
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
247,875 | Simple authentication and styling in beginner Rails 6 project | Ok so, here goes my first tech blog post. I've been trying to do this for a while, but just didn't ha... | 4,479 | 2020-01-24T13:47:42 | https://dev.to/bbborisk/simple-authetication-and-styling-in-beginner-rails-6-project-m6 | rails, bootstrap, beginners, books | Ok so, here goes my first tech blog post. I've been trying to do this for a while, but just didn't have the courage to get my self to do it. So, this is a bit about *how to do this thing* and a bit about *how to overcome imposter syndrome* for absolute beginners.
Let's just dive in. I have started a project driven by my wife's and my need to systematize hundreds of children's books we have for our toddlers. And I know, we could've made this in a few excel sheets, but my goal here is to make something of my own, customizable and editable.
And I love rails, for it is so beginner-friendly, yet so powerful. First,
I generated the project
```
rails new ChildrensBooks
```
Rails 6 takes a bit longer to generate, but it has tons of features, which I am still learning about. After making the index page, the next thing is to add gems for authentication and bootstrap templates. so, in gemfile, add gems `devise`, `devise-bootstrap-views` and `twitter-bootstrap-rails`, which is simple and easy to use. You also need `jquery-rails`.
```ruby
gem 'jquery-rails'
gem 'devise'
gem 'twitter-bootstrap-rails'
gem 'devise-bootstrap-views'
```
And, of course, install them with bundler - `bundle install`. Now, there are better ways to do this, but again, I'm doing this in the simplest way possible. Then, onto making model for the Users table.
In order to use `devise`, you must first install it with
```bash
rails generate devise:install
```
Then, generate Users model. Devise makes it so simple, also making all the routes in `routes.rb` file.
```bash
rails generate devise User
```
This is a perfect setup for me at this moment, no need for other configurations. so I just migrated the database.
```bash
rails db:migrate
```
The styling idea I got from some Udemy course I saw a while back, and it seems great now. It adds a twitter style outlook, and is both available for page layout and devise form aswell.
First, add the bootstrap requirements to the style resources file.
application.css:
```css
*= require twitter-bootstrap-static/bootstrap
```
and application.js
```javascript
//= require twitter/bootstrap
```
Also, include both files in manifest.js
```javascript
//= link_tree ../images
//= link_directory ../stylesheets .css
//= link application.js
```
Next, install the theme. I used static, but in the documentation of the gem you can find others as well.
```bash
rails generate bootstrap:install static
```
then, it is just the matter of adding `views` and updating the `application.html.erb` file.
```bash
rails g bootstrap:layout application
```
and then same for devise
```bash
rails g devise:views:locale en
```
```bash
rails g devise:views:bootsrap_templates
```
That should do it.
In my `application_controller.rb` I added the before_action for authentication
```ruby
before_action :authenticate_user!
```
so, when I run the server, it takes me straight to the login screen. From there, you can make a user and, I guess, that is it.
So, the next thing for me is making a model for books. I know this isn't the most brilliant text or groundbreaking tutorial. It is basically my experience in making the starter code following the documentation in gems. But I hope it helps someone, and it really helped me break the ice in the community.
Feel free to get in touch, share your journey into coding world, share knowledge and tips for this newbie.
Cheers! | bbborisk |
247,906 | Hello | https://www.romexsoft.com/ -check out this company is Ukrainian outsourcing provider of AWS cloud sol... | 0 | 2020-01-24T14:33:47 | https://dev.to/joanalauren/hello-35n3 | https://www.romexsoft.com/ -check out this company is Ukrainian outsourcing provider of AWS cloud solution and software engineering services. | joanalauren | |
247,912 | Pick. Squash. Drop. Rebase! (Comic) | It is a common practice to use `git rebase` to squash commits before creating or merging a pull request; nobody needs to see that you fixed 10 typos in 5 separate commits, and keeping that history is of no use. So how does a rebase look like? | 4,483 | 2020-01-24T16:06:24 | https://dev.to/erikaheidi/pick-squash-drop-rebase-comic-607 | git, beginners, illustrated, comics | ---
title: Pick. Squash. Drop. Rebase! (Comic)
published: true
description: It is a common practice to use `git rebase` to squash commits before creating or merging a pull request; nobody needs to see that you fixed 10 typos in 5 separate commits, and keeping that history is of no use. So how does a rebase look like?
series: Git Illustrated
tags: git, beginners, illustrated, comics
cover_image: https://thepracticaldev.s3.amazonaws.com/i/mipao0n3oqno93o22s7f.png
---
[Git Rebase](https://git-scm.com/docs/git-rebase) allows us to rewrite Git history. It is a common practice to use `git rebase` to squash commits before creating or merging a pull request; nobody needs to see that you fixed 10 typos in 5 separate commits, and keeping that history is of no use. So how does a rebase look like?

Let's imagine you have your deck of cards, they are ordered in a certain way that cannot be changed. Each card represents a commit in a project's branch.
When running an interactive rebase with `rebase -i`, there are mainly three actions we may want to perform in a commit (card):
- **p**ick: pick a commit.
- **s**quash: squash this commit into the previous one.
- **d**rop: drop this commit altogether.
In this game, you want to **s**quash cards together into doubles and triples. Some cards make sense on their own, so you will **p**ick them. Sometimes, a card should not even be there, so you might want to **d**rop it.
Although there are other ways of using `git rebase`, the interactive rebase used like this is a common practice observed in projects that rely on multiple contributors, both in open as well as in closed source. It enables you to commit earlier and with more frequency, because you are able to edit your history before submitting your pull request.
If you'd like a deeper introduction to Git Rebase, please check this great dev article from [@maxwell_dev](https://dev.to/maxwell_dev):
{% post https://dev.to/maxwell_dev/the-git-rebase-introduction-i-wish-id-had %} | erikaheidi |
247,923 | The Macintosh was unveiled 36 years ago today | A beautiful machine | 0 | 2020-01-24T15:18:15 | https://dev.to/ben/the-macintosh-was-unveiled-36-years-ago-today-k7f | computerhistory, news, apple, mac | A beautiful machine
{% youtube 2B-XwPjn9YY %} | ben |
247,941 | Is Ruby On Rails The Biggest Waste Of Time in 2020? | A post by codingphasedotcom | 0 | 2020-01-24T16:03:54 | https://dev.to/codingphasedotcom/is-ruby-on-rails-the-biggest-waste-of-time-in-2020-41pd | ruby, rails, webdev | {% youtube Wbh6PMUsgzk %}
| codingphasedotcom |
247,960 | JavaScript and Friends - Tech Launchers | Tech Launchers is a program to go the extra mile beyond the regular mentor and mentee program. JavaSc... | 0 | 2020-01-24T16:47:23 | https://dev.to/jsandfriends/javascript-and-friends-tech-launchers-47mo | career, mentors | Tech Launchers is a program to go the extra mile beyond the regular mentor and mentee program. JavaScript and Friends is excited to launch this program in 2020.
There is always a gap which regular coursework at college or bootcamp do not teach or self-taught programmers do not learn. Tech Launchers are those who will fill that gap.
### Why did we name the program as "Launchers"?
The most common words we get to imagine upon hearing the term Launcher is either a Rocket Launcher, Satellite Launcher or Launch Vehicle.
> Based on Wikipedia -
> A launch vehicle or carrier rocket is a rocket propelled vehicle used to carry a payload from Earth's surface to space, usually to Earth orbit or beyond.
> A rocket launcher is a device that launches an unguided, rocket-propelled projectile
Now that you have a basic understanding of the term "Launcher", Tech Launchers are those who will have both qualities in them.
### Who are Tech Launchers?
Tech Launchers are those who will guide and support college/bootcamp graduates and self-taught programmers to unleash their potential. Launchers will propel and boost college/bootcamp graduates and self-taught programmer's path to tech industry by offering support via knowledge, network, referrals and help them close the gaps making them job ready.
Tech Launchers will advise, coach and be there as support providing feedback to college/bootcamp graduates and self-taught programmer's. You can go the extra mile and be available to them until they reach their destination.
As a Tech Launcher, you can choose to launch as many as you want.
### How much time should I dedicate to be Tech Launcher?
The program is initially targeted for 14 days with a minimum overall time commitment of 10 hours. You can also go the extra mile by extending the program beyond 14 days.
On any given day, you may be tasked with helping the student understand some programming challenge / task. On another day, you may be giving career advice or reviewing a resume. You might help them understand current trends in industry and advise them on building their portfolio projects on Github.
### How do I connect and communicate with Students?
As moderator of the program, we will share with you details of students who are looking for Tech Launchers.
You can connect with them through JavaScript and Friends Slack channel "techlaunchers" initially and then choose either of the following preferred modes - email, chat, voice calls based on your preference.
You will define the rules on when you want to connect and the frequency.
### How do I participate?
Interested in being part of the program to help launch future aspiring students, leave your details in comments. Our team will reach out to you to discuss further logistics. The program is currently looking for Launchers in the USA. Once we validate the program, we will consider expanding the program to other locations.
| baskarmib |
248,055 | Daily Challenge #176 - Loopover | Create a function to solve Loopover puzzles. | 1,326 | 2020-01-30T15:36:21 | https://dev.to/thepracticaldev/daily-challenge-176-loopover-3b23 | challenge | ---
title: Daily Challenge #176 - Loopover
published: true
series: Daily Challenge
description: Create a function to solve Loopover puzzles.
tags: challenge
---
###Setup
Loopover puzzles are 2D sliding puzzles that work more like flat rubik's cubes. Instead of having one open slot for pieces to slide into, the entire grid is filled with pieces tha wrap back around when you slide a row or column.
You can try it out at this sketch here: https://www.openprocessing.org/sketch/576328
To complete this challenge, implement a function to return a list of moves that will transform an unsolved grid into a solved one.
Consider the grid:
<pre>
ABCDE
FGHIJ
KLMNO
PQRST
UVWXY
</pre>
If we make the move `R0` (move the 0th row right) then we get:
<pre>
EABCD
FGHIJ
KLMNO
PQRST
UVWXY
</pre>
Likewise, if we do `L0` (move the 0th row left), we get:
<pre>
ABCDE
FGHIJ
KLMNO
PQRST
UVWXY
Back to normal.
</pre>
Say we make the move `U2` (move the 2nd column up):
<pre>
ABHDE
FGMIJ
KLRNO
PQWST
UVCXY
</pre>
`D2` (2nd column down) would then return us to the original grid. With all of this in mind, our tests will give you the scrambled grid as input. Please return an array of the moves taken to unscramble the grid.
For example:
<pre>
SCRAMBLED GRID:
DEABC
FGHIJ
KLMNO
PQRST
UVWXY
SOLVED GRID:
ABCDE
FGHIJ
KLMNO
PQRST
UVWXY
</pre>
One possible solution would be `["L0", "L0"]` as moving the top row left twice would result in the original, solved grid. Another would be `["R0", "R0", "R0"]` etc. etc.
###Tests
`"ACDBE\nFGHIJ\nKLMNO\nPQRST\nUVWXY"`
`"ABCDE\nKGHIJ\nPLMNO\nFQRST\nUVWXY"`
Some of these can be kind of tricky. Good luck!
***
_This [challenge](https://www.codewars.com/kata/5c1d796370fee68b1e000611) comes from jaybruce1998 on CodeWars. Thank you to [CodeWars](<https://codewars.com/>), who has licensed redistribution of this challenge under the [2-Clause BSD License](<https://opensource.org/licenses/BSD-2-Clause>)!_
_Want to propose a challenge idea for a future post? Email **yo+challenge@dev.to** with your suggestions!_ | thepracticaldev |
248,060 | How this self taught developer made $70,000 whilst travelling | Guilherme Rizzo is the self-taught founder of CSS Scan which lets you easily inspect the CSS of a w... | 0 | 2020-04-01T11:29:58 | https://www.nocsdegree.com/how-this-self-taught-coder-made-70-000-whilst-travelling-the-world/ | css, beginners, webdev | ---
title: How this self taught developer made $70,000 whilst travelling
published: true
date: 2020-01-24 16:42:00 UTC
tags: CSS, Beginners, Webdev
canonical_url: https://www.nocsdegree.com/how-this-self-taught-coder-made-70-000-whilst-travelling-the-world/
---

Guilherme Rizzo is the self-taught founder of [CSS Scan](https://gumroad.com/a/997618803) which lets you easily inspect the CSS of a webpage and click and copy it for your own project. He's made $70,000 in the last year from [CSS Scan](https://gumroad.com/a/997618803) while travelling in Asia. [CSS Scan](https://gumroad.com/a/997618803) is a lot quicker than using Dev Tools and you can use it in other browsers besides Chrome. I use it a lot so it's great to be able to ask Guilherme some questions about how he learned to code, making [CSS Scan](https://gumroad.com/a/997618803) and his experience leaving Brazil with just a Mac mini to travel the world.
## Hey, so can you give us a short introduction for people who want to know more about you?
I’m [Guilherme Rizzo](https://twitter.com/gvrizzo) and I'm 21 years old (it’s my birthday today!!). I’m from Brazil but now I’ve been traveling around the world for over a year. I have made a browser extension called [CSS Scan](https://gumroad.com/a/997618803) and with it you can check or copy the CSS code of any element you see on the internet, by just moving your mouse over it. So far I’ve made over $70,000 in revenue with it and that’s my full-time job, along with CSS Scan Pro - its premium version).
## I really like CSS Scan! Why did you decide to create it?
I was always interested in what border-radius and box-shadow some elements had. So, inspired by WhatFont? I created this extension that wherever you hover your mouse over, you instantly get the CSS of the element and you can copy all of it with a single click.
So you don’t have to dig into multiple panels in the dev tools. Do you like this button? Just click and copy. Or, study how its made, and learn CSS on the way. It’s a great learning tool for beginners and a real time-saver for advanced users.
## What have you learned since coding CSS Scan?
Coding [CSS Scan](https://gumroad.com/a/997618803) was fun! I recorded all the development of the first version. It took me 50 hours, but I speed it up to 2 minutes so you can check it here:
<iframe width="480" height="270" src="https://www.youtube.com/embed/OtsNNXpXcYs?feature=oembed" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
I learned how to develop Chrome extensions, firefox add-ons, and Swift because I needed to learn it to create the Safari App Extension. A lot of javascript and optimizations techniques. But I learned much more about business.
## If you don’t have a CS degree, how did you learn coding? Did you do any particular courses or bootcamps?
I learned programming by creating 2d games. When I was 9 years old, my friend gave me a DVD with a software called RPG Maker XP. It was a very cool tool to easily create 2d games (mostly RPGs). So I started developing those games. My first game was hugely criticized because it looked remarkably weird but I kept going and got better at that.
After one or two years, I needed to create a website for my game so that’s when I first heard about HTML and CSS. While I was creating my games just for fun and for my friends, I realized I could build things that could help my city, my country or even the whole world.
So I began to make friends on the internet and started to make websites/apps with them, and learning programming on the internet along the way. We tried a lot of things and most of them failed. We created more than 6 websites together - that was when I learned how to code.
In 2017 I joined a national competition for high school students in Brazil from Google, called “Maratona de Aplicativos”, where we had to develop an educational app. Me and my friends developed an app that helped parents that have autistic children to organize a routine with in-app interactive exercises for their children - it's name is Teacch.me, it was later discontinued but still exists on the Android's Play Store. After a lot of work, we happily won the competition, and by winning it, we got free tuition at a Brazilian university called FIAP, a notebook, printer, tablet, etc…

So inspired by the TV Show "Silicon Valley" we all moved to Sao Paulo to start a fashion company and some of us also enrolled in university. I was one of them. We met a lot of people in that city and learned a lot together. It's a game-changer experience to live in the same house, with friends that share your interests. I have great memories about that, and it turned out better than I thought. I started university by studying Information Systems but decided to change to Marketing 1 year later but I ended up dropping out of that 10 months later too. So, I learned coding by doing projects and businesses.
<!--kg-card-begin: markdown-->
[](https://triplebyte.com/a/Ww4mbM6/d)
<!--kg-card-end: markdown-->
### Do you want a developer job but don't have a Computer Science degree? Pass [Triplebyte's quiz](https://triplebyte.com/a/Ww4mbM6/d) and go straight to final onsite interviews at top tech companies
## What advice would you give to people wanting to get into coding but don’t have a CS degree?
The Codecademy courses helped me a lot. For real. Especially the Javascript one. I strongly recommend it. And also, make stuff. For you, for your friends, for your city, anything. The more you practice it, the more you’ll learn, everybody already says this.
Remember that you can do anything you want. But there are 3 levels of "want". I want, I will, and I commit myself. Commit yourself to learn and make it happen. Just like Pete [committed himself to get an IndieHackers podcast.](https://twitter.com/petecodes/status/1152986101642158080)
## You took off and went travelling armed just with a Mac Mini! Do you have any advice for developers that want to go nomad and work from anywhere?
If you feel and genuinely believe you can, I’d say: just do it. Because I felt the same feeling, even when my family and some friends were against it. I felt that nothing could stop me and that it would work because I’d make it work. I’m also young so it’s easier to do these kinds of things.
By the way, that’s the way I did. If you don’t think that would be good for you, you can wait for a safer environment by saving money, doing freelance, working on side-projects, etc, but don’t wait for the perfect moment - there isn’t.
<figcaption>Guilherme with no laptop worked from hotel TV screens in Asia</figcaption>
## Can you tell us what an average day looks like for you just now?
Monday: Take a bath with elephants. Tuesday: Sail around the British Virgin Islands. Jokes aside, I wake up, stretch, read my statements (I have A LOT), cook breakfast with my wife, wash the dishes, start working on my new business, go to explore the city I’m in, lunch, go to coffee work, post on twitter (every day), answer emails, read a book, imagine myself successful, take a shower, read my statements again, sleep.
<!--kg-card-begin: markdown-->
[](http://nocsok.com)
<!--kg-card-end: markdown-->
## Have you ever had imposter syndrome and if so, how have you dealt with it?
Yes, sometimes. I always look back to times that I was and felt successful, and I try to remember how I felt, what I did, why I was successful. I do that once a month. If you start doing that you’ll feel better with yourself too.
## What are the new features in the latest release of CSS Scan?
So, one-time payment for browser extensions is already proved to work, as I did with [CSS Scan](https://gumroad.com/a/997618803). Now I’m trying to play in a different game which is subscriptions. I build CSS Scan Pro because I felt CSS Scan already did it’s purpose very well, but I felt it was limited to the click-to-copy CSS functionality.
CSS Scan Pro is developed to be the definitive browser extension to work with web design, so with it, you can:
- Pick any color from any website (works on images too)
- Get the whole color palette of the website in an instant
- Precisely select any element with the DOM control (with arrow keys to go up and down - parents, children, siblings, etc)
- Understand any CSS animation you see on the web by reading CSS keyframes
- Measure distances and elements with a real-time advanced ruler
- Scan all pseudo-classes and pseudo-elements (while Basic only scans the pseudo-class :hover)
- Check all the changes made in the CSS and copy it or export it to a file
- Visualize guidelines to check alignments
- Scan inherited styles (it gets font-size, font-weight, and other properties that Basic can't catch)
## Awesome! Well, thanks a lot for interview. And Happy Birthday!
Thank you so much, Pete, for this opportunity and thank YOU for reading this interview, appreciate it! If you have any questions or want to chat, feel free to reach me through [Twitter](https://www.nocsdegree.com/p/58d3d113-6ae6-4808-9d5c-71c03ac566ee/twitter.com/gvrizzo) . | petecodes |
248,062 | Wireframing dev.to/videos | It’s not a secret some of us prefer to learn tech ‘X’ by watching videos, rather than reading blog... | 0 | 2020-01-24T19:45:04 | https://dev.to/madza/wireframing-dev-to-videos-1ebi | wireframing | ---
title: Wireframing dev.to/videos
published: true
description:
tags: wireframing
cover_image: https://thepracticaldev.s3.amazonaws.com/i/53g508jpytaka7e35h3c.png
---
It’s not a secret some of us prefer to learn tech ‘X’ by watching videos, rather than reading blog posts.
Dev.to has a separate video page dev.to/videos. It needs some more structure and layout, so I decided to do some wireframing on initial ideas to improve the particular section of site.
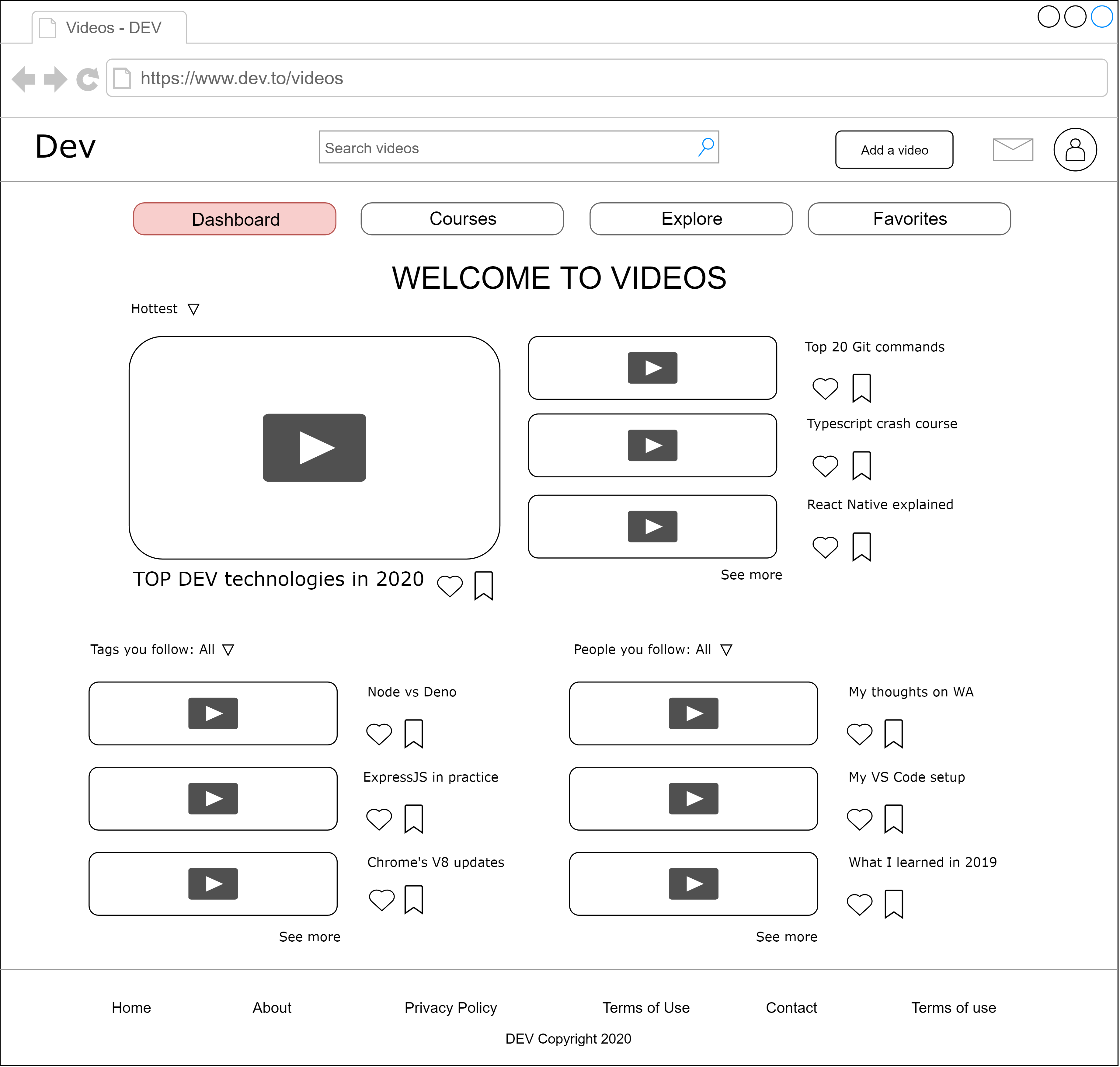
**1.Dashboard**
This would be the landing page of the video section. The main section would be dedicated for most curated videos. The content feed could be made more personalized by developing an algo for it. User would also be able to see the uploads on specific tags he/she has subscribed as well as from persons he/she follows. There would be an option to heart and save for later on each video.
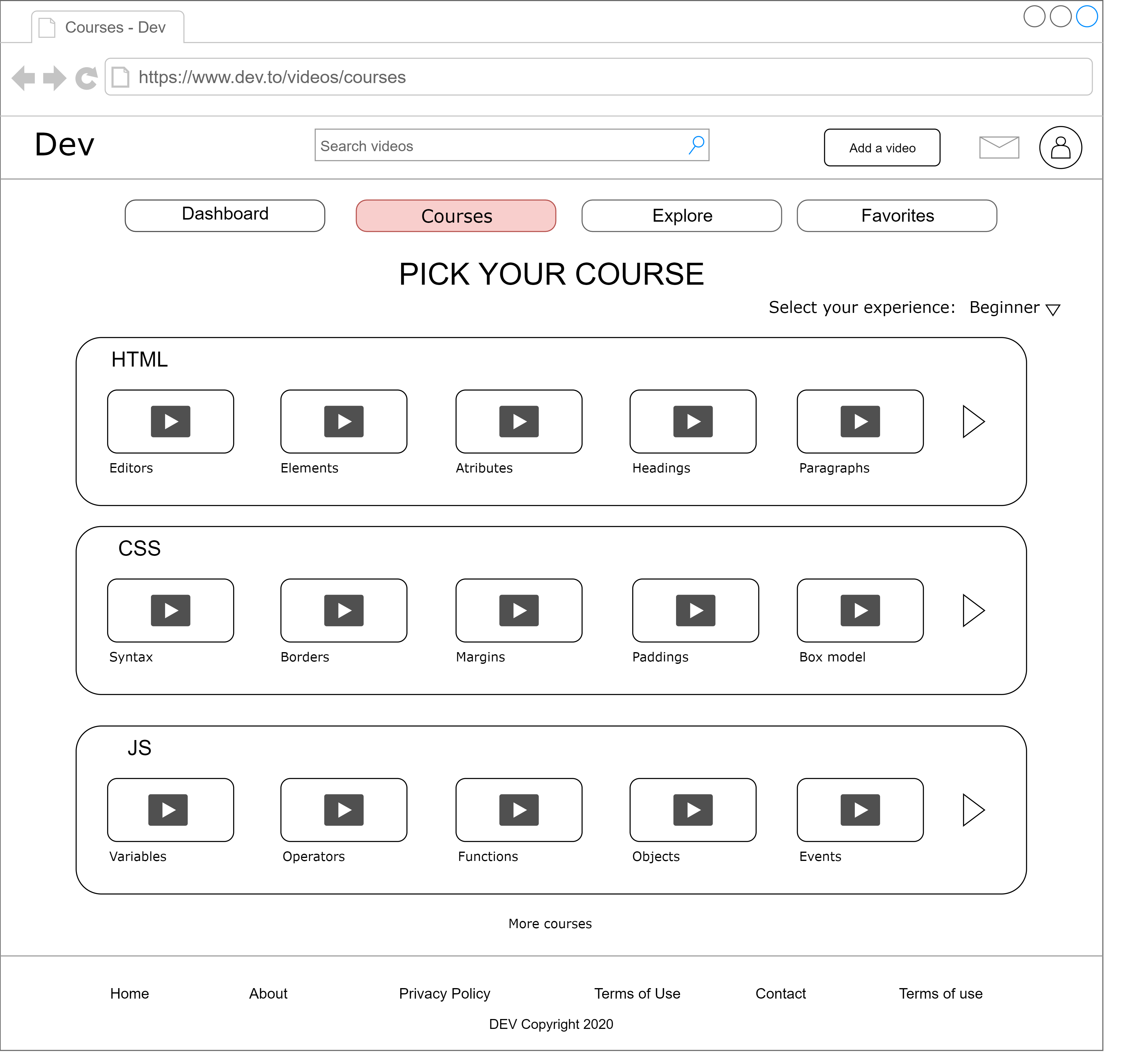
**2.Courses**
Content in each course would be hand-picked manually. User would be able to select his/her experience level (beginner-intermediate-advanced) to select the complexity of course concepts. The content would be sorted accordingly to provide a proper learning path.
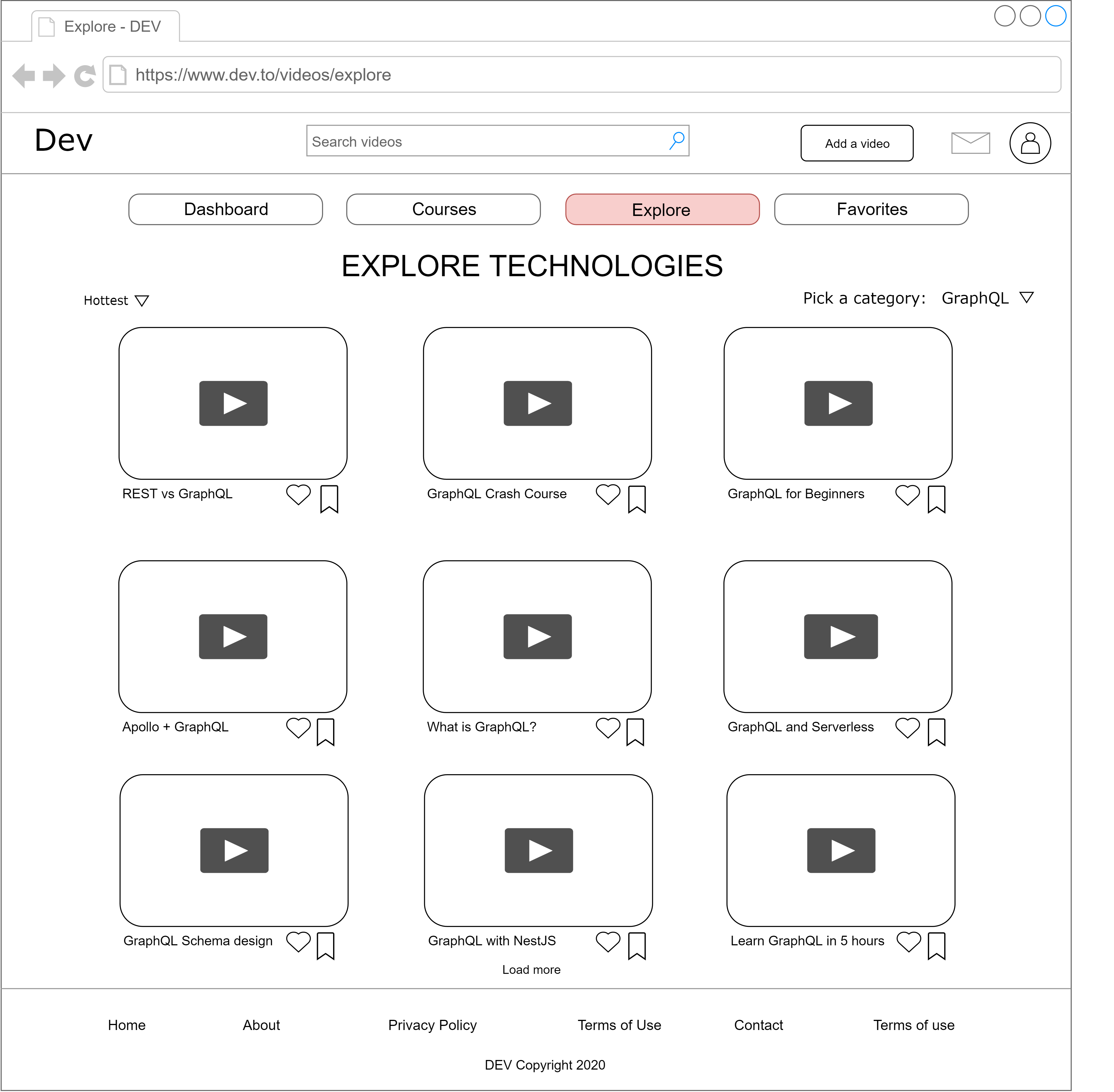
**3.Explore**
User would be able to explore the technologies of their interest (based on tags videos would get during the publish phase). There would be an option to sort displayed results based on the curates and most recent ones. There would be an option to heart and save for later as well.
**4.Favorites**
This section would display users activities - recently watched videos and saved for later list. Furthermore user would also be able to make collections, by sorting the videos he/she has liked.
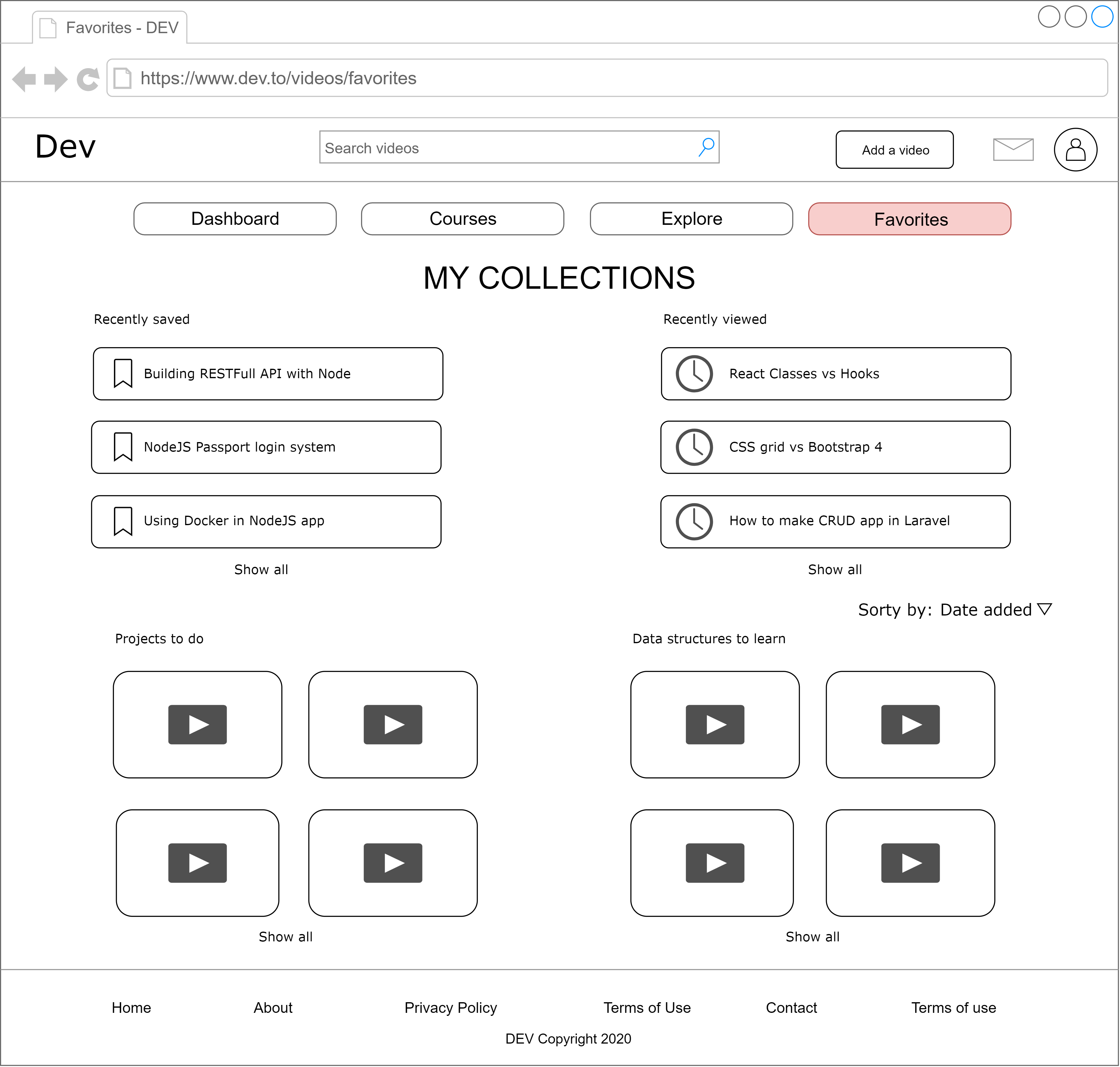
I’ve also put this in dev.to’s Github issues as a feature, where you can find better quality images.
In case if anyone wondering, I used draw.io (it's free).
| madza |
248,102 | Machine learning for logs (part 1 of 5) | In our last blog we discussed the need for Autonomous Monitoring solutions to help developers and ope... | 0 | 2020-01-24T20:48:35 | https://dev.to/gdcohen/machine-learning-for-logs-part-1-of-5-5473 | devops, machinelearning | In our [last blog](https://www.zebrium.com/blog/the-future-of-monitoring-is-autonomous) we discussed the need for Autonomous Monitoring solutions to help developers and operations users keep increasingly large and complex distributed applications up and running.
Although Autonomous Monitoring includes all three pillars of observability (metrics, traces and logs), at Zebrium we have started with logs (but stay tuned for more). This is because logs generally represent the most comprehensive source of truth during incidents, and are widely used to search for the root cause. Log management and log monitoring is also an area we feel hasn’t evolved much in the past 20 years. Most log solutions are still designed around “aggregate, index and search”. And they are mostly used reactively by skilled users who manually search for the root cause.
The main reason logging tools haven’t evolved much in the past two decades is because using Machine Learning (ML) with logs is hard. Logs are incredibly vast, noisy and mostly unstructured. To date ML work in the log space has been either purely academic, or limited to detecting basic anomalies that are both noisy and don’t easily roll up into real incidents that users need to know about.
This blog series will go into detail of how Zebrium has taken a unique approach to applying machine learning to logs, but to understand how the approach is superior, our story starts at what approaches have been tried previously.
**Machine learning for logs**
Machine Learning (ML) uses statistical models to make predictions. For monitoring logs, a useful prediction would be the ability to classify whether a particular log event, or set of events, are causing a real incident that requires action to resolve. Another useful prediction would be to correlate an incident to the root cause so users can easily rectify the issue.
In ML, usually the more data available, the more accurate the ML model will be at making predictions. This is why models usually become more accurate over time. However, this has two challenges – it leads to a long lead time to value, i.e. the system requires several days or weeks of data to serve accurate predictions and not raise false alerts (also referred to as “false positives”).
Worse, slow learning ML is actually not very useful when the behavior of the application itself keeps changing, for example because frequent updates are being deployed for each of its microservices. If the accuracy is poor, then we eventually will start ignoring the model as it will generate too many spammy alerts.
There are also two main approaches for training ML models on existing data: supervised and unsupervised. Supervised training requires a labelled data set, usually produced manually by humans, to help the model understand the cause and effect of the data. For example, we may label all log events that relate to a real incident so the model will recognize that incident again if it sees the same log events or pattern.
As you can imagine, this can take a lot of effort, especially considering the millions of potential failure modes complex software services can generate. Therefore, another approach used to train ML models, is Unsupervised training. In this approach, the model will try and figure out patterns and correlations in the data set by itself, which can then be used to serve predictions.
The challenge with using ML with logs, however, is every environment is different. Although there may be some common third-party services shared between environments (e.g. open source components like MySQL, NGinX, Kubernetes, etc.), there will likely also be custom applications that are unique to a particular environment and generating a unique stream of logs and patterns.
This means that any approach that needs to be trained on an environment’s specific data will not work unless the other environments run the same components. In addition, unless we want to invest a lot of resources and time for humans to accurately label the data, the models must be able to train unsupervised.
Another challenge, is any ML approach needs to figure out how to be accurate at predictions quickly and with limited data, to ensure the user isn’t waiting days or weeks for accurate alerts to be generated.
With these challenges in mind, we need an ML solution that can train quickly on a relatively small dataset and do this unsupervised, to ultimately generate accurate incident predictions across unique environments, and keep learning as an application continually evolves.
**Existing Approaches & Challenges**
While there have been a lot of academic papers on the subject, the approaches typically fall into two categories which are explained below:
**Generalized Algorithms**
This category refers to algorithms that have been designed to detect anomalous patterns in string-based data. Two popular models in this category are Linear Support Vector Machines (SVM) and Random Forrest.
Using SVM as an example, it classifies the probability that certain words in a log line are correlated with an incident. Some words such as “error” or “unsuccessful” may correlate with an incident and receive a higher probability score than other words such as “successful” or “connected”. The combined score of the message is used to detect an issue.
Both SVM and Random Forrest models use supervised learning for training and require a lot of data to serve accurate predictions. As we discussed earlier, unless we are only running common 3rd party software, where we can collect and label a lot of common log samples for training, this approach will not work well in new environments running bespoke custom software, as the models need to be trained on a large labelled data set from the new log samples generated by that specific environment.
These approaches also try to do anomaly detection using the raw log event messages. This may work well for individual log events but will be far too noisy to only detect real incidents. When incidents occur, we need to detect pattern changes across the entire log set, and not look for issues in individual log events.
**Deep Learning**
Deep learning is a very powerful form of ML, generally called Artificial Intelligence (AI). By training neural networks on large volumes of data, Deep Learning can find patterns in data, but generally is used with Supervised training using labeled datasets. AI has been used for hard problems such as image and speech recognition with great results.
One of the best academic papers for this approach is the Deeplog paper from the University of Utah, which uses deep learning to detect anomalies in logs. Interestingly, they have also applied ML to parse logs into event types, which is similar to Zebrium’s approach discussed later, as this significantly improves the accuracy of the anomaly detection.
The challenge with this approach again, is that it requires a large volume of data to become accurate. Which means new environments will take longer before they can serve accurate predictions, and smaller environments may never produce enough data for the model to be accurate enough.
However, unlike the statistical algorithms discussed previously, another issue with Deep Learning is it is very compute intensive to train. Many data scientists will run expensive GPU instances to train models quicker, but at significant cost. If we need to train the model on every unique environment individually, and continuously over time, this would be an extremely expensive way to detect incidents autonomously, and therefore this approach is not recommended for monitoring logs for environments running custom software.
Some vendors have trained deep learning algorithms on common 3rd party services (i.e. MySQL, NGinX etc.). This approach can work as they can take a large volume of publicly available datasets and error modes to train the model, and the trained model can be deployed to all their users. However, as no environment is only running these 3rd party services and has custom software that’s only running in that environment, this approach is limited to only discovering incidents in 3rd party services, and not the custom software running in the environment itself.
**Taking A Different Approach**
As we’ve discussed above, generalized algorithms and deep learning as has been applied up until now, have too many limitations to provide a truly autonomous, unsupervised, log monitoring solution.
Instead of applying a single approach, Zebrium has taken a multi-layer approach, first parsing the logs into normalized events, running anomaly detection across every single event, and then detecting changes in patterns that may indicate an incident is occurring.

The next blogs will go into detail on each step of this process and discuss how it helps to achieve accurate autonomous incident detection and root cause identification.
If you can’t wait for the blog series to finish, please download our white paper [here](https://www.zebrium.com/wp1?utm_campaign=Assets&utm_source=dev_to) or try our [free beta](https://www.zebrium.com/private-beta-sign-up?utm_campaign=Sign-up&utm_source=dev_to).
[Published with permission of the author David Gildeh @ Zebrium] | gdcohen |
248,122 | Introducing Pixz! Point. Shoot. Shared...Photo sharing for groups and events. | Hey everyone, I wanted to get your feedback on Pixz (pixzapp.com). It's a project I started after ret... | 0 | 2020-01-24T22:02:57 | https://dev.to/pixzapp/introducing-pixz-point-shoot-shared-photo-sharing-for-groups-and-events-5agh | showdev | Hey everyone,
I wanted to get your feedback on Pixz (pixzapp.com). It's a project I started after returning from a wedding a few months ago. I thought, wouldn't it be cool if the bride/groom could crowdsource photos from all their guests privately and instantly.
Here we are. We launch nearly a week ago. We built our app on flutter and firebase, and have gone through multiple iterations of the app.
I would love for you to check it out and would appreciate any feedback you have. If you want to join the Pixz Beta group. Here is the invite code: 1579209706055
Cheers! Michael | pixzapp |
248,175 | Day 73 : Amazing | liner notes: Professional : So yeah, haven't really been keeping up with my daily blogs. haha I cou... | 0 | 2020-01-25T00:28:09 | https://dev.to/dwane/day-73-amazing-2884 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : So yeah, haven't really been keeping up with my daily blogs. haha I could have sworn, I posted some blogs, but I guess not. To be fair, I have been on a work retreat thing for the last week and just got back today and have been sleeping. I did create a website to chronicle my adventures during that time and that can be found at https://dwane.in/PDXmiami2020
To sum it all up, it was a great time with AMAZING people! Really looking forward to the future.
Here's a pic:

(thanks to Beth for letting me use this pic)
- Personal : Got home from the work retreat, through my clothes into the washing machine and went to sleep. haha. Just got up and have been catching up on things on the internet.
For the rest of the night, I'll be working on the radio show for tomorrow and then some side projects if I have some time.
Have a great night and weekend!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube sy8uXXreMi4 %} | dwane |
248,182 | Copy to clipboard button with Stimulus 2.0 (Beta) | Stimulus is a JavaScript framework developed by a team at Basecamp, and it aims to augment your exist... | 0 | 2020-01-28T00:46:41 | https://dev.to/david_ojeda/copy-to-clipboard-button-with-stimulus-2-0-beta-1nll | stimulus, javascript, webdev | [**Stimulus**](https://stimulusjs.org/handbook/introduction) is a JavaScript framework developed by a team at [Basecamp](https://basecamp.com/), and it aims to augment your existing HTML so things work without too much "connecting" code.
Contrary to other frameworks, Stimulus doesn't take over your front-end, so you can add it without too much hassle to your already running app.
**Its documentation is very clear and digestible**. Included in its handbook is an [example of building a clipboard functionality](https://stimulusjs.org/handbook/building-something-real), which I recommend you go through if you are trying Stimulus for the first time.
Right now we are **replicating** that functionality and adding a couple more things **using a development build** specified in this Pull Request (PR)
{% github https://github.com/stimulusjs/stimulus/pull/202 %}
It **includes new APIs that will be released with version 2.0** of the framework, so they are not yet available with the current stable production release.
# What are we building?
A one-time password "copy to clipboard" button what wraps the DOM Clipboard API.
You can access the final working version on [Glitch](https://glitch.com/edit/#!/trapezoidal-seer):
{% glitch trapezoidal-seer %}
# Starting off
First, we are creating our base HTML where the one-time password will be and the actual button to copy it:
```html
<div>
<label>
One-time password:
<input type="text" value="fbbb5593-1885-4164-afbe-aba1b87ea748" readonly="readonly">
</label>
<button>
Copy to clipboard
</button>
</div>
```

