
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,917,709 | Comandos básicos do HELM | Listando o histório de deploys da release helm history {release} --namespace {namespace} ... | 0 | 2024-07-09T19:00:06 | https://dev.to/cnascimento/comandos-basicos-do-helm-2d36 | beginners, devops | Listando o histório de deploys da release
```
helm history {release} --namespace {namespace}
```
Executando o rollback
```
helm rollback {release} {revision} --namespace {namespace}
```
| cnascimento |
1,917,710 | hire skilled android app developers | Supercharge your business with Centric Tech's hire skilled android app developers expertise. Our... | 0 | 2024-07-09T19:02:08 | https://dev.to/john_michel_d7eb5159adf06/hire-skilled-android-app-developers-205a |
Supercharge your business with Centric Tech's[ hire skilled android app developers](https://centrictech.com/hire-android-app-developers/)
expertise. Our seasoned developers are ready to turn your groundbreaking ideas into reality. Elevate your brand with top-notch Android solutions tailored to meet your unique require... | john_michel_d7eb5159adf06 | |
1,917,711 | Understanding Storage Concepts in System Design | Understanding Storage Concepts in System Design In system design, storage concepts play a... | 0 | 2024-07-09T19:03:14 | https://dev.to/zeeshanali0704/understanding-storage-concepts-in-system-design-363i | javascript, systemdesign, systemdesignwithzeeshanali, learning | # Understanding Storage Concepts in System Design
In system design, storage concepts play a critical role in ensuring data reliability, accessibility, and scalability. From traditional disk-based systems to modern cloud storage solutions, understanding the fundamentals of storage architecture is crucial for designing ... | zeeshanali0704 |
1,917,712 | Master Figma Dev Mode | What is Figma Dev Mode? Figma Dev Mode is a powerful feature designed to bridge the gap... | 0 | 2024-07-09T19:17:59 | https://codeparrot.ai/blogs/figma-dev-mode | webdev, figma, frontend | ## What is Figma Dev Mode?
Figma Dev Mode is a powerful feature designed to bridge the gap between designers and developers, facilitating smoother collaboration and more efficient workflows. It provides developers with a detailed view of design files, including access to specs, assets, and code snippets, ensuring that ... | mvaja13 |
1,917,763 | Multiple ways to Clone or Copy a list in Python | Python provide multiple ways to achieve the desired result. For example, to copy a list to another... | 0 | 2024-07-09T19:41:53 | https://dev.to/pallavi_kumari_/multiple-ways-to-clone-or-copy-a-list-in-python-13c0 | python, beginners | Python provide multiple ways to achieve the desired result. For example, to copy a list to another list there are different methods:
- Through List slicing operation
**#Method 1**
lstcopy = lst[:]
print("Cloning By list slicing lst[:] ",lstcopy)
- Through copy() method
**#Method2**
lstcopy = lst.copy()
print("Clo... | pallavi_kumari_ |
1,917,713 | How To Add PrimeReact Icon In React App | Install PrimeReact and PrimeIcons: First, make sure you have primereact and primeicons installed in... | 0 | 2024-07-09T19:18:31 | https://dev.to/vishalbhuva666/how-to-add-primereact-icon-in-react-app-11ph | primereact, primereacticon, besticon, reacticon | Install PrimeReact and PrimeIcons:
First, make sure you have primereact and primeicons installed in your project.
If not, you can install them using npm or yarn:
**npm install primereact primeicons
yarn add primereact primeicons**
Import the CSS files: Import the necessary CSS files for PrimeReact and PrimeIcons i... | vishalbhuva666 |
1,917,759 | Juggling a Developer Job, Part-Time SaaS and Conference Speaking | Working on SaaS, conference speaking, and a developer job at the same time is challenging. This is how I juggle all of it. | 0 | 2024-07-09T19:22:00 | https://www.eddyvinck.com/blog/juggling-job-saas-and-conference-speaking/ | webdev, javascript, ai, react | ---
title: Juggling a Developer Job, Part-Time SaaS and Conference Speaking
published: true
description: Working on SaaS, conference speaking, and a developer job at the same time is challenging. This is how I juggle all of it.
tags: webdev, javascript, ai, react
cover_image: https://dev-to-uploads.s3.amazonaws.com/upl... | eddyvinck |
1,917,760 | ** ¡Únete a Try Catch Factory y Descubre un Mundo de Beneficios Tecnológicos! **🌐 | ¡Hola Chiquis! 👋🏻 ¿Sabes qué es una fábrica de software o los beneficios que tiene para los... | 0 | 2024-07-09T19:29:49 | https://dev.to/orlidev/-unete-a-try-catch-factory-y-descubre-un-mundo-de-beneficios-tecnologicos--5bbd | productivity, webdev, microservices, beginners | ¡Hola Chiquis! 👋🏻 ¿Sabes qué es una fábrica de software o los beneficios que tiene para los desarrolladores o futuros clientes? Si tu respuesta es no, pues ¡no te preocupes!, vamos adentrarnos en el fascinante mundo de las fábricas de software, mientras nos preparamos con bombos y platillos para el gran lanzamiento d... | orlidev |
1,917,761 | Extraction of Form Validation Object and Authenticate Class | In our previous project, we learned how to login or logout a registered user. But today, we will... | 0 | 2024-07-09T19:33:02 | https://dev.to/ghulam_mujtaba_247/extraction-of-form-validation-object-and-authenticate-class-b8m | webdev, beginners, css | In our previous project, we learned how to login or logout a registered user. But today, we will learn how to extract a form validation object and about authenticate class extraction in the project.
## On VS Code Side
To start the project, we need to add a new directory named Http, then move the controllers into th... | ghulam_mujtaba_247 |
1,917,811 | dddffg | eettttttt | 0 | 2024-07-09T20:53:23 | https://dev.to/szizyava/dddffg-4jnl | eettttttt | szizyava | |
1,917,765 | Kirill Yurovskiy: Digital Strategies and E-commerce | In the present interconnected world, organizations of all sizes are tracking down uncommon chances to... | 0 | 2024-07-09T20:00:02 | https://dev.to/alexgrace012/kirill-yurovskiy-digital-strategies-and-e-commerce-1mbg | In the present interconnected world, organizations of all sizes are tracking down uncommon chances to grow their span across borders. The computerized insurgency has destroyed customary obstructions to sections, permitting organizations to take advantage of worldwide business sectors with no sweat. Be that as it may, p... | alexgrace012 | |
1,917,766 | JavaScript to Python for Beginners | Why Learn Python? Python is one of the most popular programming languages in the world,... | 0 | 2024-07-09T20:01:45 | https://dev.to/epifania_garcia_8462512ef/javascript-to-python-for-beginners-1339 | javascript, python, beginners, programming | ## **Why Learn Python?**
Python is one of the most popular programming languages in the world, widely used in various fields such as web development, data analysis, artificial intelligence, scientific computing, and more. It is known for its readability and simplicity, making it an excellent choice for beginners and e... | epifania_garcia_8462512ef |
1,917,767 | Integrating Exchange Rate APIs for Improved Financial Accuracy | Exchange rate APIs play a crucial role in ensuring financial transactions are conducted accurately... | 0 | 2024-07-09T20:08:56 | https://dev.to/sameeranthony/integrating-exchange-rate-apis-for-improved-financial-accuracy-3fe4 | api, exchange, rate, financial | Exchange rate APIs play a crucial role in ensuring financial transactions are conducted accurately and efficiently. Whether you are running a currency exchange company or managing international transactions, integrating a reliable **[exchange rate API](https://currencylayer.com/)** can significantly enhance the accurac... | sameeranthony |
1,917,768 | How I Build a Scratch Proxy Server Using Node.js | You might be curious about how proxy servers work and how they serve data over the internet. In this... | 0 | 2024-07-09T21:29:43 | https://dev.to/avinash_tare/how-i-build-a-scratch-proxy-server-using-nodejs-55d9 | node, proxy, javascript, core |
You might be curious about how proxy servers work and how they serve data over the internet. In this blog, I am going to implement a proxy server using core NodeJs.I achieved this using a core NodeJs package called `net` which already comes with NodeJs.
