
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,119,335 | 4 Errors I Made When Building A Financial Application | 1. Not knowing which datatype to use in MySQL I once heard it’s better to use integers... | 0 | 2022-06-20T12:40:56 | https://dev.to/mratiebatie/4-errors-i-made-when-building-a-financial-application-2i0e | webdev, php, finance | ## 1. Not knowing which datatype to use in MySQL
I once heard it’s better to use integers when handling financial data. You convert a price like €10 to its lowest unit (cents in this case). This way you end up using 1000 as the amount to work with. This way you avoid the floating-point problem. The floating-point prob... | mratiebatie |
1,004,563 | Appendix: Security, Identity, and Compliance Services - AWS Certified Cloud Practitioner Study Guide | AWS Artifact No cost, self-service portal for on-demand access to AWS’ compliance reports Reports... | 17,089 | 2022-02-28T21:26:37 | https://dev.to/aidutcher/appendix-security-identity-and-compliance-services-aws-certified-cloud-practitioner-study-guide-18hg | [AWS Artifact](https://aws.amazon.com/artifact/)
- No cost, self-service portal for on-demand access to AWS’ compliance reports
- Reports include Service Organization Control (SOC) reports, Payment Card Industry (PCI) reports, and certifications from accreditation bodies across geographies and compliance verticals
- Ag... | aidutcher | |
1,004,679 | New Gmail layout | Learn about the new integrated Gmail layout Gmail has a new integrated view to organize Mail, Chat,... | 0 | 2022-02-28T23:34:52 | https://dev.to/fady_nabil10/new-gmail-layout-33cd | gsuite, gmail, googlecloud | **Learn about the new integrated Gmail layout**
Gmail has a new integrated view to organize Mail, Chat, Spaces, and Meet in one place.

With the new layout, you can:
- View Google apps integrated into the Gmail main menu
- View ... | fady_nabil10 |
1,004,831 | Vue3: setup router for NotFound page | Steps 1, Create your own "NotFound.vue" page 2, Add code to main.ts: const routes = [ ... | 0 | 2022-03-01T03:34:36 | https://dev.to/bitecode/vue3-setup-router-for-notfound-page-22p6 | vue, nginx | ## Steps
1, Create your own "NotFound.vue" page
2, Add code to `main.ts`:
```typescript
const routes = [
{
path: "/",
name: "home",
component: Home,
},
// ... other paths ...
{
path: "/:pathMatch(.*)*",
name: "not-found",
component: () => import("@/pages/NotFound.vue"),
},
]
```
3, ... | bitecode |
1,005,078 | The Importance of Conversational AI in Retail | The rising E-commerce marketing and giants like Amazon and Alibaba have quickly shaped the retail... | 0 | 2022-03-01T09:08:39 | https://dev.to/sandeepgundla/the-importance-of-conversational-ai-in-retail-42m0 | conversationalai, aiinretail, chatbots, ai | The rising E-commerce marketing and giants like Amazon and Alibaba have quickly shaped the retail industry with the help of digitization. How consumers used to buy and how the retail industry is functioning now, are different. With rising competition, consumers should not avoid the significance of conversational AI in ... | sandeepgundla |
1,005,357 | Can you list down a few common patterns you follow in your react code base | A post by Krishna Damaraju | 0 | 2022-03-01T14:18:59 | https://dev.to/sarathsantoshdamaraju/can-you-list-down-a-few-common-patterns-you-follow-in-your-react-code-base-24l0 | discuss, webdev, react | ---
title: Can you list down a few common patterns you follow in your react code base
published: true
tags: discuss, webDev, react
---
| sarathsantoshdamaraju |
1,005,911 | Nucleoid: Low-code Framework for Node.js | Nucleoid is low-code framework for Node.js, lets you build your APIs with the help of AI and built-in datastore in declarative runtime environment | 17,027 | 2022-03-02T17:55:00 | https://dev.to/nucleoid/nucleoid-low-code-framework-for-nodejs-2395 | node, javascript, lowcode, ai | ---
series: Tutorial
description: Nucleoid is low-code framework for Node.js, lets you build your APIs with the help of AI and built-in datastore in declarative runtime environment
---
## What is Nucleoid?
[Nucleoid](https://github.com/NucleoidJS/Nucleoid) is an AI-managed low-code framework, which uses symbolic (log... | canmingir |
1,006,229 | Hỏi đáp javascript | hello, em là thành viên mới xin chào tất cả mọi người | 0 | 2022-03-02T09:15:08 | https://dev.to/phquanghng/hoi-dap-javascript-1m5d | javascript | hello, em là thành viên mới xin chào tất cả mọi người | phquanghng |
1,006,284 | AMA with Uttam Singh, Developer Advocate at Polygon | Web3 is a revolutionary space which aims to help on building sustainable and incentivized... | 0 | 2022-03-02T11:03:03 | https://dev.to/aviyel/ama-with-uttam-singh-developer-advocate-at-polygon-2ok | ama, web3, opensource, podcast | Web3 is a revolutionary space which aims to help on building sustainable and incentivized communities. This might be quite fascinating by seeing the enthusiasm around but it is very essential to know the basis of Web3.
Aviyel is introducing brand new series for Web3 enthusiasts to get started with their journey. This ... | joshuapoddoku |
1,006,365 | Dependency Injection in JavaScript: Write Testable Code Easily | I struggled with two aspects of software development as a junior engineer: structuring large... | 0 | 2022-03-02T13:23:31 | https://blog.appsignal.com/2022/02/16/dependency-injection-in-javascript-write-testable-code-easily.html | javascript, node | I struggled with two aspects of software development as a junior engineer: structuring large codebases and writing testable code. Test-driven development is such a common technique that is often taken for granted, but it's not always clear how code can be made fully testable.
I remember reading examples where an autho... | nate_anderson |
1,006,704 | Detecting bit-rot with md5deep | Thanks to luxagen for getting me to actually set something up for this. Turned out to be mighty... | 0 | 2022-06-10T23:22:59 | https://timwise.co.uk/2022/03/02/detecting-bit-rot-with-md5deep/ | ---
title: Detecting bit-rot with md5deep
published: true
date: 2022-03-02 00:00:00 UTC
tags:
canonical_url: https://timwise.co.uk/2022/03/02/detecting-bit-rot-with-md5deep/
---
Thanks to [luxagen](http://luxagen.com/) for getting me to actually set something up for this. Turned out to be mighty useful when I acciden... | timabell | |
1,253,146 | Introduction to Cuelang | Introduction to Cuelang | 0 | 2022-11-11T18:42:15 | https://dev.to/eminetto/introduction-to-cuelang-2631 | cue, cuelang, go | ---
title: Introduction to Cuelang
published: true
description: Introduction to Cuelang
tags: cue, cuelang, go, golang
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2022-11-11 18:40 +0000
---
I bet that at that moment, you are thinking:
> "Another programming ... | eminetto |
1,007,917 | The 3 Best Full-Stack Hosting Platforms (2022) | I’ve compiled the 3 best full-stack hosting platforms based on 3 criteria: Ease of Use (You don’t... | 0 | 2022-03-03T16:25:34 | https://webdevwithseb.com/2022/03/03/the-3-best-full-stack-hosting-platforms-2022/?utm_source=rss&utm_medium=rss&utm_campaign=the-3-best-full-stack-hosting-platforms-2022 | fullstack, hosting, platform, webdev | ---
title: The 3 Best Full-Stack Hosting Platforms (2022)
published: true
date: 2022-03-03 13:52:00 UTC
tags: FullStack,Hosting,fullstack,hosting,platform,Platform,webdev
canonical_url: https://webdevwithseb.com/2022/03/03/the-3-best-full-stack-hosting-platforms-2022/?utm_source=rss&utm_medium=rss&utm_campaign=the-3-be... | sbmsr |
1,008,075 | The React.ReactNode type is a black hole | As developers, we use TypeScript for a few different reasons. The self-documentation aspects are huge... | 0 | 2022-03-03T16:21:51 | https://changelog.com/posts/the-react-reactnode-type-is-a-black-hole | javascript, typescript, react, webdev | ---
title: The React.ReactNode type is a black hole
published: true
date: 2022-02-16 07:00:00 UTC
tags: javascript,typescript,react,webdev
canonical_url: https://changelog.com/posts/the-react-reactnode-type-is-a-black-hole
---
As developers, we use TypeScript for a few different reasons. The self-documentation aspects... | kball |
1,008,155 | iOS vs Android gaming: development issues and platforms comparison for better game development performance | No operating system is totally better than the other one. Both iOS and Android have advantages and... | 0 | 2022-03-03T17:08:20 | https://dev.to/ruslanharanin/ios-vs-android-gaming-development-issues-and-platforms-comparison-for-better-game-development-performance-m7p | gamedev, android, ios | No operating system is totally better than the other one. Both iOS and Android have advantages and limitations.