This doesn't do anything by itself; we need to add our Stimulus controller.
# The controller definition
In Stimulus, **a controller is a JavaScript object that automatically connects to DOM elements that have certain identifiers**.
Let's define our clipboard controller. The main thing it needs to do? Grab the text on the input field and copy it to the clipboard:
```javascript
(() => {
const application = Stimulus.Application.start();
application.register("clipboard", class extends Stimulus.Controller {
// We'll get to this below
static get targets() {
return ['source']
}
copy() {
// Here goes the copy logic
}
});
})();
```
Now, this is a valid controller that doesn't do anything because it's not connected to any DOM element yet.
# Connecting the controller
Adding a `data-controller` attribute to our `div` will enable the connection:
```html
<div data-controller="clipboard">
[...]
```
Remember the `static get targets()` from above? That allows us to **access DOM elements as properties in the controller**.
Since there is already a `source` target, we can now access any DOM element with the attribute `data-clipboard-target="source"`:
```html
[...]
<input data-clipboard-target="source" type="text" value="fbbb5593-1885-4164-afbe-aba1b87ea748" readonly="readonly">
[...]
```
Also, we need the button to actually do something. We can link the "Copy to clipboard" button to the `copy` action in our controller with another identifier: `data-action="clipboard#copy"`. The HTML now looks like this:
```html
<div data-controller="clipboard">
<label>
One-time password:
<input data-clipboard-target="source" type="text" value="fbbb5593-1885-4164-afbe-aba1b87ea748" readonly="readonly">
</label>
<button data-action="clipboard#copy">
Copy to clipboard
</button>
</div>
```
Our controller is now automatically connected to the DOM, and clicking the copy button will invoke the `copy` function; let's proceed to write it.
# The copy function
This function is essentially a **wrapper of the DOM Clipboard API**. The logic goes like this:
```javascript
[...]
copy() {
this.sourceTarget.select();
document.execCommand('copy');
}
[...]
```
We take the `source` target we defined earlier, our text input that is, select its content, and use the Clipboard API to copy it to our clipboard.
At this point, **the functionality is practically done!** You can press the button and the one-time password is now available for you on your clipboard.
# Moving further
The copy button works now, but we can go further. **What if the browser doesn't support the Clipboard API or JavaScript is disabled?**
If that's the case, we are going to hide the copy button entirely.
# Checking API availability
We can check if the `copy` command is available to us by doing this:
```javascript
document.queryCommandSupported("copy")
```
One of the best places to check this is when the Stimulus controller connects to the DOM. Stimulus gives us some nice **lifecycle callbacks** so we can know when this happens.
We can create a `connect` function on our controller and it will be invoked whenever this controller connects to the DOM:
```javascript
[...]
connect() {
if (document.queryCommandSupported("copy"))
// Proceed normally
}
}
[...]
```
One way to hide/show the copy button depending on the API availability is to initially load the page with the button hidden, and then displaying it if the API is available.
To achieve this we can rely on CSS:
```css
.clipboard-button {
display: none;
}
/* Match all elements with .clipboard-button class inside the element with .clipboard--supported class */
.clipboard--supported .clipboard-button {
display: initial;
}
```
Our button is now hidden from the beginning, and will only be visible when we add the `.clipboard--supported` class to our `div`.
To do it, we modify the connect lifecycle callback.
Here is where we can start to see major differences from this latest development version. With the actual production version you would need to specify the CSS class in the controller, effectively doing this:
```javascript
[...]
connect() {
if (document.queryCommandSupported("copy"))
this.element.classList.add('clipboard--supported');
}
}
[...]
```
**There is a new, better way to achieve it.**
# Classes API
Now, **CSS classes can be actual properties of the controller**. To do so, we need to add some identifiers to our HTML and add a new array to our controller:
```html
<div data-controller="clipboard" data-clipboard-supported-class="clipboard--supported" class="clipboard">
[...]
```
```javascript
[...]
application.register("clipboard", class extends Stimulus.Controller {
[...]
static classes = ['supported']
connect() {
if (document.queryCommandSupported("copy"))
this.element.classList.add(this.supportedClass);
}
}
[...]
```
Great! Now we can access our supported class string from our controller with `this.supportedClass`. **This will help keep things loosely coupled.**
The clipboard real-life example from Stimulus' handbook ends here. Now, to show the other newest additions and use the *Classes API* once more, we're adding the following functionality:
- A new style to the "Copy to clipboard" button once it has been clicked
- A refresh interval for the one-time password. This will generate a new password every 2.5 seconds
- A data attribute to keep track of how many times the password has been generated
# Values API
This, along with the *Classes API*, is one of the new additions to Stimulus. Before this API you would need to add arbitrary values to your controller with the Data Map API, that is, adding `data-[identifier]-[variable-name]` to your DOM element, and then parsing that value in your controller.
This created boilerplate such as getters and setters with calls to `parseFloat()`, `parseInt()`, `JSON.stringify()`, etc. This is how it will work with the *Values API*:
```html
<div data-controller="clipboard" data-clipboard-supporte-class="clipboard--supported" data-clipboard-refresh-interval-value="2500" class="clipboard">
[...]
```
```javascript
[...]
application.register("clipboard", class extends Stimulus.Controller {
[...]
static values = {
refreshInterval: Number
}
connect() {
if (document.queryCommandSupported("copy"))
this.element.classList.add(this.supportedClass);
}
// Access refreshInterval value directly
this.refreshIntervalValue; // 2500
}
[...]
```
**Accessing your controller values is now cleaner since you don't need to write your getters and setters, nor do you need to parse from String to the type you need.**
Moving forward, let's write the one-time password refresh.
# Implementing password generation
We're going to define a new function to create a new random password. [I grabbed this random UUID generator snippet from the internet](https://www.arungudelli.com/tutorial/javascript/how-to-create-uuid-guid-in-javascript-with-examples/):
```javascript
([1e7]+-1e3+-4e3+-8e3+-1e11).replace(/[018]/g, c =>
(c ^ crypto.getRandomValues(new Uint8Array(1))[0] & 15 >> c / 4).toString(16));
```
Adding it to our Stimulus controller:
```javascript
connect() {
if (document.queryCommandSupported("copy"))
this.element.classList.add(this.supportedClass);
}
if(this.hasRefreshIntervalValue) {
setInterval(() => this.generateNewPassword(), this.refreshIntervalValue)
}
}
// copy function
generateNewPassword() {
this.sourceTarget.value = ([1e7]+-1e3+-4e3+-8e3+-1e11).replace(/[018]/g, c =>
(c ^ crypto.getRandomValues(new Uint8Array(1))[0] & 15 >> c / 4).toString(16));
}
[...]
```
We use `setInterval` to refresh our password text field each 2500ms since that's the value we defined in the DOM.
**Our refresh feature is now working!** Some things still missing:
- Add new style when copy button is clicked
- Keep track of how many times a password is generated
Giving all we have learned so far, this is what's need to be done:
- Add a new CSS class to the stylesheet, DOM element, and controller
- Add this new class when the button is clicked, and remove it when the password is refreshed
- Add to a counter when the password refreshes
This is how it will look at the end:
```css
/* CSS */
.clipboard-button {
display: none;
}
.clipboard--supported .clipboard-button {
display: initial;
}
.clipboard--success .clipboard-button {
background-color: palegreen;
}
```
```html
<!-- HTML -->
<div data-controller="clipboard"
data-clipboard-refresh-interval-value="2500"
data-clipboard-supported-class="clipboard--supported"
data-clipboard-success-class="clipboard--success"
data-clipboard-times-generated-value="1"
>
<label>
One-time password: <input data-clipboard-target="source" type="text" value="fbbb5593-1885-4164-afbe-aba1b87ea748" readonly="readonly">
</label>
<button data-action="clipboard#copy"
class="clipboard-button" >
Copy to Clipboard
</button>
</div>
```
```javascript
// JavaScript
(() => {
const application = Stimulus.Application.start()
application.register("clipboard", class extends Stimulus.Controller {
static get targets() {
return ['source']
}
static values = {
refreshInterval: Number,
timesGenerated: Number
}
static classes = ['supported', 'success'];
connect() {
if (document.queryCommandSupported("copy")) {
this.element.classList.add(this.supportedClass);
}
if(this.hasRefreshIntervalValue) {
setInterval(() => this.generateNewPassword(), this.refreshIntervalValue)
}
}
copy() {
this.sourceTarget.select();
document.execCommand('copy');
this.element.classList.add(this.successClass);
}
generateNewPassword() {
this.sourceTarget.value = ([1e7]+-1e3+-4e3+-8e3+-1e11).replace(/[018]/g, c =>
(c ^ crypto.getRandomValues(new Uint8Array(1))[0] & 15 >> c / 4).toString(16));
this.element.classList.remove(this.successClass);
this.timesGeneratedValue++;
}
// NEW! Read about it below
timesGeneratedValueChanged() {
if(this.timesGeneratedValue !== 0 && this.timesGeneratedValue % 3 === 0) {
console.info('You still there?');
}
}
});
})();
```
Apart from what we've already discussed about the *Values API*, there is also something new: **Value changed callbacks**.
These callbacks are called whenever a value changes, and also once when the controller is initialized. They are connected automatically given we follow the naming convention of `[valueName]ValueChanged()`.
We use it to log a message each time the password has been refreshed three times, but they can help with state management in a more complex use case.
# Wrapping up
I've created multiple Stimulus controllers for my daily job, and I must say that I always end up pleased with the results. Stimulus encourages you to keep related code together and, combined with the additional HTML markup required, ends up making your code much more readable.
If you haven't tried it yet, I highly recommend going for it! It offers a different perspective, one of magic 🧙🏻♂️.
Thanks for reading me 👋🏼.
| david_ojeda |
248,213 | Use any API in seconds with auth managed by Pipedream | Pipedream makes it easy to write Node.js and use any API in seconds! We securely manage auth for 100+... | 0 | 2020-01-25T03:25:52 | https://blog.pipedream.com/use-any-api-in-seconds-with-auth-managed-by-pipedream/ | node, javascript, github, tutorial | <p><a href="https://pipedream.com">Pipedream</a> makes it easy to write Node.js and use any API in seconds! We securely manage auth for 100+ apps (with <a href="https://github.com/PipedreamHQ/roadmap/issues?utf8=%E2%9C%93&q=is%3Aissue+is%3Aclosed+">more added daily</a>) – just connect your app accounts and use the <code>auths</code> object in code to reference tokens and keys.</p><h2 id="github-http-api">Github HTTP API</h2><p>For example, to use Github's HTTP API, just connect your account using a browser-based oauth flow and and pass <code>auths.github.access_token</code> as the value of the <code>Bearer</code> token (check out the <code>octokit</code> section below for an example of how to use <code>auths</code> with an npm package).</p><pre><code class="language-javascript">const axios = require('axios')
const response = await axios({
url: `https://api.github.com/user`,
headers: {
Authorization: `Bearer ${auths.github.oauth_access_token}`,
},
})
return response.data</code></pre><p>Here's a GIF that demonstrates how to use the Github API in 30-seconds:</p><figure class="kg-card kg-image-card"><img src="https://blog.pipedream.com/content/images/2020/01/githubdemo.gif" class="kg-image"></figure><p>In ~30-seconds, I add a code step with Github auth, paste in the code above, connect my account, query the API and inspect the results. <a href="https://pipedream.com/@pravin/github-demo-p_brCnan">Copy this template</a> to try it yourself .</p><h2 id="github-via-octokit">Github via Octokit </h2><p>You're not limited to using Pipedream managed auth with HTTP APIs – it works with npm packages too! Here's an example of the same API request as above, but using Github's <code>octokit</code> package:</p><pre><code class="language-javascript">const Octokit = require('@octokit/rest')
const octokit = new Octokit({
auth: auths.github.oauth_access_token
})
return (await octokit.users.getAuthenticated()).data</code></pre><p>Pipedream transparently installs any npm packages you require in your code when you deploy. To try it yourself, <a href="https://pipedream.com/@pravin/github-demo-p_brCnan">copy this template</a>, enable <code>steps.octokit</code>, connect your account and run the code.</p><figure class="kg-card kg-image-card"><img src="https://blog.pipedream.com/content/images/2020/01/octokitdemo.gif" class="kg-image"></figure><h2 id="scaffolding-api-auth-code">Scaffolding API + Auth Code</h2><p>Pipedream also supports actions, which are re-usable code steps. Actions provides scaffolding for popular APIs and functions. To scaffold a generic API for an app, just click the plus (+) button <strong>, </strong>select the app and choose <strong>Run Node.js with [App Name]</strong>:</p><figure class="kg-card kg-image-card"><img src="https://blog.pipedream.com/content/images/2020/01/basicscaffolding-1.gif" class="kg-image"></figure><p>To scaffold a specific API for an app, just click the plus (+) button , select the app and choose the action that you want to scaffold. Try editing the code and confirm that you want to customize it:</p><figure class="kg-card kg-image-card"><img src="https://blog.pipedream.com/content/images/2020/01/actionscaffold-1.gif" class="kg-image"></figure><h2 id="triggering-your-code">Triggering Your Code</h2><p>Trigger your code:</p><ul><li>Manually</li><li>On an interval or cron schedule</li><li>On HTTP request (Pipedream will generate a unique URL — any requests to this URL will trigger your code)</li><li>On an email (Pipedream will generate a unique email address — any emails sent to this address will trigger your code)</li><li>Via the Pipedream Node.js or Ruby SDKs</li></ul><h2 id="getting-started">Getting Started</h2><p>To get started, just sign in with your Google or Github account at <a href="https://pipedream.com">https://pipedream.com</a>. Check out the project templates at <a href="https://pipedream.com/explore">https://pipedream.com/explore</a>, and join our public Slack at <a href="https://pipedream.com/community">https://pipedream.com/community</a>!</p> | pipedream_staff |
257,264 | Importance of CEH Exam | With the emergence of security related issues across the world, the multinational organizations are l... | 4,719 | 2020-02-07T11:37:50 | https://dev.to/koenigsolutions/importance-of-ceh-exam-251n | ceh, cehexam, ethicalhacking, cybersecurity | With the emergence of security related issues across the world, the multinational organizations are looking for more number of professional and certified ethical hackers. Followed by this demand, CEH Exam is conducted to prepare and train certified ethical hackers, who can serve the MNCs for their security needs.
Importance of CEH Exam
In the digital world, breaching of security is not a much unknown phenomenon, and in order to get past these kinds of issues, one requires some special skills and training. Traditional textbooks cannot enable one with these kinds of skills, as these skills go beyond the traditional boundary of software engineering, network engineering, or mobile technologies.
How to Get Ethical hacking Certification?
The people, who can save the other from these kinds of security breaches, are called ethical hackers, and various multinational organizations recruit a large number of certified ethical hackers. These are the people, who have an in-depth knowledge of network engineering, mobile technology, database system, software engineering, and cyber law. However, anybody and everybody cannot be a specialized ethical hacker, as it requires focused training and guidance. For that reason, examinations, like CEH certification exam , are conducted for preparing an ethical hacker.
How to Prepare for the Exam?
There are several areas, which are taught and evaluated during the course of this exam. Following are those areas:
Tools and Programs
Under this category, you can learn the basic programming and scripting languages, basic and advanced network technologies, various features and background operations of operating systems, networking hardware design, antivirus technologies, security features of operating systems, and database modules.
Security Features
Under this category, you can learn the various security-related technologies required to protect a system or a network. It includes the technologies like cryptography, firewalls, validation techniques, wireless technologies, and other physical verification technologies.
Analysis
CEH certification exam aspirants should be ready to learn the basics of system analysis, the technical analysis and risk analysis of an existing system.
Regulatory Framework
For successful completion of the ethical hacking certification, it is required to know the regulatory framework regarding the existing cyber laws, cyber compliances, code of conduct, and the boundaries of a hacker.
These are the basic skills required for being an ethical hacker. Once these skills are evaluated successfully, one can earn the title of certified ethical hacker. | koenigsolutions |
257,431 | How to Fix a Typo After You've Already Pushed Your Commit | Or alternative title - How I learned to love Git rebase When I first started working with... | 0 | 2020-02-07T16:33:05 | http://bellawoo.com/blog/2020/02/02/rebase.html | git, tutorial | ### Or alternative title - How I learned to love Git rebase
When I first started working with Git, I was indoctrinated into the school of merge and was told to never rebase. Rebasing lets you re-write history. The whole point of Git is to track history. Therefore, rebasing is bad.
But there was one workflow that truly cemented my conversion and has become a regular part of my code writing process - rebasing on my active branch.
Even with linters and a spell checker extension installed in my code editor, from time to time, I'll catch a typo I've committed to git. Or I'll forget a change in a lingering file. And because the basic push workflow has become muscle memory at this point, I would push the commit before I noticed the mistake. I would fix it and do one of these...
```$ git commit -m "fix typo"```
Gross.
But we can fix this quickly with an interactive rebase!
## Fixup First
After fixing my mistakes, I'll stage the file like normal. Then instead of `-m` and the cringy message, I mark the commit with the `--fixup` option. The command expects a commit SHA-1 to attach the fix to.
```
$ git add .
$ git commit --fixup 710f0f8
```
Another neat trick is to refer to the previous commit as the parent of the current one. `HEAD~`, `HEAD^` will both work, as would `HEAD~2` to refer to the commit before last, or the grandparent of the current commit. Note that `~` and `^` [are not interchangable](https://git-scm.com/book/en/v2/Git-Tools-Revision-Selection#_ancestry_references). Git is even smart enought to be able to find the first words of a commit message.
```
# these will all fixup your commit to the previous one.
$ git commit HEAD~
$ git commit HEAD^
$ git commit :/update
```
When I run `git log`, the history will look like this:
```
f7f3f6d (HEAD) fixup! update variable name
310154e update variable name
a5f4a0d (master, origin/master, origin/HEAD) working code on master
```
## Let's rebase!
We add `-i` to run the rebase in interactive mode and supply an argument of the parent of the last commit you want to edit. I use this as a rule: add 1 to the number of commits I need to go back. Adding `--autosquash` will pick up any commits prefaced with `fixup!` and set your interactive rebase session with the commands filled in.
```
$ git rebase -i --autosquash HEAD~3
```
The result of that command will be a list of your commits in ascending order (my default opens in vim) along with the action git should apply when running the commit. Note that the last commit already has `fixup` command attached.
```
pick a5f4a0d working code on master
pick 310154e update variable name
fixup f7f3f6d fixup! update variable name
# Rebase a5f4a0d..f7f3f6d onto a5f4a0d (3 commands)
#
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message
# e, edit <commit> = use commit, but stop for amending
# s, squash <commit> = use commit, but meld into previous commit
# f, fixup <commit> = like "squash", but discard this commit's log message
# x, exec <command> = run command (the rest of the line) using shell
# d, drop <commit> = remove commit
# l, label <label> = label current HEAD with a name
# t, reset <label> = reset HEAD to a label
# m, merge [-C <commit> | -c <commit>] <label> [# <oneline>]
# . create a merge commit using the original merge commit's
# . message (or the oneline, if no original merge commit was
# . specified). Use -c <commit> to reword the commit message.
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
#
# Note that empty commits are commented out
```
At this point, if I'm doing a final clean up to push to a remote branch, I'll maybe `reword` a commit message or maybe even `squash` some extraneous commits together. It's worth having a read through the comments because this is a really powerful workflow, but `fixup` is the one I use the most.
Once you complete the rebase, your revised `git log` should have a new singular commit that has combined your fixup commit with the previous one. _*bows and accepts applause*_
```
2231360 update variable name
a5f4a0d (master, origin/master, origin/HEAD) working code on master
```
## Autosquash magic
`--autosquash` will also pick up commits with `--squash` option, but I tend to not want to keep that message, so fixup works just fine for me. Squash might be a good option if you have a significant amount of new code but want only one atomic commit.
You can also set the following git config setting to omit having to include the autosquash option every time you run an interactive rebase.
`$ git config --global rebase.autosquash true`
My setups always have this set to true, which helped make fixups and squashing commits feel like second nature since to enter a rebase session, I only have to type `git rebase -i HEAD~3` or however many commits I think I need to clean up.
## And that's how I converted to rebase!
Other helpful resources include this [git tutorial on revising history](https://git-scm.com/book/en/v2/Git-Tools-Rewriting-History). Once I digested that, I found it easier to understand the [full doc on rebase](https://git-scm.com/docs/git-rebase). | bellawoo |
257,479 | Supporting multiple configurations in Cypress | By default, Cypress will support a single configuration based on the optional file cypress.json as... | 0 | 2020-02-07T18:54:34 | http://yer.ac/blog/2020/02/07/supporting-multiple-configurations-in-cypress/ | testing, cypress, javascript, tutorial | ---
title: Supporting multiple configurations in Cypress
published: true
date: 2020-02-07 16:13:12 UTC
tags: Testing,Cypress,Javascript,tutorial
canonical_url: http://yer.ac/blog/2020/02/07/supporting-multiple-configurations-in-cypress/
---
By default, Cypress will support a single configuration based on the optional file `cypress.json` as described in their documentation [here](https://docs.cypress.io/guides/references/configuration.html).
Whilst this works fine for most, it would be great if we could have access to a `cypress.dev.json` for local development, or even better, a whole host of configuration files for use against a multi-tenant environment – for example `cypress.clientA.json`, `cypress.clientB.json` etc.
Whilst Cypress accepts a different config file during startup with the `--config-file` flag, it would be better if we could just pass the environment name through instead of the full file name and/or location, right?
### Uses for environmental variables
I personally use these environmental files to store things like:
- Base URL: Each client has its own SIT/UAT environments with different URLs
- Default username and password for test environments.
### Creating the different config files
We can create a root level folder named “Config”. Under here we can create as many files as we need to cover, for example I have `config.ClientA.json` which contains:
```
{
"baseUrl": "http://clientA.internalserver.co.uk/",
"env": {
"someVariable": "Foo"
}
}
```
And `config.ClientB.json` which contains:
```
{
"baseUrl": "http://clientB.internalserver.co.uk/",
"env": {
"someVariable": "Bar"
}
}
```
## Editing the plugin file
First we need to import “path” and “fs-extra” packages by adding the following at the top of the `index.js` file within the `/Plugins` folder (if it doesn’t already exist!). These will allow the file to be located and subsequently read.
```
const path = require("path");
const fs = require("fs-extra");
```
Next we need the method which will take in a client name/environmental variable, locate the appropriate config file (being /config/config. **name**.json), and then reading that file back to the calling method.
```
function getConfigurationFileByEnvName(env) {
const fileLocation = path.resolve("cypress/config", `config.${env}.json`);
return fs.readJson(fileLocation);
}
```
and finally we need the index.js file to export this file. This will also have a fallback in place if one is not defined.
```
module.exports = (on, config) => {
const envFile = config.env.configFile || "local";
return getConfigurationFileByEnvName(envFile);
};
```
The eagle eyed may realise that I am using `config.env.configFile` here which will mean passing an environmental flag in the command line rather than making direct use of the `--config` flag. This is personal preference, as I aim to expand on the `env` flags later so this will look cleaner.
### Consuming the configuration
Now, when running the usual open command, we can make use of the `--env` flag to pass it the environmental variable. We do so with:
`./node_modules/.bin/cypress open --env configFile=clientA`
It should now launch the test runner with your different files environmental variables available via `Cypress.env('key')`
The post [Supporting multiple configurations in Cypress](http://yer.ac/blog/2020/02/07/supporting-multiple-configurations-in-cypress/) appeared first on [yer.ac | Adventures of a developer, and other things.](http://yer.ac/blog). | yerac |
257,493 | WebScrapping articles to read offline | I don't have internet at home so I wanted to read some articles offline when I'm home.. Which approac... | 0 | 2020-02-07T17:39:26 | https://dev.to/rnrnshn/webscrapping-articles-to-read-offline-p7f | help, discuss, tutorial | I don't have internet at home so I wanted to read some articles offline when I'm home.. Which approach should I use to have those article offline?
Is there any web scrapping tutorial or tool that I should use?? | rnrnshn |
257,571 | An Intro to Elixir from a JavaScript Background | Elixir is a functional programming language that extends the Erlang language, which is an older langu... | 0 | 2020-02-08T21:00:34 | https://dev.to/ryanmoragas/an-intro-to-elixir-4k0d | beginners, elixir, productivity, javascript | Elixir is a functional programming language that extends the Erlang language, which is an older language that gained its popularity in the 80's, and is mixed with Ruby syntax. The language is fairly new, being created in 2011, and has excellent documentation. It is a functional programming language and has no classes, but instead modules with module functions. Elixir also has a mature web framework called Phoenix, which makes using it much easier when developing real world applications.
After you install Elixir you will have three new executables right out of the box, being `iex`, `elixir` and `elixirc`. If you compiled Elixir from source or are using a packaged version, you can find these inside the bin directory. For these exmaples I'll use `iex` (or `iex.bat` if you are on Windows) which stands for Interactive Elixir. In interactive mode, you can type any Elixir expression and get its result immediately in the terminal.
Before getting started it is probably best to cover the basics on Elixir, and that starts with its simple data types. There are several different types of simple data types in Elixir, being integers, floats, strings, atoms, booleans, lists, and tuples. I'll touch on each of these data types with a brief explanation of what they are.
Integers and floats are both number data types. Integers can be thought of as whole numbers, and floats are integers with decimal values. While these data types might seem similar, integers and floats are two completely different values and can never be strictly equal to each other. With that being said, you can still use integers and floats together in operations, and sometimes operations on integers will automatically produce floats.
``` ex
iex(1)> 2 + 2
4
iex(2)> 3 * 3
9
iex(3)> 3 / 3
1.0
iex(4)> 1 === 1.0
false
```
As seen from the code above, performing division on two integers will always produce a float. You can also see that even though mathematically 1 === 1.0 is true, since they are two different data types in Elixir they are not strictly equal values.
Next on the list of simple data types we have strings. All strings in Elixir must be declared using double quotes. Strings are essentially binaries converted to characters, so you can treat them the same. To append strings together, unlike using `+` in JavaScript, you use the `<>` operator. You can use simple concatenation to add strings together. You can also interpolate values but placing them into the `#{//value}` interpolation syntax.
```ex
iex(5)> intro = "hello"
"hello"
iex(6)> "#{intro} " <> "world!"
"hello world!"
```
Atoms are simple data types that will always equal themselves. The can be defined by putting a colon in front of the value. In other languages, they are sometimes called symbols. A close reference would be assigning a value to const in JavaScript, but atoms also act similar to booleans.
```ex
iex(7)> :atom === :atom
true
iex(8)> :true === true
true
iex(9)> :true === "true"
false
```
Lists are complex data types that store references to any value types in a specific order. They are defined with brackets, and very comparable to arrays in JavaScript. Any data type can be stored in a list and data is accessed in reference to the head and the tail. The head is the first value in a list and the tail is a list of all values after the head. The values in a list can be accessed with the `hd/1` and `tl/1` functions. To concatenate two lists you would use `++`, and to subtract you would use '--'.
```ex
iex(10)> list = [7, 16.6, :atom, "bird"]
[7, 16.6, :atom, "bird"]
iex(11)> list ++ ["cat", false]
[7, 16.6, :atom, "bird", "cat", false]
iex(12)> list
[7, 16.6, :atom, "bird"]
iex(13)> hd list
7
iex(14)> tl list
[16.6, :atom, "bird"]
```
Tuples are also lists of values, and defined with curly brackets. They still act more like a JavaScript array rather than an object, as the don't have key value pairs. A tuple may contain elements of different types, which are stored contiguously in memory. Accessing any element takes constant time, but modifying a tuple, which produces a shallow copy, takes linear time. Tuples are good for reading data while lists are better for traversals. Tuples are typically used either when a function has multiple return values or for error handling.
Hopefully this was a helpful first glance into Elixir. While they have some similarities, Elixir and JavaScript also have many differences. The documentation for Elixir is extremely helpful, and their website also has beginner tutorials if you'd like to learn more. | ryanmoragas |
257,579 | AES-GCM Encryption with C# | Here is example how can you use encryption with AES GCM with C#. Its currently supported in .NET Core... | 0 | 2020-02-07T21:32:52 | https://dev.to/maymeow/aes-gcm-encryption-with-c-23oi | csharp, dotnet |
Here is example how can you use encryption with AES GCM with C#. Its currently supported in .NET Core 3.0, 3.1 and .NET Standard 2.1. For .NET Framework you will need to use CBC. This code and more is awailable in my nuget package [MayMeow.Cryptography](https://www.nuget.org/packages/MayMeow.Cryptography/).
So How to encrypt data?
```csharp
public static byte[] Encrypt(byte[] toEncrypt, byte[] key, byte[] associatedData = null)
{
byte[] tag = new byte[KEY_BYTES];
byte[] nonce = new byte[NONCE_BYTES];
byte[] cipherText = new byte[toEncrypt.Length];
using (var cipher = new AesGcm(key))
{
cipher.Encrypt(nonce, toEncrypt, cipherText, tag, associatedData);
return Concat(tag, Concat(nonce, cipherText));
}
}
```
This will create byte array which looks like this
|Tag|Nonce|Encrypted Data|
|---|---|---|
|16 Bytes| 12 bytes | ...x bytes |
Everything you have to provide is key. Tag and NONCE is different for each data you vant to encrypt and its a part of array.
Function for decrypt data:
```csharp
public static byte[] Decrypt(byte[] cipherText, byte[] key, byte[] associatedData = null)
{
byte[] tag = SubArray(cipherText, 0, KEY_BYTES);
byte[] nonce = SubArray(cipherText, KEY_BYTES, NONCE_BYTES);
byte[] toDecrypt = SubArray(cipherText, KEY_BYTES + NONCE_BYTES, cipherText.Length - tag.Length - nonce.Length);
byte[] decryptedData = new byte[toDecrypt.Length];
using (var cipher = new AesGcm(key))
{
cipher.Decrypt(nonce, toDecrypt, tag, decryptedData, associatedData);
return decryptedData;
}
}
```
In those functions i using concat and subarray functions. For merging arrays together and splitting them. they are here:
```csharp
public static byte[] Concat(byte[] a, byte[] b)
{
byte[] output = new byte[a.Length + b.Length];
for (int i = 0; i < a.Length; i++)
{
output[i] = a[i];
}
for (int j = 0; j < b.Length; j ++)
{
output[a.Length + j] = b[j];
}
return output;
}
```
```csharp
public static byte[] SubArray(byte[] data, int start, int length)
{
byte[] result = new byte[length];
Array.Copy(data, start, result, 0, length);
return result;
}
```
Theese and more are part of **MayMeow.Cryptography** repository which is awailable on my [Github](https://github.com/MayMeow/MayMeow.Cryptography).
[](https://ko-fi.com/D1D5DMOTA) | maymeow |
257,747 | Peppermint OS - A Quick Review | Introduction This is a quick review of Peppermint OS 10, as I am not used to do running... | 3,426 | 2020-02-08T06:45:02 | https://dev.to/twitmyreview/peppermint-os-a-quick-review-3jg8 | productivity, ubuntu, opensource, linux |

### Introduction
This is a quick review of Peppermint OS 10, as I am not used to do running linux in a VM for my daily usage, the only thing I could do was to do a whirlwind check of Peppermint OS. My first impression from the initial flash screen and the desktop layout was that it looked right out of early 2000s desktop experience - retro by design. Running on a 4GB ram 64 bit VM, the response was snappy and reminded of early Linux OS desktops way back from 2009-10 when I mostly used as a desktop. But once you open the start menu and the applications, it was more modern and the dark theme really made me happy.

### Things I Liked
I liked the number of in-built apps and also links to web apps like Google Drive and Microsoft Word. While initially I thought it as a bloatware. After checking a tool called Ice created by Peppermint, made me like the whole concept of having Web Apps in start menu. This is one feature other light weight OS should have.

This is something I use extensively with chrome on Windows 10 and by organising websites like Gmail, Drive and Google Docs as shortcuts is very handy and I feel no need to install their desktop variants. While in Peppermint these links are opened in dedicated Firefox windows and the experience is not as clean as a Chrome dedicated window but still I feel in a real laptop or desktop this feature will be very handy.

I also liked that it had many applications out of the box that we as users will need from time to time. As a daily driver this OS is very helpful but its usability is enhanced by using ICE and the WebApps for which links are embedded in start menu and would be leveraged well when connected to internet. And the fact that its built on Ubuntu we get all the advantages of all the package managers available in the Ubuntu ecosystem.

## Issues
However aesthetically the Peppermint OS is too much retro. I had few issues with the Live ISO where I did not get the full screen mode where I can leverage the bigger real state of the desktop and check it out properly. Even during boot there were few warnings which I did not get in other ubuntu based ISOs that I have tried.
### Final Thoughts
Since I am just checking out this OS I am sure there are many features that I have not tried and would be awesome. With XFCE and host of many out of the box apps this is a good light weight OS for your old machine and a good replacement to Windows 7.
| twitmyreview |
257,757 | Using Asynchronous Processes in PHP. | Easily run code asynchronously in PHP, by running different processes in parallel. | 0 | 2020-02-08T08:33:38 | https://dev.to/webong/using-asynchronous-processes-in-php-7io | php, async, parallel | ---
title: Using Asynchronous Processes in PHP.
published: true
description: Easily run code asynchronously in PHP, by running different processes in parallel.
tags: PHP, async, parallel
---
For most programs written in PHP, its sole purpose is to execute a simple process consisting of multiple tasks, where the tasks must be executed in sequence such as data processing. We always have to tolerate the stop and wait aspect of synchronous programming. The synchronous style of code execution is referred to as blocking, this implies that tasks will be executed one by one. So what if we want to run tasks without them blocking each other, that means we need to have a non-blocking process? This approach would require applying asynchronous programming approaches in PHP, here tasks will be executed without depending on of each other.
A common approach to achieve a non-blocking execution in PHP is to implement queue processing. Tasks are persisted to a transport system e.g MySQL, Redis, Amazon SQS e.t.c, which is retrieved by a background worker and executed accordingly, thereby not blocking the main process in which it was created. A laravel application provides a queue mechanism that allows tasks in this case called jobs to be deferred for to a later time for processing.
Another approach would be to run all defined tasks in parallel. What we get out of this approach is that a particular task is done it can return control back to the main process immediately with a promise to execute code and notify us about the result later(e.g. callback). One might see little use case for the parallel processing approach; example use case could be performing image processing and making a get request to some external service.
Let’s see the difference between synchronous and asynchronous (parallel) process in PHP using a very simple use case.
Synchronous code
```php
foreach (range(1, 5) as $i) {
$output = $i * 2;
echo $output . "\n";
}
```
Asynchronous code
```php
use Spatie\Async\Pool;
$pool = Pool::create();
foreach (range(1, 5) as $i) {
$pool[] = async(function () use ($i) {
$output = $i * 2;
return $output;
})->then(function (int $output) {
echo $output . "\n";
});
}
await($pool);
```
When we execute the first code we will get the output values in this order:
2
4
6
8
10
Retrying the execution, we will get the output in this same sequence above … hence each multiplication operation waits to execute before the next one. Next, running the second code block, let’s see what we get.
6
10
2
8
4
Retrying the execution for the second time:
2
6
4
10
8
One process happens to produce two different results. This exactly is what we get for utilising the asynchronous approach … our little tasks can be executed in a fashion they don’t block each other. Each multiplication task executes independently, some faster than others hence the disorderliness in the output. Also, notice our async function as a then method attached to it, this method is responsible for taking back control and it accepts a callback function as its parameter which can now perform extra operations with the received output.
The folks at Spatie made this nice `spatie/async` package, which helps in performing tasks in parallel. You can install the package via composer:
```bash
composer require spatie/async
```
The package provides a neat way to interact with the tasks created, that are to be executed in parallel. The Event Listeners on the tasks are described below:
- Performing another operation when the task is done as the callback is achievable with its `then` method.
- Error handling is easier to control when a particular task throws an exception using the `catch` method.
- Take for instance a task does not complete its operation, a `timeout` method allows one to handle such a scenario.
The event listeners are hooked to a task as shown below:
```php
$pool
->add(function () {
// Task to be performed in a Parallel process
})
->then(function ($output) {
// On success, `$output` is returned by the process or callable you passed to the queue.
})
->catch(function ($exception) {
// When an exception is thrown from within a process, it's caught and passed here.
})
->timeout(function () {
// Ohh No! A process took too long to finish. Let's do something
})
;
```
To learn more about the `spatie/async` package read this article from one of its contributors [here](https://stitcher.io/blog/asynchronous-php) and you can also refer to the [GitHub repo](https://github.com/spatie/async).
| webong |
257,821 | How you do code reviews for your side project? | Recently, I have been doing some mini projects to learn new things or practice skills. But how can I... | 0 | 2020-02-08T10:32:21 | https://dev.to/hey_yogini/how-you-do-code-reviews-for-your-side-project-46o8 | discuss, sideprojects, webdev | Recently, I have been doing some mini projects to learn new things or practice skills. But how can I get to know I am following best practices? How to improve the quality of code and implement better logic?
What are your thoughts on this? How you improve your code and how you do code reviews for your side projects? | hey_yogini |
732,296 | React Interview Questions - Basic | Lets Begin with some of the basic ReactJs Interview Questions 1> How does React Work ? Ans.... | 0 | 2021-06-18T16:19:42 | https://dev.to/skj4ua/react-interview-questions-basic-1ja1 | react | Lets Begin with some of the basic ReactJs Interview Questions
1> How does React Work ?
Ans. React creates a virtual DOM. when there is any state changes in the DOM a diffing Algorithm runs to check what has changed in the in the virtual DOM. Next Reconciliation takes place where the where it udpates the DOM with the Difference.
2> What is Context ?
Ans. Context provides a way to pass data through the component tree without having to pass props down manually at the every level.
3> what is props in react ?
Ans. Props accept values in the component that are passed down to a child component.
primary purpose of props in react is to provide following component functionality :
1. pass custom data to your react component
2. Trigger state changes
3. use via this.props.reactProp inside Component's render() method.
4> what is the use of refs ?
Ans. Refs provide a way to access DOM nodes or React elements created in the render method.
They should be avoided in most cases, however, they can be useful when we need direct access to DOM element or an instance of a component.
Refs are created using React.createRef() and attached to React elements via the ref attribute.
Ex. class MyComponent extends React.Component {
constructor(props) {
super(props);
this.myRef = React.createRef(); }
render() {
return <div ref={this.myRef} />; }
}
5> what is JEST ?
Ans. Jest is a javascript unit testing framework made by facebook based on jasmine and provides automated mock creation and a jsdom environment. It's often used for testing React Components.
6> what are the advantages of ReactJs ?
Ans. 1> Increases the applications performanec with Virtual Dom
2> JSX makes code easy to read and write
3> it renders both on client and server side
4> Easy to integrate with other frameworks
5> Easy to write UI test case and integration with tools such as JEST.
7> How would you write an inline style in React ?
Ans. <div style= {{heigh:10}}>
8> What is React ?
Ans. React is an open source Javascript library created by facebook for building complex, interactive UIs in web and mobile applications. React's core purpose is to build UI components; It is often referred to as just the "V" (view) in
an "MVC" architecture.
9> What are major features of ReactJs ?
Ans. The major features of ReactJs are follows,
. It uses VirtualDOM instead RealDOM considering that RealDOM manipulation are expensive.
. Support server-side rendering.
. Follows Unidirectional data flow or data binding.
. Uses reuseable/composable UI components to develop the view
10> Where in a React component should you make an AJAX request ?
Ans. componentDidMount is where an AJAX request should be made in a React component.
This method will be executed when the component "mounts" (is added to the DOM) for the first time.
11> what is the difference between state and props?
Ans. The state is a data structure that starts with a default value when a Component mounts. It may be mutated across time, mostly as a result of user events.
Props (short for properties) are a component's configuration. They are received from above and immutable as far as the component receiving them is concerned.
12> What is the difference between a presentational component and a container component ?
Ans. Presentational components are concerned with how things look.
Container components are more concerned with how things work.
Thanks For Reading :)
| skj4ua |
257,827 | Rolling, secure hashes for nodes in a tree / How to reduce on-disk space consumption? | Hi all, I've implemented the storage of rolling, secure hashes for a temporal document store called... | 0 | 2020-02-08T10:57:35 | https://dev.to/johanneslichtenberger/rolling-secure-hashes-for-nodes-in-a-tree-how-to-reduce-on-disk-space-consumption-i73 | help, discuss, java, kotlin | Hi all,
I've implemented the storage of rolling, secure hashes for a temporal document store called [SirixDB](https://sirix.io).
During bulk inserts hashes are built while traversing the built tree in postorder. During updates, that is deletes, inserts or value updates hashes of ancestor nodes are adapted. We have unique node-IDs and hashes are built taking neighbour nodes into account (the 64 Bit node-IDs pointing to the sibling nodes).
For instance during an update the old hash is subtracted and a new hash basically added to parent node and that's bubbling up for all ancestors.
Now I wanted to reduce the collision possibility to a minimum and used Sha256 truncated to 128 Bits.
However, now every node optionally stores this hash, which is an additional 16 Bytes.
My idea would be to store all hashes of the nodes at the beginning of the variable sized page in a delta-encoding, for instance subtracting each consecutive hash from the former and storing some kind of variable size encoding.
Do you have any ideas how to best "compress" the hashes on-disk? Currently at most 512 nodes are stored in a page meaning 512*16 bytes only for the hashes.
Kind regards
Johannes
| johanneslichtenberger |
257,836 | Learn Nim: Create a README Template Downloader | Create a command-line tool which downloads a README template for your coding projects Why... | 0 | 2020-02-08T12:17:37 | https://www.rockyourcode.com/learn-nim-create-a-readme-template-downloader/ | tutorial, nim | ---
title: Learn Nim: Create a README Template Downloader
published: true
date: 2020-02-08 00:00:00 UTC
cover_image: https://repository-images.githubusercontent.com/842037/cf468f00-88a5-11e9-8d1a-d5fba75d3eb5
canonical_url: https://www.rockyourcode.com/learn-nim-create-a-readme-template-downloader/
---
> Create a command-line tool which downloads a README template for your coding projects
## Why Nim?
**[Nim][nimlang]** is a statically typed systems programming language.
Nim generates small, native _dependency-free_ executables. The language combines a Python-like syntax with powerful features like meta-programming.
Nim supports macOS, Linux, BSD, and Windows. The language is open-source and has no corporate affiliation.
Nim compiles to multiple backends, for example, C, C++, or JavaScript.
The ecosystem and community are small, but the language has reached its first stable release.
If you're interested in a low-level language, then you should take a look at Nim. It's easier to learn than languages like C++ or Rust, but can be a decent replacement for those languages.
More about Nim on the Nim forum: [Why use Nim?][whyusenim]
---
In this blog post, I will **show you how to create a command-line tool** with Nim.
You will learn how to:
- connect to the internet with an HTTP client
- parse command-line options
- create a file on your system (IO)
- compile a Nim application and execute it
## Install Nim
First, [install Nim on your operating system][installnim].
I like to use **[choosenim][choosenim]**. choosenim is a tool that allows you to install Nim and its toolchain easily. You can manage multiple Nim installations on your machine.
Here's how to install Nim with [choosenim][choosenim]:
- Windows:
Get the [latest release](https://github.com/dom96/choosenim/releases) and run the `runme.bat` script.
- Unix (macOS, Linux):
```bash
curl https://nim-lang.org/choosenim/init.sh -sSf | sh
```
## (Optional) Nim Basics
Nim offers [splendid tutorials and community resources to get started][learnnim].
I recommend taking a look at [Learn Nim in Y minutes](https://learnxinyminutes.com/docs/nim/) or [Nim By Example](https://nim-by-example.github.io/getting_started/) to get a sense of the language.
## Let's Create Our First Program
### The Goal
I often need a README template for my coding projects.
My favorite template is **[Best-README-Template][bestreadmetemplate]**.
But there also other good examples, e.g.:
- [PurpleBooth/README-Template][purplebooth]
- [akashnimare/README][akashnimare]
- [dbader/readme-template][dbader]
- [jehna/readme-best-practices][jehna]
We want to create a command-line utility which downloads such a template as `README.md` to the current folder.
You could achieve that goal by using a library like [curl](https://curl.haxx.se/). But what happens if your system doesn't have curl?
Our Nim utility will compile to a stand-alone C binary that will seamlessly run on your system without any dependencies like curl or [wget](https://www.gnu.org/software/wget/).
And we'll learn a bit Nim along the way.
### 1. Connect to the Internet
Create a new file called `readme_template_downloader.nim`:
```nim
import httpClient
var client = newHttpClient() ## mutable variable `var`
echo client.getContent("https://raw.githubusercontent.com/othneildrew/Best-README-Template/master/README.md")
```
These lines import the [httpclient library](https://nim-lang.org/docs/httpclient.html) and create a new instance of the HTTP client.
[`getContent`](https://nim-lang.org/docs/httpclient.html#getContent%2CHttpClient%2Cstring) is an inbuilt procedure (function) that connects to the URL and returns the content of a GET request. For now, we use `echo` to write to standard output.
Save the file. We'll now compile it to a C binary.
```bash
nim c -d:ssl readme_template_downloader.nim
```
`c` stands for compile, `-d:ssl` is a [flag that allows us to use the OpenSSL library](https://nim-lang.org/docs/httpclient.html#sslslashtls-support).
Now you can run the application. Here's the command for Unix:
```bash
./readme_template_downloader
```
You should now see the result of the README template in your terminal.
You can also compile and run the program in a single step:
```bash
nim c -d:ssl -r readme_template_downloader
```
### 2. Create a Procedure
Procedures in Nim are what most other languages call functions. Let's adjust our file:
```nim
import httpClient
var url = "https://raw.githubusercontent.com/othneildrew/Best-README-Template/master/README.md"
proc downloadTemplate(link: string) =
var client = newHttpClient()
echo client.getContent(link)
when isMainModule:
downloadTemplate(url)
```
The `when` statement is a compile-time statement. If you import the file, Nim won't run the `downloadTemplate` procedure.
Here the file represents our main module and Nim will invoke the procedure.
In the `downloadTemplate` procedure, we define the input parameter (link is of type `string`), but we allow Nim to infer the type of the output.
Don't forget to re-compile and to rerun the application:
```bash
nim c -d:ssl -r readme_template_downloader
```
### 3. Write to a File (IO)
We're able to get the content of the URL, but we haven't saved it to a file yet.
We'll use the [io module](https://nim-lang.org/docs/io.html), part of the standard library, for that. We don't have to import anything, it works out of the box.
```nim
import httpClient
var url = "https://raw.githubusercontent.com/othneildrew/Best-README-Template/master/README.md"
proc downloadTemplate(link: string) =
var client = newHttpClient()
try: ## (A)
var file = open("README.md", fmWrite) ## (B)
defer: file.close()
file.write(client.getContent(link))
echo("Success - downloaded template to `README.md`.")
except IOError as err: ## (C)
echo("Failed to download template: " & err.msg)
when isMainModule:
downloadTemplate(url)
```
On line `(A)`, we use a [`try statement`](https://nim-lang.org/docs/tut2.html#exceptions-try-statement). It's the same as in Python. With a `try statement`, you can handle an exception.
On line `(B`), we use `open` to [create a new file in write mode](https://nim-lang.org/docs/io.html#FileMode). If the file does not exist, Nim will create it. If it already exists, Nim will overwrite it.
`defer` works like a [context manager in Python](https://www.geeksforgeeks.org/context-manager-in-python/). It makes sure that Nim closes the file after the operation finishes.
With `file.write` Nim will save the result of the HTTP GET request to the file.
On line `(C)`, we handle the exception. We can append the message of the IOError to the string that we'll write to standard output.
For example, if we provide an invalid URL for the HTTP client, the CLI program will output a line like this:
```bash
Failed to download template: 404 Bad Request
```
### 4. Let's Code the CLI Interaction
When we run the program with `--help` or `-h`, we want some information about the application. Something like this:
```bash
nim_template -h
README Template Downloader 0.1.0 (download a README Template)
Allowed arguments:
- h | --help : show help
- v | --version : show version
- d | --default : dowloads "BEST-README-Template"
- t | --template : download link for template ("RAW")
```
Add these lines to the `readme_template_downloader.nim` file:
```nim
proc writeHelp() =
echo """
README Template Downloader 0.1.0 (download a README Template)
Allowed arguments:
- h | --help : show help
- v | --version : show version
- d | --default : dowloads "BEST-README-Template"
- t | --template : download link for template ("RAW")
"""
proc writeVersion() =
echo "README Template Downloader 0.1.0"
```
### 5. Let's Write the CLI Command
We'll write a procedure as the entry point of the script. We'll move the initialization of the url variable into the procedure, too.
```nim
import httpclient, os
## previous code
proc cli() =
var url: string = "https://raw.githubusercontent.com/othneildrew/Best-README-Template/master/BLANK_README.md"
if paramCount() == 0:
writeHelp()
quit(0) ## exits program with exit status 0
when isMainModule:
cli()
```
Add `os` to the list of imports at the top of the file for `paramCount` to work.
[`paramCount`](https://nim-lang.org/docs/os.html#paramCount) returns the number of command-line arguments given to the application.
In our case, we want to show the output of `writeHelp` and exit the program if we don't give any option.
Here's the whole program so far:
```nim
import httpClient, os
proc downloadTemplate(link: string) =
var client = newHttpClient()
try:
var file = open("README.md", fmWrite)
defer: file.close()
file.write(client.getContent(link))
echo("Success - downloaded template to `README.md`.")
except IOError as err:
echo("Failed to download template: " & err.msg)
proc writeHelp() =
echo """
README Template Downloader 0.1.0 (download a README Template)
Allowed arguments:
- h | --help : show help
- v | --version : show version
- d | --default : dowloads "BEST-README-Template"
- t | --template : download link for template ("RAW")
"""
proc writeVersion() =
echo "README Template Downloader 0.1.0"
proc cli() =
var url: string = "https://raw.githubusercontent.com/othneildrew/Best-README-Template/master/BLANK_README.md"
if paramCount() == 0:
writeHelp()
quit(0)
when isMainModule:
cli()
```
Compile and run. You should see the help information in your terminal.
#### 5.1. Parse Command-Line Options
Now we need a way to parse the command-line options that the program supports: `-v`, `--default`, etc.
Nim provides a [`getopt` iterator](https://nim-lang.org/docs/parseopt.html#getopt.i%2COptParser) in the [parseopt module](https://nim-lang.org/docs/parseopt.html).
Add `import parseopt` to the top of the file.
```nim
import httpclient, os, parseopt
## previous code
proc cli() =
var url: string = "https://raw.githubusercontent.com/othneildrew/Best-README-Template/master/BLANK_README.md"
if paramCount() == 0:
writeHelp()
quit(0)
for kind, key, val in getopt(): ## (A)
case kind
of cmdLongOption, cmdShortOption:
case key
of "help", "h":
writeHelp()
quit()
of "version", "v":
writeVersion()
quit()
of "d", "default": discard ## (B)
of "t", "template": url = val ## (C)
else: ## (D)
discard
else:
discard ## (D)
downloadTemplate(url) ## (E)
```
The iterator (line `A`) checks for the long form of the option (`--help`) and the short form (`-h`). The case statement is a multi-branch control-flow construct. See [case statement in the Nim Tutorial](https://nim-lang.org/docs/tut1.html#control-flow-statements-case-statement). The case statement works like the [switch/case statement from JavaScript](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/switch).
`--help` and `-h` invoke the `writeHelp` procedure. `--version` and `-v` invoke the `writeVersion` procedure we defined earlier.
`--default` or `-d` is for the default option (see line `B`). If we don't provide any arguments, our application will give us the help information. Thus, we have to provide a command-line argument for downloading the default README template. We can `discard` the value provided to the `-d` option, because we'll invoke the `downloadTemplate` procedure with the default URL later (line `E`).
The `-t` or `--template` (line `C`) change the value of the `url` variable.
Let's say we run the Nim program like this:
```bash
./readme_template_downloader -t="https://gist.githubusercontent.com/PurpleBooth/109311bb0361f32d87a2/raw/8254b53ab8dcb18afc64287aaddd9e5b6059f880/README-Template.md"
```
Now Nim will overwrite the default url variable with the provided option in `-t`.
We'll discard everything else (lines `D`), because we can ignore any other options we provide to our Nim program.
You can find the complete script as a [GitHub Gist][gist]:
```nim
import httpclient, parseopt, os
proc downloadTemplate(link: string) =
var client = newHttpClient()
try:
var file = open("README.md", fmWrite)
defer: file.close()
file.write(client.getContent(link))
echo("Success - downloaded template to `README.md`.")
except IOError as err:
echo("Failed to download template: " & err.msg)
proc writeHelp() =
echo """
README Template Downloader 0.1.0 (download a README Template)
Allowed arguments:
- h | --help : show help
- v | --version : show version
- d | --default : dowloads "BEST-README-Template"
- t | --template : download link for template ("RAW")
"""
proc writeVersion() =
echo "README Template Downloader 0.1.0"
proc cli() =
var url: string = "https://raw.githubusercontent.com/othneildrew/Best-README-Template/master/BLANK_README.md"
if paramCount() == 0:
writeHelp()
quit(0)
for kind, key, val in getopt():
case kind
of cmdLongOption, cmdShortOption:
case key
of "help", "h":
writeHelp()
quit()
of "version", "v":
writeVersion()
quit()
of "d", "default": discard
of "t", "template": url = val
else:
discard
else:
discard
downloadTemplate(url)
when isMainModule:
cli()
```
Don't forget to re-compile the finished application.
## Recap
In this blog post, you learned how to create a Nim utility that downloads a file from the internet to the current folder on your machine.
You learned how to create an HTTP Client, how to write to a file, and how to parse command-line options.
Along the way, you gained a basic understanding of the Nim language: how to use variables, procedures (functions), how to handle exceptions.
To learn more about Nim, see [Learn Nim][learnnim].
### Acknowledgments
Credits go to [xmonader for his Nim Days repository][nimdays].
## Links
- [Nim Language][nimlang]
- [Learn Nim][learnnim]
- [Why use Nim?][whyusenim]
- [Best-README-Template][bestreadmetemplate]
- [PurpleBooth/README-Template][purplebooth]
- [akashnimare/README][akashnimare]
- [dbader/readme-template][dbader]
- [jehna/readme-best-practices][jehna]
- [RichardLitt/standard-readme][richardlitt]
[bestreadmetemplate]: https://github.com/othneildrew/Best-README-Template
[nimlang]: https://nim-lang.org/
[gist]: https://gist.github.com/sophiabrandt/5c48685277002c1b1ceb618245bfd481
[nimdays]: https://xmonader.github.io/nimdays/day06_nistow.html
[purplebooth]: https://gist.github.com/PurpleBooth/109311bb0361f32d87a2
[akashnimare]: https://gist.github.com/akashnimare/7b065c12d9750578de8e705fb4771d2f
[dbader]: https://github.com/dbader/readme-template
[jehna]: https://github.com/jehna/readme-best-practices/blob/master/README-default.md
[richardlitt]: https://github.com/RichardLitt/standard-readme#readme
[installnim]: https://nim-lang.org/install.html
[choosenim]: https://github.com/dom96/choosenim#choosenim
[learnnim]: https://nim-lang.org/learn.html
[whyusenim]: https://forum.nim-lang.org/t/5214#32703 | sophiabrandt |
257,884 | Android ViewModels: Saving State across Process Death | A misconception among some android developers is that the purpose of using ViewModels is state persis... | 0 | 2020-02-08T14:09:34 | https://dev.to/ahmedrizwan/android-viewmodels-saving-state-across-process-death-3n03 | kotlin, architecture, viewmodels, android | A misconception among some android developers is that the purpose of using ViewModels is state persistence — it’s actually partly true — they do help in saving state across configuration change (e.g. device rotation) but not process death. So if Android kills your app (let’s say because of low memory), then your app state is lost.
So depending on whether you want to persist your state across process death or not — you can either use onSaveInstanceState in your Fragments/Activities or the new SavedStateHandle in your ViewModels.
Ok so why SavedStateHandle and why save/handle states in ViewModels?
Well if you handle your state (for process death) in Activities or Fragments — that’ll add extra verbosity and will cause tight coupling between state-handling & activity/fragment code. Handling your state via ViewModels solves this issue.
# Using SavedStateHandle
### Add lifecycle-viewmodel-savedstate dependency
```kotlin
dependencies {
def lifecycle_version = "2.2.0" // currently the latest version
// Saved state module for ViewModel
implementation "androidx.lifecycle:lifecycle-viewmodel-savedstate:$lifecycle_version"
}
```
### Add SavedStateHandle property in your ViewModel
```kotlin
class MainViewModel(val state: SavedStateHandle) : ViewModel() {
}
```
### Initialize your ViewModel using SavedStateViewModelFactory
```kotlin
class MainFragment : Fragment() {
private val viewModel: MainViewModel by viewModels {
SavedStateViewModelFactory(application, activity)
}
```
### Save and restore state
The SavedStateHandle has methods for setting/getting values.
- get(String key)
- contains(String key)
- remove(String key)
- set(String key, T value)
- keys()
You can save/restore primitives, bundles and parcelables.
Saving is as easy as:
```kotlin
// In your viewmodel
fun saveName(name: String) {
state.set("Name", name)
}
// In your fragment
viewModel.saveName("Ahmed Rizwan")
```
And restoring:
```kotlin
// In your viewmodel
fun getName(): String? {
state.get<String>("Name")
}
// In your fragment
val name = viewModel.getName()
```
### Restore state as a LiveData
If you want to restore your data as LiveData, theres a getter for that as well.
```kotlin
// In your viewmodel
val nameLiveData = state.getLiveData<String>("Name")
// In your activity/fragment
viewModel.nameLiveData.observe(this) { name ->
// handle changes
}
```
---
And that’s it — make sure to handle all your states!
Happy coding!
| ahmedrizwan |
257,949 | Simple tooltips on hooks | <Component ref={useTooltip('tooltip')}>Test content</Component> This method allows yo... | 0 | 2020-02-08T17:16:56 | https://dev.to/tetragius/simple-tooltips-on-hooks-1bi5 | react, javascript, css, webdev | ```jsx
<Component ref={useTooltip('tooltip')}>Test content</Component>
```
This method allows you to create tooltips close to pure html
```html
<div title="message">example</div>
```
instead of using complex wrappers like
```jsx
<Tooltip content={'message'}>
<div>example</div>
</Tooltip>
```
or etc.
{% codepen https://codepen.io/tetragius/pen/abOzEGv %} | tetragius |
258,764 | What does a basic project look like for me? | So, what was my basic app starting point look like in February 2020? Sort of like this: There is... | 4,762 | 2020-02-10T06:03:46 | https://dev.to/valley_software/what-does-a-basic-project-look-like-for-me-106c | uwp, csharp, xaml, beginners | So, what was my basic app starting point look like in February 2020?
Sort of like this:

There is some stuff added and removed from standard for me; for example I have stripped out the Settings view I normally have (I'll re-add that later).
But it gives you an idea.
I have dreams of having base ListViewModels setup, as they tend to work in VERY similar ways 90% of the time, but I have never worked that out how I want it to be.
There is significant room for improvement and reduction of duplicate load/delete/startnew code in those view models. I've moved on though for now as you can spend a lot of time "collecting underpants", so to speak, while not getting on with solving problems.
Chao,
Rob. | valley_software |
259,229 | Faking React for VSCode Webviews | I recently worked on a hackathon project at work that involved creating a custom webview for previewi... | 0 | 2020-02-10T21:48:56 | https://dev.to/jaredkent/faking-react-for-vscode-webviews-2258 | javascript, react, vscode, extensions | I recently worked on a hackathon project at work that involved creating a custom webview for previewing YAML specs. If you haven't worked with the VS Code webview API before, it is very simplistic and involves sending a string of an HTML page to VS Code that it will manually render. A very simple example would look something like this:
```js
// Taken from the visual studio docs
import * as vscode from "vscode";
export function activate(context: vscode.ExtensionContext) {
context.subscriptions.push(
vscode.commands.registerCommand("catCoding.start", () => {
// Create and show panel
const panel = vscode.window.createWebviewPanel(
"catCoding",
"Cat Coding",
vscode.ViewColumn.One,
{}
);
// And set its HTML content
panel.webview.html = getWebviewContent();
})
);
}
function getWebviewContent() {
return `<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Cat Coding</title>
</head>
<body>
<img src="https://media.giphy.com/media/JIX9t2j0ZTN9S/giphy.gif" width="300" />
</body>
</html>`;
}
```
I'm sure you can see where this post is going... this can become very cumbersome very quickly. Writing complex logic in template strings is messy and doesn't give you intellisense on errors which just makes things harder to debug. Now I write React components all day, so I wanted to be able to use JSX to make my life easier. JSX isn't something that is "react only", it's simply a bit of syntactic sugar that makes a function call look like HTML. The function it is hiding is called `createElement` which converts a html element definition into a React node that it can handle. In my case all I need is for `createElement` to spit out an HTML string so that I can pass it to VS Code. So let's see if we can write our own `createElement` that will turn JSX into a string!
If we take a look at the [React createElement](https://github.com/facebook/react/blob/master/packages/react/src/ReactElement.js) function we can see it takes 3 arguments:
```js
function createElement(type, config, children) { ... }
```
Let's go over what these mean: `type` is the type of element we are going to render (like `h1` or `div`), `config` allows us to pass options to our element like attributes and props, and finally `children` are the nested elements to render within my current element. If we look a bit harder we can also see a comment about the children:
```js
// ...
// Children can be more than one argument, and those are transferred onto
// the newly allocated props object.
const childrenLength = arguments.length - 2;
// ...
```
This lets us know that when there are multiple children it will pass them as multiple arguments, in their implementation they are opting to look at the arguments array but we can also handle this with the "rest" syntax (opposite of "spread" but with the same syntax). For our solution we don't need alot of the fancy bits React handles, in fact we don't really need custom components because we can just use functions and make our job much simpler, so instead of `config` the options are just going to be the `attributes` we want to attach to the actual DOM element. With all of that we have figured out the definition for our `createElement` function!
```js
function createElement(type, attributes, ...children) { ... }
```
Before we go much further, you may be thinking to yourself "So what if we can write our own `createElement` function? How are we going to get our JSX to use that?". So let's talk about how React deals with compiling JSX. If you are familiar with tools like `create-react-app` this process is often obfuscated from you, but it is very simple! React uses `babel` to compile everything down to vanilla JS that can run everywhere, so all we need to do is copy the build process React uses by setting up babel ourselves. We will need 3 packages:
- `@babel/cli`
- `@babel/core`
- `@babel/plugin-transform-react-jsx`
The important one here is `@babel/plugin-transform-react-jsx` which handles the transpiling of our JSX to `createElement` function calls. And the coolest part of this package is that it allows us to specify our own `createElement` function by defining a "pragma". This is just a string of the function babel should use when making the JSX calls, the default is `React.createElement` (that's why you have to import `react` in any file where you use JSX in a normal React project). In our `.babelrc` file let's set up the plugin:
```json
{
"plugins": [
["@babel/plugin-transform-react-jsx", { "pragma": "createElement" }]
]
}
```
Here we are telling babel, "When you run use the plugin `plugin-transform-react-jsx` and give it the options object that tells you to call `createElement` instead of `React.createElement`". Now the only thing we have to do to get our JSX to work is run babel and ensure we have our `createElement` function in scope anywhere we use JSX! To get our VS Code extension to run babel before the extension launches we need to add a `build` script to our `package.json` that runs babel, and then we need to define a `preLaunchTask` in our `.vscode/launch.json` file.
```js
// package.json
{
//...
"scripts": {
"build": "babel src -d dist"
}
//...
}
```
```js
{
//...
"configurations": [
{
"name": "Extension",
"type": "extensionHost",
"request": "launch",
"runtimeExecutable": "${execPath}",
"args": [
"--extensionDevelopmentPath=${workspaceFolder}"
],
"preLaunchTask": "npm: build"
}
]
//...
}
```
Now that we have all of the configuration stuff squared away we can get back to developing our `createElement` function! Remember our goal is to turn JSX into an HTML string that can be read by VS Code's webview API. Let's start simple: getting it to create the right type of element in a string:
```js
function createElement(type) {
return `<${type}></${type}>`;
}
```
Easy enough. We could add some error handling to ensure that we are only passing in valid HTML elements, but let's stick with simplicity for now. Next up is adding the attributes to our element:
```js
function createElement(type, attributes = {}) {
const attributeString = Object.entries(attributes)
.map(([attr, value]) => `${attr}="${value}"`)
.join(" ");
return `<${type} ${attributeString}></${type}>`;
}
```
All we need to do is create a string where each attribute has the format: `attribute="value"`. We can take our object and map over it's entries and then join the string we created for each. I also added a default to the `attributes` parameter so we don't have to pass it in every time. Easy peasy! Lastly let's deal with those pesky children. This one may be the most confusing, because many people's initial reaction would be to use recursion to handle creating the children strings, however that is already handled for us. Given the way that JS runs the most nested function call with be evaluated first so by the time we are looking at a child it has already been converted from it's function form into it's resulting string.
```js
function createElement(type, attributes = {}, ...children) {
const attributeString = Object.entries(attributes)
.map(([attr, value]) => `${attr}="${value}"`)
.join(" ");
const childrenString = Array.isArray(children)
? children.filter(c => c !== null).join("")
: children || "";
return `<${type} ${attributeString}>${childrenString}</${type}>`;
}
```
Voila! We have handled our children whether there are multiple or only a single one. That's really it, that will convert our JSX into stringified HTML that can be read by VS Code as long as we use valid HTML element types. Let's convert that earlier example into nice clean JSX code and add some logic real easily:
```js
const vscode = require("vscode");
// Even though we don't use this line it is required to be in scope
const createElement = require('./createElement.js');
export function activate(context: vscode.ExtensionContext) {
context.subscriptions.push(
vscode.commands.registerCommand("catCoding.start", () => {
// Create and show panel
const panel = vscode.window.createWebviewPanel(
"catCoding",
"Cat Coding",
vscode.ViewColumn.One,
{}
);
// And set its HTML content
panel.webview.html = getWebviewContent();
})
);
}
function getWebviewContent() {
const images = [
"https://media.giphy.com/media/JIX9t2j0ZTN9S/giphy.gif",
"https://media.giphy.com/media/VbnUQpnihPSIgIXuZv/giphy.gif"
];
return (
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Cat Coding</title>
</head>
<body>
{images.map(img => (
<img src={img} width="300" />
))}
</body>
</html>
);
}
```
Just like that we can write UI code just like we are used to! It is important to note that while this may feel very familiar this is *not* React, we are only imitating the syntax. We don't have any sort of vDOM or any kind of dynamic updating. Once the functions are run it's just a string not some fancy fiber tree that can detect changes for us. If we want the webview to be updated we are going to have to run everything over again with the updated values, and keep track of that manually. That isn't to say that any of our changes made this worse, we would have to do that anyways, it's just how the webviews are designed.
I hope this post was informative to anyone else who got annoyed writing wild template strings in their webviews. And don't forget this pattern can be used anywhere that you feel JSX might help you out, don't be afraid to experiment in your projects!
| jaredkent |
259,441 | Skogsrå: Simplifying Your Elixir Configuration | Once an Elixir project is large enough, maintaining config files and configuration variables becomes... | 0 | 2020-02-13T10:14:22 | https://thebroken.link/skogsra-simplifying-your-elixir-configuration | elixir, configuration, tutorial | ---
canonical_url: https://thebroken.link/skogsra-simplifying-your-elixir-configuration
---
Once an Elixir project is large enough, maintaining config files and configuration variables becomes a nightmare:
- Configuration variables are scattered throughout the code so it's very easy to forget a configuration setting.
- OS environment variables must be casted to the correct type as they are always strings.
- Required variables must be checked by hand.
- Setting defaults can sometimes be a bit cumbersome.
- No type safety.

Ideally though, configurations should be:
- Documented.
- Easy to find.
- Easy to read.
- Declarative.
In summary: __easy to maintain__.
## The problem
We'll elaborate using the the following example:
```elixir
config :myapp,
hostname: System.get_env("HOSTNAME") || "localhost",
port: String.to_integer(System.get_env("PORT") || "80")
```
The previous code is:
- Undocumented: `hostname` and `port` of what?
- Hard to read: Too many concerns in a single line.
- Hard to find: where are these `hostname` and `port` used?
- Not declarative: we're telling Elixir **_how_ to retrieve the values** instead of **_what_ are the values we want**.
Conclusion: __it's hard to maintain__.
## Writing a config module
We could mitigate some of these problems with one simple approach:
- Create a module for your configs.
- Create a function for every single configuration parameter you app has.
The following, though a bit more verbose, would be the equivalent to the previous config:
```elixir
defmodule Myapp.Config do
@moduledoc "My app config."
@doc "My hostname"
def hostname do
System.get_env("HOSTNAME") || "localhost"
end
@doc "My port"
def port do
String.to_integer(System.get_env("PORT") || "80")
end
end
```
Unlike our original code, this one is:
- Documented: Every function has `@doc` attribute.
- Easy to find: We just need to to look for calls to functions defined in this module.
However, we still have essentially the same code we had before, which is:
- Hard to read.
- Not declarative.
There's gotta be a better way!

## There is a better way - Meet Skogsrå
[Skogsrå](https://github.com/gmtprime/skogsra) is a library for loading configuration variables with ease, providing:
- Variable defaults.
- Automatic type casting of values.
- Automatic docs and spec generation.
- OS environment template generation.
- Run-time reloading.
- Setting variable's values at run-time.
- Fast cached values access by using `:persistent_term` as temporal storage.
- YAML configuration provider for Elixir releases.
The previous example can be re-written as follows:
```elixir
defmodule Myapp.Config do
@moduledoc "My app config."
use Skogsra
@envdoc "My hostname"
app_env :hostname, :myapp, :hostname,
default: "localhost",
os_env: "HOSTNAME"
@envdoc "My port"
app_env :port, :myapp, :port,
default: 80,
os_env: "PORT"
end
```
This module will have these functions:
- `Myapp.Config.hostname/0` for retrieving the hostname.
- `Myapp.Config.port/0` for retrieving the port.
With this implementation, we end up with:
- Documented configuration variables: Via `@envdoc` module attribute.
- Easy to find: Every configuration variable will be in `Myapp.Config` module.
- Easy to read: `app_env` options are self explanatory.
- Declarative: we're telling Skogsrå _what we want_.
- **Bonus**: Type-safety (see [Strong typing](#strong-typing) section).

## How it works
Calling `Myapp.Config.port()` will retrieve the value for the port in the following order:
1. From the OS environment variable `$PORT`.
2. From the configuration file e.g. our test config file might look like:
```elixir
# file config/test.exs
use Mix.Config
config :myapp,
port: 4000
```
3. From the default value, if it exists (In this case, it would return the integer `80`).
The values will be casted as the default values' type unless the option `type` is provided (see [Explicit type casting](#explicit-type-casting) section).
Though Skogsrå has [many options and features](https://github.com/gmtprime/skogsra), we will just explore the ones I use the most:
- [Explicit type casting](#explicit-type-casting).
- [Defining custom types](#defining-custom-types).
- [Required variables](#required-variables).
- [Strong typing](#strong-typing).
## Explicit type casting
When the types are not `any`, `binary`, `integer`, `float`, `boolean` or `atom`, Skogsrå cannot automatically cast values solely by the default value's type. Types then need to be specified explicitly using the option `type`. The available types are:
- `:any` (default).
- `:binary`.
- `:integer`.
- `:float`.
- `:boolean`.
- `:atom`.
- `:module`: for modules loaded in the system.
- `:unsafe_module`: for modules that might or might not be loaded in the system.
- `Skogsra.Type` implementation: a `behaviour` for defining custom types.
## Defining custom types
Let's say we need to read an OS environment variable called `HISTOGRAM_BUCKETS` as a list of integers:
```bash
export HISTOGRAM_BUCKETS="1, 10, 30, 60"
```
We could then implement `Skogsra.Type` behaviour to parse the string correctly:
```elixir
defmodule Myapp.Type.IntegerList do
use Skogsra.Type
@impl Skogsra.Type
def cast(value)
def cast(value) when is_binary(value) do
list =
value
|> String.split(~r/,/)
|> Stream.map(&String.trim/1)
|> Enum.map(String.to_integer/1)
{:ok, list}
end
def cast(value) when is_list(value) do
if Enum.all?(value, &is_integer/1), do: {:ok, value}, else: :error
end
def cast(_) do
:error
end
end
```
And finally use `Myapp.Type.IntegerList` in our Skogsrå configuration:
```elixir
defmodule Myapp.Config do
use Skogsra
@envdoc "Histogram buckets"
app_env :buckets, :myapp, :histogram_buckets,
type: Myapp.Type.IntegerList,
os_env: "HISTOGRAM_BUCKETS"
end
```
Then it should be easy to retrieve our `buckets` from an OS environment variable:
```elixir
iex(1)> System.get_env("HISTOGRAM_BUCKETS")
"1, 10, 30, 60"
iex(2)> Myapp.Config.buckets()
{:ok, [1, 10, 30, 60]}
```
or if the variable is not defined, from our application configuration:
```elixir
iex(1)> System.app_env(:myapp, :histogram_buckets)
[1, 10, 30, 60]
iex(2)> Myapp.Config.buckets()
{:ok, [1, 10, 30, 60]}
```
## Required variables
Skogsrå provides an option for making configuration variables mandatory. This is useful when there is no default value for our variable and Skogsrå it's expected to find a value in either an OS environment variable or the application configuration e.g. given the following config module:
```elixir
defmodule MyApp.Config do
use Skogsra
@envdoc "Server port."
app_env :port, :myapp, :port,
os_env: "PORT",
required: true
end
```
The function `Myapp.Config.port()` will error if `PORT` is undefined and
the application configuration is not found:
```elixir
iex(1)> System.get_env("PORT")
nil
iex(2)> Application.get_env(:myapp, :port)
nil
iex(3)> MyApp.Config.port()
{:error, "Variable port in app myapp is undefined"}
```
## Strong typing
All the configuration variables will have the correct function `@spec` definition e.g. given the following definition:
```elixir
defmodule Myapp.Config do
use Skogsra
@envdoc "PostgreSQL hostname"
app_env :db_port, :myapp, [:postgres, :port],
default: 5432
end
```
The generated function `Myapp.Config.db_port/0` will have the following `@spec`:
```elixir
@spec db_port() :: {:ok, integer()} | {:error, binary()}
```
The type is derived from:
- The `default` value (in this case the integer `5432`)
- The `type` configuration value (see the previous [Explicit type casting](#explicit-type-casting) section).
## Conclusion
[Skogsra](https://github.com/gmtprime/skogsra) provides a simple way to handle your Elixir application configurations in a type-safe and organized way. Big projects can certainly benefit from using it.
Hope you found this article useful. Happy coding!

This article is also available here: [https://thebroken.link/skogsra-simplifying-your-elixir-configuration/](https://thebroken.link/skogsra-simplifying-your-elixir-configuration/).
_Cover image by [Lukasz Szmigiel](https://unsplash.com/@szmigieldesign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)_ | alexdesousa |
259,512 | You Use Bootstrap ? Don't EVER Write Those CSS Properties | This is a list of CSS rules you don't need to write in your stylesheet file if you're using Bootstrap framework. | 0 | 2020-02-11T13:28:02 | https://dev.to/aissabouguern/you-use-bootstrap-don-t-ever-write-those-css-properties-gb2 | css, bootstrap | ---
title: You Use Bootstrap ? Don't EVER Write Those CSS Properties
published: true
description: This is a list of CSS rules you don't need to write in your stylesheet file if you're using Bootstrap framework.
tags: CSS, Bootstrap
---
Bootstrap is the most used CSS framework by web developers. It comes with a bunch of utilities that makes our work easier and improve the productivity if it is used wisely.
This is a list of CSS rules/properties you don't need to write in your stylesheet file if you're using Bootstrap framework.
## Position
You don't need to write `position: relative;` or `position: absolute;` in your CSS file! Bootstrap is giving us a list of utility classes allowing to control the positioning type from the HTML template.
```html
<div class="position-relative"></div>
<div class="position-absolute"></div>
<div class="position-sticky"></div>
<div class="position-static"></div>
<div class="position-fixed"></div>
```
## Overflow
```html
<div class="overflow-hidden"></div>
<div class="overflow-auto"></div>
```
## Text Decoration
Anchor texts are by default underlined in Bootstrap. If you want to undo this behavior you can juste use `text-decoration-none` class.
```html
<a href="#" class="text-decoration-none">This is a link</a>
```
## Visibility
```html
<!-- visibility: visible; -->
<div class="visibile"></div>
<!-- visibility: hidden; -->
<div class="invisible"></div>
```
## Font Weight
```html
<!-- font-weight: 300; -->
<div class="font-weight-light"></div>
<!-- font-weight: 400; -->
<div class="font-weight-normal"></div>
<!-- font-weight: 700; -->
<div class="font-weight-bold"></div>
<!-- font-weight: bolder; -->
<div class="font-weight-bolder"></div>
```
## Text Transform
```html
<!-- text-transform: uppercase; -->
<div class="text-uppercase"></div>
<!-- text-transform: lowercase; -->
<div class="text-lowercase"></div>
<!-- text-transform: capitalize; -->
<div class="text-capitalize"></div>
```
## Display
This is an essential CSS property that you will use massively as a frontend developer. That's why Bootstrap feeds us with a large list of classes to deal with `display` property **responsively**.
```html
<!-- display: block; -->
<!-- All screens -->
<div class="d-block"></div>
<!-- Small devices -->
<div class="d-sm-block"></div>
<!-- Medium devices -->
<div class="d-md-block"></div>
<!-- Large devices (Tablets) -->
<div class="d-lg-block"></div>
<!-- Extra large devices (Desktop) -->
<div class="d-xl-block"></div>
<!-- display: flex; -->
<!-- All screens -->
<div class="d-flex"></div>
<!-- Small devices -->
<div class="d-sm-flex"></div>
<!-- Medium devices -->
<div class="d-md-flex"></div>
<!-- Large devices (Tablets) -->
<div class="d-lg-flex"></div>
<!-- Extra large devices (Desktop) -->
<div class="d-xl-flex"></div>
<!-- display: none; -->
...
<!-- display: inline; -->
...
<!-- display: inline-block; -->
...
```
## Flexbox properties
Bootstrap is based on CSS Flexbox. This layout comes with a lot of properties that allow us to have a control over.
With Bootstrap we can make use of all those properties directly from HTML and, like we saw with `display` property, responsiveness is guaranteed out-of-the-box.
```html
<!-- justify-content; -->
<!-- All screens -->
<div class="justify-content-center"></div>
<!-- Small devices -->
<div class="justify-content-sm-center"></div>
<!-- Medium devices -->
<div class="justify-content-md-center"></div>
<!-- Large devices (Tablets) -->
<div class="justify-content-lg-center"></div>
<!-- Extra large devices (Desktop) -->
<div class="justify-content-xl-center"></div>
<div class="justify-content-start"></div>
<div class="justify-content-end"></div>
<div class="justify-content-between"></div>
<div class="justify-content-around"></div>
<!-- align-items; -->
<div class="align-items-start"></div>
<div class="align-items-end"></div>
<div class="align-items-center"></div>
<div class="align-items-baseline"></div>
<div class="align-items-stretch"></div>
<!-- align-content; -->
<div class="align-content-start"></div>
<div class="align-content-end"></div>
<div class="align-content-between"></div>
<div class="align-content-around"></div>
<div class="align-content-center"></div>
<div class="align-content-stretch"></div>
```
## Width & Height
```html
<!-- width: 25%; -->
<div class="w-25"></div>
<!-- width: 50%; -->
<div class="w-50"></div>
<!-- width: 75%; -->
<div class="w-75"></div>
<!-- width: 100%; -->
<div class="w-100"></div>
<!-- width: auto; -->
<div class="w-auto"></div>
<!-- max-width: 100%; -->
<div class="mw-100"></div>
<!-- height: 25%; -->
<div class="h-25"></div>
<!-- height: 50%; -->
<div class="h-50"></div>
<!-- height: 75%; -->
<div class="h-75"></div>
<!-- height: 100%; -->
<div class="h-100"></div>
<!-- height: auto; -->
<div class="h-auto"></div>
<!-- max-width: 100%; -->
<div class="mh-100"></div>
```
## Padding & Margin
Every layout or design depends on `padding` and `margin` properties.
Here is a list of utilities that may help you:
```html
<!-- Padding Top -->
<!-- padding-top: 0; -->
<div class="pt-0"></div>
<div class="pt-xs-0"></div>
<div class="pt-sm-0"></div>
<div class="pt-md-0"></div>
<div class="pt-lg-0"></div>
<div class="pt-xl-0"></div>
<!-- padding-top: 0.25rem; -->
<div class="pt-1"></div>
...
<!-- padding-top: 0.5rem; -->
<div class="pt-2"></div>
...
<!-- padding-top: 1rem; -->
<div class="pt-3"></div>
...
<!-- padding-top: 1.5rem; -->
<div class="pt-4"></div>
...
<!-- padding-top: 3rem; -->
<div class="pt-5"></div>
...
<!-- Padding Left -->
<div class="pl-0"></div>
...
<!-- Padding Right -->
<div class="pr-0"></div>
...
<!-- Padding Bottom -->
<div class="pb-0"></div>
...
<!-- Horizontal Padding -->
<div class="px-0"></div>
...
<!-- Vertical Padding -->
<div class="py-0"></div>
...
```
You can use the same naming convention for `margin` classes. Just replace `p` width `m`.
## Screen Reader Only
Sometimes, we need to add some text to html markup and we want it to be available **only for screen readers** for accessibility purposes.
Bootstrap provide a class utility to do that: `sr-only`.
```html
<div class="sr-only"><a href="#content">Skip to Main Content</a></div>
```
## Float
Personaly, I dont use `float` property anymore! But if you do, here is some gems for free:
```html
<div class="float-left"></div>
<div class="float-right"></div>
<div class="float-none"></div>
```
| aissabouguern |
261,209 | Introduction to Web Accessibility | In this post, you will learn about the fundamentals of accessibility to ensure your website is usable... | 4,381 | 2020-02-13T23:29:12 | https://dev.to/5t3ph/introduction-to-web-accessibility-5cmp | beginners, a11y, webdev | In this post, you will learn about the fundamentals of accessibility to ensure your website is usable by everyone.
This is the seventh post and video in a series on learning web development.
You may watch the following video or follow along with the expanded transcript that follows.
{% youtube F0iNy65L3_w %}
In this lesson, we will not create new code. Instead, I will demonstrate what accessibility is and the basic considerations for ensuring you create accessible web experiences.
[View the live link of the demo >](https://thinkdobecreate.com/demos/accessibility-basics)
First, let's start with a definition of accessibility from the [Web Accessibility Initiative (WAI)](https://www.w3.org/WAI/fundamentals/accessibility-intro/):
> Web accessibility means that websites, tools, and technologies are designed and developed so that people with disabilities can use them. More specifically people can: perceive, understand, navigate, and interact with the Web; and contribute to the Web.
The WAI goes on to point out that it isn't just folks with clearly recognized disabilities, but also temporary or less perceivable impairments, such as:
- people using devices with small screens
- changing abilities due to aging
- temporary disablements such as a broken arm
- situational limitations such as screen glare from bright lights or the sun
It is possible to account for these scenarios, but it takes a conscious effort. Fortunately, there are in-depth guidelines and a wealth of resources to learn how to do it and to test outcomes.
Fundamentally, accessibility on the web starts with using HTML semantically. So congrats! You've already learned the bare essentials to making accessible web experiences from our first few lessons!
Today, we'll look at a few additional points to keep in mind as you move forward on your coding journey. Learning how to make accessible web experiences an inherent part of how you develop code is not only the right thing to do, it will give you a leg up in the job market as surprisingly, this is an area that a lot of online experiences, unfortunately, tend to neglect.
The topics we'll cover include:
- [Hierarchy](#hierarchy)
- [Content](#content)
- [Contrast](#contrast)
- [Keyboard Interaction](#keyboard-interaction)
Note that this lesson is not exhaustive of all accessibility concerns but is intended to place basic concepts in your development toolbox.
## Hierarchy
We've actually already covered hierarchy throughout the HTML lessons. To re-cap, hierarchy begins with defining the structure of your text content with appropriate headings.
The following gif demonstrates how proper heading hierarchy can help a vision impaired user who needs to use assistive technology, often in the form of a screen reader. Being on a Mac, I have a built-in screen reader called Voice Over, or VO for short. I'm going to open that, and you'll see this window has appeared that provides written text in addition to the spoken feedback.
Within [my example web page](https://thinkdobecreate.com/demos/accessibility-basics), I triggered a keyboard command to display the Headings. Then, using my arrow keys, I scrolled through the list, and then used the return key to select one. See how a black box was added to the "Heading 3" as an additional visual indication of where Voice Over was focused on the page.
Using an additional keyboard command, I can request Voice Over to read the document to me. Again, VO places a black box as a visual indicator as it moves throughout the document.
## Content
VO was able to read that content very easily because it is using defined type elements. But there are other ways to define textual content, and a requirement for accessibility is that all content is perceivable. This means any non-text content should provide a text alternative, and there are several ways this can be done.
A common scenario that we've also already discussed is providing descriptions of images by way of the `alt` attribute. So let's move to the next section in this document, and see how VO is able to read the images thanks to the `alt` text.
## Contrast
The next key concept is contrast. Contrast generally refers to color contrast of text or interface components, but for text it can also mean legibility.

This first section shows examples of poor text contrast. The first two primarily demonstrate poor color contrast. Text must meeting a 4.5:1 contrast ratio against it's background to pass for accessibility.
This first example fails with a 2.41:1 ratio, and it also does poorly on general legibility due to tight line and letter spacing.
While it's not inherently wrong to use colorful text, it can be more difficult to ensure the paring meets contrast. The second example fails with a 2.59:1 ratio.
The third example is poor legibility from using a thin font at a small size, and the fourth also fails for legibility by using a decorative font for a long text block at a small size.
Let's look at some acceptable examples of text contrast.

The first one demonstrates the exception to the text contrast rule: text which is at least 14px and bold or larger than 18px has a reduced contrast ratio of 3:1. This example is both 18px and bold and has a ratio of 3.25:1.
The next example passes contrast with flying - and bright - colors! The ratio here is 5.17:1!
*Note that the "Fail" is false as the contrast tool in use is unaware of the text size being tested*
Next, there's an appropriate use of a thin font by increasing the size and limiting the length of the phrase. This might be acceptable for short headlines.
Finally, we've reduced the decorative font all the way down to one word to demonstrate another exception. If we imagine this is intended as the logo, then it is acceptable because logos are specifically exempt from contrast guidelines which makes the color choice ok too.
The other category for contrast is interactive user interface components such as form fields and buttons, as demonstrated here. UI components need to meet the 3:1 contrast for controls themselves, although text portions such as form labels should continue to meet 4.5:1 if not bold or smaller than 18px.

This first form field is missing the mark on contrast for both the label and the input border. The example next to it achieves appropriate contrast for both the label and input border.
The buttons comparisons are set up much the same, however, buttons typically have the expectation of a hover state, which is when the user mouses over it.

For the hover state of the "Good Button" you'll see that a dark background color has been applied and the text color swapped to white to retain contrast. Another important note is that we now must balance two levels of contrast: the button text against the button background at a 4.5:1, and the button background against the page background needs to remain at least 3:1.
## Keyboard Interaction
Now, the final key topic is keyboard interaction. There is a category of users, whether or not they use VO, who are unable to use a mouse so they rely on either spoken or manual keyboard commands. A primary way these users navigate a website is tabbing from one interactive component to the next. For sighted users, it is important that interactive components provide visual feedback when they receive focus.
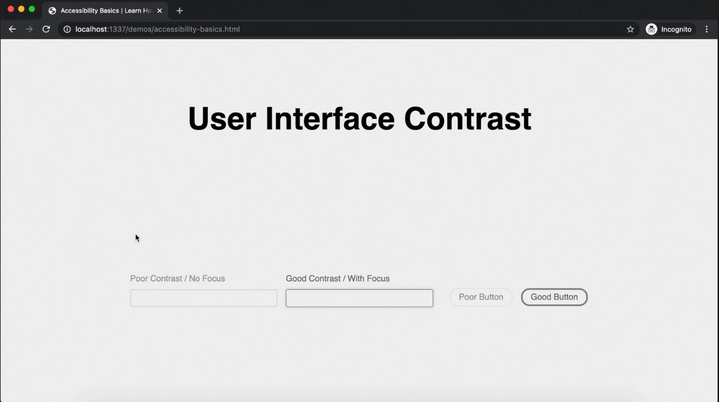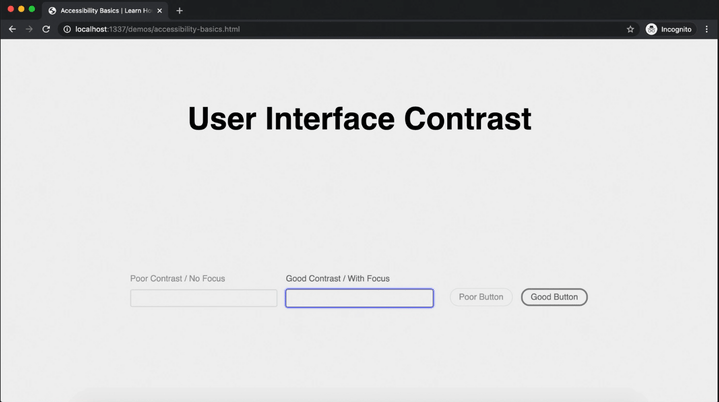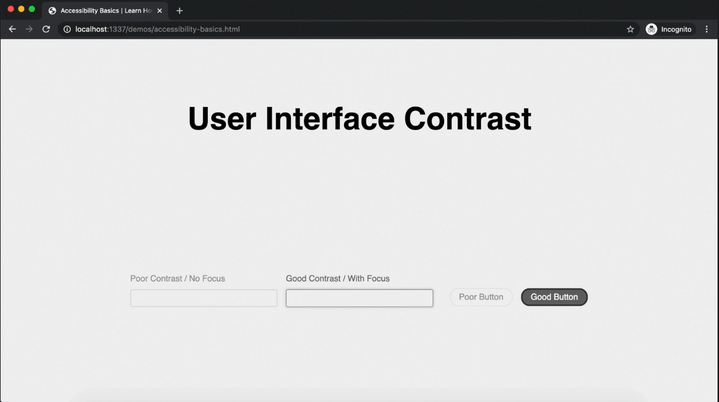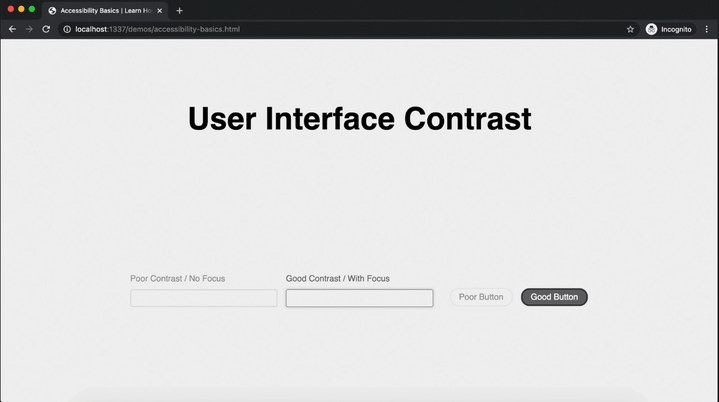
Looking at our text inputs and buttons, the gif demonstrates focus from keyboard tabbing. As I tab into the poor input field, the only indicator is the blinking text cursor. If I tab again into the good input, there is a clear visual border change. This focus is also under the same 3:1 color contrast requirement which should be measured against it's surrounding background.
When I tab to the poor button, you'll see no change. One more tab to the good button and you'll see we're using the same style offered on hover for this particular button.
### Resources
There are many more areas of accessibility to be aware of, and we will explore other areas as we continue through this series. If you would like to start learning more, here are a few resource links:
- WAI Introduction to Web Accessibility: [https://www.w3.org/WAI/fundamentals/accessibility-intro/](https://www.w3.org/WAI/fundamentals/accessibility-intro/)
- WAI Easy Checks for Accessibility: [https://www.w3.org/WAI/test-evaluate/preliminary/](https://www.w3.org/WAI/test-evaluate/preliminary/)
- WAI Intro to Accessibility Principles: [https://www.w3.org/WAI/fundamentals/accessibility-principles/](https://www.w3.org/WAI/fundamentals/accessibility-principles/)
- A condensed guide to WCAG (Web Content Accessibility Guidelines): [https://24ways.org/2017/wcag-for-people-who-havent-read-them/](https://24ways.org/2017/wcag-for-people-who-havent-read-them/)
- A11Y Style Guide accessible component reference: [https://a11y-style-guide.com/style-guide/](https://a11y-style-guide.com/style-guide/)
- WebAIM Contrast Checker: [https://webaim.org/resources/contrastchecker/](https://webaim.org/resources/contrastchecker/)
- Contraste desktop app (Mac only, used in demo): [https://contrasteapp.com/](https://contrasteapp.com/)
> **Next up in Episode 8:** Intro to CSS | 5t3ph |
261,401 | Certificate Generator With PHP Using imagettftext function | Introduction Imagettftext is a function used to write text to an image using TrueType fon... | 0 | 2020-02-14T12:53:19 | https://dev.to/olawanle_joel/certificate-generator-with-php-using-imagettftext-function-1glh | php, html | ###**Introduction**
> Imagettftext is a function used to write text to an image using TrueType fonts.
{% gist https://gist.github.com/olawanlejoel/2ce0794c595e4afc4529b5f5a7fb9e23.js %}
**Explaining all the parameters involved in this array:**
**Image:**
An image resource is returned by one of the image creation functions, such as imagecreatetruecolor(), imagecreatefrompng(), e.t.c.This image is supposed to be an empty certificate.