## How Proxy Works
a proxy server is an agent between the clien... | avinash_tare |
1,917,769 | 10 Billion Passwords Cracked: Do You Even Understand Password Cracking? Do You, Really? | Introduction If you understood how passwords were cracked, you'd never use a... | 0 | 2024-07-09T20:13:35 | https://dev.to/raddevus/10-billion-passwords-cracked-do-you-even-understand-password-cracking-do-you-really-37ho | ## Introduction
If you understood how passwords were cracked, you'd never use a natural-language word in your password again. And, that alone could make you entirely safe. Yes, I'll explain how that could make you safe further along in this article.
I'm taking a bit of an alternate view so we can think differently a... | raddevus | |
1,917,794 | From Solo Coder to Team Player: Why Two Heads are Better Than One (and Sometimes More Fun) | Alone we can do so little; together we can do so much. – Helen Keller The Power of... | 0 | 2024-07-09T20:21:55 | https://dev.to/socialcodeclub/from-solo-coder-to-team-player-why-two-heads-are-better-than-one-and-sometimes-more-fun-28hj | webdev, startup, coding, productivity |
> Alone we can do so little; together we can do so much. – Helen Keller
### The Power of Collaboration in Coding
If you've ever tried to debug a piece of code at 2 AM with a cup of cold coffee, you know this is true. As much as we might like to think of ourselves as coding ninjas, the reality is that coding is oft... | socialcodeclub |
1,917,795 | Intern level: Handling Events in React | Handling events in React is a crucial aspect of creating interactive web applications. This guide... | 0 | 2024-07-09T20:23:00 | https://dev.to/__zamora__/intern-level-handling-events-in-react-3b36 | react, webdev, javascript, programming | Handling events in React is a crucial aspect of creating interactive web applications. This guide will introduce you to the basics of event handling in React, including adding event handlers, understanding synthetic events, passing arguments to event handlers, creating custom events, and event delegation.
## Event Han... | __zamora__ |
1,917,796 | Junior level: Handling Events in React | Handling events in React is a fundamental skill that allows you to create interactive and dynamic... | 0 | 2024-07-09T20:23:54 | https://dev.to/__zamora__/junior-level-handling-events-in-react-1bob | react, webdev, javascript, programming | Handling events in React is a fundamental skill that allows you to create interactive and dynamic applications. This guide will walk you through the basics of event handling in React, including adding event handlers, understanding synthetic events, passing arguments to event handlers, creating custom events, and using ... | __zamora__ |
1,917,797 | Mid level: Handling Events in React | As a mid-level developer, you should have a solid understanding of handling events in React, which is... | 0 | 2024-07-09T20:24:41 | https://dev.to/__zamora__/mid-level-handling-events-in-react-j2e | react, webdev, javascript, programming | As a mid-level developer, you should have a solid understanding of handling events in React, which is essential for creating interactive and dynamic applications. This guide will cover advanced concepts and best practices, including adding event handlers, understanding synthetic events, passing arguments to event handl... | __zamora__ |
1,917,798 | Senior level: Handling Events in React | As a senior developer, you are expected to have a deep understanding of event handling in React. This... | 0 | 2024-07-09T20:25:48 | https://dev.to/__zamora__/senior-level-handling-events-in-react-9h8 | react, webdev, javascript, programming | As a senior developer, you are expected to have a deep understanding of event handling in React. This involves not only knowing the basics but also mastering advanced techniques to create efficient, maintainable, and scalable applications. This article covers the intricacies of event handling in React, including adding... | __zamora__ |
1,917,799 | Lead level: Handling Events in React | As a lead developer, it’s crucial to master the advanced concepts of event handling in React to... | 0 | 2024-07-09T20:26:26 | https://dev.to/__zamora__/lead-level-handling-events-in-react-406 | react, webdev, javascript, programming | As a lead developer, it’s crucial to master the advanced concepts of event handling in React to ensure your applications are efficient, maintainable, and scalable. This article will cover sophisticated techniques and best practices for handling events in React, including adding event handlers, understanding synthetic e... | __zamora__ |
1,917,800 | Architect level: Handling Events in React | As an architect-level developer, your focus should be on designing scalable, maintainable, and... | 0 | 2024-07-09T20:27:08 | https://dev.to/__zamora__/architect-level-handling-events-in-react-31ho | react, webdev, javascript, programming | As an architect-level developer, your focus should be on designing scalable, maintainable, and performant applications. Handling events efficiently in React is a crucial part of this. This article delves into advanced concepts and best practices for event handling in React, including adding event handlers, understandin... | __zamora__ |
1,917,801 | Would you happen to know about Serverless Computing? | In this video, I talked about what serverless is, why this is so cool, and how this is used in... | 0 | 2024-07-09T20:35:04 | https://dev.to/aws-builders/would-you-happen-to-know-about-serverless-computing-3cl7 | serverless, lambda, cloudoperations, cloudpractitioner | In this video, I talked about what serverless is, why this is so cool, and how this is used in practice!
I hope you can enjoy the video. If you have any points to share, please, feel free to comment here =).
The AWS level of content is between 100-200. Please don't forget about serverless. | carlosfilho |
1,917,802 | Celebrating 100 Days of Continuous GitHub Contributions | Reflecting on the journey, challenges, and achievements of maintaining a 100-day GitHub streak. | 0 | 2024-07-09T20:38:59 | https://dev.to/fmcalisto/celebrating-100-days-of-continuous-github-contributions-7h8 | github, opensource, productivity, developer | ---
title: Celebrating 100 Days of Continuous GitHub Contributions
published: true
description: Reflecting on the journey, challenges, and achievements of maintaining a 100-day GitHub streak.
tags: github, opensource, productivity, developer
cover_image: https://github.com/FMCalisto/FMCalisto/blob/main/assets/b30cc86cd... | fmcalisto |
1,917,803 | Let's Understand JavaScript Closures: A Fundamental Concept | Closures are a powerful feature in JavaScript that allow functions to retain access to their lexical... | 0 | 2024-07-09T20:39:36 | https://dev.to/readwanmd/lets-understand-javascript-closures-a-fundamental-concept-1c54 | javascript, closures | Closures are a powerful feature in JavaScript that allow functions to retain access to their lexical scope, even when the function is executed outside that scope. This can sound abstract, but with some simple examples, you'll see how closures can be both intuitive and incredibly useful in real-world applications.
