
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
264,304 | A few clean-ups to relieve stress | [This story was originally posted on my personal blog] I've always had this itch of organizing the s... | 0 | 2020-02-19T00:14:24 | http://ismail.teamfluxion.com/diary/20200218/A_few_cleanups_to_relieve_stress | watercooler, productivity | *[This story was originally posted on [my personal blog](http://ismail.teamfluxion.com/diary/20200218/A_few_cleanups_to_relieve_stress)]*
I've always had this itch of organizing the stuff that I come across every day, sometimes to an extent that it's over-organized for me to access later. It's partly because my mind keeps on shifting its perspective of how I see (and want to see) things around me and otherwise it's something that comes straight out of me being an over-thinker for things that do not need that much of thinking. I might arrange objects in a particular way, only to completely remodel the entire space, arguably making my previous attempt to make things 'right' look like a complete waste of my productive time.
The following are a few items that I enjoy cleaning up and believe to be reducing my stress.
## To-Do list
My To-Do list keeps growing like crazy. It does help me track ideas and the things that I might need to be doing, but as it grows it tends to scare me with what's upcoming (especially the looking at the count of items in the list), often leaving my mind in a state where I find it very difficult to focus on the tasks that I currently have at hand.
To me, cleaning a To-Do list could either mean scheduling items that are still in the *unscheduled* state, better organize them by re-assign tags that make more sense to me (at that particular instant), or even deleting the items that I might have added a while back and do not seem to be worth doing or even making any sense at the time of the clean-up. And yes, it also helps me look past the mess I have in front of me.
I can discover tasks that were planned way back but got lost among other 'less important' ones. Finally, it also helps me discover the 'filler' tasks that I could potentially pick up when there's relatively nothing else to do, which I know is rarely the case, but who knows?
## Digital notes or lists
My digital list collection is another place to look for those buried lists and plans that never got converted into tasks and eventually scheduled and picked up to be worked upon. On the other hand, there's so much that does not need to be worried about or carried around anymore.
It mostly does not cost anything to keep this kind of useless data around, especially if you're on a free plan on the platform or service ([Dynalist](https://dynalist.io) in my case) that you're using to maintain these lists, but when taken out, it does help me to find what I might be looking for faster and easier.
## Web-browser bookmarks
No matter how much time I spend on my collection of web bookmarks in [Google Chrome](https://www.google.com/chrome), it doesn't take long for the tree to grow out of control and very overwhelming to look at.
Bookmarks can get accumulated quickly, especially with my pattern of web-browsing. It goes like: anything interesting that I come across and/or I feel needs more time and dedicated attention gets thrown into a subtree that I usually revisit regularly. As the second step, these deferred bookmarks get further categorized and sorted according to priority and subject. When the time finally comes to visit the web-resource it points to, it either gets deleted after sharing it with people who might find it interesting or stashed into the rest of the well-organized tree for almost forever.
My tree has been growing since I first started using Google Chrome, which is almost a decade now. Funny enough, I used to maintain an excel worksheet of internet URLs that I wanted to store as a future reference instead of saving them as 'favorites' on my [Internet Explorer](https://www.microsoft.com/en-us/download/internet-explorer.aspx) as they would otherwise be lost. As the bookmarks on my Google Chrome are associated with my account and the task of maintaining the collection for me is now taken care of by Google, it is the right place to maintain that kind of data. I recently conducted a moderately deep clean-up in my bookmarks collection and what I got from the result of the time-consuming (and arguably boring) activity is what I believe to be one of the cleanest bookmark collections I've seen to date, not that I have a habit of peeking into people's bookmarks.
## Projects kitchen
On all my computers, I have a [projects graveyard](https://dev.to/isaacandsuch/github-graveyards-ill-show-you-mine-49lh) where I perform coding experiments and most of the code residing there never makes its way out. Although some developers [share their collection](https://dev.to/peter/graveyard-groundskeepers-2886) on GitHub or other similar places, I keep mine private and call it 'kitchen' on every single workstation of mine. Most of the ideas developed and polished there get life in the form of some other public project but the mess in the kitchen tends to keep growing quickly.
Visiting these directories every once in a while and getting rid of waste helps me come across any unfinished experiments or at least helps me free some space on the tiny [SSD](https://en.wikipedia.org/wiki/Solid-state_drive) on my [MacBook Pro](https://www.apple.com/macbook-pro). Regardless, cleaning the kitchen feels great.
## Digital data on hard-drive or cloud
My digital data on the cloud tends to get out of hand as well. During my early years of using computers to store data, this kind of data used to be stored in smaller hard-drives and USB flash drives that were far easier to run out of storage capacity on. With my not-so-recent move to virtually infinite cloud-storage, space is not an issue anymore, and I expect it to be that way for at least another decade before I start running out of space again. However, re-arranging files and deleting unrequired data gives me a sense of satisfaction greater than what I achieve after refactoring a piece of code that I wrote a decade back.
## Apps, extensions, etc. from my setup
It could be unused software on my computers, apps on my phone(s) that I might have never used and forgotten about, plugins on my text-editor or even extensions on my web-browser, the list can go on. Apart from the most obvious advantage of speeding up my work environment by removing the redundant bloat that not only do I not need anymore but also do not remember the reason to exist, it makes space for new stuff to come in: think new apps, extensions or productivity tools, etc.
## More...
There's much more:
- **Email subscriptions** so that I do not need to delete multiple emails from the same sender every day as if it was a daily ritual
- **Games library** so that I don't feel bad for myself every time I come across it on discovering the huge list of games that I own but do not have time to play anymore
- **Browser autofill info** so that I have a shorter list of credentials, addresses, payment methods, etc. to choose from while filling a web form
- **Physical desk** so that I have to move lesser stuff around for being able to access other stuff
- **My car** not because it helps me in any way, but I just like doing it down to the smallest detail possible
As you might have guessed, the list does not end there.
## And beyond...
More than the amount of stress relief I tag these activities with, I also believe that they grant me some sort of a short-term productivity boost. I feel a little more focused and motivated towards doing what I'm currently doing, and that too with a fresh perspective until there's need for another round of clean-up. | myterminal |
264,328 | The most elegant debounce code you'll ever write featuring XState | Debouncing is the practice of delaying the execution of a resource or time-intensive task long enough... | 0 | 2020-02-19T02:25:00 | https://dev.to/codingdive/the-most-elegant-debounce-code-you-ll-ever-write-featuring-xstate-3hn0 | javascript, react |
Debouncing is the practice of delaying the execution of a resource or time-intensive task long enough to make the application feel very responsive. This is typically done by reducing the number of times the task is executed.
Whether you're filtering a giant list or simply want to wait a few seconds until the user has stopped typing before sending a request, chances are that you'll have to deal with debouncing one way or another especially if you happen to be a front end engineer.
I claim that handling this with the popular state management, state machine and statechart library XState is as good as it can get. Before you can convince yourself, let's quickly determine the best possible debounce user experience before translating it into code.
Good debounce logic should:
- give users **instant feedback** about what they're doing. We might want to wait a second before sending a request to the server but we do not ever want to delay the input of the user by a second as they'll either think our app is broken or their computer is lagging.
- have a way to **cancel** the resource-intensive action. Not only do we want to cancel it when the user makes another keystroke before our debounce timer has finished, but we also want the ability to cancel the queued action when changing state. For example, there is no point in filtering a giant list when we've already transitioned into a state that doesn't show the list anymore.
- allow us to set the **timed delay dynamically**. This could allow us to make the delay longer for mobile users as the average typing speed decreases.
With our optimal user experience out of the way, let's dive into the code.
Check out the [codesandbox](https://codesandbox.io/s/xstate-debounce-example-7i9mw) and read below for detailed explanations.
---
Let's write an app that displays tasty plants with the ability to filter them.
Since there are soo many tasty plants, we are expecting the server to take quite a long time. Therefore, we'll need to debounce the user input before the server starts filtering.
```javascript
const tastyPlants = [
"seeds 🌱",
"mushrooms 🍄",
"nuts 🥜",
"broccoli 🥦",
"leafy greens🥬"
];
// For the extended state of the machine, we want to store the user input and the plants to render.
const machineContext = {
input: "",
filteredTastyPlants: []
};
```
In other words, we don't want to send a server request on every keystroke; instead, we want to add a minor delay of 450 milliseconds. Also, instead of using an actual HTTP request, we are going to keep things local and just use a timeout.
The code that is responsible for performing the (fake) slow filter operation might look like this:
If you're new to asynchronous code in statecharts, you may want to check out this [blog post](https://dev.to/codingdive/state-machine-advent-asynchronous-code-in-xstate-102p) before understanding what's going on below.
```javascript
// inside our machine
apiClient: {
initial: "idle",
on: {
slowFilter: {
target: ".filtering"
}
},
states: {
idle: {},
filtering: {
invoke: {
id: "long-filter-operation",
src: (context, event) =>
new Promise(resolve =>
setTimeout(
() =>
resolve(
tastyPlants.filter(plant => plant.includes(context.input))
),
1500
)
),
onDone: {
target: "idle",
actions: assign({
filteredTastyPlants: (context, event) => event.data
})
}
}
}
}
},
```
We aren't doing anything special here just yet. We pretend that our server takes 1500 milliseconds until it completes the filtering and upon resolving, we can ultimately assign the filtered plants to our `filteredTastyPlants` context.
You might have noticed that within the `slowFilter` event, we haven't actually assigned the input to the state machine yet. As you'll see shortly, the trick to make debouncing work in XState is to use two events instead of one.
## Responsiveness
For instant feedback, which was our very first constraint, we'll define an extra event that assigns the input to the machine context. This event will also have the responsibility of sending the `slowFilter` event after a delay of 450ms. That's right. A machine can send events to itself. Let's see it in **action(s)**!
```javascript
// import { actions, assign } from 'xstate'
// const { send } = actions
// within our machine
on: {
filter: {
actions: [
assign({
input: (context, event) => event.input
}),
send("slowFilter", {
delay: 450,
});
];
}
}
```
The above code guarantees that the `slowFilter` event is called 450ms after every keystroke. Cool! In our component, we treat the `slowFilter` event like an internal event of the machine, meaning we'll only ever work with the `filter` event as seen in the example below.
```jsx
const [state, send] = useMachine(filterPlantsMachine).
return (
<input value={state.context.input} onChange={(e) => void send({type: 'filter', input: e.target.value})}>
// render state.context.filteredTastyPlants
)
```
## Cancellation
To work towards our second constraint, we now need a way to cancel the `slowFilter` event that is about to be sent. We can do so by giving the event an id, then canceling the event by the same id using the `cancel` action creator.
```javascript
// import { actions, assign } from 'xstate'
// const { send, cancel } = actions
// within our machine
on: {
filter: {
actions: [
assign({
input: (context, event) => event.input
}),
cancel('debounced-filter'),
send("slowFilter", {
delay: 450,
id: "debounced-filter"
});
];
}
}
```
Because the above code cancels and resends the `event` on every keystroke, it'll **only** be sent once the user has stopped typing for at least 450ms. Pretty elegant right? For even better readability, we can expressively name the actions.
```javascript
on: {
filter: {
actions: [
'assignInput',
'cancelSlowFilterEvent',
'sendSlowFilterEventAfterDelay'
];
}
}
// ...
// pass actions as config to the second argument of the Machine({}, {/* config goes here */}) function.
{
actions: {
assignInput: assign({
input: (context, event) => event.input,
}),
cancelSlowFilterEvent: cancel('debounced-filter'),
sendSlowFilterEventAfterDelay: send('slowFilter', {
delay: 450,
id: 'debounced-filter',
}),
},
}
```
## Dynamically set debounce delay
Last but not least, to provide the best possible user experience we may want to dynamically change the delay. To account for the typing speed decrease in words per minute when going from desktop to phone, let's only start the filtering 800ms after the last keystroke when the user is on their phone.
After adding an `isPhone` boolean to our context (we could also pass it via the event), we can use a [delay expression](https://xstate.js.org/docs/guides/delays.html#delay-expressions) to dynamically set the delay.
```javascript
sendSlowFilterEventAfterDelay: send('slowFilter', {
delay: (context, event) => context.isPhone ? 800 : 450,
id: 'debounced-filter',
}),
```
___
Let me know in the comments what you think and if you have any questions. Happy debouncing! ❤️ | codingdive |
264,332 | Cypress – code coverage reports for unit tests | One of most common test reports used is code coverage reports. And while Cypress does support them, s... | 0 | 2020-02-19T09:31:51 | https://dev.to/hi_iam_chris/cypress-code-coverage-reports-for-unit-tests-2hd2 | cypress, javascript, testing, frontend | One of most common test reports used is code coverage reports. And while Cypress does support them, setting them up can be a bit of pain. In this post, I will be explaining how to set up coverage reports for unit test. If you haven’t installed Cypress yet, you can use my [previous post](https://dev.to/chriss/cypress-initial-setup-l4) as a guide on that.
## Installation
As always, lets first start with required packages that you will need for this. Those packages are:
- @cypress/code-coverage
- babel-plugin-transform-class-properties
- instanbul-lib-coverage
- mocha@^5.2.0
- nyc
You can install all of these by executing next CLI command:
```
npm install --save-de @cypress/code-coverage babel-plugin-transform-class-properties instanbul-lib-coverage mocha@^5.2.0 nyc
```
## Babel
Because you will be importing your modules into unit test, which are probably written in ES6, you will need .babelrc file for this. While your can be different, depending on your project, following code is minimum that you will need in it.
```
// .babelrc
{
"presets": ["@babel/preset-react"],
"plugins": ["transform-class-properties", "istanbul"]
}
```
## Cypress commands
Now that you installed dependencies and set your babel configuration file, we can go into Cypress configuration. First, you will need to update cypress/support/index.js file. This change will be small, just adding one line.
```
// cypress/support/index.js
import '@cypress/code-coverage/support'
```
## Cypress plugins
Next step will be updating Cypress plugins file. Once again, very small change. You need to update cypress/plugins/index.js to contain following code.
```
// cypress/plugins/index.js
module.exports = (on, config) => {
on('task', require('@cypress/code-coverage/task'));
on('file:preprocessor', require('@cypress/code-coverage/use-babelrc'));
return config
};
```
## Adding tests
When it comes to set up, we are done. Now we can start adding tests. For this, under cypress/integration we can create new folder called unit. In this file we will keep all our unit tests. Usually, we would keep all tests along our code. If nothing, to reduce need for long dot slashes in imports. And Cypress does support keeping them in different location. However, this coverage plugin doesn’t work if tests are not inside of integration folder and just generates empty report.
## Running tests
Once our tests are written, we can run them. If we are running unit tests, it is good to run them separate from e2e tests. For that we can use also different command. That command can be following:
cypress run --spec cypress/integration/unit/*
## Generated reports
All coverage reports are generated in root of project in folder called coverage. I tried to change this location, but sadly, Cypress configuration does not work for it. Only option I was left with was either manually or creating different script that would move it to needed location.
## Wrap up
Cypress does support getting coverage reports for unit tests. But setting up, however small it is, is far from clear. There are many issues, like need for tests to be only in integration folder for it to work and lack of ability to change report output location. But I do hope this guide made it simpler and easier for you to set up.
All code example for this can be found in my [Cypress setup repository](https://github.com/kristijan-pajtasev/cypress-setup).
| hi_iam_chris |
264,348 | ¿En qué se diferencian width, max-width y min-width? | Muchas veces cuando se está aplicando CSS, te topas con estas 3 propiedades parecidas, width, max-wid... | 0 | 2020-02-19T03:26:35 | https://dev.to/thedavos/en-que-se-diferencian-width-max-width-y-min-width-497a | css, espanol, spanish | Muchas veces cuando se está aplicando CSS, te topas con estas 3 propiedades parecidas, `width`, `max-width` y `min-width`. ¿Alguna vez te confundiste en usar alguna de estas pero en verdad debisteno usar unel max-width o un min-width? Pues, a todos nos ha pasado, seguramente. En este post te explicaré qué hace cada propiedad y en qué se diferencian con las demás. Pues, comencemos.

## Sobre width
El más simple de los tres. Esta propiedad es la que define un ancho específico a un elemento. Sin esta, el elemento o bloque, si es que no tiene texto o algún contenido dentro, no podría ser visualizado por el usuario.
En términos del modelo de caja de CSS. El width vendría a definir al contenido del elemento. Lo que vendŕia a ser el **Content** en la imagen. Sin embargo, cuando se coloca a un elemento la propiedad `box-sizing` y se ponga como valor `border-box`, el width vendría a definir el **Content**, **Padding** y el **Border**.
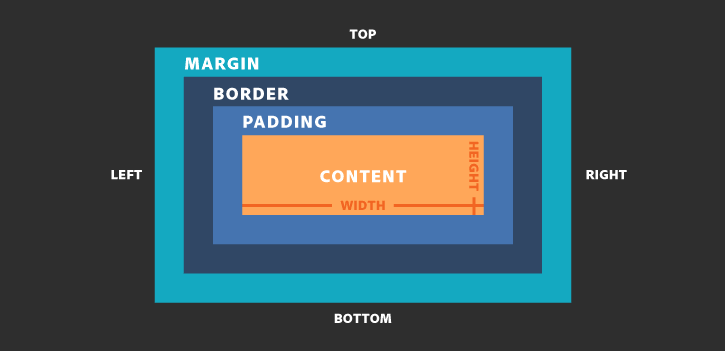
Por el lado del Responsive Design, esta propiedad no puede adaptarse por sí mismo a los diferentes tamaños de otros dispositivos o si la pantalla hace un cambio de tamaño. Para esto, necesita respaldarse de otras propiedades.
Como se ve en el vídeo de abajo, un elemento no puede adaptarse al ancho de la pantalla con tan solo la propiedad width, para esto veremos las otras dos propiedades que si pueden manejar esto.

## Sobre max-width
Según en la página de [MDN](https://developer.mozilla.org/es/docs/Web/CSS/max-width), esta propiedad se define como:
> La propiedad de CSS `max-width` coloca el máximo ancho a un elemento. Además, impide que el valor de `width` sea más largo que el valor especificado en `max-width` .
Esto quiere decir que cuando el valor que nosotros especifiquemos en width sea mayor que max-width, este último sobrescribirá el ancho del elemento al valor que tiene max-width. Así max-width define el ancho máximo que un elemento puede tener.
Tal como se ve en el vídeo/gif de la parte inferior, max-width cambia el tamaño del elemento si el valor de width es mayor que el de max-width. Sin embargo, si el width es menor entonces max-width no tendría que actualizar el tamaño ya que no se alcanzado el tamaño máximo del elemento.
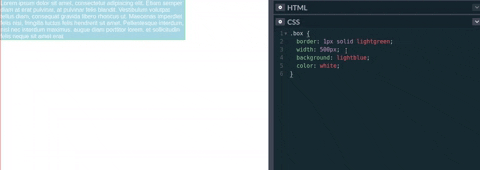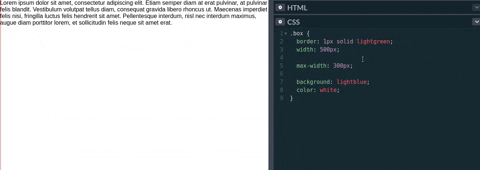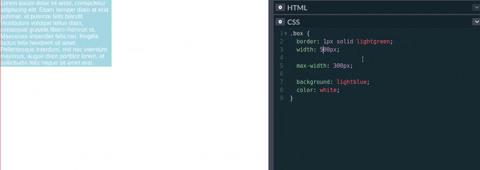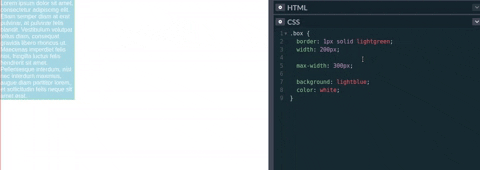
Por el lado del Responsive Design, max-width es aplicado en los media queries. Si no sabes qué son los media queries, te sugiero leer este [post](https://www.arsys.es/blog/programacion/diseno-web/media-queries-css3/). Entonces, max-width en un media query aplica estilos definidos en un determinado ancho de pantalla. Este ancho de pantalla parte desde 0 hasta lo que se haya colocado en max-width. Pasado este ancho máximo todos los estilos que se hayan puesto dejan de aplicarse en la pantalla.
```css
@media only screen and (max-width: 600px) {
body {
background-color: lightblue; /* Aplicará solo desde 0 hasta 600px */
}
}
/* Pasados los 600px, el background deja de ser lightblue */
```
## Sobre min-width
A diferencia de max-width que define el tamaño máximo, min-width define el mínimo tamaño que un elemento puede tener.
Por ejemplo, en el vídeo/gif inferior. Primero se intenta hacer un resize sin min-width. Esto disminuye el ancho del elemento hasta el mínimo posible, haciendo que el elemento se distorsione. Luego, se coloca un valor al min-width del elemento. Con min-width ya puesto se comienza el resize. Sin embargo, a diferencia de la anterior vez, el elemento no se distorsiono a su máximo valor ya que tiene un ancho mínimo especificado. Esta propiedad permite que el contenido que tenga un elemento, no se vea comprometido cuando se haga un resize en la pantalla o si este es de otros dispositivos con diferentes tamaños.
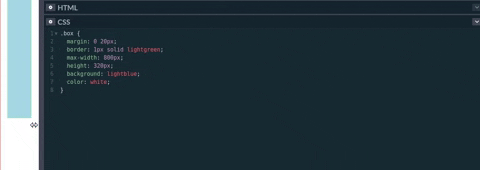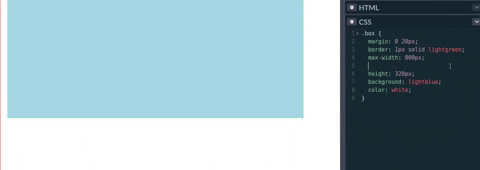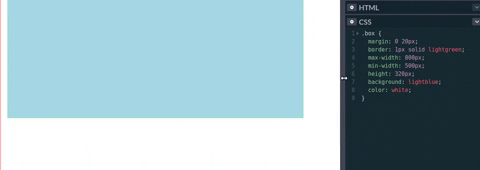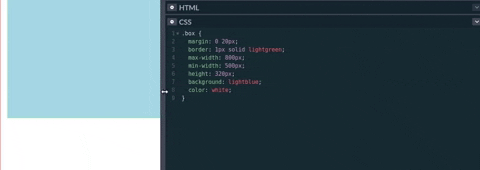
Por el lado del Responsive Design, si en un media query se especifica el min-width, entonces todos los estilos especificados serán aplicados a partir del min-width hacia adelante.
```css
@media only screen and (min-width: 800px) {
.box {
background-color: red; /* Aplicará a partir desde los 800px hacia adelante */
}
}
```
## Conclusiones
A pesar que algunos elementos del desarrollo web se parezcan, es importante no frustrarse de ello, calmarse y aprender. Aprender a diferenciar y ver la utilidad de tus herramientas puede ser clave al momento de aplicar CSS o implementar un diseño responsivo a un sitio web, inclusive puede ahorrarte líneas de código y abrirte las puertas a otros conocimientos, como el patrón de diseño Mobile First. Pero, sobre todo a ser una mejor desarrolladora o desarrollador. | thedavos |
264,351 | I published my first Ember Addon | Announcing an Ember addon for Fullcalendar 4 | 0 | 2020-02-19T03:53:33 | https://welchcanavan.com/ember-fullcalendar | javascript, ember, opensource | ---
title: I published my first Ember Addon
description: Announcing an Ember addon for Fullcalendar 4
published: true
tags: javascript, ember, opensource
canonical_url: https://welchcanavan.com/ember-fullcalendar
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/jyjz25xdurtml5xquutn.jpg
---
_Originally published at [welchcanavan.com](https://xiw.cx/2wqxO3b)_
**TL;DR**: _a new [ember-fullcalendar](https://github.com/Mariana-Tek/ember-fullcalendar) addon based on Fullcalendar v4 is released this week. Here is some of my process and experience._
## Backstory
My day job is working on a large [SaaS](https://en.wikipedia.org/wiki/Software_as_a_service) application at [Mariana Tek](https://marianatek.com/). We help boutique gyms with their business operations, which means our application serves a lot of purposes: point of sale, time clock, class scheduler, and a lot more. Having to write all this functionality from scratch would be difficult if not impossible, so I'm grateful for plugins in general and Ember's painless [addon](https://guides.emberjs.com/release/addons-and-dependencies/) system in particular.
While our application is on an earlier version Ember 3, we're in the process of a long walk to the exciting [Ember Octane](https://blog.emberjs.com/2019/12/20/octane-is-here.html). Part of this process has been gradually updating our addons. Our application, which is over four years old, had accrued some addons that are now abandoned. Most of these were easy to address, with one big exception - [Fullcalendar](https://fullcalendar.io/). Fullcalendar is a fantastic tool that allows the user to provide a fully-featured scheduling calendar (e.g. Google Calendar) with minimal code. The Ember Fullcalendar addon hadn't been updated in over a year and I really didn't want to write a calendar from the ground up. The writing was on the wall; I was going to have to write my first Ember addon.
## Well, not quite...
In actuality, my first inclination was to see if I could chip in with the _current_ Ember Fullcalendar plugin, but I found that Fullcalendar had done a major upgrade moving from [version 3 to version 4](https://fullcalendar.io/docs/upgrading-from-v3); having removed [jQuery](https://jquery.com/) and [Moment](https://momentjs.com/) as dependencies, and updated their API. If I wanted to fully get rid of jQuery as a dependency in our app it seemed I would have start from scratch.
## Inspiration
If I couldn't improve the current addon or use it as a guide for my new addon then what could I look at? For the Ember side of things I went to [Ember Observer](https://emberobserver.com/), a great resource for finding quality addons. I read through some of the popular addons that provide a similar service (bindings to a popular Javascript UI utility). This provided some hints and ideas for structure, but I still needed some ideas for the Fullcalendar side of things. I thought I'd take a peek at the [`fullcalendar-react`](https://github.com/fullcalendar/fullcalendar-react) package and was pleasantly surprised to find that it barely breaks fifty lines of code.
`fullcalendar-react` provided the idea to avoid explicit bindings for each property or attribute and simply batch updates and pass them along to Fullcalendar. `componentDidMount()` becomes `didInsertElement()`, while `componentDidUpdate()` becomes `didUpdateAttrs()`. This makes the addon easier to maintain as I can upgrade its Fullcalendar dependency version with minimal updates to the addon's code. The Ember best practice of [Data Down, Actions Up](https://dockyard.com/blog/2015/10/14/best-practices-data-down-actions-up) aligns well with React's philosophy and if you account for differences in each framework's API many patterns are easily transferable.
## Try it out
The addon can be installed using `ember install @mariana-tek/ember-fullcalendar`. You can find further instruction in the [documentation](https://github.com/Mariana-Tek/ember-fullcalendar#mariana-tekember-fullcalendar).
Please feel free to check out the [source code](https://github.com/Mariana-Tek/ember-fullcalendar/blob/master/addon/components/full-calendar.js) or [report an issue](https://github.com/Mariana-Tek/ember-fullcalendar/issues). Enjoy!
### Acknowledgement
Thanks to my employer for the support in making this! If you think you'd like to work on a kind and supportive team that talks Ember, React, and—above all—Javascript, please [check us out](https://marianatek.com/careers).
| xiwcx |
264,437 | A brief look into code quality | An intro to clean code | 0 | 2020-02-19T06:22:08 | https://dev.to/princessanjana1996/a-brief-look-into-code-quality-o7e | codequality, javascript, cleancode | ---
title: A brief look into code quality
published: true
description: An intro to clean code
tags: code-quality, javascript, clean-code
cover_image: https://anjanak.com/content/images/size/w2000/2020/02/coding-computer-data-depth-of-field-577585.jpg
---
When we are writing code, it should be human-readable and clean. This article is about some basics of writing readable and clean code.
###Syntax

Now let’s discuss these syntax and best practices in detail.
###Curly Braces
```
If (condition) {
// do this
// do this
}
```
In JavaScript language curly braces are written with the opening bracket on the same line not on a new line and there should be a space before the opening curly bracket as above example.
- Curly braces are not needed for a single-line construct.
```
if (i <= 0) {alert(`It should not be ${i}`);}
```
- If it is short, we can use it without curly braces.
```
if (i <= 0) return null;
```
- Don’t split to a separate line without braces.
```
if (i <= 0)
alert(`It should not be ${i}`);
```
- The best way. This is usually more readable.
```
if (i <= 0) {
alert(`It should not be ${i}`);
}
```
###Semicolon
The majority of developers put semicolons after each statement but it is optional and rarely used. In JavaScript there are problems where a line break is not interpreted as a semicolon, going the code vulnerable to errors.
```
let sum = a + b;
```
###Indents
- Horizontal indents
2 or 4 spaces( 4 spaces = key Tab). For instance, to align the arguments with the opening bracket.
```
function fruit(banana,
mango,
avocado
) {
}
```
- Vertical indents
Function can be divided into logical blocks. In the below example appears three vertically split. First one is initialization of variables, the second one main loop and the third one returning the result.
```
function sum(a) {
let total = 0;
while(a > 0) {
total += a;
}
return total;
}
```
If we want to make the code more readable we can add extra newline.
###Line Length
Don’t write long horizontal lines of code because no one prefers to read it. Back tick quotes(``) help to split the long string into multiple lines.
```
let pra = `
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Integer eu convallis sem.
Praesent in facilisis ligula.
Curabitur iaculis metus lacus, vitae dapibus odio iaculis vitae.
Morbi imperdiet ultricies tortor ac dignissim.
Quisque at mi a purus dignissim tincidunt eu eu ipsum.
Phasellus pharetra vitae neque id fermentum.
`;
```
Same as the if statement. For example,
```
if (
id === 10001 &&
name === 'Anjana Kumari' &&
address === 'Kandy'
) {
login();
}
```
The maximum line length is usually 80 or 120 characters but it will depend upon the team-level.
###Nesting Level
If we can use `continue` directive, we can easily avoid extra nesting. For example,
```
while (i < 10) {
if (!condition) continue;
// do that
}
```
###Style Guides
Style guides includes how to write code. If we work as a team we can use the same style guide. Then the code can see uniform. Also teams can use their own style guide too. The popular style guides are Google JavaScript Style Guide and StandardJS etc.
###Automated Linters
Automated Linter tools can automatically detect the style of our code and make suggestions. Also, the linter tools can detect typos in variable names and function names. Some of the popular linting tools are JSLint, JSHint, and ESHint.
###Summary
Carly Braces, Semicolons, Indents, Line Length and Nesting Levels rules described aim to increase the readability of our code.
We should always think about writing better code. There are two things to keep mind when we write codes. First one is what makes the code more readable and easier to understand? And the second one is what can help us avoid errors?
Finally, we should be up to date with reading the most popular style guides.
Original post in my [personal blog](https://anjanak.com/a-brief-look-into-code-quality/) | princessanjana1996 |
264,452 | PHPMyAdmin – count(): Parameter must be an array or an object that implements Countable | Edit file /usr/share/phpmyadmin/libraries/sql.lib.php: sudo nano /usr/share/phpmyadmin/libraries/sql... | 0 | 2020-02-19T07:09:13 | https://dev.to/sushmagangolu/phpmyadmin-count-parameter-must-be-an-array-or-an-object-that-implements-countable-ndb | ubuntu, php, phpmyadmin | Edit file <code>/usr/share/phpmyadmin/libraries/sql.lib.php:</code>
<code>sudo nano /usr/share/phpmyadmin/libraries/sql.lib.php</code>
On line 613 the count function always evaluates to true since there is no closing parenthesis after $analyzed_sql_results['select_expr']. Making the below replacements resolves this, then you will need to delete the last closing parenthesis on line 614, as it’s now an extra parenthesis.
Replace:
<code>
((empty($analyzed_sql_results['select_expr']))
|| (count($analyzed_sql_results['select_expr'] == 1)
&& ($analyzed_sql_results['select_expr'][0] == '*')))</code>
With:
<code>((empty($analyzed_sql_results['select_expr']))
|| (count($analyzed_sql_results['select_expr']) == 1)
&& ($analyzed_sql_results['select_expr'][0] == '*'))</code>
Restart the server apache:
<code>sudo service apache2 restart</code> | sushmagangolu |
264,479 | 4 Go-To Apps For Revision and Exam Prep | After so many weeks of writing essays, reports, term papers, and other academic assignments, it is hi... | 0 | 2020-02-19T08:27:23 | https://dev.to/jessywhite/4-go-to-apps-for-revision-and-exam-prep-5b05 | After so many weeks of writing essays, reports, term papers, and other academic assignments, it is high time to start revising for exams. This period of student life is really tough, especially for those who were not serious enough with the classroom activities. Students who didn’t take notes during lectures have much trouble preparing for the exams. As a rule, their memory isn’t sharp enough to keep in mind all the details their professor said. Learners struggle a lot before their exams. They have to spend long hours in libraries reading a pile of sources and doing thorough research. Don’t want to be among those students who have their hands full? Benefit from the most popular academic help apps that will make revision more effective and less stressful. Download them to your mobile phone and revise for college exams like a pro.
Study Blue
If you are a fan of flashcards, consider a study application Study Blue. It is a free app, so you can download it to your device and get quick help from the crowdsourced library of materials. This app can be used to make and share flashcards, to add audio and images to your study materials, to check the knowledge of the subject taking tests and keeping progress. After downloading this app, you’ll have access to an impressive library of materials for studying and helpful guides, created by students.
SpeedyPaper Adviser
One more useful application for all students is SpeedyPaper Adviser. This writing app will help you boost your grades and prepare for exams more effectively. Having SpeedyPaper Adviser on your phone, you will get unlimited access to the huge database of college and university papers. You will be able to have a look at samples of various academic assignments. Find necessary essays, reports, research papers, course works, and boost your grades. Students will know how to create, to structure, and to cite assignments. The customer support is available round-the-clock, so if you have trouble finding a required paper, you may contact managers and ask all your questions. Numerous positive reviews about this app prove that it is really great and worth giving a try. To know about all the features, download an app on your handy or visit their website.
Gojimo
This application was created to help students have a smooth revision. Undergraduates can use Gojimo both online and on mobile devices. An app contains helpful content for learners and some quizzes. You can select an exam you want to revise for, and it goes with a list of questions you may be asked. If you haven’t found a required topic, you can get in touch with the support via instant messaging.
Quizlet
It is one more helpful application for students who are going to prepare for exams. It is free, easy to use, and is a good choice for self-study. Having Quizlet on your device, you can learn with the help of flashcards, share them with your peers, learn foreign languages and get more info about coding, mathematics, science, history, and other college subjects. A lot of students benefit from Quizlet and leave their positive reviews about this study app.
https://speedypaper.app
| jessywhite | |
264,503 | How to Login 10.0.0.1 IP Address | How to connect your Comcast router login with Ip address 10.0.0.0.1, we describe it in very short. Fi... | 0 | 2020-02-19T09:11:11 | https://dev.to/routingkings/how-to-login-10-0-0-1-ip-address-4ida |
How to connect your Comcast router login with Ip address 10.0.0.0.1, we describe it in very short. First of all, write proper Ip address 10.0.0.0.1 in your address bar then enter the default username and password provided by default access gateway when you are purchasing your modem first time. Then you can maintain your admin panel, you can also change your password now you are getting connected with the internet. https://10-0-0-0-1.tech/
| routingkings | |
264,552 | Automatically detect secrets in your internal repos | At GitGuardian, we’ve been monitoring every single commit pushed to public GitHub since July... | 0 | 2020-02-19T10:44:19 | https://blog.gitguardian.com/product-launch-automated-secrets-detection-for-your-internal-repositories-now-widely-available/ | showdev, security, devops | #At GitGuardian, we’ve been monitoring every single commit pushed to public GitHub since July 2017. 2.5 years later, we’ve sent over 500k alerts to developers.
API keys, database connection strings, private keys, certificates, usernames and passwords, … As organizations embrace the power of cloud architectures, SaaS integrations and microservices, developers handle increasing amounts of sensitive information, more than ever before.
To add to that, companies are pushing for shorter release cycles to keep up with the competition, developers have many technologies to master, and the complexity of enforcing good security practices increases with the size of the organization, the number of repositories, the number of developer teams and their geographies…
As a result, secrets are spreading across organizations, particularly within the source code. This pain is so huge that it was even conceptualized under the name *“secret sprawl”.*
**After months of product iteration with security teams and developers, we’re now proud to officially introduce GitGuardian for internal repositories!**
##Credentials in private repositories: how much should you care?
Secrets stored in Version Control Systems is the current state of the world, yet VCSs are not a suitable place to store secrets for the following reasons:
* Everyone who has access to the source code has access to the secrets it contains. This often includes too many developers. It would just take a single compromised developer’s account to compromise all the secrets they have access to!
* You never know where your source code is going to end up. Because of the very nature of the git protocol, versioned code is made to be cloned in multiple places. It could end up on a compromised workstation, be inadvertently exposed on public GitHub, or released to customers.
Storing secrets in source code is a bit like storing unencrypted credit card numbers, or usernames and passwords in a Google Doc shared within the organization: good friends would not let you do this!
##As a developer or security professional, what should I do after a secret was pushed to a centralized version control?
*Every time I see a secret pushed to the git server, I consider it compromised...From one developer to another :)*
When a secret reaches centralized version control, it is always a good practice to revoke it. At this point, depending on the size of your organization, remediating is often a shared responsibility between Development, Operations and Application Security teams.
Indeed, you might need some special rights and approval to revoke the secret, some secrets might be harder to revoke than others, plus you must make sure that the secret is properly rotated and redistributed without impacting your running systems.
Apart from that, depending on your organization’s policies, you might want to clean your git history as well. This will require a ‘git push --force’, which comes with some risks as well, so there is definitely a tradeoff to consider, with no correct answer!
(Hint: if your secret is buried deep in your code, [BFG Repo-Cleaner](https://rtyley.github.io/bfg-repo-cleaner/) is a great Open Source project to help you get rid of it without having to use the intimidating ‘git-filter-branch’ command. Plus it is in Scala! We have [Roberto Tyley](https://github.com/rtyley) to thank for this.)
##When should I do secret detection?
With the nature of git comes a unique challenge: whereas most security vulnerabilities only have the potential to express themselves in the actual (and deployed) version of your source code, old commits can contain valid secrets, including deleted secrets that subsequently went unnoticed during code reviews.
First, you want to make sure that you start on a clean basis by scanning existing code repositories in depth.
Then, you want to continuously scan all incremental changes, ie every new commit in every branch of every repository.
When to do incremental scanning?
In his presentation about [“Improving your Security Posture with the Cloud”](https://speakerdeck.com/sebsto/automatisez-la-securite-de-vos-architectures-cloud-avec-le-devsecops-99e065c2-256d-45d4-8d7d-5552204622b2?slide=2), [Sébastien Stormacq](https://www.linkedin.com/in/sebastienstormacq/), Developer Evangelist @ AWS, advocates to implement security checks post-event in every case, and pre-event when possible.
We at GitGuardian share Sébastien's views. You should always implement automated secrets detection server side, in your CI/CD for example or via a native integration with GitHub / GitLab / Bitbucket repositories. Also, it is good to encourage your fellow developers to implement pre-commit hooks, but we often hear that this is hardly scalable across an entire organization.
##Try it out!
Our product will allow you to scan existing code as well as incremental changes, and benefit from secrets detection algorithms that were battle-tested at scale on the whole public GitHub activity for over two years! GitGuardian has a native integration with GitHub (GitLab and Bitbucket coming soon), and there is an on prem version available.
We offer a free version of our solution for individual developers and Open Source organizations, as well as a free trial for companies that you can access in SaaS here:
[https://dashboard.gitguardian.com/auth/signup](https://dashboard.gitguardian.com/auth/signup?utm_source=devto&utm_medium=referral&utm_campaign=prm_launch).
| cuireuncroco |
264,568 | 🎨 Micro Frontends, Chrome 80, JavaScript, DevPad and More — Weekly Picks #115 | List of most popular articles from Daily this week. | 0 | 2020-02-19T15:00:47 | https://dev.to/dailydotdev/micro-frontends-chrome-80-javascript-devpad-and-more-weekly-picks-115-76o | webdev, javascript, codenewbie, react | ---
title: 🎨 Micro Frontends, Chrome 80, JavaScript, DevPad and More — Weekly Picks #115
published: true
description: List of most popular articles from Daily this week.
tags: #webdev #javascript #codenewbie #react
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/aejk77j9kfymk3wldtxq.jpg
---
We are back again with the weekly picks of the last week. This time, the topics include micro frontends, exciting new updates in Chrome, JS libraries, and a new product — devpad.io. So, let's jump into the list. ⚡️
## 1️⃣ Introduction to micro frontends architecture
With time, new architectural solutions have been introduced for the frontend. We have moved from monolith to frontend/back and now microservices. This post describes micro frontend architecture in detail, including its perks, and why you should use it. 🌟
* [Introduction to micro frontends architecture](https://app.dailynow.co/r/83874844b5b6662a50e89ed4721f6b3e)
## 2️⃣ Chrome 80 Released
Chrome team at Google has recently launched Chrome 80. **It brings some exciting new features to life, including but not limited to Modules in Service Workers, Optional Chaining in JavaScript, and New Cookie Policy**. Learn about these features to utilize in your future projects. 💯
* [Chrome 80 Released](https://app.dailynow.co/r/a6d2eb5c0d289a66745b5c140080d2e5)
## 3️⃣ 5 Practices to Eliminate Bad Code
Writing a clean and modular with a good architecture is the key to its long term maintenance. But it takes time and experience to start writing such kind of code. This post at DZone describes a few ways to get avoid Bad Code. 🤞
* [5 Practices to Eliminate Bad Code](https://app.dailynow.co/r/27454ff1bf656d237cfdc651a1660c66)
## 4️⃣ 10 Top Javascript Libraries and Tools for an Awesome UI/UX
The best thing about JavaScript is that you can find a library to do almost everything. But the **problem is to stay up-to-date with all new libraries and pick the best one for your project**. This post list 10 such libraries that you can utilize to level up your UI/UX game. 💯
* [10 Top Javascript Libraries and Tools for an Awesome UI/UX](https://app.dailynow.co/r/d51a89160d16a02df723b21cc64bfdfe)
## 5️⃣ 36 most popular JavaScript repositories on GitHub in January 2020
⚛️ **The best way to stay updated in any technology is to find the community and see what others are doing**. Keeping an eye on the GitHub trends is one way to do it. This post list 36 most popular JS repositories from GitHub in Jan. 2020 that you can take a look at to see what other JS devs are up to.
* [36 most popular JavaScript repositories on GitHub in January 2020](https://app.dailynow.co/r/cf277be3f2331356f02723a4367d46b4)
## 6️⃣ 11 Useful Online Tools for Frontend Developers
🚀 From my experience, I can tell you this post list precisely the best tools that you must use as a frontend developer. They will not only help you save time but also become better at what you do. All the beginners out there, you should definitely check this post.
* [11 Useful Online Tools for Frontend Developers](https://app.dailynow.co/r/41ba1f305cf7afd2efc2f9d1ff6cfbe0)
## 7️⃣ Prettier is a Must-Have for Large-Scale Projects: Spent 20 Minutes Setting It Up and Forgot About Formatting for a Year
There's no doubt in the fact that you should use a code formatting tool like prettier to save time and keep the coding style consistent. **This post lists a real-world project example and describes how prettier helped them save time and improve their codebase.** 🎨
* [Prettier is a Must-Have for Large-Scale Projects: Spent 20 Minutes Setting It Up and Forgot About Formatting for a Year](https://app.dailynow.co/r/d156d403470b168e2648f84b4aacb37c)
## 8️⃣ 13 of the Best React JavaScript Frameworks
Instead of JavaScript frameworks, it lists the useful React related tools that help you build better React applications. I kind of find this title a little misleading. But the **post describes quite a useful list of tools that you should be aware of as a React developer**. 🌟
* [13 of the Best React JavaScript Frameworks](https://app.dailynow.co/r/8f9967980993cf86fac1549c704e74b7)
## 9️⃣ devpad.io — Devpad.io helps conduct the coding interview
🎯 Devpad.io is a tool that helps recruiters to improve the coding interview flow. According to their ProductHunt page, it is described as:
>Devpad.io helps conduct the coding interview, sending testing projects to the candidates and watch how they review the code. Using devpad.io in your recruiting process you save time and money. You can do more for less.
* [devpad.io — Devpad.io helps conduct the coding interview](https://app.dailynow.co/r/130588aa09ea62d5ee7aa6d62ece2b3a)
## 🔟 Learn p5.js by Making Fractals
The best way to learn a technology is to usually build something using it. p5.js is a JavaScript library that allows you to draw things on the canvas. In this post, Ben shows how he learned p5.js by making fractals using it. 🔥
* [Learn p5.js by Making Fractals](https://app.dailynow.co/r/6c5ed4165deb89caa3464683a75fc9b0)
## 🙌 Wrap Up!
This was all from the previous week. Let's know what you think of the trends this week in the comments below.
We will come back with another list of interesting development posts next week. Till then, peace! ✌️
<hr/>
<center> 👋 Follow us on [Twitter](https://r.dailynow.co/twitter) to stay up-to-date! </center>
_[Thanks to Daily](https://r.dailynow.co/web), developers can focus on code instead of searching for news. Get immediate access to all these posts and much more just by opening a new tab._
[](https://r.dailynow.co/web) | saqibameen |
264,575 | Angular - Custom Webpack Config to use SvgDocGen plugin | Hello everyone, in last time I've posted webpack plugin for generating demo and variables of your spr... | 0 | 2020-02-21T09:11:15 | https://dev.to/fasosnql/angular-custom-webpack-config-to-use-svgdocgen-plugin-3j34 | webpack, javascript, angular, tutorial | Hello everyone, in last time I've posted [webpack plugin for generating demo and variables of your sprites.svg](https://dev.to/fasosnql/svg-doc-generator-based-on-sprites-svg-1ao6) file. In this post I would like to show you how to add custom webpack configuration to your Angular project to use some plugins - in this article [SVG Doc Generator](https://github.com/Fasosnql/svg-doc-gen).
I will be working with angular project generated by `angular-cli` so to go through it with me you can just generate simple app `ng new app-name`.
When we have generated angular app we have to install some builders to build this app with additional webpack config. So let's install:
```bash
npm install @angular-builders/custom-webpack @angular-builders/dev-server --save-dev
```
Now we have to update `angular.json` to use installed builders.
```json
"architect": {
"build": {
"builder": "@angular-builders/custom-webpack:browser",
"options": {
"customWebpackConfig": {
"path": "./webpack.extends.js",
"replaceDuplicatePlugins": true
},
```
as you can see name of my webpack config is `webpack.extends.js` you can use whatever name you want.
Dump below we have to change builder for `ng serve`
```json
"serve": {
"builder": "@angular-builders/custom-webpack:dev-server",
```
In root directory according to `path` which we added to angular.json we have to create `webpack.extends.js` file. It is a file where we will be keeping our additional webpack configuration. For now let's just export empty object:
```js
module.exports = {};
```
Perfect, we've updated builders and added custom webpack config to Angular app. Everything is working so let's go to next step and let's add some custom plugin.
## Adding Custom Webpack Plugin
As I mentioned above I'm gonna add [SVG Doc Generator](https://github.com/Fasosnql/svg-doc-gen). plugin. According to instruction we have to install it via npm
```bash
npm install --save-dev svg-doc-gen
```
Great, now we can configure plugin in our `webpack.extends.js` file. But before it I will add my sprites.svg file to generate styles and demo html based on this. My SVG file looks like:
```xml
<svg version="1.1"
xmlns="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink"
viewBox="0 0 24 24">
<defs>
<style>
svg.sprites {
display: inline;
}
svg {
display: none;
}
svg:target {
display: inline;
}
svg[id^="primary-blue/"] use {
fill: #047BC1;
}
svg[id^="primary-white/"] use {
fill: #fefefe;
}
svg[id^="black/"] use {
fill: #000000;
}
svg[id^="gray/"] use {
fill: #AAAAAA;
}
svg[id^="green/"] use {
fill: #197F86;
}
svg[id^="orange/"] use {
fill: #C3561A;
}
svg[id^="red/"] use {
fill: #B21F24;
}
svg[id^="secondary-blue/"] {
fill: #002B49 !important;
}
svg[id^="white/"] {
fill: #FFFFFF;
}
</style>
<g id="def-icon1.svg">
<path d="M17 10.5V7c0-.55-.45-1-1-1H4c-.55 0-1 .45-1 1v10c0 .55.45 1 1 1h12c.55 0 1-.45 1-1v-3.5l4 4v-11l-4 4z"/>
<path d="M0 0h24v24H0z" fill="none"/>
</g>
<g id="def-icon2.svg">
<path d="M15.41 16.59L10.83 12l4.58-4.59L14 6l-6 6 6 6 1.41-1.41z"/><path fill="none" d="M0 0h24v24H0V0z"/>
</g>
<g id="def-icon3.svg">
<path d="M8.59 16.59L13.17 12 8.59 7.41 10 6l6 6-6 6-1.41-1.41z"/><path fill="none" d="M0 0h24v24H0V0z"/>
</g>
<g id="def-icon4.svg">
<path d="M0 0h24v24H0z" fill="none"/><path d="M12 2C6.48 2 2 6.48 2 12s4.48 10 10 10 10-4.48 10-10S17.52 2 12 2zm-2 15l-5-5 1.41-1.41L10 14.17l7.59-7.59L19 8l-9 9z"/>
</g>
</defs>
<!--
@SVGDoc
name: Icon1
variable: icon1
-->
<svg id="icon1.svg">
<use xlink:href="#def-icon1.svg"/>
</svg>
<!--
@SVGDoc
name: Icon2
variable: icon2
-->
<svg id="icon2.svg">
<use xlink:href="#def-icon2.svg"/>
</svg>
<!--
@SVGDoc
name: Icon3
variable: icon3
-->
<svg id="icon2.svg">
<use xlink:href="#def-icon2.svg"/>
</svg>
<!--
@SVGDoc
name: Icon4
variable: icon4
-->
<svg id="icon4.svg">
<use xlink:href="#def-icon4.svg"/>
</svg>
</svg>
```
As you see for every icon I've added `@SVGDocGen` comment according to plugin documentation. Now we can configure plugin,
Inside `webpack.extends.js` we have to add:
```js
const path = require('path');
const SVGDocGen = require('svg-doc-gen');
module.exports = {
plugins: [
new SVGDocGen({
svgDefsPath: path.resolve(__dirname, 'src/assets/sprites.svg'),
stylesConfig: {
outputPath: path.resolve(__dirname, 'src/assets/styles/svg-vars.scss'),
styleLang: 'scss',
svgPathInFile: 'assets/sprites.svg'
},
htmlConfig: {
outputPath: path.resolve(__dirname, 'src/assets/svg-demo/index.html')
}
})
]
};
```
This is configuration which is taking `sprites.svg` file from `assets` folder and generating variables and demo html with icons to `assets` folder.