**Size**
The font size of the text you intend to place on image.
**Angle**
The angle in degrees, with 0 degrees being left-to-right reading text. Higher values represent a counter-clockwise rotation. For example, a value of 90 would result in bottom-to-top reading text.
**X and Y**
The x and y axis are use to set the position of the text using the x and y co-ordinates
**Color**
The color index. we make use of the imagecolorallocate() to set color to the text we are displaying on the image in RGB format.
**Fontfile**
The path to the TrueType font you wish to use.It could have an extension of .ttf, .otf, e.t.c.
**Text**
Finally this is the name attributed to the text you intend to display on the image.
>*This is the major function behind Certificate generator. A good understanding of this would be very useful in other approaches like Id care generator, ticket generator and lots more…
This approach could also be integrated to your websites, so people get certified after performing a specific task like taking a course instead of doing everything manually which would take time*.
**Getting Started**
*To get started here are the major stuffs needed*
* Font file
* Empty certificate PNG file
* And finally a PHP file where all my codes would be for simplicity.
>Note: You can tweak anything once you perfectly understand this code and how this function works.
*You can give your file any name, but I would name mine index.php*
**Index.php**
The index file will contain the form where peoples name would be fetched from and also the PHP code.
Below is the form where data for certificate generation is gotten from.
{% gist https://gist.github.com/olawanlejoel/875009286dcf086f252ab18af2cd7ba8.js %}
From the above form we are only getting the name and then the code below is the PHP code
{% gist https://gist.github.com/olawanlejoel/889eeb7c46fff39a35295ee71063d6e1.js %}
This is the basic thing you need to know to place text on image with php.
Here is a link to the complete code - [Certificate Generator](https://github.com/olawanlejoel/certificategen) and you can test it [live Here](http://certificategen.000webhostapp.com/).
If you have any idea on more things that can be done via this function or any function for uploading image on image.Let's talk on [Twitter](https://twitter.com/OlawanleJ).
P.s: I'm looking to make new dev friends, lets connect on [Twitter](https://twitter.com/OlawanleJ).
Thanks for reading 👏
| olawanle_joel |
261,445 | 9 Productivity & personal growth rules made from my 2019 | We all are trying to do things in a better way everyday and improving is something we all strive... | 0 | 2020-02-14T12:33:26 | https://www.unsungnovelty.org/posts/02/2020/takeaways-from-2019/ | productivity | We all are trying to do things in a better way everyday and improving is something we all strive towards. Let me share what I have learned from my experiences in 2019 for better productivity and personal growth. Hope these rules becomes useful to you like it is to me.
### Rules are mutable, so don't sweat it!
The first thing I want to talk about is that none of the rules, I mean none of those productivity tips, tricks or system you have in place are forever or perfect. There is always an exception to the system/rules you have, so keep it flexible and be open to improvements. This helps you be less rigid and helps your system to evolve. Otherwise you will feel tied down and you will eventually stop following the system/rules.
A good example of this is, us trying to follow [Pomodoro Technique](https://en.wikipedia.org/wiki/Pomodoro_Technique) for better productivity. We don't have to be rigid about the 20 minutes. You can make it 30 minutes or if you are zoned-in and 20 minutes are done, you can just start the next Pomodoro session immediately. Don't worry, give yourself some room, be flexible and fine tune the rules/system so that it works for you not the other way around.
### Do NOTHING (at times)!
Yes, *do nothing.* Don't get me wrong, but give your mind some rest and go for a walk or water some plants. This is important for better mental health and memory. After consuming things like a podcast, a book or after learning something, it helps you if you give it some time before moving on to the next thing.
*Doing nothing have become extremely challenging*. We are consuming something all the time. The urge, the need for us to finish our backlog of to do lists, podcasts, the chapters in that book. Or, let's take a break and watch a movie? That is also consumption my friend! Albeit a less intensive one. Try to do nothing, you will be surprised by the results.
### Let it flooow...
I would like to call myself as an idea hamster and planner. I get a lot of ideas about the things I want to do in the future, later in the evening or NOW! So breaking the flow makes it harder for me to decide whether it is important or useless. Giving it some time without breaking the flow of thoughts helps me decide whether it is useful or not. It could be anything, an idea for a business, a project I want to do etc. Just let it flow! So instead of playing that unnecessary podcast episode, or trying to multi-task, just let it flow. I have found this useful and it helps me envision my ideas & thoughts better.
### Clean up regularly
We often make plans, goals, to-do lists. How often do you keep it updated though? That [Tsundoku](https://en.wikipedia.org/wiki/Tsundoku)/backlog you have, is *all of it* necessary? Or is it relevant any more from the day you added it to your backlog?
We often have the tendency to finish from A to Z, 100%. We are rigid and not at all flexible about our plans and goals. Most of the time this is not necessary. As a person who have a list of goals, to-do lists, list of books, 20 podcasts (down from 22 since I started writing this blog, clean up people!) shows to follow and an endless list of article bookmarks to finish, I realised last year (maybe I a bit slow with it?) it is necessary to clean it up regularly. Clean up your to-do lists, the goals, plans on how you are going to achieve them... all of it!
### Consume less
The next thing to do once you have cleaned up things is to consume less. What's wrong with consuming you ask? We get different points of views right? The problem is, we don't stop at that. We keep consuming even after we have found the silver bullet or even though you got the information or knowledge you were looking for.
A good way to explain this is by telling why I stopped reading "motivational/inspirational" articles in Medium. Have you tried reading those articles? It is crazy, you will be so pumped up by the time you finish the articles, you just found the perfect article which is inspirational as hell! Of course it will be, because it is...
- Relatable
- Inspirational as hell!
- Provides solutions to your current problem(s).
But then you read another one tomorrow and another one the day after. It is an endless cycle and you're trying out many things or just reading on and on without acting on any of those solutions. The idea is to find the perfect fit and just stop looking for solutions again! You are just going to confuse yourself if you don't stop after getting what you were looking for in the first place.
Consuming less is also generally a good practice. Read less motivational articles, less YouTube videos, less of those endless Twitter scrolling. Try to focus more on things that really matter and keep at it. This will help you reach all the goals and finish all those to-do lists.
### Unstuck, with a question?
Like all other people, I use questions a lot! I ask them, sometimes I answer them. But most of the time, my questions are to someone. It never occurred to me that I should be asking question to myself while I am stuck with something and is *trying to figure it out myself!* Even when I used to ask questions to myself, it is often in my own head and unconscious.
The whole idea of *"questioning myself"* when stuck changed the way I think about my to-do lists and tasks at hand. I realised I don't have the questions that needs to be answered to start/finish my tasks. This made me ask questions like "why am I stuck here?", or a specific question like, "Which method or approach should I use to write this function/program or problem?".
Another thing to do is writing things. I always write down the questions under each tasks. Writing the questions in a paper helps me better articulate and envision the status, progress and next actions of a task. This brings me to the next thing I wanna share...
### Write things down!
2019 was an year where I rediscovered my love for fountain pens. This gave me another excuse to write things down in a paper, purely old school. I like to document the things in a notebook along with my notebook application. I also have a to-do list application but I write down the things I have to do for the day in my notebook as a to-do list. My search for the perfect to-do list application was completed. But even then, I always come back to writing things down in my notebook. I use my to-do list application as a tool to have an online database of long term goals and plans. This helps me be productive and accountable.
### Full screen mode
Full screen mode in applications are seriously underrated! I am writing this article in an text editor with full screen mode on! It keeps me focused and less distracted. It is really easy to overlook the fact that we are constantly interrupted by other applications while working on your computer. But full screen mode can help you with that.
You might be thinking, it is just a task bar of your operating system and the application, what is the big deal? We are not losing a big chunk of real estate right? But if you want to work on an important task but cannot focus, and the solution you have is to logout from Slack/Discord or abandon that noisy/distracting app, then full screen mode is definitely something you should try out. It will help you ignore all the Slack/Discord messages or any other noisy/distracting app. It will let you work in peace, focused. You don't have to logout or abandon an application because they're distracting, all you have to do is use the full screen mode.
### Music
Still unable to be productive? Why not listen to some music while working? I have found that it helps you be focused on the tasks. I prefer a low voice music in the background which drowns the rest of the noises. And I use [freeCodeCamp's code radio](coderadio.freecodecamp.org/) for this.
The science behind this is a bit here and there, so I would suggest you to try it out and see if it's working for you. It works for me and helps me be focused on the task at hand. But at times for some tasks, I just like the music when I start the task and silence after a while. Like I said before, *"rules are mutable"*. Use it in a way that works for you, or don't if it is not helping.
### To sum it up
These are my takeaways from 2019. I try to apply these rules in my day to day life wherever possible. Not every one of these points might be appealing for everybody. So try it out yourself and see if it works for you. And remember, _"Rules/laws are mutable!"_
#### References / Links
- [Every productivity thought I've ever had, as concisely as possible by Alexey Guzey](https://guzey.com/productivity/)
- [Is Background Music a Boost or a Bummer?](https://www.psychologytoday.com/us/blog/conquering-cyber-overload/201305/is-background-music-boost-or-bummer)
Did you find these tips useful? Let me know [@unsungnovelty](https://twitter.com/unsungNovelty).
*This post was first published under the title ["Takeaways from 2019"](https://www.unsungnovelty.org/posts/02/2020/takeaways-from-2019/) in https://www.unsungnovelty.org*
| unsungnovelty |
261,495 | Introducing Commitiquette | Commitiquette is a Commitizen plugin that uses your CommitLint configuration, allowing you to maintai... | 0 | 2020-02-22T08:32:03 | https://dev.to/martinmcwhorter/introducing-commitiquette-245l | git, node, commit | Commitiquette is a Commitizen plugin that uses your CommitLint configuration, allowing you to maintain a single set of rules for commit messages.
Consistent commit messages that follow a convention are useful for automating generation of changelogs, automating versioning based on **fix** (patch), **feature** (minor) and **breaking change** (major) of the commit.
Conventional commits have the beneficial side-effect of causing developers to make more small commits, rather than fewer large commits, limited to the type and scope of the change. This may actually be the most important feature of conventional commit messages.
Commiting code should be like voting in Chicago. Commit early and commit often.
If you are already familiar with CommitLint and Commitizen, you can skip the next two sections and just configure Commitiquette.
## Commitizen
There are more options for installing and configuring Commitizen than we will go into here. See the [official documentation](http://commitizen.github.io/cz-cli/) to learn more.
To add Commitizen to your project, paste the following command in the project's root directory.
```
npx commitizen init cz-conventional-changelog --save-dev --save-exact
```
Next add Husky to manage git hooks
```
npm install husky --save-dev
```
Finally we will add the following snippet to our `packages.json`
```
"husky": {
"hooks": {
"prepare-commit-msg": "exec < /dev/tty && git cz --hook || true",
}
}
```
At this point Commitizen should be configured in your repository. When you commit changes with `git commit`you will be prompted by Commitizen.
## CommitLint
While Commitizen is helpful in guiding contributers in creating commit messages, developers using a GUI to commit won't be prompted by can easily unwittingly bypass it. This is why it is important to lint the commit messages.
CommitLint had lots of options for installation and configuration, including setup for CI. See the official [documentaion](https://commitlint.js.org/) for more options.
Install and configure CommitLint in your project
```
npm install --save-dev @commitlint/{cli,config-conventional}
echo "module.exports = {extends: ['@commitlint/config-conventional']};" > commitlint.config.js
```
Next we will need to add another like to the husky configuration within `package.json`
```
"husky": {
"hooks": {
"prepare-commit-msg": "exec < /dev/tty && git cz --hook || true",
"commit-msg": "commitlint -E HUSKY_GIT_PARAMS"
}
}
```
At this point, Commitlint should stop commits where the message fails the lint. Again, this is not bulletproof. If you require gated commits CommitLint should be configured in CI.
## Commitiquette
CommitLint and Commitizen should be somewhat in sync applying similar rules. Though as soon as you apply project or workspace specific rules, you will find you will need to maintain these rules twice.
This is where Commitiquette comes in by using the CommitLint config for Commitizen.
We will install Commitiquette
```
npm install commitiquette --save-dev
```
Next we update Commitizens's config to use Commitiquette. In `package.json` find the Commitizen config added previously by `npx commitizen init...` and update is so
```
"config": {
"commitizen": {
"path": "commitiquette"
}
},
```
Now we can change our `commitlint.config.js` and Commitizen will pick these changes up automatically!
See the CommitLint documentation for a complete list of [rules](https://commitlint.js.org/#/reference-rule) that may be applied to both CommitLint and Commitiquette.
So now let's configure CommitLint to validate our scope is an item in an array.
```
module.exports = {
extends: ['@commitlint/config-conventional'],
rules: {
'scope-enum': [2, 'always', ['docs', 'core', 'lib', 'misc', 'etc']]
}
};
```
CommitLint will now validate that the scope is one of the elements defined in the above rule. Commitizen, through the Commitiquette plugin, will prompt the contributor to select from this list for the scope of the commit.
Commitiquette can help guide contributors to make smaller, focused commits that follow a shared set of rule based conventions. | martinmcwhorter |
261,571 | Tutorial: Using Redux and Redux-Saga to handle WebSocket messages. | Since I've discovered redux-saga I've found that it's perfect for asynchronous actions that affect th... | 0 | 2020-02-14T14:41:46 | https://dev.to/matsz/tutorial-using-redux-and-redux-saga-to-handle-websocket-messages-4c8m | react, typescript, tutorial, redux | Since I've discovered redux-saga I've found that it's perfect for asynchronous actions that affect the global state - and handling WebSocket messages is one of those things. The first time I've used this is in [filedrop-web](https://github.com/mat-sz/filedrop-web) and it's been working well enough to make me consider writing a tutorial for it.
**Disclaimer:** I will be using [TypeSocket](https://github.com/mat-sz/typesocket), which is a library I've made. It makes certain WebSocket-related tasks easier without being too heavy (no special polyfills for platforms that don't support WS).
You can get TypeSocket from npm:
```
yarn add typesocket
# or
npm install typesocket
```
The way my integration works is by creating a new Redux middleware that will contain the WebSocket handling code, will dispatch WebSocket messages and connection state updates and will react to incoming send message actions.
First, I have an ActionType enum, for all the available ActionTypes:
```ts
enum ActionType {
WS_CONNECTED = 'WS_CONNECTED',
WS_DISCONNECTED = 'WS_DISCONNECTED',
WS_MESSAGE = 'WS_MESSAGE',
WS_SEND_MESSAGE = 'WS_SEND_MESSAGE',
};
```
Then I also define an interface for the message model (TypeSocket will reject all invalid JSON messages by default, but doesn't check if the message matches your type):
```ts
export interface MessageModel {
type: string,
};
```
This allows me to create an instance of TypeSocket:
```ts
import { TypeSocket } from 'typesocket';
const socket = new TypeSocket<MessageModel>(url);
```
Which is what we'll be using within our middleware. `url` refers to the WebSocket URL.
Writing a Redux middleware around TypeSocket is really simple, first we create an empty middleware:
```ts
import { MiddlewareAPI } from 'redux';
import { TypeSocket } from 'typesocket';
import { ActionType } from './types/ActionType'; // Your enum with action types.
import { MessageModel } from './types/Models'; // Your message model.
export const socketMiddleware = (url: string) => {
return (store: MiddlewareAPI<any, any>) => {
// Here we will create a new socket...
// ...and handle the socket events.
return (next: (action: any) => void) => (action: any) => {
// And here we'll handle WS_SEND_MESSAGE.
return next(action);
};
};
};
```
Now all that's left is adding our TypeSocket construction code into the middleware...
```ts
export const socketMiddleware = (url: string) => {
return (store: MiddlewareAPI<any, any>) => {
const socket = new TypeSocket<MessageModel>(url);
// We still need the events here.
return (next: (action: any) => void) => (action: any) => {
// And here we'll handle WS_SEND_MESSAGE.
return next(action);
};
};
};
```
...and adding the event handling and message sending:
```ts
export const socketMiddleware = (url: string) => {
return (store: MiddlewareAPI<any, any>) => {
const socket = new TypeSocket<MessageModel>(url);
// We dispatch the actions for further handling here:
socket.on('connected', () => store.dispatch({ type: ActionType.WS_CONNECTED }));
socket.on('disconnected', () => store.dispatch({ type: ActionType.WS_DISCONNECTED }));
socket.on('message', (message) => store.dispatch({ type: ActionType.WS_MESSAGE, value: message }));
socket.connect();
return (next: (action: any) => void) => (action: any) => {
// We're acting on an action with type of WS_SEND_MESSAGE.
// Don't forget to check if the socket is in readyState == 1.
// Other readyStates may result in an exception being thrown.
if (action.type && action.type === ActionType.WS_SEND_MESSAGE && socket.readyState === 1) {
socket.send(action.value);
}
return next(action);
};
};
};
```
Now that this is taken care of, we need to add the middlewarae to our store. Let's first save the middleware in `src/socketMiddleware.ts`.
Then we can use it like this:
```ts
import { createStore, applyMiddleware } from 'redux';
import createSagaMiddleware from 'redux-saga';
import { socketMiddleware } from './socketMiddleware';
import reducers, { StoreType } from './reducers';
import sagas from './sagas';
const sagaMiddleware = createSagaMiddleware();
const store = createStore(
reducers,
applyMiddleware(socketMiddleware('ws://localhost:5000/'), sagaMiddleware),
);
sagaMiddleware.run(sagas, store.dispatch);
```
I'm assuming that there are reducers available from `./reducers` and sagas (for Redux Saga) in `./sagas`.
Now, let's start using Redux Saga to handle our messages. This is pretty simple and comes down to utilizing Redux-Saga's `takeEvery`:
```ts
function* message(action: ActionModel) {
const msg: MessageModel = action.value as MessageModel;
// Now we can act on incoming messages
switch (msg.type) {
case MessageType.WELCOME:
yield put({ type: ActionType.WELCOME, value: 'Hello world!' });
break;
}
}
export default function* root(dispatch: (action: any) => void) {
yield takeEvery(ActionType.WS_MESSAGE, message);
}
```
Sending messages with our setup is also that easy, you will just have to dispatch the message like so:
```ts
dispatch({ type: Action.WS_SEND_MESSAGE, value: message });
```
I prefer using this method over using any other Redux WebSocket libraries because of the flexibility I get when it comes to handling actions inside of the middleware, there's a lot of things you can customize. TypeSocket can be replaced for a pure WebSocket as well, if necessary. | matsz |
261,665 | Deploy a React App to Google Cloud Platform using App Engine | Prerequisites: Node An activated Google Cloud Platform account gcloud CLI To get started, use np... | 0 | 2020-02-14T17:38:56 | https://medium.com/better-programming/deploy-a-react-app-to-google-cloud-platform-using-google-app-engine-3f74fbd537ec | react, webdev, devops, tutorial | Prerequisites:
- [Node] (https://nodejs.org/en/ "node")
- An activated [Google Cloud Platform account] (https://console.cloud.google.com/ "googleCloudConsole")
- [gcloud CLI] (https://cloud.google.com/sdk/docs/quickstarts "googleCloud")
To get started, use npx to generate a new React app using [create-react-app] (https://reactjs.org/docs/create-a-new-react-app.html "reactjs"):
```
npx create-react-app <app-name>
```
Once npx has generated all the necessary files for your React app, let’s make sure it runs fine by doing:
```
cd <app-name>
npm start
```
In your favorite browser, navigate to http://localhost:3000
You should see a screen similar to this one:

Now that your app is up and running, let’s create a production build out of it. To do so, simply run:
```
npm run build
```
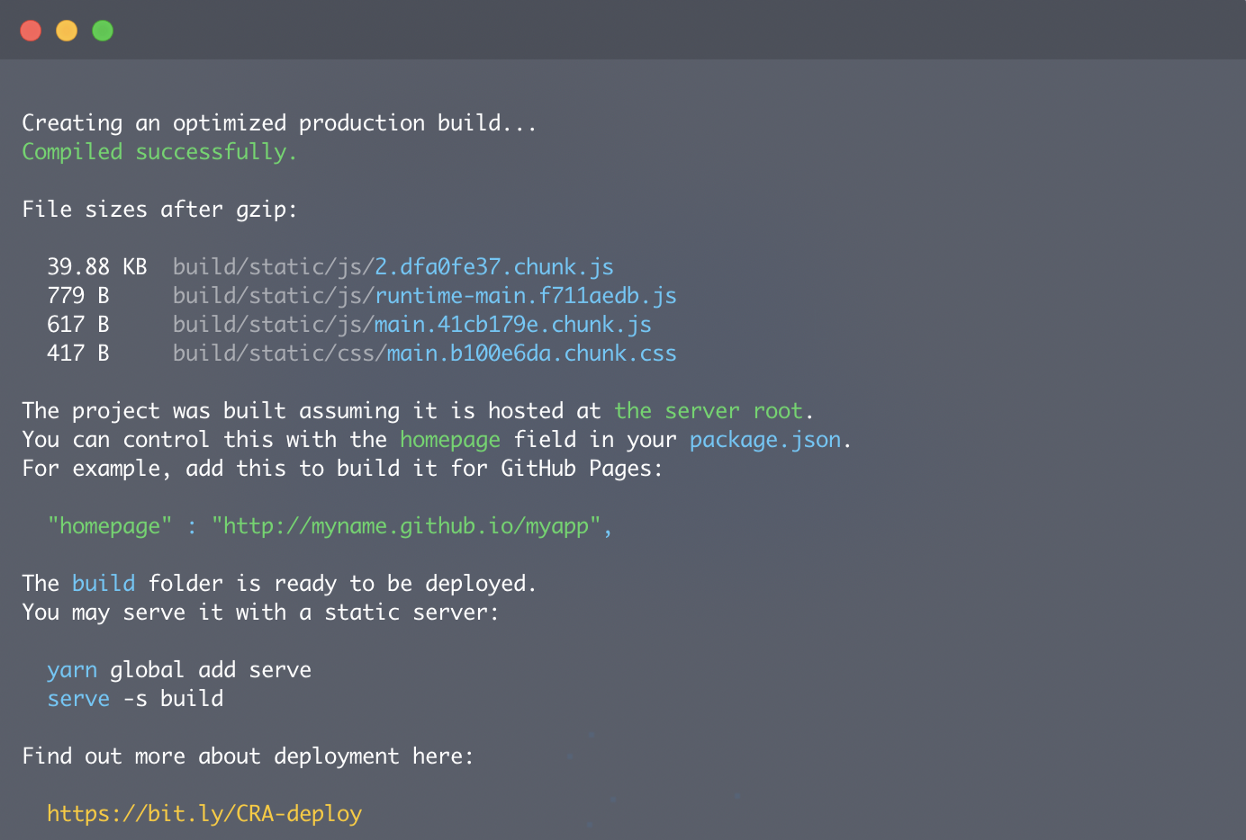
At this point, there is nothing left to do from a React perspective. The next step is to configure a new project in the App Engine. Then, all that is left to do is to use the Google Cloud SDK to deploy our freshly built React app to GCP.

Here is a series of screenshots that will walk you through how to do the first part: configure a new project in the GCP App Engine.
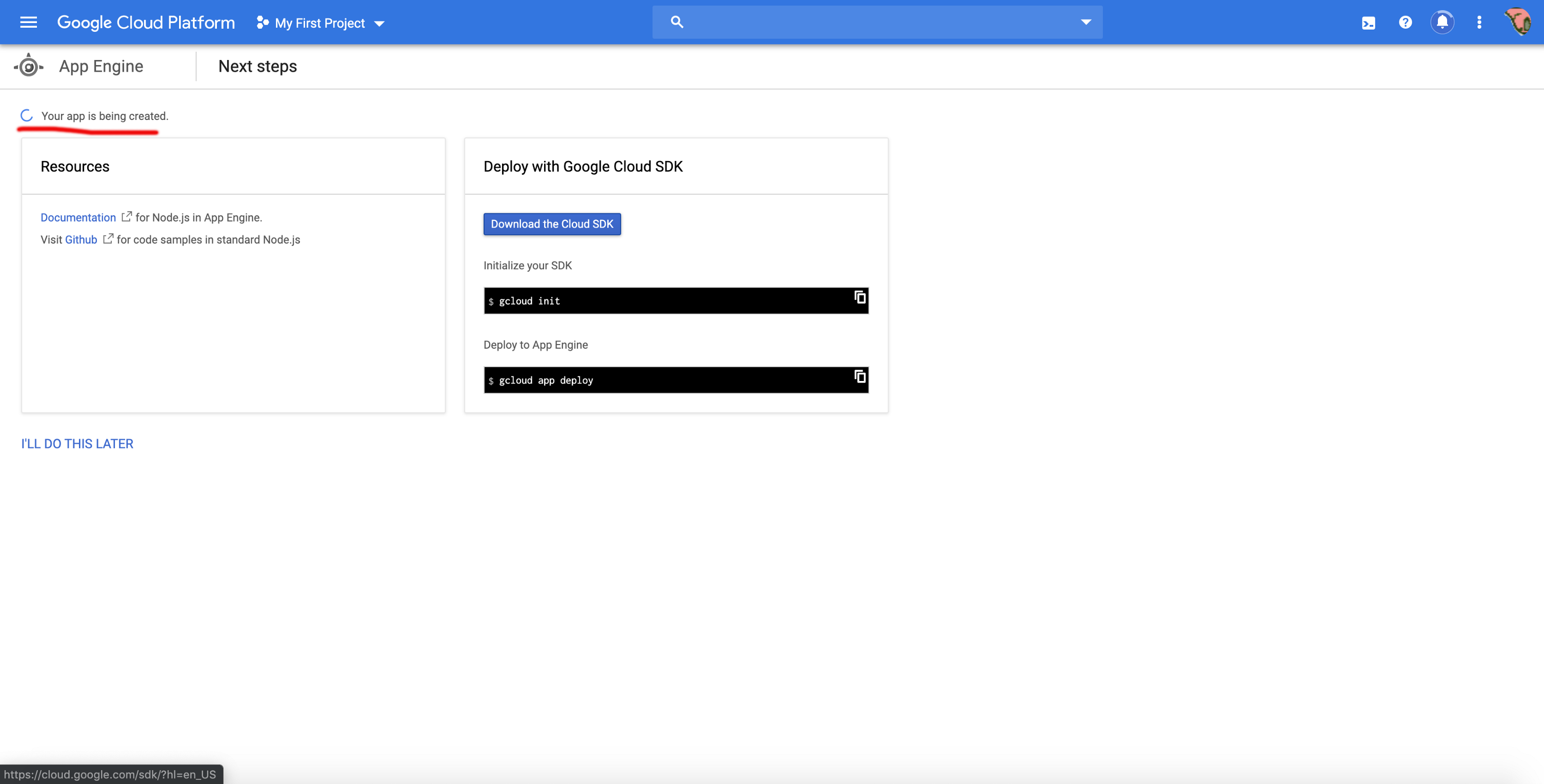
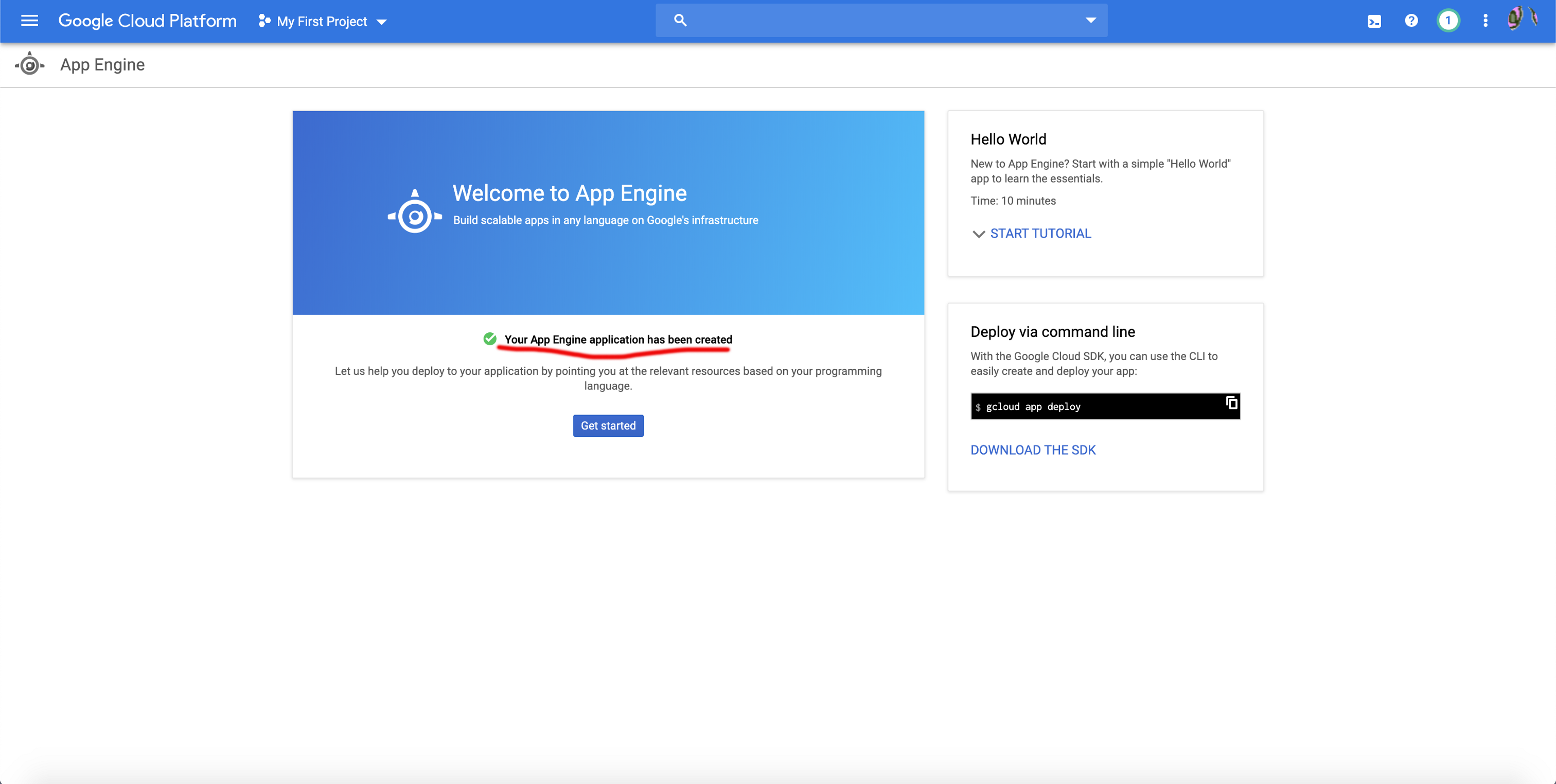
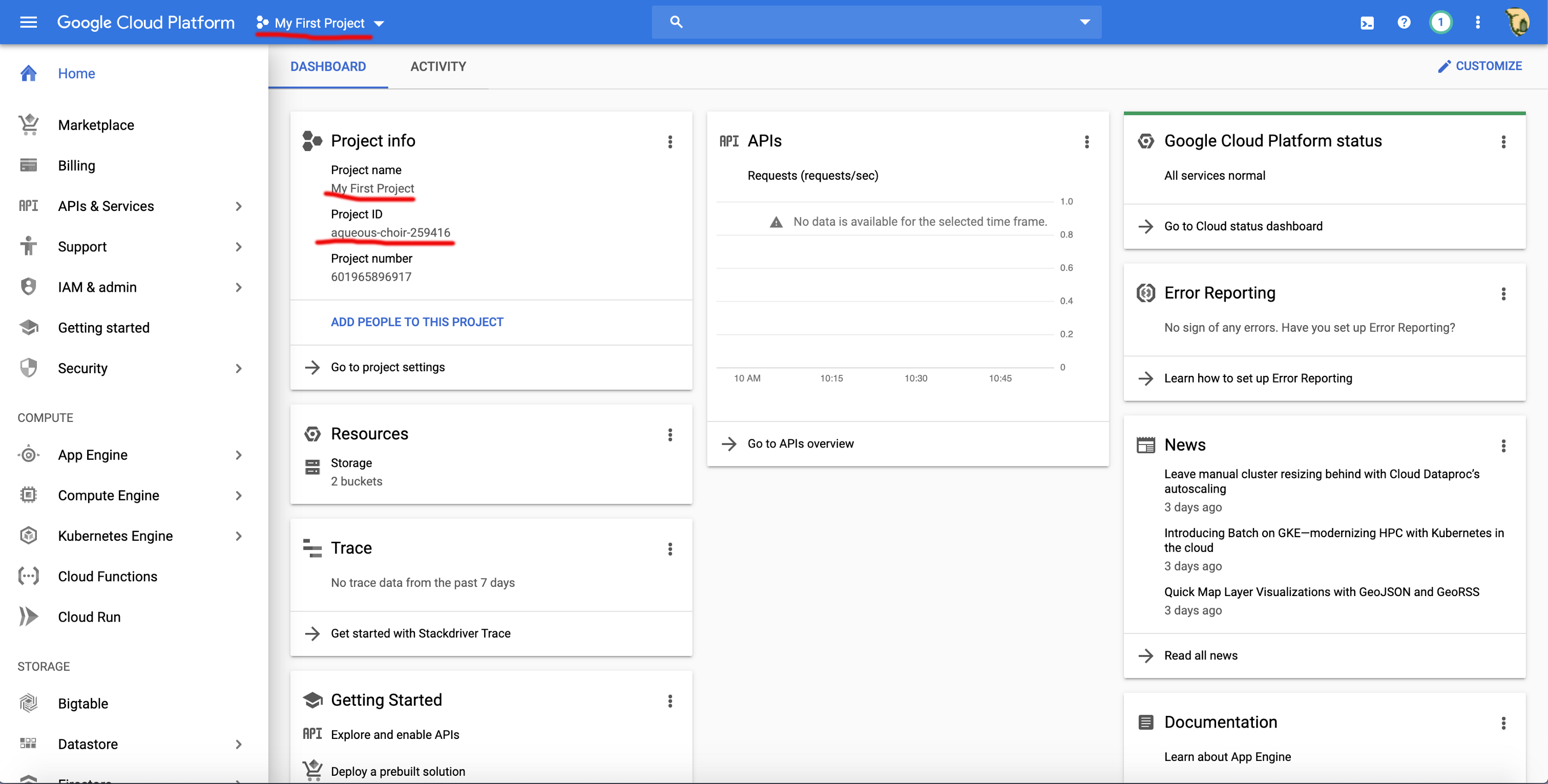
If you followed the steps successfully, you should be able to see your Google App Engine dashboard like the last picture above. That was the last thing we had to do with the App Engine web console. Now, our focus will be on using the gcloud CLI. Verify that you have it by executing:
```
gcloud -v
```
If you are having trouble installing it, here is your [official guide] (https://cloud.google.com/sdk/docs/quickstarts "googleCloud").
Now navigate to your React app folder. We need to create a new app.yaml file in the root of our project folder that the gcloud CLI will use to deploy our app to the App Engine. After you create the file, add this content to it [(official source)] (https://cloud.google.com/appengine/docs/flexible/nodejs/configuring-your-app-with-app-yaml "nodejs"):
```
runtime: nodejs
env: flex
# This sample incurs costs to run on the App Engine flexible environment.
# The settings below are to reduce costs during testing and are not appropriate
# for production use. For more information, see:
# https://cloud.google.com/appengine/docs/flexible/nodejs/configuring-your-app-with-app-yaml
manual_scaling:
instances: 1
resources:
cpu: 1
memory_gb: 0.5
disk_size_gb: 10
```
Make sure to save the file, and now we are finally ready to use the CLI:
```
gcloud init
```
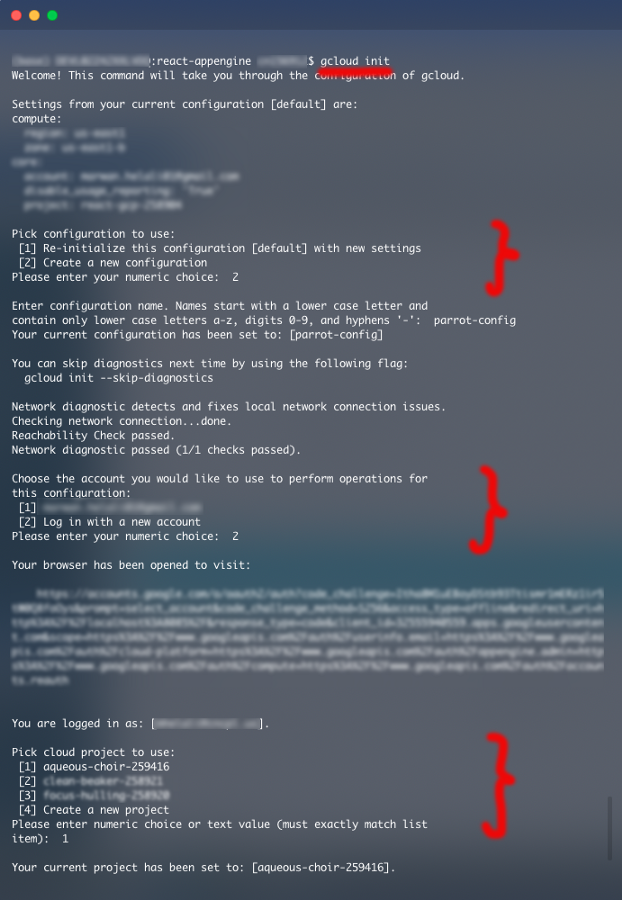
Follow the steps to add your account, region, and make sure to pick the project you just created.
Once that has been initialized successfully, we can run the final and ultimate deploy command:
```
gcloud app deploy
```
After a few minutes, you should see a link in “Deployed service [default] to”:

Visit it in your browser to find your deployed React App. Here is mine.
Congrats Champ! You did it! 🎉🎉🎉
Here is a [link] (https://github.com/Marwan01/react-appengine "gitRepo") to the git repo that contains the React app and the YAML file that was used for this article. Thank you for reading! 💟📖
Original Source: https://medium.com/better-programming/deploy-a-react-app-to-google-cloud-platform-using-google-app-engine-3f74fbd537ec | marwan01 |
261,718 | Creating and Using your OCI Free Tier VMs | One of the great things about the Oracle Cloud Infrasture (OCI) Free Tier as opposed to other 'always... | 4,858 | 2020-02-14T20:18:55 | https://dev.to/osde8info/creating-and-using-your-oci-free-tier-vms-1gi2 | cloud, linux | One of the great things about the Oracle Cloud Infrasture (OCI) Free Tier as opposed to other 'always free' cloud services is that you can have 2 Compute Virtual Machine Instances (VMs)
* https://www.oracle.com/cloud/free/
* https://docs.cloud.oracle.com/en-us/iaas/Content/FreeTier/resourceref.htm
* https://docs.cloud.oracle.com/en-us/iaas/Content/GSG/Reference/overviewworkflow.htm
* https://www.oracle.com/cloud/sign-in.html?intcmp=OcomFreeTier
The first thing to do after creating your VMs will probably be to SSH in and run `yum update` and then install `lsb` and maybe `nmap`
```
$ ssh opc@MYPUBLICIP
$ sudo -i
# yum update
# yum install redhat-lsb
# yum install nmap
# lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch: \
cxx-4.1-amd64:cxx-4.1-noarch: \
desktop-4.1-amd64:desktop-4.1-noarch: \
languages-4.1-amd64:languages-4.1-noarch: \
printing-4.1-amd64:printing-4.1-noarch
Distributor ID: OracleServer
Description: Oracle Linux Server release 7.7
Release: 7.7
Codename: n/a
```
In Part 2 we will look at how to network your VMs (10.0.0.2 & 10.0.0.3) together and in Part 3 we will look at how to install node. | osde8info |
261,725 | CSS Grid 201, let's get technical | So last week, I presented my way of talking about CSS Grid, focused on being simple to understand and... | 4,859 | 2020-02-15T14:22:36 | https://dev.to/arthurbiensur/css-grid-201-a-bit-more-technical-3ek8 | css, grid, youtube, tutorial | So last week, [I presented my way of talking about CSS Grid, focused on being simple to understand and visual](https://dev.to/arthurbiensur/learning-css-grid-the-easy-way-2d9h). This week, we are going to go a bit deeper under the hood!
As much as I think that using track numbers is unfriendly, it's still super useful to know how they work, especially before entering the "dynamic" part of the series next week.
You will find below a walk through of how to place items using the track lines, area lines, all the shorthands you will need and as a bonus, how to overlap items!
[link to the full playlist here](https://www.youtube.com/playlist?list=PLBHbfZu_dhOca_FpdUccB2KfjPfW1zklZ)
Under the hood
{% youtube xfPBhTSFjkI %}
Spanning multiple rows/columns
{% youtube reMFQYiPR4o %}
Using our named areas as tracks
{% youtube Ii85GSOK1Tw %}
Hooking to multiple areas and span across them
{% youtube Ftfk8rdA8nM %}
Overlapping items
{% youtube 9Lds75ufST4 %}
Reduce code verbosity with shorthands
{% youtube Dokj7PI0AY0 %} | arthurbiensur |
261,928 | Document your thoughts | Originally posted at michaelzanggl.com. Subscribe to my newsletter to never miss out on new content.... | 5,272 | 2020-03-05T22:36:26 | https://michaelzanggl.com/articles/document-your-thoughts | productivity | > Originally posted at [michaelzanggl.com](https://michaelzanggl.com/articles/document-your-thoughts). Subscribe to [my newsletter](https://michaelzanggl.com/) to never miss out on new content.
Here's a nice little habit I've picked up recently.
I was working on a feature for a side project, but I struggled coming up with the right approach. For a couple of days, I was procrastinating on it, working on other parts of the app (you know, coding). I tried taking notes in bulleted lists and doing some brainstorming with mind maps. But it was all still so blurry. There was no clear path.
Then I tried something different. After reading some of the stuff from the people at basecamp, I followed their recommendations and started writing. And I mean actually writing, using proper sentences rather than just bullet points. It was very casual as if I was talking to a person, telling him/her/me(?) about all the problems with the first approach, and how the other one just isn't compelling enough.
It conceptualized my thoughts, put them into order and laid everything out in front of me.
The end result was a mix of multiple approaches and things that I have not even thought of before. And it only took an hour of writing to clear my brain that has been foggy for days now.
One more thing I came to understand:
I can type pretty fast, but I realized that typing fast was paradoxically slowing me down. My thoughts couldn't catch up. I couldn't keep the "conversation" going. So try slowing down when you feel the same way. | michi |
261,965 | Using Mirage JS to create a fake api with React JS | learn how to use miragejs to fake a api endpoint | 0 | 2020-02-17T14:54:31 | https://dev.to/leandroruel/using-mirage-js-to-create-a-fake-api-with-react-js-4nnl | miragejs, react | ---
title: Using Mirage JS to create a fake api with React JS
published: true
description: learn how to use miragejs to fake a api endpoint
tags: miragejs, react
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/q5vkwvkc8j9bvny8mhd9.jpg
---
welcome to my first post, today i'm going to show you how to use Mirage JS to make a fake endpoint, after you learn it, i'm sure you will be amazed by it and will use it in your future projects.
# What is it?
from Mirage website: Mirage JS is an API mocking library that lets you build, test and share a complete working JavaScript application without having to rely on any backend services.
if you want know more, read the [getting started](https://miragejs.com/docs/getting-started/introduction/) guide.
## Before start
install the **create-react-app** to try Mirage.
```ssh
$ npx create-react-app testapp
```
## Install Mirage JS
```ssh
$ npm i --save-dev miragejs
```
## Creating the server
cd to the react folder then create a `server.js` file inside `src/` folder:
```ssh
$ cd testapp/ ; touch src/server.js
```
now open the `server.js` file and type the following code:
```js
import { Server, Model } from "miragejs"
export function makeServer({ environment = "development" } = {}) {
let server = new Server({
environment,
models: {
user: Model,
},
seeds(server) {
server.create("user", { name: "Bob" })
server.create("user", { name: "Alice" })
},
routes() {
this.namespace = "api"
this.get("/users", schema => {
return schema.users.all()
})
},
})
return server
}
```
now import this script inside your `src/index.js`:
```js
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import App from './App';
import * as serviceWorker from './serviceWorker';
import {makeServer} from './server';
if (process.env.NODE_ENV === "development") {
makeServer()
}
ReactDOM.render(<App />, document.getElementById('root'));
serviceWorker.unregister();
```
## Fetch the data
now inside our `app.js`, use the react functions `useState` and `useEffect` to help us with this job:
```js
import { useState, useEffect } from "react"
export default function App() {
let [users, setUsers] = useState([])
useEffect(() => {
fetch("/api/users")
.then(res => res.json())
.then(json => {
setUsers(json.users)
})
}, [])
return (
<ul data-testid="users">
{users.map(user => (
<li key={user.id} data-testid={`user-${user.id}`}>
{user.name}
</li>
))}
</ul>
)
}
```
now go to the terminal and start the react server:
```ssh
$ npm run start
```
now you should be able to see your users being rendered in the view. this is a simple tutorial, feel free to comment if anything is wrong. | leandroruel |
262,041 | What is a Kubernetes Pod? | In this article, I’m going to provide an explanation for Kubernetes pods, use cases, and lifecycle, a... | 0 | 2020-02-15T07:13:58 | https://dev.to/scynixit/what-is-a-kubernetes-pod-4mhh | kubernetes, devops, docker, microservices | In this article, I’m going to provide an explanation for Kubernetes pods, use cases, and lifecycle, and how to use it to deploy an application. This article assumes you recognize the purpose of the Kubernetes and you’ve got minikube and kubectl installed.
<b>What is a pod in K8S?</b>
Of object models in Kubernetes, the pod is the smallest building block. inside a cluster, a pod represents a system that’s running. The inside of a pod may have one or greater containers. Those within a single pod share:
<ul>
<li>A unique network IP</li>
<li>Network</li>
<li>Storage</li>
<li>Any additional specifications you’ve applied to the pod</li>
</ul>
To get in-Depth knowledge on Kubernetes you can enroll for a live demo on
<a href="https://onlineitguru.com/kubernetes-training.html"> kubernetes online training </a>
<img src="https://dev-to-uploads.s3.amazonaws.com/i/ibanu7d5kpgbsanbbt5g.png">
Another way to think of a pod — a “logical host” that is specific to your application and holds one or more tightly-coupled containers. For example, say we've got an app-container and a logging-container during a pod.
The only job of the logging-container is to tug logs from the app-container. Locating your containers in a pod eliminates extra communication setup because they are co-located, so everything is local and they share all the resources. This is an equivalent thing as execution on an equivalent physical server during a pre-container world.
There are other things to do with pods, of course. You might have an init container that initializes a second container. Once the second container is up and serving, the first container stops — its job is done.
**Pod model types**
There are two model types of pod you can create:
<ul>
<li><b>One-container-per-pod:</b> This model is the most popular. The post is that the “wrapper” for one container. Since pod is that the smallest object that K8S recognizes, it manages the pods rather than directly managing the containers.</li>
<li><b>Multi-container-pod:</b> during this model, a pod can hold multiple co-located containers that are tightly coupled to share resources. These containers work as a single, cohesive unit of service. The pod then wraps these multi containers with storage resources into one unit. Example use cases include sidecars, proxies, logging.</li>
</ul>
Take your career to new heights of success with <a href="https://onlineitguru.com/kubernetes-training.html"> kubernetes training </a>
Each pod runs one instance of your application. If you would like to scale the app horizontally (such as running several replicas), you’ll use a pod per instance. this is often different from running multiple containers of an equivalent app within one pod.
It is worth mentioning that pods aren’t intended as durable entities. If a node fails or if you’re maintaining nodes, the pods won’t survive. to unravel this issue, K8S has controllers — typically, a pod is often created with a type of controller.
**Pod lifecycle phases**
A pod status tells us where the pod is in its lifecycle. it’s meant to offer you thought not surely, therefore it’s good practice to debug if pod doesn’t come up cleanly. The five phases of a pod lifecycle are:
<ol>
<li><b>Pending:</b> The pod is accepted, but a minimum of one container image has not been created.</li>
<li><b>Running:</b> The pod is sure to a node, and every one container is created. One container is running or in the process of starting or restarting.</li>
<li><b>Succeeded:</b> All containers within the pod successfully terminated and can not restart.</li>
<li><b>Failed:</b> All containers are terminated, with at least one container failing. The failed container exited with a non-zero status.</li>
<li><b>Unknown:</b> The state of the pod couldn’t be obtained.</li> | scynixit |
262,060 | Build React Native WordPress App [Expo way] #2 : React Navigation Version 5 | This series intends to show how I build an app to serve content from my WordPress blog by using react... | 4,880 | 2020-02-15T16:48:27 | http://kriss.io/build-react-native-wordpress-app-expo-way-2-react-navigation-version-5/ | npmreactnavigation, reactnavigationgit, reactnavigationexa, reactnavigation5 | ---
title: Build React Native WordPress App [Expo way] #2 : React Navigation Version 5
published: true
date: 2020-02-15 01:45:13 UTC
tags: npm-react-navigation,react-navigation-git,react-navigation-exa,react-navigation-5
canonical_url: http://kriss.io/build-react-native-wordpress-app-expo-way-2-react-navigation-version-5/
series: Build React native Wordpress client app with Expo
cover_image: https://cdn-images-1.medium.com/max/1024/0*gixj-kpE4ZjGvx2e.png
---
This series intends to show how I build an app to serve content from my WordPress blog by using react-native. Since we successfully build an app on the React Native CLI path., for the next step, we try to develop this app again but using Expo. We will discover the Expo ecosystem that makes our lives comfortable and help us avoid dealing with Native modules to learn how to deal with WordPress APIs. Here, the most prominent features talked about in the book are the dark theme, offline mode, infinite scroll, in-app purchase, and many more. You can discover much more in this series. this inspiration to do this tutorial series came from the [React Native Templates](http://instamobile.io) from instamobile
in this chapter, we are getting started using react-navigation version 5 that recently release for this time I wrote this chapter that major change its component base
#### Install all required package
first, install react-navigation package
- **@react-navigation/native** — core infrastructure package provides basic navigation
- **@react-navigation/stack** — provide basic navigation behavior
- **@react-navigation/bottom-tabs** — provide tabs navigation
```
npm install @react-navigation/native @react-navigation/stack @react-navigation/bottom-tabs
```
install required dependencies
```
expo install react-native-gesture-handler react-native-reanimated react-native-screens react-native-safe-area-context @react-native-community/masked-view
```
one last thing for iOS your need install Cacoapod package
```
cd ios; pod install; cd ..
```
next, we restructure our project by creating a new place for containing only navigation

here we create folder name src for containing all of react-native code component folder for store component and screen folder for containing screen component
#### handle main navigation with Bottom Tabs
in Navigator.js firstly we import the main navigation
```
import React, { PureComponent } from 'react'
import { NavigationContainer } from "@react-navigation/native";
import { createStackNavigator } from "@react-navigation/stack";
import { createBottomTabNavigator } from "@react-navigation/bottom-tabs";
```
next, we create our screen then import and add to stack and tab navigation
then create boilerplate code like here to every screen
```
import React, { Component } from 'react'
import { Text, View } from 'react-native'
export class Bookmark extends Component {
render() {
return (
<View>
<Text> textInComponent </Text>
</View>
)
}
}
export default Bookmark
```
next import to Navigator.js again
```
import Home from '../screens/Home.js'
import Bookmark from '../screens/Bookmark.js'
import Categories from '../screens/Categories.js'
import Setting from '../screens/Setting.js'
```
and create the main function for handle class
```
export default function Navigator() {
const Tab = createBottomTabNavigator()
return (
<NavigationContainer >
<Tab.Navigator>
<Tab.Screen name="Home" component={Home} />
<Tab.Screen name="Categories" component={Categories} />
<Tab.Screen name="Bookmark" component={Bookmark} />
<Tab.Screen name="Settings" component={Setting} />
</Tab.Navigator>
</NavigationContainer>
);
}
```
then we clear default code in App.js and insert new code for handle only Navigation
```
import React from "react";
import Navigators from "./src/components/Navigator";
export default function App() {
return (
<Navigators />
);
}
```
here the first result blank navigation

#### Stack in Tab
next step in every tab screen we want to add a secondary screen that shows children data like Single post that we navigate from index screen for this step we use React navigation stack for creating a stack screen
firstly we create secondary screen
```
import SinglePost from '../screens/SinglePost.js'
```
then we create new stack navigation instance
```
const Stack = createStackNavigator();
function HomeStack() {
return (
<Stack.Navigator>
<Stack.Screen name="Home" component={HomeScreen} />
<Stack.Screen name="Post" component={SinglePost} />
</Stack.Navigator>
);
}
```
then add to Tab
```
<NavigationContainer >
<Tab.Navigator>
<Tab.Screen name="Home" component={HomeStack} />
<Tab.Screen name="Categories" component={Categories} />
<Tab.Screen name="Bookmark" component={Bookmark} />
<Tab.Screen name="Settings" component={Setting} />
</Tab.Navigator>
</NavigationContainer >
```
the last thing we add a button to make navigation to SIngle post screen
add Button for taking action in Home.js
```
export class Home extends Component {
render() {
return (
<View>
<Button title="Go to single post" onPress={() => this.props.navigation.navigate('SinglePost')} />
</View>
)
}
}
```
Now we can try to make navigation
#### conclusion
this chapter we learn how to use React navigation version 5 the lastest stable from Expo team we learn how to use Bottom tabs and Stack navigation in next section we will add an icon font to button tab using react-native-vector icons hope your enjoy and stay tuned
_Originally published at _[_Kriss_](https://kriss.io/build-react-native-wordpress-app-expo-way-2-react-navigation-version-5/)_._
* * * | kris |
262,089 | Difference between backend, frontend, full-stack, and super stack development work | I looked at archive.org and found a website I put live in 2001, which means I have been writing some... | 0 | 2020-02-15T11:20:16 | https://geshan.com.np/blog/2020/02/difference-between-backend-frontend/ | webdev, javascript, softwareengineering, softwaredevelopment | I looked at archive.org and found a website I put live in 2001, which means I have been writing some code for 20 years. Of course, I am not going to give a link to that website still it will be safe to mention 20 years back in Kathmandu when people didn’t have an email I had built websites. I uploaded it over a 33.8k modem with a dial-up connection. Kids these days will not even know the sound of that modem (yes I am old).
Coming back to the topic, this is an “oversimplified” guide to showing the difference between backend, frontend, full-stack, and (in my own terms) super stack development of course, with a web development focus. Let’s get started.
*Image from Pixabay*
## Introduction
Software engineering is a hot topic these days and hearing random people like a [minister](https://thehill.com/changing-america/enrichment/education/476391-biden-tells-coal-miners-to-learn-to-code) urging people to learn to code is amusing at times. They make it look as if learning to code is easy and getting a high paid job after you know how to code is a piece of cake. Simple common sense, it is not. Anyways, the most common things software engineers build are websites and web applications. This post highlight the paths you can take in the web development aspect of software engineering.
## Oversimplification
Yes, there is going to be a lot of oversimplification for this blog post. If I go into a lot of detail it will confuse many people and I want this piece to be beginner-friendly. So to start with below is my understanding of backend, frontend, full-stack, and super stack development:
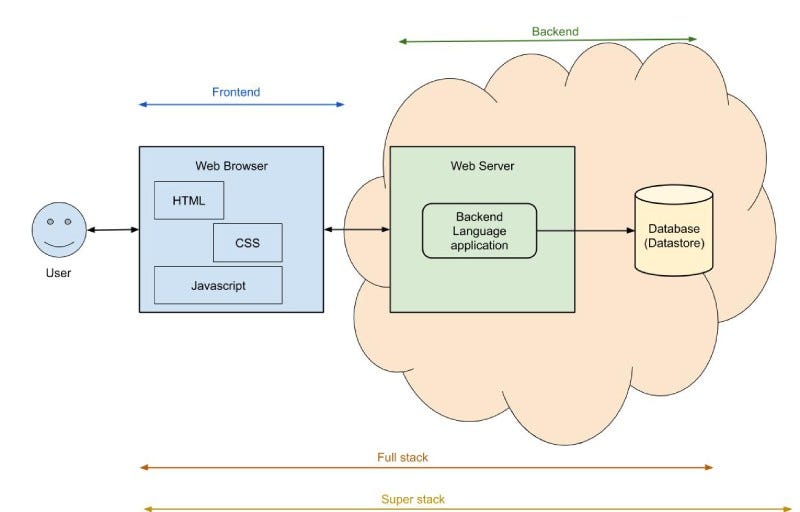*Oversimplification of the backend, frontend, full-stack, and super stack development work*
From the above image, it is pretty clear, blue thing (light and dark both) are frontend, green (+ some yellow the DB) is backend stuff. Orange is representing full stack and the bottom yellow line indicates super stack development. Let’s go into more details for each of them below:
## All ends and non-ends
It is clear that this is a comparison between ends and non-ends, backEND, frontEnd, full-stack, and super stack. A quick distinction is what you see rendered on the web browser is usually frontend, the languages that talks to the datastore are mostly backend. If the software work consists of both backend and frontend it can be termed full-stack. So what is the super stack work, read on…
Rather than segmenting yourself as a backend or frontend developer, let’s look at it from the work point of view. Generally, as software engineers, we are solution providers so sometimes doing some work that is not your specialty would be good. It is in our best interest to develop [T shaped skills](https://en.wikipedia.org/wiki/T-shaped_skills). Let’s jump to an overview of the types of development work.
I would recommend having a look at this popular [roadmap](https://github.com/kamranahmedse/developer-roadmap) for technologies you might want to be aware of to become a proficient frontend, backend or DevOps engineer.
> *I will write only points for each of the web development work categories and keep it high level. Let’s zoom in.*
### Backend development
Some of my observations about backend development:
* Backend development work will involve working with at least one backend language like [PHP](https://www.php.net/), [NodeJs](https://nodejs.org/en/), [Ruby](https://www.ruby-lang.org/en/), [Python](https://www.python.org/), [Java](https://www.java.com/en/), etc which can communicate with a database/datastore.
* Backend software development work will encompass designing of Relational databases which is generally represented as [Entity-Relationship (ER) diagrams](https://www.lucidchart.com/pages/er-diagrams)
* Backend work will require the software engineer/developer to understand more complex concepts of the database like concurrency, [locking](https://www.methodsandtools.com/archive/archive.php?id=83) and [transactions](https://vladmihalcea.com/a-beginners-guide-to-acid-and-database-transactions/).
* Of course, to do backend development knowledge of [SQL](https://www.khanacademy.org/computing/computer-programming/sql) will be indispensable
* Similarly, the work will involve setting up and/or configuring a Relational DBMS like [Mysql](https://www.mysql.com/), [Postgres](https://www.postgresql.org/), [SQL Server](https://www.microsoft.com/en-in/sql-server/), [Oracle](https://www.oracle.com/database/), etc.
* To do backend development work well knowledge of network, DNS, etc will also be very helpful.
* Depending on the work, it will involve creating APIs for other consumers like a mobile application or a frontend application. Work might include building [RESTful](https://www.mulesoft.com/resources/api/what-is-rest-api-design) API or [GraphQL](https://graphql.org/). Peeking into [gRPC](https://grpc.io/) will be beneficial too.
There are many things I am skipping here like knowledge of data structure and algorithms, HTTP, operating system knowledge, NoSQL database, Message Brokers, etc but that is intentional as this is an oversimplified high-level summary.
### Frontend development
Following are my views on Frontend development:
* Frontend development work encompasses the ability to change how things look (maybe not designing it as it will fall under [UI/UX](https://careerfoundry.com/en/blog/ux-design/the-difference-between-ux-and-ui-design-a-laymans-guide/) work), thereby includes colors, buttons, margins, etc. This will be mostly [CSS](https://developer.mozilla.org/en-US/docs/Web/CSS) work.
* Frontend work with fewer doubts includes wrangling [HTML](https://www.w3schools.com/html/). HTML might look simple, still knowledge of the latest version and [HTML 5 tags](https://www.htmlgoodies.com/tutorials/html5/new-tags-in-html5.html) like header, the footer will help. Knowing [meta tags](https://www.w3schools.com/tags/tag_meta.asp) like [viewport](https://www.w3schools.com/css/css_rwd_viewport.asp) will also be great.
* Frontend task these days will surely involve some form of [Javascript](https://developer.mozilla.org/en-US/docs/Web/JavaScript) and include working with frameworks/libraries like [Angular](https://angularjs.org/), [React](https://reactjs.org/) or [Vue](https://vuejs.org/).
* To do some meaningful frontend work you will need to understand [js package management](https://www.freecodecamp.org/news/javascript-package-managers-101-9afd926add0a/), module bundlers like [webpack](https://webpack.js.org/) and go through some [Javascript fatigue](https://medium.com/@ericclemmons/javascript-fatigue-48d4011b6fc4) too, best of [luck](https://lucasfcosta.com/2017/07/17/The-Ultimate-Guide-to-JavaScript-Fatigue.html) :).
* After you survive the fatigue, Frontend work will entail consuming APIs (mainly REST APIs).
* Frontend work in current times might involve learning some [Typescript](https://www.typescriptlang.org/), mash up some [Progressive Web Apps (PWA)](https://developers.google.com/web/progressive-web-apps) and things along these lines.
I have skipped [static site generators](https://www.staticgen.com/), [web components](https://developer.mozilla.org/en-US/docs/Web/Web_Components), [JAM stack](https://jamstack.org/), and many other things.
I would consider Mobile App development as a special category of Frontend development, that might be a discussion for another blog post.
## Full-stack development
Following is my understanding of [full-stack development](https://skillcrush.com/blog/front-end-back-end-full-stack/) work:
* Full-stack development is a mix of both backend and frontend development work. That mix is not all things in the backend + all things in frontend. It’s a selective mix depending on the task.
* A task will qualify as a full-stack work when it involves things like adding a field to a database table, writing backend code and changing frontend form and logic to deliver this new feature.
* Being able to execute a full-stack task means knowing both sides of the stack to the point that it can be carried out. It will be great to consult more experienced team members to see if anything can be improved.
The term “full-stack developer” seems over demanding to me, I have met a couple of people who are real full-stack developers, they are [mythical](https://stackoverflow.blog/2019/10/17/imho-the-mythical-fullstack-engineer/). Still, most of the software engineers I know “can” do full-stack tasks but identify themselves more as a backend or frontend engineer.
## Super stack development
Let’s unfold my views about the “super stack” development work:
* Super stack development work involves not only developing the feature/app (which is full-stack ish) on your (the developers’) machine but deploying it and making it accessible and scalable.
* This type of work encompasses knowing about the servers, cloud these days and venturing into the [DevOps](https://www.atlassian.com/devops)/[SRE](https://landing.google.com/sre/) land.
* Super stack work also includes thinking about security, employing your knowledge of things like the [OWASP top 10](https://owasp.org/www-project-top-ten/) and writing secure code.
Super stack development work focuses on real end to end delivery of the task or project. It might encompass creating and updating a CI/CD pipeline to help everyone in the team. It can also include setting up servers or [Kubernetes](https://kubernetes.io/) pods dependent on where and how the company you work for deploys its web applications.
## Conclusion
Some skills will be needed to do all kinds of above-mentioned work like using [Git](https://geshan.com.np/blog/2014/07/4-git-tips-beyond-basics/), automated testing with the [unit](https://geshan.com.np/blog/2016/03/there-are-only-two-types-of-automated-software-tests/) and other tests, doing meaningful [code reviews](https://geshan.com.np/blog/2019/12/how-to-get-your-pull-request-pr-merged-quickly/), using [Docker](https://geshan.com.np/blog/2018/11/4-ways-docker-changed-the-way-software-engineers-work-in-past-half-decade/).
This post is not about backend, frontend, full-stack, and super stack “developer”, it’s about the development work and skills a software engineer would need to carry out that task.
> *Rather than saying I am x-end or y-stack, as software engineers if we strive to add more value to the business without overstepping responsibilities, everyone wins including our customers.*
*Originally published at [https://geshan.com.np](https://geshan.com.np/blog/2020/02/difference-between-backend-frontend/) on February 15, 2020.* | geshan |
262,137 | Fixing the Iowa App, Accessible Design Systems, Principles of Icon Design — and more UX this week | A weekly selection of design links, brought to you by your friends at the UX Collective.... | 0 | 2020-02-15T14:34:05 | https://uxdesign.cc/fixing-the-iowa-app-accessible-design-systems-principles-of-icon-design-and-more-ux-this-week-9c9e1bc98a16 | productdesign, hotthisweek, marketing, design | ---
title: Fixing the Iowa App, Accessible Design Systems, Principles of Icon Design — and more UX this week
published: true
date: 2020-02-15 13:17:41 UTC
tags: product-design,hot-this-week,marketing,design
canonical_url: https://uxdesign.cc/fixing-the-iowa-app-accessible-design-systems-principles-of-icon-design-and-more-ux-this-week-9c9e1bc98a16
---
#### _A weekly selection of design links, brought to you by your friends at the UX Collective._

[**What do you think makes a good work culture?**](https://uxdesign.cc/interview-with-fabricio-teixeira-design-director-at-work-co-and-founder-of-the-ux-collective-5d3a723fdee0?source=friends_link&sk=9b4d8358b99e440512ce14fc0fe8ec5f) →
> “When we hear the word ‘culture’ we tend to think gimmicky office props, company-sponsored happy hours, and initiatives that look great from a PR perspective but don’t have a significant impact on people’s careers. We avoid the word ‘culture’; we focus on values instead. The best culture, in our opinion, is working with folks who are passionate about design and who will organically rally towards a shared value. Once that shared vision is defined, culture will naturally emerge and build itself around it.”
Had the honor of being interviewed by [Emi Knight](https://medium.com/u/ee4298b72c7b) for her [@designquestions](https://www.instagram.com/designquestions/) series this week. [**Read the full interview**](https://uxdesign.cc/interview-with-fabricio-teixeira-design-director-at-work-co-and-founder-of-the-ux-collective-5d3a723fdee0?source=friends_link&sk=9b4d8358b99e440512ce14fc0fe8ec5f)
- [**Responsive Type**](https://adrianroselli.com/2019/12/responsive-type-and-zoom.html) →
And how to deal with browser zoom.
- [**UX Animations**](https://www.nngroup.com/articles/animation-duration/) →
How to execute motion design in UX.
- [**Performance & UX**](https://www.debugbear.com/blog/performant-front-end-architecture) →
Making front-end apps load faster for better UX.
The UX Collective newsletter is a self-funded newsletter read by over 127,000 designers every week. The best way you can support it is by [sharing it with your friends](https://newsletter.uxdesign.cc/).
### Stories from the community

[**Time to get rid of UX/UI in design titles**](https://uxdesign.cc/time-to-get-rid-of-that-ux-ui-in-design-titles-927de8eee1d1?source=friends_link&sk=871d63fe0d25789a41ed1920168f08da) →
By [Rubens Cantuni](https://medium.com/u/d7ca111e7984)
[**7 principles of icon design**](https://uxdesign.cc/7-principles-of-icon-design-e7187539e4a2?source=friends_link&sk=531cc438de4aad598346813db8b6bc9f) →
By [Helena Zhang](https://medium.com/u/a81b0a6a418e)

[**I redesigned the infamous IOWA app in 30 minutes**](https://uxdesign.cc/i-redesigned-the-infamous-iowa-app-in-30-minutes-478a7ae7ffc8?source=friends_link&sk=b13309e7149e95af3ce1293da9517450) →
By [Michal Malewicz](https://medium.com/u/fde1eb3eb589)
More top stories:
- [**Who decides how disability is represented in stock photography?**](https://uxdesign.cc/disability-representation-in-stock-photography-7d4c80db0f13?source=friends_link&sk=4e71422b6337bf00239604cecab4a59f) **→**
By [Alicia Crowther](https://medium.com/u/a0d02a5aac5f)
- [**Using AI to find a partner on Tinder**](https://uxdesign.cc/how-i-used-ai-to-find-a-partner-on-tinder-c59cc0bb154c?source=friends_link&sk=53fd3fa25a154b9d59dfa17f3ee72c6d) **→**
By [Hiroo Aoyama](https://medium.com/u/c010fcca1775)
- [**How to find your niche as a UI/UX designer**](https://uxdesign.cc/how-to-find-your-niche-as-a-ui-ux-designer-aabbe5c9e396?source=friends_link&sk=7f2debf3bf6b68a757a9778560086e1b) **→**
By [Vasil Nedelchev](https://medium.com/u/9062a40070fe)
- [**What we never talk about: Facebook has a product problem**](https://uxdesign.cc/did-we-forget-that-facebooks-product-sucks-471c0aca1fcd?source=friends_link&sk=0cb5f1cecb0f8407ea7a3de64430ae73) **→**
By [Mark Gray](https://medium.com/u/67aa89db6de8)
- [**UX debt 101**](https://uxdesign.cc/ux-debt-101-fe6eacb5ebd7?source=friends_link&sk=6af3a0bf1800eb70e57b9edd95c0a04d) **→**
By [Tania Vieira](https://medium.com/u/ce20ef22bcd)
- [**Let’s talk neumorphism and accessibility**](https://uxdesign.cc/lets-talk-neumorphism-and-accessibility-44a48a6ace72?source=friends_link&sk=ecd34a31ff5e45ea0f0c421285c03083) **→**
By [Uyen Vicky Vo](https://medium.com/u/b7ede4f2dfd3)
- [**We’re not so different, you and I**](https://uxdesign.cc/were-not-so-different-you-and-i-36db9c94f525?source=friends_link&sk=536c23a9959300a3c60110aa74489287) **→**
By [Reinoud Schuijers](https://medium.com/u/e0848b675f5)
### News & ideas
- [**New Facebook App**](https://www.theverge.com/2020/2/13/21136898/facebook-pinterest-photo-sharing-app) →
Facebook quietly releases a Pinterest clone.
- [**Semantic Colors**](https://dev.to/ynab/a-semantic-color-system-the-theory-hk7) →
Exploring the idea of a semantic color system.
- [**Kill Color Trends**](https://www.fastcompany.com/90461730/the-dark-side-of-color-forecasting) →
Our obsession with trends is killing the planet.
- [**Female Leads**](https://www.nytimes.com/2020/02/07/opinion/sunday/brit-marling-women-movies.html) →
Brit Marling on why she doesn’t want to be the strong female lead.


<figcaption><a href="https://www.kayleykemple.work/">Featured work: Kayley Kemple</a> →</figcaption>
### Tools & resources
- [**Flow UI**](https://flow-ui.com/) →
An accessibility-oriented design system.
- [**DesignValley**](https://www.designvalley.club/) →
Yet another design tool repository.
- [**Img Larger**](https://imglarger.com/) →
Enlarge images without quality loss, thanks to AI.
- [**Brain Food**](https://www.brainfoodapp.co/) →
Bite-sized knowledge delivered to you weekly.
We believe designers are thinkers as much as they are makers. So we created the [design newsletter](https://newsletter.uxdesign.cc/) we have always wanted to receive.
* * * | fabriciot |
262,190 | Build React Native WordPress App [Expo way] #3 : Add Vector Icons | This series intends to show how I build an app to serve content from my WordPress blog by using react-native. Since we successfully build an app on the React Native CLI path., for the next step, we try to develop this app again but using Expo. We will discover the Expo ecosystem that makes our lives comfortable and help us avoid dealing with Native modules to learn how to deal with WordPress APIs. | 4,880 | 2020-02-15T17:09:37 | http://kriss.io/build-react-native-wordpress-app-expo-way-3-add-vector-icons/ | reactnative | ---
title: Build React Native WordPress App [Expo way] #3 : Add Vector Icons
published: true
description: This series intends to show how I build an app to serve content from my WordPress blog by using react-native. Since we successfully build an app on the React Native CLI path., for the next step, we try to develop this app again but using Expo. We will discover the Expo ecosystem that makes our lives comfortable and help us avoid dealing with Native modules to learn how to deal with WordPress APIs.
tags: react-native
canonical_url: http://kriss.io/build-react-native-wordpress-app-expo-way-3-add-vector-icons/
cover_image: https://cdn-images-1.medium.com/max/3840/0*Oqdxsq5ilvMg3jUE.png
series: Build React native Wordpress client app with Expo
---
This series intends to show how I build an app to serve content from my WordPress blog by using react-native. Since we successfully build an app on the React Native CLI path., for the next step, we try to develop this app again but using Expo. We will discover the Expo ecosystem that makes our lives comfortable and help us avoid dealing with Native modules to learn how to deal with WordPress APIs. Here, the most prominent features talked about in the book are the dark theme, offline mode, infinite scroll, in-app purchase, and many more. You can discover much more in this series. this inspiration to do this tutorial series came from the [React Native Templates](http://instamobile.io) from instamobile
in this chapter we gonna add expo vector icon to tab navigation make our bottom tabs look nice if you’re remembered for React native CLI path that so a lot of configuration on both Android and iOS but for Expo manage workflow we just install expo vector icon package and boom done
firstly we install expo-vector icon package
```
yarn add @expo/vector-icons
```
next, we import to Navigator.js
```
import { MaterialCommunityIcons } from '@expo/vector-icons';
```
this package has many icon types for but MaterialCommunityIcons provide many types of icon
for using icon we inject screenOption props of <Tab.Navigator >
```
<Tab.Navigator screenOptions={({ route }) => ({
tabBarIcon: ({ focused, color, size }) => {
let iconName;
if (route.name === 'Home') {
iconName = focused ? 'home' : 'home-outline';
} else if (route.name === 'Bookmark') {
iconName = focused ? 'bookmark' : 'bookmark-outline';
} else if (route.name === 'Categories') {
iconName = focused ? 'apps' : 'apps-box';
} else if (route.name === 'Settings') {
iconName = focused ? 'settings' : 'settings-box';
}
return <MaterialCommunityIcons name={iconName} size={size} color={color} />;
},
})}
tabBarOptions={{
activeTintColor: 'tomato',
inactiveTintColor: 'gray',
}?
```
here we use tab bar icon for add icon to tab bar then use route name for deciding what icon that we want to use in this menu and when tab bar got focus we use different icon style
here we got a nice tab bar easily than using CLI
#### Conclusion
this chapter we learn to compare for using the Expo icon package that helps us skip touch Xcode and Android studio is pretty cool . for the next chapter we learn to create a Home screen using React native paper another cool UI kit from the Expo team then interact Wordpress API Stay tuned.
---
_Originally published at [Kriss](https://kriss.io/build-react-native-wordpress-app-expo-way-3-add-vector-icons/)._
| kris |
262,226 | Rhea's Galaxy Map | Adventures in DAGs, Graph Databases, and Brownian Motion | 0 | 2020-02-15T18:21:17 | https://dev.to/willricketts/rhea-s-galaxy-map-116l | gamedev, indiegame, elixir, algorithms | ---
title: Rhea's Galaxy Map
published: false
description: Adventures in DAGs, Graph Databases, and Brownian Motion
tags: gamedev, indiegame, elixir, algorithms
published: true
---
In the [last post](https://dev.to/willricketts/introducing-rhea-46p2), I covered the various game titles and mechanics they utilize that I've drawn inspiration from for the design of Rhea. In covering Rhea's galactic map, I'd like to focus upon two of them heavily-- Eve Online and Stellaris.
### Inspiration
Eve Online and Stellaris have very similar map systems. Both have solar systems represented in a DAG-like structure. The DAG's nodes represent solar systems. In the case of Eve Online, this structure's edges are representative of Stargates, and in Stellaris, warp lanes between solar systems.
In any case, both systems function in a similar way, in that players and their fleets traverse a large DAG to move around the galaxy.
#### Stellaris
Based on a system of ephemeral matches, Stellaris's game maps are generated uniquely for each. Thus, each time the player creates a new empire or species and starts a game, a new map is generated and configured via the player's selected settings when creating the game.
One of the major strategies when starting a game of Stellaris is to rapidly expand to claim and build defenses around choke-point systems, or systems that have many connections as to control the flow of traffic through that portion of the map. This is a side-effect of this galactic map model that I'm intent upon creating.

#### Eve Online
Eve's map is persistent, in that the game has no concept of "rounds" or "matches." The game map, save for additions by their publisher, has and will remain the same since the release of the game in 2003. Being that the intent of Rhea is to be a single persistent game world, this is the path I've elected to follow.
Some very desirable but non-obvious effects arise from this kind of model for a galactic map. With a static map, various regions or sections of it become known within the playerbase for being better or worse to own from a strategic perspective. Eve has regions of the game that are notoriously difficult to invade, and has a few that are notoriously favorable for an invading military to stage their assets.

### Generating the Map
Creating a map of this size and detail was a challenging problem to solve, and at the time of this writing, still presents obstacles to overcome to achieve an optimal map structure.
#### First Attempts
When I first sat down to work on figuring out the most immediate challenges in building Rhea, my intent was to get something simple working and then expand upon the idea later. Upon researching how I would go about generating a map of this nature with DAG-like properties, I found [Astrosynthesis](https://www.nbos.com/products/astrosynthesis), a piece of software used for generating celestial structures primarily for role-playing games and hobbyist world-building. This program had a bunch of great features that'd be useful for my needs, but two features stood out in particular. Astrosynthesis has a user-created plugin ecosystem and an XML exporter.

