
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,902,085 | Selenium for automation | ___ Selenium :__ Selenium is an opensource project so many people work together to bring up... | 0 | 2024-06-27T04:44:06 | https://dev.to/revathykarthik/selenium-for-automation-390b | **___ Selenium :__**
Selenium is an opensource project so many people work together to bring up that project. It can automate a browser, the way we automate is in our hands.
For example, for a Facebook application to upload a profile picture everyday whenever we login and share it. This can be achieved b... | revathykarthik | |
1,902,084 | Mitigating disruption during Amazon EKS cluster upgrade with blue/green deployment | Co-author @coangha21 Table of Contents In-place and blue/green upgrade strategies Upgrade cluster... | 0 | 2024-06-27T04:43:13 | https://dev.to/haintkit/mitigating-disruption-during-amazon-eks-cluster-upgrade-with-bluegreen-deployments-5co | aws, eks, upgrade | Co-author @coangha21
**Table of Contents**
- In-place and blue/green upgrade strategies
- Upgrade cluster process
- Prerequisite
- Update manifests
- Bootstrap new cluster
- Re-deploy add-ons and third-party tools with compatible version
- Re-deploy workloads
- Verify workloads
- DNS switchover
- State... | haintkit |
1,902,083 | Which Database is Perfect for You? A Comprehensive Guide to MySQL, PostgreSQL, NoSQL, and More | Today, most of the applications are heavily database-oriented. The choice of a database can... | 0 | 2024-06-27T04:42:55 | https://www.webdevstory.com/choosing-the-right-database/ | database, mysql, postgres, nosql | Today, most of the applications are heavily database-oriented. The choice of a database can significantly impact the success of our project.
Choosing the right database for our needs is crucial for a small application or an extensive enterprise system.
We will explore the key characteristics, benefits, and ideal use ... | mmainulhasan |
1,902,081 | The Evolution of JavaScript: A Journey Through ECMAScript Versions 🚀 | JavaScript has come a long way since its inception in 1995. The language has evolved significantly,... | 0 | 2024-06-27T04:41:10 | https://dev.to/rishikesh_janrao_a613fad6/the-evolution-of-javascript-a-journey-through-ecmascript-versions-2d | webdev, javascript, ecma, programming | JavaScript has come a long way since its inception in 1995. The language has evolved significantly, primarily through the standardisation efforts of ECMAScript (ES), which defines how JavaScript should work. Each version of ECMAScript introduces new features, syntactic sugar, and improvements, making JavaScript more po... | rishikesh_janrao_a613fad6 |
1,902,080 | Laravel Timestamps – Automatic Handling of Created and Updated Dates | 👋 Introduction Welcome to the whimsical world of Laravel timestamps! Whether you’re a... | 27,882 | 2024-06-27T04:39:19 | https://n3rdnerd.com/laravel-timestamps-automatic-handling-of-created-and-updated-dates/ | laravel, webdev, beginners, programming | ## 👋 Introduction
Welcome to the whimsical world of Laravel timestamps! Whether you’re a seasoned developer or a curious beginner, this guide will tickle your funny bone while giving you a crystal-clear understanding of how Laravel effortlessly manages timestamps for created_at and updated_at fields. Are you ready to ... | n3rdnerd |
1,902,079 | Big Daddy Game: A Comprehensive Guide | Big Daddy Game is a captivating online game that has gained popularity among gamers of all ages.... | 0 | 2024-06-27T04:37:12 | https://dev.to/weruy/big-daddy-game-a-comprehensive-guide-25p | Big Daddy Game is a captivating online game that has gained popularity among gamers of all ages. Whether you are new to the game or an experienced player, this guide will help you understand everything about Big Daddy Game, from setting up your account to advanced gameplay strategies. We will also discuss common issues... | weruy | |
1,902,078 | Migrating from Gitlap to Github enterprise | when migrating from Gitlap to GitHub enterprise, having more than one organization, projects and... | 0 | 2024-06-27T04:34:35 | https://dev.to/basel5001/migrating-from-gitlap-to-github-enterprise-2f45 | when migrating from Gitlap to GitHub enterprise, having more than one organization, projects and repos, and many users what is the best approach to achieve successful migration with the least operational or scripting effort and having the same structure for everything?
tried searching for an approach but found all ans... | basel5001 | |
1,894,875 | The Importance of Upgrading Frameworks: A Case for Angular | Introduction In the fast-paced world of software development, staying up-to-date with the... | 0 | 2024-06-27T04:23:49 | https://dev.to/this-is-angular/the-importance-of-upgrading-frameworks-a-case-for-angular-5c91 | webdev, javascript, angular, typescript | ## Introduction
In the fast-paced world of software development, staying up-to-date with the latest technologies and frameworks is not just a matter of keeping up with trends; it's a critical component of maintaining a secure, efficient, and robust application. Despite this, many companies continue to run older or out... | sonukapoor |
1,902,077 | Unlock Your Programming Potential with Stanford's CS 106B 🚀 | Advance your programming skills with CS 106B: Programming Abstractions at Stanford University, covering recursion, algorithmic analysis, and data abstraction using C++. | 27,844 | 2024-06-27T04:32:36 | https://getvm.io/tutorials/cs-106b-programming-abstractions-stanford-university | getvm, programming, freetutorial, universitycourses |
Are you ready to take your programming skills to the next level? 🤔 If so, then you simply must check out CS 106B: Programming Abstractions at Stanford University! 🎉
As the natural successor to Programming Methodology, this course covers a wide range of advanced programming topics, including recursion, algorithmic ... | getvm |
1,902,076 | Issue with Date Range Selection and Independent Year selection for Two Calendars in svelte js | I am using Flatpickr in svelte for date range selection in my project and encountered a specific... | 0 | 2024-06-27T04:31:27 | https://dev.to/parth_shah_2a456657c11aad/issue-with-date-range-selection-and-independent-year-selection-for-two-calendars-in-svelte-js-1khn |
I am using Flatpickr in svelte for date range selection in my project and encountered a specific issue regarding the Independent Year selection for two calendars. Currently, when I change the year for one calendar, it changes the year for a second calendar as well. This behavior is not desirable as I need both calend... | parth_shah_2a456657c11aad | |
1,902,075 | Hosting a Static Website on Amazon S3 with Terraform: A Step-by-Step Guide | Introduction In the world of web development, static websites offer a straightforward and efficient... | 0 | 2024-06-27T04:30:02 | https://dev.to/mohanapriya_s_1808/hosting-a-static-website-on-amazon-s3-with-terraform-a-step-by-step-guide-3m1 | **Introduction**
In the world of web development, static websites offer a straightforward and efficient way to present content without the complexities of server-side processing. Amazon S3 provides a robust platform for hosting these static websites, ensuring high availability and scalability. To further streamline the... | mohanapriya_s_1808 | |
1,871,659 | Entry Level Developer Job Requires 2 Years Experience? | There are some myths surrounding job postings today. Maybe you came across Entry Level Developer job... | 0 | 2024-06-27T04:30:00 | https://www.jobreadyprogrammer.com/p/blog/entry-level-developer-job-requires-2-years-experience | career, interview, beginners, softwareengineering | <p class="MsoNormal"><span lang="EN-US" style="font-size: 12.0pt; mso-bidi-font-size: 11.0pt; line-height: 107%; font-family: 'Times New Roman',serif;">There are some myths surrounding job postings today. Maybe you came across Entry Level Developer job postings that required two years of experience and wondered, &ldquo... | jobreadyprogrammer |
1,900,892 | ว่าด้วย Extension บน PostgreSQL | PostgreSQL Extension เป็นคุณลักษณะที่ดีอย่างหนึ่งของฐานข้อมูล Postgres... | 0 | 2024-06-27T02:58:34 | https://dev.to/iconnext/waadwy-extension-bn-postgresql-22pn | **PostgreSQL Extension** เป็นคุณลักษณะที่ดีอย่างหนึ่งของฐานข้อมูล Postgres
ที่ช่วยเสริมที่ช่วยเพิ่มประสิทธิภาพการทำงานของระบบฐานข้อมูล โดยทำหน้าที่ขยายฟังก์ชันการทำงานของ PostgreSQL ให้ครอบคลุมไปกว่าที่ติดตั้งมาในระบบพื้นฐาน โมดูลเสริมเหล่านี้สามารถเพิ่มฟีเจอร์ใหม่ ๆ ดังต่อไปนี้
**ชนิดข้อมูลเพิ่มเติม:** โมดูลเสริมสาม... | iconnext | |
1,902,074 | Laravel Task Scheduling – Scheduling Artisan Commands | 👋 Introduction Welcome to the whimsical world of Laravel Task Scheduling! If you’re here,... | 27,882 | 2024-06-27T04:23:24 | https://n3rdnerd.com/laravel-task-scheduling-scheduling-artisan-commands/ | laravel, artisan, beginners, schedule | ## 👋 Introduction
Welcome to the whimsical world of Laravel Task Scheduling! If you’re here, it’s probably because you’ve encountered the mystical “Artisan Commands” and wondered, “How on Earth do I schedule these magical tasks?” Fret not, dear reader, for we are about to embark on an amusing yet educational journey t... | n3rdnerd |
1,902,073 | Streamlining Database Interactions with Flask-SQLAlchemy | In the realm of web development, Flask emerges as a popular Python framework renowned for its... | 0 | 2024-06-27T04:22:45 | https://dev.to/epakconsultant/streamlining-database-interactions-with-flask-sqlalchemy-3ld9 | In the realm of web development, Flask emerges as a popular Python framework renowned for its lightweight and flexible nature. However, managing database interactions within Flask applications can become cumbersome. This is where Flask-SQLAlchemy enters the scene, offering a powerful and user-friendly extension that si... | epakconsultant | |