## W... | readwanmd |
1,917,806 | AWS EC2: Creating, Connecting and Managing Your Instances | If you have read the last article, you must have some idea about an EC2 instance. Amazon EC2... | 27,845 | 2024-07-09T20:45:22 | https://dev.to/ansumannn/aws-ec2-creating-connecting-and-managing-your-instances-3efg | aws, cloud, ec2, devops | If you have read the last article, you must have some idea about an EC2 instance. Amazon EC2 instances are basically virtual machines but in the cloud. This guide will walk you through creating your EC2 instance, securely connecting to it via SSH, and managing it effortlessly using the AWS Command Line Interface (CLI).... | ansumannn |
1,917,807 | Unlocking the Power of React Conversational Agents with Sista AI | Unleash the potential of React conversational agents with Sista AI. Revolutionize user interactions and enhance engagement seamlessly! 🌐✨ | 0 | 2024-07-09T20:45:39 | https://dev.to/sista-ai/unlocking-the-power-of-react-conversational-agents-with-sista-ai-5cmd | ai, react, javascript, typescript | <h2>Introduction</h2><p>The integration of AI assistants into React applications has become a hot topic among developers. Rising demands for enhanced user engagement and accessibility have paved the way for cutting-edge solutions like <strong>Sista AI</strong>. This article delves into the transformative capabilities o... | sista-ai |
1,917,808 | What_happens_when_your_type_google_com_in_your_browser_and_press_enter | This diagram illustrates the key steps involved in the request flow: DNS Resolution : The browser... | 0 | 2024-07-09T20:47:55 | https://dev.to/mongezi_sibande_d8869a238/whathappenswhenyourtypegooglecominyourbrowserandpressenter-1b5a |
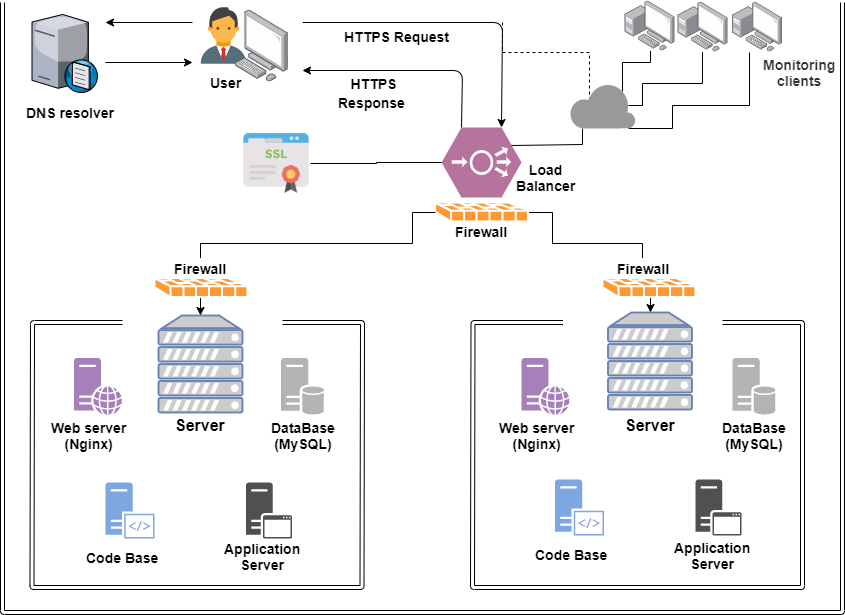
**_This diagram illustrates the key steps involved in the request flow:_**
1. DNS Resolution
: The browser performs a DNS lookup to resolve the hostname www.google.com to an IP address.
Firewall: The encrypted HT... | mongezi_sibande_d8869a238 | |
1,917,809 | shadcn-ui/ui codebase analysis: How does shadcn-ui CLI work? — Part 2.9 | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the... | 0 | 2024-07-09T20:48:40 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-how-does-shadcn-ui-cli-work-part-29-4p37 | javascript, nextjs, shadcnui, opensource | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the shadcn-ui/ui CLI.
In part 2.8, we looked at function promptForMinimalConfig and its parameters and how the shadcn-ui CLI uses chalk to highlight text in the terminal.
This is a continuation to 2.8, we will look at belo... | ramunarasinga |
1,917,810 | Software engineering principles cheat sheet | The software engineering principles cheat sheet I would give to myself If I was preparing for... | 0 | 2024-07-09T20:49:16 | https://dev.to/msnmongare/software-engineering-principles-cheat-sheet-3lpn | softwaredevelopment, javascript, beginners, webdev | The software engineering principles cheat sheet I would give to myself If I was preparing for technical interviews again
**🟠 ACID Properties**
1. Atomicity: Transactions are all-or-nothing, fully completed, or not.
2. Consistency: Transactions ensure the database remains in a valid state.
3. Isolation: Transactions o... | msnmongare |
1,917,812 | Static Methods for Lists and Collections | The Collections class contains static methods to perform common operations in a collection and a... | 0 | 2024-07-09T21:12:05 | https://dev.to/paulike/static-methods-for-lists-and-collections-4h9j | java, programming, learning, beginners | The **Collections** class contains static methods to perform common operations in a collection and a list. [The section](https://dev.to/paulike/useful-methods-for-lists-eol) introduced several static methods in the **Collections** class for array lists. The **Collections** class contains the **sort**, **binarySearch**,... | paulike |
1,917,813 | Practicing politeness in JavaScript code 🤬 | Imagine that you published a big open source project and many people are currently changing your code... | 0 | 2024-07-09T21:52:29 | https://dev.to/silentwatcher_95/practicing-politeness-in-javascript-code-535g | javascript, node, tutorial, learning | Imagine that you published a big open source project and many people are currently changing your code or updating the project documents.
what if someone accidently write something race related , gender favoring , polarizing and etc... 👀
. It's amazing how much you can learn from the right book.
Not so long ago, I started working on a new project of my own, and to my surprise, I found myself trapped and... | juanemilio31323 |
1,917,816 | Automate the tasks using Vercel Cron Jobs | Cron Jobs are commands that run automatically at specific time intervals (e.g. daily, weekly,... | 0 | 2024-07-09T21:23:38 | https://dev.to/onurhandtr/automate-the-tasks-using-vercel-cron-jobs-ieh | vercel, nextjs, typescript, cronjobs | Cron Jobs are commands that run automatically at specific time intervals (e.g. daily, weekly, hourly).
The Cron job feature can be used for operations performed at specific intervals such as data synchronization, email sending, backup operations, and more.
Vercel, on the other hand, hosts the Cron Jobs feature on its... | onurhandtr |
1,917,817 | Case Study: Bouncing Balls | This section presents a program that displays bouncing balls and enables the user to add and remove... | 0 | 2024-07-09T21:24:07 | https://dev.to/paulike/case-study-bouncing-balls-bh9 | java, programming, learning, beginners | This section presents a program that displays bouncing balls and enables the user to add and remove balls.