Before long, I had a galaxy containing ~20 solar systems and connections between them, which I exported to a large XML document, which I was able to load into the Elixir-based backend of Rhea with [elixir-XML-to-map](https://github.com/homanchou/elixir-xml-to-map).
#### Using the Data
From this _very_ large map, I perform a series of mutations on the data to order it into a list of Solar Systems and one of Gates. With these lists, I first created a DB record for each of the solar systems within PostgreSQL. With a SolarSystems table populated with data, I would need to represent the data somewhere that graph-oriented data feels right at home. This is where [Neo4j](https://neo4j.com/) comes into play.
If you're unfamiliar, Neo4j is a graph database. This turned out to be the perfect tool for Rhea. It was immediately apparent that its Cypher query language had the features needed to power several in-game systems for Rhea. Namely its ability to find the shortest path between nodes, or in the domain of Rhea, solar systems.
Claiming victory over my first set of development goals, I took a 2-month break from working on Rhea to focus on a large project I was leading at work, a large web service responsible for creating and marshaling Twilio conference calls in parallel-- also built using an Elixir umbrella, also structured with the intent of utilizing BEAM's distribution features in the future.
When I finally had time to devote to Rhea again, I revisited the map I'd generated and simply wasn't happy with the result. After generating entirely new map data, this time for 2000 solar systems, I was dismayed to learn that the XML schema for my new map data was fundamentally different than that of my previous map. This would require me to write an entirely new parser and process for loading the map data into PostgreSQL and Neo4j. This was unacceptable to me.
Not being comfortable with the idea of such a pivotal piece of the system relying upon a proprietary dependency, I started exploring ways of generating my own map from scratch, but how?
#### Enter Diffusion Limited Aggregation
A while back, I was reading about [Brownian Motion](https://en.wikipedia.org/wiki/Brownian_motion) and the aggregation of particles to form a structure. After diving back down that rabbit hole, I discovered [Diffusion Limited Aggregation](https://en.wikipedia.org/wiki/Diffusion-limited_aggregation). This seemed to be the ideal method for generating a structure akin to the galactic maps of both Stellaris and Eve Online.
I found a simple [C++ implementation of DLA](https://github.com/fogleman/dlaf) and quickly generated a set of 2000 particles. This algorithm has a CSV output of the following schema:
```
id, parent_id, x, y, z
0,-1,0,0,0
1,0,0.934937,0.354814,0
2,0,0.0525095,-0.99862,0
3,1,0.989836,1.35331,0
4,3,1.92472,1.70826,0
5,3,0.65572,2.29584,0
...
```
<iframe width="560" height="315" src="https://www.youtube.com/embed/EWks4tbH9b0" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
EUREKA!
That was precisely what I needed to generate a fully original map! I built out each point as a Solar System in Postgres and Neo4j with its coordinates. After reducing the list down to a collection of IDs and Parent IDs, I was then able to build the stargates that connect the various solar systems together.
Originally, [I built a name generator to automatically name each Solar System](https://gist.github.com/willricketts/dfc4e2ce63d8a9934434d18cdb860510), but this was quickly outgrown and I was once again searching for a solution to unblock my map work.
After finding a [super slick name generator built in Javascript](https://github.com/hbi99/namegen/blob/master/namegen.js), I was able to give each solar system a unique name that doesn't sound like a Heroku deployment.
Below: the final structure of my fractally generated galaxy map:

Below: a closer view of a group of solar system:

### Future Plans
Having a totally original galaxy map with a predictable and repeatable process for generation opens up all sorts of possibilities for new features and clever tricks. Having tied all of the generation and persistence process to a single function in the backend, rebuilding the map and trying generation with different inputs takes a matter of seconds::
```elixir
def build_universe do
construct_map_db()
construct_graph()
IO.puts "Universe created"
end
# I couldn't resist writing a function called "destroy universe"
def destroy_universe do
[{:ok, _}, _] = [Task.async(&Main.destroy_map_db/0), Task.async(&Main.destroy_graph/0)] |> Enum.map(&Task.await/1)
IO.puts "Universe destroyed"
end
```
#### Wormholes
If you're familiar with graphs, then you were probably left wondering why I refer to Rhea's map as a _directed_ acyclic graph as opposed to an _undirected_ acyclic graph. Rhea's stargates are represented in its persistence layer as pairs of gates, each unidirectional. This enables me to, at some point, build a wormhole system in which a player's fleets can travel from one part of the galaxy to another instantly, but perhaps not return home through the same wormhole.
#### Tactical Structures
Perhaps I'll introduce a player owned structure that prevents enemy fleets from leaving a Solar System once they've traveled through a stargate. This would lead to a much more robust system of player combat tactics and provide an overall more engaging experience, possibly allowing the few to overcome the many in a fleet engagement.
### Next Steps
The map is far too linear, and this needs to be fixed before proceeding. This is my primary development item on the project, and I'm currently working on an algorithm that utilizes Solar System coordinates to create connections between solar systems that share a geographic region with one another. I assure you that will get its own blog post :)
For now, I'm happy enough with my work to begin sharing the obstacles I've overcome in building the game I've always wanted.
Thanks for reading, and I'll see you in the next post. | willricketts |
262,286 | Getting Started With WSL | Curious about how to run Linux inside of Windows? Here's how you can get started with Windows Subsystem for Linux | 0 | 2020-02-15T22:26:27 | https://www.jeremymorgan.com/tutorials/linux/getting-started-windows-subsystem-linux/ | linux, beginners, productivity, dotnet | ---
title: Getting Started With WSL
published: true
description: Curious about how to run Linux inside of Windows? Here's how you can get started with Windows Subsystem for Linux
tags: linux, beginner, productivity, dotnet
canonical_url: https://www.jeremymorgan.com/tutorials/linux/getting-started-windows-subsystem-linux/
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/f0g3gyohv5pzcgf92v18.jpg
---
Windows Subsystem for Linux (WSL) is awesome.
It gives you the power to use Linux within your Windows system. A Linux shell can be difficult to learn, but the payoffs are incredible. You can become insanely productive with it. I encourage every Windows developer to give this a try.
Early in my development career, I was a Unix/Linux developer, and I loved working with the [shell](http://bit.ly/LinuxCommandLineGuide). In 2010 I was thrust into the world of Windows with GUIS. There was PowerShell and some workarounds, but it wasn't quite the same. While I eventually gained proficiency and speed at first, it was a drag.
The most significant advantage of WSL right now is improving productivity and bringing powerful Linux programs directly to your Windows desktop. So let's try it out!
## Get WSL
Open up PowerShell as an administrator:
Run the following command
```
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux
```

Restart the machine as directed.
Now we need to install a Linux system. You can find plenty of them in the Microsoft Store:
Or you can just install it on the command line. For this tutorial I'll be using Debian. You can install it from a PowerShell prompt with this command:
```
Invoke-WebRequest -Uri https://aka.ms/wsl-debian-gnulinux -OutFile Debian.appx -UseBasicParsing
.\Debian.appx
```
Now you'll be asked for a username and password. This doesn't have to be your Windows credentials, they're completely separate.
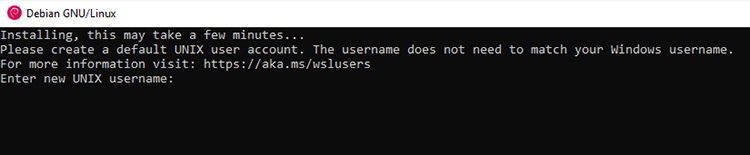
After you enter that, you're done! You've installed Linux on your Windows system.
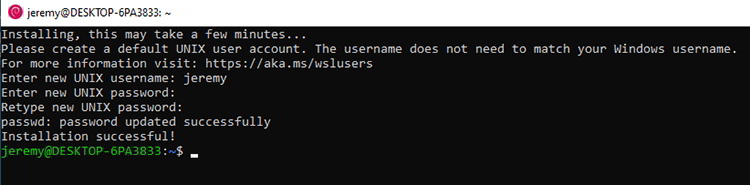
You can find it in your start menu:

And it's ready to go!
## Install Terminal
So if you're going to be using WSL and doing prompt things, Windows Terminal is pretty awesome. Let's add that. Search the Windows Store for "Windows Terminal"
Click "Get" then "Install"
With Terminal, you can keep PowerShell, command line, WSL prompts, and more all in one place. It's very convenient.
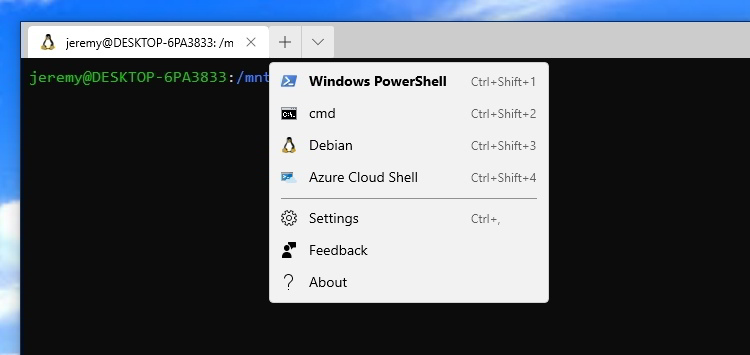
So let's do some stuff!
## The Basics
So if you've never used Linux before and want to know how to get around, you've come to the right place. Here are some basic commands you can use to get started.
### Where am I?
You can find out where you're at on the file system by typing
```
pwd
```
Result:

### Create a Folder
In Linux we call these "directories" and you create new ones by typing in
```
mkdir (name of directory)
```
We'll create one called "stuff".
```
mkdir stuff
```
### Go into that Folder
Now let's go into that folder by typing in **cd** (change directory)
```
cd stuff
```
Now type in pwd and you can see we're in the "stuff" directory.

Let's create some files in that folder:
```
touch file1.txt
```
The "touch" command creates an empty file with whatever name you specify. So now we have a blank file named "file1.txt"
Let's create a few more:
```
touch file2.txt file3.txt file4.txt
```
Now we have four files in the folder. But how would we know that?
### Show all the files in a folder
We do that by typing in
```
ls -la
```
**ls** is the command to list the directory contents, and the **-la** tells it to list everything, including hidden files.
We can see every file in the directory.
Let's create a couple more files:
```
touch testfile1.org testfile2.org testfile3.org
```
Now we run ls and see our added files.
But what if we only want to see the .org files we just created?
### Choosing Which Files to Show
We do that with wildcards (*), if we only want to see the .org files, we type in
```
ls *.org
```
The star means "everything," so we want everything with a filename that has .org at the end of it.

If we only want to see files with the number 3 in them?
```
ls *3*
```
You can place wildcards anywhere in the string, so it shows every file name with a 3 in it:

Pretty cool huh? What if we want to remove a file?
```
rm file2.txt
```
rm will remove the file. If we type in ls we'll see that it's gone now:
Wildcards also work with rm. We can remove all those .org files we just created:
```
rm *.org
```
Now if we run ls -la again we can see the files are gone:
### Removing a Folder
So what if I want to remove this folder full of files I just created?
To leave the folder and go back to my home folder, I type
```
cd ..
```
then type in
```
rm -rf stuff
```
And that removes the folder. Easy!
### Conclusion
So in this tutorial, we got familiar with WSL and how to use it. We did the following:
- Enabled WSL
- Installed Debian Linux
- Installed Windows Terminal
- Created a folder
- Created empty files
- Deleted files
This is enough to get started navigating and moving things around. We're just scratching the surface of all the cool things you can do with WSL. If there's enough interest, I'll keep building more of these tutorials and expand on it.
Want to know more about Linux Commands? Check out [this guide on Linux Command Line Fundamentals](http://bit.ly/LinuxCommandLineGuide)
[Let me know what you think](http://bit.ly/JeremyCMorgan) of this tutorial and some cool things you've done with WSL!!
| jeremycmorgan |
262,313 | Angular 9: Lazy Loading Components | Have you ever wanted to lazy load an Angular component? Here is a technique you can use with Angular 9. | 0 | 2020-02-16T20:29:59 | https://johnpapa.net/angular-9-lazy-loading-components/ | angular, webdev, typescript, html | ---
title: Angular 9: Lazy Loading Components
published: true
description: Have you ever wanted to lazy load an Angular component? Here is a technique you can use with Angular 9.
tags: angular, webdev, typescript, html
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/ck942tzser1sc7wb2h8l.png
canonical_url: https://johnpapa.net/angular-9-lazy-loading-components/
---
Angular 9 has some pretty awesome new features. The runtime, code-name Ivy, opens the doors to things like making lazy load Angular components more straightforward than ever.
This article shows you how to lazy load with Angular 9 and provides the code and resources along the way.
### 1 - Create a New App
Create a new Angular app using the Angular CLI command below. The following code will generate an app with as few files as you can get.
```bash
ng new lazy-demo
--minimal
--inline-template
--inline-style
--routing=false
--style=css
```
This command will create a new angular app in a folder named **lazy-demo**
- `--minimal` removes removes testing frameworks
- `--inline-template` puts all component templates in the `.ts` file
- `--inline-styles` puts all component styles in the `.ts` file
- `--routing=false` does not add any routing
- `--style=css` specifies to use CSS
### 2 - Create Lazy Components
Create two new components named `lazy1` and `lazy2`.
```bash
ng g c lazy1 --flat --skip-import --skip-selector
ng g c lazy2 --flat --skip-import --skip-selector
```
These commands will create the two new components in files named `lazy1.component.ts` and `lazy2.component.ts`, respectively. We won't want either component to be declared in a module, since we want to lazy load them. If we declare them in a module, then Angular will eagerly load them.
We're also not creating the selectors since we won't be referring to them in a template directly. Instead, we'll load them dynamically.
### 3 - Lazy Load the Components
Add the following code to the file **app.component.ts**. Notice the constructor injects a `ViewContainerRef` (a place to put our components) and a `ComponentFactoryResolver` (this creates our components in code).
```typescript
export class AppComponent {
title = 'lazy-comp';
constructor(
private viewContainerRef: ViewContainerRef,
private cfr: ComponentFactoryResolver
) {}
async getLazy1() {
this.viewContainerRef.clear();
const { Lazy1Component } = await import('./lazy1.component');
this.viewContainerRef.createComponent(
this.cfr.resolveComponentFactory(Lazy1Component)
);
}
async getLazy2() {
this.viewContainerRef.clear();
const { Lazy2Component } = await import('./lazy2.component');
this.viewContainerRef.createComponent(
this.cfr.resolveComponentFactory(Lazy2Component)
);
}
}
```
The `getLazy1` function clears the container. This is important is we only want to show one of the lazy-loaded components at a time. If we did not clear the container, every time we lazy load components, they would be displayed one after another.
Next, we import the components, lazily, using the `await import` syntax.
Finally, we create the component in the container.
### 4 - Adding Buttons to Lazy Load
Modify the template in `app.component.ts`, as shown below. This adds buttons that will lazy load each component when clicked.
```html
template: `
<div>
<div>Hello World! This is the {{ title }} app.</div>
<button (click)='getLazy1()'>lazy 1</button>
<button (click)='getLazy2()'>lazy 2</button>
</div>
`
```
### 5 - Watch it Lazy Load
Now run the app with `ng serve` and browser to <http://localhost:4200>. After the app loads, open the browser's developer tools. Then clear the network traffic, so we can see when the components are lazy-loaded.
When you click one of the buttons, notice that the associated component I displayed and the network traffic shows the component is lazy loaded.
### 6 - What if Lazy Loaded Components Have Children
This is cool, but what if a lazy-loaded component has child components of its own? Imagine that `Lazy2Component` needs to show two other components named `Lazy2aComponent` and `Lazy2bComponent`. We'll need to generate these two components, and once again, make sure we do not declare them in a module.
```bash
ng g c lazy2a --flat --skip-import --skip-selector
ng g c lazy2b --flat --skip-import --skip-selector
```
Now modify the `Lazy2Component` to load it's two child components. We'll once again use the `ViewContainerRef` and `ComponentFactoryResolver`.
However, this time we will not lazy-load the children. Instead, we'll create the child components in the `ngOnInit` and import them synchronously.
What's the difference? Well, in this example, these child components will load in the same bundle as their parent, `Lazy2Component`.
Modify your `Lazy2Component` code, as shown below.
```typescript
import {
Component,
ViewContainerRef,
ComponentFactoryResolver,
OnInit
} from '@angular/core';
import { Lazy2aComponent } from './lazy2a.component';
import { Lazy2bComponent } from './lazy2b.component';
@Component({
template: `
<p>lazy2 component</p>
`
})
export class Lazy2Component implements OnInit {
constructor(
private viewContainerRef: ViewContainerRef,
private cfr: ComponentFactoryResolver
) {}
ngOnInit() {
const componentFactorya = this.cfr.resolveComponentFactory(Lazy2aComponent);
const componentFactoryb = this.cfr.resolveComponentFactory(Lazy2bComponent);
this.viewContainerRef.createComponent(componentFactorya);
this.viewContainerRef.createComponent(componentFactoryb);
}
}
```
### 7 - Run the App
Now run the app again and browse to <http://localhost:4200>. Or go back to the browser if you never stopped serving it.
Open the browser's developer tools, go to the Network tab, and clear the network traffic.
Notice that when you click on the button to load the **Lazy 1** component that the bundle for that component is passed, and Lazy 1 is displayed.
When you click the button to load **Lazy 2** its bundle is passed, and Lazy 2, Lazy 2a, and Lazy 2b are all displayed.
The bundle sizes for Lazy 1 and 2 are different, too. Lazy 1 only has a single component, so it is smaller than Lazy 2 (which contains three components).
### Should You?
So now you know how to lazy load a component with Angular 9. You can lazy load a component and have its children in turn lazily load or eagerly load. But you could also do this with a module (specifically an `NgModule`). So what do you do? Lazy loading a component helps support scenarios where you want to access features without routing. Lazy loading of modules helps when you want to access features with routing. But should that line be so distinct? Perhaps that line will blur as time moves forward. There are no warning signs here, just things to consider before entering this arena.
Another scenario might be when you want to load component dynamically based on user profile or a workflow. You could dynamically load (eagerly or lazily) one or more components.
### Learn More
These examples should be able to help you get started with lazy loading components dynamically, with or without children. If you want to learn more, check out these resources:
1. [Dynamic Component Loader](https://angular.io/guide/dynamic-component-loader)
1. [7 new features in Angular 9](https://auth0.com/blog/angular-9-whats-new/).
1. [VS Code](https://code.visualstudio.com/?wt.mc_id=devto-blog-jopapa) editor
1. [Angular Essentials Extension](https://marketplace.visualstudio.com/items?itemName=johnpapa.angular-essentials&wt.mc_id=devto-blog-jopapa) for VS Code
1. [Angular Language Service](https://marketplace.visualstudio.com/items?itemName=Angular.ng-template&wt.mc_id=devto-blog-jopapa) for VS Code
1. [Angular Lazy Load Demo source code](https://github.com/johnpapa/angular-lazy-load-demo) | john_papa |
262,342 | How to write a php class that calculates the factorial of an integer? | Let's understand the two key terms used above; FACTORIAL - the product of an integer and all the in... | 0 | 2020-02-16T01:39:58 | https://dev.to/naveenkolambage/how-to-write-a-php-class-that-calculates-the-factorial-of-an-integer-1557 | fuctorial, php, class | Let's understand the two key terms used above;
- FACTORIAL - the product of an integer and all the integers below it; e.g. factorial four ( 4! ) is equal to 24.(4 X 3 X 2 X 1)
- INTEGER - Integer is a number which is not a fraction, you could also say that an integer is a whole number
COOL!
Now let's solve the problem, the class we are asked to write has two main requirements
1) It should filter out the integers
2) It should return the factorial of that filtered number/integer
To meet 1) above we can use the function is_int() in php , so using the if condition with this function, we could say "if (!is_int(n)) { Do not run the program or perhaps throw an error}"
To return a factorial of a number we can Loop through all the numbers that are less than or equal to the integer that was passed in-while storing the product of all the numbers in a variable that can be returned when the loop is over.
Here's a way of doing this,
```
<?php
public function myFactorial()
{
$factorial = 1;
for($i= 1; $i<=$this->number; $i++)
{
$factorial = $factorial*$i;
}
return $factorial;
}
?>
```
Why are we doing;
$factorial = $factorial*$i
And whats the meaning of it ?
$i in the above line is changing each time we loop (ie. it starts at 1 and increments till it reaches the value of the integer that was passed in)
Left hand side $factorial is assigned the product of right hand side $factorial and $i in each iteration.
Let's say we wanted to find the factorial of 3. (then $this->number would be 3)
First iteration - we will have the following values
$i = 2 , Right hand side $factorial = 1; (although $i starts with one it will be incremented by one during the first iteration as we have $i++ in the for loop)
Therefore Left hand side $factorial = 1 multiplied by 2 .(ie. 2)
Second iteration
$i = 3 , Right hand side $factorial = 2;
Therefore Left hand side $factorial = 2 multiplied by 3 . (ie. 6)
Ok will there be a third iteration? "NO" WHY?
Next iteration , $i = 4 and we have a condition in the for loop that says 'Continue the loop as long as $i is less than or equal to 3'.
Here's the complete solution;
```
<?php
Class find_my_factorial
{
protected $integer;
public function __construct($passedInt)
{
if(!is_int($passedInt))
{
throw new InvalidArgumentException('Not a valid integer');
}
$this->integer = $passedInt;
public function myFactorial()
{
$factorial = 1;
for($i = 1; $i<= $this->integer; $i++)
{
$factorial = $factorial *$i;
}
return $factorial;
}
}
//Instantiating the above class,
$Twofact = New find_my_factorial(2);
echo $Twofact->myFactorial();
?>
```
| naveenkolambage |
262,394 | Let’s Build: Workout tracker with React and Firebase part 1: project setup | While building a web application to track my physical activities I have learned many things which I w... | 0 | 2020-02-16T05:19:19 | https://dev.to/sanderdebr/let-s-build-workout-tracker-with-react-and-firebase-part-1-1hng | react, firebase, hooks, context | While building a web application to track my physical activities I have learned many things which I will share with you in this tutorial.
**Live demo:**
[https://master.d3963aoi020v9l.amplifyapp.com/](https://master.d3963aoi020v9l.amplifyapp.com/)
This tutorial is targeted for beginners in React who already have experience using ES6 and create-react-app. We will be using:
* 100% React Hooks, Router and Context API
* Firebase Authentication and noSQL database
* Material UI components
This tutorial is divided up in to the following sections:
1. Setting up our project
1. User authentication with Firebase
1. Creating a custom Calendar component
1. Adding, updating and deleting workouts with noSQL database
1. Deployment