Now when you run `ng serve` or `ng build` according to path if you open `src/assets/svg-demo/index.html` you should see that output:
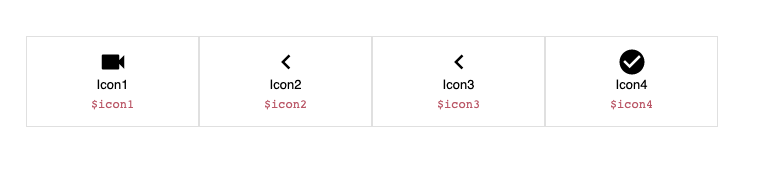
And `src/assets/styles/svg-vars.scss`:
```scss
$icon1: "assets/sprites.svg#icon1.svg";
$icon2: "assets/sprites.svg#icon2.svg";
$icon3: "assets/sprites.svg#icon2.svg";
$icon4: "assets/sprites.svg#icon4.svg";
```
Ok perfect, at the end we can just import our vars to `styles.scss` to get usage of generated variables. I.e:
```scss
@import "./assets/styles/svg-vars";
.icon1 {
background: url($icon1);
background-size: 100%;
width: 2rem;
height: 2rem;
}
```
That's all from me, If you have some questions feel free to add comments below this article. If you have some problems with configuring let's download this [zip](https://srv-file9.gofile.io/download/8APrqi/zip-svg.zip) package (this is working angular app generated for this article) and compare your code with code from this pack. | fasosnql |
264,606 | How to create own utility methods for your Rails application | Hello, As a developer, I need from time to time to quickly execute SQL, or check something in DB,... | 0 | 2020-02-19T15:33:43 | https://dev.to/igorkasyanchuk/how-to-create-own-utility-methods-for-your-rails-application-40lm | ruby, rails | ---
title: How to create own utility methods for your Rails application
published: true
description:
tags: ruby, rails
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/rlt9ue05pl4bspkxgetr.png
---
Hello,
As a developer, I need from time to time to quickly execute SQL, or check something in DB, truncate a table, etc when I'm in the rails console.
You may already know about using `ActiveRecord::Base.connection.execute("SQL query")` solution, but I must admit I'm a lazy developer when it comes to doing routine tasks or things where I need to type long pieces of code. And actually a snippet of code above is not everything that you need to type, you may also need to add `.to_a` to see the result of the query.
I know the following rule:
## laziness is the engine of progress!
So, I tried to solve my issue as a developer and create an open-source solution to use it from project to project: https://github.com/igorkasyanchuk/execute_sql
This is a demo of how it works:
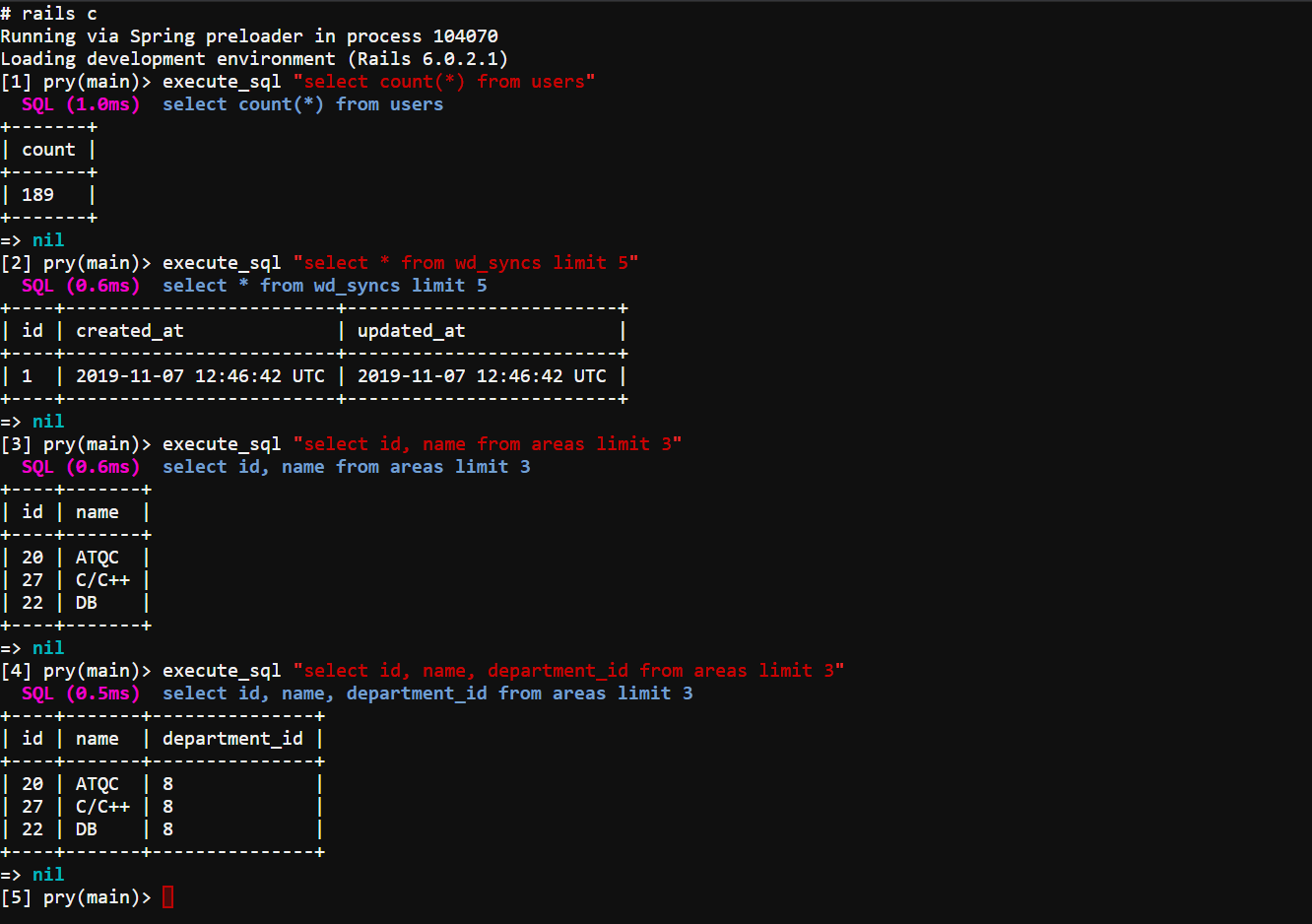
I'll explain how it works.
Step of creation gem I'll skip, but basically you need to create a new gem (`rails plugin new <name>`).
Now we need to understand how to add our own method just in the rails console.
```ruby
module ExecuteSql
class Railtie < ::Rails::Railtie
console do
TOPLEVEL_BINDING.eval('self').extend ExecuteSql::ConsoleMethods
end
end
end
```
This is a piece of code from my gem. You can see that Rails provides a helper method `console` where you can pass the code which will be executed when you starting `rails c`.
In our case this is `TOPLEVEL_BINDING.eval('self').extend ExecuteSql::ConsoleMethods`.
In case you have wondered, what this top-level constant TOPLEVEL_BINDING is all about better to check sample of usage below:
```ruby
a = 42
p binding.local_variable_defined?(:a) # => true
p TOPLEVEL_BINDING.local_variable_defined?(:a) # => true
def example_method
p binding.local_variable_defined?(:a) # => false
p TOPLEVEL_BINDING.local_variable_defined?(:a) # => true
end
example_method
```
More details about `TOPLEVEL_BINDING` you can find [here](https://idiosyncratic-ruby.com/44-top-level-binding.html).
```
[11] pry(main)> TOPLEVEL_BINDING.eval('self')
=> main
[12] pry(main)> TOPLEVEL_BINDING
=> #<Binding:0x0000000001350b00>
```
As you can see TOPLEVEL_BINDING.eval('self') is basically the context of our console app.
So the last thing for us to do is to extend the `main` app with our class methods from `ExecuteSql::ConsoleMethods` module, source code is [here](https://github.com/igorkasyanchuk/execute_sql/blob/master/lib/execute_sql.rb).
This module inside is responsible for queries DB, and basically I took most of the code from my other gem [rails_db](https://github.com/igorkasyanchuk/rails_db) and printing results using [terminal-table](https://github.com/tj/terminal-table) gem.
Now my life is easier :)
And I hope you can implement your own utility methods. | igorkasyanchuk |
272,294 | How to become Good back-end developer? | Here some point to be noted being a good back-end developer . 1.Read the official documentation care... | 0 | 2020-03-02T16:22:05 | https://dev.to/w3codeblog/how-to-become-good-back-end-developer-1620 | php, laravel, devops, career | Here some point to be noted being a good back-end developer .
1.Read the official documentation carefully of language .
2.Each topic are important for being a good back-end dev.
3.If any bug makes you unhappy take a short break than thin about problem it will help you to resolve bug .
4.Check your syntax twice and than run program .
5.Always find bug from initial to advance .
Thanks . | w3codeblog |
272,364 | Normalize your complex JS objects | The process of normalization its havily used in every software design because normalizing data has a big impact on reducing data redunancy. | 0 | 2020-03-02T18:29:34 | https://dev.to/danielpdev/normalize-your-complex-js-objects-21d9 | javascript, normalization | ---
title: Normalize your complex JS objects
published: true
description: The process of normalization its havily used in every software design because normalizing data has a big impact on reducing data redunancy.
tags: javascript, normalization
---
## Data normalization
The process of normalization its havily used in every software design because normalizing data has a big impact on reducing data redunancy.
## When to normalize your data?
Suppose we received the following data from an api:
```ts
const apiData = [
{
id: 1,
name: "Daniel Popa",
siteUrl: "danielpdev.io"
},
{
id: 2,
name: "Other Name",
siteUrl: "danielpdev.io"
}
];
```
Now, you get a task to find the item with id of 1.
### How will you solve it?
#### 1. Dummy solution with complexity O(n):
Iterate over the whole collection using a `find` and output the result.
```ts
const findId = (apiData, id) => apiData.find(el => el.id === id);
```
You finished quite fast and gone for a coffee, but over the next few months the data grows and now you don't have only two elements,
but 10000. Your time of searching for elements will increase considerabily.
#### 2. Normalized solution with complexity O(1):
Transform data from [objects] => { id: object}:
```ts
const apiData = [
{
id: 1,
name: "Daniel Popa",
siteUrl: "danielpdev.io"
},
{
id: 2,
name: "Other Name",
siteUrl: "danielpdev.io"
}
];
function assignBy(key) {
return (data, item) => {
data[item[key]] = item;
return data;
}
}
const optimizedData = apiData.reduce(assignBy("id"), {});
```
optimizedData variable looks like the following:
```ts
{
"1": {
"id": 1,
"name": "Daniel Popa",
"siteUrl": "danielpdev.io"
},
"2": {
"id": 2,
"name": "Other Name",
"siteUrl": "danielpdev.io"
}
}
```
Now, searching for an element becomes really easy. Just `optimizedData[id]` and your data is ready.
### Conclusion:
Normalize your data only when dealing with complex objects and searching for objects takes long.
Article first posted on [danielpdev.io](https://danielpdev.io/normalize-your-complex-js-data/)
[Follow me on twitter](https://twitter.com/danielpdev) | danielpdev |
272,409 | iOS: How to add Quick Actions (shortcuts) to your app icon | iOS Quick Actions are meant as a shortcut for your users. They are triggered by long-pressing on the... | 0 | 2020-03-02T20:20:29 | https://dev.to/nemecek_f/ios-how-to-add-quick-actions-shortcuts-to-your-app-icon-ol5 | ios, swift | iOS Quick Actions are meant as a shortcut for your users. They are triggered by long-pressing on the app icon. Each app can present up to four of them and they can be nice touch you can add with not that much a code.
We can have static actions that are defined in `Info.plist` or dynamic actions which are much more versatile. Let’s focus on the dynamic bunch. 🙂
### Providing Quick Actions
We can use the class `UIApplicationShortcutItem` to define one shortcut item and then set all the items we want when app is moving to background.
For example this is one item from one of my recent apps to open management section:
```swift
UIApplicationShortcutItem(type: "OpenManagement", localizedTitle: "Management", localizedSubtitle: nil, icon: UIApplicationShortcutIcon(type: .favorite), userInfo: nil)
```
The `type` is used to differentiate the shortcut when user selects it. `localizedTitle` is the text on the shortcut and you can choose from variety of prepared icons. Here `.favorite` results in filled star. You can also provide your own.
There is also `userInfo` to provide dictionary with additional details.
### Activating Quick Actions
Let’s use `AppDelegate` to activate the shortcut item shown above in the `applicationWillResignActive` method:
```swift
func applicationWillResignActive(_ application: UIApplication) {
let managementShortcut = UIApplicationShortcutItem(type: "OpenManagement", localizedTitle: "Management", localizedSubtitle: nil, icon: UIApplicationShortcutIcon(type: .favorite), userInfo: nil)
application.shortcutItems = [managementShortcut]
}
```
The first part is done. Long-pressing on app icon will show this new Quick Action.
## Responding to Quick Actions
There are two places in `AppDelegate` where we have to respond to Quick Action selection. One is the startup method `didFinishLaunchingWithOptions` where we can check the `launchOptions` like so:
```swift
if let shortCut = launchOptions?[UIApplication.LaunchOptionsKey.shortcutItem] as? UIApplicationShortcutItem {
// handle shortCut here
}
```
And then there is also dedicated method called when the app is already running in the background:
```swift
func application(_ application: UIApplication, performActionFor shortcutItem: UIApplicationShortcutItem, completionHandler: @escaping (Bool) -> Void) {
print(shortcutItem.type)
// handle shortcutItem here
}
```
I would recommend creating helper method for handling shortcut items so you don’t have to duplicate logic in those two places.
Thanks for reading!
_Is anything not clear? Do you want more information? Ask in the comments and I will do my best to help you._
Here is Quick Actions example from the Dashboardy app:
| nemecek_f |
272,514 | Am I a “real” Software Engineer yet? | Am I a “real” Software Engineer yet? This question has haunted me for years. And it seems I’m not al... | 0 | 2020-03-04T18:31:46 | https://medium.com/free-code-camp/am-i-a-real-software-engineer-yet-a0f38a2248c0 | career, firstyearincode, motivation, inclusion | *Am I a “real” Software Engineer yet?*
This question has haunted me for years. And it seems I’m not alone. Many people experience this same insecurity. They desire to know if they’ve *made it. *Are they finally *good enough?*
While “Software Engineer” is the standard title handed out by employers, many in the software community have different standards. And to new programmers joining the field, especially those without CS degrees, it can feel like the title is safe-guarded. Only bestowed on the select that have proven themselves.
Many people refer to this sense of deficiency as **Impostor Syndrome**, though it goes by many names. Developers experience it in different ways and have differing reactions. To some, it can be crippling, but others might not notice it whatsoever.
In this article, I’m going to recount my own ordeals with Impostor Syndrome. While I don’t pretend to have a cure, I hope to shed some more light on the topic and help others who are dealing with it.
**Note:** All the comments I’ve shared are real comments I’ve found on the internet. Not all of them were directed towards me, but I’ve heard similar remarks. I’m sure you have too.
## When it all began
 on [Unsplash](https://unsplash.com/search/photos/begin?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/5356/1*jUoIve_Ff3QUjRsRsL_S2g.jpeg)*Photo by [Danielle MacInnes](https://unsplash.com/photos/IuLgi9PWETU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/search/photos/begin?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)*
For me, it started in July of 2016. I had started studying web development as a New Years Resolution. I wasn’t satisfied with my career at the time and was looking for a change. A common origin story that I’m sure many people can relate to.
I focused on front-end development as I had heard that HTML, CSS and JavaScript were easy to pick up. I spent my evenings after work parsing through Treehouse, Lynda, and Codecademy tutorials. The first three months of 2016 passed by like this. By April, my notebook was full of thorough notes and my GitHub contained a few static sites. But I wasn’t satisfied. I wanted to sink my teeth into a larger project.
That was when I decided to [create a portfolio site for my wife](https://dev.to/sunnyb/a-tale-of-two-websites-4b15), who was a product designer. For my skill level at the time, it wasn’t an easy undertaking. I struggled a lot and it took the better part of four months to complete.
It’s important to note that while working on my wife’s website, I did my best to surround myself with tech culture. I watched YouTube videos, listened to podcasts, and read blog posts from experienced engineers to keep myself motivated. I daydreamed what it would be like to stand in their shoes. To have a job at a tech company, work on the latest technology, and write “Software Engineer” as my **Occupation** on tax forms. [Silicon Valley](https://en.wikipedia.org/wiki/Silicon_Valley_(TV_series)) made it all look so glorious.
That’s why I couldn’t have been happier when my wife’s website went live in July of that year. I had done it. I had made my first real website that was going to receive real traffic. Could I finally start calling myself something of a *Software Engineer*?
## “Web development isn’t real programming”
Not according to the Internet:
*“being a fully competent and complete software is much more … ”*
](https://cdn-images-1.medium.com/max/4252/1*RwHFP6lwmeA6Ki7phIq-Kg.jpeg)*“Web development is not real programming” — Read more [here](http://joequery.me/code/the-self-hating-web-developer/)*
“Web development isn’t real programming”, “JavaScript isn’t a real programming language”, and “a front-end developer isn’t a Software Engineer” were all phrases I heard often. While I was determined to change careers, I was also self-conscious. I couldn’t shake the thought that the naysayers were right.
If I’d had a Plan B or a stable career to fall back on, I might’ve given up right then and there. Fortunately, I didn’t. For better or worse, I had no other career or skills to fall back on and I had already invested too much time. So I trudged on, with the [sunk cost](https://en.wikipedia.org/wiki/Sunk_cost) keeping me afloat.
I spent the next 18 months studying software development full time. I quit my job and moved in with my in-laws — which was a journey in-and-of itself. I put everything I had into my career move. I studied Ruby, Node, and some Go and built some small web apps.
By January of 2018, it had been two years since the start of my career switch and I had learned a great deal. I knew the fundamentals, I could program in multiple languages, and I had started contributing to open-source projects. I also had a [decent portfolio](https://dev.to/sunnyb/building-conclave-a-decentralized-real-time-collaborative-text-editor-1jl0) to show for it. I was excited to finally call myself a Software Engineer.
“Not so fast,” said the Internet.
*“software engineer” after 1–2 years? yeah no.”*
*“If you don’t have a software engineering degree you’re not a real software engineer. ... You only know how to do some code.”*
At this point, I had dealt with many doubters. While it still didn’t feel great to hear criticism, I had learned to ignore it for the most part. Furthermore, I had an Ace up my sleeve. There was one final step I could accomplish to put all the doubts to rest: Getting a job.
Yes, a software engineering job. The holy grail. I would have the title, the paycheck, and the acclaim. No more self-doubt. Only deserved validation from an employer.
[And that’s what I did](https://hackernoon.com/what-it-took-to-land-my-dream-software-engineering-job-17c01240266b). I started interviewing in early 2018 and signed my first offer letter by March of 2018. My official role was “Software Engineer”. That was that, the hunt for acceptance was finally over.
## From bad to worse
*“You’re still a newbie.. and will be for a few more years at least. Software engineer by title, that’s all.*
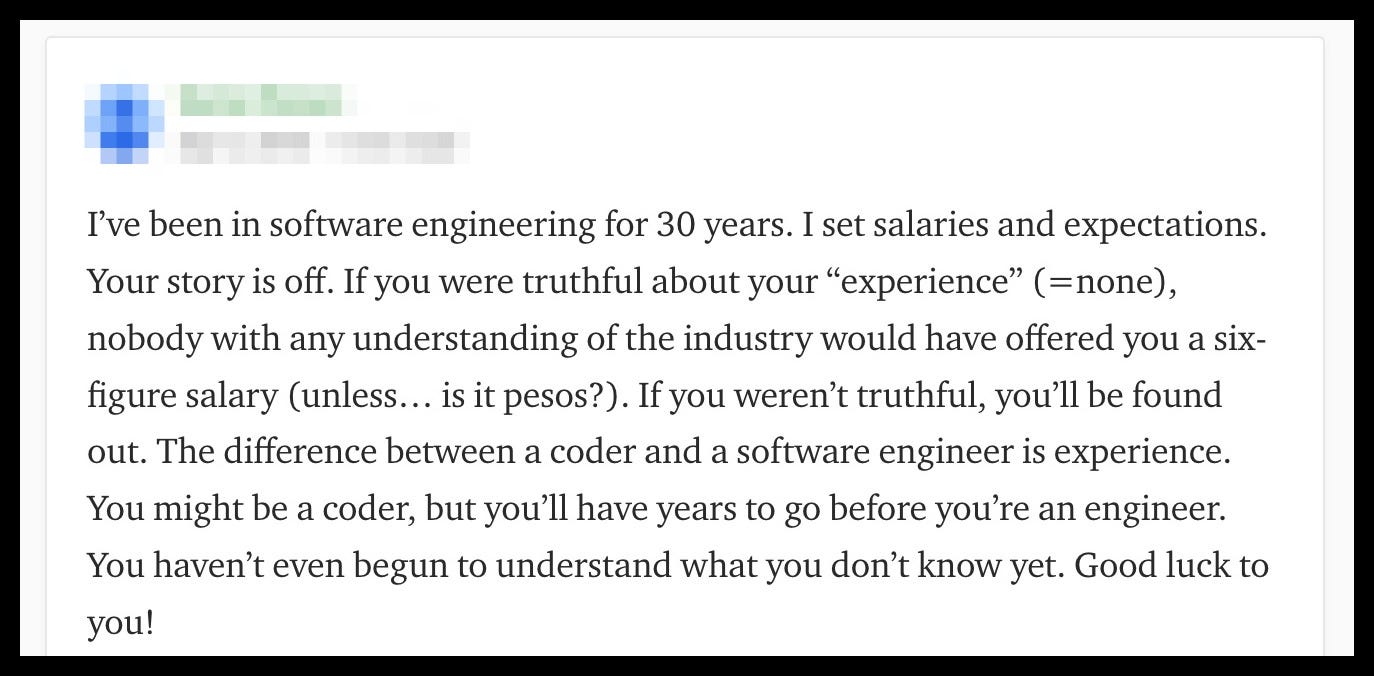*“I’ve been in software engineering for 30 years. …You haven’t even begun to understand what you don’t know yet. Good luck to you!”*
At least that’s what I thought. It seemed the gate-keeping extended even into the realm of employment. But it was over. I was a Software Engineer — I had the W4 papers to prove it. The moment I stepped into the office for my first day on the job, all my worries would disappear.
But that wasn’t the truth. Who knew that adding obligations and deadlines would make one’s insecurities worse, not better?
My anxiety hit a fever pitch the moment I arrived for my first day of onboarding. Slack conversations I didn’t understand. GitHub repositories with thousands of lines of code I didn’t comprehend. Development tools I had never heard of or used. My first week on the job was a whirlwind of stress.
Don’t get me wrong, I was thrilled to be surrounded by such experienced engineers. My team was full of some of the smartest engineers I’d ever met and they were incredibly understanding. They mentored me and ramped me up to speed. But it was still intimidating as hell.
Many of my coworkers had advanced degrees, some had been programming since they were teens, and others were core maintainers of large open source projects. And who was I? Some guy who learned to code because it looked cool on TV. I felt out of place and the feeling didn’t disappear.
My thoughts began to resemble the negative comments that I had worked so hard to prove wrong:
*How the hell did I get here? Was it luck? Did someone make a mistake?*
I realized that I didn’t need Reddit to point out my inadequacies — I was quite capable of that myself. It’s true that, with time, I became more familiar with my environment. I began to understand the Slack conversations, the code became more familiar, and I learned how to use the various tools. And yet, I couldn’t shake the feeling that I was a stranger in a foreign land. Every mistake I made only served to prove that point further.
I anticipated the day that I made one mistake too many and someone finally asked, “How on Earth did you get hired?” That fear consumed me. I began reading whitepapers, frequenting Hacker News, and taking classes to get a Computer Science degree. All in the hopes that I would finally feel like I fit in. That I was a “real” software engineer. But none of it worked.
Luckily, I found something that did.
## Finding my solution
The solution that I found for myself was simple yet terrifying.
**Talking.**
I had to talk to someone. I couldn’t keep it bottled anymore. However, I was too nervous to ask any of coworkers a question like, “Have you ever felt like a fraud?” Instead, I started with my close friends. But I soon found myself discussing the topic to anyone I could, including coworkers and teammates. Because the more I talked and listened, the more I realized I wasn’t alone.
As it turns out, impostor syndrome is so common that it has become a cliché!
*“Another impostor syndrome article …. Walking in to work everyday with a complete mastery over everything you do and write is a problem of its own.”*
Many professionals at the top of their careers experience it. [Tina Fey](https://www.instyle.com/celebrity/stars-imposter-syndrome?slide=3163098#3163098), [John Steinbeck](https://www.grammarly.com/blog/notable-people-imposter-syndrome/), and even [Albert Einstein](https://www.therebegiants.com/overcoming-impostor-syndrome/). It was comforting to find out that I was in such good company. Furthermore, when talking with a close friend, he said something that struck a chord with me:
> # “The only time impostor syndrome is bad is when you don’t have it. Feeling like a fraud is a sign that you’re learning. Having anxiety in a new and uncomfortable environment is perfectly normal. The trouble comes when you feel like you know exactly what to do and how everything works. If you find yourself in that situation, you aren’t learning anymore.”
It was in that moment that I realized impostor syndrome wasn’t something to fight or ignore. With the right mindset, it can be a tool. That may sound like some feel-good BS, but public speakers employ a similar trick to [convert anxiety into excitement](https://www.theatlantic.com/video/index/485297/turn-anxiety-into-excitement/).
This isn’t to say that my insecurities have magically disappeared. Far from it. Whenever I’m given a new project to work on, my panic makes an unwelcome return. My heart rate spikes and my mind conjures up fantastical feats of failure. However, I’ve learned to interpret this nervous energy as a sign that I’m learning and pushing myself to new heights.
When my manager gives me a complicated task, it means that they trust that I can get it done. I may need to ask for help, research the topic, or simply go for a walk to cool my nerves, but I know I’ll get through it. I still make mistakes all the time and that will never change. It’s all a part of the process.
After all, no one knows everything, not even within their own specialty. [Dan Abramov doesn’t know flexbox](https://overreacted.io/things-i-dont-know-as-of-2018/) and [David Heinemeier Hansson](https://en.wikipedia.org/wiki/David_Heinemeier_Hansson) still looks up ActiveRecord methods he wrote himself. If perfection was a feasible goal, Stack Overflow wouldn’t be as popular as it is.
## Am I a “real” software engineer?
So after all this time, am I a “real” software engineer yet? LinkedIn seems to think so.
The better question is, “Does it matter?” I haven’t always been passionate about tech and I lack the enticing origin story of a Rockstar Engineer. But I’m here now and I’m here to stay. So to those in the tech community who have strong opinions about my title, call me whatever you want. A software engineer, programmer, script kiddie...
My title no longer matters to me. What matters is what I do. And what I do is use code to solve problems and architect solutions to make peoples’ lives better.
Best of all, I’m damn good at it.
| sunnyb |
272,914 | Sarah Bartley Continues to Code in 2020 | Four years ago, I wrote my first line of code ever. This code wasn’t very amazing. I was simply... | 11,887 | 2020-03-06T06:20:42 | https://dev.to/theoriginalbpc/sarah-bartley-continues-to-code-in-2020-34e1 | wecoded | ---
title: Sarah Bartley Continues to Code in 2020
published: true
tags: shecoded
series: shecoded
---
Four years ago, I wrote my first line of code ever. This code wasn’t very amazing. I was simply trying to get “Hello World” to appear on the screen.
It was a simple task, but this was the beginning of a brand new chapter of my life and the start of my developer story. When I enrolled in Skillcrush web designer career blueprint in 2015, I had a feeling that learning how to code would change my life. Although I didn’t know what would lie ahead, I knew that surprises and experiences were coming and would shape my story.
My instincts were spot on. There have been many surprises that have happened along the road to being the developer I can be. These surprises have come in a variety of different experiences such as speaking at virtual summits, starting an online community on Elpha, and the opportunity to share posts I’ve written on different platforms within the tech community.
I’ve grown a lot since I wrote “Hello World” back in 2015. These days I’m working on improving and refining my frontend skills while learning how to build the backend of web applications. In addition to learning brand new skills, I wanted to start building the habit of building more projects.
During the summer, I started a second round of 100 Days of Code and used the challenge as a way to update many of the projects I’ve created in the past. A few months later, I participated in Hacktoberfest so I could become much more confident contributing to open-source projects. This year, I am getting even more focused on my developer job.
After looking at dozens of job postings for front-end web developer jobs and doing my first-ever tech job interviews, I set goals to learn skills to help me become a better candidate in job interviews. This includes learning skills I often have seen on job postings to including more algorithm practice to prepare for interviews.
### So what helps me continue to code four years later?
One thing that keeps me grounded on my coding journey is the coding community. There are so many great coding communities for developers to join from Twitter chats, Slack groups, and Facebook groups. Last year, I created a coding community on Elpha.
Elphas Can Code was released as part of the launch of the Communities feature on the platform. It is a place where all women in tech at all stages of their coding journeys come to get help and support. If you are a newbie just getting started learning how to code, this is one of the first things you must do.
Having a supportive community is a very important resource you need to have along your coding journey. This isn’t a place where you can go to ask how to fix your code. An amazing community is going to be your biggest cheerleader along your journey and celebrate your successes with you.
They also help you tune out the negative voices telling you to quit and give up. There are going to be a lot of negative voices that pop up during your coding journey. These voices don’t just belong to people who want to see you quit.
Many times these negative voices can be the ones that come from your head from impostor syndrome. Don’t listen to these voices! What helps me keep my negative voices at bay is something Jillian Michaels always says in her workout DVDs.
When things get tough during a workout, she tells the viewer to remember the why. Just thinking of your reason why is going to help you focus and tolerate any how life decides to throw your way. Another secret that keeps me coding is scheduling time for coding.
I set aside 25 minutes to do coding tutorials and learn a new skill. Then I set aside an hour to work on a coding project. I use the Pomodoro technique to split up the time so I get a little bit of a break in between each session.
I encourage all developers to do a coding challenge like 100 Days of Code, 301 Days of Code, or my coding challenge Disney Codes Challenge. A coding challenge isn’t a great way to just build good coding habits and make projects for your portfolio. These challenges are a great way to learn about what your strengths and weaknesses are as a developer.
You can think of coding challenges as your way to check up on where you are now as a developer and what you need to work on. Scheduling time to code just helps you make time for coding. It has allowed me to make more time to do other non-technical things in my life.
In 2018, I discovered I was spending way too much time on my computer and not making time for hobbies I wanted to do. This made me feel stressed since I wasn’t making time to allow myself to relax. So I began scheduling parts of my day so I could do some crafting, read a non-technical book, or learn a non-programming topic.
These were positive steps towards achieving the healthy balance I was looking for and getting me back on track. Throughout my coding journey, I often think about my high school version of myself and what advice I would like to give her if I ever had a chance to talk to my younger self. The advice I would give my younger self is to use this time to learn about myself and figure out what I want.
I would have encouraged her to read the book *What Color is Your Parachute* and do the flower exercises to start thinking about what career is the best fit for her. I would also encourage my younger self to try new hobbies and use this time to learn new skills. I’d especially tell her to try things she doesn’t think she might be good at because she might end up liking it.
Most importantly, I would have told my younger self to stop comparing herself to other people and try to keep up with what other people are doing. Instead, I would encourage her to compare herself to a past version of herself to see how much she has grown and accomplished since then. I would also encourage my younger self to be less worried about what her future should be and concentrate on just being the best version of herself she can be and not trying to be perfect.
| theoriginalbpc |
272,933 | Build a leader habit: Empower people around you. | A good leader has an impact on the team they join. They don't bring anyone down, they don't lower... | 2,541 | 2020-03-02T23:34:41 | https://flawedengineer.dev/empower-people-around-you/ | leadership, career, softskills | > A good leader has an impact on the team they join.
They don't bring anyone down, they don't lower standard but they make the effort to show the way, possibly the better way. I've seen over and over again engineers clinging onto their knowledge convinced that's how they remain valuable to the team or the company. I have news for you, it only works short term, it harms your career development AND damages team dynamics.
Although we might feel better about ourselves being the "go-to" person for specific things within the office, we might risk to become the only person available for it, _at all times_. This means that you get stuck or pidgeon-holed into that role. This has two major drawbacks:
1. Eventually **you might get tired** of always being the go-to person for the same issues/tasks. It feels great in the beginning but it becomes tiring in the long run.
2. It can **hamper your career development**. If you're the only one able to solve a specific issue/task, why would the manager want to move you to a different team/role/project ?
## How not to get stuck
There is a quite simple solution to this.
There's a theme you'll see across many of my posts. And it's the answer to a simple question which varies based on the context you apply it to.
> What can **YOU** do to improve the current state of things ?
How can **you** change the situation without relying on external factors ? While some of you might be lucky enough to have a supporting team and a great manager, we are engineers at heart so we need to consider the **WCS** (Worst Case Scenario). Although we hear this mostly when it comes to solving algorithmic problems, it definitely applies to many real life situations.
Here are a few things you can do to "get unstuck":
### 1. Write incredibly good docs
I wrote about this in the past [here](https://dev.to/gabcimato/how-to-make-your-future-self-happy-by-writing-good-docs-h8p), it definitely applies to the situation discussed as well. Some of the best engineers I had the pleasure to work with, were absolutely great at writing detailed-enough docs.
This means solid `Readme`s where all you had to do was follow a few steps. Explanations of the **whys** more than the **what**. Any team member should be able to be up and running by simply reading the docs and without any further need for communication. This liberates you from being the sole reference for a project and empowers other engineers to use or contribute to your work.
Writing docs is always a good idea, even just for your future self. So you have a dual benefit:
- You **empower your future self** enabling them to pick up where you left off
- You **empower junior employees** by showing them how things work passively (with docs).
Passive mentorship is a good starting point, but that's all it is. A starting point. So keep that in mind.
### 2. Automate what you can
Especially in 2020 I'm all for automation. There's so much out there to help you out, it's quite incredible. Even posting on my personal blog is now automated with a scheduler.
This can be quite useful for repetitive tasks. Instead of manually running a database query every 2 or 3 days a week to generate a report, automate it! Generate a report every day and save it somewhere where others can analyze it easily. On top of that, apply (1) again and document it all. With this you solve two problems at once: reports are automated so nobody needs to come ask, the automation is documented so other people can help fix any future issue.
- You **empower any other engineer** by allowing them to pick up and possibly fix a task you bootstrapped.
- You **empower members of other teams** by making sure they have the data they need at all times.
### 3. Teach and spread the knowledge
If you become the only source of truth for a specific piece of knowledge, you'll always be the point of reference. This ties well with my other post ([Learn how to let go](https://flawedengineer.dev/learn-how-to-let-go/)), where I suggest that a good leader knows when to let go.
> That precious piece of knowledge can grow even more if you let other people nurture it.
Share what you learned. You are a lead so you don't need to be afraid that some specific information is what keeps you in that position. I have **NEVER** seen a leader lose their credibility or position by sharing most of their knowledge with their peers.
- **Empower people around you** by showing them the ropes. Help them acquire some knowledge faster. It'll enable them to contribute sooner and become an integral part of the team.
- **Teach as much as you can** about projects, company past failures or what you learned in the past/present.
I always found the last one extremely valuable. My goal has always been to elevate juniors as fast as I could by sharing everything I know about specific topics. My intent is to bring them up to speed so that we can have a 1:1 conversation about any technical topic.
I remember spending quite some time explaining how state management works in React in great depth. Then showing the good and bad of Redux and how to use it effectively. Within a few weeks I was able to discuss with other junior devs how we should go about handling a complex feature, letting now **them** tell me how they would do it. This was only possible because I filled the gap in their knowledge by sharing and teaching them what I knew.
## Conclusion
There is no reason why you, as a lead, should keep your knowledge secret. We've seen how beneficial sharing and empowering team members can be. From a more self-centered perspective, it unlocks your growth. From a self-less perspective you allow the team to grow. That sounds absolutely great on all levels!
Be the type of leader who brings the best out of people. Their growth is your growth!
👋 Hi, I’m Gabri! I love innovation and lead R&D at Hutch. I also love React, Javascript and Machine Learning (among a million other things). You can follow me on twitter [@gabrielecimato](https://twitter.com/gabrielecimato) and on GitHub [@Gabri3l](https://github.com/Gabri3l). Leave a comment if you have any questions, or send a DM on Twitter to say hi!
| gabrielecimato |
272,942 | Crucial VS Code Hotkeys | I LOVE HOTKEYS! The less keystrokes I need to type, the better. In this blog I'll go over my favorite... | 0 | 2020-03-02T23:50:47 | https://dev.to/123jackcole/crucial-vs-code-hotkeys-g46 | newbie, beginners, vscode, hotkey | I LOVE HOTKEYS! The less keystrokes I need to type, the better. In this blog I'll go over my favorite hotkeys that I've found so far when using VS Code.
Before we dive in I'd like to address that I'm currently using a mac for my coding adventures. All of the hotkeys I'll be talking about will be for mac. Sorry windows and linux users...
##**Opening VS Code's Built In Terminal**
To open VS Code's built in terminal, use `command` + `~`. No more tabbing back and forth for me!
##**Open and Close the Sidebar**
To quickly close and open the sidebar, use `command` + `b`.
##**Switch Between Workspaces**
VS Code does a good job of recording what folders you have previously opened. To quickly navigate to these folders use `control` + `r`.
##**Search For a File**
If your project gets complex enough searching for specific files can be a pain. Use `command` + `p` to quickly search for a file or symbol by name.
##**Navigate to a Specific Line**
On the topic of `command` + `p`, if you start your search with `:` followed by a number VS Code will navigate you to that specific line. You can also use `control` + `g`.
##**Folding and Unfolding**
If your codebase is getting too large and you prefer a clean screen you can fold your classes or methods to reduce clutter. To fold your classes or methods use `command` + `option` + `[`. To unfold them use `command` + `option` + `]`.
##**Select All Instances of a Word**
To select all occurrences of a word use `command` + `shift` + `l`. From here you're able to edit all of your selections at once.
##**Select a Single Instance of a Word**
To select a single word use `command` + `d`. If you do it more than once VS Code will add the next occurrence of the word to your selection.
##**Move a Line**
To move a line up or down a line, use `option` + the `up` or `down` arrows.
##**Copy a Line**
To copy a line of code either up or down a line use `shift` + `option` + `up` or `down`.
##**Delete a Line**
To quickly delete a line use `command` + `x`. To delete the portion of the line to the left of your selection use `command` + `delete`.
##**Duplicate Your Cursor**
This one is incredibly helpful when you are doing repetitive tasks. Use `command` + `option` + `up` or `down`. Alternatively, you can hold `option` and click to add another cursor location.
Hopefully some of these hotkeys are helpful in your future coding adventures! I'm always looking for new hotkeys to add to my arsenal so please let me know if I missed any important ones.
| 123jackcole |
272,952 | Go language data types | In the Go programming language, data types are used to declare functions and variables. A variable... | 0 | 2020-03-03T00:30:20 | https://dev.to/toebes618/go-language-data-types-3n7k | go, beginners | In the <a href="https://golang.org/">Go programming language</a>, data types are used to declare functions and variables.
A <a href="https://golangr.com/variables/">variable</a> can be a boolean (True/False), a number (1,2,3), text etc. The Go language needs to know what kinds of data you want to store.
There are several types of data by category:
No. | Type and Description
--- | ---
1 | **Boolean** Boolean values can only be constants true or false. A simple example: var b bool = true.
2 | **numeric** type Int integer and floating-point float, Go language support integer and floating point numbers, and native support complex, wherein the position calculation using complement.
3 | **string type:** Character string is a string of fixed length connecting the character sequence. Go strings are connected by a single byte. Go byte language string using UTF-8 encoding of a Unicode text identifier.
4 | **derived types:** pointer, an array, struct, Union, function, slice, interface, map, channel
## numeric type
Go is also based on the type of architecture, such as: int, uint and uintptr.
No. | Type and Description
--- | ---
1 | **uint8** Unsigned 8-bit integers (0 to 255)
2 | **uint16** Unsigned 16-bit integers (0 to 65535)
3 | **uint32** Unsigned 32-bit integers (0 to 4,294,967,295)
4 | **uint64** 64-bit unsigned integer (0-18446744073709551615)
5 | **int8** Signed 8-bit integer (-128 to 127)
6 | **int16** Signed 16-bit integer (-32768 to 32767)
7 | **int32** Signed 32-bit integer (-2147483648 to 2147483647)
8 | **int64** Signed 64-bit integer (-9223372036854775808 to 9223372036854775807)
Float:
No. | Type and Description
--- | ---
1 | **float32** IEEE-754 32-bit floating point number
2 | **float64** IEEE-754 64-bit floating point number
3 | **complex64** 32-bit real and imaginary
4 | **complex128** 64-bit real and imaginary
## other numeric types
Here are more of the other types of numbers:
No. | Type and Description
--- | ---
1 | **byte** Similar uint8
2 | **rune** Similar int32
3 | **uint** 32 or 64
4 | **int** And the same size as uint
5 | **uintptr** Unsigned int, for storing a pointer | toebes618 |
272,967 | Let's make remote work mainstream! Remote work for synchronous, verbal-communication-based teams | Hello all! I just wrote an article: How remote work is done at my company. Before joining this comp... | 0 | 2020-03-03T01:23:49 | https://dev.to/hossameldeen/let-s-make-remote-work-mainstream-remote-work-for-synchronous-verbal-communication-based-teams-1fee | remote, productivity, startup, zoom | Hello all!
I just wrote an article: [How remote work is done at my company](https://gumroad.com/l/fatcPp).
Before joining this company, I'd tried a simple remote experiment in one of my previous companies and it's failed catastrophically.
It's now common knowledge that **remote work** is (1) hard to mix with non-remote teams, and (2) for **asynchronous, writing-heavy teams**. [My article](https://gumroad.com/l/fatcPp) **challenges the second point**.
So, go [give it a read](https://gumroad.com/l/fatcPp) and tell me your thoughts, please.
This is not to take from asynchronous, writing-based communication. But some people with their current skill set, and some use-cases like baby startups perhaps?, are perhaps better suited for **synchronous, verbal, screen-share communication**. And they don't have to pay the cost of commute!
[This article](https://gumroad.com/l/fatcPp) is the cultivation of my ~8-9 months of remote work, and a **couple-of-years remote experience** of my team. Sincerely hope [it](https://gumroad.com/l/fatcPp) helps!
So, if you want to know how to **work remotely successfully** with a **synchronous, verbal-communication-based team** -- a team that dislikes writing and asyncronity, **read [this article](https://gumroad.com/l/fatcPp): [How remote work is done at my company](https://gumroad.com/l/fatcPp)**.
# Update
Due to current events, the article is now free: https://gumroad.com/l/fatcPp | hossameldeen |
273,075 | Nouveau sürücüsünü pasif yapma | Bazı durumlarda nvidia sürücüsünden kaynaklı kernel hataları ile karşılaşılabilmektedir. Örneğin USB... | 0 | 2020-03-03T06:30:36 | https://dev.to/aciklab/nouveau-surucusunu-pasif-yapma-29bm | nouveau, nvidia, modprobe | Bazı durumlarda nvidia sürücüsünden kaynaklı kernel hataları ile karşılaşılabilmektedir. Örneğin USB üzerinde çalışma yapılırken /var/log/syslog üzerinde anlamsız KERNEL hataları ile karşılaşabilirsiniz.
İlgili hata kaydında genellikle ekran kartı ibaresine benzer ifadelerin yer alması bu konuda problemin ekran kartı ile ilgili olabileceğini gösterebilir.
Çözüm olarak Linux üzerindeki varsayılan sürücü'nün kullanılması ve dağıtımlar ile gelen Nouveau'nun kara listeye alınması önerilebilir. Tabi yükselerek gelen Nvidia'nın kendi sürücünün kurulması için de bu adımlarım yapmak önşart gibi düşünülebilir.
Ubuntu 18.04, Debian 9 ve 10, Pardus 17.x ve 19.x'te çalışmaktadır.
Özet ile çalışmada aşağıdaki iki satır modprobe altında blacklist oluşturmalıdır. Yapılan iş özetle nouveau modeset'ini 0'a çekmek ve nouveau'yu blacklist'e eklemektir.
```bash
sudo bash -c "echo blacklist nouveau > /etc/modprobe.d/blacklist-nvidia-nouveau.conf"
sudo bash -c "echo options nouveau modeset=0 >> /etc/modprobe.d/blacklist-nvidia-nouveau.conf"
```
Bu adımdan sonra initramfs'in tekrar güncellenmesi gerekmektedir. Bu adım olmazsa grub ekranında elle kapatmanız gerekir ki bu otomatik bir sistem için mantıksızdır.
```bash
sudo update-initramfs -u
```
İşlemin geçerli olabilmesi için sistemi yeniden başlatmanız gerekli ve yeni ayarlara sahip initramfs ile sistemin başlatılmasıdır.
```bash
sudo reboot
```
Sistem bu adımdan sonra nouveau olmadan başlatılacaktır. Bu nedenle çözünürlük ile ilgili problemler yaşamanız olasıdır. Bu gibi durumlar için nvidia'nın sürücüsünü kurmanız gerekmekte.
Ex nihilo nihil fit | aliorhun |
273,113 | React Developer Checklist | Hi everyone, I would like to ask if there's any skills checklist for React developer | 0 | 2020-03-03T07:32:35 | https://dev.to/jeffreyuvero/react-developer-checklist-2eg8 | ---
title: React Developer Checklist
published: true
description:
tags:
---
Hi everyone, I would like to ask if there's any skills checklist for React developer | jeffreyuvero | |
273,138 | Angular State Management in RxJS Services | tldr; Most Angular applications need some amount of state management. In some... | 0 | 2020-03-05T22:10:21 | https://www.prestonlamb.com/blog/angular-state-management-in-rxjs-services | ---
title: Angular State Management in RxJS Services
published: true
date: 2020-03-03 07:00:00 UTC
tags:
canonical_url: https://www.prestonlamb.com/blog/angular-state-management-in-rxjs-services
---
## [tldr;](#tldr)
Most Angular applications need some amount of state management. In some applications, a state management library like NgRX or Akita might make sense. But many times storing application state in RxJS services will work perfectly. We’ll go over how to do this using RxJS `BehaviorSubjects` and `Observables`.
## [BehaviorSubjects](#behavior-subjects)
Before jumping in to examples, let’s talk about `BehaviorSubjects`. `BehaviorSubjects` are a variant of RxJS `Subjects`. Components can subscribe to a `BehaviorSubject` and get updates when something changes. They do need to be primed with an initial value, but that value can be `null` if desired. There is one difference, though, between `Subjects` and `BehaviorSubjects`. If you subscribe to a `Subject`, you will only receive values that are emitted _after_ subscribing. But if you subscribe to a `BehaviorSubject`, you will get the last emitted value and all future emitted values. `Subjects` are great for many situations, but when managing state in an application I’ve found that `BehaviorSubjects` are better suited.
## [Managing State](#managing-state)
Okay, now that we are familiar with `BehaviorSubjects`, let’s look at an example of how to leverage those to manage state in an application.
I was recently working on an application that used information about the logged in person (a `Member`) throughout the app. The information didn’t update frequently, so I was able to get the information once and store it in a `BehaviorSubject` so that the app could store that information and give it out as needed. If it did update, I could push the new value into the `BehaviorSubject` and all subscribers were updated automatically. Here’s some skeleton code:
```ts
export class MyService {
private memberBS: BehaviorSubject<Member> = new BehaviorSubject<Member>(null);
public member$: Observable<Member> = this.memberBS.asObservable().pipe(filter(val => !!val));
}
```
The first line here in this service shows how I created the `BehaviorSubject`. I declared it as private, so it can’t be used outside the service, and I primed the `BehaviorSubject` with a `null` value. Because the `BehaviorSubject` is private, it is not actually accessible to any components that use this service. This is good though, because we don’t want every component to be able to update the `BehaviorSubject`. We want to control how new values are emitted, so making it private is a good start. So how do we access the value from the `BehaviorSubject`? That’s where the second line from above comes in to play. One of the methods of the `BehaviorSubject` is `asObservable`. It takes the `BehaviorSubject` and creates an observable. Components can then subscribe to that observable, and it will still get any new values that are emitted from the `BehaviorSubject`.
Here are a couple sample methods on the service for getting new data:
```ts
export class MyService {
// Previous stuff
getDataFromServer() {
return this._http.get('...');
}
initializeObservable() {
this.updateMemberObservableData().subscribe();
}
updateMemberObservableData() {
return this.getDataFromServer().pipe(
tap((data: Member) => {
this.memberBs.next(data);
}),
);
}
}
```
These are just a couple examples, but `getDataFromServer` is a stubbed out function for calling some server to get the data that you will need for the `Member`. `updateMemberObservableData()` gets the data from the server and then emits the data through the `BehaviorSubject`. `initializeObservable` just makes a call to and subscribes to the `updateMemberObservableData` method. This function could be called from anywhere really, but I’ve been calling it from the root `AppComponent` for my application. Then, as needed, I’ll call the `updateMemberObservableData()` from other components.
