
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
230,175 | The First Two Weeks: A Compiler Writing Journey | Photo by Nick Fewings on Unsplash Welcome back to the first update in my compiler & interpreter... | 3,825 | 2020-01-04T06:04:32 | https://dev.to/bamartindev/the-first-two-weeks-a-compiler-writing-journey-2ko8 | compilers, interpreters, standardml, devjournal | *Photo by Nick Fewings on Unsplash*
Welcome back to the first update in my compiler & interpreter journey! I want to spend some time this post to share some things I have learned about so far, as well as what I plan to tackle in the next two weeks! The first few sections will focus on Compiler / Interpreter information that I have been gathering and starting to digest. The later section will focus on my experience so far with Standard ML, the language that I will be utilizing with the book ["Modern Compiler Implementation in ML"](https://www.cs.princeton.edu/~appel/modern/ml/)
Here is a look at the sections that I want to cover:
* [What Are Compilers And Interpreters?](#what-are-compilers-and-interpreters)
* [What Are The Stages of Compilation?](#what-are-the-stages-of-compilation)
* [Lets Check Out The "Super Tiny Compiler"!](#lets-check-out-the-super-tiny-compiler)
* [What I Have Learned About Standard ML](#what-i-have-learned-about-standard-ml)
* [Useful References And Links](#useful-references-and-links)
## What Are Compilers And Interpreters?
A compiler is a program that translates code written in one language (the source language) into another language (the target language). The target language is usually something like assembly or machine code when the compiler is creating an executable, but it can also be another high level programming language like JavaScript. The [Rust](https://www.rust-lang.org/) compiler is an example of the former, while [Babel](https://babeljs.io/) is an example of the latter.
A key characteristic is that a compiler does its work **ahead of time**. You can use the compiler to generate its output and then wait to execute it at a later time. A side effect of this, is that an executable generated by the compiler can exist even if the source code is lost.
An interpreter, on the other hand, directly executes the instructions written in the source language without converting it to some target language before. It requires the source code every time it is executed!
Some examples of compiled & interpreted languages:
Compiled | Interpreted
--- | ---
C, C++, Rust, Standard ML, and Java | Lua, Python, and JavaScript
Now, an interesting thing is that *any* language can be compiled or interpreted. In fact, a lot of programming languages provide both capabilities to developers to improve the development experience. For example, if I want to write some [Elixir](https://elixir-lang.org/) code it will be compiled to bytecode to be run on the Erlang VM, but if I write an Elixir script or use the interactive mode REPL (Read-Evaluate-Print-Loop) it will behave more like an interpreted language.
As I will show in the next section, compilation (and interpretation) have multiple stages to it. The "front end" stages of parsing and lexing, and creating an abstract representation of the source will be very similar for compilers and interpreters. However, the "back end" stages will start to diverge as an interpreter is more concerned with immediate execution while a compiler is concerned with creating an executable.
## What Are The Stages of Compilation?
Compilation is broken down into two major stages, and in those stages are smaller stages that will be of focus as I work through implementing a compiler. I hope to speak to each part in my own words as I go through them!
The two major stages are the front end, and the back end. I know, super descriptive. Similar to any other piece of software, a compiler should be designed with modularity in mind. The front end is the stage of the compiler that takes the source code written in the programming language and turns it into an intermediate representation (IR). This IR is some data representation of the program, that is independent of the source programming language itself. The back end takes the IR and does optimizations and also generates the output of the compiler into some other target language.
This is a very broad description, but it is the first division that can be seen in compiler architecture. A slightly more in depth look can be seen in a lovely picture of a mountain in Crafting Interpreters, in the ["A Map of the Territory" chapter](https://www.craftinginterpreters.com/a-map-of-the-territory.html#the-parts-of-a-language). This shows some sub-steps of the front end and back end, like scanning, parsing, analysis, and code generation. The book that I am following has twelve stages listed out! Those stages are:
1. Lex
2. Parse
3. Semantic Actions
4. Semantic Analysis
5. Frame Layout
6. Translate
7. Canonicalize
8. Instruction Selection
9. Control Flow Analysis
10. Dataflow Analysis
11. Register Allocation
12. Code Emission
If I am being honest I know what *maybe* two of those stages entail (lex and parse). The rest I feel like the profit gnomes in south park.

I am excited to be able to someday intelligently speak to all of these stages in the future, and I think that will be the focus of most future posts. This post is a little all over the place as I am getting my bearings and looking at various resources as I learn Standard ML. Speaking of all over the place...
## Lets Check Out The "Super Tiny Compiler"!
Now that we have a bit of understanding of what a compiler is, I think it would be fun to look at a very simple compiler, [The Super Tiny Compiler!](https://github.com/jamiebuilds/the-super-tiny-compiler/blob/master/the-super-tiny-compiler.js) This compiler is written in JavaScript and very well annotated, so I won't dive **too** deep into it because I encourage you to take a look at the authors great work!
Essentially this compiler takes some Lisp like function calls, and compiles them into C like function calls! Essentially taking something like `(add 2 2)` and converting it to `add(2, 2)`.
What I want to take a look at is the entry point for this compiler, this function that loosely follows the lex, parse, translate, and code emission steps above:
```javascript
function compiler(input) {
let tokens = tokenizer(input);
let ast = parser(tokens);
let newAst = transformer(ast);
let output = codeGenerator(newAst);
// and simply return the output!
return output;
}
```
This takes us through the major steps: tokenization, parsing, transforming, and code generation. The first step is what finds the individual parts of the input, taking something like `(add 2 2)` and building a list like
```javascript
const tokens = [{type: 'paren', value: '('}, {type: 'string', value: 'add'},
{type: 'number', value: '2'}, {type: 'number', value: '2'},
{type: 'paren', value: ')'}];
```
to represent the input program, with added metadata about what each token is. The next step takes care of making sure that those tokens **make sense** with the semantics of the language. Luckily in the case of this compiler, there are no keywords, but there are expectations of matching parens!
After creating a correct program as defined by its semantics, the transformation of the abstract syntax can take place to change its representation to a C like function call.
Finally, after the transformation is applied, the code is generated in the C like manner! Again, this is a highly simplified overview of what is in the compiler, but I encourage you to take a look at the source - pull it down and tinker with it. See if you can add something new to it. What about transforming from C -> Lisp instead?
> As an aside, I think that is an interesting property of compilers and languages - they can be as simple or complicated as needed. That means that I might detour here and there as I am learning to write small, simple languages that focus on implementing the new techniques! 🤓
## What I Have Learned About Standard ML
This is where I spent the majority of my last two week. Standard ML (Standard Meta Language aka SML) is a modular functional programming language that is supposedly very well suited to compiler implementation. I have been posting to the GitHub repository [standard-ml-learning](https://github.com/bamartindev/standard-ml-learning) all of the code that I have been writing as a result of learning - feel free to check it out!
I have a couple of directories in this project, one for following the text "Programming in Standard ML", and the other is a workspace for me to do practice problems from an online course I found [CS 312](https://www.cs.cornell.edu/courses/cs312/2008sp/schedule.html).
One thing I have noticed is that while the text has been useful, its easy to *think* that I am learning while following along with examples. Its another thing to **know** that I am learning by tackling small coding challenges and other more free form problems and getting the correct solution!
I am lucky to have some experience with functional programming - I try and use a functional style when it makes sense at work with JavaScript and I have dabbled in Haskell and Elixir as well. The idea of coding in a declarative is a little less harsh for me coming in with that background. Even though that is the case, I still love tripping up over little things as captured in my notes:
> Ok, I have typed var and let way too many times when trying to write sml - I have to remember its val!
And even that note to myself is misleading, because there **IS** a keyword `let` as well!
One thing that I liked was the concept of sharp notation, which is the following:
```sml
val person = ("Jim", "Bob", "Software Developer", #"A", 45)
val fullName = (#1 person) ^ " " ^ (#2 person)
val jobClass = #4 person
```
The sharp notation is a way of accessing values in an n-tuple. As you can see, it isn't the most clear what it is trying to do, but I can imagine that it could be useful in an anonymous function for mapping or something like that.
Another thing that I always love with languages like this is the ease of pattern matching.
```sml
val person = ("Jim", "Bob", "Software Developer", #"A", 45)
val (firstName, lastName, _, jobClass, age) = person
```
This will bind the individual values of the tuple to the variables firstName, lastName, jobClass, and age. Note the use of `_` in the pattern matching, this ignores the field "Software Developer" and doesn't bind it to anything!
Another powerful concept is the `cons` operator which is written as `::` and is used during list processing. Can you guess what this function does?
```sml
fun mystery [] = 1
| mystery (x::xs) = x * mystery xs
```
Yeah, I cheated a bit by throwing a bunch of new syntax at you, but it takes a list of integers, like `mystery [1,2,3,4,5]` and returns `120` - thats all of the elements multiplied together! So, the new keyword introduced is fun, which is a function declaration. Then pattern matching is employed in a new way! The first pattern checks for the value `[]` which is an empty list. If there is an empty list we return 1. So calling `mystery []` would result in 1. The next part of the pattern matching uses the cons operator to destructure the list provided. By doing this, we are grabbing the head and tail of the list - x is the head, xs is the tail. If the list is `[1,2,3,4,5]`, then `x = 1` and `xs = [2,3,4,5]`! Now, given that information hopefully the function body of `x * mystery xs` makes sense. We are recursively calling the mystery function with a reduced version of the initial input: `1 * mystery [2,3,4,5]`. This will continue to happen until we reach the base case of `[]` and return 1, then the full evaluation will occur of `1 * 2 * 3 * 4 * 5 * 1`, which returns `120`. Awesome!
There have been a lot more topics that I have learned as well from recursion, to higher order functions, to exception handling. I don't think I am the right person to teach these things, as I have linked to the primary source of my learning, so instead I will conclude by sharing some of the code that I wrote that *wasn't* guided by the book - some challenges that I tackled on this site as well as some problem set code I wrote for the CS 312 course:
[Daily Challenge #148 - Disemvowel Trolls](https://dev.to/thepracticaldev/daily-challenge-148-disemvowel-trolls-h76)
```sml
val vowels = [#"a", #"e", #"i", #"o", #"u"]
fun member_of (item, list) = List.exists (fn x => x = item) list
fun disemvowel s = implode (List.filter (fn x => not(member_of(Char.toLower x, vowels))) (explode s))
```
[Daily Challenge #149 - Fun with Lamps](https://dev.to/thepracticaldev/daily-challenge-149-fun-with-lamps-11nk)
```sml
fun gen_alt (starting, next, len) = List.tabulate(len, fn x => if x mod 2 = 0 then starting else next)
fun diff ([], []) = 0
| diff (x::xs, y::ys) = (if x = y then 0 else 1) + diff(xs, ys)
| diff (_, _) = ~1 (* List lengths don't match for some reason *)
fun lamps [] = 0
| lamps i = Int.min(diff(i, gen_alt(0, 1, length i)), diff(i, gen_alt(1, 0, length i)))
```
Answers to some parts of [Problem Set 1](https://www.cs.cornell.edu/courses/cs312/2008sp/hw/ps1/ps1.html)
```sml
exception NumberFormatException
fun parseInt (s: string) : int =
let
val SOME x = Int.fromString s
in
x
end
handle Bind => raise NumberFormatException
datatype tree = Node of tree list
val tt = Node([Node([Node([Node([])])]), Node([Node([]), Node([Node([])])]), Node([Node([])])])
fun treeSize (Node([])) = 1
| treeSize (Node(x::[])) = 1 + treeSize x
| treeSize (Node(x::xs)) = (treeSize x) + (treeSize (Node(xs)))
val correctSize = treeSize tt = 10
fun rev [] = []
| rev (hd::tl) = rev tl @ [hd]
fun isWhitespace c = c = #" "
fun reverseWords words =
String.concatWith " " (rev (String.tokens isWhitespace words))
val reversed = (reverseWords "A MAN A PLAN A CANAL PANAMA") = "PANAMA CANAL A PLAN A MAN A"
```
Some answers to [Problem Set 2 - Part 2](https://www.cs.cornell.edu/courses/cs312/2008sp/hw/ps2/ps2.html)
```sml
(* Part 2 *)
(* a *)
val product = List.foldl Int.* 1
(* b *)
fun even_odd_idx (a: 'a, (b1: 'a list, b2: 'a list)) : ('a list * 'a list) =
if (length b1 = length b2) then
(b1 @ [a], b2)
else
(b1, b2 @ [a])
(* Any way I can make this point free? *)
fun partition (l: 'a list) : ('a list * 'a list) = List.foldl even_odd_idx ([], []) l
(* c *)
fun apply_twice_positive (i: int) = fn (f: int -> int, count: int) => if f(f i) > 0 then count + 1 else count
val count_positive_funcs = foldl (apply_twice_positive(~1)) 0
(* This returns 2! *)
val positive_count = count_positive_funcs [fn x => x + 1, fn x => x - 1, fn x => x * ~1, fn x => x*x]
```
> One final thought on Standard ML learning - there are a lot less resources than a popular modern language! I know this is to be expected, but I was very surprised to see that only around 1800 questions had been asked on stack overflow, as opposed to the 1.9 million you see for JavaScript. I am very happy with my progress given that fact, and I am getting close to the goal of being able to fully understand a large "real world" program implemented in SML.
## Useful References And Links
One resource I really want to give a shout out to is [Crafting Interpreters](https://www.craftinginterpreters.com/) - this is a really well written and free resource on writing an interpreter for a programming language called Lox. The first part is implemented in Java, the second part is implemented in C.
The only reason I am not using this as my primary learning text is that I wanted a more rigorous text to get started - something that dives a little more into the theory. I wouldn't be surprised to see myself reference this resource throughout my journey though!
Another place that I have been looking at is the programming languages subreddit, [/r/programminglanguages](https://www.reddit.com/r/ProgrammingLanguages/) I am using it as a gauge to see how much I am learning - at the moment a lot of the topics being discussed are way over my head, but I hope to start understanding the common problems discusses in programming language creation as I learn.
The subreddit also has an associated [discord server](https://discordapp.com/invite/yqWzmkV) for a little bit more live discussions.
## Until Next Time
If you made it this far, thanks for reading! I think that moving forward I am going to move my "publish" date to a Monday so that way I can spend a bit more time organizing my thoughts. This post felt like it was a bit more of a brain dump than I wanted it to be this time around.
By next time I hope to have finished my initial learning of Standard ML so that way I can talk a bit more about implementing a specific stage of a compiler next time. I am super excited to start!
I will post the next update on January 20th, and all future updates will be on the Monday 2 week after.
*If you have any corrections or clarifications to statements I have made, please drop a comment. The last thing I want is to be misleading anyone, even though this is about my journey to learn and not a tutorial.* | bamartindev |
230,190 | welcome me git hub community | I really appreciate your effort here, how can we easily communicate and build a genuine community her... | 0 | 2020-01-02T05:48:18 | https://dev.to/rashi07hub/welcome-me-git-hub-community-n3j | I really appreciate your effort here, how can we easily communicate and build a genuine community here. I am a programmer and hope I'll learn more skills here at Dev community.
Thanks,
Dev.to | rashi07hub | |
230,210 | Gitting gud | Git is now an essential part of my work flow. It's invaluable. I like knowing that even though I may... | 0 | 2020-01-02T07:04:46 | http://jamessessford.com/blog/gitting-gud | git, ubuntu | ---
title: Gitting gud
published: true
date: 2019-12-26 00:00:00 UTC
tags: git, ubuntu
canonical_url: http://jamessessford.com/blog/gitting-gud
---
Git is now an essential part of my work flow. It's invaluable. I like knowing that even though I may have to dig to find it, I have the history of an entire project at my fingertips.
Since moving over to Ubuntu, I've made a few optimisations to my environment to help use Git.
## Keys
I modified this from a Stack Overflow answer, it'll add the desired keys to SSH agent when you load a terminal/login through SSH and destroy the agent when the last thing using it is closed.
I have this at the bottom of my ~/.zshrc config file
```
# Start ssh-agent to keep you logged in with keys, use `ssh-add` to log in
agent=`pgrep ssh-agent -u $USER` # get only your agents
if [["$agent" == "" || ! -e ~/.ssh/.agent_env]]; then
# if no agents or environment file is missing create a new one
# remove old agents / environment variable files
if [["$agent" != ""]]; then
kill $agent;
fi
rm -f ~/.ssh/.agent_env
# restart
eval `ssh-agent`
/usr/bin/ssh-add
echo 'export SSH_AUTH_SOCK'=$SSH_AUTH_SOCK >> ~/.ssh/.agent_env
echo 'export SSH_AGENT_PID'=$SSH_AGENT_PID >> ~/.ssh/.agent_env
fi
# create our own hardlink to the socket (with random name)
source ~/.ssh/.agent_env
MYSOCK=/tmp/ssh_agent.${RANDOM}.sock
ln -T $SSH_AUTH_SOCK $MYSOCK
export SSH_AUTH_SOCK=$MYSOCK
end_agent()
{
# if we are the last holder of a hardlink, then kill the agent
nhard=`ls -l $SSH_AUTH_SOCK | awk '{print $2}'`
if [["$nhard" -eq 2]]; then
rm ~/.ssh/.agent_env
ssh-agent -k
fi
rm $SSH_AUTH_SOCK
}
trap end_agent EXIT
set +x
```
## Clone via SSH
After setting up injection of my SSH keys, I went around the projects I had on my machine and changed the remote from HTTPS to SSH. Now I can interact with remote repositories without having to enter my username and password every time!
## WIP & NAH
Earlier this year Dave Hemphill tweeted about the power of WIP. Essentially that's the only commit message you need. That gives us our first alias
```
alias wip="git add . && git commit -m 'WIP'"
```
I wouldn't advocate this behavoiur for team work or a situation where commit messages are necessary but for me to quickly save state and gaurantee that I'm storing project history, it more than works for me.
The second alias is nah. Nah is a git reset and clean to get your working tree back to the state of the last commit.
```
alias nah="git reset --hard && git clean -df"
```
## GitLens
GitLens gives VSCode super powers. I probably haven't scratched the surface of what this package can do but I can now instantly get the full commit/edit history for any project file from within the editor. | jamessessford |
230,242 | The fight between Try-Catch and If-Else | How do you decide where to use if-else and try-except? I have started this thread because many new p... | 0 | 2020-02-03T04:58:43 | https://dev.to/mrsaeeddev/the-fight-between-try-catch-and-if-else-47fa | discuss, codenewbie, help, refactorit | How do you decide where to use if-else and try-except?
I have started this thread because many new people overuse try-catch or try-except over if-else or vice versa.
## Share your thoughts!!! | mrsaeeddev |
230,278 | Creating a C# Repository in .NET Core using RepoDb | This is an article about creating a dynamic C# Repository using RepoDb | 0 | 2020-01-02T16:08:33 | https://dev.to/mikependon/creating-a-c-repository-in-net-core-using-repodb-57gn | csharp, dotnet, sql, beginners | ---
title: Creating a C# Repository in .NET Core using RepoDb
published: true
description: This is an article about creating a dynamic C# Repository using RepoDb
tags: csharp, dotnet, sql, beginner
---
In this article, we will show you how to create an entity-based C# *Repository* using *RepoDb* ORM.
## Benefits
This will give you a knowledge on how to implement a standard entity-based *Repository* in *fast* and *clean* manner.
## Before we begin
We expect that you have the following software install in your machine.
- Microsoft SQL Server (at least 2016).
- Microsoft SQL Server Management Studio (at least 2016)
- Microsoft Visual Studio (at least 2017).
To proceed, follow the steps below.
## Create a Database
In your SQL Server, execute the script below.
```
CREATE DATABASE [Inventory];
GO
```
## Create a Table
In your SQL Server, execute the script below.
```
USE [Inventory];
GO
CREATE TABLE [dbo].[Customer]
(
[Id] BIGINT IDENTITY(1,1)
, [Name] NVARCHAR(128) NOT NULL
, [Address] NVARCHAR(MAX)
, CONSTRAINT [PK_Customer] PRIMARY KEY CLUSTERED ([Id] ASC )
)
ON [PRIMARY];
GO
```
## Create a C# Project
The project information must be below:
- Name: *InventoryAPI*
- Type: *ASP.NET Core API*
- Test: *No*
- Location: *Any Location*
Leave this project an empty one as we will create our own objects moving forward.
## Create a Model Class
In your C# project, do the following.
- Add a folder named *Models*.
- Inside the *Models* folder, add a new class named *Customer.cs*.
Replace the content of the *Customer.cs* with the code snippets below.
```csharp
public class Customer
{
public long Id { get; set; }
public string Name { get; set; }
public string Address { get; set; }
}
```
## Creating a Repository Class
In your C# project, do the following.
- Add a folder named *Repositories*.
- Inside the *Repositories* folder, add a new class named *CustomerRepository.cs*.
The content of your class would be below.
```csharp
public class CustomerRepository
{
}
```
## Inherit from BaseRepository
At this point in time, you already have the following.
- A database named *Inventory*.
- A table named *Customer*.
- A C# ASP.NET Core API project.
- A class model named *Customer*.
- A repository class named *CustomerRepository*.
Before we proceed, you need to install *RepoDb*. Type the command below in your *Package Manager Console*.
```
Install-Package RepoDb
```
Now, replace the content of your class *CustomerRepository* with the one below.
```csharp
public class CustomerRepository : BaseRepository<Customer, SqlConnection>
{
public CustomerRepository() : base(@"Server=.;Database=Inventory;Integrated Security=SSPI;")
{ }
}
```
> As recommended, not covered by this tutorial, the repository must accept a *connectionString* (or *settings* object) in the constructor. Then pass the value of *connectionString* on the constructor of the base class *BaseRepository*.
The class *BaseRepository* is an embedded base repository object within *RepoDb* library. It is usually used to create an entity-based repository.
> Actually, at this point in time, you already have inherited all the operations of the *BaseRepository*. Without doing anything more, you can now call the *CustomerRepository*.
See sample codes below.
```csharp
using (var repository = new CustomerRepository())
{
var customer = new Customer
{
Name = "John Doe",
Address = "New York"
};
var id = repository.Insert<long>(customer);
...
}
```
The code above will insert a new record in your table *Customer*.
To query, you can use the code below.
```csharp
using (var repository = new CustomerRepository())
{
var customer = repository.QueryAll().FirstOrDefault();
...
}
```
Even though you already have a working *CustomerRepository*, that is still not enough as per the C# standard. By standard, we usually use an interface for dependency-injection.
**Note:** You can also inject a class, not just an interface!
## Implement a Repository Interface
In your C# project, do the following.
- Add a folder named *Interfaces*.
- Inside the *Interfaces* folder, add a new class named *ICustomerRepository.cs*.
Replace the content of the file with the code snippets below.
```csharp
public interface ICustomerRepository
{
Customer GetById(long id);
Customer GetByName(string name);
IEnumerable<Customer> GetAll();
long Insert(Customer customer);
int Update(Customer customer);
int Delete(long id);
}
```
We have created *6 methods* which would enable you to do a basic *CRUD* operations on the *Customer* entity.
## Implement your Custom Methods
First, implement the interface within the *CustomerRepository* class.
See the codes below.
```csharp
public class CustomerRepository : BaseRepository<Customer, SqlConnection>, ICustomerRepository
{
public CustomerRepository ()
: base(@"Server=.;Database=Inventory;Integrated Security=SSPI;")
{ }
}
```
Then, implement the method *one-by-one*. Simply copy and paste the code snippets provided below inside your *CustomerRepository* class.
For *GetById*:
```csharp
public Customer GetById(long id)
{
return Query(id).FirstOrDefault();
}
```
For *GetByName*:
```csharp
public Customer GetByName(string name)
{
return Query(e => e.Name == name).FirstOrDefault();
}
```
For *GetAll*:
```csharp
public IEnumerable<Customer> GetAll()
{
return QueryAll();
}
```
For *Insert*:
```csharp
public long Insert(Customer customer)
{
return Insert<long>(customer);
}
```
For *Update*:
```csharp
public int Update(Customer customer)
{
return Update(customer);
}
```
For *Delete*:
```csharp
public int Delete(long id)
{
return Delete(id);
}
```
By this time, you can now call your own customized methods inside *CustomerRepository* class.
See sample codes below to insert.
```csharp
using (var repository = new CustomerRepository())
{
var customer = new Customer
{
Name = "John Doe",
Address = "New York"
};
var id = repository.Insert(customer);
...
}
```
And the code below is for *GetByName*.
```csharp
using (var repository = new CustomerRepository())
{
var customer = repository.GetByName("John Doe");
...
}
```
## Register your Repository as Service Component
Now, in order for you to be able to use the *Repository* in your project as an injectable object within your controllers, you have to register it as a service component.
To register as a service component, follow the steps below.
- In your *Solution Explorer*, double-click the *Startup.cs* file.
- Navigate inside `ConfigureServices()` method and paste the code below before the method end.
```csharp
services.AddTransient<ICustomerRepository, CustomerRepository>();
```
- Resolve the missing namespaces by placing the mouse inside the *CustomerRepository* and press *Ctrl+Space* > *Enter*.
- Press *Ctrl+S* keys to save the changes.
The engine will register the *CustomerRepository* object (as implemented by *ICustomerRepository* interface) into the services collection. Once the registration is complete, it signifies that our *CustomerRepository* class is now ready to be used for injection.
**Note**: We can as well add it as *Singleton* via `AddSingleton()` method of *IServiceCollection* if we wish to have our `Repository` in a singleton mood.
## Create a Controller
Follow the steps below to create a *Controller* for your *Customer* entity.
- Inside the *Controllers* folder, add a new class named *CustomerController.cs*.
- The new file named *CustomerController.cs* will be created. Replace the class implementation with the script below.
```csharp
[Route("api/[controller]")]
[ApiController]
public class CustomerController : ControllerBase
{
private ICustomerRepository m_customerRepository;
public CustomerController(ICustomerRepository repository)
{
m_customerRepository = repository;
}
}
```
- Press *Ctrl+S* keys to save the changes.
The *Controller* class above accepts an injected *ICustomerRepository* service component. We hold an instance of *Interface*, not *Class*.
> The engine will do the magic for injecting the *ICustomerRepository* after your service component registration.
## Create a Get Method from your Controller
We are almost done! :)
The provided methods below will call the *CustomerRepository* operation. Please copy the provided code snippets below and paste it inside *CustomerController* class just right after the *Constructor*.
```csharp
[HttpGet()]
public ActionResult<IEnumerable<Customer>> Get()
{
return m_customerRepository.GetAll().AsList();
}
[HttpGet("{id}")]
public ActionResult<Customer> Get(long id)
{
return m_customerRepository.GetById(id);
}
```
## Testing the Controller
At this point, our solution is now ready for testing. Build the solution by simply pressing the *Alt + B + R* keys.
Once the build is complete, press the *F5* key to start.
In the browser, type the URL below.
```
http://localhost:44341/customer
```
You can also query the specific records with the link below.
```
http://localhost:44341/customer/1
```
Where the value *1* is equals to the *Customer* id you have in the database.
You will notice that the result is being displayed in the browser as *JSON* file.
## How to find a port?
- Right-click on the project *InventoryAPI* from the *Solution Explorer* and click the *Properties*.
- Click the *Debug* tab.
- Under *Web Server Settings*, you will see the *App URL* field that contains the port.
## Links
You can see and download the actual project [here](https://github.com/mikependon/Tutorials/tree/master/Blogs/DEV.to/BaseRepository/InventoryAPI).
--------
Voila! You have completed this tutorial! Thank you for reading this article. Your support is valuable to us, please do not forget to star our [GitHub](https://github.com/mikependon/RepoDb) page. | mikependon |
230,301 | Super basic: How Hashmap works in Java | Hi there! It is 2020 already and what's a better way to start off the new year than to recap what we... | 0 | 2020-01-02T11:01:04 | https://dev.to/ham8821/super-basic-of-hashmap-in-java-53be | java, devops, beginners, kotlin | Hi there!
It is 2020 already and what's a better way to start off the new year than to recap what we've already know such as how to walk and breathe and get drunk? LOL
Today I might bring up some real basic concepts of hashmap in Java. I am pretty sure a lot of you already know better than anyone on this one. If that's the case, feel free to click the go back button but if you are a little unsure or have no idea what I am talking about, it is up to you spend 2 minute reading this article!

Well, the most well known definition of has a hash map would be a data structure that implements an associative array abstract data type, a structure that can map keys to values.
To make it even easier,
you know when we think of an array, we would probably think of a number index to access to a certain value. ex) arrayName[index]= value
Same goes to hash map except that we can use key instead of number index values.
As shown in the image below, the hashmap is an array of nodes that has Key and Value which makes look ups to be much easier and more efficient by using key values.

If we look into the hashmap slightly more in detail, we can see it looks like a table that has nodes so called buckets which can represent a class having following objects:
<ol>
<li>K key : <i>key string value that we use for look ups</i></li>
<li>int hash: <i>integer hashcode from the string key value</i></li>
<li>V value: <i>the actual value that we want to access</i></li>
<li>Node next: <i>to point out the next entry or node</i></li>
</ol>
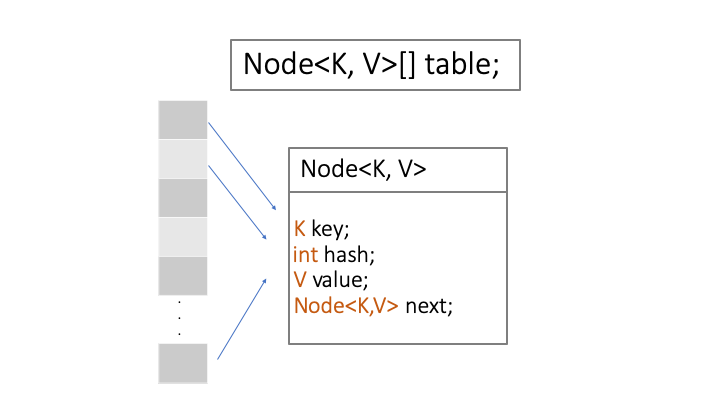
Alright, now we kinda understand what the hashmap is, then it is time for us to have a try to work with it to understand how it actually works.

To explain the steps in order to access to a certain value using key, first of all, I would like to insert some values into the map first for better understanding.
To insert the values, we can use put(k,v) method and to to that, let's quickly create a simple hashmap called scroes where we will be storing the names and scores accordingly.
```
HashMap<String, integer>scores = new HashMap<String, Integer>();
```
Once the hashmap is created, the size of the map will be automatically initialised by 16 which makes the index of the map starts from 0 and finishes to 15.
Now let's say we want to put these three records into the scores map.
<code>
scores.put("Smith","100");
scores.put("Blake","87");
scores.put("King","100");
</code>
To start with the first record, we will be going through this put() method as shown below.
```
put(K k, V v)
hash(k)
index = hash & (n-1)
```
Let's go ahead and start inserting the data.
```
put(K k, V v) // k = "Smith" and v = "100"
hash(k) // This will get the hash of the string key. in this case hash("SMITH")= 79019862
index = hash & (n-1)// n= 16 and index will be 6
```
After this process, the map will look like this
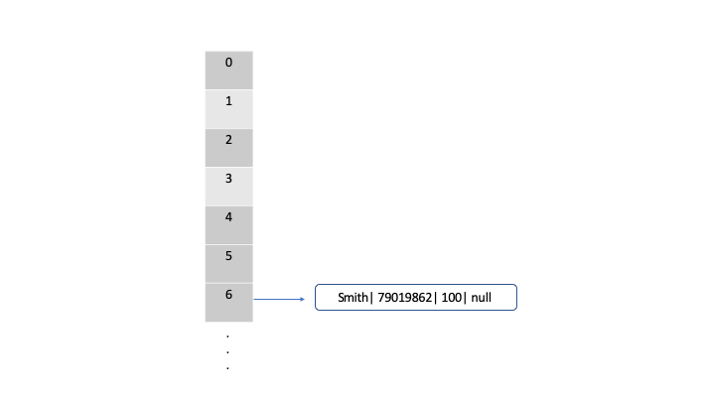
After following the same steps for all the records, the map will end up looking like below
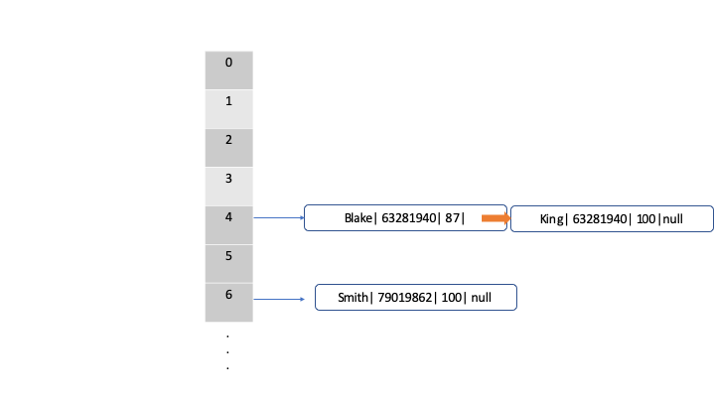
*notice: I forgot to change the hash value for the second record for Kings in the picture. just note that the hash value for king is different from the one for Blake*
Wait, hold on a second, some of you might have noticed that we have 2 records in index 4 node. How did this happen?
If we scroll back a bit up to where we get the index by hash & (n-1), we can check those two records end up having same index which is 4 in this case. Let's say we tried to put Blake's record first and there shouldn't have been any problem, like we understood the data "Blake | hash| score| null" must have been inserted.
But as we insert Kings record after, we will figure out that they have same index number, the map will automatically put the record next to the Blake's record by changing the null value to point out to the next node which is King's in this case. That is how the outcome looks like the map above.
This will also lead us to this question.
"If they have same index number, how do we access to them?"
In order to access to the nodes, we can use get(k) method.
This method looks like this.
```
V get(Object key)
hash(key)
Index = hash & (n-1)
```
Now, let's say we want to find King's score in this hashmap using
```
scores.get("King")
```
then it will get the hash which is 2306996 and will get the index number which is 4 in this case. In the first node which has index 4, it will compare hashcode between the hascode that we are looking for and the hashcode that this node has. For example, the hascode we are looking for is 2306996 and the node has 63281940 as a hash value. They don't match, so it will be pointed out to the next node which and will do the comparison again. This time the hash value do match since it has 2306996 which we are looking for.
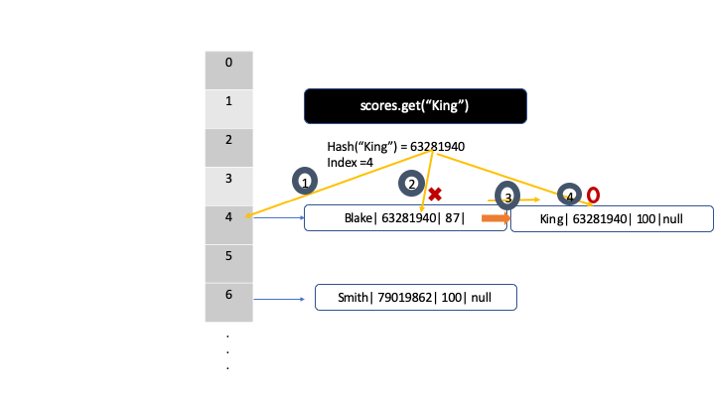
*notice: I forgot to change the hash value for the second record for Kings. just note that the hash value for king is different from the one for Blake*
Alright!
Today, we have talked about some of the basic concepts of hashmap. Actually, the reason I brought this topic up today was that I realised that hashmap come across very often we we code and it is very easy to just overlook, thinking that we understand how it works 100%. However, when I faced some complicated issues, I realised that I wasn't really understanding how it works and how to use it properly. I hope it helped for some of you guys to understand little bit better about hashmap and not get confused later when we really need to go through some concepts along the way of programming.
Thanks a lot for your time to read this article and Happy new year!!!
 | ham8821 |
230,317 | Build a Rest API with Python - The easiest way | How you can build a Rest api with Python | 0 | 2020-01-02T10:30:29 | https://dev.to/xarala221/build-a-rest-api-with-python-the-easiest-way-16f0 | python, django, djangorest, api | ---
title: "Build a Rest API with Python - The easiest way"
published: true
description: "How you can build a Rest api with Python"
tags: python, django, django-rest, api
cover_image: https://images.unsplash.com/photo-1496262967815-132206202600?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=795&q=80
---
In this tutorial we will transform our Django phonebook Application to a Rest API
> A REST API defines a set of functions which developers can perform requests and receive responses via HTTP protocol such as GET, POST, PUT and DELETE
Think REST API as a web service that provide you the data you want to use in your application(mobile or front-end client).
The key component for a REST API request are:
**GET** — The most common option, returns some data from the API based on the given endpoint .
**POST** — Creates a new record and add it to the database.
**PUT** — Update an existing record.
**DELETE** — Deletes the record on the given endpoint.
## Getting started
```sh
$ git clone https://github.com/xarala221/django-phonebook.git
$ cd django-phonebook
```
## Application setup
```sh
$ pipenv install
Creating a virtualenv for this project…
Using /usr/bin/python3.7m (3.7.5) to create virtualenv…
$ pipenv shell
Spawning environment shell (/usr/bin/zsh). Use 'exit' to leave.
. /home/username/.local/share/virtualenvs/phonebook_rest_api-9zIZds3o/bin/activate
```
## Run the application
```sh
(my-env) $ python manage.py runserver
```
Notice i use **pipenv** instead of pip but you can use pip if you want it's up to you.
The application is running at http://localhost:800/
```sh
.
├── accounts
│ ├── admin.py
│ ├── apps.py
│ ├── forms.py
│ ├── __init__.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ ├── urls.py
│ └── views.py
├── contact
│ ├── admin.py
│ ├── apps.py
│ ├── __init__.py
│ ├── migrations
│ │ ├── 0001_initial.py
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ ├── urls.py
│ └── views.py
├── db.sqlite3
├── manage.py
├── phonebook
│ ├── asgi.py
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── Pipfile
├── Pipfile.lock
├── README.md
├── requirements.txt
└── templates
├── accounts
│ ├── login.html
│ └── register.html
├── base.html
├── contact
│ ├── contact_details.html
│ ├── contact_list.html
│ ├── delete_contact.html
│ ├── new_contact.html
│ └── update_contact.html
├── index.html
└── partials
└── _navbar.html
```
This is our folder structure.
## Setup Django REST Framework
Django REST framework is a powerful and flexible toolkit for building Web APIs.
```sh
(myenv) $ pipenv install djangorestframework
```
In phonebook/settings.py add
```sh
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework', # add this
'contact',
]
```
## Serialize the contact Table(Model)
Let's create a new file -- contact/serializers.py
```sh
# contact/serializers.py
from rest_framework import serializers
from .models import Contact
class ContactSerializer(serializers.ModelSerializer):
class Meta:
model = Contact
fields = '__all__'
```
## Preparing the data
Create a new file -- contact/api.py
```sh
# contact/api.py
from rest_framework import viewsets
from .serializers import ContactSerializer
from .models import Contact
class ContactViewSet(viewsets.ModelViewSet):
serializer_class = ContactSerializer
queryset = Contact.objects.all()
```
Update our contact/urls.py
```sh
from django.urls import path, include # add this
from rest_framework.routers import DefaultRouter # add this
from .views import (
index, contact_list,
new_contact, contact_details,
update_contact, delete_contact
)
from .api import ContactViewSet # add this
router = DefaultRouter() # add this
router.register(r'contacts', ContactViewSet,
basename='contact') # add this
urlpatterns = [
path("api/", include(router.urls)),
path("", index, name="home"),
path("contacts/", contact_list, name="contacts"),
path("contacts/new/", new_contact, name="new"),
path("contacts/<int:id>/details/", contact_details, name="details"),
path("contacts/<int:id>/update/", update_contact, name="update"),
path("contacts/<int:id>/delete/", delete_contact, name="delete"),
]
```
Open your browser and go to http://localhost:8000/api/
You will see something like this :
```sh
HTTP 200 OK
Allow: GET, HEAD, OPTIONS
Content-Type: application/json
Vary: Accept
{
"contacts": "http://localhost:8000/api/contacts/"
}
```
Click on the link what you see ?
- You should see a list of contact if they exist in your database.
- You can also create new data
Let's wrap it
In this tutorial you learned how to create a REST API with Django and Django Rest Framework.
In the next tutorial i will handle the more complex topic like :
- Authentication and authorization
- Serialize nested object
- Serialize relation field
- etc..
See you in the next tutrial
| xarala221 |
230,327 | Deploying Resources to Azure with Ansible | Ansible is a configuration management tool used to control and apply configuration changes to infrast... | 4,008 | 2020-01-06T11:57:42 | https://dev.to/cloudskills/deploying-resources-to-azure-with-ansible-1pon | azure, ansible, devops | <!-- Introduction, Prerequisites, and Goals -->
Ansible is a configuration management tool used to control and apply configuration changes to infrastructure. However, before you can apply changes to the infrastructure it first has to exist. Ansible has several Azure modules that allow you to deploy resources in Azure. This tutorial will walk you through deploying a Windows virtual machine to Azure using an Ansible playbook. By the end of the tutorial you'll understand how to use several of the Azure Ansible modules to deploy workloads to Azure.
### Prerequisites
In order to follow along in this tutorial you'll need the following:
* [Ansible installed](https://docs.microsoft.com/en-us/azure/virtual-machines/linux/ansible-install-configure?toc=%2Fazure%2Fansible%2Ftoc.json&bc=%2Fazure%2Fbread%2Ftoc.json#install-ansible-on-an-azure-linux-virtual-machine)
* `ansible[azure]` pip packaged installed
* [Connection to Azure from Ansible setup](https://dev.to/joshduffney/connecting-to-azure-with-ansible-22g2)
# Table Of Contents
* [Azure Ansible Modules](#Ansible-Module-Index-Azure)
* [Playbook Contents](#playbook-contents)
* [Create a Resource Group](#create-resource-group)
* [Create a Virtual Network](#create-virtual-network)
* [Create a Public Ip](#create-public-ip)
* [Create a Network Security Group](#create-network-security-group)
* [Create a Virtual Network Interface Card](#create-virtual-network-card)
* [Create a Virtual Machine](#create-virtual-machine)
* [Deploy an Azure Windows Virtual Machine](#deploy-azure-windows-virtual-machine)
* [Conclusion](#conclusion)
# [Azure Ansible Modules](https://docs.ansible.com/ansible/latest/modules/list_of_cloud_modules.html#azure) <a name="Ansible-Module-Index-Azure"></a>
Creating a virtual machine in Azure requires several different Azure resources; a resource group, virtual network, subnet, public ip address, network security group, network interface card, and the virtual machine itself. Each of these Azure resources can be managed and modified using an Ansible module. These Ansible modules allow you to codify your infrastructure in yaml files in the form of Ansible playbooks. Below is a list of the Ansible modules that are used throughout this tutorial. However, many more Ansible modules exist and can be found in [Ansible's module index.](https://docs.ansible.com/ansible/latest/modules/list_of_cloud_modules.html#azure)
_Ansible modules required to deploy an Azure virtual machine_
* [azure_rm_resourcegroup](https://docs.ansible.com/ansible/latest/modules/azure_rm_resourcegroup_module.html#azure-rm-resourcegroup-module)
* [azure_rm_virtualnetwork](https://docs.ansible.com/ansible/latest/modules/azure_rm_virtualnetwork_module.html#azure-rm-virtualnetwork-module)
* [azure_rm_subnet](https://docs.ansible.com/ansible/latest/modules/azure_rm_subnet_module.html#azure-rm-subnet-module)
* [azure_rm_publicipaddress](https://docs.ansible.com/ansible/latest/modules/azure_rm_publicipaddress_module.html#azure-rm-publicipaddress-module)
* [azure_rm_securitygroup](https://docs.ansible.com/ansible/latest/modules/azure_rm_securitygroup_module.html#azure-rm-securitygroup-module)
* [azure_rm_networkinterface](https://docs.ansible.com/ansible/latest/modules/azure_rm_networkinterface_module.html#azure-rm-networkinterface-module)
* [azure_rm_virtualmachine](https://docs.ansible.com/ansible/latest/modules/azure_rm_virtualmachine_module.html#azure-rm-virtualmachine-module)
# Playbook Contents <a name="playbook-contents"></a>
### Create a Resource Group <a name="create-resource-group"></a>
Azure resource groups are used to logically group related resources. Resource groups help organize your cloud environment and can also be used to grant access to specific workloads within the resource group. They are also required when creating other Azure resources. Such as virtual networks. Another benefit of resource groups is easy cleanup. When you delete a resource group everything inside of it is deleted with it.
In order to create an Azure resource group with Ansible use the `azure_rm_resourcegroup` module. It requires two parameters; `name` and `location`. The name parameter will become the name of the resource group and the location is the Azure region the resource group is placed in. Placing a resource group in one region does not mean you can only use that region for other Azure resources inside the resource group. It is simply where the metadata of the resource group is located.
```yaml
- name: Create resource group
azure_rm_resourcegroup:
name: ansible-rg
location: eastus
```
### Create a Virtual Network <a name="create-virtual-network"</a>
Virtual networks allow you to build out your private network within Azure. Virtual networks are used to connect resources running within an Azure data center. Even though they are virtual and exist out of reach to you. The same networking principals apply. The virtual network requires two main parts; address space and a subnet or subnets.
In order to deploy the virtual network in Azure with Ansible you'll need use two Ansible modules; `azure_rm_virtualnetwork` and `azure_rm_subnet`. The subnet module depends on the network module and for that reason the network module will be defined first. Ansible is procedural and the order of the tasks is very important.
The task `Create virtual network` requires three parameters; `resource_group`, `name`, and `address_prefixes`. The resource_group is the name given to the previous tasks which created the resource group. `vNet` is the name given to the virtual network resource and will be used when creating the subnet. Address prefixes of `10.0.0.0/16` defines the address space of the virtual network.
```yaml
- name: Create virtual network
azure_rm_virtualnetwork:
resource_group: ansible-rg
name: vNet
address_prefixes: "10.0.0.0/16"
```
`Add subnet` is the next tasks which is used to add a subnet range to the virtual network. A subnet is a logical subdivision of an IP network and in this example it is used to carve out a section of IP addresses for web machines within that network. The task uses the `azure_rm_subnet` Ansible module. The subnet is given the name of `webSubnet` followed by the address prefix of the subnet `10.0.1.0/24` and it specifies the virtual network where the subnet will be created which is `vNet`.
```yaml
- name: Add subnet
azure_rm_subnet:
resource_group: ansible-rg
name: webSubnet
address_prefix: "10.0.1.0/24"
virtual_network: vNet
```
### Create a Public Ip <a name="create-public-ip"</a>
While the virtual network created previously will assign a private Ip address to the virtual machine the Public Ip address assigns a public Ip address to the virtual machine. Without a Public Ip address you won't be able to communicate with the virtual machine without a VPN or other means. To create an Azure Public Ip address resource using Ansible, you'll use the `azure_rm_publicipaddress` module.
In order to create an Azure Public Ip address you'll need to define the following parameters; resource group, allocation method, and name. Specifying the resource group of ansible-rg places the public ip address in the same location as the rest of the resources already created. Allocation method determines when the Ip address is assigned to the resource and when the Ip address is released. There are two options for allocation method, static and dynamic and the resource SKU determines which of these you can choose. To learn more about these options check out [IP address types and allocation methods in Azure](https://docs.microsoft.com/en-us/azure/virtual-network/virtual-network-ip-addresses-overview-arm#sku). The name of the resource is `webPublicIP`.
Perhaps you want to return the public Ip address assigned right after the resource is created. You can accomplish this by using an Ansible command called [register](https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#registering-variables_). Register allows you to populate variables based on the output of Ansible tasks. In this example the output of the task Create public IP address is assigned to a variable named `output_ip_address_`. Registering the variable does not output the information. Which is what the debug command does within the `Output public IP` task. Because output from tasks are in JSON you can parse the results to display what you want. In this example the variable output_ip_address is parsed to display only the ip address and nothing else.
```yaml
- name: Create public IP address
azure_rm_publicipaddress:
resource_group: ansible-rg
allocation_method: Static
name: webPublicIP
register: output_ip_address
- name: Output public IP
debug:
msg: "The public IP is {{ output_ip_address.state.ip_address }}"
```
### Create Network Security Group <a name="create-network-security-group"</a>
Azure Network Security Groups are what filter network traffic based on a set of rules that are defined. You can think of them as being similar to a network firewall. Without a network security group allowing traffic in, you will not be able to connect to your virtual machine within Azure. For that reason it is necessary to use the `azure_rm_securitygroup` module to create one and also define some rules allowing traffic in.
In this example you'll want to connect to the virtual machine using three different protocols; RDP, HTTP, HTTPS, and WimRM. Each of these uses different inbound ports to communicate. RDP uses 3389, HTTP uses 80, HTTPS uses 443, and WinRM uses 5985 and 5986. Each of these protocols will require a set of rules associated with the network security group allowing inbound traffic in. To create an Azure network security group you only need two pieces of information. The resource group to associate it with and the name of the network security group. However, you'll need more information to create rules associated with it.
It is a common practice to create one rule per protocol. In this example, you'll create three rules. When creating the rules each one requires you specify a name, protocol, destination port range, access, priority, and direction.
```yaml
- name: Create Network Security Group
azure_rm_securitygroup:
resource_group: ansible-rg
name: networkSecurityGroup
rules:
- name: 'allow_rdp'
protocol: Tcp
destination_port_range: 3389
access: Allow
priority: 1001
direction: Inbound
- name: 'allow_web_traffic'
protocol: Tcp
destination_port_range:
- 80
- 443
access: Allow
priority: 1002
direction: Inbound
- name: 'allow_powershell_remoting'
protocol: Tcp
destination_port_range:
- 5985
- 5986
```
### Create a Virtual Network Interface Card <a name="create-virtual-network-card"</a>
Every computer virtual or not requires some form of network interface card to communicate with computers outside of itself. That is where the Azure virtual network interface card comes in. Previous to this you've created several virtual networking components; a virtual network, subnet, a public ip address, and a network security group. All of these resources will be assigned to a virtual network interface card giving the Azure virtual machine private and public network access.
The Ansible module to create an Azure virtual network interface is `azure_rm_networkinterface`. In order to properly configure the interface you must associate it with a virtual network, subnet, network security group, and to access the virtual machine from the internet a public Ip address.
```yaml
- name: Create a network interface
azure_rm_networkinterface:
name: webNic
resource_group: ansible-rg
virtual_network: vNet
subnet_name: webSubnet
security_group: networkSecurityGroup
ip_configurations:
- name: default
public_ip_address_name: webPublicIP
primary: True
```
### Create a Virtual Machine <a name="create-virtual-machine"</a>
Everything to this point as prepared the Azure environment for you to deploy the virtual machine. You have a lot of options when it comes to deploying a virtual machine in Azure. However, in this tutorial you'll be deploying a Standard DS1 v2 Windows Server 2019 virtual machine. The Ansible module used to deploy Azure virtual machines is `azure_rm_virtualmachine`.
As with every Azure resource you've created so far the virtual machine requires a resource group and a name. The name will be used for the Azure resource and the virtual machine's hostname. The `vm_size` uses Azure a Standard_DS1_v2 instance. You can learn more about Azure's instance sizes [here](https://docs.microsoft.com/en-us/azure/virtual-machines/windows/sizes). Windows virtual machines also require a user name and password be specified when you create the virtual machine. `admin_username` is set to azureuser and will be the local user account you'll login with. `admin_password` is set to `"{{ password }}"` which is an Ansible variable. To avoid having the password stored in clear text, you'll prompt for that input in the next section.
`webNic` is the only network interface you'll need to define at this time. It will connect the virtual machine to the private and public Ip addresses you defined when creating the network resources. `os_type` defines which Operating System will be used by the virtual machine. Setting this to `Windows` changes the behavior of the default parameters passed in to the task. `image` has several sub parameters that define the image used to build the virtual machine. When choosing an image you must specify; the offer (WindowsServer), the publisher (MicrosoftWindowsServer), sku (2019-Datacenter), and version (latest).
```yaml
- name: Create VM
azure_rm_virtualmachine:
resource_group: ansible-rg
name: winWeb01
vm_size: Standard_DS1_v2
admin_username: azureuser
admin_password: "{{ password }}"
network_interfaces: webNic
os_type: Windows
image:
offer: WindowsServer
publisher: MicrosoftWindowsServer
sku: 2019-Datacenter
version: latest
```
### Deploy an Azure Windows Virtual Machine <a name="deploy-azure-windows-virtual-machine"</a>
Throughout this tutorial you've seen snippets of Ansible tasks. When putting those tasks into a playbook you have to add a few additional sections. `hosts` is used to define which target the playbook will be executed against. Setting this to localhost will run the playbook on the Ansible server itself.
`var_prompts` is used to prompt for Ansible variables when the playbook is executed. It's a simple choice for populating variables that contain sensitive information that you do not want to store in the playbook file. You'll use it to prompt for and populate the password used by the task creating the virtual machine.
`tasks` define the sequential tasks that are executed to complete the playbook. The order of these tasks is very important. For example, the task creating the resource group must be at the top. Without the resource group all the tasks after it will fail because the resource group does not exist yet.
Because the tasks used in this playbook create Azure resources a connection from Ansible to Azure must be establish before you can execute the playbook. You have several options available to connect Ansible to Azure. You can define environment variables or create an Ansible credential file. Both options are explained in dept in [Connecting to Azure with Ansible](https://dev.to/joshduffney/connecting-to-azure-with-ansible-22g2)
{% link https://dev.to/joshduffney/connecting-to-azure-with-ansible-22g2 %}
```yaml
#deployWindowsAzureVirtualMachine.yaml
---
- hosts: localhost
connection: local
vars_prompt:
- name: password
prompt: "Enter local administrator password"
tasks:
- name: Create resource group
azure_rm_resourcegroup:
name: ansible-rg
location: eastus
- name: Create virtual network
azure_rm_virtualnetwork:
resource_group: ansible-rg
name: vNet
address_prefixes: "10.0.0.0/16"
- name: Add subnet
azure_rm_subnet:
resource_group: ansible-rg
name: webSubnet
address_prefix: "10.0.1.0/24"
virtual_network: vNet
- name: Create public IP address
azure_rm_publicipaddress:
resource_group: ansible-rg
allocation_method: Static
name: webPublicIP
register: output_ip_address
- name: Output public IP
debug:
msg: "The public IP is {{ output_ip_address.state.ip_address }}"
- name: Create Network Security Group
azure_rm_securitygroup:
resource_group: ansible-rg
name: networkSecurityGroup
rules:
- name: 'allow_rdp'
protocol: Tcp
destination_port_range: 3389
access: Allow
priority: 1001
direction: Inbound
- name: 'allow_web_traffic'
protocol: Tcp
destination_port_range:
- 80
- 443
access: Allow
priority: 1002
direction: Inbound
- name: 'allow_powershell_remoting'
protocol: Tcp
destination_port_range:
- 5985
- 5986
access: Allow
priority: 1003
direction: Inbound
- name: Create a network interface
azure_rm_networkinterface:
name: webNic
resource_group: ansible-rg
virtual_network: vNet
subnet_name: webSubnet
security_group: networkSecurityGroup
ip_configurations:
- name: default
public_ip_address_name: webPublicIP
primary: True
- name: Create VM
azure_rm_virtualmachine:
resource_group: ansible-rg
name: winWeb01
vm_size: Standard_DS1_v2
admin_username: azureuser
admin_password: "{{ password }}"
network_interfaces: webNic
os_type: Windows
image:
offer: WindowsServer
publisher: MicrosoftWindowsServer
sku: 2019-Datacenter
version: latest
```
`ansible-playbook` is the Ansible command used to execute playbooks. Because the playbook is targeting localhost, the Ansible server itself no inventory or host file is required. All that is required is the name of the playbook to be executed. Save the above playbook as `deployWindowsAzureVirtualMachine.yaml` and run the following command to deploy your Windows virtual machine to Azure!
