>
<script>
document.addEventListener("DOMContentLoaded", function() {
const definition = { foo: ["bar"] };
const abilities = ["foo", "bam"];
const result = Able.flatten(definition, abilities);
const code = document.createElement("code");
code.textContent = result.join(", ");
document.body.appendChild(code);
});
</script>
```
Great. Works for me. Now let's write a readme.
## Writing a readme
A readme is the entry point of the documentation of our library and should include a short summary of the following:
- What is our library?
- Why does it exist?
- What can it be used for?
- How to install it
- How to use it
- Requirements & dependencies
Writing a good readme is outside the scope of this guide. This guide will only cover installation instructions.
#### README.md (partial)
## Installation - NPM
```sh
npm i bonaroo-able
```
## Installation - Browser
```html
<script src="https://unpkg.com/bonaroo-able@1.1.1/dist/bonaroo-able.min.js"></script>
```
The script tag in the readme now includes the version number, which will not be updated automatically. Let's add a simple script that bumps the version in the readme everytime we update the NPM version.
When using `npm version`, npm will invoke [multiple hooks](https://docs.npmjs.com/misc/scripts#description) automatically, two of which are called **preversion** (Run BEFORE bumping the package version) and **version** (Run AFTER bumping the package version, but BEFORE commit).
My approach is to dump the version before bumping the version, and after bumping the version to replace all occurances of the old version in the README.md with the new version.
#### preversion.sh
```sh
#!/usr/bin/env bash
node -e 'console.log(require("./package.json").version)' > .old-version
```
#### version.sh
```sh
#!/usr/bin/env bash
sed "s/$(cat .old-version)/$(node -e 'console.log(require("./package.json").version)')/g" < README.md > ~README.md
rm README.md .old-version
mv ~README.md README.md
git add README.md
```
#### package.json (partial)
```js
"scripts": {
// ...
"preversion": "./preversion.sh",
// ...
"version": "./version.sh",
// ...
},
```
#### sh
```sh
chmod +x preversion.sh version.sh
```
Now let's commit our changes & bump the library version.
#### sh
```sh
git add --all
git commit -am "Introduce README.md"
npm version patch
git push
npm publish
```
Our readme is now updated! Neat.
## Installation - NPM
```sh
npm i bonaroo-able
```
## Installation - Browser
```html
<script src="https://unpkg.com/bonaroo-able@1.1.2/dist/bonaroo-able.min.js"></script>
```
## Final words
Now every time you change something about your library, commit the changes, update the version, push the version change & publish your new version:
```sh
git add --all
git commit -m "Describe your changes here."
npm version minor
git push
npm publish
```
If you're still here, thanks so much for reading! And if you want to know more or have any other questions, please get in touch with us via info@bonaroo.nl
| tobyhinloopen |
211,951 | How to Update Legacy Code | 0 | 2019-11-27T12:28:59 | https://djangostars.com/blog/update-legacy-code/ | legacycode, python, django, software | ---
title: How to Update Legacy Code
canonical_url: https://djangostars.com/blog/update-legacy-code/
cover_image: https://djangostars.com/blog/uploads/2019/10/cover-3.png
published: true
description:
tags: legacy code, python, django, software
---
Imagine a situation in which you need developers to add new features to an existing and well-functioning product. Let’s say you want to add billing to your online lending platform. In cases like this, developers may conclude that they’ll need to update the app’s code. After all, they might reason, why else would the client want to update perfectly functioning code? And you, the client, might think that adding a couple of features has nothing to do with a code update and that the developers simply want to make more money. However, the truth is that their decision is based on thorough code analysis and business logic.
In this article, we’ll talk about when updates are necessary and how to make them without affecting the app’s functionality. It’s especially important in fintech, as the technology – and the users’ skills – keep developing. And as this happens, they get more demanding and want more features like better security or the ability to clear payments online.
## What is Legacy Code Update and How You Do It
What does legacy code actually mean? Legacy code is the pre-existing code of a product – already functioning or that’s just finished – but not yet launched, that needs to be completed in some way. When a business has an app that needs additional features, or the code is almost done but the original development team couldn’t complete it, it means it’s time to update the legacy code.
As you can imagine, developers can’t just smack a feature on top of the code, since everything in the code is interconnected. Numerous factors will affect this change. And since all code is unique, there’s no single recipe for how to do it. When you ask for an update to your product’s code, you may soon find out that the code doesn’t allow it because of weak code architecture, poor code quality, or insufficient test coverage. Which is why, whenever you send this type of request, the first thing the [development team](https://djangostars.com/company/team/) will do is a code review. As soon as they get the results, they will suggest a scenario that would work best for your application.
## Evaluation Criteria for Legacy Code Update
Before developers commit to changing the code, they need to know what they’re dealing with. For instance, in the nearly eight years we’ve been working in fintech, we formed criteria to evaluate projects we’re offered to gauge the potential level of difficulty. This way, we know what to do if someone comes asking for a calculator or a smiley face in the right bottom corner, and we know what solution to offer to businesses. Here are the possible scenarios:

**1. Developers don’t commit to the project** when they see the domain of the app is too complex and unclear. It’s possible that adding to it would take up too many resources with no equivalent benefits for their company. This can happen when the original code was written badly, and clearing up someone else’s mess just isn’t worth it. Or, if the request is unrealistic – like re-writing the entire software for the stock market from scratch – maybe you should take some time to rethink your request.
**2. Developers write the code from scratch** – in some cases, development teams don’t work with the pre-existing code base at all. They may use the old code to understand the product’s business logic or to analyze functionality that was planned for the future but wasn’t added. This allows them to avoid making the same mistakes the previous developers made.
At Django Stars – and I’m sure many other companies share this conviction – the biggest benefit of this approach is that we can guarantee a clear and smooth structure in the end product. At this point, it may be hard to understand why your old code doesn’t fit the bill anymore, but you should talk about it with your technical partner and go through all the pros and cons. Often, starting from zero is the faster solution and will save you a lot more money than adding to the old code.
To give you an example: once we had a client who asked us to update the code that he himself started writing years ago, before he outsourced it to someone else. But it had at least 20 spots that needed updating before new logic and/or features could be added to the code. And with such a large number of upgrades, you can easily damage one part of the code by changing something in one of those 20 code parts. But if we were to write our own code according to this client’s specification but with a more transparent architecture, there would be only one, at most two, parts that would require more work. 
**3. Developers work with the client’s code base**, adding desired features while updating (refactoring) the old code step by step, part by part. This is only possible when the code structure of your product is clear and logical, and also fully test covered. But in any case, you have to fully talk this through with your development team. Agree upon whether they should rewrite one part of the code and then build the new logic, do it simultaneously, or if some other way is more appropriate.
At this point, it’s important to understand that refactoring the legacy code is a vital part of code maintenance and, basically, of the life of any product. It’s also why you have to make sure you ***provide sufficient documentation\*** to the development team.
As you can imagine, this scenario is more demanding than #2, when you write code from scratch. Not because developers don’t know the technology used, or don’t understand the code. Code is all about the vision of the ones who write it, and about the architecture. Working on legacy code written by someone else can be difficult, as their logic most probably will be different from yours. Which is why you should accept that when developers work with someone else’s code, they can’t guarantee the same high quality as when they work with their own code logic and structure.
It’s possible, though, that your new development team will be able to give structure to the old code if there’s a mechanism that properly works. In this case, they don’t need to change or re-write this part of the code. They only have to know what format the incoming data should have, and the format of the outcome data you should get.
**4.** In the rarest cases, it’s possible to continue **working on the old code base by just adding features**. This is only possible when the code is so flawlessly written and thought through that you don’t need to change anything at all. However, this has never happened to us, as everyone has their own vision of code architecture. You’d have to be extremely lucky to find code written by a soulmate. Someone else’s code is very hard to get into.
## What Do Code Updates Depend On?
If you and your development team finally decide to start updating the code, there are several factors that define to which extent it should be changed, and how critical these changes are. These are age, code architecture, test coverage, and deployment.

- **Age**. Whether the code is one year old, or five, can make a great difference. For instance,you should understand that five years in Python and Django – the technology we work with – is a galaxy far far away. So much has changed during this time, and the code most probably will have huge holes in its security system, etc. Some parts of the code will be too old to migrate to a new version – it will be easier to re-write them.
- **Code architecture**. Is it monolithic or microservice? If developers can divide the app into parts (like CRM, CMS, website and file storage), they can update it part by part. But if there are no visible parts, the only option left is to rewrite the code. Usually, if it’s not possible to divide code into parts, it’s badly written, and refactoring it will be a pain. Which is, again, may be difficult to grasp, but it’s better to listen to your technical partner.
- **Test coverage**. This defines whether the code is properly covered with tests (and what tests exactly) or if the team needs to write them.
- **Deployment**. The team will check how the deployment goes when the new code enters the old system.
## Before the Legacy Code Update: the To-Do List
At this point, we’ve covered all the technical aspects, but there are also some managerial issues you have to resolve before you begin with the update. The to-do list isn’t long:
### Agree Upon Expectations
Make a list of what you’re expecting from the app, the changes that you want, and the goals you want to achieve. You and your team should be on the same page about what you’re going to do.
### Develop Transfer Flow
In order not to lose data (and, consequently, your client), make sure the team establishes how the app will work during the update and how the transfer from old code to new code will be done. For instance, in our [Python programming](https://djangostars.com/services/python-django-development/) practice we once created a proxy that switched users to the old or the new code base depending on their requests and the current stage of the code update.
Some other times we’ve had to transfer a large user info base, so we created a mediating script that helped us get the users one by one from the old version to the new one. This way we could test how the transfer works and see that none of the information got lost. But please note that every product will require an individual solution.
One of the reasons for this are the different risks that are characteristic of different cases. To name an easy one – a bad database structure causes slower working speed.
### Ensure Sufficient Test Coverage
If there’s enough test coverage, it’s great. If there is no test coverage, it makes sense to first write the tests – or, rather, potential ways to proceed with the update and corresponding tests. And only then will you write the implementation. This is something you have to settle on before your team begins the work.
At the same time, they need to decide which tests they will use. To give you a picture, there are unit and integration tests. Unit tests are the ones we use on a single feature, while integration tests are more laborious and test how different elements work together. An experienced team will check if there are any relevant tests in the old code base that can be used. If they use an old test on a new feature, and the test is successful, this proves that this particular update is flawlessly integrated into the old code base and everything works fine.
Now we’ve looked at the legacy code update from every possible angle. We established what it is and how it works, and what needs to be done for a smooth and successful update. First, developers evaluate what they have to work with, and whether they can work with it at all. Then, they check age of the code, its architecture, and test coverage, which will define their further steps. And as soon as you coordinate your goals and expectations from the project with your team, settle on the transfer flow, and ensure sufficient test coverage, you’re good to go.
My first and foremost motivation for writing this article was to help clear up any possible misunderstandings between businesses and teams that provide [web development services](https://djangostars.com/services/web-development/). As my team and I have learned over the years, these can occur in the places you least expect them. In conclusion, I hope I have explained the inner workings of a development team when it comes to a legacy code update, and that this information will help you and your business grow and improve.
This guide about How to Successfully Update Legacy Code was originally posted on Django Stars blog. Written by Alexander Ryabtsev - Software Engineering Lead at [Django Stars](https://djangostars.com/) | djangostars | |
212,039 | [Ruby] Awesome methods | 🚧 in developing take caller method caller_locations(1) where is th... | 0 | 2019-11-27T15:53:33 | https://dev.to/n350071/ruby-awesome-methods-19p6 | rails | ---
title: [Ruby] Awesome methods
tags: rails
published: true
---
🚧 in developing
---
### take caller method
```ruby
caller_locations(1)
```
### where is the method defined at?
```ruby
method(:recover).source_location
```
### grep the object has the method
```ruby
methods.grep(/download_files/)
```
---
## 🔗 Parent Note
{% link n350071/my-rails-note-47cj %}
| n350071 |
212,071 | How To: Database clustering with MariaDB and Galera. | The Situation MariaDB, a fork of MySQL, has had multi-master clustering support from the the initial... | 0 | 2019-11-27T17:24:06 | https://dev.to/david_j_eddy/how-to-database-clustering-with-mariadb-and-galera-323g | howto, database, mariadb, clustering | ---
title: How To: Database clustering with MariaDB and Galera.
published: true
description:
tags: howto, database, mariadb, clustering
cover_image: https://blog.davidjeddy.com/wp-content/uploads/2019/09/mariadb-logo.png
---
<!-- wp:heading -->
<h2>The Situation</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>MariaDB, a fork of MySQL, has had multi-master clustering support from the the initial version 10 release. However, the more recent releases have made it increasingly easy to setup a multi-master database cluster. By <code>easy</code> I mean it. But first, what is a <code>multi-master</code> cluster?</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>A multi-master cluster is one where each database instance is a <code>master</code> of course. The cluster contains no read-replicas, slave nodes, or 2nd class instances. Every instance is a master. The up side is no lag, the down side every instance has to confirm writes. So, the big caveat here is that the network and throughput between all the instances needs to be as good as possible. The cluster performance is limited by the slowest machine.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>Preflight Requirements</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><li><a href="https://www.linux.org/">Linux</a></li><li><a href="https://en.wikipedia.org/wiki/Terminal#Software">CLI Terminal</a></li><li>(optional) <a href="https://www.terraform.io/downloads.html">Terraform 0.12.x</a></li><li>AWS account:<ul><li><a href="https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_access-keys.html">API key and secret</a></li><li><a href="https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-key-pairs.htm">PEM key provisioned for EC2 access</a></li></ul></li></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>(optional) I put together a small project that starts three EC2 instances. Feel free to use this to start up the example environment resources.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>git clone https://github.com/davidjeddy/database_clustering_with_mariadb_and_galera.git
cd ./database_clustering_with_mariadb_and_galera
export AWS_ACCESS_KEY_ID=YOUR_API_ACCESS_KEY_ID
export AWS_SECRET_ACCESS_KEY=YOUR_API_SECRET_KEY
export AWS_PEM_KEY_NAME=NAME_OF_YOUR_PEM_KEY
terraform init
terraform plan -out plan.out -var 'key_name='${AWS_PEM_KEY_NAME}
terraform apply plan.out</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Once completed the output should look like this:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>Apply complete! Resources: 3 added, 0 changed, 0 destroyed.
Outputs:
db-a-key = maria_with_galera
db-a-ssh = ec2-3-84-95-153.compute-1.amazonaws.com
db-b-key = maria_with_galera
db-b-ssh = ec2-3-95-187-84.compute-1.amazonaws.com
db-c-key = maria_with_galera
db-c-ssh = ec2-54-89-180-243.compute-1.amazonaws.com</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>If that is what you get, we are ready to move on to the next part.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","id":1841,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://blog.davidjeddy.com/wp-content/uploads/2019/11/taylor-vick-M5tzZtFCOfs-unsplash-2560x1437.jpg" alt="" class="wp-image-1841"/><figcaption>Photo by <a href="https://unsplash.com/@tvick?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Taylor Vick</a> on <a href="https://unsplash.com/s/photos/data-center?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a></figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:heading -->
<h2>Setup</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Now that we have three EC2 instances started up and running we can dig into the configuration for each database service. Open three new terminals; so in total we will have 4: localhost, DB-A, DB-B, DB-C. Using ssh log into the three database EC2 instances. After each login execution we should have something similar to the below.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>ssh -i ~/.ssh/maria_with_galera.pem ubuntu@ec2-3-84-95-153.compute-1.amazonaws.com
The authenticity of host 'ec2-3-84-95-153.compute-1.amazonaws.com (3.84.95.153)' can't be established.
ECDSA key fingerprint is SHA256:rxmG0jtvI47tH3Yf3fAls9IsMPkho4DaRcSfA+NWNNs.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'ec2-3-84-95-153.compute-1.amazonaws.com,3.84.95.153' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-1054-aws x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Wed Nov 27 16:07:48 UTC 2019
System load: 0.0 Processes: 85
Usage of /: 13.6% of 7.69GB Users logged in: 0
Memory usage: 30% IP address for eth0: 172.31.40.213
Swap usage: 0%
0 packages can be updated.
0 updates are security updates.
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Take note of the <code>IP address for eth0</code> on each instance. This is the private IP address that will be needed later. On each of the DB instances run the following commands to update the machine and install the MariaDB service and dependencies.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>sudo apt-get update -y
sudo apt-get install -y mariadb-server rsync</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>The output this time is very long, but the ending should look like this.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>...
Created symlink /etc/systemd/system/mysql.service → /lib/systemd/system/mariadb.service.
Created symlink /etc/systemd/system/mysqld.service → /lib/systemd/system/mariadb.service.
Created symlink /etc/systemd/system/multi-user.target.wants/mariadb.service → /lib/systemd/system/mariadb.service.
Setting up mariadb-server (1:10.1.43-0ubuntu0.18.04.1) ...
Processing triggers for libc-bin (2.27-3ubuntu1) ...
Processing triggers for systemd (237-3ubuntu10.31) ...
Processing triggers for man-db (2.8.3-2ubuntu0.1) ...
Processing triggers for ureadahead (0.100.0-21) ...
</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>To be extra sure we have everything installed, lets check the version of both MariaDB and rsync.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>ubuntu@ip-172-31-40-213:~$ mysql --version && rsync --version
mysql Ver 15.1 Distrib 10.1.43-MariaDB, for debian-linux-gnu (x86_64) using readline 5.2
rsync version 3.1.2 protocol version 31
...
are welcome to redistribute it under certain conditions. See the GNU
General Public Licence for details.
</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Since we need to configure the clustering go ahead and stop the MariaDB service on each instance using the standard stop command.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>sudo systemctl stop mysql
sudo systemctl status mysql # never not always double check</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>You may have noticed that the command is <code>mysql</code> and not <code>mariadb</code>. This is because MariaDB is a fork of MySQL and the MariaDB team wants to keep binary compatibility with MySQL. This helps projects migrate with the least amount of headache.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Now do this same process on the DB-B and DB-C instances.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","id":1842,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://blog.davidjeddy.com/wp-content/uploads/2019/11/charles-pjAH2Ax4uWk-unsplash-2160x1440.jpg" alt="" class="wp-image-1842"/><figcaption>Photo by <a href="https://unsplash.com/@charlesdeluvio?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Charles 🇵🇭</a> on <a href="https://unsplash.com/s/photos/data-center?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a></figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:heading -->
<h2>Configurations</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Here is where the magic happens! We are going to create a new configuration file for each node at the location <code>/etc/mysql/conf.d/galera.cnf</code>. Open the file and add the following content. Where the configuration says [DB-A IP] replace with the PRIVATE IP address of that instance that we saw when we logged into each instance in the previous section. Also replace [DB-A NAME] with the name of the cluster node. <code>DB-A</code>, <code>DB-B</code>, or <code>DB-C</code> depending on what EC2 instance the file is located on. </p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>[mysqld]
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="test_cluster"
wsrep_cluster_address="gcomm://[DB-A IP],[DB-B IP],[DB-C IP]"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="[DB-A IP]"
wsrep_node_name="[DB-A NAME]"</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>So, DB-A configuration should look like this:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>[mysqld]
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="test_cluster"
wsrep_cluster_address="gcomm://172.31.40.213,172.31.39.251,172.31.38.71"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="172.31.40.213"
wsrep_node_name="DBA"</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>All three configurations should basically the same, minus the <code>node_address</code> and <code>node_name</code> being adjusted for each node.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>Bringing It All Together</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>This is a very important step now; when starting the database on the first instance, aka <code>DB-A</code>, we have to bootstrap the cluster. Since no other instances are running the boot strap process tells the database <code>hey, your the first one, chill out</code> when it does not detect any other cluster members. After that though, <code>DB-B</code> and <code>DB-C</code> should join the cluster without an issue. So to start this first node use the following command on the DB-A instances.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>ubuntu@ip-172-31-40-213:~$ sudo galera_new_cluster
ubuntu@ip-172-31-40-213:~$ sudo systemctl status mysql
● mariadb.service - MariaDB 10.1.43 database server
Loaded: loaded (/lib/systemd/system/mariadb.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2019-11-27 16:32:03 UTC; 5s ago
Docs: man:mysqld(8)
https://mariadb.com/kb/en/library/systemd/
...
Nov 27 16:32:03 ip-172-31-40-213 /etc/mysql/debian-start[5129]: Checking for insecure root accounts.
Nov 27 16:32:03 ip-172-31-40-213 /etc/mysql/debian-start[5133]: Triggering myisam-recover for all MyISAM tables and aria-recover for all Aria tables
</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>The important part here is the <code>Active: active (running)</code>. Now, that we have the first cluster node running lets check the cluster status.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>ubuntu@ip-172-31-40-213:~$ sudo mysql -u root -e "SHOW GLOBAL STATUS LIKE 'wsrep_cluster%';"
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_conf_id | 1 |
| wsrep_cluster_size | 1 |
| wsrep_cluster_state_uuid | 71780aba-1133-11ea-a814-beaa932daf25 |
| wsrep_cluster_status | Primary |
+--------------------------+--------------------------------------+</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Hey; Check that out! We have a single instance cluster running. Awesome. Now we need to start DB-B and DB-C. Switch to each of those terminals and run the not bootstrapping command but instead the normal service start command.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>ubuntu@ip-172-31-39-251:~$ sudo systemctl status mysql
● mariadb.service - MariaDB 10.1.43 database server
Loaded: loaded (/lib/systemd/system/mariadb.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2019-11-27 16:36:45 UTC; 11s ago
...
Nov 27 16:36:45 ip-172-31-39-251 /etc/mysql/debian-start[15042]: Checking for insecure root accounts.