Once the `Member` data is in the service, it’s usable all throughout the application. When a new component comes on the screen that needs the `Member` data, it subscribes to the `member$` observable and is on its way. It’s also made the application feel much faster as well. There’s a little delay when waiting for the member data the first time, but from then on it’s really snappy and fast.
What I really like about this way of managing state is that every component that needs that information about the member can subscribe to the observable and get the data. You don’t have to make several calls to the database to get the same information. You also don’t have to pull in a large library to manage this little piece of state for your app.
## [Conclusion](#conclusion)
Storing application state in `BehaviorSubjects` and exposing those as observables through a service is a great way to manage state in an Angular application. RxJS is really powerful and the more I learn about it the more I’ve found how useful it is. This same pattern can be used for other server data (like order history, for example), but it can also be used for UI state management too. An example of that would be if a navigation menu is open or closed. This pattern works for any type of state management issue. Let me know if you’ve done something similar and how it worked for you! | prestonjlamb | |
273,166 | audiovisualizer w/ feedback | playing with some shader-doodle's new experimental buffers | 0 | 2020-03-03T10:19:45 | https://dev.to/palashpal123/audiovisualizer-w-feedback-5e6k | codepen | <p>playing with some shader-doodle's new experimental buffers</p>
{% codepen https://codepen.io/halvves/pen/abOwJbR %} | palashpal123 |
273,267 | How to manage actual Hyperledger Fabric network on your CI pipeline | When you develop an application running on blockchain, do you know how to organize your CI environmen... | 0 | 2020-03-04T14:12:30 | https://dev.to/nekia/how-to-manage-actual-hyperledger-fabric-network-on-your-ci-pipeline-5hfa | hyperledger, go, ci, blockchain | When you develop an application running on blockchain, do you know how to organize your CI environment with using actual infrastructure? In this article, I'll share how to build a test suite for application running on blockchain network, in particularly, Hyperledger Fabric network that is one of OSS blockchain framework.
# Setup environment
You need to follow the steps described in the official document.
+ [Prerequisites](https://hyperledger-fabric.readthedocs.io/en/release-1.4/prereqs.html)
+ [Install Samples, Binaries and Docker Images](https://hyperledger-fabric.readthedocs.io/en/release-1.4/install.html)
In this article, the following environment is assumed:
* Ubuntu 18.04.3 LTS
* Go 1.13.8
* Hyperledger Fabric 1.4.6
# Create your workspace
You can clone sample code from https://github.com/nekia/devto1
```
$ mkdir -p dev/hlf-e2e-test/specs
```
After initialize go module env, you need to get fabric-test@v1.4.4 go package.
```
$ pushd dev/hlf-e2e-test/specs
$ go mod init example.com/hlftest
$ go get github.com/hyperledger/fabric-test@v1.4.4
$ popd
```
## fabric-test
fabric-test repository is tool set for testing the Hyperledger Fabric. The repository is officially maintained Hyperledger community. In this article, the following tools are mainly used:
* [Operator](https://github.com/hyperledger/fabric-test/tree/master/tools/operator)
Operator provides some go package to manage Hyperledger Fabric network with Go program. It also provides CLI as well. In this article, I'll introduce the way how to use this package.
* [PTE (Performance Traffic Engine)](https://github.com/hyperledger/fabric-test/tree/master/tools/PTE)
PTE provides CLI to interact with Hyperledger Fabric networks by sending requests to and receiving responses from the network via Hyperledger Fabric Node.js SDK. We don't cover this tool because in our use case PTE is used by Operator, there is no chance for user to use PTE directly in this scenario.
```
$ pushd dev/hlf-e2e-test
$ git clone https://github.com/hyperledger/fabric-test.git -b v1.4.4
$ ln -s fabric-test/tools/PTE PTE
$ cd PTE
$ npm install fabric-client@1.4.7
$ npm install fabric-ca-client@1.4.7
$ popd
```
User need to not only install fabric-test as a go package by using go module function, but also close fabric-test source tree to use PTE (Node.js applicaton) included in the source repository. And PTE seems to be assumed that it is used from component within the fabric-test source tree. Because of that, we still need to keep some relative layout of directory for using PTE outside of the source tree. That's why creating symbolic link above.
```
$ pushd dev/hlf-e2e-test
$ cp -a fabric-test/tools/operator/templates specs/
$ cp fabric-test/tools/operator/testdata/smoke-*.yml specs/
$ popd
```
And some files included in templates directory are also important to automatically generate each configuration file such as configtx.yaml, docker-compose.yaml, etc. These template are consumed by ytt tool.
After all the steps up to here, you need to modify network specification file copied from testdata directory. As you can see in the comment, there is special naming rule to switch docker registry. To retrieve container image from Docker Hub, we need to remove `-stable` postfix from `fabric_version`. The rest of changes are optional.
```diff
--- a/specs/smoke-network-spec.yml
+++ b/specs/smoke-network-spec.yml
@@ -7,7 +7,7 @@
#! Released images are pulled from docker hub hyperledger/, e.g. 1.4.1 or 2.0.0
#! Development stream images are pulled from
#! nexus3.hyperledger.org:10001/hyperledger/, e.g. 1.4.1-stable or 2.0.0-stable
-fabric_version: 1.4.4-stable
+fabric_version: 1.4.6
#! peer database ledger type (couchdb, goleveldb)
db_type: goleveldb
#! This parameter is used to define fabric logging spec in peers
@@ -58,18 +58,18 @@ kafka:
orderer_organizations:
- name: ordererorg1
msp_id: OrdererOrgExampleCom
- num_orderers: 1
+ num_orderers: 5
num_ca: 0
peer_organizations:
- name: org1
msp_id: Org1ExampleCom
- num_peers: 1
+ num_peers: 3
num_ca: 1
- name: org2
msp_id: Org2ExampleCom
- num_peers: 1
+ num_peers: 3
num_ca: 1
#! Capabilites for Orderer, Channel, Application groups
```
There are 2 type of specification files:
* network specification file (ex. smoke-network-spec.yml)
This file defines the specification of Hyperledger Fabric network deployed by using operator tool. This file is mainly consumed by API of networkclient package.
* input file (ex. smoke-test-input.yml)
This file defines each action such as creating channels, joining peers to a channel, etc. This file is mainly consumed by API of testclient package.
# Prepare test code
```Go
package hlftest
import (
"testing"
. "github.com/onsi/ginkgo"
"github.com/onsi/ginkgo/reporters"
. "github.com/onsi/gomega"
"github.com/hyperledger/fabric-test/tools/operator/launcher"
"github.com/hyperledger/fabric-test/tools/operator/testclient"
)
func TestSmoke(t *testing.T) {
RegisterFailHandler(Fail)
junitReporter := reporters.NewJUnitReporter("results_smoke-test-suite.xml")
RunSpecsWithDefaultAndCustomReporters(t, "Smoke Test Suite", []Reporter{junitReporter})
}
// Bringing up network using BeforeSuite
var _ = BeforeSuite(func() {
networkSpecPath := "smoke-network-spec.yml"
err := launcher.Launcher("up", "docker", "", networkSpecPath)
Expect(err).NotTo(HaveOccurred())
})
var _ = Describe("Operator Demo", func() {
It("starting fabric network", func() {
inputSpecPath := "smoke-test-input.yml"
By("1) Creating channel")
action := "create"
err := testclient.Testclient(action, inputSpecPath)
Expect(err).NotTo(HaveOccurred())
By("2) Joining Peers to channel")
action = "join"
err = testclient.Testclient(action, inputSpecPath)
Expect(err).NotTo(HaveOccurred())
})
})
// Cleaning up network launched from BeforeSuite and removing all chaincode containers
// and chaincode container images using AfterSuite
// var _ = AfterSuite(func() {
// networkSpecPath := "smoke-network-spec.yml"
// err := launcher.Launcher("down", "docker", "", networkSpecPath)
// Expect(err).NotTo(HaveOccurred())
// dockerList := []string{"ps", "-aq", "-f", "status=exited"}
// containerList, _ := networkclient.ExecuteCommand("docker", dockerList, false)
// if containerList != "" {
// list := strings.Split(containerList, "\n")
// containerArgs := []string{"rm", "-f"}
// containerArgs = append(containerArgs, list...)
// networkclient.ExecuteCommand("docker", containerArgs, true)
// }
// ccimagesList := []string{"images", "-q", "--filter=reference=dev*"}
// images, _ := networkclient.ExecuteCommand("docker", ccimagesList, false)
// if images != "" {
// list := strings.Split(images, "\n")
// imageArgs := []string{"rmi", "-f"}
// imageArgs = append(imageArgs, list...)
// networkclient.ExecuteCommand("docker", imageArgs, true)
// }
// })
```
# Now, bring up network
```
$ pushd dev/hlf-e2e-test/specs
$ ginkgo -v
Running Suite: Smoke Test Suite
===============================
Random Seed: 1583242390
Will run 0 of 0 specs
(snip)
Ran 0 of 0 Specs in 29.661 seconds
SUCCESS! -- 0 Passed | 0 Failed | 0 Pending | 0 Skipped
PASS
Ginkgo ran 1 suite in 30.376068459s
Test Suite Passed
$ docker ps --format '{{.Names}}\t{{.Status}}\t{{.Image}}' | sort
ca0-org1 Up 2 minutes hyperledger/fabric-ca:1.4.6
ca0-org2 Up 2 minutes hyperledger/fabric-ca:1.4.6
orderer0-ordererorg1 Up 2 minutes hyperledger/fabric-orderer:1.4.6
orderer1-ordererorg1 Up 2 minutes hyperledger/fabric-orderer:1.4.6
orderer2-ordererorg1 Up 2 minutes hyperledger/fabric-orderer:1.4.6
orderer3-ordererorg1 Up 2 minutes hyperledger/fabric-orderer:1.4.6
orderer4-ordererorg1 Up 2 minutes hyperledger/fabric-orderer:1.4.6
peer0-org1 Up 2 minutes hyperledger/fabric-peer:1.4.6
peer0-org2 Up 2 minutes hyperledger/fabric-peer:1.4.6
peer1-org1 Up 2 minutes hyperledger/fabric-peer:1.4.6
peer1-org2 Up 2 minutes hyperledger/fabric-peer:1.4.6
peer2-org1 Up 2 minutes hyperledger/fabric-peer:1.4.6
peer2-org2 Up 2 minutes hyperledger/fabric-peer:1.4.6
$ docker exec peer0-org1 peer channel list
Channels peers has joined:
testorgschannel0
$ popd
```
Enjoy! | nekia |
273,275 | docker | https://forums.docker.com/t/pipe-docker-engine-the-system-cannot-find-the-file-specified/71998/3 so... | 0 | 2020-03-03T13:49:49 | https://dev.to/hasanin19salah/docker-1bg2 | https://forums.docker.com/t/pipe-docker-engine-the-system-cannot-find-the-file-specified/71998/3
solve docker :
The system cannot find the file specified. In the default daemon configuration on Windows, the docker client must be run elevated to connect. This error may also indicate that the docker daemon is not running. | hasanin19salah | |
273,763 | What is UI Design? | UI is the design or visual graphics that help in the interaction between humans and devices. https:/... | 0 | 2020-03-04T05:39:59 | https://dev.to/prajval06/what-is-ui-design-khm | uiweekly, ux, typescript | UI is the design or visual graphics that help in the interaction between humans and devices.
https://bit.ly/2vdBrcq
It is also one of the ways which help users to interact with an application or a website. UI is a mixture of graphics and typography.
The main objective of UI design is to make communication with users very smoothly and efficiently and by fulfilling the user’s contentment.

A top-notch UI design helps in accomplishing any task easily without causing any unnecessary glitch.
The design of UI must be done with the utmost care, by balancing all the technical and visual elements precisely to produce a system that is usable and adaptable rather than being only operational.
Please Like, Share & Comment: https://bit.ly/2vdBrcq | prajval06 |
274,655 | Modern data practice and the SQL tradition | TL;DR notes from articles I read today. Modern data practice and the SQL tradition Bewar... | 0 | 2020-03-05T13:00:09 | https://insnippets.com/tag/issue111/ | todayilearned, database, sql | *TL;DR notes from articles I read today.*
### [Modern data practice and the SQL tradition](xhttp://bit.ly/2OBGkSl)
- Beware the schemaless nature of NoSQL systems, which can easily lead to sloppy data modeling at the outset. Start with an RDBMS in the first place, preferably with a JSON data type and indices on expressions, so you can have a single database for both structured and unstructured data and maintain ACID compliance.
- Bring ETL closer to the data and be wary of decentralized data cleaning transformation. Push data cleaning to the database level wherever possible - use type definitions, set a timestamp with timezone policy to enable ‘fail fast, fairly early’, use modern data types such as date algebra or geo algebra instead of leaving that for Pandas and Lambda functions, employ triggers and stored procedures.
- Create more features at the query level to gain flexibility with different feature vectors, so that model selection and evaluation are quicker.
- Distributed systems like MongoDB and ElasticSearch can be money-hungry (both in terms of technology and human resources), and deployment is harder to get right with NoSQL databases. Relational databases are cheaper, especially for transactional and read-heavy data, more stable and perform better out of the box.
- Be very meticulous as debugging is quite difficult for SQL, given its declarative nature. Also, be mindful of clean code and maintainability.
*[Full post here](http://bit.ly/2OBGkSl), 13 mins read*
---
### [Eventual vs strong consistency in distributed databases](http://bit.ly/32G5FRR)
- Ensure you replicate data for storage - in the case of databases, redundancy introduces reliability.
- For consistency across multiple database replicas, a write request to any node should trigger write requests for all replicas.
- In an ‘eventual consistency’ model, you can achieve low latency for read requests by delaying the updates to replicas, but you will risk returning stale data to read requests from some nodes if the update has not reached them yet.
- With a ‘strong consistency’ model, write requests to replicas will be triggered immediately. However, they will delay subsequent read/write requests to any of the databases until the consistency is reached.
*[Full post here](http://bit.ly/32G5FRR), 4 mins read*
---
*[Get these notes directly in your inbox every weekday by signing up for my newsletter, in.snippets().](https://mailchi.mp/appsmith/insnippets?utm_source=devto&utm_medium=post08&utm_campaign=is)* | mohanarpit |
275,608 | Listado con Bootstrap estilo Masonry sin JS | El HTML está maquetado con el preprocesador "Pug" y la hoja de estilos con "SCSS", no necesita JS. La... | 0 | 2020-03-06T16:01:37 | https://dev.to/badiali/bootstrap-4-masonry-layout-js-25d2 | spanish, bootstrap, css, beginners | <p>El HTML está maquetado con el preprocesador "Pug" y la hoja de estilos con "SCSS", no necesita JS. Las clases utilizadas son por defecto de Bootstrap, excepto la clase <code>.card-block</code> que la he creado para realizar el efecto en el :hover. También he utilizado la clase <code>.stretched-link</code> en el link para que sea "clicable" la tarjeta completa.</p>
<p>Espero que sea de ayuda. Cualquier comentario será bienvenido 👍</p>
<a href="https://codepen.io/badiali/full/qBdPooX" target="_blank"></a>
<p>📎 <em>Puedes cambiar el zoom de CodePen a 0.5x para ver la versión de escritorio</em></p>
{% codepen https://codepen.io/badiali/pen/qBdPooX default-tab=result %} | badiali |
276,648 | Anna still codes | Last year in March I shared my story about how I got into development:... | 0 | 2020-03-08T15:33:09 | https://dev.to/lightalloy/anna-still-codes-2p4j | wecoded, learning, career |
Last year in March I shared my story about how I got into development:
{% link https://dev.to/lightalloy/nevertheless-anna-buianova-coded-39e9 %}
This year I still code and do other things related to software development. Here are some of my accomplishments since that time:
- with {% user latefebruary %} and the team we organized the first [RailsGirls event](https://vk.com/railsgirls_spb) in Saint Petersburg. It was the second in Russia and the first within the last 5 years. And we are preparing for a new one in April!
- started public speaking. I gave a short talk at our RailsGirls event and then a [longer one](https://www.youtube.com/watch?v=mGxslHrOJ58&) at the Pyladies meetup this year.
- I wrote a series at DEV about reading and technical books
{% link https://dev.to/lightalloy/learning-to-love-software-development-books-5e4 %}
- I started writing more consistently [in Russian](https://t.me/light_codes) about it and work-related topics
- I continued to learn, as usual :)
I have more technical accomplishments this year too but they seem less noticeable to me comparing to the "brand new" stuff that I did during this time.
I have spent many years in IT already and through these years I was feeling burned out at times. But later I discovered that there are many opportunities to grow in our field besides improving our technical skills. We can teach, write, give talks, and do many other things while still staying technical. Helping others is a great motivation to grow ourselves ✨ It also helps with burnout (as long with other measures, like limiting our working time!)
Happy international women's day! Let's support each other, learn to be more compassionate to others, while not forgetting to be more self-compassionate as well.
| lightalloy |
276,768 | Unpopular opinions | I have never used Redux, even after using React for 2+ years. What's your unpopular opinion or... | 0 | 2020-03-08T19:41:42 | https://dev.to/belhassen07/unpopular-opinions-14ea | discuss, webdev, react, javascript | ---
title: Unpopular opinions
published: True
description:
tags: #discuss #webdev #react #javascript
---
I have never used Redux, even after using React for 2+ years.
What's your unpopular opinion or something you? | belhassen07 |
276,821 | Nevertheless, Kirsten Coded | My Journey of Teaching Computer Science to High School Students I'm 20+ years into career... | 0 | 2020-03-08T22:18:13 | https://dev.to/kefournier/nevertheless-kirsten-coded-4hf6 | wecoded, iwd2020, devcommunity | ---
title: Nevertheless, Kirsten Coded
published: true
tags: shecoded, NeverthelessSheCoded, IWD2020, DEVCommunity
---
<!-- ✨This template is only meant to get your ideas going, so please feel free to write your own title & narrative! ✨ -->
## **My Journey of Teaching Computer Science to High School Students**
I'm 20+ years into career life, and never would I have imagined that teaching computer science to high school students is where I would find myself at this stage of life. In fact, teaching was never even on the agenda. As a college and graduate school student, my aspirations were to work for one of the big five consulting firms of the time (Deloitte and Anderson being my top two picks), but after extensive interview rounds with each, found myself growing more and more trepidatious of the work-life balance that was being presented to me. Which was probably a good thing in hindsight; neither place offered me a job. Perhaps a blow to my 23 year old ego at the time, but in reality, quite a blessing in disguise. I would have been miserable in those jobs and that lifestyle.
Plan B turned out to be moving to a different state and working for a large cancer hospital, first in Human Resources, and then as a data analyst for clinical research trials, eventually working my way up to a systems analyst role for a software implementation project. The irony was my knowledge of software at the time was just that I used it. I had never tried to write any software myself, any programming I did was editing canned programs already established by biostatisticians I was working with, and I didn't really have the interest to learn SAS - I was fine getting by with my SPSS skills from my graduate school days.
Fast forward a few years, and I was now working for a large publisher's market research department, in which I programmed surveys to collect readership data of IT publications produced by the company's numerous divisions. I had done some survey research in graduate school, and felt like things were coming full-circle. I was finally using my graduate degree again, and getting used to the data analysis I had gotten away from. The software I was "writing" though was very template heavy, and I didn't have to progress far beyond HTML and basic Javascript to do it. As long as I could do a data dump into that trusty SPSS package I knew and loved, I was all set.
My work at the publishing company coincided with the economic downturn of 2008, as well as the birth of my daughter. After salary reductions for all employees of the company, and suspended 401K contributions, I decided to read the writing on the wall and take a step back. My daughter was still an infant, daycare costs were astronomical, and I was pretty sure my company was headed for more cuts, so I took the opportunity to be a stay at home mother for a year. I'm not going to lie, I didn't love it. I loved being with my child, was grateful that I had the opportunity to stay home with her, but I was bored out of my mind. And exhausted. Parenting is no joke.
I ended up going back to work part-time as a reference librarian (while at that previous publishing company I also pursued a master's degree in library and information science - because why not) at a community college. This job I loved. I loved the students, I loved the work and I enjoyed being surrounded by books. I eventually found myself in a school librarian position at a local high school - a job I applied for on a whim, and ended up getting. What I didn't expect was to enjoy working in a high school. I figured it was a good fit for our family, my daughter was still quite young, my hours reflected her daycare, and then preschool hours, and the income was decent for what it was (not a busy library).
Eventually, I moved on to the district I am currently in, and one thing led to another. I started out as the school librarian here too, but after a few years and some random stints of teaching single classes for a staff member on leave, I started to realize I was kind of bored in the library. A full-time teaching position opened up, I took it, and haven't really looked back. The subject matter I teach was definitely not something I would call a "natural progression" though. Most people I told (outside of work) made the assumption that I was now teaching English or history. Not computer science. I was as mystified as them - how had I gotten here and where was I going? Quite frankly, many days of being in a classroom with teenagers, trying to teach content that was new to me too, had me asking myself "what have I done by accepting this job???".
Imposter syndrome is a real thing. I felt like a fish out of water most days. I had students who were suspicious of my ability to teach the classes (they knew me as the school librarian after all), and some were even pretty vocal about their suspicions (reminding yourself that you are the adult, and teenagers are still children, helps). I didn't feel great a lot of those days, but I was teaching [AP Computer Science Principles](https://apcentral.collegeboard.org/courses/ap-computer-science-principles) for the first time and learning a TON. I picked a rigorous curriculum to teach the class which I think was the right decision for both my students and myself. We dove headfirst into [CS50](https://cs50.harvard.edu/ap/) and became budding C programmers within weeks of starting the class. We learned about internet protocols, big data, algorithmic thinking, hardware components, and even had some time to dabble in data science. Everything I learned that first year has helped me fine-tune the class each year I teach it.
Along the way, I also picked up teaching classes in Web Design, Game Design, Lego Robotics, and my current course schedule today includes teaching several sections of AP Computer Science Principles, [AP Computer Science A (Java)](https://apstudents.collegeboard.org/courses/ap-computer-science-a), and an Intro to Computer Science Class, which I typically teach in Python, with some web design (HTML & CSS) thrown into the mix. My journey as a high school computer science teacher has encompassed a lot of long hours, some sleepless nights, and I'll be honest - at this point in my teaching career the work-life balance is still not the best, but it's the first job I have had that I can say I am never bored. It's a content area where there is always something new to learn, and you also need to accept that you are never going to know everything. To me, this adds to the excitement. It's that excitement that I think helps keep students going on those days where they tell me they "want to smash their laptops against the wall". Debugging rage is also a real thing. We've all felt it.
Now that I am the thick of it, I find myself collecting more and more things I want to teach my students. I binge listen to tech podcasts ([Code Newbie](https://www.codenewbie.org/), [Command Line Heroes](https://www.redhat.com/en/command-line-heroes), and [Reset](https://www.vox.com/reset) are my top three), am a faithful subscriber of [Wired](https://www.wired.com/) magazine, and an avid reader of [Medium](https://medium.com/) content. YouTube has been a fabulous resource as well, for introducing concepts (thank you, [Crash Course](https://thecrashcourse.com/courses/computerscience)). My most recent cause in the computer science classroom is to try and reach a better gender balance. I have had classes of only male students, or one lone female student in the room. As a female myself, I can say that this is not always a great feeling. Once upon a time, I was also that lone female student in a programming class my mother made me take when I was in high school. I ended up really liking the class, but I never pursued it further because I hated being the only girl. I should have pursued it, I would have saved myself a lot of time and career jumping ;)
My department has started a [Girls Who Code](https://girlswhocode.com/) club at my current school, hosts "Girls Day" robotics events, and have done more concentrated outreach to try and attract female students to the computer science and engineering classrooms. I do think having a female computer science teacher has helped with that initiative; I have had female students tell me the only reason they finally decided to try a comp sci class was because they saw that "the teacher was also a girl". Thankfully, several of those female students have gone on to take more computer science classes, and pulled in a few of their friends, so slowly, but surely we are getting there. It's tough to walk into a room, where no one in the room looks like you - there can be safety in numbers. Which I do notice by how my students seat themselves. We sit at group tables in my classroom, and in almost every class period, the girls group themselves at a table together, whether they know each other or not. It's interesting to observe.
We need more computer science teachers, period. With the hold that technology currently has on our society, and the workforce being what it is, students are going to need solid technical skills to be successful. Coding is not for everyone, but everyone can benefit from having some basic knowledge. The problem-solving skills it teaches, as well as the resiliency it helps students develop can't be matched. And as I mentioned earlier, you'll never be bored. There will always be work to do, things to learn, and students who are interested. You just need to have the passion and determination to learn it yourself too. Make time for code every day - take the [#100DaysofCode](https://www.100daysofcode.com/) challenge to keep yourself accountable, try some [Codecademy](https://www.codecademy.com/) classes to see if it's for you, do some [Codewars](https://www.codewars.com/dashboard) challenges with your students. The interest will build, and there is room for everyone at the table, you just have to invite yourself to take a seat.
<!-- Once your post is published, it will not appear on the /t/shecoded page until an admin approves it. This is an extra step to ensure there is no abuse on this important tag. --> | kefournier |
276,836 | Creative Uses of TypeScript Discriminated Unions | The post Creative Uses of TypeScript Discriminated Unions appeared first on Kill All Defects. Let... | 4,634 | 2020-03-08T22:46:31 | https://killalldefects.com/2020/03/08/creative-uses-of-typescript-discriminated-unions/ | typescript, angular, functional | ---
title: Creative Uses of TypeScript Discriminated Unions
published: true
date: 2020-03-08 22:39:36 UTC
tags: TypeScript, Angular, Functional Programming
series: Doggo Quest
cover_image: https://i1.wp.com/killalldefects.com/wp-content/uploads/2020/03/ContextJsonComplex.png?fit=768%2C358&ssl=1
canonical_url: https://killalldefects.com/2020/03/08/creative-uses-of-typescript-discriminated-unions/
---
The post [Creative Uses of TypeScript Discriminated Unions](https://killalldefects.com/2020/03/08/creative-uses-of-typescript-discriminated-unions/) appeared first on [Kill All Defects](https://killalldefects.com).
---
Let me show you how creative use of TypeScript’s [discriminated unions](https://www.typescriptlang.org/docs/handbook/advanced-types.html#discriminated-unions), type aliases, and functions can give you a greater degree of flexibility in your own code.
I’m going to do this by illustrating how these techniques addressed a problem that I was trying to solve and then talk about some additional ideas on how these techniques can be applied.
## The Problem I’m Solving
I’m building [a text-based game](https://killalldefects.com/2020/02/01/game-design-with-event-modeling/) for a few talks I’ll be giving this spring. This is the type of game where the game engine describes something and then the player types in a command such as `look at the flowers` or `hit the mushroom with the glowing red hammer`.
In order to do that, I need to be able to represent parts of the game world as objects that have basic responses to verbs that the player can try.
This is fairly easily represented in a simple object where verbs with custom responses are defined as string properties on the object (_note: the player is a dog in my game_):

So, using the above object, the engine will give default responses to verbs that are not defined on that object (e.g. eat or pick up).
But what if I wanted a verb to actually impact the game world? I’d need something a bit more flexible.
This is where discriminated unions come into play.
## What is a Discriminated Union?
Discriminated unions in TypeScript are a way of telling TypeScript that something is going to be one of a fixed number of possibilities.
For example, if I declare a parameter as `x: string | number | boolean`, I’m telling TypeScript that it should expect `x` to be either a `string`, a `number` or a `boolean`. TypeScript will then check my usage of `x` to make sure I’m working with properties that are common on each one or doing necessary type checking / casting.
The reason this can be helpful is that it allows you to specify simple paths and complex paths for things depending on what value is passed in.
## Defining the Types
Now that we’ve established what discriminated unions are and why they might be helpful, let’s take a look at my definition of a `GameObject`. This is an object in the game world that the player can potentially interact with.
{% gist https://gist.github.com/IntegerMan/64d9badaaa6734f792b9b7dce9e00ce6 %}
Focus first on `ObjectResponse` on line 4. This is the type used to represent a verb handler on an object. For example, how a `shoe` might respond to the `eat` verb.
I define `ObjectResponse` as a `ContextAction | string` meaning that it will either be a simple string indicating a description to print out or it will be a more complex response represented by `ContextAction`.
`ContextAction` is a custom type definition that represents a function taking in a `CommandContext` object (a custom domain object representing the current state of the world and some basic response formatting capabilities) and returning `void` (nothing).
What this is essentially saying is that a verb handler on an object will either return a simple string description or it will be a more complex function that takes in a `CommandContext` object and does something with it.
Here’s a practical example that uses the two signatures to do more complex logic in its `push` and `look` verb responses:

## Interpreting Values of Different Types
Okay, so if we’re dealing with something that is a discriminated union, how do we effectively work with it?
Take a look at this TypeScript snippet:

Here we query the `gameObject` to see if it has a property named the same thing as `verbName`. If that’s _not_ present we’ll just add the generic response for the verb.
If the response _is_ present, we know it to be either a `string` or a `ContextAction` so we can switch off of the type of that value and handle it appropriately.
Here we respond to `string` values by casting the value to string and using a method on the `context` to add a simple message.
If the value was _not_ a `string` then we know it’s going to be a `ContextAction` and will be a function with a signature that takes in a `CommandContext` and returns `void`. In that case, we simply invoke the function and pass in the `context`.
## Closing Thoughts
Hopefully this illustrates the usefulness of discriminated unions and type aliases in handling a variety of scenarios and potentially gives you ideas for how to streamline some of your existing logic.
I personally consider discriminated unions and working with functions when I see patterns of similar data or the potential for a high amount of boilerplate or repetitive code.
Discriminated unions do add complexity to your code, but that price _can_ be worth it in simplicity and flexibility in other areas. Ultimately the decision is up to you and will change based on what problems you’re trying to solve. | integerman |
276,855 | A missing step: Backup Azure DevOps Repositories | Table of content To backup or not to backup? Method 1: Using Git Method 2: Using Azure De... | 0 | 2020-03-13T14:36:58 | https://dev.to/ib1/a-missing-step-backup-azure-devops-repositories-16p7 | azure, devops, backup, git | ###Table of content
* [To backup or not to backup?](#intro)
* [Method 1: Using Git](#using-git)
* [Method 2: Using Azure DevOps API](#using-api)
* [Conclusion](#conclusion)
###<a name="intro"></a>To backup or not to backup?
Don't get me wrong, I like Azure DevOps. There are some frustrations here and there, for example in managing permissions and caching build resources. And each of Azure DevOps modules (Dashboards/Wiki, Boards, Repos, Pipelines, Test Plans, Artifacts) might not be THE BEST on a market. But integration and ease of use make it greater than sum of the parts, especially for small and medium-size projects.
Still, there is one thing that puzzles me. Backing up your Git repositories seems to me like common sense and a good practise. It also can be a policy in some companies. However there is no way to do it now either manually or on schedule. Of course, Microsoft is [committed to keep the data safe](https://docs.microsoft.com/en-us/azure/devops/organizations/security/data-protection?view=azure-devops), including periodic backups and geo-replication, but we do not have any control over it. And it does not prevent from unintentional or malicious actions leading to data loss.
Microsoft's response to such requests, and I [quote] (https://developercommunity.visualstudio.com/content/problem/609097/backup-azure-devops-data.html): _"In current Azure DevOps, there is no out of the box solution to this, you could backup your projects by downloading them as zip to save it on your local and then upload it to restore them. And you also could backup your work items by open them with Excel to save in your local machine."_
I mean what, LOL. Excel as a backup tool is possibly a new high in data safety. Anyway, are there ways to twist control back into our hands?
Of course there are, and today we explore two of them.
###<a name="using-git"></a>Backup repository using plain old git bash script
One of the methods is to use a bash script to get a complete copy of the repository. Let's not run it from our laptop, but rather spin up a small VM in the cloud.
*Plan of attack:*
- Create a cheap Linux virtual machine in Azure
- Generate new SSH Key Pair
- Add SSH Public key to Azure DevOps
- Create bash script to mirror Git Repo
- Execute that script on schedule
Not diving into too much details, but it is quite easy to create a Linux VM in Azure. It already comes with everything we need: Git and shell scripts. Then we can SSH into it and create a bash script, which I named "devopsbackup.sh".
A script is rather primitive, but it gets the job done. Essentially, it deletes a previous backup and creates a mirror copy of the Git repo. Don't forget to replace variables in angle brackets with your own values.
```bash
#!/bin/bash
error_exit()
{
echo "${PROGNAME}: ${1:-"Unknown Error"}" 1>&2
exit 1
}
#
echo "Executing Azure DevOps Repos backup"
cd /home/devopsadmin
rm -rf repos/
mkdir -p repos
cd repos/
git clone --mirror git@ssh.dev.azure.com:v3/<organization>/<project>/<repo> || error_exit "$LINENO: "
cd ..
exit 0
```
Allow script execution:
```chmod 0755 devopsbackup.sh```
We also need to generate SSH key pair by using command
```ssh-keygen -C "devopsbackup"```
By default, keys will be generated in "~/.ssh" folder. We need to copy a public key "id_rsa.pub" from there and paste into Azure DevOps. Go to the profile settings on a top right and add a new key from there:
We can easily create a scheduled execution for our script. Go ahead, type "crontab -e" in the command line and add something like this to the Cron config:
```20 1 * * * /home/devopsadmin/bin/devopsbackup.sh >/dev/null 2>&1```
Next step could be to extend this script using Azure CLI and upload this archive into Azure Blob Storage or Data Lake.
Alternatively, Azure also has a great feature that allows you to create a daily/weekly backup for your VM. So you can just store a snapshot of the whole VM and don't bother with Blob storage, if you like.
###<a name="using-api"></a>Backup default branch using Azure Devops API
That's all well and good, but is there some more modern way that does not require a dedicated VM and shell scripts/cron? [Azure DevOps REST API](https://docs.microsoft.com/en-us/rest/api/azure/devops/?view=azure-devops-rest-5.1) seems to be promising and allows to manipulate Azure DevOps data, including work items and repositories. Unfortunately this API does not have a parity with Git and full code history cannot be preserved using this method.
However if all you require is a periodic snapshot of the master branch then it could be used to create a simple backup solution. One advantage over previous solution is that we can automatically retrieve information about all our projects and repos, and do not need to hardcode them. So if you add a new project, no modification is required.
*Approach:*
- Use REST API to retrieve hierarchy of projects, repositories, items and blobs
- Use Azure DevOps token (PAT) for the API authentication
- Use Azure Function with timer trigger to run this on schedule
- Use Azure Blob Storage to keep an archive.
Without further ado, here is a gist for Azure Function. It requires the following parameters that you can set up in Application Settings:
"storageAccountKey", "storageName", "token", "organization"
{% gist https://gist.github.com/i-b1/131c6f65f0255ca7202207e25f24f164 %}
###<a name="conclusion"></a>Conclusion
Comparing these two approaches we can see that newer is not always better. With a help of a simple shell script we can produce a full copy of the repository that could be easily restored or imported into the new project. On the other side, if all you want is a periodic repo snapshot, Azure DevOps REST API and scheduled Azure Function can make those things effortless.
That is all for today, and remember that you always have to protect your work, like a cat protects its spoils from a dog on the image below.

<sup><sub>Dirk Valckenburg, A Cat Protecting Spoils from a Dog, 1717</sub></sup>
<sup><sub>Cover image by <a href="https://pixabay.com/users/422737-422737/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=445155">Hebi B.</a> from <a href="https://pixabay.com/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=445155">Pixabay</a></sub></sup>
| ib1 |
277,004 | Arrow Function and "this" keyword | Arrow Function Arrow function expression are a more concise syntax for writing function ex... | 0 | 2020-03-09T06:45:29 | https://dev.to/shubhamb/arrow-functions-and-this-keyword-1kg7 | javascript, beginners, webdev, typescript | #Arrow Function#
Arrow function expression are a more concise syntax for writing function expressions although without its own bindings to the this, arguments, super, or new.target keywords. They utilize a new token, =>, that looks like a fat arrow. Arrow functions are anonymous and change the way this binds in functions.
Code samples:
{% runkit %}
//ES5 example for function
var multiplyFunction = function(x, y) {
return x * y;
};
// ES6 arrow function much concise syntax
const multiplyArrowfunction = (x, y) => { return x * y };
{%endrunkit%}
Following are the examples about arrow function
Examples:
{% runkit %}
let sumofNumber = (a, b) => a + b;
/* This arrow function is a shorter form of:
let sumofNumber = function(a, b) {
return a + b;
};
*/
alert( sumofNumber (1, 2) ); // 3
{%endrunkit%}
**In case if you have one argument only,then parentheses around parameters can be avoided,making that even shorter ans simpler syntactically**.
{% runkit %}
let multiplybytwo = n => n * 2;
// roughly the same as: let multiplybytwo = function(n) { return n * 2 }
alert( multiplybytwo (3) ); // 6
{%endrunkit%}
#this keyword #
Execution context for an execution is global — which means if a code is being executed as part of a simple function call, then this refers to a global object.
Arrow functions do not bind their own this, instead, they inherit the one from the parent scope, which is called "lexical scoping".In code with multiple nested functions, it can be difficult to keep track of and remember to bind the correct this context. In ES5, you can use workarounds like the .bind method.Because arrow functions allow you to retain the scope of the caller inside the function, you don’t need to use bind.
{% runkit %}
function printWindow () {
console.log("Simple function call")
console.log(this === window);
}
printWindow(); //prints true on console
console.log(this === window) //Prints true on console.
{%endrunkit%} | shubhamb |
277,027 | UNDERSTANDING PATTERNS WITH DATA ANALYTICS
| Patterns. Patterns are literally everywhere. From our simple surroundings to nature, from complex alg... | 0 | 2020-03-09T08:17:49 | https://dev.to/subbbu_p/understanding-patterns-with-data-analytics-43hn | analytics, datascience, 360digitmg, malaysia | Patterns. Patterns are literally everywhere. From our simple surroundings to nature, from complex algorithms to something as simple as the locks on our phones, the world just cannot exist without patterns. It simply cannot. Take for instance- the golden ratio. A pattern found in every aspect of nature. Some may say it’s just coincidence, but even coincidence happens once or twice. Patterns are what bring order from chaos.
Patterns and analytics
The question of any relation between analytics and patterns is relatively easy to answer. The field of analytics deals with nothing but data. However, with the advent of the Internet and all tasks, shifting online, the amount and variety of data generated and collected on a daily basis is huge. Sorting and searching for a particular piece of information in this heap is nothing short of a nightmare. This is where patterns kick in to make life easier. Once a pattern is noted, or observed in relation to the requirements, finding it is not a big deal then.
The need for analytics Unlike analysis (the counterpart of analytics), which deals with past events, analytics focuses on the details and future predictions of an event, which is a much more vital aspect for it deals with the in-depth analysis of the actions that lead to an event, and how the same event will unfold taking different possibilities as inputs. Basically, it deals with future planning rather than cringing about the past. It handles the past events graciously and takes measures to either prevent it from happening again or devising and implementing some safeguards to minimize the damage should the event strike again.
How does it function?
Today the world is surrounded by a large number of powerful computers capable of performing tasks at speeds and complexities that are beyond the scope of imagination. Furthermore, to perform these complex calculations, we need sophisticated algorithms, and numbers & statistics as inputs for these algorithms.
Once these two essentials are procured, all that is left is to feed them into the computer systems or trained models (that learn themselves in every instance of generating an answer to a query), and sit back and watch them come up with solutions to all kinds of problems. Sometimes, answers to queries come up which could not even be thought of.
The Expanse
The study of analytics has seen its roots spread into many core industries where it plays one of the pivotal roles in its functioning if not THE pivotal role, such as in the field of medicine, business, marketing, banking, security, cyber security, software designing, SEO and of course, needless to say, computer sciences and mathematics and a countless more.
Challenges As the field is still relatively new hence obviously it has some loopholes in it, that pose a challenge to it at different steps on its way of operating. The biggest challenge it faces is when it is used alongside big data. Finding and generating patterns in a colossal pool of totally random data is not at all easy. Unstructured data also hinders the proper workflow of any task and its analytics is also not something that happens as easily as one would want.
Resource Box
As the field of analytics is in its prime with such heavy tasks to perform, naturally, the need for expert and trained professionals for the same is also high. So in case, you are pondering over choosing this field, get a Data Science Course right now.
https://360digitmg.com/course/certification-program-in-data-science
| subbbu_p |
277,087 | show hide button | A post by bhojak rahul | 0 | 2020-03-09T10:42:18 | https://dev.to/bhojakrahul13/show-hide-button-j9b | bhojakrahul13 | ||
277,148 | A countdown clock? In an email?? In this economy?! | How would you implement a countdown clock in an html email? | 0 | 2020-03-10T09:08:52 | https://dev.to/brettimus/a-countdown-clock-in-an-email-in-this-economy-39h2 | email | ---
title: A countdown clock? In an email?? In this economy?!
published: true
description: How would you implement a countdown clock in an html email?
tags: email
---
Yesterday, I got an email from Memrise, a popular language learning tool.
The email had an animated countdown clock in it, which unfortunately I didn't think to capture with a screen recorder. Nevertheless, here is what it looks like now:

Having worked on HTML emails in the past, I was impressed.
Email is the Wild West of web development. Best practices for email would make most of us cry. You can never use javascript, you have to do layouts with tables, and most of your fancy CSS just won't work.
I wanted to know how they did this countdown magic.
First, I notice that the countdown clock was an image. Duh. It had to be!
So then I followed the source of the image and saw it was a url without a file extension. I.e., there was no `.png` or `.jpeg` at the end of the url. It was just `https://gen.sendtric.com/countdown/zkihae5gaj`.
I opened this url and inspected the headers to see what was going on:
```
HTTP/1.1 200 OK
Pragma: no-cache
Content-Type: image/gif
Transfer-Encoding: Identity
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0, max-age=0
ETag: 14126387014612041038
Date: Tue, 10 Mar 2020 08:51:54 GMT
Content-Encoding: gzip
Expires: -1
Vary: Accept-Encoding
```
Right! It's a gif.
But... how'd they get the gif to work like a countdown?
This part is just guesswork, but I'd imagine that this endpoint programmatically sends back a non-looping gif depending on the server time.
That is, the server calculates how many seconds are left until Memrise's sale finishes, then it sends back a gif that animates a new frame every second, starting from the time until sale expires and finishing at `00:00:00:00`.
Now, when I download and inspect the gif, it is only one frame, `00:00:00:00`.
I wish I had time to try to recreate this... but unfortunately, I just got to work!
If you have an alternative theory about how this magical countdown clock works, I'd love to hear it in the comments :grinning: | brettimus |
277,224 | My first Vue.js project: A Pathfinding Visualizer | Hello community members!! Recently I have made a project using Vue.js. This is my first web project.... | 0 | 2020-03-09T14:37:47 | https://dev.to/tinku10/my-first-vue-js-project-a-pathfinding-visualizer-2enl | vue, webdev | Hello community members!!
Recently I have made a project using Vue.js. This is my first web project. I have written an article about it on Medium. If you are interested, here is a friend link to it.
https://medium.com/@tinku.kvs/my-first-vue-js-project-a-pathfinding-visualizer-7229f7c3b017?source=friends_link&sk=b9dc3cd99c8f14877fa8467d71df017b
The project is called Pathfinding Visualizer. Here is the website
https://tinku10.github.io/pathfinding-visualizer/
Consider giving a star on Github if you like it. It would really help me a lot. | tinku10 |
277,778 | Usando o operador de coalescência nula do ES2020 no JavaScript | Entendendo e utilizando o operador de coalescência nula que foi introduzido no ES2020 Phot... | 0 | 2020-03-10T12:33:01 | https://dev.to/omarkdev/usando-o-operador-de-coalescencia-nula-do-es2020-no-javascript-5ecj | nullcoalescing, operators, javascript | ---
title: Usando o operador de coalescência nula do ES2020 no JavaScript
published: true
date: 2020-03-10 12:30:51 UTC
tags: null-coalescing,operators,javascript
canonical_url:
---
#### Entendendo e utilizando o operador de coalescência nula que foi introduzido no ES2020
<figcaption>Photo by <a href="https://www.freeimages.com/photographer/hossein_kh-53992">hossein khosravi</a> from <a href="https://freeimages.com/">FreeImages</a></figcaption>
Foi introduzido um novo operador para gerenciar valores indefinidos ou nulos no ECMAScript 2020. A sintaxe do novo operador são dois pontos de interrogação seguidos “??”. O operador irá retornar o valor do lado direito quando o valor do lado esquerdo for nulo ou indefinido.
Atualmente a [proposta](https://github.com/tc39/proposal-nullish-coalescing) de adicionar este operador está no estágio 4, que significa que está pronto para ser incluído. Você pode testar essa funcionalidade nas versões mais recentes do Chrome e Firefox.
A utilização é bem simples:
{% gist https://gist.github.com/omarkdev/5c49eef26805d5b4a22ed8d343a0238f %}
### Bem parecido como antigamente
A similaridade com os outros operador && e || é bem grande, mas por que não utilizar os operadores antigos? Esses operadores são utilizados para manipular valores _truthy_ e _falsy_. Os valores _falsy_ são: null, undefined, false, número 0, NaN e string vazia. Já os valores _truthy_, são todos os outros valores não _falsy_.
A particularidade dos operadores && e || algumas vezes pode nos induzir a alguns erros. Imagine que um valor null ou undefined para você é algo que você tenha que se preocupar, mas o número 0 não, se você optar por utilizar esses operadores pode ser que você seja induzido ao erro.
{% gist https://gist.github.com/omarkdev/0aed498600d96ebed7980801959f2740 %}
Com o operador ||, o valor da direita é retornado pois o valor da esquerda é um valor _falsy_, na qual no nosso caso é um problema. Utilizando o novo operador de coalescência nula, fica mais simples essa abordagem.
{% gist https://gist.github.com/omarkdev/4f7d2be1d6a15369bedb10991fdc3bb0 %}
E como já foi dito, o valor se preocupa apenas com undefined e null, todos os outros valores _falsy_ são considerados como “verdadeiro”.
{% gist https://gist.github.com/omarkdev/191b3b0eccf5640a2be20ecbfb65c052 %}
Esse operador é algo extremamente simples e útil, com a evolução da especificação estamos cada vez mais prontos para lidar com essas divergências de valores.
Espero que isso te ajude de alguma forma.
**Twitter**: [_https://twitter.com/omarkdev_](https://twitter.com/omarkdev)
**Github**: [_https://github.com/omarkdev_](https://github.com/omarkdev)
* * * | omarkdev |
277,238 | Custom Errors extend, new and rethrows | Create new Class class TypedError extends Error { constructor(message,_type,_sever... | 0 | 2020-03-09T15:01:56 | https://dev.to/dvis003/custom-errors-extend-new-and-rethrows-2i | javascript | ##### Create new Class
```javascript
class TypedError extends Error {
constructor(message,_type,_severity = 0) {
super(message);
this.type = _type;
this.severity = _severity;
}
};
```
unlike the standard *Error* that you can throw like so
```javascript
throw Error("Wunderbar")
```
the extended class should be called with ** new ** keyword
```javascript
throw new TypedError(error.message,"CustomerOnboardFailed",2)
```
and if you want to rethrow the CustomError in the trycatch block you should pass the customError object in the rethrow statement
```javascript
function gonnaThrow(){
throw new TypedError("CustomError message","InsufficientBalance",9);
};
function gonnaRethrow(){
try {
gonnaThrow();
} catch (error) {
throw error;
};
};
function main(){
try {
gonnaRethrow();
} catch (error) {
const {name,message,stack,type,severity} = error;
console.log({name,message,stack,type,severity});
};
};
```
| dvis003 |
277,248 | Fighting COVID-19 with Folding@Home & AWS CDK | Deploy Folding@Home on Amazon Fargate quick and easily with AWS CDK | 0 | 2020-03-09T15:29:53 | https://devopstar.com/2020/03/09/fighting-covid-19-with-aws-cdk | cdk, tutorial, aws, beginners | ---
title: Fighting COVID-19 with Folding@Home & AWS CDK
published: true
description: Deploy Folding@Home on Amazon Fargate quick and easily with AWS CDK
canonical_url: https://devopstar.com/2020/03/09/fighting-covid-19-with-aws-cdk
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/71bf5x8uvlehjzfi4vih.jpg
tags: cdk, tutorial, aws, beginners
---
> Please reach out to me on [Twitter @nathangloverAUS](https://twitter.com/nathangloverAUS) if you have follow up questions!
*This post was originally written on [DevOpStar](https://devopstar.com/)*. Check it out [here](https://devopstar.com/2020/03/09/fighting-covid-19-with-aws-cdk)
[Folding@Home](https://foldingathome.org/) recently announced that they are [supporting the simulation of protein folding to help study COVID-19](https://foldingathome.org/2020/02/27/foldinghome-takes-up-the-fight-against-covid-19-2019-ncov/).
In this post I'll show you how easy it is to start Folding on Amazon Fargate using [AWS CDK](https://docs.aws.amazon.com/cdk/latest/guide/home.html). It was inspired by a small project [k8s-fah](https://github.com/richstokes/k8s-fah) by [richstokes](https://github.com/richstokes) where he setup a method for running the folding client on Kubernetes clusters.
You should read this post if you are any of the following:
* Interested in **Infrastructure as Code**
* Interested in **Simulating Protein Folding**
* Have a **lot of Money** or **AWS Credits** that you need to use
> **NOTE**: I don't recommend actually running this unless you're mad rich and feel generous. It is meant as a way to practically learn how easy it is to spin up resources with AWS CDK.
## What is Folding
Protein folding simulations done through Folding@Home are done in a distributed fashion leveraging peoples computers all over the world to solve a one big problem together.
Think of it like a big cake that is cut up into small pieces, and it is your responsibility to eat your part of that cake... Okay maybe this isn't the best analogy, but you get what I mean.
[](https://phil.cdc.gov/Details.aspx?pid=23311)
> Proteins are not stagnant—they wiggle and fold and unfold to take on numerous shapes. We need to study not only one shape of the viral spike protein, but all the ways the protein wiggles and folds into alternative shapes in order to best understand how it interacts with the ACE2 receptor, so that an antibody can be designed - From [Folding@Home Takes up the fight against COVID-19](https://foldingathome.org/2020/02/27/foldinghome-takes-up-the-fight-against-covid-19-2019-ncov/)
## I want to get involved but I'm lazy
That's perfect! So am I! That's why I use [AWS CDK](https://docs.aws.amazon.com/cdk/latest/guide/home.html) for most of my projects. CDK lets you define AWS Resources as code and quickly deploy a lot of infrastructure with very little code.
