
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
213,551 | What is an engineer's worth? | An engineer's worth can be seen from the number of different perspectives they can look a problem fro... | 0 | 2019-12-01T13:45:04 | https://dev.to/anshbansal/what-is-an-engineer-s-worth-n4m | career | An engineer's worth can be seen from the number of different perspectives they can look a problem from. As a software engineer I may think about getting things across the finish line. But I have found that if I start thinking it from someone else's perspective it makes my work better. Different people in different professions may look at things differently. e.g.
- Someone who is doing software testing might think "How do I break this", "What do developers usually not test"?
- Someone who manages Infrastructure might think "In what sequence would this get deployed" or "How many servers would this change require"?
- Someone who does ETL might think where is data coming from, where is it going?
- Someone who does BI might be more interested in what each column in a table means and how does it relate to business?
- Someone in customer success might be more interested in how will this be rolled out to customers? If something happens would there be workarounds for the customer? How would the team find out before the customer has to report the problem?
- Someone who has to increase sales for a product might be more interested in reducing the number of steps customer has to take to buy something to increase the likelihood of sales.
- Someone who has been working more as a SQL dev might tend to solve problems one tabular operation at a time, someone who has been working in general purpose programming languages might tend to solve problems one row at a time.
I recently started thinking much more about how to grow more as an engineer. This is the answer that I came up with. Try and put more hats when looking at a problem to make the solutions better.
What's your take on this?
---
If you want to know when I write more articles join telegram channel for [Data posts](https://t.me/aseem_data), [software posts](https://t.me/aseem_software) or [other posts](https://t.me/aseem_life). I don't spam, promise. | anshbansal |
213,560 | Self introduction | Hello guys, I am an 11 years old programmer, engineer, photographer, composer, saxophonist and a desi... | 0 | 2019-12-01T14:35:21 | https://dev.to/saxode/self-introduction-hhg | introducing | Hello guys, I am an 11 years old programmer, engineer, photographer, composer, saxophonist and a designer from Taiwan, I code in Arduino, C, HTML, CSS, JS, Python, VBA, I am now learning C++, happy to meet you guys! | saxode |
213,613 | A Login Form built using React Hooks | Created a simple login form using React, Typescript and React Material UI featuring useReducer and us... | 0 | 2019-12-01T17:43:13 | https://dev.to/creativesuraj/a-login-form-built-using-react-hooks-2ko2 | react, typescript, javascript, opensource | Created a simple login form using **React, Typescript and React Material UI** featuring `useReducer` and `useEffect` hooks.<br/>
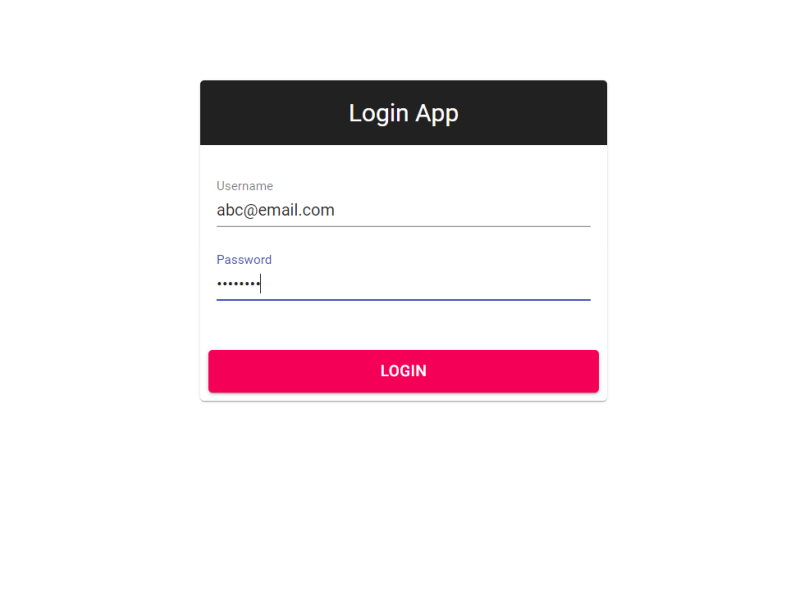
A detailed article on [How to build a React Login Form with Typescript and React hooks](https://surajsharma.net/blog/react-login-form-typescript)
| creativesuraj |
213,631 | Webview native authentication in React Native | Original published on my blog TL;DR: React Native App: https://github.com/smakosh/article-auth-a... | 0 | 2019-12-01T22:06:08 | https://smakosh.com/webview-native-authentication | reactnative, react, mobile, dev | ---
title: Webview native authentication in React Native
published: true
date: 2019-12-01 07:50:01 UTC
tags: React native, React, mobile, dev
canonical_url: https://smakosh.com/webview-native-authentication
cover_image: https://smakosh.com/static/a06a144f8099f4242540e8b94df0ac67/7a72d/webview-react-native.webp
---
> Original published on [my blog](https://smakosh.com/webview-native-authentication)
TL;DR:
- React Native App: [https://github.com/smakosh/article-auth-app](https://github.com/smakosh/article-auth-app)
- React web app: [https://github.com/smakosh/article-auth-web](https://github.com/smakosh/article-auth-web)
- REST API: [https://github.com/smakosh/article-auth-api](https://github.com/smakosh/article-auth-api)
## Theory
Before you start reading and getting into this article, you must be aware that only the minority of mobile developers get into this use case and due to that, I decided to write this article to guide you through on how to implement authentication within a native app that has a webview part included.
You may be wondering why going through this while you could have just converted the web app into a fully native app or just go fully with the webview.
Well to answer the first question, sometimes your client wants a quick & cheap MVP to deploy to TestFlight or the Beta track on the Play Store for their customers to test and share feedback.
The reason we want to have at least the authentication part being fully native is because your submitted app on the App Store unlike Google gets tested by humans, and they reject the app if it uses the webview only.
Before we move into to the practical part in this guide, let me explain how we will deal with authentication first:
1. User has to register or sign in
2. A request is sent to our REST or GraphQL API returning a JWT token
3. Token gets stored within the device storage
4. User gets redirected to the webview screen being authenticated as we pass the token to the web app using a great library called `react-native-webview-invoke`, that lets us pass values and functions to be executed within the web app.
5.
When the user signs out within the webview screen, a function will be invoked from the web app that logs out the user on the native app as well
> This way, when the user opens up the app once again, they will start from the authentication process
6. We will be getting the stored token and verifying that it is still valid, if it is, the API will return user’s data, else user has to login once again.
## Practice
So let us begin by initializing a new React Native project using `npx react-native init authApp`
> ⚠️ I’ll be using React Native `0.61.5`
Let us install all the libraries we will be using in this example:
- Navigation: react-native-navigation
- HTTP requests: axios
- Webview: react-native-webview
- Storage: @react-native-community/async-storage
- Forms & validation: formik + yup
- Styling: styled-components
## Configuring RNN
As I’m using React Native 0.61.5, it’s way easier to configure react-native-navigation now, you can follow these steps to get it configured:
### for iOS
1. `cd ios`
2. open the `Podfile`
3. add this line to your Podfile
```ruby
pod 'ReactNativeNavigation', :podspec => '../node_modules/react-native-navigation/ReactNativeNavigation.podspec'
```
1. open your xcworkspace project in Xcode
2. In Xcode, you will need to edit this file: `AppDelegate.m`
3. Its content should look like this
```objective-c
#import "AppDelegate.h"
#import <React/RCTBundleURLProvider.h>
#import <React/RCTRootView.h>
#import <ReactNativeNavigation/ReactNativeNavigation.h>
@implementation AppDelegate
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions
{
NSURL *jsCodeLocation = [[RCTBundleURLProvider sharedSettings] jsBundleURLForBundleRoot:@"index" fallbackResource:nil];
[ReactNativeNavigation bootstrap:jsCodeLocation launchOptions:launchOptions];
return YES;
}
@end
```
1. Open `AppDelegate.h` and make sure its content looks like below
```objective-c
#import <UIKit/UIKit.h>
@interface AppDelegate : UIResponder <UIApplicationDelegate>
@property (nonatomic, strong) UIWindow *window;
@end
```
### for Android
You might want to check [the official guide](https://wix.github.io/react-native-navigation/#/docs/Installing?id=android)
> ⚠️ Make sure to create `react-native.config.js` file on the root of your app and put this content:
```js
module.exports = {
dependencies: {
'@react-native-community/async-storage': {
platforms: {
android: null,
},
},
'react-native-webview': {
platforms: {
android: null,
},
},
},
}
```
We basically want to avoid auto linking those two libraries on Android.
## Registering our screens
Let’s start by opening up our `index.js` file and removing its content, then we will import `Navigation` from react-native-navigation, along with our registered screens under `src/config/index.js` and initialize our app using the `registerAppLaunchedListener` callback.
> `index.js`
```jsx
import { Navigation } from 'react-native-navigation'
import { registerScreens } from './src/config'
registerScreens()
Navigation.events().registerAppLaunchedListener(() => {
Navigation.setRoot({
root: {
component: {
name: 'Initializing',
},
},
})
})
```
We set `Initializing` as the first screen to render.
Let’s now register the rest of the screens
We have:
- **Initializing** screen, which has been explained above ☝️
- **Home** screen which will contain the webview of our web app
- **Login/Register** screens are self descriptive
> `src/config/index.js`
```jsx
import { Navigation } from 'react-native-navigation'
import Initializing from 'src/screens/Initializing'
import Home from 'src/screens/Home'
import Login from 'src/screens/Login'
import Register from 'src/screens/Register'
export const BASE_URL = 'http://localhost:5000/api'
export const REACT_APP = 'http://localhost:3000'
export const registerScreens = () => {
Navigation.registerComponent('Home', () => Home)
Navigation.registerComponent('Initializing', () => Initializing)
Navigation.registerComponent('Login', () => Login)
Navigation.registerComponent('Register', () => Register)
}
```
> `BASE_URL` is our REST API and `REACT_APP` is our React web app.
Now let’s move on creating our screens
> `src/screens/Initializing.js`
This screen is the one that will appear to users first while fetching and validating their tokens
```jsx
import React from 'react'
import Layout from 'src/components/Layout'
import Initializiation from 'src/modules/Initializiation'
export default () => (
<Layout>
<Initializiation />
</Layout>
)
```
Initialization is where the logic exists which lives under `src/modules/Initializing`
```jsx
import React, { useContext } from 'react'
import { View, Text } from 'react-native'
import { Context } from 'src/providers/UserProvider'
import useGetUser from 'src/hooks/useGetUser'
import Container from 'src/components/Container'
import CustomButton from 'src/components/CustomButton'
export default () => {
const { user, dispatch } = useContext(Context)
const { loading, isLoggedIn } = useGetUser(user, dispatch)
return (
<Container>
{loading ? (
<Text>Loading</Text>
) : isLoggedIn ? (
<View>
<Text>Welcome back {user.data.user.username}!</Text>
<CustomButton goHome={() => goHome(user.data.token)}>
Go Home
</CustomButton>
</View>
) : (
<View>
<Text>Welcome!</Text>
<CustomButton onPress={() => goToRegister()}>Register</CustomButton>
<CustomButton onPress={() => goToAuth()}>Sign In</CustomButton>
</View>
)}
</Container>
)
}
```
> Notice that I’m using a custom hook `useGetUser` that contains all that logic and I’m passing the `user` object and `dispatch` function from the User Context.
Layout is a wrapper component that wrapps the passed children with the User Provider as shown below
> You can add the header and more components that are meant to appear on all your screens
Layout lives under `src/components/Layout`
```jsx
import React from 'react'
import UserProvider from 'src/providers/UserProvider'
export default ({ children }) => <UserProvider>{children}</UserProvider>
```
And I’m using React Context API to manage my global state, here’s the User Provider component and reducer
It lives under `src/providers/UserProvider`
```jsx
import React, { useReducer, createContext } from 'react'
import UserReducer from 'src/reducers/UserReducer'
export const Context = createContext()
export default ({ children }) => {
const [user, dispatch] = useReducer(UserReducer, [])
return (
<Context.Provider
value={{
user,
dispatch,
}}
>
{children}
</Context.Provider>
)
}
```
the user reducer lives under `src/reducer/UserReducer`
```js
export default (user, action) => {
switch (action.type) {
case 'SAVE_USER':
return {
...user,
isLoggedIn: true,
data: action.payload,
}
case 'LOGOUT':
return {
...user,
isLoggedIn: false,
data: {},
}
default:
return user
}
}
```
And here’s the `useGetUser` hook which lives under `src/hooks/`
```jsx
import { useState, useEffect, useCallback } from 'react'
import { verifyToken } from 'src/modules/auth/actions'
export default (user, dispatch) => {
const [loading, setLoading] = useState(true)
const [error, _setError] = useState(null)
const fetchUser = useCallback(() => verifyToken(dispatch, setLoading), [
dispatch,
])
useEffect(() => {
if (!user.isLoggedIn) {
fetchUser()
}
}, [user.isLoggedIn, fetchUser])
return {
error,
loading,
isLoggedIn: user.isLoggedIn,
}
}
```
I’m importing `verifyToken` from the auth actions, the action simply verifies that the token hasn’t expired yet, [see Step 6 above on the Theory section](/webview-native-authentication#theory)
> It lives under `src/modules/auth/actions.js`
```jsx
import axios from 'axios'
import AsyncStorage from '@react-native-community/async-storage'
import setAuthToken from 'src/helpers/setAuthToken'
import { BASE_URL } from 'src/config'
export const verifyToken = async (dispatch, setLoading) => {
try {
const token = await AsyncStorage.getItem('token')
if (token) {
const { data } = await axios({
method: 'GET',
url: `${BASE_URL}/user/verify`,
headers: {
'Content-Type': 'application/json',
'x-auth': token,
},
})
setAuthToken(data.token)
await dispatch({ type: 'SAVE_USER', payload: data })
AsyncStorage.setItem('token', data.token)
}
} catch (err) {
setError(err)
} finally {
setLoading(false)
}
}
```
More actions will be added as we move on through this guide through.
Next, let’s prepare both the `SignIn` and `Register` screens:
Login lives under `src/screens/Login`
```jsx
import React from 'react'
import Login from 'src/modules/auth/Login'
import Layout from 'src/components/Layout'
export default () => (
<Layout>
<Login />
</Layout>
)
```
And Login module lives under `src/modules/auth/Login`
```jsx
import React, { useContext } from 'react'
import { View } from 'react-native'
import { Formik } from 'formik'
import * as Yup from 'yup'
import { Context } from 'src/providers/UserProvider'
import { login } from 'src/modules/auth/actions'
import Container from 'src/components/Container'
import InputField from 'src/components/InputField'
import ErrorField from 'src/components/ErrorField'
import CustomButton from 'src/components/CustomButton'
import DismissibleKeyboardView from 'src/components/DismissibleKeyboardView'
import { Label } from '../styles'
export default () => {
const { dispatch } = useContext(Context)
return (
<Formik
initialValues={{
email: '',
password: '',
}}
validationSchema={Yup.object().shape({
email: Yup.string()
.email()
.required(),
password: Yup.string().required(),
})}
onSubmit={async (values, { setSubmitting, setErrors }) => {
try {
login({ dispatch, setErrors, setSubmitting, values })
} catch (err) {
setSubmitting(false)
}
}}
>
{({
isSubmitting,
handleSubmit,
errors,
touched,
values,
handleChange,
handleBlur,
}) => (
<Container>
<DismissibleKeyboardView keyboardShouldPersistTaps="handled">
<View>
<Label>Email</Label>
<InputField
value={values.email}
onChangeText={handleChange('email')}
onBlur={handleBlur('email')}
selectTextOnFocus
/>
{touched.email && errors.email && (
<ErrorField>{errors.email}</ErrorField>
)}
</View>
<View>
<Label>Password</Label>
<InputField
value={values.password}
onChangeText={handleChange('password')}
onBlur={handleBlur('password')}
selectTextOnFocus
secureTextEntry
/>
{touched.password && errors.password && (
<ErrorField>{errors.password}</ErrorField>
)}
</View>
<CustomButton onPress={handleSubmit} disabled={isSubmitting}>
Login
</CustomButton>
</DismissibleKeyboardView>
</Container>
)}
</Formik>
)
}
```
I’m using the newest version of Formik with yup for validation, there is one action called `login` being dispatched there when the form is submitted.
login action lives under `src/modules/auth/actions`, the same file where `verifyToken` lives
```jsx
import axios from 'axios'
import AsyncStorage from '@react-native-community/async-storage'
import setAuthToken from 'src/helpers/setAuthToken'
import { BASE_URL } from 'src/config'
import { goHome } from 'src/config/navigation'
export const login = async ({ dispatch, setErrors, setSubmitting, values }) => {
try {
const { data } = await axios.post(`${BASE_URL}/user/login`, values)
setAuthToken(data.token)
await dispatch({ type: 'SAVE_USER', payload: data })
await AsyncStorage.setItem('token', data.token)
setSubmitting(false)
goHome(data.token)
} catch (err) {
setSubmitting(false)
setErrors({ email: err.response.data.error })
}
}
export const verifyToken = async (dispatch, setLoading) => {
try {
const token = await AsyncStorage.getItem('token')
if (token) {
const { data } = await axios({
method: 'GET',
url: `${BASE_URL}/user/verify`,
headers: {
'Content-Type': 'application/json',
'x-auth': token,
},
})
setAuthToken(data.token)
await dispatch({ type: 'SAVE_USER', payload: data })
AsyncStorage.setItem('token', data.token)
}
} catch (err) {
setError(err)
} finally {
setLoading(false)
}
}
```
We will add three more actions later on as we move on.
The `setAuthToken` function simply adds a `x-auth` header to all upcoming requests
It lives under `src/helpers/setAuthToken`
```jsx
import axios from 'axios'
export default token => {
if (token) {
axios.defaults.headers.common['x-auth'] = token
} else {
delete axios.defaults.headers.common['x-auth']
}
}
```
Register is following the same logic, you’ll be able to find the source code on the repositories as everything will be open sourced, so let’s move on to the important screen which is the **Home** screen
It lives under `src/screens/Home`
```jsx
import React from 'react'
import Home from 'src/modules/dashboard/Home'
import Layout from 'src/components/Layout'
export default ({ token }) => (
<Layout>
<Home token={token} />
</Layout>
)
```
the actual logic exists within `src/module/dashboard/Home`
let’s start by creating an invoke from the native side and add the webview of our React app
```jsx
import React, { Component } from 'react'
import { SafeAreaView } from 'react-native'
import { WebView } from 'react-native-webview'
import createInvoke from 'react-native-webview-invoke/native'
import { REACT_APP } from 'src/config/'
class Home extends Component {
webview
invoke = createInvoke(() => this.webview)
render() {
return (
<SafeAreaView style={{ flex: 1, backgroundColor: '#fff' }}>
<WebView
useWebKit
ref={webview => (this.webview = webview)}
onMessage={this.invoke.listener}
source={{
uri: `${REACT_APP}`,
}}
bounces={false}
/>
</SafeAreaView>
)
}
}
Home.options = {
topBar: {
title: {
text: 'Home',
},
visible: false,
},
}
export default Home
```
We want to pass one function and value from React Native to the React web app:
1. Passing the token as url param, not sure if it’s a good approach to follow, feel free to enlighten me if you know any better approach to achieve this.
2. A function that will log the user out from the React Native app, remove the token from the device storage and redirect them back to the `Login` screen, triggered/invoked from the React web app.
So let’s add that to the **Home** module
```jsx
import React, { Component } from 'react'
import { SafeAreaView, Alert } from 'react-native'
import { WebView } from 'react-native-webview'
import AsyncStorage from '@react-native-community/async-storage'
import createInvoke from 'react-native-webview-invoke/native'
import { goToAuth } from 'src/config/navigation'
import { REACT_APP } from 'src/config/'
class Home extends Component {
webview
invoke = createInvoke(() => this.webview)
componentDidMount() {
this.invoke.define('onLogout', this.onLogout)
}
onLogout = async () => {
try {
AsyncStorage.clear()
goToAuth()
} catch (err) {
Alert.alert('Something went wrong')
}
}
render() {
const { token } = this.props
return (
<SafeAreaView style={{ flex: 1, backgroundColor: '#fff' }}>
<WebView
useWebKit
ref={webview => (this.webview = webview)}
onMessage={this.invoke.listener}
source={{
uri: `${REACT_APP}/?token=${token}`,
}}
bounces={false}
/>
</SafeAreaView>
)
}
}
export default Home
```
Let’s now see how can we handle that from the React web app.
> I’ll skip right into the part where we handle the passed function to invoke it, the source code will be able available for you.
First of all, let’s import `invoke` from `react-native-webview-invoke/browser`
```js
import invoke from 'react-native-webview-invoke/browser'
```
All we have to do to access the function and invoke it is binding, checking if it exists and invoking it.
```js
const onLogout = invoke.bind('onLogout')
if (onLogout) {
onLogout().then(() => {})
}
```
That’s basically the guide through to implement authentication within a native app that has a webview section.
If you managed to make it until the end, make sure to subscribe to the news letter down below in order to get the latest articles delivered right to your inbox!
- React Native App: [https://github.com/smakosh/article-auth-app](https://github.com/smakosh/article-auth-app)
- React web app: [https://github.com/smakosh/article-auth-web](https://github.com/smakosh/article-auth-web)
- REST API: [https://github.com/smakosh/article-auth-api](https://github.com/smakosh/article-auth-api) | smakosh |
213,651 | Advent of Code 2019 Day 1 | Day one of Advent of Code 2019 Challenge | 0 | 2019-12-01T21:28:01 | https://dev.to/yamakasy/advent-of-code-2019-day-1-9ba | ---
title: Advent of Code 2019 Day 1
published: true
description: Day one of Advent of Code 2019 Challenge
tags:
---
# The Challenge
Advent of Code is an Advent calendar of small programming puzzles for a variety of skill sets and skill levels that can be solved in any programming language you like.
Each day two puzzles will be provided.
# Why this year?
The last 2-3 month I have been improving my Functional programming skills. First I readed about FP on Javascript and now I am focusing on Haskell. I though this would be a good oportunity to use what I am learning.
# First puzzle of the day
`Fuel required to launch a given module is based on its mass. Specifically, to find the fuel required for a module, take its mass, divide by three, round down, and subtract 2.`
Apart from this description some examples are given:
1. `For a mass of 12, divide by 3 and round down to get 4, then subtract 2 to get 2`
2. `For a mass of 14, dividing by 3 and rounding down still yields 4, so the fuel required is also 2.`
3. `For a mass of 1969, the fuel required is 654.`
4. `For a mass of 100756, the fuel required is 33583.`
`the Fuel Counter-Upper needs to know the total fuel requirement. To find it, individually calculate the fuel needed for the mass of each module (your puzzle input), then add together all the fuel values.`
# Implementation process an solution
As I am really new to Haskell I decided to also implement the puzzle in Javascript.
As some examples were given, I decide to transform them intro a test cases.
```javascript
const { calculateFuelRequired } = require('./FuelRequerimentCalculator')
describe('calculateFuelRequired', () => {
it('returns 0 when the mass is 0', () => {
const fuelRequired = calculateFuelRequired(0);
expect(fuelRequired).toBe(0);
});
it('returns 0 when the mass is less than 0', () => {
const fuelRequired = calculateFuelRequired(-1);
expect(fuelRequired).toBe(0);
});
it('returns 2 when the mass is 12', () => {
const fuelRequired = calculateFuelRequired(12);
expect(fuelRequired).toBe(2);
});
it('returns 2 when the mass is 14', () => {
const fuelRequired = calculateFuelRequired(14);
expect(fuelRequired).toBe(2);
});
it('returns 654 when the mass is 1969', () => {
const fuelRequired = calculateFuelRequired(1969);
expect(fuelRequired).toBe(654);
});
it('returns 33583 when the mass is 100756', () => {
const fuelRequired = calculateFuelRequired(100756);
expect(fuelRequired).toBe(33583);
});
})
```
The resulting code is simple:
```javascript
function calculateFuelRequired(mass) {
if (mass <= 0) return 0;
return Math.floor((mass / 3)) - 2;
}
```
To execute the code against the inputs given by the challenge and calculating the answer:
```javascript
function main() {
const values = getValues(); //function that returns an array with all the values given.
const total = values.reduce((prev, curr) => {
return prev + calculateFuelRequired(curr);
}, 0);
console.log(total);
}
```
Ones solved the challenge in Javascript I tried my best to translate it to something that the Haskell compiler wouldn't claim about:
```haskell
module FuelRequerimentCalculator where
calculateFuelRequired :: Double -> Integer
calculateFuelRequired mass | mass <= 0 = 0
| otherwise = floor(mass/3) - 2
main :: Integer
main = sum (map calculateFuelRequired getValues)
```
#Second puzzle of the day
`Fuel itself requires fuel just like a module - take its mass, divide by three, round down, and subtract 2. However, that fuel also requires fuel, and that fuel requires fuel, and so on. Any mass that would require negative fuel should instead be treated as if it requires zero fuel; the remaining mass, if any, is instead handled by wishing really hard, which has no mass and is outside the scope of this calculation.`
1. `A module of mass 14 requires 2 fuel. This fuel requires no further fuel (2 divided by 3 and rounded down is 0, which would call for a negative fuel), so the total fuel required is still just 2.`
2. `At first, a module of mass 1969 requires 654 fuel. Then, this fuel requires 216 more fuel (654 / 3 - 2). 216 then requires 70 more fuel, which requires 21 fuel, which requires 5 fuel, which requires no further fuel. So, the total fuel required for a module of mass 1969 is 654 + 216 + 70 + 21 + 5 = 966.`
3. `The fuel required by a module of mass 100756 and its fuel is: 33583 + 11192 + 3728 + 1240 + 411 + 135 + 43 + 12 + 2 = 50346.`
`What is the sum of the fuel requirements?`
# Implementation process an solution
The same examples with the updated result are given, so I create again some tests.
```javascript
describe('calculateFuelRequiredCountingWithFuel', () => {
it('returns 0 when the mass is 0', () => {
const fuelRequired = calculateFuelRequiredCountingWithFuel(0);
expect(fuelRequired).toBe(0);
});
it('returns 0 when the mass is less than 0', () => {
const fuelRequired = calculateFuelRequiredCountingWithFuel(-1);
expect(fuelRequired).toBe(0);
});
it('returns 2 when the mass is 12', () => {
const fuelRequired = calculateFuelRequiredCountingWithFuel(12);
expect(fuelRequired).toBe(2);
});
it('returns 2 when the mass is 14', () => {
const fuelRequired = calculateFuelRequiredCountingWithFuel(14);
expect(fuelRequired).toBe(2);
});
it('returns 966 when the mass is 1969', () => {
const fuelRequired = calculateFuelRequiredCountingWithFuel(1969);
expect(fuelRequired).toBe(966);
});
it('returns 50346 when the mass is 100756', () => {
const fuelRequired = calculateFuelRequiredCountingWithFuel(100756);
expect(fuelRequired).toBe(50346);
});
})
```
The solution is a bit more complicated and it includes recursion.
```javascript
function calculateFuelRequiredCountingWithFuel(mass) {
const calc = Math.floor((mass / 3)) - 2;
if (calc <= 0) return 0;
const result = calc + calculateFuelRequiredCountingWithFuel(calc);
return result;
}
```
And this is the updated main method to show both the solutions.
```javascript
function main() {
const values = getValues();
const noFueltotal = values.reduce((prev, curr) => {
return prev + calculateFuelRequired(curr);
}, 0);
const withFuelTotal = values.reduce((prev, curr) => {
return prev + calculateFuelRequiredCountingWithFuel(curr);
}, 0);
console.log('The total without adding the fuel is ' + noFueltotal);
console.log('The total adding the fuel is ' + withFuelTotal);
}
```
And finally the Haskell version:
```haskell
calculateFuelRequiredCountingWithFuel:: Double -> Integer
calculateFuelRequiredCountingWithFuel mass | calculateFuelRequired mass <= 0 = 0
| otherwise = (calculateFuelRequired mass) + (calculateFuelRequiredCountingWithFuel ( fromIntegral (calculateFuelRequired mass)))
main2 :: Integer
main2 = sum (map calculateFuelRequiredCountingWithFuel getValues)
```
#Conclusion
This was the first day, I will continue updating the repository and trying to create one post peer day.
{% github IObregon/adventofcode2019 no-readme%}
If you want to participate this is the web page of the challenge [Advent of code](https://adventofcode.com/2019/day/1) | yamakasy | |
213,662 | Refactor a function to be more functional | Functional paradigm is kind of mystical knowledge for me, as it involves a lot of hard words and conc... | 0 | 2019-12-01T21:34:01 | https://dev.to/pavelloz/refactor-a-function-to-be-more-functional-1bdj | javascript, functional, beginners | Functional paradigm is kind of mystical knowledge for me, as it involves a lot of hard words and concepts from math. But once in a while I read or watch materials about it hoping that I will understand more. This has been going for years now.
Some concepts are easy, but without a good, iterative example it is still hard to incorporate into everyday developer's life. Last night, I think I found a good example, that would help me a lot with understanding some of the basics of composition if someone showed me something like I'm about to show you. I hope you find it hopeful in your journey to writing good and easy to maintain code.
---
Function that will serve me as an example will take a string and return a number of unique letters in that string.
## Prepare the test case
I always do that first, because I prototype in [RunJS](https://runjs.dev). I find it the easiest and quickest that way. There is also Scratchpad in Firefox, but RunJS has live code evaluation.
```js
const input = 'Hi, my name is Pawel!';
const expected = 11;
const count = (string) => '';
console.log(expected === count(input));
```
## Make it work
Now let's implement the first version that will return correct result.
```js
const count = string => {
const array = Array.from(string);
const onlyLetters = array.filter(char => char.match(/[a-zA-Z]/));
const lowercase = onlyLetters.map(char => char.toLowerCase());
const unique = new Set(lowercase);
const output = unique.size;
return output;
}
```
It is pretty verbose, line by line it is pretty easy to understand what is going on. Probably the biggest downside is that it uses a lot of assignments.
Note: Im using `Set` to make array values unique.
## Make it better
Let me walk you through some of the variants I came up with when trying to find the optimal solution.
### A little bit of chaining
```js
const count = string => {
const array = Array.from(string)
.filter(char => char.match(/[a-zA-Z]/))
.map(char => char.toLowerCase());
return new Set(array).size;
}
```
Now we used less constants and used the fact that `Array` can chain methods like `filter`, and `map`. This is a first step to what is coming next.
## "The Oneliner"
```js
const count = string => {
return new Set(
Array.from(string)
.filter(char => char.match(/[a-zA-Z]/))
.map(char => char.toLowerCase())
).size;
}
```
In general I consider chaining a very nice way of making things prettier. But when your goal is only to make code shorter, usually readability hurts, like in this case. I wouldn't consider this a improvement compared to the previous version.
But its fun to know it could be done, and shows how important indentation is in those cases where you decide to go with it.
## One big chain
```js
const count = string => {
return [string]
.map(string => Array.from(string))
.map(array => array.filter(char => char.match(/[a-zA-Z]/)))
.map(array => array.map(char => char.toLowerCase()))
.map(array => new Set(array))
.map(set => set.size)[0]
}
```
This stage takes advantage of the same chaining property of `Array` from second version, but this time it takes things to the next level, literally. It puts input immediately into an array and uses `map` for composition to do the necessary operations.
## More composition
```js
const onlySmallLetters = string => {
return Array.from(string)
.filter(char => char.match(/[a-zA-Z]/))
.map(char => char.toLowerCase())
}
const count = string => {
return [string]
.map(onlySmallLetters)
.map(array => new Set(array))
.map(set => set.size)[0]
}
```
Lastly, not the most condensed version, but this implementation adds another dimension.
You might want to reuse `onlySmallLetters` function somewhere else - this would be called composition - compose functions from smaller functions. Those smaller functions are easier to test, understand and debug.
And this is where I landed at the end of my journey with this challenge that I found when learning basics of python.
---
Mixing types, accepting a string and returning an array might not be predictable, thats why, as I understand, functional programming has specific constructs to make it easier and more predictable for everybody knowing the paradigm.
Dive deeper into those mystical parts of functional programming in JS by watching "[Professor Frisby Introduces Composable Functional JavaScript](https://egghead.io/courses/professor-frisby-introduces-composable-functional-javascript)" by Brian Lonsdorf. | pavelloz |
213,711 | New rails 6 app with postgresql database and heroku deployment | I have been working with rails professionally for over a year now, and I want to share the guide I us... | 0 | 2019-12-01T23:40:06 | https://dev.to/chair/quick-guide-new-rails-6-app-with-postgresql-database-and-heroku-deployment-7ji | ruby, rails, postgres, todayilearned | I have been working with rails professionally for over a year now, and I want to share the guide I use personally to quickly spin up a new rails app with a postgresql database, and deploy to heroku.
My aim is to make it quick and easy for you to get going, and take the fuzziness out of the setup process.
Find my gist here!
https://gist.github.com/chair28980/acaa7c8f8a71dc663194ce79c44d00b9
I'd love to hear your feedback. Drop a comment here or find me on twitter: @vrycmfy | chair |
213,724 | How To Create Custom State Hook - Custom Hooks ReactJS Mini Course Part 1 | Welcome to ReactJS Custom Hooks Mini Course. In this course we'll learn how to create custom hooks in React, how to test them using React Testing Library and how to publish them as a standalone npm package. | 3,557 | 2019-12-02T01:28:06 | https://dev.to/satansdeer/how-to-create-custom-state-hook-custom-hooks-reactjs-mini-course-part-1-5mh | react | ---
title: How To Create Custom State Hook - Custom Hooks ReactJS Mini Course Part 1
published: true
description: Welcome to ReactJS Custom Hooks Mini Course. In this course we'll learn how to create custom hooks in React, how to test them using React Testing Library and how to publish them as a standalone npm package.
tags: react
series: Custom Hooks ReactJS Mini Course
---
{% youtube hTmWfTniyIk %}
Welcome to ReactJS Custom Hooks Mini Course. In this course we'll learn how to create custom hooks in React, how to test them using React Testing Library and how to publish them as a standalone npm package.
Course playlist: http://bit.ly/35FHALa
Subscribe to the channel: http://bit.ly/2QZ2UY3 | satansdeer |
213,735 | Minor Follow-up on Hacktoberfest 2019 | In a previous essay I wrote about the process behind my Hacktoberfest 2019 contri... | 0 | 2019-12-02T08:49:27 | http://hugomartins.io/essays/minor-followup-on-hacktoberfest/ | opensource, hacktoberfest | ---
title: Minor Follow-up on Hacktoberfest 2019
published: true
date: 2019-12-01 00:00:00 UTC
tags: open-source, hacktoberfest
canonical_url: http://hugomartins.io/essays/minor-followup-on-hacktoberfest/
---
In a previous essay I wrote about the process behind my Hacktoberfest 2019 contributions. It is now worthwhile to make a quick follow-up, at this point, at the status of those contributions.
It is relevant to start by mentioning I made a bit of a mess of my contributions, right after I wrote up the article. I tried to correct an issue with the email and user of the contributions and re-wrote the history of my git repositories…bummer! That forced me to close my initial PRs and having to open up new ones - and re-writing all the changes I had made.
I had opened [PR #4476](https://github.com/pyinstaller/pyinstaller/pull/4476), [PR #4499](https://github.com/pyinstaller/pyinstaller/pull/4499) and [PR #4500](https://github.com/pyinstaller/pyinstaller/pull/4500). PR #4499 had to be closed and re-opened as [PR #4516](https://github.com/pyinstaller/pyinstaller/pull/4516). PR #4500 had to be closed and re-opened as [PR #4517](https://github.com/pyinstaller/pyinstaller/pull/4517). That makes a total of 5 PRs, of which only 3 were actually valid for review by PyInstaller’s maintainers.
PR #4476 was accepted, within a two-week period. This seems to be a fairly usual time frame, by looking at previous PR reviews in the project. There was a minor wrapping issues, which the maintainers of PyInstaller promptly resolved and pushed to my branch. PR #4516 was merged within approximately the same two-week period, without any need for further modification. PR #4517 took a bit longer to merge because I had made an error when creating the changelog entry - plus there was a need for a small lint correction.
I was very happy with the end result, getting all 3 PRs approved and merged. I was surprised with how friendly the maintainers of PyInstaller were, even with the small errors. I was also thankful they completely ignored my shenanigans of duplicating the PRs.
They should be an example for the entire community, how they deal with new contributors and their mistakes. That is one of the reasons why they have 280+ contributors on Github.
Now, looking towards the future, I hope I can be of more use to them by adding more hooks. Adding hooks seems to be something that I can do, without creating a lot of work for the maintainers in terms of reviews. But , it will also allow me to start understanding more of the codebase and contribute in different areas. | caramelomartins |
213,746 | Created iPadOS/iOS browser to operate without touching | I bought iPad Pro and found that I need to touch screen to move pages. I know there is browser extens... | 0 | 2019-12-02T03:11:23 | https://dev.to/shohei/created-ipados-ios-browser-to-operate-without-touching-4fg2 | reactnative, ios, ipados, javascript |
I bought iPad Pro and found that I need to touch screen to move pages. I know there is browser extension, like [Vimium](https://github.com/philc/vimium) to operate with only keyboard. To move page, use "hit-a-hint". I like this idea and wanted to have the app. I looked for App store but I unabled to find it. Ok, it's time to develop it by myself. I spent 5 months to build this. I used React Native as I had experience on it.
I named this app as Wazari Brower and this can be downloaded from [here](https://www.wazaterm.com/wazaribrowser). I wrote documentation [here]()
This is an open source project and able to see the code inside from [the github repository](https://github.com/shohey1226/wazari). I’m sure there are tons of bugs there, so any bug report is welcome (and also PR :) )
I’ve also found that iOS doesn’t support keyboard key configuration. So I added this function to replace capslock and ctrl. The final feature is folloing. I hope you like this.
## Feature
* Customizable shortcuts to operate browser. e.g. Change tabs without touching screen.
* Panes to split views vertiacally or horizontally.
* Hit-A-Hint - without touching, click links to move pages.
* Customizable modifiers. e.g. swap capslock with ctrl key.
* Customizable default search engine - DuckDuckGo or Google
* Exclude web sites not to use keymapping. Some dynamic web site doesn't use Input type=text or textarea, which Wazari keymapping doesn't work. But you can exclude these website so you can still type on it.
* Histories to go back easily
* Integrated to Wazaterm so you can terminal - I had a separate project for this. I wanted to integrate with it too.
| shohei |
213,831 | Copying and extending Objects in javaScript | We are going to review few of the most popular techniques to copy and extend javaScript Objects | 0 | 2019-12-06T19:43:49 | https://dev.to/leolanese/copying-and-extending-objects-in-javascript-3o0o | javascrpt, deepcopy, shallowcopy, es6 | ---
title: Copying and extending Objects in javaScript
published: true
description: We are going to review few of the most popular techniques to copy and extend javaScript Objects
tags: javascrpt, deepCopy, shallowCopy, ES6
---
1) Copying Objects
--[1.1] Copying plain Objects
--[1.2] Copying deeply nested Objects
2) Extending Objects
--[2.1] Extending plain Objects
--[2.2] Extending deeply nested Objects
---
### 1) Copying plain Objects:
#### [1.1] Copying plain Objects
Simple Array of Object
```javascript
const object = {
'color': 'red'
};
// shallow copy
copyObjectAssign = Object.assign({}, object);
// shallow copy
copySpread = { ...object};
// ~deep copy
copyJSONparse = JSON.parse(JSON.stringify(object));
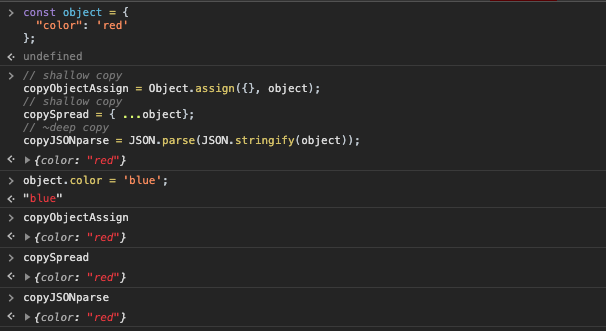
object.color = 'blue'; // changing original object
object === copyJSONparse; // FALSE
object === copyObjectAssign; // FALSE
object === copySpread ; // FALSE
```
{% runkit
// hidden setup JavaScript code goes in this preamble area
%}
const object = {
'color': 'red'
};
// shallow copy
copyObjectAssign = Object.assign({}, object);
// shallow copy
copySpread = { ...object};
// ~deep copy
copyJSONparse = JSON.parse(JSON.stringify(object));
object.color = 'blue'; // changing original object
console.log(object === copyJSONparse); // FALSE
console.log(object === copyObjectAssign); // FALSE
console.log(object === copySpread); // FALSE
{% endrunkit %}
#### [1.2] Copying deeply nested Objects
These are Objects that have more than one level deep
```javascript
const objectNested = {
"color": "red",
"car": {
"model": {
year: 2020
}
}
};
// shallow copy
copyObjectAssignNested = Object.assign({}, objectNested );
// shallow copy
copySpreadNested = { ...objectNested };
// ~deep copy
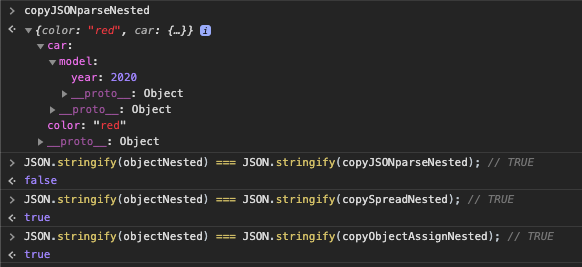
copyJSONparseNested = JSON.parse(JSON.stringify(objectNested));
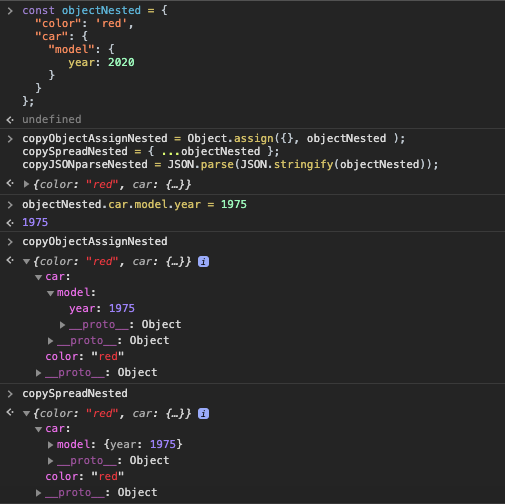
// changing the original objectNested
objectNested.car.model.year = 1975; // change here
// original object IS changed!
objectNested // {"color":"red", "car":{"model": { year: 1975 }}
// shallow-copy IS changed!
copyObjectAssignNested // {"color":"red", "car":{"model": { year: 1975 }}
copySpreadNested // {"color":"red", "car": {"model": { year: 1975 }}
// deep-copy NOT changed: deepClone Object won't have any effect if the main source object obj is modified and vice-versa
copyJSONparseNested // {"color":"red", "car": {"model": { year: 2020 }}
// let see what changes then?
JSON.stringify(objectNested) === JSON.stringify(copyObjectAssignNested); // TRUE
JSON.stringify(objectNested) === JSON.stringify(copySpreadNested); // TRUE
JSON.stringify(objectNested) === JSON.stringify(copyJSONparseNested); // FALSE (changes don't affect each other after deep-copy)
```
{% runkit
// hidden setup JavaScript code goes in this preamble area
const hiddenVar = 42
%}
const objectNested = {
"color": "red",
"car": {
"model": {
year: 2020
}
}
};
// shallow copy
copyObjectAssignNested = Object.assign({}, objectNested );
// shallow copy
copySpreadNested = { ...objectNested };
// ~deep copy
copyJSONparseNested = JSON.parse(JSON.stringify(objectNested));
// changing the original objectNested
objectNested.car.model.year = 1975; // change here
// original object IS changed!
objectNested // {"color":"red", "car":{"model": { year: 1975 }}
// shallow-copy IS changed!
copyObjectAssignNested // {"color":"red", "car":{"model": { year: 1975 }}
copySpreadNested // {"color":"red", "car": {"model": { year: 1975 }}
// deep-copy NOT changed: deepClone Object won't have any effect if the main source object obj is modified and vice-versa
copyJSONparseNested // {"color":"red", "car": {"model": { year: 2020 }}
// let see what changes then?
console.log(JSON.stringify(objectNested) === JSON.stringify(copyObjectAssignNested)); // TRUE
console.log(JSON.stringify(objectNested) === JSON.stringify(copySpreadNested)); // TRUE
console.log(JSON.stringify(objectNested) === JSON.stringify(copyJSONparseNested)); // FALSE (changes don't affect each other after deep-copy)
{% endrunkit %}

### Why:
- Object.assign({})
Can only make shallow copies of objects so it will only work in a single level (first level) of the object reference.
- Object spread:
Object spread does a 'shallow copy' of the object. Only the object itself is cloned, while "nested instances are not cloned".
- JSON.parse(JSON.stringify()):
This is a questionable solution. Why? Because this is going to work fine as long as your Objects and the nested Objects "only contains primitives", but if you have objects containing functions or 'Date' this won't work.
Changing a property value from the original object or property value from the shallow copy object it will affect each other.
The reason is how the javascript engine works internally: JS passes the primitive values as value-copy and the compound values as reference-copy to the value of the primitives on that Object. So, when copied the Object containing the nested Object, that will create a shallow-copy of that Object:
Primitive found on the first level of the original object it will be copied as value-copy: changing is reciprocal: changing the value of one will affect the other one. So they will be depending on each other
Deeply nested properties will be copied as reference-copy: changing one it will not affect the reference of the other one
> first-level properties: value-copy
> deeply nested properties: reference-copy
### <u>Solution:</u>
We can create our own or we can use the third-party libraries to achieve a future-proof deep copy and deep merge.
#### Third party solutions:
lodash's cloneDeep()
```javascript
import * as cloneDeep from 'lodash/cloneDeep';
...
clonedObject = cloneDeep(originalObject);
```
```javascript
const objectNested = {
"name":"John",
"age":30,
"cars": {
"car1":"Ford",
"car2":"BMW",
"model": {
year: 2020
}
}
};
// making a copy of the reference, a new object is created that has an exact copy of the values in the original object.
const deep = _.cloneDeep(objectNested);
console.log(JSON.stringify(deep) === JSON.stringify(objectNested)); // TRUE
console.log("deep reference", deep.cars.model === objectNested.cars.model); // FALSE
// assinging one Object to other reference
const deep2 = objectNested;
console.log('share reference', deep2.cars.model === objectNested.cars.model); // TRUE
console.log('share references', deep2 === objectNested); // TRUE
```
### Lodash cloneDeep()
```javascript
var objects = [{ 'a': 1 }, { 'b': 2 }];
var deepCopy = _.cloneDeep(objects);
console.log(deepCopy[0] === objects[0]); // => false
objects[0].a === deepCopy[0].a // true
deep[0].a = 123; // original object changes
objects[0].a === deepCopy[0].a // false = changes no affecting deepCopy
```
### Further Information:
Lodash
https://lodash.com/docs/4.17.15#cloneDeep
Lodash npm package:
https://www.npmjs.com/package/lodash.clonedeep
Immutability-helper:
A light and easy to use helper which allows us to mutate a copy of an object without changing the original source:
https://github.com/kolodny/immutability-helper
---
### 2) Extending Objects
Few options we are going to evaluate:
```html
JS | JS ES6+ | jQuey | Lodash | AngularJS
Object.assign() Spread operator $.extend() .merge() .extend()
mix() .merge()
```
#### [2.1] Extending plain Objects
Extend Objects is a simple process but required to know what we want to do with:
- Objects that have the same name attributes
- Mutation of the Object
### Object.assign({}):
```javascript
let defaults = {
container: ".main",
isActiveClass: ".is-active"
};
let options1 = {
container: ".main-container",
isActiveClass: ".is-active-element"
};
let options2 = {
aNewClass: "somethingHere",
isActiveClass: ".is-active-content"
};
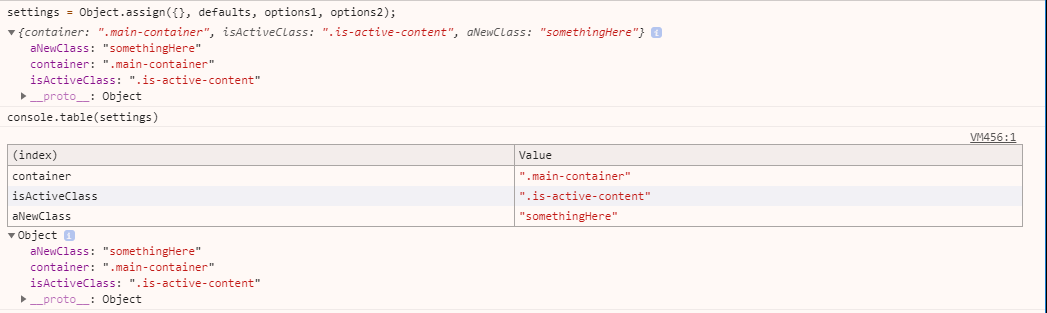
settings = Object.assign({}, defaults, options1, options2); // using {}
// { container: ".main-container", isActiveClass: ".is-active-content", aNewClass: "somethingHere"}
```
{% runkit
// hidden setup JavaScript code goes in this preamble area
const hiddenVar = 42
%}
// visible, reader-editable JavaScript code goes here
let defaults = {
container: ".main",
isActiveClass: ".is-active"
};
let options1 = {
container: ".main-container",
isActiveClass: ".is-active-element"
};
let options2 = {
aNewClass: "somethingHere",
isActiveClass: ".is-active-content"
};
console.log(settings = Object.assign({}, defaults, options1, options2)); // using {}
// { container: ".main-container", isActiveClass: ".is-active-content", aNewClass: "somethingHere"}
{% endrunkit %}
Further information:
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/assign
---
### Custom .mix() method for ES5 and earlier:
#### Flat Object
Add an Object2 to another Object1:
$.extend() like, but DO NOT replace similar keys = the FIRST OBJECT WILL PREVAIL
We are navigating thought the flat object and '=' the values.
```javascript
// source
options = {
underscored: true,
"name": 1
}
// target
products = {
foo: false,
"name": "leo"
}
function mix(source, target) {
for(var key in source) {
if (source.hasOwnProperty(key)) {
target[key] = source[key];
}
}
console.log(target)
}
mix(options, products); // { foo: false, name: 1, underscored: true }
```
{% runkit
// hidden setup JavaScript code goes in this preamble area
const hiddenVar = 42
%}
// visible, reader-editable JavaScript code goes here
options = {
underscored: true,
"name": 1
}
// target
products = {
foo: false,
"name": "leo"
}
function mix(source, target) {
for(var key in source) {
if (source.hasOwnProperty(key)) {
target[key] = source[key];
}
}
console.log(target)
}
console.log(mix(options, products)); // { foo: false, name: 1, underscored: true }
{% endrunkit %}
---
### ES6 Spread operator
```javascript
let defaults = {
container: "main",
isActiveClass: "is-active",
code: {
description: 'default code'
}
};
let options1 = {
container: "main-container",
isActiveClass: "is-active-element",
code: {
description: 'options1 code'
}
};
let options2 = {
aNewClass: "somethingHere",
isActiveClass: "is-active-content",
code: {
description: 'options2 code'
}
};
mergedObj = { ...defaults , ...options1, ...options2 };
// { aNewClass: "somethingHere"
code: {
description: "options2 code"
},
container: "main-container"
isActiveClass: "is-active-content"
}
```
{% runkit
// hidden setup JavaScript code goes in this preamble area
const hiddenVar = 42
%}
// visible, reader-editable JavaScript code goes here
let defaults = {
container: "main",
isActiveClass: "is-active",
code: {
description: 'default code'
}
};
let options1 = {
container: "main-container",
isActiveClass: "is-active-element",
code: {
description: 'options1 code'
}
};
let options2 = {
aNewClass: "somethingHere",
isActiveClass: "is-active-content",
code: {
description: 'options2 code'
}
};
console.log(mergedObj = { ...defaults , ...options1, ...options2 });
// { aNewClass: "somethingHere", code: {description: "options2 code"},container: "main-container",isActiveClass: "is-active-content"}
{% endrunkit %}
If some objects have a property with the same name, then the second object property overwrites the first. If we don't want this behaviour we need to perform a 'deep merge' or object and array recursive merge.