Nov 27 16:36:45 ip-172-31-39-251 /etc/mysql/debian-start[15046]: Triggering myisam-recover for all MyISAM tables and aria-recover for all Aria tables</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Again the <code>Active: active (running)</code> is the important part. Switch back to DB-A and run the global status check command like we did after starting the DB-A services.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>ubuntu@ip-172-31-40-213:~$ sudo mysql -u root -e "SHOW GLOBAL STATUS LIKE 'wsrep_cluster%';"
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_conf_id | 3 |
| wsrep_cluster_size | 3 |
| wsrep_cluster_state_uuid | 71780aba-1133-11ea-a814-beaa932daf25 |
| wsrep_cluster_status | Primary |
+--------------------------+--------------------------------------+</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Yea buddy! A three node database cluster up and running!</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","id":1843,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://blog.davidjeddy.com/wp-content/uploads/2019/11/stephen-dawson-qwtCeJ5cLYs-unsplash-2001x1440.jpg" alt="" class="wp-image-1843"/><figcaption>Photo by <a href="https://unsplash.com/@srd844?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Stephen Dawson</a> on <a href="https://unsplash.com/s/photos/data-center?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a></figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:heading -->
<h2>Confirmation</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To be super sure everything is running and replicating as expected lets execute a few SQL commands to change the state of the database and then check the new state. On <code>DB-A</code> lets add a new schema and table with a data point.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>sudo mysql -u root -e "CREATE DATABASE testing; CREATE TABLE testing.table1 (id int null);INSERT INTO testing.table1 SET id = 1;"</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Now let's do a select statement on <code>DB-C</code>:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>ubuntu@ip-172-31-38-71:~$ sudo mysql -u root -e "SELECT * FROM testing.table1;"
+------+
| id |
+------+
| 1 |
+------+</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>YES! The new schema, table, and data replicated from <code>DB-A</code> to <code>DB-C</code>. We can run the select command on <code>DB-B</code> and see the same result! We can write to <code>DB-C</code> and see it replicated on <code>DB-A</code> and <code>DB-B</code>. Each node takes reads and writes then replicates the changes to all the other nodes!</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Boom</strong>! A three node multi-master database cluster up and running! Log into one of the instances (does not matter since this is a multi-master) and create a new schema. Then exit and check the status of the cluster again. See the state value change? Yea, replication at work!</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>Conclusion</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>This is just the tip the functionality iceberg that is database clustering. I have had to skip over a very large number of topics like replication lag, placement geography, read-only replicas, bin_log format, and so much more. But this gives you a solid introduction to the concept of database clustering. Have fun!</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>Additional Resources</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><li><a href="https://aws.amazon.com/">AWS</a></li><li><a href="https://www.terraform.io/">Terraform</a></li><li><a href="https://mariadb.org/">MariaDB</a></li><li><a href="https://ndimensionz.com/kb/what-is-database-clustering-introduction-and-brief-explanation/">Database Clustering Concepts</a></li></ul>
<!-- /wp:list --> | david_j_eddy |
212,118 | Query PDFs with SQL | Hi, everyone! I made an app that lets you bulk-upload PDFs and then export recognized text as SQL, J... | 0 | 2019-11-27T19:31:05 | https://dev.to/siftrics/query-pdfs-with-sql-g64 | sql, ocr, pdf, saas | Hi, everyone!
I made an app that lets you bulk-upload PDFs and then export recognized text as SQL, JSON, or CSVs.
You can see a video demonstration on the front page of the website: https://siftrics.com/
MySQL, PostgreSQL, and Microsoft SQL Server are officially supported.
If you have any questions about the product itself or the engineering that makes it work, please ask!
Discussion on HN: https://news.ycombinator.com/item?id=21649918
Discussion on /r/programming: https://www.reddit.com/r/programming/comments/e2jbhn/query_pdfs_with_sql_i_made_an_app_that_lets_you/ | siftrics |
212,130 | Animating Vue with GreenSock | Written by Anjolaoluwa Adebayo-Oyetoro✏️ The average cognitive load capacity of humans (the amount... | 0 | 2019-12-02T14:37:27 | https://blog.logrocket.com/animating-vue-with-greensock/ | vue, greensock, javascript, ui | ---
title: Animating Vue with GreenSock
published: true
date: 2019-11-27 20:00:44 UTC
tags: vue,greensock,javascript,ui
canonical_url: https://blog.logrocket.com/animating-vue-with-greensock/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/z7ly7x5qpk8ang0mrki3.png
---
**Written by [Anjolaoluwa Adebayo-Oyetoro](https://blog.logrocket.com/author/anjolaoluwaadebayooyetoro/)**✏️
The [average cognitive load capacity](https://en.wikipedia.org/wiki/Cognitive_load#History) of humans (the amount of information a person can process in an instant) is seven plus or minus two units of information, and the amount of information in the working memory lasts [around 10 seconds](http://theelearningcoach.com/learning/what-is-cognitive-load/).
According to [Time](https://time.com/12933/what-you-think-you-know-about-the-web-is-wrong/), website visitors decide whether to engage with a site or bounce off the page in just 15 seconds. That means you have only a quarter of a minute to capture your visitors’ attention.
What does this have to do with animations?
Long blocks of text and boring interfaces can increase a user’s cognitive load. [Animations](https://dev.to/bnevilleoneill/animations-using-react-hooks-and-greensock-2o80) and microinteractions can help keep users engaged and reduce the cognitive load while using your website.
However, when not done right, animations can hamper user interactions with your product and negatively impact sales. Performant and easy-to-use tools like GreenSock exist to make animating our Vue apps exciting.
[](https://logrocket.com/signup/)
## What is GreenSock?
The GreenSock Animation Platform, also known as GSAP, is a powerful JavaScript animation library that helps developers build performant and engaging animations. It has a very shallow learning curve and requires little knowledge of JavaScript.
According to the platform’s [official website](https://greensock.com/gsap/), GSAP “animates anything JavaScript can touch (CSS properties, SVG, React, canvas, generic objects, whatever) and solves countless browser inconsistencies, all with blazing speed (up to [20 times faster](https://greensock.com/js/speed.html) than jQuery).”
GSAP is framework-agnostic and can be used across anywhere JavaScript runs. It has a very minimal bundle size and won’t bloat your app. It is backward-compatible and works with SVG pretty well.
In this tutorial, we’ll explore the building blocks of GreenSock and learn how to use it with a JavaScript animation library to bring user interfaces to life by animating our Vue app contents.
## Prerequisites
The following is required to follow along with this tutorial, which uses the latest version of GreenSock, GSAP 3.0:
- [Node.js 10x](https://nodejs.org/en/download/) or higher and [Yarn](https://yarnpkg.com/lang/en/)/[npm 5.2 or higher](https://www.npmjs.com/get-npm) installed on your PC
- Basic knowledge of JavaScript, [React](https://reactjs.org/docs), and/or [Vue](https://vuejs.org/v2/guide) fundamentals
- [Vue](https://vuejs.org/) CLI installed on your PC
You can install Vue CLI with the following command using Yarn:
```jsx
yarn global add @vue/cli
```
## Getting started
First, create a project with this command:
```jsx
vue create vue-gsap
```
Next, change to your project’s root directory with this command:
```jsx
cd vue-gsap
```
Type in the following to add GSAP as a package to our project:
```jsx
Using Yarn
yarn add gsap
```
You can include GSAP in your pages or component files with this command:
```jsx
import { gsap } from "gsap";
```
## The fundamentals of GSAP
Let’s take a closer look at the basic building blocks of GSAP.
### Tween
A tween is the single instance of what applies predefined property values to an object during the process of animating an object from one point to another on a webpage.
It takes in three parameters:
1. `Target` refers to the item(s) you want to animate. It could be a CSS selector or a an object
2. `varsObject` is an object that contains the properties to change in a target, also referred to as configuration variables. They can be CSS properties, but in camelCase format `background-color` becomes `backgroundColor` and `border-radius` becomes `borderRadius`
3. `position` is used to set the point of insertion of a tween in an animation sequence. It can be either a string or a number
Tweens are written in the following format:
```jsx
gsap.method('selector', { }, 'position ' )
```
### GSAP methods
GSAP provides myriad methods to create animations. The following are among the most important.
`gsap.to()` defines the values to which an object should be animated — i.e., the end property values of an animated object — as shown below:
```jsx
gsap.to('.circle', {x:500, duration: 3})
```
This command would move an element with a class of `circle` 500px across the x-axis in three seconds. If a duration is not set, a default of 500 milliseconds would be used.
Note: The CSS transform properties `translateX` and `translateY` are represented as `x` and `y` for pixel-measured transforms and `xPercent` and `yPercent` for percentage-based transforms, respectively.
{% codepen https://codepen.io/jola_adebayor/pen/oNNmzjy %}
`gsap.from()` defines the values an object should be animated from — i.e., the start values of an animation:
```jsx
gsap.from('.square', {duration:4, scale: 2})
```
This command resizes the element with a class of `square` from a scale of 2.
{% codepen https://codepen.io/jola_adebayor/pen/YzzBNKV %}
`gsap.fromTo()` lets you define the starting and ending values for an animation. It is a combination of both the `from()` and `to()` method.
```jsx
gsap.fromTo('.circle',{opacity:0 }, {opacity: 1 , x: 500 , duration: 2 });
```
This command animates the element with a class of `circle` from an opacity of 0 to an opacity of 1 across the x-axis in 2 seconds.
{% codepen https://codepen.io/jola_adebayor/pen/yLLZgzB %}
Note: When animating positional properties, such as `left` and `top`, the elements you’re animating must have a CSS `position` value of `absolute`, `relative`, or `fixed`.
### Easing
Easing determines how an object moves from one point to another. An ease controls the rate of change of an animation in GSAP and is used to set the style of an object’s animation.
GSAP provides different types of eases and options to give you more control on how your animation should behave. It also provides an [Ease Visualizer](https://greensock.com/docs/v3/Eases) to help you choose your preferred ease settings.

There are three types of eases, and they vary in how they begin or end animating.
- `in()` — Motion starts slowly, then picks up pace toward the end of the animation
- `out()` — The animation starts out fast then slows down at the end of the animation
- `inOut()` — The animation starts slow, picks up pace midway through, and ends slowly
{% codepen https://codepen.io/jola_adebayor/pen/OJJdQQg %}
In the last example, we chained three tweens that displayed the available types of eases, but we had to set a delay of the number of seconds it takes the animation to complete before starting the next one. You can avoid this by putting the tweens in a timeline.
### Timelines
A `Timeline` serves as a container for multiple tweens. It animates tweens in a sequence with each beginning just after the last one ends, except when set otherwise, and it is not dependent on the duration of the previous tween. This eliminates the need to set a delay before the next tween begins animating.
Timelines can be created in the following format:
```jsx
gsap.timeline(); //creates an instance of a timeline
```
You can also chain multiple tweens to a timeline, as shown below:
```jsx
gsap.timeline()
.add() // add tween to timeline
.to('element', {})
.from('element', {})
```
or
```jsx
const tl = gsap.timeline(); // create an instance and assign it to variable tl
tl.add(); // add tween to timeline
tl.to('element', {});
tl.from('element', {});
```
Let's recreate the previous example with a timeline:
{% codepen https://codepen.io/jola_adebayor/pen/WNNmeaM %}
### Position
The position parameter is an important factor in animating with a timeline because it sets the point of insertion of a tween in an animation sequence. As we learned earlier, it is the third parameter in a tween method and it comes after the config object.
```jsx
.method( target, {config object}, position )
```
The default position is `"+=0"`, which just inserts a tween at the end of a sequence.
You can set the position parameter as multiple types of values, but we’ll focus on some of the most important ones.
`"Number"` refers to an absolute time of that number.
```jsx
gsap.method('selector',{}, 5 )
```
The above command inserts the tween exactly 5 seconds from the beginning of the timeline.
`"+=Number"` or `"-=Number"` inserts a tween at a positive or negative relative time, as demonstrated below:
```jsx
gsap.method('selector',{}, "-=1" ) //insert a tween 1 second before end of timeline
gsap.method('selector',{}, "+=1" ) //Inserts a tween 1 second after end of timeline
```
`"<"` or `">"` inserts a tween relative to the previous tween’s start or end time.
```jsx
gsap.method('selector',{}, "<" ) //Inserts a tween at the start of the previous tween
gsap.method('selector',{}, ">" ) //Inserts a tween at the end of the previous tween
```
[GreenSock’s official website](https://greensock.com/position-parameter) offers additional tips to help you gain a thorough understanding of the position parameter.
## Alternatives to GSAP for animating Vue
While GSAP is a very good choice to animate Vue apps, there are alternatives, including:
- [Anime.js](https://animejs.com/)
- [Mo.js](https://github.com/mojs/mojs)
- [Velocity.js](http://velocityjs.org/)
- [animated-vue](https://github.com/radical-dreamers/animated-vue#readme)
## Conclusion
In this article, we’ve covered how to use GreenSock to create animations. The possibilities are endless when animating with GreenSock because you can get more done with less code without worrying about backward compatibility while maintaining great performance across browsers.
Beyond the shallow learning curve, GSAP has very large community of users, [resources](https://greensock.com/learning/) abound and active [forums](https://greensock.com/forums/) that contain many of the answers you may be looking for.
The [official GreenSock documentation](https://greensock.com/get-started) is quite extensive and covers features and other useful methods not mentioned in this article. You can also check out this [Vue animation workshop repository](https://github.com/sdras/animating-vue-workshop) open-sourced by Sarah Drasner.
* * *
**Editor's note:** Seeing something wrong with this post? You can find the correct version [here](https://blog.logrocket.com/animating-vue-with-greensock/).
## Plug: [LogRocket](https://logrocket.com/signup/), a DVR for web apps

[LogRocket](https://logrocket.com/signup/) is a frontend logging tool that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
[Try it for free](https://logrocket.com/signup/).
* * *
The post [Animating Vue with GreenSock](https://blog.logrocket.com/animating-vue-with-greensock/) appeared first on [LogRocket Blog](https://blog.logrocket.com). | bnevilleoneill |
212,139 | Soft skills - communication tips | unsplash.com/@akson Your next promotion What do you think will land you your next promo... | 0 | 2019-11-27T20:42:25 | https://dev.to/jozefchmelar/soft-skills-communication-tips-4dh3 | productivity, communication, softskills, management | 
<figcaption >unsplash.com/@akson</figcaption >
# Your next promotion
What do you think will land you your next promotion? Next framework you're going to learn? Haskell programming? Great architecture on that app you developed?
Yeah. Maybe.
You might be the best programmer around your office. However, in real world you don't have to be THE BEST to be promoted. If you can't talk to a client or no one in the office wants to talk to you, do you think you'll be promoted?
Yeah. No.
#Introduce yourself with a memorable association
I’m Jozef and I like wakeboarding🏄♀️!
- Jacob 😊
- Emma👩
- Lucas 🧑🏿
- Sarah👧🏼
They have one thing in common. You already forgot their names…and they forgot yours.
People forget names way too often. My name is the sweetest, best sounding song in the world. And I love it! And you love yours. It’s the sound you hear even when no one said it…
What was the name of that guy with wake-board 🤔? **Jozef** !
Make it easy to remember your name :) It makes it easier to talk to you.
# You are worthy

<figcaption >unsplash.com/@andrewtneel</figcaption >
Once you put someone on a pedestal there’s only way they can look at you. You’ll always be bellow them. Don’t allow this to happen. Your time has value, you have value.
- I'm sorry for the code I wrote → Yay! Good that you noticed.
- I’m sorry that I’m late → Thank you for waiting for me
- I’m sorry about the delay → Thanks for your patience
Constant apologizing may appear as you are not confident enough to appreciate yourself.
Next time you’re going to have job interview, you can refer to it as a meeting about future cooperation. Remember that the company **wants you** and you want to work there.
# Wallet is a very sensitive part of the body

<figcaption >unsplash.com/@andrea_natali</figcaption >
I found myself in a situation when I was the "sales guy" even though I'm a developer. It might happen to you! In this case, these are my notes.
I would like to offer you a presentation of our latest product…Might be the most NO-NO sentence in the universe.
- Product
- Sale
- Presentation
- Offer
Especially these words make me feel like you want to get into my wallet. I don’t like that. Don’t make it so obvious, silly.
I could show you the result of our work, I believe it may be beneficial for you. — Sounds a bit better, doesn’t it?
# But, why?

<figcaption >unsplash.com/@jannerboy62</figcaption >
- I want to give you a raise, but bla bla bla bla…
- Your job performance is great, but blah blah bla blah…
This translates into :
- I don’t want give you a raise.
- Your job performance sucks.
Notice the “.” at the end of translated sentences. They end right there. Whatever follows “but” is just irrelevant. You already know this, but…
I recommend to avoid this word. Nonetheless there’s use for it, when you turn your sentence around.
## Why
- Why did you put this code…
- Why is it written like this…
Starting a sentence with why feels very accusingly or threatening. Just use different words
- What’s the reason for …
- What was the thinking behind this …
# Be positive

<figcaption>unsplash.com/@adamjang</figcaption>
Next time you’re going to write an email try to sound friendly, positive. It’s very important to be perceived as a positive person — not a trouble maker.
It’s not easy to be positive. You have to change your thinking a bit.
- I have to go for a run.
- I have to go to the gym.
- I have to go to school.
They all sound very bad on their own. But once you attach a goal or something bigger to your activity…it’s not that bad 😊
- I want to be thin and healthy so I’m going for a run!
- I want to have that beach body so I have to lift some weights!
- I want to be educated and well perceived in the future so I want to study
Remember that you and the person on the other side of the line, may have more in common than you think :).
# Conclusion

<figcaption>unsplash.com/@alex_tsl</figcaption>
You may have heard a lot of tips like this. It’s easy to forget about them unless you apply them in your everyday life.
Communication is something you will train for the rest of your life. Just pick a few from this tips…one at a time and you’ll be amazed by the results.
Your customers will prefer you before that trouble maker. You will be the problem solver.
---
[](https://www.buymeacoffee.com/jozefchmelar)
| jozefchmelar |
212,179 | Project : Visual ts game engine | Version : Sunshine - 2019 https://github.com/zlatnaspirala/visual-ts-game-engine 2d canvas game eng... | 0 | 2019-11-27T23:31:15 | https://github.com/zlatnaspirala/visual-ts-game-engine | videochat, multiplayerphysics, webrtc, matterjs |
Version : Sunshine - 2019
https://github.com/zlatnaspirala/visual-ts-game-engine
2d canvas game engine based on Matter.js 2D physics engine for the web.
Writen in typescript current version 3.5.1.
Text editor used and recommended: Visual Studio Code. Luanch debugger configuration comes with this project.
Physics engine based on Matter.js.
Multiplatform video chat (for all browsers) implemented. SocketIO used for session staff. MultiRTC2 used for data transfer also for video chat. MultiRTC3 alias 'broadcaster' used for video chat.
visualTS
Client part
To make all dependency works in build proccess we need some plugins.
npm install
npm run build
Navigate in browser /build/app.html to see client app in action
-Client part is browser web application. No reloading or redirecting. This is single page application. I use html request only for loading local/staged html (like register, login etc.). Networking is based on webSocket full-duplex communication only. This is bad for old fasion programmers. You must be conform with classic socket connection methodology. -webRTC can be used for any proporsion. Already implemented : -video chat webRTC (SIP) chat and data communication.
-Class 'Connector' (native webSocket) used for user session staff. For main account session staff like login, register etc.
Client config
If you want web app without any networking then setup:
appUseNetwork: boolean = false;
You want to use communication for multiplayer but you don't want to use server database account sessions. The setup this on false in main client config class. appUseAccountsSystem: boolean = false;
Networking is disabled or enabled depens on current dev status.
Find configuration for client part at ./src/lib/client-config.ts
/**
* Addson
* All addson are ansync loaded scripts.
* - Cache is based on webWorkers.
* - hackerTimer is for better performace also based on webWorkers.
* - dragging is script for dragging dom elements.
*/
private addson: Addson = [
{
name: "cache",
enabled: true,
scriptPath: "externals/cacheInit.ts",
},
{
name: "hackerTimer",
enabled: true,
scriptPath: "externals/hack-timer.js",
},
{
name: "dragging",
enabled: true,
scriptPath: "externals/drag.ts",
},
];
/**
* @description This is main coordinary types of positions
* Can be "diametric-fullscreen" or "frame".
* - diametric-fullscreen is simple fullscreen canvas element.
* - frame keeps aspect ratio in any aspect.
* @property drawReference
* @type string
*/
private drawReference: string = "frame";
/**
* aspectRatio default value, can be changed in run time.
* This is 800x600
*/
private aspectRatio: number = 1.333;
/**
* domain is simple url address,
* recommendent to use for local propose LAN ip
* like : 192.168.0.XXX if you wanna run ant test app with server.
*/
private domain: string = "maximumroulette.com";
/**
* networkDeepLogs control of dev logs for webRTC context only.
*/
private networkDeepLogs: boolean = false;
/**
* masterServerKey is channel access id used to connect
* multimedia server channel.
*/
private masterServerKey: string = "multi-platformer-sever1.maximum";
/**
* rtcServerPort Port used to connect multimedia server.
* Default value is 12034
*/
private rtcServerPort: number = 12034;
/**
* connectorPort is access port used to connect
* session web socket.
*/
private connectorPort: number = 1234;
/**
* broadcasterPort Port used to connect multimedia server MultiRTC3.
* I will use it for explicit video chat multiplatform support.
* Default value is 9001
*/
private broadcasterPort: number = 9001;
/**
* @description Important note for this property: if you
* disable (false) you cant use Account system or any other
* network. Use 'false' if you wanna make single player game.
* In other way keep it 'true'.
*/
private appUseNetwork = true;
/**
* appUseAccountsSystem If you don't want to use session
* in your application just setup this variable to the false.
*/
private appUseAccountsSystem: boolean = true;
/**
* appUseBroadcaster Disable or enable broadcaster for
* video chats.
*/
private appUseBroadcaster: boolean = true;
/**
* Possible variant by default :
* "register", "login"
*/
private startUpHtmlForm: string = "register";
private gameList: any[];
/**
* Implement default gamePlay variable's
*/
private defaultGamePlayLevelName: string = "level1";
private autoStartGamePlay: boolean = true;
Start dependency system from app.ts
Fisrt game template is Platformer. This is high level programming in this software. Class Platformer run with procedural (method) level1. Class Starter is base class for my canvas part. It is injected to the Platformer to make full operated work.
gamesList args for ioc constructor is for now just simbolic for now. (WIP)
In ioc you can make strong class dependency relations. Use it for your own structural changes. If you want to make light version for build than use ioc to remove everything you don't need in build.
Main dependency file
// Symbolic for now
const plarformerGameInfo = {
name: "Crypto-Runner",
title: "PLAY PLATFORMER CRYPTO RUNNER!",
};
// Symbolic for now
const gamesList: any[] = [
plarformerGameInfo,
];
const master = new Ioc(gamesList);
const appIcon: AppIcon = new AppIcon(master.get.Browser);
master.singlton(Platformer, master.get.Starter);
console.log("Platformer: ", master.get.Platformer);
master.get.Platformer.attachAppEvents();
About runup gameplay
In client-config :
javascript
private autoStartGamePlay: boolean = false;
If you setup 'autoStartGamePlay' to false you need to run gamePlay with :
javascript
master.get.GamePlay.load()
Note : Only singleton object instance from master start with upcase letters.
Project structure
build/ is autogenerated. Don't edit or add content in this folder.
src/ is main client part (Browser web application). Main file : app.ts
src/libs/ is common and smart pack of classes, interfaces etc. easy access.
server/ folder is fully indipendent server size. I use one git repo but consider '/server' represent standalone application. There's server package.json independently from client part also config is not the common. I just like it like that.