```yaml
ansible-playbook deployWindowsAzureVirtualMachine.yaml
```
_Modified recording, actual run time 5 minutes_
### Conclusion <a name="conclusion"</a>
You've now deployed a Windows virtual machine to Azure! At this point you might be wondering what the benefit of using Ansible is over creating the resources in the Azure portal or by using a PowerShell script. The benefits of using Ansible are;
* codified infrastructure
* idempotent automation
* configuration management
If you had used the portal you'd have a difficult time recreating the environment exactly the way it was before. If you had scripted the creation of all these resources you wouldn't be able to run that same script over and over without a lot of modification and error handling. That is where the idempotent nature of Ansible is extremely valuable. | joshduffney |
230,346 | Stock charts with fl_chart library | There is no better way to present data than a pie chart as we saw in this Dilbert comic strip. But s... | 4,011 | 2020-01-02T21:34:10 | https://dev.to/kamilpowalowski/stock-charts-with-flchart-library-1gd2 | flutter, dart, charts, stock | There is no better way to present data than a pie chart as we saw in this [Dilbert comic strip](http://dilbert.com/strip/2009-03-07).
But sometimes you want to display values that changed over time. More suitable for these tasks are the line and bar charts. It doesn’t matter which type of chart you want to use in your Flutter mobile app - all of them you can create using [fl_chart Package](https://pub.dev/packages/fl_chart) made by Iman Khoshabi - imaNNeoFighT.
## Challange
To get used to **fl_chart** library I created a challenge for myself - display stock data using Flutter. The chart should look pretty and I should be able to read some information by just looking at the chart. Here is an effect of my work:
## Solution
### Get data
The first problem that I was forced to solve was a way to get data for this challenge. Most of the stock charts' data APIs are paid and required registration. After some research, I found about [eodhistoricaldata.com](https://eodhistoricaldata.com/). They provide example endpoints with fixed user token for testing purposes. To my excitation, sample data was for AAPL (Apple) stock data on NASDAQ. Using `https://eodhistoricaldata.com/api/eod/AAPL.US?from=2018-01-01&to=2018-12-31&api_token=OeAFFmMliFG5orCUuwAKQ8l4WWFQ67YX&period=d&fmt=json` URL call I was able to get Apple stock prices for whole 2018 year. To make things easier for this challenge I saved the result of this call as `data.json` in `assets` directory and added it to project in `pubspec.yaml`:
```yaml
...
flutter:
assets:
- assets/data.json
...
```
### Load data
My `data.json` file contains an array/list of items that look like this:
```json
[
{
"date": "2018-01-02",
"open": 170.16,
"high": 172.3,
"low": 169.26,
"close": 172.26,
"adjusted_close": 167.1997,
"volume": 25555934
},
...
]
```
To use them I’ve created `datum.dart` model with content:
```dart
class Datum {
Datum({this.date, this.close});
final DateTime date;
final double close;
Datum.fromJson(Map<String, dynamic> json)
: date = DateTime.parse(json['date']),
close = json['close'].toDouble();
}
```
As you can see I took only two values that I’ll need for displaying the chart - date of entry and close price. Then I prepared the code to load this stock values to memory:
```dart
import 'dart:async';
import 'dart:convert' show jsonDecode;
import 'package:flutter/services.dart' show rootBundle;
import 'package:fluttersafari/datum.dart';
Future<List<Datum>> loadStockData() async {
final String fileContent = await rootBundle.loadString('assets/data.json');
final List<dynamic> data = jsonDecode(fileContent);
return data.map((json) => Datum.fromJson(json)).toList();
}
```
For this simple project `jsonDecode` function available in `dart:convert` package is sufficient but for bigger projects, I would recommend `json_serializable` as explained in [JSON and serialization](https://flutter.dev/docs/development/data-and-backend/json) article of Flutter documentation.
### Add library
To use **fl_chart** I added the library to the project. This required another edit of `pubspec.yaml` file:
```yaml
...
dependencies:
flutter:
sdk: flutter
fl_chart: ^0.6.0
...
```
And calling `flutter pub get` after it.
### Prepare data
Before I'll pass our data to **fl_chart** I have to transfer it to form understand by this library. Axis based charts are expecting a list of `FlSpot` objects that will represent points of interest on our chart. Each `FlSpot` object contains two `double` values (`x` and `y`). My X axis will display time and Y will show a close price.
```dart
final List<Datum> data = await loadStockData();
final List<FlSpot> values = data
.map((datum) => FlSpot(datum.date.millisecondsSinceEpoch.toDouble(), datum.close))
.toList();
setState(() {
_values = values;
});
```
I've used `millisecondsSinceEpoch` to get an integer number for each data point. Full solution (attached at the end of blogpost) requires to provide `minX`, `maxX`, `minY`, `maxY` values which present lowest and highest numbers (with additional offset if needed) limiting chart in both directions.
### Display chart
Now, when I have data ready to display, it's time to create a `LineChart` widget.
```dart
LineChart(_mainData());
```
Nothing interesting here, right? The real fun starts with `LineChartData` object.
```dart
LineChartData _mainData() {
return LineChartData(
gridData: _gridData(),
titlesData: FlTitlesData(
bottomTitles: _bottomTitles(),
leftTitles: _leftTitles(),
),
lineBarsData: [_lineBarData()],
);
}
```
We can control each aspect of `LineChart` widget. From the look of the grid, color and shape of chart border to labels on any side of the cart to most important - lines that visualize our data. All available parameters can be inspected on the [documentation](https://github.com/imaNNeoFighT/fl_chart/blob/master/repo_files/documentations/line_chart.md) page.
### Line and background
Now let's focus on some elements starting from crème de la crème - the `_lineBarData()` function that will provide stock data information for `LineChartData` widget.
```dart
LineChartBarData _lineBarData() {
return LineChartBarData(
spots: _values,
colors: _gradientColors,
colorStops: const [0.25, 0.5, 0.75],
gradientFrom: const Offset(0.5, 0),
gradientTo: const Offset(0.5, 1),
barWidth: 2,
isStrokeCapRound: true,
dotData: const FlDotData(show: false),
belowBarData: BarAreaData(
show: true,
colors: _gradientColors.map((color) => color.withOpacity(0.3)).toList(),
gradientColorStops: const [0.25, 0.5, 0.75],
gradientFrom: const Offset(0.5, 0),
gradientTo: const Offset(0.5, 1),
),
);
}
```
This may look scary to you at the begging but despite providing transformed values in `spots: _values` I'm setting just a few parameters that will give this chart these awesome gradient colors. Please take a look at `belowBarData` property. Using this field I can control how the area below chart line looks. I just set it to three gradient colors stored in the `_gradientColors` variable.
```dart
final List<Color> _gradientColors = [
const Color(0xFF6FFF7C),
const Color(0xFF0087FF),
const Color(0xFF5620FF),
];
```
### Labels
displaying left and bottom labels may be a bit tricky at first. Let's take a look at this code:
```dart
SideTitles _bottomTitles() {
return SideTitles(
showTitles: true,
textStyle: TextStyle(
color: Colors.white54,
fontSize: 14,
),
getTitles: (value) {
final DateTime date =
DateTime.fromMillisecondsSinceEpoch(value.toInt());
return DateFormat.MMM().format(date);
},
margin: 8,
interval: (_maxX - _minX) / 6,
);
}
```
For each data point, `LineChart` will call `getTitles` function (which in this case converts data back to `DateTime` object and returns short month name) and tries to display it below the chart. To not clutter chart with data, I used the interval parameter to limit how often `getTitles` should be called (I decided to display only 6 labels below the chart).
A similar solution is used for `_leftTitles()` but their interval calculations are more complicated so I leave them to check in full example available at the end of the blogpost.
```dart
SideTitles _leftTitles() {
return SideTitles(
showTitles: true,
textStyle: TextStyle(
color: Colors.white54,
fontSize: 14,
),
getTitles: (value) =>
NumberFormat.compactCurrency(symbol: '\$').format(value),
reservedSize: 28,
margin: 12,
interval: _leftTitlesInterval,
);
}
```
### Grid
Last, but not least - we can control the way the grid is displayed.
```dart
FlGridData _gridData() {
return FlGridData(
show: true,
drawVerticalLine: false,
getDrawingHorizontalLine: (value) {
return const FlLine(
color: Colors.white12,
strokeWidth: 1,
);
},
checkToShowHorizontalLine: (value) {
return (value - _minY) % _leftTitlesInterval == 0;
},
);
}
```
An optional `checkToShowHorizontalLine` function will tell which horizontal lines should be displayed. To fit grid lines to horizontal values, I've used logic related to a previously computed `_leftTitlesInterval` variable (to be inspected in the full code repository).
## Summary
Making eye-appealing charts usually required two very different steps. We have to prepare data first and then load it on the user interface. The first one is fully on you. But for UI, you can use a **fl_chart** or different library that can help you with this task. I hope that my challenge will motivate you for own experiments with this awesome library.
For full implementation of this project go to [Flutter Safari](https://github.com/kamilpowalowski/fluttersafari/tree/fl_chart) repository on Github. | kamilpowalowski |
230,381 | (Most) IT Recruiters suck. Here's how to fix it. | Ask techies: How's jobhunting, nowadays? The answer is: it's HORRIBLE. I am sorry but that's the mo... | 0 | 2020-01-02T12:25:05 | https://dev.to/luisnomad/most-it-recruiters-suck-here-s-how-to-fix-it-3e95 | recruiters, it, hr, jobhunting | Ask techies: How's jobhunting, nowadays?
The answer is: it's _HORRIBLE_.
I am sorry but that's the most accurate word to describe it. It's utterly terrible, disappointing, and frustrating. Considering we developers and technical people are such a juicy prize, we're treated like shit, both by recruiters and companies. It's not my opinion, ask any developer you know. They will agree in less than two seconds, no need to think about the answer.
But why?
I am going to tell you my opinion. The fact that dealing with interviews and recruiters is crap is not debatable. That is a fact. Now, the reasons for this situation are open to discussion and what I am saying here is my point of view, purely personal, based on my own experience.
## Where are the professional, trained recruiters?
It looks to me like nowadays anyone can call themselves "recruiters". Not so long ago, recruiters were people with specialized studies, even psychology degrees. People who were trained to understand people. What happened to that? There were proper formalities, and a candidate was informed of the status of the process. There was respect.
Now, we are contacted by random people offering some positions that might or might not fit our profile. We answer that message telling them we're interested, and we might or might not get a reply. If we get a reply, it's like it was us who started begging for that job, because we have to constantly ping the recruiter to know what's going on. That is, of course, if the conversation doesn't abruptly die (from their side).
## Secrecy about the company and job conditions
Maybe we're offered an interview with a ghost company because they don't want to give away the name or any detail. We probably don't know about the salary range either. Recruiters ask us, and we have to tell them about our expectations. That's no confirmation that we'll get anything close to that. I've been offered way less than expected AFTER all the interviews, because you know, "that's the average for the position in my city".
How can we prepare for interviews or do proper filtering of where we apply to, if we don't know all the details? If a recruiter wants to know everything about me, I have to tell them or I lose my chance. It should be reciprocal.
## No, really, read my profile
If you want to understand my profile, the best way to do it is to read it in the first place. I've been told things like "oh, you seem to be a bit unstable, there's a lot of jobs in your CV". No Mister, I have been freelancing and I've had a lot of customers. That, in my dictionary, is called a success, not instability.
Also, please, just because I did some Java a million years ago doesn't mean I am a fit in that Java position you're managing today. Context, my friend. Also, most of us evolve, we started doing something, and we ended up doing something else. Or we specialized in something, who knows. So yes, consider our past, but to see if we're what you're looking for, check what we're doing now! Best clue ever, for free.
## Technical Interviews are bullshit
I've been in technical interviews with two managers and one engineer, and I've been asked questions that the engineer probably didn't know either. It's like they wanted to prove what I didn't know, instead of what I know and what I can do for the team and the company. Funny thing is, the last time I was rejected for not answering something correctly, the engineer had to read the correct answer from the script to check if I was correct. He had some random "tricky javascript questions" in front of him. He asked me something he did not know, and they rejected me for not being "Senior enough". Come on...!
I am totally open to discussing technical things in interviews, but spending 1 day coding a full website to get a position, no thanks. Especially if I don't know what am I fighting for. Tell me what the reward is, the full conditions list, and I'll decide if I want to do that long technical challenge you sent me.
If each screening process has a long technical challenge, imagine being involved in two or three. I get that companies need to vet people -if a technical challenge is their way to do it, so be it, but be reasonable. And please, don't expect people to know things by heart, especially if the engineer asking the questions doesn't know the answer either. That gives a really poor impression to candidates.
## No, developers should not be recruiters
Please, put that engineer back to their computer. Developers shouldn't be allowed near a candidate, ever. Unless they have some basic people skills and empathy, they should stay away from recruitment processes completely. It's ok for them to validate technical tests, but they shouldn't be deciding anything. Maybe developers who lead teams are an exception. They made it there because they're good both with code and with people.
Very often, developers doing recruitment make the interview a competition, a confrontation of opinionated approaches (also known as DOGMAS). Some even fear hiring someone better, more experienced, who might eventually replace them, get more money or simply be more popular. It could end up being a fight of egos. A chance to show bosses how good they are compared to anyone who shows at the door. No. Leave them out, unless you've vetted those developers first, and you're sure they can offer a fair chance to candidates.
Use this checklist to make sure that developers are fit to do recruiting:
* can they do what they expect candidates to do?
* Do they know the answer to the questions they will ask?
* Are they good team players?
* Are they good with communication?
* Can they sell the company and the project?
* Are they positive?
* Are they happy in the company?
If you can answer "YES" to "ALL", then go ahead and bring the developer into the process. Otherwise, restrict the scope of that participation to technical checking, away from the candidate. And if possible, ask for feedback to more than one dev, to avoid personal bias over legit reasons to discard someone.
## Respect & Professionalism
I get that recruiters have a job to do and that they're only paid if they find the right people. Copying and pasting a job offer mindlessly & ruthlessly to everyone fitting your "search keywords" and not properly managing answers is not the way to go. Here are some steps I suggest you follow to be a professional & respectful recruiter:
* Collect a small number of profiles you've reviewed. A number of _people_ you can manage.
* Shortlist the best ones.
* Send them a personalized message.
* If they reply positively, proceed with their candidacy. The ones who did not respond or showed no interest, save them for the next opportunity. You've shortlisted them for a reason. Don't let that work go to waste.
* Do you expect full disclosure from candidates? Well, lead by example. Provide all the details about the job opportunity. If you don't know all the details, why are you contacting candidates already? Get the answers first!
* What? You don't want to give away the name of the company in case the candidate bypasses you and you're not paid? Hey... we're not like that. Why would we do that anyway? What do we gain? That would make us look shady. Don't worry, we're not stealing from you.
* Job hunting is an emotional & energy draining experience. And chances are we're in more than one screening process at once. So keep in mind: it's harder for us than it is for you.
* Try to watch any technical person on the company's side involved in the process. If there are developers in the decision-making circle, that's potentially bad news (for the reasons explained above)
* Team up with us! Look, we might hate interviewing, but we have to do it to get jobs. So let's be friends, let's walk the path to success together, because your success and our success mean basically the same. We get the position, you're paid. Help us and you'll be helping yourself.
I don't mean to offend anyone or to pretend I know everything cause I don't. But again, recruiting is getting ridiculous and really bad according to... well, everyone I know, in several countries both in Europe and North America. I don't think I am wrong in this regard.
If you, recruiter, feel identified with the bad practices I've described, let me tell you this: you suck. But the good news is, you can get better. We, the candidates, learn from rejection (or we should). You can learn too, and shine.
Think about it.
| luisnomad |
230,414 | What I've Learned About Remote Work | Over the last few months, I have learnt a lot about working remotely through making mistakes, falling... | 0 | 2020-01-02T13:31:31 | https://dev.to/amykble/what-i-ve-learned-about-remote-work-3310 | productivity, beginners, womenintech | Over the last few months, I have learnt a lot about working remotely through making mistakes, falling into bad habits and having to correct them. I no doubt have a lot more to learn about working from home, but for now, here's my small collection of tips and pointers for getting started with remote work.
##Discipline = Freedom
I heard this a lot, i thought it was a bit cliché but it wasn't until I started working on freelance projects that I realised just how important it was. The first website I made was for my Dad's business, a static website consisting of 5 simple pages, yet it took me about a month to complete. Of course, this can in part be understood, it was the first project I had committed myself to, my web development skills have improved a lot since then through sheer practise. But it was also because my schedule was all but non-existent. Most nights I was awake until 2 a.m., which in turn meant I had no morning routine and was tired if i woke up earlier than 10 a.m.
**I wanted my evenings back.** I knew I loved frontend development, but I missed spending time with my friends without feeling guilty that I hadn't got my work done for that day.
this meant even the decision to close my laptop by 8 p.m. everyday vastly improved my routine. I had to become a bit tough on myself. **I haven't finished my work today? It can be completed tomorrow.** I can always wake up a little earlier to get in some extra work. Better that than sitting at a desk in my room whilst my family watches that film tonight that I've wanted to watch for weeks.
Don't get me wrong, sometimes when I'm in the flow and I know I can finish a project that night if I just keep coding for a couple more hours, I'll give myself the time. But these late nights are few and far between, besides, the evidence suggests that a consistent sleep routine and healthy breakfast does wonders for focus and productivity. Here's a link to [Joe Rogan's Podcast](https://www.youtube.com/watch?v=pwaWilO_Pig&t=2018s) about the importance of sleep with Matthew Walker, an expert on the subject.
##Work/Life Balance
This one goes hand in hand with the previous tip. As you can probably tell, my work/life balance was all over the place. I'd do nothing but write CSS for days in a row and then realise I hadn't spent any quality time with my girlfriend, played video games or taken time to relax and recharge.
This is pretty common for me, and I think it's the same for a lot of people. When we become interested in something new, like web development, **we can become a little obsessed.** I wanted to learn everything I could, I'd watch tutorials about CSS layouts all day, I'd read countless articles before bed about why this text editor is better than that one. Sometimes, i'd find myself doing these things when I was out with friends or family for dinner... that is unhealthy!
Sure, understanding CSS layouts is important for frontend design, and choosing the right text editor for you will speed up your work flow, I'm not disputing the importance of learning and researching your field of study, I just want to highlight finding a balance, because watching just one more video or reading one more article won't drastically improve your development skills, but it can easily eat away at your free time. Add the video to your Watch Later playlist, bookmark that article and **call it a day.**
##Make Beginning Easy
I'm going to focus now on some tips for **kickstarting good remote work practises,** and losing the bad habits. It's all well and good to want to have a healthy work/life balance, but getting started with a good morning routine when you've been staying up all night for weeks now can be hard. The saying goes **a good day starts the night before,** so lets start there.
I use [TeuxDeux](https://teuxdeux.com/) for daily ToDo planning, I can see my lists for the next few days, what I don't finish that day moves to the next day automatically and I usually leave the tab open on my tablet to quickly tick off what I complete. Having my ToDos easily available helps me start my day. Whilst I use Notion and Google Calendar also, a quick, simple ToDo app is where i'd suggest beginning when it comes to organising your day.
Often, **mental effort acts as a barrier to entry** for having a productive day, so leaving your workspace tidy, having a few things on your ToDo list ready for the next day, and even leaving your laptop open rather than closed makes the process of beginning easier. The less physical resistance to beginning work, the less mental resistance too.
##Simplicity is Your Friend
In the same vein, if your work process is simple whilst still being effective, you will find it makes remote work a lot easier. I mentioned Notion earlier - it is a great app, it's powerful, tidy and I like it for project management, but I've found it to be too complicated for general note taking and ToDo lists. It takes too long to open on my phone if I want to write an idea down quickly or check off a completed task. I like to use a smaller application for these things.
Since I store my projects in Notion, I can easily get distracted with side projects I'm working on just because I see them when I open the app, to avoid this, using a separate application in the day for general note taking is useful.
Before I finish for the day I **log everything I need to into Notion,** which helps me to stay organised. | amykble |
230,416 | 8 Myths around Accessibility | Accessibility is one of the areas which is very important yet ignored by the developers, designers, a... | 0 | 2020-01-03T06:01:40 | https://dev.to/hellonehha/10-myths-around-accessibility-k24 | a11y, webdev, webdevelopers | ---
title: 8 Myths around Accessibility
published: true
description:
tags: accessibility, web development, web developers
---
Accessibility is one of the areas which is very important yet ignored by the developers, designers, and copywriters.
Everyone assumes that Accessibility is 'only' developer thing and there are many such myths around Accessibility. Today I am going to burst such myths.
### 1. Accessibility is only the developer's job.
Accessibility (a11y), is not only the devs job. It is a team effort starting from the project manager, designers, devs, copywriters and testers. The manager needs to make sure the team is aligned for a11y implementation and its scope. Designers need to create the designs which are accessible, devs need to write the accessible code and following guidelines, copywriters need to provide the accessible content. At last, the testing team needs to test the app for accessibility.
### 2. Accessible designs are ugly
No, accessible designs are not ugly. The UX teams need to understand that a11y guidelines provided the color contrast for low vision. The designer just needs to make sure that the colors are passing the contrast and the same goes with the font-sizes. Even if your site is animation, videos, etc. heavy just make sure that you are also providing the control to slow down the animations, caption for the videos, and the content is still accessible even when the screen readers are reading the carousel content.
### 3. We need a lot of budgets (money and time) for the accessibility
No, if the team is taking care of the accessibility from the start of the project you don't need to spend extra time on the implementation of the accessibility. If designers created the designs which are following color contrast, font-sizes, and other guidelines. If the developer is writing the semantic code, labels with the forms elements, taking care of ARIA then there is no extra time or money you are investing. As well as, web by default is accessible. We are breaking it while writing the wrong code.
For testers, there are many free testing tools that are also available such as - Lighthouse extensions, Axe extensions, voice over on Mac, etc. Again you are not spending anything on these.
### 4. But the client didn't ask for it
No one is going to ask for 'accessible-site' because this is not an add-on feature. By default the web is accessible. The 1st ever site is still accessible but now while using the latest UI frameworks and attempt to create a jazzy website we are breaking the accessibility. This is the responsibility of the team to deliver the accessible site. This is the basic right, not a 'requirement'.
Hence, next time don't even bother to ask the client -"Are you looking for an accessible site?".
### 5. Testing tools for accessibility are costly
Well, the cost will depend on the tools and license but there are a few free tools that anyone can use to test the accessibility such as LightHouse extension, Axe extension, etc. For voiceover mac and Chromebook have the free tools available.
Also, not to forget nothing can beat the actual user testing. So, throw the mouse away and start testing by keyboard (which is FREE again).
### 6. Mobile apps doesn't require accessibility
This is one of the biggest myths that devs and PMs have. The good news is this is just a myth. This is the time when people are using more apps as compared to desktop websites and apps. It is very necessary to have the apps also accessible because every smartphone has accessiblilty navigation support. Next time while building an app keep accessibility on the front seat.
### 7. We have focus, alt and title tags, accessibility is done
Well, accessibility is beyond just focus, alt, the title tag. But if you are taking care of all these 3 things it is very good to start now think beyond these too. Such as, is your forms are accessible, videos are accessible, content is accessible or not? Are the animations are too fast or slow? Is the scrolling of the site is not at all controllable? etc.
### 8. We are following AA guidelines
There are 3 types of levels - A, AA, AAA. If you are following only AA it is good but you can also push yourself to see if you can achieve AAA. Also, it is not necessary that you have to follow all the AA and AAA. You can mix them as per your testing and project scope.
Remember it is good to go by the book but nothing can beat real-time user testing.
This blog is also published on my personal blog : nehasharma.dev | hellonehha |
230,426 | Quickly set up an Oracle environment on GCP | This quick-start guide is part of a series that shows how to set up databases on Google Cloud Platfor... | 4,110 | 2020-01-02T13:53:20 | https://dev.to/mesmacosta/quickly-set-up-an-oracle-environment-on-gcp-hfd | oracle, gpc, database, gce | This quick-start guide is part of a series that shows how to set up databases on Google Cloud Platform, for developing and testing purposes.
This guide will show you how to create an Oracle environment running inside your Google Cloud Project.
## Create a Compute Engine VM
Using Cloud Shell:
```
# Create the Oracle GCE instance
gcloud compute instances create oracle \
--zone=us-central1-c \
--machine-type=n1-standard-1 \
--image-project=rhel-cloud --boot-disk-size=20GB \
--image=rhel-7-v20190618 \
--boot-disk-type=pd-standard \
--boot-disk-device-name=oracle \
--scopes=cloud-platform
```
>Note: The oracle express edition has a free license for demonstrating and testing purposes, but the user needs to accept it, so you must download the binary at: https://www.oracle.com/database/technologies/appdev/xe/quickstart.html
Click on the link for Oracle Linux: Download oracle-database-xe-18c-1.0–1.x86_64.rpm
## Configure your VM with Oracle
Using Cloud Shell:
```
# Connect to the Oracle VM
gcloud compute ssh --zone=us-central1-c oracle
# Copy the oracle binary, and use the binary that you downloaded at
# this step, change it to your bucket, you can also upload it
# manually using cloud shell
gsutil cp gs://oracle_xe_binaries/oracle-database-xe-18c-1.0-1.x86_64.rpm .
# Get the oracle pre install binary
curl -o oracle-database-preinstall-18c-1.0-1.el7.x86_64.rpm https://yum.oracle.com/repo/OracleLinux/OL7/latest/x86_64/getPackage/oracle-database-preinstall-18c-1.0-1.el7.x86_64.rpm
# Install required binary
sudo yum -y localinstall oracle-database-preinstall-18c-1.0-1.el7.x86_64.rpm
# Install oracle
sudo rpm -ivh oracle-database-xe-18c-1.0-1.x86_64.rpm
# Create initial config
sudo /etc/init.d/oracle-xe-18c configure
# You will be prompted with the message: Specify a password to be
# used for database accounts.
# Choose your password and save it
# Wait for the message:
# Connect to Oracle Database using one of the connect strings
```
## Load your Oracle database with data
Using Cloud Shell:
```
# Connect to the Oracle VM
gcloud compute ssh --zone=us-central1-c oracle
# Set up Oracle environment
export ORACLE_SID=XE
export ORAENV_ASK=NO
. /opt/oracle/product/18c/dbhomeXE/bin/oraenv
# You should receive the message: The Oracle base has been set to
# /opt/oracle/product/18c/dbhomeXE
# Install git, press y when prompted
sudo yum install git
# Go to your home directory
cd ~
# Clone schema Repo
git clone https://github.com/oracle/db-sample-schemas.git
# Go to customers schema directory
cd ~/db-sample-schemas/customer_orders
# Start the Oracle sqlplus Session, change to your password
sqlplus system/YOURPASS@oracle/XEPDB1
# Run create schema and populate procedures
@co_main copw oracle/XEPDB1 users temp
# You should be presented with some query results, look for the
# value: 433 rows selected
# Quit sqlplus
quit
```
### Connect to the Oracle instance using a client
#### Set Oracle client for Linux (Cloud Shell)
Download the zip file and send to your gcs bucket
https://oracle.github.io/odpi/doc/installation.html#linux
```
# Get the zip from your bucket
gsutil cp gs://oracle_xe_binaries/instantclient-basic-linux.x64-19.5.0.0.0dbru.zip .
# Unzip it
unzip instantclient-basic-linux.x64-19.5.0.0.0dbru.zip
# Set Oracle library ENV Var on the unzip dir
export LD_LIBRARY_PATH=/oracleclient/bin/instantclient_19_5
```
#### Set Oracle client for Mac
Download the zip file and send to your gcs bucket
https://oracle.github.io/odpi/doc/installation.html#macos
```
# Get the zip from your bucket
gsutil cp gs://oracle_xe_binaries/instantclient-basic-macos.x64-19.3.0.0.0dbru.zip .
# Unzip it
unzip instantclient-basic-macos.x64-19.3.0.0.0dbru.zip
# Set Oracle library ENV Var on the unzip dir
export LD_LIBRARY_PATH=/oracleclient/bin/instantclient_19_3
```
## Booting the Compute Engine VM gracefully
```
# Start the Compute Engine VM
gcloud compute instances start oracle --zone=us-central1-c
# Connect to the Oracle VM
gcloud compute ssh --zone=us-central1-c oracle
# Start the oracle listener
sudo /etc/init.d/oracle-xe-18c start
# Wait for the message: Oracle Database instance XE started.
```
And that's it!
> Be careful, you pay Red Hat Entreprise Linux (rhel) licence every day that the VM run (about $0.55 every day). Of course, in addition of the GCP VM cost.
If you have difficulties, don’t hesitate reaching out. I would love to help you! | mesmacosta |
230,453 | #100DaysOfCode - Ano novo, novas metas | É 2020 e quais são seus objetivos? O meu é ser uma Dev melhor Durante 2019 teve um sentime... | 4,015 | 2020-01-02T14:34:43 | https://dev.to/biaherculano/100daysofcode-ano-novo-novas-metas-36dj | 100daysofcode, motivation, coding | ## É 2020 e quais são seus objetivos? O meu é ser uma Dev melhor
Durante 2019 teve um sentimento que não saiu de dentro de mim: Eu tenho que melhorar como dev. Melhorar em qualidade de código, design patterns e design de codigo e arquitetura.
Esse tipo de sensação aparece quando eu me comparo com outros devs (algo que não se deve fazer com muita frequência) e tambem quando almejo vagas de nivel maior que o meu (hoje eu sou jr, almejo vagas de pleno).
Quando se trata desse tipo de mudança, de Jr para Pleno, a maior diferença é em coisas que são ultilizadas em todas as linguagens:
- Dry code
- SOLID
- DDD
- TDD
Alem desses existem habilidades que trazem um diferencial para o desenvolvedor no mercado de trabalho como a cultura DevOps.
Para eu alcançar esse objetivo eu vou participar do desafio de 100 dias de codigo.
## O desafio de 100 dias de código - como começar
Esse desafio foi criado com base no estilo de desafio dos 100 dias de X. Voce pode olhar as regras completas no [site oficial do desafio](https://www.100daysofcode.com/), voce pode acessar as regras em português [aqui](https://github.com/kallaway/100-days-of-code/blob/master/intl/pt-br/LEIAME.md).
As regras são claras:
- Codifique durante uma hora do seu dia durante 100 dias seguidos.
- Divulgue publicamente no twitter seu progresso diario usando a #100DaysOfCode
Existem mais algumas regras, mas essas duas são as principais.
No [repositorio do github](https://github.com/kallaway/100-days-of-code) voce pode ver como usar os arquivos de log para manter um acompanhamento do seu desenvolvimento no desafio.
**Pra começar, de um fork no repositorio, leia as regras e então: publicamente**
**1. Codifique uma hora por dia**
**2. Publique seu progresso diario de forma pública**
**3.faça um commit no arquivo de log no repositorio. **
**Repita uma vez por dia, durante 100 dias.**
Obs: O desafio tem outras regras, eu estou aqui simplificando elas, mas eu vou seguir todas elas :)
No que foi que eu me meti?
## Mas por que esse desafio? Qual o problema de ler sobre os assuntos e pronto? Desenvolver mais codigo te torna um dev melhor
Por mais que os assuntos que eu vou abordar nesse chalange não sejam puramente de códigio como fazer uma API, fazer uma Rede convolutiva, criar um aplicativo assim. Esses conceito so podem ser aplicados, treinados e absorvidos enquato se desenvolve. São conceitos que devem ser praticados e experimentados.
Não adianta ler sobre TDD, voce precisa *fazer* TDD.
E o mesmo vale para todos esses conceitos, principalmente quando falamos de DevOps.
## Qual a diferença da minha jornada?
Muitas vezes esses desafios são concentrados para pessoas iniciantes na programação, fazendo projetos para aprender tecnologias, mas focar em qualidade de codigo te tira da mediocridade e te eleva como desenvolvedor. Esse tipo de desafio pode ser usado por desenvolvedores em qualquer nivel e pode ser muito bom para quando voce quer simplemente melhorar seu codigo.
**Se voce é um(a) desenvolvedor(a) Jr e que hoje quer crescer na sua carreira, eu espero que minha visão e minha tragetória te ajude a crescer também. Você não está mais no zero ou no básico, chegou a hora de se desafiar com coisas mais complexas. O mesmo vale pra mim**
## Finalizando, esse não vai ser o meu unico desafio, apenas o primeiro. Fique atento que vou postar mais
Criar hábitos é uma habilidade. Com o ano novo, vida nova nos sempre ficamos com a mente cheia de novas possibilidades.
Não tente muitos desafios por vez, se concentre em um e os proximos ficam mais faceis.
Eu tenho varias metas esse ano:
- Melhorar como Dev (esse desafio é apenas a primeira parte disso)
- Melhorar minha capacidade fisica para fazer varias trilhas (sim, a classica academia)
- Crescer a [comunidade de Flutter](https://www.meetup.com/pt-BR/FlutterNation/) que eu sou community manager (um meetup por mês)
- Um projeto bem grande e de cunho social que eu vou falar mais depois (misteeeeeriooo)
Estou ansiosa para 2020, tambem estou concentrada em não deixar essa animação morrer.
Esse artigo vai estar numa série de artigos, que será uma das minhas forma de manter o acompanhamento do meu progresso. Não bastando uma hora por dia de codigo, vai ter tambem um artigo por dia aqui.
Aos que me acompanharem nessa jornada, me desejem sorte.
| biaherculano |
230,591 | ES2020 Features in simple examples | ES2020 is the version of ECMAScript corresponding to the year 2020. This version does not include as many new features as those that appeared in ES6 (2015). However, some useful features have been incorporated. | 2,347 | 2020-01-03T08:14:05 | https://carloscaballero.io/es2020-features-in-simple-examples | javascript, webdev, node, es2020 | ---
title: ES2020 Features in simple examples
published: true
description: ES2020 is the version of ECMAScript corresponding to the year 2020. This version does not include as many new features as those that appeared in ES6 (2015). However, some useful features have been incorporated.
tags: javascript, webdev, node, ES2020
series: understanding-javascript
cover_image: https://cdn-images-1.medium.com/max/8000/1*HRBqZ6UDItqS7nNwug0HvQ.jpeg
canonical_url: https://carloscaballero.io/es2020-features-in-simple-examples
---
In this series, we are going to show the EcmaScript features from 2015 to today.
* ES2015 aka ES6
* ES2016 aka ES7
* ES2017 aka ES8
* ES2018 aka ES9
* [ES2019 aka ES10](https://dev.to/carlillo/12-es10-features-in-12-simple-examples-2cbn)
* [ES2020 aka ES11](https://carloscaballero.io/es2020-features-in-simple-examples)
---
## Introduction
ES2020 is the version of ECMAScript corresponding to the year 2020. This version does not include as many new features as those that appeared in ES6 (2015). However, some useful features have been incorporated.
This article introduces the features provided by ES2020 in easy code examples. In this way, you can quickly understand the new features without the need for a complex explanation.
Of course, it is necessary to have a basic knowledge of JavaScript to fully understand the best ones introduced.
The new **#JavaScript** features in **ES2020** are:
➡️ String.prototype.matchAll
➡️ import()
➡️ BigInt
➡️ Promise.allSettled
➡️ globalThis
➡️ for-in mechanics
➡️ Optional Chaining
➡️ Nullish coalescing Operator
## String.protype.matchAll
The matchAll() method returns an iterator of all results matching a string against a regular expression, including capturing groups.
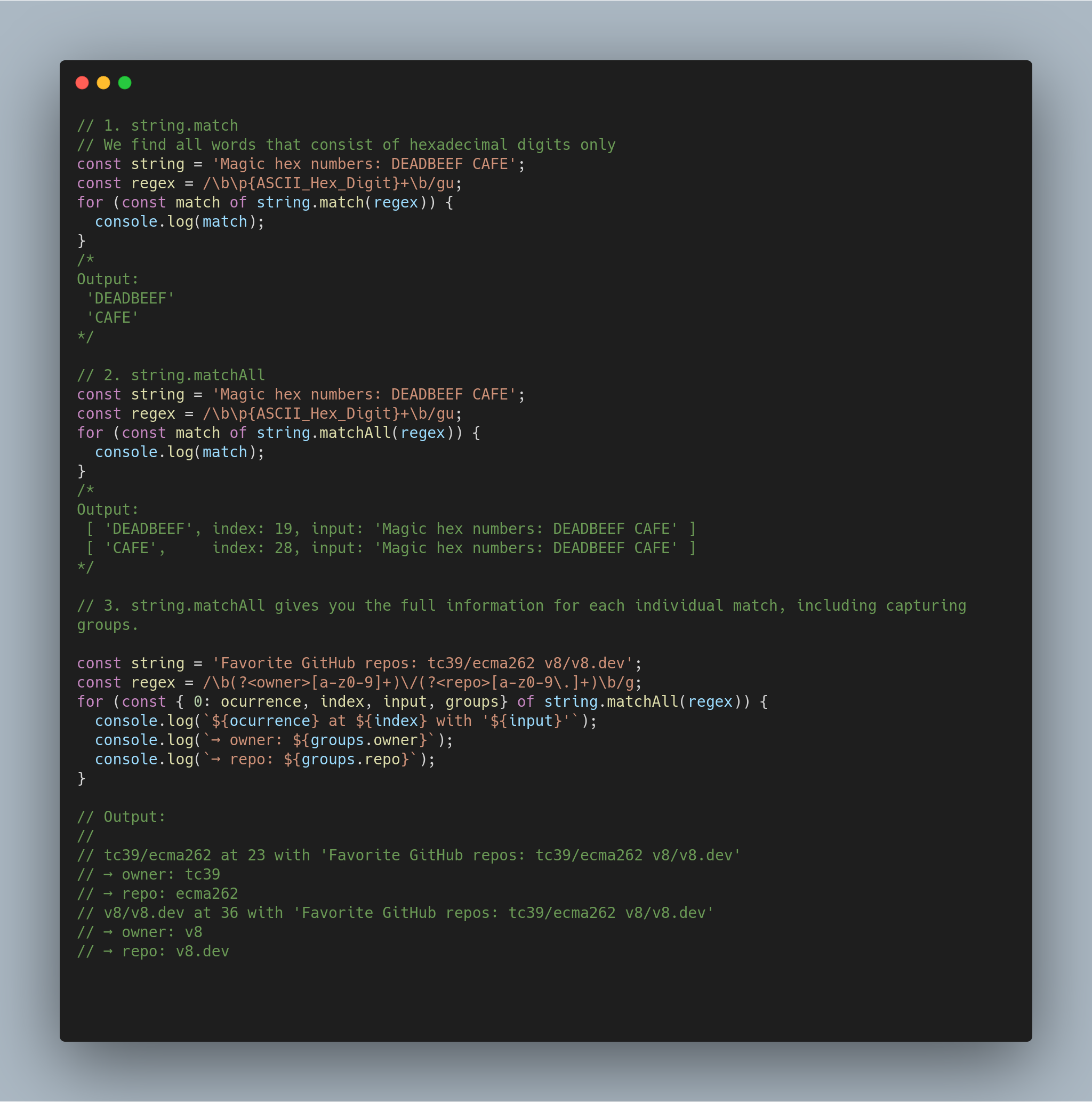
## Dynamic import
Dynamic import() returns a promise for the module namespace object of the requested module. Therefore, imports can now be assigned to a variable using async/await.
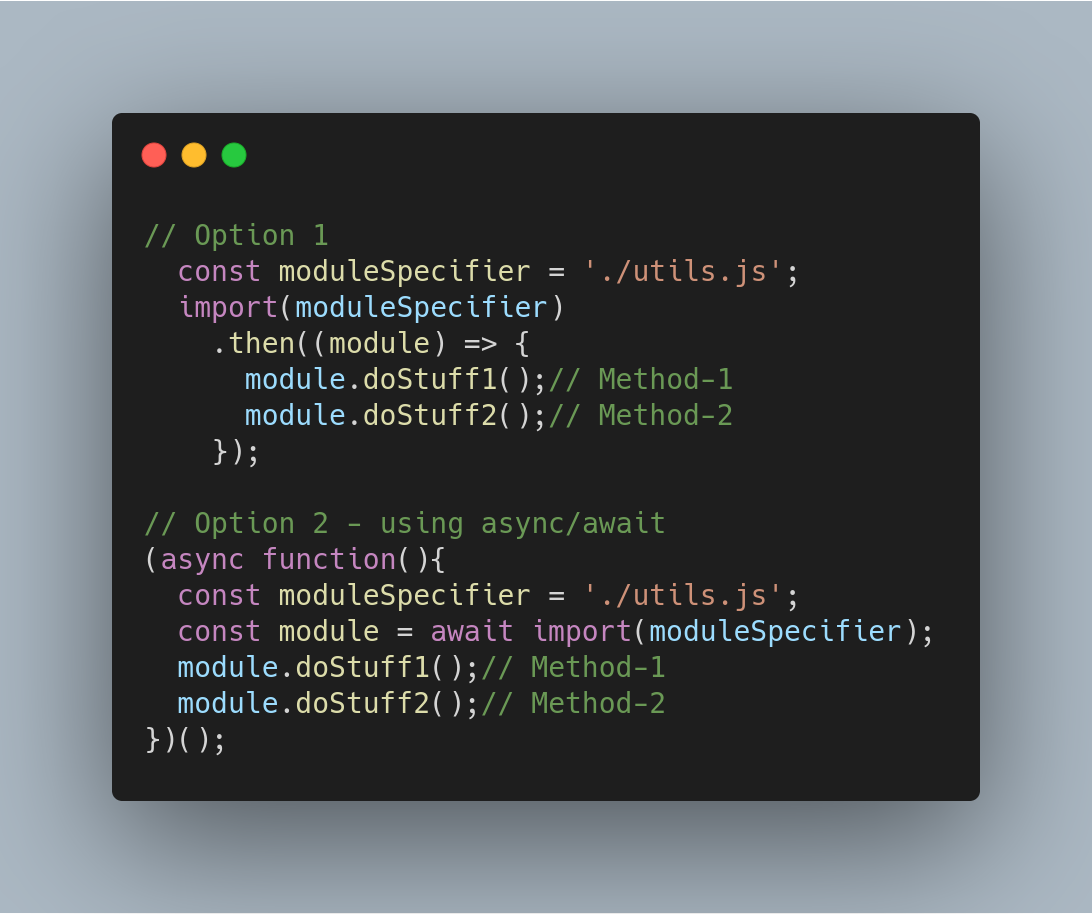
## BigInt — Arbitrary precision integers
BigInt is the 7th primitive type and It is an arbitrary-precision integer. The variables can now represent ²⁵³ numbers and not just max out at 9007199254740992.
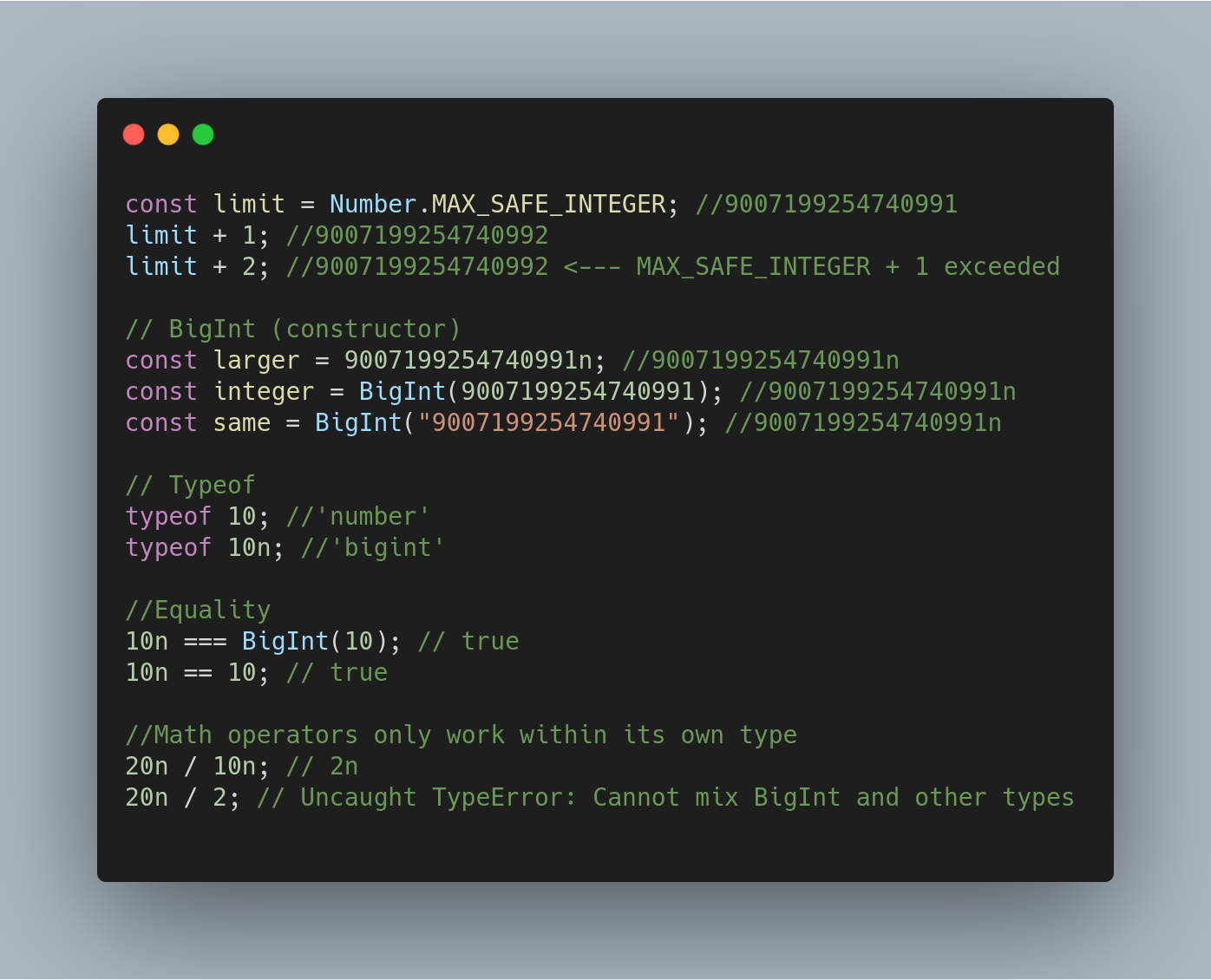
## Promise.allSettled
Promise.allSettled returns a promise that is fulfilled with an array of promise state snapshots, but only after all the original promises have settled, i.e. become either fulfilled or rejected.
We say that a promise is settled if it is not pending, i.e. if it is either fulfilled or rejected.
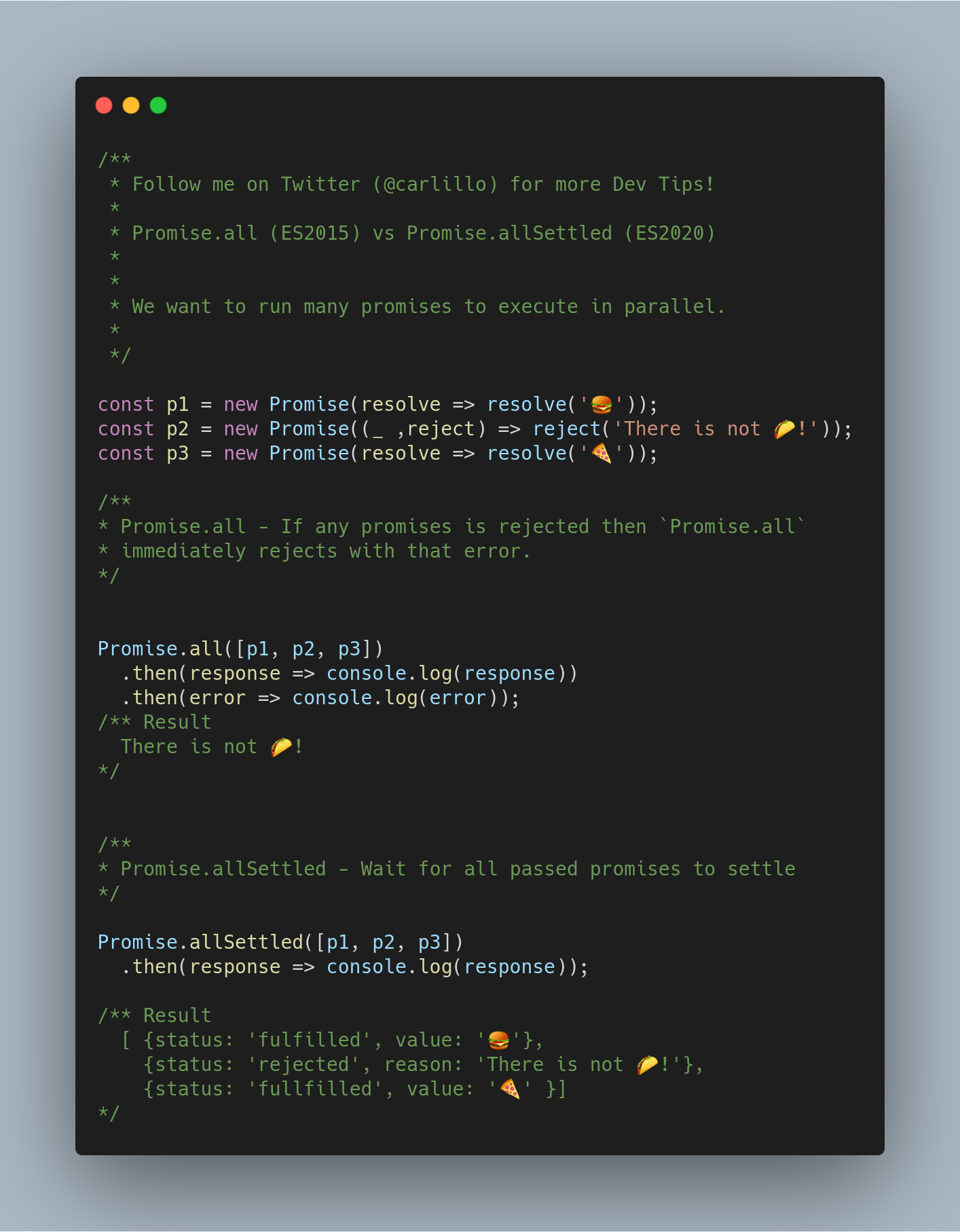
## Standardized globalThis object
The global this was not standardized before ES10.
In production code you would “standardize” it across multiple platforms on your own by writing this monstrosity:
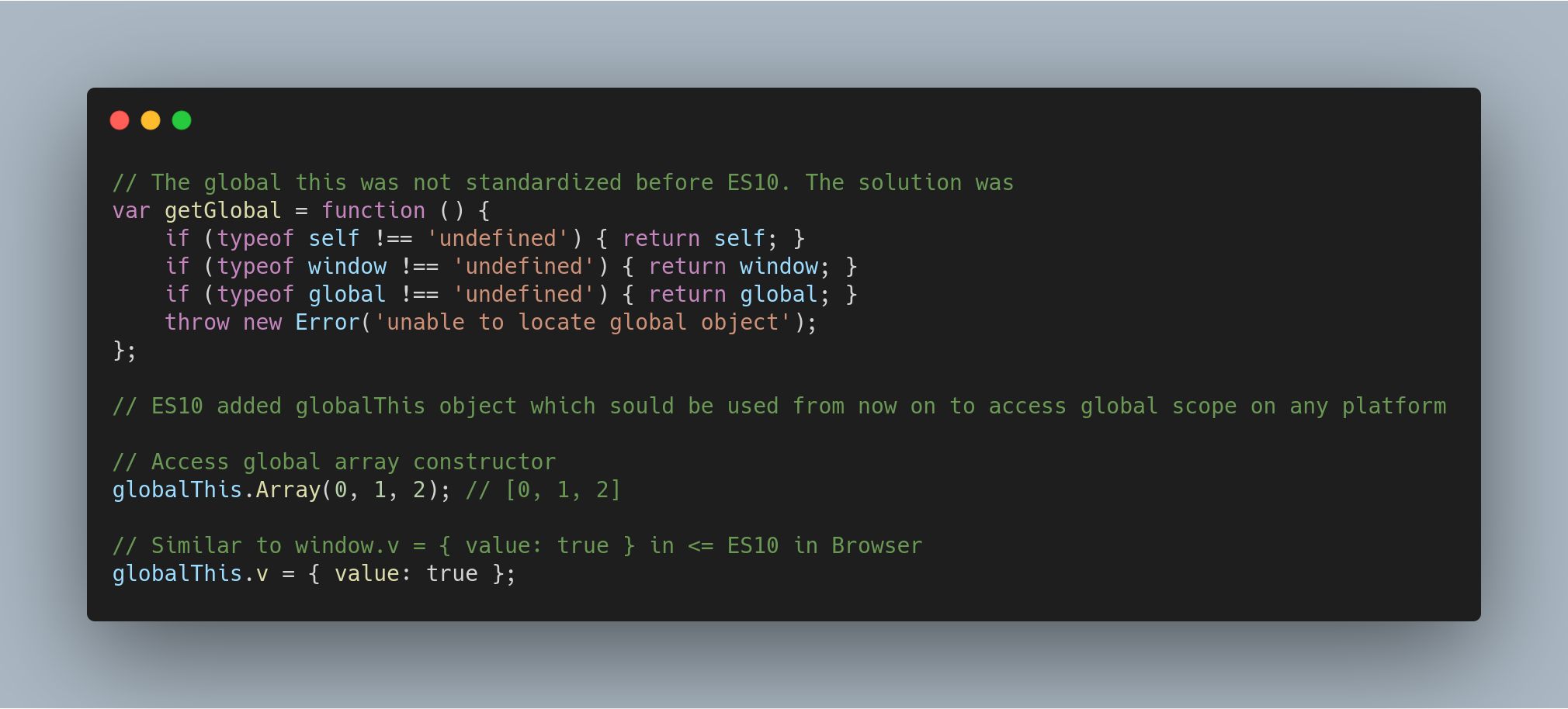
## for-in mechanics
ECMA-262 leaves the order of for (a in b)... almost totally unspecified, but real engines tend to be consistent in at least some cases.
Historical efforts to get consensus on a complete specification of the order of for-in have repeatedly failed, in part because all engines have their own idiosyncratic implementations which are the result of a great deal of work and which they don’t really want to revisit.
In conclusion, the different engines have agreed on how properties are iterated when using the for (a in b) control structure so that the behavior is standardized.
## Nullish coalescing Operator
When performing property accesses, it is often desired to provide a default value if the result of that property access is **null** or **undefined**. At present, a typical way to express this intent in JavaScript is by using the || operator.