I'll give you a spoiler now, the only code you are going to need to deploy **everything** to AWS is the following.
```javascript
const cluster = new ecs.Cluster(this, 'cluster');
const taskDefinition = new ecs.FargateTaskDefinition(this, 'task', {
memoryLimitMiB: 8192,
cpu: 4096
});
taskDefinition.addContainer('container', {
image: ecs.ContainerImage.fromAsset(path.join(__dirname, '../docker/')),
logging: new ecs.AwsLogDriver({ streamPrefix: 'covid19' })
});
new ecs.FargateService(this, 'service', {
cluster,
taskDefinition
});
```
You're probably thinking, "wow that's amazing". And you've be correct in that thinking. Now lets move on to learning how to deploy it.
## Deploying Folding@Home
Start by installing some basic dependencies on your computer, you'll need the following as a bare minimum in order to deploy the resources to.
* [NodeJS](https://nodejs.org/en/download/) - The newer the better
* [AWS Profile](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html) - Although you don't need the full AWS CLI, it's worth installing and configuring your access keys.
---
For deploying, you have two options depending on how hands on or off you want to be:
* [Build from Scratch](#Building-from-Scratch) - Go through how to create a new CDK project and add all the resources you need to deploy.
* [Just Deploy](#Just-Deploy) - Pull down the existing repository and deploy it.
### Building from Scratch <a name="Building-from-Scratch"></a>
You've taken the approach to build the entire project from scratch! Good for you, I'm proud. Start off by running the following commands to setup a new AWS CDK project
```bash
# Install aws-cdk package globally
npm install -g aws-cdk
# Create a new CDK typescript project
mkdir cdk-fah-covid19 && cd cdk-fah-covid19
cdk init --language typescript
# Install the aws-ecs CDK constructs
npm install @aws-cdk/aws-ecs
```
With the project setup and all the dependencies we'll need installed, it's time to start setting up the code. Open up the `lib/cdk-fah-covid19-stack.ts` file and add the following content (might look familiar).
```javascript
import * as cdk from '@aws-cdk/core';
import ecs = require('@aws-cdk/aws-ecs');
import path = require('path');
export class CdkFahCovid19Stack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// 1. Create a Fargate cluster
const cluster = new ecs.Cluster(this, 'cluster');
// 2. Define resource limits for task
const taskDefinition = new ecs.FargateTaskDefinition(this, 'task', {
memoryLimitMiB: 8192,
cpu: 4096
});
// 3. Add a container to the Task definition
taskDefinition.addContainer('container', {
image: ecs.ContainerImage.fromAsset(path.join(__dirname, '../docker/')),
logging: new ecs.AwsLogDriver({ streamPrefix: 'covid19' })
});
// 4. Create the service in our Fargate Cluster
new ecs.FargateService(this, 'service', {
cluster,
taskDefinition
});
}
}
```
There are four steps that are taken to configure the Amazon Fargate service to run our folding at home container.
1. **Amazon Fargate cluster is create** - by default this also included **ALL** the networking required as well
2. **Task Definition** - Specifies the resources allocated to a task, tasks can include 1 or more containers
3. **Add a container to the Task** - Along with setting up a container image, we also define some logging so we can monitor how the Folding is going.
4. **Register the task with the Fargate Cluster** - The final step connecting the task definition and the cluster together.
#### Dockerfile
You might have noticed a random reference to `../docker/` in the previous code. This is where we will need to put our Folding@Home docker container that will automatically be uploaded for us to [Amazon ECR](https://aws.amazon.com/ecr/).
Go ahead and create the file `docker/Dockerfile` in your project and add the following contents to it
```bash
FROM ubuntu:16.04
ENV DEBIAN_FRONTEND noninteractive
RUN apt update
RUN apt install wget -y
# Download/Install latest FAH client
# See here for latest - https://foldingathome.org/alternative-downloads/
RUN wget https://download.foldingathome.org/releases/public/release/fahclient/debian-stable-64bit/v7.5/fahclient_7.5.1_amd64.deb
RUN dpkg -i --force-depends fahclient_7.5.1_amd64.deb
EXPOSE 7396 36396
WORKDIR /var/lib/fahclient
CMD ["/usr/bin/FAHClient", \
"--config", "/etc/fahclient/config.xml", \
"--run-as", "fahclient", \
"--pid-file=/var/run/fahclient.pid"]
```
And that's it! Move onto the [next step](#Just-Deploy) to learn how to deploy it.
### Just Deploy <a name="Just-Deploy"></a>
If you are at this point then you've either completed the [Build from Scratch](#Building-from-Scratch) section or you've decided to pull down the existing repository and just want to deploy it. Either way you're in the right place.
If you don't already have the repository, pull it down from the github and install the dependencies
```bash
# Clone repository
git clone https://github.com/t04glovern/cdk-fah-covid19.git
# Install dependencies
cd cdk-fah-covid19
npm install -g aws-cdk
npm install
```
Now we've got to transpile the typescript and prepare it for deploy. It's usually recommended to run this command in the background while you're working on typescript. However for this example run it then `ctrl+c` to exit once it's done
```bash
npm run watch
```
Finally, you're ready to deploy the stack. It's as easy as running the following command
```bash
cdk deploy
# CdkFahCovid19Stack: deploying...
# aws-cdk/assets:bb9ebb84d6a5d2887a7406685ff3ccb2178b47cb9ee4f1e54db1a84cb899a104: image already exists, skipping build and push
# CdkFahCovid19Stack: creating CloudFormation changeset...
# 0/60 | 9:31:46 pm | UPDATE_IN_PROGRESS | AWS::ECS::TaskDefinition | task (task117DF50A)
# 0/60 | 9:31:47 pm | UPDATE_IN_PROGRESS | AWS::ECS::TaskDefinition | task (task117DF50A) Resource creation Initiated
# 59/60 | 9:31:47 pm | UPDATE_COMPLETE | AWS::ECS::TaskDefinition | task (task117DF50A)
# 59/60 | 9:31:49 pm | UPDATE_IN_PROGRESS | AWS::ECS::Service | service/Service (serviceService7DDC3B7C)
# 59/60 Currently in progress: serviceService7DDC3B7C
# 59/60 | 9:33:51 pm | UPDATE_COMPLETE | AWS::ECS::Service | service/Service (serviceService7DDC3B7C)
# 59/60 | 9:33:53 pm | UPDATE_COMPLETE_CLEA | AWS::CloudFormation::Stack | CdkFahCovid19Stack
# ✅ CdkFahCovid19Stack
```
> **Note**: the deploy can take up to 10-15 minutes as it needs to setup a whole bunch of networking services.
## Checking Status
If you want to check in the status of the Folding, navigate to the [ECS cluster portal](https://us-east-1.console.aws.amazon.com/ecs/home?region=us-east-1#/clusters) and click on your cluster.
> It will have a random name starting with `CdkFahCovid19Stack`.
Next open up the service by clicking on its name
You then want to click on the `Logs` tab and you should be able to view the logs coming out of the container currently Folding for you
## Destroying Resources
**This is important!**, the configuration I've put in the repo will cost you a pretty penny to run long term.
To completely remove all the resources associated with this project, run the following
```bash
cdk destroy
# Are you sure you want to delete: CdkFahCovid19Stack (y/n)? y
# CdkFahCovid19Stack: destroying...
```
## Summary
AWS CDK is a great way to deploy a lot of resources really fast, and putting it to the use of running Folding@Home containers is a fun little experiment.
Have you used Fargate for something interesting? Or maybe you're an avid Folding@Home contributor? Reach out to me on [Twitter @nathangloverAUS](https://twitter.com/nathangloverAUS) and let me know! | t04glovern |
277,263 | A quick overview of ES2019 | ES2019 gives us several new features. Here I’ll provide an overview of the major ones -- along with a... | 0 | 2020-03-09T15:47:43 | https://brycedooley.com/es2019 | javascript, webdev | ES2019 gives us several new features. Here I’ll provide an overview of the major ones -- along with any gotchas to be aware of -- and provide links to the additional minor updates.
Each of these features are available to use in v8 v7.3 & Chrome 73. Be sure to check for the support of these features when using them elsewhere.
## Array.prototype.flat()
By default it will flatten one level
```js
[1, 2, [3, 4]].flat();
// [1, 2, 3, 4]
[1, 2, [3, [4, 5]]].flat();
// [1, 2, 3, [4, 5]]
```
You can adjust the number of levels to flatten
```js
[1, 2, [3, [4, 5]]].flat(2);
// [1, 2, 3, 4, 5]
```
### Gotchas
A missing item will result in `undefined`, if it is nested
```js
[1, 2, [3, [4,[, 6]]]].flat(2);
// [1, 2, 3, 4, [undefined, 6]]
```
A missing item will be removed, if it is not nested
```js
[1, 2, [3, [4,[, 6]]]].flat(3);
// [1, 2, 3, 4, 6]
```
## Array.prototype.flatMap()
The value returned by the callback will be flattened one level, if it's an array
```js
[1, 2, 3, 4].flatMap((n) => [n]);
// [1, 2, 3, 4]
[1, 2, 3, 4, 5].flatMap((n) => [[n]]);
// [[1], [2], [3], [4], [5]]
```
Otherwise it returns the value as is
```js
[1, 2, 3, 4].flatMap((n) => n);
// [1, 2, 3, 4]
[[1], 2, [3], 4].flatMap((n) => n);
// [1, 2, 3, 4]
```
It is extremely useful if you need to filter and map values
```js
[1, 2, 3, 4, 5].flatMap(
(a) => a % 2 ? a + " is odd" : []
);
// ["1 is odd", "3 is odd", "5 is odd”]
```
### Gotchas
If the a second argument is provided it becomes `this`
```js
var stuff = 'stuff';
[1, 2, 3, 4, 5].flatMap(
function(n) {
return `${this.stuff} ${n}`;
},
{ stuff: 'thing' }
);
// ["thing 1", "thing 2", "thing 3", "thing 4", "thing 5"]
```
## Object.fromEntries()
Creates an object from any iterable containing `[key, value]` tuples (Map, Array or custom iterable)
```js
Object.fromEntries([['one', 1], ['two', 2], ['three', 3]]);
// { one: 1, three: 3, two: 2 }
Object.fromEntries(new Map([['one', 1]]));
// { one: 1 }
Object.fromEntries(Object.entries({ one: 1 }));
// { one: 1 }
```
### Gotchas
Will throw an error if used with a Set
```js
Object.fromEntries(new Set(["1"]));
// TypeError: Iterator value one is not an entry object
```
## String.prototype.{trimStart, trimEnd}
```js
' hello world '.trimStart();
// “hello world “
' hello world '.trimEnd();
// “ hello world”
' hello world '.trimStart().trimEnd();
// “hello world”
```
### Gotchas
trimLeft & trimRight are now aliases to trimStart & trimEnd, respectively
## Optional catch binding
Catch no longer requires an error parameter, i.e. `catch(error) {...}`
```js
let catchResult = 'uncaught';
try {
throw new Error();
} catch {
catchResult = 'caught';
}
console.log(catchResult);
// “caught”
```
### Gotchas
`catch()` is still not allowed; if `()` is present it must have a parameter
```js
try {
throw new Error();
} catch() {
catchResult = 'caught';
}
// SyntaxError: Unexpected token !
```
## Other ES2019 changes
The remaining changes are either internal or don't have many use cases, but are still useful to know about...
Symbol.prototype.description
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/description
Stable Array.prototype.sort()
https://mathiasbynens.be/demo/sort-stability
Well-formed JSON.stringify()
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify#Well-formed_JSON.stringify()
JSON superset
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON#JavaScript_and_JSON_differences (see "Any JSON text is a valid JavaScript expression”)
Revised/standardized Function.prototype.toString()
https://tc39.es/Function-prototype-toString-revision/#sec-introduction | brycedooley |
277,317 | Today no women developer showed up at work (Mexico) | Many women in Mexico didn't show up at work today (Neither my female developer/software engineer... | 0 | 2020-03-09T17:35:52 | https://dev.to/arturoaviles/today-no-women-developer-showed-up-at-work-mexico-4681 | women, humanism, wecoded | ---
title: Today no women developer showed up at work (Mexico)
published: true
description:
tags: women, humanism, shecoded
---
Many **women in Mexico** didn't show up at work today (Neither my *female developer/software engineer co-workers*). The number of reported femicides is **increasing**.
Women are **tired** of **living scared** of being *harassed, assaulted, denigrated, beaten, and murdered* at **home, school, work, in the streets, at any place, at any time**, so they decided to disappear for **1 day** after protesting in the streets yesterday, to make everybody think more about this problem.
As a man, son, brother, boyfriend, and friend, **I feel horrible that they don't feel safe**. It's a nightmare to say goodbye to them in the morning because we never know if they will come back at night.
Maybe this way of acting is not the right one, but **they are trying to make their voice be heard**. They demand *justice, security, safeness, and equal rights* (Everything they deserve as a human being).
**Today**, we **remember** their **value**, **great abilities**, **effort**, and **power**.
Without them, we wouldn't have had what we have. All women have the same value as any other recognized one. When I see my **female co-workers**, I see the next **Grace Hopper, Margaret Hamilton, Sally Kristen, etc.**
**Thanks to all the people who write in dev.to**, for creating a place where **women** can **learn** and **give their opinion** freely in the stuff they are passionate about.
| arturoaviles |
277,363 | How to use Visual Validation Testing with Dynamic Data | You’re running functional tests with visual validation, and you have dynamic data. Dynamic data looks... | 0 | 2020-03-12T18:34:43 | https://applitools.com/blog/visual-validation-dynamic-data/ | codenewbie, testing, tutorial | You’re running functional tests with visual validation, and you have dynamic data. Dynamic data looks different every time you inspect it. How do you do functional testing with visual validation, when your data changes all the time?
I arrived at [Chapter 7](https://testautomationu.applitools.com/modern-functional-testing/chapter7.html?utm_term=cat&utm_source=syndication&utm_medium=&utm_content=tau&utm_campaign=test-automation-university&utm_subgroup=devto) of [Raja Rao DV’s](https://www.linkedin.com/in/rajaraodv/?utm_term=&utm_source=web-referral&utm_medium=blog&utm_content=blog&utm_campaign=&utm_subgroup=) course on [Test Automation University](https://testautomationu.applitools.com/?utm_term=cat&utm_source=syndication&utm_medium=&utm_content=tau&utm_campaign=test-automation-university&utm_subgroup=devto), [Modern Functional Test Automation Through Visual AI](https://testautomationu.applitools.com/modern-functional-testing/?utm_term=cat&utm_source=syndication&utm_medium=&utm_content=tau&utm_campaign=test-automation-university&utm_subgroup=devto). Chapter 7 discusses dynamic data – content that changes every time you run a test.

Dynamic data pervades client screens. Just look at the screenshot above. Digital clocks. Wireless signal strength. Location services. Alarm settings. Bluetooth connectivity. All these elements change the on-screen pixels, but don’t reflect a change in functional behavior.
This bank website updates the time until the local branch closes, in case you want to visit the branch. That time information will change on the screen. And Visual AI captures visual differences. So, how do you automate tests that will contain an obvious visual difference?
Dynamic regions can be the rule, rather than the exception, in web apps. But, for the purposes of visual validation, dynamic elements on-screen comprise the group of test exceptions. You need a way to handle these exceptions.
#Match Levels
Visual validation depends on having a good range of comparison methods because dynamic data can impact visual validation. Visual AI groups pixels into visual elements and compares elements to each other. The strictness you use in your comparison is called the match level.
Applitools Visual AI determines the element relative location, boundary, and properties (colors, contents, etc.) of each visual element. If there is no prior baseline, these elements are saved as the baseline. Once a baseline exists, Applitools will check the checkpoint image against the baseline.
Raja introduces three kinds of match levels for Applitools to compare your checkpoint against your baseline. You can use these match levels to inspect a subset of a page, a screenful, or an entire web page. Here are the three main match levels:
- “Strict” – Visual AI distinguishes location, dimension, color, and content differences as a human viewer would.
- “Content” – Visual AI distinguishes location, dimension, and content differences. Color differences are ignored as long as the content can be distinguished. Imagine wanting to see the impact of a global CSS color change.
- “Layout” – Visual AI distinguishes location and dimension and ignores content like text and pictures. This match level makes it easy to validate the layout of shopping and publication sites with a consistent layout and dynamic content.
You choose the match level appropriate for your page. If you have a page with lots of changing content, you choose “Layout” – which checks the existence and of regions but ignores their content. If you just made a global color change, you use “Content.” In most cases, you use “Strict.”
You set the match level in your call to open Applitools Eyes. If you don’t specify a match level, it defaults to “Strict.”
#Handling Exceptions – Regions
We like to think of our applications on a page-by-page basis. Each locator points to a unique page that behaves a certain way. In some cases, the relevant application content resides on a single screen. Often, though, applications and pages can extend beyond the bottom of the visible screen. Occasionally, content extends across wider than the visible screen as well.
By default, Applitools captures a screenful – the current viewport. Raja covered this code specifically in the prior chapters when he showed us how to use:
eyes.checkWindow();
Using the same command, with the “fully” option, you can capture the full page, not just the current viewport. Assuming the page scrolls beyond the visible screen, you can have Applitools scroll down and across all the screens and stitch together a full page. So you can compare full pages of your application, even if it takes several screens to capture the full page.
Be aware that the default comparison uses strict mode. You can choose a different mode for your comparison. And, you can handle exceptions with regions.
So, now that you know that you can instruct Applitools to capture a full page, or a viewport, what happens when you have dynamic data, or other parts of a page that could change? You need to identify a region that behaves differently.
Applitools adds the concept of “regions.” As Raja describes, “region” describes a rectangular subset of the screen capture – identified by a starting point X pixels across and Y pixels down relative to the top of the page, plus W pixels wide and H pixels high.
#Control Region Comparisons
Once you have a region, you can use one of the following selections to control the inspection of that region:
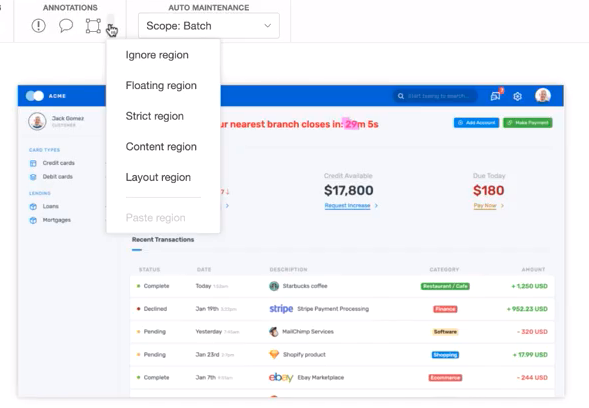
- Ignore – ignore that region completely. Its contents do not matter to the test identifying differences. Useful for counters
- Floating – the content within the region can shift around. Text that can shift around.
- Strict – content that should stay in the same place and color from screen to screen
- Content – Content that should stay in the same place with varying color from screen to screen
- Layout – Content that can change but has a common layout structure from screen to screen
Regions let you be permissive when you use a restrictive match level. “Ignore” literally means that – ignore the content of the region. There may be times you want to ignore a region. More often, though, you might want to ensure that the region boundary and content exists – for this you use “Layout.”
Regions let you handle exceptions on a more restrictive basis as well. For example, on a page using layout mode, you can create a region and use “strict” to compare content and color that should be identical – such as header or menu bar.
#Testers Choice
One big point Raja makes is that you get to choose how to deploy Visual AI. Select the mode that matches the page behavior you expect, and then set the appropriate mode for handling exceptions.
Raja demonstrates how you can choose to define exceptions in the UI or in your test code. You can choose to set the exceptions in the Applitools UI. Once you set a region with a specific match level, that region with that match level persists through future comparisons. Alternatively, you can add regions to handle exceptions directly in your test code. Those region definitions persist as long as they persist in your code.

You don’t need to capture an entire window or page. You can run your eyes.open() and use:
eyes.checkRegion()
Choose just to capture individual regions at an appropriate comparison level. This kind of test can be useful during app development when you want to distinguish the behavior of specific elements you are building.
If you’re really focused on using element-based checks, you can even run:
eyes.checkElement()
The checkElement instruction uses web element locators to find specific on-page elements. checkElement lets you use a legacy identifier in a modern functional test approach. In general, though, checkElement adds more complexity compared with visual validation.
The key understanding is that, for a given capture page, you can define your mode for the full capture and exceptions for specific regions, so that you cover the entire page.
#Handling Expected Changes
When you make changes, all your captures must be updated. CSS, icons, menus, and other changes can affect multiple pages – or even your entire site. Imagine having to maintain all those changes – page by page. Yikes.
Fortunately, Applitools makes it easy to accept common changes across multiple pages.
Whenever you encounter a difference on a single page, you are instructed to accept the change or reject it. If you reject the change – it’s an error and you can flag development. But, if you accept the change, you can also use a feature called automated maintenance to accept the change on all other pages where the change has been discovered.
Update your corporate logo. Done.
Install a new menu system. Easy.
You can use Automated Maintenance to accept changes. You can also use Automated Maintenance to deploy regions across all the pages – such as ignore regions.
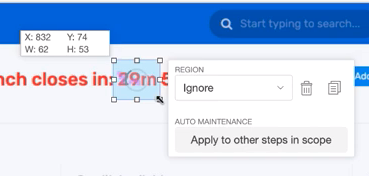
Of course, the more comprehensive your changes, the more challenging it is to use automated maintenance. If you make some significant changes in your layout, expect to create new baselines as well as use automated maintenance.
#Conclusions about Visual Validation and Dynamic Data
We all want to build applications that achieve business outcomes. We often build visually interesting pages with changing content designed to keep buyers engaged. But, we also know that testing requires repeatability – meaning that dynamic may be great for business, but testing requires predictable results.
Dynamic data can limit the benefits of visual validation. You need a way to handle dynamic data in your visual validation solution. Applitools gives you tools to handle dynamic parts of your application. You can handle truly dynamic sections by ignoring regions, treating those regions as layout regions, or even handling a whole page as a layout and let sections and content change.
And, when you make global changes, automated maintenance eases the pain of updating all your baseline images.
As Raja makes it clear, Applitools has thought not just about discovering visual changes, but handling unexpected changes that are defects, dynamic data that will produce false-positive defects, and expected global changes affecting multiple pages. All of these features make up key parts of a modern functional testing system. | michaelvisualai |
277,452 | Mechanical Keyboards | I have some Amazon vouchers and was looking at purchasing a mechanical keyboard. I did some research... | 0 | 2020-03-09T22:22:16 | https://dev.to/cguttweb/mechanical-keyboards-247c | ---
title: Mechanical Keyboards
published: true
description:
tags:
---
I have some Amazon vouchers and was looking at purchasing a mechanical keyboard. I did some research and bought this Corsair [keyboard](https://www.amazon.co.uk/gp/product/B07DNSTH51/ref=ppx_yo_dt_b_asin_title_o05_s00?ie=UTF8&psc=1) with the Cherry MX Red, but having plugged it in and setup after an hour of use I decided I wasn't keen on the noise and sent it back.
Any recommendations or suggestions? | cguttweb | |
277,556 | Rails like scope methods in Objection.js (NodeJS ORM) | Let say we have a model called Label const { Model } = require('objection') class Label extends M... | 0 | 2020-03-10T02:54:41 | https://dev.to/mistersingh179/rails-like-scope-methods-in-objection-js-nodejs-orm-dgj | node, javascript, orm, rails |

Let say we have a model called `Label`
```
const { Model } = require('objection')
class Label extends Model {
static get tableName() {
return "labels"
}
static get jsonSchema () {
return {
type: 'object',
required: [],
properties: {
id: { type: 'integer' },
name: { type: 'string' }
}
}
}
}
```
Now we want to get the last Label in the model.
```
const label = await Label.query().orderby('id', 'desc').limit(1).first()
```
Although this gets us the last label, it has a few shortcomings:
1. It is verbose
2. It requires too much repeated typing and thus prone to errors
3. Its harder to test
4. It doesn't read well
5. And things only get worse when its used in conjunction with other methods
Here are 3 ways to approach this:
1. Modifiers
2. A Regular Class Method
3. Custom QueryBuilder Object
Lets dive into each of these one-by-one.
## Approach 1: Modifiers
Modifiers is my preferred way to solve this. We specify a function on the modifiers object which:
1. receives the `query` as a param
2. it then modifies the query by adding its filters etc.
```
Label.modifiers.last = query => {
query.orderby('id', 'desc').limit(1).first()
}
```
Now lets get the last record by using this modifier
```
const label = await Label.query().modify('last')
```
This reads so much better, encapsulates all logic under one function and we can test that one function easily.
The logs show that it ran:
```
select "labels".* from "labels" order by "id" DESC limit 1
```
### With params
Lets build another modifier which gets all labels which start with the passed in letters
```
Label.modifiers.startsWith = (query, letters) => {
query.where('name', 'like', `${letters}%`)
}
```
Now lets run it
```
labels = await Label.query().modify('startsWith', 'XYYZ')
```
And logs show:
```
select "labels".* from "labels" where "name" like "AC%"
```
### Combining multiple modifier functions
This is where i think modifier functions start to shine, just like scopes do in Rails.
So lets say we need the last label which starts with 'A'. We can achieve this by using our `startsWith` & `last` modifier functions together.
```
const label = await Label.query().modify('startsWith','A').modify('last')
```
And our logs have:
```
select "labels".* from "labels" where "name" like "A%" order by "id" DESC limit 1
```
## Approach 2: Class method on Label
A regular static method on Label class. We can have this method return the last record:
```
Label.last = () => {
return await Label.orderby('id', 'desc').limit(1).first()
}
```
This gets the job done, but not as good as a modifier function. Yes it reads good and encapsulates the work but it doesn't return the query object and thus can't be chained
## Approach 3: Custom QueryBuilder
We can build our custom query object and have label class use our query object. On our custom query object we can define a custom methods which modify the `query()` object directly.
This will allow us to modify the query by calling an internal method of the query object, without writing the words `modify` and explicitly making it clear that we are modifying the query.
Lets see an example:
```
class MyQueryBuilder extends QueryBuilder {
last () {
logger.info('inside last')
this.orderBy('id', 'desc').limit(1).first()
return this
}
}
class Label exteds Model {
static get QueryBuilder () {
return MyQueryBuilder
}
}
```
Now to use it:
```
cons label = await Label.query().last()
```
I think this approach is an abuse of power. It works, but we have a cleaner way of modifying the query and we should do that instead of defining a custom query object which has special internal methods.
I think this custom query class might have good use cases though for other things like logging, making some other service calls etc.
## Conclusion
`modifiers` are great. the ability to chain them make them an asset.
## What's Next
Use modifiers with complex queries which use:
- join
- graphFetch (eager loading)
- use `ref` where we have ambiguous table names
| mistersingh179 |
277,566 | You can block a button if a field is not filled with pure CSS | learn how to block a button if a field is not filled with pure CSS | 0 | 2020-03-10T03:51:42 | https://dev.to/leandroruel/you-can-block-a-button-if-a-field-is-not-filled-with-pure-css-3019 | css, form, validation | ---
title: You can block a button if a field is not filled with pure CSS
published: true
description: learn how to block a button if a field is not filled with pure CSS
tags: css, form, validation
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/9s8cx8z85tvvi0evaqo1.jpg
---
i'm doing this trick with just one field, if want add more fields, they need be direct childrens of `<form>`, and this will fail if you wrap the input field in another element.
## HTML Structure
```html
<form action="" class="form">
<input type="text" class="form__input" placeholder="type your name..." required>
<button class="form__button">submit</button>
</form>
```
## The CSS
```css
:root {
--success-color: #319E65;
--error-color: #E8513B;
--white-color: #FFFFFF;
--silver-color: #BDC3C7;
--light-color: #ECF0F1;
}
.form {
display: flex;
flex-direction: row;
justify-content: center;
align-items: center;
max-width: 50%;
margin: 0 auto;
}
.form__input {
width: 100%;
border-radius: 4px;
border: 1px solid var(--silver-color);
padding: 10px 20px;
transition: all .3s ease-in-out;
}
.form__input:focus {
outline: 0;
}
.form__button {
background: var(--light-color);
border-radius: 4px;
border-style: solid;
border-width: 1px;
border-color: var(--silver-color);
text-decoration: none;
padding: 10px 20px;
color: var(--silver-color);
transition: all .3s ease-in-out;
pointer-events: none;
margin-left: 10px;
}
.form__input:invalid {
border-color: var(--error-color);
}
.form__input:valid {
border-color: var(--success-color);
}
.form__input:valid + button[class=form__button] {
border-color: var(--success-color);
background: var(--success-color);
color: var(--white-color);
cursor: pointer;
pointer-events: initial; /* block click and events in this button */
}
```
the trick here is `:valid` and `:invalid`, using it, you can validate the field, if empty `:invalid` will block it, if you type something, then `:valid` will make it clickable again at this line:
```css
.form__input:valid + button[class=form__button] {
border-color: var(--success-color);
background: var(--success-color);
color: var(--white-color);
cursor: pointer;
pointer-events: initial; /* the click event returns to the initial state */
}
```
## Result
{% codepen https://codepen.io/leandroruel/pen/oavYZB %} | leandroruel |
277,678 | HOW TO BUILD A USER INTERFACE FROM START TO FINISH | Today I am going to write about an interesting topic I have always wanted to write about that is a Us... | 0 | 2020-03-12T12:29:25 | https://dev.to/ingabirelydia/how-to-build-a-user-interface-from-start-to-finish-595b | Today I am going to write about an interesting topic I have always wanted to write about that is a User Interface(UI). While designing UI you will have more fun because it's all about styling, colors.. which is really interesting. But before going deeper into how to design UI you can ask yourself what is User Interface?
<b>User Interface(UI)</b>:
-is the point of human-computer interaction and communication in a device. This can include display screens, keyboards, a mouse and the appearance of a desktop.
-It is also the way through which a user interacts with an application or a website.
-It is a set of commands or menus through which a user communicates with a program.
Before starting designing UI it is good to think about users who will use it that will be a good starting point because UI focuses on anticipating what users might need to do and ensuring that the interface has elements that are easy to access, understand, and use to facilitate those actions.
Everything based on knowing your users, including understanding their goals, skills, preferences, and tendencies. Once you know about your users you can start designing.
“Obsess over customers: when given the choice between obsessing over competitors or customers, always obsess over customers. Start with customers and work backward.” – <b>Jeff Bezos</b>
Here are the best practices for designing an interface:
.<b>Keep the interface simple </b>: the best interfaces are almost invisible to the user. They avoid unnecessary elements and are clear in the language they use on labels and in messaging.
.<b>Stay consistent</b>: Users need consistency. They need to know that once they learn to do something, they will be able to do it again. Language, layout, and design are just a few interface elements that need consistency. A consistent interface enables your users to have a better understanding of how things will work, increasing their efficiency.
“The more users’ expectations prove right, the more they will feel in control of the system and the more they will like it.” – <b>Jakob Nielson</b>
.<b>Be purposeful in page layout</b>: Consider the spatial relationships between items on the page and structure the page based on importance. Careful placement of items can help draw attention to the most important pieces of information and can aid scanning and readability.
.<b>Strategically use color and texture</b>: You can direct attention toward or redirect attention away from items using color, light, contrast, and texture to your advantage.
<b>Keep moving forward</b>: It is often said when developing interfaces that you need to fail fast, and iterate often. When creating a UI, you will make mistakes. Just keep moving forward, and remember to keep your UI out of the way.
These are the basics elements you need to know if you want to be the best UI designer:
<b>Input controls</b>
allow users to input information into the system. If you need your users to tell you what country they are in, for example, you’ll use an input control to let them do so. these are a few examples of Input controls:
.<b>Checkboxes</b>: Checkboxes allow the user to select one or more options from a set
.<b>Radio buttons</b>: Radio buttons are used to allow users to select one item at a time.
.<b>Buttons</b>: A button indicates an action upon touch and is typically labeled using text, an icon, or both
.<b>Dropdown lists</b>: Dropdown lists allow users to select one item at a time
.<b>Texts fields</b>: Text fields allow users to enter text. It can allow either a single line or multiple lines of text.
<b>Navigational components</b>
help users move around a product or website.
<b>Informational components</b>
share information with users.
<b>Containers</b>
hold related content together.
if you really want to be a User Interface pro please visit these website you will thank me later.
https://www.w3schools.com/html
https://www.w3schools.com/css
https://www.freecodecamp.org/news/html-and-css-course/
| ingabirelydia | |
277,700 | Open source GUI to help make custom TTS datasets | Hey guys, I've made simple GUI too help edit clips and manually transcribe them. Its open-source so f... | 0 | 2020-03-10T08:24:00 | https://dev.to/st2ev/open-source-gui-to-help-make-custom-tts-datasets-ieh | **Hey guys, I've made simple GUI too help edit clips and manually transcribe them. Its open-source so feel free to contribute. It's built with electronjs and works with mac, windows, ubuntu, and fedora.**
**Link to blog ===>https://danklabs.tech/blog/a-gui-to-make-text-to-speech-datasetstdm/**
**Link to github ===> https://github.com/danklabs/tts_dataset_maker**
**Download Link ====> https://github.com/danklabs/tts_dataset_maker/releases**
**#DeepLearning#OpenSource** | st2ev | |
277,804 | Do you use Swagger, or document your API? | Not sure if it is needed for GraphQL as well, as you already have GraphQL playground. Swagger is a w... | 0 | 2020-03-10T13:25:38 | https://dev.to/patarapolw/do-you-use-swagger-or-document-your-api-4hc6 | discuss, devops, swagger, webdev | Not sure if it is needed for GraphQL as well, as you already have GraphQL playground.
[Swagger](https://swagger.io/resources/open-api/) is a way of documenting REST API.
Recently, I have been using [fastify](https://github.com/fastify/fastify) (which validates schema with [ajv](https://github.com/epoberezkin/ajv)), and integrate with OpenAPI v3 via [fastify-oas](https://www.npmjs.com/package/fastify-oas). Still, I feel that it needs some more validation layers.
- Frontend layer
- Database layer -- I had better use SQL / ODM (on top of NoSQL)? | patarapolw |
277,836 | Sourcery now available in VS Code! | Get instant Python refactorings as a VS Code extension | 0 | 2020-03-10T14:24:59 | https://sourcery.ai/blog/sourcery-vscode/?utm_souce=Blog&utm_medium=RSS | python, vscode, refactoring, extension | ---
title: Sourcery now available in VS Code!
description: Get instant Python refactorings as a VS Code extension
published: true
date: 2020-03-10 00:00:00 UTC
tags: python, vscode, refactoring, extension
canonical_url: https://sourcery.ai/blog/sourcery-vscode/?utm_souce=Blog&utm_medium=RSS
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/omd08vlw418j1zfqh6t9.png
---
We're excited to announce that Sourcery is now available as a VS Code [extension](https://marketplace.visualstudio.com/items?itemName=sourcery.sourcery).
This means you can use all of the great features of Sourcery directly in your VS Code editor:
* **Instant refactoring suggestions.** We're the only tool that will refactor your code for you!
As you type Sourcery will analyse your code and suggest improvements
which you can add with one click.
* **We don't break your code.** Sourcery uses extensive static analysis to ensure that its refactorings
don't change the existing functionality - backed up by testing on open source repositories.
* **Runs locally.** Sourcery runs completely locally on your machine - no code is ever sent to the cloud.
Here's an example of a Sourcery refactoring from inside VS Code:
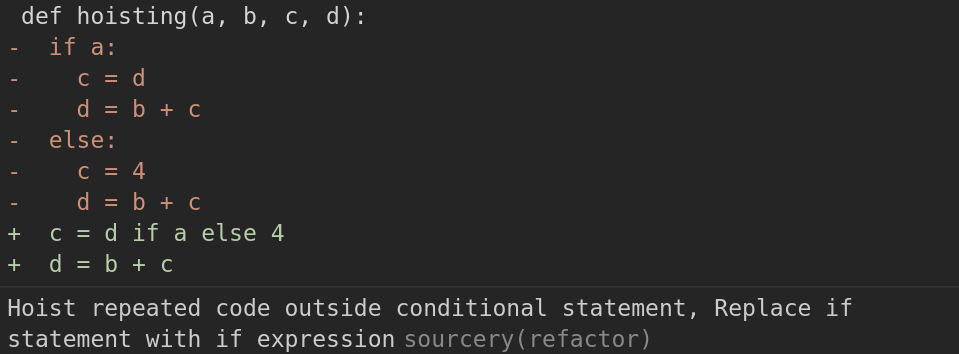
To get it for free just follow these steps:
* Open VS Code and press `Ctrl+P` (`Cmd+P` on Mac) then paste in `ext install sourcery.sourcery` and press `Enter`.
* Click [here](https://sourcery.ai/download/?editor=vscode) to get a free token.
* Enter the token into the provided input, or search for `sourcery` in the VS Code settings and enter it into the ```Sourcery Token``` field.
| nthapen |
277,840 | React/Redux application with Azure DevOps: Part 8 Integrate backend/frontend and CI/CD | React/Redux application with Azure DevOps | 0 | 2020-03-11T06:54:02 | https://dev.to/kenakamu/react-redux-application-with-azure-devops-part-8-integrate-backend-frontend-and-ci-cd-lb3 | azuredevops, react, redux, unittest | ---
title: React/Redux application with Azure DevOps: Part 8 Integrate backend/frontend and CI/CD
published: true
description: React/Redux application with Azure DevOps
tags: AzureDevOps,React,Redux,UnitTest
---
In the [previous post](https://dev.to/kenakamu/react-redux-application-with-azure-devops-part-7-use-backend-from-react-frontend-2ef), I update frontend so that it can interact with backend. There are two applications at the moment, and I need to integrate them into one application.
# React and express
React is just another frontend web application framework, thus once transpiled, produced results are static html/js/css files. In that case, express can serve it without any special configuration.
1\. First thing first, transpile react into static files.
```shell
npm run build
```
2\. Once the process completed, I can see build folder and items are added.
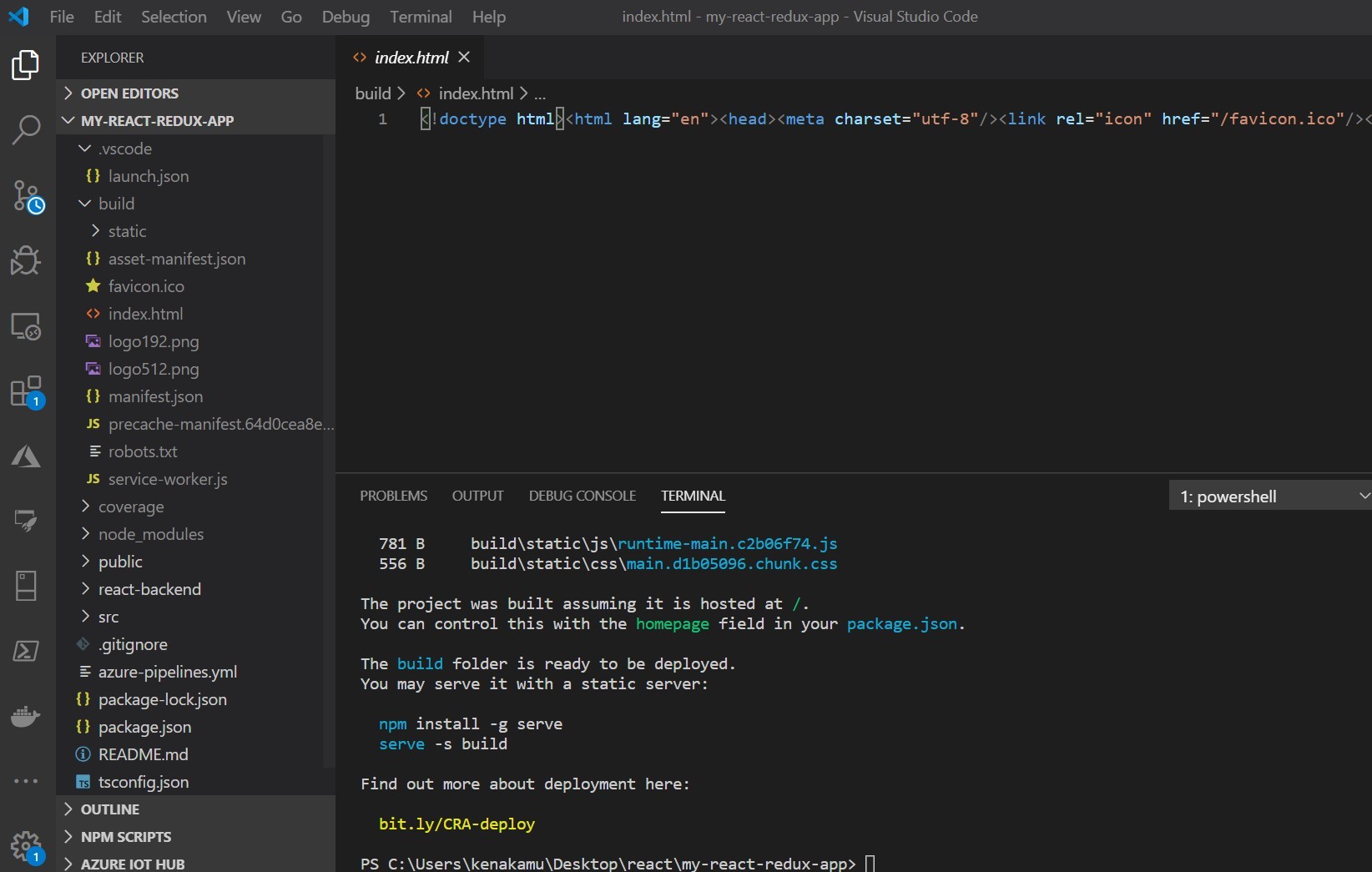
3\. Update Server.ts in react-backend/src folder to serve the build folder as static folder. Use it as root, too.
```typescript
/// Server.ts
import cookieParser from 'cookie-parser';
import express from 'express';
import { Request, Response } from 'express';
import logger from 'morgan';
import path from 'path';
import BaseRouter from './routes';
// Init express
const app = express();
// Add middleware/settings/routes to express.
app.use(logger('dev'));
app.use(express.json());
app.use(express.urlencoded({extended: true}));
app.use(cookieParser());
app.use('/api', BaseRouter);
/**
* Point express to the 'views' directory. If you're using a
* single-page-application framework like react or angular
* which has its own development server, you might want to
* configure this to only serve the index file while in
* production mode.
*/
const buildDir = path.join(__dirname, '../../build');
app.set('buildDir', buildDir);
const staticDir = path.join(__dirname, '../../build');
app.use(express.static(staticDir));
app.get('*', (req: Request, res: Response) => {
res.sendFile('index.html', {root: buildDir});
});
// Export express instance
export default app;
```
4\. Run the backend server by start debugging or npm command in react-backend folder.
```shell
npm run start:dev
```
5\. Open browser and access to localhost:3001. I can see the application is up and running.
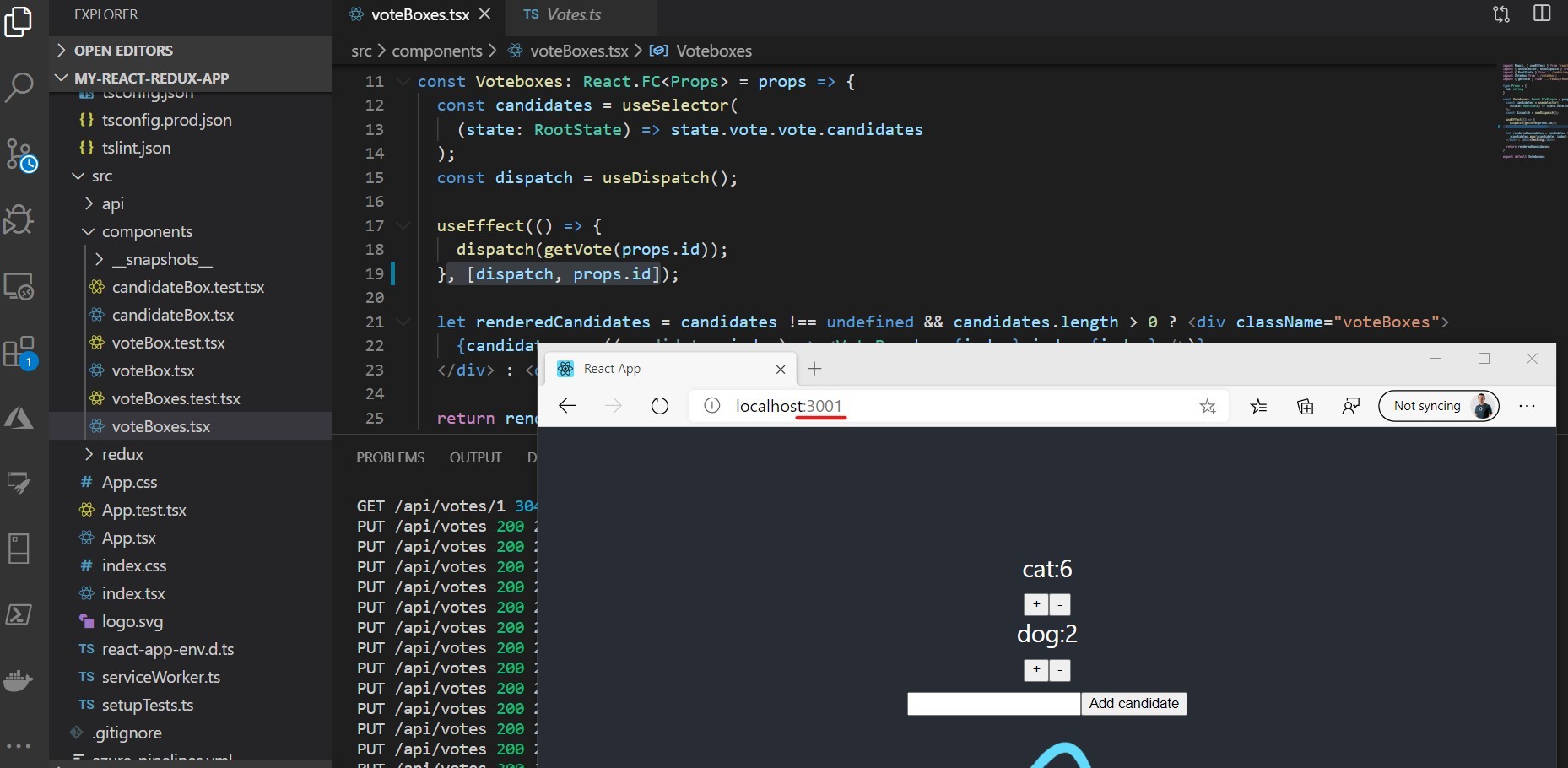
6\. Now I confirm how it work. Next I update the package.json to copy the build output into backend src folder so that I can package them together. The "postbuild" section runs after build script.
```json
"scripts": {
"start": "react-scripts start",
"build": "react-scripts build",
"postbuild": "mv build ./react-backend/src",
"test": "react-scripts test",
"eject": "react-scripts eject"
},
```
7\. Update Server.ts to point new build folder.
```typescript
const buildDir = path.join(__dirname, './build');
```
8\. Update util/build.js to copy the build folder into dist when transpile the backend. This is necessary as it clears the folder every time. I also comment out unused folder copy.
```javascript
const fs = require('fs-extra');
const childProcess = require('child_process');
try {
// Remove current build
fs.removeSync('./dist/');
// Copy front-end files
fs.copySync('./src/build', './dist/build');
//fs.copySync('./src/public', './dist/public');
//fs.copySync('./src/views', './dist/views');
// Transpile the typescript files
childProcess.exec('tsc --build tsconfig.prod.json');
} catch (err) {
console.log(err);
}
```
9\. I deleted all unused code from backend, such as MockDB, UserRoute, Views, etc so that I only have what I need.
# Update .gitignore and commit
I didn't update .gitignore after added backend, which affect push to git server. I added following entries.
```
# backend
/react-backend/node_modules
/react-backend/env
/react-backend/logs
/react-backend/dist
/react-backend/src/build
/react-backend/spec/junitresults*.xml
```
Then commit the change, but not push yet.
```shell
git add .
git commit -m "backend integration"
```
# Pipeline
Before push the changes to the repo, it's time to update build pipeline.
As I have done so many changes, I need to think about how to accommodate the change.
There are several things I need to think.
- Build order: At the moment, I need to build frontend first, then backend.
- Environment file: I cannot commit plan file with secure key, that's why I ignore env folder, but backend server needs it.
- Artifact: I don't need entire files but I just need backend project now.
1\. First of all, upload env files to Azure DevOps Secure File where I can sacurly store the file. Go to Azure DevOps | Pipelines | Library | Secure files.
Upload production.env, development.env and test.env which contains environment information.
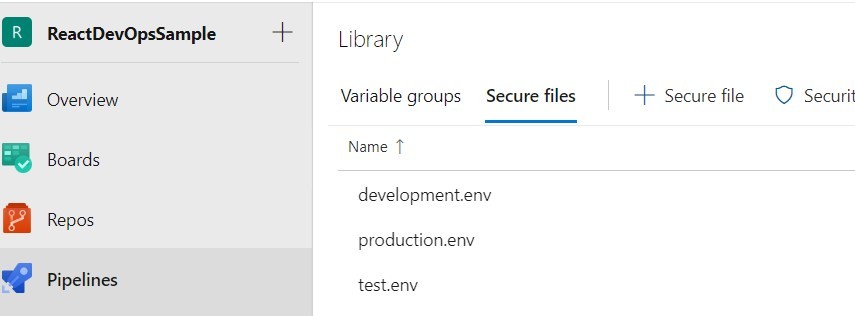
2\. Edit current pipeline. I added/removed/modified several things to accommodate the changes.
- Download and copy environment files
- Update trigger so that it won't trigger by pipeline definition change
- Update build section to test and build backend/frontend
- Publish test results to cover both backend/frontend
- Create drop based on react-backend folder
- Update publish as it's express application rather than react and pass -- --env=development to control the environment settings.