Further information:
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Spread_syntax
---
### $.extend()
It is a jQuery function that will extend and replace similar keys.
#### $.extend() replace similar keys:
```javascript
const defaults = { d1: false, d2: 5, d3: "foo" };
const options = { d4: true, d6: "bar" };
// jQuery Merge object2 into object1 (modifying there results)
$.extend( defaults, options );
// Object {d1: false, d2: 5, d3: "foo", d4: true, d6: "bar"}
```
#### $.extend() without replace similar keys:
Remember that Javascript objects are mutable and store by reference.
```javascript
const defaults = { validate: false, limit: 5, name: "foo" };
const options = { validate: true, name: "bar" };
// Merge defaults and options, without modifying defaults
settings = $.extend({}, defaults, options);
Object {validate: true, limit: 5, name: "bar"}
```
Further information:
jquery.extend()
https://api.jquery.com/jquery.extend
---
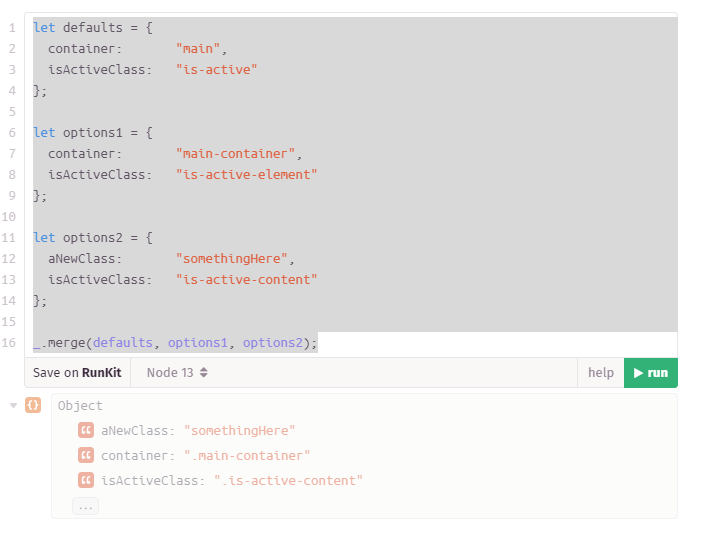
### Lodash .merge()
"This method is like _.assign except that it recursively merges own and inherited enumerable string keyed properties of source objects into the destination object. Source properties that resolve to undefined are skipped if a destination value exists. Array and plain object properties are merged recursively. Other objects and value types are overridden by assignment. Source objects are applied from left to right. Subsequent sources overwrite property assignments of previous sources."
<sub><sub>https://lodash.com/docs/4.17.15#merge</sub></sub>
> Note: This method mutates object.
Using Lodash .merge() with first level (flat) object
```javascript
let defaults = {
container: "main",
isActiveClass: "is-active"
};
let options1 = {
container: "main-container",
isActiveClass: "is-active-element"
};
let options2 = {
aNewClass: "somethingHere",
isActiveClass: "is-active-content"
};
_.merge(defaults, options1, options2);
_.merge(defaults, options1, options2);
// { aNewClass: "somethingHere", container: "main-container", isActiveClass: "is-active-content"}
```
Using Lodash .merge() with deeply nested object:
```javascript
let defaults = {
container: "main",
isActiveClass: "is-active",
code: {
description: 'default code'
}
};
let options1 = {
container: "main-container",
isActiveClass: "is-active-element",
code: {
description: 'options1 code'
}
};
let options2 = {
aNewClass: "somethingHere",
isActiveClass: "is-active-content",
code: {
description: 'options2 code'
}
};
_.merge(defaults, options1, options2);
// {
aNewClass: "somethingHere"
code: {
description: "options2 code"
},
container: "main-container"
isActiveClass: "is-active-content"
}
```
#### [2.2] Extending deeply nested Objects
#### AngularJS 'angular.extend()' and 'angular.merge()':
> angular.merge() it will be preserving properties in child objects.
> angular.extend() it will not preserve, it will replace similar properties
It does a deep copy of all properties from source to destination preserving properties in child objects. Note how we can also use multiple source objects that will be merged in order:
```javascript
const person1 = {
name: 'Leo',
address: {
description: 'Oxford Street'
}
}
const person2 = {
id: 1,
address : {
postcode: 'SW1'
}
}
const merged = angular.merge(person1, person2); // ALL the similar WILL PREVAIL
// merged object
// {id: 1, name:'Leo', address:{description:'Oxford Street',postcode: 'SW1'}}
const extended = angular.extend(person1, person2); // replace similar properties
// extended object
// {id: 1, name:'John', address:{postcode:'SW1'}}
```
---
<h5> { 'Leo Lanese',<br>
'Building Inspiring Responsive Reactive Solutions',<br>
'London, UK' }<br>
</h5>
<h5>Portfolio
<a href="http://www.leolanese.com" target="_blank">http://www.leolanese.com</a>
</h5>
<h5>Twitter:
<a href="http://twitter.com/LeoLaneseltd" target="_blank">twitter.com/LeoLaneseltd</a>
</h5>
<h5>Questions / Suggestion / Recommendation ?
<a href="mail:to">developer@leolanese.com</a>
</h5>
<h5>DEV.to:
<a href="http://www.dev.to/leolanese" target="_blank">www.dev.to/leolanese</a>
</h5>
<h5>Blog:
<a href="http://www.leolanese.com/blog" target="_blank">leolanese.com/blog</a>
</h5>
| leolanese |
213,851 | Steps For Integrating MD Bootstrap In Jhipster Project | Hi everyone I a gonna share one of my first posts I written on Medium, I hope you all will like it us... | 0 | 2019-12-02T09:04:33 | https://medium.com/@erbalvindersingh/steps-for-integrating-md-bootstrap-in-jhipster-project-84e5d0cc9aa1 | design, angular, css, jhipster | Hi everyone I a gonna share one of my first posts I written on Medium, I hope you all will like it useful. We were working with a Jhipster project and wanted to integrate MD Bootstrap that is a material design + Bootstrap framework.JHipster is a web application generator using Spring Boot for backend and Angular for front End with multiple technologies.
>Before starting you must have Sass support in your project
*Link to Jhipster* :[http://jhipster.tech/](http://jhipster.tech/)
MD Bootstrap provides various design components based on material design and layouts. You can check here :
*Link to MD Bootstrap* :
[https://mdbootstrap.com/getting-started/](https://mdbootstrap.com/getting-started/)
### So let’s start steps for integrating MD Bootstrap with JHipster
1. First create a directory in your system with name let myAPP or any you want.
2. CD using terminal or file explorer in your system into above created myApp folder.
3. Open terminal in myApp (If you have not JHipster setup follow link https://www.jhipster.tech/installation/).
4. Enter Command to generate JHipster project in your folder```yo jhipster```
5. After JHipster is installed. In the same terminal give the command for installing external libraries```npm install -–save chart.js@2.5.0 font-awesome hammerjs```
6. To app.module.ts add```typescript
import { NgModule,Injector,NO_ERRORS_SCHEMA } from ‘@angular/core’;
import { MDBBootstrapModule } from ‘angular-bootstrap-md’;
@NgModule({
imports: [
MDBBootstrapModule.forRoot(),
],
schemas: [ NO_ERRORS_SCHEMA ]
});
```
7. To Vendor.scss add```scss
/* after changing this file run ‘yarn run webpack:build’ */
$fa-font-path: ‘~font-awesome/fonts’;
// Images Path for angular-bootstrap-md
$image-path: ‘../../../../../node_modules/angular-bootstrap-md/img’ !default;
// Fonts Path for angular-bootstrap-md
$roboto-font-path: “../../../../../node_modules/angular-bootstrap-md/font/roboto/” !default;
/***************************
put Sass variables here:
eg $input-color: red;
****************************/
// Override Boostrap variables
@import “bootstrap-variables”;
// Import Bootstrap source files from node_modules
@import ‘node_modules/font-awesome/scss/font-awesome’;
@import ‘node_modules/angular-bootstrap-md/scss/bootstrap/bootstrap’;
@import ‘node_modules/angular-bootstrap-md/scss/mdb-free’;
```
8. In angular-cli.json add```
“styles”: [
“../node_modules/font-awesome/scss/font-awesome.scss”,
“../node_modules/angular-bootstrap-md/scss/mdb-free.scss”,
“./styles.scss”,
“content/scss/vendor.scss”,
“content/scss/global.scss”
],
“scripts”: [
“../node_modules/chart.js/dist/Chart.js”,
“../node_modules/hammerjs/hammer.min.js”
]
```
9. Add the following into tsconfig.json file located in root folder```“inlcude”: [ “node_modules/angular-bootstrap-md/**/*.ts ”,
“src/**/*.ts”
]```
10. Run in terminal to compile styles and scripts and inject to project```yarn webpack:build```
11. That are all steps for integrating MD Bootstrap with Jhipster
> Note : If you got any warnings in terminal after running yarn “webpack:build” then you can fix using tsLint manually
> Note 2: If you got compile failed errors then you may have styles conflict
You can fix by removing normal bootstrap styles or comment it if you do not want to remove
//@import ‘node_modules/bootstrap/scss/bootstrap’;
Here is the link to my Git Repository with sample project integrated with MD BootStrap :
https://github.com/balvinder294/MaterialThemeJhipster
Thanks for reading. Hope I helped you. if you find it useful then write below and share your views, also let me know if anything needs to be updated if something not works, I will look into it.
Looking forward to sharing more with the community.
> Originally published at [Tekraze.com](https://medium.com/@erbalvindersingh/steps-for-integrating-md-bootstrap-in-jhipster-project-84e5d0cc9aa1) | balvinder294 |
214,012 | Web layouts like it’s 2020 | Written by Facundo Corradini✏️ If you ever get the feeling that designers and developers are from... | 0 | 2019-12-03T14:22:25 | https://blog.logrocket.com/web-layouts-like-its-2020/ | featuredposts, css | ---
title: Web layouts like it’s 2020
published: true
date: 2019-12-02 14:00:59 UTC
tags: Featuredposts,css
canonical_url: https://blog.logrocket.com/web-layouts-like-its-2020/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/q5kp2coygk1dgukfolbx.jpg
---
**Written by [Facundo Corradini](https://blog.logrocket.com/author/facundocorradini/)**✏️
If you ever get the feeling that designers and developers are from different worlds, you should have seen what it was like 10 or 20 years ago. In the early days of the internet, we were building websites _while_ trying to figure out what a website was and how it should work.
Coming from a print background, designers were used to the features (and limitations) of a known-dimension canvas and tried to replicate them in a medium that’s essentially designed as _exactly not that_. Developers were struggling mightily with the extremely limited features of early CSS, trying to implement those designs in browsers that were radically different from one another.
In the middle of all that, the users were getting a web experience that was quite inaccessible, hard to use, and simply unaesthetic.
Over time, we agreed on a core rule set for how a website should look and feel based on the concept of symmetrical columns such as [960.gs](https://960.gs/), which later on was implemented in many popular frameworks, including Bootstrap. This streamlined the process, providing a common _language_ that designers, developers, and users felt comfortable with.
But I’m sure I’m not alone when I get the feeling that web layouts have stagnated since. We all have seen those “all websites look the same” parodies, to the point that all those parodies are starting to look the same.

CSS has come a long way since those early days, with the development cycle greatly accelerating in the last couple years. Finally, web layouts are not a hack anymore (floats were originally meant to simply float text around an image).
We got multicol, flex, and grid to allow us a degree of freedom we’ve never seen before. We can finally break out of that symmetric columns paradigm and use all sorts of [effects](https://dev.to/bnevilleoneill/new-in-chrome-76-the-frosted-glass-effect-with-backdrop-filter-hgb) and features that we would’ve never dreamed of. We are not in the early 2000s anymore.
The newer specs allow us to build layouts that we would have discarded for being unusable or for lack of responsiveness just a couple of years ago. So I believe it’s time to start revisiting those concepts. Maybe we can bring back some of those print-like layouts in a way that adapts to the unknown canvas of the web.
[](https://logrocket.com/signup/)
Early this year, Jenn Simmons posted these magazine layouts as inspiration, wondering how they could work for the web. I went ahead and turned them to code, so we can explore the core concepts of building a web layout that’s different from what everyone seems to be doing. Here’s how to build web layouts like it’s 2020.
{% twitter 1084494889214193666 %}
## Thinking responsive, progressive layouts
Designing for the web is, by definition, [designing for an unknown canvas](https://www.youtube.com/watch?v=aHUtMbJw8iA). The web can be accessed from all sorts of devices with radically different dimensions and through all kinds of browsers — from a tiny mobile device or even a watch to a ginormous 4K smart TV, not to mention all sorts of alternate approaches that are not even based on graphic display.
So the first challenge in converting a magazine layout for web use is considering how it should adapt to whatever device is accessing it. Where are the boundaries where this approach doesn’t work anymore? How should the alternative look? What are some technical limitations that a browser can have trouble implementing?
Considering this layout, I identify the parts that can be challenging.

1. The multicolumn layout can work on the wider devices, but it’s certainly a no-go for smaller screen sizes.
2. The title itself with a “center float” is something most browsers won’t know how to deal with.
3. The intro paragraph between the columns can be somewhat tricky.
Luckily, the solution pretty much works itself out if we consider a progressive enhancement approach from the start. We can think of all the different layers as progressive enhancement: from the layout for different viewport sizes via the use of media queries, adding newer features in a safe way with feature queries, or even adding accessibility goodies such as [prefers-reduced-motion](https://blog.logrocket.com/new-in-chrome-74-prefers-reduced-motion-media-query-50cd89d3e769/) or [dark mode with prefers-color-scheme](https://blog.logrocket.com/whats-new-in-firefox-67-prefers-color-scheme-and-more-195be81df03f/). Every layer can work over the previous to create the best user experience for a given device.
Personally, I like to start from how the website should look if no CSS is loaded at all. This means using nothing but semantic markup in a reasonable order. This will ensure that the web is usable even if we strip it all the way down to the browser’s default styling.
```jsx
<article class="print-like">
<header class="intro">
<h1 class="title">Print-like Layouts on the web</h1>
<p class="summary">We've been stuck for decades in the simetrical columns paradign. Let's try to spice things up a little.</p>
<address class="author">By <a rel="author" href="https://twitter.com/fcorradini">Facundo Corradini</a><br/>
</address>
</header>
<img class= "main-image" src="https://placeimg.com/640/480/animals/sepia" alt="random image"/>
<section class="main-text">
<p>...</p>
<p>...</p>
<p>...</p>
</section>
</article>
```
<figcaption id="caption-attachment-10528">Even without any CSS, the document structure ensures the browser provides a somewhat usable default.</figcaption>
The semantic markup in a logical order means that we can get away with title on top, intro, paragraphs, then progressively enhance the layout for the wider screens and the different features.
Best thing about it is that mobile layouts are usually not that different from the browser defaults. Sure, we put a great deal of effort into our typography, spacing, and such, but the mobile content is rarely seen in any format other than the traditional blocky layout were elements flow one below the other.
<figcaption id="caption-attachment-10529">A little bit of styling provides a decent layout for small mobile devices.</figcaption>
We can then think of a slightly bigger screen size. What if the viewport is wide enough to fit two columns, but not quite wide enough for the full layout?
It’d make sense to keep the title and intro above everything else, but have the paragraphs as two columns with a variable width, growing as needed.
Simply turning the text container to multicolumn layout in a media query does the trick.
```jsx
@media screen and (min-width: 600px){
.print-like{
display: grid;
}
.main-image{
grid-row: 3/4;
}
.main-text{
column-count: 2;
}
.main-text :first-child{
margin-top:0;
}
.main-text :last-child{
margin-bottom: 0;
}
}
```
<figcaption id="caption-attachment-10531">Multicolumn + CSS grid to move the image to the bottom.</figcaption>
When the viewport becomes big enough to fit all columns (including the container in the middle), we can use the column-gap property to clear the space in the middle for the title and intro, then position the elements with a simple grid declaration in the container. Although the original design was based on thirds, I chose to keep the central column in fixed width and let the side ones adjust to the container, just as an experiment to see what happens when we break the symmetric columns paradigm.
```jsx
@media screen and (min-width: 900px){
.print-like{
grid-template-columns: 1fr 300px 1fr;
align-items: center;
}
.intro{
grid-row:1;
grid-column: 2/3;
max-width: 0px;
}
.main-text{
column-gap: 310px;
grid-row: 1;
grid-column: 1/4;
}
.main-image{
grid-column: 1 / -1;
margin: 0 auto;
}
}
```
<figcaption id="caption-attachment-10534">A CSS grid declaration allows us to position the title and intro in the space cleared by the grid-gap.</figcaption>
The final touch — and the one that makes the layout — is the text wrapping around the title. Unfortunately, we need to use CSS exclusions to create that effect, as there’s no such thing as `float: center`. This means that only IE11 and Edge will provide that experience, which is quite ironic. But other browsers still provide a perfectly usable layout, and the code will most likely work when they finally decide to implement that feature (perhaps with minor tweaking if the spec changes).
```jsx
@media screen and (min-width: 900px){
@supports (-ms-wrap-flow: both){
.title{
-ms-wrap-flow: both; /* CSS exclusions! */
position: absolute;
right: 25%;
padding: 10px 20px;
}
}
}
```
<figcaption id="caption-attachment-10535">Visualization in a browser that supports grid, multicol, and exclusions (MS Edge).</figcaption>
With all those layers, the final layout will work like this:
{% codepen https://codepen.io/facundocorradini/pen/abzozVe %}
## Conclusion
Let’s be clear: I’m not saying the current paradigm is _wrong_, and definitely not trying to say that websites should look like magazines — or even defending the use of multicol. I just think a little innovation might make our layouts stand out from the rest. We finally have the right tools, let’s make web layouts more diverse!
* * *
**Editor's note:** Seeing something wrong with this post? You can find the correct version [here](https://blog.logrocket.com/web-layouts-like-its-2020/).
## Plug: [LogRocket](https://logrocket.com/signup/), a DVR for web apps

[LogRocket](https://logrocket.com/signup/) is a frontend logging tool that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
[Try it for free](https://logrocket.com/signup/).
* * *
The post [Web layouts like it’s 2020](https://blog.logrocket.com/web-layouts-like-its-2020/) appeared first on [LogRocket Blog](https://blog.logrocket.com). | bnevilleoneill |
214,037 | CSS Layout: A collection of popular layouts and patterns made with CSS | Being a front-end engineer, I have to deal with a lot of layouts and components. There are a lot of... | 0 | 2019-12-02T15:01:50 | https://dev.to/phuocng/css-layout-a-collection-of-popular-layouts-and-patterns-made-with-css-39mc | showdev, css, react, typescript |
Being a front-end engineer, I have to deal with a lot of layouts and components.
There are a lot of CSS frameworks out there that provide popular layouts and components but I usually don't want to include entire framework in my project because
* It's giant and there are a lot of stuffs I don't need
* Each layout or component provides a lot of unnecessary options because it serves many functionalities, for many people
For each project with different requirements, I often google for the most basic part of particular layout or UI pattern and build up from there.
So I collect most popular layouts and components that can be built with pure CSS. They are powered by modern CSS features such as flexbox and grid.
And here it is: https://csslayout.io 🎉🎉🎉
They are great starting points to be picked and customized easily for each specific need. By composing them, you can have any possible layout that exists in the real life.
It helps me a lot and hopefully it will help you!
## Source code
This is fake JavaScript codes but it covers all the tools that I use to build the website:
```
this
.madeWith([react,typescript])
.then(r => lint(tslint))
.then(r => lazyLoad(@loadable/component))
.then(r => optimizeAndBundle(webpack))
.then(r => exportHtml(react-snap))
.then(r => deploy(Netlify))
.then(r => {
expect(r).is(scalableCode);
expect(r).is(superFastWebsite);
expect(r).is(seoFriendly);
})
.finally(() => {/* Give me 1 star */}) 🎉
```
The entire website is open source, so let's explore and give me one Github star :)
| phuocng |
214,061 | Introduction to Music Information Retrieval Pt. 2 | A more in depth look at processing and analyzing music pieces | 0 | 2019-12-04T00:38:00 | https://dev.to/bfdykstra/introduction-to-music-information-retrieval-pt-2-19aj | python, music, librosa, datascience | ---
title: Introduction to Music Information Retrieval Pt. 2
published: true
description: A more in depth look at processing and analyzing music pieces
tags: python, music, Librosa, data-science
---
# Segmentation and Feature Extraction
(You can view the version with all the audio segments [here](https://bfdykstra.github.io/2019/11/05/Introduction-to-Music-Information-Retrieval-Pt.-2.html)
In [part 1](https://bfdykstra.github.io/2019/04/14/Introduction-to-Music-Information-Retrieval-Pt.-1.html) we learned some basic signal processing terminology, as well as how to load and visualize a song. In this post we will discuss how to break up a signal (segment) and extract various features from it. Then, we'll do some exploratory analysis on the features so that we can get an idea of the interactions among features.
### Why do we want to segment a song?
Songs vary a lot over time. By breaking up this heterogenous signal in to small segments that are more homogenous, we can keep the information about how a song changes. For example, say that we have some features such as 'danceability'. Imagine a song that is at first very quiet and low energy, but as the song progresses, it becomes a full blown Rihanna club anthem. If we just examined the average danceability of the entire song, it might be lower than how danceable the song actually is. This context and distinction is important because if we are running a classifier or clustering algorithm on each segment of a song, we could classify that song as the club anthem that it is, not just it's (below) average.
### Segment a song using onset detection
An onset in a signal is often described as the beginning of a note or other sound. This is usually found by measuring peaks in energy along a signal. If we find that peak in energy, and then backtrack to a local minimum, we have found an onset, and can use that as a boundary for a segment of a song.
here are some good resources for learning more about onsets and onset detection: https://musicinformationretrieval.com/onset_detection.html, https://en.wikipedia.org/wiki/Onset_(audio), https://www.music-ir.org/mirex/wiki/2018:Audio_Onset_Detection
```python
%matplotlib inline
import librosa
import numpy as np
import IPython.display as ipd
import sklearn
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
plt.rcParams['figure.figsize'] = (16, 7)
```
By default, onset_detect returns an array of _frame_ indices that correspond to frames in a signal. We actually
want the _sample_ indices so that we can slice and dice our signal neatly with those indices. We'll continue to use our Rock & Roll example from the previous post.
```python
signal, sr = librosa.load('/Users/benjamindykstra/Music/iTunes/Led Zeppelin/Led Zeppelin IV/02 Rock & Roll.m4a')
# use backtrack=True to go back to local minimum
onset_samples = librosa.onset.onset_detect(signal, sr=sr, backtrack=True, units='samples')
print onset_samples.shape
```
(132,)
We have found 132 segments in the song. Now, lets use the sample indices to split up the song in to subarrays like so:
[[segment 1], [segment 2], ..... [segment n]]. Each segment will be a different length, but when we calculate a feature vector for a segment, the feature vector will be a standard size. The final dimensions of the data after segmenting and calculating features for each segment will be (# segments, # features).
```python
# return np array of audio segments, within each segment is the actual audio data
prev_ndx = 0
segmented = []
for sample_ndx in onset_samples:
# get the samples from prev_ndx to sample_ndx
segmented.append(np.array(signal[prev_ndx:sample_ndx]))
prev_ndx = sample_ndx
segmented.append(np.array(signal[onset_samples[-1]:])) # gets the last segment from the signal
segmented = np.array(segmented)
```
```python
segmented.shape
```
(133,)
As a sanity check, if we concatenate all the segments together, it should be equal in shape to the original signal.
```python
print "difference in shapes: {}".format(signal.shape[0] - np.concatenate(segmented).shape[0])
```
difference in shapes: 0
Listen to a few segments together!
```python
ipd.Audio(np.concatenate(segmented[25:30]), rate=sr)
```
or just a single short segment
```python
ipd.Audio(segmented[21], rate=sr)
```
Lets define a more generic segmentation function for use later on
```python
def segment_onset(signal, sr=22050, hop_length=512, backtrack=True):
"""
Segment a signal using onset detection
Parameters:
signal: numpy array of a timeseries of an audio file
sr: int, sampling rate, default 22050 samples per a second
hop_length: int, number of samples between successive frames
backtrack: bool, If True, detected onset events are backtracked to the nearest preceding minimum of energy
returns:
dictionary with attributes segemented and shape
"""
# Compute the sample indices for estimated onsets in a signal
onset_samples = librosa.onset.onset_detect(signal, sr=sr, hop_length=hop_length, backtrack=backtrack, units='samples')
# return np array of audio segments, within each segment is the actual audio data
prev_ndx = 0
segmented = []
for sample_ndx in onset_samples:
segmented.append(np.array(signal[prev_ndx:sample_ndx]))
prev_ndx = sample_ndx
segmented.append(np.array(signal[onset_samples[-1]:]))
return { 'data': np.array(segmented), 'shape': np.array(segmented).shape }
```
## Feature Extraction
Now that we have a way to break up a song, we would like to be able to derive some features from the raw signal. Librosa has a plethora of features to choose from. They fall in to two categories, spectral and rhythmic features. Spectral features are features that have to do with the frequency, pitch and timbre of a signal, where as rhythmic features (you guessed it) give you info about the rhythm of the signal.
The objective with feature extraction is to feed a single function a single segment of a song, that returns an array of the calculated features for that segment
Some of the feature methods return arrays of differing shapes and we need to account for those differences in our implementation. For example, when calculating the Mel-frequency cepstral coefficients for a segment, the return shape is (# of coefficients, # of frames in a segment). Since we're assuming that a segment is a homogenous piece of signal, we should take the average of the coefficients across all the frames so we get a shape of (# of coefficients, 1).
First I will define all the feature functions, and then I will explain what information they add/describe.
```python
def get_feature_vector(segment):
'''
Extract features for a given segment
Parameters:
segment: numpy array, a time series of audio data
Returns:
numpy array
'''
if len(segment) != 0:
feature_tuple = (avg_energy(segment), avg_mfcc(segment), zero_crossing_rate(segment), avg_spectral_centroid(segment), avg_spectral_contrast(segment), bpm(segment))
all_features = np.concatenate([feat if type(feat) is np.ndarray else np.array([feat]) for feat in feature_tuple])
n_features = len(all_features)
return all_features
return np.zeros((30,)) # length of feature tuple
def avg_energy(segment):
'''
Get the average energy of a segment.
Parameters:
segment: numpy array, a time series of audio data
Returns:
float, the mean energy of the segment
'''
if len(segment) != 0:
energy = librosa.feature.rmse(y=segment)[0]
# returns (1,t) array, get first element
return np.array([np.mean(energy)])
def avg_mfcc(segment, sr=22050, n_mfcc=20):
'''
Get the average Mel-frequency cepstral coefficients for a segment
The very first MFCC, the 0th coefficient, does not convey information relevant to the overall shape of the spectrum.
It only conveys a constant offset, i.e. adding a constant value to the entire spectrum. We discard it.
BE SURE TO NORMALIZE
Parameters:
segment: numpy array, a time series of audio data
sr: int, sampling rate, default 22050
n_mfcc: int, the number of cepstral coefficients to return, default 20.
Returns:
numpy array of shape (n_mfcc - 1,)
'''
if (len(segment) != 0):
components = librosa.feature.mfcc(y=segment,sr=sr, n_mfcc=n_mfcc ) # return shape (n_mfcc, # frames)
return np.mean(components[1:], axis=1)
def zero_crossing_rate(segment):
'''
Get average zero crossing rate for a segment. Add a small constant to the signal to negate small amount of noise near silent
periods.
Parameters:
segment: numpy array, a time series of audio data
Returns:
float, average zero crossing rate for the given segment
'''
rate_vector = librosa.feature.zero_crossing_rate(segment+ 0.0001)[0] # returns array with shape (1,x)
return np.array([np.mean(rate_vector)])
def avg_spectral_centroid(segment, sr=22050):
'''
Indicate at which frequency the energy is centered on. Like a weighted mean, weighting avg frequency by the energy.
Add small constant to audio signal to discard noise from silence
Parameters:
segment: numpy array, a time series of audio data
sr: int, sampling rate
Returns:
float, the average frequency which the energy is centered on.
'''
centroid = librosa.feature.spectral_centroid(segment+0.01, sr=sr)[0]
return np.array([np.mean(centroid)])
def avg_spectral_contrast(segment, sr=22050, n_bands=6):
'''
considers the spectral peak, the spectral valley, and their difference in each frequency subband
columns correspond to a spectral band
average contrast : np.ndarray [shape=(n_bands + 1)]
each row of spectral contrast values corresponds to a given
octave-based frequency, take average across bands
Parameters:
segment: numpy array, a time series of audio data
sr: int, sampling rate
n_bands: the number of spectral bands to calculate the contrast across.
Returns:
numpy array shape (n_bands,)
'''
contr = librosa.feature.spectral_contrast(segment, sr=sr, n_bands=n_bands)
return np.mean(contr, axis=1) # take average across bands
def bpm(segment, sr=22050):
'''
Get the beats per a minute of a song
Parameters:
segment: numpy array, a time series of audio data,
sr: int, sampling rate
Returns:
int, beats per minute
'''
tempo = librosa.beat.tempo(segment) #returns 1d array [bpm]
return np.array([tempo[0]])
```
## Selected Feature Justification
### Energy:
The energy for a segment is important because it gives a feel for tempo and/or mood of a segment. It's actually just the root mean square of a signal.
### MFCC:
The Mel-frequency cepstral coefficients relay information about the timbre of a song. Timbre describes the 'quality' of a sound. If you think about how an A note on a trumpet sounds vastly different than that same A on a piano, those differences are due to timbre.
### Zero Crossing Rate:
Literally the rate at which a signal crosses the horizontal axis. It often corresponds to events in the signal such as a snare drum or some other percussive event.
### Spectral Centroid:
I think the spectral centroid is actually really cool. It's a weighted average of the magnitude of the frequencies in a signal and a 'center of mass'. It's often perceived as a measure of the brightness of a sound.
### Spectral Contrast:
An octave based feature, it more directly represents the spectral characteristics of a segment. Coupled with MFCC features, they can provide a lot of information about a signal.
### Beats Per Minute:
Provides information about the tempo and (some) percussive elements of a song.
Now what do we actually do with all these features??? We can use them to cluster!!
```python
def extract_features(all_songs):
'''
all_songs is a list of dictionaries. Each dictionary contains the attributes song_name and data.
The data are the segments of the song.
'''
all_song_features = []
song_num = 0
for song in all_songs:
print "Processing {} with {} segments".format(song['song_name'], len(song['data']))
song_name = song['song_name']
segment_features = []
for segment in song['data']:
feature_vector = get_feature_vector(segment)
segment_features.append(feature_vector)
song_feature_vector = np.array(segment_features)
print "shape of feature vector for entire song: {}".format(song_feature_vector.shape)
print "shape of segment feature vector: {}".format(song_feature_vector[0].shape)
n_seg = song_feature_vector.shape[0]
feature_length = song_feature_vector[0].shape[0]
song_feature_vector = np.reshape(song_feature_vector, (n_seg, feature_length))
all_song_features.append(song_feature_vector)
song_num += 1
all_feature_vector = np.vstack(all_song_features)
return all_feature_vector
```
## Visualizing the features of two very different songs
Lets look at the features of Rock 'n Roll by Led Zeppelin, and I Remember by Deadmau5.
```python
rock_n_roll = segment_onset(signal)
rock_n_roll['data'].shape
```
(133,)
```python
feature_vec_rock = extract_features([{'song_name': '02 Rock & Roll.m4a', 'data': rock_n_roll['data']}])
feature_vec_rock.shape
```
Processing 02 Rock & Roll.m4a with 133 segments
shape of feature vector for entire song: (133, 30)
shape of segment feature vector: (30,)
(133, 30)
```python
i_remember, sr = librosa.load('/Users/benjamindykstra/Music/iTunes/Deadmau5/Random Album Title/07 I Remember.m4a')
i_remember_segmented = segment_onset(i_remember)
feature_vec_remember = extract_features([{'song_name': '07 I Remember.m4a', 'data': i_remember_segmented['data']}])
```
Processing 07 I Remember.m4a with 1852 segments
shape of feature vector for entire song: (1852, 30)
shape of segment feature vector: (30,)
These two songs are very different
```python
ipd.Audio(np.concatenate(i_remember_segmented['data'][:30]), rate= sr)
```
```python
ipd.Audio(np.concatenate(rock_n_roll['data'][:20]), rate= sr)
```
### We need to scale the features to a common range, the feature ranges differ wildly
```python
col_names = ['energy'] + ["mfcc_" + str(i) for i in xrange(19)] + ['zero_crossing_rate', 'spectral_centroid'] + ['spectral_contrast_band_' + str(i) for i in xrange(7)] + ['bpm']
rnr = pd.DataFrame(feature_vec_rock, columns = col_names)
i_remember_df = pd.DataFrame(feature_vec_remember, columns = col_names)
min_max_scaler = sklearn.preprocessing.MinMaxScaler(feature_range=(-1, 1))
rnr_scaled = pd.DataFrame(min_max_scaler.fit_transform(feature_vec_rock), columns = col_names)
i_remember_scaled = pd.DataFrame(min_max_scaler.fit_transform(feature_vec_remember), columns = col_names)
features_scaled = pd.DataFrame(np.vstack((rnr_scaled, i_remember_scaled)), columns = col_names)
```
```python
rnr_scaled.head()
```
<div>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>energy</th>
<th>mfcc_0</th>
<th>mfcc_1</th>
<th>mfcc_2</th>
<th>mfcc_3</th>
<th>mfcc_4</th>
<th>mfcc_5</th>
<th>mfcc_6</th>
<th>mfcc_7</th>
<th>mfcc_8</th>
<th>...</th>
<th>zero_crossing_rate</th>
<th>spectral_centroid</th>
<th>spectral_contrast_band_0</th>
<th>spectral_contrast_band_1</th>
<th>spectral_contrast_band_2</th>
<th>spectral_contrast_band_3</th>
<th>spectral_contrast_band_4</th>
<th>spectral_contrast_band_5</th>
<th>spectral_contrast_band_6</th>
<th>bpm</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>-1.000000</td>
<td>0.122662</td>
<td>1.000000</td>
<td>-0.516018</td>
<td>1.000000</td>
<td>0.602426</td>
<td>1.000000</td>
<td>1.000000</td>
<td>1.000000</td>
<td>0.540636</td>
<td>...</td>
<td>-1.000000</td>
<td>-1.000000</td>
<td>0.827903</td>
<td>-1.000000</td>
<td>-0.962739</td>
<td>-1.000000</td>
<td>-1.000000</td>
<td>-1.000000</td>
<td>-0.538654</td>
<td>-0.503759</td>
</tr>
<tr>
<th>1</th>
<td>-0.242285</td>
<td>-0.648073</td>
<td>0.381125</td>
<td>-0.786313</td>
<td>-0.091164</td>
<td>-0.080649</td>
<td>-0.601857</td>
<td>-0.673427</td>
<td>-0.444300</td>
<td>-0.700703</td>
<td>...</td>
<td>0.604015</td>
<td>0.709584</td>
<td>0.099070</td>
<td>-0.187083</td>
<td>-0.375223</td>
<td>-0.307743</td>
<td>-0.114691</td>
<td>-0.157464</td>
<td>0.903511</td>
<td>-0.250000</td>
</tr>
<tr>
<th>2</th>
<td>-0.067639</td>
<td>-0.850079</td>
<td>0.421647</td>
<td>-0.732783</td>
<td>-0.226694</td>
<td>-0.404820</td>
<td>-0.733511</td>
<td>-0.860285</td>
<td>-0.528783</td>
<td>-0.503516</td>
<td>...</td>
<td>0.781001</td>
<td>0.850525</td>
<td>0.758635</td>
<td>-0.287418</td>
<td>-0.213330</td>
<td>-0.196650</td>
<td>-0.161395</td>
<td>0.109064</td>
<td>0.427987</td>
<td>-0.503759</td>
</tr>
<tr>
<th>3</th>
<td>-0.433760</td>
<td>-0.969241</td>
<td>0.401582</td>
<td>-0.620675</td>
<td>-0.046703</td>
<td>0.055861</td>
<td>-0.502694</td>
<td>-0.516944</td>
<td>0.055559</td>
<td>-0.147803</td>
<td>...</td>
<td>0.831207</td>
<td>0.924291</td>
<td>0.801980</td>
<td>0.226105</td>
<td>-0.535366</td>
<td>-0.160115</td>
<td>0.185044</td>
<td>0.142246</td>
<td>0.299663</td>
<td>-0.503759</td>
</tr>
<tr>
<th>4</th>
<td>-0.282242</td>
<td>-0.686175</td>
<td>0.325491</td>
<td>-0.689084</td>
<td>-0.086337</td>
<td>-0.026573</td>
<td>-0.474765</td>
<td>-0.471087</td>
<td>-0.126714</td>
<td>-0.212362</td>
<td>...</td>
<td>0.496496</td>
<td>0.731278</td>
<td>0.755725</td>
<td>0.126388</td>
<td>0.024655</td>
<td>-0.247040</td>
<td>0.625841</td>
<td>0.129373</td>
<td>0.113422</td>
<td>-0.503759</td>
</tr>
</tbody>
</table>
<p>5 rows × 30 columns</p>
</div>
```python
i_remember_scaled.head()
```
<div>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>energy</th>
<th>mfcc_0</th>
<th>mfcc_1</th>
<th>mfcc_2</th>
<th>mfcc_3</th>
<th>mfcc_4</th>
<th>mfcc_5</th>
<th>mfcc_6</th>
<th>mfcc_7</th>
<th>mfcc_8</th>
<th>...</th>
<th>zero_crossing_rate</th>
<th>spectral_centroid</th>
<th>spectral_contrast_band_0</th>
<th>spectral_contrast_band_1</th>
<th>spectral_contrast_band_2</th>
<th>spectral_contrast_band_3</th>
<th>spectral_contrast_band_4</th>
<th>spectral_contrast_band_5</th>
<th>spectral_contrast_band_6</th>
<th>bpm</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>0.058494</td>
<td>-0.647307</td>
<td>0.539341</td>
<td>-0.121477</td>
<td>0.541506</td>
<td>0.437682</td>
<td>-0.272703</td>
<td>0.223814</td>
<td>-0.016933</td>
<td>-0.048312</td>
<td>...</td>
<td>-0.114140</td>
<td>0.491343</td>
<td>0.292913</td>
<td>0.271760</td>
<td>0.192199</td>
<td>-0.773597</td>
<td>-0.625672</td>
<td>-0.067422</td>
<td>0.317499</td>
<td>-0.676113</td>
</tr>
<tr>
<th>1</th>
<td>-0.005999</td>
<td>-0.534543</td>
<td>-0.160968</td>
<td>-0.374121</td>
<td>0.505839</td>
<td>0.547995</td>
<td>-0.180246</td>
<td>0.333693</td>
<td>-0.098430</td>
<td>0.029649</td>
<td>...</td>
<td>-0.273774</td>
<td>0.318984</td>
<td>0.266204</td>
<td>-0.026715</td>
<td>-0.369555</td>
<td>-0.694350</td>
<td>-0.538811</td>
<td>-0.494475</td>
<td>0.247816</td>
<td>-0.676113</td>
</tr>
<tr>
<th>2</th>
<td>-0.014792</td>
<td>-0.465639</td>
<td>-0.168007</td>
<td>-0.570869</td>
<td>0.449955</td>
<td>0.559676</td>
<td>-0.168267</td>
<td>0.279917</td>
<td>-0.095737</td>
<td>-0.053418</td>
<td>...</td>
<td>-0.327139</td>
<td>0.187170</td>
<td>0.507119</td>
<td>0.038864</td>
<td>-0.463672</td>
<td>-0.728928</td>
<td>-0.451278</td>
<td>-0.269847</td>
<td>0.223124</td>
<td>-0.676113</td>
</tr>
<tr>
<th>3</th>
<td>0.127275</td>
<td>-0.410650</td>
<td>0.045166</td>
<td>-0.534741</td>
<td>0.485562</td>
<td>0.635807</td>
<td>-0.145189</td>
<td>0.292996</td>
<td>-0.003948</td>
<td>0.145229</td>
<td>...</td>
<td>-0.474190</td>
<td>0.109161</td>
<td>0.216147</td>
<td>-0.372901</td>
<td>-0.184409</td>
<td>-0.732067</td>
<td>-0.453334</td>
<td>-0.383937</td>
<td>0.103847</td>
<td>-0.676113</td>
</tr>
<tr>
<th>4</th>
<td>0.099671</td>
<td>-0.368250</td>
<td>0.332703</td>
<td>-0.435360</td>
<td>0.505144</td>
<td>0.570220</td>
<td>-0.128529</td>
<td>0.181684</td>
<td>-0.068506</td>
<td>-0.032707</td>
<td>...</td>
<td>-0.539708</td>
<td>0.116126</td>
<td>0.209937</td>
<td>-0.236042</td>
<td>-0.115957</td>
<td>-0.544722</td>
<td>-0.496779</td>
<td>-0.378822</td>
<td>-0.068973</td>
<td>-0.676113</td>
</tr>
</tbody>
</table>
<p>5 rows × 30 columns</p>
</div>
### Lets take a look at the descriptive statistics for the energy
```python
sns.boxplot(x=i_remember_scaled.energy, palette='muted').set_title('I Remember Energy');
plt.show();
print i_remember_scaled.energy.describe()
sns.boxplot(rnr_scaled.energy).set_title('Rock n Roll Energy');
plt.show();
print rnr_scaled.energy.describe()
```
count 1852.000000
mean 0.184555
std 0.373220
min -1.000000
25% -0.009499
50% 0.176136
75% 0.478511
max 1.000000
Name: energy, dtype: float64
count 133.000000
mean 0.354920
std 0.391389
min -1.000000
25% 0.117536
50% 0.439199
75% 0.639228
max 1.000000
Name: energy, dtype: float64
I remember has a lower mean and median energy, but similar spread to Rock n Roll. I'd say that this fits, as I Remember has almost a melancholic energy, where as Rock n Roll really makes you to get up and move.
### What about the zero crossing rate and BPM?
Since zero crossing rate and bpm correlate pretty highly with percussive events, I'd predict that the song with the higher BPM will have a higher zero crossing rate
```python
print 'Rock n Roll average BPM: {}'.format(rnr.bpm.mean())
print 'Rock n Roll average Crossing Rate: {}'.format(rnr.zero_crossing_rate.mean())
print 'I Remember average BPM: {}'.format(i_remember_df.bpm.mean())
print 'I Remember average Crossing Rate: {}'.format(i_remember_df.zero_crossing_rate.mean())
```
Rock n Roll average BPM: 150.784808472
Rock n Roll average Crossing Rate: 0.14643830815
I Remember average BPM: 136.533708743
I Remember average Crossing Rate: 0.0362864360563
Some scatterplots with spectral centroid on the x axis, and energy on the y axis.
```python
sns.scatterplot(x = rnr.spectral_centroid, y = rnr.energy);
plt.show();
sns.scatterplot(x = i_remember_df.spectral_centroid, y = i_remember_df.energy );
plt.show();
```
Recall that spectral centroid is where the spectral 'center of mass' is for a given segment. That means that it's picking out the dominant frequency for a segment. I like this because it shows that there's not real relation between the frequency of a segment and its energy. They are both contributing unique information.
## build labels and cluster using k means!
```python
song_labels = np.concatenate([np.full((label_len), i) for i, label_len in enumerate([len(rnr), len(i_remember_df)])])
```
```python
model = sklearn.cluster.KMeans(n_clusters=3)
labels = model.fit_predict(features_scaled)
```
```python
plt.scatter(features_scaled.zero_crossing_rate[labels==0], features_scaled.energy[labels==0], c='b')
plt.scatter(features_scaled.zero_crossing_rate[labels==1], features_scaled.energy[labels==1], c='r')
plt.scatter(features_scaled.zero_crossing_rate[labels==2], features_scaled.energy[labels==2], c='g')
plt.xlabel('Zero Crossing Rate (scaled)')
plt.ylabel('Energy (scaled)')
plt.legend(('Class 0', 'Class 1', 'Class 2'))
```
<matplotlib.legend.Legend at 0x13f054f10>
```python
unique_labels, unique_counts = np.unique(model.predict(rnr_scaled), return_counts=True)
print unique_counts
print 'cluster for rock n roll: ', unique_labels[np.argmax(unique_counts)]
```
[29 9 95]
cluster for rock n roll: 2
```python
unique_labels, unique_counts = np.unique(model.predict(i_remember_scaled), return_counts=True)
print unique_counts
print 'cluster for I remember: ', unique_labels[np.argmax(unique_counts)]
```
[396 877 579]
cluster for I remember: 1
I suspect that zero crossing rate and energy are not what the determining factors are for a cluster :)
## We can actually listen to the segments that were assigned certain labels
Note that these aren't necessarily consecutive segments
First lets look at I remember
```python
i_remember_clusters = model.predict(i_remember_scaled)
label_2_segs = i_remember_segmented['data'][i_remember_clusters==2]
label_1_segs = i_remember_segmented['data'][i_remember_clusters==1]
label_0_segs = i_remember_segmented['data'][i_remember_clusters==0]
```
Almost all of theses have some of the vocals in them
```python
ipd.Audio(np.concatenate(label_2_segs[:50]), rate = sr)
```
These are the lighter segments, mostly just synths
```python
ipd.Audio(np.concatenate(label_1_segs[:50]), rate = sr)
```
0 labels seem to be the heavy bass and percussive parts
```python
ipd.Audio(np.concatenate(label_0_segs[:50]), rate = sr)
```
#### Now Rock n Roll
```python
rnr_clusters = model.predict(rnr_scaled)
rock_label_2_segs = rock_n_roll['data'][rnr_clusters==2]
rock_label_1_segs = rock_n_roll['data'][rnr_clusters==1]
rock_label_0_segs = rock_n_roll['data'][rnr_clusters==0]
```
Again, higher frequencies, vocals included. A lot of consecutive segments included in this class.
```python
ipd.Audio(np.concatenate(rock_label_2_segs[10:40]), rate = sr)
```
<audio controls="controls" >
Your browser does not support the audio element.
</audio>
Lighter sounds, minor key vocals, part of final drum solo
```python
ipd.Audio(np.concatenate(rock_label_1_segs), rate = sr)
```
<audio controls="controls" >
Your browser does not support the audio element.
</audio>
All John Bonham here (only drums). Similar to how in I remember label 0 corresponded to the heavy bass
```python
ipd.Audio(np.concatenate(rock_label_0_segs), rate = sr)
```
<audio controls="controls" >
Your browser does not support the audio element.
</audio>
## Conclusion
We've used two very different songs to build vectors of spectral and rhythmic features. We then examined how those features related to each other with boxplots, scatterplots and descriptive statistics. Using those features, we have clustered different segments of the songs together to compare how the different clusters sound together.
More exploration is needed to figure out how to assign a feature value for an entire song that is representative. With more work doing that, it would then be possible to get summary features for entire songs. More on this later!
### The rest of this is just some undirected exploring of different features
```python
print rnr_scaled[rnr_clusters==0]['spectral_centroid'].describe()
print rnr_scaled[rnr_clusters==1]['spectral_centroid'].describe()
print rnr_scaled[rnr_clusters==2]['spectral_centroid'].describe()
```
count 9.000000
mean -0.360693
std 0.250294
min -1.000000
25% -0.370240
50% -0.280334
75% -0.260073
max -0.148394
Name: spectral_centroid, dtype: float64
count 29.000000
mean 0.066453
std 0.363603
min -0.483240
25% -0.211871
50% 0.012854
75% 0.156281
max 0.814435
Name: spectral_centroid, dtype: float64
count 95.000000
mean 0.354971
std 0.261067
min -0.669203
25% 0.218433
50% 0.318239
75% 0.427016
max 1.000000
Name: spectral_centroid, dtype: float64
```python
i_remember_df['mfcc_2'].plot.hist(bins=20, figsize=(14, 5))
```
<matplotlib.axes._subplots.AxesSubplot at 0x139127290>
```python
sns.boxplot(x=i_remember_scaled.zero_crossing_rate, palette='muted').set_title('I Remember Zero Crossing Rate');
plt.show();
print i_remember_scaled.zero_crossing_rate.describe()
sns.boxplot(rnr_scaled.zero_crossing_rate).set_title('Rock n Roll Zero Crossing Rate');
plt.show();
print rnr_scaled.zero_crossing_rate.describe()
```
count 1852.000000
mean -0.683760
std 0.255792
min -1.000000
25% -0.880912
50% -0.762325
75% -0.535427
max 1.000000
Name: zero_crossing_rate, dtype: float64
count 133.000000
mean -0.152444
std 0.421004
min -1.000000
25% -0.393116
50% -0.198213
75% -0.045042
max 1.000000
Name: zero_crossing_rate, dtype: float64
```python
print rnr.zero_crossing_rate.describe()
print i_remember_df.zero_crossing_rate.describe()
```
count 133.000000
mean 0.146438
std 0.072255
min 0.000977
25% 0.105133
50% 0.138583
75% 0.164871
max 0.344226
Name: zero_crossing_rate, dtype: float64
count 1852.000000
mean 0.036286
std 0.025857
min 0.004319
25% 0.016357
50% 0.028345
75% 0.051281
max 0.206489
Name: zero_crossing_rate, dtype: float64
```python
print rnr.bpm.describe()
print i_remember_df.bpm.describe()
```
count 133.000000
mean 150.784808
std 31.793864
min 86.132812
25% 135.999178
50% 135.999178
75% 172.265625
max 287.109375
Name: bpm, dtype: float64
count 1852.000000
mean 136.533709
std 7.140772
min 112.347147
25% 135.999178
50% 135.999178
75% 135.999178
max 258.398438
Name: bpm, dtype: float64
```python
# rnr_scaled['energy'].plot();
i_remember_scaled['energy'].plot();
# rnr_scaled['zero_crossing_rate'].plot();
# rnr_scaled['spectral_centroid'].plot();
# rnr_scaled['mfcc_4'].plot();
plt.show()
```
```python
rnr_scaled[['mfcc_' + str(i) for i in xrange(4)]].plot();
plt.show();
```
```python
sns.scatterplot(x=rnr_scaled['energy'], y = rnr_scaled['bpm'])
```
<matplotlib.axes._subplots.AxesSubplot at 0x131c69ad0>
```python
sns.pairplot(rnr_scaled[['mfcc_' + str(i) for i in xrange(5)]], palette='pastel')
```
<seaborn.axisgrid.PairGrid at 0x15f503c10>
```python
```
| bfdykstra |
214,082 | Mobile Marketing Glossary: A Comprehensive List of Terms You Need to Know | ARPDAU, CPC, MAU, DAU, ASO... No, I’m not having a stroke, I’m just listing some terms from our mobil... | 0 | 2019-12-02T16:51:15 | https://dev.to/udonismarketing/mobile-marketing-glossary-a-comprehensive-list-of-terms-you-need-to-know-49ag | ARPDAU, CPC, MAU, DAU, ASO... No, I’m not having a stroke, I’m just listing some terms from our <a href="https://www.blog.udonis.co/mobile-marketing/mobile-games/what-is-mobile-marketing">mobile marketing</a> glossary. Do you know what all of them mean?
If you work or have an interest in mobile marketing, you hear many <strong>technical terms</strong> thrown around. As new mobile marketing practices emerge, we need a way to effectively describe and communicate them. That’s why new words and terms are being invented all the time.
That’s all fine and dandy, but the challenge is keeping up with <strong>mobile marketing terminology</strong>. Let’s be honest, it can get quite confusing, no matter how knowledgeable you are. That’s why you need to go over this mobile marketing glossary. Nobody wants to look stupid in front of a coworker or in a business meeting.
If you’re a beginner and just getting into mobile marketing, this glossary is the perfect <strong>cheat sheet</strong>. Read it, learn it, and master it because you’re going to need it.
If you’re an expert in the field, you probably know many of these terms. Congratulations! But don’t be so quick to dismiss it. It’s always a good idea to refresh your memory. It will help you <strong>stay on top of your game</strong>. And who knows, perhaps you’ll find a couple of mobile marketing terms you’re not familiar with?
This mobile marketing glossary will be helpful to you regardless of your level of expertise. So, let’s take a deep dive into the mysterious and often confusing world of mobile marketing terminology. Once we’re done, you’ll know them like the back of your hand!
<img class="alignnone wp-image-18824 size-full" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketing-glossary-letter-a-Copy.jpg" alt="mobile marketing glossary letter a" width="940" height="788" />
<h2>A/B Testing</h2>
Also known as split testing. A process of comparing two variants.
<h2>Ad Campaign</h2>
A set of advertisement messages that have a common idea and goal.
<h2>App Monetization</h2>
Making money from a mobile app through different techniques. Find out how to choose an app monetization platform <a href="https://www.blog.udonis.co/mobile-marketing/mobile-apps/app-monetization-platform">here.</a>
<h2>App Personalization</h2>
A process of personalizing the app experience in order to meet the needs of specific groups of users.
You can learn more about mobile app personalization <a href="https://www.blog.udonis.co/mobile-marketing/mobile-apps/mobile-app-personalization">here</a>.
<h2>ARPU</h2>
A ratio of average revenue per user.
<h2>ARPDAU</h2>
A ration of average revenue per daily active user. Find out more about ARPU and ARPDAU <a href="https://www.blog.udonis.co/analytics/calculate-and-increase-arpu-and-arpdau">here.</a>
<h2>ASO</h2>
Stands for <a href="https://www.blog.udonis.co/mobile-marketing/mobile-games/app-store-optimization-mobile-games">App store optimization</a>. A process of optimizing the app store page to increase the visibility of an app.
If you want to learn more about app store optimization, check out our <a href="https://www.blog.udonis.co/mobile-marketing/mobile-apps/complete-guide-to-app-store-optimization">simple ASO guide</a>.
<img class="alignnone wp-image-18825 size-full" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketing-glossary-letter-b-Copy.jpg" alt="mobile marketing glossary letter b" width="940" height="788" />
<h2>Backlinks</h2>
Inbound links to a webpage.
<h2>Bounce Rate</h2>
Percentage of website visitors who leave the site after viewing only one page.
<img class="alignnone size-full wp-image-18838" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketing-glossary-letter-c-Copy.jpg" alt="letter c" />
<h2>Churn Rate</h2>
A percentage of users who discontinued using an app.
<h2>Chatbot</h2>
A piece of AI software engaged with a real person in a mimicked conversation.
<h2>Click to Call</h2>
Mobile ads created with the goal of getting people to call a business.
<h2>CPA</h2>
Stands for cost per acquisition. It’s a metric that calculates the cost for a specific action user takes.
<h2>CPC</h2>
Stands for cost per click. The cost of one ad click in a pay-per-click campaign.
<h2>CPCV</h2>
Stands for cost per completed view. It measures the cost of one completed video view.
<h2>CPE</h2>
Stands for cost per engagement. It measures how much you pay when a user engages with an ad.
<h2>CPI</h2>
Stands for cost per install. It measures the cost of one install of a mobile app.
<h2>CTA</h2>
Stands for call to action. It is a piece of content (text, image, etc.) that encourages a user to take a specific action.
<h2>CTR</h2>
Stands for click-through rate. It is a ratio of users who click on an ad to the number of impressions (times an ad is shown).
<h2>Conversion</h2>
A conversion happens when the user completes a desired goal or takes a specific action. Usually, it’s a response to a CTA.
<h2>CPM</h2>
Stands for cost per mile. It measures how much one thousand ad clicks or views cost.
<h2>CR</h2>
Stands for conversion rate. It is the number of users who have taken a desired action.
<h2>CRO</h2>
Stands for conversion rate optimization. It is a process of increasing conversions through different methods and strategies.
<h2>Cohort Analysis</h2>
A method of studying the behavior of groups of similar users (cohorts).
<h2>DAU</h2>
Stands for daily active users. It is the percentage of unique daily users that visit a website or use an app.
<h2>Engagement Rate</h2>
It measures how much users engage with a piece of content.ž
<h2>Funnel</h2>
It is a model used in marketing that describes an assumed journey a customer takes from awareness to purchase.
<img class="alignnone size-full wp-image-18808" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketing-terms-letter-g.jpg" alt="mobile marketing glossary letter g" />
<h2>Geo-conquesting</h2>
A location-based mobile marketing technique of targeting users who are in near proximity of your competitor’s location.
<h2>Geo-fencing</h2>
A location-based mobile marketing technique of setting a virtual fence around a desired location with the goal of targeting users who enter it.
<h2>Geo-targeting</h2>
A subdomain of geo-fencing. It is a technique of targeting users based on their location and demographics.
<h2>Geo-location</h2>
A process of identifying a device’s geographic location.
<img class="alignnone size-full wp-image-18809" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketing-terms-letter-i.jpg" alt="mobile marketing glossary letter i" />
<h2>Impressions</h2>
The number of times an ad has been shown to the target audience, regardless of whether the users clicked on it or not.
<h2>IAP</h2>
Stands for in-app purchase. It describes a product or feature a user buys inside the app.
<h2>In-app Ads</h2>
A type of ads served inside mobile apps.
<h2>In-app Message</h2>
A type of message or notification that is displayed inside a mobile app.
<h2>Influencer</h2>
An individual who has authority in their field, great connection with their audience, and can influence people’s purchasing decisions.
<h2>Interstitial Ads</h2>
A popular type of full-screen ad format.
<h2>Incent Traffic</h2>
A type of traffic where users receive a reward for completing an action like installing an app.
<img class="alignnone size-full wp-image-18810" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketing-terms-letter-k.jpg" alt="mobile marketing glossary letter k" />
<h2>Keywords</h2>
One of the key parts of search engine optimization. Keywords are the phrases people use to conduct a search.
<h2>KPI</h2>
Stands for key performance indicator. It measures a company’s progress towards achieving the desired goals.
<img class="alignnone size-full wp-image-18811" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketing-terms-letter-l.jpg" alt="mobile marketing glossary letter l" />
<h2>Landing Page</h2>
A standalone web page created with the goal of conversions.
<h2>LTV</h2>
Stands for lifetime value. It is a metric that shows you revenue that each user got you in the entire lifetime of using the app.
<h2>Location-based Mobile Marketing</h2>
A marketing strategy that targets mobile users based on their geographic location using different techniques like geotargeting and geo-conquesting.
You can learn more about location-based marketing <a href="https://www.blog.udonis.co/mobile-marketing/location-based-mobile-marketing">here.</a>
<h2>MAU</h2>
Stands for monthly active users. It is a percentage of unique monthly users that visit a website or use an app.
<img class="alignnone size-full wp-image-18813" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketing-terms-letter-n.jpg" alt="mobile marketing glossary letter n" />
<h2>Native App</h2>
An app that is created for use on a specific platform or device.
<h2>Non-incent Traffic</h2>
It is organic traffic achieved by advertising.
<h2>Onboarding</h2>
It is a process used to get new users familiar with a mobile app.
<img class="alignnone size-full wp-image-18815" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketintg-terminology-letter-p.jpg" alt="mobile marketing glossary letter p" />
<h2>Organic Traffic</h2>
It is a type of non-paid traffic that comes from search engines.
<h2>PPC</h2>
Stands for pay-per-click. A type of advertising where you pay every time a user clicks on your ad.
<h2>Programmatic Media Buying</h2>
Use of automation when purchasing ads.
<h2>Push Notifications</h2>
A pop-up message from an app that appears on the user’s mobile device.
<h2>QR Code</h2>
A barcode that is scannable with mobile devices.
<img class="alignnone size-full wp-image-18816" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketintg-terminology-letter-r.jpg" alt="mobile marketing glossary letter r" />
<h2>ROI</h2>
Stands for return on investment. It measures the net profit of an investment relative to the amount of money that was invested.
<h2>Reach</h2>
The number of users who have seen an ad.
<h2>Remarketing</h2>
A strategy of showing ads to users who have visited your website previously.
<h2>Retention Rate</h2>
It shows you how many users return to your app after installing it. Read about why you need to track user retention in mobile apps and games <a href="https://www.blog.udonis.co/mobile-marketing/why-you-need-to-track-user-retention-in-mobile-apps-and-games">here.</a>
<img class="alignnone size-full wp-image-18817" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketintg-terminology-letter-s.jpg" alt="mobile marketing glossary letter s" />
<h2>Segmentation</h2>
The process of diving users into groups based on similar characteristics.
<h2>SEO</h2>
Stands for search engine optimization. It’s the process of optimizing a website with the goal of getting more organic traffic.
<h2>Session Intervals</h2>
The amount of time that passes between two app sessions.
<h2>Session Length</h2>
The amount of time a user spends using the app.
<img class="alignnone size-full wp-image-18818" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketintg-terminology-letter-t.jpg" alt="mobile marketing glossary letter t" />
<h2>Targeting</h2>
It refers to selecting a group of people you want to reach with your marketing efforts.
<h2>Time of Inactivity</h2>
The amount of time that has passed from the user’s last interaction with an app.
<img class="alignnone size-full wp-image-18819" src="https://www.blog.udonis.co/wp-content/uploads/2019/12/mobile-marketintg-terminology-letter-u.jpg" alt="mobile marketing glossary letter u" />
<h2>UX</h2>
Stands for user experience. It refers to the experience a user has while using your app or website.
<h2>User Acquisition</h2>
The process of acquiring new users on a platform like an app or website.
<h2>To Summarize</h2>
Hopefully, now you have a much better grasp of mobile marketing terminology. Bookmark it and come back to it whenever you need. Our memory is a tricky thing, so it’s always good to have a reminder.
Also, we’ll keep updating our mobile marketing glossary with new terms, so check in from time to time to get the new updates.
<strong>Have we missed any important marketing terms? Let us know! If you need more clarification on a specific term you find hard to understand, reach out to us in the comments below! </strong>
<h2><strong>Read More About Mobile Marketing </strong></h2>
<ul>
<li><a href="https://www.blog.udonis.co/mobile-marketing/mobile-marketing-trends-in-2020#Voice_Search_Optimization">Mobile Marketing Trends in 2020</a></li>
<li><a href="https://www.blog.udonis.co/mobile-marketing/mobile-games/what-is-mobile-marketing">What is Mobile Marketing</a></li>
<li><a href="https://www.blog.udonis.co/mobile-marketing/benefits-of-mobile-marketing">8 Benefits of Mobile Marketing</a></li>
<li><a href="https://www.blog.udonis.co/mobile-marketing/winning-mobile-marketing-strategy">How to Start a Winning Mobile Marketing Strategy</a></li>
<li><a href="https://www.blog.udonis.co/mobile-marketing/types-of-mobile-marketing-strategies-2020">10 Types of Mobile Marketing Strategies to Master in 2020</a></li>
<li><a href="https://www.blog.udonis.co/mobile-marketing/mobile-marketing-strategies-2019">The Hottest Marketing Strategies for Mobile Games Right Now</a></li>
</ul>
<h2><strong>About </strong><a href="https://udonis.co/"><strong>Udonis</strong></a><strong>:</strong></h2>
In 2018 & 2019, Udonis Inc. served over 14.1 billion ads & acquired over 50 million users for mobile apps & games. We’re recognized as <a href="https://udonis.co/about?utm_source=blog&utm_medium=post">a leading mobile marketing agency</a> by 5 major marketing review firms. We helped over 20 mobile apps & games reach the top charts. Want to know how we make it look so effortless? <a href="https://udonis.co/contact?utm_source=blog&utm_medium=post">Meet us</a> to find out. | udonismarketing | |
214,093 | QuestDB - fast relational time-series DB, zero GC java | Hi all, We have just released QuestDB open source (apache 2.0), and we would welcome your feedback.... | 0 | 2019-12-02T17:06:52 | https://dev.to/nicquestdb/questdb-fast-relational-time-series-db-zero-gc-java-hhi | database, java, opensource, sql | Hi all,
We have just released QuestDB open source (apache 2.0), and we would welcome your feedback.
QuestDB is an open-source NewSQL relational database designed to process time-series data, faster. Our approach comes from low-latency trading; QuestDB’s stack is engineered from scratch, zero-GC Java and dependency-free.
https://www.questdb.io/
https://github.com/questdb/questdb
thanks
Nic | nicquestdb |
223,524 | Querying your Spring Data JPA Repository - Introduction | In this series of posts I'll show you several methods to query your Java JPA repositories using Sprin... | 3,801 | 2020-01-06T23:14:36 | https://www.drugowick.dev/2020/01/06/querying-your-jpa-repository.html | java, spring, jpa, repository | In this series of posts I'll show you several methods to query your `Java` `JPA` `repositories` using `Spring Data JPA`. Throwing in some `Spring Boot` and `JPQL` and you have *too many words*!
## So... what do you need to know?
- Java and Spring: the [language](https://docs.oracle.com/en/java/javase/13/) and the [framework](https://spring.io), respectively.
- Java Persistence API (JPA): the specification for a ORM (Object-Relational Mapping) born from Hibernate, the first and most popular implementation of the JPA specification.
- It's how you persist data to a relational database.
- Spring Data JPA: a [sub-project](https://spring.io/projects/spring-data-jpa) of [Spring Data](https://spring.io/projects/spring-data), one of the many (many!) projects of Spring Framework.
- Spring Data JPA Repository: a Java interface/class annotated with `@Repository` from `org.springframework.stereotype` package.
Also noteworthy:
- Spring Boot: opinionated modules of the Spring Framework and third-party libraries. It means the libraries come with sensible defaults so you kick-start your development without much configuration of libraries.
- Java Persistence Query Language (JPQL): a query language similar to SQL. I don't know much more than what you'll see here in this series of posts.
If this brief explanation is not sufficient for you to comfortably continue reading, please, *let me know* and I'll do my best to update with more links and references (or maybe even write something).
Otherwise, you may continue on this awesome series of posts! =P
## Content
I'm going to cover 8 methods to query your data using Spring Data JPA Repositories. I'll develop [an app for this series of posts](https://github.com/brunodrugowick/jpa-queries-blog-post) so you can follow along.
<!-- Remove after completion -->
In the mean time, this post links to another GitHub repository.
### 1. Query Methods
Awesome Spring Data JPA implementation!
{% post https://dev.to/brunodrugowick/spring-data-jpa-query-methods-l43 %}
### 2. JPQL within the source code
@Query annotation.
{% post https://dev.to/brunodrugowick/using-jpql-with-spring-data-jpa-48c0 %}
### 3. Externalized JPQL with `orm.xml` file
Well, there's this. =|
{% post https://dev.to/brunodrugowick/using-jpql-on-orm-xml-file-with-spring-data-jpa-39ej %}
### 4. Custom Spring Data JPA Repository method
Java code is added to the mix and dynamic stuff is now possible!
{% post https://dev.to/brunodrugowick/four-steps-to-extend-a-spring-data-jpa-repository-with-your-own-code-53b0 %}
### 5. Use of Criteria API
More dynamic.
- Article (to be written).
- If you consider yourself self-taught, see: [this](https://github.com/brunodrugowick/algafood-api/commit/e19a606fa2db4d7a9ecc297568922922dd5ff70f).
### 6. Use of Specification design pattern
More and more dynamic!
- Article (to be written).
- If you consider yourself self-taught, see: [this](https://github.com/brunodrugowick/algafood-api/commit/9ffb6ecb2c9769dbf76760cf0a0b125ee80064ca).
### 7. Overriding Spring's default implementation for JpaRepository
Now you'll feel like a JPA god!
- Article (to be written).
- If you consider yourself self-taught, see: [this](https://github.com/brunodrugowick/algafood-api/commit/dad7e2a187d1f3fba56d61793436b5c20d924a74).
### 8. BONUS: use of [Querydsl](http://www.querydsl.com/)
I don't even know what this is right now but I'll figure it out. Looks cool, though!
- Article (to be written).
- If you consider yourself self-taught, see: [to be developed](https://github.com/brunodrugowick/algafood-api/commit/b771e424b2825e88a6bb7dabd117f7bae609df32).
## Thanks to
Most of what you see here I learnt on a [course from Algaworks (in Portuguese)](https://cafe.algaworks.com/lista-espera-spring-rest/) about REST APIs with Spring, where JPA is a huge section. I recommend the course if you speak Portuguese.
## Not Included
I won't cover any of this:
- Database configuration.
- Spring Boot app creation.
- Entity relationships.
- Etc...
Nevertheless, I'll provide a public GitHub repository with everything that I mention here and also would love to help if you drop a question on the Comments section. | brunodrugowick |
223,539 | Secure score in Azure Security Center | Secure score in Azure Security Center | 0 | 2020-04-05T23:43:26 | https://dev.to/cheahengsoon/secure-score-in-azure-security-center-4j4g | azure, azuresecurity | ---
title: Secure score in Azure Security Center
published: true
description: Secure score in Azure Security Center
tags: #Azure, #AzureSecurity
---
With so many services offering security benefits, it's often hard to know what steps to take first to secure and harden your workload. The Azure secure score reviews your security recommendations and prioritizes them for you, so you know which recommendations to perform first. This helps you find the most serious security vulnerabilities so you can prioritize investigation. Secure score is a tool that helps you assess your workload security posture.
**Secure score calculation**
Security Center mimics the work of a security analyst, reviewing your security recommendations, and applying advanced algorithms to determine how crucial each recommendation is. Azure Security center constantly reviews you active recommendations and calculates your secure score based on them, the score of a recommendation is derived from its severity and security best practices that will affect your workload security the most.
Security Center also provides you with an Overall secure score.
Overall secure score is an accumulation of all your recommendation scores. You can view your overall secure score across your subscriptions or management groups, depending on what you select. The score will vary based on subscription selected and the active recommendations on these subscriptions.
**Improve your secure score in Azure Security Center.**
#### View the secure score in the Azure Portal
1. In the Azure dashboard, click Security Center and then click Secure score.
2. At the top you can see Secure score highlights:
- The Overall secure score represents the score per policies, per selected subscription
- Secure score by category shows you which resources need the most attention
- Top recommendations by secure score impact provides you with a list of the recommendations that will improve your secure score the most if you implement them.
3. Click View recommendations to see the recommendations for that subscription that you can remediate to improve your secure score.
4. In the list of recommendations, you can see that for each recommendation there is a column that represents the Secure score impact. This number represents how much your overall secure score will improve if you follow the recommendations. For example, in the screen below, if you Remediate vulnerabilities in container security configurations, your secure score will increase by 35 points.
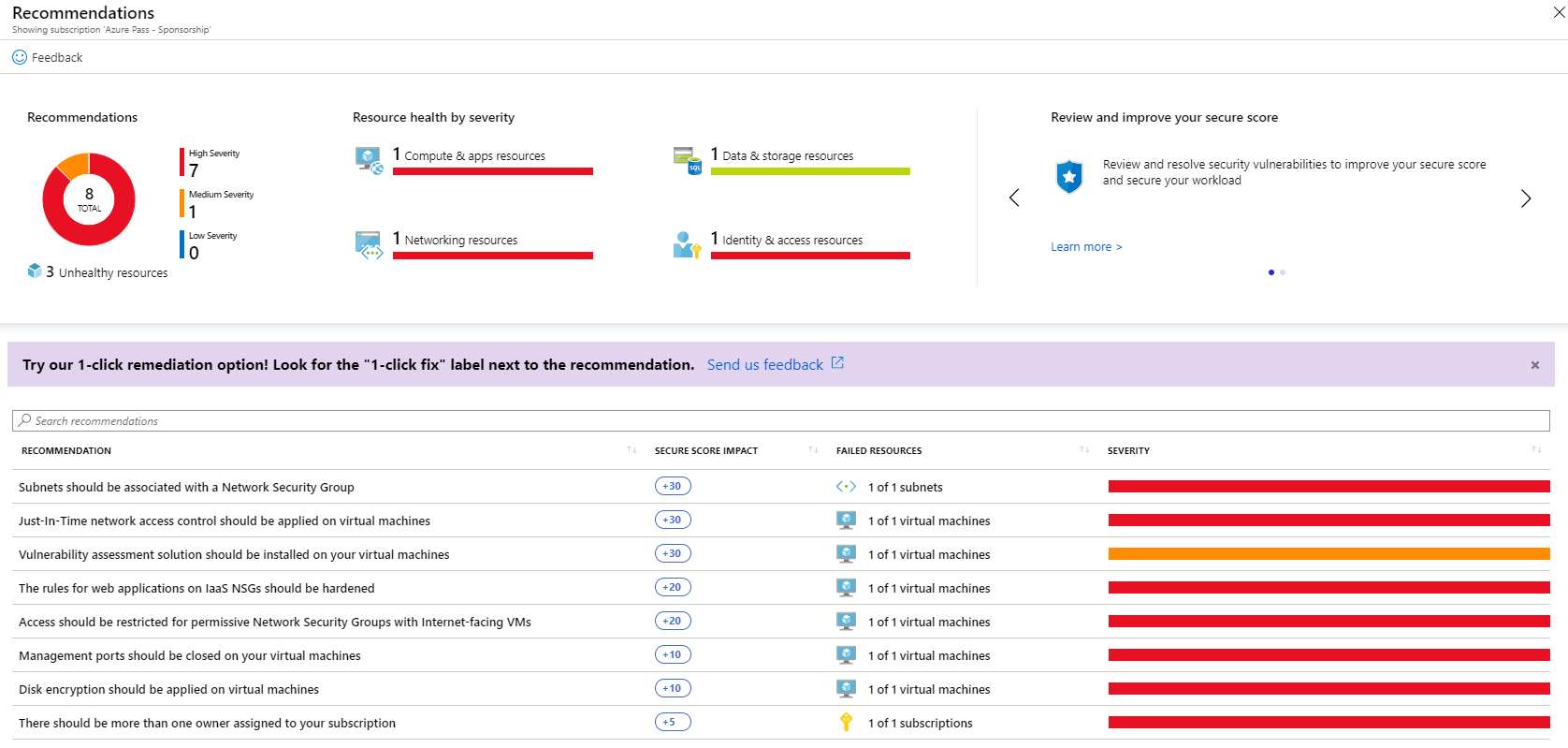
#### View the individual secure scores
In addition, to view individual secure scores, you can find these within the individual recommendation blade.
The Recommendation secure score is a calculation based on the ratio between your healthy resources and your total resources. If the number of healthy resources is equal to the total number of resources, you get the maximum secure score of the recommendation of 50. To try to get your secure score closer to the max score, fix the unhealthy resources by following the recommendations.
The Recommendation impact lets you know how much your secure score improves if you apply the recommendation steps. For example, if your secure score is 42 and the Recommendation impact is +3, performing the steps outlined in the recommendation improve your score to become 45.
1. Click any of the recommendations in the Secure Score blade.
The recommendation shows which threats your workload is exposed to if the remediation steps are not taken.
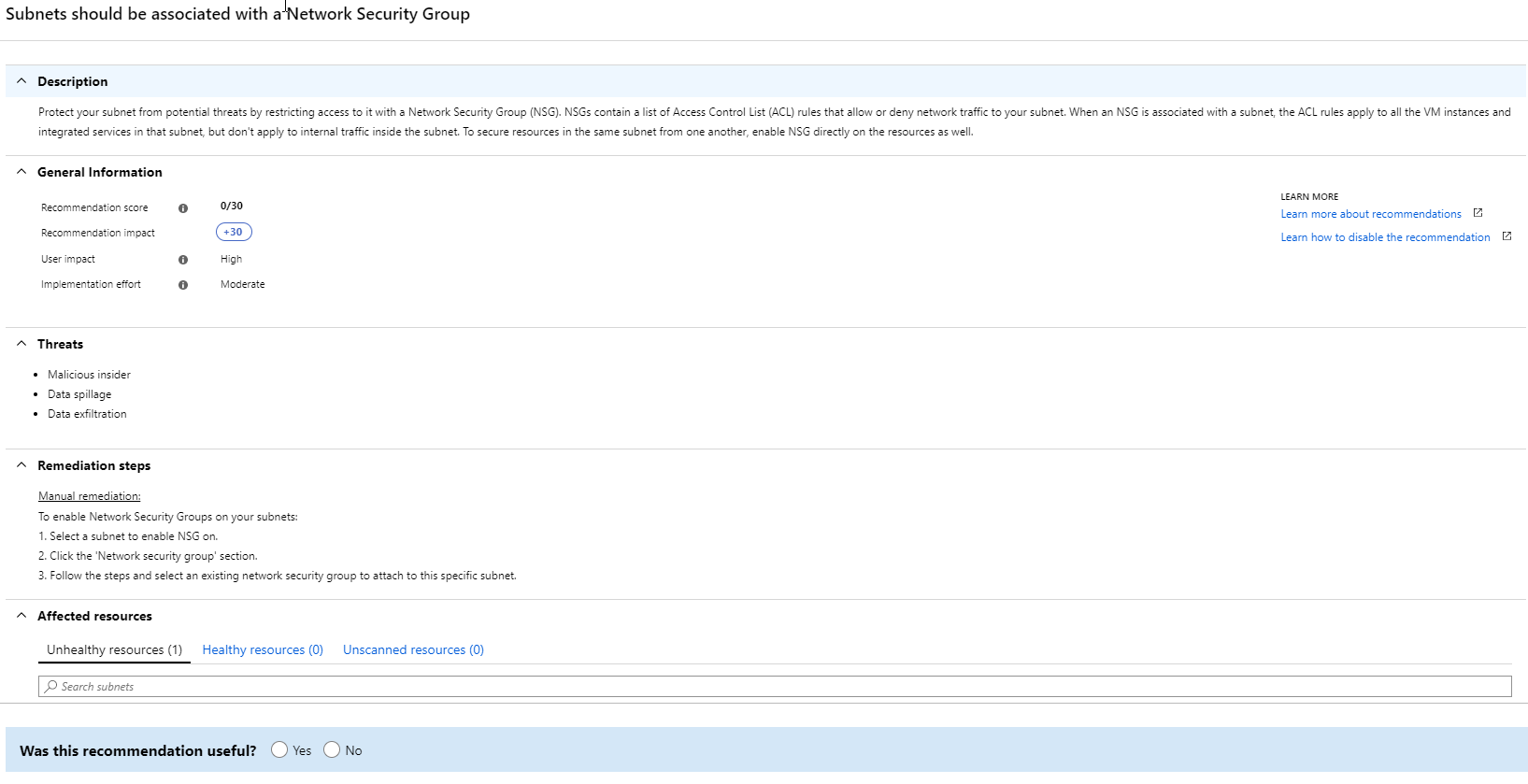 | cheahengsoon |
223,544 | Create an Azure Security Center baseline | Create an Azure Security Center baseline | 0 | 2020-04-01T23:37:29 | https://dev.to/cheahengsoon/create-an-azure-security-center-baseline-16ok | azure, azuresecurity | ---
title: Create an Azure Security Center baseline
published: true
description: Create an Azure Security Center baseline
tags: #Azure , #AzureSecurity
---
Azure Security Center (ASC) provides unified security management and advanced threat protection for workloads running in Azure, on-premises, and in other clouds. The following are Security Center recommendations that, if followed, will set various security policies on an Azure subscription.
These policies define the set of controls that are recommended for your resources with an Azure subscription.
### Enable System Updates
Azure Security Center monitors daily Windows and Linux virtual machines (VMs) and computers for missing operating system updates. Security Center retrieves a list of available security and critical updates from Windows Update or Windows Server Update Services (WSUS), depending on which service is configured on a Windows computer. Security Center also checks for the latest updates in Linux systems. If your VM or computer is missing a system update, Security Center will recommend that you apply system updates.
1. Sign in to the Azure portal.
2. Select **Security Policy** on the **Security Center** main menu.
3. The **Policy Management** screen is displayed.
4. Choose your subscription from the displayed list.
5. Check that **System updates should be installed on your machines** is one of the policies.
6. Click the Enable Monitoring in Azure Security Center link (This may also be displayed as ASC Default witha GUID).
7. In this example, the ASC agent has not been deployed to a VM or physical machine so the message AuditIfNotExists is displayed. AuditIfNotExists enables auditing on resources that match the if condition. If the resource is not deployed, NotExists is displayed.
If enabled, Audit is displayed. If deployed but disabled, Disabled is displayed.

### Enable Security Configurations
Azure Security Center monitors security configurations by applying a set of over 150 recommended rules for hardening the OS, including rules related to firewalls, auditing, password policies, and more. If a machine is found to have a vulnerable configuration, Security Center generates a security recommendation.
1. Sign in to the Azure portal.
2. Select **Security Policy** on the **Security Center** main menu.
3. The Policy Management screen is displayed.
4. Choose your subscription from the displayed list.
5. Check that **Vulnerabilities in security configuration on your virtual machine scale sets should be remediated** is one of the policies.
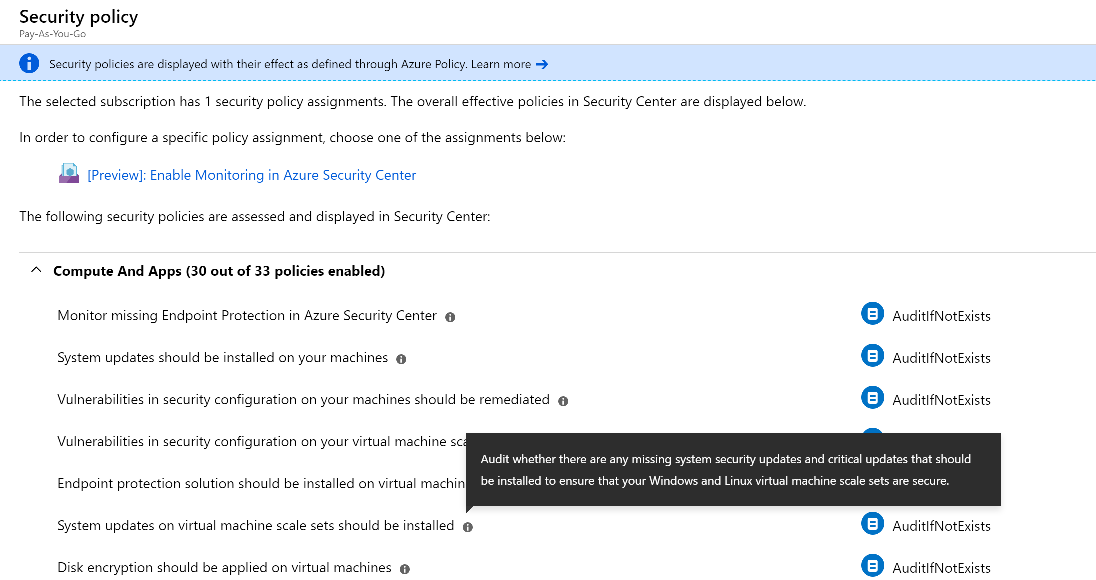
- **Enable Endpoint Protection** - _Endpoint protection is recommended for all virtual machines._
- **Enable Disk Encryption** - _Azure Security Center recommends that you apply disk encryption if you have Windows or Linux VM disks that are not encrypted using Azure Disk Encryption. Disk Encryption lets you encrypt your Windows and Linux IaaS VM disks. Encryption is recommended for both the OS and data volumes on your VM._
- **Enable Network Security Groups** _Azure Security Center recommends that you enable a network security group (NSG) if one is not already enabled. NSGs contain a list of Access Control List (ACL) rules that allow or deny network traffic to your VM instances in a Virtual Network. NSGs can be associated with either subnets or individual VM instances within that subnet. When an NSG is associated with a subnet, the ACL rules apply to all the VM instances in that subnet. In addition, traffic to an individual VM can be restricted further by associating an NSG directly to that VM._
- **Enable Web Application Firewall** - _Azure Security Center may recommend that you add a web application firewall (WAF) from a Microsoft partner to secure your web applications._
- **Enable Vulnerability Assessment** - _The vulnerability assessment in Azure Security Center is part of the Security Center virtual machine (VM) recommendations. If Security Center doesn't find a vulnerability assessment solution installed on your VM, it recommends that you install one. A partner agent, after being deployed, starts reporting vulnerability data to the partner's management platform. In turn, the partner's management platform provides vulnerability and health monitoring data back to Security Center._
- **Enable Storage Encryption** - _When this setting is enabled, any new data in Azure Blobs and Files will be encrypted._
- **Enable JIT Network Access** - _Just-in-time (JIT) virtual machine (VM) access can be used to lock down inbound traffic to your Azure VMs, reducing exposure to attacks while providing easy access to connect to VMs when needed._
- **Enable Adaptive Application Controls** - _Adaptive application control is an intelligent, automated end-to-end application whitelisting solution from Azure Security Center. It helps you control which applications can run on your Azure and non-Azure VMs (Windows and Linux), which, among other benefits, helps harden your VMs against malware. Security Center uses machine learning to analyze the applications running on your VMs and helps you apply the specific whitelisting rules using this intelligence. This capability greatly simplifies the process of configuring and maintaining application whitelisting policies._
- **Enable SQL Auditing & Threat Detection** - Azure Security Center will recommend that you turn on auditing and threat detection for all databases on your Azure SQL servers if auditing is not already enabled. Auditing and threat detection can help you maintain regulatory compliance, understand database activity, and gain insight into discrepancies and anomalies that could indicate business concerns or suspected security violations.
- **Enable SQL Encryption** - _Azure Security Center will recommend that you enable Transparent Data Encryption (TDE) on SQL databases if TDE is not already enabled. TDE protects your data and helps you meet compliance requirements by encrypting your database, associated backups, and transaction log files at rest, without requiring changes to your application._
- **Set Security Contact Email and Phone Number** - _Azure Security Center will recommend that you provide security contact details for your Azure subscription if you haven't already. This information will be used by Microsoft to contact you if the Microsoft Security Response Center (MSRC) discovers that your customer data has been accessed by an unlawful or unauthorized party. MSRC performs select security monitoring of the Azure network and infrastructure and receives threat intelligence and abuse complaints from third parties._
6. Select **Cost Management + Billing**.
7. The Contact info screen is displayed.
8. Enter or validate the contact information displayed.
### Enable Send me emails about alerts
Azure Security Center will recommend that you provide security contact details for your Azure subscription if you haven't already.
1. Select **Cost Management + Billing**.
2. The Pricing & settings screen is displayed.
3. Click on the subscription.
4. Click **Email notifications**.
5. Select **Save**.
### Enable Send email also to subscription owners
Azure Security Center will recommend that you provide security contact details for your Azure subscription if you haven't already.
1. Using the above Email notifications form, additional emails can be added separated by commas.
2. Click **Save**.
| cheahengsoon |
223,548 | Create a logging and monitoring baseline | Create a logging and monitoring baseline | 0 | 2020-04-08T23:05:20 | https://dev.to/cheahengsoon/create-a-logging-and-monitoring-baseline-35nc | azure, azuresecurity | ---
title: Create a logging and monitoring baseline
published: true
description: Create a logging and monitoring baseline
tags: #Azure, #AzureSecurity
---
Logging and monitoring are a critical requirement when trying to identify, detect, and mitigate security threats. Having a proper logging policy can ensure you can determine when a security violation has occurred, but also potentially identify the culprit responsible. Azure Activity logs provide data about both external access to a resources and diagnostic logs, which provide information about the operation of that specific resource.
### Ensure that a log profile exists
The Azure Activity Log provides insight into subscription-level events that have occurred in Azure. This includes a range of data, from Azure Resource Manager operational data to updates on Service Health events. The Activity Log was previously known as Audit Logs or Operational Logs, since the Administrative category reports control-plane events for your subscriptions. There is a single Activity Log for each Azure subscription. It provides data about the operations on a resource from the outside. Diagnostic Logs are emitted by a resource and provide information about the operation of that resource. You must enable diagnostic settings for each resource.
1. In the Azure Portal go to **Monitor**, then select **Activity log**.
2. Click on **Export to Event Hub**.
3. Configure the following settings then click **Save**.
- **Region**: EastUS
- **Select**: Export to Storage Account
- **Storage Account**: Select your storage account and click OK
- **Retention**: 90 days
4. Select **Save**.
### Change activity log retention is set to 365 days or more
Setting the Retention (days) to 0 retains the data forever.
1. Follow the steps listed above. Adjust the Retention days slider bar.
### Create an activity log alert for "Creating, updating, or deleting a Network Security Group"
By default, no monitoring alerts are created when NSGs are created/updated/deleted. Changing or deleting a security group can allow internal resources to be accessed from improper sources, or for unexpected outbound network traffic.
1. In to the Azure portal go to **Monitor**, then select **Alerts**.
2. Select **+ New alert rule**.
3. In the **Resource** section click **Select**.
4. Select your subscription and click **Done**.
5. In the **Condition** section click **Add**.
6. Search for **Create or Update Network Security Group** and select it.
7. On the Configure signal logic blade, in the Event initiated by enter **any** and click **Done**.
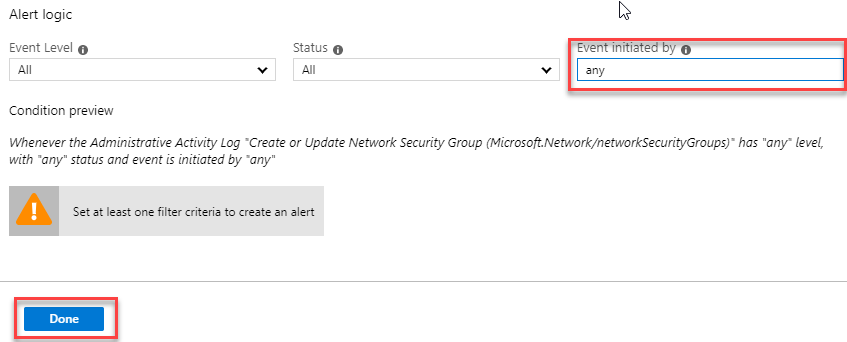
8. In the **Actions** section click **Create action group**.
9. On the Add action group blade enter the following details:
- **Action group name**: NSG Alert
- **Short name**: NSGAlert
- **Action Name**: NSG Alert
- **Action type**: Email/SMS/Push/Voice
10. On the **Email/SMS/Push/Voice** blade check the email box and enter your email address and click **OK**.
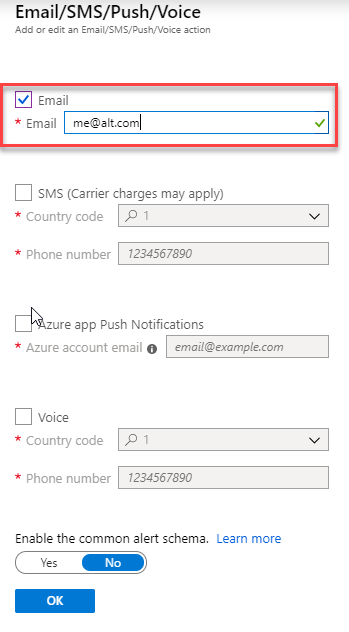
11. On the Add action group blade click **OK**.
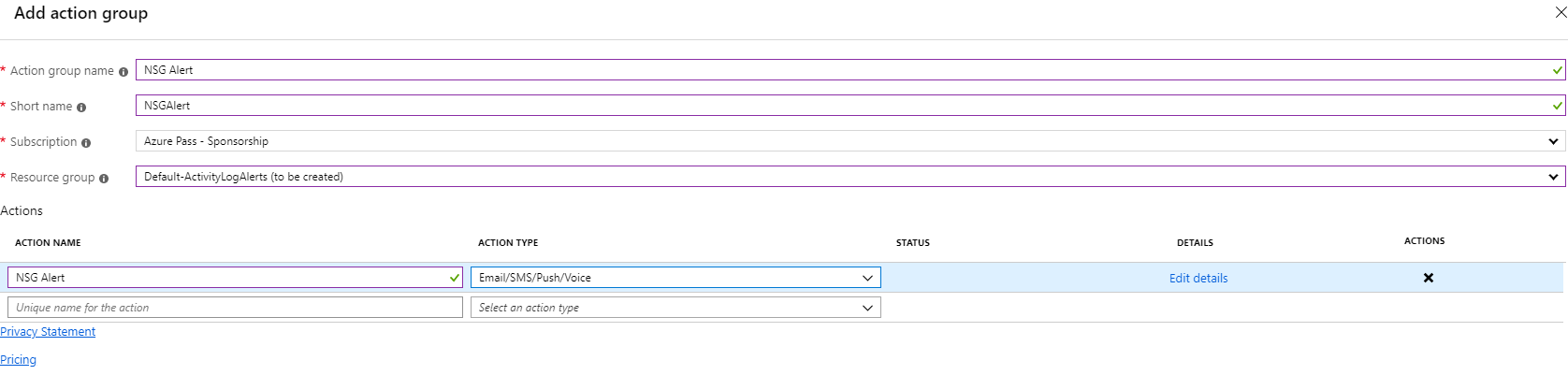
12. On the Create rule blade, in the **Alert Details** section enter the following details:
- **Alert rule name**: NSG Alert
- **Save to resource group**: myResourceGroup
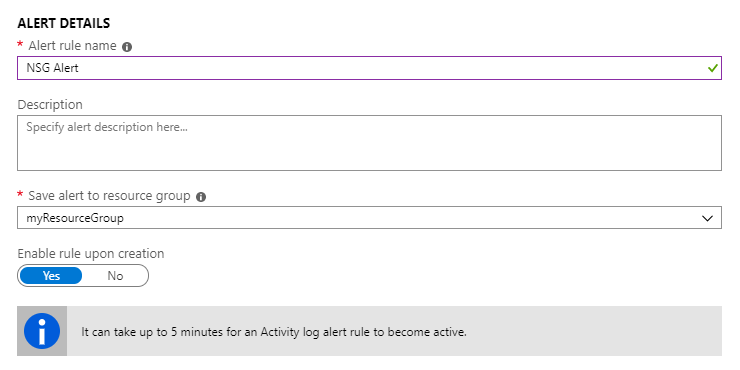
6. Click **Create alert rule**
| cheahengsoon |
223,636 | Emoji Island Dispatch: Play on your phone with an Emoji URL 🤯 | Updates to emoji island and a warning about emoji urls | 3,790 | 2019-12-19T09:09:30 | https://dev.to/shiftyp/emoji-island-dispatch-play-on-your-phone-with-an-emoji-url-39g | showdev, devops, mobile, gamedev | ---
title: Emoji Island Dispatch: Play on your phone with an Emoji URL 🤯
published: true
description: Updates to emoji island and a warning about emoji urls
tags: showdev, devops, mobile, gamedev
series: Emoji Island
---
Hello all!
Two updates to the emoji island project:
1. I modified the UI so you can play on your phone! I'd welcome any feedback, or even a pull request! There should be a way for you to do it all in CodeSandbox, so let me know if you need help!
2. To make it super mobile friendly, I registered an [emoji domain](https://🏝.fm) — literally `https://🏝.fm` — for emoji island! And through much struggle I managed to get it to work.
Want to register your own emoji domain? My tips are, if you run into problems with a registrar (which you probably will):
1. Definitely let them know about your issues. Nobody fixes what they don't see or know customers care about.
2. It may be possible (as it was for me) to manually edit some of their API calls to replace the emoji domain with an alternate code (for `🏝.fm` the code is `xn--rm8h.fm`) This is a pain but it may allow you to update dns records you otherwise couldn't
3. Be very careful with transfers! I tried and it failed. I thought I lost it all together, but it stayed at the original registrar. I suspect this is also related to special characters and systems unable to process them.
Anyway, I'm happy this works! If it doesn't, let me know! And thanks!
With ❤️ from Emoji Island:
-- Ryan | shiftyp |
223,665 | Responsive websites that are not so responsive | I embrace the fluidity of the web. People use all kinds of devices, from smartwatches to TVs. It’s al... | 0 | 2019-12-19T09:45:13 | https://dev.to/francoscarpa/responsive-websites-that-are-not-so-responsive-h4f | discuss, css, responsive, typography | I embrace the fluidity of the web. People use all kinds of devices, from smartwatches to TVs. It’s almost impossible to provide the same, exact UX to all of them.
In this regard, I wonder what’s the best way to make a website really responsive. Most of the sites use a fixed-width body after a specific (break)point, with auto margins to center it horizontally. This image is a screenshot of a webpage seen on a 4K TV:

I find it to be a not so good philosophy when building truly responsive websites: why do I have to see a site in so an uncomfortable way when I see it on a TV, therefore viewing it from afar? Shouldn’t we build websites that scale well, in a way that lets them take advantage of all the screen’s space? Shouldn’t we use truly responsive typography and layouts? Of course, using fixed-width after a breakpoint we think is appropriate is a good way to give us more control, but again, I think this doesn’t embrace the responsive philosophy completely.
| francoscarpa |
223,691 | 5 reasons that make me want go back to Devoxx Morocco-2020 |
5 reasons that make me want go back to Devoxx Morocco-2020 🇲🇦
I had an... | 0 | 2019-12-20T05:07:38 | https://medium.com/@isantoshv/5-reasons-that-make-me-want-go-back-to-devoxx-morocco-2020-d079560d34b4 | mozillatechspeaker, conference, devoxx, morocco | ---
title: 5 reasons that make me want go back to Devoxx Morocco-2020
published: true
date: 2019-12-19 09:34:44 UTC
tags: mozilla-tech-speaker,conference,devoxx,morocco
canonical_url: https://medium.com/@isantoshv/5-reasons-that-make-me-want-go-back-to-devoxx-morocco-2020-d079560d34b4
---
### 5 reasons that make me want go back to Devoxx Morocco-2020 🇲🇦
I had an opportunity to speak at [Devoxx Morocco](https://devoxx.ma/) last month(Nov 2019), It was my second Voxxed Event and one of the best conferences I have been to so far. I gave a talk on A Practical approach to CSS Grid and I liked the conference both from a perspective of a speaker and an attendee. I got some amazing pictures from the conference(Finally 🖼) and thought I could share few things I liked about Devoxx Morocco with you all.
### Content of the Conference
The conference got amazing content and a great speaker line up. There were [10 different tracks](https://devoxx.ma/#tracks) at the conference Including Robotics, VR, Cloud, Containers, etc. Though I was a speaker I attending multiple sessions and Keynotes around Performance, IoT, Documentation, Containers, etc. and Explore/learn from my co-speakers. All I wish to see is a little more talks under Modern Web and UX track next year. 🤞
<figcaption>Opening Keynote</figcaption>
### Hospitality of the Conference
The hospitality at Devoxx was one of the best I have had at a conference so far. Starting from confirming my presence as a Speaker at Devoxx to returning back home, they were the best of the kind. I was worried about getting to the hotel, going around in Adagir, My way around in Casablanca(where I had to stay for a night), but they took care of everything. There was already a guy waiting for me at the airport when I arrived, A team to take care of registrations when I arrive at the hotel, Everyone made it so easy around the conference. It is always a bit hard and can be stressful when you travel to a new city for the first time but they sorted out the hard part of our speaker's lives.

### Culture of Morocco
I’m glad that I got an opportunity to dress like the locals, eat local food, dance in the Moroccan style, Celebrate a Moroccan wedding and much more. On the second day of the conference, All the participants and speakers were invited to a Moroccan Dinner where we dressed like the locals from different provinces, Had the local food(I loved it), Danced a lot and got a chance to check out how the weddings Happen in Moroccan Traditions. I was told that In Morocco they dance along all night and get married at midnight just before sunrise. Truly, they got one of the best wedding celebrations around the world.

### **Diversity**
I have never been to a conference that is as diverse as Devoxx Morocco. I’m not just talking about speakers, I’m talking about audience, Organizing, and Volunteer community/teams. and I’m not just talking about diversity in terms of Gender(which is the best here among all the conferences I have been too), I’m talking about geographical distribution, Age groups, the Experience level of speakers and ethnicity. and Each one of them is as energized/excited as any other person in the room.

### People
The people of Morocco are Kind, Helpful and Most friendly. A funny thing happened to me multiple times when I was in Morocco. Apparently many Moroccans watch Bollywood movies and they love them, so whenever I walk into a store to buy something they used to ask me where I’m from, If I say Indiathen they used to start singing Bollywood songs and we used to do a short karaoke session then and there. I used to get India discount too(I bought 2 beautiful fridge magnets for 20MAD, Hope it was a good deal 😄). Even at the speakers trip after the conference, We danced for Bollywood bits, They taught me some Moroccan moves, Had great conversations about everything but nothing. I was a bit worried as I didn’t know anyone when I decided to go to the conference. But from the moment I arrived at the conference, they made it easy for me and I felt home.

{% youtube syFyD3l7Y8U %}
Finally, This is me giving my talk(The photographers at Devoxx were amazing 😍).
<figcaption>Talking about A Practical approach to CSS Grid</figcaption>
I’m glad that my talk got selected. This was truly an experience of a lifetime and I hope I will visit back again next year for Devoxx Morocco — 2020. 🤞 | devcer |
223,745 | Practical DevOps #2: On shaming and blaming | As I often state when I do talks or courses on the topic of DevOps, I'm a firm believer that DevOps h... | 2,832 | 2019-12-21T21:30:14 | https://simme.dev/posts/practical-devops-on-shaming-and-blaming/ | devops, shaming, blaming, agile | As I often state when I do talks or courses on the topic of DevOps, I'm a firm believer that DevOps has very little to do with technology, and a whole lot to do with culture.
We, as developers, are often very good at performing root cause analysis and present a conclusion whenever things go south. Usually, we're also as good at pinning that mistake onto someone, whether it's a colleague or ourselves.
I get it, we're analytically inclined and wont rest until we've found the root cause. This in itself is something positive that we should keep on doing. However, when even our tools use terms as blame (git blame anyone), it's clear that we might need to change how we do this.
Throughout the years, I've been in many organisations where, when someone detected an outage or bug in our production systems, everyone got real busy trying to find out who was "responsible" or "caused" it. This is a super-effective way to make sure that there is:
### Fear of punishment
If every failure is met with punishment, whether it's intended or not, the organisation will quickly become less prone to take risks or experiment. This stands in direct contradiction to the DevOps goal of promoting experimentation and collaboration.
No one wants to be called out as a failure. If the possible outcomes of trying something new ranges between silence or blame, why would anyone ever try to do something differently?
### Missed learning opportunities
Picture yourself learning something new. Maybe a new language, or an instrument. Every time you make a mistake, your friends or partner would call that out and tell you how your mistake ruined the whole song.
Even if they followed that up by giving constructive, actionable feedback on how you could improve. Would you be inclined to listen and learn from it? I know I wouldn't. Likely, I'd even stop trying altogether if it happened frequently.
---
## So what should we do?
A former colleague of mine had such an excellent saying on blame and shame:
> ### Focus on making it easier to succeed, not harder to fail
### Blameless post-mortems
Make sure you take every chance you get to inspect the outcome and make sure to understand *why* it happened and how to improve, not *who* did it and how to punish them.
### Practice acceptance
Things go south and mistakes happen. Until we learn to accept this fact, the expectations we have of ourselves and others won't be reasonable and will only lead to unnecessary stress and disappointment.
### Encourage change
Someone, unfortunately I don't really remember who, told me that they've actually renamed git blame to git praise, as in `finding out who to praise for having the courage to change something`. While it might not be feasible to replace the word in your tools, the sentiment is great.
---
Thank you for reading. 🙏🏼
If you enjoyed this article, click the ❤️ button and subscribe to make sure you won't miss the next part. | simme |
223,795 | Building Sudoku in Vue.js - Part 2 | Earlier this week I blogged about my attempt to build a Sudoku game in Vue.js. At the time, I felt li... | 0 | 2019-12-19T22:05:02 | https://www.raymondcamden.com/2019/12/19/building-sudoku-in-vuejs-part-2 | vue, javascript, webdev | ---
title: Building Sudoku in Vue.js - Part 2
published: true
date: 2019-12-19 00:00:00 UTC
tags: vuejs,javascript,webdev
canonical_url: https://www.raymondcamden.com/2019/12/19/building-sudoku-in-vuejs-part-2
cover_image: https://static.raymondcamden.com/images/banners/papers.jpg
---
Earlier this week I [blogged](https://www.raymondcamden.com/2019/12/16/building-sudoku-in-vuejs-part-1) about my attempt to build a Sudoku game in Vue.js. At the time, I felt like I had done a good majority of the work, but that I was at a good stopping point to write it up and blog. Well last night I “finished” the app (to be clear, there’s absolutely room for polish) and I’m kind of embarrassed at how little I had left to do. I’m going to assume I’m just far more intelligent than I think and am an awesome coder despite failing the Google test more than once.
In this update I tackled three things:
- Added the ability start a new game with a custom difficulty.
- Marking incorrect entries. Which again is a personal preference, it wouldn’t be too hard to make this optional.
- Added the ability to notice when you won.
Let me tackle each part separately. For difficulty, I began by adding the supported difficulty levels to my state:
```js
difficulties: ["easy", "medium", "hard", "very-hard", "insane", "inhuman"],
```
I then modified `initGrid` to handle an optional difficulty:
```js
mutations: {
initGrid(state, difficulty) {
if(!difficulty) difficulty = state.difficulties[0];
state.origString = sudokuModule.sudoku.generate(difficulty);
```
Finally, over in my main `App.vue`, I added UI to render the difficulties and a button to start a new game. There’s no restriction on when you can do this. First the HTML:
```html
<select v-model="difficulty">
<option v-for="(difficulty,idx) in difficulties" :key="idx">{{difficulty}}</option>
</select> <button @click="newGame">Start New Game</button>
```
And here’s the code behind this.
```js
import { mapState } from 'vuex';
import Grid from '@/components/Grid';
export default {
name: 'app',
components: {
Grid
},
data() {
return {
difficulty: null
}
},
computed: mapState([
'difficulties', 'wonGame'
]),
created() {
this.$store.commit('initGrid');
this.difficulty = this.difficulties[0];
},
methods: {
newGame() {
this.$store.commit('initGrid', this.difficulty);
}
}
}
```
I’m using `mapState` to bring in the difficulties and then added a method, `newGame`, that calls `initGrid` with the selected difficulty.
Now let’s look at marking incorrect values. I modified `setNumber` in my store to simply check if the new value matches the solution value:
```js
// highlight incorrect answers
if(x !== state.grid[state.selected.x][state.selected.y].solution) {
row[state.selected.y].error = true;
} else {
row[state.selected.y].error = false;
}
```
Then in Grid.vue, I check for this value and apply a class:
```html
<td v-for="(cell,idy) in row" :key="idy"
:class="{
locked: grid[idx][idy].locked,
selected:grid[idx][idy].selected,
error:grid[idx][idy].error
}"
@click="setSelected(grid[idx][idy], idx, idy)"> {{ grid[idx][idy].value }}</td>
```
Finally, to handle if you’ve won the game, I further modified `setNumber` by adding in this code:
```js
/*
did we win? this feels like it should be it's own method
*/
let won = true;
for(let i=0;i<state.grid.length;i++) {
for(let x=0;x<state.grid[i].length;x++) {
if(state.grid[i][x].value !== state.grid[i][x].solution) won = false;
}
}
if(won) state.wonGame = true;
```
As the comment says, it really felt like this should be it’s own method. Looking over my code now, I’d probably consider moving my Sudoku “game” logic in it’s own file and keep my store focused on just the data. I say this again and again but I still struggle, or not struggle, but really think about, where to put my logic when it comes to Vue and Vuex. I love that Vue is flexible in this regard though!
The final part of handling “game won” logic is a simple conditional in the main component:
```html
<div v-if="wonGame">
<h2 class="wonGame">YOU WON!</h2>
</div>
```
That’s pretty simple and could be much more exciting, but I’m happy with it. You can see the code at [https://github.com/cfjedimaster/vue-demos/tree/master/sudoku](https://github.com/cfjedimaster/vue-demos/tree/master/sudoku). If you want to see it in your browser, visit [https://sudoku.raymondcamden.now.sh/](https://sudoku.raymondcamden.now.sh/). Please let me know what you think by leaving me a comment below!
_Header photo by [Tienda Bandera](https://unsplash.com/@tiendabandera?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on Unsplash_ | raymondcamden |
223,814 | What is your Favorite Browser? | I assume most of the web developers out there have many browsers installed for cross browser testing.... | 0 | 2019-12-20T12:18:08 | https://dev.to/devmount/what-is-your-favorite-browser-210l | watercooler, discuss, question, webdev | I assume most of the web developers out there have many browsers installed for cross browser testing.
What is your favorite browser for personal use on desktop and mobile? I'm also curious if/how your opinion changed over time and what features you prefer.
*Plus: The one who can first comment the correct names of all browsers of the cover image in the correct order (left to right, top to bottom) gets a little christmas surprise from me...* 🎁🎄 | devmount |
224,833 | String functions in C | Analyzing and converting strings in the C programming language | 3,822 | 2019-12-21T01:13:37 | https://dev.to/mikkel250/string-functions-in-c-48i7 | c, strings, basics, beginners | ---
title: String functions in C
published: true
description: Analyzing and converting strings in the C programming language
tags: c, strings, basics, beginners
series: Basics of the C programming language
---
###String functions in the C programming language
Since a character string is actually a char array terminated with a null character `\0`, strings are not a variable/data type, so you can't use the same operators on them that can be used with other data types. In the standard and string libraries, however, there are many functions that are designed to work with strings.
Some of the most commonly used operators are listed below.
- strlen() gets the length of the string.
- returned as size_t
For example:
```c
#include <stdio.h>
#include <string.h>
int main() {
char myString[] = "my string";
printf("The length of my string is %d", strlen(myString));
return 0;
}
```
####Copying strings: strncpy()
While there is an alternative strcpy() function, the easier and safer method to use is strncpy() -- note the "n".
The syntax is:
```c
strncpy(destination, source, maximumNumberOfCharactersToCopy);
```
The size of the last argument should correspond to the size of the destination array, minus 1 to account for the null terminator at the end to prevent buffer overflows.
####Concatenation: strncat()
The strncat() function takes two strings as arguments and the second argument is tacked on to the end of the first. The combined version becomes the new first string, and the original second string is not altered. It returns the value of its first argument -- the address of the first character of the string to which the second string is appended. The third argument is how many character to copy.
The syntax is:
```c
strncat(destination, source, numberOfCharacterToCopy);
```
Like the copy function above, there is also a strcat() function, but will result in a buffer overflow if the second string does not fit into the first array's size.
####Comparing strings: strncmp()
Compares the contents of the two strings, and returns the following values:
```c
stncmp(string1, string2, numberOfCharactersToCompare);
/*
results in:
0 if the strings are equal
< 0 if string1 is less than string2
> 0 if string1 is greater than string2
*/
char firstString[] = "astronomy";
char secondString[] = "astro";
char thirdString[] = "astounding";
// a common use case for the compare function:
if (stncmp(firstString, secondString, 5) == 0) {
printf("Found: "astromony");
}
if (strncmp(thirdString, secondString, 5) == 0) {
printf("Found: "astounding");
}
```
Note that lowercase characters are greater than uppercase characters because of the way that the different letters are handled by the UTF standard, which can be researched, but suffice it to say that that a lowercase letter will always result in returning a lower value than any capital letter ('a' will be less than 'Z', despite their relative positions in the alphabet). If you want a strict comparison, the strings must both be the same case.
###String parsing and manipulation
One thing to note is that many of the following functions return pointers. If you are not familiar with pointers, then I'd recommend reading the installment in the series on pointers.
####Searching a string: strchr() and strstr()
Including the `<string.h>` header file will give you access to some string searching functions. These searches are case sensitive.
`strchr()` searches a given string for a specified character. The first argument is the string to be searched (which will be the address of a char array), and the second argument is the character you are looking for.
The function will search the string starting at the beginning and return a pointer to the first position in the string where the character is found. This return value is not the character itself, but a pointer to the position in memory where the character is stored. The address is essentially the index in the array, and is a special type char\*, described as the "pointer to char."
To store the value that's returned, create a variable that can store the address of a character.
If the character is not found, the function returns NULL, meaning the pointer does not point to anything.
```c
char str[] = "A quality example"; // string to be searched
char ch = 'q'; // the character to search for
char * pFoundChar = NULL; // pointer to hold the address of the character, if found, initialized to NULL
pFoundChar = strchr(str, ch); // stores address where ch is found
```
In the example above `pFoundChar` will point to "quality example", because it will start at 'q' but will go until it finds a null terminator (end of string).
To display the character, use `printf("%s", pFoundChar);`
Searching for a substring with strstr() is much the same as searching for a single character in a string, and will return the address plus the rest of the string until it encounters a null terminator:
```c
char str[] = "A quality example";
char word = 'quality';
char * pFoundWord = NULL;
pFoundWord = strstr(str, word);
```
#####Tokenizing a string
A token is a sequence of characters in a string that are bounded by a delimiter (commonly a space, comma, period, etc.), and breaking sentences into words is called tokenizing. Use the `strtok()` function to split a string into separate words.
`strtok()` takes two arguments: the string to be tokenized, and a string containing all possible delimiter characters.
This operator is great for parsing (breaking a long string into shorter bits). One handy way to to do this is with a while loop:
```c
int main() {
char str[80] = "Hello, my name is Mikkel. It's nice to meet you. I'm learning C, how about you?";
const char s[2] = ".";
char *token;
// get the first token
token = strtok(str, s);
// walk through the other tokens
while (token != NULL) {
printf("%s\n", token);
token = strtok(NULL, s);
}
return 0;
}
```
####Analyzing strings: booleans
The following is a list of other string functions that return a boolean (true/false) value, and do what you would expect based on the the descriptions.
The arguments to each of these functions is the letter to be tested.
A common use for these is to use a loop to test a string for the value in question.
| Function | Tests for |
| :--------: | :----------------------------------------------------------------: |
| Islower() | lowercase letter |
| isupper() | UpperCase Letter |
| isalpha() | any Letter |
| isalnum() | UpperCase or lowercase Letter or a digit |
| iscntrl() | control character |
| isprint() | any printing character including a space |
| isgraph() | any printing character except a space |
| isdigit() | decimal digit (0-9) |
| isxdigit() | hexadecimal digit (0-9, A-F, a-f) |
| isblank() | standard blank characters (space, tab ['\t']) |
| isspace() | any whitespace character (space, '\n', '\t', '\v', '\r') |
| ispunct() | printing character for which isspace() and isalnum() return false |
| toupper() | converts the character to uppercase (use a loop to convert string) |
| tolower() | converts the character to lowercase (use a loop to convert string) |
You can use the toupper() or tolower() along with the strstr() function to search an entire string and ignore case.
The example below illustrates how one could use some of the methods above to test a user's password for strength.
```c
int main() {
char buf[100]; // input buffer
int nLetters = 0; // number of letters in input
int nDigits = 0; // number of digits in input
int nPunct = 0; // number of punctuation characters
printf("Enter password of more than 8 and less than 100 characters, with at least one digit, and one punctuation mark: ");
scanf("%s", buf);
int i = 0;
while(buf[i])
{
if (isalpha(buf[i]))
{
++nLetters;
}
else if (isdigit(buf[i]))
{
++nDigits;
}
else if (ispunct(buf[i]))
{
++nPunct;
}
++i;
}
if (nLetters < 8 || nLetters > 100 || nDigits < 1 || nPunct < 1)
{
printf("Sorry, password too weak! Try again.\n");
}
else
}
printf("Password saved!");
}
return 0;
}
```
####Converting strings to numbers
The stdlib.h header file declares functions that you can use to convert a string to a numerical value.
Note that all functions below, leading whitespace is ignored.
| Function | Returns |
| :------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| atof() | A value of type double that is produced from the string argument. Infinity as a double value is recognized from the string's `INF` or `INFINITY` where any character can be uppercase or lowercase and `not a number` is recognized from the string `NAN` in uppercase or lowercase. |
| atoi() | A value of type int that is produced from the string argument |
| atol() | A value of type long that is produced from the string argument |
| atoll() | A value of type long long that is produced from the string argument |
These functions are used to convert numbers that are found in strings to actual numbers, e.g.
```c
char tempString[] = "98.6";
float tempFloat = atof(tempString);
// tempFloat will have the float value of 98.6
```
That covers the basics of string functions!
| mikkel250 |
225,051 | Open source shameless promotion thread | go ahead, what are you making? | 0 | 2019-12-21T19:51:26 | https://dev.to/fultonbrowne/open-source-shameless-promotion-thread-3ck4 | discuss, showdev | go ahead, what are you making? | fultonbrowne |
226,290 | OzCode a new way to debug your code | Photo by Ramón Salinero on Unsplash
Back in 2016, I saw a demo at a conference a... | 0 | 2019-12-24T13:23:31 | https://medium.com/@dvirsegal/ozcode-a-new-way-to-debug-your-code-25e39b22b8f6 | softwaredevelopment, csharp, visualstudio, debugging | ---
title: OzCode a new way to debug your code
published: true
date: 2019-12-24 12:29:43 UTC
tags: software-development,csharp,visual-studio,debugging
canonical_url: https://medium.com/@dvirsegal/ozcode-a-new-way-to-debug-your-code-25e39b22b8f6
---
<figcaption>Photo by <a href="https://unsplash.com/@donramxn?utm_source=medium&utm_medium=referral">Ramón Salinero</a> on <a href="https://unsplash.com?utm_source=medium&utm_medium=referral">Unsplash</a></figcaption>
Back in 2016, I saw a demo at a conference about a new visual studio extension that presumes to change the way an engineer debugs, they called it, magic debugging. Little that I know, it turned my debugging way of thinking upside down, indeed a magical approach.
Before I’ll continue, I owe a **_disclaimer_** for the readers. A previous colleague of mine is one of OzCode’s co-founders ([Omer Raviv](https://twitter.com/omerraviv)). Although it might harm the credibility of this blog-post, I’ll take the risk; for the reason that these lines were written by a happy user 🤓. My goal is to share with you my perspective on some of OzCode’s helpful features and why you should try it out too.
### What can OzCode do?
The primary purpose of this visual studio extension is to help you debug code and find the root cause of problems, a sort of **_online_** [ReSharper](https://www.jetbrains.com/resharper/). In the next paragraphs, I write about my favorite features, yet OzCode has more to offer.
#### DataTip
One of the valuable features is the DataTip; it replaces the dole visual studio tool-tip with much information, and it helped me in various defect debugging situations.
It contains a swift **search** functionally. It will go through any object’s fields and values and into several levels in the object’s hierarchy. Note that you can define as many levels as you want.
<figcaption>How useful is that, aha?</figcaption>
Each item is presented by the _ToString()_ implementation of the class (_seen as OzCodeDemo.Customer_ in the gif below_)_, but here comes OzCode to the rescue with the neat feature — **reveal**. By staring properties, you’ll be able to the ones that interest you the most.
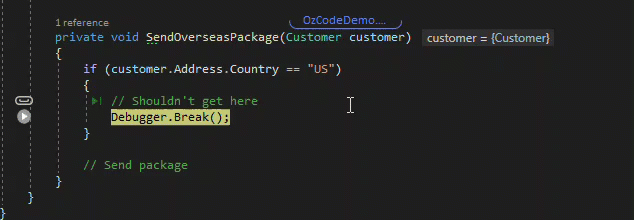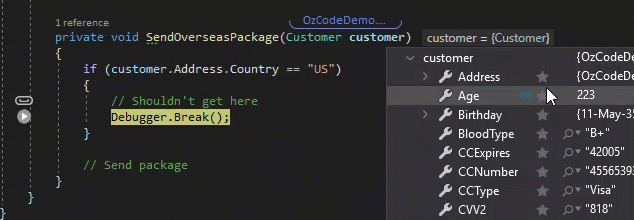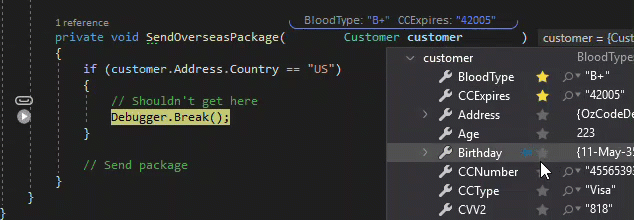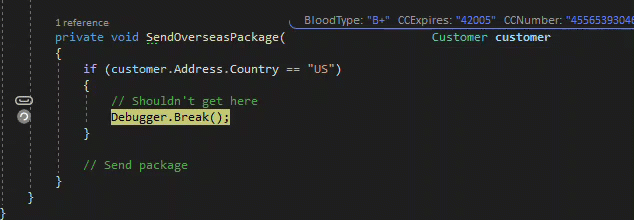<figcaption>Reveal, adding most interesting fields</figcaption>
Another useful option is the Export feature. You can extract each object internal into JSON/XML/C#, a helpful capability for creating mocked objects during unit testing, which saved me time. Also, the basic VS functionality is not neglect, you can instantly copy value or add a quick watch.
{% youtube JGl8DXxS0bY %}<figcaption>Export</figcaption>
#### LINQ Debugging
LINQ is one of the used features in C#, while one of his pitfalls is when debugging it. Developers have tried to overcome this by evaluating part of the query using Visual Studio’s QuickWatch window, placing (conditional) breakpoints in the lambda expressions for assessing each element individually, or by logging your progress. As you can see, it’s pretty cumbersome to debug it, so OzCode solves that exact need.
When hovering over LINQ expressions, you’ll see bubbles containing numbers. You can click on each bubble to analyze the evaluated LINQ expressions, each term in his stage. Combine it with the **Reveal** feature, and you are a rockstar.
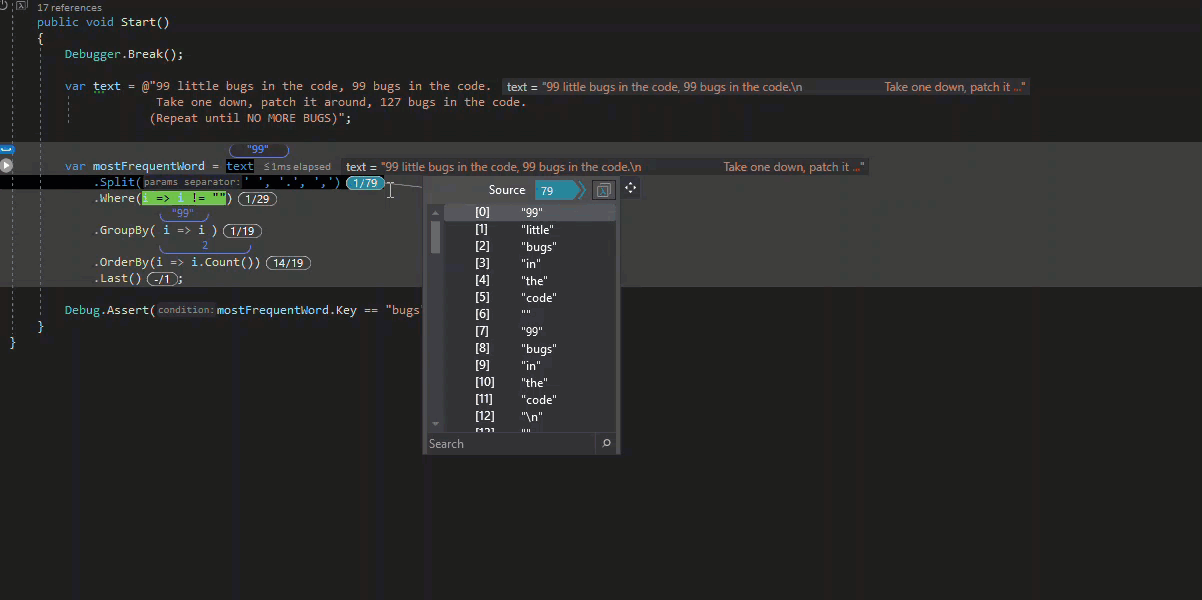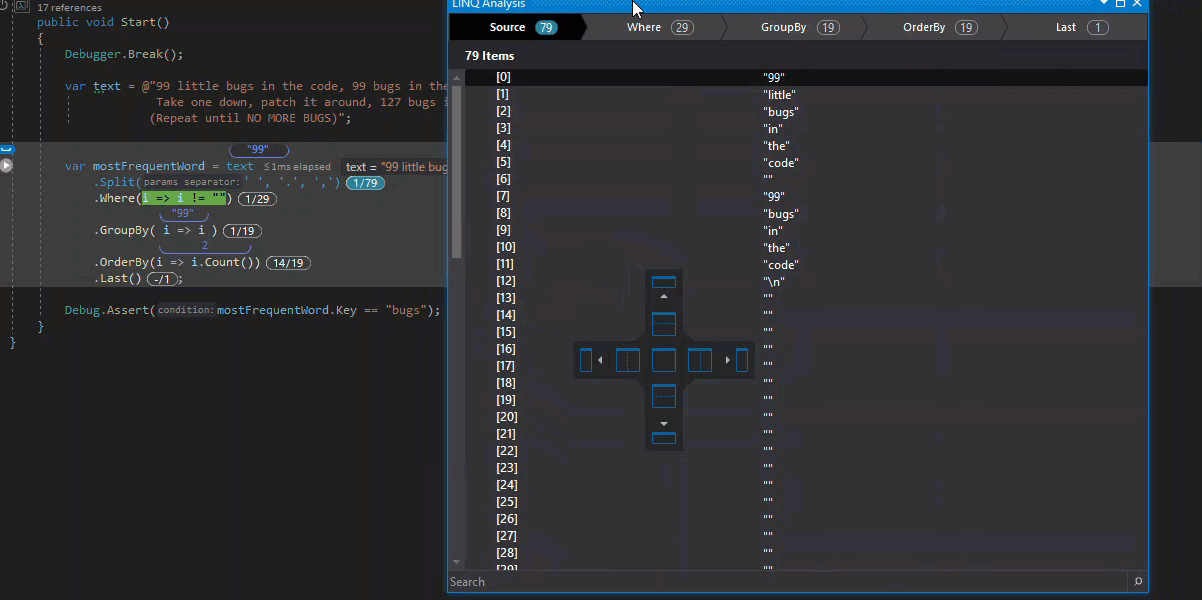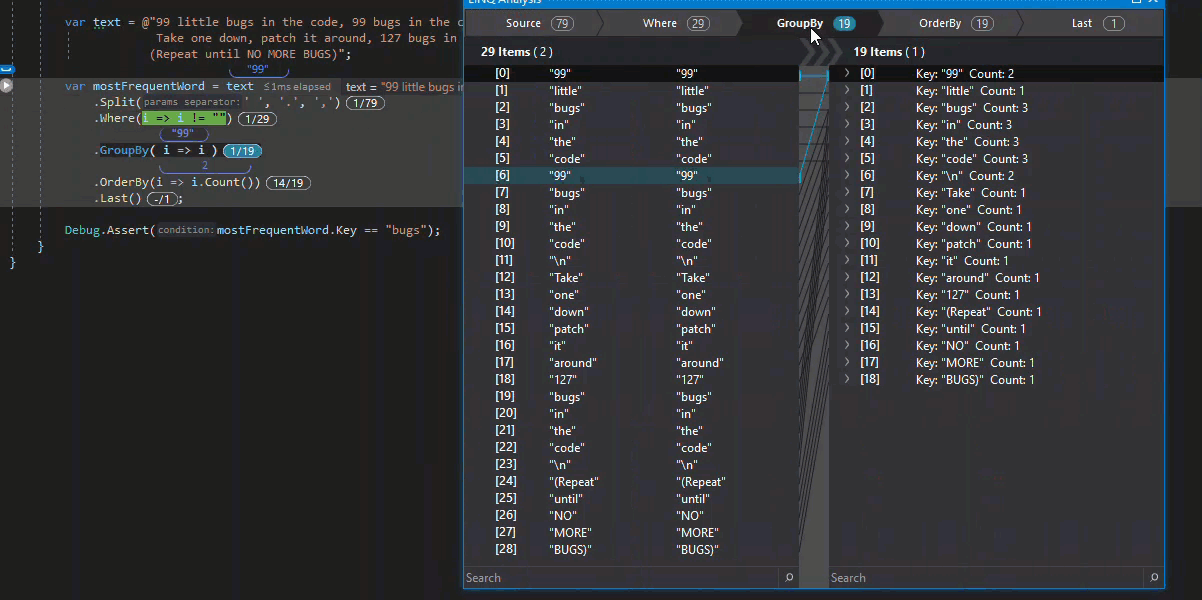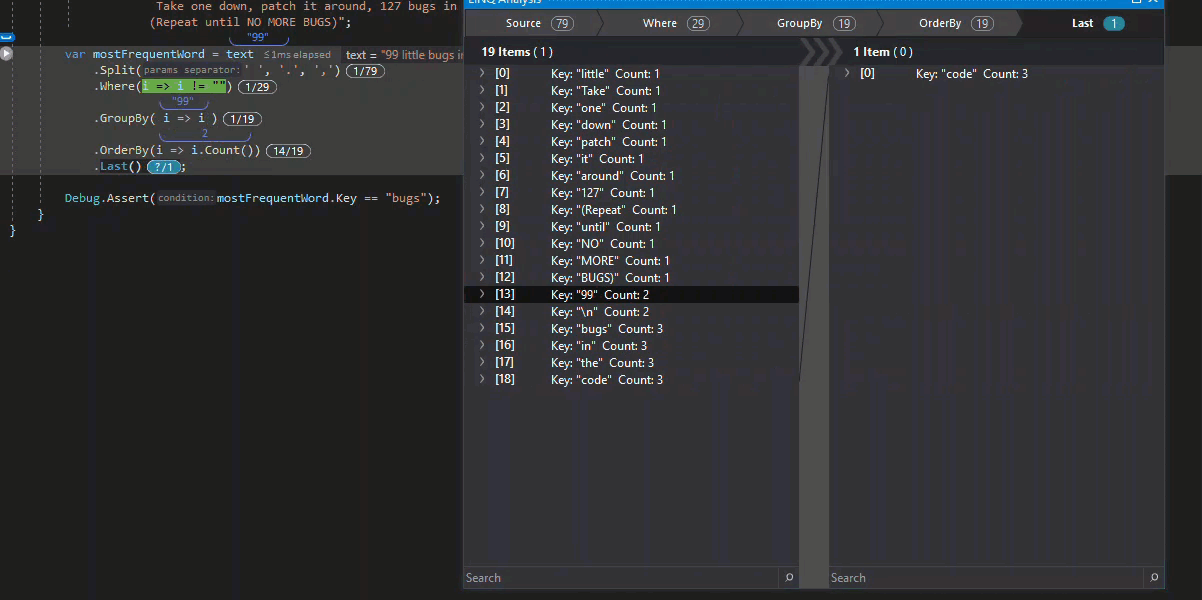
<figcaption>LINQ expression debugging</figcaption>
#### Time Travel
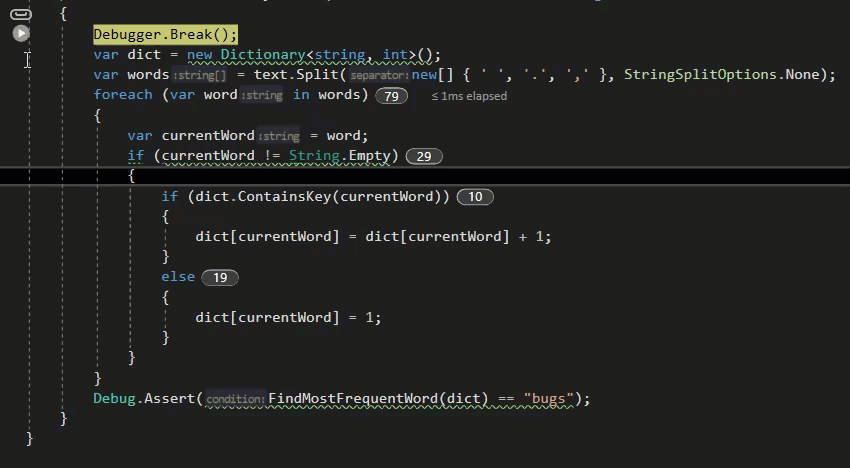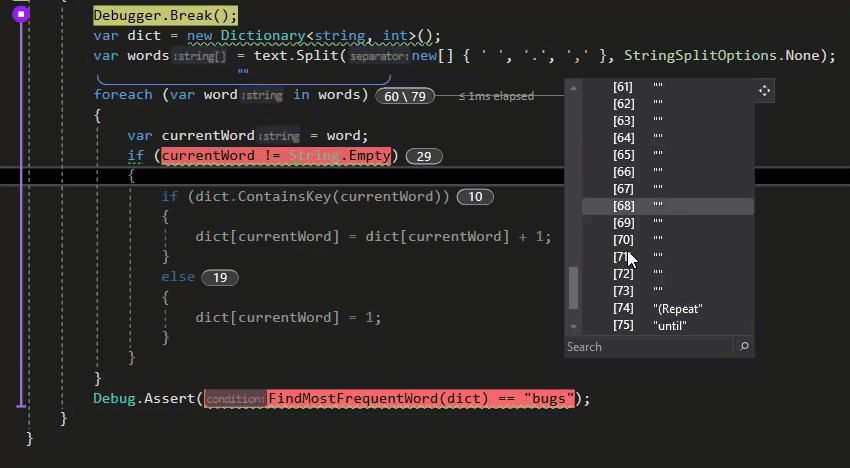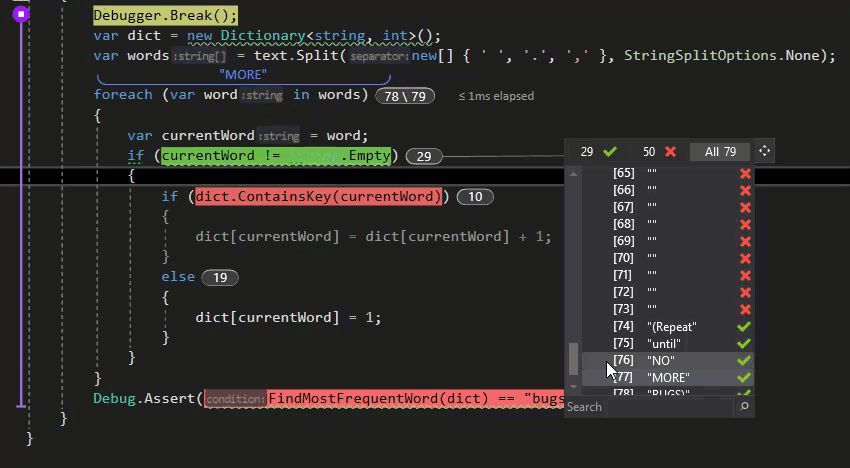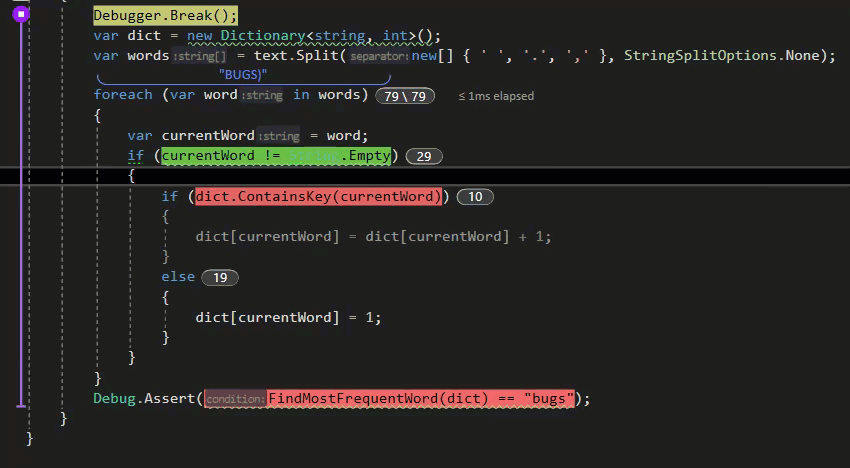<figcaption>Time travel — jump into specific iteration</figcaption>
OzCode simulates the results of future code execution without actually running it. In such a way, you’ll be able to detect bugs by jumping into specific loop iteration to the exact moment of failure without the need to step over your code in real-time. Using the **heads up display** feature that highlights the evaluated value of your code, a powerful feature by itself (extremely UX-oriented), you can investigate what happened. It saves you time for re-running a defect’s scenario multiple times while hunting for root-cause.
{% youtube u_1Lgzf3Y00 %}<figcaption>The powerful heads up display</figcaption>
Note that time travel doesn’t work when accessing external resources such as a database or native code since it can’t be simulated without affecting the application’s state.
#### Tracepoints
Another useful feature is Tracepoints, which allows logging your debugging scenario into the editor’s viewer. Thus, quickly analyze any issue, even a multi-threaded one, as can be seen in the image below where different messages arrive from various processes and threads’ Ids.
<figcaption>Tracepoint viewer — demonstrate multithreaded info</figcaption>
#### Compare
You can even compare objects and collections in memory. One excellent option is to take a snapshot and compare the same object across different points in time.
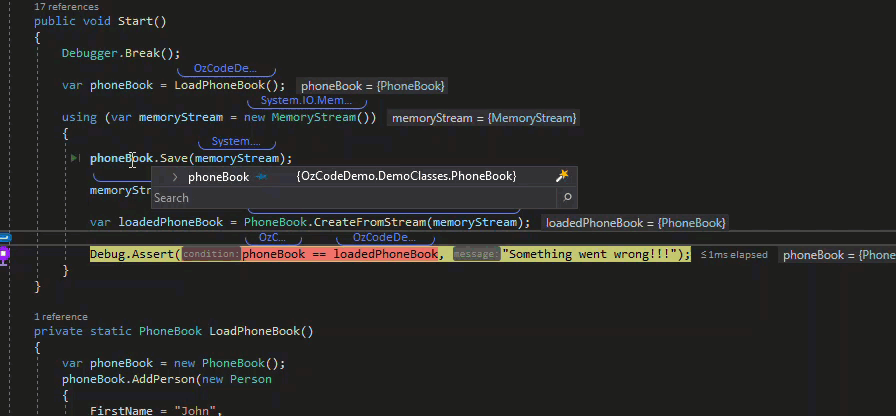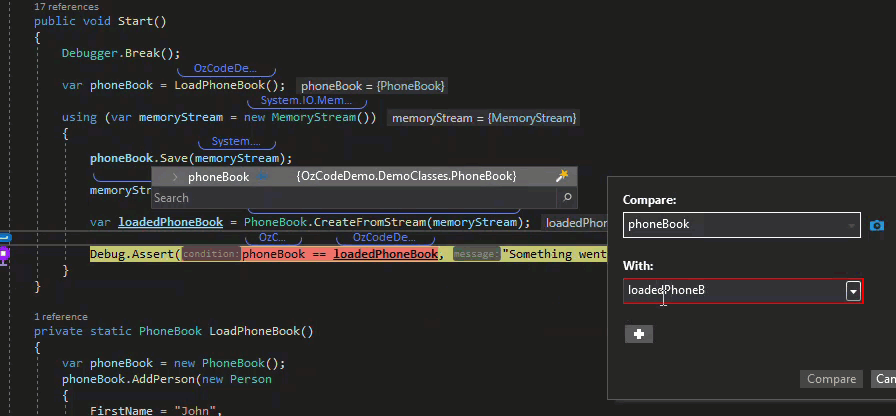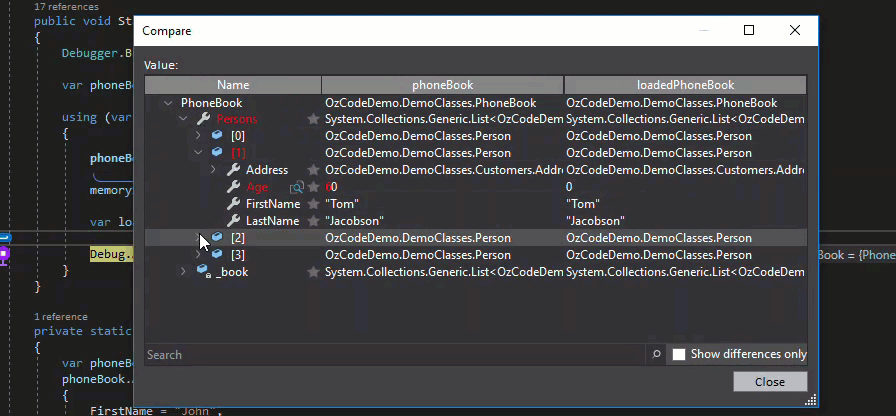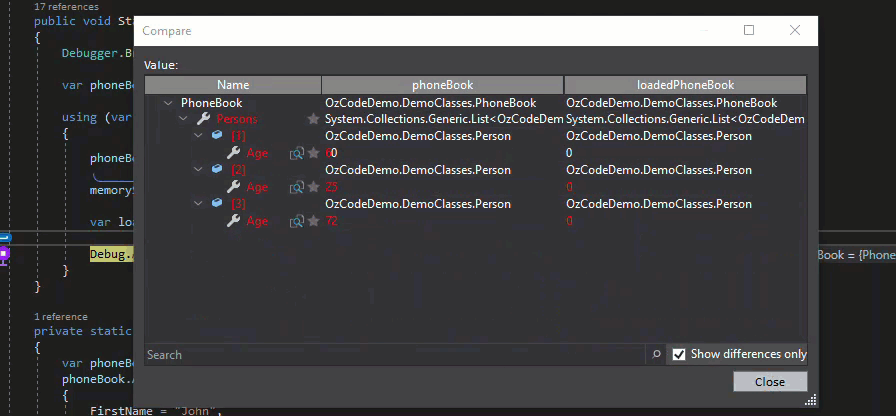<figcaption>Compare in action</figcaption>
#### Exception trail and prediction
This feature has proved himself as valuable (for me) over and over again. It allows you to view all relevant exception information. Furthermore, inner-exception can navigate easily along the StackTrace, all in an interactive and clean UI.
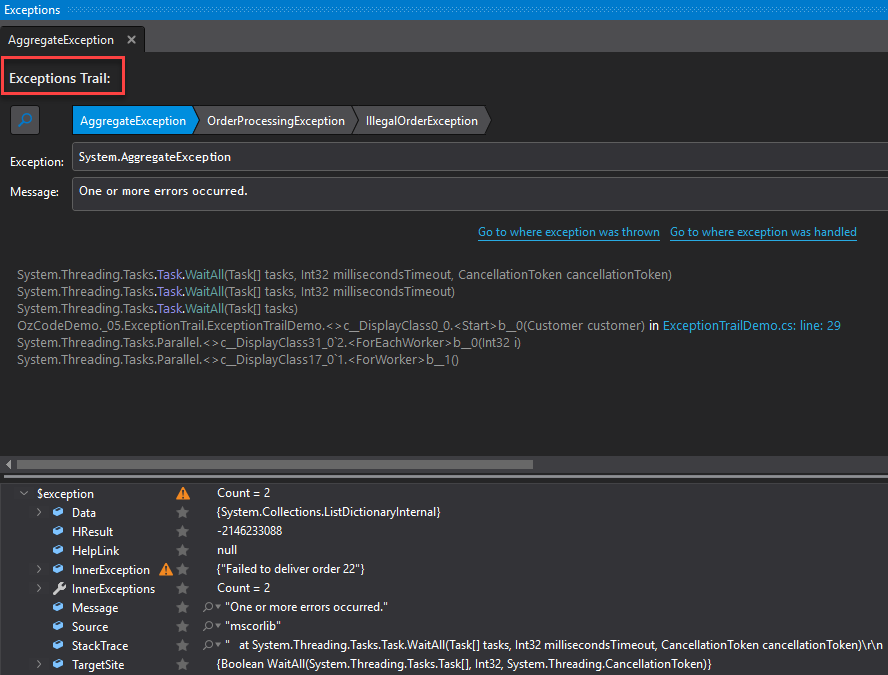<figcaption>Exception trail</figcaption>
Using the heads-up display, you get an alert that an exception is going to happen. When encountered, you can quickly skip and ignore it for smooth debugging or decide to handle it.
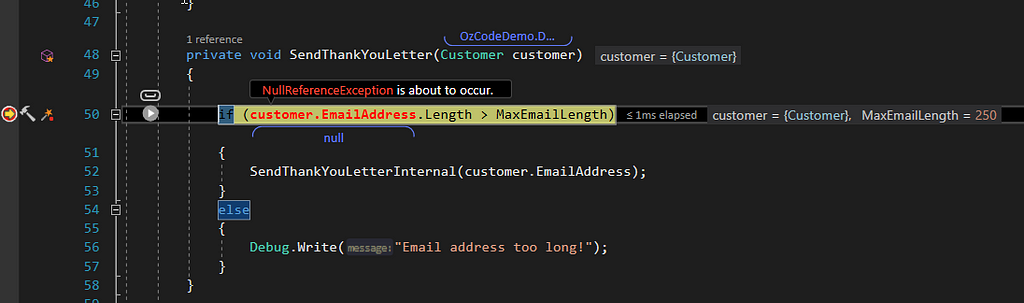<figcaption>An exception is about to happen</figcaption>
#### Show all instances
Search for any object in memory. That simple.
It might be used to understand if an object is still alive and why.
{% youtube Uk9YUubB5Mk %}<figcaption>Show all instances</figcaption>
There are more features in OzCode, which I’ve not described, such as — quick attach to process, custom expressions, quicker breakpoints, and more. That being said, one can leverage his debugging skills and bring more value efficiently while using it, making OzCode a must-have tool in any C# developer’s toolbox.
Note that, a free trial can be downloaded from [here](https://oz-code.com/download/)
Furthermore, OzCode team made sure to create a digital walk-through of all their features (which I’ve used as part of writing this blog-post), accessible here:
{% github https://github.com/oz-code/OzCodeDemo %} | dejavo |
226,874 | New Year - New Sports Challenges! | I usually start to think about my plans for the next year already in September. Big dreams, big plans... | 0 | 2019-12-26T08:28:44 | https://dev.to/sarajam76155187/new-year-new-sports-challenges-2ceb | I usually start to think about my plans for the next year already in September. Big dreams, big plans but as we got closer my ambitions somehow seem to shrink a bit and transform to something more realistic. Sport is usually on top of my list of things I want to improve, each year.
For 2020 I plan to:
1. Remember to eat healthy foods, and never to exercises soon after a meal
3. Remember that daily training of a few minutes is better one hour once a month
3. Remember to prioritize my daily exercises
4. Remember that I can improve my results if I follow these simple rules and give my body the attention it deserves.