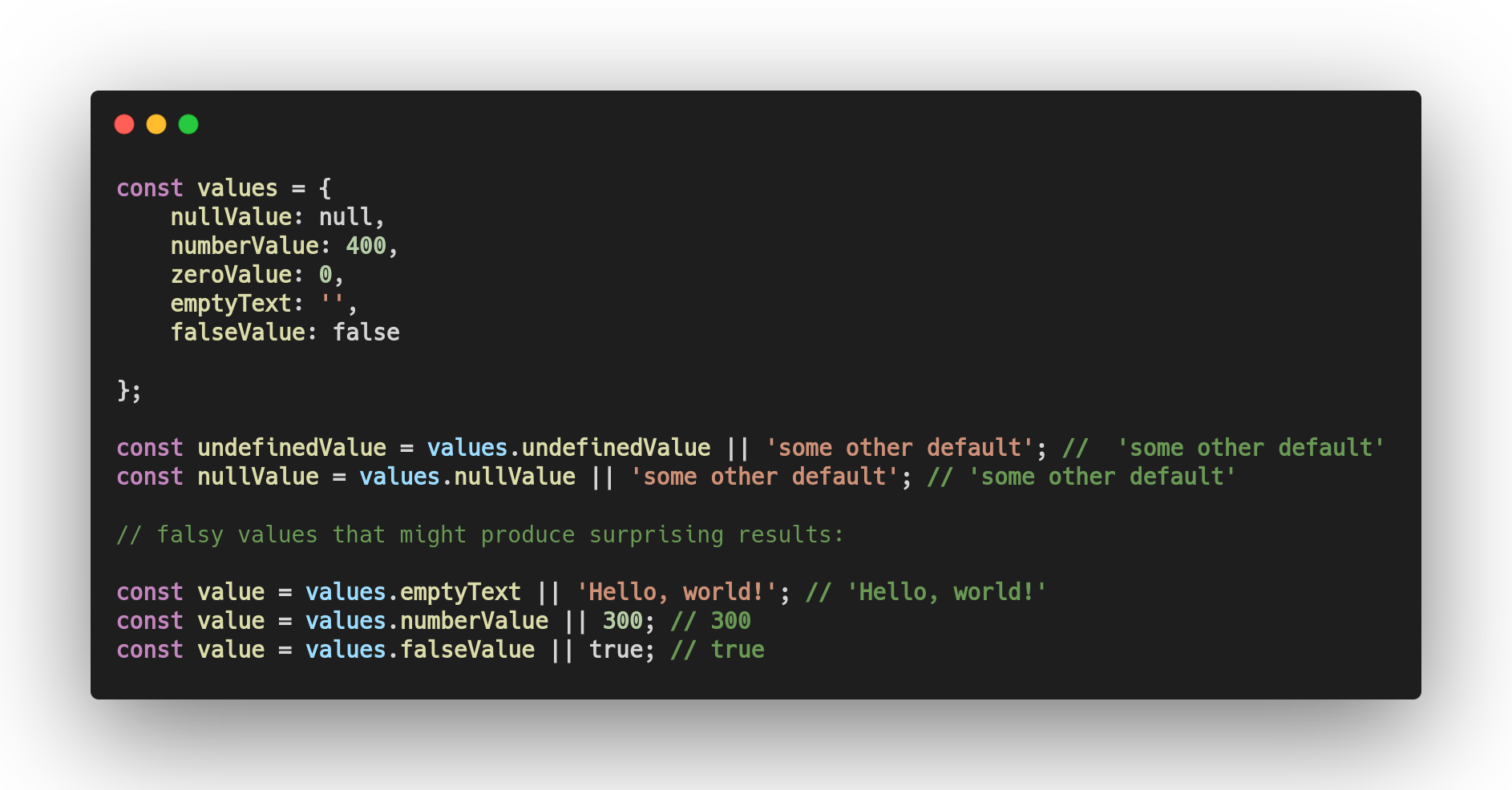
This works well for the common case of null and undefined values, but there are a number of falsy values that might produce surprising results.
The nullary **coalescing operator** is intended to handle these cases better and serves as an equality check against nullary values (**null or undefined**). If the expression at the left-hand side of the ?? operator evaluates to **undefined or null**, its right-hand side is returned.
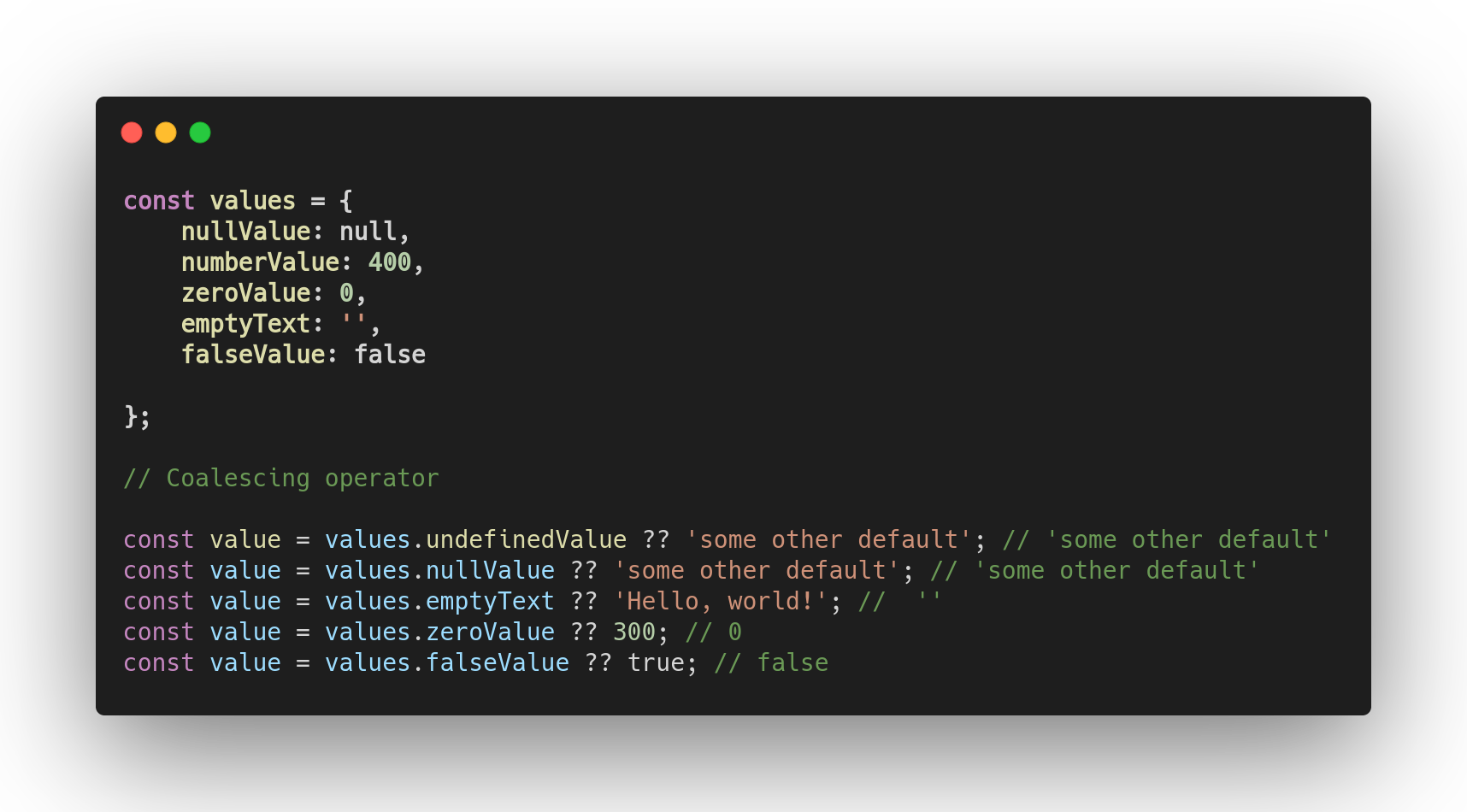
## Optional Chaining
When looking for a property value that’s deep in a tree-like structure, one often has to check whether intermediate nodes exist.
The **Optional Chaining Operator** allows handle many of those cases without repeating themselves and/or assigning intermediate results in temporary variables.
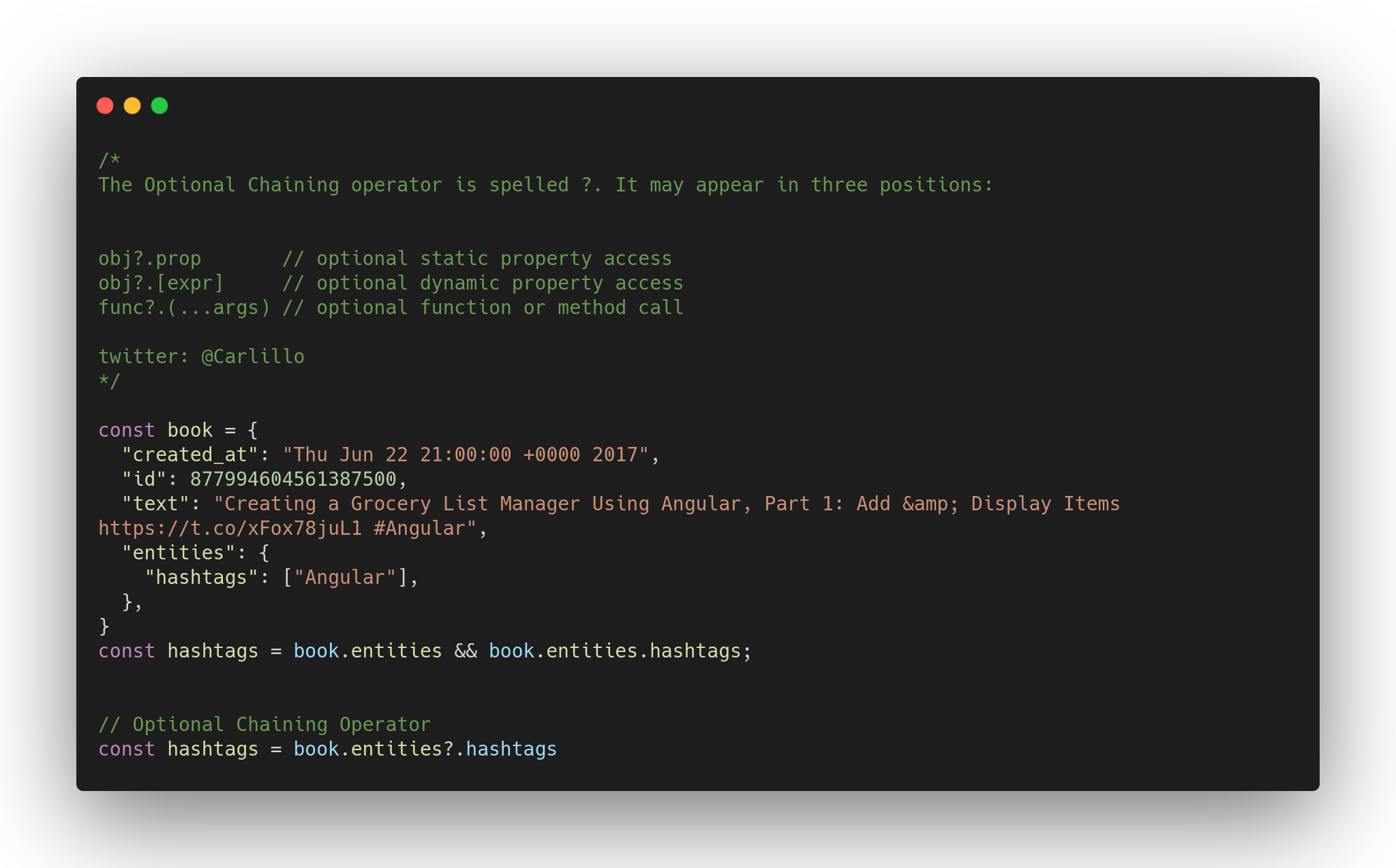
Also, many API return either an object or null/undefined, and one may want to extract a property from the result only when it is not null:
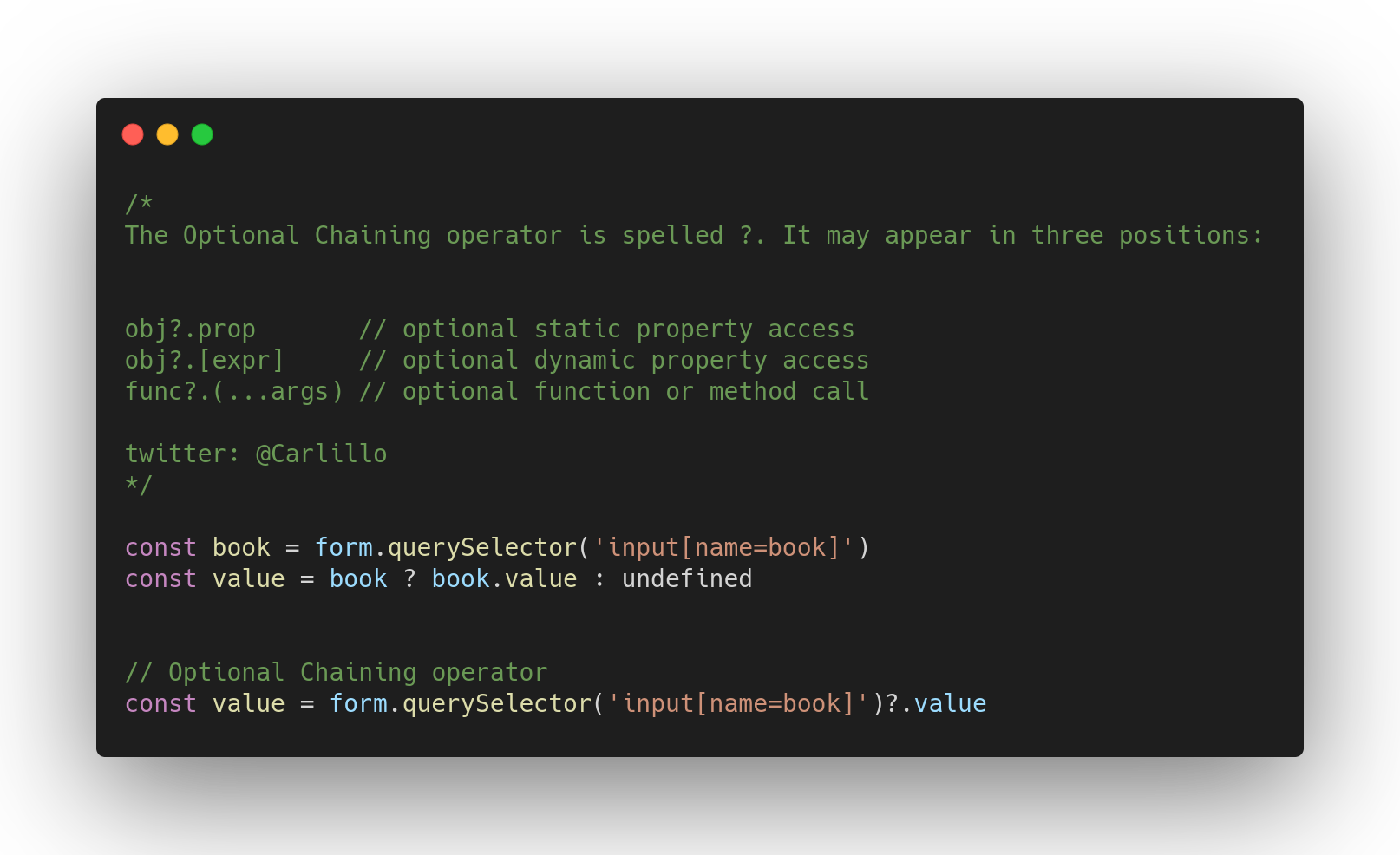
When some other value than *undefined* is desired for the missing case, this can usually be handled with the **Nullish coalescing** operator:

## Conclusion
JavaScript is a live language, and that is something very healthy for web development. Since the appearance of ES6 in 2015 we are living a vibrant evolution in the language. In this post we have reviewed the features that arise in **ES2020**.
Although many of these features may not be essential for the development of your Web application, they are giving possibilities that could be achieved before with tricks or a lot of verbosity.
| carlillo |
238,078 | The Design Elements of Effective YouTube Thumbnails | YouTube is the second largest search engine. But before you bust out the camcorder you need to learn... | 0 | 2020-01-14T18:06:15 | https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/ | design | ---
title: The Design Elements of Effective YouTube Thumbnails
published: true
date: 2020-01-14 16:46:18 UTC
tags: Design
canonical_url: https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/
---
YouTube is the second largest [search engine](https://www.searchenginejournal.com/seo-101/meet-search-engines/#close). But before you bust out the camcorder you need to learn about **thumbnail design**.
Before YouTube, if you did a Google search and you wanted someone to click on your link, you needed a strong headline that would encourage people to click through to the article.
With YouTube, we have what I’m calling **Headline 2.0**. And that’s **video thumbnails**. You’re no longer limited to text, You have your video title (_text_) and the **thumbnail**.
**Are thumbnails really that big a deal??**
Thumbnails are the gatekeeper to your content. Your video could be amazing but if your thumbnail sucks, the chances that anyone will watch your video decrease dramatically.
## What Makes Thumbnails So Powerful?
YouTube thumbnails can do a lot of the heavy lifting, more than the headline can do on its own. You have more variety and flexibility in the visual elements that you can have in your thumbnail.
You can have multiple _graphics_, _images_, and _icons_.
You can use _**typography:** font-families, font-weights_ and _font-sizes._
And of course, you have a lot more control over the _layout_ as well.
What makes YouTube thumbnails so powerful is the opportunities for using multiple visual elements and tailoring them to your brand or channel.
**_They become another design element for your brand._**
To give you a better understanding of the power of thumbnails, we need to look at the difference in user experience and behaviour between YouTube and Google.
## Google (Active Search) vs. YouTube (Active & Passive Related Suggestions (expanded search)
### Active Search (Google)
When you go to Google you have a specific goal or question in mind for your search. Once you click an article Google loses its ability to suggest related content (_this is ignoring ads and remarketing ads that follow you around of course)_.
### Active Search + Passive Discovery (YouTube)
People search YouTube in a similar way, but there’s also the addition of **_Passive Discovery_** throughout the platform. This is through **Recommendations** , **Suggestions** , and **Up Next Videos** and it’s often how you end up down the YouTube rabbit hole.
<figcaption id="caption-attachment-1211">Recommendations on the YouTube homepage based on past searches and viewing.</figcaption>
Searching may be the beginning but once you’ve clicked a video, Passive Discovery begins. For example if you watch a video on photography it may return related topics to photography like _Photoshop_, _Lightroom_, or _camera reviews_.
You’ll continue to get suggestions that relate to or expand on the video you just watched or previous videos you’ve watched.
<figcaption id="caption-attachment-1214">Examples of Related/Up Next video’s based off a camera review</figcaption>
This increases the chance you’ll discover a new channel or video that’s related to your search and your recent views. The most visible element in any of the related or suggested video sections is the **thumbnail.**
**A well-designed thumbnail is often the first exposure to an audience that may not know you exist.**
In recent years Google has also started placing YouTube video’s first in their search results.
<figcaption id="caption-attachment-1213">Google is frequently placing video results first on the search results page. In some cases you’ll have to scroll by videos and ads before even hitting an organic result.</figcaption>
For this entry in Dissecting Design, I want to look at a collection of thumbnails and analyze the common patterns and design elements that are used.
Before we look at design elements we need to quickly address a design principle, **_consistency._**
## Consistency – The Design Principle Behind Recognizable Thumbnails
When you see thumbnails that appear familiar, you’re seeing consistency at work, specifically **visual consistency.**
> **Visual Consistency**
>
> Similar elements that are perceived the same way make up the visual consistency. **It increases learnability of the product.** Fonts, sizes, buttons, labeling and similar need to be consistent across the product to keep visual consistency. _source: [Design Principle Consistency](https://uxdesign.cc/design-principle-consistency-6b0cf7e7339f)_
The quote above refers to products but in this we’re applying the principle to a branded element ( **_thumbnails_** )
In a sea of thumbnails, you can quickly recognize and associate a thumbnail with a particular channel.
This doesn’t mean that the thumbnails are exact duplicates (_although there are common patterns)_ but they use similar combinations of elements to achieve consistency.
Now lets look at the different design elements you have at your disposal and how they’re used to make consistent thumbnails.
## Design Elements
### Typography
Typography gives you a lot of variations that you can play with. If you’re not a “designer” and can’t create your own custom logos or graphics, typography is a great element to use and can have a lot of power on its own. You’ll get a lot of variation from a single font-family:
- Font-Size
- Font-Weight
- Font-Family
- Color
**[The Futur](https://www.youtube.com/user/TheSkoolRocks)** is a great example of this where the fonts, the typography is consistent in all their thumbnails. They also use different font families to associate the thumbnails with a particular video series or playlist.
<figcaption id="caption-attachment-1191">For this series The Futur uses all uppercase titles with the second line bolded. And the same font-family is used to tie this series together.</figcaption>
### Color
Color is great to use as an overlay and to connect thumbnails when the content may change. For example, if you’re using a photo and you don’t have a lot of control over the content in the photo, it can be difficult to make multiple images feel connected.
And your colors can change to communicate a different context or meaning.
As I mentioned in the previous example of **The Futur** you have yellow as the main color for this series. But they’ll also use their signature blue color.
<figcaption id="caption-attachment-1192">Colors don’t have to be the exact same for all video’s. In the previous example The Futur only used on color. Here they’ve mixed colors and overlays to distinguish between video types: Live episodes and regular episodes.</figcaption>
**[Webflow](https://www.youtube.com/channel/UCELSb-IYi_d5rYFOxWeOz5g)** also uses different colors based on the series topic/name.
[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/pixelsnap-2019-10-07-at-14-47-412x/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/pixelsnap-2019-10-07-at-14-46-402x/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/cleanshot-2019-10-07-at-14-49-092x/)
### Icons and Logos
When you look at something like Webflow, they place their icon or their logo in the top left corner, and then they’ve got the title below. If you have a logo or brand mark, this is a chance to put it on display.
Icons can also be used to give more context for what the video is about. YouTuber [Dansky](https://www.youtube.com/user/ForeverDansky) who creates design related tutorials, uses the icons for the various Adobe programs.
[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/clipboard-image-2019-10-07-02-29-59-pm/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/clipboard-image-2019-10-07-02-29-53-pm/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/clipboard-image-2019-10-07-02-28-53-pm/)
### Titles
Titles are closely related to typography but with the addition of the content, what words are being using in the title? There are a few different approaches to use titles in your thumbnails.
- **Double dip** – Use the video title again in the thumbnail. This gives you the ability to make it stand out from other thumbnails with bold typography.
- **Support the headline** – Give more context to the video title with additional elements (logos, icons, additional text and styling)
- **Create Intrigue With Time or Steps** – _Learn X in 20 Minutes, Setup Your Camera in 3 easy steps_
[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/cleanshot-2019-10-07-at-14-25-422x/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/cleanshot-2019-10-07-at-14-24-102x/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/cleanshot-2019-10-07-at-14-23-592x/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/clipboard-image-2019-10-07-02-28-37-pm/)
### Frames/Borders
Another example is frames or borders. This element can be seen on the channel **[Flux/Ran Sigall ](https://www.youtube.com/channel/UCN7dywl5wDxTu1RM3eJ_h9Q)**
**Ran Sigall** uses a turquoise frame on a lot of his videos.
Even though the topics vary slightly on his channel, the coloured frame makes it easy to connect these videos to his channel.
[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/pixelsnap-2019-12-16-at-07-27-02/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/pixelsnap-2019-10-07-at-14-47-082x/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/pixelsnap-2019-10-07-at-14-48-192x/)
Even if the elements within the frame change, the frame helps give some consistency across the different layouts and different styles. The coloured frame also draws your attention and stands out amongst other thumbnails with no frame.
## People
A very common practice on YouTube is to have the channel host either on the left or the right side of the thumbnail and they’re either looking at you, or they’re looking off into the distance at an icon, topic title, or the subject of the video. Or they’re pointing at the subject of the video and this draws your eye to it.
Both [DesignCourse](https://www.youtube.com/user/DesignCourse) and [Kevin Powell](https://www.youtube.com/user/KepowOb) primarily use this style of thumbnail.
[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/clipboard-image-2019-10-07-02-34-32-pm/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/clipboard-image-2019-10-07-02-33-13-pm/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/clipboard-image-2019-10-07-02-31-36-pm/)
This builds familiarity with the person behind the brand and channel whether you actually click the video or not.
In the future if you’re given the choice between 2 video thumbnails, one without a person and another with a person, you may choose the one with the person because you like their presentation style.
## Layout
Keeping a consistent structure and layout for your thumbnail makes it easy to recreate thumbnails. It saves time since you don’t have to think about where you’re going to place elements.
We’ll revisit **WebFlow** and **The Futur.** Webflow has the same layout of elements in their “Intro” series: logo up top, the title or main topic of the video in the center, and then they’ve got the video series text in the bottom left. The only thing they need to adjust for additional thumbnails is the background image and the title.
[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/pixelsnap-2019-10-07-at-14-44-212x-3/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/cleanshot-2019-10-07-at-14-49-092x-2/)[](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/cleanshot-2019-10-07-at-23-17-352x/)
### Up Next: Applying These Design Elements To Your Videos
There are a lot of elements to consider when it comes to creating your own thumbnails. And that’s without even considering the video content itself. In a future article I’ll be looking at how channels use these design elements and the content itself to help group their content together. Hopefully this can give you some ideas of how you may start creating your own thumbnails.
The post [The Design Elements of Effective YouTube Thumbnails](https://ryandejaegher.com/the-design-elements-of-effective-youtube-thumbnails/) appeared first on [Ryan Dejaegher](https://ryandejaegher.com). | ryandejaegher |
238,205 | Automagic Puppet Function Updater | Last week I wrote about porting legacy Ruby Puppet functionsto the modern API. It struck me how progr... | 0 | 2020-01-14T20:37:25 | https://www.binford2k.com/2019/11/27/automagic-function-port/ | ---
title: Automagic Puppet Function Updater
published: true
date: 2019-11-27 00:00:00 UTC
tags:
canonical_url: https://www.binford2k.com/2019/11/27/automagic-function-port/
---
Last week I wrote about [porting legacy Ruby Puppet functions](/2019/11/19/refactoring-legacy-functions/)to the modern API. It struck me how programatic the refactoring process was, so I wrote a tool to automate much of it. The functions it generates are not great but they’re a start, and they’re validated to at least _work_ during the process.
## Installing
The tool is distributed as a Ruby gem with no dependencies, so simply `gem install`.
```
$ gem install puppet-function-updater
```
## Usage
Run the command `puppet_function_updater` in the root of a Puppet module, then inspect all the generated functions for suitability when it’s done. If you pass the `--clean` argument it will **delete the legacy function file from disk** after validating that the new function works.
### Example:
```
[~/Projects/puppetlabs-stdlib]$ puppet_function_updater --verbose
INFO: Creating lib/puppet/functions/stdlib/abs.rb
INFO: Creating lib/puppet/functions/stdlib/any2array.rb
INFO: Creating lib/puppet/functions/stdlib/any2bool.rb
INFO: Creating lib/puppet/functions/stdlib/assert_private.rb
INFO: Creating lib/puppet/functions/stdlib/base64.rb
INFO: Creating lib/puppet/functions/stdlib/basename.rb
[...]
INFO: Creating lib/puppet/functions/stdlib/values_at.rb
INFO: Creating lib/puppet/functions/stdlib/zip.rb
INFO: Functions generated. Please inspect for suitability and then
INFO: update any Puppet code with the new function names.
INFO: See https://puppet.com/docs/puppet/latest/custom_functions_ruby.html
INFO: for more information about Puppet's modern Ruby function API.
```
You may notice some warnings inline. Generally they can be ignored. For example, the following warning only means that the `deep_merge()` function has a `require`statement outside the block defining the new function. This doesn’t prevent my tool from porting the function to the modern API.
```
INFO: Creating lib/puppet/functions/stdlib/deep_merge.rb
WARN: The function attempted to load libraries outside the function block.
WARN: cannot load such file -- puppet/parser/functions (ignored)
```
However, the following error means that the porting process generated invalid Ruby code and so the port was aborted without the new function being written. My tool cannot fix poor code, only port it directly and it gives up quickly if it cannot do it properly.
```
INFO: Creating lib/puppet/functions/stdlib/validate_x509_rsa_key_pair.rb
ERROR: Oh crap; the generated function isn't valid Ruby code!
ERROR: <compiled>:47: dynamic constant assignment
NUM_ARGS = 2 unless defined? NUM_ARGS
^
```
Two files will be generated, the function file and the spec test for that function.
- `lib/puppet/functions/<namespace>/<function>.rb`
- `spec/functions/<namespace>_<function>_spec.rb`
Now that all the new functions are written comes the most important part, your part! Now you should inspect each function and update their documentation or clean up anything about the implementation that you’d like.
Note that all their names have changed slightly. They’ve been namespaced with the module name. This means that you’ll need to update any Puppet code that uses these functions to account for that.
And that’s it. You can stop here if you like.
Well, unless you want to take advantage of the new function API hotness, that is. Read on if you’re interested in improving the function and removing pointless boilerplate code.
## Writing new function signatures
The old API didn’t capture any information about the function signature. It always just passed the arguments as a single untyped array, which you as the programmer were expected to handle. Unfortunately, that means that I cannot programmatically infer what the argument types are expected to be.
For this reason, the generated function uses a single dispatch using a `repeated_param`to capture all arguments into a single untyped array and passes that to the implementation method. Gross hack, but it works.
``` ruby
dispatch :default_impl do
# Call the method named 'default_impl' when this is matched
# Port this to match individual params for better type safety
repeated_param 'Any', :arguments
end
```
To improve the parameter handling, you should read the implementation code and convert the manual handling into proper dispatch definitions. In the case of the`abs()` function, the parameter handling looks like this:
``` ruby
def default_impl(*arguments)
raise(Puppet::ParseError, "abs(): Wrong number of arguments given (#{arguments.size} for 1)") if arguments.empty?
value = arguments[0]
# Numbers in Puppet are often string-encoded which is troublesome ...
if value.is_a?(String)
if value =~ %r{^-?(?:\d+)(?:\.\d+){1}$}
value = value.to_f
elsif value =~ %r{^-?\d+$}
value = value.to_i
else
raise(Puppet::ParseError, 'abs(): Requires float or integer to work with')
end
end
# We have numeric value to handle ...
result = value.abs
return result
end
```
This can be improved by converting it into one or more dispatches and simplified implementation methods. Notice how little code is now required because we can now trust that the language will enforce the proper data types.
**Notice that we removed the splat (`*`) from the method signature!**
``` ruby
dispatch :default_impl do
param 'Numeric', :value
end
def default_impl(value)
value.abs
end
```
Let’s look at a more complex function, `join()`. This function takes one or two parameters. The first is an array of values, and the second is an _optional_ separator. The function will join the array into a string, separated by the separator string.
The originally ported implementation looks like
``` ruby
dispatch :default_impl do
# Call the method named 'default_impl' when this is matched
# Port this to match individual params for better type safety
repeated_param 'Any', :arguments
end
def default_impl(*arguments)
# Technically we support two arguments but only first is mandatory ...
raise(Puppet::ParseError, "join(): Wrong number of arguments given (#{arguments.size} for 1)") if arguments.empty?
array = arguments[0]
unless array.is_a?(Array)
raise(Puppet::ParseError, 'join(): Requires array to work with')
end
suffix = arguments[1] if arguments[1]
if suffix
unless suffix.is_a?(String)
raise(Puppet::ParseError, 'join(): Requires string to work with')
end
end
result = suffix ? array.join(suffix) : array.join
return result
end
```
We can see that there are two signatures, so let’s update the dispatch definition.
``` ruby
dispatch :default_impl do
param 'Array', :values
end
dispatch :separator_impl do
param 'Array', :values
param 'String', :separator
end
def default_impl(values)
values.join
end
def separator_impl(values, separator)
values.join(separator)
end
```
Now we have functions that enjoy all the benefits of the modern API, plus they’re approximately 9,000x easier to read without all the extra boilerplate code.
## Documentation
I’m sure you’ve noticed that the documentation comments in the function are hot garbage. That’s all right. It was probably time for you to take a look at that anyway. You should clean up the documentation to be both readable and to match the [`puppet-strings`](https://puppet.com/docs/puppet/latest/puppet_strings.html)format. This will help you automatically document your module on the[Puppet Forge](https://forge.puppet.com/) on your module’s _Reference_ tab.
## Testing
The test simply validates that the function compiles and defines a function properly, so you’ll also want to write more test cases. If your legacy function has unit tests, you might consider porting them to the new function, following the examples provided as comments.
## Got feedback?
I’d really love feedback. Post issues on the [project](https://github.com/binford2k/puppet-function-updater). And if you can provide your feedback as a pull request, that’s even better!
## Learn more
- Check out the [`puppet-function-updater` project on GitHub](https://github.com/binford2k/puppet-function-updater)
- Read more about [custom functions](https://puppet.com/docs/puppet/latest/custom_functions_ruby.html).
- Read more about [documenting your functions or other Puppet code](https://puppet.com/docs/puppet/latest/puppet_strings.html). | binford2k | |
238,427 | Tell me about the worst CSS you've ever had to deal with | Story time! | 0 | 2020-01-15T00:40:54 | https://dev.to/ben/tell-me-about-the-worst-css-you-ve-ever-had-to-deal-with-hf0 | discuss, css, webdev | Story time! | ben |
238,428 | React router dom: Nested routes | In this tutorial, we are going to build a nested route, or commonly called nested routing params. If... | 0 | 2020-01-20T21:10:04 | https://dev.to/itnext/react-router-dom-nested-routes-4ank | react, reactrouterdom | In this tutorial, we are going to build a nested route, or commonly called nested routing params.
If you prefer videos this is the [youtube video](https://youtu.be/gIMD83QSvNk)
I consider this tutorial an example of nested routing because it is on the API level. However for the sake of simplicity they are only defined as routing parameters within the scope of the what is declared in the App.js that this tutorial shows how to build.
__Who is this tutorial for.__
This is for any one that has a list of information being displayed to a user, when a user clicks a specific item in the list, that item will display a new page only showcasing that item.
__How it should be used.__
I highly recommend doing this tutorial. deleting what you did. checking how far you can get from memory. referencing the tutorial when you get stuck. Deleting the app after you finish until you can do nested routes from memory.
I'm a huge advocate of memorizing how to code vs... reference, copy and paste, move on.
Memorizing how to do basic pieces of functionality __will__ make you a faster dev in the long run.
__Why nested routing is useful.__
Having the ability to display more information that a user clicks on in a dynamic way like this keeps your web sites more organized and therefore, scalable.
This is also foundational for almost every e-commerce website, so knowing how to do this could mean the difference between you and your dream job as a developer, or the ability to make an online business.
__Why this can be hard.__
the reason why nested routes are tricky to learn is because you are representing 1 piece of information in two very different ways and they look very similar in the browser.
__Prerequisites__
knowledge of javascript and react.
basic knowledge of command line to install npm packages.
if you don't have npm installed on your computer, these commands work on mac or pc. you can get find out how [here](https://www.tutorialsteacher.com/nodejs/what-is-node-package-manager).
a text editor, I'll be using vs-code.
let us get started. Make a new react app.
```bash
create-react-app nested-routes-exp
```
after it installs, cd into the project folder.
```bash
cd nested-routes-exp
```
inside the root of the project directory, on the command-line, install react-router-dom.
```bash
npm i react-router-dom
```
open your project in your text editor of choice. This is how on the command-line with vs-code.
```bash
code .
```
the top section of your package.json file, _also in your root directory_,you should have a place that says react-router-dom inside the curly brackets for the dependencies section.
```json
{
"name": "nested-routes-exp",
"version": "0.1.0",
"private": true,
"dependencies": {
"@testing-library/jest-dom": "^4.2.4",
"@testing-library/react": "^9.4.0",
"@testing-library/user-event": "^7.2.1",
"react": "^16.12.0",
"react-dom": "^16.12.0",
// *you should have this below
"react-router-dom": "^5.1.2",
// * you should have this above.
"react-scripts": "3.3.0"
},
```
__NOTE:__ DO NOT change this file directly if it isn't there. run _npm i react-router-dom_ on the command line as shown above.
Now that we know that we know react-router-dom is installed, make sure that the whole app has access to this functionality.
to do this...
1. Open the index.js file in your text editor.
2. import {BrowserRouter} from "react-router-dom"
3. BrowserRouter is just a piece of context that you didn't make but imported instead. so wrap your <App/> in BrowserRouter so that you can access it down the component tree.
The whole file should look like this.
```javascript
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import App from './App';
import * as serviceWorker from './serviceWorker';
//import BrowerRouter
import {BrowserRouter} from 'react-router-dom'
ReactDOM.render(
//sandwich the App with some BrowserRouter bread
<BrowserRouter>
<App />
</BrowserRouter>
, document.getElementById('root'));
// If you want your app to work offline and load faster, you can change
// unregister() to register() below. Note this comes with some pitfalls.
// Learn more about service workers: https://bit.ly/CRA-PWA
serviceWorker.unregister();
```
_index.js in the src folder._
To ensure that this worked, open your App.js and we will import the pieces of functionality we want from react-router-dom and console.log them.
we are going to use {Route, Switch } from "react-router-dom"
__Route__ gives us a way to declare components that appear when we type in a url.
__Switch__ gives the ability to customize which components will display. In this case, the list of things we want and then on the click event displaying that item from the list.
The App.js should look something like this.
```javascript
import React from 'react';
import logo from './logo.svg';
import './App.css';
// add imports
import {Route, Switch} from 'react-router-dom'
//add props as an argument
function App(props) {
console.log('route',Route)
console.log('switch',Switch)
return (
<div className="App">
</div>
);
}
export default App;
```
now start this project on a local server.
```bash
npm start
```
if your App.js is like the one above and you inspect the page you should see 2 console logged functions along with a blank white screen.
we know Route and Switch are here in the App.js to make sure we can use them lets make a Home.js and a NoMatch.js as a 404 page to see if we can get them to display separately.
if you are using vscode, you can right-click the src folder and choose to make a new folder called components, then you can make and name the 2 files.
make the skeleton of these two components.
_Home.js_
```javascript
import React from 'react';
const Home = (props) => {
return (
<div>
Home
</div>
);
};
export default Home;
```
_NoMatch.js_
```javascript
import React from 'react';
const NoMatch = (props) => {
return (
<div>
Error 404
</div>
);
};
export default NoMatch;
```
import these components in your App.js
```javascript
import Home from "./components/Home"
import NoMatch from "./components/NoMatch"
```
add these components to the return on the App.js
```javascript
return (
<div className="App">
//testing if they show up
<Home />
<NoMatch />
</div>
);
```
now we want to add Switch to get the functionality we want by adding the <Switch> inside the return
```javascript
return (
<div className="App">
{/* add Switch notice that the no match component isn't rendering. */}
<Switch>
<Home />
<NoMatch />
</Switch>
</div>
);
```
we are only getting one component right now because Switch reads from top to bottom.
lets add a route.
there are two ways to do this, change your home component to look like this.
```javascript
<Route exact path='/home'> <Home /> </Route>
```
this allows us to only render the home component when we type into the Url /home. give it a try
and if we don't designate a path we get a page not found.
There are a few ways to define routes, another syntax is component={} prop for the route
```javascript
<Route path component={NoMatch} />
```
Now the only time any other component will show up besides the 404 page is when we define that path here in our App.js
Normally this would be your home page, but for demonstration purposes, I wanted to show how you explicitly define them any way you want.
also, render is better than component because you can pass your own props along with render props. rProps for short.
now we are ready to map through a list on the home page.
I will be using the starwars API to demonstrate.
import {useEffect, useState} on the Home.js like so...
```javascript
import React, {useEffect, useState} from 'react'
```
this means that we should install and import axios to make life a little easier.
```bash
npm i axios
```
in the Home.js at the top.
```javascript
import axios from 'axios'
```
inside the function make an array for the starwars characters
```javascript
const [characters, setCharacters] = useState([])
```
and a useEffect to handle the get request.
```javascript
useEffect( () => {
axios.get(`https://swapi.co/api/people`)
.then(res => {
console.log(res.data.results)
})
}, [])
```
This should give you 10 objects in the console.log
Set these objects to state by replacing the console.log with setCharacters.
```javascript
setCaracters(res.data.results)
```
now display the characters to the browser by mapping them in the return.
```javascript
Home:
{characters.map(character => {
return <h1>{character.name}</h1>
})}
```
cool almost there.
Next objectives
1. get the characters name to show up in the url by replacing h1 with a Link .
2. make the link render a Character component.
import {Link} from react-router-dom
add the name link
```javascript
<Link to={'/' + character.name}>{character.name}</Link>
```
click a character and you should see there name appear in the URL.
Make a Character.js we are going to need a axios.get useEffect and useState in this component.
We also need useParams from react router dom. so that we can get the names from the url.
here is the skeleton.
```javascript
import React, {useEffect, useState} from 'react';
import axios from 'axios'
import {useParams} from 'react-router-dom'
const Character = (props) => {
return (
<div>
Character:
</div>
);
};
export default Character;
```
Now let's make it so that this component shows up when we click a character by declaring that route in the App.js
Add this Route inside the Switch.
```javascript
<Route exact path='/:name'> <Character /> </Route>
```
It’s important to understand that if we were to write the path=“/people/:name” it would be an example of a nested Route, since it’s not it’s considered a routing parameter.
Notice the path='/:name' the __:__ makes it so that we can have an id representing the name.
We need access to a thing that react-router-dom provides called match from params
console.log(useParams()) in the Character.js
```javascript
console.log(useParams())
```
Walk down the object so that the character's name is just a string and not a key-value pair.
```javascript
console.log(useParmas().name)
```
the console.log save that string to a variable so that you can add it to the url.
Note: react will throw an error if you try and call useParams directly in the useEffect. This means you must call useParams outside the useEffect.
```javascript
const name = useParams().name
```
Make the useEffect and the useState
```javascript
const [character, setCharacter] = useState([])
//above the return.
```
Since we want a single character, useEffect has to do a couple things.
1. do a get request for a single character with a search.
2. add that character to state.
this is what that useEffect looks like.
```javascript
useEffect( () => {
axios.get(`https://swapi.co/api/people/?
search=${name}`)
.then(res => {
setCharacter(res.data.results)
})
}, [])
```
This is how you set up a search of an API by a click event with react-router-dom.
Make the info about the character appear on the screen you can add anything you want but this is what I wanted to show for this tutorial.
Inside the return statement add the extra info you wanted to display.
```javascript
return (
<div>
Character:
{character.map(char => {
return <>
<h1>{char.name}</h1>
<p>eye color: {char.eye_color}</p>
<p>hair color: {char.hair_color}</p>
<p>birth year: {char.birth_year}</p>
<p> gender: {char.gender}</p>
</>
})}
<Link to='/home'>back to home</Link>
</div>
);
```
This is my end result.
```javascript
import React, {useEffect, useState} from 'react';
import axios from 'axios'
import {Link, useParams} from 'react-router-dom'
const Character = (props) => {
const [character, setCharacter] = useState([])
const name = useParams().name
console.log('character',character)
useEffect( () => {
axios.get(`https://swapi.co/api/people/?search=${name}`)
.then(res => {
setCharacter(res.data.results)
})
}, [])
return (
<div>
Character:
{character.map(char => {
return <>
<h1>{char.name}</h1>
<p>eye color: {char.eye_color}</p>
<p>hair color: {char.hair_color}</p>
<p>birth year: {char.birth_year}</p>
<p> gender: {char.gender}</p>
</>
})}
<Link to='/home'>back to home</Link>
</div>
);
};
export default Character;
```
That's it! I would suggest playing around and adding upon this tutorial to get the most out of it.
the API is kind of slow but it might be cool to make your own back-end and database and see what you could do.
I hope this tutorial was helpful.
If there is anything you would like me to add or if there are errors to fix, any kind of feedback in general, add them to the comments below.
[github](https://github.com/TallanGroberg/nested-routes-tutorial)
[other react tutorials](https://dev.to/tallangroberg)
Thanks so much for checking out my silly write up!!
| tallangroberg |
238,456 | How You Can Make a Browser Extension with Vue.js | Subscribe to my email list now at http://jauyeung.net/subscribe/ Follow me on Twitter at https://twi... | 0 | 2020-01-15T03:04:30 | https://dev.to/aumayeung/how-to-make-a-browser-extension-with-vue-js-1lh8 | webdev, html, javascript, tutorial | **Subscribe to my email list now at http://jauyeung.net/subscribe/**
**Follow me on Twitter at https://twitter.com/AuMayeung**
**Many more articles at https://medium.com/@hohanga**
The most popular web browsers, Chrome and Firefox support extensions. Extensions are small apps that you can add to your browser to get the functionality that is not included in your browser. This makes extending browser functionality very easy. All a user has to do is to add browser add-ons from the online stores like the Chrome Web Store or the Firefox Store to add browser add-ons.
Browser extensions are just normal HTML apps packages in a specific way. This means that we can use HTML, CSS, and JavaScript to build our own extensions.
Chrome and Firefox extensions follow the Web Extension API standard. The full details are at [https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions)
In this article, we will make a Chrome extension that displays the weather from the OpenWeatherMap API. We will add a search to let users look up the current weather and forecast from the API and display it in the extension’s popup box.
We will use Vue.js to build the browser extension. To begin building it, we start with creating the project with Vue CLI. Run `npx @vue/cli create weather-app` to create the project. In the wizard, select Babel and Vuex.
The OpenWeatherMap API is available at [https://openweathermap.org/api](https://openweathermap.org/api). You can register for an API key here. Once you got an API key, create an `.env` file in the root folder and add `VUE_APP_APIKEY` as the key and the API key as the value.
Next, we use the vue-cli-plugin-browser-extension to add the files for writing and compiling the Chrome extension. The package settings and details are located at [https://www.npmjs.com/package/vue-cli-plugin-browser-extension](https://www.npmjs.com/package/vue-cli-plugin-browser-extension).
To add it to our project, we run `vue add browser-extension` to add the files needed to build the extension. The command will change the file structure of our project.
After that command is run, we have to remove some redundant files. We should remove `App.vue` and `main.js` from the `src` folder and leave the files with the same name in the `popup` folder alone. Then we run `npm run serve` to build the files as we modify the code.
Next, we have to install the Extension Reload to reload the extension as we are changing the files. Install it from [https://chrome.google.com/webstore/detail/extensions-reloader/fimgfedafeadlieiabdeeaodndnlbhid](https://chrome.google.com/webstore/detail/extensions-reloader/fimgfedafeadlieiabdeeaodndnlbhid) to get hot reloading of our extension in Chrome.
Then we go to the chrome://extensions/ URL in Chrome and toggle on Developer Mode. We should see the Load unpacked button on the top left corner. Click that, and then select the `dist` folder in our project to load our extension into Chrome.
Next, we have to install some libraries that we will use. We need Axios for making HTTP requests, BootstrapVue for styling, and Vee-Validate for form validation. To install them, we run `npm i axios bootstrap-vue vee-validate` to install them.
With all the packages installed we can start writing our code. Create `CurrentWeather.vue` in the `components` folder and add:
```javascript
<template>
<div>
<br />
<b-list-group v-if="weather.main">
<b-list-group-item>Current Temparature: {{weather.main.temp - 273.15}} C</b-list-group-item>
<b-list-group-item>High: {{weather.main.temp_max - 273.15}} C</b-list-group-item>
<b-list-group-item>Low: {{weather.main.temp_min - 273.15}} C</b-list-group-item>
<b-list-group-item>Pressure: {{weather.main.pressure }}mb</b-list-group-item>
<b-list-group-item>Humidity: {{weather.main.humidity }}%</b-list-group-item>
</b-list-group>
</div>
</template>
<script>
import { requestsMixin } from "@/mixins/requestsMixin";
export default {
name: "CurrentWeather",
mounted() {},
mixins: [requestsMixin],
computed: {
keyword() {
return this.$store.state.keyword;
}
},
data() {
return {
weather: {}
};
},
watch: {
async keyword(val) {
const response = await this.searchWeather(val);
this.weather = response.data;
}
}
};
</script>
<style scoped>
p {
font-size: 20px;
}
</style>
```
This component displays the current weather from the OpenWeatherMap API as the `keyword` from the Vuex store is updated. We will create the Vuex store later. The `this.searchWeather` function is from the `requestsMixin` , which is a Vue mixin that we will create. The `computed` block gets the `keyword` from the store via `this.$store.state.keyword` and return the latest value.
Next, create `Forecast.vue` in the same folder and add:
```javascript
<template>
<div>
<br />
<b-list-group v-for="(l, i) of forecast.list" :key="i">
<b-list-group-item>
<b>Date: {{l.dt_txt}}</b>
</b-list-group-item>
<b-list-group-item>Temperature: {{l.main.temp - 273.15}} C</b-list-group-item>
<b-list-group-item>High: {{l.main.temp_max - 273.15}} C</b-list-group-item>
<b-list-group-item>Low: {{l.main.temp_min }}mb</b-list-group-item>
<b-list-group-item>Pressure: {{l.main.pressure }}mb</b-list-group-item>
</b-list-group>
</div>
</template>
<script>
import { requestsMixin } from "@/mixins/requestsMixin";
export default {
name: "Forecast",
mixins: [requestsMixin],
computed: {
keyword() {
return this.$store.state.keyword;
}
},
data() {
return {
forecast: []
};
},
watch: {
async keyword(val) {
const response = await this.searchForecast(val);
this.forecast = response.data;
}
}
};
</script>
<style scoped>
p {
font-size: 20px;
}
</style>
```
It’s very similar to `CurrentWeather.vue`. The only difference is that we are getting the current weather instead of the weather forecast.
Next, we create a `mixins` folder in the `src` folder and add:
```javascript
const APIURL = "http://api.openweathermap.org";
const axios = require("axios");
export const requestsMixin = {
methods: {
searchWeather(loc) {
return axios.get(
`${APIURL}/data/2.5/weather?q=${loc}&appid=${process.env.VUE_APP_APIKEY}`
);
},
searchForecast(loc) {
return axios.get(
`${APIURL}/data/2.5/forecast?q=${loc}&appid=${process.env.VUE_APP_APIKEY}`
);
}
}
};
```
These functions are for getting the current weather and the forecast respectively from the OpenWeatherMap API. `process.env.VUE_APP_APIKEY` is obtained from our `.env` file that we created earlier.
Next in `App.vue` inside the `popup` folder, we replace the existing code with:
```javascript
<template>
<div>
<b-navbar toggleable="lg" type="dark" variant="info">
<b-navbar-brand href="#">Weather App</b-navbar-brand>
</b-navbar>
<div class="page">
<ValidationObserver ref="observer" v-slot="{ invalid }">
<b-form @submit.prevent="onSubmit" novalidate>
<b-form-group label="Keyword" label-for="keyword">
<ValidationProvider name="keyword" rules="required" v-slot="{ errors }">
<b-form-input
:state="errors.length == 0"
v-model="form.keyword"
type="text"
required
placeholder="Keyword"
name="keyword"
></b-form-input>
<b-form-invalid-feedback :state="errors.length == 0">Keyword is required</b-form-invalid-feedback>
</ValidationProvider>
</b-form-group>
<b-button type="submit" variant="primary">Search</b-button>
</b-form>
</ValidationObserver><br />
<b-tabs>
<b-tab title="Current Weather">
<CurrentWeather />
</b-tab>
<b-tab title="Forecast">
<Forecast />
</b-tab>
</b-tabs>
</div>
</div>
</template>
<script>
import CurrentWeather from "@/components/CurrentWeather.vue";
import Forecast from "@/components/Forecast.vue";
export default {
name: "App",
components: { CurrentWeather, Forecast },
data() {
return {
form: {}
};
},
methods: {
async onSubmit() {
const isValid = await this.$refs.observer.validate();
if (!isValid) {
return;
}
localStorage.setItem("keyword", this.form.keyword);
this.$store.commit("setKeyword", this.form.keyword);
}
},
beforeMount() {
this.form = { keyword: localStorage.getItem("keyword") || "" };
},
mounted(){
this.$store.commit("setKeyword", this.form.keyword);
}
};
</script>
<style>
html {
min-width: 500px;
}
.page {
padding: 20px;
}
</style>
```
We add the BootstrapVue `b-navbar` here to add a top bar to show the extension’s name. Below that, we added the form for searching the weather info. Form validation is done by wrapping the form in the `ValidationObserver` component and wrapping the input in the `ValidationProvider` component. We provide the rule for validation in the `rules` prop of `ValidationProvider` . The rules will be added in `main.js` later.
The error messages are displayed in the `b-form-invalid-feedback` component. We get the errors from the scoped slot in `ValidationProvider` . It’s where we get the `errors` object from.
When the user submits the number, the `onSubmit` function is called. This is where the `ValidationObserver` becomes useful as it provides us with the `this.$refs.observer.validate()` function for form validation.
If `isValid` resolves to `true` , then we set the `keyword` in local storage, and also in the Vuex store by running `this.$store.commit(“setKeyword”, this.form.keyword);` .
In the `beforeMount` hook, we set the `keyword` so that it will be populated when the extension first loads if a `keyword` was set in local storage. In the `mounted` hook, we set the keyword in the Vuex store so that the tabs will get the `keyword` to trigger the search for the weather data.
Then in `store.js` , we replace the existing code with:
```
import Vue from "vue";
import Vuex from "vuex";Vue.use(Vuex);export default new Vuex.Store({
state: {
keyword: ""
},
mutations: {
setKeyword(state, payload) {
state.keyword = payload;
}
},
actions: {}
});
```
to add the Vuex store that we referenced in the components. We have the `keyword` state for storing the search keyword in the store, and the `setKeyword` mutation function so that we can set the `keyword` in our components.
Next in `popup/main.js` , we replace the existing code with:
```javascript
import Vue from 'vue'
import App from './App.vue'
import store from "../store";
import "bootstrap/dist/css/bootstrap.css";
import "bootstrap-vue/dist/bootstrap-vue.css";
import BootstrapVue from "bootstrap-vue";
import { ValidationProvider, extend, ValidationObserver } from "vee-validate";
import { required } from "vee-validate/dist/rules";/\* eslint-disable no-new \*/
extend("required", required);
Vue.component("ValidationProvider", ValidationProvider);
Vue.component("ValidationObserver", ValidationObserver);
Vue.use(BootstrapVue);Vue.config.productionTip = false;new Vue({store,
render: h => h(App)
}).$mount("#app");
```
We added the validation rules that we used in the previous files here, as well as include all the libraries we use in the app. We registered `ValidationProvider` and `ValidationObserver` by calling `Vue.component` so that we can use them in our components. The validation rules provided by Vee-Validate are included in the app so that they can be used by the templates by calling `extend` from Vee-Validate. We called `Vue.use(BootstrapVue)` to use BootstrapVue in our app.
Finally in `index.html` , we replace the existing code with:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width,initial-scale=1.0" />
<link rel="icon" href="<%= BASE_URL %>favicon.ico" />
<title>Weather App</title>
</head>
<body>
<noscript>
<strong
>We're sorry but vue-chrome-extension-tutorial-app doesn't work properly
without JavaScript enabled. Please enable it to continue.</strong
>
</noscript>
<div id="app"></div>
<!-- built files will be auto injected -->
</body>
</html>
```
to replace the title. | aumayeung |
238,545 | Android-Kotlin MVVM clean arch. | https://github.com/furkanaskin/Weatherapp Weatherapp is a simple forecast app, which uses some APIs... | 0 | 2020-01-15T07:11:35 | https://dev.to/furkanaskin/android-kotlin-mvvm-clean-arch-5di2 | android | https://github.com/furkanaskin/Weatherapp
Weatherapp is a simple forecast app, which uses some APIs to fetch 5 day / 3 hour forecast data from the OpenWeatherMap and to fetch places,cities,counties,coords etc. from Algolia Places. The main goal of this app is to be a sample of how to build an high quality Android application that uses the Architecture components, Dagger etc. in Kotlin. | furkanaskin |
238,558 | Key android developer best practices to keep in mind. | Hello Coders! So, today I'll be talking about best practices to adopt as an android developer. Keep... | 0 | 2020-01-15T10:43:00 | https://dev.to/rocqjones/key-android-developer-best-practices-to-keep-in-mind-2k33 | Hello Coders!
So, today I'll be talking about best practices to adopt as an android developer. Keep in mind that it's all about simplicity, readable code, and most important other developers might end up maintaining your code. I've summarized some of the key practices as follows, I thought it would be helpful.
## 1. Project structure.
When starting a new project, Android Studio automatically creates some of these files for you, as shown and populates them based on realistic defaults.
## 2. Keep your colors.xml short and clean, just define the palette.
There should be nothing in your colors.xml other than a mapping color name to an RGBA value. This helps to avoid repetition of values thus making it easy to change or refactor colors, and also will make it explicit how many different colors are being used. Normally for a aesthetic UI, it is important to reduce the variety of colors being used.
