
code stringlengths 2.5k 150k | kind stringclasses 1 value |
|---|---|
```
!pip install elm
import elm
import numpy as np
import random
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn import datasets
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
%matplotlib inline
np.random.seed(42)
iris = load_iris()
X = iris['data']
y = iris['target']
names = iris['target_names']
feature_names = iris['feature_names']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
for target, target_name in enumerate(names):
X_plot = X[y == target]
ax1.plot(X_plot[:, 0], X_plot[:, 1],
linestyle='none',
marker='o',
label=target_name)
ax1.set_xlabel(feature_names[0])
ax1.set_ylabel(feature_names[1])
ax1.axis('equal')
ax1.legend();
for target, target_name in enumerate(names):
X_plot = X[y == target]
ax2.plot(X_plot[:, 2], X_plot[:, 3],
linestyle='none',
marker='o',
label=target_name)
ax2.set_xlabel(feature_names[2])
ax2.set_ylabel(feature_names[3])
ax2.axis('equal')
ax2.legend();
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Split the data set into training and testing
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=True)
print("Training Shape", X_train.shape, y_train.shape)
print("Testing Shape", X_test.shape, y_test.shape)
# load dataset
iris = elm.read("/content/iris.data")
# create a classifier
elmk = elm.ELMKernel()
# search for best parameter for this dataset
# define "kfold" cross-validation method, "accuracy" as a objective function
# to be optimized and perform 10 searching steps.
# best parameters will be saved inside 'elmk' object
elmk.search_param(iris, cv="kfold", of="accuracy", eval=10)
# split data in training and testing sets
# use 80% of dataset to training and shuffle data before splitting
tr_set, te_set = elm.split_sets(iris, training_percent=.8, perm=True)
#train and test
# results are Error objects
tr_result = elmk.train(tr_set)
te_result = elmk.test(te_set)
print(te_result.get_accuracy)
import numpy as np
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from scipy.linalg import pinv2
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
%matplotlib inline
np.random.seed(42)
def relu(x):
return np.maximum(x, 0, x)
def hidden_nodes(X):
G = np.dot(X, input_weights)
G = G + biases
H = relu(G)
return H
def predict(X,output_weights):
out = hidden_nodes(X)
out = np.dot(out, output_weights)
return out
iris = load_iris()
X = iris['data']
y = iris['target']
names = iris['target_names']
feature_names = iris['feature_names']
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Split the data set into training and testing
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=True)
print("Training Shape", X_train.shape, y_train.shape)
print("Testing Shape", X_test.shape, y_test.shape)
input_size = X_train.shape[1]
hidden_size = 10
input_weights = np.random.normal(size=[input_size,hidden_size])
biases = np.random.normal(size=[hidden_size])
output_weights = np.dot(pinv2(hidden_nodes(X_train)), y_train)
prediction = predict(X_test, output_weights)
correct = 0
total = X_test.shape[0]
for i in range(total):
predicted = np.round(prediction[i])
actual = y_test[i]
if predicted == actual:
correct += 1
else:
correct += 0
accuracy = correct/total
print('Accuracy for ', hidden_size, ' hidden nodes: ', accuracy)
#For single sample prediction
k=40
pred = predict(X_test[k], output_weights)
predicted = np.round(pred)
if predicted == y_test[k]:
correct = 1
else:
correct = 0
print("Actual:",y_test[k], "Predicted:", predicted)
print("Accuracy:", correct*100)
import pickle
pickle.dump(output_weights, open('elm_iris.pkl', 'wb'))
# Deserialization of the file
new_weights = pickle.load(open('elm_iris.pkl','rb'))
#For single sample prediction
k=17
pred = predict(X_test[k], new_weights)
predicted = np.round(pred)
if predicted == y_test[k]:
correct = 1
else:
correct = 0
print("Actual:",y_test[k], "Predicted:", predicted)
print("Accuracy:", correct*100)
##http://wdm0006.github.io/sklearn-extensions/extreme_learning_machines.html
!pip install sklearn_extensions
import numpy as np
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn_extensions.extreme_learning_machines.elm import GenELMClassifier
from sklearn_extensions.extreme_learning_machines.random_layer import RBFRandomLayer, MLPRandomLayer
np.random.seed(42)
def make_classifiers():
"""
:return:
"""
names = ["ELM(10,tanh)", "ELM(10,sinsq)", "ELM(10,tribas)", "ELM(hardlim)", "ELM(20,rbf(0.1))"]
nh = 1000
# pass user defined transfer func
sinsq = (lambda x: np.power(np.sin(x), 2.0))
srhl_sinsq = MLPRandomLayer(n_hidden=nh, activation_func=sinsq)
# use internal transfer funcs
srhl_tanh = MLPRandomLayer(n_hidden=nh, activation_func='tanh')
srhl_tribas = MLPRandomLayer(n_hidden=nh, activation_func='tribas')
srhl_hardlim = MLPRandomLayer(n_hidden=nh, activation_func='hardlim')
# use gaussian RBF
srhl_rbf = RBFRandomLayer(n_hidden=nh*2, rbf_width=0.1, random_state=0)
classifiers = [GenELMClassifier(hidden_layer=srhl_tanh),
GenELMClassifier(hidden_layer=srhl_sinsq),
GenELMClassifier(hidden_layer=srhl_tribas),
GenELMClassifier(hidden_layer=srhl_hardlim),
GenELMClassifier(hidden_layer=srhl_rbf)]
return names, classifiers
if __name__ == '__main__':
#datasets = make_datasets()
names, classifiers = make_classifiers()
# pre-process dataset, split into training and test part
iris = load_iris()
X = iris['data']
y = iris['target']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Split the data set into training and testing
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=True)
y_test = y_test.reshape(-1, )
y_train = y_train.reshape(-1, )
print("Training Shape", X_train.shape, y_train.shape)
print("Testing Shape", X_test.shape, y_test.shape)
# iterate over classifiers
for name, clf in zip(names, classifiers):
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
print('Model %s score: %s' % (name, score))
!pip install numpy --upgrade
%%writefile elm.py
import numpy as np
np.random.seed(42)
class ELM(object):
def __init__(self, inputSize, outputSize, hiddenSize):
"""
Initialize weight and bias between input layer and hidden layer
Parameters:
inputSize: int
The number of input layer dimensions or features in the training data
outputSize: int
The number of output layer dimensions
hiddenSize: int
The number of hidden layer dimensions
"""
self.inputSize = inputSize
self.outputSize = outputSize
self.hiddenSize = hiddenSize
# Initialize random weight with range [-0.5, 0.5]
self.weight = np.matrix(np.random.uniform(-0.5, 0.5, (self.hiddenSize, self.inputSize)))
# Initialize random bias with range [0, 1]
self.bias = np.matrix(np.random.uniform(0, 1, (1, self.hiddenSize)))
self.H = 0
self.beta = 0
def sigmoid(self, x):
"""
Sigmoid activation function
Parameters:
x: array-like or matrix
The value that the activation output will look for
Returns:
The results of activation using sigmoid function
"""
return 1 / (1 + np.exp(-1 * x))
def predict(self, X):
"""
Predict the results of the training process using test data
Parameters:
X: array-like or matrix
Test data that will be used to determine output using ELM
Returns:
Predicted results or outputs from test data
"""
X = np.matrix(X)
y = self.sigmoid((X * self.weight.T) + self.bias) * self.beta
return y
def train(self, X, y):
"""
Extreme Learning Machine training process
Parameters:
X: array-like or matrix
Training data that contains the value of each feature
y: array-like or matrix
Training data that contains the value of the target (class)
Returns:
The results of the training process
"""
X = np.matrix(X)
y = np.matrix(y)
# Calculate hidden layer output matrix (Hinit)
self.H = (X * self.weight.T) + self.bias
# Sigmoid activation function
self.H = self.sigmoid(self.H)
# Calculate the Moore-Penrose pseudoinverse matriks
H_moore_penrose = np.linalg.inv(self.H.T * self.H) * self.H.T
# Calculate the output weight matrix beta
self.beta = H_moore_penrose * y
return self.H * self.beta
%%writefile test_elm_iris.py
from elm import ELM
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score, classification_report, confusion_matrix
np.random.seed(42)
# Create random classification datasets with 1000 samples
iris = load_iris()
X = iris['data']
y = iris['target']
names = iris['target_names']
feature_names = iris['feature_names']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Create instance of ELM object with 10 hidden neuron
elm = ELM(X.shape[1], 1, 10)
# Split the data set into training and testing
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=True)
print("Training Shape", X_train.shape, y_train.shape)
print("Testing Shape", X_test.shape, y_test.shape)
# Train data
elm.train(X_train,y_train.reshape(-1,1))
# Make prediction from training process
y_pred = elm.predict(X_test)
y_pred = np.round(np.abs(y_pred))
print(y_test, "\n", y_pred.T)
print('Accuracy: ', accuracy_score(y_test, y_pred))
print("F1 Score: ", f1_score(y_test, y_pred, average="macro"))
print("Precision Score: ", precision_score(y_test, y_pred, average="macro"))
print("Recall Score: ", recall_score(y_test, y_pred, average="macro"))
print(classification_report(y_test, y_pred, target_names=names))
!python test_elm_iris.py
%%writefile run_elm_iris.py
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score, classification_report, confusion_matrix
from sklearn.metrics import roc_curve, auc, roc_auc_score
np.random.seed(42)
class ELM(object):
def __init__(self, inputSize, outputSize, hiddenSize):
"""
Initialize weight and bias between input layer and hidden layer
Parameters:
inputSize: int
The number of input layer dimensions or features in the training data
outputSize: int
The number of output layer dimensions
hiddenSize: int
The number of hidden layer dimensions
"""
self.inputSize = inputSize
self.outputSize = outputSize
self.hiddenSize = hiddenSize
# Initialize random weight with range [-0.5, 0.5]
self.weight = np.matrix(np.random.uniform(-0.5, 0.5, (self.hiddenSize, self.inputSize)))
# Initialize random bias with range [0, 1]
self.bias = np.matrix(np.random.uniform(0, 1, (1, self.hiddenSize)))
self.H = 0
self.beta = 0
def sigmoid(self, x):
"""
Sigmoid activation function
Parameters:
x: array-like or matrix
The value that the activation output will look for
Returns:
The results of activation using sigmoid function
"""
return 1 / (1 + np.exp(-1 * x))
def predict(self, X):
"""
Predict the results of the training process using test data
Parameters:
X: array-like or matrix
Test data that will be used to determine output using ELM
Returns:
Predicted results or outputs from test data
"""
X = np.matrix(X)
y = self.sigmoid((X * self.weight.T) + self.bias) * self.beta
return y
def train(self, X, y):
"""
Extreme Learning Machine training process
Parameters:
X: array-like or matrix
Training data that contains the value of each feature
y: array-like or matrix
Training data that contains the value of the target (class)
Returns:
The results of the training process
"""
X = np.matrix(X)
y = np.matrix(y)
# Calculate hidden layer output matrix (Hinit)
self.H = (X * self.weight.T) + self.bias
# Sigmoid activation function
self.H = self.sigmoid(self.H)
# Calculate the Moore-Penrose pseudoinverse matriks
H_moore_penrose = np.linalg.inv(self.H.T * self.H) * self.H.T
# Calculate the output weight matrix beta
self.beta = H_moore_penrose * y
return self.H * self.beta
def cm_analysis(y_true, y_pred, labels, ymap=None, figsize=(10,10)):
"""
Generate matrix plot of confusion matrix with pretty annotations.
The plot image is saved to disk.
args:
y_true: true label of the data, with shape (nsamples,)
y_pred: prediction of the data, with shape (nsamples,)
filename: filename of figure file to save
labels: string array, name the order of class labels in the confusion matrix.
use `clf.classes_` if using scikit-learn models.
with shape (nclass,).
ymap: dict: any -> string, length == nclass.
if not None, map the labels & ys to more understandable strings.
Caution: original y_true, y_pred and labels must align.
figsize: the size of the figure plotted.
"""
if ymap is not None:
y_pred = [ymap[yi] for yi in y_pred]
y_true = [ymap[yi] for yi in y_true]
labels = [ymap[yi] for yi in labels]
cm = confusion_matrix(y_true, y_pred)
cm_sum = np.sum(cm, axis=1, keepdims=True)
cm_perc = cm / cm_sum.astype(float) * 100
annot = np.empty_like(cm).astype(str)
nrows, ncols = cm.shape
for i in range(nrows):
for j in range(ncols):
c = cm[i, j]
p = cm_perc[i, j]
if i == j:
s = cm_sum[i]
annot[i, j] = '%.1f%%\n%d/%d' % (p, c, s)
elif c == 0:
annot[i, j] = ''
else:
annot[i, j] = '%.1f%%\n%d' % (p, c)
cm = pd.DataFrame(cm, index=labels, columns=labels)
cm.index.name = 'Actual'
cm.columns.name = 'Predicted'
fig, ax = plt.subplots(figsize=figsize)
sns.heatmap(cm, annot=annot, cmap="YlGnBu", fmt='', ax=ax, linewidths=.5)
#plt.savefig(filename)
plt.show()
# Create random classification datasets with 1000 samples
iris = load_iris()
X = iris['data']
y = iris['target']
names = iris['target_names']
feature_names = iris['feature_names']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Create instance of ELM object with 10 hidden neuron
elm = ELM(X.shape[1], 1, 10)
# Split the data set into training and testing
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=True)
print("Training Shape", X_train.shape, y_train.shape)
print("Testing Shape", X_test.shape, y_test.shape)
# Train data
elm.train(X_train,y_train.reshape(-1,1))
# Make prediction from training process
y_pred = elm.predict(X_test)
y_pred = np.round(np.abs(y_pred))
print(y_test, "\n", y_pred.T)
print("\nAccuracy: ", accuracy_score(y_test, y_pred))
print("F1 Score: ", f1_score(y_test, y_pred, average="macro"))
print("Precision Score: ", precision_score(y_test, y_pred, average="macro"))
print("Recall Score: ", recall_score(y_test, y_pred, average="macro"))
print("\n", classification_report(y_test, y_pred, target_names=names))
cm_analysis(y_test, y_pred, names, ymap=None, figsize=(6,6))
cm = confusion_matrix(y_test, y_pred, normalize='all')
cmd = ConfusionMatrixDisplay(cm, display_labels=names)
cmd.plot()
cmd.ax_.set(xlabel='Predicted', ylabel='True')
#plt.savefig("Confusion_Matrix.png")
%matplotlib inline
%run run_elm_iris.py
#https://hpelm.readthedocs.io/en/latest/
!pip install git+https://github.com/akusok/hpelm
import warnings
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from hpelm import ELM
from mlxtend.plotting import plot_confusion_matrix
from scipy import ndimage
import seaborn as sns
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score, classification_report, confusion_matrix
from sklearn.metrics import roc_curve, auc, roc_auc_score
%matplotlib inline
np.random.seed(42)
def cm_analysis(y_true, y_pred, labels, ymap=None, figsize=(10,10)):
"""
Generate matrix plot of confusion matrix with pretty annotations.
The plot image is saved to disk.
args:
y_true: true label of the data, with shape (nsamples,)
y_pred: prediction of the data, with shape (nsamples,)
filename: filename of figure file to save
labels: string array, name the order of class labels in the confusion matrix.
use `clf.classes_` if using scikit-learn models.
with shape (nclass,).
ymap: dict: any -> string, length == nclass.
if not None, map the labels & ys to more understandable strings.
Caution: original y_true, y_pred and labels must align.
figsize: the size of the figure plotted.
"""
if ymap is not None:
y_pred = [ymap[yi] for yi in y_pred]
y_true = [ymap[yi] for yi in y_true]
labels = [ymap[yi] for yi in labels]
cm = confusion_matrix(y_true, y_pred, normalize='all')
cm_sum = np.sum(cm, axis=1, keepdims=True)
cm_perc = cm / cm_sum.astype(float) * 100
annot = np.empty_like(cm).astype(str)
nrows, ncols = cm.shape
for i in range(nrows):
for j in range(ncols):
c = cm[i, j]
p = cm_perc[i, j]
if i == j:
s = cm_sum[i]
annot[i, j] = '%.1f%%\n%d/%d' % (p, c, s)
elif c == 0:
annot[i, j] = ''
else:
annot[i, j] = '%.1f%%\n%d' % (p, c)
cm = pd.DataFrame(cm, index=labels, columns=labels)
cm.index.name = 'Actual'
cm.columns.name = 'Predicted'
fig, ax = plt.subplots(figsize=figsize)
sns.heatmap(cm, annot=annot, cmap="YlGnBu", fmt='', ax=ax, linewidths=.5)
#plt.savefig(filename)
plt.show()
# Threshold value for classification (<= negative, > positive)
THRESHOLD = 0.5
# Create random classification datasets with 1000 samples
iris = load_iris()
X = iris['data']
y = iris['target']
names = iris['target_names']
feature_names = iris['feature_names']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Create ELM
elm = ELM(4, 1)
elm.add_neurons(10, 'sigm')
elm.add_neurons(9, 'lin')
# Split the data set into training and testing
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.1, random_state=True)
print("Training Shape", X_train.shape, y_train.shape)
print("Testing Shape", X_test.shape, y_test.shape)
# Train data
with warnings.catch_warnings():
warnings.simplefilter("ignore")
elm.train(X_train, y_train)
y_pred = elm.predict(X_test)
y_pred = np.round(np.abs(y_pred))
y_pred = np.array(y_pred)
y_pred = np.where(y_pred >= 2, 2, y_pred)
print('\nAccuracy: ', accuracy_score(y_test, y_pred))
print("F1 Score: ", f1_score(y_test, y_pred, average="macro"))
print("Precision Score: ", precision_score(y_test, y_pred, average="macro"))
print("Recall Score: ", recall_score(y_test, y_pred, average="macro"))
print("\n",classification_report(y_test, y_pred, target_names=names))
cm_analysis(y_test, y_pred, names, ymap=None, figsize=(6,6))
```
| github_jupyter |
```
import seaborn as sns
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
## 데이터 읽어오기.## 데이터 읽어오기.
raw_df = pd.read_csv("../dataset/house_price_of_unit_area.csv")
print(raw_df.info())
print(raw_df.head())
## data copy
dataset=raw_df.copy()
## data 분포도 확인
sns.pairplot(dataset[["house age", "distance to the nearest MRT station", "number of convenience stores", "latitude", "longitude","house price of unit area"]], diag_kind="kde")
plt.show()
## label data 추출
label_data=dataset.pop("house price of unit area")
#label_data = label_data/10
## 입력 데이터 열 별로 min, max, mean, std 구하기.
dataset_stats = dataset.describe()
dataset_stats = dataset_stats.transpose()
## data normalization
def min_max_norm(x):
return (x - dataset_stats['min']) / (dataset_stats['max'] - dataset_stats['min'])
def standard_norm(x):
return (x - dataset_stats['mean']) / dataset_stats['std']
## 데이터 normalization 하기.
normed_train_data=standard_norm(dataset)
# 모델의 설정
input_Layer = tf.keras.layers.Input(shape=(5,))
x = tf.keras.layers.Dense(50, activation='sigmoid')(input_Layer)
x= tf.keras.layers.Dense(100, activation='sigmoid')(x)
x= tf.keras.layers.Dense(300, activation='sigmoid')(x)
Out_Layer= tf.keras.layers.Dense(1, activation=None)(x)
model = tf.keras.Model(inputs=[input_Layer], outputs=[Out_Layer])
model.summary()
loss=tf.keras.losses.mean_squared_error
optimizer=tf.keras.optimizers.SGD(learning_rate=0.007)
metrics=tf.keras.metrics.RootMeanSquaredError()
model.compile(loss=loss,
optimizer=optimizer,
metrics=[metrics])
result=model.fit(normed_train_data, label_data, epochs=5000, batch_size=1000)
## model fit은 histoy를 반환한다. 훈련중의 발생하는 모든 정보를 담고 있는 딕셔너리.
## histoy는 딕셔너리이므로 keys()를 통해 출력의 key(카테고리)를 알 수 있다.
print(result.history.keys())
### history에서 loss key를 가지는 값들만 추출
loss = result.history['loss']
### loss를 그래프화
epochs = range(1, len(loss) + 1)
plt.subplot(211) ## 2x1 개의 그래프 중에 1번째
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.title('Training loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
### history에서 mean_absolute_error key를 가지는 값들만 추출
mae = result.history['root_mean_squared_error']
epochs = range(1, len(mae) + 1)
### mean_absolute_error 그래프화
plt.subplot(212) ## 2x1 개의 그래프 중에 2번째
plt.plot(epochs, mae, 'ro', label='Training rmse')
plt.title('Training rmse')
plt.xlabel('Epochs')
plt.ylabel('rmse')
plt.legend()
print("\n Test rmse: %.4f" % (model.evaluate(normed_train_data, label_data)[1]))
plt.show()
```
| github_jupyter |
# VacationPy
----
#### Note
* Keep an eye on your API usage. Use https://developers.google.com/maps/reporting/gmp-reporting as reference for how to monitor your usage and billing.
* Instructions have been included for each segment. You do not have to follow them exactly, but they are included to help you think through the steps.
```
# Dependencies and Setup
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import gmaps
import os
from pprint import pprint
# Import API key
from api_keys import g_key
```
### Store Part I results into DataFrame
* Load the csv exported in Part I to a DataFrame
```
file_to_load = "city_data.csv"
raw_city_data = pd.read_csv(file_to_load)
raw_city_data.head()
```
### Humidity Heatmap
* Configure gmaps.
* Use the Lat and Lng as locations and Humidity as the weight.
* Add Heatmap layer to map.
```
gmaps.configure(api_key = g_key)
#sets format display parameters
figure_layout = {"width": "500px",
"height": "500px",
"boarder": "1px solid black",
"padding": "1px",
"margin": "0 auto 0auto"}
fig = gmaps.figure(layout=figure_layout)
#adds the heat layer by grabing lat and lng values and then intencity via humidity
heatmap_layer = gmaps.heatmap_layer(
raw_city_data[['Lat', 'Lng']], weights=raw_city_data['Humidity'],)
fig.add_layer(heatmap_layer)
fig
#improves zoom fuctionality
heatmap_layer.max_intensity = 100
heatmap_layer.point_radius = 5
```
### Create new DataFrame fitting weather criteria
* Narrow down the cities to fit weather conditions.
* Drop any rows will null values.
```
#Narrow down the cities to fit weather conditions
good_weather = raw_city_data[raw_city_data["Max Temp"] < 80]
good_weather = good_weather[good_weather["Max Temp"] > 70]
good_weather = good_weather[good_weather["Wind speed"] < 10]
good_weather = good_weather[good_weather["Cloudiness"] == 0]
hotel_df = good_weather
```
### Hotel Map
* Store into variable named `hotel_df`.
* Add a "Hotel Name" column to the DataFrame.
* Set parameters to search for hotels with 5000 meters.
* Hit the Google Places API for each city's coordinates.
* Store the first Hotel result into the DataFrame.
* Plot markers on top of the heatmap.
```
#adds locatons for new data to sit
hotel_df["Hotel Name"] = ""
hotel_df["Hotel Lat"] = ""
hotel_df["Hotel Lng"] = ""
#isolates coordinates for API request
coord = hotel_df[["Lat", "Lng"]]
hotel_df.head()
#lists to place API requested data
name_list = []
lat_list = []
lng_list = []
#iterates through the coordinates to put together the parameters for the API request
for index , row in coord.iterrows():
lat = (row["Lat"])
lng = (row["Lng"])
LOCATION = str(lat) + "," + str(lng)
RADIUS = 5000
KEYWORD = "lodging"
AUTH_KEY = g_key
#creates the actual url from parameters
MyUrl = ('https://maps.googleapis.com/maps/api/place/nearbysearch/json'
'?location=%s'
'&radius=%s'
'&type=%s'
'&sensor=false&key=%s') % (LOCATION, RADIUS, KEYWORD, AUTH_KEY)
#trys to pull all the information from the API request
response = requests.get(MyUrl).json()
try:
h_name = response["results"][0]["name"]
h_lat = response["results"][0]["geometry"]["location"]["lat"]
h_lng = response["results"][0]["geometry"]["location"]["lng"]
#returns null values upon failure
except:
h_name = np.nan
h_lat = np.nan
h_lng = np.nan
print("city not found.skipping")
pass
#adds new info to there designated lists to be parced into the dataframe
name_list.append(h_name)
lat_list.append(h_lat)
lng_list.append(h_lng)
#puts data from API into the hotel_df dataframe in there respective column
hotel_df["Hotel Name"] = name_list
hotel_df["Hotel Lat"] = lat_list
hotel_df["Hotel Lng"] = lng_list
hotel_df.head()
# NOTE: Do not change any of the code in this cell
# Using the template add the hotel marks to the heatmap
info_box_template = """
<dl>
<dt>Name</dt><dd>{Hotel Name}</dd>
<dt>City</dt><dd>{City}</dd>
<dt>Country</dt><dd>{Country}</dd>
</dl>
"""
# Store the DataFrame Row
# NOTE: be sure to update with your DataFrame name
hotel_info = [info_box_template.format(**row) for index, row in hotel_df.iterrows()]
locations = hotel_df[["Lat", "Lng"]]
# Add marker layer ontop of heat map
marker_layer = gmaps.marker_layer(locations, info_box_content=hotel_info)
fig.add_layer(marker_layer)
# Display figure
fig
```
| github_jupyter |
<a id="title_ID"></a>
# JWST Pipeline Validation Notebook:
# calwebb_detector1, refpix unit tests
<span style="color:red"> **Instruments Affected**</span>: NIRCam, NIRISS, NIRSpec, FGS
### Table of Contents
<div style="text-align: left">
<br> [Introduction](#intro)
<br> [JWST Unit Tests](#unit)
<br> [Defining Terms](#terms)
<br> [Test Description](#description)
<br> [Data Description](#data_descr)
<br> [Imports](#imports)
<br> [Convenience Functions](#functions)
<br> [Perform Tests](#testing)
<br> [About This Notebook](#about)
<br>
</div>
<a id="intro"></a>
# Introduction
This is the validation notebook that displays the unit tests for the Reference Pixel Correction in calwebb_detector1. This notebook runs and displays the unit tests that are performed as a part of the normal software continuous integration process. For more information on the pipeline visit the links below.
* Pipeline description: https://jwst-pipeline.readthedocs.io/en/latest/jwst/refpix/index.html
* Pipeline code: https://github.com/spacetelescope/jwst/tree/master/jwst/
[Top of Page](#title_ID)
<a id="unit"></a>
# JWST Unit Tests
JWST unit tests are located in the "tests" folder for each pipeline step within the [GitHub repository](https://github.com/spacetelescope/jwst/tree/master/jwst/), e.g., ```jwst/refpix/tests```.
* Unit test README: https://github.com/spacetelescope/jwst#unit-tests
[Top of Page](#title_ID)
<a id="terms"></a>
# Defining Terms
These are terms or acronymns used in this notebook that may not be known a general audience.
* JWST: James Webb Space Telescope
* NIRCam: Near-Infrared Camera
[Top of Page](#title_ID)
<a id="description"></a>
# Test Description
Unit testing is a software testing method by which individual units of source code are tested to determine whether they are working sufficiently well. Unit tests do not require a separate data file; the test creates the necessary test data and parameters as a part of the test code.
[Top of Page](#title_ID)
<a id="data_descr"></a>
# Data Description
Data used for unit tests is created on the fly within the test itself, and is typically an array in the expected format of JWST data with added metadata needed to run through the pipeline.
[Top of Page](#title_ID)
<a id="imports"></a>
# Imports
* tempfile for creating temporary output products
* pytest for unit test functions
* jwst for the JWST Pipeline
* IPython.display for display pytest reports
[Top of Page](#title_ID)
```
import tempfile
import pytest
import jwst
from IPython.display import IFrame
```
<a id="functions"></a>
# Convenience Functions
Here we define any convenience functions to help with running the unit tests.
[Top of Page](#title_ID)
```
def display_report(fname):
'''Convenience function to display pytest report.'''
return IFrame(src=fname, width=700, height=600)
```
<a id="testing"></a>
# Perform Tests
Below we run the unit tests for the Reference Pixel Correction.
[Top of Page](#title_ID)
```
with tempfile.TemporaryDirectory() as tmpdir:
!pytest jwst/refpix -v --ignore=jwst/associations --ignore=jwst/datamodels --ignore=jwst/stpipe --ignore=jwst/regtest --html=tmpdir/unit_report.html --self-contained-html
report = display_report('tmpdir/unit_report.html')
report
```
<a id="about"></a>
## About This Notebook
**Author:** Alicia Canipe, Staff Scientist, NIRCam
<br>**Updated On:** 01/07/2021
[Top of Page](#title_ID)
<img style="float: right;" src="./stsci_pri_combo_mark_horizonal_white_bkgd.png" alt="stsci_pri_combo_mark_horizonal_white_bkgd" width="200px"/>
| github_jupyter |
# Analyse wavefields
This notebook checks the velocity models and FD simulations output by `generate_velocity_models.py` and `generate_forward_simulations.py` are sensible.
```
import glob
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import numpy as np
import scipy as sp
import sys
sys.path.insert(0, '../shared_modules/')
import plot_utils
%matplotlib inline
```
## Load example velocity model and FD simulation
```
# PARAMETERS
VEL_RUN = "marmousi"
SIM_RUN = "marmousi_2ms"
VEL_DIR = "velocity/" + VEL_RUN + "/"
OUT_SIM_DIR = "gather/" + SIM_RUN + "/"
isim=(20,1)
wavefields = np.load(OUT_SIM_DIR + "wavefields_%.8i_%.8i.npy"%(isim[0],isim[1]))
wavefields = wavefields[::4]
gather = np.load(OUT_SIM_DIR + "gather_%.8i_%.8i.npy"%(isim[0],isim[1]))
velocity = np.load(VEL_DIR + "velocity_%.8i.npy"%(isim[0]))
source_is = np.load(OUT_SIM_DIR + "source_is.npy")
receiver_is = np.load(OUT_SIM_DIR + "receiver_is.npy")
DELTAT = 0.002
source_i = source_is[isim[0],isim[1]]
print(velocity.shape, velocity[0,0])
print(wavefields.shape, np.max(wavefields))
print(gather.shape)
print(receiver_is.shape, source_is.shape)
#print(receiver_is)
#print(source_is)
print(source_i)
```
## Create wavefield animation
```
%matplotlib notebook
# define initial plots
fig = plt.figure(figsize=(13.5,6))
plt.subplot(1,2,2)
plt.imshow(velocity.T, cmap="viridis")
cb = plt.colorbar()
cb.ax.set_ylabel('P-wave velocity (m/s)')
plt.subplot(1,2,1)
plt.imshow(velocity.T, alpha=0.4, cmap="gray_r")
im = plt.imshow(wavefields[0].T, aspect=1, cmap=plot_utils.rgb, alpha=0.4, vmin = -2, vmax=2)
cb = plt.colorbar()
cb.ax.set_ylabel('P-wave amplitude')
plt.scatter(receiver_is[:,0], receiver_is[:,1])
plt.scatter(source_i[0], source_i[1])
# define animation update function
def update(i):
# set the data in the im object
plt.title("t = %i"%(i))
im.set_data(wavefields[i].T)
return [im]# tells the animator which parts of the plot to update
# start animation
# important: keep the instance to maintain timer
ani = animation.FuncAnimation(fig, update, frames=range(0,wavefields.shape[0],10), interval=100, blit=False)
plt.subplots_adjust(left=0.0, right=1., bottom=0.05, top=0.95, hspace=0.0, wspace=0.0)
plt.show()
ani._stop()
```
## Check wavefields and gather match
```
# check wavefields and gather match
gather_test = wavefields[:,receiver_is[:,0], receiver_is[:,1]].T
print(gather.shape, gather_test.shape)
print(np.allclose(gather, gather_test))
# plot gather
%matplotlib inline
print(gather.mean(), 5*gather.std())
gathern = gather/(1)
t = np.arange(gather.shape[1], dtype=np.float32)
t_gain = (t**2.5)
t_gain = t_gain/np.median(t_gain)
plt.figure(figsize=(12,8))
plt.imshow((gathern*t_gain).T, aspect=0.1, cmap="Greys", vmin=-1, vmax=1)
plt.colorbar()
plt.figure(figsize=(20,10))
plt.plot(t.flatten(),(gathern*t_gain)[10,:])
plt.scatter(t.flatten(),np.zeros(gather.shape[1]), s=0.1)
```
## Plot average frequency spectrum of gather
```
# plot average frequency spectrum of gather
s = np.abs(np.fft.fft(gather, axis=1))
s = np.sum(s, axis=0)
f = np.fft.fftfreq(s.shape[0], DELTAT)
plt.figure(figsize=(10,5))
plt.plot(f[np.argsort(f)], s[np.argsort(f)])
plt.xlim(0, 250)
plt.show()
print(f[np.argmax(s)])# dominant frequency
plt.plot(t,t_gain)
```
| github_jupyter |
递归回溯法:叫称为试探法,按选优条件向前搜索,当搜索到某一步,发现原先选择并不优或不达到目的时,就退回一步重新选择
经典问题:骑士巡逻
```
import os
import sys
import time
SIZE = 5
total = 0
def print_board(board):
for row in board:
for col in row:
print(str(col).center(4),end='')
print()
def patrol(board,row,col,step=1):
if row >= 0 and row <SIZE and \
col >= 0 and col <SIZE and \
board[row][col] == 0:
board[row][col] = step
if step ==SIZE * SIZE:
global total
total += 1
print(f'第{total}种走法:')
print_board(board)
patrol(board, row - 2, col - 1, step + 1)
patrol(board, row - 1, col - 2, step + 1)
patrol(board, row + 1, col - 2, step + 1)
patrol(board, row + 2, col - 1, step + 1)
patrol(board, row + 2, col + 1, step + 1)
patrol(board, row + 1, col + 2, step + 1)
patrol(board, row - 1, col + 2, step + 1)
patrol(board, row - 2, col + 1, step + 1)
board[row][col] = 0
def main():
board = [[0] * SIZE for _ in range(SIZE)]
patrol(board,SIZE - 1,SIZE - 1)
if __name__ == '__main__':
main()
```
序列化和反序列化
序列化 - 将对象变成字节序列(bytes)或者字符序列(str) - 串行化/腌咸菜
反序列化 - 把字节序列或者字符序列还原成对象
Python标准库对序列化的支持:
json - 字符形式的序列化
pickle - 字节形式的序列化
哈希摘要 - 数字签名/指纹 - 单向哈希函数
```
class StreamHasher():
"""摘要生成器"""
def __init__(self,algorithm='md5',size=4096):
"""初始化方法
@params:
algorithm - 哈希摘要算法
size - 每次读取数据的大小
"""
self.size = size
cls = getattr(__import__('hashlib'),algorithm.lower())
self.hasher = cls()
def digest(self,file_stream):
"""生成器十六进制的摘要字符串"""
for data in iter(lambda:file_stream.read(self.size),b''):
self.hasher.update(data)
return self.hasher.hexdigest()
def __call__(self,file_stream):
return self.digest(file_stream)
def main():
"""主函数"""
hasher1 = StreamHasher()
hasher2 = StreamHasher('sha1')
hasher3 = StreamHasher('sha256')
with open('C:\\Users\\a\\Desktop\\as.txt', 'rb') as file_stream:
print(hasher1.digest(file_stream))
file_stream.seek(0, 0)
print(hasher2.digest(file_stream))
file_stream.seek(0, 0)
print(hasher3(file_stream))
if __name__ == '__main__':
main()
加密和解密
对称加密 - 加密和解密是同一个密钥 - DES / AES
非对称加密 - 加密和解密是不同的密钥 - RSA
import base64
from hashlib import md5
from Crypto.Cipher import AES
from Crypto import Random
from Crypto.PublicKey import RSA
def main():
"""主函数"""
# 生成密钥对
key_pair = RSA.generate(1024)
# 导入公钥
pub_key = RSA.importKey(key_pair.publickey().exportKey())
# 导入私钥
pri_key = RSA.importKey(key_pair.exportKey())
message1 = 'hello, world!'
# 加密数据
data = pub_key.encrypt(message1.encode(), None)
# 对加密数据进行BASE64编码
message2 = base64.b64encode(data[0])
print(message2)
# 对加密数据进行BASE64解码
data = base64.b64decode(message2)
# 解密数据
message3 = pri_key.decrypt(data)
print(message3.decode())
if __name__ == '__main__':
main()
```
装饰器 - 装饰器中放置的通常都是横切关注(cross-concern)功能
所谓横切关注功能就是很多地方都会用到但跟正常业务又逻辑没有必然联系的功能
装饰器实际上是实现了设计模式中的代理模式 - AOP(面向切面编程)
```
from functools import wraps
from random import randint
from time import time, sleep
import pymysql
def record(output):
def decorate(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time()
ret_value = func(*args, **kwargs)
output(func.__name__, time() - start)
return ret_value
return wrapper
return decorate
def output_to_console(fname, duration):
print('%s: %.3f秒' % (fname, duration))
def output_to_file(fname, duration):
with open('log.txt', 'a') as file_stream:
file_stream.write('%s: %.3f秒\n' % (fname, duration))
def output_to_db(fname, duration):
con = pymysql.connect(host='localhost', port=3306,
database='test', charset='utf8',
user='root', password='123456',
autocommit=True)
try:
with con.cursor() as cursor:
cursor.execute('insert into tb_record values (default, %s, %s)',
(fname, '%.3f' % duration))
finally:
con.close()
@record(output_to_console)
def random_delay(min, max):
sleep(randint(min, max))
def main():
for _ in range(3):
# print(random_delay.__name__)
random_delay(3, 5)
if __name__ == '__main__':
main()
```
装饰类的装饰器 - 单例模式 - 一个类只能创建出唯一的对象
上下文语法:
__enter__ / __exit__
```
import threading
from functools import wraps
def singleton(cls):
"""单例装饰器"""
instances = {}
lock = threading.Lock()
@wraps(cls)
def wrapper(*args, **kwargs):
if cls not in instances:
with lock:
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return wrapper
@singleton
class President():
def __init__(self, name, country):
self.name = name
self.country = country
def __str__(self):
return f'{self.country}: {self.name}'
def main():
print(President.__name__)
p1 = President('特朗普', '美国')
p2 = President('奥巴马', '美国')
print(p1 == p2)
print(p1)
print(p2)
if __name__ == '__main__':
main()
```
| github_jupyter |
# Week 3: Transfer Learning
Welcome to this assignment! This week, you are going to use a technique called `Transfer Learning` in which you utilize an already trained network to help you solve a similar problem to the one it was originally trained to solve.
Let's get started!
```
import os
import zipfile
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import Model
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing.image import img_to_array, load_img
```
## Dataset
For this assignment, you will use the `Horse or Human dataset`, which contains images of horses and humans.
Download the `training` and `validation` sets by running the cell below:
```
# Get the Horse or Human training dataset
!wget -q -P /content/ https://storage.googleapis.com/tensorflow-1-public/course2/week3/horse-or-human.zip
# Get the Horse or Human validation dataset
!wget -q -P /content/ https://storage.googleapis.com/tensorflow-1-public/course2/week3/validation-horse-or-human.zip
test_local_zip = './horse-or-human.zip'
zip_ref = zipfile.ZipFile(test_local_zip, 'r')
zip_ref.extractall('/tmp/training')
val_local_zip = './validation-horse-or-human.zip'
zip_ref = zipfile.ZipFile(val_local_zip, 'r')
zip_ref.extractall('/tmp/validation')
zip_ref.close()
```
This dataset already has an structure that is compatible with Keras' `flow_from_directory` so you don't need to move the images into subdirectories as you did in the previous assignments. However, it is still a good idea to save the paths of the images so you can use them later on:
```
# Define the training and validation base directories
train_dir = '/tmp/training'
validation_dir = '/tmp/validation'
# Directory with training horse pictures
train_horses_dir = os.path.join(train_dir, 'horses')
# Directory with training humans pictures
train_humans_dir = os.path.join(train_dir, 'humans')
# Directory with validation horse pictures
validation_horses_dir = os.path.join(validation_dir, 'horses')
# Directory with validation human pictures
validation_humans_dir = os.path.join(validation_dir, 'humans')
# Check the number of images for each class and set
print(f"There are {len(os.listdir(train_horses_dir))} images of horses for training.\n")
print(f"There are {len(os.listdir(train_humans_dir))} images of humans for training.\n")
print(f"There are {len(os.listdir(validation_horses_dir))} images of horses for validation.\n")
print(f"There are {len(os.listdir(validation_humans_dir))} images of humans for validation.\n")
```
Now take a look at a sample image of each one of the classes:
```
print("Sample horse image:")
plt.imshow(load_img(f"{os.path.join(train_horses_dir, os.listdir(train_horses_dir)[0])}"))
plt.show()
print("\nSample human image:")
plt.imshow(load_img(f"{os.path.join(train_humans_dir, os.listdir(train_humans_dir)[0])}"))
plt.show()
```
`matplotlib` makes it easy to see that these images have a resolution of 300x300 and are colored, but you can double check this by using the code below:
```
# Load the first example of a horse
sample_image = load_img(f"{os.path.join(train_horses_dir, os.listdir(train_horses_dir)[0])}")
# Convert the image into its numpy array representation
sample_array = img_to_array(sample_image)
print(f"Each image has shape: {sample_array.shape}")
```
As expected, the sample image has a resolution of 300x300 and the last dimension is used for each one of the RGB channels to represent color.
## Training and Validation Generators
Now that you know the images you are dealing with, it is time for you to code the generators that will fed these images to your Network. For this, complete the `train_val_generators` function below:
**Important Note:** The images have a resolution of 300x300 but the `flow_from_directory` method you will use allows you to set a target resolution. In this case, **set a `target_size` of (150, 150)**. This will heavily lower the number of trainable parameters in your final network, yielding much quicker training times without compromising the accuracy!
```
# GRADED FUNCTION: train_val_generators
def train_val_generators(TRAINING_DIR, VALIDATION_DIR):
### START CODE HERE
# Instantiate the ImageDataGenerator class
# Don't forget to normalize pixel values and set arguments to augment the images
train_datagen = None
# Pass in the appropriate arguments to the flow_from_directory method
train_generator = train_datagen.flow_from_directory(directory=None,
batch_size=32,
class_mode=None,
target_size=(None, None))
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
# Remember that validation data should not be augmented
validation_datagen = None
# Pass in the appropriate arguments to the flow_from_directory method
validation_generator = validation_datagen.flow_from_directory(directory=None,
batch_size=32,
class_mode=None,
target_size=(None, None))
### END CODE HERE
return train_generator, validation_generator
# Test your generators
train_generator, validation_generator = train_val_generators(train_dir, validation_dir)
```
**Expected Output:**
```
Found 1027 images belonging to 2 classes.
Found 256 images belonging to 2 classes.
```
## Transfer learning - Create the pre-trained model
Download the `inception V3` weights into the `/tmp/` directory:
```
# Download the inception v3 weights
!wget --no-check-certificate \
https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5 \
-O /tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5
```
Now load the `InceptionV3` model and save the path to the weights you just downloaded:
```
# Import the inception model
from tensorflow.keras.applications.inception_v3 import InceptionV3
# Create an instance of the inception model from the local pre-trained weights
local_weights_file = '/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
```
Complete the `create_pre_trained_model` function below. You should specify the correct `input_shape` for the model (remember that you set a new resolution for the images instead of the native 300x300) and make all of the layers non-trainable:
```
# GRADED FUNCTION: create_pre_trained_model
def create_pre_trained_model(local_weights_file):
### START CODE HERE
pre_trained_model = InceptionV3(input_shape = (None, None, None),
include_top = False,
weights = None)
pre_trained_model.load_weights(local_weights_file)
# Make all the layers in the pre-trained model non-trainable
for None in None:
None = None
### END CODE HERE
return pre_trained_model
```
Check that everything went well by comparing the last few rows of the model summary to the expected output:
```
pre_trained_model = create_pre_trained_model(local_weights_file)
# Print the model summary
pre_trained_model.summary()
```
**Expected Output:**
```
batch_normalization_v1_281 (Bat (None, 3, 3, 192) 576 conv2d_281[0][0]
__________________________________________________________________________________________________
activation_273 (Activation) (None, 3, 3, 320) 0 batch_normalization_v1_273[0][0]
__________________________________________________________________________________________________
mixed9_1 (Concatenate) (None, 3, 3, 768) 0 activation_275[0][0]
activation_276[0][0]
__________________________________________________________________________________________________
concatenate_5 (Concatenate) (None, 3, 3, 768) 0 activation_279[0][0]
activation_280[0][0]
__________________________________________________________________________________________________
activation_281 (Activation) (None, 3, 3, 192) 0 batch_normalization_v1_281[0][0]
__________________________________________________________________________________________________
mixed10 (Concatenate) (None, 3, 3, 2048) 0 activation_273[0][0]
mixed9_1[0][0]
concatenate_5[0][0]
activation_281[0][0]
==================================================================================================
Total params: 21,802,784
Trainable params: 0
Non-trainable params: 21,802,784
```
To check that all the layers in the model were set to be non-trainable, you can also run the cell below:
```
total_params = pre_trained_model.count_params()
num_trainable_params = sum([w.shape.num_elements() for w in pre_trained_model.trainable_weights])
print(f"There are {total_params:,} total parameters in this model.")
print(f"There are {num_trainable_params:,} trainable parameters in this model.")
```
**Expected Output:**
```
There are 21,802,784 total parameters in this model.
There are 0 trainable parameters in this model.
```
## Creating callbacks for later
You have already worked with callbacks in the first course of this specialization so the callback to stop training once an accuracy of 99.9% is reached, is provided for you:
```
# Define a Callback class that stops training once accuracy reaches 99.9%
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('accuracy')>0.999):
print("\nReached 99.9% accuracy so cancelling training!")
self.model.stop_training = True
```
## Pipelining the pre-trained model with your own
Now that the pre-trained model is ready, you need to "glue" it to your own model to solve the task at hand.
For this you will need the last output of the pre-trained model, since this will be the input for your own. Complete the `output_of_last_layer` function below.
**Note:** For grading purposes use the `mixed7` layer as the last layer of the pre-trained model. However, after submitting feel free to come back here and play around with this.
```
# GRADED FUNCTION: output_of_last_layer
def output_of_last_layer(pre_trained_model):
### START CODE HERE
last_desired_layer = None
print('last layer output shape: ', last_desired_layer.output_shape)
last_output = None
print('last layer output: ', last_output)
### END CODE HERE
return last_output
```
Check that everything works as expected:
```
last_output = output_of_last_layer(pre_trained_model)
```
**Expected Output (if `mixed7` layer was used):**
```
last layer output shape: (None, 7, 7, 768)
last layer output: KerasTensor(type_spec=TensorSpec(shape=(None, 7, 7, 768), dtype=tf.float32, name=None), name='mixed7/concat:0', description="created by layer 'mixed7'")
```
Now you will create the final model by adding some additional layers on top of the pre-trained model.
Complete the `create_final_model` function below. You will need to use Tensorflow's [Functional API](https://www.tensorflow.org/guide/keras/functional) for this since the pretrained model has been created using it.
Let's double check this first:
```
# Print the type of the pre-trained model
print(f"The pretrained model has type: {type(pre_trained_model)}")
```
To create the final model, you will use Keras' Model class by defining the appropriate inputs and outputs as described in the first way to instantiate a Model in the [docs](https://www.tensorflow.org/api_docs/python/tf/keras/Model).
Note that you can get the input from any existing model by using its `input` attribute and by using the Funcional API you can use the last layer directly as output when creating the final model.
```
# GRADED FUNCTION: create_final_model
def create_final_model(pre_trained_model, last_output):
# Flatten the output layer to 1 dimension
x = layers.Flatten()(last_output)
### START CODE HERE
# Add a fully connected layer with 1024 hidden units and ReLU activation
x = None
# Add a dropout rate of 0.2
x = None
# Add a final sigmoid layer for classification
x = None
# Create the complete model by using the Model class
model = Model(inputs=None, outputs=None)
# Compile the model
model.compile(optimizer = RMSprop(learning_rate=0.0001),
loss = None,
metrics = [None])
### END CODE HERE
return model
# Save your model in a variable
model = create_final_model(pre_trained_model, last_output)
# Inspect parameters
total_params = model.count_params()
num_trainable_params = sum([w.shape.num_elements() for w in model.trainable_weights])
print(f"There are {total_params:,} total parameters in this model.")
print(f"There are {num_trainable_params:,} trainable parameters in this model.")
```
**Expected Output:**
```
There are 47,512,481 total parameters in this model.
There are 38,537,217 trainable parameters in this model.
```
Wow, that is a lot of parameters!
After submitting your assignment later, try re-running this notebook but use the original resolution of 300x300, you will be surprised to see how many more parameters are for that case.
Now train the model:
```
# Run this and see how many epochs it should take before the callback
# fires, and stops training at 99.9% accuracy
# (It should take a few epochs)
callbacks = myCallback()
history = model.fit(train_generator,
validation_data = validation_generator,
epochs = 100,
verbose = 2,
callbacks=callbacks)
```
The training should have stopped after less than 10 epochs and it should have reached an accuracy over 99,9% (firing the callback). This happened so quickly because of the pre-trained model you used, which already contained information to classify humans from horses. Really cool!
Now take a quick look at the training and validation accuracies for each epoch of training:
```
# Plot the training and validation accuracies for each epoch
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'r', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend(loc=0)
plt.figure()
plt.show()
```
You will need to submit this notebook for grading. To download it, click on the `File` tab in the upper left corner of the screen then click on `Download` -> `Download .ipynb`. You can name it anything you want as long as it is a valid `.ipynb` (jupyter notebook) file.
**Congratulations on finishing this week's assignment!**
You have successfully implemented a convolutional neural network that leverages a pre-trained network to help you solve the problem of classifying humans from horses.
**Keep it up!**
| github_jupyter |
# Introduction to Taxi ETL Job
This is the Taxi ETL job to generate the input datasets for the Taxi XGBoost job.
## Prerequirement
### 1. Download data
All data could be found at https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
### 2. Download needed jars
* [cudf-21.12.2-cuda11.jar](https://repo1.maven.org/maven2/ai/rapids/cudf/21.12.2/)
* [rapids-4-spark_2.12-21.12.0.jar](https://repo1.maven.org/maven2/com/nvidia/rapids-4-spark_2.12/21.12.0/rapids-4-spark_2.12-21.12.0.jar)
### 3. Start Spark Standalone
Before running the script, please setup Spark standalone mode
### 4. Add ENV
```
$ export SPARK_JARS=cudf-21.12.2-cuda11.jar,rapids-4-spark_2.12-21.12.0.jar
```
### 5.Start Jupyter Notebook with spylon-kernal or toree
```
$ jupyter notebook --allow-root --notebook-dir=${your-dir} --config=${your-configs}
```
## Import Libs
```
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.DataTypes.{DoubleType, IntegerType, StringType}
import org.apache.spark.sql.types.{FloatType, StructField, StructType}
```
## Script Settings
### 1. File Path Settings
* Define input file path
```
val dataRoot = sys.env.getOrElse("DATA_ROOT", "/data")
val rawPath = dataRoot + "/taxi/taxi-etl-input-small.csv"
val outPath = dataRoot + "/taxi/output"
```
## Function and Object Define
### Define the constants
* Define input file schema
```
val rawSchema = StructType(Seq(
StructField("vendor_id", StringType),
StructField("pickup_datetime", StringType),
StructField("dropoff_datetime", StringType),
StructField("passenger_count", IntegerType),
StructField("trip_distance", DoubleType),
StructField("pickup_longitude", DoubleType),
StructField("pickup_latitude", DoubleType),
StructField("rate_code", StringType),
StructField("store_and_fwd_flag", StringType),
StructField("dropoff_longitude", DoubleType),
StructField("dropoff_latitude", DoubleType),
StructField("payment_type", StringType),
StructField("fare_amount", DoubleType),
StructField("surcharge", DoubleType),
StructField("mta_tax", DoubleType),
StructField("tip_amount", DoubleType),
StructField("tolls_amount", DoubleType),
StructField("total_amount", DoubleType)
))
def dataRatios: (Int, Int, Int) = {
val ratios = (80, 20)
(ratios._1, ratios._2, 100 - ratios._1 - ratios._2)
}
val (trainRatio, evalRatio, trainEvalRatio) = dataRatios
```
* Build the spark session and dataframe
```
// Build the spark session and data reader as usual
val sparkSession = SparkSession.builder.appName("taxi-etl").getOrCreate
val df = sparkSession.read.option("header", true).schema(rawSchema).csv(rawPath)
```
* Define some ETL functions
```
def dropUseless(dataFrame: DataFrame): DataFrame = {
dataFrame.drop(
"dropoff_datetime",
"payment_type",
"surcharge",
"mta_tax",
"tip_amount",
"tolls_amount",
"total_amount")
}
def encodeCategories(dataFrame: DataFrame): DataFrame = {
val categories = Seq("vendor_id", "rate_code", "store_and_fwd_flag")
(categories.foldLeft(dataFrame) {
case (df, category) => df.withColumn(category, hash(col(category)))
}).withColumnRenamed("store_and_fwd_flag", "store_and_fwd")
}
def fillNa(dataFrame: DataFrame): DataFrame = {
dataFrame.na.fill(-1)
}
def removeInvalid(dataFrame: DataFrame): DataFrame = {
val conditions = Seq(
Seq("fare_amount", 0, 500),
Seq("passenger_count", 0, 6),
Seq("pickup_longitude", -75, -73),
Seq("dropoff_longitude", -75, -73),
Seq("pickup_latitude", 40, 42),
Seq("dropoff_latitude", 40, 42))
conditions
.map { case Seq(column, min, max) => "%s > %d and %s < %d".format(column, min, column, max) }
.foldLeft(dataFrame) {
_.filter(_)
}
}
def convertDatetime(dataFrame: DataFrame): DataFrame = {
val datetime = col("pickup_datetime")
dataFrame
.withColumn("pickup_datetime", to_timestamp(datetime))
.withColumn("year", year(datetime))
.withColumn("month", month(datetime))
.withColumn("day", dayofmonth(datetime))
.withColumn("day_of_week", dayofweek(datetime))
.withColumn(
"is_weekend",
col("day_of_week").isin(1, 7).cast(IntegerType)) // 1: Sunday, 7: Saturday
.withColumn("hour", hour(datetime))
.drop(datetime.toString)
}
def addHDistance(dataFrame: DataFrame): DataFrame = {
val P = math.Pi / 180
val lat1 = col("pickup_latitude")
val lon1 = col("pickup_longitude")
val lat2 = col("dropoff_latitude")
val lon2 = col("dropoff_longitude")
val internalValue = (lit(0.5)
- cos((lat2 - lat1) * P) / 2
+ cos(lat1 * P) * cos(lat2 * P) * (lit(1) - cos((lon2 - lon1) * P)) / 2)
val hDistance = lit(12734) * asin(sqrt(internalValue))
dataFrame.withColumn("h_distance", hDistance)
}
// def preProcess(dataFrame: DataFrame): DataFrame = {
// val processes = Seq[DataFrame => DataFrame](
// dropUseless,
// encodeCategories,
// fillNa,
// removeInvalid,
// convertDatetime,
// addHDistance
// )
// processes
// .foldLeft(dataFrame) { case (df, process) => process(df) }
// }
```
* Define main ETL function
```
def preProcess(dataFrame: DataFrame, splits: Array[Int]): Array[DataFrame] = {
val processes = Seq[DataFrame => DataFrame](
dropUseless,
encodeCategories,
fillNa,
removeInvalid,
convertDatetime,
addHDistance
)
processes
.foldLeft(dataFrame) { case (df, process) => process(df) }
.randomSplit(splits.map(_.toDouble))
}
val dataset = preProcess(df, Array(trainRatio, trainEvalRatio, evalRatio))
```
## Run ETL Process and Save the Result
```
val t0 = System.currentTimeMillis
for ((name, index) <- Seq("train", "eval", "trans").zipWithIndex) {
dataset(index).write.mode("overwrite").parquet(outPath + "/parquet/" + name)
dataset(index).write.mode("overwrite").csv(outPath + "/csv/" + name)
}
val t1 = System.currentTimeMillis
println("Elapsed time : " + ((t1 - t0).toFloat / 1000) + "s")
sparkSession.stop()
```
| github_jupyter |
# Self-Driving Car Engineer Nanodegree
## Project: **Finding Lane Lines on the Road**
***
In this project, you will use the tools you learned about in the lesson to identify lane lines on the road. You can develop your pipeline on a series of individual images, and later apply the result to a video stream (really just a series of images). Check out the video clip "raw-lines-example.mp4" (also contained in this repository) to see what the output should look like after using the helper functions below.
Once you have a result that looks roughly like "raw-lines-example.mp4", you'll need to get creative and try to average and/or extrapolate the line segments you've detected to map out the full extent of the lane lines. You can see an example of the result you're going for in the video "P1_example.mp4". Ultimately, you would like to draw just one line for the left side of the lane, and one for the right.
In addition to implementing code, there is a brief writeup to complete. The writeup should be completed in a separate file, which can be either a markdown file or a pdf document. There is a [write up template](https://github.com/udacity/CarND-LaneLines-P1/blob/master/writeup_template.md) that can be used to guide the writing process. Completing both the code in the Ipython notebook and the writeup template will cover all of the [rubric points](https://review.udacity.com/#!/rubrics/322/view) for this project.
---
Let's have a look at our first image called 'test_images/solidWhiteRight.jpg'. Run the 2 cells below (hit Shift-Enter or the "play" button above) to display the image.
**Note: If, at any point, you encounter frozen display windows or other confounding issues, you can always start again with a clean slate by going to the "Kernel" menu above and selecting "Restart & Clear Output".**
---
**The tools you have are color selection, region of interest selection, grayscaling, Gaussian smoothing, Canny Edge Detection and Hough Tranform line detection. You are also free to explore and try other techniques that were not presented in the lesson. Your goal is piece together a pipeline to detect the line segments in the image, then average/extrapolate them and draw them onto the image for display (as below). Once you have a working pipeline, try it out on the video stream below.**
---
<figure>
<img src="examples/line-segments-example.jpg" width="380" alt="Combined Image" />
<figcaption>
<p></p>
<p style="text-align: center;"> Your output should look something like this (above) after detecting line segments using the helper functions below </p>
</figcaption>
</figure>
<p></p>
<figure>
<img src="examples/laneLines_thirdPass.jpg" width="380" alt="Combined Image" />
<figcaption>
<p></p>
<p style="text-align: center;"> Your goal is to connect/average/extrapolate line segments to get output like this</p>
</figcaption>
</figure>
**Run the cell below to import some packages. If you get an `import error` for a package you've already installed, try changing your kernel (select the Kernel menu above --> Change Kernel). Still have problems? Try relaunching Jupyter Notebook from the terminal prompt. Also, consult the forums for more troubleshooting tips.**
## Import Packages
```
#importing some useful packages
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import numpy as np
import cv2
%matplotlib inline
```
## Read in an Image
```
#reading in an image
image = mpimg.imread('test_images/solidWhiteRight.jpg')
#printing out some stats and plotting
print('This image is:', type(image), 'with dimensions:', image.shape)
plt.imshow(image) # if you wanted to show a single color channel image called 'gray', for example, call as plt.imshow(gray, cmap='gray')
```
## Ideas for Lane Detection Pipeline
**Some OpenCV functions (beyond those introduced in the lesson) that might be useful for this project are:**
`cv2.inRange()` for color selection
`cv2.fillPoly()` for regions selection
`cv2.line()` to draw lines on an image given endpoints
`cv2.addWeighted()` to coadd / overlay two images
`cv2.cvtColor()` to grayscale or change color
`cv2.imwrite()` to output images to file
`cv2.bitwise_and()` to apply a mask to an image
**Check out the OpenCV documentation to learn about these and discover even more awesome functionality!**
## Helper Functions
Below are some helper functions to help get you started. They should look familiar from the lesson!
```
import math
def grayscale(img):
"""Applies the Grayscale transform
This will return an image with only one color channel
but NOTE: to see the returned image as grayscale
(assuming your grayscaled image is called 'gray')
you should call plt.imshow(gray, cmap='gray')"""
return cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Use RGB2GRAY when read with matplaolib mpimg.imread
# return cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# Or use BGR2GRAY if you read an image with cv2.imread()
# return cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
def canny(img, low_threshold, high_threshold):
"""Applies the Canny transform"""
return cv2.Canny(img, low_threshold, high_threshold)
def gaussian_blur(img, kernel_size):
"""Applies a Gaussian Noise kernel"""
return cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)
def region_of_interest(img, vertices):
"""
Applies an image mask.
Only keeps the region of the image defined by the polygon
formed from `vertices`. The rest of the image is set to black.
`vertices` should be a numpy array of integer points.
"""
#defining a blank mask to start with
mask = np.zeros_like(img)
#defining a 3 channel or 1 channel color to fill the mask with depending on the input image
if len(img.shape) > 2:
channel_count = img.shape[2] # i.e. 3 or 4 depending on your image
ignore_mask_color = (255,) * channel_count
else:
ignore_mask_color = 255
#filling pixels inside the polygon defined by "vertices" with the fill color
cv2.fillPoly(mask, vertices, ignore_mask_color)
#returning the image only where mask pixels are nonzero
masked_image = cv2.bitwise_and(img, mask)
return masked_image
def draw_lines(img, lines, color=[255, 0, 0], thickness=5):
"""
NOTE: this is the function you might want to use as a starting point once you want to
average/extrapolate the line segments you detect to map out the full
extent of the lane (going from the result shown in raw-lines-example.mp4
to that shown in P1_example.mp4).
Think about things like separating line segments by their
slope ((y2-y1)/(x2-x1)) to decide which segments are part of the left
line vs. the right line. Then, you can average the position of each of
the lines and extrapolate to the top and bottom of the lane.
This function draws `lines` with `color` and `thickness`.
Lines are drawn on the image inplace (mutates the image).
If you want to make the lines semi-transparent, think about combining
this function with the weighted_img() function below
"""
'''
for line in lines:
for x1,y1,x2,y2 in line:
cv2.line(img, (x1, y1), (x2, y2), color, thickness)
'''
leftSlope = np.zeros(0)
leftLength = np.zeros(0)
leftXCenter = np.zeros(0)
leftYCenter = np.zeros(0)
rightSlope = np.zeros(0)
rightLength = np.zeros(0)
rightXCenter = np.zeros(0)
rightYCenter = np.zeros(0)
MinY = 450
MaxY = img.shape[0]-1
for line in lines:
for x1,y1,x2,y2 in line:
if x2-x1:
slope = (y2-y1)/(x2-x1)
length = ((x2-x1)**2+(y2-y1)**2)**(0.5)
xCenter = (x2+x1)/2
yCenter = (y2+y1)/2
if slope >= 0.2:
rightSlope = np.append(rightSlope, slope)
rightLength = np.append(rightLength, length)
rightXCenter = np.append(rightXCenter, xCenter)
rightYCenter = np.append(rightYCenter, yCenter)
elif slope <= -0.2:
leftSlope = np.append(leftSlope, slope)
leftLength = np.append(leftLength, length)
leftXCenter = np.append(leftXCenter, xCenter)
leftYCenter = np.append(leftYCenter, yCenter)
leftSlopeAvg = np.average(leftSlope, weights=leftLength)
leftXCenterAvg = np.average(leftXCenter, weights=leftLength)
leftYCenterAvg = np.average(leftYCenter, weights=leftLength)
rightSlopeAvg = np.average(rightSlope, weights=rightLength)
rightXCenterAvg = np.average(rightXCenter, weights=rightLength)
rightYCenterAvg = np.average(rightYCenter, weights=rightLength)
xleft1 = leftXCenterAvg - (leftYCenterAvg-MinY)/leftSlopeAvg
xleft2 = leftXCenterAvg - (leftYCenterAvg-MaxY)/leftSlopeAvg
xright1 = rightXCenterAvg - (rightYCenterAvg-MinY)/rightSlopeAvg
xright2 = rightXCenterAvg - (rightYCenterAvg-MaxY)/rightSlopeAvg
cv2.line(img, (int(round(xleft1)), MinY), (int(round(xleft2)), MaxY), color, thickness)
cv2.line(img, (int(round(xright1)), MinY), (int(round(xright2)), MaxY), color, thickness)
def hough_lines(img, rho, theta, threshold, min_line_len, max_line_gap):
"""
`img` should be the output of a Canny transform.
Returns an image with hough lines drawn.
"""
lines = cv2.HoughLinesP(img, rho, theta, threshold, np.array([]), minLineLength=min_line_len, maxLineGap=max_line_gap)
line_img = np.zeros((img.shape[0], img.shape[1], 3), dtype=np.uint8)
draw_lines(line_img, lines)
return line_img
# Python 3 has support for cool math symbols.
def weighted_img(img, initial_img, α=0.8, β=1., γ=0.):
"""
`img` is the output of the hough_lines(), An image with lines drawn on it.
Should be a blank image (all black) with lines drawn on it.
`initial_img` should be the image before any processing.
The result image is computed as follows:
initial_img * α + img * β + γ
NOTE: initial_img and img must be the same shape!
"""
return cv2.addWeighted(initial_img, α, img, β, γ)
def to_hls(img):
return cv2.cvtColor(img, cv2.COLOR_RGB2HLS)
# Image should have already been converted to HLS color space
def isolate_yellow_hls(img):
# Caution - OpenCV encodes the data in ****HLS*** format
# Lower value equivalent pure HSL is (30, 45, 15)
low_threshold = np.array([15, 38, 115], dtype=np.uint8)
# Higher value equivalent pure HSL is (75, 100, 80)
high_threshold = np.array([35, 204, 255], dtype=np.uint8)
yellow_mask = cv2.inRange(img, low_threshold, high_threshold)
return yellow_mask
# Image should have already been converted to HLS color space
def isolate_white_hls(img):
# Caution - OpenCV encodes the data in ***HLS*** format
# Lower value equivalent pure HSL is (30, 45, 15)
low_threshold = np.array([0, 200, 0], dtype=np.uint8)
# Higher value equivalent pure HSL is (360, 100, 100)
high_threshold = np.array([180, 255, 255], dtype=np.uint8)
white_mask = cv2.inRange(img, low_threshold, high_threshold)
return white_mask
def combine_hsl_isolated_with_original(img, hsl_yellow, hsl_white):
hsl_mask = cv2.bitwise_or(hsl_yellow, hsl_white)
return cv2.bitwise_and(img, img, mask=hsl_mask)
def filter_img_hls(img):
hls_img = to_hls(img)
hls_yellow = isolate_yellow_hls(hls_img)
hls_white = isolate_white_hls(hls_img)
return combine_hsl_isolated_with_original(img, hls_yellow, hls_white)
```
## Test Images
Build your pipeline to work on the images in the directory "test_images"
**You should make sure your pipeline works well on these images before you try the videos.**
```
import os
os.listdir("test_images/")
```
## Build a Lane Finding Pipeline
Build the pipeline and run your solution on all test_images. Make copies into the `test_images_output` directory, and you can use the images in your writeup report.
Try tuning the various parameters, especially the low and high Canny thresholds as well as the Hough lines parameters.
```
# TODO: Build your pipeline that will draw lane lines on the test_images
# then save them to the test_images_output directory.
image = cv2.imread('test_images/solidYellowCurve2.jpg')
kernel_size = 3
low_threshold = 50
high_threshold = 150
imshape = image.shape
vertices = np.array([[(0,imshape[0]),(460, 320), (495, 320), (imshape[1],imshape[0])]], dtype=np.int32)
rho = 1
theta = np.pi/180
threshold = 15
min_line_len = 20
max_line_gap = 10
#rgbTemp = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
#hlsTemp = filter_img_hls(rgbTemp)
#plt.imshow(hlsTemp)
# Convert to Gray Scale
grayImg = grayscale(image)
# Apply Gaussian Blur
blurGrayImg = gaussian_blur(grayImg, kernel_size)
# Canny Edge Detection
edges = canny(blurGrayImg, low_threshold, high_threshold)
# Select Region of Interest and mask others out
maskedEdges = region_of_interest(edges, vertices)
# Hough Line Detection
lineImg = hough_lines(maskedEdges, rho, theta, threshold, min_line_len, max_line_gap)
resultImg = weighted_img(lineImg, image, α=1, β=0.5, γ=0.)
print('This image is:', type(resultImg), 'with dimensions:', resultImg.shape)
rgbImg = cv2.cvtColor(resultImg, cv2.COLOR_BGR2RGB)
plt.imshow(rgbImg)
cv2.imwrite('test_images_output/test.jpg', resultImg)
```
## Test on Videos
You know what's cooler than drawing lanes over images? Drawing lanes over video!
We can test our solution on two provided videos:
`solidWhiteRight.mp4`
`solidYellowLeft.mp4`
**Note: if you get an import error when you run the next cell, try changing your kernel (select the Kernel menu above --> Change Kernel). Still have problems? Try relaunching Jupyter Notebook from the terminal prompt. Also, consult the forums for more troubleshooting tips.**
**If you get an error that looks like this:**
```
NeedDownloadError: Need ffmpeg exe.
You can download it by calling:
imageio.plugins.ffmpeg.download()
```
**Follow the instructions in the error message and check out [this forum post](https://discussions.udacity.com/t/project-error-of-test-on-videos/274082) for more troubleshooting tips across operating systems.**
```
# Import everything needed to edit/save/watch video clips
from moviepy.editor import VideoFileClip
from IPython.display import HTML
def process_image(image):
# NOTE: The output you return should be a color image (3 channel) for processing video below
# TODO: put your pipeline here,
# you should return the final output (image where lines are drawn on lanes)
kernel_size = 5
low_threshold = 50
high_threshold = 150
imshape = image.shape
# vertices = np.array([[(100,imshape[0]),(450, 330), (500, 330), (imshape[1],imshape[0])]], dtype=np.int32)
vertices = np.array([[(200,imshape[0]),(580, 450), (760, 450), (imshape[1],imshape[0])]], dtype=np.int32)
rho = 1
theta = np.pi/180
threshold = 15
min_line_len = 15
max_line_gap = 10
# Convert to Gray Scale directly
grayImg = grayscale(image)
# Convert to HLS Scale for challenge
# hlsImg = filter_img_hls(image)
# Convert to Gray Scale
# grayImg = grayscale(hlsImg)
# Apply Gaussian Blur
blurGrayImg = gaussian_blur(grayImg, kernel_size)
# Canny Edge Detection
edges = canny(blurGrayImg, low_threshold, high_threshold)
# Select Region of Interest and mask others out
maskedEdges = region_of_interest(edges, vertices)
# Hough Line Detection
lineImg = hough_lines(maskedEdges, rho, theta, threshold, min_line_len, max_line_gap)
result = weighted_img(lineImg, image, α=0.8, β=1, γ=0.)
return result
```
Let's try the one with the solid white lane on the right first ...
```
white_output = 'test_videos_output/solidWhiteRight.mp4'
## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video
## To do so add .subclip(start_second,end_second) to the end of the line below
## Where start_second and end_second are integer values representing the start and end of the subclip
## You may also uncomment the following line for a subclip of the first 5 seconds
##clip1 = VideoFileClip("test_videos/solidWhiteRight.mp4").subclip(0,5)
clip1 = VideoFileClip("test_videos/solidWhiteRight.mp4")
white_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!!
%time white_clip.write_videofile(white_output, audio=False)
```
Play the video inline, or if you prefer find the video in your filesystem (should be in the same directory) and play it in your video player of choice.
```
HTML("""
<video width="960" height="540" controls>
<source src="{0}">
</video>
""".format(white_output))
```
## Improve the draw_lines() function
**At this point, if you were successful with making the pipeline and tuning parameters, you probably have the Hough line segments drawn onto the road, but what about identifying the full extent of the lane and marking it clearly as in the example video (P1_example.mp4)? Think about defining a line to run the full length of the visible lane based on the line segments you identified with the Hough Transform. As mentioned previously, try to average and/or extrapolate the line segments you've detected to map out the full extent of the lane lines. You can see an example of the result you're going for in the video "P1_example.mp4".**
**Go back and modify your draw_lines function accordingly and try re-running your pipeline. The new output should draw a single, solid line over the left lane line and a single, solid line over the right lane line. The lines should start from the bottom of the image and extend out to the top of the region of interest.**
Now for the one with the solid yellow lane on the left. This one's more tricky!
```
yellow_output = 'test_videos_output/solidYellowLeft.mp4'
## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video
## To do so add .subclip(start_second,end_second) to the end of the line below
## Where start_second and end_second are integer values representing the start and end of the subclip
## You may also uncomment the following line for a subclip of the first 5 seconds
##clip2 = VideoFileClip('test_videos/solidYellowLeft.mp4').subclip(0,5)
clip2 = VideoFileClip('test_videos/solidYellowLeft.mp4')
yellow_clip = clip2.fl_image(process_image)
%time yellow_clip.write_videofile(yellow_output, audio=False)
HTML("""
<video width="960" height="540" controls>
<source src="{0}">
</video>
""".format(yellow_output))
```
## Writeup and Submission
If you're satisfied with your video outputs, it's time to make the report writeup in a pdf or markdown file. Once you have this Ipython notebook ready along with the writeup, it's time to submit for review! Here is a [link](https://github.com/udacity/CarND-LaneLines-P1/blob/master/writeup_template.md) to the writeup template file.
## Optional Challenge
Try your lane finding pipeline on the video below. Does it still work? Can you figure out a way to make it more robust? If you're up for the challenge, modify your pipeline so it works with this video and submit it along with the rest of your project!
```
challenge_output = 'test_videos_output/challenge.mp4'
## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video
## To do so add .subclip(start_second,end_second) to the end of the line below
## Where start_second and end_second are integer values representing the start and end of the subclip
## You may also uncomment the following line for a subclip of the first 5 seconds
##clip3 = VideoFileClip('test_videos/challenge.mp4').subclip(0,5)
clip3 = VideoFileClip('test_videos/challenge.mp4')
challenge_clip = clip3.fl_image(process_image)
%time challenge_clip.write_videofile(challenge_output, audio=False)
HTML("""
<video width="960" height="540" controls>
<source src="{0}">
</video>
""".format(challenge_output))
```
| github_jupyter |
```
# default_exp cli
#hide
from nbdev.showdoc import *
#export
from dash_oop_components.core import *
#export
import os
import webbrowser
from pathlib import Path
import click
```
# dashapp CLI
> a simple way of launching dashboards directly from the commandline
With `dash_oop_components` you can easily dump the configuration for a `dash` dashboard to a configuration `.yaml` file. Along with the library a `dashapp` command line tool (CLI) gets installed to make it easy to directly launch a dashboard from the commandline.
This is useful for when:
- you quickly want to launch a dashboard without starting python or jupyter, or finding the correct gunicorn config
- you want to instruct others how to easily launch your dashboard without messing around with python or gunicorn
## `dashapp` command line tool
You first need to store your dash app to a config yaml file using e.g
```python
db = DashApp(dashboard_component, port=8000, querystrings=True, bootstrap=True)
db.to_yaml("dashboard.yaml")
```
You can then run the app directly from the commandline and have it opened in a browser:
```sh
$ dashapp dashboard.yaml
```
To try loading the figure factory from pickle, add the `--try-pickles` flag:
```sh
$ dashapp --try-pickles dashboard.yaml
```
You can also store a `DashComponent` and run it from the command-line, by saving it to yaml:
```python
dashboard_component = CovidDashboard(plot_factory)
dashboard_component.to_yaml("dashboard_component.yaml")
```
And running it:
```sh
$ dashapp dashboard_component.yaml
```
To include the bootstrap css and store parameters in url querystring and set port to 9000:
```sh
$ dashapp dashboard_component.yaml --querystrings --bootstrap --port 9000
```
If you follow the naming convention of storing the yaml to `dashboard.yaml`,
or `dashboard_component.yaml`, you can omit the argument and simply run:
```sh
$ dashapp
```
```
Options:
-nb, --no-browser Launch a dashboard, but do not launch a browser.
-tp, --try-pickles if DashFigureFactory parameter config has filepath
defined, try to load it from pickle.
-fp, --force-pickles if DashFigureFactory parameter config has filepath
defined, load it from pickle or raise exception.
-q, --querystrings Store state in url querystring
-b, --bootstrap include default bootstrap css
-p, --port INTEGER specific port to run dashboard on
--help Show this message and exit.
```
```
#export
@click.command()
@click.argument("dashboard_yaml", nargs=1, required=False)
@click.option("--no-browser", "-nb", "no_browser", is_flag=True,
help="Launch a dashboard, but do not launch a browser.")
@click.option("--try-pickles", "-tp", "try_pickles", is_flag=True,
help="if DashFigureFactory parameter config has filepath defined, try to load it from pickle.")
@click.option("--force-pickles", "-fp", "force_pickles", is_flag=True,
help="if DashFigureFactory parameter config has filepath defined, load it from pickle or raise exception.")
@click.option("--querystrings", "-q", "querystrings", is_flag=True,
help="Store state in url querystring")
@click.option("--bootstrap", "-b", "bootstrap", is_flag=True,
help="include default bootstrap css")
@click.option("--port", "-p", "port", default=None, type=click.INT,
help="specific port to run dashboard on")
def dashapp(dashboard_yaml, no_browser, try_pickles, force_pickles, querystrings, bootstrap, port):
"""
dashapp is a CLI tool from the dash_oop_components library, used to launch a dash app from the commandline.
You first need to store your dash app to a config yaml file using e.g
\b
db = DashApp(dashboard_component, port=8000)
db.to_yaml("dashboard.yaml")
\b
You can then run the app directly from the commandline with and open it in a browser:
$ dashapp dashboard.yaml
or try the load figure factory from pickle:
$ dashapp --try-pickles dashboard.yaml
You can also store and run a DashComponent, by saving it to yaml:
\b
dashboard_component = CovidDashboard(plot_factory)
dashboard_component.to_yaml("dashboard_component.yaml")
And running it:
$ dashapp dashboard_component.yaml
To include the bootstrap css and store parameters in url querystring:
$ dashapp dashboard_component.yaml --querystrings --bootstrap
If you follow the naming convention of storing the yaml to `dashboard.yaml`,
or `dashboard_component.yaml`, you can omit the argument and simply run:
$ dashapp
"""
if dashboard_yaml is None:
if (Path().cwd() / "dashboard.yaml").exists():
dashboard_yaml = Path().cwd() / "dashboard.yaml"
elif (Path().cwd() / "dashboard_component.yaml").exists():
dashboard_yaml = Path().cwd() / "dashboard_component.yaml"
else:
click.echo("No argument given and could find neither a "
"default filename dashboard.yaml or dashboard_component.yaml."
"Try `dashapp --help` for options. Aborting.")
return
if not str(dashboard_yaml).endswith(".yaml"):
click.echo("you need to pass a .yaml file to start a dashboard! Aborting.")
return
kwargs = {}
if try_pickles: kwargs["try_pickles"] = True
if force_pickles: kwargs["force_pickles"] = True
dashboard_component = DashComponentBase.from_yaml(dashboard_yaml, **kwargs)
if isinstance(dashboard_component, DashApp):
db = dashboard_component
elif isinstance(dashboard_component, DashComponent):
db_kwargs = {}
if querystrings: db_kwargs["querystrings"] = True
if bootstrap: db_kwargs["bootstrap"] = True
db = DashApp(dashboard_component, **db_kwargs)
if port is None:
port = db.port
if port is None:
port = 8050
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(2)
result = sock.connect_ex(('127.0.0.1',port))
if result == 0:
click.echo(f"dashapp ===> Port {port} already in use! Please override with e.g. --port {port+1}")
return
if not no_browser and not os.environ.get("WERKZEUG_RUN_MAIN"):
click.echo(f"explainerdashboard ===> launching browser at {f'http://localhost:{port}/'}")
webbrowser.open_new(f"http://localhost:{port}/")
click.echo(f"dashapp ===> Starting dashboard:")
db.run(port)
```
| github_jupyter |
# Bag of Tricks Experiment
Analyze the effects of our different "tricks".
1. Sample matches off mask
2. Scale by hard negatives
3. L2 pixel loss on matches
We will compare standard network, networks missing one trick only, and a network without any tricks (i.e same as Tanner Schmidt)
```
import dense_correspondence_manipulation.utils.utils as utils
utils.add_dense_correspondence_to_python_path()
from dense_correspondence.training.training import *
import sys
import logging
# utils.set_default_cuda_visible_devices()
utils.set_cuda_visible_devices([0]) # use this to manually set CUDA_VISIBLE_DEVICES
from dense_correspondence.training.training import DenseCorrespondenceTraining
from dense_correspondence.dataset.spartan_dataset_masked import SpartanDataset
logging.basicConfig(level=logging.INFO)
dataset_config_filename = os.path.join(utils.getDenseCorrespondenceSourceDir(), 'config', 'dense_correspondence',
'dataset', 'composite', "caterpillar_baymax_starbot_all_front_single_only.yaml")
train_config_file = os.path.join(utils.getDenseCorrespondenceSourceDir(), 'config', 'dense_correspondence',
'training', 'training.yaml')
logging_dir = "code/data_volume/pdc/trained_models/trick_analysis"
num_iterations = 3500
num_image_pairs = 100
debug = False
TRAIN = True
EVALUATE = True
# num_image_pairs = 10
# num_iterations = 10
d = 3
network_dict = dict()
```
## Standard
```
dataset_config = utils.getDictFromYamlFilename(dataset_config_filename)
dataset = SpartanDataset(config=dataset_config)
train_config = utils.getDictFromYamlFilename(train_config_file)
name = "standard_%d" %(d)
print "training %s" %(name)
train_config = utils.getDictFromYamlFilename(train_config_file)
train = DenseCorrespondenceTraining(dataset=dataset, config=train_config)
train._config["training"]["logging_dir"] = logging_dir
train._config["training"]["logging_dir_name"] = name
train._config["training"]["num_iterations"] = num_iterations
train._config["dense_correspondence_network"]["descriptor_dimension"] = d
if TRAIN:
train.run()
print "finished training descriptor of dimension %d" %(d)
# now do evaluation
print "running evaluation on network %s" %(name)
model_folder = os.path.join(logging_dir, name)
model_folder = utils.convert_to_absolute_path(model_folder)
network_dict[name] = model_folder
if EVALUATE:
DCE = DenseCorrespondenceEvaluation
DCE.run_evaluation_on_network(model_folder, num_image_pairs=num_image_pairs)
print "finished running evaluation on network %s" %(name)
```
## With L2 on masked non_matches
```
dataset_config = utils.getDictFromYamlFilename(dataset_config_filename)
dataset = SpartanDataset(config=dataset_config)
train_config = utils.getDictFromYamlFilename(train_config_file)
name = "l2_masked_%d" %(d)
print "training %s" %(name)
train_config = utils.getDictFromYamlFilename(train_config_file)
train = DenseCorrespondenceTraining(dataset=dataset, config=train_config)
train._config["training"]["logging_dir"] = logging_dir
train._config["training"]["logging_dir_name"] = name
train._config["training"]["num_iterations"] = num_iterations
train._config["dense_correspondence_network"]["descriptor_dimension"] = d
train._config["loss_function"]["use_l2_pixel_loss_on_masked_non_matches"] = True
if TRAIN:
train.run()
print "finished training descriptor of dimension %d" %(d)
# now do evaluation
print "running evaluation on network %s" %(name)
model_folder = os.path.join(logging_dir, name)
model_folder = utils.convert_to_absolute_path(model_folder)
network_dict[name] = model_folder
if EVALUATE:
DCE = DenseCorrespondenceEvaluation
DCE.run_evaluation_on_network(model_folder, num_image_pairs=num_image_pairs)
print "finished running evaluation on network %s" %(name)
```
## Dont scale by hard negatives
```
dataset_config = utils.getDictFromYamlFilename(dataset_config_filename)
dataset = SpartanDataset(config=dataset_config)
train_config = utils.getDictFromYamlFilename(train_config_file)
name = "dont_scale_hard_negatives_%d" %(d)
print "training %s" %(name)
train_config = utils.getDictFromYamlFilename(train_config_file)
train = DenseCorrespondenceTraining(dataset=dataset, config=train_config)
train._config["training"]["logging_dir"] = logging_dir
train._config["training"]["logging_dir_name"] = name
train._config["training"]["num_iterations"] = num_iterations
train._config["dense_correspondence_network"]["descriptor_dimension"] = d
train._config["loss_function"]["scale_by_hard_negatives"] = False
if TRAIN:
train.run()
print "finished training descriptor of dimension %d" %(d)
# now do evaluation
print "running evaluation on network %s" %(name)
model_folder = os.path.join(logging_dir, name)
model_folder = utils.convert_to_absolute_path(model_folder)
network_dict[name] = model_folder
if EVALUATE:
DCE = DenseCorrespondenceEvaluation
DCE.run_evaluation_on_network(model_folder, num_image_pairs=num_image_pairs)
print "finished running evaluation on network %s" %(name)
```
## Dont sample off mask
```
dataset_config = utils.getDictFromYamlFilename(dataset_config_filename)
dataset = SpartanDataset(config=dataset_config)
train_config = utils.getDictFromYamlFilename(train_config_file)
name = "dont_sample_from_mask_%d" %(d)
print "training %s" %(name)
train_config = utils.getDictFromYamlFilename(train_config_file)
train = DenseCorrespondenceTraining(dataset=dataset, config=train_config)
train._config["training"]["logging_dir"] = logging_dir
train._config["training"]["logging_dir_name"] = name
train._config["training"]["num_iterations"] = num_iterations
train._config["dense_correspondence_network"]["descriptor_dimension"] = d
train._config["training"]["sample_matches_only_off_mask"] = False
train._config["training"]["use_image_b_mask_inv"] = False
train._config["training"]["fraction_masked_non_matches"] = 0.01
train._config["training"]["fraction_background_non_matches"] = 0.99
if TRAIN:
train.run()
print "finished training descriptor of dimension %d" %(d)
# now do evaluation
print "running evaluation on network %s" %(name)
model_folder = os.path.join(logging_dir, name)
model_folder = utils.convert_to_absolute_path(model_folder)
network_dict[name] = model_folder
if EVALUATE:
DCE = DenseCorrespondenceEvaluation
DCE.run_evaluation_on_network(model_folder, num_image_pairs=num_image_pairs)
print "finished running evaluation on network %s" %(name)
```
## No tricks
```
dataset_config = utils.getDictFromYamlFilename(dataset_config_filename)
dataset = SpartanDataset(config=dataset_config)
train_config = utils.getDictFromYamlFilename(train_config_file)
name = "no_tricks_%d" %(d)
print "training %s" %(name)
train = DenseCorrespondenceTraining(dataset=dataset, config=train_config)
train_config = utils.getDictFromYamlFilename(train_config_file)
train._config["training"]["logging_dir"] = logging_dir
train._config["training"]["logging_dir_name"] = name
train._config["training"]["num_iterations"] = num_iterations
train._config["dense_correspondence_network"]["descriptor_dimension"] = d
train._config["loss_function"]["scale_by_hard_negatives"] = False
train._config["loss_function"]["use_l2_pixel_loss_on_masked_non_matches"] = False
train._config["training"]["sample_matches_only_off_mask"] = False
train._config["training"]["use_image_b_mask_inv"] = False
train._config["training"]["fraction_masked_non_matches"] = 0.01
train._config["training"]["fraction_background_non_matches"] = 0.99
if TRAIN:
train.run()
print "finished training descriptor of dimension %d" %(d)
# now do evaluation
print "running evaluation on network %s" %(name)
model_folder = os.path.join(logging_dir, name)
model_folder = utils.convert_to_absolute_path(model_folder)
network_dict[name] = model_folder
if EVALUATE:
DCE = DenseCorrespondenceEvaluation
DCE.run_evaluation_on_network(model_folder, num_image_pairs=num_image_pairs)
print "finished running evaluation on network %s" %(name)
```
## L2 and dont scale hard negatives
```
dataset_config = utils.getDictFromYamlFilename(dataset_config_filename)
dataset = SpartanDataset(config=dataset_config)
train_config = utils.getDictFromYamlFilename(train_config_file)
name = "l2_dont_scale_hard_negatives_run_2_%d" %(d)
print "training %s" %(name)
train_config = utils.getDictFromYamlFilename(train_config_file)
train = DenseCorrespondenceTraining(dataset=dataset, config=train_config)
train._config["training"]["logging_dir"] = logging_dir
train._config["training"]["logging_dir_name"] = name
train._config["training"]["num_iterations"] = num_iterations
train._config["dense_correspondence_network"]["descriptor_dimension"] = d
train._config["loss_function"]["scale_by_hard_negatives"] = False
train._config["loss_function"]["use_l2_pixel_loss_on_masked_non_matches"] = True
if TRAIN:
train.run()
print "finished training descriptor of dimension %d" %(d)
# now do evaluation
print "running evaluation on network %s" %(name)
model_folder = os.path.join(logging_dir, name)
model_folder = utils.convert_to_absolute_path(model_folder)
network_dict[name] = model_folder
if EVALUATE:
DCE = DenseCorrespondenceEvaluation
DCE.run_evaluation_on_network(model_folder, num_image_pairs=num_image_pairs)
print "finished running evaluation on network %s" %(name)
```
| github_jupyter |
# Solar Production Data Analysis
## Objective
This notebook will analysis solar production data using the data science lifecyce outlined here: link
https://docs.google.com/document/d/1gKr6j7s02hjilNhqYrjDK7t6jqR092hzezn-MB09EZo/edit#heading=h.mbjsiz6n6jlo
## Contents:
1. Business Understanding
2. Data Understanding
3. Data Preparation
4. Modeling
5. Evaluation
6. Deployment
python version: 3.9.0
requirements:
see imports
## 1 Business Understanding
### Sections
#### 1.1 Question Definition
First, define your question(s) of interest from a business perspective.