```yaml
# Node.js React Web App to Linux on Azure
# Build a Node.js React app and deploy it to Azure as a Linux web app.
# Add steps that analyze code, save build artifacts, deploy, and more:
# https://docs.microsoft.com/azure/devops/pipelines/languages/javascript
trigger:
branches:
include:
- master
paths:
exclude:
- azure-pipelines.yml
variables:
# Azure Resource Manager connection created during pipeline creation
azureSubscription: '2e4ad0a4-f9aa-4469-be0d-8c8f03f5eb85'
# Web app name
devWebAppName: 'mycatdogvoting-dev'
prodWebAppName: 'mycatdogvoting'
# Environment name
devEnvironmentName: 'Dev'
prodEnvironmentName: 'Prod'
# Agent VM image name
vmImageName: 'ubuntu-latest'
stages:
- stage: Build
displayName: Build stage
jobs:
- job: Build
displayName: Build
pool:
vmImage: $(vmImageName)
steps:
- task: DownloadSecureFile@1
name: productionEnv
inputs:
secureFile: 'production.env'
- task: DownloadSecureFile@1
name: developmentEnv
inputs:
secureFile: 'development.env'
- task: DownloadSecureFile@1
name: testEnv
inputs:
secureFile: 'test.env'
- script: |
mkdir $(System.DefaultWorkingDirectory)/react-backend/env
mv $(productionEnv.secureFilePath) $(System.DefaultWorkingDirectory)/react-backend/env
mv $(developmentEnv.secureFilePath) $(System.DefaultWorkingDirectory)/react-backend/env
mv $(testEnv.secureFilePath) $(System.DefaultWorkingDirectory)/react-backend/env
displayName: 'copy env file'
- task: NodeAndNpmTool@1
inputs:
versionSpec: '12.x'
- script: |
npm install
CI=true npm test -- --reporters=jest-junit --reporters=default
npm run build
displayName: 'test and build frontend'
- script: |
cd react-backend
npm install
npm run test
npm run build
displayName: 'test and build backend'
- task: PublishTestResults@2
inputs:
testResultsFormat: 'JUnit'
testResultsFiles: |
junit.xml
**/*junit*.xml
failTaskOnFailedTests: true
- task: ArchiveFiles@2
displayName: 'Archive files'
inputs:
rootFolderOrFile: '$(Build.SourcesDirectory)/react-backend'
includeRootFolder: false
archiveType: zip
archiveFile: $(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip
replaceExistingArchive: true
- upload: $(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip
artifact: drop
- stage: DeployToDev
displayName: Deploy to Dev stage
dependsOn: Build
condition: succeeded()
jobs:
- deployment: Deploy
displayName: Deploy to Dev
environment: $(devEnvironmentName)
pool:
vmImage: $(vmImageName)
strategy:
runOnce:
deploy:
steps:
- task: AzureRmWebAppDeployment@4
displayName: 'Azure App Service Deploy: $(devWebAppName)'
inputs:
azureSubscription: $(azureSubscription)
appType: webAppLinux
WebAppName: $(devWebAppName)
packageForLinux: '$(Pipeline.Workspace)/drop/$(Build.BuildId).zip'
RuntimeStack: 'NODE|12-lts'
StartupCommand: 'npm run start -- --env=development'
- stage: DeployToProd
displayName: Deploy to Prod stage
dependsOn: DeployToDev
condition: succeeded()
jobs:
- deployment: Deploy
displayName: Deploy to Prod
environment: $(prodEnvironmentName)
pool:
vmImage: $(vmImageName)
strategy:
runOnce:
deploy:
steps:
- task: AzureRmWebAppDeployment@4
displayName: 'Azure App Service Deploy: $(prodWebAppName)'
inputs:
ConnectionType: 'AzureRM'
azureSubscription: '$(azureSubscription)'
appType: 'webAppLinux'
WebAppName: '$(prodWebAppName)'
packageForLinux: '$(Pipeline.Workspace)/drop/$(Build.BuildId).zip'
RuntimeStack: 'NODE|12-lts'
StartupCommand: 'npm run start'
```
3\. Save the change and confirm it won't trigger the pipeline.
# CI/CD
Now it's time to run the pipeline.
1\. Make sure to commit all from local. I need to run git pull first to get latest yaml change from the repo.
```shell
git add .
git commit -m 'backend added'
git pull
git push
```
2\. The pipeline is triggered. Once all the deployment completed, confirm everything worked as expected.
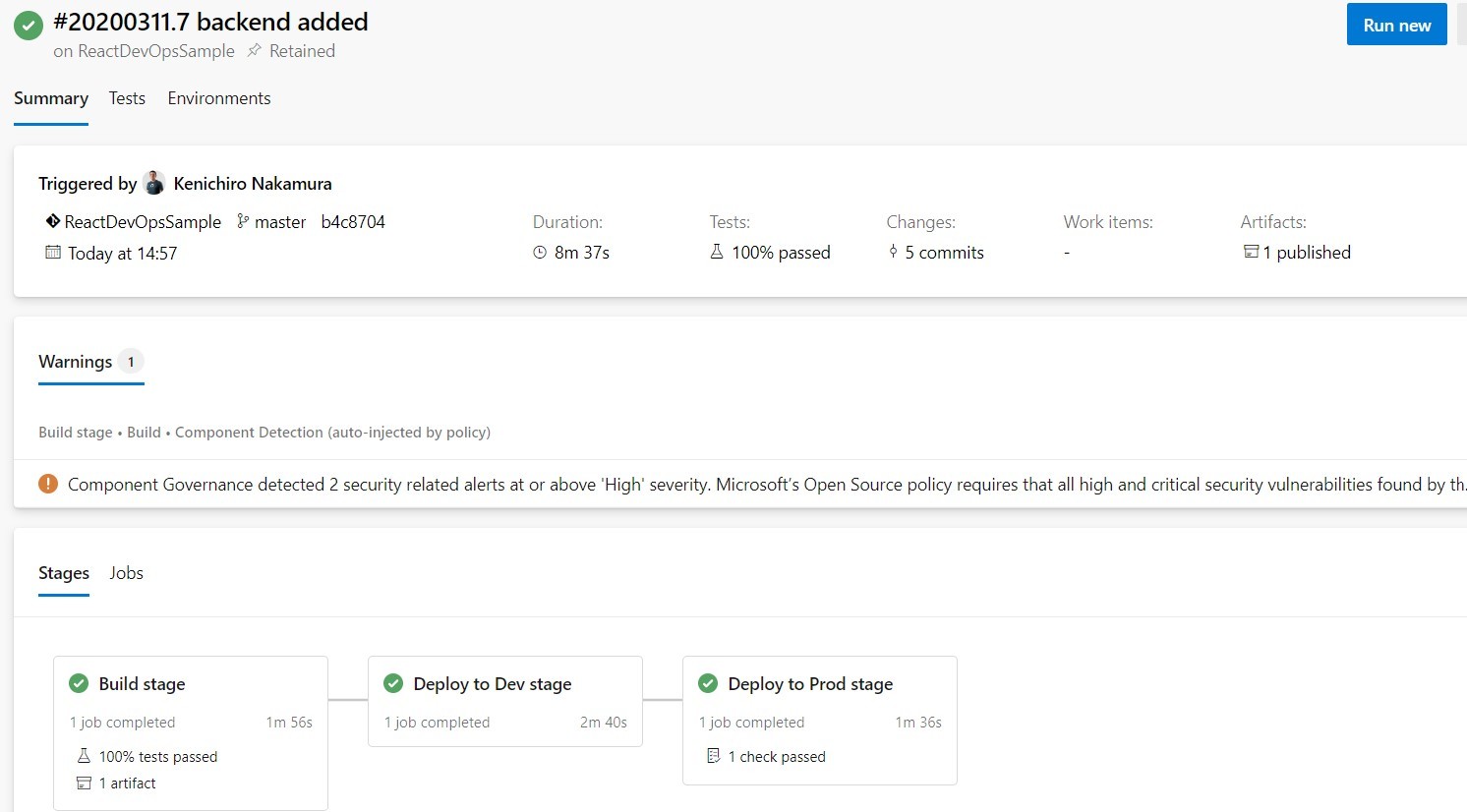
3\. I can confirm the test results for both frontend and backend are published.
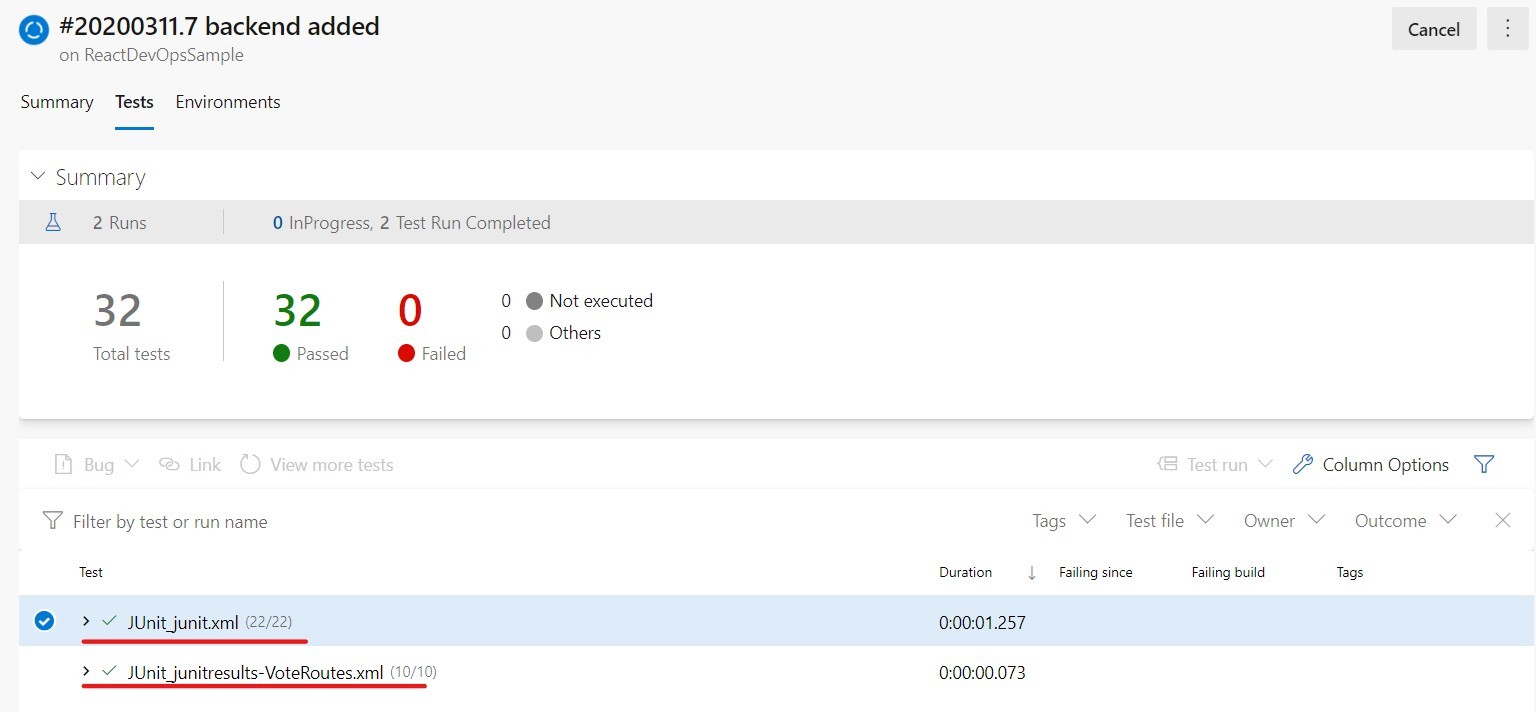
4\. Application runs as expected on both environment.
I know that both environment points to same Redis Cache, but you got the idea how to use different configuration file, right?
# Summary
I merged backend and frontend and run CI/CD successfully. I will take a look for integration in the next article.
[Go to next article](https://dev.to/kenakamu/react-redux-application-with-azure-devops-part-9-integration-test-and-end-to-end-test-3k0d) | kenakamu |
277,863 | Vuex state and getters | With vuex is there a reason why it's better to access state directly than via a getter if the getter is just returning the state? | 0 | 2020-03-10T14:58:20 | https://blog.ticabri.com/vuex-state-and-getters/ | development, vuex, cleancode | ---
title: Vuex state and getters
published: true
date: 10/03/2020
tags: development,vuex,clean code
description: With vuex is there a reason why it's better to access state directly than via a getter if the getter is just returning the state?
canonical_url: https://blog.ticabri.com/vuex-state-and-getters/
---
_**(edit)** I have evolved my thinking on the subject, which I have expressed in a new article: https://dev.to/enguerran/vuex-state-and-getters-2-2l34_
> With vuex is there a reason why it's better to access state directly than via a getter if the getter is just returning the state?

Let us first take care to illustrate this issue:
## the store
```
const store = new Vuex.Store({
state: {
messages: [
{ from: "Bob", to: "Alice", content: "Hello, Alice!" },
{ from: "Alice", to: "Bob", content: "Hi, Bob!" },
{
from: "Bob",
to: "Alice",
content:
`What is the difference between accessing the state directly
rathen than using a getter?`
},
{
from: "Alice",
to: "Bob",
content: `This is your last chance.
After this, there is no turning back.
You take the blue pill—the story ends,
you wake up in your bed and believe whatever you want to believe.
You take the red pill—you stay in Wonderland,
and I show you how deep the rabbit hole goes.
Remember: all I'm offering is the truth. Nothing more.`
}
]
},
getters: {
messages: state => state.messages
}
});
```
<figcaption>Vuex store</figcaption>
## two very different components
In both components, messages are the responsibility of a Vuex store.
### RedPill: direct access to the state
```
export default {
name: "HelloWorld",
computed: {
messages() {
return this.$store.state.messages;
}
}
};
```
<figcaption>RedPill component</figcaption>
In the component `<RedPill />`, we access the state directly via the store object which is [injected](https://vuex.vuejs.org/guide/state.html#getting-vuex-state-into-vue-components) to all root child components.
The component retrieves the list of messages and can display their content:
```
<template>
<div class="hello">
<h1>Dependant of the state organization</h1>
<ul v-for="(message, index) in messages" :key="index">
<li>{{message.from}} to {{message.to}}: {{message.content}}</li>
</ul>
</div>
</template>
```
<figcaption>Vue template to display messages</figcaption>
### BluePill: using a getter
```
export default {
name: "HelloWorld",
computed: {
messages() {
return this.$store.getters.messages;
}
}
};
```
<figcaption>BluePill component</figcaption>
In the other component `<BluePill />`, we access the state via a getter which is not complex since it returns directly the object: `const messages = state => state.messages`.
From a component and the application point of view, there is no difference.
## how deep does the rabbit hole go?
The `RedPill` is dependant of the internal state organization. Every time the state is reorganized, the `RedPill` should be updated. The `RedPill` has a big responsibility: to know where it can find the list of messages.
On the other hand, the `BluePill` is independent of the internal organization of the state because it asks the store, whenever it needs it, to return the list of messages. The `BluePill` does not have the responsibility to know where it can find the list of messages.
Let's say that the Vuex store is redesigned to allow organization in modules.
```
const store = new Vuex.Store({
state: {
messages: [
{ from: "Bob", to: "Alice", content: "Hello, Alice!" },
{ from: "Alice", to: "Bob", content: "Hi, Bob!" },
{
from: "Bob",
to: "Alice",
content:
`What is the difference between accessing the state directly
rathen than using a getter?`
},
{
from: "Alice",
to: "Bob",
content: `This is your last chance.
After this, there is no turning back.
You take the blue pill—the story ends,
you wake up in your bed and believe whatever you want to believe.
You take the red pill—you stay in Wonderland,
and I show you how deep the rabbit hole goes.
Remember: all I'm offering is the truth. Nothing more.`
}
]
},
getters: {
messages: state => state.messages
}
});
```
<figcaption>Vuex store before refactoring</figcaption>
Now we want to use [Vuex modules](https://vuex.vuejs.org/guide/modules.html):
```
const store = new Vuex.Store({
modules: {
messages: {
state: {
messages: [
{ from: "Bob", to: "Alice", content: "Hello, Alice!" },
{ from: "Alice", to: "Bob", content: "Hi, Bob!" },
{
from: "Bob",
to: "Alice",
content: `What is the difference between accessing the state directly
rathen than using a getter?`
},
{
from: "Alice",
to: "Bob",
content: `This is your last chance.
After this, there is no turning back.
You take the blue pill—the story ends,
you wake up in your bed and believe whatever you want to believe.
You take the red pill—you stay in Wonderland,
and I show you how deep the rabbit hole goes.
Remember: all I'm offering is the truth. Nothing more.`
}
]
},
getters: {
messages: state => state.messages
}
}
}
});
```
<figcaption>Vuex store with modules</figcaption>
I have to update the `RedPill` computed data:
```
export default {
name: "HelloWorld",
computed: {
messages() {
return this.$store.state.messages.messages;
}
}
};
```
<figcaption>Tightly coupled to the store</figcaption>
But not the `BluePill`'s one.
```
export default {
name: "HelloWorld",
computed: {
messages() {
return this.$store.getters.messages;
}
}
};
```
<figcaption>Weakly coupled to the store</figcaption>
And that is the same about adding a new feature.
Let's say messages are updated to have a boolean that expresses the need to be displayed or not: `draft: true`.
You just need to update the getter and everything is right:
```
getters: {
messages: state => state.messages.filter(message => !message.draft)
}
```
<figcaption><a href="https://refactoring.guru/smells/shotgun-surgery">Shotgun surgery</a> avoidance</figcaption>
That is an introduction to [coupling in software development](https://en.wikipedia.org/wiki/Coupling_(computer_programming)). | enguerran |
277,894 | Why Use Flutter for Cross-Platform Apps | In their latest 'The State of the Octoverse' report, GitHub puts Flutter UI framework in the list of... | 0 | 2020-03-11T13:24:58 | https://dev.to/diachenko_maria/why-use-flutter-for-cross-platform-apps-15mm | flutter, programming, dart, appdevelopment | In their latest '[The State of the Octoverse](https://octoverse.github.com/)' report, GitHub puts Flutter UI framework in the list of three trending open-source projects.
What's the reason for such popularity? Well, Google knows how to do their work. They offer a tremendous cross-platform tool that can be used to build mobile, web, and desktop apps.
Technologies like are Flutter time-savers for devs and budget-cutters for ap owners.
Let's figure out what exactly is Flutter, why programmers use it, and how it works.
## What's Flutter?
First, the basics.
Flutter is an open-source, cross-platform toolkit that helps developers build native interfaces for Android and iOS.
As of March 2020, [1.12.13](https://flutter.dev/docs/development/tools/sdk/releases) version is available.
**What's so special about Flutter?** It lets programmers combine the quality of native apps with the flexibility of cross-platform development.
Native compilation for ARM processors helps to make the development go smoother and faster. Simple rendering, integrated widgets, tools, and new features help, too.
What's more, Flutter is an open-source framework. That means any programmer can make changes in the framework on GitHub.
One of the most exciting features in Flutter is the Hot Reload button. When you click the button, all changes in code are instantly displayed on gadgets, emulators, and simulators.

There's a catch though: Dart is the language Flutter is written in. It's an open-source and object-oriented programming language created by Google. Dart applies to both client- and server-side development.
So, to build cross-platform apps with Flutter, devs should know Dart programming.
Actually, Dart has a lot of common with Kotlin, Java, C#, JavaScript, and Swift. If a developer knows some of these languages, it won't be hard for them to switch to Flutter.
Flutter uses Dart, and its UI layout doesn't require any additional templating languages (e.g., XML or JSX) nor special visual tools. This allows programmers to create a structural, platform, and interactive widgets and reuse them. Flutter has an architecture that includes widgets that feel and look good. They are fast, customizable, and extensible.
Aside from widgets, a ton of controls, libraries with animations, and other customizable tools speed up native UI development.
And programmers don't need to switch to a design mode thinking what to do in a program way. In Dart coding, everything is done in a program way and available in one place. The idea is to reuse code, and Flutter does it well for standard app cases.
## Why Use Flutter for Cross-Platform Apps?
On GitHub, [flutter/flutter](https://github.com/flutter/flutter) repository has 17,855 comments, 25,760 closed issues, and 87,8k stars. Since its 1.0 release in December 2018, flutter/flutter has climbed to #2 in GitHub's fastest-growing open-source projects.
Developers actively use Flutter, and Google plays a large part in that. For example, their AdWords platform was built with the help of Flutter.
Why is Flutter so popular? First, **it's pretty easy to get started** with this framework. Here are the steps:
1. Devs download the package and unzip it.
2. Then they need to create an environment variable pointing to a folder inside of the unzipped one.
Second, **Flutter has well-organized documentation**. As always, Google tries to provide clear and in-depth documentation for their products. They did it for Angular, Goland, and for Flutter too.
Finally, in terms of performance, Flutter can be described as **Flutter = Native real-time app**.
Today, Flutter helps bring the popular [Ken Ken puzzle](https://www.nytimes.com/games/prototype/kenken#/) to Android, iOS, Mac, Windows, and the web for **The New York Times**. It powers an ever-growing number of **Google Assistant** apps, and Google's **Stadia** app is also built using Flutter.
Here are some other apps built with Flutter:
- **Xianyu** — 50 000 000+ downloads;
- **GoogleAds** — 5 000 000+
- **Hamilton Musical app** — 500 000+
- **Reflectly** — 100 000+ (was rewritten entirely from React)
## How Flutter Works
As I've said, Flutter uses Dart programming language. But there also is high-speed C++ in its core. The resulting app produces high FPS and feels like a native-built one.
Flutter's app performance is **60 fps or 120 fps** when it comes to animations. It's higher than the one of React Native, another famous framework for multi-platform development.
Flutter uses its own UI components instead of OS native ones. That's how Flutter makes it easier to customize the components and increases their flexibility.
Flutter UI elements:
- Material widgets for Android;
- Cupertino for iOS;
- Platform-independent widgets.
Apps build with Flutter look good on up-to-date OS and their older versions. As they have a single codebase, apps look and run similarly on iOS and Android.
But if you need to imitate the platform design itself, there's a way out.
Flutter has two sets of widgets that comply with specific design languages:
- Material Design widgets implement Google's design language.
- Cupertino widgets imitate iOS design.
That's why the Flutter app looks and runs naturally on both Android and iOS, imitating their native components.
So Flutter apps have tons of advantages, including their cost. After all, product owners don’t need to [hire Android app developers](https://www.cleveroad.com/blog/hire-android-app-developer-see-an-ultimate-guide) and iOS programmers to cover both the platforms. Instead, they find someone experienced with Flutter and start the development.
## Pros and Cons of Using Flutter
Sure, Flutter is not without cons and I suggest discussing them too.
Flutter is a promising cross-platform solution that has its advantages and disadvantages. Flutter can be used for building lots of apps, but still, it cannot cover all the use cases like browsers, launchers, or the apps that rely heavily on platform API.
So, **what are the advantages of using Flutter**?
- **Hot Reload**. Most UI changes start working immediately while the app is running.
- **Cross-platforming**. Flutter allows building UI both for iOS and Android using IntelliJ, Android Studio, and Visual Studio Code.
- **Native-like apps**. Using Flutter, devs build first-rate native apps fast and without tech issues due to plugins and other iOS and Android elements.
- **Free and open-source**. Flutter is available for any programmer: no costs, no restrictions, not rocket-science-level to learn.
- **Fast rendering**. Devs create images and 2D models faster due to quick rendering.
- **Screen reader**. Software for partially sighted programmers that can now create UI with the help of voice prompts and signals.

On the whole, Flutter is the right choice if you need to build a cross-platform app. **And what about the not-so-goods**?
- **Language**. Dart may be a pretty simple language, but it's still a new language to learn.
- **App size**. Flutter apps use build-in widgets whose size is usually bigger. Right now, Flutter-made apps weigh no less than 4MB.
- **Universal apps**. Flutter works great for cross-platform development, but if you need to tie the app to Android more than to iOS, Flutter isn't the best choice.
- **Support**. Not all devices are supported by Flutter. For example, you cannot build apps for 32-bit iOS devices like iPhone 5. Flutter simply doesn't support them.
- **Limited libraries**. Flutter is a relatively new framework, and there are no many really useful libs yet.

Still, the Flutter dev community is very active in creating new and excellent libraries. For now, Flutter devs use libs for drawing graphics, displaying images, biometric authentication. They even have a [sliding tutorial](https://github.com/Cleveroad/flutter_sliding_tutorial) that helps to create user onboarding screens with parallax effect and many more.

## Wrapping Up
Flutter has a ton of potential, it's easy to get started with it, there's well-structured documentation and fast-growing community.
The community is growing really fast, but it's still small, and some plugins are still missing (or there isn't much choice of them). There are not yet as many useful libraries as native languages can offer. That's why devs need to build the majority of libs themselves, and that takes time.
So, Flutter works best when you need to build the application asap for both iOS and Android. Maybe you're a startup owner that needs to reach the widest user base (and do it really quick).
Or maybe you're a single programmer who just wants to make coding faster, more efficient, and compatible.
| diachenko_maria |
277,928 | How Data Science Can be Helpful in Social Media Marketing | Social media is an integral part of the millennial lifestyle. People of all ages, cultures and countr... | 0 | 2020-03-10T16:39:39 | https://dev.to/amdatascientist/how-data-science-can-be-helpful-in-social-media-marketing-m5b | datasciencecourse, datascienceinternship, datasciencedefination, datasciencesalary | Social media is an integral part of the millennial lifestyle. People of all ages, cultures and countries are connected and engaged through different types of social media platforms and, with the rise of sophisticated digital devices, the use of social media has become easier.
Now that everyone is on social media, it has become a great platform for marketing different products and services. Today, from large to small businesses, everyone uses social media for marketing purposes to reach customers more easily and also interact with them on a daily basis. Social networks also have a large amount of data that can be used by companies to market the product.
Some of the ways big data can be used for social media marketing are:
Visit Now:https://360digitmg.com/usa/data-science-for-managers
<h4>Image recognition</h4>
Data can be recognized through images and images posted by users of social networks on different social media platforms. Big Data allows you to recognize different objects, places and products that can be identified from these images, then these recognized ideas are used by companies to take advantage of personalized marketing. Recognizing logos, events and objects can help businesses recognize their loyal customers from whom they can receive effective feedback.
<h4>Know the customer</h4>
An effective salesperson is one who knows his customers and their requirements. Big Data makes it possible to analyze data from social networks to find different personality attributes and group them according to their activity on social networks. This will give the seller an overview of the client's values, ideas and personalities. This will help the company to design an effective marketing approach that will be useful in reaching customers on a holistic level and attracting them over a longer period of time.
<h4>The promotion</h4>
Marketing has a basic core of promotion and advertising. Each company must find its target audience to whom it can regularly reach out to promote its products and services. This is where companies use <a href="https://360digitmg.com/usa/data-science-using-python-and-r-programming">Data Science</a> extensively to discover their target market. Big data devastates the large amount of data created by millions of social network users, in order to reduce the number of users interested in the same type of products and services according to their tastes, comments, page visits and publications.
<h4>Find the right channel</h4>
Data science helps understand which social media platform is most effective in the long run. Finding the right channel is very important for effective marketing, otherwise you will end up spending a lot of time and resources in the wrong place without growing sales.
<h4>Product improvement</h4>
Who can be better than customers to inform the seller of the pros and cons of a particular product or service, and what better place than social media platforms to chat with customers in real time and get their feedback? Big Data helps quantitative and qualitative research through surveys, chats, etc. to collect and analyze customer reviews. These customer reviews end up helping a business improve and improve its product.
With the help of different courses and certifications in data science, one can become more proficient with data science tools and techniques which eventually facilitate social media marketing.
<h4>Resource Box</h4>
With the rise of social media and social media users, there will be many opportunities as a data scientist in social media companies. This is a great opportunity for anyone aspiring to become a data scientist to participate in the best data science course available in Excel that you can participate in today.
Get certified for the best data science course in Hyderabad
Visit Now: https://360digitmg.com/data-science-course-training-in-hyderabad | amdatascientist |
277,969 | Challenge: Get started with GSAP 3 | Mini challenges and solutions to get up and running with GSAP 3 | 0 | 2020-03-10T18:47:04 | https://dev.to/coffeecraftcode/challenge-get-started-with-gsap-3-4ie3 | svg, webdev, javascript, challenge | ---
title: Challenge: Get started with GSAP 3
published: true
description: Mini challenges and solutions to get up and running with GSAP 3
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/zuadvb3ctcutj9l6khro.jpg
tags: #svg, #webdev, #javascript, #challenge
---
GreenSock updated it's API to version 3. If you would like to explore how to get started with GSAP 3 check out the mini-challenges and solutions below.
**For reference while animating**
[GreenSock's Docs](https://greensock.com/docs/)
[Ease Visualizer](https://greensock.com/ease-visualizer/)
To get started with GreenSock, use the [gsap.to method](https://greensock.com/docs/v3/GSAP/gsap.to())
Use the CodePen below and follow the directions. Once you give it a try you can check out the solution I provided.
✅ **Good first objective. Try to animate these divs.**
{% codepen https://codepen.io/cgorton/pen/vYYXoEQ %}
1. Make one of the divs move left and right
2. make on of the divs move up and down
3. make one of the divs scale up or down
4. make one of the dives fade in and out
5. Try out GreenSock's stagger property to make all of the divs animate.
**Solution examples:**
{% codepen https://codepen.io/cgorton/pen/wvapbRJ %}
Check out after you have tried the stagger yourself
{% codepen https://codepen.io/cgorton/pen/MNbYBP %}
## Animating SVGs
✅ Here are basic SVG shapes. Use what you learned above to animate the SVGs. You can look for each SVGs ID in the HTML and animate them individually.
{% codepen https://codepen.io/cgorton/pen/wLRPXN %}
**Solution example:**
{% codepen https://codepen.io/cgorton/pen/OJVzeWj %}
## Timeline animations
In the pens below I challenge you to set up reusable functions that you can add to a single master timeline.
This helps clean up your code and allows you to add the same animations to several different elements.
Check out the documentation for [Timelines](https://greensock.com/docs/v3/GSAP/Timeline) and then check out the solution pen.
In it I break down how I use `gsap.set`, `gsap.timeline`, reusable functions and then how I combine them all in to a single master timeline.
✅ You can use this pen to either keep practicing animating SVG's with tweens or [with timelines](https://greensock.com/docs/v3/GSAP/Timeline).
{% codepen https://codepen.io/cgorton/pen/xxxEvQQ %}
**Solution:**
Check out this pen after you have tried to use reusable functions and a master timeline.
{% codepen https://codepen.io/cgorton/pen/NWqXZXz %}
**More Resources:**
[How to animate on the web with GreenSock](https://css-tricks.com/how-to-animate-on-the-web-with-greensock/)
[GSAP 3 features](https://tympanus.net/codrops/2019/11/14/the-new-features-of-gsap-3/)
Getting started examples:
[Finding inspiration and Creating SVG](https://dev.to/coffeecraftcode/finding-inspiration-and-creating-svg-3m7b)
[Have fun with GreenSock's Draggable and Hello Kitty](https://dev.to/coffeecraftcode/have-fun-with-greensock-s-draggable-and-hello-kitty-996)
Great resource to explore writing TimeLines
[Writing Smarter Animation Code](https://css-tricks.com/writing-smarter-animation-code/)
**Extra courses:**
Sarah Drasner: [Frontend Masters: SVG essentials & Animation](https://frontendmasters.com/courses/svg-essentials-animation/)
My course: [Intro to SVG and GreenSock Animations](https://designcode.io/svg-intro) | coffeecraftcode |
277,984 | 📣Startups, Check your Database EOL before using it | A Cautionary tale 🐺👩🦰👵 In our startup, we develop a solution for the fin-tech section. Ye... | 0 | 2020-03-10T18:23:12 | https://dev.to/yonixw/startups-check-your-database-eol-before-using-it-1g1o | support, couchdb, enterprise, fintech | # A Cautionary tale 🐺👩🦰👵
In our startup, we develop a solution for the fin-tech section. Yesterday we realised that our clients will scan our dockers with a security radar agent every quater. It will probably be some McAfee product.
For the inexperienced me, That was quite a shock. It essentially creates another trigger for a development process other than adding features and fixing bugs.
After speaking with someone experienced, he told me that as long as a product did not reach its end of life (EOL) support, I don't need to update it. *Side note*: MongoDB 4.2 breaks our product, unlike mongo 4.0.
# Apache, do you got me? 😎🤙
Now, because we were evaluating CouchDB (Apache project), I was looking for the EOL and I found the following [[Source]](https://cwiki.apache.org/confluence/display/COUCHDB/Current+Releases) : **When a security-related release occurs, affected versions are immediately deprecated and no longer supported by the CouchDB team**
Well, That is just unacceptable 🤢. You do realise that I can't put a DB in my production and fearing everyday that its end of support might just happen? Making me use an updated version that who knows if compatible or not?
Luckily, Both mongo [[source]](https://www.mongodb.com/support-policy) and elasticsearch [[source]](https://www.elastic.co/support/eol) have a 1.5 year of support for each version. Giving that, I will have to use them as our production database candidates - only this way I can plan in advance when to upgrade and not be hit with it at the next security scanning.
| yonixw |
277,990 | What is the equivalent of a static variable in JS | I am starting to get my feet wet with js, I am wondering is there an equivalent to Java static variab... | 0 | 2020-03-10T18:30:56 | https://dev.to/fultonbrowne/what-is-the-equivalent-of-a-static-variable-in-js-2fm9 | explainlikeimfive, help, javascript, java | I am starting to get my feet wet with js, I am wondering is there an equivalent to Java static variable in node js. | fultonbrowne |
278,026 | 💪Review 1: Tribute Page by FreeCodeCamp, Developer: Kyle | #elefDoesCode | ⬇️I will review your... 🤓The process: Every week I will do a live stream on my youtube channel re... | 0 | 2020-03-10T20:45:50 | https://dev.to/eleftheriabatsou/review-1-tribute-page-by-freecodecamp-developer-kyle-elefdoescode-4006 | review, code, design, freecodecamp | ⬇️I will review your...
🤓The process:
1. Every week I will do a live stream on my youtube channel reviewing your site
2. I will give feedback and suggestions according to your needs.
3. If I have a way to contact you, I'll gladly do so :)
4. If you have any question don't hesitate to contact me!
Take part [here](https://forms.gle/9AxiCUQ8YudTVYzs9) (I only need a URL and your name).
It doesn't matter if you are a beginner or more advanced.
You can submit as many sites as you want.
🙏Thank you for taking part with your website into my live streams.
It takes courage to let someone you don't know to review your work...
But remember feedback is important and all of us need it...
🤗The review is FREE. You don't pay for anything. I won't be paid by anyone.
----------------------------
In particular, in this video you'll find:
🤓The developer: Kyle
💪The projects: Tribute page & Survey from FreeCodeCamp, implemented in Codepen
⌨Links:
From FreeCodeCamp
[Tribute page](https://www.freecodecamp.org/learn/responsive-web-design/responsive-web-design-projects/build-a-tribute-page)
[Survey form](https://www.freecodecamp.org/learn/responsive-web-design/responsive-web-design-projects/build-a-survey-form)
In codepen
- https://codepen.io/kylekibet/pen/yLNbyzQ
- https://codepen.io/kylekibet/full/KKpqWoR
----------------------------
👋Hello, I' m Eleftheria, an app developer, master student, freelancer, public speaker, and chocolate lover.
😎Top 3 list:
- How to stay motivated | A developer's edition | @BatsouElef: https://youtu.be/qMvEtb5OxNo
- How to be a Better Problem Solver | Tips and solutions: https://youtu.be/dELt7yKIxIA
- Simple Tips to Build a Personal Brand as a Developer (+ personal examples): https://youtu.be/7s0o1gi0iP0
🥰If you liked this video please share
🍩Would you care about buying me a coffee? You can do it here: [paypal.me/eleftheriabatsou](paypal.me/eleftheriabatsou) but If you can't that's ok too!
**************************************
🙏It would be nice to subscribe to my [Youtube](https://www.youtube.com/c/EleftheriaBatsou) channel. It’s free and it helps to create more content.
🌈[Youtube](https://www.youtube.com/c/EleftheriaBatsou) | [Codepen](https://codepen.io/EleftheriaBatsou) | [GitHub](https://github.com/EleftheriaBatsou) | [Twitter](https://twitter.com/BatsouElef) | [Site](http://eleftheriabatsou.com/) | [Instagram](https://www.instagram.com/eleftheriabatsou/) | eleftheriabatsou |
278,069 | Secure Remote File Access for
Network Attached Storage (NAS) | Network Attached Storage (NAS) have enjoyed wide adoption both at home and in enterprises, offering a... | 0 | 2020-03-10T22:20:50 | https://dev.to/nknorg/secure-remote-file-access-for-network-attached-storage-nas-5fnd | security, serverless, linux, blockchain | Network Attached Storage (NAS) have enjoyed wide adoption both at home and in enterprises, offering a more secure and lower cost local storage as an alternative or complement to cloud based storage. With NKN’s secure remote file access service, users can access their NAS files from anywhere without the need to host a central server, saving development and maintenance effort, as well as time and money. And users can enjoy even higher levels of security and privacy when accessing NAS remotely.
### Key Benefits
* Secure Access from Anywhere - Access your files securely from anywhere even if your NAS is behind a router/firewall with no public IP address or open ports, by using NKN’s unique NKN addressing and network architecture
* Reliable - NKN’s network of up to 20,000 servers in more than 40 countries ensures there is always a relay node available.
* One Connection - Access all the files and services on your NAS from one connection.
### Solution Overview
NKN secure remote file access service creates an end-to-end encrypted tunnel between the NAS device and the remote application. In order to accomplish this, internet connections are established by both the NAS device and remote application to a series of relay nodes within NKN’s public server network. Multiple nodes are used for both reliability as well as to enable faster transfer speed via multi-path data routing and aggregation . These relay nodes provide the interconnect to establish a single virtual tunnel between the NAS device and remote application. Relay nodes also provide a publicly available connection point for the NAS device, which are often connected behind a firewall or NAT gateway and do not have a public IP address or open ports. Please see figure 1 below.
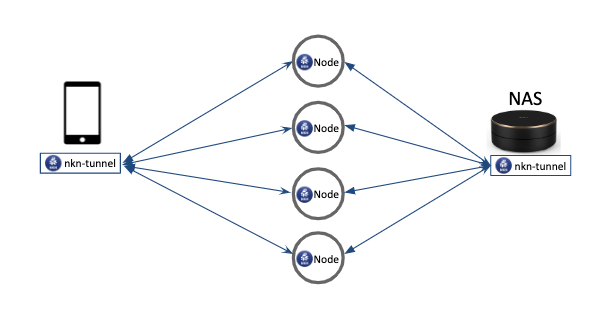
Once a connection between the NAS device and relay node is established it will begin listening on a unique NKN Address (For example: 20d72feef55…) as shown in Figure 2. This is a routable address within the NKN network and will be used by the remote application to establish a connection to the same relay nodes as the NAS. In addition, this NKN Address also includes a public key which will help establish E2E encryption without the need to consult a 3rd party Certificate Authority (CA).
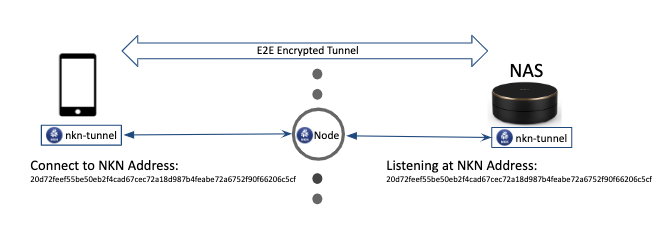
Once the tunnel is established, the remote application will have access to any of the local services available on the NAS including access to the users content such as photos, movies, and other files.
There are additional security measures that the NAS device can set up for even more protection:
* Create a whitelist of allowed user applications, as identified by user app’s NKN address
* Enforce user IAM (Identity and Access Management) roles and privileges to better manage file access rights in a finer grain
### Setup
Typically for best user experience, NAS vendors work with NKN technical team to integrate NKN tunnel service with their NAS firmware and their mobile app. However, if you just want to try out NKN secure remote file access solution without commiting to integration, you can use the following steps to test it out.
## Download the nkn-tunnel SDK
In order to implement NKN’s secure remote file access solution, you must run nkn-tunnel as a standalone program or SDK on both the NAS device and remote application.
Download the latest Mac, Windows, and Linux releases at:
https://github.com/nknorg/nkn-tunnel/releases
NOTE: nkn-tunnel is written in Go and can be compiled to work in your preferred environment such as [Android, iOS,](https://github.com/golang/go/wiki/Mobile) and more.
## Start nkn-tunnel service
## NAS Setup
To start nkn-tunnel on NAS (server side), you can run the following command:
```command
./nkn-tunnel -from nkn -to 127.0.0.1:8080 -s <seed>
```
The use of -s is optional, for example if you wish to recover a pre-existing encryption key (or seed, 64 digit HEX). Otherwise a new key will be generated if this option is not set.
The nkn-tunnel application will connect to the nkn network and will begin listening for secure connections on port 8080. The output will show an NKN specific listening-address (see example below) which will be used by the remote application to connect.
Example Output:
```command
2020/03/02 13:33:53 Listening at
5177bc471bed64cc98b8d39c1b465b5d316cb756c1eeeb99d6b13700d86809f9
```
## Remote Application Setup
To start nkn-tunnel on the remote application (client side), you can run the following command:
```command
./nkn-tunnel -from 127.0.0.1:8081 -to <listening-address>
```
The listening-address is the unique NKN address that was displayed when launching nkn-tunnel on the NAS device.
For more information on nkn-tunnnel and its usage, please visit our [github](https://github.com/nknorg/nkn-tunnel) for the latest release notes.
### Success Stories
NKN’s Secure Remote File Access service has been successfully integrated and available on our customer’s consumer product deployed to more than 15,000 customers worldwide.
### Summary
NKN’s Secure Remote File Access service for Network Attached Storage turns your local storage into a universally accessible global storage. You can remotely connect to your NAS, even if your device is behind a firewall or gateway, with no public IP address or open ports, and our all of your data is accessed via end-to-end encrypted tunnel for security. The service also offers accelerated performance for downloading data from your NAS with several times faster download experience compared to a cloud based solution. It only takes a few steps to setup and configure and we offer a free open source SDK to get you started.
You can also find more product information and web-based test drive at:
https://dataride.nkn.org/filetransfer/
Universally accessible NAS, accelerated data transfer, and low cost to deploy… Enhance your NAS product today with NKN!

Home: https://nkn.org/
Email: contact@nkn.org
Telegram: https://t.me/nknorg
Twitter: https://twitter.com/NKN_ORG
Forum: https://forum.nkn.org
Medium: https://medium.com/nknetwork
Linkedin: https://www.linkedin.com/company/nknetwork/
Github: https://github.com/nknorg
Discord: https://discord.gg/yVCWmkC
YouTube: http://www.youtube.com/c/NKNORG
| dixonal |
278,118 | DevOps and Containers Security: Security and Monitoring in Docker Containers | devops,containers,security,docker | 0 | 2020-03-10T23:09:46 | https://dev.to/jmortega/devops-and-containers-security-security-and-monitoring-in-docker-containers-1dd0 | ---
title: DevOps and Containers Security: Security and Monitoring in Docker Containers
published: true
description: devops,containers,security,docker
tags:
---
https://www.amazon.es/dp/B085NMP3CV/
![Alt Text]
(https://miro.medium.com/max/357/1*MJdLbxivHn_VwMWWrN1Ehw.jpeg)
Through this book, we will introduce the DevOps tools ecosystem and the main containers orchestration tools through an introduction to some platforms such as Kubernetes, Docker Swarm, and OpenShift.
Among other topics, both good practices will be addressed when constructing the Docker images as well as best security practices to be applied at the level of the host in which those containers are executed, from Docker’s own daemon to the rest of the components that make up its technological stack.
We will review the topics such as static analysis of vulnerabilities on Docker images, the signing of images with Docker Content Trust and their subsequent publication in a Docker Registry will be addressed. Also, we will review the security state in Kubernetes.
In the last section, we will review container management and administration open source tools for IT organizations that need to manage and monitor container-based applications, reviewing topics such as monitoring, administration, and networking in Docker.
What will you learn
● Learn fundamental DevOps skills and tools, starting with the basic components and concepts of Docker.
● Learn about Docker as a platform for the deployment of containers and Docker images taking into account the security of applications.
● Learn about tools that allow us to audit the security of the machine where we execute Docker images, finding out how to secure your Docker host.
● Learn how to secure your Docker environment and discover vulnerabilities and threats in Docker images.
● Learn about creating and deploying containers in a security way with Docker and Kubernetes.
● Learn about monitoring and administration in Docker with tools such as cadvisor, sysdig, portainer, and Rancher.
Table of Contents
1. Getting started with DevOps
2. Container platforms
3. Managing Containers and Docker images
4. Getting started with Docker security
5. Docker host security
6. Docker images security
7. Auditing and analyzing vulnerabilities in Docker containers
8. Kubernetes security
9. Docker container networking
10. Docker container monitoring
11. Docker container administration
| jmortega | |
278,131 | Shift and Push vs Splice in Javascript | A classmate of mine had a whiteboard challenge as follows: make a function that accepts an array and... | 0 | 2020-03-11T00:02:12 | https://dev.to/lfriedrichs/shift-and-push-vs-splice-in-javascript-158 | javascript | A classmate of mine had a whiteboard challenge as follows: make a function that accepts an array and a number, N. Rotate the values in that array to the left N times. Two solutions were suggested. Use array.push() and array.shift() or use array.slice(). Below are the two code snippets:
function arrayRotationUnshiftPush(array, numberOfRotations) {
for (let i = 0; i < numberOfRotations%array.length; i++) {
array.push(array.shift());
}
return array
}
function arrayRotationSplice(array, numberOfRotations) {
index = numberOfRotations%array.length;
return [...array.splice(index), ...array]
}
To test out which approach is faster, I created a dummy array if integers:
let array = []
for (i = 0; i<20000; i++) {
array[i] = i;
}
Then I called the functions on the array and used Date.now() to record the time before and after:
let time = Date.now();
for (i = 0; i<20; i++) {
arrayRotationUnshiftPush(array, 1500);
}
console.log(Date.now() - time);
The results were surprising. When the array length became very long, splice was significantly faster. When the number of times each function was called became very long, splice was again much faster. Finally, the deeper into the array, the faster splice became compared to shift and push. All of this suggest that invoking a method adds additional runtime on a very small level that when scaled up creates a noticeable difference in run time. | lfriedrichs |
278,139 | Transitioning from React class components to function components with hooks | It has been approximately one year since React v16.8 was released, marking the introduction of Hooks.... | 0 | 2020-03-11T02:09:51 | https://labs.thisdot.co/blog/transitioning-from-react-class-components-to-function-components-with-hooks | react | ---
title: Transitioning from React class components to function components with hooks
published: true
date: 2020-03-10 23:53:50 UTC
tags: react
canonical_url: https://labs.thisdot.co/blog/transitioning-from-react-class-components-to-function-components-with-hooks
---
It has been approximately one year since React v16.8 was released, marking the introduction of Hooks. Yet, there are still people used to React class components who still haven't experienced the full potential of this new feature, along with functional components, including myself. The aim of this article is to summarize and encompass the most distinguishable features of the class components, and respectively show their alternatives when using React hooks.
## Functional components
Before we start with Hooks examples, we will shortly discuss functional components in case you aren't familiar. They provide an easy way to create new units without the need of creating a new class and extending `React.Component`.
**Note:** Keep in mind that functional components have been part of React since it's creation.
Here is a very simple example of a functional component:
```
const Element = () => (
<div className="element">
My Element
</div>
);
```
And just like class components, we can access the properties. They are provided as the first argument of the function.
```
const Element = ({ text }) => (
<div className="element">
{text}
</div>
);
```
However, these type of components--while very convenient for simple UI elements--used to be very limited in terms of life cycle control, and usage of state. This is the main reason they had been neglected until React v16.8.
## Component state
Let's take a look at the familiar way of how we add state to our object-oriented components. The example will represent a component which renders a space scene with stars; they have the same color. We are going to use few utility functions for both functional and class components.
- `createStars(width: number): Star[]` - Creates an array with the star objects that are ready for rendering. The number of stars depends on the window width.
- `renderStars(stars: Star[], color: string): JSX.Element` - Builds and returns the actual stars markup.
- `logColorChange(color: string)` - Logs when the color of the space has been changed.
and some less important like `calculateDistancesAmongStars(stars: Star[]): Object`.
We won't implement these. Consider them as black boxes. The names should be sufficient enough to understand their purpose.
**Note:** You may find a lot of demonstrated things unnecesary. The main reason I included this is to showcase the hooks in a single component.
And the example:
### Class components
```
class Space extends React.Component {
constructor(props) {
super(props);
this.state = {
stars: createStars(window.innerWidth)
};
}
render() {
return (
<div className="space">
{renderStars(this.state.stars, this.props.color)}
</div>
);
}
}
```
### Functional components
The same can be achieved with the help of the first React Hook that we are going to introduce--`useState`. The usage is as follows: `const [name, setName] = useState(INITIAL_VALUE)`. As you can see, it uses array destructuring in order to provide the value and the set function:
```
const Space = ({ color }) => {
const [stars, setStars] = useState(createStars(window.innerWidth));
return (
<div className="space">
{renderStars(stars, color)}
</div>
);
};
```
The usage of the property is trivial, while `setStars(stars)` will be equivalent to `this.setState({ stars })`.