### DON'T
```
<resources>
<color name="button_foreground">#FFFFFF</color>
<color name="button_background">#2A91BD</color>
</resources>
```
### DO:
```
<resources>
<!-- grayscale -->
<color name="white">#FFFFFF</color>
<!-- basic colors -->
<color name="blue">#2A91BD</color>
</resources>
```
## 3. Also keep dimens.xml clean, define generic constants.
You should define a "palette" of typical spacing and font sizes, for basically the same purposes as for colors. A good example of a dimens file:
```
<resources>
<!-- font sizes -->
<dimen name="font_larger">22sp</dimen>
<dimen name="font_large">18sp</dimen>
<!-- typical spacing between two views -->
<dimen name="spacing_huge">40dp</dimen>
<dimen name="spacing_large">24dp</dimen>
<!-- typical sizes of views -->
<dimen name="button_height_tall">60dp</dimen>
<dimen name="button_height_normal">40dp</dimen>
</resources>
```
You should use the spacing_**** dimensions for layouting, in margins and padding, instead of hard-coded values, much like strings are normally treated. This will give a consistent look-and-feel, while making it easier to organize and change styles and layouts.
## 4. Do not make a deep hierarchy of ViewGroups.
* Sometimes you might be tempted to just add yet another LinearLayout, to be able to accomplish an arrangement of views. Take a look at this case:
```
<LinearLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical"
>
<RelativeLayout
...
>
<LinearLayout
...
>
<LinearLayout
...
>
<LinearLayout
...
>
</LinearLayout>
</LinearLayout>
</LinearLayout>
</RelativeLayout>
</LinearLayout>
```
* A couple of problems may occur. You might experience performance problems, because there is a complex UI tree that the processor needs to handle. Another more serious issue is a possibility of errors because of too many nested layouts.
Therefore, try to keep your views hierarchy as flat as possible: learn how to use ConstraintLayout, how to optimize your layouts and to use the ***<merge>*** [tag](https://developer.android.com/training/improving-layouts/reusing-layouts).
## 5. User Experience.
* It's the context of satisfaction of a user’s interaction with your app. Some notes to improving the experience of your apps:
### 1. Excellent UI.
To have a a excellent feel and experience of an app starts with a good design that matches the Google material design principles.
* Consistency in color combinations. For this case use [Material Design Color Tool](https://material.io/resources/color/)
* Use of proper icons to portray functionality. Use [Material Design Tool](https://material.io/design/introduction/#)
### 2. Configuration Change Handling.
This is the most annoying scenarios android developers face. When you rotate your device and the screen changes orientation, Android usually destroys your application’s existing Activities and Fragments and recreates them. This is done so that the application can reload resources based on the new configuration and this is basically like starting afresh. Improper handling of this scenario is an instance of bad user experience. Below are some solutions to this:
* With the [ViewModel](https://developer.android.com/topic/libraries/architecture/viewmodel.html) as part of the [architecture components](https://developer.android.com/topic/libraries/architecture/index.html) released by Google.
Below, is an image that shows the life-cycle of an Activity as compared to that of a ViewModel.
* consider is persisting your data in the database after it has been fetched from a remote source so that when the phone is rotated, data can quickly be gotten from the database instead of having to fetch again.
## 6. Compatibility.
There are two types of compatibility: device compatibility and app compatibility.
* Device compatibility. Because Android is an open source project, any hardware manufacturer can build a device that runs the Android operating system.
* App compatibility. Because Android runs on a wide range of device configurations, some features are not available on all devices.
## 7. Understand build process.
The build process involves tools and processes that convert your project into an Android Application Package (APK) so it's important to understand.
* The compilers convert your source code into DEX (Dalvik Executable) files, which include the bytecode that runs on Android devices, and everything else into compiled resources.
* The APK Packager combines the DEX files and compiled resources into a single APK. Before your app can be installed and deployed onto an Android device, however, the APK must be signed.
* Before generating your final APK, the packager uses the zipalign tool to optimize your app to use less memory when running on a device.
## 8. Security & Privacy.
Security is one of the most neglected areas when building apps because it is large in scope and it's almost impossible to perfect. Google has released features that significantly reduce the frequency of security issues. Some of which include:
* Google play protect: this is built into every device with Google Play to automatically take action to keep data and device safe.
* Encryption from Android M to protect user data.
* SafetyNet attestation: evaluates if an Android device is a certified secure .
* reCAPTCHA for Android: This ensures that an app is not automated i.e handled by a robot.
However, notice that some security vulnerabilities are out of their control like:
### Communicate Securely with a Server.
* At some point our apps needs to communicate with an APIs and back-end services to fetch data or send data which should be done in a securely. On that note, [Network security configuration](https://developer.android.com/training/articles/security-config.html) was introduced to ensure adequate validation of the servers our apps intend to communicate with.
* If you are building a social app or anything related that requires authentication and user management, you could use the service provided to us by Auth0 to manage our identities while you focus on other functionalities which uses a secure protocol.
Below is a generic workflow of the protocol.
## 9. Keep the Long Running Tasks Away.
* Use a background thread for all long running tasks. Doing this counts for a better performance and better user experience in the long run.
* Android Studio provides us with the profiler to check the performance of our app while still in development. The profiler helps us gauge the device’s resource usage of our app during execution. It is usually located at the bottom of your screen and only shows up when the app is running.
 | rocqjones | |
238,630 | Meeting rules | I was having a conversation with some tech people recently about meetings, those things that we all s... | 0 | 2020-04-09T14:55:29 | https://dev.to/joro550/meeting-rules-ii0 | leadership, meetings | I was having a conversation with some tech people recently about meetings, those things that we all seem to dislike. But why do we dislike them when communication and collaboration seems to be the words on peoples lips, aren't meetings just a slot of time that is focused on those particular things?
Well let's look at some of the rules to make your meetings better!
# Rule 1. Have less of them
We live in a world where less really is more sometimes, and I feel that some people call meetings for things that can really just be a chat around a desk - or worse call a meeting for what could have been an email. There should be a list of avenues that you attempt before calling that meeting:
- Have you tried talking about the subject
- Have you tried emailing?
- Have you tried messaging people
If non of these avenues are working only then you should think about taking time away from people.
# Rule 2. Sometimes more is fine but structure and time box them
If you having a lot of meetings - in my mind you may be doing something incorrectly and maybe you need to learn how to talk with your team again. But in some scenarios sometimes meetings are a good thing! We want more callaboration and more communication, getting people in a room together to talk face to face is probably the best way to get people to focus, but remember to structure your meetings (talked about later on) don't overrun and have an agenda.
# Rule 3. Finish at least 5 minutes before the end.
Be ready to evacuate the area, start packing away your meeting 5 minutes early so that the next meeting can get underway, don't waste other peoples time by packing up after your meeting has ended, you will not be thanked.
# Rule 4. Turn up on time
No one likes someone who is late for a meeting, if you do turn up late then it is on you to catch up with what is going on, don't walk in 20 minutes late and ask for a summary of whats been discussed because your just wasting peoples time.
# Rule 5. Have an agenda
Be sure to have an agenda in mind, if you must make a detailed bullet point list of things that you would like to discuss and how long you feel the discussion should go on for, set a timer. Try it and see how it feels, no one wants to talk about a singular thing for more than 25 mintues, people tend to drift and not have a vested interest after that amount of time. Be sure to get what you need from people about a particular subject then move onto the next
# Rule 6. Have an outcome in mind
You need to know the actionable points that you want to get out a meeting - heer's a really good and easy example we are going to discuss this new api we are building here are some actionable questions that we need answers to before we continue onwards
- Is it going to be versioned
- Is this a restful api?
- What url template are we going to use
- What status codes are we going to use in x scenario
# Rule 7. Be ready for what's going to be discussed
Do some research, do more research than nessasary, if it's about a new project or new infrastructure have a advantage/disadvantage list ready so that you can make informed decisions. One of the worst things that you can do (take it from my personal experience) is walk away from a meeting saying that you need another meeting to decide what you wanted to decide in the meeting that you just went through.
Make sure you are fully informed on what is about to be discussed - don't go in cold turkey and "wing it".
# Rule 8. Constructive thoughts only please
Much like improv you need to "yes and" people a lot, if you say "no" you automatically block off that avenue of thought, you don't want to restrict yourself to this. Never say no, say "how about", "what if", "That's a good idea, thinking about it in another way....", build on ideas.
# Rule 9. Don't "bulldoze" the meeting
Please don't go off on a massive tangeant about things that may not matter, if you feel that something is worth discussing in depth and isn't an immediate blocker then schedule it for another discussion, if it is an immediate blocker I then in my opinion it should have been pointed out before the meeting so that people could've contributed towards pushing past it.
I can say from personal experience no one enjoys that 20 minute rant that some people go on about "the future" of the project - keep to the points outlined, if you need to vent or rant then do it when your not wasting meeting times.
# Rule 10. If it's not applicable to you - leave
I have been in too many meetings where the subject matter just didn't concern me in the slightest, you can leave! Just do so curteously, pick up your items and quietly leave the room.
# Rule 11. Take notes.
Once you have your actionable items you need to well action them! So be sure to take notes of what has been discussed and what conclusions you have come to so that you don't forget them by the time you get back to your desk.
# Rule 12. Take breaks
After each item, take a five minute breather, easy rule. Not everyone can think about one item in depth and then move directly onto another subject one after another, allow some time to relax after one deep conversation and get ready to start the next one, encourage people to get out of their seat.
# Rule 13. Don't just sit down
GET OUT OF YOUR SEAT! draw on a white board, write stuff on sticky notes and post them on a wall, literally anything to get people out of their seat, people get more involved when their not slumpping in their chair!
# Rule 14. Have discussions before/during/after the meetings
I once worked in a team where it felt like the only time we talked as a team is in meetings. We normally spent meetings talking about massive blockers we just thought of, which meant that we'd have to go away and book more meetings!
Please learn from that teams mistakes, you need to discuss the agenda with the team, you need to inform the team on what is going to be discussed and if they have any major blockers that they could see to bring it up before the meeting so that can be discussed before the item that is going to be blocked.
# Rule 15. Don't be afraid to sound stupid
We've all bene there, sat quiet in our chair afraid that the idea that we have in our head is a stupid one, but maybe it will be great, or maybe I will be mocked for it, oh no, scary.
You need to let go of this feeling, you need to just "think out loud" no matter the thought we can note it down and build on it, ideas create more ideas. | joro550 |
238,636 | Answer: How to use moment.js library in angular 2 typescript app? | answer re: How to use moment.js libra... | 0 | 2020-01-15T09:50:10 | https://dev.to/ikungolf/answer-how-to-use-moment-js-library-in-angular-2-typescript-app-h61 | {% stackoverflow 43257938 %} | ikungolf | |
238,641 | Searching for React and Nodejs remotely job ..... | Searching for React and Nodejs remotely job ..... | 0 | 2020-01-15T10:03:39 | https://dev.to/abdullhrtima/hello-world-54pc | reactnodejs | ---
title: Searching for React and Nodejs remotely job .....
published: true
description: Searching for React and Nodejs remotely job .....
tags: react nodejs
---
| abdullhrtima |
238,694 | Header with growing shadow | A post by AMBIVA | 0 | 2020-01-15T12:49:17 | https://dev.to/ambiva_platform/header-with-growing-shadow-3hjm | codepen | {% codepen https://codepen.io/ambiva/pen/mdyjGaY %} | ambiva_platform |
238,697 | Using pattern matching to compare two strings | Elixir’s pattern matching feature is the gift that keeps on giving. I love this neat trick to check i... | 0 | 2020-01-15T12:56:53 | https://til.ryanwill.dev/posts/f2kgyinezp-using-pattern-matching-to-compare-two-strings | elixir, todayilearned | ---
title: Using pattern matching to compare two strings
published: true
tags: elixir, todayilearned
canonical_url: https://til.ryanwill.dev/posts/f2kgyinezp-using-pattern-matching-to-compare-two-strings
---
Elixir’s pattern matching feature is the gift that keeps on giving. I love this neat trick to check if two strings are the same. It is an easy way to check if a password and password confirmation match.
```elixir
def passwords_match?(password, password), do: true
def passwords_match?(_, _), do: false
passwords_match?("password", "password") # true
passwords_match?("password", "notpassword") # false
``` | ryanwilldev |
238,761 | Answer: How to use sweetalert in nodejs? | answer re: How to use sweetalert in... | 0 | 2020-01-15T13:41:59 | https://dev.to/pprathameshmore/answer-how-to-use-sweetalert-in-nodejs-2hc2 | ---
title: Answer: How to use sweetalert in nodejs?
published: true
---
{% stackoverflow 59696880 %} | pprathameshmore | |
239,357 | Daily Developer Jokes - Thursday, Jan 16, 2020 | Check out today's daily developer joke! (a project by Fred Adams at xtrp.io) | 4,070 | 2020-01-16T13:00:15 | https://dev.to/dailydeveloperjokes/daily-developer-jokes-thursday-jan-16-2020-3e4j | jokes, dailydeveloperjokes | ---
title: "Daily Developer Jokes - Thursday, Jan 16, 2020"
description: "Check out today's daily developer joke! (a project by Fred Adams at xtrp.io)"
series: "Daily Developer Jokes"
cover_image: "https://private.xtrp.io/projects/DailyDeveloperJokes/thumbnail_generator/?date=Thursday%2C%20Jan%2016%2C%202020"
published: true
tags: #jokes, #dailydeveloperjokes
---
Generated by Daily Developer Jokes, a project by [Fred Adams](https://xtrp.io/) ([@xtrp](https://dev.to/xtrp) on DEV)
___Read about Daily Developer Jokes on [this blog post](https://xtrp.io/blog/2020/01/12/daily-jokes-bot-release/), and check out the [Daily Developer Jokes Website](https://dailydeveloperjokes.github.io/).___
### Today's Joke is...

---
*Have a joke idea for a future post? Email ___[xtrp@xtrp.io](mailto:xtrp@xtrp.io)___ with your suggestions!*
*This joke comes from [Dad-Jokes GitHub Repo by Wes Bos](https://github.com/wesbos/dad-jokes) (thank you!), whose owner has given me permission to use this joke with credit.*
<!--
Joke text:
___Q:___ Why did the computer keep sneezing?
___A:___ It had a virus!
-->
| dailydeveloperjokes |
239,575 | How to use JetBrainsMono in VSCode (New font in the town) | how to use JetBrainsMono in vs code | 0 | 2020-01-16T17:14:16 | https://dev.to/shofol/how-to-use-jetbrainsmono-in-vscode-jb8 | opensource, vscode | ---
title: How to use JetBrainsMono in VSCode (New font in the town)
published: true
description: how to use JetBrainsMono in vs code
tags: opensource, vscode
---
JetBrains has released a typeface for all of their IDEs and this is opensource!:blush: So, VSCode lovers or other IDE guys can also try this! For VSCode users-
* Install the Font Pack in your computer (Guide is here-https://www.jetbrains.com/lp/mono/)
* Go to Preferences->Settings->Font and then change the font to JetBrains Mono. You can Follow this gif-

Use it or not, you should have a look at their site at least. It is great! People are twitting about it!
{% twitter 1217558350201872384 %} | shofol |
240,738 | Compute MD5 checksum hash for a File in Typescript | When implementing a file uploader component in your webapp, you may need to compute the MD5 checksum... | 0 | 2020-01-18T09:56:22 | https://dev.to/qortex/compute-md5-checksum-for-a-file-in-typescript-59a4 | javascript, typescript, webdev | When implementing a file uploader component in your webapp, you may need to compute the MD5 checksum of a file.
It is typically useful when your frontend uploads a file to some cloud storage and needs to make your backend aware of the file that was just uploaded. Armed with the MD5 hash of the file, the backend can then validate the integrity of the file when accessing it later on.
At least, that's the way it works in Ruby on Rails & [Active Storage](https://edgeguides.rubyonrails.org/active_storage_overview.html).
Quite surprisingly though, there is no easy straightforward way to get the MD5 checksum for a [File](https://developer.mozilla.org/en-US/docs/Web/API/File) object in Typescript / Javascript.
Building on this [SO post](https://stackoverflow.com/questions/768268/how-to-calculate-md5-hash-of-a-file-using-javascript?noredirect=1&lq=1), the great [Spark-MD5 library](https://github.com/satazor/js-spark-md5) and its test examples, here is a simple solution.
The [spark-md5](https://github.com/satazor/js-spark-md5) package needs to be installed in your project:
```shell
yarn add spark-md5
# or npm install --save spark-md5
```
Then the following function does the computation itself, returning a [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) of the MD5 hash as a base64 encoded string. It reads the file in chunks to avoid loading the whole file into memory at once, which could be a performance disaster.
```typescript
import * as SparkMD5 from 'spark-md5';
// ...
computeChecksumMd5(file: File): Promise<string> {
return new Promise((resolve, reject) => {
const chunkSize = 2097152; // Read in chunks of 2MB
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader();
let cursor = 0; // current cursor in file
fileReader.onerror = function(): void {
reject('MD5 computation failed - error reading the file');
};
// read chunk starting at `cursor` into memory
function processChunk(chunk_start: number): void {
const chunk_end = Math.min(file.size, chunk_start + chunkSize);
fileReader.readAsArrayBuffer(file.slice(chunk_start, chunk_end));
}
// when it's available in memory, process it
// If using TS >= 3.6, you can use `FileReaderProgressEvent` type instead
// of `any` for `e` variable, otherwise stick with `any`
// See https://github.com/Microsoft/TypeScript/issues/25510
fileReader.onload = function(e: any): void {
spark.append(e.target.result); // Accumulate chunk to md5 computation
cursor += chunkSize; // Move past this chunk
if (cursor < file.size) {
// Enqueue next chunk to be accumulated
processChunk(cursor);
} else {
// Computation ended, last chunk has been processed. Return as Promise value.
// This returns the base64 encoded md5 hash, which is what
// Rails ActiveStorage or cloud services expect
resolve(btoa(spark.end(true)));
// If you prefer the hexdigest form (looking like
// '7cf530335b8547945f1a48880bc421b2'), replace the above line with:
// resolve(spark.end());
}
};
processChunk(0);
});
}
```
Now, profit:
```typescript
// your_file_object: File
// ...
computeChecksumMd5Hash(your_file_object).then(
md5 => console.log(`The MD5 hash is: ${md5}`)
);
// Output: The MD5 hash is: fPUwM1uFR5RfGkiIC8Qhsg==
``` | qortex |
240,784 | Woocommerce order report plugin does not show multiple product names & customer notes | Woocommerce order report plugin does... | 0 | 2020-01-18T10:19:19 | https://dev.to/_pagla_/woocommerce-order-report-plugin-does-not-show-multiple-product-names-customer-notes-277i | {% stackoverflow 59784289 %} | _pagla_ | |
241,077 | Adding Drag and Drop to JavaScript Apps | Subscribe to my email list now at http://jauyeung.net/subscribe/ Follow me on Twitter at https://twi... | 0 | 2020-01-19T01:19:22 | https://dev.to/aumayeung/adding-drag-and-drop-to-javascript-apps-3a69 | webdev, javascript, tutorial, beginners | **Subscribe to my email list now at http://jauyeung.net/subscribe/**
**Follow me on Twitter at https://twitter.com/AuMayeung**
**Many more articles at https://medium.com/@hohanga**
In JavaScript, events are actions that happen in an app. They’re triggered by various things like inputs being entered, forms being submitted, changes in an element like resizing, or errors that happen when an app is running, etc.
We can assign event handlers to events so we can take perform an action when one is triggered. Events that happen to DOM elements can be handled by assigning an event handler to properties of the DOM object for the corresponding events. In this article, we will look at the `ondragstart` and `ondrop` event handlers.
ondragstart event
=================
The `ondragstart` property of an HTML element lets us assign an event handler for the `dragstart` event which is triggered when the user starts dragging an element or text selection. For example, if we want to tracking when an element has started to be dragged and when it’s dropped, we can write the following HTML code:
```html
<p id='drag-start-tracker'>
</p>
<div id='drag-box' draggable="true">
</div>
<div id='drop-zone'>
</div>
```
In the code above, we have a `p` element to show when something is dragged and the ID of the element that's being dragged. We have an element with the ID `drag-box` that's being dragged. Below that, we have a `div` with the ID `drop-`zone that will accept any element that is being dragged to be dropped in it. Then we can add the following CSS to style the HTML elements we added above:
```css
#drag-box {
width: 100px;
height: 100px;
background-color: red;
}
#drop-zone {
width: 200px;
height: 200px;
background-color: purple
}
```
We can see that `drag-box` is red and `drop-zone` is purple and that `drop-zone` is bigger than `drag-box`. Next, we can assign our own event handler function to the `ondragstart` property for the DOM object representing the `drag-box` element to track it when it’s being dragged and update our `drag-start-tracker` `p` element to show that `drag-box` is being dragged with the following code:
```javascript
const dragBox = document.getElementById('drag-box');
const dropZone = document.getElementById('drop-zone');
const dragStartTracker = document.getElementById('drag-start-tracker');
dragBox.ondragstart = (e) => {
dragStartTracker.innerHTML = `Element with ID ${e.target.id} is being dragged.`;
};
dragBox.ondragend = (e) => {
dragStartTracker.innerHTML = '';
dropZone.appendChild(e.srcElement);
};
```
In the code above, we can see that ‘Element with ID drag-box is being dragged’ when the `drag-box` element is being dragged, and when we stop dragging the box and drop it into the `drop-zone` element, we should see that the text disappears and the `drag-box` element stays inside the `drop-zone` element. How it works is that when we first start dragging the `drag-box` element, the `dragstart` event will be fired and the `dragBox.ondragstart` will be called with the `DragEvent` object passed in, which has the `e.target.id` property that we reference to get the ID of the `drag-box` element.
When we release the mouse button when the `drag-box` is over the `drop-zone` , the event handler that we assigned to the `ondragend` event handler is called since the `dragend` event is triggered by releasing the mouse button, ending the dragging of the `drag-box` .
Inside the function, we have a `DragEvent` object passed in when the function is called and we can use the `srcElement` to get the DOM element object of the element being dragged, so we can use `appendChild` method of the `dropZone` object to append the `drag-box` element, which is what we get with the `srcElement` property to the `drop-zone` element.
ondrop event
============
We can set the `ondrop` property of a DOM element to handle the `drop` event for the element. The `drop` event is fired when an element or text selection is dropped into a valid drop target. For example, we can use it to make a `div` element that can be dragged to 2 different boxes and use the `ondrop` event handler to handle the dropping. First, we add the following HTML code to make our draggable `div` element and 2 `div` elements where we can drop the draggable `div` element into the following code:
```html
<div id='drag-box' draggable="true">
</div>
<div id='drop-zones'>
<div id='drop-zone'>
</div>
<div id='drop-zone-2'>
</div>
</div>
```
Then we can add some CSS code to style the `div` elements with the following code:
```css
#drag-box {
width: 100px;
height: 100px;
background-color: red;
}
#drop-zone {
width: 200px;
height: 200px;
background-color: purple
}
#drop-zone-2 {
width: 200px;
height: 200px;
background-color: green
}
#drop-zones {
display: flex;
}
```
In the code above, we make the `drop-zone` `div` elements side by side by add a `div` with the ID `drop-zones` to contain the 2 `div` elements inside. We use the `display: flex` CSS code to display `drop-zone` and `drop-zone-2` `div` elements side by side. Then we change the background color of each div so we can distinguish them. Next, we add the JavaScript code to handle the dragging of the `drag-box` `div` elements and the dropping of it into either of the `drop-zone` elements with the with `ondrop` event handler that we define with the following code:
```javascript
const dragBox = document.getElementById('drag-box');
dragBox.ondragstart = (e) => {
e
.dataTransfer
.setData('text/plain', event.target.id);
};
document.ondragover = (e) => {
e.preventDefault();
};
document.ondrop = (e) => {
const id = e
.dataTransfer
.getData('text');
e.srcElement.appendChild(document.getElementById(id));
}
```
The code above works by handling the `ondragstart` event handler to get the ID of the element that’s being dragged. The `ondragstart` handler is called when users start dragging the `drag-box` `div` . Inside the `ondragstart` event handler function that we defined, we called the `e.dataTransfer.setData` method to set the `'text'` attribute of the `DataTransfer` object, which we need later when we’re dropping the `drag-box` inside one of the `drop-zone` or `drop-zone-2` `div` elements. It’s very important that we have:
```javascript
document.ondragover = (e) => {
e.preventDefault();
};
```
This prevents the `ondragover` event handler from handling the event since once it’s handled with that event handler, then the `drop` event won’t be fired, and our `ondrop` event handler won’t be run. With that out of the way, we can define our `ondrop` event handler and then assign it to the `document.ondrop` property to handle the `document`’s `drop` event.
The event handler function has an `e` parameter which is a `DragEvent` object, which has some useful properties that we can use to handle the dropping of our `drag-box` element. Inside that event handler, we get the ID of the element that we’re dragging by calling the `e.dataTransfer.getData` method with the `'text'` string to get the ID of the element that we’re dragging.
Then we can use the `srcElement` property of the `e` object to get the DOM element of which our `drag-box` `div` is being dropped and call `appendChild` on it with the `document.getElementById(id)` argument, where `id` should be `'drag-box'` since that’s what should return from `e.dataTransfer.getData(‘text’);` since we set the ID of the `drag-box` element in the `dragBox.ondragstart` event handler.
Wrap Up
=======
The `ondragstart` and `ondrop` properties are very useful for making drag and drop features in our web page. The `ondragstart` property lets us assign an event handler for the `dragstart` event, which is triggered when the user starts dragging an element or text selection. We can set the `ondrop` property of a DOM element to handle the `drop` event for the element. The `drop` event is fired when an element or text selection is dropped into a valid drop target.
Note that we have made set an event handler function for the `ondragover` property of `document` and call `e.preventDefault()` inside the function to prevent the `ondragover` event handler from handling the `dragover` event, which stops the `drop` event from triggering. With that out of the way, we can assign an event handler to the `ondrop` property to append the draggable element as a child to the drop target element. | aumayeung |
241,440 | lesson 11 | Why do you think conditionals are important? Sometimes you want code to execute only if a certain co... | 0 | 2020-01-19T22:25:55 | https://dev.to/antonioprican/lesson-11-33j | 1. Why do you think conditionals are important?
- Sometimes you want code to execute only if a certain condition is true, and in Swift that is represented primarily by the if and else statements. You give Swift a condition to check, then a block of code to execute if that condition is true.
2. Give a set of instructions on how you think a thermostat program should work and “bold/underline” the conditionals.
- | antonioprican | |
245,144 | Form Validation with Combine | In WWDC 2019 session Combine in Practice we learned how to apply the Combine Framework to perform val... | 0 | 2020-01-20T17:19:12 | https://swiftui.diegolavalle.com/posts/combine-form-validation/ | ios, swift, swiftui, combine | In _WWDC 2019_ session [Combine in Practice](https://developer.apple.com/videos/play/wwdc2019/721) we learned how to apply the _Combine Framework_ to perform validation on a basic sign up form built with _UIKit_. Now we want to apply the same solution to the _SwiftUI_ version of that form which requires some adaptation.
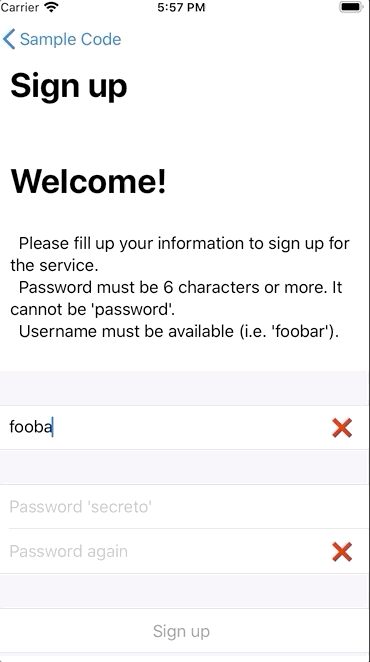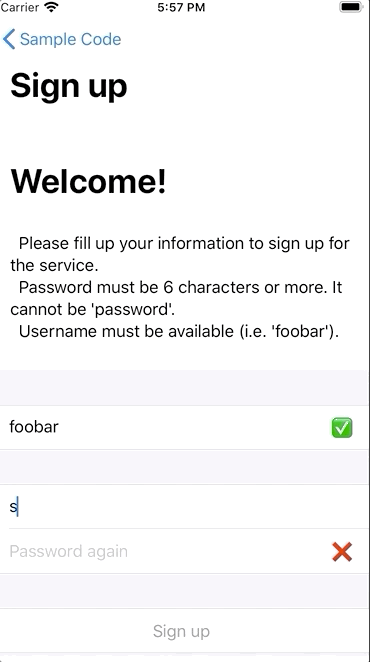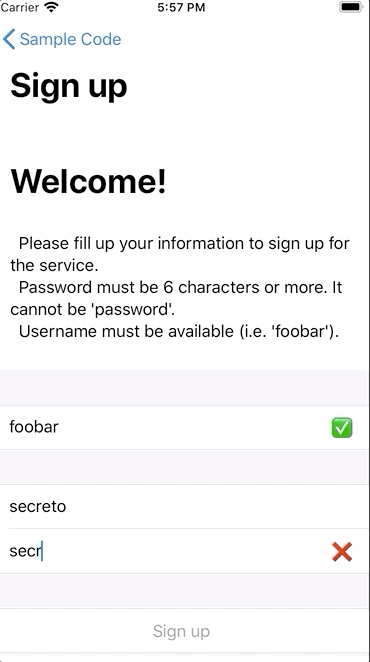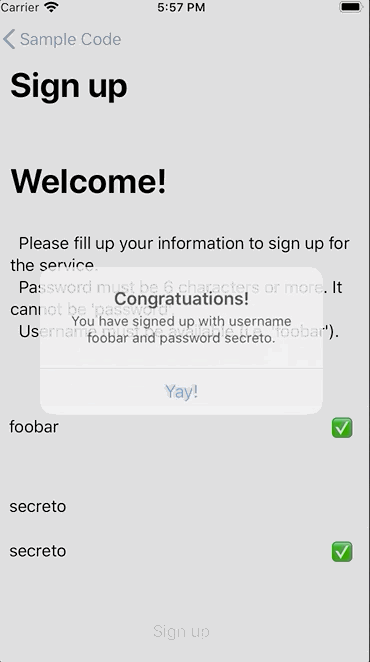
We begin by declaring a simple form model **separate** from the view…
```swift
class SignUpFormModel: ObservableObject {
@Published var username: String = ""
@Published var password: String = ""
@Published var passwordAgain: String = ""
}
```
And link each property to the corresponding `TextField` control…
```swift
struct SignUpForm: View {
@ObservedObject var model = SignUpFormModel()
var body: some View {
…
TextField("Username", text: $model.username)
…
TextField("Password 'secreto'", text: $model.password)
…
TextField("Password again", text: $model.passwordAgain)
…
```
Now we can begin declaring the publishers in our `SignUpFormModel`. First we want to make sure the password has mor than six characters, and that it matches the confirmation field. For simplicity we will not use an error type, we will instead return `invalid` when the criteria is not met…
```swift
var validatedPassword: AnyPublisher<String?, Never> {
$password.combineLatest($passwordAgain) { password, passwordAgain in
guard password == passwordAgain, password.count > 6 else {
return "invalid"
}
return password
}
.map { $0 == "password" ? "invalid" : $0 }
.eraseToAnyPublisher()
}
```
For the user name we want to simultate an asynchronous network request that checks whether the chosen moniker is already taken…
```swift
func usernameAvailable(_ username: String, completion: @escaping (Bool) -> ()) -> () {
DispatchQueue.main .async {
if (username == "foobar") {
completion(true)
} else {
completion(false)
}
}
}
```
As you can see, the only available name in our fake server is _foobar_.
We don't want to hit our API every second the user types into the name field, so we leverage `debounce()` to avoid this…
```swift
var validatedUsername: AnyPublisher<String?, Never> {
return $username
.debounce(for: 0.5, scheduler: RunLoop.main)
.removeDuplicates()
.flatMap { username in
return Future { promise in
usernameAvailable(username) { available in
promise(.success(available ? username : nil))
}
}
}
.eraseToAnyPublisher()
}
```
Now to make use of this publisher we need some kind of indicator next to the text box to tell us whether we are making an acceptable choice. The indicator should be backed by a private `@State` variable in the view and outside the model.
To connect the indicator to the model's publisher we leverage the `onReceive()` modifier. On the completion block we manually update the form's current state…
```swift
Text(usernameAvailable ? "✅" : "❌")
.onReceive(model.validatedUsername) {
self.usernameAvailable = $0 != nil
}
```
An analog indicator can be declared for the password fields.
Finally, we want to combine our two publishers to create an overall validation of the form. For this we create a new publisher…
```swift
var validatedCredentials: AnyPublisher<(String, String)?, Never> {
validatedUsername.combineLatest(validatedPassword) { username, password in
guard let uname = username, let pwd = password else { return nil }
return (uname, pwd)
}
.eraseToAnyPublisher()
}
```
We can then hook this validation directly into our _Sign Up_ button and its disabled state.
```swift
Button("Sign up") { … }
.disabled(signUpDisabled)
.onReceive(model.validatedCredentials) {
guard let credentials = $0 else {
self.signUpDisabled = true
return
}
let (validUsername, validPassword) = credentials
guard validUsername != nil else {
self.signUpDisabled = true
return
}
guard validPassword != "invalid" else {
self.signUpDisabled = true
return
}
self.signUpDisabled = false
}
}
```
Check out the associated Working Example to see this technique in action.
FEATURED EXAMPLE: [Fake Signup - Validate your new credentials](https://swiftui.diegolavalle.com/examples/fake-signup/) | diegolavalle |
245,148 | SDKMAN! - Multiple versions of Java | What is SDKMAN! SDKMAN! is a development tool that allows you to install and manage Java,... | 0 | 2020-01-20T17:43:13 | https://wpanas.github.io/tools/2017/12/25/sdkman.html | java, sdkman, tools, opensource | ---
title: SDKMAN! - Multiple versions of Java
published: true
date: 2017-12-25 00:00:00 UTC
tags: java, sdkman, tools, opensource
canonical_url: https://wpanas.github.io/tools/2017/12/25/sdkman.html
---
# What is SDKMAN!
[SDKMAN!](https://sdkman.io/) is a development tool that allows you to install and manage Java, Scala, Groovy, Maven and many other tools, libraries and programming languages united under JVM platform. It is created for GNU/Linux's and MacOS' users.
# Installation
The first step is to paste this command in your terminal and submit it.
```shell
curl -s "https://get.sdkman.io" | bash
```
This will launch the process of installation, which might require your input. After successful installation paste this command and you are ready to work.
```shell
source "$HOME/.sdkman/bin/sdkman-init.sh"
```
# Usage
You can list all available versions of desired SDK using below command:
```shell
sdk list <sdk>
```
Here is output of this command for Groovy.
```shell
sdk list groovy
================================================================================
Available Groovy Versions
================================================================================
3.0.0-beta-3 2.4.8 2.1.4 1.7.6
3.0.0-beta-2 2.4.7 2.1.3 1.7.5
3.0.0-beta-1 2.4.6 2.1.2 1.7.4
3.0.0-alpha-4 2.4.5 2.1.1 1.7.3
3.0.0-alpha-3 2.4.4 2.1.0 1.7.2
3.0.0-alpha-2 2.4.3 2.0.8 1.7.1
3.0.0-alpha-1 2.4.2 2.0.7 1.7.0
2.6.0-alpha-4 2.4.1 2.0.6 1.6.9
2.6.0-alpha-3 2.4.0 2.0.5 1.6.8
2.6.0-alpha-2 2.3.11 2.0.4 1.6.7
2.6.0-alpha-1 2.3.10 2.0.3 1.6.6
2.5.8 2.3.9 2.0.2 1.6.5
2.5.7 2.3.8 2.0.1 1.6.4
2.5.6 2.3.7 2.0.0 1.6.3
2.5.5 2.3.6 1.8.9 1.6.2
2.5.4 2.3.5 1.8.8 1.6.1
2.5.3 2.3.4 1.8.7 1.6.0
2.5.2 2.3.3 1.8.6 1.5.8
2.5.1 2.3.2 1.8.5 1.5.7
2.5.0 2.3.1 1.8.4 1.5.6
2.4.17 2.3.0 1.8.3 1.5.5
2.4.16 2.2.2 1.8.2 1.5.4
2.4.15 2.2.1 1.8.1 1.5.3
2.4.14 2.2.0 1.8.0 1.5.2
2.4.13 2.1.9 1.7.11 1.5.1
2.4.12 2.1.8 1.7.10 1.5.0
2.4.11 2.1.7 1.7.9
2.4.10 2.1.6 1.7.8
2.4.9 2.1.5 1.7.7
================================================================================
+ - local version
* - installed
> - currently in use
================================================================================
```
Installation is effortless. Select any of available versions or just skip it and install the currently stable version.
```shell
sdk install <sdk> (<version>)
```
Let's try install Java 11. Paste `sdk install java 11.0.4-hs-adpt` and hit Enter.
```shell
sdk install java 11.0.4.hs-adpt
Downloading: java 11.0.4.hs-adpt
In progress...
######################################################################## 100,0%
Repackaging Java 11.0.4.hs-adpt...
Done repackaging...
Installing: java 11.0.4.hs-adpt
Done installing!
Do you want java 11.0.4.hs-adpt to be set as default? (Y/n):
Setting java 11.0.4.hs-adpt as default.
```
All installed Java versions will be available in the folder `$SDKMAN_DIR/candiadates/java`.
```shell
ls $SDKMAN_DIR/candidates/java -l
total 8
drwxr-xr-x. 9 wpanas wpanas 4096 10-18 17:44 8u152-zulu
drwxr-xr-x. 10 wpanas wpanas 4096 11-04 16:22 9.0.1-zulu
lrwxrwxrwx. 1 wpanas wpanas 47 12-25 17:23 current -> /home/wpanas/.sdkman/candidates/java/11.0.4.hs-adpt
```
You can check if installation was successful by checking current Java version. The command `java --version` will not work in Java 8 or any previous, so let's try it.
```shell
java --version
openjdk 11.0.4 2019-07-16
OpenJDK Runtime Environment AdoptOpenJDK (build 11.0.4+11)
OpenJDK 64-Bit Server VM AdoptOpenJDK (build 11.0.4+11, mixed mode)
```
As you can see Java 11 is installed and ready to work. If you want to switch default Java's version use command `sdk default java <version>`, but you can also switch version only for current terminal session using `sdk use java <version>`. It's very convenient, if you want to check, how your code would behave on different Java version.
# Summary
SDKMAN! is an essential tool for developers using Java, Groovy or any other JVM language. Check it out and you will not be disappointed. | wpanas |
245,175 | Tuning up | What music do you guys listen to when you work? | 0 | 2020-01-20T17:44:55 | https://dev.to/codefired/tuning-up-553g | discuss | What music do you guys listen to when you work? | codefired |
245,240 | I'm Joining the Team at DEV | Some professional news | 0 | 2020-01-21T18:10:11 | https://joshpuetz.com/2020/01/20/Im-joining-the-team-at-dev.html | career, meta | ---
title: I'm Joining the Team at DEV
published: true
description: Some professional news
tags: career, meta
cover_image: https://thepracticaldev.s3.amazonaws.com/i/ezurs3dxcwrnavib9obf.png
canonical_url: https://joshpuetz.com/2020/01/20/Im-joining-the-team-at-dev.html
---
This is my first week as a member of the team at DEV! I'm beyond excited to be joining this team of dedicated, passionate humans.
I've been a huge fan of the DEV community since way back when it started at @thepracticaldev on Twitter. As a longtime lurker (and very, very occasional contributor), I've learned so much from DEV community members sharing what they've learned. It's time to give back, and I'm excited to get started!
## A Little About Me
Hi there! 👋 I'm 42 years old, and live with my husband and daughter in Sturgeon Bay, Wisconsin: a tiny town on the shores of Lake Michigan. Our part of the state is in Door County, which is a popular tourist area: it's a peninsula full of beaches, state parks, and cherry orchards. My family has been vacationing here since I was a baby, and a few years ago we were lucky enough to finally make this place our home. Expect the #DoorCounty hastag on DEV to blow up now that I'm here 😂
I've been a software engineer for two decades, working mostly in small startups. Most of my development work over the past few years has been with Ruby: I started using Rails with version 0.9. For the past decade I've worked remotely: remote work has allowed me to remain in this industry despite living far from a metro area.
When I'm not writing software, I'm an avid chef, photographer, and gamer. I'm also one of those crazy CrossFit people 🏋️♂️
## Goals at DEV
The vast majority of my career has been spent in private, closed source software. I'm excited to be more involved with the open source community, and help DEV accomplish their longer term goals that Ben outlined in his [recent post](https://dev.to/devteam/the-future-of-dev-160n). I'm also going to be focused on helping the DEV team to be an even better remote team by lending my experiences working across multiple time zones.
Want to get in touch? My DM's are open here, and I'm also available on twitter ([@joshpuetz](https://twitter.com/joshpuetz)) or via email (josh@dev.to). | joshpuetz |
245,405 | The Ember Times - Issue No. 131 | Привет, Эмберисты! Hello, Emberistas! 🐹 Help improve Ember's autotracking and reactivity system 💬, r... | 2,173 | 2020-01-21T00:56:15 | https://blog.emberjs.com/2020/01/17/the-ember-times-issue-131.html | ember, javascript, webdev | Привет, Эмберисты! <span style="font-style: italic;">Hello, Emberistas!</span> 🐹
Help improve Ember's autotracking and reactivity system 💬, read the new test waiters RFC ⏳, optimize your app with Ember Data 📈, the Russian Ember community 🇷🇺, and learn about powerful debugging at EmberConf 💻!
---
## [4 RFCs on improving Ember's autotracking and reactivity system 💬](https://github.com/emberjs/rfcs/blob/use-and-resources/text/0567-use-and-resources.md#introducing-use-and-resources)
Ember Octane features a **new reactivity system** thanks to **tracked properties**. They simplify syncing the DOM with JavaScript changes. Find out how autotracking works from the [Ember Guides](https://guides.emberjs.com/release/in-depth-topics/autotracking-in-depth/).
To help address some shortcomings, [Chris Garrett (@pzuraq)](https://github.com/pzuraq) proposed introducing the decorators and classes listed below. We encourage you to participate in RFCs and provide feedback!
### [566. `@memo` decorator](https://github.com/emberjs/rfcs/pull/566)
Unlike computed properties, autotracked getters don't cache their values. `@memo` will let you opt in to memoization.
### [567. `@use` decorator](https://github.com/emberjs/rfcs/pull/567)
The `@use` API will leverage autotracking to solve two issues:
- Allow Glimmer components to define a behavior with its own lifecycle, independently of the template
- Provide a standard way to mix declarative and imperative code
### [569. `TrackedList` class](https://github.com/emberjs/rfcs/pull/569)
`TrackedList` will autotrack changes to arrays. This class, designed to replace `EmberArray`, will follow the native array API closely and be performant.
### [577. `TrackedMap` and `TrackedSet` classes](https://github.com/emberjs/rfcs/pull/577)
`TrackedMap` and `TrackedSet`, along with their weak analogs, will autotrack changes to maps and sets (dynamic collections of values). These classes will follow the native APIs exactly.
---
## [New test waiters RFC ⏳](https://github.com/emberjs/rfcs/pull/581)
[Steve Calvert (@scalvert)](https://github.com/scalvert) proposed replacing the existing test waiters with the [ember-test-waiters](https://github.com/rwjblue/ember-test-waiters) in the [New Test Waiters RFC](https://github.com/emberjs/rfcs/pull/581).
The new test waiter system will provide a few benefits:
- A **new API that removes the existing foot guns** given we will be more explicit when declaring the start and end of the waiter through the waiter `beginAsync` and `endAsync` methods
- A more robust way to gather **debugging information** for the test waiter since the waiter is identifiable by the name provided
- Default test waiters with the **ability to author your own, more complex test waiters** through annotating the asynchronous operations in your code base that are not tracked by an `await settled()` check
Share your thoughts, feedback, and requests on the [New Test Waiters RFC](https://github.com/emberjs/rfcs/pull/581)!
---
## [Optimizing your app with Ember Data 📈](https://runspired.com/2019/12/15/optimizing-your-app-with-ember-data/)
[Chris Thoburn (@runspired)](https://github.com/runspired) is blogging about how to build and optimize an app with Ember Data. You'll start by building an app, Listicle. Listicle starts as a small app shell with rich content lists, but balloons in size over time. Build times slow to a crawl as a result.
At the beginning of the series, Listicle builds and renders in greater than 5 seconds. But as the posts progress, you'll end with an app with builds and renders in **less than 1 second** by optimizing only the app's data management! Then for fun, you'll optimize the render.
You can check out [Part 1](https://runspired.com/2019/12/15/optimizing-your-app-with-ember-data/) and [Part 2](https://runspired.com/2019/12/18/optimizing-your-app-with-ember-data-part-2/) now, with more posts to come! And you can follow along with the code for the series by watching the [Listicle repository](https://github.com/runspired/listicle).
For some Ember Data context, check out the [Guides](https://guides.emberjs.com/release/models/). You can learn about the architecture and history in Chris's EmberFest [Ember Data 2019](https://www.youtube.com/watch?v=zbqbsOyLM30&list=PLN4SpDLOSVkT0e094BZhGkUnf2WBF09xx&index=23&t=0s) conference talk.
---
## [Russian Ember community 🇷🇺](https://habr.com/ru/post/483630/)
[Habr.com](https://habr.com/) is a popular geek media site among Russian developers. It's somewhat similar to Hacker News, except that it's populated by user-submitted articles instead of links. [Iaroslav Popov (@chilicoder)](https://github.com/chilicoder) recognized a shortage of Ember articles on Habr.com and recently started translating our very own Ember Times ([Issue #129](https://habr.com/ru/post/482988/), [Issue #130](https://habr.com/ru/post/483630/)) on Habr.com, as well as [Octane is Here](https://habr.com/ru/post/482158/) and [Super Rentals tutorial - Part 1](https://habr.com/ru/post/482296/)!
@chilicoder also mentioned to check out the [Ember telegram channel](https://t.me/ember_js), moderated by [Alex Kanunnikov (@lifeart)](https://github.com/lifeart). It's one of the best ways to get help with **Ember in Russian**, and they welcome everyone to join! Thank you both for your help in fostering the Russian Ember community!
---
## [Master powerful debugging strategies at EmberConf 💻](https://emberconf.com/#/speakers/samanta-de-barros)
You've undoubtedly heard her talk about [creating progressive web applications with Ember](https://www.youtube.com/watch?v=OR1Tk_bwmZo)
and [bulletproof addon testing](https://www.youtube.com/watch?v=31kVznd-zys) before, but now [Samanta de Barros (@sdebarros)](https://github.com/sdebarros)
is ready to share more useful knowledge that is crucial for any professional JavaScript developer.
At [this year's EmberConf](https://emberconf.com/) she's going to teach us about [**The Power of Debugging**](https://emberconf.com/#/speakers/samanta-de-barros); which tools you can use to track down bugs swiftly in development and production environments, and how you can find your way around Ember's architecture while doing so.
In an exclusive interview with The Ember Times, Samanta shares with us, what makes debugging tools and strategies so powerful when developing Ember applications:
> I think learning about debugging techniques is important. Mostly, because it will help you to have a better time finding bugs and even how an app works. In part I think it’s necessary because it will help you on your job!
>
> I also think that when you start looking at other people’s code it is hard at first, but after a while you lose the fear of seeing these complex frameworks, you get a better idea of everything and you start to realise - it’s just JavaScript in the end. So I think debugging techniques are good for finding bugs and demystifying frameworks.
What's our experience like when we start to learn more about debugging strategies? Here, Samanta can share from both her own experience and from those she worked together with:
> When you are pairing with someone or you’re trying to solve an issue, you often run into something and it makes people go like: “Oh, that’s interesting!” When I’ve seen other people’s talks or see them working, I see that they have some tips about things that I don’t know about yet and that’s cool! You realise that there are a lot of tools that make working with the frontend easier.
>
> People who learn more about debugging usually say: “Oh yeah, that’s cool, that really simplifies these tasks I need to do” or “Oh, I didn’t know you could find that information there in the app.”
EmberConf is a unique experience, one that you and your team should definitely not miss out on. Samanta shares her perspective on what makes the conference
so outstanding:
> I think it’s a different experience when you go to a conference as a speaker or as attendee. When you just go to listen to the talks, you get a lot of inspiration, you discover things that people are you doing that you might not do yet and it sparks something in you that makes you want to learn something new or improve something in your job. […]
>
> I would say both getting inspiration and connecting are the nicest things about EmberConf. If I had to recommend anything to an attendee, I’d say: “Just go and ask questions to the other attendees or speakers.” Just listening to the talks is good enough, but the chance to connect with others makes the conference really great.
If you want to learn more about successfully debugging Ember apps, join more than 800 other Ember developers at [EmberConf in Portland, OR from March 16 - 18, 2020](https://emberconf.com/). Prices for regular attendee tickets start from $449, so don't hesitate to [register today](https://emberconf.com/#/register)!
---
## [Contributors' Corner 👏](https://guides.emberjs.com/release/contributing/repositories/)
<p>This week we'd like to thank <a href="https://github.com/bobisjan" target="gh-user">@bobisjan</a>, <a href="https://github.com/pzuraq" target="gh-user">@pzuraq</a>, <a href="https://github.com/locks" target="gh-user">@locks</a>, <a href="https://github.com/mjanjic01" target="gh-user">@mjanjic01</a>, <a href="https://github.com/runspired" target="gh-user">@runspired</a>, <a href="https://github.com/igorT" target="gh-user">@igorT</a>, <a href="https://github.com/dmuneras" target="gh-user">@dmuneras</a>, <a href="https://github.com/mixonic" target="gh-user">@mixonic</a>, <a href="https://github.com/chancancode" target="gh-user">@chancancode</a>, <a href="https://github.com/nummi" target="gh-user">@nummi</a>, <a href="https://github.com/efx" target="gh-user">@efx</a>, <a href="https://github.com/josemarluedke" target="gh-user">@josemarluedke</a>, <a href="https://github.com/mansona" target="gh-user">@mansona</a>, <a href="https://github.com/pichfl" target="gh-user">@pichfl</a>, <a href="https://github.com/skaterdav85" target="gh-user">@skaterdav85</a>, <a href="https://github.com/jenweber" target="gh-user">@jenweber</a>, <a href="https://github.com/mcfiredrill" target="gh-user">@mcfiredrill</a>, <a href="https://github.com/tomdale" target="gh-user">@tomdale</a>, <a href="https://github.com/conormag" target="gh-user">@conormag</a>, <a href="https://github.com/rwjblue" target="gh-user">@rwjblue</a>, <a href="https://github.com/Turbo87" target="gh-user">@Turbo87</a>, <a href="https://github.com/stefanpenner" target="gh-user">@stefanpenner</a>, <a href="https://github.com/xg-wang" target="gh-user">@xg-wang</a> for their contributions to Ember and related repositories! 💖</p>
---

## [Got a question? Ask Readers' Questions! 🤓](https://docs.google.com/forms/d/e/1FAIpQLScqu7Lw_9cIkRtAiXKitgkAo4xX_pV1pdCfMJgIr6Py1V-9Og/viewform)
<p>Wondering about something related to Ember, Ember Data, Glimmer, or addons in the Ember ecosystem, but don't know where to ask? Readers’ Questions are just for you!</p>
<p><strong>Submit your own</strong> short and sweet <strong>question</strong> under <a href="https://bit.ly/ask-ember-core" target="rq">bit.ly/ask-ember-core</a>. And don’t worry, there are no silly questions, we appreciate them all - promise! 🤞</p>
</div>
---
## [#embertimes 📰](https://blog.emberjs.com/tags/newsletter.html)
Want to write for the Ember Times? Have a suggestion for next week's issue? Join us at [#support-ember-times](https://discordapp.com/channels/480462759797063690/485450546887786506) on the [Ember Community Discord](https://discordapp.com/invite/zT3asNS) or ping us [@embertimes](https://twitter.com/embertimes) on Twitter.
Keep on top of what's been going on in Emberland this week by subscribing to our [e-mail newsletter](https://the-emberjs-times.ongoodbits.com/)! You can also find our posts on the [Ember blog](https://emberjs.com/blog/tags/newsletter.html).
---
That's another wrap! ✨
Be kind,
Chris Ng, Amy Lam, Isaac Lee, Jessica Jordan and the Learning Team | embertimes |
245,410 | Renaming your default git branch | Following discourse around harmful technical terms, I decided to rename my default branch on git. Here's how I went about it. | 0 | 2020-01-22T01:06:25 | https://dev.to/deusmxsabrina/renaming-your-default-git-branch-1oki | git, tutorial, writing | ---
title: Renaming your default git branch
published: true
description: Following discourse around harmful technical terms, I decided to rename my default branch on git. Here's how I went about it.
tags: git, tutorial, writing
---
I've seen discourse about technical terminology with harmful origins, specifically the slave/master paradigm. It made me consider the places where I see these terms frequently in my work as a software developer, and one that came to mind is the default branch name in git.
Granted, git branching isn't explicitly defined as a master/slave relationship, but I feel the terms are pervasive enough to warrant avoiding use of either of them. I'm opting to replace my default `master` branch with a `release` branch on all of my non-archived repositories.
### How to rename your default git branch
I used the following steps, as outlined in [this stackoverflow answer](https://stackoverflow.com/a/8762728). These are the commands you'd want to run in your terminal if you're using the command line version of git. I'm not familiar with how this maps to any graphical git tools, but the git operations you'd need to perform would be the same.
```bash
git checkout -b release master # create and switch to the release branch
git push -u origin release # push the release branch to the remote and track it
# This is the point where I change the default branch on Github, explained more below.
git branch -d master # delete local master
git push --delete origin master # delete remote master
git remote prune origin # delete the remote tracking branch
```
If you're using a third party site/hosting service, you'll need to follow their steps for renaming the default branch as well. I followed [the steps for doing this on Github](https://help.github.com/en/github/administering-a-repository/setting-the-default-branch). I've included a gif of exactly what this process looked like below.
To save a bit of time I did chain the commands like so `git checkout -b release master && git push -u origin release`then went and did the changes on the web user interface and then ran `git branch -d master && git push --delete origin master && git remote prune origin` in my terminal to wrap it all up.
What does it look like to pull down a repository that's had the default branch changed in this way?
I run `git pull` which pullls down the new `release` branch. Then I need to do a bit of local cleanup as follows:
```bash
#* [new branch] release -> origin/release
# Your configuration specifies to merge with the ref 'refs/heads/master'
# from the remote, but no such ref was fetched.
git checkout release
# Branch 'release' set up to track remote branch 'release' from 'origin'.
# Switched to a new branch 'release'
git branch -d master
# Deleted branch master
git remote prune origin
# * [pruned] origin/branch-name
# refs/remotes/origin/HEAD has become dangling!
git remote set-head origin release # so that git knows where the new HEAD is
```
A final note for this procedure is that I didn't have any repositories with open pull requests when I made this change, so unfortunately I cannot say for sure if the base branch for those would also need to get changed over to the new default, I'm assuming so.
### Conclusion
I did this renaming so that my personal work better represents my intent and hopefully contributes towards an easier read for others by eliminating terminology with harmful connotations. I think that it's great to see communities really challenging longstanding terms and trying to do better, and am grateful to have learned something.