## 1. Project setup
We will start with creating the new project folder and installing all needed dependencies. I’m using Visual Studio Code, with the shortcut CTRL + ~ you can toggle the command line inside Visual Studio Code. Run the following command:
npx-create-react-app activity-tracker
This will create a new folder with our new react app.
Then delete all the files in /src except App.js, App.css, Index.js, Index.css
Inside App.js: delete the logo import, remove everything inside the return and add <h1>Hello World!</h1> in the return.
Inside Index.js: delete the serviceworker import and unregister line. Now run npm run start to check if the app displays *Hello World!*
### Material UI
To speed up our development we will use pre-build components from Material-UI framework which you can find here: [https://material-ui.com/](https://material-ui.com/)
Run the following commands:
npm install @material-ui/core
npm install @material-ui/icons
### Folders
Next up we will create our folders, which will be: components, pages and config. Open up command prompt and use the following commands:
cd src
mkdir components pages config
This way we have our app running in the command line of Visual Code and can run command with command prompt separately.
### Router
To navigate inside our App we will use react-router. We are creating a single-page-application which is basically one big page that does not need to be refreshed, we will just show and load only the components we want the user to see.
Install react-router by running the command:
npm install react-router-dom
Then inside App.js we will import react-router and add a switch to navigate between paths. We will create a path for home “/” and a path for signing up “/sign-up”:
{% gist https://gist.github.com/sanderdebr/b9a0cea2aca7a96946abcfe50f817791 %}
Now you should see “Signin” in your browser and if you’ll browse to /sign-up you should see “Signup”. Great, our router is working!
**In part 2 we will actually start building our application and adding authentication.**
Checkout the final result: [https://master.d2e0orovu8bxyk.amplifyapp.com/](https://master.d2e0orovu8bxyk.amplifyapp.com/)**
**Source code: [https://github.com/sanderdebr/workout-tracker](https://github.com/sanderdebr/workout-tracker) | sanderdebr |
262,409 | Introduction to Datalog(Bashlog) in Python | TLDR: Datalog is like SQL + Recursion. It's derivatives have reduced the code base by 50%... | 0 | 2020-02-16T06:27:18 | https://blog.rajivabraham.com/posts/bashlog | datalog, python | ###### TLDR:
Datalog is like SQL + Recursion. It's derivatives have reduced the code base by 50% or more.
#### Datalog
Today, I would like to explore a constrained language called Datalog. It's a constrained form of Prolog and may not be as expressive as C++ or Python. But it's derivatives have been known to reduce the numbers of lines of code down by 50% or more([Overlog](https://dl.acm.org/citation.cfm?id=1755913.1755937), [Yedalog](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43462.pdf)).
Let's get started:
Datalog has a *minimalist syntax* which I love. Let's take an example.
Suppose our data is about fathers and sons, mothers and daughters. If we had an excel sheet, we would enter the data like:
```
Father Son
Aks Bob
Bob Cad
Yan Zer
```
and another excel sheet for mothers and daughters:
```
Mother Daughter
Mary Marla
Marla Kay
Jane Zanu
```
In Datalog, we express the same data as(together):
```
father('Aks', 'Bob')
father('Bob', 'Cad')
father('Yan', 'Zer')
mother('Mary', 'Marla')
mother('Marla', 'Kay')
mother('Jane', 'Zanu')
```
Here we are trying to say Aks is the father of 'Bob' and 'Bob' is the father of 'Cad'. The datum father('Aks', 'Bob') is called a _**fact**_ i.e. it is true.
So Datalog can be used to express data. Not very interesting so far but a building block. These facts above can also be viewed as the existing state of the system, like we store state in files, or databases.
But that's not enough. What about code? For Datalog, code are specified as _*rules*_ to be applied declaratively.
Let's say our program needs to find out who's a grandfather. We could write a rule like:
'A person X is the grandfather of Z if X is the father of Y and Y is the father of Z'. In Datalog, this rule is written as:
```datalog
grandfather(X, Z) :- father(X,Y), father(Y, Z)
```
The LHS (i.e. grandfather) is known as the `head` and the RHS after the `:-` is known as the body
X, Y, Z are special variables called logic variables. They are different from regular variables. They are more used to represent a pattern or to link the head and the body.
To further understand logical variables, consider these two rules:
```bash
grandfather(X, Z) :- father(X,Y), father(Y, Z)
grandmother(X, Z) :- mother(X,Y), mother(Y, Z)
```
Here the `X`, `Z` and `Y` used in `grandfather` are completely different from the `X`, `Y` and `Z` in `grandmother`. In rules, the variables only make sense `in` that single rule. So we can reuse the same logic variables in different rules without worrying that they have some logical connection.
The next concept is _*queries*_. How do we feed input and get back some output.
Queries are similar to rules but without a head.
```bash
father(X, 'Aks'), mother(Z, 'Aks')
```
we mean, find the mother and father of 'Aks'
or
```bash
father(X, 'Raj'), mother(Z, 'Raj')
```
we mean, find the father and mother of 'Raj'
Suppose, we want to say find the mother and father of all the children in the database, we make the query
```bash
father(X, Y), mother(Z, Y)
```
Datalog will link `Y` for all `mother` and `father` facts and find the mothers and fathers for a child. It will not mix up fathers and mothers :)
Now, If you opened a datalog interpreter and fed the above and made the following queries, you would get the results shown after the # sign
```
father(X,_) # ['Aks', 'Bob', 'Yan']
father(_,X) # ['Bob', 'Cad', 'Zer']
father(X, Y) # [('Aks', 'Bob'), ('Bob', 'Cad'), ('Yan', 'Zer')
father(X, 'Zer'), father('Zer', Y) # [] as there are no facts that match the query
grandfather(X, Y) # [('Aks', 'Cad')]
grandfather(X,_) # ['Aks']
```
Here '_' is a special variable indicating that you don't care for the result.
I was always interested in the Datalog syntax and it's power. I kept delaying it until I met [Bashlog](https://github.com/thomasrebele/bashlog). Because, the *syntax of datalog is so simple*, it makes it *easy to write interpeters* for different targets. What Bashlog did was take Datalog syntax and convert it to bash scripts! Because, it used awk(mawk actually), sed, grep, which are tuned for high performance on Unix like platforms, it was incredibly fast in parsing big text files, comparable with all the specialized databases out there. **Just Bash Scripts**. It blew my mind. So if you are interested in pure Datalog, check out Bashlog
With Bashlog, you can run any bash like command and read that using Bashlog. Imagine there was a file('~/data.tsv') with tab separated values of
```bash
Aks Bob
Bob Cad
Yan Zer
```
We could read that data like:
```bash
facts(F, S) :~ cat ~/data.tsv
father(X, Y) :- facts(X, Y)
```
And then we proceed the same manner like before. What's awesome is that you can run any Unix command(e.g. `ls -l`) as long as it returns an output of tab separated values.
But I wanted to use Datalog in my day to day programming. I wanted to see if I could use and leverage Datalog along with Python. Some benefits of Datalog in Python are:
- Modularity. How do we abstract out patterns in our rules and facts.
- Possible access to exisitng rich source of libraries.
So I built [Mercylog](https://github.com/RAbraham/mercylog) in Python.
So let's translate the above rules to Mercylog syntax.
### Installation
If you are using the Bashlog variant,
- then you need Java 8 already installed
```bash
git clone https://github.com/RAbraham/mercylog_tutorial.git
cd mercylog_tutorial
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python tutorial.py
```
That should print
```bash
['Aks']
['Mary']
```
Read below on the explanation and make tweaks if you want and run `python tutorial.py` again.
### Usage
```python
import mercylog
m = mercylog.BashlogV1()
```
```python
# father('Aks', 'Bob')
# father('Bob', 'Cad')
# father('Yan', 'Zer')
# mother('Mary', 'Marla')
# mother('Marla', 'Kay')
# mother('Jane', 'Zanu')
father = m.relation('father')
mother = m.relation('mother')
facts = [
father('Aks', 'Bob'),
father('Bob', 'Cad'),
father('Yan', 'Zer'),
mother('Mary', 'Marla'),
mother('Marla', 'Kay'),
mother('Jane', 'Zanu'),
]
```
```python
# grandfather(X, Z) :- father(X,Y), father(Y, Z)
grandfather = m.relation('grandfather')
X, Y, Z = m.variables('X', 'Y', 'Z')
grandfather(X, Z) <= [father(X, Y), father(Y, Z)]
```
While in Datalog, you don't have to explicitly state the variables and the relation, as it is baked in to the language, in our library in Python, we need to (e.g. X, Y, Z and father, grandfather)
Making a query in python has the following syntax
```python
m.run(facts, rules, query)
```
A concrete example would be:
```python
m.run(facts, rules, grandfather(X, Y)) # which gives [('Aks', 'Cad')]
m.run(facts, rules, father(X,_)) # ['Aks', 'Bob', 'Yan']
m.run(facts, rules,father(_,X)) # ['Bob', 'Cad', 'Zer']
m.run(facts, rules,father(X, Y)) # [('Aks', 'Bob'), ('Bob', 'Cad'), ('Yan', 'Zer')
m.run(facts, rules, granfather(X,_)) # ['Aks']
```
Creating this DSL in python gives us some unique benefits. For e.g if we had these two relations
```python
paternal_grandfather = m.relation('paternal_grandfather')
maternal_grandmother = m.relation('maternal_grandmother')
father = m.relation('father')
mother = m.relation('mother')
X, Y, Z = m.variables('X', 'Y', 'Z')
rules = [
paternal_grandfather(X, Z) <= [father(X, Y), father(Y, Z)],
maternal_grandmother(X, Z) <= [mother(X, Y), mother(Y, Z)]
]
```
If you notice, the rule for `paternal_grandfather` and `maternal_grandmother` are very similar. I could perhaps encapsulate that into a function. I'll use the word `transitive` though I believe it is incorrect to use it.. but I don't know what to call this for now. Rewriting the above code:
```python
def transitive(head, clause):
X, Y, Z = m.variables('X', 'Y', 'Z')
return head(X, Z) <= [clause(X, Y), clause(Y, Z)]
paternal_grandfather = m.relation('paternal_grandfather')
maternal_grandmother = m.relation('maternal_grandmother')
father = m.relation('father')
mother = m.relation('mother')
rules = [
transitive(paternal_grandfather, father),
transitive(maternal_grandmother, mother)
]
```
In this way, using Python, we have modularized a pattern using the `transitive` function.
Let's recap the benefits of Mercylog
- Simple Syntax. All you need to know is facts and rules. Because of such simplicity, it is also easy to build compilers for it.
- Expressive. Rules give a powerful mechanism
- Declarative. Like SQL but more expressive. So we can optimize it's engines without affecting the code
I'll continue to update you with my future learnings! | rabraham |
262,425 | A Racket macro tutorial – get HTTP parameters easier | A few days ago, I post this answer to respond to a question about Racket's web framework. When... | 0 | 2020-02-16T08:27:50 | https://dannypsnl.github.io/docs/cs/a-racket-macro-tutorial-get-http-parameters-easier/ | metaprogramming, racket | ---
title: A Racket macro tutorial – get HTTP parameters easier
published: true
date: 2020-02-16 00:00:00 UTC
tags: metaprogramming,racket
canonical_url: https://dannypsnl.github.io/docs/cs/a-racket-macro-tutorial-get-http-parameters-easier/
---
A few days ago, I post this [answer](https://dev.to/dannypsnl/comment/ldl8) to respond to a question about Racket's web framework. When researching on which frameworks could be used. I found no frameworks make get values from HTTP request easier. So I start to design a macro, which based on [routy](github.com/Junker/routy) and an assuming function `http-form/get`, as following shows:
```racket
(get "/user/:name"
(lambda ((name route) (age form))
(format "Hello, ~a. Your age is ~a." name age)))
```
Let me explain this stuff. `get` is a macro name, it's going to take a string as route and a "lambda" as a request handler. `((name route) (age form))` means there has a parameter `name` is taken from `route` and a parameter `age` is taken from `form`. And `(format "Hello, ~a. Your age is ~a." name age)` is the body of the handler function.
Everything looks good! But we have no idea how to make it, not yet ;). So I'm going to show you how to build up this macro step by step, as a tutorial.
First, we have to ensure the target. I don't want to work with original Racket HTTP lib because I never try it, so I pick [routy](github.com/Junker/routy) as a routing solution. A [routy](github.com/Junker/routy) equivalent solution would look like:
```racket
(routy/get "/user/:name"
(lambda (req params)
(format "Hello, ~a. Your age is ~a." (request/param params 'name) (http-form/get req "age"))))
```
> WARNING: There has no function named `http-form/get`, but let's assume we have such program to focus on the topic of the article: **macro**
Now we can notice that there was no `name`, `age` in `lambda` now. But have to get it by using `request/param` and `http-form/get`. But there also has the same pattern, the route! To build up macro, we need the following code at the top of the file `macro.rkt` first:
```racket
#lang racket
(require (for-syntax racket/base racket/syntax syntax/parse))
```
Then we get our first macro definition:
```racket
(define-syntax (get stx)
(syntax-parse stx
[(get route:str)
#'(quote
(routy/get route
(lambda (req params)
'body)))]))
(get "/user/:name")
; output: '(routy/get "/user/:name" (lambda (req params) 'body))
```
Let's take a look at each line, first, we have `define-syntax`, which is like `define` but define a macro. It contains two parts, **name** and `syntax-parse`. The name part was `(get stx)`, so the macro called `get`, with a syntax object `stx`. The `syntax-parse` part was:
```racket
(syntax-parse stx
[(get route:str)
#'(quote
(routy/get route
(lambda (req params)
'body)))])
```
The `syntax-parse` part works on the syntax object, so it's arguments are a syntax object and patterns! Yes, patterns! It's ok to have multiple patterns like this:
```racket
(define-syntax (multiple-patterns? stx)
(syntax-parse stx
[(multiple-patterns? s:str) #'(quote ok-str)]
[(multiple-patterns? s:id) #'(quote ok-id)]))
(multiple-patterns? "")
; output: 'ok-str
(multiple-patterns? a)
; output: 'ok-id
```
Now we want to add handler into `get`, to reduce the complexity, we introduce another feature: `define-syntax-class`. The code would become:
```racket
(define-syntax (get stx)
(define-syntax-class handler-lambda
#:literals (lambda)
(pattern (lambda (arg*:id ...) clause ...)
#:with
application
#'((lambda (arg* ...)
clause ...)
arg* ...)))
(syntax-parse stx
[(get route:str handler:handler-lambda)
#'(quote
(routy/get route
(lambda (req params)
handler.application)))]))
```
First we compare `syntax-parse` block, we add `handler:handler-lambda` and `handler.application` here:
```racket
(syntax-parse stx
[(get route:str handler:handler-lambda)
#'(quote
(routy/get route
(lambda (req params)
handler.application)))]))
```
This is how we use a `define-syntax-class` in a higher-level syntax. `handler:handler-lambda` just like `route:str`, the only differences are their pattern. `route:str` always expected a string, `handler:handler-lambda` always expected a `handler-lambda`. And notice that `handler:handler-lambda` would be the same as `a:handler-lambda`, just have to use `a` to refer to that object. But better give it a related name.
Then dig into `define-syntax-class`:
```racket
(define-syntax-class handler-lambda
#:literals (lambda)
(pattern (lambda (arg*:id ...) clause* ...)
#:with
application
#'((lambda (arg* ...)
clause* ...)
arg* ...)))
```
`define-syntax-class` allows us add some `stxclass-option`, for example: `#:literals (lambda)` marked `lambda` is not a pattern variable, but a literal pattern. The body of `define-syntax-class` is a pattern, which takes a pattern and some `pattern-directive`. The most important `pattern-directive` was `#:with`, which stores how to transform this pattern, it takes a `syntax-pattern` and an `expr`, as you already saw, this is usage: `handler.application`.
The interesting part was `...` in the pattern, it means zero to many patterns. A little tip makes such variables with a suffix `*` like `arg*` and `clause*` at here.
Now take a look at usage:
```racket
(get "/user/:name"
(lambda (name age)
(format "Hello, ~a. Your age is ~a." name age)))
; output: '(routy/get "/user/:name" (lambda (req params) ((lambda (name age) (format "Hello, ~a. Your age is ~a." name age)) name age)))
```
There are some issues leave now, since we have to distinguish `route` and `form`, current pattern of `handler-lambda` is not enough. The `handler-lambda.application` also incomplete, we need
```racket
(lambda (req params)
(format "Hello, ~a. Your age is ~a."
(request/param params 'name)
(http-form/get req "age")))
```
but get
```racket
(lambda (req params)
((lambda (name age)
(format "Hello, ~a. Your age is ~a."
name
age)) name age))
```
right now.
To decompose the abstraction, we need another `define-syntax-class`.
```racket
(define-syntax-class argument
(pattern (arg:id (~literal route))
#:with get-it #'[arg (request/param params 'arg)])
(pattern (arg:id (~literal form))
#:with get-it #'[arg (http-form/get req (symbol->string 'arg))]))
(define-syntax-class handler-lambda
#:literals (lambda)
(pattern (lambda (arg*:argument ...) clause* ...)
#:with
application
#'(let (arg*.get-it ...)
clause* ...)))
```
There are two changes, replace `lambda` with `let` in `handler-lambda.application`(it's more readable), and use `argument` syntax type instead of `id`.
`argument` has two patterns, `arg:id (~literal route)` and `arg:id (~literal form)` to match `(x route)` and `(x form)`. Notice that `#:literals (x)` and `(~literal x)` has the same ability, just pick a fit one. `symbol->string` converts an atom to a string, here is an example:
```racket
(symbol->string 'x)
; output: "x"
```
Let's take a look at usage:
```racket
(get "/user/:name"
(lambda ((name route) (age form))
(format "Hello, ~a. Your age is ~a." name age)))
; output: '(routy/get "/user/:name" (lambda (req params) (let ((name (request/param params 'name)) (age (http-form/get req (symbol->string 'age)))) (format "Hello, ~a. Your age is ~a." name age))))
```
Manually pretty output:
```racket
'(routy/get "/user/:name"
(lambda (req params)
(let ((name (request/param params 'name))
(age (http-form/get req (symbol->string 'age))))
(format "Hello, ~a. Your age is ~a." name age))))
```
### Summary
With make up this tutorial, I learn a lot of macro tips in Racket that I don't know before. I hope you also enjoy this, also hope you can use everything you learn from here to create your helpful macro. Have a nice day.
### End up, all code
```racket
#lang racket
(require (for-syntax racket/base racket/syntax syntax/parse))
(define-syntax (get stx)
(define-syntax-class argument
(pattern (arg:id (~literal route))
#:with get-it #'[arg (request/param params 'arg)])
(pattern (arg:id (~literal form))
#:with get-it #'[arg (http-form/get req (symbol->string 'arg))]))
(define-syntax-class handler-lambda
#:literals (lambda)
(pattern (lambda (arg*:argument ...) clause* ...)
#:with
application
#'(let (arg*.get-it ...)
clause* ...)))
(syntax-parse stx
[(get route:str handler:handler-lambda)
#'(quote
(routy/get route
(lambda (req params)
handler.application)))]))
(get "/user/:name"
(lambda ((name route) (age form))
(format "Hello, ~a. Your age is ~a." name age)))
```
| dannypsnl |
262,434 | Get random posts from Dev (Indonesian language) | Mengambil postingan-postingan dari Dev secara acak. | 4,873 | 2020-02-16T09:46:12 | https://dev.to/mzaini30/get-random-posts-from-dev-indonesian-language-7e6 | dev, jquery, ajax, posts | ---
title: Get random posts from Dev (Indonesian language)
published: true
description: Mengambil postingan-postingan dari Dev secara acak.
tags: dev, jquery, ajax, posts
series: Javascript
---
Salah satu yang aku suka dari Dev ini adalah editornya yang menggunakan Markdown. Ya, aku suka Markdown. Dan aku juga suka dengan berbagai konten teknologi yang ada di website ini.
Namun sayang, di halaman beranda, artikelnya sering nggak update.
Maksudku, ketika aku reload lagi halaman beranda, yang tampil postingannya ya yang itu-itu aja. Maka, aku membuat Random Dev.
Bisa dikunjungi di <https://mzaini30.com/dev/>.
Ini tampilannya:
Dan ketika diklik, maka ia akan menampilkan artikel Dev di tab baru:
Source codenya:
{% github laptopzen/dev %}
# Bahas kodenya
## `index.html`
Atur judulnya dulu:
```html
<title>Random Dev</title>
```
Gunakan charset UTF-8:
```html
<meta charset="utf-8">
```
Atur tampilan mobile:
```html
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no">
```
Import CSS dari Bootstrap dan dari buatanku sendiri:
```html
<link rel="stylesheet" type="text/css" href="vendor/bootstrap/css/bootstrap.min.css">
<link rel="stylesheet" type="text/css" href="app/style.css">
```
Bagian navbar:
```html
<div class="navbar navbar-default navbar-fixed-top">
<div class="container">
<div class="navbar-header">
<div class="navbar-brand">Random Dev</div>
</div>
</div>
</div>
```
Bagian isi yang akan kita manipulasi:
```html
<div class="container isi">
<p>Loading...</p>
</div>
```
Ambil jQuery:
```html
<script type="text/javascript" src="vendor/jquery/jquery.min.js"></script>
<script type="text/javascript" src="app/app.js"></script>
```
## `app/app.js`
Kita buat AJAXnya nggak selalu sinkron. Jadi, ketika di callback mereturn suatu value, maka value tersebut jadi global.
```javascript
$.ajaxSetup({async: false})
```
Kita gunakan jika deskripsi postingan yang akan kita ambil nanti kosong.
```javascript
baca = [
'I think, you can love it',
'I was explain this',
'Wow. It\'s crazy',
"It's very cool",
"Wow. I'll try this"
]
kosong = () => baca[Math.floor(Math.random() * baca.length)]
```
sebuah function.
```javascript
olah_isi = () => {}
```
Kita dapatkan dulu jumlah semua artikel di Dev lalu kita masukkan ke `banyak`. Misalnya aja: `banyak = 1000`.
```javascript
$.get('https://dev.to/api/articles?per_page=1', data => banyak = data[0].id)
```
Kita ambil 20 aja postingan acak.
```javascript
mau_diambil = 20
```
Kan tadi kisahnya banyak artikelnya ada 1000 ya, kita ambil tuh 20 aja secara acak. Misalnya: 128, 723, 12, 412, 23, 12, dst.
```javascript
list_artikel_acak = [];
while(list_artikel_acak.length < mau_diambil){
r = Math.floor(Math.random() * banyak) + 1;
if(list_artikel_acak.indexOf(r) === -1) list_artikel_acak.push(r);
}
```
Kita ambil JSON dari masing-masing artikel itu terus dipush ke `isi_artikel`.
```javascript
isi_artikel = []
for(y of list_artikel_acak){
$.get(`https://dev.to/api/articles/${y}`, data => isi_artikel.push(data))
}
```
Nah, baru deh kita isi ke `.isi`.
```javascript
$('.isi').html(isi_artikel.map(x => `
<a href="${x.url}" class="anggap-aja-bukan-link" target='_blank'>
<table class="table table-ajaib">
<tr>
<td>
<img src="${x.user.profile_image_90}" alt="">
</td>
<td>
<div class="panel panel-default">
<div class="panel-heading">${x.title} ~ <em>by ${x.user.name}</em></div>
<div class="panel-body">${x.description ? x.description : kosong()}</div>
</div>
</td>
</tr>
</table>
</a>`))
```
Oh iya, tadi masih function. Maka, kita jalankan dulu dengan `olah_isi()`.
```javascript
olah_isi()
```
Kalau `.navbar-brand` diklik, reload lagi isinya.
```javascript
$('.navbar-brand').click(() => {
$('.isi').html('Loading...')
olah_isi()
})
``` | mzaini30 |
262,736 | Makers Week 12: The End of the End | Weakly Goal: Can you use high-quality processes to build an extended project in a team? This week w... | 2,836 | 2020-02-16T23:24:39 | https://dev.to/kealanheena/makers-week-12-the-end-of-the-end-224m | makers, unreal, debugging | Weakly Goal:
*Can you use high-quality processes to build an extended project in a team?*
This week was the final week of our final project and our final week of the Makers course. The final week was fun if a little stressful but that's to be expected. But we got it done, it looked good and most importantly it worked.
Day 1
So over the weekend, I started on damage types while I was learning about them I found out something useful called *structures*. Structures are a list of variable that you can add to a blueprint. This was invaluable to me it meant I could add type advantages and weaknesses to each of the enemies. It also allowed me to add types to the attacks too. We also decided to change our project to do a free roam game instead of a turn-based battle game. This wasn’t hard to do because we already had all the things we needed it was just a matter of making some small tweaks.
Day 2
I got started on the damage types on day two because I knew about structures already this was a lot easier than I was expecting. Although it still took some time to set up. I spent the rest of the day trying to solve a bug that popped up the enemies weren't taking any damage. After a while, I thought I'd be better for me to get some rest and look at it with fresh eyes in the morning.
Day 3
So Wednesday I spent the morning fixing the bug the problem was I was casting to the wrong enemy. The reason that was happening was when we split off into different branches we were working on separate enemies. We also started the preparation for our presentation which we had to do Friday we split the presentation into sections I was given the closing section on development tools so a lot of technical talk which gave me a chance to sharpen my knowledge.
Day 4
There was a feature freeze on Wednesday so we stopped adding things and started working on animations. I was doing the spell and attack animations which were a lot of fun. But I also had to make sure to blend animations so that they would look smooth. It was nice to get to throw in some cool looking animations, they tied everything together.
Day 5
The final day we had to three o'clock to get everything done we had to get everything up and running. We had a couple of bugs but we managed to get them working with time to spare so we could practice our presentation. Luckily we got to do our showcase first which gave me a chance to explain our project which gave me a lot more confidence for the presentation and I think it went quite well.
Summary
This was a stressful week due purely because it was the final week but we got everything done. We also had a beautiful looking game and I learned a lot. If I were to do it again it'd a lot easier. Even the presentation went well although it was nerve-racking. So overall an amazing week and let job hunt begin!! | kealanheena |
262,460 | Difference between tilde and caret in package.json | Difference between tilde and caret in package.json If you have updated your npm to the latest version... | 0 | 2020-02-16T10:42:54 | https://dev.to/hossamhilal/difference-between-tilde-and-caret-in-package-json-d5h | Difference between tilde and caret in package.json
If you have updated your npm to the latest version and tried installing the package using npm install moment — save you will see the package moment.js get saved in packages.json with a caret(^)prefix and in the previous version it was saved with tilde(~)prefix. You might think what is the difference between these symbols.
The tilde prefix simply indicates that the tilde (~) symbol will match the most recent patch version or the most recent minor version i.e. the middle number. For example, ~1.2.3 will match all 1.2.x versions but it will not match 1.3.0 or 1.3.x versions.
The caret indicates the first number i.e. the most recent major version. An example is in 1.x.x release the caret will update you and it will match with 1.3.0 but not 2.0.0. | hossamhilal | |
262,547 | C#: What will make you choose RepoDb over Dapper (ORM) | A page that describe the compelling reason why choose RepoDb over Dapper. | 0 | 2020-02-16T14:27:06 | https://dev.to/mikependon/c-what-will-make-you-choose-repodb-over-dapper-orm-3eb8 | csharp, dotnet, sql, tutorial | ---
title: C#: What will make you choose RepoDb over Dapper (ORM)
published: true
description: A page that describe the compelling reason why choose RepoDb over Dapper.
tags: #csharp #dotnet #sql #tutorial
---
## Introduction
In this page, we will share you the differences and what sets [*RepoDb*](https://github.com/mikependon/RepoDb) apart from [*Dapper*](https://github.com/StackExchange/Dapper). We tried our best to make a *1-to-1* comparisson for most area. This page will hopefully help you decide as a developer to choose *RepoDb* as your micro-ORM (*with compelling reason*).
*"I am an open source contributor and I am here to share you what I had done. I worked hard for it to improve the space of data access in .NET. I personally ask your support towards this library. I hope you share, you blog and use it."*
> All the contents of this tutorial is written by me (the author itself). Our knowledge to *Dapper* is not that deep enough when compared to our knowledge with *RepoDb*. So, please allow yourselves to *check* or *comments* right away if you think we made this page bias for *RepoDb*.
## Before we begin
The programming language and database provider we are using on our samples below are *C#* and *SQL Server*.
Both library is an *ORM* framework for *.NET*. They are both lightweight, fast and efficient. The *Dapper* is a full-fledge *micro-ORM* whereas *RepoDb* is a *hybrid-ORM*.
> To avoid the bias on the comparisson, we will not cover the features that is present in *RepoDb* but is absent in *Dapper* (ie: *Cache*, *Trace*, *QueryHints*, *Extensibility*, *StatementBuilder* and *Repositories*) (vice-versa). Also, the comparisson does not included any other extension libraries of both (ie: *RepoDb.SqLite*, *RepoDb.MySql*, *RepoDb.PostgreSql*, *Dapper.Contrib*, *DapperExtensions*, *Dapper.SqlBuilder*, etc).
### Tables
Let us assumed we have the following database tables.
```
CREATE TABLE [dbo].[Customer]
(
[Id] BIGINT IDENTITY(1,1)
, [Name] NVARCHAR(128) NOT NULL
, [Address] NVARCHAR(MAX)
, CONSTRAINT [PK_Customer] PRIMARY KEY CLUSTERED ([Id] ASC )
)
ON [PRIMARY];
GO
CREATE TABLE [dbo].[Product]
(
[Id] BIGINT IDENTITY(1,1)
, [Name] NVARCHAR(128) NOT NULL
, [Price] Decimal(18,2)
, CONSTRAINT [PK_Product] PRIMARY KEY CLUSTERED ([Id] ASC )
)
ON [PRIMARY];
GO
CREATE TABLE [dbo].[Order]
(
[Id] BIGINT IDENTITY(1,1)
, [ProductId] BIGINT NOT NULL
, [CustomerId] BIGINT
, [OrderDateUtc] DATETIME(5)
, [Quantity] INT
, CONSTRAINT [PK_Order] PRIMARY KEY CLUSTERED ([Id] ASC )
)
ON [PRIMARY];
GO
```
### Models
Let us assumed we have the following class models.
```csharp
public class Customer
{
public long Id { get; set; }
public string Name { get; set; }
public string Address { get; set; }
}
public class Product
{
public long Id { get; set; }
public string Name { get; set; }
public decimal Price { get; set; }
}
public class Order
{
public long Id { get; set; }
public long ProductId { get; set; }
public long CustomerId { get; set; }
public int Quantity { get; set; }
public DateTime OrderDateUtc{ get; set; }
}
```
## Basic CRUD Differences
### Querying multiple rows
**Dapper:**
- Query:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = connection.Query<Customer>("SELECT * FROM [dbo].[Customer];");
}
```
**RepoDb:**
- Raw-SQL:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = connection.ExecuteQuery<Customer>("SELECT * FROM [dbo].[Customer];");
}
```
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = connection.QueryAll<Customer>();
}
```
### Querying a single record
**Dapper:**
- Query
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customer = connection.Query<Customer>("SELECT * FROM [dbo].[Customer] WHERE (Id = @Id);", new { Id = 10045 }).FirstOrDefault();
}
```
**RepoDb:**
- Raw-SQL:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customer = connection.ExecuteQuery<Customer>("SELECT * FROM [dbo].[Customer] WHERE (Id = @Id);", new { Id = 10045 }).FirstOrDefault();
}
```
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customer = connection.Query<Customer>(e => e.Id == 10045).FirstOrDefault();
}
```
### Inserting a record
**Dapper:**
- Execute:
By default, it returns the number of affected rows.
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customer = new Customer
{
Name = "John Doe",
Address = "New York"
};
var affectedRows = connection.Execute("INSERT INTO [dbo].[Customer] (Name, Address) VALUES (@Name, @Address);", customer);
}
```
- Query:
Returning the identity value.
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customer = new Customer
{
Name = "John Doe",
Address = "New York"
};
var id = connection.Query<long>("INSERT INTO [dbo].[Customer] (Name, Address) VALUES (@Name, @Address); SELECT CONVERT(BIGINT, SCOPE_IDENTITY());", customer).Single();
}
```
**RepoDb:**
- Raw-SQL:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customer = new Customer
{
Name = "John Doe",
Address = "New York"
};
var id = connection.ExecuteScalar<long>("INSERT INTO [dbo].[Customer] (Name, Address) VALUES (@Name, @Address); SELECT CONVERT(BIGINT, SCOPE_IDENTITY());", customer);
}
```
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customer = new Customer
{
Name = "John Doe",
Address = "New York"
};
var id = (long)connection.Insert<Customer>(customer); // or connection.Insert<Customer, long>(customer);
}
```
### Updating a record
**Dapper:**
- Execute:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var affectedRows = connection.Execute("UPDATE [dbo].[Customer] SET Name = @Name, Address = @Address WHERE Id = @Id;",
new
{
Id = 10045,
Name = "John Doe",
Address = "New York"
});
}
```
**RepoDb:**
- Raw-SQL:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var affectedRows = connection.ExecuteScalar<int>("UPDATE [dbo].[Customer] SET Name = @Name, Address = @Address WHERE Id = @Id;",
new
{
Id = 10045,
Name = "John Doe",
Address = "New York"
});
}
```
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customer = new Customer
{
Id = 10045,
Name = "John Doe",
Address = "New York"
};
var affectedRows = connection.Update<Customer>(customer);
}
```
### Deleting a record
**Dapper:**
- Execute:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var affectedRows = connection.Execute("DELETE FROM [dbo].[Customer] WHERE Id = @Id;", new { Id = 10045 });
}
```
**RepoDb:**
- Raw-SQL:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var affectedRows = connection.ExecuteScalar<int>("DELETE FROM [dbo].[Customer] WHERE Id = @Id;", new { Id = 10045 });
}
```
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var affectedRows = connection.Delete<Customer>(10045);
}
```
## Advance Calls Differences
### Querying a parent and its children
Let us assumed we have added the *Orders (of type IEnumerable<Order>)* property on our *Customer* class.
- Customer
```csharp
public class Customer
{
public long Id { get; set; }
public string Name { get; set; }
public string Address { get; set; }
public IEnumerable<Order> Orders { get; set; }
}
```
- Order
```csharp
public class Order
{
public long Id { get; set; }
public long ProductId { get; set; }
public long CustomerId { get; set; }
public int Quantity { get; set; }
public DateTime OrderDateUtc{ get; set; }
}
```
**Dapper:**
- Query:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var sql = "SELECT C.Id, C.Name, C.Address, O.ProductId, O.Quantity, O.OrderDateUtc FROM [dbo].[Customer] C INNER JOIN [dbo].[Order] O ON O.CustomerId = C.Id WHERE C.Id = @Id;";
var customers = connection.Query<Customer, Order, Customer>(sql,
(customer, order) =>
{
customer.Orders = customer.Orders ?? new List<Order>();
customer.Orders.Add(order);
return customer;
},
new { Id = 10045 });
}
```
- QueryMultiple:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var sql = "SELECT * FROM [dbo].[Customer] WHERE Id = @CustomerId; SELECT * FROM [dbo].[Order] WHERE CustomerId = @CustomerId;";
using (var result = connection.QueryMultiple(sql, new { CustomerId = 10045 }))
{
var customer = result.Read<Customer>().First();
var orders = result.Read<Order>().ToList();
}
}
```
**RepoDb:**
The *JOIN* feature is purposely not being supported yet. We have explained it on our [Multiple Resultsets via QueryMultiple and ExecuteQueryMultiple](https://github.com/mikependon/RepoDb/wiki/Multiple-Resultsets-via-QueryMultiple-and-ExecuteQueryMultiple#querying-multiple-resultsets) page. Also, we have provided an answer already on our [FAQs](https://github.com/mikependon/RepoDb/wiki#will-you-support-join-operations).
However, the support to this feature will soon to be developed. We are now doing a poll-survey on how to implement this one based on the perusal of the community. The discussion can be seen [here](https://github.com/mikependon/RepoDb/issues/355) and we would like to hear yours!
> No question to this. The most optimal way is to do an actual *INNER JOIN* in the database like what *Dapper* is doing!
However, there is an alternative way to do this in *RepoDb*. It can be done via *Multi-Query* that executes *packed SELECT-statements* in a single-call.
- Raw-SQL:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var sql = "SELECT * FROM [dbo].[Customer] WHERE Id = @CustomerId; SELECT * FROM [dbo].[Order] WHERE CustomerId = @CustomerId;";
var extractor = connection.ExecuteQueryMultiple(sql, new { CustomerId = 10045 });
var customer = extractor.Extract<Customer>().FirstOrDefault();
var orders = extractor.Extract<Order>().AsList();
customer.Orders = orders;
}
```
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customerId = 10045;
var tuple = connection.QueryMultiple<Customer, Order>(customer => customer.Id == customerId, order => order.CustomerId == customerId);
var customer = tuple.Item1.FirstOrDefault();
var orders = tuple.Item2.AsList();
customer.Orders = orders;
}
```
### Querying multiple parent and their children
Almost the same as previous section.
- Query:
```csharp
var customers = new List<Customer>();
using (var connection = new SqlConnection(ConnectionString))
{
var sql = "SELECT C.Id, C.Name, C.Address, O.ProductId, O.Quantity, O.OrderDateUtc FROM [dbo].[Customer] C INNER JOIN [dbo].[Order] O ON O.CustomerId = C.Id;";
var customers = connection.Query<Customer, Order, Customer>(sql,
(customer, order) =>
{
customer = customers.Where(e => e.Id == customer.Id).FirstOrDefault() ?? customer;
customer.Orders = customer.Orders ?? new List<Order>();
customer.Orders.Add(order);
return customer;
});
}
```
**Note:** The hacking technique happens on the developer side, not embedded inside the library.
- QueryMultiple:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var sql = "SELECT * FROM [dbo].[Customer]; SELECT * FROM [dbo].[Order];";
using (var result = connection.QueryMultiple(sql, new { CustomerId = 10045 }))
{
var customers = result.Read<Customer>().ToList();
var orders = result.Read<Order>().ToList();
customers.ForEach(customer =>
customer.Orders = orders.Where(o => o.CustomerId == customer.Id).ToList()); // Client memory processing
}
}
```
**RepoDb:**
- Raw-SQL:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var extractor = connection.ExecuteQueryMultiple("SELECT * FROM [dbo].[Customer]; SELECT * FROM [dbo].[Order];");
var customers = extractor.Extract<Customer>().AsList();
var orders = extractor.Extract<Order>().AsList();
customers.ForEach(customer =>
customer.Orders = orders.Where(o => o.CustomerId == customer.Id).AsList()); // Client memory processing
}
```
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customerId = 10045;
var tuple = connection.QueryMultiple<Customer, Order>(customer => customer.Id == customerId, order => order.CustomerId == customerId);
var customers = tuple.Item1.FirstOrDefault();
var orders = tuple.Item2.AsList();
customers.ForEach(customer =>
customer.Orders = orders.Where(o => o.CustomerId == customer.Id).AsList()); // Client memory processing
}
```
### Inserting multiple rows
**Dapper:**
- Query:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = GenerateCustomers(1000);
var identities = connection.Query<long>("INSERT INTO [dbo].[Customer] (Name, Address) VALUES (@Name, @Address); SELECT CONVERT(BIGINT, SCOPE_IDENTITY());", customers);
}
```
**Actually, this is not clear to me:**
- Is it creating an implicit transaction? What if one row fails?
- Is it iterating the list and call the *DbCommand.Execute<Method>* multiple times?
Please correct me here so I can update this page right away.
**RepoDb:**
- Batch operation:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = GenerateCustomers(1000);
var affectedRows = connection.InsertAll<Customer>(customers);
}
```
The above operation can be batched by passing a value on the *batchSize* argument.
**Note:** You can target a specific column. In addition, the *identity* values are automatically set back to the entities.
- Bulk operation:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = GenerateCustomers(1000);
var affectedRows = connection.BulkInsert<Customer>(customers);
}
```
The above operation can be batched by passing a value on the *batchSize* argument.
**Note:** This is just an FYI. The operation is using the *SqlBulkCopy* of *ADO.Net*. This should not be compared to *Dapper* performance due to the fact that this is a real *bulk-operation*. This is far (*extremely fast*) when compared to both *Dapper* (multi-inserts) and *RepoDb* (*InsertAll*) operations.
### Merging multiple rows
**Dapper:**
- Query:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var sql = @"MERGE [dbo].[Customer] AS T
USING
(SELECT @Name, @Address) AS S
ON
S.Id = T.Id
WHEN NOT MATCH THEN
INSERT INTO
(
Name
, Address
)
VALUES
(
S.Name
, S.
Address)
WHEN MATCHED THEN
UPDATE
SET Name = S.Name
, Address = S.Address
OUTPUT INSERTED.Id AS Result;";
var customers = GenerateCustomers(1000);
var identities = connection.Query<long>(sql, customers);
}
```
Here, I have the same question as the previous section.
**RepoDb:**
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = GenerateCustomers(1000);
var affectedRows = connection.MergeAll<Customer>(customers);
}
```
The above operation can be batched by passing a value on the *batchSize* argument.
**Note:** You can set the *qualifier fields*. In addition, the *identity* values are automatically set back to the entities for the newly inserted records.
### Updating multiple rows
**Dapper:**
- Query:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = GenerateCustomers(1000);
var affectedRows = connection.Execute("UPDATE [dbo].[Customer] SET Name = @Name, Address = @Address WHERE Id = @Id;", customers);
}
```
**RepoDb:**
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = GenerateCustomers(1000);
var affectedRows = connection.UpdateAll<Customer>(customers);
}
```
The above operation can be batched by passing a value on the *batchSize* argument.
**Note:** You can set the *qualifier fields*.
### Bulk-inserting multiple rows
**Dapper:**
- ADO.NET:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = GenerateCustomers(1000);
var table = ConvertToTable(customers);
using (var sqlBulkCopy = new SqlBulkCopy(connection, options, transaction))
{
sqlBulkCopy.DestinationTableName = "Customer";
sqlBulkCopy.WriteToServer(table);
}
}
```
**Note:** You can as well pass an instance of *DbDataReader* (instead of *DataTable*).
**RepoDb:**
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = GenerateCustomers(1000);
var affectedRows = connection.BulkInsert<Customer>(customers);
}
```
**Note:** You can as well pass an instance of *DbDataReader*.
- Fluent (Targetted):
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = GenerateCustomers(1000);
var affectedRows = connection.BulkInsert("[dbo].[Customer]", customers);
}
```
### Querying the rows by batch
**Dapper:**
- Query:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var sql = @"WITH CTE AS
(
SELECT TOP (@Rows) ROW_NUMBER() OVER(ORDER BY Name ASC) AS RowNumber
FROM [dbo].[Customer]
WHERE (Address = @Address)
)
SELECT Id
, Name
, Address
FROM
CTE
WHERE
RowNumber BETWEEN @From AND (@From + @Rows);";
using (var connection = new SqlConnection(ConnectionString))
{
var customers = connection.Query<Customer>(sql, new { From = 0, Rows = 100, Address = "New York" });
}
}
```
**Note:** You can as well execute it via (*LIMIT*) keyword. It is on your preference.
**RepoDb:**
- Fluent:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var customers = connection.BatchQuery<Customer>(e => e.Address == "New York",
page: 0,
rowsPerBatch: 100,
orderBy: OrderField.Parse(new { Name = Order.Ascending }));
}
```
### Replicate records from different database
**Dapper:**
- Query:
```csharp
using (var sourceConnection = new SqlConnection(SourceConnectionString))
{
var customers = sourceConnection.Query<Customer>("SELECT * FROM [dbo].[Customer];");
using (var destinationConnection = new SqlConnection(DestinationConnectionString))
{
var identities = destinationConnection.Query<long>("INSERT INTO [dbo].[Customer] (Name, Address) VALUES (@Name, @Address); SELECT CONVERT(BIGINT, SCOPE_IDENTITY());", customers);
}
}
```
**RepoDb:**
- Fluent (InsertAll):
```csharp
using (var sourceConnection = new SqlConnection(SourceConnectionString))
{
var customers = sourceConnection.QueryAll<Customer>();
using (var destinationConnection = new SqlConnection(DestinationConnectionString))
{
var affectedRows = destinationConnection.InsertAll<Customer>(customers);
}
}
```
- Fluent (BulkInsert):
```csharp
using (var sourceConnection = new SqlConnection(SourceConnectionString))
{
var customers = sourceConnection.QueryAll<Customer>();
using (var destinationConnection = new SqlConnection(DestinationConnectionString))
{
var affectedRows = destinationConnection.BulkInsert<Customer>(customers);
}
}
```
- Fluent (Streaming):
This is the most optimal and recommended calls for large datasets. We do not bring the data as class objects in the client application.
```csharp
using (var sourceConnection = new SqlConnection(SourceConnectionString))
{
using (var reader = sourceConnection.ExecuteReader("SELECT * FROM [dbo].[Customer];"))
{
using (var destinationConnection = new SqlConnection(DestinationConnectionString))
{
var affectedRows = destinationConnection.BulkInsert<Customer>(reader);
}
}
}
```
**Note:** Check for collation constraints. It is an *ADO.NET* thing.
## Passing of Parameters
**Dapper:**
- Dynamic:
```csharp
Query<T>(sql, new { Id = 10045 });
```
It is always an *Equal* operation. You control the query through *SQL Statement*.
- Dynamic Parameters:
```csharp
var parameters = new DynamicParameters();
parameters.Add("Name", "John Doe");
parameters.Add("Address", "New York");
Query<T>(sql, parameters);
```
**RepoDb:**
- Dynamic:
```csharp
Query<T>(new { Id = 10045 });
```
Same as *Dapper*, it is always referring to an *Equal* operation. You control the query through *SQL Statement*.
- Linq Expression:
```csharp
Query<T>(e => e.Id == 10045);
```
- QueryField:
```csharp
Query<T>(new QueryField("Id", 10045));
```
- QueryField(s) or QueryGroup:
```csharp
var queryFields = new[]
{
new QueryField("Name", "John Doe")
new QueryField("Address", "New York")
};
Query<T>(queryFields); // or Query<T>(new QueryGroup(queryFields));
```
## Array of Parameters
**Dapper:**
- Query:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var addresses = new [] { "New York", "Washington" };
var customers = connection.Query<Customer>("SELECT * FROM [dbo].[Customer] WHERE Address IN (@Addresses);", new { Addresses = addresses });
}
```
**RepoDb:**
- ExecuteQuery:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var addresses = new [] { "New York", "Washington" };
var customers = connection.ExecuteQuery<Customer>("SELECT * FROM [dbo].[Customer] WHERE Address IN (@Addresses);", new { Addresses = addresses });
}
```
For further explanation, you can visit our [documentation](https://repodb.readthedocs.io/en/latest/pages/rawsql.html#array-values).
- Query:
```csharp
using (var connection = new SqlConnection(ConnectionString))
{
var addresses = new [] { "New York", "Washington" };
var customers = connection.Query<Customer>(e => addresses.Contains(e => e.Address));
}
```
## Expression Trees
- Dapper do not support *Linq Expressions*, only *dynamics* and *DynamicParameters*.
- RepoDb supports *Linq Expressions*, *dynamics* and *QueryObjects*.
**Note:** The *Dapper.DynamicParameters* is just a subset of *RepoDb.QueryObjects*. The *QueryObjects* has much more capability that can further support the *Linq Expressions*.
Please visit both documentation.
- [Dapper](https://dapper-tutorial.net/parameter-dynamic)
- [RepoDb](https://github.com/mikependon/RepoDb/wiki/Expression-Trees)
## Supported Databases
**Dapper:**
Supports all RDBMS data providers.
**RepoDb:**
1. Raw-SQLs support all RDBMS data providers.
2. Fluent calls only supports *SQL Server*, *SqLite*, *MySql* and *PostgreSql*.
## Performance and Efficiency
We only refer to one of the the community-approved ORM bencher, the [RawDataAccessBencher](https://github.com/FransBouma/RawDataAccessBencher).
**Net Core:**
Here is our observation from the official execution results. The official result can be found [here](https://github.com/FransBouma/RawDataAccessBencher/blob/master/Results/20190520_netcore.txt).
Performance:
- RepoDb is the fastest ORM when fetching set-records. Both *raw-SQL* and *Fluent* calls.
- Dapper and RepoDb speed is identical when fetching single-record.
- Dapper is faster than RepoDb's *Fluent* calls when fetching single-record.
Efficiency:
- RepoDb is the most-efficient ORM when fetching set-records. Both *raw-SQL* and *Fluent* calls.
- Dapper is must more efficient than RepoDb when fetching single-record.
**NetFramework:**
RepoDb is the *fastest* and the *most-efficient* ORM for both *set* and *single* record(s) fetching. Official results can been found [here](https://github.com/FransBouma/RawDataAccessBencher/blob/master/Results/20190520_netfx.txt).
## Quality
**Dapper:**
Dapper is already running since 2012 and is being used by *StackOverflow.com*. It has a huge consumers and is hugely backed by the community.
**RepoDb:**
We did our best to write *one-test per scenario* and we have delivered *thousand of items (approximately 6.5K)* for both *Unit* and *IntegrationTests*. We would like your help to review it as well.
Below are the links to our test suites.
- [Core Unit Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.Core/RepoDb.Tests/RepoDb.UnitTests)
- [Core Integration Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.Core/RepoDb.Tests/RepoDb.IntegrationTests)
- [SqlServer Unit Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.SqlServer/RepoDb.SqlServer.UnitTests)
- [SqlServer Integration Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.SqlServer/RepoDb.SqlServer.IntegrationTests)
- [SqLite Unit Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.SqLite/RepoDb.SqLite.UnitTests)
- [SqLite Integration Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.SqLite/RepoDb.SqLite.IntegrationTests)
- [MySql Unit Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.MySql/RepoDb.MySql.UnitTests)
- [MySql Integration Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.MySql/RepoDb.MySql.IntegrationTests)
- [PostgreSql Unit Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.PostgreSql/RepoDb.PostgreSql.UnitTests)
- [PostgreSql Integration Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.PostgreSql/RepoDb.PostgreSql.IntegrationTests)
- [RepoDb.SqlServer.BulkOperations Integration Tests](https://github.com/mikependon/RepoDb/tree/master/RepoDb.Extensions/RepoDb.SqlServer.BulkOperations/RepoDb.SqlServer.BulkOperations.IntegrationTests)
> We (or I as an author) has been challenged that the quality of the software does not depends on the number of tests. However, we strongly believe that *spending* much efforts on writing a test will give confidence to the library consumers (ie: *.NET community*). Practially, it helps us to avoid manual revisits on the *already-working* features if somebody is doing a *PR* to us; it prevents the library from any surprising bugs.
**Conclusion to the Quality:**
Both is with *high-quality* but the *Dapper* is far matured over *RepoDb*. We will not contest this!
## Library Support
**Dapper:**
Proven and is backed hugely by the .NET Community; funded by *StackOverflow.com*.
**RepoDb:**
Backed by *one person* and is *not funded nor sponsored* by any entity. Just starting to expand and asking for more supports from the .NET Community.
## Licensing and Legality
Both is under the [Apache-2.0](http://apache.org/licenses/LICENSE-2.0.html) license.
**Disclaimer:**
We are not an expert in legal but we are consulting. If any conflict arises on the copyright or trademark in-front of *RepoDb*, then that is not yet addressed.
---------
## Overall Conclusion
We hope that you somehow consider and revisits this library. It has improve a lot from where it has start.
### Simplicity
Dapper is lightweight but will drag you to the most complex-level of code development. It is always tedious to write raw-SQLS and it is hard to maintain due to the fact that it is not a compiler friendly. In addition, to obtain necessary task, you need to implement necessary features.
RepoDb is a very easy-to-use ORM with enough feature sets that you can play on.
### Performance
RepoDb is faster than Dapper, enough reason to choose this library if the only factor is performance.
> RepoDb is the fastest ORM in .NET. This claim is supported by the official run of the community-approved ORM bencher [RawDataAccessBencher](https://github.com/FransBouma/RawDataAccessBencher).
### Efficiency
RepoDb is more efficient than Dapper (same claim as in Performance).
### Experience
It is more easier and faster to develop the codes with RepoDb. It has a rich feature sets which can be used right-away (ie: 2nd-Layer Cache, Fluent Methods). It will help you as a developer deliver more codes in fast and clean manner.
### Features
In RepoDb, by having the necessary features within the space of a micro-ORM will help you a lot on your development.
The features of like Bulk & Batch Operations, Property Handlers, 2nd-Level Cache, Expression Trees, Multi Queries and Inline Hints are the most common in-used features. The major pain points are, it is absent in Dapper.
---------
Thank you for reading this article. The original article was [here](https://github.com/mikependon/RepoDb/blob/master/RepoDb.Docs/RepoDb%20vs%20Dapper.md).
We are asking your help to please support this repository and solution. Your stars to our [Github](https://github.com/mikependon/RepoDb) page is very valuable.
| mikependon |
262,557 | A path for open source contributions | Today Open Source is ubiquitous in a typical application. This post shares tools to your oss contributions and triaging. | 0 | 2020-02-16T15:10:49 | https://dev.to/opensauced/a-path-for-open-source-contributions-2oa2 | opensource, github, opensauced | ---
title: A path for open source contributions
published: true
description: Today Open Source is ubiquitous in a typical application. This post shares tools to your oss contributions and triaging.
tags: opensource, github, opensauced
---
## My path to open source
I was introduced to programming in high school while taking a computer-based math course in my sophomore year in high school. Unimpressed with learning Visual Basic to solve math trivia, I did not pursue this as a hobby after that. I was re-introduced into programming 10 years later when I had an idea for a mobile application built that application exclusively using free open source libraries.
Thanks to these open source libraries, I was able to realize my goal of building an idea in ~6months. Not only were these libraries useable, but they were also open and viewable to all willing to peer into lines of code.
## The importance of open source
**According to the annual* [BlackDuck open source 360 survey](https://www.slideshare.net/blackducksoftware/open-source-360-survey-key-takeaways):
- Open source is now present in IT workloads in 90% of organizations
- Sixty-six percent (66%) of companies surveyed now contribute to open source projects
- Of 1,071 applications audited throughout 2016, 96% contained open source
Today Open Source is ubiquitous and comprises nearly 80% – 90% of the code in a “typical” application. Based on [GitHub’s 2019 Octoverse](https://github.blog/2019-11-06-the-state-of-the-octoverse-2019/), the average project is built on ~180 open source packages of dependencies. There is a need to use Open Source to stay competitive, but what about the need to use open source to advance your career?
**According to the annual** [Linux Foundation/Dice Jobs Report](https://www.linuxfoundation.org/publications/2018/06/open-source-jobs-report-2018/) _(300 hiring managers and 1800 open-source professional surveyed)_:
- Demand for open source professionals is increasing rapidly
- Eighty-nine percent (89%) of hiring managers say it’s difficult to find open source talent
- Sixty percent (60%) of companies are now looking for open source full-time hires
- Sixty-seven percent (67%) of managers say hiring open source professionals will increase more than other areas in the next 6 months
## Open source contributions
I have used open source to build my career and grow new skills as a programmer, but I rarely contribute back to the projects I use. Though embarrassed by this, I realize I am not an anomaly, there is a clear deficit in the individuals contributing to open source compared to those using. This problem has grown to be a big enough issue that maintainers of projects have turned to tools like Patreon to cover their costs while they maintain their projects full-time, the same projects that support the web presences of the largest corporations.
Knowing the clear need for open source and the need to support projects in the community, you may very well have an interest in contributing yourself. So where do you start?
## How to start contributing to open source?
If you are absolutely brand new, consider going through Kent’s series, [How to Contribute to an Open Source Project on GitHub](https://egghead.io/courses/how-to-contribute-to-an-open-source-project-on-github). If you are familiar with the basics there are tools like [CodeTriage](https://www.codetriage.com/) to find open issues for projects you are already familiar with and use.
Finally, there is a tool, I have built to support my open source contributions and triaging. I tend to have extra time to learn and contribute in ebbs and flows, so there is a cap to the amount of time I have available to contribute back. For that reason, I created [Open Sauced](https://opensauced.pizza), a tool to find and manage my next open source contribution with the time I have available.
{% github bdougie/open-sauced no-readme %}
I do this by leveraging my project to track my contributions and future contributions in a unique dashboard built on top of the [GitHub GraphQL API](https://developer.github.com/v4/). The decision to use GitHub as a backend is intentional since doesn’t require me to store user data and allows to take advantage of the platform where open source happens.
I would love feedback on the project and encourage you to sign up and start tracking contributions today. You can find the project at [opensauced.pizza](https://opensauced.pizza).
{% youtube BkLMOg36md0 %}
Finally, if you are interested in watching me stream while contributing to open source -- follow that story on [bdougie.live](https://bdougie.live).
| bdougieyo |
262,610 | Securing Your GitHub Account | Let's talk about some of the simple & practical steps you can take to improve your GitHub account... | 0 | 2020-03-11T18:38:51 | https://dev.to/ecnepsnai/securing-your-github-account-boo | github, security | Let's talk about some of the simple & practical steps you can take to improve your GitHub account security.
There's plenty of good reasons why you should try to keep any online account safe, but I feel that GitHub deserves special attention among developers. With automation through CI and CD taking center stage, it's not only important to you but also anybody who might rely on your code to ensure your GitHub account is secure.
# The Basics
Let's start with the basics, things that don't just apply to GitHub but to nearly any online service.
## Passwords
Let's face it, passwords freaking suck. We all know we're supposed to make them hard to guess and not to reuse them, but who has time to remember each and every password? Nobody, that's who.
But what if there was a solution where you could have unique passwords for each of your accounts, not have to remember them all, and have strong passwords that are difficult for both humans and computers alike to guess?
The solution is a Password Manager. A password manager is a bit of an abstract term that describes a way to record passwords for your accounts in a secure location. These managers can range from web-based services that tie in to your browser, or something as simple as a physical book you write in.
There are advantages and disadvantages to all of these options, but by properly using a manager you're protecting yourself from many common attack scenarios, the most common being password reuse.
If you're looking for a web-based solution, check out 1Password or LastPass. If you want something in-between consider KeepassX. If you want to kick it old school with a book, most office supply stores sell password books - but a good old fashioned phone book will work just as well.
## Two-Factor Authentication
Two-Factor authentication, sometimes called "Two-Step" or "Multi-Factor" (MFA), is a security measure provided by some websites to enhance your accounts security.
To understand why Two-Factor authentication works, you first need to understand what a "Factor" is.
### Authentication Factors
There are three common authentication factors: "What you know", "What you are", and "What you have".
Passwords and passphrases are things you know. Fingerprints and facial recognition are things your are. Lastly, your cell phone or a physical key are things you have.
One of the many problems with passwords is that while you may know them, other people can know them as well. To a website, it's very difficult to be sure who's who. With two-factor authentication, a website will require that you provide two forms of authentication. Most commonly this is your password, plus a one-time password generated by an app on your phone.
In the event somebody happens to have your password, with two-factor authentication they would also require your cell phone to get in to your account.
### Enable Two-Factor Authentication
1. Click on your Avatar in the top right and select "Settings"
2. Click on "Security" on the left hand side
3. Click on "Enable" under "Two-factor Authentication"
4. Click on "Set up using an app" 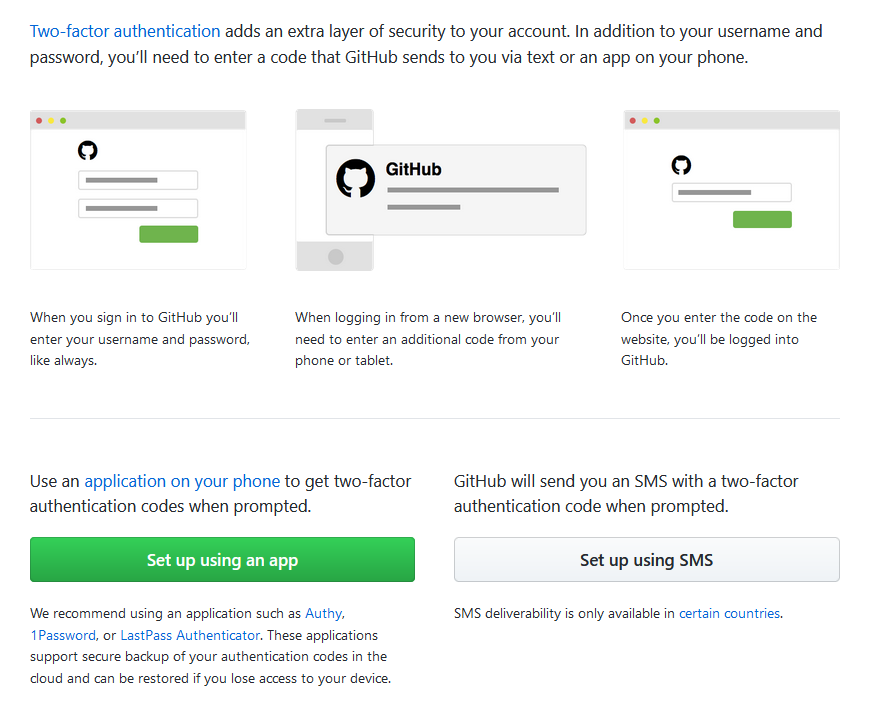
5. Save the recovery codes (Protip: If you're using a password manager, record the codes in the notes section for the websites entry)
6. Scan the QR code using authenticator app of your choosing
7. Enter the one-time password from your phone to finish setting up two-factor authentication
## Connected Apps
Like many online services, GitHub uses a technology known as OAuth to allow applications to interact with your GitHub account without requiring your username and password.
It's very important that you periodically review the applications you've authorized to use your GitHub account and remove any you no longer use.
1. Click on your Avatar in the top right and select "Settings"
2. Click on "Applications" on the left hand side
3. Click on the "Authorized OAuth Apps" tab
4. To revoke an app, tap on the "..." for the app and select "Revoke" 
## Active Sessions
GitHub lets you view active login sessions, and approximately where that computer or device is. It's always a good idea to periodically take a look at the list and ensure that only the devices you intend to use GitHub with are listed. If you see any login sessions from weird devices, or from the wrong country, it could be an indicator that your account is compromised.
To see your active sessions:
1. Click on your Avatar in the top right and select "Settings"
2. Click on "Security" on the left hand side
3. Scroll to the bottom of the page
Take the following example, where my current session is in Canada but a recent login occurred in Romania.
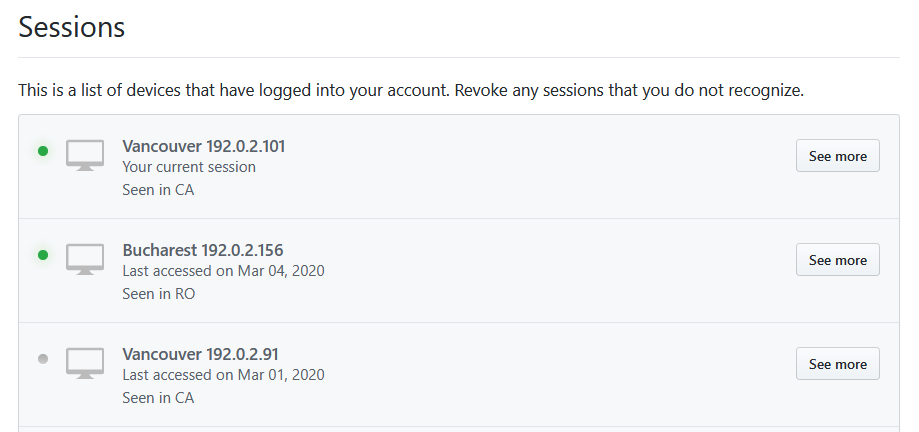
If you see something out of the ordinary here, change your password immediately.
# GitHub as a Git Remote
Now that we've covered the basics, let's dive into the real reason why I'm writing this guide: GitHub is, obviously, a Git service.
## Avoid using SSH
GitHub, like nearly all Git services, lets you connect to it either one of two ways: using SSH or HTTPS.
From a cryptographic perspective, both of these provide strong encryption and protection against tampering, but there's a huge benefit to using HTTPS that SSH lacks: Public Key Infrastructure, or PKI.
### Quick Primer: How PKI works for HTTPS
When you connected to dev.to to read this article your browser performed a TLS Handshake and trust verification with the web server hosting this site. Part of this process is the web server presenting its certificate to your browser. Your browser then looked at the parents of the servers certificate. If the browser trusts the root (or top-level) of the certificate chain, it can mathematically prove that the certificate was issued from a trusted authority, and after performing some additional tests, confirm that the web server is who they say they are.
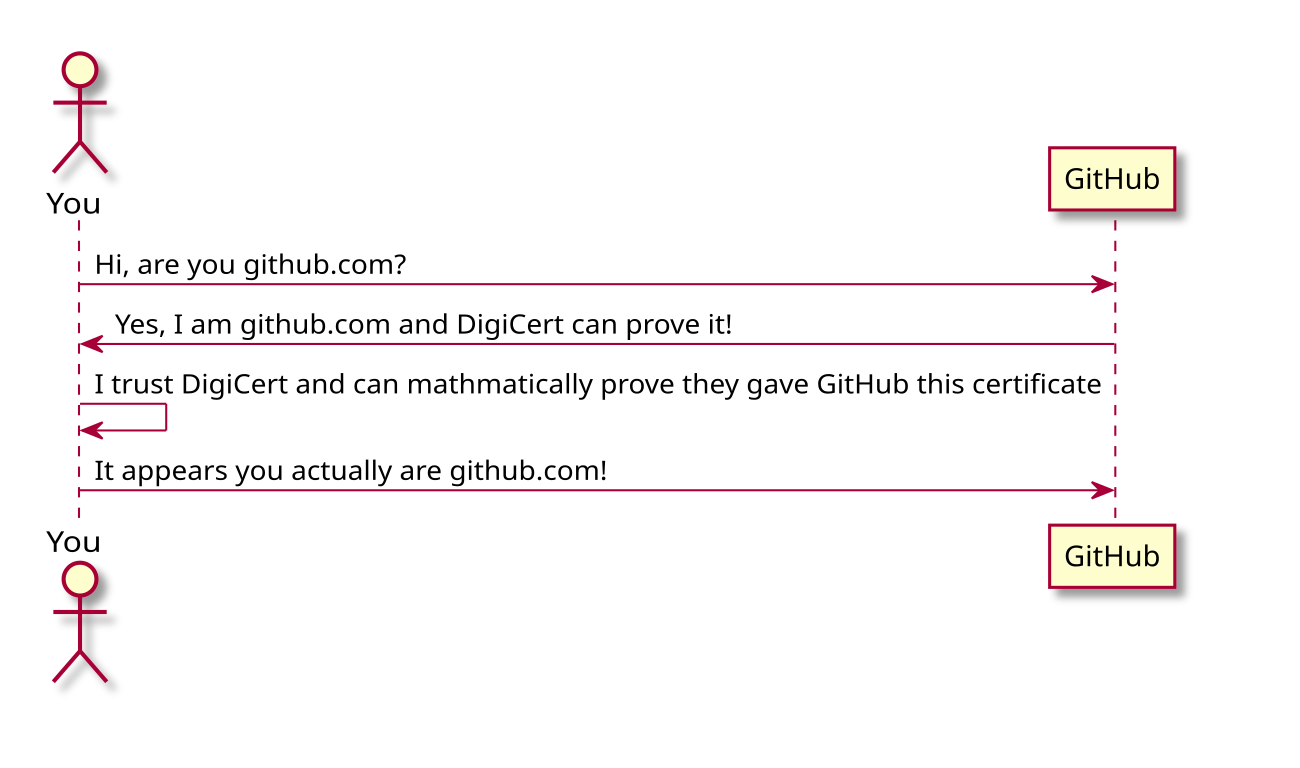
### Why SSH is the wrong choice for Git
SSH lacks nearly all of this, especially all of those additional checks that are done.
When you connect to a host using SSH your computer only has the servers public key to go on to determine trust. If you've never connected to server before, it will prompt you if you want to trust their public key. The next time, if the public key matches it will connect without asking you, but if the public key changes it will show this scary warning at you.
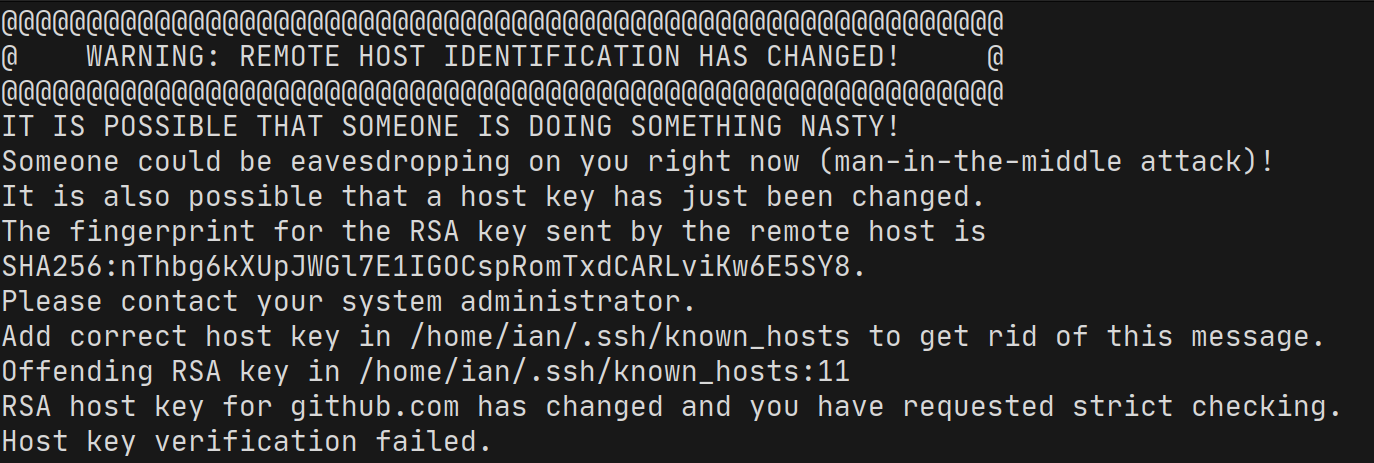
The fatal flaw with SSH's trust mechanism is placing ultimate and permanent trust in the hosts key. Once you've trusted a key, that key can never change without causing errors as seen above. In GitHub's case changing their key would cause huge confusion among its users.
Whereas with HTTPS, GitHub's certificates are [rotated regularly without you even realizing it](https://crt.sh/?q=*.github.com).
SSH also lacks a large amount of other security enhancements that HTTPS has, such as: certificate lifespans, revocation and automatic status checks, transparency, and key usage restrictions.
Now that I've lectured you enough on why SSH is not the right choice, let's look at how we can go about using HTTPS.
## Using Access Tokens
Git over HTTPS works just like Git over SSH, you just have to sign in to GitHub with your username and password instead of adding your SSH key to your account.
However, if you're using Two-Factor authentication (You are, right? See the section above). You won't be able to use Git over HTTPS since there's no way to prompt for your one-time password.
Not to worry though, GitHub has you covered with so-called "Access Tokens". These are sometimes called "Application Passwords" on other services and let you sign in on applications that don't support multi-factor authentication. The idea is that you sign in and generate these passwords but only use them for a specific application.
Here's how you generate an access token:
1. Click on your Avatar in the top right and select "Settings"
2. Click on "Developer Settings" on the left hand side
3. Click on "Personal Access Tokens" on the left hand side
4. Click on "Generate New Token"
5. Give the token a name and select only the required permissions for the token
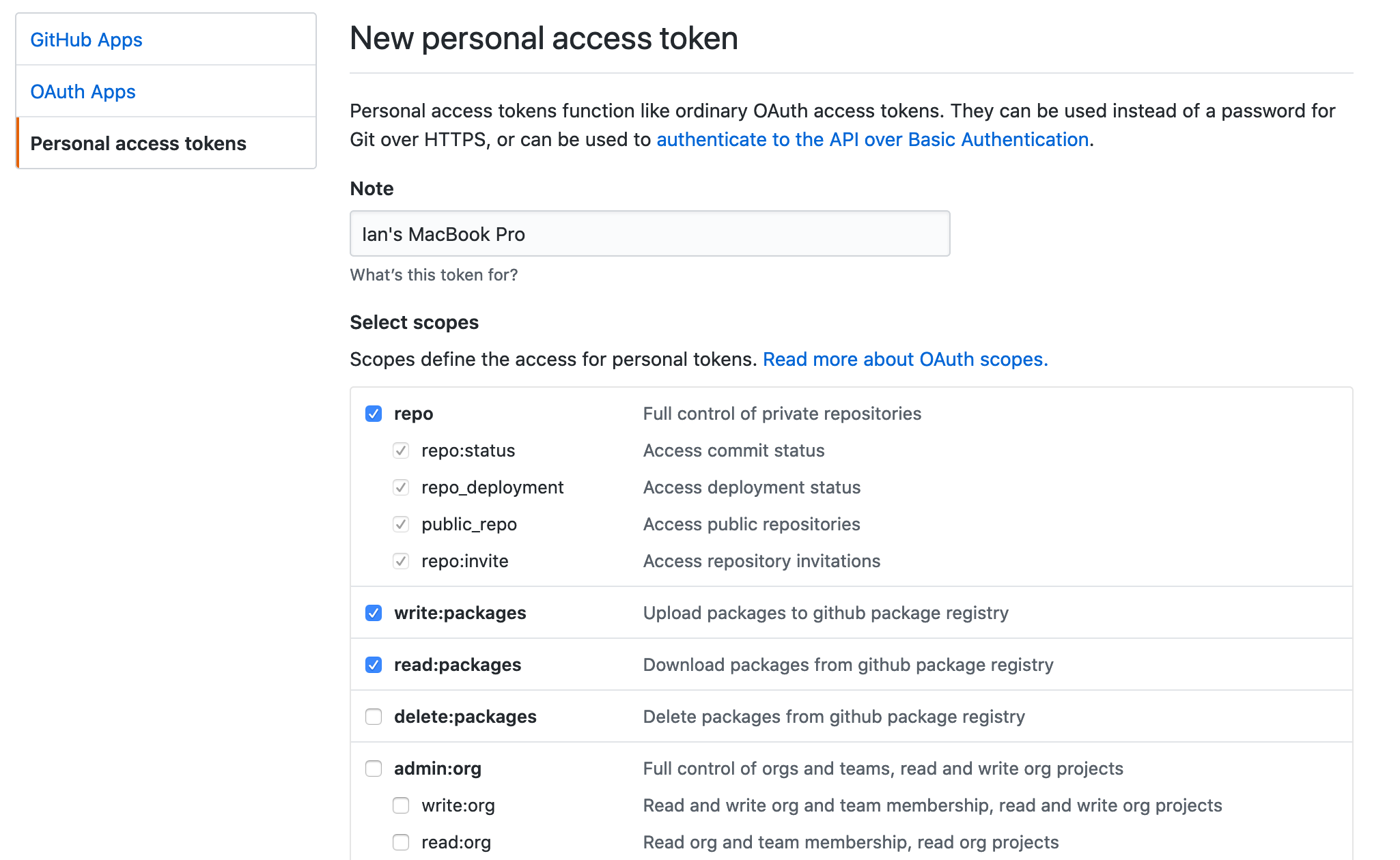
Then, when you configure your git remote to use HTTPS you'll be asked to provide your username and password. Use the access token as your password and you've authenticated.
```
$ git fetch
Username for 'https://github.com': ecnepsnai
Password for 'https://ecnepsnai@github.com': <my access token>
```
## Storing Access Tokens
There are 4 options to store your credentials if you don't want to type your access token every time (Who would?)
**Option 1: Don't store them**
Didn't I just ask who wants to type their access token out each time? With this, git doesn't remember your credentials. Each time you access the remote, you have to type in your credentials.
**Option 2: Cache them for a limited time**
This method is marginally better than option 1. Git will remember your username and access token for a limited period of time before requiring you to enter them again. This is similar to how `sudo` works if you've used that before.
You can enable this method using:
```
$ git config --global credential.helper 'cache --timeout=3600'
```
Where `3600` is the number of seconds to cache the credentials.
**Option 3: Store them in a plain-text file**
This method is the easiest to set up, but not the most secure. With this, git will store your username and access token in a plain-text file in your home directory. It won't prompt you for your username or access token once saved.
You can enable this method using:
```
$ git config --global credential.helper store
```
**Option 4: Store them using a credential helper**
This method can be tricky to set up but provides the best balance of convenience and security. A credential helper is an application that stores keys in a secure location that git can use.
On macOS you can use the systems Keychain, which is encrypted with your users password. See [GitHub's documentation](https://help.github.com/en/github/using-git/caching-your-github-password-in-git) on how to setup and configure the credential helper.
On Linux you can use the `gnome-keyring` package, which is very similar to the Keychain from macOS. Setup varies depending on your distribution and isn't covered in this document.
# Anything Else?
That's all for the tips I have in this guide. Do you have any other ideas on ways to protect your account? Let me know in the comments! | ecnepsnai |
262,729 | Refactoring Personal Data out of a Devise Model | I'm working on Ruby on Rails application. It's an ecommerce platform for print creators. My minimum v... | 0 | 2020-02-16T23:00:18 | https://ogdenstudios.xyz/blog/refactor-personal-data-out-of-devise/ | rails, ruby, devise, activerecord | I'm working on [Ruby on Rails](https://rubyonrails.org/) application. It's an ecommerce platform for print creators. My minimum viable product is working, and it's time to roll up my sleeves and refactor the code to get it production-ready.
## What needs to change about my Reader Model?
The basic authentication model is the `Reader`. It represents what you might consider to be a `User` in other applications.
This model is built with [Devise](https://github.com/heartcombo/devise). When I first wrote it, I also used it to store profile information for each reader.
After some great conversations in the [Ruby on Rails Link Slack](https://www.rubyonrails.link/), I've come to understand that my authentication model shouldn't be responsible for managing user data. It sort of violates the [single responsibility principle](https://www.rubyonrails.link/). And practically speaking, every attribute follows the `current_reader` object in controllers and views. So if I have a logged-in `Reader` on the home page, the view knows all of its attributes. In my case, that only includes a `first_name` and `last_name` column, but this approach can lead to problems down the road.
If I continue to add reader data in the `Reader` model, I will be loading a lot of unnecessary data in each request with the `current_reader` object.
I want to contain these attributes in a new class called `ReaderProfile`, of which each `Reader` object will `have_one`.
## The Current Reader Model
This is my current `ApplicationRecord` subclass:
```rb
# frozen_string_literal: true
class Reader < ApplicationRecord
# Include default devise modules. Others available are:
# :confirmable, :lockable, :timeoutable, :trackable and :omniauthable
devise :database_authenticatable, :registerable,
:recoverable, :rememberable, :validatable
has_many :works, :through => :purchases
has_many :followings
has_many :purchases
has_many :reading_list_items
has_many :works_to_read, through: :reading_list_items, source: :work
has_many :reviews
end
```
And the relevant schema from `db/schema.rb`.
```rb
create_table "readers", force: :cascade do |t|
t.string "email", default: "", null: false
t.string "encrypted_password", default: "", null: false
t.string "reset_password_token"
t.datetime "reset_password_sent_at"
t.datetime "remember_created_at"
t.datetime "created_at", precision: 6, null: false
t.datetime "updated_at", precision: 6, null: false
t.string "first_name"
t.string "last_name"
t.index ["email"], name: "index_readers_on_email", unique: true
t.index ["reset_password_token"], name: "index_readers_on_reset_password_token", unique: true
end
```
## The Current Reader Tests
I'm using [RSpec](https://github.com/rspec/rspec-rails) to test my Rails application, along with [FactoryBot](https://github.com/thoughtbot/factory_bot_rails) for my factories.
I have unit tests in `spec/models/reader_spec.rb`. Here's what I test for:
```rb
# frozen_string_literal: true
require 'rails_helper'
RSpec.describe Reader, type: :model do
it 'has a valid factory' do
expect(build(:reader)).to be_valid
end
describe 'associations' do
it { should have_many(:followings) }
it { should have_many(:purchases) }
it { should have_many(:reading_list_items) }
it { should have_many(:reviews) }
it { should have_many(:works) }
end
end
```
## The ReaderProfile Model
I can create my new `ReaderProfile` model with the command:
```
rails g model ReaderProfile first_name:string last_name:string reader:references
```
This creates the relevant ActiveRecord class, Rails migration, and tests for the class.
## Testing the ReaderProfile
I'm going to make `first_name` and `last_name` information optional for readers, so all I want to do is make sure I've got a test in `spec/models/reader_profile_spec.rb` that checks for a valid factory and it belongs to a `Reader` object. Here's what that unit test looks like:
```rb
RSpec.describe ReaderProfile, type: :model do
it 'has a valid factory' do
expect(build(:reader_profile)).to be_valid
end
end
```
My factory in `spec/factories/reader_profiles.rb` looks like:
```rb
FactoryBot.define do
factory :reader_profile do
first_name { "MyString" }
last_name { "MyString" }
reader { create(:reader) }
end
end
```
I add the `belongs_to` code in my `ReaderProfile` model like so:
```rb
# app/models/reader_profile.rb
class ReaderProfile < ApplicationRecord
belongs_to :reader
end
```
And when I run `rspec spec/models/reader_profile_spec.rb`, my tests pass.
## Adding to the Reader Tests
I want every `Reader` object to have one `ReaderProfile`. To test that, I add the following to `spec/models/reader_spec.rb`:
```rb
it { should have_one(:reader_profile) }
```
And I update the `Reader` model to look like:
```rb
# frozen_string_literal: true
class Reader < ApplicationRecord
# Include default devise modules. Others available are:
# :confirmable, :lockable, :timeoutable, :trackable and :omniauthable
devise :database_authenticatable, :registerable,
:recoverable, :rememberable, :validatable
has_many :works, :through => :purchases
has_many :followings
has_many :purchases
has_many :reading_list_items
has_many :works_to_read, through: :reading_list_items, source: :work
has_many :reviews
has_one :reader_profile
end
```
When I run `rspec spec/models/reader_spec`, everything passes.
## Updating the impacted Views and Controllers
I've been focusing on the model layer of this refactoring. It's worth noting that I have `current_reader.first_name` and `current_reader.last_name` strewn through my application. I'll need to find-and-replace those instances to `current_reader.reader_profile.first_name` and `current_reader.reader_profile.last_name`.
I'll also need to drop the `first_name` and `last_name` parameters from the `ReadersController`, and create endpoints for readers to create, update, and delete their profiles.
## Conclusion
Aside from my remaining TODOs, I've made good progress today. Now I have a `ReaderProfile` model to encapsulate personal information associated with each `Reader`. This makes it easier to add more pieces of `Reader` data without bloating the authentication class. It also means I can extend my authentication class to include different types of profiles if I like. Here's what my refactoring is really saying:
* The `Reader` model handles authentication and authorization for readers. When a reader signs in, they can access their associated `ReaderProfile`.
* The `ReaderProfile` model stores personal information about the `Reader` it belongs to. | ogdenstudios |
262,752 | Cypress – generating mochawesome reports | When using Cypress for testing applications, there are some reports you get out of the box. Those are... | 0 | 2020-02-17T01:20:23 | https://dev.to/hi_iam_chris/cypress-generating-mochawesome-reports-mo1 | react, cypress, javascript, testing |
When using Cypress for testing applications, there are some reports you get out of the box. Those are video recording of test and if test fails, screenshot in the moment it fails. Quite often, that is not enough. You want some HTML output for report. That is what I will cover in this post. You will get step by step guide on how to generate report with [mochawesome](https://www.npmjs.com/package/mochawesome) for e2e tests. If you are brand new to Cypress, you can read into on how to set it up in [this](https://dev.to/chriss/cypress-initial-setup-l4) article.
## Installation
Let’s start with required packages you will need to generate mochawesome reports. First package you will need is mochawesome, which you can get by executing:
```
npm install --save-dev mochawesome
```
At this moment, there are some issues with mocha that were supposed to be solved in Cypress version 4. Sadly, they haven’t, but it can be solved by installing older version of mocha by executing:
```
npm install --save-dev mocha@^5.2.0
```
## Setup
Once you install required dependencies, you need to do some configuration to use it. You can generate these reports by using reporter flag when running tests.
Example
```
cypress run --reporter mochawesome
```
Usually you do not want to add those flags to CLI commands. Just makes everything less clear. Therefore, we will add configuration to our cypress.json file. When you run cypress first time, this file will be generated in root folder of your project and in initial version it just contains empty object. To define which reporter to use, we will need to add reporter property.
```
{
"reporter": "mochawesome"
}
```
This will generate mochawesome-report folder containing our report looking like one in an image bellow.
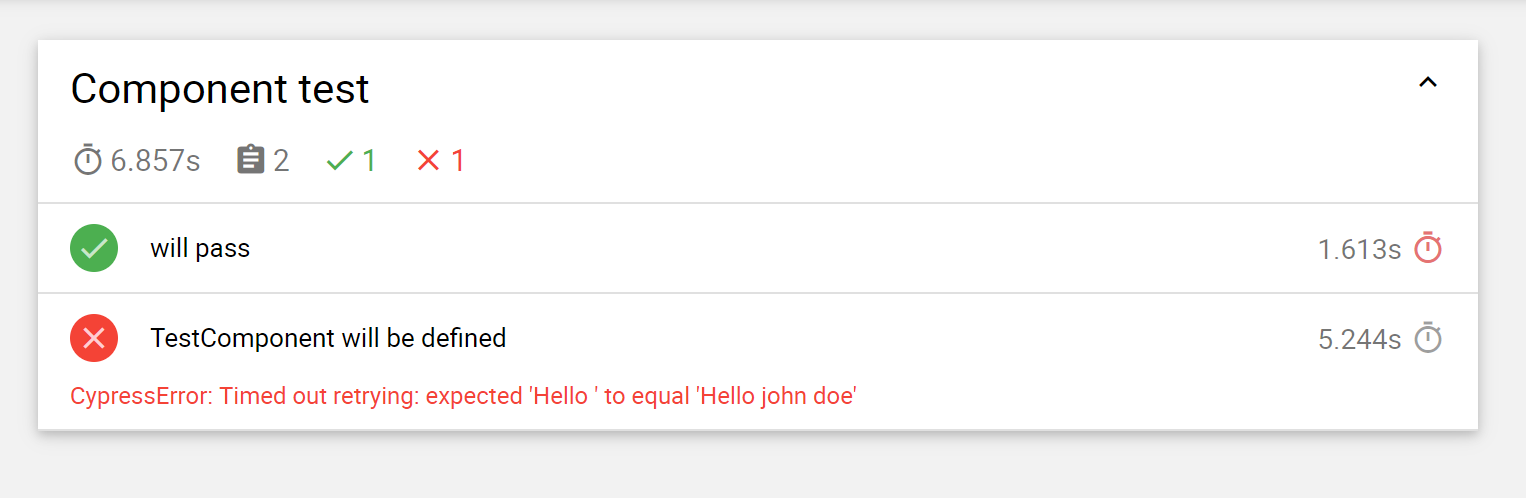
More often, we want to configure some options. So first, let’s add some charts for our test suits. We can configure that in reporterOptions property. This property is object containing different reporter configurations. To generate charts, add charts property with value true.
```
{
"reporter": "mochawesome",
"reporterOptions": {
"charts": true
}
}
```
These are not great charts, but they do give sense on passing and failing tests.

You can generate report in few different outputs, HTML and JSON. Maybe you just want to use this default display, then you can just use HTML. But if you want to build something custom, then you could export JSON, and use those data to generate your own reports. This you can control by setting flags of desired output to true.
```
{
"reporter": "mochawesome",
"reporterOptions": {
"html": true,
"json": true
}
}
```
Output location and name of report is something that also can be configured in this file. We can do that by using reportDir and reportFilename fields.
```
{
"reporter": "mochawesome",
"reporterOptions": {
"charts": false,
"html": true,
"json": true,
"reportDir": "cypress/reports",
"reportFilename": "report"
}
}
```
Mochawesome generates new report for every spec we have. And since by default it overwrites old reports, this means it will only keep last test spec run. This we can fix by setting overwrite flag to false. Changing this flag to false would just generate new file at each run. So you should delete old ones before running, manually or by using some script.
```
{
“reporter”: “mochawesome”,
“reporterOptions”: {
“charts”: false,
“html”: true,
“json”: true,
“reportDir”: “cypress/reports”,
“reportFilename”: “report”,
“overwrite”: true
}
}
```
If we would run this, we would get separate report for every spec file. This is something that usually we don’t want to do, and we can merge them into single report by using [mochawesome-merge](https://www.npmjs.com/package/mochawesome-merge) npm package. As I prefer keeping articles smaller, I will be covering that in separate article.
Code examples for this setup you can find at my [Github repository](https://github.com/kristijan-pajtasev/cypress-setup).
| hi_iam_chris |
262,766 | Blender Destructive Physics | Standard Blender with Bullet is missing python callbacks for collision events. Work is underway now... | 0 | 2020-02-17T01:34:07 | https://dev.to/djraptor11/blender-destructive-physics-19o4 | blender | Standard Blender with Bullet is missing python callbacks for collision events. Work is underway now to integrate ODE Physics with Blender2.83. In this is the first stage of integration, a new object property `breakable` will trigger my modified cell fracture script to run, and smash your mesh apart when it hits the ground. Collision and fracture events can also be scripted, allowing you to attach a python script to the on-collision and on-fracture events.
Metaballs also work with ODE in Blender, and can split apart on collision with the ground.
 | djraptor11 |
262,824 | Running (debugging) a bash script line-by-line | The other day I was running a Bash script. It wasn't working as expected so it needed some debugging.... | 0 | 2020-02-17T02:50:23 | https://medium.com/@mrodz/running-debugging-a-bash-script-line-by-line-6fb88acbd335 | bash, debugging, coding, linux | The other day I was running a `Bash` script. It wasn't working as expected so it needed some debugging.
I needed a quick-and-dirty solution.
After some googling, I found this answer. It ended up being quite easy and handy.
All you have to do is place this line on the top of your script and Bash will prompt you after executing every line. Hitting `enter` key is enough to execute the next line of your script.
```
#!/usr/bin/env bash
set -x
trap read debug
< YOUR CODE HERE >
```
It is reported that this works "with bash v4.2.8 and v3.2.25."
For me, it worked like a charm.
Here is the [original answer in stackoverflow](https://stackoverflow.com/questions/9080431/how-execute-bash-script-line-by-line/9080645).
<hr />
Do you have other tips for debugging Bash? I'd like to know.
| anrodriguez |
262,853 | 6 major innovations to enhance mobile app development in 2020
| Mobile apps are the most usual thing to expect in today’s tech-savvy world. As the on-demand economy... | 0 | 2020-02-17T05:22:37 | https://dev.to/sachindev87/6-major-innovations-to-enhance-mobile-app-development-in-2020-277k | mobile, android, devop | <span style="font-weight: 400;">Mobile apps are the most usual thing to expect in today’s tech-savvy world. As the on-demand economy started soaring, there was a surge in the app market that has continued its run. Last year, app markets produced </span><a href="https://www.statista.com/statistics/269025/worldwide-mobile-app-revenue-forecast/"><span style="font-weight: 400;">revenues close to $461.7 billion</span></a><span style="font-weight: 400;"> and will continue to </span><a href="https://www.statista.com/statistics/269025/worldwide-mobile-app-revenue-forecast/"><span style="font-weight: 400;">grow up to $935 billion by 2023</span></a><span style="font-weight: 400;">.</span>