#### 1.2 Success Criteria
What is the goal of the project you propose, and what are the criteria for a successful or useful outcome? Assess the situation, including resources, constraints, assumptions, requirements.
#### 1.3 Statistical Criteria
Then, translate business objective(s) and metric(s) for success to data mining goals. If the business goal is to increase sales, the data mining goal might be to predict variance in sales based on advertising money spent, production costs, etc.
#### 1.4 Project Plan
Finally, produce a project plan specifying the steps to be taken throughout the rest of the project, including initial assessment of tools and techniques, durations, dependencies, etc.
What is the goal of this project?
What are the criteria for a successful outcome?
Business goals are:
What will the production be of a new system?
What will the performance be of a new system?
Other questions to answer if time permits:
What is the quality of the data?
understand the fleet better - how many systems, when were they installed
indentify and predict poor performance?
how might we improve performance?
Can we predict future production?
## 1.1 Question Definition
First, define your question(s) of interest from a business perspective.
```
"""
Solar systems convert light energy from the sun to electricity. The amount of electricity produced is called "production" and the amount of electricity produced in reality compared to expectation is called "performance".
A commercial and residential solar installer is interested to learn if they can predict the production and performance of a new solar system.
They have provided data on the production and performance of their fleet with the hopes that it can be used as training data for a model.
Among other things, the model and analysis should tell them basic information, like growth of their fleet, average performance, and top performing systems, but also advanced statistics, like if the financial company is correlated to performance, which months are the best to install a new system, and what is the best estimation for annual degradation.
"""
```
## 1.2 Success Criteria
What is the goal of the project you propose, and what are the criteria for a successful or useful outcome? Assess the situation, including resources, constraints, assumptions, requirements.
#### 1.2.1 Goal
#### 1.2.2 Criteria for success
#### 1.2.3 Resources
#### 1.2.4 Constraints
#### 1.2.5 Assumptions
#### 1.2.6 Requirements
## 1.3 Statistical Criteria
Then, translate business objective(s) and metric(s) for success to data mining goals. If the business goal is to increase sales, the data mining goal might be to predict variance in sales based on advertising money spent, production costs, etc.
## Load Data
```
df = pd.import_data()
```
## 2 Data Understanding
### 2.1 List all datasets required
Collect initial data and list all datasets acquired, locations, methods of acquisition, and any problems encountered.
### 2.2 Gross properties of the data
Describe the gross properties of the data, including its format, shape, field identities, etc.
### 2.3 Feature Analysis
Explore key attributes, simple statistics, visualizations. Identify potential relationships and interesting data characteristics to inform initial hypotheses.
#### 2.3.1 Portfolio
#### 2.3.2 Holding Co
#### 2.3.3 Project Co
#### 2.3.4 Contract id
#### 2.3.5 Date
#### 2.3.6 Production
### 2.4 Summary on Data Quality
In this section, I'll examine the quality of the data, e.g. completeness, consistency, formatting, and report any potential problems and solutions.
# 3 Data Preparation
## 3.1 Feature Selection
Determine which data will be used (selection of attributes/columns and observations/rows) and document reasons for inclusion or exclusion.
## 3.2 Data Cleaning
Clean the data and describe actions taken. Techniques could include selection of subsets for examination, insertion of defaults or estimations using modelling for missing values. Note outliers/anomalies and potential impacts of these transformations on analysis results.
## 3.3 Feature Engineering
It may be useful to derive new attributes from the data as combinations of existing attributes, and describe their creation. It may also be useful to merge or aggregate datasets, in which case you should be careful of duplicate values.
## 3.4 Data Reformating
Finally, re-format the data as necessary (e.g. shuffling the order of inputs to a neural network or making syntactic changes like trimming field lengths).
# 4 Modelling
## 4.1 Model Selection
Select and document any modeling techniques to be used (regression, decision tree, neural network) along with assumptions made (uniform distribution, data type).
## 4.2 Test Design
Before building the model, generate test design - will you need to split your data (e.g. into training, test, and validation sets), and if so, how?
## 4.3 Parameter tuning
Next, run the selected modeling tool(s) on your data, list parameters used with justifications, and describe and interpret resulting models.
## 4.4 Model Evaluation
Generally, you want to run different models with different parameters, then compare the results across the evaluation criteria established in earlier steps. Assess the quality or accuracy of each model, revise and tune iteratively.
# 5 Evaluation
## 5.1 Results
Summarize the results of the previous step in business terms - how well were your business objective(s) met? Models that meet business success criteria become approved models.
## 5.2 Summary
After selecting appropriate models, review the work accomplished. Make sure models were correctly built, no important factors or tasks were overlooked, and all data are accessible/replicable for future analyses.
## 5.3 Next Steps
Depending on assessed results, decide next steps, whether to move on to deployment, initiate further iterations, or move on to new data mining projects.
# 6 Deployment
## 6.1 Deployment Plan
Develop a plan for deploying relevant model(s).
## 6.2 Monitoring Plan
Further develop a monitoring and maintenance plan to ensure correct usage of data mining results and avoid issues during the operational phase of model(s).
## 6.3 Conduct Retrospective
Summarize results, conclusions and deliverables. Conduct any necessary retrospective analysis of what went well, what could be improved, and general experience documentation.
| github_jupyter |
```
for row in range(5):
for col in range(5):
if (col==2)or(row==4)or(row==1and col==1):
print("*",end=" ")
else:
print(" ",end=" ")
print()
for row in range(5):
for col in range(5):
if (row==0 and col==3)or(row==1 and col==2)or(row==1 and col==4)or(row==2 and col==4)or(row==3 and col==2)or(row==4 and col==2)or(row==4 and col==3)or(row==4 and col==4):
print("*",end=" ")
else:
print(" ",end=" ")
print()
for row in range(5):
for col in range(5):
if row==0 or (row==4)or(row==2 and col==2)or(row==1 and col==3)or(row==3 and col==3):
print("*",end=" ")
else:
print(" ",end=" ")
print()
for row in range(7):
for col in range(5):
if (col==0 and row<=4)or(row==4)or(row==3 and col==2)or(row==2 and col==2)or(row==5 and col==2)or(row==6 and col==2):
print("*",end=" ")
else:
print(" ",end=" ")
print()
for row in range(7):
for col in range(5):
if (row==0)or(row==6)or(row==3 and(col>=0 and col<=5))or(row==1 and col==0)or(row==2 and col==0)or(row==4 and col==4)or(row==5 and col==4):
print("*",end=" ")
else:
print(" ",end=" ")
print()
for row in range(6):
for col in range(5):
if row==0 and col==3or(row==1 and col==2)or(row==2 and col==1)or(row==3 and col==0)or(row==4 and col==0)or(row==5 and col==1)or(row==5 and col==2)or(row==4 and col==3)or(row==3 and col==3)or(row==2 and col==2):
print("*",end=" ")
else:
print(" ",end=" ")
print()
for row in range(7):
for col in range(5):
if (row==0 ) or (col==4):
print("*",end=" ")
else:
print(" ",end=" ")
print()
for row in range(5):
for col in range(5):
if row==0 and (col==1 or col==2 or col==3)or(row==4 and (col==1 or col==2 or col==3))or(row==2 and (col==1 or col==2 or col==3))or(row==1 and col==0)or(row==1 and col==4)or(row==3 and col==0)or(row==3 and col==4):
print("*",end=" ")
else:
print(" ",end=" ")
print()
for row in range(7):
for col in range(5):
if (row==0 and col==3) or (row==1 and col==2)or(row==1 and col==4)or(row==2 and col==2)or(row==2 and col==4)or(row==3and col==3)or(row==4 and col==4)or(row==3 and col==4)or(row==5 and col==4)or(row==6 and col==3)or(row==5 and col==2):
print("*",end=" ")
else:
print(" ",end=" ")
print()
for row in range(4):
for col in range(4):
if row==0 and col==1 or (row==0 and col==2) or (row==1 and col==0) or (row==1 and col==3) or (row==2 and col==0) or (row==2 and col==3) or (row==3 and col==1) or (row==3 and col==2):
print("*", end=" ")
else:
print(" ",end=" ")
print()
```
| github_jupyter |
```
%load_ext autoreload
%autoreload 2
from pathlib import Path
from smtag.config import config
config
from transformers import __version__
__version__
```
## Download SourceData data
This takes a very long time! It advised to run this within a tmux session rather than in this notebook.
```
! python -m smtag.cli.prepo.get_sd # files saved in xml_destination_files
! # mv xml_destination_files/ data/xml/<name_of_source_data_compendium>
```
## Split dataset
```
from smtag.split import distribute
distribute(Path("data/xml/220304_sd"), ext="xml")
```
## Extracting examples for TOKCL
```
from smtag.extract import ExtractorXML
```
#### Dataset with individual panels
```
xml_panel_examples = "/data/text/220304_sd_panels"
! rm -fr /data/text/220304_panels_sd
extractor_tokcl = ExtractorXML(
"/data/xml/220304_sd",
destination_dir=xml_panel_examples,
sentence_level=False,
xpath=".//sd-panel",
keep_xml=True,
inclusion_probability=1.0
)
extractor_tokcl.extract_from_corpus()
```
same via CLI:
```bash
python -m smtag.cli.prepro.extract /data/xml/191012/ /data/text/sd_test --xpath ".//sd-panel" --sentence_level --keep_xml --inclusion_probability 1.0
```
#### Dataset with full figures (used for panelization training)
```
xml_figure_examples = "/data/text/220304_sd_fig"
! rm -fr "/data/text/220304_sd_fig"
extractor_tokcl_2 = ExtractorXML(
"/data/xml/220304_sd",
destination_dir=xml_figure_examples,
sentence_level=False,
xpath=".//fig",
keep_xml=True,
inclusion_probability=1.0
)
extractor_tokcl_2.extract_from_corpus()
```
## Preparing tokenized dataset for TOKCL
```
from smtag.dataprep import PreparatorTOKCL
from smtag.xml2labels import SourceDataCodes as sd
```
#### Tokenize panels
```
! rm -fr /data/json/220304_sd_panels
tokenized_panel_examples = "/data/json/220304_sd_panels"
code_maps: code_maps = [
sd.ENTITY_TYPES,
sd.GENEPROD_ROLES,
sd.SMALL_MOL_ROLES,
sd.BORING,
sd.PANELIZATION
]
prep_tokcl = PreparatorTOKCL(
xml_panel_examples,
tokenized_panel_examples,
code_maps,
max_length=config.max_length
)
prep_tokcl.run()
```
same vie CLI:
```bash
python -m smtag.cli.tokcl.dataprep /data/text/sd_test /data/json/sd_test
```
#### Tokenize figures
```
tokenized_figure_examples = "/data/json/220304_sd_fig"
code_maps: code_maps = [
sd.PANELIZATION
]
! rm -fr /data/json/220304_sd_fig
prep_tokcl_2 = PreparatorTOKCL(
xml_figure_examples,
tokenized_figure_examples,
code_maps,
max_length=config.max_length
)
prep_tokcl_2.run()
```
## Train model for TOKCL
```
from smtag.config import config
from smtag.train.train_tokcl import (
train as train_tokcl,
TrainingArgumentsTOKCL
)
training_args = TrainingArgumentsTOKCL(
logging_steps=50,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
)
loader_path = "./smtag/loader/loader_tokcl.py"
tokenizer = config.tokenizer
model_type = "Autoencoder"
from_pretrained = "EMBO/bio-lm" # "roberta-base" # specialized model from huggingface.co/embo # "roberta-base" # general lm model
```
Reload the datasets afresh (to prevent this behavior, set `no_cache` to `False`):
```
no_cache = True
! rm -fr /runs/*
! rm -fr /tokcl_models/*
```
### Train NER
```
training_args.overwrite_output_dir=False
training_args.num_train_epochs=0.6
training_args.prediction_loss_only=True
training_args.masking_probability=.0
training_args.replacement_probability=.0
training_args
train_tokcl(
training_args,
loader_path,
"NER",
tokenized_panel_examples,
no_cache,
tokenizer,
model_type,
from_pretrained
)
```
#### Train GENEPROD ROLES
```
training_args.num_train_epochs = 0.9
training_args.prediction_loss_only=True
training_args.masking_probability=1.
training_args.replacement_probability=.0
training_args
training_args.output_dir
train_tokcl(
training_args,
loader_path,
"GENEPROD_ROLES",
tokenized_panel_examples,
no_cache,
tokenizer,
model_type,
from_pretrained
)
```
### Train SMALL MOL ROLES
```
training_args.num_train_epochs = 0.33
training_args.prediction_loss_only=True
training_args.masking_probability=1.0
training_args.replacement_probability=.0
training_args
train_tokcl(
training_args,
loader_path,
"SMALL_MOL_ROLES",
tokenized_panel_examples,
no_cache,
tokenizer,
model_type,
from_pretrained
)
```
### Train PANELIZATION
```
training_args.num_train_epochs = 1.3
training_args.prediction_loss_only=True
training_args.masking_probability=.0
training_args.replacement_probability=.0
training_args.logging_steps=20
training_args
train_tokcl(
training_args,
loader_path,
"PANELIZATION",
tokenized_figure_examples, # Use Figure-level data here!
no_cache,
tokenizer,
model_type,
from_pretrained
)
! ls /tokcl_models/
```
### Alternative via CLI:
Useful for testing and debugging from within `tmux` session and `docker-compose exec nlp bash`
```bash
python -m smtag.cli.tokcl.train \
./smtag/loader/loader_tokcl.py \
PANELIZATION \
--data_dir /data/json/sd_test \
--num_train_epochs=1 \
--logging_steps=50 \
--per_device_train_batch_size=16 \
--per_device_eval_batch_size=16 \
--replacement_probability=0 \
--masking_probability=0 \
--model_type=Autoencoder \
--from_pretrained="EMBO/bio-lm"
```
## Try it!
```
from smtag.pipeline import SmartTagger
smarttagger = SmartTagger(
tokenizer_source="roberta-base",
panelizer_source="/tokcl_models/PANELIZATION",
ner_source="/tokcl_models/NER",
geneprod_roles_source="/tokcl_models/GENEPROD_ROLES",
small_mol_roles_source="/tokcl_models/SMALL_MOL_ROLES"
)
tags = smarttagger("This creb1-/- mutant mouse has a strange brain after aspirin treatment.")
print(tags)
```
With CLI:
python -m smtag.cli.inference.tag --local_model_dir /tokcl_models "This creb1-/- mutant mouse has a strange brain after aspirin treatment."
# Before sharing
Save the tokenizer in the respective model directories to enable inference
```
tokenizer.save_pretrained("/tokcl_models/NER")
tokenizer.save_pretrained("/tokcl_models/GENEPROD_ROLES")
tokenizer.save_pretrained("/tokcl_models/SMALL_MOL_ROLES")
tokenizer.save_pretrained("/tokcl_models/PANELIZATION")
!ls tokcl_models/NER
dir(tokenizer)
```
| github_jupyter |
# Calculate Shapley values
Shapley values as used in coalition game theory were introduced by William Shapley in 1953.
[Scott Lundberg](http://scottlundberg.com/) applied Shapley values for calculating feature importance in [2017](http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions.pdf).
If you want to read the paper, I recommend reading:
Abstract, 1 Introduction, 2 Additive Feature Attribution Methods, (skip 2.1, 2.2, 2.3), and 2.4 Classic Shapley Value Estimation.
Lundberg calls this feature importance method "SHAP", which stands for SHapley Additive exPlanations.
Here’s the formula for calculating Shapley values:
$ \phi_{i} = \sum_{S \subseteq M \setminus i} \frac{|S|! (|M| - |S| -1 )!}{|M|!} [f(S \cup i) - f(S)]$
A key part of this is the difference between the model’s prediction with the feature $i$, and the model’s prediction without feature $i$.
$S$ refers to a subset of features that doesn’t include the feature for which we're calculating $\phi_i$.
$S \cup i$ is the subset that includes features in $S$ plus feature $i$.
$S \subseteq M \setminus i$ in the $\Sigma$ symbol is saying, all sets $S$ that are subsets of the full set of features $M$, excluding feature $i$.
##### Options for your learning journey
* If you’re okay with just using this formula, you can skip ahead to the coding section below.
* If you would like an explanation for what this formula is doing, please continue reading here.
## Optional (explanation of this formula)
The part of the formula with the factorials calculates the number of ways to generate the collection of features, where order matters.
$\frac{|S|! (|M| - |S| -1 )!}{|M|!}$
#### Adding features to a Coalition
The following concepts come from coalition game theory, so when we say "coalition", think of it as a team, where members of the team are added, one after another, in a particular order.
Let’s imagine that we’re creating a coalition of features, by adding one feature at a time to the coalition, and including all $|M|$ features. Let’s say we have 3 features total. Here are all the possible ways that we can create this “coalition” of features.
<ol>
<li>$x_0,x_1,x_2$</li>
<li>$x_0,x_2,x_1$</li>
<li>$x_1,x_0,x_2$</li>
<li>$x_1,x_2,x_0$</li>
<li>$x_2,x_0,x_1$</li>
<li>$x_2,x_1,x_0$</li>
</ol>
Notice that for $|M| = 3$ features, there are $3! = 3 \times 2 \times 1 = 6$ possible ways to create the coalition.
#### marginal contribution of a feature
For each of the 6 ways to create a coalition, let's see how to calculate the marginal contribution of feature $x_2$.
<ol>
<li>Model’s prediction when it includes features 0,1,2, minus the model’s prediction when it includes only features 0 and 1.
$x_0,x_1,x_2$: $f(x_0,x_1,x_2) - f(x_0,x_1)$
<li>Model’s prediction when it includes features 0 and 2, minus the prediction when using only feature 0. Notice that feature 1 is added after feature 2, so it’s not included in the model.
$x_0,x_2,x_1$: $f(x_0,x_2) - f(x_0)$</li>
<li>Model's prediction including all three features, minus when the model is only given features 1 and 0.
$x_1,x_0,x_2$: $f(x_1,x_0,x_2) - f(x_1,x_0)$</li>
<li>Model's prediction when given features 1 and 2, minus when the model is only given feature 1.
$x_1,x_2,x_0$: $f(x_1,x_2) - f(x_1)$</li>
<li>Model’s prediction if it only uses feature 2, minus the model’s prediction if it has no features. When there are no features, the model’s prediction would be the average of the labels in the training data.
$x_2,x_0,x_1$: $f(x_2) - f( )$
</li>
<li>Model's prediction (same as the previous one)
$x_2,x_1,x_0$: $f(x_2) - f( )$
</li>
Notice that some of these marginal contribution calculations look the same. For example the first and third sequences, $f(x_0,x_1,x_2) - f(x_0,x_1)$ would get the same result as $f(x_1,x_0,x_2) - f(x_1,x_0)$. Same with the fifth and sixth. So we can use factorials to help us calculate the number of permutations that result in the same marginal contribution.
#### break into 2 parts
To get to the formula that we saw above, we can break up the sequence into two sections: the sequence of features before adding feature $i$; and the sequence of features that are added after feature $i$.
For the set of features that are added before feature $i$, we’ll call this set $S$. For the set of features that are added after feature $i$ is added, we’ll call this $Q$.
So, given the six sequences, and that feature $i$ is $x_2$ in this example, here’s what set $S$ and $Q$ are for each sequence:
<ol>
<li>$x_0,x_1,x_2$: $S$ = {0,1}, $Q$ = {}</li>
<li>$x_0,x_2,x_1$: $S$ = {0}, $Q$ = {1} </li>
<li>$x_1,x_0,x_2$: $S$ = {1,0}, $Q$ = {} </li>
<li>$x_1,x_2,x_0$: $S$ = {1}, $Q$ = {0} </li>
<li>$x_2,x_0,x_1$: $S$ = {}, $Q$ = {0,1} </li>
<li>$x_2,x_1,x_0$: $S$ = {}, $Q$ = {1,0} </li>
</ol>
So for the first and third sequences, these have the same set S = {0,1} and same set $Q$ = {}.
Another way to calculate that there are two of these sequences is to take $|S|! \times |Q|! = 2! \times 0! = 2$.
Similarly, the fifth and sixth sequences have the same set S = {} and Q = {0,1}.
Another way to calculate that there are two of these sequences is to take $|S|! \times |Q|! = 0! \times 2! = 2$.
#### And now, the original formula
To use the notation of the original formula, note that $|Q| = |M| - |S| - 1$.
Recall that to calculate that there are 6 total sequences, we can use $|M|! = 3! = 3 \times 2 \times 1 = 6$.
We’ll divide $|S|! \times (|M| - |S| - 1)!$ by $|M|!$ to get the proportion assigned to each marginal contribution.
This is the weight that will be applied to each marginal contribution, and the weights sum to 1.
So that’s how we get the formula:
$\frac{|S|! (|M| - |S| -1 )!}{|M|!} [f(S \cup i) - f(S)]$
for each set $S \subseteq M \setminus i$
We can sum up the weighted marginal contributions for all sets $S$, and this represents the importance of feature $i$.
You’ll get to practice this in code!
```
import sys
!{sys.executable} -m pip install numpy==1.14.5
!{sys.executable} -m pip install scikit-learn==0.19.1
!{sys.executable} -m pip install graphviz==0.9
!{sys.executable} -m pip install shap==0.25.2
import sklearn
import shap
import numpy as np
import graphviz
from math import factorial
```
## Generate input data and fit a tree model
We'll create data where features 0 and 1 form the "AND" operator, and feature 2 does not contribute to the prediction (because it's always zero).
```
# AND case (features 0 and 1)
N = 100
M = 3
X = np.zeros((N,M))
X.shape
y = np.zeros(N)
X[:1 * N//4, 1] = 1
X[:N//2, 0] = 1
X[N//2:3 * N//4, 1] = 1
y[:1 * N//4] = 1
# fit model
model = sklearn.tree.DecisionTreeRegressor(random_state=0)
model.fit(X, y)
# draw model
dot_data = sklearn.tree.export_graphviz(model, out_file=None, filled=True, rounded=True, special_characters=True)
graph = graphviz.Source(dot_data)
graph
```
### Calculate Shap values
We'll try to calculate the local feature importance of feature 0.
We have 3 features, $x_0, x_1, x_2$. For feature $x_0$, determine what the model predicts with or without $x_0$.
Subsets S that exclude feature $x_0$ are:
{}
{$x_1$}
{$x_2$}
{$x_1,x_2$}
We want to see what the model predicts with feature $x_0$ compared to the model without feature $x_0$:
$f(x_0) - f( )$
$f(x_0,x_1) - f(x_1)$
$f(x_0,x_2) - f(x_2)$
$f(x_0,x_1,x_2) - f(x_1,x_2)$
## Sample data point
We'll calculate the local feature importance of a sample data point, where
feature $x_0 = 1$
feature $x_1 = 1$
feature $x_2 = 1$
```
sample_values = np.array([1,1,1])
print(f"sample values to calculate local feature importance on: {sample_values}")
```
## helper function
To make things easier, we'll use a helper function that takes the entire feature set M, and also a list of the features (columns) that we want, and puts them together into a 2D array.
```
def get_subset(X, feature_l):
"""
Given a 2D array containing all feature columns,
and a list of integers representing which columns we want,
Return a 2D array with just the subset of features desired
"""
cols_l = []
for f in feature_l:
cols_l.append(X[:,f].reshape(-1,1))
return np.concatenate(cols_l, axis=1)
# try it out
tmp = get_subset(X,[0,2])
tmp[0:10]
```
## helper function to calculate permutation weight
This helper function calculates
$\frac{|S|! (|M| - |S| - 1)!}{|M|!}$
```
from math import factorial
def calc_weight(size_S, num_features):
return factorial(size_S) * factorial(num_features - size_S - 1) / factorial(num_features)
```
Try it out when size of S is 2 and there are 3 features total.
The answer should be equal to $\frac{2! \times (3-2-1)!}{3!} = \frac{2 \times 1}{6} = \frac{1}{3}$
```
calc_weight(size_S=2,num_features=3)
```
## case A
Calculate the prediction of a model that uses features 0 and 1
Calculate the prediction of a model that uses feature 1
Calculate the difference (the marginal contribution of feature 0)
$f(x_0,x_1) - f(x_1)$
#### Calculate $f(x_0,x_1)$
```
# S_union_i
S_union_i = get_subset(X,[0,1])
# fit model
f_S_union_i = sklearn.tree.DecisionTreeRegressor()
f_S_union_i.fit(S_union_i, y)
```
Remember, for the sample input for which we'll calculate feature importance, we chose values of 1 for all features.
```
# This will throw an error
try:
f_S_union_i.predict(np.array([1,1]))
except Exception as e:
print(e)
```
The error message says:
>Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
So we'll reshape the data so that it represents a sample (a row), which means it has 1 row and 1 or more columns.
```
# feature 0 and feature 1 are both 1 in the sample input
sample_input = np.array([1,1]).reshape(1,-1)
sample_input
```
The prediction of the model when it has features 0 and 1 is:
```
pred_S_union_i = f_S_union_i.predict(sample_input)
pred_S_union_i
```
When feature 0 and feature 1 are both 1, the prediction of the model is 1
#### Calculate $f(x_1)$
```
# S
S = get_subset(X,[1])
f_S = sklearn.tree.DecisionTreeRegressor()
f_S.fit(S, y)
```
The sample input for feature 1 is 1.
```
sample_input = np.array([1]).reshape(1,-1)
```
The model's prediction when it is only training on feature 1 is:
```
pred_S = f_S.predict(sample_input)
pred_S
```
When feature 1 is 1, then the prediction of this model is 0.5. If you look at the data in X, this makes sense, because when feature 1 is 1, half of the time, the label in y is 0, and half the time, the label in y is 1. So on average, the prediction is 0.5
#### Calculate difference
```
diff_A = pred_S_union_i - pred_S
diff_A
```
#### Calculate the weight
Calculate the weight assigned to the marginal contribution. In this case, if this marginal contribution occurs 1 out of the 6 possible permutations of the 3 features, then its weight is 1/6
```
size_S = S.shape[1] # should be 1
weight_A = calc_weight(size_S, M)
weight_A # should be 1/6
```
## Quiz: Case B
Calculate the prediction of a model that uses features 0 and 2
Calculate the prediction of a model that uses feature 2
Calculate the difference
$f(x_0,x_2) - f(x_2)$
#### Calculate $f(x_0,x_2)$
```
# TODO
S_union_i = get_subset(X,[0,2])
f_S_union_i = sklearn.tree.DecisionTreeRegressor()
f_S_union_i.fit(S_union_i, y)
sample_input = np.array([1,1]).reshape(1,-1)
pred_S_union_i = f_S_union_i.predict(sample_input)
pred_S_union_i
```
Since we're using features 0 and 2, and feature 2 doesn't help with predicting the output, then the model really just depends on feature 0. When feature 0 is 1, half of the labels are 0, and half of the labels are 1. So the average prediction is 0.5
#### Calculate $f(x_2)$
```
# TODO
S = get_subset(X,[2])
f_S = sklearn.tree.DecisionTreeRegressor()
f_S.fit(S, y)
sample_input = np.array([1]).reshape(1,-1)
pred_S = f_S.predict(sample_input)
pred_S
```
Since feature 2 doesn't help with predicting the labels in y, and feature 2 is 0 for all 100 training observations, then the prediction of the model is the average of all 100 training labels. 1/4 of the labels are 1, and the rest are 0. So that prediction is 0.25
#### Calculate the difference in predictions
```
# TODO
diff_B = pred_S_union_i - pred_S
diff_B
```
#### Calculate the weight
```
# TODO
size_S = S.shape[1] # is 1
weight_B = calc_weight(size_S, M)
weight_B # should be 1/6
```
# Quiz: Case C
Calculate the prediction of a model that uses features 0,1 and 2
Calculate the prediction of a model that uses feature 1 and 2
Calculate the difference
$f(x_0,x_1,x_2) - f(x_1,x_2)$
#### Calculate $f(x_0,x_1,x_2) $
```
# TODO
S_union_i = get_subset(X,[0,1,2])
f_S_union_i = sklearn.tree.DecisionTreeRegressor()
f_S_union_i.fit(S_union_i, y)
sample_input = np.array([1,1,1]).reshape(1,-1)
pred_S_union_i = f_S_union_i.predict(sample_input)
pred_S_union_i
```
When we use all three features, the model is able to predict that if feature 0 and feature 1 are both 1, then the label is 1.
#### Calculate $f(x_1,x_2)$
```
# TODO
S = get_subset(X,[1,2])
f_S = sklearn.tree.DecisionTreeRegressor()
f_S.fit(S, y)
sample_input = np.array([1,1]).reshape(1,-1)
pred_S = f_S.predict(sample_input)
pred_S
```
When the model is trained on features 1 and 2, then its training data tells it that half of the time, when feature 1 is 1, the label is 0; and half the time, the label is 1. So the average prediction of the model is 0.5
#### Calculate difference in predictions
```
# TODO
diff_C = pred_S_union_i - pred_S
diff_C
```
#### Calculate weights
```
# TODO
size_S = S.shape[1]
weight_C = calc_weight(size_S,M) # should be 2 / 6 = 1/3
weight_C
```
## Quiz: case D: remember to include the empty set!
The empty set is also a set. We'll compare how the model does when it has no features, and see how that compares to when it gets feature 0 as input.
Calculate the prediction of a model that uses features 0.
Calculate the prediction of a model that uses no features.
Calculate the difference
$f(x_0) - f()$
#### Calculate $f(x_0)$
```
# TODO
S_union_i = get_subset(X,[0])
f_S_union_i = sklearn.tree.DecisionTreeRegressor()
f_S_union_i.fit(S_union_i, y)
sample_input = np.array([1]).reshape(1,-1)
pred_S_union_i = f_S_union_i.predict(sample_input)
pred_S_union_i
```
With just feature 0 as input, the model predicts 0.5
#### Calculate $f()$
**hint**: you don't have to fit a model, since there are no features to input into the model.
```
# TODO
# with no input features, the model will predict the average of the labels, which is 0.25
pred_S = np.mean(y)
pred_S
```
With no input features, the model's best guess is the average of the labels, which is 0.25
#### Calculate difference in predictions
```
# TODO
diff_D = pred_S_union_i - pred_S
diff_D
```
#### Calculate weight
We expect this to be: 0! * (3-0-1)! / 3! = 2/6 = 1/3
```
# TODO
size_S = 0
weight_D = calc_weight(size_S,M) # weight is 1/3
weight_D
```
# Calculate Shapley value
For a single sample observation, where feature 0 is 1, feature 1 is 1, and feature 2 is 1, calculate the shapley value of feature 0 as the weighted sum of the differences in predictions.
$\phi_{i} = \sum_{S \subseteq N \setminus i} weight_S \times (f(S \cup i) - f(S))$
```
# TODO
shap_0 = # ...
shap_0
```
## Verify with the shap library
The [shap](https://github.com/slundberg/shap) library is written by Scott Lundberg, the creator of Shapley Additive Explanations.
```
sample_values = np.array([1,1,1])
shap_values = shap.TreeExplainer(model).shap_values(sample_values)
print(f"Shapley value for feature 0 that we calculated: {shap_0}")
print(f"Shapley value for feature 0 is {shap_values[0]}")
print(f"Shapley value for feature 1 is {shap_values[1]}")
print(f"Shapley value for feature 2 is {shap_values[2]}")
```
## Quiz: Does this make sense?
The shap libary outputs the shap values for features 0, 1 and 2. We can see that the shapley value for feature 0 matches what we calculated. The Shapley value for feature 1 is also given the same importance as feature 0.
* Given that the training data is simulating an AND operation, do you think these values make sense?
* Do you think feature 0 and 1 are equally important, or is one more important than the other?
* Does the importane of feature 2 make sense as well?
* How does this compare to the feature importance that's built into sci-kit learn?
## Answer
## Note
This method is general enough that it works for any model, not just trees. There is an optimized way to calculate this when the complex model being explained is a tree-based model. We'll look at that next.
## Solution
[Solution notebook](calculate_shap_solution.ipynb)
| github_jupyter |
<a href="https://colab.research.google.com/github/FKLC/Torrent-To-Google-Drive-Downloader/blob/master/Torrent_To_Google_Drive_Downloader.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Torrent To Google Drive Downloader
**Important Note:** To get more disk space:
> Go to Runtime -> Change Runtime and give GPU as the Hardware Accelerator. You will get around 384GB to download any torrent you want.
### Install libtorrent and Initialize Session
```
!python -m pip install --upgrade pip setuptools wheel
!python -m pip install lbry-libtorrent
!apt install python3-libtorrent
import libtorrent as lt
ses = lt.session()
ses.listen_on(6881, 6891)
downloads = []
```
### Mount Google Drive
To stream files we need to mount Google Drive.
```
from google.colab import drive
drive.mount("/content/drive")
```
### Add From Torrent File
You can run this cell to add more files as many times as you want
```
from google.colab import files
source = files.upload()
params = {
"save_path": "/content/drive/My Drive/Torrent",
"ti": lt.torrent_info(list(source.keys())[0]),
}
downloads.append(ses.add_torrent(params))
```
### Add From Magnet Link
You can run this cell to add more files as many times as you want
```
params = {"save_path": "/content/drive/My Drive/Torrent"}
while True:
magnet_link = input("Enter Magnet Link Or Type Exit: ")
if magnet_link.lower() == "exit":
break
downloads.append(
lt.add_magnet_uri(ses, magnet_link, params)
)
```
### Start Download
Source: https://stackoverflow.com/a/5494823/7957705 and [#3 issue](https://github.com/FKLC/Torrent-To-Google-Drive-Downloader/issues/3) which refers to this [stackoverflow question](https://stackoverflow.com/a/6053350/7957705)
```
import time
from IPython.display import display
import ipywidgets as widgets
state_str = [
"queued",
"checking",
"downloading metadata",
"downloading",
"finished",
"seeding",
"allocating",
"checking fastresume",
]
layout = widgets.Layout(width="auto")
style = {"description_width": "initial"}
download_bars = [
widgets.FloatSlider(
step=0.01, disabled=True, layout=layout, style=style
)
for _ in downloads
]
display(*download_bars)
while downloads:
next_shift = 0
for index, download in enumerate(downloads[:]):
bar = download_bars[index + next_shift]
if not download.is_seed():
s = download.status()
bar.description = " ".join(
[
download.name(),
str(s.download_rate / 1000),
"kB/s",
state_str[s.state],
]
)
bar.value = s.progress * 100
else:
next_shift -= 1
ses.remove_torrent(download)
downloads.remove(download)
bar.close() # Seems to be not working in Colab (see https://github.com/googlecolab/colabtools/issues/726#issue-486731758)
download_bars.remove(bar)
print(download.name(), "complete")
time.sleep(1)
```
| github_jupyter |
# Allosteric pathways with current flow analysis on protein-cofactor networks
*This tutorial shows how to build and analyze networks that include protein residues and cofactors (e.g. lipids or small molecules).*
***Note***: To build and analyze a residue interaction network of the isolated protein only, just skip the steps in Section 2b and 3a, and inputs named *interactor_atom_inds_file.npy* or *additional_interactor_**.
## Citing this work
The code and developments here are described in two papers. <br>
**[1]** P.W. Kang, A.M. Westerlund, J. Shi, K. MacFarland White, A.K. Dou, A.H. Cui, J.R. Silva, L. Delemotte and J. Cui. <br>
*Calmodulin acts as a state-dependent switch to control a cardiac potassium channel opening*. 2020<br><br>
**[2]** A.M. Westerlund, O. Fleetwood, S. Perez-Conesa and L. Delemotte. <br>
*Network analysis reveals how lipids and other cofactors influence membrane protein allostery*. 2020
[1] is an applications-oriented paper describing how to analyze **residue interaction networks** of **isolated proteins**. <br>
[2] is a methods-oriented paper of how to build and analyze **residue interaction networks** that include **proteins and cofactors**.
## Short background
A residue interaction network is typically obtained from the element-wise product of two matrices: <br>
  1) Contact map. <br>
  2) Correlation (of node fluctuations) map.
For protein residue interaction networks, the node fluctuations correspond to protein residue fluctuations around an equilibrium position [1]. The method used to build contact and correlation maps which include cofactor nodes is described in details in [2].
### Contact map
The contact map here is defined using a truncated Gaussian kernel $K$ to smooth the contacts. For a frame with given a distance $d$ between two nodes
$$
K(d) =
\begin{cases}
1 & \text{if } d \le c \\
\exp (-\frac{d^2}{2\sigma^2}) / \exp (-\frac{c^2}{2\sigma^2}) & \text{otherwise}
\end{cases}
$$
By default, $c=0.45$ nm and $\sigma=0.138$ nm. <br>
The cutoff, $c=0.45$, ensures a contact if $d \le 4.5$ Å. The standard deviation, $\sigma=0.138$, is chosen such that $K(d=0.8 \text{ nm}) = 10^{-5}$. <br><br>
The final contact map is averaged over frames.
### Correlation map
The correlation of node (protein residues in the case of isolated proteins) fluctuations is calculated using mutual information.
$$
M_{ij} = H_i + H_j - H_{ij},
$$
where
$$
H_i = -\int\limits_X \rho(x)\ln \rho(x).
$$
$\rho_i(x)$ is the density of distances from the node equilibrium position. This is estimated with Gaussian mixture models and the Bayesian information criterion model selection.
### Including cofactors in the network
Cofactors, such as lipids and small molecules, are treated slighlty differently than protein residues. The details are described in [2]. Practically, cofactors are processesed and added to the network in separate steps than the protein residues. The network nodes that represent cofactors are called *interactor nodes*. The following is needed to add cofactors in the network:
1. **Trajectory (and .pdb file) with protein and cofactors**: If the trajectory is centered on the protein, make sure that the other molecules are not split across simulation box boundaries. In gromacs, for example, this may be avoided in *gmx trjconv* by using the option *-pbc res*. <br>
2. **Definition of interactors**: A cofactor may be described by one or several *interactors*. An interactor could e.g. be the lipid head group. We therefore have to specify which cofactor atoms form an interactor. More details are found in Section 2b. <br>
3. **Contact map and fluctuations**: The practical details are outlined in Sections 2b and 3a.
### Current flow analysis
The networks are analyzed using a current flow analysis [3,4] framework. The code supports both current flow betweenness and current flow closeness analysis. In short, the current flow computes the net diffusion along edges between network nodes. The net throughput of a node is given by the sum over edges.
Current flow betweenness is useful for identifying allosteric pathways [5,1]. Specifically, it shows how important each residue is for transmitting allosteric pathways from a source (allosteric site) to a sink (functional site). Current flow closeness centrality [3], instead indicates signaling efficiency within the network (using a "distance" measured in current flow).
To perform current flow analysis, you need a contact map and a similarity map (e.g. mutual information or Pearson correlation). These are computed in Section 2-3. The practical details are described in Section 4.
## Additional references
[3] U. Brandes and D. Fleischer, Springer, Berlin, Heidelberg, 2005 <br>
[4] M. E. J. Newman, Social Networks, 2005 <br>
[5] W.M. Botello-Smith and Y. Luo, J. Chem. Theory Comput., 2019
## 1. Setup
```
import allopath
import numpy as np
# Set the trajectory that should be analyzed.
structure=['input_data/my_system.pdb']
trajs=['input_data/system_traj1.dcd','input_data/system_traj2.dcd']
# Specify how many cores to run the calculations on.
n_cores=4
# Set the output directories (out_dir is where the main data will be saved,
# while out_dir_MI will contain the MI matrix data, see below on how they are used).
out_dir='Results_data/'
out_dir_MI='Results_data/MI_data/'
file_label='my_system' # Simulation label which will be appended to filenames of all written files (optional)
dt=1 # Trajectory stride (default=1)
```
## 2. Semi-binary contact maps
------------------------------------------
### 2a. Protein residue contact map
To compute the protein (only including protein residue-residue interactions) contact map we will use _ContactMap_.
***allopath.ContactMap***(**self,** *topology_file*, \**kwargs)
where *kwargs* is a dictionary with the keyword arguments (https://docs.python.org/2/glossary.html). This means that to contruct a _ContactMap_ object we have to give at least the topology_file (_structure_) as input (but in principle we want the average over a trajectory):
> CM = allopath.ContactMap(structure)
We now create a dictionary, *kwargs*, to define the named/keyword arguments that should not assume default values, such as the trajectory, ie. you may include all named input arguments that you want to modify and remove those that you wish to keep at default value.
List of input keyword parameters:
* **trajectory_files**: Input trajectory files (.xtc, .dcd, etc)
* **trajectory_file_directory**:Input directory with trajectory files (.xtc, .dcd, etc.). This will load all trajectory files in the specified directory (this is complementary to *trajectory_files*).
* **file_label**: "File end name": label of the system that will be appended to the end of the produced files.
* **out_directory**: The directory where data should be written.
* **dt**: Trajectory stride.
* **query**: Atom-selection used on the trajectory, e.g. "protein and !(type H)" or "protein and name CA".
* **n_cores**: Number of jobs to run with joblib.
* **cutoff**: Cutoff value, $c$, in the truncated Gaussian kernel. For distances < cutoff, the contact will be set to one (default $c=0.45$ nm, see "Background: contact map" for definition).
* **std_dev**: Standard deviation value, $\sigma$, in the truncated Gaussian kernel. (default $\sigma=0.138$ nm => 1e-5 contact at 0.8 nm, see "Background: contact map" for definition)
* **per_frame**: Whether or not to compute contact map per frame instead of averaging over the trajectory (default=False).
* **start_frame**: Defines which frame to start calculations from. Used in combination with *per_frame*=True.
* **end_frame**: Defines which frame to end calculations at. Used in combination with *per_frame*=True.
* **ref_cmap_file**: File with reference cmap (e.g. average over all frames). Is used to make computations sparse/speed up calculation. Used in combination with *per_frame*=True.
The default values are: <br>
{'trajectory_files': '', <br>
'trajectory_file_directory': '', <br>
'dt': 1, <br>
'n_cores': 4, <br>
'out_directory': '', <br>
'file_label': '', <br>
'cutoff': 0.45, <br>
'query': 'protein and !(type H)', <br>
'start_frame': 0, <br>
'end_frame': -1, <br>
'ref_cmap_file': '', <br>
'per_frame': False, <br>
'std_dev': 0.138} <br>
Note that the trajectory files can either be given by explicitly naming them and inputting as *trajectory_files* (as we do with _trajs_, see below), or by simply inputting a directory containing all the '.xtc' or '.dcd' files that should be analyzed (*trajectory_file_directory*).
```
# Set inputs
kwargs={
'trajectory_files': trajs,
'file_label': file_label,
'out_directory': out_dir,
'dt': dt,
'n_cores': n_cores
}
# Compute contact map and write to file
CM = allopath.ContactMap(structure, **kwargs)
CM.run()
```
### 2b. Interactor node - protein residue contact map
The contact map of interactor-interactor and interactor-protein residue node contacts wille be computed using *CofactorInteractors*.
***allopath.CofactorInteractors***(**self,** *topology_file*, \**kwargs)
The *CofactorInteractors* is used to both compute the interactions that include cofactors, and the cofactor fluctuations. The cofactor fluctuations will be used as input to the MI calculations.
List of input keyword parameters to create a contact map:
* **trajectory_files**: Input trajectory files (.xtc, .dcd, etc)
* **trajectory_file_directory**:Input directory with trajectory files (.xtc, .dcd, etc.). This will load all trajectory files in the specified directory.
* **file_label**: "File end name": label of the system that will be appended to the end of the produced files.
* **out_directory**: The directory where data should be written.
* **dt**: Trajectory stride.
* **cofactor_domain_selection**: A file containing cofactor-interactor selections. Each row should list the atoms that make up an interactor. Example of a domain selection file content: <br><br>
*resname POPC and name N C11 C12 C13 C14 C15 P O13 O14 O12 O11 C1 C2 <br>
resname POPC and name O21 C21 C22 O22 C23 C24 C25 C26 C27 C28 C29 C210 C211 C212 C213 C214 C215 C216 C217 C218 <br>
resname POPC and name C3 O31 C31 C32 O32 C33 C34 C35 C36 C37 C38 C39 C310 C311 C312 C313 C314 C315 C316*
<br><br>
* **cutoff**: Cutoff value, $c$, for binary residue-lipid contacts. For distances < cutoff, the contact will be set to one (default=0.45 nm).
* **std_dev**: Standard deviation value, $\sigma$, on the semi-binary Gaussian-kernel. (default=0.138 nm => 1e-5 contact at 0.8 nm)
The default values are: <br>
{'trajectory_files': '', <br>
'trajectory_file_directory': '', <br>
'dt': 1, <br>
'out_directory': '', <br>
'file_label': '', <br>
'cofactor_domain_selection': '', <br>
'cofactor_interactor_inds': '', <br>
'cofactor_interactor_coords':, '', <br>
'compute_cofactor_interactor_fluctuations': False, <br>
'cofactor_interactor_atom_inds': '', <br>
'cutoff': 0.45, <br>
'std_dev': 0.138} <br>
```
# Set inputs
cofactor_domain_selection_file='input_data/cofactor_domain_selection.txt'
kwargs={
'trajectory_files': trajs,
'file_label': file_label,
'out_directory': out_dir,
'dt': dt,
'cofactor_domain_selection': cofactor_domain_selection_file
}
# Compute contact map and write to file
CI = allopath.CofactorInteractors(structure, **kwargs)
CI.run()
```
## 3. Mutual information
-----------------------------------
To compute mutual information (MI) between nodes we use *MutualInformation* and *CofactorInteractors*.
The MI is done in **four** steps. <br>
**(a)** Computing the interactor node fluctuations using *CofactorInteractors*. These will be given as input to *MutualInformation*.<br>
**(b)** Computing the off-diagonal elements in the MI matrix using *MutualInformation*. Because this is computationally demanding, we can 1) use the contact map as input to ignore non-contacting residues and 2) split the matrix into blocks that can be processed in parallel (although we will do it in sequence in this tutorial).
> We will divide the matrix into 4 blocks along the column and 4 blocks along the rows. As we include the diagonal blocks but use symmetry on off-diagonal blocks, we get *n_matrix_block_cols=4 and *n_blocks*= n_matrix_block_cols(n_matrix_block_cols-1)/2 + n_matrix_block_cols = 10 number of blocks. The input argument *i_block* should be between 1 and *n_blocks*, denoting which block should be constructed. <br>
**(c)** Computing the diagonal elements in the MI matrix using *MutualInformation*. This requires *do_diagonal*=True as input. *Note: This is only needed if you normalize the mutual information in allopath.CurrentFlow.* (Section 4)<br>
**(d)** Building the full off-diagonal matrix based on blocks.<br><br>
*Note:* The calculations in **(b)** and **(c)** are time consuming, but they are structured so that they can be launched in parallel. **(d)** cannot be done until the calculations in **(b)** have finished.
### 3a. Computing interactor node fluctuations
The interactor fluctuations will be computed using *CofactorInteractors*.
***allopath.CofactorInteractors***(**self,** *topology_file*, \**kwargs)
As mentioned, *CofactorInteractors* is used to both compute the interactions that include cofactors, and the cofactor fluctuations. To compute interactor fluctuations, we need to set **compute_cofactor_interactor_fluctuations=True** in *kwargs*.
List of input keyword parameters to compute interactor fluctuations:
* **trajectory_files**: Input trajectory files (.xtc, .dcd, etc)
* **trajectory_file_directory**:Input directory with trajectory files (.xtc, .dcd, etc.). This will load all trajectory files in the specified directory.
* **file_label**: "File end name": label of the system that will be appended to the end of the produced files.
* **out_directory**: The directory where data should be written.
* **dt**: Trajectory stride.
* **cofactor_interactor_inds**: (generated when computing the interactor node contact map).
* **cofactor_interactor_coords**:(generated when computing the interactor node contact map).
* **compute_interactor_node_fluctuations**: Whether or not to compute the fluctuations. Default is False. Set to True.
The default values are: <br>
{'trajectory_files': '', <br>
'trajectory_file_directory': '', <br>
'dt': 1, <br>
'out_directory': '', <br>
'file_label': '', <br>
'cofactor_domain_selection': '', <br>
'cofactor_interactor_inds': '', <br>
'cofactor_interactor_coords':, '', <br>
'compute_cofactor_interactor_fluctuations': False, <br>
'cofactor_interactor_atom_inds': '', <br>
'cutoff': 0.45, <br>
'std_dev': 0.138} <br>
```
# Set inputs
cofactor_interactor_inds = out_dir+'cofactor_interactor_indices_'+file_label+'.npy'
cofactor_interactor_coords = out_dir+'cofactor_interactor_coords_'+file_label+'.npy'
kwargs={
'trajectory_files': trajs,
'file_label': file_label,
'out_directory': out_dir,
'dt': dt,
'cofactor_interactor_inds': cofactor_interactor_inds,
'cofactor_interactor_coords': cofactor_interactor_coords,
'compute_interactor_node_fluctuations': True
}
# Compute interactor node fluctuations and write to file
CI = allopath.CofactorInteractors(structure, **kwargs)
CI.run()
```
### 3b. Computing off-diagonal elements
The MI matrix is obtained with *MutualInformation*.
***allopath.MutualInformation*** (**self,** *topology_file*, \**kwargs)
Similarly to *ContactMap* and *CofactorInteractors* it is in principle enough to input the structure.
> MI = allopath.MutualInformation(structure)
List of input keyword parameters:
* **trajectory_files**: Input trajectory files (.xtc, .dcd, etc)
* **trajectory_file_directory**:Input directory with trajectory files (.xtc, .dcd, etc.). This will load all trajectory files in the specified directory.
* **file_label**: "File end name": label of the system that will be appended to the end of the produced files.
* **out_directory**: The directory where data should be written.
* **dt**: Trajectory stride.
* **n_cores**: Number of jobs to run with joblib.
* **n_matrix_block_cols**: Number of blocks of the column of the MI matrix. Example: 4 blocks => 10 parts (upper triangle + diagonal). See part (a) above.
* **i_block**: The matrix block for which MI should be calculated. See part (a) above.
* **n_split_sets**: Number of sampled sets with the same size as the original data set to use for more accurate estimate of entropy. Can also be used to check unceratinty of the MI matrix.
* **additional_interactor_protein_contacts**: The interactor contact map (computed in Section 2b).
* **additional_interactor_fluctuations**: The interactor fluctuations (computed in Section 3a).
* **n_components_range:** Array with the lower and upper limit of GMM components used to estimate densities.
* **do_diagonal**: Whether or not to compute diagonal of residue-residue mutual information (default=False).
The default values are: <br>
{'trajectory_files': '', <br>
'trajectory_file_directory': '', <br>
'dt': 1, <br>
'out_directory': '', <br>
'file_label': '', <br>
'n_cores': -1, <br>
'contact_map_file': '', <br>
'i_block': 0, <br>
'n_matrix_block_cols': 1 <br>
'n_split_sets': 0, <br>
'additional_interactor_protein_contacts': '', <br>
'additional_interactor_fluctuations': '', <br>
'n_components_range': [1,4], <br>
'do_diagonal': False
} <br>
To compute the off-diagonal elements, we use the default *do_diagonal*=False and split the matrix into 10 blocks. We also do 10 bootstrap samplings to obtain a better entropy estimate.
```
n_blocks = 10
n_cols = 4
n_bootstraps = 10
contact_map = out_dir+'distance_matrix_semi_bin_'+file_label+'.txt'
additional_interactor_fluctuations = out_dir+'interactor_centroid_fluctuations_'+file_label+'.npy'
additional_interactor_protein_contacts = out_dir+'cofactor_protein_residue_semi_binary_cmap_'+file_label+'.npy'
n_components_range = [1,4]
for i_block in range(1,n_blocks+1):
# Set inputs
kwargs={
'trajectory_files': trajs,
'dt': dt,
'contact_map_file': contact_map,
'additional_interactor_fluctuations': additional_interactor_fluctuations,
'additional_interactor_protein_contacts': additional_interactor_protein_contacts,
'i_block': i_block,
'n_matrix_block_cols': n_cols,
'n_split_sets': n_bootstraps,
'n_components_range': n_components_range,
'file_label': file_label,
'out_directory': out_dir_MI,
'n_cores': n_cores,
}
# Compute mutual information matrix
MI = allopath.MutualInformation(structure, **kwargs)
MI.run()
```
### 3c. Computing diagonal elements
To estimate the diagonal elements, we use the same inputs as above except setting *do_diagonal*=True. Moreover, the matrix is not divided into blocks since the diagonal is much faster to compute.
***Note:*** *This step is only needed if you choose to normalize the mutual information in allopath.CurrentFlow (Section 4).*
```
# Set inputs
kwargs={
'trajectory_files': trajs,
'dt': dt,
'additional_interactor_fluctuations': additional_interactor_fluctuations,
'n_split_sets': n_bootstraps,
'file_label': file_label,
'out_directory': out_dir_MI,
'n_components_range': n_components_range,
'n_cores': n_cores,
'do_diagonal': True
}
# Compute diagonal of the MI matrix
MI = allopath.MutualInformation(structure, **kwargs)
MI.run()
```
### 3d. Building matrix from blocks
Next, the full MI matrix is built.
***allopath.from_matrix.build_matrix*** (*base_file_name*, *n_blocks*, file_label='', out_directory='')
We use the same parameters as above.
List of input parameters:
* **base_file_name**: the base name of each file to be processed. This is given by *base_file_name*=*path_to_data*+'res_res_MI_part_' .
* **n_blocks**: Total number of generated matrix blocks.
* **file_label**: "File end name": label of the system that will be appended to the end of the produced files (default is '').
* **out_directory**: The directory where data should be written to (default is '').
The input *base_file_name* is named after the files in "Results_data/MI_data/".
```
base_file_name=out_dir+'MI_data/res_res_MI_part_'
# Set inputs
kwargs={
'file_label': file_label,
'out_directory': out_dir+'MI_data/'
}
# Build matrix
allopath.from_matrix_blocks.build_matrix(base_file_name, n_blocks, **kwargs)
```
## 4. Current flow analysis
-----------------------------------
Current flow analysis is done with *CurrentFlow*.
***allopath.CurrentFlow*** (**self,** *similarity_map_filename*, *contact_map_filenames*, *sources_filename*, *sinks_filename*, \**kwargs)
To run current flow analysis in its simplest form, the files containing the similarity map (ie. our MI matrix), the contact map and the source and sink indices are needed.
> allopath.CurrentFlow(similarity_map_filename, contact_map_filename, sources_filename, sinks_filename)
Explanation of input (positional) parameters:
* **similarity_map_filename**: File containing the similarity map (ie. the mutual information matrix).
* **contact_map_filenames**: File containing the contact map(s). If multiple are given, one current flow profile per contact map will be computed (*Note: multiple network calculations are only supported for isolated-protein networks*).
* **sources_filename**: File containing the residue indices of the sources.
* **sinks_filenams**: File containing the residues indices of the sinks.
Explanation of input keyword parameters:
* **similarity_map_diagonal_filename**: File containing the diagonal elements of the mutual information matrix.
* **additional_interactor_protein_contacts**: The interactor contact map (computed in Section 2b).
* **out_directory**: The directory where data should be written.
* **file_label**: "File end name": label of the system that will be appended to the end of the produced files.
* **n_chains**: The number of (homomeric) chains/subunits in the main-protein (e.g. a tetrameric ion channel => n_chains = 4).
* **n_cores**: Number of jobs to run with joblib.
* **cheap_write**: If set to True, fewer files will be written.
* **start_frame**: Used if multiple contact maps are supplied. *start_frame* is the index of the first frame to analyze.
* **normalize_similarity_map**: Whether or not to normalize the similarity map with symmetric unertainty (*Note: applies to mutual information maps; Witten & Frank, 2005*)
* **auxiliary_protein_indices**: Residue indices of auxiliary subunits. This is used when symmeterizing current flow over subunits (chains). The auxiliary subunits will also be averaged over chains, ie. one auxiliary subunit per chain is assumed. If there is no auxiliary subunit, just ignore this input to the current flow script.
* **compute_current_flow_closeness**: Whether or not to compute current flow closeness instead of current flow betweenness.
The default values are: <br>
{'out_directory': '', <br>
'file_label': '', <br>
'similarity_map_diagonal_filename': '', <br>
'n_chains': 1, <br>
'n_cores': 1, <br>
'cheap_write': False, <br>
'start_frame': 0, <br>
'normalize_similarity_map': False, <br>
'auxiliary_protein_indices': '', <br>
'additional_interactor_protein_contacts': '', <br>
'compute_current_flow_closeness': False } <br>
```
similarity_map = out_dir+'MI_data/res_res_MI_compressed_'+file_label+'.npy'
similarity_map_diagonal = out_dir+'MI_data/diagonal_MI_'+file_label+'.npy'
contact_maps = [out_dir+'distance_matrix_semi_bin_'+file_label+'.txt']
additional_interactor_protein_contacts = out_dir+'cofactor_protein_residue_semi_binary_cmap_'+file_label+'.npy'
n_chains=4
source_inds='input_data/inds_sources.txt'
sink_inds='input_data/inds_sinks.txt'
aux_inds='input_data/auxiliary_prot_inds.txt'
compute_current_flow_closeness = False # False (ie. default) => will compute current flow betweenness.
# Set this to True to compute current flow closeness centrality between each
# source and all sinks instead.
kwargs={
'file_label': file_label,
'out_directory': out_dir,
'n_chains': n_chains,
'n_cores': n_cores,
'similarity_map_diagonal_filename': similarity_map_diagonal,
'normalize_similarity_map': False,
'auxiliary_protein_indices': aux_inds,
'additional_interactor_protein_contacts': additional_interactor_protein_contacts,
'compute_current_flow_closeness': compute_current_flow_closeness
}
CF = allopath.CurrentFlow(similarity_map, contact_maps, source_inds, sink_inds, **kwargs)
CF.run()
```
## 5. Project current flow on structure
----------------------------------------------------
As a last step, we project the current flow onto the structure (PDB file) with *make_pdb*. The current flow of ech residue will be mapped to the beta-column in the PDB. This can be visualized in VMD by setting the "Coloring method" to "Beta" in "Graphical Representations".
> ***allopath.make_pdb.project_current_flow***(*pdb_file*, *current_flow_file*, \**kwargs)
Explanation of input (positional arguments) parameters:
* **pdb_file**: The .pdb file corresponding to the first trajectory frame. *Note: .gro does not work.*
* **current_flow_file**: File containing the current flow. This is created by *CurrentFlow*, Section 4. **Note:** For homomultimers (using *n_chains > 1* in *CurrentFlow*), the file is *out_dir+'average_current_flow_'+file_label+'.npy'*. For *n_chains = 1*, the file is *out_dir+'current_flow_betweenness_'+file_label+'.npy'*.
Explanation of input keyword arguments:
* **out_directory**: The directory where pdb should be written.
* **file_label**: "File end name": label of the system that will be appended to the end of the produced pdb.
* **max_min_normalize**: Whether or not to scale the current flow between 0 and 1.
* **interactor_atom_inds_file**: The atom indices used to define the interactors (generated in Section 2b).
The default values are: <br>
{'out_directory': '', <br>
'file_label': '', <br>
'max_min_normalize': False,<br>
'interactor_atom_inds_file': None }
```
out_file = out_dir+'PDBs/current_flow_'+file_label+'.pdb'
current_flow = out_dir+'average_current_flow_'+file_label+'.npy'
interactor_atom_inds_file = out_dir+'cofactor_interactor_atom_indices_'+file_label+'.npy'
kwargs={
'out_directory': out_dir+'PDBs/',
'file_label': file_label,
'interactor_atom_inds_file': interactor_atom_inds_file
}
# Create PDB with current flow values on the beta column
allopath.make_pdb.project_current_flow(structure[0], current_flow, **kwargs)
```
| github_jupyter |
# GIS GZ – Übung 4: Geoprocessing von Vektordaten <span style="color:red">(Musterlösung)</span>
## Einleitung
In der letzten Übung haben Sie gelernt, wie Sie Geodaten mit Fiona verarbeiten können. Die Datenverarbeitung wird in dieser Übung weiter vertieft. Sie werden lernen wie man die Projektion zwischen zwei Koordinatensystemen berechnet und anschliessend einen Verschnitt von geographischen Flächen durchführen.
### Grobziele
* Sie können Python einsetzen, um mehrere Datensätze gleichzeitig zu verarbeiten.
* Sie können Outputs korrekt interpretieren und eigenständig nach Quellen suchen, die das Lösen eines Problems unterstützen.
* Sie können geometrische Objektklassen erstellen, abrufen und darstellen.
### Feinziele
* Sie können Datensätze mit Fiona laden und speichern.
* Sie können Vektordaten in ein anderes Koordinatensystem projizieren.
* Sie können Polygone unterschiedlicher Datensätze miteinander verschneiden und als separate Datei ausgeben.
* Sie können die Fläche von Polygonen bestimmen.
### Projekt
* Sie arbeiten an der Lösung Ihrer Fragestellung.
* Sie besprechen Ihr Konzept und das weiteres Vorgehen mit der Übungsleitung.
## Aufgabe 1: Projektionen, Verschnitt
In dieser Aufgabe erhalten Sie zwei Dateien (Quelle: https://data.stadt-zuerich.ch/dataset?tags=geodaten):
* `stadtkreise.json`
* `clc_wald_kanton_zh.json`
Die erste Datei enthält die Kreise der Stadt Zürich. Die zweite Datei enthält alle Waldflächen des Kantons Zürich.
Ihre Aufgabe ist es zunächst herauszufinden, in welchen Koordinatensystemen die Daten gespeichert sind, und sie in ein gemeinsames Koordinatensystem zu überführen (vorzugsweise CH1903+/LV95). Anschliessend werden Sie beide Datensätze miteinander verschneiden, um die Waldfläche pro Stadtkreis bestimmen zu können.
### Verwendete libraries und Funktionen
Zuerst importieren wir die nötigen libraries der heutigen Übung. Standardmässig verwenden wir für `numpy`, `pandas` und `matplotlib` Abkürzungen.
```
import os
import fiona
from pprint import pprint
import pyproj
import matplotlib.pyplot as plt
import geopandas
from fiona.crs import from_epsg
from shapely.geometry import MultiPolygon, Polygon, mapping
from shapely.ops import cascaded_union
from pyproj import Transformer
```
### Zusatzfunktion zum Plotten der Resultate
```
def show_map(map_layer_1, map_layer_2):
"""
Plots the map with the canton of Zurich and the rivers
:param map_layer_1: The first layer.
:param map_layer_2: The second layer.
:return:
"""
# Plot the map with the districts
districts = geopandas.read_file(map_layer_1)
fig, ax = plt.subplots(figsize=(10, 8))
ax.set_aspect('equal')
districts.plot(ax=ax, color='white', edgecolor='black')
# Plot the map with the rivers
forests = geopandas.read_file(map_layer_2)
forests.plot(ax=ax, color='red')
# Show the whole plot and return
plt.draw()
return
```
### Zusatzfunktion zum Transformieren der Geometrie
#### Aufgabe
Wenden Sie an der markierten Stelle pyproj.transform() an, um die projizierten x- und y-Koordinaten zu berechnen. Sie dürfen die ursprünglichen Variablen überschreiben.
```
def transform_geometry(src_data, output_proj, tgt_object):
"""
Transforms Polygons to MultiPolygons and projects to the target CRS, if it is not already saved in this CRS
:param src_data: The opened source Fiona object
:param output_proj: The target output projection
:param tgt_object: The opened target Fiona object
:return: The united geometry object
"""
# Determine the input projection
input_proj = pyproj.Proj(init=src_data.crs['init'])
# Define the projection
transformer = Transformer.from_proj(src_data.crs['init'], output_proj, always_xy=True)
# Initialize an empty list in which the geometries will be written
list_with_shapely_objects = []
# Iterate through all entries and determine the type for each entry and the coordinates
for f in src_data:
geom_type = f['geometry']['type']
full_coords = f['geometry']['coordinates']
# As it can occur that the input geometry object is a Polygon or a MultiPolygon, we must
# assert that the dimensionality stays the same for both cases. Thus, put the coordinates into a
# further list, if the geometry type should be a LineString
if geom_type == 'Polygon':
full_coords = [full_coords]
# Now, the structure should correspond to MultiPolygons in every case. Define an empty list for the
# coordinates and append the sublists determined by iteration through the original list.
record = []
for level_1 in full_coords:
level_2_list = []
for level_2 in level_1:
level_3_list = []
for (x2, y2, *z2) in transformer.itransform(level_2):
level_3_list.append((x2, y2, *z2))
level_2_list.append(level_3_list)
list_with_shapely_objects.append(Polygon(level_3_list))
record.append(level_2_list)
# Overwrite the type and the coordinates with the new entries and add the new attribute entries
f['geometry']['type'] = 'MultiPolygon'
f['geometry']['coordinates'] = record
tgt_object.write(f)
# Conduct a cascaded union and return the united object
united_geometry = cascaded_union(list_with_shapely_objects)
return united_geometry
```
### Zusatzfunktion zum Schreiben von Shapely-Geometrien in Files
```
def write_geometries_to_files(shapely_objects, out_path, driver, crs, properties_schema=None,
properties_entries=None):
"""
Writes shapely objects to an output file with the same properties for each row. Replaces write_vector_file()
:param list shapely_objects: A list containing all shapely objects
:param out_path: The output path including the target file ending
:param driver: The driver that should be used for writing the output file
:param crs: The CRS in which the coordinates are stored
:param dict properties_schema: The attribute scheme that must be written into the output. If the same schema as the
blueprint should be used, then pass it here separately
:param dict properties_entries: The properties that should be written into the output file
:return: Nothing, as files are generated
"""
# Check, whether the properties_entries have a subdictionary. If so, raise an Exception, as this is not implemented
# yet.
try:
properties_have_subdictionary = isinstance(type(properties_entries.values()), dict)
except AttributeError:
properties_have_subdictionary = False
if properties_have_subdictionary:
raise Exception('***ERROR!!! A dictionary with many properties has been passed while this function is only '
'capable to write one property for all rows at the same time. Thus, reconsider the lower '
'part of this function.')
# Check whether a schema and properties have been passed and write the information into two dictionaries
if (properties_schema is None) or (properties_entries is None):
new_schemes = dict()
new_entries = dict()
else:
new_schemes = properties_schema
new_entries = properties_entries
# INFO: in_object must be a Shapely geometry object (LineString, Point, MultiPoint, etc.)
# NOTE that all geometry objects must be of the same type!!!
# Determine the geometry type and define the target schema (crs is passed as an argument)
try:
geometry = shapely_objects[0].geometryType()
except TypeError: # If not a list has been passed, but a single object
shapely_objects = [shapely_objects]
geometry = shapely_objects[0].geometryType()
target_schema = {'properties': new_schemes,
'geometry': geometry}
# Write the objects to an output file
with fiona.open(out_path, 'w', driver=driver, schema=target_schema, crs=crs, encoding='utf-8') as dst:
for i in shapely_objects:
rec = dict()
rec['geometry'] = mapping(i)
rec['properties'] = new_entries
dst.write(rec)
print('GeoJSON file written.')
return
```
### Hauptfunktion
Wir definieren zuerst die Pfade, in welchen wir die Dateien finden oder speichern sollen. Dann definieren wir die Koordinatensysteme und das pyproj-Objekt, das die Output-Projektion bestimmt. Dannn initialisieren wir zwei Variablen, die wir später brauchen werden. Darin werden die vereinigten Geometrien der Wälder und der Stadtkreise geschrieben.
```
# Create the output dir, if it does not exist
out_dir = os.path.join(os.path.abspath(''), 'results')
if not os.path.exists(out_dir):
os.makedirs(out_dir)
# Define the input and the output file
in_file_districts = os.path.join(os.path.abspath(''), 'data', 'stadtkreise.json')
out_file_districts = os.path.join(out_dir, 'stadtkreise_proj.json')
in_file_forests = os.path.join(os.path.abspath(''), 'data', 'clc_wald_kanton_zh.json')
out_file_forests = os.path.join(out_dir, 'clc_wald_kanton_zh_proj.json')
out_file_forests_in_zurich = os.path.join(out_dir, 'clc_wald_stadt_zuerich_proj.json')
out_file_stadt_zuerich = os.path.join(out_dir, 'stadt_zuerich.json')
# Define the output projection and the output driver for every file
out_crs = 'epsg:2056'
output_proj = pyproj.Proj(out_crs)
out_driver = 'GeoJSON'
# Initialize the geometry objects that are determined by the upcoming loops
united_forests = None
united_districts = None
```
Dann führen wir zwei Mal dasselbe aus: Wir öffnen das Ausgangsfile, iterieren über alle Einträge, projizieren die Koordinaten allenfalls in das Ziel-Koordinatensystem, speichern die Polygone neu als MultiPolygons ab und geben ein geometrisches Objekt heraus, das die Vereinigungsmenge aller Teilpolygone umfasst. Das tun wir für die Wälder des ganzen Kantons und für die Stadtkreise.
```
# ---------------------------------------------
# PART 1) TRANSFORM THE FILE WITH THE DISTRICTS
# Open the source file and determine the CRS, the projection, copy the schema (because dictionaries are mutable),
# and set the geometry in every case to MultiPolygon.
with fiona.open(in_file_forests) as forests_src:
forests_schema = forests_src.schema.copy()
forests_schema['geometry'] = 'MultiPolygon'
# Open the file that should be written
with fiona.open(out_file_forests, 'w', driver=out_driver, schema=forests_schema,
crs=out_crs, encoding='utf-8') as forests_tgt:
united_forests = transform_geometry(forests_src, output_proj, forests_tgt)
# ---------------------------------------------
# PART 2) TRANSFORM THE FILE WITH THE FORESTS
# Open the source file and determine the CRS, the projection, copy the schema (because dictionaries are mutable),
# and set the geometry in every case to MultiPolygon.
with fiona.open(in_file_districts) as districts_src:
districts_schema = districts_src.schema.copy()
districts_schema['geometry'] = 'MultiPolygon'
# Open the files that should be written and iterate through the entries
with fiona.open(out_file_districts, 'w', driver=out_driver, schema=districts_schema,
crs=out_crs, encoding='utf-8') as districts_tgt:
united_districts = transform_geometry(districts_src, output_proj, districts_tgt)
```
#### Aufgabe
Nun sind Sie an der Reihe: Erstellen Sie dort, wo `None`steht, ein geometrisches Shapely-Objekt, das die Wälder innerhalb Zürichs zurückgibt. Benutzen Sie dafür den vorgegebenen Variablennamen. Ähnlich bei der Anzahl an Hektaren, die der Wald in Zürich umfasst: Ersetzen Sie das zweite `None` durch eine Formel (siehe Shapely-Manual), die Ihnen die Fläche in Hektaren zurückgbit.
Sie können die Funktion `write_geometries_to_files()` anwenden, um andere geometrische Objekte in einem bestimmten File zu speichern. Die Stadtgrenzen als File zu haben, ist sicher sinnvoll. Speichern Sie deshalb das Shapley-Objekt von `cascaded_union()` (siehe oben) in einem separaten File ab.
```
# ---------------------------------------------
# PART 3) DETERMINE THE FORESTS IN THE CITY OF ZURICH
# Intersect both objects and write the shapely geometry object to a new file
forests_within_zurich = united_districts.intersection(united_forests)
forests_area_ha = round(forests_within_zurich.area / 10000, 2)
print('Die Fläche des Waldes in Zürich beträgt {} ha.'.format(forests_area_ha))
write_geometries_to_files(forests_within_zurich, out_file_forests_in_zurich, out_driver, out_crs)
# Write the united geometry of Zurich to a file
write_geometries_to_files(united_districts, out_file_stadt_zuerich, out_driver, out_crs)
# Plot the results
show_map(map_layer_1=out_file_districts, map_layer_2=out_file_forests_in_zurich)
print('Done.')
```
## Aufgabe 2 (optional)
Berechnen Sie für jeden Stadtkreis deren Waldfläche mit einer geeigneten Shapely-Methode und speichern Sie diese Information als neues Attribut direkt ins File mit den Stadtkreisen. Beachten Sie, dass Sie hierfür das Schema anpassen müssen.
# Erkenntnisse
Mit grosser Wahrscheinlichkeit beinhaltete die heutige Übung viel Neues für Sie. Welche Parameter konnten Sie modellieren, welche nicht? Notieren Sie im anschliessenden Feld Ihre wichtigsten Erkenntnisse von heute:
*[Ihre Notizen]*
# Projekt
Arbeiten Sie am Projekt weiter und wenden Sie das, was Sie heute gelernt haben, auf Ihr Projekt an. Bereiten Sie die Daten so vor, dass wir nächste Woche mit der vektorbasierten Datenverarbeitung beginnen können. Bestimmen Sie zudem alle Referenzsysteme Ihrer Daten – es kann nämlich vorkommen, dass die Daten in unterschiedlichen Referenzsystemen gespeichert sind.
| github_jupyter |
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-59152712-8"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-59152712-8');
</script>
# Start-to-Finish Example: Validating Shifted Kerr-Schild initial data against ETK version:
## Author: Patrick Nelson
**Notebook Status:** <font color='green'><b>Validated</b></font>
**Validation Notes:** This module validates all expressions used to set up initial data in
* [Tutorial-ADM_Initial_Data-ShiftedKerrSchild](../Tutorial-ADM_Initial_Data-ShiftedKerrSchild.ipynb)
against the C-code implementation of these expressions found in the original (trusted) [`GiRaFFEfood` Einstein Toolkit thorn](link), and confirms roundoff-level agreement.
### NRPy+ Source Code for this module:
* [BSSN/ShiftedKerrSchild.py](../../edit/BSSN/ShiftedKerrSchild.py) [\[**tutorial**\]](../Tutorial-ADM_Initial_Data-ShiftedKerrSchild.ipynb) Generates Exact Wald initial data
## Introduction:
This notebook validates the initial data routines that set up the Shifted Kerr-Schild initial spacetime data against the ETK implementation of the same equations.
When this notebook is run, the significant digits of agreement between the old ETK and new NRPy+ versions of the algorithm will be evaluated. If the agreement falls below a thresold, the point, quantity, and level of agreement are reported [here](#compile_run).
<a id='toc'></a>
# Table of Contents
$$\label{toc}$$
This notebook is organized as follows
1. [Step 1](#setup): Set up core functions and parameters for unit testing the initial data algorithms
1. [Step 1.a](#spacetime) Generate the spacetime metric
1. [Step 1.b](#download) Download original ETK files
1. [Step 1.c](#free_params) Output C codes needed for declaring and setting Cparameters; also set `free_parameters.h`
1. [Step 1.d](#interface) Create dummy files for the CCTK version of the code
1. [Step 2](#mainc): `ShiftedKerrSchild_unit_test.c`: The Main C Code
1. [Step 2.a](#compile_run): Compile and run the code to validate the output
1. [Step 3](#drift_notes): Output this notebook to $\LaTeX$-formatted PDF file
1. [Step 4](#latex_pdf_output): Output this notebook to $\LaTeX$-formatted PDF file
<a id='setup'></a>
# Step 1: Set up core functions and parameters for unit testing the initial data algorithms" \[Back to [top](#toc)\]
$$\label{setup}$$
We'll start by appending the relevant paths to `sys.path` so that we can access sympy modules in other places. Then, we'll import NRPy+ core functionality and set up a directory in which to carry out our test. We will also declare the gridfunctions that are needed for this portion of the code.
```
import os, sys # Standard Python modules for multiplatform OS-level functions
# First, we'll add the parent directory to the list of directories Python will check for modules.
nrpy_dir_path = os.path.join("..")
if nrpy_dir_path not in sys.path:
sys.path.append(nrpy_dir_path)
nrpy_dir_path = os.path.join("..","..")
if nrpy_dir_path not in sys.path:
sys.path.append(nrpy_dir_path)
from outputC import outCfunction, lhrh # NRPy+: Core C code output module
import sympy as sp # SymPy: The Python computer algebra package upon which NRPy+ depends
import finite_difference as fin # NRPy+: Finite difference C code generation module
import NRPy_param_funcs as par # NRPy+: Parameter interface
import grid as gri # NRPy+: Functions having to do with numerical grids
import indexedexp as ixp # NRPy+: Symbolic indexed expression (e.g., tensors, vectors, etc.) support
import reference_metric as rfm # NRPy+: Reference metric support
import cmdline_helper as cmd # NRPy+: Multi-platform Python command-line interface
out_dir = "Validation/"
cmd.mkdir(out_dir)
thismodule = "Start_to_Finish_UnitTest-GiRaFFEfood_NRPy"
# Register the gridfunctions we need for this function
gammaDD = ixp.register_gridfunctions_for_single_rank2("AUXEVOL","gammaDD","sym01")
betaU = ixp.register_gridfunctions_for_single_rank1("AUXEVOL","betaU")
alpha = gri.register_gridfunctions("AUXEVOL","alpha")
```
<a id='spacetime'></a>
## Step 1.a: Generate the spacetime metric \[Back to [top](#toc)\]
$$\label{spacetime}$$
While many of the initial data we will use assume a flat background spacetime, some will require a specific metric. We will set those up as needed here.
```
# Exact Wald is more complicated. We'll need the Shifted Kerr Schild metric in Cartesian coordinates.
import BSSN.ShiftedKerrSchild as sks
sks.ShiftedKerrSchild(True)
import reference_metric as rfm
par.set_parval_from_str("reference_metric::CoordSystem","Cartesian")
rfm.reference_metric()
# Use the Jacobian matrix to transform the vectors to Cartesian coordinates.
drrefmetric__dx_0UDmatrix = sp.Matrix([[sp.diff(rfm.xxSph[0],rfm.xx[0]), sp.diff(rfm.xxSph[0],rfm.xx[1]), sp.diff(rfm.xxSph[0],rfm.xx[2])],
[sp.diff(rfm.xxSph[1],rfm.xx[0]), sp.diff(rfm.xxSph[1],rfm.xx[1]), sp.diff(rfm.xxSph[1],rfm.xx[2])],
[sp.diff(rfm.xxSph[2],rfm.xx[0]), sp.diff(rfm.xxSph[2],rfm.xx[1]), sp.diff(rfm.xxSph[2],rfm.xx[2])]])
dx__drrefmetric_0UDmatrix = drrefmetric__dx_0UDmatrix.inv()
gammaDD = ixp.zerorank2()
for i in range(3):
for j in range(3):
for k in range(3):
for l in range(3):
gammaDD[i][j] += drrefmetric__dx_0UDmatrix[(k,i)]*drrefmetric__dx_0UDmatrix[(l,j)]*sks.gammaSphDD[k][l].subs(sks.r,rfm.xxSph[0]).subs(sks.th,rfm.xxSph[1])
betaU = ixp.zerorank1()
for i in range(3):
for j in range(3):
betaU[i] += dx__drrefmetric_0UDmatrix[(i,j)]*sks.betaSphU[j].subs(sks.r,rfm.xxSph[0]).subs(sks.th,rfm.xxSph[1])
# We only need to set alpha and betaU in C for the original Exact Wald
name = "Shifted_Kerr_Schild_initial_metric"
desc = "Generate a spinning black hole with Shifted Kerr Schild metric."
values_to_print = [
lhrh(lhs=gri.gfaccess("auxevol_gfs","gammaDD00"),rhs=gammaDD[0][0]),
lhrh(lhs=gri.gfaccess("auxevol_gfs","gammaDD01"),rhs=gammaDD[0][1]),
lhrh(lhs=gri.gfaccess("auxevol_gfs","gammaDD02"),rhs=gammaDD[0][2]),
lhrh(lhs=gri.gfaccess("auxevol_gfs","gammaDD11"),rhs=gammaDD[1][1]),
lhrh(lhs=gri.gfaccess("auxevol_gfs","gammaDD12"),rhs=gammaDD[1][2]),
lhrh(lhs=gri.gfaccess("auxevol_gfs","gammaDD22"),rhs=gammaDD[2][2]),
lhrh(lhs=gri.gfaccess("auxevol_gfs","betaU0"),rhs=betaU[0]),
lhrh(lhs=gri.gfaccess("auxevol_gfs","betaU1"),rhs=betaU[1]),
lhrh(lhs=gri.gfaccess("auxevol_gfs","betaU2"),rhs=betaU[2]),
lhrh(lhs=gri.gfaccess("auxevol_gfs","alpha"),rhs=sks.alphaSph.subs(sks.r,rfm.xxSph[0]).subs(sks.th,rfm.xxSph[1]))
]
outCfunction(
outfile = os.path.join(out_dir,name+".h"), desc=desc, name=name,
params ="const paramstruct *params,REAL *xx[3],REAL *auxevol_gfs",
body = fin.FD_outputC("returnstring",values_to_print,params="outCverbose=False").replace("IDX4","IDX4S"),
loopopts ="AllPoints,Read_xxs")
```
<a id='download'></a>
## Step 1.b: Download original ETK files \[Back to [top](#toc)\]
$$\label{download}$$
Here, we download the relevant portion of the original `GiRaFFE` code from Bitbucket.
```
# First download the original GiRaFFE source code
import urllib
original_file_url = [
"https://bitbucket.org/zach_etienne/wvuthorns/raw/0a82c822748baf754c153db484d8bd2d0b7e39cb/ShiftedKerrSchild/src/ShiftedKerrSchild.c",
]
original_file_name = [
"ShiftedKerrSchild.c",
]
for i in range(len(original_file_url)):
original_file_path = os.path.join(out_dir,original_file_name[i])
# Then download the original GiRaFFE source code
# We try it here in a couple of ways in an attempt to keep
# the code more portable
try:
original_file_code = urllib.request.urlopen(original_file_url[i]).read().decode('utf-8')
except:
original_file_code = urllib.urlopen(original_file_url[i]).read().decode('utf-8')
# Write down the file the original GiRaFFE source code
with open(original_file_path,"w") as file:
file.write(original_file_code)
```
<a id='free_params'></a>
## Step 1.c: Output C codes needed for declaring and setting Cparameters; also set `free_parameters.h` \[Back to [top](#toc)\]
$$\label{free_params}$$
Based on declared NRPy+ Cparameters, first we generate `declare_Cparameters_struct.h`, `set_Cparameters_default.h`, and `set_Cparameters[-SIMD].h`.
Then we output `free_parameters.h`, which sets some basic grid parameters as well as the speed limit parameter we need for this function.
```
# Step 3.d
# Step 3.d.ii: Set free_parameters.h
with open(os.path.join(out_dir,"free_parameters.h"),"w") as file:
file.write("""
// Set free-parameter values.
const int NGHOSTS = 3;
// Set free-parameter values for the initial data.
// Override parameter defaults with values based on command line arguments and NGHOSTS.
const int Nx0x1x2 = 5;
params.Nxx0 = Nx0x1x2;
params.Nxx1 = Nx0x1x2;
params.Nxx2 = Nx0x1x2;
params.Nxx_plus_2NGHOSTS0 = params.Nxx0 + 2*NGHOSTS;
params.Nxx_plus_2NGHOSTS1 = params.Nxx1 + 2*NGHOSTS;
params.Nxx_plus_2NGHOSTS2 = params.Nxx2 + 2*NGHOSTS;
// Step 0d: Set up space and time coordinates
// Step 0d.i: Declare \Delta x^i=dxx{0,1,2} and invdxx{0,1,2}, as well as xxmin[3] and xxmax[3]:
const REAL xxmin[3] = {-1.5,-1.5,-1.5};
const REAL xxmax[3] = { 1.5, 1.5, 1.5};
params.dxx0 = (xxmax[0] - xxmin[0]) / ((REAL)params.Nxx0);
params.dxx1 = (xxmax[1] - xxmin[1]) / ((REAL)params.Nxx1);
params.dxx2 = (xxmax[2] - xxmin[2]) / ((REAL)params.Nxx2);
params.invdx0 = 1.0 / params.dxx0;
params.invdx1 = 1.0 / params.dxx1;
params.invdx2 = 1.0 / params.dxx2;
params.r0 = 0.4;
params.a = 0.0;
\n""")
# Generates declare_Cparameters_struct.h, set_Cparameters_default.h, and set_Cparameters[-SIMD].h
par.generate_Cparameters_Ccodes(os.path.join(out_dir))
```
<a id='interface'></a>
## Step 1.d: Create dummy files for the CCTK version of the code \[Back to [top](#toc)\]
$$\label{interface}$$
The original `GiRaFFE` code depends on some functionalities of the CCTK. Since we only care about this one small function, we can get around this by creating some nearly-empty, non-functional files that can be included to satisfy the pre-processor without changing functionality. We will later replace what little functionality we need with some basic global variables and macros.
```
#include "cctk.h"
#include "cctk_Arguments.h"
#include "cctk_Parameters.h"
with open(os.path.join(out_dir,"cctk.h"),"w") as file:
file.write("""//""")
with open(os.path.join(out_dir,"cctk_Arguments.h"),"w") as file:
file.write("""#define DECLARE_CCTK_ARGUMENTS //
#define CCTK_ARGUMENTS void
""")
with open(os.path.join(out_dir,"cctk_Parameters.h"),"w") as file:
file.write("""#define DECLARE_CCTK_PARAMETERS //
""")
```
<a id='mainc'></a>
# Step 2: `ShiftedKerrSchild_unit_test.C`: The Main C Code \[Back to [top](#toc)\]
$$\label{mainc}$$
Now that we have our vector potential and analytic magnetic field to compare against, we will start writing our unit test. We'll also import common C functionality, define `REAL`, the number of ghost zones, and the faces, and set the standard macros for NRPy+ style memory access.
```
%%writefile $out_dir/ShiftedKerrSchild_unit_test.C
// These are common packages that we are likely to need.
#include "stdio.h"
#include "stdlib.h"
#include "math.h"
#include "stdint.h" // Needed for Windows GCC 6.x compatibility
#define REAL double
#include "declare_Cparameters_struct.h"
// Standard NRPy+ memory access:
#define IDX4S(g,i,j,k) \
( (i) + Nxx_plus_2NGHOSTS0 * ( (j) + Nxx_plus_2NGHOSTS1 * ( (k) + Nxx_plus_2NGHOSTS2 * (g) ) ) )
// Standard formula to calculate significant digits of agreement:
#define SDA(a,b) 1.0-log10(2.0*fabs(a-b)/(fabs(a)+fabs(b)))
// Memory access definitions for NRPy+
#define GAMMADD00GF 0
#define GAMMADD01GF 1
#define GAMMADD02GF 2
#define GAMMADD11GF 3
#define GAMMADD12GF 4
#define GAMMADD22GF 5
#define BETAU0GF 6
#define BETAU1GF 7
#define BETAU2GF 8
#define ALPHAGF 9
#define KDD00GF 10
#define KDD01GF 11
#define KDD02GF 12
#define KDD11GF 13
#define KDD12GF 14
#define KDD22GF 15
#define NUM_AUXEVOL_GFS 16
// Include the functions that we want to test:
#include "Shifted_Kerr_Schild_initial_metric.h"
// Define CCTK macros
#define CCTK_REAL double
#define CCTK_INT int
#define CCTK_VPARAMWARN(...) //
#define CCTK_EQUALS(a,b) 1
struct cGH{};
const cGH* cctkGH;
// More definitions to interface with ETK code:
const int cctk_lsh[3] = {11,11,11};
const int grid_size = cctk_lsh[0]*cctk_lsh[1]*cctk_lsh[2];
import os
gfs_list = ['x','y','z','r','SKSgrr','SKSgrth','SKSgrph','SKSgthth','SKSgthph','SKSgphph','SKSbetar','SKSbetath','SKSbetaph']
with open(os.path.join(out_dir,"ShiftedKerrSchild_unit_test.C"), 'a') as file:
for gf in gfs_list:
file.write("CCTK_REAL *"+gf+" = (CCTK_REAL *)malloc(sizeof(CCTK_REAL)*grid_size);\n")
%%writefile -a $out_dir/ShiftedKerrSchild_unit_test.C
CCTK_REAL *alp;
CCTK_REAL *betax;
CCTK_REAL *betay;
CCTK_REAL *betaz;
CCTK_REAL *gxx;
CCTK_REAL *gxy;
CCTK_REAL *gxz;
CCTK_REAL *gyy;
CCTK_REAL *gyz;
CCTK_REAL *gzz;
CCTK_REAL *kxx;
CCTK_REAL *kxy;
CCTK_REAL *kxz;
CCTK_REAL *kyy;
CCTK_REAL *kyz;
CCTK_REAL *kzz;
CCTK_REAL KerrSchild_radial_shift;
CCTK_REAL BH_mass;
CCTK_REAL BH_spin;
// Dummy ETK function:
#define CCTK_GFINDEX3D(cctkGH,i,j,k) (i) + cctk_lsh[0] * ( (j) + cctk_lsh[1] * (k) )
#include "ShiftedKerrSchild.c"
int main() {
paramstruct params;
#include "set_Cparameters_default.h"
// Step 0c: Set free parameters, overwriting Cparameters defaults
// by hand or with command-line input, as desired.