As always, thanks for reading! | deusmxsabrina |
245,419 | Modern Front-end with Older Tech | If you just want to see the code: Here's our finished project: https://codesandbox.io/s/component-e... | 0 | 2020-01-23T21:39:20 | https://dev.to/tamb/modern-front-end-with-older-tech-625 | javascript, webdev, react, frontend | ---
title: Modern Front-end with Older Tech
published: true
description:
tags: JavaScript, webdev, react, Front-end,
cover_image: https://frontendmasters.com/books/front-end-handbook/2019/assets/images/web-tech-employed.jpg
---
If you just want to see the code:
1. Here's our finished project: https://codesandbox.io/s/component-example-9796w
2. Here's the project with my very lightweight library (note the fewer lines): https://codesandbox.io/s/domponent-example-ij1zs
Hey, so I'm a Senior Front-end Developer. I've built performant web UI Components for enterprise-level apps and multi-national companies with AngularJS, React, Vue, jQuery Plugins, and Vanilla JS.
They all have their pluses. Let's go over them quickly:
1. AngularJS, you can just augment your HTML and build full-fledged complex UIs.
2. jQuery Plugins, you can just add some classes and attributes to HTML and the plugins will do the rest.
3. React, the entire app is component based, easy to read, and trivial to reuse.
4. Vue, you can implement an AngularJS-type solution with an entirely component-driven approach.
5. Vanilla JS, you don't have pull in any libraries and you can choose whatever lightweight solution you want.
For each approach you can implement UI as a function of state. For some (Vue and React) it's easier done with use of Virtual DOM (look it up if you need. It's super cool).
However, what if you're stuck with older tech? What if you're working with Razor or Pug or Thymeleaf? And additionally, you're not using REST APIs? You have some advantages (SSR by default, SEO-friendly), but you have a TON of drawbacks (lack of Virtual DOM, ergo difficult/verbose rerenders).
With classic front-end web development you lack simplified component state, component lifecycles, scoped models, granular control over model changes. These are all complex to implement and a built-in part of React, Vue, Knockout, Angular, etc.
But with some build tools (webpack, parcel, rollup, grunt, gulp) and some incredibly battle-tested template languages (Thymeleaf, Pug, Razor) you can build UI Components with incredible ease.
Here's how I do it with my older tech stack:
## The directory structure
```
FrontEnd
|
|___components
|
|__MyComponent
| |
| |___MyComponent.pug/.html/.cshtml
| |___MyComponent.scss
| |___MyComponent.js
|
|__MyOtherComponent
|
|___MyOtherComponent.pug/.html/.cshtml
|___MyOtherComponent.scss
|___MyOtherComponent.js
```
Let's run through this.
In a React app, you would have 1 less file. You might even have two less files.
You'd remove the `html` and possibly the `scss`. You'd have your HTML as part of a `JSX` file. You may even have CSS in JS. So it might be a single file component. This is similar to a `.vue` file.
We're just actually breaking it out here. Screw 1 file, let's go classic and have 3. Logic in JS, Structure in HTML, Look in SCSS. Now, each file:
### HTML
Let's make a simple Counter. It's going to show the count and offer and increment and decrement option
```html
<div>
<p>Your Count:
<span>0</span>
</p>
<button type="button">
-
</button>
<button type="button">
+
</button>
</div>
```
Cool! This is gonna look terrible and make people cry. So let's write some styles.
### SCSS
We will be using SCSS and BEM syntax. It will be imported into the .js file for the component. Let's boogie:
```scss
.Counter{
padding: 1rem;
&__count{
font-size: 2.5rem;
}
&__btn{
padding:.5rem;
margin: .5rem;
&--increment{
background: lightgreen;
}
&--decrement{
background: lightblue;
}
}
}
```
And let's update our HTML
```html
<div class="Counter">
<p>Your Count:
<span class="Counter__count">0</span>
</p>
<button type="button" class="Counter__btn Counter__btn--decrement">
-
</button>
<button type="button" class="Counter__btn Counter__btn--increment">
+
</button>
</div>
```
Hold up! What's with the capitalized class name?
This is simply a preference of mine since it's standard practice in React apps to name your components Capitalized. But you can do whatever you want.
### JS
Ok, let's make this reusable JS with a default `count` of `0`. We're going to do this poorly at first and then fix it up slowly. So stay with me here :)
```js
import './Counter.scss'
class Counter {
constructor() {
this.count = 0;
this.countEl = document.querySelector(".Counter__count");
this.incBtn = document.querySelector(".Counter__btn--increment");
this.decBtn = document.querySelector(".Counter__btn--decrement");
this.incBtn.addEventListener("click", this.increment.bind(this));
this.decBtn.addEventListener("click", this.decrement.bind(this));
}
increment() {
++this.count;
this.updateDOM();
}
decrement() {
--this.count;
this.updateDOM();
}
updateDOM() {
this.countEl.textContent = this.count;
}
}
new Counter();
```
NOTE: I'm using `bind` under the assumption you are not using Babel... yet
Read this:
https://www.freecodecamp.org/news/react-binding-patterns-5-approaches-for-handling-this-92c651b5af56/
Ok there are more than a few issues with this approach. Let's focus on one:
_Using CSS classes (meant for styling only) to handle UI_
This is a big one. Relying on CSS classes or even HTML element types to access DOM is a big boo boo. If you change your class name or the element type you could be breaking functionality of your app!
So how do we address this? There are a couple approaches:
1. JS-specific classes in your HTML
2. Using special `data-` attributes
We're going to use method #2:
```html
<div class="Counter">
<p>Your Count:
<span class="Counter__count" data-count="true">0</span>
</p>
<button type="button" data-dec-btn="true" class="Counter__btn Counter__btn--decrement">
-
</button>
<button type="button" data-inc-btn="true" class="Counter__btn Counter__btn--increment">
+
</button>
</div>
```
```js
import './Counter.scss'
class Counter {
constructor() {
this.count = 0;
this.countEl = document.querySelector("[data-count]");
this.incBtn = document.querySelector("[data-inc-btn]");
this.decBtn = document.querySelector("[data-dec-btn]");
this.incBtn.addEventListener("click", this.increment.bind(this));
this.decBtn.addEventListener("click", this.decrement.bind(this));
}
increment() {
++this.count;
this.updateDOM();
}
decrement() {
--this.count;
this.updateDOM();
}
updateDOM() {
this.countEl.textContent = this.count;
}
}
new Counter();
```
Ok a little better. The DOM is looking slightly more declarative and we can mess with our CSS all we want now. We just added super blunt and really poorly thought-out attributes.
We can make this even better. What if we set our own standard for DOM querying attributes? Moreover, what if the values of those attributes meant something too?
Let's enhance our HTML.
We're going to draw from React and Vue by using something called `refs`. `refs` are short for "reference" as in DOM reference. It's simply caching a DOM element in JS. So let's use a standard `data-ref` attribute:
```html
<div class="Counter">
<p>Your Count:
<span class="Counter__count" data-ref="count">0</span>
</p>
<button type="button" data-ref="decrement" class="Counter__btn Counter__btn--decrement">
-
</button>
<button type="button" data-ref="increment" class="Counter__btn Counter__btn--increment">
+
</button>
</div>
```
```js
import './Counter.scss'
class Counter {
constructor() {
this.count = 0;
this.countEl = document.querySelector('[data-ref="count"]');
this.incBtn = document.querySelector('[data-ref="increment"]');
this.decBtn = document.querySelector('[data-ref="decrement"]');
this.incBtn.addEventListener("click", this.increment.bind(this));
this.decBtn.addEventListener("click", this.decrement.bind(this));
}
increment(){
++this.count;
this.updateDOM();
}
decrement(){
--this.count;
this.updateDOM();
}
updateDOM(){
this.countEl.textContent = this.count;
}
}
new Counter();
```
Ok this isn't the worst thing in the world. The DOM is slightly more declarative.
Let's address one minor issue:
1. How do we differentiate state fields from DOM fields?
Let's wrap state fields in a `state` object and `refs` in a `$refs` object ( a la Vue):
```js
import './Counter.scss'
class Counter {
constructor() {
this.state = {
count: 0
};
this.$refs = {
countEl: document.querySelector('[data-ref="count"]'),
incBtn: document.querySelector('[data-ref="increment"]'),
decBtn: document.querySelector('[data-ref="decrement"]')
};
this.$refs.incBtn.addEventListener("click", this.increment.bind(this));
this.$refs.decBtn.addEventListener("click", this.decrement.bind(this));
}
increment(){
++this.state.count;
this.updateDOM();
}
decrement(){
--this.state.count;
this.updateDOM();
}
updateDOM(){
this.$refs.countEl.textContent = this.count;
}
}
new Counter();
```
But we have at least two major issues:
1. How do we know what object `data-ref` belongs to?
2. How can we get rid of these `.bind` calls?
Enter Babel!
Babel can take modern and proposed syntax and make is ES5 readable.
We're going to rely on two things:
1. `class-public-fields` https://github.com/tc39/proposal-class-public-fields
2. `template literals` https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals
Let's tackle #1:
```js
import './Counter.scss'
class Counter {
constructor() {
this.state = {
count: 0
};
this.$refs = {
countEl: document.querySelector('[data-ref="count"]'),
incBtn: document.querySelector('[data-ref="increment"]'),
decBtn: document.querySelector('[data-ref="decrement"]'),
};
this.$refs.incBtn.addEventListener("click", this.increment);
this.$refs.decBtn.addEventListener("click", this.decrement);
}
increment = () => {
++this.state.count;
this.updateDOM();
}
decrement = () =>{
--this.state.count;
this.updateDOM();
}
updateDOM = () => {
this.$refs.countEl.textContent = this.count;
}
}
new Counter();
```
bingo bongo! No more `bind`!
Now let's tackle #2.
For this we are going to assume we may want to update the attribute name `data-ref` in the future (it's far-fetched, but trust me these refactors happen!)
Let's preface our HTML attribute values with our component name
```html
<div class="Counter">
<p>Your Count:
<span class="Counter__count" data-ref="Counter.count">0</span>
</p>
<button type="button" data-ref="Counter.decrement" class="Counter__btn Counter__btn--decrement">
-
</button>
<button type="button" data-ref="Counter.increment" class="Counter__btn Counter__btn--increment">
+
</button>
</div>
```
Let's update the JS
```js
import './Counter.scss'
const ref = 'data-ref'
class Counter {
constructor() {
this.state = {
count: 0
};
this.$refs = {
countEl: document.querySelector(`[${ref}="Counter.count"]`),
incBtn: document.querySelector(`[${ref}="Counter.increment"]`),
decBtn: document.querySelector(`[${ref}="Counter.decrement"]`)
};
this.$refs.incBtn.addEventListener("click", this.increment);
this.$refs.decBtn.addEventListener("click", this.decrement);
}
increment = () => {
++this.state.count;
this.updateDOM();
}
decrement = () =>{
--this.state.count;
this.updateDOM();
}
updateDOM = () => {
this.$refs.countEl.textContent = this.count;
}
}
new Counter();
```
This is pretty darn good so far. But it's not reusable. What if we have multiple Counters? The fix is pretty simple. We're going to create a `$root` DOM reference.
```html
<div class="Counter" data-component="Counter">
<p>Your Count:
<span class="Counter__count" data-ref="Counter.count">0</span>
</p>
<button type="button" data-ref="Counter.decrement" class="Counter__btn Counter__btn--decrement">
-
</button>
<button type="button" data-ref="Counter.increment" class="Counter__btn Counter__btn--increment">
+
</button>
</div>
```
Let's update the JS
```js
import './Counter.scss'
const ref = 'data-ref'
class Counter {
constructor(root) {
this.$root = root;
this.state = {
count: 0
};
this.$refs = {
countEl: this.$root.querySelector(`[${ref}="Counter.count"]`),
incBtn: this.$root.querySelector(`[${ref}="Counter.increment"]`),
decBtn: this.$root.querySelector(`[${ref}="Counter.decrement"]`)
};
this.$refs.incBtn.addEventListener("click", this.increment);
this.$refs.decBtn.addEventListener("click", this.decrement);
}
increment = () => {
++this.state.count;
this.updateDOM();
}
decrement = () =>{
--this.state.count;
this.updateDOM();
}
updateDOM = () => {
this.$refs.countEl.textContent = this.state.count;
}
}
```
Now we can instantiate multiple Counters like so:
```js
const counters = Array.from(document
.querySelectorAll('[data-component="Counter"]'))
.map(element => new Counter(element));
```
So there is a framework-less way to make components. You can prepopulate your DOM using HTML fragments/mixins/partials (whatever your template language refers to as "chunks reusable of HTML".
There are obviously some bigger things to deal with here:
Passing state in, scoping components, etc. And that's where I've made a small 2kb library for handling all those things and more without you having to manually scrape any DOM and bind any events. You can declare it all in your HTML and let the library take over.
Check it out. Let me know your thoughts! I find this is a pretty decent solution for enterprise applications:
My Library for Handling Above Code and MORE!
https://github.com/tamb/domponent
And here is the end result of what we just made:
https://codesandbox.io/s/component-example-ij1zs | tamb |
245,457 | Erlang/OTP 18.0 で AES-GCM を使う | Erlang/OTP 18.0 から AEAD な AES-GCM と ChaCha20-Poly1305 に対応しています。 AES-GCM は 128/256 です。とりあえず AES-GCM の... | 0 | 2020-01-21T03:16:17 | https://dev.to/voluntas/erlang-otp-18-0-aes-gcm-2bnn | erlang |
Erlang/OTP 18.0 から AEAD な AES-GCM と ChaCha20-Poly1305 に対応しています。
AES-GCM は 128/256 です。とりあえず AES-GCM の 256 を試してみます。
crypto:supports/0 で ciphers の中に aes_gcm がいることを確認して下しださい。
chacha20_poly1305 は boringssl でしかまだ対応していないらしく、OpenSSL では非対応です。
## AES-GCM
crypto:block_encrypt(aes_gcm, Key, IV, {Nonce, Plain}) で使えます。戻りが {CipherText, CipherTag} なので気をつけてください。
```
Erlang/OTP 18 [erts-7.0] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:10] [hipe] [kernel-poll:false] [dtrace]
Eshell V7.0 (abort with ^G)
> crypto:supports().
[{hashs,[md4,md5,sha,ripemd160,sha224,sha256,sha384,sha512]},
{ciphers,[des_cbc,des_cfb,des3_cbc,des_ede3,blowfish_cbc,
blowfish_cfb64,blowfish_ofb64,blowfish_ecb,aes_cbc128,
aes_cfb8,aes_cfb128,aes_cbc256,rc2_cbc,aes_ctr,rc4,aes_ecb,
des3_cbf,aes_ige256,aes_gcm]},
{public_keys,[rsa,dss,dh,srp,ec_gf2m,ecdsa,ecdh]}]
> crypto:block_encrypt(aes_gcm, binary:copy(<<0>>, 32), binary:copy(<<0>>, 24), {<<"">>, <<"1234567890">>}).
{<<41,96,181,164,113,168,138,253,250,8>>,
<<205,178,48,121,244,0,208,72,72,4,142,93,114,149,83,137>>}
> crypto:block_decrypt(aes_gcm, binary:copy(<<0>>, 32), binary:copy(<<0>>, 24), {<<"">>, <<41,96,181,164,113,168,138,253,250,8>>, <<205,178,48,121,244,0,208,72,72,4,142,93,114,149,83,137>>}).
<<"1234567890">>
```
| voluntas |
245,841 | Custom Cursor with CSS and jQuery [Detailed] | Hey everyone! 2 days ago i posted I Built My Personal Website and one of the questions was What libra... | 0 | 2020-01-21T16:49:54 | https://dev.to/b4two/how-to-make-a-custom-cursor-with-css-and-jquery-5g3m | css, javascript, tutorial, webdev | Hey everyone! 2 days ago i posted [`I Built My Personal Website`](https://dev.to/b4two/i-built-my-personal-website-4mpf) and one of the questions was _What library did you use for the mouse pointer effect?_. The answer is i used no library. I did it all by myself and today i am going to show you how i did it.
First things first, we have to create our custom cursor style.
##Cursor Style
```css
.cursor{
position: fixed;
width: 20px;
height: 20px;
border-radius: 50%;
background-color: #f5f5f5;
pointer-events: none;
mix-blend-mode: difference;
z-index: 999;
transition: transform 0.2s;
}
```
**Why do we use?**
```css
position: fixed;
```
It is because when we start to scroll we don't want our custom cursor to stay where we start to scroll. If you use `position: absolute` instead of fixed, cursor won't be moving as you scroll down or up the page. To prevent that you have to give the `fixed` value to `position`.
**Why do we use?**
```css
pointer-events: none;
```
Your cursor is right on top of the custom cursor you created. And whenever you want to click a link or see a hover statement this custom cursor will prevent that to be happen. If you give the `none` value to `pointer-events` you will be able to click anything you want.
**What is...**
```css
mix-blend-mode: difference;
```
The `mix-blend-mode` property defines how an element’s content should blend with its background.
`difference`: this subtracts the darker of the two colors from the lightest color.
And so this allows you to see the content behind your cursor easily.
<hr>
##jQuery DOM Manipulation
It is time to use some jQuery to make our
```html
<div class="cursor"></div>
```
element follow the default cursor.
```javascript
$(document).ready(function(){
var cursor = $('.cursor');
});
```
Instead of writing `$('.cursor')` everytime and to make our job easier we stored it in a variable named cursor. Now let's make it follow as we move the mouse.
```javascript
$(document).ready(function(){
var cursor = $('.cursor');
$(window).mousemove(function(e) {
cursor.css({
top: e.clientY - cursor.height() / 2,
left: e.clientX - cursor.width() / 2
});
});
});
```
We selected our window object and when we move our mouse in it we want our cursor's top and left positions to change. To make it happen we manipulate its css from here.
**What is...**
```javascript
top: e.clientY
left: e.clientX
```
`clientY` and `clientX` are relative to the upper left edge of the content area (the viewport) of the browser window. This point does not move even if the user moves a scrollbar from within the browser.
`pageY` and `pageX` are relative to the top left of the fully rendered content area in the browser. This reference point is below the URL bar and back button in the upper left.
And by using `clientY` instead of `pageY` we maintain our custom cursor to stay at the same position.
As you can see, to keep our custom cursor in the right position we have to give both
```css
position: fixed;
```
(in css)
and
```javascript
top: e.clientY
left: e.clientX
```
(in jQuery)
properties.
**Why do we add...**
```javascript
top: e.clientY - cursor.height() / 2
left: e.clientX - cursor.width() / 2
```
Because we want the cursor we created to be perfectly centered to our default one. As you can see above we gave `height: 20px` and `width: 20px` to our cursor.
To get the right point and center it we give
```javascript
- cursor.height() / 2
- cursor.width() / 2
```
If you didn't get it, to center absolute positioned elements we give
```css
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
```
This `transform: translate(-50%, -50%)` perfectly centers the element by taking off half of its height and width. This example is similar to what we did on jQuery. `-cursor.height()/2` and `-cursor.width()/2` are doing the same thing.
**What is going to happen when we leave our mouse from browser screen?**
```javascript
$(window)
.mouseleave(function() {
cursor.css({
opacity: "0"
});
})
.mouseenter(function() {
cursor.css({
opacity: "1"
});
});
```
We don't want our custom cursor to be visible at the position where we left the screen.
With this code
```javascript
$(window).mouseleave(function(){
cursor.css({opacity: "0"});
});
```
whenever we leave the screen our custom cursor's `opacity` will be `0` and can't be seen.
And with this one
```javascript
$(window).mouseenter(function(){
cursor.css({opacity: "1"});
});
```
whenever our mouse is on the screen the custom cursor's `opacity` will be `1` and can be seen.
**How do you understand if you click or not?**
```javascript
$(window)
.mousedown(function() {
cursor.css({
transform: "scale(.2)"
});
})
.mouseup(function() {
cursor.css({
transform: "scale(1)"
});
});
```
With these lines of code when we click (which is `mousedown`) our cursor `scales` down to `0.2` and when we don't (which is `mouseup`) it comes to its normal statement and `scales` back to `1`.
**Managing the hover statements**
```javascript
$(".link")
.mouseenter(function() {
cursor.css({
transform: "scale(3.2)"
});
})
.mouseleave(function() {
cursor.css({
transform: "scale(1)"
});
});
```
As you can see we have a class named `link`. If you have elements which have some effects on hover or you want your clickable items to be seen by user and want your custom cursor to change whenever you hover these elements, you can give every element that have this effect a class named link and so you can manipulate it from jQuery.
If your mouse is on the element(which is `mouseenter`) which has a link class, your cursor `scales` up to `3.2` and if you leave the hover state (which is `mouseleave`) it `scales` back to its normal state which is `1`. You can give any class name you want and manipulate your custom cursor as you wish. This is just an example, you don't have to do the same.
##Final
Don't forget these lines
```css
html,
*{
cursor: none;
}
```
to make the default cursor unseen.
At last we have our custom cursor created and functioning as we desire.
Don't forget to place your cursor element right on top of the closing `body` tag.
```html
<body>
<!--Some other elements -->
<div class="cursor"></div>
</body>
```
Whole jQuery Code
```javascript
$(document).ready(function(){
var cursor = $(".cursor");
$(window).mousemove(function(e) {
cursor.css({
top: e.clientY - cursor.height() / 2,
left: e.clientX - cursor.width() / 2
});
});
$(window)
.mouseleave(function() {
cursor.css({
opacity: "0"
});
})
.mouseenter(function() {
cursor.css({
opacity: "1"
});
});
$(".link")
.mouseenter(function() {
cursor.css({
transform: "scale(3.2)"
});
})
.mouseleave(function() {
cursor.css({
transform: "scale(1)"
});
});
$(window)
.mousedown(function() {
cursor.css({
transform: "scale(.2)"
});
})
.mouseup(function() {
cursor.css({
transform: "scale(1)"
});
});
});
```
**An example for you to see how it works**
(To get the true experience please go to codepen)
{% codepen https://codepen.io/batuhangulgor/pen/dyPwGyY %}
Also you can use [`TweenMax`](https://greensock.com/tweenmax/) for custom cursor animations. I didn't use it before but you can give it a shot if you want.
_Thanks for your time. Have a good day <3_
| b4two |
245,584 | An Ode to Code Reviews | Code Reviews are hard by nature, especially in a multi-project company. In this article, we explore why we do them, how to do them properly, and we introduce a new idea: the Review Buddy. | 0 | 2020-01-21T10:23:21 | https://www.codegram.com/blog/an-ode-to-code-reviews/ | codereviews, teamwork, developerproductivity | ---
title: An Ode to Code Reviews
published: true
date: 21-01-2020
tags: code-reviews, teamwork, developer-productivity
description: Code Reviews are hard by nature, especially in a multi-project company. In this article, we explore why we do them, how to do them properly, and we introduce a new idea: the Review Buddy.
canonical_url: https://www.codegram.com/blog/an-ode-to-code-reviews/
cover_image: https://www.codegram.com/assets/static/an-ode-to-code-reviews.a98966c.2664713909e44e452b2d6fe6b440815e.jpg
---
At [Codegram](https://www.codegram.com), we truly believe that **Code Reviews** are a **crucial activity** in any software development endeavor. That's a mantra we've been repeating over and over inside our company, but honestly, we think we can get way better at it.
This article is an ode to the beauties of **Code Reviews** and how they can make your team share **better** & be more **accountable** for its decisions while making it all more **enjoyable** for everyone. We'll explore why peer reviews matter and we'll introduce an idea — the _Review Buddy_ — to help you improve the way you review code as a team. But first...
## ❓What even is a Code Review?
Code Reviews are a **quality assurance** process in which a developer exposes their code to an individual or a team in order to get feedback and change it until a consensus is achieved. Depending on your tool of choice, you're going to use GitHub's [Pull Requests](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests), GitLab's [Merge Requests](https://docs.gitlab.com/ee/user/project/merge_requests/) and so on.
## 🙃 But why code review at all?
We developers love code so much that **we'd probably rather spend all day throwing lines at the editor** , leaving aside other mundane activities like meetings, answering e-mails or... reviewing other people's code.
That's okay and sure everybody can understand that feeling. We just love code _so much_! But writing code is not a science but rather an engineering task (some might say there's even some art in it), and successful engineers take the human factor into account **every step of the way.**
> "Taking the human factor into account". A-ha.
See, what's made of a bunch of humans? Teams! So let's take a step back and think about what we're collaborating over: **_code_**. If we look at programming languages themselves, they're not meant to _just_ solve the problem at hand, they're also meant to be _expressive, clean_ and _reusable_. Arguably, sometimes at the expense of efficiency solving the problem itself.
Why is that? Because **we care about how other humans** (or the future human you!) **deal with code** so they can understand it, build on top of it, extend it and re-shape it as pleased.
If you think about it, _code reviews_ are the ultimate form of expressiveness. They just happen to encompass another dimension: **time**. When you create a _Pull Request_ on _GitHub_, you do it to solve a specific need _at that moment in time_, with a specific context in mind that might change in the future.
Maybe a colleague — or yourself — need to revisit a decision you made a while ago and hey, revisiting that nice **Pull Request** might just be what you need.
You might be thinking: Okay, so code reviews are mainly a bookkeeping tool. Yes and no! They are **way more powerful than that.** Keep reading to know why (mini-clickbait) 👇🏼!
## 🧠 Code Reviews help with knowledge transfer.
If you're reading this, you're probably the **curious** type. Being curious in the tech industry usually means constantly looking for new & effective solutions to solve your everyday problems, or even trying to jump to _that new cool framework_ and going for a quick ride on the _hype_ train.
What's better for that than being able to see what other _humans_ are doing? Code Reviews enable precisely this - the ability to peek into someone else's code to learn new stuff.
## 🤝 Code Reviews create a sense of shared responsibility.
**Continuously having to make decisions on your own** on a piece of code without any help, let alone a whole project is **mentally draining & stressful**. By having others review your code, you'll be able to get some relief while knowing there'll be someone else there for you in times of need. ~~And that can be the start of a friendship that lasts forever.~~
## 👀 Code Reviews will improve code quality even when nobody is watching.
You might be familiar with the "rubber duck debugging" technique, a concept introduced in _[The Pragmatic Programmer](https://pragprog.com/book/tpp20/the-pragmatic-programmer-20th-anniversary-edition)_ book. Dave Thomas, the author, makes a case on how the mere act of **explaining** code to a peer can help you debug a problem without any actual interaction needed — so we might as well be talking to a rubber duck 🦆.
I like to think the same principle applies to Code Reviews as well. By writing code as if someone would review it (even it that doesn't happen), you're going to **write better code**.
**\*Rule of thumb:** Assume you always have a bunch of ducks around when writing and delivering code.\*
> But the humans...?
Ok, back to the main point! When you **do** get your code reviewed by other humans:
- **You gain a better understanding** of your own decisions by being questioned over them.
- **You will get useful contributions** that can help to fix bugs, to find new edge cases, and maybe even lead to rethinking a flawed architecture.
- **You will learn from people** that might have more experience or insights about a particular area.
## 🤩 OMG Code reviews are so cool!
<small>Code Review all the things!</small>
...so **why don't we do it more often**? Well, I think that's because coming up with an effective way to present & review code is **hard by nature.** And because of that, some people see it as a burden and put it in the same box as _reading e-mails_ or _attending meetings_.
Let me introduce you to some advice on how Pull Requests need to be dealt with at the grass-roots level, and then we can talk about _team dynamics_, which is a whole different thing.
## 🦄 Here's how to step up your code reviewing game
> There are three sides to every story: yours, mine & the truth.— _anonymous_, but also the title of a [rock album](https://open.spotify.com/album/2TV8JqednqRKb2injBMYGd) I really like
### As an author, you should:
- **Be verbose and provide enough context:** A Pull Request needs to have a clear structure & description. More than _what_ and _how —_ which can often be guessed by the code itself — one must focus on the _Why_. Why did you choose a particular path? Were you under a tight deadline and did you have to compromise? Whom does it affect? Does this affect any business logic?
- **Write tests:** Tests are a great way to express the boundaries of a problem and provide specific examples of how the code behaves in real-life scenarios. Reviewers will appreciate having them gain a better understanding (and your customers probably will too, but that's another story)!
- **Checks, checks everywhere:** GitHub, GitLab, et al allow for automated checks such as linters, code coverage analysis, and others to be embedded just within your Pull Request. By doing that, we leave some low-value topics such as styling out of the conversation and let our dear reviewers focus on what's important.
- **Get your Pull Request deployed somewhere** : Sometimes _seeing_ something is better than just reading about its internals. Using tools like [Heroku's Review Apps](https://devcenter.heroku.com/articles/github-integration-review-apps) or [Netlify's Deploy Previews](https://www.netlify.com/blog/2016/07/20/introducing-deploy-previews-in-netlify/) can be really helpful, providing a separate deployment _per Pull Request_.
- **Don't let your Pull Requests block your progress** : Quality code reviews take some time and you don't want to rush people into accepting them just because they're blocking you. If you're being smart about it, you'll have come up with an architecture that will allow you to have **multiple Pull Requests going on** without one depending on another. It takes some practice and it's not always possible, but it's definitely worth the effort!
- **Don't take criticism personally:** When getting your code reviewed, you might sometimes feel personally attacked. That feeling might come from a vulnerable position — _am I not smart enough?_ — or even from a defensive position — _they're over their head_! Just keep in mind _you_ are not your _code._ Take a breathe and remember: they're challenging **your code, not you**.
- **Be cooperative:** Even if you think a reviewer's suggestion isn't _right_, be cooperative and walk them along with _why_ you think that's the case. Dismissing another person's opinions just because isn't nice — think about how you'd want to be treated if the situation was reversed. Plus, if you think the issue lies in the reviewer not understanding the problem at hand, chances are you didn't provide enough context, to begin with.
### As a reviewer, you should:
- **Be empathetic:** Keep in mind a Pull Request done properly took a lot of effort. You'll get a way better conversation if you keep an upbeat, engaging tone in your comments.
- **Write thoughtful, unambiguous comments:** Tone is difficult to grasp on written communication. Be sure you don't leave space for ambiguity and that your writing is clear & concise while providing enough context.
- **Suggest specific changes** : If you think something can be improved, don't just say so, suggest a specific change. But again, don't _just_ suggest a change, it can stike the other side as passive-aggressive. Take some time to explain _why_ you think something can be changed.
- **Don't be judgmental:** There are lots of reasons why code doesn't look _the way you think it should look_. Don't make judgments and try to understand why they came up with that particular solution. After all, you're both aiming at the same goal.
- **If you need it, download the code and run it:** Superficial reviews are not useful at all. It's a temptation you need to fight. If you need to, download the code and run it. It's fun!
- **Beware of the impostor syndrome:** Have confidence in your feelings on the code and don't be afraid to start a discussion, even when reviewing more experienced developers' code. Also, comments on Code Reviews don't always need to be about suggestions - asking questions to gain better understanding of what's happening is perfectly fine.
- **Be responsive:** When asking for changes, don't just leave and come back days after just to find your suggestions addressed in a couple of minutes. That's not nice. Just keep on top of what you review so everybody can get done with it!
## 🖖 Nice tips! Give me my CodeReviewMaster© shirt already.
Well, wait a minute. These tips & tricks are really cool, but for these to work, **Code Reviews need to actually _happen_**. As it turns out, that isn't always that easy. It certainly isn't for us, being a consultancy that works in lots of different projects at the same time. Why is that?
On one hand, **when working within a really small team, getting quality code reviews can be hard:** Imagine you're working on a project and you're the only front-end developer. Who can review your outstanding _Vue.js_ code if there's no one else in the team that knows about it? You could always ask someone else outside of the team, but then, on the other hand, **collaboration cross-project is just tedious.** Creating a `#code-reviews` channel on Slack where everybody can go get their PRs reviewed looked like a nice idea at first, but doesn't really cut it. You can't possibly get valuable reviews out of them -- reviewers are missing a lot of context due to them not being actively involved on the project. Soon enough, the channel ends up being cluttered of unanswered cries for help and, eventually, people stop asking for reviews at all.
One **could reach the conclusion that Code Reviews can only happen in mid-sized teams and up** , and that collaborating outside of the team's boundaries is just a pipe dream. A sad reality to live in.
## 😓 So we're doomed. Back to writing code alone in the dark.
<small>Coding alone with a blanket at night</small>
Please don't close this tab yet! We've come up with ways to **get your Code Reviews** _to be way more effective_! Or at least, we think so 😏.
We're about to change how we collaborate over code at Codegram and we expect this will lead to improved _team dynamics_ (see! I said we would talk about it). **Code Reviews are about to be second-class citizens no longer**. Here's our plan:
1. **Every developer working alone on a project or in an area will get a _review buddy_** : A _review buddy_ might not need to be involved in the actual coding, but will be there to **preventing PRs from becoming stale** with their helpful reviews. A _review buddy_ knows about the history of a project and thus understands all the decisions behind every step taken, leading to in-depth, spot-on appreciations. A _review buddy_ has no reason to ignore your PRs. A _review buddy_ is your best friend.
2. **Developers can still ask someone else for help:** In the event that a developer and their _review buddy_ (I love this name) are stuck, they can always ask for help to someone else — since they won't receive a constant stream of impersonal review requests anymore, they'll appreciate being chosen for the task and be more willing to help. Note than one must **keep the list of reviewers short** for this to work.
3. **We'll leverage better tools:** We'll ditch that `#code-reviews` channel on Slack and promote the use of other tools like [Pull Reminders](https://pullreminders.com/) — a free _Slack_ integration that will keep in touch with every developer and make sure they follow up on their duties. In addition, using [GitHub's CODEOWNERS](https://help.github.com/en/github/creating-cloning-and-archiving-repositories/about-code-owners) file in our projects will also help to streamline the process of _asking_ for Code Reviews in the first place.
It's **just three simple steps** but we expect them to have a high impact leading to _healthier reviews_, _happier developers_, and, in the end, _better software_. Sometimes things are not that complicated!
## 🚀 Collaboration doesn't stop on Code Reviews
While we've seen Code Reviews are incredibly useful, they're **not the one and only way to collaborate over code**. Sometimes you just need to do some pair programming - and that's an incredibly nice experience _when you really need it_! At Codegram, we particularly like **[Visual Studio Code's Live Share](https://marketplace.visualstudio.com/items?itemName=MS-vsliveshare.vsliveshare)** feature and we use it quite a lot. Damn, it looks like _Microsoft_ is killing it these days.
Finally, you should always keep in mind that everything said in this article **can't make up for missing documentation or bad architecture**. More than that — clean, documented code leads to **easier-to-deal-with** Code Reviews, and Code Reviews can help you **keep your code clean & documented**. Use that power for good!
<video src="https://www.codegram.com/blog/an-ode-to-code-reviews/yoda.mp4" autoplay loop muted></video><small>Did you seriously think there wouldn't be any Baby Yodas in this article?</small>
## 👋 That'll be all!
I hope you've enjoyed my humble views on the topic — with any luck it'll have inspired you to adopt some or all of these techniques and that'll help you and your team to be more collaborative. Or maybe you just think _this is bananas!_
In any case, I'd love to hear your feedback — you can send us an e-mail to [hello@codegram.com](mailto:hello@codegram.com), ping us on **Twitter** at [@codegram](https://twitter.com/codegram) or just yell at the programming gods! | josepjaume |
245,720 | 🐾 Does your microservice deserve its own database? | Monolith vs microservice, monorepo vs polyrepo - endless discussions have been held, industry trends... | 4,311 | 2020-01-29T15:53:57 | https://dev.to/lbelkind/does-your-microservice-deserve-its-own-database-np2 | microservices, architecture, database, refactorit | Monolith vs microservice, monorepo vs polyrepo - endless discussions have been held, industry trends and deeply rooted personal beliefs have been voiced and dies have been cast (wouldn't be my first choice) to decide on the chosen approach in various software projects.
In this article we will assume, that, for whatever reason known to the leaders of the project, microservices were chosen. We will additionally assume, that, at least, some of these microservices require storing a state somewhere in a database (SQL or NoSQL), whether they are CRUD services representing some business flow or entity, or for any other reason.
How should the databases serving different microservices be treated? Should different tables for microservices created in the same database with foreign keys connecting between them? Should there be a strict separation prohibiting any cross-reference or even access from one microservice's code to another one's data?
As always - there are pros and cons to different options and we will try to examine them.
## 1⃣ Separate database for each microservice
This approach is, probably, the most widely used pattern for micro-services databases. The main benefits of this approach are:
a) Guarantee that there is absolutely no way there could be cross-relations/dependencies between data of different microservices
b) Contain the "blast radius" if one of the microservices becomes compromised or is "stressing" the database.
This approach guarantees the strictest level of separation between the data elements managed by different microservices. It also the easiest way to scale-out microservices storage in case of a significant growth. (Consider offloading certain database connections to completely different database clusters).
Additional benefit (although not an extremely strong one) of this approach is the ease of backup/restore and schema change (where relevant) for data related to specific microservice, without any impact on other microservices.
One of the challenges of this approach is the overhead required to combine the data for each microservice with cross-system elements (for example, tenants for a multi-tenant environment). Consider an effort of creating a new tenant (various strategies for multi-tenant databases can be found in my previous blog: {% link https://dev.to/lbelkind/strategies-for-using-postgresql-as-a-database-for-multi-tenant-services-4abd %}
The combination of this approach with various multi-tenant approaches creates the following architecture:
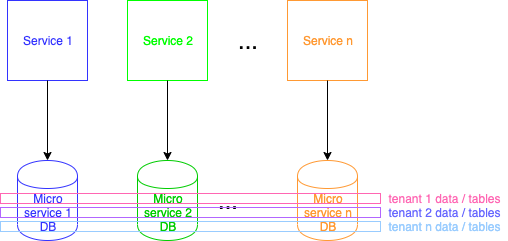
On-boarding and off-boarding of new tenants will need to take place in each database separately. Additionally, creation of new microservices will require more databases that will need to be aligned to reflect the existing tenants.
## 2⃣ Single database with schemas (a-la PostgreSQL) for different microservices
Somewhat similar to the previous approach, albeit using a single logical database that supports "workspaces" for logical separation between various objects. PostgreSQL Schemas, or, to an extent MySQL are such mechanisms.
This approach is also quite widely used. Its main advantage over the previous approach is the ability to provide cross-schema references (foreign keys in SQL Databases) where supported, for example in PostgreSQL. This can be used leveraged for optimizing operations, such as cascading delete of all data related to cross-microservice entities, such as user or organization.
When using such an approach, though, one needs to exercise caution not to create logical references and allow encapsulation of data for different microservices. When separating access control of different roles (allocated to microservices) to different schemas/workspaces, "blast radius" can be controlled in a way similar to the previous approach of completely separate databases, and then the benefit of allocating dedicated schemas/workspaces to cross-microservice data is achieved almost without any trade-offs.
When layering the multi-tenant challenge on top of such a configuration the options are more restricted, basically additional namespacing/pseudo-namespacing (using object name) can be used, or, alternatively, data of multiple tenants can be interleaved.
## 3⃣ Single database with different tables for different microservices
With this approach, there is a single "logical" database for configuration/storage of all microservices. Each microservice will have its own tables, with an optional ability to implement references / foreign keys to other tables.
While many purists may consider this approach an anti-pattern for microservices environment, in fact, if working properly, the only capability that is really more difficult here is the scale-out, as described in the first approach. Backup/restore of data related only to specific microservice is a rare requirement, but, if needed, it is also more difficult to implement using this approach.
In many databases, one can manage pseudo-namespaces for objects by using strong naming conventions, such as "microserviceX.tableY" and provide access roles accordingly only for tables/objects that relate to a specific microservice. When working this way, the real differences between this approach and the previous ones are becoming less evident.
Layering multi-tenant data on top of this approach can be done either by further pseudo-namespacing the objects "microserviceX.tenantY.tableZ" or by interleaving data of different tenants.
## Summary
While the approaches presented above can be the architecture of choice for different use-cases, the most important considerations to have in mind when choosing the most suitable one are:
* Access Control / Blast Radius Control / Microservice Encapsulation
* Scale-Out Considerations
* Overhead in creating new Microservices
* Further multi-tenant considerations
Kudos to [@kostyay](https://dev.to/kostyay) and [@eldadru](https://dev.to/eldadru) for the research that lead to this article.
| lbelkind |
245,777 | RDBMS or NoSQL: The question that pops up with every new project! | Barun is starting his next software development assignment soon, but his biggest worry is - SQL or... | 0 | 2020-01-22T05:48:42 | https://dev.to/pareshjoshi/rdbms-or-nosql-the-question-that-pops-up-with-every-new-project-1gpc | database, sql, nosql, backend | 
Barun is starting his next software development assignment soon, but his biggest worry is - SQL or NoSQL and he is pondering about these questions:
* Which database to use for this new project?
* Should I use relational database or NoSQL?
* MongoDB is nice, it is schema-less and it does not require creating tables and normalize the structure, should I just select it for this project?
* Or whether I just use cloud-native databases like Amazon DynamoDB or Cosmos DB?
* No wait, I heard Redis can also be used for persistence and it is a key-value pair so that may also fit well here! The choices are endless...
Have you ever come across these questions or a debate on which database is right for your project? The decision depends on number of factors and there are dozens of articles available over internet explaining pros and cons of different options. I am not going to repeat them here. I am rather interested in documenting what some of the popular internet apps are using as their data store. I'd done this exercise in the past, but lost the record. While doing this exercise again, I thought this could be useful for wider #DEVCommunity.
> It would be interesting to know from you if you have gone through the process of making decision on choosing the right data store for your application. Feel free to add your comments to build this knowledge base.
+ Twitter - Twitter was built on MySQL and everything was stored in a single instance of database. However, as platform evolved, it is using number of different database technologies - MySQL, PostgreSQL, Vertica, Blobstore, Graph store, Hadoop. You can read more information about this [here](https://blog.twitter.com/engineering/en_us/topics/infrastructure/2017/the-infrastructure-behind-twitter-scale.html)
+ Facebook - MySQL, Memcached, Haystack (for photo storage), Hadoop and Hive. Read more about complete technology stack used by Facebook [here](https://royal.pingdom.com/the-software-behind-facebook)
+ Youtube - MySQL, Bigtable
+ LinkedIn - traditionally used Oracle and key-value stores such as Voldemort. But then moved to distributed data store, [Espresso](https://engineering.linkedin.com/espresso/introducing-espresso-linkedins-hot-new-distributed-document-store).
+ Instagram - [Instagram mainly uses two database systems: PostgreSQL and Cassandra.](https://instagram-engineering.com/instagration-pt-2-scaling-our-infrastructure-to-multiple-data-centers-5745cbad7834)
+ DEV.together - [PostgreSQL as primary datastore and Redis for cached data](docs.dev.to/technical-overview/stack/).
> Note: this information is collected from different forums, engineering blogs and Q&A sites, if you think anything is incorrect, feel free to point out, I will be happy to update the post. | pareshjoshi |
245,781 | quick backup of a file | Recently I started trying to get competent at bash's string expansion phase and realized I could do t... | 0 | 2020-01-21T15:23:41 | https://dev.to/kwstannard/quick-backup-of-a-file-50ag | bash | Recently I started trying to get competent at bash's string expansion phase and realized I could do the following to backup a file:
`$ mv path/to/file.txt{,_}`
Then to restore the file, swap the , and _ in the brackets.
`$ mv path/to/file.txt{_,}`
String expansion is a step that runs before executing the shell command so what is really being run can be viewed with the following:
```
$ echo mv path/to/file.txt{_,}
mv path/to/file.txt path/to/file.txt_
``` | kwstannard |
245,790 | How to create a maintenance system on a Symfony 4 project | https://www.titocode.fr/article-standard/11/Syst%C3%A8me-de-maintenance-sur-un-projet-Symfony-4 Here... | 4,407 | 2020-01-21T15:47:28 | https://www.titocode.fr/article-standard/11/Syst%C3%A8me-de-maintenance-sur-un-projet-Symfony-4 | webdev, tutorial, php, symfony | ERROR: type should be string, got "\nhttps://www.titocode.fr/article-standard/11/Syst%C3%A8me-de-maintenance-sur-un-projet-Symfony-4\n\nHere is a french version of \"How to create a maintenance system on a Symfony 4 project\"\n\nTitocode.fr" | gregouz66 |
245,890 | 30 principles to level-up your Soft Skills (Carnegie’s wisdom remix) | Photo by Jens Johnsson on Unsplash Note: I originally put this article together as a resource for de... | 0 | 2020-01-21T19:00:56 | https://dev.to/chingu/30-principles-to-level-up-your-soft-skills-carnegie-s-wisdom-remix-4j3b | career, softskills, motivation | ---
title: 30 principles to level-up your Soft Skills (Carnegie’s wisdom remix)
published: true
description:
tags: #career #softskills #motivation
cover_image: https://thepracticaldev.s3.amazonaws.com/i/mpmy2v6u7z3c03yqibtz.png
---
*Photo by Jens Johnsson on Unsplash*
**Note: I originally put this article together as a resource for developers joining their first remote developer team at [Chingu](https://www.chingu.io/). After a few years and thousands of remote developer collaborations launched, I remain convinced that soft skills are grossly underestimated. I hope you find this valuable.**
Your Skills Stack should not be limited to just technical skills.
## BECOME A FRIENDLIER PERSON
1. **Don’t criticize, condemn, or complain.**
2. **Give honest and sincere appreciation.**
3. Arouse in the other person an eager need or want.
4. **Become genuinely interested in other people.**
5. Smile.[emojis work just as well]
6. Remember that a person’s name is to that person the sweetest and most important sound in any language.
7. **Be a good listener.** Encourage others to talk about themselves.
8. Talk in terms of the other person’s interests.
9. Make the other person feel important — and do it sincerely.
10. **The only way to get the best of an argument is to avoid it.**
## WIN PEOPLE TO YOUR WAY OF THINKING
1. **Show respect for other person’s opinions. Never say, “You’re wrong.”**
2. **If you are wrong, admit it quickly and emphatically.**
3. **Begin in a friendly way.**
4. Get the other person saying “yes, yes” immediately.
5. Let the other person do a a great deal of the talking.
6. Let the other person feel that the idea is his or hers.
7. **Try honestly to see things from the other persons point of view.**
8. **Be sympathetic with the other person’s ideas and desires.**
9. Appeal to the other nobler motives.
10. Dramatize your ideas.
## BE A LEADER
1. Throw down a challenge.
2. Begin with praise and honest appreciation.
3. Call attention to people’s mistakes indirectly.
4. **Talk about your own mistakes before criticizing the other person.**
5. Ask questions instead of giving direct orders.
6. Let the other person save face.
7. **Praise the slightest improvement and praise every improvement. Be “hearty in your appreciation and lavish in your praise.”**
8. **Give the other person a fine reputation to live up to.**
9. Use encouragement. Make the fault seem easy to correct.
10. Make the other person happy about doing the thing you suggest.
*All the above are Carnegie principles.*
{% youtube 0uMZi1gc0Nc %} | tropicalchancer |
245,900 | Basic linux commands | Basic linux commands This is a list of all basic linux commands you should know. Of cours... | 0 | 2020-01-21T18:51:53 | https://dev.to/tomschwarz/basic-linux-commands-1icf | linux, bash, terminal | # Basic linux commands
This is a list of all basic linux commands you should know.
Of course this is my personal opinion.
What do you think?
## Files and navigation
> ls - directory listing of current directory
> ls -l - formatted listing
> ls -la - formatted listing including hidden files
> cd dir - change directory to dir (dir = name of directory)
> cd .. - change to parent directory
> cd - change to home directory
> cd - - change to previous visited directory
> cd ../dir - change to dir in parent directory
> pwd - show current directory
> mkdir dir - create a direcotry "dir"
> rm filename - delete file
> rm -f filename - force remove filename
> rm -r dir - delete directory
> rm -rf dir - force delete of directory
> cp file1 file2 - copy file1 to file2
> mv file1 file2 - rename file1 to file2
> mv file1 dir/file2 - move file1 to dir as file2
> touch filename - create or update file
> cat file - output contents of file
> cat > file - write standard input into file
> cat >> file - append standard input into file
> tail -f file - outputs contents of file as it grows
## Networking
> ping host - ping the host
> whois domain - get whois for domain
> dig domain - get DNS for domain
> dig -x host - reverse lookup host
> wget file - download file
> wget -c file - continue stopped download
> wget -r url - recusivley download files from url
> curl url - outputs the webpage from url
> curl -o output.html url - writes the page to output.html
> ssh user@host - connect to host as user
> ssh -p port user@host - connect using port
> ssh -D user@host - connect & user bind port
## Processes
> ps - display currently active processes
> ps aux - detailed outputs
> kill pid - kill process with process id (pid)
> killall proc - kill all processes named proc
## System info
> date - show current date/time
> uptime - show uptime
> whoami - who you are logged in as
> w - display who is online
> cat /proc/cpuinfo - display cpu info
> cat /proc/meminfo - memory info
> free - show memory and swap usage
> du - show directory space usage
> du -sh - displays readable sizes in GB
> df - show disk usage
> uname -a - show kernel config
## Compressing
> tar cf file.tar files - tar files into file.tar
> tar xf file.tar - untar into current directory
> tar tf file.tar - show contents of archive
>
> options:
> * c - create archive
> * t - table of contents
> * x - extract
> * z - use zip/gzip
> * f - specify filename
> * j - bzip2 compression
> * w - ask for confirmation
> * k - do not overwrite
> * T - files from file
> * v - verbose
## Permissions
> chmod octal file - change permissions of file
> * 4 - read (r)
> * 2 - write (w)
> * 1 - execute (x)
>
> order: owner/group/world
>
> chmod 777 - rwx for everyone
> chmod 755 - rw for owner, rx for group and world
## Some others
> grep pattern files - search in files for pattern
> grep -r pattern dir - search for pattern recursively in directory
> locate file - find all instances of file
> whereis app - show possible locations of app
> man command - show manual page for command
| tomschwarz |
246,039 | Top 5 DEV Comments from the Past Week | Highlighting some of the best DEV comments from the past week. | 0 | 2020-01-21T23:13:14 | https://dev.to/devteam/top-5-dev-comments-from-the-past-week-2206 | bestofdev | ---
title: Top 5 DEV Comments from the Past Week
published: true
description: Highlighting some of the best DEV comments from the past week.
tags: bestofdev
cover_image: https://res.cloudinary.com/practicaldev/image/fetch/s--7VrAA2ln--/c_imagga_scale,f_auto,fl_progressive,h_420,q_auto,w_1000/https://thepracticaldev.s3.amazonaws.com/i/qmb5wkoeywj06pd7p8ku.png
---
This is a weekly roundup of awesome DEV comments that you may have missed. You are welcome and encouraged to boost posts and comments yourself using the **[#bestofdev](/t/bestofdev)** tag.
@cassandraspruit leads things off by describing their answer to **[What are the hardest coding terms to search for?](https://dev.to/ben/what-are-the-hardest-coding-terms-to-search-for-2n9n)**:
{% devcomment ka9o %}
@tobiassn offers their opinion in **[What's the most wasteful software?](https://dev.to/ben/what-s-the-most-wasteful-software-l78)**:
{% devcomment kdma %}
@aleksandrhovhannisyan shares some useful perspective about perfection vs. progress in response to **[Clean code, dirty code, human code](https://dev.to/d_ir/clean-code-dirty-code-human-code-6nm)**:
{% devcomment keeg %}
The **[Tell me about the worst CSS you've ever had to deal with](https://dev.to/ben/tell-me-about-the-worst-css-you-ve-ever-had-to-deal-with-hf0)** thread had some great replies, but none better than @lukeshiru who talks about a true war of sorts:
{% devcomment k9ha %}
@ryansmith provides some great tips in response to **[Has your job impacted your physical health?](https://dev.to/jess/has-your-job-impacted-your-physical-health-4fbg)**:
{% devcomment kemb %}
See you next week for more great comments ✌ | peter |
246,078 | Recursion and the Call Stack Explained By Reading A Book | If you have ever read a book in English, then you can understand recursion 🙂 | 0 | 2020-01-22T02:14:19 | https://dev.to/kbk0125/recursion-and-the-call-stack-explained-by-reading-a-book-4khm | beginners, webdev, tutorial | ---
title: Recursion and the Call Stack Explained By Reading A Book
published: true
description: If you have ever read a book in English, then you can understand recursion 🙂
tags: #beginners, #webdev, #tutorial
cover_image: https://i2.wp.com/blog.codeanalogies.com/wp-content/uploads/2020/01/aaron-burden-G6G93jtU1vE-unsplash.jpg?resize=900%2C676&ssl=1
---
Recursion is one of the most exciting principles of all programming languages.
A non-recursive function (in other words, the functions that you have used in the past) will run once every time it is called, and output via a return statement.
However, a _recursive_ function can be called once and then **call itself an undetermined number of times** before combining the output of all the function calls in one return statement.
It kind of looks like this.
Static version:
Dynamic version:
The idea that a single function can be called one to infinity times via a single statement is what makes it so exciting!
At the same time, it is difficult to think of a real-world analogy to this situation. And it gets especially difficult once we discuss the **call stack** , which we will cover later.
Some have suggested a series of infinite boxes:
*Image Cred: [Grokking Algorithm](https://www.manning.com/books/grokking-algorithms)*
Others have suggested the imagery of “Russian nesting dolls”:

However, this is also unhelpful when understanding the call stack.
So, in this tutorial, we will show two popular examples of recursion, and build a visual language for understanding the function and the **call stack** , which determines how to make sense of the many function calls in a row.
Before continuing with this tutorial, you should have a firm understanding of functions in JavaScript. [Check out this guide to arrow functions](https://blog.codeanalogies.com/2019/04/14/javascripts-arrow-functions-explained-by-going-down-a-slide/) to learn more.
### Example 1- Factorials
Factorials are the most popular example of recursion.
You might be familiar with factorials from algebra class.
They are expressed like: 3!
And that notation evaluates to 3\*2\*1, or 6.
We could express this as a “for” loop where we update a variable outside the loop:
```javascript
let factorial = 4;
let result = 1;
for (i=factorial; i>= 1; i--){
result = result*i;
}
```
But, here we will use recursion instead. Rather than have a loop that updates a variable outside of its scope, we can use recursion with a function and have _n-1_ calls, where _n_ is the factorial we want to find.
I will show the code first, and then we can evaluate how it works.
```javascript
let getFactorial = (num) => {
if (num == 1)
return 1;
else
return num * getFactorial(num-1);
}
getFactorial(4);
// 24
```
Woah! This accomplishes the same thing as the code block above.
But, if you look at line 5, you can see that the _return_ statement includes a reference to the function itself.
So… when does this function return a final value, exactly? How do we link the 4 calls of the function together to return the value of 24?
This is where the **call stack** becomes useful. It determines the rules for the order that these function calls will return.
But, now we are stacking two concepts on top of each other: recursion and call stack. That’s a lot at once.
In order to visualize the call stack, let’s think of a stack that builds **from left to right**. Every time a block gets added, it is added to the left side of the stack and pushes the other blocks to the right.
So, as we go through this recursive function, we generate a stack like this:

The call stack is being generated at the bottom of the screen throughout the GIF above. At the end, we are left with 1\*2\*3\*4 which results in 24.
The call stack is composed of 4 function calls, and **none of them run until the function returns 1**. They sit on the stack until the last value is added, in this case 1.
This is because each of the first 3 calls includes a reference to the next call on the stack!
So, when num=4, the function returns 4\*getFactorial(3). Of course, that cannot actually return a value until we know the value of getFactorial(3). That’s why we need a call stack!
So, recursion allows a function to be called an indefinite number of times in a row AND it updates a call stack, which returns a value after the final call has been run.
The call stack updates from left to right, and then you can read all the calls in the order they are resolved. Most recent is resolved first, first call resolved last.
However, our GIF above did not do a good job of showing this relationship between each call. So, here’s an updated version that shows how all the calls are connected via the _return_ statement:

### Example 2- Splitting a String
In the example above, we used a mathematical example that resembled a question from algebra class.
This works, but there are also plenty of examples of recursion that go beyond math. In this example, we will show how you can use recursion to manipulate a string.
Here’s the challenge: Reverse a string.
In other words, return a string with the letters of an input string in the opposite order.
You can also do this with a “for” loop, but we will use recursion in this example.