[Section](https://dev.to/paulike/case-study-bouncing-ball-39cj) presents a program that displays one bouncing ball. This section presents a program that displays multiple bouncing balls. You can use two buttons ... | paulike |
1,917,818 | Mastering Django: A Workflow Guide | Understanding the Django Framework: A Deep Dive into its Working Flow Django is a... | 0 | 2024-07-09T21:29:39 | https://dev.to/tejas_khanolkar_473f3ed1a/mastering-django-a-workflow-guide-mdm | chaiaurcode, python, django, webdev |
## Understanding the Django Framework: A Deep Dive into its Working Flow
Django is a full-stack framework created in Python. To understand Django, it’s essential first to grasp the concept of a framework. A framework is the structure or skeleton of your application. It provides a basic foundation upon which you buil... | tejas_khanolkar_473f3ed1a |
1,917,819 | Vector and Stack Classes | Vector is a subclass of AbstractList, and Stack is a subclass of Vector in the Java API. The Java... | 0 | 2024-07-09T21:33:03 | https://dev.to/paulike/vector-and-stack-classes-k4 | java, programming, learning, beginners | **Vector** is a subclass of **AbstractList**, and **Stack** is a subclass of **Vector** in the Java API. The Java Collections Framework was introduced in Java 2. Several data structures were supported earlier, among them the **Vector** and **Stack** classes. These classes were redesigned to fit into the Java Collection... | paulike |
1,917,820 | Nomeação de Variáveis CSS: Boas Práticas e Abordagens | Recentemente, enquanto navegava na internet, como todo bom desenvolvedor front-end, quis "roubar" a... | 0 | 2024-07-10T10:09:19 | https://dev.to/leomunizq/nomeacao-de-variaveis-css-boas-praticas-e-abordagens-48o3 | Recentemente, enquanto navegava na internet, como todo bom desenvolvedor front-end, quis "roubar" a paleta de cores de um site. Então, abri o inspetor de elementos para copiar os valores hexadecimais das cores e me deparei com uma surpresa inusitada: as variáveis CSS estavam nomeadas de forma inconsistente.
<br><br>
<... | leomunizq | |
1,917,821 | How to recover stolen USDT | Formerly I presumed I would never be able to retrieve the money I had lost to fraudsters. I made an... | 0 | 2024-07-09T21:39:22 | https://dev.to/kate_wille_2c1b4f093d4450/how-to-recover-stolen-usdt-pah | Formerly I presumed I would never be able to retrieve the money I had lost to fraudsters. I made an investment with a bitcoin investing website in the First quarter of 2024 just to discover that it was a scam. I got in touch with a few hackers in an effort to get my money back, but they all turned out to be swindlers w... | kate_wille_2c1b4f093d4450 | |
1,917,823 | Explication de SeleniumWebDriver : Automatisez votre Flux de Tests Web | Salut à tous, Aujourd'hui, je vais vous parler de Selenium WebDriver, une nouvelle notion que je... | 0 | 2024-07-10T15:53:18 | https://dev.to/laroseikitama/explication-de-seleniumwebdriver-automatisez-votre-flux-de-tests-web-e88 | webdev, selenium, testing, learning | Salut à tous,
Aujourd'hui, je vais vous parler de Selenium WebDriver, une nouvelle notion que je viens d'apprendre. Dans cet article, nous nous concentrerons principalement sur la théorie afin de comprendre ce qu'est Selenium WebDriver, son utilité et bien d'autres concepts associés.
## Table des matières
- [Qu'est... | laroseikitama |
1,917,824 | How Founding a Startup is Curing my Perfectionism (1/3) | From childhood, many of us learn to tie our self-worth to our performance. When achievements aren't... | 0 | 2024-07-09T21:45:30 | https://dev.to/ladam0203/how-launching-my-startup-is-curing-my-perfectionism-13-44d7 | startup, mentalhealth, productivity | From childhood, many of us learn to tie our self-worth to our performance. When achievements aren't acknowledged or appreciated appropriately, this mindset can affect our hobbies, projects, career paths, and even relationships throughout life. Launching a startup, (alongside proper therapy,) has been, - I dare to say -... | ladam0203 |
1,917,825 | Enhancing Your React Native App with Reanimated 3 Using Expo | Animations can significantly enhance the user experience of any mobile application. They make... | 0 | 2024-07-09T21:45:45 | https://devtoys.io/2024/07/08/enhancing-your-react-native-app-with-reanimated-3-using-expo/ | reactnative, animation, mobile, devtoys | ---
canonical_url: https://devtoys.io/2024/07/08/enhancing-your-react-native-app-with-reanimated-3-using-expo/
---
Animations can significantly enhance the user experience of any mobile application. They make interactions feel more intuitive, provide feedback, and create a polished, professional look. However, achievi... | 3a5abi |
1,917,826 | IT Staff Augmentation: Empowering Your Team for Success | Introduction In today's rapidly evolving technological landscape, businesses face increasing demands... | 0 | 2024-07-09T21:48:06 | https://dev.to/andrew_morgan_fef3e706051/it-staff-augmentation-empowering-your-team-for-success-271a | webdev, ai, news, discuss | **Introduction**
In today's rapidly evolving technological landscape, businesses face increasing demands to innovate, scale, and stay competitive. To meet these challenges, organizations are turning to IT staff augmentation as a strategic solution. This approach allows companies to enhance their existing teams with ski... | andrew_morgan_fef3e706051 |
1,917,827 | Desafio Decodificador - Chanllenge | Check out this Pen I made! | 0 | 2024-07-09T21:49:20 | https://dev.to/veronicacostaui/desafio-decodificador-chanllenge-3e61 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Veronicacosta-ui/pen/qBzEbXx %} | veronicacostaui |
1,917,828 | Queues and Priority Queues | In a priority queue, the element with the highest priority is removed first. A queue is a first-in,... | 0 | 2024-07-09T21:54:52 | https://dev.to/paulike/queues-and-priority-queues-3aji | java, programming, learning, beginners | In a priority queue, the element with the highest priority is removed first. A _queue_ is a first-in, first-out data structure. Elements are appended to the end of the queue and are removed from the beginning of the queue. In a _priority queue_, elements are assigned priorities. When accessing elements, the element wit... | paulike |
1,917,829 | Building A SimpleNote to Obsidian notes converter | Building A SimpleNote to Obsidian notes converter See it in... | 0 | 2024-07-09T21:57:06 | https://dev.to/ayush_saran/building-a-simplenote-to-obsidian-notes-converter-33j9 | showdev, simplenote, obsidian, converter | # Building A SimpleNote to Obsidian notes converter
# See it in action:
https://simplenote-to-obsidian.fly.dev/
[](https://simplenote-to-obsidian.fly.dev/)
# WHY... | ayush_saran |
1,917,830 | "Amazon SAA-C03 PDF Dumps: Your Ultimate Guide to Achieve Success Effortlessly With CertifieDumps" | "Amazon SAA-C03 PDF Dumps: Your Ultimate Guide to Achieve Success Effortlessly With... | 0 | 2024-07-09T21:58:15 | https://dev.to/ella_henry_990efd16d535c5/amazon-saa-c03-pdf-dumps-your-ultimate-guide-to-achieve-success-effortlessly-with-certifiedumps-4bah | dumps, examdumps, saac03 |

"Amazon SAA-C03 PDF Dumps: Your Ultimate Guide to Achieve Success Effortlessly With CertifieDumps"
Finding success in the ever-evolving IT industry is not feasible without the Amazon Associate & AWS Certified Soluti... | ella_henry_990efd16d535c5 |
1,917,831 | Unlock Instant Success: Exclusive Top Picks for Refreshed EX200 Dumps Exam Questions 2024/2025 | Are you craving to conquer the Red Hat exam on your first attempt? Leverage the authentic... | 0 | 2024-07-09T22:01:46 | https://dev.to/ella_henry_990efd16d535c5/unlock-instant-success-exclusive-top-picks-for-refreshed-ex200-dumps-exam-questions-20242025-3pji |

Are you craving to conquer the Red Hat exam on your first attempt? Leverage the authentic CertifiesDumps EX200 dumps (questions). By authenticating your knowledge and skills with the EX200 certification exam, you ca... | ella_henry_990efd16d535c5 | |
1,917,833 | latest Microsoft AZ-700 Questions - Right Path for Your Career | CertifieDumpds is one of the best brands in the market that offers updated & accurate exam... | 0 | 2024-07-09T22:04:44 | https://dev.to/ella_henry_990efd16d535c5/latest-microsoft-az-700-questions-right-path-for-your-career-4l7f |

CertifieDumpds is one of the best brands in the market that offers updated & accurate exam preparation material for the certification exam. If you are looking for certification exam preparation material then you do ... | ella_henry_990efd16d535c5 | |
1,917,834 | Klein Bottle | Check out this Pen I made! | 0 | 2024-07-09T22:08:48 | https://dev.to/dan52242644dan/klein-bottle-3haf | codepen, ai, html, javascript | Check out this Pen I made!