1,902,072 | Handling Large Numbers of Promises in Node JS | Practical Tips for Managing Multiple Promises in Node JS Applications Handling Large Numbers of... | 0 | 2024-06-27T04:20:54 | https://dev.to/manojgohel/handling-large-numbers-of-promises-in-node-js-53h0 | node, javascript, promises, beginners | > Practical Tips for Managing Multiple Promises in Node JS Applications

Handling Large Numbers of Promises in Node J... | manojgohel |
1,902,063 | Are Microservices Really Necessary for Your Project? | Introduction Microservices have taken the software development world by storm. They... | 0 | 2024-06-27T04:19:59 | https://dev.to/srijan_karki/are-microservices-really-necessary-for-your-project-461f | microservices, programming, productivity, architecture | ## Introduction
Microservices have taken the software development world by storm. They promise scalability, flexibility, and organizational benefits that monolithic architectures often struggle to provide. But are microservices always the best choice? In this article, we’ll explore the hidden costs and benefits of mic... | srijan_karki |
1,902,062 | JavaScript Project Design Patterns: A Comprehensive Guide 🚀 | Design patterns are essential tools in a developer's toolkit. They provide tried-and-tested solutions... | 0 | 2024-06-27T04:16:24 | https://dev.to/rishikesh_janrao_a613fad6/javascript-project-design-patterns-a-comprehensive-guide-55o9 | webdev, javascript, designpatterns | Design patterns are essential tools in a developer's toolkit. They provide tried-and-tested solutions to common problems, making code more manageable, scalable, and maintainable. In JavaScript, design patterns play a crucial role, especially as projects grow in complexity.
In this article, we'll explore five popular d... | rishikesh_janrao_a613fad6 |
1,902,061 | Building Your AI Companion: The Essentials of Creating a ChatGPT-Based Personal Assistant | Imagine a personal assistant readily available to answer your questions, handle tasks, and streamline... | 0 | 2024-06-27T04:15:02 | https://dev.to/epakconsultant/building-your-ai-companion-the-essentials-of-creating-a-chatgpt-based-personal-assistant-4aep | chatgpt | Imagine a personal assistant readily available to answer your questions, handle tasks, and streamline your daily workflow. With the rise of large language models like ChatGPT, this vision becomes a reality. This article explores the foundational concepts of creating your own AI personal assistant powered by ChatGPT, e... | epakconsultant |
1,902,060 | Laravel Mix – Asset Compilation Simplified | 👋 Introduction Let’s begin our journey with Laravel Mix, the superhero of asset... | 27,882 | 2024-06-27T04:10:43 | https://n3rdnerd.com/laravel-mix-asset-compilation-simplified/ | laravel, beginners, assets, webdev | ## 👋 Introduction
Let’s begin our journey with Laravel Mix, the superhero of asset compilation. Think of it as the Batman of your web development arsenal. No, it’s not a cocktail mixer, although that would be cool (and maybe delicious?). Laravel Mix is a tool that simplifies tasks like compiling and minifying CSS and ... | n3rdnerd |
1,902,058 | Demystifying the Low Power Wide Area Network: Unveiling the Fundamentals of LoRaWAN | In the ever-expanding realm of the Internet of Things (IoT), efficient communication between devices... | 0 | 2024-06-27T04:08:32 | https://dev.to/epakconsultant/demystifying-the-low-power-wide-area-network-unveiling-the-fundamentals-of-lorawan-411d | lorawan | In the ever-expanding realm of the Internet of Things (IoT), efficient communication between devices is paramount. LoRaWAN emerges as a dominant force in this arena, offering a Low Power Wide Area Network (LPWAN) solution specifically designed for connecting battery-powered devices over long distances. This article del... | epakconsultant |
1,902,057 | Mastering Multifield Searches in MS Access: A Beginner's Guide | In the world of databases, efficient search functionality is paramount. Microsoft Access offers... | 0 | 2024-06-27T04:04:22 | https://dev.to/epakconsultant/mastering-multifield-searches-in-ms-access-a-beginners-guide-3df5 | access | In the world of databases, efficient search functionality is paramount. Microsoft Access offers robust capabilities for creating customized searches. This article unveils how to create multifield searches in MS Access, allowing you to search across multiple data fields simultaneously, refining your search results and ... | epakconsultant |
1,899,579 | Little PRs make the mighty refactor | Need of the hour Refactoring is a crucial part of software development. It involves... | 0 | 2024-06-27T04:03:30 | https://dev.to/chinmaypurav/little-prs-make-the-mighty-refactor-1kc | ## Need of the hour
Refactoring is a crucial part of software development. It involves altering the structure of the code without changing its functionality. However, it's a process that can be fraught with risk if not carefully and thoroughly reviewed. This risk becomes exacerbated when automated tests, which serve as... | chinmaypurav | |
1,902,056 | Scheduling IT and Engineering on-call rotations just got easier | Introducing UI improvements to the on-call schedules and rotations feature on Squadcast. It... | 0 | 2024-06-27T04:02:22 | https://www.squadcast.com/blog/scheduling-it-and-engineering-on-call-rotations-just-got-easier | oncallrotation, incidentresponse | _Introducing UI improvements to the on-call schedules and rotations feature on Squadcast._
It shouldn’t take you more time than a few seconds to understand your on-call schedule and rotations and how you could make changes to it. It is important for on-call scheduling and alerting tools to make this as simple as possi... | squadcastcommunity |
1,900,978 | How to Install and Manage Multiple Node.js Versions on macOS Using NVM | As a developer working with Node.js, we might need to work on various projects and each project has... | 0 | 2024-06-27T04:02:15 | https://dev.to/mesonu/how-to-install-and-manage-multiple-nodejs-versions-on-macos-using-nvm-2jfh | webdev, programming, node, macos | As a developer working with Node.js, we might need to work on various projects and each project has its configuration. So maybe some of the projects have different versions of Node.js, and then we need to switch between different versions of Node.js for multiple projects. The Node Version Manager (NVM) is a fantastic t... | mesonu |
1,902,054 | GBase 8s Database Locking Issues and Performance Optimization Strategies | Database locking issues have always been a challenging aspect of database management. In the GBase 8s... | 0 | 2024-06-27T04:00:22 | https://dev.to/congcong/gbase-8s-database-locking-issues-and-performance-optimization-strategies-297p | Database locking issues have always been a challenging aspect of database management. In the GBase 8s database, table locks can lead to locking of table headers, data rows, and other components, which can result in various error messages. This article provides an in-depth understanding of the locking situations in GBas... | congcong | |
1,902,046 | AWS S3 Bucket Website Hosting using Terraform | In previous blog Deploy Terraform resources to AWS using GitHub Actions via OIDC, I explained how to... | 0 | 2024-06-27T03:59:47 | https://dev.to/camillehe1992/aws-s3-bucket-website-hosting-using-terraform-4fk5 | aws, terraform, githubactions, s3 | In previous blog [Deploy Terraform resources to AWS using GitHub Actions via OIDC](https://dev.to/camillehe1992/deploy-terraform-resources-to-aws-using-github-actions-via-oidc-3b9g), I explained how to configure OpenID Connect within GitHub Actions workflows to authenticate with AWS, then demonstrated the process using... | camillehe1992 |
1,902,053 | Laravel Telescope – Insightful Debugging and Profiling | 👋 Introduction Greetings, fellow coder! Do you ever feel like your debugging process is as... | 27,882 | 2024-06-27T03:55:54 | https://n3rdnerd.com/laravel-telescope-insightful-debugging-and-profiling/ | laravel, debugging, profiling, beginners | ## 👋 Introduction
Greetings, fellow coder! Do you ever feel like your debugging process is as chaotic as trying to herd cats? Enter Laravel Telescope, your new best friend in the realm of debugging and profiling in Laravel applications. Think of it as your very own Sherlock Holmes, armed with a magnifying glass and a ... | n3rdnerd |
1,902,052 | Khám phá game nổ hũ Avengers đỉnh cao tại SunWin | Khám phá game nổ hũ Avengers đỉnh cao tại SunWin Nổ hũ Avengers hiện đang làm mưa làm gió... | 0 | 2024-06-27T03:55:16 | https://dev.to/sunwinaus/kham-pha-game-no-hu-avengers-dinh-cao-tai-sunwin-31db | webdev, sunwin, beginners, taiappsunwin | # Khám phá game nổ hũ Avengers đỉnh cao tại SunWin
Nổ hũ Avengers hiện đang làm mưa làm gió tại cổng game **[SunWin](https://sunwina.us/)**, thu hút đông đảo người chơi. Đặc biệt, những ai yêu thích trò chơi nổ hũ ăn tiền sẽ có được những trải nghiệm khó quên với Avengers. Trong bài viết này, SunWin sẽ hướng dẫn bạn c... | sunwinaus |
1,902,051 | Maximum Likelihood Estimation with Logistic Regression | In our previous article, we introduce logistic regression, a fundamental technique in machine... | 0 | 2024-06-27T03:52:13 | https://dev.to/harsimranjit_singh_0133dc/maximum-likelihood-estimation-with-logistic-regression-2g3n | In our previous article, we introduce logistic regression, a fundamental technique in machine learning used for binary classification. Logistic regression predicts the probability of binary outcomes based on input features.