The topic of which one is better for gaming has a variety of opinions. Most of them are largely subjective. That is why, in this blog, you can find facts and figures supported by the opinions of the develope... | ruslanharanin |
1,008,723 | Writing a business plan for a startup or app solution. | A business plan is fundamental for business success. Just like you need goals and... | 0 | 2022-03-04T05:00:44 | https://dev.to/mrpaulishaili/writing-a-business-plan-for-a-startup-or-app-solution-2djm | businessplan, tutorial, development, strategicplanning | > ## A business plan is fundamental for business success.
Just like you need goals and direction to succeed in life, you need a game plan to succeed in business, and it’s not as simple as it might initially sound.
It’s not just about setting goals of what you want to achieve, you actually have to back up all your c... | mrpaulishaili |
1,009,704 | Day:37 Training at Ryaz : Mongoose-modeling relationship b/w connected data | Date:4/02/2022 Day:Friday Today I started at about 10:30 am as I was finished with seventh module... | 0 | 2022-03-04T16:26:36 | https://dev.to/mahin651/day37-training-at-ryaz-mongoose-modeling-relationship-bw-connected-data-26jn | webdev, beginners, node, programming | - Date:4/02/2022
- Day:Friday
Today I started at about 10:30 am as I was finished with seventh module so, I started with eighth module as it was about mongoose: modeling relationships between connected data so, I started with it firstly the instructor taught about model relationships between connected data, we can ei... | mahin651 |
1,010,199 | How To Use GitHub For Project Collaboration — Based on Agile Method | Hello Fellow CodeNewbies 👋, A few months ago, I had a great experience participating in a project... | 15,234 | 2022-03-04T23:28:00 | https://adiati.com/how-to-use-github-for-project-collaboration-based-on-agile-method | github, git, tutorial, codenewbie | Hello Fellow CodeNewbies 👋,
A few months ago, I had a great experience participating in a project collaboration program with [The Collab Lab](https://the-collab-lab.codes/). I can't thank The Collab Lab enough for giving me the opportunity and experience to learn how to collaborate with other developers 💖.
Based on... | adiatiayu |
1,010,493 | String Manipulation Methods to Memorize | A common tech interview question I’ve received a lot is on string manipulation. This involves a... | 0 | 2022-03-05T04:38:32 | https://dev.to/yani82/string-manipulation-methods-to-memorize-49e0 | javascript, strings, methods, techinterviews | A common tech interview question I’ve received a lot is on [string](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String) manipulation. This involves a request to return a desired value out of a given string.
In this blog, I list down the most common string manipulation methods to me... | yani82 |
1,010,626 | SwitchMap RxJS Operator | SwitchMap RxJS Operator | 0 | 2022-03-05T06:56:16 | https://dev.to/pawankkumawat/switchmap-rxjs-operator-1m8h | javascript, angular, programming, performance | [SwitchMap RxJS Operator](https://pawan-kumawat.medium.com/rxjs-switchmap-operator-4b045e2fbbda) | pawankkumawat |
1,011,319 | Understanding Docker in a visual way (in 🎥 video): part 11 – Pass build args | Serie of videos about Docker. Explaining in a visual way Docker principles. | 15,506 | 2022-03-05T16:26:43 | https://dev.to/aurelievache/understanding-docker-in-a-visual-way-in-video-part-11-pass-build-args-30k0 | docker, devops, containers, beginners | ---
title: Understanding Docker in a visual way (in 🎥 video): part 11 – Pass build args
published: true
description: Serie of videos about Docker. Explaining in a visual way Docker principles.
tags: Docker, DevOps, containers, beginners
series: Understanding Docker in a visual way - in video
cover_image: https://dev-t... | aurelievache |
1,012,411 | Mastering Bash arguments with getopts | In this article, I show you how to mastering the Bash arguments with getopts to have a software who... | 0 | 2022-03-06T10:48:34 | https://dev.to/hamdyaea/mastering-bash-arguments-with-getopts-iac | bash, linux, arg, getopts | > In this article, I show you how to mastering the Bash arguments with getopts to have a software who run with professional arguments like
<pre>
mysoft.bsh -f [arg1] -g [arg2]
</pre>
I also show you how to add a default value if the argument is not given.
Here's an example of code :
<pre>
f=10
g=5
while getopts ... | hamdyaea |
1,012,558 | Step by Step guide on building a custom React hook in Typescript | According to the results of the annual survey of the State of Javascript, it doesn’t seem like React... | 0 | 2022-03-06T11:58:52 | https://relatablecode.com/step-by-step-guide-on-building-a-custom-react-hook-in-typescript/ | typescript, programming, javascript, webdev | ---
title: Step by Step guide on building a custom React hook in Typescript
published: true
date: 2022-03-06 11:54:09 UTC
tags: typescript,programming,javascript,webdevelopment
canonical_url: https://relatablecode.com/step-by-step-guide-on-building-a-custom-react-hook-in-typescript/
cover_image: https://cdn-images-1.me... | diballesteros |
1,014,301 | Terminal Comand | Bugun Terminal komandalirini organdik ls hozirgi papkadagi barcha narsalarni... | 0 | 2022-03-07T11:42:24 | https://dev.to/justakrom/terminal-comand-273c | programming, terminal, cpp, uzbek | ### Bugun Terminal komandalirini organdik
# `ls`
- hozirgi papkadagi barcha narsalarni chop etadi
- `-a` tanlovi orqali yashirin fayl va papkalar ham chop etiladi
### `pwd`
-hozirgi biz turgan papka manzilini chop etadi
- `~` manzili `$HOME` manzilga teng
###`cd` (current directory)
- joriy papkani ozgartiradi, ya'n... | justakrom |
1,014,626 | Difference between web2 and web3 | In this article I’ll be explaining the difference between the trending technologies we’ve been seeing... | 0 | 2022-03-07T15:23:10 | https://dev.to/tuasegun/difference-between-web2-and-web3-278o | zuri, blockchain, blockgames, web3 |
In this article I’ll be explaining the difference between the trending technologies we’ve been seeing recently which is the web 2 and web 3 technologies.
To make us understand the difference we first have to know the meaning and the similarities between each of them and the meaning of each and everyone of the the tec... | tuasegun |
1,014,829 | Reactjs Explore | Component Lifecycle: React web apps are actually a collection of independent components that run... | 0 | 2022-03-07T16:24:34 | https://dev.to/rajukst/reactjs-explore-1oc2 | Component Lifecycle: React web apps are actually a collection of independent components
that run according to the interactions made with them. Every React Component has a
lifecycle of its own; lifecycle of a component can be defined as the series of methods that
are invoked in different stages of the component’s existe... | rajukst | |
1,015,015 | We did it! | Just finished my first code challenge and the anxiety was through the roof. Had to display elements... | 0 | 2022-03-07T18:46:49 | https://dev.to/danielarmbruster0314/we-did-it-3o | webdev, beginners, programming, codenewbie | Just finished my first code challenge and the anxiety was through the roof. Had to display elements to the DOM by utilizing an API on a local server sounds a lot scarier than it turned out but definitely not a fan of timed challenges too much pressure. wishing all fellow programmers a moment of resolve. | danielarmbruster0314 |
1,015,109 | Difference between web3 and web2 | Web2 is the Internet as we know it today, whereas Web3 refers to the evolution and next generation of... | 0 | 2022-03-07T21:54:34 | https://dev.to/somtozech/difference-between-web3-and-web2-1h3a | blockchain, web3, web2 | Web2 is the Internet as we know it today, whereas Web3 refers to the evolution and next generation of the Internet.
Web2 is based on a server-client structure, meaning that a corporation or entity controls and owns your personal data in exchange for their service. In web3, anyone can participate without having to sha... | somtozech |
1,015,285 | pnpm and Parcel based monorepo | The problem I have tried several ways of managing JavaScript/TypeScript Library Monorepos... | 0 | 2022-03-13T15:57:16 | https://dev.to/pklaschka/pnpm-and-parcel-based-monorepo-4ojc | javascript, monorepo, parcel, pnpm | ## The problem
I have tried several ways of managing JavaScript/TypeScript Library Monorepos in the past: `lerna`, `yarn workspaces`, etc.
Now don't get me wrong: These are great tools and I very much appreciate the effort their authors have put into them.
**But they always felt a little bit like gambling.** It neve... | pklaschka |
1,015,307 | Cara menggunakan Environment Variables di NextJS | Pertama-tama buat lah sebuah file di root project dengan nama .env MY_NAME=AWAN; Enter... | 0 | 2022-03-08T02:00:43 | https://dev.to/awan/cara-menggunakan-environment-variables-di-nextjs-756 | nextjs, indonesia, pemula | Pertama-tama buat lah sebuah file di root project dengan nama .env
```
MY_NAME=AWAN;
```
Setelah itu kita bisa memanggil environment variable di codingan dengan cara
```
const name = process.env.MY_NAME;
console.log(name);
```
Dan hasilnya akan keluar seperti ini
 | Part 2 of the Series on Emojicode. Let's dive deep into coding with emojis. In this part, I'll try... | 17,219 | 2022-03-09T09:52:06 | https://dev.to/knaagar/emojicode-variables-3jde | programming, tutorial, beginners, codenewbie | _Part 2 of the Series on Emojicode._
Let's dive deep into coding with emojis.