#include "free_parameters.h"
#include "set_Cparameters-nopointer.h"
// Set CCTK parameters to match NRPy+ parameters
KerrSchild_radial_shift = r0;
BH_mass = M;
BH_spin = a;
// Step 0d.ii: Set up uniform coordinate grids
REAL *xx[3];
xx[0] = (REAL *)malloc(sizeof(REAL)*Nxx_plus_2NGHOSTS0);
xx[1] = (REAL *)malloc(sizeof(REAL)*Nxx_plus_2NGHOSTS1);
xx[2] = (REAL *)malloc(sizeof(REAL)*Nxx_plus_2NGHOSTS2);
for(int j=0;j<Nxx_plus_2NGHOSTS0;j++) xx[0][j] = xxmin[0] + (j-NGHOSTS)*dxx0;
for(int j=0;j<Nxx_plus_2NGHOSTS1;j++) xx[1][j] = xxmin[1] + (j-NGHOSTS)*dxx1;
for(int j=0;j<Nxx_plus_2NGHOSTS2;j++) xx[2][j] = xxmin[2] + (j-NGHOSTS)*dxx2;
for(int k=0;k<Nxx_plus_2NGHOSTS2;k++)
for(int j=0;j<Nxx_plus_2NGHOSTS1;j++)
for(int i=0;i<Nxx_plus_2NGHOSTS0;i++) {
int index = CCTK_GFINDEX3D(cctkGH,i,j,k);
x[index] = xx[0][i];
y[index] = xx[1][j];
z[index] = xx[2][k];
r[index] = sqrt(x[index]*x[index] + y[index]*y[index] + z[index]*z[index]);
}
//for(int j=0;j<Nxx_plus_2NGHOSTS0;j++) printf("x[%d] = %.5e\n",j,xx[0][j]);
// This is the array to which we'll write the NRPy+ variables.
REAL *auxevol_gfs = (REAL *)malloc(sizeof(REAL) * NUM_AUXEVOL_GFS * Nxx_plus_2NGHOSTS2 * Nxx_plus_2NGHOSTS1 * Nxx_plus_2NGHOSTS0);
REAL *auxevol_ETK_gfs = (REAL *)malloc(sizeof(REAL) * NUM_AUXEVOL_GFS * Nxx_plus_2NGHOSTS2 * Nxx_plus_2NGHOSTS1 * Nxx_plus_2NGHOSTS0);
// Memory access for metric gridfunctions for Exact Wald:
gxx = auxevol_ETK_gfs + (grid_size*GAMMADD00GF);
gxy = auxevol_ETK_gfs + (grid_size*GAMMADD01GF);
gxz = auxevol_ETK_gfs + (grid_size*GAMMADD02GF);
gyy = auxevol_ETK_gfs + (grid_size*GAMMADD11GF);
gyz = auxevol_ETK_gfs + (grid_size*GAMMADD12GF);
gzz = auxevol_ETK_gfs + (grid_size*GAMMADD22GF);
alp = auxevol_ETK_gfs + (grid_size*ALPHAGF);
betax = auxevol_ETK_gfs + (grid_size*BETAU0GF);
betay = auxevol_ETK_gfs + (grid_size*BETAU1GF);
betaz = auxevol_ETK_gfs + (grid_size*BETAU2GF);
kxx = auxevol_ETK_gfs + (grid_size*KDD00GF);
kxy = auxevol_ETK_gfs + (grid_size*KDD01GF);
kxz = auxevol_ETK_gfs + (grid_size*KDD02GF);
kyy = auxevol_ETK_gfs + (grid_size*KDD11GF);
kyz = auxevol_ETK_gfs + (grid_size*KDD12GF);
kzz = auxevol_ETK_gfs + (grid_size*KDD22GF);
Shifted_Kerr_Schild_initial_metric(¶ms,xx,auxevol_gfs);
ShiftedKS_ID();
int all_agree = 1;
for(int i0=0;i0<Nxx_plus_2NGHOSTS0;i0++){
for(int i1=0;i1<Nxx_plus_2NGHOSTS1;i1++){
for(int i2=0;i2<Nxx_plus_2NGHOSTS2;i2++){
if(SDA(auxevol_gfs[IDX4S(BETAU0GF, i0,i1,i2)],betax[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)])<10.0){
printf("Quantity betaU0 only agrees with the original GiRaFFE to %.2f digits at i0,i1,i2=%d,%d,%d!\n",
SDA(auxevol_gfs[IDX4S(BETAU0GF, i0,i1,i2)],betax[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)]),i0,i1,i2);
all_agree=0;
}
if(SDA(auxevol_gfs[IDX4S(BETAU1GF, i0,i1,i2)],betay[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)])<10.0){
printf("Quantity betaU1 only agrees with the original GiRaFFE to %.2f digits at i0,i1,i2=%d,%d,%d!\n",
SDA(auxevol_gfs[IDX4S(BETAU1GF, i0,i1,i2)],betay[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)]),i0,i1,i2);
all_agree=0;
}
if(SDA(auxevol_gfs[IDX4S(BETAU2GF, i0,i1,i2)],betaz[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)])<10.0){
printf("Quantity betaU2 only agrees with the original GiRaFFE to %.2f digits at i0,i1,i2=%d,%d,%d!\n",
SDA(auxevol_gfs[IDX4S(BETAU2GF, i0,i1,i2)],betaz[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)]),i0,i1,i2);
all_agree=0;
}
if(SDA(auxevol_gfs[IDX4S(GAMMADD00GF, i0,i1,i2)],gxx[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)])<10.0){
printf("Quantity betaU0 only agrees with the original GiRaFFE to %.2f digits at i0,i1,i2=%d,%d,%d!\n",
SDA(auxevol_gfs[IDX4S(GAMMADD00GF, i0,i1,i2)],gxx[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)]),i0,i1,i2);
all_agree=0;
}
if(SDA(auxevol_gfs[IDX4S(GAMMADD11GF, i0,i1,i2)],gyy[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)])<10.0){
printf("Quantity betaU1 only agrees with the original GiRaFFE to %.2f digits at i0,i1,i2=%d,%d,%d!\n",
SDA(auxevol_gfs[IDX4S(GAMMADD11GF, i0,i1,i2)],gyy[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)]),i0,i1,i2);
all_agree=0;
}
if(SDA(auxevol_gfs[IDX4S(GAMMADD22GF, i0,i1,i2)],gzz[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)])<10.0){
printf("Quantity betaU2 only agrees with the original GiRaFFE to %.2f digits at i0,i1,i2=%d,%d,%d!\n",
SDA(auxevol_gfs[IDX4S(GAMMADD22GF, i0,i1,i2)],gzz[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)]),i0,i1,i2);
all_agree=0;
}
//printf("NRPy: %.15e,%.15e,%.15e\n",auxevol_gfs[IDX4S(BETAU0GF, i0,i1,i2)],auxevol_gfs[IDX4S(BETAU1GF, i0,i1,i2)],auxevol_gfs[IDX4S(BETAU2GF, i0,i1,i2)]);
//printf("CCTK: %.15e,%.15e,%.15e\n",betax[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)],betay[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)],betaz[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)]);
//printf("NRPy: %.15e,%.15e,%.15e\n",auxevol_gfs[IDX4S(GAMMADD01GF, i0,i1,i2)],auxevol_gfs[IDX4S(GAMMADD02GF, i0,i1,i2)],auxevol_gfs[IDX4S(GAMMADD12GF, i0,i1,i2)]);
//printf("CCTK: %.15e,%.15e,%.15e\n",gxy[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)],gxz[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)],gyz[CCTK_GFINDEX3D(cctkGH,i0,i1,i2)]);
}
}
}
if(all_agree) printf("All quantities agree at all points!\n");
with open(os.path.join(out_dir,"ShiftedKerrSchild_unit_test.C"), 'a') as file:
for gf in gfs_list:
file.write(" free("+gf+");\n")
%%writefile -a $out_dir/ShiftedKerrSchild_unit_test.C
free(auxevol_gfs);
free(auxevol_ETK_gfs);
}
```
<a id='compile_run'></a>
## Step 2.a: Compile and run the code to validate the output \[Back to [top](#toc)\]
$$\label{compile_run}$$
Finally, we can compile and run the code we have written. Once run, this code will output the level of agreement between the two codes and some information to help interpret those numbers.
```
import time
print("Now compiling, should take ~2 seconds...\n")
start = time.time()
# cmd.C_compile(os.path.join(out_dir,"ShiftedKerrSchild_unit_test.c"), os.path.join(out_dir,"ShiftedKerrSchild_unit_test"))
!g++ -Ofast -fopenmp -march=native -funroll-loops Validation/ShiftedKerrSchild_unit_test.C -o Validation/ShiftedKerrSchild_unit_test -lstdc++
end = time.time()
print("Finished in "+str(end-start)+" seconds.\n\n")
results_file = "out_ShiftedKerrSchild_test.txt"
# os.chdir(out_dir)
os.chdir(out_dir)
# cmd.Execute(os.path.join("GiRaFFEfood_NRPy_unit_test"))
cmd.Execute("ShiftedKerrSchild_unit_test",file_to_redirect_stdout=results_file)
os.chdir(os.path.join("../"))
```
Here, we add some emergency brakes so that if the output from the test isn't good, we throw an error to stop the notebook dead in its tracks. This way, our automatic testing infrastructure can let us know if something goes wrong. We will also print the output from the test for convenience's sake.
```
with open(os.path.join(out_dir,results_file),"r") as file:
output = file.readline()
print(output)
if output!="All quantities agree at all points!\n": # If this isn't the first line of this file, something went wrong!
sys.exit(1)
```
<a id='latex_pdf_output'></a>
# Step 4: Output this notebook to $\LaTeX$-formatted PDF file \[Back to [top](#toc)\]
$$\label{latex_pdf_output}$$
The following code cell converts this Jupyter notebook into a proper, clickable $\LaTeX$-formatted PDF file. After the cell is successfully run, the generated PDF may be found in the root NRPy+ tutorial directory, with filename
[Tutorial-Start_to_Finish_UnitTest-GiRaFFEfood_NRPy.pdf](Tutorial-Start_to_Finish_UnitTest-GiRaFFEfood_NRPy.pdf) (Note that clicking on this link may not work; you may need to open the PDF file through another means.)
```
import cmdline_helper as cmd # NRPy+: Multi-platform Python command-line interface
cmd.output_Jupyter_notebook_to_LaTeXed_PDF("Tutorial-Start_to_Finish_UnitTest-GiRaFFEfood_NRPy")
```
| github_jupyter |
# Basics 3: Add a new dimension table to database and create data pipeline for it
In this lesson we add a new dimension table to our data model. The new **dim_stores** dimension describes the store where the sale was made. It also contains location information like postal code, region, city, and country. We could model location as a separate dimension, as it would be more reusable that way, but this time we choose to include location attributes directly in the **dim_stores** dimension.
## Step 1: Add a new database migration
1. Execute `taito db add dim_stores`.
2. Add the following content to the newly created files (**database/deploy/dim_stores.sql**, **database/revert/dim_stores.sql**, and **database/verify/dim_stores.sql**).
```sql
-- Deploy dim_stores to pg
BEGIN;
CREATE TABLE dim_stores (
key text PRIMARY KEY,
name text NOT NULL,
postal_code text NOT NULL,
city text NOT NULL,
country text NOT NULL
);
CREATE VIEW load_stores AS SELECT * FROM dim_stores;
CREATE OR REPLACE FUNCTION load_stores() RETURNS TRIGGER AS $$
BEGIN
INSERT INTO dim_stores VALUES (NEW.*)
ON CONFLICT (key) DO
UPDATE SET
name = EXCLUDED.name,
postal_code = EXCLUDED.postal_code,
city = EXCLUDED.city,
country = EXCLUDED.country;
RETURN new;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER load_stores
INSTEAD OF INSERT ON load_stores
FOR EACH ROW EXECUTE PROCEDURE load_stores();
COMMIT;
```
```sql
-- Revert dim_stores from pg
BEGIN;
DROP TRIGGER load_stores ON load_stores;
DROP FUNCTION load_stores;
DROP VIEW load_stores;
DROP TABLE dim_stores;
COMMIT;
```
```sql
-- Verify dim_stores on pg
BEGIN;
SELECT key FROM load_stores LIMIT 1;
SELECT key FROM dim_stores LIMIT 1;
ROLLBACK;
```
3. Deploy the new database migration to local database with `taito db deploy`.
## Step 2: Create a CSV files for districts and stores, and upload them to bucket
1. Create district.csv file with the following content:
```excel
Postal Code,City,Country
Unknown,Unknown,Unknown
00100,Helsinki,Finland
11122,Stockholm,Sweden
```
2. Create stores.csv file with the following content:
```excel
Name,Postal Code
Unknown,Unknown
Super Shop,00100
Super Shop,11122
```
3. Upload both files to the root folder of the bucket
## Step 3: Load the CSV file to database
Execute the following code:
```
# Imports
import pandas as pd
# Load generic helper functions
%run ../../common/jupyter.ipynb
import src_common_database as db
import src_common_storage as st
import src_common_util as util
# Read CSV files from the storage bucket
bucket = st.create_storage_bucket_client(os.environ['STORAGE_BUCKET'])
districts_csv = bucket.get_object_contents("/districts.csv")
stores_csv = bucket.get_object_contents("/stores.csv")
# Read CSV data into a Pandas dataframe
districts_df = pd.read_csv(districts_csv)
stores_df = pd.read_csv(stores_csv)
# Merge
df = pd.merge(stores_df, districts_df, on=['Postal Code','Postal Code'])
# Change dataframe schema to match the database table
db_df = df.rename(
columns = {
'Name': 'name',
'Postal Code': 'postal_code',
'City': 'city',
'Country': 'country',
},
inplace = False
)
# Generate unique key by concatenating concatenating name and country
db_df["key"] = db_df["country"] + " - " + db_df["name"]
# Write the data to the "load_stores" view
database = db.create_engine()
db_df.to_sql('load_stores', con=database, if_exists='append', index=False)
# DEBUG: Show the data stored in fact_sales. You manual data changes should have been overwritten.
pd.read_sql('select * from dim_stores', con=database).style
```
## Step 4: Add dim_store reference to the fact_sales table
This time you cannot just add the new columns to the existing fact_sales migration files, because fact_sales migration was created before the dim_sales migration. However, if you want to avoid creating a new migration just for one new column, you can do the following:
1. Move the dim_stores migration one step up in **database/sqitch.plan** so that it will be executed before fact_sales.
2. Add the new store_key column to the **database/deploy/fact_sales.sql** file:
```sql
CREATE TABLE fact_sales (
...
store_key text NOT NULL REFERENCES dim_stores (key),
...
);
UPDATE SET
...
store_key = EXCLUDED.store_key,
...
```
3. Add at least one example store to the **database/data/dev.sql** file. If the file contains fact_sales rows, add the store rows before them.
4. If the file contains fact_sales rows, add a store_key value for each example sale defined in **database/data/dev.sql**. If the file does not contain any fact_sales rows, add at least couple of example fact_sales rows.
5. Redeploy all database migrations and example data with `taito init --clean`. Redeploy is required because you altered the sqitch.plan order instead of creating a new ALTER TABLE database migration.
## Step 5 (optional): Generate database documentation
1. Generate database documentation with `taito db generate`.
2. Open the `docs/database/index.html` file with your web browser. Note that your code editor may not display these files as they have been placed in .gitignore.
3. Browse to **Relationships**.
As you can see, our database model is based on [star schema](https://en.wikipedia.org/wiki/Star_schema).
## Next lesson: [Basics 4 - Create a dataset view on top of star schema](04.ipynb)
| github_jupyter |
# Basis Functions
### 20th October 2015 Neil Lawrence
We've now seen how we may perform linear regression. Now, we are going to consider how we can perform *non-linear* regression. However, before we get into the details of how to do that we first need to consider in what ways the regression can be non-linear.
Multivariate linear regression allows us to build models that take many features into account when making our prediction. In this session we are going to introduce *basis functions*. The term seems complicated, but they are actually based on rather a simple idea. If we are doing a multivariate linear regression, we get extra features that *might* help us predict our required response variable (or target value), $y$. But what if we only have one input value? We can actually artificially generate more input values with basis functions.
## Non-linear in the Inputs
When we refer to non-linear regression, we are normally referring to whether the regression is non-linear in the input space, or non-linear in the *covariates*. The covariates are the observations that move with the target (or *response*) variable. In our notation we have been using $\mathbf{x}_i$ to represent a vector of the covariates associated with the $i$th observation. The coresponding response variable is $y_i$. If a model is non-linear in the inputs, it means that there is a non-linear function between the inputs and the response variable. Linear functions are functions that only involve multiplication and addition, in other words they can be represented through *linear algebra*. Linear regression involves assuming that a function takes the form
$$
f(\mathbf{x}) = \mathbf{w}^\top \mathbf{x}
$$
where $\mathbf{w}$ are our regression weights. A very easy way to make the linear regression non-linear is to introduce non-linear functions. When we are introducing non-linear regression these functions are known as *basis functions*.
### Basis Functions
Here's the idea, instead of working directly on the original input space, $\mathbf{x}$, we build models in a new space, $\boldsymbol{\phi}(\mathbf{x})$ where $\boldsymbol{\phi}(\cdot)$ is a *vector valued* function that is defined on the space $\mathbf{x}$.
Remember, that a vector valued function is just a vector that contains functions instead of values. Here's an example for a one dimensional input space, $x$, being projected to a *quadratic* basis. First we consider each basis function in turn, we can think of the elements of our vector as being indexed so that we have
\begin{align*}
\phi_1(x) = 1, \\
\phi_2(x) = x, \\
\phi_3(x) = x^2.
\end{align*}
Now we can consider them together by placing them in a vector,
$$
\boldsymbol{\phi}(x) = \begin{bmatrix} 1\\ x \\ x^2\end{bmatrix}.
$$
This is the idea of the vector valued function, we have simply collected the different functions together in the same vector making them notationally easier to deal with in our mathematics.
When we consider the vector valued function for each data point, then we place all the data into a matrix. The result is a matrix valued function,
$$
\boldsymbol{\Phi}(\mathbf{x}) =
\begin{bmatrix} 1 & x_1 & x_1^2 \\
1 & x_2 & x_2^2\\
\vdots & \vdots & \vdots \\
1 & x_n & x_n^2
\end{bmatrix}
$$
where we are still in the one dimensional input setting so $\mathbf{x}$ here represents a vector of our inputs with $n$ elements.
Let's try constructing such a matrix for a set of inputs. First of all, we create a function that returns the matrix valued function
```
import numpy as np # import numpy for the arrays.
def quadratic(x):
"""Take in a vector of input values and return the design matrix associated
with the basis functions."""
return np.hstack([np.ones((n, 1)), x, x**2])
```
This function takes in an $n\times 1$ dimensional vector and returns an $n\times 3$ dimensional *design matrix* containing the basis functions. We can plot those basis functions against there input as follows.
```
# ensure plots appear in the notebook.
%matplotlib inline
import pylab as plt
# first let's generate some inputs
n = 100
x = np.zeros((n, 1)) # create a data set of zeros
x[:, 0] = np.linspace(-1, 1, n) # fill it with values between -1 and 1
Phi = quadratic(x)
fig, ax = plt.subplots(figsize=(12,4))
ax.set_ylim([-1.2, 1.2]) # set y limits to ensure basis functions show.
ax.plot(x[:,0], Phi[:, 0], 'r-', label = '$\phi=1$')
ax.plot(x[:,0], Phi[:, 1], 'g-', label = '$\phi = x$')
ax.plot(x[:,0], Phi[:, 2], 'b-', label = '$\phi = x^2$')
ax.legend(loc='lower right')
ax.set_title('Quadratic Basis Functions')
```
The actual function we observe is then made up of a sum of these functions. This is the reason for the name basis. The term *basis* means 'the underlying support or foundation for an idea, argument, or process', and in this context they form the underlying support for our prediction function. Our prediction function can only be composed of a weighted linear sum of our basis functions.
### Different Basis
Before we look at the different types of basis functions available, we need to run the following cell of code that will be used in the rest of the notebook.
```
# Initial code: it uses pods.notebook.display_prediction, but with a minor modification to
# allow the use of ipywidgets
from ipywidgets import *
def display_prediction(basis, num_basis=4, wlim=(-1.,1.), fig=None, ax=None, xlim=None, ylim=None, num_points=1000, offset=0.0, **kwargs):
"""Interactive widget for displaying a prediction function based on summing separate basis functions.
:param basis: a function handle that calls the basis functions.
:type basis: function handle.
:param xlim: limits of the x axis to use.
:param ylim: limits of the y axis to use.
:param wlim: limits for the basis function weights."""
#import numpy as np
#import pylab as plt
if fig is not None:
if ax is None:
ax = fig.gca()
if xlim is None:
if ax is not None:
xlim = ax.get_xlim()
else:
xlim = (-2., 2.)
if ylim is None:
if ax is not None:
ylim = ax.get_ylim()
else:
ylim = (-1., 1.)
# initialise X and set up W arguments.
x = np.zeros((num_points, 1))
x[:, 0] = np.linspace(xlim[0], xlim[1], num_points)
param_args = {}
for i in range(num_basis):
lim = list(wlim)
if i ==0:
lim[0] += offset
lim[1] += offset
param_args['w_' + str(i)] = tuple(lim)
# helper function for making basis prediction.
def predict_basis(w, basis, x, num_basis, **kwargs):
Phi = basis(x, num_basis, **kwargs)
f = np.dot(Phi, w)
return f, Phi
if type(basis) is dict:
use_basis = basis[list(basis.keys())[0]]
else:
use_basis = basis
f, Phi = predict_basis(np.zeros((num_basis, 1)),
use_basis, x, num_basis,
**kwargs)
if fig is None:
fig, ax=plt.subplots(figsize=(12,4))
ax.set_ylim(ylim)
ax.set_xlim(xlim)
predline = ax.plot(x, f, linewidth=2)[0]
basislines = []
for i in range(num_basis):
basislines.append(ax.plot(x, Phi[:, i], 'r')[0])
ax.set_ylim(ylim)
ax.set_xlim(xlim)
def generate_function(basis, num_basis, predline, basislines, basis_args, display_basis, offset, **kwargs):
w = np.zeros((num_basis, 1))
for i in range(num_basis):
w[i] = kwargs['w_'+ str(i)]
f, Phi = predict_basis(w, basis, x, num_basis, **basis_args)
predline.set_xdata(x[:, 0])
predline.set_ydata(f)
for i in range(num_basis):
basislines[i].set_xdata(x[:, 0])
basislines[i].set_ydata(Phi[:, i])
if display_basis:
for i in range(num_basis):
basislines[i].set_alpha(1) # make visible
else:
for i in range(num_basis):
basislines[i].set_alpha(0)
display(fig)
if type(basis) is not dict:
basis = fixed(basis)
plt.close(fig)
interact(generate_function,
basis=basis,
num_basis=fixed(num_basis),
predline=fixed(predline),
basislines=fixed(basislines),
basis_args=fixed(kwargs),
offset = fixed(offset),
display_basis = False,
**param_args)
```
Our choice of basis can be made based on what our beliefs about what is appropriate for the data. For example, the polynomial basis extends the quadratic basis to arbitrary degree, so we might define the $j$th basis function associated with the model as
$$
\phi_j(x_i) = x_i^j
$$
which can be implemented as a function in code as follows
```
def polynomial(x, num_basis=4, data_limits=[-1., 1.]):
Phi = np.zeros((x.shape[0], num_basis))
for i in range(num_basis):
Phi[:, i:i+1] = x**i
return Phi
```
To aid in understanding how a basis works, we've provided you with a small interactive tool for exploring this polynomial basis. The tool can be summoned with the following command.
```
display_prediction(basis=polynomial, num_basis=10, ylim=[-3.,3])
```
Try moving the sliders around to change the weight of each basis function. Click the control box `display_basis` to show the underlying basis functions (in red). The prediction function is shown in a thick blue line. *Warning* the sliders aren't presented quite in the correct order. `w_0` is associated with the bias, `w_1` is the linear term, `w_2` the quadratic and here (because we have four basis functions) we have `w_3` for the *cubic* term. So the subscript of the weight parameter is always associated with the corresponding polynomial's degree.
### Question 1
Try increasing the number of basis functions (thereby increasing the *degree* of the resulting polynomial). Describe what you see as you increase number of basis up to 10. Is it easy to change the function in intuitive ways?
#### Question 1 Answer
When the number of basis functions increases, the complexity of the model also increases. With so many degrees of freedom, it is not easy to change the function in an intuitive way. It might be easier to change the coefficients manualy for lower degrees but not so easy for higher degrees.
## Radial Basis Functions
Another type of basis is sometimes known as a 'radial basis' because the effect basis functions are constructed on 'centres' and the effect of each basis function decreases as the radial distance from each centre increases.
```
# %load -s radial mlai.py
def radial(x, num_basis=4, data_limits=[-1., 1.]):
"Radial basis constructed using exponentiated quadratic form."
if num_basis>1:
centres=np.linspace(data_limits[0], data_limits[1], num_basis)
width = (centres[1]-centres[0])/2.
else:
centres = np.asarray([data_limits[0]/2. + data_limits[1]/2.])
width = (data_limits[1]-data_limits[0])/2.
Phi = np.zeros((x.shape[0], num_basis))
for i in range(num_basis):
Phi[:, i:i+1] = np.exp(-0.5*((x-centres[i])/width)**2)
return Phi
display_prediction(basis=radial, num_basis=4, ylim=[-2., 2.])
```
## Fourier Basis
Fourier noticed that any *stationary* function could be converted to a sum of sines and cosines. A Fourier basis is a linear weighted sum of these functions.
```
# %load -s fourier mlai.py
def fourier(x, num_basis=4, data_limits=[-2., 2.]):
"Fourier basis"
tau = 2*np.pi
span = float(data_limits[1]-data_limits[0])
Phi = np.zeros((x.shape[0], num_basis))
for i in range(num_basis):
count = float((i+1)//2)
frequency = count/span
if i % 2:
Phi[:, i:i+1] = np.sin(tau*frequency*x)
else:
Phi[:, i:i+1] = np.cos(tau*frequency*x)
return Phi
```
In this code, basis functions with an *odd* index are sine and basis functions with an *even* index are cosine. The first basis function (index 0, so cosine) has a frequency of 0 and then frequencies increase to 1, 2, 3, 4 etc every time a sine and cosine are included.
```
display_prediction(basis=fourier, num_basis=4, ylim=[-1.5, 1.5])
# %load -s relu mlai.py
def relu(x, num_basis=4, data_limits=[-1., 1.], gain=None):
"Rectified linear units basis"
if num_basis>2:
centres=np.linspace(data_limits[0], data_limits[1], num_basis)
else:
centres = np.asarray([data_limits[0]/2. + data_limits[1]/2.])
if gain is None:
gain = np.ones(num_basis-1)
Phi = np.zeros((x.shape[0], num_basis))
# Create the bias
Phi[:, 0] = 1.0
for i in range(1, num_basis):
Phi[:, i:i+1] = (gain[i-1]*x>centres[i-1])*(x-centres[i-1])
return Phi
display_prediction(basis=relu, num_basis=4, ylim=[-2., 2.])
```
## Fitting to Data
Now we are going to consider how these basis functions can be adjusted to fit to a particular data set. We will return to the olympic marathon data from last time. First we will scale the output of the data to be zero mean and variance 1.
```
import pods
data = pods.datasets.olympic_marathon_men()
y = data['Y']
x = data['X']
y -= y.mean()
y /= y.std()
```
### Question 2
Now we are going to redefine our polynomial basis. Have a careful look at the operations we perform on `x` to create `z`. We use `z` in the polynomial computation. What are we doing to the inputs? Why do you think we are changing `x` in this manner?
#### Question 2 Answer
We scale the inputs $x$ to be in the range of $[-1, 1]$. We change the $x$ this way, because polynomials (high order polynomials ) are better behaved in this range.
```
# %load -s polynomial mlai.py
def polynomial(x, num_basis=4, data_limits=[-1., 1.]):
"Polynomial basis"
centre = data_limits[0]/2. + data_limits[1]/2.
span = data_limits[1] - data_limits[0]
z = x - centre
z = 2*z/span
Phi = np.zeros((x.shape[0], num_basis))
for i in range(num_basis):
Phi[:, i:i+1] = z**i
return Phi
#x[:, 0] = np.linspace(1888, 2020, 1000)
fig, ax = plt.subplots(figsize=(12,4))
ax.plot(x, y, 'rx')
display_prediction(basis=dict(radial=radial, polynomial=polynomial, fourier=fourier, relu=relu),
ylim=[-2.0, 4.],
data_limits=(1888, 2020),
fig=fig, ax=ax,
offset=0.,
wlim = (-4, 4),
num_basis=4)
```
### Question 3
Use the tool provided above to try and find the best fit you can to the data. Explore the parameter space and give the weight values you used for the
(a) polynomial basis
(b) RBF basis
(c) Fourier basis
Write your answers in the code box below creating a new vector of parameters (in the correct order!) for each basis.
```
# Question 3 Answer Code
# (a) polynomial
###### Edit these lines #####
w_0 = -0.2
w_1 = -1
w_2 = 1
w_3 = -1
##############################
w_polynomial = np.asarray([[w_0], [w_1], [w_2], [w_3]])
# (b) rbf
###### Edit these lines #####
w_0 = 2.2
w_1 = 0
w_2 = -1
w_3 = -1
##############################
w_rbf = np.asarray([[w_0], [w_1], [w_2], [w_3]])
# (c) fourier
###### Edit these lines #####
w_0 = 0.1
w_1 = 0
w_2 = -1
w_3 = -1
##############################
w_fourier = np.asarray([[w_0], [w_1], [w_2], [w_3]])
np.asarray([[1, 2, 3, 4]]).shape
```
We like to make use of *design* matrices for our data. Design matrices, as you will recall, involve placing the data points into rows of the matrix and data features into the columns of the matrix. By convention, we are referincing a vector with a bold lower case letter, and a matrix with a bold upper case letter. The design matrix is therefore given by
$$
\boldsymbol{\Phi} = \begin{bmatrix} 1 & \mathbf{x} & \mathbf{x}^2\end{bmatrix}
$$
### Non-linear but linear in the Parameters
One rather nice aspect of our model is that whilst it is non-linear in the inputs, it is still linear in the parameters $\mathbf{w}$. This means that our derivations from before continue to operate to allow us to work with this model. In fact, although this is a non-linear regression it is still known as a *linear model* because it is linear in the parameters,
$$
f(\mathbf{x}) = \mathbf{w}^\top \boldsymbol{\phi}(\mathbf{x})
$$
where the vector $\mathbf{x}$ appears inside the basis functions, making our result, $f(\mathbf{x})$ non-linear in the inputs, but $\mathbf{w}$ appears outside our basis function, making our result *linear* in the parameters. In practice, our basis function itself may contain its own set of parameters,
$$
f(\mathbf{x}) = \mathbf{w}^\top \boldsymbol{\phi}(\mathbf{x}; \boldsymbol{\theta}),
$$
that we've denoted here as $\boldsymbol{\theta}$. If these parameters appear inside the basis function then our model is *non-linear* in these parameters.
### Question 4
For the following prediction functions state whether the model is linear in the inputs, the parameters or both.
(a) $f(x) = w_1x_1 + w_2$
(b) $f(x) = w_1\exp(x_1) + w_2x_2 + w_3$
(c) $f(x) = \log(x_1^{w_1}) + w_2x_2^2 + w_3$
(d) $f(x) = \exp(-\sum_i(x_i - w_i)^2)$
(e) $f(x) = \exp(-\mathbf{w}^\top \mathbf{x})$
*25 marks*
#### Question 4 Answer
(a) The model is linear in both the inputs and the parameters.
(b) The model is non-linear in the inputs, but linear in the parameters.
(c) The model is non-linear in the inputs, but linear in the parameters.
(d) The model is non-linear in both the inputs and the parameters.
(e) The model is non-linear in both the inputs and the parameters.
## Fitting the Model Yourself
You now have everything you need to fit a non-linear (in the inputs) basis function model to the marathon data.
### Question 5
Choose one of the basis functions you have explored above. Compute the design matrix on the covariates (or input data), `x`. Use the design matrix and the response variable `y` to solve the following linear system for the model parameters `w`.
$$
\boldsymbol{\Phi}^\top\boldsymbol{\Phi}\mathbf{w} = \boldsymbol{\Phi}^\top \mathbf{y}
$$
Compute the corresponding error on the training data. How does it compare to the error you were able to achieve fitting the basis above? Plot the form of your prediction function from the least squares estimate alongside the form of you prediction function you fitted by hand.
```
# Question 5 Answer Code
# Write code for you answer to this question in this box
import pods
data = pods.datasets.olympic_marathon_men()
y = data['Y']
x = data['X']
y -= y.mean()
y /= y.std()
Phi = radial(x, num_basis=4, data_limits=[1896, 2012])
w = np.linalg.solve(np.dot(Phi.T, Phi), np.dot(Phi.T, y))
f = np.dot(Phi, w)
e = ((y-f)**2).sum()
print ('Calculated error:', e)
f_estimate = np.dot(Phi, w_rbf)
e_estimate = ((y-f_estimate)**2).sum()
print ('Estimated error:', e_estimate)
plt.plot(x, y, 'rx')
plt.plot(x, f, 'b-')
plt.plot(x, f_estimate, 'g-')
```
## Lecture on Basis Functions from GPRS Uganda
```
from IPython.display import YouTubeVideo
YouTubeVideo('PoNbOnUnOao')
```
## Use of QR Decomposition for Numerical Stability
In the last session we showed how rather than computing $\mathbf{X}^\top\mathbf{X}$ as an intermediate step to our solution, we could compute the solution to the regressiond directly through [QR-decomposition](http://en.wikipedia.org/wiki/QR_decomposition). Now we will consider an example with non linear basis functions where such computation is critical for forming the right answer.
Can you solve *Question 5* using QR decomposition?
| github_jupyter |
# Aerospace and Defense Portfolio Risk and Returns
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import math
import warnings
warnings.filterwarnings("ignore")
# fix_yahoo_finance is used to fetch data
import yfinance as yf
yf.pdr_override()
# input
# Aerospace and Defense
symbols = ['LMT','NOC','RTN']
start = '2019-01-01'
end = '2020-04-24'
df = pd.DataFrame()
for s in symbols:
df[s] = yf.download(s,start,end)['Adj Close']
from datetime import datetime
from dateutil import relativedelta
d1 = datetime.strptime(start, "%Y-%m-%d")
d2 = datetime.strptime(end, "%Y-%m-%d")
delta = relativedelta.relativedelta(d2,d1)
print('How many years of investing?')
print('%s years' % delta.years)
number_of_years = delta.years
days = (df.index[-1] - df.index[0]).days
days
df.head()
df.tail()
plt.figure(figsize=(12,8))
plt.plot(df)
plt.title('Aerospace and Defense Stocks Closing Price')
plt.legend(labels=df.columns)
# Normalize the data
normalize = (df - df.min())/ (df.max() - df.min())
plt.figure(figsize=(18,12))
plt.plot(normalize)
plt.title('Aerospace and Defense Stocks Normalize')
plt.legend(labels=normalize.columns)
stock_rets = df.pct_change().dropna()
plt.figure(figsize=(12,8))
plt.plot(stock_rets)
plt.title('Aerospace and Defense Stocks Returns')
plt.legend(labels=stock_rets.columns)
plt.figure(figsize=(12,8))
plt.plot(stock_rets.cumsum())
plt.title('Aerospace and Defense Stocks Returns Cumulative Sum')
plt.legend(labels=stock_rets.columns)
sns.set(style='ticks')
ax = sns.pairplot(stock_rets, diag_kind='hist')
nplot = len(stock_rets.columns)
for i in range(nplot) :
for j in range(nplot) :
ax.axes[i, j].locator_params(axis='x', nbins=6, tight=True)
ax = sns.PairGrid(stock_rets)
ax.map_upper(plt.scatter, color='purple')
ax.map_lower(sns.kdeplot, color='blue')
ax.map_diag(plt.hist, bins=30)
for i in range(nplot) :
for j in range(nplot) :
ax.axes[i, j].locator_params(axis='x', nbins=6, tight=True)
plt.figure(figsize=(7,7))
corr = stock_rets.corr()
# plot the heatmap
sns.heatmap(corr,
xticklabels=corr.columns,
yticklabels=corr.columns,
cmap="Reds")
# Box plot
stock_rets.plot(kind='box',figsize=(12,8))
rets = stock_rets.dropna()
plt.figure(figsize=(12,8))
plt.scatter(rets.mean(), rets.std(),alpha = 0.5)
plt.title('Stocks Risk & Returns')
plt.xlabel('Expected returns')
plt.ylabel('Risk')
plt.grid(which='major')
for label, x, y in zip(rets.columns, rets.mean(), rets.std()):
plt.annotate(
label,
xy = (x, y), xytext = (50, 50),
textcoords = 'offset points', ha = 'right', va = 'bottom',
arrowprops = dict(arrowstyle = '-', connectionstyle = 'arc3,rad=-0.3'))
rets = stock_rets.dropna()
area = np.pi*20.0
sns.set(style='darkgrid')
plt.figure(figsize=(12,8))
plt.scatter(rets.mean(), rets.std(), s=area)
plt.xlabel("Expected Return", fontsize=15)
plt.ylabel("Risk", fontsize=15)
plt.title("Return vs. Risk for Stocks", fontsize=20)
for label, x, y in zip(rets.columns, rets.mean(), rets.std()) :
plt.annotate(label, xy=(x,y), xytext=(50, 0), textcoords='offset points',
arrowprops=dict(arrowstyle='-', connectionstyle='bar,angle=180,fraction=-0.2'),
bbox=dict(boxstyle="round", fc="w"))
rest_rets = rets.corr()
pair_value = rest_rets.abs().unstack()
pair_value.sort_values(ascending = False)
# Normalized Returns Data
Normalized_Value = ((rets[:] - rets[:].min()) /(rets[:].max() - rets[:].min()))
Normalized_Value.head()
Normalized_Value.corr()
normalized_rets = Normalized_Value.corr()
normalized_pair_value = normalized_rets.abs().unstack()
normalized_pair_value.sort_values(ascending = False)
print("Stock returns: ")
print(rets.mean())
print('-' * 50)
print("Stock risks:")
print(rets.std())
table = pd.DataFrame()
table['Returns'] = rets.mean()
table['Risk'] = rets.std()
table.sort_values(by='Returns')
table.sort_values(by='Risk')
rf = 0.01
table['Sharpe Ratio'] = (table['Returns'] - rf) / table['Risk']
table
table['Max Returns'] = rets.max()
table['Min Returns'] = rets.min()
table['Median Returns'] = rets.median()
total_return = stock_rets[-1:].transpose()
table['Total Return'] = 100 * total_return
table
table['Average Return Days'] = (1 + total_return)**(1 / days) - 1
table
initial_value = df.iloc[0]
ending_value = df.iloc[-1]
table['CAGR'] = ((ending_value / initial_value) ** (252.0 / days)) -1
table
table.sort_values(by='Average Return Days')
```
| github_jupyter |
```
import pandas as pd
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
# Função para construir o modelo
def build_model(my_learning_rate):
"""
Modelo de regressão linear simples.
Optimizador: Adam
Função de perda: Mean Squared Error
Metrica: Root Mean Squared Error
Argumentos:
my_learning_rate -- learning rate, float
Return:
model: Um modelo sequencial
"""
# Modelo sequencial.
model = tf.keras.models.Sequential()
# Topografia do modelo: Um único nó numa única camada.
# Adiciona uma camada
model.add(tf.keras.layers.Dense(units=1, input_shape=(1,)))
# Compilar o modelo
model.compile(optimizer=tf.keras.optimizers.Adam(my_learning_rate),
loss="mean_squared_error",
metrics=[tf.keras.metrics.RootMeanSquaredError()])
return model
def train_model(model, feature, label, epochs, batch_size):
"""
Treinar o modelo.
Argumentos:
modelo -- O modelo a ser treinado, tf.keras.models.Sequential
feature -- um vector de features, float
label -- um vector de labels, float
epochs -- número de épocas
batch_size -- tamnho do batch
Returns:
"""
history = model.fit(x=feature,
y=label,
batch_size=2,
epochs=epochs)
# vector com os pesos
trained_weight = model.get_weights()[0]
#vector com os biases
trained_bias = model.get_weights()[1]
# uma lista com as épocas
epochs = history.epoch
# histórico das épocas
hist = pd.DataFrame(history.history)
# histórico dos erros (root mean sqared)
rmse = hist["root_mean_squared_error"]
return trained_weight, trained_bias, epochs, rmse
print("create_model e train_model definidos")
#@title Funções para mostrar o modelo treinado
def plot_the_model(trained_weight, trained_bias, feature, label):
"""
Mostra graficamente o modelo treinado contra as features de
treino e as labels
Arguments:
trained_weight -- vector com os resultados finais dos pesos treinados pela rede
trained_bias -- valor do parâmetro de bias, float
features -- vector das features apresentadas à rede, float
label -- vector das labels apresentadas à rede, float
"""
# Label para os eixos
plt.xlabel("Celsius")
plt.ylabel("Fahrenheit")
# Mostra o gráfico dos valores das features contra os valores das labels
plt.scatter(feature, label)
# formatação dos eixos
x0 = -50
y0 = trained_bias
x1 = my_feature[-1]
y1 = trained_bias + (trained_weight * x1)
plt.plot([x0, x1], [y0, y1], c='r')
# Faz o render do scatter plot e da linha vermelha
plt.show()
def plot_the_loss_curve(epochs, rmse):
"""
Mostra a curva de perda em função da época
Arguments:
epochs -- épocas
rmse -- Root Mean Squared Error
"""
plt.figure()
plt.xlabel("Epoch")
plt.ylabel("Root Mean Squared Error")
plt.plot(epochs, rmse, label="Loss")
plt.legend()
plt.ylim([rmse.min()*0.97, rmse.max()])
plt.show()
print("plot_the_model e plot_the_loss_curve definidos.")
```
O problema que vamos resolver é converter graus Celsius para Fahrenheit, onde
a fórmula aproximada é
T(°F) = T(°C) × 1.8 + 32
Vamos passar ao modelo alguns exemplos de valores em graus Celsius (0, 8, 15, 22, 38) e os
seus correspondentes em graus Fahrenheit (32, 46, 59, 72, 100)
De seguida treinamos o modelo que vai aprender a fórmula supra através do processo de treino
```
celsius_q = np.array([-40, -10, 0, 8, 15, 22, 38], dtype=float)
fahrenheit_a = np.array([-40, 14, 32, 46, 59, 72, 100], dtype=float)
for i,c in enumerate(celsius_q):
print("{} graus Celsius = {} graus Fahrenheit".format(c, fahrenheit_a[i]))
learning_rate=0.1
epochs=500
my_batch_size=2
my_model = build_model(learning_rate)
trained_weight, trained_bias, epochs, rmse = train_model(my_model, celsius_q,
fahrenheit_a, epochs,
my_batch_size)
plot_the_model(trained_weight, trained_bias, celsius_q, fahrenheit_a)
plot_the_loss_curve(epochs, rmse)
print(my_model.predict([100.0]))
print(trained_weight)
print(trained_bias)
```
| github_jupyter |
```
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import models, transforms
from federated_learning import available_models
from torchsummary import summary
import numpy as np
from collections import OrderedDict, defaultdict
class ClientDataset(Dataset):
def __init__(self, img_tensors, lbl_tensors, transform=None):
self.img_tensors = img_tensors
self.lbl_tensors = lbl_tensors
self.transform = transform
def __len__(self):
return self.lbl_tensors.shape[0]
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
return self.img_tensors[idx], self.lbl_tensors[idx]
def create_client_data_loaders(client_nums, data_folder, batch_size, random_mode=False):
data_loaders = []
for idx in range(client_nums):
# loading data to tensors
img_tensor_file = data_folder + f'client_{idx}_img.pt'
lbl_tensor_file = data_folder + f'client_{idx}_lbl.pt'
img_tensors = torch.load(img_tensor_file) # this contains 494 images, currently 76
lbl_tensors = torch.load(lbl_tensor_file)
# creating a dataset which can be fed to dataloader
client_dataset = ClientDataset(img_tensors, lbl_tensors)
data_loader = DataLoader(client_dataset, batch_size=batch_size, shuffle=random_mode)
data_loaders.append(data_loader)
return data_loaders
# Save the tensor of images and labels for clients
username = 'fnx11'
data_folder = f'/home/{username}/thesis/codes/Playground/data/fed_data/'
client_nums = 20
client_data_loaders = create_client_data_loaders(client_nums, data_folder, 8)
```
### Let's see some of the loaders
```
import matplotlib.pyplot as plt
%matplotlib inline
# helper function to un-normalize and display an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
plt.imshow(np.transpose(img, (1, 2, 0)))
def visualize(images, labels):
images = images.numpy() # convert images to numpy for display
# plot the images in the batch, along with the corresponding labels
fig = plt.figure(figsize=(25, 4))
# display 20 images
for idx in np.arange(8):
ax = fig.add_subplot(2, 8/2, idx+1, xticks=[], yticks=[])
imshow(images[idx])
ax.set_title(classes[labels[idx]])
client_iter = iter(client_data_loaders[15])
# specify the image classes
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
for step in range(len(client_iter)):
images, labels = next(client_iter)
# visualize(images, labels)
print(images.shape)
print(labels.shape)
break
from sklearn.cluster import KMeans
import numpy as np
arr1 = np.array([1,2,3,4,5,80,90,100,110,120]).reshape(-1, 1)
arr2 = np.array([11,12,13,14,15,16,17,20,220,230]).reshape(-1, 1)
arr3 = np.array([100,120,105,8,9,10,11,12,13,14]).reshape(-1, 1)
kmeans1 = KMeans(n_clusters=2, random_state=0).fit(arr1)
centers1 = kmeans1.cluster_centers_
print(centers1)
kmeans2 = KMeans(n_clusters=2, random_state=0).fit(arr2)
centers2 = kmeans2.cluster_centers_
print(centers2)
kmeans3 = KMeans(n_clusters=2, random_state=0).fit(arr3)
centers3 = kmeans3.cluster_centers_
print(centers3)
mins = []
labels1 = kmeans1.predict(arr1)
val1, count1 = np.unique(labels1, return_counts=True)
print(count1)
mins.append(np.min(count1))
labels2 = kmeans2.predict(arr2)
val2, count2 = np.unique(labels2, return_counts=True)
print(count2)
mins.append(np.min(count2))
labels3 = kmeans3.predict(arr3)
val3, count3 = np.unique(labels3, return_counts=True)
print(count3)
mins.append(np.min(count3))
print(mins)
min_arr = np.array(mins).reshape(-1, 1)
kmeans = KMeans(n_clusters=2, random_state=0).fit(min_arr)
centers = kmeans.cluster_centers_
print(centers)
labels = kmeans.predict(min_arr)
print(labels)
val, count = np.unique(labels, return_counts=True)
import numpy as np
arr = np.array([4,2,1,3,6,5])
brr = np.argsort(arr)[-3:]
print(arr)
print(brr)
arr[brr]
len(arr)
arr.size
from sklearn.metrics.pairwise import cosine_similarity
arr1 = np.arange(10).reshape(1, -1)
arr2 = np.arange(10).reshape(1, -1)
print(cosine_similarity(arr1, arr2)[0][0])
arr = arr.reshape(2,3)
arr
row_sum = arr.sum(axis=1)
print(row_sum)
import numpy as np
import pandas as pd
import plotly.express as px
# assuming 10 clients and 8 itrs,
total_clients = 10
fdrs = 8
trust_scores = (np.random.random_sample((8, 10))*10000).astype(int)
initial_validation_clients = [1, 6]
poisoned_clients = [2,5,7]
start_cosdefence = 2
## client type means if client is honest(0), malicious(1), or initial validation client(-1)
# client_types = np.zeros((total_clients), dtype=int)
# client_types[initial_validation_clients] = -1
# client_types[poisoned_clients] = 1
client_types = ["honest" for _ in range(total_clients)]
print(client_types)
for val_client in initial_validation_clients:
client_types[val_client] = "init_val"
for p_client in poisoned_clients:
client_types[p_client] = "poisoned"
print(client_types)
```
```
trust_scores_df = pd.DataFrame(trust_scores, columns=[f"client{i}" for i in range(total_clients)])
trust_scores_df.head()
import plotly.graph_objects as go
# Create random data with numpy
# Create traces
fig = go.Figure()
for i in range(total_clients):
fig.add_trace(go.Scatter(x=list(range(start_cosdefence, fdrs)), y=trust_scores_df[f"client{i}"], mode='lines'))
fig.show()
trust_scores_df = pd.DataFrame(columns=["fed_round","trust_score", "client_id", "client_type"])
# [r for r in range(fdrs)], trust_scores[i], i, client_types[i]
for client in range(total_clients):
temp_df = pd.DataFrame({"fed_round" : pd.Series(list(range(fdrs)), dtype="int"),
"trust_score" : trust_scores[:, client],
"client_id" : client,
"client_type":client_types[client]})
trust_scores_df = trust_scores_df.append(temp_df, ignore_index=True)
print(trust_scores_df.shape)
trust_scores_df.head()
score_curves_fig = px.line(trust_scores_df, x="fed_round", y="trust_score", color="client_type",
line_group="client_id", hover_name="client_id")
score_curves_fig.update_layout(title="Trust Score Evolution")
score_curves_fig.show()
# score_curves_fig.write_html(os.path.join(save_location,'{}_trust_score_curves_{}.html'.format(config_details, time.strftime("%Y-%m-%d %H:%M:%S", current_time))))
df = px.data.gapminder().query("continent != 'Asia'") # remove Asia for visibility
fig = px.line(df, x="year", y="lifeExp", color="continent",
line_group="country", hover_name="country")
fig.show()
from sklearn.cluster import KMeans
import numpy as np
comp_trusts = [0.45,0.47,0.50,0.80,0.7,0.75, 0.79, 0.81, 0.78, 0.65]
trust_arr = np.array(comp_trusts).reshape(-1, 1)
kmeans = KMeans(n_clusters=2, random_state=0).fit(trust_arr)
labels = kmeans.predict(trust_arr)
_vals, counts = np.unique(labels, return_counts=True)
trust_arr = trust_arr.flatten()
print(f"_labels: {_vals}, counts: {counts}")
if counts[0] > counts[1]:
trust_arr = np.where(labels == _vals[0], trust_arr, 0.2)
elif counts[0] < counts[1]:
trust_arr = np.where(labels == _vals[1], trust_arr, 0.2)
else:
kmeans_centers = kmeans.cluster_centers_
if kmeans_centers[0][0] > kmeans_centers[1][0]:
trust_arr = np.where(labels == _vals[0], trust_arr, 0.2)
else:
trust_arr = np.where(labels == _vals[1], trust_arr, 0.2)
print(trust_arr)
kmeans_centers = kmeans.cluster_centers_
center_dist = abs(kmeans_centers[0][0] - kmeans_centers[1][0])
labels = kmeans.predict(trust_arr)
_vals, counts = np.unique(labels, return_counts=True)
print(_vals, counts)
if counts[0] > counts[1]:
## center 0 is majority similarty mean value
majority_mean = kmeans_centers[0][0]
minortiy_mean = kmeans_centers[1][0]
else:
majority_mean = kmeans_centers[1][0]
minortiy_mean = kmeans_centers[0][0]
# lower_trust_bound = majority_mean*(1 - 0.07/center_dist)
# upper_trust_bound = majority_mean*(1 + 0.07/center_dist)
# print("Trust Cutting using Clustering")
print("majority_mean, minortiy_mean, center_dist, lower_trust_bound, upper_trust_bound")
print(majority_mean, minortiy_mean, center_dist, lower_trust_bound, upper_trust_bound)
trust_arr = np.where((trust_arr >= lower_trust_bound) & (trust_arr <= upper_trust_bound), trust_arr, 0.2)
print(trust_arr)
import numpy as np
arr1 = np.array([1.0,2.0, 3.0, 4.0])
arr2 = np.array(([8.0, 8.0, 2.0, 2.0]))
selected = np.argsort(arr1 + arr2)[-(2):]
print(selected)
tup1 = (1,2,4)
tup2 = (2,3,5)
total = sum(tup1) + sum(tup2)
print(total)
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import scipy
print(f"SciPy version: {scipy.__version__}")
from collections import OrderedDict
import scipy.sparse as sp
import time
import random
from constants import (DATA_OCT, DATA_NOV, EXPORT_DIR, UX_CONSTANTS, SEED, NEW_USER_ID, NEW_PRODUCT_ID, T, USECOLS,
EVENT_THRESHOLD, ALL_DATA_PATH, TRAIN_DATA_PATH, VAL_DATA_PATH, TEST_DATA_PATH, VAL_THRESHOLD, TEST_THRESHOLD)
random.seed(SEED)
ux_constants = pd.Series(pd.read_csv(UX_CONSTANTS, index_col=0, squeeze=True, header=None), dtype='float32')
VIEW = ux_constants['view_to_purchase']
CART = ux_constants['cart_to_purchase']
REMOVE = ux_constants['remove_to_purchase']
PURCHASE = ux_constants['purchase_to_purchase']
def event_to_ux(event):
event_weights = {
'view': VIEW,
'cart': CART,
'remove_from_cart': REMOVE,
'purchase': PURCHASE,
}
return event_weights.get(event, 0)
df = pd.concat([pd.read_csv(DATA_OCT, engine='c', sep=',',usecols=USECOLS)
,pd.read_csv(DATA_NOV, engine='c', sep=',',usecols=USECOLS)])
df["event_type"] = df["event_type"].astype("category")
df.info()
start_time = time.time() # we start the timer after loading the dataframe
start_dim = df.shape
start_dim
print(f"We start with {len(df.user_id.unique()):,} unique users.")
```
# Data Reduction
```
drop_visitors = set(df.user_id.value_counts()[df.user_id.value_counts()<EVENT_THRESHOLD].index)
print(f"We will {T.R}drop {len(drop_visitors):,} ({len(drop_visitors)*100/len(df.user_id.unique()):.2f}%) users,{T.E} "+
f"for not meeting the minimum {T.R}{EVENT_THRESHOLD}{T.E} event requirement.")
df = df[~df.user_id.isin(drop_visitors)]
df.reset_index(inplace=True,drop=True)
print(f"This way we have reduced the number of total events by {T.G}{100-len(df)*100/start_dim[0]:.2f}%{T.E}.")
new_user_id = pd.DataFrame()
new_user_id['user_id']=df.user_id.unique()
print(f"We will have {T.B}{len(new_user_id):,} unique users.{T.E}")
new_user_id.to_csv(NEW_USER_ID, index = True, header=True)
uid_lookup = pd.Series(index=new_user_id.user_id,data=new_user_id.index)
uid_lookup = uid_lookup.to_dict(OrderedDict)
del new_user_id
new_product_id = pd.DataFrame()
new_product_id['product_id']=df.product_id.unique()
print(f"We will have {T.B}{len(new_product_id):,} unique features{T.E} (products for e-commerce).")
new_product_id.to_csv(NEW_PRODUCT_ID, index = True, header=True)
pid_lookup = pd.Series(index=new_product_id.product_id,data=new_product_id.index)
pid_lookup = pid_lookup.to_dict(OrderedDict)
del new_product_id
```
# Feature engineering
```
number_of_users = df['user_id'].unique().shape[0]
number_of_features = df['product_id'].unique().shape[0]
def user_experience_matrix(df):
last_index = df.shape[0]-1
# Use np.float32 for torch.cuda.FloatTensor.or np.float16 for torch.cuda.HalfTensor (float64 not recommended)
uxm = sp.dok_matrix((number_of_users, number_of_features), dtype=np.float32)
print(f" Event | User | Product | Event | Previous | {T.b}New UX{T.E}")
for row in df.itertuples():
uid = uid_lookup[row.user_id]
pid = pid_lookup[row.product_id]
prev_ux = uxm[uid,pid]
ux = np.tanh(prev_ux+event_to_ux(row.event_type))
# ux = prev_ux + 1 # test case calculating the number of events between the user-product pair
uxm[uid,pid] = ux
if (row.Index % 500000 == 0) or (row.Index == last_index):
print(f"{row.Index:8} | "+
f"{uid:6} | "+
f"{pid:7} | "+
f"{row.event_type[:4]} | "+
f"{prev_ux:8.5f} | "+
f"{T.b}{ux:8.5f}{T.E}")
return uxm
uxm = user_experience_matrix(df)
print(f"Elapsed time: {time.time()-start_time:.2f} seconds") # we stop the timer before the train-test-validaiton split
```
# Train - test - validation split
```
def save_to_npz(X,path):
X = X.tocoo()
sp.save_npz(path,X)
print(f"{T.G}Sparse matrix saved to: {path}{T.E}")
print(f"Train: {VAL_THRESHOLD*100:.2f}% \nValidation: {(1-TEST_THRESHOLD)*100:.2f}% \nTest: {(1-TEST_THRESHOLD)*100:.2f}%")
NNZ = uxm.nnz
print(f"Number of stored values: {NNZ:,}")
uxm_train = sp.dok_matrix.copy(uxm)
uxm_val = sp.dok_matrix((number_of_users, number_of_features), dtype=np.float32)
uxm_test = sp.dok_matrix((number_of_users, number_of_features), dtype=np.float32)
rows,cols = uxm_train.nonzero()
for row,col in zip(rows,cols):
rnd = random.random()
if rnd > TEST_THRESHOLD:
uxm_test[row,col] = uxm_train[row,col]
uxm_train[row,col] = 0
elif rnd > VAL_THRESHOLD:
uxm_val[row,col] = uxm_train[row,col]
uxm_train[row,col] = 0
print(f"Number of train data values: {uxm_train.nnz:,} ({uxm_train.nnz*100/NNZ:.2f}%)")
print(f"Number of validation data values: {uxm_val.nnz:,} ({uxm_val.nnz*100/NNZ:.2f}%)")
print(f"Number of test data values: {uxm_test.nnz:,} ({uxm_test.nnz*100/NNZ:.2f}%)")
errormessage = '''All datapoints should be in either the train, the test of the validation datasets.
The reason might be a change in how .nnz of a DOK matrix (scipy.sparse.dok_matrix) is calculated.
In version 1.4.1 SciPy setting the value to zero explicitly (X[i,j]=0) is not counted by .nnz'''
assert NNZ - uxm_train.nnz - uxm_val.nnz - uxm_test.nnz == 0, errormessage
save_to_npz(uxm,ALL_DATA_PATH)
save_to_npz(uxm_train,TRAIN_DATA_PATH)
save_to_npz(uxm_val,VAL_DATA_PATH)
save_to_npz(uxm_test,TEST_DATA_PATH)
```
| github_jupyter |
# ADITYA SAHU
# Pre processing of Abalone dataset to make imbalance ratio of training and testing same
```
import numpy as np
from numpy import linalg
import pandas as pd
train = pd.read_csv("Abalone.csv")
train.head()
train=train.replace(to_replace=['M', 'F', 'I'], value=[1, 2, 3])
train['rings'] = train['rings'].map({15: 1, 1:-1,2:-1,3:-1,4:-1,5:-1,6:-1,7:-1,8:-1,9:-1,10:-1,11:-1,12:-1,13:-1,14:-1,16:-1,17:-1,18:-1,19:-1,20:-1,21:-1,22:-1,23:-1,24:-1,25:-1,26:-1,27:-1,28:-1,29:-1})
print(train['rings'])
train=np.asarray(train)
min_train=np.zeros((103,9))
max_train=np.zeros((4074,9))
min_train=np.asarray(min_train)
max_train=np.asarray(max_train)
k=0
l=0
for i in range(0,4177):
if(train[i][8]==1):
for j in range(0,9):
min_train[k][j]=train[i][j]
k=k+1
else :
for j in range(0,9):
max_train[l][j]=train[i][j]
l=l+1
print(min_train)
data1=np.zeros((834,9))
data2=np.zeros((835,9))
data3=np.zeros((836,9))
data4=np.zeros((836,9))
data5=np.zeros((836,9))
for i in range(0,103):
for j in range(0,9):
if(i<20):
data1[i][j]=min_train[i][j]
elif(19<i and i<40):
data2[i-20][j]=min_train[i][j]
elif(39<i and i<61):
data3[i-40][j]=min_train[i][j]
elif(60<i and i<82):
data4[i-61][j]=min_train[i][j]
elif(81<i and i<103):
data5[i-82][j]=min_train[i][j]
print(data5[20])
for i in range(0,4074):
for j in range(0,9):
if(i<814):
data1[i+20][j]=max_train[i][j]
elif(813<i and i<1629):
data2[i-794][j]=max_train[i][j]
elif(1628<i and i<2444):
data3[i-1608][j]=max_train[i][j]
elif(2443<i and i<3259):
data4[i-2423][j]=max_train[i][j]
elif(3258<i and i<4074):
data5[i-3238][j]=max_train[i][j]
print(data5[0])
print(data5.shape)
data5
import csv
with open('newab.csv', 'w') as csvFile:
writer = csv.writer(csvFile)
writer.writerows(data1)
csvFile.close()
import csv
with open('newab.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerows(data2)
csvFile.close()
import csv
with open('newab.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerows(data3)
csvFile.close()
import csv
with open('newab.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerows(data4)
csvFile.close()
import csv
with open('newab.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerows(data5)
csvFile.close()
df = pd.read_csv("newab.csv")
#checking the number of empty rows in th csv file
print (df.isnull().sum())
#Droping the empty rows
modifiedDF = df.dropna()
#Saving it to the csv file
modifiedDF.to_csv('modifiedabalone.csv',index=False)
```
| github_jupyter |
By: 顾 瞻 GU Zhan (Sam)
July 2017
# [2] Data pre-porcessing
Explore and visualize data
```
# from __future__ import print_function, division
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import pandas as pd
import operator
from scipy import interp
from itertools import cycle
from sklearn import svm
from sklearn.utils.validation import check_random_state
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import BaggingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc
from statsmodels.graphics.mosaicplot import mosaic
print(__doc__)
```
### Read raw data
```
df_history_ts = pd.read_csv('data/history_ts.csv')
df_history_ts_process = df_history_ts.copy()
df_history_ts_process.tail()
df_history_table = pd.read_csv('data/history_table.csv')
df_history_table_process = df_history_table.copy()
df_history_table_process.tail()
```
### Parameters
```
parm_ts_cycle = 61 # seconds/records per month
print('parm_ts_cycle : %d seconds' % parm_ts_cycle)
parm_ts_month = int(len(df_history_ts) / parm_ts_cycle)
print('parm_ts_month : %d months' % parm_ts_month)
parm_calculate_base_price_second = 15 # Use the current month's bid-price as base-price at this seconds. Later to derive increment-price
parm_calculate_prev_bp = 15 # Number of previous price/increment to include, i.e. previous 2sec, 3sec, 4sec, 5sec ... 15sec
parm_calculate_mv = 15 # Number of previous price/increment Moving Average to calculate, i.e. previous 2sec, 3sec, 4sec, 5sec ... 15sec
parm_calculate_target_second = 7 # How many seconds in future to predict: target variable
parm_calculate_prev_month = 3 # Number of previous month to include (need to remove earliest x month from training data)
parm_record_cut_row_head = max(parm_calculate_base_price_second, parm_calculate_prev_bp, parm_calculate_mv)
parm_record_cut_row_tail = parm_calculate_target_second
parm_record_cut_month_head = parm_calculate_prev_month + 1
parm_ts_valid_cycle = parm_ts_cycle - parm_record_cut_row_head - parm_record_cut_row_tail
print('parm_ts_valid_cycle : %d seconds' % parm_ts_valid_cycle)
parm_ts_valid_month = parm_ts_month - parm_record_cut_month_head
print('parm_ts_valid_month : %d months' % parm_ts_valid_month)
if parm_record_cut_month_head < 10:
parm_record_cut_ccyy = pd.to_datetime('2015-0'+str(parm_record_cut_month_head))
else:
parm_record_cut_ccyy = pd.to_datetime('2015-'+str(parm_record_cut_month_head))
print('parm_record_cut_ccyy : %s' % parm_record_cut_ccyy)
print('parm_record_cut_month_head : %d months' % parm_record_cut_month_head)
print('parm_record_cut_row_head : %d seconds' % parm_record_cut_row_head)
print('parm_record_cut_row_tail : %d seconds' % parm_record_cut_row_tail)
print(' : ' )
print(' : ' )
print(' : ' )
df_history_ts_process.head()
```
### Prepare derived features
### Process: df_history_ts_process
```
# date of current month
df_history_ts_process['date-curr'] = df_history_ts_process.apply(lambda row: pd.to_datetime(row['ccyy-mm']), axis=1)
# date of previous month
df_history_ts_process['date-prev'] = df_history_ts_process.apply(lambda row: row['date-curr'] - pd.offsets.MonthBegin(1), axis=1)
# Year
df_history_ts_process['year'] = df_history_ts_process.apply(lambda row: row['ccyy-mm'][0:4], axis=1)
# Month
df_history_ts_process['month'] = df_history_ts_process.apply(lambda row: row['ccyy-mm'][5:7], axis=1)
# Hour
df_history_ts_process['hour'] = df_history_ts_process.apply(lambda row: row['time'][0:2], axis=1)
# Minute
df_history_ts_process['minute'] = df_history_ts_process.apply(lambda row: row['time'][3:5], axis=1)
# Second
df_history_ts_process['second'] = df_history_ts_process.apply(lambda row: row['time'][6:8], axis=1)
# df_history_ts_process
# df_history_ts_process[1768:]
# new ['base-price']
gap = 1 # only one new feature/column
for gap in range(1, gap+1):
col_name = 'base-price'+str(parm_calculate_base_price_second)+'sec'
col_name_base_price = col_name
col_data = pd.DataFrame(columns=[col_name])
print('Creating : ', col_name)
for month in range(0, parm_ts_month):
for i in range(0, parm_ts_cycle):
col_data.loc[month*parm_ts_cycle+i] = df_history_ts_process['bid-price'][month*parm_ts_cycle+parm_calculate_base_price_second]
df_history_ts_process[col_name] = col_data
print('Total records processed : ', len(col_data))
# df_history_ts_process
# df_history_ts_process[1768:]
# new ['increment-price'] = ['bid-price'] - ['base-price']
df_history_ts_process['increment-price'] = df_history_ts_process.apply(lambda row: row['bid-price'] - row[col_name_base_price], axis=1)
# df_history_ts_process
# df_history_ts_process[1768:]
plt.figure()
plt.plot(df_history_ts_process['bid-price'])
plt.plot(df_history_ts_process[col_name_base_price])
plt.plot()
plt.figure()
plt.plot(df_history_ts_process['increment-price'])
plt.plot()
```
### ['increment-price-target']
```
# previous N sec ['increment-price-target']
for gap in range(1, 2):
col_name = 'increment-price-target'
col_data = pd.DataFrame(columns=[col_name])
print('Creating : ', col_name)
for month in range(0, parm_ts_month):
# print('month : ', month)
for i in range(0, (parm_ts_cycle - parm_calculate_target_second)):
col_data.loc[month*parm_ts_cycle+i] = df_history_ts_process['increment-price'][month*parm_ts_cycle+i+parm_calculate_target_second]
for i in range((parm_ts_cycle - parm_calculate_target_second), parm_ts_cycle):
col_data.loc[month*parm_ts_cycle+i] = 0
df_history_ts_process[col_name] = col_data
print('Total records processed : ', len(col_data))
plt.figure()
plt.plot(df_history_ts_process['increment-price'])
plt.plot(df_history_ts_process['increment-price-target'])
plt.plot()
plt.figure()
plt.plot(df_history_ts_process['increment-price'][1768:])
plt.plot(df_history_ts_process['increment-price-target'][1768:])
plt.plot()
# previous 'parm_calculate_prev_bp' sec ['increment-price']
gap = parm_calculate_prev_bp
for gap in range(1, gap+1):
col_name = 'increment-price-prev'+str(gap)+'sec'
col_data = pd.DataFrame(columns=[col_name])
# col_data_zeros = pd.DataFrame({col_name: np.zeros(gap)})
print('Creating : ', col_name)
for month in range(0, parm_ts_month):
# print('month : ', month)
# col_data.append(col_data_zeros)
for i in range(0, gap):
col_data.loc[month*parm_ts_cycle+i] = 0
for i in range(gap, parm_ts_cycle):
col_data.loc[month*parm_ts_cycle+i] = df_history_ts_process['increment-price'][month*parm_ts_cycle+i-gap]
df_history_ts_process[col_name] = col_data
print('Total records processed : ', len(col_data))
# previous 'parm_calculate_mv' sec Moving Average ['increment-price']
gap = parm_calculate_mv
for gap in range(2, gap+1): # MV starts from 2 seconds, till parm_calculate_mv
col_name = 'increment-price-mv'+str(gap)+'sec'
col_data = pd.DataFrame(columns=[col_name])
print('Creating : ', col_name)
for month in range(0, parm_ts_month):
# print('month : ', month)
for i in range(0, gap):
col_data.loc[month*parm_ts_cycle+i] = 0
for i in range(gap, parm_ts_cycle):
col_data.loc[month*parm_ts_cycle+i] = \
np.mean(df_history_ts_process['increment-price'][month*parm_ts_cycle+i-gap:month*parm_ts_cycle+i])
df_history_ts_process[col_name] = col_data
print('Total records processed : ', len(col_data))
# df_history_ts_process[1768:]
plt.figure()
plt.plot(df_history_ts_process['increment-price'][1768:])
plt.plot(df_history_ts_process['increment-price-prev3sec'][1768:])
plt.plot(df_history_ts_process['increment-price-prev7sec'][1768:])
plt.plot(df_history_ts_process['increment-price-prev11sec'][1768:])
plt.plot(df_history_ts_process['increment-price-prev15sec'][1768:])
plt.plot()
plt.figure()
plt.plot(df_history_ts_process['increment-price'][1768:])
plt.plot(df_history_ts_process['increment-price-mv3sec'][1768:])
plt.plot(df_history_ts_process['increment-price-mv7sec'][1768:])
plt.plot(df_history_ts_process['increment-price-mv11sec'][1768:])
plt.plot(df_history_ts_process['increment-price-mv15sec'][1768:])
plt.plot()
```
### Process: df_history_table_process
```
df_history_table_process.tail()
# date of current month
df_history_table_process['date-curr'] = df_history_table_process.apply(lambda row: pd.to_datetime(row['ccyy-mm']), axis=1)
df_history_table_process['d-avg-low-price'] = df_history_table_process.apply(lambda row: row['deal-price-avg'] - row['deal-price-low'], axis=1)
df_history_table_process['ratio-bid'] = df_history_table_process.apply(lambda row: row['volume-plate'] / row['volume-bidder'], axis=1)
```
### Merge dataframe
```
df_history_ts_process = pd.merge(df_history_ts_process, df_history_table_process[['date-curr', 'volume-plate', 'ratio-bid']], how = 'left', left_on = 'date-curr', right_on = 'date-curr')
df_history_ts_process = pd.merge(df_history_ts_process, df_history_table_process[['date-curr', 'volume-plate', 'ratio-bid', 'deal-early-second', 'deal-price-avg']], how = 'left', left_on = 'date-prev', right_on = 'date-curr')
```
### Shift to copy previous 'parm_calculate_prev_month' month's data into current row
### Housekeeping to remove some invald data during pre-processing
```
df_history_ts_process.columns
# housekeeping: delete some columns
df_history_ts_process.drop('date-curr_y', axis=1, inplace=True)
# remove first 'parm_record_cut_ccyy' months from dataset
df_history_ts_process = df_history_ts_process[df_history_ts_process['date-curr_x'] > parm_record_cut_ccyy]
df_history_ts_process = df_history_ts_process[df_history_ts_process['date-prev'] > parm_record_cut_ccyy]
# total 61 seconds/rows per month:
# remove first 'parm_record_cut_row_head' reconds
# remove last 'parm_record_cut_row_tail' reconds
df_history_ts_process = df_history_ts_process[df_history_ts_process['second'] >= str(parm_record_cut_row_head) ]
df_history_ts_process = df_history_ts_process[df_history_ts_process['second'] <= str(60 - parm_record_cut_row_tail) ]
# df_history_ts_process = df_history_ts_process[df_history_ts_process['second'] > parm_record_cut_row_head ]
# Reset index after housekeeping
df_history_ts_process = df_history_ts_process.reset_index(drop=True)
df_history_ts_process.tail()
plt.figure()
plt.plot(df_history_ts_process['increment-price'][974:])
plt.plot(df_history_ts_process['increment-price-mv3sec'][974:])
plt.plot(df_history_ts_process['increment-price-mv7sec'][974:])
plt.plot(df_history_ts_process['increment-price-mv11sec'][974:])
plt.plot(df_history_ts_process['increment-price-mv15sec'][974:])
plt.plot()
```
# [3] Modeling Part 2: Python scikit-learn
### Models to use:
* GradientBoostingClassifier
* RandomForestClassifier
* AdaBoostClassifier
* ExtraTreesClassifier
* BaggingClassifier
* LogisticRegression
* SVM kernal RBF
* SVM kernal Linear
* KNeighborsClassifier
### Import pre-processed data
```
df_history_ts_process.head()
```
### Include relevant features
```
X = df_history_ts_process[[
# 'ccyy-mm', 'time', 'bid-price', 'date-curr_x', 'date-prev', 'year',
'month',
# 'hour', 'minute',
'second', 'base-price15sec',
'increment-price',
# 'increment-price-target',
'increment-price-prev1sec',
'increment-price-prev2sec', 'increment-price-prev3sec',
'increment-price-prev4sec', 'increment-price-prev5sec',
'increment-price-prev6sec', 'increment-price-prev7sec',
'increment-price-prev8sec', 'increment-price-prev9sec',
'increment-price-prev10sec', 'increment-price-prev11sec',
'increment-price-prev12sec', 'increment-price-prev13sec',
'increment-price-prev14sec', 'increment-price-prev15sec',
'increment-price-mv2sec', 'increment-price-mv3sec',
'increment-price-mv4sec', 'increment-price-mv5sec',
'increment-price-mv6sec', 'increment-price-mv7sec',
'increment-price-mv8sec', 'increment-price-mv9sec',
'increment-price-mv10sec', 'increment-price-mv11sec',
'increment-price-mv12sec', 'increment-price-mv13sec',
'increment-price-mv14sec', 'increment-price-mv15sec', 'volume-plate_x',
'ratio-bid_x', 'volume-plate_y', 'ratio-bid_y', 'deal-early-second',
'deal-price-avg', 'deal-price-avg'
]]
X_col = X.columns # get the column list
# X = StandardScaler().fit_transform(X.as_matrix())
X = X.as_matrix()
# y = StandardScaler().fit_transform(df_wnv_raw[['increment-price-target']].as_matrix()).reshape(len(df_wnv_raw),)
y = df_history_ts_process[['increment-price-target']].as_matrix().reshape(len(df_history_ts_process),)
X_col
plt.figure()
plt.plot(X)
plt.figure()
plt.plot(y)
```
# [4] Evaluation
### K-fold Cross-Validation
```
rng = check_random_state(0)
# GB
classifier_GB = GradientBoostingRegressor(n_estimators=1500, # score: 0.94608 (AUC 0.81419), learning_rate=0.001, max_features=8 <<< Best
# loss='deviance',
# subsample=1,
# max_depth=5,
# min_samples_split=20,
learning_rate=0.002,
# max_features=10,
random_state=rng)
# AB
classifier_AB = AdaBoostRegressor(n_estimators=1500, # score: 0.93948 (AUC 0.88339), learning_rate=0.004 <<< Best
learning_rate=0.002,
random_state=rng)
# RF
classifier_RF = RandomForestRegressor(n_estimators=1500, # score: 0.94207 (AUC 0.81870), max_depth=3, min_samples_split=20, <<< Best
# max_features=10,
# max_depth=3,
# min_samples_split=20,
random_state=rng)
# ET
classifier_ET = ExtraTreesRegressor(n_estimators=1000, # score: 0.94655 (AUC 0.84364), max_depth=3, min_samples_split=20, max_features=10 <<< Best
# max_depth=3,
# min_samples_split=20,
# max_features=10,
random_state=rng)
# BG
classifier_BG = BaggingRegressor(n_estimators=500, # score: 0.70725 (AUC 0.63729) <<< Best
# max_features=10,
random_state=rng)
```
### LR
```
classifier_LR = LinearRegression() # score: 0.90199 (AUC 0.80569)
```
### SVM Linear
```
# classifier_SVCL = svm.SVC(kernel='linear', probability=True, random_state=rng) # score: 0.89976 (AUC 0.70524)
classifier_SVRL = svm.SVR() # score: 0.89976 (AUC 0.70524)
```
### SVM
```
classifier_SVRR = svm.SVR(kernel='rbf') # score: 0.80188 (AUC 0.50050)
# classifier_SVRR = svm.SVR(kernel='poly') # score: 0.80188 (AUC 0.50050)
```
### KNN
```
classifier_KNN = KNeighborsRegressor(n_neighbors=2) # score: 0.94018 (AUC 0.72792)
cv = cross_val_score(classifier_KNN,
X,
y,
cv=StratifiedKFold(parm_ts_valid_month))
print('KNN CV score: {0:.5f}'.format(cv.mean()))
```
### Select Model
```
# classifier = classifier_GB # 324.632308296
classifier = classifier_AB # 429.646733221
# classifier = classifier_RF # 175.504322802
# classifier = classifier_ET # 172.097916817, 0.0724812030075
# classifier = classifier_BG # 175.451381872
# classifier = classifier_LR # 128.465059749, 0.11
# classifier = classifier_SVRL # 3789.82169312
# classifier = classifier_SVRR # 3789.82169312, 0.10754224349
```
### Split Data
```
n_splits = parm_ts_valid_cycle
print(n_splits)
# n_splits=54 # 19 seconds/records for each bidding month
# n_splits=19 # 19 seconds/records for each bidding month
n_fold = parm_ts_valid_month
print(n_fold)
# X_train_1 = X[0:(len(X)-batch*n_splits)]
# y_train_1 = y[0:(len(X)-batch*n_splits)]
# X_test_1 = X[(len(X)-batch*n_splits):((len(X)-batch*n_splits)+n_splits)]
# y_test_1 = y[(len(X)-batch*n_splits):((len(X)-batch*n_splits)+n_splits)]
```
### CV
```
n_fold=5
y_pred = {}
y_test = {}
y_pred_org = {}
y_test_org = {}
i = 0
for batch in range(1, n_fold):
X_train_1 = X[0:(len(X)-batch*n_splits)]
y_train_1 = y[0:(len(X)-batch*n_splits)]
X_test_1 = X[(len(X)-batch*n_splits):((len(X)-batch*n_splits)+n_splits)]
y_test_1 = y[(len(X)-batch*n_splits):((len(X)-batch*n_splits)+n_splits)]
print(len(X_train_1))
# ReScale
ScalerX = StandardScaler()
ScalerX.fit(X_train_1)
X_train_1 = ScalerX.transform(X_train_1)
X_test_1 = ScalerX.transform(X_test_1)
ScalerY = StandardScaler()
ScalerY.fit(y_train_1.reshape(-1, 1))
y_train_1 = ScalerY.transform(y_train_1.reshape(-1, 1))
y_test_1 = ScalerY.transform(y_test_1.reshape(-1, 1))
y_pred[i] = classifier.fit(X_train_1, y_train_1).predict(X_test_1)
y_test[i] = y_test_1
y_pred_org[i] = ScalerY.inverse_transform(y_pred[i])
y_test_org[i] = ScalerY.inverse_transform(y_test[i])
plt.figure()
plt.plot(y_train_1)
plt.plot()
plt.figure()
plt.plot(y_test[i])
plt.plot(y_pred[i])
plt.plot()
i += 1
```
### no inverse-scale
```
k = []
for i in range(0, len(y_test)):
k.append(np.mean(np.sqrt(np.square(y_test[i] - y_pred[i]))))
k_mean = np.mean(k)
print(k_mean)
print()
print(k)
k = []
for i in range(0, len(y_test)):
k.append(np.mean(np.sqrt(np.square(y_test[i][35:37] - y_pred[i][35:37]))))
k_mean = np.mean(k)
print(k_mean)
print()
print(k)
```
### inverse-scale
```
k = []
for i in range(0, len(y_test)):
k.append(np.mean(np.sqrt(np.square(y_test_org[i] - y_pred_org[i]))))
k_mean = np.mean(k)
print(k_mean)
print()
print(k)
k = []
for i in range(0, len(y_test)):
k.append(np.mean(np.sqrt(np.square(y_test_org[i][35:37] - y_pred_org[i][35:37]))))
k_mean = np.mean(k)
print(k_mean)
print()
print(k)
# 50 second predicts 57 second
k = []
for i in range(0, len(y_test)):
k.append(np.mean(np.sqrt(np.square(y_test_org[i][35:36] - y_pred_org[i][35:36]))))
k_mean = np.mean(k)
print(k_mean)
print()
print(k)
plt.plot(y_test_org[0])
plt.plot(y_pred_org[0])
plt.plot(k)
y_test[1][13:]
y_pred[1][13:]
np.mean(np.sqrt(np.square(y_test[4] - y_pred[4])))
np.mean(np.sqrt(np.square(y_test[4][13:16] - y_pred[4][13:16])))
y_pred_df = pd.DataFrame.from_dict(y_pred)
y_pred_df.columns=['month 7','month 6','month 5','month 4','month 3','month 2','month 1']
y_pred_df.to_csv('bid_results_v001.csv', index=False)
y_pred_df
# previous N sec ['bid-price']
gap = parm_calculate_prev_bp
for gap in range(1, gap+1):
col_name = 'bid-price-prev'+str(gap)+'sec'
col_data = pd.DataFrame(columns=[col_name])
col_data_zeros = pd.DataFrame({col_name: np.zeros(gap)})
print('Creating : ', col_name)
for month in range(0, parm_ts_month):
# print('month : ', month)
col_data.append(col_data_zeros)
for i in range(0, gap):
col_data.loc[month*parm_ts_cycle+i] = 0
for i in range(gap, parm_ts_cycle):
col_data.loc[month*parm_ts_cycle+i] = df_history_ts_process['bid-price'][month*parm_ts_cycle+i-gap]
df_history_ts_process[col_name] = col_data
print('Total records processed : ', len(col_data))
# previous 2 sec Moving Average ['bid-price']
gap = parm_calculate_mv
for gap in range(2, gap+1): # MV starts from 2 seconds, till parm_calculate_mv
col_name = 'bid-price-mv'+str(gap)+'sec'
col_data = pd.DataFrame(columns=[col_name])
col_data_zeros = pd.DataFrame({col_name: np.zeros(gap)})
print('Creating : ', col_name)
for month in range(0, parm_ts_month):
# print('month : ', month)
col_data.append(col_data_zeros)
for i in range(0, gap):
col_data.loc[month*parm_ts_cycle+i] = 0
for i in range(gap, parm_ts_cycle):
col_data.loc[month*parm_ts_cycle+i] = \
np.mean(df_history_ts_process['bid-price'][month*parm_ts_cycle+i-gap:month*parm_ts_cycle+i])
df_history_ts_process[col_name] = col_data
print('Total records processed : ', len(col_data))
df_history_ts_process[1768:]
# previous 2 sec Moving Average ['bid-price']
gap = parm_calculate_mv
for gap in range(1, gap+1):
col_name = 'bid-price-mv'+str(gap)+'sec'
col_data = pd.DataFrame(columns=[col_name])
print('Creating : ', col_name)
for month in range(0, parm_ts_month):
# print('month : ', month)
col_data.append(col_data_zeros)
for i in range(0, gap):
col_data.loc[month*parm_ts_cycle+i] = 0
for i in range(gap, parm_ts_cycle):
col_data.loc[month*parm_ts_cycle+i] = df_history_ts_process['bid-price'][month*parm_ts_cycle+i-gap]
df_history_ts_process[col_name] = col_data
print('len : ', len(col_data))
# previous N sec
gap = 1
gap = 2
gap = 3
gap = 4
gap = 5
gap = 6
gap = 7
gap = 8
gap = 9
gap = 10
col_name = 'bid-price-prev'+str(gap)+'sec'
col_data = pd.DataFrame(columns=[col_name])
for month in range(0, parm_ts_month):
# print('month : ', month)
col_data.append(col_data_zeros)
for i in range(0, gap):
col_data.loc[month*parm_ts_cycle+i] = 0
for i in range(gap, parm_ts_cycle):
col_data.loc[month*parm_ts_cycle+i] = df_history_ts_process['bid-price'][month*parm_ts_cycle+i]
print('len : ', len(col_data))
df_history_ts_process[col_name] = col_data
len(col_data)
# previous 1 sec
gap = 10
col_data = pd.DataFrame({'bid-price-prev'+str(gap)+'sec': np.zeros(gap)})
# for i in range(gap, len(df_history_ts)-1768):
for i in range(gap, parm_ts_cycle):
# print(df_history_ts['bid-price'][i])
col_data.loc[i] = df_history_ts['bid-price'][i]
print(len(col_data))
df_history_ts_process = df_history_ts.copy()
df_history_table_process['tmp'] = col_data['bid-price-prev'+str(gap)+'sec']
df_history_table_process.tail()
col_data
```
---
### The End
| github_jupyter |
# **Working memory training**: Module allegiance matrix calculation
**Last edited:** 04-10-2018
Step 0: Loading libraries
--------------------------------
```
import sys
sys.path.append("..")