This article dives into the mathematical foundation of logistic regression.
## Understanding ... | harsimranjit_singh_0133dc | |
1,902,048 | What is AMP (Amplified Mobile Pages) | A technology called Amplified Mobile Pages (AMP) was created to enhance the functionality and speed... | 0 | 2024-06-27T03:42:55 | https://dev.to/chidera_kanu/what-is-amp-amplified-mobile-pages-3i82 | webdev, beginners, programming | A technology called Amplified Mobile Pages ([AMP](https://amp.dev/)) was created to enhance the functionality and speed of web pages on mobile devices. They ensure that users have a seamless and effective experience by speeding up the loading of websites. Given that the majority of people use smartphones to access the ... | chidera_kanu |
1,902,047 | enlio vietnam | Enlio là thương hiệu hàng đầu thế giới về sản xuất thảm sàn thể thao, đặc biệt là thảm cầu lông. Với... | 0 | 2024-06-27T03:39:26 | https://dev.to/enliovietnamet/enlio-vietnam-55go | Enlio là thương hiệu hàng đầu thế giới về sản xuất thảm sàn thể thao, đặc biệt là thảm cầu lông. Với uy tín và chất lượng đã được kiểm chứng qua việc tài trợ và cung cấp thảm cho nhiều giải đấu cầu lông quốc tế lớn, Enlio khẳng định vị thế là đối tác tin cậy của các vận động viên và tổ chức thể thao chuyên nghiệp.
Thả... | enliovietnamet | |
1,841,026 | Lo nuevo de React 19 | Después de más de 2 años, se acerca una nueva versión mayor de React, una de las librerías más... | 0 | 2024-06-27T03:35:59 | https://iencotech.github.io/posts/lo-nuevo-de-react-19/ | react, español, webdev, javascript | Después de más de 2 años, se acerca una nueva versión mayor de React, una de las librerías más populares para construir interfaces de usuario en la web.
La [versión beta de React 19](https://react.dev/blog/2024/04/25/react-19) ya está disponible para probar en npm. Aunque todavía no está lista para que actualicemos nu... | iencotech |
1,902,045 | 了解用户中心与单点登录 (SSO) | 在当今互联的数字环境中,有效管理用户身份对于安全性和用户体验都至关重要。该领域的两个基本组件是用户中心和单点登录 (SSO) 系统。虽然两者都有助于用户身份验证和访问控制,但它们具有不同的目的并提供独特... | 0 | 2024-06-27T03:35:03 | https://dev.to/hotentbpm/liao-jie-yong-hu-zhong-xin-yu-dan-dian-deng-lu-sso-1ao9 | webdev, javascript, python, ai | 在当今互联的数字环境中,有效管理用户身份对于安全性和用户体验都至关重要。该领域的两个基本组件是用户中心和单点登录 (SSO) 系统。虽然两者都有助于用户身份验证和访问控制,但它们具有不同的目的并提供独特的优势。
用户中心:集中式身份管理
用户中心,通常称为用户管理系统 (UMS),充当集中式存储库,用于在特定应用程序或平台生态系统中存储和管理用户身份、配置文件和访问权限。它的主要功能围绕着维护一个全面的用户信息数据库,其中包括个人详细信息、偏好、角色和权限。
用户中心的主要特点:
集中式身份存储:所有用户数据都存储在一个地方,确保一致性和易于管理。
精细访问控制:管理员可以定义和强制实施针对不同用户角色或组定制的访问权限。
... | hotentbpm |
1,902,044 | 用户中心研究报告 | 用户中心的定义和作用 用户中心通常指的是一个专门负责管理用户信息和授权的应用程序。在大型应用系统中,用户中心将用户的登录认证、权限控制、个人信息管理等功能独立出来,形成一个单独的模块或服务。这样做的好处... | 0 | 2024-06-27T03:34:24 | https://dev.to/hotentbpm/yong-hu-zhong-xin-yan-jiu-bao-gao-2oj4 | webdev, beginners, programming, tutorial | 用户中心的定义和作用
用户中心通常指的是一个专门负责管理用户信息和授权的应用程序。在大型应用系统中,用户中心将用户的登录认证、权限控制、个人信息管理等功能独立出来,形成一个单独的模块或服务。这样做的好处是可以集中管理用户信息,提高系统的安全性和稳定性,同时也便于维护和扩展。
用户中心的设计原则
用户中心的设计原则通常遵循以用户为中心的设计理念,即通过深入了解用户的需求和使用习惯,来设计符合用户期望的功能和服务。这种设计方法强调用户的参与和反馈,确保产品能够满足用户的实际需求,提升用户体验
用户中心功能
用户服务中心:负责管理用户的基本信息,如用户名、密码、电子邮件地址、手机号码等,并提供用户注册、登录、密码找回、修改个人信息等... | hotentbpm |
1,902,043 | 统一门户如何帮助企业实现自动化转型 | 在企业数字化转型过程中,统一门户扮演着重要的角色,其主要作用包括: 提供一站式入口 统一门户作为企业信息的集中入口,允许员工通过单一的平台访问所有必要的应用程序和服务,减少了在不同系统之间切换的时间,提... | 0 | 2024-06-27T03:32:56 | https://dev.to/hotentbpm/tong-men-hu-ru-he-bang-zhu-qi-ye-shi-xian-zi-dong-hua-zhuan-xing-5956 | webdev, beginners, ai, node | 在企业数字化转型过程中,统一门户扮演着重要的角色,其主要作用包括:
提供一站式入口
统一门户作为企业信息的集中入口,允许员工通过单一的平台访问所有必要的应用程序和服务,减少了在不同系统之间切换的时间,提高了工作效率。
实现系统集成
通过统一门户,企业可以将现有的ERP、HR、OA、BPM、PLM等系统集成在一起,打破信息孤岛,实现数据和信息的集中管理和共享。
支持个性化服务
统一门户可以根据不同用户的角色和需求提供个性化的服务和界面,如企业门户、领导决策门户、个人工作门户等,以满足不同用户的个性化展示需求。
促进业务协同
统一门户通过业务流程重塑,实现企业内外部平台、用户协同,提高业务执行效率,支持业务流程的优化和创新。
提高信... | hotentbpm |
1,902,042 | BPM(业务流程管理)的好处研究报告 | 一、引言 在当今快速变化的商业环境中,企业为了保持竞争力,需要不断地优化和改进其业务流程。BPM(业务流程管理)作为一种有效的管理工具,通过提供一套全面的方法来设计、执行、监控和优化业务流程,帮助企业... | 0 | 2024-06-27T03:32:17 | https://dev.to/hotentbpm/bpmye-wu-liu-cheng-guan-li-de-hao-chu-yan-jiu-bao-gao-395c | webdev, javascript, python, ai | 一、引言
在当今快速变化的商业环境中,企业为了保持竞争力,需要不断地优化和改进其业务流程。BPM(业务流程管理)作为一种有效的管理工具,通过提供一套全面的方法来设计、执行、监控和优化业务流程,帮助企业实现这一目标。本报告旨在探讨BPM的好处,并为其在企业管理中的应用提供理论支持。
二、BPM概述
BPM是一种对企业业务流程进行全面管理的方法论,它强调流程的持续改进和优化。BPM通过对业务流程的建模、分析、优化和监控,帮助企业实现流程的可视化、标准化和自动化,从而提高企业的运营效率、灵活性和竞争力。
三、BPM的好处
提高效率:BPM通过优化业务流程,减少冗余和浪费,提高资源利用率和作业效率。企业可以更快地响应市场需求,缩短... | hotentbpm |
1,432,278 | Dynamic Website 101 | It's well known that static websites have become a thing of the past, so in order to make an... | 0 | 2023-04-11T05:15:33 | https://dev.to/ulisesvina/dynamic-website-101-4dbo | webdev, javascript, programming, tutorial | It's well known that static websites have become a thing of the past, so in order to make an attractive website you'll need to make it as dynamic as possible, that means, the less hard-coded content, the better. Today, I'll talk about all the integrations I've made to my website to make it attractive.