In this part, I'll try to introduce you to what variables are and how are they implemented in Emojicode 💪.
#### Variable 🙄❓
A variable is simply a name that represents a particular piece of your computer’s memory that has been set aside f... | knaagar |
1,022,495 | Designing an API for a Video Game | I am working on a video game for programmers. The game is played by writing code that interacts... | 0 | 2022-03-14T17:24:02 | https://www.jdno.dev/designing-an-api-for-a-video-game/ | gamedev, devlog | ---
title: Designing an API for a Video Game
published: true
date: 2022-03-13 17:00:00 UTC
tags: gamedev,devlog
canonical_url: https://www.jdno.dev/designing-an-api-for-a-video-game/
---
[](https://github.com/anuraghazra/github-readme-stats)
A tool to automatically generate dynamic statistics for your GitHub readmes.
______
##[12ft](h... | vincenius |
1,113,354 | Divide a String Into Groups of Size k | A string s can be partitioned into groups of size k using the following procedure: The first... | 18,343 | 2022-06-13T23:00:48 | https://dev.to/theabbie/divide-a-string-into-groups-of-size-k-48mj | leetcode, dsa, theabbie | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if... | theabbie |
1,115,590 | Looking for App Developers for Web3 Wallet Startup? | Add me on Telegram, or Twitter @julianauxm for details! Very interesting project for anyone looking... | 0 | 2022-06-16T03:32:02 | https://dev.to/julianauxm/looking-for-app-developers-for-web3-wallet-startup-1p99 | web3, hiring, mobile, crypto | Add me on Telegram, or Twitter @julianauxm for details!
Very interesting project for anyone looking to change the web3 space. | julianauxm |
1,181,056 | Programming Update: Aug | August was a programming-filled month for me. It focused entirely on Python and I mostly continued... | 0 | 2022-11-02T21:50:55 | https://www.ericsbinaryworld.com/2022/08/31/programming-update-aug/ | python, adventofcode, amortization, civilizationvi | ---
title: Programming Update: Aug
published: true
date: 2022-08-31 23:42:58 UTC
tags: python,AdventofCode,Amortization,CivilizationVI
canonical_url: https://www.ericsbinaryworld.com/2022/08/31/programming-update-aug/
---
August was a programming-filled month for me. It focused entirely on Python and I mostly continue... | djotaku |
1,127,348 | How to Build a Clubhouse Clone App with Android and ZEGOCLOUD - A Social Audio App Development | Because of a conversation with Musk, ClubHouse caught fire worldwide and reached a staggering 9.6... | 0 | 2022-06-29T09:00:14 | https://www.zegocloud.com/blog/clubhouse-clone | android, mobile, programming, tutorial | Because of a conversation with Musk, ClubHouse caught fire worldwide and reached a staggering 9.6 million monthly downloads.
Faced with a new social model, how to quickly clone Clubhouse's social gameplay. Enrich the interaction form of your own application.
Today we will introduce how to use [ZEGOCLOUD's ZEGOLiveAud... | davidrelo |
1,128,783 | Blog: Changes to Supported Modules | We are continually reviewing our Supported modules list and understanding usage and value to users.... | 0 | 2022-07-01T16:16:28 | https://puppetlabs.github.io/content-and-tooling-team/blog/posts/2022-06-30-changes-to-supported-modules/ | ---
title: Blog: Changes to Supported Modules
published: true
date: 2022-06-30 00:00:00 UTC
tags:
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/posts/2022-06-30-changes-to-supported-modules/
---
We are continually reviewing our Supported modules list and understanding usage and value to us... | puppetdevx | |
1,128,875 | How do you write technical documentation? | I joined dev.to to learn more about how others write and to join a growing community of writers.... | 0 | 2022-06-30T19:35:53 | https://dev.to/jordanplows/how-do-you-write-technical-documentation-37fj | I joined dev.to to learn more about how others write and to join a growing community of writers.
One problem I found is maintaining and updating technical documentation is a real pain, even for simple things like a readme.
- Do you [GitHub Actions](https://github.com/actions)?
- [MarkDoc Plugins](markdoc.io)?
W... | jordanplows | |
1,129,657 | Roadmap, Quick cheatsheet, Study materials for Front End Web Development | This is the roadmap I'm following to become a Frontend Web Developer in 2022 You can do the... | 0 | 2022-07-01T17:05:47 | https://dev.to/gaurbprajapati/roadmap-quick-cheetsheet-study-materials-nia | webdev, javascript, programming, react | This is the roadmap I'm following to become a Frontend Web Developer in 2022
You can do the same!
Basics of CS
↓
HTML
↓
CSS
↓
Tailwind / Bootstrap
↓
JavaScript
↓
DOM
↓
Git (Version Control)
↓
React JS
↓
TypeScript
↓
Next JS
↓
GraphQL
You can prefer udemy paid course for... | gaurbprajapati |
1,129,778 | RoadRunner video tutorials | First fifteen videos about RoadRunner have been committed. Videos about Spiral Framework in... | 0 | 2022-07-01T18:15:59 | https://dev.to/roxblnfk/roadrunner-video-tutorials-nim | roadrunner, php, spiral, tutorial | First fifteen videos about RoadRunner [have been committed](https://www.youtube.com/playlist?list=PLL6_RArGSORJ2OU4qn8rJmIwSGBIc8C_X).
Videos about Spiral Framework in progress.
Do you use the RoadRunner with your PHP Application? | roxblnfk |
1,130,080 | Web Developer Tools Fundamentals | Breaking down essential tools used by web developers. | 0 | 2022-07-02T07:59:29 | https://blog.rainwater.io/2022/07/02/web-developer-tools-fundamentals | webdev, beginners, tutorial, tooling |
You know how to write code... now what?
A common challenge new developers run into is making the transition from writing code in a closed environment, such as a tutorial or course, to building a real project. Suddenly there's a whole new world of tools that are mentioned but not explained.
Perhaps you are trying to ... | rain2o |
1,130,214 | I want to convert this code from php to nodejs | Hello I want to convert this code from php to nodejs <?php include 'config.php'; include... | 0 | 2022-07-02T13:00:52 | https://dev.to/abidi12/i-want-to-convert-this-code-from-php-to-nodejs-1424 | Hello
I want to convert this code from php to nodejs
```
<?php
include 'config.php';
include 'connect.php';
session_start();
function numeric($num){
if (preg_match('/^[0-9]+$/', $num)) {
$status = true;
} else {
$status = false;
}
return $status;
}
////////////////////////////////////// RESET THE BUZZ ON... | abidi12 | |
1,130,753 | My first 2 months working as a programmer | This won’t be a long and tiring post that are known to exist throughout the internet, but more of a... | 0 | 2022-07-03T09:29:37 | https://dev.to/welschmoor/my-first-2-months-working-as-a-programmer-37bg | This won’t be a long and tiring post that are known to exist throughout the internet, but more of a summary of what I have learned in the first two months of my developer journey.
Before May 1st, 2022 I have never worked as a programmer, having learned the craft for 1 year I was able to find a job. Right upfront I wan... | welschmoor | |
1,130,904 | How to vertically center text and HTML elements with CSS | Vertically centering something in CSS is not as easy as you'd think, and until we got tools like... | 0 | 2022-07-03T15:14:07 | https://fjolt.com/article/css-vertically-center | css, webdev, tutorial | Vertically centering something in CSS is not as easy as you'd think, and until we got tools like **flexbox**, it was really hard. Fortunately, vertically centering something within a container is quite easy now. Let's look at how to accomplish it.
## Vertically centering an item in CSS
Let's assume we have some simpl... | smpnjn |
1,130,983 | 1095. Leetcode Solution in Cpp | /** * // This is the MountainArray's API interface. * // You should not implement it, or speculate... | 0 | 2022-07-03T17:32:59 | https://dev.to/chiki1601/1095-leetcode-solution-in-cpp-2m3o | cpp | ```
/**
* // This is the MountainArray's API interface.
* // You should not implement it, or speculate about its implementation
* class MountainArray {
* public:
* int get(int index);
* int length();
* };
*/
class Solution {
public:
int findInMountainArray(int target, MountainArray& mountainArr) {
... | chiki1601 |
343,241 | Modern Java for the Modern Dev | Bursting the myths of Java | 0 | 2020-05-25T09:52:54 | https://dev.to/munukutla/modern-java-for-the-modern-dev-5dd | java, serverless, helidon, graal | ---
title: Modern Java for the Modern Dev
published: true
description: Bursting the myths of Java
tags: java, serverless, helidon, graal
---
This is my personal experience while trying to push Java to the edge of my requirements of a Cloud-native environment. So these were the myths that are afloat about Java (or why ... | munukutla |
1,131,419 | Scaling up with Strapi: how RemitBee adapts the CMS to their needs since 2019 | RemitBee has been using Strapi for their website since 2019. In three years, their team grew from 5... | 0 | 2022-07-04T08:58:02 | https://strapi.io/blog/scaling-up-with-strapi-how-remit-bee-adapts-the-cms-to-their-needs-since-2019?utm_campaign=Strapi%20Blog&utm_source=devto&utm_medium=blog | cms, javascript, userstory, seo | ---
canonical_url: https://strapi.io/blog/scaling-up-with-strapi-how-remit-bee-adapts-the-cms-to-their-needs-since-2019?utm_campaign=Strapi%20Blog&utm_source=devto&utm_medium=blog
---
_RemitBee has been using Strapi for their website since 2019. In three years, their team grew from 5 to 50, they have successfully cust... | strapijs |
1,132,081 | Things Every Product Manager Must Know About Testing | Being responsible for the development and maintenance of a rapidly evolving tech product is arguably... | 0 | 2022-07-05T03:25:46 | https://www.browserstack.com/guide/product-manager-must-know-about-testing | testing, productivity | Being responsible for the development and maintenance of a rapidly evolving tech product is arguably one of the most technical and fast-paced jobs out there. The fact that the whole landscape of relevant technologies is also evolving outside your company and product adds another layer of complexity to the mix.