import os
%matplotlib inline
import scipy.io as sio
import numpy as np
from nilearn import plotting
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy import stats
from fctools import networks, figures
#---- matplotlib settings
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
plt.rcParams['font.family'] = 'Helvetica'
```
Step 1: Getting modules names and color pallete
----------------------------------------
```
labels = pd.read_csv(f'../support/modules.txt', sep = " ", header = None)
power_colors_new = {'AU':'#d182c6',
'CER':'#9fc5e8',
'CO':'#7d009d',
'DA':'#75df33',
'DM':'#ed1126',
'FP':'#f6e838',
'MEM':'#bebab5',
'SAL':'#2a2a2a',
'SOM':'#6ccadf',
'SUB':'#980000',
'UNC':'#f58c00',
'VA':'#00a074',
'VIS':'#5131ac',}
modules = sorted(labels[0].values)
network_pal = (sns.color_palette(power_colors_new.values()))
sns.palplot(sns.color_palette(power_colors_new.values()))
network_lut = dict(zip(map(str, np.unique(modules)), network_pal))
network_colors = pd.Series(modules).map(network_lut)
network_colors = np.asarray(network_colors)
n_roi = len(labels)
n_net = len(np.unique(modules))
```
Step 2: Loading module assignment matrices
-------------------------------------------------------------------------------
```
top_dir = '/home/finc/Dropbox/Projects/LearningBrain/'
mat = sio.loadmat(f'{top_dir}data/neuroimaging/03-modularity/dynamic/02-module_assignment/power_modules.mat')
idx = np.argsort(labels[0])
module_assignment = mat['modules']
module_assignment = module_assignment[:, :, :, idx, :]
```
Step 3: calculating allegiance matrices
-------------------------------------------
```
# Calculating allegiance matrices (mean over optimizations)
n_sub = module_assignment.shape[0]
n_ses = module_assignment.shape[1]
n_opt = module_assignment.shape[2]
n_nod = module_assignment.shape[3]
P = np.zeros((n_sub, n_ses, n_nod, n_nod))
for i in range(n_sub):
print(f'Subject {i+1}')
for j in range(n_ses):
P[i,j,:,:] = networks.allegiance_matrix_opti(module_assignment[i,j,:,:,:])
np.save(f'{top_dir}data/neuroimaging/03-modularity/dynamic/03-allegiance_matrices/allegiance_matrix_power_opt_mean.npy', P)
# Calculating allegiance matrices for each window (mean over optimizations)
n_sub = len(module_assignment.shape[0])
n_ses = len(module_assignment.shape[1])
n_nod = len(module_assignment.shape[3])
n_win = len(module_assignment.shape[4])
W = np.zeros((n_sub, n_ses, n_win, n_nod, n_nod))
for i in range(n_sub):
print(f'Subject {i+1}')
W[i,j,:,:,:] = networks.all_window_allegiance_mean(module_assignment[i, j, :, :, :])
np.save(f'{top_dir}data/neuroimaging/03-modularity/dynamic/03-allegiance_matrices/window_allegiance_matrix_power_dualnback.npy', W)
```
| github_jupyter |
```
edges = [(1,2), (1,3), (1,4),(2,3), (2,4), (2,5), (2, 6), (3,4),
(3,5), (3,6), (3,7),(4,6), (4,7), (5,6), (6,7)]
f=Graph(edges)
f.show(graph_border=True,figsize=4)
show(f.adjacency_matrix());show(f.incidence_matrix())
F=matrix([[0,1,1,0,1,0,0],
[1,0,1,0,0,1,0],
[1,1,0,0,0,0,1],
[0,0,0,0,1,1,1],
[1,0,0,1,1,0,0],
(0,1,0,1,0,1,0),
[0,0,1,1,0,0,1]]);F
Fa=Graph(F)
Fa.show(graph_border=True,figsize=4)
G = graphs.HeawoodGraph().copy(sparse=True)
for u,v,l in G.edges():
G.set_edge_label(u,v,'(' + str(u) + ',' + str(v) + ')')
G.graphplot(edge_labels=True).show()
G.show(figsize=4,graph_border=True)
G.incidence_matrix()
f.incidence_matrix()
from sage.plot.colors import rainbow
C = graphs.CubeGraph(3)
R = rainbow(3)
edge_colors = {}
for i in range(3):
edge_colors[R[i]] = []
for u,v,l in C.edges():
for i in range(3):
if u[i] != v[i]:
edge_colors[R[i]].append((u,v,l))
C.graphplot(vertex_labels=False,
vertex_size=0, edge_colors=edge_colors).show()
from sage.plot.colors import rainbow
C = graphs.CubeGraph(2)
R = rainbow(2)
edge_colors = {}
for i in range(2):
edge_colors[R[i]] = []
for u,v,l in C.edges():
for i in range(2):
if u[i] != v[i]:
edge_colors[R[i]].append((u,v,l))
C.graphplot(vertex_labels=False,
vertex_size=0, edge_colors=edge_colors).show()
from sage.plot.colors import rainbow
C = graphs.CubeGraph(3)
R = rainbow(3)
edge_colors = {}
for i in range(3):
edge_colors[R[i]] = []
for u,v,l in C.edges():
for i in range(3):
if u[i] != v[i]:
edge_colors[R[i]].append((u,v,l))
C.graphplot(vertex_labels=False,
vertex_size=0, edge_colors=edge_colors).show()
from sage.plot.colors import rainbow
C = graphs.CubeGraph(4)
R = rainbow(4)
edge_colors = {}
for i in range(4):
edge_colors[R[i]] = []
for u,v,l in C.edges():
for i in range(4):
if u[i] != v[i]:
edge_colors[R[i]].append((u,v,l))
C.graphplot(vertex_labels=False,
vertex_size=0, edge_colors=edge_colors).show()
from sage.plot.colors import rainbow
C = graphs.CubeGraph(5)
R = rainbow(5)
edge_colors = {}
for i in range(5):
edge_colors[R[i]] = []
for u,v,l in C.edges():
for i in range(5):
if u[i] != v[i]:
edge_colors[R[i]].append((u,v,l))
C.graphplot(vertex_labels=False,
vertex_size=0, edge_colors=edge_colors).show()
from sage.plot.colors import rainbow
C = graphs.CubeGraph(6)
R = rainbow(6)
edge_colors = {}
for i in range(6):
edge_colors[R[i]] = []
for u,v,l in C.edges():
for i in range(6):
if u[i] != v[i]:
edge_colors[R[i]].append((u,v,l))
C.graphplot(vertex_labels=False,
vertex_size=0, edge_colors=edge_colors).show()
```
| github_jupyter |
```
import pandas as pd
import numpy as np
from scipy.stats import norm
import scipy
EuroOptionClean = pd.read_csv(r'C:\Users\HP\Desktop\Fintech\final\final_project\EuropeanOptionCleanData.csv')
EuroOptionClean=EuroOptionClean.drop(columns='Unnamed: 0')
myData=EuroOptionClean.copy()
#myData=myData.drop([245,269,357,648,779,831,834])
#myData.set_index(pd.Index(index))
myData
Call = myData[myData['Type']=='Call']
Put = myData[myData['Type']=='Put']
Type=myData['Type'].values
S = myData['StockPrice'].values
K = myData['StrikePrice'].values
T = myData['T'].values
P=myData['Last'].values
Vol =myData['IV'].values
```
Function definition
```
def OptionValue(S, K, T, r , Type ,sigma):
d1 = (np.log(S /K) + (r + 0.5 * sigma**2) * T )/(sigma * np.sqrt(T))
d2 = (np.log(S /K) + (r - 0.5 * sigma**2) * T )/(sigma * np.sqrt(T))
if Type == 'Call':
p = (S * norm.cdf(d1, 0, 1) - K * np.exp(-r * T) * norm.cdf(d2, 0, 1))
elif Type == 'Put':
p = (K*np.exp(-r*T)*norm.cdf(-d2, 0.0, 1.0) - S*norm.cdf(-d1, 0.0, 1.0))
return p
def vega(S, K, T, sigma, r = 0.03):
d1 = (np.log(S/K) + (r + 0.5*sigma**2)*T)/(sigma*np.sqrt(T))
vega = (S * norm.pdf(d1, 0, 1) * np.sqrt(T))
return vega
def vomma(S, K, T, sigma, r = 0.03):
d1 = (np.log(S/K) + (r + 0.5*sigma**2)*T)/(sigma*np.sqrt(T))
d2=d1-sigma*np.sqrt(T)
vomma=vega(S, K, T, sigma, r = 0.03)*d1*d2/sigma
return vomma
def Bisection(S,K,T,l,r,rf,price,Type,tol=0.000000000001):
count=1
while r-l>tol:
count=count+1
mid=float((l+r)/2);
if OptionValue(S,K,T,rf,Type,mid)>price:
r=mid
else:
l=mid
return l,count
def imp_vol_using_Newton(S, K, T, r, Price,Type,e,x0):
count=1
def newtons_method(S, K, T, r, Price,Type,x0, e):
global count
count=1
delta = OptionValue (S,K,T,r,Type,x0) - (Price)
while delta > e:
count=count+1
#print(count)
x0 = (x0 - (OptionValue (S,K,T,r,Type,x0) - Price)/vega (S,K,T,x0,0.03))
delta = abs(OptionValue (S,K,T,r,Type,x0) - Price)
return x0,count
sig ,count= newtons_method(S, K, T, r, Price,Type,x0 , e)
return sig,count
from scipy import optimize
def implied_vol_using_blent(S, K, T, r, Price,Type):
def blent(x0):
p1=OptionValue (S,K,T,r,Type,x0)-Price
return p1
root=optimize.brentq(blent,0.0000001,0.9999999)
return root
def imp_vol_using_Halley(S, K, T, r, Price,Type,e,x0):
count=1
def Halley_method(S, K, T, r, Price,Type,x0, e):
global count
count=1
delta = OptionValue (S,K,T,r,Type,x0) - (Price)
while delta > e:
count=count+1
v=vega(S, K, T, x0, r = 0.03)
vv=vomma(S, K, T, x0, r = 0.03)
x0 = x0 - 2*delta*v/(2*v*v-vv*delta)
delta = abs(OptionValue (S,K,T,r,Type,x0) - Price)
return x0,count
sig,count = Halley_method(S, K, T, r, Price,Type,x0 , e)
return sig,count
def Muller(S, K, T, x0, x1, x2, Price, r = 0.03, Type = 'Call'):
f0 = OptionValue(S, K, T, r, Type,x0)-Price
f1 = OptionValue(S, K, T, r, Type,x0)-Price
f2 = OptionValue(S, K, T, r, Type,x0)-Price
c = f2
b = ((x0-x2)**2 * (f1-f2)-(x1-x2)**2 * (f0-f2))/((x0-x2)*(x1-x2)*(x0-x1))
a = ((x1-x2)*(f0-f2)-(x0-x2)*(f1-f2))/((x0-x2)*(x1-x2)*(x0-x1))
if ((b-np.sqrt(b**2-4*a*c))>(b+np.sqrt(b**2-4*a*c))):
x3 = x2-2*c/(b-np.sqrt(b**2-4*a*c))
return x3
else:
x3 = x2-2*c/(b+np.sqrt(b**2-4*a*c))
return x3
def MullerBisection(S, K, T, Xsmall, Xbig, Price, eps, r = 0.03, Type = 'Call'):
count = 1
while Xbig-Xsmall>eps:
count = count + 1
Xmid = float((Xsmall+Xbig)/2);
XmiddleNew = Muller(S, K, T, Xsmall, Xbig, Xmid, Price, r, Type)
if OptionValue(S, K, T, r, Type ,Xmid ) > Price:
Xbig = Xmid
if (Xsmall < XmiddleNew < Xbig):
Xmiddle = XmiddleNew
else:
Xmiddle = (Xsmall+Xbig)/2.0
else:
Xsmall = Xmid
if (Xsmall < XmiddleNew < Xbig):
Xmiddle = XmiddleNew
else:
Xmiddle = (Xsmall+Xbig)/2.0
return Xsmall,count
MullerBisection(S[245], K[245], T[245], 0.000001, 0.99999, P[245], 0.00000000001, 0.03, Type [245])
```
Apply all methods to the whole dataset and get the est sigma
```
sig_Bisection=[]
sig_Brent=[]
sig_MullerSection=[]
sig_NewTon=[]
sig_Halley=[]
for i in range(len(myData)):
sig_Bisection.append(Bisection(S[i],K[i],T[i],0.00001,0.99999,0.03,P[i],Type[i],0.000000000001))
sig_NewTon.append(imp_vol_using_Newton(S[i], K[i], T[i], 0.03, P[i],Type[i],0.000000000001,1))
sig_MullerSection.append(MullerBisection(S[i], K[i], T[i], 0.00000001, 0.999999, P[i], 0.000000000001, 0.03, Type[i]))
sig_Halley.append(imp_vol_using_Halley(S[i], K[i], T[i], 0.03, P[i],Type[i],0.000000000001,1))
try:
sig_Brent.append(implied_vol_using_blent(S[i], K[i], T[i], 0.03, P[i],Type[i]))
except:
sig_Brent.append(-1)
sig_new_Newton=[]
sig_new_Halley=[]
for i in range(len(myData)):
if(sig_Brent[i]==1):
sig_new_Newton.append(-1)
sig_new_Halley.append(-1)
else:
sig_new_Newton.append(imp_vol_using_Newton(S[i], K[i], T[i], 0.03, P[i],Type[i],0.000000000001,sig_Brent[i]))
sig_new_Halley.append(imp_vol_using_Halley(S[i], K[i], T[i], 0.03, P[i],Type[i],0.000000000001,sig_Brent[i]))
pd.DataFrame(sig_Bisection).iloc[:,1]
sig_NewTon
```
Locate the invalid data
```
x=[]
for i in range(len(sig_Brent)):
if sig_Brent[i]==-1:
x.append(i)
x
myData.iloc[x,:]
```
Use nsolve from sympy to get a more accurate implied Volatility
```
from sympy import nsolve,Symbol
import sympy
vol=Symbol('sigma')
# European call option
#d1=(log(s/k)+(r-d+sigma*sigma/2)*tao)/(sigma*math.sqrt(tao))
#d2=d1-sigma*math.sqrt(tao)
def normcdf(x):
return (1+sympy.erf(x/sympy.sqrt(2)))/2
def Euro(s,k,sigma,tao,r,d,Type):
if Type=='Call':
d1=(sympy.log(s/k)+(r-d+sigma*sigma/2)*tao)/(sigma*sympy.sqrt(tao))
d2=d1-sigma*sympy.sqrt(tao)
call=s*sympy.exp(-d*tao)*normcdf(d1)-k*sympy.exp(-r*tao)*normcdf(d2)
return call
else:
d1=(sympy.log(s/k)+(r-d+sigma*sigma/2)*tao)/(sigma*sympy.sqrt(tao))
d2=d1-sigma*sympy.sqrt(tao)
put=k*sympy.exp(-r*tao)*normcdf(-d2)-s*sympy.exp(-d*tao)*normcdf(-d1)
return put
ImVol=[]
tag=[]
for i in range(len(myData)):
try:
ImVol.append(nsolve(Euro(S[i],K[i],vol,T[i],0.03,0,Type[i])-P[i],vol,1))
except:
ImVol.append(str(i)+'--1')
```
Create a df and drop the invalid rows
```
#est vol value
sig_Bisection_v=pd.DataFrame(sig_Bisection).iloc[:,0]
sig_Brent_v=pd.DataFrame(sig_Brent).iloc[:,0]
sig_MullerSection_v=pd.DataFrame(sig_MullerSection).iloc[:,0]
sig_NewTon_v=pd.DataFrame(sig_NewTon).iloc[:,0]
sig_Halley_v=pd.DataFrame(sig_Halley).iloc[:,0]
sig_new_Newton_v=pd.DataFrame(sig_new_Newton).iloc[:,0]
sig_new_Halley_v=pd.DataFrame(sig_new_Halley).iloc[:,0]
ImVol_v=pd.DataFrame(ImVol).iloc[:,0]
#steps
sig_Bisection_s=pd.DataFrame(sig_Bisection).iloc[:,1]
#sig_Brent_s=pd.DataFrame(sig_Brent).iloc[:,0]
sig_MullerSection_s=pd.DataFrame(sig_MullerSection).iloc[:,1]
sig_NewTon_s=pd.DataFrame(sig_NewTon).iloc[:,1]
sig_Halley_s=pd.DataFrame(sig_Halley).iloc[:,1]
sig_new_Newton_s=pd.DataFrame(sig_new_Newton).iloc[:,1]
sig_new_Halley_s=pd.DataFrame(sig_new_Halley).iloc[:,1]
#ImVol_s=pd.DataFrame(ImVol).iloc[:,1]
df_step=pd.DataFrame(list(zip(sig_Bisection_s,sig_MullerSection_s,sig_NewTon_s,sig_Halley_s,sig_new_Newton_s,sig_new_Halley_s)),columns=['Bisection','MullerSection','NewTon','Halley','new_Newton','new_Halley'])
df_step=df_step.drop(x)
idx=pd.Series(list(range(2254)))
df_step=df_step.set_index([idx])
df_step=df_step.drop(1130)
idx=pd.Series(list(range(2253)))
df_step=df_step.set_index([idx])
df_step
df=pd.DataFrame(list(zip(sig_Bisection_v,sig_Brent_v,sig_MullerSection_v,sig_NewTon_v,sig_Halley_v,sig_new_Newton_v,sig_new_Halley_v,ImVol_v)),columns=['Bisection','Brent','MullerSection','NewTon','Halley','new_Newton','new_Halley','ImVol'])
df=df.drop(x)
idx=pd.Series(list(range(2254)))
df=df.set_index([idx])
df=df.drop(1130)
idx=pd.Series(list(range(2253)))
df=df.set_index([idx])
df
```
Evaluation
```
def mse(df):
M=[]
for j in range(7): #del last col
sum=0
for i in range(len(df)):
sum=sum+(df.iloc[i,j]-df.iloc[i,-1])**2
mean=sum/len(df)
#print(mean)
M.append(mean)
return M
import math
def Efficiency(mse,DF_Step):
meanStep=DF_Step.mean().tolist()
del mse[1] #delete blent's column,
M=[]
for i in range(len(mse)):
M.append(1/((1+mse[i])*math.log2(1+meanStep[i])))
return M
Mse_ans=mse(df)
# 7 values
Mse_ans
Mse1=Mse_ans.copy()
#6 values
effi=Efficiency(Mse1,df_step)
effi
```
Visualization
```
Mse=Mse_ans.copy()
Mse
names=list(df.columns)
names
import matplotlib.pyplot as plt
names=list(df.columns)
del names[-1]
del names[1]
steps=df_step.mean().tolist()
del Mse[1] #del Brent
values=Mse
plt.figure(figsize=(9, 9))
plt.suptitle('MSE Comparation')
plt.bar(names,values)
plt.figure(figsize=(9, 9))
plt.suptitle('Step Comparation')
plt.bar(names,steps,color='g')
plt.figure(figsize=(9, 9))
plt.suptitle('Efficiency Comparation')
plt.bar(names,effi,color='r')
```
| github_jupyter |
# BIG DATA ANALYTICS PROGRAMMING : Regression Task
### Regression(회귀) 문제를 처음 부터 끝까지 다뤄 봅니다
---
References
- https://github.com/rickiepark/handson-ml2/blob/master/02_end_to_end_machine_learning_project.ipynb
## 1. Load Dataset
```
import pandas as pd
import numpy as np
df = pd.read_csv("data/housing.csv")
```
## 2. Data에 대한 기본적인 정보 확인
```
df.head()
df.info()
df['ocean_proximity'].value_counts()
df.describe()
%matplotlib inline
import matplotlib.pyplot as plt
df.hist(bins=50, figsize=(20,15))
plt.show()
```
## 3. 미리 훈련/테스트 데이터셋 나누기
```
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import train_test_split
df["income_cat"] = pd.cut(df["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
df.head()
df["income_cat"].value_counts()
df["income_cat"].hist()
train_set_random, test_set_random = train_test_split(df, test_size=0.2, random_state=42)
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(df, df["income_cat"]):
strat_train_set = df.loc[train_index]
strat_test_set = df.loc[test_index]
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
test_set_random['income_cat'].value_counts() / len(test_set_random)
df["income_cat"].value_counts() / len(df)
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
compare_props = pd.DataFrame({
"Overall": income_cat_proportions(df),
"Stratified": income_cat_proportions(strat_test_set),
"Random": income_cat_proportions(test_set_random),
}).sort_index()
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Strat. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100
compare_props
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)
df = strat_train_set.copy()
```
## 4. 탐색적 데이터 분석
```
df.plot(kind="scatter", x="longitude", y="latitude")
df.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
df.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=df["population"]/100, label="population", figsize=(10,7),
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
sharex=False)
plt.legend()
import matplotlib.image as mpimg
california_img=mpimg.imread("data/california.png")
ax = df.plot(kind="scatter", x="longitude", y="latitude", figsize=(10,7),
s=df['population']/100, label="Population",
c="median_house_value", cmap=plt.get_cmap("jet"),
colorbar=False, alpha=0.4,
)
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5,
cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude", fontsize=14)
plt.xlabel("Longitude", fontsize=14)
prices = df["median_house_value"]
tick_values = np.linspace(prices.min(), prices.max(), 11)
cbar = plt.colorbar(ticks=tick_values/prices.max())
cbar.ax.set_yticklabels(["$%dk"%(round(v/1000)) for v in tick_values], fontsize=14)
cbar.set_label('Median House Value', fontsize=16)
plt.legend(fontsize=16)
plt.show()
corr_matrix = df.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(df[attributes], figsize=(12, 8))
df.plot(kind="scatter", x="median_income", y="median_house_value",
alpha=0.1)
plt.axis([0, 16, 0, 550000])
```
## 5. 추가 속성 생성
```
df["rooms_per_household"] = df["total_rooms"]/df["households"]
df["bedrooms_per_room"] = df["total_bedrooms"]/df["total_rooms"]
df["population_per_household"]=df["population"]/df["households"]
corr_matrix = df.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
df.plot(kind="scatter", x="bedrooms_per_room", y="median_house_value",
alpha=0.2)
plt.show()
df.describe()
```
## 6. 데이터 전처리
### 6-1. Label 분리 및 결측값 핸들링
```
df = strat_train_set.drop("median_house_value", axis=1) # 훈련 세트를 위해 레이블 삭제
df_labels = strat_train_set["median_house_value"].copy()
sample_incomplete_rows = df[df.isnull().any(axis=1)].head()
sample_incomplete_rows
sample_incomplete_rows.dropna(subset=["total_bedrooms"]) # 옵션 1
sample_incomplete_rows.drop("total_bedrooms", axis=1) # 옵션 2
median = df["total_bedrooms"].median()
df["total_bedrooms"].fillna(median, inplace=True) # 옵션 3
df.info()
```
### 6-2. Categorical 데이터 인코딩
```
df_cat = df[["ocean_proximity"]]
df_cat.head(10)
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
df_cat_encoded = ordinal_encoder.fit_transform(df_cat)
df_cat_encoded[:10]
ordinal_encoder.categories_
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
df_cat_1hot = cat_encoder.fit_transform(df_cat)
df_cat_1hot
cat_encoder.get_feature_names()
df_cat_1hot.toarray()
for index, category in enumerate(cat_encoder.get_feature_names()):
print(index)
print(category)
df[category] = df_cat_1hot.toarray()[:,index]
df.head()
organized_df = df.drop("ocean_proximity", axis=1)
organized_df
```
### 6-3. Numerical 데이터 정규화
```
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X = scaler.fit_transform(organized_df)
y = df_labels.values
X
y
```
## 7. 정리된 데이터셋을 확인 하기 위한 간단한 모델 적용
```
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X, y)
```
### 7-1. 테스트 데이터셋에 전처리 적용
```
def organizing(encoder, scaler, data):
for index, category in enumerate(encoder.get_feature_names()):
df_cat = data[["ocean_proximity"]]
data[category] = encoder.transform(df_cat).toarray()[:,index]
data.drop("ocean_proximity", axis=1, inplace=True)
X = scaler.transform(data)
return X
test_y = strat_test_set['median_house_value']
test_X = strat_test_set.drop("median_house_value", axis=1) # 훈련 세트를 위해 레이블 삭제
test_X.info()
test_X["total_bedrooms"].fillna(median,inplace=True)
test_X.info()
test_X = organizing(cat_encoder, scaler, test_X)
print(test_X)
```
### 7-2. 예측
```
pred_y = reg.predict(test_X)
mse = mean_squared_error(test_y, pred_y)
rmse = np.sqrt(mse)
print(rmse)
mae = mean_absolute_error(test_y, pred_y)
print(mae)
```
## 8. 최적의 모델 찾기
```
from sklearn.utils import all_estimators
estimators = all_estimators(type_filter='regressor')
all_regs = []
for name, RegressorClass in estimators:
try:
reg = RegressorClass()
all_regs.append(reg)
print('Appending', name)
except:
pass
results = []
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(random_state=42)
scores = cross_val_score(rfr, X, y,
scoring="neg_mean_squared_error", cv=10)
scores = np.sqrt(-scores)
print("점수:", scores)
print("평균:", scores.mean())
print("표준 편차:", scores.std())
SUPER_SLOW_REGRESSION = ["GaussianProcessRegressor","KernelRidge"]
for reg in all_regs:
reg_name = reg.__class__.__name__
if reg_name not in SUPER_SLOW_REGRESSION:
try:
# reg.fit(X, y)
scores = cross_val_score(reg, X, y, scoring="neg_mean_squared_error", cv=5)
scores = np.sqrt(-scores)
if not scores.mean():
break
print("{}: RMSE {}".format(reg.__class__.__name__, scores.mean()))
result = {
"Name":reg.__class__.__name__,
"RMSE":scores.mean()
}
results.append(result)
except:
pass
result_df = pd.DataFrame(results)
result_df
result_df.sort_values(by="RMSE")
```
### 9. 모델 세부 튜닝
```
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [50, 70, 100, 120, 150], 'max_features': [2, 4, 6, 8]},
]
forest_reg = RandomForestRegressor(random_state=42)
grid_search = GridSearchCV(forest_reg, param_grid, cv=5, verbose=2,
scoring='neg_mean_squared_error',
return_train_score=True)
grid_search.fit(X, y)
grid_search.best_params_
reg = RandomForestRegressor(max_features=6, n_estimators=150,random_state=42)
reg.fit(X,y)
pred_y = reg.predict(test_X)
mse = mean_squared_error(test_y, pred_y)
rmse = np.sqrt(mse)
mae = mean_absolute_error(test_y, pred_y)
print("RMSE {}, MAE {}".format(rmse,mae))
```
## Q. 중요하지 않은 속성 제거뒤 다시 해보기!
```
feature_importances = grid_search.best_estimator_.feature_importances_
print(feature_importances)
features_with_importance = zip(df.columns, grid_search.best_estimator_.feature_importances_)
sorted(features_with_importance,key=lambda f : f[1], reverse=True)
```
| github_jupyter |
```
import pandas as pd
#This is the Richmond USGS Data gage
river_richmnd = pd.read_csv('JR_Richmond02037500.csv')
river_richmnd.dropna();
#Hurricane data for the basin - Names of Relevant Storms - This will be used for getting the storms from the larger set
JR_stormnames = pd.read_csv('gis_match.csv')
# Bring in the Big HURDAT data, from 1950 forward (satellites and data quality, etc.)
HURDAT = pd.read_csv('hurdatcleanva_1950_present.csv')
VA_JR_stormmatch = JR_stormnames.merge(HURDAT)
# Now the common storms for the James Basin have been created. We now have time and storms together for the basin
#checking some things about the data
# How many unique storms within the basin since 1950? 62 here and 53 in the Data on the Coast.NOAA.gov's website.
#I think we are close enough here, digging may show some other storms, but I think we have at least captured the ones
#from NOAA
len(VA_JR_stormmatch['Storm Number'].unique());
#double ck the lat and long parameters
print(VA_JR_stormmatch['Lat'].min(),
VA_JR_stormmatch['Lon'].min(),
VA_JR_stormmatch['Lat'].max(),
VA_JR_stormmatch['Lon'].max())
#Make a csv of this data
VA_JR_stormmatch.to_csv('storms_in_basin.csv', sep=',',encoding = 'utf-8')
#names of storms
len(VA_JR_stormmatch['Storm Number'].unique())
VA_JR_stormmatch['Storm Number'].unique()
numbers = VA_JR_stormmatch['Storm Number']
#grab a storm from this list and lok at the times
#Bill = pd.DataFrame(VA_JR_stormmatch['Storm Number'=='AL032003'])
storm = VA_JR_stormmatch[(VA_JR_stormmatch["Storm Number"] == 'AL061961')]
storm
#so this is the data for a storm named Bill that had a pth through the basin * BILL WAS A BACKDOOR Storm
# plotting for the USGS river Gage data
import matplotlib
import matplotlib.pyplot as plt
from climata.usgs import DailyValueIO
from datetime import datetime
from pandas.plotting import register_matplotlib_converters
import numpy as np
register_matplotlib_converters()
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = (20.0, 10.0)
# set parameters
nyears = 1
ndays = 365 * nyears
station_id = "02037500"
param_id = "00060"
datelist = pd.date_range(end=datetime.today(), periods=ndays).tolist()
#take an annual average for the river
annual_data = DailyValueIO(
start_date="1961-01-01",
end_date="1962-01-01",
station=station_id,
parameter=param_id,)
for series in annual_data:
flow = [r[1] for r in series.data]
si_flow_annual = np.asarray(flow) * 0.0283168
flow_mean = np.mean(si_flow_annual)
#now for the storm
dischg = DailyValueIO(
start_date="1961-09-11",
end_date="1961-09-25",
station=station_id,
parameter=param_id,)
#create lists of date-flow values
for series in dischg:
flow = [r[1] for r in series.data]
si_flow = np.asarray(flow) * 0.0283168
dates = [r[0] for r in series.data]
plt.plot(dates, si_flow)
plt.axhline(y=flow_mean, color='r', linestyle='-')
plt.xlabel('Date')
plt.ylabel('Discharge (m^3/s)')
plt.title("TS Unnamed - 1961 (Atlantic)")
plt.xticks(rotation='vertical')
plt.show()
percent_incr= (abs(max(si_flow)-flow_mean)/abs(flow_mean))*100
percent_incr
#take an annual average for the river
annual_data = DailyValueIO(
start_date="1961-03-01",
end_date="1961-10-01",
station=station_id,
parameter=param_id,)
for series in annual_data:
flow = [r[1] for r in series.data]
si_flow_annual = np.asarray(flow) * 0.0283168
flow_mean_season = np.mean(si_flow_annual)
print(abs(flow_mean-flow_mean_season))
```
| github_jupyter |
# Plant Recommender Project
## Cluster Modeling
```
# Imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans, DBSCAN, SpectralClustering
```
#### DBSCAN
Clustering plays an important part in this project - it will provide the basis for the suggestion engine later. To create the best possible clustering model, I will need to have a rough estimate of the number of datapoint clusters. I don't intuitively know the number of clusters necessary since the data has a high degree of dimensionality, so to estimate it I will utilize `DBSCAN` clustering:
```
# Load in the data and scale it
df = pd.read_csv('../datasets/cleaned-data.csv')
df.dropna(inplace=True)
X = df.drop(columns=['id', 'Scientific_Name_x'])
species = df[['id', 'Scientific_Name_x']]
sc = StandardScaler()
X_sc = sc.fit_transform(X)
X.isnull().sum().any()
# Fit a DBSCAN model
db = DBSCAN(eps=10, min_samples=2)
db.fit(X_sc)
# Find the number of clusters and look at the silouette score
labels = db.labels_
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_clusters_
silhouette_score(X_sc, db.labels_)
```
This score is not great, but that doesn't particularly matter, as this model was instead meant to give a best estimate on the number of clusters needed to represent the data well. The `n_clusters_` of about 70 found here will be indispensable for testing other clustering models, such as KMeans.
#### KMeans
To see if this silhouette score can be improved upon, let's try to use a KMeans clustering model:
```
km = KMeans(n_clusters=70, random_state=42)
km.fit(X_sc)
silhouette_score(X_sc, km.labels_)
```
This actually performed worse than the `DBSCAN` model, so I will scrap this model in favor of a better one for now.
#### Spectral Clustering
In pursuit of a better silhouette score, I will now try using `SpectralClustering`, another clustering model from `scikitlearn`:
```
spc = SpectralClustering(n_clusters=70)
spc.fit(X_sc)
silhouette_score(X_sc, spc.labels_)
spc.get_params
```
This is by far the best performance I've gotten out of a clustering model thus far. Perhaps this can even be improved upon by tuning the model's hyperparameters:
```
# Iterate over different combinations of hyperparameters
def spec_clustering_tuner(data, n_clusters=[6, 10], eigen_solvers=None,
gammas=[1],
assign_labels=None, n_inits=[10], cores=-1):
"""Takes in lists of hyperparameters to tune over a spectral clustering model as well as scaled data.
Outputs a plot of silhoutte scores against a chosen metric and the best parameters found.
"""
# Initialize empty params dict and scores list for plotting
params = {}
scores = []
# Looping, fitting and testing a new model each iteration
# for label in assign_labels:
for gamma in gammas:
for cluster in n_clusters:
for num in n_inits:
model = SpectralClustering(n_clusters=cluster, gamma=gamma, n_init=num,
n_jobs=cores)
model.fit(data)
# Save the parameters used alongside the associated score
score = silhouette_score(data, model.labels_)
scores.append(score)
# Make sure the loop can continue just in case two scores are identical
if score in params.keys():
continue
params[score] = model.get_params
# Finding the best score
best_model_params = sorted(params.items(), reverse=True)[0]
return best_model_params
best = spec_clustering_tuner(data=X_sc, n_clusters=[5, 20, 70, 90],
gammas=[0.5, 1], n_inits=[5, 20], plot=False)
best
```
Tuning this clustering model has led to an even greater improvement in silhouette score. This will be the model that I'll use for the recommendation engine.
## Building the Recommendation System
To build this engine, I will use [this](https://towardsdatascience.com/build-your-own-clustering-based-recommendation-engine-in-15-minutes-bdddd591d394) blog on building recommender systems from clustering models.
```
# Build out the final model based on the best parameters found
spec = SpectralClustering(gamma=0.5, n_clusters=5, n_init=5, n_jobs=-1)
spec.fit(X_sc)
silhouette_score(X_sc, spec.labels_)
# Bring in the lists of features from the previous notebook to help sort through the X dataframe
categorical_features = ['Category', 'Family', 'Growth_Habit', 'Native_Status',
'Active_Growth_Period', 'Fall_Conspicuous', 'Flower_Color',
'Flower_Conspicuous', 'Fruit_Conspicuous', 'Bloom_Period', 'Fire_Resistance']
ordinal_features = ['Toxicity', 'Drought_Tolerance', 'Hedge_Tolerance',
'Moisture_Use', 'Salinity_Tolerance', 'Shade_Tolerance', 'Growth_Rate', 'Lifespan']
other_features = ['id', 'Scientific_Name_x', 'pH_Minimum', 'pH_Maximum',
'Temperature_Minimum_F']
# Now for a small sample user input - create a function to replicate the streamlit app
def plant_input(df, neighbors):
# Create dummy entry to feed into the clustering model with the same columns as the cleaned dataset
dummy = {}
dummy['id'] = 42
dummy['Scientific_Name_x'] = 'sample'
# Inputs for simple user-chosen features
dummy['Lifespan'] = input('Enter a lifespan')
dummy['Toxicity'] = input('Enter toxicity value')
dummy['Drought_Tolerance'] = input('Input drought tolerance')
dummy['Hedge_Tolerance'] = input('Enter desired hedge tolerance')
dummy['Moisture_Use'] = input('Enter desired moisture use')
# Fill in the other columns with dummy values if they are not specified
for col in df.columns:
if col not in dummy.keys():
dummy[col] = np.nan
# Scale the dummy data and concat it to the whole dataset
df_d = pd.DataFrame(dummy, index=[0])
df_d.fillna(0, inplace=True)
data = df.append(df_d)
labels = data[['id', 'Scientific_Name_x']]
data.drop(columns=['id', 'Scientific_Name_x'], inplace=True)
data_sc = sc.transform(data)
# Predict the labels of all of the data, including the dummy entry
spec.fit_predict(data_sc)
data['cluster'] = spec.labels_
out_cluster = spec.labels_[-1]
# Recombine the data with the label features
data = pd.concat([data, labels], axis=1)
# Filter down to the dummy entry and its nearest neighbors
output = data.loc[data['cluster'] == out_cluster]
# Sample from the filtered dataset
return output[['id', 'Scientific_Name_x']].sample(neighbors)
plant_input(df, 10)
```
The function above is just a simple proof of concept, but it is an effective proof of concept. Since the query was not very detailed, the suggestions the model made here don't make a lot of sense. In the final version of this model, however, users will be able to make much more precise queries to narrow down their searches. To see this in action, make sure to look at [this script](./plant_recommender.py). This script, `plant_recommender.py`, runs using `streamlit` [(*source*)](https://streamlit.io/).
| github_jupyter |
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import scipy.misc
import glob
import sys
# you shouldn't need to make any more imports
class NeuralNetwork(object):
"""
Abstraction of neural network.
Stores parameters, activations, cached values.
Provides necessary functions for training and prediction.
"""
def __init__(self, layer_dimensions, drop_prob=0.0, reg_lambda=0.0):
"""
Initializes the weights and biases for each layer
:param layer_dimensions: (list) number of nodes in each layer
:param drop_prob: drop probability for dropout layers. Only required in part 2 of the assignment
:param reg_lambda: regularization parameter. Only required in part 2 of the assignment
"""
# initialize paramters
np.random.seed(1)
self.parameters = {}
self.num_layers = len(layer_dimensions)
self.drop_prob = drop_prob
self.reg_lambda = reg_lambda
self.layer_dimensions = layer_dimensions.copy()
X_size = self.layer_dimensions[0]
self.layer_dimensions.pop(0)
self.sample_mean = 0
self.sample_stdDev = 0
self.momentum_solver = 0
self.decay_alpha = 0
self.batch_count = 1
self.predict_mode = 0
ncells_prev = X_size
# W and b are initiliazed here (Random initialization - maybe later switch to Xvier init)
for layer_id,cells in enumerate(self.layer_dimensions):
self.parameters['W'+str(layer_id+1)] = np.random.randn(cells, ncells_prev) * 0.02
self.parameters['V'+str(layer_id+1)] = np.zeros((cells,ncells_prev))
self.parameters['b'+str(layer_id+1)] = np.zeros((cells, 1))
ncells_prev = cells
def affineForward(self, A, W, b):
"""
Forward pass for the affine layer.
:param A: input matrix, shape (L, S), where L is the number of hidden units in the previous layer and S is
the number of samples
:returns: the affine product WA + b, along with the cache required for the backward pass
"""
Z = np.dot(W,A)+b
return Z,(Z,A,W)
def activationForward(self, A, activation="relu"):
"""
Common interface to access all activation functions.
:param A: input to the activation function
:param prob: activation funciton to apply to A. Just "relu" for this assignment.
:returns: activation(A)
"""
if activation == 'relu':
A = self.relu(A)
else:
A = self.softmax(A)
return A
def relu(self, X):
return np.maximum(0,X)
def softmax(self,X):
shiftx = X - np.max(X)
s= np.sum(np.exp(shiftx), axis=0, keepdims=True)
return np.exp(shiftx) / s
def dropout(self, A, prob):
"""
:param A:
:param prob: drop prob
:returns: tuple (A, M)
WHERE
A is matrix after applying dropout
M is dropout mask, used in the backward pass
"""
#M = np.random.binomial(1, 1-prob, size=A.shape)
p = prob
M = (np.random.rand(*A.shape) < p) / p # first dropout mask. Notice /p!
if self.predict_mode == 1:
A = A
else:
A *= M
return A, M
def forwardPropagation(self, X):
"""
Runs an input X through the neural network to compute activations
for all layers. Returns the output computed at the last layer along
with the cache required for backpropagation.
:returns: (tuple) AL, cache
WHERE
AL is activation of last layer
cache is cached values for each layer that
are needed in further steps
"""
cache_all = []
parameters = self.parameters
layers = self.layer_dimensions
AL = X
for layer_id, cells in enumerate(layers):
W = parameters['W'+str(layer_id+1)]
b = parameters['b'+str(layer_id+1)]
Z, cache = self.affineForward(AL,W,b)
M = None
if layer_id != len(layers)-1:
A = self.activationForward(Z)
if(self.drop_prob > 0 and layer_id > 0):
A,M = self.dropout(A,self.drop_prob)
else:
A = self.activationForward(Z,'softmax')
cache_all.append((cache,M))
AL = A
cache_all.append((None, AL, None))
return AL, cache_all
def costFunction(self, AL, y):
"""
:param AL: Activation of last layer, shape (num_classes, S)
:param y: labels, shape (S)
:param alpha: regularization parameter
:returns cost, dAL: A scalar denoting cost and the gradient of cost
"""
# compute loss
probs = np.copy(AL.T)
num_samples = probs.shape[0]
corect_logprobs = -np.log(probs[range(num_samples),y])
data_loss = np.sum(corect_logprobs)/num_samples
sum_reg = 0
if self.reg_lambda > 0:
# add regularization
for layer_id in range(len(self.layer_dimensions)):
W = self.parameters['W'+str(layer_id+1)]
sum_reg += np.sum(W*W)
Loss = data_loss+sum_reg*self.reg_lambda*0.5
# gradient of cost
dscores = probs
dscores[range(num_samples),y] -= 1
dscores /= num_samples
dAL = dscores.T
'''
dAL = probs.T
Y = one_hot(y)
dAL = np.multiply(Y,dAL)
for i in range(num_samples):
dAL[y[i],i] = 1/dAL[y[i],i]
'''
return Loss+sum_reg, dAL
def affineBackward(self, dA_prev, cache):
"""
Backward pass for the affine layer.
:param dA_prev: gradient from the next layer.
:param cache: cache returned in affineForward
:returns dA: gradient on the input to this layer
dW: gradient on the weights
db: gradient on the bias
"""
Z,A_Prev,W = cache
dZ = self.activationBackward(dA_prev, cache)
m = dZ.shape[1] # I still don't know why move 1/m here from backpropagate_cost.
dA = np.dot(W.T, dZ)
dW = np.dot(dZ, A_Prev.T)
db = (1/m)*np.sum(dZ, axis=1).reshape(-1,1)
return dA, dW, db
def activationBackward(self, dA, cache, activation="relu"):
"""
Interface to call backward on activation functions.
In this case, it's just relu.
"""
Z,A_Prev,W = cache
if activation == "relu":
dA[Z <=0] = 0
return dA
def relu_derivative(self, dx, cached_x):
return np.multiply(dx, (cached_x >=0).astype(np.float32))
def dropout_backward(self, dA, cache):
M = cache
dA = dA*M*(1/self.drop_prob)
return dA
def backPropagation(self, dAL, Y, cache):
"""
Run backpropagation to compute gradients on all paramters in the model
:param dAL: gradient on the last layer of the network. Returned by the cost function.
:param Y: labels
:param cache: cached values during forwardprop
:returns gradients: dW and db for each weight/bias
"""
# gardient would be a dictionary storing in the form of gradients[key] = tuple
# key = layer id
# tuple = (dZ,dA,db)
gradients = {}
n = len(self.layer_dimensions)
# Last Layer getting dZ from the softmax function and the computing db
(Z, A_prev, W),M = cache[n-1]
tmp_z,AL,tmp_w = cache[n]
dZL = dAL
#dZL = np.multiply(dAL, (AL-np.power(AL,2)))
m = dZL.shape[1]
#print(Z.shape, A_prev.shape, W.shape, dAL.shape, dZL.shape)
dbL = 1/m * np.sum(dZL, axis=1).reshape(-1,1)
dWL = np.dot(dZL, A_prev.T)
dA = np.dot(W.T, dZL)
gradients[n] = (dAL,dWL,dbL)
dA_prev = dA
# for the rest of layers upto 1
for i in np.arange(start=(len(cache)-2),stop = 0,step = -1):
cache_layer, M = cache[i-1]
if self.drop_prob > 0 and M is not None:
#call dropout_backward
dA_prev = self.dropout_backward(dA_prev,M)
dA,dW,db = self.affineBackward(dA_prev,cache_layer)
if self.reg_lambda > 0:
# add gradients from L2 regularization to each dW
dW += cache_layer[2]*self.reg_lambda
gradients[i] = (dA_prev,dW,db)
dA_prev = dA
return gradients
def updateParameters(self, gradients, alpha):
"""
:param gradients: gradients for each weight/bias
:param alpha: step size for gradient descent
"""
gamma = 0.9
for i in range(len(self.layer_dimensions)):
dA, dW, db = gradients[i+1]
if(self.momentum_solver == 0):
self.parameters['W'+str(i+1)] -= dW * alpha
self.parameters['b'+str(i+1)] -= db * alpha
else:
self.parameters['V'+str(i+1)] = gamma * self.parameters['V'+str(i+1)] - dW * alpha
self.parameters['W'+str(i+1)] += self.parameters['V'+str(i+1)]
self.parameters['b'+str(i+1)] -= db * alpha
def train(self, X, y, iters=1000, alpha=0.0001, batch_size=5000, print_every=100):
"""
:param X: input samples, each column is a sample
:param y: labels for input samples, y.shape[0] must equal X.shape[1]
:param iters: number of training iterations
:param alpha: step size for gradient descent
:param batch_size: number of samples in a minibatch
:param print_every: no. of iterations to print debug info after
"""
#normalise the data
X = X.T.copy()
self.sample_mean = np.mean(X, axis = 0)
self.sample_stdDev = np.std(X, axis = 0)
X -= self.sample_mean
X /= self.sample_stdDev
X = X.T
X_train, Y_train = X[:,5000:], y[5000:]
X_dev, Y_dev = X[:,:5000], y[:5000]
for i in range(0, iters+1):
if i == 5000 and (self.decay_alpha == 1):
alpha /= 10
# get minibatch
X_batch, Y_batch = self.get_batch(X_train,Y_train, batch_size)
# forward prop
AL, cache = self.forwardPropagation(X_batch)
# compute loss
cost, dAL = self.costFunction(AL,Y_batch)
# compute gradients
gradients = self.backPropagation(dAL, Y_batch, cache)
# update weights and biases based on gradient
self.updateParameters(gradients,alpha)
if i % print_every == 0:
# prediction
Y_predict = np.argmax(AL, axis=0)
# train accuracy
train_accuracy = np.sum(np.equal(Y_predict, Y_batch)) / Y_predict.shape[0]
# For dev set:
self.predict_mode = 1
AL,cache = self.forwardPropagation(X_dev)
Y_predict = np.argmax(AL,axis=0)
self.predict_mode = 0
dev_accuracy = np.sum(np.equal(Y_predict, Y_dev))/Y_predict.shape[0]
# print cost, train and validation set accuracies
print('Iteration: '+str(i)+'| cost = '+str(cost)+'| train accuracy = '+str(train_accuracy*100)+'| dev_accuracy = '+str(dev_accuracy*100))
def predict(self, X):
"""
Make predictions for each sample
"""
# Normalize the data:
X = X.T.copy()
X -= self.sample_mean
X /= self.sample_stdDev
X = X.T
# call forwardpropagation:
self.predict_mode = 1
AL, cache = self.forwardPropagation(X)
self.predict_mode = 0
return np.argmax(AL,axis=0)
def set_momentum_solver(self, val):
'''
param val: turns on/off the momentum solver:
'''
self.momentum_solver = val
def set_alpha_decay(self, val):
'''
param val: turns on/off the alpha decay:
'''
self.decay_alpha = val
def get_batch(self, X, Y, batch_size):
"""
Return minibatch of samples and labels
:param X, y: samples and corresponding labels
:parma batch_size: minibatch size
:returns: (tuple) X_batch, y_batch
"""
n = self.batch_count
if n*batch_size > X.shape[1]:
permutation = np.random.permutation(X.shape[1])
X = X[:, permutation]
Y = Y[permutation]
self.batch_count = 2
n = 1
else:
self.batch_count += 1
lb = batch_size*(n-1)
ub = batch_size*(n)
X = X[:,lb:ub]
Y = Y[lb:ub]
return X,Y
# Helper functions, DO NOT modify this
def get_img_array(path):
"""
Given path of image, returns it's numpy array
"""
return scipy.misc.imread(path)
def get_files(folder):
"""
Given path to folder, returns list of files in it
"""
filenames = [file for file in glob.glob(folder+'*/*')]
filenames.sort()
return filenames
def get_label(filepath, label2id):
"""
Files are assumed to be labeled as: /path/to/file/999_frog.png
Returns label for a filepath
"""
tokens = filepath.split('/')
label = tokens[-1].split('_')[1][:-4]
if label in label2id:
return label2id[label]
else:
sys.exit("Invalid label: " + label)
# Functions to load data, DO NOT change these
def get_labels(folder, label2id):
"""
Returns vector of labels extracted from filenames of all files in folder
:param folder: path to data folder
:param label2id: mapping of text labels to numeric ids. (Eg: automobile -> 0)
"""
files = get_files(folder)
y = []
for f in files:
y.append(get_label(f,label2id))
return np.array(y)
def one_hot(y, num_classes=10):
"""
Converts each label index in y to vector with one_hot encoding
"""
y_one_hot = np.zeros((num_classes, y.shape[0]))
y_one_hot[y, range(y.shape[0])] = 1
return y_one_hot
def get_label_mapping(label_file):
"""
Returns mappings of label to index and index to label
The input file has list of labels, each on a separate line.
"""
with open(label_file, 'r') as f:
id2label = f.readlines()
id2label = [l.strip() for l in id2label]
label2id = {}
count = 0
for label in id2label:
label2id[label] = count
count += 1
return id2label, label2id
def get_images(folder):
"""
returns numpy array of all samples in folder
each column is a sample resized to 30x30 and flattened
"""
files = get_files(folder)
images = []
count = 0
for f in files:
count += 1
if count % 10000 == 0:
print("Loaded {}/{}".format(count,len(files)))
img_arr = get_img_array(f)
img_arr = img_arr.flatten() / 255.0
images.append(img_arr)
X = np.column_stack(images)
return X
def get_train_data(data_root_path):
"""
Return X and y
"""
train_data_path = data_root_path + 'train'
id2label, label2id = get_label_mapping(data_root_path+'labels.txt')
print(label2id)
X = get_images(train_data_path)
y = get_labels(train_data_path, label2id)
return X, y
def save_predictions(filename, y):
"""
Dumps y into .npy file
"""
np.save(filename, y)
# Load the data
data_root_path = 'cifar10-hw1/'
X_train, y_train = get_train_data(data_root_path) # this may take a few minutes
X_test = get_images(data_root_path + 'test')
print('Data loading done')
```
## Part 1
#### Simple fully-connected deep neural network
```
layer_dimensions = [X_train.shape[0], 150, 250, 10]
NN = NeuralNetwork(layer_dimensions)
NN.train(X_train, y_train, iters=15000, alpha=0.01, batch_size=128, print_every=1000)
y_predicted = NN.predict(X_test)
save_predictions('ans1-ck2840', y_predicted)
# test if your numpy file has been saved correctly
loaded_y = np.load('ans1-ck2840.npy')
print(loaded_y.shape)
loaded_y[:10]
```
## Part 2: Regularizing the neural network
#### Add dropout and L2 regularization
```
layer_dimensions = [X_train.shape[0], 150, 250, 10]
NN2 = NeuralNetwork(layer_dimensions, drop_prob=0.5, reg_lambda=0.01)
NN2.train(X_train, y_train, iters=10000, alpha=0.01, batch_size=256, print_every=1000)
y_predicted2 = NN2.predict(X_test)
save_predictions('ans2-ck2840', y_predicted2)
```
## Part 3: Optional effort to boost accuracy:
#### Added alpha decay
```
layer_dimensions = [X_train.shape[0], 150, 250, 10]
NN3 = NeuralNetwork(layer_dimensions, drop_prob=0.5, reg_lambda=0.01)
NN3.set_alpha_decay(1)
NN3.train(X_train, y_train, iters=7000, alpha=0.1, batch_size=256, print_every=1000)
y_predicted3 = NN3.predict(X_test)
save_predictions('ans3-ck2840', y_predicted3)
```
| github_jupyter |
<div>
<p style="float: right;"><img width="66%" src="templates/logo_fmriflows.gif"></p>
<h1>Functional Preprocessing</h1>
<p>This notebooks preprocesses functional MRI images by executing the following processing steps:
1. Image preparation
1. Reorient images to RAS
1. Removal of non-steady state volumes
1. Brain extraction with Nilearn
1. Motion correction
1. Either direct motion correction with FSL
1. Or, if low-pass filter specified, multistep motion correction with FSL and Python
1. Slice-wise correction with SPM
1. Two-step coregistration using Rigid and BBR with FSL, using WM segmentation from SPM
1. Temporal filtering with AFNI (optional)
1. Spatial filtering (i.e. smoothing) with Nilearn
Additional, this workflow also computes:
- Friston's 24-paramter model for motion parameters
- Framewise Displacement (FD) and DVARS
- Average signal in total volume, in GM, in WM and in CSF
- Anatomical CompCor components
- Temporal CompCor components
- Independent components in image before smoothing
**Note:** This notebook requires that the anatomical preprocessing pipeline was already executed and that it's output can be found in the dataset folder under `dataset/derivatives/fmriflows/preproc_anat`. </p>
</div>
## Data Structure Requirements
The data structure to run this notebook should be according to the BIDS format:
dataset
├── fmriflows_spec_preproc.json
├── sub-{sub_id}
│ └── func
│ └── sub-{sub_id}_task-{task_id}[_run-{run_id}]_bold.nii.gz
└── task-{task_id}_bold.json
**Note:** Subfolders for individual scan sessions and `run` identifiers are optional.
`fmriflows` will run the preprocessing on all files of a particular subject and a particular task.
## Execution Specifications
This notebook will extract the relevant processing specifications from the `fmriflows_spec_preproc.json` file in the dataset folder. In the current setup, they are as follows:
```
import json
from os.path import join as opj
spec_file = opj('/data', 'fmriflows_spec_preproc.json')
with open(spec_file) as f:
specs = json.load(f)
# Extract parameters for functional preprocessing workflow
subject_list = specs['subject_list_func']
session_list = specs['session_list_func']
task_list = specs['task_list']
run_list = specs['run_list']
ref_timepoint = specs['ref_timepoint']
res_func = specs['res_func']
filters_spatial = specs['filters_spatial']
filters_temporal = specs['filters_temporal']
n_compcor_confounds = specs['n_compcor_confounds']
outlier_thr = specs['outlier_thresholds']
n_independent_components = specs['n_independent_components']
n_proc = specs['n_parallel_jobs']
```
If you'd like to change any of those values manually, overwrite them below:
```
# List of subject identifiers
subject_list
# List of session identifiers
session_list
# List of task identifiers
task_list
# List of run identifiers
run_list
# Reference timepoint for slice time correction (in ms)
ref_timepoint
# Requested voxel resolution after coregistration of functional images
res_func
# List of spatial filters (smoothing) to apply (separetely, i.e. with iterables)
# Values are given in mm
filters_spatial
# List of temporal filters to apply (separetely, i.e. with iterables)
# Values are given in seconds
filters_temporal
# Number of CompCor components to compute
n_compcor_confounds
# Threshold for outlier detection (3.27 represents a threshold of 99.9%)
# Values stand for FD, DVARS, TV, GM, WM, CSF
outlier_thr
# Number of independent components to compute
n_independent_components
# Number of parallel jobs to run
n_proc
res_norm = [2.0, 2.0, 2.0]
norm_func = True
```
# Creating the Workflow
To ensure a good overview of the functional preprocessing, the workflow was divided into three subworkflows:
1. The Main Workflow, i.e. doing the actual preprocessing. Containing subworkflows for...
1. Image preparation
1. Motion correction
1. Image coregistration
1. Temporal filtering (optional)
2. The Confound Workflow, i.e. computing confound variables
3. Report Workflow, i.e. visualizating relevant steps for quality control
## Import Modules
```
import os
import numpy as np
from os.path import join as opj
from nipype import Workflow, Node, IdentityInterface, Function
from nipype.interfaces.image import Reorient
from nipype.interfaces.fsl import FLIRT
from nipype.interfaces.io import SelectFiles, DataSink
from nipype.algorithms.confounds import (
ACompCor, TCompCor, FramewiseDisplacement, ComputeDVARS)
# Specify SPM location
from nipype.interfaces.matlab import MatlabCommand
MatlabCommand.set_default_paths('/opt/spm12-r7219/spm12_mcr/spm12')
```
## Relevant Execution Variables
```
# Folder paths and names
exp_dir = '/data/derivatives'
out_dir = 'fmriflows'
work_dir = '/workingdir'
```
## Create a subworkflow for the Main Workflow
### Image preparation subworkflow
```
# Reorient anatomical images to RAS
reorient = Node(Reorient(orientation='RAS'), name='reorient')
# Extract brain from functional image
def extract_brain(in_file):
from nipype.interfaces.fsl import BET
from nipype.interfaces.ants import N4BiasFieldCorrection
from nilearn.image import mean_img, new_img_like, load_img
from scipy.ndimage import binary_dilation, binary_fill_holes
from os.path import basename, abspath
# Compute mean image
img_mean = mean_img(in_file).to_filename('mean.nii.gz')
# Apply N4BiasFieldCorrection on mean file
res = N4BiasFieldCorrection(input_image='mean.nii.gz',
dimension=3, copy_header=True).run()
# Create brain mask based on functional bias corrected mean file
res = BET(in_file=res.outputs.output_image, mask=True,
no_output=True, robust=True).run()
# Dilate mask and fill holes
img_mask = load_img(res.outputs.mask_file)
mask = binary_fill_holes(binary_dilation(img_mask.get_data(),
iterations=2))
img_mask = new_img_like(in_file, mask, copy_header=True)
# Save mask image
mask_file = abspath(basename(in_file).replace('.nii', '_mask.nii'))
img_mask.to_filename(mask_file)
return mask_file
mask_func_brain = Node(Function(input_names=['in_file'],
output_names=['mask_file'],
function=extract_brain),
name='mask_func_brain')
# Detect Non-Steady State volumes and save information to file
def detect_non_stead_states(in_file):
import numpy as np
from os.path import basename, abspath
from nipype.algorithms.confounds import NonSteadyStateDetector
# Detect Non-Steady State volumes
res = NonSteadyStateDetector(in_file=in_file).run()
t_min = res.outputs.n_volumes_to_discard
nss_file = abspath(basename(in_file).replace('.nii.gz', '_nss.txt'))
np.savetxt(nss_file, [t_min], fmt='%d')
return t_min, nss_file
nss_detection = Node(Function(input_names=['in_file'],
output_names=['t_min', 'nss_file'],
function=detect_non_stead_states),
name='nss_detection')
# Create image preparation workflow
prepareflow = Workflow(name='prepareflow')
# Add nodes to workflow and connect them
prepareflow.connect([(reorient, nss_detection, [('out_file', 'in_file')]),
(reorient, mask_func_brain, [('out_file', 'in_file')]),
])
```
### Motion & Slice-time correction nodes
```
# Remove NSS volumes and estimate original motion parameters on masked brain
def estimate_motion_parameters(in_file, mask_file, t_min):
import os
from nipype.interfaces.fsl import MCFLIRT
from nilearn.image import load_img, math_img, new_img_like
from os.path import basename, abspath, dirname
# Specify name of output file
out_file = abspath(basename(in_file).replace('.nii.gz', '_mcf.nii.gz'))
# Remove NSS volumes from functional image
img = load_img(in_file).slicer[..., t_min:]
# Apply brain mask to functional image, reset header and save file as NIfTI
img_clean = math_img('img * mask[..., None]', img=img, mask=mask_file)
img_clean = new_img_like(img, img_clean.get_data(), copy_header=True)
img_clean.to_filename(out_file)
# Performe initial motion correction
res = MCFLIRT(mean_vol=True,
save_plots=True,
output_type='NIFTI',
save_mats=True,
in_file=out_file,
out_file=out_file).run()
# Remove mcf file to save space
os.remove(out_file)
# Aggregate outputs
outputs = [res.outputs.mean_img,
res.outputs.par_file,
dirname(res.outputs.mat_file[0])]
return outputs
estimate_motion = Node(Function(input_names=['in_file', 'mask_file', 't_min'],
output_names=['mean_file', 'par_file', 'mat_folder'],
function=estimate_motion_parameters),
name='estimate_motion')
# Apply low-pass filters to motion parameters and prepare MAT-files
def filter_motion_parameters(mean_file, par_file, mat_folder, tFilter, TR):
import os
import numpy as np
from glob import glob
from math import cos, sin
from scipy.signal import butter, filtfilt
from os.path import basename, abspath, exists
import subprocess
import warnings
# Specify name of output file
out_file = abspath(basename(par_file))
# Collect MAT files
mat_file = sorted(glob('%s/MAT_????' % mat_folder))
new_mats = abspath('mats_files')
# Function to low-pass filter FSL motion parameters
def clean_par(pars, TR, low_pass):
# Taken from nilearn.signal
def _check_wn(freq, nyq):
wn = freq / float(nyq)
if wn >= 1.:
wn = 1 - 10 * np.finfo(1.).eps
warnings.warn(
'The frequency specified for the low pass filter is '
'too high to be handled by a digital filter (superior to '
'nyquist frequency). It has been lowered to %.2f (nyquist '
'frequency).' % wn)
if wn < 0.0: # equal to 0.0 is okay
wn = np.finfo(1.).eps
warnings.warn(
'The frequency specified for the low pass filter is too low'
' to be handled by a digital filter (must be non-negative).'
' It has been set to eps: %.5e' % wn)
return wn
# Taken from nilearn.signal
def butterworth(signals, sampling_rate, low_pass, order=5):
nyq = sampling_rate * 0.5
critical_freq = _check_wn(low_pass, nyq)
b, a = butter(order, critical_freq, 'low', output='ba')
signals = filtfilt(b, a, signals, axis=0)
return signals
# Filter signal
pars_clean = butterworth(pars, 1./TR, low_pass)
return pars_clean
# Function to compute affine rotation matrix based on FSL rotation angles
def rot_mat(theta):
R_x = np.array([[1, 0, 0],
[0, cos(theta[0]), sin(theta[0])],
[0,-sin(theta[0]), cos(theta[0])]])
R_y = np.array([[cos(theta[1]), 0,-sin(theta[1])],
[0, 1, 0],
[sin(theta[1]), 0, cos(theta[1])]])
R_z = np.array([[ cos(theta[2]), sin(theta[2]), 0],
[-sin(theta[2]), cos(theta[2]), 0],
[ 0, 0, 1]])
return np.dot(R_z, np.dot(R_y, R_x))
# Perform second motion correction with low-pass filter if specified
if tFilter[0]:
# Extract low-pass filter value
low_pass = 1. / tFilter[0]
# Low-pass filter rotation angles
radi = np.loadtxt(par_file)[:, :3]
clean_radi = clean_par(radi, TR, low_pass)
#Extract translation parameters from FSL's MAT files
trans = []
for m in mat_file:
M = np.loadtxt(m)
R = M[:3,:3]
# Back-project translation parameters into origin space
trans.append(np.array(np.dot(np.linalg.inv(R), M[:3, -1])))
trans_o = np.array(trans)
# Low-pass filter translation parameters
clean_trans_o = clean_par(trans_o, TR, low_pass)
# Create output folder for new MAT files
if not exists(new_mats):
os.makedirs(new_mats)
# Forward-project translation parameter into FSL space and save them
mat_files = []
clean_trans = []
for i, p in enumerate(clean_trans_o):
R = rot_mat(clean_radi[i])
tp = np.array(np.dot(R, clean_trans_o[i]))
clean_trans.append(tp)
mat = np.vstack((np.hstack((R, tp[..., None])), [0,0,0,1]))
new_mat_path = '%s/MAT_%04d' % (new_mats, i)
mat_files.append(new_mat_path)
np.savetxt(fname=new_mat_path, X=mat, delimiter=" ", fmt='%.6f')
# Overwrite FSL's pars file with new parameters
new_radi = []
new_trans = []
for m in mat_files:
cmd = 'avscale --allparams %s %s' % (m, mean_file)
process = subprocess.Popen(cmd.split(), stdout=subprocess.PIPE)
pout = process.communicate()[0].decode("utf-8").split('\n')
for p in pout:
if 'Rotation Angles (x,y,z)' in p:
new_radi.append(np.array(p[32:].split(), dtype='float'))
if 'Translations (x,y,z)' in p:
new_trans.append(np.array(p[27:].split(), dtype='float'))
new_pars = np.hstack((new_radi, new_trans))
np.savetxt(out_file, new_pars, fmt='%.8e')
else:
out_file = abspath(basename(par_file))
np.savetxt(out_file, np.loadtxt(par_file), fmt='%.8e')
new_mats = mat_folder
return out_file, new_mats
motion_parameters = Node(Function(input_names=['mean_file', 'par_file', 'mat_folder',
'tFilter', 'TR'],
output_names=['par_file', 'mat_folder'],
function=filter_motion_parameters),
name='motion_parameters')
# Correct for slice-wise acquisition
def correct_for_slice_time(in_files, TR, slice_order, nslices,
time_acquisition, ref_timepoint):
import os
import numpy as np
from nilearn.image import load_img, new_img_like
from nipype.interfaces.spm import SliceTiming
from os.path import basename, abspath
# Check if slice-time correction need to be performed or not
if len(np.unique(slice_order)) == 1:
timecorrected_files = in_files
else:
# Specify name of output file and decompress it for SPM
out_file = abspath(basename(in_files).replace('.nii.gz', '_stc.nii'))
load_img(in_files).to_filename(out_file)
# Perform slice time correction
res = SliceTiming(in_files=out_file,
ref_slice=ref_timepoint,
time_repetition=TR,
slice_order=slice_order,
num_slices=nslices,
time_acquisition=time_acquisition).run()
os.remove(out_file)
stc_file = res.outputs.timecorrected_files
# Reset TR value in header and compress output to reduce file size
timecorrected_files = stc_file.replace('.nii', '.nii.gz')
img_out = load_img(stc_file)
img_out = new_img_like(in_files, img_out.get_data(), copy_header=True)
img_out.header.set_zooms(list(img_out.header.get_zooms()[:3]) + [TR])
img_out.to_filename(timecorrected_files)
os.remove(stc_file)
return timecorrected_files
slice_time = Node(Function(input_names=['in_files', 'TR', 'slice_order', 'nslices',
'time_acquisition', 'ref_timepoint'],
output_names=['timecorrected_files'],
function=correct_for_slice_time),
name='slice_time')
slice_time.inputs.ref_timepoint = ref_timepoint
# Apply warp Motion Correction, Coregistration (and Normalization)
def apply_warps(in_file, mat_folder, coreg, brain, transforms,
template, norm_func, t_min, TR):
import os
import numpy as np
from glob import glob
from os.path import basename, abspath
from nipype.interfaces.ants import ApplyTransforms
from nipype.interfaces.c3 import C3dAffineTool
from nilearn.image import (iter_img, load_img, mean_img, concat_imgs,
new_img_like, resample_to_img, threshold_img)
# Specify name of output file and decompress it for SPM
out_file = abspath(basename(in_file.replace('.nii', '_warped.nii')))
if norm_func:
reference = template
else:
reference = 'temp_func.nii.gz'
# Apply warp for each volume individually
out_list = []
mat_files = sorted(glob(mat_folder + '/MAT_????'))
# Remove NSS volumes from functional image
img = load_img(in_file).slicer[..., t_min:]
for i, e in enumerate(iter_img(img)):
temp_file = 'temp_func.nii.gz'
e.to_filename(temp_file)
c3d_coreg = C3dAffineTool(fsl2ras=True,
transform_file=coreg,
source_file='temp_func.nii.gz',
reference_file=brain,
itk_transform='temp_coreg.txt').run()
c3d_mc = C3dAffineTool(fsl2ras=True,
transform_file=mat_files[i],
source_file='temp_func.nii.gz',
reference_file='temp_func.nii.gz',
itk_transform='temp_mats.txt').run()
if norm_func:
transform_list = [transforms,
c3d_coreg.outputs.itk_transform,
c3d_mc.outputs.itk_transform]
else:
transform_list = [c3d_coreg.outputs.itk_transform,
c3d_mc.outputs.itk_transform]
norm = ApplyTransforms(
input_image='temp_func.nii.gz',
reference_image=reference,
transforms=transform_list,
dimension=3,
float=True,
input_image_type=3,
interpolation='LanczosWindowedSinc',
invert_transform_flags=[False] * len(transform_list),
output_image='temp_out.nii.gz',
num_threads=1).run()
out_list.append(load_img(norm.outputs.output_image))
print(mat_files[i])
# Concatenate image and add TR value to header
imgs = concat_imgs(out_list)
imgs = new_img_like(reference, imgs.get_data(), copy_header=True)
imgs.header.set_zooms(list(imgs.header.get_zooms()[:3]) + [TR])
imgs.to_filename(out_file)
return out_file
apply_warp = Node(Function(input_names=[
'in_file', 'mat_folder', 'coreg', 'brain', 'transforms',
'template', 'norm_func', 't_min', 'TR'],
output_names=['out_file'],
function=apply_warps),
name='apply_warp')
apply_warp.inputs.norm_func = norm_func
```
### Image coregistration subworkflow
```
# Pre-alignment of functional images to anatomical image
coreg_pre = Node(FLIRT(dof=6,
output_type='NIFTI_GZ'),
name='coreg_pre')
# Coregistration of functional images to anatomical image with BBR
# using WM segmentation
coreg_bbr = Node(FLIRT(dof=9,
cost='bbr',
schedule=opj(os.getenv('FSLDIR'),
'etc/flirtsch/bbr.sch'),
output_type='NIFTI_GZ'),
name='coreg_bbr')
# Create coregistration workflow
coregflow = Workflow(name='coregflow')
# Add nodes to workflow and connect them
coregflow.connect([(coreg_pre, coreg_bbr, [('out_matrix_file', 'in_matrix_file')])])
```
### Temporal and spatial filter subworkflow
```
# Create again a brain mask for the functional image and one for the confounds
def create_warped_mask(in_file):
import numpy as np
from nipype.interfaces.fsl import BET
from nipype.interfaces.ants import N4BiasFieldCorrection
from nilearn.image import mean_img, new_img_like, load_img
from scipy.ndimage import binary_dilation, binary_erosion, binary_fill_holes
from os.path import basename, abspath
# Compute mean image
mean_file = abspath(basename(in_file).replace('.nii', '_mean.nii'))
mean_img(in_file).to_filename(mean_file)
# Apply N4BiasFieldCorrection on mean file
res = N4BiasFieldCorrection(input_image=mean_file,
dimension=3, copy_header=True).run()
# Create brain mask based on functional bias corrected mean file
res = BET(in_file=res.outputs.output_image, mask=True,
no_output=True, robust=True).run()
# Dilate the brain mask twice and fill wholes for functional mask
brain = load_img(res.outputs.mask_file).get_data()
mask_func = binary_fill_holes(binary_dilation(brain, iterations=2))
# Dilate brain mask once, fill wholes and erode twice for confound mask
mask_conf = binary_erosion(binary_fill_holes(
binary_dilation(brain, iterations=1)), iterations=2)
# Warping an image can induce noisy new voxels in the edge regions
# of a slab, which can be problematic for temporal filtering or
# later ICA. For this reason, we first drop any voxels that have
# zero-activation in more than 1% of all volumes and combine this
# with our previous brain mask
def remove_zero_voxels(in_file, bin_thr=1, vol_thr=0.99):
data = np.abs(load_img(in_file).get_data())
bins = np.histogram_bin_edges(np.ravel(data[data>0]), bins=100)
bin_cutoff = bins[bin_thr]
mask_zeros = np.sum(data>bin_cutoff, axis=-1)>(data.shape[-1] * vol_thr)
return binary_fill_holes(mask_zeros)
# Combine the functional brain mask with zero voxel mask and fill holes
mask_zeros = remove_zero_voxels(in_file, bin_thr=1, vol_thr=0.99)
data_mask = mask_zeros * mask_func
mask_func = binary_fill_holes(data_mask)
# Combine the confound brain mask with zero voxel mask, dilate once,
# fill wholes and erode twice
mask_zeros = remove_zero_voxels(in_file, bin_thr=5, vol_thr=0.95)
data_mask = mask_zeros * mask_conf
mask_conf = binary_erosion(binary_fill_holes(
binary_dilation(data_mask, iterations=1)), iterations=2)
# Save masks as NIfTI images
img_mask_func = new_img_like(in_file, mask_func.astype('int'),
copy_header=True)
mask_func = abspath(basename(in_file).replace('.nii', '_mask_func.nii'))
img_mask_func.to_filename(mask_func)
img_mask_conf = new_img_like(in_file, mask_conf.astype('int'),
copy_header=True)
mask_conf = abspath(basename(in_file).replace('.nii', '_mask_conf.nii'))
img_mask_conf.to_filename(mask_conf)
return mask_func, mask_conf
masks_for_warp = Node(Function(input_names=['in_file'],
output_names=['mask_func', 'mask_conf'],
function=create_warped_mask),
name='masks_for_warp')
masks_for_warp.inputs.norm_func = norm_func
# Apply temporal filter to functional image
def apply_temporal_filter(in_file, mask, tFilter, tr):
import numpy as np
from nipype.interfaces.afni import Bandpass
from nilearn.image import load_img, math_img, mean_img, new_img_like
from os.path import basename, abspath
# Extract low- and high-pass filter
low_pass = tFilter[0]
high_pass = tFilter[1]
lowpass = 1. / low_pass if low_pass != None else 999999
highpass = 1. / high_pass if high_pass != None else 0
# Temporal filtering to get rid of high and/or low-pass frequencies
res = Bandpass(in_file=in_file,
mask=mask,
lowpass=lowpass,
highpass=highpass,
tr=tr,
num_threads=-1,
no_detrend=True,
outputtype='NIFTI_GZ').run()
# Add mean image back to functional image and apply mask
img_mean = mean_img(in_file)
img_out = math_img(
'(img + mean[..., None]) * mask[..., None]', mask=mask,
img=res.outputs.out_file, mean=img_mean)
# Intensity normalize image to the white matter histogram density peak
img_mean = mean_img(img_out)
count, bins = np.histogram(np.ravel(np.abs(img_mean.get_data())), bins=128)
sigma = bins[32 + np.argmax(count[32:])]
sigma /= 10000
data = img_out.get_data() / sigma
# Save output into NIfTI file
img_out = new_img_like(in_file, data, copy_header=True)
out_file = abspath(basename(in_file).replace('.nii', '_tf.nii'))
img_out.to_filename(out_file)
mean_file = abspath(basename(in_file).replace('.nii', '_tf_mean.nii'))
img_mean.to_filename(mean_file)
return out_file, mean_file
temporal_filter = Node(Function(input_names=['in_file', 'mask', 'tFilter', 'tr'],
output_names=['out_file', 'mean_file'],
function=apply_temporal_filter),
name='temporal_filter')
# Applies gaussian spatial filter as in Sengupta, Pollmann & Hanke, 2018
def gaussian_spatial_filter(in_file, sFilter, mask, bandwidth=2):
import numpy as np
from nilearn.image import load_img, smooth_img, math_img, new_img_like
from os.path import basename, abspath
# Extract smoothing type and FWHM value
ftype, fwhm = sFilter
if fwhm == 0:
img = load_img(in_file)
elif ftype == 'LP':
img = smooth_img(in_file, fwhm=fwhm)
elif ftype == 'HP':
img_smooth = smooth_img(in_file, fwhm=fwhm)
img = math_img('img1 - img2', img1=img_smooth, img2=in_file)
elif ftype == 'BP':
img_smooth_high = smooth_img(in_file, fwhm=fwhm)
img_smooth_low = smooth_img(in_file, fwhm=fwhm - bandwidth)
img = math_img('img1 - img2', img1=img_smooth_high, img2=img_smooth_low)
# Mask smoothed image
mask = load_img(mask).get_data()
data = img.get_data() * mask[..., None]
# Before we can save the final output NIfTI in 'int16' format, we need
# to make sure that there's no data overflow, i.e. values above 32768
data = img.get_data()
max_value = 30000
max_data = np.max(np.abs(data))
if max_data > max_value:
data /= max_data
data *= max_value
print('Max-value was adapted: From %f to %f' % (max_data, max_value))
# Now we can reset the header and save image to file with data type 'int'
out_img = new_img_like(in_file, data.astype('int16'), copy_header=True)
out_img.set_data_dtype('int16')
out_file = abspath(basename(in_file).replace('.nii', '_%s_%smm.nii' % (ftype, fwhm)))
out_img.to_filename(out_file)
return out_file
# Spatial Band-Pass Filter
spatial_filter = Node(Function(input_names=['in_file', 'sFilter', 'mask'],
output_names=['out_file'],
function=gaussian_spatial_filter),
name='spatial_filter')
spatial_filter.iterables = ('sFilter', filters_spatial)
# Create temporal and spatial filter workflow
filterflow = Workflow(name='filterflow')
# Add nodes to workflow and connect them
filterflow.connect([(masks_for_warp, temporal_filter, [('mask_func', 'mask')]),
(masks_for_warp, spatial_filter, [('mask_func', 'mask')]),
(temporal_filter, spatial_filter, [('out_file', 'in_file')]),
])
```
### Create Main Workflow
**Note:** Slice time correction is applied after motion correction, as recommended by Power et al. (2017): http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0182939
```
# Create main preprocessing workflow
mainflow = Workflow(name='mainflow')
# Add nodes to workflow and connect them
mainflow.connect([(prepareflow, estimate_motion, [('reorient.out_file', 'in_file'),
('mask_func_brain.mask_file', 'mask_file'),
('nss_detection.t_min', 't_min'),
]),
(estimate_motion, motion_parameters, [('mean_file', 'mean_file'),
('par_file', 'par_file'),
('mat_folder', 'mat_folder')]),
(prepareflow, slice_time, [('reorient.out_file', 'in_files')]),
(slice_time, apply_warp, [('timecorrected_files', 'in_file')]),
(prepareflow, apply_warp, [('nss_detection.t_min', 't_min')]),
(estimate_motion, coregflow, [('mean_file', 'coreg_pre.in_file'),
('mean_file', 'coreg_bbr.in_file')]),
(coregflow, apply_warp, [('coreg_bbr.out_matrix_file', 'coreg')]),
(motion_parameters, apply_warp, [('mat_folder', 'mat_folder')]),
(apply_warp, filterflow, [('out_file', 'masks_for_warp.in_file'),
('out_file', 'temporal_filter.in_file')]),
])
```
## Create a subworkflow for the Confound Workflow
### Implement Nodes
```
# Run ACompCor (based on Behzadi et al., 2007)
aCompCor = Node(ACompCor(num_components=n_compcor_confounds,
pre_filter='cosine',
save_pre_filter=False,
merge_method='union',
components_file='compcorA.txt'),
name='aCompCor')
# Create binary mask for ACompCor (based on Behzadi et al., 2007)
def get_csf_wm_mask(mean_file, wm, csf, brainmask,
temp_wm, temp_csf, norm_func):
from os.path import basename, abspath
from nilearn.image import load_img, threshold_img, resample_to_img, new_img_like
from scipy.ndimage.morphology import binary_erosion, binary_closing
# Specify name of output file
out_file = abspath(basename(mean_file).replace('.nii', '_maskA.nii'))
if norm_func:
# Create eroded WM binary mask
bin_wm = threshold_img(temp_wm, 0.5)
mask_wm = binary_erosion(bin_wm.get_data(), iterations=2).astype('int8')
# Create eroded CSF binary mask (differs from Behzadi et al., 2007)
bin_csf = threshold_img(temp_csf, 0.5)
close_csf = binary_closing(bin_csf.get_data(), iterations=1)
mask_csf = binary_erosion(close_csf, iterations=1).astype('int8')
else:
# Create eroded WM binary mask
thr_wm = resample_to_img(threshold_img(wm, 0.99), mean_file)
bin_wm = threshold_img(thr_wm, 0.5)
mask_wm = binary_erosion(bin_wm.get_data(), iterations=2).astype('int8')
# Create eroded CSF binary mask (differs from Behzadi et al., 2007)
thr_csf = resample_to_img(threshold_img(csf, 0.99), mean_file)
bin_csf = threshold_img(thr_csf, 0.5)
close_csf = binary_closing(bin_csf.get_data(), iterations=1)
mask_csf = binary_erosion(close_csf, iterations=1).astype('int8')
# Load brain mask
mask_brain = load_img(brainmask).get_data()
# Combine WM and CSF binary masks into one and apply brainmask
binary_mask = (((mask_wm + mask_csf) * mask_brain) > 0).astype('int8')
mask_img = new_img_like(mean_file, binary_mask.astype('int16'), copy_header=True)
mask_img.to_filename(out_file)
return out_file
acomp_masks = Node(Function(input_names=['mean_file', 'wm', 'csf', 'brainmask',
'temp_wm', 'temp_csf', 'norm_func'],
output_names=['out_file'],
function=get_csf_wm_mask),
name='acomp_masks')
acomp_masks.inputs.norm_func = norm_func
# Run TCompCor (based on Behzadi et al., 2007)
tCompCor = Node(TCompCor(num_components=n_compcor_confounds,
percentile_threshold=0.02,
pre_filter='cosine',
save_pre_filter=False,
components_file='compcorT.txt'),
name='tCompCor')
# Compute ICA components
def extract_ica_components(in_file, mask_file, n_components):
import numpy as np
from nilearn.image import load_img
from scipy.stats import zscore, pearsonr
from nilearn.decomposition import CanICA
from os.path import basename, abspath
# Load functiona image and mask
img = load_img(in_file)
img_mask= load_img(mask_file)
# Compute average inplane resolution for light smoothing
fwhm = np.mean(img.header.get_zooms()[:2])
# Specify CanICA object
canica = CanICA(n_components=n_components, smoothing_fwhm=fwhm,
mask=mask_file, threshold='auto', n_jobs=1,
standardize=True, detrend=True)
# Fit CanICA on input data
canica.fit(img)
# Save components into NIfTI file
comp_file = abspath(basename(in_file).replace('.nii', '_ICA_comp.nii'))
img_comp = canica.components_img_
img_comp.to_filename(comp_file)
# Extract data and mask from images
data = img.get_data()
mask = img_mask.get_data()!=0
# Compute the pearson correlation between the components and the signal
curves = zscore([[pearsonr(img_comp.get_data()[mask, j],
data[mask, i])[0] for i in range(data.shape[-1])]
for j in range(n_components)], axis=-1)
comp_signal = abspath(basename(in_file).replace('.nii.gz', '_ICA_comp.txt'))
np.savetxt(comp_signal, curves, fmt='%.8e', delimiter=' ', newline='\n')
return comp_file, comp_signal
compute_ica = Node(Function(input_names=['in_file', 'mask_file', 'n_components'],
output_names=['comp_file', 'comp_signal'],
function=extract_ica_components),
name='compute_ica')
compute_ica.inputs.n_components = n_independent_components
# Compute framewise displacement (FD)
FD = Node(FramewiseDisplacement(parameter_source='FSL',
normalize=False),
name='FD')
# Compute DVARS
dvars = Node(ComputeDVARS(remove_zerovariance=True,
save_vxstd=True),
name='dvars')
# Computes Friston 24-parameter model (Friston et al., 1996)
def compute_friston24(in_file):
import numpy as np
from os.path import basename, abspath
# Load raw motion parameters
mp_raw = np.loadtxt(in_file)
# Get motion paremter one time point before (first order difference)
mp_minus1 = np.vstack(([0] * 6, mp_raw[1:]))
# Combine the two
mp_combine = np.hstack((mp_raw, mp_minus1))
# Add the square of those parameters to allow correction of nonlinear effects
mp_friston = np.hstack((mp_combine, mp_combine**2))
# Save friston 24-parameter model in new txt file
out_file = abspath(basename(in_file).replace('.txt', 'friston24.txt'))
np.savetxt(out_file, mp_friston,
fmt='%.8e', delimiter=' ', newline='\n')
return out_file
friston24 = Node(Function(input_names=['in_file'],
output_names=['out_file'],
function=compute_friston24),
name='friston24')
# Compute average signal in total volume, in GM, in WM and in CSF
def get_average_signal(in_file, gm, wm, csf, brainmask, template_file,
temp_mask, temp_gm, temp_wm, temp_csf, norm_func):
from scipy.stats import zscore
from nilearn.image import load_img, threshold_img, resample_to_img, math_img
from nilearn.masking import apply_mask
if norm_func:
res_brain = temp_mask
res_gm = threshold_img(temp_gm, 0.99)
res_wm = threshold_img(temp_wm, 0.99)
res_csf = threshold_img(temp_csf, 0.99)
else:
res_brain = resample_to_img(brainmask, template_file)
res_gm = resample_to_img(threshold_img(gm, 0.99), template_file)
res_wm = resample_to_img(threshold_img(wm, 0.99), template_file)
res_csf = resample_to_img(threshold_img(csf, 0.99), template_file)
# Create masks for signal extraction
bin_brain = math_img('(mask>=0.5) * template',
mask=res_brain, template=template_file)
bin_gm = math_img('(mask>=0.5) * template',
mask=res_gm, template=template_file)
bin_wm = math_img('(mask>=0.5) * template',
mask=res_wm, template=template_file)
bin_csf = math_img('(mask>=0.5) * template',
mask=res_csf, template=template_file)
# Load data from functional image and zscore it
img = load_img(in_file)
# Compute average signal per mask and zscore timeserie
signal_gm = zscore(apply_mask(img, bin_gm).mean(axis=1))
signal_wm = zscore(apply_mask(img, bin_wm).mean(axis=1))
signal_csf = zscore(apply_mask(img, bin_csf).mean(axis=1))
signal_brain = zscore(apply_mask(img, bin_brain).mean(axis=1))
return [signal_brain, signal_gm, signal_wm, signal_csf]
average_signal = Node(Function(input_names=[
'in_file', 'gm', 'wm', 'csf', 'brainmask', 'template_file',
'temp_mask', 'temp_gm', 'temp_wm', 'temp_csf', 'norm_func'],
output_names=['average'],
function=get_average_signal),
name='average_signal')
average_signal.inputs.norm_func = norm_func
# Combine confound parameters into one TSV file
def consolidate_confounds(FD, DVARS, par_mc, par_mc_raw, par_friston,
compA, compT, average, ica_comp):
import numpy as np
from os.path import basename, abspath
conf_FD = np.array([0] + list(np.loadtxt(FD, skiprows=1)))
conf_DVARS = np.array([1] + list(np.loadtxt(DVARS, skiprows=0)))
conf_mc = np.loadtxt(par_mc)
conf_mc_raw = np.loadtxt(par_mc_raw)
conf_friston = np.loadtxt(par_friston)
conf_compA = np.loadtxt(compA, skiprows=1)
conf_compT = np.loadtxt(compT, skiprows=1)
conf_average = np.array(average)
conf_ica = np.loadtxt(ica_comp).T
# Aggregate confounds
confounds = np.hstack((conf_FD[..., None],
conf_DVARS[..., None],
conf_average.T,
conf_mc,
conf_mc_raw,
conf_friston,
conf_ica,
conf_compA,
conf_compT))
# Create header
header = ['FD', 'DVARS']
header += ['TV', 'GM', 'WM', 'CSF']
header += ['Rotation%02d' % (d + 1) for d in range(3)]
header += ['Translation%02d' % (d + 1) for d in range(3)]
header += ['Rotation%02d_raw' % (d + 1) for d in range(3)]
header += ['Translation%02d_raw' % (d + 1) for d in range(3)]
header += ['Friston%02d' % (d + 1) for d in range(conf_friston.shape[1])]
header += ['ICA%02d' % (d + 1) for d in range(conf_ica.shape[1])]
header += ['CompA%02d' % (d + 1) for d in range(conf_compA.shape[1])]
header += ['CompT%02d' % (d + 1) for d in range(conf_compT.shape[1])]
# Write to file
out_file = abspath(basename(par_mc).replace('.par', '_confounds.tsv'))
with open(out_file, 'w') as f:
f.write('\t'.join(header) + '\n')
for row in confounds:
f.write('\t'.join([str(r) for r in row]) + '\n')
return out_file
combine_confounds = Node(Function(input_names=['FD', 'DVARS', 'par_mc', 'par_mc_raw',
'par_friston', 'compA', 'compT',
'average', 'ica_comp'],
output_names=['out_file'],
function=consolidate_confounds),
name='combine_confounds')
```
### Create Confound Workflow
```
# Create confound extraction workflow
confflow = Workflow(name='confflow')
# Add nodes to workflow and connect them
confflow.connect([(acomp_masks, aCompCor, [('out_file', 'mask_files')]),
# Consolidate confounds
(FD, combine_confounds, [('out_file', 'FD')]),
(dvars, combine_confounds, [('out_vxstd', 'DVARS')]),
(aCompCor, combine_confounds, [('components_file', 'compA')]),
(tCompCor, combine_confounds, [('components_file', 'compT')]),
(friston24, combine_confounds, [('out_file', 'par_friston')]),
(average_signal, combine_confounds, [('average', 'average')]),
(compute_ica, combine_confounds, [('comp_signal', 'ica_comp')]),
])
```
## Create a subworkflow for the report Workflow
### Implement Nodes
```
# Plot mean image with brainmask and ACompCor and TCompCor mask ovleray
def plot_masks(sub_id, ses_id, task_id, run_id, mean, maskA, maskT, brainmask):
import numpy as np
import nibabel as nb
from matplotlib.pyplot import figure
from nilearn.plotting import plot_roi, find_cut_slices
from os.path import basename, abspath
# If needed, create title for output figures
title_txt = 'Sub: %s - Task: %s' % (sub_id, task_id)
if ses_id:
title_txt += ' - Sess: %s' % ses_id
if run_id:
title_txt += ' - Run: %d' % run_id
# Establish name of output file
out_file = basename(mean).replace('_mean.nii.gz', '_overlays.png')
# Prepare maskA, maskT and brainmask (otherwise they create strange looking outputs)
img = nb.load(mean)
data = np.stack((np.zeros(img.shape),
nb.load(brainmask).get_data(),
nb.load(maskA).get_data() * 2,
nb.load(maskT).get_data() * 3),
axis= -1)
label_id = np.argmax(data, axis=-1)
masks = nb.Nifti1Image(label_id, img.affine, img.header)
# Get content extent of mean img and crop all images with it
content = np.nonzero(img.get_data())
c = np.ravel([z for z in zip(np.min(content, axis=1), np.max(content, axis=1))])
img = img.slicer[c[0]:c[1], c[2]:c[3], c[4]:c[5]]
masks = masks.slicer[c[0]:c[1], c[2]:c[3], c[4]:c[5]]
# Plot functional mean and different masks used (compcor and brainmask)
fig = figure(figsize=(16, 8))
from matplotlib.colors import ListedColormap
colormap = ListedColormap([(0.86, 0.3712, 0.34),
(0.3712, 0.34, 0.86),
(0.34, 0.86, 0.3712)])
for i, e in enumerate(['x', 'y', 'z']):
ax = fig.add_subplot(3, 1, i + 1)
cuts = find_cut_slices(img, direction=e, n_cuts=10)[1:-1]
plot_roi(masks, cmap=colormap, dim=1, annotate=False, bg_img=img,
display_mode=e, title=title_txt + ' - %s-axis' % e,
resampling_interpolation='nearest', cut_coords=cuts,
axes=ax, alpha=0.66)
# Establish name of output file
out_file = abspath(basename(mean).replace('_mean.nii.gz', '_overlays.png'))
fig.savefig(out_file, bbox_inches='tight', facecolor='black',
frameon=True, dpi=300, transparent=False)
return out_file
compcor_plot = Node(Function(input_names=['sub_id', 'ses_id', 'task_id', 'run_id',
'mean', 'maskA', 'maskT', 'brainmask'],
output_names=['out_file'],
function=plot_masks),
name='compcor_plot')
# Plot confounds and detect outliers
def plot_confounds(confounds, outlier_thr):
# This plotting is heavily based on MRIQC's visual reports (credit to oesteban)
import numpy as np
import pandas as pd
from scipy.stats import zscore
from matplotlib.backends.backend_pdf import FigureCanvasPdf as FigureCanvas
import seaborn as sns
sns.set(style="darkgrid")
from matplotlib import pyplot as plt
from matplotlib.gridspec import GridSpec
from os.path import basename, abspath
def plot_timeseries(dataframe, elements, out_file, outlier_thr=None, motion=False):
# Number of rows to plot
n_rows = len(elements)
# Prepare for motion plot
if motion:
n_rows = int(n_rows / 2)
# Create canvas
fig = plt.Figure(figsize=(16, 2 * n_rows))
FigureCanvas(fig)
grid = GridSpec(n_rows, 2, width_ratios=[7, 1])
# Specify color palette to use
colors = sns.husl_palette(n_rows)
# To collect possible outlier indices
outlier_idx = []
# Plot timeseries (and detect outliers, if specified)
for i, e in enumerate(elements[:n_rows]):
# Extract timeserie values
data = dataframe[e].values
# Z-score data for later thresholding
zdata = zscore(data)
# Plot timeserie
ax = fig.add_subplot(grid[i, :-1])
if motion:
ax.plot(dataframe[e + '_raw'].values, color=[0.66] * 3)
ax.plot(data, color=colors[i])
ax.set_xlim((0, len(data)))
ax.set_ylabel(e)
ylim = ax.get_ylim()
# Detect and plot outliers if threshold is specified
if outlier_thr:
threshold = outlier_thr[i]
if threshold != None:
outlier_id = np.where(np.abs(zdata)>=threshold)[0]
outlier_idx += list(outlier_id)
ax.vlines(outlier_id, ylim[0], ylim[1])
# Plot observation distribution
ax = fig.add_subplot(grid[i, -1])
sns.distplot(data, vertical=True, ax=ax, color=colors[i])
ax.set_ylim(ylim)
fig.tight_layout()
fig.savefig(out_file)
return np.unique(outlier_idx)
# Load confounds table
df = pd.read_csv(confounds, sep=' ')
df.fillna(0, inplace=True)
# Aggregate output plots
out_plots = []
confounds = basename(confounds)
# Plot main confounds
elements = ['FD', 'DVARS', 'TV', 'GM', 'WM', 'CSF']
out_file = abspath(confounds.replace('.tsv', '_main.png'))
out_plots.append(out_file)
outliers = plot_timeseries(df, elements, out_file, outlier_thr)
# Save outlier indices to textfile
outlier_filename = abspath(confounds.replace('.tsv', '_outliers.txt'))
np.savetxt(outlier_filename, outliers, fmt='%d')
# Plot Motion Paramters
elements = [k for k in df.keys() if 'Rotation' in k or 'Translation' in k]
out_file = abspath(confounds.replace('.tsv', '_motion.png'))
out_plots.append(out_file)
plot_timeseries(df, elements, out_file, motion=True)
# Plot CompCor components
for comp in ['A', 'T']:
elements = [k for k in df.keys() if 'Comp%s' % comp in k]
out_file = abspath(confounds.replace('.tsv', '_comp%s.png' % comp))
out_plots.append(out_file)
plot_timeseries(df, elements, out_file)
# Reset seaborn
sns.reset_orig()
return [outlier_filename] + out_plots
confound_inspection = Node(Function(input_names=['confounds', 'outlier_thr'],
output_names=['outlier_file', 'plot_main', 'plot_motion',
'plot_compA', 'plot_compT'],
function=plot_confounds),
name='confound_inspection')
confound_inspection.inputs.outlier_thr = outlier_thr
# Creates carpet plot
def create_carpet_plot(in_file, sub_id, ses_id, task_id, run_id,
seg_gm, seg_wm, seg_csf, nVoxels, brainmask):
from os.path import basename, abspath
from nilearn.image import load_img, resample_to_img
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import zscore
import seaborn as sns
# Load functional image and mask
img = load_img(in_file)
data = img.get_data()
mask = load_img(brainmask).get_data()
# Resample masks to functional space and threshold them
mask_gm = resample_to_img(seg_gm, img, interpolation='nearest').get_data() >= 0.5
mask_wm = resample_to_img(seg_wm, img, interpolation='nearest').get_data() >= 0.5
mask_csf = resample_to_img(seg_csf, img, interpolation='nearest').get_data() >= 0.5
# Restrict signal to plot to specific mask
data_gm = data[(mask_gm * mask).astype('bool')]
data_wm = data[(mask_wm * mask).astype('bool')]
data_csf = data[(mask_csf * mask).astype('bool')]
# Remove voxels without any variation over time
data_gm = data_gm[data_gm.std(axis=-1)!=0]
data_wm = data_wm[data_wm.std(axis=-1)!=0]
data_csf = data_csf[data_csf.std(axis=-1)!=0]
# Compute stepsize and reduce datasets
stepsize = int((len(data_gm) + len(data_wm) + len(data_csf)) / nVoxels)
data_gm = data_gm[::stepsize]
data_wm = data_wm[::stepsize]
data_csf = data_csf[::stepsize]
# Sort voxels according to correlation to mean signal within a ROI
data_gm = data_gm[np.argsort([np.corrcoef(d, data_gm.mean(axis=0))[0, 1] for d in data_gm])]
data_wm = data_wm[np.argsort([np.corrcoef(d, data_wm.mean(axis=0))[0, 1] for d in data_wm])]
data_csf = data_csf[np.argsort([np.corrcoef(d, data_csf.mean(axis=0))[0, 1] for d in data_csf])]
# Create carpet plot, zscore and rescale it
carpet = np.row_stack((data_gm, data_wm, data_csf))
carpet = np.nan_to_num(zscore(carpet, axis=-1))
carpet /= np.abs(carpet).max(axis=0)
# Create title for figure
title_txt = 'Sub: %s - Task: %s' % (sub_id, task_id)
if ses_id:
title_txt += ' - Sess: %s' % ses_id
if run_id:
title_txt += ' - Run: %d' % run_id
# Plot carpet plot and save it
fig = plt.figure(figsize=(12, 6))
plt.imshow(carpet, aspect='auto', cmap='gray')
plt.hlines((data_gm.shape[0]), 0, carpet.shape[1] - 1, colors='r')
plt.hlines((data_gm.shape[0] + data_wm.shape[0]), 0, carpet.shape[1] - 1, colors='b')
plt.title(title_txt)
plt.xlabel('Volume')
plt.ylabel('Voxel')
plt.tight_layout()
out_file = abspath(basename(in_file).replace('.nii.gz', '_carpet.png'))
fig.savefig(out_file)
# Reset seaborn
sns.reset_orig()
return out_file
carpet_plot = Node(Function(input_names=['in_file', 'sub_id', 'ses_id', 'task_id', 'run_id',
'seg_gm', 'seg_wm', 'seg_csf', 'nVoxels', 'brainmask'],
output_names=['out_file'],
function=create_carpet_plot),
name='carpet_plot')
carpet_plot.inputs.nVoxels = 6000
# Creates carpet plot
def plot_ica_components(comp_signal, comp_file, mean_file, TR):
import matplotlib.pyplot as plt
from matplotlib.backends.backend_pdf import FigureCanvasPdf as FigureCanvas
from matplotlib.gridspec import GridSpec
import seaborn as sns
sns.set(style="darkgrid")
import numpy as np
from nilearn.image import iter_img, load_img, coord_transform
from nilearn.plotting import plot_stat_map, find_cut_slices
from scipy.signal import welch
from os.path import basename, abspath
# Read data
img_comp = load_img(comp_file)
comp_data = np.loadtxt(comp_signal)
n_components = comp_data.shape[0]
elements = ['ICA%02d' % (d + 1) for d in range(n_components)]
# Plot singal components and their power spectrum density maps
fig = plt.Figure(figsize=(16, 2 * n_components))
FigureCanvas(fig)
grid = GridSpec(n_components, 2, width_ratios=[6, 2])
# Specify color palette to use
colors = sns.husl_palette(n_components)
# Plot timeseries
freq, power_spectrum = welch(comp_data, fs=1. / TR)
for i, e in enumerate(elements):
# Extract timeserie values
data = comp_data[i].T
# Plot timeserie
ax = fig.add_subplot(grid[i, :-1])
ax.plot(data, color=colors[i])
ax.set_xlim((0, len(data)))
ax.set_ylabel(e)
ylim = ax.get_ylim()
# Plot power density spectrum of all components
ax = fig.add_subplot(grid[i, -1])
ax.plot(freq, power_spectrum[i], color=colors[i])
fig.tight_layout()
# Save everyting in output figure
fig_signal = abspath(basename(comp_signal).replace('.txt', '_signal.png'))
fig.savefig(fig_signal, bbox_inches='tight', frameon=True, dpi=300, transparent=False)
# Plot individual components on functional mean image
fig = plt.figure(figsize=(16, 2 * n_components))
for i, cur_img in enumerate(iter_img(img_comp)):
ax = fig.add_subplot(n_components, 1, i + 1)
cuts = find_cut_slices(cur_img, direction='z', n_cuts=12)[1:-1]
plot_stat_map(cur_img, title='%s' % elements[i], colorbar=False,
threshold=np.abs(cur_img.get_data()).max() * 0.1,
bg_img=mean_file, display_mode='z', dim=0,
cut_coords=cuts, annotate=False, axes=ax)
fig_brain = abspath(basename(comp_signal).replace('.txt', '_brain.png'))
fig.savefig(fig_brain, bbox_inches='tight', facecolor='black', transparent=False)
# Reset seaborn
sns.reset_orig()
return fig_signal, fig_brain
ica_plot = Node(Function(input_names=['comp_signal', 'comp_file', 'mean_file',
'sub_id', 'ses_id', 'task_id', 'run_id', 'TR'],
output_names=['fig_signal', 'fig_brain'],
function=plot_ica_components),
name='ica_plot')
# Update report
def write_report(sub_id, ses_id, task_list, run_list, tFilter):
# Load template for functional preprocessing output
with open('/reports/report_template_preproc_func.html', 'r') as report:
func_temp = report.read()
# Create html filename for report
html_file = '/data/derivatives/fmriflows/sub-%s.html' % sub_id
if ses_id:
html_file = html_file.replace('.html', '_ses-%s.html' % ses_id)
# Old template placeholder
func_key = '<p>The functional preprocessing pipeline hasn\'t been run yet.</p>'
# Add new content to report
with open(html_file, 'r') as report:
txt = report.read()
# Reset report with functional preprocessing template
cut_start = txt.find('Functional Preprocessing</a></h2>') + 33
cut_stop = txt.find('<!-- Section: 1st-Level Univariate Results-->')
txt = txt[:cut_start] + func_key + txt[cut_stop:]
txt_amendment = ''
# Go through the placeholder variables and replace them with values
for task_id in task_list:
for t_filt in tFilter:
if run_list:
for run_id in run_list:
func_txt = func_temp.replace('sub-placeholder', 'sub-%s' % sub_id)
func_txt = func_txt.replace('task-placeholder', 'task-%s' % task_id)
func_txt = func_txt.replace('run-placeholder', 'run-%02d' % run_id)
func_txt = func_txt.replace(
'tFilter_placeholder', 'tFilter_%s.%s' % (
str(t_filt[0]), str(t_filt[1])))
if ses_id:
func_txt = func_txt.replace(
'ses-placeholder', 'ses-%s' % ses_id)
else:
func_txt = func_txt.replace('ses-placeholder', '')
func_txt = func_txt.replace('__', '_')
txt_amendment += func_txt
else:
func_txt = func_temp.replace('sub-placeholder', 'sub-%s' % sub_id)
func_txt = func_txt.replace('task-placeholder', 'task-%s' % task_id)
func_txt = func_txt.replace('run-placeholder', '')
func_txt = func_txt.replace(
'tFilter_placeholder', 'tFilter_%s.%s' % (
str(t_filt[0]), str(t_filt[1])))
func_txt = func_txt.replace('__', '_')
if ses_id:
func_txt = func_txt.replace(
'ses-placeholder', 'ses-%s' % ses_id)
else:
func_txt = func_txt.replace('ses-placeholder', '')
func_txt = func_txt.replace('__', '_')
txt_amendment += func_txt
# Add pipeline graphs
txt_amendment += '<h3 class="h3" style="position:left;font-weight:bold">Graph of'
txt_amendment += ' Functional Preprocessing pipeline</h3>\n <object data="preproc_func/graph.png"'
txt_amendment += ' type="image/png+xml" style="width:100%"></object>\n '
txt_amendment += ' <object data="preproc_func/graph_detailed.png" type="image/png+xml"'
txt_amendment += ' style="width:100%"></object>\n'
# Insert functional preprocessing report
txt = txt.replace(func_key, txt_amendment)
# Overwrite previous report
with open(html_file, 'w') as report:
report.writelines(txt)
create_report = Node(Function(input_names=['sub_id', 'ses_id', 'task_list',
'run_list', 'tFilter'],
output_names=['out_file'],
function=write_report),
name='create_report')
create_report.inputs.run_list = run_list
create_report.inputs.task_list = task_list
create_report.inputs.tFilter = filters_temporal
```
### Create report Workflow
```
# Create report workflow
reportflow = Workflow(name='reportflow')
# Add nodes to workflow and connect them
reportflow.add_nodes([compcor_plot,
confound_inspection,
create_report,
carpet_plot,
ica_plot])
```
## Specify Input & Output Stream
```
# Iterate over subject, session, task and run id
info_source = Node(IdentityInterface(fields=['subject_id',
'session_id',
'task_id',
'run_id']),
name='info_source')
iter_list = [('subject_id', subject_list),
('task_id', task_list)]
if session_list:
iter_list.append(('session_id', session_list))
else:
info_source.inputs.session_id = ''
if run_list:
iter_list.append(('run_id', run_list))
else:
info_source.inputs.run_id = ''
info_source.iterables = iter_list
# Create path to input files
def create_file_path(subject_id, session_id, task_id, run_id):
from bids.layout import BIDSLayout
layout = BIDSLayout('/data/')
# Find the right functional image
search_parameters = {'subject': subject_id,
'return_type': 'file',
'suffix': 'bold',
'task': task_id,
'extensions': 'nii.gz',
}
if session_id:
search_parameters['session'] = session_id
if run_id:
search_parameters['run'] = run_id
func = layout.get(**search_parameters)[0]
# Collect structural images
template_path = '/data/derivatives/fmriflows/preproc_anat/sub-{0}/sub-{0}_'
if session_id:
template_path += 'ses-%s_' % session_id
template_anat = template_path + '{1}.nii.gz'
# Collect normalization matrix
trans_path = template_path + '{1}.h5'
transforms = trans_path.format(subject_id, 'transformComposite')
brain = template_anat.format(subject_id, 'brain')
brainmask = template_anat.format(subject_id, 'brainmask')
gm = template_anat.format(subject_id, 'seg_gm')
wm = template_anat.format(subject_id, 'seg_wm')
csf = template_anat.format(subject_id, 'seg_csf')
return func, brain, brainmask, gm, wm, csf, transforms
select_files = Node(Function(input_names=['subject_id', 'session_id', 'task_id', 'run_id'],
output_names=['func', 'brain', 'brainmask', 'gm', 'wm', 'csf',
'transforms'],
function=create_file_path),
name='select_files')
# Compute Brain Mask and Extract Brain
def crop_images(brain, brainmask, gm, wm, csf):
# Cropping image size to reduce memory load during coregistration
from nilearn.image import crop_img, resample_img
from os.path import basename, abspath
brain_crop = crop_img(brain)
affine = brain_crop.affine
bshape = brain_crop.shape
brainmask_crop = resample_img(brainmask, target_affine=affine, target_shape=bshape)
gm_crop = resample_img(gm, target_affine=affine, target_shape=bshape)
wm_crop = resample_img(wm, target_affine=affine, target_shape=bshape)
csf_crop = resample_img(csf, target_affine=affine, target_shape=bshape)
# Specify output name and save file
brain_out = abspath(basename(brain))
brainmask_out = abspath(basename(brainmask))
gm_out = abspath(basename(gm))
wm_out = abspath(basename(wm))
csf_out = abspath(basename(csf))
brain_crop.to_filename(brain_out)
brainmask_crop.to_filename(brainmask_out)
gm_crop.to_filename(gm_out)
wm_crop.to_filename(wm_out)
csf_crop.to_filename(csf_out)
return brain_out, brainmask_out, gm_out, wm_out, csf_out
crop_brain = Node(Function(input_names=['brain', 'brainmask', 'gm', 'wm', 'csf'],
output_names=['brain', 'brainmask', 'gm', 'wm', 'csf'],
function=crop_images),
name='crop_brain')
# Compute Brain Mask and Extract Brain
def create_templates(template_dir, res_norm):
# Resample template brain to desired resolution
from nibabel import load, Nifti1Image
from nibabel.spaces import vox2out_vox
from nilearn.image import resample_img
from os.path import basename, abspath
# Resample template images into requested resolution
out_files = []
for t in ['brain', 'mask', 'tpm_gm', 'tpm_wm', 'tpm_csf']:
template = template_dir + '/1.0mm_%s.nii.gz' % t
img = load(template)
target_shape, target_affine = vox2out_vox(img, voxel_sizes=res_norm)
img_resample = resample_img(img, target_affine, target_shape, clip=True)
norm_template = abspath('template_{}_{}.nii.gz'.format(
t, '_'.join([str(n) for n in res_norm])))
img_resample.to_filename(norm_template)
out_files.append(norm_template)
return out_files
template_repository = Node(Function(input_names=['template_dir', 'res_norm'],
output_names=['brain', 'mask',
'tpm_gm', 'tpm_wm', 'tpm_csf'],
function=create_templates),
name='template_repository')
template_repository.inputs.template_dir = '/templates/mni_icbm152_nlin_asym_09c'
template_repository.inputs.res_norm = res_norm
# Extract sequence specifications of functional images
def get_parameters(func, ref_slice):
from bids.layout import BIDSLayout
layout = BIDSLayout("/data/")
parameter_info = layout.get_metadata(func)
# Read out relevant parameters
import numpy as np
import nibabel as nb
n_slices = nb.load(func).shape[2]
TR = parameter_info['RepetitionTime']
# If slice time onset are available, use them
if 'SliceTiming' in parameter_info.keys():
slice_order = parameter_info['SliceTiming']
if np.mean(slice_order) <= 20:
slice_order=[s*1000 for s in slice_order]
else:
# If not available, set time onset of all slices to zero
slice_order = [0] * n_slices
nslices = len(slice_order)
time_acquisition = float(TR)-(TR/nslices)
return TR, slice_order, nslices, time_acquisition
get_param = Node(Function(input_names=['func', 'ref_slice'],
output_names=['TR', 'slice_order',
'nslices', 'time_acquisition'],
function=get_parameters),
name='get_param')
get_param.inputs.ref_slice = ref_timepoint
# Iterate over the different temporal filters
def get_temporal_filters(tFilter):
# Extract high-pass value for CompCor
high_pass = tFilter[1] if tFilter[1] != None else 100.