├── package.json
├── package-lock.json
├── webpack.config.js
├── tsconfig.json
├── tslint.json
├── launch.json
├── workplace.code-workspace
├── LICENCE
logo.png
LICENSE
├── build/ (This is auto generated)
| ├── externals/
| ├── templates/
| ├── imgs/
| ├── styles/
| | └── favicon.ico
| ├── visualjs2.js
| ├── app.html
├── src/
| ├── style/
| | ├── styles.css
| ├── libs/
| | ├── class/
| | | ├── networking/
| | | | ├── rtc-multi-connection/
| | | | | ├── FileBufferReader.js
| | | | | ├── RTCMultiConnection2.js
| | | | | ├── RTCMultiConnection3.js
| | | | | ├── linkify.js
| | | | | ├── getHTMLMediaElement.js
| | | | | ├── socket.io.js
| | | | ├── broadcaster-media.ts
| | | | ├── broadcaster.ts
| | | | ├── connector.ts
| | | | ├── network.ts
| | | ├── visual-methods/
| | | | ├── sprite-animation.ts
| | | | ├── text.ts
| | | | ├── texture.ts
| | | ├── browser.ts
| | | ├── math.ts
| | | ├── position.ts
| | | ├── resources.ts
| | | ├── sound.ts
| | | ├── system.ts
| | | ├── view-port.ts
| | | ├── visual-render.ts
| | ├── interface/
| | | ├── drawI.ts
| | | ├── global.ts
| | | ├── visual-components.ts
| | ├── multiplatform/
| | | ├── mobile/
| | | | ├── player-controls.ts
| | | ├── global-event.ts
| | ├── types/
| | | ├── global.ts
| | ├── client-config.ts
| | ├── ioc.ts
| | ├── starter.ts
| ├── icon/ ...
| ├── examples/
| | ├── platformer/
| ├── html-components/
| | ├── register.html
| | ├── login.html
| | ├── games-list.html
| | ├── user-profile.html
| | ├── store.html
| | ├── broadcaster.html
| ├── index.html
| ├── app-icon.ts
| └── app.ts
| └── manifest.web
└── server/
| ├── package.json
| ├── package-lock.json
| ├── server-config.js
| ├── database/
| | ├── database.js
| | ├── common/
| | ├── email/
| | | ├── templates/
| | | | ├── confirmation.html.js
| | | ├── nocommit.js (no commited for now)
| | └── data/ (ignored - db system folder)
| ├── rtc/
| | ├── server.ts
| | ├── connector.ts
| | ├── self-cert/
Server part
Installed database : mongodb@3.1.8
-No typescript here, we need keep state clear no. Node.js is best options.For email staff i choose : npm i gmail-send .
-Run services database server (Locally and leave it alive for develop proccess):
npm run dataserver
Looks like this :
mongod --dbpath ./server/database/data
Fix : "failed: address already in use" :
netstat -ano | findstr :27017
taskkill /PID typeyourPIDhere /F
Also important "Run Visual Studio Code as Administrator".
-Command for kill all node.js procces for window users :
taskkill /im node.exe /F
Networking multimedia communication : WebSocketServer running on Node.js
Text-based protocol SIP (Session Initiation Protocol) used for signaling and controlling multimedia sessions.
General networking config:
Config property defined in constructor from ServerConfig class.
this.networkDeepLogs = false;
this.rtcServerPort = 12034;
this.rtc3ServerPort = 12034;
this.connectorPort = 1234;
this.domain = "192.168.0.14";
this.masterServerKey = "multi-platformer-sever1.maximum";
this.protocol = "http";
this.isSecure = false;
this.appUseAccountsSystem = true;
this.appUseVideoChat = true;
this.databaseName = "masterdatabase";
this.databaseRoot = "mongodb://localhost:27017";
- Running server is easy :
npm run rtc
With this cmd : npm run rtc we run server.js and connector.ts websocket. Connector is our account session used for login , register etc.
Implemented video chat based on webRTC protocol.
- Running rtc3 server is also easy :
Command 'npm run broadcaster' is not nessesery for begin. Features comes with broadcaster:
Multiplatform video chat works with other hybrid frameworks or custom implementation throw the native mobile application web control (Chrome implementation usually).
npm run broadcaster
Documentation :
Follow link for API: Application documentation
Possible to install from :
npm visual-ts
If you wanna generate doc you will need manual remove comment from plugin section in webpack.config.js. Restart 'npm run dev' Best way to fully healty build.
If you wanna insert some new html page just define it intro webpack.config.js :
plugins : [
new HtmlWebpackPlugin({
filename: '/templates/myGameLobby.html',
template: 'src/html-components/myGameLobby.html'
}),
...
See register and login example.
Code format :
npm run fix
npm run tslint
or use :
tslint -c tslint.json 'src/**/*.ts' --fix
tslint -c tslint.json 'src/**/*.ts'
Licence
Visual Typescript Game engine is under:
MIT License generaly
except ./src/lib. Folder lib is under:
GNU LESSER GENERAL PUBLIC LICENSE Version 3
External licence in this project :
- Networking based on :
Muaz Khan MIT License www.WebRTC-Experiment.com/licence
- Base physics beased on :
Matter.js https://github.com/liabru/matter-js
Crypto icons downloaded from : https://www.behance.net/JunikStudio
Sprites downloaded from : dumbmanex.com opengameart.org/content/animated-flame-texture
Todo list for 2019
I'am still far a away from project objective :
Make visual nodes for editor mode in game play.
Item's selling for crypto values.
Create examples demos in minimum 20 game play variants (table games, actions , platformers , basic demo trow the api doc etc.).
Implementing AR and webGL2.
Platformer
Live demo Platformer | zlatnaspirala |
212,244 | JavaScript in parallel - web workers explained | An example along with an explanation on how to use web workers to parallelize JavaScript and run JavaScript code in parallel. | 0 | 2019-11-29T08:20:41 | https://dev.to/g33konaut/javascript-in-parallel-web-workers-explained-5588 | javascript, web, webworkers | ---
title: JavaScript in parallel - web workers explained
published: true
description: An example along with an explanation on how to use web workers to parallelize JavaScript and run JavaScript code in parallel.
tags: javascript, web, webworkers
---
[This is a repost from my personal blog](https://50linesofco.de/post/2017-02-06-javascript-in-parallel-web-workers-transferables-and-sharedarraybuffer)

## TL;DR
* JavaScript is single-threaded and long-running scripts make the page unresponsive
* Web Workers allow running JavaScript in separate threads, communicating with the main thread using messages.
* Messages that transfer large amount of data in TypedArrays or ArrayBuffers cause large memory cost due to data being cloned
* Using transfers mitigates the memory cost of cloning, but makes the data inaccessible to the sender
* All code can be found [in this repository](https://github.com/AVGP/js-parallelism-demos)
* Depending on the type of work that our JavaScript carries out, `navigator.hardwareConcurrency` might help us spread the work across processors.
## An example application
As an example we want to build a web application that constructs a table where each entry denotes if the number that belongs to it is [prime](https://en.m.wikipedia.org/wiki/Prime_number) or not.
We will use an [ArrayBuffer](https://developer.mozilla.org/en/docs/Web/JavaScript/Reference/Global_Objects/ArrayBuffer) to hold our booleans for us and we will be bold and make it 10 megabyte large.
Now this just serves to have our script do some heavy lifting - it isn't a very useful thing, but I may use techniques described here in future posts dealing with binary data of different sorts (images, audio, video for instance).
Here we will use a very naive algorithm (there are much better ones available):
```javascript
function isPrime(candidate) {
for(var n=2; n <= Math.floor(Math.sqrt(candidate)); n++) {
// if the candidate can be divided by n without remainder it is not prime
if(candidate % n === 0) return false
}
// candidate is not divisible by any potential prime factor so it is prime
return true
}
```
Here is the rest of our application:
### index.html
```html
<!doctype html>
<html>
<head>
<style>
/* make the page scrollable */
body {
height: 300%;
height: 300vh;
}
</style>
<body>
<button>Run test</button>
<script src="app.js"></script>
</body>
</html>
```
We make the page scrollable to see the effect of our JavaScript code in a moment.
### app.js
```javascript
document.querySelector('button').addEventListener('click', runTest)
function runTest() {
var buffer = new ArrayBuffer(1024 * 1024 * 10) // reserves 10 MB
var view = new Uint8Array(buffer) // view the buffer as bytes
var numPrimes = 0
performance.mark('testStart')
for(var i=0; i<view.length;i++) {
var primeCandidate = i+2 // 2 is the smalles prime number
var result = isPrime(primeCandidate)
if(result) numPrimes++
view[i] = result
}
performance.mark('testEnd')
performance.measure('runTest', 'testStart', 'testEnd')
var timeTaken = performance.getEntriesByName('runTest')[0].duration
alert(`Done. Found ${numPrimes} primes in ${timeTaken} ms`)
console.log(numPrimes, view)
}
function isPrime(candidate) {
for(var n=2; n <= Math.floor(Math.sqrt(candidate)); n++) {
if(candidate % n === 0) return false
}
return true
}
```
We are using the [User Timing API](https://developer.mozilla.org/en-US/docs/Web/API/User_Timing_API/Using_the_User_Timing_API#Removing_performance_measures) to measure time and add our own information into the timeline.
Now I let the test run on my trusty "old" Nexus 7 (2013):

Okay, that's not very impressive, is it?
Making matters worse is that the website stops reacting to anything during these 39 seconds - no scrolling, no clicking, no typing. The page is frozen.
This happens because JavaScript is single-threaded and in a single thread only one thing can happen at the same time. Making matters worse, pretty much anything that is concerned with interactions for our page (so browser code for scrolling, entering text etc.) runs *on the same thread*.
So is it that we just cannot do any heavy lifting?
## Web Workers to the rescue
No. This is just the kind of work we can use [Web Workers](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API).
A Web Worker is a JavaScript file from the same origin as our web application that will be running in a separate thread.
Running in a separate thread means:
* it will run in parallel
* it will not make the page unresponsive by blocking the main thread
* it will not have access to the DOM or any variable or function in the main thread
* it can use the network and communicate with the main thread using messages
So how do we keep our page responsive while the prime-searching work goes on? Here is the procedure:
* We start a worker and send the ArrayBuffer to it
* The worker does its job
* When the worker is done, it sends the ArrayBuffer and the number of primes it found back to the main thread
Here is the updated code:
### app.js
```javascript
document.querySelector('button').addEventListener('click', runTest)
function runTest() {
var buffer = new ArrayBuffer(1024 * 1024 * 10) // reserves 10 MB
var view = new Uint8Array(buffer) // view the buffer as bytes
performance.mark('testStart')
var worker = new Worker('prime-worker.js')
worker.onmessage = function(msg) {
performance.mark('testEnd')
performance.measure('runTest', 'testStart', 'testEnd')
var timeTaken = performance.getEntriesByName('runTest')[0].duration
view.set(new Uint8Array(buffer), 0)
alert(`Done. Found ${msg.data.numPrimes} primes in ${timeTaken} ms`)
console.log(msg.data.numPrimes, view)
}
worker.postMessage(buffer)
}
```
### prime-worker.js
```javascript
self.onmessage = function(msg) {
var view = new Uint8Array(msg.data),
numPrimes = 0
for(var i=0; i<view.length;i++) {
var primeCandidate = i+2 // 2 is the smalles prime number
var result = isPrime(primeCandidate)
if(result) numPrimes++
view[i] = result
}
self.postMessage({
buffer: view.buffer,
numPrimes: numPrimes
})
}
function isPrime(candidate) {
for(var n=2; n <= Math.floor(Math.sqrt(candidate)); n++) {
if(candidate % n === 0) return false
}
return true
}
```
And here is what we get when run again on my Nexus 7:

Well, uhm, did all that ceremony give us anything then? After all now it is even *slower*!
The big win here wasn't making it faster, but try scrolling the page or otherwise interacting... **it stays responsive at all times**! With the calculation being ferried off to its own thread, we don't get in the way of the main thread taking care of responding to the user.
But before we move on to make things faster, we shall figure out an important detail on how `postMessage` works.
## The cost of cloning
As mentioned earlier the main thread and worker thread are separated so we need to shuttle data between them using messages
But how does that actually move data between them? The answer for the way we have done it before is [structured cloning](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Structured_clone_algorithm).
This means we are **copying** our 10 megabyte ArrayBuffer to the worker and then copy the ArrayBuffer from the worker back.
I assumed this would total in 30 MB memory usage: 10 in our original ArrayBuffer, 10 in the copy sent to the worker and another 10 in the copy that is sent back.
Here is the memory usage before starting the test:

And here right after the test:

Wait, that is 50 megabytes more. As it turns out:
* we start with 10mb for the ArrayBuffer
* the cloning itself* creates another +10mb
* the clone is copied to the worker, +10mb
* the worker clones its copy again, +10mb
* the cloned copy is copied to the main thread, +10mb
*) I am not exactly sure why the clone is not moved to the target thread instead of being copied, but the serialialisation itself seems to be incurring the unexpected memory cost
## Transferables save the day
Luckily for us there is a different way of transferring data between the threads in the optional second parameter of `postMessage`, called the *transfer list*.
This second parameter can hold a list of [Transferable](https://developer.mozilla.org/en-US/docs/Web/API/Transferable) objects that will be excluded from cloning and will be moved or *transferred* instead.
Transferring an object, however, neutralises it in the source thread, so for instance our ArrayBuffer won't contain any data in the main thread after it's been transferred to the worker and its `byteLength` will be zero.
This is to avoid the cost of having to implement mechanisms to deal with a bunch of issues that can happen when multiple threads access shared data.
Here is the adjusted code using transfers:
### app.js
```javascript
worker.postMessage(buffer, [buffer])
```
### prime-worker.js
```javascript
self.postMessage({
buffer: view.buffer,
numPrimes: numPrimes
}, [view.buffer])
```
And here are our numbers:

So we got a little faster than the cloning worker, close to the original main-thread-blocking version. How are we doing in terms of memory?

So having started with 40mb and ending up with a little more than 50mb sounds about right.
## More workers = more speed?
So up until now we have
* unblocked the main thread
* removed the memory overhead from cloning
Can we speed it up as well?
We could split the range of numbers (and our buffer) among multiple workers, run them in parallel and merge the results:
### app.js
Instead of launching a single worker, we are about to launch four. Each worker will receive a message instructing it with the offset to begin with and how many numbers to check.
When a worker finishes, it reports back with
* an ArrayBuffer containing the information about which entries are prime
* the amount of primes it found
* its original offset
* its original length
We then copy the data from the buffer into the target buffer, sum up the total number of primes found.
Once all workers completed, we display the final results.
```javascript
document.querySelector('button').addEventListener('click', runTest)
function runTest() {
const TOTAL_NUMBERS = 1024 * 1024 * 10
const NUM_WORKERS = 4
var numbersToCheck = TOTAL_NUMBERS, primesFound = 0
var buffer = new ArrayBuffer(numbersToCheck) // reserves 10 MB
var view = new Uint8Array(buffer) // view the buffer as bytes
performance.mark('testStart')
var offset = 0
while(numbersToCheck) {
var blockLen = Math.min(numbersToCheck, TOTAL_NUMBERS / NUM_WORKERS)
var worker = new Worker('prime-worker.js')
worker.onmessage = function(msg) {
view.set(new Uint8Array(msg.data.buffer), msg.data.offset)
primesFound += msg.data.numPrimes
if(msg.data.offset + msg.data.length === buffer.byteLength) {
performance.mark('testEnd')
performance.measure('runTest', 'testStart', 'testEnd')
var timeTaken = performance.getEntriesByName('runTest')[0].duration
alert(`Done. Found ${primesFound} primes in ${timeTaken} ms`)
console.log(primesFound, view)
}
}
worker.postMessage({
offset: offset,
length: blockLen
})
numbersToCheck -= blockLen
offset += blockLen
}
}
```
### prime-worker.js
The worker creates a Uint8Array view large enough to hold the `length` bytes as ordered by the main thread.
The prime checks start at the desired offset and finally data is transferred back.
```javascript
self.onmessage = function(msg) {
var view = new Uint8Array(msg.data.length),
numPrimes = 0
for(var i=0; i<msg.data.length;i++) {
var primeCandidate = i+msg.data.offset+2 // 2 is the smalles prime number
var result = isPrime(primeCandidate)
if(result) numPrimes++
view[i] = result
}
self.postMessage({
buffer: view.buffer,
numPrimes: numPrimes,
offset: msg.data.offset,
length: msg.data.length
}, [view.buffer])
}
function isPrime(candidate) {
for(var n=2; n <= Math.floor(Math.sqrt(candidate)); n++) {
if(candidate % n === 0) return false
}
return true
}
```
And here are the result:


So this solution took approximately half the time with quite some memory cost (40mb base memory usage + 10mb for the target buffer + 4 x 2.5mb for the buffer in each worker + 2mb overhead per worker.
Here is the timeline of the application using 4 workers:

We can see that the workers run in parallel, but we aren't getting a 4x speed-up as some workers take longer than others. This is the result of the way we divided the number range: As each worker needs to divide each number `x` by all numbers from 2 to `√x`, the workers with larger numbers need to do more divisions, i.e. more work. This can surely minimised by dividing the numbers in a way that ends up spreading the operations more equally among them. I will leave this as an exercise to you, the keen reader ;-)
Another question is: Could we just throw more workers at it?
Here is the result for 8 workers:

Well, this got slower! The timeline shows us why this happened:

We see that, aside from minor overlaps, no more than 4 workers are active at the same time.
This will depend on the system and worker characteristics and isn't a hard-and-fast number.
A system can only do so much at the same time and work is usually either *I/O-bound* (i.e. limited by network or file throughput) or *CPU-bound* (i.e. limited by running calculations on the CPU).
In our case each worker hogs the CPU for our calculations. As my Nexus 7 has four cores, it can deal with four of our fully CPU-bound workers simultaneously.
Usually you will end up with a mix of CPU- and I/O bound workloads or problems that aren't easy to chunk in smaller workloads, so the number of workers is sometimes a little hard to judge. If you are looking to find out how many logical CPUs are available, you can use [`navigator.hardwareConcurrency`](https://developer.mozilla.org/en-US/docs/Web/API/NavigatorConcurrentHardware/hardwareConcurrency) though.
## Wrap up
This was quite a lot to take in, so let's recap!
We found out that **JavaScript is single-threaded** and runs on the same thread as the browser tasks to keep our UI fresh and snappy.
We then used **Web Workers** to offload our work to separate threads and used `postMessage* to.communicate between the threads.
We noticed that threads don't scale infinitely, so some consideration for the amount of threads we run is advised.
When doing so we found out that **data gets cloned by default** which easily incurs more memory toll than meets the eye.
We fixed that via **transferring data** which is a viable option for certain types of data, referred to as [Transferables]( https://developer.mozilla.org/en-US/docs/Web/API/Transferable).
| g33konaut |
212,258 | Step-By-Step Guide To Build A Simple Chat App With React Native | React Native has made the mobile application development comprehensive and quicker. Brands and busine... | 0 | 2019-11-28T06:12:37 | https://dev.to/harikrishnakundariya/step-by-step-guide-to-build-a-simple-chat-app-with-react-native-4i7 | reactnative, chatapp, mobileapps | React Native has made the mobile application development comprehensive and quicker. Brands and businesses can build helpful apps for both Android and iOS by utilizing the same platform.
Today, we are going to build a simple chat application by React Native.
Here’s a detailed guide for you to build a simple chat app with React Native.
##**Step 1: Install Required Tools**
Since we are using React Native for successfully developing the cross-platform mobile app, we will need some essential tools already installed in our systems so that we can easily synchronize native platforms and react native.
First of all, make sure that that the React Native is installed in your system. Since there are so many resources available online, we are not going to add a sub-guide on how to install React Native in Windows/Mac.
Then, based on your choice on Android or iOS, You will have to download Android Studio or Xcode in your system. We can also go with other 3rd party simulators to test the code.
When are you building a mobile application, you will need to run the app on a mobile simulator. From our experience, we will use Expo to execute this task efficiently.
For advanced development in the subsequent steps, verify that the installed version of Node.js is 10+ before installing Expo.
Just type Node --version to identify its version, and make sure it is above 10.
Now, we are going to install expo command-line tools. You can replace npm with yarn in this step if you are more comfortable with Yarn.

Then, we need to create a project file for building our simple chat app with React Native. You can write below snippet in the CLI to create a project ‘AwesomeChat.’

##**Step 2: Use Stream Chat**
We'll build a simple chat application. As a developer, we must avoid writing an extended line of code for building a chat application from scratch, as it will take a lot of time and increase the size of your source code file.
Therefore, it is a smart choice to create a library file and intelligently synchronized with the main application. There are so many relevant libraries available that can help you with your requirements for developing a chat application.
We are going to use the Stream Chat library here to leverage attractive and elegant chat UI components in our system.
With Stream Chat, you can quickly add chat functionality in your mobile application of any kind.
This is the smartest way to conduct the [**React Native App Development**](https://www.esparkinfo.com/mobile-application-development/react-native.html) process by smartly enable the chatting feature in your mobile application.
In this process, we will add a simple chat screen in our mobile application using Stream Chat.
Now, open the App.js file in a text editor. Write below code snippet inside the file and save it.


Please note that this code snippet is the foundation behind the smooth working of our chat application built from React Native.
So, make sure that you are making these changes without any glitches or typos or syntax errors.
The above code snippet will handle all the API calls in your mobile chat application and maintain the state of the app along with manipulating all the other child components.
Therefore, the fundamental working of a simple chat application is heavily dependent on the above code snippet.
You can see from the above code snippet; we have a chat component that is responsible for managing all the API calls.
Any developer or tester should know where they are going invalid [**developing mobile applications**](https://www.esparkinfo.com/mobile-application-development.html). An efficient way to determine the development cycle is to run the mobile app on the smartphone.
As soon as you run the application on the smartphone, you will get certain types of screens and layouts that will help you identify your code is behaving.
In our case, to get the preview of the screen that we have written below, we are going to install Expo on our smartphone.
After installing Expo in your phone, make sure that the smartphone is connected with the same Wi-Fi network where your computer system is connected with.
It might happen that you are using the Android Studio or Xcode to develop the application. In that case, you can also utilize your inbuilt simulator to evaluate the performance of your code.

After writing the above line, the React Native development server will be initiated. Please note that the server will keep your application changing as soon as you make any changes in your code snippet.
##**Step 3: Manage Multiple Chats on One Screen**
The feasibility of any application or software is determined by the way it can handle multiple tasks in a given moment. The more task it can execute, the better the app is.
Similarly, the chat application must be able to manage multiple conversations in a given moment and provide efficient notifications as receiving multiple messages from multiple contacts.
In the single application, you will be able to talk with multiple users simultaneously.
You cannot run the application again or from the other device to chat with another user.
Just like Facebook messenger, Hike, Telegram, WhatsApp, and most of the other chat applications, you must be able to talk to several contacts simultaneously within a single login.
Therefore, we need a screen where we can have a list of conversations with whom you are talking to.
Moreover, we will also need robust navigation facilities in our chat application to effortlessly roam around the mobile app and have a seamless chatting experience with our contacts.
The package which we have installed earlier can execute all the tasks efficiently and help us enable multiple chats efficiently.
So, we would again go to the App.js file and make the following changes.



After making changes in the App.js file and saving it, you can go back to the simulator or the application on your mobile phones to see the changes.