Let’s think about how we should reverse the string “cat”.
Every time we run a function call, we need to isolate the first or last letter of the string, and then chop off a letter from the string. When we run the function again, we should again grab the first or last letter.
At the end, the call stack will allow us to return the letters in the correct order.
Here’s the code:
```javascript
let testStr = 'cat';
let revStr = (str) => {
if (str.length == 0)
return '';
else
return revStr(str.substr(1)) + str[0];
};
revStr(testStr);
// 'tac'
```
Okay. Let’s dig in, just like we did above.

Again, although the GIF above makes it look easy, we need to dig deeper into the final _return_ statement if we want to truly understand these function calls.
There is one more important difference in this example compared to the one above- we are doing string concatenation rather than multiplication.
Therefore, the order of the strings in that _return_ statement matters quite a bit, because it determines which order we will use for concatenation.
Since this is not a series of multiplication problems, the call stack is a little easier to understand. Here is a visual:

This is why the order of the strings matters so much- as we build the call stack in the GIF above, there is a specific order of the recursive function call and the string fragment (_str[0]_).
As we run all the calls in the stack, this order allows us to rebuild the string in the reverse order.
### Get The Latest Tutorials
Did you enjoy this tutorial? Check out the [CodeAnalogies blog](https://codeanalogies.com) to get the latest visual web development tutorials.
| kbk0125 |
246,087 | My initial post. This will help those dealing with FIPS on Linux | My initial post. ### for those that use FIPS with CentOS or RHEL 7, here's a script # that I made... | 0 | 2020-01-22T02:52:47 | https://dev.to/rhelrj/my-initial-post-sorry-if-it-is-a-duplicate-5872 | linux | My initial post.
~~~
### for those that use FIPS with CentOS or RHEL 7, here's a script
# that I made and posted at the Red Hat Discussion Forum
https://access.redhat.com/discussions/3487481
~~~
~~~
#!/bin/bash
#
# 10/17/2018 changed uname directives to use "uname -r" which works better in some environments. Additionally ensured quotes were paired (some were not in echo statements)
#
# this script was posted originally at https://access.redhat.com/discussions/3487481 and the most current edition is most likely (maybe) posted there... maybe.
# updated 8/24/2018 (thanks for those who provided inputs for update)
#
# Purpose, implement FIPS 140-2 compliance using the below article as a reference
# See Red Hat Article https://access.redhat.com/solutions/137833
## -- I suspect Red-Hatter Ryan Sawhill https://access.redhat.com/user/2025843 put that solution together (Thanks Ryan).
# see original article, consider "yum install dracut-fips-aesni"
# --> And special thanks to Dusan Baljevic who identified typos and tested this on UEFI
# NOTE: You can create a Red Hat Login for free if you are a developer,
# - Go to access.redhat.com make an account and then sign into
# - developers.redhat.com with the same credentials and then check your email and accept the Developer's agreement.
# Risks... 1) Make sure ${mygrub} (defined in script) is backed up as expected and the directives are in place prior to reboot
# Risks... 2) Make sure /etc/default/grub is backed up as expected and the proper directives are in place prior to reboot
# Risks... 3) Check AFTER the next kernel upgrade to make sure the ${mygrub} (defined in script) is properly populated with directives
# Risks... 4) Be warned that some server roles either do not work with FIPS enabled (like a Satellite Server) or of other issues, and you've done your research
# Risks... 5) There are more risks, use of this script is at your own risk and without any warranty
# Risks... 6) The above list of risks is -not- exhaustive and you might have other issues, use at your own risk.
# Recommend using either tmux or screen session if you are using a remote session, in case your client gets disconnected.
#
##### Where I found most of the directives... some was through my own pain with the cross of having to do stig compliance.
rhsolution="https://access.redhat.com/solutions/137833"
manualreview="Please manually perform the steps found at $rhsolution"
####### check if root is running this script, and bail if not root
# be root or exit
if [ "$EUID" -ne 0 ]
then echo "Please run as root"
exit
fi
### bail if command sysctl crypto.fips_enable returns with "1" with the variable $answer below
configured="The sysctl crypto.fips_enabled command has detected fips is already configured, Bailing...."
notconfigured="fips not currently activated, so proceeding with script."
## Dusan's good suggestion...
answer=`sysctl crypto.fips_enabled`
yes='crypto.fips_enabled = 1'
if [ "$answer" == "$yes" ] ; then
echo -e "\n\t $configured \n"
exit 1
else
echo -e "\n\t $notconfigured \n"
fi
##### uefi check, bail if uefi (I do not have a configured uefi system to test this on)
######- Added 7/5/2018, do not proceed if this is a UEFI system... until we can test it reliably
[ -d /sys/firmware/efi ] && fw="UEFI" || fw="BIOS"
echo -e "$fw"
if [ "$fw" == "UEFI" ] ; then
echo -e "\n\tUEFI detected, this is a ($fw) system.\n\setting \$fw variable to ($fw)..."
mygrub='/boot/efi/EFI/redhat/grub.cfg'
### Thanks Dusan Baljevic for testing this.
### exit 1
else
echo -e "\n\t($fw) system detected, proceeding...\n"
mygrub='/boot/grub2/grub.cfg'
fi
##### rhel6 check really don't run this on a rhel6 box... and bail if it is rhel 6
myrhel6check=`uname -r | egrep 'el6'`
if [ "$myrhel6check" != "" ] ; then
echo -e "\n\tThis system is not RHEL 7, and Red Hat 6 is detected, \n\tThis script is intended for RHEL 7 systems only, bailing!!!\n"
exit 1
else
echo -e "\n\tRHEL 7 detectd, proceeding\n"
fi
##### rhel5 check really don't run this on a rhel5 box... and bail if it is rhel5
myrhel5check=`uname -r | egrep el5`
if [ "$myrhel5check" != "" ] ; then
echo -e "\n\tThis system is not RHEL 7, and Red Hat 5 is detected, \n\tThis script is intended for RHEL 7 systems only, bailing!!!\n"
exit 1
else
echo -e "\n\tNot RHEL 5, so proceeding...\n"
fi
##### only run if this returns el7 in the grep
# overkill? you bet, don't run unless this is rhel7
myrhel7check=`uname -r | grep el7`
if [ "$myrhel7check" != "" ] ; then
echo "RHEL 7 detected, Proceeding"
else
echo -e "\n\tThis system is not rhel7, \n\tBailing..."
echo exit 1
fi
######- add a second to $mydate variable
sleep 1
mydate=`date '+%Y%m%d_%H_%M_%S'`;echo $mydate
##### make backup copy $mygrub defined earlier
cp -v ${mygrub}{,.$mydate}
##### check fips in grub, if it's there, bail, if not proceed
myfipscheckingrub=`grep fips $mygrub | grep linux16 | egrep -v \# | head -1`
if [ "$myfipscheckingrub" != "" ] ; then
echo -e "FIPS directives detected in ($mygrub), \n\t\t($myfipscheckingrub)\n\tSo, recommend AGAINST running this script\n\t$manualreview"
exit 1
else
echo -e "\n\tFIPS directives not detected in ($mygrub)\n\tproceeding..."
fi
##### fips should not be in /etc/default/grub, if so, bail
etcdefgrub='/etc/default/grub'
myfipschecketcdefgrub=`grep fips $etcdefgrub | grep -v \#`
if [ "$myfipschecketcdefgrub" != "" ] ; then
echo -e "FIPS directives detected in ($etcdefgrub), \n\t\t($myfipschecketcdefgrub)\n\tSo, recommend AGAINST running this script\n\t$manualreview"
echo exit 1
else
echo -e "\n\tFIPS directives not detected in ($etcdefgrub)\n\tproceeding..."
fi
##### verify that this system is actually in the same kernel as we're going to install this in..., or bail
# if they don't match, the script bails.
mydefkern=`grubby --default-kernel | sed 's/.*vmlinuz\-//g'| awk '{print $1}'`
myuname=`uname -r`
if [ "$mydefkern" != "$myuname" ] ; then
echo -e "\n\tKernel Mismatch between running and installed kernel...\n\tThe default kernel is: $mydefkern\n\tThe running kernel is $myuname\n\n\tPlease reboot this system and then re-run this script\n\tBailing...\n"
exit 1
else
echo "Default Kernel ($mydefkern) and Current Running Kernel ($myuname) match, proceeding"
fi
##### overkill, yes
# yes, there's an number of checks above, but I'm still persisting with this, just in case someone runs this script twice.
# it will never reach this if it fails any of the previous checks, but I'll leave it.
##### a file named "/root/fipsinstalled" is created at the end of this script. So I'll check for it at the beginning so that this script is only ran once.
if [ -f /root/fipsinstalled ] ; then
sysctl crypto.fips_enabled
echo -e "\tThis script was ran previously,\n\t nothing to do, \n\texiting..."
exit 1
else
echo "continuing" >/dev/null
echo proceeding...
fi
############################################################################################
############################################################################################
############################################################################################
##### this is where the script actually begins to make modifications.
# -- everything before was either a check, or a backup of a config
# Only install dracut-fips if it is not installed (that's the "||" below)
rpm -q dracut-fips > /dev/null || yum -y install dracut-fips
##### warn people not to bail at this point, pause 4 seconds so they might see it if they're watching the screen.
echo -e "\n\n\n\tWARNING!!!: \n\tWARNING!!!DO NOT INTERRUPT THIS SCRIPT OR IT CAN CAUSE \n\tTHE SYSTEM TO BECOME UNBOOTABLE!!!!\n\tPlease be patient it will take some time...\n\tWARNING!!!\n\tWARNING\n\n\n"
sleep 4
##### next disable prelinking
rpm -q prelink >/dev/null && grep PRELINKING /etc/sysconfig/prelink
##### slightly lesser known use of sed, it only flips PRELINKING to "no"
# this flips "yes" to "no" in the prelink config file, next kills prelinking
rpm -q prelink >/dev/null && sed -i '/^PRELINKING/s,yes,no,' /etc/sysconfig/prelink
rpm -q prelink >/dev/null && prelink -uav 2>/tmp/err
/bin/cp -v /etc/aide.conf{,.undofips}
rpm -q prelink >/dev/null && sed -i 's/^NORMAL.*/NORMAL = FIPSR+sha512/' /etc/aide.conf
##### update the $mydate variable which is used to copy off backups of various configs throughout the rest of this script.
mydate=`date '+%Y%m%d_%H_%M_%S'`;echo $mydate
###-----###
# back up existing initramfs
mv -v /boot/initramfs-$(uname -r).img{,.$mydate}
##### warn people not to bail at this point, pause 4 seconds so they might see it if they're watching the screen.
##### really, don't interrupt this portion.
echo -e "\n\n\n\tWARNING!!!: \n\tWARNING!!!DO NOT INTERRUPT THIS SCRIPT OR IT CAN CAUSE \n\tTHE SYSTEM TO BECOME UNBOOTABLE!!!!\n\tPlease be patient it will take some time...\n\tWARNING!!!\n\tWARNING!!!\n\n\n"
# this pauses as before so the person running this script gets a chance to see the above, it also is to allow the $mydate variable below to get a new value
sleep 3
# run dracut
dracut
mydate=`date '+%Y%m%d_%H_%M_%S'`
###-----###
###### The Red Hat solution I cited earlier in the comments, this is where this came from
# this section below updates /boot/grub/grub.cfg with fips and the uuid of the boot device
# first back it up
/bin/cp ${mygrub}{,.$mydate}
grubby --update-kernel=$(grubby --default-kernel) --args=fips=1
###### this displays the kernel lines in grub with fips
grep fips ${mygrub} | grep linux16
###### that Red Hat solution I cited earlier in the comments, this is where this came from
# set the uuid variable to be used later
uuid=$(findmnt -no uuid /boot)
echo -e "\n\t Just for reference, the /boot uuid is: ($uuid)\n"
###### that Red Hat solution I cited earlier in the comments, this is where this came from
# update the boot uuid for fips in ${mygrub}
# the 2nd line is to satisfy the disa stig checker which checks every single menu entry linux16 line. without it, the check fails.
[[ -n $uuid ]] && grubby --update-kernel=$(grubby --default-kernel) --args=boot=UUID=${uuid}
# update 7/23/2019. The next line is excessive. The impact of the next line, when the system goes to emergency mode, and you select **any** kernel at grub, you are faced with a system that **will not** accept any password. I've removed it for the rescue kernel.
## so maybe your security people require this. **IF** the do, then know that when you go to emergency mode, you **will** require the grub password (know it in advance!) and you ought to set **one time only** the grub line to fips=0 **for a one time only boot**
#
#sed -i "/linux16 \/vmlinuz-0-rescue/ s/$/ fips=1 boot=UUID=${uuid}/" ${mygrub}
###### that Red Hat solution I cited earlier in the comments, this is where this came from
# update /etc/default/grub for subsequent kernel updates. this APPENDS to the end of the line.
sed -i "/^GRUB_CMDLINE_LINUX/ s/\"$/ fips=1 boot=UUID=${uuid}\"/" /etc/default/grub
grep -q GRUB_CMDLINE_LINUX_DEFAULT /etc/default/grub || echo 'GRUB_CMDLINE_LINUX_DEFAULT="fips=1"' >> /etc/default.grub
echo -e "\n\tThe next line shows the new grub line with fips in the two locations below:\n"
grep $uuid ${mygrub} | grep linux16
echo;grep $uuid /etc/default/grub
### warning ### warning ###
### Note, if you do not change Ciphers and MACs prior to reboot, you will NOT be able to ssh to the system. That could be a problem depending on the distance or difficulty of getting a console or physical access to fix after reboot. Be warned.
###
mydate=`date '+%Y%m%d_%H_%M_%S'`;echo $mydate
cp -v /etc/ssh/sshd_config{,.$mydate}
# without this, no ssh, really, ask me how I know
sed -i 's/^Cipher.*/Ciphers aes128-ctr,aes192-ctr,aes256-ctr/' /etc/ssh/sshd_config
sed -i 's/^MACs.*/MACs hmac-sha2-256,hmac-sha2-512/' /etc/ssh/sshd_config
# bread crumbs
touch /root/fipsinstalled
chattr +i /root/fipsinstalled
###### the command to check this after reboot is: sysctl crypto.fips_enabled
echo -e "\n\tScript has completed. \n\tSystem must be rebooted for fips to be enabled. \n\tPlease check the following 2 files for sane entries:\n\t/etc/default/grub \n\t${mygrub}. \n\n\tAlso, --AFTER--REBOOT--as-root-- run sysctl crypto.fips_enabled and the output must be \n\t'crypto.fips_enabled = 1' \n"
##### without this, the disa provided stig checker fails fips compliance, you're welcome
echo 'GRUB_CMDLINE_LINUX_DEFAULT="fips=1"' >> /etc/default/grub
rpm -q prelink > /dev/null && rpm -e prelink > /dev/null
##### Same with this...
/bin/chmod 0600 /etc/ssh/ssh_host*key
###
~~~ | rhelrj |
246,141 | Sitecore Commerce - Entity-Component-Policy | Previous Article Introduction to Sitecore Commerce Sitecore Commerce - Entity-Component-Policy... | 4,389 | 2020-01-22T08:15:36 | https://dev.to/mdarifuzzaman/sitecore-commerce-entity-component-policy-50pa | sitecore, sitecorecommerce, sitecorecommerce92, entity | <sm>Previous Article</sm>
<ul>
<li><a href='https://dev.to/mdarifuzzaman/sitecore-commerce-introduction-59k5'>Introduction to Sitecore Commerce</a></li>
</ul>
<h4>Sitecore Commerce - Entity-Component-Policy</h4>
Those who are just landing in this article, please complete the earlier article to grab the context from the above list.
We need to first understand what is an entity in Sitecore Commerce. This is the very primary terms to know. In a simple definition, we can say, the entity is an object which encapsulates a cart and all its behavior. An entity is stored in a database as a serialized object.
<h4>Getting familiar with entity: </h4> Let me show you a sample entity as below
Let me elaborate on this object a bit although it's kind of self-explanatory.
<li>ShopName : </li> It is your shop. Every commerce system is based on a shop. We can configure multiple shops in a single commerce server that's why each of the API calls, this information must be passed through. (We will see that in my later article)
<li>Item Count : </li> Total number of item in the cart
<li>Lines: </li> How many line (product) do you have in the cart.
<li>Adjustment: </li> If cart has any adjustment (Discount)
<li>Components: </li> Components can be Cart level or Line level. This is one of the extension points of our cart entity. It requires a bit of explanation below.
<h4>Components: </h4> As I said before, this is an extension point of a Cart. It is a list. The number of Components varies based on Cart behavior or property. We can add or remove components based on the different behavior of the cart. Sample example is:
You can see, this cart entity has 3 components (I only expanded one). The easiest way to create a component is as follow:
```c#
namespace Plugin.Sample.AdventureWorks.Components
{
public class LogComponent: Component
{
public string Name { get; set; }
public string Message { get; set; }
public string ErrorCode { get; set; }
}
}
```
If we need to extend anything in the cart level, we will create Component as above and will add that to Cart -> Components. Now, the "Lines" object from the above image is also a component that has a list of CartLineComponent. The CartLineComponent is also extended from Component and includes some extra properties as necessary. We can place components as a nested way as well.
Let's expand the Lines object from cart entity and see component is being used there:
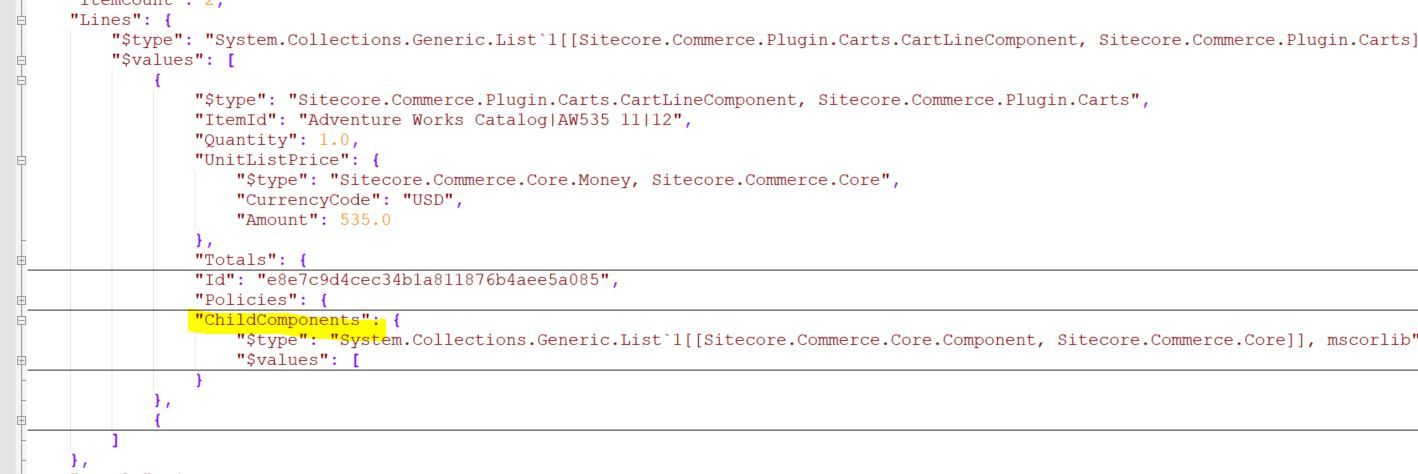
I expanded one of the lines and found "ChildComponents" array (Each line is a component therefore it says ChildComponent). It also stores the same component object. And obviously it is also the extension point of your lines.
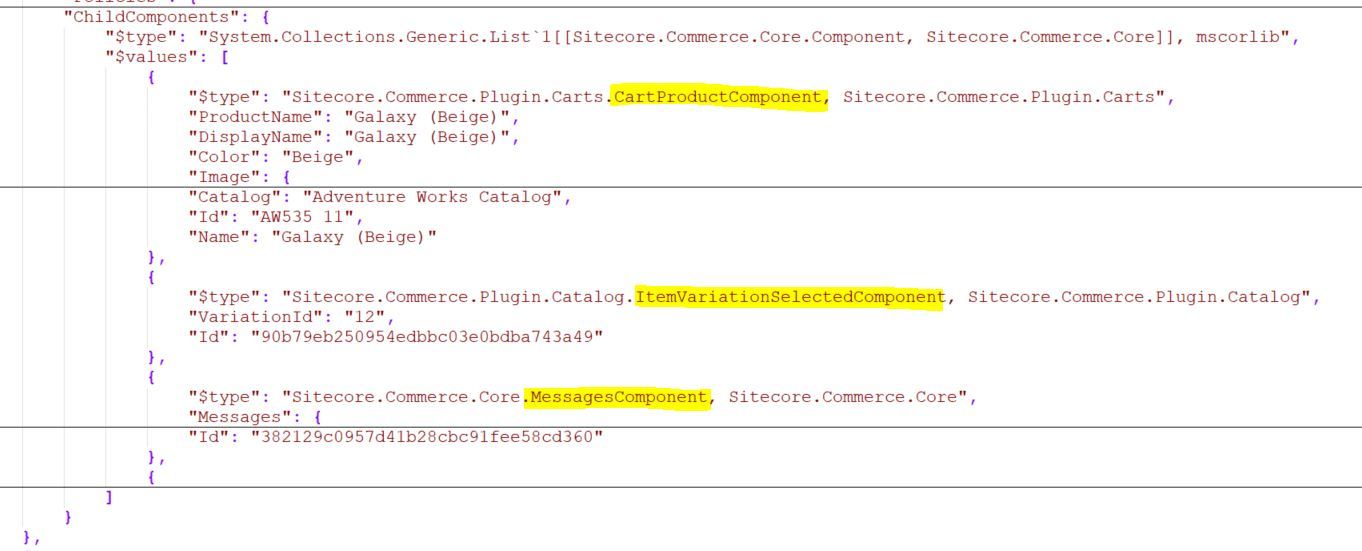
You can see, it has a product information component that holds all the information about your product of that line along with some other components.
Now if you have any particular business requirement i.e to store some extra information about the product or maybe we want to display an extra message for delivery of this product or anything, we can create components and store that information. Now the benefit we are going to get here is, that particular information will be saved in the database as part of the cart entity which can be retrieved (deserialized) later on and can be used.
<h4>Policy: </h4> Policy is a part of Component and will define extra behavior or rights. Let me give you an idea. If we see, the Line component doesn't have any pricing information. Then how will the price be calculated? Well, pricing is a very variable thing and it's not a good idea that your product will carry that property. Rather, there will be a policy that will carry pricing information.
```json
"Policies": {
"$type": "System.Collections.Generic.List`1[[Sitecore.Commerce.Core.Policy, Sitecore.Commerce.Core]], mscorlib",
"$values": [
{
"$type": "Sitecore.Commerce.Plugin.Pricing.PurchaseOptionMoneyPolicy, Sitecore.Commerce.Plugin.Pricing",
"SellPrice": {
"$type": "Sitecore.Commerce.Core.Money, Sitecore.Commerce.Core",
"CurrencyCode": "USD",
"Amount": 535.0
},
"FixedSellPrice": false,
"Expires": "2020-01-03T00:23:02.1622096+00:00",
"PolicyId": "f7bfaa51df064886923450a6ca5d17f3"
}
]
},
```
Have a look at the above. Policies array is part of each product line. Now, PurchaseOptionMoneyPolicy will give you the selling price. If based on any business cases, we need to give a special price for a special product, we can use a different custom pricing policy instead.
Another example would be, you need to get the price from an external system i.e your own inventory system may be (which is not a Sitecore system). You might store a new policy that will hold all the information to talk to that server like Server URL, AuthKey, ProductId whichever are required we can store and that way we can extend the behavior of our components.
Creating a Policy is pretty easy. What you need to do is below:
```c#
public class RedisCachePolicy : Policy
{
public string Connection { get; set; }
public string Timeout { get; set; }
}
```
Here you can see we have created a policy to define the cache behavior. So for any reasons if we want our line will be cached somewhere in Redis, we can do that.
The only thing we need to know before implementing a commerce solution is different commerce environments. Next article I will cover :
<b> What is Sitecore Commerce environment and will explain Shops, Authoring and Minions environment briefly</b>
Till then bye,
Arif
https://www.linkedin.com/in/mdarifuzzaman/
channel: https://www.youtube.com/channel/UCNV_WMRXkq6E4EojTX8XJPw | mdarifuzzaman |
246,171 | gmail mobile feature or bug ? | when i go to my gmail sent items folder it lists me as having sent every email i would prefer to see... | 4,424 | 2020-01-22T06:39:17 | https://dev.to/osde8info/gmail-mobile-feature-or-bug-2jm | gmail, bug, feature | when i go to my gmail sent items folder it lists me as having sent every email i would prefer to see everyone i had sent an email to (not from me) !
btw the last time i spent hours logging a bug the unnamed vendor said it was a feature
| osde8info |
246,268 | Developing 30 JS Applications in 10 days | 30DaysOfJavaScript challenge has been running for 20 days. In this challenge students solve more than... | 0 | 2020-01-22T08:57:39 | https://dev.to/asabeneh/10-days-challenge-of-developing-js-applications-1ikf | javascript, react, python, 100daysofcode | 30DaysOfJavaScript challenge has been running for 20 days. In this challenge students solve more than 500 JS problems and develop about 30 JS applications.
Today is the 21 day and we will start developing applications. You can join us for 10 days of developing JavaScript application. In 10 days, you will master JavaScript by building applications and connecting dots.
💻 30DaysOfJavaScript Github: https://lnkd.in/efqy_df
💻 30DaysOfPython Github: https://lnkd.in/epW6d_U
Follow me on LinkedIn: https://www.linkedin.com/in/asabeneh/
👥 Join the 30DaysOfJavaScript group: https://lnkd.in/er7kdTE
👥 Join the 30DaysOfPython group: https://lnkd.in/eE5Qgqd
📅 Start your new year or monthly resolution with coding.
Good Luck!! ✨
🔥🔥🔥
| asabeneh |
246,283 | 5G the honest truth - its not for you its for IOT | “5G won’t have much impact on the consumer beyond enabling faster speeds, however it will revolutioni... | 0 | 2020-01-22T09:23:20 | https://dev.to/osde8info/5g-the-honest-truth-its-not-for-you-its-for-iot-4a5d | 4g, 5g, mobile, broadband | “5G won’t have much impact on the consumer beyond enabling faster speeds, however it will revolutionise the connected world and industries”
CEO, NOKIA
{% twitter 1219911024763121664 %} | osde8info |
246,294 | RxJS in-depth: Github repo ‘utils’ directory review (part 1) | Curiosity leads to discoveries.
RxJS is quite a popular library in Angular wor... | 0 | 2020-01-23T17:01:32 | https://medium.com/angular-in-depth/rxjs-in-depth-github-repo-utils-directory-review-part-1-d0aa15adaeb9 | angular, rxjs, webdev | ---
title: RxJS in-depth: Github repo ‘utils’ directory review (part 1)
published: true
date: 2020-01-22 09:37:00 UTC
tags: angular,rxjs,web-development
canonical_url: https://medium.com/angular-in-depth/rxjs-in-depth-github-repo-utils-directory-review-part-1-d0aa15adaeb9
cover_image: https://thepracticaldev.s3.amazonaws.com/i/fu3b3dbaht3y1cyt4kws.jpeg
---
_Curiosity leads to discoveries._
_RxJS is quite a popular library in Angular world so for me it is always interesting to find out something new about its internals. Today I want to dig into_ [**_utils_**](https://github.com/ReactiveX/rxjs/tree/6.5.1/src/internal/util) _folder of its GitHub_ [_repo_](https://github.com/ReactiveX/rxjs)_. This article is written not for some practical usage but rather for reverse engineering enthusiasts and my curiosity._
Here is a link to RxJS 6.5 /[src](https://github.com/ReactiveX/rxjs/tree/6.5.1/src)/[internal](https://github.com/ReactiveX/rxjs/tree/6.5.1/src/internal)/[util](https://github.com/ReactiveX/rxjs/tree/6.5.1/src/internal/util)/ dir. This folder is full of files. Let’s review them one by one. Some of them can bring something interesting 🔍.
#### #1 [ArgumentOutOfRangeError.ts](https://github.com/ReactiveX/rxjs/blob/6.5.1/src/internal/util/ArgumentOutOfRangeError.ts)
The main code is next:
```ts
function **ArgumentOutOfRangeErrorImpl** (this: any) {
Error.call(this);
this.message = 'argument out of range';
this.name = 'ArgumentOutOfRangeError';
return this;
}
_ArgumentOutOfRangeErrorImpl_.prototype = Object._create_(Error.prototype);
_export const_ ArgumentOutOfRangeError : ArgumentOutOfRangeErrorCtor = _ArgumentOutOfRangeErrorImpl as any_;
```
**What is interesting here?**
a) We inherit from built-in Error class here. So we can _throw_ calls instance with the message we need.
b) superclass constructor is called in an explicit way: Error.call(this);
**Where it is used in RxJS source code?**
Let's take a look at [**_takeLast_**](https://rxjs-dev.firebaseapp.com/api/operators/takeLast)**_(count)_** operator — it should emit last _count_ values after the source observable is complete. Of cause it cannot accept negative count — [so](https://github.com/ReactiveX/rxjs/blob/6.5.1/src/internal/operators/takeLast.ts#L40):
```
When using takeLast(i), it delivers an ArgumentOutOrRangeError to the Observer's error callback if i < 0
```
at [line 63](https://github.com/ReactiveX/rxjs/blob/6.5.1/src/internal/operators/takeLast.ts#L63):
```ts
if (this.total < 0) { throw new ArgumentOutOfRangeError; }
```
**Why should I know this?**
Reading source code can help you to understand how the library works in edge cases. And sometimes it is the only way to understand why it works how it works.
#### #2 [EmptyError.ts](https://github.com/ReactiveX/rxjs/blob/6.5.1/src/internal/util/EmptyError.ts)
It looks very similar to ArgumentOutOfRangeError
```ts
function EmptyErrorImpl(this: any) {
Error.call(this);
this.message = 'no elements in sequence';
this.name = 'EmptyError';
return this;
}
EmptyErrorImpl.prototype = Object.create(Error.prototype);
export const EmptyError: EmptyErrorCtor = EmptyErrorImpl as any;
```
But the application scope is different.
**Where it is used in code?**
Let's review [**_first_**](https://rxjs-dev.firebaseapp.com/api/operators/first) operator — it should emit only the first value (or the first value that meets some condition) emitted by the source Observable.
But what is sequence is empty? We can find an answer at [line 69](https://github.com/ReactiveX/rxjs/blob/6.5.1/src/internal/operators/first.ts#L69) of [rxjs](https://github.com/ReactiveX/rxjs/tree/6.5.1)/[src](https://github.com/ReactiveX/rxjs/tree/6.5.1/src)/[internal](https://github.com/ReactiveX/rxjs/tree/6.5.1/src/internal)/[operators](https://github.com/ReactiveX/rxjs/tree/6.5.1/src/internal/operators)/[first.ts](https://github.com/ReactiveX/rxjs/blob/6.5.1/src/internal/operators/first.ts)
```
Delivers an EmptyError to the Observer's `error` callback if the Observable completes before any `next` notification was sent.
```
And this happens in lines 86–90:
```ts
return (source: Observable<T>) => source.pipe(
predicate ? filter((v, i) => predicate(v, i, source)) : identity,
take(1),
hasDefaultValue ? defaultIfEmpty<T | D>(defaultValue) : throwIfEmpty(() => new **EmptyError** ()),
);
```
**\*Interesting remark:** you can use **take(1)** instead of **first()** with almost the same result:
```ts
source$.pipe(take(1))
vs
source$.pipe(first())
```
The only difference that **_take_** operator will not emit **EmptyError** if source$ completes before producing value.
**Why should I know this?**
Since **first** operator uses **EmptyError** — a final code bundle should contain [**EmptyError.ts**](https://github.com/ReactiveX/rxjs/blob/6.5.1/src/internal/util/EmptyError.ts) file too. So when you use **first** operator — a final bundle size will be a bit bigger. You can read more about it [here](https://swalsh.org/blog/rxjs-first-vs-take1/).
[Continue reading...](https://medium.com/angular-in-depth/rxjs-in-depth-github-repo-utils-directory-review-part-1-d0aa15adaeb9)
***
I am preparing my future video-course with advanced techniques of mastering Angular/RxJS. Want to get a notification when it is done? Leave your email here (and get free video-course): http://eepurl.com/gHF0av
Like this article? Follow me on [Twitter](https://twitter.com/El_Extremal)! | oleksandr |
246,330 | Get a Head Start Developing Multitenant SaaS Cloud Applications Using ASP.NET Core and Microsoft Azure | The next revolution in the software industry will be SaaS cloud-based applications. In 2020, you will... | 0 | 2020-01-23T10:01:09 | https://www.syncfusion.com/blogs/post/get-a-head-start-developing-multitenant-saas-cloud-applications-using-asp-net-core-and-microsoft-azure.aspx | dotnet, csharp, productivity | ---
title: Get a Head Start Developing Multitenant SaaS Cloud Applications Using ASP.NET Core and Microsoft Azure
published: true
date: 2020-01-22 11:30:51 UTC
tags: dotnet, csharp, productivity
canonical_url: https://www.syncfusion.com/blogs/post/get-a-head-start-developing-multitenant-saas-cloud-applications-using-asp-net-core-and-microsoft-azure.aspx
cover_image: https://www.syncfusion.com/blogs/wp-content/uploads/2020/01/Multitenant-SaaS-application-672x372.png
---
The next revolution in the software industry will be [SaaS](https://en.wikipedia.org/wiki/Software_as_a_service) cloud-based applications. In 2020, you will see many SaaS applications coming out on the market. Nowadays, there are many technologies available that make building SaaS applications easier. The recent release of the cross-platform [ASP.NET Core 3.1](https://docs.microsoft.com/en-us/aspnet/core/), which is battle-tested and performs on par with other technologies, is an ideal choice to build a SaaS application if you are already familiar with .NET.
In this post, you will find some useful tips and libraries that will help you get a head start on your SaaS application using ASP.NET Core and Azure.
## Setting up a project structure
First, to start your application, set up a project structure. There are some good projects and architectural references that I listed in my [previous blog](https://dev.to/karthickramasamy08/awesome-list-of-top-asp-net-core-based-open-source-application-projects-24d1-temp-slug-6256439). Some top project templates to look at when starting a project are:
- [Dotnet-Boxed](https://github.com/Dotnet-Boxed/Templates)
- [CleanArchitecture](https://github.com/JasonGT/CleanArchitecture)
- [Angular starter-kit](https://github.com/ngx-rocket/starter-kit)
Also, I suggest watching this [video](https://www.youtube.com/watch?v=5OtUm1BLmG0) on clean architecture by Jason Taylor.
## Multitenancy
The next important step in building a SaaS application is to handle multitenancy, the serving of multiple tenants using a single instance of an application. To handle multitenancy, there are several open-source libraries available that will provide boilerplate code. Some of the top libraries in this category are:
- [saaskit](https://github.com/saaskit/saaskit)
- [MultiTenant](https://github.com/Finbuckle/Finbuckle.MultiTenant)
- [cloudscribe](https://github.com/cloudscribe/cloudscribe)
- [OrchardCore](https://github.com/OrchardCMS/OrchardCore)
- [aspnetboilerplate](https://aspnetboilerplate.com/Pages/Documents/Multi-Tenancy)
You can also check out blog posts on multitenancy by [Ben Foster](https://benfoster.io/blog/tagged/saaskit) or [Gunnar Peipman](https://gunnarpeipman.com/series/multi-tenant-aspnet-core/). These blogs will help you in setting up multitenancy in your project.
## Error logging
Error logging is also one of the important things to include in your project. There are several open-source libraries available, some of the top libraries in this category are:
- [Exceptionless](https://exceptionless.com/)
- [NLog](https://github.com/NLog/NLog)
- [Serilog](https://github.com/serilog/serilog)
## Health checks
Health checks are used to monitor an application. When you are developing a system with microservice architecture, this is one of the important things to consider. ASP.NET Core provides inbuilt health check options, and if you need a UI for monitoring the health of your microservices, then check out this library [AspNetCore.Diagnostics.HealthChecks](https://github.com/Xabaril/AspNetCore.Diagnostics.HealthChecks).
## Authentication
ASP.NET Core now ships with IdenityServer4. This library provides most authentication-related functionalities. Check out this project, [JPProject.IdentityServer4.AdminUI](https://github.com/brunohbrito/JPProject.IdentityServer4.AdminUI), which demonstrates many features of identity server. Also, you can check out blog posts by [Scott Brady](https://www.scottbrady91.com/), as he writes useful, informative posts about Identity Server.
## Authorization
Authorization is important in an application. There are different types of authorization techniques:
- Role-based authorization
- Policy-based authorization
Based on your application, select the one that best suits your needs. I recommend you check out this blog post on a [better way to handle authorization in ASP.NET Core](https://www.thereformedprogrammer.net/a-better-way-to-handle-asp-net-core-authorization-six-months-on/).
## Feature management
In a SaaS application, you may have different pricing plans for products. Depending on the pricing plan, some features will be shown or hidden. Microsoft Feature Management is handy for implementing pricing plan-based features. Check out blogs by [Andrew Lock](https://andrewlock.net/introducing-the-microsoft-featuremanagement-library-adding-feature-flags-to-an-asp-net-core-app-part-1/) related to [Microsoft.FeatureManagement](https://github.com/microsoft/FeatureManagement-Dotnet).
## Security
Web applications are prone to vulnerabilities, so you must pay attention to the security of your application by adding strong authentication, authorization, encryption, and security headers. Some informative posts and resources related to security are:
- [OWASP CheatSheetSeries](https://github.com/OWASP/CheatSheetSeries/blob/master/cheatsheets/DotNet_Security_Cheat_Sheet.md)
- [Damien Bod](https://damienbod.com/2018/02/08/adding-http-headers-to-improve-security-in-an-asp-net-mvc-core-application/)
- [Karthick](https://dev.to/syncfusion/10-best-practices-to-secure-asp-net-core-mvc-web-applications-5c31)
## Validation
ASP.NET Core provides built-in attribute-based validations. But if you need a cleaner way to write validation, then do check out the [Fluent Validation](https://fluentvalidation.net/) library.
## Caching
Caching helps in improving the performance of an application and is one of the areas that needs to be considered, especially in a multitenant application. There are two types of caching:
- In-memory caching
- Distributed caching—Redis is preferred for SaaS applications
If you are using Redis for caching, then this library will help you: [StackExchange.Redis](https://github.com/StackExchange/StackExchange.Redis).
## Microservice communication
In microservices, there needs to be reliable intercommunication among APIs. There are two types of communication:
- HTTP-based
- gRPC
If you are using HTTP-based communication, then check out the [Polly](https://github.com/App-vNext/Polly) library.
## API gateway and reverse proxy
In microservice applications, you will need an API gateway to serve as a front-end for the back-end. Two popular libraries are:
- [Ocelot](https://github.com/ThreeMammals/Ocelot)
- [ProxyKit](https://github.com/proxykit/ProxyKit)
You can also use Ngnix or the Azure API gateway for this purpose.
## Documentation
There are several libraries available for documentation. Some of the top open-source libraries in this category are:
- [AspNetCore](https://github.com/domaindrivendev/Swashbuckle.AspNetCore)
- [redoc](https://github.com/Redocly/redoc)
- [docsify](https://github.com/docsifyjs/docsify)
## Scheduler
To run background jobs for your application, there are some good libraries:
- [Quartz](https://github.com/quartznet/quartznet)
- [Hangfire](https://github.com/HangfireIO/Hangfire/)
You can also build background jobs using .NET Core Worker services and host in Azure as a Web Jobs.
## Testing
Automated testing is one of the important areas to consider. There are different types of automated testing available:
- [Unit testing](https://docs.microsoft.com/en-us/aspnet/core/mvc/controllers/testing?view=aspnetcore-3.1)
- Functional testing
- [Integration testing](https://docs.microsoft.com/en-us/aspnet/core/test/integration-tests?view=aspnetcore-3.1)
In Entity Framework Core, an in-memory database was introduced that helps make testing for database logics easier without the overhead of actual database operations.
There are some good libraries available that will help you in writing unit testing:
- [moq](https://github.com/moq/moq)
- [NSubstitute](https://nsubstitute.github.io/)
- [AutoFixture](https://github.com/AutoFixture/AutoFixture)
- [fluentassertions](https://github.com/fluentassertions/fluentassertions)
**A few more useful libraries:**
- [MediatR](https://github.com/jbogard/MediatR)
- [NSwag](https://github.com/RicoSuter/NSwag)
- [AutoWrapper](https://github.com/proudmonkey/AutoWrapper)
- [NRules](https://github.com/NRules/NRules)
- [dynamic-linq-query-builder](https://github.com/castle-it/dynamic-linq-query-builder)
- [Dapper](https://github.com/StackExchange/Dapper)
## Code quality analyzers and linting
Code quality static analyzers tools help in writing code with proper standards and in maintaining quality. There are several open-source analyzers available in .NET Core. You can find the top 10 analyzers [in this article](https://medium.com/@bharatdwarkani/top-10-code-quality-static-analysers-for-asp-net-core-1660ad7a8d61). This process can be integrated in continuous integration using Cake Script.
## Front-end
Three popular front-end frameworks are Angular, React, and Vue. There is a long-running debate on which is better. In my opinion, Angular is good for building enterprise applications, even though it has a steep learning curve. Angular is a complete framework that has several functionalities built into its framework, unlike React or Vue. As I said, superiority is debatable based on your expertise and needs. You can choose any one of them and do well.
## Database
There are two popular databases available in Azure
- MS SQL—Elastic Pool
- Cosmo DB—NoSQL database
If you are going to use database-per-tenant architecture, then MS SQL Elastic Pool is a better choice. You can add up to 500 databases in one elastic pool, so it’s cost-effective. There are other storage models as well in SaaS, and which you choose depends on your application needs. A reference for other models can be found [on this Microsoft page](https://docs.microsoft.com/en-us/azure/sql-database/saas-tenancy-app-design-patterns#d-multi-tenant-app-with-database-per-tenant).
## Deployment
For deployment of an application, there are several options available. The best option is to deploy on the cloud, which allows you to scale, monitor, and load-balance your application. There are several ways to do this
- Deploy app in Azure App Service for Linux, containers, or Windows.
- Deploy app in Azure Kubernetes or Google Kubernetes.
- Deploy in VMs.
The simplest of all these is to deploy in the Azure App Service. You can find a guide on how to do that [in this article](https://medium.com/@bharatdwarkani/how-to-publish-asp-net-core-3-0-app-in-azure-linux-app-service-explained-from-scratch-6e45392ca256). Azure App Service supports scaling up to 20 instances with its Traffic Manager. If your app needs more scaling options, then Kubernetes is best.
## Azure service
There are several Azure services available for SaaS application development. Some of the most commonly used services are:
- [App Service](https://azure.microsoft.com/services/app-service): Managed hosting platform for deploying and scaling applications.
- [Azure SQL Database](https://azure.microsoft.com/services/sql-database/): Managed SQL database as a service.
- [Azure Cosmos DB](https://azure.microsoft.com/services/cosmos-db/): Globally distributed, multimodel database service for any scale. It also provides single-digit millisecond latency for read and write.
- [Azure Cache for Redis](https://azure.microsoft.com/services/cache/): Managed Redis cache.
- [Azure Functions](https://azure.microsoft.com/services/functions/): A managed service to run serverless, event-driven or trigger-based workloads.
- [Service Bus](https://azure.microsoft.com/services/service-bus/): Scalable managed service providing reliable queuing and a publish/subscribe messaging service. Useful for handling loads at scale in distributed systems.
- [Event Grid](https://azure.microsoft.com/services/event-grid/): Managed event routing service using publish/subscribe model. Useful for event-driven microservices.
- [Azure Blob Storage](https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction): For all kinds of file storage needs.
- [Logic Apps](https://azure.microsoft.com/services/logic-apps/): Out-of-the-box logic connectors for integration. Can be integrated with Event Grid or Service Bus for logical routing of messages.
- [Application Gateway](https://azure.microsoft.com/services/application-gateway/): A load balancer supporting SSL termination, cookie-based authentication, and a round-robin load balancer.
- [Azure Kubernetes Service](https://azure.microsoft.com/services/kubernetes-service/): An orchestrator for containerized applications.
- [Azure Search](https://azure.microsoft.com/services/search/): Full-text search service.
- [Azure Synapse Analytics](https://azure.microsoft.com/services/synapse-analytics/): Data warehouse to process complex queries.
- [Azure DevOps](https://azure.microsoft.com/services/devops/): A cloud service for continuous integration and deployment.
A directory of Azure Services can be found [on the Azure site](https://azure.microsoft.com/en-in/services/).
## Conclusion
I hope these tips and libraries will help you get a head start on your SaaS application. You can also check out the [Azure Application Architecture Guide](https://docs.microsoft.com/en-us/azure/architecture/guide/).
Syncfusion also provides several controls for Angular, React, Vue, and ASP.NET Core that will further ease your development of a SaaS application. For example, Syncfusion provides 70+ high-performance, lightweight, modular, and responsive [ASP.NET Core UI controls](https://www.syncfusion.com/aspnet-core-ui-controls) such as [DataGrid](https://www.syncfusion.com/aspnet-core-ui-controls/grid), [Charts](https://www.syncfusion.com/aspnet-core-ui-controls/charts), and [Scheduler](https://www.syncfusion.com/aspnet-core-ui-controls/scheduler). You can use them to improve your application development.
Please share your feedback in the comments section. You can also contact us through our [support forum](https://www.syncfusion.com/forums), [Direct-Trac](https://www.syncfusion.com/account/login), or [feedback portal](https://www.syncfusion.com/feedback). We are waiting to hear your feedback!
The post [Get a Head Start Developing Multitenant SaaS Cloud Applications Using ASP.NET Core and Microsoft Azure](https://www.syncfusion.com/blogs/post/get-a-head-start-developing-multitenant-saas-cloud-applications-using-asp-net-core-and-microsoft-azure.aspx) appeared first on [Syncfusion Blogs](https://www.syncfusion.com/blogs). | sureshmohan |
246,350 | 🥑 Get on an “information diet“ to be even more effective developer! | Introduction 2020 💥 People on the Internet create so much content every day that it's not... | 4,440 | 2020-01-22T21:52:51 | https://dev.to/koddr/get-on-an-information-diet-to-be-even-more-effective-developer-4pco | codenewbie, productivity, motivation, dx | ## Introduction
2020 💥 People on the Internet create so much content every day that it's not possible to use it even in the next 100 years...
Did you feel when you read an article and/or watched a video from your favorite social feed and your brain was getting too much, but your memory **didn’t save** any of this?
> In other words, you literally can’t even say "_what this content was about?_" and "_why did you completely «eat it» now?_".
Yes, that's first bell to "_informational obesity_". The information received didn't bring anything useful, you just spent time and filled your brain with extra ballast.
Today we will deal with it! 😎
## Diet, not a complete rejection of information!
These rules will help you separate _useful_ information from _harmful_. Before you start reading a new article or watching a video or listening a podcast, try to follow these sequence:
### 1 → Ask _stop_ questions
✅ Why I need this now?
✅ How it helps me now?
### 2 → Understand author motivation
✅ Is this content is just _Ad_ without any other motivation?
### 3 → Search for helpers
✅ TL;DR or Introduction section (text content);
✅ Time code for jump to needed section (video/audio content);
✅ Code snippets or links to repository (code content);
✅ Quick preview for all pictures (graphical content);

## What if a newbie friend asks for advice (some recent real life example)?
Quick answer is: apply rules above _not only_ for yourself, but also for the people around you and do **not** feed them _harmful_ to their brain!
> ❗️ And I tell you full example, because it's important to understand.
A few days ago, my friend asked me:
— _I want to learn HTML, CSS and JS for build my first website [...] before I start googling, maybe you give me good point where to start?_
And it's **serious** question, because this topics are very common on the Internet and have huge dose of _harmful_ information.
> Almost every second wants to talk about their knowledge and sell their courses... unfortunately, not always of good quality and revealing the topiс! 🤷♂️
Realizing this (_and because my friend is not indifferent to me_), I advised him to start from the **very beginning** — read [W3C Standards](https://www.w3.org/standards/) and do small exercises with learned material.
Next, gradually increase the sources of information:
1. Eric A. Meyer's [Grid Layout in CSS](http://shop.oreilly.com/product/0636920041696.do) book;
2. Lea Verou's [CSS Secrets](http://shop.oreilly.com/product/0636920031123.do) book;
3. Heydon Pickering's [Inclusive Components](https://inclusive-components.design) blog;
4. JS Community's [The Modern JavaScript Tutorial](https://javascript.info/);
And so on and so forth... I immediately put my friend on an _informational diet_ with _extremely delicious_ mind food! 🥑
## Final words
🎁 While you're _hungry_ — you're able to **learn** information without achieving _informational obesity_! Remember it.
## Photos by
[Title] NordWood Themes https://unsplash.com/photos/nqPe1juwcdQ
[1] Annie Spratt https://unsplash.com/photos/XMpXzzWrJ6g
<a name=""></a>
## P.S.
If you want more articles (like this) on this blog, then post a comment below and subscribe to me. Thanks! 😻
And of course, you can help me make developers' lives even better! Just connect to one of my projects as a contributor. It's easy!
My projects that need your help (and stars) 👇
- 🔥 [gowebly][gowebly_url]: A next-generation CLI tool for easily build amazing web applications with Go on the backend, using htmx & hyperscript and the most popular atomic/utility-first CSS frameworks on the frontend.
- ✨ [create-go-app][cgapp_url]: Create a new production-ready project with Go backend, frontend and deploy automation by running one CLI command.
- 🏃 [yatr][yatr_url]: Yet Another Task Runner allows you to organize and automate your routine operations that you normally do in Makefile (or else) for each project.
- 📚 [gosl][gosl_url]: The Go Snippet Library provides snippets collection for working with routine operations in your Go programs with a super user-friendly API and the most efficient performance.
- 🏄♂️ [csv2api][csv2api_url]: The parser reads the CSV file with the raw data, filters the records, identifies fields to be changed, and sends a request to update the data to the specified endpoint of your REST API.
- 🚴 [json2csv][json2csv_url]: The parser can read given folder with JSON files, filtering and qualifying input data with intent & stop words dictionaries and save results to CSV files by given chunk size.
<!-- Footer links -->
[gowebly_url]: https://github.com/gowebly
[cgapp_url]: https://github.com/create-go-app
[yatr_url]: https://github.com/koddr/yatr
[gosl_url]: https://github.com/koddr/gosl
[csv2api_url]: https://github.com/koddr/csv2api
[json2csv_url]: https://github.com/koddr/json2csv | koddr |
246,352 | Start your Teen Patti online business | A post by Ashish sharma | 0 | 2020-01-22T12:07:35 | https://dev.to/ashishs70194238/start-your-teen-patti-online-business-5ba2 | ashishs70194238 | ||
246,496 | 🖋Find synonyms in 15+ languages directly from your terminal | I created a small bash utility to quickly find synonyms in 15 different languages directly from comma... | 0 | 2020-01-22T13:31:12 | https://dev.to/smallwat3r/find-synonyms-in-15-languages-directly-from-your-terminal-326m | showdev, bash, writing, productivity | I created a small bash utility to quickly find synonyms in 15 different languages directly from command line.
I couldn't imagine how handy this would be, specially when writing READMEs or using Vim 😄!
Thought I'd share it with you here!
Repo: https://github.com/smallwat3r/synonym
| smallwat3r |
246,500 | How To Stop Automatic Updates On Ubuntu Or Debian | Ubuntu installs some updates automatically, and so does Debian 9+ with GNOME. This is due to unattend... | 0 | 2020-01-22T13:55:27 | https://dev.to/logix2/how-to-stop-automatic-updates-on-ubuntu-or-debian-2nf7 | linux, ubuntu | [Ubuntu]([https://ubuntu.com/](https://ubuntu.com/)) installs some updates automatically, and so does [Debian]([https://www.debian.org/](https://www.debian.org/)) 9+ with GNOME. This is due to unattended-upgrades being installed and enabled by default.
When enabled, unattended upgrades automatically downloads and installs some important updates, and that's ok in many cases except:
- if you need to quickly shut down or reboot the system
- when you need to install some package ASAP and you notice you can't, because an upgrade is in process
What's more, I've noticed on multiple systems that this can cause quite frequent errors like: "Could not get lock /var/lib/dpkg/lock - open (11 Resource temporarily unavailable)", which are not easy to fix, especially for new users (by the way, see [Linux Uprising Blog](https://www.linuxuprising.com/2018/07/how-to-fix-could-not-get-lock.html) for a how-to on recovering from such dpkg lock errors). Sometimes this error never goes away without user intervention (probably because some upgrade failed) which is quite bad since because of this error you're not able to install or upgrade packages until you fix it.
For this reason, I personally prefer to disable unattended upgrades, and just perform the upgrades myself when time permits it. **To stop automatic updates on Ubuntu or Debian, you have two options:**
1) **Reconfigure unattended-upgrades to stop installing updates automatically**
Use this command:
sudo dpkg-reconfigure unattended-upgrades
This will ask you if you want to automatically download and install stable updates or not. Choose No and you're done, Debian / Ubuntu should stop installing automatic updates.
2) **Remove the unattended-upgrades package**
You also have the option of removing the unattended-upgrades package. This will stop future automatic upgrades, but do note that unattended-upgrades may be pulled in as a dependency (e.g. if it's a "recommended" dependency for some other package - Ubuntu installs these [automatically](https://askubuntu.com/questions/179060/how-to-not-install-recommended-and-suggested-packages)) in the future. So while this will stop automatic upgrades, it may come back in the future.
If you want to go this route, remove unattended-upgrades using:
sudo apt remove unattended-upgrades
| logix2 |
246,513 | react native | ** BUILD FAILED ** The following build commands failed: CompileC /Users/ahmednawasrah/Deskto... | 0 | 2020-01-22T14:12:40 | https://dev.to/zaidraddad94/react-native-260f |
** BUILD FAILED **
The following build commands failed:
CompileC /Users/ahmednawasrah/Desktop/Khareta_RN_AWS-master\ 2/ios/build/Khareta/Build/Intermediates.noindex/Khareta.build/Debug-iphonesimulator/Khareta.build/Objects-normal/x86_64/AppDelegate.o /Users/ahmednawasrah/Desktop/Khareta_RN_AWS-master\ 2/ios/Khareta/AppDelegate.m normal x86_64 objective-c com.apple.compilers.llvm.clang.1_0.compiler
(1 failure)
whyyyyyyyy | zaidraddad94 | |
246,603 | Code Splitting by Routes and Components in React | When your app's bundle starts to grow it will slow things down. That's why we see a lot more use of c... | 0 | 2020-01-30T09:06:37 | https://dev.to/jakeprins/code-splitting-by-routes-and-components-in-react-525c | react, tutorial, javascript | When your app's bundle starts to grow it will slow things down. That's why we see a lot more use of code-splitting in modern web development. Code-splitting is the process of taking one large bundle containing your entire app and splitting them up into multiple smaller bundles which contain separate parts of your app. This technique allows you to load chunks of code only when needed.
For example, when a visitor enters your application on the homepage, there is no need to load in all the code related to a completely separate page. That user might not even go to that route at all, so we only want to load it when the user navigates to that page. If we can load only the code necessary for the home page this means our initial loading time will be a lot faster, especially on slow networks.
In this post, we will take a look at how we can boost the performance of our React applications by implementing code-splitting using [React Loadable](https://github.com/jamiebuilds/react-loadable). If you rather save time and start with a boilerplate that includes code-splitting, try out [React Milkshake](https://www.reactmilkshake.com/).
### Route-based splitting
A great way to get started is to implement route-based code-splitting, which means we load code chucks according to the current route.