return tFilter, high_pass
get_tfilters = Node(Function(input_names=['tFilter'],
output_names=['tFilter', 'high_pass'],
function=get_temporal_filters),
name='get_tfilters')
get_tfilters.iterables = ('tFilter', filters_temporal)
# Save relevant outputs in a datasink
datasink = Node(DataSink(base_directory=exp_dir,
container=out_dir),
name='datasink')
# Apply the following naming substitutions for the datasink
substitutions = [('/asub-', '/sub-'),
('_bold', ''),
('_ras', ''),
('_tf', ''),
('_mcf', ''),
('_stc', ''),
('_warped', ''),
('.nii.gz_', '_'),
('_mean_', '_'),
('mask_000', 'maskT'),
('.nii.gz.par', '.par'),
]
substitutions += [('tFilter_%s.%s/' % (t[0], t[1]),
'tFilter_%s.%s_' % (t[0], t[1]))
for t in filters_temporal]
substitutions += [('_sFilter_%s.%s/' % (s[0], s[1]), '')
for s in filters_spatial]
substitutions += [('%s_%smm' % (s[0], s[1]),
'sFilter_%s_%smm' % (s[0], s[1]))
for s in filters_spatial]
for sub in subject_list:
substitutions += [('sub-%s' % sub, '_')]
for sess in session_list:
substitutions += [('ses-%s' % sess, '_')]
for task in task_list:
substitutions += [('task-%s' % task, '_')]
for run in run_list:
substitutions += [('run-%02d' % run, '_')]
for sub in subject_list:
for task in task_list:
substitutions += [('_subject_id_%s_task_id_%s/' % (sub, task),
'sub-{0}/sub-{0}_task-{1}_'.format(sub, task))]
for sess in session_list:
substitutions += [('_session_id_{0}sub-{1}/sub-{1}_task-{2}_'.format(sess, sub, task),
'sub-{0}/sub-{0}_ses-{1}_task-{2}_'.format(sub, sess, task))]
for run in run_list:
substitutions += [('_run_id_{0:d}sub-{1}/sub-{1}_ses-{2}_task-{3}_'.format(run, sub, sess, task),
'sub-{0}/sub-{0}_ses-{1}_task-{2}_run-{3:02d}_'.format(sub, sess, task, run))]
for run in run_list:
substitutions += [('_run_id_{0:d}sub-{1}/sub-{1}_task-{2}_'.format(run, sub, task),
'sub-{0}/sub-{0}_task-{1}_run-{2:02d}_'.format(sub, task, run))]
substitutions += [('__', '_')] * 100
substitutions += [('_.', '.')]
datasink.inputs.substitutions = substitutions
```
## Create Functional Preprocessing Workflow
```
# Create functional preprocessing workflow
preproc_func = Workflow(name='preproc_func')
preproc_func.base_dir = work_dir
# Connect input nodes to each other
preproc_func.connect([(info_source, select_files, [('subject_id', 'subject_id'),
('session_id', 'session_id'),
('task_id', 'task_id'),
('run_id', 'run_id')]),
(select_files, crop_brain, [('brain', 'brain'),
('brainmask', 'brainmask'),
('gm', 'gm'),
('wm', 'wm'),
('csf', 'csf'),
]),
(select_files, get_param, [('func', 'func')]),
])
# Add input and output nodes and connect them to the main workflow
preproc_func.connect([(crop_brain, mainflow, [('brain', 'coregflow.coreg_pre.reference'),
('brain', 'coregflow.coreg_bbr.reference'),
('wm', 'coregflow.coreg_bbr.wm_seg'),
]),
(get_param, mainflow, [('TR', 'slice_time.TR'),
('TR', 'filterflow.temporal_filter.tr'),
('TR', 'motion_parameters.TR'),
('TR', 'apply_warp.TR'),
('slice_order', 'slice_time.slice_order'),
('nslices', 'slice_time.nslices'),
('time_acquisition', 'slice_time.time_acquisition'),
]),
(get_tfilters, mainflow, [('tFilter', 'motion_parameters.tFilter'),
('tFilter', 'filterflow.temporal_filter.tFilter'),
]),
(select_files, mainflow, [('func', 'prepareflow.reorient.in_file'),
('transforms', 'apply_warp.transforms')]),
(template_repository, mainflow, [('brain', 'apply_warp.template')]),
(crop_brain, mainflow, [('brain', 'apply_warp.brain')]),
(mainflow, datasink, [
('prepareflow.nss_detection.nss_file', 'preproc_func.@nss'),
('estimate_motion.par_file', 'preproc_func.@par'),
('motion_parameters.par_file', 'preproc_func.@par_filtered'),
('filterflow.masks_for_warp.mask_func', 'preproc_func.@mask_func'),
('filterflow.masks_for_warp.mask_conf', 'preproc_func.@mask_conf'),
('filterflow.temporal_filter.mean_file', 'preproc_func.@mean'),
('filterflow.spatial_filter.out_file', 'preproc_func.@func')]),
])
# Add input and output nodes and connect them to the confound workflow
preproc_func.connect([(crop_brain, confflow, [('brainmask', 'average_signal.brainmask'),
('gm', 'average_signal.gm'),
('wm', 'average_signal.wm'),
('csf', 'average_signal.csf'),
('wm', 'acomp_masks.wm'),
('csf', 'acomp_masks.csf')]),
(template_repository, confflow, [('mask', 'average_signal.temp_mask'),
('tpm_gm', 'average_signal.temp_gm'),
('tpm_wm', 'average_signal.temp_wm'),
('tpm_csf', 'average_signal.temp_csf'),
('tpm_wm', 'acomp_masks.temp_wm'),
('tpm_csf', 'acomp_masks.temp_csf')]),
(get_param, confflow, [('TR', 'aCompCor.repetition_time'),
('TR', 'tCompCor.repetition_time'),
('TR', 'FD.series_tr'),
('TR', 'dvars.series_tr'),
]),
(get_tfilters, confflow, [('high_pass', 'aCompCor.high_pass_cutoff'),
('high_pass', 'tCompCor.high_pass_cutoff'),
]),
(confflow, datasink, [
('tCompCor.high_variance_masks', 'preproc_func.@maskT'),
('acomp_masks.out_file', 'preproc_func.@maskA'),
('combine_confounds.out_file', 'preproc_func.@confound_tsv')
]),
])
# Connect main workflow with confound workflow
preproc_func.connect([(mainflow, confflow, [
('filterflow.temporal_filter.mean_file', 'acomp_masks.mean_file'),
('filterflow.masks_for_warp.mask_conf', 'dvars.in_mask'),
('filterflow.masks_for_warp.mask_conf', 'acomp_masks.brainmask'),
('filterflow.masks_for_warp.mask_conf', 'tCompCor.mask_files'),
('filterflow.masks_for_warp.mask_conf', 'average_signal.template_file'),
('filterflow.masks_for_warp.mask_conf', 'compute_ica.mask_file'),
('filterflow.temporal_filter.out_file', 'compute_ica.in_file'),
('filterflow.temporal_filter.out_file', 'aCompCor.realigned_file'),
('filterflow.temporal_filter.out_file', 'tCompCor.realigned_file'),
('filterflow.temporal_filter.out_file', 'average_signal.in_file'),
('filterflow.temporal_filter.out_file', 'dvars.in_file'),
('motion_parameters.par_file', 'combine_confounds.par_mc'),
('estimate_motion.par_file', 'combine_confounds.par_mc_raw'),
('motion_parameters.par_file', 'friston24.in_file'),
('motion_parameters.par_file', 'FD.in_file'),
])
])
# Add input and output nodes and connect them to the report workflow
preproc_func.connect([(info_source, reportflow, [('subject_id', 'compcor_plot.sub_id'),
('session_id', 'compcor_plot.ses_id'),
('task_id', 'compcor_plot.task_id'),
('run_id', 'compcor_plot.run_id'),
('subject_id', 'create_report.sub_id'),
('session_id', 'create_report.ses_id'),
('subject_id', 'carpet_plot.sub_id'),
('session_id', 'carpet_plot.ses_id'),
('task_id', 'carpet_plot.task_id'),
('run_id', 'carpet_plot.run_id'),
]),
(crop_brain, reportflow, [('gm', 'carpet_plot.seg_gm'),
('wm', 'carpet_plot.seg_wm'),
('csf', 'carpet_plot.seg_csf'),
]),
(get_param, reportflow, [('TR', 'ica_plot.TR')]),
(mainflow, reportflow, [('filterflow.masks_for_warp.mask_conf',
'carpet_plot.brainmask')]),
(reportflow, datasink, [
('compcor_plot.out_file', 'preproc_func.@compcor_plot'),
('carpet_plot.out_file', 'preproc_func.@carpet_plot'),
('confound_inspection.outlier_file', 'preproc_func.@conf_inspect'),
('confound_inspection.plot_main', 'preproc_func.@conf_main'),
('confound_inspection.plot_motion', 'preproc_func.@conf_motion'),
('confound_inspection.plot_compA', 'preproc_func.@conf_compA'),
('confound_inspection.plot_compT', 'preproc_func.@conf_compT'),
('ica_plot.fig_signal', 'preproc_func.@fig_signal'),
('ica_plot.fig_brain', 'preproc_func.@fig_brain'),
]),
])
# Connect main and confound workflow with report workflow
preproc_func.connect([(mainflow, reportflow, [
('filterflow.temporal_filter.mean_file', 'compcor_plot.mean'),
('filterflow.temporal_filter.mean_file', 'ica_plot.mean_file'),
('filterflow.masks_for_warp.mask_conf', 'compcor_plot.brainmask'),
('filterflow.temporal_filter.out_file', 'carpet_plot.in_file'),
]),
(confflow, reportflow, [
('tCompCor.high_variance_masks', 'compcor_plot.maskT'),
('acomp_masks.out_file', 'compcor_plot.maskA'),
('combine_confounds.out_file', 'confound_inspection.confounds'),
('compute_ica.comp_signal', 'ica_plot.comp_signal'),
('compute_ica.comp_file', 'ica_plot.comp_file'),
])
])
```
## Visualize Workflow
```
# Create preproc_func output graph
preproc_func.write_graph(graph2use='colored', format='png', simple_form=True)
# Visualize the graph in the notebook (NBVAL_SKIP)
from IPython.display import Image
Image(filename=opj(preproc_func.base_dir, 'preproc_func', 'graph.png'))
```
# Run Workflow
```
# Run the workflow in parallel mode
res = preproc_func.run(plugin='MultiProc', plugin_args={'n_procs' : n_proc})
# Save workflow graph visualizations in datasink
preproc_func.write_graph(graph2use='flat', format='png', simple_form=True)
preproc_func.write_graph(graph2use='colored', format='png', simple_form=True)
from shutil import copyfile
copyfile(opj(preproc_func.base_dir, 'preproc_func', 'graph.png'),
opj(exp_dir, out_dir, 'preproc_func', 'graph.png'))
copyfile(opj(preproc_func.base_dir, 'preproc_func', 'graph_detailed.png'),
opj(exp_dir, out_dir, 'preproc_func', 'graph_detailed.png'));
```
| github_jupyter |
---
_You are currently looking at **version 1.0** of this notebook. To download notebooks and datafiles, as well as get help on Jupyter notebooks in the Coursera platform, visit the [Jupyter Notebook FAQ](https://www.coursera.org/learn/python-machine-learning/resources/bANLa) course resource._
---
## Applied Machine Learning, Module 1: A simple classification task
### Import required modules and load data file
```
%matplotlib notebook
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
fruits = pd.read_table('fruit_data_with_colors.txt')
fruits.head()
# create a mapping from fruit label value to fruit name to make results easier to interpret
lookup_fruit_name = dict(zip(fruits.fruit_label.unique(), fruits.fruit_name.unique()))
lookup_fruit_name
```
The file contains the mass, height, and width of a selection of oranges, lemons and apples. The heights were measured along the core of the fruit. The widths were the widest width perpendicular to the height.
### Examining the data
```
# plotting a scatter matrix
from matplotlib import cm
X = fruits[['height', 'width', 'mass', 'color_score']]
y = fruits['fruit_label']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
cmap = cm.get_cmap('gnuplot')
scatter = pd.scatter_matrix(X_train, c= y_train, marker = 'o', s=40, hist_kwds={'bins':15}, figsize=(9,9), cmap=cmap)
# plotting a 3D scatter plot
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.add_subplot(111, projection = '3d')
ax.scatter(X_train['width'], X_train['height'], X_train['color_score'], c = y_train, marker = 'o', s=100)
ax.set_xlabel('width')
ax.set_ylabel('height')
ax.set_zlabel('color_score')
plt.show()
```
### Create train-test split
```
# For this example, we use the mass, width, and height features of each fruit instance
X = fruits[['mass', 'width', 'height']]
y = fruits['fruit_label']
# default is 75% / 25% train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
```
### Create classifier object
```
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 5)
```
### Train the classifier (fit the estimator) using the training data
```
knn.fit(X_train, y_train)
```
### Estimate the accuracy of the classifier on future data, using the test data
```
knn.score(X_test, y_test)
```
### Use the trained k-NN classifier model to classify new, previously unseen objects
```
# first example: a small fruit with mass 20g, width 4.3 cm, height 5.5 cm
fruit_prediction = knn.predict([[20, 4.3, 5.5]])
lookup_fruit_name[fruit_prediction[0]]
# second example: a larger, elongated fruit with mass 100g, width 6.3 cm, height 8.5 cm
fruit_prediction = knn.predict([[100, 6.3, 8.5]])
lookup_fruit_name[fruit_prediction[0]]
```
### Plot the decision boundaries of the k-NN classifier
```
from adspy_shared_utilities import plot_fruit_knn
plot_fruit_knn(X_train, y_train, 5, 'uniform') # we choose 5 nearest neighbors
```
### How sensitive is k-NN classification accuracy to the choice of the 'k' parameter?
```
k_range = range(1,20)
scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors = k)
knn.fit(X_train, y_train)
scores.append(knn.score(X_test, y_test))
plt.figure()
plt.xlabel('k')
plt.ylabel('accuracy')
plt.scatter(k_range, scores)
plt.xticks([0,5,10,15,20]);
```
### How sensitive is k-NN classification accuracy to the train/test split proportion?
```
t = [0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2]
knn = KNeighborsClassifier(n_neighbors = 5)
plt.figure()
for s in t:
scores = []
for i in range(1,1000):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 1-s)
knn.fit(X_train, y_train)
scores.append(knn.score(X_test, y_test))
plt.plot(s, np.mean(scores), 'bo')
plt.xlabel('Training set proportion (%)')
plt.ylabel('accuracy');
```
| github_jupyter |
<div align="right">Python 3.6 [conda env: PY36]</div>
# Performance Testing in iPython/Jupyter NBs
The `timeit()` command appears to have strict limitations in how you can use it within a Jupyter Notebook. For it to work most effectively:
- organize the code to test in a function that returns a value
- ensure it is not printing to screen or the code will print 1000 times (or however many times `timeit()` is configured to iterate)
- make sure that `timeit()` is the only line in the test cell as shown in these examples
- for more advanced use of `timeit()` and open more options for how to use it and related functions, check the [documentation](https://docs.python.org/2/library/timeit.html). This library was creatd in Python 2 and is compatible (and may have updated in [Python 3](https://docs.python.org/3/library/timeit.html).
To get around this limitation, examples are also provided using `%timeit()` and `%time()`
To understand the abbreviations in timeit, %timeit, and %time performance metrics, see [this wikipedia post](https://en.wikipedia.org/wiki/Metric_prefix).
For additional research on performance testing and code time metrics: [timing and profiling](http://pynash.org/2013/03/06/timing-and-profiling/)
## Simple Example: timeit(), %time, %timeit, %%timeit.
The function here is something stupid and simple just to show how to use these capabilities ...
```
def myFun(x):
return (x**x)**x
myFun(9)
```
For this example, `timeit()` needs to be the only function in the cell, and then your code is called in as a valid function call as in this demo:
```
timeit(myFun(12))
```
Should this malfunction and/or throw errors, try restarting the kernel and re-running all pre-requisite cells and then this syntax should work.
```
%timeit 10*1000000
# this syntax allows comments ... note that if you leave off the numeric argument, %timeit seems to do nothing
myFun(12)
```
If you get the 'slowest run took ...' message, try re-running the code cell to over-write the caching
```
%timeit 10*1000000
# this syntax allows comments ... note that if you leave off the numeric argument, %timeit seems to do nothing
myFun(12)
%%timeit
# this syntax allows comments ... if defaults the looping argument
myFun(12)
%time
# generates "wall time" instead of CPU time
myFun(12)
# getting more detail using %time on a script or code
%time {for i in range(10*1000000): x=1}
%timeit -n 1 10*1000000
# does it just once which may be inaccurate due to random events
myFun(12)
```
Unlike `timeit()`, the other options provided here (using iPython cell magics) can test any snippet of code within a python cell.
## Symmetric Difference Example
This code from hackerrank shows increasingly smaller snippets of code to find the symmentric difference between two sets. Symmetric difference of sets A and B is the set of values from both sets that do not intersect (i.e., values in A not found in B plus the values in B not found in A). This code was written to accept 4 lines of input as per a www.hackerrank.com specification. The problem itself is also from www.hackerrank.com.
Performance tests are attempted but are hard to know what is really going on since variance in the time to input the values could also account for speed differences just as easily as the possibility of coding efficiencies.
```
def find_symmetricDiff_inputSetsAB_v1():
len_setA = int(input())
set_A = set([int(i) for i in input().split()])
len_setB = int(input())
set_B = set([int(i) for i in input().split()])
[print(val) for val in sorted(list(set_A.difference(set_B).union(set_B.difference(set_A))))]
def find_symmetricDiff_inputSetsAB_v2():
setsLst = [0,0]
for i in range(2):
int(input()) # eat value ... don't need it
setsLst[i] = set([int(i) for i in input().split()])
[print(val) for val in sorted(list(setsLst[0].difference(setsLst[1]).union(setsLst[1].difference(setsLst[0]))))]
''' understanding next two versions:
* key=int, applies int() to each value to be sorted so the values are sorted as 1,2,3 ... not: '1', '2', '3'
* a^b is the same as a.symmetric_difference(b)
these two come from discussion boards on hackerrank
'''
def find_symmetricDiff_inputSetsAB_v3():
a,b = [set(input().split()) for _ in range(4)][1::2]
return '\n'.join(sorted(a.symmetric_difference(b), key=int))
def find_symmetricDiff_inputSetsAB_v4():
a,b = [set(input().split()) for _ in range(4)][1::2]
return '\n'.join(sorted(a^b, key=int))
```
These tests use the following inputs. As per requirements in the challenge problem, what each line mean is also given here:
<pre>
10
999 10001 574 39 12345678900100111, 787878, 999999, 1000000000000000000008889934567, 8989, 1111111111111111111111110000009999999
5
999 10001 574 39 73277773377737373000000000000007777888
</pre>
```
i1 = int(1000000000000000000008889934567)
i2 = int(73277773377737373000000000000007777888)
print(i1)
print(i2)
%timeit -n 1 10*1000000
find_symmetricDiff_inputSetsAB_v1()
# timeit(find_symmetricDiff_inputSetsAB_v1(), 1)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/wnoyan/Machine-Learning/blob/master/Applying%20KNN%20Classifier%20on%20Iris%20Dataset.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Loading Required Libraries
```
# Loading Required Libraries
import numpy as np
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from matplotlib import pyplot as plt
from sklearn import datasets
from sklearn import tree
```
## Exploring Iris Dataset
```
# Loading Datasets
iris_data = load_iris()
iris = pd.DataFrame(iris_data.data)
iris_targets = pd.DataFrame(iris_data.target)
# Priting Features Name of Iris Data
print ("Features Name : ", iris_data.feature_names)
# Priting Targets Name of Iris Data
print ("Targets Name : ", iris_data.target_names)
# Shape of Datasets
print ("Dataset Shape: ", iris.shape)
# First Five Sample features
print ("Dataset: ",iris.head())
# First Five Sample Targets
print ("Dataset: ",iris_targets.head())
```
## Splitting Dataset into training and testing sets
```
# Features and Targets
X = iris_data.data
Y = iris_data.target
# Splitting the Dataset into Training and Testing sets
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2, random_state = 42)
```
## Normalizing the dataset
```
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
X_train[0:4,:]
```
## KNN Classifier
```
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors = 5)
KNN.fit(X_train, y_train)
```
## Predicting
```
Y_pred = KNN.predict(X_test)
```
## Accuracy & Confusion Matrix
```
from sklearn.metrics import confusion_matrix
#Accuray of the Model
print("Accuracy:", accuracy_score(y_test, Y_pred)*100, "%")
print(confusion_matrix(y_test, Y_pred))
```
## Calculating Error for K Values
```
error = []
# Calculating error for K values between 1 and 40
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error.append(np.mean(pred_i != y_test))
print(np.mean(pred_i != y_test))
```
## Plotting Error for K Values
```
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
```
| github_jupyter |
## Dependencies
```
import json, warnings, shutil, glob
from jigsaw_utility_scripts import *
from scripts_step_lr_schedulers import *
from transformers import TFXLMRobertaModel, XLMRobertaConfig
from tensorflow.keras.models import Model
from tensorflow.keras import optimizers, metrics, losses, layers
SEED = 0
seed_everything(SEED)
warnings.filterwarnings("ignore")
pd.set_option('max_colwidth', 120)
pd.set_option('display.float_format', lambda x: '%.4f' % x)
```
## TPU configuration
```
strategy, tpu = set_up_strategy()
print("REPLICAS: ", strategy.num_replicas_in_sync)
AUTO = tf.data.experimental.AUTOTUNE
```
# Load data
```
database_base_path = '/kaggle/input/jigsaw-data-split-roberta-192-ratio-2-clean-polish/'
k_fold = pd.read_csv(database_base_path + '5-fold.csv')
valid_df = pd.read_csv("/kaggle/input/jigsaw-multilingual-toxic-comment-classification/validation.csv",
usecols=['comment_text', 'toxic', 'lang'])
print('Train samples: %d' % len(k_fold))
display(k_fold.head())
print('Validation samples: %d' % len(valid_df))
display(valid_df.head())
base_data_path = 'fold_1/'
fold_n = 1
# Unzip files
!tar -xf /kaggle/input/jigsaw-data-split-roberta-192-ratio-2-clean-polish/fold_1.tar.gz
```
# Model parameters
```
base_path = '/kaggle/input/jigsaw-transformers/XLM-RoBERTa/'
config = {
"MAX_LEN": 192,
"BATCH_SIZE": 128,
"EPOCHS": 3,
"LEARNING_RATE": 1e-5,
"ES_PATIENCE": None,
"base_model_path": base_path + 'tf-xlm-roberta-large-tf_model.h5',
"config_path": base_path + 'xlm-roberta-large-config.json'
}
with open('config.json', 'w') as json_file:
json.dump(json.loads(json.dumps(config)), json_file)
config
```
## Learning rate schedule
```
lr_min = 1e-7
lr_start = 0
lr_max = config['LEARNING_RATE']
step_size = len(k_fold[k_fold[f'fold_{fold_n}'] == 'train']) // config['BATCH_SIZE']
total_steps = config['EPOCHS'] * step_size
hold_max_steps = 0
warmup_steps = step_size * 1
decay = .9997
rng = [i for i in range(0, total_steps, config['BATCH_SIZE'])]
y = [exponential_schedule_with_warmup(tf.cast(x, tf.float32), warmup_steps, hold_max_steps,
lr_start, lr_max, lr_min, decay) for x in rng]
sns.set(style="whitegrid")
fig, ax = plt.subplots(figsize=(20, 6))
plt.plot(rng, y)
print("Learning rate schedule: {:.3g} to {:.3g} to {:.3g}".format(y[0], max(y), y[-1]))
```
# Model
```
module_config = XLMRobertaConfig.from_pretrained(config['config_path'], output_hidden_states=False)
def model_fn(MAX_LEN):
input_ids = layers.Input(shape=(MAX_LEN,), dtype=tf.int32, name='input_ids')
attention_mask = layers.Input(shape=(MAX_LEN,), dtype=tf.int32, name='attention_mask')
base_model = TFXLMRobertaModel.from_pretrained(config['base_model_path'], config=module_config)
last_hidden_state, _ = base_model({'input_ids': input_ids, 'attention_mask': attention_mask})
cls_token = last_hidden_state[:, 0, :]
output = layers.Dense(1, activation='sigmoid', name='output')(cls_token)
model = Model(inputs=[input_ids, attention_mask], outputs=output)
return model
```
# Train
```
# Load data
x_train = np.load(base_data_path + 'x_train.npy')
y_train = np.load(base_data_path + 'y_train_int.npy').reshape(x_train.shape[1], 1).astype(np.float32)
x_valid = np.load(base_data_path + 'x_valid.npy')
y_valid = np.load(base_data_path + 'y_valid_int.npy').reshape(x_valid.shape[1], 1).astype(np.float32)
x_valid_ml = np.load(database_base_path + 'x_valid.npy')
y_valid_ml = np.load(database_base_path + 'y_valid.npy').reshape(x_valid_ml.shape[1], 1).astype(np.float32)
#################### ADD TAIL ####################
x_train_tail = np.load(base_data_path + 'x_train_tail.npy')
y_train_tail = np.load(base_data_path + 'y_train_int_tail.npy').reshape(x_train_tail.shape[1], 1).astype(np.float32)
x_train = np.hstack([x_train, x_train_tail])
y_train = np.vstack([y_train, y_train_tail])
step_size = x_train.shape[1] // config['BATCH_SIZE']
valid_step_size = x_valid_ml.shape[1] // config['BATCH_SIZE']
valid_2_step_size = x_valid.shape[1] // config['BATCH_SIZE']
# Build TF datasets
train_dist_ds = strategy.experimental_distribute_dataset(get_training_dataset(x_train, y_train, config['BATCH_SIZE'], AUTO, seed=SEED))
valid_dist_ds = strategy.experimental_distribute_dataset(get_validation_dataset(x_valid_ml, y_valid_ml, config['BATCH_SIZE'], AUTO, repeated=True, seed=SEED))
valid_2_dist_ds = strategy.experimental_distribute_dataset(get_validation_dataset(x_valid, y_valid, config['BATCH_SIZE'], AUTO, repeated=True, seed=SEED))
train_data_iter = iter(train_dist_ds)
valid_data_iter = iter(valid_dist_ds)
valid_2_data_iter = iter(valid_2_dist_ds)
# Step functions
@tf.function
def train_step(data_iter):
def train_step_fn(x, y):
with tf.GradientTape() as tape:
probabilities = model(x, training=True)
loss = loss_fn(y, probabilities)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_auc.update_state(y, probabilities)
train_loss.update_state(loss)
for _ in tf.range(step_size):
strategy.experimental_run_v2(train_step_fn, next(data_iter))
@tf.function
def valid_step(data_iter):
def valid_step_fn(x, y):
probabilities = model(x, training=False)
loss = loss_fn(y, probabilities)
valid_auc.update_state(y, probabilities)
valid_loss.update_state(loss)
for _ in tf.range(valid_step_size):
strategy.experimental_run_v2(valid_step_fn, next(data_iter))
@tf.function
def valid_2_step(data_iter):
def valid_step_fn(x, y):
probabilities = model(x, training=False)
loss = loss_fn(y, probabilities)
valid_2_auc.update_state(y, probabilities)
valid_2_loss.update_state(loss)
for _ in tf.range(valid_2_step_size):
strategy.experimental_run_v2(valid_step_fn, next(data_iter))
# Train model
with strategy.scope():
model = model_fn(config['MAX_LEN'])
lr = lambda: exponential_schedule_with_warmup(tf.cast(optimizer.iterations, tf.float32),
warmup_steps=warmup_steps, lr_start=lr_start,
lr_max=lr_max, decay=decay)
optimizer = optimizers.Adam(learning_rate=lr)
loss_fn = losses.binary_crossentropy
train_auc = metrics.AUC()
valid_auc = metrics.AUC()
valid_2_auc = metrics.AUC()
train_loss = metrics.Sum()
valid_loss = metrics.Sum()
valid_2_loss = metrics.Sum()
metrics_dict = {'loss': train_loss, 'auc': train_auc,
'val_loss': valid_loss, 'val_auc': valid_auc,
'val_2_loss': valid_2_loss, 'val_2_auc': valid_2_auc}
history = custom_fit_2(model, metrics_dict, train_step, valid_step, valid_2_step, train_data_iter,
valid_data_iter, valid_2_data_iter, step_size, valid_step_size, valid_2_step_size,
config['BATCH_SIZE'], config['EPOCHS'], config['ES_PATIENCE'], save_last=False)
# model.save_weights('model.h5')
# Make predictions
# x_train = np.load(base_data_path + 'x_train.npy')
# x_valid = np.load(base_data_path + 'x_valid.npy')
x_valid_ml_eval = np.load(database_base_path + 'x_valid.npy')
# train_preds = model.predict(get_test_dataset(x_train, config['BATCH_SIZE'], AUTO))
# valid_preds = model.predict(get_test_dataset(x_valid, config['BATCH_SIZE'], AUTO))
valid_ml_preds = model.predict(get_test_dataset(x_valid_ml_eval, config['BATCH_SIZE'], AUTO))
# k_fold.loc[k_fold[f'fold_{fold_n}'] == 'train', f'pred_{fold_n}'] = np.round(train_preds)
# k_fold.loc[k_fold[f'fold_{fold_n}'] == 'validation', f'pred_{fold_n}'] = np.round(valid_preds)
valid_df[f'pred_{fold_n}'] = valid_ml_preds
# Fine-tune on validation set
#################### ADD TAIL ####################
x_valid_ml_tail = np.hstack([x_valid_ml, np.load(database_base_path + 'x_valid_tail.npy')])
y_valid_ml_tail = np.vstack([y_valid_ml, y_valid_ml])
valid_step_size_tail = x_valid_ml_tail.shape[1] // config['BATCH_SIZE']
# Build TF datasets
train_ml_dist_ds = strategy.experimental_distribute_dataset(get_training_dataset(x_valid_ml_tail, y_valid_ml_tail, config['BATCH_SIZE'], AUTO, seed=SEED))
train_ml_data_iter = iter(train_ml_dist_ds)
# Fine-tune on validation set
history_ml = custom_fit_2(model, metrics_dict, train_step, valid_step, valid_2_step, train_ml_data_iter,
valid_data_iter, valid_2_data_iter, valid_step_size_tail, valid_step_size, valid_2_step_size,
config['BATCH_SIZE'], 2, config['ES_PATIENCE'], save_last=False)
# Join history
for key in history_ml.keys():
history[key] += history_ml[key]
model.save_weights('model.h5')
# Make predictions
valid_ml_preds = model.predict(get_test_dataset(x_valid_ml_eval, config['BATCH_SIZE'], AUTO))
valid_df[f'pred_ml_{fold_n}'] = valid_ml_preds
### Delete data dir
shutil.rmtree(base_data_path)
```
## Model loss graph
```
plot_metrics_2(history)
```
# Model evaluation
```
# display(evaluate_model_single_fold(k_fold, fold_n, label_col='toxic_int').style.applymap(color_map))
```
# Confusion matrix
```
# train_set = k_fold[k_fold[f'fold_{fold_n}'] == 'train']
# validation_set = k_fold[k_fold[f'fold_{fold_n}'] == 'validation']
# plot_confusion_matrix(train_set['toxic_int'], train_set[f'pred_{fold_n}'],
# validation_set['toxic_int'], validation_set[f'pred_{fold_n}'])
```
# Model evaluation by language
```
display(evaluate_model_single_fold_lang(valid_df, fold_n).style.applymap(color_map))
# ML fine-tunned preds
display(evaluate_model_single_fold_lang(valid_df, fold_n, pred_col='pred_ml').style.applymap(color_map))
```
# Visualize predictions
```
print('English validation set')
display(k_fold[['comment_text', 'toxic'] + [c for c in k_fold.columns if c.startswith('pred')]].head(10))
print('Multilingual validation set')
display(valid_df[['comment_text', 'toxic'] + [c for c in valid_df.columns if c.startswith('pred')]].head(10))
```
# Test set predictions
```
x_test = np.load(database_base_path + 'x_test.npy')
test_preds = model.predict(get_test_dataset(x_test, config['BATCH_SIZE'], AUTO))
submission = pd.read_csv('/kaggle/input/jigsaw-multilingual-toxic-comment-classification/sample_submission.csv')
submission['toxic'] = test_preds
submission.to_csv('submission.csv', index=False)
display(submission.describe())
display(submission.head(10))
```
| github_jupyter |
# Data pre-processing steps
1. Remove columns that contain "Call" data
2. Transpose the dataframe so that each row is a patient and each column is a gene
3. Remove gene description and set the gene accession numbers as the column headers
4. Merge the data (expression values) with the class labels (patient numbers)
```
import itertools
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scipy
testfile='../input/data_set_ALL_AML_independent.csv'
trainfile='../input/data_set_ALL_AML_train.csv'
patient_cancer='../input/actual.csv'
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
patient_cancer = pd.read_csv(patient_cancer)
train.head()
# Remove "call" columns from training a test dataframes
train_keepers = [col for col in train.columns if "call" not in col]
test_keepers = [col for col in test.columns if "call" not in col]
train = train[train_keepers]
test = test[test_keepers]
train.head()
# Transpose the columns and rows so that genes become features and rows become observations
train = train.T
test = test.T
train.head()
# Clean up the column names for training data
train.columns = train.iloc[1]
train = train.drop(["Gene Description", "Gene Accession Number"]).apply(pd.to_numeric)
# Clean up the column names for training data
test.columns = test.iloc[1]
test = test.drop(["Gene Description", "Gene Accession Number"]).apply(pd.to_numeric)
train.head()
```
### Combine the data (gene expression) with class labels (patient numbers)
```
# Reset the index. The indexes of two dataframes need to be the same before you combine them
train = train.reset_index(drop=True)
# Subset the first 38 patient's cancer types
pc_train = patient_cancer[patient_cancer.patient <= 38].reset_index(drop=True)
# Combine dataframes for first 38 patients: Patient number + cancer type + gene expression values
train = pd.concat([pc_train,train], axis=1)
# Handle the test data for patients 38 through 72
# Clean up the index
test = test.reset_index(drop=True)
# Subset the last patient's cancer types to test
pc_test = patient_cancer[patient_cancer.patient > 38].reset_index(drop=True)
# Combine dataframes for last patients: Patient number + cancer type + gene expression values
test = pd.concat([pc_test,test], axis=1)
```
# EDA
---
There's a bunch of data, so to speed things up, only using a small sample of the training data for the EDA.
```
sample = train.iloc[:,2:].sample(n=100, axis=1)
sample["cancer"] = train.cancer
sample.describe().round()
from sklearn import preprocessing
```
### Distribution of the random sample before standardizing
---
```
sample = sample.drop("cancer", axis=1)
sample.plot(kind="hist", legend=None, bins=20, color='k')
sample.plot(kind="kde", legend=None);
```
### Distribution of the random sample after standardizing
---
```
sample_scaled = pd.DataFrame(preprocessing.scale(sample))
sample_scaled.plot(kind="hist", normed=True, legend=None, bins=10, color='k')
sample_scaled.plot(kind="kde", legend=None);
```
# Process the full set
---
```
# StandardScaler to remove mean and scale to unit variance
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(train.iloc[:,2:])
scaled_train = scaler.transform(train.iloc[:,2:])
scaled_test = scaler.transform(test.iloc[:,2:])
x_train = train.iloc[:,2:]
y_train = train.iloc[:,1]
x_test = test.iloc[:,2:]
y_test = test.iloc[:,1]
```
# Classifiers
---
```
# Grid Search for tuning parameters
from sklearn.model_selection import GridSearchCV
# RandomizedSearch for tuning (possibly faster than GridSearch)
from sklearn.model_selection import RandomizedSearchCV
# Bayessian optimization supposedly faster than GridSearch
from bayes_opt import BayesianOptimization
# Metrics
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, log_loss
## Models
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
```
# Helper functions
```
# CHERCHEZ FOR PARAMETERS
def cherchez(estimator, param_grid, search):
"""
This is a helper function for tuning hyperparameters using teh two search methods.
Methods must be GridSearchCV or RandomizedSearchCV.
Inputs:
estimator: Logistic regression, SVM, KNN, etc
param_grid: Range of parameters to search
search: Grid search or Randomized search
Output:
Returns the estimator instance, clf
"""
try:
if search == "grid":
clf = GridSearchCV(
estimator=estimator,
param_grid=param_grid,
scoring=None,
n_jobs=-1,
cv=10,
verbose=0,
return_train_score=True
)
elif search == "random":
clf = RandomizedSearchCV(
estimator=estimator,
param_distributions=param_grid,
n_iter=10,
n_jobs=-1,
cv=10,
verbose=0,
random_state=1,
return_train_score=True
)
except:
print('Search argument has to be "grid" or "random"')
sys.exit(0)
# Fit the model
clf.fit(X=scaled_train, y=y_train)
return clf
# Function for plotting the confusion matrices
def plot_confusion_matrix(cm, title="Confusion Matrix"):
"""
Plots the confusion matrix. Modified verison from
http://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
Inputs:
cm: confusion matrix
title: Title of plot
"""
classes=["AML", "ALL"]
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.bone)
plt.title(title)
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
plt.ylabel('Actual')
plt.xlabel('Predicted')
thresh = cm.mean()
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] < thresh else "black")
```
# Models being tested
1. Logisitc Regresison
- Using Grid search and Randomized search for tuning hyperparameters
2. C-Support Vector Classification (SVM)
- Using Grid search and Randomized search for tuning hyperparameters
3. K-Nearest Neighbors Classifier
- Using Grid search and Randomized search for tuning hyperparameters
4. Decision Tree Classifier
- Using only Grid search
```
# Logistic Regression
# Paramaters
logreg_params = {}
logreg_params["C"] = [0.01, 0.1, 10, 100]
logreg_params["fit_intercept"] = [True, False]
logreg_params["warm_start"] = [True,False]
logreg_params["random_state"] = [1]
lr_dist = {}
lr_dist["C"] = scipy.stats.expon(scale=.01)
lr_dist["fit_intercept"] = [True, False]
lr_dist["warm_start"] = [True,False]
lr_dist["random_state"] = [1]
logregression_grid = cherchez(LogisticRegression(), logreg_params, search="grid")
acc = accuracy_score(y_true=y_test, y_pred=logregression_grid.predict(scaled_test))
cfmatrix_grid = confusion_matrix(y_true=y_test, y_pred=logregression_grid.predict(scaled_test))
print("**Grid search results**")
print("Best training accuracy:\t", logregression_grid.best_score_)
print("Test accuracy:\t", acc)
logregression_random = cherchez(LogisticRegression(), lr_dist, search="random")
acc = accuracy_score(y_true=y_test, y_pred=logregression_random.predict(scaled_test))
cfmatrix_rand = confusion_matrix(y_true=y_test, y_pred=logregression_random.predict(scaled_test))
print("**Random search results**")
print("Best training accuracy:\t", logregression_random.best_score_)
print("Test accuracy:\t", acc)
plt.subplots(1,2)
plt.subplots_adjust(left=-0.5, bottom=None, right=None, top=None, wspace=0.5, hspace=None)
plot_confusion_matrix(cfmatrix_rand, title="Random Search Confusion Matrix")
plt.subplot(121)
plot_confusion_matrix(cfmatrix_grid, title="Grid Search Confusion Matrix")
# SVM
svm_param = {
"C": [.01, .1, 1, 5, 10, 100],
"gamma": [0, .01, .1, 1, 5, 10, 100],
"kernel": ["rbf"],
"random_state": [1]
}
svm_dist = {
"C": scipy.stats.expon(scale=.01),
"gamma": scipy.stats.expon(scale=.01),
"kernel": ["rbf"],
"random_state": [1]
}
svm_grid = cherchez(SVC(), svm_param, "grid")
acc = accuracy_score(y_true=y_test, y_pred=svm_grid.predict(scaled_test))
cfmatrix_grid = confusion_matrix(y_true=y_test, y_pred=svm_grid.predict(scaled_test))
print("**Grid search results**")
print("Best training accuracy:\t", svm_grid.best_score_)
print("Test accuracy:\t", acc)
svm_random = cherchez(SVC(), svm_dist, "random")
acc = accuracy_score(y_true=y_test, y_pred=svm_random.predict(scaled_test))
cfmatrix_rand = confusion_matrix(y_true=y_test, y_pred=svm_random.predict(scaled_test))
print("**Random search results**")
print("Best training accuracy:\t", svm_random.best_score_)
print("Test accuracy:\t", acc)
plt.subplots(1,2)
plt.subplots_adjust(left=-0.5, bottom=None, right=None, top=None, wspace=0.5, hspace=None)
plot_confusion_matrix(cfmatrix_rand, title="Random Search Confusion Matrix")
plt.subplot(121)
plot_confusion_matrix(cfmatrix_grid, title="Grid Search Confusion Matrix")
# KNN
knn_param = {
"n_neighbors": [i for i in range(1,30,5)],
"weights": ["uniform", "distance"],
"algorithm": ["ball_tree", "kd_tree", "brute"],
"leaf_size": [1, 10, 30],
"p": [1,2]
}
knn_dist = {
"n_neighbors": scipy.stats.randint(1,33),
"weights": ["uniform", "distance"],
"algorithm": ["ball_tree", "kd_tree", "brute"],
"leaf_size": scipy.stats.randint(1,1000),
"p": [1,2]
}
knn_grid = cherchez(KNeighborsClassifier(), knn_param, "grid")
acc = accuracy_score(y_true=y_test, y_pred=knn_grid.predict(scaled_test))
cfmatrix_grid = confusion_matrix(y_true=y_test, y_pred=svm_grid.predict(scaled_test))
print("**Grid search results**")
print("Best training accuracy:\t", knn_grid.best_score_)
print("Test accuracy:\t", acc)
knn_random = cherchez(KNeighborsClassifier(), knn_dist, "random")
acc = accuracy_score(y_true=y_test, y_pred=knn_random.predict(scaled_test))
cfmatrix_rand = confusion_matrix(y_true=y_test, y_pred=knn_random.predict(scaled_test))
print("**Random search results**")
print("Best training accuracy:\t", knn_random.best_score_)
print("Test accuracy:\t", acc)
plt.subplots(1,2)
plt.subplots_adjust(left=-0.5, bottom=None, right=None, top=None, wspace=0.5, hspace=None)
plot_confusion_matrix(cfmatrix_rand, title="Random Search Confusion Matrix")
plt.subplot(121)
plot_confusion_matrix(cfmatrix_grid, title="Grid Search Confusion Matrix")
# Decision tree classifier
dtc_param = {
"max_depth": [None],
"min_samples_split": [2],
"min_samples_leaf": [1],
"min_weight_fraction_leaf": [0.],
"max_features": [None],
"random_state": [4],
"max_leaf_nodes": [None], # None = infinity or int
"presort": [True, False]
}
dtc_grid = cherchez(DecisionTreeClassifier(), dtc_param, "grid")
acc = accuracy_score(y_true=y_test, y_pred=dtc_grid.predict(scaled_test))
cfmatrix_grid = confusion_matrix(y_true=y_test, y_pred=dtc_grid.predict(scaled_test))
print("**Grid search results**")
print("Best training accuracy:\t", dtc_grid.best_score_)
print("Test accuracy:\t", acc)
plot_confusion_matrix(cfmatrix_grid, title="Decision Tree Confusion Matrix")
```
| github_jupyter |
# 1A.e - Correction de l'interrogation écrite du 14 novembre 2014
coût algorithmique, calcul de séries mathématiques
```
from jyquickhelper import add_notebook_menu
add_notebook_menu()
```
## Enoncé 1
### Q1
Le code suivant produit une erreur. Corrigez le programme.
```
nbs = [ 1, 5, 4, 7 ] #
for n in nbs: #
s += n #
```
L'objectif de ce petit programme est de calculer la somme des éléments de la liste ``nbs``. L'exception est déclenché la variable ``s`` n'est jamais créé. Il manque l'instruction ``s=0``.
```
nbs = [ 1, 5, 4, 7 ]
s = 0
for n in nbs:
s += n
s
```
### Q2
Que vaut ``nbs`` dans le programme suivant :
```
def f(x) : return x%2
nbs = { i:f(i) for i in range(0,5) }
nbs
```
### Q3
On considère le programme suivant, il affiche ``None``, pourquoi ?
```
def ma_fonction(x1,y1,x2,y2):
d = (x1-x2)**2 +(y1-y2)**2
print(d)
d = ma_fonction(0,0,1,1)
print(d)
```
Le ``2`` correspond au premier ``print(d)``, le ``None`` correspond au second. Pour s'en convaincre, il suffit d'ajouter quelques caractères supplémentaires :
```
def ma_fonction(x1,y1,x2,y2):
d = (x1-x2)**2 +(y1-y2)**2
print("A",d)
d = ma_fonction(0,0,1,1)
print("B",d)
```
Donc la variable ``d`` en dehors de la fonction vaut ``None``, cela veut que le résultat de la fonction ``ma_fonction`` est ``None``. Il peut être ``None`` soit parce que la fonction contient explicitiement l'instruction ``return None`` soit parce qu'aucune instruction ``return`` n'ext exécutée. C'est le cas ici puisqu'il n'y a qu'une instruction ``print``. On remplace ``print`` par ``return``.
```
def ma_fonction(x1,y1,x2,y2):
d = (x1-x2)**2 +(y1-y2)**2
return d
d = ma_fonction(0,0,1,1)
print(d)
```
### Q4
Que vaut ``n`` en fonction de ``N`` ?
```
n = 0
N = 100
for i in range(0,N):
for k in range(0,i):
n += N
n
```
Pour être plus précis, 495000 = $\frac{N^2(N-1)}{2}$.
### Q5
Une des lignes suivantes provoque une erreur, laquelle ?
```
a = 3 #
b = "6" #
a+b #
a*b #
```
Lorsqu'on multiplie une chaîne de caractères par un entier, cela revient à la répliquer : ``3*"6" = "666"``. L'addition est impossible car on ne peut pas additionner un nombre avec une chaîne de caractères.
## Enoncé 2
### Q1
Le code suivant produit une erreur. Proposez une correction.
```
nbs = ( 1, 5, 4, 7 ) #
nbs[0] = 0 #
```
Le type [tuple](https://docs.python.org/3.4/tutorial/datastructures.html#tuples-and-sequences) sont [immutable](http://fr.wikipedia.org/wiki/Objet_immuable). On ne peut pas le modifier. Mais les listes peuvent l'être.
```
nbs = [ 1, 5, 4, 7 ]
nbs[0] = 0
nbs
```
### Q2
Que vaut ``c`` ?
```
d = {4: 'quatre'}
c = d.get('4', None)
print(c)
```
La méthode [get](https://docs.python.org/3.4/library/stdtypes.html#dict.get) retourne la valeur associée à une clé ou une autre valeur (ici ``None``) si elle ne s'y trouve pas. La raison pour laquelle le résultat est ``None`` ici est que '4' != 4. La clé '4' ne fait pas partie du dictionnaire.
### Q3
Que vaut ``x`` ?
```
N = 8
s = 0
while N > 0 :
for i in range(N):
s += 1
N //= 2
x = (s+1)//2
x
```
A chaque passage dans la boucle ``for``, on ajoute ``N`` à ``s``. A chaque passage dans la boucle ``while``, on divise ``N`` par 2. Donc, après la boucle ``while``, $s = N + N/2 + N/4 + N/8 + ...$. On répète cela jusqu'à ce que $N / 2^k$ soit plus grand que 0. Or, les divisions sont entières (symbole ``//``), ``1//2`` vaut 0. La condition devient jusqu'à ce que $N / 2^k <1$.
Pour le reste, c'est une suite géométrique. Si on pose $N=2^k$, on calcule donc la somme :
$$s = 2^k + 2 ^{k-1} + ... + 1 = \sum_{i=1}^{k} 2^i = \frac{2^{k+1}-1}{2-1} = 2^{k+1}-1$$
Et comme :
$$x = \frac{s+1}{2} = 2^k = N$$
### Q4
Que vaut ``c`` ?
```
l = ['a', 'b', 'c']
c = l[1]
c
```
### Q5
Par quoi faut-il remplacer les ``???`` pour avoir l'erreur ci-dessous ?
```
def fonction(N):
li = None # on évite la variable l pour ne pas la confondre avec 1
for i in range(N):
if li is None:
li = [ ]
li.append(i)
return li
ma_liste = fonction(0)
ma_liste.append(-1)
```
Cette erreur se produit car ``ma_liste`` vaut ``None``. Si la fonction ``fonction`` retourne ``None``, c'est que l'instruction ``l = [ ]`` n'est jamais exécutée, donc que la condition ``if l is None`` n'est jamais vérifiée. On ne passe donc jamais dans la boucle ``for`` et ceci arrive si ``N`` est négatif ou nul.
## Enoncé 3
### Q1
Que se passe-t-il ?
```
l = [ 0, 1,2,3]
for i in range(len(l)):
print(i)
del l[i] #
```
L'erreur est due au fait que la boucle parcourt la liste en même temps qu'elle supprime des éléments. Le résultat est souvent une erreur. On vérifie en affichant ``i`` et ``l``.
```
l = [ 0, 1,2,3]
for i in range(len(l)):
print("i=",i,"l=",l)
del l[i] #
```
### Q2
Que vaut ``a`` ?
```
a = 2
for i in range(1,5):
a += a
a
```
La variable ``a`` double à chaque fois qu'on passe dans la boucle. On y passe **4** fois et on part de ``a=2``. Donc : $2*2*2*2*2=2^5=32$.
### Q3
Que vaut ``y`` ?
```
x = 2.67
y = int ( x * 2 ) / 2
y
```
La fonction revient à arrondir au demi inférieur, donc $2.5$.
### Q4
Combien d'étoiles le programme suivant affiche ?
```
import random
def moyenne(l):
s = 0
for x in l :
print("*")
s += x
return s / len(l)
def variance(l):
return sum ( [ (x - moyenne(l))**2 for x in l ] ) / len(l)
l = [ random.random() for i in range(0,100) ]
print(variance(l)**0.5)
```
C'est un peu long à afficher, modifions le programme pour compter les étoiles plutôt que de les afficher.
```
star = 0
def moyenne(l):
global star
s = 0
for x in l :
star += 1
s += x
return s / len(l)
def variance(l):
return sum ( [ (x - moyenne(l))**2 for x in l ] ) / len(l)
l = [ random.random() for i in range(0,100) ]
print(variance(l)**0.5)
print("star=",star)
```
Si $n$ est la longueur de la liste ``l``, le coût de la fonction ``moyenne`` est $O(n)$. Le coût de la fonction ``variance`` est $n$ fois le coût de la fonction ``moyenne``, soit $O(n^2)$. Celle-ci pourrait être beaucoup plus efficace en écrivant :
```
star = 0
def moyenne(l):
global star
s = 0
for x in l :
star += 1
s += x
return s / len(l)
def variance(l):
m = moyenne(l) # on mémorise le résultat
return sum ( [ (x - m)**2 for x in l ] ) / len(l)
l = [ random.random() for i in range(0,100) ]
print(variance(l)**0.5)
print("star=",star)
```
### Q5
Que vaut ``x`` ?
```
import random
x = random.randint(0,100)
while x != 50:
x = random.randint(0,100)
x
```
``x`` vaut nécessairement 50 puisque c'est la seule valeur qui permette de sortir de la boucle.
| github_jupyter |
```
import sys, os
if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week1_intro/submit.py
!touch .setup_complete
# This code creates a virtual display to draw game images on.
# It will have no effect if your machine has a monitor.
if type(os.environ.get("DISPLAY")) is not str or len(os.environ.get("DISPLAY")) == 0:
!bash ../xvfb start
os.environ['DISPLAY'] = ':1'
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
```
### OpenAI Gym
We're gonna spend several next weeks learning algorithms that solve decision processes. We are then in need of some interesting decision problems to test our algorithms.
That's where OpenAI Gym comes into play. It's a Python library that wraps many classical decision problems including robot control, videogames and board games.
So here's how it works:
```
import gym
env = gym.make("MountainCar-v0")
env.reset()
plt.imshow(env.render('rgb_array'))
print("Observation space:", env.observation_space)
print("Action space:", env.action_space)
```
Note: if you're running this on your local machine, you'll see a window pop up with the image above. Don't close it, just alt-tab away.
### Gym interface
The three main methods of an environment are
* `reset()`: reset environment to the initial state, _return first observation_
* `render()`: show current environment state (a more colorful version :) )
* `step(a)`: commit action `a` and return `(new_observation, reward, is_done, info)`
* `new_observation`: an observation right after committing the action `a`
* `reward`: a number representing your reward for committing action `a`
* `is_done`: True if the MDP has just finished, False if still in progress
* `info`: some auxiliary stuff about what just happened. For now, ignore it.
```
obs0 = env.reset()
print("initial observation code:", obs0)
# Note: in MountainCar, observation is just two numbers: car position and velocity
print("taking action 2 (right)")
new_obs, reward, is_done, _ = env.step(2)
print("new observation code:", new_obs)
print("reward:", reward)
print("is game over?:", is_done)
# Note: as you can see, the car has moved to the right slightly (around 0.0005)
```
### Play with it
Below is the code that drives the car to the right. However, if you simply use the default policy, the car will not reach the flag at the far right due to gravity.
__Your task__ is to fix it. Find a strategy that reaches the flag.
You are not required to build any sophisticated algorithms for now, and you definitely don't need to know any reinforcement learning for this. Feel free to hard-code :)
```
from IPython import display
# Create env manually to set time limit. Please don't change this.
TIME_LIMIT = 250
env = gym.wrappers.TimeLimit(
gym.envs.classic_control.MountainCarEnv(),
max_episode_steps=TIME_LIMIT + 1,
)
actions = {'left': 0, 'stop': 1, 'right': 2}
def policy(obs, t):
# Write the code for your policy here. You can use the observation
# (a tuple of position and velocity), the current time step, or both,
# if you want.
position, velocity = obs
if velocity<=0:
return actions['left']
else:
return actions['right']
# This is an example policy. You can try running it, but it will not work.
# Your goal is to fix that. You don't need anything sophisticated here,
# and you can hard-code any policy that seems to work.
# Hint: think how you would make a swing go farther and faster.
#return actions['right']
plt.figure(figsize=(4, 3))
display.clear_output(wait=True)
obs = env.reset()
for t in range(TIME_LIMIT):
plt.gca().clear()
action = policy(obs, t) # Call your policy
obs, reward, done, _ = env.step(action) # Pass the action chosen by the policy to the environment
# We don't do anything with reward here because MountainCar is a very simple environment,
# and reward is a constant -1. Therefore, your goal is to end the episode as quickly as possible.
# Draw game image on display.
plt.imshow(env.render('rgb_array'))
display.display(plt.gcf())
display.clear_output(wait=True)
if done:
print("Well done!")
break
else:
print("Time limit exceeded. Try again.")
display.clear_output(wait=True)
from submit import submit_interface
submit_interface(policy, 'sumeetsk@gmail.com', 'yG9lDhAJ8UxyGx6Y')
```
| github_jupyter |
```
import os
import pandas as pd
import yaml
import cea
import cea.scripts
schemas_yml = os.path.join(os.path.dirname(cea.__file__), "schemas.yml")
schemas = yaml.load(open(schemas_yml))
glossary_csv = os.path.join(os.path.dirname(cea.__file__), "glossary.csv")
glossary_df = pd.read_csv(glossary_csv)
glossary_df.columns
output_folder = r"c:\Users\darthoma\polybox\2637-single-point-of-reference-for-variables"
# first handle non-excel (worksheet) style schemas
for lm in schemas.keys():
schema = schemas[lm]["schema"]
if "columns" in schema:
# not an excel-type file
for col in schema["columns"].keys():
g = glossary_df
g = g[g.LOCATOR_METHOD == lm]
g = g[g.VARIABLE == col]
try:
description = g.DESCRIPTION.values[0]
unit = g.UNIT.values[0]
values = g.VALUES.values[0]
assert len(g.DESCRIPTION.values) <= 1
print lm, col, description, unit, values
schema["columns"][col]["description"] = description
schema["columns"][col]["unit"] = unit
schema["columns"][col]["values"] = values
except IndexError:
schema["columns"][col]["description"] = "TODO"
schema["columns"][col]["unit"] = "TODO"
schema["columns"][col]["values"] = "TODO"
yaml.dump(schemas, open(schemas_yml, 'w'), indent=2, default_flow_style=False)
# next handle excel (worksheet) style schemas
for lm in schemas.keys():
schema = schemas[lm]["schema"]
if not "columns" in schema:
# yay! an excel-type file!
for worksheet in schema.keys():
ws_schema = schema[worksheet]
for col in ws_schema["columns"].keys():
g = glossary_df
g = g[g.LOCATOR_METHOD == lm]
g = g[g.VARIABLE == col]
g = g[g.WORKSHEET == worksheet]
try:
description = g.DESCRIPTION.values[0]
unit = g.UNIT.values[0]
values = g.VALUES.values[0]
assert len(g.DESCRIPTION.values) <= 1
print lm, col, description, unit, values
ws_schema["columns"][col]["description"] = description
ws_schema["columns"][col]["unit"] = unit
ws_schema["columns"][col]["values"] = values
except IndexError:
ws_schema["columns"][col]["description"] = "TODO"
ws_schema["columns"][col]["unit"] = "TODO"
ws_schema["columns"][col]["values"] = "TODO"
yaml.dump(schemas, open(schemas_yml, 'w'), indent=2, default_flow_style=False)
# write out a hints file for the variables
variables = {} # map str -> set(str)
for lm in schemas:
file_type = schemas[lm]["file_type"]
if file_type in {"xls", "xlsx"}:
for ws in schemas[lm]["schema"]:
for variable in schemas[lm]["schema"][ws]["columns"]:
hints = variables.get(variable, set())
hints.add(schemas[lm]["schema"][ws]["columns"][variable]["description"])
variables[variable] = hints
else:
for variable in schemas[lm]["schema"]["columns"]:
hints = variables.get(variable, set())
hints.add(schemas[lm]["schema"]["columns"][variable]["description"])
variables[variable] = hints
with open(os.path.join(output_folder, "__hints__.csv"), "w") as f:
for variable in sorted(variables.keys()):
hints = variables[variable]
if not "TODO" in hints:
# no need to hint this variable - it's always defined
continue
hints.remove("TODO")
if not hints:
# no hints found
continue
f.write("{variable}, {hints}\n".format(variable=variable, hints=",".join(sorted(hints))))
# next, create a file so that we can document all the stuff
for lm in schemas:
if schemas[lm]["file_type"].startswith("xls"):
for worksheet in schemas[lm]["schema"]:
ws_schema = schemas[lm]["schema"][worksheet]["columns"]
fname = os.path.join(output_folder, "{lm}_{ws}.csv".format(lm=lm, ws=worksheet))
with open(fname, "w") as f:
f.write("variable,description,unit,values\n")
for col in ws_schema:
variable = col
description = ws_schema[col]["description"]
if description == "TODO" and variables[variable]:
# add a hint
description = "TODO (hint: {hints})".format(hints=", ".join(variables[variable]))
unit = ws_schema[col]["unit"]
values = ws_schema[col]["values"]
f.write("{variable},{description},{unit},{values}\n".format(
variable=variable, description=description, unit=unit, values=values))
elif schemas[lm]["file_type"] in {"csv", "shp", "dbf"}:
print lm
schema = schemas[lm]["schema"]["columns"]
fname = os.path.join(output_folder, "{lm}.csv".format(lm=lm))
with open(fname, "w") as f:
f.write("variable,description,unit,values\n")
for col in schema:
variable = col
description = schema[col]["description"]
if description == "TODO" and variables[variable]:
# add a hint
description = "TODO (hint: {hints})".format(hints=", ".join(variables[variable]))
unit = schema[col]["unit"]
values = schema[col]["values"]
f.write("{variable},{description},{unit},{values}\n".format(
variable=variable, description=description, unit=unit, values=values))
# write out am overview file for coordination
with open(os.path.join(output_folder, "__coordination__.csv"), "w") as f:
f.write("locator_method,file_path,responsible,done,remarks\n")
for lm in schemas:
fn = schemas[lm]["file_path"]
if schemas[lm]["file_type"] in {"csv", "dbf", "shp", "xls", "xlsx"}:
f.write("{lm},{fn},TBD,n,-\n".format(lm=lm, fn=fn))
```
# Read in the edited csv files to schemas.yml
```
# we'll need to skip some files for the moment
skip_lms = {
"get_building_weekly_schedules",
"get_optimization_individuals_in_generation",
"get_optimization_slave_cooling_activation_pattern",
}
# we'll need to check these (maybe send emails to the authors?)
check_lms = {
"get_street_network",
}
def fix_tripple_dots(fname):
"""read in fname and fix all occurrences of the excel tripple dots thing to three periods."""
with open(fname, "r") as fp:
contents = fp.read()
patterns = ["\x85", "\xc9"]
for pattern in patterns:
if pattern in contents:
print("Found in {fname}".format(fname=fname))
contents = contents.replace(pattern, "...")
with open(fname, "w") as fp:
fp.write(contents)
# NOTE: make sure we don't have columns in the schemas.yml that are not present in the csv files...
reload(cea.scripts)
schemas = cea.scripts.schemas()
for lm in schemas:
if lm in skip_lms:
# skip this one for now...
continue
print("Processing {lm}".format(lm=lm))
if schemas[lm]["file_type"].startswith("xls"):
for worksheet in schemas[lm]["schema"]:
print("...{ws}".format(ws=worksheet))
ws_schema = schemas[lm]["schema"][worksheet]["columns"]
fname = os.path.join(output_folder, "{lm}_{ws}.csv".format(lm=lm, ws=worksheet))
fix_tripple_dots(fname)
schema_df = pd.read_csv(fname)
schema_df_cols = set(schema_df["variable"].values)
difference = schema_df_cols ^ set(ws_schema.keys())
for col in difference:
if col in ws_schema.keys():
del ws_schema[col]
difference = schema_df_cols ^ set(ws_schema.keys())
assert not difference, "Found difference {difference} for {lm}, {ws}".format(
difference=difference, lm=lm, ws=worksheet)
for _, row in schema_df.iterrows():
ws_schema[row.variable]["description"] = row.description
ws_schema[row.variable]["unit"] = row.unit
ws_schema[row.variable]["values"] = row["values"]
elif schemas[lm]["file_type"] in {"csv", "shp", "dbf"}:
schema = schemas[lm]["schema"]["columns"]
fname = os.path.join(output_folder, "{lm}.csv".format(lm=lm))
fix_tripple_dots(fname)
schema_df = pd.read_csv(fname)
schema_df_cols = set(schema_df["variable"].values)
difference = schema_df_cols ^ set(schema.keys())
for col in difference:
if col in schema.keys():
del schema[col]
elif col in schema_df_cols:
row = schema_df[schema_df.variable == col].iloc[0]
schema[col] = {
"description": row.description,
"unit": row.unit,
"values": row["values"]
}
difference = schema_df_cols ^ set(schema.keys())
assert not difference, "Found difference {difference} for {lm}".format(
difference=difference, lm=lm)
for _, row in schema_df.iterrows():
schema[row.variable]["description"] = row.description
schema[row.variable]["unit"] = row.unit
schema[row.variable]["values"] = row["values"]
# write out the new schemas file
yaml.dump(schemas, open(schemas_yml, 'w'), indent=2, default_flow_style=False)
```
| github_jupyter |
```
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
%matplotlib inline
plt.style.use('seaborn-dark-palette')
import warnings
warnings.filterwarnings('ignore')
file = glob.iglob('*.csv')
df = pd.read_csv(*file)
print(f'The dimension of the data is - {df.shape}')
df.head()
df.tail()
X = df.iloc[:, :-1].values
Y = df.iloc[:, -1].values
X
Y
print("Size of X: {}".format(X.shape))
print("Size of Y: {}".format(Y.shape))
X_train, X_test, Y_train, Y_test = train_test_split(X,
Y,
test_size=0.25,
random_state=0,
shuffle=True)
print("Size of X_train: {}".format(X_train.shape))
print("Size of X_test: {}".format(X_test.shape))
print("Size of Y_train: {}".format(Y_train.shape))
print("Size of Y_test: {}".format(Y_test.shape))
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
classifier = SVC(kernel = 'rbf')
classifier.fit(X_train, Y_train)
y_pred = classifier.predict(X_test)
y_pred
cm = confusion_matrix(Y_test, y_pred)
cm
acc = accuracy_score(Y_test, y_pred)
print(f"The accuracy in percentage - {acc*100}%")
report = classification_report(Y_test, y_pred)
print(report)
acc = cross_val_score(estimator = classifier,
X = X_train,
y = Y_train,
n_jobs = -1,
verbose = 0,
cv = 10)
print(f"Accuracy Score: {acc.mean()*100:.3f}%")
print(f"Standard Deviation: {acc.std()*100:.2f} %")
start = time.time()
parameters = [{'C': [0.25, 0.5, 0.75, 1],
'kernel': ['linear']},
{'C': [0.25, 0.5, 0.75, 1],
'kernel': ['rbf'],
'gamma': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]}]
grid_search = GridSearchCV(estimator = classifier,
param_grid = parameters,
scoring = 'accuracy',
n_jobs = -1,
cv = 10,
verbose = 1
)
grid_search.fit(X_train, Y_train)
best_accuracy = grid_search.best_score_
best_parameters = grid_search.best_params_
print(f"Accuracy Score: {best_accuracy*100:.3f}%")
print(f"Best Parameters: {best_parameters}")
end = time.time()
print(f"Total Time Taken {end - start}")
# Training Set
figure = plt.figure(figsize = (10,10))
x_set, y_set = X_train, Y_train
X1, X2 = np.meshgrid(np.arange(start = x_set[:, 0].min() - 1,
stop = x_set[:, 0].max() + 1,
step = 0.01),
np.arange(start = x_set[:, 1].min() - 1,
stop = x_set[:, 1].max() + 1,
step = 0.01))
plt.contourf(X1,
X2,
classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.4,
cmap = ListedColormap(('red', 'green')))
for i, j in enumerate(np.unique(y_set)):
plt.scatter(x_set[y_set == j, 0],
x_set[y_set == j, 1],
color = ListedColormap(('red', 'green'))(i),
s = 15,
marker = '*',
label = j
)
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
plt.title('Kernel - SVM Classifier (Training Set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
# Visuaizing the test case result
figure = plt.figure(figsize = (10,10))
x_set, y_set = X_test, Y_test
X1, X2 = np.meshgrid(np.arange(start = x_set[:, 0].min() - 1,
stop = x_set[:, 0].max() + 1,
step = 0.01),
np.arange(start = x_set[:, 1].min() - 1,
stop = x_set[:, 1].max() + 1,
step = 0.01))
plt.contourf(X1,
X2,
classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
cmap = ListedColormap(('red', 'green')),
alpha = 0.4
)
for i, j in enumerate(np.unique(y_set)):
plt.scatter(x_set[y_set == j, 0],
x_set[y_set == j, 1 ],
color = ListedColormap(('red', 'green'))(i),
s = 15,
label = j,
marker = '^'
)
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
plt.title("Kernel SVM - Test Case")
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
```
| github_jupyter |
```
import numpy as np
import cv2
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
image = mpimg.imread('bbox-example-image.jpg')
# Here is your draw_boxes function from the previous exercise
def draw_boxes(img, bboxes, color=(0, 0, 255), thick=6):
# Make a copy of the image
imcopy = np.copy(img)
# Iterate through the bounding boxes
for bbox in bboxes:
# Draw a rectangle given bbox coordinates
cv2.rectangle(imcopy, bbox[0], bbox[1], color, thick)
# Return the image copy with boxes drawn
return imcopy
# Define a function that takes an image,
# start and stop positions in both x and y,
# window size (x and y dimensions),
# and overlap fraction (for both x and y)
def slide_window(img, x_start_stop=[None, None], y_start_stop=[None, None],
xy_window=(64, 64), xy_overlap=(0.5, 0.5)):
# If x and/or y start/stop positions not defined, set to image size
if x_start_stop[0] == None:
x_start_stop[0] = 0
if x_start_stop[1] == None:
x_start_stop[1] = img.shape[1]
if y_start_stop[0] == None:
y_start_stop[0] = 0
if y_start_stop[1] == None:
y_start_stop[1] = img.shape[0]
# Compute the span of the region to be searched
xspan = x_start_stop[1] - x_start_stop[0]
yspan = y_start_stop[1] - y_start_stop[0]
# Compute the number of pixels per step in x/y
nx_pix_per_step = np.int(xy_window[0]*(1 - xy_overlap[0]))
ny_pix_per_step = np.int(xy_window[1]*(1 - xy_overlap[1]))
# Compute the number of windows in x/y
nx_buffer = np.int(xy_window[0]*(xy_overlap[0]))
ny_buffer = np.int(xy_window[1]*(xy_overlap[1]))
nx_windows = np.int((xspan-nx_buffer)/nx_pix_per_step)
ny_windows = np.int((yspan-ny_buffer)/ny_pix_per_step)
# Initialize a list to append window positions to
window_list = []
# Loop through finding x and y window positions
# Note: you could vectorize this step, but in practice
# you'll be considering windows one by one with your
# classifier, so looping makes sense
for ys in range(ny_windows):
for xs in range(nx_windows):
# Calculate window position
startx = xs*nx_pix_per_step + x_start_stop[0]
endx = startx + xy_window[0]
starty = ys*ny_pix_per_step + y_start_stop[0]
endy = starty + xy_window[1]
# Append window position to list
window_list.append(((startx, starty), (endx, endy)))
# Return the list of windows
return window_list
windows = slide_window(image, x_start_stop=[None, None], y_start_stop=[None, None],
xy_window=(128, 128), xy_overlap=(0.5, 0.5))
window_img = draw_boxes(image, windows, color=(0, 0, 255), thick=6)
plt.imshow(window_img)
plt.show()
```
| github_jupyter |
# Spark JDBC to Databases
- [Overview](#spark-jdbc-overview)
- [Setup](#spark-jdbc-setup)
- [Define Environment Variables](#spark-jdbc-define-envir-vars)
- [Initiate a Spark JDBC Session](#spark-jdbc-init-session)
- [Load Driver Packages Dynamically](#spark-jdbc-init-dynamic-pkg-load)
- [Load Driver Packages Locally](#spark-jdbc-init-local-pkg-load)
- [Connect to Databases Using Spark JDBC](#spark-jdbc-connect-to-dbs)
- [Connect to a MySQL Database](#spark-jdbc-to-mysql)
- [Connecting to a Public MySQL Instance](#spark-jdbc-to-mysql-public)
- [Connecting to a Test or Temporary MySQL Instance](#spark-jdbc-to-mysql-test-or-temp)
- [Connect to a PostgreSQL Database](#spark-jdbc-to-postgresql)
- [Connect to an Oracle Database](#spark-jdbc-to-oracle)
- [Connect to an MS SQL Server Database](#spark-jdbc-to-ms-sql-server)
- [Connect to a Redshift Database](#spark-jdbc-to-redshift)
- [Cleanup](#spark-jdbc-cleanup)
- [Delete Data](#spark-jdbc-delete-data)
- [Release Spark Resources](#spark-jdbc-release-spark-resources)
<a id="spark-jdbc-overview"></a>
## Overview
Spark SQL includes a data source that can read data from other databases using Java database connectivity (**JDBC**).
The results are returned as a Spark DataFrame that can easily be processed in Spark SQL or joined with other data sources.
For more information, see the [Spark documentation](https://spark.apache.org/docs/2.3.1/sql-programming-guide.html#jdbc-to-other-databases).
<a id="spark-jdbc-setup"></a>
## Setup
<a id="spark-jdbc-define-envir-vars"></a>
### Define Environment Variables
Begin by initializing some environment variables.
> **Note:** You need to edit the following code to assign valid values to the database variables (`DB_XXX`).