Now, you will get a dedicated screen with a list of conversations. You can tap on each of the conversations to evaluate the things we have discussed above.
On all leading chatting applications, you will observe that a particular conversation comes at the top of the list as soon as it gets a new message.
In case of multiple your messages, the list is sorted by brining the conversation with the most recent messages at the top of the list.
Technically, each conversation is considered as an independent channel, and the conversation list is updated as soon as there is a new message from a channel.
Tool deal with all these States, we have a component called ChannelList that handles custom query and ordering.
Remember messaging someone for the first time, and their name is automatically added to the list? This is also done by ChannelList as it works as pagination and updates the conversation list as soon as a new channel is created.
##**Step 4: Add Channel Preview**
When you open chat application after some time, you would have more than one message from a single conversation.
Since we have already covered the list of the conversation in the above step, now we have to enable preview count to show how many messages have come has from a particular conversation.
To enable this, you will have to do a lot more manual coding on your native programming languages.
Since you are using React Native, you can manipulate code effortlessly and achieve this feature without doing a lot of manual programming.





##**Step 5: Create Message Threads**
Stream Chat supports multiple Threads under the same conversation to easily bifurcate your messages as per your comfort.
In technical language, you will be able to generate sub-conversations from a single channel without initiating different communication modes.
Stream Chat will enable thread component React Navigation in our mobile application to achieve this functionality.
In the code below, we will create the ThreadScreen component. Then register the new chat screen to navigation.
For knowing more about it, you should contact & [**Hire React Native Developer**](https://www.esparkinfo.com/hire-dedicated-developer/react-native.html) from a reputed firm. He/She will be able to guide you on this subject.
We would be leveraging the onThreadSelect prop to navigate to ThreadScreen.





##**Step 6: Applying Custom Message**
You must also take care of how the messages are rendered in your mobile application.
In the below code snippet, we have made a custom message component that uses the compact layout for messages.


##**Step 7: Integrate Custom Styles**
Custom styling makes your mobile app’s layout more appealing and elegant to use. We are going to leverage the React Native platform for this without writing extended CSS and HTML code.
In Fact, this is one of the [**Top Reasons Why People Opt For React Native**](https://www.esparkinfo.com/react-vs-angular.html). SO, you should also start preparing for this technology, right now.!

This code will update the default color to green.
##**Conclusion**
I’m curious to know how do you find this detailed guide of creating a chat app with React Native. Please drop your comments below and let me know.
If you are using any other method or have added some additional features with the similar methods discussed above, don’t forget to mention your approach below to help other programmers grow. | harikrishnakundariya |
212,262 | About tiling window managers | I have been using tiling windows managers for a couple of years now and I love it! ... | 0 | 2019-11-28T05:55:12 | https://dev.to/glpzzz/about-tiling-window-managers-4ggb | linux, productivity, tiling, windowmanager | I have been using tiling windows managers for a couple of years now and I love it!
## what?
Tiling windows managers (just) focus on the layout of windows on the screen making sure of two things:
- every window will use all the available space on screen
- if several windows open, all of them will be shown according to certain rules.
## why?
Because is simple, is less, is better (for me). Most of the implementations dont even decorate the windows. So, closing it depends on app specifics or a keyboard binding.
## how?
There are many options. I have tried extensively:
- i3: the nicer one. Good defaults and also provides an status bar and desktop changer. Configuration is done by editing a file. It also have a locker and status monitor.
- bspwm: the lightest. No bar at all. Is up to you. Configuration is just a script that calls a program that handles the window manager. This event don't handle keyboard bindings. Normally you will use sxhkd for this.
- dwm: my current choice. It's a suckless.org project. So, you will be compiling C code to configure stuff. But it's not hard. It provides a good bar and the chance to have current active window title on top. In reminds me Unity experience.
## important
- the layouts: most tiling provides different ways to organize the windows. The tiles, columns, rows, master and slave, master on the center, monocle, floating (sometimes is good)
- don't need to start from scratch: you can just setup the window manager for your current desktop environment. I'm currently using lxqt desktop environment with dwm as windows managers instead of openbox, This way I can use a regular graphical session with all the components wired in and also enjoy my favorite window manager in less than 5 minutes. Especially with lxqt that allows to change the window manager in the configuration as a very normal thing.
You can also replace kwin in a KDE session of xfwm on XFCE and rely on that DE setup instead of configuring everything from scratch. The methodnis different in each one, but is in general about this 2 steps:
- avoid the start or kill the default window manager
- start the tiling one.
## conclusion
I have learned a lot while playing with windows managers because they give you the chance to create your desktop environment from scratch and decide which pieces do you really need.
I'm open to questions! | glpzzz |
212,549 | New browser on the block! | Photo by Jacalyn Beales on Unsplash Well, it looks like the web browser ecosystem is getting another... | 0 | 2019-11-28T23:19:29 | https://www.iamdeveloper.com/posts/new-browser-on-the-block-k7k/ | browsers, discuss | Photo by [Jacalyn Beales](https://unsplash.com/@jacalynbeales?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/s/photos/evergreen-tree?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)
Well, it looks like the web browser ecosystem is getting another browser.
{%twitter 1200188106584023040 %}
This is healthy for the web assuming standards are followed. From the Tweets I've seen it appears to be fast, but it is early days and from what I can tell there is no preview version to download yet.
What are your thoughts on another browser entering into the browser ecosystem?
 | nickytonline |
212,297 | What Is Wordpress? Create a profitable wordpress blog? | Wordpress is best website for creating a blog website for own business. Wordpress has more plugins.... | 0 | 2019-11-28T08:36:45 | https://dev.to/jainish06915235/what-is-wordpress-create-a-profitable-wordpress-blog-201o | wordpressblog, wordpress | Wordpress is best website for creating a blog website for own business.
Wordpress has more plugins. Which helps to us to get less effort.and also helpful to improve search engine result in quickly.
You can see this blog to step by step process.
Read more: <a href="https://shiv1367.com/what-is-wordpress">Wordpress Blog</a> | jainish06915235 |
212,318 | List Comprehension and Creating lists from range function in Python🤙🤙 | The list is the most versatile python data structure and stores an ordered sequence of elements, just... | 0 | 2020-01-04T18:52:40 | https://dev.to/abhishekjain35/list-comprehension-and-creating-lists-from-range-function-in-python-1a5i | python, datastructures, list, productivity | The list is the most versatile python data structure and stores an ordered sequence of elements, just like the to-do-list.In Python, Lists are **mutable**, meaning that the details can be altered, unlike tuples or even strings. These elements of a list are called items and can be any data type.
Now for understanding this article, we need to understand the range() function.
```python
my_list = list(range(0,10,2)) #my_list becomes [0, 2, 4, 6, 8]
```
So, the range() function creates a sequence of numbers. First parameter of range() function is the starting number, the second parameter is number to stop before it and the third parameter is steps between these numbers(By default it is 1).
Now, we are going to look at some awesome tricks we can do on the lists in python ...
So, let's create a list first.
```python
my_list = list(range(1,10,2)) #creates my_list with the values of [1, 3, 5, 7, 9]
print(my_list[2]) #prints the value at given index i.e. 5
```
Now, we know that we can get the desired value by index. Here comes the cool part, we can give a range in the [] brackets And get the values within that range. For example-
```python
print(my_list[0:4]) #Prints [1, 3, 5, 7]
```
The first parameter 0 means the starting point. The second parameter means how many numbers you want to get. We can give the 3rd parameter to get the interval also.
Now, coming back to list comprehension in python. First, let me tell you the problem list comprehension is trying to solve.
Suppose we have given a list of string.
names = ["react", "angular", "ember"]
and we need to use upper case on every string
```python
upper_case_names = []
for name in names:
upper_case_word = name.upper()
upper_case_names.append(upper_case_word) #["REACT","ANGULAR","EMBER"]
```
What if we could do the above code in one line only! So, here comes the list comprehension.
```python
upper_case_names = [name.upper() for name in names] #["REACT","ANGULAR","EMBER"]
```
And Done!
Explanation: We start with the empty list []. Then on the right-hand side, we put the iterator or conditional, and on the left side, we put statements that we need to execute. That's it.
You can do so many cool stuff with the list comprehension.
And that's it for this article.
 | abhishekjain35 |
212,326 | React HOC for dummies | Let's get down and dirty with what HOCs are and why they matter! But let us first explore the concept of currying (in contrast to popular belief - not the spice) and how this concept from functional programming can help us create more usable code and really let us understand what Higher Order Component are. | 0 | 2020-02-27T08:05:53 | https://dev.to/johansaldes/react-hoc-for-dummies-4cad | react, hoc, currying, javascript | ---
title: React HOC for dummies
published: true
description: Let's get down and dirty with what HOCs are and why they matter! But let us first explore the concept of currying (in contrast to popular belief - not the spice) and how this concept from functional programming can help us create more usable code and really let us understand what Higher Order Component are.
tags: react, hoc, currying, javascript
---
In my work-life I often get the opportunity to teach and share skills with more junior developers regarding development with React and frontend development in general. I decided it was time to put these small sessions into a more compact and sharable format and hence here I am!
Despite the title of this article Higher Order Components (or simply HOCs) aren't really a dummy concept and can be quite tricky for people to wrap their head around.
So a word of caution, this is a "for dummies" but it does assume some React knowledge and ES6!
Now with that out of the way; let me give you a little background. It might not be super obvious how this relates to the topic but bare with me. It should all make sense soon enough!
# Currying
Despite the somewhat culinary sounding tone of this word it's actually very much a serious and useful mathematical concept best described by wikipedia:
> In mathematics and computer science, currying is the technique of translating the evaluation of a function that takes multiple arguments into evaluating a ...
Just kidding, it's obviously best understood with `code`, so here you go! :)
```js
const multiply = x => y => x * y;
```
So we now have a function `multiply` that takes an argument `x` and replies a new function which takes an argument `y` and returns `x * y`. Or order to invoke this function we could type:
```js
multiply(2)(2);
// Or using a console.log
console.log(multiply(2)(3));
// Output: 6
```
We said argument `x` is `2` and argument `y` is `3` which mean that what we'll get returned is `2 * 6` - if that wasn't already obvious to you!

<figcaption>Cool story bro, is it useful?</figcaption>
```js
const fetch = require('node-fetch');
let api = x => y => fetch(`https://jsonplaceholder.typicode.com/${x}/${y}`);
```
You can run this by initialising an _npm_ project and installing `node-fetch`. There's plenty of tutorials on how to do this, and to save time I'll presume that you already know it but in case you need a reminded it's `npm init` and `npm i -S node-fetch` :)
In this example we have a RESTful API that we're communicating with. Now what we could do is this:
```js
const fetch = require('node-fetch');
let api = x => y => fetch(`https://jsonplaceholder.typicode.com/${x}/${y}`);
const albums = api('albums');
const firstAlbum = albums(1);
firstAlbum
.then(res => res.json())
.then(console.log);
// { userId: 1, id: 1, title: 'quidem molestiae enim' }
```
And suddenly currying is starting to look a bit more powerful and useful. Now with this technique we can create very reusable code.
Oh, I never mentioned it. But now since I got you hooked: curry comes from the logician Haskell Curry. You'll find more Haskell (i.e. the language named after the very same logician) tutorials on my page soon :)
```js
const fetch = require('node-fetch');
let api = x => y => fetch(`https://jsonplaceholder.typicode.com/${x}/${y}`);
const albums = api('albums');
[1, 2, 3, 4, 5].map(n =>
albums(n)
.then(res => res.json())
.then(res => console.log(res))
);
```
This will fetch all albums starting from id 1 to id 5. Now if you're anything like me you're now bursting with ideas on how to implement this into your latest code base. That's all good my dude - go ahead! But remember, this was a HOC tutorial and what does currying have to do with HOCs?
# The Higher Order Component
```react
import React from 'react';
const withSecret = Component => class extends React.Component {
state = {
secret: 'Very53cr37Token'
}
render() {
return (
<Component secret={this.state.secret} />
)
}
}
const App = ({ secret }) => (
<div>{secret}</div>
);
export default withSecret(App);
```
Now you can run this code by going to [this repository](https://github.com/johansaldes/react-hoc-tutorial) and cloning it, this piece of code is located in `src/App.js`. Now to begin with, what's happening here is that we're exporting `withSecret`.
It takes one argument and immediately returns an _"anonymous class"_ (basically meaning we haven't given it a specific name) extending `React.Component`. Notice how in the `render` method we're returning some JSX. But what we're returning is the argument from above.
**And yes, of course I know that this secret isn't very secret at all. This is no way to store actual secrets. But as far as scoping goes this variable is inaccessible (hence, secret) from other components.**
```react
const withSecret = Component => ...
```
```react
render() {
return (
<Component secret={this.state.secret} />
)
}
```
So we're assuming (and it won't run unless it is as far as we're concerned) that the `Component` argument is a component of some sort i.e. a (React) component, functional component or a PureComponent. But we're also giving this component a new prop called `secret` which is also being rendered in our `App` component.
```react
const App = ({ secret }) => (
<div>{secret}</div>
);
```
So by wrapping our App component in `withSecret` we're giving it access to the prop `secret` which is now being rendered. Now we're not limited to rendering out strings like this. We can also give components access to functionality by wrapping them in a HOC.
# Adding functionality
```react
import React from 'react';
const withSecret = Component => class extends React.Component {
state = {
secret: 'Very53cr37Token'
}
setSecret = e => this.setState({
secret: e.target.value
})
render() {
return (
<Component secret={this.state.secret} setSecret={this.setSecret} />
)
}
}
const App = ({ secret, setSecret }) => (
<div>
{secret}
<input type="text" onChange={setSecret} />
</div>
);
export default withSecret(App);
```
You can find this code checking out the `adding-functionality` branch of the repository (like this `git checkout adding-functionality`).
This time we added a method to our HOC.
```react
setSecret = e => this.setState({
secret: e.target.value
})
```
You should be fairly familiar with what this does. But it takes the value of some HTML element that emits a event (in our case a `<input />` and sets the state property `secret` to whatever value it receives. The value is being set down in our App component on line 21.
```react
<input type="text" onChange={setSecret} />
```
The method `setSecret` is now exposed to our App because it's being inherited by our HOC on line 12.
```react
<Component secret={this.state.secret} setSecret={this.setSecret} />
```
You can run the script and type something into the input field that shows up. Voila, you've successfully updated the secret. But not only that, you now have a fully reusable piece of code that you can wrap around any other component we're you wish to add functionality. Of course you could also add styling or for example, a navigation bar (navbar), and wrap all component that needs a navbar with your `withNavbar` HOC etc.
The possibilities are endless. If you're familiar with Redux, then you might have heard that the `connect` function is a HOC? Well, now you can start to understand why that is and how that works!
*Now, if we think about it. I'm sure you've used a curried function before. Do you remember ever using `map` or `filter`? Because what are they? They are functions that takes functions as an argument and applies that function to every element in a list/array.*
Happy hacking! | johansaldes |
212,370 | A Complete Autonomous Drone Study Plan | If you already know programming basics and want to understand how rotorcraft function, what they can... | 0 | 2019-11-28T13:12:56 | https://dev.to/zarkopafilis/a-complete-autonomous-drone-study-plan-3d18 | drones, ai, deeplearning, autonomous | If you already know programming basics and want to understand how rotorcraft function, what they can do and how to make them do stuff, you are in the right place.
The drone industry is worth more than 130 billion dollars and is growing rapidly.
**Don’t feel you are not smart enough**
Successful software engineers are smart, but many have an insecurity that they aren’t smart enough.
I originally created this as a short to-do list of study topics for becoming a software engineer, I am publishing this list to share my 3 year list of topics that I studied on the side during the curriculum of a Computer Engineering and Informatics degree. This is a list of short and medium length study topics to obtain knowledge regarding autonomous rotorcraft. The items listed here will give you enough knowledge to be able to understand how they work, their limitations and effort required to make them fly. Happy studying!
[The complete list is published on Github. Click here to access it.](https://github.com/Zarkopafilis/awesome-dronecraft)
**Table of Contents**
- What is it?
- Why use it?
- How to use it
- Don’t feel you aren’t smart enough
- You can’t pick only one language
- Book List
- Before you Get Started
- What you Won’t See Covered
- Prerequisite Knowledge
- Optional Courses
- Simulation and Control
- Control Theory
- Sensors and State Estimation
- Simultaneous Localization and Mapping
- Path Planning
- Mechatronics
- Existing Drone Software
- Existing Drone Hardware
- The Flight Controller
- Building a Racing FPV Quadcopter
- Building Fully Autonomous Rotorcraft
- Once You’ve Finished
- Other Resources
- Drone Usage in Industry
- Other Kinds of Vehicles
- More Advanced Topics
- Other Interesting
## Simulation and Control
- This is the basis of rotorcraft that is going to get covered first. These few resources will make you understand what a drone needs to fly bad, good, with the help of extra autonomy engines or with the help of a pilot.
- After this part, the corks and screws of each subsystem is going to be investigated thoroughly.
- [ ] [Matlab Tech Talks - Understanding Control Systems](https://www.mathworks.com/videos/series/understanding-control-systems-123420.html)
- [ ] [Matlab Tech Talks - Drone Simulation and Control](https://www.mathworks.com/videos/drone-simulation-and-control-part-1-setting-up-the-control-problem-1539323440930.html)
- [ ] [Introduction to 6-DOF Simulation of Air Vehicles (pdf)](http://avionics.nau.edu.ua/files/doc/VisSim.doc/6dof.pdf)
- [ ] [Betaflight: PID Tuning Guide](https://www.youtube.com/watch?v=27lMKi2inpk)
__At this point, you might wonder: This is only for four rotors. Don't worry, the extra ones are only used to have resilience. In the future this is going to be populated with more types of rotorcraft like submarines, VTOL drones and wings.__
[Continue Studying at Github](https://github.com/Zarkopafilis/awesome-dronecraft)
#drones #ai #autonomous
| zarkopafilis |
212,554 | Using Segment with Ember.js | I've been working on College Conductor to help serve Independent Educational Consultants (like this o... | 0 | 2019-12-11T18:01:48 | https://www.mattlayman.com/blog/2016/ember-segment/ | javascript, ember, segment | I've been working on [College Conductor](https://www.collegeconductor.com/) to help serve Independent Educational Consultants (like [this one](https://laymancollegeconsulting.com/) :) and high school guidance counselors. To find product market fit, I'm using [Segment](https://segment.com/) which gets the data I need to decide how to improve the service. In this post, **I'll describe how I connected Segment to College Conductor's [Ember.js](http://emberjs.com/) frontend.**
Working with Segment in Ember can be done with [ember-cli-segment](https://github.com/josemarluedke/ember-cli-segment), an Ember addon that provides an Ember [service](https://guides.emberjs.com/v2.1.0/applications/services/) to communicate with Segment. The first thing I did was install the addon with:
```bash
$ ember install ember-cli-segment
```
`ember-cli-segment` has a solid README on their GitHub page that instructs users what to do at a very detailed level. Before getting buried in details, I had two initial goals with this addon.
1. Connect to Segment to record basic analytics.
2. Utilize the [identify](https://segment.com/docs/sources/server/http/#identify) API to connect users to their actions.
Once these two goals were completed, I could monitor enough behavior to make data based decisions about what to improve in the product.
## Connect to Segment
Connecting the Ember app to Segment involved adding my Segment write key to the app's configuration. The result in my `environment.js` file was something like:
```javascript
ENV['segment'] = {
WRITE_KEY: 'my_segment_write_key'
}
```
With that much configuration, data started flowing from College Conductor to Segment. Exciting!
## Identifying users
My second goal of identifying users was done with an application route hook. If you create a method named `identifyUser` in your application route, then `ember-cli-segment` will make the `identify` API call on your behalf.
I had to supply a user ID and whatever other information I wanted. At this stage in my product development, including the account username is all the extra data I want.
My code in `app/application/route.js` looks like:
```javascript
identifyUser() {
const user = this.get('currentUser.user');
if (user) {
this.get('segment').identifyUser(
user.get('id'), {username: user.get('username')});
}
}
```
This code grabs the authenticated user from the `currentUser` service that I created and identifies that user with Segment.
## Thankful
By the time I finished with this work, I was very grateful for `ember-cli-segment`. The addon made my job much easier. This is one of the things that I really like about the Ember community. Ember CLI addons can take out some of the very heavy development work. That means I can spend more time on College Conductor and less time on the nuts and bolts of service integration.
This article first appeared on [mattlayman.com](https://www.mattlayman.com/blog/2016/ember-segment/).
| mblayman |
212,402 | 100+ Hottest Black Friday and Cyber Monday Deals For Dev.to Community. | We have compiled the following list of great bargains on industry-leading themes, plugins extensions for WordPress, Magento, and Marketing tools. | 0 | 2019-11-28T14:27:05 | https://dev.to/jamilaliahmed/100-hottest-black-friday-and-cyber-monday-deals-for-dev-to-community-2ae9 | webdev | ---
title: 100+ Hottest Black Friday and Cyber Monday Deals For Dev.to Community.
published: true
description: We have compiled the following list of great bargains on industry-leading themes, plugins extensions for WordPress, Magento, and Marketing tools.
tags: #webdev
---
We have compiled the following list of great bargains on industry-leading themes, plugins extensions for WordPress, Magento, and Marketing tools.
Plus Cloudways is giving 40% OFF for the next three months.
Promo code BFCM40 . Valid till 4th December 2019 and for new users only.
<a href="https://www.cloudways.com/blog/thanksgiving-black-friday-cyber-monday-deal/">. 100+ Hottest Black Friday and Cyber Monday Deals For Dev.to Community</a>
| jamilaliahmed |
212,452 | PHP Comment System With Replies | I have code that is able to capture the initial comment and the 1st level of replies, but it doesn’t... | 0 | 2019-11-28T16:23:55 | https://dev.to/aaronesteban1/php-comment-system-with-replies-4d4c | php, comment, system | I have code that is able to capture the initial comment and the 1st level of replies, but it doesn’t seem to capture the reply to a reply. I know that it requires an indefinite code using some form of recursion, but not quite sure how to properly implement it. Here's the code I'm using:
<?php
$conn = new mysqli('localhost', 'root', 'Jordan123', 'commentsystem2');
$sql1 = "SELECT * FROM comments WHERE r_to = 0";
$result1 = $conn->query($sql1);
while($row1 = $result1->fetch_assoc()) {
$c_id = $row1['id'];
$c_name = $row1['name'];
$c_comment = $row1['comment'];
echo '
<div class="comments" style="position:relative; margin:auto; width:25%;">
<div>ID# '.$c_id.'</div>
<div style="font-weight:bold;">'.$c_name.'</div>
<div>'.$c_comment.'<br><br></div>
</div>
';
$sql2 = "SELECT * FROM comments WHERE r_to = $c_id";
$result2 = $conn->query($sql2);
while($row2 = $result2->fetch_assoc()) {
$r_id = $row2['id'];
$r_name = $row2['name'];
$r_comment = $row2['comment'];
$r_to = $row2['r_to'];
echo '
<div class="comments" style="position:relative; margin:auto; width:25%; padding-left:80px;">
<div>ID# '.$r_id.'</div>
<div style="font-weight:bold;">'.$r_name.' replied to '.$c_name.'</div>
<div>'.$r_comment.'<br><br></div>
</div>
';
}//end of 1st while loop that captures comments.