## Component initialization
Another prominent limitation of functional components was the inability to hook to lifecycle events. Unlike class components, where you could simply define the `componentDidMount` method, if you want to execute code on component creation, you can't hook to lifecycle events. Let's extend our demo by adding a resize listener to `window` which will change the number of rendered stars in our space when the user changes the width of the browser:
### Class components
```
class Space extends React.Component {
constructor(props) { ... }
componentDidMount() {
window.addEventListener('resize', () => {
const stars = createStars(window.innerWidth, this.props.color);
this.setState({ stars });
});
}
render() { ... }
}
```
### Functional components
You may say: "We can attach the listener right above the return statement", and you will be partially correct. However, think about the functional component as the `render` method of a class component. Would you attach the event listener there? No. Just like `render`, the function of a functional component could be executed multiple times throughout the the lifecycle of the instance. This is why we are going to use the `useEffect` hook.
It is a bit different from `componentDidMount` though--it incorporates `componentDidUpdate`, and `componentDidUnmount` as well. In other words, the provided callback to `useEffect` is executed on every update. Anyhow, you can have certain control with the second argument of `useState` - it represents an array with the values/dependencies which are monitored for change. If they do, the hook is executed. In case the array is empty, the hook will be executed only once, during initialization, since after that there won't be any values to be observed for change.
```
const Space = ({ color }) => {
const [stars, setStars] = useState(createStars(window.innerWidth));
useEffect(() => {
window.addEventListener('resize', () => {
const stars = createStars(window.innerWidth, color);
setStars(stars);
});
}, []); // <-- Note the empty array
return (
...
);
};
```
## Component destruction
We added an event listener to `window`, so we will have to remove it on component unmount in order to save us from memory leaks. Respectively, that'll require keeping a reference to the callback:
### Class components
```
class Space extends React.Component {
constructor(props) { ... }
componentDidMount() {
window.addEventListener('resize', this.__resizeListenerCb = () => {
const stars = createStars(window.innerWidth, this.props.color);
this.setState({ stars });
});
}
componentDidUnmount() {
window.removeEventListener('resize', this.__resizeListenerCb);
}
render() { ... }
}
```
### Functional component
For the equivalent version of the class component, the `useEffect` hook will execute the returned function from the provided callback when the component is about to be destroyed. Here's the code:
```
const Space = ({ color }) => {
const [stars, setStars] = useState(createStars(window.innerWidth));
useEffect(() => {
let resizeListenerCb;
window.addEventListener('resize', resizeListenerCb = () => {
const stars = createStars(window.innerWidth, color);
setStars(stars);
});
return () => window.removeEventListener('resize', resizeListenerCb);
}, []); // <-- Note the empty array
return (
...
);
};
```
#### An important remark
It is worth mentioning that, when you work with event listeners or any other methods that defer the execution in the future of a callback/function, you should take into account that the state provided to them is not mutable.
Taking the `window` listener we use in our demo as an example; if we used the`stars` state inside the callback, we would get the exact value at the moment of the definition (callback), which means that, when the callback is executed, we risk having a stale state.
There are various ways to handle that, one of which is to re-register the listener every time the stars are changed, by providing the `stars` value to the observed dependency array of `useEffect`.
## Changed properties
We already went through `useEffect` in the sections above. Now, we will briefly show an example of `componentDidUpdate`. Let's say that we want to log the occurances of color change to the console:
### Class components
```
class Space extends React.Component {
...
componentDidUpdate(prevProps) {
if (this.props.color !== prevProps.color) {
logColorChange(this.props.color);
}
}
...
}
```
### Functional components
We'll introduce another `useEffect` hook:
```
const Space = ({ color }) => {
...
useEffect(() => {
logColorChange(color);
}, [color]); // <-- Note that this time we add `color` as observed dependency
...
};
```
Simple as that!
#### Changed properties and memoization
Just as an addition to the example above, we will quickly showcase `useMemo`; it provides an easy way to optimize your component when you have to perform a heavy calculation only when certain dependencies change:
```
const result = useMemo(() => expensiveCalculation(), [color]);
```
## References
Due to the nature of functional components, it becomes hard to keep a reference to an object between renders. With class components, we can simply save one with a class property, like:
```
class Space extends React.Component {
...
methodThatIsCalledOnceInALifetime() {
this.__distRef = calculateDistancesAmongStars(this.state.stars);
}
...
}
```
However, here is an example with a functional component that might look correct but it isn't:
```
const Space = ({ color }) => {
...
let distRef; // Declared on every render.
function thatIsCalledOnceInALifetime() {
distRef = caclulateDistancesAmongStars(stars);
}
...
};
```
As you can see, we won't be able to preserve the output object with a simple variable. In order to do that, we will take a look at yet another hook named `useRef`, which will solve our problem:
```
const Space = ({ color }) => {
...
const distRef = useRef();
function thatIsCalledOnceInALifetime() {
// `current` keeps the same reference
// throughout the lifetime of the component instance
distRef.current = caclulateDistancesAmongStars(stars);
}
...
}
```
The same hook is used when we want to keep a reference to a DOM element.
## Conclusion
Hopefully this should give you a starting point when it comes to using React Hooks for the things that you are already used to doing with class components. Obviously, there are more hooks to explore, including the definition of custom ones. For all of that, you can head to the official docs. Give them a try and experience the potential of functional React! | georgii |
278,167 | Options, options everywhere | More recently, I've been wondering if the best thing would be to quit my job, move back home and focu... | 0 | 2020-03-11T01:42:37 | https://dev.to/jasterix/options-options-everywhere-31mj | More recently, I've been wondering if the best thing would be to quit my job, move back home and focus the next 6 months on hard core studying and interviews.
I've also wondered if the best thing would really be to give up the job search altogether and direct my energy towards applying to computer science programs. An even better decision might be to do another bootcamp, focusing on core fundamental CS concepts and interview prep.
Obviously, I don't know where to go next. The great thing about attending Flatiron is that I've discovered a passion for learning about all thins computer and software. The tragic thing is that I'm not able to progress as much on my own.
In a perfect world, I would 100%, without hesitation pursue a BS and Masters in computer science. Since my undergrad major was Finance, I have some, but not all of the pre-requisites to finish BS computer science. In a more attainable, ideal world, I would start my career as a full stack developer in a challenging supportive company that promotes personal development.
As much as I focus my attention or seek out feedback from others in the field, it ultimately comes down to 2 things:
1. There's so much I need to learn
2. I need to make money
This brings me back to my Chingu project.
My last 5 weeks have gone towards building the backend for my Chingu project. If you read my last post, you know that time management has been challenging because of the points above.
In either of the ideal scenarios above, my project might have been done this week, along with everyone else's. But my frustration isn't at not having finished my project. I'm so glad to have attempted a Chingu voyage and to have part of something to show for it. How great is it that I persevered.
So what is the issue, then?
The most frustrating thing is knowing what you want to do and yet be unable to pursue it. I want to code, learn how to code, to understand the math behind problems and solutions, and scope a project before executing said project.
And...?
I've thought about this post for the past 24 hours. There's an obvious so what missing to this post. Yes, I've identified some barriers to my best, but so what? What happens now? It might feel like the post is somehow unfinished without these answers. Maybe I should throw out my best guesses, but somehow that doesn't seem right either.
So here is what I can do at this moment in time:
1. Identify the companies that align with what I'm looking for
2. Keep doing my best
Number 2 might feel like a cop-out. But at this moment, its probably the most important. | jasterix | |
278,194 | Docker Build Best Practices | As more and more applications are being containerized it is important to point out some best practice... | 0 | 2020-03-11T02:54:12 | https://dev.to/leading-edje/docker-build-best-practices-32fh | docker, devops | As more and more applications are being containerized it is important to point out some best practices to optimize and better support the building of those images.
## Optimize Build Context
The one argument that is passed to a `docker build` command is the context location. This location represents the directory that the build is going to have access to for all of the instructions it is going to process. Any `COPY` or `ADD` instruction uses this location as the base directory. The build also uses this location to determine if a file has changed and thus should break the layer cache. It is for this reason that careful consideration should be made to the .dockerignore file to make sure directories or files that are not needed are not included in the context. Examples are excluding things like reports, documentation, the node_modules directory, and most commonly the .git directory. A common example is the `COPY . .` command putting the .git files in the image.
## Use Labels
Labels are useful to store metadata about the image such as the git commit hash or the maintainer. If your organization builds many images it is a good practice to store such metadata in a common form so that the information can be retrieved in a common way. Here is an example of how to add the git commit hash to the image as a label and then retrieve it.
Dockerfile contents:
```
ARG GIT_COMMIT=unspecified
LABEL git_commit=$GIT_COMMIT
```
Build command:
```
docker build --build-arg GIT_COMMIT=$(git log -1 --format=%h) -t my-image .
```
Get the value:
```
docker inspect –f {{index .Config.Labels.git_commit}} my-image
```
## Document Ports
The `EXPOSE` directive in a Dockerfile does not actually expose the port to the host at runtime. The only thing it can automatically do at runtime is bind that port to a random port on the host machine if the `-P` option is used in the run command. It is for this reason that the `EXPOSE` directive is most commonly used, and should be used, to document that if you run the image as a container then you should map a host port to the port specified. This is useful for times when an application has configured the server runtime to use a different port than the default.
## COPY vs ADD
Both the `COPY` and `ADD` directives provide the ability to transfer files into the image. However, `ADD` has two additional features in that the first argument can be a URL and if the first argument is an archive it will automatically be extracted. It is for this reason that it is useful to only use the `ADD` directive if you are doing one of those two things. Otherwise it is preferred to use the `COPY` directive.
## Optimize Layer Cache
Each directive in a Dockerfile results in a layer and each layer is evaluated during the build to determine if the cached layer should be used vs executing the directive. Once a layer is determined to not use the cache all other subsequent directives are executed and the cache will not be considered or used. It is for this reason that careful consideration should be made to the order of which directives are listed in the Dockerfile. The things that change the least should come before things that change more often.
Here is an example of the difference between two Dockerfiles and what would happen if a change was made to some code written in node:
```
FROM node
WORKDIR /usr/src/app
COPY . . <------- Cache is broken here
RUN npm install
EXPOSE 8080
CMD [“npm”, ”start”]
```
With a subtle change the layer cache will only be broken if a change is made to package.json. The `npm install` command will only run in that case but the cached layer will be used if the change was made to a file other than package.json.
```
FROM node
WORKDIR /usr/src/app
COPY package*.json .
RUN npm install
COPY . . <------- Cache is broken here
EXPOSE 8080
CMD [“npm”, ”start”]
```
## Summary
These are just some of the best practices that can be adopted to save build time, save development time and also provide documentation to avoid confusion. There are many ways an image can be built and provide the same functionality so careful consideration should be made with these details in mind.
| edlegaultle |
278,312 | Data Lineage On Redshift | Data Lineage is important for data governance and security. In Data warehouses and data lakes, a team... | 5,797 | 2020-03-11T08:52:10 | https://dev.to/vrajat/data-lineage-on-redshift-39pk | database, lineage, aws, opensource | Data Lineage is important for data governance and security. In Data warehouses and data lakes, a team of data engineers maintain a canonical set of base tables. The source of data of these base tables
maybe events from the product, logs or third-party data from SalesForce, Google Analytics or Segment.
Data analysts and scientists use the base tables for their reports and machine learning algorithms. They may create derived tables to help with their work. It is not uncommon for a data warehouse or lake to have hundreds or thousands of tables. In such a scenario it is important to use automation and visual tools to track data lineage.
This post describes automated visualization of data lineage in AWS Redshift from query logs of the data warehouse. The techniques are applicable to other technologies as well.
{% github tokern/data-lineage %}
## Workload System of Record
A system of record of all activity in databases is a prerequisite for any type of analysis. For example, AWS Redshift has many system tables and views that record all the activity in the database. Since these tables retain data for a limited time, it is important to persist the data. AWS provides scripts to store the data in tables within Redshift itself. For performance analysis the query log stored in STL_QUERY and STL_QUERYTEXT are the most important.
Tokern reads and processes the records in STL_QUERY & STL_QUERYTEXT at regular intervals. It adds the following information for every query:
* Type of query such as SELECT, DML, DDL, COPY, UNLOAD etc
* Source tables & columns which are read by the query if applicable.
* Source files in S3 for COPY queries.
* Target table & columns where the data was loaded if applicable.
* Target files in S3 for UNLOAD queries.
## Data Lineage
Tokern uses the system of record to build a network graph for every table & pipeline. An example for infallible_galois is visualized below.
In the network graph, data moves from left to right. Every node (or circle) represents a table. There is an edge (left to right) to a node if the data load reads from that table. A table can be loaded with data from many tables. For example, the data load for hopeful_matsumoto reads data from hungry_margulis.
The graph can be analyzed programmatically or used to create interactive charts to help data engineers glean actionable information.
## Reduce copies of sensitive data
The security engineers at Company S used a scanning tool to find all tables and columns that stored sensitive data like
PII, financial and business sensitive data. They found that there were many more copies than anticipated. An immediate goal
was to reduce the number of copies to reduce the security vulnerability surface area. To achieve the goal they had to:
* Identify the owners of the copy.
* Understand their motivation to create copies.
* Work with owners to eliminate copies or use masked copies of the data.
The challenges to achieving these goals were:
* Determine the owners of the data.
* Number of conversations required to understand the need for copies and agree on a workaround.
Due to the sheer number of tables, the task was daunting and required an automation tool.
## Table specific Network Graphs
Tokern provided security team with actionable information to discover
* Owners of copies of data
* A profile consisting of the queries used to create the table and read it.
The profile helped the security engineers prepare for the conversation with the owners. On a number of occasions,
duplicate tables were eliminated. In other cases, the workflow was changed to eliminate temporary tables for
intermediate data.
In the example below for *upbeat_ellis*, two intermediate tables with sensitive data were eliminated from the workflow.
## Large Network graphs
Another example of a network graph for *crazy_terseshkova* is shown below.
As seen, the data path is much more complicated with close to a hundred tasks required to eventually load data into the table. The graph is interactive and can be panned & zoomed to focus on specific parts. Metadata of tasks such as start time, run time and table names are shown by hovering over the nodes in the network graph to deal with such
complicated data pipelines.
## Conclusion
Security Engineers need data lineage and related automation tools to manage database security. All databases provide a workload system of record. [Data Lineage tools](https://tokern.io/lineage/) can use this information to visualize data lineage as well as use rules to automate checks.
If open source data lineage tools are interesting to you, check out the lineage github project.
{% github tokern/data-lineage %}
| vrajat |
278,397 | Marker cluster click in google maps | agm-map(1.0.0-beta.7) cluster click is not working in angular(7.2.12). So I started working with goog... | 0 | 2020-03-11T12:13:08 | https://dev.to/bhavyaharini/marker-cluster-click-in-google-maps-4ppo | googlemapsclusterclick | agm-map(1.0.0-beta.7) cluster click is not working in angular(7.2.12). So I started working with google map API with same angular version.But I couldn't able fetch the cluster info. My requirement is to populate the markers info from marker cluster like cluster size, marker label etc. Kindly provide the solution ASAP by agm-marker-cluster or basic google maps API. | bhavyaharini |
278,465 | Streaming Wi-Fi trace data from Raspberry Pi to Apache Kafka | Wi-fi is now ubiquitous in most populated areas, and the way the devices communicate leaves a lot of... | 0 | 2020-03-13T09:50:09 | https://rmoff.net/2020/03/11/streaming-wi-fi-trace-data-from-raspberry-pi-to-apache-kafka-with-confluent-cloud/ | raspberrypi, showdev, apachekafka, wifi | ---
title: Streaming Wi-Fi trace data from Raspberry Pi to Apache Kafka
published: true
date: 2020-03-11 00:00:00 UTC
tags: raspberrypi ,showdev,apachekafka,wifi
canonical_url: https://rmoff.net/2020/03/11/streaming-wi-fi-trace-data-from-raspberry-pi-to-apache-kafka-with-confluent-cloud/
---
Wi-fi is now ubiquitous in most populated areas, and the way the devices communicate leaves a lot of 'digital exhaust'. Usually a computer will have a Wi-Fi device that’s configured to connect to a given network, but often these devices can be configured instead to pick up the background Wi-Fi chatter of surrounding devices.
There are good reasons—and bad—for doing this. Just like taking apart equipment to understand how it works teaches us things, so being able to [dissect and examine protocol traffic](https://rmoff.net/2019/11/29/using-tcpdump-with-docker/) lets us learn about this. However, by collecting this type of traffic it can be possible to track and analyse behaviour in ways that we may or may not feel comfortable with. [Improving public transport](https://tfl.gov.uk/corporate/privacy-and-cookies/wi-fi-data-collection)? Sure. [Tracking shopper behaviour](https://www.theguardian.com/technology/datablog/2014/jan/10/how-tracking-customers-in-store-will-soon-be-the-norm)? Meh, less sure.
So, here’s how to do it, and go ahead and make sure you’re doing it for the right reasons. A plague o' your house if you don’t!
## Kit list
- Raspberry Pi Model B Rev 2, 512MB, running Raspbian GNU/Linux 10 (buster)
- [ASUS USB-BT400 3Mbps USB Bluetooth v4.0 Mini Dongle](https://www.amazon.co.uk/gp/product/B00CM83SC0/)
- [Confluent Cloud](https://confluent.cloud/signup)
I had the Raspberry Pi plugged into my network on its Ethernet port, since the Wi-Fi dongle will be otherwise occupied :)
## Set up the wireless interface
First up, delete the existing wireless network interface that’s probably there already:
```
sudo iw dev wlan0 del
```
Check that that Wi-Fi physical device supports _monitor_ mode (which is what we’re using), and make a note of its name (here, `phy0`):
```
$ sudo iw phy
Wiphy phy0
max # scan SSIDs: 4
max scan IEs length: 2257 bytes
…
Supported interface modes:
* IBSS
* managed
* AP
* AP/VLAN
* monitor
* mesh point
…
```
Now create a new monitoring interface (`type monitor`) bound to the physical device (`phy0`), and bring it up.
```
sudo iw phy phy0 interface add mon0 type monitor
sudo ifconfig mon0 up
```
If you check its status you should see it in monitor mode:
```
$ iwconfig mon0
mon0 IEEE 802.11 Mode:Monitor Frequency:2.417 GHz Tx-Power=20 dBm
Retry short long limit:2 RTS thr:off Fragment thr:off
Power Management:off
```
You should have a network config that looks something like this - a loopback (`lo`), a network connection to your LAN (`eth0`), and a monitor interface (`mon0`):
```
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether b8:27:eb:3f:dc:66 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.106/24 brd 192.168.10.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fd00::1:6332:fcea:9237:246c/64 scope global dynamic mngtmpaddr noprefixroute
valid_lft 7158sec preferred_lft 7158sec
inet6 fe80::8b6b:8c75:94a0:1aac/64 scope link
valid_lft forever preferred_lft forever
4: mon0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc mq state UNKNOWN group default qlen 1000
link/ieee802.11/radiotap 00:0f:60:04:ef:a4 brd ff:ff:ff:ff:ff:ff
```
## Here comes the tools
Let’s install some useful things:
```
sudo apt-get install -y tcpdump tshark jq kafkacat
```
Check everything’s working by running `tcpdump` to dump out the Wi-Fi traffic as it’s received:
```
$ sudo tcpdump -i mon0 -n
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on mon0, link-type IEEE802_11_RADIO (802.11 plus radiotap header), capture size 262144 bytes
10:36:49.640924 1.0 Mb/s 2417 MHz 11b -81dBm signal antenna 1 Data IV:28ee Pad 20 KeyID 2
10:36:55.497519 1.0 Mb/s 2417 MHz 11b -77dBm signal antenna 1 Probe Request (RNM0) [1.0 2.0 5.5 11.0 Mbit]
10:36:57.511322 1.0 Mb/s 2417 MHz 11b -69dBm signal antenna 1 Probe Request (RNM0) [1.0* 2.0* 5.5* 6.0 9.0 11.0* 12.0 18.0 Mbit]
10:36:57.512419 1.0 Mb/s 2417 MHz 11b -69dBm signal antenna 1 Probe Request () [1.0* 2.0* 5.5* 6.0 9.0 11.0* 12.0 18.0 Mbit]
10:36:57.679522 1.0 Mb/s 2417 MHz 11b -67dBm signal antenna 1 Acknowledgment RA:48:d3:43:xx:xx:xx
```
There’s five packets of real live Wi-Fi data! And there’s a bunch you can do with `tcpdump` and filters etc, but because we want this data out in a structured manner (i.e. key/values) I’m going to cut over to `tshark` now.
`tshark` is the CLI companion to the well known network tool, Wireshark. You can use it standalone, or you can even use it as a source for Wireshark - which is pretty cool.
Let’s start with a quick `tshark`:
```
$ sudo tshark -i mon0
Running as user "root" and group "root". This could be dangerous.
Capturing on 'mon0'
1 0.000000000 Apple_17:17:d3 → Broadcast 802.11 175 Probe Request, SN=672, FN=0, Flags=........, SSID=RNM0
2 0.009712480 Apple_17:17:d3 → Broadcast 802.11 175 Probe Request, SN=673, FN=0, Flags=........, SSID=RNM0
3 20.711944424 66:9f:b3:xx:xx:xx → Broadcast 802.11 106 Probe Request, SN=772, FN=0, Flags=........, SSID=Wildcard (Broadcast)
4 20.719399794 → Bskyb_13:16:82 (3c:89:94:xx:xx:xx) (RA) 802.11 28 Acknowledgement, Flags=........
```
There’s that Wi-Fi data again!
But how to get this data out in a truly structured way that’s going to be useful in subsequent processing?
## Writing structured JSON from `tshark`
As you can see from above `tshark` by default writes data in a loosely-structured way that would be impossible to parse programatically. We want a structured format such as JSON, and that’s _kind of_ possible with the `-T` flag and `ek` argument:
```
$ sudo tshark -i mon0 -T ek
Running as user "root" and group "root". This could be dangerous.
Capturing on 'mon0'
{"index" : {"_index": "packets-2020-03-11", "_type": "pcap_file"}}
{"timestamp" : "1583923701818", "layers" : {"frame": {"frame_frame_interface_id": "0","frame_interface_id_frame_interface_name": "mon0","frame_frame_encap_type": "23","frame_frame_time": "Mar 11, 2020 10:48:21.818766344 GMT","frame_frame_offset_shift": "0.000000000","frame_frame_time_epoch": "1583923701.818766344","frame_frame_time_delta": "0.000000000","frame_frame_time_delta_displayed": "0.000000000","frame_frame_time_relative": "0.000000000","frame_frame_number": "1","frame_frame_len": "28","frame_frame_cap_len": "28","frame_frame_marked": "0","frame_frame_ignored": "0","frame_frame_protocols": "radiotap:wlan_radio:wlan"},"radiotap": {"radiotap_radiotap_version": "0","radiotap_radiotap_pad": "0","radiotap_radiotap_length": "18","radiotap_radiotap_present": "","radiotap_present_radiotap_present_word": "0x0000482e","radiotap_present_word_radiotap_present_tsft": "0","radiotap_present_word_radiotap_present_flags": "1","radiotap_present_word_radiotap_present_rate": "1","radiotap_present_word_radiotap_present_channel": "1","radiotap_present_word_radiotap_present_fhss": "0","radiotap_present_word_radiotap_present_dbm_antsignal": "1","radiotap_present_word_radiotap_present_dbm_antnoise": "0","radiotap_present_word_radiotap_present_lock_quality": "0","radiotap_present_word_radiotap_present_tx_attenuation": "0","radiotap_present_word_radiotap_present_db_tx_attenuation": "0","radiotap_present_word_radiotap_present_dbm_tx_power": "0","radiotap_present_word_radiotap_present_antenna": "1","radiotap_present_word_radiotap_present_db_antsignal": "0","radiotap_present_word_radiotap_present_db_antnoise": "0","radiotap_present_word_radiotap_present_rxflags": "1","radiotap_present_word_radiotap_present_xchannel": "0","radiotap_present_word_radiotap_present_mcs": "0","radiotap_present_word_radiotap_present_ampdu": "0","radiotap_present_word_radiotap_present_vht": "0","radiotap_present_word_radiotap_present_timestamp": "0","radiotap_present_word_radiotap_present_he": "0","radiotap_present_word_radiotap_present_he_mu": "0","radiotap_present_word_radiotap_present_reserved": "0x00000000","radiotap_present_word_radiotap_present_rtap_ns": "0","radiotap_present_word_radiotap_present_vendor_ns": "0","radiotap_present_word_radiotap_present_ext": "0","radiotap_radiotap_flags": "0x00000000","radiotap_flags_radiotap_flags_cfp": "0","radiotap_flags_radiotap_flags_preamble": "0","radiotap_flags_radiotap_flags_wep": "0","radiotap_flags_radiotap_flags_frag": "0","radiotap_flags_radiotap_flags_fcs": "0","radiotap_flags_radiotap_flags_datapad": "0","radiotap_flags_radiotap_flags_badfcs": "0","radiotap_flags_radiotap_flags_shortgi": "0","radiotap_radiotap_datarate": "1","radiotap_radiotap_channel_freq": "2417","radiotap_radiotap_channel_flags": "0x000000a0","radiotap_channel_flags_radiotap_channel_flags_turbo": "0","radiotap_channel_flags_radiotap_channel_flags_cck": "1","radiotap_channel_flags_radiotap_channel_flags_ofdm": "0","radiotap_channel_flags_radiotap_channel_flags_2ghz": "1","radiotap_channel_flags_radiotap_channel_flags_5ghz": "0","radiotap_channel_flags_radiotap_channel_flags_passive": "0","radiotap_channel_flags_radiotap_channel_flags_dynamic": "0","radiotap_channel_flags_radiotap_channel_flags_gfsk": "0","radiotap_channel_flags_radiotap_channel_flags_gsm": "0","radiotap_channel_flags_radiotap_channel_flags_sturbo": "0","radiotap_channel_flags_radiotap_channel_flags_half": "0","radiotap_channel_flags_radiotap_channel_flags_quarter": "0","radiotap_radiotap_dbm_antsignal": "-69","radiotap_radiotap_antenna": "1","radiotap_radiotap_rxflags": "0x00000000","radiotap_rxflags_radiotap_rxflags_badplcp": "0"},"wlan_radio": {"wlan_radio_wlan_radio_phy": "4","wlan_radio_wlan_radio_short_preamble": "0","wlan_radio_wlan_radio_data_rate": "1","wlan_radio_wlan_radio_channel": "2","wlan_radio_wlan_radio_frequency": "2417","wlan_radio_wlan_radio_signal_dbm": "-69","wlan_radio_wlan_radio_duration": "272","wlan_radio_duration_wlan_radio_preamble": "192"},"wlan": {"wlan_wlan_fc_type_subtype": "29","wlan_wlan_fc": "0x0000d400","wlan_fc_wlan_fc_version": "0","wlan_fc_wlan_fc_type": "1","wlan_fc_wlan_fc_subtype": "13","wlan_fc_wlan_flags": "0x00000000","wlan_flags_wlan_fc_ds": "0x00000000","wlan_flags_wlan_fc_tods": "0","wlan_flags_wlan_fc_fromds": "0","wlan_flags_wlan_fc_frag": "0","wlan_flags_wlan_fc_retry": "0","wlan_flags_wlan_fc_pwrmgt": "0","wlan_flags_wlan_fc_moredata": "0","wlan_flags_wlan_fc_protected": "0","wlan_flags_wlan_fc_order": "0","wlan_wlan_duration": "0","wlan_wlan_ra": "c8:d1:2a:xx:xx:xx","wlan_wlan_ra_resolved": "Comtrend_96:cc:64","wlan_wlan_addr": "c8:d1:2a:xx:xx:xx","wlan_wlan_addr_resolved": "Comtrend_96:cc:64"}}}
```
There’s a couple of points to deal with here. The first is that for each packet there are _two_ rows emitted; an index header for Elasticsearch (since `ek` is designed for ingest into it), and then the _full_ payload. We don’t want the whole payload but just a few columns. We can use the `-e` parameter to specify the fields that we’re interested in, and a simple `grep` to drop the Elasticsearch header message. I’ve also added `-l` to stop the output being buffered:
```
$ sudo tshark -i mon0 \
-T ek \
-l \
-e wlan.fc.type \
-e wlan.fc.type_subtype \
-e wlan_radio.channel | \
grep timestamp
{"timestamp" : "1583923966878", "layers" : {"wlan_fc_type": ["1"],"wlan_fc_type_subtype": ["27"],"wlan_radio_channel": ["2"]}}
{"timestamp" : "1583923967196", "layers" : {"wlan_fc_type": ["1"],"wlan_fc_type_subtype": ["27"],"wlan_radio_channel": ["2"]}}
{"timestamp" : "1583923967296", "layers" : {"wlan_fc_type": ["1"],"wlan_fc_type_subtype": ["27"],"wlan_radio_channel": ["2"]}}
```
This is starting to look rather useful. Let’s add in a bit of `jq` magic to merge the `timestamp` field in with the rest of the payload which we’ll pull up to the root level:
```
$ sudo tshark -i mon0 \
-T ek \
-l \
-e wlan.fc.type \
-e wlan.fc.type_subtype \
-e wlan_radio.channel | \
grep timestamp | \
jq --unbuffered -c '{timestamp: .timestamp} + .layers'
{"timestamp":"1583924233530","wlan_fc_type":["0"],"wlan_fc_type_subtype":["4"],"wlan_radio_channel":["2"]}
{"timestamp":"1583924235474","wlan_fc_type":["1"],"wlan_fc_type_subtype":["25"],"wlan_radio_channel":["2"]}
{"timestamp":"1583924235613","wlan_fc_type":["1"],"wlan_fc_type_subtype":["25"],"wlan_radio_channel":["2"]}
```
## Streaming Wi-Fi data into Apache Kafka
Now, let’s stream this data into Kafka. Once it’s in Kafka we can use it for lots of things! We can use Kafka Connect to stream it onwards to places like Elasticsearch, Neo4j, S3. We can write ksqlDB applications to analyse and aggregate it. We can use it to drive services that subscribe to a stream of Wi-Fi data. The world will be our oyster!
Instead of the faff of running Kafka for myself I’m using Confluent Cloud. Its [pricing](https://www.confluent.io/confluent-cloud-faqs/#how-is-pricing-calculated-for-confluent-cloud) is such that you just pay for the data you use, making it very cheap to start playing around with, especially with the current $50 credit per month for first three months offer. [Sign up](https://confluent.cloud/signup) and create your cluster and get your API key and broker details.
Create a file with your Confluent Cloud details in:
```
$ cat .env
CCLOUD_BROKER_HOST=foo-bar.us-central1.gcp.confluent.cloud
CCLOUD_API_KEY=XXXXXXXXXXX
CCLOUD_API_SECRET=YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
```
We installed `kafkacat` above, and can now use it to connect to our cloud environment. The `-L` argument tells `kafkacat` to do a metadata query across the brokers and topics:
```
$ source .env
$ kafkacat -X security.protocol=SASL_SSL -X sasl.mechanisms=PLAIN -X api.version.request=true \
-b ${CCLOUD_BROKER_HOST}:9092 \
-X sasl.username="${CCLOUD_API_KEY}" \
-X sasl.password="${CCLOUD_API_SECRET}" \
-L
Metadata for all topics (from broker -1: sasl_ssl://foobar.us-central1.gcp.confluent.cloud:9092/bootstrap):
18 brokers:
broker 0 at b0-foobar.us-central1.gcp.confluent.cloud:9092
broker 5 at b5-foobar.us-central1.gcp.confluent.cloud:9092
broker 10 at b10-foobar.us-central1.gcp.confluent.cloud:9092
broker 15 at b15-foobar.us-central1.gcp.confluent.cloud:9092
broker 9 at b9-foobar.us-central1.gcp.confluent.cloud:9092
…
8 topics:
topic "wibble" with 6 partitions:
partition 0, leader 13, replicas: 13,2,5, isrs: 13,2,5
partition 1, leader 14, replicas: 14,6,7, isrs: 14,6,7
…
```
Now that this is working, go ahead and create a topic called `pcap`, either through the Confluent Cloud web UI or the command line tool. It’s important that you create this topic, as auto-topic creation is not enabled on Confluent Cloud.
With the topic created, let’s populate it! We are going to hook up the output from `tshark` in the previous section with the mighty power of `kafkacat` courtesy of unix pipes:
```
sudo tshark -i mon0 \
-T ek \
-l \
-e wlan.fc.type -e wlan.fc.type_subtype -e wlan_radio.channel \
-e wlan_radio.signal_dbm -e wlan_radio.duration -e wlan.ra \
-e wlan.ra_resolved -e wlan.da -e wlan.da_resolved \
-e wlan.ta -e wlan.ta_resolved -e wlan.sa \
-e wlan.sa_resolved -e wlan.staa -e wlan.staa_resolved \
-e wlan.tagged.all -e wlan.tag.vendor.data -e wlan.tag.vendor.oui.type \
-e wlan.tag.oui -e wlan.ssid -e wlan.country_info.code \
-e wps.device_name |\
grep timestamp|\
jq -c '{timestamp: .timestamp} + .layers' |\
kafkacat -X security.protocol=SASL_SSL -X sasl.mechanisms=PLAIN -X api.version.request=true\
-b ${CCLOUD_BROKER_HOST}:9092 \
-X sasl.username="${CCLOUD_API_KEY}" \
-X sasl.password="${CCLOUD_API_SECRET}" \
-P \
-t pcap \
-T
```
A few notes about what’s going on here. We’ve added in a bunch more fields from the Wi-Fi payload to capture in `tshark`. We’re also specifying `-P` to tell `kafkacat` to act as producer, `-t` to specify the topic, and `-T` to echo the messages to stdout as well as write them to the topic (just like `tee` does).
With this running you’ll see the messages arriving in the topic, either through `kafkacat` run as a producer:
```
$ kafkacat -X security.protocol=SASL_SSL -X sasl.mechanisms=PLAIN -X api.version.request=true \
-b ${CCLOUD_BROKER_HOST}:9092 \
-X sasl.username="${CCLOUD_API_KEY}" -X sasl.password="${CCLOUD_API_SECRET}" \
-C -t pcap
{"timestamp":"1583925922825","wlan_fc_type":["2"],"wlan_fc_type_subtype":["36"],"wlan_radio_channel":["2"],"wlan_radio_signal_dbm":["-71"],"wlan_radio_duration":["384"],"wlan_ra":["00:11:22:33:44:55"],"wlan_ra_resolved":["00:11:22:33:44:55"],"wlan_da":["00:11:22:33:44:55"],"wlan_da_resolved":["00:11:22:33:44:55"],"wlan_ta":["00:11:22:33:44:55"],"wlan_ta_resolved":["00:11:22:33:44:55"],"wlan_sa":["00:11:22:33:44:55"],"wlan_sa_resolved":["00:11:22:33:44:55"],"wlan_staa":["00:11:22:33:44:55"],"wlan_staa_resolved":["00:11:22:33:44:55"]}
{"timestamp":"1583925941754","wlan_fc_type":["1"],"wlan_fc_type_subtype":["29"],"wlan_radio_channel":["2"],"wlan_radio_signal_dbm":["-71"],"wlan_radio_duration":["272"],"wlan_ra":["00:11:22:33:44:55"],"wlan_ra_resolved":["Comtrend_96:cc:64"]}
{"timestamp":"1583925963170","wlan_fc_type":["1"],"wlan_fc_type_subtype":["28"],"wlan_radio_channel":["2"],"wlan_radio_signal_dbm":["-71"],"wlan_radio_duration":["40"],"wlan_ra":["00:11:22:33:44:55"],"wlan_ra_resolved":["Broadcom_08:04:20"]}
{"timestamp":"1583925991920","wlan_fc_type":["2"],"wlan_fc_type_subtype":["36"],"wlan_radio_channel":["2"],"wlan_radio_signal_dbm":["-79"],"wlan_radio_duration":["384"],"wlan_ra":["00:11:22:33:44:55"],"wlan_ra_resolved":["00:11:22:33:44:55"],"wlan_da":["00:11:22:33:44:55"],"wlan_da_resolved":["00:11:22:33:44:55"],"wlan_ta":["00:11:22:33:44:55"],"wlan_ta_resolved":["00:11:22:33:44:55"],"wlan_sa":["00:11:22:33:44:55"],"wlan_sa_resolved":["00:11:22:33:44:55"],"wlan_staa":["00:11:22:33:44:55"],"wlan_staa_resolved":["00:11:22:33:44:55"]}
```
or through the Confluent Cloud UI:
## What’s next?
So now we’ve got the data streaming into Kafka, what’s next? Well, how about some [ksqlDB](https://ksqldb.io/) to analyse it:
```
ksql> SELECT TIMESTAMPTOSTRING(WINDOWSTART,'yyyy-MM-dd HH:mm:ss','Europe/London') AS WINDOW_START_TS,
> DISTINCT_TA_MACS,
> DISTINCT_RA_MACS,
> EVENT_COUNT
>FROM PROBE_REQUESTS_BY_5MIN
>WHERE ROWKEY=4
> AND WINDOWSTART > '2020-03-11T08:00:00.000'
> AND WINDOWSTART <= '2020-03-11T09:00:00.000';
+----------------------+------------------+------------------+-------------+
|WINDOW_START_TS |DISTINCT_TA_MACS |DISTINCT_RA_MACS |EVENT_COUNT |
+----------------------+------------------+------------------+-------------+
|2020-03-11 08:05:00 |13 |2 |30 |
|2020-03-11 08:10:00 |15 |1 |63 |
|2020-03-11 08:15:00 |9 |2 |29 |
|2020-03-11 08:20:00 |10 |1 |28 |
|2020-03-11 08:25:00 |8 |1 |37 |
|2020-03-11 08:30:00 |12 |2 |57 |
|2020-03-11 08:35:00 |14 |1 |42 |
|2020-03-11 08:40:00 |22 |1 |77 |
|2020-03-11 08:45:00 |21 |2 |64 |
|2020-03-11 08:50:00 |10 |1 |40 |
|2020-03-11 08:55:00 |17 |1 |58 |
|2020-03-11 09:00:00 |27 |2 |54 |
Query terminated
ksql>
```
or property graph analysis to look at the relationship between things like SSIDs and devices?
Stay tuned!
### Acknowledments and References
- [https://frdmtoplay.com/counting-wireless-devices-on-a-raspberry-pi-with-tcpdump/](https://frdmtoplay.com/counting-wireless-devices-on-a-raspberry-pi-with-tcpdump/)
- [https://sandilands.info/sgordon/capturing-wifi-in-monitor-mode-with-iw](https://sandilands.info/sgordon/capturing-wifi-in-monitor-mode-with-iw)
- [https://www.cisco.com/c/en/us/support/docs/wireless-mobility/80211/200527-Fundamentals-of-802-11-Wireless-Sniffing.html](https://www.cisco.com/c/en/us/support/docs/wireless-mobility/80211/200527-Fundamentals-of-802-11-Wireless-Sniffing.html)
- [https://www.semfionetworks.com/uploads/2/9/8/3/29831147/wireshark\_802.11\_filters\_-\_reference\_sheet.pdf](https://www.semfionetworks.com/uploads/2/9/8/3/29831147/wireshark_802.11_filters_-_reference_sheet.pdf)
- [https://www.wireshark.org/docs/dfref/w/wlan.html](https://www.wireshark.org/docs/dfref/w/wlan.html) | rmoff |
278,510 | Generating Color Palette Using ColdFusion & ImageMagick | I read Ben Nadel's recent ColdFusion post on Exploring Color Histograms In GraphicsMagick And Lucee C... | 0 | 2020-03-11T16:32:01 | https://dev.to/gamesover/generating-color-palette-using-coldfusion-imagemagick-25bp | coldfusion, imagemagick | I read Ben Nadel's recent ColdFusion post on [Exploring Color Histograms In GraphicsMagick And Lucee CFML 5.2.9.31](https://www.bennadel.com/blog/3785-exploring-color-histograms-in-graphicsmagick-and-lucee-cfml-5-2-9-31.htm) and thought I'd compare it with [ImageMagick](https://imagemagick.org/).
ImageMagick returns a list of color data in a low-to-high order. I used [ReMatch](https://cfdocs.org/rematch) to identify the hex colors via regex, generated an array and then reversed it.
NOTE: I wanted to compare performance using Ben's script, but his "Lucee CFML" script wasn't written to be compatible with ColdFusion 2016. :(
## Usage
```js
colors = extractPalette(imagePath, numberOfColors);
```
## [Source Code](https://gist.github.com/JamoCA/d2814588b6f518c72713becb3625c5bb)
{% gist https://gist.github.com/JamoCA/d2814588b6f518c72713becb3625c5bb %}
| gamesover |
278,540 | Tutorial NumPy | Tutorial for one of the most important libraries. | 0 | 2020-03-11T16:41:03 | https://dev.to/seijind/tutorial-numpy-21g6 | python, numpy, tutorial, data | ---
title: Tutorial NumPy
published: true
description: Tutorial for one of the most important libraries.
tags: python, numpy, tutorial, data
---
#### What is NumPy?
Numpy is the core library for scientific computing in Python. It provides a high-performance multidimensional array object, and tools for working with these arrays.
NumPy is often used along with packages like SciPy (Scientific Python) and Matplotlib (plotting library). This combination is widely used as a replacement for MatLab, a popular platform for technical computing. However, Python alternative to MatLab is now seen as a more modern and complete programming language.
#### Install NumPy
```python
pip install numpy
```
#### Import NumPy
```python
import numpy as np
```
#### Create Arrays
```python
a = np.array([1,2,3])
b = np.array([(1.5,2,3), (4,5,6)], dtype = float)
c = np.array([[(1.5,2,3), (4,5,6)], [(3,2,1), (4,5,6)]], dtype = float)
d = np.array( [ [1,2], [3,4] ], dtype=complex )
```
#### Print Arrays
```python
>>> a = np.arange(6) # 1d array
>>> print(a)
[0 1 2 3 4 5]
>>>
>>> b = np.arange(12).reshape(4,3) # 2d array
>>> print(b)
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
>>>
>>> c = np.arange(24).reshape(2,3,4) # 3d array
>>> print(c)
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
```
For many resources on NumPy or anything else on Python, check out Github:
https://github.com/SeijinD/Python-World/blob/master/main/extends_libraries/numpy.md | seijind |
278,942 | Offer to mentor someone in tech for the next few days | Hector Minaya @hectorminaya... | 0 | 2020-03-12T00:21:51 | https://dev.to/hminaya/offer-to-mentor-someone-in-tech-for-the-next-few-days-55io | {% twitter 1237895705416495104 %} | hminaya | |
278,822 | When not to apply programming principles | This post (When not to apply programming principles) was originally published on Sargalias. When exa... | 5,110 | 2020-03-11T19:18:17 | https://www.sargalias.com/blog/when-not-to-apply-programming-principles/ | programming, webdev, learning, development | This post ([When not to apply programming principles](https://www.sargalias.com/blog/when-not-to-apply-programming-principles/)) was originally published on [Sargalias](https://www.sargalias.com).
When examining each principle, we focused on how to strictly apply it.
But we didn't really touch on pragmatism as much, or when we shouldn't apply some of the principles.
Well, except for the principle of abstraction. We touched on abstracting too early and over-generalizing a fair bit. For a lot more detail on that one, see [programming first principles - abstraction](https://www.sargalias.com/blog/programming-first-principles-first-principle-abstraction/).
As for the rest...
## When should we not apply programming principles?
Okay, so the real answer to this question is "never". We should always apply programming principles, unless for some reason it's impossible.
The subtlety is that sometimes the principle of least astonishment and KISS principle conflict with the others.
Particularly when the code we just wrote is quite small and simple, it may be detrimental to religiously apply separation of concerns or some of the other principles. It may actually make the code harder to understand and add more boilerplate.
Another reason is, as mentioned in the abstraction principle, we don't want to abstract or generalize the code too early, otherwise we might over-generalize. This means we might create an abstraction we'll never need to reuse, effectively making the code more complicated with no benefit, or an incorrect abstraction that will need refactoring again later.
## Downsides of not applying principles immediately
There are also downsides to waiting.
**(Future) code changes are error prone**
[Code changes are error prone](https://www.sargalias.com/blog/why-code-changes-are-error-prone/), meaning that a change to already existing functionality in the future is far more dangerous than changing brand new code when we first create it.
**Future changes are more difficult to make**
If we just wrote the code, it's still fresh to us.
We understand it well, we know what effect changes will have, etc.
It's easier to make changes now than make them in the future.
**Code may stay "difficult to understand"**
Code that doesn't follow good principles can be more difficult to understand.
This will slow down future efforts every time the code needs to be re-read and understood.
**Code potentially stays harder to test**
Easier testability is one of the advantages of following good software development principles and separation of concerns.
## Suggestions
**Rule of three**
As mentioned in [abstraction](https://www.sargalias.com/blog/programming-first-principles-first-principle-abstraction/), use the [rule of three](<https://en.wikipedia.org/wiki/Rule_of_three_(computer_programming)>) as a good rule of thumb.
Its benefits are:
- Creates more robust abstractions.
- Increases the chance that the abstractions are semantically significant.
However remember that it is just a rule of thumb. Don't be afraid to break it in the rare cases where it's beneficial to do so.
**Consider whether the code is simple enough that splitting it further may make it more difficult to work with, rather than easier**
Sometimes this is a possibility. The code may be simple, and dogmatically applying separation of concerns may add boilerplate, split it into different files, etc. The end result may be that the code was easier to work with and understand in its original state.
In this case, it may be perfectly acceptable and preferable to leave the code as it is. We can always **refactor later**, if needed.
Additional factors to consider may be things like:
- Size of the project.
- Length of the project.
- Size of the team.
If a project is very large, long, or has a large team, it may be preferable to follow conventions and split things diligently even if it will add boilerplate and make the code less simple.
This is because convention and familiarity may be better for the codebase than the benefit of keeping the particular code as simple as possible. In other words, splitting the code may actually better apply the principle of least astonishment to the particular codebase.
[Unidirectional data flow](<https://en.wikipedia.org/wiki/Unidirectional_Data_Flow_(computer_science)>) is an example. All code is strongly encouraged to follow a particular path, architecture and structure. This sometimes greatly increases the boilerplate of some otherwise trivial things. However, considering the project as a whole, this architecture and adherence to it is very beneficial. It's generally very clear what's going on at all times. In comparison, the odd case where something doesn't follow the convention could be very confusing to developers.
So in the end, you and your team will decide. Sometimes it's best to leave the code simple and easy to work with. Sometimes it's best to diligently separate concerns regardless.
**If in doubt, I personally suggest leaning towards applying principles early, rather than applying them late**
## Summary
To summarize all the points...
Advantages of waiting before applying programming principles:
- If the code is simple enough, separating it may make it harder to understand and add more boilerplate.
- By abstracting early we may over-generalize, adding unnecessary boilerplate to code or creating incorrect abstractions that will need refactoring later.
Disadvantages to waiting before applying programming principles:
- Future code changes are error prone.
- Changes are easiest to make when the code is new.
- Code with clearly separated concerns is generally easier to understand. This will pay dividends for the duration of the project.
- Code with good programming principles is generally easier to test.
Suggestions:
- Use the rule of three, but remember that it's a rule of thumb which in rare cases is beneficial to break.
- Consider whether the code is simple enough that splitting it further may make it more difficult to work with, rather than easier.
- If in doubt, I personally suggest leaning towards applying principles early, rather than applying them late.
| sargalias |
278,831 | A PWA Expo Web using CRA - From ZERO to Deploy | Creating a PWA using Create React App tool and Expo SDK | 0 | 2020-03-11T19:42:37 | https://dev.to/expolovers/a-pwa-expo-web-using-cra-from-zero-to-deploy-acm | expo, reactnative, react, pwa | ---
title: A PWA Expo Web using CRA - From ZERO to Deploy
published: true
description: Creating a PWA using Create React App tool and Expo SDK
tags: expo,react-native,react,pwa
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/znm7apcalbmpnlv9e5us.png
---
## Introduction
In this post, basically, I will init a Create React App using CRA CLI and inject the Expo SDK Tools to generate a PWA, and with the same codebase, have an iOS and Android App.
To begin, lets annotate the main tools that we'll use:
- Create React App Boilerplate
- Expo SDK
- **Expo HTML Elements**
- React Native
- React Native Web
- Styled Components
- Netlfy/Now Deploy
## Using the CRA Boilerplate
To get our first boilerplate, lets try this command:
You will get the full React Application provided by Facebook Team
```
npx create-react-app pwaExpoTutorial
```
## Adding React Native Ecosystem
For adding a React Native ecosystem we should add some libraries:
yarn add expo react-native react-native-web @expo/html-elements
After that, we can remove some irrelevant files
- `public` folder
- `*.css` files
- `*.test` files (you can add your own test tool after)
## Adding secondary libraries
expo install react-native-svg
yarn add react-native-web-hooks react-native-animatable styled-components
1. **React Native SVG:** SVG Support (Installed with Expo, because it uses Yarn and install the appropriate version to the Expo SDK)
2. **React Native Web Hooks:** React Hooks to be used in Web platform
3. **React Native Animatable:** A library to add animation to our SVG, simulating the initial CRA boilerplate
## Babel configuration
It's good to configure Babel in our project, so install the expo preset and insert a **babel.config.js** on project root folder
yarn add -D babel-preset-expo
**babel.config.js**
```js
module.exports = { presets: ['expo'] };
```
## Creating shared styled components
Create a file called **componentsWithStyles** inside something like `src/shared`
```jsx
import styled from 'styled-components/native';
import * as Animatable from 'react-native-animatable';
import { Header as H, P as Paragraph, A as Anchor } from '@expo/html-elements' ;
export const Container = styled.View.attrs(() => ({
as: Animatable.View
}))`
flex: 1;
align-items: center;
justify-content: center;
text-align: center;
width: 100%;
`;
export const Header = styled(H)`
background-color: #282c34;
flex: 1;
justify-content: center;
align-items: center;
width: 100%;
`;
export const P = styled(Paragraph)`
color: white;
`;
export const A = styled(Anchor)`
color: #61dafb;
`;
export const Image = styled(Animatable.Image).attrs(() => ({
animation: 'rotate',
iterationCount: 'infinite',
easing: 'linear',
duration: 20 * 1000,
style: { aspectRatio: 1 }
}))`
width: ${props => props.dimension*0.4}px;
height: ${props => props.dimension*0.4}px;
`;
```
Thinking in our logo (the SVG provided on initial CRA boilerplate), we need to set an aspect ratio to it, so create a file called **AspectView.js** inside some folder, I put it inside `src/components`
```jsx
import React, {useState} from "react";
import {StyleSheet} from "react-native";
import { Image } from '../shared/componentsWithStyles';
export default function AspectView(props) {
const [layout, setLayout] = useState(null);
const { aspectRatio = 1, ...inputStyle } =
StyleSheet.flatten(props.style) || {};
const style = [inputStyle, { aspectRatio }];
if (layout) {
const { width = 0, height = 0 } = layout;
if (width === 0) {
style.push({ width: height * aspectRatio, height });
} else {
style.push({ width, height: width * aspectRatio });
}
}
return (
<Image
{...props}
style={style}
onLayout={({ nativeEvent: { layout } }) => setLayout(layout)}
/>
);
}
```
[Thank you `@baconbrix` to share it](https://snack.expo.io/@bacon/aspectratio)
I created an **index.js** in the same folder (`src/components`)
```js
export { default as AspectView } from './AspectView';
```
You can do the same with the folder `src/shared` (create an **index.js** file), but this is not the purpose of this post, you can improve on your own.