{% codepen https://codepen.io/Dancodepen-io/pen/rNEaxrz %} | dan52242644dan |
1,917,836 | Build Generative AI Chatbot | Introduction In this article, you will learn how to build a generative AI chatbot that... | 0 | 2024-07-09T22:15:23 | https://dev.to/jhonnyarm/build-generative-ai-chatbot-4epc | gradio, openapi, sqlalchemy, langchain | ## Introduction
In this article, you will learn how to build a generative AI chatbot that leverages OpenAI's GPT-3.5 to provide personalized and accurate responses to user queries. By integrating a pretrained LLM with a dynamic SQLite database, you'll create an intelligent chatbot capable of handling domain-specific q... | jhonnyarm |
1,917,856 | Bet88 - Link Truy Cập Nhà Cái BET88 Chính Thức - Uy Tín | Bet88 - Nhà cái cá cược trực tuyến an toàn⭐️đa dạng sản phẩm cá cược: Casino, Thể Thao ⭐️ Đăng ký... | 0 | 2024-07-09T22:23:24 | https://dev.to/bet88how/bet88-link-truy-cap-nha-cai-bet88-chinh-thuc-uy-tin-eob | Bet88 - Nhà cái cá cược trực tuyến an toàn⭐️đa dạng sản phẩm cá cược: Casino, Thể Thao ⭐️ Đăng ký ngay để nhận 199k miễn phí!
Địa chỉ: 235 Đồng Khởi, Phường Bến Nghé, Quận 1, TPHCM
SĐT: 093.222.9536
Email: bet88how@gmail.com
#bet88 #bet88how #bet88casino https://bet88.how/
https://www.spigotmc.org/members/bet88how... | bet88how | |
1,917,857 | Case Study: Evaluating Expressions | Stacks can be used to evaluate expressions. Stacks and queues have many applications. This section... | 0 | 2024-07-09T22:26:22 | https://dev.to/paulike/case-study-evaluating-expressions-1bgg | java, programming, learning, beginners | Stacks can be used to evaluate expressions. Stacks and queues have many applications. This section gives an application that uses stacks to evaluate expressions. You can enter an arithmetic expression from Google to evaluate the expression, as shown in Figure below.
 do dev júnior que apagou a base de dados em... | 0 | 2024-07-09T22:33:58 | https://dev.to/ramonborges15/nao-deveria-ser-tao-simples-inserir-um-bug-na-sua-aplicacao-e-eu-te-conto-o-porque-902 | beginners, testing, career, developers | Quem nunca ouviu aquela história (fictícia ou não) do dev júnior que apagou a base de dados em produção? Ou quantos de nós ao implementar aquela nova melhoria, sem perceber inseriu um bug dentro da aplicação? Normalmente, a nossa primeira atitude é culpar ou a pessoa (quando ela comete o erro) ou a nós mesmos (quando n... | ramonborges15 |
1,917,859 | Efficiency of Data Structure | Data structures are the fundamental components of computer programming, enabling efficient data... | 0 | 2024-07-10T04:16:45 | https://dev.to/brightpatani/data-structure-145a | Data structures are the fundamental components of computer programming, enabling efficient data organization, storage, and manipulation. Despite their importance, In this post, we will dive the world of data structures, their types, and their importance in programming.
**Data Structures vs. Data Types**
Many programm... | brightpatani | |
1,917,860 | Creating a Simple Generative AI Chatbot with Python and TensorFlow | Introduction: In this article, we'll walk through the process of creating a basic generative AI... | 0 | 2024-07-09T22:33:39 | https://dev.to/csar_fabinchvezlinar/creating-a-simple-generative-ai-chatbot-with-python-and-tensorflow-13mc | **Introduction:**
In this article, we'll walk through the process of creating a basic generative AI chatbot using Python and TensorFlow. This chatbot will be capable of generating responses based on input text, showcasing the fundamentals of natural language processing and neural networks.
Prerequisites:
Basic knowled... | csar_fabinchvezlinar | |
1,917,861 | BigQuery Schema Generation Made Easier with PyPI’s bigquery-schema-generator | When importing data into BigQuery, a crucial step is defining the table's structure - its schema.... | 0 | 2024-07-09T22:35:35 | https://dev.to/noela_tenku/bigquery-schema-generation-made-easier-with-pypis-bigquery-schema-generator-3iej | data, dataengineering, bigquery, python | When importing data into BigQuery, a crucial step is defining the table's structure - its schema. This schema can be auto-detected or defined manually.
### Auto-Detection with BigQuery’s LoadJobConfig Method (for Smaller Datasets)
When we load data from a CSV file, we use the LoadJobConfig method with the autodetect... | noela_tenku |
1,917,862 | AI Workforce Evolution: Emerging Roles and Future Perspectives | 1. Introduction The landscape of work and employment has been significantly reshaped by... | 27,673 | 2024-07-09T22:44:59 | https://dev.to/rapidinnovation/ai-workforce-evolution-emerging-roles-and-future-perspectives-433j | ## 1\. Introduction
The landscape of work and employment has been significantly reshaped by the
advent of artificial intelligence (AI). As technology continues to advance, AI
is becoming increasingly integral to various industries, driving efficiency,
innovation, and transformation. This evolution is not only changing... | rapidinnovation | |
1,917,866 | An excellent Modbus slave (server) simulator and serial port debugging tool. | Main Features Download URL: Modbus Slave Emulator Supports various Modbus protocols,... | 0 | 2024-07-09T22:54:32 | https://dev.to/redisant/an-excellent-modbus-slave-server-simulator-and-serial-port-debugging-tool-c0a | modbus, slave, tooling, developer | ### Main Features
**Download URL: [Modbus Slave Emulator](https://www.redisant.com/mse)**
- Supports various Modbus protocols, including:
- Modbus RTU
- Modbus ASCII
- Modbus TCP/IP
- Modbus UDP/IP
- Modbus RTU Over TCP/IP
- Modbus RTU Over UDP/IP
- Monitors communication data on serial lines ... | redisant |
1,917,879 | Day 0 - Beginning My Full-Stack Development Journey with JavaScript | Today marks the first step of my journey towards becoming a full-stack developer. Despite being in a... | 0 | 2024-07-09T23:29:33 | https://dev.to/ryoichihomma/day-1-beginning-my-full-stack-development-journey-with-javascript-2dld | Today marks the first step of my journey towards becoming a full-stack developer. Despite being in a non-tech role, I've decided to kick things off with the "JavaScript Essential Training" course on LinkedIn Learning.