New... | vivekmannotra |
1,132,225 | How to contribute to an open-source project | One of the During my career as a software developer, I started getting involved in some open-source... | 0 | 2022-07-05T08:38:20 | https://memphis.dev/blog/how-to-contribute-to-an-open-source-project// | opensource, github, contributorswanted, devrel |
One of the During my career as a software developer, I started getting involved in some open-source communities and actively contributor, I never thought to myself that it will leverage my knowledge and experience to that level it did.
Hence, in the spirit of open-source, I co-founded Memphis.dev together with my 3 b... | team_memphis |
1,132,435 | Functions in JavaScript | method-1 let name2="pushan"; function greet(name2 ) { console.log(This is my name... | 0 | 2022-07-05T11:35:16 | https://dev.to/pushanverma/functions-in-javascript-2knh | webdev, javascript, beginners, programming | _method-1_
let name2="pushan";
function greet(name2 )
{
console.log(`This is my name ->${name2}`);
}
greet(name2);
_method-2_
function greet2(name2,rollno)
{
console.log(`This is my name ->${name2} and rollno ->${rollno}`);
}
greet2(name2,114);
_method-3_
function greet3(name2,rollno="114")
{
console.log... | pushanverma |
1,132,439 | Hoisting and Temporal Dead Zone | Hoisting console.log('varname',varName); var varName; console.log('varname',varName); varName... | 0 | 2022-07-05T11:38:44 | https://dev.to/pushanverma/hoisting-and-temporal-dead-zone-1m0f | webdev, javascript, beginners, programming | **Hoisting**
console.log('varname',varName);
var varName;
console.log('varname',varName);
varName ="captain america";
console.log('varname',varName);
fn();
function fn()
{
console.log("hello from fn");
}
fn();

**Inferno JS** is a JavaScript framework for building Front-End User Interfaces (UI). The [official website of the framework](https://www.infernojs.org/) states that "Inferno is an insanely fast, React-like library for building high-perf... | asayerio_techblog |
1,132,778 | O que são testes e como funcionam? | O que é um teste? Um teste é um trecho de código, que quando executado chama a... | 0 | 2022-07-05T17:41:09 | https://dev.to/cristuker/tdd-o-que-e-e-como-comecar-15g0 | javascript, tdd, beginners, tutorial | ### O que é um teste?
Um teste é um trecho de código, que quando executado chama a funcionalidade a qual quer testar e submete ela a um cenário com parâmetros e retornos totalmente controlados por você. Assim você consegue entender como o seu código se comporta em diferentes cenários e como trata-lós, dessa forma traz... | cristuker |
1,133,197 | Commenting on Comments | A well-crafted comment, placed in the right spot, can be one of the most helpful and clarifying... | 18,788 | 2022-07-08T10:44:02 | https://dev.to/kalkwst/commenting-on-comments-3dn3 | programming, beginners, discuss | A well-crafted comment, placed in the right spot, can be one of the most helpful and clarifying things in a codebase. On the other hand, nothing can clutter up a module more and slow down developers than frivolous, dogmatic, or irrelevant comments.
Comments are a feature of a language, and thus, they are not inherentl... | kalkwst |
1,133,252 | Educational App Development: 15 Must-Have Features for Smart and Systematic Learning | Technology becomes more excellent and influential every day, and several modifications come each day.... | 0 | 2022-07-06T10:22:30 | https://dev.to/ameliawenham/educational-app-development-15-must-have-features-for-smart-and-systematic-learning-1mc | webdev, javascript, programming, beginners |
Technology becomes more excellent and influential every day, and several modifications come each day. The smartphone app is one of the biggest successes we have ever seen. In a short period, the practice has found its way across the industry. From enjoyment to meditation there are applications for everything these da... | ameliawenham |
1,133,635 | 1671. Leetcode Solution in CPP | class Solution { public: int minimumMountainRemovals(vector<int>& nums) { ... | 0 | 2022-07-06T14:44:05 | https://dev.to/chiki1601/1671-leetcode-solution-in-cpp-1b | cpp | ```
class Solution {
public:
int minimumMountainRemovals(vector<int>& nums) {
vector<int> l = lengthOfLIS(nums);
vector<int> r = reversed(lengthOfLIS(reversed(nums)));
int maxMountainSeq = 0;
for (int i = 0; i < nums.size(); ++i)
if (l[i] > 1 && r[i] > 1)
maxMountainSeq = max(maxMounta... | chiki1601 |
1,324,131 | How to Generate Lower-Case URLs in ASP.NET Core? | In this article, we will look at how to generate lower-case URLs in ASP.NET Core using the built-in... | 0 | 2023-01-10T19:49:08 | https://mbarkt3sto.hashnode.dev/how-to-generate-lower-case-urls-in-aspnet-core | ---
title: How to Generate Lower-Case URLs in ASP.NET Core?
published: true
date: 2022-12-24 18:57:26 UTC
tags:
canonical_url: https://mbarkt3sto.hashnode.dev/how-to-generate-lower-case-urls-in-aspnet-core
---
In this article, we will look at how to generate lower-case URLs in [ASP.NET](http://ASP.NET) Core using the... | mbarkt3sto | |
1,134,179 | 394. Leetcode Solution in CPP | class Solution { public: string decodeString(string s) { stack<pair<string, int>>... | 0 | 2022-07-07T05:04:43 | https://dev.to/chiki1601/394-leetcode-solution-in-cpp-4mj2 | cpp | ```
class Solution {
public:
string decodeString(string s) {
stack<pair<string, int>> stack; // (prevStr, repeatCount)
string currStr;
int currNum = 0;
for (const char c : s)
if (isdigit(c)) {
currNum = currNum * 10 + (c - '0');
} else {
if (c == '[') {
stack.e... | chiki1601 |
1,134,242 | Batch delete Docker images in a Azure Container Repository | This is mostly a note to self and i no credit whatsoever to myself. Info collected mainly from this... | 0 | 2022-07-07T07:35:11 | https://dev.to/olaj/batch-delete-docker-images-in-a-azure-container-repository-5429 | docker, azure | This is mostly a note to self and i no credit whatsoever to myself. Info collected mainly from this SO question, but i had some issues with the info there, mainly stuff caused by changes to Azure CLI and some code formatting issues.
https://stackoverflow.com/questions/41446962/how-to-delete-image-from-azure-container-... | olaj |
1,135,008 | Agora sim, o grande ganho do enum no Dart 2.17 | Liquid syntax error: Tag '{% https://medium.com/dartlang/dart-2-15-7e7a598e508a %}' was not properly... | 0 | 2022-07-08T00:14:45 | https://dev.to/kmartins/agora-sim-o-grande-ganho-do-enum-no-dart-217-2ije | dart, flutter, enum, news |
Como mencionado no [artigo anterior](https://kmartins.dev/enum-no-dart-215), não era possível declarar **membros** nos nossos `enums` e de certa forma vários `devs` ficavam chateados(as) e magoados(as) 😤
Mas para nossa alegria, isso finalmente mudou, fique tranquilo(a), você não leu errado, melhoria implementa e [is... | kmartins |
1,135,409 | My Six Months Strategy Plan for Building Up A Community. | Communities are an integral part of any product’s journey in tech. They help you grow at... | 0 | 2022-07-08T12:38:59 | https://dev.to/shrutiiaroraaa/my-six-months-strategy-plan-for-building-a-community-1736 | productivity, community, blog, opensource | Communities are an integral part of any product’s journey in tech. They help you grow at lightning-fast speed while not burning out and having fun!
For me, the community is more like “commUNITY”.
So, here’s what my 6 Months plan looks like -
1st Month -> I call the first phase “Create, Set and Address”.
So, in this ... | shrutiiaroraaa |
1,139,594 | 100 Days of Learning From My Mistakes – Day 2 | Why aren't my styles updating?! I've tried everything. Debugged my entire Sass project file by file.... | 0 | 2022-07-13T15:37:03 | https://dev.to/kondaguey/100-days-of-learning-from-my-mistakes-day-2-1ko5 | sass, css, cli, beginners | Why aren't my styles updating?! I've tried everything. Debugged my entire Sass project file by file. All imports correct. Everything peachy. What. The. Hell!