So many people in the world like to play sport because of the sense of challenge. Actually, some sports allow the players to face front-to-front opponents – a great occasion to show the public specific skills and capabilities, like physical endurance, strength and technical competence of that particular sport discipline rules. The sense of challenge, this strong call to compete against other people, is not the only reason why many people love to play sports of all types:
Sports can improve the physical look and healthy conditions
* Certain sports are excellent to develop better flexibility or muscle power
* Sports are a very good way to use your free time
* You can make friends if you attend a sports club or a gym
* Sports offer the players the opportunity to learn new things
| sarajam76155187 | |
226,923 | Greengrass - Secure Tunneling | AWS IoT Secure Tunneling is a managed proxy meant for devices positioned behind secure firewalls on remote sites. A secure tunnel can be created using temporary credentials allowing access to the device on configurable ports. The secure tunneling process requires a bidirectional link to be established before communication can proceed. | 4,866 | 2020-01-25T10:50:42 | https://devopstar.com/2019/12/25/greengrass-secure-tunneling/ | aws, iot, greengrass, raspberrypi | ---
title: Greengrass - Secure Tunneling
published: true
description: AWS IoT Secure Tunneling is a managed proxy meant for devices positioned behind secure firewalls on remote sites. A secure tunnel can be created using temporary credentials allowing access to the device on configurable ports. The secure tunneling process requires a bidirectional link to be established before communication can proceed.
canonical_url: https://devopstar.com/2019/12/25/greengrass-secure-tunneling/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/ufh3pfjlnheybnwdajun.jpg
tags: aws, iot, greengrass, raspberrypi
series: AWS Greener Grass
---
*This post was originally written on [DevOpStar](https://devopstar.com/)*. Check it out [here](https://devopstar.com/2019/12/25/greengrass-secure-tunneling/)
## Introduction
AWS IoT Secure Tunneling is a managed proxy meant for devices positioned behind secure firewalls on remote sites. A secure tunnel can be created using temporary credentials allowing access to the device on configurable ports. The secure tunneling process requires a bidirectional link to be established before communication can proceed.
This post aims to demystifying the setup and management process of AWS IoT Secure Tunneling by demonstrating an end to end example.
## How it works
I found that [the documentation on this topic](https://docs.aws.amazon.com/iot/latest/developerguide/secure-tunneling.html) was a little lacking so I created the following diagram with annotations

1. Device uses x509 certificates with specific permissions to subscribe to the amazon managed `tunnels/notify` topic.
2. Tunnel is opened either using the GUI or CLI. device name defined to target specific device.
* Device receives destination access token from its subscription to the `tunnels/notify` topic
3. [localproxy](https://github.com/aws-samples/aws-iot-securetunneling-localproxy) runs in destination mode using the access token it received from the topic.
* At this point half (left side) of the secure tunnel is up and running
4. Listener for the destination tunnel also starts up. In this example we are exposing port 22 for SSH.
* Note that any port / service could be exposed
5. [localproxy](https://github.com/aws-samples/aws-iot-securetunneling-localproxy) runs in source mode using the access token generated when the tunnel was created in *step 2*.
* At this point both sides of the secure tunnel are up and running.
6. Client can now open a connection on the defined port (in this example we used port 5555) and it will be tunnelled through to the IoT device.
Now that you have an idea how this process works, let's go through and implement a simple SSH tunnel to a Raspberry Pi.
## Prerequisites
It would help tremendously if you have either setup or done the following:
* [AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html) installed and setup
* Briefly skimmed the [AWS IoT Secure Tunneling documentation](https://docs.aws.amazon.com/iot/latest/developerguide/secure-tunneling.html)
* Have completed the device setup post: [Greengrass - Greengrass Device Setup](https://devopstar.com/2019/11/24/greener-grass-device-setup/)
* If not this, then at-least know how to create AWS IoT certificates with a policy `iot*`
## Build localproxy
---
As usual we will be tackling this problem from the Raspberry Pi 3B+ (armv7l) perspective. I am actually shooting myself in the foot on purpose however, as the documentation for this process is extremely lacking currently.
Currently there are no mirriors of localproxy so you'll either have to:
* Build it yourself
* Use my pre-compiled mirrors
### Ubuntu (x86_64)
The [documentation for this compile](https://github.com/aws-samples/aws-iot-securetunneling-localproxy) should work however to save you sometime I've bundled the binaries and can be downloaded and installed from the following.
* [localproxy](https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxy-x86_64)
* [localproxytest](https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxytest-x86_64)
```bash
# Download binaries
wget https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxy-x86_64 -O localproxy
wget https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxytest-x86_64 -O localproxytest
# Copy binaries
sudo mv localproxy /usr/bin/localproxy
sudo mv localproxytest /usr/bin/localproxytest
```
### Raspberry Pi (armv7l)
Instructions for the Raspberry Pi (arm7l) compile can also be found in the [aws-iot-securetunneling-localproxy repository](https://github.com/aws-samples/aws-iot-securetunneling-localproxy). Before jumping into how to compile however, you can optionally jump in and use the binaries below.
* [localproxy](https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxy-armv7l)
* [localproxytest](https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxytest-armv7l)
```bash
# Download binaries
wget https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxy-armv7l -O localproxy
wget https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxytest-armv7l -O localproxytest
# Copy binaries
sudo mv localproxy /usr/bin/localproxy
sudo mv localproxytest /usr/bin/localproxytest
```
#### Install pre-requirements
```bash
sudo apt-get install cmake git
```
#### Install pre-compiled localproxy
```bash
# Zlib dependency
cd ~
wget https://www.zlib.net/zlib-1.2.11.tar.gz -O /tmp/zlib-1.2.11.tar.gz
tar xzvf /tmp/zlib-1.2.11.tar.gz
cd zlib-1.2.11
./configure
make
sudo make install
# Boost dependency
cd ~
wget https://dl.bintray.com/boostorg/release/1.69.0/source/boost_1_69_0.tar.gz -O /tmp/boost.tar.gz
tar xzvf /tmp/boost.tar.gz
cd boost_1_69_0
./bootstrap.sh
sudo ./b2 install
# Protobuf dependency
cd ~
wget https://github.com/protocolbuffers/protobuf/releases/download/v3.11.2/protobuf-all-3.11.2.tar.gz -O /tmp/protobuf-all-3.11.2.tar.gz
tar xzvf /tmp/protobuf-all-3.11.2.tar.gz
cd protobuf-3.11.2
mkdir build
cd build
cmake ../cmake
make
sudo make install
# OpenSSL development libraries
sudo apt install libssl-dev
# Catch2 test framework
cd ~
git clone https://github.com/catchorg/Catch2.git
cd Catch2
mkdir build
cd build
cmake ../
make
sudo make install
# localproxy build
cd ~
git clone https://github.com/aws-samples/aws-iot-securetunneling-localproxy
cd aws-iot-securetunneling-localproxy
mkdir build
cd build
cmake ../ -DCMAKE_CXX_FLAGS=-latomic
make
# Install binary
sudo cp bin/* /bin/
```
## localproxy Test
---
Now that the `localproxy` binary is installed you can run the pre-flight tests by running the following
```bash
localproxytest
# Test server is listening on address: 127.0.0.1 and port: 39985
# [2019-12-23 11:52:10.957851] [0x7616b3a0] [info] Starting proxy in source mode
# [2019-12-23 11:52:10.972793] [0x7616b3a0] [trace] Setting up web socket...
# [2019-12-23 11:52:10.973425] [0x7616b3a0] [info] Attempting to establish web socket connection with endpoint wss://127.0.0.1:39985
# [2019-12-23 11:52:11.425299] [0x7696c3a0] [info] Disconnected from: 127.0.0.1:34989
# ...
# ...
# ...
# [2019-12-23 11:52:11.425688] [0x7696c3a0] [trace] Both socket drains complete. Setting up TCP socket again
# ===============================================================================
# All tests passed (32 assertions in 2 test cases)
```
## secure_tunnel Install
For a tunnel connection to be setup for us, we must create an IoT listener that triggers `localproxy` for us on request. For this I've written a simple block of code that an be found below.
```python
#!/usr/bin/python3
import argparse
import boto3
import botocore.exceptions
import logging
import json
import random
import string
import subprocess
import time
from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTClient
parser = argparse.ArgumentParser()
parser.add_argument("-a", "--rootCA", action="store", dest="rootCAPath", default="/greengrass/certs/AmazonRootCA1.pem", help="Root CA file path")
parser.add_argument("-c", "--cert", action="store", dest="certificatePath", default="/greengrass/certs/device.cert.pem", help="Certificate file path")
parser.add_argument("-k", "--key", action="store", dest="privateKeyPath", default="/greengrass/certs/device.private.key", help="Private key file path")
parser.add_argument("-t", "--topic", action="store", required=True, dest="topic", help="Topic to subscribe to")
parser.add_argument("-r", "--region", action="store", dest="region", default="us-east-1", help="AWS region")
parser.add_argument("-e", "--endpoint", action="store", dest="endpoint", help="AWS IoT Endpoint")
# Parse Arguments
args = parser.parse_args()
rootCAPath = args.rootCAPath
certificatePath = args.certificatePath
privateKeyPath = args.privateKeyPath
topic = args.topic
region = args.region
def random_client_id(size=6, chars=string.ascii_uppercase + string.digits):
return ''.join(random.choice(chars) for x in range(size))
def tunnel_callback(client, userdata, message):
json_message = json.loads(message.payload.decode('utf-8'))
if message.topic == topic:
subprocess.run([
"localproxy",
"-t", json_message['clientAccessToken'],
"-r", region,
"-d", "localhost:22"
])
# Configure logging
logger = logging.getLogger("AWSIoTPythonSDK.core")
logger.setLevel(logging.DEBUG)
streamHandler = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
streamHandler.setFormatter(formatter)
logger.addHandler(streamHandler)
# Init IoT Client
if args.endpoint:
endpoint = args.endpoint
else:
try:
iot_client = boto3.client('iot', region_name=region)
iot_endpoint_response = iot_client.describe_endpoint(endpointType='iot:Data-ATS')
endpoint = iot_endpoint_response['endpointAddress']
except botocore.exceptions.NoCredentialsError as e:
print('Boto3 could not authenticate IoT call: {}'.format(e))
# Init AWSIoTMQTTClient
aws_iot_mqtt_client = None
aws_iot_mqtt_client = AWSIoTMQTTClient(random_client_id())
aws_iot_mqtt_client.configureEndpoint(endpoint, 443)
aws_iot_mqtt_client.configureCredentials(rootCAPath, privateKeyPath, certificatePath)
# Connect and subscribe to AWS IoT
aws_iot_mqtt_client.connect()
aws_iot_mqtt_client.subscribe(topic, 1, tunnel_callback)
while True:
time.sleep(1)
```
Make a copy of the code above into a location on your device. I recommend in `/usr/bin`
```bash
# Paste contents above in here
sudo nano /usr/bin/secure_tunnel
# Change permissions
sudo chmod +x /usr/bin/secure_tunnel
```
Next step is to install the requirements required for this script to run. If you have pip3 installed (specifically python3 pip) you can install the two requirements yourself with the following.
```bash
sudo pip3 install AWSIoTPythonSDK
sudo pip3 install boto3
```
### secure_tunnel Arguments
Check the requirements for the `secure_tunnel` cli by running:
```bash
secure_tunnel -h
# usage: secure_tunnel [-h] [-a ROOTCAPATH] [-c CERTIFICATEPATH]
# [-k PRIVATEKEYPATH] -t TOPIC [-r REGION] [-e ENDPOINT]
# optional arguments:
# -h, --help show this help message and exit
# -a ROOTCAPATH, --rootCA ROOTCAPATH
# Root CA file path
# -c CERTIFICATEPATH, --cert CERTIFICATEPATH
# Certificate file path
# -k PRIVATEKEYPATH, --key PRIVATEKEYPATH
# Private key file path
# -t TOPIC, --topic TOPIC
# Topic to subscribe to
# -r REGION, --region REGION
# AWS region
# -e ENDPOINT, --endpoint ENDPOINT
# AWS IoT Endpoint
```
Most of the arguments above I'll explain later, however for the certificates you should be able to run the script using the certificates we installed at in the first set of tutorials. These are found in the `/greengrass/certs` folder.
Find the names of these by running the following:
```bash
ls -al /greengrass/certs
# drwxr-xr-x 2 501 staff 4096 Dec 12 12:43 .
# drwxr-xr-x 6 root root 4096 Nov 25 21:52 ..
# -rw-r--r-- 1 501 staff 1674 Dec 12 12:43 efa556d93df7d7b53674b3e40496a8994700702b90077ff7e24efa07812f21c9.key
# -rw-r--r-- 1 501 staff 1219 Dec 12 12:43 efa556d93df7d7b53674b3e40496a8994700702b90077ff7e24efa07812f21c9.pem
# -rw-r--r-- 1 root root 45 Nov 25 21:52 README
# -rw-r--r-- 1 501 staff 1188 Apr 12 2019 root.ca.pem
```
In my case I can use the following:
```bash
secure_tunnel \
-a "/greengrass/certs/root.ca.pem" \
-c "/greengrass/certs/efa556d93df7d7b53674b3e40496a8994700702b90077ff7e24efa07812f21c9.pem" \
-k "/greengrass/certs/efa556d93df7d7b53674b3e40496a8994700702b90077ff7e24efa07812f21c9.key" \
-t "TODO" \
-r "TODO" \
-e "TODO"
```
The final parts of the command can be found below:
* **topic (-t)** - [Based on the documentation](https://docs.aws.amazon.com/iot/latest/developerguide/agent-snippet.html) the topic should be in the following format
* `$aws/things/thing_name/tunnels/notify`. Note: make sure to string escape the $.
* **region (-r)** - Should match your deployed IoT region.
* In my case `us-east-1`.
* **endpoint (-e)** - IoT Endpoint can be found in the settings section of the AWS IoT portal. Alternatively it can be obtained through the CLI using the following command:
```bash
aws iot describe-endpoint --endpoint-type iot:Data-ATS
```
So for my example, the final command would be:
```bash
secure_tunnel \
-a "/greengrass/certs/root.ca.pem" \
-c "/greengrass/certs/efa556d93df7d7b53674b3e40496a8994700702b90077ff7e24efa07812f21c9.pem" \
-k "/greengrass/certs/efa556d93df7d7b53674b3e40496a8994700702b90077ff7e24efa07812f21c9.key" \
-t "\$aws/things/lila/tunnels/notify" \
-r "us-east-1" \
-e "xxxxxxxxxxxxx-ats.iot.us-east-1.amazonaws.com"
```
### secure_tunnel Run
Run the `secure_tunnel` command with your arguments in preparation for the next steps. When you run `secure_tunnel` it will monitor the **$aws/things/thing_name/tunnels/notify** topic for a particular message. This message comes in the following format:
```json
{
"clientAccessToken": "destination-client-access-token",
"clientMode": "destination",
"region": "aws-region",
"services": ["destination-service"]
}
```
To create this message, an AWS IoT Secure Tunnel needs to be created; either through the GUI or the CLI.
#### Secure Tunnel Create [GUI]
Navigate to the [AWS IoT location to create a new Secure Tunnel](https://console.aws.amazon.com/iot/home?region=us-east-1#/open/tunnel).

Provide details similar to the following:
* **Select your device**
* In my case it's `lila`
* **List the services**
* technically you don't need to provide anything here. The idea being that you could toggle between different types of services based on a check in this field.

There is also an option to specify a timeout on the credentials. I recommend keeping this low so that if your tokens get leaked somehow, they will naturally expire.

When the tunnel is created, make sure to save a copy of the two files it asks you to download. Specifically we will need the **sourceAccessToken**.
#### Secure Tunnel Create [CLI]
Performing the same actions above with the CLI is just as easy.
```bash
aws iotsecuretunneling open-tunnel \
--destination-config thingName=lila,services=SSH \
--timeout-config maxLifetimeTimeoutMinutes=30
```
When a connection is opened, you should see a response like the following from your `secure_tunnel` program.
```bash
# [2019-12-24T09:03:54.438901]{2945}[info] Starting proxy in destination mode
# [2019-12-24T09:03:54.453509]{2945}[info] Attempting to establish web socket connection with endpoint wss://data.tunneling.iot.us-east-1.amazonaws.com:443
# [2019-12-24T09:03:55.888157]{2945}[info] Web socket session ID: 12871efffedc21d9-00005e57-00015f58-73ec57264871633d-780e6658
# [2019-12-24T09:03:55.888385]{2945}[info] Successfully established websocket connection with proxy server: wss://data.tunneling.iot.us-east-1.amazonaws.com:443
```
This tells you that a session has opened on the destination end. Take a copy of the `sourceAccessToken` that it spits out to your on the CLI for the next step. Now we must open a client on our end using the `localproxy` binary from before.
## localproxy Client
In order to use the `localproxy` client, it will need to be built for your operating system. Unfortunately there aren't binaries published for all of them so the best I can offer you currently is the `x86_64` binary from before to use on a Linux operating system.
* [localproxy - Ubuntu (x86_64)](https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxy-x86_64)
```bash
# Download the binary and make it executable
wget https://github.com/t04glovern/aws-greener-grass/raw/master/.blog/greengrass-secure-tunnel/binaries/localproxy-x86_64 -O localproxy
chmod +x localproxy
```
Open up a tunnel using the `sourceAccessToken`, along with providing the port you would like to tunnel through.
```bash
./localproxy \
-r "us-east-1" \
-s "5555" \
-t "AQGAAXix2C93kcy5UyP3Hlyt5ckZABsAAgABQ......."
# [2019-12-24T17:14:26.690125]{8685}[info] Attempting to establish web socket connection with endpoint wss://data.tunneling.iot.us-east-1.amazonaws.com:443
# [2019-12-24T17:14:28.104106]{8685}[info] Web socket session ID: 0e4af2fffe6d4d67-00002f7b-00015ec0-45fd2fc3cba468d4-6860ed80
# [2019-12-24T17:14:28.104165]{8685}[info] Successfully established websocket connection with proxy server: wss://data.tunneling.iot.us-east-1.amazonaws.com:443
# [2019-12-24T17:14:28.104485]{8685}[info] Listening for new connection on port 5555
```
You should be notified that the tunnel is open and ready to use. In my case I have port 5555 listening. Now I can simply SSH to that port and provide the usually credentials I would have used to login to that device normally.
```bash
ssh pi@localhost -p 5555
```
## Summary
Secure Tunneling is a fantastic way to provide encrypted, temporary access to remote devices behind a firewall in the field. I also see there being a lot of opportunity to make use of this service for device vending (more on this in future posts).
**NOTE**: *It should be noted that tunneling in this manner could be considered a major security risk if keys fall in the wrong hands. I recommend working with your Security teams internally to ensure they are okay with the risks associated with opening SSL tunnels.*
Please reach out to me on [Twitter](https://twitter.com/nathangloverAUS) if you have any further queries or would like help designing your own system!
## Other Reading
* [Greengrass - Device Setup](https://devopstar.com/2019/11/24/greener-grass-device-setup/)
* [Greengrass - Device Setup - Raspberry Pi](https://devopstar.com/2019/11/24/greener-grass-device-setup-raspberry-pi/)
* [Greengrass - Device Defender - Detect](https://devopstar.com/2019/11/24/greener-grass-device-defender-detect/)
* [Greengrass - Docker Deployments](https://devopstar.com/2019/12/14/greener-grass-docker-deployments/) | t04glovern |
227,324 | Why Writing is Important for Your Developer Career | Introduction When you first started to learn about programming. Are you forced to learn... | 0 | 2019-12-27T03:32:58 | https://www.maxongzb.com/why-writing-is-important-for-your-developer-career-reading-time-3-mins/ | career, writing | # Introduction
When you first started to learn about programming.
Are you forced to learn to write documentation you are just given something to "write hello world"?
As I progress as a developer, it did not occur to me that learning to **write** is one of the most essential skills we need to learn as a developer.
As without it, tons of wasted hours of work is done.
Due to our lack of understanding and clarity in conveying it to people.
I encountered the same problem while I was trying to communicate to doing something.
Which resulted in a drastic difference in technical implementation when another developer was implementing it.
# Clear Thinking
I remember while I was listening to one of the Tim Ferriss show.
He was interviewing one of the founders of Airbnb or Spotify on recruiting engineers for their startup.
The founder responded that he looks at other areas and not just the technical code that the engineer wrote.
Instead, it was the **scribbles** in the piece of paper to understand how they broke down and solve the problem.
As an engineer are hired based upon how they wrote on the solution before coding their first line of code.
# Ease of Communication
The additional perk of writing well and clear is the need for **back** and **forth** exchange on what is to be implemented.
When you are communicating with the **client** or **user**.
I always love the idea of [KISS][1] so that you communicate your **intent**.
Even when someone does not have the **background knowledge** or **context** to understand the whole project.
Therefore I would advise that you strive to write for a layman.
Plus with the rise of tools like [Grammarly][2].
It has become much easier to write better through the rapid feedback from either an actual person or AI to help you to write better.
# Ripple Effect for the Community
If you are an API developer, one of the keys for API adoption is the existence of high quality [documentation][3].
Which till this day, I love how companies like [Twillio][4], [Postman][5], [DigitalOcean][6], [Kong][7] & [Stripe][8].
Invest and place a **premium** in quality writing for their technical documentation.
Since without that, I believe they will be unable to **attract** new developers or **convince** development teams to use their product or services.
So that it allows me to get started by installing and using that package to **accomplish** a feature that I would like to deliver for my project.
Beside **contributing code**, you could always help through [documentation][9].
To make it easier for someone to get started in using the software.
I did something similar when I was rewriting documentation for one of the Python guides in Freecodeamp.
# Conclusion
I hope that you can gain a better insight and would be interested to learn to write well as a developer.
Instead, it is about the [human problems][10] we are trying to solve with the right context.
If you like this article **sign up** for my [Adventurer's Newsletter](https://maxongzb.activehosted.com/f/1) for a weekly update in the area of **Python**, **Startup** and **Web Development**.
You can also **follow** me to get the **latest** update of my article on **Dev**
The original post was on [Why Writing is Important for Your Developer Career - Reading Time: 3 Mins](https://www.maxongzb.com/why-writing-is-important-for-your-developer-career-reading-time-3-mins/) and cover image by [Photo by Aaron Burden on Unsplash](https://unsplash.com/photos/y02jEX_B0O0)
# Reference
* [The Importance of Writing][11]
* [Draft No 4 Writing Process][12]
* [On Writing Well][13]
* [Why Developers Should Know How To Write][14]
* [Writing Developer Content that Delivers][15]
* [KISS][1]
* [Grammarly][2]
* [10 Ways to Create Easy-to-Use, Compelling API Documentation][3]
* [Twillio][4]
* [Postman][5]
* [DigitalOcean][6]
* [Kong][7]
* [Stripe](https://stripe.com/en-sg
* [How To Contribute][9]
* [Jim Collins — A Rare Interview with a Reclusive Polymath (#361)][10]
[1]: https://www.interaction-design.org/literature/article/kiss-keep-it-simple-stupid-a-design-principle
[2]: https://www.grammarly.com/
[3]: https://swagger.io/blog/api-documentation/create-compelling-easy-to-use-api-documentation/
[4]: https://www.twilio.com/
[5]: https://www.getpostman.com/
[6]: https://www.digitalocean.com/
[7]: https://konghq.com/kong/
[8]: https://stripe.com/en-sg
[9]: https://opensource.guide/how-to-contribute/
[10]: https://tim.blog/2019/02/18/jim-collins/
[11]: https://benmccormick.org/2019/03/02/the-importance-of-writing
[12]: https://www.amazon.com/Draft-No-4-Writing-Process/dp/0374142742/ref=as_li_ss_tl?keywords=Draft+No.+4&qid=1550449942&s=gateway&sr=8-1&linkCode=ll1&tag=offsitoftimfe-20&linkId=5cf47809d4744d927aafe34315cb9d69&language=en_US
[13]: https://www.amazon.com/Writing-Well-Classic-Guide-Nonfiction/dp/0060891548/ref=sr_1_1?keywords=writing+well&qid=1577415253&sr=8-1
[14]: https://www.freecodecamp.org/news/why-developers-should-know-how-to-write-dc35aa9b71ab/
[15]: https://devada.com/writing-developer-content-that-delivers/ | steelwolf180 |
691,139 | Host your Flutter Project as a REST API | After you build your flutter project you may want to reuse the models and business logic from your li... | 0 | 2021-05-07T16:32:34 | https://rodydavis.com/posts/host-flutter-rest-api/ | ---
title: Host your Flutter Project as a REST API
published: true
date: 2019-10-18 00:00:00 UTC
tags:
canonical_url: https://rodydavis.com/posts/host-flutter-rest-api/
---
After you build your flutter project you may want to reuse the models and business logic from your lib folder. I will show you how to go about setting up the project to have iOS, Android, Web, Windows, MacOS, Linux and a REST API interface with one project. The REST API can also be deploy to Google Cloud Run for Dart everywhere.

> One Codebase for Client and Sever.
This will allow you to expose your Dart models as a REST API and run your business logic from your lib folder while the application runs the models as they are. [Here](https://github.com/AppleEducate/shared_dart) is the final project.
## Setting Up [#](#setting-up)
As with any Flutter project I am going to assume that you already have [Flutter](https://flutter.dev/) installed on your machine and that you can create a project. This is a intermediate level difficulty so read on if you are up to the challenge. You will also need to know the basics of [Docker](https://www.docker.com/).
## Why one project? [#](#why-one-project%3F)
It may not be obvious but when building complex applications you will at some point have a server and an application that calls that server. [Firebase](https://firebase.google.com/) is an excellent option for doing this and I use it in almost all my projects. [Firebase Functions](https://firebase.google.com/products/functions/) are really powerful but you are limited by Javascript or Typescript. What if you could use the same packages that you are using in the Flutter project, or better yet what if they both used the same?

When you have a server project and a client project that communicate over a rest api or client sdk like Firebase then you will run into the problem that the server has models of objects stored and the client has models of the objects that are stored. This can lead to a serious mismatch when it changed without you knowing. GraphQL helps a lot with this since you define the model that you recieve. This approach allows your business logic to be always up to date for both the client and server.
## Client Setup [#](#client-setup)
The first step is to just build your application. The only difference that we will make is keeping the UI and business logic separate. When starting out with Flutter it can be very easy to throw all the logic into the screen and calling setState when the data changes. Even the application when creating a new Flutter project does this. That's why [choosing a state management solution](https://flutter.dev/docs/development/data-and-backend/state-mgmt/options)is so important.
<iframe src="https://medium.com/media/64311732193c2dd39b2cdbc42965b538" frameborder="0"></iframe>
To make things clean and concise we will make 2 folders in our lib folder.
-
ui for all Flutter Widgets and Screens
-
src for all business logic, classes, models and utility functions
This will leave us with main.dart being only the entry point into our client application.
```
import 'package:flutter/material.dart';import 'plugins/desktop/desktop.dart';import 'ui/home/screen.dart';void main() { runApp(MyApp());}class MyApp extends StatelessWidget { @override Widget build(BuildContext context) { return MaterialApp( title: 'Flutter Demo', theme: ThemeData.light(), darkTheme: ThemeData.dark(), home: HomeScreen(), ); }}
```
Let’s Start by making a tab bar for the 2 screens. Create a file in the folder ui/home/screen.dart and add the following:
```
import 'package:flutter/material.dart';import '../counter/screen.dart';import '../todo/screen.dart';class HomeScreen extends StatefulWidget { @override _HomeScreenState createState() => _HomeScreenState();}class _HomeScreenState extends State<HomeScreen> { int _currentIndex = 0;@override Widget build(BuildContext context) { return Scaffold( body: IndexedStack( index: _currentIndex, children: <Widget>[CounterScreen(), TodosScreen(),], ), bottomNavigationBar: BottomNavigationBar( currentIndex: _currentIndex, onTap: (val) { if (mounted) setState(() { _currentIndex = val; }); }, type: BottomNavigationBarType.fixed, items: [BottomNavigationBarItem( icon: Icon(Icons.add), title: Text('Counter'), ), BottomNavigationBarItem( icon: Icon(Icons.list), title: Text('Todos'), ),], ), ); }}
```
This is just a basic screen and should look very normal.
### Counter Example [#](#counter-example)
Now create a file ui/counter/screen.dart and add the following:
```
import 'package:flutter/material.dart';import 'package:shared_dart/src/models/counter.dart';class CounterScreen extends StatefulWidget { @override _CounterScreenState createState() => _CounterScreenState();}class _CounterScreenState extends State<CounterScreen> { CounterModel _counterModel = CounterModel();void _incrementCounter() { setState(() { // This call to setState tells the Flutter framework that something has // changed in this State, which causes it to rerun the build method below // so that the display can reflect the updated values. If we changed // _counter without calling setState(), then the build method would not be // called again, and so nothing would appear to happen. _counterModel.add(); }); }@override Widget build(BuildContext context) { // This method is rerun every time setState is called, for instance as done // by the _incrementCounter method above. // // The Flutter framework has been optimized to make rerunning build methods // fast, so that you can just rebuild anything that needs updating rather // than having to individually change instances of widgets. return Scaffold( appBar: AppBar( // Here we take the value from the MyCounterPage object that was created by // the App.build method, and use it to set our appbar title. title: Text('Counter Screen'), ), body: Center( // Center is a layout widget. It takes a single child and positions it // in the middle of the parent. child: Column( // Column is also a layout widget. It takes a list of children and // arranges them vertically. By default, it sizes itself to fit its // children horizontally, and tries to be as tall as its parent. // // Invoke "debug painting" (press "p" in the console, choose the // "Toggle Debug Paint" action from the Flutter Inspector in Android // Studio, or the "Toggle Debug Paint" command in Visual Studio Code) // to see the wireframe for each widget. // // Column has various properties to control how it sizes itself and // how it positions its children. Here we use mainAxisAlignment to // center the children vertically; the main axis here is the vertical // axis because Columns are vertical (the cross axis would be // horizontal). mainAxisAlignment: MainAxisAlignment.center, children: <Widget>[Text( 'You have pushed the button this many times:', ), Text( '${_counterModel.count}', style: Theme.of(context).textTheme.display1, ),], ), ), floatingActionButton: FloatingActionButton( onPressed: _incrementCounter, tooltip: 'Increment', child: Icon(Icons.add), ), // This trailing comma makes auto-formatting nicer for build methods. ); }}
```
This is the default counter app you get when you create a Flutter application but with one change, it uses `CounterModel` to hold the logic.
Create the counter model at src/models/counter.dart and add the following:
```
class CounterModel { CounterModel(); int _count = 0; int get count => _count; void add() => _count++; void subtract() => _count--; void set(int val) => _count = val;}
```
As you can see it is really easy to expose only what we want to while still having complete flexibility. You could use provider here if you choose, or even bloc and/or streams.
### Todo Example [#](#todo-example)

Lets create a file at ui/todos/screen.dart and add the following:
```
import 'package:flutter/material.dart';import '../../src/classes/todo.dart';import '../../src/models/todos.dart';class TodosScreen extends StatefulWidget { @override _TodosScreenState createState() => _TodosScreenState();}class _TodosScreenState extends State<TodosScreen> { final _model = TodosModel(); List<ToDo> _todos;@override void initState() { _model.getList().then((val) { if (mounted) setState(() { _todos = val; }); }); super.initState(); }@override Widget build(BuildContext context) { return Scaffold( appBar: AppBar( title: Text('Todos Screen'), ), body: Builder( builder: (_) { if (_todos != null) { return ListView.builder( itemCount: _todos.length, itemBuilder: (context, index) { final _item = _todos[index]; return ListTile( title: Text(_item.title), subtitle: Text(_item.completed ? 'Completed' : 'Pending'), ); }, ); } return Center( child: CircularProgressIndicator(), ); }, ), ); }}
```
You will see that we have the logic in TodosModel and uses the class ToDo for toJson and fromJson.
Create a file at the location src/classes/todo.dart and add the following:
```
// To parse this JSON data, do//// final toDo = toDoFromJson(jsonString);import 'dart:convert';List<ToDo> toDoFromJson(String str) => List<ToDo>.from(json.decode(str).map((x) => ToDo.fromJson(x)));String toDoToJson(List<ToDo> data) => json.encode(List<dynamic>.from(data.map((x) => x.toJson())));class ToDo { int userId; int id; String title; bool completed;ToDo({ this.userId, this.id, this.title, this.completed, });factory ToDo.fromJson(Map<String, dynamic> json) => ToDo( userId: json["userId"], id: json["id"], title: json["title"], completed: json["completed"], );Map<String, dynamic> toJson() => { "userId": userId, "id": id, "title": title, "completed": completed, };}
```
and create the model src/models/todo.dart and add the following:
```
import 'dart:convert';import 'package:http/http.dart' as http;import 'package:shared_dart/src/classes/todo.dart' as t;class TodosModel { final kTodosUrl = '[https://jsonplaceholder.typicode.com/todos'](https://jsonplaceholder.typicode.com/todos');Future<List<t.ToDo>> getList() async { final _response = await http.get(kTodosUrl); if (_response != null) { final _todos = t.toDoFromJson(_response.body); if (_todos != null) { return _todos; } } return []; }Future<t.ToDo> getItem(int id) async { final _response = await http.get('$kTodosUrl/$id'); if (_response != null) { final _todo = t.ToDo.fromJson(json.decode(_response.body)); if (_todo != null) { return _todo; } } return null; }}
```
Here we just get dummy data from a url that emits json and convert them to our classes. This is an example I want to show with networking. There is only one place that fetches the data.
### Run the Project (Web) [#](#run-the-project-(web))


As you can see when you run your project on chrome you will get the same application that you got on mobile. Even the networking is working in the web. You can call the model and retrieve the list just like you would expect.
## Server Setup [#](#server-setup)
> Now time for the magic..
In the root of the project folder create a file Dockerfile and add the following:
```
# Use Google's official Dart image.# [https://hub.docker.com/r/google/dart-runtime/](https://hub.docker.com/r/google/dart-runtime/)FROM google/dart-runtime
```
Create another file at the root called service.yaml and add the following:
```
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: PROJECT_NAME namespace: default spec: template: spec: containers: - image: docker.io/YOUR_DOCKER_NAME/PROJECT_NAME env: - name: TARGET value: "PROJECT_NAME v1"
```
Replace PROJECT\_NAME with your project name, mine is shared-dart for this example.
You will also need to replace YOUR\_DOCKER\_NAME with your docker username so the container can be deployed correctly.
Update your pubspec.yaml with the following:
```
name: shared_dartdescription: A new Flutter project.publish_to: noneversion: 1.0.0+1environment: sdk: ">=2.1.0 <3.0.0"dependencies: flutter: sdk: flutter shelf: ^0.7.3 cupertino_icons: ^0.1.2 http: ^0.12.0+2dev_dependencies: flutter_test: sdk: flutterflutter: uses-material-design: true
```
The important package here is shelf as it allows us to run a http server with dart.
Create a folder in the root of the project called bin then add a file server.dart and replace it with the following:
```
import 'dart:io';import 'package:shelf/shelf.dart' as shelf;import 'package:shelf/shelf_io.dart' as io;import 'src/routing.dart';void main() { final handler = const shelf.Pipeline() .addMiddleware(shelf.logRequests()) .addHandler(RouteUtils.handler);final port = int.tryParse(Platform.environment['PORT'] ?? '8080'); final address = InternetAddress.anyIPv4;io.serve(handler, address, port).then((server) { server.autoCompress = true; print('Serving at [http://${server.address.host}:${server.port}'](http://${server.address.host}:${server.port}')); });}
```
This will tell the container what port to listen for and how to handle the requests.
Create a folder src in the bin folder and add a file routing.dart and replace the contents with the following:
```
import 'dart:async';import 'package:shelf/shelf.dart' as shelf;import 'controllers/index.dart';import 'result.dart';class RouteUtils { static FutureOr<shelf.Response> handler(shelf.Request request) { var component = request.url.pathSegments.first; var handler = _handlers(request)[component]; if (handler == null) return shelf.Response.notFound(null); return handler; }static Map<String, FutureOr<shelf.Response>> _handlers( shelf.Request request) { return { 'info': ServerResponse('Info', body: { "version": 'v1.0.0', "status": "ok", }).ok(), 'counter': CounterController().result(request), 'todos': TodoController().result(request), }; }}
```
There is still nothing imported from our main project but you will start to see some similarities. Here we specify controllers for todos and counter url paths.
```
'counter': CounterController().result(request),'todos': TodoController().result(request),
```
that means any url with the following:[https://mydomain.com/todos](https://mydomain.com/todos) , [https://mydomain.com/todos](https://mydomain.com/todos)/1
will get routed to the TodoController to handle the request.
> This is also the first time I found out about FutureOr. It allows you to return a sync or async function.
And important part about build a REST API is having a consistent response body, so here we can create a wrapper that adds fields we always want to return, like the status of the call, a message and the body.
Create a file at src/result.dart and add the following:
```
import 'dart:convert';import 'package:shelf/shelf.dart' as shelf;class ServerResponse { final String message; final dynamic body; final StatusType type;ServerResponse( this.message, { this.type = StatusType.success, this.body, });Map<String, dynamic> toJson() { return { "status": type.toString().replaceAll('StatusType.', ''), "message": message, "body": body ?? '', }; }String toJsonString() { return json.encode(toJson()); }shelf.Response ok() { return shelf.Response.ok( toJsonString(), headers: { 'Content-Type': 'application/json', }, ); }}enum StatusType { success, error }abstract class ResponseImpl { Future<shelf.Response> result(shelf.Request request);}
```
This will always return json and the fields that we want to show. You could also include your paging meta data here.
Create a file in at the location src/controllers/counter.dart and add the following:
```
import 'package:shared_dart/src/models/counter.dart';import 'package:shelf/shelf.dart' as shelf;import '../result.dart';class CounterController implements ResponseImpl { const CounterController();@override Future<shelf.Response> result(shelf.Request request) async { final _model = CounterModel(); final _params = request.url.queryParameters; if (_params != null) { final _val = int.tryParse(_params['count'] ?? '0'); _model.set(_val); } else { _model.add(); } return ServerResponse('Info', body: { "counter": _model.count, }).ok(); }}
```
You will see the import to the lib folder of the root project. Since it shares the pubspec.yaml all the packages can be shared. You can import the CounterModel that we created earlier.
Create a file in at the location src/controllers/todos.dart and add the following:
```
import 'package:shared_dart/src/models/todos.dart';import 'package:shelf/src/request.dart';import 'package:shelf/src/response.dart';import '../result.dart';class TodoController implements ResponseImpl { @override Future<Response> result(Request request) async { final _model = TodosModel(); if (request.url.pathSegments.length > 1) { final _id = int.tryParse(request.url.pathSegments[1] ?? '1'); final _todo = await _model.getItem(_id); return ServerResponse('Todo Item', body: _todo).ok(); } final _todos = await _model.getList(); return ServerResponse( 'List Todos', body: _todos.map((t) => t.toJson()).toList(), ).ok(); }}
```
Just like before we are importing the TodosModel model from the lib folder.
For convenience add a file at the location src/controllers/index.dart and add the following:
```
export 'counter.dart';export 'todo.dart';
```
This will make it easier to import all the controllers.
## Run the Project (Server) [#](#run-the-project-(server))
If you are using [VSCode](https://code.visualstudio.com/) then you will need to update your launch.json with the following:
```
{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: [https://go.microsoft.com/fwlink/?linkid=830387](https://go.microsoft.com/fwlink/?linkid=830387) "version": "0.2.0", "configurations": [{ "name": "Client", "request": "launch", "type": "dart", "program": "lib/main.dart" }, { "name": "Server", "request": "launch", "type": "dart", "program": "bin/server.dart" }]}
```
Now when you hit run with Server selected you will see the output:
You can navigate to this in a browser but you can also work with this in [Postman](https://www.getpostman.com/).


Just by adding to the url todos and todos/1 it will return different responses.
For the counter model we can use query parameters too!
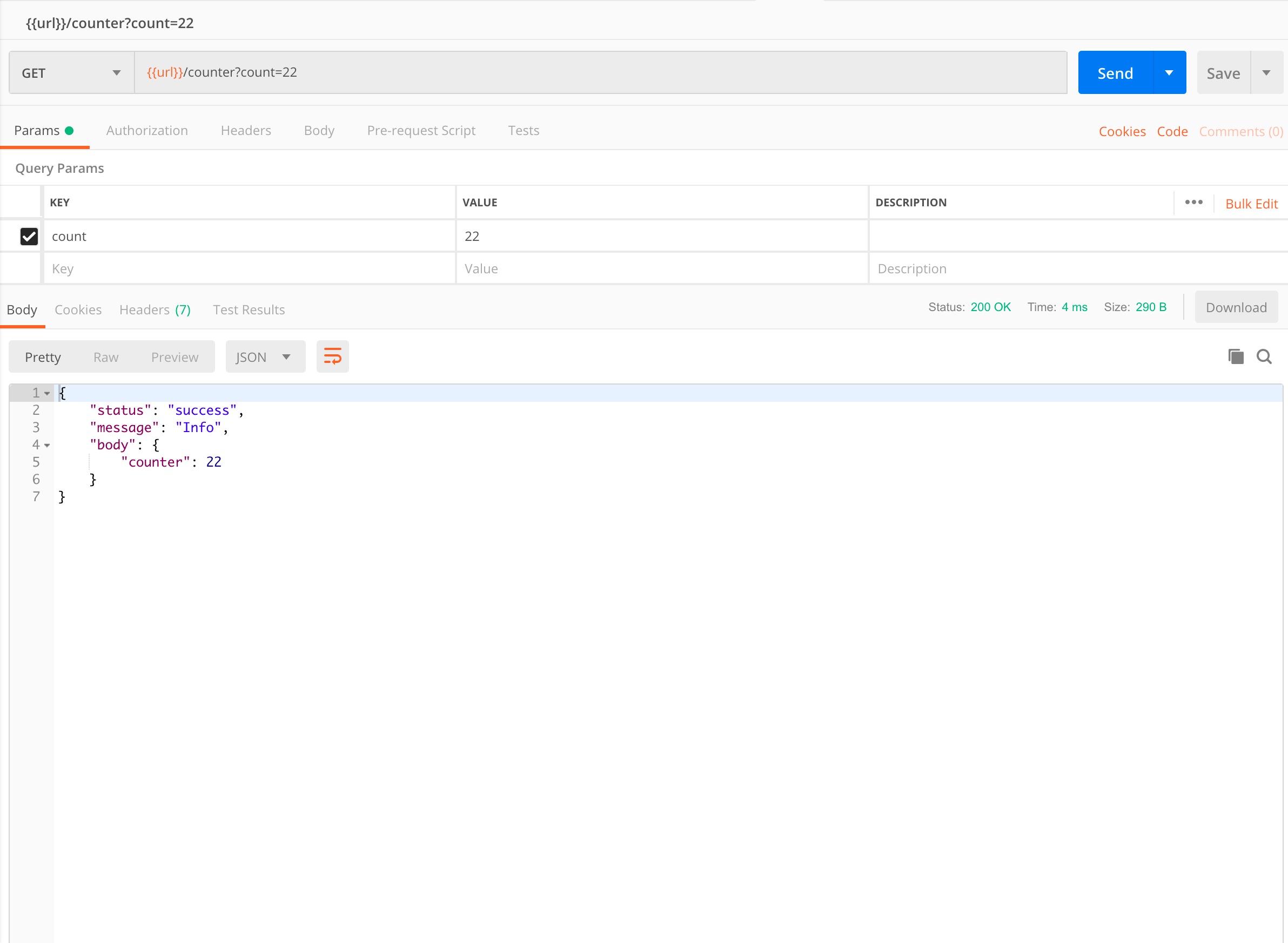

Just by adding ?count=22 it will update the model with the input.
> Keep in mind this is running your Dart code from you lib folder in your Flutter project without needing the Flutter widgets!
As a side benefit we can also run this project on Desktop. Check out the final project for the desktop folders needed from [Flutter Desktop Embedding](https://github.com/google/flutter-desktop-embedding).


## Conclusion [#](#conclusion)
Now if you wanted to deploy the container to Cloud Run you could with the following command:
gcloud builds submit — tag [gcr.io/YOUR\_GOOGLE\_PROJECT\_ID/PROJECT\_NAME](http://gcr.io/YOUR_GOOGLE_PROJECT_ID/PROJECT_NAME) .
Replace PROJECT\_NAME with your project name, mine is shared-dart for this example.
You will also need to replace YOUR\_GOOGLE\_PROJECT\_ID with your Google Cloud Project ID. You can create one [here](https://cloud.google.com/cloud-build/docs/quickstart-docker).
Again the final project source code is [here](https://github.com/AppleEducate/shared_dart). Let me know your thoughts!
 | rodydavis | |
227,532 | Enzyme | Hello everyone, What diference between Shallow and Mount render when I test a React component? | 0 | 2019-12-27T14:03:05 | https://dev.to/eduaugustus/enzyme-5059 | react, testing, javascript | Hello everyone,
What diference between Shallow and Mount render when I test a React component? | eduaugustus |
227,724 | Fighting scope creep / creeping featuritis | You know that all too common problem - you keep thinking of new ideas, expanding the scope of your pr... | 0 | 2019-12-27T18:52:07 | https://dev.to/wrldwzrd89/fighting-scope-creep-creeping-featuritis-3pp0 | You know that all too common problem - you keep thinking of new ideas, expanding the scope of your project, and forget that you have to prioritize them and ship the thing first? What do you do to tame this beast?
I've found that creating a simple idea checklist works wonders - GitHub Boards are one of many ways this can be done - and set a periodic reminder to check development against the plan so I don't drift too far.
What works best for you? I'm interested in your methods! | wrldwzrd89 | |
227,809 | New React Select Box! | I've recently implemented a react select box component which is extremely easy to use. Feel free to u... | 0 | 2019-12-28T00:28:06 | https://dev.to/sepehr1313/new-react-select-box-2jn5 | typescript, react, javascript, emotion | I've recently implemented a react select box component which is extremely easy to use. Feel free to use it or contribute to make it better!
Github: https://github.com/sepehr1313/react-select-tile
NPM: https://www.npmjs.com/package/react-select-tile | sepehr1313 |
227,810 | How to switch from learning one stuff to another while being as flexible as you can? | A new year is approaching, shortlists are coming! Let's imagine the following scenario: using the Wa... | 0 | 2019-12-28T00:29:52 | https://dev.to/samureira/how-to-switch-from-learning-one-stuff-to-another-while-being-as-flexible-as-you-can-270o | productivity, discuss, beginners | A new year is approaching, shortlists are coming!
Let's imagine the following scenario: using the Warren Buffett 25/5 rule you came across with a mixed list of 5 things you need/want to learn next year. Technology (i.e. - JavaScript), tool (i.e. - Power Bi) or tech topic (i.e - Agile), whatever... all mixed.
1st Question: How would you switch from one topic to another and how much time would you dedicate on each learning on average? Some not-so-random options:
a) One topic each day?
b) One topic every two-four weeks (Sprint style)?
c) The First 20 Hours method?
d) Other way, your way...?
2nd Question (extra): In terms of learning a language, would you consider converting programs from one language to another as a good approach? Like, following a tutorial of a To-Do List project in C# and coding in Java and/or vice-versa. | samureira |
227,812 | Exploring Blogging With Scully - the Angular Static Site Generator | Did you know that there's a new static site generator for Angular apps? Yep, it's called Scully. In this post, we'll look at how it can be used to render a blazing-fast, ultra-compact markdown blog. | 0 | 2019-12-28T02:18:19 | https://owlypixel.com/exploring-blog-feature-with-scully-angular-static-site-generator/ | javascript, webdev, angular, typescript | ---
title: Exploring Blogging With Scully - the Angular Static Site Generator
published: true
description: "Did you know that there's a new static site generator for Angular apps? Yep, it's called Scully. In this post, we'll look at how it can be used to render a blazing-fast, ultra-compact markdown blog."
tags: javascript, webdev, angular, typescript
canonical_url: https://owlypixel.com/exploring-blog-feature-with-scully-angular-static-site-generator/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/wfarploqbdfdbptiqn1x.png
---
[HeroDevs](https://twitter.com/herodevs) team recently released a static site generator for Angular projects - [Scully](https://github.com/scullyio/scully).
Aside from rendering regular apps, they announced that it can be used to build a static blog with markdown. This is what got me curious, so I decided to dive in and explore how this works.
So, If you're an Angular developer who wants to make the most secure and fastest possible version of their markdown blog, hop on the ride and enjoy this quick tour.
## What is Scully?
Scully is a JAM stack solution for Angular developers. It's a static site generator that takes your new or existing Angular app and pre-renders it to HTML and CSS.
If you take for example the smallest possible Angular website, it'll be around 300K. Now, if you take this app and pre-render it with Scully, you'll be able to cut the size down to 2.5K.
This is a huge deal for someone using a low-end device on a flaky mobile connection.
## Why should I use it?
There are a number of benefits when using Scully, especially for Angular devs. Here are some of them:
- It works with the Angular ecosystem.
- You don't have to write your app in any specific way, it doesn't require any structural changes.
- Much faster load times, hence increased conversions for your app.
- Your app can work on a much larger number of devices where JavaScript is disabled or not supported.
- Faster TTI (Time to interactive). Due to the lack of a large number of scripts your app can respond to user interactions much quicker.
## How does it work?
It takes your Angular app and renders it in a series of HTML pages. Then, once the user downloads the initial page it'll then download the rest of the Angular app and bootstrap it on top, so you still get all the benefits of a Single Page App.
The cool thing about it that with the machine learning algorithm it can find all the routes in your app and render the entire app to a series of static HTML files, which then can be simply uploaded to the CDN of your choice.
## What should I have installed to follow along?
First, if you haven't already done this, you need to install Angular CLI 9.x.x.
```shell
npm install -g @angular/cli@next
```
## Scaffolding an Angular app
For starters, Scully requires a working Angular app using **Angular 9.x.x.** Great, let's generate one!
```shell
ng new awesome-angular-blog
```
Next, select **Yes** for Angular routing and pick **SCSS** from the list of available styling options.

After it's finished generating a new project we can `cd` into it.
```shell
cd awesome-angular-blog
```
Ok, let's try running the app to make sure that it works.
```shell
ng serve --open
```
You'll see a default Angular app opened in the browser on `http://localhost:4200/`.
So far so good, now let's get rid of the boilerplate and add something very simple for starters.
Open `src\app\app.component.html` file and replace its contents with the following:
```
<h1>The Blog Header</h1>
<router-outlet></router-outlet>
<footer>Awesome Scully Blog</footer>
```
The development server is watching our files, so now our page should look like this.
Stop the development server by pressing `Ctrl+C`.
## Installing Scully
> **A Quick Note:** Keep in mind that this is an early alpha release, so there may be some 🐛. At the moment it only supports v9 of Angular (v8 support will be added later).
Here comes the interesting part. Now we're ready to install Scully. The first thing that we need to do is to run this command:
```shell
ng add @scullyio/init
```
This will install all necessary dependencies, import `HttpClientModule`, add `scully.config.js` file which will be used for plugins management and add some code to existing files.
## Generating the blog
Scully allows us to generate a blog using [Angular generate schematic](https://angular.io/guide/schematics#generation-schematics). But we have to keep in mind that we need to build a project before running Scully because it uses the results of our build - `dist` folder to see what routes we have. So, let's build it now.
```shell
ng build
```
After that, you should see a `dist` folder created. Now let's generate the blog:
```shell
ng g @scullyio/init:blog
```
After you ran that command, Scully created a blog module with routes for us so we don't have to configure that manually. Also, to get you started it created a blog folder with the default markdown file. Every time Scully builds, it'll render this markdown file to HTML.
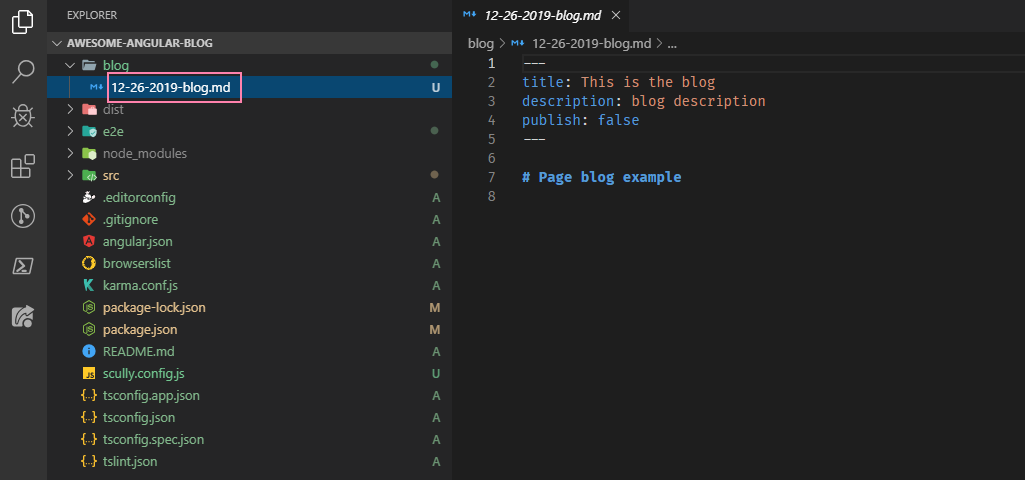
We can now add new blog posts with the following command:
```shell
ng g @scullyio/init:post --name="awesome-owls"
```
Cool, let's open up our newly created post `/blog/awesome-owls.md` and add some content there:
```
---
title: awesome-owls
description: blog description
publish: false
---
# awesome-owls
Owls can almost turn their heads all the way around, but it's not quite a 360 turn.
They can turn their necks 135 degrees in either direction, which gives them 270 degrees total movement.
```
Because Angular still can't read markdown, to see the contents of our post we need to build the project and run Scully again. Then they will be rendered and we'll see our static content.
```shell
ng build && npm run scully
```
If we look at our `dist` folder, we'll see a `static` directory there which was created by Scully.
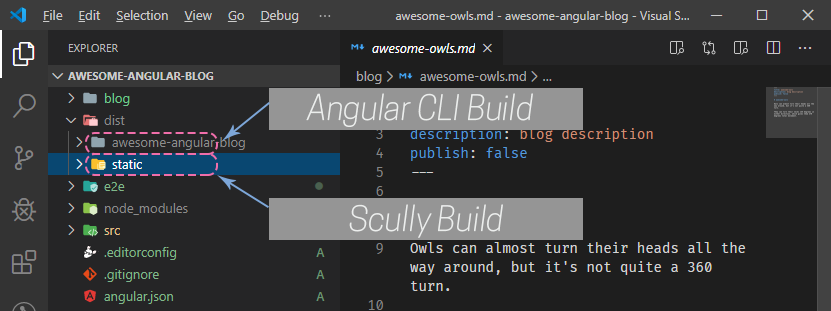
We can now serve this folder with any server like Nginx or Apache and see the contents of our post. The easiest option for us to check it out is to use NodeJS [http-server](https://www.npmjs.com/package/http-server).
Change into the `static` directory and run the following command in your terminal:
```shell
http-server -p 5555
```
After that, open `http://127.0.0.1:5555/blog/awesome-owls` in your browser and you should see the content of our markdown post.
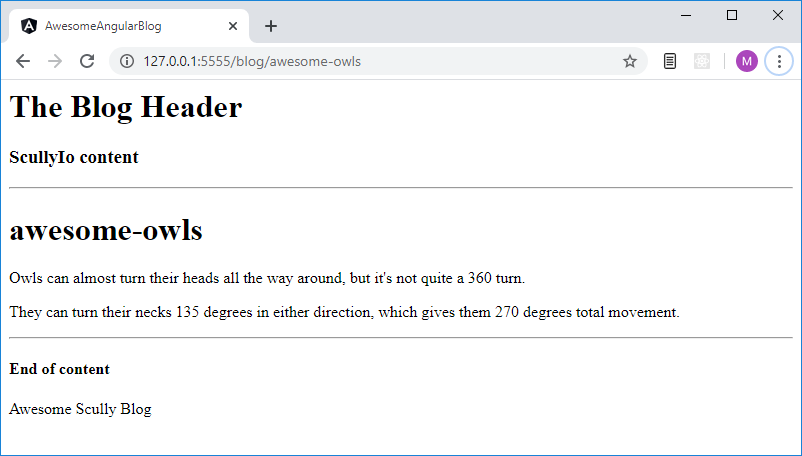
## Setting up a home page
Alright, let's add a list of available routes to our home page. For this, Scully has a special `ScullyRoutesService`.
Open the main `src\app\app.component.ts` file and import it at the top, then assign the `ScullyRoutesService` to `scully`.
```javascript
import {IdleMonitorService, ScullyRoutesService} from '@scullyio/ng-lib';
import { Component } from '@angular/core';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.scss']
})
export class AppComponent {
constructor (
private idle: IdleMonitorService,
public scully: ScullyRoutesService
) { }
title = 'awesome-angular-blog';
}
```
Next, in the view file `src\app\app.component.html` add an [ngFor](https://angular.io/api/common/NgForOf) loop that goes through all the routes and displays them on the page using [routerLink](https://angular.io/api/router/RouterLink).
```html
<ul>
<li *ngFor="let route of scully.available$ | async">
<a [routerLink]="route.route">{{ route.title || route.route }}</a>
</li>
</ul>
```
Ok, let's rebuild everything again by running `ng build && npm run scully` and visit our root page `http://127.0.0.1:5555/`.
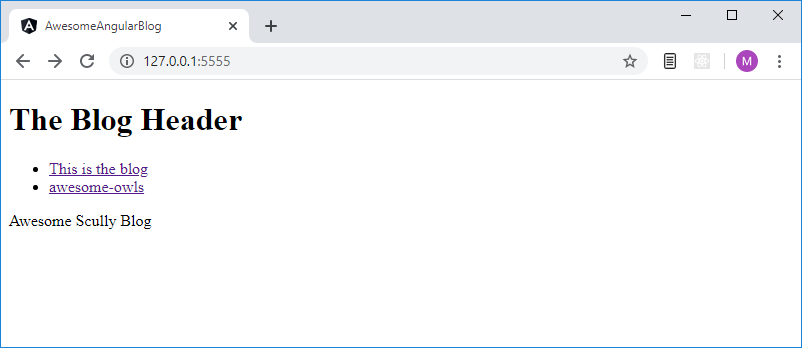
Here we go. We have the basic functionality of the blog working.
From here you can add a bit of styling to make it more visually appealing, add more pages like About, Contact, create a list of categories, all the usual blog things.
The cool thing is that no matter what your blog will look like, it still can be rendered to static assets and served via any available CDN.
Keep in mind that this is an early alpha release, so there will be bugs, but with the team like HeroDevs I'm sure the product is in good hands.
## Next Steps
If you got interested and want to know more, [the docs have a lot of useful information](https://github.com/scullyio/scully/blob/master/docs/scully.md) like how to use the plugin system, how to get this to work with the existing Angular project, and so on.
Also, here are some useful resources on the topic:
- [What's Angular in the JAMstack? It Sounds Delicious!](https://www.netlify.com/blog/2019/10/30/whats-angular-in-the-jamstack-it-sounds-delicious/)
- [Scully Live Demo](https://www.youtube.com/watch?v=Sh37rIUL-d4)
- [ScullyIO Twitter](https://twitter.com/ScullyIO)
Thanks for joining me, have a wonderful day!
This post was originally published on [OwlyPixel Blog](https://owlypixel.com/).
| owlypixel |
227,878 | Top 10 Courses to Learn Spring Boot and Microservices for Java Programmers | Best Courses to learn Spring Boot in-depth for Java Developers | 0 | 2019-12-28T06:01:33 | https://dev.to/javinpaul/top-10-courses-to-learn-spring-boot-and-microservices-for-java-programmers-3hjg | java, programming, springboot, webdev | ---
title: Top 10 Courses to Learn Spring Boot and Microservices for Java Programmers
published: true
description: Best Courses to learn Spring Boot in-depth for Java Developers
tags: java, programming, springboot, webdev
cover_image: https://thepracticaldev.s3.amazonaws.com/i/ztq03jwcwkeredzi11rm.png
---
*Disclosure: This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article.*
Hello guys, if you are interested in learning [**Spring Boot**](https://hackernoon.com/tagged/spring-boot) and looking for some awesome resources like books, tutorials, and online courses to start with then you have come to the right place.
Earlier I have shared some great books to learn Spring Framework, including Spring Boot ([see](http://www.java67.com/2016/12/5-spring-framework-books-for-java-programmers.html)) and today I'll share some of the **best online Spring Boot courses** you can join to learn Spring Boot by yourself.
In the past, I was a big fan of learning from a book, but online courses have changed that completely. Now I prefer to start with an online course like the [**Spring Boot Essentials**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-essentials%2F) and then move on to a book like [**Spring Boot in Action**](https://www.amazon.com/Spring-Boot-Action-Craig-Walls/dp/1617292540?tag=javamysqlanta-20) for more comprehensive learning.
Anyway, before going through those Spring Boot courses, let's first revise what is Spring Boot and it's benefits and why you should learn it.
> Spring Boot is one of the best frameworks for Java developers and if you don't know yet, probably today is the best time to learn Spring Boot.
Just like Spring makes Java development easier, **Spring Boot makes Java Application development easier using Spring Framework** by taking out all pains related to dependency management, configuration, and bean declaration, etc.
[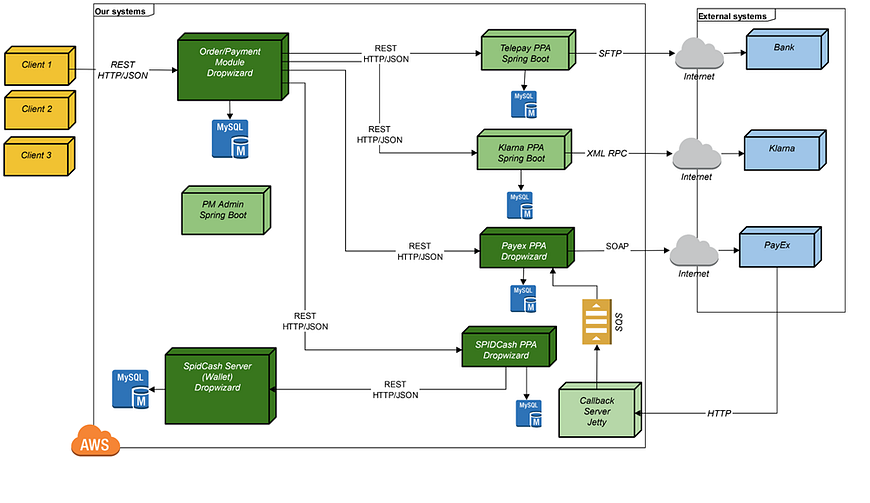](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fhands-on-cloud-native-java-apps-with-spring-boot-and-aws%2F)
It seriously makes the Java development fun, particularly web development ridiculously easy by providing features like [starter dependency](https://javarevisited.blogspot.com/2018/11/top-5-spring-boot-features-java.html), auto-configuration, Spring Boot CLI, Spring Initializer, and Spring Boot Actuator, but, the best thing you would love about Spring Boot is **how it allows you to run your Java application**. Can you guess?
> Yup, you guessed it right, now with Spring Boot, you can run your Spring application just like a core Java application by using the classic [main method](http://www.java67.com/2014/02/can-you-run-java-program-without-main-method.html).
No need to set up a web server, build a war file and deploy that into a servlet container. Just create a Spring boot jar for your project and run it as a core java application using jar command as we run any core Java application from the command prompt.
You might be wondering then how would you deploy that JAR into a traditional [web server](http://www.java67.com/2016/06/3-difference-between-web-server-vs-application-server-vs-servlet-container.html) like Tomcat which your company is using in production? Well, not to worry.
Spring Boot gives you options to create [JAR](http://www.java67.com/2014/04/how-to-make-executable-jar-file-in-Java-Eclipse.html) or [WAR](https://javarevisited.blogspot.com/2014/11/dont-use-systemexit-on-java-web-application.html) file and the best thing is that you can even run the WAR file from the command prompt because Spring Boot has an embedded tomcat server in it.
So, **learning Spring Boot** will help you to develop Java development easily because you can now focus on the application logic more rather than worrying about configuration and dependency management.
It's also now becoming a standard way to use the [Spring framework](https://javarevisited.blogspot.com/2018/06/top-6-spring-framework-online-courses-Java-programmers.html) in many companies and they are looking for Java developers with some Spring Boot experience.
So, if you are looking for your next Job in Java and Spring development, learning **Spring Boot** can seriously boost your chance.
##What is the best way to learn Spring Boot?
Some of my readers also ask me **what is the best way to learn a new framework?** Well, I was a big fan of books a year ago but now I think online courses are a better choice.
They are more interactive and you learn a lot of things in very little time. They are also very cheap nowadays, for another important reason.
Some of these Spring Boot courses on Udemy cost less money then just taking a taxi to go to a supermarket, btw, if you still like to start with books, [**Spring Boot in Action by Craig Walls**](https://www.amazon.com/Spring-Boot-Action-Craig-Walls/dp/1617292540?tag=javamysqlanta-20)**,** author of [**Spring in Action**](https://www.amazon.com/Spring-Action-Craig-Walls/dp/1617294942?tag=javamysqlanta-20) is the best book to start with.
[](https://www.amazon.com/Spring-Boot-Action-Craig-Walls/dp/1617292540?tag=javamysqlanta-20)
##Top 10 Spring Boot Online Courses for Java Programmers
Here is my list of some of the best online courses to learn Spring Boot for Java and Spring developers. It's good to have some Spring experience when you start with Spring Boot but that's not mandatory.
In fact, I suggest all first-timers start with Spring Boot, it's better to start with the latest and popular technology than traditional ones, btw, if you still want to start with Spring first, then you should first check out the [**Spring Framework 5: Beginner to Guru**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-framework-5-beginner-to-guru%2F) before going through any of these Spring Boot courses.
In this list, I have included courses for both beginners as well as intermediate and experienced developers. Most of these courses will help you to learn all-important Spring Boot features like **auto-configuration**, **starter dependency**, Spring Initializer, [Spring Actuator](https://dzone.com/articles/top-5-spring-boot-features-java-developers-should), and Spring CLI but some courses are goal-oriented and they will also teach you how to develop Microservices and Cloud-based application using Spring Boot and Spring Cloud.
###[**1\. Spring Boot Essentials**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-essentials%2F)
This is a short and simple course to start with Spring Boot. I pick this course for its clarity. The instructor is very focused and has a good voice and explanation skills which makes it easy to digest new Spring Boot concepts.
The instructor, Nelson Djalo, explains Spring Boot concepts by developing a [RESTful web service](https://javarevisited.blogspot.sg/2018/01/7-reasons-for-using-spring-to-develop-RESTful-web-service.html), which will also spark your interest in this field.
You should take this course if you are in a real hurry of learning Spring Boot. By following this course, you can learn Spring Boot in just a couple of days.
Btw, if you are very new to the Spring world and don't know about [dependency injection](https://javarevisited.blogspot.com/2015/06/difference-between-dependency-injection.html), Spring container, and other basic concepts, I won't recommend you to join this course.
You better start with other Spring boot courses on this list which explains the Spring framework along the way like [**Spring Framework MasterClass --- Beginner to Expert**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-tutorial-for-beginners%2F)**.**
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-essentials%2F)
###[2\. Spring Boot Microservices with Spring Cloud Beginner to Guru](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fspring-boot-microservices-with-spring-cloud-beginner-to-guru%2F)
In this course, you will learn how to develop Spring Boot Microservices and deploy them with Spring Cloud!
Traditionally, large enterprise-class Java applications were developed as large monolithic applications. The Spring Framework started as an alternative to J2EE (now JEE) for building these large monolithic enterprise applications.
However, the industry has evolved to favor [Microservices](https://dzone.com/articles/five-best-soa-and-microservice-courses-for-program). There are a number of benefits to using microservices. Which, you will learn about in this course.
As the industry has evolved, so has the Spring Framework. Spring Boot and [Spring Cloud](https://dzone.com/articles/5-courses-to-learn-spring-cloud-in-2019) are tools specifically for the development of microservices. This is another gem from [John S Thompson] , who has many super Spring courses on Udemy.
###[3\. Learn Spring Boot --- Rapid Spring Application Development](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-intro%2F)
This is another [excellent course](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-intro%2F) for learning Spring Boot for beginners i.e. someone with no prior experience with Spring Boot.
It will not only teach you Spring Boot basics but also the basics of Spring framework like [dependency injection](https://javarevisited.blogspot.sg/2015/06/difference-between-dependency-injection.html), [inversion of control](https://javarevisited.blogspot.com/2012/12/inversion-of-control-dependency-injection-design-pattern-spring-example-tutorial.html#axzz5N1cdCqrn), application context, etc.
In this course, instructor Dan Vega, a popular Spring framework instructor on Udemy will teach you how to develop a web application using Spring Boot. You will create Spring MVC application end-to-end.
> *Link to Join the course:* [***Learning Spring Boot --- The Rapid Application***](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-intro%2F)
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-intro%2F)
You will build REST services using Spring Boot, connect to the database using Spring Data, and secure your application using Spring Security. You will also learn how to create and an executable JAR of your application.
The course also explains key Spring Boot concepts like Spring Initializer to automatically create the project structure, Starter POMs or starter dependencies and auto-configuration.
In short, a comprehensive course to learn Java application development using Spring Framework. You will learn [Spring MVC](https://javarevisited.blogspot.com/2018/11/top-20-spring-mvc-interview-questions-answers-for-java-developers.html), [REST](https://javarevisited.blogspot.com/2018/02/top-5-restful-web-services-with-spring-courses-for-experienced-java-programmers.html), Spring Data JPA, [Spring Security](http://www.java67.com/2017/12/top-5-spring-security-online-training-courses.html) and all other related libraries in just one course.
###4\. [Learn Spring: The Certification Class](https://courses.baeldung.com/p/ls-certification-class?utm_source=javarevisited&utm_medium=web&utm_campaign=lss&affcode=22136_bkwjs9xa)
This is another [new course](https://courses.baeldung.com/p/ls-certification-class?utm_source=javarevisited&utm_medium=web&utm_campaign=lss&affcode=22136_bkwjs9xa) to learn Spring 5 and Spring Boot 2 from scratch, in a guided, code-focused way by Eugen Paraschiv of Baeldung. This is a bit expensive as compared to other courses on this list but if you can afford then its also a good resource.
Eugen has a knack of teaching and making things simpler and he also shows how to develop Spring Boot application following Modern tools and practices.
> *Link to Join the Course:* [***Learn Spring: The Certification Class***](https://courses.baeldung.com/p/ls-certification-class?utm_source=javarevisited&utm_medium=web&utm_campaign=lss&affcode=22136_bkwjs9xa)
Btw, if the price is something which is stopping you to join this course there are other options as well like the [**Spring: The Master Class**](https://courses.baeldung.com/p/ls-master-class?utm_source=javarevisited&utm_medium=web&utm_campaign=lss&affcode=22136_bkwjs9xa) which costs much lesser than Certification class, but obviously covers fewer topics.
###5\. [Learn Spring Boot in 100 Steps --- Beginner to Expert](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-tutorial-for-beginners%2F)
This is another [comprehensive course](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-tutorial-for-beginners%2F) to learn Spring Boot and related libraries for beginners. Ranga is also another popular Spring framework instructor in Udemy and has a lot of experience in teaching Spring.
In this course, you will not only learn all key Spring Boot concepts e.g. [auto-configuration](http://www.java67.com/2018/06/top-15-spring-boot-interview-questions-answers-java-jee-programmers.html), Starter dependencies, Spring Initializer but also explore more advanced concepts like Spring Boot Actuator and other Spring Boot dev tools.
The course also covers [Spring MVC](https://javarevisited.blogspot.sg/2017/06/how-spring-mvc-framework-works-web-flow.html) and teaches you to create a web application using Spring MVC and [Hibernate/JPA](https://javarevisited.blogspot.com/2018/01/top-5-hibernate-and-jpa-courses-for-java-programmers-learn-online.html). If you don't know anything about Spring MVC, don't worry.
You will learn enough in this course to create your own web application e.g. [DispatcherServlet](http://javarevisited.blogspot.sg/2017/09/dispatcherservlet-of-spring-mvc-10-points-to-remember.html), [ViewResolvers](https://javarevisited.blogspot.com/2017/08/what-does-internalresourceviewresolver-do-in-spring-mvc.html), Model, [Controllers](https://javarevisited.blogspot.com/2017/08/difference-between-restcontroller-and-controller-annotations-spring-mvc-rest.html), etc.
> *Link to Join the Course:* [***Learn Spring Boot in 100 Steps***](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-tutorial-for-beginners%2F)
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-boot-tutorial-for-beginners%2F)
Another good thing about this course is that it will teach you to write great Unit and Integration testing using Spring Boot.
You will also learn [JUnit 5](http://bit.ly/2Q7jFNs) and [Mockito](http://bit.ly/2OXM8IR), two of the [leading testing](https://javarevisited.blogspot.sg/2018/01/10-unit-testing-and-integration-tools-for-java-programmers.html) frameworks for Java application development.
In short, a great course for beginners to start learning Java development with Spring Boot and related technology.
###[**6\. Creating Your First Spring Boot Application**](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fspring-boot-first-application)
This is a great introductory course on Spring Boot Framework and you will learn What is Spring Boot, How it works and how it works with other Spring modules like Spring MVC, REST, etc.
In [**this course**](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fspring-boot-first-application), you will learn Spring Boot by creating a demo application. You will explore different Spring Boot features along the way like Spring Initializers, Spring Boot Dependency management i.e. starter POMs which allows you to just declare one starter package instead of several individual libraries.
You will also learn to develop a modern Java web application using Spring Boot, a [RESTful web service](https://javarevisited.blogspot.sg/2017/02/how-to-consume-json-from-restful-web-services-Spring-RESTTemplate-Example.html) and integrating a JavaScript-based UI. Most importantly the Spring MVC Integration.
[](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fspring-boot-first-application)
You will also learn how to externalize properties and take full advantage of Spring Boot auto-configuration to reduce configuration in your project.
In short, one of the best courses to learn Spring Boot for beginners. After completing this course you should have a good idea about Spring Boot architecture and how it works together with [Core Spring](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-framework-5-beginner-to-guru%2F).
###[**7\. Master Microservices with Spring Boot and Spring Cloud**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fmicroservices-with-spring-boot-and-spring-cloud%2F)
This is a task-based course and a little bit different from other courses. It's also a more advanced course and more suited for experienced Java programmers who have good knowledge of Spring framework and some basic understanding of Spring Boot and Spring Cloud, two leading framework from Spring umbrella to build modern-day Java application for the cloud.
In [**this course**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fmicroservices-with-spring-boot-and-spring-cloud%2F), you will first start with developing RESTful web service using Spring Boot and then slowly move towards [Spring Cloud](http://javarevisited.blogspot.sg/2018/04/top-5-spring-cloud-courses-for-java.html#axzz5DbV6r2Ll) and [Microservice pattern](https://javarevisited.blogspot.sg/2018/02/top-5-spring-microservices-courses-with-spring-boot-and-spring-cloud.html#axzz5Cz1R4cHw).
You will learn about key Microservice and cloud concepts e.g. client-side load balancing using Ribbon, Dynamic Scaling using Eureka Naming Server, Fault tolerance for microservices with Hystrix, etc.
[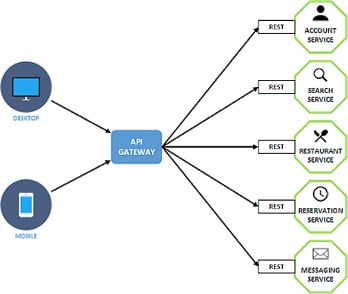](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fmicroservices-with-spring-boot-and-spring-cloud%2F)
You will also learn some advanced REST concepts like [*how to version your RESTful Web service and document them using Swagger*](http://courses.baeldung.com/p/rest-with-spring-the-master-class?affcode=22136_bkwjs9xa). Overall a great course for Java developers moving towards cloud and microservices by using Spring Boot and Spring Cloud.
###**8\.** [**Testing Spring Boot: Beginner to Guru**](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Ftesting-spring-boot-beginner-to-guru%2F)
This is a good course to learn how to write a test while you are using Spring Boot for your project development. The primary focus of this course is on the JUnit 5 release.
There are some very notable differences between JUnit 4 and JUnit 5. This course contains a dedicated section showing you how to migrate your JUnit 4 tests to [JUnit 5](https://javarevisited.blogspot.com/2019/04/top-5-junit-and-unit-testing-courses-java-programmers.html).
As your testing needs become more complex, you will need to mock dependent objects. [Mockito](https://medium.com/javarevisited/5-courses-to-learn-junit-and-mockito-in-2019-best-of-lot-f217d8b93688) is the most popular mocking library used by Java developers.
If you are writing Spring Framework applications, you're likely to be injecting dependent objects into your classes. You will learn how to use the robust mocking capabilities of [Mocktio](https://medium.com/javarevisited/top-10-courses-to-learn-eclipse-junit-and-mockito-for-java-developers-4de1e8d62b96) to mock dependent objects in your unit tests.
###9\. [Spring Framework for Beginners with Spring Boot](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fspring-5-with-spring-boot-2%2F)
In this course, you will learn the highly demanded frameworks of the enterprise world: Spring Framework 5 with Spring Boot. The instructor of Navin Reddy from Telusko is a great instructor and I have watched so many of his Youtube videos.
This course offers hands-on experience building Spring Framework applications using [Spring Boot](https://dzone.com/articles/top-5-books-to-learn-spring-boot-and-spring-cloud).
This course is interactive and fun as you will see Navin code all the projects from scratch. By taking this course you will have the latest skills that you need to build real applications using the Spring Framework.
###[10\. Deploy Java Spring Boot Apps to AWS with Elastic Beanstalk](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fdeploy-java-spring-boot-to-aws-amazon-web-service%2F)
Software Development is moving towards the cloud and so is all the Java application. This course would be a **perfect first step as an introduction to AWS** and the Cloud, especially for Java Developers.
You will learn about automating deployments with Elastic Beanstalk CLI and creating a continuous delivery pipeline with AWS Code Pipeline. You will learn how to Auto Scale applications based on load as well as deploy multiple instances behind a load balancer using Elastic Beanstalk.
You will be using a **number of AWS Services** --- EC2, S3, AWS CodePipeLine, AWS CodeBuild, SQS, IAM, CloudWatch.
That's all about some of the **best courses to learn Spring boot for beginners and experienced Java programmers**. Spring Boot is an immensely useful framework, it gives you all the power of the Spring framework without all of its complexity which really boosts productivity.
If you happen to use [Groovy](https://dev.to/javinpaul/scala-groovy-or-kotlin-which-programming-language-java-developers-should-learn-5an5) then you can further reduce the development time of Java web application using Spring CLI. If you ask me one thing to learn this year, I would suggest [Spring Boot](http://www.java67.com/2019/01/top-5-spring-boot-annotations-java-programmers-should-know.html).
It will not only help you to write Spring-based Java application easily but also gives your career a boost.
Other **Java and Spring Articles** you may like to explore
[The Complete Java Developer RoadMap](https://javarevisited.blogspot.com/2019/10/the-java-developer-roadmap.html)
[10 Things Java Developer Should Learn this Year](http://javarevisited.blogspot.sg/2017/12/10-things-java-programmers-should-learn.html)
[Top 5 Courses to Learn and Master Spring Cloud](http://javarevisited.blogspot.sg/2018/04/top-5-spring-cloud-courses-for-java.html)
[5 Free Courses to Learn Spring Framework for Beginners](http://www.java67.com/2017/11/top-5-free-core-spring-mvc-courses-learn-online.html)
[5 Courses to Learn Spring Security in 201](http://www.java67.com/2017/12/top-5-spring-security-online-training-courses.html)
[5 Spring Books Experienced Java Developer Should Read](http://javarevisited.blogspot.sg/2018/04/5-spring-framework-books-experienced-Java-developers-2018.html)
[10 Tips to become a better Java Developer in 201](http://javarevisited.blogspot.sg/2018/05/10-tips-to-become-better-java-developer.html)
[Top 5 Frameworks Java Developer Should Know](https://javarevisited.blogspot.sg/2018/04/top-5-java-frameworks-to-learn-in-2018_27.html)
[20 Spring and REST Interview Questions for Java Programmers](https://javarevisited.blogspot.com/2018/02/top-20-spring-rest-interview-questions-answers-java.html#axzz57Kv4wGXe)
###Closing Notes
Thanks, You made it to the end of the article ... Good luck with your Spring Boot journey! It's certainly not going to be easy, but by following these courses, you are one step ahead in your goal to master Spring boot.
If you like this article, then please share it with your friends and colleagues, and don't forget to follow [javinpaul](https://twitter.com/javinpaul) on Twitter and [javinpaul] on here!
**P.S.** If you like books then you can also check out my list of [**top Spring Boot books**](https://javarevisited.blogspot.com/2018/07/top-5-books-to-learn-spring-boot-and-spring-cloud-java.html) for Java developers.
**P. P. S.** --- If you need some FREE resources, you can check out this list of [**free Spring Boot courses**](http://www.java67.com/2017/11/top-5-free-core-spring-mvc-courses-learn-online.html) to start your journey.
| javinpaul |
227,963 | Unity UI System ဆိုတာဘာလဲ | အခုတခါမှာတော့ Unity မှာ User Interface (UI) ကို ဘယ်လိုဆောက်သလဲ ကြည့်ရအောင်။ UI တစ်ခုဆောက်တော့မယ်ဆို... | 0 | 2019-12-29T04:39:28 | https://dev.to/arkarmintun1/unity-ui-system-30hp | အခုတခါမှာတော့ Unity မှာ User Interface (UI) ကို ဘယ်လိုဆောက်သလဲ ကြည့်ရအောင်။
UI တစ်ခုဆောက်တော့မယ်ဆို အရင်ဆုံး Canvas တခုလိုအပ်တယ်။ ပုံဆွဲသလိုပဲပေါ့။ Canvas ပေါ်မှာ ကိုယ်လိုချင်တာတွေကို တခုပြီးတခု ဆွဲသွားရတာ။ တကယ်လို့ Button ဖြစ်စေ၊ Text ဖြစ်စေ UI Component တခုခုက Canvas ရဲ့ child အနေနဲ့ ရှိမနေရင် UI ပေါ်မှာ ပေါ်လာမှာ မဟုတ်ပါဘူး။

စစချင်း Unity ကိုလုပ်မယ့်သူတွေအတွက်ဆို UI အောက်မှာပါတဲ့ Text တို့၊ Button တို့၊ Dropdown တို့၊ TextInput တို့မှာ နှစ်ခုစီဖြစ်နေတာ နည်းနည်း confusing ဖြစ်တတ်တယ်။ ဘယ်နေရာမှာ ဘယ်ဟာသုံးမလဲပေါ့။

နောက်မှာ ဘာမှမပါတဲ့ Text တို့၊ Button တို့ဆိုတာ အရင်ထဲကပါတဲ့ဟာတွေဖြစ်ပြီး TextMeshPro ဆိုတဲ့စာပါတာတွေက နောက်ပိုင်းမှာ အသစ်ထည့်လိုက်တဲ့ဟာတွေပါ။ ဘာကွာသလဲဆိုတော့ TextMeshPro ပါတဲ့ Components တွေကပိုပြီး Customize လုပ်လို့ရလာတယ်၊ Screen မှာပေါ်တဲ့အခါလဲ ဝါးတာမှုန်တာတွေ မဖြစ်အောင် ပိုပြီး လုပ်ရလွယ်သွားတယ်။
UI အောက်မှာ ပါတဲ့ Component တွေကို အကြမ်းဖျင်း ကြည့်ကြည့်ရအောင်...
- Text
စာတွေဖော်ပြချင်တဲ့အခါသုံးတယ်။
- Text - TextMeshPro
စာတွေဖော်ပြချင်တဲ့အခါသုံးတယ်။ ရိုးရိုး Text ထက်ပိုပြီး Customize လုပ်လို့ရတယ်။
- Image
Sprite ပုံတွေ ပြချင်တဲ့အခါသုံးတယ်။ ပြတဲ့အခါ ပုံစံအမျိုးမျိုး လိုအပ်သလို customize လုပ်လို့ရတယ်။
- RawImage
Texture ပုံတွေ ပြချင်တဲ့အခါသုံးတယ်။
- Button
User နှိပ်ဖို့ Button တွေအတွက်သုံးတယ်။
- Button - TextMeshPro
Button မှာပေါ်တဲ့စာကို ပိုပြီး Customize လုပ်နိုင်တယ်။
- Toggle
On/Off အနေနဲ့ သတ်မှတ်တာတွေ လုပ်ချင်တဲ့အခါသုံးတယ်။
- Slider
Value တွေကို Maximum နဲ့ Minimum နှစ်ခုကြားမှာ ရွေးစေချင်တဲ့အခါ သုံးတယ်။
- Scrollbar
တခုထဲသုံးတာထက် ScrollView ထဲမှာ ထည့်သုံးလေ့ရှိတယ်။ ဘယ်ညာ အပေါ်အောက် Scroll လုပ်တာလုပ်ဖို့သုံးတယ်။
- Dropdown
နာမည်မှာပြထားတဲ့အတိုင်းပဲ User တွေကို ရွေးချယ်ဖို့ Option တွေပြချင်တဲ့အခါသုံးတယ်။
- Dropdown - TextMeshPro
နာမည်မှာပြထားတဲ့အတိုင်းပဲ User တွေကို ရွေးချယ်ဖို့ Option တွေပြချင်တဲ့အခါသုံးတယ်။
- InputField
User ဆီက နာမည်တို့၊ emailတို့ စသဖြင့် သူတို့ကို ရိုက်ထည့်စေချင်တဲ့အခါ သုံးတယ်။
- InputField - TextMeshPro
User ဆီက နာမည်တို့၊ emailတို့ စသဖြင့် သူတို့ကို ရိုက်ထည့်စေချင်တဲ့အခါ သုံးတယ်။
- Canvas
UI Components တွေပြဖို့ မရှိမဖြစ်လိုအပ်တဲ့ Component တခုဖြစ်တယ်။
- Panel
UI Components တွေကို သပ်သပ်စီ စုထားချင်တဲ့အခါ သုံးတယ်။ ဥပမာ Button တခုကိုနှိပ်လိုက်ရင် alert box တပ်လာသလိုပေါ့။
- ScrollView
Contents ပြစရာများတဲ့အခါ Scroll လို့ရတဲ့ View တခုအနေနဲ့ ပြချင်တဲ့အခါသုံးတယ်။
- EventSystem
UI တွေကို နှိပ်လို့ ရွှေ့လို့ရအောင်လုပ်ဖို့ နောက်ကွယ်ကနေ handle လုပ်ပေးနေတဲ့ EventSystem ဖြစ်တယ်။
| arkarmintun1 | |
228,010 | Elasticsearch Comrade Part #1 - SQL Queries | This is the first part of an Elasticsearch Comrade introduction series. Elasticsearch Comrade is a ma... | 0 | 2019-12-30T09:47:59 | https://dev.to/moshe/elasticsearch-comrade-part-1-sql-queries-1i8c | elasticsearch, elastic, sql, vue | This is the first part of an Elasticsearch Comrade introduction series.
Elasticsearch Comrade is a management UI for common operations within elastic products.
In this post, I will cover the SQL Editor feature.
{% github moshe/elasticsearch-comrade %}
## Starting up Comrade server
You can install comrade with `pip` / `docker` / `source`
Follow the [installation guide](https://moshe-1.gitbook.io/comrade/installation) for more details
## The SQL UI
Once you configured Comrade and started the server, click on the desired server. Next, open the navbar and click on `🔎SQL` nav item
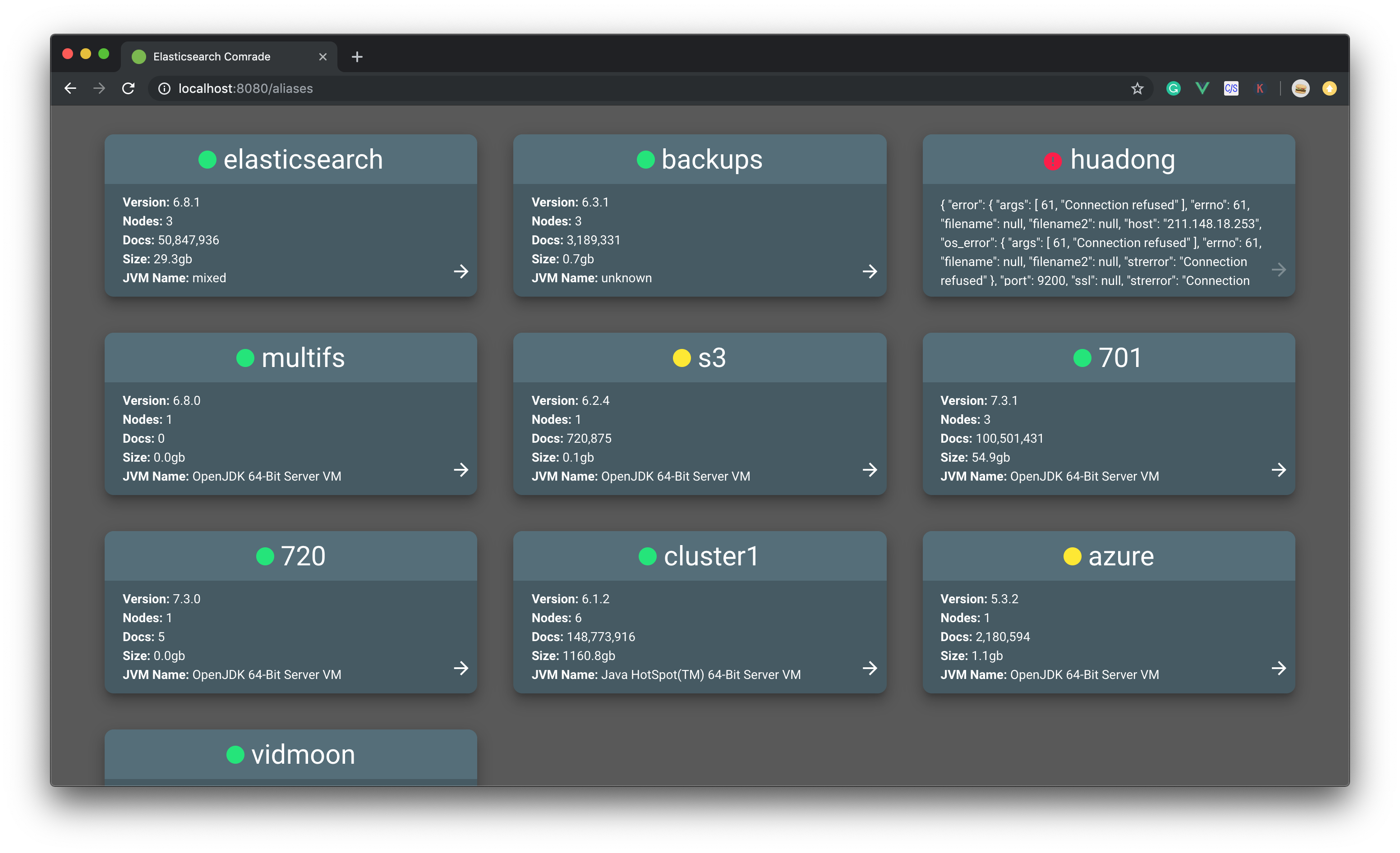
## Sending queries and getting results
Now, The SQL editor will show up, and you free to send you queries 🙂
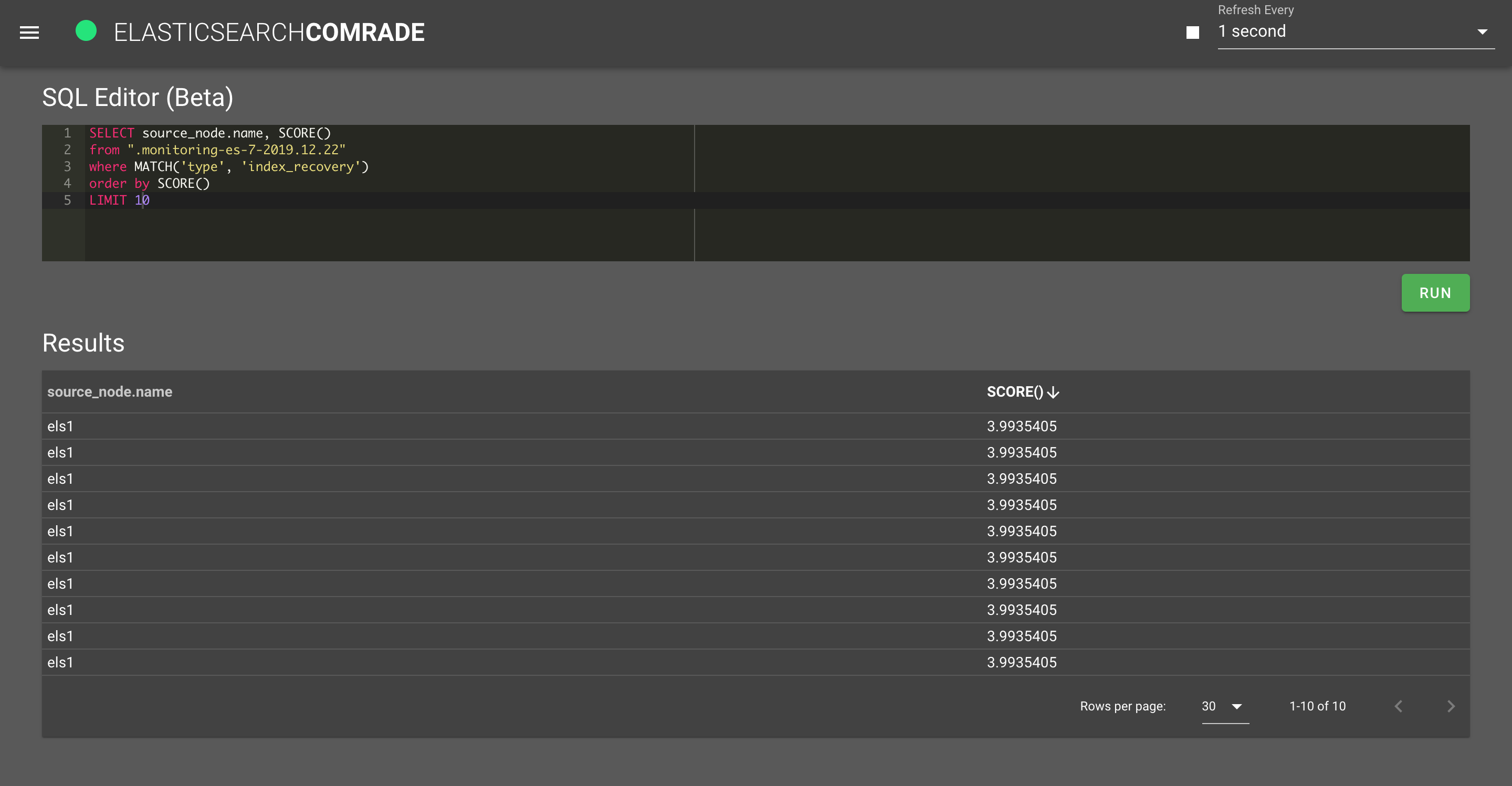
Some things you need to know before running queries:
- SQL is only supported in ES version 7 and above
- The SQL syntax is quite standard except a few changes
- You can refer several indices at once using elasticsearch index [expansion syntax](https://www.elastic.co/guide/en/elasticsearch/reference/current/multi-index.html), for instance (Notice the second line)
```sql
SELECT count(*), source_node.name
FROM ".monitoring-es-*"
WHERE type = 'index_recovery'
GROUP BY source_node.name
LIMIT 100
```
- You can apply Elasticsearch query function like match, query, and score by using them as a function
```sql
SELECT source_node.name, SCORE() -- Add score to selected fields
from ".monitoring-es-7-2019.12.22"
where MATCH('type', 'index_recovery') -- Use match query
order by SCORE() -- order by score
LIMIT 100
```
**Found this post useful? Add a ⭐️ to my Github project nor my [twitter profile](https://twitter.com/moshe_zada)🙂**
{% github moshe/elasticsearch-comrade %} | moshe |
228,044 | Using Rook / Ceph with PVCs on Azure Kubernetes Service | Introduction As you all know by now, Kubernetes is a quite popular platform for running cl... | 0 | 2019-12-28T15:40:21 | https://dev.to/cdennig/using-rook-ceph-with-pvcs-on-azure-kubernetes-service-djc | ceph, kubernetes, rook, aks | ---
title: Using Rook / Ceph with PVCs on Azure Kubernetes Service
published: true
date: 2019-12-08 22:37:03 UTC
tags: ceph,kubernetes,rook,aks
canonical_url:
---
# Introduction
As you all know by now, Kubernetes is a quite popular platform for running cloud-native applications at scale. A common recommendation when doing so, is to ousource as much state as possible, because managing state in Kubernetes is not a trivial task. It can be quite hard, especially when you have a lot of attach/detach operations on your workloads. Things can go terribly wrong and – of course – your application and your users will suffer from that. A solution that becomes more and more popular in that space is Rook in combination with Ceph.
Rook is described on their homepage [rook.io](https://rook.io) as follows:
> Rook turns distributed storage systems into self-managing, self-scaling, self-healing storage services. It automates the tasks of a storage administrator: deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management.
Rook is a project of the [Cloud Native Computing Foundation](https://www.cncf.io/projects/), at the time of writing in status “incubating”.
Ceph in turn is a free-software storage platform that implements storage on a cluster, and provides interfaces for object-, block- and file-level storage. It has been around for many years in the open-source space and is a battle-proven distributed storage system. Huge storage systems have been implemented with Ceph.
So in a nutshell, Rook enables Ceph storage systems to run on Kubernetes using Kubernetes primitives. The basic architecture for that inside a Kubernetes cluster looks as follows:
<figcaption id="caption-attachment-2150">Rook in-cluster architecture</figcaption>
I won’t go into all of the details of Rook / Ceph, because I’d like to focus on simply running and using it on AKS in combination with PVCs. If you want to have a step-by-step introduction, there is a pretty good “Getting Started” video by [Tim Serewicz](https://www.linkedin.com/in/serewicz/) on Vimeo:
{% vimeo 377611372 %}
## First, we need a Cluster!
So, let’s start by creating a Kubernetes cluster on Azure. We will be using different nodepools for running our storage (nodepool: _npstorage_) and application workloads (nodepool: _npstandard_).
```shell
# Create a resource group
$ az group create --name rooktest-rg --location westeurope
# Create the cluster
$ az aks create \
--resource-group rooktest-rg \
--name myrooktestclstr \
--node-count 3 \
--kubernetes-version 1.14.8 \
--enable-vmss \
--nodepool-name npstandard \
--generate-ssh-keys
```
###
### Add Storage Nodes
After the cluster has been created, add the _npstorage_ nodepool:
```shell
$ az aks nodepool add --cluster-name myrooktestclstr \
--name npstorage --resource-group rooktest-rg \
--node-count 3 \
--node-taints storage-node=true:NoSchedule
```
Please be aware that we add **taints** to our nodes to make sure that no pods will be scheduled on this nodepool as long as we explicitly tolerate it. We want to have these nodes exclusively for storage pods!
> If you need a refresh regarding the concept of “taints and tolerations”, please see the [Kubernetes documentation](https://kubernetes.io/docs/concepts/configuration/taint-and-toleration).
So, now that we have a cluster and a dedicated nodepool for storage, we can download the cluster config.
```shell
$ az aks get-credentials \
--resource-group rooktest-rg \
--name myrooktestclstr
```
Let’s look at the nodes of our cluster:
```shell
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-npstandard-33852324-vmss000000 Ready agent 10m v1.14.8
aks-npstandard-33852324-vmss000001 Ready agent 10m v1.14.8
aks-npstandard-33852324-vmss000002 Ready agent 10m v1.14.8
aks-npstorage-33852324-vmss000000 Ready agent 2m3s v1.14.8
aks-npstorage-33852324-vmss000001 Ready agent 2m9s v1.14.8
aks-npstorage-33852324-vmss000002 Ready agent 119s v1.14.8
```
So, we now have three nodes for storage and three nodes for our application workloads. From an infrastructure level, we are now ready to install Rook.
## Install Rook
Let’s start installing Rook by cloning the repository from GitHub:
```shell
$ git clone https://github.com/rook/rook.git
```
After we have downloaded the repo to our local machine, there are three steps we need to perform to install Rook:
1. Add Rook CRDs / namespace / common resources
2. Add and configure the Rook operator
3. Add the Rook cluster
So, switch to the _/cluster/examples/kubernetes/ceph_ directory and follow the steps below.
### 1. Add Common Resources
```shell
$ kubectl apply -f common.yaml
```
The _common.yaml_ contains the namespace _rook-ceph,_ common resources (e.g. clusterroles, bindings, service accounts etc.) and some Custom Resource Definitions from Rook.
### 2. Add the Rook Operator
The operator is responsible for managing Rook resources and needs to be configured to run on Azure Kubernetes Service. To manage Flex Volumes, AKS uses a directory that’s different from the “default directory”. So, we need to tell the operator which directory to use on the cluster nodes.
Furthermore, we need to adjust the settings for the CSI plugin to run the corresponding daemonsets on the storage nodes (remember, we added taints to the nodes. By default, the pods of the daemonsets Rook needs to work, won’t be scheduled on our storage nodes – we need to “tolerate” this).
So, here’s the full operator.yaml file
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: rook-ceph-operator
namespace: rook-ceph
labels:
operator: rook
storage-backend: ceph
spec:
selector:
matchLabels:
app: rook-ceph-operator
replicas: 1
template:
metadata:
labels:
app: rook-ceph-operator
spec:
serviceAccountName: rook-ceph-system
containers:
- name: rook-ceph-operator
image: rook/ceph:master
args: ["ceph", "operator"]
volumeMounts:
- mountPath: /var/lib/rook
name: rook-config
- mountPath: /etc/ceph
name: default-config-dir
env:
- name: ROOK_CURRENT_NAMESPACE_ONLY
value: "false"
- name: FLEXVOLUME_DIR_PATH
value: "/etc/kubernetes/volumeplugins"
- name: ROOK_ALLOW_MULTIPLE_FILESYSTEMS
value: "false"
- name: ROOK_LOG_LEVEL
value: "INFO"
- name: ROOK_CEPH_STATUS_CHECK_INTERVAL
value: "60s"
- name: ROOK_MON_HEALTHCHECK_INTERVAL
value: "45s"
- name: ROOK_MON_OUT_TIMEOUT
value: "600s"
- name: ROOK_DISCOVER_DEVICES_INTERVAL
value: "60m"
- name: ROOK_HOSTPATH_REQUIRES_PRIVILEGED
value: "false"
- name: ROOK_ENABLE_SELINUX_RELABELING
value: "true"
- name: ROOK_ENABLE_FSGROUP
value: "true"
- name: ROOK_DISABLE_DEVICE_HOTPLUG
value: "false"
- name: ROOK_ENABLE_FLEX_DRIVER
value: "false"
# Whether to start the discovery daemon to watch for raw storage devices on nodes in the cluster.
# This daemon does not need to run if you are only going to create your OSDs based on StorageClassDeviceSets with PVCs. --> CHANGED to false
- name: ROOK_ENABLE_DISCOVERY_DAEMON
value: "false"
- name: ROOK_CSI_ENABLE_CEPHFS
value: "true"
- name: ROOK_CSI_ENABLE_RBD
value: "true"
- name: ROOK_CSI_ENABLE_GRPC_METRICS
value: "true"
- name: CSI_ENABLE_SNAPSHOTTER
value: "true"
- name: CSI_PROVISIONER_TOLERATIONS
value: |
- effect: NoSchedule
key: storage-node
operator: Exists
- name: CSI_PLUGIN_TOLERATIONS
value: |
- effect: NoSchedule
key: storage-node
operator: Exists
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumes:
- name: rook-config
emptyDir: {}
- name: default-config-dir
emptyDir: {}
```
### 3. Create the Cluster
Deploying the Rook [cluster](https://rook.io/docs/rook/v1.1/ceph-cluster-crd.html) is as easy as installing the Rook operator. As we are running our cluster with the Azure Kuberntes Service – a managed service – we don’t want to manually add disks to our storage nodes. Also, we don’t want to use a directory on the OS disk (which most of the examples out there will show you) as this will be deleted when the node will be upgraded to a new Kubernetes version.
In this sample, we want to leverage [Persistent Volumes / Persistent Volume Claims](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#introduction) that will be used to request Azure Managed Disks which will in turn be dynamically attached to our storage nodes. Thankfully, when we installed our cluster, a corresponding storage class for using Premium SSDs from Azure was also created.
```shell
$ kubectl get storageclass
NAME PROVISIONER AGE
default (default) kubernetes.io/azure-disk 15m
managed-premium kubernetes.io/azure-disk 15m
```
Now, let’s create the Rook Cluster. Again, we need to adjust the tolerations and add a node affinity that our OSDs will be scheduled on the storage nodes:
```yaml
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
dataDirHostPath: /var/lib/rook
mon:
count: 3
allowMultiplePerNode: false
volumeClaimTemplate:
spec:
storageClassName: managed-premium
resources:
requests:
storage: 10Gi
cephVersion:
image: ceph/ceph:v14.2.4-20190917
allowUnsupported: false
dashboard:
enabled: true
ssl: true
network:
hostNetwork: false
storage:
storageClassDeviceSets:
- name: set1
# The number of OSDs to create from this device set
count: 4
# IMPORTANT: If volumes specified by the storageClassName are not portable across nodes
# this needs to be set to false. For example, if using the local storage provisioner
# this should be false.
portable: true
# Since the OSDs could end up on any node, an effort needs to be made to spread the OSDs
# across nodes as much as possible. Unfortunately the pod anti-affinity breaks down
# as soon as you have more than one OSD per node. If you have more OSDs than nodes, K8s may
# choose to schedule many of them on the same node. What we need is the Pod Topology
# Spread Constraints, which is alpha in K8s 1.16. This means that a feature gate must be
# enabled for this feature, and Rook also still needs to add support for this feature.
# Another approach for a small number of OSDs is to create a separate device set for each
# zone (or other set of nodes with a common label) so that the OSDs will end up on different
# nodes. This would require adding nodeAffinity to the placement here.
placement:
tolerations:
- key: storage-node
operator: Exists
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: agentpool
operator: In
values:
- npstorage
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-osd
- key: app
operator: In
values:
- rook-ceph-osd-prepare
topologyKey: kubernetes.io/hostname
resources:
limits:
cpu: "500m"
memory: "4Gi"
requests:
cpu: "500m"
memory: "2Gi"
volumeClaimTemplates:
- metadata:
name: data
spec:
resources:
requests:
storage: 100Gi
storageClassName: managed-premium
volumeMode: Block
accessModes:
- ReadWriteOnce
disruptionManagement:
managePodBudgets: false
osdMaintenanceTimeout: 30
manageMachineDisruptionBudgets: false
machineDisruptionBudgetNamespace: openshift-machine-api
```
So, after a few minutes, you will see some pods running in the _rook-ceph_ namespace. Make sure, that the OSD pods a running, before continuing with configuring the storage pool.
```shell
$ kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-4qxsv 3/3 Running 0 28m
csi-cephfsplugin-d2klt 3/3 Running 0 28m
csi-cephfsplugin-jps5r 3/3 Running 0 28m
csi-cephfsplugin-kzgrt 3/3 Running 0 28m
csi-cephfsplugin-provisioner-dd9775cd6-nsn8q 4/4 Running 0 28m
csi-cephfsplugin-provisioner-dd9775cd6-tj826 4/4 Running 0 28m
csi-cephfsplugin-rt6x2 3/3 Running 0 28m
csi-cephfsplugin-tdhg6 3/3 Running 0 28m
csi-rbdplugin-6jkx5 3/3 Running 0 28m
csi-rbdplugin-clfbj 3/3 Running 0 28m
csi-rbdplugin-dxt74 3/3 Running 0 28m
csi-rbdplugin-gspqc 3/3 Running 0 28m
csi-rbdplugin-pfrm4 3/3 Running 0 28m
csi-rbdplugin-provisioner-6dfd6db488-2mrbv 5/5 Running 0 28m
csi-rbdplugin-provisioner-6dfd6db488-2v76h 5/5 Running 0 28m
csi-rbdplugin-qfndk 3/3 Running 0 28m
rook-ceph-crashcollector-aks-npstandard-33852324-vmss00000c8gdp 1/1 Running 0 16m
rook-ceph-crashcollector-aks-npstandard-33852324-vmss00000tfk2s 1/1 Running 0 13m
rook-ceph-crashcollector-aks-npstandard-33852324-vmss00000xfnhx 1/1 Running 0 13m
rook-ceph-crashcollector-aks-npstorage-33852324-vmss000001c6cbd 1/1 Running 0 5m31s
rook-ceph-crashcollector-aks-npstorage-33852324-vmss000002t6sgq 1/1 Running 0 2m48s
rook-ceph-mgr-a-5fb458578-s2lgc 1/1 Running 0 15m
rook-ceph-mon-a-7f9fc6f497-mm54j 1/1 Running 0 26m
rook-ceph-mon-b-5dc55c8668-mb976 1/1 Running 0 24m
rook-ceph-mon-d-b7959cf76-txxdt 1/1 Running 0 16m
rook-ceph-operator-5cbdd65df7-htlm7 1/1 Running 0 31m
rook-ceph-osd-0-dd74f9b46-5z2t6 1/1 Running 0 13m
rook-ceph-osd-1-5bcbb6d947-pm5xh 1/1 Running 0 13m
rook-ceph-osd-2-9599bd965-hprb5 1/1 Running 0 5m31s
rook-ceph-osd-3-557879bf79-8wbjd 1/1 Running 0 2m48s
rook-ceph-osd-prepare-set1-0-data-sv78n-v969p 0/1 Completed 0 15m
rook-ceph-osd-prepare-set1-1-data-r6d46-t2c4q 0/1 Completed 0 15m
rook-ceph-osd-prepare-set1-2-data-fl8zq-rrl4r 0/1 Completed 0 15m
rook-ceph-osd-prepare-set1-3-data-qrrvf-jjv5b 0/1 Completed 0 15m
```
## Configuring Storage
Before Rook can provision persistent volumes, either a filesystem or a storage pool should be configured. In our example, a **Ceph Block Pool** is used:
```yaml
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
failureDomain: host
replicated:
size: 3
```
Next, we also need a storage class that will be using the Rook cluster / storage pool. In our example, we will not be using Flex Volume (which will be deprecated in furture versions of Rook/Ceph), instead we use **Container Storage Interface**.
```yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
clusterID: rook-ceph
pool: replicapool
imageFormat: "2"
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
csi.storage.k8s.io/fstype: xfs
reclaimPolicy: Delete
```
## Test
Now, let’s have a look at the dashboard which was also installed when we created the Rook cluster. Therefore, we are port-forwarding the dashboard service to our local machine. The service itself is secured by username/password. The default username is _admin_ and the password is stored in a K8s secret. To get the password, simply run the following command.
```shell
$ kubectl -n rook-ceph get secret rook-ceph-dashboard-password \
-o jsonpath="{['data']['password']}" | base64 --decode && echo
# copy the password
$ kubectl port-forward svc/rook-ceph-mgr-dashboard 8443:8443 \
-n rook-ceph
```
Now access the dasboard by heading to [https://localhost:8443/#/dashboard](https://localhost:8443/#/dashboard)
<figcaption id="caption-attachment-2153">Ceph Dashboard</figcaption>
As you can see, everything looks healthy. Now let’s create a pod that’s using a newly created PVC leveraging that Ceph storage class.
#### PVC
```yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ceph-pv-claim
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
```
#### Pod
```yaml
apiVersion: v1
kind: Pod
metadata:
name: ceph-pv-pod
spec:
volumes:
- name: ceph-pv-claim
persistentVolumeClaim:
claimName: ceph-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: ceph-pv-claim
```
As a result, you will now have an NGINX pod running in your Kuberntes cluster with a PV attached/mounted under /usr/share/nginx/html.
# Wrap Up
So…what exactly did we achieve with this solution now? We have created a Ceph storage cluster on an AKS that uses PVCs to manage storage. Okay, so what? Well, the usage of volume mounts in your deployments with Ceph is now **super-fast and rock-solid** , because we do not have to attach physical disks to our worker nodes anymore. We just use the ones we have created during Rook cluster provisioning (remember these four 100GB disks?)! We minimized the amount of “physical attach/detach” actions on our nodes. That’s why now, you won’t see these popular “_WaitForAttach”- or “Can not find LUN for disk”-_errors anymore.
Hope this helps someone out there! Have fun with it.
## Update: Benchmarks
Short update on this. Today, I did some benchmarking with _dbench_ ([https://github.com/leeliu/dbench/](https://github.com/leeliu/dbench/)) comparing Rook Ceph and “plain” PVCs with the same Azure Premium SSD disks (default AKS StorageClass _managed-premium_, VM types: Standard\_DS2\_v2). Here are the results…as you can see, it depends on your workload…so, judge by yourself.
### Rook Ceph
==================
= Dbench Summary =
==================
Random Read/Write IOPS: 10.6k/571. BW: 107MiB/s / 21.2MiB/s
Average Latency (usec) Read/Write: 715.53/31.70
Sequential Read/Write: 100MiB/s / 43.2MiB/s
Mixed Random Read/Write IOPS: 1651/547
### PVC with Azure Premium SSD
> 100GB disk used to have a fair comparison
==================
= Dbench Summary =
==================
Random Read/Write IOPS: 8155/505. BW: 63.7MiB/s / 63.9MiB/s
Average Latency (usec) Read/Write: 505.73/
Sequential Read/Write: 63.6MiB/s / 65.3MiB/s
Mixed Random Read/Write IOPS: 1517/505 | cdennig |
228,084 | A CLI tool to create universal boilerplates | As I created new React components over and over again, I noticed that I wrote a lot of boilerplate co... | 0 | 2019-12-28T17:09:01 | https://dev.to/eyk/a-cli-tool-to-create-universal-boilerplates-5f9f | productivity, javascript, npm, node | As I created new React components over and over again, I noticed that I wrote a lot of boilerplate code and I wanted to stop doing that. Sure, there are existing solutions to that specific problem, but I wanted to use a universal one, which could fit all my needs for boilerplates.
So I came up with this idea and open-sourced it. Any feedback appreciated!
https://github.com/eykrehbein/cook | eyk |
228,180 | Cloud: Virtual Machine Monitoring and Security Challenges | Virtual Machine Monitoring (VMM) is a software program that enables the creation, management and gove... | 0 | 2019-12-28T23:34:13 | https://dev.to/sciencebae/cloud-virtual-machine-monitoring-and-security-challenges-1ll8 | cloud, cloudcomputing, azure, vmm |
Virtual Machine Monitoring (VMM) is a software program that enables the creation, management and governance of virtual machines (VM) and manages the operation of a virtualized environment on top of a physical host machine.
When VM Monitoring is enabled, the VM Monitoring service evaluates whether each virtual machine is in the cluster and up and running by checking for regular heartbeats and I/O activity from the processes running inside the guest. If there are no heartbeats or I/O activity received, this is probably because the guest operating system has failed. In this case, VM Monitoring service determines that the virtual machine has failed, and the virtual machine is rebooted to restore service.
**Security Challenges**
Monitoring of the virtual machines with high security is always important, especially in the environments with hundreds of machines running on dozens of physical servers. There are several security challenges in Virtual Machine Monitoring.
**SaaS security challenges:**
• Hypervisor security challenges
• Cross-side channel attacks between VMs.
**Security issues in cloud environment:**
Resources, such as servers, networks, and so on, are provided by IaaS in the form of virtualized systems. These systems are accessed through the Internet. The biggest security threats to cloud are:
• Data breaches
• Data loss with no back up
• Insider threats
• DDoS attacks
• Insecure APIs
• Exploits
• Account hijacking
**Cross VM Side channel attacks:**
Attackers can use security gaps to attack any component that may have an effect on other components. Attacks can take place through the major vulnerabilities identified in hypervisors.
• *VM Hopping* is an attack that can have an effect on denial of service, which makes resources unavailable to the user.
• *VM Escape* is a vulnerability that allows guest-level VM to attack its host.
• *VM Mobility* is when a VM can move from one physical host to another.
**Security techniques:**
• Encryption and key management
• Encryption of data-at-rest (encrypting the data on desk storage that protects data from illegal usage)
• Encryption of data-at-transit (encrypting the confidential information such)
• Encryption of data on backup media (external or internal storage)
• Access control mechanisms
• Virtual trusted platform module (vTPM)
• Each VM has its associated vTPM instance that emulates the TPM functionality to extend the chain of trust from the physical TPM to each vTPM via careful management of signing keys and certificates.
• Virtual firewall (VF)
• It is a service running in virtualized environment which provides usual packet filtering and monitoring services that a physical firewall provides.
• Trusted virtual domains
• It is a security technique that groups the related VMs running on separate physical machine into a single network domain with a unified security policy.
| sciencebae |
228,236 | From Coffee to Techie: My journey from being a Barista to a Full-time Front-End Developer. | From Coffee to Techie: When I was 21, I moved to Jeddah, Saudi Arabia to work as a barista in Starbuc... | 3,932 | 2019-12-29T03:32:26 | https://kevinnisay.com/from-coffee-to-techie/ | webdev, career, beginners | From Coffee to Techie: When I was 21, I moved to Jeddah, Saudi Arabia to work as a barista in Starbucks. It wasn’t my dream job, to be honest; I always knew that it was a temporary role and that I will later revert to another career in the Tech industry. Of course, I wasn’t exactly sure how I was going to pull it off. But I figured that the best place to start was from the bottom up. For anyone who’s ever wanted to be a Web developer—here’s what I did, what worked and what I learned along the way.
I have always wanted to work in the tech industry, but I was terrified to take any major steps toward my dream. Ever since I was a kid, I am extremely passionate about video games. A few of my favorite games are Dota 2, Final Fantasy, Resident Evil, Call of Duty, and many more. I can’t even tell you how many times I’ve been accused of being a “nerd” just for saying how much I enjoy a game, a console, or a service. I even started learning C# (pretty fu**ed up right) because I wanted to create a game of my own. Well, I did create a one-level game called nyan nyan adventure” lool https://www.facebook.com/groups/IndieGameDevs/permalink/10153541951551573/. It was a good exercise to learn the basics of C# though.
It has always been my dream to turn my love for games and tech into a functioning career. However, that’s always easier said than done.
A leap of faith
As I was going through my typical day after the morning rush at Starbucks, I overheard two of my regular customers conversing about their start-up business and started asking everyone (including me) in the cafe if someone knows a web developer who can work on their company’s website. Feeling burnout, yet exuberant and spontaneous that day, I volunteered without any hesitation even though the only background knowledge I have in coding is the fundamentals of C#.
Since they were my regular customers turned friends, they completely trusted me. They hired me on the spot. They didn’t even ask for my portfolio! I believed it was a joke until they arranged a meeting 2 days later. I had no idea what to do, where to start, how much to charge nor was I aware of the average market pricing. Consequently, I turned to my girlfriend for help. She was working for Ogilvy at that time and her field in advertising is relatively associated with web dev so she was able to help me out on web project management, art direction, content organization, setting up a timeline and drafting a quotation.
No Pain, No Gain
As a Barista(From Coffee to Techie), It was shocking to know that a market price value of a single website (at least in Jeddah, KSA) can costs up to 5 figures in Saudi Riyals. That’s the same amount as my three months’ salary as Barista! Anyway, the pressure to deliver got even higher when the client approved my quotation. That time I knew I had to take this thing more seriously.
To put it briefly, I took a web development crash course of Rob Percival in Udemy, finished it within a week and forced myself to learn the basic fundamentals of HTML, CSS, and JavaScript. As I have mentioned, I do have the basic knowledge in C# (thanks to my love of gaming), which makes it easier for me to understand the logic and algorithm of HTML and CSS. I did a LOT of research. Every time I felt stuck, I practice the Read-Search-Ask method, a technique I learned from freecodecamp. Quick tip, always remembers that Stack overflow, Google and Youtube are your “best friends”.
To be honest, at first, I was driven because of the money (I’m not gonna lie) But as I delve deeper into the topic of Front-End Web development, I started to realize that this is my passion, Coding is my passion. I began accepting more freelance jobs on the side while keeping my day job at Starbucks. Although there were times where I’ll only get 3 hours of sleep at night, I enjoyed it, nonetheless. To me, it was like a dream becoming a reality.
Putting Myself Out There
One way to get more clients is to contact everyone you slightly knew in the industry like regular Starbucks customers, administrative assistants, designers, back-end developers, start-up business owners, it doesn’t matter. In my case, I’m thankful to my girlfriend because she introduced me to some creative directors, art directors, account executives and directors in the advertising industry, She definitely helped me get acquainted with a lot of people in the industry which leads me to land more freelancing jobs.
The fact of the matter is that no one in this industry will give you a chance unless you know someone else. I know, it is awkward to sit with a stranger, introduce yourself, and pitch your idea, but I forced myself to do so. Because if you are really eager to shift your career, you need to expand your network.
Hard work pays off. Period
So finally, after years of hard work; juggling my day job as a Barista, rigorously studying front-end web development, taking online courses, and accepting freelance jobs, I finally manned up. I had moved with a purpose, and it was time to fulfill that purpose.
One media company in Jeddah reached out to me and offered me a full-time job as a front-end web developer. Needless to say, I accepted the job and fortunately for me, the company still allows me to get an online freelancing gig despite being fully employed.
If you are trying to learn coding from scratch, I advise you to study online courses in Udemy, freecodecamp.org, skillshare, coursera, and Treehouse.
I do encourage people to turn their passion into a career, it may not be the right path for many people and it doesn’t always pay off, but when it does, it feels like you’re building something you love and can continue with it for a lifetime.
Thanks for reading this article 🙂 Happy coding.
FROM COFFEE TO TECHIE
kevin-nisay.com
kevinnisay.com | kevkevkevin |
228,312 | Numba Introduction Video | Numba Introduction Video | 0 | 2019-12-29T08:03:27 | https://dev.to/safijari/numba-introduction-video-j47 | python, numpy, numba | ---
title: Numba Introduction Video
published: true
description: Numba Introduction Video
tags: python, numpy, numba
---
Published a tutorial covering the most important basics of using Numba. You can find it here: https://youtu.be/x58W9A2lnQc
Hope it's useful to someone :) | safijari |
228,417 | How to Open Link in New Tab with Hugo's new Goldmark Markdown Renderer | This post was originally published on my blog, find original post here. Hugo is a blazing fast stati... | 0 | 2019-12-29T16:14:29 | https://agrimprasad.com/post/hugo-goldmark-markdown/ | tips, hugo, markdown, webdev | ---
title: How to Open Link in New Tab with Hugo's new Goldmark Markdown Renderer
published: true
date: 2019-12-29 00:00:00 UTC
cover_image: https://thepracticaldev.s3.amazonaws.com/i/qoj5eqegwwugern9wkrt.png
tags: tips,hugo,markdown,webdev
canonical_url: https://agrimprasad.com/post/hugo-goldmark-markdown/
---
This post was originally published on my blog, find original post [here](https://agrimprasad.com/post/hugo-goldmark-markdown/).
[Hugo](https://gohugo.io/ "Hugo") is a blazing fast static site generator, which makes it a terrific choice to create your blogs. It's written in Go and uses Go's templating language to generate blog content with customizable templates for styling.
Check out [this article](https://dev.to/effingkay/build-your-own-blog-with-hugo-and-netlify-oi7) for a good overview of Hugo, and how to get your blog online with Hugo + Netlify.
Furthermore, Hugo uses Markdown to render your content, which is similar to the rendering mechanisms used by other blogging engines, such as [Jekyll](https://jekyllrb.com/ "Jekyll") (used by [Github Pages](https://pages.github.com/ "Github Pages")) and [DEV.TO](dev.to "Dev Community").
## How to open links in a new tab with markdown in Hugo?
When creating my blog in Hugo, I wanted to open links in a new tab (i.e. add a `target="_blank"` attribute to the links). However, by default, an inline style link in Markdown opens in the same tab, which means that your reader may leave your blog and go to a different site, never to return.
Until recent versions of Hugo, it had been using the `Blackfriday` Markdown renderer, which while convenient, is not [CommonMark](https://spec.commonmark.org/0.29/ "CommonMark") standards-compliant. With `Blackfriday`, I could achieve my desired behaviour by adding the following configuration to the `config.toml` file:
```
[blackfriday]
hrefTargetBlank = true
```
However, in the latest Hugo v0.62.0, this doesn't work anymore as the default markdown renderer has changed to [Goldmark](https://github.com/yuin/goldmark), which is CommonMark compliant and allows for custom templates to render links and images from markdown. Thus, if you want to open your blog's links in a new tab (which is not supported by default), you'll have to use a custom markdown render hook to add the `target="_blank"` attribute to the links.
## Render Hooks with Goldmark
Goldmark and [Markdown Render Hooks](https://gohugo.io/getting-started/configuration-markup/#markdown-render-hooks "Markdown Render Hooks") are a new feature in Hugo v0.62.0 so please make sure that your Hugo version is equal to or greater than this version.
Markdown Render Hooks offer you several ways to extend the default markdown behaviour, e.g. resizing of uploaded images, or opening links in new tabs. You can do this by creating templates in the `layouts/_default/_markup` directory with base names `render-link` or `render-image`. Your directory layout may look like this:
```
layouts
└── _default
└── _markup
├── render-image.html
├── render-image.rss.xml
└── render-link.html
```
### Sample render hook to open link in new tab
Say you have an inline-style link in Markdown such as the follows with the `Destination` as `https://en.wikipedia.org/wiki/Pizza`, `Text` as `Pizza` and `Title` as `Yum Yum`:
```
[Pizza](https://en.wikipedia.org/wiki/Pizza "Yum Yum")
```
By default, this link would open in the same tab.
Now add the following HTML template file (or render hook) at `layouts/_default/_markup/render-link.html`:
```
<a href="{{ .Destination | safeURL }}"{{ with .Title}} title="{{ . }}"{{ end }}{{ if strings.HasPrefix .Destination "http" }} target="_blank"{{ end }}>{{ .Text }}</a>
```
You'll find that the previous link now opens in a new tab!
For internal blog links (which you would want to open in the same tab), you can use the relative link of the post, e.g. for a `sample-post.md` file within the `posts` directory, you could use
```
[Sample post](/posts/sample-post/)
```
## TL;DR
1. The Markdown renderer has changed in the latest Hugo v0.62.0 from `Blackfriday` to `Goldmark` which should allow Hugo markdown to be more compatible with other markdown flavours, such as that of GitHub.
2. In order to open links in new tab with the `Goldmark` markdown renderer, create a file at `layouts/_default/_markup/render-link.html` with the following content:
```
<a href="{{ .Destination | safeURL }}"{{ with .Title}} title="{{ . }}"{{ end }}{{ if strings.HasPrefix .Destination "http" }} target="_blank"{{ end }}>{{ .Text }}</a>
``` | agrim |
228,430 | Why Deep Learning has a Bright Future |
Would you like to see the future? This post aims at predicting what will hap... | 0 | 2019-12-29T16:28:31 | https://www.neuraxio.com/en/blog/deep-learning/2019/12/29/why-deep-learning-has-a-bright-future.html | deeplearning | ---
title: Why Deep Learning has a Bright Future
published: true
date: 2019-12-29 14:37:43 UTC
tags: deep-learning
canonical_url: https://www.neuraxio.com/en/blog/deep-learning/2019/12/29/why-deep-learning-has-a-bright-future.html
---