### Why JavaScript?
Well, before diving headfirst into frameworks like React.js, I wanted to revisit ... | ryoichihomma | |
1,917,869 | Day 9 : Deploying Microservices on Kubernetes - Project Journey | Hey guys, it's Day 9 of my SRE and Cloud Security journey, and I'm pumped to share what I... | 0 | 2024-07-09T23:06:30 | https://dev.to/arbythecoder/day-9-deploying-microservices-on-kubernetes-project-journey-3c39 | microservices, kubernetes, devops, beginners | Hey guys, it's Day 9 of my SRE and Cloud Security journey, and I'm pumped to share what I accomplished today! I successfully deployed a three-microservice application on Kubernetes – it was definitely a challenge, but I tackled it head-on and learned a ton in the process. Let's just say, I had more than a few "oh, no,... | arbythecoder |
1,917,871 | O que é e como usar o axios? | O que é? Axios é uma biblioteca de JavaScript que permite fazer requisições HTTP de... | 0 | 2024-07-09T23:11:03 | https://dev.to/nathanndos/o-que-e-e-como-usar-o-axios-3i3l | ## O que é?
Axios é uma biblioteca de JavaScript que permite fazer requisições HTTP de maneira simples e eficiente, em resumo é um cliente HTTP baseado em promises.
## Como instalar?
`yarn add axios`
| nathanndos | |
1,917,872 | Evoluindo sua estratégia de Testes para FileUpload com Spring Test e Amazon S3 | Em meu último artigo, discutimos como pode ser implementado um serviço de file upload utilizando... | 0 | 2024-07-10T11:15:01 | https://dev.to/jordihofc/evoluindo-sua-estrategia-de-testes-para-fileupload-com-spring-test-e-amazon-s3-22ap | testing, spring, aws, amazons3 | Em meu último artigo, discutimos como pode ser implementado um serviço de file upload utilizando Spring Boot e Amazon S3. Lá entendemos quais são as preocupações e ferramentas necessárias para permitir que você customize as regras de como gerenciar seus arquivos. Se você não leu ainda, recomendo que o faça, antes de le... | jordihofc |
1,917,873 | How can i recover my lost bitcoin investment from fake online investment | I will forever be grateful to Saclux Comptech Specialst. I almost lost my life after falling victim... | 0 | 2024-07-09T23:18:25 | https://dev.to/charlotte_hannahleia_e5e/how-can-i-recover-my-lost-bitcoin-investment-from-fake-online-investment-58h5 | bitcoin, cryptocurrency, softwaredevelopment, news | I will forever be grateful to Saclux Comptech Specialst. I almost lost my life after falling victim to a scam that went on for weeks, I got contacted by a man on Linkedin pretending to be a Forex trader investor, and he told me I’d make huge profits if I invested on his platform not knowing that I was being targeted, H... | charlotte_hannahleia_e5e |
1,917,878 | Liberar consumo de API C# | Apesar de parecer simples liberar API para uso no visual studio, no meu caso sempre veio com algum... | 0 | 2024-07-09T23:55:22 | https://dev.to/nathanndos/liberar-consumo-de-api-c-48j6 | Apesar de parecer simples liberar API para uso no visual studio, no meu caso sempre veio com algum problema que fizesse com que desse erro nas requisições pelo postman, dispositivo móvel ou por algum projeto.
Dito isso, eu fiquei quebrando cabeça pra resolver e abaixo eu listei algumas coisas que podem resolver esse pr... | nathanndos | |
1,917,880 | List of 45 databases in the world | Under the Hood Let’s not waste time here is the list of all databases SQL... | 0 | 2024-07-09T23:34:04 | https://dev.to/shreyvijayvargiya/list-of-45-databases-in-the-world-57e8 | database, vectordatabase, fauna, mongodb | Under the Hood
--------------
Let’s not waste time here is the list of all databases
SQL Databases
-------------
### Traditional RDBMS
* [PostgreSQL](https://www.postgresql.org/) — Advanced, open-source relational database known for its reliability, feature robustness, and performance.
* [Oracle](https://www.or... | shreyvijayvargiya |
1,917,881 | Framer Motion | Giriş - Part 1 | Nedir ? Framer Motion, React uygulamalarında kolayca animasyon yapmanızı sağlayan bir kütüphanedir.... | 0 | 2024-07-10T00:08:55 | https://dev.to/boraacici/framer-motion-giris-part-1-1a8j | react, javascript, tutorial, webdev | **Nedir ?**
Framer Motion, React uygulamalarında kolayca animasyon yapmanızı sağlayan bir kütüphanedir. Geçiş ve sürükleme gibi animasyon efektleri eklemek için kullanılır.
**Kim Tarafından Oluşturulmuştur ?**
Framer firması tarafından oluşturulmuştur. Framer, özellikle kullanıcı arayüzü (UI) tasarımı ve prototiplem... | boraacici |
1,917,882 | The Making of Solitaire for Mini Micro | Over the weekend I got the urge to create a Solitaire card game for Mini Micro. I completed it... | 0 | 2024-07-10T16:28:51 | https://dev.to/joestrout/the-making-of-solitaire-for-mini-micro-19hf | miniscript, minimicro, programming, gamedev | Over the weekend I got the urge to create a Solitaire card game for [Mini Micro](https://miniscript.org/MiniMicro/). I completed it Sunday night, the day after I started it. You can play it [here](https://joestrout.itch.io/solitaire), or download the source code [from GitHub](https://github.com/JoeStrout/ms-solitaire... | joestrout |
1,917,883 | [Game of Purpose] Day 52 | Today I was working on making Manny go along the spline. And it is functioning somewhat... | 27,434 | 2024-07-09T23:38:30 | https://dev.to/humberd/game-of-purpose-day-52-50cj | gamedev | Today I was working on making Manny go along the spline. And it is functioning somewhat properly.
{% embed https://youtu.be/rfgzU8qpxWs %}
I am really considering moving some functions to C++. The reason is that the onse using multiple variables are really hard to read and write.