Did I forget CSS? Am I a terrible developer? Is this even for me? Why is the world against me?!
Oh. I forgot to run my Sass compiler...
```
npm run compile:sa... | kondaguey |
1,148,869 | Luos integrations: survey | A few days ago, we created a poll to find out what integrations would be most useful for you who are... | 0 | 2022-07-22T15:44:51 | https://dev.to/luos/luos-integrations-survey-58f | opensource, microservices, embedded, luos | A few days ago, we created a poll to find out what integrations would be most useful for you who are using or discovering Luos.
Thanks for your opinion, it will help us to add your ideas in our roadmap.
As a result of this survey, we have added Zephyr, cloud providers (like AWS, Azure etc.), Zapier and Silicon Labs t... | emanuel_allely |
1,151,674 | How to change React Native app name (iOS / Android) | In the example below I have a sample app that I named owler_franchise in the setup process. Now I... | 0 | 2022-07-26T10:03:00 | https://dev.to/nomanoff_tech/how-to-change-react-native-app-name-ios-android-5fnf | tutorial, mobile, reactnative | In the example below I have a sample app that I named **owler_franchise** in the setup process.
Now I want to change that to Owler Franchise.
- **iOS**
For **iOS**, go to **ios** folder and find the folder n... | nomanoff_tech |
1,180,422 | Simple Component ReactJS | A post by aboey | 0 | 2022-08-31T09:50:08 | https://dev.to/aboeywahab/simple-component-reactjs-39l8 | codepen | {% codepen https://codepen.io/aboeywahab/pen/MWVNMNb %} | aboeywahab |
1,180,488 | Top Flutter Benefits In Mobile And IoT Development. | We all know the power of Flutter when it comes to cross-platform mobile app development. But, Flutter... | 0 | 2022-08-31T12:28:43 | https://dev.to/bacancytechnology/top-flutter-benefits-in-mobile-and-iot-development-47l7 | flutter, mobileapp, iot, development | We all know the power of Flutter when it comes to cross-platform mobile app development. But, Flutter with IoT development is something interesting and more powerful. It already impressed the many developers around the world and day by day it's become more popular.
If you are about to do the IoT development, Flutter ... | bacancytech |
1,181,082 | Refactoring the Game | Our game is almost finished (at least part of it). But we can improve the module game and do it... | 19,513 | 2022-09-01T05:15:49 | https://dev.to/dnovais/refactoring-the-game-j7a | elixir, algorithms, webdev, tutorial | ---
series: Rock, Paper, and Scissors with Elixir
---
Our **game** is almost finished (_at least part of it_). But we can improve the module game and do it together.
**Let's start...**
I found modular arithmetic, looking for something with a mathematical approach to solving the logic of our game (if you are interest... | dnovais |
1,181,374 | Design Patterns 2 | Types | Before diving into the types of design patterns, we need to brush up our memories on what design... | 0 | 2022-09-05T07:29:33 | https://dev.to/abdulhameedanofi/design-patterns-2-types-1jgk | Before diving into the types of design patterns, we need to brush up our memories on what design patterns are. Design patterns are templates for solving recurring problems in our software designs.
Now that we know what design patters are, understanding the types of design patterns will make it easy to know the right o... | abdulhameedanofi | |
1,181,688 | React Life Cycle | Every React web app comprises of components and these components go through some life cycle methods.... | 0 | 2022-09-01T18:09:53 | https://dev.to/abhinav707/react-life-cycle-4pj1 | webdev, react, javascript | Every React web app comprises of components and these components go through some life cycle methods.
[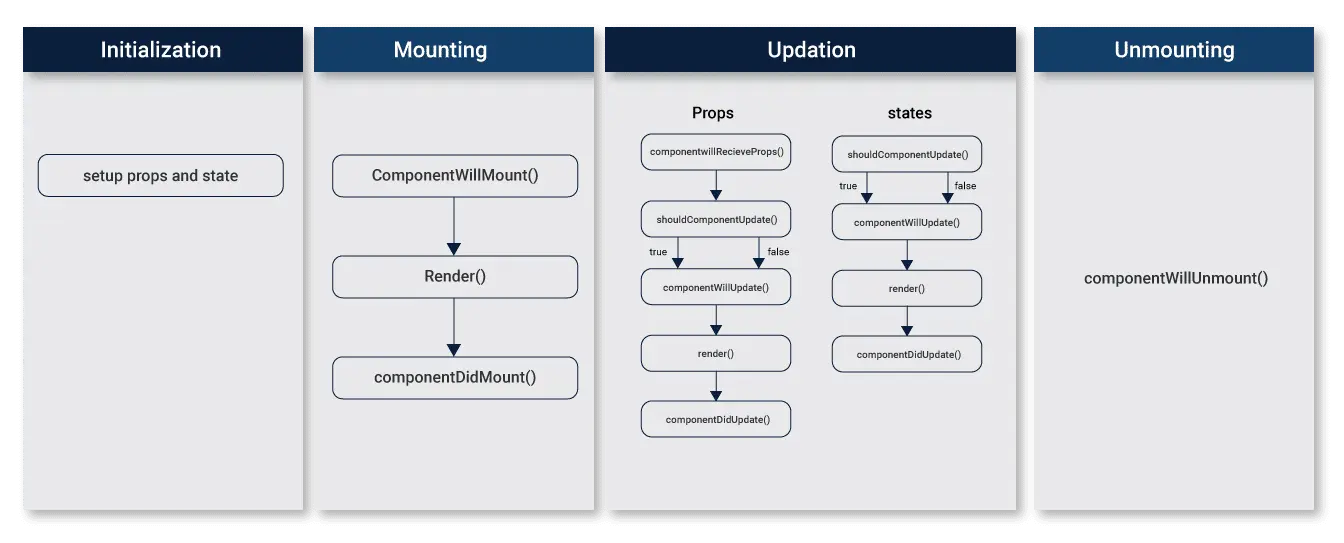](https://www.cuelogic.com/blog/reactjs-lifecycle#:~:text=Initialisation,constructor%20of%20a%20component%... | abhinav707 |
1,181,829 | My Experience as a Mentor | Spanish Version "The circle is now complete. When I left you, I was but the learner. Now, I am the... | 0 | 2022-09-07T19:04:34 | https://dev.to/smmd/my-experience-as-a-mentor-4min | grow, programming, 100daysofcode, community | [Spanish Version](https://blog.thedojo.mx/2022/09/19/mi-experiencia-como-mentora.html)
"The circle is now complete. When I left you, I was but the learner. Now, I am the master." - Darth Vader.
Avoid being a master of evil; in the last months, I had the opportunity of being the mentor of two incredible women.
The tr... | smmd |
1,181,964 | First Post! | So I have decided to keep on track of my developer journal. I am going to try to post here daily with... | 0 | 2022-09-02T05:30:10 | https://dev.to/adamsteradam/first-post-4km3 | So I have decided to keep on track of my developer journal.
I am going to try to post here daily with what I have been doing, and what I have learned etc.
cheers.
| adamsteradam | |
1,182,052 | Install these 9 apps to 10x productivity 👇 | Do you have a smartphone without these apps? THROW IT!! Because, what’s the point if your smartphone... | 0 | 2022-09-02T08:04:52 | https://dev.to/areedev/install-these-9-apps-to-10x-productivity-2p1h | productivity, career, programming, beginners | **Do you have a smartphone without these apps? THROW IT!!**
**Because, what’s the point if your smartphone doesn’t make you smarter?**
.
.
.
.
.
## Install these 9 apps to 10x productivity 👇
**1. Readwise**
Readwise allows you to organize and review your e-book and article highlights.