}//end of 1st while loop that captures comments.
$conn->close();
?>
Notice how some of the replies to replies that are in the table, are missing on output.
| aaronesteban1 |
212,462 | Get a notification at the client when using the Firebase Cloud Messaging service on .NET | I am exploiting some APIs of mobile applications on Android operating system. In it they use Google's... | 0 | 2019-11-28T17:19:07 | https://dev.to/mincasoft/get-a-notification-at-the-client-when-using-the-firebase-cloud-messaging-service-on-net-1kd5 | csharp, dotnet, firebase, fcm | I am exploiting some APIs of mobile applications on Android operating system. In it they use Google's FCM service. After decompiling the source code using Apktool, I get a device_token string, and an API function to call the server to return a message (notification).
I want to use the exploited API functions to port to the desktop application as an automated tool. Unfortunately, Google's FCM does not support .NET (only on Android, iOS, Web platforms) I want every time I make a call API to their server, I call a function so they return OTP to confirm the transaction. This OTP is contained in the server's return notification.
In the Google FCM document, a google-service.json file is imported into Firebase's Android project and SDK, I'm programming a .NET application, so how can I get a notification like when calling the onMessageReceived () function in the Firebase SDK | mincasoft |
212,474 | Updating your existing apps for accessibility | Written by Raphael Ugwu✏️ The web has an ever-growing user base, and more activities than ever are... | 0 | 2019-12-02T14:45:50 | https://blog.logrocket.com/updating-your-existing-apps-for-accessibility/ | a11y, react, vue, javscript | ---
title: Updating your existing apps for accessibility
published: true
date: 2019-11-28 17:00:26 UTC
tags: accessibility,react,vue,javscript
canonical_url: https://blog.logrocket.com/updating-your-existing-apps-for-accessibility/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/unecx8dlc03delj7jxae.png
---
**Written by [Raphael Ugwu](https://blog.logrocket.com/author/raphaelugwu/)**✏️
The web has an ever-growing user base, and more activities than ever are centered around web applications. It’s important for developers and product managers to build interfaces that are applicable to not only a lot of use cases, but a wide range of abilities as well. The [World Wide Web Consortium (W3C)](https://www.w3.org/WAI/standards-guidelines/wcag/) created a set of specifications to show how web apps can be made accessible to individuals who may face challenges when using them. This includes people with physical, visual, speech, auditory, and intellectual impairments.
JavaScript is arguably the most popular language used to build web apps, and its two most popular frameworks are [React](https://github.com/facebook/react) and [Vue](https://github.com/vuejs/vue). Let’s take a look at how we can make web apps built with either framework more accessible to users with limitations.
[](https://logrocket.com/signup/)
## Improving markup with ARIA Attributes
Accessible Rich Internet Applications (ARIA) attributes are huge part of accessibility in web apps. You can use them to specify attributes that define the way an element is translated into the [accessibility tree](https://developers.google.com/web/fundamentals/accessibility/semantics-builtin/the-accessibility-tree).
To demonstrate how ARIA attributes can be used to improve accessibility in React apps, let’s say we have an e-commerce app and we want to make the checkout process easy.
```jsx
render() {
return (
<div>
<h3>"Click below to use Prime's lifetime access at $10.99 per month"</h3>
<button onClick={this.makePayment}>Pay Here</button>
</div>
);
}
}
render(<Payment />, document.getElementById("root"));
```
Here’s the problem: if a [screen reader](https://accessibility.its.uconn.edu/2018/08/22/what-is-a-screen-reader-and-how-does-it-work/#) is being used on this web app, it might detect the button but not the text in the `<h3>` tag. As a result, a visually impaired user who doesn’t detect this might unknowingly sign up for a service where they’ll be deducted every other month. We can use an ARIA attribute to make this more accessible.
```jsx
render() {
return (
<div>
<h3> Click below to use Prime's lifetime access at $10.99 per month </h3>
<button
onClick={this.makePayment}
aria-label="Click below to use Prime's lifetime access at $10.99 per month"
>
Pay Here
</button>
</div>
);
}
```
In the code sample above, `aria-label` tells the app’s users what exactly the button pays for. But what if the text in the `<h3>` tag is really long? We wouldn’t want to fit in an entire paragraph in `aria-label`. Let’s modify our `return` statement to include another ARIA attribute:
```jsx
render() {
return (
<div>
<h3 id="lifetimeAccess">
Click below to use Prime's lifetime access at $10.99 per month
</h3>
<button
onClick={this.makePayment}
aria-labelledby="lifetimeAccess"
>
Pay Here
</button>
</div>
);
}
```
With the `aria-labelledby` attribute, a screen reader can detect that the element with the `id` of lifetime access is the button’s label.
With Vue, this is almost the same thing except for changes in syntax:
```jsx
<template>
<div>
<h3 :id="`lifetimeAccess`">
Click below to use Prime's lifetime access at $10.99 per month
</h3>
<button
@click="makePayment()"
:aria-labelledby="`lifetimeAccess`"
>
Pay Here
</button>
</div>
</template>
```
## Managing Focus
It’s important to give users options for how to handle focus when accessing your app. Keyboard focus is a good option because it allows people who have limited mobility in their wrists to access your app easily. Vue implements keyboard focus through the use of [custom directives](https://vuejs.org/v2/guide/custom-directive.html).
```jsx
<template>
<div id="app">
<div v-if="flow == 'search'">
<input type="text" placeholder="Enter your query" v-model="search" v-focus>
<button>Search</button>
</div>
</div>
</template>
<script>
import Vue from "vue";
Vue.directive("focus", {
inserted: function(el) {
el.focus();
},
update: function(el) {
Vue.nextTick(function() {
el.focus();
});
}
});
export default {
name: "App",
data() {
return {
flow: "search",
search: null
};
}
};
</script>
```
In the code sample above, `v-focus` is registered globally as a custom directive. It is then inserted into the DOM and wrapped in a `nextTick`. This will [hold the focus event until the DOM is updated](https://vuejs.org/v2/api/#Vue-nextTick) and the input is displayed.
{% youtube IpdlakY6Wjg %}
As shown in the short clip above, the focused element is the one currently receiving input. React accomplishes the same thing with `refs`. You can [use refs to access DOM nodes or React elements](https://reactjs.org/docs/refs-and-the-dom.html) created in the `render` method.
Here we’ll create a ref for the component to which we want to add an element and then update the focus using the `componentDidMount` lifecycle method:
```jsx
import React, { Component } from "react";
import { render } from "react-dom";
class App extends Component {
constructor(props) {
super(props);
this.focusDiv = React.createRef();
}
componentDidMount() {
this.focusDiv.current.focus();
}
render() {
return (
<div className="app">
<input tabIndex="-1" ref={this.focusDiv} placeholder="Enter your query" />
<button>Search</button>
</div>
);
}
}
render(<App />, document.getElementById("root"));
```
The `tabIndex` value is set to `-1` to allow you to set programmatic focus on an element that is not natively focusable. When configuring keyboard focus, do not add CSS styles that remove the outline or border of elements, since these could affect the outline that appears when an element is in focus.
## Accessibility in route transitions
Screen readers have certain limitations with navigating routes in single-page apps built with React or Vue. During navigation, the routing software of these frameworks handles some of the navigation actions from the browser to prevent constant reloading of the host HTML page.
Screen readers depend on the browser to feed them updates on navigation, but since this functionality is being handled by frameworks, what follows is a totally silent page transition for visually challenged users. Other examples are error situations and content and state changes in our application that could be very clear visually but go undetected by screen readers.
`react-aria-live` is a React library that uses [ARIA live regions](https://developer.mozilla.org/en-US/docs/Web/Accessibility/ARIA/ARIA_Live_Regions) to announce route changes in an application. Suppose we want a visually impaired user to know that the `Order` page in an e-commerce app has loaded:
```jsx
import React, { Component } from "react";
import { LiveAnnouncer, LiveMessage } from "react-aria-live";
class App extends Component {
state = {
message: ""
};
componentDidMount() {
document.title = "Orders Page";
setTimeout(() => {
this.setState({ message: "The Orders page has loaded" });
}, 3000);
}
render() {
return (
<LiveAnnouncer>
<h1 tabIndex="-1"> Confirm your orders here</h1>
<LiveMessage message={this.state.message} aria-live="polite" />
); }
</LiveAnnouncer>
);
}
}
export default App;
```
In the code sample above, `LiveAnnouncer` wraps the entire app and renders a visually hidden message area that can broadcast `aria-live` messages. The `LiveMessage` component does not have to exist in the same component as `LiveAnnouncer`; as long as it exists inside a component tree wrapped by `LiveAnnouncer` , it is used to convey the message using either an `assertive` or `polite` tone.
Vue informs screen readers of route changes with `vue-announcer`, a library similar to `react-aria-live`. Here you may also have to manually configure messages. Let’s replicate the same `Orders` page, only this time using Vue:
```jsx
<template>
<div id="app">
<h1 tabindex="-1">Confirm your orders here</h1>
</div>
</template>
<script>
export default {
name: "App",
head: {
title: {
inner: "Orders Page"
}
},
methods: {
mounted() {
setTimeout(() => {
let message = `The Orders page has loaded`;
this.$announcer.set(message);
}, 3000);
}
}
};
</script>
```
In the code sample above, `this.$announcer` notifies the user by sending an auditory message three seconds after the page has loaded.
## Summary
A huge first step toward [achieving accessibility](https://www.netlify.com/blog/2019/02/25/accessibility-is-not-a-react-problem/) is acknowledging that there are people out there who do not use your apps and devices in a conventional manner. Building apps that address their needs can help increase user retention and demonstrate your commitment to inclusiveness.
* * *
**Editor's note:** Seeing something wrong with this post? You can find the correct version [here](https://blog.logrocket.com/updating-your-existing-apps-for-accessibility/).
## Plug: [LogRocket](https://logrocket.com/signup/), a DVR for web apps

[LogRocket](https://logrocket.com/signup/) is a frontend logging tool that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
[Try it for free](https://logrocket.com/signup/).
* * *
The post [Updating your existing apps for accessibility](https://blog.logrocket.com/updating-your-existing-apps-for-accessibility/) appeared first on [LogRocket Blog](https://blog.logrocket.com). | bnevilleoneill |
212,483 | 5 ReactJS libraries to make life fun and easy | Curated list of React Libraries | 0 | 2019-11-28T18:30:19 | https://dev.to/zsumair/5-reactjs-libraries-to-make-life-fun-and-easy-58a7 | javascipt, react, webdev, frontend | ---
title:5 ReactJS libraries to make life fun and easy
published: true
description: Curated list of React Libraries
tags: #javascipt,#react,#webdev,#frontend
---
**If you are a React beginner or just looking for some good Libraries/Components to use in your app, I have curated a categorised collection of React Libraries and Components at http://applibslist.xyz/ which i keep updating and also send newsletter every week to notify about the cool libraries/components in React community.**
Here i curate a list of 5 libraries that you might find fun and easy to work with
#### 1. React Helmet :
[react-helmet](https://github.com/nfl/react-helmet) is a reusable component for html head. It allows you to set meta tags dynamically that will be read by search engines and social media crawlers.Which in turn helps your website's SEO. In SPA(single page apps), SEO is the hard part because we use same html page throughout the website. React Helmet lets us dynamically override the meta tags of its parent page from a leaf page.Good thing about it is, it takes plain HTML tags and outputs plain HTML tags and is dead simple.
#### 2. Motion :
[Motion](https://www.framer.com/motion/) is a simple animation and gesture API from the Framer X team. It has a simple declarative API which makes it easy to create smooth animations and even complex animations can be created with minimal amount of code. It is so simple to animate using this library, you just need to set final css values on the animation prop and voila.
#### 3. React-Toastify :
[react-toastify](https://fkhadra.github.io/react-toastify/) makes you add notifications to your website so simple and easy that you barely need a minute to set it up and running. Cool thing about this library is you can go to their website, customise your notification toast visually and just take the code from it and plug it your app. Animation and transitions are so smooth and they are responsive as well
#### 4. React Credit Cards:
[react-credit-cards](https://ovvwzkzry9.codesandbox.io/) slick credit card component will make your website checkout look fun and cool.This component is very easy to setup and plug in your app.You will get a good looking card checkout in your app, which definitely will impress your users and gives them seamless experience on your app.
#### 5. React-Switch-Input :
[react-switch-input](https://erikaperugachi.github.io/react-switch-input/) is a simple switch component, which simulates the ios switch.Using this is as simple as adding `<Switch/>` to your component. It is a small library that you use to add this effect to your website/app form.
Well that's it from me folks. Hope you like the list.
These libraries and components can also be found on the website http://applibslist.xyz/
| zsumair |
212,587 | 8th language release v19.08 | While I'm sharing news about programming languages I use, here's another which was released earlier t... | 3,518 | 2019-11-29T03:41:43 | https://dev.to/bugmagnet/8th-language-release-v19-08-16lm | eighth, forth, concatenative, crossplatform | While I'm sharing news about programming languages I use, here's another which was [released](https://8th-dev.com/forum/index.php/topic,1939.0.html) earlier this month.
> 8th™ is an innovative, secure, cross-platform, robust, and fun
concatenative programming language for mobile, desktop, server, and
embedded application development.
8th is a [FORTH](https://en.wikipedia.org/wiki/Forth_(programming_language)). If you're comfortable with using [RPN (Reverse Polish Notation)](https://en.wikipedia.org/wiki/Reverse_Polish_notation) you're well on the way toward being able to do FORTH programming. And if cross-platform is your thing, 8th is well worth a look.
Disclaimer: I have no connection to Aaron High-Tech Ltd. I'm just a happy user of their product. | bugmagnet |
212,590 | Installing Linux on your Android Device | Linux on Android? You must be using your Android device to make calls or maybe read messag... | 0 | 2019-11-29T03:57:42 | https://dev.to/imprakharshukla/installing-linux-on-your-android-device-25cf | android, linux, ubuntu, design |
# Linux on Android?
You must be using your Android device to make calls or maybe read messages but ever thought of using it for running **Blender**, making 3D models with it or using **IntelliJ** on your Android phone? If no is the answer, just keep reading. I promise it's easier than making a cup of coffee!
# But why?
Running your favourite Linux distribution on a handheld device unlocks an entirely new realm of possibilities. You can run any app that supports ARM-based processors (we are looking into supporting x86 as well) and voila! You have a computer running inside your phone. You can run it completely offline once you have installed it completely, connect to a VNC viewer and enjoy the aesthetics of the distro you love, on your phone.
# How to get started?
Installing Linux on Desktops is difficult than installing that on your Android Device 😅. Here's the step by step guide on how to do it but before that let me introduce **Andronix**, an app made with 💙 for Android, Linux and is proudly open-source (*Linux back-end is completely open-source*).
Andronix lets you install Linux on your **non-rooted Android devices** with just a couple of clicks.
More info - https://andronix.app
1. Install Andronix from the Google Play Store. Here's a [link](https://play.google.com/store/apps/details?id=studio.com.techriz.andronix&hl=en_IN) to make that easier for you. Now Install Termux from [here](https://play.google.com/store/apps/details?id=com.termux&hl=en_IN).
2. Open the app and select your favourite distribution that you want to install.
3. Click on *Install*, this should bring up an installation sheet. Click on *Copy* and paste the copied command in the Termux app and run it by pressing the *enter key* on your keyboard.
4. Wait till the installation completes and then you have to start the Linux instance just by using the start script. Like *./start-ubuntu.sh for Ubuntu* or *./start-kali.sh for Kali Linux*
5. This should bring up the terminal for the distro you've installed. Now from here, it's your call either to use a bare-bone Linux terminal or install a **Desktop Environment** to make it look pretty and in essence, usable.
6. You can choose from XFCE, LXQt, LXDE or MATE (KDE is only available with one of our Andronix Modded OS). To select a desktop environment return to the app and scroll down in the installation sheet to find the section for the environment. Click on the one you want to install and paste that in your Linux shell (*Your Linux Shell will look something like **$ root@username** after using the start script.*)
7. Here you are now with a full-fledged Linux desktop on your Android phone. Just use this guide to connect to a [VNC client](https://docs.andronix.app/1.0/connecting-to-a-vnc-viewer/starting-the-vnc-server).
## Facing Trouble?
Here are a few links that can help you -
YouTube tutorial - https://tinyurl.com/andronixYoutube
Andronix Docs - https://docs.andronix.app
Andronix GitHub - https://github.com/andronixApp
Official website - https://andronix.app
Tutorials and Blogs - https://blog.andronix.app
# How can I extend my powers?
To be honest, installing apps for ARM-based processors can be a bit of work, finding a suitable repository and checking the compatibility. We have made it extra easy for you.
Presenting **Andronix Modded OS** that include Ubuntu Xfce and KDE, Debian Xfce and Manjaro Xfce. These are pre-configured to save your time in debugging those pesky bugs and build fails.
All the essential software like ***VSCode, Chromium, Firefox*** etc. are pre-installed. ***Jetbrain IDEs*** are fully supported. You can use **sudo** because you have a non-root account by default, a great thing to have. The feature list is endless so here's a link to help you [more](https://andronix.app/modded-os/).
# Linux is okay, but what else?
Andronix is not at all limited to only installing Linux but has so many cool features. One of the main highlights of the app besides the Linux part is **Andronix Commands**. It allows you to save your most used terminal commands (*at least we have made it for that, but you might use it for any other purpose* :p) to the cloud and then access them on any internet-connected device with our web-app. So you can use Andronix on your computer, maybe your raspberry-pi or anywhere else. Besides saving them, you can also colour code them, enabling you to filter your commands based on colours.
Andronix comes with a Feed section with our latest posts and blog about Andronix or Linux in general.
# Community?
Andronix is a rapidly growing app. Our Discord and Telegram communities are ready to help you if you face any problems with anything.
Discord - https://discord.gg/jywhBH4
Telegram - https://t.me/andronixApp
Email - [andronix@techriz.com](mailto://andronix@techriz.com)
# Donation
Andronix is an **open-source** project. It is completely **ad-free**. Please consider doing an in-app purchase or donating us.
Donations - https://andronix.app/donation/ | imprakharshukla |
212,716 | GraphQL and Tree Data Structures with Postgres on Hasura GraphQL engine | Modelling a tree data structure on postgres and using GraphQL to add and get data from the tree.... | 0 | 2019-12-19T08:48:15 | https://blog.hasura.io/graphql-and-tree-data-structures-with-postgres-on-hasura-dfa13c0d9b5f/ | graphql, postgres, database, tutorial | ---
title: GraphQL and Tree Data Structures with Postgres on Hasura GraphQL engine
published: true
date: 2018-05-08 00:00:00 UTC
tags: graphql, postgres, database, tutorial
canonical_url: https://blog.hasura.io/graphql-and-tree-data-structures-with-postgres-on-hasura-dfa13c0d9b5f/
---
Modelling a tree data structure on postgres and using GraphQL to add and get data from the tree.

## When are tree data structures used ?
Recursive or Tree Data Structures are commonly used to model your schema to store data that has a hierarchy.
Common use-cases of tree data structures include:
- Storing a directory structure for an application like Google Drive where you would have a root directory. Within this root directory you may have other directories or files. Every directory at any level of nesting can have any number of files or directories inside it.
- Comment threads for blogs or forums where each post or topic can have comments and each comment can in turn have comments (or replies).
- Finding common connections or friends for a networking application like LinkedIn or Facebook.
In this blog post we are going to take a look at how you can model your database to build a comment thread feature for your application. Moreover, we will also be using GraphQL to add and delete comments.
Let’s take an example of a very simple blog and work on enabling comments for each post. To elaborate on what we need
- Every post can have comments
- Every comment can have replies (child comments)
- We want to list these comments in an ordered fashion sorted by when they were created.
We are going to go with Hasura GraphQL engine as it provides a Postgres database with instant GraphQL queries.
## Getting started
We will use the Hasura GraphQL engine for instantly getting GraphQL APIs over Postgres. Click on the button below to deploy the GraphQL engine to Heroku’s free tier.
[](https://heroku.com/deploy?template=https://github.com/hasura/graphql-engine-heroku)<figcaption>Click this button to deploy the GraphQL engine to Heroku</figcaption>
This will deploy the `graphql-engine` to Heroku. You might need to create a Heroku account if you don’t have one. The `graphql-engine` will be running at `https://your-app.herokuapp.com` (replace `your-app` with your heroku app name).
## _**API Console**_
Every Hasura cluster comes with an `API Console` that you can use to build the backend for your application.
The API Console is available at [`https://your-app.herokuapp.com`](https://your-app.herokuapp.com)`/console`

## Creating a table
Head to the `Data` tab and click on `Create Table` to create a new table
Let’s call our table `post_comments` to store the comments for each post. The table will have the following columns
- **`id`** Integer(auto increment) _Primary Key_
- **`parent_id`** Integer _Nullable_
- **`comment`** Text
- **`created_at`** Timestamp _default now()_
- **`post_id`** Integer
- **`user_id`** Integer

Hit the `create` button to create the table.
This is the table where we will store all the comments for each of the blog posts.
### Creating a self reference
Next, let’s define a foreign key constraint on the `parent_id` column to the `id` column.
To do this, head to the `Modify` tab and click on the `Edit` button next to `parent_id`. Check the `Foreign Key` checkbox, select `post_comments` as the reference table and `id` as the reference column.

### Adding a [relationship](https://docs.hasura.io/0.15/manual/data/relationships/index.html) to fetch the child comments
Next, click on the `Relationship` tab and click on the `Add` button under the `Suggested Array Relationship` column. Name the relationship `children_comments`

Hit `Save` to add this relationship.
## Fetching and adding comments
The mutation to **insert a comment** will be
```
mutation add_comment {
insert_post_comments(objects: $objects) {
returning{
id
parent_id
comment
created_at
user_id
post_id
}
}
}
```
The `$objects` variable will be
```
{
"objects": [
{
"user_id": 1,
"post_id": 1,
"comment": "First comment on post 1",
"parent_id": null
}
]
}
```
Similarly, the `$objects` variable to add a reply to a comment
```
{
"objects": [
{
"user_id": 1,
"post_id": 1,
"comment": "First comment on post 1",
"parent_id": 1 //Or id of the comment to which this comment is a reply to
}
]
}
```
### Fetching comments
If we are aware of the level of nesting in our comments, then the GraphQL query to fetch comments and all children comments for a post would be
```
query get_comments_for_post {
post_comments(
where: {
post_id: 1
parent_id: null
}
order_by: ["+created_at"]
) {
id
parent_id
comment
created_at
user_id
post_id
children_comments (
order_by: ["+created_at"]
){
id
parent_id
comment
created_at
user_id
post_id
}
}
}
```
Here, we are fetching all the comments for a post with an `id` value of `1` and whose `parent_id` is `null`. We are then fetching all the replies (`children_comments`) as a relationship. The `+created_at` in the `order_by` field denotes that the comments should be fetched in the ascending order (based on the value of `created_at` ). Alternatively, `-` would denote descending. If no symbol is specified in the query, then `+` is assumed by default.