> Would you like to see the future? This post aims at predicting what will happen to the field of Deep Learning. Scroll on.
## Microprocessor Trends
Who doesn’t like to see the real cause of trends?
### “Get Twice the Power at a Constant Price Every 18 months”
Some people have said that Moore’s Law was coming to an end. A version of this law is that every 18 months, computers have 2x the computing power than before, at a constant price. However, as seen on the chart, it seems like improvements in computing got to a halt between 2000 and 2010.
### See the Moore’s Law Graph
### But the Growth Stalled…
This halt is in fact that we’re reaching the limit size of the transistors, an essential part in CPUs. Making them smaller than this limit size will introduce computing errors, because of quantic behavior. Quantum computing will be a good thing, however it won’t replace the function of classical computers as we know them today.
### Faith isn’t lost: invest in parallel computing
Moore’s Law isn’t broken yet on another aspect: the number of transistors we can stack in parallel. This means that we can still have a speedup of computing when doing parallel processing. In simpler words: having more cores. GPUs are growing towards this direction: it’s fairly common to see GPUs with 2000 cores in the computing world, already.
### That means Deep Learning is a good bet
Luckily for Deep Learning, it comprise matrix multiplications. This means that deep learning algorithms can be massively parallelized, and will profit from future improvements from what remains of Moore’s Law.
[](https://github.com/guillaume-chevalier/Awesome-Deep-Learning-Resources)See also: [Awesome Deep Learning Resources](https://github.com/guillaume-chevalier/Awesome-Deep-Learning-Resources)
## The AI Singularity in 2029
### A prediction by Ray Kurtzweil
Ray Kurtzweil predicts that the singularity will happen in 2029. That is, as he defines it, the moment when a 1000$ computer will contain as much computing power as the brain. He is confident that this will happen, and he insists that what needs to be worked on to reach true singularity is better algorithms.