For example the one, which moves Mann... | humberd |
1,917,884 | How to Create a Blog Using NextJS v14 and MDX: A Comprehensive Guide | It is very effective to develop a blog since it helps to showcase and share acquired knowledge,... | 0 | 2024-07-09T23:42:31 | https://www.ginos.codes/blog/create-blog-nextjs-mdx | webdev, react, nextjs, typescript | It is very effective to develop a blog since it helps to showcase and share acquired knowledge, pertinent experiences, and updates to a larger audience. More recently, I integrated a blog functionality on my web site with NextJS v14, MDX, and other libs. This blog post will guide you through the steps that I followed t... | pineapplegrits |
1,917,885 | The Evolution of Hand Surgery: Innovations and Contributions by SunMay Clinic | Introduction Hand surgery has advanced significantly over the years, playing a crucial role in... | 0 | 2024-07-09T23:49:34 | https://dev.to/sunmayclinic/the-evolution-of-hand-surgery-innovations-and-contributions-by-sunmay-clinic-cdc | socialmedia, mentalhealth, microsoftgraph | **Introduction**
Hand surgery has advanced significantly over the years, playing a crucial role in restoring hand function and improving quality of life for patients. SunMay Clinic in Astana stands at the forefront of these advancements, integrating cutting-edge technologies and personalized care to achieve remarkable... | sunmayclinic |
1,917,886 | Bullshit Tech Roles (satire) | In any sufficiently well-funded or otherwise successful tech company, a set of new roles will... | 0 | 2024-07-09T23:50:55 | https://dev.to/anttiviljami/bullshit-tech-roles-satire-54f | satire, techjobs | In any sufficiently well-funded or otherwise successful tech company, a set of new roles will inevitably emerge—so crucial and revered by our industry that they've practically transcended the need to produce any tangible work. These roles specialize in the fine art of enabling others, in the hopes that, one day, the ac... | anttiviljami |
1,917,887 | Creating a Generative AI Chatbot with JavaScript | Introduction Generative AI has become a popular topic in the technology field over the past year.... | 0 | 2024-07-09T23:56:04 | https://dev.to/rodliraa/creating-a-generative-ai-chatbot-with-javascript-3flk | Introduction
Generative AI has become a popular topic in the technology field over the past year. Many developers are creating interesting projects using this technology. Google has developed its own generative AI model called Gemini.
In this article, we will build a simple ChatBot with Node.js and integrate Google Gem... | rodliraa | |
1,917,888 | Hack The Box — Archetype Walkthrough | This box gives exposure to: Protocols MSSQL SMB Powershell Reconnaissance Remote Code... | 0 | 2024-07-10T04:45:51 | https://dev.to/gabe-blog/hack-the-box-archetype-walkthrough-p5n | > This box gives exposure to:
> Protocols
> MSSQL
> SMB
> Powershell
> Reconnaissance
> Remote Code Execution
> Clear Text Credentials
> Information Disclosure
> Anonymous/Guest Access
Starting off with the ping command to verify that my machine can reach the target machine.
** And Download `sqlite-tools-win-________.zip`

.
2-... | karim_abdallah | |
1,917,956 | Composing JavaScript Decorators | A walkthrough and best practices guide on how to compose JavaScript decorators that use... | 27,975 | 2024-07-10T01:33:34 | https://dev.to/frehner/composing-javascript-decorators-2o38 | webdev, javascript | A walkthrough and best practices guide on how to compose JavaScript decorators that use auto-accessors.
## Table of Contents
Consider skipping straight to [Best Practices](#best-practices)!
- [Context and Specification](#context-and-specification)
- [Preface](#preface)
- [Composing Decorators](#composing-decorators)... | frehner |
1,917,957 | DBOS-Cloud Simple and Robust Workflow Orchestration | This post gives a simple example which: 1) sets up api endpoints, 2) sends emails using Postmark when an api is hit, inserts events in to Postgres, and queries for those events. | 0 | 2024-07-10T02:50:18 | https://dev.to/vince_hirefunnel_co/dbos-cloud-simple-and-robust-workflow-orchestration-cn4 | dbos, workflows, postgres, orchestration | ---
title: DBOS-Cloud Simple and Robust Workflow Orchestration
published: true
description: This post gives a simple example which: 1) sets up api endpoints, 2) sends emails using Postmark when an api is hit, inserts events in to Postgres, and queries for those events.
tags: dbos, workflows, postgres, orchestration
cov... | vince_hirefunnel_co |
1,917,961 | Comparing Limit-Offset and Cursor Pagination | Comparing Limit-Offset and Cursor Pagination There are two popular methods for pagination... | 0 | 2024-07-10T01:56:38 | https://dev.to/jacktt/comparing-limit-offset-and-cursor-pagination-1n81 | database, backend | ## Comparing Limit-Offset and Cursor Pagination
There are two popular methods for pagination that are `limit-offset pagination` and `cursor pagination`. Each has its own strengths and weaknesses, making them suitable for different scenarios. Let's explore these methods, comparing their performance, complexity, and use ... | jacktt |
1,917,962 | Unlocking the Power of Alibaba Cloud Elasticsearch: A Step-by-Step Guide to Accessing Your Cluster | Introduction Incorporating new technologies into museum displays or any data-intensive... | 0 | 2024-07-10T01:57:52 | https://dev.to/a_lucas/unlocking-the-power-of-alibaba-cloud-elasticsearch-a-step-by-step-guide-to-accessing-your-cluster-3jg1 | tutorial, programming, learning, ai | ## Introduction
Incorporating new technologies into museum displays or any data-intensive environment can significantly enhance user experiences and operational efficiency. Alibaba Cloud Elasticsearch offers robust solutions tailored for these needs. This guide will walk you through using PHP, Python, Java, and Go cli... | a_lucas |
1,917,963 | How to Do Android App Security Testing: A Guide for Developers and Testers | Introduction As a die-hard fan of Android phones, if your phone suddenly drops, would your... | 0 | 2024-07-10T01:57:57 | https://dev.to/wetest/how-to-do-android-app-security-testing-a-guide-for-developers-and-testers-3j8b | javascript, programming, devops, beginners | ## Introduction
As a die-hard fan of Android phones, if your phone suddenly drops, would your first thought be "Oh my god!" or that your money in Google Pay or Paypal is not safe? If the latest downloaded app not only pops up various boring ads but also unexpected notifications, would you think it might be a phishing a... | wetest |
1,917,964 | Good ways to teach software development? | Hello! Just a few weeks ago I started to organize myself to teach others about software development,... | 0 | 2024-07-10T02:00:49 | https://dev.to/tonyrome/good-ways-to-teach-software-development-55d0 | discuss, learning, teaching, education | Hello!