## Introduction
... | ulisesvina |
1,902,041 | 低代码平台的好处研究报告 | 一、引言 随着信息技术的飞速发展,软件开发行业面临着前所未有的挑战。传统的软件开发方法,如手工编写代码,不仅效率低下,而且容易出错。为了应对这些挑战,低代码平台应运而生。低代码平台通过提供图形化界面和... | 0 | 2024-06-27T03:31:45 | https://dev.to/hotentbpm/di-dai-ma-ping-tai-de-hao-chu-yan-jiu-bao-gao-4dpb | webdev, beginners, react, ai | 一、引言
随着信息技术的飞速发展,软件开发行业面临着前所未有的挑战。传统的软件开发方法,如手工编写代码,不仅效率低下,而且容易出错。为了应对这些挑战,低代码平台应运而生。低代码平台通过提供图形化界面和预构建的模块,使开发者能够更快速、更高效地构建应用程序。本报告旨在探讨低代码平台的好处,并为其在软件开发领域的应用提供理论支持。
二、低代码平台概述
低代码平台是一种软件开发工具,它允许开发者通过图形化界面和预构建的模块来构建应用程序,而无需手动编写大量代码。这种平台降低了开发门槛,使得更多的人能够参与到软件开发中来。同时,低代码平台也提高了开发效率,缩短了开发周期。
三、低代码平台的好处
提高开发效率
低代码平台通过提供预构... | hotentbpm |
1,902,030 | The Problems with dotenv and How dotenvx Solves Them | Managing environment variables is crucial but can be fraught with challenges. The traditional dotenv... | 0 | 2024-06-27T03:31:23 | https://dev.to/adarshbp/the-problems-with-dotenv-and-how-dotenvx-solves-them-35io | Managing environment variables is crucial but can be fraught with challenges. The traditional dotenv approach, while popular, has notable shortcomings:
- **Leaking Your .env File:** This is the most significant risk, potentially exposing sensitive information.
- **Juggling Multiple Environments:** Managing different c... | adarshbp | |
1,902,040 | 10 Tips for Leaders to Cultivate Humility and Stay Grounded in Power | Here are 10 content nuggets for 10 Tips for Leaders to Cultivate Humility and Stay Grounded in... | 27,881 | 2024-06-27T03:30:13 | https://dev.to/nasrulhazim/10-tips-for-leaders-to-cultivate-humility-and-stay-grounded-in-power-pcp | leadership | Here are 10 content nuggets for **10 Tips for Leaders to Cultivate Humility and Stay Grounded in Power**:
1. **Listen Actively:** Engage in active listening during conversations. Show genuine interest in others' opinions and perspectives to foster mutual respect.
2. **Seek Feedback:** Regularly ask for feedback from ... | nasrulhazim |
1,902,038 | Create a wxPython Application with Math Text Display | This lab will guide you through creating a wxPython application that displays math text in a wx.Bitmap for display in various controls on wxPython. It uses the Matplotlib library to convert text to images and the wxPython library to display the images. | 27,880 | 2024-06-27T03:23:34 | https://labex.io/tutorials/python-mathtext-wx-sgskip-48826 | coding, programming, tutorial, matplotlib |
## Introduction
This lab will guide you through creating a wxPython application that displays math text in a wx.Bitmap for display in various controls on wxPython. It uses the Matplotlib library to convert text to images and the wxPython library to display the images.
### VM Tips
After the VM startup is done, click... | labby |
1,902,029 | Top 10 der Programmiersprachen mit den besten Job-Aussichten | Quelle:... | 0 | 2024-06-27T02:56:06 | https://dev.to/emilia/top-10-der-programmiersprachen-mit-den-besten-job-aussichten-ap7 | javascript, programming, python, webdev | Quelle: https://www.octoparse.de/blog/it-trends-und-top-10-der-programmiersprachen-mit-den-besten-job-aussichten?utm_source=dev&utm_medium=social&utm_campaign=hannaq2&utm_content=post
Technologie entwickelt sich fortwährend weiter, und die IT-Branche macht da keine Ausnahme. Im Jahr 2024 werden voraussichtlich zahlrei... | emilia |
1,902,037 | Master Abstract Factory Design Pattern for Programming Interviews with 5 easy steps | Abstract factory design pattern is advanced-level programming interview question, candidates are... | 0 | 2024-06-27T03:21:18 | https://dev.to/rk042/master-abstract-factory-design-pattern-for-programming-interviews-with-5-easy-steps-6gi | programming, career, algorithms, designpatterns | Abstract factory design pattern is advanced-level programming interview question, candidates are often asked to demonstrate their understanding of design patterns, specifically the Abstract Factory design pattern. This pattern is essential for creating families of related objects without specifying their concrete class... | rk042 |
1,902,035 | Biography of Riccardo Spagni | Riccardo Spagni Detail Information Name Riccardo... | 0 | 2024-06-27T03:15:36 | https://dev.to/okabarack/biography-of-riccardo-spagni-32n7 | webdev, javascript, programming, cryptocurrency | ## Riccardo Spagni
| **Detail** | **Information** |
|-----------------------------|-------------------------------------------------------------------------------------------------|
| **Name** | Riccardo... | okabarack |
1,902,033 | Public vs Private vs Hybrid Cloud: Which One Should You Use? | Salesforce is a powerful cloud-based platform that is used by businesses of all sizes to manage their... | 0 | 2024-06-27T03:11:16 | https://dev.to/elle_richard_232/public-vs-private-vs-hybrid-cloud-which-one-should-you-use-43a1 | softwaredevelopment, cloud, technology | Salesforce is a powerful cloud-based platform that is used by businesses of all sizes to manage their customer relationships, sales, marketing, and other operations. However, with its wide range of features and functionality, Salesforce can be a complex system to manage and optimize.