### “We’re limited by the algorithms we use”
So we’d be mostly limited by not having found the best mathematical formulas yet. Until then, for learning to properly take place using deep learning, one needs to feed a lot of data to deep learning algorithms.
We, at Neuraxio, predict that Deep Learning algorithms built for time series processing will be something very good to build upon to get closer to [where the future of deep learning is headed](https://guillaume-chevalier.com/limits-of-deep-learning-and-its-future/).
## Big Data and AI
Yes, this keyword is so 2014. It still holds relevant.
### “90% of existing data was created in the last 2 years”
It is reported by IBM New Vantage that 90% of the financial data was accumulated in the past 2 years. That’s a lot. At this rate of growth, we’ll be able to feed deep learning algorithms abundantly, more and more.
### “By 2020, 37% of the information will have a potential for analysis”
That is what The Guardian reports, according to big data statistics from IDC. In contrast, only 0.5% of all data was analyzed in 2012, according to the same source. Information is more and more structured, and organization are now more conscious of tools to analyze their data. This means that deep learning algorithms will soon have access to the data more easily, wheter the data is stored locally or in the cloud.

## It’s about intelligence.
Is about what defines us humans compared to all previous species: our intelligence.
The key of intelligence and cognition is a very interesting subject to explore and is not yet well understood. Technologies related to this field are are promising, and simply, interesting. Many are driven by passion.
On top of that, deep learning algorithms may use Quantum Computing and will apply to [machine-brain interfaces in the future](https://guillaume-chevalier.com/random-thoughts-on-brain-computer-interfaces-productivity-and-privacy/). Trend stacking at its finest: a recipe for success is to align as many stars as possible while working on practical matters.