Normally, our routes could something look like this:
import React from 'react';
import { Route, Switch } from 'react-router-dom';
import Home from 'pages/Home';
import Example from 'pages/Example';
const Routes = () => {
return (
<Switch>
<Route path='/' exact component={Home} />
<Route path='/example' component={Example} />
</Switch>
);
};
export default Routes;
Now, let's refactor these routes to implement code splitting using React Loadable. The `Loadable` higher-order component takes an object with two keys: `loader` and `loading`.
import React from 'react';
import { Route, Switch } from 'react-router-dom';
import Loadable from 'react-loadable';
const AsyncHome = Loadable({
loader: () => import('./pages/Home'),
loading: <div>Loading...</div>
});
const AsyncExample = Loadable({
loader: () =>
import('./pages/Example'),
loading: <div>Loading...</div>
});
const Routes = () => {
return (
<Switch>
<Route path='/' exact component={AsyncHome} />
<Route path='/example' component={AsyncExample} />
</Switch>
);
};
export default Routes;
With this simple setup, the code related to the `Example` component will only load when that route is active. If you open your inspector in your browser and go to your network tab (js), you can see that if you change your routes a new code chunk will be loaded.
Pro-tip. If you want to give your chunk a name instead of a generated hash, so you can clearly see which chunk just loaded, you can set the `webpackChunkName` like this:
const AsyncExample = Loadable({
loader: () =>
import(/* webpackChunkName: "Example" */ './pages/Example'),
loading: <div>Loading...</div>
});
Sometimes components load really quickly (<200ms) and the loading screen only quickly flashes on the screen. A number of user studies have proven that this causes users to perceive things taking longer than they really have. If you don't show anything, users perceive it as being faster. Thankfully, your loading component will also get a pastDelay prop which will only be true once the component has taken longer to load than a set delay. Be default, delay is set to 200ms.
To do that, let's create a `Loader` component that we can use in our sample component that will now look like this:
const AsyncExample = Loadable({
loader: () =>
import(/* webpackChunkName: "Example" */ './pages/Example'),
loading: Loader
});
And our `Loader` component:
import React from 'react';
const Loader = (props) => {
if (props.pastDelay) {
return <h2>Loading...</h2>
} else {
return null
}
}
export default Loader;
But what if something goes wrong while loading the code? Well, luckily React Loadable also provides users with an `error` prop. This means our final `Loader` component will look like this:
import React from 'react';
const Loader = ({ pastDelay, error }) => {
if (error) {
return (
<h2>Sorry, there was a problem loading the page.</h2>
);
} else if (pastDelay) {
return (
<h2>Loading...</h2>
);
} else {
return null;
}
};
export default Loader;
And that's it!
### Load on hover
Now we can even go a little further. We can also start loading the next chunk as soon as the user starts to hover over the link. To achieve this, all we have to do is call `preload()` on our Loadable component. It will look something like this:
import React, { useState } from 'react';
import { Link } from 'react-router-dom';
import { AsyncExample } from 'routes';
const SideBar = () => {
return (
<div className='sidebar'>
<Link to='/' exact={true}>Home</Link>
<Link
to='/example'
onMouseOver={() => AsyncExample.preload()}>
Example
</Link>
</div>
);
};
export default SideBar;
And that's it, awesome!
### Component-based splitting
Now that we know how to code split based on the current route, let's take it even a little further and look at how we can code split on component level. Inside your container component, you might render different components based on a certain state, like if a user is logged in or not. We can achieve this with the same Loadable component. Take a look at this example, in which a component is only rendered into the view once the user clicks on the button.
import React, { useState } from 'react';
import Loadable from 'react-loadable';
import Loader from 'components/Loader';
const SomeComponent = Loadable({
loader: () => import('components/SomeComponent'),
loading: Loading
});
const App = () => {
const [showComponent, setShowComponent] = useState(false);
return (
if (showComponent) {
return <SomeComponent />;
} else {
return (
<>
<h1>Hello! 👋</h1>
<button onClick={() => setShowComponent(true)}>Click me!</button>
</>
);
}
);
};
export default App;
Obviously, with such a simple component, it doesn’t make a difference, but with larger components in an app, it can be a good idea to implement code-splitting on component-level like this.
And with this, you should be ready to implement code splitting in your React apps! Check out the repo of [React Loadable](https://github.com/jamiebuilds/react-loadable) for more options. If you are looking for a nice boilerplate that comes with code-splitting out of the box, try out [React Milkshake](https://www.reactmilkshake.com/).
Thanks for reading! If you want to ben notified when I release new projects or articles then follow me on twitter: [@jakeprins_nl](https://twitter.com/jakeprins_nl). | jakeprins |
246,713 | Welcome Thread - v57 | Welcome to DEV! A thread of hellos and intros. | 0 | 2020-01-22T19:24:30 | https://dev.to/thepracticaldev/welcome-thread-v57-37 | welcome | ---
title: Welcome Thread - v57
published: true
description: Welcome to DEV! A thread of hellos and intros.
tags: welcome
---

### Welcome to DEV!
1. Leave a comment below to introduce yourself! You can talk about what brought you here, what you're learning, or just a fun fact about yourself.
2. Reply to someone's comment, either with a question or just a hello. 👋
**Great to have you in the community!**
| thepracticaldev |
246,753 | MySQL Schema Change Without Downtime | When altering large MySQL tables (> 200MB) it can block reads or writes for a long time. In this p... | 0 | 2020-01-22T20:12:53 | http://seymour.co.za/2019/11/13/mysql-online-schema-change/ | mysql, database | When altering large MySQL tables (> 200MB) it can block reads or writes for a long time. In this post, I'll explain how to alter a large table without any downtime.
First, let's look at how MySQL does an `ALTER TABLE`:
1. Lock the table
2. Make a copy of the table
3. Modify the copy (the "new table")
4. Copy all the rows into the new table
5. Swap the old and new tables
6. Unlock the table
How can we avoid the blocking (steps 1 & 6)? Here are some options:
* Do it at 2am on Sunday morning
* Problem: Not fun for developers, lowers developer productivity.
* Do a planned failover (aka. "rolling schema upgrade")
* Start with slaves and, once the schema change is applied to the slave, promote one of the slaves to the new master, demote the old master to a slave and execute the schema change on it.
* Problem: Can break replication for some schema changes, requires high availability infrastructure.
* Make MySQL use row versioning
* Tell MySQL this table has a new version of the schema. Then, you can still read from old row versions but when writing a new row, it writes in the new row format.
* Problem: MySQL still doesn't support row versioning.
* Handle the `ALTER` process yourself
* Manually perform the same steps the server takes (without locking).
* Problems: discussed below
The last option is my preferred so I'll go ahead and explain that. You perform the `ALTER` steps manually, with the following changes:
1. ~~Lock the table~~
2. Make a copy of the table
3. Modify the copy (the "new table")
4. Copy all the rows into the new table
1. Add triggers to keep track of changes
5. Swap the old and new tables
6. ~~Unlock the table~~
As we're not locking the table, your application can continue to read/write to the original table. It will take some time to copy rows to the new table, so we add triggers to the old table that update or insert corresponding rows in the new table.
Some notes on the above process:
* Remember to make backups before trying this
* Do multiple, smaller chunks of `INSERT..SELECT` when copying data to the new table
* Helps to avoid deadlocks
* Try make the chunks small enough so each one takes about 0.5s
* Start at the low-end of the primary key
* The triggers should only copy columns that are common between the 2 tables.
* To swap the old and new tables, we can atomically rename the old table to something else and the new table to the old table.
* Don't forget to alter the foreign keys to point to the new table
Problems with above process:
* It's a lot slower than just letting MySQL handle the `ALTER`
* The table you're altering can't have triggers already defined
I hope this post has helped if you find yourself altering some large tables. If you have any questions or corrections, you can message me [@mikeseym](https://twitter.com/mikeseym) on twitter. | seymour |
246,760 | Starting C# Backend using Razor pages | An option for creating backends is to use C# ASP.NET Core, this article shows how to get started | 0 | 2020-01-22T20:25:53 | https://dev.to/muncey/starting-c-backend-using-razor-pages-4bc8 | dotnetcore, csharp, razor | ---
title: Starting C# Backend using Razor pages
published: true
description: An option for creating backends is to use C# ASP.NET Core, this article shows how to get started
tags: dotnetcore, Csharp, razor
---
I am creating a backend for my SPA using C#, ASP.NET Core and using the dotnet CLI to generate the project as follows:
```
dotnet new webapp -o MyPortal
```
Doing this will create a new project with the following structure:
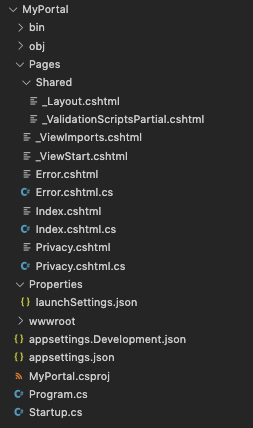
And then running `dotnet run` will run a website on your local PC that can be accessed at `https://localhost:5001`.
 | muncey |
246,771 | Simple Python Email Spammer | This is used to spam people's inboxes. It can send up to 100+! | 0 | 2020-01-22T20:46:28 | https://dev.to/c00lhawk607/simple-python-email-spammer-1bi7 | replit, python | This is used to spam people's inboxes. It can send up to 100+!
{% replit @JordanDixon1/Email %} | c00lhawk607 |
246,779 | Routing - Building an API in Python with Flask | Live stream recap notes from Twitch with Cecil Phillip and Brian Clark on January 22, 2020 | 0 | 2020-01-22T21:02:50 | https://www.clarkio.com/stream/python/2020-01-22 | python, webdev, beginners, twitch | ---
title: Routing - Building an API in Python with Flask
published: true
description: Live stream recap notes from Twitch with Cecil Phillip and Brian Clark on January 22, 2020
tags: python,webdev,beginners,twitch
cover_image: https://user-images.githubusercontent.com/6265396/72930158-54918d80-3d29-11ea-90f7-51afaa712cea.png
canonical_url: https://www.clarkio.com/stream/python/2020-01-22
---
In this session, Cecil, Brian and chat learn about routing with Flask as they build out an API in Python. They started off by getting stuck on an issue with VS Live share but work around it and learn of the different ways to set up routing.
The following are notes and details recapping a past live stream where we live code together. The idea behind these streams is that they provide real-world examples of running into problems and solving them or working towards solving them live. Enjoy this latest one on Python 🙂👍
# Wednesday - January 22, 2019
- [Twitch](https://www.twitch.tv/videos/540148313)
- [YouTube](https://youtu.be/LdJELLfzdP8)
## Things we learned
- What routes are in Flask
- How to add and use route parameters
- How to specify the route parameter types
## Next Steps
- Dive deeper into decorators
## Resources
- [How Netflix Uses Python](https://www.techrepublic.com/article/how-netflix-uses-python-streaming-giant-reveals-its-programming-language-libraries-and-frameworks/)
- [Nina Zakharenko](https://www.twitch.tv/nnjaio)
- [Project Repo](https://github.com/cecilphillip/python-flask-stream)
- [Visual Studio Online Configuration](https://docs.microsoft.com/en-us/visualstudio/online/reference/configuring?WT.mc_id=devto-blog-cxa)
- [VS Code Containers Documentation](https://github.com/microsoft/vscode-dev-containers/?WT.mc_id=devto-blog-cxa)
- [GitHub CLI Tool](https://github.com/github/hub)
- [Flask](https://palletsprojects.com/p/flask/)
- [Python Cheat Sheet](https://www.pythoncheatsheet.org/)
- [Microsoft Developer's Python for Beginners](https://www.youtube.com/watch?v=jFCNu1-Xdsw&list=PLlrxD0HtieHhS8VzuMCfQD4uJ9yne1mE6)
## VS Code Extensions Shown/Used
- [Python](https://marketplace.visualstudio.com/items?itemName=ms-python.python&WT.mc_id=devto-blog-cxa)
- [VS Live Share](https://marketplace.visualstudio.com/items?itemName=MS-vsliveshare.vsliveshare-pack&WT.mc_id=devto-blog-cxa)
- [Visual Studio Online VS Code Extension](https://marketplace.visualstudio.com/items?itemName=ms-vsonline.vsonline&WT.mc_id=devto-blog-cxa)
## Clips
Clips are a feature on Twitch that let you cut and capture segments of the live stream in the moment (up to 60 seconds). See [how to use clips on Twitch](https://help.twitch.tv/s/article/how-to-use-clips) for more details. The following are some fun moments captured from this stream:
- [Discussing HTTP Verbs and Headers](https://clips.twitch.tv/GlamorousRoughSandpiperLeeroyJenkins)
- [Routing Parameters in a Python API with Flask](https://clips.twitch.tv/LazyWiseLegOhMyDog)
- [Weird and Frustrating Bug in a VS Live Share Session](https://clips.twitch.tv/BillowingPiliableSlothHotPokket)
## Segments
> Links not working on Twitch? It's most likely because Twitch will only save my stream recordings for about 60 days. Use the YouTube link at the top of this page instead.
This table helps point out different segments of the stream (highlighted in bold) or moments we learned something (not bold). The timestamps link to the video on Twitch at that point in the recording. If you'd like the YouTube link above will have similar timestamps and link to those same points in the recording as well.
| Timestamp | Topic |
| ------------------------ | ----------- |
| [00:20:25](https://www.twitch.tv/videos/540148313?t=00h20m25s) | **Quick break** |
| [00:24:42](https://www.twitch.tv/videos/540148313?t=00h24m42s) | **Back from break** |
| [00:37:40](https://www.twitch.tv/videos/540148313?t=00h37m40s) | **Moving on from the issue we were seeing in vs code with live share.** |
| [00:38:12](https://www.twitch.tv/videos/540148313?t=00h38m12s) | **Really looking into routing and decorators now** |
| [01:32:54](https://www.twitch.tv/videos/540148313?t=01h32m54s) | **Recap and raid** |
## YouTube Video
{% youtube LdJELLfzdP8 %}
## Get connected with Cecil Phillip
- [Twitter](https://twitter.com/cecilphillip)
- [Twitch](https://twitch.tv/cecilphillip)
- [Instagram](https://instagram.com/cecilphillip)
- [GitHub](https://github.com/cecilphillip)
- [Website](https://cecilphillip.com/)
## Get connected with Brian Clark
- [Twitter](https://twitter.com/_clarkio)
- [Twitch](https://twitch.tv/clarkio)
- [Instagram](https://instagram.com/_clarkio)
- [YouTube](https://youtube.com/clarkio)
- [GitHub](https://github.com/clarkio)
- [Website](https://www.clarkio.com)
-----
Thanks for reading this article. If you're interested in finding more content from Microsoft Cloud Advocates check out this monthly curated newsletter: [Developer Community Newsletter](https://azure.microsoft.com/en-us/resources/join-the-azure-developer-community/?WT.mc_id=pythonfromscratch-devto-cxa)
| clarkio |
246,802 | I am live! 02. User log in | https://www.twitch.tv/rimproverato | 0 | 2020-01-22T21:42:23 | https://dev.to/davidkimolo/i-am-live-02-user-log-in-47l9 | python, json, tutorial, refactorit | https://www.twitch.tv/rimproverato | davidkimolo |
246,810 | 💡 How to dynamically create and access properties on JavaScript objects | Today we'll learn how to dynamically create and access properties on JS objects. There are two ways... | 3,484 | 2020-01-22T22:15:42 | https://codesnacks.net// | javascript, beginners, webdev, tutorial | Today we'll learn how to **dynamically create and access properties** on JS objects.
There are two ways to set and access properties on objects:
* the do notation
* the bracket notation
Let's see these in action:
```js
// create an empty object
const pastry = {}
// set a name property on the object using the dot notation
pastry.name = "waffle"
// set a deliciousness property on the object using the bracket notation
pastry["deliciousness"] = 11
// you can also use both notations to access properties again
console.log(pastry.deliciousness) // 11
console.log(pastry["name"]) // waffle
```
But how would we dynamically set and read these properties? Let's say we would have the name of the property in a variable?
An example could be a `get` or a `set` method in which you can pass an object and a property. The `set` would of course also take a value.
Let's see these functions:
```js
function get(obj, prop) {
// return prop on obj
}
function set(obj, prop, value) {
// set value for prop on obj
}
// create an empty object
const pastry = {};
// use set
set(pastry, "name", "waffle")
// use get
console.log(get(pastry, "name")
```
So how would it work? We can use the bracket notation to dynamically set and get properties.
```js
function get(obj, prop) {
// return prop on obj
return obj[prop]
}
function set(obj, prop, value) {
// set value for prop on obj
obj[prop] = value
}
// create an empty object
const pastry = {};
// use set
set(pastry, "name", "waffle")
// use get
console.log(get(pastry, "name")) // waffle
```
---
Want to get better at Web Development?
[🚀🚀🚀subscribe to the Tutorial Tuesday ✉️newsletter](https://codesnacks.net/subscribe/)
| benjaminmock |
246,892 | Laravel model factories with relation sharing foreign keys | Larevel users lets say you have three models User, Store and Product, and both Store and Product have... | 0 | 2020-01-23T01:19:39 | https://dev.to/luisgmoreno/laravel-model-factories-with-relation-sharing-foreign-keys-92l | laravel, testing | Larevel users lets say you have three models User, Store and Product, and both Store and Product have a user_id foreign key to the users table, your Product factory may look like this:
```php
<?php
//ProductFactory.php
/** @var \Illuminate\Database\Eloquent\Factory $factory */
use App\Product;
use Faker\Generator as Faker;
$factory->define(Product::class, function (Faker $faker) {
return [
'name' => $faker->productName,
'description' => $faker->text(),
'price' => $faker->randomNumber(4),
'sku' => $faker->uuid,
'user_id' => function() {
return factory(\App\User::class)->create()->id;
},
'store_id' => function() {
return factory(\App\Store::class)->create()->id;
}
];
});
```
And your StoreFactory like this:
```php
<?php
//StoreFactory.php
/** @var \Illuminate\Database\Eloquent\Factory $factory */
use App\Store;
use Faker\Generator as Faker;
$factory->define(Store::class, function (Faker $faker) {
return [
'name' => $faker->city,
'location' => 'SRID=4326;POINT(-74.069891 4.605246)',
'address' => $faker->address,
'user_id' => function(){
return create(\App\User::class)->id;
},
'code' => 'S' . $faker->randomNumber(5)
];
});
```
The problem is that then when generating products, the store they belong to doesn't belongs to the same user, and that makes no sense, these three models are just an example the same logic is valid for your specific database model, the solution is to access the current instance generated fields in the callback of the foreign key is:
```php
<?php
/** @var \Illuminate\Database\Eloquent\Factory $factory */
use App\Product;
use Faker\Generator as Faker;
$factory->define(Product::class, function (Faker $faker) {
return [
'name' => $faker->productName,
'description' => $faker->text(),
'price' => $faker->randomNumber(4),
'sku' => $faker->uuid,
'user_id' => function() {
return create(\App\User::class)->id;
},
'store_id' => function(array $product) {
return factory(\App\Store::class)->create(['user_id' => $product['user_id']])->id;
}
];
});
```
The callback argument `array $product` has the current instance fields, this way you can pass the dynamic generated User to the "sibling" Store model.
Hope it is useful!.
| luisgmoreno |
247,676 | I want help | Hello , I want your help about the best paper-book for learn JavaScript ! | 0 | 2020-01-24T06:06:04 | https://dev.to/iiioi95/i-want-help-3f44 | Hello ,
I want your help about the best paper-book for learn JavaScript ! | iiioi95 | |
246,899 | Watch: JavaScript apps going Inter-Planetary | Last December, I gave a talk at Node+JS Interactive in Montreal, with the title JavaScript apps going... | 0 | 2020-01-23T01:41:06 | https://withblue.ink/2020/01/21/watch-javascript-apps-going-inter-planetary.html | javascript, distributedweb, ipfs | Last December, I gave a talk at Node+JS Interactive in Montreal, with the title **_JavaScript apps going Inter-Planetary_**.
I was very excited to have the opportunity to speak for the first time at a large tech event, and I got to explain and demo something I'm very passionate about: building static web apps for the Distributed Web, and making them "production ready".
After briefly explaining **what is the Inter-Planetary File System** (IPFS) and how to interact with it, I showed how to **run a static JavaScript app** ([JAMstack](https://withblue.ink/2019/11/16/your-next-app-may-not-have-a-backend.html)) deployed through IPFS.
To make that app accessible to anyone in an easy manner, I then introduced using public **IPFS gateways** with Cloudflare, and **simpler URLs** thanks to the IPNS, or Inter-Planetary Name Service.
Lastly, I demoed how you can enable a full DevOps pipeline with **Continuous Integration and Continuous Delivery**, to automatically publish apps on the IPFS network.
📺 The full talk has been recorded and is now on YouTube:
{% youtube OY-YnkVHJcc %}
🖥 You can also find all the [slides in PDF here](https://static.sched.com/hosted_files/njsi2019/0f/JavaScript%20Apps%20Going%20Inter-Planetary.pdf).
🧑💻 The code used for the demo, as well as all the instructions to replicate it yourself, are published on GitHub at **[ItalyPaleAle/calendar-next-demo](https://github.com/ItalyPaleAle/calendar-next-demo)**.
📖 Lastly, if you're interested in reading more, check out my other articles about IPFS:
- [Distributed Web: host your website with IPFS clusters, Cloudflare, and DevOps](https://withblue.ink/2018/11/14/distributed-web-host-your-website-with-ipfs-clusters-cloudflare-and-devops.html)
- [Hugo and IPFS: how this blog works (and scales to serve 5,000% spikes instantly!)](https://withblue.ink/2019/03/20/hugo-and-ipfs-how-this-blog-works-and-scales.html)
Hope you enjoy the content, and let me know if you have any feedback! | italypaleale |
246,981 | Grover's Algorithm for NISQ Machines | https://youtu.be/L8hws23LZrk Grover's algorithm for NISQ machines (Part 1 / Sub-oracle) Update: Wat... | 0 | 2020-01-23T06:30:03 | https://dev.to/dncolomer/grover-s-algorithm-for-nisq-machines-dg6 | https://youtu.be/L8hws23LZrk
Grover's algorithm for NISQ machines (Part 1 / Sub-oracle)
Update: Watch the series grow here: https://www.youtube.com/playlist?list=PLsedzcQz4wyWYTgeTsR_JjJ_UMYyaEKKT
Original paper: https://arxiv.org/abs/2001.06575
Subdivided Phase Oracle for NISQ Search Algorithms
Takahiko Satoh, Yasuhiro Ohkura, Rodney Van Meter | dncolomer | |
247,046 | LINE API Command Line Interface | LINE API CLI helps you to work with LINE-API-related projects faster as you do not need to switch bet... | 0 | 2020-01-23T07:32:41 | https://dev.to/mick/line-api-command-line-interface-5611 | line, api, cli | LINE API CLI helps you to work with LINE-API-related projects faster as you do not need to switch between a web browser and IDE ( after your first-time setup :P ). If you already are a hardcore "Terminal/Console" fanboy that using cURL to work with LINE APIs, using this package will reduce your time typing same long API cURL commands.
### Available commands, operations, and options
#### LINE API configuration and token management
- `line`
- `init`
- `token`
- `--issue`
- `--revoke`
#### Richmenu API
- `richmenu`
- `add`
- `remove`
- `list`
- `default`
- `link`
- `unlink`
#### LIFF API v1
- `liff`
- `add`
- `remove`
- `update`
- `list`
#### LINE Things API
- `things`
- `add:trial`
- `remove:trial`
- `list:trial`
- `get:device`
- `get:devices`
- `get:product`
#### Scenario management API for automatic communication
- `things`
- `register:scenario-set`
- `remove:scenario-set`
- `get:scenario-set`
#### LINE TV API
- `linetv`
- `list:modules`
- `get:spotlight`
- `list:category`
- `get:category`
- `list:station`
- `get:station`
- `ranking`
- `search`
- `live`
## Installation
```
npm i @intocode-io/line-api-cli -g
```
<img width="414" alt="npm i @intocode-io/line-api-cli -g" src="https://user-images.githubusercontent.com/1315909/64685066-7e4fc380-d4b0-11e9-9c69-11f85fe6dd97.png">
## Project setup with `line` command
Let's start, to initialize project configuration file. Please go to your [LINE Developer Console](https://developers.line.biz/console/) and get Channel ID and Channel secret. If you do not want to issue a short-lived access token later on, you will also need a long-lived access token.
Once you have the information, run `line` command with `init` operation.
```
line init
```
This command will create `.line-api-cli.yml` configuration file containing necessary information for the CLI to handle API request/response for you.
<img width="507" alt="line init" src="https://user-images.githubusercontent.com/1315909/64685306-f28a6700-d4b0-11e9-94cc-dced718b1c9c.png">
### Issue a short-lived access token
Long-lived access token is nice and easy to use for developers but it is not as secured as a short-lived access token.
To issue a short-lived access token, run the following command.
```
line token --issue
```
It will issue a short-lived access token. You can choose whether to replace the token into `.line-api-cli.yml`
<img width="529" alt="line token --issue" src="https://user-images.githubusercontent.com/1315909/64685575-6e84af00-d4b1-11e9-8438-6614e81f3d9d.png">
Do not forget to replace a short-lived. It is recommended to write a script to replace the token monthly.
### Revoke access token
Ok, sometime you may feel insecure after exposing access token somewhere. No problem, you can revoke it with `--revoke` option.
```
line token --revoke
```
## Working with `richmenu` command
It's time to display nice UI menu to your users, or maybe some menu to some specific user(s). You can do those tasks with `richmenu` command.
### Add a rich menu
First you need to prepare a data file and an image file for rich menu. After you have those in your project directory, you can run `richmenu` command with `add` operation to add a rich menu.
```
richmenu add
```
<img width="482" alt="richmenu add" src="https://user-images.githubusercontent.com/1315909/64861793-138ebb80-d65b-11e9-8881-b8aaaf185e93.png">
### List rich menus
Rich menus can be listed with `list` operation.
```
richmenu list
```
<img width="612" alt="richmenu list" src="https://user-images.githubusercontent.com/1315909/64861824-31f4b700-d65b-11e9-8367-2c782bb8c4c4.png">
### Remove a rich menu
Get bored of old rich menu? You can remove a rich menu with `remove` operation.
```
richmenu remove
```
Then choose a rich menu to be removed.
<img width="480" alt="richmenu remove" src="https://user-images.githubusercontent.com/1315909/64874774-ef8ca380-d675-11e9-8e53-ac6e334f64b8.gif">
### Set a rich menu as default
If you'd like to set a rich menu as default for all users, run the following command.
```
richmenu default
```
### Link a rich menu to a user
Rich menu can be linked to a specific user. For example, if you want a rich menu assigned only to LINE user with Administrator role. You can get a user ID and link a rich menu for the user with this command.
```
richmenu link
```
### Unlink a rich menu from a user
Rich menu can be unlinked from a specific user using `unlink` operation.
```
richmenu unlink
```
## Working with LIFF app using `liff` command
To develop more advanced LINE Bot, LIFF app may required. You can use `liff` command to manage LIFF apps.
### Add a LIFF app
```
liff add
```
<img width="640" alt="liff add" src="https://user-images.githubusercontent.com/1315909/64910629-a3f3fb80-d742-11e9-94a7-600d5db096e2.gif">
### List LIFF apps
```
liff list
```
### Remove a LIFF app
```
liff remove
```
### Update a LIFF app
```
liff update
```
## Working with LINE Things using `things` command
### List all LINE Things trial products
```
things list:trial
```
### Add a trial product
```
things add:trial
```
### Remove a trial product
```
things remove:trial
```
### Get device information by device ID and user ID
```
things get:device
```
### Specify the product ID and user ID, and acquire the device information
```
things get:devices
```
### Specify the device ID, and acquire the product ID and PSDI
```
things get:product
```
## Scenario management API for automatic communication
### Register (create or update) a scenario set for automatic communication under a product
```
things register:scenario-set
```
### Get the scenario set registered under a product
```
things get:scenario-set
```
### Delete a scenario set registered under a product
```
things remove:scenario-set
```
## Working with LINE TV using `linetv` command
### List sportlight curation module types
```
linetv list:modules
```
To get sportlight curation module types in JSON use `--format` option.
```
linetv list:modules --format json
```
### Get sportlight data
```
linetv get:spotlight
```
To get sportlight data in JSON use `--format` option.
```
linetv get:sportlight --format json
```
### Category List
```
linetv list:category
```
To get category list in JSON use `--format` option.
```
linetv get:sportlight --format json
```
### Gets category home data
```
linetv get:category
```
To get category home data in JSON use `--format` option.
```
linetv get:category --format json
```
To get category home data start from selected page use `--page` option.
```
linetv get:station --page <number>
```
### Gets clip ranking data
```
linetv ranking
```
To get clip ranking data in JSON use `--format` option.
```
linetv ranking --format json
```
To get clip ranking data start from selected page use `--page` option.
```
linetv ranking --page <number>
```
### Gets a clip search result
```
linetv search
```
To get clip search result in JSON use `--format` option.
```
linetv search --format json
```
To get clip search result from selected page use `--page` option.
```
linetv search --page <number>
```
### Gets the station home (TV station) list.
```
linetv list:station
```
To get station home (TV station) list in JSON use `--format` option.
```
linetv list:station --format json
```
### Gets the Station Home (TV Station) data.
```
linetv get:station
```
To get TV Station data in JSON use `--format` option.
```
linetv get:station --format json
```
To get TV Station data start from selected page use `--page` option.
```
linetv get:station --page <number>
```
### Gets live schedule information.
```
linetv live
```
To get live schedule data in JSON use `--format` option.
```
linetv live --format json
```
## Comprehensive usage
We provide comprehensive usage of each command / operation / option with CLI. Simply run a command with/without operation and follow by `--help` option. For example,
```
line token --help
```
Or
```
line --help
```
<img width="680" alt="line --help" src="https://user-images.githubusercontent.com/1315909/64685826-d20edc80-d4b1-11e9-82fc-596009d85a87.png"> | mick |
247,116 | Video Snippets: [2 => Test Processes] 🎥 | Fundamental test process activities include planning and control, analysis and design, implementation... | 0 | 2020-01-23T10:01:30 | https://dev.to/calvinoea/video-snippets-2-test-processes-1c5d | testing, codenewbie, todayilearned | Fundamental test process activities include planning and control, analysis and design, implementation and execution, evaluating exit criteria and reporting, and test closure activities.
📝 <bold>Test Planning</bold>
Test planning is the first activity in the test process. The test plan is a key document, providing a record of the test planning process.
📝 <bold>Test Control</bold>
Test control is performed throughout the project. This process involves the tracking of testing activities and comparisons with the plan.
📝 <bold>Test Analysis and Design</bold>
Test analysis and design activities include the design and prioritization of high-level test cases, identification of test data and software needed for test case execution, and creation of traceability document between test basis and test cases to determine test coverage. These activities help to set up a test environment.
📝 <bold>Implementation and Execution</bold>
Test implementation activities should start before test execution. Test implementation activities help to finalize, implement and prioritize test cases, create test suits from test cases and write automated test scripts if needed.
Test execution activities include comparison of actual results with expected results, recording the outcomes of test execution, and re-testing as well as regression testing.
📝 <bold>Evaluating Exit Criteria and Reporting</bold>
In evaluating exit criteria and reporting, information on test execution may be compared with test plan, assessments of criteria may be made, and a test summary report prepared. The exit criteria determine if a test can be considered as completed.
📝 <bold>Test Closure Activities</bold>
Test closure activities involve the closure of defect reports, finalization and archiving of testware, and handover of testware to the maintenance organization.
<kbd>Source: <a href="https://www.youtube.com/watch?v=UWqhewGlHVs"> Smart Software Testing</a></kbd> | calvinoea |
247,149 | Can you improve your creativity? | Definition People are different - that's the fact. Some of us are super creative since... | 0 | 2020-01-23T11:33:34 | https://scipios.netlify.com/posts/can-you-improve-your-creativity-37pn/ | productivity | <a href="https://www.buymeacoffee.com/peacefullatom" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" style="height: 51px !important;width: 217px !important;" ></a>
# Definition
People are different - that's the fact.
Some of us are super creative since birth.
Others (falsely) believe that they are not able to be creative.
But first things first.
Let's have a look at the [definition](https://en.wikipedia.org/wiki/Creativity):
Creativity is a phenomenon whereby something new and somehow valuable is formed. The created item may be intangible (such as an idea, a scientific theory, a musical composition, or a joke) or a physical object (such as an invention, a literary work, or a painting).
# Experiment
Now ask yourself - are you able to create something new?
The answer is obvious - yes!
If you don't agree with me, then take a pen and paper (or something similar, even sand and a stick is a good option). Now draw a line.
Voila! You have created something new! And it was simple.
But you can contr argue: wasn't that too simple? what about something sophisticated? something beautiful? something highly technological?
Let's have a look at the line we have drawn recently.
Now imagine any painted masterpiece you like.
Initially, it was the line just like yours! So, anything that looks impossible for you is starting like this - from something incredibly simple!
> Big things have small beginnings
# Recipe
Now I hope that you agreed with me, and let's understand how creativity can be trained.
Here is my recipe:
- be persistent
- don't set goals, create habits
- always learn
- don't be afraid of failures
> As a side note, I want to mention that all of these points are connected. And even are parts of each other.
# Be persistent
To be persistent means for me to keep doing some activity. So, if you've tried something once and failed, it doesn't mean that you should stop.
In my case, it took about 7 years before I've created my first solo project. It was an interface for the [Set-top box](https://en.wikipedia.org/wiki/Set-top_box). It was interesting: the user had nothing but the remote control. But the users were able to see tv guides, horoscopes, weather forecasts, play games, record shows, schedule time to turn on or off the TV, check their balance, etc.
# Don't set goals, create habits
Pretty early in my life, I've discovered that it is hard to follow multiple goals. But it is very easy to create habits which will lead you to your goals.
There were times when I wanted:
- a car
- an apartment
- travel the world
- become a developer
- lead a healthy way of life
- learn to speak English
- a countryside house
- get married
- etc.
And that's only the top of the list!
By looking at that list, you can easily separate it in two categories:
- exact result (e.g., an apartment)
- vague result (e.g., become a developer)
In the case of exact results, you can say when the goal is achieved: I have documents that tell that I'm the owner now.
But what about my dream about becoming a developer?
Ok. I wrote 10 lines of code, and they are even working! Am I a developer already?
So, it is much easier to create habits:
Want to buy something expensive? Set aside 10% of your income.
Want to be a developer? Find a junior position.
Want to learn English? Practice every day for one hour.
This way, you'll keep on going to your dreams with ease.
# Always learn
You will never know what knowledge may become handy in the future. The answer is simple - always learn.
The real-life example. Steve Jobs followed a class in calligraphy. It inspired him to add beautiful typography to the first Mac.
But remember - be persistent. Dive deeper than: "I read about this topic a few years ago". To solidify your knowledge, start to use it.
# Don't be afraid of failures
The failure is your friend. And it is so: you should use your failures as a source of knowledge.
Another personal example: I've passed the exam and obtained a driver's license only from the third attempt!
Yes, I've failed two times in a row. But every time I've failed, I've returned to the driver's school and trained again. Today I am a driver with more than ten years of experience.
# Outcomes
At this point in my story, my oldest son asked: "That's cool! But how will this help me improve my creativity?".
Well, creativity is a skill as any other skill that you have.
So, to improve creativity - start to create things!
Yes, it's all that simple. And all of the above will help you in your efforts:
- be persistent in your efforts
- create habits that will lead you to your goals
- always learn new stuff: the more you know, the more freedom you have
- don't be afraid to fail, be afraid to not to try | peacefullatom |
257,564 | love coding, not the language... | So before you get me wrong let me just say, while you are working with language obviously love the la... | 0 | 2020-02-07T20:57:47 | https://dev.to/ninadmhatre/love-coding-not-the-language-29o7 | coding | So before you get me wrong let me just say, while you are working with language obviously love the language to learn it but when you are done learning and there is nothing more to learn or you have potential to learn something new, do it! don’t hesitate to learn something even if it’s not useful at that moment.
I started my career in Perl about 14 years ago in 2016. I was very new to any kind of programming and I was fascinated by the coding. I learned Perl, Shell Scripting & Linux on the job and then read the books. There is a concept of reference in Perl which I only understood after reading book but I was using it for well over 3 months.
The only problem with Perl was when I picked up it was already on a decline as a new version (Perl 6) was in making for almost 8 years then and others were moving to new languages. But I loved the language so much that I just kept on using it and refusing to learn new languages, oh, I wish what if I had picked Python back in 2008? What's done is done now.
I worked on Perl till 2011 almost the first 5 years of my career till I saw that there are no jobs in the market for Perl and it forced me to learn something new, it was C#. I love this language but I never got a chance to do a deep dive into the language as it was only specific to Windows (i did use it on Linux using Mono project - which is officially supported now). I decided I will not make the same mistake of loving a programming language and pick something which is interesting and that where Python came. I picked it because it was in demand back then and I was desperately looking for a job. Luckily after 6 months of self-study, I found 1 in 2013. I am still with Python which evolving and getting more popular day by day but I am still keeping an eye on new stuff to learn.
In 13+ years, I learned that as a developer don’t stick to one language try to pick something new and keep yourself relevant.
Keep learning, keep exploring! | ninadmhatre |
247,157 | Tic Tac Toe with TypeScript - Part 1 | Why TypeScript? If you're like me and Javascript is the only programing language you've ev... | 0 | 2020-01-23T12:13:34 | https://dev.to/bornasepic/tic-tac-toe-with-typescript-part-1-3l9a | typescript, tutorial, javascript, beginners | ##Why TypeScript?
If you're like me and Javascript is the only programing language you've ever learned you might be a bit repulsed to get into Typescript, at the end of the day your apps work just fine, why would you need to add another layer of complexity to it?
Well, the short answer is... __It makes you a better developer__.
It can also drastically reduce the number of run time bugs you encounter and make the developer experience far better and more efficient (once you get into it).
As always there is a bit of a learning curve to it, and it can really be frustrating sometimes to have your trusted IDE scream at you on every save. But it's a worthwhile tradeoff in the long run.
So without further ado, __let's convert a small app from regular Javascript into its typed superset that is Typescript__ :rocket:
------
##The setup
For our application, we'll use the Tic Tac Toe we've written in the [last article](https://dev.to/bornasepic/pure-and-simple-tic-tac-toe-with-javascript-4pgn).
If you don't have it already you can grab it from [Github here](https://github.com/BornaSepic/Tic-Tac-Toe).
First things first, we'll need to install Typescript.
You'll first want to position your terminal at the root of the project and run `npm init -y`. This will create our `package.json` file (without asking too many questions :innocent:) and allow us to install typescript via NPM.
Next up we'll run `npm i typescript` to actually install Typescript and all it needs.
I'd recommend moving our project files (`index.html, styles.css, script.js`) into a new folder, just to keep things nice and clean, I've named the folder `src` but that's totally up to you.
This is how the project should look like at this point:
You'll also want to run `tsc --init`. This will generate our `tsconfig.json` file to allow us to have more control over the TS compiler.
Before continuing you'll want to change the `// "lib": [],` line in the config file (line 7) and replace it with `"lib": ["es6", "dom", "es2017"],`. This will allow us to use some more advanced features of JavaScript in our code.
To actually get started all we need to do is change our `script.js` into `script.ts`. And run `tsc script.ts` (this will compile our TypeScript file into good old regular JavaScript).
_You've probably gotten an error compiling your `script.ts` file, but that's expected._
Please note we are still only including the `script.js` file in our `index.html`. Since _"TypeScript is a typed superset of JavaScript"_, your browser will never actually run TypeScript. So it a nutshell your users won't notice in any way whether your app is written in TypeScript or not (except for the lack of bugs, and a :smiley: on your face).
------
##Actual TypeScript
Now let's get to the fun part and write ourselves some TypeScript! We'll go through the script line by line and convert what we can to TypeScript.
To keep things nice and "short", for this article we'll just go through the initial variables and finish the app in another one.
In the previous tutorial, we've created some variables that are storing our game state. Let's first take a look at them.
```js
const statusDisplay = document.querySelector('.game--status');
let gameActive = true;
let currentPlayer = "X";
let gameState = ["", "", "", "", "", "", "", "", ""];
const winningMessage = () => `Player ${currentPlayer} has won!`;
const drawMessage = () => `Game ended in a draw!`;
const currentPlayerTurn = () => `It's ${currentPlayer}'s turn`;
```
We first have a `document.querySelector` method that returns an element with the class of 'game--status'. By doing a quick search on [MDN](https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelector) we can see that the `.querySelector` returns an Element.
So we'll add a type to our `statusDisplay` variable to let TS know it should contain and Elemenet, like this:
```js
const statusDisplay: Element = document.querySelector('.game--status');
```
You should be getting an error warning here saying `type 'Element | null' is not assignable to type 'Element'.`
When you think about it this error makes sense, we have no guarantee that the element with a class of "game--status" exists in our DOM. If this was a bigger app we might want to handle this case just to future proof our code but since it's a small application and we know that that element will always be there and we can tell TS that it will never return null by adding an exclamation point to the end, like this:
```js
const statusDisplay: Element = document.querySelector('.game--status')!;
```
Next up we have our `gameActive` variable. Since we know this will only contain a boolean value (either `true` or `false`) we can assign the type of `boolean` to our variable.
```js
let gameActive: boolean = true;
```
After that we have the `currentPlayer` variable. This technically does only contain a string, and there would be nothing wrong with just writing something like:
```js
let currentPlayer: string = "X";
```
But because we have only two distinct cases here (the variable can only be `"X"` or `"O"`, we can use a more appropriate functionality of TypeScript here called [Enum](https://www.typescriptlang.org/docs/handbook/enums.html). So the end product should look something like this:
```js
enum PlayerSigns {
X = "X",
O = "O"
}
let currentPlayer: PlayerSigns = PlayerSigns.X;
```
We have created an Enum that will hold our player signs, and assigned the value of our `currentPlayer` variable to that enum.
After that we have our `gameState` variable, where... we hold our game state (:sunglasses:).
```js
let gameState = ["", "", "", "", "", "", "", "", ""];
```
We can see that this will always be an array of strings, so we can pass that on to our comipler like this:
```js
let gameState: string[] = ["", "", "", "", "", "", "", "", ""];
```
And lastly, we have our three functions that return our game status messages:
```js
const winningMessage = () => `Player ${currentPlayer} has won!`;
const drawMessage = () => `Game ended in a draw!`;
const currentPlayerTurn = () => `It's ${currentPlayer}'s turn`;
```
Since they are all simple functions, without any inputs, that return strings we can use the same types for all of them.
```js
const winningMessage: () => string = () => `Player ${currentPlayer} has won!`;
const drawMessage: () => string = () => `Game ended in a draw!`;
const currentPlayerTurn: () => string = () => `It's ${currentPlayer}'s turn`;
```
-----
It can seem a bit annoying at times to have to write all the types yourself, but it's another one of those things that become second nature after a brief adjustment period.
Hopefully, by the end of this series, you'll be convinced on the benefits of using TypeScript for your project.
As always, thanks for reading, and until the next one :v:
| bornasepic |
247,166 | Postgresql com Backup Incremental — parte 4— Restore da base de dados | Para esta etapa, devemos ter o Postgresql instalado na máquina onde o restore será feito. Devemos co... | 4,460 | 2020-01-23T12:15:42 | https://dev.to/mayronceccon/postgresql-com-backup-incremental-parte-4-restore-da-base-de-dados-1g3 | postgres, backup, database | Para esta etapa, devemos ter o Postgresql instalado na máquina onde o restore será feito.
Devemos copiar o arquivo **base.tar.gz** criado a partir do comando pg_basebackup no servidor principal e os arquivos incrementais que estão sendo salvos na pasta **/var/lib/postgresql/pg_log_archive**.
O aconselhável é sempre fazer a transferência destes arquivos para outro lugar, se ocorrer um problema físico na máquina principal, não será possível acessar estes arquivos e o backup não terá utilidade. Podemos utilizar scp, rsync, ou qualquer outro programa para a transferência.
Devemos parar o serviço do Postgresql da máquina onde será feito o restore.
```bash
/etc/init.d/postgresql stop
```
Dentro da pasta **/var/lib/pgsql** temos a pasta **data**, esta pasta é onde encontramos os dados referentes ao Postgresql, como vamos fazer o restore do banco de outra máquina, devemos renomear a pasta data para tmp (ou qualquer outro nome)
```bash
mv /var/lib/pgsql/data /var/lib/pgsql/tmp
```
Agora vamos descompactar o arquivo de backup feito no servidor principal. Se as versões do Linux forem as mesmas, a pasta será criada diretamente dentro de /var/lib/pgsql, se atentar onde a pasta data será criada.
```bash
tar xvfP /var/lib/pgsql/base.tar.gz
```
Ao listar as pastas, você verá que foi criada novamente a pasta data, onde está é a cópia do servidor principal.
Depois desta etapa devemos remover os logs antigos da pasta pg_xlog do arquivo descompactado, para evitar problemas com dados antigos
```bash
rm -rf /var/lib/pgsql/data/pg_xlog/*.*
```
No servidor master "Principal" temos os logs que ainda não foram salvos no arquivo incremental, estes logs estão dentro da pasta pg_xlog. Se não for possível recuperar estes logs, o restore de dados será feito somente a partir do último arquivo incremental.
Se for possível acessar o servidor principal então devemos copiar os arquivos da pasta pg_xlog, para a pasta pg_xlog do servidor onde será feito o restore.
Agora devemos criar um arquivo chamado recovery.conf dentro da pasta /var/lib/pgsql/data/, neste arquivo colocaremos a linha abaixo:
```bash
restore_command = 'cp /var/lib/pgsql/pg_log_archive/%f %p'
```
Onde o caminho **/var/lib/pgsql/pg_log_archive/** são os logs incrementais que buscamos do servidor principal.
Devemos também dar permissão ao postgres executar o arquivo
```bash
chown postgres.postgres recovery.conf
```
Após estes passos devemos iniciar o Postgresql novamente, para a importação dos logs
```bash
/etc/init.d/postgresql start
```
Com isso a rotina de backup e restore incremental esta concluída. | mayronceccon |
247,206 | Mental Health Pixel - Develop confidence | I remember the beginning of my career, as a self-taught, I was struggling to feel confident about my... | 4,465 | 2020-02-01T13:10:03 | https://dev.to/valentinprgnd/mental-health-pixel-develop-confidence-9im | I remember the beginning of my career, as a self-taught, I was struggling to feel confident about my skills, I had what the community refers to as «Imposter Syndrome». Here are 4 ways I managed to change my mindset and turn this «Imposter Syndrome» to my advantage:
## 1 - Practice

We all have busy lifestyles, but practicing your skills frequently will help you build confidence, schedule some time every day, even a few minutes to practice your skills.
On that note, a lot of folks struggle to find projects or tasks to work on. What I usually do when I don’t have ideas: rebuild a product/app you like yourself, look at your favorite repositories/packages and see if there are issues to tackle or documentation to contribute to. Practice can also be «Offline», go on dev.to to read interesting articles, follow fellow developers, designers, «techies» on Twitter to see what they are up to, or even pick up a book.
## 2 - Mentor others

At the beginning of my career, I didn’t think I could help anybody, as I didn’t know enough. Turns out, there are always people behind you on their journey and could use the extra help to make progress. It is also a great way to consolidate your knowledge and realize that you know more than you think.
## 3 - Don’t overthink

I am guilty as charged when it comes to overthinking. I spent years in my early career overthinking every solution, every conversation at work, with my friends and family. I was driving me crazy. It’s only a few years back that I made the decision for myself to stop overthinking and assuming things. Assumptions were the real killer for me, I would always try to assume what people think or why people do some things. It wasn’t easy to stop, but telling myself every day that I don’t know and can’t control what other people think, but I know what I think and what I can control, so I should focus on that, helped me tremendously.
## 4 - You are not alone

Sometimes, we are so focused on our life that we forget that other people are living too and they most likely struggle with the same things as us. Helping someone with their project/task/learning, telling them they can do it, they got this will not only help them build confidence, but it will also help you.
—
You can also find these pixels on my Instagram: https://instagram.com/valentinprgnd. I will publish Pixels every Monday, Wednesday, and Friday about career development in tech, code, mental health and health for developers. Follow me for more tips @valentinprngd and check out my podcast https://rebased.whatdafox.com. | valentinprgnd | |
247,209 | My uses page with my setup, gear, software and config | Another quick one today. I was recently listening to an episode of syntax.fm where wes bos was talki... | 0 | 2020-01-25T22:45:36 | https://dev.to/solrevdev/my-uses-page-with-my-setup-gear-software-and-config-1c54 | uses, setup, config | ---
title: My uses page with my setup, gear, software and config
published: true
date: 2020-01-23 00:00:00 UTC
tags: uses,setup,config
canonical_url:
---
Another quick one today.
I was recently listening to an [episode of syntax.fm](https://syntax.fm/show/215/hasty-treat-picking-the-stack-for-uses-tech-gatsby-react-context-styled-components) where wes bos was talking about a new site [uses.tech](https://uses.tech/).

This is a site that lists /uses pages detailing developer setups, gear, software and configs.
This inspired me to create my own [/uses](https://solrevdev.com/uses/) page.
Success 🎉 | solrevdev |
247,267 | Deploy a Django app on Heroku from a GitHub repo | In this guide we are going to show you how to deploy a Django application on Heroku from a GitHub rep... | 0 | 2020-01-24T06:47:10 | https://dev.to/tsolakoua/deploy-a-django-app-on-heroku-from-a-github-repo-3fmi | django, heroku, github | In this guide we are going to show you how to deploy a Django application on Heroku from a GitHub repository step by step.
The points we are going to cover in this guide are:
* Take care of Static files
* Configure Debug mode using environmental variables
* Configure Allowed Hosts
* Create a Heroku Dyno
* Create a new app on Heroku
* Connection to GitHub repository and deployment
In order to deploy your project, we need to make a few changes in the code. For the ones who don’t have experience in deploying applications it might seem a bit complicated at first but trust me, the next times it’s going to be much smoother.
## Static Files
The hosted application has to collect and serve the static files (media, css etc.) in the browser. Make sure the *settings.py* has the following lines of code.
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
STATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles')
STATIC_URL = '/static/'
STATICFILES_DIRS = (
os.path.join(BASE_DIR, 'static'),
)
Also, Django does not support serving static files in production automatically so we install [WhiteNoise](http://whitenoise.evans.io/en/stable/index.html). Don’t forget to add it in the *requirements.txt* file after the installation is done. Let’s run the commands in our terminal!
pip install whitenoise
pip freeze > requirements.txt
And let's add it in the MIDDLEWARE components in *settings.py*,
MIDDLEWARE = ['whitenoise.middleware.WhiteNoiseMiddleware']
## Debug mode
When we run the application locally, the DEBUG mode is True, but when we run it in **production** it should be **False**. Imagine all the users being able to see the debug messages! But what if we want to use the same repo for both production and local development. How can we do that? How can the DEBUG mode take the right value depending the environment? For that case we take advantage of the environmental variables. Let’s see how we can use them.
In the *settings.py* file
import os
DEBUG = os.environ.get(‘DEBUG_VALUE’)
In Heroku’s settings we can easily configure the environmental variables, where in our case we set the **DEBUG_VALUE** to **FALSE.**

Accordingly, for our local machine we can use the wanted value for the debug mode in our operating system’s environmental variables file, like below:
export DEBUG_VALUE=”True”
## Allowed Hosts
Now we are going to configure the Allowed Hosts in the *settings.py* file. The first one is the Heroku domain and the second one is for running the application locally.
ALLOWED_HOSTS = [‘smart-flight-search.herokuapp.com’, ‘0.0.0.0’]
## Set up Dyno & Procfile
In order to execute the application we need to configure a Heroku Dyno, which is mainly an instance of a server.
Now let’s create a file called **Procfile **in the root directory of the project.
web: gunicorn -w 2 --chdir amadeus_demo_api/ amadeus_demo_api.wsgi:application --reload --timeout 900
If you want to check locally the Procfile is configured properly, you can run the above command in your terminal. Just don’t forget to install [gunicorn](https://gunicorn.org/) and add it in the requirements file.
## Create the new application
Now it’s time to move on with the actual deployment process on Heroku! After we login in Heroku web, we can click on **create new app** and we choose a unique app name also the region.
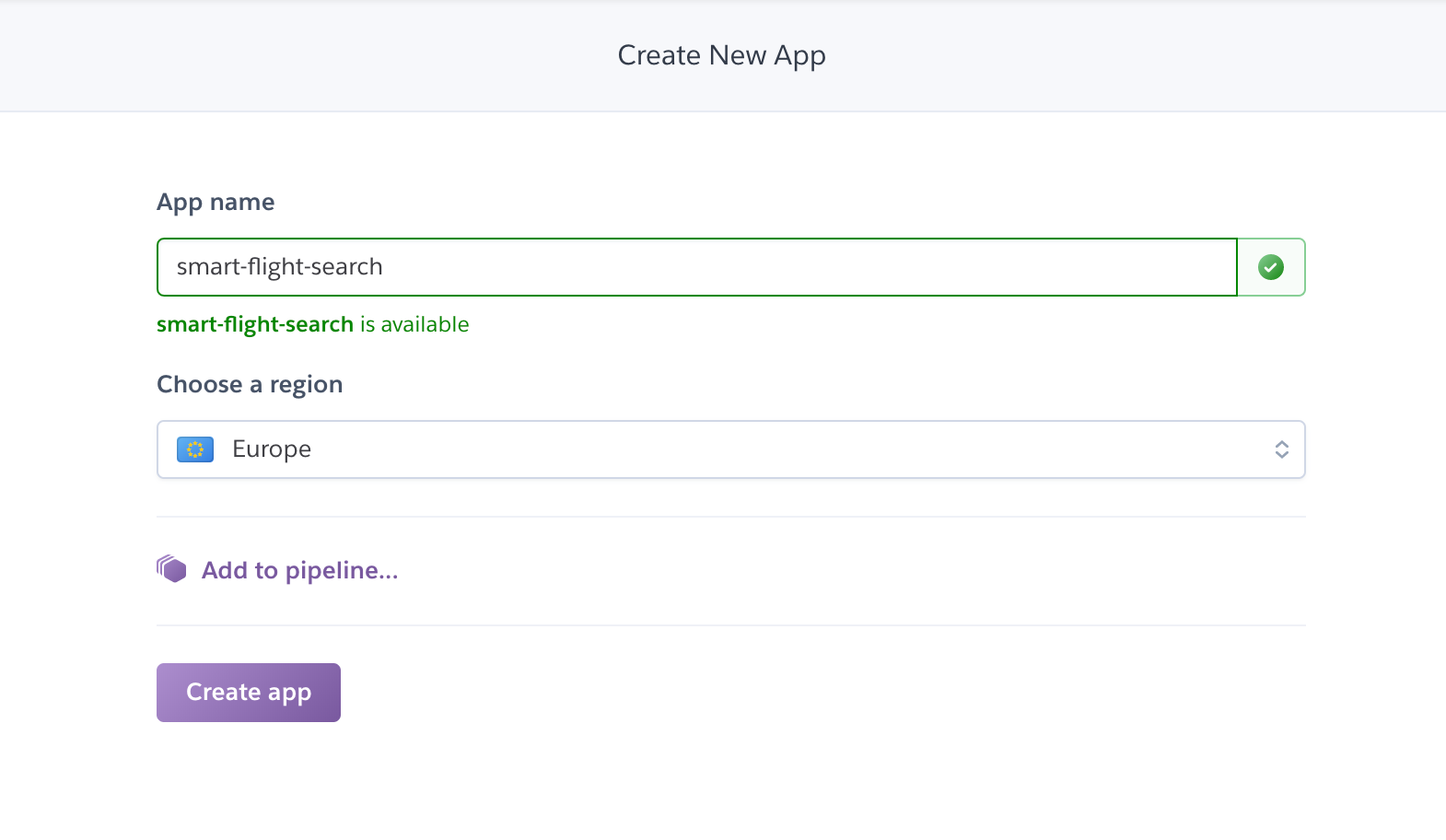*create-heroku-app*
## Connect to GitHub
When the app is created, we have to go to the **Deploy tab** and choose **GitHub** as a deployment method. Then we choose the repository with the project we want to host on Heroku.