One of the most important aspects ... | elle_richard_232 |
1,902,032 | Building Next-Generation Conversational Experiences with Amazon Lex | Building Next-Generation Conversational Experiences with Amazon Lex ... | 0 | 2024-06-27T03:10:41 | https://dev.to/virajlakshitha/building-next-generation-conversational-experiences-with-amazon-lex-2bab | 
# Building Next-Generation Conversational Experiences with Amazon Lex
### Introduction
In today's digital age, customers expect seamless and intuitive interactions with businesses. This is where conversational interfaces powered b... | virajlakshitha | |
1,902,031 | Types of Software Test | Software testing encompasses a wide range of practices aimed at ensuring the quality and... | 0 | 2024-06-27T03:06:16 | https://dev.to/fridaymeng/types-of-software-test-1e7l |
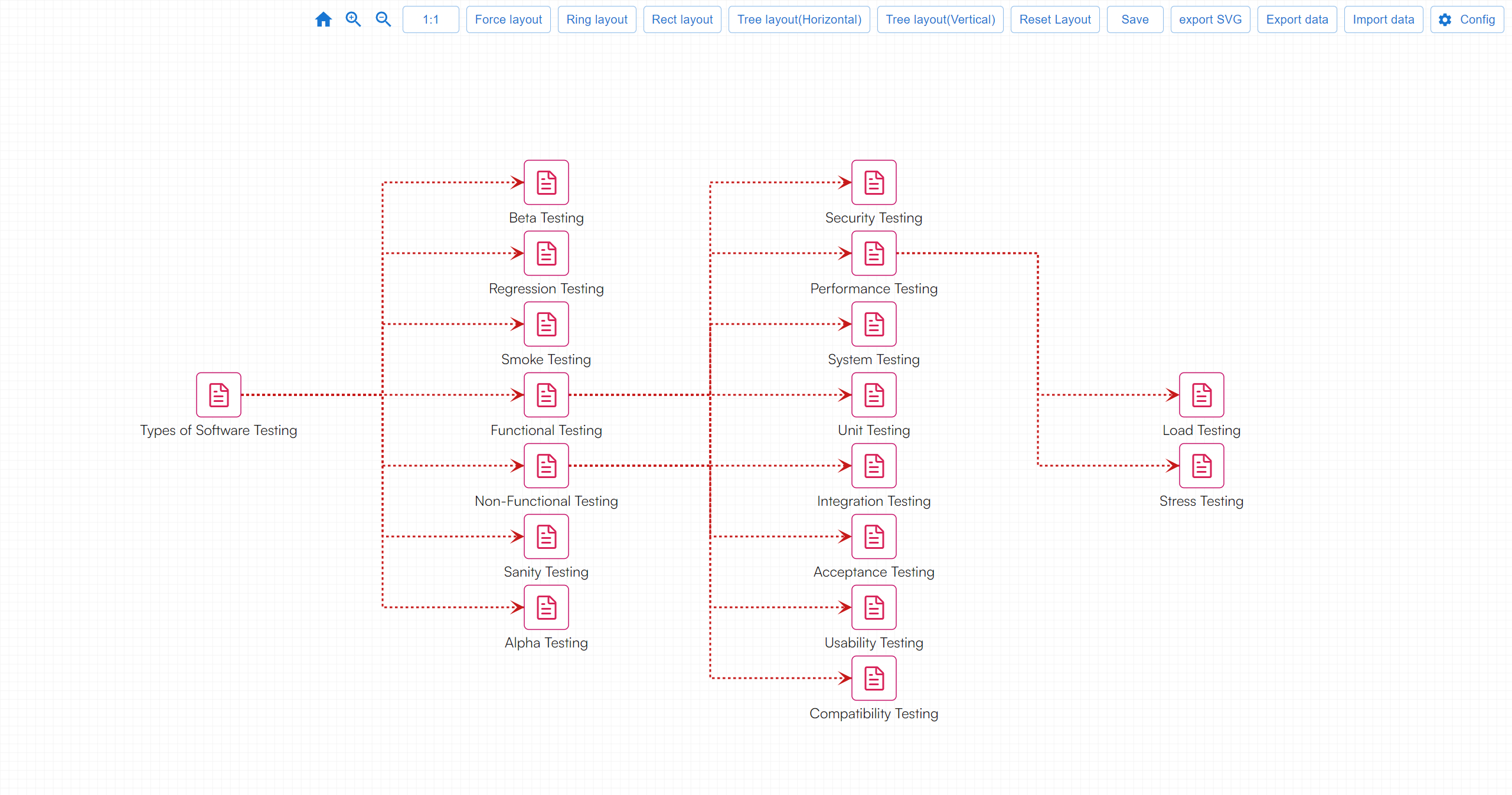
Software testing encompasses a wide range of practices aimed at ensuring the quality and reliability of software applications. Here are some common types of software tests, categorized by different criteria:
### B... | fridaymeng | |
1,902,028 | Optimizing Re-Rendering in React: Why It Matters and How to Do It | React is a powerful and popular JavaScript library for building user interfaces, particularly... | 0 | 2024-06-27T02:55:26 | https://dev.to/vyan/optimizing-re-rendering-in-react-why-it-matters-and-how-to-do-it-1gob | webdev, javascript, react, beginners | React is a powerful and popular JavaScript library for building user interfaces, particularly single-page applications where performance and responsiveness are critical. One of the core concepts in React is the component lifecycle, and a key part of this is rendering and re-rendering components. While React is highly e... | vyan |
1,902,027 | Puppet Vs Trojan virus working principle. | Puppet configuration management tool. Its purpose is to automate the process of configuring and... | 0 | 2024-06-27T02:55:09 | https://dev.to/mibii/puppet-vs-trojan-virus-working-principle-2pcb | chef, devops, puppet, ansible | Puppet configuration management tool. Its purpose is to automate the process of configuring and maintaining computer systems. It achieves this by defining the desired state of a system and ensuring that the system remains in that state.
Puppet is agent-based (it mean that Puppet is using the Trojan virus working p... | mibii |
1,902,024 | Lattice Generation using GPU computing in realtime | Here I am sharing a opensource software through which possibility to create lattice structure which... | 0 | 2024-06-27T02:53:12 | https://dev.to/design4additive/lattice-generation-using-gpu-computing-in-realtime-44hf | cuda, vulkan, additivemanufacturing, lattice | Here I am sharing a opensource software through which possibility to create lattice structure which can change shape and size spatially that too in real time (almost) . Even though heavy computation are happening in the background , with the help of GPU computing it is achieved with element wise computation executing p... | design4additive |
1,902,023 | Why are cookies ";" seperated | Hi Guys, This article is straightforward and adheres to standard practices. In a recent interview,... | 0 | 2024-06-27T02:51:15 | https://dev.to/zeeshanali0704/why-are-cookies-seperated-163f | javascript, systemdesignwithzeeshanali | Hi Guys,
This article is straightforward and adheres to standard practices.
In a recent interview, I was asked why cookies are separated by a semicolon (`;`) and not by any other unique character.
The answer is:
Important reason for using `;` as a separator in cookies is to comply with the syntax rules defined by t... | zeeshanali0704 |
1,902,022 | Squig | A post by Zevan Rosser | 0 | 2024-06-27T02:49:02 | https://dev.to/zevanrosser/squig-5hh0 | webdev, javascript | {% codepen https://codepen.io/ZevanRosser/pen/pomBpaY %} | zevanrosser |
466,004 | Parsing the Interwebs | My first cli project I created from scratch used Nokogiri. I found that using the The Bastards Book o... | 0 | 2020-09-25T20:51:04 | https://dev.to/glennanj1/parsing-the-interwebs-4bk2 | ruby, scraping, beginners, nokogiri | My first cli project I created from scratch used Nokogiri. I found that using the The Bastards Book of Ruby was a great resource. I highly recommend checking out their website to refer to, if your looking to make a web scraper cli. Grabbing css selectors for the first time was not an easy task. The internet is deep and... | glennanj1 |
1,902,021 | A Comprehensive Guide to Becoming a Great Tech Lead | Table of Contents Introduction Team Management Building and Motivating the... | 27,881 | 2024-06-27T02:47:04 | https://dev.to/nasrulhazim/a-comprehensive-guide-to-becoming-a-great-tech-lead-j8c | techlead, developers, programmer, manager | <h2>Table of Contents</h2>
<ul>
<li><a href="#introduction">Introduction</a></li>
<li>
<a href="#team-management">Team Management</a>
<ul>
<li><a href="#building-and-motivating">Building and Motivating the Team</a></li>
<li><a href="#resolving-conflicts">Resolving Conflicts within the Team</a></... | nasrulhazim |
1,902,019 | The Lifecycle of a JavaScript File in the Browser: Request, Load, Execute1 | Lifecycle of a JavaScript file in the browser: request, load, and execution In this... | 0 | 2024-06-27T02:31:14 | https://dev.to/mhmd-salah/the-lifecycle-of-a-javascript-file-in-the-browser-request-load-execute-1j24 | javascript, execution, backstage, browser | ## Lifecycle of a JavaScript file in the browser: request, load, and execution
In this article, we'll walk through the life of a JavaScript file and see the full version of a file request, from its download, all the way to its execution. Understanding this method can help developers improve the performance of web page... | mhmd-salah |
1,899,973 | Behavioral Interviews For Software Engineers | Use Glassdoor The next major thing that I would suggest is going and looking at Glassdoor,... | 0 | 2024-06-27T02:31:00 | https://dev.to/thekarlesi/behavioral-interviews-for-software-engineers-4p68 | interview, webdev, beginners, programming | ## Use Glassdoor
The next major thing that I would suggest is going and looking at Glassdoor, because you can get a lot of good information about what to expect in the interviewing process.