```
import os
# Read Iguazio Data Science Platform ("the platform") environment variables into local variables
V3IO_USER = os.getenv('V3IO_USERNAME')
V3IO_HOME = os.getenv('V3IO_HOME')
V3IO_HOME_URL = os.getenv('V3IO_HOME_URL')
# Define database environment variables
# TODO: Edit the variable definitions to assign valid values for your environment.
%env DB_HOST = "" # Database host as a fully qualified name (FQN)
%env DB_PORT = "" # Database port number
%env DB_DRIVER = "" # Database driver [mysql/postgresql|oracle:thin|sqlserver]
%env DB_Name = "" # Database|schema name
%env DB_TABLE = "" # Table name
%env DB_USER = "" # Database username
%env DB_PASSWORD = "" # Database user password
os.environ["PYSPARK_SUBMIT_ARGS"] = "--packages mysql:mysql-connector-java:5.1.39 pyspark-shell"
```
<a id="spark-jdbc-init-session"></a>
### Initiate a Spark JDBC Session
You can select between two methods for initiating a Spark session with JDBC drivers ("Spark JDBC session"):
- [Load Driver Packages Dynamically](#spark-jdbc-init-dynamic-pkg-load) (preferred)
- [Load Driver Packages Locally](#spark-jdbc-init-local-pkg-load)
<a id="spark-jdbc-init-dynamic-pkg-load"></a>
#### Load Driver Packages Dynamically
The preferred method for initiating a Spark JDBC session is to load the required JDBC driver packages dynamically from https://spark-packages.org/ by doing the following:
1. Set the `PYSPARK_SUBMIT_ARGS` environment variable to `"--packages <group>:<name>:<version> pyspark-shell"`.
2. Initiate a new spark session.
The following example demonstrates how to initiate a Spark session that uses version 5.1.39 of the **mysql-connector-java** MySQL JDBC database driver (`mysql:mysql-connector-java:5.1.39`).
```
from pyspark.conf import SparkConf
from pyspark.sql import SparkSession
# Configure the Spark JDBC driver package
# TODO: Replace `mysql:mysql-connector-java:5.1.39` with the required driver-pacakge information.
os.environ["PYSPARK_SUBMIT_ARGS"] = "--packages mysql:mysql-connector-java:5.1.39 pyspark-shell"
# Initiate a new Spark session; you can change the application name
spark = SparkSession.builder.appName("Spark JDBC tutorial").getOrCreate()
```
<a id="spark-jdbc-init-local-pkg-load"></a>
#### Load Driver Packages Locally
You can also load the Spark JDBC driver package from the local file system of your Iguazio Data Science Platform ("the platform").
It's recommended that you use this method only if you don't have internet connection ("dark-site installations") or if there's no official Spark package for your database.
The platform comes pre-deployed with MySQL, PostgreSQL, Oracle, Redshift, and MS SQL Server JDBC driver packages, which are found in the **/spark/3rd_party** directory (**$SPARK_HOME/3rd_party**).
You can also copy additional driver packages or different versions of the pre-deployed drivers to the platform — for example, from the **Data** dashboard page.
To load a JDBC driver package locally, you need to set the `spark.driver.extraClassPath` and `spark.executor.extraClassPath` Spark configuration properties to the path to a Spark JDBC driver package in the platform's file system.
You can do this using either of the following alternative methods:
- Preconfigure the path to the driver package —
1. In your Spark-configuration file — **$SPARK_HOME/conf/spark-defaults.conf** — set the `extraClassPath` configuration properties to the path to the relevant driver package:
```python
spark.driver.extraClassPath = "<path to a JDBC driver package>"
spark.executor.extraClassPath = "<path to a JDBC driver package>"
```
2. Initiate a new spark session.
- Configure the path to the driver package as part of the initiation of a new Spark session:
```python
spark = SparkSession.builder. \
appName("<app name>"). \
config("spark.driver.extraClassPath", "<path to a JDBC driver package>"). \
config("spark.executor.extraClassPath", "<path to a JDBC driver package>"). \
getOrCreate()
```
The following example demonstrates how to initiate a Spark session that uses the pre-deployed version 8.0.13 of the **mysql-connector-java** MySQL JDBC database driver (**/spark/3rd_party/mysql-connector-java-8.0.13.jar**)
```
from pyspark.conf import SparkConf
from pyspark.sql import SparkSession
# METHOD I
# Edit your Spark configuration file ($SPARK_HOME/conf/spark-defaults.conf), set the `spark.driver.extraClassPath` and
# `spark.executor.extraClassPath` properties to the local file-system path to a pre-deployed Spark JDBC driver package.
# Replace "/spark/3rd_party/mysql-connector-java-8.0.13.jar" with the relevant path.
# spark.driver.extraClassPath = "/spark/3rd_party/mysql-connector-java-8.0.13.jar"
# spark.executor.extraClassPath = "/spark/3rd_party/mysql-connector-java-8.0.13.jar"
#
# Then, initiate a new Spark session; you can change the application name.
# spark = SparkSession.builder.appName("Spark JDBC tutorial").getOrCreate()
# METHOD II
# Initiate a new Spark Session; you can change the application name.
# Set the same `extraClassPath` configuration properties as in Method #1 as part of the initiation command.
# Replace "/spark/3rd_party/mysql-connector-java-8.0.13.jar" with the relevant path.
# local file-system path to a pre-deployed Spark JDBC driver package
spark = SparkSession.builder. \
appName("Spark JDBC tutorial"). \
config("spark.driver.extraClassPath", "/spark/3rd_party/mysql-connector-java-8.0.13.jar"). \
config("spark.executor.extraClassPath", "/spark/3rd_party/mysql-connector-java-8.0.13.jar"). \
getOrCreate()
import pprint
# Verify your configuration: run the following code to list the current Spark configurations, and check the output to verify that the
# `spark.driver.extraClassPath` and `spark.executor.extraClassPath` properties are set to the correct local driver-pacakge path.
conf = spark.sparkContext._conf.getAll()
pprint.pprint(conf)
```
<a id="spark-jdbc-connect-to-dbs"></a>
## Connect to Databases Using Spark JDBC
<a id="spark-jdbc-to-mysql"></a>
### Connect to a MySQL Database
- [Connecting to a Public MySQL Instance](#spark-jdbc-to-mysql-public)
- [Connecting to a Test or Temporary MySQL Instance](#spark-jdbc-to-mysql-test-or-temp)
<a id="spark-jdbc-to-mysql-public"></a>
#### Connect to a Public MySQL Instance
```
#Loading data from a JDBC source
dfMySQL = spark.read \
.format("jdbc") \
.option("url", "jdbc:mysql://mysql-rfam-public.ebi.ac.uk:4497/Rfam") \
.option("dbtable", "Rfam.family") \
.option("user", "rfamro") \
.option("password", "") \
.option("driver", "com.mysql.jdbc.Driver") \
.load()
dfMySQL.show()
```
<a id="spark-jdbc-to-mysql-test-or-temp"></a>
#### Connect to a Test or Temporary MySQL Instance
> **Note:** The following code won't work if the MySQL instance has been shut down.
```
dfMySQL = spark.read \
.format("jdbc") \
.option("url", "jdbc:mysql://172.31.33.215:3306/db1") \
.option("dbtable", "db1.fruit") \
.option("user", "root") \
.option("password", "my-secret-pw") \
.option("driver", "com.mysql.jdbc.Driver") \
.load()
dfMySQL.show()
```
<a id="spark-jdbc-to-postgresql"></a>
### Connect to a PostgreSQL Database
```
# Load data from a JDBC source
dfPS = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.load()
dfPS2 = spark.read \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"})
# Specify DataFrame column data types on read
dfPS3 = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.option("customSchema", "id DECIMAL(38, 0), name STRING") \
.load()
# Save data to a JDBC source
dfPS.write \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.save()
dfPS2.write \
properties={"user": "username", "password": "password"})
# Specify create table column data types on write
dfPS.write \
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)") \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", properties={"user": "username", "password": "password"})
```
<a id="spark-jdbc-to-oracle"></a>
### Connect to an Oracle Database
```
# Read a table from Oracle (table: hr.emp)
dfORA = spark.read \
.format("jdbc") \
.option("url", "jdbc:oracle:thin:username/password@//hostname:portnumber/SID") \
.option("dbtable", "hr.emp") \
.option("user", "db_user_name") \
.option("password", "password") \
.option("driver", "oracle.jdbc.driver.OracleDriver") \
.load()
dfORA.printSchema()
dfORA.show()
# Read a query from Oracle
query = "(select empno,ename,dname from emp, dept where emp.deptno = dept.deptno) emp"
dfORA1 = spark.read \
.format("jdbc") \
.option("url", "jdbc:oracle:thin:username/password@//hostname:portnumber/SID") \
.option("dbtable", query) \
.option("user", "db_user_name") \
.option("password", "password") \
.option("driver", "oracle.jdbc.driver.OracleDriver") \
.load()
dfORA1.printSchema()
dfORA1.show()
```
<a id="spark-jdbc-to-ms-sql-server"></a>
### Connect to an MS SQL Server Database
```
# Read a table from MS SQL Server
dfMS = spark.read \
.format("jdbc") \
.options(url="jdbc:sqlserver:username/password@//hostname:portnumber/DB") \
.option("dbtable", "db_table_name") \
.option("user", "db_user_name") \
.option("password", "password") \
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver" ) \
.load()
dfMS.printSchema()
dfMS.show()
```
<a id="spark-jdbc-to-redshift"></a>
### Connect to a Redshift Database
```
# Read data from a table
dfRS = spark.read \
.format("com.databricks.spark.redshift") \
.option("url", "jdbc:redshift://redshifthost:5439/database?user=username&password=pass") \
.option("dbtable", "my_table") \
.option("tempdir", "s3n://path/for/temp/data") \
.load()
# Read data from a query
dfRS = spark.read \
.format("com.databricks.spark.redshift") \
.option("url", "jdbc:redshift://redshifthost:5439/database?user=username&password=pass") \
.option("query", "select x, count(*) my_table group by x") \
.option("tempdir", "s3n://path/for/temp/data") \
.load()
# Write data back to a table
dfRS.write \
.format("com.databricks.spark.redshift") \
.option("url", "jdbc:redshift://redshifthost:5439/database?user=username&password=pass") \
.option("dbtable", "my_table_copy") \
.option("tempdir", "s3n://path/for/temp/data") \
.mode("error") \
.save()
# Use IAM role-based authentication
dfRS.write \
.format("com.databricks.spark.redshift") \
.option("url", "jdbc:redshift://redshifthost:5439/database?user=username&password=pass") \
.option("dbtable", "my_table_copy") \
.option("tempdir", "s3n://path/for/temp/data") \
.option("aws_iam_role", "arn:aws:iam::123456789000:role/redshift_iam_role") \
.mode("error") \
.save()
```
<a id="spark-jdbc-cleanup"></a>
## Cleanup
Prior to exiting, release disk space, computation, and memory resources consumed by the active session:
- [Delete Data](#spark-jdbc-delete-data)
- [Release Spark Resources](#spark-jdbc-release-spark-resources)
<a id="spark-jdbc-delete-data"></a>
### Delete Data
You can optionally delete any of the directories or files that you created.
See the instructions in the [Creating and Deleting Container Directories](https://www.iguazio.com/docs/v3.0/data-layer/containers/working-with-containers/#create-delete-container-dirs) tutorial.
For example, the following code uses a local file-system command to delete a **<running user>/examples/spark-jdbc** directory in the "users" container.
Edit the path, as needed, then remove the comment mark (`#`) and run the code.
```
# !rm -rf /User/examples/spark-jdbc/
```
<a id="spark-jdbc-release-spark-resources"></a>
### Release Spark Resources
When you're done, run the following command to stop your Spark session and release its computation and memory resources:
```
spark.stop()
```
| github_jupyter |
## 1. Regression discontinuity: banking recovery
<p>After a debt has been legally declared "uncollectable" by a bank, the account is considered to be "charged-off." But that doesn't mean the bank simply <strong><em>walks away</em></strong> from the debt. They still want to collect some of the money they are owed. The bank will score the account to assess the expected recovery amount, that is, the expected amount that the bank may be able to receive from the customer in the future (for a fixed time period such as one year). This amount is a function of the probability of the customer paying, the total debt, and other factors that impact the ability and willingness to pay.</p>
<p>The bank has implemented different recovery strategies at different thresholds (\$1000, \$2000, etc.) where the greater the expected recovery amount, the more effort the bank puts into contacting the customer. For low recovery amounts (Level 0), the bank just adds the customer's contact information to their automatic dialer and emailing system. For higher recovery strategies, the bank incurs more costs as they leverage human resources in more efforts to contact the customer and obtain payments. Each additional level of recovery strategy requires an additional \$50 per customer so that customers in the Recovery Strategy Level 1 cost the company \$50 more than those in Level 0. Customers in Level 2 cost \$50 more than those in Level 1, etc. </p>
<p><strong>The big question</strong>: does the extra amount that is recovered at the higher strategy level exceed the extra \$50 in costs? In other words, was there a jump (also called a "discontinuity") of more than \$50 in the amount recovered at the higher strategy level? We'll find out in this notebook.</p>
<p>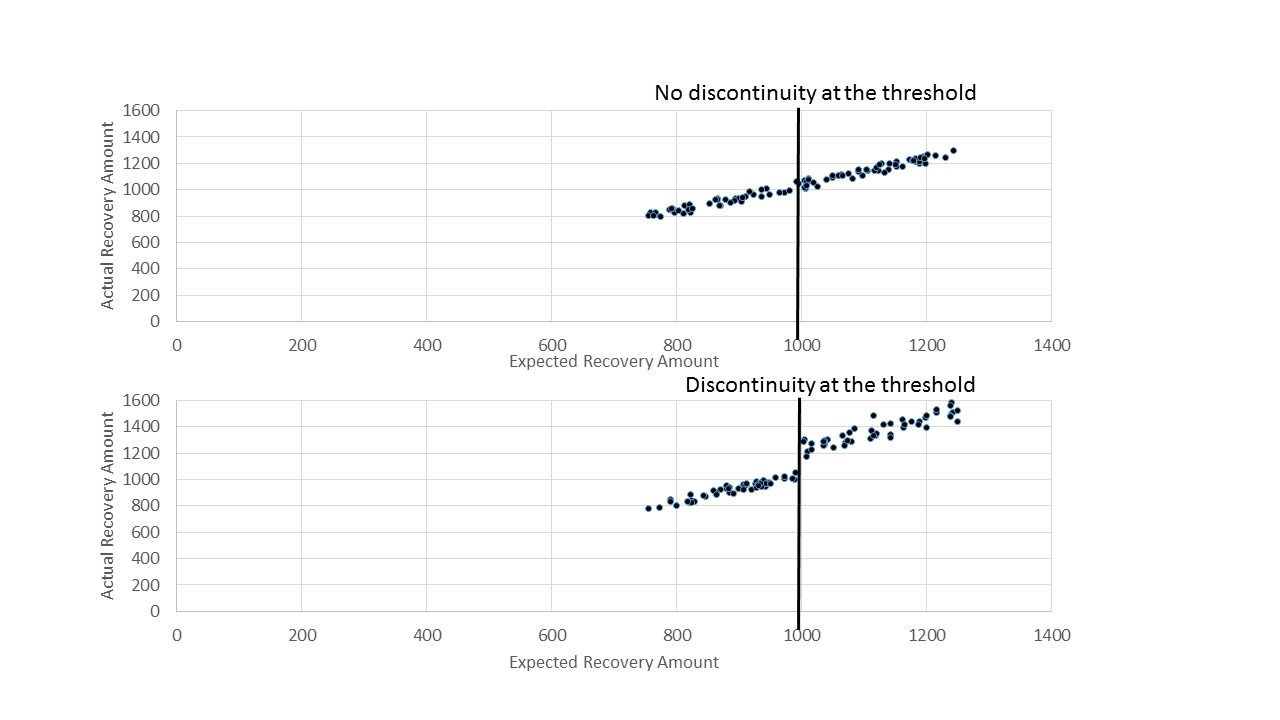</p>
<p>First, we'll load the banking dataset and look at the first few rows of data. This puts us in a good position to understand the dataset itself and begin thinking about how to analyze the data.</p>
```
# Import modules
import pandas as pd
import numpy as np
# Read in dataset
df = pd.read_csv("datasets/bank_data.csv")
# Print the first few rows of the DataFrame
df.head()
```
## 2. Graphical exploratory data analysis
<p>The bank has implemented different recovery strategies at different thresholds (\$1000, \$2000, \$3000 and \$5000) where the greater the Expected Recovery Amount, the more effort the bank puts into contacting the customer. Zeroing in on the first transition (between Level 0 and Level 1) means we are focused on the population with Expected Recovery Amounts between \$0 and \$2000 where the transition between Levels occurred at \$1000. We know that the customers in Level 1 (expected recovery amounts between \$1001 and \$2000) received more attention from the bank and, by definition, they had higher Expected Recovery Amounts than the customers in Level 0 (between \$1 and \$1000).</p>
<p>Here's a quick summary of the Levels and thresholds again:</p>
<ul>
<li>Level 0: Expected recovery amounts >\$0 and <=\$1000</li>
<li>Level 1: Expected recovery amounts >\$1000 and <=\$2000</li>
<li>The threshold of \$1000 separates Level 0 from Level 1</li>
</ul>
<p>A key question is whether there are other factors besides Expected Recovery Amount that also varied systematically across the \$1000 threshold. For example, does the customer age show a jump (discontinuity) at the \$1000 threshold or does that age vary smoothly? We can examine this by first making a scatter plot of the age as a function of Expected Recovery Amount for a small window of Expected Recovery Amount, \$0 to \$2000. This range covers Levels 0 and 1.</p>
```
# Scatter plot of Age vs. Expected Recovery Amount
from matplotlib import pyplot as plt
%matplotlib inline
plt.scatter(x=df['expected_recovery_amount'], y=df['age'], c="g", s=2)
plt.xlim(0, 2000)
plt.ylim(0, 60)
plt.xlabel("Expected Recovery Amount")
plt.ylabel("Age")
plt.legend(loc=2)
plt.show()
```
## 3. Statistical test: age vs. expected recovery amount
<p>We want to convince ourselves that variables such as age and sex are similar above and below the \$1000 Expected Recovery Amount threshold. This is important because we want to be able to conclude that differences in the actual recovery amount are due to the higher Recovery Strategy and not due to some other difference like age or sex.</p>
<p>The scatter plot of age versus Expected Recovery Amount did not show an obvious jump around \$1000. We will be more confident in our conclusions if we do statistical analysis examining the average age of the customers just above and just below the threshold. We can start by exploring the range from \$900 to \$1100.</p>
<p>For determining if there is a difference in the ages just above and just below the threshold, we will use the Kruskal-Wallis test which is a statistical test that makes no distributional assumptions.</p>
```
# Import stats module
from scipy import stats
# Compute average age just below and above the threshold
era_900_1100 = df.loc[(df['expected_recovery_amount']<1100) &
(df['expected_recovery_amount']>=900)]
by_recovery_strategy = era_900_1100.groupby(['recovery_strategy'])
by_recovery_strategy['age'].describe().unstack()
# Perform Kruskal-Wallis test
Level_0_age = era_900_1100.loc[df['recovery_strategy']=="Level 0 Recovery"]['age']
Level_1_age = era_900_1100.loc[df['recovery_strategy']=="Level 1 Recovery"]['age']
stats.kruskal(Level_0_age,Level_1_age)
```
## 4. Statistical test: sex vs. expected recovery amount
<p>We were able to convince ourselves that there is no major jump in the average customer age just above and just
below the \$1000 threshold by doing a statistical test as well as exploring it graphically with a scatter plot. </p>
<p>We want to also test that the percentage of customers that are male does not jump as well across the \$1000 threshold. We can start by exploring the range of \$900 to \$1100 and later adjust this range.</p>
<p>We can examine this question statistically by developing cross-tabs as well as doing chi-square tests of the percentage of customers that are male vs. female.</p>
```
# Number of customers in each category
crosstab = pd.crosstab(df.loc[(df['expected_recovery_amount']<2000) &
(df['expected_recovery_amount']>=0)]['recovery_strategy'],
df['sex'])
print(crosstab)
# Chi-square test
chi2_stat, p_val, dof, ex = stats.chi2_contingency(crosstab)
print(p_val)
```
## 5. Exploratory graphical analysis: recovery amount
<p>We are now reasonably confident that customers just above and just below the \$1000 threshold are, on average, similar in terms of their average age and the percentage that are male. </p>
<p>It is now time to focus on the key outcome of interest, the actual recovery amount.</p>
<p>A first step in examining the relationship between the actual recovery amount and the expected recovery amount is to develop a scatter plot where we want to focus our attention at the range just below and just above the threshold. Specifically, we will develop a scatter plot of Expected Recovery Amount (Y) vs. Actual Recovery Amount (X) for Expected Recovery Amounts between \$900 to \$1100. This range covers Levels 0 and 1. A key question is whether or not we see a discontinuity (jump) around the \$1000 threshold.</p>
```
# Scatter plot of Actual Recovery Amount vs. Expected Recovery Amount
plt.scatter(x=df['expected_recovery_amount'], y=df['actual_recovery_amount'], c="g", s=2)
plt.xlim(900, 1100)
plt.ylim(0, 2000)
plt.xlabel("Expected Recovery Amount")
plt.ylabel("Actual Recovery Amount")
plt.legend(loc=2)
plt.show()
```
## 6. Statistical analysis: recovery amount
<p>Just as we did with age, we can perform statistical tests to see if the actual recovery amount has a discontinuity above the \$1000 threshold. We are going to do this for two different windows of the expected recovery amount \$900 to \$1100 and for a narrow range of \$950 to \$1050 to see if our results are consistent.</p>
<p>Again, the statistical test we will use is the Kruskal-Wallis test, a test that makes no assumptions about the distribution of the actual recovery amount.</p>
<p>We will first compute the average actual recovery amount for those customers just below and just above the threshold using a range from \$900 to \$1100. Then we will perform a Kruskal-Wallis test to see if the actual recovery amounts are different just above and just below the threshold. Once we do that, we will repeat these steps for a smaller window of \$950 to \$1050.</p>
```
# Compute average actual recovery amount just below and above the threshold
by_recovery_strategy['actual_recovery_amount'].describe().unstack()
# Perform Kruskal-Wallis test
Level_0_actual = era_900_1100.loc[df['recovery_strategy']=='Level 0 Recovery']['actual_recovery_amount']
Level_1_actual = era_900_1100.loc[df['recovery_strategy']=='Level 1 Recovery']['actual_recovery_amount']
stats.kruskal(Level_0_actual,Level_1_actual)
# Repeat for a smaller range of $950 to $1050
era_950_1050 = df.loc[(df['expected_recovery_amount']<1050) &
(df['expected_recovery_amount']>=950)]
Level_0_actual = era_950_1050.loc[df['recovery_strategy']=='Level 0 Recovery']['actual_recovery_amount']
Level_1_actual = era_950_1050.loc[df['recovery_strategy']=='Level 1 Recovery']['actual_recovery_amount']
stats.kruskal(Level_0_actual,Level_1_actual)
```
## 7. Regression modeling: no threshold
<p>We now want to take a regression-based approach to estimate the impact of the program at the \$1000 threshold using the data that is just above and just below the threshold. In order to do that, we will build two models. The first model does not have a threshold while the second model will include a threshold.</p>
<p>The first model predicts the actual recovery amount (outcome or dependent variable) as a function of the actual recovery amount (input or independent variable). We expect that there will be a strong positive relationship between these two variables. </p>
<p>We will examine the adjusted R-squared to see the percent of variance that is explained by the model. In this model, we are not trying to represent the threshold but simply trying to see how the variable used for assigning the customers (expected recovery amount) relates to the outcome variable (actual recovery amount).</p>
```
# Import statsmodels
import statsmodels.api as sm
# Define X and y
X = era_900_1100['expected_recovery_amount']
y = era_900_1100['actual_recovery_amount']
X = sm.add_constant(X)
# Build linear regression model
model = sm.OLS(y, X).fit()
predictions = model.predict(X)
# Print out the model summary statistics
model.summary()
```
## 8. Regression modeling: adding true threshold
<p>From the first model, we see that the regression coefficient is statistically significant for the expected recovery amount and the adjusted R-squared value was about 0.26. As we saw from the graph, on average the actual<em>recovery</em>amount increases as the expected<em>recovery</em>amount increases. We could add polynomial terms of expected recovery amount (such as the squared value of expected recovery amount) to the model but, for the purposes of this practice, let's stick with using just the linear term.</p>
<p>The second model adds an indicator of the true threshold to the model. If there was no impact of the higher recovery strategy on the actual recovery amount, then we would expect that the relationship between the expected recovery amount and the actual recovery amount would be continuous. </p>
<p>In this case, we know the true threshold is at \$1000. </p>
<p>We will create an indicator variable (either a 0 or a 1) that represents whether or not the expected recovery amount was greater than \$1000. When we add the true threshold to the model, the regression coefficient for the true threshold represents the additional amount recovered due to the higher recovery strategy. That is to say, the regression coefficient for the true threshold measures the size of the discontinuity for customers just above and just below the threshold.</p>
<p>If the higher recovery strategy did help recovery more money, then the regression coefficient of the true threshold will be greater than zero. If the higher recovery strategy did not help recover more money than the regression coefficient will not be statistically significant.</p>
```
# Create indicator (0 or 1) for expected recovery amount >= $1000
df['indicator_1000'] = np.where(df['expected_recovery_amount']<1000, 0, 1)
era_900_1100 = df.loc[(df['expected_recovery_amount']<1100) &
(df['expected_recovery_amount']>=900)]
# Define X and y
X = era_900_1100[['expected_recovery_amount','indicator_1000']]
y = era_900_1100['actual_recovery_amount']
X = sm.add_constant(X)
# Build linear regression model
model = sm.OLS(y,X).fit()
# Print the model summary
model.summary()
```
## 9. Regression modeling: adjusting the window
<p>The regression coefficient for the true threshold was statistically significant with an estimated impact of around \$278 and a 95 percent confidence interval of \$132 to \$424. This is much larger than the incremental cost of running the higher recovery strategy which was \$50 per customer. At this point, we are feeling reasonably confident that the higher recovery strategy is worth the additional costs of the program for customers just above and just below the threshold. </p>
<p>Before showing this to our managers, we want to convince ourselves that this result wasn't due just to us choosing a window of \$900 to \$1100 for the expected recovery amount. If the higher recovery strategy really had an impact of an extra few hundred dollars, then we should see a similar regression coefficient if we choose a slightly bigger or a slightly smaller window for the expected recovery amount. Let's repeat this analysis for the window of expected recovery amount from \$950 to \$1050 to see if we get similar results.</p>
<p>The answer? Whether we use a wide window (\$900 to \$1100) or a narrower window (\$950 to \$1050), the incremental recovery amount at the higher recovery strategy is much greater than the \$50 per customer it costs for the higher recovery strategy. So we can say that the higher recovery strategy is worth the extra \$50 per customer that the bank is spending.</p>
```
era_950_1050 = df.loc[(df['expected_recovery_amount']<1050) &
(df['expected_recovery_amount']>=950)]
# Define X and y
X = era_950_1050[['expected_recovery_amount','indicator_1000']]
y = era_950_1050['actual_recovery_amount']
X = sm.add_constant(X)
# Build linear regression model
model = sm.OLS(y,X).fit()
# Print the model summary
model.summary()
```
| github_jupyter |
# Comparison of Uncertainty Estimation on Toy Example
```
import numpy as np
import numpy.matlib
import seaborn as sns
import matplotlib.pyplot as plt
import tensorflow as tf
from spinup.algos.uncertainty_estimate.core import MLP, BeroulliDropoutMLP, BootstrappedEnsemble, get_vars, ReplayBuffer
```
# Generate Training Data
```
# Target from "Deep Exploration via Bootstrapped DQN"
# y = x + sin(alpha*(x+w)) + sin(beta*(x+w)) + w
# w ~ N(mean=0, var=0.03**2)
# Training set: x in (0, 0.6) or (0.8, 1), alpha=4, beta=13
def generate_label(x, noisy=True):
num = len(x)
alpha, beta = 4, 13
if noisy:
sigma = 0.03
else:
sigma = 0
omega = np.random.normal(0, sigma, num)
y = x + np.sin(alpha*(x+omega)) + np.sin(beta*(x+omega)) + omega
return y
def plot_training_data_and_underlying_function(train_size=20, train_s1=0, train_e1=0.6, train_s2=0.8, train_e2=1.4):
x_f = np.arange(-1, 2, 0.005)
# True function
y_f = generate_label(x_f, noisy=False)
# Noisy data
y_noisy = generate_label(x_f, noisy=True)
# Training data
x_train = np.concatenate((np.random.uniform(train_s1, train_e1, int(train_size/2)), np.random.uniform(train_s2, train_e2, int(train_size/2))))
y_train = generate_label(x_train)
plt.figure()
plt.plot(x_f, y_f, color='k')
plt.plot(x_f, y_noisy, '.', color='r', alpha=0.3)
plt.plot(x_train, y_train, '.', color='b')
plt.legend(['underlying function', 'noisy data', '{} training data'.format(train_size)])
plt.tight_layout()
plt.savefig('./underlying_function_for_generating_data.jpg', dpi=300)
plt.show()
return x_train, y_train, x_f, y_f
# sns.set(style="darkgrid", font_scale=1.5)
training_data_size = 200#20#50
x_train, y_train, x_f, y_f = plot_training_data_and_underlying_function(train_size=training_data_size,
train_s1=0, train_e1=0.6, train_s2=0.8, train_e2=1.4)
x_train = x_train.reshape(-1,1)
X_train = np.concatenate([x_train, x_train**2], axis=1)
# X_train = x_train
# X_train = np.concatenate([x_train, x_train, x_train], axis=1)
X_train.shape
```
# Build Neural Networks
```
seed=0
x_dim=X_train.shape[1]
y_dim = 1
hidden_sizes = [300, 300]
x_low = -10
x_high = 10
max_steps=int(1e6)
learning_rate=1e-3
batch_size=100
replay_size=int(1e6)
BerDrop_n_post=50#100
dropout_rate = 0.05
bootstrapp_p = 0.75
tf.set_random_seed(seed)
np.random.seed(seed)
# Define input placeholder
x_ph = tf.placeholder(dtype=tf.float32, shape=(None, x_dim))
y_ph = tf.placeholder(dtype=tf.float32, shape=(None, y_dim))
layer_sizes = hidden_sizes + [y_dim]
hidden_activation=tf.keras.activations.relu
output_activation = tf.keras.activations.linear
# 1. Create MLP to learn RTN:
# which is only used for generating target value.
mlp_replay_buffer = ReplayBuffer(x_dim=x_dim, y_dim=y_dim, size=replay_size)
with tf.variable_scope('MLP'):
mlp = MLP(layer_sizes, hidden_activation=hidden_activation, output_activation=output_activation)
mlp_y = mlp(x_ph)
mlp_loss = tf.reduce_mean((y_ph - mlp_y)**2) # mean-square-error
mlp_optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
mlp_train_op = mlp_optimizer.minimize(mlp_loss, var_list=mlp.variables)
# 2. Create BernoulliDropoutMLP:
# which is trained with dropout masks and regularization term
with tf.variable_scope('BernoulliDropoutUncertaintyTrain'):
bernoulli_dropout_mlp = BeroulliDropoutMLP(layer_sizes, weight_regularizer=1e-6, dropout_rate=dropout_rate,
hidden_activation = hidden_activation,
output_activation = output_activation)
ber_drop_mlp_y = bernoulli_dropout_mlp(x_ph, training=True) # Must set training=True to use dropout mask
ber_drop_mlp_reg_losses = tf.reduce_sum(
tf.losses.get_regularization_losses(scope='BernoulliDropoutUncertaintyTrain'))
ber_drop_mlp_loss = tf.reduce_sum(
(y_ph - ber_drop_mlp_y) ** 2 + ber_drop_mlp_reg_losses) # TODO: heteroscedastic loss
ber_drop_mlp_optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
ber_drop_mlp_train_op = ber_drop_mlp_optimizer.minimize(ber_drop_mlp_loss,
var_list=bernoulli_dropout_mlp.variables)
# 3. Create lazy BernoulliDropoutMLP:
# which copys weights from MLP by:
# lazy_bernoulli_dropout_mlp_sample.set_weights(mlp.get_weights())
# then post sample predictions with dropout masks.
with tf.variable_scope('LazyBernoulliDropoutUncertaintySample'):
lazy_bernoulli_dropout_mlp = BeroulliDropoutMLP(layer_sizes, weight_regularizer=1e-6, dropout_rate=dropout_rate,
hidden_activation=hidden_activation,
output_activation=output_activation)
lazy_ber_drop_mlp_y = lazy_bernoulli_dropout_mlp(x_ph, training=True) # Set training=True to sample with dropout masks
lazy_ber_drop_mlp_update = tf.group([tf.assign(v_lazy_ber_drop_mlp, v_mlp)
for v_mlp, v_lazy_ber_drop_mlp in zip(mlp.variables, lazy_bernoulli_dropout_mlp.variables)])
# Create BootstrappedEnsembleNN
with tf.variable_scope('BootstrappedEnsembleUncertainty'):
boots_ensemble = BootstrappedEnsemble(ensemble_size=BerDrop_n_post, x_dim=x_dim, y_dim=y_dim, replay_size=replay_size,
x_ph=x_ph, y_ph=y_ph, layer_sizes=layer_sizes,
hidden_activation=hidden_activation,
output_activation=output_activation,
learning_rate=learning_rate)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
```
# Training
```
# Add training set to bootstrapped_ensemble
for i in range(X_train.shape[0]):
boots_ensemble.add_to_replay_buffer(X_train[i], y_train[i], bootstrapp_p=bootstrapp_p)
training_epoches = 500#1000#500
ber_drop_mlp_train_std = np.zeros((training_epoches,))
ber_drop_mlp_train_loss = np.zeros((training_epoches,))
lazy_ber_drop_mlp_train_std = np.zeros((training_epoches,))
lazy_ber_drop_mlp_train_loss = np.zeros((training_epoches,))
boots_ensemble_train_std = np.zeros((training_epoches,))
boots_ensemble_train_loss = np.zeros((training_epoches,))
for ep_i in range(training_epoches):
if ep_i%100==0:
print('epoch {}'.format(ep_i))
# TODO: uncertainty on training set
# repmat X_train for post sampling: N x BerDrop_n_post x x_dim
ber_drop_mlp_post = np.zeros([X_train.shape[0], BerDrop_n_post, y_dim])
lazy_ber_drop_mlp_post = np.zeros([X_train.shape[0], BerDrop_n_post, y_dim])
boots_ensemble_post = np.zeros([X_train.shape[0], BerDrop_n_post, y_dim])
for x_i in range(X_train.shape[0]):
x_post = np.matlib.repmat(X_train[x_i,:], BerDrop_n_post, 1) # repmat x for post sampling
# BernoulliDropoutMLP
ber_drop_mlp_post[x_i,:,:] = sess.run(ber_drop_mlp_y, feed_dict={x_ph: x_post})
# LazyBernoulliDropoutMLP
lazy_ber_drop_mlp_post[x_i,:,:] = sess.run(lazy_ber_drop_mlp_y, feed_dict={x_ph: x_post})
# BootstrappedEnsemble
boots_ensemble_post[x_i,:,:] = boots_ensemble.prediction(sess, X_train[x_i,:])
# Everage std on training set
ber_drop_mlp_train_std[ep_i] = np.mean(np.std(ber_drop_mlp_post,axis=1))
lazy_ber_drop_mlp_train_std[ep_i] = np.mean(np.std(lazy_ber_drop_mlp_post,axis=1))
boots_ensemble_train_std[ep_i] = np.mean(np.std(boots_ensemble_post,axis=1))
# Train MLP
mlp_outs = sess.run([mlp_loss, mlp_train_op], feed_dict={x_ph: X_train, y_ph: y_train.reshape(-1,y_dim)})
lazy_ber_drop_mlp_train_loss[ep_i] = mlp_outs[0]
sess.run(lazy_ber_drop_mlp_update) # copy weights
# Train BernoulliDropoutMLP on the same batch with MLP
ber_drop_outs = sess.run([ber_drop_mlp_loss, ber_drop_mlp_train_op], feed_dict={x_ph:X_train, y_ph: y_train.reshape(-1,y_dim)})
ber_drop_mlp_train_loss[ep_i] = ber_drop_outs[0]
# Train BootstrappedEnsemble
boots_ensemble_loss = boots_ensemble.train(sess, batch_size)
boots_ensemble_train_loss[ep_i] = np.mean(boots_ensemble_loss)
marker = '.'
markersize = 1
# Loss
f, axes = plt.subplots(1, 3)
f.set_figwidth(18)
f.set_figheight(3.5)
axes[0].plot(lazy_ber_drop_mlp_train_loss, marker, markersize=markersize)
axes[0].set_title('LazyBernoulliDropout (MLP) Average Training Loss')
axes[0].set_xlabel('Training Epochs')
axes[0].set_ylabel('Loss Value on Training Data')
axes[1].plot(ber_drop_mlp_train_loss, marker, markersize=markersize)
axes[1].set_title('BernoulliDropout Average Training Loss')
axes[1].set_xlabel('Training Epochs')
axes[2].plot(boots_ensemble_train_loss, marker, markersize=markersize)
axes[2].set_title('BootsEnsemble Average Training Loss')
axes[2].set_xlabel('Training Epochs')
f.savefig('./toy_example_loss_on_training_data.jpg', dpi=300)
# Uncertainty
f, axes = plt.subplots(1, 3, sharey=True)
f.set_figwidth(18)
f.set_figheight(3.5)
axes[0].plot(lazy_ber_drop_mlp_train_std, markersize=markersize)
axes[0].set_title('Lazy Bernoulli Dropout Average Uncertainty')
axes[0].set_xlabel('Training Epochs')
axes[0].set_ylabel('Average Uncertainty on Trainig Data')
axes[1].plot(ber_drop_mlp_train_std,marker, markersize=markersize)
axes[1].set_title('Bernoulli Dropout Average Uncertainty')
axes[1].set_xlabel('Training Epochs')
axes[2].plot(boots_ensemble_train_std, marker, markersize=markersize)
axes[2].set_title('Bootstrapped Ensemble Average Uncertainty')
axes[2].set_xlabel('Training Epochs')
f.savefig('./toy_example_uncertainty_on_training_data.jpg', dpi=300)
```
# Post Sampling to Estimate Uncertainty
```
x_test = np.arange(-1, 2, 0.005)
x_test = x_test.reshape(-1,1)
X_test = np.concatenate([x_test, x_test**2], axis=1)
# X_test = x_test
# X_test = np.concatenate([x_test, x_test, x_test], axis=1)
X_test.shape
# post sampling
mlp_postSamples = np.zeros([X_test.shape[0], BerDrop_n_post, y_dim])
ber_drop_mlp_postSamples = np.zeros([X_test.shape[0], BerDrop_n_post, y_dim])
lazy_ber_drop_mlp_postSamples = np.zeros([X_test.shape[0], BerDrop_n_post, y_dim])
boots_ensemble_postSamples = np.zeros([X_test.shape[0], BerDrop_n_post, y_dim])
for i in range(X_test.shape[0]):
x = X_test[i,:]
x_postSampling = np.matlib.repmat(x, BerDrop_n_post, 1) # repmat x for post sampling
# MLP
mlp_postSamples[i,:,:] = sess.run(mlp_y, feed_dict={x_ph: x_postSampling})
# BernoulliDropoutMLP
ber_drop_mlp_postSamples[i,:,:] = sess.run(ber_drop_mlp_y, feed_dict={x_ph: x_postSampling})
# LazyBernoulliDropoutMLP
sess.run(lazy_ber_drop_mlp_update) # copy weights
lazy_ber_drop_mlp_postSamples[i,:,:] = sess.run(lazy_ber_drop_mlp_y, feed_dict={x_ph: x_postSampling})
# BootstrappedEnsemble
boots_ensemble_postSamples[i,:,:] = boots_ensemble.prediction(sess, x)
mlp_mean = np.mean(mlp_postSamples,axis=1)
mlp_std = np.std(mlp_postSamples,axis=1)
ber_drop_mlp_mean = np.mean(ber_drop_mlp_postSamples,axis=1)
ber_drop_mlp_std = np.std(ber_drop_mlp_postSamples,axis=1)
lazy_ber_drop_mlp_mean = np.mean(lazy_ber_drop_mlp_postSamples,axis=1)
lazy_ber_drop_mlp_std = np.std(lazy_ber_drop_mlp_postSamples,axis=1)
boots_ensemble_mean = np.mean(boots_ensemble_postSamples,axis=1)
boots_ensemble_std = np.std(boots_ensemble_postSamples,axis=1)
markersize = 5
f, axes = plt.subplots(1,4,sharey=True)
# f.suptitle('n_training_data={}, n_post_samples={}, dropout_rate={}, n_trainig_epochs={}, bootstrapp_p={}'.format(training_data_size,
# BerDrop_n_post,
# dropout_rate,
# training_epoches,
# bootstrapp_p),
# fontsize=20)
f.set_figwidth(20)
f.set_figheight(4)
axes[0].plot(x_test, mlp_mean, 'k')
axes[0].plot(x_train, y_train, 'r.', markersize=markersize)
axes[0].plot(x_f, y_f,'m', alpha=0.5)
axes[0].fill_between(x_test.flatten(),
(mlp_mean+mlp_std).flatten(),
(mlp_mean-mlp_std).flatten())
axes[0].set_title('MLP', fontsize=15)
axes[1].plot(x_test, lazy_ber_drop_mlp_mean, 'k')
axes[1].plot(x_train, y_train, 'r.', markersize=markersize)
axes[1].plot(x_f, y_f,'m', alpha=0.5)
axes[1].fill_between(x_test.flatten(),
(lazy_ber_drop_mlp_mean+lazy_ber_drop_mlp_std).flatten(),
(lazy_ber_drop_mlp_mean-lazy_ber_drop_mlp_std).flatten())
axes[1].set_title('LazyBernoulliDropoutMLP', fontsize=15)
axes[2].plot(x_test, ber_drop_mlp_mean, 'k')
axes[2].plot(x_train, y_train, 'r.', markersize=markersize)
axes[2].plot(x_f, y_f,'m', alpha=0.5)
axes[2].fill_between(x_test.flatten(),
(ber_drop_mlp_mean+ber_drop_mlp_std).flatten(),
(ber_drop_mlp_mean-ber_drop_mlp_std).flatten())
axes[2].set_title('BernoulliDropoutMLP', fontsize=15)
prediction_mean_h, = axes[3].plot(x_test, boots_ensemble_mean, 'k')
training_data_h, = axes[3].plot(x_train, y_train, 'r.', markersize=markersize)
underlying_function_h, = axes[3].plot(x_f, y_f,'m', alpha=0.5)
prediction_std_h = axes[3].fill_between(x_test.flatten(),
(boots_ensemble_mean+boots_ensemble_std).flatten(),
(boots_ensemble_mean-boots_ensemble_std).flatten())
axes[3].set_title('BootstrappedEnsemble', fontsize=15)
axes[3].set_ylim(-6, 9)
axes[0].legend(handles=[underlying_function_h, training_data_h, prediction_mean_h, prediction_std_h],
labels=['underlying function', '{} training data'.format(training_data_size), 'prediction mean', 'prediction mean $\pm$ standard deviation'])
plt.tight_layout()
f.subplots_adjust(top=0.8)
plt.savefig('./toy_example_comparison_of_uncertainty_estimation.jpg', dpi=300)
```
| github_jupyter |
```
#experiment name and snapshot folder (used for model persistence)
from __future__ import print_function
experiment_setup_name = "tutorial.wikicat.advanced"
snapshot_path = "./agentnet_snapshots/"
!mkdir ./agentnet_snapshots
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
#theano imports
#the problem is too simple to be run on GPU. Seriously.
%env THEANO_FLAGS='device=cpu'
import theano
import theano.tensor as T
floatX = theano.config.floatX
import lasagne
%load_ext autoreload
%autoreload 2
```
# This tutorial builds above the basic tutorial and shows several advanced tools
* multi-layer (and in principle, arbitrary) agent memory
* different reinforcement learning algorithms
* model persistence
__[todo: add more]__
# Experiment setup
* Here we load an experiment environment (description below)
* Designing one from scratch is explained in later tutorials
```
import agentnet.experiments.wikicat as experiment
print(experiment.__doc__)
#Create an environment with all default parameters
env = experiment.WikicatEnvironment()
from sklearn.cross_validation import train_test_split
attrs, categories, feature_names = env.get_dataset()
train_attrs,test_attrs,train_cats,test_cats = train_test_split(attrs,categories,test_size=0.99,random_state=32)
print("train size:", train_attrs.shape,train_cats.shape)
print("train size:", test_attrs.shape,test_cats.shape)
print("features:",feature_names[::20])
env.load_random_batch(train_attrs,train_cats,5)
```
# agent setup
* An agent implementation has to contain three parts:
* Memory layer(s)
* in this case, we train two GRU layers [details below]
* Q-values evaluation layers
* in this case, a lasagne dense layer based on memory layer
* Resolver - acton picker layer
* in this case, the resolver has epsilon-greedy policy
### two-layer memory architecture
We train two memory states:
* first one, based on observations,
* second one, based on first one;
Note that here we update the second memory layer based on the CURRENT state
of the first one. Instead, you can try to feed it with a previous state.
The q-values are estimated on a concatenated state, effectively on both memory
states together, but there is no problem with limiting q-evaluator to only one:
just pass the correct gru layer as an incoming layer to the q-evaluator.
### Implementation:
We concatenate both memories into 1 state to pass it through the session loop.
To perform memory update, we need to slice the concatenated state back into
two memory states.
We do so by defining an input map function and passing it into agent.
We than concatenate two new states back to form a new memory state.
```
theano.function
from agentnet.resolver import EpsilonGreedyResolver
from agentnet.memory.rnn import GRUCell
from agentnet.memory import GRUMemoryLayer
from agentnet.agent import Agent
import lasagne
n_hid_1=512 #first GRU memory
n_hid_2=512 #second GRU memory
_observation_layer = lasagne.layers.InputLayer([None]+list(env.observation_shapes),name="obs_input")
_prev_gru1_layer = lasagne.layers.InputLayer([None,n_hid_1],name="prev_gru1_state_input")
_prev_gru2_layer = lasagne.layers.InputLayer([None,n_hid_2],name="prev_gru2_state_input")
#memory
gru1 = GRUMemoryLayer(n_hid_1,
_observation_layer,
_prev_gru1_layer,
name="gru1")
gru2 = GRUMemoryLayer(n_hid_2,
gru1, #note that it takes CURRENT gru1 output as input.
#replacing that with _prev_gru1_state would imply taking previous one.
_prev_gru2_layer,
name="gru2")
concatenated_memory = lasagne.layers.concat([gru1,gru2])
#q_eval
n_actions = len(feature_names)
q_eval = lasagne.layers.DenseLayer(concatenated_memory, #taking both memories.
#Replacing with gru1 or gru2 would mean taking one
num_units = n_actions,
nonlinearity=lasagne.nonlinearities.linear,name="QEvaluator")
#resolver
epsilon = theano.shared(np.float32(0.1),"e-greedy.epsilon")
resolver = EpsilonGreedyResolver(q_eval,epsilon=epsilon,name="resolver")
from collections import OrderedDict
#all together
agent = Agent(_observation_layer,
OrderedDict([
(gru1,_prev_gru1_layer),
(gru2,_prev_gru2_layer)
]),
q_eval,resolver)
#Since it's a single lasagne network, one can get it's weights, output, etc
weights = lasagne.layers.get_all_params(resolver,trainable=True)
weights
```
## Agent setup in detail
* __Memory layers__
* One-step recurrent layer
* takes input and one's previous state
* returns new memory state
* Can be arbitrary lasagne layer
* Several one-step recurrent units are implemented in __agentnet.memory__
* Note that lasagne's default recurrent networks roll for several steps at once
* in other words, __using lasagne recurrent units as memory means recurrence inside recurrence__
* Using more than one memory layer is explained in farther tutorials
* __Q-values evaluation layer__
* Can be arbitrary lasagne network
* returns predicted Q-values for each action
* Usually depends on memory as an input
* __Resolver__ - action picker
* Decides on what action is taken
* Normally takes Q-values as input
* Currently all experiments require integer output
* Several resolver layers are implemented in __agentnet.resolver__
# Interacting with environment
* an agent has a method that produces symbolic environment interaction sessions
* interactions result in sequences of observations, actions, q-values,etc
* one has to pre-define maximum session length.
* in this case, environment implements an indicator of whether session has ended by current tick
* Since this environment also implements Objective methods, it can evaluate rewards for each [batch, time_tick]
```
#produce interaction sequences of length <= 10
(state_seq),observation_seq,agent_state,action_seq,qvalues_seq = agent.get_sessions(
env,
session_length=10,
batch_size=env.batch_size,
)
gru1_seq = agent_state[gru1]
gru2_seq = agent_state[gru2]
#get rewards for all actions
rewards_seq = env.get_reward_sequences(state_seq,action_seq)
#get indicator whether session is still active
is_alive_seq = env.get_whether_alive(observation_seq)
```
# Evaluating loss function
* This part is similar to the basic tutorial but for the fact that we use 3-step q-learning
* we evaluate the Q-loss manually, so this entire block is in essence equivalent to `qlearning_n_step.get_elementwise_objective(...)`
#### Get (prediction,reference) pairs
```
#get reference Qvalues according to Qlearning algorithm
from agentnet.learning import qlearning_n_step
#gamma - delayed reward coefficient - what fraction of reward is retained if it is obtained one tick later
gamma = theano.shared(np.float32(0.95),name = 'q_learning_gamma')
reference_Qvalues = qlearning_n_step.get_elementwise_objective(qvalues_seq,
action_seq,
rewards_seq,
n_steps=3,
gamma_or_gammas=gamma,
return_reference=True)
#zero-out future rewards at session end
from agentnet.learning.helpers import get_end_indicator
end_action_ids = get_end_indicator(is_alive_seq).nonzero()
# "set reference Qvalues at end action ids to just the immediate rewards"
reference_Qvalues = T.set_subtensor(reference_Qvalues[end_action_ids],
rewards_seq[end_action_ids])
#prevent gradient updates over reference Qvalues (since they depend on predicted Qvalues)
from theano.gradient import disconnected_grad
reference_Qvalues = disconnected_grad(reference_Qvalues)
from agentnet.learning.helpers import get_action_Qvalues
action_Qvalues = get_action_Qvalues(qvalues_seq,action_seq)
```
#### Define loss functions
```
#tensor of elementwise squared errors
squared_error = lasagne.objectives.squared_error(reference_Qvalues,action_Qvalues)
#zero-out ticks after session ended
squared_error = squared_error * is_alive_seq
#all code from Evaluation Loss Function beginning to this point is equivalent to
#squared_error = qlearning_n_step.get_elementwise_objective(...)
#compute average of squared error sums per session
mse_loss = squared_error.sum() / is_alive_seq.sum()
#regularize network weights
from lasagne.regularization import regularize_network_params, l2
reg_l2 = regularize_network_params(resolver,l2)*10**-4
loss = mse_loss + reg_l2
```
#### Compute weight updates
```
updates = lasagne.updates.adadelta(loss,
weights,learning_rate=0.01)
```
#### Some auxilary evaluation metrics
```
mean_session_reward = rewards_seq.sum(axis=1).mean()
#...
```
# Compile train and evaluation functions
```
train_fun = theano.function([],[loss,mean_session_reward],updates=updates)
evaluation_fun = theano.function([],[loss,mse_loss,reg_l2,mean_session_reward])
```
# session visualization tools
* this is a completely optional step of visualizing agent's sessions as chains of actions
* usually useful to get insight on what worked and what din't
* in this case, we print strings following pattern
* [action_name] ([predicted action qvalue]) -> reward [reference qvalue] | next iteration
* plot shows
* time ticks over X, abstract values over Y
* bold lines are Qvalues for actions
* dots on bold lines represent what actions were taken at each moment of time
* dashed lines are agent's hidden state neurons
* blue vertical line - session end
__Warning! the visualization tools are underdeveloped and only allow simple operations.__
if you found yourself struggling to make it do what you want for 5 minutes, go write your own tool [and contribute it :)]
```
from agentnet.display.sessions import print_sessions
get_printables = theano.function([], [
gru2_seq,qvalues_seq, action_seq,rewards_seq,reference_Qvalues,is_alive_seq
])
def display_sessions(with_plots = False):
hidden_log,qvalues_log,actions_log,reward_log, reference_qv_log, is_alive_log = get_printables()
print_sessions(qvalues_log,actions_log,reward_log,
is_alive_seq = is_alive_log,
#hidden_seq=hidden_log, #do not plot hidden since there's too many actions already
reference_policy_seq = reference_qv_log,
action_names=feature_names,
legend = False, #do not show legend since there's too many labeled objects
plot_policy = with_plots)
#visualize untrained network performance (which is mostly random)
env.load_random_batch(train_attrs,train_cats,1)
display_sessions(with_plots=True)
```
# Training loop
```
#tools for model persistence
from agentnet.utils.persistence import save,load
import os
from agentnet.display import Metrics
score_log = Metrics()
#starting epoch
epoch_counter = 1
#moving average estimation
alpha = 0.1
ma_reward_current = -7.
ma_reward_greedy = -7.
%%time
n_epochs = 100000
batch_size= 10
for i in range(n_epochs):
#train
env.load_random_batch(train_attrs,train_cats,batch_size)
resolver.rng.seed(i)
loss,avg_reward = train_fun()
##update resolver's epsilon (chance of random action instead of optimal one)
if epoch_counter%10 ==0:
current_epsilon = 0.05 + 0.95*np.exp(-epoch_counter/10000.)
resolver.epsilon.set_value(np.float32(current_epsilon))
##record current learning progress and show learning curves
if epoch_counter%100 ==0:
##update learning curves
full_loss, q_loss, l2_penalty, avg_reward_current = evaluation_fun()
ma_reward_current = (1-alpha)*ma_reward_current + alpha*avg_reward_current
score_log["expected e-greedy reward"][epoch_counter] = ma_reward_current
#greedy train
resolver.epsilon.set_value(0)
avg_reward_greedy = evaluation_fun()[-1]
ma_reward_greedy = (1-alpha)*ma_reward_greedy + alpha*avg_reward_greedy
score_log["expected greedy reward"][epoch_counter] = ma_reward_greedy
#back to epsilon-greedy
resolver.epsilon.set_value(np.float32(current_epsilon))
print("epoch %i,loss %.5f, epsilon %.5f, rewards: ( e-greedy %.5f, greedy %.5f) "%(
epoch_counter,full_loss,current_epsilon,ma_reward_current,ma_reward_greedy))
print("rec %.3f reg %.3f"%(q_loss,l2_penalty))
if epoch_counter %1000 ==0:
print("Learning curves:")
score_log.plot()
print("Random session examples")
env.load_random_batch(train_attrs,train_cats,3)
display_sessions(with_plots=False)
#save snapshot
if epoch_counter %10000 ==0:
snap_name = "{}.epoch{}.pcl".format(os.path.join(snapshot_path,experiment_setup_name), epoch_counter)
save(resolver,snap_name)
print("saved", snap_name)
epoch_counter +=1
# Time to drink some coffee!
```
# Evaluating results
```
score_log.plot("final")
print("Random session examples")
env.load_random_batch(train_attrs,train_cats,10)
display_sessions(with_plots=True)
#load earlier snapshot.
#warning - this overrides the latest network params with earlier ones.
#Replace 20000 with some 100000 (or whatever last snapshot epoch) if you wish to load latest snapshot back.
snap_name = "{}.epoch{}.pcl".format(os.path.join(snapshot_path,experiment_setup_name), 20000)
load(resolver,snap_name)
print("Random session examples: early snapshot")
env.load_random_batch(train_attrs,train_cats,10)
display_sessions(with_plots=True)
```
| github_jupyter |
# [Strings](https://docs.python.org/3/library/stdtypes.html#text-sequence-type-str)
```
my_string = 'Python is my favorite programming language!'
my_string
type(my_string)
len(my_string)
```
### Respecting [PEP8](https://www.python.org/dev/peps/pep-0008/#maximum-line-length) with long strings
```
long_story = ('Lorem ipsum dolor sit amet, consectetur adipiscing elit.'
'Pellentesque eget tincidunt felis. Ut ac vestibulum est.'
'In sed ipsum sit amet sapien scelerisque bibendum. Sed '
'sagittis purus eu diam fermentum pellentesque.')
long_story
```
## `str.replace()`
If you don't know how it works, you can always check the `help`:
```
help(str.replace)
```
This will not modify `my_string` because replace is not done in-place.
```
my_string.replace('a', '?')
print(my_string)
```
You have to store the return value of `replace` instead.
```
my_modified_string = my_string.replace('is', 'will be')
print(my_modified_string)
```
## `str.format()`
```
secret = '{} is cool'.format('Python')
print(secret)
print('My name is {} {}, you can call me {}.'.format('John', 'Doe', 'John'))
# is the same as:
print('My name is {first} {family}, you can call me {first}.'.format(first='John', family='Doe'))
```
## `str.join()`
```
pandas = 'pandas'
numpy = 'numpy'
requests = 'requests'
cool_python_libs = ', '.join([pandas, numpy, requests])
print('Some cool python libraries: {}'.format(cool_python_libs))
```
Alternatives (not as [Pythonic](http://docs.python-guide.org/en/latest/writing/style/#idioms) and [slower](https://waymoot.org/home/python_string/)):
```
cool_python_libs = pandas + ', ' + numpy + ', ' + requests
print('Some cool python libraries: {}'.format(cool_python_libs))
cool_python_libs = pandas
cool_python_libs += ', ' + numpy
cool_python_libs += ', ' + requests
print('Some cool python libraries: {}'.format(cool_python_libs))
```
## `str.upper(), str.lower(), str.title()`
```
mixed_case = 'PyTHoN hackER'
mixed_case.upper()
mixed_case.lower()
mixed_case.title()
```
## `str.strip()`
```
ugly_formatted = ' \n \t Some story to tell '
stripped = ugly_formatted.strip()
print('ugly: {}'.format(ugly_formatted))
print('stripped: {}'.format(ugly_formatted.strip()))
```
## `str.split()`
```
sentence = 'three different words'
words = sentence.split()
print(words)
type(words)
secret_binary_data = '01001,101101,11100000'
binaries = secret_binary_data.split(',')
print(binaries)
```
## Calling multiple methods in a row
```
ugly_mixed_case = ' ThIS LooKs BAd '
pretty = ugly_mixed_case.strip().lower().replace('bad', 'good')
print(pretty)
```
Note that execution order is from left to right. Thus, this won't work:
```
pretty = ugly_mixed_case.replace('bad', 'good').strip().lower()
print(pretty)
```
## [Escape characters](http://python-reference.readthedocs.io/en/latest/docs/str/escapes.html#escape-characters)
```
two_lines = 'First line\nSecond line'
print(two_lines)
indented = '\tThis will be indented'
print(indented)
```
| github_jupyter |
# Coches results
```
# Scientific libraries
import numpy as np
import scipy
# Graphic libraries
import matplotlib.pyplot as plt
%matplotlib widget
plt.style.use("presentation")
plt.rcParams["figure.figsize"] = (4, 3)
# Creating alias for magic commands
# LPPview Classes
from LPPview import *
from LPPview.Classes.LPPic_temporal import History
root = "/DATA/tavant/"
folders = ["220_Coche_same_FakeR_2cm/", "219_Coche_same_fakeR/", "214_Coche_same_CE/"]
names = ["$L_R=2$ cm", "$L_R=2$ mm", "No $L_R$"]
paths = [root+f for f in folders]
def plot_ne():
plt.figure()
for i in [2, 0]:
path=paths[i]
F = field(path)
H = History(path)
temporal_data = H.return_history()
#print(temporal_data.keys())
time = temporal_data["time"]*1e6
# rate = (temporal_data["elec_SEE"] + temporal_data["elec_SEE_sup"])/ temporal_data["elec_wal"]
# rate[0] = 0
mob = temporal_data["mobi"]
ne = temporal_data["elec"]
plt.plot(time, F._qf*ne, label=names[i])
plt.xlim(0, 300)
plt.xlabel("Time [$\mu$s]")
plt.ylabel("Mean electron density $n_e$ [m$^{-3}$]")
plt.legend()
plt.ylim(bottom=0, top=5e15)
plot_ne()
from mpl_toolkits.axes_grid1.axes_divider import make_axes_locatable, Divider, AxesDivider
from mpl_toolkits.axes_grid1.colorbar import colorbar
t_mus = 214
t_mus = 236
path=paths[2]
F = field(path)
F.definecoords()
t_index = int( t_mus//(F._dT*F._Na*1e6))
print(t_index)
fig, axarr = plt.subplots(1, 2, figsize=(6, 3))
fig.subplots_adjust(top=0.9, bottom=0.2, right=0.99, left=0.08)
keys = ["Ej(1)", "Nume"]
for ax, key in zip(axarr, keys):
tab = F.return_fromkey(t_index, key)
if key == "Ej(1)":
tab *= 1e-3
label= "$E_{\\theta}$ [kV/m]"
elif key == "Nume":
tab *= 1e-17
label= "$10^{17}\, n_e$ [m$^{-3}$]"
ax.set_xlabel("Axial position $z$ [cm]")
im = ax.imshow(tab, extent=[0, F._Ly*100, 0, F._Lx*100])
ax2_divider = make_axes_locatable(ax, )
ax.text(2.2, 4.8, label, fontsize=11 )
# add an axes above the main axes.
cax2 = ax2_divider.append_axes("top", size="5%", pad="7%",)
cax2.set_axis_off()
box = cax2.get_position()
print(box)
width = box.width
height = box.height
inax_position = ax.transAxes.transform([0.5, 0.5])
transFigure = fig.transFigure.inverted()
infig_position = transFigure.transform(inax_position)
x = infig_position[0]
y = infig_position[1]
cax2 = plt.axes([box.x0, 0.85, width*0.5, height*0.05])
cb2 = colorbar(im, cax=cax2, orientation="horizontal", )
# change tick position to top. Tick position defaults to bottom and overlaps
# the image.
cax2.xaxis.set_ticks_position("top")
axarr[0].set_ylabel("Azimuthal position $\\theta$ [cm]")
plt.savefig(f"Coche_example_t={t_mus}.png", dpi=400)
```
# Boeuf
```
path_ref = "/DATA/tavant/266_Boeuf_166Thomas/"
path_L2 = "/DATA/tavant/158_Beauf_fakeR/"
path_L4 = "/DATA/tavant/163_Beauf_fakeR2/"
paths = [path_ref, path_L4, path_L2]
names = ["no $L_R$", "$L_R$=4cm", "$L_R$=2cm"]
t_mus = 8
path=paths[0]
F = field(path)
F.definecoords()
t_index = int( t_mus//(F._dT*F._Na*1e6))
print(t_index)
fig, axarr = plt.subplots(1, 2, figsize=(6, 3))
fig.subplots_adjust(top=0.9, bottom=0.2, right=0.95, left=0.1)
keys = ["Ej(1)", "Nume"]
for ax, key in zip(axarr, keys):
tab = F.return_fromkey(t_index, key)
if key == "Ej(1)":
tab *= 1e-3
label= "$E_{\\theta}$ [kV/m]"
elif key == "Nume":
tab *= 1e-17
label= "$10^{17}\, n_e$ [m$^{-3}$]"
ax.set_xlabel("Axial position $z$ [cm]")
im = ax.imshow(tab, extent=[0, F._Ly*100, 0, F._Lx*100])
ax2_divider = make_axes_locatable(ax, )
ax.text(1.3, 1.4, label, fontsize=11 )
# add an axes above the main axes.
cax2 = ax2_divider.append_axes("top", size="5%", pad="7%",)
cax2.set_axis_off()
box = cax2.get_position()
print(box)
width = box.width
height = box.height
inax_position = ax.transAxes.transform([0.5, 0.5])
transFigure = fig.transFigure.inverted()
infig_position = transFigure.transform(inax_position)
x = infig_position[0]
y = infig_position[1]
cax2 = plt.axes([box.x0, 0.85, width*0.5, height*0.05])
cb2 = colorbar(im, cax=cax2, orientation="horizontal", )
# change tick position to top. Tick position defaults to bottom and overlaps
# the image.
cax2.xaxis.set_ticks_position("top")
axarr[0].set_ylabel("Azimuthal position $\\theta$ [cm]")
plt.savefig(f"Boeuf_example_t={t_mus}.png", dpi=400)
```
| github_jupyter |
# Neural Machine Translation with Attention
## Clone the repository
for data
```
!git clone https://github.com/IamShivamJaiswal/sign-board
```
This notebook trains a sequence to sequence (seq2seq) model for Hindi to English word translation. This is an advanced example that assumes some knowledge of sequence to sequence models.
After training the model in this notebook, you will be able to input a english word, such as *"shivam"*, and return the Hindi translation: *"शिवम"*
The translation quality is reasonable for a toy example, but the generated attention plot is perhaps more interesting.
```
from __future__ import absolute_import, division, print_function
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
print(tf.__version__)
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import os
import io
import time
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
import unicodedata
import re
import time
```
## Preprocessing
1. Add a *start* as `0` and *end* as `1` token to each sentence.
2. Clean the sentences by removing special characters.
3. Create a word index and reverse word index (dictionaries mapping from word → id and id → word).
4. Pad each sentence to a maximum length.
```
def unicode_to_ascii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def preprocess_sentence(w):
w = unicode_to_ascii(w.lower().strip())
w = w.replace('-', ' ').replace(',', ' ')
# creating a space between a word and the punctuation following it
# eg: "he is a boy." => "he is a boy ."
# Reference:- https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation
w = re.sub(r"([?.!,¿])", r" \1 ", w)
w = re.sub(r'[" "]+', " ", w)
# replacing everything with space except (a-z, A-Z, ".", "?", "!", ",")
w = re.sub(r"[^a-zA-Z?.!,¿]+", " ", w)
w = w.rstrip().strip()
# adding a start and an end token to the sentence
# so that the model know when to start and stop predicting.
w = '0' + w + '1'
return w.split()
def preprocess_sentence_hindi(w):
w = unicode_to_ascii(w.lower().strip())
w = w.replace('-', ' ').replace(',', ' ')
# creating a space between a word and the punctuation following it
# eg: "he is a boy." => "he is a boy ."
# Reference:- https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation
w = re.sub(r"([?.!,¿])", r" \1 ", w)
w = re.sub(r'[" "]+', " ", w)
w = w.rstrip().strip()
# adding a start and an end token to the sentence
# so that the model know when to start and stop predicting.
w = '0' + w + '1'
return w.split()
word = "shivam"
hindi = "शिवम"
print(preprocess_sentence(word))
print(preprocess_sentence_hindi(hindi))
import xml.etree.ElementTree as ET
def create_dataset(filename):
transliterationCorpus = ET.parse(filename).getroot()
lang1_words = []
lang2_words = []
for line in transliterationCorpus:
wordlist1 = preprocess_sentence(line[0].text) # clean English words.
wordlist2 = preprocess_sentence_hindi(line[1].text)# clean hindi words.
#to check consistency in the input vs output mapping
if len(wordlist1) != len(wordlist2):
print('Skipping: ', line[0].text, ' - ', line[1].text)
continue
for word in wordlist1:
lang1_words.append(word)
for word in wordlist2:
lang2_words.append(word)
return [lang1_words,lang2_words]
PATH = "/content/sign-board/transliteration/data/"
train_data = create_dataset(PATH+'NEWS2012TrainingEnHi.xml')
test_data = create_dataset(PATH+'NEWS2012TestingEnHi1000.xml')
train_data[0][:10],train_data[1][:10]
print(len(train_data[0]),len(train_data[1]))
class WordIndex():
def __init__(self, lang):
self.lang = lang
self.word2idx = {}
self.idx2word = {}
self.vocab = set()
self.create_index()
def create_index(self):
for phrase in self.lang:
for l in phrase:
self.vocab.update(l)
self.vocab = sorted(self.vocab)
self.word2idx['<pad>'] = 0
for index, word in enumerate(self.vocab):
self.word2idx[word] = index + 1
for word, index in self.word2idx.items():
self.idx2word[index] = word
def tokenize(lang):
index_lang = WordIndex(lang)
input_tensor = [[index_lang.word2idx[s] for s in en] for en in lang]
max_length = max(len(t) for t in input_tensor)
input_tensor = tf.keras.preprocessing.sequence.pad_sequences(input_tensor,
maxlen=max_length,
padding='post')
return input_tensor, index_lang , max_length
def max_length(tensor):
return max(len(t) for t in tensor)
def load_dataset(pairs):
# index language using the class defined above
targ_lang, inp_lang = pairs[1],pairs[0]
input_tensor, inp_lang_tokenizer ,max_length_inp = tokenize(inp_lang)
target_tensor, targ_lang_tokenizer,max_length_tar = tokenize(targ_lang)
return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer,max_length_inp,max_length_tar
input_tensor, target_tensor, inp_lang, targ_lang,max_length_inp, max_length_targ = load_dataset(train_data)
def convert(lang, tensor):
for t in tensor:
if t!=0:
print ("%d ----> %s" % (t, lang.idx2word[t]))
convert(inp_lang,input_tensor[-1])
convert(targ_lang,target_tensor[-1])
input_tensor_train, input_tensor_val, target_tensor_train, target_tensor_val = train_test_split(input_tensor, target_tensor, test_size=0.05)
# Show length
len(input_tensor_train), len(target_tensor_train), len(input_tensor_val), len(target_tensor_val)
BUFFER_SIZE = len(input_tensor_train)
BATCH_SIZE = 128
steps_per_epoch = len(input_tensor_train)//BATCH_SIZE
embedding_dim = 256
units = 1024
vocab_inp_size = len(inp_lang.word2idx)+1
vocab_tar_size = len(targ_lang.word2idx)+1
dataset = tf.data.Dataset.from_tensor_slices((input_tensor_train, target_tensor_train)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
example_input_batch, example_target_batch = next(iter(dataset))
example_input_batch.shape, example_target_batch.shape
```
## Define the optimizer and the loss function
```
optimizer = tf.keras.optimizers.Adam()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask*1.5
return tf.reduce_mean(loss_)
```
## Checkpoints (Object-based saving)
```
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(optimizer=optimizer,
encoder=encoder,
decoder=decoder)
@tf.function
def train_step(inp, targ, enc_hidden):
loss = 0
with tf.GradientTape() as tape:
enc_output, enc_hidden = encoder(inp, enc_hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([targ_lang.word2idx['0']] * BATCH_SIZE, 1)
# Teacher forcing - feeding the target as the next input
for t in range(1, targ.shape[1]):
# passing enc_output to the decoder
predictions, dec_hidden, _ = decoder(dec_input, dec_hidden, enc_output)
loss += loss_function(targ[:, t], predictions)
# using teacher forcing
dec_input = tf.expand_dims(targ[:, t], 1)
batch_loss = (loss / int(targ.shape[1]))
variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return batch_loss
EPOCHS = 20
for epoch in range(EPOCHS):
start = time.time()
enc_hidden = encoder.initialize_hidden_state()
total_loss = 0
for (batch, (inp, targ)) in enumerate(dataset.take(steps_per_epoch)):
batch_loss = train_step(inp, targ, enc_hidden)
total_loss += batch_loss
if batch % 100 == 0:
print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,
batch,
batch_loss.numpy()))
# saving (checkpoint) the model every 2 epochs
if (epoch + 1) % 2 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print('Epoch {} Loss {:.4f}'.format(epoch + 1,
total_loss / steps_per_epoch))
print('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
```
## Translitrate
* The evaluate function is similar to the training loop, except we don't use *teacher forcing* here. The input to the decoder at each time step is its previous predictions along with the hidden state and the encoder output.
* Stop predicting when the model predicts the *end token*.
* And store the *attention weights for every time step*.
Note: The encoder output is calculated only once for one input.
```
def evaluate(sentence):
attention_plot = np.zeros((max_length_targ, max_length_inp))
sentence = preprocess_sentence(sentence)[0]
inputs = [inp_lang.word2idx[i] for i in sentence]
inputs = tf.keras.preprocessing.sequence.pad_sequences([inputs],
maxlen=max_length_inp,
padding='post')
inputs = tf.convert_to_tensor(inputs)
result = ''
hidden = [tf.zeros((1, units))]
enc_out, enc_hidden = encoder(inputs, hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([targ_lang.word2idx['0']], 0)
for t in range(max_length_targ):
predictions, dec_hidden, attention_weights = decoder(dec_input,
dec_hidden,
enc_out)
# storing the attention weights to plot later on
attention_weights = tf.reshape(attention_weights, (-1, ))
attention_plot[t] = attention_weights.numpy()
predicted_id = tf.argmax(predictions[0]).numpy()
result += targ_lang.idx2word[predicted_id] + ' '
if targ_lang.idx2word[predicted_id] == '1':
return result, sentence, attention_plot
# the predicted ID is fed back into the model
dec_input = tf.expand_dims([predicted_id], 0)
return result, sentence, attention_plot
# function for plotting the attention weights
def plot_attention(attention, sentence, predicted_sentence):
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(1, 1, 1)
ax.matshow(attention, cmap='viridis')
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
def translitrate(sentence):
result, sentence, attention_plot = evaluate(sentence)
print('Input: %s' % (sentence[1:-1]))
print('Predicted translation: {}'.format(''.join(result.split(' '))[:-1]))
attention_plot = attention_plot[:len(result.split(' ')), :len(list(sentence))]
plot_attention(attention_plot, list(sentence), result.split(' '))
```
## Restore the latest checkpoint and test
```
# restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
translitrate(shivam)
translitrate('jaiswal')
translitrate("Nachiket")
```
## Exact Match Accuracy
```
def lcs(X, Y):
# find the length of the strings
m = len(X)
n = len(Y)
# declaring the array for storing the dp values
L = [[None]*(n + 1) for i in range(m + 1)]
"""Following steps build L[m + 1][n + 1] in bottom up fashion
Note: L[i][j] contains length of LCS of X[0..i-1]
and Y[0..j-1]"""
for i in range(m + 1):
for j in range(n + 1):
if i == 0 or j == 0 :
L[i][j] = 0
elif X[i-1] == Y[j-1]:
L[i][j] = L[i-1][j-1]+1
else:
L[i][j] = max(L[i-1][j], L[i][j-1])
# L[m][n] contains the length of LCS of X[0..n-1] & Y[0..m-1]
return L[m][n]
def exactmatch(predict,actual):
#length of Longest Common Subsequence
l = lcs(predict,actual)
return l / len(actual)
len(test_data[0])
tot = 0.0
for i in range(len(test_data[0])):
inputstr , resultstr = test_data[0][i][1:-1],test_data[1][i][1:-1]
result,_,_ = evaluate(inputstr)
temppredict = ''.join(result.split(' '))[:-1]
acc = exactmatch(temppredict,resultstr)
tot = tot + acc
print(inputstr,resultstr,temppredict,acc)
print("Average acuracy :",tot/len(test_data[0]))
```
| github_jupyter |
# Math Part 1
```
from __future__ import print_function
import tensorflow as tf
import numpy as np
from datetime import date
date.today()
author = "kyubyong. https://github.com/Kyubyong/tensorflow-exercises"
tf.__version__
np.__version__
sess = tf.InteractiveSession()
```
NOTE on notation
* _x, _y, _z, ...: NumPy 0-d or 1-d arrays
* _X, _Y, _Z, ...: NumPy 2-d or higer dimensional arrays
* x, y, z, ...: 0-d or 1-d tensors
* X, Y, Z, ...: 2-d or higher dimensional tensors
## Arithmetic Operators
Q1. Add x and y element-wise.
```
_x = np.array([1, 2, 3])
_y = np.array([-1, -2, -3])
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
```
Q2. Subtract y from x element-wise.
```
_x = np.array([3, 4, 5])
_y = np.array(3)
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
```
Q3. Multiply x by y element-wise.
```
_x = np.array([3, 4, 5])
_y = np.array([1, 0, -1])
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
```
Q4. Multiply x by 5 element-wise.
```
_x = np.array([1, 2, 3])
x = tf.convert_to_tensor(_x)
```
Q5. Predict the result of this.
```
_x = np.array([10, 20, 30], np.int32)
_y = np.array([2, 3, 5], np.int32)
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
out1 = tf.div(x, y)
out2 = tf.truediv(x, y)
print(np.array_equal(out1.eval(), out2.eval()))
print(out1.eval(), out1.eval().dtype) # tf.div() returns the same results as input tensors.
print(out2.eval(), out2.eval().dtype)# tf.truediv() always returns floating point results.
```
Q6. Get the remainder of x / y element-wise.
```
_x = np.array([10, 20, 30], np.int32)
_y = np.array([2, 3, 7], np.int32)
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
```
Q7. Compute the pairwise cross product of x and y.
```
_x = np.array([1, 2, 3], np.int32)
_y = np.array([4, 5, 6], np.int32)
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
```
## Basic Math Functions
Q8. Add x, y, and z element-wise.
```
_x = np.array([1, 2, 3], np.int32)
_y = np.array([4, 5, 6], np.int32)
_z = np.array([7, 8, 9], np.int32)
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
z = tf.convert_to_tensor(_y)
```
Q9. Compute the absolute value of X element-wise.
```
_X = np.array([[1, -1], [3, -3]])
X = tf.convert_to_tensor(_X)
```
Q10. Compute numerical negative value of x, elemet-wise.
```
_x = np.array([1, -1])
x = tf.convert_to_tensor(_x)
```
Q11. Compute an element-wise indication of the sign of x, element-wise.
```
_x = np.array([1, 3, 0, -1, -3])
x = tf.convert_to_tensor(_x)
```
Q12. Compute the reciprocal of x, element-wise.
```
_x = np.array([1, 2, 2/10])
x = tf.convert_to_tensor(_x)
```
Q13. Compute the square of x, element-wise.
```
_x = np.array([1, 2, -1])
x = tf.convert_to_tensor(_x)
```
Q14. Predict the results of this, paying attention to the difference among the family functions.
```
_x = np.array([2.1, 1.5, 2.5, 2.9, -2.1, -2.5, -2.9])
x = tf.convert_to_tensor(_x)
```
Q15. Compute square root of x element-wise.
```
_x = np.array([1, 4, 9], dtype=np.float32)
x = tf.convert_to_tensor(_x)
```
Q16. Compute the reciprocal of square root of x element-wise.
```
_x = np.array([1., 4., 9.])
x = tf.convert_to_tensor(_x)
```
Q17. Compute $x^y$, element-wise.
```
_x = np.array([[1, 2], [3, 4]])
_y = np.array([[1, 2], [1, 2]])
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
```
Q17. Compute $e^x$, element-wise.
```
_x = np.array([1., 2., 3.], np.float32)
x = tf.convert_to_tensor(_x)
```
Q18. Compute natural logarithm of x element-wise.
```
_x = np.array([1, np.e, np.e**2])
x = tf.convert_to_tensor(_x)
```
Q19. Compute the max of x and y element-wise.
```
_x = np.array([2, 3, 4])
_y = np.array([1, 5, 2])
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
```
Q20. Compute the min of x and y element-wise.
```
_x = np.array([2, 3, 4])
_y = np.array([1, 5, 2])
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
```
Q21. Compuete the sine, cosine, and tangent of x, element-wise.
```
_x = np.array([-np.pi, np.pi, np.pi/2])
x = tf.convert_to_tensor(_x)
```
Q22. Compute (x - y)(x - y) element-wise.
```
_x = np.array([2, 3, 4])
_y = np.array([1, 5, 1])
x = tf.convert_to_tensor(_x)
y = tf.convert_to_tensor(_y)
```
| github_jupyter |
# Predicting sentiment from product reviews
The goal of this first notebook is to explore logistic regression and feature engineering with existing GraphLab functions.
In this notebook you will use product review data from Amazon.com to predict whether the sentiments about a product (from its reviews) are positive or negative.
* Use SFrames to do some feature engineering
* Train a logistic regression model to predict the sentiment of product reviews.
* Inspect the weights (coefficients) of a trained logistic regression model.
* Make a prediction (both class and probability) of sentiment for a new product review.
* Given the logistic regression weights, predictors and ground truth labels, write a function to compute the **accuracy** of the model.
* Inspect the coefficients of the logistic regression model and interpret their meanings.
* Compare multiple logistic regression models.
Let's get started!
## Fire up GraphLab Create
Make sure you have the latest version of GraphLab Create.
```
# from __future__ import division
# import graphlab
import math
import string
import turicreate as tc
import numpy as np
import pandas as pd
```
# Data preparation
We will use a dataset consisting of baby product reviews on Amazon.com.
```
products = tc.SFrame('amazon_baby.gl/')
```
Now, let us see a preview of what the dataset looks like.
```
products
```
## Build the word count vector for each review
Let us explore a specific example of a baby product.
```
products[269]
```
Now, we will perform 2 simple data transformations:
1. Remove punctuation using [Python's built-in](https://docs.python.org/2/library/string.html) string functionality.
2. Transform the reviews into word-counts.
**Aside**. In this notebook, we remove all punctuations for the sake of simplicity. A smarter approach to punctuations would preserve phrases such as "I'd", "would've", "hadn't" and so forth. See [this page](https://www.cis.upenn.edu/~treebank/tokenization.html) for an example of smart handling of punctuations.
```
def remove_punctuation(text):
import string
# return text.translate(None, string.punctuation)
return text.translate(string.punctuation)
review_without_punctuation = products['review'].apply(remove_punctuation)
products['word_count'] = tc.text_analytics.count_words(review_without_punctuation)
products[269]
```
Now, let us explore what the sample example above looks like after these 2 transformations. Here, each entry in the **word_count** column is a dictionary where the key is the word and the value is a count of the number of times the word occurs.
```
products[269]['word_count']
```
## Extract sentiments
We will **ignore** all reviews with *rating = 3*, since they tend to have a neutral sentiment.
```
products = products[products['rating'] != 3]
len(products)
```
Now, we will assign reviews with a rating of 4 or higher to be *positive* reviews, while the ones with rating of 2 or lower are *negative*. For the sentiment column, we use +1 for the positive class label and -1 for the negative class label.
```
products['sentiment'] = products['rating'].apply(lambda rating : +1 if rating > 3 else -1)
products
```
Now, we can see that the dataset contains an extra column called **sentiment** which is either positive (+1) or negative (-1).
## Split data into training and test sets
Let's perform a train/test split with 80% of the data in the training set and 20% of the data in the test set. We use `seed=1` so that everyone gets the same result.
```
train_data, test_data = products.random_split(.8, seed=1)
print(len(train_data))
print(len(test_data))
```
# Train a sentiment classifier with logistic regression
We will now use logistic regression to create a sentiment classifier on the training data. This model will use the column **word_count** as a feature and the column **sentiment** as the target. We will use `validation_set=None` to obtain same results as everyone else.
**Note:** This line may take 1-2 minutes.
```
sentiment_model = tc.logistic_classifier.create(train_data,
target = 'sentiment',
features=['word_count'],
validation_set=None)
sentiment_model
```
**Aside**. You may get a warning to the effect of "Terminated due to numerical difficulties --- this model may not be ideal". It means that the quality metric (to be covered in Module 3) failed to improve in the last iteration of the run. The difficulty arises as the sentiment model puts too much weight on extremely rare words. A way to rectify this is to apply regularization, to be covered in Module 4. Regularization lessens the effect of extremely rare words. For the purpose of this assignment, however, please proceed with the model above.
Now that we have fitted the model, we can extract the weights (coefficients) as an SFrame as follows:
```
weights = sentiment_model.coefficients
weights.column_names()
```
There are a total of `121713` coefficients in the model. Recall from the lecture that positive weights $w_j$ correspond to weights that cause positive sentiment, while negative weights correspond to negative sentiment.
Fill in the following block of code to calculate how many *weights* are positive ( >= 0). (**Hint**: The `'value'` column in SFrame *weights* must be positive ( >= 0)).
```
num_positive_weights = sum(weights['value'] >= 0)
num_negative_weights = sum(weights['value'] < 0)
print("Number of positive weights: %s " % num_positive_weights)
print("Number of negative weights: %s " % num_negative_weights)
```
**Quiz Question:** How many weights are >= 0?
## Making predictions with logistic regression
Now that a model is trained, we can make predictions on the **test data**. In this section, we will explore this in the context of 3 examples in the test dataset. We refer to this set of 3 examples as the **sample_test_data**.
```
sample_test_data = test_data[10:13]
print(sample_test_data['rating'])
sample_test_data
```
Let's dig deeper into the first row of the **sample_test_data**. Here's the full review:
```
sample_test_data[0]['review']
```
That review seems pretty positive.
Now, let's see what the next row of the **sample_test_data** looks like. As we could guess from the sentiment (-1), the review is quite negative.
```
sample_test_data[1]['review']
```
We will now make a **class** prediction for the **sample_test_data**. The `sentiment_model` should predict **+1** if the sentiment is positive and **-1** if the sentiment is negative. Recall from the lecture that the **score** (sometimes called **margin**) for the logistic regression model is defined as:
$$
\mbox{score}_i = \mathbf{w}^T h(\mathbf{x}_i)
$$
where $h(\mathbf{x}_i)$ represents the features for example $i$. We will write some code to obtain the **scores** using GraphLab Create. For each row, the **score** (or margin) is a number in the range **[-inf, inf]**.
```
scores = sentiment_model.predict(sample_test_data, output_type='margin')
print(scores)
```
### Predicting sentiment
These scores can be used to make class predictions as follows:
$$
\hat{y} =
\left\{
\begin{array}{ll}
+1 & \mathbf{w}^T h(\mathbf{x}_i) > 0 \\
-1 & \mathbf{w}^T h(\mathbf{x}_i) \leq 0 \\
\end{array}
\right.
$$
Using scores, write code to calculate $\hat{y}$, the class predictions:
```
def predicting_sentiment(scores):
yhat = [-1 if s <= 0 else 1 for s in scores]
return yhat
predicting_sentiment(scores)
```
Run the following code to verify that the class predictions obtained by your calculations are the same as that obtained from GraphLab Create.
```
print("Class predictions according to GraphLab Create:")
print(sentiment_model.predict(sample_test_data))
```
**Checkpoint**: Make sure your class predictions match with the one obtained from GraphLab Create.
### Probability predictions
Recall from the lectures that we can also calculate the probability predictions from the scores using:
$$
P(y_i = +1 | \mathbf{x}_i,\mathbf{w}) = \frac{1}{1 + \exp(-\mathbf{w}^T h(\mathbf{x}_i))}.
$$
Using the variable **scores** calculated previously, write code to calculate the probability that a sentiment is positive using the above formula. For each row, the probabilities should be a number in the range **[0, 1]**.
```
def probability_predictions(scores):
yhat = [1/(1+np.exp(-s)) for s in scores]
return yhat
probability_predictions(scores)
```
**Checkpoint**: Make sure your probability predictions match the ones obtained from GraphLab Create.
```
print("Class predictions according to GraphLab Create:")
print(sentiment_model.predict(sample_test_data, output_type='probability'))
```
** Quiz Question:** Of the three data points in **sample_test_data**, which one (first, second, or third) has the **lowest probability** of being classified as a positive review?
# Find the most positive (and negative) review
We now turn to examining the full test dataset, **test_data**, and use GraphLab Create to form predictions on all of the test data points for faster performance.
Using the `sentiment_model`, find the 20 reviews in the entire **test_data** with the **highest probability** of being classified as a **positive review**. We refer to these as the "most positive reviews."
To calculate these top-20 reviews, use the following steps:
1. Make probability predictions on **test_data** using the `sentiment_model`. (**Hint:** When you call `.predict` to make predictions on the test data, use option `output_type='probability'` to output the probability rather than just the most likely class.)
2. Sort the data according to those predictions and pick the top 20. (**Hint:** You can use the `.topk` method on an SFrame to find the top k rows sorted according to the value of a specified column.)
```
prob = sentiment_model.predict(test_data, output_type='probability')
prob = prob.is_topk(topk=50, reverse=False)
df = pd.DataFrame()
df['Name'] = test_data['name']
df['Probability'] = prob
df.sort_values(by='Probability', inplace=True, ascending=False)
df.head(50)
```
**Quiz Question**: Which of the following products are represented in the 20 most positive reviews? [multiple choice]
Now, let us repeat this exercise to find the "most negative reviews." Use the prediction probabilities to find the 20 reviews in the **test_data** with the **lowest probability** of being classified as a **positive review**. Repeat the same steps above but make sure you **sort in the opposite order**.
```
prob = sentiment_model.predict(test_data, output_type='probability')
prob = prob.is_topk(topk=20, reverse=True)
df = pd.DataFrame()
df['Name'] = test_data['name']
df['Probability'] = prob
df.sort_values(by='Probability', inplace=True, ascending=False)
df.head(20)
```
**Quiz Question**: Which of the following products are represented in the 20 most negative reviews? [multiple choice]
## Compute accuracy of the classifier
We will now evaluate the accuracy of the trained classifier. Recall that the accuracy is given by
$$
\mbox{accuracy} = \frac{\mbox{# correctly classified examples}}{\mbox{# total examples}}
$$
This can be computed as follows:
* **Step 1:** Use the trained model to compute class predictions (**Hint:** Use the `predict` method)
* **Step 2:** Count the number of data points when the predicted class labels match the ground truth labels (called `true_labels` below).
* **Step 3:** Divide the total number of correct predictions by the total number of data points in the dataset.
Complete the function below to compute the classification accuracy:
```
def get_classification_accuracy(model, data, true_labels):
# First get the predictions
## YOUR CODE HERE
scores = np.array(model.predict(data, output_type='margin'))
# Compute the number of correctly classified examples
## YOUR CODE HERE
yhat = np.array(predicting_sentiment(scores))
correct = [i for i, j in zip(yhat, true_labels.to_numpy()) if i == j]
correct = np.array(correct)
# Then compute accuracy by dividing num_correct by total number of examples
## YOUR CODE HERE
accuracy = len(correct)/len(yhat)
return accuracy
```
Now, let's compute the classification accuracy of the **sentiment_model** on the **test_data**.