Spaced Repetition's scientif... | areedev |
1,182,146 | 0xDC is live! 🎉 | https://0xdc.me | 0 | 2022-09-02T11:16:48 | https://dev.to/0xdc/0xdc-is-live-361a | blog, devops, opensource, cloud | ERROR: type should be string, got "\nhttps://0xdc.me" | 0xdc |
1,182,286 | James Altucher? | Curious whether anyone out there follows James Altucher? I have been researching how to hone the... | 19,654 | 2022-09-02T15:03:35 | https://dev.to/echristian74/james-altucher-2iac | jamesaltucher, ideas, trainyourbrain | Curious whether anyone out there follows James Altucher? I have been researching how to hone the ability to develop new ideas and James is rocking my world. [James Altucher Blog](https://jamesaltucher.com/blog/) | echristian74 |
1,182,928 | Commenting == Account Takeover | Hi y'all, how are you doing? Hope you are doing great 🤗 It's been quite a long time since my last... | 0 | 2022-09-03T23:08:20 | https://dev.to/therealbrenu/commenting-account-takeover-c54 | hacking, security, bugbounty, lowcode | Hi y'all, how are you doing? Hope you are doing great 🤗
It's been quite a long time since my last released blog, mostly because I didn't like the themes I've been coming up with. But today, I'm here to share the process that recently got me to find [CVE-2022-3019](https://huntr.dev/bounties/a610300b-ce3c-4995-8337-11... | therealbrenu |
1,183,025 | Must have Custom hooks for NextJs | useLocalStorage the custom hook strapped this together to help save and retrieve... | 0 | 2022-09-03T08:15:51 | https://dev.to/tigawanna/must-have-custom-hooks-for-nextjs-3b5k | nextjs, typescript, localstorage, darkmode | # useLocalStorage the custom hook
### strapped this together to help save and retrieve the `user-theme` and `token` from the localstorage
was working on [a react vite app ](https://github.com/tigawanna/gitpals) and had to port it over to Next Js [the ported next js app](https://github.com/tigawanna/gitdeck) and i ve... | tigawanna |
1,183,032 | Custom react icon context wrapper | React icons are cool and all but tey do have that pesky issue of hvving to wrap them in an in order... | 0 | 2022-09-03T08:33:25 | https://dev.to/tigawanna/custom-react-icon-context-wrapper-58b | reactic, react, context, tailwindcss | React icons are cool and all but tey do have that pesky issue of hvving to wrap them in an <IconContext.provider> in order to be able to resize them or change their colors so i made this wrapper
```ts
import React from 'react'
import { IconContext, IconType } from "react-icons";
type MyProps = {
// using `interfac... | tigawanna |
1,183,610 | ReactJS Installation & Setup Tutorial | React is currently one of the most popular JavaScript library for building UIs —and that trend looks... | 19,680 | 2022-09-06T18:56:09 | https://dev.to/rembertdesigns/reactjs-installation-setup-tutorial-449l | programming, productivity, tutorial, react | React is currently one of the most popular JavaScript library for building UIs —and that trend looks set to continue for the foreseeable future. In this article, we’re going to focus on the ways we can setup React, quickly and painlessly so we can dive right into coding!
## Why React?
For the uninitiated, React allows... | rembertdesigns |
1,183,852 | Javascript: Declarative vs Imperative programming style | These are programming paradigms: Declarative: tells What to do Imperative: tells How to... | 19,800 | 2022-09-04T13:57:27 | https://dev.to/urstrulyvishwak/js-declarative-vs-imperative-programming-style-5g57 | javascript, programming, functional, tutorial | These are programming paradigms:
Declarative: tells `What to do`
Imperative: tells `How to do`
**Example: Find the summation of salary for the employees with dept 'justCode'**
### Imperative Style:
```javascript
const employees = [
{id: 1, name: 'james', dept: 'admin', salary: 10000},
{id: 1, name: 'Tom', dept: 'f... | urstrulyvishwak |
1,184,887 | when u rich | A post by murkings | 0 | 2022-09-05T00:56:46 | https://dev.to/murk/when-u-rich-alf | murk | ||
1,184,977 | A Trick to Further Breaking Down Angular Components | The usual Angular way of dealing with things is placing business logic in services and presentation... | 0 | 2022-09-05T05:40:21 | https://dev.to/bwca/a-trick-to-further-breaking-down-angular-components-1i8a | typescript, angular | The usual Angular way of dealing with things is placing business logic in services and presentation logic in components. It is a good approach, as all the heavy lifting is delegated to services which are imported and re-used by different components. Yet, sometimes components start acquiring logic of their own, with tim... | bwca |
1,185,163 | Build custom front-end on top of Snowflake database | Create customised Snowflake dashboards with DronaHQ Create custom Snowflake dashboards with DronaHQ... | 0 | 2022-09-05T11:15:53 | https://www.dronahq.com/snowflake-dashboard/ | tutorial, database, lowcode, frontend | <h2><b>Create customised Snowflake dashboards with DronaHQ</b></h2>
<span style="font-weight: 400;">Create custom Snowflake dashboards with [DronaHQ](https://www.dronahq.com/) and visualize your business metrics and KPIs in real time. Import your data directly from Snowflake and create your own dashboards. </span>
<sp... | aaikansh_22 |
1,185,183 | Deploying Next.js app on Netlify [Building Personal Blog Website Part 4] | Now it’s finally time to put your app online! First you need to push your Git repository (create... | 23,655 | 2022-09-05T11:52:11 | https://www.hwlk.dev/blog/personal-blog-tutorial-4 | strapi, nextjs, javascript, headlesscms | Now it’s finally time to put your app online!
First you need to push your *Git* repository (create automatically while creating *Next.js* app) to GitHub. Go to [github.com](http://github.com) and log in (or create an account if you didn’t do this already). Create a new repository clicking on the upper right corner:
... | hwlkdev |
1,185,613 | PHP+Nginx+Docker | At one time or another I have to create a project from scratch, but sometimes I end up wasting a lot... | 0 | 2022-09-05T20:01:23 | https://dev.to/walternascimentobarroso/phpnginxdocker-nih | php, docker, nginx, xdebug | At one time or another I have to create a project from scratch, but sometimes I end up wasting a lot of time just creating the environment, so to make it easier I'll leave something ready with php and nginx using docker
## Readme
Start by adding a `README` to the project and as the project progresses you will edit it... | walternascimentobarroso |
1,185,960 | Ben 10- Omnitrix | Hello Developers. I'm new to this kind of community thing. Hope I'll get to know about this soon.... | 0 | 2022-09-06T09:52:40 | https://dev.to/thisissherlock1/ben-10-omnitrix-fkb | javascript, css | Hello Developers. I'm new to this kind of community thing. Hope I'll get to know about this soon.
First let me know, What is your favourite cartoon character in your childhood? The character must brought you back to your childhood and make you feel so Nostalgic?
For me, It's **BEN 10**. Hope You know about that show. ... | thisissherlock1 |
1,186,117 | Remote Debugging Webpages In iOS Safari | Safari is one of the most popular web browsers. Developed and promoted by Apple , it is based on the... | 0 | 2022-09-06T13:41:37 | https://www.lambdatest.com/blog/remote-debugging-webpages-in-ios-safari/ | debugging, ios, safari, webpages | Safari is one of the most popular web browsers. Developed and promoted by Apple , it is based on the WebKit engine. The first version of the browser was released in 2003 with Mac OS X Panther. With the launch of the iPhone in 2007, a mobile version of the browser has been included in [iOS ](https://en.wikipedia.org/wik... | saifsadiq1234 |
1,186,326 | Building my blog with AWS Amplify and Next.JS | Is it me or everyone has the experience of going back and forth between having a custom personal blog... | 19,716 | 2022-09-26T21:17:53 | https://www.farmin.dev/posts/beafb161-bc14-498f-90d3-1cc4366dfe52 | nextjs, amplify, webdev, tutorial | Is it me or everyone has the experience of going back and forth between having a custom personal blog or writing on a platform like `Dev.to`?!
I changed my mind multiple times in the last decade, I had my blogs done with WordPress, Jekyll, and Gatsby but then I moved to Dev.to and Medium and to be honest I might have ... | farminf |
1,186,695 | useContext in React | We use React Context to manage the state at a global level. Components can get data from the React... | 19,685 | 2022-09-07T05:02:00 | https://dev.to/savvyshivam/usecontext-in-react-5c9h | webdev, tutorial, beginners, react | We use React Context to **manage the state at a global level**. Components can get data from the React context **no matter how far down the components tree they are**.
The very first step used in creating Context is to import “**createContext**”

##... | savvyshivam |
1,186,716 | 606. Leetcode Solution in cpp | /** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode... | 0 | 2022-09-07T05:50:35 | https://dev.to/chiki1601/606-leetcode-solution-in-cpp-3bgk | chiki1601, misspoojaanilkumarpatel, cpp | ```
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x... | chiki1601 |
1,186,836 | How to build an amazing wallet component using next.js wagmi rainbowkit tailwindcss | 1.overview I have been building some web3 projects. All of these projects would need a... | 0 | 2022-09-07T09:04:41 | https://dev.to/coffiasd/how-to-build-an-amazing-wallet-component-using-nextjs-wagmi-rainbowkit-tailwindcss-4hi9 | ## 1.overview
I have been building some web3 projects. All of these projects would need a wallet connect UI.That's why i write this post. Hand in hand, I will show you how to build an amazing wallets connect UI using next.js tailwindcss daisyUI wagmi and the most important rainbowkit. Here we go!
, where we show how simply you can modify a localization string in your App. But when I need to type something into input, I always make like 5 mistakes and my typing is not very nice to look at. So I crea... | jancizmar |
1,187,082 | How to manage dependencies between Gradle modules? | Using Gradle version catalog for easier dependencies management in a multimodule project. | 0 | 2022-09-07T15:31:45 | https://dev.to/aldok/how-to-manage-dependencies-between-gradle-modules-4jih | gradle, kotlin, android, java | ---
title: How to manage dependencies between Gradle modules?
published: true
description: Using Gradle version catalog for easier dependencies management in a multimodule project.
tags: #gradle #kotlin #android #java
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/wauzftb0iwln4sqkld1b.jpg
---
In... | aldok |
1,187,594 | Recommendation system #4 - Algorithm and final results | In the previous post we looked closer at the algorithm and connection between Redis and Node. Today,... | 19,699 | 2022-09-08T04:28:40 | https://dev.to/meatboy/writing-recommendation-system-3-algorithm-and-final-results-5c70 | redishackathon, typescript, node, showdev | In the previous [post](https://dev.to/meatboy/writing-recommendation-system-2-redis-node-architecture-kje) we looked closer at the algorithm and connection between Redis and Node. Today, quickly I summarize how the recommendation is made.