Similarly, in case you had another level of nesting, the query would be
```
query get_comments_for_post {
post_comments(
where: {
post_id: 2
parent_id: null
}
order_by: ["+created_at"]
) {
id
parent_id
comment
created_at
user_id
post_id
children_comments (
order_by: ["+created_at"]
){
id
parent_id
comment
created_at
user_id
post_id
children_comments(
order_by: ["+created_at"]
) {
id
parent_id
comment
created_at
user_id
post_id
}
}
}
}
```
## Working with unknown levels of nesting
Sites like [https://news.ycombinator.com/](https://news.ycombinator.com/) allow any level of nesting. Which means that every comment can have one more child comments. In this case, fetching our comment like we did above does not work since we do not know how many levels we need to fetch.
One of the ways of handling this is to fetch the complete list of comments for the particular topic (in this case a blog post) and then arrange it in memory on your client.
```
query get_comments_for_post {
post_comments(
where: {
post_id: 1
}
order_by: ["created_at"]
) {
id
parent_id
comment
created_at
user_id
post_id
}
}
```
You could also have another table that keeps a track of ancestry, something like `post_comment_ancestry`
- **`comment_id`**
- **`ancestor_id`**
Here, for each comment you will store a list of all of its ancestors. For eg: if comment `A` has two child comments `B` and `C` and comment C has a child comment `D`,
```
A
| - B
| - C
| - D
```
the entry in the `post_comment_ancestry` table would be
```
+------------------------+
|comment_id | ancestor_id|
+------------------------+
| B | A |
| C | A |
| D | C |
| D | A |
+------------------------+
```
As you can see, comment `D` has two entries for `A` and `C` respectively. Using this table you can fetch a list of all child comments to any arbitrary amount of nesting for a particular comment.
## Conclusion
In this blog post we took a look at one of the ways in which we can work with tree data structures on Postgres.
If you would like to see any other use-cases or suggest improvements to the ideas mentioned above, let me know in the comments.
[_**Hasura**_](https://goo.gl/QfCiQV) _gives you instant realtime GraphQL APIs over any Postgres database without having to write any backend code._
_For those of you who are new to the Hasura GraphQL engine,_ [_**this**_](https://docs.hasura.io/1.0/graphql/manual/index.html) _is a good place to get started._
* * * | hasurahq_staff |
212,887 | A Vue.js particle background component that makes your page sparkle | github https://github.com/lindelof/particles-bg-vue A vue.js particles animation ba... | 0 | 2019-11-29T12:12:22 | https://dev.to/lindelof/a-vue-js-particle-background-component-that-makes-your-page-sparkle-33pe | vue, webdev, github, opensource | <p align="center">
<img src="https://github.com/lindelof/particles-bg-vue/blob/master/images/logo.png?raw=true"/>
</p>
### github [https://github.com/lindelof/particles-bg-vue](https://github.com/lindelof/particles-bg-vue)
> A vue.js particles animation background component
### Online demo
* demo1 [https://codesandbox.io/s/particles-bg-vue-bg145](https://codesandbox.io/s/particles-bg-vue-bg145)
* demo2 [https://codesandbox.io/s/particles-bg-vue-qc1b5](https://codesandbox.io/s/particles-bg-vue-qc1b5)
* custom [https://codesandbox.io/s/particles-bg-vue-2fkvr](https://codesandbox.io/s/particles-bg-vue-2fkvr)





## Install
```bash
npm install --save particles-bg-vue
```
## Usage
### Method 1: Import and use in the component
```vue
<particles-bg type="lines" :bg="true" />
...
import { ParticlesBg } from "particles-bg-vue";
export default {
name: "App",
components: {
ParticlesBg
}
};
```
### Method 2: Use it globally
```vue
import VueParticlesBg from "particles-bg-vue";
Vue.use(VueParticlesBg);
....
<particles-bg type="random" :bg="true" />
```
## Parameter Description
```vue
<particles-bg color="#ff0000" num=200 type="circle" :bg={true} />
```
#### * type - Is the type of particle animation
Is the type of particle animation, `random` is a random selection. You are also free to customize use `custom`.
```js
"color"
"ball"
"lines"
"thick"
"circle"
"cobweb"
"polygon"
"square"
"tadpole"
"fountain"
"random"
"custom"
```
#### * num - The number of particles emitted each time, generally not set
#### * color - The background color or particle color of the particle scene
Notice: which should be an array under type=`color`
#### * canvas - canvas dom style
```vue
:canvas="canvasObject"
...
```
#### * bg - Set to html background
Is set the following properties
```css
position: "absolute",
zIndex: -1,
top: 0,
left: 0
```
## About Custom

You can use type="custom" to achieve a higher degree of freedom for the particle background.
```vue
<particles-bg type="custom" :config="config" :bg="true"/>
...
data: function() {
return {
config: {
num: [4, 7],
rps: 0.1,
radius: [5, 40],
life: [1.5, 3],
v: [2, 3],
tha: [-30, 30],
body: icon,
alpha: [0.6, 0],
scale: [0.1, 0.4],
position: "all",
cross: "dead",
random: 15
}
};
}
```
## License
https://opensource.org/licenses/MIT
| lindelof |
213,356 | Creating Foodexplorer v1 | The Original Intent My intent was to design a simple command line application, called Macr... | 3,770 | 2019-12-19T06:14:17 | https://dev.to/wrightdotclick/creating-foodexplorer-v1-4if | ruby, flatironschool, cli, crossfit | ### __The Original Intent__
My intent was to design a simple command line application, called __Macrocounter__, that could calculate a person's recommended macronutrient ratio for their specific fitness or weight-loss goals. Typically this is broken into three categories: lose weight, maintain weight, gain weight. There's research behind the approach of balancing our intake of proteins, carbs, and fats that support different fitness-specific goals. Using some fun little math formulas developed by researchers, we can take in a user's attributes (hereafter: attr) and use that to calculate their macronutrient ratio. From there, users would then be able to search for a food, display it's macronutrient content, log it to their daily food list, and it would calculate their current intake of nutrients vs their allowable intake. The set-up was simple, and the objectives achievable:
- Create a `User` class with an `attr_accessor` for name, age, weight, height, goal. Use a formula to determine their ideal macronutrient ratio and set that as a `:ratio` attr.
- Create a `Meal` class with an `attr_accessor` for description, protein, carbs, fats, and overall calories.
- Create a `Product` class with an `attr_accessor` for each individual product and have a belongs_to relationship to the meal class.
- The plan looked like this: When the user logged a meal, it would instantiate an object of the `Product` class. The product class would be responsible for making a search call to the API, the API would return some results (probably limited), and we could select an item. The product would then set the protein, carbs, fats, calories for that particular Product, as well as link it to a meal. The meal class would keep track of the accumulated macros and calories for all the products identified with that particular meal object.
But, if you have played with the CLI gem, you'll immediately notice _none of this is there_. So what happened to the plan?
#### The Limitations
##### Time
The amount of time it would've taken to fully develop out some of these details for this particular project meant it would take a bit longer than it really should take... after all, there's more advanced things to learn that could make this project a whole lot easier, and --- assuming it ever saw the light of day as a useful tool --- most people who would benefit from it probably aren't looking for a command line gems to track their food! Especially one without the utility of persistent user data from session to session.
##### Scope
The scope of the project was to demonstrate the ability to write Ruby classes that could interact, as well as gather data and assign data from an API or scraper. That goal could be accomplished in a far simpler project.
##### Data
Using APIs is, at times, unpredictable and can present it's own challenges. In the course of this project, I attempted to use several different APIs. For nutritional information, it's surprisingly difficult to find well-managed, clean, _public_ APIs. Why? Well, there's a lot of money to be made with ulities like this. Adidas, Nike, UnderArmor.... they all have their own nutrition trackers just like mine that need to get data _from somewhere_. So, obviously, all of those somewheres like to charge money. Can you blame them? That led me to look for some free, public alternatives. Unsurprisingly, the free alternatives had masses of data --- far more than I would need --- and were somewhat complex in their implementations and somewhat lacking in documentation for a project with modest goals like mine. Eventually I landed on the API of the good folks at [Spoonacular](google.com). Their free version had enough API calls included to be useful, and the data returned was exactly what was needed... _almost_.
##### Search
It turns out --- who knew! --- search is _hard_. After getting the Spoonacular API up and running, writing some methods to allow the user to search for a product, I quickly found out that the results the Spoonacular API returned were... really, kind of awful. I was hoping displaying the first results of a search would land on at least one result that, for demonstration purposes, could approximate something useful. This turned out to be extremely unpredictable... searches for "carrots" would return results like "carrot cake" or "carrot-flavor add-in." Searches for "chicken" returned, as a first result, "buffalo chicken dip." It was clear it would take some work to get the search to be useful, or else it'd be a wasted endeavor.
Intentionally, I allowed the above challenges to limit my project --- after all, if I were truly let loose to create something, we'd be looking at a fully decked-out, killer app! Resisting that urge was practically the most difficult part.
I decided instead to produce a __minimum viable product__ for this project, even it meant jettisoning the utility and practicality of my coveted __Macrocounter__. The new goal was to create more of a random game, called __Foodexplorer__. The user would open a cabinet in their kitchen to discover some items, and they could then explore the nutritional value of those items. There was no more logging by the User --- it was suggested that I save this functionality for when we introduce things like databases. There was no more searching --- let's leave that for a bigger project, or at least one with a more useful UI. What remained was the satisfaction of the project's modest goals: manipulate data received from an API or scraper as Ruby objects, including maintaining relationships between different objects.
### __Producing an MVP__
#### Defining and Ideating
With our new goal in mind, I began dissecting the pieces that would need to fit together to make the gem run. I knew I needed to have at least three classes: the `Product`, the `Cabinet`, and the `CLI` to control the user's flow through the interface. Let's step into each one of these classes, starting with the _lowest_ in the heirarchy.
##### Product
Products are objects which have nutritional attributes, such as `:protein, :fat, :carbs, :calories`. They have a `:name` and they are located in a `:cabinet`. Initially, when I approached the problem, I didn't include `:cabinet` as an attribute. Although this should've been immediately obvious, it was something I had overlooked. It wasn't until I began writing a method that would allow the user to look up the products in each cabinet that I realized this would have significant utility. For each of these attributes, I intentionally used an `attr_accessor` --- that meant each attribute could be written or read. At instantiation, a `Product` stores the `result` of an API call to Spoonacular Spooonacular actually provides a huge amount of data in their JSON reply. Since the `title` and `nutrition` data I wanted was in a nested hash, I used `result["title"]` and `result["nutrition"]["calories"]`(etc) to set the `Product`'s `attr` for each corresponding value.
##### Cabinet
Cabinets store products. But which products? The `Cabinet` class was responsible for creating new objects, since a cabinet needed to be opened to see what was in inside! To determine the amount of items inside, I'd pick a random number between 0 and 3. Limiting the amount of products inside each cabinet to three or fewer was a simply pragmatic. The `Cabinet` class then uses a loop to create a new `Product` object. On initialization, a `product` object is generated by randomizing a number up to six digits, interpolating the number into the API call, and returning JSON asssociated with the random ID.
##### CLI
The `CLI` class handles the user's flow through the application. It prompts the user for input and uses that input to make decisions about what to do next. It also gives instructions and generally guides the user. It also handles exiting for every possible command.
#### Testing and Revising
In testing, many issues came to light which I was unprepared for. I'll outline a few of the most pressing concerns that required some quick-witted solutions.
##### Handling words and integers
I made the choice to give the user the option to use both words and numbers at various points through the CLI gem. This was probably an unnecessary difficulty, but it felt like a more natural way to interact. I would've liked to have made products selectable by their names, as well, but in the end it was just simpler to use numbers for identifying items in lists.
##### Referring to the products by their cabinet number
Early on, I didn't include a `:cabinet` attribute for a `Product` instance. Absentmindedly, I ran into a lot of issues trying to recall which product instances were in which cabinet instances, and I ended up writing some very, very overdone code. After a day or two off from working on the project, I returned to it with new eyes and realized that I had just been spinning my wheels on something that could be solved way simpler! Live and learn.
##### Nonexistent products
One thing I didn't anticipate was that *not all random six-ish digit numbers would return a result*. It wasn't until testing my app over and over and over again that I ran into this issue of getting back empty products. I spent a while debugging my code, thinking there was a problem with the way it was returning values from Spoonacular or a problem with the way it was displaying them. What I realized was simply that __there was no item for that numeric ID in Spoonacular__. I decided to write a new instance method, `Product#try_again` that would simply retry the randomization procedure if `nil` was returned. My motivation for using an entirely new method, specifically named `try_again`, was so that if bash displayed the errors in the traceback, I'd be able to see whether it had been called. Later on during testing, I found another issue with Spoonacular not returning values for some IDs for various other reasons. I decided to rewrite the conditional in the `initialize` to a `case` statement that checks `result["code"]` for errors `400` or `404`. If so, they'd call `Product#try_again`, else they'd run as normal to do the attribute assignment for the instance.
### __TODO__
Although I likely won't develop this project further --- at least, not as a command line tool --- it was important that I include a few notes on functionalities I'd like to see included. Without substantially changing the intention or spirit of __Foodexplorer__, here's a few things I would add:
##### Store the Randomized Product ID
It would take all of one or two lines to store the randomized six-ish digit number that the `Product` creates on initialization to get data. Having this number stores as an ID for each instance of the class would be useful if I were to ever add features to the app that searched through the API's JSON for more information than simply nutritional data --- for example, serving sizes, etc. Not having that value stored means that recalling the full JSON for each product is currently impossible.
##### Look-Up or Order by Nutrient Content
Using something like a `Product.all.sort_by { |product| product.fat }` could sort all of the objects by their fat content, for example. I could also use something like `Product.all.select { |product| product.fat == input }` if I wanted to give the option to look up by an amount of fat, or more likely something like `<=` or `>=`. (For what it's worth, in the original __Macrocounter__ gem, this feature would've been useful for allowing users to figure out what else they could eat to fulfill their recommended percentages.)
##### Search
Obviously, bringing the ability to search through products would be a useful feature. Even in its current implementation, searching would be a fun addition --- after all, you ought to be able to search through your cabinets for something! This feature isn't included since it would really just be some icing on the cake; it was by no means a _necessary_ functionality for __Foodexplorer__. Since I can't claim any fame to being an expert in RegEx, I would've either spent a huge amount of time working on coming up with good RegEx _or_ using an `.select` method that iterated through `Product.all.name` to match characters with the `.include?` method.
##### A User and Kitchen Class
I really, _really_ wanted to develop a `User` class that would allow a `Cabinet` to be assigned to `Kitchen` and a `Kitchen` to be assigned to a `User`. Although it would've been a fun addition, that level of abstraction for this particular project was really unnecessary --- especially after leaving behind the __Macrocounter__ project.
| wrightdotclick |
212,944 | I still didn't receive a shipping notification e-mail from Hacktoberfest. | I completed Hacktoberfest 2019 successfully but I didn't even receive any shipping confirmation e-mai... | 0 | 2019-11-29T14:00:16 | https://dev.to/auniversebeyond/i-still-didn-t-receive-a-shipping-notification-e-mail-from-hacktoberfest-540m | hacktoberfest | I completed Hacktoberfest 2019 successfully but I didn't even receive any shipping confirmation e-mail. I got in contact and mailed but I got a response which says shippings may delay. I already knew that but isn't it very late? Are such things normal? Did anyone encounter a kind of problem? | auniversebeyond |
212,986 | Javascript call and apply 101 | They are more like twins | 0 | 2019-12-01T21:52:31 | https://irian.to/blogs/javascript-call-and-apply-101 | javascript, call, apply, webdev | ---
title: Javascript call and apply 101
published: true
description: They are more like twins
tags: javascript, call, apply, webdev
canonical_url: https://irian.to/blogs/javascript-call-and-apply-101
---
If you spent enough time reading Javascript codes, you probably saw `call` and `apply`. If you are like me, you get confused real fast. Don't worry, these methods are pretty easy to understand. I will cover some of the basics to get you all started!
I will go over:
1. How to use call
2. How to use apply
3. When to use call and when to use apply
Before we start, keep in mind that these two are very similar. Learning one allows us to understand the other.
# Using call
Suppose we have an object and a function:
```
const breakfastObj = {
food: 'blueberry waffles',
drink: 'orange juice'
}
function sayBreakfast(){
console.log(`I had ${this.food} and ${this.drink} for breakfast`)
}
```
When we call `sayBreakfast()`, it will return
```
sayBreakfast() // I had undefined and undefined for breakfast
```
To "call" the function `sayBreakfast()` with `breakfastObj` as `this`:
```
sayBreakfast.call(breakfastObj) // I had blueberry waffles and orange juice for breakfast
```
Recall that `this`, if not defined, refers to global object (if you are on browser, your global object is probably `window` object). So we can do this:
```
window.food = 'French toast'
window.drink = 'Apple juice'
sayBreakfast() // ... French toast and Apple juice
```
This is equivalent to:
```
sayBreakfast.call() // ... French toast and Apple juice
```
Call also accepts 2nd, 3rd, ...nth arguments. These arguments are used as function's arguments. Let's look at example to clarify:
```
const lunchObj = {
food: 'tacos',
drink: 'water'
}
function sayLunch(location){
console.log(`I had ${this.food} and ${this.drink} for lunch at ${location}`)
}
sayLunch.call(lunchObj, "Taco Bell") // I had tacos and water for lunch at Taco Bell
```
Hmm, tacos sound good 🤤. If the function accepts multiple arguments, we can pass them too:
```
function sayLunch(location, company, time){
console.log(`I had ${this.food} and ${this.drink} for lunch at ${location} with ${company} in the ${time}`)
}
sayLunch.call(lunchObj, "Taco Bell", "Jon and Juan", "afternoon") // I had tacos and water for lunch at Taco Bell with Jon and Juan in the afternoon
```
# Using apply
`apply` works like `call`. The only difference is the way they accept function arguments. `apply` uses array instead of separated by comma: `myFunction.apply(obj, [arg1, arg2, argn])`
Using our example earlier, but with `apply`:
```
const lunchObj = {
food: 'tacos',
drink: 'water'
}
function sayLunch(location, company, time){
console.log(`I had ${this.food} and ${this.drink} for lunch at ${location} with ${company} in the ${time}`)
}
sayLunch.apply(lunchObj, ["Taco Bell", "Jon and Juan", "afternoon"])
```
We can take advantage of `apply`'s array arguments with ES6's [spread operator](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Spread_syntax)
Here is a shameless copy-paste from mozilla page:
```
function sum(x, y, z) {
return x + y + z;
}
const numbers = [1, 2, 3];
console.log(sum(...numbers));
// expected output: 6
console.log(sum.apply(null, numbers));
// expected output: 6
```
Keep in mind we can use `call` and/or `apply` into built-in functions, not custom functions. Something like this:
```
const someArr = ["foo", "bar", "baz"];
console.log.apply(null, someArr) // foo bar baz
```
And if we want to get fancy and append a new argument into `someArr`:
```
console.log.apply(null, ['hello', ...someArr]) // hello foo bar baz
```
# How to remember call vs apply arguments
A trick to remember which one is which is to look at their first letter (credit [SO](https://stackoverflow.com/questions/1986896/what-is-the-difference-between-call-and-apply))
- *A* -> **A**pply -> **A**rray
- *C* -> **C**omma -> **C**all
We only scratched the surface, but hopefully this should be enough to _apply_ (pun intended 😎) your knowledge for more advanced stuff!
# Resources/ more readings:
- [Using 'apply' to Emulate JavaScript's Upcoming Spread Operator](http://adripofjavascript.com/blog/drips/using-apply-to-emulate-javascripts-upcoming-spread-operator.html)
- [Understanding This, Bind, Call, and Apply in JavaScript](https://dev.to/digitalocean/understanding-this-bind-call-and-apply-in-javascript-dla)
- [`Function.prototype.call()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/call)
- [`Function.prototype.apply()
`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/apply)
- [What is the difference between call and apply?](https://stackoverflow.com/questions/1986896/what-is-the-difference-between-call-and-apply)
- [Function.apply and Function.call in JavaScript](https://odetocode.com/blogs/scott/archive/2007/07/04/function-apply-and-function-call-in-javascript.aspx)
| iggredible |
212,991 | Friday Night Deploys: # 5 - Side Projects! (DMX Has A Net Worth Of Negative Ten Million Dollars) | This week the DevPlebs talk about: The British Bulldog! Having babies! Hating episode 4! Doing things... | 0 | 2019-11-29T16:44:44 | https://dev.to/phizzard/friday-night-deploys-5-side-projects-dmx-has-a-net-worth-of-negative-ten-million-dollars-2jbf | jokes, webdev, podcast | This week the DevPlebs talk about: The British Bulldog! Having babies! Hating episode 4! Doing things! High school nicknames! The regrets of starting a podcast! Ugh, anime! Chain-smoking! Peer pressure! Starting a cult! Shredding! Standing on the backs of better people! Gatekeeping! Sucking (listen to find out more)! Top Friends on Facebook! Wilson from Home Improvement! DMX's net worth! Side projects!
## Listen to The Full Episode!
{% spotify spotify:episode:2LpPeqDs3ZGE43Y7Qoxg8a %}
**We're also on...**
**Apple Podcasts:** https://apple.co/37JeyMF
**Google Music Podcasts:** https://bit.ly/35MX1kY
## New Stuff!
We also upload all of our podcast episodes onto YouTube if that's your thing. Keith has been putting extra special attention in the thumbnails and waiting for the painful upload times. He deserves a round of applause!👏👏👏👏
Because of this new episodes will usually appear on youtube a little later than Friday.
**Channel link:** https://bit.ly/2R3FmRW
If YouTube is your thing then totes make sure you like, subscribe and ring the notification bell (YouTube media training right there), there could be some additional content one day! 😉
## Get In Touch With Us!
If you would like to share any side projects or want to tell us who your top facebook friends were @ or DM us on our twitter [@devplebs](https://twitter.com/DevPlebs?s=20).
## Follow Our Twitters... If You Want!
[DevPlebs](https://twitter.com/DevPlebs).
[Keith Brewster](https://twitter.com/brewsterbhg).
[Phil Tietjen](https://twitter.com/phizzard).