<img class=" size-full wp-image-930 aligncenter" src="https://kunshtechsoftwaredevelopmentcompany.files.wordpress.com/2020/02/app-market-revenue-stats.png" alt="app market revenue stats" width="512" height="357" />
<i><span style="font-weight: 400;">"In mobile, there's a big premium on creating single-purpose first-class experiences,"</span></i><span style="font-weight: 400;">- </span><a href="https://www.fool.com/investing/general/2015/06/25/facebook-incs-ultimate-unbundling-messenger.aspx"><span style="font-weight: 400;">Mark Zuckerberg, CEO Facebook</span></a><span style="font-weight: 400;">.</span>
<span style="font-weight: 400;">As Zuckerberg stated above, mobile app development has offered businesses that premium tools to cater to excellent user experiences. With major innovations in the fields of Artificial Intelligence and Machine Learning algorithms, the mobile app development paradigm is set to see a drastic shift.</span>
<span style="font-weight: 400;">Let us discover six such innovations that will shape the future of mobile app development.</span>
<ol>
<li><b>Intelligent Apps:</b></li>
</ol>
<img class=" size-full wp-image-931 aligncenter" src="https://kunshtechsoftwaredevelopmentcompany.files.wordpress.com/2020/02/intelligent-apps.jpg" alt="Intelligent Apps" width="1280" height="853" />
<span style="font-weight: 400;">Intelligent apps are the next evolution of mobile app development. Think about an app that can generate automated responses, predicting the behavioral patterns, user’s data and context. These responses are delivered using NLP(Natural Language Processing) to deliver human-like natural conversations.</span>
<span style="font-weight: 400;">With innovations in the neural engine technologies, integration of training modules to train algorithms for data capture, process and respond to the user’s queries have become relatively easy. </span>
<span style="font-weight: 400;">Have you ever wondered why you would always choose the TV series recommended by machine learning algorithms of Netflix or prefer a product recommendation of Amazon? They know what you prefer and recommend the same. </span>
<b><i>How do they do that?</i></b>
<span style="font-weight: 400;">Every algorithm can be trained in three simple ways:</span>
<b>Supervised Learning: </b><span style="font-weight: 400;">The algorithm is taught through data sets and human mentoring!</span>
<b>Unsupervised Learning:</b><span style="font-weight: 400;"> The self-learning module helps algorithms to learn by itself through datasets and patterns without human intervention.</span>
<b>Reinforced Learning: </b><span style="font-weight: 400;">This is a kind of trial and error learning, where the algorithm is taught to respond to queries by learning responses, patterns and data sets about certain scenarios. </span>
<ol start="2">
<li><b> Voice bots: </b></li>
</ol>
<img class=" size-full wp-image-932 aligncenter" src="https://kunshtechsoftwaredevelopmentcompany.files.wordpress.com/2020/02/voice-bots.jpg" alt="Voice bots" width="1280" height="851" />
<span style="font-weight: 400;">A personalized bot to talk to! Not a fantasy anymore, most companies are </span><a href="https://www.kunshtech.com/blog/transforming-your-mobile-app-idea-into-reality/"><span style="font-weight: 400;">transforming their app ideas into reality</span></a><span style="font-weight: 400;"> through such state-of-the-art technologies now. </span>
<span style="font-weight: 400;">And this has also revamped the e-commerce economy to create more business opportunities. 2019 saw shipments of voice bot-based </span><a href="https://www.futuresource-consulting.com/press-release/consumer-electronics-press/virtual-assistants-to-exceed-25-billion-shipments-in-2023/"><span style="font-weight: 400;">smart IoT(Internet of Things) devices over 1.1 billion</span></a><span style="font-weight: 400;"> and with a growth rate of year over year of 25%, </span><a href="https://www.futuresource-consulting.com/press-release/consumer-electronics-press/virtual-assistants-to-exceed-25-billion-shipments-in-2023/"><span style="font-weight: 400;">it will cross 2.5 billion shipments by 2023</span></a><span style="font-weight: 400;">.</span>
<span style="font-weight: 400;">Whether it is Alexa, Siri or Cortana, voice bots have been phenomenal, as far as business conversion is concerned. They have expanded the e-commerce paradigm and created a new economic gig- “Voice Commerce”.</span>
<ol start="3">
<li><b> New reality:</b></li>
</ol>
<img class=" size-full wp-image-933 aligncenter" src="https://kunshtechsoftwaredevelopmentcompany.files.wordpress.com/2020/02/new-reality.jpg" alt="new reality" width="1280" height="853" />
<span style="font-weight: 400;">We are all familiar with Augmented Reality(AR) and Virtual Reality(VR). Technologies as these have started to revolutionize the businesses on the whole and when a technology startup MojoVision announced </span><a href="https://techcrunch.com/2020/01/16/mojo-visions-ar-contact-lenses-are-very-cool-but-many-questions-remain/"><span style="font-weight: 400;">the development of an AR lens</span></a><span style="font-weight: 400;"> that will directly fit into your eye, it was future, right there!</span>
<b>Video Source:</b> <a href="https://www.youtube.com/watch?v=pV52DF5IrEc"><span style="font-weight: 400;">https://www.youtube.com/watch?v=pV52DF5IrEc</span></a>
<span style="font-weight: 400;">Here, as you can see Michael Wiemmer, the CFO of MojoVision, giving us a brief about how his team has been working on an AR contact lens for almost four and a half years and succeeded to create a prototype with </span><a href="https://venturebeat.com/2019/05/30/mojo-vision-reveals-the-worlds-smallest-and-densest-micro-display/"><span style="font-weight: 400;">word’s smallest microdisplay</span></a><span style="font-weight: 400;">. </span>
<img class=" size-full wp-image-934 aligncenter" src="https://kunshtechsoftwaredevelopmentcompany.files.wordpress.com/2020/02/ar-vr-market-stats.png" alt="AR-VR market stats" width="784" height="533" />
<span style="font-weight: 400;">With such innovations in AR wearables and devices, we can expect it to be the new reality of mobile app development. The AR/VR market </span><a href="https://www.statista.com/statistics/591181/global-augmented-virtual-reality-market-size/"><span style="font-weight: 400;">is set to reach $18.8 billion by 2020</span></a><span style="font-weight: 400;">. As the market has already seen a surge in AR-related technologies for mobile apps and its integration, it will help businesses provide rich UX(User Experience)!</span>
<ol start="4">
<li><b> At Your Service:</b></li>
</ol>
<img class=" size-full wp-image-935 aligncenter" src="https://kunshtechsoftwaredevelopmentcompany.files.wordpress.com/2020/02/at-your-service.jpg" alt="At Your Service" width="1280" height="960" />
<span style="font-weight: 400;">Brands and businesses spend a huge amount on after-sales services. This expenditure can be reduced through the usage of AI technologies. Chatbots have already revolutionized many customer support services, especially in the financial and banking sectors.</span>
<span style="font-weight: 400;">With app developed integrating such AI technologies can certainly, transform the customer support paradigm. When Bank of America introduced Erica, in June 2018, none would have expected, that Erica would complete more </span><a href="https://www.businesswire.com/news/home/20190528005646/en/Bank-America%E2%80%99s-Erica%C2%AE-Completes-50-Million-Client"><span style="font-weight: 400;">than 50 million service requests successfully</span></a><span style="font-weight: 400;">.</span>
<b>Video Source: </b><a href="https://www.youtube.com/watch?v=0lrg83riPzo"><span style="font-weight: 400;">https://www.youtube.com/watch?v=0lrg83riPzo</span></a>
<span style="font-weight: 400;">As you can see above, customers can use the voice assistant integrated into their app to not only transact but, even for banking services like unblocking a debit card. Such revolutionary technologies will certainly boost mobile apps and the integration of chatbots in it.</span>
<ol start="5">
<li><b> The Fifth Horseman:</b></li>
</ol>
<img class=" size-full wp-image-936 aligncenter" src="https://kunshtechsoftwaredevelopmentcompany.files.wordpress.com/2020/02/the-fifth-horseman.jpg" alt="The Fifth Horseman" width="1280" height="853" />
<span style="font-weight: 400;">The fifth horseman of networks has already arrived with 5G. The new generation network capability will </span><a href="https://www.kunshtech.com/blog/how-5g-technology-will-change-the-mobile-app-world/"><span style="font-weight: 400;">boost mobile app development</span></a><span style="font-weight: 400;"> and create greater UX! We have already seen network giants in the US like Verizon, providing 5G capabilities in certain areas.</span>
<img class=" size-full wp-image-938 aligncenter" src="https://kunshtechsoftwaredevelopmentcompany.files.wordpress.com/2020/02/arpu.png" alt="ARPU" width="512" height="250" />
<span style="font-weight: 400;">In 2016, almost all the businesses depending on the smartphone apps and other services for revenues saw a decline in </span><a href="https://www2.deloitte.com/content/dam/Deloitte/us/Documents/technology-media-telecommunications/us-tmt-5g-deployment-imperative.pdf"><span style="font-weight: 400;">Average Revenue Per User(ARPU)</span></a><span style="font-weight: 400;">, which never got the boost required through LTE-based mobile apps. But, with 5G set to replace 4G in many demographic regions, it will increase the overall ARPUs.</span>
<ol start="6">
<li><b> Automated Testing:</b></li>
</ol>
<img class=" size-full wp-image-939 aligncenter" src="https://kunshtechsoftwaredevelopmentcompany.files.wordpress.com/2020/02/automated-testing.jpg" alt="Automated Testing" width="1280" height="853" />
<span style="font-weight: 400;">With the increase in the number of mobile OS and smartphones in the market, testing the apps with real physical devices has become a time-consuming and costly affair.</span>
<span style="font-weight: 400;">RPA(Robotic Process Automation) testing has changed the testing of apps forever. Such systems provide excellent virtual environments to test functionality, response to users and system interaction of mobile apps.</span>
<span style="font-weight: 400;">Automated testing can improve app-performances with all the required integrations of user feedback and necessary changes in the app features with successive iterations.</span>
<h4><b><span style="text-decoration: underline;">Signing Off</span>:</b></h4>
<span style="font-weight: 400;">Mobile applications have been an integral part of many businesses over the years and as long as there is a need for faster and richer user experiences for companies, apps are there to rule! </span>
<span style="font-weight: 400;">The new trend of real-time responsive and reactive apps has already made its mark among conventional native apps. Such trends need technological innovations to nurture mobile app’s performance that can provide excellent UX!</span>
<span style="font-weight: 400;">If you are a startup or an established business, you will need intelligent apps with features like voice assistants, speech recognition, facial recognition and many such to reach your consumers and personalize your services for them. So, tap into some innovations for your mobile app development and make the world more exciting!</span>
| sachindev87 |
262,857 | How to Provide Value As Non-Tech Founder (without learning to code) | Whenever I talk to non-technical people, I feel some kind of deep frustration. They are trying to bui... | 4,926 | 2020-02-17T05:40:27 | https://dev.to/domenicosolazzo/how-to-provide-value-as-non-tech-founder-without-learning-to-code-4k8p | startup, business, productivity, coding | Whenever I talk to non-technical people, I feel some kind of deep frustration. They are trying to build a software product, but something doesn’t feel right.
They are moving too slow, not being able to contribute to the code, missing deadlines, and so on. They feel that they are not providing enough value to their team. They feel powerless while waiting for their polished first release of the product.
> “My tech co-founder is building the platform for our great idea. We are waiting for him to finish version one, so we can show it to our customers…”
> “My engineering team is building the product but moving too slow. I wish I could be hands-on and code the missing parts...”
> “We are already missing deadlines. We are just missing that simple feature: it should not be hard to code...”
Does it sound familiar?
I feel the pain. I do. It is understandable.
You want to see things moving faster. You want to contribute and people around you always suggest the same: **learn to code**!
Don’t get me wrong. I am a developer myself and I love coding.
It is a great way to get into the developer’s mindset and if you are up for the challenge, just do it!
**[Codecademy](https://www.codecademy.com/)** is a great place to start or **[CodeCombat](https://codecombat.com/)** if you like learning while playing a game.
Yet, if you just need an **MVP** to show to your customers, you can contribute by building it yourself. Without one single line of code. Many products let you create clickable prototypes without writing a single line of code.
So, if you are still wondering how you can, even more, contribute to your team, **continue reading**.
You can do tons of things to provide value without waiting an entire year while learning to code.
Paul Graham once said that __[“a non-tech founder can contribute with sales and… bringing coffee and cheeseburgers to the programmers!”](http://genius.com/4248046)__
{% youtube ii1jcLg-eIQ %}
Well, that’s a good start from a developer perspective.😜
At the start of product development, you should free the team’s path from any obstacle. Let them focus on building the product while you take care of everything else.
**You can provide huge value**; let’s see what **you** can do…
## How can you provide value and help your team?
### 1. Customer development
Talking to your users can be hard. No doubts about that!
Much easier to sit in a room, strategizing and talking about how great company and product will be. You can always use **all the kind of tactics** afterward to get your users, right? I don’t think so.
Often, founders will start with building a product and raising money. Even before having clear evidence if it is **something that people love**.
Understanding the user’s pain is **priceless**! Don’t forget this.
That’s why you should continue learning from your users, either you have a product or not.
The most important responsibility you will have in the startup.
No growth hack will save you (and your team) if you don’t build a product that your users love.

###### Credits: http://dilbert.com/strip/2012-05-07
Talk to your target market!
Offline or online.
Wherever they are!
Go where your users are. If you do this, you are already **providing great value**.
Try to reach some of those people and ask them what they think about your product by phone, email, online surveys or whatever user research method that you prefer.
Take some of your mockups and drawings, create a folder on your phone and upload them. Then, go out and show what you got to your customers. Feedback is a relevant part of getting something people to love.
**Should your engineers do the same?**
**Sure**, and it is great if they do **but** you can take the load off of your engineers, so they can focus on building v.1 (or v 0.1?!)
After, search what people say online about the problem that you are trying to tackle. People share their painful problems and opinions, and it is up to you to find them on the internet.
Browse sites like **Quora, Facebook Groups, Linkedin Groups or famous blogs** in your space. Start analyzing the threads and the comments for the users. See what they are saying, which pains they are experiencing and how they are dealing with them.
##### Actions steps
> Go to Quora, Facebook Groups, LinkedIn Groups.
> Search for threads about the problem that you are solving.
> Take notes about their pain and how they are solving the problem today.
> Check the Udacity Course “[How to start a startup](https://www.udacity.com/course/how-to-build-a-startup--ep245)” by Steve Blank
> Read these (funny) slides by Roy Fitzpatrick about Customer Interviews ([first](http://www.slideshare.net/robfitz/mom-test-customer-development-30m) and [second slide](http://www.slideshare.net/xamde/summary-of-the-mom-test))
> Watch these [videos](https://vimeo.com/groups/204136/videos) on Customer Development by Steve Blank
> Check [Just Wilcox’s site](http://customerdevlabs.com/): practical tips on customer interviews, MVP and customer development.
> Read the [Startup Owner’s Manual](https://www.amazon.com/gp/product/0984999302) by Steve Blank
> Read [Running Lean](https://www.amazon.com/Running-Lean-Iterate-Works-OReilly/dp/1449305172) by Ash Maurya
Find what your customers really want, and make sure your product provides the same. Be sure that you are in the direction to reach [product-market fit](https://www.linkedin.com/pulse/marc-andreessen-product-market-fit-startups-marc-andreessen).
### 2.Product Management
You can bring some excellent product management skills. Planning the right features of your product. Testing and creating mockups. Bringing feedback to your team from your customer.
Creating mockups can be helpful for creating a common understanding of the business idea. If you can help with those, your team will be thankful.
You just need low-fidelity mockups. So, do not get frustrated if you are not a Photoshop master.
##### Action Steps
> Do you want to create low-fidelity mockups? [Balsamiq](https://balsamiq.com/) or [Moqups](https://app.moqups.com/) can help you.
> Do you want to create diagrams and flowcharts? [Gliffy](https://www.gliffy.com/) and [LucidaChart](https://www.lucidchart.com/) are two tools that can do the job for you.
> Create your mockups and share them with your team.
> Explain every link and button on the mockups and what is the expected result.
You should also be able to create a roadmap with the essential features for the next few releases. This is important for giving a clear direction to your team.
This brings **huge value** to your team.
Why? Two things mainly:
**One is prioritization**: you need to prioritize the features based on the stage of your company.
You should know which are your next features and how they will affect your business.
Maybe, do you want to increase monetization? What about virality? Retention? Do you just need a fast MVP to show your customers?
At different stages of your company, you will need to build different features.
Your job is to give a clear direction to your team and what they need to build based on your customer needs.
Just to be clear: **this is not _micromanagement_**.
Your team should be able to be creative about how to bring these features to life.
Another important point of product management is that **your developer’s resources can be scarce**. They should spend time building features with the most returnable ROI. At any stage of your company.
Connect the main milestones in your roadmap with your customer needs. It will help the team to keep the big picture while building the product.

Giving feedback and test your product can be really helpful for your team. Do it daily.
You can notify your team of bugs, missing features or that do not work as you would expect.
Take screenshots, create videos describing how you expect your software to work. Send them daily to your team.
These are things that you should be able to focus on for your team. At least, at the beginning of your company.
##### Action steps
> Do you know that you can create a roadmap using tools like **[ProdPad](https://www.prodpad.com/)** or **[Craft](https://craft.io/)**?
> __Use Screenflow and describe how the software works or describe a bug to your team.
> Or, you can use RecordIT to create a GIF from a recording.__
### 3. Nurture the team
Keep your team’s good spirit up. Keep everyone motivated.
This would provide **great value** to your team.
You should talk often to your team, to your co-founders, to your advisors.
Ask questions. Share ideas and brainstorm together.
Being focused on development can make you forget about all the other important parts of the business. It is up to you to **keep your team engaged** in your big picture.
##### Action Steps
> Spend time with your team.
> Have a 1–1 chat with your team members once a month
> Bring them out for beers and keep bonding the team together.
> Bring food and coffee in the morning: it really helps the team’s morale.
### What else can I do?
These were only a small list of things where you can help. Some other areas where you can provide help are:
- Research: Stay updated on the latest trends and what the competitors are doing.
- Marketing: You need to get stuff done in marketing.
- Marketing strategy
- Mapping market segments
- Set up your CRM
- Create your sales process
- Connect with contacts in the industry.
- Can you find beta users? What about early adopters?
- Sales: Well, pretty clear!
- Administrative tasks: No job is too small for the CEO to handle at the beginning. Take the lead and let your team focusing on the product.
- Filing required paperwork
- Looking for office space
- Setting up the company mailbox
- Picking up the company mail
- Getting liability insurance, etc.
- Legal: Deal with lawyers yourself
- Copywriting: You need to contribute on how to communicate the vision of your product.
- Finance: Keeping track of your cash flow is a great challenge for entrepreneurs.
You can be a **powerful** non-tech founder if you can handle many of them at the same time.
Start from the top and keep helping your team. One task at the time!
**Are you still unsure how you can provide value?**
**Are you sure that learning to code would be the best way to spend your time as non-tech founder**?
Think about it!

#### QUESTION: How are you helping your team as the non-technical founder?
##### AUTHOR
Domenico is a software developer with a passion for design, psychology, and leadership.
If you need help with software development, you need consultancy for your technical challenges or you need a leader for your software team or just want to collaborate online, feel free to contact me!
##### FOLLOW ME
Do you know that I have a YouTube channel? [Subscribe!](http://bit.ly/YT_DOMENICOSOLAZZO)
Where can you find me?
**Youtube:** [Domenico Solazzo's Channel](http://bit.ly/YT_DOMENICOSOLAZZO)
**Instagram**: [domenicosolazzo](https://www.instagram.com/domenicosolazzo/)
**Linkedin**: [solazzo](https://www.linkedin.com/in/solazzo/)
**Medium**: [domenicosolazzo](https://medium.com/@domenicosolazzo)
**Facebook**: [domenicosolazzo](https://www.facebook.com/domenicosolazzo.labs/)
**Twitter**: [domenicosolazzo](https://twitter.com/domenicosolazzo)
**Snapchat**: [domenicosolazzo](https://twitter.com/domenicosolazzo)
**Github**: [domenicosolazzo](https://github.com/domenicosolazzo)
**Website**: [https://www.domenicosolazzo.com](https://www.domenicosolazzo.com)
**Hashnode**: [https://hashnode.com/@domenicosolazzo](https://hashnode.com/@domenicosolazzo)
| domenicosolazzo |
262,865 | Code Smell: Side Effects — Solution | Recently I wrote about a particular code smell: Side Effects. Several people called me out for not pr... | 4,528 | 2020-02-17T17:07:49 | https://medium.com/thinkster-io/code-smell-side-effects-solution-d0c6fca55758?source=friends_link&sk=221def8ed1f97dcfc119f60689b41ee6 | codesmells, webdev, productivity, javascript | Recently I wrote about a particular code smell: Side Effects. Several people called me out for not providing a suggested fix to the identified problem. If you didn't read the original article, you can find it [here](https://is-tracking-link-api-prod.appspot.com/api/v1/click/5078485544730624/5570275139911680). You will want to be familiar with what I wrote to continue on here with the solution.
In that article, we saw how we have a side effect in our loadUser function. Let's go through options for addressing this code smell.
Our first task is to look at the calling code. Ultimately this is where the code smell is coming from because it's in the calling code that we SHOULD be handling the responsibility of emptying the cart, but instead, it got put into the loadUser function.
Let's look at some example calling code.
Here our handleUserLogin method first creates a new empty user, sets it into the session object's user variable, and finally asks the session to load the User. It's inside this call that the cart is emptied. This is the crux of our issue. That operation of loading the user has some specific tasks. But it's ALSO emptying out the cart. That is perfectly appropriate in the situation of handling the user login. But if we ever needed to load user data and didn't want the side effect of emptying out the cart to happen, (maybe while refreshing data from the server) we don't have that option. A function should only do one thing. The loadUser function does two.
So let's fix that by extracting the cart.empty call out of the loadUser function. The simplest answer is just to move it up one level into our calling code.

And our loadUser is now clean of side effects:

Now, when someone else comes along and calls loadUser, they will get the result they want, and no unnecessary side effects.
Happy Coding!
Signup for my newsletter at [here.](https://is-tracking-link-api-prod.appspot.com/api/v1/click/4616255200034816/5570275139911680)
Visit Us: [thinkster.io](https://thinkster.io/) | Facebook: @gothinkster | Twitter: @GoThinkster | gothinkster |
262,867 | SVG/ReactJS math patterns | I have always been crazy about math generating drawings. So here you are. Using ReactJS to generate S... | 0 | 2020-02-17T06:07:25 | https://dev.to/netsi1964/svg-reactjs-math-patterns-81j | codepen | ---
title: SVG/ReactJS math patterns
published: true
tags: codepen
---
<p>I have always been crazy about math generating drawings. So here you are. Using ReactJS to generate SVG can be very interesting. Do share your favourite drawing by writing the Step, Subtract and Accelerate values in a comment :-)
I have saved some examples in the dropdown, try viewing them.
To inverse colors: Click/touch drawing.
UPDATED: Copy SVG to clipboard, Select line type</p>
{% codepen https://codepen.io/netsi1964/pen/qqXBmx %}
| netsi1964 |
262,908 | Golang Om Telolet Om Server | Tahun 2016 lalu ramai sekali tentang om telolet om, dan disalah satu website e-commerse di Indonesia... | 0 | 2020-02-17T07:04:53 | https://lumochift.org/posts/golang-om-telolet-om-server/ | go, header, webserver | ---
title: Golang Om Telolet Om Server
published: true
date: 2018-01-03 01:49:20 UTC
tags: golang, go, header, web-server
canonical_url: https://lumochift.org/posts/golang-om-telolet-om-server/
---
Tahun 2016 lalu ramai sekali tentang om telolet om, dan disalah satu website e-commerse di Indonesia menambahkan `x-om-telolet-om` di response header. Mungkin banyak yang tidak mengetahuinya, karena hanya tambahan response header dan tidak terlihat di tampilan website.
# Golang Om Telolet Om Server
Pertanyaannya bagaimana menambahkan respon http header menggunakan golang? Jawabnya tentu bisa dan sangat mudah sekali bahkan tidak perlu menggunakan eksternal dependensi tambahan.
Pertama perlu kita buat web server sederhana menggunakan `net/http` package seperti dibawah ini.
```
package main
import (
"fmt"
"net/http"
)
func helloWorldHandler(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello World!")
}
func main() {
http.HandleFunc("/", helloWorldHandler)
http.ListenAndServe(":8080", nil)
}
// run dengan perintah `go run main.go`
```
Kita tes menggunakan `curl` hasilnya seperti di bawah ini masih tanpa ada tambahan om telolet om di header dan _response body_ menampilkan string `Hello World!`
```
$curl -X HEAD -I localhost:8080
HTTP/1.1 200 OK
Date: Wed, 03 Jan 2018 02:13:14 GMT
Content-Length: 12
Content-Type: text/plain; charset=utf-8
$curl localhost:8080
Hello World!
```
Cara sederhana menambahkan header x-telolet hanya dengan menambahkan code `w.Header().Add("x-telolet", "OM telolet OM")` sebelum `fmt.Fprint(w, "Hello World!")` sehingga jadi seperti ini.
```
package main
import (
"fmt"
"net/http"
)
func helloWorldHandler(w http.ResponseWriter, r *http.Request) {
w.Header().Add("x-telolet", "OM telolet OM")
fmt.Fprint(w, "Hello World!")
}
func main() {
http.HandleFunc("/", helloWorldHandler)
http.ListenAndServe(":8080", nil)
}
```
Jika dicek menggunakan curl hasilnya sudah berubah.
```
$curl -X HEAD -I localhost:8080
HTTP/1.1 200 OK
X-Telolet: OM telolet OM
Date: Wed, 03 Jan 2018 02:18:58 GMT
Content-Length: 12
Content-Type: text/plain; charset=utf-8
```
## Middleware
Kemudian muncul pertanyaan bagaimana jika handlernya banyak tidak hanya `HelloWorldHandler` saja? Untuk keperluan seperti ini bisa menggunakan `middleware`. Jadi menjalankan satu atau lebih fungsi tertentu sebelum menjalankan handler utama seperti `helloWorldHandler`.
Struktur `middleware` yang akan kita buat menggunakan `func(w http.ResponseWriter, r *http.Request)` sebagai tipe data. Jadi passing fungsi kedalam fungsi dan return fungsi lagi. Lebih jelasnya kita lihat code dibawah ini.
```
package main
import (
"fmt"
"net/http"
)
// OmTeloletOm middleware
func OmTeloletOm(handler func(w http.ResponseWriter, r *http.Request)) func(w http.ResponseWriter, r *http.Request) {
return func(w http.ResponseWriter, r *http.Request) {
w.Header().Add("x-telolet", "OM telolet OM pake middleware")
handler(w, r)
}
}
func helloWorldHandler(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello World!")
}
func main() {
http.HandleFunc("/", OmTeloletOm(helloWorldHandler))
http.ListenAndServe(":8080", nil)
}
```
Jika kita cek lagi dengan curl hasilnya seperti ini.
```
$curl -X HEAD -I localhost:8080
HTTP/1.1 200 OK
X-Telolet: OM telolet OM pake middleware
Date: Wed, 03 Jan 2018 02:34:48 GMT
Content-Length: 12
Content-Type: text/plain; charset=utf-8
```
Sangat mudah ternyata menambahkan custom header menggunakan golang. Sampai jumpa lagi di tulisan selanjutnya. | lumochift |
262,943 | PHP extract PPTX or PPT powerpoint files format to TXT Example | function pptx_to_text($input_file){ $zip_handle = new ZipArchive; $output_text =... | 0 | 2020-02-17T07:55:12 | https://dev.to/kevinmel2000/php-extract-pptx-or-ppt-powerpoint-files-format-to-txt-20c1 | php, pptx, ppt | function pptx_to_text($input_file){
$zip_handle = new ZipArchive;
$output_text = "";
if(true === $zip_handle->open($input_file)){
$slide_number = 1; //loop through slide files
while(($xml_index = $zip_handle->locateName("ppt/slides /slide".$slide_number.".xml")) !== false){
$xml_datas = $zip_handle->getFromIndex($xml_index);
$xml_handle = DOMDocument::loadXML($xml_datas, LIBXML_NOENT | LIBXML_XINCLUDE | LIBXML_NOERROR | LIBXML_NOWARNING);
$output_text .= strip_tags($xml_handle->saveXML());
$slide_number++;
}
if($slide_number == 1){
$output_text .="";
}
$zip_handle->close();
}else{
$output_text .="";
}
return $output_text;
} | kevinmel2000 |
262,947 | PHP PDF convert to txt extract Content txt Example | class PDF2Text { // Some settings var $multibyte = 4; // Use setUnicode(TRUE|FALSE) var $... | 0 | 2020-02-17T08:04:25 | https://dev.to/kevinmel2000/php-pdf-convert-to-txt-extract-content-txt-7e6 | php, pdf, extract, ocr |
class PDF2Text {
// Some settings
var $multibyte = 4; // Use setUnicode(TRUE|FALSE)
var $convertquotes = ENT_QUOTES; // ENT_COMPAT (double-quotes), ENT_QUOTES (Both), ENT_NOQUOTES (None)
var $showprogress = true; // TRUE if you have problems with time-out
// Variables
var $filename = '';
var $decodedtext = '';
function setFilename($filename) {
// Reset
$this->decodedtext = '';
$this->filename = $filename;
}
function output($echo = false) {
if($echo) echo $this->decodedtext;
else return $this->decodedtext;
}
function setUnicode($input) {
// 4 for unicode. But 2 should work in most cases just fine
if($input == true) $this->multibyte = 4;
else $this->multibyte = 2;
}
function decodePDF() {
// Read the data from pdf file
$infile = @file_get_contents($this->filename, FILE_BINARY);
if (empty($infile))
return "";
// Get all text data.
$transformations = array();
$texts = array();
// Get the list of all objects.
preg_match_all("#obj[\n|\r](.*)endobj[\n|\r]#ismU", $infile . "endobj\r", $objects);
$objects = @$objects[1];
// Select objects with streams.
for ($i = 0; $i < count($objects); $i++) {
$currentObject = $objects[$i];
// Prevent time-out
@set_time_limit ();
if($this->showprogress) {
// echo ". ";
flush(); ob_flush();
}
// Check if an object includes data stream.
if (preg_match("#stream[\n|\r](.*)endstream[\n|\r]#ismU", $currentObject . "endstream\r", $stream )) {
$stream = ltrim($stream[1]);
// Check object parameters and look for text data.
$options = $this->getObjectOptions($currentObject);
if (!(empty($options["Length1"]) && empty($options["Type"]) && empty($options["Subtype"])) )
// if ( $options["Image"] && $options["Subtype"] )
// if (!(empty($options["Length1"]) && empty($options["Subtype"])) )
continue;
// Hack, length doesnt always seem to be correct
unset($options["Length"]);
// So, we have text data. Decode it.
$data = $this->getDecodedStream($stream, $options);
if (strlen($data)) {
if (preg_match_all("#BT[\n|\r](.*)ET[\n|\r]#ismU", $data . "ET\r", $textContainers)) {
$textContainers = @$textContainers[1];
$this->getDirtyTexts($texts, $textContainers);
} else
$this->getCharTransformations($transformations, $data);
}
}
}
// Analyze text blocks taking into account character transformations and return results.
$this->decodedtext = $this->getTextUsingTransformations($texts, $transformations);
}
function decodeAsciiHex($input) {
$output = "";
$isOdd = true;
$isComment = false;
for($i = 0, $codeHigh = -1; $i < strlen($input) && $input[$i] != '>'; $i++) {
$c = $input[$i];
if($isComment) {
if ($c == '\r' || $c == '\n')
$isComment = false;
continue;
}
switch($c) {
case '\0': case '\t': case '\r': case '\f': case '\n': case ' ': break;
case '%':
$isComment = true;
break;
default:
$code = hexdec($c);
if($code === 0 && $c != '0')
return "";
if($isOdd)
$codeHigh = $code;
else
$output .= chr($codeHigh * 16 + $code);
$isOdd = !$isOdd;
break;
}
}
if($input[$i] != '>')
return "";
if($isOdd)
$output .= chr($codeHigh * 16);
return $output;
}
function decodeAscii85($input) {
$output = "";
$isComment = false;
$ords = array();
for($i = 0, $state = 0; $i < strlen($input) && $input[$i] != '~'; $i++) {
$c = $input[$i];
if($isComment) {
if ($c == '\r' || $c == '\n')
$isComment = false;
continue;
}
if ($c == '\0' || $c == '\t' || $c == '\r' || $c == '\f' || $c == '\n' || $c == ' ')
continue;
if ($c == '%') {
$isComment = true;
continue;
}
if ($c == 'z' && $state === 0) {
$output .= str_repeat(chr(0), 4);
continue;
}
if ($c < '!' || $c > 'u')
return "";
$code = ord($input[$i]) & 0xff;
$ords[$state++] = $code - ord('!');
if ($state == 5) {
$state = 0;
for ($sum = 0, $j = 0; $j < 5; $j++)
$sum = $sum * 85 + $ords[$j];
for ($j = 3; $j >= 0; $j--)
$output .= chr($sum >> ($j * 8));
}
}
if ($state === 1)
return "";
elseif ($state > 1) {
for ($i = 0, $sum = 0; $i < $state; $i++)
$sum += ($ords[$i] + ($i == $state - 1)) * pow(85, 4 - $i);
for ($i = 0; $i < $state - 1; $i++) {
try {
if(false == ($o = chr($sum >> ((3 - $i) * 8)))) {
throw new Exception('Error');
}
$output .= $o;
} catch (Exception $e) { /*Dont do anything*/ }
}
}
return $output;
}
function decodeFlate($data) {
return @gzuncompress($data);
}
function getObjectOptions($object) {
$options = array();
if (preg_match("#<<(.*)>>#ismU", $object, $options)) {
$options = explode("/", $options[1]);
@array_shift($options);
$o = array();
for ($j = 0; $j < @count($options); $j++) {
$options[$j] = preg_replace("#\s+#", " ", trim($options[$j]));
if (strpos($options[$j], " ") !== false) {
$parts = explode(" ", $options[$j]);
$o[$parts[0]] = $parts[1];
} else
$o[$options[$j]] = true;
}
$options = $o;
unset($o);
}
return $options;
}
function getDecodedStream($stream, $options) {
$data = "";
if (empty($options["Filter"]))
$data = $stream;
else {
$length = !empty($options["Length"]) ? $options["Length"] : strlen($stream);
$_stream = substr($stream, 0, $length);
foreach ($options as $key => $value) {
if ($key == "ASCIIHexDecode")
$_stream = $this->decodeAsciiHex($_stream);
elseif ($key == "ASCII85Decode")
$_stream = $this->decodeAscii85($_stream);
elseif ($key == "FlateDecode")
$_stream = $this->decodeFlate($_stream);
elseif ($key == "Crypt") { // TO DO
}
}
$data = $_stream;
}
return $data;
}
function getDirtyTexts(&$texts, $textContainers) {
for ($j = 0; $j < count($textContainers); $j++) {
if (preg_match_all("#\[(.*)\]\s*TJ[\n|\r]#ismU", $textContainers[$j], $parts))
$texts = array_merge($texts, array(@implode('', $parts[1])));
elseif (preg_match_all("#T[d|w|m|f]\s*(\(.*\))\s*Tj[\n|\r]#ismU", $textContainers[$j], $parts))
$texts = array_merge($texts, array(@implode('', $parts[1])));
elseif (preg_match_all("#T[d|w|m|f]\s*(\[.*\])\s*Tj[\n|\r]#ismU", $textContainers[$j], $parts))
$texts = array_merge($texts, array(@implode('', $parts[1])));
}
}
function getCharTransformations(&$transformations, $stream) {
preg_match_all("#([0-9]+)\s+beginbfchar(.*)endbfchar#ismU", $stream, $chars, PREG_SET_ORDER);
preg_match_all("#([0-9]+)\s+beginbfrange(.*)endbfrange#ismU", $stream, $ranges, PREG_SET_ORDER);
for ($j = 0; $j < count($chars); $j++) {
$count = $chars[$j][1];
$current = explode("\n", trim($chars[$j][2]));
for ($k = 0; $k < $count && $k < count($current); $k++) {
if (preg_match("#<([0-9a-f]{2,4})>\s+<([0-9a-f]{4,512})>#is", trim($current[$k]), $map))
$transformations[str_pad($map[1], 4, "0")] = $map[2];
}
}
for ($j = 0; $j < count($ranges); $j++) {
$count = $ranges[$j][1];
$current = explode("\n", trim($ranges[$j][2]));
for ($k = 0; $k < $count && $k < count($current); $k++) {
if (preg_match("#<([0-9a-f]{4})>\s+<([0-9a-f]{4})>\s+<([0-9a-f]{4})>#is", trim($current[$k]), $map)) {
$from = hexdec($map[1]);
$to = hexdec($map[2]);
$_from = hexdec($map[3]);
for ($m = $from, $n = 0; $m <= $to; $m++, $n++)
$transformations[sprintf("%04X", $m)] = sprintf("%04X", $_from + $n);
} elseif (preg_match("#<([0-9a-f]{4})>\s+<([0-9a-f]{4})>\s+\[(.*)\]#ismU", trim($current[$k]), $map)) {
$from = hexdec($map[1]);
$to = hexdec($map[2]);
$parts = preg_split("#\s+#", trim($map[3]));
for ($m = $from, $n = 0; $m <= $to && $n < count($parts); $m++, $n++)
$transformations[sprintf("%04X", $m)] = sprintf("%04X", hexdec($parts[$n]));
}
}
}
}
function getTextUsingTransformations($texts, $transformations) {
$document = "";
for ($i = 0; $i < count($texts); $i++) {
$isHex = false;
$isPlain = false;
$hex = "";
$plain = "";
for ($j = 0; $j < strlen($texts[$i]); $j++) {
$c = $texts[$i][$j];
switch($c) {
case "<":
$hex = "";
$isHex = true;
$isPlain = false;
break;
case ">":
$hexs = str_split($hex, $this->multibyte); // 2 or 4 (UTF8 or ISO)
for ($k = 0; $k < count($hexs); $k++) {
$chex = str_pad($hexs[$k], 4, "0"); // Add tailing zero
if (isset($transformations[$chex]))
$chex = $transformations[$chex];
$document .= html_entity_decode("&#x".$chex.";");
}
$isHex = false;
break;
case "(":
$plain = "";
$isPlain = true;
$isHex = false;
break;
case ")":
$document .= $plain;
$isPlain = false;
break;
case "\\":
$c2 = $texts[$i][$j + 1];
if (in_array($c2, array("\\", "(", ")"))) $plain .= $c2;
elseif ($c2 == "n") $plain .= '\n';
elseif ($c2 == "r") $plain .= '\r';
elseif ($c2 == "t") $plain .= '\t';
elseif ($c2 == "b") $plain .= '\b';
elseif ($c2 == "f") $plain .= '\f';
elseif ($c2 >= '0' && $c2 <= '9') {
$oct = preg_replace("#[^0-9]#", "", substr($texts[$i], $j + 1, 3));
$j += strlen($oct) - 1;
$plain .= html_entity_decode("&#".octdec($oct).";", $this->convertquotes);
}
$j++;
break;
default:
if ($isHex)
$hex .= $c;
elseif ($isPlain)
$plain .= $c;
break;
}
}
$document .= "\n";
}
return $document;
}
}
example call :
$a = new PDF2Text();
$a->setFilename($input_file);
$a->decodePDF();
$txt = $a->output(); | kevinmel2000 |
263,089 | Reactive architecture benefits & use cases | While the term reactive architecture has been around for a long time, only relatively recently has it... | 0 | 2020-03-10T10:13:13 | https://apiumhub.com/tech-blog-barcelona/reactive-architecture-benefits-use-cases/ | softwarearchitectur, softwaredeveloper | ---
title: Reactive architecture benefits & use cases
published: true
date: 2020-02-17 08:20:58 UTC
tags: Software architectur,Software Architectur,Software developer
canonical_url: https://apiumhub.com/tech-blog-barcelona/reactive-architecture-benefits-use-cases/
---
While the term reactive architecture has been around for a long time, only relatively recently has it been recognized by the industry and hit mainstream adoption. The goal of this article is to analyze what reactive really is and why to adopt it.
Its core meaning has been formalized with the creation of the [Reactive Manifesto2](https://www.reactivemanifesto.org/) in 2013, when Jonas Bonér collected some of the brightest minds in the distributed and high-performance computing industry – Dave Farley, Roland Kuhn, and Martin Thompson to collaborate and solidify what the core principles were for building reactive applications and systems. The goal was to clarify some of the confusion around reactive and build a strong basis for what would become a viable development style. Later on in the article we will look at the manifesto more in detailes, but now, let’s see what is reactive?
## **What does reactive really mean? **
Reactive programming is an asynchronous programming paradigm, concerned with streams of information and the propagation of changes. This differs from imperative programming, where that paradigm uses statements to change a program’s state.
Reactive Architecture is nothing more than the combination of reactive programming and software architectures. Also known as reactive systems, the goal is to make the system responsive, resilient, elastic, and message driven.
A Reactive system is an architectural style that allows multiple individual applications to coalesce as a single unit, reacting to its surroundings while aware of each other, and enable automatic scale up and down, load balancing, responsiveness under failure, and more.
Reactive Architecture can elastically scale in the face of varying incoming traffic. Scaling usually serves one of two purposes: either we need to scale out (by adding more machines) and up (by adding beefier machines), or we need to scale down, reducing the number of resources occupied by our application. An interesting scaling pattern popularized by the likes of Netflix is predictive scaling, in which we know when spikes are going to hit so we can proactively provision servers for that period, and once traffic starts going down again, decrease the cluster size incrementally.
As for the reactive libraries, they often resort to using some kind of event loop, or shared dispatcher infrastructure based on a thread pool. Thanks to sharing the expensive resources (i.e., threads) among cheaper constructs, be it simple tasks, actors, or a sequence of callbacks to be invoked on the shared dispatcher, these techniques enable us to scale a single application across multiple cores. This multiplexing techniques allow such libraries to handle millions of entities on a single box. Thanks to this, we can afford to have one actor per user in our system, which makes the modelling of the domain using actors also more natural.
## **Reactive architecture benefits**
- Be responsive to interactions with its users
- Handle failure and remain available during outages
- Strive under varying load conditions
- Be able to send, receive, and route messages in varying network conditions
Systems built as Reactive Systems are more flexible, loosely-coupled and scalable. This makes them easier to develop and amenable to change. They are significantly more tolerant of failure and when failure does occur they meet it with elegance rather than disaster. Reactive Systems are highly responsive, giving users effective interactive feedback.
_“Reactive systems are the most productive systems architectures for production deployment today,” said Bonér. “They allow for systems that cope well under failure, varying load and change over time, all while offering a low cost of ownership.”_
## **Reactive manifesto **
Authors of Reactive Manifesto believe that Reactive Systems are:
**1. Responsive**
The system responds in a timely manner if at all possible. Problems may be detected quickly and dealt with effectively. Responsive systems focus on providing rapid and consistent response times, establishing reliable upper bounds so they deliver a consistent quality of service. This consistent behaviour in turn simplifies error handling, builds end user confidence, and encourages further interaction.
**2. Resilient**
The system stays responsive in the face of failure. This applies not only to highly-available, mission-critical systems — any system that is not resilient will be unresponsive after a failure. Resilience is achieved by replication, containment, isolation and delegation. Failures are contained within each component, isolating components from each other and thereby ensuring that parts of the system can fail and recover without compromising the system as a whole. Recovery of each component is delegated to another (external) component and high-availability is ensured by replication where necessary. The client of a component is not burdened with handling its failures.
**3. Elastic**
The system stays responsive under varying workload. Reactive Systems can react to changes in the input rate by increasing or decreasing the resources allocated to service these inputs. This implies designs that have no contention points or central bottlenecks, resulting in the ability to shard or replicate components and distribute inputs among them. Reactive Systems support predictive, as well as Reactive, scaling algorithms by providing relevant live performance measures. They achieve elasticity in a cost-effective way on commodity hardware and software platforms.
**4. Message Driven**
Reactive Systems rely on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation and location transparency. This boundary also provides the means to delegate failures as messages. Employing explicit message-passing enables load management, elasticity, and flow control by shaping and monitoring the message queues in the system and applying back-pressure when necessary. Location transparent messaging as a means of communication makes it possible for the management of failure to work with the same constructs and semantics across a cluster or within a single host. Non-blocking communication allows recipients to only consume resources while active, leading to less system overhead.
## **Reactive Architecture: use cases **
Hundreds of enterprises in every major market around the world have embraced the principles of Reactive to build and deploy production systems that deliver industry-disruptive benefits for competitive business advantage. Let me give you several well-known examples:
1. Capital One redesigned its auto loan application around Reactive principles to simplify online car shopping and financing. Customers can browse more than four million cars from over 12,000 dealers and pre-qualify for financing in seconds, without impacting credit scores.
2. LinkedIn turned to Reactive principles to build real-time presence indicators (online indicators) for the half billion users on its social network.
3. Verizon Wireless, operators of the largest 4G LTE network in the United States, slashed response times in half using Reactive principles in the upgrade of its e-commerce website that supports 146 million subscribers handling 2.5 billion transactions a year.
4. Walmart Canada rebuilt its entire Web application and mobile stack as a Reactive system and saw a 20 percent increase in conversion to sales from web traffic and a 98 percent increase in mobile orders while cutting page load times by more than a third.
The technology industry has rallied around Reactive systems to help solve some of its customers’ most complex business challenges. As today’s modern systems scale by orders of magnitude, architectures have to deal with new ways to share data among services without crashing the system.
If you are interested in reactive architecture, I highly recommend you to read these books:
- [Front-End Reactive Architectures](https://www.amazon.es/Front-End-Reactive-Architectures-JavaScript-Frameworks-ebook/dp/B077GCMHNS) by Luca Mezzalira
- [Reactive Microservices Architecture](https://www.oreilly.com/library/view/reactive-microservices-architecture/9781491975664/) by Jonas Bonér
- [Reactive Systems Architecture](https://www.amazon.co.uk/Reactive-Systems-Architecture-Jan-Machacek/dp/1491980710) by Jan Machacek, Martin Zapletal, Michal Janousek , Anirvan Chakraborty
Btw, one of the Co-authors of Reactive Manifesto, Dave Farley, gave several talks on this topic in several software architecture events like [Global Software Architecture Summit](https://gsas.io/), here you have them:
- [GSAS: Reactive Architecture Patterns Debate](https://www.youtube.com/watch?v=j_-cnb6Esuk&t=1s)
- [What is a Reactive Application? • Panel Debate](https://www.youtube.com/watch?v=OPhQvG1-32k)
- [Reactive Systems: 21st Architecture for 21st Century Systems by Dave Farley](https://www.youtube.com/watch?v=RuHkNGrwD5o&list=ULVM1lu_ibxNg&index=564)
I would like to end this article with Dave’s quote which summarizes the article very well:
_“We need to think about new ways of architecting our systems. Old ways are built on the compromises that were imposed on us by certain performance profiles in the hardware we were all used to. And those assumptions no longer hold.” – Dave Farley_
The post [Reactive architecture benefits & use cases](https://apiumhub.com/tech-blog-barcelona/reactive-architecture-benefits-use-cases/) appeared first on [Apiumhub](https://apiumhub.com). | apium_hub |
262,961 | Working with Expression Trees in C# | Expression trees is an obscure, although very interesting feature in .NET. Most people probably think... | 0 | 2020-02-17T08:42:03 | https://tyrrrz.me/blog/expression-trees | dotnet, functional, computerscience, oop | Expression trees is an obscure, although very interesting feature in .NET. Most people probably think of it as something synonymous with object-relational mapping frameworks, but despite being its most common use case, it's not the only one. There are a lot of creative things you can do with expression trees, including code generation, transpilation, metaprogramming, and more.
In this article I will give an overview of what expression trees are and how to work with them, as well as show some interesting scenarios where I've seen them used to great effect.
## What is an expression tree?
When it comes to programming languages, an expression describes some operation on data that produces a certain result. It's one of the foundational constructs of any language.
As an example of a very simple expression, consider `2 + 3`. It consists of a constant, a plus operator, and another constant. We can evaluate this expression and get the result, which is `5`.
Of course, expressions vary in complexity and can contain different combinations of constants, variables, operators and function calls. For example, the following piece of code is also an expression:
```csharp
!string.IsNullOrWhiteSpace(personName)
? "Greetings, " + personName
: null;
```
Looking at the above expression, we can also consider two of its aspects: **what it does** and **how it does it**.
When it comes to the former, the answer is pretty simple -- it generates a greeting based on the person's name, or produces a `null`. If this expression was returned by a function, that would be the extent of information we could derive from its signature:
```csharp
string? GetGreeting(string personName) { /* ... */ }
```
As for how it does it, however, the answer is a bit more detailed. This expression consists of a ternary conditional operator, whose condition is evaluated by negating the result of a call to method `string.IsNullOrWhiteSpace` with parameter `personName`, whose positive clause is made up of a "plus" binary operator that works with a constant string expression `"Greetings, "` and the parameter expression, and whose negative clause consist of a sole `null` expression.
The description above may seem like a mouthful, but it outlines the exact syntactic structure of the expression. It is by this higher-order representation that we're able to tell how exactly it's evaluated.
To make things more clear, we can also illustrate this representation with the following diagram:
```csharp
{ Ternary conditional }
| | |
+-+ | +-----+
| | |
(true) (false) (condition)
| | |
| | +---- { (!) }
| +------+ |
{ (+) } | |
| | { null } { Method call }
| | | |
| +---------+ | |
| | | +------- { string.IsNullOrWhiteSpace }
| | |
| { personName } +-------- { personName }
|
+---- { "Greetings, " }
```
As you can see, at the highest level we have the ternary conditional operator which is itself made up of other expressions, which are made up of other expressions, and so on. The relationship between individual components is hierarchical, resembling an upside-down tree.
Although it's inherently obvious to us as humans, in order to interpret this representation programmatically, we need a special data structure. This data structure is what we call an _expression tree_.
## Constructing expression trees manually
In C#, expression trees can be used in either of two directions: we can create them directly via an API and then compile them into runtime instructions, or we can disassemble them from supplied lambda expressions. In this part of the article we will focus on the first one.
The framework offers us with an API to construct expression trees through the [`Expression`](https://docs.microsoft.com/en-us/dotnet/api/system.linq.expressions.expression) class located in the `System.Linq.Expressions` namespace. It exposes various factory methods that can be used to produce expressions of different types.
Some of these methods are:
- `Expression.Constant(...)` -- creates an expression that represents a value.
- `Expression.Variable(...)` -- creates an expression that represents a variable.
- `Expression.New(...)` -- creates an expression that represents an initialization of a new instance.
- `Expression.Assign(...)` -- creates an expression that represents an assignment operation.
- `Expression.Equal(...)` -- creates an expression that represents an equality comparison.
- `Expression.Call(...)` -- creates an expression that represents a specific method call.
- `Expression.Condition(...)` -- creates an expression that represents branching logic.
- `Expression.Loop(...)` -- creates an expression that represents repeating logic.
As a simple exercise, let's recreate the expression we've looked into in the previous part of the article:
```csharp
public Expression ConstructGreetingExpression()
{
var personNameParameter = Expression.Parameter(typeof(string), "personName");
// Condition
var isNullOrWhiteSpaceMethod = typeof(string)
.GetMethod(nameof(string.IsNullOrWhiteSpace));
var condition = Expression.Not(
Expression.Call(isNullOrWhiteSpaceMethod, personNameParameter));
// True clause
var trueClause = Expression.Add(
Expression.Constant("Greetings, "),
personNameParameter);
// False clause
var falseClause = Expression.Constant(null, typeof(string));
// Ternary conditional
return Expression.Condition(condition, trueClause, falseClause);
}
```
Let's digest what just happened here.
First of all, we're calling `Expression.Parameter` in order to construct a parameter expression. We will be able to use it to resolve the value of a particular parameter.
Following that, we are relying on reflection to resolve a reference to the `string.IsNullOrWhiteSpace` method. We use `Expression.Call` to create a method invocation expression that represents a call to `string.IsNullOrWhiteSpace` with the parameter resolved by the expression we created earlier. To perform a logical "not" operation on the result, we're calling `Expression.Not` to wrap the method call. Incidentally, this expression constitutes the condition part of the ternary expression we're building.
To compose the positive clause, we're constructing an "add" operation with the help of `Expression.Add`. As the operands, we're providing a constant expression for string `"Greetings, "` and the parameter expression from earlier.
Then, for the negative clause, we're using `Expression.Constant` to create a `null` constant expression. To ensure that the `null` value is typed correctly, we explicitly specify the type as the second parameter.
Finally, we're combining all of the above parts together to create our ternary conditional operator. If you take a moment to trace what goes into `Expression.Condition`, you will realize that we have essentially replicated the tree diagram we've seen earlier.
However, this expression isn't particularly useful on its own. Since we've created it ourselves, we're not really interested in its structure -- we want to be able to evaluate it instead.
In order to do that, we have to create an entry point by wrapping everything in a lambda expression. To turn it into an actual lambda, we can call `Compile` which will produce a delegate that we can invoke.
Let's update the method accordingly:
```csharp
public Func<string, string?> ConstructGreetingFunction()
{
var personNameParameter = Expression.Parameter(typeof(string), "personName");
// Condition
var isNullOrWhiteSpaceMethod = typeof(string)
.GetMethod(nameof(string.IsNullOrWhiteSpace));
var condition = Expression.Not(
Expression.Call(isNullOrWhiteSpaceMethod, personNameParameter));
// True clause
var trueClause = Expression.Add(
Expression.Constant("Greetings, "),
personNameParameter);
// False clause
var falseClause = Expression.Constant(null, typeof(string));
var conditional = Expression.Condition(condition, trueClause, falseClause);
var lambda = Expression.Lambda<Func<string, string?>>(conditional, personNameParameter);
return lambda.Compile();
}
```
As you can see, we were able to construct a lambda expression by specifying its body (which is our conditional expression) and the parameter that we defined earlier. We also indicated the exact type of the function this expression represents by supplying a generic argument.
By compiling the expression tree, we can convert the code it represents into runtime instructions. The delegate returned by this method can be used to evaluate the expression:
```csharp
var getGreeting = ConstructGreetingFunction();
var greetingForJohn = getGreeting("John");
```
However, if we try to run this, we will get an error:
```ini
The binary operator Add is not defined for the types 'System.String' and 'System.String'.
```
Hmm, that's weird. I'm pretty sure the `+` operator is defined for strings, otherwise how else would I be able to write `"foo" + "bar"`?
Well, actually the error message is correct, this operator is indeed not defined for `System.String`. Instead what happens is that the C# compiler automatically converts expressions like `"foo" + "bar"` into `string.Concat("foo", "bar")`. In cases with more than two strings this provides better performance because it avoids unnecessary allocations.
When dealing with expression trees, we're essentially writing the "final" version of the code. So instead of `Expression.Add` we need to call `string.Concat` directly.
Let's change our code to accommodate for that:
```csharp
public Func<string, string?> ConstructGreetingFunction()
{
var personNameParameter = Expression.Parameter(typeof(string), "personName");
// Condition
var isNullOrWhiteSpaceMethod = typeof(string)
.GetMethod(nameof(string.IsNullOrWhiteSpace));
var condition = Expression.Not(
Expression.Call(isNullOrWhiteSpaceMethod, personNameParameter));
// True clause
var concatMethod = typeof(string)
.GetMethod(nameof(string.Concat), new[] {typeof(string), typeof(string)});
var trueClause = Expression.Call(
concatMethod,
Expression.Constant("Greetings, "),
personNameParameter);
// False clause
var falseClause = Expression.Constant(null, typeof(string));
var conditional = Expression.Condition(condition, trueClause, falseClause);
var lambda = Expression.Lambda<Func<string, string?>>(conditional, personNameParameter);
return lambda.Compile();
}
```
Now, if we try to compile and run our function, it behaves as expected:
```csharp
var getGreetings = ConstructGreetingFunction();
var greetingsForJohn = getGreetings("John"); // "Greetings, John"
var greetingsForNobody = getGreetings(" "); // <null>
```
I think this is pretty awesome. We built an expression tree, compiled it in-memory, and now we can evaluate it using a delegate.
## Constructing statements
So far we've only talked about expressions, but what about statements? Can we dynamically compile code that contains multiple statements or are we limited to expressions?
The main difference between expressions and statements is that statements don't produce results. That means we can't really string them into a single expression.
For example, consider the following two statements:
```csharp
// Two statements:
Console.Write("Hello ");
Console.WriteLine("world!");
```
There's no way for us to compose these into one expression, like we could have with `StringBuilder`, for instance:
```csharp
// Single expression:
new StringBuilder().Append("Hello ").AppendLine("world!");
```
Fortunately, the expression tree model allows us to represent statements as well. To do that, we need to put them inside a `Block` expression.
Here is how it works:
```csharp
public Expression CreateStatementBlock()
{
var consoleWriteMethod = typeof(Console)
.GetMethod(nameof(Console.Write), new[] {typeof(string)});
var consoleWriteLineMethod = typeof(Console)
.GetMethod(nameof(Console.WriteLine), new[] {typeof(string)});
return Expression.Block(
Expression.Call(consoleWriteMethod, Expression.Constant("Hello ")),
Expression.Call(consoleWriteLineMethod, Expression.Constant("world!")));
}
```
We can then similarly compile a delegate and invoke it:
```csharp
var block = CreateStatementBlock();
var lambda = Expression.Lambda<Action>(block).Compile();
lambda();
// Hello world!
```
Now, if we inspect the `block.Type` property, which denotes the result type of the expression, we will see that it's `System.Void`. Essentially the lambda expression we've built is just this:
```csharp
var lambda = () =>
{
Console.Write("Hello ");
Console.WriteLine("world!");
};
```
For more complex use cases, we may declare and reference variables from inside the block expression:
```csharp
public Expression CreateStatementBlock()
{
var consoleWriteMethod = typeof(Console)
.GetMethod(nameof(Console.Write), new[] {typeof(string)});
var consoleWriteLineMethod = typeof(Console)
.GetMethod(nameof(Console.WriteLine), new[] {typeof(string)});
var variableA = Expression.Variable(typeof(string), "a");
var variableB = Expression.Variable(typeof(string), "b");
return Expression.Block(
// Declare variables in scope
new[] {variableA, variableB},
// Assign values to variables
Expression.Assign(variableA, Expression.Constant("Foo ")),
Expression.Assign(variableB, Expression.Constant("bar")),
// Call methods
Expression.Call(consoleWriteMethod, variableA),
Expression.Call(consoleWriteLineMethod, variableB));
}
```
If we compile and evaluate this expression, we will see the following output in the console:
```csharp
var block = CreateStatementBlock();
var lambda = Expression.Lambda<Action>(block).Compile();
lambda();
// Foo bar
```
So despite the fact that we are building _expression_ trees, we are not actually limited only to expressions. We can just as easily model blocks of statements too.
## Converting expressions to readable code
We know how to compile our expressions into runtime instructions, but what about readable C# code? It could be useful if we wanted to display it or just to have some visual aid while testing.
The good news is that all types that derive from `Expression` override the `ToString` method with a more specific implementation. That means we can do the following:
```csharp
var s1 = Expression.Constant(42).ToString(); // 42
var s2 = Expression.Multiply(
Expression.Constant(5),
Expression.Constant(11)).ToString(); // (5 * 11)
```
The bad news, however, is that it only works nicely with simple expressions like the ones above. For example, if we try to call `ToString` on the ternary expression we compiled earlier, we will get:
```csharp
var s = lambda.ToString();
// personName => IIF(Not(IsNullOrWhiteSpace(personName)), Concat("Greetings, ", personName), null)
```
While fairly descriptive, this is probably not the text representation one would hope to see.
Luckily, we can use the [ReadableExpressions](https://github.com/agileobjects/ReadableExpressions) NuGet package to get us what we want. By installing it, we should be able to call `ToReadableString` to get the actual C# code that represents the expression:
```csharp
var code = lambda.ToReadableString();
// personName => !string.IsNullOrWhiteSpace(personName) ? "Greetings, " + personName : null
```
As you can see, it even replaced the `string.Concat` call with the plus operator to make it closer to code that a developer would typically write.
Additionally, if you are using Visual Studio and want to inspect expressions by visualizing them as code, you can install [this extension](https://marketplace.visualstudio.com/items?itemName=vs-publisher-1232914.ReadableExpressionsVisualizers). It's very helpful when debugging large or really complex expressions.
## Optimizing reflection calls
When it comes to compiled expressions, one of the most common usage scenarios is reflection-heavy code. As we all know, reflection can be quite slow because of late binding, however by compiling the code at runtime we can achieve better performance.
Let's imagine we have a class which has a private method that we want to invoke from the outside:
```csharp
public class Command
{
private int Execute() => 42;
}
```
With the help of reflection, this is quite simple:
```csharp
public static int CallExecute(Command command) =>
(int) typeof(Command)
.GetMethod("Execute", BindingFlags.NonPublic | BindingFlags.Instance)
.Invoke(command, null);
```
Of course, invoking the method like that can cause significant performance issues if we put it in a tight loop. Let's see if we can optimize it a bit.
Before we jump into expressions, we can first optimize the above code by separating the part that resolves `MethodInfo` from the part that invokes it. If we're going to call this method more than once, we don't have to use `GetMethod` every time:
```csharp
public static class ReflectionCached
{
private static MethodInfo ExecuteMethod { get; } = typeof(Command)
.GetMethod("Execute", BindingFlags.NonPublic | BindingFlags.Instance);
public static int CallExecute(Command command) => (int) ExecuteMethod.Invoke(command, null);
}
```
That should make things better, but we can push it even further by using `Delegate.CreateDelegate`. This way we can create a re-usable delegate and avoid the overhead that comes with `MethodInfo.Invoke`. Let's do that as well:
```csharp
public static class ReflectionDelegate
{
private static MethodInfo ExecuteMethod { get; } = typeof(Command)
.GetMethod("Execute", BindingFlags.NonPublic | BindingFlags.Instance);
private static Func<Command, int> Impl { get; } =
(Func<Command, int>) Delegate.CreateDelegate(typeof(Func<Command, int>), ExecuteMethod);
public static int CallExecute(Command command) => Impl(command);
}
```
Alright, that's probably as good as it can get with reflection. Now let's try to do the same using compiled expressions:
```csharp
public static class ExpressionTrees
{
private static MethodInfo ExecuteMethod { get; } = typeof(Command)
.GetMethod("Execute", BindingFlags.NonPublic | BindingFlags.Instance);
private static Func<Command, int> Impl { get; }
static ExpressionTrees()
{
var instance = Expression.Parameter(typeof(Command));
var call = Expression.Call(instance, ExecuteMethod);
Impl = Expression.Lambda<Func<Command, int>>(call, instance).Compile();
}
public static int CallExecute(Command command) => Impl(command);
}
```
In all of these approaches we're relying on static constructors to initialize the properties in a lazy and thread-safe manner. This ensures that all of the heavy-lifting happens only once, the first time the members of these classes are accessed.
Now let's pit all of these techniques against each other and compare their performance using [Benchmark.NET](https://github.com/dotnet/BenchmarkDotNet):
```csharp
public class Benchmarks
{
[Benchmark(Description = "Reflection", Baseline = true)]
public int Reflection() => (int) typeof(Command)
.GetMethod("Execute", BindingFlags.NonPublic | BindingFlags.Instance)
.Invoke(new Command(), null);
[Benchmark(Description = "Reflection (cached)")]
public int Cached() => ReflectionCached.CallExecute(new Command());
[Benchmark(Description = "Reflection (delegate)")]
public int Delegate() => ReflectionDelegate.CallExecute(new Command());
[Benchmark(Description = "Expressions")]
public int Expressions() => ExpressionTrees.CallExecute(new Command());
public static void Main() => BenchmarkRunner.Run<Benchmarks>();
}
```
```r
| Method | Mean | Error | StdDev | Ratio |
|---------------------- |-----------:|----------:|----------:|------:|
| Reflection | 192.975 ns | 1.6802 ns | 1.4895 ns | 1.00 |
| Reflection (cached) | 123.762 ns | 1.1063 ns | 1.0349 ns | 0.64 |
| Reflection (delegate) | 6.419 ns | 0.0646 ns | 0.0605 ns | 0.03 |
| Expressions | 5.383 ns | 0.0433 ns | 0.0383 ns | 0.03 |
```
As you can see, compiled expressions outperform reflection across the board, even though the approach with `CreateDelegate` comes really close. Note however that while the execution times are similar, `CreateDelegate` is more limited than compiled expressions -- for example, it cannot be used to call constructor methods.
This approach of using expression trees for dynamic method invocation is commonplace in various frameworks and libraries. For example:
- [AutoMapper](https://github.com/AutoMapper/AutoMapper) uses them to speed up object conversion
- [NServiceBus](https://github.com/Particular/NServiceBus) uses them to speed up its behavior pipeline
- [Marten](https://github.com/JasperFx/marten) uses them to speed up entity mapping
## Implementing generic operators
Something else we can do with compiled expressions is implement generic operators. These can be pretty useful if you're writing a lot of mathematical code and want to avoid duplication.
As you know, operators in C# are not generic. This means that every numeric type defines its own version of the multiply and divide operators, among other things. As a result, code that uses these operators also can't be generic either.
Imagine that you had a function that calculates three-fourths of a number:
```csharp
public int ThreeFourths(int x) => 3 * x / 4;
// ThreeFourths(18) -> 13
```
Defined as it is, it only works when used with numbers of type `int`. If we wanted to extend it to support other types, we'd have to add some overloads:
```csharp
public int ThreeFourths(int x) => 3 * x / 4;
public long ThreeFourths(long x) => 3 * x / 4;
public float ThreeFourths(float x) => 3 * x / 4;
public double ThreeFourths(double x) => 3 * x / 4;
public decimal ThreeFourths(decimal x) => 3 * x / 4;
```
This is suboptimal. We are introducing a lot of code duplication which only gets worse as this method is referenced from other places.
It would've been better if we could just do something like this instead:
```csharp
public T ThreeFourths<T>(T x) => 3 * x / 4;
```
But unfortunately that doesn't compile, seeing as the `*` and `/` operators are not available on every type that can be specified in place of `T`. Sadly, there's also no constraint we could use to limit the generic argument to numeric types.
However, by generating code dynamically with expression trees we can work around this problem:
```csharp
public T ThreeFourths<T>(T x)
{
var param = Expression.Parameter(typeof(T));
// Cast the numbers '3' and '4' to our type
var three = Expression.Convert(Expression.Constant(3), typeof(T));
var four = Expression.Convert(Expression.Constant(4), typeof(T));
// Perform the calculation
var operation = Expression.Divide(Expression.Multiply(param, three), four);
var lambda = Expression.Lambda<Func<T, T>>(operation, param);
var func = lambda.Compile();
return func(x);
}
// ThreeFourths(18) -> 13
// ThreeFourths(6.66) -> 4.995
// ThreeFourths(100M) -> 75
```
That works well and we can reuse this method for numbers of any type. Although, seeing as our generic operation doesn't have type safety, you may be wondering how is this approach any different from just using `dynamic`?
Surely, we could just write our code like this and avoid all the trouble:
```csharp
public dynamic ThreeFourths(dynamic x) => 3 * x / 4;
```
Indeed, functionally these two approaches are the same. However, the main difference and the advantage of expression trees is the fact they are compiled, while `dynamic` isn't. Compiled code has the potential to perform much faster.
That said, in the example above we're not benefitting from this advantage at all because we're recompiling our function every time anyway. Let's try to change our code so that it happens only once.
In order to achieve that, we can apply the same pattern as the last time. Let's put the delegate inside a generic static class and have it initialized from the static constructor. Here's how that would look:
```csharp
public static class ThreeFourths
{
private static class Impl<T>
{
public static Func<T, T> Of { get; }
static Impl()
{
var param = Expression.Parameter(typeof(T));
var three = Expression.Convert(Expression.Constant(3), typeof(T));
var four = Expression.Convert(Expression.Constant(4), typeof(T));
var operation = Expression.Divide(Expression.Multiply(param, three), four);
var lambda = Expression.Lambda<Func<T, T>>(operation, param);
Of = lambda.Compile();
}
}
public static T Of<T>(T x) => Impl<T>.Of(x);
}
// ThreeFourths.Of(18) -> 13
```
Due to the fact that the compiler generates a version of the `Impl` class for each argument of `T`, we end up with an implementation of three-fourths for each type encapsulated in a separate class. This approach gives us a thread-safe lazy-evaluated generic dynamic function.
Now, with the optimizations out of the way, let's again use Benchmark.NET to compare the different ways we can calculate three-fourths of a value:
```csharp
public class Benchmarks
{
[Benchmark(Description = "Static", Baseline = true)]
[Arguments(13.37)]
public double Static(double x) => 3 * x / 4;
[Benchmark(Description = "Expressions")]
[Arguments(13.37)]
public double Expressions(double x) => ThreeFourths.Of(x);
[Benchmark(Description = "Dynamic")]
[Arguments(13.37)]
public dynamic Dynamic(dynamic x) => 3 * x / 4;
public static void Main() => BenchmarkRunner.Run<Benchmarks>();
}
```
```r
| Method | x | Mean | Error | StdDev | Ratio | RatioSD |
|------------ |------ |-----------:|----------:|----------:|------:|--------:|
| Static | 13.37 | 0.6077 ns | 0.0176 ns | 0.0147 ns | 1.00 | 0.00 |
| Dynamic | 13.37 | 19.3267 ns | 0.1512 ns | 0.1340 ns | 31.82 | 0.78 |
| Expressions | 13.37 | 1.9510 ns | 0.0163 ns | 0.0145 ns | 3.21 | 0.08 |
```
As you can see, the expression-based approach performs about nine times faster than when using `dynamic`. Considering that these are the only two options we can use to implement generic operators, this is a pretty good case for compiled expression trees.
## Compiling dictionary into a switch expression
Another fun way we can use expression trees is to create a dictionary with a compiled lookup. Even though the standard .NET `System.Collections.Generic.Dictionary` is insanely fast on its own, it's possible to make its read operations even faster.
While a typical dictionary implementation may be pretty complicated, a lookup can be represented in a form of a simple switch expression:
```csharp
// Pseudo-code
public TValue Lookup(TKey key) => key.GetHashCode() switch
{
// No collisions
9254 => value1,
-101 => value2,
// Collision
777 => key switch
{
key3 => value3,
key4 => value4
},
// ...
// Not found
_ => throw new KeyNotFoundException(key.ToString())
};
```
The function above attempts to match the hash code of the specified key with the hash code of one of the keys contained within the dictionary. If it's successful, then the corresponding value is returned.
Even though hash codes are designed to be unique, inevitably there will be collisions. In such cases, when the same hash code matches with multiple different values, there is an inner switch expression that compares the actual key and determines which value to return.
Finally, if none of the cases matched, it throws an exception signifying that the dictionary doesn't contain the specified key.
The idea is that, since a switch is faster than a hash table, dynamically compiling all key-value pairs into a switch expression like the one above should result in a faster dictionary lookup.
Let's try it out. Here's how the code for that would look:
```csharp
public class CompiledDictionary<TKey, TValue> : IDictionary<TKey, TValue>
{
private readonly IDictionary<TKey, TValue> _inner = new Dictionary<TKey, TValue>();
private Func<TKey, TValue> _lookup;
public CompiledDictionary() => UpdateLookup();
public void UpdateLookup()
{
// Parameter for lookup key
var keyParameter = Expression.Parameter(typeof(TKey));
// Expression that gets the key's hash code
var keyGetHashCodeCall = Expression.Call(
keyParameter,
typeof(object).GetMethod(nameof(GetHashCode)));
// Expression that converts the key to string
var keyToStringCall = Expression.Call(
keyParameter,
typeof(object).GetMethod(nameof(ToString)));
// Expression that throws 'not found' exception in case of failure
var exceptionCtor = typeof(KeyNotFoundException)
.GetConstructor(new[] {typeof(string)});
var throwException = Expression.Throw(
Expression.New(exceptionCtor, keyToStringCall),
typeof(TValue));
// Switch expression with cases for every hash code
var body = Expression.Switch(
typeof(TValue), // expression type
keyGetHashCodeCall, // switch condition
throwException, // default case
null, // use default comparer
_inner // switch cases
.GroupBy(p => p.Key.GetHashCode())
.Select(g =>
{
// No collision, construct constant expression
if (g.Count() == 1)
return Expression.SwitchCase(
Expression.Constant(g.Single().Value), // body
Expression.Constant(g.Key)); // test values
// Collision, construct inner switch for the key's value
return Expression.SwitchCase(
Expression.Switch(
typeof(TValue),
keyParameter, // switch on actual key
throwException,
null,
g.Select(p => Expression.SwitchCase(
Expression.Constant(p.Value),
Expression.Constant(p.Key)
))),
Expression.Constant(g.Key));
}));
var lambda = Expression.Lambda<Func<TKey, TValue>>(body, keyParameter);
_lookup = lambda.Compile();
}
public TValue this[TKey key]
{
get => _lookup(key);
set => _inner[key] = value;
}
// The rest of the interface implementation is omitted for brevity
}
```
The method `UpdateLookup` takes all of the key-value pairs contained within the inner dictionary and groups them by the hash codes of their keys, which are then transformed into switch cases. If there is no collision for a particular hash code, then the switch case is made up of a single constant expression that produces the corresponding value. Otherwise, it contains an inner switch expression that further evaluates the key to determine which value to return.
Let's see how well this dictionary performs when benchmarked against the standard implementation:
```csharp
public class Benchmarks
{
private readonly Dictionary<string, int> _normalDictionary =
new Dictionary<string, int>();
private readonly CompiledDictionary<string, int> _compiledDictionary =
new CompiledDictionary<string, int>();
[Params(10, 1000, 10000)]
public int Count { get; set; }
public string TargetKey { get; set; }
[GlobalSetup]
public void Setup()
{
// Seed the dictionaries with values
foreach (var i in Enumerable.Range(0, Count))
{
var key = $"key_{i}";
_normalDictionary[key] = i;
_compiledDictionary[key] = i;
}
// Recompile lookup
_compiledDictionary.UpdateLookup();
// Try to get the middle element
TargetKey = $"key_{Count / 2}";
}
[Benchmark(Description = "Standard dictionary", Baseline = true)]
public int Normal() => _normalDictionary[TargetKey];
[Benchmark(Description = "Compiled dictionary")]
public int Compiled() => _compiledDictionary[TargetKey];
public static void Main() => BenchmarkRunner.Run<Benchmarks>();
}
```
```r
| Method | Count | Mean | Error | StdDev | Ratio |
|-------------------- |------ |----------:|----------:|----------:|------:|
| Standard dictionary | 10 | 24.995 ns | 0.1821 ns | 0.1704 ns | 1.00 |
| Compiled dictionary | 10 | 9.366 ns | 0.0511 ns | 0.0478 ns | 0.37 |
| | | | | | |
| Standard dictionary | 1000 | 25.105 ns | 0.0665 ns | 0.0622 ns | 1.00 |
| Compiled dictionary | 1000 | 14.819 ns | 0.1138 ns | 0.1065 ns | 0.59 |
| | | | | | |
| Standard dictionary | 10000 | 29.047 ns | 0.1201 ns | 0.1123 ns | 1.00 |
| Compiled dictionary | 10000 | 17.903 ns | 0.0635 ns | 0.0530 ns | 0.62 |
```
We can see that the compiled dictionary performs lookups about 1.6-2.8 times faster. While the performance of the hash table is consistent regardless of how many elements are in the dictionary, the expression tree implementation becomes slower as the dictionary gets bigger. This can potentially be remedied by adding another switch layer for indexing.
## Parsing DSLs into expressions
One other interesting usage scenario, that I'm personally really fond of, is parsing. The main challenge of writing an interpreter for a custom domain-specific language is turning the syntax tree into runtime instructions. By parsing the grammar constructs directly into expression trees, this becomes a solved problem.
As an example, let's write a simple program that takes a string representation of a mathematical expression and evaluates its result. To implement the parser, we will use the [Sprache](https://github.com/sprache/Sprache) library.
```csharp
public static class SimpleCalculator
{
private static readonly Parser<Expression> Constant =
Parse.DecimalInvariant
.Select(n => double.Parse(n, CultureInfo.InvariantCulture))
.Select(n => Expression.Constant(n, typeof(double)))
.Token();
private static readonly Parser<ExpressionType> Operator =
Parse.Char('+').Return(ExpressionType.Add)
.Or(Parse.Char('-').Return(ExpressionType.Subtract))
.Or(Parse.Char('*').Return(ExpressionType.Multiply))
.Or(Parse.Char('/').Return(ExpressionType.Divide));
private static readonly Parser<Expression> Operation =
Parse.ChainOperator(Operator, Constant, Expression.MakeBinary);
private static readonly Parser<Expression> FullExpression =
Operation.Or(Constant).End();
public static double Run(string expression)
{
var operation = FullExpression.Parse(expression);
var func = Expression.Lambda<Func<double>>(operation).Compile();
return func();
}
}
```
As you can see, the parsers defined above (`Constant`, `Operator`, `Operation`, `FullExpression`) all yield objects of type `Expression` and `ExpressionType`, which are both defined in `System.Linq.Expressions`. The expression tree is essentially our syntax tree, so once we parse the input we have all the required information to compile the runtime instructions represented by it.
You can try it out by calling `Run`:
```csharp
var a = SimpleCalculator.Run("2 + 2"); // 4
var b = SimpleCalculator.Run("3.15 * 5 + 2"); // 17.75
var c = SimpleCalculator.Run("1 / 2 * 3"); // 1.5
```