So, if you head over to Glassdoor, search for the company that you are interviewing for, and in particular, try to search for th... | thekarlesi |
1,902,016 | Which SEO Strategies Are Always Effective? | In the realm of SEO, while technologies and trends continually evolve, certain fundamental strategies... | 0 | 2024-06-27T02:29:00 | https://dev.to/juddiy/which-seo-strategies-are-always-effective-4ldm | seo, website, learning | In the realm of SEO, while technologies and trends continually evolve, certain fundamental strategies consistently prove their value. Regardless of technological advancements, these methods remain indispensable for optimizing websites and enhancing search engine rankings. Here are some timeless SEO strategies:
#### 1.... | juddiy |
1,902,015 | I'm looking for a Full Stack Software Developer Role | 👋🏼 Hey y'all, I hope you've been doing and feeling great! My name is Himanshu Kumar, and I'm... | 0 | 2024-06-27T02:28:54 | https://dev.to/himanshuk/im-looking-for-a-full-stack-software-developer-role-9kl | programming, webdev, coding | 👋🏼 Hey y'all, I hope you've been doing and feeling great! My name is Himanshu Kumar, and I'm currently looking for opportunities as a FullStack software developer.
I'm a passionate Full-stack software engineer with over three years of experience specializing in front-end technologies and full-stack development. I ha... | himanshuk |
1,901,975 | Hello everyone👤I'm Rishabh. Currently I'm working with php. Suggest me some good things to follow in my dev journey. | A post by Rishabh Mishra | 0 | 2024-06-27T02:20:12 | https://dev.to/indrishabhtech/hello-everyoneim-rishabh-currently-im-working-with-php-suggest-me-some-good-things-to-follow-in-my-dev-journey-15jb | welcome, webdev | indrishabhtech | |
1,901,974 | 程序员在企业中是如何做需求的 | 在后端接口封装中,我们一般都会对返回的数据做一个封装,以防止系统出现不可预期的数据结构和类型。比如这样: 结构体 1 { "success": true, "code": 200, ... | 0 | 2024-06-27T02:19:11 | https://dev.to/javapub/cheng-xu-yuan-zai-qi-ye-zhong-shi-ru-he-zuo-xu-qiu-de-3g6a | 用户中心项目组, java | 在后端接口封装中,我们一般都会对返回的数据做一个封装,以防止系统出现不可预期的数据结构和类型。比如这样:
结构体 1
{
"success": true,
"code": 200,
"message": "成功",
"data": {
"items": [
{
"id": "1",
"name": "小王",
"identified": "JavaPub博主"
}
]
}
}
结构体 2
{
"ret": 200,
"data": {
"title": "Default Api",
... | javapub |
1,901,968 | Deploying Next.js to Your Local IP Address with Dynamic Port Assignment for Network Access | Ever tried to start your Next.js development server and wanted to access your dev server from another... | 0 | 2024-06-27T02:13:28 | https://dev.to/xanderselorm/how-to-dynamically-assign-ports-and-access-your-nextjs-app-across-the-network-3p57 | javascript, react, webdev, nextjs | Ever tried to start your Next.js development server and wanted to access your dev server from another device but didn't know how? Say goodbye to those issues and hello to smooth, network-wide access! In this tutorial, we’ll show you how to dynamically find an available port, display the network IP, and allow access to ... | xanderselorm |
1,901,973 | What happens when you Enter a URL in the browser & Hit enter | When you type a URL into a browser and press Enter, several steps occur to retrieve and display the... | 0 | 2024-06-27T02:09:58 | https://dev.to/zeeshanali0704/what-happens-when-you-enter-a-url-in-browser-hit-enter-2i2a | javascript, systemdesignwithzeeshanali | When you type a URL into a browser and press Enter, several steps occur to retrieve and display the webpage:
Let's understand what is URL first
A URL (Uniform Resource Locator) is the address used to access resources on the internet. It consists of several parts, each with a specific function. Here’s a breakdown of ... | zeeshanali0704 |
1,903,420 | Environment Variables In Shopify Checkout Ui Extension | This post refersShopify Checkout UI extensions. Seethis post for a brief introduction to UI... | 0 | 2024-06-28T17:32:35 | https://blog.waysoftware.dev/blog/environment-variables-in-shopify-checkout-ui-extension/ | ---
title: Environment Variables In Shopify Checkout Ui Extension
published: true
date: 2024-06-27 00:00:00 UTC
tags:
canonical_url: https://blog.waysoftware.dev/blog/environment-variables-in-shopify-checkout-ui-extension/
---
This post refers[Shopify Checkout UI extensions](https://shopify.dev/docs/api/checkout-ui-e... | johnmcguin | |
1,901,972 | VMSS CREATION AND CONNECTING. | A Blog On Creating Virtual Machine Scale Set ** A Virtual Machine Scale Set(VMSS) is a... | 0 | 2024-06-27T02:03:54 | https://dev.to/collins_uwa_1f4dc406f079c/vmss-creation-and-connecting-1g3f | azure, vm, vmss | ## **A Blog On Creating Virtual Machine Scale Set ****
A Virtual Machine Scale Set(VMSS) is a service in Microsoft Azure that allows you to create and manage a group of load-balanced virtual
machines(VMS). It enables you to scale out and in the number of VMS based on demand or a predefined schedule , ensuring high a... | collins_uwa_1f4dc406f079c |
1,901,971 | Software design using OOP + FP — Part 1 | Software design using OOP + FP — Part 1 Let’s do crazy solutions combining OOP and FP... | 0 | 2024-06-27T02:01:16 | https://dev.to/fedelochbaum/software-design-using-oop-fp-part-1-2fgh |
## Software design using OOP + FP — Part 1
Let’s do crazy solutions combining OOP and FP :)

The idea for this article is to summarize several patterns and provide examples of how to solve certain problem cases by mixing Object-Oriented Prog... | fedelochbaum | |
1,901,970 | Polyfill supply chain attack embeds malware in JavaScript CDN assets | On June 25, 2024, the Sansec security research and malware team announced that a popular JavaScript polyfill project had been taken over by a foreign actor identified as a Chinese-originated company. | 0 | 2024-06-27T02:00:16 | https://snyk.io/blog/polyfill-supply-chain-attack-js-cdn-assets/ | applicationsecurity, opensourcesecurity, javascript | On June 25, 2024, the Sansec security research and malware team [announced](https://sansec.io/research/polyfill-supply-chain-attack) that a popular JavaScript polyfill project had been taken over by a foreign actor identified as a Chinese-originated company, embedding malicious code in JavaScript assets fetched from th... | snyk_sec |
1,901,090 | Deploy Terraform resources to AWS using GitHub Actions via OIDC | The article explains how to configure OpenID Connect within your GitHub Actions workflows to... | 0 | 2024-06-27T01:56:51 | https://dev.to/camillehe1992/deploy-terraform-resources-to-aws-using-github-actions-via-oidc-3b9g | terraform, githubactions, aws | The article explains how to configure OpenID Connect within your GitHub Actions workflows to authenticate with AWS, so that the workflow can access AWS resources. The common use case is define AWS infrastructure as code, using CloudFormation, CDK or Terraform, etc, then sync the infrastructure update in AWS through wor... | camillehe1992 |
1,901,966 | Build a GPT That Talks to Your Database in One Day | Have you ever wondered how challenging it is to create a Custom GPT with user authentication and... | 0 | 2024-06-27T01:52:13 | https://dev.to/jfbloom22/build-a-gpt-that-talks-to-your-database-in-one-day-1kf0 | oauth2, openai, chatgpt, node | Have you ever wondered how challenging it is to create a Custom GPT with user authentication and database access? I found the lack of examples of this disheartening. So, I create a comprehensive guide myself and am pleased to say, with a small amount of coding skills you can build your own in day.
* [GitHub Reposito... | jfbloom22 |
1,901,965 | Catch, Optimize Client-Side Data Fetching in Next.js Using SWR | How to Optimize, Memorise Client-Side Data Fetching in Next.js Using SWR In modern web... | 0 | 2024-06-27T01:49:23 | https://dev.to/sh20raj/catch-optimize-client-side-data-fetching-in-nextjs-using-swr-51hf | webdev, javascript, beginners, programming | ### How to Optimize, Memorise Client-Side Data Fetching in Next.js Using SWR
In modern web applications, efficient data fetching is crucial for providing a smooth and responsive user experience. Next.js, a popular React framework, offers several ways to fetch data. One effective method is using the SWR (stale-while-re... | sh20raj |
1,901,963 | Challenges in Live Call Transcription and Translation | Recently, I had the opportunity to work on a project called AIPhone.AI that pushed the boundaries of... | 0 | 2024-06-27T01:47:04 | https://dev.to/pamutton/challenges-in-live-call-transcription-and-translation-1i47 | Recently, I had the opportunity to work on a project called [AIPhone.AI](https://www.aiphone.ai/) that pushed the boundaries of live call functionality – a concept that involved both transcription and translation.Developing a sophisticated iOS app that features real-time call transcription and translation involves se... | pamutton | |
1,901,962 | understanding react hooks | back in 2018, Sophie Alpert, Dan Abramov, and Ryan Florence did one of the most important talks of... | 0 | 2024-06-27T01:45:42 | https://dev.to/yelldutz/understanding-react-hooks-3e69 | react, javascript, webdev, programming | back in 2018, Sophie Alpert, Dan Abramov, and Ryan Florence did one of the most important talks of the history of web development.
they were at the ReactConf introducing the React Hooks to the developer community.