You can also ask questions or give us some feedback about the show! | phizzard |
213,057 | Get release tag from GitHub Actions to debug on Heroku | In TNP we’ve moved everything to GitHub Actions and we’re very happy about it. :-) But… this article... | 0 | 2019-11-29T22:02:50 | http://javaguirre.me/2019/11/28/getting-release-github-heroku-debug | github, actions, cicd, heroku | ---
title: Get release tag from GitHub Actions to debug on Heroku
published: true
date: 2019-11-28 09:00:00 UTC
tags: github,actions,cicd,heroku
canonical_url: http://javaguirre.me/2019/11/28/getting-release-github-heroku-debug
cover_image: https://user-images.githubusercontent.com/488556/69891326-16b15380-12fc-11ea-944e-6b90128cb8a5.jpg
---
In TNP we’ve moved everything to GitHub Actions and we’re very happy about it. :-)
But… this article is not about how happy we are using it but a small tip on how we could simplify every day debugging with some simple improvements.
As a good metric oriented company, We measure and monitor everything we believe relevant, this is a solution to control which release we have in production and being able to monitor its breaking changes in a simple way.
We decided to add the git release tag to our deploy and our app footers, with the following steps.
First, We push to production only when a git tag (a release) is created on GitHub.
```yaml
jobs:
...
deploy_production:
...
if: success() && contains(github.ref, 'tags')
```
We deploy to Heroku where is super easy to set a config variable via API, so we decided to:
- Get the release tag from the current release
- Update a `RELEASE_VERSION` variable on Heroku every time a new deploy is successful.
- Profit!
```yaml
steps:
- name: Push to Heroku
run: git push -f https://heroku:${{ secrets.HEROKU_API_TOKEN }}@git.heroku.com/${{ secrets.HEROKU_APP_PRODUCTION }}.git origin/master:master
- name: Update RELEASE_VERSION on Heroku production
if: success()
run: |
curl -n -X PATCH https://api.heroku.com/apps/${{ secrets.HEROKU_APP_PRODUCTION }}/config-vars \
-d '{
"RELEASE_VERSION”: "${{ github.ref }}",
}’ \
-H "Authorization: Bearer ${{ secrets.GITHUB_API_TOKEN }}"
-H "Content-Type: application/json" \
-H "Accept: application/vnd.heroku+json; version=3"
```
We need to set two variables:
- `HEROKU_API_TOKEN`: Your personal token, you can get it from your [account settings](https://dashboard.heroku.com/account).
- `HEROKU_APP_PRODUCTION`: Your production app name on Heroku, we don’t hardcode it, so it’s easier to share these recipes in other projects.
That’s It! You’ll have something like this on your Heroku app if all goes well.

*Cover Image Garett Mizunaka - Unsplash* | javaguirre |
213,070 | #7DaysJS: Factorial and Average | Welcome to day 1 of #7DaysJS! | 0 | 2019-11-30T02:19:28 | https://lautarolobo.xyz/blog/7-days-of-js-factorial-and-average/ | javascript, challenge, beginners | ---
title: #7DaysJS: Factorial and Average
published: true
date: 2019-11-29 22:32:00 UTC
tags: javascript, challenge, beginners
canonical_url: https://lautarolobo.xyz/blog/7-days-of-js-factorial-and-average/
cover_image: https://lautarolobo.xyz/images/7daysJS-7f7d8328.webp
description: Welcome to day 1 of #7DaysJS!
---
Welcome to day 1 of 7 Days of JavaScript! A 7 days challenge to crack your head up into some simple but complex algorithms. Today we’ll work on writing two math functions, factorial and average.
To test and run JavaScript, you need the JSC compiler.
Just kidding! A compiler?! You can run it in your own browser!
But, I’ve found this website: [Playcode.io](https://playcode.io/). It has all I want, a minimalistic dark theme and a clean console. You can run the code wherever you want, but I encourage you to use Playcode, everything is just nicer.
Enough introduction, let’s dive right in!
## Factorial
So the factorial function takes a Natural number `n`, and returns the product between all the Naturales numbers that are between 1 and `n`, like this:
~~~java
5
//1*2*3*4*5
120
~~~
## Average
The average function is a well known one. It takes an array of numbers, sums them and divides that sum by the length of the initial array. Here’s an example:
```java
[1,5,8,4]
//(1+5+8+4)/4
4.5
```
Now it’s your turn. Give them a try, especially if you are kinda newbie on JavaScript because you’ll build a good understanding of how loops work.
Did you solve them already? Try a different approach! Making more than one solution will strengthen your knowledge, giving you some flexibility when facing problems. And that’s key when programming.
[Here](https://lautarolobo.xyz/blog/solution-to-day-1-of-7-days-of-js "Solution to Day 1 of 7 Days of JS") are the solutions.
See ya! | lautarolobo |
213,073 | Sorry C# and Java developers, this is not how TypeScript works | JavaScript is a loosely typed programming language and TypeScript does not change that. | 0 | 2019-11-29T23:36:59 | https://dev.to/this-is-learning/sorry-c-and-java-developers-this-is-not-how-typescript-works-401 | typescript, csharp, java, javascript | ---
title: Sorry C# and Java developers, this is not how TypeScript works
cover_image: https://thepracticaldev.s3.amazonaws.com/i/kx5cwrk2jlvwnut63l8c.jpeg
published: true
description: JavaScript is a loosely typed programming language and TypeScript does not change that.
tags: typescript, csharp, java, javascript
---
*Cover photo by [Lina Trochez](https://unsplash.com/photos/ktPKyUs3Qjs) on [Unsplash](https://unsplash.com/).*
So you took a look at TypeScript. Classes and a C-like syntax. Seems easy enough.
Your manager *asks* you to rush the edit todo item feature in your brand new TypeScript application.

*Boss meme by [Make a Meme](https://makeameme.org/meme/if-you-could-hk290u)*
On the server-side you have this C# class.
```csharp
// TodoItem.cs
public class TodoItem
{
public string Id { get; set; }
public bool IsDone { get; set; }
public string Title { get; set; }
public async Task Save()
{
// Write to database
}
}
```
*C#: Todo item.*
On the client-side, you create a similar class.
```typescript
// todo-item.ts
class TodoItem {
id: string;
isDone: boolean;
title: string;
save(): Promise<void> {
return fetch("/todo/" + this.id, {
body: JSON.stringify(this),
method: "POST",
})
.then(() => undefined);
}
}
```
*TypeScript: Todo item.*
Not too bad.
We have a view for editing a todo item. The view class reads the todo item from the server using `fetch` which returns an `HttpResponse`.
```typescript
// edit-todo-item-view.ts
class EditTodoItemView {
todoItem: TodoItem;
onInitialize(id: string): Promise<void> {
return this.readTodoItem(id)
.then(todoItem => this.todoItem = todoItem)
.then(() => undefined);
}
readTodoItem(id: string): Promise<TodoItem> {
return fetch("/todo/" + id)
.then((response: HttpResponse) => response.json());
}
saveTodoItem(): Promise<void> {
return this.todoItem.save();
}
}
```
*TypeScript: Edit todo item view.*
`HttpResponse`s can be parsed as JSON by using the `HttpResponse#json` method.
We add the `TodoItem` type to the returned promise of the `readTodoItem` method.
The application transpiles to JavaScript without errors, so we deploy it on a web server.
We tell our manager that the edit todo item feature is done and move on to the next task.

*Borat meme by [Meme Generator](https://memegenerator.net/instance/38220950/borat-meme-another-job-done-nais)*
Everything is fine… Until we start getting bug reports from users telling that they edited a todo item and saved it. But when they navigated back to the todo list, the todo item was not updated.

*Bug meme by [Nepho](https://imgflip.com/i/loizf)*
But… It compiled! Did TypeScript let us down?
>JavaScript is a loosely typed programming language and TypeScript does not change that; even if it seems that way.
TypeScript was not lying to us. We were lying to TypeScript. It is easy to miss, but we told TypeScript to give the JSON object the `TodoItem` **type**.
The problem is that the JSON object was never constructed from the `TodoItem` class with the `new` keyword. It was actually an anonymous object without access to the `TodoItem` prototype.
To fix the bug, we have to make a few changes.
```typescript
// todo-item.ts
class TodoItem {
id: string;
isDone: boolean;
title: string;
constructor(properties) {
this.id = properties.id;
this.isDone = properties.isDone;
this.title = properties.title;
}
save(): Promise<void> {
return fetch("/todo/" + this.id, {
body: JSON.stringify(this),
method: "POST",
})
.then(() => undefined);
}
}
```
*TypeScript: Todo item with constructor.*
We add a constructor that we can pass the JSON object to and get back an instance of `TodoItem`.
```typescript
// edit-todo-item-view.ts
class EditTodoItemView {
todoItem: TodoItem;
onInitialize(id: string): Promise<void> {
return this.readTodoItem(id)
.then(todoItem => this.todoItem = todoItem)
.then(() => undefined);
}
readTodoItem(id: string): Promise<TodoItem> {
return fetch("/todo/" + id)
.then((response: HttpResponse) => response.json())
.then(json => new TodoItem(json));
}
saveTodoItem(): Promise<void> {
return this.todoItem.save();
}
}
```
*TypeScript: Edit todo item view using the new keyword.*
After reading the JSON from the server, we pass it to the `TodoItem` constructor and get an actual instance of the class back.
We transpile the code, deploy it to the web server and this time we remember to test it… In production of course 🤪

*Obama meme by [Meme Generator](https://memegenerator.net/instance/68651984/relief-obama-crisis-averted).*
*Dedicated to all the hard-working back-end developers who are forced to learn client-side web development.*
| layzee |
213,177 | Step to Step Guide Netgear Nighthawk | Netgear Nighthawk X65 is one of the most promising wireless extenders to fill in the cracks in your h... | 0 | 2019-11-30T07:36:57 | https://dev.to/patrickcummins/step-to-step-guide-netgear-nighthawk-3o3m | Netgear Nighthawk X65 is one of the most promising wireless extenders to fill in the cracks in your home WiFi network. It's a tri-band extender with mesh technology that has adequate power to cover all the bothersome dead zones.
But in case you're looking for something small that plugs unobtrusively in a wall socket, X65 EX8000 won't be your love at first sight. In fact, it has a size as of a full-blown router and a physique that makes it tricky to hide within your home décor items.
Yet the unusual size of this extender is perfectly justified with its performance. Unlike the most Wi-Fi extenders, Nighthawk EX8000 possess intrinsic tri-band distribution. In which the 2.4 GHz band is partnered along with the two 5Ghz bands, one among these takes care of back-end communications with the router and other band broadcasts the boosted network.
And the results speak from themselves. It is the top performer for 5Ghz performance in every corner of the premise with providing a full bandwidth speed. However, 2.4 GHz performance is just satisfactory but overall this bleeding-edge gadget has managed to leave every other comparable wireless extender into the dust.
So if you're considering purchasing one, here's the guide for your Netgear extender Setup.
Netgear Nighthawk X65 EX8000 Setup
Netgear EX8000 mesh extender setup can be executed either via installation assistant or using the WPS. Let's delve into each so that you can go with the best one.
Setup via Installation Assistant
Connect the extender to the power supply.
Ensure that there is the least possible distance between the router and the extender.
Now press the "power" button.
Now link your computer – laptop or PC to the extender through a WiFi or wired connection.
For WiFi connection, turn on the Wi-Fi manager and search for the available wireless networks.
Tap on the extender network's SSID. Mostly it is of the form - NETGEAR_EXT.
Once your computer is connected with the extender's network, the client LED on the extender will glow white.
For the wired connection, use an Ethernet cable to connect the Ethernet port of the extender to the Ethernet port of the computer.
After the connection, launch a web-browser such as Chrome or Firefox and navigate to <a href="http://mywifeixt.net/">mywifiext</a>.
This web address will take you to the Netgear installation assistant.
Further, execute the on-screen prompts to connect the extender to the existing network.
Use the Link status LED to place your extender in the most suitable spot, that is exactly in the midway of the distance between the router and the area with least Wi-Fi connectivity.
In case the Link status LED denotes a poor connection, move the extender near to the router.
Once you get to the appropriate spot, you're all set to connect the client device to the extended network and start surfing.
Tip: You can also use Netgear Genie setup for the choosing the adequate location of the extender.
Check the power LED, it should be lit now.
If the power LED doesn't glow, restart your extender.
Connecting Using WPS
For WPS setup, first place the extender as much as near to the router.
• Now press the WPS button on both – router and the extender simultaneously.
• Repeat the process if you don't see a solid white light on the Link status LED.
• Thereafter, you can start internet surfing using the extended wireless network.
• Connect it to the power supply and let the power LED lit.
Note: After the setup, your extender will use the same network settings as your router has for 2.4 Ghz and 5Ghz networks. For any queries, feel free to comment in the comment section below.
| patrickcummins | |
213,202 | Meteor 1.8.2 is out | As the title suggest a new minor version of Meteor is out. The biggest update I'd like to highlight i... | 0 | 2019-11-30T09:44:00 | https://dev.to/harryadel/meteor-1-8-2-is-out-43j9 | meteor, node | As the title suggest a new minor version of [Meteor](https://www.meteor.com/) is out. The biggest update I'd like to highlight is the inclusion of typescript, which you can add to existing projects by running `meteor add typescript` or creating an new one with `meteor create --typescript new-typescript-app`.
[Filipe Névola](https://twitter.com/FilipeNevola), the new Meteor evangelist, wrote a beautiful [article](https://blog.meteor.com/announcing-meteor-1-8-2-13eab70a4bec) on medium detailing the changes that I highly recommend.
I hope you have a nice day, bye! | harryadel |
213,238 | I struggle with pacing, do you? | I've been programming since 1977. I have used programming as part of my professional life as an IT Su... | 0 | 2019-11-30T13:53:37 | https://dev.to/bugmagnet/i-struggle-with-pacing-do-you-5egk | contentcreation, writing | I've been programming since 1977. I have used programming as part of my professional life as an IT Support Technician since 1985 and since 2006 as a full-time software developer. In the last couple of days I've been posting items about the programming languages I use or have used.
I find myself wrestling with a compulsion to write, to go flat out and post a write-up about every language I've ever known replete with links to the current implementation and anything else helpful I can think of. I actually don't have the time to do that but I'd almost happily give up food and sleep just for the endorphin rush of researching and writing. I remember having similar experiences when I was running my own [programming-related blog](http://codeaholic.blogspot.com/). (Nothing much happens there now because I'm writing straight into DEV.)
At the same time, there's the desire to pace things out a bit. I have to ask myself, "What's better: 52 articles at one per week and still be sane and productive at the end of a year, or one per hour and be institutionalized before the end of the week?"
Someone once said, "it's better to burn out than rust out." With my 60th birthday 15 months away I'm wondering if there's a third alternative. My mind keeps coming back to the account in the book of Exodus where Moses sees a bush that is burning but the bush isn't being consumed by the fire. It's in Exodus 3:2. The Latin motto of many Presbyterian churches throughout the world (including Australia) refers to that event in the words *NEC TAMEN CONSUMEBATUR* meaning "And yet it was not consumed". Can I too burn but not burn out?
I'm probably stuck with having to continue to wrestle, but I am going keep trying to pace myself.
To the other content creators on DEV: how to do you keep yourself from going bananas yet keep a consistent amount of content flowing? How do you keep the fire of the passion of your craft from burning you up? How do you deal with the push from the other direction that slows you down toward inactivity and oxidization? | bugmagnet |
213,268 | #7DaysJS: Even or Odd | Second day of #7DaysJS! | 0 | 2019-11-30T16:06:01 | https://lautarolobo.xyz/blog/7-days-of-js-even-or-odd/ | javascript, beginners, challenge | ---
title: #7DaysJS: Even or Odd
published: true
date: 2019-11-30 15:17:00 UTC
tags: javascript, beginners, challenge
canonical_url: https://lautarolobo.xyz/blog/7-days-of-js-even-or-odd/
cover_image: https://lautarolobo.xyz/images/7daysJS-7f7d8328.webp
description: Second day of #7DaysJS!
---
Welcome to day 2 of 7 Days of JavaScript!
Let’s begin our journey today. We need to write a function that takes an array and gives back two values: one with the sum of all the odd numbers of the array, and other with the sum of all the even numbers on the array.
It can’t be that hard right?
You can read the solution to today’s challenge [here](https://lautarolobo.xyz/blog/solution-to-day-2-of-7-days-of-js "Solution to Day 2 of 7 Days of JS"). | lautarolobo |
213,477 | Contribute Beyond Code: Open Source for Everyone | Participating in open source is a gift that keeps on giving. Everyone participating in open source can benefit from increased learning and visibility. Yet, so many lurk or consume rather than join in active contribution. How can they get started? | 0 | 2019-12-05T03:30:20 | https://dev.to/sigje/contribute-beyond-code-open-source-for-everyone-593j | opensource, devops, community | ---
title: Contribute Beyond Code: Open Source for Everyone
published: true
description: Participating in open source is a gift that keeps on giving. Everyone participating in open source can benefit from increased learning and visibility. Yet, so many lurk or consume rather than join in active contribution. How can they get started?
tags: opensource, devops, community
cover_image: https://thepracticaldev.s3.amazonaws.com/i/qnuxphcysec9wl49zoqq.jpg
---
Developers are often encouraged to contribute to open source. If you don't consider yourself a developer, it can feel daunting to start on the journey to contributing. In the last year, I've found that the number of folks participating in open source is minimal in part to imposter syndrome associated with "but I'm not a developer". In this article, I will share a little about why you should contribute, and provide some information about where to contribute, including some additional resources to get you started.
## Why should you contribute to an open source project?
Participating in open source is a gift that keeps on giving. Everyone has their motivations, but some of the benefits of connecting with the community in an active role include:
* **Promotes learning and development of skills.** You can practice collaboration skills in roles that aren't tied directly to performance reviews. You can develop other skills driven by your interests that are not part of your day job.
* **Builds and promotes visibility.** Your employer benefits from your participation in open source communities. You can find new job opportunities and potential co-workers.
## What do you need?
First, figure out your employer's policies for contributing to open source and review your employment agreement. While I think every company using open source software should give their employees time to contribute, often the contribution policies are problematic even if individuals contribute during personal time and on personal equipment. If your company doesn't have a policy (or has a restrictive policy), sharing [A Model IP and Open Source Contribution Policy](https://processmechanics.com/2015/07/22/a-model-ip-and-open-source-contribution-policy/) may be helpful in providing guidance to improving the situation.
Specific software requirements will vary based on the project. Your skills in infrastructure as code or configuring continuous deployment pipelines may be extremely helpful to a project that hasn't already implemented these practices. Your experience in these areas might drive the direction of software requirements; for example, a specific version of docker or cloud provider CLI.
If you've never done a pull request, the [first-contributions project](https://github.com/firstcontributions/first-contributions) has a walkthrough as part of the repository. Every project will have a workflow and may have different recommendations on how to submit a pull request. It's helpful to learn the fundamentals here rather than learning from scratch on a project of interest.
## What kind of contributions?
Operations engineers have a lot to offer to open source projects. Beyond developing features, areas of contribution can include:
* Reporting and replicating issues
* Mentoring
* Documentation
* Architecture diagrams
* CI/CD pipeline
* Infrastructure as code
* Separating secrets from code
* Maintaining tests
* Review pull requests
* Project management
* Supporting other community members
Many large projects have contributor summits that allow individuals to meet and collaborate in-person as well. For example, in these summits, providing a ops, design, project management, test, or security perspective can help guide the project to be more robust and resilient.
## What project?
Sometimes, the best question to ask is _who_ rather than _what_. Who do you want to collaborate with? Understanding the who can help guide your focus to specific projects that allow you to work with those folks.
Another question to ask yourself up front: How long do you want to contribute? For example, is this a one-time contribution, or something you are willing to provide on-going support? Being clear with your objectives can help you be successful in your selection of projects and contributions.
> 💡 Just because something is "public" on GitHub or Gitlab, and even if there are `CONTRIBUTING` files, it doesn't mean that the repository owner wants collaborators or contributors. Sometimes folks are coding in the open. Before you invest a lot of work into a contribution, send an initial query through an issue or via a contact address.
It is often helpful to contribute to something that your company already depends on. This may help you fix something for the community at large that also helps you in your day job (and doesn't require you maintaining a separate fork forever!).
You can also explore things that aren't related to your company at all! This will help you to learn about other areas that can help you grow your skills and filter future job opportunities.
### Strategies for identifying projects
One method to find projects is to look for **active projects in your skill sets**. I'm going to walk through a couple of different processes I have gone through to find projects to contribute to with my Chef, Go and infrastructure skills.
> 💡 Communities may have a specific artifact repository that can help you identify popular projects. [Chef Supermarket](https://supermarket.chef.io/), [Puppet Forge](https://forge.puppet.com/), [Go Packages](https://godoc.org/), and [RubyGems](https://rubygems.org/) can help you find chef, puppet, and ruby projects for example.
By searching cookbooks, and then choosing to order by "Recently Updated", I first find cookbooks that have recent activity. I then click on the project to get more information.
One of the first things I do when evaluating a project is to verify that the project is properly [licensed](https://opensource.org/licenses) for open source. Just because something is available within a repository whether the Chef Supermarket or GitHub doesn't mean that it's available to use, modify or share. If it doesn't have an explicit license that allows for using, modifying, and sharing, then it's a non-starter for contributions.
> 💡 The Open Source Initiative maintains the [list of open source licenses](https://opensource.org/licenses) that comply with the Open Source Definition. Licenses that are included in this list allow software to be freely used, modified, and shared.
Next, I want to make sure that the code is available and accessible in a shared version control repository not just a downloadable artifact from the Chef Supermarket.
Here, the `lampp_platform` project from the University of Alaska has an MIT License, and the [source code](https://github.com/UAlaska-IT/lampp_platform) and [issues](https://github.com/UAlaska-IT/lampp_platform/issues) are linked.
I then check whether the project has explicit contributing guidelines defined in a `README.md` or [`CONTRIBUTING.md`](https://github.com/UAlaska-IT/lampp_platform/blob/master/CONTRIBUTING.md).
If I don't know what I could contribute to the project, and need to know what would be a strategic investment of my time to help others, I could check the open unclaimed issues.
I also look at the number of contributors on the project; I will still support a project that only has a few contributors, but it does give me insight into how overloaded they might be (especially if the project is popular).
Overall, when I look at the [lampp_platform](https://github.com/UAlaska-IT/lampp_platform) cookbook a lot is going for it:
* It's currently active, i.e. has regular contributions.
* The `README` follows Chef conventions with a purpose, requirements, supported platforms, dependencies, and examples.
* The `CONTRIBUTING` documentation is present, and while sparse it does include information about testing.
* The project has a [`kitchen.yml`](https://github.com/UAlaska-IT/lampp_platform/blob/master/kitchen.yml) configuration.
From here, I could verify whether the kitchen configuration allows me to spin up the infrastructure as intended. A project might have specific configurations for the organization that aren't as helpful to others. For example, maybe there are tags in use that wouldn't make sense for general use or maybe it's using a specific cloud provider. This is a good example of a project where small contributions can have a big impact.
Next, I'll walk through finding and assessing a Go project.
Lots of Go projects are on GitHub. Searching for go, and then limiting the Languages to Go specifically will give me a sorted list of projects based on "Best Match".