---
## Let's dive into React Native
You can create a file in the application root folder called **app.json** to define some info about your app:
```json
{
"expo": {
"name": "PWAExpoWeb",
"description": "A PWA using Expo Web",
"slug": "pwaingexpo",
"privacy": "public",
"version": "1.0.0",
"orientation": "portrait",
"icon": "./assets/icon.png",
"splash": {
"image": "./assets/splash.png",
"resizeMode": "cover",
"backgroundColor": "#ffffff"
},
"web": { "barStyle": "black-translucent" }
}
}
```
Then, create an **App.js** file on the root folder
```jsx
import React from 'react';
import logo from './src/logo.svg';
import { Code } from '@expo/html-elements';
import { useDimensions } from 'react-native-web-hooks';
import { AspectView } from './src/components';
import {
Container,
Header,
P,
A,
} from './src/shared/componentsWithStyles';
function App() {
const { window: { height } } = useDimensions();
return (
<Container>
<Header>
<AspectView source={logo} dimension={height} />
<P>
Edit <Code>src/App.js</Code> and save to reload.
</P>
<A
href="https://reactjs.org"
target="_blank"
rel="noopener noreferrer"
>
Learn React
</A>
</Header>
</Container>
);
}
export default App;
```
Expo has a **special configuration** so you need to set entrypoint in **package.json**
```json
// ...
"main": "expo/AppEntry.js",
// ...
```
Continuing on **package.json**, we need to add our scripts:
```json
// ...
"scripts": {
"start": "expo start",
"android": "expo start --android",
"ios": "expo start --ios",
"eject": "expo eject",
"build": "expo build:web",
"debug-prod": "expo build:web && npx serve ./web-build",
"now-build": "yarn build && expo-optimize"
},
// ...
```
Did you notice that after the `build`, there is the `expo-optimize`, so let's insert it on our project:
yarn add -D sharp-cli expo-optimize expo-cli@3.13.0
It's using specific version of **Expo CLI (v3.13.0)** because, at the time of this post, the last version of the CLI was having a problem when being referenced by the Workbox, so, as a precaution, one of the last versions was added
Last but not least, we should increment some folders in `.gitignore`:
#expo
.expo
web-build
#IDE
.idea
.vscode
1. **.expo:** Cache folder
2. **web-build:** The web bundle
3. **.idea & .vscode:** IDEs folders
That's it, so you can try it running `yarn debug-prod`. =-]
## Deploy via Netlify or Now
You can use this project as a Git repository, so on Netlify or Now, you can use the Github/Gitlab/Bitbucket repo synced with the `master`. You have only to set the **build command** as `yarn now-build` and the **output folder** as `web-build/`, so everytime you push commit to master, it will be deployed in the services (Netlify/Now).
## Whats next?
- Typescript - Expo has an incredible support for TS
- Workbox
- GraphQL
### References
- source: https://github.com/mauriciord/pwa-expo-web
- demo: https://pwa-expo-web.netlify.com/
- lighthouse: https://googlechrome.github.io/lighthouse/viewer/?psiurl=https%3A%2F%2Fpwa-expo-web.netlify.com%2F&strategy=mobile&category=performance&category=accessibility&category=best-practices&category=seo&category=pwa&utm_source=lh-chrome-ext
Thanks, 😎
| mauriciord |
278,832 | How to create a fully functional blog with Alpas, Kotlin, and Tailwind — part 1: setup project… | How to create a fully functional blog with Alpas, Kotlin, and Tailwind — part 1: setup proje... | 0 | 2020-03-11T19:44:11 | https://dev.to/armiedema/how-to-create-a-fully-functional-blog-with-alpas-kotlin-and-tailwind-part-1-setup-project-112g | framework, alpas, blog, kotlin | ---
title: How to create a fully functional blog with Alpas, Kotlin, and Tailwind — part 1: setup project…
published: true
date: 2020-03-11 19:39:59 UTC
tags: framework,alpas,blog,kotlin
canonical_url:
---
### How to create a fully functional blog with Alpas, Kotlin, and Tailwind — part 1: setup project, database, and routes
In this multi-part series, I’ll walk you through, step-by-step, on how to create your very own, fully functional blog using [Alpas](https://alpas.dev), [Kotlin](https://kotlinlang.org/), and [Tailwind CSS](https://tailwindcss.com/).
> In this part 1 guide, we will setup an Alpas project, database, and routes.
With just a little added TLC and a dash of personal flair, you will be in the position to deploy your very own blog with its own lightweight Content Management System (CMS) - all built by you! 📰
#### The main features of the blog that you will create are
- Ability to create a new blog post
- Ability to manage (edit/delete) blog posts
- Validation that proper metadata and content exists before post submission
- Ability to page and navigate between blog posts
#### The main Alpas features you will use and learn are
- Connecting to and working with a database
- Create custom validation rules
- Convert markdown to HTML
- Persisting inputted content on failed form validations
- Page blog posts, including previous/next navigation
### Step 1: Start your project
Head over to the [Alpas Starter project](https://github.com/alpas/starter) on GitHub and setup your new blog using the stater template. Perform the initial steps required to successfully run your starter template.
💡 If you need help on getting started, review the Alpas [Installation Doc](https://alpas.dev/docs/installation) and the first couple steps of the [Quick Start Guide](https://alpas.dev/docs/quick-start-guide-todo-list) to get rolling on setting up an Alpas project.
### Step 2: Setup your database and blogs table
1. Setup a new local database and connect to it from within your project.
2. Create a new blog entity using `./alpas make:entity` blog command
3. Update the **Blog.kt** entity file to include id, content, created\_at, and updated\_at fields
4. Create a blogs table using `./alpas make:migration create\_blogs\_table --create=blogs` command
5. Migrate your blogs table to your database using `./alpas db:migrate` command
**Perfecto! We have completed the database portion. Now, let’s get into creating routes.**
💡 Check your progress against [blog.kt](https://github.com/armgitaar/blogify/blob/master/src/main/kotlin/entities/Blog.kt) and don’t forget to uncomment `addConnections(env)` in the DatabaseConfig file
#### 📄 **Related Documentation**
- [Entity Relationship](https://alpas.dev/docs/entity-relationship#main)
- [Migrations](https://alpas.dev/docs/migrations/)
### Step 3: Setup your database and blogs table
Routes. It’s where routing happens! 😂
Open the **routes.kt** file and add the following:
```
private fun RouteGroup.webRoutesGroup() {
get("/", BlogController::index).name("welcome")
get("/<page>", BlogController::pages).name("pages")
get("blog/<id>/<page>", BlogController::show).name("blog.show")
get("blog/new", BlogController::new).name("blog.new")
post("blog/submit", BlogController::submit).name("blog.submit")
get("blog/edit/<id>", BlogController::edit).name("blog.edit")
patch("blog/edit/<id>", BlogController::update).name("blog.update")
delete("blog/<id>", BlogController::delete).name("blog.delete")
}
```
Notice, we removed the WelcomeController route as we will only use BlogController. You can update the WelcomeController import to be BlogController as well. We will create the BlogController in future post within this series.
**Browsing through the different routes, you can easily gather what the main front-end user interactions will be:**
- Main index / welcome page
- Paging for when your blog has multiple posts — in this exercise we will display 9 posts per page
- Showing the blog post detail page
- Submitting a new blog post
- Enter an Edit mode for blog posts where you update the post’s content
- Remove a blog post
💡 Check your progress against [routes.kt](https://github.com/armgitaar/blogify/blob/master/src/main/kotlin/routes.kt)
#### 📄 Related Documentation
- [Routing](https://alpas.dev/docs/routing)
That’s it for part 1 of this series. You can always jump ahead and [look at the finished project on GitHub](https://github.com/armgitaar/blogify).
**In part 2 of this series, we will work on creating a service provider, a markdown to HTML convertor, and a controller.**
[Read part 2](https://dev.to/armiedema/how-to-create-a-fully-functional-blog-with-alpas-kotlin-and-tailwind-part-2-setup-service-38b2)
[Read part 3](https://dev.to/armiedema/how-to-create-a-fully-functional-blog-with-alpas-kotlin-and-tailwind-part-3-validation-rule-4bin)
* * * | armiedema |
278,860 | Building an Idle game Part 1 - Theory | I want to build a Idle RPG game, I'm pretty new to Node so it's going to be an adventure, a bit of tr... | 5,534 | 2020-03-11T21:24:46 | https://dev.to/1e4_/building-an-idle-game-part-1-theory-3fb3 | node, vue, javascript, game | _I want to build a Idle RPG game, I'm pretty new to Node so it's going to be an adventure, a bit of trial an error, it should be fun :). This is a multi part series, in which by the end, you will be able to build your own game. I am taking inspiration from the likes of https://idlescape.com, https://melvoridle.com/, https://pendoria.net/._
Tick based systems are pretty interesting, I've never made one before, only theorized a few possibilities. After recently joining a project that uses a tick system, I decided to look into it more from scratch to get more of an understanding of it. What better use than building a real world example.
**So where do you start with a tick system?**
We need to start by describing what the system will do, we will be using Woodcutting as an example as it doesn't contain so much logic. It should be straightforward, you chop, you gain xp and gain logs. We will go over combat and other skills later.
### Woodcutting
There are a few things that needs to happen for this skill - and for several others.
- The timer for skill must be dynamic, so that we can change the time depending on the level of the skill or any buffs active
- The skill can generate items and experience so it needs to update the user both locally in Node and in a database somewhere
- It needs to be able to emit events to the client such as xp, progress bar movement, messages etc.
#### Queues
My first thought was thinking that it would be best to separate out each skill into a "job" and put it into a Queue. This would elevate much of the processing onto a separate server elsewhere. Initially it sounded great, but when it came to implementation it became quite convoluted, especially when it came to communicating from inside the job to the outside.
Latency also becomes a factor, as everything needs to happen fast so the next action can take place.
So I went with putting everything inside a `setInterval()` and left it at that. It reduces the complexity so much that avoiding queues for this is the best thing to do.
#### Conclusion
Sometimes the straightforward answer can be the right one.
So now we have an outline of what a skill will possess and a rough idea of how the tick system will work.
Part 2 will cover the actual code behind the tick system along with the Github repos which contains some other scaffold such as Vue frontend. | 1e4_ |
278,898 | How to remember JavaScript's shift() and unshift() ? | Sometimes it is easy to do the exact opposite when we mean to add some value to the front of the arra... | 0 | 2020-03-11T21:49:10 | https://dev.to/kennethlum/how-to-remember-javascript-s-shift-and-unshift-1i49 | javascript | Sometimes it is easy to do the exact opposite when we mean to add some value to the front of the array. Is it `shift()` or `unshift()`? If it is a whiteboard interview or online interview, it may help if we can remember which is which, instead of looking it up online.
To add the value to the front of the array, it is `unshift()`. Maybe the "un" part of "unshift" makes us think it is unloading something or undoing something. But in fact, it is the "opposite". We can remember `unshift()`, opposite to what it sounds like, adds the value to the front, and `shift()` takes the value out of the array.
And just like other traditional Array methods before ES6, it is "in-place" modification (only `slice()` and `concat()` create new arrays, if we don't consider the `map()` and `filter()`, which are the newer array methods.)
```javascript
> arr = [2,4,6]
[ 2, 4, 6 ]
> arr.unshift(1,3,5) // the length is returned
6
> arr
[ 1, 3, 5, 2, 4, 6 ]
> arr.shift()
1
> arr.shift()
3
> arr.shift(2) // the 2 has no use. Only one value is shifted out
5
> arr.shift()
2
> arr
[ 4, 6 ]
```
| kennethlum |
278,936 | 👨🚀 Client side only! How far can we go? 👩🚀 | In a nutshell, serverless means to use sombody else's server, I find it unfortunately named because t... | 0 | 2020-03-11T23:43:13 | https://dev.to/adam_cyclones/client-side-only-how-far-can-we-go-ljb | javascript, webdev | In a nutshell, serverless means to use sombody else's server, I find it unfortunately named because the term PWA is misslabeled as well, it used to be called offline first, atleast that was when everything came first.
- mobile first
- desktop first
- content first
- offline first
Ironically everyone's a winner for taking part and they all came first, good job, gold star 🌟
Okay so that is my little silly rant out of the way, what serverless should mean is cutting down the need for a server by
moving everything further than the "edge" moving everything local,. (technically falling off a cliff at this point) .
### what are you talking about?
Static websites became popular not because they are simple, but because they have no calls to slow backends and databases, they make requests and they sometimes serve spa or frontend framework based UI's to add that dynamic feeling UX.
But what if I told you, everything you know is a lie, 🕵️ we don't need servers to load webpages.. what if I told you, you can persist data in a database whilst remaining offline.
## Webpage navigation without servers
⚠️*Note:* Dev markdown is freaking out about the bellow example, the address needs to have the `L`(lowercase) added back into data / htm`l`.
Once you have read the above, take the address from the href attribute in yellow, don't forget to remove the outer quotes, and paste that into your browser bar then gasp and come back to me, I've got you 🤗.
``` html
<a href="data:text/htm,<h1>This is your browser talking</h1>">just a normal link</a>
```
Okay what gives?
Addresses can have `data:` or `javascript:` to treat a link with a different context instead of using a protocol like https.
In-fact this is how Base64 encoded strings like images SVGs, (lots more) and evidently html can be loaded in a similar way (both as encoded and not encoded). The browser expands the string that it got and returns it for browser things like rendering. Data, I suspect is like prepared content and that is returned without a get, in the case of html this would start the process to render a Dom. We did all the hard work for the browser, the result is ⚡⚡⚡ fast!
Okay I demonstrated that you can render a html document without a server in just one string. There is no CSS, no JavaScript you say? Well actually script and style tags work just fine in this mega string.
~~Soo you want a 4 page website in a single string? Hmm maybe this string could include links to other data: URIs using the same technique? The result would be a mega string x 4.~~
Edit: Thats not entirely correct.
Despite what I said about a 4 page websites. navigation is disabled in Chrome and Firefox using another data:url, meaning the only way to navigate is actually, through an SPA, maybe Portals or iframes too. I don't really mind that I was wrong, this is a silly post. However I am sure that there are flags to turn off web security, I am also sure that in an Electron style app, this could be turned off as well.
Now you have a really really big string let's think about making it into a React app with a router. Now we have a really really really big string, you get the picture, unless you are going to sit there and manually write this string I would save your blood pressure for another time, hypothetically I suggest looking into a Webpack tool that can inline all the things and give you this string to rule them all.
⚠️ Due to string concatenation issues you will need to solve this with encoding and bacticks.
Hmm, we need a database now? Enter indexdb, okay so admittedly you could use local storage, session storage but that's not cool enough. I'd personally shoehorn pouchdb library into your megastring this will make working with indexdb a lot more fun.
But how do we back this website up? A thumb drive of course!
Okay so we actually could go very far without a server, could it be practical? Maybe with the right tooling, you certainly couldn't run a shop client side or do any authentication, (maybe, I don't know enough to trust client side crypto) sooner or later you would have to make a request for some resource, it's just not possible on the modern web. Despite this, it's an interesting thought experiment around thin and fat clients that I challenge you to explore, if you made something cool please come back and show me ♥️ your feedback!
Bonus round: here's some tips for PWA's 10 years before they where a thing. https://hacks.mozilla.org/2010/01/offline-web-applications/ | adam_cyclones |
279,000 | Is JavaScript Synchronous or Asynchronous? | Please share your thoughts on this. Someone might learn from your submission. | 0 | 2020-03-12T01:45:39 | https://dev.to/buzzedison/is-javascript-synchronous-or-asynchronous-5bch | javascript, help, discuss | Please share your thoughts on this. Someone might learn from your submission. | buzzedison |
279,072 | Getting started with Amazon S3 storage in Laravel | I'll show you how to set up an Amazon S3 bucket to store images and files with your Laravel app using a few built-in methods. | 0 | 2020-03-12T06:41:31 | https://dev.to/aschmelyun/getting-started-with-amazon-s3-storage-in-laravel-5b6d | laravel, php, tutorials, webdev | ---
title: Getting started with Amazon S3 storage in Laravel
published: true
description: I'll show you how to set up an Amazon S3 bucket to store images and files with your Laravel app using a few built-in methods.
tags: laravel, php, tutorials, web dev
---
I've worked in the past on a few projects that use Amazon's S3 service to store images and files from Laravel applications. Even though the functionality is pretty much built into the framework, the process of getting started can be a little jarring, especially to those who don't have a whole lot of experience with the AWS suite.
The benefits of using S3 can be pretty huge however, so I thought it was worthwhile to throw together this brief tutorial on how to get started tying your new (or existing) Laravel application's storage to an Amazon S3 bucket.
**Don't want to continue reading? Watch the video on it instead!**
{% youtube BQ0gi9YHuek %}
## Creating our project
To showcase the storage functionality, I'm going to build a super barebones image uploader in Laravel.
First thing's first, we're going to need three routes for this. Open up your `routes/web.php` file and create two GET requests, and a POST. These will be for the initial landing page, storing an image, and displaying a single image that was uploaded. These three will all use the same controller, `ImageController.php`, for the sake of simplicity.
Here's what I have for that:
```php
Route::get('/', 'ImageController@create');
Route::post('/', 'ImageController@store');
Route::get('/{image}', 'ImageController@show');
```
Then in our console at the project root, we can create that controller using artisan. Additionally, we can also generate the model with its migration using make:model with the `--migration` flag. Let's see how that looks.
```bash
php artisan make:controller ImageController
php artisan make:model Image --migration
```
For this demonstration app, we don't exactly need a ton of columns in our database table for the images. I think a filename and a url should suit that purpose just fine.
Opening up the new migration in the `database/migrations/` directory, let's modify it so that it looks like the following:
```php
public function up()
{
Schema::create('images', function(Blueprint $table) {
$table->bigIncrements('id');
$table->string('filename');
$table->string('url');
$table->timestamps();
});
}
```
If we look back at our `routes/web.php` file, we can see that we're going to need **three** methods in our ImageController. create(), store(), and update().
Create is an easy one, we literally just want to return a view that displays an image upload form so that we can add in an image and click a button to submit a form. Store needs a request parameter though, so that we can pull out the image data after that form has been submitted, and store it on our S3 bucket. Finally, update can have an Image parameter so that we can type-hint the return and stream the stored image directly to our user's browser.
Let's start with our form. Using TailwindCSS and a `resources/views/images/create.blade.php` file, I've made probably the most basic upload form I could think of.

The markup for this is equally simple, it's a form that posts to the root page, where we've created our route that sends data to the `ImageController@store` method.
```html
<div class="max-w-sm mx-auto py-8">
<form action="/" method="post" enctype="multipart/form-data">
<input type="file" name="image" id="image">
<button type="submit">Upload</button>
</form>
</div>
```
## Saving an image locally
As with most everything else, Laravel makes it insanely easy to grab our file after it's uploaded and store it locally. In the `store()` method of our ImageController, we can call the file method on the $request object, passing through the name of our file input (`image`).
Chaining to that we can use the store method and specify a local path, that will automatically save the image file (with a randomly generated name and correct extension) to our local disk.
It's all wrapped up in a super simple, single line of code:
```php
$path = $request->file('image')->store('images');
```
Let's return that path back out to the browser for now.
If we then go back to our form in our web browser, select an image to upload, and click the 'Upload' button, we're presented with a relative file path to the stored image.
Going through to our Laravel app's `storage/app` directory, we can see that a new `/images` directory was created, and our image resides inside of it.
That's great! It works locally! Now it's time to migrate this functionality to Amazon. As I mentioned earlier, Laravel has most of this taken care of out-of-the-box. The only thing that we need to get this tied in is 4 different values in our application's `.env` file:
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
- AWS_DEFAULT_REGION
- AWS_BUCKET
Let's see how we can get those.
## Setting up an S3 bucket
Head on over to [aws.amazon.com](https://aws.amazon.com) and create an account (or sign in with your existing one). After you're in, take a look at the top menu bar and find the 'Services' item. If you click on that, you open up a box with Amazon's massive list of AWS services. Scroll down, and under the Storage section, select 'S3'.
On the following screen, you'll see a list of any S3 buckets that you've created, along with a blue "Create bucket" button. Click that! On the following pages, enter in your bucket name (which has to be unique across the entire AWS platform), and select the region most applicable for your bucket.
The rest of the pages should remain with the default values, and continue clicking the next button until your bucket is successfully created.
Alright, we have our bucket, but now we need credentials in order to access it programmatically. Clicking the 'Services' menu item again, search for **IAM**. This stands for **I**dentity and **A**ccess **M**anagement, and it's where we're going to create id/secret pairs for our newly-created bucket.
On the left-hand side of this screen, click the 'Users' item under the Access management group. On the following page, click the blue 'Add user' button.
Fill out a user name for your user, and check the box next to **Programmatic access**, this let's AWS know that we want to generate a key ID and secret access key for this user.

The next page will probably be the most confusing part of this tutorial, and honestly it's pretty straight forward. Amazon let's you determine permissions on a per-user basis, and users can also be attached to groups if you have large amounts of them to manage.
For our simple demo (and honestly for most of my projects), I prefer going to the "Attach existing policies directly" section, searching for `S3`, and checking the box next to **AmazonS3FullAccess**. This ensures that our user (with the ID/secret attached), has full read/write access to our S3 bucket.
Click through the next few screens, leaving everything unchanged, and your user will be created successfully!
You'll be on a screen that contains your user created, along with its Access key ID and Secret access key. Copy these two values into your application's `.env` file under the appropriate headings listed above.
The other two items we'll need in our `.env` file we can pull straight from our bucket. The name that you used when you created it, and the region that you chose during the same step.
Now, we just have to tell Laravel to use S3 instead of our local disk.
## Connecting S3 to our application
Back in the `store()` method of our ImageController, all we have to do is make a single change to the one-liner that stores our files. In the `store()` method after 'images', add a comma and the string 's3':
```php
$path = $request->file('image')->store('images', 's3');
```
This tells Laravel that you want to use the S3 disk service, provisioned already in the services config of our app.
The final piece of this connection, is installing the package that Laravel uses as the bridge between our app and our S3 bucket. You can do that with the following line from your application's root:
```bash
composer require league/flysystem-aws-s3-v3
```
Okay, now let's go back to our application, and try uploading a file.
It works! A path is returned, but if we look at our `storage/app/images` directory, there's nothing new. That's because it was sent to our S3 bucket. If we refresh our bucket, there's now a folder called images, and clicking into it, we see our image that we uploaded!
Let's put those models we created earlier to use.
## Saving the image to the database
Back in our `store()` method in our ImageController, let's create a new image object after we store our image. Remember, we need just two values, a filename and a url. The filename we can get with the `basename` PHP method, and the url we can retrieve through the Storage facade's URL helper. Passing through our image's saved path, it conveniently returns back the full URL to our Amazon S3 image object.
This is what that model object creation looks like:
```php
$image = Image::create([
'filename' => basename($path),
'url' => Storage::disk('s3')->url($path)
]);
```
Now instead of returning the $path like we were previously, let's return the whole $image object.
Let's go back to our app's upload form, pick an image, and hit Upload. This time, we're given back some JSON that contains our image model's ID, filename, and URL.

That image URL is also under a private lockdown right now, by default. If you click it, AWS returns an Access Denied error, and you're unable to view the image directly. Instead, we'll have to go about it a different way.
Back on our ImageController, we have a `show()` method, taking in our Image ID. We can use the type-hinted Image object, and thanks to the Storage facade again, we can both retrieve the image from S3 and stream it as a browser response with the appropriate content type. All of that with a single line of code:
```php
return Storage::disk('s3')->response('images/' . $image->filename);
```
If we go to a path on our app with the Image ID that was just returned to us, Laravel retrieves the image from our S3 bucket, and displays it directly in the browser.
## That's all
That's about it for now!
You've successfully learned how to:
- Upload image files and store them locally
- Set up an Amazon S3 bucket and assign credentials
- Convert local disk storage to use an Amazon S3 bucket
- Retrieve images from an S3 bucket with Laravel
If you'd like to learn more about Laravel development, Amazon AWS, or other general web dev topics, feel free to follow me on my [YouTube channel](https://youtube.com/user/aschmelyun) or my [Twitter](https://twitter.com/aschmelyun).
If you have any questions at all, don't hesitate to get in touch! | aschmelyun |
279,370 | GitHub Actions | GitHub Actions 入门教程 GitHub Actions 教程:定时发送天气邮件 | 0 | 2020-03-12T09:32:53 | https://dev.to/jacobhsu/github-actions-5nc | [GitHub Actions 入门教程](http://www.ruanyifeng.com/blog/2019/09/getting-started-with-github-actions.html)
GitHub Actions 教程:[定时发送天气邮件](http://www.ruanyifeng.com/blog/2019/12/github_actions.html) | jacobhsu | |
279,987 | How to speak at tech conferences, with Karl Hughes | Trick question of the week: How do you go about speaking at tech conferences? Speaking in conference... | 3,792 | 2020-03-12T11:47:55 | https://dev.to/slashdatahq/how-to-speak-at-tech-conferences-with-karl-hughes-41pd | podcast, devrel | Trick question of the week:
*How do you go about speaking at tech conferences?*
Speaking in conferences is an integral part of DevRel.
**Why?**
Because in DevRel, to build trust, **you need to be helpful**. When you stand in front of a crowd to show how people are solving problems, you are being helpful to developers.
This is one of the reasons why you should be speaking at conferences. There are a lot of benefits but there are also challenges. Where do you apply? How? How do you prepare?
In our latest episode, we welcome Karl Hughes to help us walk through the process of speaking at conferences: from finding CFPs to apply to, all the way to dealing with stage fright, right before you deliver your talk.
Ready to get up on that stage and leave everyone in awe? [Listen to the episode and you will.] (https://www.developermarketingpodcast.com/?utm_source=devto&utm_medium=KarlHughes_Article)
**Karl Hughes** is a hands-on technical leader dedicated to helping startups figure out teams and technology. He is the CTO of The Graide Network and helps tech conference speakers find speaking opportunities at CFP Land.
 | slashdatahq |
280,118 | Why is image4io a good alternative for Cloudinary? | image4io is a website that provides customers and visitors with a variety of information about the sp... | 0 | 2020-03-12T15:29:38 | https://dev.to/brkk_oz/why-is-image4io-a-good-alternative-for-cloudinary-5aa0 | imageoptimization, webperf, websitespeed, digitalassetmanagement | [image4io](https://image4.io/en?utm_source=Devto&utm_medium=post&utm_campaign=growth&utm_term=m5&utm_content=w11_2020) is a website that provides customers and visitors with a variety of information about the speed at which websites uploaded. Cloudinary is also a company that offers services to its customers to ensure that their websites are loaded up much faster and used efficiently. In this context, before we talk about how image4io is an excellent alternative to Cloudinary, let's talk about why things like site upload speed, image optimization, and web performance are essential for websites.
##Importance of Website Loading Time
In our social life, we have many situations where we have to endure, such as waiting for public transport, waiting in line at the bank, waiting for the plane at the airport, even though we don't want to. While we don't like to wait also to get our jobs done, seeing the web site that we click on while surfing the internet opens late will cause many people to experience a negative experience. A page that takes a long time to open causes us to close it immediately and consider other options. In this respect, we can mention that there are various effects on website speed. We can explain these effects as follows.

##Impact of Website Speed On SEO
Google released a statement in 2010 regarding the effects of the speed of websites on SEO. In this respect, the slow or fast loading of web sites is of great interest to SEO. We know that site speed is now one of the ranking factors. In fact, according to some experts, site speed is one of the most critical issues of Google. [(*)](https://searchengineland.com/google-now-counts-site-speed-as-ranking-factor-39)
##Impact of Website Speed on User Experience
Research on the effects of website speed on the user experience found that due to the slow speed of the site, many users left the site without browsing the site. A survey conducted in the United States showed that 51 percent of online shoppers in the United States leave the site without purchasing a product if the site is slow to load. [(*)](https://blog.radware.com/applicationdelivery/applicationaccelerationoptimization/2013/05/case-study-page-load-time-conversions/) Given this figure, which is too high for an e-commerce site, the number of potential missed customers is much higher than the number of earned customers! That is not only on e-commerce sites but also on sites that provide information. But don't let those numbers scare you. With image4io, you can learn the speed of your website and make various changes to increase speed. It is up to you to create a good experience for your visitors!
##Why Do Websites Load Slowly?
As a result of your tests through image4io, you will be able to observe why your website loads slowly. In this respect, the reasons for the slow loading of web sites can be listed as follows.
###Host
The host is the most critical factor affecting the speed of websites. In this respect, you can see if there is a problem with the host service you receive during your test through image4io.
###Image Format / Image Optimization
image4io presents smart optimization solutions. It determines visitors’ browsers. Then image4io sends the fastest format to visitors. Thanks to that, visitors don’t wait to download images.

###Design
The design of your website also directly affects the speed of your website. At some points, it would be more accurate to emphasize the Ease of use rather than visual appeal. With the tests offered by image4io, you can find out whether the slowness on your website is due to design.
#Why Image4io?
image4io offers a [testing method](https://webspeedtest.image4.io/?utm_source=Devto&utm_medium=post&utm_campaign=growth&utm_term=m5&utm_content=w11_2020) to help you understand why your website speed is slow and provide solutions to it. Using image4io, you can eliminate the problem by learning the source of the problem. It has easy integration and dashboard. You can control you images easily. Thanks to SEO tool your images are compatible SEO structure. image4io integrated with [Zapier](https://zapier.com/apps/image4io/integrations) and [Slack](https://image4.io/en/integrations/slack). You can use this channel and start to use image4io. They have a similar performance but image4io cheaper and faster than Cloudinary. You can [sign up](https://console.image4.io/?utm_source=Devto&utm_medium=post&utm_campaign=growth&utm_term=m5&utm_content=w11_2020) and [use for free!](https://image4.io/en/pricing?utm_source=Devto&utm_medium=post&utm_campaign=growth&utm_term=m5&utm_content=w11_2020) | brkk_oz |
280,121 | Many-To-Many Relationship with Entity Framework Core | Get your .NET Core 3.1 skills up and running in no time. | 4,247 | 2020-03-31T06:28:41 | https://dev.to/_patrickgod/many-to-many-relationship-with-entity-framework-core-4059 | beginners, tutorial, webdev, dotnet | ---
title: Many-To-Many Relationship with Entity Framework Core
published: true
description: Get your .NET Core 3.1 skills up and running in no time.
tags: beginners, tutorial, webdev, dotnet
series: .NET Core 3.1 Web API & Entity Framework Jumpstart
cover_image: https://thepracticaldev.s3.amazonaws.com/i/lj3esendnc5dgxt8mywg.png
---
> This tutorial series is now also available as an online video course. You can [watch the first hour on YouTube](https://youtu.be/H4qg9HJX_SE) or [get the complete course on Udemy](https://www.udemy.com/course/net-core-31-web-api-entity-framework-core-jumpstart/?referralCode=CA390CA392FF8B003518). Or you just keep on reading. Enjoy! :)
{%youtube H4qg9HJX_SE %}
#Advanced Relationships with Entity Framework Core (continued)
##Many-To-Many Relation with Skills
Implementing many-to-many relations with Entity Framework Core looks a bit different than implementing the other ones.
In our role-playing game example, we add a bunch of skills, that will be available to *all* characters. This means, there is no upgrading of one specific skill for a character. There’s just a pool of skills that every character can choose from. So, in general, even a knight could throw a *fireball* and a mage can smash his opponent in a *frenzy*.
The first thing to do is adding the `Skill` model, of course.
We create a new C# class and add the properties `Id`, `Name` and `Damage`.
```csharp
public class Skill
{
public int Id { get; set; }
public string Name { get; set; }
public int Damage { get; set; }
}
```
Notice, that we *don’t* add a list of type `Character` here. We *would* do that if we wanted to implement a *one-to-many* relation, but for a *many-to-many* relationship, we need a special implementation - and that would be a *joining table*.
Entity Framework Core is currently not able to create a joining table by itself. So we have to add one manually and tell Entity Framework how to join the two entities `Skill` and `Character`.
Let’s add the model for this entity first. We create a new C# class and call it `CharacterSkill`. To join skills and characters now, we have to add them as properties. So, we add a `Character` and a `Skill`.
Additionally, we need a primary key for this entity. This will be a composite key of the `Skill` and the `Character`. To be able to do that, by convention we add a property `CharacterId` for the `Character`, and a property `SkillId` for the `Skill`.
```csharp
public class CharacterSkill
{
public int CharacterId { get; set; }
public Character Character { get; set; }
public int SkillId { get; set; }
public Skill Skill { get; set; }
}
```
But that’s not the whole magic. We still have to tell Entity Framework Core that we want to use these two Ids as a composite primary key. We do that with the help of the *Fluent API*.
We’re switching our focus to the `DataContext` class. First, we add the new `DbSet` properties `Skills` and `CharacterSkills`.
```csharp
public DbSet<Skill> Skills { get; set; }
public DbSet<CharacterSkill> CharacterSkills { get; set; }
```
After that we have to add something new. We override the method `OnModelCreating()`. This method takes a `ModelBuilder` argument, which “defines the shape of your entities, the relationships between them and how they map to the database”. Exactly what we need.
The only thing we have to configure here is the composite key of the `CharacterSkill` entity which consists of the `CharacterId` and the `SkillId`. We do that with `modelBuilder.Entity<CharacterSkill>().HasKey(cs => new { cs.CharacterId, cs.SkillId });`.
```csharp
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<CharacterSkill>()
.HasKey(cs => new { cs.CharacterId, cs.SkillId });
}
```
That’s it. Thanks to using the naming conventions for the `CharacterId` and the `SkillId` we don’t have to configure anything else. Otherwise, we would have to use the Fluent API to configure the relationship between characters and skills with methods like `HasOne()` and `WithMany()`. But Entity Framework Core will get this and we can see the correct implementation in a minute in the migration files.
There’s one last thing we have to do and that is adding the `CharacterSkill` list to the `Character` and the `Skill` models.
So, in both C# classes, we add a new property `CharacterSkills` of type `List<CharacterSkill>`.
```csharp
public class Skill
{
public int Id { get; set; }
public string Name { get; set; }
public int Damage { get; set; }
public List<CharacterSkill> CharacterSkills { get; set; }
}
```
```csharp
public class Character
{
public int Id { get; set; }
public string Name { get; set; } = "Frodo";
public int HitPoints { get; set; } = 100;
public int Strength { get; set; } = 10;
public int Defense { get; set; } = 10;
public int Intelligence { get; set; } = 10;
public RpgClass Class { get; set; } = RpgClass.Knight;
public User User { get; set; }
public Weapon Weapon { get; set; }
public List<CharacterSkill> CharacterSkills { get; set; }
}
```
Alright. When everything is saved, we’re ready to run the migration.
First, we add the new migration with `dotnet ef migrations add Skill`.
In the created migration file you can see that two new tables will be generated for us, `Skills` and `CharacterSkills`.
In the migration design file, a bit further down, you can now see the configuration of the relationship between the joining entity `CharacterSkill` and the entities `Character` and `Skill`.
```csharp
modelBuilder.Entity("dotnet_rpg.Models.CharacterSkill", b =>
{
b.HasOne("dotnet_rpg.Models.Character", "Character")
.WithMany("CharacterSkills")
.HasForeignKey("CharacterId")
.OnDelete(DeleteBehavior.Cascade)
.IsRequired();
b.HasOne("dotnet_rpg.Models.Skill", "Skill")
.WithMany("CharacterSkills")
.HasForeignKey("SkillId")
.OnDelete(DeleteBehavior.Cascade)
.IsRequired();
});
```
Again, thanks to using the naming conventions for the `Id` properties, we don’t have to do this manually.
It’s time to add this migration to the database with `dotnet ef database update`.
As soon as the update is done, you can refresh the database in SQL Server Management Studio and see the new tables `Skills` and `CharacterSkills` with the proper keys.
Great! It’s time to fill these tables with some content.
##Add Skills to RPG Characters
Adding new skills to the pool of skills in the database would work pretty straight forward. We need a service, an interface, the controller and so on. I’d say, we focus more on adding the relation between RPG characters and those skills.
So, instead of adding the service for the skills, let’s add some skills manually in the database with SQL Server Management Studio.
Simply right-click the `Skills` table and select “Edit Top 200 Rows”.
Now we can add some skills like Fireball, Frenzy or Blizzard.
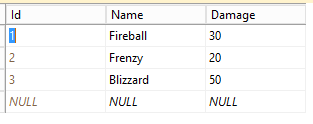
Great. Now we can concentrate on the relations. I can already spoiler, that we will need some DTOs. Let’s create a new folder `CharacterSkill` and add the new C# class `AddCharacterSkillDto` with the properties `CharacterId` and `SkillId`.
```csharp
namespace dotnet_rpg.Dtos.CharacterSkill
{
public class AddCharacterSkillDto
{
public int CharacterId { get; set; }
public int SkillId { get; set; }
}
}
```
Next, we create the folder `Skill` and create the DTO `GetSkillDto`, because we only need that one to display the skills of a character. The properties we need are `Name` and `Damage`.
```csharp
namespace dotnet_rpg.Dtos.Skill
{
public class GetSkillDto
{
public string Name { get; set; }
public int Damage { get; set; }
}
}
```
After that, we add one more property to the `GetCharacterDto` and that would be the `Skills` of type `List<GetSkillsDto>`.
```csharp
public class GetCharacterDto
{
public int Id { get; set; }
public string Name { get; set; } = "Frodo";
public int HitPoints { get; set; } = 100;
public int Strength { get; set; } = 10;
public int Defense { get; set; } = 10;
public int Intelligence { get; set; } = 10;
public RpgClass Class { get; set; } = RpgClass.Knight;
public GetWeaponDto Weapon { get; set; }
public List<GetSkillDto> Skills { get; set; }
}
```
Notice that we already access the skills directly, without using the joining entity `CharacterSkill` first. You’ll see how we realize that in a minute.
Okay, the DTOs are ready, now we can move on to the service and controller files.
We create a new folder called `CharacterSkillService` and add a new interface called `ICharacterSkillService`.
We add only one method that will return a `ServiceResponse` with a `GetCharacterDto` because similar to the `WeaponService` we can see the added skills then. We call the method `AddCharacterSkill()` and give it an `AddCharacterSkillDto` as a parameter. Of course, while we’re doing that, we have to add some using directives.
```csharp
using System.Threading.Tasks;
using dotnet_rpg.Dtos.Character;
using dotnet_rpg.Dtos.CharacterSkill;
using dotnet_rpg.Models;
namespace dotnet_rpg.Services.CharacterSkillService
{
public interface ICharacterSkillService
{
Task<ServiceResponse<GetCharacterDto>> AddCharacterSkill(AddCharacterSkillDto newCharacterSkill);
}
}
```
Now we can already create the `CharacterSkillService`. This service will look pretty similar to the `WeaponService`. We start by implementing the `ICharacterSkillService` interface and add the `AddCharacterSkill()` method automatically and add the `async` keyword already.
```csharp
public class CharacterSkillService : ICharacterSkillService
{
public async Task<ServiceResponse<GetCharacterDto>> AddCharacterSkill(AddCharacterSkillDto newCharacterSkill)
{
throw new NotImplementedException();
}
}
```
Before we write the actual code of this method, we add the constructor. Similar to the `WeaponService` we inject the `DataContext`, the `IHttpContextAccessor` and the `IMapper`. We add the using directives, initialize all fields from the parameters and if you want, add the underscore in front of every field.
```csharp
private readonly DataContext _context;
private readonly IHttpContextAccessor _httpContextAccessor;
private readonly IMapper _mapper;
public CharacterSkillService(DataContext context, IHttpContextAccessor httpContextAccessor, IMapper mapper)
{
_mapper = mapper;
_httpContextAccessor = httpContextAccessor;
_context = context;
}
```
Now to the `AddCharacterSkill()` method.
First, we initialize the returning `ServiceResponse` and build an empty try/catch block.
In case of an exception, we can already set the `Success` state of the `response` to `false` and set the `Message` to the exception message.
```csharp
public async Task<ServiceResponse<GetCharacterDto>> AddCharacterSkill(AddCharacterSkillDto newCharacterSkil
{
ServiceResponse<GetCharacterDto> response = new ServiceResponse<GetCharacterDto>();
try
{
}
catch (Exception ex)
{
response.Success = false;
response.Message = ex.Message;
}
return response;
}
```
Next would be to receive the correct `Character` from the database that was given by the `CharacterId` through the `AddCharacterSkillDto`.
Again, it’s pretty similar to the `WeaponService`.
First, we access the `Characters` from the `_context` and filter them with the method `FirstOrDefaultAsync()` by the `newCharacterSkill.CharacterId` and additionally by the authenticated `User`. You remember this long line to receive the user id from the claims, right?
```csharp
Character character = await _context.Characters
.FirstOrDefaultAsync(c => c.Id == newCharacterSkill.CharacterId &&
c.User.Id == int.Parse(_httpContextAccessor.HttpContext.User.FindFirstValue(ClaimTypes.NameIdentifier)));
```
But that’s not all. To receive *all* skills and also the related `Weapon` of the user, we have to *include* them.
We can start with the `Weapon`. After `_context.Characters` we add `.Include(c => c.Weapon)`. The skills are getting a bit more interesting. Again we add `.Include()`, but first we access the `CharacterSkills` and after that we access the child property `Skill` of the `CharacterSkills` with `.ThenInclude()`.
That way, we get every property from the `character` that is stored in the database.
```csharp
Character character = await _context.Characters
.Include(c => c.Weapon)
.Include(c => c.CharacterSkills).ThenInclude(cs => cs.Skill)
.FirstOrDefaultAsync(c => c.Id == newCharacterSkill.CharacterId &&
c.User.Id == int.Parse(_httpContextAccessor.HttpContext.User.FindFirstValue(ClaimTypes.NameIdentifier)));
```
With that out of the way, we add the usual null-check. So, if the `character` is `null` we set the `Success` state and the `Message` and return the `response`.
```csharp
Character character = await _context.Characters
.Include(c => c.Weapon)
.Include(c => c.CharacterSkills).ThenInclude(cs => cs.Skill)
.FirstOrDefaultAsync(c => c.Id == newCharacterSkill.CharacterId &&
c.User.Id == int.Parse(_httpContextAccessor.HttpContext.User.FindFirstValue(ClaimTypes.NameIdentifier))
if (character == null)
{
response.Success = false;
response.Message = "Character not found.";
return response;
}
```
Next is the `Skill`. With the given `SkillId` from the `newCharacterSkill` parameter, we grab the skill from the database.
```csharp
Skill skill = await _context.Skills
.FirstOrDefaultAsync(s => s.Id == newCharacterSkill.SkillId);
```
Similar to the `character`, if we cannot find the skill with the given `SkillId`, we set the `ServiceResponse` and return it.
```csharp
if (skill == null)
{
response.Success = false;
response.Message = "Skill not found.";
return response;
}
```
Now we have everything we need to create a new `CharacterSkill`.
We initialize a new `characterSkill` object and set the `Character` and `Skill` properties of that object to the `character` and the `skill` we got from the database before.
```csharp
CharacterSkill characterSkill = new CharacterSkill
{
Character = character,
Skill = skill
};
```
After that, we add this new `CharacterSkill` to the database with `AddAsync(characterSkill)`, save all changes to the database and finally set the `response.Data` to the mapped `character`.
```csharp
await _context.CharacterSkills.AddAsync(characterSkill);
await _context.SaveChangesAsync();
response.Data = _mapper.Map<GetCharacterDto>(character);
```
And that’s the whole `AddCharacterSkill()` method.
```csharp
public async Task<ServiceResponse<GetCharacterDto>> AddCharacterSkill(AddCharacterSkillDto newCharacterSkill)
{
ServiceResponse<GetCharacterDto> response = new ServiceResponse<GetCharacterDto>();
try
{
Character character = await _context.Characters
.Include(c => c.Weapon)
.Include(c => c.CharacterSkills).ThenInclude(cs => cs.Skill)
.FirstOrDefaultAsync(c => c.Id == newCharacterSkill.CharacterId &&
c.User.Id == int.Parse(_httpContextAccessor.HttpContext.User.FindFirstValue(ClaimTypes.NameIdentifier))
if (character == null)
{
response.Success = false;
response.Message = "Character not found.";
return response;
}
Skill skill = await _context.Skills
.FirstOrDefaultAsync(s => s.Id == newCharacterSkill.SkillId);
if (skill == null)
{
response.Success = false;
response.Message = "Skill not found.";
return response;
}
CharacterSkill characterSkill = new CharacterSkill
{
Character = character,
Skill = skill
};
await _context.CharacterSkills.AddAsync(characterSkill);
await _context.SaveChangesAsync();
response.Data = _mapper.Map<GetCharacterDto>(character);
}
catch (Exception ex)
{
response.Success = false;
response.Message = ex.Message;
}
return response;
}
```
To be able to call the service, we need the `CharacterSkillController`, so let’s create this new C# file.
As always, we derive from `ControllerBase` and add the attributes `[Route(“[controller]”)]`, `[ApiController]` and `[Authorize]`. We need the user information, hence this controller should only be accessed by authenticated users.
```csharp
[Authorize]
[ApiController]
[Route("[controller]")]
public class CharacterSkillController : ControllerBase
```
Then we need a constructor that only injects the `ICharacterSkillService`.
```csharp
private readonly ICharacterSkillService _characterSkillService;
public CharacterSkillController(ICharacterSkillService characterSkillService)
{
_characterSkillService = characterSkillService;
}
```
And finally we add the `public async` `POST` method `AddCharacterSkill()` with an `AddCharacterSkillDto` as parameter which is passed to the `AddCharacterSkill()` method of the `_characterSkillService`.
```csharp
[HttpPost]
public async Task<IActionResult> AddCharacterSkill(AddCharacterSkillDto newCharacterSkill)
{
return Ok(await _characterSkillService.AddCharacterSkill(newCharacterSkill));
}
```
So far the controller.
Now we register the new service in the `Startup.cs` file. As almost always, we use `services.AddScoped()` for that in the `ConfigureServices()` method.
```csharp
services.AddScoped<ICharacterSkillService, CharacterSkillService>();
```
The last thing is a change to the `AutoMapperProfile`.
The easy part is a new map for the `GetSkillDto`.
```csharp
CreateMap<Skill, GetSkillDto>();
```
Now it’s getting more interesting. I already told you, that we want to access the skills of a character directly, without displaying the joining entity `CharacterSkill`. We can do that with the help of AutoMapper and the help of the `Select()` function.
First we utilize the `ForMember()` function for the `<Character, GetCharacterDto>`-Map. With this function, we can define a special mapping for a specific member of the mapped type.
In our case, we properly want to set the `Skills` of the DTO.
To do that, we access the `Character` object and from that object - hence the function `MapFrom()` - we grab the `CharacterSkills` and *select* the `Skill` from every `CharacterSkill`.
```csharp
CreateMap<Character, GetCharacterDto>()
.ForMember(dto => dto.Skills, c => c.MapFrom(c => c.CharacterSkills.Select(cs => cs.Skill)));
```
That’s how we make the jump to the skills directly.
Great! It’s time to test this.
Make sure to have your user logged in and the correct token in place. Then we can use the URL `http://localhost:5000/characterskill` with the HTTP method `POST`. The body of the call consists of the `characterId` and the `skillId`.
```json
{
"characterid" : 5,
"skillid" : 1
}
```
Executing this call, we get the complete RPG character back with its weapon and the new skill.
```json
{
"data": {
"id": 5,
"name": "Frodo",
"hitPoints": 200,
"strength": 10,
"defense": 10,
"intelligence": 10,
"class": 1,
"weapon": {
"name": "The Master Sword",
"damage": 10
},
"skills": [
{
"name": "Fireball",
"damage": 30
}
]
},
"success": true,
"message": null
}
```
When we add another skill, we see the complete array of skills.
```json
{
"data": {
"id": 5,
"name": "Frodo",
"hitPoints": 200,
"strength": 10,
"defense": 10,
"intelligence": 10,
"class": 1,
"weapon": {
"name": "The Master Sword",
"damage": 10
},
"skills": [
{
"name": "Fireball",
"damage": 30
},
{
"name": "Frenzy",
"damage": 20
}
]
},
"success": true,
"message": null
}
```
In the database, you can also see that the joining table is filled with the new IDs.
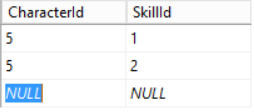
Perfect! The RPG character is equipped with a weapon and skills.
Feel free to play around with this.
If you want to use the `GetCharacterById()` method in the `CharacterService` to see the equipment of any character, make sure to add the `Include()` method as shown before, meaning include the `Weapon` as well as the `Skills` of the `CharacterSkills`.
```csharp
public async Task<ServiceResponse<GetCharacterDto>> GetCharacterById(int id)
{
ServiceResponse<GetCharacterDto> serviceResponse = new ServiceResponse<GetCharacterDto>();
Character dbCharacter =
await _context.Characters
.Include(c => c.Weapon)
.Include(c => c.CharacterSkills).ThenInclude(cs => cs.Skill)
.FirstOrDefaultAsync(c => c.Id == id && c.User.Id == GetUserId());
serviceResponse.Data = _mapper.Map<GetCharacterDto>(dbCharacter);
return serviceResponse;
}
```
When all your RPG characters are set, I guess it’s time to fight!