[React Today and Tomorrow and 90% Cleaner React With Hooks](https://www.youtube.com/watch?v=dpw9EHDh2bM)... | yelldutz |
1,901,908 | i18n in React Native with Expo | This article is about implementing i18n in a React Native app with react-i18next | 0 | 2024-06-27T01:43:47 | https://dev.to/lucasferreiralimax/i18n-in-react-native-with-expo-2j0j | i18next, i18n, react, reactnative | ---
title: i18n in React Native with Expo
published: true
description: This article is about implementing i18n in a React Native app with react-i18next
tags: i18next, i18n, react, reactnative
# cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/57kzjdm4nupsf4jiy45v.jpg
# Use a ratio of 100:42 for bes... | lucasferreiralimax |
1,178,717 | Empowering Diversity: Imposter Syndrome and Economic Inclusion in Tech Worldwide | Definitions Imposter Syndrome Imposter syndrome, also known as impostor phenomenon or impostorism,... | 0 | 2024-06-27T01:30:32 | https://dev.to/frtechy/empowering-diversity-imposter-syndrome-and-economic-inclusion-in-tech-worldwide-59pe | womenintech, inclusion, a11y |
**Definitions**
**Imposter Syndrome**
Imposter syndrome, also known as impostor phenomenon or impostorism, is a psychological occurrence in which an individual doubts their skills, talents, or accomplishments and has a persistent internalized fear of being exposed as a fraud. This phenomenon is characterized by an i... | frtechy |
1,901,961 | How to Memoize Client-Side Fetched Data in Next.js Using the App Router | How to Memoize Client-Side Fetched Data in Next.js Using the App Router With the release... | 0 | 2024-06-27T01:26:37 | https://dev.to/sh20raj/how-to-memoize-client-side-fetched-data-in-nextjs-using-the-app-router-2fp7 | nextjs, javascript, webdev, beginners | ### How to Memoize Client-Side Fetched Data in Next.js Using the App Router
With the release of Next.js 13, the App Router introduces a new way to define routes and manage data fetching in a more flexible and powerful manner. In this guide, we will demonstrate how to memoize client-side fetched data using the App Rout... | sh20raj |
1,901,939 | Gym Planner | My Coding Adventure as a Code Newbie | I am a gap year student, currently on a journey of my own, learning how to code, to upskill in... | 0 | 2024-06-27T01:26:28 | https://dev.to/s-city/gym-planner-my-coding-adventure-as-a-code-newbie-h8p | computerscience, python, codenewbie, codecademy | I am a gap year student, currently on a journey of my own, learning how to code, to upskill in different areas in computer science. This path that I find myself on, a path of learning and adventure, with the guidance of Codecademy, is what led me too write my first program, and to write this first blog of mine. I must ... | s-city |
1,901,940 | Understanding Network Access Control Lists and Security Groups in AWS | In an article I published exactly a year ago, I wrote about VPCs and subnets in the AWS cloud and all... | 0 | 2024-06-27T01:02:09 | https://dev.to/aws-builders/understanding-network-access-control-lists-and-security-groups-in-aws-3bk4 | aws, securitygroup, accesscontrol | In an article I published exactly a year ago, I wrote about VPCs and subnets in the AWS cloud and all one needs to know about these foundational AWS networking concepts. However, I did not go into the details of Network Access Control Lists (NACLs) and Security Groups (SGs). This doesn't mean the significance of these ... | brandondamue |
1,901,933 | Programação Orientada a Objetos: Encapsulamento | Encapsulamento | 27,708 | 2024-06-27T00:41:39 | https://dev.to/fabianoflorentino/programacao-orientada-a-objetos-encapsulamento-n0n | programming, braziliandevs, poo | ---
title: "Programação Orientada a Objetos: Encapsulamento"
published: true
description: Encapsulamento
series: Programação Orientada a Objetos
tags: programming, braziliandevs, poo
cover_image: https://i.ibb.co/m69Qnf6/Screenshot-2024-06-26-at-21-39-20.png
---
# Encapsulamento
é um dos princípios fundamentais da pr... | fabianoflorentino |
1,901,937 | Comandos importantes Git | Como trocar de branch git fetch git checkout nome-branch | 0 | 2024-06-27T00:41:19 | https://dev.to/nathanndos/comandos-importantes-git-2nmi | ## Como trocar de branch
`git fetch`
`git checkout nome-branch`
| nathanndos | |
1,901,936 | Building a Scalable API with NestJS: A Comprehensive Guide | NestJS is a progressive Node.js framework for building efficient, reliable, and scalable server-side... | 0 | 2024-06-27T00:36:54 | https://devtoys.io/2024/06/26/building-a-scalable-api-with-nestjs-a-comprehensive-guide/ | webdev, typescript, devtoys, tutorial | ---
canonical_url: https://devtoys.io/2024/06/26/building-a-scalable-api-with-nestjs-a-comprehensive-guide/
---
NestJS is a progressive Node.js framework for building efficient, reliable, and scalable server-side applications. Leveraging TypeScript, it integrates elements from modern frameworks such as Angular to crea... | 3a5abi |
1,901,935 | Building a Custom Analytics Dashboard with React and D3.js | Introduction In today's fast-paced and data-driven world, every business needs a reliable... | 0 | 2024-06-27T00:32:54 | https://dev.to/kartikmehta8/building-a-custom-analytics-dashboard-with-react-and-d3js-3amf | webdev, javascript, beginners, programming | ## Introduction
In today's fast-paced and data-driven world, every business needs a reliable and efficient tool to track and analyze their performance. This is where custom analytics dashboards come in. A custom analytics dashboard is a personalized interface that allows users to visualize and analyze data in a concis... | kartikmehta8 |
1,901,934 | W | A post by volkan ural | 0 | 2024-06-27T00:28:12 | https://dev.to/wikivu/w-m03 | wikivu | ||
1,901,932 | 🚀 Authentication and Authorization in Node.js 🚀 | Your instructor here again #KOToka 🔐 Authentication: Verifying the identity of users. It's the... | 0 | 2024-06-27T00:22:08 | https://dev.to/erasmuskotoka/authentication-and-authorization-in-nodejs-4j5b |
Your instructor here again #KOToka
🔐 Authentication: Verifying the identity of users. It's the process of ensuring users are who they claim to be.
In Node.js, popular libraries like Passport.js simplify this process by providing strategies for local and third-party (OAuth) authentication.
🔓 Authorization... | erasmuskotoka | |
1,901,928 | Como Escanear Portas em um Website com Python | Você já deve ter ouvido falar do Nmap e de escaneamento de portas em servidores, bem, nesse script... | 0 | 2024-06-27T00:05:12 | https://dev.to/moprius/como-escanear-portas-em-um-website-com-python-bdm | python, website, network, tutorial | Você já deve ter ouvido falar do Nmap e de escaneamento de portas em servidores, bem, nesse script feito em Python vamos fazer algo bem semelhante, vamos verificar as portas abertas em websites. Vamos explorar um pouco de maneira simples e fácil de entender
## Introdução
Portas abertas em um servidor são como portas ... | moprius |
1,901,925 | Dial Up Success: Supercharge Your Google Ads Call-Only Campaigns with AI | Learn how AI is revolutionizing Google Ads call-only campaigns, boosting efficiency and conversion rates by leveraging natural language processing and machine learning. | 0 | 2024-06-26T23:46:00 | https://dev.to/tarwiiga/dial-up-success-supercharge-your-google-ads-call-only-campaigns-with-ai-8h2 | googleads, aimarketing, callonlycampaigns, adcopyoptimization | In today's fast-paced digital world, capturing attention and driving conversions is more challenging than ever. Businesses need a competitive edge, especially when it comes to Google Ads. For businesses focused on phone leads, call-only ads can significantly outperform traditional text ads. By offering a direct line to... | tarwiiga |
1,901,924 | Supercharge Your Google Ads: Leveraging LLMs and Generative AI | This blog post explores how LLMs and Generative AI are revolutionizing Google Ads, enabling marketers to optimize campaigns, improve ad copywriting, and leverage data-driven insights for enhanced efficiency and ROI. | 0 | 2024-06-26T23:42:52 | https://dev.to/tarwiiga/supercharge-your-google-ads-leveraging-llms-and-generative-ai-1a9d | In today's digital landscape, staying ahead in advertising is crucial. The global AI marketing market is projected to reach \$107.5 billion by 2028, highlighting the transformative potential of artificial intelligence (AI). Among the most promising AI advancements are Large Language Models (LLMs) and Generative AI, tec... | tarwiiga | |
1,902,012 | Agregando el Stage Deploy | Introducción Siguiendo con nuestros tutoriales, vamos a conectar Argo CD con Azure Devops,... | 0 | 2024-06-27T15:08:04 | https://www.ahioros.info/2024/06/agregando-el-stage-deploy.html | azure, cloud, devops, spanish | ---
title: Agregando el Stage Deploy
published: true
date: 2024-06-26 23:42:00 UTC
tags: Azure,Cloud,DevOps, spanish
canonical_url: https://www.ahioros.info/2024/06/agregando-el-stage-deploy.html
---
## Introducción
Siguiendo con nuestros tutoriales, vamos a conectar Argo CD con Azure Devops, pero antes debemos prepa... | ahioros |
1,901,923 | Dynamically Adding To The Webpage | The code iterates through an array called userList, and for each user object (el), it creates a card... | 0 | 2024-06-26T23:35:19 | https://dev.to/__khojiakbar__/dynamically-adding-to-the-webpage-5bnl | dynamic, webpage, dom | The code iterates through an array called `userList`, and for each user object `(el)`, it creates a card element using the `createElement` function. This card contains the user's avatar, name, and email. The card is then appended to an element called `servicesContent`.