"Best Match" generally isn't super helpful for exploring projects to support with contributions. I can modify my sort options, for example to "Most stars" to find the buzz factor of a project, or "Recently updated" to find fresh projects.
"Recently updated" is an interesting sort factor to find all kinds of obscure projects that might not get noticed otherwise. It also will have any projects that folks might be coding in the open where they are working with go, so that can be distracting.
Choosing "Most stars" will start with huge projects like [go](https://github.com/golang/go), [kubernetes](https://github.com/kubernetes/kubernetes), and [moby](https://github.com/moby/moby). These projects will have a significant amount of governance and processes to understand prior to contributing. These are great projects to contribute to, but the processes would be much longer than a blog post to describe the evaluation process.
> 💡 To contribute to the [Go](https://github.com/golang/go) project directly, the [Go contributing guidelines](https://golang.org/doc/contribute.html) provide some insight into code contributions but not as much for other non-code contributions. As a really large project, there are a number of folks and processes in place. If you are new to contributing to Open Source, I wouldn't suggest jumping in there with non-code contributions without direct support from active folks already contributing in that community.
The [Hugo](https://github.com/gohugoio/hugo) project is a little bit further down in the search list and looks like a great project that is slightly smaller but still has a lot of support and impact.
Next, I verify the license. The `hugo` project has an [Apache-2.0 License](https://opensource.org/licenses/Apache-2.0) so it's good for contributions.
Next, I look at the one liner for the GitHub repo listed at the top of the project. For Hugo, it's "The world’s fastest framework for building websites." and includes a link to the [website](https://gohugo.io/).
For GitHub projects, the `README.md` is shown below the main file directory of the project. The top few lines are helpful at a quick glance for additional information about the project.
A logo for a project shows that there is some amount of investment into the project beyond just code. The one liner here is more clear about what this project is "A Fast and Flexible Static Site Generator built with love". Finally, there is a set of badges that help provide clarity about the state of the projects and answers potential questions:
* does it have CI? [build](https://travis-ci.org/gohugoio/hugo)
* do they value documentation? [godoc](https://godoc.org/github.com/gohugoio/hugo)
* do they lint and follow recommended practices? [go report](https://goreportcard.com/report/github.com/gohugoio/hugo)
I then check whether the project has explicit contributing guidelines defined in a `README.md` or `CONTRIBUTING.md`.
The first great sign I see is that the Hugo project explicitly shares a number of different type of non-code contributions that they value including a link to the [hugoDocs](https://github.com/gohugoio/hugoDocs) project.
Overall, when I look at the [Hugo project](https://github.com/gohugoio/hugo) a lot is going for it:
* It's currently active, i.e. has regular contributions from a lot of different people.
* The `README` is current with a quality one liner description of the project, supported documentation, and steps to install for binary and from source.
* The `CONTRIBUTING` documentation is detailed with links to the hugoDocs project, support questions, reporting issues, and PR process.
* There is a more detailed [contributing guide on the website](https://gohugo.io/contribute/development/).
* There is a "Proposal" label that shows that the team welcomes input from the community.
* I know from [external sources](https://www.staticgen.com/), that Hugo is an immensely popular tool for building out static websites so the impact of contribution is large.
From here, there are a number of directions I could go. If I was interested in doing a one off contribution, for example maybe I discovered some weirdness between behaviors of a specific version of Hugo I was using for my website and documentation. I could spin up the latest version and see if I can replicate it in latest. If it still is a problem in latest, I could submit an issue describing the problem, and a PR to update documentation.
If I was looking to do bigger contributions, I could ask on one of the issues labeled "Proposals" whether it's "ok for me to pick this up", and collaborate with maintainers. I could work with maintainers to improve the process for testing and document it within the contributing guidelines.
A different method for identifying projects within a specific skill set is to look at **broader community opportunities**. TThese will vary and be specific to that particular project. These can be harder to find because often community opportunities require being aware of the groups doing work within the community.
For example, within the Chef community, the [Sous Chefs](https://sous-chefs.org/) are individuals that collaborate on cookbooks intended for the wider Chef community. These opportunities can be hard to find unless you are already active in a given community. For example, if you don't already participate in the [Chef Community Slack](https://community-slack.chef.io/), or attend the [Chef Community Summit](https://events.chef.io/events/seattle-chef-community-summit/), it might not be obvious how to find out about the Sous Chef team.
Within the Go community, some avenues to follow include:
* [GopherCon](https://www.gophercon.com/) is one example of a great Go community event with a broad base of support with the contributor summit, workshops, and wide range of talks.
* [Go events](https://www.meetup.com/pro/go) is a list of world-wide Go meetups.
* [Gophers slack](https://invite.slack.golangbridge.org/) is the Go community slack.
Another method to find a project to contribute to is to look at **aggregating platforms** for insight into available projects. Many of these are organized from a developer perspective. For example, [CodeTriage](https://www.codetriage.com/) provides a list of popular projects on GitHub, sorted by language. [Mozilla](https://whatcanidoformozilla.org) provides a more nuanced "choose your adventure" process that helps you drill down to a possible project to get involved with.
A final method is to look for **community inquiries**. These can come via different channels; the community slack or Twitter, for example.
* [Karthik Gaekwad](https://twitter.com/iteration1) [requested feedback for VirtualBox and its website](https://twitter.com/iteration1/status/1198992315932725255) on Twitter at the end of November 2019. Providing feedback about VirtualBox _is_ contributing to open source. (There are other [ways](https://www.virtualbox.org/wiki/Contributor_information) to contribute to VirtualBox as well if this is of interest.)
* [Carolyn Van Slyck](https://twitter.com/carolynvs) [put out a call for Porter contributors](https://twitter.com/carolynvs/status/1174373191998943234) on Twitter in September of 2019. [Porter](https://porter.sh/contribute/) has a welcoming website that states the project values and guidelines upfront and lists the steps to take to get started contributing.
* In December of 2019 on Twitter, [Aaron Schesinger](https://twitter.com/arschles/status/1201966836083875840) shared a call for support for [Athens on Azure Kubernetes Service](https://arschles.com/blog/athens-on-azure-kubernetes-service/) with a more detailed [blog post](https://arschles.com/blog/athens-on-azure-kubernetes-service/) describing in broad strokes the plan.
### Identify possible contributions
Some projects use labels to mark issues that are good for new contributors. These issues generally focus on documentation or code issues but are good way to learn about the project as a beginner. It's helpful to lurk and examine both open and closed issues to see how contributors participate and maintainers support contributions.
> 💡 Be kind in your contributions. If you find that your chosen project has toxicity that makes contributing negative, it's OK to walk away from the project and find something new. Toxicity can look and feel different to each contributor.
Sometimes projects will use Trello or GitHub Projects to organize planned issues. Larger projects may have a regular scheduled online community hangout to plan and identify areas of concern.
Here is an example of the [Porter project](https://github.com/orgs/deislabs/projects/2) project and prioritized tasks using a [GitHub Project board](https://help.github.com/en/github/managing-your-work-on-github/managing-project-boards):
The Porter project has a rich set of labels from this prioritized view to see "good first issue" tasks as well as more specific classification of issues.
## Wrap Up
While many of the resources out there focus on developers, we all have a lot to contribute to go projects in open source. We don't have to accept software as-is. We can shape, define, and help move industry practices in our desired directions.
If you want to have a greater impact and support open source as a whole, [join the Open Source Initiative](https://opensource.org/membership), a member-driven community non-profit that promotes the use of open source software.
If you want to dig more into how to contribute to open source, read [Forge Your Future with Open Source](https://pragprog.com/book/vbopens/forge-your-future-with-open-source) by VM Brasseur.
I'd love to hear about your open source contributions (especially the ones that aren't visible because they aren't PRs). Share in the comments or with `#OSSandTell` on Twitter.
Do you have a specific process you follow when identifying projects to contribute to? Are there other challenges to contributing? Please share your process or challenges below.
Thank you to
* [Dan Maher](https://twitter.com/phrawzty) for editing the [original version](https://sysadvent.blogspot.com/2019/12/day-3-contributing-to-open-source.html) of this article for Sysadvent.
* [Aaron Schlesinger](https://twitter.com/arschles) for his invaluable time in the Go project walkthrough, as well as early feedback for this article.
* [Carolyn Van Slyck](https://twitter.com/carolynvs) for quality project maintership that encourages contribution. | sigje |
213,524 | Using Event Grid, Azure Keyvault and Azure Functions | Azure KeyVault is an essential tool. It stores password and key and can be using during ARM Template... | 0 | 2019-12-01T14:20:23 | https://dev.to/omiossec/using-event-grid-azure-keyvault-and-azure-functions-2fch | serverless, azure, powershell, azurefunctions | Azure KeyVault is an essential tool. It stores password and key and can be using during ARM Template provisioning, so you don’t have to leave any password in a script. It’s a best practice and another good practice is to change the password used for VM provisioning often.
Azure KeyVault is a service to store passwords, encryption keys and certificates. Access to a secret in Azure KeyVault requires authentication and authorization.
To use Azure KeyVault for VM provisioning, the user (or the tools) need to be authenticated in the Azure Subscription where the key vault is hosted and to be authorized to use the secret. For each type of secret, there is a set of authorization to list, read or set the secret. And about ARM template provisioning you also need to set the option “Azure Resource Manager for template deployment”
If passwords are stored in Azure Keyvault, how can you automate password update? How can you be sure to update the password without having to connect to the Azure Portal?
There are several options, a PowerShell script, Azure Automation, …. And also the support of Azure Event Grid for Azure Key Vault (in preview).
Event Grid is an event service to manage event between Azure services and event consumers. Event Grid manages event routing, high availability and scaling.
In this case, the service is Azure KeyVault and for the event consumer, I choose Azure Functions.
To build this system two things are needed.
* At least on Azure keyVault with multiple secrets (and enabled for deployment if they are using with ARM templates)
* An Azure function with a managed identity to handle password change when it expires
The first step is to deploy the Azure Functions App, the KeyVault and the Managed Identity. To build it, I choose to use ARM Template.
This template will deploy the function app plan, the storage account and the function App. But as we need to interact with Azure Keyvault, we need an identity for the function App. Managed Identity is like a service account, it allows to run the service with a special kind of Azure Ad account that can be used in Role-Based Access Control.
There are two types a managed identity for Azure Functions, System Assigned and User Assigned. System Managed Identity tied the identity to the function while the user assigned is a separate object that can be shared across several objects.
I choose System Managed Identity because it’s the most robust option. But you can try User Managed Identity. This option allows you to use the object in multiple services, Azure Functions and Logic App for example.
In arm Template creating a System Managed Identity is done with few lines of code in the website resource.
```json
"identity": {
"type": "SystemAssigned"
},
```
Next, The Keyvault. The service must be deployed with two options, it must allow the managed identity to perform secret management and the Azure Resource Manager for template deployment must be enabled.
To add the managed identity object to the Keyvault definition is a little more complex. First, you need to retrieve the current Tenant ID.
```json
"TenantID": "[subscription().tenantId]"
```
Then you need to retrieve the ObjectId of the System Managed Identity.
```json
"tenantId": "[variables('TenantID')]",
"objectId": "[reference(concat('Microsoft.Web/sites/', parameters('functionAppName'), '/providers/Microsoft.ManagedIdentity/Identities/default'), '2015-08-31-PREVIEW').principalId]",
```
You can find the complete template [here](https://github.com/omiossec/AzureFunctions_Demo/blob/master/KeyvaultEventGrid/functionsapp.json)
Now that we must create the script to update secrets and configure the event to send notifications to the function.
We need to create a function with an Event Grid trigger
```json
{
"type": "eventGridTrigger",
"name": "eventGridEvent",
"direction": "in"
}
```
The function app needs one extension Microsoft.Azure.WebJobs.Extensions.EventGrid. The extension is part of the Azure Functions Extension Bundle. It can be installed via the host.json file.
```powershell
"extensionBundle" = @{
"id" = "Microsoft.Azure.Functions.ExtensionBundle"
"version"= "[1.*, 2.0.0)"
}
```
I noticed that you may need to wait a few minutes before using the function.
The binding object, eventGridEventObject will contain the JSON object send by Event Grid. This object contains the event data generated by Event Grid when something happens on Key vault.
The data are always the same regardless of the event, password expiration, key expired, …
The schema looks like
```json
{
"id":"00eccf70-95a7-4e7c-8299-2eb17ee9ad64",
"topic":"/subscriptions/<SubscriptionId>/resourceGroups/<ResourceGroupName>/providers/Microsoft.KeyVault/vaults/<VaultName>",
"subject":"my",
"eventType":"Microsoft.KeyVault.SecretExpired",
"eventTime":"2019-07-25T01:08:33.1036736Z",
"data":{
"Id":"https://<VaultName>.vault.azure.net/secrets/my/1bd018e9ff404bab8a63667861cbb34f",
"vaultName":"<VaultName>",
"objectType":"Secret",
"objectName":"my",
"version":" ee059b2bb5bc48398a53b168c6cdcb10",
"nbf":"1559081980",
"exp":"1559082102"
},
"dataVersion":"1",
"metadataVersion":"1"
}
```
Only password expiration needs to be managed, we only need to take care to the Microsoft.KeyVault.SecretExpired. To see which secret has expired, the data is in data.ObjectName.
We need the vault name to make the function work with any Keyvault in the subscription, to get the keyvaultname data.vaultName.
Now that we know which secret to change how to update the password?
Azure function imports automatically the Azure PowerShell module. This enables the use of Set-AzKeyVaultSecret to set a password and the expiration date.
To generate a new password we can not use the System.Web.Security.MemberShip class. This class is part of the .Net Framework and not .Net Core Framework. It will not work.
```powershell
$InputArray= ([char[]]([char]33..[char]95) + [char[]]([char]97..[char]126))
$GeneratedPassword = (Get-Random -Count 26 -InputObject ([char[]]$InputArray)) -join ''
```
The GeneratedPassord variable type is System.String but the Set-AzKeyVaultSecret only accept SecureString data
Last thing, the function needs to trace what happened. We need to log the action, the KeyVault Name, the date of the change and the secret name, but not the password.
To do this, I use a simple Azure Storage Table in an output binding.
```powershell
$logData = @{
"VaultName" = $eventGridEventObject.data.vaultName
"partitionKey" = "vaultlog"
"SecretName" = $eventGridEventObject.data.objectName
"SecretChangeDate"= Get-Date
"rowKey" = (new-guid).guid
}
Push-OutputBinding -Name keyvaultlogtable -Value $logData
```
Finally we need to connect the keyvault to the function to capture the password expiration event and get the data.
As Event Grid in Azure Keyvault is still in preview there is no direct link. If you look in the portal the Events section is absent.
You will need to use this [URL](https://ms.portal.azure.com/?Microsoft_Azure_KeyVault_ShowEvents=true&Microsoft_Azure_EventGrid_publisherPreview=true)
Go to Events and click + Event Subscription
Give a name for the event and in Event Types select only Secret Expired.
In the Endpoint, type select Azure Function and choose the functions App created before and the function.
In ARM it should look like something like this
```json
{
"name": "test",
"properties": {
"topic": "/subscriptions/<SubscriptionId>/resourceGroups/<KeyvaultResourceGroupName>/providers/Microsoft.KeyVault/vaults/<VaultName>",
"destination": {
"endpointType": "AzureFunction",
"properties": {
"resourceId": "/subscriptions/<SubscriptionId>/resourceGroups/<FunctionAppResourceGroupName>/providers/Microsoft.Web/sites/<FunctionAppName>/functions/<FunctionName>",
"maxEventsPerBatch": 1,
"preferredBatchSizeInKilobytes": 64
}
},
"filter": {
"includedEventTypes": [
"Microsoft.KeyVault.SecretExpired"
],
"advancedFilters": []
},
"labels": [],
"eventDeliverySchema": "EventGridSchema"
}
}
```
Now that the event grid is in place, you can test by creating a secret with an expiration date in a few minutes and by checking the table in the Function App storage account.
Event Grid in Azure KeyVault is in preview, but you can start to build solutions.
The complete solution is visible [here](https://github.com/omiossec/AzureFunctions_Demo)
| omiossec |
213,541 | Is Startup For Me? | Introduction If you are just starting out I'm pretty sure, you have tons of questions in... | 0 | 2019-12-01T12:23:24 | https://www.maxongzb.com/is-startup-for-me-reading-time-4-mins/ | beginners, career, startup | # Introduction
![undraw stand out 1oag][1]
If you are just starting out I'm pretty sure, you have tons of questions in some form or another when you are thinking of being in a startup.
The questions could be in the lines of:
* "What will my friends or family think about me?"
* "Does it make sense for me to join one?"
* "Will I be paid well?"
* "Will I be able to fit into the company's culture?"
* "What is it in for me to join a startup?"
* "Will there be work-life balance "
Fortunately, for me, my focus was on choosing a path of being either a **technology sales professional** or **software engineer** after graduating from university.
I personally believe that it will eventually lead me to become a **tech entrepreneur**.
For you, the first question might be a **deal-breaker** for people.
Who are from an Asian background where **prestige**, **education** and **job security** are intertwined to form our identity.
Therefore thinking about it hard is one of the top priority for yourself,
As it is not a [common career choice][2] among your peers if you are in Singapore.
# Dealing with Ambiguity & Wearing Multiple Hats
![undraw home settings 8rlf][3]
Daily in a startup, you have a high chance to deal with different situations that will challenge you.
To become **resourceful** to get things done, to be **adaptable** to "
seemly **impossible** situations that may be **uncomfortable**, or partake in one or two **death marches**.
Which requires you to be at work for a longer duration. This is especially the case for early-stage startups.
The good part is that you **learn** and **grow** at a much **faster** pace.
Without being **pidgeon hole** to do only a **single** thing in an MNC or another larger company.
Due to this mindset, you may pick up **bad habits** along the way.
In favour of just getting the **result** without **thinking through** in the **impacts** of what you had done.
# What is Your Purpose for Joining a Startup?
![undraw thought process 67my][4]
If your purpose for joining a startup is to be on the next Uber, WeWork or Airbnb.
So you could make lot's of money and retire on the tropical beach sipping your mojitos in just a few years.
I'm afraid that I have to burst your bubble. That you might have to prepare for the long haul of **5** to **10** years.
Since that is the usual timeline, which a startup might be brought by another company or might be able to be listed in the public stock exchange.
But if your purpose is something else, like say working in a startup as a [tours of duty][5].
To gain **Insight** into how to run a **future startup** for yourself or a **well-round** education as a developer.
Which allows you to take on more senior-level positions that might require more years of experience than your peers.
# What Type of Startup Fits Me?
![undraw right places h9n3][6]
Here are some of the questions that I would ask myself when selecting a startup.
## Is the startup funded by VC or are They a Bootstrapped startup?
This is important as it is a good gauge for the startup if they can stay alive after a few years.
Search for startups that are **bootstrapped** or is **self-sustaining** themselves or had recently closed their "funding" round to sustain themselves for a few years.
## What is Stage of the Startup In Now?
**Later-stage** startups might be able to provide a **structured environment** and **better** salary & benefits above the market rate.
It usually requires a **specialist** with experience in what they do.
For an early-stage startup, they do not offer a better **salary**.
Instead, they might provide **employee stock options**, a **lesser structure**, **health insurances** and other benefits.
With room for **leadership** positions as you perform and duration of stay increases in the startup.
Do note that regardless of the stage of the startup. You should always look for **market-level** salary in your area & **negotiate** on it based upon your **comfort** level and **geographic** location.
[Employee stock options][7] sound good on paper but do note that it's just a **paper**.
Unless the startup is **brought** by another company or has been **listed** in a public stock exchange which could take 5 - 10 years to realise it.
Take "employee stocks option" as a pinch of salt of just an add on benefit to the startup you are working in.
# Conclusion
![undraw destinations fpv7][8]
I hope that the questions and some of my answers are helpful for you to gauge yourself and allow you to make a choice to be part of a startup.
Please do not be attracted to **fluff** in the technology used.
Instead, focus on the **problem** the startup is trying to solve, the **management team** and hopefully their **business model** to help them survive as a startup.
Lastly, please do at the **minimum** read and adopt the principles of [The Richest Man in Babylon][9] to deal with the **instability** of startup life.
If you like my article, please **sign up** for Max [Adventurer's Newsletter](http://eepurl.com/dOUoUb) for awesome content I stumble across weekly in **Python**, **Startup** and **Web Development**.
You can also **follow** me to get the **latest** update of my article on **Dev**
This post was originally posted on Max's blog at [Is Startup For Me? - Reading Time: 4 Mins](https://www.maxongzb.com/is-startup-for-me-reading-time-4-mins/) and [Photo by Austin Distel on Unsplash](https://unsplash.com/photos/wD1LRb9OeEo)
# References
* [Fresh Graduates in SG Want to Work In Tech, but Not At Startups][2]
* [Think like an Investor When Deciding Which Startup to Join][10]
* [Tours of Duty][5]
* [How Employee Stock Options Work in Startup Compaines][7]
* [Startup Just Aren't for You][11]
* [Pros and Cons of Working for a Startup Company][12]
* [Illustrations - unDraw][13]
[1]: //images.ctfassets.net/ly2f59p4unnn/Sf4RQQ3CrxLDzoAStS4vt/f4bccd815c2f4b53ff5be79d6d003c2e/undraw_stand_out_1oag.png
[2]: https://www.techinasia.com/fresh-graduates-singapore-work-tech-not-startups
[3]: //images.ctfassets.net/ly2f59p4unnn/Up9MCT8ThMZjrp9sAS64g/e43ed09a958a5e58f1b1d873c9718b10/undraw_home_settings_8rlf.png
[4]: //images.ctfassets.net/ly2f59p4unnn/677VcDhUI9hPVcOVTtIhB5/42c7e8415ec68db54f7dd7251a069a4e/undraw_thought_process_67my.png
[5]: https://hbr.org/2013/06/tours-of-duty-the-new-employer-employee-compact
[6]: //images.ctfassets.net/ly2f59p4unnn/6uKdxJYgsnVhW9VHWrqNoy/e3f31fc18192b35642dcee5a556336b5/undraw_right_places_h9n3.png
[7]: https://www.forbes.com/sites/allbusiness/2016/02/27/how-employee-stock-options-work-in-startup-companies/#643863a36633
[8]: //images.ctfassets.net/ly2f59p4unnn/4bJ742ZzVdKRwhaTr9t6JR/cf2d0dfe2cb0d8bae558b97e0f6d2fa9/undraw_destinations_fpv7.png
[9]: https://www.amazon.com/Richest-Man-Babylon-George-Clason/dp/1505339111
[10]: https://www.connectone.com.sg/insights/2019/4/29/think-like-an-investor-when-deciding-which-startup-to-join
[11]: https://www.inc.com/anne-gherini/startups-just-arent-for-you.html
[12]: https://www.monster.com/career-advice/article/pros-and-cons-of-working-for-a-startup-company
[13]: https://undraw.co/illustrations?source=post_page--------------------------- | steelwolf180 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.