## Conclusion
First, Moore’s Law and computing trends indicate that more and more things will be parallelized. Deep Learning will exploit that.
Second, the AI singularity is predicted to happen in 2029 according to Ray Kurtzweil. Advancing Deep Learning research is a way to get there to reap the rewards and do good.
Third, data doesn’t sleep. More and more data is accumulated every day. Deep Learning will exploit that.
Finally, deep learning is about intelligence. It is about technology, it is about the brain, it is about learning, it is about what defines humans compared to all previous species: their intelligence. Curious people will know their way around deep learning.
If you liked this article, consider following us for more! | guillaumechevalier |
228,450 | How to Quickly Build a REST API in Node.js with TypeScript (for Absolute Beginners) - PART 1 of 4 | Let's build a simple a REST API in Node.js using TypeScript. This series will be split into four part... | 3,939 | 2019-12-29T17:37:21 | https://zaiste.net/building-rest-api-nodejs-typescript-1/ | javascript, webdev, beginners, tutorial | Let's build a simple a REST API in Node.js using [TypeScript](https://www.typescriptlang.org/). This series will be split into **four parts** as there is a lot to discuss. It is also aimed for absolute beginners or people just starting with programming. At the same time I will be mentioning few some advanced topics so that even if you know how to build a REST API, you will hopefully still gain something from reading this tutorial.
If you prefer to watch me coding this application instead of reading the article, check this video:
{% youtube AqanhZQJfrw %}
Also, if you liked it, consider subscribing to <a href="https://www.youtube.com/zaiste">my YouTube channel</a> for more.
---
In this series I will be using [Huncwot](https://github.com/huncwotjs/huncwot), which is a tool to quickly build web applications. It is an integrated solution that covers both frontend, backend and everything in between.
Let's start by installing [Huncwot](https://github.com/huncwotjs/huncwot). It's better to do it globally.
```shell
npm install -g huncwot
```
## A bit of theory
Before we jump into the code, let's start with some theory. This won't be a comprehensive introduction. My goal is to explain a few concepts, and then show you some practical examples. I believe this is the best way to quickly gain proper intuition on the subject.
### APIs
API stands for Application Program Interface. The important bit here is the word /interface/. An interface is this point where we meet to interact with something. For example the screen of our phone is an interface, a user interface (or UI) to be exact. This interface allows us to interact with the device. By touching, pressing and swapping the screen we instruct the phone to do some actions. Those gestures are the middle ground: for humans it would be easier just to think about the action to do, for phones it would be easier to receive the instructions directly as a chain of 0s and 1s; instead we have a compromise, a point in between how to humans can interact with phones - the interface.
### Web APIs
There are many types of APIs. In this tutorial we will be discussing a Web API, which are places on the web where we go to interact with something by getting or sending data to it. In other words, a Web API is an interface exposed through an endpoint (an URL) which allows us to interact with some system by exchanging messages. Those messages are requests we send in and responses that we receive. A Web API is a message system, which conceptually is somehow close to object-oriented programming.
### URLs
Requests instruct Web APIs do something for us. In order to send it we need an address: a URL. URLs have several parts. There is protocol: for Web APIs it's `http(s)`. There is a domain which designates a place on the web where this Web API lives. Finally there is a path, which is a location within that domain that describes a specific subset of information.
### Resources
Let's imagine we want to build a Web API for technical events so that we could ask for the upcoming events in our area, or the best tech conferences which happened in the past. We start by creating necessary abstractions for all entities within that contexts. Those abstractions are called resources. We could start with an `Event` resource where each one would have a `name` field and a `date` field. Later on we could imagine adding other resources such as `Attendee`, `Organizer`, `Speaker` and more.
We can now expose each resource as the path in the URL of our Web API, e.g. the `/event` path for the `Event` resource, the `/speaker` path for the `Speaker` resources and so on. Once the resource is exposed, we can start interacting with it by sending requests and receiving responses. We may, for example, fetch the current state of a particular resource, filter a resource based on a specific criteria, or update a resource because you found a typo in its name.
### Headers
When sending requests and receiving responses to our Web API we may need to parametrize how this API behaves. This is unrelated to the specific context of that API, whether we are building an API for technical events, to manage a bookstore or to schedule appointments. For example, we may want to change the response format. We communicate that to the API via headers.
### Handlers
Each path is associated with a function, which describes what should happen once this path visited or this resource requested. We call those functions **handlers**. A handler receives a request as input and produces a response as output.
### Routes
A Web API is a mapping between paths (that may describe resources) and handlers. A particular pair of a path and its handler is called **route**. This is a data-driven approach for defining routes. We use a simple data structure already available in most programming languages, a map to represent the relation between exposed paths and functions being triggered once that path is visited.
## Practical Example
Let's finally jump to the code and let's create our project: `techevents`.
```shell
huncwot new techevents
```
Let's open the project in VS Code. We are only interested in the `config/server/routes.ts` file.
```typescript
import { Routes } from 'huncwot';
import { OK } from 'huncwot/response';
const routes: Routes = {
GET: {
// implicit `return` with a `text/plain` response
'/hello': _ => 'Hello Huncwot',
// explicit `return` with a 200 response of `application/json` type
'/json': _ => {
return OK({ a: 1, b: 2 });
},
// set your own headers
'/headers': _ => {
return { body: 'Hello B', statusCode: 201, headers: { 'Authorization': 'PASS' } };
}
},
POST: {
// request body is parsed in `params` by default
'/bim': request => {
return `Hello POST! ${request.params.name}`;
}
}
};
export default routes;
```
Huncwot generated for us a basic structure for routes. Let's start the server to test it out:
```
huncwot server
```
This command will start the server on the port `:5544`. We can now send some requests to see how it works. I'll use HTTPie to send requests directly from the command line, but you may also use something like the [Postman API Client](https://www.typescriptlang.org/).
Let's send a request to the `/hello` path:
```
http :5544/hello
```
```
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 13
Content-Type: text/plain
Date: Sun, 29 Dec 2019 16:56:23 GMT
Hello Huncwot
```
Since the server is running on the `localhost` I can skip that part and only specify the port along with the path.
```
http :5544/json
```
```
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 13
Content-Type: application/json
Date: Sun, 29 Dec 2019 16:56:44 GMT
{
"a": 1,
"b": 2
}
```
Huncwot is able to automatically transform a JavaScript object into JSON. Additionally, you may use the response helpers such as `OK` to specify an HTTP status code of your choice.
```
http :5544/headers
```
```{2}
HTTP/1.1 201 Created
Authorization: PASS
Connection: keep-alive
Content-Length: 7
Content-Type: text/plain
Date: Sun, 29 Dec 2019 16:57:11 GMT
Hello B
```
Since responses in Huncwot are just objects, you can add the `headers` field to the response object with headers of your choice. In this case, the `Authorization` header with the value `PASS`.
In Huncwot, the changes to your routes are automatically reload. There is no need to restart the server nor to install something like `nodemon`. It works out of the box. You don't have to worry about this.
The `config/server/routes.ts` is a simple JavaScript hash map (or an object to be exact). We can use the `Routes` type from Huncwot to further constrain that fact. Each handler receives a request as input (which has the `Request` type) and returns a response (which has the `Response` type).
---
We have now a good understanding of a few concepts related to Web APIs. We built a foundation for a future REST API. We are not yet there as few important elements are still missing. I will cover that in the upcoming articles. Stay tuned!
| zaiste |
228,457 | javascript: DOM (document object model) | What is the DOM? The DOM is a representation of the html elements in your document as a tr... | 0 | 2019-12-29T17:59:52 | https://dev.to/german/javascript-dom-document-object-model-ofp | beginners, dom, javascript, html | ---
title: javascript: DOM (document object model)
published: true
description:
tags: #beginners #dom #javascript #html
---
# What is the DOM?
The DOM is a representation of the html elements in your document as a tree.
## What does this mean?
It means that this html gets represented as a tree, so you can manipulate it with javascript.
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>DOM</title>
</head>
<body>
<div class="container">
<p id="pragraph">my paragraph</p>
</div>
<section>
<header>
<h1>header</h1>
</header>
<div class="container">
<p class="counter">0</p>
</div>
</section>
</body>
</html>
```
### How do I access the DOM through javascript?
Well there are a couple of ways, however you need the global property called document, here is an example:
```js
// By using querySelector or getElementById or getElementsByClassName
// Query selector
const paragraph = document.querySelector('#pragraph');
console.log(paragraph); // this will get the paragraph element.
// Or get element By id
const paragraphById = document.getElementById('pragraph');
console.log(paragraphById);
```
To access any element we can just call querySelector:
```js
const div = document.querySelector('div'); // first div
const divs = document.querySelectorAll('div'); // all divs
/*
One thing to notice here is that
document.querySelectorAll will get all the divs,
and document.querySelector will get the first div it encounters.
*/
```
Also by accessing the DOM with javascript you can manipulate it however you want, for example we can access the counter element and increment it by 1
```js
const counter = document.querySelector('.counter');
counter.textContent = '1';
```
One import thing to say is that js must be inside the script tag or you can import a file
```html
<!--- no file --->
<script>
// here goes your js
</script>
<!--- file --->
<script src="./somescriptfile"> </script>
```
Thank you and please leave some feedback :) I hope you enjoy the reading. | german |
228,476 | Why are you blogging/writing? | I'm really interested what are the different reason that people here are writing and sharing content?... | 0 | 2019-12-29T20:28:39 | https://dev.to/mikister/why-are-you-blogging-writing-3oh7 | discuss, writing | I'm really interested what are the different reason that people here are writing and sharing content?
For me it's both wanting to better understand those topics that I write about, but also meeting other devs and seeing what they're doing. | mikister |
228,479 | Just Jump Into the Stream | Sometimes it can be rewarding, both personally and professionally, to break out of your technology bubble and dive into something completely new! | 0 | 2019-12-29T19:23:34 | https://dev.to/rionmonster/just-jump-into-the-stream-43jo | softwareengineering, learning, career | ---
title: "Just Jump Into the Stream"
description: Sometimes it can be rewarding, both personally and professionally, to break out of your technology bubble and dive into something completely new!
tags: software-engineering, learning, career
cover_image: https://thepracticaldev.s3.amazonaws.com/i/kbgvcvxkgkuqndri7q35.jpg
published: true
---
_This was originally posted on [my blog](http://rion.io)._
I've spent the better part of my ten-year career as a developer in a relatively safe bubble, technology-wise.
Falling in love with a programming language or technology is a bit like the software version of having your first _real_ girlfriend/boyfriend. They might change the ways that you think, the related technology choices that you make, and it might cause you to potentially not realize what they are good (and not good at) until to try something else.
I was incredibly fortunate to be introduced to C# in my early computer science courses in college and fell in love with it (at least compared to some of the other languages being taught at the time). The language stuck with me throughout college and I used in whenever the opportunity presented itself. Plenty of languages were sprinkled in during my time there: C, C++, Python, Java, Lisp, Visual Basic, x86 Assembly, and countless others, but C# always just _felt_ the best.
At any rate, eventually it landed me my first intern position at a petrochemical company where it was the language du jour and I fit right in. It was here that I was introduced to the rest of the Microsoft Stack of:
- C#
- ASP.NET
- SQL Server
- IIS
These technologies have been a huge part of my career at every position I've had as a professional and any major side-projects or consulting work I've been a part of. There have been plenty of other technologies and languages along the way, but these few have been at the forefront for ... at least until recently.
A project came along that required the need for something _different_. **It was something that I had never worked with previously, using technologies that I hadn't touched since exercises in college (or ever), and they would be sure to burst any safe bubble that I had been living in, in a good way.**
##Bubble Burst

In a nutshell, the project required building a real-time streaming infrastructure to replace long-running batch processing jobs for a legacy application. Languages would change, technologies would change, databases and storage would change, and finally the entire programming paradigm itself would change.
The new stack would look something like this:
- Kotlin
- Apache Kafka
- Postgres
- IntelliJ
As you can see, not a ton of overlap with the previous stack, and by not a ton, I mean _none_. I had never written a line of Kotlin, downloaded IntelliJ, touched Postgres, or been in the same building as Kafka. Being an experienced engineer, I didn't have much concern for a few of them. Languages come and go and once you learn one, it's pretty darn easy to pick up another. IDEs, meh, basically the same way. A new database technology? Just a bit of new syntax. All these changes are totally manageable and basically negligible.
Except streaming. Streaming was a whole new paradigm to wrap my head around. Calls and operations weren't as procedural like most applications, you had to think about _when_ code was being executed, and any "race-conditions" that you had encountered earlier in your career immediately become totally irrelevant as everything is much, much crazier in the streams world.
> In a nutshell, I was taking everything I had done previously in my career and _voluntarily_ throwing it out the window to shift to an entirely different stack, programming paradigm, language, etc. I suppose it could have been terrifying, but of all things it was... exciting.
Pivoting over to a Java-oriented ecosystem was different. A different build system (Gradle/Maven) had a bit of a learning curve, but after dealing with countless Javascript frameworks, it was a walk in the park. **They key takeaway is that you'd think with all of these changes, this would be a scary proposition, but if you enjoy learning, and enjoy becoming a more well-rounded developer, you'd probably be just as excited as I was to get started.**
## Don't Dip Your Toe In, Dive!

As I mentioned earlier, my entire career has been spent in various versions of the same silos. I knew C# and was _comfortable_ with it, I could write it all day, in my sleep, in a box, with a fox, etc. The Microsoft stack in general was what I had lived professionally (and in my free time) to write everything in, and while I had tinkered with some languages and technologies on the side to play with, it wasn't anything like _actually_ writing production applications and code for projects.
> I'd encourage any developer, if presented with the opportunity, to step out of your comfort zone with open arms. You know what you know, but you absolutely don't know what you don't. Working with different technologies, languages, tooling, will all make you better. Software engineering is cumulative.
The project that I reference in this post is still very much ongoing. It's still exciting (and at times frustrating), but I'm so glad that I made the decision to take the reins on it. Even after just a few months it still feels novel, probably because I spent 10+ years basically doing everything in a similar way, but most of all _it's fun_. Fun can be rare in engineering, especially if you've been doing it for a long time but having fun while learning and solving complex business problems, can be extremely rewarding, both personally and professionally.
**The opportunity to jump into real-time streaming applications might not present itself, but that's beside the point. It's about taking advantage of _any_ opportunity to learn something new, or more specifically, something different.** It's not just a matter of doing it but taking the time to _learn_ it. Learn why it works the way it does, what makes it so different that what you've done in the past, and carry that with you into every project that you work on, regardless of the technology or stack, in the future. | rionmonster |
228,552 | How to create cards on a grid with CSS | Recently I've heard people having trouble creating cards on a grid in css, so I decided to make a qui... | 0 | 2019-12-30T01:41:43 | https://dev.to/joellehelm/how-to-create-cards-on-a-grid-with-css-4cpe | Recently I've heard people having trouble creating cards on a grid in css, so I decided to make a quick tutorial to show you how to do that.
First you'll want to create a div to be the container for the grid and connect your css file to your html file or react component if you're using react.
```
<div class="cardContainer">
</div>
```
Let's go ahead and add some cards into our container.
```
<div class="cardContainer">
<div class="card"><h2>Hello I'm a card</h2></div>
<div class="card"><h2>Hello I'm a card</h2></div>
<div class="card"><h2>Hello I'm a card</h2></div>
<div class="card"><h2>Hello I'm a card</h2></div>
<div class="card"><h2>Hello I'm a card</h2></div>
<div class="card"><h2>Hello I'm a card</h2></div>
<div class="card"><h2>Hello I'm a card</h2></div>
<div class="card"><h2>Hello I'm a card</h2></div>
</div>
```
Next open your css file and set your display to grid, create margin spacing, and create your grid columns.
```
.cardContainer {
margin: 100px 100px 100px 100px;
display: grid;
/* you can change the 4 below to 3 if you only want 3 cards per row */
grid-template-columns: repeat(4, 1fr);
grid-gap: 40px;
}
```
Now you'll want to style your cards. You can make them any size you want, heres an example of some cards.
```
.card {
width: 300px;
height: 200px;
color: white;
background-color: red;
text-align: center;
}
```
Cool now we have some cards on a grid. Play around with the sizing and see what you can create!
| joellehelm | |
228,567 | MEAN, MERN Expert. | Hello, everyone. Now I have some project related MEAN and MERN. If you have enough experience with t... | 0 | 2019-12-30T02:14:53 | https://dev.to/superman1207/mean-mern-expert-5430 | react, mongodb, node, angular | Hello, everyone.
Now I have some project related MEAN and MERN. If you have enough experience with them, please let me know. My skp name is Roshan Webmaster. Please contact me.
Best regard. | superman1207 |
228,597 | Docker and Java Spring Boot [Part.1: Continuous Integration] | This post was originally published in jaxenter. In this tutorial, we will learn how Continuous Integ... | 3,953 | 2020-01-22T18:12:07 | https://jaxenter.com/cicd-microservices-docker-162408.html | java, docker, devops, microservices | *This post was originally published in [jaxenter](https://jaxenter.com/cicd-microservices-docker-162408.html).*
In this tutorial, we will learn how Continuous Integration and Delivery can help us to test and prepare a Java application for Docker.
A Continuous Integration (CI) setup will test our code on every update. The practice creates a strong feedback loop that reveals errors as soon as they are introduced. Consequently, we can spend more of our time coding features rather than hunting bugs.
We will use Docker for packaging since it’s supported universally across all cloud providers. Furthermore, Docker is a requirement for more advanced deployments such as Kubernetes. In the second part of the tutorial, we’ll learn your we can use Continuous Deployment (also CD) to deploy new versions to Kubernetes at the push of a button.
## Getting Ready
Here’s a list of the things you’ll need to get started.
- Your favorite code IDE and the Java SDK.
- A [Docker Hub](https://hub.docker.com/) account and Docker.
- A [GitHub](https://github.com) account and [Git](https://git-scm.com).
Let’s get everything ready. First, fork the [repository with the demo](https://github.com/semaphoreci-demos/semaphore-demo-java-spring) and clone it to your machine.
The application is built in Java Spring Boot and it exposes some API endpoints. The project includes tests, benchmarks and everything needed to create the Docker image.
## Continuous Integration
We’ll use Semaphore as our [Continuous Integration](https://semaphoreci.com/continuous-integration) solution. Our CI/CD workflow will:
1. Download Java dependencies.
2. Build the application JAR.
3. Run the tests and [Jmeter](https://jmeter.apache.org/) benchmarks. And, if all goes well…
4. Create a Docker image and push it to Docker Hub.
But first, open your browser at [Semaphore](https://semaphoreci.com) and sign up with GitHub; that will link up both services. The free account includes 1300 monthly build minutes. Click on the **+** (plus sign) next to **Projects** to add your repository to Semaphore:
The repository has a sample CI/CD workflow. Choose “I will use the existing configuration”.
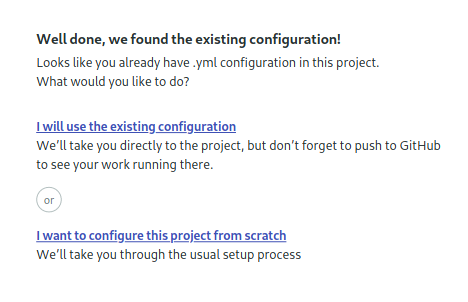
Semaphore will show the CI/CD pipelines as soon as you make a push to GitHub. You can create an empty file and push it with Git:
```bash
$ touch some_file
$ git add some_file
$ git commit -m "add Semaphore"
$ git push origin master
```
Or do it directly from the GitHub using the **Create New File** button.
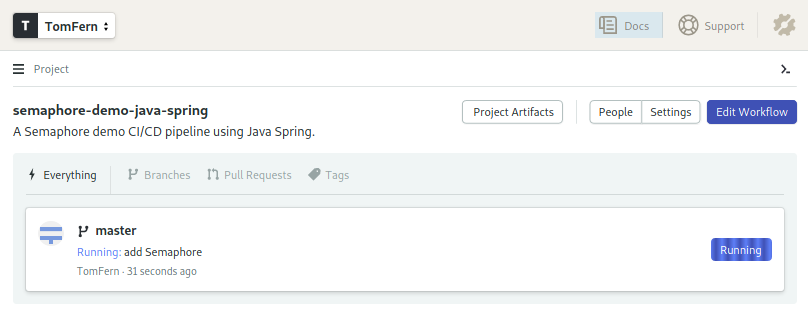
Click on the **Edit Workflow** button to view the recently-released Workflow Builder UI.
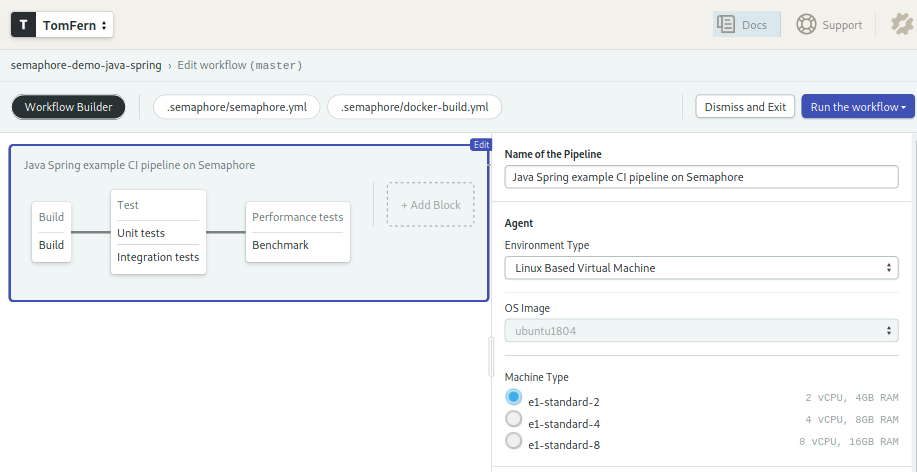
Each pipeline has a **name** and an **agent**. The agent is the virtual machine type that powers the jobs. Semaphore offers several [machine types](https://docs.semaphoreci.com/article/20-machine-types), we’ll use the free **e1-standard-2** model with an [Ubuntu 18.04](https://docs.semaphoreci.com/article/32-ubuntu-1804-image).
**Jobs** define the commands that give life to the CI/CD process, they are grouped in **blocks**. Click on the “Build” block to view its job:
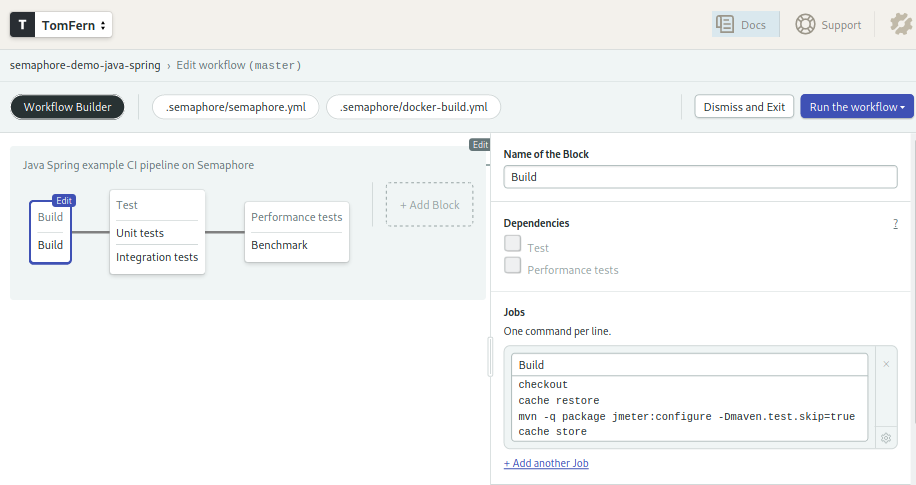
Jobs in a block run concurrently. Once all jobs in a block are complete, the next block begins.
The first job downloads the dependencies and builds the application JAR without running any tests:
```bash
checkout
cache restore
mvn -q package jmeter:configure -Dmaven.test.skip=true
cache store
```
The block uses some of the Semaphore's toolbox scripts: [checkout](https://docs.semaphoreci.com/article/54-toolbox-reference#checkout) to clone the repository and [cache](https://docs.semaphoreci.com/article/54-toolbox-reference#cache) to store and retrieve the Java dependencies.
The second block has two test jobs. The commands that we define in the [prologue](https://docs.semaphoreci.com/article/50-pipeline-yaml#prologue) run before each job in the block:
```bash
checkout
cache restore
mvn -q test-compile -Dmaven.test.skip=true
```
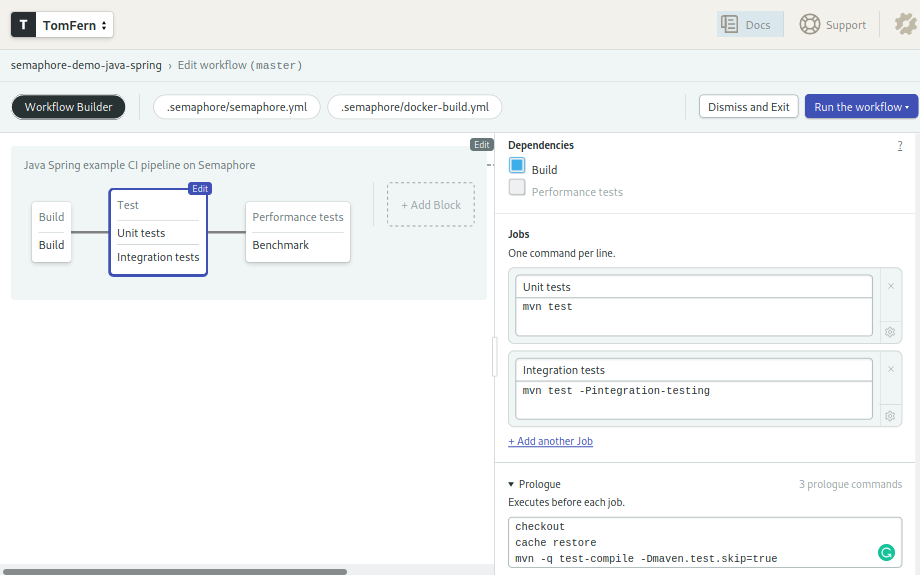
The third block starts the application and runs the benchmarks:
```bash
java -version
java -jar target/spring-pipeline-demo.jar > /dev/null &
sleep 20
mvn -q jmeter:jmeter
mvn jmeter:results
```
### Store Your Docker Hub Credentials
To securely store passwords, Semaphore provides the [secrets](https://docs.semaphoreci.com/article/66-environment-variables-and-secrets) feature. Create a secret with your Docker Hub username and password. Semaphore will need them to push images into your repository:
- Under **Configuration** click on **Secrets**.
- Press the **Create New Secret** button.
- Create a secret called “dockerhub” with your username and password:
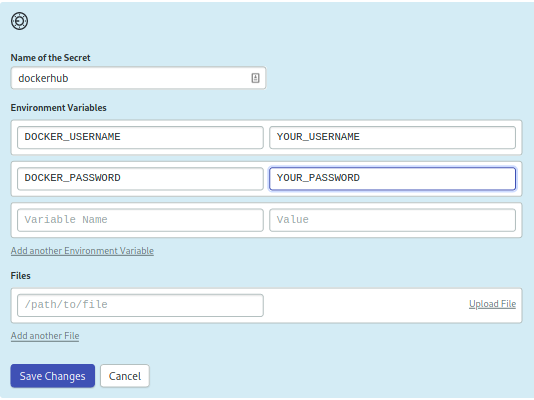
### Continuous Delivery
Next to the benchmark block we find the a [promotion](https://docs.semaphoreci.com/guided-tour/deploying-with-promotions/) which connects the CI and the “Dockerize” pipelines together. Promotions connect pipelines to create branching workflows. Check the **Enable automatic promotion** option to start the build automatically.
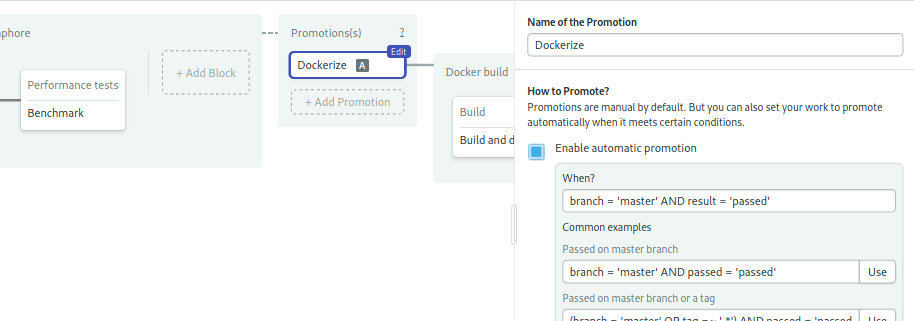
The demo includes a [Dockerfile](https://docs.docker.com/engine/reference/builder/) to package the application into a Docker image:
```Dockerfile
FROM openjdk:8-jdk-alpine
ARG ENVIRONMENT
ENV ENVIRONMENT ${ENVIRONMENT}
COPY target/*.jar app.jar
ENTRYPOINT ["java","-Dspring.profiles.active=${ENVIRONMENT}", "-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
```
The “Dockerize” pipeline is made of one block with a single job which:
- Logins to Docker Hub
- Pulls the latest image
- Builds the new image with the updated code
- Pushes the new image
```bash
mvn -q package -Dmaven.test.skip=true
echo "$DOCKER_PASSWORD" | docker login --username "$DOCKER_USERNAME" --password-stdin
docker pull "$DOCKER_USERNAME"/semaphore-demo-java-spring:latest || true
docker build --cache-from "$DOCKER_USERNAME"/semaphore-demo-java-spring:latest \
--build-arg ENVIRONMENT="${ENVIRONMENT}" \
-t "$DOCKER_USERNAME"/semaphore-demo-java-spring:latest .
docker push "$DOCKER_USERNAME"/semaphore-demo-java-spring:latest
```
### Testing the Image
Click on the **Run the workflow** button and then choose **Start**.
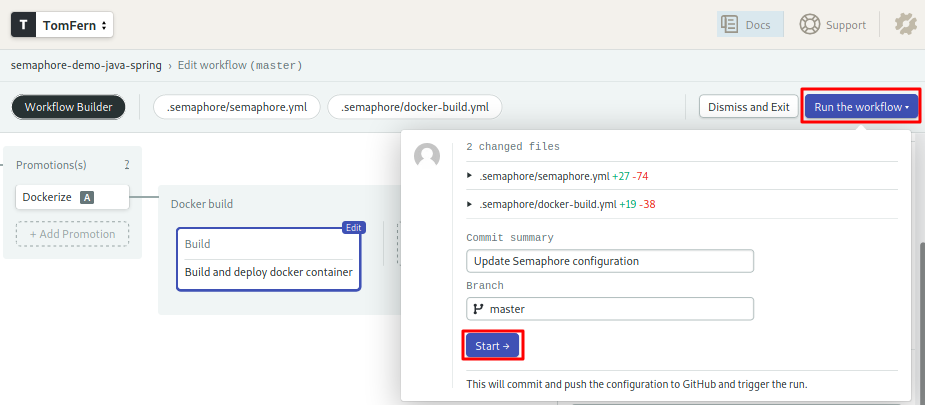
After a couple of minutes the workflow should be complete and you should have a new Docker image with your application in Docker Hub:
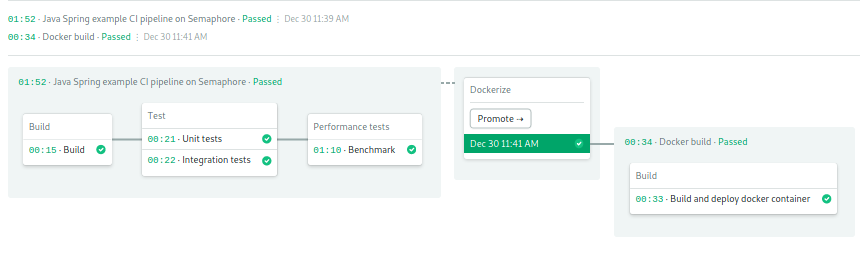
By now, you should have a ready Docker image in your repository. Let’s give it a go. Pull the newly created image to your machine:
```bash
$ docker pull YOUR_DOCKER_USER/semaphore-demo-java-spring:latest
```
And start it in your machine:
```bash
$ docker run -it -p 8080:8080 YOUR_DOCKER_USER/semaphore-demo-java-spring
```
You can create a user with a POST request:
```bash
$ curl -w "\\n" -X POST \
-d '{ "email": "wally@example.com", "password": "sekret" }' \
-H "Content-type: application/json" localhost:8080/users
{"username":"wally@example.com"}
```
With the user created, you can authenticate and see the
secure webpage:
```bash
$ curl -w "\n" --user wally@example.com:sekret localhost:8080/admin/home
<!DOCTYPE HTML>
<html>
<div class="container">
<header>
<h1>
Welcome <span>tom@example.com</span>!
</h1>
</header>
</div>
```
You can also try it with login page at [localhost:8080/admin/home](http://localhost:8080/admin/home)
## Next Stop: Kubernetes
See you in Part 2 to learn how to deploy the image to *any* Kubernetes:
{% link https://dev.to/semaphore/kubernetes-and-java-spring-boot-part-2-continuous-deployment-47l9 %}
## Conclusion
You have set up your first CI/CD pipeline. With this system in place you can work in your code, secure in the feeling that it’s being constantly tested.
Stay tuned for part 2 of the tutorial next week, we’ll see how to do Continuous Deployment to a Kubernetes cluster.
Did you find the post useful? Let me know by ❤️-ing or 🦄-ing below! Do you have any questions or suggestions for other tutorials? Let me know in the comments.
Thank you for reading!
| tomfern |
228,614 | Learning to Be Noisy - Collab Lab Week 2 | I am one of four developers in The Collab Lab cohort 3. We are in our second of eight weeks. From the... | 3,980 | 2019-12-30T03:12:11 | https://dev.to/nikema/learning-to-be-noisy-collab-lab-week-2-3n9p | collablab | I am one of four developers in [The Collab Lab](https://the-collab-lab.codes/) cohort 3. We are in our second of eight weeks. From the beginning it's been an incredibly valuable experience.
There are so many things about working on a team that just can't be duplicated when working alone. The practice and act of collaborating is a big one.
When I agreed to participate in this cohort, I said I'd "try" to document my experience. We all know how that goes. I'm gonna go ahead and publicly commit to documenting my experience and everything I'm learning.
Because I am kind to myself, I'm not going to try to go back and recall everything I wanted to say about The Collab Lab so far. Today is a start! Tomorrow is an opportunity to build on what I just started.
I'm sharing the two weekly sync videos that exist. It's totally embarrassing because I have a lot of practicing to do in getting comfortable with speaking about my work and verbal communication in general.
{% youtube zkMbD8i4znI %}
{% youtube 75vlSEHHVTA %}
Here are my pair's wiki pages for the first two weeks, too.
- [Week 1](https://github.com/the-collab-lab/tcl-3-smart-shopping-list/wiki/(Week-1)-Nikema-&-Mike----(As-a-user,-I-want-to-be-able-to-navigate-within-the-app))
- [Week 2](https://github.com/the-collab-lab/tcl-3-smart-shopping-list/wiki/(Week-2)-Monica-&-Nikema-(As-a-user,-I-want-to-set-up-a-new-shopping-list))
I had a lot of fun setting these up and adding to them. I have a goal to improve upon my documentation and communication (through commit messages, slack, reviews) each week.
Good thing yer girl has a growth mindset. I'm okay with being temporarily embarrassed. I'm sure at the end of eight weeks I'll be fine, maybe even comfortable.
| nikema |
228,624 | Error the process cannot access the file because it is being used by another process while building project by CLI on .NET Core | answer re: Error the process cannot a... | 0 | 2019-12-30T03:54:21 | https://dev.to/kiranshahi/error-the-process-cannot-access-the-file-because-it-is-being-used-by-another-process-while-building-project-by-cli-on-net-core-4hk9 | {% stackoverflow 47991484 %} | kiranshahi | |
228,677 | Brace matching, it's harder than it sounds! | When writing a language with braces (I can see why whitespace sensitive languages are a thing now), o... | 3,923 | 2019-12-30T07:24:02 | https://dev.to/adam_cyclones/brace-matching-it-s-harder-than-it-sounds-59bi | javascript | When writing a language with braces (I can see why whitespace sensitive languages are a thing now), one vital thing you will need to know is what thing is inside what brace. I am writing a sort of subset of JavaScript in the style of es5 (more like es 5.5 because some es6 features are just good!). I need to know how many braces are within a range of line no's, between L1 and L5 for example.
Given the sample:
```js
const input = `
{
{
// Depth 2
}
}
`;
```
Initially I thought line by line we step through the input, when we encounter the token `{ L_BRACE` we should increment a count by one, when we encounter a `} R_BRACE` we should decrement.
In the sample we should have the following count.
```js
0
1
2
2
2
1
0
```
That looks great doesn't it! Not only do we know block we are in we also know the depth, ideal, but an object literal is not a block scope, so how do we avoid that, what about destructuring? Okay so we could avoid this whole mess with a simple (yet incorrect assumption), what do blocked scoped things have in common?
```
function name(){
function (){
class Foo {
class {
for () {
try {
while {
do {
with {
if {
switch {
{
```
Okay that's all I could remember this time In the morning ☕. In answering my previous question Where should the brace sit? At the End Of Line (EOL), so I could check that the opening brace is preceded by a whitelist of words, or it is not an assignment AND the brace is at EOL. Great sorted yes? No, because some programmers like my brother care not for good formatting and could do this.
``` js
function anoying () { const imATroll = true;
// I laugh at your feable algorithms
}
```
My brother is such a pain, because now the brace is not at the end of the line, we can't use this algorithm. I'm stumped 🙄, I'm sure I will solve it and that's my goal for this week.
What other problems could I solve?
Well mismatched braces are easier to detect, nievely you could filter the lines containing the braces that fit the above unsolved criteria, then count the length, if the number is odd, we can say stop! This program is broken... But where?
Looping through line by line will not tell you where the program broke because we need the entire program to determine what looks a bit off.
This problem is so simple in theory, anyway wish me luck and add your suggestions in the comments! | adam_cyclones |
228,705 | Tracking players using ML solutions | A challenging problem is tracking individuals using machine learning solutions. I will investigate... | 0 | 2019-12-30T08:59:04 | https://dev.to/stephan007/tracking-players-using-ml-solutions-kc0 | machinelearning |
A challenging problem is tracking individuals using machine learning solutions. I will investigate several possible solutions for my open source sports analysis project.
For each solution I will use the same short basketball video which starts with several isolated players and ends with multiple occlusions. The output video is in slow motion so we can more easily observe what's happening.
>Occlusion occurs if an object you are tracking is hidden (occluded) by another object. Like two persons walking past each other, or a car that drives under a bridge.
First the players need to be localised, this is often done using a convolutional neural network (for example Mask-RCNN). In the second phase the tracking needs to happen where often key points of the human body are linked to a unique person and visualised.
If we would have multiple cameras we could actually track each player based on his/her face recognition. See my article on [Face Recognition at Devoxx](https://www.linkedin.com/pulse/face-recognition-action-devoxx-stephan-janssen/).
As always, please don't hesitate to suggest any other possible techniques or solutions which I should investigate.

## Tracking with OpenCV
OpenCV has build-in support to track objects and the actual implementation is very straight forward. With just a couple of lines of code you can track a moving object as follows:
```python
import cv2
# ...
# Create MultiTracker object
multiTracker = cv2.MultiTracker_create()
# Initialize MultiTracker
for pBox in players_boxes:
# Add rectangle to track within given frame
multiTracker.add(cv2.TrackerCSRT_create(), frame, pBox)
# ...
# get updated location of objects in subsequent frames
success, boxes = multiTracker.update(frame)
# draw new boxes on current frame
# ...
```
As you can see from the annotated video it does a pretty good job right until a player passes (overlaps) another player (= occlusion).
A total of 6 persons were tracked, only the referee and one yellow player was tracked correctly until the end. Hmmm not the result I was hoping for.
Video result can be viewed on [YouTube](https://www.youtube.com/watch?v=6b__GMsoW4k).
<img width="970" alt="KeyPointsTracking" src="https://user-images.githubusercontent.com/179457/71574448-04882800-2ae9-11ea-88df-b422d0fb71dc.png">
## Tracking with Key Points
The next experiment is with COCO R-CNN KeyPoints which can easily be enabled using Detectron2.
As you can see from the output below, the rectangle around each person uses the same colour as long as it's tracking the same person. However when occlusion happens the same result is experienced as with OpenCV.... chaos.
Video result can be viewed on [YouTube](https://www.youtube.com/watch?v=QjRLdIkTbo4).
## Tracking with Pose Flow
Pose Flow shows a unique number for each person that it tracks and uses the same coloured rectangle around the same person in addition to the key points of the human body.
It starts out really confident but again (as with the previous experiments) when occlusion appears it basically looses track of the overlapping players.
Video result can be viewed on [YouTube](https://www.youtube.com/watch?v=JeBNX8YHBY4)
BTW Full scientific details on the Pose Flow algorithm can be download [here](https://arxiv.org/pdf/1802.00977.pdf).
Shout out to [Jarosław Gilewski](https://www.linkedin.com/in/jgilewski/) for his [Detectron2 Pipeline](https://github.com/jagin/detectron2-pipeline) project which allowed me to rapidly run the above simulations!
## The Pose Track challenge
> PoseTrack is a large-scale benchmark for human pose estimation and articulated tracking in video. We provide a publicly available training and validation set as well as an evaluation server for benchmarking on a held-out test set.
[PoseTrack](https://posetrack.net/leaderboard.php) organises every year tracking and detection competitions for single frame and multiple frames pose datasets.
<img width="1089" alt="PoseTrackingCompetition" src="https://user-images.githubusercontent.com/179457/71574487-2bdef500-2ae9-11ea-83bf-96638158d126.png">
In 2018 the "Pose Flow team" ended on the 13th position and the "Key Track" team won the multi-person tracking challenge.
> Pose tracking is an important problem that requires identifying unique human pose-instances and matching them temporally across different frames of a video. However, existing pose tracking methods are unable to accurately model temporal relationships and require significant computation, often computing the tracks offline.
<img width="1149" alt="KeyTrack" src="https://user-images.githubusercontent.com/179457/71574573-9b54e480-2ae9-11ea-9a12-ec64e0afbb04.png">
## The Key Track solution
>KeyTrack introduces Pose Entailment, where a binary classification is made as to whether two poses from different time steps are the same person.
Unfortunately I was unable to find an (open source) Key Track implementation. If you know where to find it please let me know and I will try it out.
The scientific paper can be downloaded [here](https://arxiv.org/pdf/1912.02323.pdf).
## The ideal camera setup?
One idea is to change the angle of the stationary camera(s) so you get a birds-eye view hopefully limiting the number of occlusions that can happen.
The ideal setup would be a top-down stationary camera above the middle of the court. The IP enabled camera should need a super wide angle lens. Similar to the [European APIDIS](https://sites.uclouvain.be/ispgroup/Softwares/APIDIS) basketball project where the Université catholique de Louvain were involved.

The APIDIS project used seven 2 megapixel colour IP cameras ([Arecont Vision AV2100](https://sales.arecontvision.com/product/MegaVideo+Series/AV2100)) recording at 22 fps with timestamp for each frame at 1600x1200 pixels.
And (as shown below) an additional two cameras, each recording a side of the basketball court.

| stephan007 |
228,723 | Day 26 – Working with EJS (Part 3) - Learning Node JS In 30 Days [Mini series] | We already know about templating engine right? Now tell me one thing, if you have 10 pages, how you’l... | 0 | 2019-12-30T09:57:38 | https://blog.nerdjfpb.com/day26-nodejsin30days/ | node, javascript, codenewbie | We already know about templating engine right? Now tell me one thing, if you have 10 pages, how you’ll handle the navbar ? Can we reuse the navbar for every page ?
Answer is YES. We can but we need to make the navbar as partials. Partials is a concept in ejs
So create a folder inside our view folder call it partials. We’ll store the partial files here.
Let’s start creating from head files. Like the cdn’s we are going to use. Let’s try bootstrap in our case.
I’m using the navbar from bootstrap 4 too. https://getbootstrap.com/docs/4.4/components/navbar/
Let’s add the footer also
Now we can easily use this partial parts easily
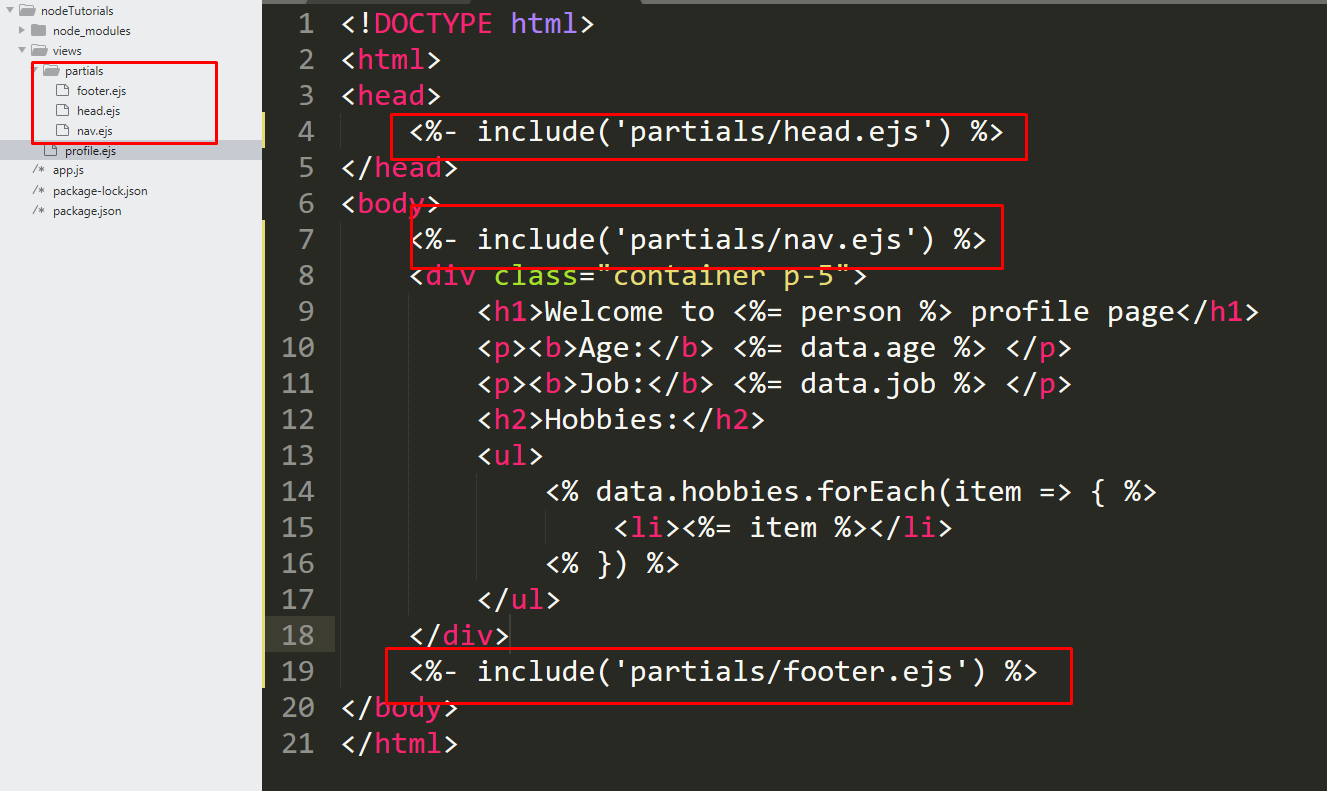
See the result
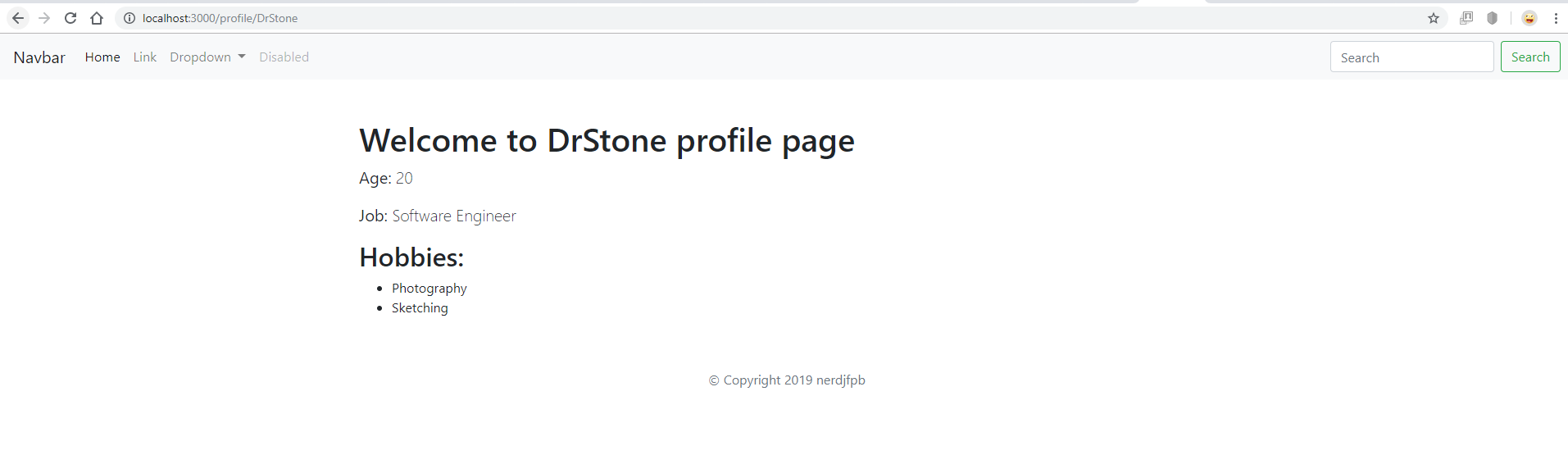
###Do you understand how we can easily do many things using partial templating ?
You can see the graphical version here
{% instagram B6q2UIDgeHy %}
Originally it published on [nerdjfpbblog](https://blog.nerdjfpb.com/day26-nodejsin30days/). You can connect with me in [twitter](https://twitter.com/nerdjfpb) or [linkedin](https://www.linkedin.com/in/nerdjfpb/) !
###__You can read the old posts from this series (below)__
{% post nerdjfpb/day-1-learning-node-js-in-30-days-mini-series-55e7 %}
{% post nerdjfpb/day-2-learning-node-js-in-30-days-mini-series-5023 %}
{% post nerdjfpb/day-3-learning-node-js-in-30-days-mini-series-24i4 %}
{% post nerdjfpb/day-4-learning-node-js-in-30-days-mini-series-1koc %}
{% post nerdjfpb/day-5-learning-node-js-in-30-days-mini-series-21jm %}
{% post nerdjfpb/day-6-learning-node-js-in-30-days-mini-series-758 %}
{% post nerdjfpb/day-7-learning-node-js-in-30-days-mini-series-3023 %}
{% post nerdjfpb/day-8-var-vs-let-vs-const-learning-node-js-in-30-days-mini-series-1i72 %}
{% post nerdjfpb/day-9-mastering-eventemitter-learning-node-js-in-30-days-mini-series-2dfe %}
{% post nerdjfpb/day-10-mastering-eventemitter-learning-node-js-in-30-days-mini-series-2802 %}
{% post nerdjfpb/day-11-creating-and-deleting-folders-learning-node-js-in-30-days-mini-series-3a2d %}
{% post nerdjfpb/day-12-creating-own-server-learning-node-js-in-30-days-mini-series-3ef %}
{% post nerdjfpb/day-13-buffer-stream-learning-node-js-in-30-days-mini-series-5c5d %}
{% post nerdjfpb/day-14-serving-html-pages-learning-node-js-in-30-days-mini-series-2hl3 %}
{% post nerdjfpb/day-15-sending-json-to-client-learning-node-js-in-30-days-mini-series-21pc %}
{% post nerdjfpb/day-16-routing-basic-learning-node-js-in-30-days-mini-series-5hk6 %}
{% post nerdjfpb/day-17-npm-node-package-manager-learning-node-js-in-30-days-mini-series-1nek %}
{% post nerdjfpb/day-18-why-express-js-learning-node-js-in-30-days-mini-series-b5a %}
{% post nerdjfpb/day-19-nodemon-learning-node-js-in-30-days-mini-series-m39 %}
{% post nerdjfpb/day-20-express-js-introduction-learning-node-js-in-30-days-mini-series-2pg5 %}
{% post nerdjfpb/day-21-http-methods-learning-node-js-in-30-days-mini-series-hci %}
{% post nerdjfpb/day-22-route-parameters-learning-node-js-in-30-days-mini-series-4knk %}
{% post nerdjfpb/day-23-template-engines-learning-node-js-in-30-days-mini-series-4f7d %}
{% post nerdjfpb/day-24-working-with-ejs-part-1-learning-node-js-in-30-days-mini-series-493 %}
{% post nerdjfpb/day-25-working-with-ejs-part-2-learning-node-js-in-30-days-mini-series-19gp %}
| nerdjfpb |
228,765 | 🦸 My popular post on Stackoverflow | The only way to modify web.xml to support for multiple servlet in JSPs, there is a way as shown in th... | 0 | 2019-12-30T10:43:29 | https://dev.to/orestispantazos/my-popular-post-on-stackoverflow-979 | stackoverflow, java, servlets, configuration | The only way to modify web.xml to support for multiple servlet in JSPs, there is a way as shown in the following post on Stackoverflow network:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
<servlet>
<servlet-name>LoginForm</servlet-name>
<servlet-class>com.project.system.LoginForm</servlet-class>
</servlet>
<servlet>
<servlet-name>RegisterForm</servlet-name>
<servlet-class>com.project.system.RegisterForm</servlet-class>
</servlet>
<servlet>
<servlet-name>UserController</servlet-name>
<servlet-class>com.project.controller.UserController</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>LoginForm</servlet-name>
<url-pattern>/LoginForm</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>RegisterForm</servlet-name>
<url-pattern>/RegisterForm</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>UserController</servlet-name>
<url-pattern>/UserController</url-pattern>
</servlet-mapping>
<session-config>
<session-timeout>
30
</session-timeout>
</session-config>
</web-app>
```
https://stackoverflow.com/questions/43559372/how-to-modify-web-xml-for-multiple-servlet | orestispantazos |
228,776 | Lyra : Command Line Parser for C++ | Parsing conmmand line arguments is a tedious task and many programming languages have libraries for i... | 3,951 | 2019-12-30T11:31:15 | https://dev.to/hniemeye/lyra-command-line-parser-for-c-4ale | cpp | Parsing conmmand line arguments is a tedious task and many programming languages have libraries for it. While researching such libraries for C++
I found [Lyra](https://github.com/bfgroup/Lyra) which works as a header-only library for C++11 and higher.
It supports the usual positional and optional arguments known from POSIX style command line tools and has the possibility to automatically generate a help text.
For a full set of examples see the [documentation](https://bfgroup.github.io/Lyra/#_license).
## Example: Optional Arguments and Help Text
```cpp
#include <iostream>
#include <lyra/lyra.hpp>
int main(int argc, const char** argv)
{
// Variables to put arguments into:
int width = 0;
int height = 0;
bool show_help = false;
const auto cli = lyra::help(show_help)
| lyra::opt(width, "width")
["-w"]["--width"]("How wide should it be?")
| lyra::opt(height, "height")
["-x"]["--height"]("How high should it be?");
// Parse the program arguments:
const auto result = cli.parse({ argc, argv });
if (!result)
{
std::cerr << result.errorMessage() << std::endl;
std::cerr << cli;
exit(1);
}
if(show_help)
{
std::cout << cli << '\n';
exit(0);
}
std::cout << "width * height: " << width * height << '\n';
}
```
Starting the programm without arguments yields the default values, using -h triggers the help text:
```bash
./a.out
width * height: 0
./a.out -w 15 -x 10
width * height: 150
./a.out -h
Usage:
a.out [-?|-h|--help] [-w|--width] [-x|--height]
Options, arguments:
-?, -h, --help
Display usage information.
-w, --width <width>
How wide should it be?
-x, --height <height>
How high should it be?
```
Entering wrong arguments also leads to the help text being printed
```bash
./a.out --blabla dddd
Unrecognized token: --blabla
Usage:
a.out [-?|-h|--help] [-w|--width] [-x|--height]
Options, arguments:
-?, -h, --help
Display usage information.
-w, --width <width>
How wide should it be?
-x, --height <height>
How high should it be?
```
## Non-optional Arguments
Non-optional parameters can be specified by using `lyra::arg` instead of `lyra::opt`. Non-optional arguments are just specified by their position in the CLI.
```cpp
const auto cli = lyra::help(show_help)
| lyra::arg(width, "width")("How wide?")
| lyra::arg(height, "height")("How high should it be?");
```
```bash
./a.out
width * height: 0
./a.out 10 10
width * height: 100
```
| hniemeye |
228,797 | How To Install MongoDB Server On Windows & Linux | Installation of MongoDB takes less than 5 minutes on both Windows and Linux. Here are the steps you... | 0 | 2019-12-30T12:27:33 | https://dev.to/djnitehawk/how-to-install-mongodb-server-on-windows-linux-4in | nosql, mongodb, database, tutorial | Installation of MongoDB takes less than 5 minutes on both Windows and Linux. Here are the steps you need to take in order to be up and running as fast as possible.
**Note:** *MongoDB is at version 5.0.0 as of writing this article. Please post a comment below if you'd like me to update the tutorial for the latest version.*
# On Linux
open up a terminal and issue the following commands to install the server. these commands are for a 64-bit ubuntu system. if you're linux flavor is different, please [click here](https://docs.mongodb.com/manual/administration/install-on-linux/) for instructions.
```shell
wget -qO - https://www.mongodb.org/static/pgp/server-5.0.asc | sudo apt-key add -
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu focal/mongodb-org/5.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-5.0.list
sudo apt-get update
sudo apt-get install -y mongodb-org
mkdir /mongodb
mkdir /mongodb/log
sudo chown -R mongodb:mongodb /mongodb
echo "" > /etc/mongod.conf
nano /etc/mongod.conf
```
then copy & paste the following into nano, save & exit.
```yaml
storage:
dbPath: /mongodb
directoryPerDB: true
journal:
enabled: true
systemLog:
destination: file
logAppend: true
path: /mongodb/log/mongod.log
net:
port: 27017
bindIp: 127.0.0.1
```
then enter the following in the terminal, which will show that mongodb server is active and running.
```shell
systemctl enable mongod.service
sudo service mongod start
sudo service mongod status
```
# On Windows
first download the installer msi from this [direct link] (https://fastdl.mongodb.org/windows/mongodb-windows-x86_64-5.0.0-signed.msi) and run it. do the following during installation:
- choose the `complete` installation option
- check the install mongodb as a service box
- select run service as `network service` user
- change data directory to: `C:\MongoDB\Data`
- change log directory to: `C:\MongoDB\Log`
- uncheck the install mongodb compass box
**note:** the installer will try to start the mongodb service and fail sometimes. if that happens simply choose to `ignore` and finish the installation.
if starting the service did not fail, enter the following command in an *administrator* cmd window to stop the service before proceeding to the next step:
```shell
net stop mongodb
```
next, create a text file called `mongod.cfg` somewhere and paste the following in to it. save & close the file afterwards.
```yaml
storage:
dbPath: C:\MongoDB\Data
directoryPerDB: true
journal:
enabled: true
systemLog:
destination: file
logAppend: true
path: C:\MongoDB\Log\mongod.log
net:
port: 27017
bindIp: 127.0.0.1
```
now, copy `mongod.cfg` file over to the following location replacing the existing file there: `C:\Program Files\MongoDB\Server\5.0\bin`
then open up an *administrator* cmd window and enter the following to start the mongodb service:
```shell
net start mongodb
```
next, add the above folder to the system path environment variable by running the following command in an *administrator* cmd window:
```java
setx path /M "%path%";"%ProgramFiles%\MongoDB\Server\5.0\bin"
exit
```
# Test Your Installation
open up a terminal/ cmd window and enter the following command:
```shell
mongo
```
enter the following at the mongo shell prompt that comes up:
```shell
show dbs
```
it should give you an output similar to this:
```shell
admin 0.000GB
config 0.000GB
local 0.000GB
```
that's it for the installation and configuration of mongodb server. if you don't like dealing with the mongo shell, you can use a gui database manager. below is a list of such managers in order of personal preference:
1. [NoSQLBooster](https://nosqlbooster.com/)
2. [Navicat for Mongodb](https://navicat.com/en/products/navicat-for-mongodb)
3. [Mongodb Compass](https://www.mongodb.com/products/compass) | djnitehawk |
228,949 | Daily Challenge #154 - Stable Arrangement | A unique challenge that plays with manipulating arrays. | 1,326 | 2020-01-06T16:22:57 | https://dev.to/thepracticaldev/daily-challenge-154-stable-arrangement-c1m | challenge | ---
title: Daily Challenge #154 - Stable Arrangement
published: true
series: Daily Challenge
description: A unique challenge that plays with manipulating arrays.
tags: challenge
---
###Setup
Write a function that will take an array of unique positive integers, and two additional integers as input. With this method, try to rearrange the array so that the sum of any `n` consecutive values does not exceed `q`.
Test constraints:
- 2 <= `n` <= 6
- 4 <= `arr` length < 12
- `n` < `arr` length
- Every value in `arr` will be less than `q`
###Example
<pre>
const arr = [3,5,7,1,6,8,2,4];
const n = 3; // span length
const q = 13; // weight threshold
solver(arr,n,q); // one possible solution: [4,7,1,5,6,2,3,8]
</pre>
###Tests
<pre>
[[3,5,7,1,6,8,2,4], 3, 13]
[[7,12,6,10,3,8,5,4,13,2,9], 4, 28]
[[9,16,11,6,15,14,19,3,12,18,7], 3, 35]
</pre>
Good luck!
***
_This [challenge](https://www.codewars.com/kata/5d6eef37f257f8001c886d97) comes from docgunthrop on CodeWars. Thank you to [CodeWars](<https://codewars.com/>), who has licensed redistribution of this challenge under the [2-Clause BSD License](<https://opensource.org/licenses/BSD-2-Clause>)!_
_Want to propose a challenge idea for a future post? Email **yo+challenge@dev.to** with your suggestions!_ | thepracticaldev |
228,823 | The Swift Programming Language Companion: Strings and Characters | This article is part of a series on learning Swift by writing code to The Swift Programming Language... | 2,560 | 2020-01-05T21:25:49 | https://app-o-mat.com/article/swift-companion/strings | swift, ios, beginners | This article is part of a series on learning Swift by writing code to The Swift Programming Language book from Apple.
Read each article after you have read the corresponding chapter in the book. This article is a companion to [Strings and Characters](https://docs.swift.org/swift-book/LanguageGuide/StringsAndCharacters.html).
### Set up a reading environment
If you are jumping around these articles, make sure you read the [Introduction](https://dev.to/loufranco/the-swift-programming-language-companion-introduction-4k0a) to see my recommendation for setting up a reading environment.
### Generate exercises from a app idea
In the [second article in this series](https://dev.to/loufranco/the-swift-programming-language-companion-the-basics-3kd7), I recommended:
> if you have an app idea, keep that in mind. If you don't, just pick some app you use and know well and keep that in mind. [...] I will show you how I use that to generate exercises for myself.
Sometimes when you want to practice a programming language you don't know yet, it can be daunting to figure out what to do. Like practicing scales to learn piano, it's beneficial to practice one new thing at a time in isolation.
So, for the examples I am going to provide, I will only use knowledge that we have gotten from the chapters we have already read.
### Exercises for Strings and Characters
At this point, you should have read [Strings and Characters](https://docs.swift.org/swift-book/LanguageGuide/StringsAndCharacters.html) in _The Swift Programming Language_. You should have a Playground page for this chapter with code in it that you generated while reading the book.
To generate examples, I am going to us the app idea of Flash Cards that help you study a foreign language. Use google translate to find out how to say things in other languages.
In your Playground write code to do the following
1. Declare five strings called `hello1`, `hello2`, etc and set them to strings that are "Hello, World" in other languages. Include languages that don't use the latin alphabet (like Japanese) and languages that display right-to-left (like Arabic or Hebrew).
2. Concatenate the Strings (using `+`) with a space separating each one.
3. Create a multiline string (using `"""`) with a [verse from "It's a Small World" in another language](https://lyricsplayground.com/alpha/songs/i/itsasmallworld.html).
4. Use flag emojis in your strings from Exercise 1.
5. Enumerate the characters in a string using `for c in "string"`
6. Create the same string as you did in exercise 2, but use interpolation: (e.g. `"\(s)"`)
7. Create a string with interpolation that has the lengths of each `hello` string rather than the string itself.
8. Use substrings to get just the "Hello" part out of each string (skip the ones you don't understand). So, for example, for Spanish, you could use "Hola Mundo" -- so for this exercise, get the substring containing "Hola" into another variable.
9. Concatenate the variables you created in step 8.
10. Declare a boolean that is set to the result of comparing your hello strings with `<`
11. Go back and read the section of the chapter called _Unicode Representations of Strings_. Practice your understanding with your example strings.
### Next:
The next article will provide exercises for the [Collection Types](https://docs.swift.org/swift-book/LanguageGuide/CollectionTypes.html) chapter.
| loufranco |
228,841 | Video Snippets [1] | Float is better used as a way to wrap text around images. Using float just for text can lead to sever... | 0 | 2019-12-30T13:57:31 | https://dev.to/calvinoea/video-snippets-1-iga | css, html, beginners | Float is better used as a way to wrap text around images. Using float just for text can lead to several challenges that are not experienced with grid and flex. For example, it can be hard to make two elements (with text) that use float be identical in size unless the amount of text used is the same in both elements.
<b><small> Source: </small></b> <small><i> CSS Layouts - Flexbox vs Grid vs Float </i>(https://www.youtube.com/watch?v=hYJvxsgnGMA)</small> | calvinoea |
228,849 | The Best Kubernetes Tutorials | We have been looking for the best Kubernetes tutorials out there and thought of sharing some of what... | 3,233 | 2019-12-30T14:13:32 | https://www.magalix.com/blog/the-best-kubernetes-tutorials | kubernetes, azure, aws, gcp | We have been looking for the best Kubernetes tutorials out there and thought of sharing some of what we found interesting to get started with Kubernetes.
The Official Kubernetes.io Tutorials
It is more of a collection of the existing content on Kubernetes.io. It focuses more on introducing the general concepts and constructs of Kubernetes. But it doesn’t provide necessary lessons that build upon each other. Covered Topics:
- The Basics.
- Configuring Kubernetes.
- Stateless Applications.
- Stateful Applications.
- CI/CD Pipeline.
- Managing Kubernetes Clusters.
- Services.
DigitalOcean Tutorials
It is a collection of articles that are nicely written and well organized. They are sometimes focused on Running Kubernetes on top of DigitalOcean however. But you are still going to learn a lot of Kubernetes basics that are applicable to any other infrastructure. Some of the notable topics are:
- An Introduction to Kubernetes
- An introduction to Kubernetes DNS Services
- An introduction to Helm, the package manager for Kubernetes
- Modernizing Applications for Kubernetes
- Building Optimized Containers for Kubernetes
- Kubernetes Networking Under the Hood
- Architecting Applications for Kubernetes
- Building Blocks for Doing CI/CD with Kubernetes
- How to Back up and restore a Kubernetes Cluster on DigitalOcean using Heptio Ark.
- How to Setup a Nginix Ingress with Cert-Manager on DigitalOcean Kubernetes
- How to Inspect Kubernetes Networking | ahmedat71538826 |
228,880 | Using Containers for Ansible Development | Table Of Contents Life Before Containers Introducing the Operations Box Why Use a Cont... | 3,930 | 2020-01-07T10:57:21 | https://dev.to/cloudskills/using-containers-for-ansible-development-2n9n | devops, ansible, docker, vscode | ## Table Of Contents
* [Life Before Containers](#Live-Before-Containers)
* [Introducing the Operations Box](#Introducing-Ops-Box)
* [Why Use a Container](#Why-Use-a-Container)
* [Building a Docker Container Image](#Building-a-Docker-Container-Image)
* [Running a Container](#Running-a-Container)
* [Removing on Exit](#Remove-On-Exit)
* [Volumes](#Volumes)
* [Working Directory](#Working-Directory)
* [Environment Variables](#Environment-Variables)
* [Using Ansible inside a Container](#Using-Ansible-inside-a-Container)
# Life Before Containers <a name="Live-Before-Containers"></a>
As someone who focuses on systems development instead of application development I didn't see how containers would fit into my daily workflow. But I was unsatisfied with my current development experience and wanted to see if containers could improve it. It was super heavy and slow. At the time I had an entire vagrant lab consisting of two Linux virtual machines and one Windows virtual machine. Vagrant would stand up an Ansible control server and two target machines; one Windows and one Linux to run playbooks against.
After I was done developing a playbook I'd have to; commit it, push it, ssh somewhere else, pull it down, then run it again. If I had to debug it I was using vi. No IDE to save me from the white space hell I was about to enter. And sometimes I'd forget to update the other Ansible environments and my code would fail. It was... kind of a nightmare and made me wonder why I bothered with Ansible. I wanted a better workflow. No, I needed a better workflow.
### Summary of Misery
* Very heavy and slow to rebuild development environment.
* Unable to use an IDE outside of lab environment.
* Lots of git'ing around
* inconsistent Ansible environments
* I :q
# Introducing the Operations Box (OpsBox) <a name="Introducing-Ops-Box"></a>
I had used containers before. Mainly to build lab environments for applications like TeamCity and OctopusDeploy. Basically things that already had solid base images. I had not considered using them as a replacement for my development environment. Until, one day a co-worker shared this article [Ansible, AWS CLI, and Kubectl in a Portable Docker OpsBox](https://dzone.com/articles/ansible-aws-cli-and-kubectl-in-a-portable-docker-o). It introduced me to the idea of an Operations Box or OpsBox.
The article talks you through how they wrote a Dockerfile with instructions on how to setup their development environment. Which for them was the aws cli tools, ansible, and at the time aws's kubectl for Kubernetes. I thought "Well, I don't need the AWS and kubectl stuff just yet. What if I write my own?" So I did. It didn't take too long until I ran into an issue. I put the error I was getting into my team chat and asked for help. Funny enough, one team member asked "What are you trying to do?" I said "Building a Docker image that has Ansible in it" Which he replied "Oh, I already did that." After using the container for Ansible development for about two minutes I started to evangelize it.
## Why Use a Container <a name="Why-Use-a-Container"></a>
My favorite part about using a container is the ability to mount a volume to it from my local machine. Which means I can share an Ansible repository and make changes directly to the playbooks without having to git commit, push, pull the code around. I can simply make changes and run the playbooks against a dev environment before pushing them into a release pipeline. Now the first valid question here is "Why not just install Ansible on your laptop for local development?" Great question, the answer is my second favorite part. Using a container instead of my laptop means my entire team has a consistent development environment and we're much more likely to run into the same problems and when we do encounter those problems and fix them it fixes the problem for the entire team.
Another reason I prefer the container is because it decouples the Ansible environment from the target environment. Target environment in this context is a cluster of servers typically all in the same Active Directory domain that Ansible is targeting. It is common practice in system administration to replicate all the infrastructure components per environment. The portability of the container proved we didn't need to do that. Which in the end gave us fewer things to manage, update, and patch. That reduction in management overhead lead to a much more stable and consistent Ansible environment.
The last amazing benefit I'll mention about using a container is the ability to easily recreate your development environment in seconds. Have you even been working on some automation and it works everywhere else except from one specific machine? As a result you roll up your sleeves and start debugging it using the OSI model as your troubleshooting guide. After about an hour you realize it's some weird environment issue with the machine you're running it from. This is yet another benefit of using a container. Because the container is immutable if I now run into a weird DNS issue, I just exit the container which deletes it for me and run a new one. My first troubleshooting step now is to refresh my development environment to ensure it's as clean as possible.
### Summary of Benefits
* Consistent development experience for you and your team
* Decouples the Ansible environment from the target environment.
* Portability reduces management overhead
* Immutable manages the mutable
### Common Questions
_why not install Ansible locally? why use a container?_
* containers offer a consistent environment for my entire team.
_What about the production environment? Surely you're not running everything manually?_
* After the changes are tested against a development environment a pull request is sent in and merged. At which point a release pipeline is in charge of introducing the change to the infrastructure. The deployment step of that release pipeline uses the same container image as we defined in the development environment. Keeping the two the same.
_How do you manage changes to the Dockerfile and the container?_
* Pull requests
The rest of this blog post will walk you through how to setup an OpsBox for Ansible development against Azure resources. This idea can be taken and applied to any other infrastructure as code tooling. Be it Terraform, AWS, vmWare, PowerCLI, etc... There are two main components; the tooling and the platform. You'll just have to build the container to fit your environment requirements.
## Building a Docker Container Image <a name="Building-a-Docker-Container-Image"></a>
In order to build a container image you first start with a Dockerfile. A Dockerfile is a set of instructions Docker uses to build the layers of the container image. I understand this might be uncharted territory for some, but it's really not that different from a bootstrap script or a configuration for a virtual machine.
### FROM
The Dockerfile starts by declaring the base image to use. Just like when you create a new virtual machine from a golden image. This is the foundation of the container. Ansible runs on a few different Linux distribution, but for this article I've chosen centos. The first line will read _FROM centos:centos7.4.1708_. You'll notice that there is more in that than just the distribution name. A version is also included which in Docker terms is called a tag. I'm using the tag to version lock the base container image.
```
FROM centos:centos7.4.1708
```
### RUN
Docker builds the image in layers. Without going into to much details, it's important to have a basic understanding. Each command in the Dockerfile such as FROM and RUN each create a layer for the container image. To reduce the number of layers and complexity of the image it's common to issue multiple commands within a single RUN as seen below. At this point I have a base image or operating system if you will and now I need to install everything needed for Ansible.
1. Install updates
2. Install several development packs gcc, libffi-devel, python-devel, epel-release
3. Install python-pip and python-wheel
4. Upgrade pip
```bash
RUN yum check-update; \
yum install -y gcc libffi-devel python-devel openssl-devel epel-release; \
yum install -y python-pip python-wheel; \
pip install --upgrade pip;
```
Because I'm creating a Docker container that will manage Azure resource I also need the ansible[azure] pip package. As you can see this is on it's own line. When I included with the previous commands I receive errors indicating that pip was not working correctly. The reason being it hadn't been fully installed. Moving it to another line resolved the issue because pip is available in the lower layer.
```bash
RUN pip install ansible[azure];
```
### Dockerfile
```bash
FROM centos:centos7.4.1708
RUN yum check-update; \
yum install -y gcc libffi-devel python-devel openssl-devel epel-release; \
yum install -y python-pip python-wheel; \
pip install --upgrade pip;
RUN pip install ansible[azure];
```
### Build the Container Image
The final step in building a Docker image is to run the `docker build` command. You can consider this the compile step. I have my container codified in a Dockerfile now I need to run that in order to create an image that future containers will use when starting up. `docker build` is the command used to build the image.
`-t` is a parameter that tags the image, essentially giving it a name. The portion after the tag parameter has three sections _repository/imageName/tagVersion_. Breaking this down duffney is the name of my DockerHub repository, ansibleopsbox is the name of the image, and 1.0 is the tag indicating the version. At the every end you see a `.` that is the path to the Dockerfile that contains the instructions for building the image, `.` means the current directory.
```
docker build -t duffney/ansibleopsbox:1.0 .
```
### Pushing the Image to a Registry
At this point you have the image on your local machine and can run the containers, but what about your team mates? In order for others to use the image you've just built you'll have to upload the container image to a registry. It can be a public registry such as DockerHub or a private registry using something like Azure Container Registry or Artifactory to host the repository for you. Below is an example of how to push the image to DockerHub. The username of duffney is used to upload it to my DockerHub account. I have already connected Docker Desktop to DockerHub on my laptop which takes care of all the authentication etc...
```
docker push duffney/ansibleopsbox:1.0
```
## Running a Container <a name="Running-a-Container"></a>
It's now time to start running containers! Interacting with container is a little different than virtual machines. Instead of ssh and WinRM or RDP you interact with them through Docker commands. The Docker command to start up a new container is `docker run`. By default containers run detached which means in the background. To change that behavior you can add the `-it` argument after the docker run command which indicates the container will be run interactively and you're command prompt will change. At the end of the command you must specify which image you want to use for the container. Which in this example is `duffney/ansibleopsbox:latest`. Noticed I used the tag of `latest` not `1.0`. If you don't want to change the version every time you can chose to use that tag.
* `docker run`
* docker cmd to start container
* `-it`
* switches to interactive terminal mode
* `duffney/ansibleopsbox:latest`
* Docker image and tag to use for the container
```
docker run -it duffney/ansibleopsbox:latest
```
### Removing the Container on Exit <a name="Remove-On-Exit"></a>
Using the Docker run command as is will work, but it will lead to a giant mess on your machine. As the command is now every time you exit a container it will stay on your system in a stopped state. You then have the option to start it and re-enter the interactive terminal but why do that when you can just use a new one? To prevent the mess add the `--rm` argument to the Docker run command. --rm automatically remove the container when it exits.
* `--rm`
* Automatically remove the container when it exits
```
docker run -it --rm duffney/ansibleopsbox:latest
```
### Volumes <a name="Volumes"></a>
Volumes are what make the container such a fantastic development environment. Volumes allow you to mount a local directory to a directory inside the container. With the volume mounted you can make changes locally from your development machine using your IDE of choice. Those changes are then reflected inside the container! To mount a volume inside a container you add another argument to the docker run command. The argument is `-v` followed by the `sourcePath:targetPath`. sourcePath is the location on your development machine you want to mount to the container. targetPath is the location inside the container you want to mount the volume.
* `-v "$(pwd)":/sln`
* mounts the current working directory to /sln inside the container.
```
docker run -it --rm -v "$(pwd)":/sln duffney/ansibleopsbox:latest
```