```
get_classification_accuracy(sentiment_model, test_data, test_data['sentiment'])
get_classification_accuracy(sentiment_model, train_data, train_data['sentiment'])
```
**Quiz Question**: What is the accuracy of the **sentiment_model** on the **test_data**? Round your answer to 2 decimal places (e.g. 0.76).
**Quiz Question**: Does a higher accuracy value on the **training_data** always imply that the classifier is better?
## Learn another classifier with fewer words
There were a lot of words in the model we trained above. We will now train a simpler logistic regression model using only a subset of words that occur in the reviews. For this assignment, we selected a 20 words to work with. These are:
```
significant_words = ['love', 'great', 'easy', 'old', 'little', 'perfect', 'loves',
'well', 'able', 'car', 'broke', 'less', 'even', 'waste', 'disappointed',
'work', 'product', 'money', 'would', 'return']
len(significant_words)
```
For each review, we will use the **word_count** column and trim out all words that are **not** in the **significant_words** list above. We will use the [SArray dictionary trim by keys functionality]( https://dato.com/products/create/docs/generated/graphlab.SArray.dict_trim_by_keys.html). Note that we are performing this on both the training and test set.
```
train_data['word_count_subset'] = train_data['word_count'].dict_trim_by_keys(significant_words, exclude=False)
test_data['word_count_subset'] = test_data['word_count'].dict_trim_by_keys(significant_words, exclude=False)
```
Let's see what the first example of the dataset looks like:
```
train_data[0]['review']
```
The **word_count** column had been working with before looks like the following:
```
print(train_data[0]['word_count'])
```
Since we are only working with a subset of these words, the column **word_count_subset** is a subset of the above dictionary. In this example, only 2 `significant words` are present in this review.
```
print(train_data[0]['word_count_subset'])
```
## Train a logistic regression model on a subset of data
We will now build a classifier with **word_count_subset** as the feature and **sentiment** as the target.
```
simple_model = tc.logistic_classifier.create(train_data,
target = 'sentiment',
features=['word_count_subset'],
validation_set=None)
simple_model
```
We can compute the classification accuracy using the `get_classification_accuracy` function you implemented earlier.
```
get_classification_accuracy(simple_model, test_data, test_data['sentiment'])
```
Now, we will inspect the weights (coefficients) of the **simple_model**:
```
simple_model.coefficients
```
Let's sort the coefficients (in descending order) by the **value** to obtain the coefficients with the most positive effect on the sentiment.
```
simple_model.coefficients.sort('value', ascending=False).print_rows(num_rows=21)
```
**Quiz Question**: Consider the coefficients of **simple_model**. There should be 21 of them, an intercept term + one for each word in **significant_words**. How many of the 20 coefficients (corresponding to the 20 **significant_words** and *excluding the intercept term*) are positive for the `simple_model`?
```
len(simple_model.coefficients[simple_model.coefficients['value'] >= 0])-1
```
**Quiz Question**: Are the positive words in the **simple_model** (let us call them `positive_significant_words`) also positive words in the **sentiment_model**?
```
simple_model.coefficients[simple_model.coefficients['value'] >= 0]
sentiment_model.coefficients[sentiment_model.coefficients['value'] >= 0]
```
# Comparing models
We will now compare the accuracy of the **sentiment_model** and the **simple_model** using the `get_classification_accuracy` method you implemented above.
First, compute the classification accuracy of the **sentiment_model** on the **train_data**:
```
get_classification_accuracy(sentiment_model, train_data, train_data['sentiment'])
```
Now, compute the classification accuracy of the **simple_model** on the **train_data**:
```
get_classification_accuracy(simple_model, train_data, train_data['sentiment'])
```
**Quiz Question**: Which model (**sentiment_model** or **simple_model**) has higher accuracy on the TRAINING set?
Now, we will repeat this exercise on the **test_data**. Start by computing the classification accuracy of the **sentiment_model** on the **test_data**:
```
get_classification_accuracy(sentiment_model, test_data, test_data['sentiment'])
```
Next, we will compute the classification accuracy of the **simple_model** on the **test_data**:
```
get_classification_accuracy(simple_model, test_data, test_data['sentiment'])
```
**Quiz Question**: Which model (**sentiment_model** or **simple_model**) has higher accuracy on the TEST set?
## Baseline: Majority class prediction
It is quite common to use the **majority class classifier** as the a baseline (or reference) model for comparison with your classifier model. The majority classifier model predicts the majority class for all data points. At the very least, you should healthily beat the majority class classifier, otherwise, the model is (usually) pointless.
What is the majority class in the **train_data**?
```
num_positive = (train_data['sentiment'] == +1).sum()
num_negative = (train_data['sentiment'] == -1).sum()
print(num_positive)
print(num_negative)
```
Now compute the accuracy of the majority class classifier on **test_data**.
**Quiz Question**: Enter the accuracy of the majority class classifier model on the **test_data**. Round your answer to two decimal places (e.g. 0.76).
```
num_positive/(num_negative + num_positive)
```
**Quiz Question**: Is the **sentiment_model** definitely better than the majority class classifier (the baseline)?
| github_jupyter |
```
import random
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import torch,torchvision
from torch.nn import *
from tqdm import tqdm
import cv2
from torch.optim import *
# Preproccessing
from sklearn.preprocessing import (
StandardScaler,
RobustScaler,
MinMaxScaler,
MaxAbsScaler,
OneHotEncoder,
Normalizer,
Binarizer
)
# Decomposition
from sklearn.decomposition import PCA
from sklearn.decomposition import KernelPCA
# Feature Selection
from sklearn.feature_selection import VarianceThreshold
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import RFECV
from sklearn.feature_selection import SelectFromModel
# Model Eval
from sklearn.compose import make_column_transformer
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score,train_test_split
from sklearn.metrics import mean_absolute_error,mean_squared_error
# Other
import pickle
import wandb
PROJECT_NAME = 'Netflix-Stock-Price'
device = 'cuda:0'
np.random.seed(21)
random.seed(21)
torch.manual_seed(21)
data = pd.read_csv('./data.csv')
data = data['Open']
data.to_csv('./Cleaned-Data.csv')
data.to_json('./cleaned-data.json')
data = pd.read_csv('./Cleaned-Data.csv')
data = data['Open']
data = data.tolist()
data = torch.from_numpy(np.array(data)).view(1,-1).to(device)
data_input = data[:1,:-1].to(device).float()
data_target = data[:1,1:].to(device).float()
class Model(Module):
def __init__(self):
super().__init__()
self.hidden = 512
self.lstm1 = LSTMCell(1,self.hidden).to(device)
self.lstm2 = LSTMCell(self.hidden,self.hidden).to(device)
self.linear1 = Linear(self.hidden,1).to(device)
def forward(self,X,future=0):
preds = []
batch_size = X.size(0)
h_t1 = torch.zeros(batch_size,self.hidden).to(device)
c_t1 = torch.zeros(batch_size,self.hidden).to(device)
h_t2 = torch.zeros(batch_size,self.hidden).to(device)
c_t2 = torch.zeros(batch_size,self.hidden).to(device)
for X_batch in X.split(1,dim=1):
X_batch = X_batch.to(device)
h_t1,c_t1 = self.lstm1(X_batch,(h_t1,c_t1))
h_t1 = h_t1.to(device)
c_t1 = c_t1.to(device)
h_t2,c_t2 = self.lstm2(h_t1,(h_t2,c_t2))
h_t2 = h_t2.to(device)
c_t2 = c_t2.to(device)
pred = self.linear1(h_t2)
preds.append(pred)
for _ in range(future):
h_t1,c_t1 = self.lstm1(X_batch,(h_t1,c_t1))
h_t1 = h_t1.to(device)
c_t1 = c_t1.to(device)
h_t2,c_t2 = self.lstm2(h_t1,(h_t2,c_t2))
h_t2 = h_t2.to(device)
c_t2 = c_t2.to(device)
pred = self.linear1(h_t2)
preds.append(pred)
preds = torch.cat(preds,dim=1)
return preds
model = Model().to(device)
criterion = MSELoss()
optimizer = LBFGS(model.parameters(),lr=0.8)
epochs = 100
torch.save(data,'./data.pt')
torch.save(data,'./data.pth')
torch.save(data_input,'data_input.pt')
torch.save(data_input,'data_input.pth')
torch.save(data_target,'data_target.pt')
torch.save(data_target,'data_target.pth')
wandb.init(project=PROJECT_NAME,name='baseline')
for _ in tqdm(range(epochs)):
def closure():
optimizer.zero_grad()
preds = model(data_input)
loss = criterion(preds,data_target)
loss.backward()
wandb.log({'Loss':loss.item()})
return loss
optimizer.step(closure)
with torch.no_grad():
future = 100
preds = model(data_input,future)
loss = criterion(preds[:,:-future],data_target)
wandb.log({'Val Loss':loss.item()})
preds = preds[0].view(-1).cpu().detach().numpy()
n = data_input.shape[1]
plt.figure(figsize=(12,6))
plt.plot(np.arange(n),data_target.view(-1).cpu().detach().numpy(),'b')
plt.plot(np.arange(n,n+future),preds[n:],'r')
plt.savefig('./img.png')
plt.close()
wandb.log({'Img':wandb.Image(cv2.imread('./img.png'))})
wandb.finish()
torch.save(model,'custom-model.pt')
torch.save(model,'custom-model.pth')
torch.save(model.state_dict(),'custom-model-sd.pt')
torch.save(model.state_dict(),'custom-model-sd.pth')
torch.save(model,'model.pt')
torch.save(model,'model.pth')
torch.save(model.state_dict(),'model-sd.pt')
torch.save(model.state_dict(),'model-sd.pth')
```
| github_jupyter |
```
import matplotlib as mpl
import matplotlib.pyplot as plt
age_x = [25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35]
dev_x = [38496, 42000, 46752, 49320, 53200,
56000, 62316, 64928, 67317, 68748, 73752]
ax = plt.bar(age_x, dev_x)
for index, value in zip(age_x, dev_x):
plt.text(index, value+5000, f'{value:,}', ha='center', va='center',
rotation=45)
# alternatif cara untuk mengatur ukuran font, dengan menggunakan parameter fontsize
plt.title('Salary By Age', fontsize=20)
plt.xlabel('Age', fontsize=14)
plt.ylabel('Salary (USD)', fontsize=14)
plt.grid(axis='y', ls='--', alpha=.5)
plt.show()
```
```
ax = plt.bar(age_x, dev_x)
# misalkan kita ingin set warna pada bar age = 30 menjadi berwarna latar merah
ax.patches[5].set_facecolor('red')
plt.title('Salary By Age', fontsize=20)
plt.xlabel('Age')
plt.ylabel('Salary (USD)')
plt.grid(axis='y', ls='--', alpha=.5)
plt.show()
```
```
plt.bar(age_x, dev_x)
for index, value in zip(age_x, dev_x):
plt.text(index, value+7000 if index != 30 else value+12000,
f'{value:,}', ha='center', va='center',
color='red' if index==30 else 'black',
fontsize=16 if index==30 else 10 , rotation=90)
plt.title('Salary By Age', fontsize=20)
plt.xlabel('Age')
plt.ylabel('Salary (USD)')
plt.grid(axis='y', ls='--', alpha=.5)
plt.show()
```
```
ax = plt.bar(age_x, dev_x)
# misalkan kita ingin set warna pada bar age = 30 menjadi berwarna latar merah
ax.patches[5].set_facecolor('red')
for index, value in zip(age_x, dev_x):
plt.text(index, value+7000 if index != 30 else value+12000,
f'{value:,}', ha='center', va='center',
color='red' if index==30 else 'black',
fontsize=16 if index==30 else 10 , rotation=90)
plt.title('Salary By Age', fontsize=20)
plt.xlabel('Age')
plt.ylabel('Salary (USD)')
plt.grid(axis='y', ls='--', alpha=.5)
plt.show()
```
```
ax = plt.bar(age_x, dev_x)
for index, value in enumerate(age_x):
if value % 2 != 0:
ax.patches[index].set_facecolor('red')
plt.title('Salary By Age', fontsize=20)
plt.xlabel('Age')
plt.ylabel('Salary (USD)')
plt.grid(axis='y', ls='--', alpha=.5)
plt.show()
```
```
colors = ['red' if age % 2 else 'blue' for age in age_x]
ax = plt.bar(age_x, dev_x, color=colors)
plt.title('Salary By Age', fontsize=20)
plt.xlabel('Age')
plt.ylabel('Salary (USD)')
plt.grid(axis='y', ls='--', alpha=.5)
plt.show()
```
```
colors = ['red', 'green', 'blue', 'cyan', 'magenta', 'black', 'white', 'olive', 'pink', 'purple', 'brown']
ax = plt.bar(age_x, dev_x, color=colors, edgecolor='k')
plt.title('Salary By Age', fontsize=20)
plt.xlabel('Age')
plt.ylabel('Salary (USD)')
plt.grid(axis='y', ls='--', alpha=.5)
plt.show()
```
| github_jupyter |
# RandomForestRegressor with the Blue Book for Bulldozers
We will be looking at the Blue Book for Bulldozers Kaggle Competition: "The goal of the contest is to predict the sale price of a particular piece of heavy equiment at auction based on it's usage, equipment type, and configuration. The data is sourced from auction result postings and includes information on usage and equipment configurations."
This is a very common type of dataset and prediciton problem, and similar to what you may see in your project or workplace.
https://www.kaggle.com/c/bluebook-for-bulldozers
Using a Random Forest Regressor from the sklearn library and the fastai library, we will predict the price.
#### Initialisation
```
%load_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.imports import *
from fastai.structured import *
from pandas_summary import DataFrameSummary
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from IPython.display import display
from sklearn import datasets, linear_model
from sklearn import metrics
```
### The data
Set the path to the folder containing the data set
```
Mac = "no"
if Mac == "yes":
PATH = "/Users/mortenjensen/fastai/data/bulldozer/above100mb/"
else:
PATH = "/home/ubuntu/fastai/data/bulldozer/"
```
Using pandas the .csv file is read to a dataframe. Columns containing dates should be included in "parse_dates="
```
df_raw = pd.read_csv(f'{PATH}Train.csv', low_memory=False,
parse_dates=["saledate"])
```
The bull book data set contains 401125 rows of observations and 53-1 features.
```
df_raw.shape
```
To inspect the dateframe, we define a function to display a maximum of 1000 elements in each direction:
```
def display_all(df):
with pd.option_context("display.max_rows", 1000, "display.max_columns", 1000):
display(df)
```
#### Display the dataframe
```
display_all(df_raw.head())
display_all(df_raw.describe(include='all'))
df_raw.dtypes
```
### Data Processing
The blue book Bulldozer competition specify the predictions should be evaluated by RMSLE (root mean squared log error) between the actual and predicted auction prices. Therefore we take the log of the prices, so that RMSE (root mean squared error) will give us what we need. You could do this step later as well.
```
df_raw.SalePrice = np.log(df_raw.SalePrice)
```
##### Date column
Regarding the saledate, you should always consider a feature extraction step. Without expanding your date-time into these additional fields, you can't capture any trend/cyclical behavior as a function of time at any of these granularities. Thease trend/cyclical behavior could be week number, quater, holidays and so on.
The following method extracts particular date fields from a complete datetime for the purpose of constructing categoricals.
```
add_datepart(df_raw, 'saledate')
display_all(df_raw.head())
```
Notice that the SaleDate column have been expanded into 12 new featues [saleYear, saleMonth,...sales_year_start]
However, the add_datepart command from fastai, won't give you information on trend/cyclical behavior such as superbowl, sunny day, rain day and so on you have to know your domain for this!.
##### Input to the randomforestregressor - =! Strings
Before running the RandomForestRegressor we need to transform some of our features. The reason:
The RandomForestRegressor code is written as:
`m = RandomForestRegressor(n_jobs=-1)`
`m.fit(features), target)`
The first line sets the parameters controlling the RandomForestRegressor, here `n_jobs=-1` means using all processors for parallelized computing. Another parameter could be n_estimators, which specify the number of trees in the forest.
The second line builds the forest of trees from the training set and features fit(Features, Target). The training input samples. Internally, its dtype will be converted to `dtype=np.float3`
. Therefore, it is important to transform stings in the dateframe to categories, which can be converted to np.float32, in contrast to strings.
The categorical variables are currently stored as strings, which is inefficient, and doesn't provide the numeric coding required for a random forest. Therefore we call `train_cats` from Fastai to convert strings to pandas categories.
```
train_cats(df_raw)
```
Show colums changed to category
```
display_all(df_raw.dtypes)
```
Focusing on the column with UsageBand, we can see that it contains three categories:
```
df_raw.UsageBand.cat.categories
```
Optionally one can change the order of the categories, however it it not neassary for the randomforestregressor algorithm.
```
df_raw.UsageBand.cat.set_categories(['High', 'Medium', 'Low'], ordered=True, inplace=True)
df_raw.UsageBand.cat.categories
```
Normally, pandas will continue displaying the text categories, while treating them as numerical data internally. Optionally, we can replace the text categories with numbers, which will make this variable non-categorical, like so:.
```
df_raw.Hydraulics = df_raw.Hydraulics.cat.codes
df_raw.Hydraulics.head()
```
##### Missing values
We're still not quite done - for instance we have lots of missing values, which we can't pass directly to a random forest.
We can show the procentage of missing values in each column by:
```
display_all(df_raw.isnull().sum().sort_index()/len(df_raw))
```
To handle the missing values the `proc_df` code from fastai is used. The `proc_df` not only handles missing values, it also replace categories with their numeric codes and split the dependent variable into a separate variable (split features and target values).
For each column of the dataframe which is not in skip_flds nor in ignore_flds, NaN values are replaced by the median value of the column.
skip_flds: A list of fields that dropped from df.
ignore_flds: A list of fields that are ignored during processing.
###### Save point for df_raw before running Proc_df
```
os.makedirs('tmp', exist_ok=True)
df_raw.to_feather('tmp/bulldozers-raw')
ls
df_raw = pd.read_feather('tmp/bulldozers-raw')
```
##### Run proc_df continued from before save point.
```
df, y, nas = proc_df(df_raw, 'SalePrice')
```
## RandomForestRegressor
Now we have a dataframe with features and target values ready for the RandomForestRegressor
##### Validation set
Just because a learning algorithm fits a training set well, that does not mean it is a good hypothesis. It could over fit and as a result your predictions on the test set would be poor.

The error of your hypothesis as measured on the data set with which you trained the parameters will be lower than the error on any other data set.
Given many models with different polynomial degrees, we can use a systematic approach to identify the 'best' function. In order to choose the model of your hypothesis, you can test each degree of polynomial and look at the error result.
One way to break down our dataset into the three sets is:
Training set: 60%
Cross validation set: 20%
Test set: 20%
We can now calculate three separate error values for the three different sets using the following method:
1. Optimize the parameters in Θ using the training set for each polynomial degree.
2. Find the polynomial degree d with the least error using the cross validation set.
3. Estimate the generalization error using the test set
Kaggle's Blue book bulldozers competition already supply us with a vaildation and test set. However, for practice we will spilt the dataframe into a training and validation set.
```
def split_vals(a,n): return a[:n].copy(), a[n:].copy()
n_valid = 12000 # same as Kaggle's test set size
n_trn = len(df)-n_valid
raw_train, raw_valid = split_vals(df_raw, n_trn)
X_train, X_valid = split_vals(df, n_trn)
y_train, y_valid = split_vals(y, n_trn)
X_train.shape, y_train.shape, X_valid.shape, y_valid.shape
```
`Notice` that since we are dealing a data set that has a time/date column, we use the latest oberservations to our validation set.
Use your domain knowledge to chooses the right subset for validation and testing. It might be a random subset!
Next we define a function to first calcualte the roor mean squard error:
```
def rmse(x,y): return math.sqrt(((x-y)**2).mean())
def meanse(x,y): return ((x-y)**2).mean()
```
Define function to display results of training and validation errors.
```
def print_score(m):
res = ['Train RMSLE ={:05f}'.format(rmse(m.predict(X_train), y_train)), 'Vaild RMSLE={:05f}'.format(rmse(m.predict(X_valid), y_valid)),
'Train R squared = {:05f}'.format(m.score(X_train, y_train)), 'Vaild R squared = {:05f}'.format(m.score(X_valid, y_valid))]
if hasattr(m, 'oob_score_'): (res.append('OOB Score = {:05f}'.format(m.oob_score_)))
print(res)
```
### Speeding things up!
#### 1. method - Subset
First we use proc_df to divide our dataframe in features and target values. Furthermore we add the subset parameter which choose a random subset of size from df.
```
df_trn, y_trn, nas = proc_df(df_raw, 'SalePrice', subset=30000, na_dict=nas)
X_train, _ = split_vals(df_trn, 20000)
y_train, _ = split_vals(y_trn, 20000)
m = RandomForestRegressor(n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)
```
## Random forest regressor explained
We are going to build a single tree. In scikit-learn, they do not call them trees but estimators.
Parameters:
- `n_estimators=` — create a forest with just one tree
- `max_depth=` — to make it a small tree
- `bootstrap=Fals`? — random forest randomizes bunch of things, we want to turn that off by this parameter
```
m = RandomForestRegressor(n_estimators=1, max_depth=3, bootstrap=False, n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)
```
This small deterministic tree has R^2 of 0.39 after fitting so this is not a good model but better than the mean model since it is greater than 1 and we can actually draw the three
```
draw_tree(m.estimators_[0], df_trn, precision=3)
```
A tree consists of a sequence of binary decisions.
When building a random forest from scratch.
- We want to pick a feature and it's threshold to select the best single binary spilt we can make.
- The best single binary spilt we can make is determine by the weighted average of the mean squared errors over the new nodes(Ture/False).
Conclusion: We simply try every feature and every threshold of that feature to see which feature and which value that will give us the spilt with the best possiable weighted average of the nodes.
Regrading the tree above:
- The first line indicates the binary split criteria
- `sample` at the root is 20,000 since that is what we specified when splitting the data.
- `value` is aveage of the log of price, and if we built a model where we just used the average all the time, then the mean squared error mse would be 0.445
- The best single binary split we can make turns out to be `Coupler_system ≤ 0.5` which will improve mse to `0.115` in false path and `0.397` in true path
- Darker color indicates higher value
The average log(remember we took the "log" previous) price in first node:
```
value_mean = np.mean(y_train)
print(value_mean)
```
Mean squard error calculation in the first node:
```
y_pred_line=np.ones(y_train.shape[0])
y_pred_line[:]= value_mean[0]
print('Mean squared error: %.3f'
% metrics.mean_squared_error(y_train, y_pred_line))
```
This is the entirety of creating a decision tree. Stopping condition:
- When you hit the limit that was requested (max_depth)
- When your leaf nodes only have one thing in them
##### Let’s make our decision tree better
As of now, we have specified the `max_depth = 3`, by removing the max_dept parameter the single tree can grow bigger
```
m = RandomForestRegressor(n_estimators=1, bootstrap=False, n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)
```
By doing so, the training R^2 becomes 1 because with no max depth the single tree regressor can keep splitting the features until every leafnode only have one thing in it. Hence, it overfit.
However, the validation R² is 0.73 — which is better than the shallow tree but not as good as we would like.( Overfitting!! )
This is why we need to use bagging of multiple trees to get more generalizable results.
##### Creating the forest - Statistical technique called bagging
So what is bagging? Bagging is an interesting idea which is what if we created five different models each of which was only somewhat predictive but the models gave predictions that were not correlated with each other. That would mean that the five models would have profound different insights into the relationships in the data. If you took the average of those five models, you are effectively bringing in the insights from each of them. So this idea of averaging models is a technique for Ensembling.
What if we created a whole a lot of trees — big, deep, massively overfit trees but each one, let’s say, we only pick a random 1/10 of the data. Let’s say we do that a hundred times (different random sample every time). They are overfitting terribly but since they are all using different random samples, they all overfit in different ways on different things. In other words, they all have errors but the errors are random. The average of a bunch of random errors is zero. If we take the average of these trees each of which have been trained on a different random subset, the error will average out to zero and what is left is the true relationship — and that’s the random forest.
The key insight here is to construct multiple models which are better than nothing and where the errors are, as much as possible, not correlated with each other.
Below we will create a forest of 10 trees and specify `bootstrap=True`(default) to choose a random subset of the data (uncorrelated)
```
m = RandomForestRegressor(n_estimators=10, bootstrap=True,n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)
```
We'll grab the predictions for each individual tree, and look at one example.
```
preds = np.stack([t.predict(X_valid) for t in m.estimators_])
preds[:,0], np.mean(preds[:,0]), y_valid[0]
```
The mean of 10 predictions for the first data is 9.4, and the actual value is 9.10. As you can see, none of the individual prediction is close to 9.10, but the mean ends up pretty good.
Conclusion: Taking the average of ten bad uncorrelated models gives a good model.
In bagging, that means that each of your individual estimators, you want them to be as predictive as possible but for the predictions of your individual trees to be as uncorrelated as possible. The research community found that the more important thing seems to be creating uncorrelated trees rather than more accurate trees. In scikit-learn, there is another class called `ExtraTreeClassifier` which is an extremely randomized tree model. Rather than trying every split of every variable, it randomly tries a few splits of a few variables which makes training much faster and it can build more trees — better generalization. If you have crappy individual models, you just need more trees to get a good end model.
###### Chooseing the number of trees
```
plt.plot([metrics.r2_score(y_valid, np.mean(preds[:i+1], axis=0)) for i in range(10)]);
```
The shape of this curve suggests that adding more trees isn't going to help us much. Let's check. (Compare this to our original model on a sample)
```
m = RandomForestRegressor(n_estimators=20, bootstrap=True,n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)
m = RandomForestRegressor(n_estimators=80, bootstrap=True,n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)
```
Conclusion adding more tree does not improve the validation R^2. Note: we are working with a small subset of the whole data set. Generally adding more tree helps to a point. Therefore, plot the curve above.
So when Jeremy builds most of his models, he starts with 20 or 30 trees and at the end of the project or at the end of the day’s work, he will use 1000 trees and run it over night.
##### Out-of-bag (OOB) score
Our model above show a training R^2 of 0.98 and a validation R^2 of 0.78
Is our validation set worse than our training set because we're over-fitting, or because the validation set is for a different time period, or a bit of both? With the existing information we've shown, we can't tell. However, random forests have a very clever trick called *out-of-bag (OOB) error* which can handle this (and more!)
The idea is to calculate error on the training set, but only include the trees in the calculation of a row's error where that row was *not* included in training that tree. This allows us to see whether the model is over-fitting, without needing a separate validation set.
This also has the benefit of allowing us to see whether our model generalizes, even if we only have a small amount of data so want to avoid separating some out to create a validation set.
This is as simple as adding one more parameter to our model constructor. We print the OOB error last in our `print_score` function below.
OOB error can also be used if your dataset is small and you will not want to pull out a validation set because doing so means you now do not have enough data to build a good model.
```
m = RandomForestRegressor(n_estimators=40, n_jobs=-1, oob_score=True)
%time m.fit(X_train, y_train)
print_score(m)
```
The oob score is higher than our validation R^2 but lower than our Train R^2, hence both the time difference and over-fitting are making an impact.
Note: The accuracy tends to be lower because each row appears in less trees in the OOB samples than it does in the full set of trees. So OOB R² will slightly underestimate how generalizable the model is, but the more trees you add, the less serious that underestimation is.
OOB score will come in handy when setting hyper parameters. There will be quite a few hyper parameters that we are going to set and we would like to find some automated say to set them. One way to do that is to do grid search. Scikit-learn has a function called grid search and you pass in a list of all the hyper parameters you want to tune and all of the values of these hyper parameters you want to try. It will run your model on every possible combination of all these hyper parameters and tell you which one is the best. OOB score is a great choice for getting it to tell you which one is the best.
#### Reducing over-fitting
It turns out that one of the easiest ways to avoid over-fitting is also one of the best ways to speed up analysis: subsampling. Lets return to using our full dataset, so that we can demonstrate the impact of this technique.
#### 2. method - Subsampling - Speeding things up continue
It turns out that one of the easiest ways to avoid over-fitting is also one of the best ways to speed up analysis: subsampling. Let's return to using our full dataset, so that we can demonstrate the impact of this technique.
```
df_trn, y_trn, nas = proc_df(df_raw, 'SalePrice')
X_train, X_valid = split_vals(df_trn, n_trn)
y_train, y_valid = split_vals(y_trn, n_trn)
```
The basic idea is this: rather than limit the total amount of data that our model can access, let's instead limit it to a different random subset per tree. That way, given enough trees, the model can still see all the data, but for each individual tree it'll be just as fast as if we had cut down our dataset as before.
Earlier, we took 30,000 rows and created all the models which used a different subset of that 30,000 rows. Why not take a totally different subset of 30,000 each time? In other words, let’s leave the entire 389,125 records as is, and if we want to make things faster, pick a different subset of 20,000 each time. So rather than bootstrapping the entire set of rows, just randomly sample a subset of the data.
```
set_rf_samples(20000)
```
`set_rf_samples` is a custom function by fastaiset_rf_samples is a custom function by fastai`.
Scikit-learn does not support this out of box, so `set_rf_samples` is a custom function. So OOB score needs to be turned off when using `set_rf_samples` as they are not compatible.
`reset_rf_samples()` will turn it back to the way it wasreset_rf_samples() will turn it back to the way it was`.
```
m = RandomForestRegressor(n_estimators=40, n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)
```
Since each additional tree allows the model to see more data, this approach can make additional trees more useful. Therefore we use the n_estimators parameter to calculate on 100 trees(below).
```
preds = np.stack([t.predict(X_valid) for t in m.estimators_])
plt.plot([metrics.r2_score(y_valid, np.mean(preds[:i+1], axis=0)) for i in range(preds[:,0].shape[0])]);
m = RandomForestRegressor(n_estimators=80, n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)
```
The biggest tip: Most people run all of their models on all of the data all of the time using their best possible parameters which is just pointless. If you are trying to find out which feature is important and how they are related to each other, having that 4th decimal place of accuracy is not going to change any of your insights at all. Do most of your models on a large enough sample size that your accuracy is reasonable (within a reasonable distance of the best accuracy you can get) and taking a small number of seconds to train so that you can interactively do your analysis.
We revert to using a full bootstrap sample in order to show the impact of other over-fitting avoidance methods.
```
reset_rf_samples()
```
Let’s get a baseline for this full set to compare to:
```
m = RandomForestRegressor(n_estimators=40, n_jobs=-1, oob_score=True)
%time m.fit(X_train, y_train)
print_score(m)
```
Define function to display the max depth of the random forest model.
```
def dectree_max_depth(tree):
children_left = tree.children_left
children_right = tree.children_right
def walk(node_id):
if (children_left[node_id] != children_right[node_id]):
left_max = 1 + walk(children_left[node_id])
right_max = 1 + walk(children_right[node_id])
return max(left_max, right_max)
else: # leaf
return 1
root_node_id = 0
return walk(root_node_id)
t=m.estimators_[0].tree_
dectree_max_depth(t)
```
Another way to reduce over-fitting is to grow our trees less deeply. We do this by specifying (with min_samples_leaf) that we require some minimum number of rows in every leaf node. This has two benefits:
There are less decision rules for each leaf node; simpler models should generalize better
The predictions are made by averaging more rows in the leaf node, resulting in less volatility
Stop training the tree further when a leaf node has 5 or less samples (before we were going all the way down to 1). This means there will be one or two less levels of decision being made which means there are half the number of actual decision criteria we have to train (i.e. faster training time).
For each tree, rather than just taking one point, we are taking the average of at least three points that we would expect the each tree to generalize better. But each tree is going to be slightly less powerful on its own.
The numbers that work well are 1, 3, 5, 10, 25, but it is relative to your overall dataset size.
```
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=5, n_jobs=-1, oob_score=True)
%time m.fit(X_train, y_train)
print_score(m)
t=m.estimators_[0].tree_
dectree_max_depth(t)
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, n_jobs=-1, oob_score=True)
%time m.fit(X_train, y_train)
print_score(m)
```
Here OOB is less but almost the same as the validation set. This is because our validation set is a different time period whereas OOB samples are random. It is much harder to predict a different time period.
We can also increase the amount of variation amongst the trees by not only use a sample of rows for each tree, but to also using a sample of columns for each split. We do this by specifying max_features, which is the proportion of features to randomly select from at each split.
The number of features to consider when looking for the best split:
- If int, then consider max_features features at each split.
- If float, then max_features is a fraction and int(max_features * n_features) features are considered at each split.
- If “auto”, then max_features=n_features.
- If “sqrt”, then max_features=sqrt(n_features).
- If “log2”, then max_features=log2(n_features).
- If None, then max_features=n_features.
```
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True)
%time m.fit(X_train, y_train)
print_score(m)
m = RandomForestRegressor(n_estimators=300, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True)
%time m.fit(X_train, y_train)
print_score(m)
```
The RMSLE of 0.226 would get us to the top 20 of this competition — with brainless random forest with some brainless minor hyper parameter tuning. This is why Random Forest is such an important not just first step but often only step of machine learning. It is hard to screw up.
We can't compare our results directly with the Kaggle competition, since it used a different validation set (and we can no longer to submit to this competition) - but we can at least see that we're getting similar results to the winners based on the dataset we have.
The sklearn docs show an example of different max_features methods with increasing numbers of trees - as you see, using a subset of features on each split requires using more trees, but results in better models:
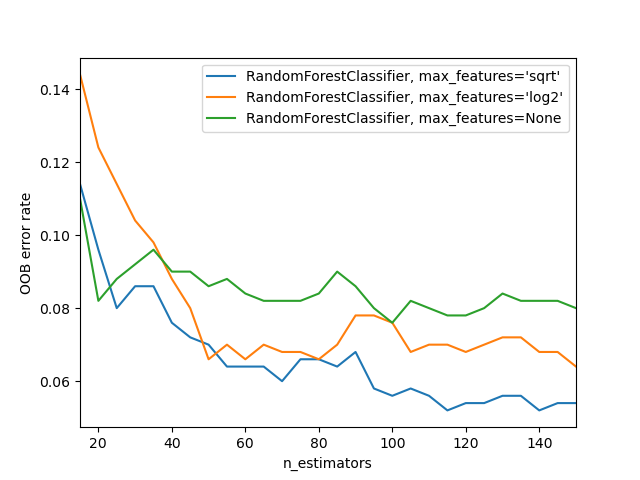
## End of lesson 2
| github_jupyter |
```
import sqlite3
import geojson
def dict_factory(cursor, row):
d = {}
for idx,col in enumerate(cursor.description):
d[col[0]] = row[idx]
return d
def get_wildfires_by_bb(south, west, north, east):
fires = None
with sqlite3.connect('data/nbac.sqlite') as conn:
conn.enable_load_extension(True)
conn.execute('SELECT load_extension("mod_spatialite");')
conn.row_factory = dict_factory
q = f"""
select
year
, nfireid
, basrc
, firemaps
, firemapm
, firecaus
, burnclas
, sdate
, edate
, afsdate
, afedate
, capdate
, poly_ha
, adj_ha
, adj_flag
, agency
, bt_gid
, version
, comments
, basrc_1
, new_flg
, asgeojson(GEOMETRY) as geom
from nbac
where ST_Intersects(
polygonfromtext(
'POLYGON((
{west} {south},
{west} {north},
{east} {north},
{east} {south},
{west} {south}
))')
, GEOMETRY)
limit 500
"""
fires = conn.execute(q).fetchall()
features = list()
for row in fires:
geom = geojson.loads(row['geom'])
row.pop('geom')
feature = geojson.Feature(geometry=geom, properties=row)
features.append(feature)
fireCollection = geojson.FeatureCollection(features)
#fireCollection['crs'] = { "type": "name", "properties": { "name": "urn:ogc:def:crs:OGC:1.3:CRS84" } }
return fireCollection
east = -114.46294784545898
north = 55.17151537567731
south = 55.09300655867381
west = -114.60027694702148
west = -114.95171070098877
north = 55.13349468079407
east = -114.91737842559814
south = 55.11386325016275
west = -120.39764404296875
north = 55.88095201504089
east = -100.29901123046875
south = 49.243964309850995
west = -115.68878173828125
north = 55.66984035430873
east = -113.49151611328125
south = 54.41093863702367
q = f"""
select
year
, nfireid
, basrc
, firemaps
, firemapm
, firecaus
, burnclas
, sdate
, edate
, afsdate
, afedate
, capdate
, poly_ha
, adj_ha
, adj_flag
, agency
, bt_gid
, version
, comments
, basrc_1
, new_flg
, centroid_x
, centroid_y
, asgeojson(GEOMETRY) as geom
, Cluster as cluster
from nbac
where ST_Intersects(
polygonfromtext(
'POLYGON((
{west} {south},
{west} {north},
{east} {north},
{east} {south},
{west} {south}
))'
, 4326)
, GEOMETRY)
limit 2
"""
print(q)
f = get_wildfires_by_bb(south, west, north, east)
len(f['features'])
f['crs']
fires.keys()
len(fires['features'])
```
| github_jupyter |
# Publications markdown generator for academicpages
Takes a TSV of publications with metadata and converts them for use with [academicpages.github.io](academicpages.github.io). This is an interactive Jupyter notebook ([see more info here](http://jupyter-notebook-beginner-guide.readthedocs.io/en/latest/what_is_jupyter.html)). The core python code is also in `publications.py`. Run either from the `markdown_generator` folder after replacing `publications.tsv` with one containing your data.
TODO: Make this work with BibTex and other databases of citations, rather than Stuart's non-standard TSV format and citation style.
## Data format
The TSV needs to have the following columns: pub_date, title, venue, excerpt, citation, site_url, and paper_url, with a header at the top.
- `excerpt` and `paper_url` can be blank, but the others must have values.
- `pub_date` must be formatted as YYYY-MM-DD.
- `url_slug` will be the descriptive part of the .md file and the permalink URL for the page about the paper. The .md file will be `YYYY-MM-DD-[url_slug].md` and the permalink will be `https://[yourdomain]/research/YYYY-MM-DD-[url_slug]`
This is how the raw file looks (it doesn't look pretty, use a spreadsheet or other program to edit and create).
```
!cat research.tsv
```
## Import pandas
We are using the very handy pandas library for dataframes.
```
import pandas as pd
```
## Import TSV
Pandas makes this easy with the read_csv function. We are using a TSV, so we specify the separator as a tab, or `\t`.
I found it important to put this data in a tab-separated values format, because there are a lot of commas in this kind of data and comma-separated values can get messed up. However, you can modify the import statement, as pandas also has read_excel(), read_json(), and others.
```
research = pd.read_csv("research.tsv", sep="\t", header=0)
research
```
## Escape special characters
YAML is very picky about how it takes a valid string, so we are replacing single and double quotes (and ampersands) with their HTML encoded equivilents. This makes them look not so readable in raw format, but they are parsed and rendered nicely.
```
html_escape_table = {
"&": "&",
'"': """,
"'": "'"
}
def html_escape(text):
"""Produce entities within text."""
return "".join(html_escape_table.get(c,c) for c in text)
```
## Creating the markdown files
This is where the heavy lifting is done. This loops through all the rows in the TSV dataframe, then starts to concatentate a big string (```md```) that contains the markdown for each type. It does the YAML metadata first, then does the description for the individual page.
```
import os
for row, item in research.iterrows():
md_filename = str(item.pub_date) + "-" + item.url_slug + ".md"
html_filename = str(item.pub_date) + "-" + item.url_slug
year = item.pub_date[:4]
## YAML variables
md = "---\ntitle: \"" + item.title + '"\n'
md += """collection: research"""
md += """\npermalink: /publication/""" + html_filename
if len(str(item.excerpt)) > 5:
md += "\nexcerpt: '" + html_escape(item.excerpt) + "'"
md += "\ndate: " + str(item.pub_date)
md += "\nvenue: '" + html_escape(item.venue) + "'"
if len(str(item.paper_url)) > 5:
md += "\npaperurl: '" + item.paper_url + "'"
md += "\ncitation: '" + html_escape(item.citation) + "'"
md += "\n---"
## Markdown description for individual page
if len(str(item.excerpt)) > 5:
md += "\n" + html_escape(item.excerpt) + "\n"
if len(str(item.paper_url)) > 5:
md += "\n[Download paper here](" + item.paper_url + ")\n"
md += "\nRecommended citation: " + item.citation
md_filename = os.path.basename(md_filename)
with open("../_research/" + md_filename, 'w') as f:
f.write(md)
```
These files are in the publications directory, one directory below where we're working from.
```
!ls ../_research/
!cat ../_research/2009-10-01-paper-title-number-1.md
```
| github_jupyter |
# Dask pipeline
## Example: Tracking the International Space Station with Dask
In this notebook we will be using two APIs:
1. [Google Maps Geocoder](https://developers.google.com/maps/documentation/geocoding/overview)
2. [Open Notify API for ISS location](http://api.open-notify.org/)
We will use them to keep track of the ISS location and next lead time in relation to a list of cities. To create our diagrams and intelligently parallelise data, we use Dask, especially [Dask Delayed](../refactoring/performance/dask.html#Dask-Delayed).
### 1. Imports
```
import requests
import logging
import sys
import numpy as np
from time import sleep
from datetime import datetime
from math import radians
from dask import delayed
from operator import itemgetter
from sklearn.neighbors import DistanceMetric
```
### 2. Logger
```
logger = logging.getLogger()
logger.setLevel(logging.INFO)
```
### 3. Latitude and longitude pairs from a list of cities
see also [Location APIs](https://locationiq.com/)
```
def get_lat_long(address):
resp = requests.get(
'https://eu1.locationiq.org/v1/search.php',
params={'key': '92e7ba84cf3465',
'q': address,
'format': 'json'}
)
if resp.status_code != 200:
print('There was a problem with your request!')
print(resp.content)
return
data = resp.json()[0]
return {
'name': data.get('display_name'),
'lat': float(data.get('lat')),
'long': float(data.get('lon')),
}
get_lat_long('Berlin, Germany')
locations = []
for city in ['Seattle, Washington',
'Miami, Florida',
'Berlin, Germany',
'Singapore',
'Wellington, New Zealand',
'Beirut, Lebanon',
'Beijing, China',
'Nairobi, Kenya',
'Cape Town, South Africa',
'Buenos Aires, Argentina']:
locations.append(get_lat_long(city))
sleep(2)
locations
```
## 4. Retrieve ISS data and determine lead times for cities
```
def get_spaceship_location():
resp = requests.get('http://api.open-notify.org/iss-now.json')
location = resp.json()['iss_position']
return {'lat': float(location.get('latitude')),
'long': float(location.get('longitude'))}
def great_circle_dist(lon1, lat1, lon2, lat2):
"Found on SO: http://stackoverflow.com/a/41858332/380442"
dist = DistanceMetric.get_metric('haversine')
lon1, lat1, lon2, lat2 = map(np.radians, [lon1, lat1, lon2, lat2])
X = [[lat1, lon1], [lat2, lon2]]
kms = 6367
return (kms * dist.pairwise(X)).max()
def iss_dist_from_loc(issloc, loc):
distance = great_circle_dist(issloc.get('long'),
issloc.get('lat'),
loc.get('long'), loc.get('lat'))
logging.info('ISS is ~%dkm from %s', int(distance), loc.get('name'))
return distance
def iss_pass_near_loc(loc):
resp = requests.get('http://api.open-notify.org/iss-pass.json',
params={'lat': loc.get('lat'),
'lon': loc.get('long')})
data = resp.json().get('response')[0]
td = datetime.fromtimestamp(data.get('risetime')) - datetime.now()
m, s = divmod(int(td.total_seconds()), 60)
h, m = divmod(m, 60)
logging.info('ISS will pass near %s in %02d:%02d:%02d',loc.get('name'), h, m, s)
return td.total_seconds()
iss_dist_from_loc(get_spaceship_location(), locations[4])
iss_pass_near_loc(locations[4])
```
## 5. Create a `delayed` pipeline
```
output = []
for loc in locations:
issloc = delayed(get_spaceship_location)()
dist = delayed(iss_dist_from_loc)(issloc, loc)
output.append((loc.get('name'), dist))
closest = delayed(lambda x: sorted(x,
key=itemgetter(1))[0])(output)
closest
```
## 6. Show DAG
```
closest.visualize()
```
## 7. `compute()`
```
closest.compute()
```
| github_jupyter |
```
%matplotlib inline
```
Working with Operators Using Tensor Expression
==============================================
**Author**: `Tianqi Chen <https://tqchen.github.io>`_
In this tutorial we will turn our attention to how TVM works with Tensor
Expression (TE) to define tensor computations and apply loop optimizations. TE
describes tensor computations in a pure functional language (that is each
expression has no side effects). When viewed in context of the TVM as a whole,
Relay describes a computation as a set of operators, and each of these
operators can be represented as a TE expression where each TE expression takes
input tensors and produces an output tensor.
This is an introductory tutorial to the Tensor Expression language in TVM. TVM
uses a domain specific tensor expression for efficient kernel construction. We
will demonstrate the basic workflow with two examples of using the tensor expression
language. The first example introduces TE and scheduling with vector
addition. The second expands on these concepts with a step-by-step optimization
of a matrix multiplication with TE. This matrix multiplication example will
serve as the comparative basis for future tutorials covering more advanced
features of TVM.
Example 1: Writing and Scheduling Vector Addition in TE for CPU
---------------------------------------------------------------
Let's look at an example in Python in which we will implement a TE for
vector addition, followed by a schedule targeted towards a CPU.
We begin by initializing a TVM environment.
```
import tvm
import tvm.testing
from tvm import te
import numpy as np
# You will get better performance if you can identify the CPU you are targeting
# and specify it. If you're using llvm, you can get this information from the
# command ``llc --version`` to get the CPU type, and you can check
# ``/proc/cpuinfo`` for additional extensions that your processor might
# support. For example, you can use "llvm -mcpu=skylake-avx512" for CPUs with
# AVX-512 instructions.
tgt = tvm.target.Target(target="llvm", host="llvm")
```
Describing the Vector Computation
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
We describe a vector addition computation. TVM adopts tensor semantics, with
each intermediate result represented as a multi-dimensional array. The user
needs to describe the computation rule that generates the tensors. We first
define a symbolic variable ``n`` to represent the shape. We then define two
placeholder Tensors, ``A`` and ``B``, with given shape ``(n,)``. We then
describe the result tensor ``C``, with a ``compute`` operation. The
``compute`` defines a computation, with the output conforming to the
specified tensor shape and the computation to be performed at each position
in the tensor defined by the lambda function. Note that while ``n`` is a
variable, it defines a consistent shape between the ``A``, ``B`` and ``C``
tensors. Remember, no actual computation happens during this phase, as we
are only declaring how the computation should be done.
```
n = te.var("n")
A = te.placeholder((n,), name="A")
B = te.placeholder((n,), name="B")
C = te.compute(A.shape, lambda i: A[i] + B[i], name="C")
```
<div class="alert alert-info"><h4>Note</h4><p>Lambda Functions
The second argument to the ``te.compute`` method is the function that
performs the computation. In this example, we're using an anonymous function,
also known as a ``lambda`` function, to define the computation, in this case
addition on the ``i``th element of ``A`` and ``B``.</p></div>
Create a Default Schedule for the Computation
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
While the above lines describe the computation rule, we can compute ``C`` in
many different ways to fit different devices. For a tensor with multiple
axes, you can choose which axis to iterate over first, or computations can be
split across different threads. TVM requires that the user to provide a
schedule, which is a description of how the computation should be performed.
Scheduling operations within TE can change loop orders, split computations
across different threads, group blocks of data together, amongst other
operations. An important concept behind schedules is that they only describe
how the computation is performed, so different schedules for the same TE will
produce the same result.
TVM allows you to create a naive schedule that will compute ``C`` in by
iterating in row major order.
.. code-block:: c
for (int i = 0; i < n; ++i) {
C[i] = A[i] + B[i];
}
```
s = te.create_schedule(C.op)
```
Compile and Evaluate the Default Schedule
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
With the TE expression and a schedule, we can produce runnable code for our
target language and architecture, in this case LLVM and a CPU. We provide
TVM with the schedule, a list of the TE expressions that are in the schedule,
the target and host, and the name of the function we are producing. The result
of the output is a type-erased function that can be called directly from Python.
In the following line, we use tvm.build to create a function. The build
function takes the schedule, the desired signature of the function (including
the inputs and outputs) as well as target language we want to compile to.
```
fadd = tvm.build(s, [A, B, C], tgt, name="myadd")
```
Let's run the function, and compare the output to the same computation in
numpy. The compiled TVM function is exposes a concise C API that can be invoked
from any language. We begin by creating a device, which is a device (CPU in this
example) that TVM can compile the schedule to. In this case the device is an
LLVM CPU target. We can then initialize the tensors in our device and
perform the custom addition operation. To verify that the computation is
correct, we can compare the result of the output of the c tensor to the same
computation performed by numpy.
```
dev = tvm.device(tgt.kind.name, 0)
n = 1024
a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), dev)
b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), dev)
c = tvm.nd.array(np.zeros(n, dtype=C.dtype), dev)
fadd(a, b, c)
tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
```
To get a comparison of how fast this version is compared to numpy, create a
helper function to run a profile of the TVM generated code.
```
import timeit
np_repeat = 100
np_running_time = timeit.timeit(
setup="import numpy\n"
"n = 32768\n"
'dtype = "float32"\n'
"a = numpy.random.rand(n, 1).astype(dtype)\n"
"b = numpy.random.rand(n, 1).astype(dtype)\n",
stmt="answer = a + b",
number=np_repeat,
)
print("Numpy running time: %f" % (np_running_time / np_repeat))
def evaluate_addition(func, target, optimization, log):
dev = tvm.device(target.kind.name, 0)
n = 32768
a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), dev)
b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), dev)
c = tvm.nd.array(np.zeros(n, dtype=C.dtype), dev)
evaluator = func.time_evaluator(func.entry_name, dev, number=10)
mean_time = evaluator(a, b, c).mean
print("%s: %f" % (optimization, mean_time))
log.append((optimization, mean_time))
log = [("numpy", np_running_time / np_repeat)]
evaluate_addition(fadd, tgt, "naive", log=log)
```
Updating the Schedule to Use Paralleism
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Now that we've illustrated the fundamentals of TE, let's go deeper into what
schedules do, and how they can be used to optimize tensor expressions for
different architectures. A schedule is a series of steps that are applied to
an expression to transform it in a number of different ways. When a schedule
is applied to an expression in TE, the inputs and outputs remain the same,
but when compiled the implementation of the expression can change. This
tensor addition, in the default schedule, is run serially but is easy to
parallelize across all of the processor threads. We can apply the parallel
schedule operation to our computation.
```
s[C].parallel(C.op.axis[0])
```
The ``tvm.lower`` command will generate the Intermediate Representation (IR)
of the TE, with the corresponding schedule. By lowering the expression as we
apply different schedule operations, we can see the effect of scheduling on
the ordering of the computation. We use the flag ``simple_mode=True`` to
return a readable C-style statement.
```
print(tvm.lower(s, [A, B, C], simple_mode=True))
```
It's now possible for TVM to run these blocks on independent threads. Let's
compile and run this new schedule with the parallel operation applied:
```
fadd_parallel = tvm.build(s, [A, B, C], tgt, name="myadd_parallel")
fadd_parallel(a, b, c)
tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
evaluate_addition(fadd_parallel, tgt, "parallel", log=log)
```
Updating the Schedule to Use Vectorization
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Modern CPUs also have the ability to perform SIMD operations on floating
point values, and we can apply another schedule to our computation expression
to take advantage of this. Accomplishing this requires multiple steps: first
we have to split the schedule into inner and outer loops using the split
scheduling primitive. The inner loops can use vectorization to use SIMD
instructions using the vectorize scheduling primitive, then the outer loops
can be parallelized using the parallel scheduling primitive. Choose the split
factor to be the number of threads on your CPU.
```
# Recreate the schedule, since we modified it with the parallel operation in
# the previous example
n = te.var("n")
A = te.placeholder((n,), name="A")
B = te.placeholder((n,), name="B")
C = te.compute(A.shape, lambda i: A[i] + B[i], name="C")
s = te.create_schedule(C.op)
# This factor should be chosen to match the number of threads appropriate for
# your CPU. This will vary depending on architecture, but a good rule is
# setting this factor to equal the number of available CPU cores.
factor = 4
outer, inner = s[C].split(C.op.axis[0], factor=factor)
s[C].parallel(outer)
s[C].vectorize(inner)
fadd_vector = tvm.build(s, [A, B, C], tgt, name="myadd_parallel")
evaluate_addition(fadd_vector, tgt, "vector", log=log)
print(tvm.lower(s, [A, B, C], simple_mode=True))
```
Comparing the Diferent Schedules
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
We can now compare the different schedules
```
baseline = log[0][1]
print("%s\t%s\t%s" % ("Operator".rjust(20), "Timing".rjust(20), "Performance".rjust(20)))
for result in log:
print(
"%s\t%s\t%s"
% (result[0].rjust(20), str(result[1]).rjust(20), str(result[1] / baseline).rjust(20))
)
```
<div class="alert alert-info"><h4>Note</h4><p>Code Specialization
As you may have noticed, the declarations of ``A``, ``B`` and ``C`` all
take the same shape argument, ``n``. TVM will take advantage of this to
pass only a single shape argument to the kernel, as you will find in the
printed device code. This is one form of specialization.
On the host side, TVM will automatically generate check code that checks
the constraints in the parameters. So if you pass arrays with different
shapes into fadd, an error will be raised.
We can do more specializations. For example, we can write :code:`n =
tvm.runtime.convert(1024)` instead of :code:`n = te.var("n")`, in the
computation declaration. The generated function will only take vectors with
length 1024.</p></div>
We've defined, scheduled, and compiled a vector addition operator, which we
were then able to execute on the TVM runtime. We can save the operator as a
library, which we can then load later using the TVM runtime.
Targeting Vector Addition for GPUs (Optional)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
TVM is capable of targeting multiple architectures. In the next example, we
will target compilation of the vector addition to GPUs.
```
# If you want to run this code, change ``run_cuda = True``
# Note that by default this example is not run in the docs CI.
run_cuda = False
if run_cuda:
# Change this target to the correct backend for you gpu. For example: cuda (NVIDIA GPUs),
# rocm (Radeon GPUS), OpenCL (opencl).
tgt_gpu = tvm.target.Target(target="cuda", host="llvm")
# Recreate the schedule
n = te.var("n")
A = te.placeholder((n,), name="A")
B = te.placeholder((n,), name="B")
C = te.compute(A.shape, lambda i: A[i] + B[i], name="C")
print(type(C))
s = te.create_schedule(C.op)
bx, tx = s[C].split(C.op.axis[0], factor=64)
################################################################################
# Finally we must bind the iteration axis bx and tx to threads in the GPU
# compute grid. The naive schedule is not valid for GPUs, and these are
# specific constructs that allow us to generate code that runs on a GPU.
s[C].bind(bx, te.thread_axis("blockIdx.x"))
s[C].bind(tx, te.thread_axis("threadIdx.x"))
######################################################################
# Compilation
# -----------
# After we have finished specifying the schedule, we can compile it
# into a TVM function. By default TVM compiles into a type-erased
# function that can be directly called from the python side.
#
# In the following line, we use tvm.build to create a function.
# The build function takes the schedule, the desired signature of the
# function (including the inputs and outputs) as well as target language
# we want to compile to.
#
# The result of compilation fadd is a GPU device function (if GPU is
# involved) as well as a host wrapper that calls into the GPU
# function. fadd is the generated host wrapper function, it contains
# a reference to the generated device function internally.
fadd = tvm.build(s, [A, B, C], target=tgt_gpu, name="myadd")
################################################################################
# The compiled TVM function is exposes a concise C API that can be invoked from
# any language.
#
# We provide a minimal array API in python to aid quick testing and prototyping.
# The array API is based on the `DLPack <https://github.com/dmlc/dlpack>`_ standard.
#
# - We first create a GPU device.
# - Then tvm.nd.array copies the data to the GPU.
# - ``fadd`` runs the actual computation
# - ``numpy()`` copies the GPU array back to the CPU (so we can verify correctness).
#
# Note that copying the data to and from the memory on the GPU is a required step.
dev = tvm.device(tgt_gpu.kind.name, 0)
n = 1024
a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), dev)
b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), dev)
c = tvm.nd.array(np.zeros(n, dtype=C.dtype), dev)
fadd(a, b, c)
tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
################################################################################
# Inspect the Generated GPU Code
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# You can inspect the generated code in TVM. The result of tvm.build is a TVM
# Module. fadd is the host module that contains the host wrapper, it also
# contains a device module for the CUDA (GPU) function.
#
# The following code fetches the device module and prints the content code.
if (
tgt_gpu.kind.name == "cuda"
or tgt_gpu.kind.name == "rocm"
or tgt_gpu.kind.name.startswith("opencl")
):
dev_module = fadd.imported_modules[0]
print("-----GPU code-----")
print(dev_module.get_source())
else:
print(fadd.get_source())
```
Saving and Loading Compiled Modules
-----------------------------------
Besides runtime compilation, we can save the compiled modules into a file and
load them back later.
The following code first performs the following steps:
- It saves the compiled host module into an object file.
- Then it saves the device module into a ptx file.
- cc.create_shared calls a compiler (gcc) to create a shared library
```
from tvm.contrib import cc
from tvm.contrib import utils
temp = utils.tempdir()
fadd.save(temp.relpath("myadd.o"))
if tgt.kind.name == "cuda":
fadd.imported_modules[0].save(temp.relpath("myadd.ptx"))
if tgt.kind.name == "rocm":
fadd.imported_modules[0].save(temp.relpath("myadd.hsaco"))
if tgt.kind.name.startswith("opencl"):
fadd.imported_modules[0].save(temp.relpath("myadd.cl"))
cc.create_shared(temp.relpath("myadd.so"), [temp.relpath("myadd.o")])
print(temp.listdir())
```
<div class="alert alert-info"><h4>Note</h4><p>Module Storage Format
The CPU (host) module is directly saved as a shared library (.so). There
can be multiple customized formats of the device code. In our example, the
device code is stored in ptx, as well as a meta data json file. They can be
loaded and linked separately via import.</p></div>
Load Compiled Module
~~~~~~~~~~~~~~~~~~~~
We can load the compiled module from the file system and run the code. The
following code loads the host and device module separately and links them
together. We can verify that the newly loaded function works.
```
fadd1 = tvm.runtime.load_module(temp.relpath("myadd.so"))
if tgt.kind.name == "cuda":
fadd1_dev = tvm.runtime.load_module(temp.relpath("myadd.ptx"))
fadd1.import_module(fadd1_dev)
if tgt.kind.name == "rocm":
fadd1_dev = tvm.runtime.load_module(temp.relpath("myadd.hsaco"))
fadd1.import_module(fadd1_dev)
if tgt.kind.name.startswith("opencl"):
fadd1_dev = tvm.runtime.load_module(temp.relpath("myadd.cl"))
fadd1.import_module(fadd1_dev)
fadd1(a, b, c)
tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
```
Pack Everything into One Library
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In the above example, we store the device and host code separately. TVM also
supports export everything as one shared library. Under the hood, we pack
the device modules into binary blobs and link them together with the host
code. Currently we support packing of Metal, OpenCL and CUDA modules.
```
fadd.export_library(temp.relpath("myadd_pack.so"))
fadd2 = tvm.runtime.load_module(temp.relpath("myadd_pack.so"))
fadd2(a, b, c)
tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
```
<div class="alert alert-info"><h4>Note</h4><p>Runtime API and Thread-Safety
The compiled modules of TVM do not depend on the TVM compiler. Instead,
they only depend on a minimum runtime library. The TVM runtime library
wraps the device drivers and provides thread-safe and device agnostic calls
into the compiled functions.
This means that you can call the compiled TVM functions from any thread, on
any GPUs, provided that you have compiled the code for that GPU.</p></div>
Generate OpenCL Code
--------------------
TVM provides code generation features into multiple backends. We can also
generate OpenCL code or LLVM code that runs on CPU backends.
The following code blocks generate OpenCL code, creates array on an OpenCL
device, and verifies the correctness of the code.
```
if tgt.kind.name.startswith("opencl"):
fadd_cl = tvm.build(s, [A, B, C], tgt, name="myadd")
print("------opencl code------")
print(fadd_cl.imported_modules[0].get_source())
dev = tvm.cl(0)
n = 1024
a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), dev)
b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), dev)
c = tvm.nd.array(np.zeros(n, dtype=C.dtype), dev)
fadd_cl(a, b, c)
tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
```
<div class="alert alert-info"><h4>Note</h4><p>TE Scheduling Primitives
TVM includes a number of different scheduling primitives:
- split: splits a specified axis into two axises by the defined factor.
- tile: tiles will split a computation across two axes by the defined factors.
- fuse: fuses two consecutive axises of one computation.
- reorder: can reorder the axises of a computation into a defined order.
- bind: can bind a computation to a specific thread, useful in GPU programming.
- compute_at: by default, TVM will compute tensors at the outermost level
of the function, or the root, by default. compute_at specifies that one
tensor should be computed at the first axis of computation for another
operator.
- compute_inline: when marked inline, a computation will be expanded then
inserted into the address where the tensor is required.
- compute_root: moves a computation to the outermost layer, or root, of the
function. This means that stage of the computation will be fully computed
before it moves on to the next stage.
A complete description of these primitives can be found in the
[Schedule Primitives](https://tvm.apache.org/docs/tutorials/language/schedule_primitives.html) docs page.</p></div>
Example 2: Manually Optimizing Matrix Multiplication with TE
------------------------------------------------------------
Now we will consider a second, more advanced example, demonstrating how with
just 18 lines of python code TVM speeds up a common matrix multiplication operation by 18x.
**Matrix multiplication is a compute intensive operation. There are
two important optimizations for good CPU performance:**
1. Increase the cache hit rate of memory access. Both complex
numerical computation and hot-spot memory access can be
accelerated by a high cache hit rate. This requires us to
transform the origin memory access pattern to a pattern that fits
the cache policy.
2. SIMD (Single instruction multi-data), also known as the vector
processing unit. On each cycle instead of processing a single
value, SIMD can process a small batch of data. This requires us
to transform the data access pattern in the loop body in uniform
pattern so that the LLVM backend can lower it to SIMD.
The techniques used in this tutorial are a subset of tricks mentioned in this
`repository <https://github.com/flame/how-to-optimize-gemm>`_. Some of them
have been applied by TVM abstraction automatically, but some of them cannot
be automatically applied due to TVM constraints.
Preparation and Performance Baseline
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
We begin by collecting performance data on the `numpy` implementation of
matrix multiplication.
```
import tvm
import tvm.testing
from tvm import te
import numpy
# The size of the matrix
# (M, K) x (K, N)
# You are free to try out different shapes, sometimes TVM optimization outperforms numpy with MKL.
M = 1024
K = 1024
N = 1024
# The default tensor data type in tvm
dtype = "float32"
# You will want to adjust the target to match any CPU vector extensions you
# might have. For example, if you're using using Intel AVX2 (Advanced Vector
# Extensions) ISA for SIMD, you can get the best performance by changing the
# following line to ``llvm -mcpu=core-avx2``, or specific type of CPU you use.
# Recall that you're using llvm, you can get this information from the command
# ``llc --version`` to get the CPU type, and you can check ``/proc/cpuinfo``
# for additional extensions that your processor might support.
target = tvm.target.Target(target="llvm", host="llvm")
dev = tvm.device(target.kind.name, 0)
# Random generated tensor for testing
a = tvm.nd.array(numpy.random.rand(M, K).astype(dtype), dev)
b = tvm.nd.array(numpy.random.rand(K, N).astype(dtype), dev)
# Repeatedly perform a matrix multiplication to get a performance baseline
# for the default numpy implementation
np_repeat = 100
np_running_time = timeit.timeit(
setup="import numpy\n"
"M = " + str(M) + "\n"
"K = " + str(K) + "\n"
"N = " + str(N) + "\n"
'dtype = "float32"\n'
"a = numpy.random.rand(M, K).astype(dtype)\n"
"b = numpy.random.rand(K, N).astype(dtype)\n",
stmt="answer = numpy.dot(a, b)",
number=np_repeat,
)
print("Numpy running time: %f" % (np_running_time / np_repeat))
answer = numpy.dot(a.numpy(), b.numpy())
```
Now we write a basic matrix multiplication using TVM TE and verify that it
produces the same results as the numpy implementation. We also write a
function that will help us measure the performance of the schedule
optimizations.
```
# TVM Matrix Multiplication using TE
k = te.reduce_axis((0, K), "k")
A = te.placeholder((M, K), name="A")
B = te.placeholder((K, N), name="B")
C = te.compute((M, N), lambda x, y: te.sum(A[x, k] * B[k, y], axis=k), name="C")
# Default schedule
s = te.create_schedule(C.op)
func = tvm.build(s, [A, B, C], target=target, name="mmult")
c = tvm.nd.array(numpy.zeros((M, N), dtype=dtype), dev)
func(a, b, c)
tvm.testing.assert_allclose(c.numpy(), answer, rtol=1e-5)
def evaluate_operation(s, vars, target, name, optimization, log):
func = tvm.build(s, [A, B, C], target=target, name="mmult")
assert func
c = tvm.nd.array(numpy.zeros((M, N), dtype=dtype), dev)
func(a, b, c)
tvm.testing.assert_allclose(c.numpy(), answer, rtol=1e-5)
evaluator = func.time_evaluator(func.entry_name, dev, number=10)
mean_time = evaluator(a, b, c).mean
print("%s: %f" % (optimization, mean_time))
log.append((optimization, mean_time))
log = []
evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="none", log=log)
```
Let's take a look at the intermediate representation of the operator and
default schedule using the TVM lower function. Note how the implementation is
essentially a naive implementation of a matrix multiplication, using three
nested loops over the indices of the A and B matrices.
```
print(tvm.lower(s, [A, B, C], simple_mode=True))
```
Optimization 1: Blocking
~~~~~~~~~~~~~~~~~~~~~~~~
A important trick to enhance the cache hit rate is blocking, where you
structure memory access such that the inside a block is a small neighborhood
that has high memory locality. In this tutorial, we pick a block factor of
32. This will result in a block that will fill a 32 * 32 * sizeof(float) area
of memory. This corresponds to a cache size of 4KB, in relation to a
reference cache size of 32 KB for L1 cache.
We begin by creating a default schedule for the ``C`` operation, then apply a
``tile`` scheduling primitive to it with the specified block factor, with the
scheduling primitive returning the resulting loop order from outermost to
innermost, as a vector ``[x_outer, y_outer, x_inner, y_inner]``. We then get
the reduction axis for output of the operation, and perform a split operation
on it using a factor of 4. This factor doesn't directly impact the blocking
optimization we're working on right now, but will be useful later when we
apply vectorization.
Now that the operation has been blocked, we can reorder the computation to
put the reduction operation into the outermost loop of the computation,
helping to guarantee that the blocked data remains in cache. This completes
the schedule, and we can build and test the performance compared to the naive
schedule.
```
bn = 32
# Blocking by loop tiling
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
(k,) = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=4)
# Hoist reduction domain outside the blocking loop
s[C].reorder(xo, yo, ko, ki, xi, yi)
evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="blocking", log=log)
```
By reordering the computation to take advantage of caching, you should see a
significant improvement in the performance of the computation. Now, print the
internal representation and compare it to the original:
```
print(tvm.lower(s, [A, B, C], simple_mode=True))
```
Optimization 2: Vectorization
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Another important optimization trick is vectorization. When the memory access
pattern is uniform, the compiler can detect this pattern and pass the
continuous memory to the SIMD vector processor. In TVM, we can use the
``vectorize`` interface to hint the compiler this pattern, taking advantage
of this hardware feature.
In this tutorial, we chose to vectorize the inner loop row data since it is
already cache friendly from our previous optimizations.
```
# Apply the vectorization optimization
s[C].vectorize(yi)
evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="vectorization", log=log)
# The generalized IR after vectorization
print(tvm.lower(s, [A, B, C], simple_mode=True))
```
Optimization 3: Loop Permutation
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
If we look at the above IR, we can see the inner loop row data is vectorized
and B is transformed into PackedB (this is evident by the `(float32x32*)B2`
portion of the inner loop). The traversal of PackedB is sequential now. So we
will look at the access pattern of A. In current schedule, A is accessed
column by column which is not cache friendly. If we change the nested loop
order of `ki` and inner axes `xi`, the access pattern for A matrix will be
more cache friendly.
```
s = te.create_schedule(C.op)
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
(k,) = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=4)
# re-ordering
s[C].reorder(xo, yo, ko, xi, ki, yi)
s[C].vectorize(yi)
evaluate_operation(
s, [A, B, C], target=target, name="mmult", optimization="loop permutation", log=log
)
# Again, print the new generalized IR
print(tvm.lower(s, [A, B, C], simple_mode=True))
```
Optimization 4: Array Packing
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Another important trick is array packing. This trick is to reorder the
storage dimension of the array to convert the continuous access pattern on
certain dimension to a sequential pattern after flattening.

:align: center
Just as it is shown in the figure above, after blocking the computations, we
can observe the array access pattern of B (after flattening), which is
regular but discontinuous. We expect that after some transformation we can
get a continuous access pattern. By reordering a ``[16][16]`` array to a
``[16/4][16][4]`` array the access pattern of B will be sequential when
grabing the corresponding value from the packed array.
To accomplish this, we are going to have to start with a new default
schedule, taking into account the new packing of B. It's worth taking a
moment to comment on this: TE is a powerful and expressive language for
writing optimized operators, but it often requires some knowledge of the
underlying algorithm, data structures, and hardware target that you are
writing for. Later in the tutorial, we will discuss some of the options for
letting TVM take that burden. Regardless, let's move on with the new
optimized schedule.
```
# We have to re-write the algorithm slightly.
packedB = te.compute((N / bn, K, bn), lambda x, y, z: B[y, x * bn + z], name="packedB")
C = te.compute(
(M, N),
lambda x, y: te.sum(A[x, k] * packedB[y // bn, k, tvm.tir.indexmod(y, bn)], axis=k),
name="C",
)
s = te.create_schedule(C.op)
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
(k,) = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=4)
s[C].reorder(xo, yo, ko, xi, ki, yi)
s[C].vectorize(yi)
x, y, z = s[packedB].op.axis
s[packedB].vectorize(z)
s[packedB].parallel(x)
evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="array packing", log=log)
# Here is the generated IR after array packing.
print(tvm.lower(s, [A, B, C], simple_mode=True))
```
Optimization 5: Optimizing Block Writing Through Caching
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Up to this point all of our optimizations have focused on efficiently
accessing and computing the data from the `A` and `B` matrices to compute the
`C` matrix. After the blocking optimization, the operator will write result
to `C` block by block, and the access pattern is not sequential. We can
address this by using a sequential cache array, using a combination of
`cache_write`, `compute_at`, and `unroll`to hold the block results and write
to `C` when all the block results are ready.
```
s = te.create_schedule(C.op)
# Allocate write cache
CC = s.cache_write(C, "global")
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
# Write cache is computed at yo
s[CC].compute_at(s[C], yo)
# New inner axes
xc, yc = s[CC].op.axis
(k,) = s[CC].op.reduce_axis
ko, ki = s[CC].split(k, factor=4)
s[CC].reorder(ko, xc, ki, yc)
s[CC].unroll(ki)
s[CC].vectorize(yc)
x, y, z = s[packedB].op.axis
s[packedB].vectorize(z)
s[packedB].parallel(x)
evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="block caching", log=log)
# Here is the generated IR after write cache blocking.
print(tvm.lower(s, [A, B, C], simple_mode=True))
```
Optimization 6: Parallelization
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
So far, our computation is only designed to use a single core. Nearly all
modern processors have multiple cores, and computation can benefit from
running computations in parallel. The final optimization is to take advantage
of thread-level parallelization.
```
# parallel
s[C].parallel(xo)
x, y, z = s[packedB].op.axis
s[packedB].vectorize(z)
s[packedB].parallel(x)
evaluate_operation(
s, [A, B, C], target=target, name="mmult", optimization="parallelization", log=log
)
# Here is the generated IR after parallelization.
print(tvm.lower(s, [A, B, C], simple_mode=True))
```
Summary of Matrix Multiplication Example
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
After applying the above simple optimizations with only 18 lines of code, our
generated code can begin to approach the performance of `numpy` with the Math
Kernel Library (MKL). Since we've been logging the performance as we've been
working, we can compare the results.
```
baseline = log[0][1]
print("%s\t%s\t%s" % ("Operator".rjust(20), "Timing".rjust(20), "Performance".rjust(20)))
for result in log:
print(
"%s\t%s\t%s"
% (result[0].rjust(20), str(result[1]).rjust(20), str(result[1] / baseline).rjust(20))
)
```
Note that the outputs on the web page reflect the running times on a
non-exclusive Docker container, and should be considered unreliable. It is
highly encouraged to run the tutorial by yourself to observe the performance
gain achieved by TVM, and to carefully work through each example to
understand the iterative improvements that are made to the matrix
multiplication operation.
Final Notes and Summary
-----------------------
As mentioned earlier, how to apply optimizations using TE and scheduling
primitives can require some knowledge of the underlying architecture and
algorithms. However, TE was designed to act as a foundation for more complex
algorithms that can search the potential optimization. With the knowledge you
have from this introduction to TE, we can now begin to explore how TVM can
automate the schedule optimization process.
This tutorial provided a walkthrough of TVM Tensor Expresstion (TE) workflow
using a vector add and a matrix multiplication examples. The general workflow
is
- Describe your computation via a series of operations.
- Describe how we want to compute use schedule primitives.
- Compile to the target function we want.
- Optionally, save the function to be loaded later.
Upcoming tutorials expand on the matrix multiplication example, and show how
you can build generic templates of the matrix multiplication and other
operations with tunable parameters that allows you to automatically optimize
the computation for specific platforms.
| github_jupyter |
```
%load_ext autoreload
%autoreload 2
import compartmental_models
import matplotlib.pyplot as plt
import numpy as np
from EpiModel import EpiModel
import pandas as pd
colors={
'S':"#053c5e",
'I':"#E71D36",
'R':"#9BC53D",
'Q':"#ff9f1c"
}
#ff9f1c
#d0cd94
#matplotlib.rc('xtick', labelsize=20)
#matplotlib.rc('ytick', labelsize=20)
#plt.rcParams.update({'font.size': 22})
SMALL_SIZE = 14
MEDIUM_SIZE = 18
BIGGER_SIZE = 22
plt.rc('font', size=SMALL_SIZE) # controls default text sizes
plt.rc('axes', titlesize=SMALL_SIZE) # fontsize of the axes title
plt.rc('axes', labelsize=MEDIUM_SIZE) # fontsize of the x and y labels
plt.rc('xtick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('ytick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('legend', fontsize=SMALL_SIZE) # legend fontsize
plt.rc('figure', titlesize=BIGGER_SIZE) # fontsize of the figure title
plt.rcParams['figure.figsize'] = [9, 5]
```
# SI Model
```
beta = 0.2
SI = EpiModel()
SI.add_interaction('S', 'I', 'I', beta)
N = 100000
I0 = 10
SI.integrate(100, S=N-I0, I=I0)
SI.values_['tiempo']=SI.values_.index
plt.plot(SI.values_['tiempo'], 100.0*SI.values_['I']/N, lw=3, color=colors['I'])
plt.xlabel('Tiempo')
plt.ylabel('Población')
plt.grid()
plt.savefig('SI.png', dpi=300, transparent=True)
plt.show()
beta = 0.4
SI2 = EpiModel()
SI2.add_interaction('S', 'I', 'I', beta)
SI2.integrate(100, S=N-I0, I=I0)
SI2.values_['tiempo']=SI.values_.index
plt.plot(SI.values_['tiempo'], 100.0*SI.values_['I']/N, lw=3, color=colors['I'])
plt.plot(SI.values_['tiempo'], 100.0*SI2.values_['I']/N, lw=3, ls='--', color=colors['I'])
plt.xlabel('Tiempo')
plt.ylabel('Población')
plt.grid()
plt.savefig('SI2.png', dpi=300, transparent=True)
plt.show()
```
# SIR Model
```
beta = 0.2
mu = 0.1
SIR = EpiModel()
SIR.add_interaction('S', 'I', 'I', beta)
SIR.add_spontaneous('I', 'R', mu)
SIR.integrate(365, S=N-I0, I=I0, R=0)
SIR.values_['tiempo']=SIR.values_.index
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['I']/N, lw=3, color=colors['I'])
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['R']/N, lw=3, color=colors['R'])
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['S']/N, lw=3, color=colors['S'])
plt.xlabel('Tiempo')
plt.ylabel('Población')
plt.grid()
plt.savefig('SIR.png', dpi=300, transparent=True)
plt.show()
Ro = beta/mu
I_approx = 100.0*I0*np.exp(mu*(Ro-1)*SIR.values_['tiempo'])/N
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['I']/N, lw=3, color=colors['I'])
plt.plot(SIR.values_['tiempo'], I_approx, lw=3)
plt.xlabel('Tiempo')
plt.ylabel('Población')
plt.yscale('log')
plt.grid()
plt.savefig('SIR_Ro.png', dpi=300, transparent=True)
plt.show()
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['I']/N, lw=3, color=colors['I'])
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['R']/N, lw=3, color=colors['R'])
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['S']/N, lw=3, color=colors['S'])
plt.hlines(100.0/Ro, 0, 365, linestyle='--', color='gray')
plt.xlabel('Tiempo')
plt.ylabel('Población')
plt.grid()
plt.savefig('SIR_Ro2.png', dpi=300, transparent=True)
plt.show()
```
# Cuarentena
```
beta = 0.2
mu = 0.1
SIR2 = EpiModel()
SIR2.add_interaction('S', 'I', 'I', beta)
SIR2.add_spontaneous('I', 'R', mu)
SIR2.integrate(75, S=N-I0, I=I0, R=0)
Quarantine = EpiModel('SIR')
Quarantine.add_spontaneous('I', 'R', mu)
population = SIR2.values_.iloc[-1]
S0 = population.S
I0 = population.I
R0 = population.R
Quarantine.integrate(365-74, S=S0, I=I0, R=R0)
values = pd.concat([SIR2.values_, Quarantine.values_], axis=0, ignore_index=True)
values['tiempo']=values.index
plt.plot(values['tiempo'], 100.0*values['I']/N, lw=3, color=colors['I'])
plt.plot(values['tiempo'], 100.0*values['R']/N, lw=3, color=colors['R'])
plt.plot(values['tiempo'], 100.0*values['S']/N, lw=3, color=colors['S'])
plt.xlabel('Tiempo')
plt.ylabel('Población')
plt.grid()
plt.savefig('SIR_cuarentena1.png', dpi=300, transparent=True)
plt.show()
beta = 0.2/4 # Reduce R0 by 4.
mu = 0.1
Quarantine2 = EpiModel()
Quarantine2.add_interaction('S', 'I', 'I', beta)
Quarantine2.add_spontaneous('I', 'R', mu)
Quarantine2.integrate(365-74, S=S0, I=I0, R=R0)
values2 = pd.concat([SIR2.values_, Quarantine2.values_], axis=0, ignore_index=True)
values2['tiempo']=values2.index
plt.plot(values['tiempo'], 100.0*values['I']/N,lw=1, linestyle='-', c=colors['I'])
plt.plot(values['tiempo'], 100.0*values['R']/N, lw=1, linestyle='-', c=colors['R'])
plt.plot(values['tiempo'], 100.0*values['S']/N, lw=1, linestyle='-', c=colors['S'])
plt.plot(values2['tiempo'], 100.0*values2['I']/N, lw=3, c=colors['I'])
plt.plot(values2['tiempo'], 100.0*values2['R']/N, lw=3, c=colors['R'])
plt.plot(values2['tiempo'], 100.0*values2['S']/N, lw=3,c=colors['S'])
plt.xlabel('Tiempo')
plt.ylabel('Población')
plt.grid()
plt.savefig('SIR_cuarentena2.png', dpi=300, transparent=True)
plt.show()
population = values2.iloc[100]
S0 = population.S
I0 = population.I
R0 = population.R
SIR2.integrate(365-99, S=S0, I=I0, R=R0)
values3 = values2.iloc[:100].copy()
values3 = pd.concat([values3, SIR2.values_], axis=0, ignore_index=True)
values3['tiempo']=values3.index
fig, ax = plt.subplots(1)
ax.plot(values3['tiempo'], 100.0*values3['I']/N, lw=3, c=colors['I'])
ax.plot(values3['tiempo'], 100.0*values3['R']/N, lw=3, c=colors['R'])
ax.plot(values3['tiempo'], 100.0*values3['S']/N, lw=3, c=colors['S'])
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['I']/N, lw=1, ls='--', c=colors['I'])
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['R']/N, lw=1, ls='--', c=colors['R'])
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['S']/N, lw=1, ls='--', c=colors['S'])
plt.plot(values2['tiempo'], 100.0*values2['I']/N, lw=1, c=colors['I'])
plt.plot(values2['tiempo'], 100.0*values2['R']/N, lw=1, c=colors['R'])
plt.plot(values2['tiempo'], 100.0*values2['S']/N, lw=1,c=colors['S'])
ax.axvspan(xmin=74, xmax=100, alpha=0.3, color=colors['Q'])
ax.set_xlabel('Tiempo')
ax.set_ylabel('Población')
ax.grid()
plt.savefig('SIR_cuarentena_3.png', dpi=300, transparent=True)
plt.show()
fig, ax = plt.subplots(1)
ax.plot(values3['tiempo'], 100.0*values3['I']/N, lw=3, c=colors['I'])
plt.plot(SIR.values_['tiempo'], 100.0*SIR.values_['I']/N, lw=1, ls='--', c=colors['I'])
plt.plot(values2['tiempo'], 100.0*values2['I']/N, lw=1, c=colors['I'])
ax.axvspan(xmin=74, xmax=100, alpha=0.3, color=colors['Q'])
ax.set_xlabel('Tiempo')
ax.set_ylabel('Población')
ax.grid()
plt.savefig('SIR_cuarentena_4.png', dpi=300, transparent=True)
plt.show()
```
| github_jupyter |
# BHSA and OSM: comparison on part-of-speech
We will investigate how the morphology marked up in the OSM corresponds and differs from the BHSA linguistic features.
In this notebook we investigate the markup of *part-of-speech*.
We use the `osm` and `osm_sf` features compiled by the
[BHSAbridgeOSM notebook](BHSAbridgeOSM.ipynb).
```
import operator
import collections
from functools import reduce
from tf.app import use
from helpers import show
```
# Load data
We load the BHSA data in the standard way, and we add the OSM data as a module of the features `osm` and `osm_sf`.
Note that we only need to point TF to the right GitHub org/repo/directory, in order to load the OSM features.
```
A = use("bhsa", mod="etcbc/bridging/tf", hoist=globals())
```
# Part of speech
The BHSA has two features for part-of-speech:
[sp](https://etcbc.github.io/bhsa/features/hebrew/2017/sp)
and
[pdp](https://etcbc.github.io/bhsa/features/hebrew/2017/pdp).
The first one, `sp`, is lexical part of speech, a context-insensitve assignment of part-of-speech labels to
occurrences of lexemes.
The second one, `pdp`, is *phrase dependent part of speech*. This assignment is sensitive to
cases where adjectives are used as noun, nouns as prepositions, etc.
A preliminary check has revealed that the OSM part-of-speech resembles `sp` more than `pdp`, so
we stick to `sp`.
The OSM has part-of-speech as the second letter of the morph string.
See [here](http://openscriptures.github.io/morphhb/parsing/HebrewMorphologyCodes.html).
The BHSA makes a few more distinctions in its [sp](https://etcbc.github.io/bhsa/features/hebrew/2017/sp) feature,
so we map the OSM values to sets of BHSA values.
But the OSM has a subclassification of particles (`T`) that we should use.
One of the OSM values is `S` (suffix).
The BHSA has no counterpart for this, but we expect that all morph strings in the `osm_sf` features will show
the `S`.
We'll test that as well.
Here is the default mapping between OSM part-of-speech and BHSA part-of-speech.
We'll see later that this results in many discrepancies.
We'll analyze the discrepancies, and try to overcome them by making lexeme-dependent exceptions to these rules.
It turns out that we need a few dozen lexeme-based exception rules and we'll have nearly 1000
left-over cases that merit closer inspection.
```
particleTypes = dict(
a="affirmation",
d="definite article",
e="exhortation",
i="interrogative",
j="interjection",
m="demonstrative",
n="negative",
o="direct object marker",
r="relative",
)
pspBhsFromOsm = {
"A": {"adjv"}, # adjective
"C": {"conj"}, # conjunction
"D": {"advb"}, # adverb
"N": {"subs", "nmpr"}, # noun
"P": {"prps", "prde"}, # pronoun
"R": {"prep"}, # preposition
"S": {"_suffix_"}, # suffix
"Ta": {"advb"},
"Td": {"art"},
"Te": {"intj"},
"Ti": {"prin", "inrg"},
"Tj": {"intj"},
"Tm": {"intj", "advb"},
"Tn": {"nega"},
"To": {"prep"}, # object marker
"Tr": {"conj"}, # relative
"T": {"intj"},
"V": {"verb"}, # verb
"×": set(), # no morphology
}
```
Just for ease of processing, we make a mapping from slots to OSM part-of-speech.
We assign `×` slot `w` if there is no valid OSM part-of-speech label available for `w`.
```
osmPsp = {}
noPsp = 0
nonEmpty = 0
for w in F.otype.s("word"):
osm = F.osm.v(w)
word = F.g_word_utf8.v(w)
if not word:
continue
nonEmpty += 1
if not osm or osm == "*" or len(osm) < 2:
psp = "×"
noPsp += 1
else:
psp = osm[1]
if psp == "T":
psp = osm[1:3]
osmPsp[w] = psp
allPsp = len(osmPsp)
withPsp = allPsp - noPsp
print(
"""{} BHSA words:
having OSM part of speech: {:>3}% = {:>6}
without OSM part of speech: {:>3}% = {:>6}
""".format(
nonEmpty,
round(100 * withPsp / allPsp),
withPsp,
round(100 * noPsp / allPsp),
noPsp,
)
)
```
We organize the osm-bhs combinations that show up in the text in several ways.
`psp` is keyed by: osm, bhs, lexeme node.
`pspLex` is keyed by: lexeme node, osm, bhs, and then contains a list of slots where this combination occurs.
Both mappings contains a list of slots where the combinations occur.
```
psp = {}
pspLex = {}
for lx in F.otype.s("lex"):
ws = [w for w in L.d(lx, otype="word") if F.g_word_utf8.v(w)]
for w in ws:
osm = osmPsp[w]
bhs = F.sp.v(w)
psp.setdefault(osm, {}).setdefault(bhs, {}).setdefault(lx, set()).add(w)
pspLex.setdefault(lx, {}).setdefault(osm, {}).setdefault(bhs, set()).add(w)
```
For each osm-bhs combination, we want to see how many lexemes and how many occurrences have that combination.
```
pspCount = {}
for (osm, osmData) in psp.items():
for (bhs, bhsData) in osmData.items():
nlex = len(bhsData)
noccs = reduce(operator.add, (len(x) for x in bhsData.values()), 0)
pspCount.setdefault(osm, {})[bhs] = (nlex, noccs)
```
Now we are going to present an overview of osm-bhs combinations.
We mark a combination with `OK` if the combination is according to the default OSM-BHS mapping.
We use the mark `*` if there is no OSM part-of-speech available.
Otherwise we mark it with a `?`.
```
mismatches = []
for osm in pspCount:
print(osm)
totalOccs = sum(x[1] for x in pspCount[osm].values())
for (bhs, (nlex, noccs)) in sorted(
pspCount[osm].items(), key=lambda x: (-x[1][1], -x[1][0], x[0])
):
perc = round(100 * noccs / totalOccs)
status = bhs in pspBhsFromOsm[osm]
statusLabel = "OK" if status else "?"
if not status:
if osm == "×":
statusLabel = "*"
else:
mismatches.append((osm, bhs, nlex, noccs))
print(
"\t=> {:<4} ({:<2}) in {:>4} lexemes and {:>3}% = {:>6} occurrences".format(
bhs,
statusLabel,
nlex,
perc,
noccs,
)
)
total = 0
for (osm, bhs, nlex, noccs) in mismatches:
total += noccs
print("\n{:<24} {:>6} occurrences".format("Total number of mismatches", total))
```
It is not as bad as it seems.
The number of *lexemes* involved in a mismatch is limited:
```
mismatchLexemes = set()
for (osm, bhs, nlex, noccs) in mismatches:
lexemes = psp[osm][bhs].keys()
mismatchLexemes |= lexemes
print("Lexemes to be researched: {}".format(len(mismatchLexemes)))
```
We are going to investigate the lexemes that are involved in a mismatch.
It turns out that:
* for most of the lexemes there is a dominant combination of OSM and BHSA assigned part-of-speech;
* non-dominant combinations mostly have a very limited number of occurrences.
This is what we are going to do:
* for each lexeme we go along with the dominant combination.
If that is different from the default marking, we add a lexeme-bound exception to the rule
that maps OSM part-of-speech to BHSA part-of-speech.
* if even the dominant combination has less than 10 occurrences, we do not add a lexeme-bound rule,
but we add the case to the list of exceptional cases.
* we spell out the exceptional cases, so that readers can manually check the part-of-speeches as assigned by
OSM and BHSA.