---
```
// Iterate through each user object in t... | __khojiakbar__ |
1,901,919 | 100 days of python challenge | Starting this to document my 100 days of python challenge. Feels a better fit than other socials. I... | 0 | 2024-06-26T23:28:30 | https://dev.to/myrojyn/100-days-of-python-challenge-4oja | Starting this to document my 100 days of python challenge. Feels a better fit than other socials.
I am using "Master Python by building 100 projects in 100 days. Learn data science, automation, build websites, games and apps!" by Dr. Angela.
Don't @ me because I am enjoying it so haters to the left.
Wrote a band ... | myrojyn | |
1,901,918 | Reusable createElement() | Function Explanation The createElement function creates a new HTML element with optional... | 0 | 2024-06-26T23:20:47 | https://dev.to/__khojiakbar__/reusable-createelement-2ogn | createelement, dom, javascript | ## Function Explanation
The **createElement** function creates a new HTML element with optional classes and content.
### Parameters
**tagName**: The type of element you want to create (e.g., `'div'`, `'h1'`).
**classList**: (Optional) A string of classes you want to add to the element.
**content**: (Optional) The inn... | __khojiakbar__ |
1,901,909 | Entendendo o Protocolo IP: A Base das Comunicações na Internet | A internet é uma rede global que conecta milhões de dispositivos em todo o mundo, permitindo a troca... | 0 | 2024-06-26T23:16:37 | https://dev.to/iamthiago/entendendo-o-protocolo-ip-a-base-das-comunicacoes-na-internet-5332 | beginners, programming, discuss, linux | A internet é uma rede global que conecta milhões de dispositivos em todo o mundo, permitindo a troca de informações de maneira rápida e eficiente. No centro desse vasto sistema de comunicação está o Protocolo de Internet (IP), uma das peças fundamentais que tornam possível a comunicação entre dispositivos. Neste artigo... | iamthiago |
1,901,907 | Project Zomboard: Zombies cap is now almost 2000 | https://www.youtube.com/watch?v=fdYwanSgPvk Project Zomboard: Zombies cap is now almost 2000 ^^ but... | 0 | 2024-06-26T23:03:42 | https://dev.to/tonicatfealidae/project-zomboard-zombies-cap-is-now-almost-2000-2bpo | https://www.youtube.com/watch?v=fdYwanSgPvk
Project Zomboard: Zombies cap is now almost 2000 ^^ but unless I can reach the 3000 limit without lag I can't move on to the next step!!!
#zomboard #nekoniiistudio #unitydev #unity #devlog #developer #gamedev #taniafelidae #indiegame | tonicatfealidae | |
1,901,906 | 测试 iOS app 的后台行为 | 最近在开发中碰到用 SwiftUI 的 backgroundTask(_:action:) 修饰符来实现“真后台”下载数据的功能。代码实现本身就已经有点儿绕了,而测试更是令人挠头。主要在于 iOS... | 0 | 2024-06-26T23:03:11 | https://dev.to/yo1995/ce-shi-ios-app-de-hou-tai-xing-wei-1dbh | ios, swift, swiftui, testing | 最近在开发中碰到用 SwiftUI 的 [`backgroundTask(_:action:)`](https://developer.apple.com/documentation/swiftui/scene/backgroundtask(_:action:)) 修饰符来实现“真后台”下载数据的功能。代码实现本身就已经有点儿绕了,而测试更是令人挠头。主要在于 iOS 和其他桌面操作系统相比,最初就没有想着如何精确控制后台程序的行为,导致很多的行为都是靠操作系统自己来协调。因此,测试起来也颇费一番周折。
在测试过程中,我们发现了一些小的技巧,在此记录一二。
## 打印日志
iOS 14 引入的 `OSLog` 库能够让我们用现... | yo1995 |
1,901,799 | You don't always have to be doing something | Ideas on working on what matters | 0 | 2024-06-26T21:06:04 | https://dev.to/akotek/you-dont-always-have-to-do-something-44o3 | rnd, productivity, leadership, code | ---
title: You don't always have to be doing something
published: true
description: Ideas on working on what matters
tags: RND, productivity, leadership, code
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-26 19:58 +0000
---
It often surprises people wh... | akotek |
1,900,836 | Power Platform Dataverse | Dataverse What is Dataverse Dataverse is cloud base data platform for Microsoft... | 0 | 2024-06-26T22:58:18 | https://dev.to/mubashar1009/power-platform-dataverse-oen | ## **Dataverse**
## What is Dataverse
Dataverse is cloud base data platform for Microsoft Platform that is secure, scalable and globally available. It store data in the form of tables for apps. Tables are the building block of Dataverse.
## Diagram
 cus... | peterborough_treeremoval |
1,901,902 | Augmented Reality and the Metaverse | Introduction Augmented Reality (AR) and the Metaverse are transforming how we interact... | 27,673 | 2024-06-26T22:46:59 | https://dev.to/rapidinnovation/augmented-reality-and-the-metaverse-28en | ## Introduction
Augmented Reality (AR) and the Metaverse are transforming how we interact with
the digital world. AR adds digital elements to a live view, often using a
smartphone camera, while the Metaverse is a collective virtual shared space
created by the convergence of virtually enhanced physical and digital real... | rapidinnovation | |
1,901,900 | বুবল সর্ট, সিলেকশন সর্ট এবং ইনসার্টশন সর্ট | কম্পিউটার বিজ্ঞানে সর্টিং অ্যালগরিদমগুলি ডেটা সংগঠনের জন্য অত্যন্ত গুরুত্বপূর্ণ। এখানে আমরা তিনটি... | 0 | 2024-06-26T22:36:47 | https://dev.to/rihanthedev/bubl-srtt-silekshn-srtt-ebn-insaarttshn-srtt-3a2a |
কম্পিউটার বিজ্ঞানে সর্টিং অ্যালগরিদমগুলি ডেটা সংগঠনের জন্য অত্যন্ত গুরুত্বপূর্ণ। এখানে আমরা তিনটি বেসিক সর্টিং অ্যালগরিদম নিয়ে আলোচনা করব: বুবল সর্ট, সিলেকশন সর্ট, এবং ইনসার্টশন সর্ট। প্রতিটি অ্যালগরিদমের নিজস্ব পদ্ধতি এবং কার্যকারিতা রয়েছে।
**১. বুবল সর্ট (Bubble Sort)**
**সংক্ষিপ্ত বিবরণ:**
বুবল সর্ট একটি সহজ ... | rihanthedev | |
1,901,899 | [Game of Purpose] Day 39 | Today I managed to make the drone properly spawn granades. When dropping the granade it correctly... | 27,434 | 2024-06-26T22:36:07 | https://dev.to/humberd/game-of-purpose-day-39-4n66 | gamedev | Today I managed to make the drone properly spawn granades. When dropping the granade it correctly inherits drones velocity and angular momentum.
{% embed https://youtu.be/bb0M8MwTkX8 %}
I also organized my Drone's Event graph into smaller graphs and do a Sequence calling each one.

Financial success requires more than just formal schooling; it demands practical knowledge about managing personal finances. Understanding core concepts li... | devmercy |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.