##Summary
Congrats! You implemented all types of relationships into your application.
But that’s not all.
In this chapter, first, you learned how to grab the authenticated user from a web service call and receive proper data based on that user from the database. That way you were able to show every user her own characters.
After that, we covered a one-to-one relationship. An RPG character can now be equipped with one weapon and only that one single weapon.
Regarding the many-to-many relationship, we added skills to our characters together with the necessary joining entity or table `CharacterSkills`. Characters are allowed to have several skills and skills can have several characters.
Apart from that you created all the necessary services and controllers to add weapons and skills and you learned how to *include* deeper nested entities and how to define *custom mappings* with AutoMapper.
In the next chapter, we will go one step further and implement functions to let the RPG characters fight against each other.
---
That's it for the 11th part of this tutorial series. I hope it was useful for you. To get notified for the next part, simply follow me here on [dev.to](https://dev.to/_patrickgod) or [subscribe to my newsletter](https://mailchi.mp/96620175570f/dotnetcore). You'll be the first to know.
See you next time!
Take care.
---
*Next up: More Than Just CRUD with .NET Core 3.1*
<small><i>Image created by cornecoba on [freepik.com](https://www.freepik.com/free-vector/flying-rocket-background_1130797.htm).</i></small>
---
### But wait, there’s more!
* Let’s connect on [Twitter](https://twitter.com/_PatrickGod), [YouTube](https://www.youtube.com/channel/UCq8LldVrjqe61KQttZlLW8g), [LinkedIn](https://www.linkedin.com/in/patrickgod) or here on [dev.to](https://dev.to/_patrickgod).
* Get the [5 Software Developer’s Career Hacks](http://patrickgod.com/5-software-developers-career-hacks/) for free.
* Enjoy more valuable articles for your developer life and career on [patrickgod.com](http://patrickgod.com). | _patrickgod |
280,169 | Java Nullpointerexception | This blog will be a quick look at the Java language and its Nullpointerexception. What is... | 0 | 2020-03-16T17:19:38 | https://dev.to/caffiendkitten/java-nullpointerexception-5d77 | codenewbie, java, null | This blog will be a quick look at the Java language and its Nullpointerexception.
<img src="https://upload.wikimedia.org/wikipedia/en/thumb/3/30/Java_programming_language_logo.svg/1200px-Java_programming_language_logo.svg.png" width="100" height="200" />
# What is Java?
Developed by James Gosling at Sun Microsystems (since been acquired by Oracle) and released in 1995; Java is a "general-purpose, concurrent, strongly typed, class-based object-oriented language" that is intended to let application developers write a program once, and run it anywhere on all platforms that support Java. (3)
That sounds great right? Run anywhere that supports Java. This means that it can be created on a Windows computer and run on a Mac or Linux computer, so it is a very versatile language.
# Where do you see Java?
Because Java is a "Write Once, Run Everyone" language, it is used all over. To name a few...
It is commonly used as the programming language for Android applications and can be seen in major projects that were written using Java, including processing frameworks such as Yarn and Hadoop, as well as Microservices development platforms and integration platforms. It can be used in the cloud where developers can build, deploy, debug, and monitor Java applications on Google Cloud at a scalable level. And, frameworks such as Struts and JavaServer Faces all use a Java servlet to implement the front controller design pattern for centralizing requests.

# So what is a Java NullPointerException?
NullPointerException is a Runtime Exception that is expected to crash or break down the program/application when it occurs.

With Java, a special null value can be assigned to an object reference (a way to keep memory address information of an object which is stored in memory). The NullPointerException is thrown by the Java Virtual Machine when a program performs some operations on a certain object considered as null or is calling for some method on the null object.
(5)
__Some of the common reasons for NullPointerException are:__(5)
- Invoking a method on an object instance, but at runtime the object is null.
- Accessing variables of an object instance that is null at runtime.
- Throwing null in the program as if it were a Throwable value.
- Accessing index or modifying value of an index of an array that is null.
- Checking length of an array that is null at runtime.
- Accessing or modifying the field of a null object.
- When you try to synchronize over a null object.
# How to prevent the NullPointerExcetion?
Because a NullPointerException is an unchecked exception, we don’t have to catch it. Instead, usually the NullPointerExceptions can be prevented using null checks and preventive coding techniques.
This includes:
- Ensuring that all the objects are initialized properly, before use.
- The use of `String.valueOf()` rather than `toString()` method.
- Use of ternary operators.
- Add a null check for an argument and throw a "IllegalArgumentException" if required.
- Write methods returning empty objects rather than null wherever possible.
<hr>
Happy Hacking

#### References
1. https://docs.oracle.com/javase/8/docs/api/java/lang/NullPointerException.html
2. https://www.geeksforgeeks.org/null-pointer-exception-in-java/
3. https://docs.oracle.com/javase/8/docs/technotes/guides/language/index.html
4. https://www.tutorialspoint.com/how-to-handle-the-runtime-exception-in-java
5. https://www.journaldev.com/14544/java-lang-nullpointerexception
6. https://www.theserverside.com/definition/Java
###### Please Note that I am still learning. If something that I have stated is incorrect please let me know. I would love to learn more about what I may not understand fully. | caffiendkitten |
280,234 | Adding local jar files to a Maven project | I was developing a project with spring and maven, however when performing the build I came across a s... | 0 | 2020-03-12T18:01:12 | https://dev.to/wakeupmh/adding-local-jar-files-to-a-maven-project-1h9n | java, todayilearned | I was developing a project with spring and maven, however when performing the build I came across a strange error
```bash
org.springframework.beans.factory.unsatisfieddependencyexception error creating bean with name
```
Even though my jar is in the build path, the error persisted, I tried to install it with the `java -cp` of life, but the problem persisted, that's when I tried something a little different, directly add the dependency in **pom.xml**, after all it is an abstraction of the **manifest** in spring application
# Solution
There are many ways to add local jar files to a Maven project:
- Install manually the JAR into a local Maven repository
use this command:
```bash
mvn install:install-file –Dfile=C:\dev\app.jar -DgroupId=com.mh.tutorial-DartifactId=my-example-app -Dversion=1.0
```
Now, add the dependency to your Maven project by adding these lines to your **pom.xml** file:
```xml
<dependency>
<groupId>com.mh.tutorial</groupId>
<artifactId>my-example-app</artifactId>
<version>1.0</version>
</dependency>
```
- Adding directly the dependency as system scope
Consider that the JAR is located in `<PROJECT_ROOT_FOLDER>/lib`.
After this add the dependency in your **pom.xml** file as following:
```xml
<dependency>
<groupId>com.mh.tutorial</groupId>
<artifactId>my-example-app</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${basedir}/lib/myCustomJAR.jar</systemPath>
</dependency>
```
 | wakeupmh |
280,278 | GraphQL for server-side resource aggregation | In this post, I will explain how GraphQL can help with composing data coming from several services | 0 | 2020-03-12T19:44:40 | https://dev.to/hhccvvmm/graphql-for-server-side-resource-aggregation-4o9h | graphql, microservices, apigateway, bff | ---
title: GraphQL for server-side resource aggregation
published: true
description: In this post, I will explain how GraphQL can help with composing data coming from several services
tags: graphql,microservices,apigateway,bff
---
When implementing service oriented and microservices architectures, sooner or later, the aggregation of data coming from different services becomes a problem to face. In this post, we will see how GraphQL can help with this.
(A basic knowledge of GraphQL is required. You can learn GraphQL basics on the [official website](https://graphql.org/learn/)).
We are developing a property rental API, and the consumer needs an endpoint to fetch information about a property and its landlord. An example response would look like this:
```
GET /properties/1234
{
id: 1234,
address: "10 Downing Street",
area: 90,
landlord: {
id: 882,
name: "John Doe"
email: "john.doe@mail.com"
}
}
```
We can see two [aggregates](https://martinfowler.com/bliki/DDD_Aggregate.html) involved in this piece of information: _Property_ and _Landlord_.
In a monolithic application, we would write a query, with some SQL `JOIN` maybe, to fetch the data from a database, and marshall it to the above _JSON_.
However, let's assume in our rental organization we have a microservices architecture; we have a _Property Microservice_ and _Landlord Microservice_, [with a database for each one](https://microservices.io/patterns/data/database-per-service.html). For that reason, we can't just `JOIN` two database tables; integration between services is made across the network and not through database sharing.
We need an [API Gateway](https://hvalls.dev/posts/microservice-pattern-api-gateway) or [BFF](https://samnewman.io/patterns/architectural/bff/) to aggregate data from both services and serve it to the API consumer.
We could perform aggregation "by hand":
```kotlin
//This code belongs to API Gateway / BFF
fun getProperty(id: Int) : JsonObject {
val property = propertyService.getById(id)
val landlord = landlordService.getById(property.landlordId)
return buildJson(property, landlord)
}
```
Note that `property` object, fetched from `propertyService::getById`, does not contain information about its `landlord`, but only its identifier; `landlordId`. We use that field to fetch the whole landlord info, through `landlordService`, and construct the full response `JsonObject`.
When implementing this approach, due to its stream-based nature, reactive programming tools like ReactiveX are quite useful.
An alternative to this, is letting GraphQL engine do the job.
### Resource aggregation using GraphQL
First, we are going to define the GraphQL schema:
```graphql
type Query {
getProperty(id: String!): Property
}
type Property {
id: String
address: String
area: Int
landlord: Landlord
}
type Landlord {
id: String
name: String
email: String
}
```
Now, we have to define a data fetcher for `getProperty` operation:
```kotlin
fun getPropertyDataFetcher() : DataFetcher {
return DataFetcher { env -> {
val propertyId = env.getArgument("id")
return propertyService.getProperty(propertyId)
}
}
```
So far, we have the information about the property. Now, we need to implement the data fetcher for its landlord:
```kotlin
fun getLandlordDataFetcher() : DataFetcher {
return DataFetcher { env -> {
val property = env.getSource<Property>()
val landlordId = property.landlordId
return landlordService.getLandlord(landlordId)
}
}
```
With the schema and the fetchers, we are ready to build our `GraphQL` instance and make the query:
```kotlin
val graphQL = buildGraphQLFromSchemaAndFetchers()
executeQuery(graphQL, """{ query:
getProperty(id: 1234) {
id
address
area
landlord {
id
name
email
}
}
}""")
```
With this approach, we delegate the logic of the data composition to GraphQL library implementation, this way being less error-prone than doing it manually.
It looks like a declarative way; you tell it how to fetch properties, and how to fetch landlords. Then, just ask for the data you need and data aggregation is managed by GraphQL.
---
Sometimes, we tend to think of GraphQL just as a type of HTTP API; an alternative to REST.
This is true, but using GraphQL does not mean starting a GraphQL server. You don't need to expose an API of this type at all, depending on the use case you are trying to solve.
In this example, I have shown how to use GraphQL as a query engine and data aggregator, but I haven't mentioned anything about GraphQL servers.
Let's consider this code, that could be written using some modern REST tool:
```kotlin
@GET
fun getProperty(@PathParam("id") id: String) : Property {
val property = executeQuery(graphQL, """{ query:
getProperty(id: $id) {
id
address
area
landlord {
id
name
email
}
}
}""")
return property
}
```
This is a REST API resource, but, under-the-hood, a GraphQL engine is responsible for aggregation of data from several sources. **There is no need to run any GraphQL server**.
There are many reasons you may not want to expose a pure GraphQL API. e.g. hard integration with frontend or other services, maintain compatibility, lack of GraphQL knowledge amongst the developers, or even organizational convention. Anyway, you can take advantage of GraphQL power and use it as a query engine, like we have just seen above.
I hope you enjoyed the article!
| hhccvvmm |
280,299 | Easy as a pie Big O notation: A note about Objects | An object is an unordered data structure where everything is stored in key-value pairs. Let superDog... | 5,380 | 2020-03-12T20:47:26 | https://dev.to/misselliev/easy-as-a-pie-big-o-notation-a-note-about-objects-3gn9 | beginners, codenewbie, webdev, algoritms |
An object is an unordered data structure where everything is stored in key-value pairs.
Let superDog = {
Name: “Dulce”,
Breed: “Chihuahua”,
Weight: “2 pounds” }
Objects are great when storing in order is not a concern and we need to be fast at inserting and removing data.
### But exactly, how fast?
- Insertion: *O(1)*
- Removal: *O(1)*
- Access: *O(1)*
- Searching: *O(N)*
It works in constant time because since we have no order in our data, we technically don’t have a beginning or end so it doesn’t really matter in which order data is added.
Got something to add? Please feel free to [reach out](https://twitter.com/miss_elliev) for any question, comment or meme. | misselliev |
280,465 | Day 2 [D&D Character Sheets] | Report Today I started by setting up my database. In my digital life I'm a pretty tidy p... | 5,355 | 2020-03-13T04:48:42 | https://dev.to/approachingapathy/day-2-d-d-character-sheets-3d0c | 100daysofcode | # Report
Today I started by setting up my database.
In my digital life I'm a pretty tidy person, I like consistent, rigid folder structures, don't like a crowded desktop, and I'm striving to install as few apps as I can on my devices. But I also have use different databases all the time.
This means that not only would I have databases installed that I don't use often, but many of them will run at startup! (Okay I could make it not run at startup, but then I'd have start them manually every time I worked a project.)
That's why I use Docker Desktop to containerize my database servers. Docker allows me to quickly create an instance of whatever database I like, use it, and then delete or forget about it. It also has a bunch of pre-made containers so it's often as easy as running one or two commands. I still have to start the databases manually, but they're all in one place and can be started from a easy-to-use GUI.
These commands install the latest container, and maps the container's port 27017 to the host's port 27017.
```
docker pull mongo
docker run -p 27017:27017 --name mongo -d mongo:latest
```
With Mongo setup, and a connection established in MongoDB-Compass. I began working on setting up the database client for my app. After some time with the documentation I used mongoose to establish a connection with the database, and started setting up mongoose schemas. This is still very work-in-progress, so no code today.
# Project
{% github ApproachingApathy/100days-dnd-character-sheets %}
The First project will be an app to keep D&D character sheets.
## Stack
I'll be using Node.js and building a full-stack Express app with MongoDB.
### Requirements
#### Minimum Viable
- [ ] Present a D&D Character Sheet
- [ ] The sheet should display all the same info as the first page of the 5e Official sheet.
- [ ] Users should be able to log in and create player-characters.
- [ ] Users should be able to edit character sheets.
- [ ] Users should be able to organize character sheets into groups (parties/tables)
- [ ] Sheets should auto calculate basic stats like ability modifiers.
- [ ] Support Proficiency Bonuses
### Cake
- [ ] Extend character creation to allow the user to use any of the three common stat gen methods.
- [ ] Point Buy
- [ ] Standard Array
- [ ] Roll
- [ ] Extend the character sheet to all the info in the 5e official sheet.
- [ ] Allow for image uploads for character portraits.
- [ ] Allow for extended descriptions/backstories.
- [ ] Characters should have nice full page backstories.
- [ ] Preferably use a markdown editor. | approachingapathy |
280,310 | Designing Learn JavaScript's course portal (Part 3) | This is the third article where I explain how I designed Learn JavaScript's course portal. | 4,982 | 2020-03-12T21:19:55 | https://zellwk.com/blog/learn-javascript-portal-design-3 | design | ---
title: Designing Learn JavaScript's course portal (Part 3)
description: This is the third article where I explain how I designed Learn JavaScript's course portal.
canonical_url: https://zellwk.com/blog/learn-javascript-portal-design-3
tags: design
series: learnjavascript-portal-design
cover_image: https://zellwk.com/images/2020/ljs-portal-3/account-page.png
published: true
---
This is the third article in the Learn JavaScript design series. Today, I'll talk about how I built the Account and Component Page.
## Account page
I gave each student a default password. I want to let them change their password, so I created the Account page.
<figure role="figure">
<img src="https://zellwk.com/images/2020/ljs-portal-3/account-page.png" alt="The account page.">
</figure>
There's only one important activity here: The changing of passwords.
You need three fields to change passwords:
1. The old password
2. The new password
3. Confirmation for the new password
We can put the fields in a single column.
<figure role="figure">
<img src="https://zellwk.com/images/2020/ljs-portal-3/change-password-1.png" alt="Password fields in a single column.">
</figure>
This works on mobile, but it looks weird on desktop; there's too much whitespace on the right.
I tried to reduce the awkwardness by reducing the whitespace. I did this by creating a two-column grid in the form. Labels on the left, fields on the right.
<figure role="figure">
<img src="https://zellwk.com/images/2020/ljs-portal-3/change-password-2.png" alt="Labes on the left, fields on the right.">
</figure>
It looks much better than before, but there's still room for improvement.
Here each label looks disjointed from their respective fields. This happens because the whitespace between labels and fields are quite large.
According to proximity rule, related fields should be close to each other. The easiest way to do this is to right-align the labels.
<figure role="figure">
<img src="https://zellwk.com/images/2020/ljs-portal-3/change-password-3.png" alt="Aligned labels to the right.">
</figure>
This looks better, but it's still weird. Why? It looks weird because the button is full-width. It's not aligned to anything (on the left edge).
Since a "button" is kinda like a "field", we can align it like a field.
<figure role="figure">
<img src="https://zellwk.com/images/2020/ljs-portal-3/change-password-done.png" alt="Aligned buttons to the right.">
</figure>
This looks better since the entire form looks well aligned.
## Components page
There are 20 components in Learn JavaScript. Students progress through the course like this:
1. Learn concepts
2. Build simple components
3. Learn more complicated concepts
4. Improve the things they built (plus build more things)
This means a single component can be separated into different modules. For example, the simplest component, an off-canvas menu, is separated into 4 modules.
1. Module 3: Building simple components
2. Module 7: Animations
3. Module 15: Keyboard
4. Module 16: Accessibility
Students may want to go through the lessons for one component in sequence, so I created a Components page.
I could build this page like the Content page (with a list), but it's not enough. Each lesson comes with starter files and source code. I want to allow students to download these files easily too.
So I chose to go with a table instead. Here's what it looks like:
<figure role="figure">
<img src="https://zellwk.com/images/2020/ljs-portal-3/components-table.png" alt="Example of a table of lessons for each component. It contains three columns: Lesson, starter files, source code. ">
</figure>
That's it!
## Ending thoughts
I hope this series helped you learn to think more about design.
I hesitate to write this series because I feel my design skills still not refined. I feel that there are things I can improve in, but I'm not sure what.
I'm always on the lookout to improve my design skills though. Please let me know if you have any thoughts or suggestions!
<hr>
Thanks for reading. This article was originally posted on [my blog](https://zellwk.com/blog/learn-javascript-portal-design-3). Sign up for my newsletter if you want more articles to help you become a better frontend developer.
| zellwk |
280,326 | Advanced GIT tutorial - Interactive rebase | Introduction It can often happen that you did something wrong by using GIT: you gave the wrong commi... | 0 | 2020-03-12T22:44:55 | https://howtosurviveasaprogrammer.blogspot.com/2020/03/advanced-git-tutorial-interactive-rebase.html | changecommitmessag, changeoldcommit, deletecommit, git | ---
title: Advanced GIT tutorial - Interactive rebase
published: true
date: 2020-03-12 21:53:00 UTC
tags: change commit messag,change old commit,delete commit,git
canonical_url: https://howtosurviveasaprogrammer.blogspot.com/2020/03/advanced-git-tutorial-interactive-rebase.html
---
Introduction
It can often happen that you did something wrong by using GIT: you gave the wrong commit message, created too few or too many commits, you have commits in the wrong order or with the wrong content. To change such things you have to change history in GIT. Interactive rebase in GIT is an efficient and powerful tool for that.
# The idea of interactive rebase
Git rebase can change the commits between the current HEAD and a dedicated commit. You can define the commit either by its hash or by its index relative to the current HEAD by giving HEAD~n, where n is the index. So HEAD~10 means the 10.th commit before the current HEAD.
To change the last 3 commits before the current HEAD type git rebase --interactive HEAD~3 or git rebase --interactive hash\_of\_the\_third\_commit\_after\_head. Pay attention, the third commit after HEAD is practically the fourth commit in git log, since the first is the HEAD itself. Instead of --interactive you can also type -i. This command will open your default editor and list your last three commits. The format is something like:
pick hash\_id commit\_message for each commit.
The very first thing you can do is to change the order of the commits in this file. It is pretty straight-forward, just change to order of the lines
Other than that you have the following options with each of the commits:
-
Pick (p): You would like to keep that commit as it is, this is the default action.
-
Reword (r): You would like to change the commit message of the commit.
-
Edit (e): You would like to change the content of the commit
-
Squash (s): It merges the commit with the previous one, keeping both the commit messages
-
Fixup (f): Same as squash, but it keeps the commit message of the previous commit
-
Exec (x): Executes a custom shell command
-
Break (b): It stops the rebasing at that commit, you can continue later with git rebase --continue
-
Drop (d): It drops that commit together with its content. That’s the best way of getting rid of a commit
-
Label (l): It attaches a label to the given which is the actual HEAD: Pay attention! The parameter here is not a commit id.
-
Reset (t): It resets the label of the current HEAD commit. It is also not expecting a commit id.
-
Merge (m): It creates a merge commit.
You should just write the right keyword or its abbreviation (in brackets) before he commit id.
# Resolve issues by interactive rebase
Here is a small collection of real life scenarios which can be resolved by interactive rebase.
## Change commit order
As already mentioned, you can change the order of the commits. If you want to change the order of the last 10 commits:
1.
Type git rebase --interactive HEAD~10
2.
You see now the list of commits is your default editor. Change their order as you wish.
3.
Save this file, resolve all conflicts
There’s a huge chance that you have to resolve some rebase conflicts, in this case change them, add the changed file with calling git add and type git rebase --continue at the end. Since the rebasing is commit based it can be that you have to fix similar conflicts in the same file multiple times.
## Get rid of unnecessary commits
It can happen, that you would like to remove a commit with its content, do the following:
1.
Type git rebase --interactive HEAD~10 (to remove some commits from the last 10)
2.
Change the “pick” to “drop” in the lines of commits to be removed
3.
Save the file and resolve the conflicts
That’s it, you removed the unnecessary commits with all their content.
## One commit instead of multiple commits
Sometimes you created too many simple commits and you would like to make your history more clean with less commits. You can simply merge the content of multiple commits into one.
1.
Type git rebase --interactive HEAD~10 (to merge some commits from the last 10)
2.
Change the “pick” to “fixup” in the lines of commits to be merged into the previous ones
3.
Save the file
## Change the commit message of old commits
What to do if you want to change the commit message of an older commit?
1.
Type git rebase --interactive HEAD~10 (to change the message of some commits from the last 10)
2.
Change the “pick” to “reword” in the lines of commits to be renamed
3.
Save the file
4.
The current commit message will appear in your editor, change it and save it
## Edit an old commit
How to change the content of an older commit?
1.
Type git rebase --interactive HEAD~10 (to change some commits from the last 10)
2.
Change the “pick” to “edit” in the lines of commits to be edited
3.
Save the file
4.
Do the changes you want, add them by git add and commit them by git commit --amend
5.
Type git rebase --continue
6.
Resolve all the conflicts
## Split commit
How to split an already existing commit?
1.
Type git rebase --interactive HEAD~10 (to split a commit from the last 10)
2.
Change the “pick” to “edit” in the lines of the commit to be splitted
3.
Save the file
4.
Type git reset
5.
Add the changes for the first commit and commit it
6.
Add the changes for the second commit and commit it
7.
git rebase --continue
# Summary
In my view interactive rebasing in git is a very powerful option which can make several scenarios easier and faster. But in order to use it in an efficient way you have to really know how it works. | rlxdprogrammer |
280,344 | How can I volunteer my extra time while self-isolating due to COVID-19? | My place of work has made the decision to implement working from home starting tomorrow. And most of... | 0 | 2020-03-12T23:05:34 | https://dev.to/ohryan/how-can-i-volunteer-my-extra-time-while-self-isolating-due-to-covid-19-4lej | discuss | My place of work has made the decision to implement working from home starting tomorrow. And most of the country, if now the world is likely to do the same.
Skipping the daily commute by working from home will unlock a bunch of free time for most of us.
I'm wondering if anybody has any interesting or creative suggestions for how to volunteer or time online.
Contributing to your favourite open source project seems like a nobrainer.
How about for non-developers?
I've heard people suggest editing Wikipedia.
What other ideas can we come up with? | ohryan |
280,395 | Open Source programs and initiatives | In this blog post, I will mention some open source initiatives and programs that can help you get started or more involved with Open Source. | 0 | 2020-03-12T23:44:19 | https://dev.to/isabelcmdcosta/open-source-programs-and-initiatives-3in6 | opensource, beginners, gsoc | ---
title: Open Source programs and initiatives
published: true
description: In this blog post, I will mention some open source initiatives and programs that can help you get started or more involved with Open Source.
tags: opensource, beginners, gsoc
---

_Credit to #WOCinTech Chat https://www.wocintechchat.com/_
In this blog post, I will mention some open source initiatives and programs that can help you get started or more involved with Open Source.
## Google Summer of Code
[Google Summer of Code](https://summerofcode.withgoogle.com/) (GSoC) is a program for university students to collaborate remotely with an open source organization during the summer. Students earn a stipend during this period. I participated in this initiative [as a student](https://summerofcode.withgoogle.com/archive/2018/projects/6592097335377920/) collaborating with [Systers Open Source](https://github.com/systers) organization. This is how I really got into understanding the spirit of Open Source and got to learn about it on many levels, initially as a contributor and then also as a maintainer. This year I am participating as a GSoC Admin with [AnitaB.org Open Source](https://github.com/anitab-org) (previously Systers Open Source).
## Outreachy
[Outreachy](https://www.outreachy.org/) is a similar program to Google Summer of Code, but instead of targeting university students, it supports participants from underrepresented groups in tech (not required to be in university). These are paid remote internships.
## 24 Pull Requests
[24 Pull Requests](https://24pullrequests.com/) happens during December. You can find on this website a list of issues ready to be taken or projects that are looking for contributors. I did my first contribution to open source, contributing to a markdown based project with resources for people looking for jobs ([my PR #9](https://github.com/fvcproductions/hire-me/pull/9)).
## Google Code-in
[Google Code-in](https://codein.withgoogle.com/) (GCI) is a competition for pre-university students between 13 and 17 years old. Participants have to complete tasks created by multiple Open Source Organizations in many categories, such as coding, documentation, research/outreach, design, and quality assurance. This year I had the pleasure to work as a GCI Mentor and witness creative work from participants. I really like that this program does not focus on coding contributions and explicitly promotes different types of contributions.
## Hacktoberfest
[Hacktoberfest](https://hacktoberfest.digitalocean.com/) happens during the month of October. This is a great way for people to give back to open source during the month of October, just like 24 Pull Requests. You can win Hacktoberfest t-shirts once you submit a 4 amount of pull requests. I never participated as a contributor, but I did as a maintainer when I labeled certain issues form the projects I maintain with “Hacktoberfest” label.
## Other programs and initiatives
There are plenty of other programs that help people get into open source, a few examples are [Rails Girls Summer of Code](https://railsgirlssummerofcode.org/), [Season of Docs](https://developers.google.com/season-of-docs/), etc.
There are some open source organizations that have their own programs that help people contribute in a structured way to their projects.
A while ago I found this collection of Open Source programs that has an extensive list of initiatives: [tapaswenipathak/Open-Source-Programs](https://github.com/tapaswenipathak/Open-Source-Programs).
If you are interested in finding open source projects but are not interested in participating in a specific program, it can still be useful to check projects and organizations that participate in these programs. Some of them can be well established and actively welcome contributions from the community (e.g.: [organizations accepted on GSoC](https://summerofcode.withgoogle.com/organizations)).
---
[_Originally posted on Medium_](https://medium.com/@isabelcmdcosta/open-source-programs-and-initiatives-328940d39565)
You can find me on [GitHub](https://github.com/isabelcosta), [Twitter](https://twitter.com/isabelcmdcosta), [LinkedIn](https://www.linkedin.com/in/isabelcmdcosta), and [my personal website](https://isabelcosta.github.io/).
| isabelcmdcosta |
280,430 | Afinal, por que Python? | De todas as perguntas e dúvidas que recebo, acredito que essa seja universal. Vou tentar... | 0 | 2020-03-13T02:07:25 | https://dev.to/dii_lua/afinal-por-que-python-3p3m | python, begginers, programming, diversity | > De todas as perguntas e dúvidas que recebo, acredito que essa seja universal. Vou tentar respondê-la.
Bonito é melhor que feio.
Explícito é melhor que implícito.
Simples é melhor que complexo.
Complexo é melhor que complicado.
Linear é melhor do que aninhado.
Esparso é melhor que denso.
Legibilidade conta.
Casos especiais não são especiais o bastante para quebrar as regras.
Ainda que praticidade vença a pureza.
Erros nunca devem passar silenciosamente.
A menos que sejam explicitamente silenciados.
Diante da ambiguidade, recuse a tentação de adivinhar.
Deveria haver um — e preferencialmente só um — modo óbvio para fazer algo.
Embora esse modo possa não ser óbvio a princípio a menos que você seja holandês.
Agora é melhor que nunca.
Embora nunca freqüentemente seja melhor que já.
Se a implementação é difícil de explicar, é uma má idéia.
Se a implementação é fácil de explicar, pode ser uma boa idéia.
Namespaces são uma grande ideia — vamos ter mais dessas!
- Zen of Python | Tim Peters.
#### Para ler o poema acima, basta instalar o Python no seu computador (tutorial disponível [aqui](https://www.python.org/downloads/)) e chamar o comando:
import this
Ocupando a 3ª posição de linguagem mais utilizada no mundo (fonte: [TIOBE](https://www.tiobe.com/tiobe-index/)), Python vem tendo uma procura cada vez mais constante, tanto de pessoas desenvolvedoras quanto de empresas. Sua alta performance com grandes volumes de dados fez a tecnologia crescer expoencialmente, e a tendência é que suas aplicações aumentem cada vez mais.
## Mas como a linguagem surgiu?
Um holandês, chamado Guido Van Rossum, criou a linguagem no natal de **1989**. Ela é baseada em C, e seu nome é uma referência ao seriado humorístico [Monty Python](https://pt.wikipedia.org/wiki/Monty_Python%27s_Flying_Circus).
Seus objetivos são:
* ser intuitiva e de fácil aprendizado, ainda assim sendo tão boa quanto as linguagens consideradas "poderosas";
* ter um sintaxe tão inteligível quanto o inglês;
* ser open source (de código aberto), permitindo assim que outras pessoas consigam contribuir com ideias e funcionalidades;
* ser perfeita para solucionar problemas diários, proporcionando um desenvolvimento mais rápido e uma curva de aprendizado mais baixa.
## Por que devo aprendê-la?
Se os tópicos acima não forem suficientes para te convencer a aprender a linguagem, eu te dou uma ajudinha. Como disse, a curva de aprendizado da linguagem é baixa, o que significa que o aprendizado da linguagem é rápido e a tendência é que você produza códigos cada vez mais intuitivos - e rápidos.
Há alguns anos, o **MIT** (Instituto de Tecnologia de Massachusets) resolveu utilizar Python para introduzir a lógica de programação para seus alunos. A estratégia foi feita porque muitos alunos reprovavam na disciplina. Na Suíça, a universidade **Fachhochschule de Zurique** trabalha com a linguagem nos cursos de pós graduação.
Já aqui no Brasil, temos essas instituições ensinando as disciplinas de lógica de programação / programação com Python (até onde consegui listar):
* **FATEC** (Faculdade de Tecnologia de São Paulo) - algumas unidades;
* **IMPACTA** (faculdade particular de São Paulo);
* **USP** (Universidade de São Paulo);
* **IFRO** (Instituto Federal de Rondônia);
* **PUC-Rio** (Pontifícia Universidade Católica do Rio de Janeiro);
* **UFC** (Universidade Federal do Ceará);
* **UFSCar** (Universidade Federal de São Carlos, São Paulo);
* **Mackenzie** (faculdade particular de São Paulo);
* **Insituto Infnet** (faculdade particular do Rio de Janeiro);
* **UEFS** (Universidade Estadual de Feira de Santana, Bahia);
* **UNICSAL** (Universidade Estadual de Ciências da Saúde de Alagoas);
* **UEA** (Universidade do Estado do Amazonas);
* **IFPB** (Instituto Federal da Paraíba);
* **UERJ** (Universidade Estadual do Rio de Janeiro);
* **UFSC** (Universidade Federal de Santa Catarina);
* **Instituto Superior Tupy** (Faculdade privada de Joinville, Santa Catarina);
* **UEPB** (Universidade Estadual da Paraíba);
* **IFPI - Campus Picos** (Instituto Federal do Piauí);
* **UNIFEI** (Universidade Federal de Itajubá - Minas Gerais);
* **Universidade Estácio de Sá** (filial do Rio de Janeiro);
* **UFV** (Universidade Federal de Viçosa - Minas Gerais);
* **UNB** (Universidade Federal de Brasília - Distrito Federal);
* **UFMG** (Universidade Federal de Minas Gerais);
* **IFF** (Instituto Federal Fluminense - RJ);
* **IFRN** (Instituto Federal do Rio Grande do Norte);
* **UFCG** (Universidade Federal de Campina Grande - Paraíba);
* **UFMS** (Universidade Federal de Mato Grosso do Sul);
* **IFSP São Carlos** (Insituto Federal de São Carlos, São Paulo);
* **UFPR Litoral** (Universidade Federal do Paraná);
* **UCL** (Universidade do Centro Leste - Espírito Santo);
* **IFRN - Campus Ceará-Mirim** (Instituto Federal do Rio Grande do Norte).
##### **Agradecimento aos [seguimores](https://twitter.com/dii_lua/status/1238225579239002117) que contribuíram pra essa lista de instituições - amo vocês!**
## E para o quê ela serve?
Bem, eis uma pergunta ampla. Quando falamos de Python, o assunto vai de desde aplicações desenvolvidas para a web até algoritmos de aprendizado de máquina. Lembra da primeira foto do buraco negro que ficou famosa em 2019? Pois então, diversas bibliotecas de Python foram utilizadas para atingir tal feito. Empresas como Youtube, Google, Pinterest, Instagram, Spotify, Reddit, Dropbox e Quora também a utilizam em suas aplicações.
Abaixo, segue de exemplo uma lista de tecnologias desenvolvidas em Python e suas respectivas áreas de atuação:
* **Desenvolvimento web**
* Django;
* Flask;
* Tornado;
* Web2Py;
* CherryPy;
* Bottle;
* TurboGears.
* **Segurança da informação**
* URLLib;
* Requests;
* Socket;
* HTTPLib;
* PyAesCrypt.
* **Ciência de Dados**
* Scikit learn;
* NumPy;
* SciPy;
* Numba;
* TensorFlow;
* PyTorch;
* Keras;
* NLTK;
* SpaCy;
* Gensim;
* Scrapy;
* Beautiful Soup;
* Requests;
* PyOD;
* QGrid;
* LightGBM;
* Vaex;
* XGBoost;
* CatBoost;
* Matplotlib;
* Pandas;
* Plotly;
* LIME;
* Featuretools;
* StatsModels;
* Seaborn;
* Bokeh;
* Pydot.
* **Bioinformática**
* DB-API;
* Pillow;
* NumPy;
* HTMLgen;
* PyGTK;
* WxPython.
* **Estatística**
* RPy;
* Scipy;
* PyChem.
* **Processamento de Imagens**
* Pillow;
* OpenCV;
* Scikit-image;
* SciPy;
* NumPy.
## Por que ficou tão conhecida?
Diferente de outras linguagens famosas que são proprietárias de grandes empresas, Python sempre teve o seu código aberto e disponível para quem quisesse contribuir. Isso ajuda no fato de pessoas adeptas do movimento *open source* se sentirem atraídas para o universo dessa tecnologia, mas não para por aí.
* É uma linguagem simples, que não requer o uso de caracteres especiais em demasia, e que facilita muito o seu uso;
* Também é multiparadigma, o que proporciona uma maior flexibilidade no jeito de se escrever o código;
* Possui uma extensa biblioteca interna, que facilita o uso da linguagem e não necessita realizar importações de bibliotecas externas a todo momento;
* Suas funções *built-ins*, ou seja, funções nativas/internas, sempre estão disponíveis para uso;
* É extremamente abrangente e utilizada por diversas áreas que não são, necessariamente, de tecnologia. Por exemplo: existem diversos jornalistas que são ótimos programadores Python e já conheci biomédicos, contadores, físicos, geográfos, matemáticos, neurocientistas, engenheiros, e pessoas de diversas profissões que programam na linguagem;
* Tem uma comunidade incrível, que preza por diversidade e inclusão, além de ser muito acolhedora.
## Pessoas > Tecnologia
E chegamos a minha parte favorita desse tema. Para muita gente, ouvir falar de comunidade pode parecer estranho ou confuso, mas eu explico. São pessoas (que não precisam saber Python ou desenvolver na linguagem) que se reúnem para aprender e compartilhar conhecimento. Como uma pessoa me ensinou uma vez (**<3**), tem uma frase que define bem isso:
"Comunidade de software é quando você junta pessoas interessadas em ensinar, pessoas interessadas em aprender, e pessoas que têm níveis de conhecimento diferentes que interagem entre si para fazer um mesmo projeto."
E com essa definição, consigo explicar um pouco melhor como são as comunidades. Nesse ambiente, pessoas de diferentes níveis se juntam para se ajudar, aprender, se apoiar, fazer networking, ter ideias e desenvolvê-las, promover iniciativas (como por exemplo, ensinar programação para grupos considerados minoria em TI), propor discussões e buscar evoluir e dar oportunidades para quem precisa.
Dentro da comunidade de Python, existem muitos desses grupos. Saca só:
* Tem os **GruPy's** ou **PUG's**, que são os grupos de usuários Python e abertos para todas as pessoas;
* O **PyLadies**, uma iniciativa para inserir, incentivar, e empoderar mulheres na área de programação utilizando Python;
* O **SciPy**, que é a comunidade científica da linguagem;
* O **AfroPython**, voltado para pessoas negras;
* **PyData**, para pessoas que gostam e/ou trabalham com dados;
E há diversos outros grupos específicos da linguagem! Para saber mais, você pode acessar [aqui](https://python.org.br/comunidades-locais/) para saber sobre os grupos locais, e [aqui](http://brasil.pyladies.com/locations/) para grupos locais do PyLadies.
E é no meio dessa galera que nascem conexões pro resto da vida. Tá achando exagero? Já vi rolar oferta de emprego, pedido de namoro, casamento, sociedade de empresa, parcerias diversas, muitas amizades e rolês que ficam marcados para sempre na memória. Segue a dica: vá em um evento de Python e fique para o PyBar. Você não vai se arrepender :D
#### PS.: Se não tiver um grupo local aí onde você mora, bora criar um? Pra começar uma comunidade, basta ter vontade e iniciativa!
Agora que te contei um pouco de Python, acho que ficou claro por que tanta gente gosta da linguagem né?! Então não perde tempo e venha pro lado Pythônico da força!
##### Beijinhos! [Lê](twitter.com/dii_lua) <3

| dii_lua |
294,793 | Spiral Traversal | Take my hand. What are you afraid of? Afraid of finding something out about yourself...? Maybe even... | 0 | 2020-03-30T07:26:04 | https://dev.to/je_we/spiral-traversal-36jo | <img src="https://dev-to-uploads.s3.amazonaws.com/i/8dsv9jl2xap2phzbzxty.PNG" width="384" height="461">
Take my hand.
What are you afraid of?
Afraid of finding something out about yourself...?
Maybe even about the fabric of reality itself?
Let's see what lies at the center of this spiral.
Yes, of course, I'm talking about the spiral on my shirt.
What am I talking about? I don't know. It probably has something to do with the toy problem I worked on this week called: Spiral Traversal. I had a lot of fun solving this problem and I'd like to walk you through my journey.
First an explanation of the problem: given a matrix, return an array that traces all the values found in a spiral from the matrix's upper left corner into its center.
Here's a matrix:

A spiral traversal looks something like this:
Writing that out, the array we'd want to return is:
[1, 2, 3, 4, 5, 10, 15, 20, 25, 24, 23, 22, 21, 16, 11, 6, 7, 8, 9, 14, 19, 18, 17, 12, 13]
Now that's a mouthful.
Let's take it step by step, following the diagram above. The first thing we want to do is grab the whole first row of the matrix and load it into our spiral. This could easily be accomplished by grabbing matrix[0] and pushing it into our spiral array. However, wouldn't it be nice to no longer have this row on the playing field moving forward? We can kill two birds with one stone by using shift.
```javascript
let spiral = matrix.shift();
```
Because shift returns what it removes, we have now set our spiral equal to that first row. Now, we probably want our function to be pure, so we should make a copy of matrix before we rudely splice off part of it. The most obvious approach would be:
```javascript
matrix = [...matrix];
```
However, if we think ahead a little bit, some parts of the traversal will only be grabbing PARTS of rows, which will mean altering the matrix's sub-arrays. These sub-arrays have their own references, so even if we make a copy of the matrix, any changes made to its rows will actually be side-effects. Knowing this, a more thorough approach is to make a copy of each row instead:
```javascript
matrix = matrix.map(row => [...row]);
```
Now we are safe from accidentally altering both the matrix itself and any of its rows.
Let's get back to it. Our matrix now looks like this:

The next part of the traversal is down the right-most column (10, 15, 20, 25). So, we want to iterate through the matrix, popping off the last element of each row and tacking it onto our spiral.
```javascript
matrix.forEach(row => {
spiral.push(row.pop());
});
```
Pop, like shift, returns what it removes, so we can push the elements into our spiral at the same time as we remove them from the matrix rows. Pretty cool!
Our matrix is getting smaller...
Up next we have to do a fancy little trick: add the bottom row...BACKWARDS! Actually, it's not that fancy because JS has a reverse method.
```javascript
spiral = spiral.concat(matrix.pop().reverse());
```
Look at that cute little matrix:
Alright, next we need to traverse up the left-most column. So, we iterate BACKWARDS through the matrix, removing the first element of each row and adding it to our spiral.
```javascript
for(let i = matrix.length - 1; i >= 0; i--) {
spiral.push(matrix[i].shift());
}
```
Wow! Our matrix is almost bite-size!
Cool! So...what next? Grab the first row from left to right, correct? Well...this is awkward. Aren't we about to repeat the same sequence of actions we just went through? What if we were dealing with a much larger matrix? How would we know how many times to repeat this sequence. We wouldn't! So let's recurse, like so:
```javascript
return spiral.concat(spiralTraversal(matrix));
```
Easy enough. But what are our stopping conditions? Let's take a moment to visualize. When we call spiralTraversal on this 3 x 3 matrix, we will be performing this sequence:
So, when we get to the end of the sequence we'll be recursing again on the poor lonely 1 x 1 matrix: [ [ 13 ] ]. That 13 is totally the end of our spiral, so our stopping condition can be something like this:
```javascript
if(matrix.length === 1) return matrix[0]
```
This stopping condition is essentially saying: if the matrix only has one row, go ahead and add that row as the end of the spiral. Now, up till now we've only considered square matrices. But let's consider a wide matrix and see if this stopping condition still works.
Starting matrix:
First traversal:
Matrix to recurse on:
We just want to tack this final [ 6 , 7 ] onto our spiral, and our base case will do just that. Looks like we're safe. How about a tall matrix?
Starting matrix:

First traversal:
Matrix to recurse on:
This matrix has only one column. Isn't safe we want the end of our spiral to be the contents of this column: [5, 8] ? We have one base case right now that says to add the whole row if there's only one left. How about we make another base case that says to add the whole column if there's only one left?
```javascript
if(matrix.every(row => row.length === 1)) {
return matrix.reduce((col, row) => col.concat(row));
}
```
If every row in the matrix has only one element, that means there's only one column. We use the reduce to transform [ [5], [8] ] into [5, 8] for easy concatenation onto the end of our spiral.
Whew! All done, right? Wrong. We haven't considered one possibility: a square matrix with even-numbered dimensions! Let's visualize the simplest case.
Starting matrix:
First traversal:
Matrix to recurse on:
The first thing you might notice is that we didn't even get to complete our sequence on the first traversal! When it came time to traverse up the left-most column, there was already nothing left in the matrix. If you recall our code for this part of the traversal:
```javascript
for(let i = matrix.length - 1; i >= 0; i--) {
spiral.push(matrix[i].shift());
}
```
We won't get an error, because i will initialize at a value of -1 (since the length is 0), meaning the loop never runs. After this, we call spiralTraversal on an empty matrix. Wouldn't you say we're done with our spiral though? I sure hope so. So it looks like we've found our final base case. If the matrix is empty we should just return an empty array to end it all.
```javascript
if(matrix.length === 0) return [];
```
So now, if we put it all together with our base cases preceding our traversal sequence, it should look a something like this:
```javascript
const spiralTraversal = (matrix) => {
//if matrix is empty, return empty array
if(matrix.length === 0) return [];
//if matrix only has one row, return that row
if(matrix.length === 1) return matrix[0];
//if matrix has just one column, return that column
if(matrix.every(row => row.length === 1)) {
return matrix.reduce((col, row) => col.concat(row));
}
//make a copy of matrix
matrix = matrix.map(row => [...row]);
//start with spiral set to the entire first row of the matrix
let spiral = matrix.shift();
//iterate through remaining rows, adding each row's final element to spiral
matrix.forEach(row => {
spiral.push(row.pop());
});
//add a reversed version of final row to spiral
spiral = spiral.concat(matrix.pop().reverse());
//iterate backwards through remaining rows, adding each row's first element
//to spiral
for(let i = matrix.length - 1; i >= 0; i--) {
spiral.push(matrix[i].shift());
}
//return the spiral so far, concatenated with a spiral traversal of the
//remaining matrix
return spiral.concat(spiralTraversal(matrix));
};
```
And that's it! Hope you enjoyed reading. See you on the other side...
| je_we | |
280,467 | Getting Started with AWS SQS using Node.js - Part 2 | Introduction In the previous part i.e. Getting Started with AWS SQS using Node.js - Part 1... | 0 | 2020-03-13T05:09:05 | https://dev.to/singhs020/getting-started-with-aws-sqs-using-node-js-part-2-1o78 | aws, node, javascript | ## Introduction
In the previous part i.e. [Getting Started with AWS SQS using Node.js - Part 1](https://dev.to/singhs020/getting-started-with-aws-sqs-using-node-js-part-1-4p8h), we had a look on how to send messages in the SQS. You can also call this as the producer of the message.
In this part we will see how can we connect to SQS and receive message for further processing.
## Pre-requisites
You should have followed the previous part of the article and can produce messages to a SQS.
## The Application Flow
In the previous part we were building an e-commerce app where an order service is producing messages to the SQS for further processing. In this part we will be looking at a fulfilment service which will receive the message and process it further.
## Receiving a message
This was the message which was produced in the last part for fulfilment service
```
{
"orderId": "this-is-an-order-id",
"date": "2020–02–02",
"shipBy": "2020–02–04",
"foo": "bar"
}
```
Like we did last time, we have to import the AWS SDK for node.js and use it to send a message . The SDK is capable of using the credentials stored in your env. It looks for the following environment variable:-
```
export AWS_ACCESS_KEY_ID=your_access_key_idexport
AWS_SECRET_ACCESS_KEY=your_secret_access_keyexport
AWS_REGION=the_region_you_are_using
```
Following is the code to receive the message:-
```
/* Getting Started with AWS SQS using node js. This part shows how to consume message from the SQS */
// Load the AWS SDK for Node.js
const AWS = require("aws-sdk");
const sqs = new AWS.SQS({apiVersion: "2012-11-05"});
const qurl = "ADD YOUR SQS URL HERE";
const params = {
"QueueUrl": qurl,
"MaxNumberOfMessages": 1
};
sqs.receiveMessage(params, (err, data) => {
if (err) {
console.log(err, err.stack);
} else {
if (!Array.isArray(data.Messages) || data.Messages.length === 0) {
console.log("There are no messages available for processing.");
return;
}
const body = JSON.parse(data.Messages[0].Body);
console.log(body);
// process the body however you see fit.
// once the processing of the body is complete, delete the message from the SQS to avoid reprocessing it.
const delParams = {
"QueueUrl": qurl,
"ReceiptHandle": data.Messages[0].ReceiptHandle
};
sqs.deleteMessage(delParams, (err, data) => {
if (err) {
console.log("There was an error", err);
} else {
console.log("Message processed Successfully");
}
});
}
});
```
Do, not forget to delete the message after you are done with your task. This is important to avoid any re-processing of the message. The above is implemented using callback. if you wish to achieve the implementation using promise, following is the code.
```
// the above message can be implemented using promise as well.
sqs.receiveMessage(params).promise()
.then(data => {
console.log(data);
// do the processing here
});
```
You can also find the code sample in my [github repo](https://github.com/singhs020/examples/blob/master/src/SQS/consumingMessage.js).
## Conclusion
AWS SQS is a powerful messaging service which allows you to use your own creativity to find the right fit for it in your application. The most common way to consume messages is using a polling mechanism which can poll the SQS and process all the message. This is a very basic integration of SQS in an application, there are other advanced use cases too like dead-letter queues, FIFO queues and Lambda integration with SQS to process streams. | singhs020 |
280,476 | Archivador Físico | Figura con apariencia de un archivador físico. Solo tiene que colocar el cursor sobre ella y luego ha... | 0 | 2020-03-13T05:42:27 | https://dev.to/dlunamontilla/archivador-fisico-3e9o | codepen | <p>Figura con apariencia de un archivador físico. Solo tiene que colocar el cursor sobre ella y luego hacer clic.</p>
{% codepen https://codepen.io/dlunamontilla/pen/NWqYxOV %} | dlunamontilla |
280,529 | neumorphic design | https://codepen.io/uiswarup/full/BaNrWLV | 0 | 2020-03-13T08:41:47 | https://dev.to/uiswarup/neumorphic-design-1h2d | design, html, css, black | https://codepen.io/uiswarup/full/BaNrWLV | uiswarup |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.