### Working Directory <a name="Working-Directory"></a>
One small inconvenience introduced by mounting a volume is you have to change to the `/sln` directory after you start the container. That's an inconvenience easily solved by using another argument for the docker run command. The argument is `-w` which specifies the working directory for the container when it starts up. This changes the interactive prompt location to the value given to the parameter.
* `-w /sln`
* specifies working directory of /sln
```
docker run -it --rm -v "$(pwd)":/sln -w /sln duffney/ansibleopsbox:latest
```
### Environment Variables <a name="Environment-Variables"></a>
Inevitably you are going to have to authenticate to something. In the case of Ansible, you'll likely have to authenticate to an infrastructure platform. Such as Azure, AWS, vmWare, etc... Ansible utilizes specific environment variables to connect to these platforms when running playbooks. Using environment variables to store this information is very convenient and can be populated by Docker.
Docker offers several ways to populate environment variables. One way is to pass them in at run time with the docker run command. I'll be using Azure as my infrastructure platform and to connect to it I'll have to specify four environment variables; AZURE_SUBSCRIPTION_ID, AZURE_CLIENT_ID, AZURE_SECRET, AZURE_TENANT. By using the `-e` option followed by the environment variable name and then the value of that variable I can populate the environment variables for the container.
* `-e "ENVIRONMENT_VARIABLE_NAME=<VALUE>"`
* populates environment variables inside the container
```
docker run -it -w /sln -v "$(pwd)":/sln --rm \
-e "AZURE_SUBSCRIPTION_ID=<subscription_id>" \
-e "AZURE_CLIENT_ID=<security-principal-appid>" \
-e "AZURE_SECRET=<security-principal-password>" \
-e "AZURE_TENANT=<security-principal-tenant>" \
duffney/ansibleopsbox:latest
```
_Using environment variables are only one of several ways to connect to Azure from Ansible. For more information check out Connecting to Azure with Ansible._
{% post https://dev.to/joshduffney/connecting-to-azure-with-ansible-22g2 %}
## Using Ansible inside a Container <a name="Using-Ansible-inside-a-Container"></a>
At this point it is up to you to determine how to integrate the Ansible container into your development workflow. The two most common uses I've seen are running it in a stand-alone terminal and running it within an IDE using an integrated terminal such as VS Code. Each approach is exactly the same from the perspective of using the container. You will interact with Ansible at the command line from inside the container.
Personally for me, most of my time is spent using an integrated terminal with VS Code. The reason is, I can quickly edit all the files inside the mounted volume with all the comfort and gadgets available in VS Code. However, there are times where I start up a container at the command line to execute or debug playbooks.
__Common Environments__
* Standalone Terminal
* Integrated Terminal within an IDE (VS Code)
### Standalone Terminal
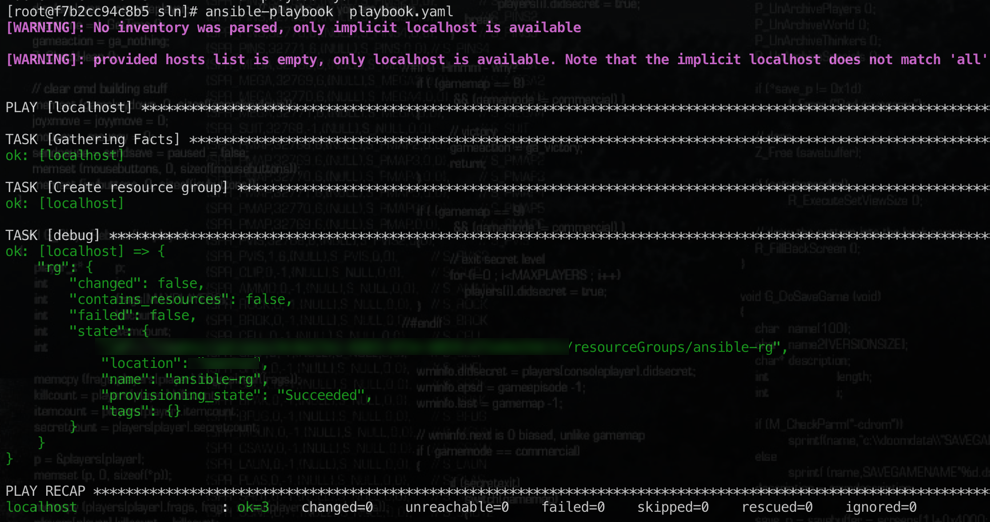
### Integrated Terminal VS Code
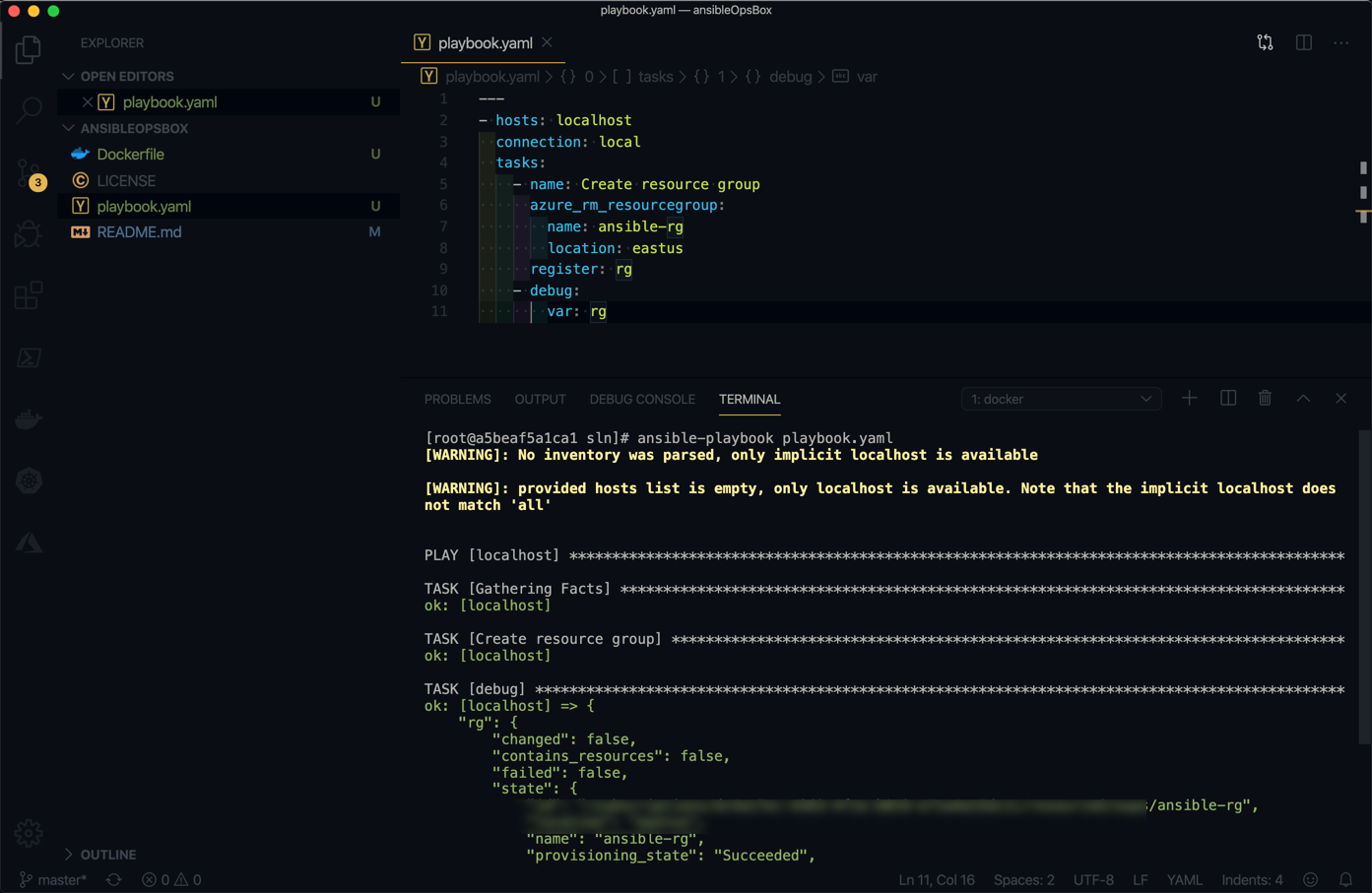
### Additional Reading & Sources
[Quickstart: Install Ansible on Linux virtual machines in Azure](https://docs.microsoft.com/en-us/azure/virtual-machines/linux/ansible-install-configure)
[Best practices for writing Dockerfiles](https://docs.docker.com/develop/develop-images/dockerfile_best-practices/)
[Azure Container Registry](https://docs.microsoft.com/en-us/azure/container-registry/container-registry-get-started-docker-cli)
[DockerHub sign-up](https://hub.docker.com/signup)
I turned this blog post into the first chapter of an ebook on Ansible! You can get the first chapter free at [becomeansible.com](https://becomeansible.com/).
| joshduffney |
228,924 | The 7 Most Popular DEV Posts from the Past Week | A round up of the most-read and most-loved contributions from the community this past week. | 0 | 2019-12-30T16:10:14 | https://dev.to/devteam/the-7-most-popular-dev-posts-from-the-past-week-2gfb | top7 | ---
title: The 7 Most Popular DEV Posts from the Past Week
published: true
description: A round up of the most-read and most-loved contributions from the community this past week.
tags: icymi
cover_image: https://thepracticaldev.s3.amazonaws.com/i/sfwcvweirpf2qka2lg2b.png
---
Every Monday we round up the previous week's top posts based on traffic, engagement, and a hint of editorial curation. The typical week starts on Monday and ends on Sunday, but don't worry, we take into account posts that are published later in the week. ❤️
#1. Entry Point
Aleksandar introduces us to three common web attacks and the methods to prevent them. This is a great entry point of understanding existing web security standards.
{% link https://dev.to/maleta/cors-xss-and-csrf-with-examples-in-10-minutes-35k3 %}
#2. Pretty Impressive 💯
Florin explains why they pursued the #100Days100Projects challenge and answers some commonly asked questions from the community. You'll learn about how Florin stayed motivated, how they came up with ideas, and more.
{% link https://dev.to/florinpop17/how-i-built-100-projects-in-100-days-5be7 %}
#3. Fun Fun Fun!
Fanny is learning about functional programming and in this post, they share some of the benefits they've learned. Fanny also shares a bunch of additional resources at the end of the post.
{% link https://dev.to/fannyvieira/the-beauty-of-functional-programming-32ck %}
#4. Blazin' Cool
Jeremy shares an overview of Blazor, a framework from Microsoft that lets you build interactive web UIs using C# instead of JavaScript.
{% link https://dev.to/pluralsight/how-blazor-is-going-to-change-web-development-14n4 %}
#5. Programming Patterns
Tomaz shares an alternative to 'if' statements which leads to a big community discussion around imperative vs declarative programming.
{% link https://dev.to/tomazlemos/keeping-your-code-clean-by-sweeping-out-if-statements-4in8 %}
#6. Fingers Crossed
C# is trending towards supporting more functional programming techniques. In this post, Matt shares the proposed aspects they're most excited about for C# 9.
{% link https://dev.to/integerman/the-dream-of-c-9-0-5fc7 %}
#7. Weird but Good
Have you used `mix-blend-mode` before? Cyd shares five cool tips and tricks for the front end.
{% link https://dev.to/cydstumpel/5-things-in-web-development-i-learned-this-year-8p5 %}
_That's it for our weekly wrap up! Keep an eye on dev.to this week for daily content and discussions...and if you miss anything, we'll be sure to recap it next Monday!_ | jess |
228,950 | Implementing stripe card for fun & profit | Today I want to write about a little side project that I did recently: what I learned from it, what... | 0 | 2019-12-30T17:57:51 | https://krzysztofzuraw.com/blog/2019/implementing-stripe-card | html, css | ---
title: Implementing stripe card for fun & profit
published: true
date: 2019-12-30 09:12:03 UTC
tags: html, css
canonical_url: https://krzysztofzuraw.com/blog/2019/implementing-stripe-card
---
Today I want to write about a little side project that I did recently: what I learned from it, what went good and what went bad. Let’s go 🎉.
Most of the time I see some advice on how to be better on writing CSS and be better at design overall - take a piece of a website like [stripe.com](https://stripe.com/en-pl) and implement it.
I did exactly this. I took a small card and try as I can best to implement it without looking at source code. Then I went back to see differences and similarities.

Part of stripe website I decided to implement by myself.
## Card
### My implementation
I’ve started with card implementation card - it is `div` that has `border-radius` and `box-shadow`. I used `flexbox` to position elements inside it. This second property was really hard for me to implement as I normally always copy shadow values either from designs or from source code. As you can see it below:

It stills create an effect that the card is elevated a little bit than the background.
### Stripe
The first thing that I’ve noticed was that they used `a` tag as a card instead of `div`. A clever trick that automatically allows a user to be redirected into another page without having `onClick` handlers as in case of my implementation. Interesting is also `box-shadow` property - instead of one value they used 3 slightly different to create an effect of shadows from 3 different sides:

## Header & Paragraph
### My implementation
At first, I have to [reset](%5Bhttps://meyerweb.com/eric/tools/css/reset/%5D(https://meyerweb.com/eric/tools/css/reset/)) CSS for `h2` and `p` tags. The rest was fun to implement besides the font that stripe has used - `Camphor`. It turns out that this is a paid font so I’ve chosen `Open Sans` from google fonts.
### Stripe
They added a little bit of spacing by using the`letter-spacing` property. You can read more about this property [here](%5Bhttps://css-tricks.com/almanac/properties/l/letter-spacing/%5D(https://css-tricks.com/almanac/properties/l/letter-spacing/))
## Image
### My implementation
Here things start to be a little bit tricky as I do not want to create YouTube logo (To be honest I don’t have yet skills to do so). So I’ve added a SVG circle and I fill it with color. On hover, I’ve changed it to be darker but my implementation has one weak point - changing of color occurs only when a user hovers over circle directly.

### Stripe
In the beginning, the SVG image has its initial color. Then on hover, they added new color with `!important` and SVG has `transition` property. Thanks to that changing of color is smooth.
## Summary
I this blog post I decided to implement a card found on [stripe](https://stripe.com/en-pl). You can check my implementation on [codepen](https://codepen.io/krzysztofzuraw/pen/OJPLRbp). Implementing card & elements inside it went good, but `box-shadows` & styling of SVG is something that I need to work on more. I also learn a lot:
- box-shadow
- `letter-spacing` in header
- dynamically changing SVG color
- using `a` tag as a card container
Below you can find embedded code pen.
See the Pen [Stripe card](https://codepen.io/krzysztofzuraw/pen/OJPLRbp) by Krzysztof Żuraw ([@krzysztofzuraw](https://codepen.io/krzysztofzuraw)) on [CodePen](https://codepen.io).
| krzysztofzuraw |
229,040 | Top Benefits of Schema Markup for Your Website | Whether you have a blogging website or a business website, the new feature introduced by Google Schem... | 0 | 2019-12-30T20:33:45 | https://dev.to/darklabmedia/top-benefits-of-schema-markup-for-your-website-jj4 | Whether you have a blogging website or a business website, the new feature introduced by Google Schema markup will give you benefits in many ways. If you don't anything about the feature. get help from <a href="https://www.darklabmedia.com/search-engine-optimization-seo/">search engine optimization services in Texas</a>. A professional SEO company will help you set up the feature.
<strong>What is Schema Markup?</strong>
It is a code that you put on your website to help search engines feature more information results to users without browsing the website. If you know the rich snippets, understanding schema markup will be easy for you. The feature is supported by many major search engines.
<strong>Benefits of Schema Markup</strong>
It helps search engines to understand your site's content better. The major goal of SEO is to let search engines understand your site and services. That is why schema markup is created. So, the number one benefit of the feature is to help the search engine understands your content so that it can display your website to relevant searchers.
It helps in improving brand presence. For businesses, the feature has come up as a bonus to boost their brand presence online. Using the feature, then Google will display the pertinent business information that customers want such as social accounts, phone number reviews, etc. It will help you display logo, hours of operation, website links and much more.
The feature helps to increase CTR because of rich results. In this case, only those users land to your website who are interested in your services. When they spend time on your site, it will increase the CTR and decrease the bounce rate. Adding product schema can increase the CTR rate by up to 10% according to experts.
You can able to outperform your competitors. Since the schema markup feature has included in a countable number of websites. If you add the feature before your competitors, it would give a boost to your ranking. Google and Bing will improve your ranking. Thus, you can increase your website visibility online.
Adding the schema markup feature helps to improve the position of the site for Alexa, Google Assistant, and voice search. If your website is according to emerging SEO trends, you can get the benefits of improving your position for voice search. Many times, a site with the search schema feature displays top on search results.
Contact your SEO company to add the schema markup feature on your website. Don't stay behind in the race.
| darklabmedia | |
229,088 | Cheers to 2019! Bring on 2020! | Thanks for the memories 2019. You were a good one. 2019 wasn’t without some struggles, but there... | 0 | 2019-12-30T22:59:55 | https://baldbeardedbuilder.com/posts/cheers-to-2019-bring-on-2020/ | review, meta | ---
title: Cheers to 2019! Bring on 2020!
published: true
date: 2019-12-29 01:00:00 UTC
tags: review, meta
canonical_url: https://baldbeardedbuilder.com/posts/cheers-to-2019-bring-on-2020/
cover_image: https://res.cloudinary.com/dk3rdh3yo/image/upload/w_auto,c_scale/Artboard_2_k3mgba.png
---
Thanks for the memories 2019. You were a good one.
2019 wasn’t without some struggles, but there were several huge wins that I’ll never forgot. One of the things that I started in earnest in 2019 that led to one of the most dramatic changes in my life was live-streaming on [Twitch](https://twitch.tv/baldbeardedbuilder). In addition to the amazing people I met, it awakened a passion in me to help others succeed which led me to a career change. In the last quarter of the year, I started as a Developer Advocate at [Nexmo](https://nexmo.com). So now I get to learn, teach and help others succeed and get paid for it!
So yeah, 2019’s been a good one, but let’s see how I did versus the goals I set to start the year and plan some goals for 2020.
<!--more-->
# How did I do?
At the start of 2019, I made a [blog post](https://baldbeardedbuilder.com/posts/2018-year-in-review/) reviewing 2018 and setting goals for 2019. It’s the first time I’ve made a blog post like that. Looking back, I’m glad I did because now I can compare the start and end of the year.
## Goals for 2019
### Don’t stop be-logging
I set a goal of one blog post a month with a stretch goal of 2 per month. Looking back, I posted exactly 12 blog posts during 2019 between this website and the [Nexmo](https://nexmo.com) blog. I did miss some months, but also blogged twice a few months to reach the goal. Honestly, there was a bit of luck involved in hitting this goal. I did a very poor job of prioritizing it.
**Verdict:** Achieved.
### I’ve got a Twitch that needs to be scratched
Another goal for 2019 was to start streaming regularly on [Twitch](https://twitch.tv/baldbeardedbuilder). Little did I know how much this decision would change my life. Let’s take a look at some of the ways I was impacted:
- Met and now interact with amazing viewers who have taught me way more than I’ve taught them
- Joined some of the most impressive people I know on the [Live Coders](https://livecoders.dev) team
- Made life-long friendships that have provided an ear when I was struggling and feedback when I was trying something new
- Hosted a series of streams, the [Heroines of JavaScript](https://women-in-tech.online/) series, highlighting women in technology where my two daughters were able to interact and interview some amazing developers.
**Verdict:** Achieved.
### I like to lose it, lose it
After losing about 40 pounds near the end of 2018, my goal was to drop another 40 pounds in 2019. How did it go? Well… at least I didn’t gain any of that weight back. I’ve basically maintained that weight loss this year but never continued. In February, I started working from home exclusively so I lost access to our office gym. This drop in activity coupled with a major case of runner’s knee, which sidelined me for a few weeks, really stifled the momentum I had gained.
**Verdict:** Failed
### Level up the wood working

I really enjoyed wood working in 2018 and wanted to level-up my skills in 2019 with a goal of being proficient enough to build a new dining room table for the family by the end of the year. Fast forward, we actually had a friend of mine build the dining room table, but I did get to build some shelves for the girls bedroom and frames to screen in our back porch. So while I didn’t build the table, I did level up my wood working in 2019.
**Verdict:** Achieved.
### Hanging with my girl
The last of the 2019 goals was setting up regular date nights with the wife. All of the social and family events we are involved in really hindered us from having regular date nights, but we definitely need to make this a higher priority moving forward.
**Verdict:** Failed miserably.
## Goals for 2020
### Family time FTW
This is my #1 goal for 2020. During the holidays I purchased several games for the family and we’ve been playing together three to four nights a week for the last few weeks of December. We are loving it. From card games to Monopoly, the quality time is so amazing. This isn’t just a game night goal though. I’ve got a couple wood working projects I want to complete this year and I want my kids involved in all of them. And with this year marking our 20th anniversary, I really want to focus on spending time away from kids. The only way to accomplish that will be to schedule it in advance so that’s what we’re doing now.
**Goal:** At least one date night with the wife a month and a minimum of 2 days/nights with the family playing, building, etc.
### A tube of you’s
Ever since I started streaming on [Twitch](https://twitch.tv/baldbeardedbuilder), I’ve been archiving the streams in an un-edited form to [YouTube](https://www.youtube.com/channel/UCn2FoDbv_veJB_UbrF93_jw). But in 2020 my goal is to start creating original content for [YouTube](https://www.youtube.com/channel/UCn2FoDbv_veJB_UbrF93_jw). I’ve got a few ideas, some longer form, some shorter, but overall the purpose will be to provide helpful tips, interviews and learning guides. So if you’re not subscribed to the channel, get over there and hit the subscribe button so you know when the floodgates open.
**Goal:** Generate at least 2 original videos for [YouTube](https://www.youtube.com/channel/UCn2FoDbv_veJB_UbrF93_jw) each month, but the stretch goal will be to have something up weekly.
### Bloggers?! We don’t need no stinking bloggers!
I hit my goal of one post a month in 2019, but I’m finally ready to step it up. As part of my job, I’ll be generating one or two posts a month, but for the purposes of these goals, I only want to include posts hosted here.
**Goal:** Write at least 2 posts per month, not including those for [Nexmo](https://nexmo.com).
## Sum it up
2019 was very good to the bald, bearded household and we’re really excited about what 2020 holds. We also wish that 2020 is the best you’ve ever had.
Do you have any goals for 2020? I’d love to hear them. Feel free to leave them in the comments.
* * *
Credit to [Heather Durham Photography](https://blog.heatherdurhamphotography.com/) for the Thunder on the Mountain image used in the header. | michaeljolley |
229,162 | 5 Productivity Tips for Digital Marketer | Being a digital marketer have you ever felt like you are always active or busy but rarely productive?... | 0 | 2019-12-31T05:06:23 | https://dev.to/snehaj5/5-productivity-tips-for-digital-marketer-97b | beginners, productivity, motivation, management | Being a digital marketer have you ever felt like you are always active or busy but rarely productive?
Well, I’m not going to blame you entirely for that. Because the digital world, after all, is a busy world. As a digital marketer, you have to be a pioneer and constantly championing the new changes in the industry. In order to drive top-notch results and succeed in each task in a rapidly changing digital world, it’s easy for any digital marketer to get overwhelmed and fall victim to procrastination.
It’s important to work smarter to improve your performance and complete the tasks in a timely manner. Sometimes it may seem like you are operating non-stop and still struggle to complete some of the important things you set for yourself. Why?
Because you may be busy all day without being truly productive. In this post, I’ve come up with the top 6 productivity hacks just for this situation. These hacks are often overlooked but they can do wonders for you if you follow them.
#1. Just Say No...to Meetings
Useless or unnecessary meetings are one of the biggest time wasters in the modern workspace. Such meetings either slows down or completely stops your productivity
Systematic meetings accomplish business goals but valueless meetings distract you from important tasks and make employees work overtime to finish up the work.
#2. Multitasking is a Myth
It's easy to fall in the trap of multitasking, but it's important to remember that it's impossible to multitask. Have you ever been to a situation where you're complaining about how your computer "slows down" when you have too many tabs open?
Well, our brain exactly works the similar way it can't handle various duties at once. Ultimately, you may finish your work, but you will definitely harm your productivity. Studies have found that [multitasking reduces your productivity by 40%.](https://www.dailymail.co.uk/health/article-1205669/Is-multi-tasking-bad-brain-Experts-reveal-hidden-perils-juggling-jobs.html)
#3. Eliminate All Distractions
So how do you minimize digital distractions and increase productivity?
Self-discipline is the first step that you need to learn. We all should adopt this self-disciplinary principle to get rid of the digital distractions. If you find this difficult then there is one more way to manage such distractions is by turning off the notifications. You can mute all your notifications during work time and can unmute them during the breaks.
#4. Schedule a Time to Check your Emails
Email is probably the most harmful of all the distractions that take your attention away. You need to stop scanning your inbox throughout the day in order to recover your time. Or else you'll find yourself endlessly reading and replying messages all day long.
I usually check emails after lunch and before I leave. This way I can focus on my other work too.
#5. Promodoro Technique
Promodoro technique is a time management structure that encourages you to split your work into small intervals of 25mins. That means you can divide your tasks in intervals where each task will have a 25mins of timer to complete it, separated by 5 mins of break. These intervals are called Promodoro.
This will help you focus on only one task at a time and because of the timer, you won't mindlessly scroll through social media.
#Wrap Up:
I've given some of the great hacks to manage your time. Now brace yourself and accept the challenge.
P.S: Digital marketing involves many tasks; you can use some [digital marketing tools](https://www.freshproposals.com/top-digital-marketing-tools-for-startups/) to automate these tasks which can also help you save your time.
About me
I'm a Digital Marketer at Freshproposals- [Proposal Templates](https://www.freshproposals.com/proposal-templates/). You will find my blogs mostly on SEO, Digital Marketing, Email Marketing, etc. I love meeting new people, they bring new joy, colors, and beauty to our life. Besides that, I have a good vocal. Singing Can Make Me Forget My Problems.
| snehaj5 |
229,170 | Happy New Year! | Happy New Year 🎉 to everyone in this awesome Dev.to community, It's been a great alternative to other... | 0 | 2019-12-31T05:37:31 | https://dev.to/keevcodes/happy-new-year-1ncp | community, gratitude | ---
title: Happy New Year!
published: true
description:
tags: #community #gratitude
cover_image: https://user-images.githubusercontent.com/17259420/71611201-5d15fe80-2b97-11ea-8912-22386ce5eb9b.jpg
---
Happy New Year 🎉 to everyone in this awesome Dev.to community, It's been a great alternative to other blog platforms. I also would like to thank everyone for reading and following me this year. When I started I had a goal of reaching 500 followers at the year's end; I've now reached 2800 followers! Thank you all for taking interest in my writing and being a wonderful community. I hope everyone has been relaxing and enjoying time with families and loved ones this past week.
See you all in 2020! 🥳 | keevcodes |
229,187 | Install Flutter without Android Studio | In this tutorial, we will install Flutter and configure it, without installing Android Studio or any... | 0 | 2019-12-31T06:36:14 | https://dev.to/sir-geronimo/install-flutter-without-android-studio-58bi | flutter, dart, android, openjdk | In this tutorial, we will install Flutter and configure it, without installing Android Studio or any device emulator.

### Prerequisites ###
* Terminal.
* Git.
* Access to system environment.
* VS Code and Flutter extension.
### Steps ###
1. First let's create a folder called _src_ or something you want in our _**C**_ drive.
2. Now let's go to install the Flutter SDK. We proceed to enter to the _C:\src_ folder and run
`git clone https://github.com/flutter/flutter.git`
the Flutter sdk starts to download.
3. When the Flutter sdk has been downloaded, type "env" in the Windows search (or press windows key), and click on "Environment Variables...", edit the Path of the User Variables and add a new one "_C:\src\flutter\bin_".
4. Run the command `flutter`, if the command is found it will start downloading some dependencies, after that run `flutter doctor`.
5. Download OpenJDK8, I recommend using this one [http://download.java.net/openjdk/jdk8u40/ri/openjdk-8u40-src-b25-10_feb_2015.zip](http://download.java.net/openjdk/jdk8u40/ri/openjdk-8u40-src-b25-10_feb_2015.zip)
Just extract the files on a folder like "_C:\Program Files\Java\openjdk8_".
6. Add the _JAVA_HOME_ and the path to the System Variables, go to edit the Environment Variables and click on "New..." under the System Variables
After you add the new system variable you can set the path for java, edit the Path of the System Environment and add "_%JAVA_HOME%\bin"
7. Download Android SDK, Head to [https://developer.android.com/studio#downloads](https://developer.android.com/studio#downloads) and download **Command line tools only** for Windows. After downloaded, just extract the folder (tools) in a new folder on "_C:\Android_".
8. Install Android dependencies. Move to "_C:\Android\tools\bin_" and run the `sdkmanager.bat --list` (with the Terminal), run the following commands:
`sdkmanager.bat “platform-tools”`
`sdkmanager.bat “build-tools;28.0.3”`
`sdkmanager.bat “platforms;android-28”`
`sdkmanager.bat "platform-tools"`
8. Add the _ANDROID_HOME_ to the System Variables, add a new entry called "ANDROID_HOME" and the value is the path of your installation
9. Allow debugging mode on your phone, you can follow this tutorial [https://developer.android.com/studio/debug/dev-options](https://developer.android.com/studio/debug/dev-options), allow the connection from your PC prompted on your phone's screen.
10. Run `flutter doctor`. | sir-geronimo |
229,316 | My 2019 in Review | As 2019 is about to end, here is the list of work and achievements that I have done in 2019. Joined... | 0 | 2019-12-31T12:45:47 | https://dev.to/delta456/my-2019-in-review-26ml | showdev, 2019, career | As 2019 is about to end, here is the list of work and achievements that I have done in 2019.
- Joined [V](https://vlang.io/) and being an active contributor then soon became a member.
- Made [Monkey Language in V](https://github.com/Delta456/monkey_v) which still needs to be finished and is pending due to current limitations
- Took part in Hacktoberfest 2019 and did 22 PRs in October.
- Founding Members of [V Community](https://github.com/v-community).
- Started [V by Examples](https://github.com/v-community/v_by_example) which is about to be completed.
- Learning how a compiler and interpreter works with [Interpreter Book](https://interpreterbook.com/) and [Compiler Book](https://compilerbook.com/).
- Started Learning by making an interpreter and porting a Python Library.
- 2k Followers on Dev in just 3 months!
- My implementation of Monkey Language in V got listed [here](https://monkeylang.org/).
- New Pixel Art Posts in my [DeviantArt](https://www.deviantart.com/delta2318) Account
- My [Python article](https://dev.to/delta456/python-init-is-not-a-constructor-12on) was listed and featured in [Python LibHunt Weekly Newsletter](https://twitter.com/PythonLibHunt/status/1207778623979061248) and got 54k views in just 2 days!
- My [Modern C++ article](https://dev.to/delta456/modern-c-an-introduction-36kg) was listed and featured in [C++ LibHunt Weekly Newsletter](https://twitter.com/CppLibHunt/status/1209415174236471296).
- Started learning Modern C++ and making a series of tutorials for it.
- Added content and fixed grammar for [Modern C++ Book](https://github.com/changkun/modern-cpp-tutorial) and will contribute more to it.
## Dashboard
## Hacktoberfest Profile and T-Shirt

## Github Activity
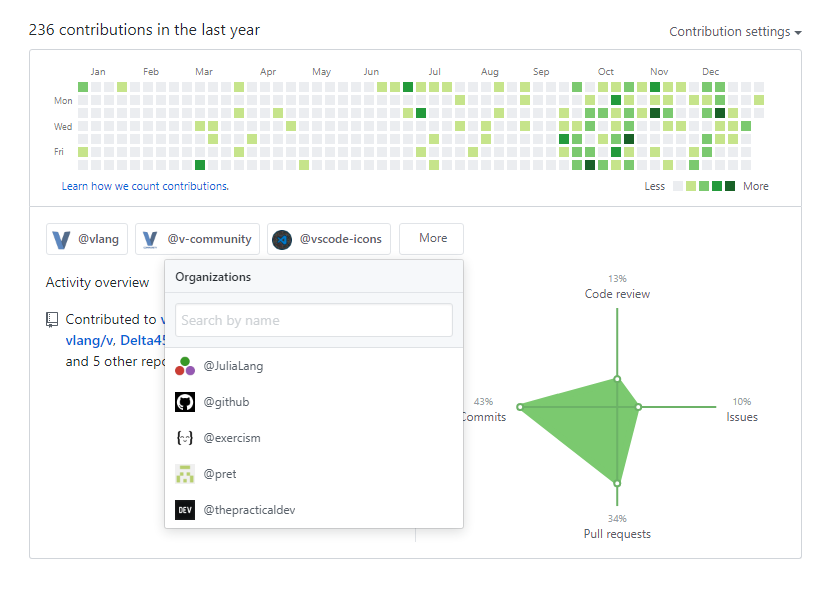
I hope that I will be able to do more in 2020 and learn a lot of new things and meet new people.
Happy New Year Eve!
| delta456 |
229,383 | Growing a Result-Driven Mindset | <h1>Growing a Result-Driven Mindset</h1>
<p>
T... | 0 | 2020-01-01T23:49:43 | https://yiming.dev/blog/2019/12/31/growing-a-result-driven-mindset | mindset, growthmindset, yearlyreview, goal | ---
title: Growing a Result-Driven Mindset
published: true
date: 2019-12-31 00:00:00 UTC
tags: mindset, growth mindset, yearly review, goal
canonical_url: https://yiming.dev/blog/2019/12/31/growing-a-result-driven-mindset
---
<section id="content" role="main">
<div id="outline-container-sec-" style="padding-top: 70px">
<div></div>
Today is the last day of 2019.
It's time for me to review the last year.
Put everything aside, I think the biggest change of me is the mindset transition from a process-focused one to a result-driven one.
</p>
<div id="outline-container-org72f53ae">
<h2 id="org72f53ae">Connecting the dots (that led to a mindset shift)</h2>
<div id="text-org72f53ae">
<p>
Inspired by <a href="https://charity.wtf/2017/05/11/the-engineer-manager-pendulum/">The Engineer/Manager Pendulum</a> written by Honeycomb CEO Charity Majors, I've been doing more management work in the past 12 months.
Management works like hiring, on-boarding, organizing meetings, planning, and goal setting really opened my mind.
When looking back, I realize that I've been unconsciously pushing myself and my team to a more result-driven style of working.
Let's see what I've done in a chronological order:
</p>
<ol>
<li>
<p>
Setting up a goal-driven on-boarding program
</p>
<p>
On-boarding is the most important thing if we want everyone to become a superstar in this team.
So I think of it as the highest leverage task for a team.
The goal of on-boarding in my team is to help the new-hire get familiar with our team and our way of work, so he/she can start delivering value as soon as possible.
</p>
<p>
After some trial and error, we developed an on-boarding program for our team.
This program looks like this:
</p>
<ol>
<li>On the first day a new member joins our team, a mentor would help him define a two-month roadmap.
This roadmap would define goals and tasks for the trial period.
For most developer roles, one of the most important goals is to deliver a feature to production (within one or two weeks).
Tasks are just checklists for guiding the new member to achieve the goals.</li>
<li>At the end of every week, the mentor would have a catch-up meeting with the new member.
In this quick catch-up, they would review the past week, see if goals are achieved and maybe adjust/define the next goal.</li>
<li>By the end of first month, the new member would join a more formal feedback meeting.
In this meeting, we would share feedback to the new member.
And the new member can share his/her feedback to the team, or the company.</li>
<li>By the end of second month, our team would decide whether this new member passes the probation period or not.
Note that the decision is mostly based on if he/she has achieved the goal defined previously.</li>
</ol>
<p>
With this program, we successfully on-boarded four backend developers.
They now all work at their full speed in various projects.
We also identified a mismatch between another web developer and our team.
He/She didn't achieve the goals we defined together even after we adjusted the goals accordingly.
Sadly, we had to let him/her go.
</p>
<p>
As you can see, the goal plays an important role in the whole on-boarding process.
And we found that this process worked the best when the goal is clear and it's reviewed often.
If the goal is not clear, on-boarding would take much longer.
</p>
</li>
<li>
<p>
Defining expected results when writing a Tech Plan
</p>
<p>
Turning the focus back to our internal team, I noticed that two of our major projects have the same delivery issue:
<b>a high rework rate.</b>
</p>
<p>
Team members rarely discuss the code change they are gonna make until they need to deploy it to production.
So, rework is often required during the code review phase (if there is one).
Or worse, sometimes hotfix is needed after deploy the change to production and there is a bug.
</p>
<p>
This time, I introduced <a href="https://yiming.dev/blog/2019/07/11/%E7%94%A8-tech-plan-%E6%9D%A5%E4%B8%BA%E5%BC%80%E5%8F%91%E6%8F%90%E9%80%9F/">Tech Plan</a> (or RFC) to the team.
The purpose of defining a Tech Plan is for team members to have a common understanding of and how we are going to solve a problem.
</p>
<p>
After introduced Tech Plan to more team members, we realized that the most important thing to do when defining a plan is <b>defining the problem</b>.
Or put it in another way, defining the result we want to achieve.
Only when the result is clearly defined, can we come up with different solutions targeting at the same result, compare them, and make tradeoffs.
</p>
</li>
<li>
<p>
Clarifying expected results for each Sprint
</p>
<p>
Next, I found our sprint meeting was not delivering the value as it should be.
Team members only go through the todo lists together, report the progress over the past sprint, and finally define the tasks for next sprint.
To me, the missing piece is the expectation of results, again.
People know what they should do (add sorting to a table),
but they don't know why they should do it or what result it is for (users can find the info they want more easily),
so they can't provide a better solution (add search functionality).
</p>
<p>
So I helped clarify the purpose of sprint meeting:
sprint meetings is for reviewing the results from the previous sprint and getting aligned on the goal for the next sprint.
Most importantly, the goal here is not only a feature, but a hypothesis that if we ship feature A, then we can get outcome X.
Without this hypothesis, we don't know what we are targeting at.
</p>
<p>
(And it also led me to <a href="https://yiming.dev/clipping/2019/06/10/say-no-to-processes/">Say NO to Processes</a>.)
</p>
</li>
<li>
<p>
Implementing OKR to define clear expectations
</p>
<p>
Finally, I started working at every level of our team to help define OKRs for the next year/quarter.
</p>
<p>
The idea is the same as before: to reach a common understanding of what results we want to achieve.
</p>
<p>
There are still many challenges along the way, like how to define measurable key results for team building, design, project management.
Let's see how we can tackle these obstacles in 2020. :)
</p>
</li>
</ol>
</div>
</div>
<div id="outline-container-orge8f2db6">
<h2 id="orge8f2db6">What's the difference?</h2>
<div id="text-orge8f2db6">
<p>
Hopefully these stories sound interesting to you.
But you may ask what's the difference between action-driven (or process-focused) and result-driven, anyway?
</p>
<p>
When I started working as a developer, I treated process as the heart of our work.
As long as we can use a new/fashion/professional process (like TDD), we can improve our efficiency.
Better processes can definitely do that, but probably not as efficient as if people are driven by results.
</p>
<p>
When driven by results, we can experiment with different tools, different processes, compare them, and choose the best one for the current situation.
Let's see a few examples:
</p>
<ul>
<li>
<p>
Testing or not?
</p>
<p>
I used to believe if a project doesn't have good test coverage, then it needs to be fixed.
But this thinking changed after I become more result-driven.
</p>
<p>
What's the purpose of testing?
Or what's the desired results of well-tested code?
Correct behaviour and easier refactoring!
To achieve these result, we have way more tools than testing.
For example, a well defined type system can also help us ensure our code is correct and make refactoring easy.
(I guess that's why TypeScript is becoming more and more popular, and strict typed languages like Elm and Haskell can be so appealing.)
</p>
<p>
More importantly, every tool has its pros and cons.
UI testing is a huge headache for automated tests.
Manual testing is probably a more efficient and more cost-effective choice.
</p>
<p>
So now, I'm still a proponent of TDD, but also more open to other methods that can achieve the same result.
</p>
</li>
<li>
<p>
Detailed documentation or not?
</p>
<p>
I used to ask for comments and documentations for most methods/classes/modules.
I used to copy private project discussion from Slack and paste it to our issue trackers.
But again, these practices changed after I become more result-driven.
</p>
<p>
What's the purpose of writing everything down?
Better communication, better understanding, and not forgetting anything!
To achieve these results, detailed documentation may not help much.
For example, when there's a language barrier (people can hardly read English), descriptive notes can hardly help.
When others prefer discussing in person, sending an email can hardly lead to a receipt.
When everyone has a different way organizing their notes, documenting everything may not help because it's only useful to the author.
</p>
<p>
So now, I still prefer to write things down, but only for myself, and I'll let everyone else to choose his/her preferable way to remember important things.
</p>
</li>
<li>
<p>
Single best solution or not?
</p>
<p>
I used to want to write the best code, the best article, etc.
I used to think there is a best solution for every problem out there, everything is like an exam.
But again, this thinking becomes ridiculous when I become more result-driven.
</p>
<p>
For most problems, its solution space is way larger than the problem itself.
The best thing we can do is to try as many solutions we can and choose the best one among them.
(In a geeky sense, most problems are NP-problems.)
</p>
<p>
Because the solution space is so large that we cannot try them all, we can never know if a solution is the best or not.
There is always a better solution out there.
</p>
<p>
So now, I would start a continuous experiment for a problem if I want to get the best result.
</p>
<ol>
<li>Set a goal for the result.</li>
<li>Find a hypothesis that may achieve this goal.</li>
<li>Execute a plan to test the hypothesis.</li>
<li>Revise the execution and see if the goal is achieved.</li>
</ol>
</li>
</ul>
<p>
As you can see from these examples, being result-driven doesn't equal to not taking actions.
On the contrary, it needs more actions being taken.
</p>
<ol>
<li>Defining expectations clearly.</li>
<li>Finding different solutions.</li>
<li>Executing and comparing them.
(Maybe not taking any action achieves the best result.)</li>
</ol>
<p>
These all requires more efforts than just taking actions as a nobrainer.
Taking action is not the goal, achieving a better result is.
</p>
<p>
Being result-driven doesn't equal to ditching every process, neither.
On the contrary, it means to always trying different solutions and always improving.
</p>
<ol>
<li>If a process leads to a good result, then use it;</li>
<li>If another process leads to a better result, then switch to it.</li>
</ol>
<p>
Improving process is not the goal, achieving a better result is.
</p>
</div>
</div>
<div id="outline-container-orgf2b361a">
<h2 id="orgf2b361a">Drawbacks of result-driven mindset</h2>
<div id="text-orgf2b361a">
<p>
That being said, result-driven mindset has its cons as well.
The biggest one is that the desired results need to be clear and explicit.
So when facing a problem that's unclear and requires some explorations, a result-driven mindset won't help us (and may even draw us back).
</p>
<p>
Another thing is that if a goal is clear but doesn't reflect the result we want, it may lead us to a wrong direction.
For example, daily page view is a common metric for marketing.
And we set a goal for achieving 10,000 daily page view.
But what can we get out of it?
Maybe not what we want.
</p>
<p>
Finally, focusing on the result too much may let us use whatever method to achieve it.
Take the same page view example.
To achieve the goal of 10,000 daily page view, we can buy a lot of fake clicks.
But by doing so, we've already lost what we really want.
</p>
<p>
So, setting goals is an art on its own.
Let me explain it in a future post.
</p>
</div>
</div>
<div id="outline-container-org7055621">
<h2 id="org7055621">What I've read</h2>
<div id="text-org7055621">
<p>
Here are the books that guided me to this mindset in 2019:
</p>
<dl>
<dt><a href="https://www.amazon.com/gp/product/0996006028/">Radical Focus: Achieving Your Most Important Goals with Objectives and Key Results: Christina R Wodtke, Marty Cagan</a></dt>
<dd>How to set clear OKRs (goals) to help you achieve your desired results.</dd>
<dt><a href="https://www.amazon.com/Right-Many-Ideas-Yours-Succeed/dp/0062884654/ref=sr_1_1?ie=UTF8&qid=1540239839&sr=8-1&keywords=alberto+savoia">The Right It: Why So Many Ideas Fail and How to Make Sure Yours Succeed</a></dt>
<dd>Experiment quickly and cheaply to test if your hypothesis can bring you your desired results.</dd>
<dt><a href="https://basecamp.com/shapeup">SHAPE UP: Stop Running in Circles and Ship Work that Matters</a></dt>
<dd>Invest time and human resources once you've made your desired results clear.</dd>
<dt><a href="https://www.amazon.com/gp/product/1942788290/">The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win</a></dt>
<dd>Find your constraints/bottle-necks when you want to optimize for a better result.</dd>
<dt><a href="https://jonathanstark.com/hbin">Hourly Billing Is Nuts by Jonathan Stark</a></dt>
<dd>
<a href="https://yiming.dev/blog/2019/11/12/why-billing-by-hours-is-a-bad-idea/">Focus on the results you've produced</a>, instead of the sunk cost.</dd>
</dl>
</div>
</div>
<div id="outline-container-org16c9cbf">
<h2 id="org16c9cbf">From result-driven mindset to growth mindset</h2>
<div id="text-org16c9cbf">
<blockquote>
<p>
A growth mindset is the ability to not be fixed on a single solution, but to be consistently testing and iterating on your idea, and improving upon what you know so that you're focusing on the problem you are trying to solve, not the solution in your head.
</p>
</blockquote>
<p>
-- from <a href="https://www.youtube.com/watch?v=k__XkwIpiCU&feature=share">Bot Thoughts: Growth Mindset</a>
</p>
<p>
Result-driven mindset is only a start point.
My goal for 2020 is to grow a growth mindset.
We'll see what results I can achieve then.
Happy New Year!
</p>
</div>
</div>
</div>
</section> | dsdshcym |
229,387 | A Month of Learning | This is what I learned in a month | 0 | 2019-12-31T15:47:13 | https://dev.to/cseeman/a-month-of-learning-3kbo | learning, ruby, rails, git | ---
title: A Month of Learning
published: true
description: This is what I learned in a month
tags: learning, ruby, rails, git
cover_image: https://thepracticaldev.s3.amazonaws.com/i/tyf979sb2p7cxzh9c9ox.jpeg
---
#My month(ish) of learning
One of my goals has to been to dive deeper into Ruby and Rails, try to learn a new thing (maybe technical, maybe not) every work day. Then write that thing down. This goal was to help with accountability, you know actually doing it, as well as to help remember and learn it better. It also allows me to have proof that I know more now then I did a day, a week, or even a month ago.
Sometimes it feels like you are making progress in your career. Maybe becoming a better programmer, better at understanding patterns, helping out on more code reviews, but how can you tell when you know more?
##How can you tell if you have leveled up?

This was one way for me to attempt to quantify it. Below is my list of learning items for around one month, I kept these in a note and tried to make sure to update every day. Some days I might have made note of more than one item, especially if I was trying to get it fixed in my brain. I used Notes for this, but is this the best app to keep these in? Probably not, but it was the most convenient (at least on my Mac), but it sucks for formatting little code segments.
**11/21** - git log --oneline = display git log history with only the first line of the commit message, easy for scanning and to get commit hash. For git commit --fixup 1e30877 . I can then specify the hash of the commit I want to fixup to, not just the last one as how amend works. This then can be used with an auto squash workflow git rebase -i --autosquash HEAD~3, and --autosquash is just an option added onto the typical interactive rebase that automatically marks the fixup items with f in there.
YML can do comments # this == is a comment.
Cron is hard, use [CronTab Guru](https://crontab.guru/#*_12I_w_*_*_*)
**11/22** - API rate limits suck, and changing them up for different endpoints in the same API seem arbitrary, and unnecessary and if you have a default but it only applies to your first get on an API is it really a default??
Resque::TermException == see this error when the dynos are restarted (referring to [Heroku Dynos](https://www.heroku.com/dynos))
**11/25** - Mutex pattern = Mutual Exclusion Object only one process at a time can access the given resource. Allows multiple threads to use a same resource but one at a time, not simultaneously. ([Java implementation example](https://java-design-patterns.com/patterns/mutex/))
**11/26** - .() is an alias for .call (We are working on a lot of [Railway oriented programming](https://fsharpforfunandprofit.com/rop/), Ruby dry-transaction, and do-notation right now, so really understanding these [patterns](https://www.morozov.is/2018/05/27/do-notation-ruby.html) are critical)
crontab syntax- if you have five **(asterisks), it's every minute. If you have six **(asterisks), it's extended crontab syntax which is every second.
**11/27** - PostGres to_tsvector(text) reads the string and does some normalization (taking language settings into account) on the string.
**12/2** - Don't schedule appointments on the Monday after a holiday, probably not on a Monday ever. For an Rspec 'expect', it should probably be called before actually testing the part of code you are working on.
**12/3** - Testing command objects can be tricky, make sure your expectations are correct
&block is an explicit block with the name "block"
**12/4** - With the do notation (dry-monds) when you are doing a block on the ResultMatcher (on.success/on.failure) You have to take both paths into account, otherwise you get a Dry::Matcher::NonExhaustiveMatchError: cases +failure+ not handled.
Use ~~ on GitHub for markdown to add strikethrough text.
A lambda is a way to define a block & its parameters with some special syntax. { puts "This is a lambda" }. But the lambda won't just run, like when you define a method, it won't run until it is called.
my_lambda.call, .() (that call alias peeks its head up again, other call aliases are [], .===.). Lambda's can take arguments too
times_two = ->(x) { x * 2 } times_two.call(10)
**12/5** - Naming stuff is hard, when in doubt reexamine the docs for each individual part, ask people, get descriptive
**12/6** - You can stash untracked files, git stash --include-untracked, git stash --all, TIL DON'T USE --all!! That is a memory hog!! Use --include-untracked. Maybe just git alias this.
**12/9** - When reporting to Honeybadger.notify, there is a ton of [options](https://docs.honeybadger.io/lib/ruby/getting-started/reporting-errors.html) :context hash context to associate with exception. :tags string, comma-separated list.
**12/10** - text selection in [VIM] (https://www.cs.swarthmore.edu/oldhelp/vim/selection.html) V - select entire lines, (out of insert mode)
**12/11** - describe and it are the same method in rspec just use whichever one describes the situation that is being tested best.
**12/12** - You can do sum on array but also pass it a block, (1..10).sum {|v| v * 2 } (v == value)
**12/13** - Ruby Enumerable map, this method on a enumerable object returns a new array with the results of running block once for every element in the enum.
PostgreSQL COALESCE. Function accepts an unlimited number of arguments, return the first argument that is not null. If all arguments are null then will return null.
ORM - object relational mapping
**12/16** - You can add in untracked files in git if needed git add --force my/ignore/file.yml
**12/17** - Don't have an order on a [scope](https://apidock.com/rails/ActiveRecord/NamedScope/ClassMethods/scope), not a best practice.
[Ruby gsub](https://ruby-doc.org/core-2.6.5/String.html#method-i-gsub) Returns a copy of a string, with all occurrence of pattern substituted for the second argument.
**12/18** - Ruby ['transform_values!'](https://ruby-doc.org/core-2.4.0/Hash.html#method-i-transform_values-21) takes a hash, returns a new one with the results of the running block once for every values. Doesn't change the keys,
**12/19** - [ActiveSupport presence](https://scottw.com/blog/active-support-presence/), returns self if present? == true, otherwise returns nil, so code could go from name = user.name.present? ? user.name : 'N.A.' to name = user.name.presence || 'N.A.'
**12/23** - curl the Honeybadger API for getting quick data back on a [certain error](https://docs.honeybadger.io/api/data.html#faults-and-notices), and your AUTH_TOKEN is under the profile.
**12/30** - Cmd + P to search for file name in VSCode, works kind of similar to RubyMine's shift-shift for searching for files.
**12/31** - Rails ActiveRecord [touch method](https://apidock.com/rails/ActiveRecord/Persistence/touch) easier way of updating an active record models updated_at timestamp and pass symbol argument of other timestamp to update too. Ex. product.touch(:started_at)
###Well that's all my notes.
They are a bit rambly, and I take notes in pseudo-code a lot. But to me, these are an accomplishment. I feel like I have leveled up with coding with dry-monads and do notation (functional programming implementations in Ruby). I not only can exit successfully in VIM, I can select lines and words every time. I have been diving in on ActiveRecord/ActiveSupport documentation a lot, and when I have a Ruby question, my new go to is to look at the [source docs](https://ruby-doc.org/core-2.6.3/).
This was a huge change from being a Java programmer for me, I don't think I looked at a lot of Java code implementation documentation. Sure there are [Oracle API docs](https://docs.oracle.com/javase/7/docs/api/) but do you ever look at Java source code? Can you look at Java source code? I can say it something that I now do regularly in Ruby.
###How do **you** level up?
For me? I am going to stick with my notes, maybe find myself a better place to keep them (maybe with markdown, and makes my code a bit prettier). Any suggestions for a good notes app? Also, I am going to continue to writing down one thing I learn a day (or at least on work days)
**Phew**. I'm done with my learning till 2020 😉
 | cseeman |
229,425 | My first interactive email | I recently coded my first interactive email using punched card coding. I wrote about what I did and how it works. | 0 | 2020-01-02T13:33:52 | https://dev.to/tedgoas/my-first-interactive-email-94 | todayilearned, html, css, emaildev | ---
title: My first interactive email
published: true
description: I recently coded my first interactive email using punched card coding. I wrote about what I did and how it works.
tags: #todayilearned #html #css #emaildev
cover_image: https://i.imgur.com/ZiUUzhX.jpg
---
**TL;DR:** I coded my first interactive email using radio buttons to toggle on/off states without using JavaScript.
---
I was first introduced to interactive email in 2015 when I attended Mark Robbins’ presentation at Litmus Live in Boston.
JavaScript isn’t supported in any email client, so up to that point the only interactive things I’d done in email were relatively basic (like creating a `:hover` effect on a button using CSS).
But in his presentation, Mark introduced me to the concept of punched card coding: using checkbox and radio button tags in email to mimic on/off functionally that JavaScript typically enables on the web.
I was blown away by [Mark’s talk](https://www.youtube.com/watch?v=xhUfiOSOk3g). I told myself to look out for an opportunity to use what I learned at work, but promptly forgot about it for four years as “regular” work took the front seat 😬.
# The Pilot
Fast forward to 2019, I now work on Stack Overflow’s private Q&A products. Teams can ask questions, post answers, and vote on the best ones in a private setting.
However some teams have mentioned they’d like to improve their culture of voting. Eg. The team posts useful answers, but folks don’t upvote or accept the best ones to signal a high quality answer to rest of the team.
Folks don't spend all day with Stack Overflow open in a browser tab, so how can we meet folks where they already are?
> “What if you could vote on questions right from your email, without even visiting the site? I bet that’s something an interactive email would be able to do!”
Four years after learning about punched card coding, I finally found a good pilot project, tied it to a business need, and set aside a day to code my first interactive email.
# What We Built
The “Happy Path UX" allows someone to view an answer to their question and optionally vote on or accept it as the best answer, all without leaving their inbox. This is what I built:
<figure>
{% codepen https://codepen.io/tedgoas/pen/MWYpazJ %}
<figcaption>Try clicking the icons on the left!</figcaption>
</caption>
# The Code
The HTML uses the radio input along with the `:checked` attribute to show and hide content using CSS.
### HTML
```
<input type="radio" name="vote" id="ArrowUpLg" style="display: none !important; max-height: 0; visibility: hidden;">
<label for="ArrowUpLg" class="ArrowUpLg" style="cursor: pointer;">
<img src="ArrowUpLg.png" height="36" width="36">
</label>
<input type="radio" name="vote" id="ArrowUpLgactive" style="display: none!important; max-height: 0; visibility: hidden;">
<label for="ArrowUpLgactive" class="ArrowUpLgactive" style="cursor: pointer; display: none;">
<img src="ArrowUpLgactive.png" height="36" width="36">
</label>
```
The actual radio button is visually hidden and linked to from their `<label>` tag using the `for` and `id` attributes. The image file is wrapped inside the `<label>` to make the click/tap area nice and big.
For each icon, I created two almost identical versions of the code: one for the “initial” state and another for the “active” state. The “active” state is hidden by default with inline CSS (Inline CSS is still the most universal way to style HTML in email).
So the base HTML and CSS inserts and positions each icon state in the email, and hides the “active” image for each icon. With this foundation, the CSS in the `<head>` adds the functionality.
### CSS
```
#ArrowUpLg:checked + .ArrowUpLg {
display: none !important;
}
#ArrowUpLg:checked ~ .ArrowUpLgactive {
display: block !important;
}
#ArrowDownLg:checked + .ArrowDownLg {
display: none !important;
}
```
When an icon is clicked, the `<label>` tag, it checks the hidden radio button.
In the CSS, the `:checked` selector is used to toggle the `display` property of the adjacent `<img>` between `block` and `none`. The first time an icon is clicked or tapped, I hide the initial state (`display: none !important`) and show the “active” state (`display: block !important`). The `!important` is necessary to override inline CSS styles.
# The Happy Path UX
The end result is an email with working upvote and downvote arrows, and a checkmark to accept the answer.
We should only be able to upvote or downvote an answer, but not both. So we used radio buttons and included the upvote and downvote arrows in a single group using the `name` attribute. This means that if the upvote arrow is active, and then the downvote arrow is selected, the upvote arrow is unselected in the process.
The “accepted” checkmark is independent of the voting arrows, so I gave that its own `name`.
# Email Client Fallbacks
I’ve been using the term “Happy Path UX” to describe the ideal state. Unfortunately not all email clients support [this level of interactivity](http://freshinbox.com/resources/css.php), so I have to think about fallbacks.
For instance, desktop Outlook on Windows does not support HTML form tags in email. Left alone, Outlook would display each icon… but nothing would happen when they’re clicked. Both confusing and frustrating for a user.
In this cases like this, we can target email clients that don’t support our desired UX and code in a fallback (Like say, static image files that click to the website).
In this example, I targeted Outlook using `<!--[if mso]><![endif]—>` tags to hide the interactive form content from Outlook but display it in other email clients.
[How to Target Email](https://howtotarget.email/) contains a long list of ways to target different email clients. I'll use this to display the interactivity to clients that support it and hide it from the rest.
# Punched Card Coding
This was my first foray into punched card coding. It’s a pretty steep learning curve, but I had a giant “A-Ha!” moment the first time I got a proof of concept working.

Punched card coding can involve radio buttons, checkboxes, or button tags to achieve a number of things. Javascript still isn’t supported in any email client, but we can still toggle state, build tabs, reveal a hidden menu, build a carousel, and more.
<img src="https://i.imgur.com/b1b23iq.png" alt="illustrations of types of interactive emails, c/o Email Monks">
[More on punched card coding](https://www.webdesignerdepot.com/2015/10/punched-card-coding-the-secret-of-interactive-email/)
# Known Issues and Questions
My example above poses several questions outside of the HTML and CSS.
* **Can we maintain state?** Eg. What happens if I vote in an email, close the email, and re-open it? Is the arrow still active? If it’s not and I vote again, what happens?
* **What about security?** Eg. If I forward my email, can someone else vote on my behalf?
* **What about testing?** Eg. Emulators like Litmus only produce static screenshots. I’ll need a working version of every email client we want to test.
If you’re a Stack Overflow user, I’m not sure when we’ll figure this out, but I’m working on it! This is simply and exploration of what’s possible using interactive email.
If you’ve written markup using punched card coding or "the checkbox hack,” I’ve love input on how I could improve and optimize this.
**If you’re a Stack Overflow user, would this be useful?**
💌 ✌️
| tedgoas |
229,578 | The Web We Share | Considerations for building beautiful, accessible, interoperable HTML | 0 | 2019-12-31T23:17:52 | https://dev.to/mpuckett/the-web-we-share-55bp | html, a11y, semanticweb, webdev | ---
title: The Web We Share
published: true
description: Considerations for building beautiful, accessible, interoperable HTML
tags: #html #a11y #semanticweb #webdev
---
## Introduction
It’s a tale from another dimension: HTML markup representing not just a graphical experience but also virtual objects and their state.
HTML allows for a single element to have multiple meanings for different use cases.
You could imagine your markup as a topology with multiple layers of semantics. Or, as 3 different dimensions: visual, accessible, and machine-readable.
(And with WebXR and other emerging technologies being grafted onto the web platform, there will soon be more dimensions to consider! Spooky!)
## Visual
An element’s `class` and `style` attributes are most relevant to the rendering engine that displays the visual interface. For a lot of web developers, this is just the air we breathe.
## Accessibility
An element's `role` and `aria‑*` attributes are most relevant to screen readers.
Never heard of a screen reader? Most blind people don't use a mouse. Instead, they use a keyboard to operate an application that speaks the content and metadata of the currently focused element. People who are deaf-blind might use a screen reader with a refreshable Braille display.
When using a screen reader, properly marked up elements can be acted upon in unique ways. For instance, marking up all headings using heading elements (h1-h6) will compile them and make them available as a list for easier page navigation.
## Interoperability
Metadata attributes such as `itemprop` are most relevant to digital assistants and search engines, for things like indexing and repurposing.
Audio-enabled digital assistants often parse web pages' structured data and document outlines to find information. The relevant data can be packaged into an experience that is native to that service's voice UI.
## Engineering Strategies
To account for the wide range of ways HTML code can be utilized, always adhere to the HTML, ARIA, and Schema.org specifications.
In my experience, building a library of reusable, spec-compliant web components is the best way to deliver beautiful, accessible, interoperable websites. | mpuckett |
229,440 | Why I'll definitely use mapDispatchToProps in Redux | Why using the second argument of Redux's `connect` function will lead to more maintainable and higher quality React code, as well as significantly improving how you're able to test your components. | 0 | 2020-01-05T23:31:18 | https://www.chakshunyu.com/why-use-mapdispatchtoprops/ | webdev, testing, react, redux | ---
title: Why I'll definitely use mapDispatchToProps in Redux
published: true
description: Why using the second argument of Redux's `connect` function will lead to more maintainable and higher quality React code, as well as significantly improving how you're able to test your components.
tags: webdev, testing, react, redux
canonical_url: https://www.chakshunyu.com/why-use-mapdispatchtoprops/
---
Not too uncommon, at my job we make use of Redux in our React frontend stack for state management. A lot of components are connected to the store using Redux's `connect` and retrieve data from it through `mapStateToProps` using selectors. Components also need to interact with the store through actions or thunks, which is possible with the `dispatch` function that `connect` injects. With those concepts in mind, I've passed along the `dispatch` function to the component and used it inside its callbacks and lifecycle methods for quite some time now, without ever second guessing this approach. Until recently that is, when I learned about the second argument of the `connect` function: `mapDispatchToProps`.
## What is `mapDispatchToProps`?
In short, `mapDispatchToProps` is a function that maps the `dispatch` function and returns an object of functions, which will be merged into the existing props and made available to your component as additional ones. It's very similar to `mapStateToProps`, which maps the state to props for your component, but then for the `dispatch` function and the values of the return object have to be functions. If you want to learn more about what `mapDispatchToProps` is and how to use it, you should read [the Redux docs](https://react-redux.js.org/using-react-redux/connect-mapdispatch) as they explain it in quite some detail.
```react
function mapDispatchToProps(dispatch) {
return {
doSomething: () => {
dispatch(somethingDispatchable());
},
};
}
class SomeComponent extends React.Component {
componentDidMount() {
// Instead of `this.props.dispatch(somethingDispatchable());`
this.props.doSomething();
}
// or...
render() {
const { doSomething, ...otherProps } = this.props;
return <button onClick={doSomething} />;
}
}
export const SomeConnectedComponent = connect(null, mapDispatchToProps)(SomeComponent);
```
## Why use `mapDispatchToProps`?
First of all, it shares a lot of benefits with `mapStateToProps`, like making your code more declarative and making sure that Redux related code is more grouped together. The latter might not seem so impactful for `mapStateToProps`, as it's only responsible for retrieving data from the store. But in the case of `mapDispatchToProps`, it's definitely something not to overlook as it's responsible for defining the logic of the component's interactions with the store. Logic code has always been difficult to maintain, and keeping related logic together is one way of making this process easier. A concrete example is [the introduction of Hooks in React](https://twitter.com/threepointone/status/1056594421079261185).
It also reduces boilerplate code in your components as less callbacks are required in which `dispatch` is called and the logic is moved somewhere else. This in turn reduces how bloated your components are, thus resulting into components that are easier to read and maintain. This is especially the case for class components, which are more verbose in general.
However, the main benefit that I see in using `mapDispatchToProps` is the separation it creates between store related logic and the view of the component and the testing benefits that come with it. Components are not aware anymore of `dispatch` and thus don't need to know *how* things have to be done anymore. Rather, all the logic is abstracted away. Which means that the components only see the resulting props and only need to bother with *what* they do and when to use them. This significantly increases the reusability and testability of the component.
While it's up for debate whether components should be tested with or without the store, there are use cases in which you need the unconnected component or where it makes more sense to test the component without an attached store. In those cases, having `mapDispatchToProps` means you can more properly and easily test the logic. Rather than mocking the `dispatch` function and then verifying whether it's called with the appropriate action creator/thunk, in which case you're actually testing implementation details, you can now mock the logic and inject it directly into the component as dependencies.
```react
// Example of how `mapDispatchToProps` makes testing more straightforward.
test('SomeComponent should do something correctly', () => {
const mockedDoSomething = jest.fn();
const component = mount(<SomeComponent doSomething={mockedDoSomething} />);
// Interact with the component to trigger the callback. In this case it's done on mount,
// but here you would simulate click events if it's attached to a button for example.
expect(mockedDoSomething).toHaveBeenCalled();
// Other verifications.
});
```
Just like the React community, my testing focus is shifting towards verifying behaviour/interactions of my React code, which I've also advocated for to do so at my job. Good practices that allow me to write more proper and meaningful tests in an easier way for my React component have interested me a lot since then. The `mapDispatchToProps` is a great example of this as it clearly separates Redux related code, the logic, from the React component code, the view. Ultimately, this leads to more reusable and testable components, which is one of the core values of React.
## References
- https://react-redux.js.org/using-react-redux/connect-mapdispatch
- https://kentcdodds.com/blog/inversion-of-control
- https://twitter.com/threepointone/status/1056594421079261185
---
*After graduation, my career is entirely centered around learning and improving as a developer. I've began working full time as a React developer and I'll be blogging about everything that I encounter and learn during this journey. This will range from improving communicational skills in a technical environment, becoming a better developer, improving technical skills in React and JavaScript, and discussing career related topics. In all of my posts, the focus will be on my personal experiences, learnings, difficulties, solutions (if present), and also flaws.*
If you're either interested in these topics, more personalised technical stories, or the perspective of a beginning developer, you can follow me either here or over on Twitter at [@Keraito](https://twitter.com/keraito) to keep up to date with my posts. I'm always learning, so stay tuned for more stories! 🎉 | keraito |
229,461 | McLear: From typo to a fun alias 🍔🍟 | A fun bash alias made from a typo | 0 | 2019-12-31T17:57:28 | https://dev.to/shiftyp/mclear-from-typo-to-a-fun-alias-3eml | showdev, shell, bash, zsh | ---
title: McLear: From typo to a fun alias 🍔🍟
published: true
description: A fun bash alias made from a typo
tags: showdev, shell, bash, zsh
---
I mistakenly typed `mclear` in place of `clear` in my zsh terminal, and came up with a fun alias! Enjoy!
```bash
alias mclear='FOOD=(🍔 🍟); for i in {1..10000}; do printf "${FOOD[($RANDOM % ${#FOOD[@]}) + 1]}"; done'
```
 | shiftyp |
229,522 | Day 28 – Middlewares - Learning Node JS In 30 Days [Mini series] | Middleware functions are functions that have access to the request object (req), the response object... | 0 | 2019-12-31T19:51:25 | https://blog.nerdjfpb.com/day28-nodejsin30days/ | node, javascript, codenewbie, tutorial | Middleware functions are functions that have access to the request object (req), the response object (res), and the next middleware function in the application’s request-response cycle. The next middleware function is commonly denoted by a variable named next. (official document)
Do you understand anything of it ?
In short, normally we use middleware to checking something. Like – if anyone is a authentic user or is the user is admin.
Middleware functions can perform the following tasks:
- Execute any code.
- Make changes to the request and the response objects.
- End the request-response cycle.
- Call the next middleware function in the stack.
An Express application can use the following types of middleware:
- Application-level middleware
- Router-level middleware
- Error-handling middleware
- Built-in middleware
- Third-party middleware
You can check the more details – https://expressjs.com/en/guide/using-middleware.html
Let’s use a middleware
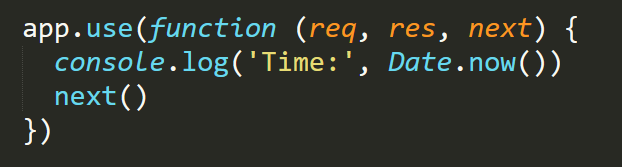
we have 3 elements here – request, response and next cycle here. In the middleware we just console log the time. So when we’ll call the route, this function will be called always.
See the result when we hit the url –
You can see the graphical version here
{% instagram B6v5wTLlGyc %}
Originally it published on [nerdjfpbblog](https://blog.nerdjfpb.com/day28-nodejsin30days/). You can connect with me in [twitter](https://twitter.com/nerdjfpb) or [linkedin](https://www.linkedin.com/in/nerdjfpb/) !
###__You can read the old posts from this series (below)__
{% post nerdjfpb/day-1-learning-node-js-in-30-days-mini-series-55e7 %}
{% post nerdjfpb/day-2-learning-node-js-in-30-days-mini-series-5023 %}
{% post nerdjfpb/day-3-learning-node-js-in-30-days-mini-series-24i4 %}
{% post nerdjfpb/day-4-learning-node-js-in-30-days-mini-series-1koc %}
{% post nerdjfpb/day-5-learning-node-js-in-30-days-mini-series-21jm %}
{% post nerdjfpb/day-6-learning-node-js-in-30-days-mini-series-758 %}
{% post nerdjfpb/day-7-learning-node-js-in-30-days-mini-series-3023 %}
{% post nerdjfpb/day-8-var-vs-let-vs-const-learning-node-js-in-30-days-mini-series-1i72 %}
{% post nerdjfpb/day-9-mastering-eventemitter-learning-node-js-in-30-days-mini-series-2dfe %}
{% post nerdjfpb/day-10-mastering-eventemitter-learning-node-js-in-30-days-mini-series-2802 %}
{% post nerdjfpb/day-11-creating-and-deleting-folders-learning-node-js-in-30-days-mini-series-3a2d %}
{% post nerdjfpb/day-12-creating-own-server-learning-node-js-in-30-days-mini-series-3ef %}
{% post nerdjfpb/day-13-buffer-stream-learning-node-js-in-30-days-mini-series-5c5d %}
{% post nerdjfpb/day-14-serving-html-pages-learning-node-js-in-30-days-mini-series-2hl3 %}
{% post nerdjfpb/day-15-sending-json-to-client-learning-node-js-in-30-days-mini-series-21pc %}
{% post nerdjfpb/day-16-routing-basic-learning-node-js-in-30-days-mini-series-5hk6 %}
{% post nerdjfpb/day-17-npm-node-package-manager-learning-node-js-in-30-days-mini-series-1nek %}
{% post nerdjfpb/day-18-why-express-js-learning-node-js-in-30-days-mini-series-b5a %}
{% post nerdjfpb/day-19-nodemon-learning-node-js-in-30-days-mini-series-m39 %}
{% post nerdjfpb/day-20-express-js-introduction-learning-node-js-in-30-days-mini-series-2pg5 %}
{% post nerdjfpb/day-21-http-methods-learning-node-js-in-30-days-mini-series-hci %}
{% post nerdjfpb/day-22-route-parameters-learning-node-js-in-30-days-mini-series-4knk %}
{% post nerdjfpb/day-23-template-engines-learning-node-js-in-30-days-mini-series-4f7d %}
{% post nerdjfpb/day-24-working-with-ejs-part-1-learning-node-js-in-30-days-mini-series-493 %}
{% post nerdjfpb/day-25-working-with-ejs-part-2-learning-node-js-in-30-days-mini-series-19gp %}
{% post nerdjfpb/day-26-working-with-ejs-part-3-learning-node-js-in-30-days-mini-series-1ofd %}
{% post nerdjfpb/day-26-working-with-ejs-part-3-learning-node-js-in-30-days-mini-series-1ofd %}
{% post nerdjfpb/day-27-working-with-static-files-learning-node-js-in-30-days-mini-series-5h1f %} | nerdjfpb |
229,545 | Start with Html and css | Let's discuss this! Yes this!! Must all newbies start with html and css? if yes..please help clarify... | 0 | 2019-12-31T20:38:26 | https://dev.to/jirois/start-with-html-and-css-2jaf | Let's discuss this! Yes this!!
Must all newbies start with html and css? if yes..please help clarify why...
But if no, why then do most persons always suggest that (i.e learn html and css) to newbies? | jirois | |
229,549 | Inbox Zero | Want the TL;DR version? Click here. Okay, for the rest of you, here we go: If you want to be effec... | 0 | 2019-12-31T20:53:49 | https://jspizziri.com/blog/inbox-zero-stop-emailing-like-a-caveman/ | productivity, email | ---
title: Inbox Zero
published: true
date: 2019-07-19 00:00:00 UTC
tags: productivity,email
canonical_url: https://jspizziri.com/blog/inbox-zero-stop-emailing-like-a-caveman/
---