A single recommendation is an overlap between item tags and actor tag-event inte... | meatboy |
1,187,988 | Career Meetups That Will Blow Your Mind | In the times of such uncertainty and job hopping on the job market you have to be sure you make every... | 0 | 2022-09-08T13:16:15 | https://blog.meetupfeed.io/career-meetups-august-2022/ | career, programming, tutorial, beginners | In the times of such uncertainty and job hopping on the job market you have to be sure you make every effort to stand out of the crowd. That’s why we’ve brought you the finest [career tech talks](https://blog.meetupfeed.io/career-meetups-august-2022/) in August that will instantly level up your game. Enjoy!
[Growing T... | meetupfeedio |
1,188,012 | Do you need global state? | It's no secret that global state is an absolute nightmare - and not just in React. In this post I'm... | 0 | 2022-09-08T14:15:11 | https://dev.to/mitchelmore/do-you-need-global-state-8i1 | react, javascript | It's no secret that global state is an absolute nightmare - and not just in React. In this post I'm going to show you how to use the Context API and possibly save you the headache of setting up Redux.
## The Context API
React's Context API is often overlooked by newer developers because it's not talked about as it pr... | mitchelmore |
1,188,071 | Hacking Javascript Objects - I | Most of us deal with Objects pretty much every day and it's one of the most commonly used data... | 0 | 2022-09-08T17:17:08 | https://aakansha.dev/hacking-javascript-objects-i | javascript, beginners, frontend, webdev | ---
title: Hacking Javascript Objects - I
published: true
date: 2022-07-18 17:07:04 UTC
tags: #Javascript, #Beginner, #frontend, #webdev
canonical_url: https://aakansha.dev/hacking-javascript-objects-i
---
Most of us deal with `Objects` pretty much every day and it's one of the most commonly used data structures. But ... | aakansha1216 |
1,188,389 | Download Button: Interaction Animation Effects | Demo: If you don't feel like reading the text, see:... | 0 | 2022-09-08T22:42:41 | https://dev.to/mohammadsahragard/download-button-animation-3085 | javascript, css, tutorial, beginners | ### Demo:
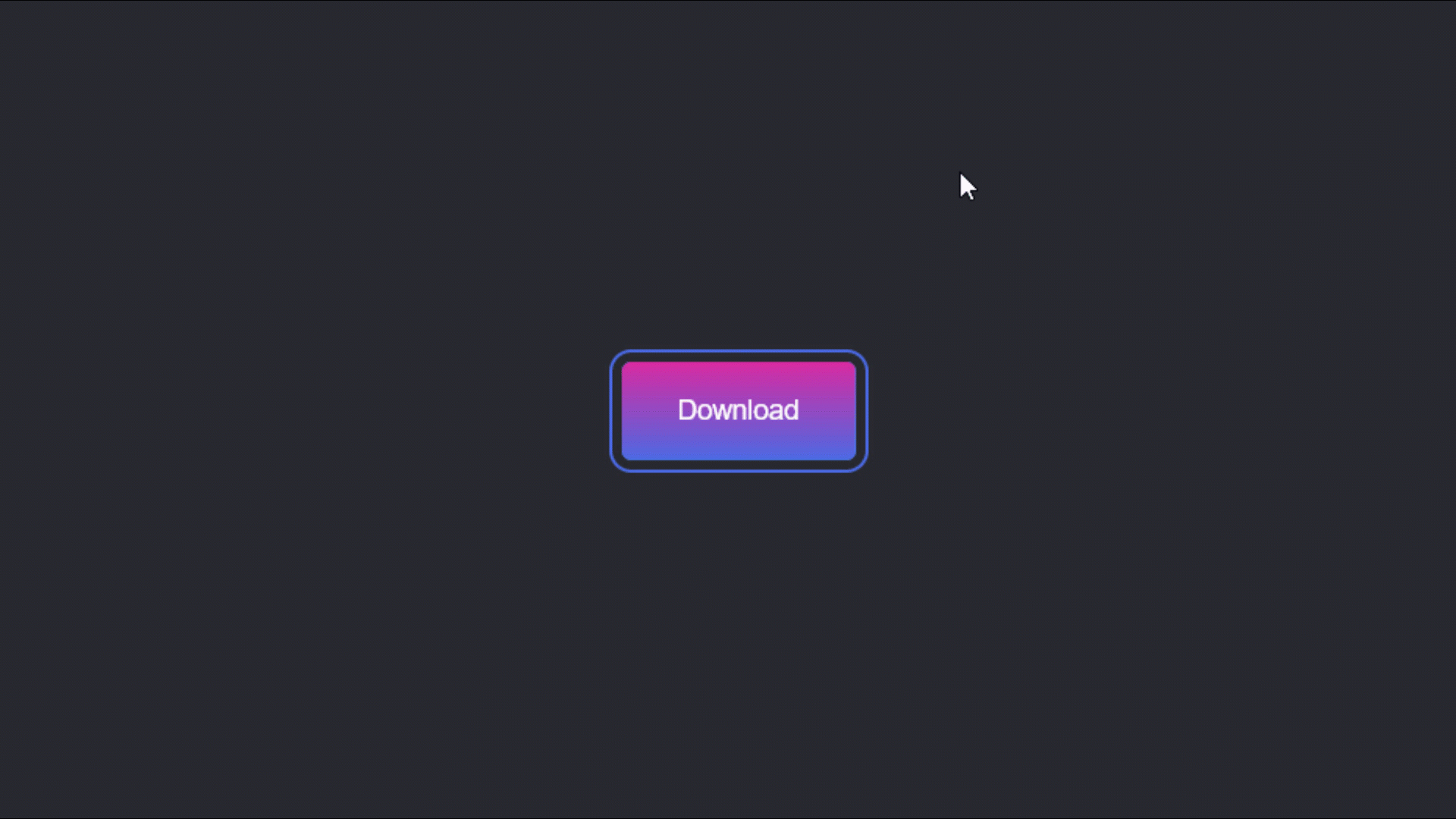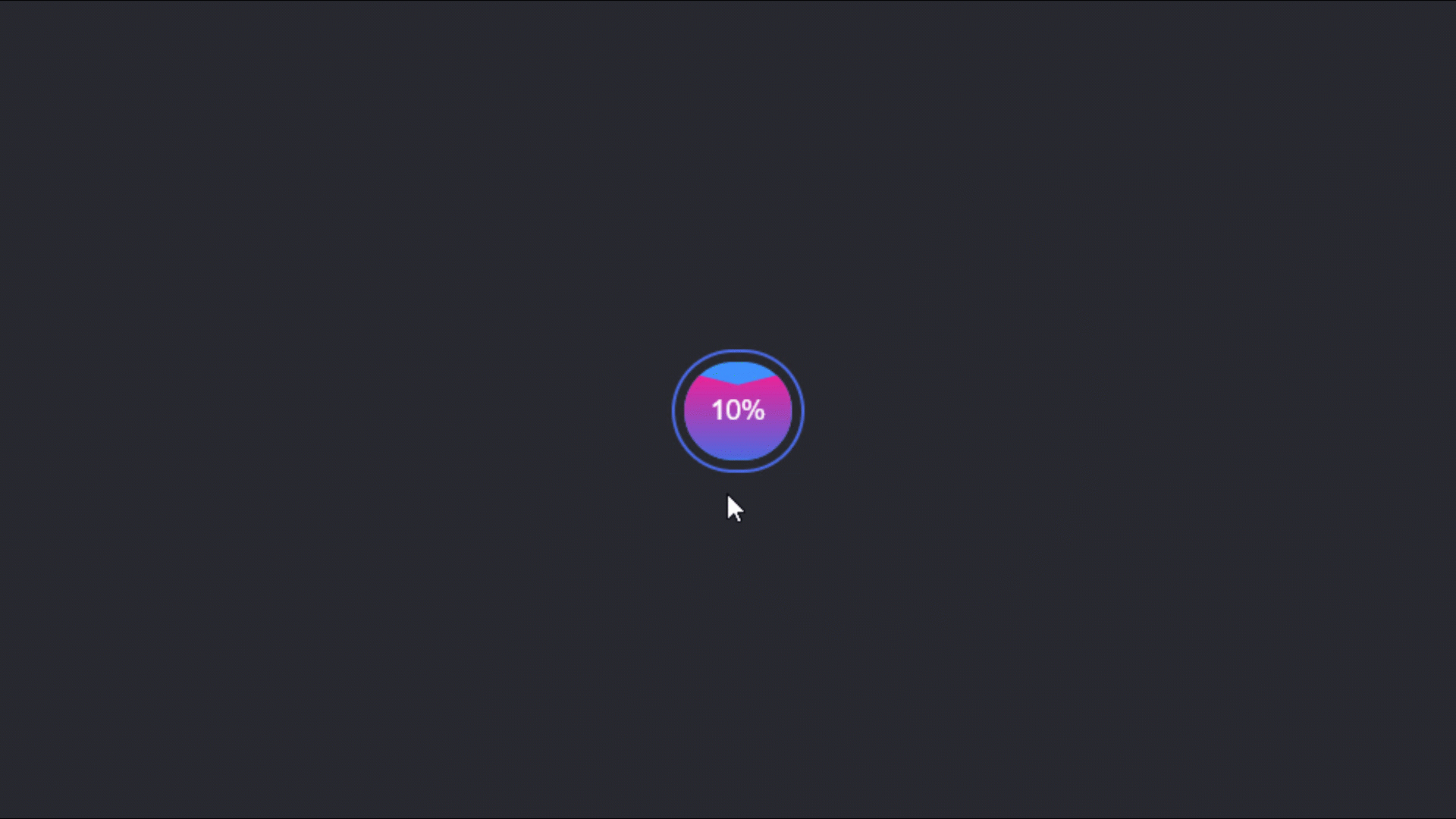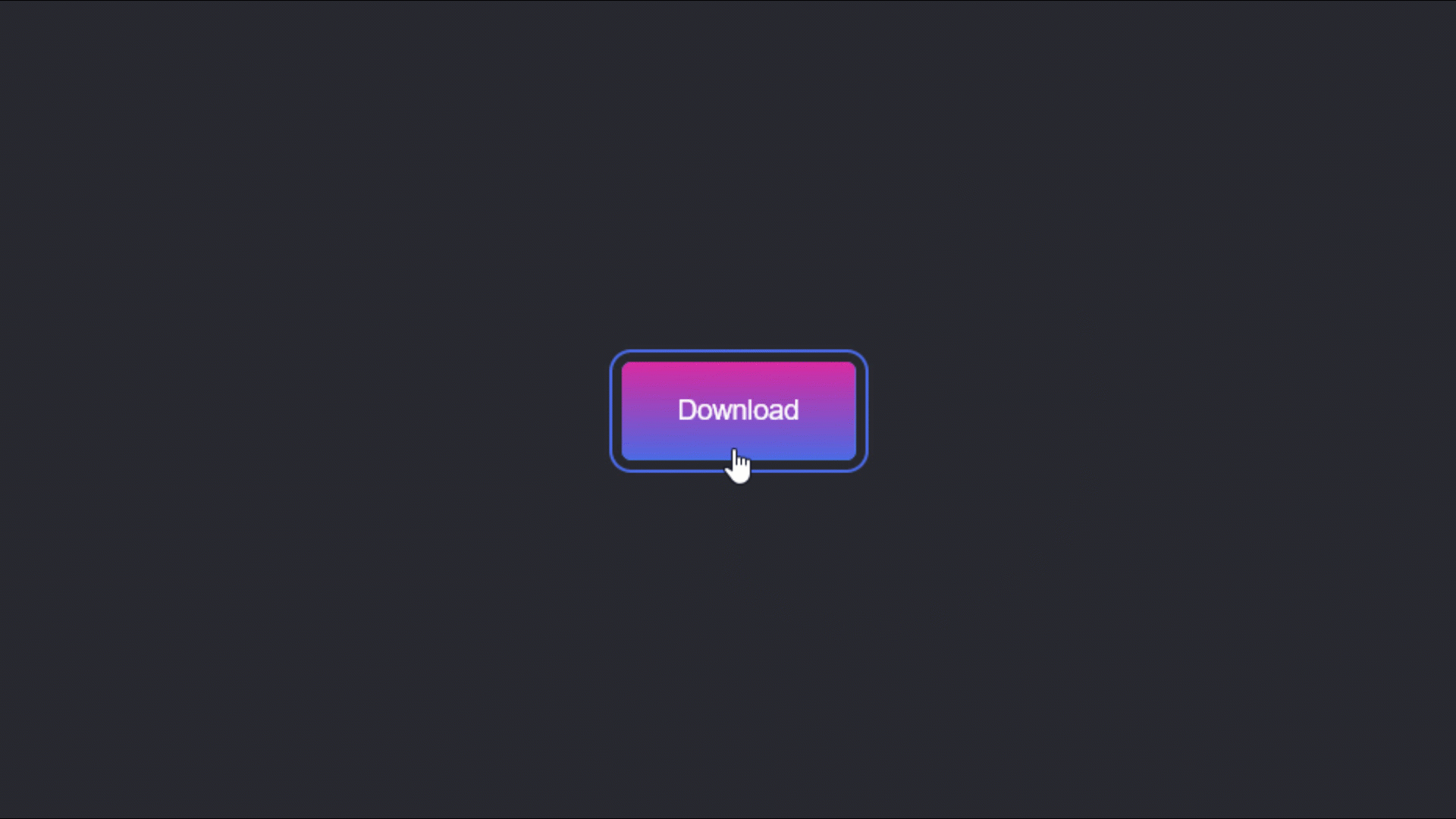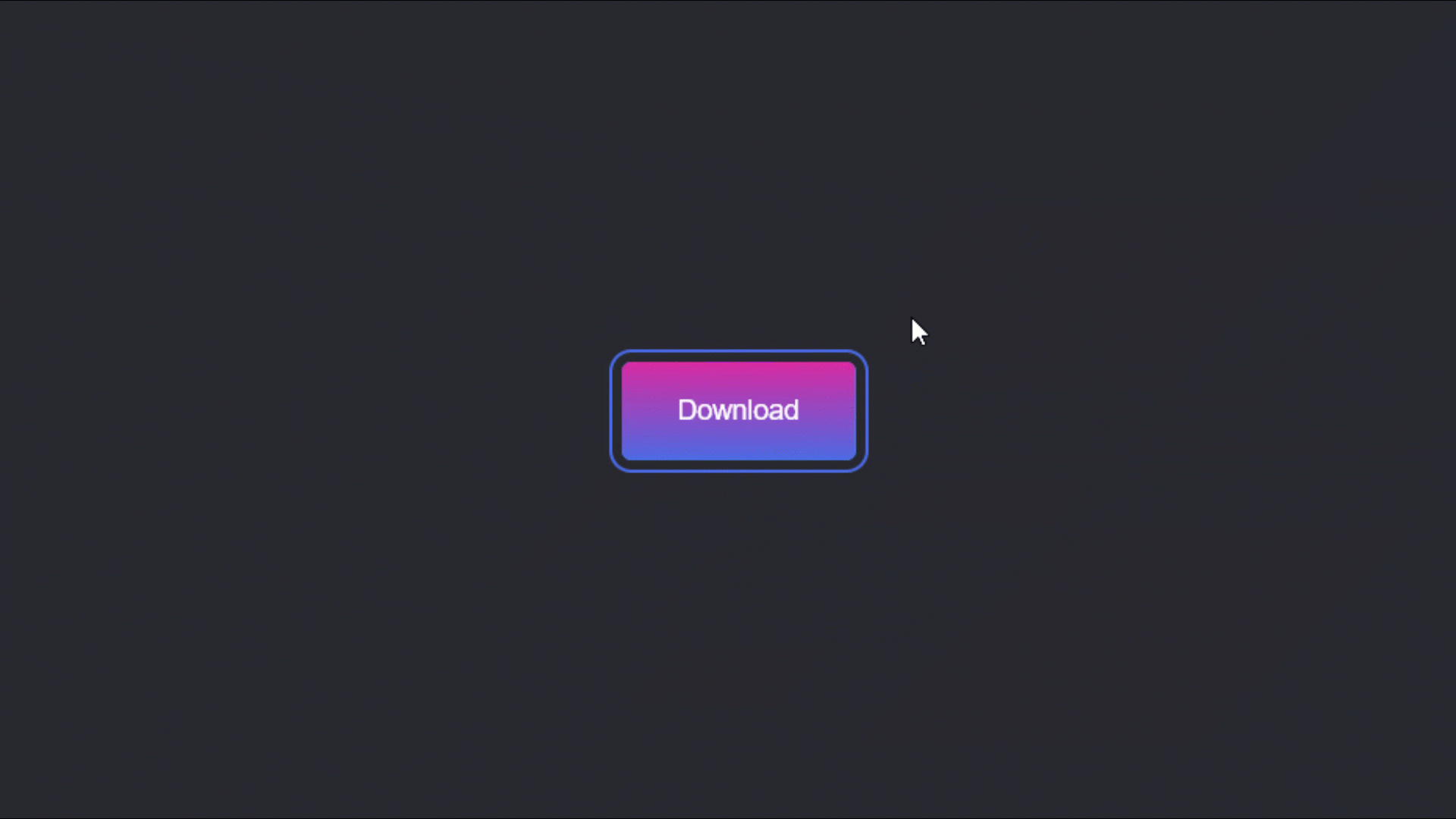
###### If you don't feel like reading the text, see: https://youtu.be/GqeuTyft0kE
**Description:**
This is a cool effect and animation for download buttons. Useful and without empty lines, let's count, th... | mohammadsahragard |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.