*connect-repo*
As we can see, we have the option to choose automatic deployment or manual one. That really depends on you, but you have to make sure your branch is always in the right state in case you chose the automatic option, as it’s going to be deployed every time you push to your branch.
If we choose manual deployment we have to click on Deploy Branch and that’s it! Heroku displays the log of the deployment process until it’s done so we can see if it’s successfully executed or if there are errors.
Sometimes the application has been deployed but when we go to the page we can see there are errors. This can happen for many reasons, for example problem with the dynos, the allowed hosts etc. In order to view the errors while our server is running the best way is to install Heroku on your terminal and check the logs with the following command:
heroku logs — app APP_NAME
## Conclusion
In this guide we went through the steps we have to do in order to deploy a Django project from a GitHub repository on Heroku. We saw the changes we have to do in our code to make it work properly in production and then how we can deploy the application via the Heroku webpage.
| tsolakoua |
247,291 | Why coordinated security vulnerability disclosure policies are important | We believe that working with maintainers to create coordinated security vulnerability policies is imp... | 0 | 2020-01-23T16:20:10 | https://dev.to/tidelift/why-coordinated-security-vulnerability-disclosure-policies-are-important-3k6k | opensource, security | We believe that working with maintainers to create coordinated security vulnerability policies is important. Why? Here’s one story to illustrate.
Last year, a new [security vulnerability](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-11324) was found in the [urllib3 library](https://tidelift.com/subscription/pkg/pypi-urllib3)—a powerful HTTP client for Python. If you are using Python, then you’re probably using urllib3.
When one of the core developers of Python 3, Christian Heimes, discovered this security vulnerability, he followed the disclosure policy on the urllib3 GitHub page, which gave instructions on how to notify the maintainers via Tidelift. Tidelift works with all of our participating maintainers to set up coordinated security vulnerability disclosure policies for their projects, which helps avoid risky [zero-day security vulnerability scenarios](https://blog.tidelift.com/enough-of-zero-day-fire-drills).
Tidelift then took the following measures:
1. We worked with MITRE to coordinate the allocation of a CVE for the vulnerability. CVEs provide an industry standard way to refer to a vulnerability across vendors.
1. Next, we collaborated with the urllib3 maintainers to implement a fix and have it tested by the original reporter.
1. We alerted our subscribers about the existence of this new vulnerability.
1. In addition to the information on the security vulnerability’s existence, we also gave subscribers information on which new releases would resolve the vulnerability in their codebases.
1. We linked the release notes for users to understand any other changes present in the urllib3 update.
This process—which historically has often taken months with many open source projects—all occurred within 1 day.
If the package hadn’t had a maintainer watching over it, a scenario like this might require that your team spend time forking the library, patching it yourselves, and crossing your fingers that an official patch would be released before you descend into [dependency hell](https://blog.tidelift.com/dependency-hell-is-inevitable).
This is where Tidelift helps. Tidelift ensures that there are maintainers standing behind covered packages who have the financial incentives to fix problems quickly once they are discovered.
In the case of urllib3, all of this was handled before our customers even knew there was an issue. This same scenario has been repeated a number of times since we launched our security vulnerability disclosure process in December 2018.
"Tidelift has made the process of offering a comprehensive vulnerability disclosure process simple for the urllib3 team,” said co-maintainer of urllib3, [Seth Larson](https://github.com/sethmlarson?tab=overview&from=2017-12-01&to=2017-12-31&org=urllib3). “This makes delivering secure code and responding quickly to vulnerabilities easy even for a small team." | katzj |
247,297 | Desktop Apps with Avalonia and FSharp | I'm a pretty much the average person on different languages Javascript, C#, Python, Java some Scala a... | 4,761 | 2020-01-23T16:57:24 | https://dev.to/tunaxor/desktop-apps-with-avalonia-and-fsharp-4n21 | dotnet, avalonia, fsharp, fsharpcandothat | I'm a pretty much the average person on different languages Javascript, C#, Python, Java some Scala and some F#
I mostly work with Javascript and if you're like me perhaps you have tried to do some .net but didn't find C#/XAML that much interested in the mid-run.
Perhaps you tried F# liked it but didn't find a reason to use it that much because you are already using another back-end stack.
Well this time I tried out doing Cross-Platform Desktop Apps with F# let's see how it turns out
### MVU Architecture
The MVU architecture also known as the Elm architecture is rather a simple one and born in the browser (as far as I know),
every time I see a language showing the MVU architecture is always the same counter sample
I did try many many many times to grasp this concept and use it but I failed several times and I want to believe the reason many of us that don't get it at first glance is due to having to deal with browser only things:
- Promises
- HTML5 Routing
- DOM Elements
- Javascript Interoperability
So, your usual counter app works nice but once you need to deal with these other things it can get messy real quick if you're not used to the architecture yet.
## Enter Avalonia and Avalonia.FuncUI
{% github AngelMunoz/AvaFunc %}
This is a small project which aims to test some aspects of Avalonia and Avalonia.FuncUI
In particular the following
1. "***MultiPage***" apps
2. Reusability
3. Crossplatform Electron Replacement
## 1. "***MultiPage***" Apps
First of all, we're in the desktop ***Pages*** don't really exist so you have multiple modules that look almost the same as your usual counter sample let's see one
```fsharp
namespace AvaFunc
module Shell =
type State =
{ (* ... *) }
let init =
{ (* ... *) }
type Msg =
// omitted code
let update (msg: Msg) (state: State) =
// omitted code
let view (state: State) dispatch =
// omitted code
```
Every time you need to create a different ***Page*** you can create a different file that includes these same elements:
- State (also known as Model)
- init
- Msg
- update
- view
let's add some code to have a "*routing*" like thing here
```fsharp
namespace AvaFunc
open Avalonia.Controls
open Avalonia.Layout
open Avalonia.Media
open Avalonia.FuncUI.DSL
module Shell =
type Page =
| Home
| About
type State =
{ currentPage: Page }
let init =
{ currentPage = Page.Home }
type Msg =
| NavigateTo of Page
let update (msg: Msg) (state: State) =
match msg with
| NavigateTo page ->
{ state with currentPage = page }
let viewMenu state dispatch =
Menu.create [
Menu.viewItems [
MenuItem.create [
MenuItem.onClick (fun _ -> dispatch (NavigateTo Home))
MenuItem.header "Home"
]
MenuItem.create [
MenuItem.onClick (fun _ -> dispatch (NavigateTo About))
MenuItem.header "About"
]
]
let view (state: State) dispatch =
DockPanel.create [
DockPanel.children [
yield viewMenu state dispatch
match state.currentPage with
| Home ->
yield TextBox.create [ TextBox.dock Dock.Bottom TextBox.text "Hello Home" ]
| About ->
yield TextBox.create [ TextBox.dock Dock.Bottom TextBox.text "Hello About" ]
]
]
```
Quite a length right? let's go piece by piece, First, declare your page types
and save it in your state
```fsharp
type Page =
| Home
| About
type State =
{ currentPage: Page }
let init =
{ currentPage = Page.Home }
```
then, declare your "***events***" and what will you do when they get called
here we have a single "***event***" which is `NavigateTo of Page`
the reason I call it "***event***" is because it is not an event like any other js event, in reality, it's just named (message) that identifies an action in kind of this way
>hey! this action has been performed what are you going to do about it?
```fsharp
type Msg =
| NavigateTo of Page
let update (msg: Msg) (state: State) =
match msg with
| NavigateTo page ->
{ state with currentPage = page }
```
in response to the NavigateTo and the page it brings with it, we simply update the state and set the actual page.
Now the most verbose part of it, the one that concerns to the views (the actual UI stuff)
```fsharp
let viewMenu state dispatch =
// omited code
let view (state: State) dispatch =
DockPanel.create [
DockPanel.children [
yield viewMenu state dispatch
match state.currentPage with
| Home ->
yield TextBox.create [ TextBox.dock Dock.Bottom TextBox.text "Hello Home" ]
| About ->
yield TextBox.create [ TextBox.dock Dock.Bottom TextBox.text "Hello About" ]
]
]
```
This view is as simple as you are guessing it, it has a dock panel that has two children a Menu and a TextBox. The first child is a `viewMenu` function creates a Menu control for us and puts it where we want it (spoilers, you can put these functions somewhere else and make then shareable) the second child is a TextBox control, but depending on which page we are, it will be a different TextBox
- Home for the "Hello Home"
- About for the "Hello About"
You can use that to render/call a complete module, that means... Yes multiple pages being rendered! It could look something like this
```fsharp
let view state dispatch =
DockPanel.create [
DockPanel.children [
match state.CurrentView with
| Home -> yield HomeModule.view state.homeState (HomeMsg >> dispatch)
| About -> yield AboutModule.view state.aboutState (AboutMsg >> dispatch)
]
]
```
Whereas you guessed it, HomeModule has the same structure
```fsharp
namespace AvaFunc
module HomeModule =
type State =
{ (* ... *) }
let init =
{ (* ... *) }
type Msg =
// omitted code
let update (msg: Msg) (state: State) =
// omitted code
let view (state: State) dispatch =
// omitted code
```
and the same applies to the About module.
At this point, I should mention to you that there's a [TabControl](https://github.com/AvaloniaCommunity/Avalonia.FuncUI/blob/master/src/Avalonia.FuncUI.ControlCatalog/Views/MainView.fs), Control in Avalonia which actually can be used to navigate your whole application instead of something DIY.
That didn't stop me though since I didn't know this and went DIY we're also trying to learn after all. That's why I said I'm the most average guy you'll ever see so even your most average teammates can archive fairly complex stuff with surprisingly fewer bugs than expected (Even I was surprised)
## 2. Re-usability
I'm not an expert in MVU so perhaps there's a way to do it better but you should be able to some of your view
functions, you can take a look at this [module](https://github.com/AngelMunoz/AvaFunc/blob/d4e706b671c398ce5387d7959a00628b800bbbe3/AvaFunc.App/SharedViews.fs) and see it's being used [here](https://github.com/AngelMunoz/AvaFunc/blob/master/AvaFunc.App/QuickNotes.fs#L203) and [here](https://github.com/AngelMunoz/AvaFunc/blob/master/AvaFunc.App/QuickNoteDetail.fs#L101) so... if the most average guy could find a way to
share some code, there could be a better way to do it and it most certainly will fit the architecture
## 3. Cross-platform Electron Replacement
This is a very important point for me, when I want to do things for myself I don't want to have a lot of
resources being consumed by a note-taking app, I used to do my personal stuff with Javascript + UWP
I have a couple of posts on that but... sometimes it seems Microsoft is looking over your happiness because decided to remove Javascript + UWP in VS2019.
Back to square 0... Avalonia does run in Linux/MacOS/Windows thanks to .net core
and thanks to the [Avalonia.FuncUI](https://github.com/AvaloniaCommunity/Avalonia.FuncUI) project I can use F#
in a simple way that feels really good, I've always wanted todo desktop software with F# but I felt that you always had to do
some workaround or magic stuff to get into the official .net Microsoft GUI solutions like WPF which were still Windows only.
With Avalonia and Avalonia.FuncUI this is not the case you are writing F#, you can add F#/C# .netstandard Libraries
and all are at the reach of two simple commands
```
dotnet new --install JaggerJo.Avalonia.FuncUI.Templates
dotnet new funcUI.full -o MyCrossPlatformApp
```
I see myself writing more F# from now on, in some sense F# is pretty similar to Javascript so if you like things like
React or Functional Programming in Javascript, you will feel at home using F#.
Avalonia itself is an interesting project, it's not handled by Microsoft it's just something that was born from the community for the community.
Now if you head to the Avalonia [Website](https://avaloniaui.net/) and then head to the docs you'll see it's pretty empty
that might get you to consider if this is actually usable, and here's the [official word](https://avaloniaui.net/blog/#production-ready) of that
there are still a couple of things missing out there like tray menu for windows, some fancy controls but
I think you can start working on some really cool stuff here it's powered by .net core so anything that is a .net standard library should be at your fingertips
### Bonus: Styling
You can do styling in somewhat a css like style take the following example
```xml
<Styles
xmlns="https://github.com/avaloniaui"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml">
<Style Selector=".detailbtn /template/ ContentPresenter">
<Setter Property="Background" Value="#1da1db"/>
<Setter Property="BorderBrush" Value="#a4d9f0"/>
<Setter Property="Height" Value="28"/>
</Style>
<Style Selector=".detailbtn:pointerover /template/ ContentPresenter">
<Setter Property="Background" Value="#116083"/>
</Style>
<Style Selector=".tobottom /template/ ContentPresenter">
<Setter Property="VerticalAlignment" Value="Bottom"/>
</Style>
</Styles>
```
those styles are applied to the following button (using the classes)
```fsharp
Button.create
[ Button.row 2
Button.column 0
Button.content "📃"
Button.classes [ "detailbtn"; "tobottom" ]
Button.onClick (fun _ -> dispatch (NavigateToNote note)) ]
```
So if you have better skills at UI design than I (most certainly you have)
I bet you will be able to do pretty nice stuff.
## Closing Thoughts
Avalonia + F# is A-W-E-S-O-M-E
when I saw the project I just went into and do random stuff trying to see if it would work, then I tried stuff that I'm used to in web applications, create a list of items then click on it and see the details of it, navigation between pages, CRUD like operations and it might not seem like a "Big App" but I tested basic concepts that I've used to build "Big Apps" at work, there's also input validation in the project, I just check for the title being `length > 3` but if you can do that, then you can do the wildest validation you need.
Some projects when you test these things, they just don't feel right or feel clunky, I don't feel that this time.
I can't want to see what people write with this :)
Please feel free to share your thoughts below | tunaxor |
247,301 | January 2020 Orchid Newsletter: Gaining Traction | It's so incredible to see this project grow from a tiny seedling to the maturing sprout it is now. Es... | 3,357 | 2020-01-23T16:08:40 | https://orchid.run/news/2020/1/23/gaining-traction | showdev, orchid, jamstack, webdev |
<p>It's so incredible to see this project grow from a tiny seedling to the maturing sprout it is now. Especially since the
0.18.0 release, I've seen more people try out Orchid and adopt it for their documentation sites, and I'm so incredibly
grateful for each and every download. But this is only the beginning, Orchid still has lots of growing-up to do, so why
don't you come along for the ride and help shape the future of Orchid!</p>
<p>This is the official Orchid newsletter, the newest and best documentation site generator. There is a growing need to
keep the community up-to-date on all the happenings around Orchid, and here I will share Orchid's progress, milestones,
and future plans! Follow along with this series to stay on top of Orchid's newest features, track adoption on Github,
and see who's using Orchid!</p>
<h2 id="on-github"><a href="#on-github" id="on-github" class="anchor"></a>On Github</h2>
<p>Orchid has been growing so much since December's 0.18.0 release! Its now at 313 stars and version 0.18.2, with more
downloads, new sites, and issues created than ever before! And it's all thanks to this wonderful community of
individuals believing in a better way to do documentation, so thank you all!</p>
<p>The holidays were fairly quiet in terms of new releases and contributions, but <a href="https://github.com/tomb50">Tom Beadman</a>
helped immensely with improving the asciidoctor integration. A small PR with huge impact for improving the
quality-of-life for Asciidoctor fans, which now includes support for <code>include::[]</code> macros!</p>
<p>I also merged work <a href="https://github.com/DanySK">Danilo Pianini</a> had done for improving the YouTube tag to support
aspect-ratios instead of fixed sized.</p>
<h2 id="whats-new"><a href="#whats-new" id="whats-new" class="anchor"></a>What's New?</h2>
<p>Now that 0.18.0 is released, I've been able to work on some smaller features I've been wanting to support for a while. I
had to restrain myself from working on them for 0.18.0 to prevent feature-creep, but it's been nice finally getting to
add the following features:</p>
<ul>
<li>The <a href="https://orchid.run/plugins/orchidbible">OrchidBible</a> plugin has been broken for some time, as the APIs driving it had been decommissioned.
I have removed the previously-broken <code>bible()</code> function, which pre-rendered Bible verses, and replaced it with a new
<a href="https://faithlife.com/products/reftagger">Faithlife Reftagger</a> meta-component, which will automatically create
popups for all Bible verses it finds on the page!</li>
<li>Support for <a href="https://mermaid-js.github.io/mermaid">Mermaid JS</a> markup has been added to the
<a href="https://orchid.run/plugins/orchiddiagrams">OrchidDiagrams</a> plugin. As Mermaid is a javascript library, support is added through a meta-component
instead of using pre-rendered markup like PlantUML.</li>
<li>The <code>youtube</code> template tag in <a href="https://orchid.run/plugins/orchidwritersblocks">OrchidWritersBlocks</a> can now display videos of a given aspect-ratio,
making them better-suited for responsive designs.</li>
<li><a href="https://orchid.run/plugins/orchidchangelog">OrchidChangelog</a> now supports single-file changelogs, such as the
<a href="https://keepachangelog.com/en/1.0.0/">Keep A Changelog format</a> format.</li>
</ul>
<h1 id="in-progress"><a href="#in-progress" id="in-progress" class="anchor"></a>In Progress</h1>
<p>Supporting include macros for Asciidoctor was a huge step forward, but there's still work to be done to improve that
integration, and you can expect more Asciidoctor improvements in the coming weeks, with <code>image::[]</code> being the next
target.</p>
<p>In addition to a few more quality-of-life improvements planned for the near-future, I've begun work on a new
<code>OrchidSnippets</code> plugin! More details will come in a future post, but I'd love to get your feedback and suggestions for
its implementation and usage in <a href="https://github.com/orchidhq/Orchid/issues/293">this issue</a> on GitHub!</p>
<hr>
<p>Are you interested in getting started with Orchid? There simply is no better way to manage all the documentation for
your project, and I'd love to help you get set up!</p>
<p>If you have an open-source project that needs docs, are building a new portfolio, or are building any other kind of
static site, I want to work with you to get you set up with Orchid! Comment on this post, send me a PM here on Dev.to,
reach out on <a href="https://gitter.im/JavaEden/Orchid">Gitter</a>, or <a href="https://www.caseyjbrooks.com/contact/">contact me here</a>
and I will be with you every step of the way.</p>
<p>And as always, let me know if you start using Orchid so I can feature you in the next update!</p>
| cjbrooks12 |
247,317 | How to install mysql workbench in debian buster? | How to install mysql workbench in deb... | 0 | 2020-01-23T16:31:21 | https://dev.to/kss682/how-to-install-mysql-workbench-in-debian-buster-31b5 | {% stackoverflow 59882548 %}
| kss682 | |
247,372 | What the hell is property pattern matching? | I'vealready made some posts about pattern matching, with the last one about positional pattern match... | 4,347 | 2020-02-10T11:08:58 | https://dev.to/alexdhaenens/what-the-hell-is-property-pattern-matching-2008 | csharp, dotnet | I'vealready made some posts about pattern matching, with the last one about [positional pattern matching](https://dev.to/alexdhaenens/what-the-hell-is-positional-pattern-matching-9dn-temp-slug-8210505). Pattern matching made it possible to do a type check, cast to that checked type into a variable and then deconstruct its properties into variables:
```c#
if (person is Elf(int age, string elfishName))
{
Console.WriteLine($"Elf with elfish name{elfishName} is {age} years old");
}
```
And it made it also possible to do a value check while deconstructing:
```c#
if (person is Elf(110, string elfishName))
{
Console.WriteLine($"Elf with elfish name{elfishName} is 110 years old");
}
```
One of the drawbacks of this technique is that a deconstructor is needed (more about that in my blogpost about [object deconstructing](https://dev.to/alexdhaenens/what-the-hell-is-object-deconstructing-kj0)). Luckely for us, __C# 8.0__ provides us with property pattern matching!
#What is it?
Well property pattern matching does the __same as positional pattern matching__ but __without the need of a _Deconstructor___ . The code above, which checks if the _person_ is an _Elf_ then deconstructs it and checks if his/her _age_ is 110, looks like this with property pattern matching:
```c#
if (person is Elf{ Age: 110, ElfishName: var elfishName })
{
Console.WriteLine($"Elf with elfish name{elfishName} is 110 years old");
}
```
As you can see, the syntax is quite similar to its counterpart. The downside however, is that it is more (computationally) expensive.
#Sources
https://docs.microsoft.com/en-us/dotnet/csharp/deconstruct
Demo project: https://bitbucket.org/aldhaenens/p-d-demo/src/master/ | alexdhaenens |
247,384 | CSS COURSES | Can someone suggest best courses from which I could learn css. | 0 | 2020-01-23T18:39:26 | https://dev.to/jmjjeena/css-courses-3c0d | css, styledcomponents, react, javascript | Can someone suggest best courses from which I could learn css. | jmjjeena |
247,401 | JavaScript Promises vs. RxJS Observables | Compare JavaScript Promises and RxJS Observables to find the one that meets your needs. | 0 | 2020-01-23T19:34:11 | https://auth0.com/blog/javascript-promises-vs-rxjs-observables/ | javascript, rxjs, programming | ---
title: JavaScript Promises vs. RxJS Observables
published: true
description: Compare JavaScript Promises and RxJS Observables to find the one that meets your needs.
tags: #javascript #rxjs #programming
canonical_url: https://auth0.com/blog/javascript-promises-vs-rxjs-observables/
---
TL;DR: Have you ever thought to yourself, which should I use, JavaScript Promises or RxJS Observables? In this article, we are going to go over some pros and cons of each one. We'll see which one might be better for a project. Remember, this is a constant debate, and there are so many different points to cover. I will be covering only five points in this article. [Read on 🚀](https://auth0.com/blog/javascript-promises-vs-rxjs-observables/?utm_source=dev&utm_medium=sc&utm_campaign=jspromises_rxjsobservables) | bachiauth0 |
247,409 | Fractional Knapsack Problem With Solution | What is Greedy Method Before discussing the Fractional Knapsack, we talk a bit about the Greedy Algor... | 0 | 2020-01-23T19:54:57 | https://dev.to/techmahedy/fractional-knapsack-problem-with-solution-3oek | greedymethod, algorithms | What is Greedy Method
Before discussing the Fractional Knapsack, we talk a bit about the Greedy Algorithm. Here is our main question is when we can solve a problem with Greedy Method? Each problem has some common characteristic, as like the greedy method has too. Such as if a problem contains those following characteristic , then we can solve this problem using greedy algorithm. Such as
https://www.codechief.org/article/fractional-knapsack-problem-with-solution | techmahedy |
247,428 | This.JavaScript- State of Frameworks and Libraries-Node Update | Hosted by This.JavaScript, an online event where developers learn about the latest news in... | 0 | 2021-08-03T13:54:43 | https://www.thisdot.co/thisjavascript-state-of-frameworks-and-libraries-node-update | ---
title: This.JavaScript- State of Frameworks and Libraries-Node Update
published: true
date: 2019-10-28 21:02:05 UTC
tags:
canonical_url: https://www.thisdot.co/thisjavascript-state-of-frameworks-and-libraries-node-update
---
Hosted by This.JavaScript, an online event where developers learn about the latest news in JavaScript, State of Frameworks and Libraries covered all the breaking news in the world of frameworks.On Feb. 19, State of Frameworks speakers, including many of the best and brightest from the development world, gave us updates on all things frameworks.[Michael Dawson, a Node.js Technical Steering Committee co-chair,](https://twitter.com/mhdawson1) Node collaborator, and Community Committee member who works with a number of working groups on Node and on teams in IBM as well, shared his thoughts on what’s coming up at Node.js.## Michael Dawson — TSC Co-Chair, Node.JS — @mhdawson1## Upcoming releasesNode.js follows a regular release cadence meaning there will be some major transitions in April 2019. These will include the following changes.### Node 6.X6.X is going EOL in April. If you’re not already moved over to 6.X, make sure to do so immediately.### Active LTS releasesNode 8.X, an active LTS release, has been in service for a while. We had to shift from the active to maintenance phase in order to line up with the end of life of OpenSSL 1.0.2. This means changes pulled into 8.x will now focus on only critical fixes and security fixes.Node 10.X features significant performance improvements and a new version of npm. It also boasts new features like http/2.Meanwhile, Node 12.X, will release in April, then transition to the next LTS in October.Finally, the current release is Node 11.X. It has a newer version of V8 and also has workers without a flag, still in its experimental phase. 11.X also features report functionality to help with diagnostic processes.## Key new features in 10.XNode 10.X has a number of notable new features that improve performance and user experience.Node 10.X includes N-API, which greatly simplifies and streamlines Node development and deployment. This is a standard API that you can use to build native add-ons. This will be available in all the LTS releases and is already stable in both 8.X and 10.X. In April, it will be stable in all the releases.Node 10.X also features http/2, which allows for request/response multiplexing, efficient compression, and server push.Additionally, 10.X has open SSL 1.1.0, while open SSL 1.1.1 has opened in master. TLS 1.3 introduces some wrinkles, however, so it’s not guaranteed. Developers are still working on it in hopes that they can smooth out those issues in the future.## Features in progressSome of the features currently in progress for Node include Workers, which is experimental in Core.Node Report is a diagnostic feature that used to be available as a native module, but posed a number of challenges in that it required compilers. To solve this issue, it has been integrated into the core of Node.js..ES6 Modules are also being continuously developed. Node engineers want to provide an implementation that balances keeping implementations and existing users happy while providing something as ES6-compatible as possible.Core promises APIs are still in the experimentation phase. A few APIs return promises, but developers are still looking at what these might look like in the future and how they can be best implemented.Finally, async hooks are also in the works for Node. These are diagnostic features you can use to keep track of what’s going on asynchronously, and they’re also still in the experimental phase.## More on WorkersNode’s Workers are based on Web Workers, though the differences between them aren’t yet called out in the documentation but we are working on thatNo flag is yet needed in 11.7 or later for Workers, but it’s still experimental. But this is more of a reflection that the API hasn’t changed much for a while.In Workers, each thread is a separate JS execution environment. You can exchange data between those environments through messaging. You’ll get object cloning by default. You can also do handoff, where the object is transferred from a main thread to, for example, a Worker thread. In those cases you can only access the object from one thread or the other, but not both at the same time.Memory sharing, in which you pass SharedArrayBuffers and manage concurrency through Atomics, is also now possible.Despite the usefulness of this feature, there are a few limitations. You can’t transfer handles yet, for example. And there’s still overhead to starting Worker threads, so re-use and pooling are still recommended at this time.## ReportNode developers have been working tirelessly to improve the diagnostic process. A diagnostic Report feature, still in experimental form, is now integrated into Node Core.This report will give you important information about your environment. It’s in a lightweight, easy-to-read format and serves as a great first step in your diagnostic process.Look for more developments on Report in upcoming releases of Node.## Other initiativesNode isn’t all about features. The community is also actively working to improve many other aspects of the user experience and to troubleshoot problems.For example, many Node modules are heavily depended on. But module maintainers may have moved on from the project or may not have time to maintain them. Sometimes there’s a mismatch between consumer demand and maintainers’ available time. The community is trying to come up with ways to solve this problem through Package Maintenance initiatives and groups.Many other community groups, meetups, committees, and projects focus on deepening the Node safety net, growing involvement, and supporting end users through greater convenience and strong decision-making. Security, automation, and management are the name of the game when it comes to Node’s bright future.## Node.js Foundation and JS Foundation collaborationIn October, there was an initiative to bring the JS Foundation and the Node.js Foundation together. The Node.js Bootstrap Committee has been working on the documentation to make this a reality. If you have an interest in the combined foundation, read to find out more [here!](https://venturebeat.com/2019/03/12/node-js-and-js-foundations-are-merging-to-form-openjs/) This announcement of the merger [was made just recently](https://js.foundation/announcements/2019/03/12/introducing-the-openjs-foundation).\*Need JavaScript consulting, mentoring, or training help? Check out our list of services at [This Dot Labs](thisdot.co).\* | thisdotmedia_staff | |
247,486 | Learning to code after 40: my first 100 days | 100 days. It only takes 21 to make a habit (depending on who you ask). You can't do something for 100... | 0 | 2020-01-24T06:36:18 | https://dev.to/andevr/learning-to-code-after-40-my-first-100-days-1g07 | 100daysofcode, codenewbie, beginners | 100 days. It only takes 21 to make a habit (depending on who you ask). You can't do something for 100 days without learning something about yourself. Whether it's something as simple as "hey, I can stick with something" to "I can write an algorithm that calculates the square root of a chimp in motion" or some other big thing.
It really doesn't matter what you learn, as long as you do. So what did I learn in the last 100 days? Well first, some stats:
Hours programmed: I have no idea. (Great stat huh?)It was well over 100 hours. If I had to guess, it was over 200. Some days I managed to get in 3 or 4 hours, but I'm not sure of the exact total. At the very least, it was an hour a day average.
Days missed: 3. I'm counting 3 days missed, because there a couple days where programming was insanely difficult, and I barely got anything done. It's normal, by the way, to miss days sometimes. Just try not to make a habit of it.
Exercises written: 33
All written in Java for the course Tim Buchalka's Java Masterclass for Developers. Aimed at new people, it's the most comprehensive course out of the 28 I've purchased. While it isn't perfect, it has a ton of real coding exercises where he gives a problem and you have to solve it. Some of them took me as long as two weeks. The point behind them is to learn how to code on your own. By the way, I'm still not done with it. It's that big.
<b>Stuff I Learned</b>
I struggled for the first half of the challenge trying to learn JavaScript. That was partly due to my expectation of how courses are supposed to work, and how I learn.
Once I realized I need repetition, it really changed things for me.
Once I started the Java course, and started doing the exercises, it was like night and day. I was writing code on my own, with out watching someone else do it on video. I was solving problems.
I'm not going to say there werent any hiccups. But I'd made up my mind to write the challenges without googling solutions. That forced me to take each problem and break them into really small pieces and then write each tiny piece instead of looking at the whole.
I learned not to put pressure on myself to complete the goal of getting that developer job. My job is out there waiting; I know that already. I learned to focus just on the tiny step I make every day in the general direction.
I learned to let the IDE do its thing. After all the writing code out, using shortcuts like Sout (System.out.println() which is a damn mouthful to type) is a life saver. There's a ton of other things it does, such as letting you know if you've written something wrong before you ever compile.
With Java, an IDE is your best friend. It even taught me stuff while coding my exercises, such as offering ways of refactoring. Not that I always used the suggestions. But they were nice to have. Using an IDE almost feels like having someone more experienced offering help along the way.
<b>What's Next?</b>
I've always been interested in learning Android. Towards the end of my challenge, I went home for two weeks and decided to take a break from Java challenges and do something fun. I picked up some books from Packt, one of them was an android book. The last week or so I've been going through it.
The next 100 days I'm probably going to be working on learning android development. I've got some ideas for some games/apps, and after looking through all the options for a Java programmer, it's one of the few things that light my fire. I'll continue to learn Java, and probably mix in Kotlin since they are so closely entwined, especially in android development. Kotlin for the most part writes pretty close to Java, so it's not really a stretch to pick up.
I'm really excited about my next 100 days, and about what the future holds. | andevr |
247,657 | In the beginning there was a primordial soup | I've had a fascination with living things for as long as I can remember. And for a somewhat shorter p... | 5,694 | 2020-03-31T20:54:48 | https://dev.to/palm86/in-the-beginning-there-was-a-primordial-soup-47ai | elixir, biology | I've had a fascination with living things for as long as I can remember. And for a somewhat shorter part of my life, I've been intrigued by the idea of simulating life with code.
This is the first of hopefully many posts in which I aim to develop an artificial life system. In code and biology. Most of the posts will be fairly academic/technical, but I will try to make it as digestible as possible. I hope it will be fun.
## Biology
We all recognize life when we see it. But it is hard to pinpoint the exact properties that make something alive. Some candidates include reproduction, energy metabolism, homeostasis, adaptation to the immediate environment, evolution. But perhaps the most fundamental property of any living system is the ability to self-produce or to self-fabricate.
At the molecular level, every part of a living system is expendable. And yet, all living things are able to continuously self-fabricate from a biological recipe - its genetic material. And crucially, even the recipe and the systems that are able to read and execute this recipe must be continuously fabricated faithfully.
This self-fabrication property of living systems is sometimes referred to as semantic closure or closure to efficient causation. The concept of closure to efficient causation is unpacked most thoroughly in the work of Robert Rosen and Jan-Hendrik Hofmeyr. Much of the underlying theory in this series of posts is based on their work. If you are willing to accept self-fabrication as the most fundamental property of life, then invariably the following questions come up:
How did it all begin? How do you bootstrap life?
Whatever the answer to these questions may be, what happened was so unlikely that, as far as we know, it only ever happened once. I will not dwell on these questions, but when you build a self-fabricating artificial life system, you need to start somewhere. Knowing which components are required initially, is critical.
In the beginning there was a primordial soup, a slimy pool.
## Code
We will be building the artificial life system using the Elixir programming language. You don't have to know Elixir to follow, and I'll highlight some non-obvious things, but this will potentially be much more fun if you actually like Elixir.
Despite being built in Elixir, we will rely extensively on concepts from stack-based, concatenative languages, and combinatory logic. These features are best exemplified in the language Joy; at least in my humble opinion and for our current purposes. Joy was developed by Manfred von Thun as an alternative to applicative languages, such as Lisp, which are influenced by the lambda calculus. You don't have to be an expert in Joy, and neither am I.
An empty pool is not very interesting. So we start by agreeing that a pool can contain things (elements). And perhaps things can be added to a pool or removed from it. We will not yet link any biological meaning to pool membership, or the comings and goings of things in the pool. So don't push any analogy too far just yet.
A pool has state, its current elements, and the standard way to keep state in Elixir is to use a process. A `GenServer` is an abstraction around low-level process callbacks such as sending and receiving synchronous or asynchronous messages to the process inbox. It keeps state by essentially calling its own internal functions (or callbacks) in a kind of loop, continuously passing its state to itself as an argument. Callbacks receive state, potentially modify it, and then return it. Rinse and repeat.
We represent our pool with a `GenServer` that has a list of elements as its initial state (`[:a, :b, :c]`). The pool has an external facing client or public API and an internal facing server or callback API.
Processes are usually started by supervisors that are themselves processes. This goes all the way up to the application level. For now, it is enough to know that a supervisor is tasked with restarting and restoring any crashed process that it supervises to its initial state. We can also start the pool outside of a supervision tree using the `start_link` function that is part of its public API (we are doing this interactively with IEx):
``` elixir
iex(1)> Slyk.Pool.start_link()
{:ok, #PID<0.176.0>}
```
The result is a tuple with a process id (pid) as its second element. All our future interactions with the pool will use this pid under the hood.
Once the pool has been started, elements can be added to and removed from the pool:
``` elixir
iex(2)> Slyk.Pool.put(:d)
:ok
iex(3)> Slyk.Pool.get()
{:ok, :a}
```
The elements in the pool are all atoms. An atom is a special primitive type with the property that its name is also its value. You can think of an atom as a glorified string literal prefixed with a colon. So we added the atom `:d` to the pool. And then we randomly retrieved (and removed) the atom `:a` from the pool.
Let's have a look at the implementation and the docs for the public API and then discuss the internal API.
``` elixir
defmodule Slyk.Pool do
require Logger
use GenServer
# Client (public API)
@doc """
Start the pool.
Under the hood this starts a process and associates the pid with the
name Slyk.Pool, so that future calls can use Slyk.Pool instead of the
pid, which will change if the process needs to be restarted.
The state is initialized by calling the init callback with the provided
init_args.
"""
def start_link(init_args \\ []) do
# Start the process and associate the pid with the name Slyk.Pool
GenServer.start_link(Slyk.Pool, init_args, name: Slyk.Pool)
end
@doc """
Add the element to the pool synchronously.
Under the hood, this will call the handle_call callback with
{:put, element} as first argument.
"""
def put(element) do
GenServer.call(Slyk.Pool, {:put, element})
end
@doc """
Retrieve a random element from the pool synchronously.
Under the hood, this will call the handle_call callback with
:get as first argument.
"""
def get() do
GenServer.call(Slyk.Pool, :get)
end
# Server (callbacks)
def init(_init_args) do
# Ignore the init_args and initialize the state to [:a, :b, :c]
{:ok, [:a, :b, :c]}
end
def handle_call({:put, element}, _from, state) do
{:reply, :ok, [element | state]}
end
def handle_call(:get, _from, [] = state) do
{:reply, {:error, :empty}, state}
end
def handle_call(:get, _from, state) do
[head | tail] = Enum.shuffle(state)
{:reply, {:ok, head}, tail}
end
end
```
The callbacks (internal API) deal with the concurrency and "thread-safety" of calls and also implements the state transformations involved in each case. To insert a pool element, we set the state to a new list with the element at its head and the old state as the rest.
To retrieve a pool element, we shuffle the list of elements, return the head, and update the process state to what is left. There is only one problem. If the state is empty, there is nothing to retrieve. So we have to add a function clause that will match on the state being empty and return `{:error, :empty}` without altering the state and without crashing.
Note that we have three function clauses for the `handle_call` function. On each invocation of `handle_call`, Elixir will match the provided arguments to each function clause, starting at the top and execute the first (and only the first) one that matches.
In closing, our pool is essentially a complicated stack. Except that the stack is randomized just-in-time before each retrieval or "pop". In fact, if all you need is a stack, you can rely on a plain old Elixir list. Elixir lists are linked lists and thus ideal for stack implementations. We could have implemented our pool as just a list. The only reason for wrapping it in a `GenServer` is so that it becomes addressable and accessible to other processes. | palm86 |
247,680 | DigitalOcean Kubernetes VS AWS EKS from My Perspective when Used Both of Them | Digital Ocean and AWS show their support for Kubernetes with creating special product for Kubernetes... | 0 | 2020-01-28T03:09:01 | https://dev.to/iilness2/digitalocean-kubernetes-vs-aws-eks-from-my-perspective-when-used-both-of-them-3g20 | kubernetes, digitalocean, aws, devops |
Digital Ocean and AWS show their support for Kubernetes with creating special product for Kubernetes which we can use directly for each cloud. Each of them has their advantages and disadvantages. With this article, I would like to share my experiences during use each of the services.
Here are a few summaries I can conclude using both of the services:
### Creating the cluster
Digitalocean support creating Kubernetes cluster directly with their control panel and CLI, Although you can't find official support for creating cluster with CLI(only in community question). Find the docs how to do it at
[Digital Ocean Docs with control panel](https://www.digitalocean.com/docs/kubernetes/how-to/create-clusters/) and [Digital Ocean Docs with CLI](https://www.digitalocean.com/community/questions/can-we-use-doctl-as-a-cli-to-create-and-destroy-kubernetes-clusters)
For Kubernetes Cluster with AWS, you need to create the cluster on top of the VPC. If you don't specify the VPC, it will create the new one. If you want to create the cluster on top of exiting VPC, you can follow my guide at [here](https://dev.to/iilness2/practical-basic-approach-for-running-aws-eks-with-existing-vpc-2e1m)
### Support Kubernetes Version
For Kubernetes version, Looks like Digital Ocean always support the last three version from Kubernetes. You can see at below (when this article publish)
For AWS side, it's a little bit different. AWS doesn't support a latest Kubernetes version that fasts. When publishing this article, this is what AWS support for Kubernetes version right now:

Check full documentation at [here](https://docs.aws.amazon.com/eks/latest/userguide/kubernetes-versions.html)
### Ingress support
Digital Ocean supports all popular ingress controllers like the Nginx, Contour, HAProxy, and Traefik. You just need to choose one of them.
AWS itself has their ingress controller, which support and used their ALB services. Here the [docs](https://docs.aws.amazon.com/eks/latest/userguide/alb-ingress.html#w243aac23b7c17c10b3b1)
and How to use it in real case, you can follow this [guide](https://dev.to/iilness2/practical-way-to-setup-redirect-http-to-https-with-aws-eks-3m5i)
Another ingress controller which support by AWS is Nginx controller for NLB. this is the [docs](https://aws.amazon.com/blogs/opensource/network-load-balancer-nginx-ingress-controller-eks/)
### Support by third party (marketplace)
Digital Ocean has a marketplace that supports their Kubernetes services directly. You can check below or open [here](https://marketplace.digitalocean.com/category/kubernetes)
For AWS, You can check this [docs](https://aws.amazon.com/about-aws/whats-new/2019/09/aws-marketplace-now-supports-paid-container-software-on-amazon-elastic-kubernetes-eks/) which they announce, some of paid container supported at EKS
### Cost
For Cost, Digital Ocean gives a free for the cluster. We only need to pay for worker nodes we used. Check at images below:
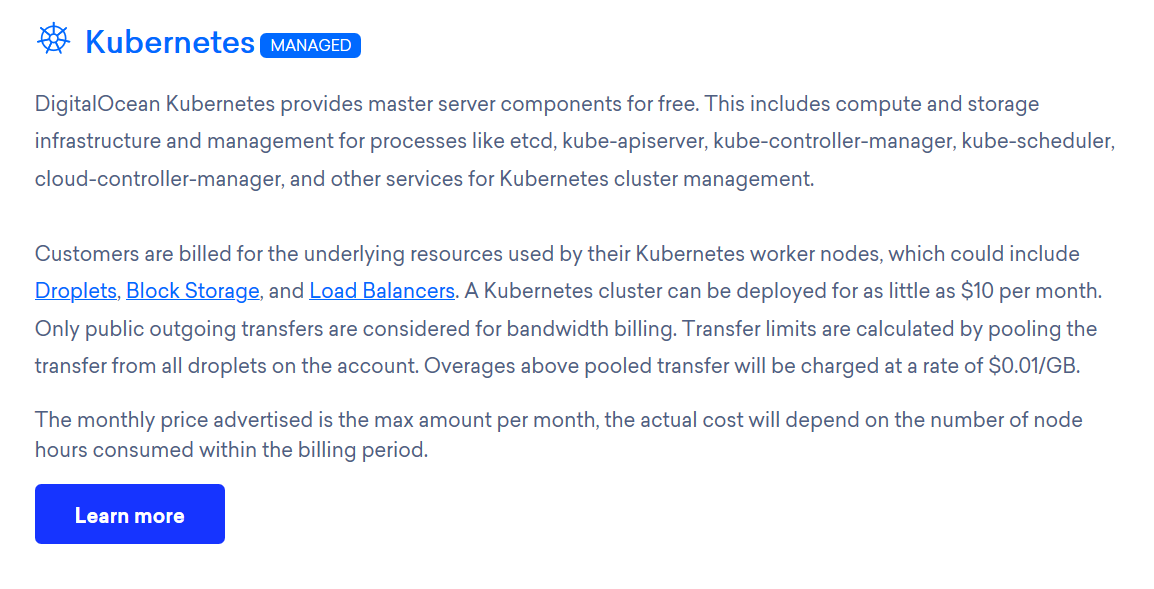
or check [here](https://www.digitalocean.com/pricing/)
AWS just announce they cut a cost for deploy the cluster (yes, we still need to pay for their cluster services and for each worker node we used).
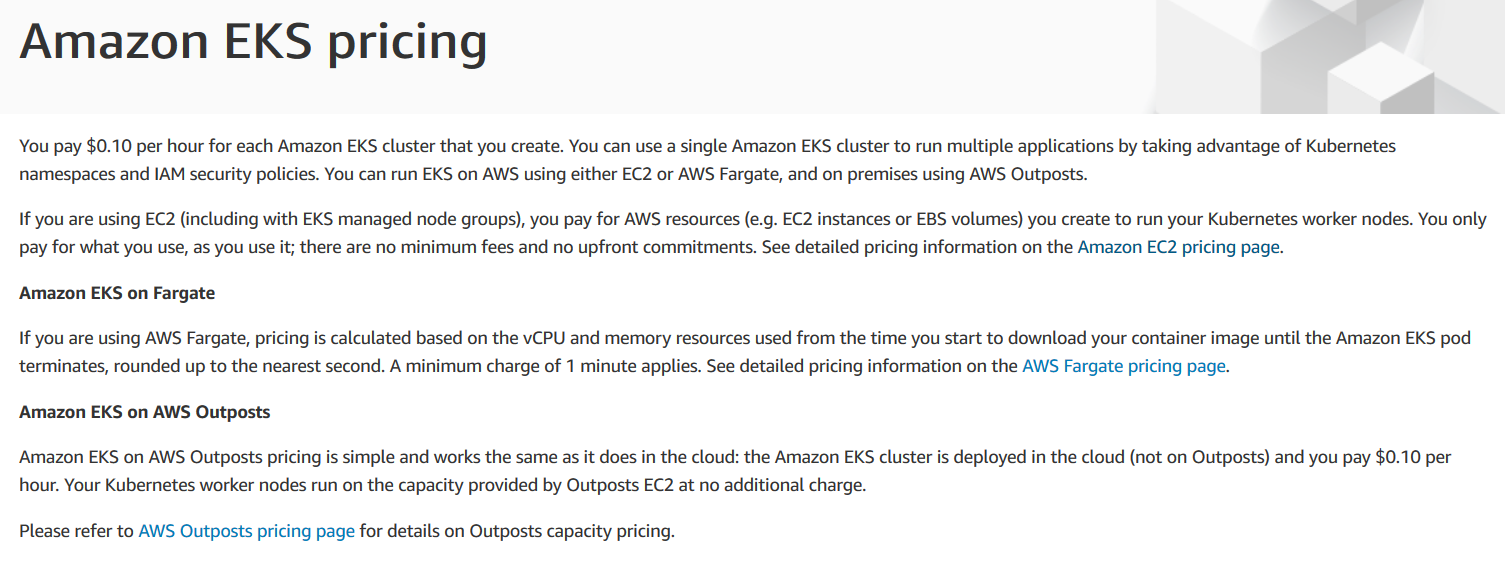
Full news check at [here](https://aws.amazon.com/blogs/aws/eks-price-reduction/)
AWS also apply some restriction for total pods which we can deploy and have access to the interfaces. Check [here](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-eni.html#AvailableIpPerENI). So we need to be extra cautious when we plan our cluster.
### Conclusion
From the several comparisons above, we can conclude, Every platform have their advantages and disadvantages. Looks like AWS will be more good if we use their Kubernetes product with their supporting application like ALB, VPC, etc. If not, Maybe we can consider using Kubernetes services from Digital Ocean since their Kubernetes services support almost all the open source like ingress directly. Try to match with your needs is the key. Have fun when doing the explore.
I think that's it for this article discussion. Leave a comment at below about your thoughts! Thanks. | iilness2 |
247,768 | Making Command-line interface (CLI) for fun and profit | Next time you have an idea 💡 "I know... Why don't I write a script to automate this thing?" Actually,... | 0 | 2020-01-24T09:54:16 | https://dev.to/cklee/making-command-line-interface-cli-for-fun-and-profit-3fj0 | node, javascript, devops | Next time you have an idea 💡 "I know... Why don't I write a script to automate this thing?" Actually, you should not, you should write a *CLI* instead.
CLI has better structure than scripts. CLI uses flags and help text to avoid mistakes. For example:
```
$ moa --help
Moa makes it easier to run your local node.js apps.
USAGE
$ moa
OPTIONS
-c, --commands=commands [default: start] commands to run.
-h, --help show CLI help
-r, --root=root [default: ../] root path to run.
DESCRIPTION
...
Have some fun
```
Scripts are messy. And can get out of control.
At [Taggun](https://www.taggun.io), we run a lot of node.js application. We make APIs for receipt OCR scanning, by the way. So, I recommend [oclif: The Open CLI Framework by Heroku](https://oclif.io/).
## How to create a new CLI
Install [node.js](https://nodejs.org/en/) first.
### Start by scaffolding
```
$ npx oclif single moa
? npm package name (moa): moa
$ cd moa
```
### Modify your flags in `src\index.js`
```
MoaCommand.flags = {
// add --help flag to show CLI version
help: flags.help({char: 'h'}),
commands: flags.string({char: 'c', description: 'commands to run. Comma-separated.', default: 'start'}),
root: flags.string({char: 'r', description: 'root path to run.', default: '../'}),
}
```
### Modify your description in `src\index.js`
```
MoaCommand.description = `Moa makes it easier to run your local node.js apps.
```
### Modify your command in `src\index.js`
```
class MoaCommand extends Command {
async run() {
const {flags} = this.parse(MoaCommand)
const commands = flags.commands.split(',')
const {root} = flags
find.file(/(?<!node_modules\/.*)\/package\.json$/, root, files => {
files.forEach(async file => {
const cwd = require('path').dirname(file)
commands.forEach(async command => {
this.log(cwd, `npm run ${command}`)
const npm = spawn('npm', ['run', command], {cwd})
for await (const output of npm.stdout) {
this.log(`${file}: ${output}`)
}
})
})
})
}
}
```
In this example, you will need to run `npm i find` to install `find` npm module.
This simple CLI will look for all node.js application in the `[root]` and run `npm run [command]`. Great if you need to run multiple node.js application to start coding.
### Run it
```
./bin/run -c start -c ../taggun/
```
### Publish and share your CLI
See https://oclif.io/docs/releasing | cklee |
247,785 | When and How Should You Use Merge Purge Software | Merging data entries from your company’s database, especially when it is coming in from multiple sour... | 0 | 2020-01-24T10:39:41 | https://dev.to/mskshahrukh/when-and-how-should-you-use-merge-purge-software-18j0 | database, productivity | <p>Merging data entries from your company’s database, especially when it is coming in from multiple sources, is enough to ruin an IT team’s day. The average enterprise makes use of at least 464 applications that stream data to your company. This includes CRMs (like Salesforce), POS data stores, Excel sheets, and content marketing platforms (such as Hubsoft). Unless you use a merge purge software, consolidating all that data in one place is easier said than done.
<p><a href="https://dataladder.com/merge-purge-software/">Merge purge</a> is a process that combines two or more lists/files by scanning databases and simultaneously identifying and merging similar records. It also gets rid of unwanted data entries. Ultimately, you end up with a unique record, complete with properly arranged names and addresses.</p>
<p><h3>Why do you need to merge data?</h3></p>
<p>It is not uncommon to come across inaccurate, inconsistent, and duplicate data entries in most databases. This usually happens when different people write a customer’s name and address in different ways. These data entries may also be entered in different sources, be it from billing records, websites, social media advertising information, and more.</p>
<p>As you can imagine, the data is all over the place. If your company decides to migrate to a new system or CRM, you are setting yourself up for a setback. Let’s walk you through one example:</p>
<p><b>Your Company wants to move to a New CRM Platform to Take Advantage of Automation</b></p>
<p>Suppose your company is looking to automate processes related to social media, email, lead generation, etc. To accomplish this, you need to move to a CRM platform that supports these processes. Migrating to a new CRM involves transferring customer data from many different departments. Your IT team initiates the data transfer but ends up discovering massive data quality issues that threaten to derail the whole data migration.</p>
<p>You find that most email addresses entered for your customers are either wrong, invalid or just left incomplete. Addresses like 1456@gmail.com, Arnold_schartz405@xyz.com, and so on are found in your database. Upon further inspection and verification, it was found that 15% of email addresses were entered incorrectly. And this is just one thing. What if this inconsistency is not limited to email addresses? What if names are spelled wrong, and other information similarly missing or incomplete?</p>
<p>Why does this happen? Perhaps the same customer gave the right address to the billing department, but a wrong one to the online survey team. Perhaps the address contained a typo when it was being manually entered.</p>
As you can see, this mismatched data creates hurdles if the company decides to initiate an email marketing campaign. It’s clear you need to carry out a merge purge before you can do so.</p>
<p>Before you decide to do a merge purge, what do you need to keep in mind? A data quality check process that’s what.</p>
<p><h3>Steps Before Merging Data from Multiple Sources</h3></p>
<p>Assuming your company has data quality issues as described above, you need to take this approach to ready your data for merging.</p>
<p>1. Data profiling activity</p>
<p>2. Data quality fixes once done with the profiling process</p>
<p>3. Roll out a final data profiling check</p>
<p>Data profiling is done to examine your data from existing sources. It takes a look at how accurate, complete and valid your data is. Once done, the <a href="https://www.trendmut.com/data-deduplication-software/">software creates a summary</a> for later use. You can now identify data at its source level, with the help of inaccurate formats, null values, even missing information. Basically, you now know what needs to be fixed in your database.</p>
<p>Once done with the profiling, the next thing you need to do is fix issues related to data quality. Because an enterprise has multiple systems working independently of each other, there is no single source to represent a customer’s data.</p>
<p>By using multiple data entry points, errors related to the difference in names, abbreviations, spellings and more is widely observed. This results in:</p>
<p>1. duplicate data – multiple entries of the same person, etc.</p>
<p>2. incomplete data – missing phone numbers, addresses, etc.</p>
<p>3. outdated information – old home or office addresses, contact info, etc.</p>
<p>4. inconsistent formats – wrong dates, country codes, zip codes, etc.</p>
<p>Last but not least, a final data profiling check is carried so to confirm if no data was missed during the process. This is necessary because sometimes, you may accidentally end up creating new errors while fixing data.<p>
<p>Now that everything has been done, it is finally time to merge purge your data and create an entirely unique database with unique entries and records. Instead of juggling with a number of different platforms, all your data is neatly nested in one place.</p>
| mskshahrukh |
247,798 | Layer 2 / Plasma watcher to protect against invalid exits and malicious behavior | Plasma service The goal of this project is for a plasma user (or a plasma service provider... | 0 | 2020-01-24T11:06:54 | https://dev.to/williamzmorgan/layer-2-plasma-watcher-to-protect-against-invalid-exits-and-malicious-behavior-1528 | plasma, javascript, layer2, blockchain | # Plasma service
The goal of this project is for a plasma user (or a plasma service provider) to be able to run a watcher on a server or their own computer that listens for any issues on the Plasma chain and immediately react and exit the Plasma chain or challenge invalid data
## Workflows
Based on https://github.com/omisego/elixir-omg/blob/master/docs/api_specs/status_events_specs.md#byzantine-events
| Event | Task | Implementation |
| - | - | - |
| invalid_exit | challengeStandardExit | [invalid-exit.yml](invalid-exit.yml) |
| unchallenged_exit | startInFlightExit | TODO |
| invalid_block | startInFlightExit | TODO |
| block_withholding | startInFlightExit | TODO |
| noncanonical_ife | challengeInFlightExitNotCanonical | TODO |
| invalid_ife_challenge | respondToNonCanonicalChallenge | TODO |
<!-- | piggyback_available | |
| invalid_piggyback | | -->
## Architecture
```
+-------------------+ +-------------------+
| | | |
| Plasma Watcher | | Plasma Contract |
| | | |
+-------------------+ +-------------------+
| ^
| |
invalid_exit challengeStandardExit
| |
| |
| +------------------+ |
+--->| |--------+
| Plasma Process |
| |
+------------------+
| PRIVATE_KEY |
+------------------+
```
## Start the Plasma Guard
If you don't already have MESG you should install and run it with:
```bash
npm i -g mesg-cli
mesg-cli daemon:start
```
[more information](https://docs.mesg.com/guide/installation.html)
```bash
mesg-cli process:dev ./invalid-exit.yml \
--env PRIVATE_KEY=$ALICE_PRIVATE_KEY \
--env PROVIDER_ENDPOINT=$PROVIDER_ENDPOINT \
--env PLASMA_ADDRESS=$PLASMA_ADDRESS \
--env PLASMA_ABI="$(curl -s https://raw.githubusercontent.com/omisego/omg-js/v2.0.0-v0.2/packages/omg-js-rootchain/src/contracts/RootChain.json | jq .abi)"
```
## Create an invalid exit
[Check how to create an invalid exit](./create-invalid-exit.md)
| williamzmorgan |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.