Note that this simple calculator is just an example of what you can do, it doesn't respect operator precedence and doesn't understand nested expressions. Implementing a parser for that would be out of scope of covering expression trees, but if you want to see how a proper calculator like that would look, check out [Sprache.Calc](https://github.com/yallie/Sprache.Calc/blob/master/Sprache.Calc/SimpleCalculator.cs). Also, if you want to learn more about parsing, check out my blog posts about [parsing in C#](https://tyrrrz.me/blog/monadic-parser-combinators) and [parsing in F#](https://tyrrrz.me/blog/parsing-with-fparsec).
## Making things even faster
While compiled expressions execute really fast, compiling them can be relatively expensive.
In most cases that's completely fine, but you may want to take the performance even further by using [FastExpressionCompiler](https://github.com/dadhi/FastExpressionCompiler). This library provides a drop-in replacement for the `Compile` method called `CompileFast`, which executes much faster.
For example, here's a simple benchmark that shows the difference:
```csharp
public class Benchmarks
{
private static Expression Body { get; } =
Expression.Add(Expression.Constant(3), Expression.Constant(5));
[Benchmark(Description = "Compile", Baseline = true)]
public Func<int> Normal() => Expression.Lambda<Func<int>>(Body).Compile();
[Benchmark(Description = "Compile (fast)")]
public Func<int> Fast() => Expression.Lambda<Func<int>>(Body).CompileFast();
public static void Main() => BenchmarkRunner.Run<Benchmarks>();
}
```
```r
| Method | Mean | Error | StdDev | Ratio | Allocated |
|--------------- |----------:|----------:|----------:|------:|----------:|
| Compile | 38.435 us | 0.2131 us | 0.1889 us | 1.00 | 3.53 KB |
| Compile (fast) | 4.497 us | 0.0662 us | 0.0619 us | 0.12 | 1.21 KB |
```
As you can see, the performance improvement is pretty noticeable. The reason it runs so fast is because the `CompileFast` version skips all the verifications that normal `Compile` does to ensure that the expression tree is valid.
This library (as part of `FastExpressionCompiler.LightExpression`) also offers a drop-in replacement for `Expression` and all of its static factory methods. These alternative implementations construct expressions which may in some cases perform much faster than their default counterparts. However, I still recommend to benchmark it on your particular use cases to ensure that it actually provides an improvement.
## Inferring expression trees from code
So far we've explored how to construct expression trees manually. The cool thing about expression trees in .NET though is that they can also be created automatically as well.
The way this works is that you can infer an expression tree by simply specifying a lambda expression like you would if you were to define a delegate. C# compiler will take care of the rest.
Consider this snippet of code:
```csharp
Func<int, int, int> div =
(a, b) => a / b;
Expression<Func<int, int, int>> divExpr =
(a, b) => a / b;
```
Both of these assignments look exactly the same, but the actual assigned value is different. While in the first case we will get a delegate which can be executed directly, the second will provide us with an expression tree that represents the structure of the supplied lambda expression. This is essentially the same `LambdaExpression` that we were creating when compiling code ourselves, only now it represents code written statically as opposed to dynamically.
For example, we can inspect the expression tree produced by the compiler:
```csharp
Expression<Func<int, int, int>> divExpr =
(a, b) => a / b;
foreach (var param in divExpr.Parameters)
Console.WriteLine($"Param: {param.Name} ({param.Type.Name})");
// Param: a (Int32)
// Param: b (Int32)
```
And, just like with expression trees created manually, we can compile it into a delegate:
```csharp
Expression<Func<int, int, int>> divExpr =
(a, b) => a / b;
var div = divExpr.Compile();
var c = div(10, 2); // 5
```
Essentially, in this context, you can think of `divExpr` as a recipe that contains the ingredients needed to create `div`, the final product.
Note, however, that while direct assignment shown previously works, you can't do something like this:
```csharp
Func<int, int, int> div = (a, b) => a / b;
// Compilation error
Expression<Func<int, int, int>> divExpr = div;
```
The expression must be defined in-place in order to work. Because the disassembly happens during compile time, not runtime, the compiler needs to know exactly what it's dealing with.
Although this approach is incredibly useful, it has certain limitations. Specifically, the supplied lambda expression must not contain any of the following:
- Null-coalescing operator (`obj?.Prop`)
- Dynamic variables (`dynamic`)
- Asynchronous code (`async`/`await`)
- Default or named parameters (`func(a, b: 5)`, `func(a)`)
- Parameters passed by reference (`int.TryParse("123", out var i)`)
- Multi-dimensional array initializers (`new int[2, 2] { { 1, 2 }, { 3, 4 } }`)
- Assignment operations (`a = 5`)
- Increment and decrement (`a++`, `a--`, `--a`, `++a`)
- Base type access (`base.Prop`)
- Dictionary initialization (`new Dictionary<string, int> { ["foo"] = 100 }`)
- Unsafe code (via `unsafe`)
- Throw expressions (`throw new Exception()`)
- Tuple literals (`(5, x)`)
On top of all that, you cannot use this method to construct expression trees from multi-line lambdas. That means this won't compile:
```csharp
// Compilation error
Expression<Func<int, int, int>> divExpr = (a, b) =>
{
var result = a / b;
return result;
};
```
And, more importantly, this won't work either:
```csharp
// Compilation error
Expression<Action> writeToConsole = () =>
{
Console.Write("Hello ");
Console.WriteLine("world!");
};
```
Most of these limitations come from the fact that this feature was designed with `IQueryable` in mind and many of the language constructs listed above don't really make sense when it comes to querying data. That said, there are a lot of other scenarios where they can be useful.
There is a suggestion to extend compile-time expression trees and it's tracked [by this issue on GitHub](https://github.com/dotnet/csharplang/issues/158). We'll see where it goes.
For now, let's move these limitations aside and explore some of the ways we can use expression trees constructed with this approach.
## Identifying type members
The most common use case for expression trees obtained in such manner is to identify type members. This approach allows us to extract information on fields, properties, or methods from a supplied lambda expression.
For example, assume we have the following class:
```csharp
public class Dto
{
public Guid Id { get; set; }
public string Name { get; set; }
}
```
If we wanted to get the `PropertyInfo` that represents its `Id` property, we could use reflection to do it like this:
```csharp
var idProperty = typeof(Dto).GetProperty(nameof(Dto.Id));
Console.WriteLine($"Type: {idProperty.DeclaringType.Name}");
Console.WriteLine($"Property: {idProperty.Name} ({idProperty.PropertyType.Name})");
// Type: Dto
// Property: Id (Guid)
```
That works completely fine. For example, if we were designing an API for a validation library, it could look like this:
```csharp
public class Validator<T>
{
// Add validation predicate to the list
public void AddValidation<TProp>(string propertyName, Func<TProp, bool> predicate)
{
var propertyInfo = typeof(T).GetProperty(propertyName);
if (propertyInfo is null)
throw new InvalidOperationException("Please provide a valid property name.");
// ...
}
// Evalute all predicates
public bool Validate(T obj) { /* ... */ }
/* ... */
}
```
Which we would be able to use like this:
```csharp
var validator = new Validator<Dto>();
validator.AddValidation<Guid>(nameof(Dto.Id), id => id != Guid.Empty);
validator.AddValidation<string>(nameof(Dto.Name), name => !string.IsNullOrWhiteSpace(name));
var isValid = validator.Validate(new Dto { Id = Guid.NewGuid() }); // false
```
However, the problem here is that all of our validators are effectively untyped. We have to specify the generic argument in `AddValidation` so that our predicates are aware of what they're working with, but this setup is very volatile.
If we were to, for example, change the type of `Dto.Id` from `Guid` to `int`, everything will still compile but the code will no longer work correctly because our predicate expects the type to be `Guid`. Also, we'd be lucky if our users were to provide the property names using `nameof`, in reality there will probably be magic strings instead. All in all, this code is not refactor-safe.
With expressions we can completely remedy this:
```csharp
public class Validator<T>
{
public void AddValidation<TProp>(
Expression<Func<T, TProp>> propertyExpression,
Func<TProp, bool> predicate)
{
var propertyInfo = (propertyExpression.Body as MemberExpression)?.Member as PropertyInfo;
if (propertyInfo is null)
throw new InvalidOperationException("Please provide a valid property expression.");
// ...
}
public bool Validate(T obj) { /* ... */ }
/* ... */
}
```
With the new interface we can write our code like this instead:
```csharp
var validator = new Validator<Dto>();
validator.AddValidation(dto => dto.Id, id => id != Guid.Empty);
validator.AddValidation(dto => dto.Name, name => !string.IsNullOrWhiteSpace(name));
var isValid = validator.Validate(new Dto { Id = Guid.NewGuid() }); // false
```
This works exactly the same, except that now we don't need to specify generic arguments manually, there are no magic strings, and the code is completely safe to refactor. If we change the type of `Dto.Id` from `Guid` to `int`, our code will rightfully no longer compile.
Many existing libraries are using expression trees for this purpose, including:
- [FluentValidation](https://github.com/JeremySkinner/FluentValidation) uses it to setup validation rules
- [EntityFramework](https://github.com/dotnet/efcore) uses it for entity configuration
- [Moq](https://github.com/moq/moq4) uses it to build mocks
## Providing context to assertions
Often when I'm writing test suites for my projects, I find myself spending time decorating assertions with informational error messages. For example:
```csharp
[Test]
public void IntTryParse_Test()
{
// Arrange
const string s = "123";
// Act
var result = int.TryParse(s, out var value);
// Assert
Assert.That(result, Is.True, "Parsing was unsuccessful");
Assert.That(value, Is.EqualTo(124), "Parsed value is incorrect");
}
```
By doing that, the errors produced by failed assertions become more descriptive. This makes it easier to understand what went wrong without having to look inside the test implementation:
```ini
X IntTryParse_Test [60ms]
Error Message:
Parsed value is incorrect
Expected: 124
But was: 123
```
In a perfect world, however, it would be nice if the error message simply contained the code of the assertion. That way I would know which exact check failed and why.
Luckily, this is something we can do with the help of expressions. To facilitate that, we can create a helper method that will wrap the assertion in an expression:
```csharp
public static class AssertEx
{
public static void Express(Expression<Action> expression)
{
var act = expression.Compile();
try
{
act();
}
catch (AssertionException ex)
{
throw new AssertionException(
expression.Body.ToReadableString() +
Environment.NewLine +
ex.Message);
}
}
}
```
This method is really simple. All it does is try to run the delegate represented by the expression and, if the underlying assertion fails, it prints the expression along with the error.
Let's update our test code to make use of this method:
```csharp
[Test]
public void IntTryParse_Test()
{
// Arrange
const string s = "123";
// Act
var result = int.TryParse(s, out var value);
// Assert
AssertEx.Express(() => Assert.That(result, Is.True));
AssertEx.Express(() => Assert.That(value, Is.EqualTo(124)));
}
```
Now, when this test fails we will instead get the following error message:
```ini
X IntTryParse_Test [99ms]
Error Message:
Assert.That(value, Is.EqualTo(124))
Expected: 124
But was: 123
```
As you can see, the error message now specifies the exact assertion that failed. This gives us more context which helps determine what actually went wrong.
___
With the advent of .NET Core 3.0, the .NET team has also added a new attribute, `CallerArgumentExpression`. This attribute was meant to be supported by a [language feature](https://github.com/dotnet/csharplang/issues/287) that was planned for C# 8 but unfortunately it didn't make it. Currently, the attribute doesn't do anything, but we should see this change in one of the future versions of the language.
The goal of this attribute is to provide the ability to "sniff" the expression passed to the specified parameter. For example, we should be able to define a method like this:
```csharp
public static void Assert(
bool condition,
[CallerArgumentExpression("condition")] string expression = "")
{
if (!condition)
throw new AssertionFailedException($"Condition `{expression}` is not true");
}
```
Which will then produce a detailed exception message if the assertion fails:
```csharp
Assert(2 + 2 == 5);
// Exception:
// Condition `2 + 2 == 5` is not true
```
Note that with this approach we will only be able to obtain the expression as a string, which will be the same expression specified in the source code. This can be used to provide a somewhat similar experience as shown with `AssertEx.Express` above.
## Traversing and rewriting expression trees
In order to analyze expression trees, we need to be able to traverse them in a recursive descent manner, starting from the body of the lambda expression and going down to every expression it's made out of. This could be done manually with a large switch expression that calls into itself.
Fortunately, we don't have to reinvent the wheel because the framework already provides a special class for this purpose called [`ExpressionVisitor`](https://docs.microsoft.com/en-us/dotnet/api/system.linq.expressions.expressionvisitor). It's an abstract class that has a visitor method for every expression type so you can simply inherit from it and override the methods you're interested in.
For example, we can implement a visitor that prints out all the binary and method call expressions it encounters:
```csharp
public class Visitor : ExpressionVisitor
{
protected override Expression VisitMethodCall(MethodCallExpression node)
{
Console.WriteLine($"Visited method call: {node}");
return base.VisitMethodCall(node);
}
protected override Expression VisitBinary(BinaryExpression node)
{
Console.WriteLine($"Visited binary expression: {node}");
return base.VisitBinary(node);
}
}
```
```csharp
Expression<Func<double>> expr = () => Math.Sin(Guid.NewGuid().GetHashCode()) / 10;
new Visitor().Visit(expr);
// Visited binary expression: (Sin(Convert(NewGuid().GetHashCode(), Double)) / 10)
// Visited method call: Sin(Convert(NewGuid().GetHashCode(), Double))
// Visited method call: NewGuid().GetHashCode()
// Visited method call: NewGuid()
```
As you can see by the order of the logs, the visitor first encounters the binary expression that makes up the lambda body, then digs inside, revealing a call to `Math.Sin` whose parameter is also expressed as a call to `GetHashCode` on the result of `NewGuid`.
You may have noticed that the visitor methods on `ExpressionVisitor` all return `Expression`s. That means that besides merely inspecting them, the visitor can choose to rewrite or completely replace expressions with different ones.
Let's change our visitor so that it catches all calls to method `Math.Sin` and rewrites them into `Math.Cos`:
```csharp
public class Visitor : ExpressionVisitor
{
protected override Expression VisitMethodCall(MethodCallExpression node)
{
var newMethodCall = node.Method == typeof(Math).GetMethod(nameof(Math.Sin))
? typeof(Math).GetMethod(nameof(Math.Cos))
: node.Method;
return Expression.Call(newMethodCall, node.Arguments);
}
}
```
```csharp
Expression<Func<double>> expr = () => Math.Sin(Guid.NewGuid().GetHashCode()) / 10;
var result = expr.Compile()();
Console.WriteLine($"Old expression: {expr.ToReadableString()}");
Console.WriteLine($"Old result: {result}");
var newExpr = (Expression<Func<double>>) new Visitor().Visit(expr);
var newResult = newExpr.Compile()();
Console.WriteLine($"New expression: {newExpr.ToReadableString()}");
Console.WriteLine($"New result value: {newResult}");
// Old expression: () => Math.Sin((double)Guid.NewGuid().GetHashCode()) / 10d
// Old result: 0.09489518488876232
// New expression: () => Math.Cos((double)Guid.NewGuid().GetHashCode()) / 10d
// New result value: 0.07306426748550407
```
As you can see, the new expression is structurally identical but with `Math.Sin` replaced by `Math.Cos`. Both expressions are completely independent and can be compiled to produce their respective delegates.
Using this approach we can arbitrarily rewrite supplied expressions, generating derivatives that behave differently. It can be very helpful when creating dynamic proxies. For example, a popular mocking library [Moq](https://github.com/moq/moq4) uses this technique to build stubs at runtime.
## Transpiling code into a different language
Now that we know that we can use `ExpressionVisitor` to analyze and rewrite expression trees, it's not too hard to guess that we can also use it to transpile expressions into another language. The goal of such a tool would be to convert code from one language to another, while retaining its functional behavior.
Let's imagine we're building a library that allows users to convert C# expressions to their equivalent F# representations. For example, we want to be able to do this:
```csharp
Expression<Action<int, int>> expr = (a, b) => Console.WriteLine("a + b = {0}", a + b));
var fsharpCode = FSharpTranspiler.Convert(expr);
```
To facilitate that, we can create a class called `FSharpTranspiler` which will internally use a special `ExpressionVisitor` to traverse the expression tree and write valid F# code. It could look something like this:
```csharp
public static class FSharpTranspiler
{
private class Visitor : ExpressionVisitor
{
private readonly StringBuilder _buffer;
public Visitor(StringBuilder buffer)
{
_buffer = buffer;
}
// ...
}
public static string Convert<T>(Expression<T> expression)
{
var buffer = new StringBuilder();
new Visitor(buffer).Visit(expression);
return buffer.ToString();
}
}
```
With this setup, we can inject a `StringBuilder` into our visitor and use that as the output buffer. While the visitor takes care of navigating the tree, we need to make sure we're emitting valid code on each expression type.
Writing a full C# to F# transpiler would be too complicated and way outside of the scope of this article. For the sake of simplicity let's limit our job to support expressions similar to the one we've seen in the initial example. To handle these, we will need to translate `Console.WriteLine` into correct usage of `printfn`.
Here's how we can do it:
```csharp
public static class FSharpTranspiler
{
private class Visitor : ExpressionVisitor
{
private readonly StringBuilder _buffer;
public Visitor(StringBuilder buffer)
{
_buffer = buffer;
}
protected override Expression VisitLambda<T>(Expression<T> node)
{
_buffer.Append("fun (");
_buffer.AppendJoin(", ", node.Parameters.Select(p => p.Name));
_buffer.Append(") ->");
return base.VisitLambda(node);
}
protected override Expression VisitMethodCall(MethodCallExpression node)
{
if (node.Method.DeclaringType == typeof(Console) &&
node.Method.Name == nameof(Console.WriteLine))
{
_buffer.Append("printfn ");
if (node.Arguments.Count > 1)
{
// For simplicity, assume the first argument is a string (don't do this)
var format = (string) ((ConstantExpression) node.Arguments[0]).Value;
var formatValues = node.Arguments.Skip(1).ToArray();
_buffer.Append("\"");
_buffer.Append(Regex.Replace(format, @"\{\d+\}", "%O"));
_buffer.Append("\" ");
_buffer.AppendJoin(" ", formatValues.Select(v => $"({v.ToReadableString()})"));
}
}
return base.VisitMethodCall(node);
}
}
public static string Convert<T>(Expression<T> expression)
{
var buffer = new StringBuilder();
new Visitor(buffer).Visit(expression);
return buffer.ToString();
}
}
```
So now we can try to convert our expression from earlier and see what it returns:
```csharp
var fsharpCode = FSharpTranspiler.Convert<Action<int, int>>(
(a, b) => Console.WriteLine("a + b = {0}", a + b));
// fun (a, b) -> printfn "a + b = %O" (a + b)
```
This produces a string that contains valid F# code which should compile into an equivalent anonymous function. Let's run it in F# interactive to make sure it works correctly:
```fsharp
> let foo = fun (a, b) -> printfn "a + b = %O" (a + b)
val foo : a:int * b:int -> unit
> foo (3, 5)
a + b = 8
val it : unit = ()
```
Translating code from one language to another is definitely not a simple task, but it can be incredibly useful in certain scenarios. One example could be sharing validation rules between backend and frontend by converting C# predicate expressions into JavaScript code.
## Summary
Expression trees provide us with a formal structure of code that lets us analyze existing expressions or compile entirely new ones directly at runtime. This feature makes it possible to do a bunch of cool things, including writing transpilers, interpreters, code generators, optimize reflection calls, provide contextual assertions, and more. I think it's a really powerful tool that deserves a lot more attention.
Some other interesting articles on the topic:
- [Introduction to expression trees (Microsoft Docs)](https://docs.microsoft.com/en-us/dotnet/csharp/expression-trees)
- [10X faster execution with compiled expression trees (Particular Software)](https://particular.net/blog/10x-faster-execution-with-compiled-expression-trees)
- [AutoMapper 5.0 speed increases (Jimmy Bogard)](https://lostechies.com/jimmybogard/2016/06/24/automapper-5-0-speed-increases)
- [How we did (and did not) improve performance and efficiency in Marten 2.0 (Jeremy D. Miller)](https://jeremydmiller.com/2017/08/01/how-we-did-and-did-not-improve-performance-and-efficiency-in-marten-2-0)
- [Optimizing Just in Time with Expression Trees (Craig Gidney)](http://twistedoakstudios.com/blog/Post2540_optimizing-just-in-time-with-expression-trees)
I also recommend reading about [code quotations in F#](https://docs.microsoft.com/en-us/dotnet/fsharp/language-reference/code-quotations) which is a similar feature to expression trees but with more powerful language support.
___
[Follow me on Twitter](https://twitter.com/Tyrrrz) to get notified when I post a new article ✨ | tyrrrz |
262,984 | Chingu Weekly 106 | News, Shout-outs & Showcases 🔥Check out this article by Matthew Burfield called Auto d... | 0 | 2020-02-19T19:10:49 | https://dev.to/chingu/chingu-weekly-106-215 | career | ---
title: Chingu Weekly 106
published: true
description:
tags: #career
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/802hw7bylz7qie93ejsd.jpeg
---
## News, Shout-outs & Showcases
🔥Check out this article by Matthew Burfield called [Auto deployment to now.sh and Heroku from Github](https://dev.to/chingu/auto-deployment-to-now-sh-and-heroku-from-github-2p8)!
🔥A [Favorite Fonts app](https://chingu-solo.github.io/solo-koala-128/index.html) from @ makneta!
🔥@ nellie wrote this awesome article called Lessons from [Blue Collar - How soft skills can come from customer service experience}(https://dev.to/nelliesnoodles_90/lessons-from-blue-collar-bg4).
🔥Here is an Adam Shaffer wrote called [Looping over arrays and objects in JavaScript](https://medium.com/chingu/looping-over-arrays-and-objects-in-javascript-57e1188c1ba2
)!
## Overheard in Chingu
>Does my oldest son's wedding this Saturday count as my wife's Valentines Day present?
work for valentines day - perfect.
You know what would be nice, if github had a way to make an in between two repos system. Like, the front-end html goes through the in between, to a backend, backend stuff gets added, and that file, separate goes into the in between too. So changes just aren't all master branch, and front/back can easily compare file alterations that are done, and it's easier for either one to pull a single file over to either side without conflicts.
I actually don't buy waffles so I don't know when they go on sale.
waffles are pretentious pancakes
I'm doing a project right now and I've decided to simply make the most insanely semantic html layout for it as possible. I think I've been focused too much on visual design of a page instead of the legit straight-up content. I'm making a page like it's 1991, then I'll bring the design into current century :)
HELLO EVERYONE!!
someone find me a web dev who is a cat person!
## Resource of the week
From @ kish!
>"I had a lot of trouble deploying my react-app to a Github user page (not project page) last week and found a very handy solution. It is not straightforward so I wrote a Medium article on how to do it."
https://medium.com/@kishandth.sivapalasundaram/how-to-deploy-your-react-app-to-a-github-user-page-d4b925cf5543
## Meme to go
 | tropicalchancer |
263,011 | What Is the Discovery Phase, and Why Should You Include It? | What’s the secret of the lucky 10% of startups that survive? The secret is the “discovery” (or “pre-development”) phase. And this is what I’ll discuss in this blog post. | 0 | 2020-02-17T10:25:39 | https://djangostars.com/blog/discovery-phase-in-software-development/ | startup, discovery, development, strategy | ---
title: What Is the Discovery Phase, and Why Should You Include It?
canonical_url: https://djangostars.com/blog/discovery-phase-in-software-development/
cover_image: https://djangostars.com/blog/uploads/2020/01/cover-03.png
published: true
description: What’s the secret of the lucky 10% of startups that survive? The secret is the “discovery” (or “pre-development”) phase. And this is what I’ll discuss in this blog post.
tags: Startup, Discovery, Development, Strategy
---
If you think that a breakthrough idea, strict development deadlines, and marketing strategy are all you need to make your product hit the mark – think again. The reality is, on top of fierce competition and demanding customers, [9 out of 10 startups fail](https://www.cbinsights.com/research/startup-failure-reasons-top/) because their solution has no market fit.
What’s the secret of the lucky 10% of startups that survive? The secret is the “discovery” (or “pre-development”) phase. And this is what I’ll discuss in this blog post.
You’ll learn about the ins and outs of the discovery phase, its process, and how it can make your product more competitive and customer-oriented.
Let’s dive right in.
## Table of Contents
- [What Is the Discovery Phase?](https://djangostars.com/blog/discovery-phase-in-software-development/#1)
- The Role of the Discovery Stage
- [Establish business goals](https://djangostars.com/blog/discovery-phase-in-software-development/#3)
- [Understand what a successful outcome looks like](https://djangostars.com/blog/discovery-phase-in-software-development/#4)
- [Carry out user research](https://djangostars.com/blog/discovery-phase-in-software-development/#5)
- [Map the customer journey](https://djangostars.com/blog/discovery-phase-in-software-development/#6)
- [Analyze the competitors](https://djangostars.com/blog/discovery-phase-in-software-development/#7)
- [Reasons for the Discovery Phase and its Benefits](https://djangostars.com/blog/discovery-phase-in-software-development/#8)
- [Discovery Phase Team: Its Roles and Responsibilities](https://djangostars.com/blog/discovery-phase-in-software-development/#9)
- [The Role of the Discovery Phase in Product Development](https://djangostars.com/blog/discovery-phase-in-software-development/#10)
- [The Discovery Phase Process](https://djangostars.com/blog/discovery-phase-in-software-development/#11)
- What You Get After the Discovery Stage
- [MVP Milestones and Expected Timeline](https://djangostars.com/blog/discovery-phase-in-software-development/#13)
- [Wrapping Up](https://djangostars.com/blog/discovery-phase-in-software-development/#14)
## What Is the Discovery Phase?
The project discovery phase (or stage) is when you analyze the target market, define your product-market fit (need for a product on the market), and gather all the project requirements and goals.
Some people skip the discovery stage, mistakenly considering it to be a waste of time and money. However, this stage helps companies understand their customers better and roll out products that will actually solve their customers’ problems.
As a result, the discovery stage helps organize the development process better and connect your clients’ business goals with their users’ needs.
## The Role of the Discovery Stage
First and foremost, the discovery stage is meant to foresee and eliminate risks such as a lack of market demand, unexpected expenses, and the possibility of not being able to pay for them.
Mistakes made during the planning stage are the most expensive to fix later. That’s why the main goals of the discovery stage are to test your ideas and implementation strategies, and optimize development costs and the speed of the product launch.
The discovery stage is suitable for products in any industry and of any complexity. But we’ll explain the process based on our experience in developing a fintech product – an online mortgage platform.
So, again, the discovery stage helps you:
### Establish business goals
The discovery stage includes the creation of a product scope, the product’s requirements, and business goals. It’s important to stick to these goals throughout the development process and keep them in mind when making any changes to the product.
### Understand what a successful outcome looks like
It’s essential not only to outline the goals of the product, but also to define how many of them will be enough to achieve a successful result. As a business owner, you have to understand what you want to achieve with your product. For example, you can strive to reach 100% of your goals, but even 70% of them might be enough to satisfy your initial requirements.
### Carry out user research
You can’t develop a successful product blindly, without knowing your potential users’ needs and wants. For example, when doing market research for an online mortgage platform, the following facts was realized:
> When a customer considers a lender, he usually takes into account not only the lender’s reputation and the size of the deposit, mortgage rates and fees, but also the duration of the mortgage process, transparency, and the speed of communication (customers support).
This proves that the quality of the software product matters a lot to a user, as it is the main link between the customer and the service provider.
If the product doesn’t work as expected, the customer will not trust it, no matter how beneficial it is. That is why contemporary applications should also be adapted to the realities of the target region.
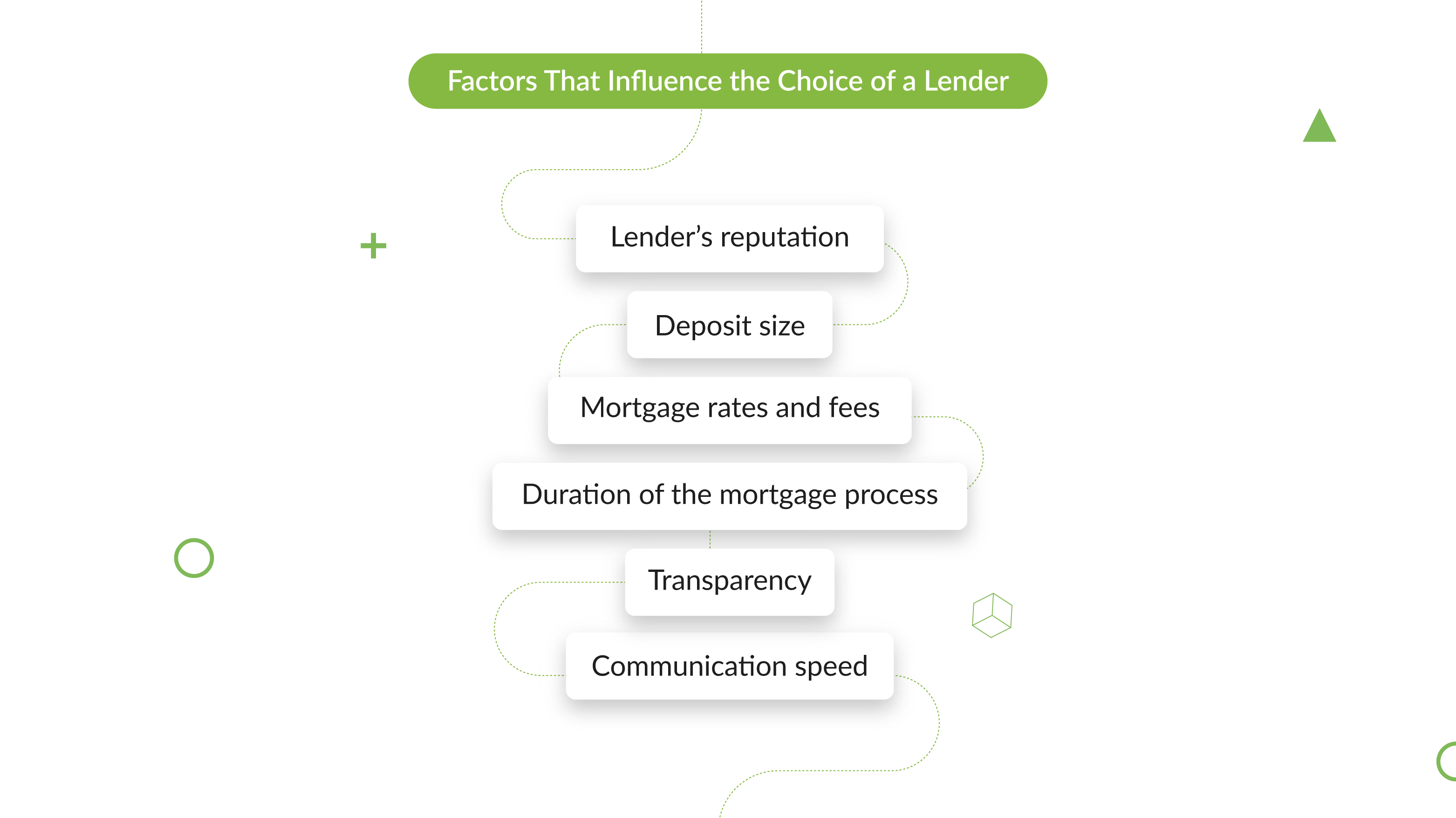
For example, in some countries it’s essential to set a premises server, while in others, cloud servers are acceptable. security and legal regulations should also be investigated during the discovery stage.
### Map the customer journey
A customer journey map helps you create a product that’s easy to use, identify the main touchpoints that users interact with, and think about what difficulties users might encounter and how to prevent them.
To be successful in the current digital market, even MVPs should be mapped out to the smallest details. If their first contact with an application isn’t satisfactory, a customer will rarely return.
Returning to the example online mortgage application example, the mortgage application process (which is a customer journey) is a core factor in product success and the conversion level. It’s important to analyze why users don’t complete the journey of your product and exactly what is blocking them – whether it’s an inadequate UX/UI or the reluctance of these users to buy.
That’s why this journey should be developed and tested during the discovery stage. It ensures that nothing will prevent the customer from getting to the main goal – receiving a mortgage.
### Analyze the competitors
A thorough analysis of your competitors’ strengths and weaknesses is also a vital part of the discovery stage. It helps you find the gap in your industry and understand how your product can fill it. It will also help you to develop your Unique Value Proposition and make your product stand out.
## Reasons for the Discovery Phase and Its Benefits
If you still doubt the importance of the discovery phase, here is a brief summary of what you get after it:
- Fewer expenses and a properly planned budget
- A better understanding of the scope and goals of your product
- Knowledge of the pain points and needs of your customers
- A Unique Value Proposition and defined market positioning
- The ability to outperform your competitors by learning their weaknesses and making your product better
**If you ignore the discovery phase and start development right away, you risk creating a product without a market demand and increase the chances of a product pivot.**
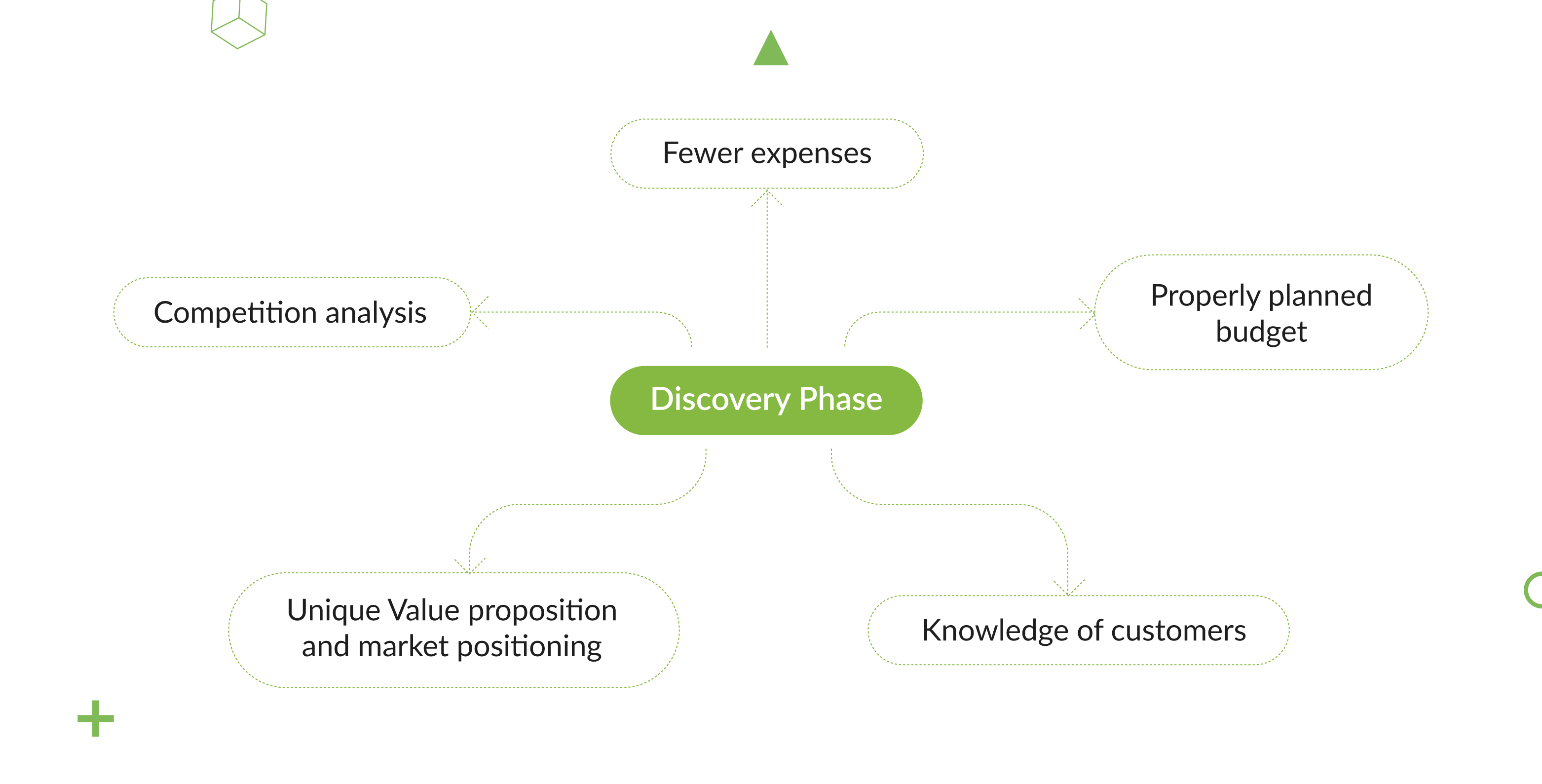
## Discovery Phase Team: Its Roles and Responsibilities
One factor that influences your product’s success is the team that participates in the discovery stage. The number of specialists on the team depends on the project’s complexity and goals. In my opinion, a team should be formed individually for each client based on two factors:
- The documentation the client provides, and its accuracy
- A team on the client’s side and its expertise
Below are the people you’ll want on a typical discovery-phase team:
- **Project Manager**
The project manager is responsible for planning and organizing meetings with the client, taking notes of all the important project details discussed during the meetings, and organizing fruitful cooperation between the product discovery and development team. The Project Manager also prepares all the essential documentation for the discovery stage.
- **Business Analyst**
The BA is responsible for market research and analysis, defining the user pain points and needs, as well as analyzing the product’s market potential and profitability. The Business Analyst also defines and monitors the quality of data metrics and reporting. Also, business analysts define functional and non-functional project requirements and align them with business objectives.
- **Tech leads**
Tech leads communicate closely with the customer, define the product’s technical requirements, create a development approach and sequence, and give estimates on the timeline.
- **UX/UI designer**
The UX designer is responsible for product usability and intuitive navigation. Based on the results of user and product research, the UX designer creates storyboards, sitemaps and process flows, and interface elements. The UI designer focuses on the look and layout of the product and its elements, which together work to ensure that the product is both visually attractive and easy to use.
- **Solution architect**
The Solution Architect is responsible for analyzing the technology environment and the performance, scalability, and maintainability of the product. Solution architects also investigate third-party frameworks and platforms, along with their risks and benefits.
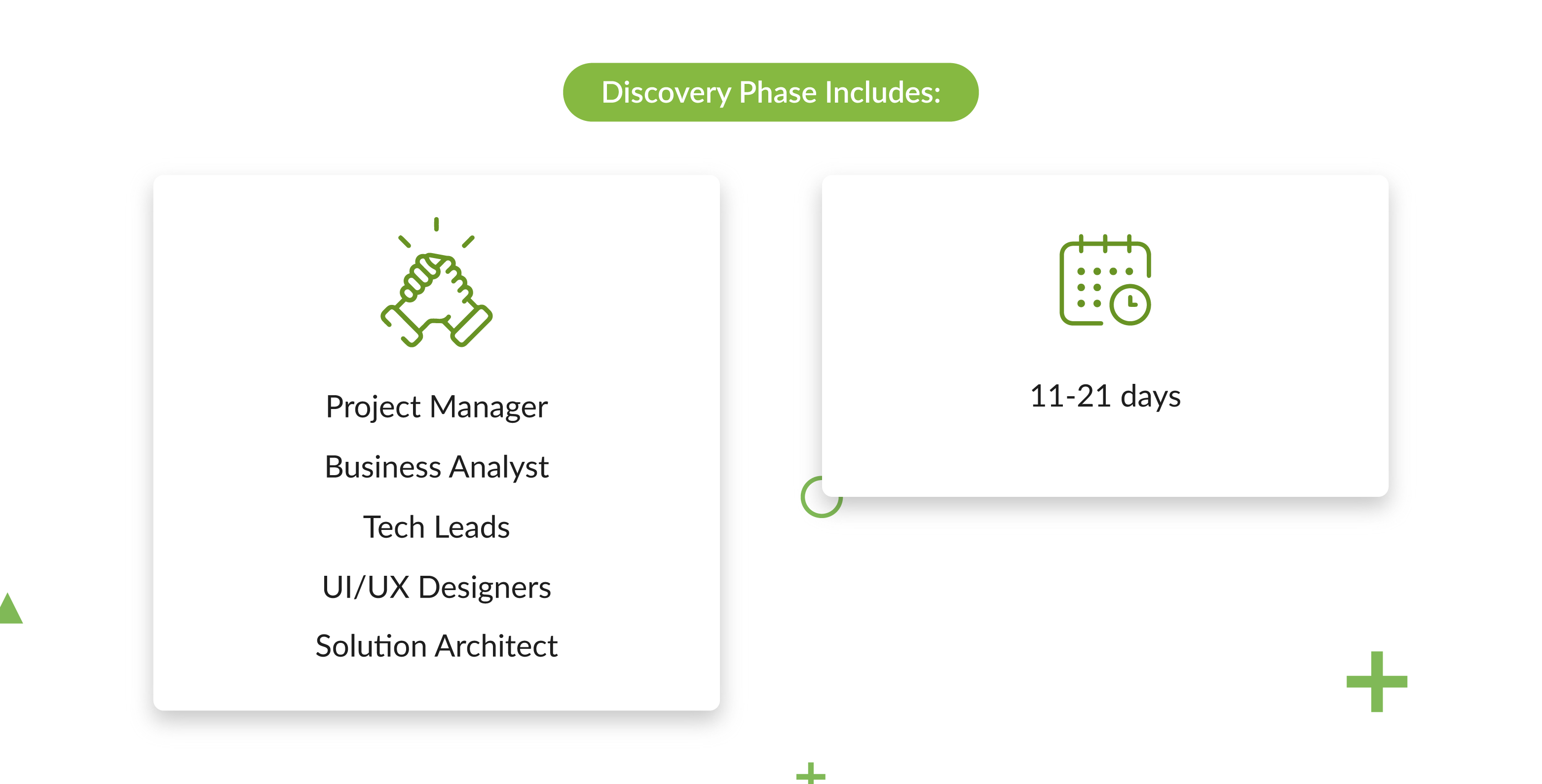
It’s a good practice to involve people with different types of expertise in the discovery process. Their experience and ideas will bring maximum value to your product, as they will analyze it from different perspectives. Before hiring a team, ensure each member has the relevant experience to participate meaningfully in the discovery phase.
## The Role of the Discovery Phase in Product Development
The discovery stage is the path from the theoretical concept to factual realization. The discovery stage starts with the understanding, collection, and systematization of the client’s requirements, research on the target audience’s needs, and an analysis of the product benefits for potential users.
Some people think that the discovery stage is part of development. The answer is both yes and no. The discovery phase is the initial stage of product development; however, these two processes can be separated. For example, you can order the discovery stage for one company, but product development in another. If the agency isn’t a good fit for a long-standing cooperation, it’s better to know about it sooner rather than later.
## The Discovery Phase Process
We highly recommend that you include a discovery phase as the first step in any project.
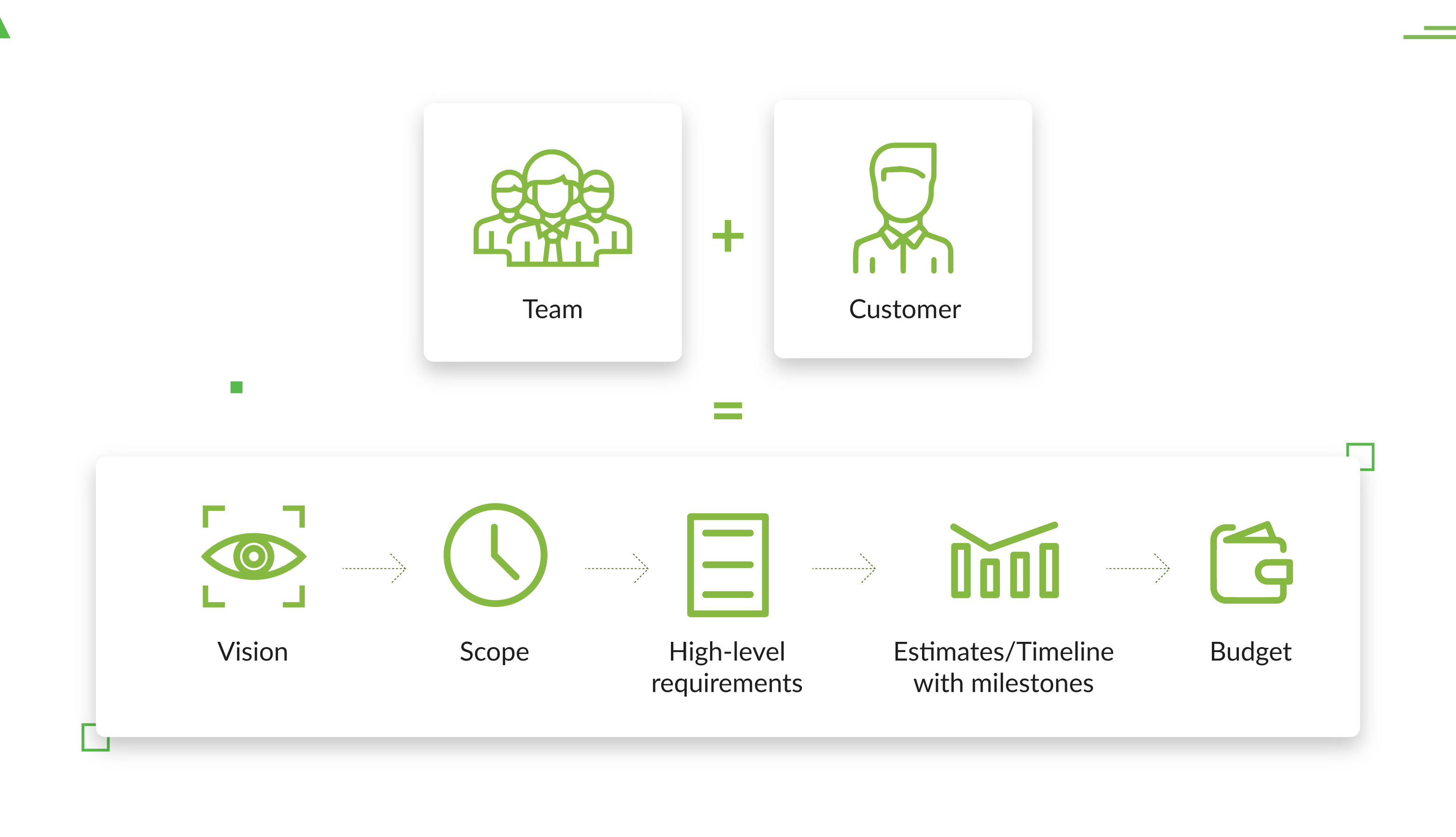
Here are the main steps in the discovery phase:
- Forming a discovery stage team that cooperates closely with the customer
- Validating the current data and conducting deep research
- Asking the right questions to discover any pitfalls in advance
- Forming the vision and scope of the future product
- Testing possible changes and solutions
- Creating estimates and timelines, with milestones
The main two questions I’ve encountered when working with customers are:
- When will my product be ready?
- How much will it cost?
Regardless of the complexity of the product and its requirements, the discovery stage includes a complex analysis of the source data.
Usually, it takes from 11 to 21 working days to complete the discovery stage. Apart from a number of documents and specifications, the client also receives answers on the two questions mentioned above.
## What You Get After the Discovery Stage
Here is what you’ll end up with after the discovery stage:
- A Customer Journey Map – the path that user should take to realize the product goals
- Architecture – a schematic, high-level outline of the dependencies between the main parts of the system infrastructure; the environment and physical layer that a new web application will run in and a list of the cloud provider technologies to be used
- Wireframes – user interface screens based on CJM
- A clickable prototype – a prototype based on Wireframes
- A user flow diagram – the path that users should follow
- UX/UI concept – the concept/examples of the future application, based on the wireframe
- API integration documentation – a short specification of all API endpoints required for the new application
- Project Backlog – a breakdown of the work structure needed to develop the application
- Project Roadmap – A project timeline and milestones, with dependencies
- A budget and engagement model
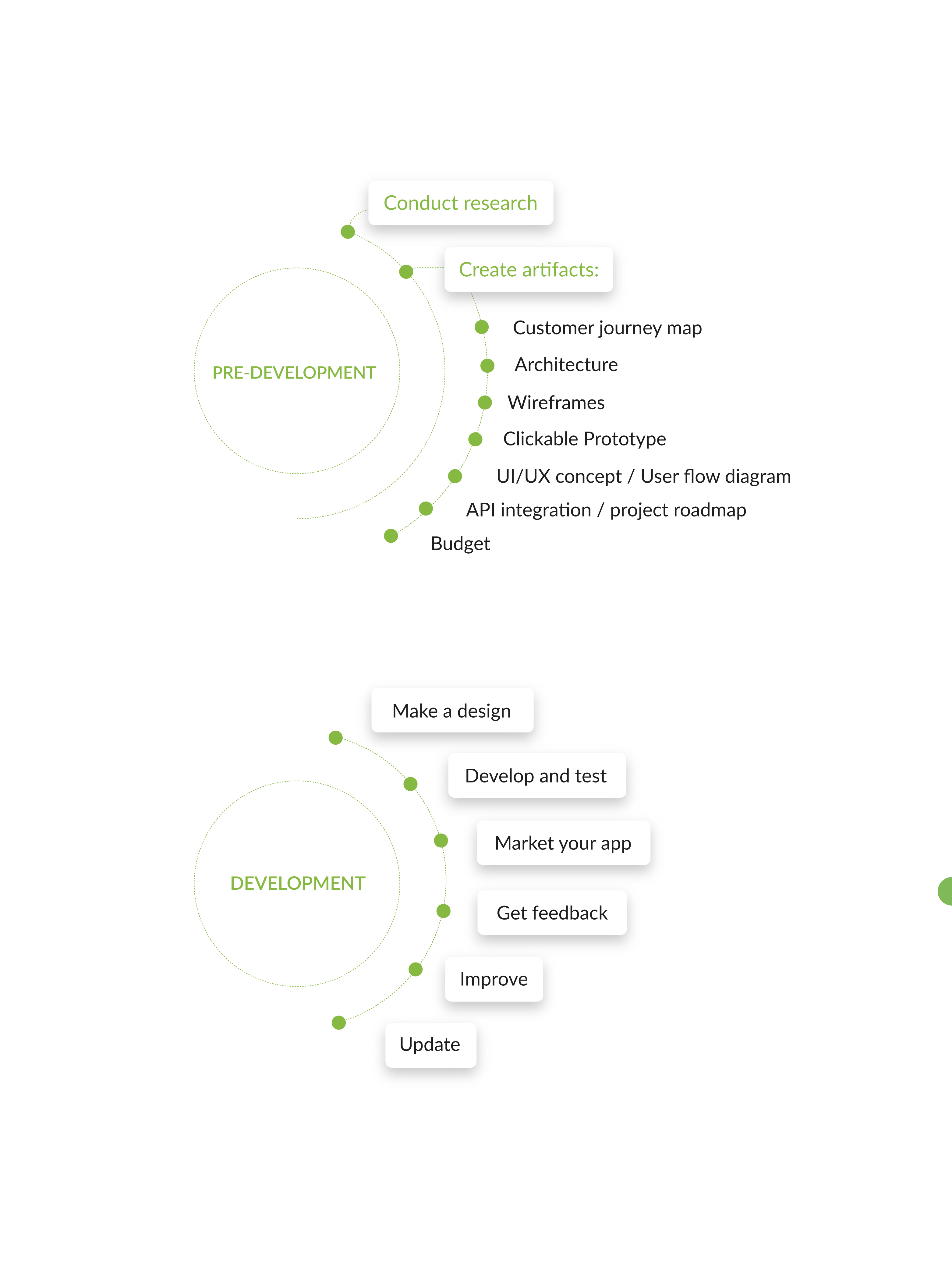
Note that this is a standard list that can be changed depending on the existence or absence of technical expertise on the client’s side, the project size, etc.
Also, it’s important to take into account the team on the client’s side, its level of industry knowledge, and its readiness to actively collaborate during the discovery stage.
### MVP Milestones and Expected Timeline
One of the main results of an effective discovery stage is a backlog with systemized epics and high-level stories, estimates, milestones, and a timeline.
Another outcome is written recommendations for the task execution sequences, dependencies and risks, and recommendations on the technology stack. Based on this data, it’s possible to define a product development timeline and a production schedule.
**As a bonus, we’ve also prepared a list of questions a product owner should ask when choosing a team for the discovery stage.**
**Q1: Who will take part in the discovery phase? Do the team members have experience in developing such systems?**
Team members should have relevant experience in the development of the product you’re working on, as well as specific knowledge about industry and its market trends.
**Q2: Are there any third-party integrations?**
Let’s get back to the online mortgage system example. It’s impossible to build a digital mortgage system without integrations. Integration, in this case, is one of the riskiest parts of development. If the development company has established relations with the third-party vendors, it will speed up the development process.
**Q3: Is the team experienced in product development for your region?**
The team should have solid experience in product development for your region and know its user preferences, regulations, and the specifics of working with third-party vendors.
**Q4: How is the future development team formed?**
The discovery stage team should be also involved in the software development process. They will have a comprehensive vision of your product, know its scope and requirements, and therefore will have a vision of how to build it. In addition, the level of trust between the team and the customer will be higher, as they will already have worked together and demonstrated their proficiency.
**Q5: Should I ask for examples of discovery stage results?**
Yes, the company you will work with should present to you the documents they created during the discovery stage. Note that all confidential data should be removed or blurred out (not doing so would violate customer privacy). Pay attention to the structure and accuracy of the documents – this is an indicator of service quality.
**Q6: What is the documentation management process? How are the discussions recorded?**
The discovery stage is a creative process, as it includes a lot of brainstorming sessions and idea generation. That’s why it’s important to document all details, suggestions, and requirements. The development team should be aware of each detail. If anything is omitted, the whole process may suffer.

**Q7: Is there a standard set of documents I have to get after a discovery stage?**
This really depends on the development company. We strongly believe that the set of documents you get will be defined individually, depending on the project and requirements.
**Q8: How often should the representative of the customer’s team be involved in the discovery phase?**
Ideally, at least one person from the client’s side will be actively engaged in the discovery stage. That’s because this person has in-depth knowledge about the product goals and requirements, which will make the discovery stage more effective.
## Wrapping Up
During the discovery stage, you build a foundation for your product, which will impact its future success. Discovery helps you define the goals of your product, study the needs of your target audience, analyze the competitors, plan the budget, and come up with a well-planned strategy.
This post ["What Is the Discovery Phase, and Why Should You Include It?"](https://djangostars.com/blog/discovery-phase-in-software-development/) was originally published on Django Stars blog. Written by Nataliia Peterheria - Project Manager & Software Engineer at [Django Stars](https://djangostars.com/) | djangostars |
263,028 | where can i find more DEVs worth following ? | it seems that some great DEVs are shy and dont create many posts ! so how can i find and follow them... | 0 | 2020-02-17T11:23:39 | https://dev.to/osde8info/where-can-i-find-more-devs-worth-following-7f8 | watercooler, smn, bmn | it seems that some great DEVs are shy and dont create many posts ! so how can i find and follow them ?
here are a couple of ideas
* follow people who have commented on other peoples posts
* reverse lookup people who have created DEV [github bugs](https://github.com/thepracticaldev/dev.to/issues?q=is%3Aissue+is%3Aopen+label%3A%22type%3A+bug%22)
* reverse lookup people who have created DEV [github feature requests](https://github.com/thepracticaldev/dev.to/issues?q=is%3Aissue+is%3Aopen+label%3A%22type%3A+feature+request%22)
BTW DEV-DEVs you do know you have ~200 open bugs and ~300 open feature requests ? oooh :lightbulbmoment: maybe thats 500 starter projects right there for coing `#newbies`
are there any more ways to find DEVs worth following ? | osde8info |
263,063 | How to Deploy a Static Website to AWS with GitLab CI | Want to deploy your static website to AWS? Our experienced specialists have prepared a detailed guide where they share knowledge about web hosting on Amazon. | 0 | 2020-02-17T12:58:13 | https://www.codica.com/blog/deploying-a-static-website-on-aws-web-hosting-with-gitlab-ci/ | tutorial, aws, cloud | ---
title: How to Deploy a Static Website to AWS with GitLab CI
published: true
description: Want to deploy your static website to AWS? Our experienced specialists have prepared a detailed guide where they share knowledge about web hosting on Amazon.
tags: tutorial, aws, cloud
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/uk4n09ss3b6v6zey1vb6.jpg
canonical_url: https://www.codica.com/blog/deploying-a-static-website-on-aws-web-hosting-with-gitlab-ci/
---
*This article was originally published on [Codica Blog](https://www.codica.com/blog/deploying-a-static-website-on-aws-web-hosting-with-gitlab-ci/).*
When it comes to placing static websites on a hosting platform like Amazon, GitLab and AWS are very helpful tools for automating the deployment process.
In this article, we want to share our experience in deploying the project static files to Amazon S3 (Simple Storage Service) with the help of GitLab CI (Continuous Integration) and ACM (Certificate Manager) for getting SSL-based encryption.
More precisely, we will discuss the process of deployment static sites to Amazon Web Services (storing files on S3 and distributing them with CloudFront).
## Glossary of terms
Before going ahead with the detailed guide, we would like to explain some of the terms that you will come across in this article.
**Simple Storage Service (S3)** is a web service offered by AWS. Basically, it is cloud object storage that allows uploading, storing, downloading, and retrieving almost any file or object. At Codica, we use this service to upload files of static websites.
**CloudFront (CF)** is a fast content delivery network (CDN) with globally-distributed proxy servers. It is based on S3 or another file source. Distribution is created and fixed on the S3 bucket or another source set by a user.
**Amazon Certificate Manager (ACM)** is a service by AWS that offers provision and management of free private and public SSL/TLS certificates. In our development practice, we use this helpful tool for deploying static files on Amazon CloudFront distributions. In such a way, we can secure all network communications.
**Identity and Access Management (IAM)** is an entity that you create in AWS to represent the person or application that uses it to interact with AWS. We create IAM users to permit GitLab to access and upload data to our S3 bucket.
## Configuring AWS account (S3, CF, ACM) and GitLab CI
We assume that you already have an active GitLab account. Now you need to sign up/in to your AWS profile to get access to the instruments mentioned above.
If you create a new profile, you automatically go under Amazon’s free tier which allows deploying to S3 during the first year. However, you should be aware that there are certain limitations in the [trial period usage](https://aws.amazon.com/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc).
### 1. Setting up an S3 Bucket
To set up S3, go to the S3 management console, create a new bucket, type in any name (i.e., yourdomainname.com) and the region. In the end, leave the default settings.

After that, set permissions to the public access in a new bucket. This way you make the website files accessible to users.
When permissions are set to public, move to the Properties tab and select the Static website hosting card. Tick the box “Use this bucket to host a website” and type your root page path (index.html by default) into the “Index document” field. Also, fill in the required information in the “Error document” field.
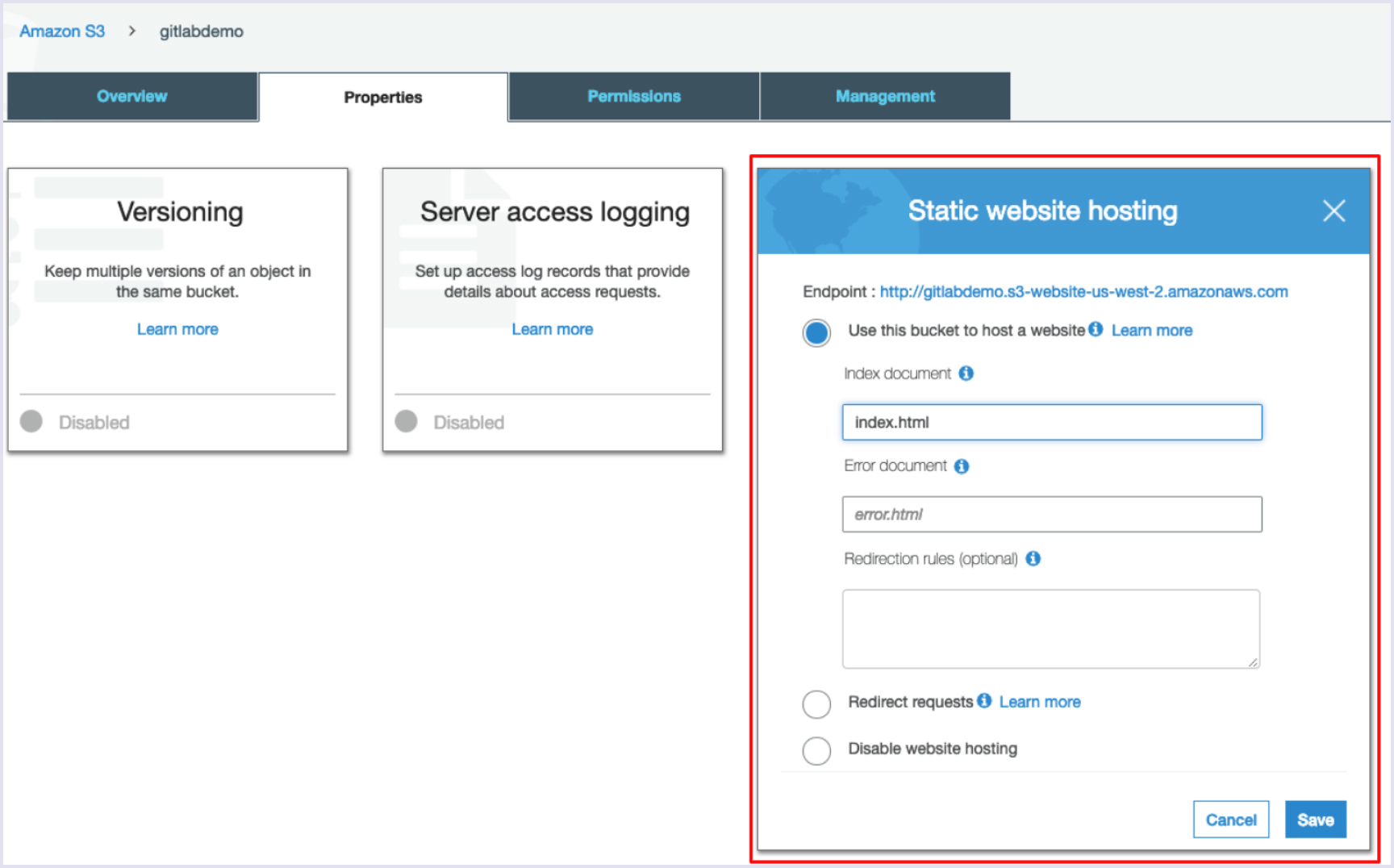
Finally, offer permissions to your S3 bucket to make your website visible and accessible to users. Go to the Permissions tab and click Bucket policy. Insert the following code snippet in the editor that appears:
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadForGetBucketObjects",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::yourdomainname.com/*"
}
]
}
```
### 2. Creating an IAM user that will upload content to the S3 bucket
At this stage, you should create an IAM user to access and upload data to your bucket. To accomplish this, move to the IAM management console and press the ‘Add User’ button to create a new policy with the chosen name.
After that, add the following code. Do not forget to replace the ‘Resource’ field value with the name you created. Thus, you enable users to get data from your bucket.
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::yourdomainname.com/*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "*"
}
]
}
```
The next step is creating a new user. Tick the Programmatic access in the access type section and assign it to the newly created policy.
Finally, click the ‘Create user’ button. There will be two important values: `AWS_ACCES_KEY_ID` and `AWS_SECRET_ACCESS_KEY` variables.
If you close the page, you will lose access to the `AWS_SECRET_ACCESS_KEY`. That is why we recommend that you write down the key or download the `.csv` file.
### 3. Setting up GitLab CI configuration
In the next stage of web hosting on Amazon, you need to establish the deployment process of your project to the S3 bucket. This stage supposes the correct set up of GitLab CI. Log in to your GitLab account and navigate to the project. Click Settings, then go to the CI / CD section and press the ‘Variables’ button in the dropdown menu. Here enter all the required variables, namely:
* `AWS_ACCESS_KEY_ID`
* `AWS_SECRET_ACCESS_KEY`
* `AWS_REGION`
* `S3_BUCKET_NAME`
* `CDN_DISTRIBUTION_ID`.
You do not have a `CDN_DISTRIBUTION_ID` variable yet, but it is not a problem. You will get it after creating CloudFront distribution.
After that, you need to tell GitLab how your website should be deployed to AWS S3. This can be done by adding the file `.gitlab-ci.yml` to your app’s root directory. Simply put, GitLab Runner executes the scenarios described in this file.
Let’s now get familiar with `.gitlab-ci.yml` and discuss its content step by step:
```yaml
image: docker:latest
services:
- docker:dind
```
An image is a read-only template that contains the instructions for creating a Docker container. So, we specify the image of the latest version as a basis for executing jobs.
```yaml
stages:
- build
- deploy
variables:
# Common
AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
AWS_REGION: $AWS_REGION
S3_BUCKET_NAME: $S3_BUCKET_NAME
CDN_DISTRIBUTION_ID: $CDN_DISTRIBUTION_ID
```
On the code snippet above, we specify the steps to pass during our CI/CD process (build and deploy) with the variables they require.
```yaml
cache:
key: $CI_COMMIT_REF_SLUG
paths:
- node_modules/
```
Here we cache the content of `/node_modules` to get the needed packages from it later, without downloading.
```yaml
######################
## BUILD STAGE ##
######################
Build:
stage: build
image: node:11
script:
- yarn install
- yarn build
- yarn export
artifacts:
paths:
- build/
expire_in: 1 day
```
At the build stage, we collect and save the results in the build/ folder. The data is kept in the directory for 1 day.
```yaml
######################
## DEPLOY STAGE ##
######################
Deploy:
stage: deploy
when: manual
before_script:
- apk add --no-cache curl jq python py-pip
- pip install awscli
- eval $(aws ecr get-login --no-include-email --region $AWS_REGION | sed 's|https://||')
```
In the `before_script` parameter, we specify necessary dependencies to install for the deployment process.
```yaml
script:
- aws s3 cp build/ s3://$S3_BUCKET_NAME/ --recursive --include "*"
- aws cloudfront create-invalidation --distribution-id $CDN_DISTRIBUTION_ID --paths "/*"
```
`Script` parameter allows deploying project changes to your S3 bucket and updating the CloudFront distribution.
When it comes to our development practice, there are two steps to pass during our CI/CD process: build and deploy. During the first stage, we make changes in the project code and save results in the /build folder. At the deployment stage, we upload the building results to the S3 bucket that updates the CloudFront distribution.
### 4. Creating CloudFront Origin
When you upload the important changes to S3, your final goal is to distribute content through your website pages by means of CloudFront. Let’s specify how this service works.
When users visit your static website, CloudFront offers them a cached copy of an application stored in different data centres all over the world.
Let’s assume that users open your website from the east coast of the USA. CloudFront will deliver the website copy from one of the servers there (New York, Atlanta, etc). This way, the service decreases the page load time and improves the overall performance.
To start with, navigate to the CloudFront dashboard and click the ‘Create Distribution’ button. Then type your S3 bucket endpoint in the ‘Origin Domain Name’ field. Origin ID will be generated automatically by autocompletion.
After that, move to the next section and tick ‘Redirect HTTP to HTTPS’ option under the Viewer Protocol Policy section. This way, you ensure serving the website over SSL.
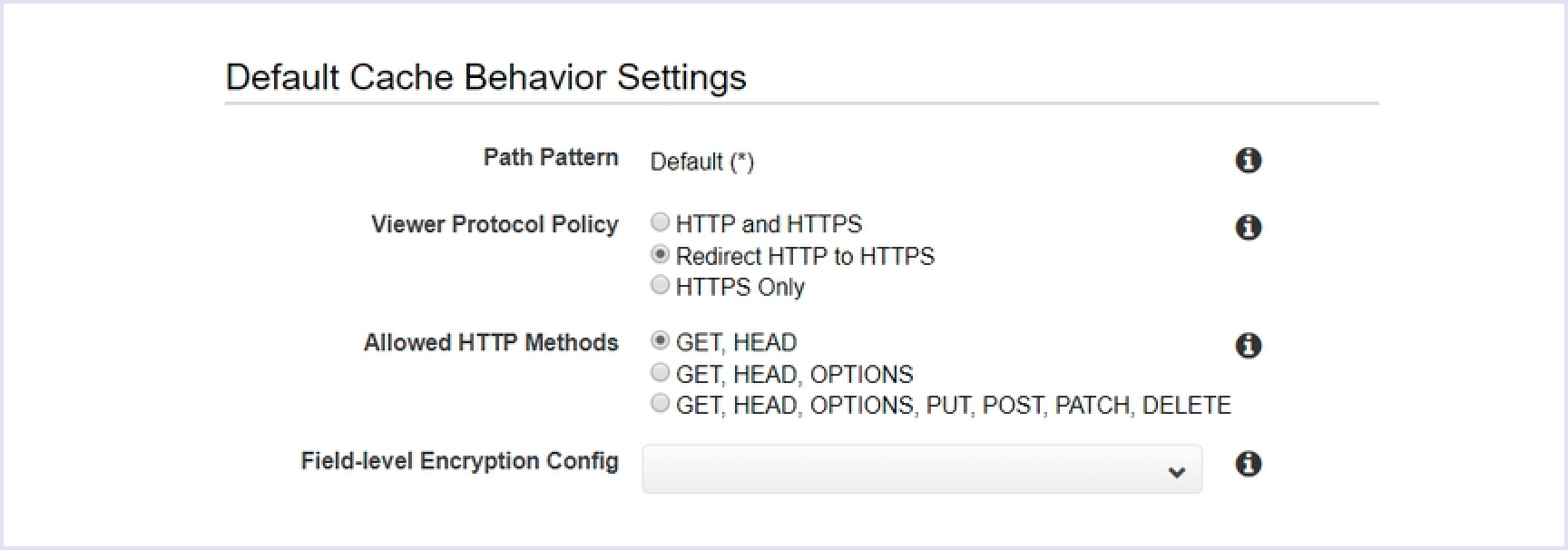
Then, enter your real domain name within Alternate Domain Names (CNAMEs) field. For example, www.yourdomainname.com.
You get a default CloudFront SSL certificate so that your domain name will contain the `.cloudfront.net` domain part.
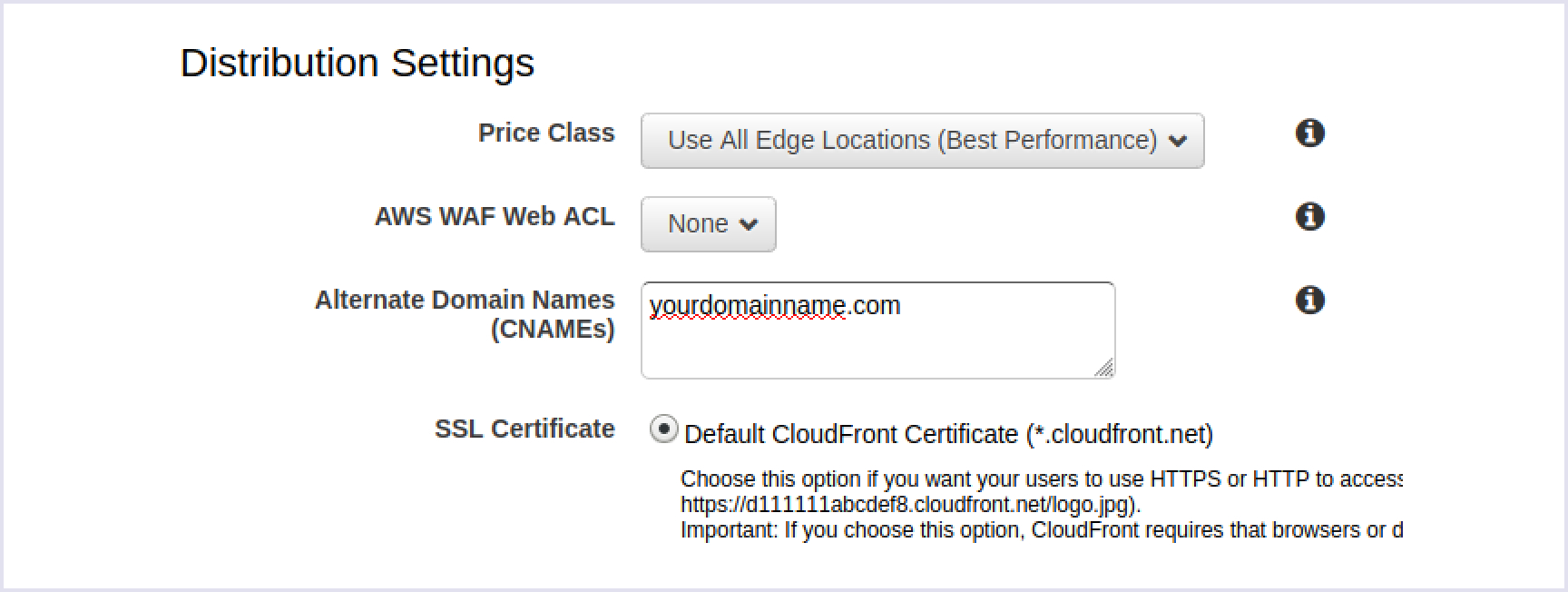
In case you need to get a custom SSL, click the Request or Import a Certificate with the ACM button.
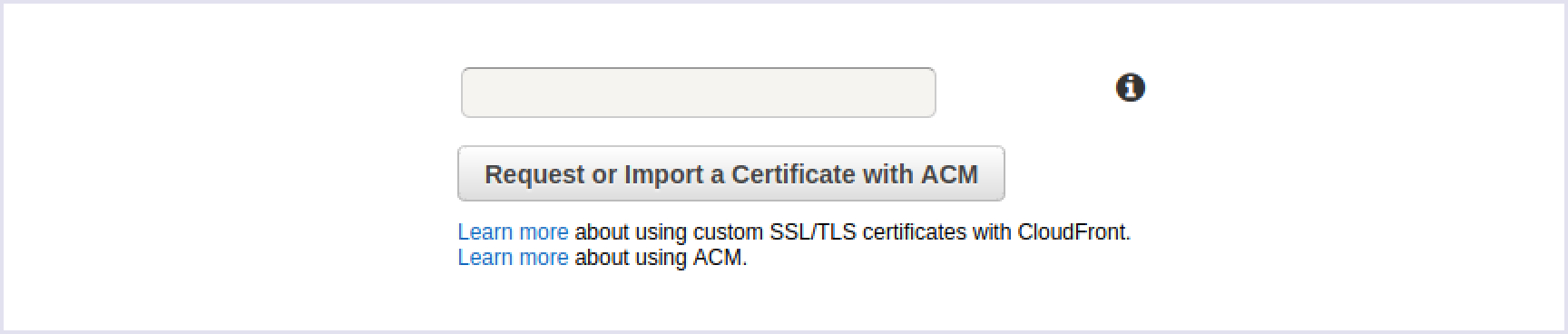
Replace your region with us-east-1, navigate to Amazon Certification Manager and add the desired domain name.
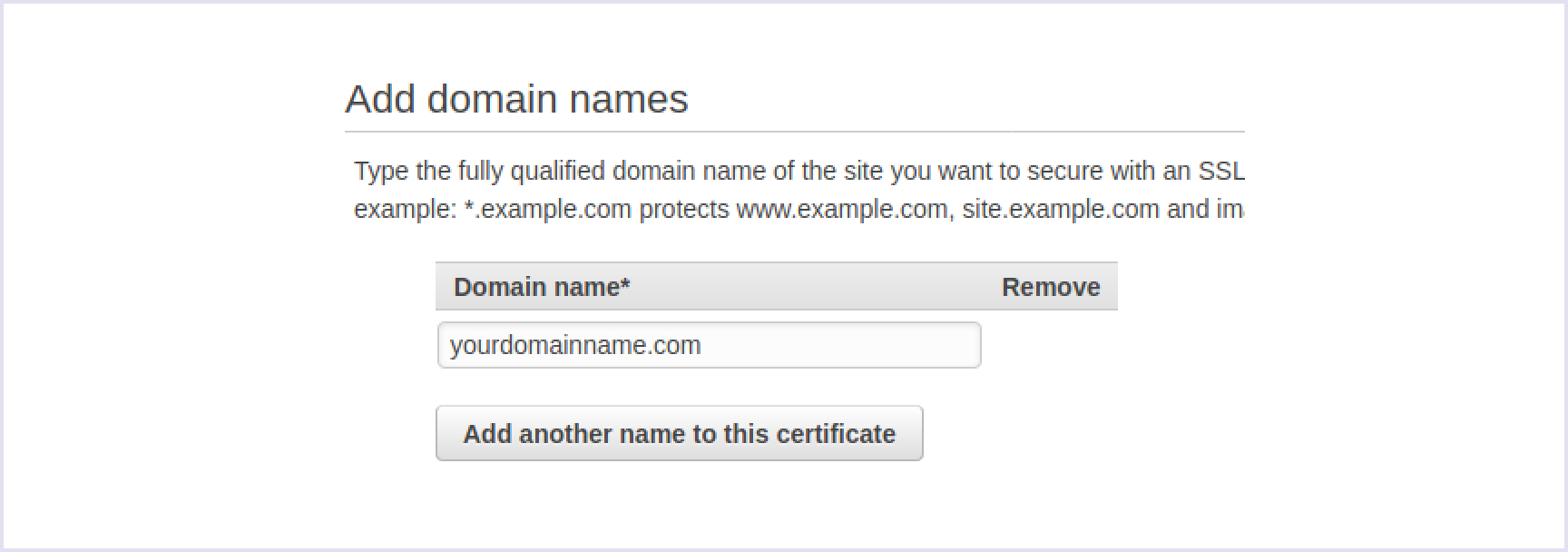
To confirm that you are the owner of the domain name, navigate to the settings of DNS, and specify CNAME there.
As soon as an SSL certificate is generated, choose the “Custom SSL Certificate” in this section.
At last, leave the remaining parameters set by default and click the ‘Create Distribution’ button.
This way, a new CloudFront origin is created that will be added to all the AWS edge networks within 15 minutes. You can navigate to the dashboard page and take a look at the State field which displays two conditions: pending or enabled.
As soon as the provisioning process is completed, you will see that the State field’s value is changed to Enabled. After that, you can visit the website by entering the created domain name address in an address bar.
## Final thoughts
We were happy to share our practices on AWS web hosting and deploying static sites to Amazon (storing files on S3 and distributing them with CloudFront) using GitLab CI.
*Read the [full version of this article](https://www.codica.com/blog/deploying-a-static-website-on-aws-web-hosting-with-gitlab-ci/) or check our [other articles](https://www.codica.com/blog/categories/development/) to get more tips on adopting the latest web app development techniques.*
| codicacom |
263,291 | I made a bash script to help automate adding new ssh keys | At my work, we have tons of ssh keys that we store in central repo. We have to move them to our .ssh... | 0 | 2020-02-17T17:47:50 | https://dev.to/george/i-made-a-bash-script-to-help-automate-adding-new-ssh-keys-1cnh | ssh, bash, showdev, zsh | At my work, we have tons of ssh keys that we store in central repo. We have to move them to our `.ssh` folder so we can ssh into server. But you also need to set the permissions on the key file after you move it.
I started to get annoyed with having to set permissions every time so I created a bash file to automate this.
```bash
#!/bin/bash
# add_ssh_key - A script to move ssh key and set permissions
##### Constants
SSH_DIR=~/.ssh/
# Check for path
if [ -z "$1" ]; then
echo "Please provide the path to the ssh key"
exit 1
fi
cp $1 $SSH_DIR
chmod 600 $SSH_DIR$(basename $1)
echo "Copied ${1} to .ssh dir and set permissions to 600"
```
I also have a [gist](https://gist.github.com/GeorgeNance/2a00ab91f225c84ae89b1abbbbbcb489) for it
Download and move that to whatever bin folder you have and run
`chmod +x` on the filename. For me, I made a bin folder at `~/bin` but you can put it wherever you want.
Then add an alias to your `.bashrc` or whatever file your terminals sources. For me that is a file called `.zshrc`
```bash
alias add_ssh_key="~/bin/add_ssh_key.sh"
```
Then open up a new terminal and you should be able to run:
```bash
add_ssh_key path/to/current/key
```
And pretso! 🎉 You have a key with proper permissions.
Thanks for reading! Let me know any ssh automation you have set up. | george |
263,335 | Swift | 1) We learned about structure types. This is a simple form of models. 2)Both of them are reusable ch... | 0 | 2020-02-17T18:50:54 | https://dev.to/rodman864/swift-4ag | 1) We learned about structure types. This is a simple form of models.
2)Both of them are reusable chunks of code, but methods belong to classes, structs, and enums, whereas functions do not.
3)Because it groups different values of other times together. | rodman864 | |
263,393 | Random notes taken while preparing for AWS Certified Developer Associate exam | Before we start - I'm working on https://cloudash.dev, a brand new way of monitoring serverless apps... | 0 | 2020-03-04T10:32:46 | https://dev.to/tlakomy/random-notes-taken-while-preparing-for-aws-certified-developer-associate-exam-2h4p | aws | ---
title: Random notes taken while preparing for AWS Certified Developer Associate exam
published: true
description:
tags: aws
---
Before we start - I'm working on [https://cloudash.dev](https://cloudash.dev), a brand new way of monitoring serverless apps 🚀. Check it our if you're tired of switching between 50 CloudWatch tabs when debugging a production incident.
<hr/>
I'm currently studying for the AWS Certified Developer Associate exam and I'll be taking my notes here, maybe you'll find it useful
BTW - I also produce my own **free** content for [egghead.io](https://egghead.io/s/km6vr) which will help you pass the Certified Developer Exam:
- [Learn AWS Lambda from scratch](https://egghead.io/playlists/learn-aws-lambda-from-scratch-d29d?af=6p5abz)
- [Build serverless applications with AWS Serverless Application Model (AWS SAM)
](https://egghead.io/playlists/learn-aws-serverless-application-model-aws-sam-framework-from-scratch-baf9?af=6p5abz)
- [Learn DynamoDB from scratch (work in progress)](https://egghead.io/playlists/learn-aws-dynamodb-from-scratch-21c3)
## Notes
- Elastic Beanstalk provides platforms for programming languages (Go, Java, Node.js, PHP, Python, Ruby), application servers (Tomcat, Passenger, Puma), and Docker containers.
- DynamoDB: One **read request unit** represents one strongly consistent read request, or two eventually consistent read requests, for an item up to 4 KB in size. Transactional read requests require 2 read request units to perform one read for items up to 4 KB.
- DynamoDB: One **write request unit** represents one write for an item up to 1 KB in size. If you need to write an item that is larger than 1 KB, DynamoDB needs to consume additional write request units. Transactional write requests require 2 write request units to perform one write for items up to 1 KB.
- If you'd like to create an API with API Gateway that will be available to other developers for $$, the feature you should use is Usage Plans and API Keys - you can configure usage plans and API keys to allow customers to access selected APIs at agreed-upon request rates and quotas that meet their business requirements and budget constraints.
- AWS Systems Manager Parameter Store provides secure, hierarchical storage for configuration data management and secrets management. You can store data such as passwords, database strings, and license codes as parameter values.
- Route 53: CNAME record are used to map one name to another. An A record is used to point a domain or subdomain to an IP address
- CloudTrail is used to record all API calls
- X-Ray is used to provide tracing data and debug your applications. It also be used cross accounts.
- Cognito User Pools are managed by AWS, if you'd like to use a 3rd party authorizer, you need to implement a Lambda Authorizer
- KMS Encryption SDK allows you to implement encryption best practices in your application. KMS Encrypt API Call might be used to encrypt small amounts of data (like a password) but they are not designed to encrypt application data.
- **AWS Storage Gateway** - The Storage Gateway service is primarily used for attaching infrastructure located in a Data center to the AWS Storage infrastructure. The AWS documentation states that; "You can think of a file gateway as a file system mount on S3."
- **Cognito** - A user authenticates against the **Cognito User Pool** to receive a set of JWT tokens. Those tokes are later exchanged for temporary AWS credentials in **Cognito Identity Pool**
## Cloudwatch
By default Cloudwatch monitors: CPU, Network, Disk and Status Check.
**RAM Utilization is a custom metric. By default EC2 monitoring is 5 minute intervals, unless you enable detailed monitoring (not free) which will then make it 1 minute intervals**
By default CloudWatch logs will store the data indefinitely (and you can change the retention of each Log Group at any time)
**You can receive data from any terminated EC2 or ELB instance after its termination**
CloudWatch custom metrics - the minimum granularity that you can have is 1 minute
Cloudwatch can be used on premise (just download the CloudWatch agent)
- Cloudwatch monitors performance (for instance - CPU utilization on an EC2 instance)
- Cloudtrail monitors API calls in the AWS platform
- AWS Config records the state of your AWS environment and can notify you of changes
## Kinesis:
- Kinesis Streams - has shards which can handle up to 1000 writes per second and 5 reads, both in range of single digit MBs. Requires an EC2 fleet of consumers that are going to process the data.
- Kinesis Hirehose - allows for automatic data processing with a Lambda function and the data is stored directly in S3 (both analyzed and non-analyzed data). Data can be also moved into RedShift but it'll need to be stored in S3 and copied to RedShift afterwards.

- The number of shards can waaay exceed the number of EC2 consumers, since they can process multiple shards at the same time.
>A shard is a uniquely identified sequence of data records in a stream. A stream is composed of one or more shards, each of which provides a fixed unit of capacity.
>Each shard can support up to 5 transactions per second for reads, up to a maximum total data read rate of 2 MB per second and up to 1,000 records per second for writes, up to a maximum total data write rate of 1 MB per second (including partition keys). The data capacity of your stream is a function of the number of shards that you specify for the stream. The total capacity of the stream is the sum of the capacities of its shards.
## Random stuff:
- SQS Delay Queues allow you to postpone delivery of new messages for a number of seconds. For instance we might want to add a delay of few seconds to allow for updates to the database to process before sending a notification to customers.
- The maximum size of an SQS message is 256kB, for something bigger (up to 2GB) we can use S3 to store them. You'd need to use Amazon SQS Extended Client Library for Java to manage them.
- When using AWS CLI, the default page size (that is - the number of responses) is 1000. That may cause problems, timeouts etc. In order to fix those errors use the `--page-size X` option of AWS CLI which will set the page size to X (so if you have 1000 items in a bucket and the page size is 100, it'll send 10 requests to the API). You can also limit maximum number of items returned with `--max-items`
- An AWS Lambda function can access VPC Resources and to do that you need to provide a subnetId and a securityGroupId to the lambda function\
- AWS CLI `--dry-run` option: The `--dry-run` option checks whether you have the required permissions for the action, without actually making the request, and provides an error response. If you have the required permissions, the error response is DryRunOperation, otherwise it is UnauthorizedOperation. | tlakomy |
263,416 | Harmony Modern Slim Boilerplate [NEED Upgrade] | Harmony Modern Slim Boilerplate [NEED Upgrade] I'm still developing and refactoring code, coz... | 0 | 2020-02-17T22:10:43 | https://dev.to/darkterminal/harmony-modern-slim-boilerplate-need-upgrade-86d | help, php, slimphp | ---
title: Harmony Modern Slim Boilerplate [NEED Upgrade]
published: true
description:
tags: help, php, slimphp, discuss
---
Harmony Modern Slim Boilerplate [NEED Upgrade]
I'm still developing and refactoring code, coz migrate from @slimphp 3 to 4 is a little bit hard. So give me time or anyone can help me past through.
Github Repository: [Harmony Modern Slim Boilerplate](https://github.com/harmony-betta/harmony/tree/dev-master)
Documentation: [Harmony Modern Slim Boilerplace Docs](https://bettadevindonesia.github.io/harmony-betta) | darkterminal |
263,435 | Online Business Ideas You Can Start Today | Blogging Blogging about your favorite topic is a low cost, low-risk way to produce somethi... | 0 | 2020-02-17T22:57:25 | https://dev.to/tychoo/online-business-ideas-you-can-start-today-34id | career, productivity | # Blogging
Blogging about your favorite topic is a low cost, low-risk way to produce something that is valuable to people. When you create value for people then you'll receive money. Money is made through selling products, books, consulting services, affiliate marketing and more.
With 10000+ visits a month, you can make money without much trouble. Ads are also a great way to monetize your traffic if you have this much traffic.
Once you find a web host to host your blog, you can make money fast.
# Become An Affiliate Marketer
Once again, a blog is a way to promote affiliate products. Companies also provide affiliate links for people to click to buy their products. If your blog has traffic, then you can promote your affiliate links with your blog.
# Sell Your Own Images and Designs
You can sell your own designs and photos online on many websites. If you have a talent for creating designs or photography, you can get people to buy them if you promote them to enough people.
Also, you can put your images of T-shirts, bags, hats, greeting cards, calendars and more and make more money.
# Build Apps
If you know how to program, then building apps is a great way to make money online. There're still lots of problems that need solving by people with apps. You just have to find out what people have problems with and then solve those problems accordingly.
Apps can be custom solutions for business and also mass-market solutions for a large audience.
# Buy and Sell Domains
A lot of domains are available for sales and many are popular because of their name. We can get ideas from domain auction sites to see what people like, and then we can buy the ones that are popular and then flip them for a profit.
# Conclusion
These are a few ways to make money online with varying amounts of upfront costs. We can make money off these ideas by experimenting with which ones of these take off for you. It takes time and perseverance to succeed, so you've to prepare not to give up even when times are tough. | aumayeung |
263,498 | React Concurrent Mode | Regardless of all the optimizations, we do in React apps, rendering process so far has been blocking and cannot be interrupted. With the introduction of new experimental React Concurrent Mode, rendering becomes interruptible. | 0 | 2020-02-18T03:27:50 | https://dev.to/szaranger/react-concurrent-mode-574e | react | ---
title: React Concurrent Mode
published: true
description: Regardless of all the optimizations, we do in React apps, rendering process so far has been blocking and cannot be interrupted. With the introduction of new experimental React Concurrent Mode, rendering becomes interruptible.
tags: React
---

## Previous workarounds
Debounce and throttle are common workarounds to mitigate for example stutter in an input field while typing.
Debounce – Only update the list after the user stops typing Throttle – Update the list with a certain maximum frequency
Similar to git branches
Concurrent Mode is like React working on git branches.
Eg:- Navigating between two screens in an app
In React Concurrent Mode, we can tell React to keep showing the old screen(like another git branch), fully interactive, with an inline loading indicator. And when the new screen is ready, React can take us to it.
Read more about React Concurrent Mode [in this article](https://seanamarasinghe.com/developer/react-concurrent-mode) | szaranger |
263,507 | Is there a free PHP deploy besides Heroku? | Tempat deploy PHP | 0 | 2020-02-18T03:44:07 | https://dev.to/mzaini30/is-there-a-free-php-deploy-besides-heroku-2md4 | discuss, help, php | ---
title: Is there a free PHP deploy besides Heroku?
published: true
description: Tempat deploy PHP
tags: discuss, help, php
---
| mzaini30 |
263,557 | Dancer2 Template-Toolkit Integrations with Routes | Dancer2 Template Integration with Routes This article is in continuation of our previous a... | 0 | 2020-02-18T06:18:13 | https://dev.to/akuks/dancer2-template-toolkit-integrations-with-routes-1gfm | perl, dancer2, webdev | # Dancer2 Template Integration with Routes
This article is in continuation of our previous article Basic Dancer2 Routes. If you are a new visitor, you can visit the previous article [here](https://ashutosh.dev/blog/post/2020/02/basic-dancer2-routing).
In this article, we learn about the templates (Template::Toolkit), and, it's integration with the Dancer2 routes. Assuming you already have a basic understanding of Dancer2 framework, HTML and CSS, we directly jump into the subject.
open the config.yml file

Let's open the app name.pm file and write the following:
```perl
get '/home' => sub {
template = 'home.tt';
};
```
As you observe by using the 'template' keyword, we tell the route to look for the template file under the *views* folder.
PS: 'home.tt' is the name of the template file.
At present, we did not create the 'home.tt' file, hence if we go to the /home on the browser, it throughs an error. Create the home.tt under the *views* folder, and, write the following text **I am at home** in it.

We are on the right track.
Have you noticed, we didn't write any CSS, headers, and footers but, we can still see CSS on our page. How we get these style sheets on our page?
We got the design from the main.tt template under the '*app_dir*/views/*layout* folder'.
Here is another question where we tell the application to include the main.tt template in the home.tt file?
The answer is in the *config.yml* file. See the screenshot for more details.

Instantly, delete all the contents of the main.tt template, and refresh the browser. What do you see right now?A blank page??? Where is the content vanished? We already defined the template in the config file, however there is no content on the web page. It is true the layout is defined in the config file but in the main.tt file we did not specify to render the content from other templates. Add [% content %] to the main.tt template and refresh the webpage.
```perl
[% content %]
```

This is what we want to see.
## Pass Template Variable
While developing the web application implementing the framework, the idea is to make it as dynamic as possible. For this, we need rendering the data at the server side and then pass to the standard template to display it on the web page.
```perl
get '/home' => sub {
my $name = 'Michael.';
template 'home.tt', { name => $name };
};
```
And to render the "name" in the home.tt template.
```html
I am at home. You can call me anytime [% name %].
```
Refresh the webpage and you can see the content.
### Pass array to the template
Just like variables, we can pass arrays and hashes to the templates.
```perl
get '/home' => sub {
my @numbers = ("One", "Two", "Three", "Four", "Five");
template 'home.tt', { numbers => \@numbers };
};
```
And in the template.
```html
Following are the numbers:
[% FOREACH num IN numbers %]
<p> [% num %] </p>
[% END %]
```
### Pass Hash to the template
```perl
get '/home' => sub {
my %hash_to_pass = (
{
1 => 'one',
2 => 'two',
3 => 'three',
4 => 'four'
}
);
template 'home.tt', { hash_num => \%hash_to_pass };
};
```
And in the template file, write the following
```html
Following are the numbers:
[% FOREACH num IN hash_num.keys %]
<p> [% num %] - [% hash_num.$num %] </p>
[% END %]
```
If you notice the FOREACH loop to iterate array and hash is almost same. The only difference is '.keys' which tell the template, this variable is a type of hash.
*[% hash_num.$num %]* is to print the value of the keys.
Refresh, the browser.

Nature of the hash, keys are not sorted.
Use *[% FOREACH num IN hash_num.keys.sort %]* for sorted results.
We can also hook the templates in the routes. We will cover it in a separate story of 'Hooks'. Stay tuned.
| akuks |
263,608 | How to Get Videos to Work in Safari With Gatsby and Service Workers | Adding service workers to a site breaks videos in Safari and iOS devices Photo by Thomas Russell on... | 0 | 2020-02-18T08:59:48 | https://medium.com/better-programming/how-to-get-videos-to-work-in-safari-with-gatsby-and-service-workers-9e1f099249ac | gatsby, react, javascript, serviceworkers | *Adding service workers to a site breaks videos in Safari and iOS devices*
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/10808/0*hXI8dA6cR4Q34Wr8)_Photo by [Thomas Russell](https://unsplash.com/@truss?utm_source=medium&utm_medium=referral) on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)_
I was making a website where [hero components](https://en.wikipedia.org/wiki/Hero_image) have videos, and before adding [gatsby-plugin-offline](https://www.gatsbyjs.org/packages/gatsby-plugin-offline/), everything was working fine. I did some browser testing and all browsers seemed fined, videos were fine. Then I decided that it’s time to add the service worker and to make the website installable and work offline. I added the plug-in and tested everything with Chrome and Android. Everything as it should be! But then I opened it with my iPad and saw that videos are not playing at all, not even loading.
That seemed odd as videos were implemented with the `<video>` HTML tag and they were standard MP4 files. Luckily, I had only added the service worker, so I started suspecting it had something to do with that.
I came across [Jeremy Keiths’ article](https://adactio.com/journal/14452) where he describes how he had the same problem. He refers to a solution and a more in-depth explanation in a [post by Phil Nash](https://philna.sh/blog/2018/10/23/service-workers-beware-safaris-range-request/). It looks like Safari needs service workers to support _byte-range requests_ to play media. As the [documentation for Safari](https://developer.apple.com/library/archive/documentation/AppleApplications/Reference/SafariWebContent/CreatingVideoforSafarioniPhone/CreatingVideoforSafarioniPhone.html#//apple_ref/doc/uid/TP40006514-SW6) says:
> “HTTP servers hosting media files for iOS must support byte-range requests, which iOS uses to perform random access in media playback.”
They both went with different approaches to a solution. Phil fixed the service worker to cache video files, but Jeremy opted for always loading videos from the network and never caching them.
I’m going to show you how to implement both solutions with `gatsby-plugin-offline`.
## Get Videos From the Cache
`gatsby-plugin-offline` uses [Workbox](https://developers.google.com/web/tools/workbox) for generating service workers. Luckily, Workbox already has an [advanced recipe](https://developers.google.com/web/tools/workbox/guides/advanced-recipes?authuser=0#cached-av) for how to serve videos and audio. This is exactly how we’ll implement it. We’ll just have to append it to the service worker generated by Gatsby.
First, we need to add attribute `crossOrigin="anonymous"` to our HTML `<video>` tag:
```javascript
<video src="movie.mp4" crossOrigin="anonymous"></video>
```
Second, we create a file that will be appended to the generated service worker file. Let’s name it `sw-range-request-handler.js`. We’ll put that into the root folder of our project.
Content of this file will be:
```javascript
// Add Range Request support to fetching videos from cache
workbox.routing.registerRoute(
/.*\.mp4/,
new workbox.strategies.CacheFirst({
plugins: [
new workbox.cacheableResponse.Plugin({ statuses: [200] }),
new workbox.rangeRequests.Plugin(),
],
}),
'GET',
);
```
We match all requested MP4 files and use `CacheFirst` strategy to search for video files from the cache. If there isn’t a cache match, then the file will be served from the network.
If you look at the example from [Workbox advanced recipes](https://developers.google.com/web/tools/workbox/guides/advanced-recipes?authuser=0#cached-av), you’ll see that the usage of plugin functions are a bit different. That’s because as of now, `gatsby-plugin-offline` uses Workbox v.4, but the example is for v.5.
You’ll see that we didn’t import any functions from Workbox, either. That’s because we only append our file content to the generated service worker file, where all those plugins are already added to the `workbox` object.
When `gatsby-plugin-offline` updates to v.5 of Workbox, we’ll need to update how we use the plugins:
```javascript
// Add Range Request support to fetching videos from cache
workbox.routing.registerRoute(
/.*\.mp4/,
new workbox.strategies.CacheFirst({
plugins: [
new workbox.cacheableResponse.CacheableResponsePlugin({
statuses: [200],
}),
new workbox.rangeRequests.RangeRequestsPlugin(),
],
}),
'GET',
);
```
Now we need to use the [appendScript](https://www.gatsbyjs.org/packages/gatsby-plugin-offline/#available-options) option in `gatsby-plugin-offline` config to append our file to the service worker. Add the `options` object to `gatsby-config.js`:
```javascript
{
resolve: `gatsby-plugin-offline`,
options: {
appendScript: require.resolve(`./sw-range-request-handler.js`),
},
},
```
Now running `gatsby build` command and looking into `public/sw.js` file, you’ll see that at the very end is our code. Showing videos in Safari and iOS devices will work again after the service worker is updated.
But this caches all our videos to Cache API storage, and when you have a lot them or they’re big files, then it’s probably not a very good idea to take that much space from the user’s device. And are the videos really that important when the user is offline?
## Get Videos From the Network
To never cache videos to storage and only get them from the network, you need to overwrite the Workbox config. That can be done by overwriting the [workboxConfig](https://www.gatsbyjs.org/packages/gatsby-plugin-offline/#overriding-workbox-configuration) object inside the `options` object.
First, we should still add the `crossOrigin="anonymous"` attribute to our HTML `<video>` tag:
```javascript
<video src="movie.mp4" crossOrigin="anonymous"></video>
```
Second, we modify the `gatsby-config.js` file to overwrite the existing `workboxConfig`:
```javascript
{
resolve: `gatsby-plugin-offline`,
options: {
workboxConfig: {
runtimeCaching: [
{
urlPattern: /.*\.mp4/,
handler: `NetworkOnly`,
},
],
},
},
},
```
We use `NetworkOnly` strategy to get our MP4 file. It will never be searched from the cache.
But be aware that our code now overwrites the default caching for `gatsby-plugin-offline`. It would be better to add it to the [existing list of caching options](https://www.gatsbyjs.org/packages/gatsby-plugin-offline/#overriding-workbox-configuration) so that everything else will still be cached, and with the right strategies.
## Conclusion
At first, it can be very confusing to understand why videos are not playing when the page has service workers, but these two solutions should fix that. This problem doesn’t occur only when using Gatsby, and there are solutions for those other situations, too.
If you’re using Workbox, then look at their [advanced recipes](https://developers.google.com/web/tools/workbox/guides/advanced-recipes?authuser=0#cached-av). If you’re using pure service worker implementation, then look at Jeremy Keith’s article “[Service Workers and Videos in Safari](https://adactio.com/journal/14452)” or the post by Phil Nash, “[Service Workers: Beware Safari’s Range Request](https://philna.sh/blog/2018/10/23/service-workers-beware-safaris-range-request/).” They give a more in-depth explanation about that problem.
Thanks.
| glukmann |
263,618 | MESG testnet using Cosmos & Tendermint | The MESG Foundation is building a blockchain of executions powered by the community's sharable micros... | 0 | 2020-02-18T09:15:46 | https://dev.to/williamzmorgan/mesg-testnet-using-cosmos-tendermint-247o | javascript, blockchain, cosmossdk, tendermint | The MESG Foundation is building a blockchain of executions powered by the community's sharable microservices and processes. They're using Cosmos & Tendermint to build the network(s), and just released a new testnet.
## New testnet
The new testnet was published on January 15th, 2020. It uses four validators spread around the world.
One validator is located in San Francisco, another is in Singapore, the third is in Frankfurt and the final validator is in Toronto. Four was chosen because it is the number of validators needed to tolerate a situation in which a single validator stops, or acts maliciously, without affecting the blockchain.
The goal of this testnet is to learn how the blockchain behaves under real-world conditions. We haven’t stress-tested the network yet, but this will come in the following weeks, so stay tuned :)
## Explorer
Feel free to [check out the network Explorer here](https://explorer.testnet.mesg.com/?utm_source=devto).
We also connected Grafana to the testnet for additional monitoring. The monitoring tool can be found [here.](https://monitoring.testnet.mesg.com)
For additional information on the testnet, head over to https://docs.mesg.com/guide/network, or to start your Engine on the testnet, execute the following command:
```
mesg-cli daemon:start --network mesg-testnet-01 --path $HOME/.mesg-testnet-01
```
## What's next?
Next, we will be working on updating the Engine to a classic Cosmos-SDK architecture, which will allow us to reuse the existing tools in the Cosmos ecosystem, while also allowing us to share the tools we create with the other parts of the Cosmos ecosystem. [Here are some of our recent contributions.](https://github.com/search?utf8=%E2%9C%93&q=user%3Atendermint+user%3Acosmos+author%3Anicolasmahe+author%3Aantho1404+author%3Akrhubert&type=Issues&ref=advsearch&l=&l=)
Also, we will be working on enabling the Engine to run in specific roles, such as orchestrator, service manager, or blockchain validator-only configurations. The goal of this is to reduce the computational requirements of individual Engines, thus allowing more users to run their own Engine.
View the [full article here](https://blog.mesg.com/mesg-product-update-february-20/?utm_source=devto). | williamzmorgan |
263,671 | Deploy NestJS on Google Cloud Run | Repository: WhatDaFox/nestjs-cloud-run-poc Configure Google Cloud To be able to build... | 0 | 2020-02-18T10:22:16 | https://whatdafox.com/deploy-nest-js-on-google-cloud-run/ | gcp, devops, tutorials | ---
title: Deploy NestJS on Google Cloud Run
published: true
date: 2020-02-18 00:00:00 UTC
tags: gcp, devops, tutorials
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/1e27ubcsxspm68bkgqk5.jpg
canonical_url: https://whatdafox.com/deploy-nest-js-on-google-cloud-run/
---
> Repository: [WhatDaFox/nestjs-cloud-run-poc](https://github.com/WhatDaFox/nestjs-cloud-run-poc)
## Configure Google Cloud
To be able to build and deploy, you will need a Google Cloud project, with a billing account set up, as well as
the [Google Cloud CLI](https://cloud.google.com/sdk/gcloud) installed.