Want the TL;DR version? Click here. Okay, for the rest of you, here we go:
If you want to be effective in your job or even maybe your life, you **need** to be effective at email. But it can be maddening! You're getting floods of emails constantly, how do you keep them straight? How do you not get stressed? How do make sure you're getting everyone the answers they need? How do you make sure you don't forget something?
Enter: Inbox Zero, an email management _strategy_ that can work with pretty much any email provider.
#### You before Inbox Zero

#### You after Inbox Zero\*\*

\*\*Note: inbox zero will not magically make you able to do a backflip
## How Does it Work?
Inbox Zero is pretty simple. The basic idea is that at any given point in time, your inbox should contain 0 emails. That's the goal: zero, zilch, zip. **We want no emails 0 our inbox!** Before you freak out, the below concept will easily help you achieve this.
The first thing that we do is we start thinking about our emails in 3 distinct categories:
1. Emails that are actionable immediately.
2. Emails that are non-actionable.
3. Emails that are actionable, but not immediately (actionable at some future point).
**Note:** By "actionable" here, we mean emails that require _you_ to do something with them (or in other words to take some action).
Then change your behavior:
1. Archive any email that is non-actionable.
2. Archive any email that you just responded to.
3. Snooze any email that are actionable at some future point.
## Deep Dive
If at this point you get it, no need to read further. There's just more juicy details below.
#### Emails that are actionable immediately
Really, this is the only kind of email that you should _actually_ be concerned with. These are the emails that require you to do something. So what do you do? Take the necessary action. Respond with the answer to someones question, etc.
Once you've done this these emails are now considered part of "Non-actionable" category. Why? Well... because you've just taken the action that was needed, and the ball is no longer in your court.
#### Emails that are non-actionable
These emails are done :confetti\_ball:. They could be spam emails, marketing emails, or even the emails we just responded to in from the first category. We still want to keep them around for historical purposes, so we don't delete them, however we need to get them out of our inbox. What do we do?
We **ARCHIVE** them. This gets them out of your inbox, and out of your face!
Don't know how to archive an email? Here, [this may help](https://lmgtfy.com/?q=how+to+archive+emails+in+gmail&s=).
#### Emails that are actionable, but not immediately
A lot of the time these are the worst offenders for cluttering up our inbox and creating stress:
We get an important looking email, we open it and read through it only to find that it is important, but not until next week, or some time in the future where we need to do something (respond/perform some task and then let someone know, etc.). So now we have this email, which is marked as "read" sitting in our inbox, and slowly being buried alive. Quite naturally this creates stress in a normal human. We need to make a mental note, or some sort of note to make sure we **don't forget about that email** until next Wednesday or whenever.
This is where your email tool will help you out. Any modern email service will provide a "snooze" functionality, which effectively allows you to pick a date that you want that email to magically reappear in your inbox, as if it had just been sent to you.
Here's how to [do it with Gmail](https://support.google.com/mail/answer/7622010?co=GENIE.Platform%3DDesktop&hl=en) (for real this time).
If your email provider doesn't have a "snooze" feature, well... I'm sorry, you're pretty much out of luck. When we have caveman tools we have to live like cavemen. I'd suggest switching email providers at this point.
## TL;DR / Conclusion
Think about our emails in 3 distinct categories:
1. Emails that are actionable immediately.
2. Emails that are non-actionable.
3. Emails that are actionable, but not immediately (actionable at some future point).
Then change your behavior:
1. Archive any email that is non-actionable.
2. Archive any email that you just responded to.
3. Snooze any email that are actionable at some future point. | jspizziri |
229,571 | Deceptive Sales Tactics at Halfords | On December 16th 2019 I went into Halfords, Carrickmines, Dublin 18, to buy a bicycle for my daughter... | 0 | 2019-12-31T22:29:53 | https://dev.to/martinmcwhorter/deceptive-sales-tactics-at-halfords-3m1b | On December 16th 2019 I went into Halfords, Carrickmines, Dublin 18, to buy a bicycle for my daughter's birthday. I spoke with a sales person and explained I am only interested in the bicycle if it is in stock, as with the holidays -- I would not have faith that they would be able to order one for me to pickup on the 27th of December, the day before my daughters birthday.
They checked the backroom and told me it was indeed in stock and I could take it in the box that day, or have it assembled by the staff and pick it up on the 27th.
I agreed to have the in stock bike assembled, with the addition of stabilisers, and pick it up on the 27th. I was then quoted a price for the bike, assembly and stabilisers for €192. I paid that in full on the day with a credit card. I noted to the sales person that the assembly and stabilisers were not on the receipt. He told me not to worry, that they are included in the price.
On the day I was to pick up the bike I got a telephone call at 9:56 am to tell me that they did not have the bike I had purchased, that they sold it to someone else. I asked if the in store display was in good condition, as if not I could still go to another bike shop. The store employee agreed to check and ring me back. I never got a call back and spent the next four hours at work trying to ring the store, they never answered the phone that day.
The next day, the 28th (my daughters birthday). I finally got through to the store to -- and then to the manager. He said he would look into it and call me back. I missed a few of his calls as we were driving in the car to my daughter's birthday party when he rang. Though I rang him back and he said they could give me a 15% discount on the damaged in store display (prominent scratch on the frame and badly discoloured white tyres) -- or that they would build a new bike the following Monday -- but would not do anything to remedy selling the bicycle I had already purchased to another customer.
Then when I went to the shop to pickup the display model, they told me they would need to charge me extra for the stabilisers, even though this was included in the quoted price on the 16th of December by the sales person.
In my view their are two deceptive practices here:
* Selling a product as in stock -- then selling that stock to another customer. I would have left the shop and gone to another shop if they were honest and told me they were going to do this. I stipulated upfront I was only interested in purchasing the bike if it was in stock.
* Claiming the stabilisers were included at time of the sale and then changing this when I went to pick up the bike.
I left the shop without the bicycle because it was clear to me that they are engaged in deceptive practices. I felt bullied and condescended-to by the manager when I brought up these deceptive tactics.
After contacting Halfords customer support and reporting the above, this is the response I received:
> Dear Martin,
> Thank you for the response. After speaking to the store and my managers here at Head Office, we have come to the conclusion that we would stick by the store with this matter.
> I can advise if you wish to go to the store to get your refund for the bike you can go there with the card this was paid for and I can then advise the store of this for you. The other option is that the store are advising the most they can do is the 15% off the bike as discussed in the store.
> I am ever so sorry about this. If you are unhappy with the outcome you can seek legal advice regarding this
> I hope this helps and if I can be of any further assistance, please do not hesitate to contact me via email or on 0330 135 9779.
>Kind regards,
> Niamh
> Customer Support Team
| martinmcwhorter | |
229,651 | New Year New Goals - My 2020 Resolutions | 2019 was a crazy year for myself, both professionally and personally. In the span of 2 months I got m... | 0 | 2020-01-01T05:01:41 | https://dev.to/naismith/new-year-new-goals-my-2020-professional-resolutions-1ehd | 2020, personal, resolutions | 2019 was a crazy year for myself, both professionally and personally. In the span of 2 months I got married, bought and moved into my first house, and started a new job. Talk about stress. But in the final moments of 2019, I hope to plan out and goal set for the upcoming year and decade.
Hopefully writing down my goals and sharing them, will encourage me to stick to them.
## 💻 Writing More
I wrote my first blog post on dev.to in 2019. In 2020 I plan to write 12 different blog posts by the end of the year. Sharing knowledge is incredibly important, either for your team or bettering the community.
I had been meaning to write much more in 2019, but every time I was close to publishing a post I always second guessed myself. But hopefully by jumping 'into the deep end' I can keep up this momentum and continue to share my insights/knowledge with others, and learn back from them.
## 📚 Reading More
Reading is a great way to learn from others. Wether it's books, blog posts, articles you can always learn something new. This year, similar to writing more, I'd like to read 12 new books. As a kid I loved reading, and in 2019 I started reading again after not reading for so long.
In addition to books, I plan to read more blog posts and articles. I have no specific goal in mind, but I look forward to the new content that 2020 has in store.
## ⌨️ A New Front End Framework
In our industry we joke about new frameworks coming out every month, day or hour. When developing on the front end, I tend to lean towards React. While I love React, I am interested in playing with some alternatives in either strengthening my love for React or finding something better.
Being comfortable for far too long in anything can cause you to plateau in your skills. Which is why I plan in 2020 to pickup Vue.JS or Svelte for a small project to see if the grass is greener on the other side.
## 🌐 Open Source
Hacktoberfest came and went this year and I failed to participate. Obviously it's optional but the idea of contributing to the community in which I benefit from is of huge interest to me. I'm hoping by the end of the year to have made a beneficial impact on at least 1 open source project.
My current interest is in creating a plugin for the open source CMS Strapi. If you are not familiar with it, I recommend taking a look at it.
## 👫 Community
I created a developer meetup in the city I grew up in as there's little to no social community. I hope to continue the success of it in 2020 by making new friendships, helping educate others, and learn from others over some pizza.
## 📣 Talking
I had never given a tech talk until this year. I hope to continue some talks in the new year as it has been a lot of fun (in fact my most recent talk I converted into my first ever blog post - 2 birds with one stone!).
## ☯️ Balance
I recently just stopped a part time job as it was severely cutting into my personal time. Early mornings and late nights was starting to cause strain on my mental health and relationships as it would take time to recover. But one thing I hope to do in this new decade is take the time to enjoy the world around me and my life with my new wife. Noone on their death bed wishes they worked more.
# Conclusion
There's certainly more I could add to this list, getting promotions, or a raise. But I think that would be in most people's resolutions.
What's on your list? Got any book recommendations? Did you meet your goals? I'd love to hear your comments down below. | naismith |
229,739 | My First Seed of Blog Post | Intro Photo by cottonbro from Pexels Hello guys! First I want to say Happy New Year to... | 0 | 2020-01-01T09:55:32 | https://dev.to/vijaykumarktg18/my-first-seed-of-blog-post-4e7l | webdev, javascript | ##Intro

<figcaption>Photo by cottonbro from Pexels</figcaption>
Hello guys!
First I want to say *Happy New Year* to all of my friends.
##Bio
My name is Vijay Kumar. I'm a student from University of Computer Studies, Mandalay. Currently, I'm studying computer technology (computer engineering).
##Learning
Although I'm a hardware student, I'm learning full stack web development . After all this doesn't matter what you do or who you are. Actually I'm studying full stack web development to make some money during this joyful university life and get some experiences from web projects.
##Blog
This is my first ever blog and may be reading this blog will be like a block of texts with full of necessities what a good blog should have.I'll try to overcome with those necessities with the help of feedback from all of my friends.I also wanna ask for guidance if anyone found something wrong in any of my blog posts.In my future blogs, I'm going to write full stack web development related topics and some computer science and engineering topics too.
##New Year Resolution

<figcaption>Photo by ***[freestocks.org](https://www.pexels.com/@freestocks)*** from *Pexels*</figcaption>
As today is new year day, everyone is goint to make some resolutions. I made mine too. Writing blog post is also included in my resolution. I hope all of my friends have also made some resolution and I wish they gonna meet their goals in near future.
##Starting my blogging journey
I'm starting to blog on *** Dev Community *** form now and I hope I'll get full support from my senior developers and my friends.
Thank You Everyone and enjoy this new year's first day.
Please don't forget to comment.
{% user vijaykumarktg18 %}
Cover Photo by ***[Dom J](https://www.pexels.com/@dom-j-7304)*** from *Pexels* | vijaykumarktg18 |
229,783 | Bootstrap Datetimepicker Disable Dates Dynamically | Hi guysIn this tutoriali will give you simple example of Bootstrap datetimepicker disable dates dynam... | 0 | 2020-01-10T13:26:46 | https://dev.to/kevalkashiyani/bootstrap-datetimepicker-disable-dates-dynamically-2gj3 | ---
title: Bootstrap Datetimepicker Disable Dates Dynamically
published: true
date: 2020-01-01 00:00:00 UTC
tags:
canonical_url:
---
Hi guysIn this tutoriali will give you simple example of Bootstrap datetimepicker disable dates dynamically you can disable dynamically dates bootstrap datetimepicker using disabledDates methodwe are disabled bootstrap datetimepicker in specific datesit will useing disabledDates options to | kevalkashiyani | |
229,790 | Introduction to Datasist (A Python Library for Data Scientist) | Lol. Here is my gift for you this 2020 🎊 Datasist is a python library that ease the workflow for Da... | 0 | 2020-01-01T12:11:02 | https://dev.to/emekaborisama/introduction-to-datasist-a-python-library-for-data-scientist-363a | data, machinelearning |
Lol. Here is my gift for you this 2020 🎊
Datasist is a python library that ease the workflow for Data Scientist and Analyst.
Everything you want to achieve with Datasist is in one line of code.
I made a quick video on getting started with datasist
https://youtu.be/ErWa_WWu7vM | emekaborisama |
229,810 | What the heck is the dbcreator role? | Microsoft docs defines the dbcreator role as: Members of the dbcreator fixed server role can crea... | 0 | 2020-01-01T15:10:24 | https://am2.co/2019/12/what-the-heck-is-the-dbcreator-role/ | sql, sqlserver, security | ---
title: What the heck is the dbcreator role?
published: true
date: 2019-12-19 12:30:14 UTC
tags: sql, sqlserver, security
canonical_url: https://am2.co/2019/12/what-the-heck-is-the-dbcreator-role/
---
[](https://www.youtube.com/watch?v=7UbY3lmCSb0)
[Microsoft docs](https://docs.microsoft.com/en-us/sql/relational-databases/security/authentication-access/server-level-roles?view=sql-server-ver15#fixed-server-level-roles) defines the dbcreator role as:
> Members of the dbcreator fixed server role can create, alter, drop, and restore any database.
But what specific permissions are actually included in that role? If we scroll down in the docs just a little, we’ll see a diagram that tells us that `dbcreator` grants two permissions:
- `ALTER ANY DATABASE`
- `CREATE ANY DATABASE`
OK, that seems fine, right?
## Do you need dbcreator?
Except… that’s a little bit more than what “database creator” would seem to imply. Not only can `dbcreator` _create_ databases, it can also _alter_ databases. If you are granting `dbcreator` to some user, do want them to be able to drop _ANY_ database? Including your DBA database, application databases, etc? Maybe it would be better to grant the more granular `CREATE DATABASE` permission?
Let’s take a close look at this:
- Create two logins
- Add one login to the `dbcreator` role; Grant the other `CREATE ANY DATABASE`
- Using the new logins, try to drop some database that the logins don’t have permission to.
That code would look something like this (I’m using [`EXECUTE AS` syntax](http://am2.co/2019/12/testing-as-another-user-without-their-password/) to make these permission tests easy):
```sql
CREATE LOGIN DbCreatorTest WITH PASSWORD = 'Notorious_RBG';
ALTER SERVER ROLE dbcreator ADD MEMBER DbCreatorTest;
GO
CREATE LOGIN CreateDbTest WITH PASSWORD = 'Notorious_RBG';
GRANT CREATE ANY DATABASE TO CreateDbTest;
GO
CREATE DATABASE DontDropMe;
EXECUTE AS LOGIN = 'DbCreatorTest';
DROP DATABASE DontDropMe;
REVERT;
CREATE DATABASE DontDropMe;
EXECUTE AS LOGIN = 'CreateDbTest';
DROP DATABASE DontDropMe;
REVERT;
```
You’ll notice that the `DbCreatorTest` login is able to drop the `DontDropMe` database that it doesn’t have permission to. On the other hand, the `CreateDbTest` login is _NOT_ able to drop that database.
Let’s think about some different user stories where you might want to grant permission to create databases:
- An automation service account, such as a [DevOps pipeline](https://www.red-gate.com/simple-talk/sysadmin/devops/introduction-to-devops-the-application-delivery-pipeline/), which creates databases
- A non-DBA PowerUser, such as a Database Engineer, who you trust to create new databases. A DBA may provide review, but the Database Engineer can create their own databases to improve velocity
- A third-party application, which creates and drops databases for staging imports & exports, or for creating historical cold-storage archives.
In all these cases, the process/user is empowered to create and drop their own databases–but oughtn’t be able to drop other databases. In fact–allowing automation to drop _other_ databases is a potentially dangerous scenario. A bug could result in dropping a production database, resulting in downtime and likely data loss.
I can hear someone saying, “But the third party application needs to be able to drop it’s databases after they are done with them–they are essentially temporary databases. Hence, it needs the `ALTER ANY DATABASE` permission, as well.” Specifically, I can hear that third-party software vendor telling me this.
Alas, it is not necessary. If we only grant permission to create the database, the login which creates the database will be the owner of the database. Because it is the database owner, it will be able to do _ANYTHING_ do that database, including dropping that database (and only that database).
The post [What the heck is the dbcreator role?](https://am2.co/2019/12/what-the-heck-is-the-dbcreator-role/) appeared first on [Andy M Mallon - AM²](https://am2.co). | amtwo |
229,812 | 10 Coding principles and acronyms demystified! | This post was taken from my blog, so be sure to check it out for more up-to-date content. The progra... | 0 | 2020-01-01T12:44:20 | https://areknawo.com/10-coding-principles-and-acronyms-demystified/ | codequality, coding | **This post was taken from [my blog](https://areknawo.com), so be sure to check it out for more up-to-date content.**
The programming industry has a lot to offer when it comes to _acronyms_. _KISS_ this, _SLAP_ that - there are a lot of these intriguing, but meaningful abbreviations out there. If you're only getting started, seeing them pop up from left and right might be a bit stressful. Especially if you don't know what they mean! Anyway, if that's the case, here's a blog post for you!
In this article, we'll explore 10 different _coding principles_ that come with some pretty cryptic acronyms. Some are well-known, while others - less so. The difficulty in understanding and applying them to your code also varies. With that said, I'll try to explain the whole theory behind each of these terms in detail. The fun part - their implementation - is left to you.
# [KISS](http://principles-wiki.net/principles:keep_it_simple_stupid)
Let's start with some more popular principles. _Keep It Stupid Simple_ (KISS) is one of the most well-known ones. It also has a pretty clear, but very broad meaning.
Basically, this principle dictates that you should keep your code _very simple_, which is a no-brainer. The simpler the code, the easier it is to understand for you and other people maintaining it. The simplicity mostly refers to not utilizing sneaky tricks (like [these](https://areknawo.com/5-interesting-and-not-necessarily-useful-javascript-tricks/)), and not overcomplicating things that don't require that.
The basic examples of breaking this rule would be writing a separate function only to conduct addition operation, or using a bitwise operator (_right shift_ `>>1`) to divide integers by 2. The latter is surely more performant than its usual counterpart (`/2`), but greatly reduced the "understandability" of the code. By doing this, you're committing what's called _clever coding_ and _over-optimization_. Both of which aren't very good for the long-time "health" of your code.
# [DRY](http://principles-wiki.net/principles:don_t_repeat_yourself)
_Don't Repeat Yourself_ (DRY) principle in its nature is very similar to KISS. It's quite simple and yet has a broad meaning at the same time.
Copy-pasting and duplicating fragments of own code happens to many programmers. There's nothing wrong about doing that. Everybody sometimes needs to quickly check something (expected behavior or whatever) to later determine if it's worth the hassle to write it properly. But it's surely unacceptable to ship such code to _production_.
DRY reminds us that every repetitive behavior in the code can and should be extracted (e.g. within a function) for later reuse. Having two fragments of the same code in your codebase isn't good. It can often lead to _desynchronization_ and other bugs happening in your code, not even mentioning increment in the program's _size_.
Resources:
- [Software Design Principles DRY and KISS](https://dzone.com/articles/software-design-principles-dry-and-kiss)
# [YAGNI](http://principles-wiki.net/principles:you_ain_t_gonna_need_it)
YAGNI is actually the longest acronym on this list. _You Aren't Gonna Need It_ (YAGNI) is a principle that might conflict with some programmers' perspectives.
Being prepared for the _future_ is usually a good thing, but not in programming. Leaving any code that's meant only for future _extendability_ isn't good. But, if it conflicts with your beliefs, let's discuss it a bit further.
Coding projects aren't things that have a clear ending. Unless the creator abandons the idea (and don't pass it to someone else), the project is, in fact, going to end. But, otherwise, there's pretty much no point at which the code is "good enough". There's always some room for improvement. It's good to look into the future, and think about what you want your code to look like. But, in production, leaving "extension points" (places meant to easily allow for new functionalities), unless intelligently utilized or a required feature, isn't desired. It adds unnecessary _complexity_ and increases the size of your codebase. If you think about it, it even conflicts with the previously-discussed KISS principle.
Resources:
- [Yagni](https://martinfowler.com/bliki/Yagni.html)
# [SLAP](http://principles-wiki.net/principles:single_level_of_abstraction)
Guess what! You can not only KISS or DRY but also SLAP your code! _Single Level of Abstraction Principle_ (SLAP) dictates the way you should _organize_ your code (_functions_ to be specific) to keep it maintainable.
Long and complex functions are hard to live with. They're difficult to understand for others, are hard to test and often require scrolling to see all of their content! If you come across such an abomination, you should restructure it to a few smaller functions immediately! Remember that:
>Functions should do just one thing, and they should do it well. _Robert Martin_
But how exactly should you organize your smaller functions? What is this one thing they should do? Well, as you get more experience in the programming, you'll start to feel where certain things should go, and the SLAP will help you.
Your functions should do only one thing, or, with the SLAP in mind, should have only a single _level of abstraction_. Basically, a function that, for example, reads the user input, shouldn't also process it. Instead, it'll use a separate function, which is on the other, lower level of abstraction. The more general the function is and the more other functions it utilizes, the higher it is in the abstraction hierarchy.
Resources:
- [Object Oriented Tricks: #6 SLAP your functions](https://hackernoon.com/object-oriented-tricks-6-slap-your-functions-a13d25a7d994)
# [SRP](http://principles-wiki.net/principles:single_responsibility_principle)
_Single Responsibility Principle_ (SRP) is somewhat similar to the SLAP but directed towards _Object-Oriented Programming_ (OOP). It says that you should organize your objects and classes (but also functions and methods), for them to have only one responsibility each.
Responsibilities of objects and classes are easy to organize when they reflect more life-like objects. However, when we're dealing with entities that have e.g. "controller" or "service" in their names, then the situation starts to complicate. These _high-level_ units are hard to organize, as in theory, you could put pretty much everything inside them and call it a day. In such a case, the number of responsibilities of such an entity sky-rockets, making the whole code increasingly harder to understand.
How to fix this issue? Let's say that our controller is responsible e.g. a computer. It has to control and store the CPU temperature, fan speed, disk space, external devices and all that sorts of stuff. Mind you that it means not only properties but also methods that we're dealing with. Instead of keeping everything directly in one class, how about splitting it into multiple classes? Now we'd have `DevicesController`, `DiskSpaceController`, etc. Then we'd use all these classes to form the high-level `Controller` class, which now is way easier to maintain. Of course, in reality, such a code would need a lot more organization, but I hope you get the idea.
# [OCP](http://principles-wiki.net/principles:open-closed_principle)
We've already talked about code extendability when discussing YAGNI. _Open-Closed Principle_ (OCP) is somewhat related to that previous rule but features a different perspective.
The OCP requires your code to be open to new, _future additions_, without having to modify the already-written code. It's more about the overall _architecture_ of your code rather than the code itself.
Does the OCP conflicts with YAGNI? After all, we're talking about the future of the code from two different perspectives here, right? Well, no. As I said earlier, YAGNI prevents you from adding code that you aren't currently using. On the other hand, the OCP goes deeper - into your code architecture - to make it future-proof right from the core. You aren't meant to write any currently-unused code, rather than design the whole codebase in such a manner, that it supports easy _extendability_.
Make your "core" extendable, built the current functionality upon that, and have a good, future-proof architecture down the road, without having to write any _dead code_.
# [LSP](http://principles-wiki.net/principles:liskov_substitution_principle)
_Liskov Substitution Principle_ (LSP) named after its creator - [Barbara Liskov](https://en.wikipedia.org/wiki/Barbara_Liskov) - is an OOP principle, related to classes, interfaces, _types_, and _subtypes_.
The rule itself is pretty simple and logical, but might be hard to grasp at first. It indicates that any subtype must be _substitutable_ for its base type. I think an example is needed to illustrate this better.
Let's take the infamous rectangle and square problem, that's usually used to illustrate this principle. We've got a `Rectangle` class (a base type), which has properties like `width` and `height` and methods to set them and calculate the area. By inheritance, we create a `Square` class (a subtype), which has an additional method to set both `width` and `height` at the same time (say `setSide`).
If we use these classes separately - nothing would happen. But, as the `Square` class is a subtype of a Rectangle class, it can be assigned to the variable which accepts `Rectangle`s. This might then result in a wrong `setHeight` and `setWidth` calls, causing our `Square` instance to have incorrect dimensions and miscalculating the area (or throwing an error if a check is implemented).
We could easily resolve the issue by checking whether the entity is of a `Square` subtype, directly in the `setHeight`/`setWidth` methods of the `Rectangle` class. Sadly, in the process, we would acknowledge the existence of a `Square` subtype and thus break the LSP. You could also override the `setHeight`/`setWidth` methods, but now they wouldn't be compatible with the original class, resulting, again, in breaking the LSP.
# [ISP](http://principles-wiki.net/principles:interface_segregation_principle)
_Interface Segregation Principle_ (ISP) is yet another principle that says how to organize your code. As it's mainly focused on interfaces and _statically-typed_ programming languages, those who write in e.g. JavaScript won't use it very often. However, the sole knowledge that the ISP brings to the table can still be used to improve your code in other ways.
_Interfaces_ serve as a way to work with the form of the data, rather than the data itself. Writing and organizing them properly gives you a great way to improve the maintainability of your code, without much performance loss.
That's pretty much what the ISP is all about - using the interfaces to segregate your code, while also keep the interfaces themselves organized as well. Take a class inheritance for example. Maybe you don't care about certain methods or properties from the base class and want to "skip" them? A simple interface can help you do that! In compiled and statically-typed languages, it also gives you advantages like cleaner scope and faster _compilation time_ (subclasses don't have to recompile when its parent properties, aside from the interface-specified ones, change).
# [DIP](http://principles-wiki.net/principles:dependency_inversion_principle)
Like OCP, the _Dependency Inversion Principle_ (DIP) also refers to the more general architecture of your code. In fact, it's one of the most important principles in the code architecture design.
The DIP is a bit complex, but there are only two things you need to understand to follow it correctly. Firstly, your code should be written in a way, where _implementation details_ (e.g. User Interface (UI), database) should be dependent on the _main logic_ (aka _business rules_) - not otherwise.
Secondly, all these dependencies shouldn't be direct. You should _abstract_ them through e.g. interfaces, so that your main logic would work with anything you'll throw at it, only requiring some simple "bridge" code to be implemented.
# SOLID
5 of the previously-discussed principles - SRP, OCP, LSP, ISP, DIP - come together to form _SOLID_ - a set of principles that instructs you on how to write good, object-oriented (but not only) code, created by [Robert C. Martin](https://en.wikipedia.org/wiki/Robert_C._Martin). With the descriptions from this blog post, I hope I provided "logical-enough" explanations for starters in this full of principles programming world. However, if you're interested in the topic, I recommend you search the web or visit the linked resources to learn more.
Resources:
- [SOLID Principles: Explanation and examples](https://itnext.io/solid-principles-explanation-and-examples-715b975dcad4)
- [SOLID Principles made easy](https://hackernoon.com/solid-principles-made-easy-67b1246bcdf)
- [S.O.L.I.D: The First 5 Principles of Object Oriented Design](https://scotch.io/bar-talk/s-o-l-i-d-the-first-five-principles-of-object-oriented-design)
# The Only Principle
Lastly, we've got _The Only Principle_ (TOP). OK, I'm just kidding! But really, all the coding principles discussed in this article (and even [all the others](http://principles-wiki.net/)) have only one goal - to help you write good, maintainable code. That's their TOP priority. And while knowing them certainly helps, it's only you who has control over your code and how it'll look like.
I hope you've enjoyed this blog post, and learn something new in the process! If so, consider _sharing it_, and _following me_ on [Twitter](https://twitter.com/areknawo), [Facebook](https://www.facebook.com/areknawoblog), or checking out [my personal blog](https://areknawo.com) for more! Also, I've got a [YouTube channel](https://www.youtube.com/channel/UCUw6bg379ONlG1E_oxhwi-A/) if you're interested. As always, thank you so much for reading this piece, and have a nice day! | areknawo |
229,824 | When to use CSS Grid and when to use Flexbox for Multiline Layout | Introduction Flexbox and CSS Grid are both powerful layout technologies built into CSS. Th... | 0 | 2020-01-01T17:22:07 | https://dev.to/mpuckett/when-to-use-css-grid-and-when-to-use-flexbox-for-multiline-layout-no3 | css, webdev | ---
title: When to use CSS Grid and when to use Flexbox for Multiline Layout
published: true
description:
Cover_image: https://thepracticaldev.s3.amazonaws.com/i/t4ax5rwen9tto0j00mfn.png
tags: #css #webdev
---
## Introduction
Flexbox and CSS Grid are both powerful layout technologies built into CSS. They have many overlapping abilities. For most tasks, such as vertical centering, I could reach for either one. In some cases, one or the other is the only way to get the job done.
Is one better than the other, given the current state of web standards?
In the event that either Grid or Flexbox would work, I’m now reaching for Grid. I’ll explain why after discussing some various multiline scenarios.
## Gap
Soon there will be a uniform way to apply consistent spacing between child items, as defined by the parent: `gap`. So, `gap: 5px` will not affect the outside margin, only the spacing between interior items.
This was inspired by and will eventually supersede Grid’s `grid-gap` property. Unfortunately, the only way achieve the same result on multiline (wrapping) items in Flexbox using any browser other than Firefox is the Negative Margin Hack. This is where all the child items get a margin equal to half of the gap. Then to account for the extra space on the outside, the container gets a margin of the same value multiplied by -1. You can only use `:first-child` and `:last-child` on the items to account for the extra space when you have a single row (non-wrapping flex container).
For multiline grid containers, just apply a `grid-gap`.
**Winner**: Grid, but hopefully `gap` for flex layout will soon be added to Chrome and Safari.
## Consistent Sizing vs Automatic Sizing
If you have tracks in both directions (a multi-column and multi-row layout) then your choice depends on the widths of the child items relative to others.
If you want all the items to line up evenly and stack vertically, use Grid.

If you want the items to retain their natural width and not line up vertically, use Flexbox.

The code for Grid requires a `repeat()` function to be defined on the container’s `grid-template-columns` property. The `repeat` function accepts two values. The first for our purpose is either `auto-fill` or `auto-fit`. And the second is a `minmax` function, which accepts a value with a fixed unit, and another fixed or relative value.
All together it might look like this:
```
grid-template-columns: repeat(auto-fill, minmax(200px, 1fr));
```
This will give each item a base width of 200px that will scale up as needed.
For Flexbox, just add `flex-wrap: wrap`.
**Winner**: Depends on the use case, but Flexbox is a lot simpler. 🙃
## Container Control vs Item Control
There may be some cases — such as the boundary between two components — where you only want to modify the parent container’s CSS or the children’s CSS.
If you have control over the parent element, use Grid, which defines the children with `grid-template-*` and `grid-auto-*`.
If you have control over the child elements, use Flexbox, where the children define their own `flex-basis`.
If you must use Flexbox for some other reason, you can still define a CSS variable on the parent that will be inherited by the children.
**Winner**: Depends on the use case, but Flexbox gets a point for versatility. Personally I like having the ability to control all the items on the parent in one place whenever possible, so Grid gets a point too.
## Nested Layout
One killer CSS Grid feature that’s only landed in Firefox is `subgrid`. This allows a child grid item to define its grid children according to the same track definition as the top level parent.

If you had a set of items that internally are split into a top and bottom section with variable amounts of content, you could define two repeating `auto` grid tracks at the top level. Then the middle-level child items take up two each of the repeating rows. Then they pass down the track definition so that the top part receives one `auto` track and the bottom part receives the other. Now, across the items, the split will be at the same place, so internally they all line up.
**Winner**: Grid, but you’ll still have uneven layouts in any browser other than Firefox.
## Conclusion
For most other use cases, especially when working with one track in one direction with no spacing between items, I would be comfortable using either. That goes for situations where you need vertical centering and relative sizing.
But I find it easier to reason about how the children should be laid out when I’m defining them in one place on the parent element — so Grid wins out most of the time.
**Overall Winner**: Grid, but know its limitations!
As I mentioned, Firefox has taken the lead in this area. Please ⭐️ / CC yourself on these issues on Chromium and WebKit to make both Flexbox and Grid more powerful in the future!
* `gap` for Flexbox (Chromium): https://bugs.chromium.org/p/chromium/issues/detail?id=762679
* `gap` for Flexbox (WebKit): https://bugs.webkit.org/show_bug.cgi?id=206767
* `subgrid` (Chromium): https://bugs.chromium.org/p/chromium/issues/detail?id=618969
* `subgrid` (WebKit): https://bugs.webkit.org/show_bug.cgi?id=202115 | mpuckett |
229,940 | Django’s auto_now and auto_now_add fields for auditing creation and modification timestamps | Adding fields to database schemas to audit the creation and modification is a common best practice, u... | 0 | 2020-01-01T16:42:43 | https://adriennedomingus.com/blog/djangos-autonow-and-autonowadd-fields-for-auditing-creation-and-modification-timestamps | django | ---
title: Django’s auto_now and auto_now_add fields for auditing creation and modification timestamps
published: true
tags: Django
canonical_url: https://adriennedomingus.com/blog/djangos-autonow-and-autonowadd-fields-for-auditing-creation-and-modification-timestamps
---
Adding fields to database schemas to audit the creation and modification is a common best practice, useful for any number of things, most commonly debugging and cache invalidation. The good news is, Django has field-types built for just this purpose!
## auto_now and auto_now_add fields
As always, let’s start with the docs!
* [auto_now](https://docs.djangoproject.com/en/3.0/ref/models/fields/#django.db.models.DateField.auto_now)
* [auto_now_add](https://docs.djangoproject.com/en/3.0/ref/models/fields/#django.db.models.DateField.auto_now_add)
These fields are built into Django for expressly this purpose - auto_now fields are updated to the current timestamp every time an object is saved and are therefore perfect for tracking when an object was last modified, while an auto_now_add field is saved as the current timestamp when a row is first added to the database, and is therefore perfect for tracking when it was created.
It’s worth noting that that both fields are set on initial creation, whether they go through .save() or bulk_create - they may be a few milliseconds different, but will be effectively the same, but an auto_now_add field won’t change again after it’s set.
Let’s dive in and talk through some quirks of these fields.
## Read-only fields
Django’s DateField definition includes this on init:
```
if auto_now or auto_now_add:
kwargs['editable'] = False
kwargs['blank'] = True
super(DateField, self).__init__(verbose_name, name, **kwargs)
```
This has some implications for both your Django admin set-up, as well as different-than-usual options, should you need to update these yourself.
### Django Admin
Because both of these fields are read only, by default they won’t show up in your django admin view. If you try to explicitly include them via the fields option, you’ll see an error that looks like this:
`'created_at' cannot be specified for <ModelClass> model form as it is a non-editable field`
If you want them to appear anyway, you can add them to `readonly_fields` on a `ModelAdmin` class, and they will be displayed on the form in a non-editable way. They can also be included in `list_display`.
### Manually changing the values
Because an `auto_now_add` field is only set on initial creation, not on can be changed manually in the same way you’d update any other field - by setting the value and calling `.save()`.
However, if you were to do this with an `auto_now` field, because calling `.save()` would itself change the value, the value you manually set would not be reflected. But fear not - there are a couple ways you can update it!
Because the function of an auto_now_add field relies on Django’s `.save()` mechanism, any value can be changed using a SQL update statement
You can also do this via `.update()` - for the same reason calling `.update()` does not update the value even if you might want it to, we can take advantage of this fact and pass a value to the statement, and it will be persisted. You can always do this for a single row with a statement like `<Model>.objects.filter(id=<object_id>).update(modified_at=<desired timestamp>)`
## Unintended Consequences - User-facing values & backfills
Customers often want to know when something was created or updated - this can be useful information for sorting, display, etc. However, these fields may not be the right choice for displaying this information to users. In general, I’d recommend using them only for internal auditing purposes.
A customer imports data and wants the reflected date of creation to be when the resource was originally created, not when it was created within your system
You as a developer need to backfill some data, which results in an update of every row in the table - customers might be dismayed to find that all of their resources were updated at the same time now!
For reasons like these, I recommend having separate customer-facing fields that only update on customer actions, and only using these built-in Django fields for internal auditing purposes.
## Bonus: automatically adding this to all your models!
If you know you want these auditing fields added to all of your models, and you don’t want to have to remember to add them each time you create a new model, you can create a base class that looks something like this:
```
class YourBaseClass(models.Model):
created_at = models.DateTimeField(auto_now_add=True)
modified_at = models.DateTimeField(auto_now=True)
class Meta:
abstract = True
```
And then instead of your model classes being instances of models.Model, they can use YourBaseClass instead.
| adriennedomingus |
229,947 | Create powerful fast pre-rendered Angular Apps using Scully static site generator | You probably heard of the JAMStack. It is a new way of building websites and apps via static site generators that deliver better performance and higher security. With this blog post, I will show you how you can easily create a blogging app by using the power of Angular and the help of Scully static site generator. It will automatically detect all app routes and create static pages out of them that are ready to ship for production. | 8,530 | 2020-01-01T17:12:44 | https://k9n.dev/blog/2020-01-angular-scully |
# Create powerful fast pre-rendered Angular Apps using _Scully_ static site generator
**You probably heard of the JAMStack. It's a new way of building websites and apps via static site generators that deliver better performance and higher security. There have been tools for many platforms, but surprisingly not yet for Angular. These times are finally over. With this blog post, I want to show you how you can easily create an Angular blogging app by to pre-render your complete app.**
<hr>
> On _Dec 16, 2019_ the static site generator _Scully_ for Angular [was presented](https://www.youtube.com/watch?v=Sh37rIUL-d4).
> _Scully_ automatically detects all app routes and creates static sites out of it that are ready to ship for production.
> This blog post is based on versions of Angular and Scully:
>
> ```
> "@angular/core": "~13.0.0",
> "@angular/cli": "~13.0.3",
> "@scullyio/init": "^2.0.5",
> "@scullyio/ng-lib": "^2.0.0",
> "@scullyio/scully": "^2.0.0",
> "@scullyio/scully-plugin-puppeteer": "^2.0.0",
> ```
<hr>
## About Scully
Scully is a static site generator (SSG) for Angular apps.
It analyses a compiled Angular app and detects all the routes of the app.
It will then call every route it found, visit the page in the browser, renders the page and finally put the static rendered page to the file system.
This process is also known as **pre-rendering** – but with a new approach.
The result compiled and pre-rendered app ready for shipping to your web server.
> **Good to know:** _Scully_ does not use [Angular Universal](https://angular.io/guide/universal) for the pre-rendering.
> It uses a Chromium browser to visit and check all routes it found.
All pre-rendered pages contain just plain HTML and CSS.
In fact, when deploying it, a user will be able to instantly access all routes and see the content with almost no delay.
The resulting sites are very small static sites (just a few KBs) so that even the access from a mobile device with a very low bandwidth is pretty fast.
It's significantly faster compared to the hundreds of KBs that you are downloading when calling a “normal” Angular app on initial load.
But that’s not all: Once the pre-rendered page is shipped to the user, _Scully_ loads and bootstraps the “real” Angular app in the background on top of the existing view.
In fact _Scully_ will unite two great things:
The power of pre-rendering and very fast access to sites and the power of a fully functional Single Page Application (SPA) written in Angular.
## Get started
The first thing we have to do is to set up our Angular app.
As _Scully_ detects the content from the routes, we need to configure the Angular router as well.
Therefore, we add the appropriate flag `--routing` (we can also choose this option when the CLI prompts us).
```bash
npx -p @angular/cli ng new scully-blog --routing # create an angular workspace
cd scully-blog # navigate into the project
```
The next step is to set up our static site generator _Scully_.
Therefore, we are using the provided Angular schematic:
```bash
ng add @scullyio/init # add Scully to the project
```
Et voilà here it is: We now have a very minimalistic Angular app that uses the power of _Scully_ to automatically find all app routes, visit them and generate static pages out of them.
It's ready for us to preview.
Let's try it out by building our site and running _Scully_.
```bash
npm run build # build our Angular app
npx scully # let Scully run over our app and build it
npx scully serve # serve the scully results
```
> _Scully_ will run only once by default. To let _Scully_ run and watch for file changes, just add the `--watch` option (`npx scully --watch`).
After _Scully_ has checked our app, it will add the generated static assets to our `dist/static` directory by default.
Let's quickly compare the result generated from _Scully_ with the result from the initial Angular build (`dist/scully-blog`):
```
dist/
┣ scully-blog/
┃ ┣ assets/
┃ ┣ ...
┃ ┗ styles.ef46db3751d8e999.css
┗ static/
┣ assets/
┃ ┗ scully-routes.json
┣ ...
┗ styles.ef46db3751d8e999.css
```
If we take a look at it, except of the file `scully-routes.json`, that contains the configured routes used by _Scully_, we don't see any differences between the two builds.
This is because currently we only have the root route configured, and no further content was created.
Nonetheless, when running `npx scully serve` or `npx scully --watch` we can check out the result by visiting the following URL: `localhost:1668`.
This server serves the static generated pages from the `dist/static` directory like a normal web server (e.g. _nginx_ or _apache_).
## The `ScullyLibModule`
You may have realized, that after running the _Scully_ schematic, the `ScullyLibModule` has been added to your `AppComponent`:
```ts
// ...
import { ScullyLibModule } from '@scullyio/ng-lib';
@NgModule({
// ...
imports: [
// ...
ScullyLibModule
]
})
export class AppModule { }
```
This module is used by _Scully_ to hook into the angular router and to determine once the page _Scully_ tries to enter is fully loaded and ready to be rendered by using the `IdleMonitorService` from _Scully_ internally.
If we remove the import of the module, _Scully_ will still work, but it takes much longer to render your site as it will use a timeout for accessing the pages.
So in that case even if a page has been fully loaded, _Scully_ would wait until the timer is expired.
## Turn it into a blog
Let’s go a bit further and turn our site into a simple blog that will render our blog posts from separate Markdown documents.
_Scully_ brings this feature out of the box, and it’s very easy to set it up:
```bash
ng g @scullyio/init:blog # setup up the `BlogModule` and related sources
ng g @scullyio/init:post --name="First post" # create a new blog post
```
After these two steps we can see that _Scully_ has now added the `blog` directory to our project root.
Here we can find the markdown files for creating the blog posts — one file for each post.
We now have two files there: The initially created example file from _Scully_ and this one we created with `ng g @scullyio/init:post`.
## Let's go further
Now that we've got Scully installed and working, let's modify our Angular app to look more like an actual blog, and not just like the default Angular app.
Therefore, we want to get rid of the Angular auto generated content in the `AppComponent` first.
We can simply delete all the content of `app.component.html` except of the `router-outlet`:
```html
<router-outlet></router-outlet>
```
Let’s run the build again and have a look at the results.
Scully assumes by default the route configuration hasn't changed meanwhile, and it can happen that it's not detecting the new bog entry we just created.
To be sure it will re-scan the routes, we will pass through the parameter `--scan`:
```bash
npm run build # Angular build
npx scully --scan # generate static build and force checking new routes
npx scully serve # serve the scully results
```
When checking out our `dist/static` directory we can see that there are new subdirectories for the routes of our static blogging sites.
But what's that: When we will check the directory `dist/static/blog/`, we see somewhat like this:
```
blog/
┣ ___UNPUBLISHED___k9pg4tmo_2DDScsUiieFlld4R2FwvnJHEBJXcgulw
┗ index.html
```
This feels strange, doesn't it?
But Checking the content of the file `index.html` inside will tell us it contains actually the content of the just created blog post.
This is by intention: This _Scully_ schematic created the markdown file with a meta flag called `published` that is by default set to `false`.
The internally used renderer plugin from _Scully_ will handle this flag, and it creates an unguessable name for the route.
This allows us to create blog post drafts that we can already publish and share by using the link for example to let someone else review the article.
You can also use this route if you don't care about the route name.
But normally you would just like to change the metadata in the Markdown file to:
```yaml
published: true
```
After this, run the build process again and the files `index.html` in `dist/static/blog/<post-name>/` contain now our static pages ready to be served.
When we are visiting the route path `/blog/first-post` we can see the content of our markdown source file `blog/first-post.md` is rendered as HTML.
If you want to prove that the page is actually really pre-rendered, just disable JavaScript by using your Chrome Developer Tools.
You can reload the page and see that the content is still displayed.
Awesome, isn't it?

> When JavaScript is enabled, _Scully_ configures your static sites in that way, that you will see initially the static content.
> In the background it will bootstrap your Angular app, and refresh the content with it.
> You won't see anything flickering.
Hold on a minute! 😳
You may have realized: We haven’t written one line of code manually yet, and we have already a fully functional blogging site that’s server site rendered. Isn’t that cool?
Setting up an Angular based blog has never been easier.
> **Good to know:** _Scully_ also detects new routes we are adding manually to our app, and it will create static sites for all those pages.
## Use the `ScullyRoutesService`
We want to take the next step.
Now we want to list an overview of all existing blog posts we have and link to their sites in our `AppComponent`.
Therefore, we can easily inject the `ScullyRoutesService`.
It will return us a list of all routes _Scully_ found with the parsed information as a `ScullyRoute` array within the `available$` observable.
We can easily inject the service and display the information as a list in our `AppComponent`.
```ts
import { Component } from '@angular/core';
import { ScullyRoutesService, ScullyRoute } from '@scullyio/ng-lib';
import { Observable } from 'rxjs';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
links$: Observable<ScullyRoute[]> = this.scully.available$;
constructor(private scully: ScullyRoutesService) {}
}
```
To display the results, we can simply use `ngFor` with the `async` pipe and list the results.
A `ScullyRoute` will give us the routing path inside the `route` key and all other markdown metadata inside their appropriate key names.
So we can extend for example our markdown metadata block with more keys (e.g. `thumbnail: assets/thumb.jpg`) and we can access them via those (`blog.thumbnail` in our case).
We can extend `app.component.html` like this:
```html
<ul>
<li *ngFor="let link of links$ | async">
<a [routerLink]="link.route">{{ link.title }}</a>
</li>
</ul>
<hr />
<router-outlet></router-outlet>
```
This will give us a fully routed blog page:

The `ScullyRoutesService` contains all the available routes in your app.
In fact, any route that we add to our Angular app will be detected by _Scully_ and made available via the `ScullyRoutesService.available$` observable.
To list only blog posts from the `blog` route and directory we can just filter the result:
```ts
/* ... */
import { map, Observable } from 'rxjs';
/* ... */
export class AppComponent {
links$: Observable<ScullyRoute[]> = this.scully.available$.pipe(
map(routeList => {
return routeList.filter((route: ScullyRoute) =>
route.route.startsWith(`/blog/`),
);
})
);
constructor(private scully: ScullyRoutesService) {}
}
```
Wow! That was easy, wasn’t it?
Now you just need to add a bit of styling and content and your blog is ready for getting visited.
## Fetch dynamic information from an API
As you may have realized: _Scully_ needs a data source to fetch all dynamic routes in an app.
In case of our blog example _Scully_ uses the `:slug` router parameter as a placeholder.
Scully will fill this placeholder with appropriate content to visit and pre-render the site.
The content for the placeholder comes in our blog example from the files in the `/blog` directory.
This has been configured from the schematics we ran before in the file `scully.scully-blog.config.ts`:
```ts
import { ScullyConfig } from '@scullyio/scully';
/** this loads the default render plugin, remove when switching to something else. */
import '@scullyio/scully-plugin-puppeteer';
export const config: ScullyConfig = {
projectRoot: "./src",
projectName: "scully-blog",
outDir: './dist/static',
routes: {
'/blog/:slug': {
type: 'contentFolder',
slug: {
folder: "./blog"
}
},
}
};
```
I would like to show a second example.
Imagine we want to display information about books from an external API.
So our app needs another route called `/books/:isbn`.
To visit this route and pre-render it, we need a way to fill the `isbn` parameter.
Luckily _Scully_ helps us with this too.
We can configure [_Router Plugin_](https://scully.io/docs/plugins#router-plugin) that will call an API, fetch the data from it and pluck the `isbn` from the array of results to fill it in the router parameter.
In the following example we will use the public service [BookMonkey API](https://api3.angular-buch.com) (we provide this service for the readers of our [German Angular book](https://angular-buch.com/)) as an API to fetch a list of books:
```js
/* ... */
export const config: ScullyConfig = {
/* ... */
routes: {
/* ... */
'/books/:isbn': {
'type': 'json',
'isbn': {
'url': 'https://api3.angular-buch.com/books',
'property': 'isbn'
}
}
}
};
```
The result from the API will have this shape:
```json
[
{
"title": "Angular",
"subtitle": "Grundlagen, fortgeschrittene Themen und Best Practices – mit NativeScript und NgRx",
"isbn": "9783864906466",
// ...
},
{
"title": "Angular",
"subtitle": "Grundlagen, fortgeschrittene Techniken und Best Practices mit TypeScript - ab Angular 4, inklusive NativeScript und Redux",
"isbn": "9783864903571",
// ...
},
// ...
]
```
After _Scully_ plucks the ISBN, it will just iterate over the final array: `['9783864906466', '9783864903571']`.
In fact, when running _Scully_ using `npx scully`, it will visit the following routes, **after we have configured the route `/books/:isbn` in the Angular router** (otherwise non-used routes will be skipped).
```
/books/9783864906466
/books/9783864903571
```
We can see the result in the log:
```
enable reload on port 2667
☺ new Angular build imported
☺ Started servers in background
--------------------------------------------------
Watching blog for change.
--------------------------------------------------
☺ new Angular build imported
Finding all routes in application.
Using stored unhandled routes
Pull in data to create additional routes.
Finding files in folder "/<path>/blog"
Route list created in files:
"/<path>/src/assets/scully-routes.json",
"/<path>/dist/static/assets/scully-routes.json",
"/<path>/dist/scully-blog/assets/scully-routes.json"
Route "/books/9783864903571" rendered into file: "/<path>/dist/static/books/9783864903571/index.html"
Route "/books/9783864906466" rendered into file: "/<path>/dist/static/books/9783864906466/index.html"
Route "/blog/12-27-2019-blog" rendered into file: "/<path>/dist/static/blog/12-27-2019-blog/index.html"
Route "/blog/first-post" rendered into file: "/<path>/dist/static/blog/first-post/index.html"
Route "/" rendered into file: "/<path>/dist/static/index.html"
Generating took 3.3 seconds for 7 pages:
That is 2.12 pages per second,
or 473 milliseconds for each page.
Finding routes in the angular app took 0 milliseconds
Pulling in route-data took 26 milliseconds
Rendering the pages took 2.58 seconds
```
This is great. We have efficiently pre-rendered normal dynamic content!
And that was it for today.
With the shown examples, it's possible to create a full-fledged website with Scully.
> Did you know that **this blogpost** and the overall website you are right now reading has also been created using _Scully_?
> Feel free to check out the sources at:
> [github.com/d-koppenhagen/k9n.dev](https://github.com/d-koppenhagen/k9n.dev)
If you want to follow all the development steps in detail, check out my provided Github repository
[scully-blog-example](https://github.com/d-koppenhagen/scully-blog-example).
## Conclusion
Scully is an awesome tool if you need a pre-rendered Angular SPA where all routes can be accessed immediately without loading the whole app at once.
This is a great benefit for users as they don’t need to wait until the bunch of JavaScript has been downloaded to their devices.
Visitors and **search engines** have instantly access to the sites' information.
Furthermore, _Scully_ offers a way to create very easily a blog and renders all posts written in Markdown.
It will handle and pre-render dynamic routes by fetching API data from placeholders and visiting every route filled by this placeholder.
Compared to "classic" pre-rending by using [Angular Universal](https://angular.io/guide/universal), _Scully_ is much easier to use, and it doesn't require you to write a specific flavor of Angular.
Also, _Scully_ can easily pre-render hybrid Angular apps or Angular apps with plugins like jQuery in comparison to Angular Universal.
If you want to compare _Scully_ with Angular Universal in detail, check out the blog post from Sam Vloeberghs: [Scully or Angular Universal, what is the difference?](https://samvloeberghs.be/posts/scully-or-angular-universal-what-is-the-difference)
If you want to dig a bit deeper into the features _Scully_ offers, check out my [second article](https://k9n.dev/blog/2020-03-dig-deeper-into-scully-ssg).
**Thank you**
Special thanks go to [Aaron Frost (Frosty ⛄️)](https://twitter.com/aaronfrost) from the _Scully_ core team, [Ferdinand Malcher](https://twitter.com/fmalcher01) and [Johannes Hoppe](https://twitter.com/JohannesHoppe) for revising this article.
| dkoppenhagen | |
229,969 | 5 Minutes Tutorial Series - NodeJS upload files to Minio | Hello everyone, I am starting a new series called "5 Minutes Tutorial Series". In this tutorial, I'll... | 0 | 2020-01-01T18:52:27 | https://dev.to/gokayokyay/5-minutes-tutorial-series-nodejs-upload-files-to-minio-3dj0 | node, minio, javascript, api | Hello everyone, I am starting a new series called "5 Minutes Tutorial Series". In this tutorial, I'll show how can you upload a file to a Node server and then upload it to Minio Object Storage. Since it is about Minio, I'm assuming that you know what it is, but if you don't click [here](https://min.io/) to learn more.
We'll be using [fastify](https://www.fastify.io/) as our server framework. If you're using express, you can find an awesome post by [thepolygotdeveloper](https://www.thepolyglotdeveloper.com/2017/03/upload-files-minio-object-storage-cloud-node-js-multer/) here. Let's begin!
```bash
# create new project
mkdir fastify-minio
cd fastify-minio
# initialize npm project
npm init -y
# install fastify, fastify-file-upload, minio
npm i fastify fastify-file-upload minio
```
Create a file named index.js then add following code.
```javascript
const fastify = require('fastify');
const app = fastify();
app.register(require('fastify-file-upload'));
app.post('/upload', function(req, res) {
const files = req.raw.files;
res.send(files);
});
app.listen(3000, err => {
if (err) {
throw err;
}
console.log('App is listening on port 3000!');
});
```
Here we have a very basic fastify server. Next create a file named minioClient.js with the following code.
```javascript
const Minio = require('minio');
const minioClient = new Minio.Client({
endPoint: 'play.minio.io',
port: 9000,
secure: true,
accessKey: 'Q3AM3UQ867SPQQA43P2F',
secretKey: 'zuf+tfteSlswRu7BJ86wekitnifILbZam1KYY3TG'
});
module.exports = minioClient;
```
We're using minio's playground but feel free to change the configuration as you wish. Next we'll modify our index.js code to:
```javascript
const fastify = require('fastify');
const app = fastify();
// ->CHANGED
const minioClient = require('./minioClient');
// CHANGED<-
app.register(require('fastify-file-upload'));
app.post('/upload', function(req, res) {
const files = req.raw.files;
// ->CHANGED
minioClient.putObject("test", files.image.name, files.image.data, function(error, etag) {
if(error) {
return console.log(error);
}
res.send(`https://play.minio.io:9000/test/${files.image.name}`);
});
// CHANGED<-
});
app.listen(3000, err => {
if (err) {
throw err;
}
console.log('App is listening on port 3000!');
});
```
You can see what's changed by looking at //CHANGED code blocks. But I want you to focus on minioClient part. We put object to a bucket named "test" with filename and data buffer. By the way notice the files.image part, in this case the file's key is "image". And the file's url is MINIO_ENDPOINT:MINIO_PORT/BUCKET_NAME/FILE_NAME. Since minio uses a technique called "presigned url" the file won't be accessible from that url. But we can change it by changing bucket policy. Here's the policy I use:
```json
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Principal":{
"AWS":[
"*"
]
},
"Action":[
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource":[
"arn:aws:s3:::bucket"
]
},
{
"Effect":"Allow",
"Principal":{
"AWS":[
"*"
]
},
"Action":[
"s3:GetObject"
],
"Resource":[
"arn:aws:s3:::bucket/*"
]
}
]
}
```
When you apply this policy via "setBucketPolicy" method of client, the files in the bucket will be accessible publicly and the url will be available permanently. You can see the method's docs [here](https://docs.min.io/docs/javascript-client-api-reference.html#setBucketPolicy).
Last thing, it can be problematic to use files' original names. I suggest trying some package like [uuid](https://www.npmjs.com/package/uuid) to prevent it.
Okay it's been 5 minutes already, see you in another tutorial! | gokayokyay |
229,986 | Create a Custom User Model in Django | In this article, we will be learning how to create a custom user model in Django. Why do you need a c... | 0 | 2020-01-03T12:23:33 | https://dev.to/thadeveloper/create-a-custom-user-model-in-django-2n89 | django, python | In this article, we will be learning how to create a custom user model in Django. Why do you need a custom user while Django has it's own auth models? Well, the default user class doesn't offer adequate fields that may fully describe a user based on the type of application you're building. For instance, you may want to add the full name, gender, location, etc. Worry not since even with all that abstraction that comes with Django we can still be able to tweak a couple of things. Let's get to it.
#### Let's Build
I am assuming you've already created a Django app and configured the database. I will be using Django 3.0.1 and Postgres 12.1. First, since the user model overrides the default user we need to define a custom `UserManager` class that extends `BaseUserManager`. We also have to ensure the class defines two methods; `create_user` and `create_superuser` methods. Create the user manager file under your startapp folder. Mine is in the path `src/authentication/user_manager.py`. Below is my project directory structure:
`user_manager.py`
```python
"""User manager model module"""
from django.contrib.auth.models import BaseUserManager
class UserManager(BaseUserManager):
"""
custom user model
"""
def create_user(
self,
email,
password,
is_active=False,
is_staff=False,
is_admin=False
):
"""Create user."""
if not email:
raise ValueError('Users must have an email address')
user = self.model(email=self.normalize_email(email))
user.is_active=is_active
user.is_staff=is_staff
user.is_admin=is_admin
user.set_password(password)
user.save(using=self._db)
return user
def create_superuser(self, email, password):
"""Create a superuser."""
return self.create_user(
email,
password,
is_active=True,
is_staff=True,
is_admin=True
)
```
For the user to have superuser permissions like site administration, you have to add `is_superuser=True` or have the `has_perm` class method in your user model that references the admin field. In this case, we're going with the latter.
Create a `User ` model in the models file as below. Feel free to add any other fields as deemed necessary.
`models.py`
```python
from django.db import models
from django.contrib.auth.models import AbstractBaseUser, PermissionsMixin
from authentication.user_manager import UserManager
class User(AbstractBaseUser, PermissionsMixin):
"""User model."""
email = models.EmailField(unique=True, null=False)
first_name = models.CharField(max_length=30, null=True)
last_name = models.CharField(max_length=30, null=True)
password = models.CharField(max_length=128, blank=True)
date_joined = models.DateTimeField(auto_now_add=True)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True, null=True)
is_active = models.BooleanField(default=False)
is_admin = models.BooleanField(default=False)
is_staff = models.BooleanField(default=False)
objects = UserManager()
#unique identifier
USERNAME_FIELD = 'email'
# any required fields besides email and password
REQUIRED_FIELDS = []
def __str__(self):
return f'{self.first_name} {self.last_name}'
@property
def is_superuser(self):
return self.is_admin
def has_perm(self, perm, obj=None):
return self.is_admin
```
`AbstractBaseUser`: Allows us to create a completely new User model.
`PermissionsMixin`: It will add fields that are specific for objects that have permissions, like `is_admin`.
Now add `{app_name}.User` to your `settings.py` file:
```python
AUTH_USER_MODEL = 'authentication.User'
```
Finally run the migrations. `$ python manage.py makemigrations && python manage.py migrate`
To be able to login to the admin dashboard we have to register our custom `User` model in Django admin sites. Open `app_name/admin.py` and add the code below.
```python
"""Register models to django admin."""
from django.contrib import admin
from django.contrib.auth.models import Group
from authentication.models import User
# list other models here
MODELS = []
class UserAdmin(admin.ModelAdmin):
"""Customize user/admin view on djano admin."""
search_fields = ('email', )
list_display = ('email', 'is_admin')
list_filter = ('is_active', 'is_admin')
ordering = ('email', )
fieldsets = (
(None, {'fields': ('email', 'password')}),
('Permissions', {'fields': ('is_admin','is_staff')}),
('Primary personal information', {
'fields': ('first_name', 'last_name')}),
('Status', {'fields': ('is_active', )}),
)
admin.site.register(User, UserAdmin)
for model in MODELS:
admin.site.register(model)
```
To test the app start by creating a superuser:

Great! Now visit `http://127.0.0.1:8000/admin/` to login.
#### Conclusion
That's all for this article. You should now be able to tweak your user model to fit your application needs. Remember to add any new models under `MODELS` list of the admin file. I hope you found it valuable and look out for more in the future! | thadeveloper |
230,081 | Ignore ESLint rules on specific lines | ESLint let you ignore the lint rules by putting comments on line. | 0 | 2020-01-01T23:28:11 | https://dev.to/ymotongpoo/ignore-eslint-rules-on-specific-lines-4ej4 | typescript, javascript, eslint | ---
title: Ignore ESLint rules on specific lines
published: true
description: ESLint let you ignore the lint rules by putting comments on line.
tags: TypeScript, JavaScript, ESLint
---
On writing codes for [Google Apps Script](https://developers.google.com/apps-script) with [clasp](https://github.com/google/clasp), it is often the case you get warning from ESLint like "@typescript-eslint/no-unused-vars" on the functions because they are called from triggers in most cases.

For that, you can use inline comments to disable rule of ESLint as follows:
```typescript
function mp4Organize(): void { // eslint-disable-line @typescript-eslint/no-unused-vars
...
}
```
## Reference
* [ESLint: Configuring ESLint - Disabling Rules with Inline Comments](https://eslint.org/docs/2.13.1/user-guide/configuring#disabling-rules-with-inline-comments)
| ymotongpoo |
230,125 | Clickable link text for Android TextView — Kotlin Extension |
Clickable link text for Android TextView — Kotlin Extension
Recently I... | 0 | 2020-01-13T12:11:06 | https://medium.com/@hossainkhan/clickable-link-text-for-android-textview-kotlin-extension-a36b9e03180b | android, kotlinextensionfun, androidtextview, kotlin | ---
title: Clickable link text for Android TextView — Kotlin Extension
published: true
date: 2020-01-02 00:53:57 UTC
tags: android,kotlin-extension-fun,android-textview,kotlin
canonical_url: https://medium.com/@hossainkhan/clickable-link-text-for-android-textview-kotlin-extension-a36b9e03180b
---
### Clickable link text for Android TextView — Kotlin Extension
Recently I have had to create UI that required user tappable/clickable text in the same text view. I know this is kind of unusual as the touch target for the view will likely be smaller compared to a button with no outline style. However, I wanted to share a quick Kotlin extension function that is dynamic and well tested.
<figcaption>Android TextView where “Register Now” is a tappable link with a callback.</figcaption>
Here is an example usage for generating clickable link within the same TextView
So, if your project requires something like this take a look at the following extension function for android.widget.TextView.
{% gist https://gist.github.com/amardeshbd/c0983ee766301f3ff706a4aa65d4e819 %}
You should be able to easily convert this to Java if needed. Let me know if you find this useful. Cheers ✌️ | hossain |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.