Just a few weeks ago I started to organize myself to teach others about software development, the basics, computational thinking, backend, frontend, some professional tips and other topics from scratch. For now I only have a general idea and roadmap about what and how to teach, but nowadays there are a lot of t... | tonyrome |
1,917,965 | Simplify File Uploads with @fluidjs/multer-cloudinary in Express.js | Simplify File Uploads with @fluidjs/multer-cloudinary in Express.js ... | 0 | 2024-07-10T02:02:02 | https://dev.to/imani_brown_1a7d9bc29dd27/simplify-file-uploads-with-fluidjsmulter-cloudinary-in-expressjs-1i1m | javascript, multer, fileupload | # Simplify File Uploads with @fluidjs/multer-cloudinary in Express.js
## Introduction
Handling file uploads can be a daunting task, but with `@fluidjs/multer-cloudinary`, the process becomes straightforward and manageable. In this article, we'll walk through setting up an Express.js application to upload files direct... | imani_brown_1a7d9bc29dd27 |
1,917,967 | Tier 1 Support | We are USA based Multi-lingual Technical Support Experts. They provide Tier 1, 2 & 3 Support,... | 0 | 2024-07-10T02:11:53 | https://dev.to/peaceysystems/tier-1-support-21lm | We are USA based Multi-lingual Technical Support Experts. They provide Tier 1, 2 & 3 Support, Network Operations Support, Installation support since 2007.
| peaceysystems | |
1,917,968 | Post-mortem on the Test of Insanity | Howdy, today I'm here to discuss the development process of our latest game: THE TEST OF... | 0 | 2024-07-10T04:19:42 | https://dev.to/jacklehamster/post-mortem-on-the-test-of-insanity-14a6 | gamedev, godot, insanity, crazy | Howdy,
today I'm here to discuss the development process of our latest game:
## THE TEST OF INSANITY
This game is published under a new brand: [Big Nuts](https://bignutsgames.itch.io/), and developed using Godot
### A rocky start
Originally, KC and I were thinking of the kind of games we liked. Immediately, we foun... | jacklehamster |
1,917,970 | ANTlabs SG Express 5100 | BOOK A DEMO https://calendly.com/richard-720/30min Start small with this full-featured gateway for... | 0 | 2024-07-10T02:14:35 | https://dev.to/peaceysystems/antlabs-sg-express-5100-84m | BOOK A DEMO https://calendly.com/richard-720/30min
Start small with this full-featured gateway for quality Hotel WiFi, and pick only the features you need for your network.
An all-in-one Service Management Platform, the ANTlabs SG Express 5100 is ideal for smaller (100-150 room) properties such as boutique hotels, h... | peaceysystems | |
1,917,971 | ANTlabs SG Express 5200 | BOOK A DEMO https://calendly.com/richard-720/30min A better all-in-one Service Management Platform to... | 0 | 2024-07-10T02:15:07 | https://dev.to/peaceysystems/antlabs-sg-express-5200-38a5 | BOOK A DEMO https://calendly.com/richard-720/30min
A better all-in-one Service Management Platform to monetize existing Internet services, maximize limited bandwidth, and improve user experience
Designed for the hospitality sector, the ANTlabs SG Express 5200 meets the High Speed Internet Access (HSIA) needs of guest n... | peaceysystems | |
1,917,972 | MAX232 IC:Features,Applications and Types | The MAX232 integrated circuit (IC) was engineered by Maxim Integrated Products and functions as a... | 0 | 2024-07-10T02:16:14 | https://dev.to/candice88771483/max232-icfeaturesapplications-and-types-2ln0 | programming | The MAX232 integrated circuit (IC) was engineered by Maxim Integrated Products and functions as a voltage logic converter, transforming TTL logic levels into TIA or EIA-232-F levels. It serves as a crucial intermediary for communication between PCs and microcontrollers. This IC finds application in various fields inclu... | candice88771483 |
1,917,973 | What integrated circuit chip is | What it is An integrated circuit chip design that integrates compound semiconductors with silicon... | 0 | 2024-07-10T02:17:17 | https://dev.to/candice88771483/what-integrated-circuit-chip-is-2pmo | programming |
What it is
An [integrated circuit chip](https://www.blikai.com/blog/components-parts/integrated-circuit-chip-types-applications-and-faq) design that integrates compound semiconductors with silicon complementary metal-oxide semiconductor (CMOS) technology, which is the basis for most of today’s integrated circuits.
Wh... | candice88771483 |
1,917,983 | Building a Reminder App with Html, Css & javascript | Introduction I am excited to share the journey of building a Reminder app, a React Native... | 0 | 2024-07-10T02:46:15 | https://dev.to/bigelan/building-a-reminder-app-with-html-css-javascript-1bce |
Introduction
I am excited to share the journey of building a Reminder app, a React Native application developed as a portfolio project.The project kicked off on July 4, 2024, and had to be completed by July 11, 2024. Our goal was to create an App that manages different tasks effortlessly, Organize, prioritize, and t... | bigelan | |
1,917,977 | How to Build a Data Entry System (Quick & Easy Guide) | Build a Data Entry System In 3 Steps In this guide, we detail the steps necessary to construct and... | 0 | 2024-07-10T02:25:25 | https://five.co/blog/how-to-build-a-data-entry-system/ | database, datascience, mysql, tutorial | <!-- wp:heading -->
<h2 class="wp-block-heading">Build a Data Entry System In 3 Steps</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In this guide, we detail the steps necessary to construct and deploy a data entry system using Five's rapid application development environment.</p>
<!-- /wp:paragraph -->
<!-- wp:e... | domfive |
1,917,978 | 3 Rs of Software Architecture for iOS based in SwiftUI | Software Architecture After over 50 years of software engineering, we still haven't... | 0 | 2024-07-10T02:33:58 | https://dev.to/maatheusgois/3-rs-of-software-architecture-for-ios-based-in-swiftui-c6j | ios, refactoring, swiftui, cleancode | ## Software Architecture
After over 50 years of software engineering, we still haven't settled on a precise definition of software architecture. It remains the art within computer science, persistently evading our efforts to pin it down. Nevertheless, its importance to the industry and applications is undeniable.
Des... | maatheusgois |
1,917,979 | LM358 Overview | Introduction As far as we know, there are various configurations available for 555 timers, single... | 0 | 2024-07-10T02:33:40 | https://dev.to/candice88771483/lm358-overview-2de | lm358 | Introduction
As far as we know, there are various configurations available for 555 timers, single logic gates, microcontrollers, microprocessors, voltage regulators, and op-amps. These ICs include the LM741, LM7805, LM35, LM324 IC, LM337 IC, LM338 IC, LM339 IC, LM1117, and many others.
The most commonly used integrate... | candice88771483 |
1,917,980 | Decode the 10K Resistor Color Code Like a Pro! | Discovering the secret language of resistors, particularly the 10k resistor color code, is like... | 0 | 2024-07-10T02:39:54 | https://dev.to/candice88771483/decode-the-10k-resistor-color-code-like-a-pro-51d0 | webdev | Discovering the secret language of resistors, particularly the [10k resistor color code](https://www.blikai.com/blog/components-parts/10k-resistor-color-code-everything-you-need-to-know), is like cracking a cryptic code.
Think of resistors as traffic wardens for electrons in an electrical circuit. They control the flo... | candice88771483 |
1,917,981 | Small-pitch LED display market: new opportunities and challenges | Introduction With the continuous advancement of technology and the growing market demand, the... | 0 | 2024-07-10T02:42:53 | https://dev.to/sostrondylan/small-pitch-led-display-market-new-opportunities-and-challenges-fd8 | led, display, pitch | Introduction
With the continuous advancement of technology and the growing market demand, the [small-pitch LED display](https://sostron.com/products/cobra-cob-led-display/) market is becoming the new favorite of the LED display industry. Despite the fierce competition and overcapacity in the domestic market, the rapid... | sostrondylan |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.