Then you will need to create a configuration for your project:
```bash
$ gcloud config configurations create cloud-run
$ gcloud auth login # and follow the steps
$ gcloud config set project YOUR_PROJECT_ID
```
## Create the project
For this proof of concept, I will only use the default NestJS application, that contains a single endpoint `/` returning `Hello world!`:
```bash
$ npm i -g @nestjs/cli
$ nest new cloud-run
```
Cloud Run will decide the port of our application, so we have to update the `main.ts` file to reference the `PORT` environment variable, like so:
```typescript
import { NestFactory } from '@nestjs/core';
import { AppModule } from './app.module';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
app.enableCors();
await app.listen(process.env.PORT || 3000);
}
bootstrap();
```
Now we are ready to create the `Dockerfile`.
## Create the Dockerfile
We need to containerize our application to be able to run on Cloud Run. Create a Dockerfile at the root of your project and copy/paste the following:
> For better performance, I decided to build the app beforehand and run the `start:prod` command.
```dockerfile
# Use the official lightweight Node.js 12 image.
# https://hub.docker.com/_/node
FROM node:12-alpine
# Create and change to the app directory.
WORKDIR /usr/src/app
# Copy application dependency manifests in the container image.
# A wildcard is used to ensure both package.json AND package-lock.json are copied.
# Copying this separately prevents re-running npm install on every code change.
COPY package*.json ./
# Install dependencies
RUN npm install
# Copy local code to the container image.
COPY . ./
# Build the application
RUN npm run build
# Run the web service on container startup.
CMD [ "npm", "run", "start:prod" ]
```
## Build & Deploy
Now, we can use Cloud Build to build our docker image. Cloud Build will automatically detect our `Dockerfile`, build,
and push our image in Google Container Registry:
```bash
$ gcloud builds submit --tag gcr.io/YOUR_PROJECT/helloworld
```
Once that's done, we can run the following command to deploy our new revision to Cloud Run:
```bash
$ gcloud run deploy --image gcr.io/YOUR_PROJECT/helloworld --platform managed
```
## Benchmark
When testing, I ran a small (to avoid crazy costs) benchmark with Apache Benchmark.
Here is the command I ran:
```bash
$ ab -n 1000 -c 80 https://cloud-run-url/
```
Here are the results:
```
This is ApacheBench, Version 2.3 <$Revision: 1843412 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking cloud-run-url (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Completed 600 requests
Completed 700 requests
Completed 800 requests
Completed 900 requests
Completed 1000 requests
Finished 1000 requests
Server Software: Google
Server Hostname: cloud-run-url
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-CHACHA20-POLY1305,2048,256
Server Temp Key: ECDH X25519 253 bits
TLS Server Name: cloud-run-url
Document Path: /
Document Length: 12 bytes
Concurrency Level: 80
Time taken for tests: 8.624 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 486004 bytes
HTML transferred: 12000 bytes
Requests per second: 115.95 [#/sec] (mean)
Time per request: 689.939 [ms] (mean)
Time per request: 8.624 [ms] (mean, across all concurrent requests)
Transfer rate: 55.03 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 61 402 219.1 375 2652
Processing: 29 207 117.5 192 1328
Waiting: 24 168 114.6 146 1279
Total: 163 609 236.4 567 2819
Percentage of the requests served within a certain time (ms)
50% 567
66% 622
75% 681
80% 714
90% 804
95% 920
98% 1221
99% 1754
100% 2819 (longest request)
```
## Conclusion
It is pretty straightforward to build and deploy a container to Cloud Run. The response time can sometimes be pretty slow,
but overall, if the container is small and quick to start, it should run pretty smoothly. | valentinprgnd |
263,676 | How to start a comic blog like xkcd | Hello, I was wondering if someone with blogging experience could give me some insights about it. I al... | 0 | 2020-02-18T10:22:53 | https://dev.to/alebiagini/how-to-start-a-comic-blog-like-xkcd-5efl | help | ---
title: How to start a comic blog like xkcd
published: true
tags: help
---
Hello,
I was wondering if someone with blogging experience could give me some insights about it. I already have someone with drawing skills and we have some strips ready; My doubts were about the technologies we should use (wordpress, asp.net + angular spa etc), the hosting..
Any help is appreciated!
| alebiagini |
263,740 | Reverse Ordering | While working on a project, I needed to change the position of two divs based on screen size. This me... | 0 | 2020-02-18T12:04:07 | https://dev.to/ovieduke/reverse-ordering-4g84 | bootstrap, css, flexbox, webdev | While working on a project, I needed to change the position of two divs based on screen size. This meant that when the website is viewed on desktop, the divs are stacked same way as designed but when viewed on mobile, the divs should be reversed. I already knew there was a css property using display: none but that would mean duplicating code. Several solutions found only discussed row/column reverse. After some experimentation, I realized I could just reverse the flex direction. The goal of this tutorial is to show both div reverse ordering and column reverse ordering based on screen width <500px. Let us begin.
##The Goals
**Div Reverse**

**Div Reverse Mobile**

**Column Reverse**

**Column Reverse Mobile**

##The Markup
Since I am using bootstrap, I added a few inline styles:
```code`
<div class="divReverse p-5 mt-5 mb-4">
<div class="mb-5 mt-5 p-5 bg-primary">
<h1 class="first">Desktop 1st DIV </h1>
</div>
<div class="mb-5 mt-5 p-5 bg-info">
<h1>Desktop 2nd DIV </h1>
</div>
</div>
```
##Basic Styles
Used some CSS methods to reverse the div order
```code`
@media only screen and (max-width: 600px) {
.divReverse {
background: #A9A9A9;
display: flex;
flex-wrap: wrap-reverse;
}
}
```
##Conclusion
In this tutorial, we saw how we can easily reverse a div. For the complete code and that of column-reverse ordering, I have added a link to codepen https://codepen.io/dukeofwest/pen/JjdKbEV | ovieduke |
263,792 | The tools for the job - How I code frontend apps in 2020 | Introduction This is an exciting time to be a coder, especially a javascript one. Not only... | 0 | 2020-02-18T14:17:47 | https://dev.to/olup/the-tools-for-the-job-how-i-code-frontend-apps-in-2020-e03 | react, javascript, graphql | ## Introduction
This is an exciting time to be a coder, especially a javascript one. Not only is the market large, the pay high, but our tooling has never been so powerful, allowing one to build apps and systems at a speed unprecedented. Long are gone the days of my teens trying to painfully hack together a site with PHP, Dreamweaver and some buggy javascript snippets pushed online with FTP. With a clean decoupling between the front and the back, the entry of major frameworks to allow declarative code and single-page applications, source control and pain-free deployment process, we are living a golden age of web coding. And this is especially true in Javascript, be it server-side or client-side: I can't think of another ecosystem as steaming with ideas and changes as this one.
The tradeoff is the abundantly-discussed "js fatigue", the pain of discovering that one cannot rely on what was taught to him five years ago. In JS-land, you have to be always on the lookout for new libraries, good practices, trends. The reason for this is the huge participation of the community in trying to find better solutions to universal problems. In this booming environment, a change in one corner of the world can transform the trade quickly. Some solutions that were leading two years ago are now considered old fashion. Sometimes it's just trends. Sometimes paradigm shifts for the better. Evaluating the solidity of a JS library is a skill in itself that javascript devs have to learn. So doing javascript is engaging in a life of questioning and experimenting (and that may be why autodidact fare so well in this environment too, as they adapt very well) and I believe that this is exactly _why_ doing javascript is so exciting to me.
So in this post, I just wanted to share the latest setup I have found working when I start a frontend project. Nothing revolutionary here, this won't be news, and at times you might disagree with my views. But on the other hand that might make you curious about something you haven't heard of, or find the last push to finally try this stuff everyone has been talking about.
## Language
I am talking here about front-side development, a land completely dominated by javascript since it's the only dynamic programming language that can execute in a browser. Or until recently with the rise of WebAssembly. But even if we can find some amazing early work of react-like or vue-like framework for other languages (for example [Vugu](https://www.vugu.org/)), JS will likely keep managing the bulk of front end apps for a long time, and give way to native implementations only for heavy computing (like, say, video editing or 3d). So javascript is the language of choice for front end apps.
But for new projects, I now always use Typescript - the clear winner of the js types battle, and a very pleasant subset to use. It is so good and actually easy that I rarely code without it, even on a technical interview test or when coding a micro app to track my newborn daughter's diapers. So good that I started to refuse jobs when they don't use typescript, as I don't want to go back to refactoring hell. Pretty strong move from a guy that was saying he _"did not believe in it"_ a bit over three years ago.
Anyone saying such things hasn't probably used it, or only barely. But just give it a real try and you will see the enormous amounts of problems it solves. Not only does it imposes good standard practice and replace the chain of transpiling, but it also gives you the beautiful IDE intelliscence, the thing that boosts your productivity tenfold and provides strong confidence in your code. This is not the perfect silver bullet, you still have to test your code. But never again did I have to fry my brain while deciding to change the signature of one function: my IDE would tell me straight that it needed refactoring in ten different files.
The intellectual and time investment is small - or at least to get started and use basic types and inference - but the payoff is unfathomable before feeling it in everyday life.
**So bottom line: I use [TypeScript](https://www.typescriptlang.org/) for frontend projects, and I strongly believe you should, too.**
## Framework
Javascript is a language that can run in the browser (but also not in the browser, think node.js). In this particular position, it has access to the DOM, the list of all elements on our page, and can manipulate it. Javascript is _imperative_: you are telling your `div` with id `title` to change its content to the title you got from an XHR request. But when you have fifty such divs and a mighty complicated routing strategy, things become quite unmanageable. This is why the javascript frontend frameworks are so popular: because they shift to a _declarative_ paradigm. Link some variables to the 50 divs. Change the content of the js variable, and the 50 divs will change at once, without you worrying about making this happen. Also, it helps to decouple your app into reusable components, dividing the code into manageable chunks.
There are but three frameworks widely enough used today, and one of them is used way more than the other two, for, I believe, very good reasons. I won't launch into a comparison of them, whatever suits your boat, contract, abilities, etc... For me, having tried all of them, I go **React** all the way. If you have never tried it, or still think that it's arcane and complicated, I'd invite you to type `npx create-react-app myApp --typescript` in your terminal and see what fun it is to start a new React project. I actually start all my (non-SSR, see below) projects with `create-react-app` it has a perfect blend of opinions and freedom. I never feel any needs to eject.
React is pushing new ideas and practices. I would recommend following those as they steam from a simple yet powerful understanding of recurring pains in a coder's ass. React is truly elegant at heart. So there is no excuse not to use the latest features, like hooks and context, and keep moving as they get released.
To be honest, it's been a year that I haven't written a class component - and for the best!
Finally, typescript plays extremely well with React, an elegant way to type props and state.
**So bottom line: I use [React](https://reactjs.org/), with the latest features.**
## API
You are feeling that I am taking no risk here, just following the classic hype? Well, I am going to do it again!
You don't always have a say in the API the backend team is choosing. But when it's early enough (or when I also work on the backend team) I always try to push in the GraphQL direction.
An API is a language a server will understand when another machine asks it a question. There are many specifications one can use to build an API but as far as the communication between a browser javascript application and a server is concerned, we mainly see REST (or REST-like implementation) or more recently **Graphql**.
GraphQL, in terms of services rendered, would be the Typescript of API. It changed the way I worked as a React front end coder and made it so much better that I wish to never go back to REST. For those who haven't heard much more of it than the name, I could start describing it as what would your rest endpoint look like if you made a particularly complex query system to select each field you want returned - plus each field of any relations, for any level of nesting. And that it would also self-document, self validate, generates a playground to test it and allow you to load the typescripts types for any query in a single CLI command. So, yeah, pretty good.
GraphQL shines everywhere, but especially bright in javascript, where amazing tooling exists - as I should speak about again in a few paragraphs - and companies like [Apollo](https://www.apollographql.com/) or [Prisma](https://www.prisma.io/) and taking the technology to new levels every year. Major companies already have shifted towards it, and the trend can only go further.
It is always a good attitude to say about it (like about anything) "well, it depends on your project if you should choose it are not". But as far as my front end experience goes, I haven't met one situation, however small, where Graphql was not a good fit.
**Bottom line: when possible, choose [graphQL](https://graphql.org/)with the [Apollo client](https://www.apollographql.com/docs/react/), and if not, I would complain a little.**
## Routing
Once you understand you should separate the data management (backend) from the UI generation (front end), and as you have a powerful language working on the browser, it makes good sense to have it manage the whole site or app. And thus Single Page Apps where born. Every React/Vue/Angular/Whatever project will need some routing to map (declaratively, remember) the URLs to this or this component/page.
For this task, the safe React bet is React Router. It's mature, well maintained, kind of too big to fail. And now with propper hook API, it is getting better than ever.
But I would like to submit another powerful library (that I hope will keep being updated): [Hook Router](https://github.com/Paratron/hookrouter). Its API is very elegant, simple to reason about, and way less verbose than the leader I talked about. I would recommend it absolutely, weren't there some little issues that still have to be ironed out (trailing slash management, for example, is a small detail that tells you: maybe not mature enough).
**Bottom line: I would love to use Hook Router, but still am turning to [React Router](https://reacttraining.com/react-router/web/guides/quick-start) for professional projects. To be continued.**
## Styles
CSS are a pain. Because they rely on arbitrary namings that don't get type-checked; because they rely on a global scope and you can declare some class as many times as you want - making it easy to overload some rules, and hard to debug. And because they involve different professionals with different concerns and technical mindset (from designer to integrators to coders).
As HTML has been blended into JS code by the major javascript frameworks, they too are better handled in the javascript, so that the elements and components that we build get packaged with their styles, without said styles interfering with any other part of our application. That is called CSS-in-js, and as the other stuff I have been pointing here they are a game-changer, something you would deeply miss once tasted.
Many options here, CSS-in-js have just come out of the lush booming phase, as some stuff seems to start fading in the distance, others to slowly become mainstream. I have been trying quite some of them in the latest years, from basic CSS modules to Jss, Styletron or Radium.
But to me and many others, the big API winner is _Styled-Components_. It's elegant, fast, let's you write real CSS while injecting anything from the js in the form of a string template. Componentalizing and reuse are flawless. It's a bit of a change compared to a big stylesheet with atomic naming convention, so your integrator will have to adapt, and start working in the codebase - however, as it is still regular _(sa|le|c)css_, the shift is not too big to make.
As much as I enjoy _Styled-Components_, I think _Emotion_ even comes ahead. They offer the same API than SC, but adds some other niceties, like the `CSS` prop, and play way better with SSR in my experience.
**Bottom line: [Emotion](https://emotion.sh/) or [Styled-Component](https://styled-components.com/) is the way.**
## UI Kit
When building a front end application, coding the UI elements is a big part of the work. As a coder is not a designer (he might think he is - but he's not) and that you might want to spend your time to more interesting problems, using a UI kit is always a big win - for a quick POC, even for production use when the product is fairly generic.
There are just so many of them out there that you can't check them all out. Some seem mature and beautiful, others just kinds of _bla_. The key for me is: a nice API on the component props, beautiful styles, a large variety of components and proper styling abilities so that I can adapt the kit to my own design - or a client identity, and save everyone a lot of time and money.
I tried _Material UI_ (one of the biggest in the field), _Semantic UI_, _Evergreen_, _Blueprint_, _Atlaskit_, _Ant Design_, the One from Uber and even _React-Bootstrap_ (well, a long time ago). I must admit that I am a big geek of those and is always on the lookout for a new best solution.
[Material UI](https://material-ui.com/) was a direct dislike. Their theming system is - to my taste - painful and weird. I had a better story with [Ant Design](https://ant.design/), but again, their sass theming system is far from ideal (see the section before) plus it was kind of buggy to set up with SSR.
But sooner this year I stumbled upon **Chakra Ui**, and until now it checks all the boxes. Carefully made, nice looking, varied, and most of all: it's built with **Emotion** and follows the _Styled System Theme Specification_ for theming, which is extremely nice to use. Every component exports all the useful CSS attributes so that you can add a margin here or there without needing the `style` prop or adding CSS.
And on top of that, someone did https://openchakra.app/, a visual editor with Chakra Ui that produces React code. Not a big believer in those visual editors in general, but it's worth checking out.
**Bottom line: use whatever makes you happy, but I will keep starting up my projects with [Chakra Ui](https://chakra-ui.com/), and you should check it out if you haven't yet.**
## State Management
This is the time to bring up sate management. Once your app is well componentized, well decoupled, you start wondering how to inject, update and react to some global variables. The user data, for example, that are repeated in many discreet places - or a list of posts, the number of stars, the state of the UI, menu, top bar buttons, etc...
Since the introduction of the context API in React, you can inject a state - and have your components react to it - on any level of the tree. However, such a simple state sharing can become very messy: you quickly discover that debugging this shared state is often really difficult. The other essential thing that lacks in the `context+state or reducer hook solution` is the notion of _selectors_: when your shared state changes, all the components that listen to this state gets rerendered - and if this state was an object, you cannot link the component to specific keys of it. So your component gets rerendered every time any key changes, even though it doesn't use it. Of course, you can use memoization to temper the problem, but it becomes quite messy.
The big, golden standard in global state management is, of course, [Redux](https://redux.js.org/). Brought to us by _Our Dan Who Art In Facebook_, it combines flux design, immutability and good practices with an excellent debugging experience - and even a chrome extension to follow every step of your state changes. For me, it shines in big projects when many different developers work on the same app. If you do React you should know Redux, as you will have to use it sometime in your career.
However Redux is not without its faults. The main one would be the developer experience. Redux is not hard to understand or to set up, but it requires a lot of boilerplate code. It's extremely verbose - and this verbosity is sometimes a strength - but it feels tedious to use time and again. Adding async actions (you always need async actions) demands to add thunks or sagas, to your Redux setup - and it's more stuff to write.
Now, remember how I said GraphQL has amazing tooling for javascript? Apollo offers many nice features in its GraphQL client, one of them is a very powerful caching system. Every query you make will keep in memory everything that gets returned from the server, deserialized, and stored by type and ID. So that even if the queries are not the same - or that an object is deeply nested - it will update its local version. Then every component relying on query data containing the changed object will update on cache update. Again, this is very, very powerful. On mutations, you can easily update the cache yourself for optimistic changes - or ask for the updated data in response, and Apollo will do it for you - as long as you query the ID's on every cached object.
So, when building an app with Apollo, you don't need to store your data in a global state - which makes the bulk of Redux use - but only rely on Apollo queries, and let the magic happen. This is one of the boons of Graphql, and why it is so good to front-end coders. Should I add that there is a very good chrome extension to watch and debug your cache? Apollo offers many other features, but this is beyond this humble piece.
But then what about the data that doesn't come from the API? Ui states, for example? It's likely to be a small amount. However, even for this, I feel reluctant to use either a simple context state either the full Redux machinery.
Apollo offers a way to use their cache for any data you want, even local ones, and it can seem like a good fit for the task. However, it feels very strange to declare graphQL types, mutations and queries for simple state updates. I tried it but ended looking elsewhere.
For me the solution came from this very pleasant (and vegan) library, Easy-Peasy. It uses redux and Immer under the hood, but leverages react hooks and context API to provide for a very intuitive system. You build an object with your data and your actions (and type it with TS) and get a Provider on one side, some hooks on the other, that are selectors to actions or values. So, the best of everything: simple API, hooks ready, typescript ready, multiple global states are possibles, you get real selectors and - best of all: you have access to the Redux debug tool for a perfect debugging workflow.
**So bottom line: I use Apollo cache for server-sent data, and [Easy-Peasy](https://easy-peasy.now.sh/) for the rest - or almost all the rest, see the next section.**
## Forms
So, forms. At some point, it's difficult to manage one `useState` per field on your page. Then there is validation, that involves clean/dirty detection, error messages, rules, etc... Once you work on one form, you understand the underlying complexity of doing it properly.
So we want a library to do it. And one that is simple, not too bloated, and hook-ready. Well, there is one just here: [React Hook Form](https://react-hook-form.com/). It's elegant, powerful, simple. And, how good, there is a page in Chakra Ui documentation on how to implement Hook Form with it. Doesn't it feel like everything fits together?
Hook Form is my last piece for the state management triangle. I use it on every creation/edition page and plug it straight with apollo queries/mutations.
**Bottom line: [React Hook Form](https://react-hook-form.com/)**
## SSR and Prerendering
As with every JS framework, building the page on the client has one drawback: bots cannot crawl it's meta tags, and Google bots, even though they are supposed to be able to execute Javascript, will not do it in a consistent way (there is timeouts, etc...). So better not rely on that for SEO, and sharing preview is a no go.
For this, you need to serve the bots a fully built version of your site. As everyone knows, you have two ways to achieve this. Either you build the whole site on the server before sending it to any client (including bots) and let js then manage it from the browser - this is **SSR (server-side rendering)**; Or, you render the site only when a bot asks for it, on the cloud, with some headless chrome instance doing the work - and this is called **pre-rendering**.
So which one to use?
Here it depends on the project. But doing full SSR involves many tricks, and changing an existing codebase to enable it is a real pain. From my experience, doing prerendering is most of the time easier to build, mainly because it abstracts the rendering question from the react codebase. So then this is not a front-end concern, but an architecture/back end problematic. There are a few docker images that will do Prerendering out of the box if the team ever asks.
When it comes to full SSR, there is one major framework that does it well, it's [Next.js](https://nextjs.org/). My complaints with it are only related to the routing system: they follow the file system for it, and I didn't leave PHP behind to go back to this convention hell. Otherwise, coupled with Apollo, it's very efficient, and they have good code-splitting out of the box.
The last time I built SSR I used another tool called [Razzle](https://github.com/jaredpalmer/razzle), that felt more elegant at the time. If Razzle is very promising, it is not as well maintained as it is not backed by any company, and support is lagging a bit. Worth having a look, but for professional take-no-risk project, go with Next.
**Bottom line: For SEO and bots only, I'd say go with _prerendering_. SSR for end-user means gaining a bit of a better experience only on the first render of the site. It is some work for not so much gain.**
## Static site rendering
When your site is not very big or doesn't update that often, you may be interested in static rendering. That means SSRing all the pages your site contains in one pass, and serve everything from a static hosting then. No need for backend or API - at least not for your end-users - as all the data you need are included in the site at rendering time.
This is not limited to the front end, by the way. I static render an [API of French synonyms](https://synonymes.netlify.com/mot) that is huge (35000+ JSON documents) but will probably never renders another time.
I am no expert on the subject, but I very much dislike the leader of the field, Gatsby, for their weird data loading API. For my needs, I tend to favor either Next (the SSR framework has a pretty neat static rendering feature) or _React Static_, which is extremely versatile.
**Bottom line: for a blog or a simple presentational site - where data is no changing much - static rendering makes good sense. You can have a look at [React Static](https://react-static.js.org) for the most natural DX I could find.**
## Last words
There are other things that I don't have the energy to start about now. For example, I recommend integrating [Storybook](https://storybook.js.org/) as early as you can for any codebase beyond the odd side project, especially if some UI coding is involved - will save you a world of pain.
We could address testing - or the project's files organization. But that will be for another time.
Before leaving you, I wanted to stress how tiring it can feel to have new tools to learn, and how small the payoff can seem before you experience it yourself. This is a natural attitude. We learned once to adapt, to grow around the problems we had until we don't even see them anymore. But they are still here. When someone tells us "this lib is awesome, it solves this and this" and we think "I already have solutions for that" - well maybe we should give it a try. Remember how Jquery seemed once all we needed to build anything, and how we would never ever go back to it now that we worked with JS frameworks?
Javascript asks that we keep a keen mind - and never stop exploring. New solutions are found every day, and when they find their way to the main public it's usually because they solve real problems that you might have too - even if it seems that you don't. It's never a bad idea to take an hour and to try.
_Photo by Lachlan Donald on Unsplash_ | olup |
263,803 | Get Proximity switches and sensors in USA – HTM Sensors | HTM sensors offers high quality proximity switches and inductive proximity sensors tested by a variet... | 0 | 2020-02-18T14:09:04 | https://www.htmsensors.com/inductive-proximity-sensors/ | inductiveproximitysensors | HTM sensors offers high quality proximity switches and inductive proximity sensors tested by a variety of industries. Get in touch with HTM Sensors for competitive price and details about proximity switches. https://www.htmsensors.com/inductive-proximity-sensors/ | htmsensors |
263,852 | Learn how to make a Triangle in CSS once and for all | Warning: This is a new format of content that I tried to make which is very fast hopefully engaging.... | 0 | 2020-02-18T15:12:28 | https://dev.to/adriantwarog/learn-how-to-make-a-triangle-in-css-once-and-for-all-2pfe | webdev, html, beginners, css | <strong>Warning: This is a new format of content that I tried to make which is very fast hopefully engaging.</strong>
CSS triangles always frustrate me because I seem to always have to google how to make them every time I plan to add one. So I've made a video to both teach myself (and hopefully you) how to do it once and for all.
{% youtube UDxydHR91U8%}
In this video I cover:
* Fun and fast (hopefully enjoyable) format
* 3 properties a CSS triangle is made of
* Explaining how to make a CSS triangle go a certain direction
* Some examples of CSS triangles
* Making more complex triangles with CSS
<pre>
.css-triangle {
height:0px;
width:0px;
border-top:50px solid transparent;
border-bottom:50px solid transparent;
border-left:50px solid red;
}
</pre>
For more information, please watch the video and tell me what you think about this sort of format. Thanks!!!
## Follow and support me:
Special thanks if you subscribe to my channel :)
* [Youtube](https://www.youtube.com/channel/UCvM5YYWwfLwpcQgbRr68JLQ?sub_confirmation=1)
* [Patreon](https://www.patreon.com/adriantwarog)
* [Twitter](https://twitter.com/twarogadrian)
## Want to see more:
I will try to post new great content every day. Here are the latest items:
* [Full Tutorial on how to use SASS to improve your CSS](https://dev.to/adriantwarog/full-tutorial-on-how-to-use-sass-to-improve-your-css-57on)
* [4 Simple CSS Hover Transitions for your Elements Background](https://dev.to/adriantwarog/4-simple-css-hover-transitions-for-your-elements-background-4mlg)
* [How to implement Dark Mode with CSS new media call: prefers-color-scheme](https://dev.to/adriantwarog/how-to-implement-dark-mode-with-css-new-media-call-prefers-color-scheme-3h65)
* [Creating a Mobile Design and Developing it](https://dev.to/adriantwarog/creating-a-mobile-design-and-developing-it-5c4o) | adriantwarog |
263,888 | Best Side Project Ideas for Web developers | Side projects are one of the best ways to learn new things in web development. But it is often confus... | 0 | 2020-02-18T15:55:52 | https://dev.to/digvijaysingh/best-side-project-ideas-for-web-developers-1ghe | webdev, beginners, sideprojects |
Side projects are one of the best ways to learn new things in web development. But it is often confusing to choose the best project to invest time which will help us to learn different things and can also be profitable.
This part 2 of my previous post of [full Stack Web development Coding Project ideas](https://holycoders.com/full-stack-web-development-coding-project-ideas/)
Here are some of the best side projects which are helpful to learn new things and also profitable if you can SEO optimize them.
## Budget and Expense Tracker
This will be a great beginner level side project for web developers. Almost all of us need to budget and track our expenses.
It is generally a frontend project but you can extend it with user management feature that save the users data on the server. There are many other functionalities which you can add like a beautiful dashboard, import and export data, notifications and other which you seem fit.
You will learn a lot of new things like user management, advanced javascript and dealing with complex operations.
UI and UX are most important in these projects as they will make your project stand apart from the crowd.
## Custom Audio and Video Player
The native audio and video player in HTML are not that interactive. To overcome this problem you can create your own audio and video player with javascript.
Javascript has audio and video object which you can use to create and manage audio and video respectively. Creativity is the limit of features which you can add to these.
There are [many custom video players](https://blog.bitsrc.io/5-open-source-html5-video-players-for-2018-38fa85932afb) which you can use for inspirations. Very few custom Audio players are on the web so this is a great opportunity to create something useful in your side project.
You will learn many things with this project such as audio and video management with javascript and advanced styling.
## Desktop Wallpaper Application
Web technologies are expanding in different fields including desktop development. There are many frameworks to develop desktop applications, [Electron.js](https://www.electronjs.org/) is the most popular among them.
You can build a wallpaper application for different platforms using Electron.js. For wallpaper images, you can use Unsplash and Pixabay API.
Wallpaper applications are generally popular on mobile devices and there are tons of them. But in case of desktop, there are very few wallpaper applications.
It is one of the best projects for web developers because there are several things to learn here. You will learn about the development of software applications for desktop, API's, working with node and npm.
## Javascript and CSS Minifier
Javascript and stylesheet size really matters on the web because it affects the loading time of web pages.
One way to reduce the size of Javascript and CSS files is to minify them. Minifying is the process of removing any redundant or unnecessary data without affecting the performance. It generally includes the removal of comments, whitespace and renaming variable names (in case of javascript) to reduce size. Comments are removed because these files are not for human reading but only for browsers.
You can create your own algorithm to minify Javascript and CSS files if you are an advanced programmer or just use any npm package to do this heavy task.
## Online FTP Client
This may be a hard side project for web developers but you will learn a lot of things which be super useful in your future career.
You can create a simple FTP client to browse files using FTP or any website using its credentials.
The FTP client has functionality like create, update, edit and delete files and folders. It is not necessary to include all the features as it will take a lot of time, but you add some important ones which you seem fit.
This will be a great project for your portfolio also which will further help you to get a better job.
# Conclusion
These are some of the ideas to start coding and create something useful. Some web developers use to clone already existing websites and services for their side projects which may be good for learning purpose but we don't need to reinvent the wheel.
If there is an already existing service that lacks some functionality then that would be an opportunity to create something useful.
You must choose some challenging projects instead of old TODO type projects as there is no value of TODO type projects in the portfolio.
## Bonus: Infographics of 12 best web development side project ideas

Image by [HolyCoders Infographics](https://holycoders.com/infographics).
If you have more ideas, feel free to add them in comments. I will add them in the next post if they seem fit. | digvijaysingh |
263,894 | Best Monero Wallets (XMR Wallet) | Monero(XMR) is one of the top cryptocurrency focused on privacy and censorship-resistance. There are... | 0 | 2020-02-18T16:03:32 | https://blog.coincodecap.com/best-monero-wallets | monero, wallet, cryptocurrency, crypto | Monero(XMR) is one of the top cryptocurrency focused on privacy and censorship-resistance. There are a lot of [crypto wallets](https://blog.coincodecap.com/tag/crypto-wallet/) support Monero, but we have picked the best Monero wallets for you.
> Check out the complete list of [crypto wallets on CoinCodeCap](https://coincodecap.com/category/wallets).
### [Cake Wallet](https://cakewallet.com/?utm_source=coincodecap.com)
Cake Wallet is a Monero-only wallet with easy onboarding and multiple exciting features. It allows you to create multiple wallets with the same app, and you will control all your keys.
In addition, the wallet has multiple security features such as biometric authentication, pin support, and cloud backup.
Cake wallet is very beginner-friendly with advanced features such as adding your own remote Monero node.
Above all, it also integrated [ChangeNow](https://coincodecap.com/product/changenow-9) inside the app using which you can convert Monero with different cryptocurrencies.
**Features of Cake wallet**:
* You control your keys
* Completely Open source
* Monero’s unique subaddress
* Create multiple wallets and accounts with cloud backup
* Remote node support
* support [crypto exchange](https://blog.coincodecap.com/tag/crypto-exchange/) (ChangeNow, MorphTrade, XMR.to)
* Easy onboarding, Dark mode, and biometric authentication
* Maintain Address book
* Multi-language support
* Available only on Mobile
### [Monerujo wallet](https://www.monerujo.io/?utm_source=coincodecap.com)
Monerujo is a monero-only wallet for advance users with tons of features. It is entirely open-source and supports multiple wallet and account creation.
Because Monerujo a light wallet, therefore you need to select Monero node (It scan all the available nodes and shows you). You can also add your own Monero node.
The wallet offers the password and fingerprint feature for security. However, Monerujo is suitable for advanced users.
**Features of Monerujo wallet**:
* You hold your keys
* Completely open source
* Pay BTC Addresses through XMR.to
* View only XMR wallet
* Add your remote node
* Allow you to use a specific remote node for every transaction
* Multiple accounts and wallet support
* Secure your wallet using Password and fingerprint
* Available only on Mobile
### [MyMonero](https://mymonero.com/?utm_source=coincodecap.com)
Mymonero is an open-source Monero-only wallet. It has a simple design and beginner-friendly.
With MyMonero, you can create multiple wallets and control your keys. In addition, you can create contacts for a better payment experience.
It’s a lightweight, minimalist wallet with a good user experience.
**Features of MyMonero wallet**:
* You control your keys
* Linux and as well as web XMR wallet
* Create contracts
* Multi-wallet support
* Desktop, mobile, and online monero wallet
* Use password for security
### [Edge Wallet](https://edge.app/?utm_resource=coincodecap.com)
Edge is a multicurrency wallet with Monero support. It is open-source and provides basic privacy features. However, the Edge wallet doesn’t allow you to add your custom monero node.
It creates an account on the device which will be used to unlock and restore your wallet but do not provide your private keys, though private keys and account information never leave your device.
Edge wallet also allows you to buy and sell Monero using fiat and swap XMR with other altcoins and vice-versa.
**Features of Edge wallet**:
* Complete control over your Monero
* Basic privacy and transparency
* Supports multicurrency
* Available on Andriod and IOS
* Buy, sell Monero using fiat
* Swap cryptocurrencies
### [Monero Official Wallet](https://web.getmonero.org/downloads/#gui)
Monero’s official desktop wallet is an open-source Monero-only wallet. It has a simple design and supports different modes based on the user’s requirement.
1. Simple mode (Light wallet)
2. Simple mode with Monero full node
3. Advance node with Monero full node
For instance, if you are a beginner, you would like to use the simple light wallet, however, you can also support the network by running a full node with your wallet.
In addition, the wallet lets you control your keys and support all basic wallet features.
Official [crypto wallets](https://blog.coincodecap.com/tag/crypto-wallet/) are best for security; however, always double-check if you are downloading the wallet from the official website.
**Monero Official Wallet** **Features **
* Maintained by Monero team
* Support view-only XMR wallet
* Multiple accounts and wallet support
* Available only on Desktop
* Manage contacts using the address book
* Support simple and advance
* 30+ language support
### Monero (XMR) Hardware Wallets
Monero also funded a dedicated Monero hardware wallet project, [Kastelo](https://kastelo.org/). It’s an Open Source hardware wallet focus on private and censorship-resistant transactions.
Other than that latest versions [Trezor](https://coincodecap.com/product/trezor-9) and [Ledger](https://coincodecap.com/product/ledger-1) also support Monero.
Let us know what you think about our best monero wallets list and which XMR wallet you use and why?
**Also, read**
* [**Crypto Wallets**](https://blog.coincodecap.com/best-crypto-wallets-app/)
* [**Smart Contract Wallets**](https://blog.coincodecap.com/best-smart-contract-wallet/)
* **[BTC Wallets For Android](https://blog.coincodecap.com/best-btc-wallets-for-android/)**
* **[Hardware Wallets](https://blog.coincodecap.com/best-hardware-wallet-bitcoin/)**
| coincodecap_ |
263,901 | Coding useless stuff | “Creativity is intelligence having fun” – Albert Einstein Context: I recenlty made a talk about op... | 0 | 2020-02-18T16:24:56 | https://manfred.life/coding-useless-stuff/ | opensource, philosophy | ---
title: Coding useless stuff
published: true
date: 2020-01-20 00:00:00 UTC
tags: opensource, philosophy
canonical_url: https://manfred.life/coding-useless-stuff/
---
> “Creativity is intelligence having fun” – Albert Einstein
_Context: I recenlty made a [talk](/opensource-communities-presentation/) about open-source communities. At the end of the talk, I had very interesting questions from the audience. In this blog post, I will share with you why I love coding useless stuff!_
As children, we are encouraged to learn and try new things, we love experimenting and aren’t afraid of failure. But with time, we become more self-conscious and feel more pressure to perform. It’s not rare that people don’t even try doing something because they think this activity or its results will look “ridiculous” to observers.
I started coding over a decade ago and spoke to many programmers along the way, and noticed a tendency for stifling perfectionism in the IT community. Worrying about being scrutinized, that the projects aren’t “serious” enough, or the libraries used aren’t “fancy” enough. Like those high school rules we see in the movies – you should always try to sit at the table with the “cool kids”, and if anyone spots you sitting with that weird nerd, you’ll be labeled a loser.
Personally, I love, if not prefer, coding things that are “useless”. As Simone Giertz, a self-taught inventor who got famous building purposefully crappy robots, says in her talk: “Building these robots is an expression of joy and humility that often gets lost in engineering, and for me it was a way to learn about hardware without having my performance anxiety get in the way”.
It can start as abstract or quirky as I want it to, and I have a blank slate do develop it into anything I want, with no time pressure or being limited by specific tools. Implementing an idea is like solving a puzzle, I need to find the languages and libraries that are best suited for it, and learn a lot in the process. And it often turns out that the ideas and methods that were developed would give ideas that are implemented in my main projects, sometimes the very next day.
So, even though the result of such experimental coding might not be “useful” in and of itself, the overall experience brings a lot of fun and knowledge, and it often gives insights that help with the “serious” projects.
I have important projects that I do and often talk about, related to privacy, surveillance, censorship. But just as often I code for fun, and thoroughly enjoy it. It is entertaining as well as educational.
Learning isn’t passive; we need to fiddle with things to feel their structure, usages and limitations. As Kurt Lewin said, “If you want to truly understand something, try to change it.” | moul |
264,069 | New form generator is in the hood! Welcome Jafar 🌟 | New Form Generator by Verizon Media (Yahoo & Aol) was recently shared as an open source on Github... | 0 | 2020-02-18T16:47:07 | https://dev.to/galhavivi/new-form-generator-is-in-the-hood-welcome-jafar-b8k | react, javascript, opensource, form | New Form Generator by Verizon Media (Yahoo & Aol) was recently shared as an open source on Github! Its a based on a cool pure javascript form class, that any UI library (such as React, Angular and Vue) can use to expose Form and Field components. Currently contains also integration to React. Check it out, Try it out and I guarantee you wont go back to implement forms / manage pages without it again! :)
GitHub:
https://github.com/yahoo/jafar
Website:
https://yahoo.github.io/jafar/
Medium Post:
https://medium.com/@galhavivi/new-form-generator-is-in-the-hood-welcome-jafar-5b3b638aa0c | galhavivi |
264,136 | How to Integrate Auth0 with Oracle CX Commerce | Oracle CX Commerce customers can now leverage the Auth0 Platform. | 0 | 2020-02-18T18:42:52 | https://auth0.com/blog/how-to-integrate-auth0-with-oracle-cx-commerce/ | oraclecx, webdev, programming | ---
title: How to Integrate Auth0 with Oracle CX Commerce
published: true
description: Oracle CX Commerce customers can now leverage the Auth0 Platform.
tags: #oraclecx #webdev #programming
canonical_url: https://auth0.com/blog/how-to-integrate-auth0-with-oracle-cx-commerce/
---
TL;DR: In this article, we are going to discuss how Oracle CX Commerce and Auth0 can now be connected! We will walk through that process to see just how we can accomplish that!
Auth0 + Oracle CX Commerce
Auth0 and Oracle have partnered together to find a great opportunity that brings added value to our users. Oracle and Auth0 now empower customers to leverage the Auth0 platform to add identity and access management capabilities to commerce storefronts that are built and hosted on CX Commerce.
Oracle CX Commerce
Okay, but what is Oracle CX Commerce? CX Commerce is a leading enterprise SaaS commerce solution -- scalable, flexible, cloud-native, and built to support both B2B and B2C. Want to build an enterprise, highly customizable, feature-rich digital commerce business? CX Commerce’s solution provides for all of that!
[Read on 📖](https://auth0.com/blog/how-to-integrate-auth0-with-oracle-cx-commerce/?utm_source=twitter&utm_medium=sc&utm_campaign=auth0_oraclecx) | bachiauth0 |
264,283 | Moving Towards Domain Driven Design in Go | Domain driven design sounds great in theory, but how is it applied in Go? In this article we explore some code as it slowly evolves into DDD, learning how and why each decision is made along the way and what benefits it will provide us in the future. We then discuss the pros and cons of starting with a more domain-focuses design. | 2,880 | 2020-02-18T23:00:55 | https://www.calhoun.io/moving-towards-domain-driven-design-in-go/ | go, webdev | ---
title: Moving Towards Domain Driven Design in Go
published: true
description: Domain driven design sounds great in theory, but how is it applied in Go? In this article we explore some code as it slowly evolves into DDD, learning how and why each decision is made along the way and what benefits it will provide us in the future. We then discuss the pros and cons of starting with a more domain-focuses design.
tags: golang, go, webdev
canonical_url: https://www.calhoun.io/moving-towards-domain-driven-design-in-go/
series: Structuring Web Applications in Go
---
> *This article is part of a [larger series on Go application structure](https://www.calhoun.io/structuring-web-applications-in-go/) that was originally posted on [calhoun.io](https://www.calhoun.io/moving-towards-domain-driven-design-in-go/), where I write about Go, web dev, testing, and more. I will be porting the entire series over to Dev.to, but I appreciate you checking out on my website and the Go courses that I create 😀*
The goal of this article is to help illustrate how an application might evolve over time so that we can understand some of the problems that a more domain driven design might help with. To that end, we are going to look at a fairly trivial project as it evolves over time. This project won't be complete - the sample code won't compile, isn't tested with a compiler, and doesn't even list imports. It is simply meant to be an example to follow along with. That said, if anything seems wrong feel free to reach out and I'll fix it up or answer your questions (if I can!)
First, let's discuss the project. Imagine that you are at work and your boss asks you to create a way to authenticate users via the GitHub API. More specifically, you are going to be given a user's personal access token, and you need to look up the user as well as all of their organizations. That way you can later restrict their access based on what orgs they are a part of.
*Note: We are using access tokens to simplify the examples.*
Sounds easy enough, so you fire up your editor and whip up a `github` package that provides this functionality.
```go
package github
type User struct {
ID string
Email string
OrgIDs []string
}
type Client struct {
Key string
}
func (c *Client) User(token string) (User, error) {
// ... interact with the github API, and return a user if they are in an org with the c.OrgID
}
```
*Note: I am not really using the GitHub API here - this is a mostly made up example.*
Next you to take your `github` package and write some middleware that can be used to protect some of our HTTP handlers. In this middleware you will retrieve a user's access token from a basic auth header and then use the GitHub code to look up the user, check to see if they are part of the provided org, then grant or deny access accordingly.
```go
package mw
func AuthMiddleware(client *github.Client, reqOrgID string, next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
token, _, ok := r.BasicAuth()
if !ok {
http.Error(w, "Unauthorized", http.StatusUnauthorized)
return
}
user, err := client.User(token)
if err != nil {
http.Error(w, "Unauthorized", http.StatusUnauthorized)
return
}
permit := false
for _, orgID := range user.OrgIDs {
if orgId == reqOrgID {
permit = true
break
}
}
if !permit {
http.Error(w, "Unauthorized", http.StatusUnauthorized)
return
}
// user is authenticated, let them in
next.ServeHTTP(w, r)
})
}
```
You present this to your peers and they are concerned with the lack of tests. More specifically, there doesn't seem to be a way to verify this `AuthMiddleware` works as advertised. "No problem," you say, "I'll just use an interface so we can test it!"
```go
package mw
type UserService interface {
User(token string) (github.User, error)
}
func AuthMiddleware(us UserService, reqOrgID string, next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
token, _, ok := r.BasicAuth()
if !ok {
http.Error(w, "Unauthorized", http.StatusUnauthorized)
return
}
user, err := us.User(token)
if err != nil {
http.Error(w, "Unauthorized", http.StatusUnauthorized)
return
}
permit := false
for _, orgID := range user.OrgIDs {
if orgId == reqOrgID {
permit = true
break
}
}
if !permit {
http.Error(w, "Unauthorized", http.StatusUnauthorized)
return
}
// user is authenticated, let them in
next.ServeHTTP(w, r)
})
}
```
Now you can test this code with a mock user service.
```go
package mock
type UserService struct {
UserFn func(token string) (github.User, error)
}
func (us *UserService) Authenticate(token string) (github.User, error) {
return us.UserFn(token)
}
```
There are a bunch of different ways to create this mock user service, but this is a pretty common approach to test both cases where authentication works and cases where it returns an error.
The authentication middleware is then tested, released, and life seems jolly.
And then tragedy strikes. Your CEO hears that Godzilla is on his way to San Francisco and your company just can't keep using GitHub with that kind of uncertainty. What if their entire office is crushed and no engineers are around who know the product?!? Nope, that won't do. Completely unacceptable.
Luckily there is this alternative company named GitLab that seems to do a lot of the same things GitHub does, but they have a remote team. That means Godzilla can never wipe out all of their engineers, right? 🎉
The higher ups at your company seem to agree with this logic and they start to make the transition. Your job? You are tasked with making sure all of that authentication code you wrote works with the new system!
You spend some time looking at the GitLab API docs, and the good news is it looks like the same overall strategy will still work. GitLab has personal access tokens, organizations, and you just need to re-implement the client. The code in the middleware shouldn't need changed at all because you were a smart cookie and you used an INTERFACE! 😁 You get to work creating the GitLab client...
```go
package gitlab
type User struct {
ID string
Email string
OrgIDs []string
}
type Client struct {
Key string
}
func (c *Client) User(token string) (User, error) {
// ... interact with the gitlab API, and return a user if they are in an org with the c.OrgID
}
```
Then you go to plug that into the `AuthMiddleware`, but wait a minute, it won't work!
It turns out even interfaces can fall victim to coupling. In this case it is because your interface expects a `github.User` to be returned by the `User` method.
```go
type UserService interface {
User(token string) (github.User, error)
^^^^^^^^^^^
}
```
What are you to do? Your boss wants this shipped yesterday!
At this point you have a few options:
1. Change your middleware so that the `UserService` interfaces expects a `gitlab.User` instead of a `github.User`
2. Create a new authentication middleware specifically for GitLab.
3. Create a common user type that will allow both your github and gitlab implementations to be interchangeable in the `AuthMiddleware`
(1) might make sense if you were confident that your company was going to stick with GitLab. Sure, you will need to change both the user service interface and the mocks, but if it is a one time change isn't so bad.
On the other hand, you don't really know that your org will stick with GitLab. After all, who let's Godzilla attacks dictate their decision process?
This option can also be problematic if many pieces of code throughout your application are reliant on the `github.User` type returned by this package.
(2) would work, but it seems a bit silly. Why would we want to rewrite ALL of that code and all of those tests when none of the logic is changing? Surely there must be a way to make this interface thing work as you originally intended. After all, that middleware really doesn't care how the user is looked up as long as we have a few critical pieces of information to work with.
So you decide to give (3) a shot. You will create a `User` type in your `mw` package and then you will write an adapter to connect it with the GitLab client you created.
```go
package mw
type User struct {
OrgIDs []string
}
type UserService interface {
User(token string) (User, error)
}
```
As you write the code, you come to another realization; because you don't really care about things like a user's ID or email you can drop those fields entirely from your `mw.User` type. All you need to specify here are fields you actually care about, which should make things easier to maintain and test. Neato!
Next up you need to create an adapter, so you get to work on it.
```go
// Package adapter probably isn't a great package name, but this is a
// demo so deal with it.
package adapter
type GitHubUserService struct {
Client *github.Client
}
func (us *GitHubUserService) User(token string) (mw.User, error) {
ghUser, err := us.Client.User(token)
if err != nil {
return mw.User{}, err
}
return mw.User{
OrgIDs: ghUser.OrgIDs,
}, nil
}
type GitLabUserService struct {
Client *gitlab.Client
}
func (us *GitLabUserservice) User(token string) (mw.User, error) {
glUser, err := us.Client.User(token)
if err != nil {
return mw.User{}, err
}
return mw.User{
OrgIDs: glUser.OrgIDs,
}, nil
}
```
You also need to update your mock, but that is a pretty quick change.
```go
package mock
type UserService struct {
UserFn func(token string) (mw.User, error)
}
func (us *UserService) Authenticate(token string) (mw.User, error) {
return us.UserFn(token)
}
```
And now if you want to use our `AuthMiddleware` with either GitHub or GitLab you can do so with code something like this:
```go
var myHandler http.Handler
var us mw.UserService
us = &GitLabUserservice{
Client: &gitlab.Client{
Key: "abc-123",
},
}
// This protects your handler
myHandler = mw.AuthMiddleware(us, "my-org-id", myHandler)
```
Alas, we finally have a solution that is completely decoupled. We can easily switch between GitHub and GitLab, and when the new hip source control company kicks off we are prepared to hop on that bandwagon.
## Finding a middle ground
In the previous example, we gradually watched the code go from what I consider tightly coupled to completely decoupled. We did this using the `adapter` package, which handles translating between these decoupled `mw` and `github/gitlab` packages.
The primary benefit is what we saw at the very end - we can now decide whether to use a GitHub or GitLab authentication strategy when setting up our handlers and our authentication middleware is entirely agnostic of which we choose.
While these benefits are pretty awesome, it isn't fair to explore these benefits without also exploring the costs. All of these changes presented more and more code, and if you look at the original version of out `gitlab` and `mw` packages they were significantly simpler than the final versions that need to make use of the `adapter` package. This final setup can also lead to more setup, as somewhere in our code we need to instantiate all of these adapters and plug things together.
If we continued down this route, we might quickly find that we need many different `User` types as well. For example, we might need to associate an internal user type with external user IDs in services like GitHub (or GitLab). This could lead to defining an `ExternalUser` in our database package and then writing an adapter to convert a `github.User` into this type so that our database code is agnostic to which service we are using.
I actually tried doing this on one project with my HTTP handlers just to see how it turned out. Specifically, I isolated every endpoint in my web application to its own package with no external dependencies specific to my web application and ended up with packages like this:
```go
// Package enroll provides HTTP handlers for enrolling a user into a new
// course.
// This package is entirely for demonstrative purposes and hasn't been tested,
// but if you do see obvious bugs feel free to let me know and I'll address
// them.
package enroll
import (
"io"
"net/http"
"github.com/gorilla/schema"
)
// Data defines the data that will be provided to the HTML template when it is
// rendered.
type Data struct {
Form Form
// Map of form fields with errors and their error message
Errors map[string]string
User User
License License
}
// License is used to show the user more info about what they are enrolling in.
// Eg if they URL query params have a valid key, we might show them:
//
// "You are about to enroll in Gophercises - FREE using the key `abc-123`"
// ^ ^ ^
// Course Package Key
//
type License struct {
Key string
Course string
Package string
}
// User defines a user that can be enrolled in courses.
type User struct {
ID string
// Email is used when rendering a navbar with the user's email address, among
// other areas of an HTML page.
Email string
Avatar string
// ...
}
// Form defines all of the HTML form fields. It assumes the Form will be
// rendered using struct tags and a form package I created
// (https://github.com/joncalhoun/form), but it isn't really mandatory as
// long as the form field names match the `schema` part here.
type Form struct {
License string `form:"name=license;label=License key;footer=You can find this in an email sent over by Gumroad after purchasing a course. Or in the case of Gophercises it will be in an email from me (jon@calhoun.io)." schema:"license"`
}
// Handler provides GET and POST http.Handlers
type Handler struct {
// Interfaces and function types here serve roughly the same purpose. funcs
// just tend to be easier to write adapters for since you don't need a
// struct type with a method.
UserFn func(r *http.Request) (User, error)
LicenseFn func(key string) (License, error)
// Interface because this one is the least likely to need an adapter
Enroller interface {
Enroll(userID, licenseKey string) error
}
// Typically satisfied with an HTML template
Executor interface {
Execute(wr io.Writer, data interface{}) error
}
}
// Get handles rendering the Form for a user to enroll in a new course.
func (h *Handler) Get() http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
user, err := h.UserFn(r)
if err != nil {
// redirect or render an error
return
}
var data Data
data.User = user
var form Form
err := r.ParseForm()
if err != nil {
// maybe log this? We can still render
}
dec := schema.NewDecoder()
dec.IgnoreUnknownKeys(true)
err = dec.Decode(&form, r.Form)
if err != nil {
// maybe log this? We can still render
}
data.Form = form
if form.License != "" {
lic, err := h.LicenseFn(form.License)
data.License = lic
if err != nil {
data.Errors = map[string]string{
"license": "is not valid",
}
}
}
h.Executor.Execute(r, data)
}
}
// Post handles processing the form and enrolling a user.
func (h *Handler) Post() http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
user, err := h.UserFn(r)
if err != nil {
// redirect or render an error
return
}
var data Data
data.User = user
var form Form
err := r.ParseForm()
if err != nil {
// maybe log this? We can still render
}
dec := schema.NewDecoder()
dec.IgnoreUnknownKeys(true)
err = dec.Decode(&form, r.Form)
if err != nil {
// maybe log this? We can still render
}
data.Form = form
err = h.Enroller.Enroll(user.ID, form.License)
if err != nil {
data.Errors = map[string]string{
"license": "is not valid",
}
// Re-render the form
h.View.Execute(r, data)
return
}
http.Redirect(w, r, "/courses", http.StatusFound)
}
}
```
In theory this idea sounded pretty cool. I could now define all of my HTTP handlers in isolation without worrying about the rest of my application. Each package could be tested easily, and when I was writing these individual pieces I found myself incredibly productive. I even had an interface named `Executor`, and who doesn't want an executor in their code?!?
In practice, this idea was awful for my particular use case. Yes, there were benefits, but they weren't outweighing the cost of writing all this code. I was productive when creating the internals of the `enroll` and similar packages, but I spent so much time writing adapters and connecting pieces together that it crushed my productivity overall. I couldn't find a quick way to plug this into my code without needing to write a custom `UserFn`, `LicenseFn`, and I found myself writing a bunch of virtually identical variants of `UserFn` for every package with http handlers.
This leads to the topic of this section - **is there a way to come up with a reasonable middle ground?**
I like to decouple my code from third party dependencies. I like writing testable code. But I don't like doubling my coding efforts to make this happen. Surely there must be a middle ground here that gives us most of the benefits without all that extra code, right?
**Yes, yes there is a middle ground** and the key to finding it isn't to remove all coupling, but to intentionally pick and choose what your code is coupled to.
Let's go back to our original example with the `github` and `gitlab` packages. In our first version - the tightly coupled version - we had a `github.User` type that our `mw` package had a dependency on. It works well enough to get started, and we can even build interfaces around it, but we are still tightly coupled to the `github` package.
In our second version - the decoupled version - we had a `github.User`, a `gitlab.User`, and `mw.User`. This allowed us to decouple everything, but we have to create adapters that attach these decoupled pieces together.
The middle ground, and the third version we will explore, is to intentionally define a `User` type that every package is allowed to be tightly coupled to. By doing this, we are intentionally choosing where that coupling happens and can make that decision in a way that still makes it easy to test, swap implementations, and do everything else we desire from decoupled code.
First up is our `User` type. This will be created in a `domain` package that any other packages in our application can import.
```go
package domain
type User struct {
ID string
Email string
OrgIDs []string
}
```
Next we will rewrite our `github` and `gitlab` packages to leverage this `domain.User` type. These are basically the same since I stubbed out all the real logic, so I'll only show one.
```go
package gitlab // github is the same basically
type Client struct {
Key string
}
// Note the return type is domain.User here - this code is now coupled to our
// domain.
func (c *Client) User(token string) (domain.User, error) {
// ... interact with the gitlab API, and return a user if they are in an org with the c.OrgID
}
```
And finally we have the `mw` package.
```go
package mw
type UserService interface {
User(token string) (domain.User, error)
}
func AuthMiddleware(us UserService, reqOrgID string, next http.Handler) http.Handler {
// unchanged
}
```
We can even write a mock package using this setup.
```go
package mock
type UserService struct {
UserFn func(token string) (domain.User, error)
}
func (us *UserService) Authenticate(token string) (domain.User, error) {
return us.UserFn(token)
}
```
## Domain Driven Design
I have tried to avoid any confusing terms up to this point because I find that they often complicate matters rather than simplify them. If you don't believe me, go try to read any articles, books, or other resources on domain driven design (DDD). They will almost always leave you with more questions and less clarity about how to actually implement the ideas in your code.
I'm not suggesting that DDD isn't useful, nor am I suggesting that you shouldn't ever read those books. What I am saying is that many (most?) of my readers are here looking for more practical advice on how to improve their code, not to discuss the theory of software development.
From a practical perspective, the key benefit of domain driven design is writing software that can evolve and change over time. The best way I have discovered to achieve this in Go is to clearly define your domain types, and to then write implementations that depend upon these types. This still results in coupled code, but because your domain is so tightly linked to the problem you are solving this coupling is rarely problematic. In fact I often find that needing a clear definition of domain models to be enlightening rather than troubling.
*Note: This idea of defining concrete domain types and coupling code to them isn't unique or new. Ben Johnson [wrote about it in 2016](https://medium.com/@benbjohnson/standard-package-layout-7cdbc8391fc1) and this is still an incredibly valuable article for any new Gopher.*
Going back to the previous example, we saw our domain being defined in the `domain` package:
```go
package domain
type User struct {
ID string
Email string
OrgIDs []string
}
```
Taking that a step further, we could even start to define basic building blocks that the rest of our application can either (a) implement, or (b) make use of without being coupled to implementations details. For instance in the case of our `UserService`:
```go
package domain
type User struct { ... }
type UserService interface {
User(token string) (User, error)
}
```
This is implemented by the `github` and `gitlab` packages, and relied upon by the `mw` package. It could also be relied upon by other packages in our code without worrying about how it gets implemented. And because it is defined at the domain, we don't need to worry about each implementation altering slightly in return types - they all have a common definition to build from.
As an application evolves and changes over time this idea of defining common interfaces to build from becomes even more powerful. For instance, imagine we had a `UserService` that is a little more complex; perhaps it handles creating users, authenticating users, looking them up via tokens, password reset tokens, changing passwords, and more.
```go
package domain
type UserStore interface {
Create(NewUser) (*User, RememberToken, error)
Authenticate(email, pw string) (*User, RememberToken, error)
ByToken(RememberToken) (*User, error)
ResetToken(email string) (ResetToken, error)
UpdatePw(pw string, tok ResetToken) (RememberToken, error)
}
```
We might start by implementing this with pure SQL code and a local database:
```go
package sql
type UserStore struct {
DB *sql.DB
}
func (us *UserStore) Create(newUser domain.NewUser) (*domain.User, domain.RememberToken, error) {
// ...
}
// ... and more methods
```
This makes complete sense when we have a single application, but perhaps we start to grow into another Google and we decide that we need a centralized user management system that all of our separate applications can utilize.
If we had coupled our code to the `sql` implementation this might be challenging to achieve, but because most of our code is coupled to the `domain.UserService` we can just write a new implementation and use it instead.
```go
package userapi
type UserStore struct {
HTTPClient *http.Client
}
func (us *UserStore) Create(newUser domain.NewUser) (*domain.User, domain.RememberToken, error) {
// interact with a third party API instead of a local SQL database
}
// ...
```
More generally speaking, coupling to a domain rather than a specific implementation allows us to stop worrying about details like:
- **Are we interacting with a microservice or a local database?** We can write code with reasonable timeouts regardless of whether our user management system is a local SQL database or a microservice.
- **Do we communicate with our user API via JSON, GraphQL, gRPC, or something else?** While our implementation will need to know how to communicate with the users API, the rest of our code will continue to operate the same regardless of which specific technology we are using.
- And much more...
At its crux, this is what I consider to be the primary benefit of domain driven design. It isn't fancy terms, colorful graphics, or looking smart in front of your peers. It is purely about designing software that is capable of evolving to meet your ever-changing requirements.
## Why don't we just start here?
The obvious followup question at this point is, "Why didn't we just start with domain driven design if it is so great?"
Anyone with some experience using Model-View-Controller (MVC) can tell you that it is susceptible to the tight coupling. Nearly all of our application will need to depend on our models, and we just explored how that can be problematic. So what gives?
While building from a common domain can be useful, it can also be a nightmare if misused. Domain driven design has a fairly steep learning curve; not because the ideas are particularly hard to grasp, but because you rarely learn where you went wrong in applying them until a project grows to a reasonable size. As a result, it may take a few years until you really start to grasp all the dynamics involved. I have been writing software for quite a while, and I still don't feel like I have a full grasp on all the ways things can go wrong or get complicated.
*Note: This is one of the big reasons why I have taken so long to publish this article. I was hesitant to share when, in many ways, I still don't feel like I am an expert on this topic. I ultimately decided to share because I believe others can learn from my limited understanding, and I believe this article can evolve and improve over time as I have discussions with other developers. So feel free to reach out to discuss it - <jon@calhoun.io>*
MVC presents you with a reasonable starting point for organizing your code. Database interacts go here (models), http handlers go here (controllers), and rendering code goes here (views). It might lead to tight coupling, but it allows you to get started pretty quickly.
Unlike MVC, domain driven design doesn't present you with a reasonable starting point for how to organize your code. In fact, starting with DDD is pretty much the exact opposite of starting with MVC - rather than jumping right into building controllers and seeing how your models evolve, you instead have to spend a great deal of time upfront deciding what your domain should be. This likely involves mocking up some ideas and having peers review them, discussing what is/isn't right, a few iteration cycles, and only then can you dive into writing some code. You can see this in [Ben Johnson's WTF Dial project](https://medium.com/wtf-dial/wtf-dial-domain-model-9655cd523182) where he creates a PR and discusses the domain with Peter Bourgon, Egon Elbre, and Marcus Olsson.
This isn't specifically a bad thing, but it also isn't easy to get right and it requires a great deal of upfront work. As a result, I often find this working best if you have a larger team where everyone needs to agree on some common domain before development can start.
Given that I am often coding in smaller teams (or by myself), I find that my projects evolve much more naturally if I start with something simpler. Maybe that is a [flat structure](https://www.calhoun.io/flat-application-structure), maybe it is [an mvc structure](https://www.calhoun.io/using-mvc-to-structure-go-web-applications), or maybe it is something else entirely. I don't get too caught up in those details, as long as I am open to my code evolving. This allows it to eventually take the form of something like DDD, but it doesn't require me to start there. As I stated before, this may be harder to do with a larger org where everyone is developing the same application together, so more upfront design discussion is often merited.
In our sample application we did something very similar to this "let it evolve" concept. Every step was taken for a specific purpose; we added a `UserService` interface because we needed to test our authentication middleware. When we started to migrate from GitHub to GitLab we realized that our interface didn't suffice, so we explored alternative options. It is around that point that I think a more DDD approach starts to make sense and rather than guessing at what the `User` and `UserService` should look like, we have real implementations to base it off of.
Another potential issue with starting of with DDD is that types can be defined poorly because we are often defining them before we have concrete use cases. For instance, we might decide that authenticating a user looks like this:
```go
type UserAuthenticator interface {
Authenticate(email, pw string) (error)
}
```
Only later we might realize that in practice every single time we authenticate a user we really want to have the user (or maybe a remember token) returned, and that by defining this interface upfront we missed this detail. Now we need to either introduce a second method to retrieve this information, or we need to alter our `UserAuthenticator` type and refactor any code that implements or utilizes this.
The same thing applies to your models. Before actually implementing a `github` and `gitlab` package we might think that the only identifying information we need on a `User` model is an `Email` field, but we might later learn through implementing these services that an email address can change, and what we also need is an `ID` field to uniquely identify users.
Defining a domain model before using it is challenging. We are extremely unlikely to know what information we do and don't need unless we already have a very strong grasp of the domain we are working in. Yes, this might mean that we have to refactor code later, but doing so will be much easier than refactoring your entire codebase because you defined a your domain incorrectly. This is another reason why I don't mind starting with tightly-coupled code and refactoring at a later date.
Finally, not all code needs this sort of decoupling, it doesn't always provide the benefits it promises, and in some circumstances (eg DBs) we rarely take advantage of this decoupling.
For a project that isn't evolving, you likely don't need to spend all the time decoupling your code. If the code isn't evolving, changes are far less likely to occur and the extra effort of preparing for them may just be wasted effort.
Additionally, decoupling doesn't always provide the benefits it promises and we don't always take advantage of that decoupling. As [Mat Ryer](https://twitter.com/matryer) likes to point out, we very rarely just swap out our database implementation. And even if we do decouple everything, and even if we do happen to be in the very small minority of applications who are transitioning databases, this transition often requires a complete rethinking of how we interact with our data store; after all, a NoSQL database behaves completely differently from a SQL database and to really take advantage of either we have to write code that is specific to the database being used. The final result is that these abstractions don't always provide us with the magical, "the implementation doesn't matter" results that we want.
That doesn't mean DDD can't provide benefits, but it does mean we shouldn't simply [drink the Kool-Aid](https://en.wikipedia.org/wiki/Drinking_the_Kool-Aid) and expect magical results. We need to stop and think for ourselves.
## In Summary
In this article we looked firsthand at the problems encountered when code is tightly coupled, and we explored how defining domain types and interfaces can help improve this coupling. We also discussed some of the reasons why it might not be the best idea to start off with this decoupled design, and to instead let our code evolve over time.
In the next article in this series I hope to expand upon the idea of writing Go code using domain driven design. Specifically, I want to discuss:
- How interface tests can help ensure implementations can be interchanged without issue.
- How subdomains can also stem from different contexts.
- Ways you can visualize this all using the traditional DDD hexagon, as well as how code like a third party library might fit into the equation.
I also want to mention that this article is by no means a hard set of rules. It is just my meager attempt at sharing some insights and ideas that have helped me improve my Go software.
I'm also not the first to discuss or explore DDD and design patterns in Go. You should definitely check out some of the following for a more rounded understanding:
- [GoDDD by Marcus Olsen](https://github.com/marcusolsson/goddd) - This is a GitHub repo along with a writeup and a talk where Marcus Olsen explores porting the traditional sample DDD Java app into Go.
- [WTF Dial by Ben Johnson](https://medium.com/wtf-dial) - I've already linked to Ben's Standard Pacakage Layout article; this is a series where Ben applies what he discusses in that article. I also recommend checking out the accompanying PRs and reading through the comments.
- [How Do You Structure Your Go Apps by Kat Zien](https://www.youtube.com/watch?v=oL6JBUk6tj0) - In this talk Kat goes through quite a few ways to structure your Go apps. Also check out the repo and slides that accompany this talk.
- [Design Philosophy On Packaging by Bill Kennedy](https://www.ardanlabs.com/blog/2017/02/design-philosophy-on-packaging.html) - While not specifically about structuring your application, this series discusses package design which is tightly linked to structure.
## Want to learn Go?
Interested in learning or practicing Go? Check out my FREE courses:
- [Gophercises](https://gophercises.com) - Programming Exercises for Budding Gophers
- [Algorithms with Go](https://algorithmswithgo.com/) - An introduce to algorithms, data structures, and more using Go
I also have some premium courses that cover [Web Dev with Go](https://www.usegolang.com/) and [Testing with Go](https://testwithgo.com/) that you can check out as well. | joncalhoun |
264,288 | i wonder if i can run netdata and sumologic at the same time | i wonder if i can run netdata and sumologic at the same time (probably a nonsense thing to do but who... | 0 | 2020-02-18T23:20:10 | https://dev.to/osde8info/i-wonder-if-i-can-run-netdata-and-sumologic-at-the-same-time-4a56 | devops, sysadmin, performance, monitoring | i wonder if i can run netdata and sumologic at the same time (probably a nonsense thing to do but who cares)
ive got netdata up and running on both my OCI OL3 vms
* https://docs.netdata.cloud/packaging/installer/
loving the one line installer BUT dont forget to use the SECRET `--stable-channel` switch
```
$ sudo -i
# bash <(curl -Ss https://my-netdata.io/kickstart.sh) --stable-channel
```
then i create some ssh tunnels so i can see both cloud servers locally
```
$ ssh -L 3001:localhost:19999 opc@ol7a.oci.vm -N &
$ ssh -L 3002:localhost:19999 opc@ol7b.oci.vm -N &
```
now lets see how easy it is to install sumologic
UPDATE @ 11:28
OH DEAR sumologic is utterly unintuitive !
can anyone point me to a quick start instead of the 1000 page manual ? | osde8info |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.