In order to determine what is dominant: if a combination has 50% or more of occurrences of a lexeme
then that combination is dominant.
So, for each lexeme there is at least one dominant case.
There may not be a dominant case if not all occurrences of a lexeme have been marked up in the OSM.
The next cell computes the new rules and the exceptions.
It will show all new rules, and all kinds of exceptions.
But it only shows at most 10 instances of each kind of exception.
All exceptions are written to a tab-separated file
[pspCases.tsv](pspCases.tsv).
```
closerLook = set()
rules = []
text = []
def getOSMpsp(w):
return "{} - {}".format(str(F.osm.v(w)), str(F.osm_sf.v(w)))
fields = """
passage
slot
occurrence
lex-node
lex
lex-pointed
gloss
bhsa-psp
osm-psp
#cases-like-this
""".strip().split()
lineFormat = ("{}\t" * (len(fields) - 1)) + "{}\n"
casesLikeThis = {}
for lx in sorted(mismatchLexemes, key=lambda x: -F.freq_lex.v(x)):
freqLex = F.freq_lex.v(lx)
text.append(
'\n{:<15} {:>6}x [{}] "{}"'.format(
F.lex.v(lx),
freqLex,
F.gloss.v(lx),
F.voc_lex_utf8.v(lx),
)
)
nRealCases = freqLex
if "×" in pspLex[lx]:
for (bhs, ws) in pspLex[lx]["×"].items():
nRealCases -= len(ws)
osmCount = collections.Counter()
for (osm, osmData) in pspLex[lx].items():
for ws in osmData.values():
osmCount[osm] += len(ws)
for osm in sorted(pspLex[lx], key=lambda x: -osmCount[x]):
if osm == "×":
continue
osmData = pspLex[lx][osm]
for (bhs, ws) in sorted(osmData.items(), key=lambda x: (-len(x[1]), x[0])):
showCases = False
nws = len(ws)
status = bhs in pspBhsFromOsm[osm]
statusLabel = "OK" if status else "?"
if 2 * nws > freqLex and nws >= 10:
if status:
pass
else:
statusLabel = "NN"
rules.append((lx, osm, bhs, ws))
else:
if status:
statusLabel = "OK?"
else:
showCases = True
text.append(
"\t{:<2} ~ {:<4} ({:<3}) {:>6}x".format(
bhs,
osm,
statusLabel,
nws,
)
)
if showCases:
for w in sorted(ws)[0:10]:
text.append(
show(
T,
F,
[w],
F.sp.v,
getOSMpsp,
indent="\t\t\t\t\t",
asString=True,
)
)
if nws > 10:
text.append("\t\t\t\t\tand {} more occurrences".format(nws - 10))
closerLook |= set(ws)
for w in ws:
casesLikeThis[w] = nws
with open("pspCases.tsv", "w") as fh:
fh.write(lineFormat.format(*fields))
for w in sorted(closerLook):
closerLook.add(w)
fh.write(
lineFormat.format(
"{} {}:{}".format(*T.sectionFromNode(w)),
w,
F.g_word_utf8.v(w),
lx,
F.lex.v(lx),
F.voc_lex_utf8.v(lx),
F.gloss.v(lx),
F.sp.v(w),
F.osm.v(w),
casesLikeThis[w],
)
)
print("Written {} cases to file".format(len(closerLook)))
if rules:
print("Lexeme-bound exceptions : {:>4}".format(len(rules)))
else:
print("No lexeme-bound exceptions")
if closerLook or text:
print("Cases that need attention: {:>4}".format(len(closerLook)))
else:
print("All cases clear")
print("\nLEXEME-BOUND EXCEPTIONS\n")
casesSolved = set()
for (lx, osm, bhs, ws) in rules:
casesSolved |= set(ws)
print(
'\t{:<15} {:<4} ~ {:<2} ({:>5}x) [{:<20}] "{}"'.format(
F.lex.v(lx),
bhs,
osm,
len(ws),
F.gloss.v(lx),
F.voc_lex_utf8.v(lx),
)
)
print("This solves {} cases".format(len(casesSolved)))
print("Remaining cases: {}".format(total - len(casesSolved)))
```
We show the top of the file with the cases for attention.
```
nLines = 50
print(f"\nCASES FOR ATTENTION (showing first {nLines} entries\n")
for t in text[0:nLines]:
print(t)
print(f"\n ... AND {len(text) - nLines} entries more")
```
# SP versus PDP
Here is the computation that shows that the BHS feature
[sp](https://etcbc.github.io/bhsa/features/hebrew/2017/sp)
matches the OSM part-of-speech better than
[pdp](https://etcbc.github.io/bhsa/features/hebrew/2017/pdp).
```
discrepancies = {}
for w in F.otype.s("word"):
if not F.g_word_utf8.v(w):
continue
osm = osmPsp[w]
if osm == "×":
continue
lex = F.lex.v(w)
trans = pspBhsFromOsm[osm]
if F.sp.v(w) not in trans:
discrepancies.setdefault("sp", set()).add(w)
if F.pdp.v(w) not in trans:
discrepancies.setdefault("pdp", set()).add(w)
lexDiscrepancies = {} # discrepancies per lexeme
for (ft, ws) in sorted(discrepancies.items()):
for w in sorted(ws):
lexNode = L.u(w, otype="lex")[0]
lexInfo = lexDiscrepancies.setdefault(ft, {})
if lexNode in lexInfo:
continue
lexInfo[lexNode] = w
if discrepancies:
print("Discrepancies")
for (ft, lexInfo) in sorted(lexDiscrepancies.items()):
print("\n--- {:<4}: {:>4} lexemes ---\n".format(ft, len(lexInfo)))
for (ft, ws) in sorted(discrepancies.items()):
n = len(ws)
print("\n--- {:<4}: {:>6}x ---\n".format(ft, n))
for w in sorted(ws)[0:10]:
show(T, F, [w], Fs(ft).v, getOSMpsp)
if n > 10:
print("\tand {} more".format(n - 10))
strangePsp = {}
strangeSuffix = {}
for w in F.otype.s("word"):
if not F.g_word_utf8.v(w):
continue
osm = osmPsp[w]
if osm == "×":
continue
if osm == "S" or osm not in pspBhsFromOsm:
strangePsp.setdefault(osm, set()).add(w)
osm_sf = F.osm_sf.v(w)
if osm_sf:
osmSuffix = None if len(osm_sf) < 2 else osm_sf[1]
if osmSuffix != "S":
strangeSuffix.setdefault(osmSuffix, set()).add(w)
if strangePsp:
print("Strange psp")
for (ln, ws) in sorted(strangePsp.items()):
print("\t{:<5}: {:>5}x".format(ln, len(ws)))
for w in sorted(ws)[0:5]:
show(T, F, [w], F.sp.v, getOSMpsp, indent="\t\t")
n = len(ws)
if n > 5:
print("and {} more".format(n - 5))
else:
print("No other psps encountered than {}".format(", ".join(pspBhsFromOsm)))
if strangeSuffix:
print("Strange suffix psp")
for (ln, ws) in sorted(strangeSuffix.items()):
print("\t{:<5}: {:>5}x".format(ln, len(ws)))
for w in sorted(ws)[0:5]:
show(T, F, [w], F.sp.v, getOSMpsp, indent="\t\t")
n = len(ws)
if n > 5:
print("and {} more".format(n - 5))
else:
print("No other suffix psps encountered than S")
```
| github_jupyter |
## Assignment 1 | Data Types
Add code cells as needed for your answers.
### Exercise 1: Manipulating Lists
Create a list containing the numbers 10, 20, and 30. Store your list as a variable named `a`. Then create a second list containing the numbers 30, 60, and 90. Call this this `b`.
```
a = [10,20,30]
b = [30, 60,90]
print (a)
print (b)
```
In the cells below, write Python expressions to create the following four outputs by combining `a` and `b` in creative ways:
1. [[10, 20, 30], [30, 60, 90]]
2. [10, 20, 30, 30, 60, 90]
3. [10, 20, 60, 90]
4. [20, 40, 60]
```
c =[a]+[b]
print (c)
d = a+b
print (d)
e = a+b
del e [2:4]
print (e)
a = [10,20,30]
b = [30, 60,90]
difference = []
for num, item in zip(a,b):
difference.append(item-num)
print(difference)
```
### Exercise 2. Working with Lists
Create a list that contains the sums of each of the lists in G.
`G = [[13, 9, 8], [14, 6, 12], [10, 13, 11], [7, 18, 9]]`
Your output should look like:
- `[30, 32, 34, 34]`
Hint: try computing the sum for just one list first.
```
G = [[13, 9, 8], [14, 6, 12], [10, 13, 11], [7, 18, 9]]
add = [sum(G[0]), sum(G[1]), sum(G[2]), sum(G[3])]
print(add)
```
### Exercise 3: String Manipulation
Turn the string below into 'all good countrymen' using the minimum amount of code, using only the methods we've covered so far. A couple of lines of code should do the trick. Note: this requires string and list methods.
```
s = 'Now is the time for all good men to come to the aid of their country!'
m=s.split(" ")
t=m[5:8]
u=m[15:]
v= t+u
order = [0, 1, 3, 2]
v = [v[i] for i in order]
stringList = ' '.join([str(item) for item in v ])
print(stringList.replace('!', ''))
```
### Exercise 4: String Manipulation and Type Conversion
Define a variable `a = "Sarah earns $96500 in a year"`. Then maniuplate the value of `a` in order to print the following string: `Sarah earns $8041.67 monthly`
Start by doing it in several steps and then combine them one step at a time until you can do it in one line.
```
a = "Sarah earns $96500 in a year"
print(a.replace('$96500 in a year', '$8041.67 monthly'))
```
### Exercise 5: Create and Query a Dictionary on State Demographics
Create two dictionaries, one for California and one for New York state, based on the data in the following table:
| States | Pop Density | Prop White | Prop Afr Amer | Prop Asian | Prop Other | Owners | Renters |
| --- | ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| CA | 239.1 | 0.57 | 0.06 | 0.13 | 0.22 | 7035371 | 5542127 |
| NY | 411.2 | 0.65 | 0.15 | 0.07 | 0.22 | 3897837 | 3419918 |
Each dictionary should have the following keys and value types: `name: (string)` , `population density: (float)`, `race (dict)`, `tenure: (dict)`.
1. Create one dictionary called CA and one called NY that contain dictionaries containing name, pop_density, race as a dictionary, and tenure for California and New York. Now combine these into a dictionary called "states", making it a dictionary of dictionaries, or a nested dictionary.
1. Check if Texas is in our state dictionary (we know it isn't but show us).
1. Print the White population in New York as a percentage
1. Assume there was a typo in the data, and update the White population fraction of NY to 0.64. Verify that it was updated by printing the percentage again.
1. Print the percentage of households that are renters in California, with two decimal places
```
CA_state = {'name': 'CA' , 'population density': '239.1', 'race':{'White':0.57, 'Afr Amer':0.06,'Asian':0.13,'Other':0.22}, 'tenure': {'Owners':7035371,'Renters':5542127}}
NY_state = {'name': 'NY' , 'population density': '411.2', 'race':{'White':0.65, 'Afr Amer':0.15,'Asian':0.07,'Other':0.22}, 'tenure': {'Owners':3897837,'Renters':3419918}}
states = {'CA':CA_state, 'NY':NY_state}
print(states)
print('Texas' in states)
float(NY_state['race'] ['White']*100)
NY_state['race'] ['White']=0.64
NY_state
round((float (CA_state['tenure']['Renters']))/(float (CA_state['tenure']['Owners'] + CA_state['tenure']['Renters']))*100,2)
```
### Exercise 6: Working with Numpy Arrays
1. Create and print a 4 x 4 array named `a` with value 3 everywhere.
1. Create and print a 4 x 4 array named `b` with elements drawn from a uniform random distribution
1. Create and print array `c` by dividing a by b
1. Compute and print the min, mean, max, median, and 90th percentile values of `c`
1. Compute and print the sum of the second column in `c`
```
import numpy as np
a = np.array([[3, 3, 3, 3]]*4)
a
b = np.random.randint([3, 5, 7, 9], [[10], [20], [30], [40]])
b
c=a/b
c
np.min(c)
np.mean(c)
np.max(c)
np.median(c)
print("Minimum of c is : ",end="")
print (np.min(c))
print("Mean of c is : ",end="")
print (np.mean(c))
print("Maximum of c is : ",end="")
print (np.max(c))
print("Median of c is : ",end="")
print (np.median(c))
print("90th percentile of c : ",
np.percentile(c, 90))
second_column = c[:, [1]]
print(second_column)
np.sum(second_column)
```
| github_jupyter |
# Multi-Timescale Prediction
This notebook showcases some ways to use the **MTS-LSTM** from our recent publication to generate predictions at multiple timescales: [**"Rainfall-Runoff Prediction at Multiple Timescales with a Single Long Short-Term Memory Network"**](https://arxiv.org/abs/2010.07921).
Let's assume we have a set of daily meteorological forcing variables and a set of hourly variables, and we want to generate daily and hourly discharge predictions.
Now, we could just go and train two separate LSTMs: One on the daily forcings to generate daily predictions, and one on the hourly forcings to generate hourly ones.
One problem with this approach: It takes a _lot_ of time, even if you run it on a GPU.
The reason is that the hourly model would crunch through a years' worth of hourly data to predict a single hour (assuming we provide the model input sequences with the same look-back that we usually use with daily data).
That's $365 \times 24 = 8760$ time steps to process for each prediction.
Not only does this take ages to train and evaluate, but also the training procedure becomes quite unstable and it is theoretically really hard for the model to learn dependencies over that many time steps.
What's more, the daily and hourly predictions might end up being inconsistent, because the two models are entirely unrelated.
## MTS-LSTM
MTS-LSTM solves these issues: We can use a single model to predict both hourly and daily discharge, and with some tricks, we can push the model toward predictions that are consistent across timescales.
### The Intuition
The basic idea of MTS-LSTM is this: we can process time steps that are far in the past at lower temporal resolution.
As an example, to predict discharge of September 10 9:00am, we'll certainly need fine-grained data for the previous few days or weeks.
We might also need information from several months ago, but we probably _don't_ need to know if it rained at 6:00am or 7:00am on May 15.
It's just so long ago that the fine resolution doesn't matter anymore.
### How it's Implemented
The MTS-LSTM architecture follows this principle: To predict today's daily and hourly dicharge, we start feeding daily meteorological information from up to a year ago into the LSTM.
At some point, say 14 days before today, we split our processing into two branches:
1. The first branch just keeps going with daily inputs until it outputs today's daily prediction.
So far, there's no difference to normal daily-only prediction.
2. The second branch is where it gets interesting: We take the LSTM state from 14 days before today, apply a linear transformation to it, and then use the resulting states as the starting point for another LSTM, which we feed the 14 days of _hourly_ data until it generates today's 24 hourly predictions.
Thus, in a single forward pass through the MTS-LSTM, we've generated both daily and hourly predictions.
If you prefer visualizations, here's what the architecture looks like:
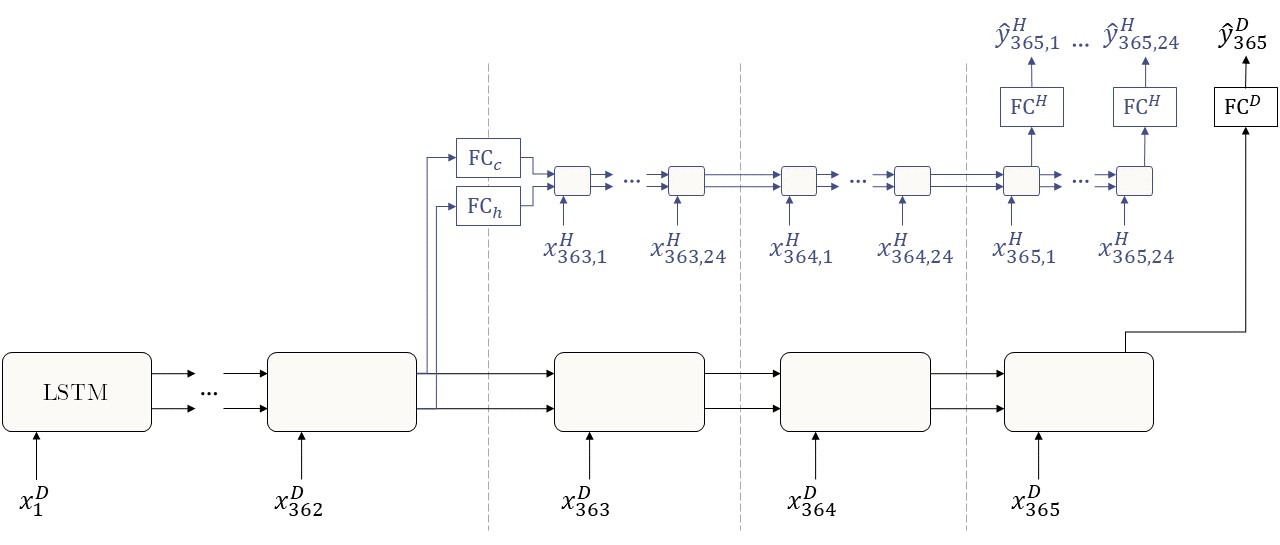
You can see how the first 362 input steps are done at the daily timescale (the visualization uses 362 days, but in reality this is a tunable hyperparameter).
Starting with day 363, two things happen:
- The _daily_ LSTM just keeps going with daily inputs.
- We take the hidden and cell states from day 362 and pass them through a linear layer. Starting with these new states, the _hourly_ LSTM begins processing hourly inputs.
Finally, we pass the LSTMs' outputs through a linear output layer ($\text{FC}^H$ and $\text{FC}^D$) and get our predictions.
### Some Variations
Now that we have this model, we can think of a few variations:
1. Because the MTS-LSTM has an individual branch for each timescale, we can actually use a different forcings product at each timescale (e.g., daily Daymet and hourly NLDAS). Going even further, we can use _multiple_ sets of forcings at each timescale (e.g., daily Daymet and Maurer, but only hourly NLDAS). This can improve predictions a lot (see [Kratzert et al., 2020](https://hess.copernicus.org/preprints/hess-2020-221/)).
2. We could also use the same LSTM weights in all timescales' branches. We call this model the shared MTS-LSTM (sMTS-LSTM). In our results, the shared version generated slightly better predictions if all we have is one forcings dataset. The drawback is that the model doesn't support per-timescale forcings. Thus, if you have several forcings datasets, you'll most likely get better predictions if you use MTS-LSTM (non-shared) and leverage all your datasets.
3. We can link the daily and hourly predictions during training to nudge the model towards predictions that are consistent across timescales. We do this by means of a regularization of the loss function that increases the loss if the average daily prediction aggregated from hourly predictions does not match the daily prediction.
## Using MTS-LSTM
So, let's look at some code to train and evaluate an MTS-LSTM!
The following code uses the `neuralhydrology` package to train an MTS-LSTM on daily and hourly discharge prediction.
For the sake of a quick example, we'll train our model on just a single basin.
When you actually care about the quality of your predictions, you'll generally get much better model performance when training on hundreds of basins.
```
import pickle
from pathlib import Path
import matplotlib.pyplot as plt
from neuralhydrology.evaluation import metrics, get_tester
from neuralhydrology.nh_run import start_run, eval_run
from neuralhydrology.utils.config import Config
```
Every experiment in `neuralhydrology` uses a configuration file that specifies its setup.
Let's look at some of the relevant configuration options:
```
run_config = Config(Path("1_basin.yml"))
print('model:\t\t', run_config.model)
print('use_frequencies:', run_config.use_frequencies)
print('seq_length:\t', run_config.seq_length)
```
`model` is obvious: We want to use the MTS-LSTM. For the sMTS-LSTM, we'd set `run_config.shared_mtslstm = True`.
In `use_frequencies`, we specify the timescales we want to predict.
In `seq_length`, we specify for each timescale the look-back window. Here, we'll start with 365 days look-back, and the hourly LSTM branch will get the last 14 days ($336/24 = 14$) at an hourly resolution.
As we're using the MTS-LSTM (and not sMTS-LSTM), we can use different input variables at each frequency.
Here, we use Maurer and Daymet as daily inputs, while the hourly model component uses NLDAS, Maurer, and Daymet.
Note that even though Daymet and Maurer are daily products, we can use them to support the hourly predictions.
```
print('dynamic_inputs:')
run_config.dynamic_inputs
```
## Training
We start model training of our single-basin toy example with `start_run`.
```
start_run(config_file=Path("1_basin.yml"))
```
## Evaluation
Given the trained model, we can generate and evaluate its predictions.
```
run_dir = Path("runs/test_run_1410_151521") # you'll find this path in the output of the training above.
# create a tester instance and start evaluation
tester = get_tester(cfg=run_config, run_dir=run_dir, period="test", init_model=True)
results = tester.evaluate(save_results=False, metrics=run_config.metrics)
results.keys()
```
Let's take a closer look at the predictions and do some plots, starting with the daily results.
Note that units are mm/h even for daily values, since we predict daily averages.
```
# extract observations and simulations
daily_qobs = results["01022500"]["1D"]["xr"]["qobs_mm_per_hour_obs"]
daily_qsim = results["01022500"]["1D"]["xr"]["qobs_mm_per_hour_sim"]
fig, ax = plt.subplots(figsize=(16,10))
ax.plot(daily_qobs["date"], daily_qobs, label="Observed")
ax.plot(daily_qsim["date"], daily_qsim, label="Simulated")
ax.legend()
ax.set_ylabel("Discharge (mm/h)")
ax.set_title(f"Test period - daily NSE {results['01022500']['1D']['NSE_1D']:.3f}")
# Calculate some metrics
values = metrics.calculate_all_metrics(daily_qobs.isel(time_step=-1), daily_qsim.isel(time_step=-1))
print("Daily metrics:")
for key, val in values.items():
print(f" {key}: {val:.3f}")
```
...and finally, let's look more closely at the last few months' hourly predictions:
```
# extract a date slice of observations and simulations
hourly_xr = results["01022500"]["1H"]["xr"].sel(date=slice("10-1995", None))
# The hourly data is indexed with two indices: The date (in days) and the time_step (the hour within that day).
# As we want to get a continuous plot of several days' hours, we select all 24 hours of each day and then stack
# the two dimensions into one consecutive datetime dimension.
hourly_xr = hourly_xr.isel(time_step=slice(-24, None)).stack(datetime=['date', 'time_step'])
hourly_xr['datetime'] = hourly_xr.coords['date'] + hourly_xr.coords['time_step']
hourly_qobs = hourly_xr["qobs_mm_per_hour_obs"]
hourly_qsim = hourly_xr["qobs_mm_per_hour_sim"]
fig, ax = plt.subplots(figsize=(16,10))
ax.plot(hourly_qobs["datetime"], hourly_qobs, label="Observation")
ax.plot(hourly_qsim["datetime"], hourly_qsim, label="Simulation")
ax.set_ylabel("Discharge (mm/h)")
ax.set_title(f"Test period - hourly NSE {results['01022500']['1H']['NSE_1H']:.3f}")
_ = ax.legend()
```
| github_jupyter |
# Helium Hydride (Tapered HeH+) Exemplar
## Step 0: Import various libraries
```
# Imports for QSCOUT
import jaqalpaq
from jaqalpaq.core import circuitbuilder
from jaqalpaq.core.circuit import normalize_native_gates
from jaqalpaq import pygsti
from qscout.v1 import native_gates
# Imports for basic mathematical functionality
from math import pi
import numpy as np
# Imports for OpenFermion(-PySCF)
import openfermion as of
from openfermion.hamiltonians import MolecularData
from openfermionpyscf import run_pyscf
# Import for VQE optimizer
from scipy import optimize
```
## Step 1: SCF calculation to assmble the second-quantized Hamiltonian
```
# Set the basis set, spin, and charge of the H2 molecule
basis = 'sto-3g'
multiplicity = 1
charge = 1 #Charge is 1 for HeH+
# Set calculation parameters
run_scf = 1
run_fci = 1
delete_input = True
# Note: this option is critical as it ensures that the integrals are written out to an HDF5 file
delete_output = False
# Generate molecule at some bond length (0.8 Angstroms here)
geometry = [('He', (0., 0., 0.)), ('H', (0., 0., 0.8))]
molecule = MolecularData(
geometry, basis, multiplicity, charge,
filename='./HeH+_2_sto-3g_single_0.8') #Set file location of data
# Run pyscf to generate new molecular data for sto-3g HeH+
molecule = run_pyscf(molecule,
run_scf=run_scf,
run_fci=run_fci,
verbose=False)
print("Bond Length in Angstroms: {}".format(0.8))
print("FCI (Exact) energy in Hartrees: {}".format(molecule.fci_energy))
```
## Step 2: Convert the fermionic Hamiltonian to a qubit Hamiltonian
```
#Get the Hamiltonian for HeH+
hamiltonian = molecule.get_molecular_hamiltonian()
hamiltonian_ferm = of.get_fermion_operator(hamiltonian)
hamiltonian_bk = of.symmetry_conserving_bravyi_kitaev(hamiltonian_ferm, active_orbitals=4, active_fermions=2)
#Define terms and coefficients of our Hamiltonian
terms = []
cs = [] #Coefficients
for term in hamiltonian_bk.terms:
paulis = [None, None]
for pauli in term:
paulis[pauli[0]] = pauli[1]
terms += [paulis]
cs += [hamiltonian_bk.terms[term]]
```
## Step 3: Define UCC Ansatz circuit in JaqalPaq
```
def ansatz(theta):
term_probs = []
for i in range(len(terms)):
sexpr = [
'circuit',
#Define constants +-pi/2
('let', 'pi2', pi/2),
('let', 'npi2', -pi/2),
#Create a qubit register
('register', 'q', 2),
('map', 'q0', 'q', 0),
('map', 'q1', 'q', 1),
#Define a hadamard macro
('macro',
'hadamard',
'a',
('sequential_block',
('gate', 'Sy', 'a'),
('gate', 'Px', 'a'),
),
),
#Prepare the state |11>
('gate', 'prepare_all'),
('gate', 'Px', 'q0'),
('gate', 'Px', 'q1'),
#Apply the UCC Ansatz exp[-i*theta(X1 Y0)]
('gate', 'MS', 'q1', 'q0', 'npi2', 0),
('gate', 'Rz', 'q1', theta),
('gate', 'MS', 'q1', 'q0', 'pi2', 0),
]
#Change basis for measurement depending on term
for j, qubit in enumerate(terms[i]):
if qubit == 'X':
sexpr+=('gate', 'hadamard', ('array_item', 'q', j)),
if qubit == 'Y':
sexpr+=('gate', 'Sxd', ('array_item', 'q', j)),
sexpr+=('gate', 'measure_all'),
circuit=circuitbuilder.build(sexpr, native_gates=normalize_native_gates(native_gates.NATIVE_GATES))
#Format results of simulation as a list of lists
sim_result = pygsti.forward_simulate_circuit(circuit)
probs = []
for state in sim_result:
probs += [sim_result[state]] #Append probabilities of each state for a particular term
term_probs += [probs] #Combine lists of probabilities of each term in Hamiltonian
return term_probs
```
## Step 4: Define functions to calculate energy expectation value of Ansatz state
```
#Calculate energy of one term of the Hamiltonian for one possible state
def term_energy(term, state, coefficient, prob):
parity = 1
for i in range(len(term)):
#Change parity if state is occupied and is acted on by a pauli operator
if term[i] != None and state[i] == '1':
parity = -1*parity
return coefficient*prob*parity
#Calculate energy of the molecule for a given value of theta
def calculate_energy(theta):
energy = 0
probs = ansatz(theta[0]) #Convert tuple (from optimization) to float for circuit
for i in range(len(terms)): #For each term in the hamiltonian
for j in range(len(probs[0])): #For each possible state
term = terms[i]
state = '{0:02b}'.format(j) #convert state to binary (# of qubits)
coefficient = cs[i].real
prob = probs[i][j]
energy += term_energy(term, state, coefficient, prob)
return energy
```
## Step 5: Minimize the energy expectation value in 𝜃
```
#Minimize the energy using classical optimization
optimize.minimize(fun=calculate_energy, x0=[0.01], method="COBYLA") #Can use "L-BFGS-B" instead
```
## Step 6: Loop over previous steps to calculate ground state energy at different bond lengths
```
# Set the basis set, spin, and charge of the H2 molecule
basis = 'sto-3g'
multiplicity = 1
charge = 1
# Set calculation parameters
run_scf = 1
run_fci = 1
delete_input = True
# Note: this option is critical as it ensures that the integrals are written out to an HDF5 file
delete_output = False
optimized_energies = []
exact_energies = []
#Loop over bond lengths from 0.5 to 2.0 angstroms
n_pts = 16 #Number of points
bond_lengths = np.linspace(0.5,2.0,n_pts)
for diatomic_bond_length in bond_lengths:
# Generate molecule at some bond length
geometry = [('He', (0., 0., 0.)), ('H', (0., 0., diatomic_bond_length))]
molecule = MolecularData(
geometry, basis, multiplicity, charge,
description=str(round(diatomic_bond_length, 2)),
filename='./HeH+_2_sto-3g_single_dissociation')
# Run pyscf
molecule = run_pyscf(molecule,
run_scf=run_scf,
run_fci=run_fci,
verbose=False)
# Get the fermionic Hamiltonian for H2 and map it into qubits using the Bravyi-Kitaev encoding
hamiltonian = molecule.get_molecular_hamiltonian()
hamiltonian_ferm = of.get_fermion_operator(hamiltonian)
hamiltonian_bk = of.symmetry_conserving_bravyi_kitaev(hamiltonian_ferm, active_orbitals=4, active_fermions=2)
#Define terms and coefficients of our Hamiltonian
terms = []
cs = [] #Coefficients
for term in hamiltonian_bk.terms:
paulis = [None, None]
for pauli in term:
paulis[pauli[0]] = pauli[1]
terms += [paulis]
cs += [hamiltonian_bk.terms[term]]
# Minimize the expectation value of the energy using a classical optimizer (COBYLA)
result = optimize.minimize(fun=calculate_energy, x0=[0.01], method="COBYLA")
optimized_energies.append(result.fun)
exact_energies.append(molecule.fci_energy)
print("R={}\t Optimized Energy: {}".format(str(round(diatomic_bond_length, 2)), result.fun))
```
## Step 7: Plot the dissociation curve
```
import matplotlib
import matplotlib.pyplot as pyplot
# Plot the various energies for different bond lengths
fig = pyplot.figure(figsize=(10,7))
pyplot.rcParams['font.size']=18
bkcolor = '#ffffff'
ax = fig.add_subplot(1, 1, 1)
pyplot.subplots_adjust(left=.2)
ax.set_xlabel('R (Angstroms)')
ax.set_ylabel(r'E (Hartrees)')
ax.set_title(r'HeH+ 2-qubit bond dissociation curve')
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
bond_lengths = [float(x) for x in bond_lengths]
ax.plot(bond_lengths, optimized_energies, 'o', label='UCCSD', color='red')
ax.plot(bond_lengths, exact_energies, '-', label='Full-CI', color='black')
ax.legend(frameon=False)
pyplot.show()
fig.savefig("HeH+ Bond Dissociation Curve.pdf")
```
| github_jupyter |
# Regularization
Welcome to the second assignment of this week. Deep Learning models have so much flexibility and capacity that **overfitting can be a serious problem**, if the training dataset is not big enough. Sure it does well on the training set, but the learned network **doesn't generalize to new examples** that it has never seen!
**You will learn to:** Use regularization in your deep learning models.
Let's first import the packages you are going to use.
```
# import packages
import numpy as np
import matplotlib.pyplot as plt
from reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_dec
from reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parameters
import sklearn
import sklearn.datasets
import scipy.io
from testCases import *
%matplotlib inline
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
```
**Problem Statement**: You have just been hired as an AI expert by the French Football Corporation. They would like you to recommend positions where France's goal keeper should kick the ball so that the French team's players can then hit it with their head.
<img src="images/field_kiank.png" style="width:600px;height:350px;">
<caption><center> <u> **Figure 1** </u>: **Football field**<br> The goal keeper kicks the ball in the air, the players of each team are fighting to hit the ball with their head </center></caption>
They give you the following 2D dataset from France's past 10 games.
```
train_X, train_Y, test_X, test_Y = load_2D_dataset()
```
Each dot corresponds to a position on the football field where a football player has hit the ball with his/her head after the French goal keeper has shot the ball from the left side of the football field.
- If the dot is blue, it means the French player managed to hit the ball with his/her head
- If the dot is red, it means the other team's player hit the ball with their head
**Your goal**: Use a deep learning model to find the positions on the field where the goalkeeper should kick the ball.
**Analysis of the dataset**: This dataset is a little noisy, but it looks like a diagonal line separating the upper left half (blue) from the lower right half (red) would work well.
You will first try a non-regularized model. Then you'll learn how to regularize it and decide which model you will choose to solve the French Football Corporation's problem.
## 1 - Non-regularized model
You will use the following neural network (already implemented for you below). This model can be used:
- in *regularization mode* -- by setting the `lambd` input to a non-zero value. We use "`lambd`" instead of "`lambda`" because "`lambda`" is a reserved keyword in Python.
- in *dropout mode* -- by setting the `keep_prob` to a value less than one
You will first try the model without any regularization. Then, you will implement:
- *L2 regularization* -- functions: "`compute_cost_with_regularization()`" and "`backward_propagation_with_regularization()`"
- *Dropout* -- functions: "`forward_propagation_with_dropout()`" and "`backward_propagation_with_dropout()`"
In each part, you will run this model with the correct inputs so that it calls the functions you've implemented. Take a look at the code below to familiarize yourself with the model.
```
def model(X, Y, learning_rate = 0.3, num_iterations = 30000, print_cost = True, lambd = 0, keep_prob = 1):
"""
Implements a three-layer neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SIGMOID.
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (1 for blue dot / 0 for red dot), of shape (output size, number of examples)
learning_rate -- learning rate of the optimization
num_iterations -- number of iterations of the optimization loop
print_cost -- If True, print the cost every 10000 iterations
lambd -- regularization hyperparameter, scalar
keep_prob - probability of keeping a neuron active during drop-out, scalar.
Returns:
parameters -- parameters learned by the model. They can then be used to predict.
"""
grads = {}
costs = [] # to keep track of the cost
m = X.shape[1] # number of examples
layers_dims = [X.shape[0], 20, 3, 1]
# Initialize parameters dictionary.
parameters = initialize_parameters(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.
if keep_prob == 1:
a3, cache = forward_propagation(X, parameters)
elif keep_prob < 1:
a3, cache = forward_propagation_with_dropout(X, parameters, keep_prob)
# Cost function
if lambd == 0:
cost = compute_cost(a3, Y)
else:
cost = compute_cost_with_regularization(a3, Y, parameters, lambd)
# Backward propagation.
assert(lambd==0 or keep_prob==1) # it is possible to use both L2 regularization and dropout,
# but this assignment will only explore one at a time
if lambd == 0 and keep_prob == 1:
grads = backward_propagation(X, Y, cache)
elif lambd != 0:
grads = backward_propagation_with_regularization(X, Y, cache, lambd)
elif keep_prob < 1:
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)
# Update parameters.
parameters = update_parameters(parameters, grads, learning_rate)
# Print the loss every 10000 iterations
if print_cost and i % 10000 == 0:
print("Cost after iteration {}: {}".format(i, cost))
if print_cost and i % 1000 == 0:
costs.append(cost)
# plot the cost
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
```
Let's train the model without any regularization, and observe the accuracy on the train/test sets.
```
parameters = model(train_X, train_Y)
print ("On the training set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
```
The train accuracy is 94.8% while the test accuracy is 91.5%. This is the **baseline model** (you will observe the impact of regularization on this model). Run the following code to plot the decision boundary of your model.
```
plt.title("Model without regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
```
The non-regularized model is obviously overfitting the training set. It is fitting the noisy points! Lets now look at two techniques to reduce overfitting.
## 2 - L2 Regularization
The standard way to avoid overfitting is called **L2 regularization**. It consists of appropriately modifying your cost function, from:
$$J = -\frac{1}{m} \sum\limits_{i = 1}^{m} \large{(}\small y^{(i)}\log\left(a^{[L](i)}\right) + (1-y^{(i)})\log\left(1- a^{[L](i)}\right) \large{)} \tag{1}$$
To:
$$J_{regularized} = \small \underbrace{-\frac{1}{m} \sum\limits_{i = 1}^{m} \large{(}\small y^{(i)}\log\left(a^{[L](i)}\right) + (1-y^{(i)})\log\left(1- a^{[L](i)}\right) \large{)} }_\text{cross-entropy cost} + \underbrace{\frac{1}{m} \frac{\lambda}{2} \sum\limits_l\sum\limits_k\sum\limits_j W_{k,j}^{[l]2} }_\text{L2 regularization cost} \tag{2}$$
Let's modify your cost and observe the consequences.
**Exercise**: Implement `compute_cost_with_regularization()` which computes the cost given by formula (2). To calculate $\sum\limits_k\sum\limits_j W_{k,j}^{[l]2}$ , use :
```python
np.sum(np.square(Wl))
```
Note that you have to do this for $W^{[1]}$, $W^{[2]}$ and $W^{[3]}$, then sum the three terms and multiply by $ \frac{1}{m} \frac{\lambda}{2} $.
```
# GRADED FUNCTION: compute_cost_with_regularization
def compute_cost_with_regularization(A3, Y, parameters, lambd):
"""
Implement the cost function with L2 regularization. See formula (2) above.
Arguments:
A3 -- post-activation, output of forward propagation, of shape (output size, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
parameters -- python dictionary containing parameters of the model
Returns:
cost - value of the regularized loss function (formula (2))
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"]
cross_entropy_cost = compute_cost(A3, Y) # This gives you the cross-entropy part of the cost
### START CODE HERE ### (approx. 1 line)
L2_regularization_cost = (lambd/(2*m))*(np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3)))
### END CODER HERE ###
cost = cross_entropy_cost + L2_regularization_cost
return cost
A3, Y_assess, parameters = compute_cost_with_regularization_test_case()
print("cost = " + str(compute_cost_with_regularization(A3, Y_assess, parameters, lambd = 0.1)))
```
**Expected Output**:
<table>
<tr>
<td>
**cost**
</td>
<td>
1.78648594516
</td>
</tr>
</table>
Of course, because you changed the cost, you have to change backward propagation as well! All the gradients have to be computed with respect to this new cost.
**Exercise**: Implement the changes needed in backward propagation to take into account regularization. The changes only concern dW1, dW2 and dW3. For each, you have to add the regularization term's gradient ($\frac{d}{dW} ( \frac{1}{2}\frac{\lambda}{m} W^2) = \frac{\lambda}{m} W$).
```
# GRADED FUNCTION: backward_propagation_with_regularization
def backward_propagation_with_regularization(X, Y, cache, lambd):
"""
Implements the backward propagation of our baseline model to which we added an L2 regularization.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
cache -- cache output from forward_propagation()
lambd -- regularization hyperparameter, scalar
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
### START CODE HERE ### (approx. 1 line)
dW3 = 1./m * np.dot(dZ3, A2.T) + lambd*W3/m
### END CODE HERE ###
db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
### START CODE HERE ### (approx. 1 line)
dW2 = 1./m * np.dot(dZ2, A1.T) + lambd*W2/m
### END CODE HERE ###
db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
### START CODE HERE ### (approx. 1 line)
dW1 = 1./m * np.dot(dZ1, X.T) + lambd*W1/m
### END CODE HERE ###
db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
X_assess, Y_assess, cache = backward_propagation_with_regularization_test_case()
grads = backward_propagation_with_regularization(X_assess, Y_assess, cache, lambd = 0.7)
print ("dW1 = "+ str(grads["dW1"]))
print ("dW2 = "+ str(grads["dW2"]))
print ("dW3 = "+ str(grads["dW3"]))
```
**Expected Output**:
<table>
<tr>
<td>
**dW1**
</td>
<td>
[[-0.25604646 0.12298827 -0.28297129]
[-0.17706303 0.34536094 -0.4410571 ]]
</td>
</tr>
<tr>
<td>
**dW2**
</td>
<td>
[[ 0.79276486 0.85133918]
[-0.0957219 -0.01720463]
[-0.13100772 -0.03750433]]
</td>
</tr>
<tr>
<td>
**dW3**
</td>
<td>
[[-1.77691347 -0.11832879 -0.09397446]]
</td>
</tr>
</table>
Let's now run the model with L2 regularization $(\lambda = 0.7)$. The `model()` function will call:
- `compute_cost_with_regularization` instead of `compute_cost`
- `backward_propagation_with_regularization` instead of `backward_propagation`
```
parameters = model(train_X, train_Y, lambd = 0.7)
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
```
Congrats, the test set accuracy increased to 93%. You have saved the French football team!
You are not overfitting the training data anymore. Let's plot the decision boundary.
```
plt.title("Model with L2-regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
```
**Observations**:
- The value of $\lambda$ is a hyperparameter that you can tune using a dev set.
- L2 regularization makes your decision boundary smoother. If $\lambda$ is too large, it is also possible to "oversmooth", resulting in a model with high bias.
**What is L2-regularization actually doing?**:
L2-regularization relies on the assumption that a model with small weights is simpler than a model with large weights. Thus, by penalizing the square values of the weights in the cost function you drive all the weights to smaller values. It becomes too costly for the cost to have large weights! This leads to a smoother model in which the output changes more slowly as the input changes.
<font color='blue'>
**What you should remember** -- the implications of L2-regularization on:
- The cost computation:
- A regularization term is added to the cost
- The backpropagation function:
- There are extra terms in the gradients with respect to weight matrices
- Weights end up smaller ("weight decay"):
- Weights are pushed to smaller values.
## 3 - Dropout
Finally, **dropout** is a widely used regularization technique that is specific to deep learning.
**It randomly shuts down some neurons in each iteration.** Watch these two videos to see what this means!
<!--
To understand drop-out, consider this conversation with a friend:
- Friend: "Why do you need all these neurons to train your network and classify images?".
- You: "Because each neuron contains a weight and can learn specific features/details/shape of an image. The more neurons I have, the more featurse my model learns!"
- Friend: "I see, but are you sure that your neurons are learning different features and not all the same features?"
- You: "Good point... Neurons in the same layer actually don't talk to each other. It should be definitly possible that they learn the same image features/shapes/forms/details... which would be redundant. There should be a solution."
!-->
<center>
<video width="620" height="440" src="images/dropout1_kiank.mp4" type="video/mp4" controls>
</video>
</center>
<br>
<caption><center> <u> Figure 2 </u>: Drop-out on the second hidden layer. <br> At each iteration, you shut down (= set to zero) each neuron of a layer with probability $1 - keep\_prob$ or keep it with probability $keep\_prob$ (50% here). The dropped neurons don't contribute to the training in both the forward and backward propagations of the iteration. </center></caption>
<center>
<video width="620" height="440" src="images/dropout2_kiank.mp4" type="video/mp4" controls>
</video>
</center>
<caption><center> <u> Figure 3 </u>: Drop-out on the first and third hidden layers. <br> $1^{st}$ layer: we shut down on average 40% of the neurons. $3^{rd}$ layer: we shut down on average 20% of the neurons. </center></caption>
When you shut some neurons down, you actually modify your model. The idea behind drop-out is that at each iteration, you train a different model that uses only a subset of your neurons. With dropout, your neurons thus become less sensitive to the activation of one other specific neuron, because that other neuron might be shut down at any time.
### 3.1 - Forward propagation with dropout
**Exercise**: Implement the forward propagation with dropout. You are using a 3 layer neural network, and will add dropout to the first and second hidden layers. We will not apply dropout to the input layer or output layer.
**Instructions**:
You would like to shut down some neurons in the first and second layers. To do that, you are going to carry out 4 Steps:
1. In lecture, we dicussed creating a variable $d^{[1]}$ with the same shape as $a^{[1]}$ using `np.random.rand()` to randomly get numbers between 0 and 1. Here, you will use a vectorized implementation, so create a random matrix $D^{[1]} = [d^{[1](1)} d^{[1](2)} ... d^{[1](m)}] $ of the same dimension as $A^{[1]}$.
2. Set each entry of $D^{[1]}$ to be 0 with probability (`1-keep_prob`) or 1 with probability (`keep_prob`), by thresholding values in $D^{[1]}$ appropriately. Hint: to set all the entries of a matrix X to 0 (if entry is less than 0.5) or 1 (if entry is more than 0.5) you would do: `X = (X < 0.5)`. Note that 0 and 1 are respectively equivalent to False and True.
3. Set $A^{[1]}$ to $A^{[1]} * D^{[1]}$. (You are shutting down some neurons). You can think of $D^{[1]}$ as a mask, so that when it is multiplied with another matrix, it shuts down some of the values.
4. Divide $A^{[1]}$ by `keep_prob`. By doing this you are assuring that the result of the cost will still have the same expected value as without drop-out. (This technique is also called inverted dropout.)
```
# GRADED FUNCTION: forward_propagation_with_dropout
def forward_propagation_with_dropout(X, parameters, keep_prob = 0.5):
"""
Implements the forward propagation: LINEAR -> RELU + DROPOUT -> LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID.
Arguments:
X -- input dataset, of shape (2, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape (20, 2)
b1 -- bias vector of shape (20, 1)
W2 -- weight matrix of shape (3, 20)
b2 -- bias vector of shape (3, 1)
W3 -- weight matrix of shape (1, 3)
b3 -- bias vector of shape (1, 1)
keep_prob - probability of keeping a neuron active during drop-out, scalar
Returns:
A3 -- last activation value, output of the forward propagation, of shape (1,1)
cache -- tuple, information stored for computing the backward propagation
"""
np.random.seed(1)
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
### START CODE HERE ### (approx. 4 lines) # Steps 1-4 below correspond to the Steps 1-4 described above.
D1 = np.random.rand(A1.shape[0],A1.shape[1]) # Step 1: initialize matrix D1 = np.random.rand(..., ...)
D1 = D1<keep_prob # Step 2: convert entries of D1 to 0 or 1 (using keep_prob as the threshold)
A1 = np.multiply(A1, D1) # Step 3: shut down some neurons of A1
A1 = A1/keep_prob # Step 4: scale the value of neurons that haven't been shut down
### END CODE HERE ###
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
### START CODE HERE ### (approx. 4 lines)
D2 = np.random.rand(A2.shape[0],A2.shape[1]) # Step 1: initialize matrix D2 = np.random.rand(..., ...)
D2 = D2<keep_prob # Step 2: convert entries of D2 to 0 or 1 (using keep_prob as the threshold)
A2 = np.multiply(A2,D2) # Step 3: shut down some neurons of A2
A2 = A2/keep_prob # Step 4: scale the value of neurons that haven't been shut down
### END CODE HERE ###
Z3 = np.dot(W3, A2) + b3
A3 = sigmoid(Z3)
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)
return A3, cache
X_assess, parameters = forward_propagation_with_dropout_test_case()
A3, cache = forward_propagation_with_dropout(X_assess, parameters, keep_prob = 0.7)
print ("A3 = " + str(A3))
```
**Expected Output**:
<table>
<tr>
<td>
**A3**
</td>
<td>
[[ 0.36974721 0.00305176 0.04565099 0.49683389 0.36974721]]
</td>
</tr>
</table>
### 3.2 - Backward propagation with dropout
**Exercise**: Implement the backward propagation with dropout. As before, you are training a 3 layer network. Add dropout to the first and second hidden layers, using the masks $D^{[1]}$ and $D^{[2]}$ stored in the cache.
**Instruction**:
Backpropagation with dropout is actually quite easy. You will have to carry out 2 Steps:
1. You had previously shut down some neurons during forward propagation, by applying a mask $D^{[1]}$ to `A1`. In backpropagation, you will have to shut down the same neurons, by reapplying the same mask $D^{[1]}$ to `dA1`.
2. During forward propagation, you had divided `A1` by `keep_prob`. In backpropagation, you'll therefore have to divide `dA1` by `keep_prob` again (the calculus interpretation is that if $A^{[1]}$ is scaled by `keep_prob`, then its derivative $dA^{[1]}$ is also scaled by the same `keep_prob`).
```
# GRADED FUNCTION: backward_propagation_with_dropout
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
"""
Implements the backward propagation of our baseline model to which we added dropout.
Arguments:
X -- input dataset, of shape (2, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
cache -- cache output from forward_propagation_with_dropout()
keep_prob - probability of keeping a neuron active during drop-out, scalar
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1./m * np.dot(dZ3, A2.T)
db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
### START CODE HERE ### (≈ 2 lines of code)
dA2 = dA2*D2 # Step 1: Apply mask D2 to shut down the same neurons as during the forward propagation
dA2 = dA2/keep_prob # Step 2: Scale the value of neurons that haven't been shut down
### END CODE HERE ###
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1./m * np.dot(dZ2, A1.T)
db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
### START CODE HERE ### (≈ 2 lines of code)
dA1 = dA1*D1 # Step 1: Apply mask D1 to shut down the same neurons as during the forward propagation
dA1 = dA1/keep_prob # Step 2: Scale the value of neurons that haven't been shut down
### END CODE HERE ###
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1./m * np.dot(dZ1, X.T)
db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
X_assess, Y_assess, cache = backward_propagation_with_dropout_test_case()
gradients = backward_propagation_with_dropout(X_assess, Y_assess, cache, keep_prob = 0.8)
print ("dA1 = " + str(gradients["dA1"]))
print ("dA2 = " + str(gradients["dA2"]))
```
**Expected Output**:
<table>
<tr>
<td>
**dA1**
</td>
<td>
[[ 0.36544439 0. -0.00188233 0. -0.17408748]
[ 0.65515713 0. -0.00337459 0. -0. ]]
</td>
</tr>
<tr>
<td>
**dA2**
</td>
<td>
[[ 0.58180856 0. -0.00299679 0. -0.27715731]
[ 0. 0.53159854 -0. 0.53159854 -0.34089673]
[ 0. 0. -0.00292733 0. -0. ]]
</td>
</tr>
</table>
Let's now run the model with dropout (`keep_prob = 0.86`). It means at every iteration you shut down each neurons of layer 1 and 2 with 14% probability. The function `model()` will now call:
- `forward_propagation_with_dropout` instead of `forward_propagation`.
- `backward_propagation_with_dropout` instead of `backward_propagation`.
```
parameters = model(train_X, train_Y, keep_prob = 0.86, learning_rate = 0.3)
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
```
Dropout works great! The test accuracy has increased again (to 95%)! Your model is not overfitting the training set and does a great job on the test set. The French football team will be forever grateful to you!
Run the code below to plot the decision boundary.
```
plt.title("Model with dropout")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
```
**Note**:
- A **common mistake** when using dropout is to use it both in training and testing. You should use dropout (randomly eliminate nodes) only in training.
- Deep learning frameworks like [tensorflow](https://www.tensorflow.org/api_docs/python/tf/nn/dropout), [PaddlePaddle](http://doc.paddlepaddle.org/release_doc/0.9.0/doc/ui/api/trainer_config_helpers/attrs.html), [keras](https://keras.io/layers/core/#dropout) or [caffe](http://caffe.berkeleyvision.org/tutorial/layers/dropout.html) come with a dropout layer implementation. Don't stress - you will soon learn some of these frameworks.
<font color='blue'>
**What you should remember about dropout:**
- Dropout is a regularization technique.
- You only use dropout during training. Don't use dropout (randomly eliminate nodes) during test time.
- Apply dropout both during forward and backward propagation.
- During training time, divide each dropout layer by keep_prob to keep the same expected value for the activations. For example, if keep_prob is 0.5, then we will on average shut down half the nodes, so the output will be scaled by 0.5 since only the remaining half are contributing to the solution. Dividing by 0.5 is equivalent to multiplying by 2. Hence, the output now has the same expected value. You can check that this works even when keep_prob is other values than 0.5.
## 4 - Conclusions
**Here are the results of our three models**:
<table>
<tr>
<td>
**model**
</td>
<td>
**train accuracy**
</td>
<td>
**test accuracy**
</td>
</tr>
<td>
3-layer NN without regularization
</td>
<td>
95%
</td>
<td>
91.5%
</td>
<tr>
<td>
3-layer NN with L2-regularization
</td>
<td>
94%
</td>
<td>
93%
</td>
</tr>
<tr>
<td>
3-layer NN with dropout
</td>
<td>
93%
</td>
<td>
95%
</td>
</tr>
</table>
Note that regularization hurts training set performance! This is because it limits the ability of the network to overfit to the training set. But since it ultimately gives better test accuracy, it is helping your system.
Congratulations for finishing this assignment! And also for revolutionizing French football. :-)
<font color='blue'>
**What we want you to remember from this notebook**:
- Regularization will help you reduce overfitting.
- Regularization will drive your weights to lower values.
- L2 regularization and Dropout are two very effective regularization techniques.
| github_jupyter |
```
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# The two-dimensional domain of the fit.
xmin, xmax, nx = -5, 4, 75
ymin, ymax, ny = -3, 7, 150
x, y = np.linspace(xmin, xmax, nx), np.linspace(ymin, ymax, ny)
X, Y = np.meshgrid(x, y)
# Our function to fit is going to be a sum of two-dimensional Gaussians
def gaussian(x, y, x0, y0, xalpha, yalpha, A):
return A * np.exp( -((x-x0)/xalpha)**2 -((y-y0)/yalpha)**2)
# A list of the Gaussian parameters: x0, y0, xalpha, yalpha, A
gprms = [(0, 2, 2.5, 5.4, 1.5),
(-1, 4, 6, 2.5, 1.8),
(-3, -0.5, 1, 2, 4),
(3, 0.5, 2, 1, 5)
]
# Standard deviation of normally-distributed noise to add in generating
# our test function to fit.
noise_sigma = 0.1
# The function to be fit is Z.
Z = np.zeros(X.shape)
# for p in gprms:
p = gprms[1]
Z += gaussian(X, Y, *p)
Z += noise_sigma * np.random.randn(*Z.shape)
# Plot the 3D figure of the fitted function and the residuals.
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z, cmap='plasma')
ax.set_zlim(0,np.max(Z)+2)
plt.show()
# This is the callable that is passed to curve_fit. M is a (2,N) array
# where N is the total number of data points in Z, which will be ravelled
# to one dimension.
def _gaussian(M, x0, y0, xalpha, yalpha, A):
x, y = M
arr = gaussian(x, y, x0, y0, xalpha, yalpha, A)
return arr
# Initial guesses to the fit parameters.
guess_prms = [(0, 0, 1, 1, 2),
(-1.5, 5, 5, 1, 3),
(-4, -1, 1.5, 1.5, 6),
(4, 1, 1.5, 1.5, 6.5)
]
# Flatten the initial guess parameter list.
p0 = [p for prms in guess_prms for p in prms]
print(p0)
# We need to ravel the meshgrids of X, Y points to a pair of 1-D arrays.
xdata = np.vstack((X.ravel(), Y.ravel()))
print(Z)
# Do the fit, using our custom _gaussian function which understands our
# flattened (ravelled) ordering of the data points.
popt, pcov = curve_fit(_gaussian, xdata, Z.ravel())
fit = np.zeros(Z.shape)
for i in range(len(popt)//5):
fit += gaussian(X, Y, *popt[i*5:i*5+5])
print('Fitted parameters:')
print(popt)
rms = np.sqrt(np.mean((Z - fit)**2))
print('RMS residual =', rms)
# Plot the 3D figure of the fitted function and the residuals.
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, fit, cmap='plasma')
cset = ax.contourf(X, Y, Z-fit, zdir='z', offset=-4, cmap='plasma')
ax.set_zlim(-4,np.max(fit))
plt.show()
# Plot the test data as a 2D image and the fit as overlaid contours.
fig = plt.figure()
ax = fig.add_subplot(111)
ax.imshow(Z, origin='lower', cmap='plasma',
extent=(x.min(), x.max(), y.min(), y.max()))
ax.contour(X, Y, fit, colors='w')
plt.show()
```
| github_jupyter |
### Global and Local Scopes
In Python the **global** scope refers to the **module** scope.
The scope of a variable is normally defined by **where** it is (lexically) defined in the code.
```
a = 10
```
In this case, **a** is defined inside the main module, so it is a global variable.
```
def my_func(n):
c = n ** 2
return c
```
In this case, **c** was defined inside the function **my_func**, so it is **local** to the function **my_func**. In this example, **n** is also **local** to **my_func**
Global variables can be accessed from any inner scope in the module, for example:
```
def my_func(n):
print('global:', a)
c = a ** n
return c
my_func(2)
```
As you can see, **my_func** was able to reference the global variable **a**.
But remember that the scope of a variable is determined by where it is assigned. In particular, any variable defined (i.e. assigned a value) inside a function is local to that function, even if the variable name happens to be global too!
```
def my_func(n):
a = 2
c = a ** 2
return c
print(a)
print(my_func(3))
print(a)
```
In order to change the value of a global variable within an inner scope, we can use the **global** keyword as follows:
```
def my_func(n):
global a
a = 2
c = a ** 2
return c
print(a)
print(my_func(3))
print(a)
```
As you can see, the value of the global variable **a** was changed from within **my_func**.
In fact, we can **create** global variables from within an inner function - Python will simply create the variable and place it in the **global** scope instead of the **local scope**:
```
def my_func(n):
global var
var = 'hello world'
return n ** 2
```
Now, **var** does not exist yet, since the function has not run:
```
print(var)
```
Once we call the function though, it will create that global **var**:
```
my_func(2)
print(var)
```
#### Beware!!
Remember that whenever you assign a value to a variable without having specified the variable as **global**, it is **local** in the current scope. **Moreover**, it does not matter **where** the assignment in the code takes place, the variable is considered local in the **entire** scope - Python determines the scope of objects at compile-time, not at run-time.
Let's see an example of this:
```
a = 10
b = 100
def my_func():
print(a)
print(b)
my_func()
```
So, this works as expected - **a** and **b** are taken from the global scope since they are referenced **before** being assigned a value in the local scope.
But now consider the following example:
```
a = 10
b = 100
def my_func():
print(a)
print(b)
b = 1000
my_func()
```
As you can see, **b** in the line ``print(b)`` is considered a **local** variable - that's because the **next** line **assigns** a value to **b** - hence **b** is scoped as local by Python for the **entire** function.
Of course, functions are also objects, and scoping applies equally to function objects too. For example, we can "mask" the built-in `print` Python function:
```
print = lambda x: 'hello {0}!'.format(x)
def my_func(name):
return print(name)
my_func('world')
```
You may be wondering how we get our **real** ``print`` function back!
```
del print
print('hello')
```
Yay!!
If you have experience in some other programming languages you may be wondering if loops and other code "blocks" have their own local scope too. For example in Java, the following would not work:
``for (int i=0; i<10; i++) {
int x = 2 * i;
}
system.out.println(x);
``
But in Python it works perfectly fine:
```
for i in range(10):
x = 2 * i
print(x)
```
In this case, when we assigned a value to `x`, Python put it in the global (module) scope, so we can reference it after the `for` loop has finished running.
| github_jupyter |
# EDA: basic
### References
- [MLMastery: 17 Statistical Hypothesis Tests in Python (Cheat Sheet)](https://machinelearningmastery.com/statistical-hypothesis-tests-in-python-cheat-sheet/)
- [How to Use Statistical Significance Tests to Interpret Machine Learning Results](https://machinelearningmastery.com/use-statistical-significance-tests-interpret-machine-learning-results/)
- [p-values problemas fail for too large samles](https://www.semanticscholar.org/paper/Research-Commentary-Too-Big-to-Fail%3A-Large-Samples-Lin-Lucas/7241c748932deb734fff1681e951e50be0853a39?p2df)
```
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
from scipy.stats import kurtosis
from scipy.stats import skew
```
## load data
```
# load dataset
dataset = load_iris()
dataset.keys()
# dataset to df
data = pd.DataFrame(dataset.data, columns = dataset.feature_names)
data['class'] = dataset.target
dclass = dict()
for i, ic in enumerate(dataset.target_names):
dclass[i] = ic
data['class'] = data['class'].map(dclass)
```
## df format
```
# check what columns are NUMERICAL or CATEGORICAL
cols_num = data.select_dtypes(include=['float64', 'int64']).columns.values # numerical columns
cols_cat = data.select_dtypes(include=['object']).columns.values # categorical columns
# columns name converters: numerical
dcols_num_name_to_alias = dict()
dcols_num_alias_to_name = dict()
for i, ic in enumerate(cols_num):
dcols_num_name_to_alias[ic] = 'n{}'.format(i)
dcols_num_alias_to_name['n{}'.format(i)] = ic
# columns name converters: categorical
dcols_cat_name_to_alias = dict()
dcols_cat_alias_to_name = dict()
for i, ic in enumerate(cols_cat):
dcols_cat_name_to_alias[ic] = 'c{}'.format(i)
dcols_cat_alias_to_name['c{}'.format(i)] = ic
# rename columns
data.rename(columns = dcols_num_name_to_alias, inplace = True)
data.rename(columns = dcols_cat_name_to_alias, inplace = True)
# list of alias
cols_num_alias = list(dcols_num_name_to_alias.values())
cols_cat_alias = list(dcols_cat_name_to_alias.values())
```
# descriptive analysis
### numerical
```
# describe
dfn = data[cols_num_alias].describe(include = 'all', percentiles = [.05, .25, .5, .75, .95]).T
# add percent of nan values
dfn['%nan'] = (data[cols_num_alias].isnull().sum()*100 / len(data)).values
# kurtosis
dfn['kurtosis'] = kurtosis(data[cols_num_alias])
# skew
dfn['skew'] = skew(data[cols_num_alias])
# rename index
dfn.index = dfn.index.map(dcols_num_alias_to_name)
dfn
```
### categorical
```
# describe
dfc = data[cols_cat_alias].describe(include = 'all').T[['count', 'unique']]
# add percent of nan values
dfc['%nan'] = (data[cols_cat_alias].isnull().sum()*100 / len(data)).values
## add categories percenets
# maximum number of categories to be showed
max_size_cats = 5
# set columns
col_temp = ['var'] + ['value{}'.format(i) for i in range(max_size_cats)] + ['%value{}'.format(i) for i in range(max_size_cats)]
# initialize
values_temp = list()
# loop of variables
for col in cols_cat_alias:
# count categories
temp = data[col].value_counts(normalize=True,sort=True,ascending=False)*100.
# collect values and names
c = temp.index.values
v = temp.values
# resize
if len(v) > max_size_cats:
v = np.append(v[:max_size_cats-1], np.sum(v[-(max_size_cats):]))
c = np.append(c[:max_size_cats-1], 'others')
else:
v = np.pad(v,(0, max_size_cats-len(v)), 'constant', constant_values=np.nan)
c = np.pad(c,(0, max_size_cats-len(c)), 'constant', constant_values=np.nan)
# append
values_temp.append([col] + list(np.append(c,v)))
# add new information
dfc = pd.concat([dfc, pd.DataFrame(values_temp, columns = col_temp).set_index('var')], axis = 1)
# rename index
dfc.index = dfc.index.map(dcols_cat_alias_to_name)
dfc
```
# TEST DE NORMALIDAD
## hapiro-Wilk Test / D’Agostino’s K^2 Test / nderson-Darling Test
Tests whether a data sample has a Gaussian distribution.
### Assumptions
- Observations in each sample are independent and identically distributed (iid).
### Interpretation
- H0: the sample has a Gaussian distribution.
- H1: the sample does not have a Gaussian distribution.
```
def test_shapiro(data):
from scipy.stats import shapiro
stat, p = shapiro(data)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably Gaussian')
else:
print('Probably not Gaussian')
def test_k2(data):
from scipy.stats import normaltest
stat, p = normaltest(data)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably Gaussian')
else:
print('Probably not Gaussian')
def test_anderson(data):
from scipy.stats import anderson
result = anderson(data)
print('stat=%.3f' % (result.statistic))
for i in range(len(result.critical_values)):
sl, cv = result.significance_level[i], result.critical_values[i]
if result.statistic < cv:
print('Probably Gaussian at the %.1f%% level' % (sl))
else:
print('Probably not Gaussian at the %.1f%% level' % (sl))
```
## prueba 1: caso de si normalidad
```
mu = 0; sigma = .1
v = np.random.normal(mu, sigma, 1000)
test_shapiro(v)
test_k2(v)
test_anderson(v)
```
## prueba 2: caso de no normalidad
```
mu1 = 0; sigma1 = .1
mu2 = 0.5; sigma2 = .05
v = np.array(list(np.random.normal(mu1, sigma1, 1000)) + list(np.random.normal(mu2, sigma2, 1000)))
# plot
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.hist(v)
plt.show()
test_shapiro(v)
test_k2(v)
test_anderson(v)
```
# TESTEAR variable numerica es RANDOM UNIFORM
Basado en **Kolmogorov-Smirnov (2 samples)** para ver si la variable tiene una distribucion igual a una distribucion uniforme artificial.
```
def test_ks2(data1, data2):
from scipy.stats import ks_2samp
stat, p = ks_2samp(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
def test_uniform_num(data):
from scipy.stats import uniform, ks_2samp
dismin=np.amin(data)
dismax=np.amax(data)
T=uniform(dismin,dismax-dismin).rvs(data.shape[0])
stat, p = ks_2samp(data, T)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably is Uniform')
else:
print('Probably is not Uniform')
```
### prueba 1: si es uniforme
```
v = np.array([np.random.uniform() for i in range(1000)])
test_uniform_num(v)
```
### prueba 2: no es uniforme
```
mu = 0; sigma = .1
v = np.random.normal(mu, sigma, 1000)
test_uniform_num(v)
```
# TESTEAR variable categorica es RANDOM UNIFORM
He usado un **Kolmogorov-Smirnov (2 samples)** entre el sample y su correspondiente uniforme despues de transformar las categorias en valores numericos.
> NOTA: Introduje una validacion para samples demasiado grandes, pues en estos casos se vuelve demasiado fino. de esta manera le doy algo de margen para considerar que no es Uniforme.
```
def test_uniform_cat(data):
from scipy.stats import ks_2samp
# number of categories
cats = np.unique(data)
# resize if data is too large
if len(data)>1000 and len(cats)*1000 < len(data):
data = np.random.choice(data, size = len(cats)*1000)
# create artificial data with uniform distribution
data_uniform = np.random.choice(cats, size = len(data), p = np.ones(len(cats)) / len(cats))
# cat to num of input data
temp = list()
for ii, ic in enumerate(cats):
temp += list(np.ones(len(data[data==ic])) * ii)
data_modif = np.array(temp)
# cat to num of artificial data
temp = list()
for ii, ic in enumerate(cats):
temp += list(np.ones(len(data_uniform[data_uniform==ic])) * ii)
data_uniform_modif = np.array(temp)
# test
stat, p = ks_2samp(data, data_uniform)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably is Uniform')
else:
print('Probably is not Uniform')
```
### prueba 1: si es uniforme
```
v = np.random.choice(np.array(['1', '2', '3']), size = 10000, p = [0.33, 0.33, 0.34])
test_uniform_cat(v)
```
### prueba 2: no es uniforme
```
v = np.random.choice(np.array(['1', '2', '3']), size = 100000, p = [0.25, 0.5, 0.25])
test_uniform_cat(v)
```
# MONOTONIC RELATIONSHIP (non-parametric tests)
Tests whether two samples have a monotonic relationship.
## Spearman's / Kendall's Rank Correlation Test
### Assumptions
- Observations in each sample are independent and identically distributed (iid).
- Observations in each sample can be ranked.
### Interpretation
- H0: the two samples are independent.
- H1: there is a dependency between the samples.
```
# columns selection
x1_col = cols_num_alias[2]
x2_col = cols_num_alias[3]
# collect data
df = data[[x1_col, x2_col]]
data1 = df[x1_col].values
data2 = df[x2_col].values
# Example of the Spearman's Rank Correlation Test
from scipy.stats import spearmanr
stat, p = spearmanr(data1, data2)
print('stat=%.3f, p=%.5f' % (stat, p))
if p > 0.05:
print('Probably independent')
else:
print('Probably dependent')
# Example of the Kendall's Rank Correlation Test
from scipy.stats import kendalltau
stat, p = kendalltau(data1, data2)
print('stat=%.3f, p=%.5f' % (stat, p))
if p > 0.05:
print('Probably independent')
else:
print('Probably dependent')
df.plot(kind = 'scatter', x = x1_col, y = x2_col)
```
# IDENTIFICACION DE HETEROGENEIDAD (non-parametric test for non-paired samples)
## Kruskal-Wallis H Test
Tests whether the distributions of **two or more** independent samples are equal or not.
### Assumptions
- Observations in each sample are independent and identically distributed (iid).
- Observations in each sample can be ranked.
### Interpretation
- H0: the distributions of all samples are equal.
- H1: the distributions of one or more samples are not equal.
```
def test_kruskal2(data1, data2):
from scipy.stats import kruskal
stat, p = kruskal(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
def test_kruskal3(data1, data2, data3):
from scipy.stats import kruskal
stat, p = kruskal(data1, data2, data3)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
```
### prueba 1: deberia identificarse heterogeneidad
```
col_num = dcols_num_name_to_alias['petal length (cm)']
col_cat = dcols_cat_name_to_alias['class']
v1 = data[data[col_cat] == 'setosa'][col_num].values
v2 = data[data[col_cat] == 'versicolor'][col_num].values
v3 = data[data[col_cat] == 'virginica'][col_num].values
test_kruskal2(v1, v2)
test_kruskal2(v1, v3)
test_kruskal2(v2, v3)
test_kruskal3(v1, v2, v3)
```
### prueba 2: no deberia identificarse heterogeneidad
```
mu = 0; sigma = .1
v = np.random.normal(mu, sigma, 1000)
v1 = v[:600]
v2 = v[600:]
v1.shape, v2.shape
test_kruskal2(v1, v2)
```
# TEST IF SAME DISTRIBUTION (non-parametric test for paired samples)
## Wilcoxon Signed-Rank Test
Tests whether the distributions of two paired samples are equal or not.
### Assumptions
- Observations in each sample are independent and identically distributed (iid).
- Observations in each sample can be ranked.
- Observations across each sample are paired.
### Interpretation
- H0: the distributions of both samples are equal.
- H1: the distributions of both samples are not equal.
```
# Example of the Wilcoxon Signed-Rank Test
def test_wilcoxon(data1:np.array, data2:np.array):
from scipy.stats import wilcoxon
stat, p = wilcoxon(data1, data2)
print('stat=%.5f, p=%.5f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
```
### prueba 1: 2 samples de una misma distribucion normal (homegeneidad)
```
mu = 0; sigma = .1
v1 = np.random.normal(mu, sigma, 100)
v2 = np.random.normal(mu, sigma, 100)
test_wilcoxon(v1, v2)
```
### prueba 2: 2 samples de dos distribuciones normales muy parecidas pero no iguales (heterogeneidad)
```
mu1 = 0; sigma1 = .1
mu2 = 0.05; sigma2 = .1
v1 = np.random.normal(mu1, sigma1, 1000)
v2 = np.random.normal(mu2, sigma2, 1000)
test_wilcoxon(v1, v2)
```
| github_jupyter |
# Ungraded Lab: Walkthrough of ML Metadata
Keeping records at each stage of the project is an important aspect of machine learning pipelines. Especially in production models which involve many iterations of datasets and re-training, having these records will help in maintaining or debugging the deployed system. [ML Metadata](https://www.tensorflow.org/tfx/guide/mlmd) addresses this need by having an API suited specifically for keeping track of any progress made in ML projects.
As mentioned in earlier labs, you have already used ML Metadata when you ran your TFX pipelines. Each component automatically records information to a metadata store as you go through each stage. It allowed you to retrieve information such as the name of the training splits or the location of an inferred schema.
In this notebook, you will look more closely at how ML Metadata can be used directly for recording and retrieving metadata independent from a TFX pipeline (i.e. without using TFX components). You will use TFDV to infer a schema and record all information about this process. These will show how the different components are related to each other so you can better interact with the database when you go back to using TFX in the next labs. Moreover, knowing the inner workings of the library will help you adapt it for other platforms if needed.
Let's get to it!
## Imports
```
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
import tensorflow as tf
print('TF version: {}'.format(tf.__version__))
import tensorflow_data_validation as tfdv
print('TFDV version: {}'.format(tfdv.version.__version__))
import urllib
import zipfile
```
## Download dataset
You will be using the [Chicago Taxi](https://data.cityofchicago.org/Transportation/Taxi-Trips/wrvz-psew) dataset for this lab. Let's download the CSVs into your workspace.
```
# Download the zip file from GCP and unzip it
url = 'https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip'
zip, headers = urllib.request.urlretrieve(url)
zipfile.ZipFile(zip).extractall()
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R data
```
## Process Outline
Here is the figure shown in class that describes the different components in an ML Metadata store:
<img src='images/mlmd_overview.png' alt='image of mlmd overview'>
The green box in the middle shows the data model followed by ML Metadata. The [official documentation](https://www.tensorflow.org/tfx/guide/mlmd#data_model) describe each of these and we'll show it here as well for easy reference:
* `ArtifactType` describes an artifact's type and its properties that are stored in the metadata store. You can register these types on-the-fly with the metadata store in code, or you can load them in the store from a serialized format. Once you register a type, its definition is available throughout the lifetime of the store.
* An `Artifact` describes a specific instance of an ArtifactType, and its properties that are written to the metadata store.
* An `ExecutionType` describes a type of component or step in a workflow, and its runtime parameters.
* An `Execution` is a record of a component run or a step in an ML workflow and the runtime parameters. An execution can be thought of as an instance of an ExecutionType. Executions are recorded when you run an ML pipeline or step.
* An `Event` is a record of the relationship between artifacts and executions. When an execution happens, events record every artifact that was used by the execution, and every artifact that was produced. These records allow for lineage tracking throughout a workflow. By looking at all events, MLMD knows what executions happened and what artifacts were created as a result. MLMD can then recurse back from any artifact to all of its upstream inputs.
* A `ContextType` describes a type of conceptual group of artifacts and executions in a workflow, and its structural properties. For example: projects, pipeline runs, experiments, owners etc.
* A `Context` is an instance of a ContextType. It captures the shared information within the group. For example: project name, changelist commit id, experiment annotations etc. It has a user-defined unique name within its ContextType.
* An `Attribution` is a record of the relationship between artifacts and contexts.
* An `Association` is a record of the relationship between executions and contexts.
As mentioned earlier, you will use TFDV to generate a schema and record this process in the ML Metadata store. You will be starting from scratch so you will be defining each component of the data model. The outline of steps involve:
1. Defining the ML Metadata's storage database
1. Setting up the necessary artifact types
1. Setting up the execution types
1. Generating an input artifact unit
1. Generating an execution unit
1. Registering an input event
1. Running the TFDV component
1. Generating an output artifact unit
1. Registering an output event
1. Updating the execution unit
1. Seting up and generating a context unit
1. Generating attributions and associations
You can then retrieve information from the database to investigate aspects of your project. For example, you can find which dataset was used to generate a particular schema. You will also do that in this exercise.
For each of these steps, you may want to have the [MetadataStore API documentation](https://www.tensorflow.org/tfx/ml_metadata/api_docs/python/mlmd/MetadataStore) open so you can lookup any of the methods you will be using to interact with the metadata store. You can also look at the `metadata_store` protocol buffer [here](https://github.com/google/ml-metadata/blob/r0.24.0/ml_metadata/proto/metadata_store.proto) to see descriptions of each data type covered in this tutorial.
## Define ML Metadata's Storage Database
The first step would be to instantiate your storage backend. As mentioned in class, there are several types supported such as fake (temporary) database, SQLite, MySQL, and even cloud-based storage. For this demo, you will just be using a fake database for quick experimentation.
```
# Instantiate a connection config
connection_config = metadata_store_pb2.ConnectionConfig()
# Set an empty fake database proto
connection_config.fake_database.SetInParent()
# Setup the metadata store
store = metadata_store.MetadataStore(connection_config)
```
## Register ArtifactTypes
Next, you will create the artifact types needed and register them to the store. Since our simple exercise will just involve generating a schema using TFDV, you will only create two artifact types: one for the **input dataset** and another for the **output schema**. The main steps will be to:
* Declare an `ArtifactType()`
* Define the name of the artifact type
* Define the necessary properties within these artifact types. For example, it is important to know the data split name so you may want to have a `split` property for the artifact type that holds datasets.
* Use `put_artifact_type()` to register them to the metadata store. This generates an `id` that you can use later to refer to a particular artifact type.
*Bonus: For practice, you can also extend the code below to create an artifact type for the statistics.*
```
# Create ArtifactType for the input dataset
data_artifact_type = metadata_store_pb2.ArtifactType()
data_artifact_type.name = 'DataSet'
data_artifact_type.properties['name'] = metadata_store_pb2.STRING
data_artifact_type.properties['split'] = metadata_store_pb2.STRING
data_artifact_type.properties['version'] = metadata_store_pb2.INT
# Register artifact type to the Metadata Store
data_artifact_type_id = store.put_artifact_type(data_artifact_type)
# Create ArtifactType for Schema
schema_artifact_type = metadata_store_pb2.ArtifactType()
schema_artifact_type.name = 'Schema'
schema_artifact_type.properties['name'] = metadata_store_pb2.STRING
schema_artifact_type.properties['version'] = metadata_store_pb2.INT
# Register artifact type to the Metadata Store
schema_artifact_type_id = store.put_artifact_type(schema_artifact_type)
print('Data artifact type:\n', data_artifact_type)
print('Schema artifact type:\n', schema_artifact_type)
print('Data artifact type ID:', data_artifact_type_id)
print('Schema artifact type ID:', schema_artifact_type_id)
```
## Register ExecutionType
You will then create the execution types needed. For the simple setup, you will just declare one for the data validation component with a `state` property so you can record if the process is running or already completed.
```
# Create ExecutionType for Data Validation component
dv_execution_type = metadata_store_pb2.ExecutionType()
dv_execution_type.name = 'Data Validation'
dv_execution_type.properties['state'] = metadata_store_pb2.STRING
# Register execution type to the Metadata Store
dv_execution_type_id = store.put_execution_type(dv_execution_type)
print('Data validation execution type:\n', dv_execution_type)
print('Data validation execution type ID:', dv_execution_type_id)
```
## Generate input artifact unit
With the artifact types created, you can now create instances of those types. The cell below creates the artifact for the input dataset. This artifact is recorded in the metadata store through the `put_artifacts()` function. Again, it generates an `id` that can be used for reference.
```
# Declare input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = './data/train/data.csv'
data_artifact.type_id = data_artifact_type_id
data_artifact.properties['name'].string_value = 'Chicago Taxi dataset'
data_artifact.properties['split'].string_value = 'train'
data_artifact.properties['version'].int_value = 1
# Submit input artifact to the Metadata Store
data_artifact_id = store.put_artifacts([data_artifact])[0]
print('Data artifact:\n', data_artifact)
print('Data artifact ID:', data_artifact_id)
```
## Generate execution unit
Next, you will create an instance of the `Data Validation` execution type you registered earlier. You will set the state to `RUNNING` to signify that you are about to run the TFDV function. This is recorded with the `put_executions()` function.
```
# Register the Execution of a Data Validation run
dv_execution = metadata_store_pb2.Execution()
dv_execution.type_id = dv_execution_type_id
dv_execution.properties['state'].string_value = 'RUNNING'
# Submit execution unit to the Metadata Store
dv_execution_id = store.put_executions([dv_execution])[0]
print('Data validation execution:\n', dv_execution)
print('Data validation execution ID:', dv_execution_id)
```
## Register input event
An event defines a relationship between artifacts and executions. You will generate the input event relationship for dataset artifact and data validation execution units. The list of event types are shown [here](https://github.com/google/ml-metadata/blob/master/ml_metadata/proto/metadata_store.proto#L187) and the event is recorded with the `put_events()` function.
```
# Declare the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = dv_execution_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Submit input event to the Metadata Store
store.put_events([input_event])
print('Input event:\n', input_event)
```
## Run the TFDV component
You will now run the TFDV component to generate the schema of dataset. This should look familiar since you've done this already in Week 1.
```
# Infer a schema by passing statistics to `infer_schema()`
train_data = './data/train/data.csv'
train_stats = tfdv.generate_statistics_from_csv(data_location=train_data)
schema = tfdv.infer_schema(statistics=train_stats)
schema_file = './schema.pbtxt'
tfdv.write_schema_text(schema, schema_file)
print("Dataset's Schema has been generated at:", schema_file)
```
## Generate output artifact unit
Now that the TFDV component has finished running and schema has been generated, you can create the artifact for the generated schema.
```
# Declare output artifact of type Schema_artifact
schema_artifact = metadata_store_pb2.Artifact()
schema_artifact.uri = schema_file
schema_artifact.type_id = schema_artifact_type_id
schema_artifact.properties['version'].int_value = 1
schema_artifact.properties['name'].string_value = 'Chicago Taxi Schema'
# Submit output artifact to the Metadata Store
schema_artifact_id = store.put_artifacts([schema_artifact])[0]
print('Schema artifact:\n', schema_artifact)
print('Schema artifact ID:', schema_artifact_id)
```
## Register output event
Analogous to the input event earlier, you also want to define an output event to record the ouput artifact of a particular execution unit.
```
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = schema_artifact_id
output_event.execution_id = dv_execution_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
print('Output event:\n', output_event)
```
## Update the execution unit
As the TFDV component has finished running successfully, you need to update the `state` of the execution unit and record it again to the store.
```
# Mark the `state` as `COMPLETED`
dv_execution.id = dv_execution_id
dv_execution.properties['state'].string_value = 'COMPLETED'
# Update execution unit in the Metadata Store
store.put_executions([dv_execution])
print('Data validation execution:\n', dv_execution)
```
## Setting up Context Types and Generating a Context Unit
You can group the artifacts and execution units into a `Context`. First, you need to define a `ContextType` which defines the required context. It follows a similar format as artifact and event types. You can register this with the `put_context_type()` function.
```
# Create a ContextType
expt_context_type = metadata_store_pb2.ContextType()
expt_context_type.name = 'Experiment'
expt_context_type.properties['note'] = metadata_store_pb2.STRING
# Register context type to the Metadata Store
expt_context_type_id = store.put_context_type(expt_context_type)
```
Similarly, you can create an instance of this context type and use the `put_contexts()` method to register to the store.
```
# Generate the context
expt_context = metadata_store_pb2.Context()
expt_context.type_id = expt_context_type_id
# Give the experiment a name
expt_context.name = 'Demo'
expt_context.properties['note'].string_value = 'Walkthrough of metadata'
# Submit context to the Metadata Store
expt_context_id = store.put_contexts([expt_context])[0]
print('Experiment Context type:\n', expt_context_type)
print('Experiment Context type ID: ', expt_context_type_id)
print('Experiment Context:\n', expt_context)
print('Experiment Context ID: ', expt_context_id)
```
## Generate attribution and association relationships
With the `Context` defined, you can now create its relationship with the artifact and executions you previously used. You will create the relationship between schema artifact unit and experiment context unit to form an `Attribution`.
Similarly, you will create the relationship between data validation execution unit and experiment context unit to form an `Association`. These are registered with the `put_attributions_and_associations()` method.
```
# Generate the attribution
expt_attribution = metadata_store_pb2.Attribution()
expt_attribution.artifact_id = schema_artifact_id
expt_attribution.context_id = expt_context_id
# Generate the association
expt_association = metadata_store_pb2.Association()
expt_association.execution_id = dv_execution_id
expt_association.context_id = expt_context_id
# Submit attribution and association to the Metadata Store
store.put_attributions_and_associations([expt_attribution], [expt_association])
print('Experiment Attribution:\n', expt_attribution)
print('Experiment Association:\n', expt_association)
```
## Retrieving Information from the Metadata Store
You've now recorded the needed information to the metadata store. If we did this in a persistent database, you can track which artifacts and events are related to each other even without seeing the code used to generate it. See a sample run below where you investigate what dataset is used to generate the schema. (**It would be obvious which dataset is used in our simple demo because we only have two artifacts registered. Thus, assume that you have thousands of entries in the metadata store.*)
```
# Get artifact types
store.get_artifact_types()
# Get 1st element in the list of `Schema` artifacts.
# You will investigate which dataset was used to generate it.
schema_to_inv = store.get_artifacts_by_type('Schema')[0]
# print output
print(schema_to_inv)
# Get events related to the schema id
schema_events = store.get_events_by_artifact_ids([schema_to_inv.id])
print(schema_events)
```
You see that it is an output of an execution so you can look up the execution id to see related artifacts.
```
# Get events related to the output above
execution_events = store.get_events_by_execution_ids([schema_events[0].execution_id])
print(execution_events)
```
You see the declared input of this execution so you can select that from the list and lookup the details of the artifact.
```
# Look up the artifact that is a declared input
artifact_input = execution_events[0]
store.get_artifacts_by_id([artifact_input.artifact_id])
```
Great! Now you've fetched the dataset artifact that was used to generate the schema. You can approach this differently and we urge you to practice using the different methods of the [MetadataStore API](https://www.tensorflow.org/tfx/ml_metadata/api_docs/python/mlmd/MetadataStore) to get more familiar with interacting with the database.
### Wrap Up
In this notebook, you got to practice using ML Metadata outside of TFX. This should help you understand its inner workings so you will know better how to query ML Metadata stores or even set it up for your own use cases. TFX leverages this library to keep records of pipeline runs and you will get to see more of that in the next labs. Next up, you will review how to work with schemas and in the next notebook, you will see how it can be implemented in a TFX pipeline.
| github_jupyter |
# Board Game Review Using Linear Regression & Random Forest
```
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import seaborn as sns
import pandas as pd
import numpy as np
# Load the data
games = pd.read_csv("games.csv")
# Columns in games.csv
print(games.columns)
# Shape of dataset
print(games.shape)
# Make a histogram of ratings in 'average_rating'
plt.hist(games['average_rating'])
plt.show()
# Print the first row of games with score of zero
print(games[games['average_rating'] == 0].iloc[0])
# Print the first row of games with score greater than zero
print(games[games['average_rating'] > 0].iloc[0])
# Remove the games with no user reviews
games = games[games['users_rated'] > 0]
# Remove the row with missing values
games = games.dropna(axis=0)
# Another histogram
plt.hist(games['average_rating'])
plt.show()
print(games.columns)
```
##### Correlation Coefficient:
Link -- http://www.statisticshowto.com/probability-and-statistics/correlation-coefficient-formula/
##### Correlation Matrix:
Link -- http://www.statisticshowto.com/correlation-matrix/
```
# Correlation Matrix
co_mat = games.corr()
fig = plt.figure(figsize = (12,9))
sns.heatmap(co_mat, vmax=0.8, square=True)
plt.show()
# Get all the columns from dataFrame
col = games.columns.tolist()
# Filter the columns to remove useless data
col = [c for c in col if c not in ['bayes_average_rating', 'average_rating', 'type', 'name', 'id']]
# Store the variable we will be predicting
target = "average_rating"
# Generate train(80%) and test(20%) datasets
from sklearn.cross_validation import train_test_split
# Generate training dataset
train = games.sample(frac=0.8, random_state=1)
# Anything not in training set is in test set
test = games.loc[~games.index.isin(train.index)]
# shapes
print(train.shape)
print(test.shape)
```
# Linear Regression Model
```
# Import linear regrassion model
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Initialize the model class
LR = LinearRegression()
# fit the model
LR.fit(train[col], train[target])
# Generate predictions for test set
predictions = LR.predict(test[col])
# Compute error between our prediction and actual test set
m = mean_squared_error(predictions, test[target])
print(m)
# Accuracy of model
print('Accuracy of linear model is:{:.3f}'.format(LR.score(test[col], test[target])))
```
# Random Forest Model
```
from sklearn.ensemble import RandomForestRegressor
RFR = RandomForestRegressor(n_estimators=100, min_samples_leaf=10, random_state=1)
RFR.fit(train[col], train[target])
predictions_RFR = RFR.predict(test[col])
# Compute error between our prediction and actual test set
m = mean_squared_error(predictions_RFR, test[target])
print(m)
# Accuracy of model
print('Accuracy of random forest model is:{:.3f}'.format(RFR.score(test[col], test[target])))
test[col].iloc[0]
rating_LR = LR.predict(test[col].iloc[0].values.reshape(1, -1))
rating_RFR = RFR.predict(test[col].iloc[0].values.reshape(1, -1))
print(rating_LR)
print(rating_RFR)
test[target].iloc[0]
```
| github_jupyter |
## Exercise: Pricing a European Call Option under Risk Neutrality
#### John Stachurski
Let's price a European option under the assumption of risk neutrality (for simplicity).
Suppose that the current time is $t=0$ and the expiry date is $n$.
We need to evaluate
$$ P_0 = \beta^n \mathbb E_0 \max\{ S_n - K, 0 \} $$
given
* the discount factor $\beta$
* the strike price $K$
* the stochastic process $\{S_t\}$
A common model for $\{S_t\}$ is
$$ \ln \frac{S_{t+1}}{S_t} = \mu + \sigma \xi_{t+1} $$
where $\{ \xi_t \}$ is IID and standard normal. However, its predictions are in some ways counterfactual. For example, volatility is not stationary but rather changes over time. Here's an improved version:
$$ \ln \frac{S_{t+1}}{S_t} = \mu + \sigma_t \xi_{t+1} $$
where
$$
\sigma_t = \exp(h_t),
\quad
h_{t+1} = \rho h_t + \nu \eta_{t+1}
$$
Compute the price of the option $P_0$ by Monte Carlo, averaging over realizations $S_n^1, \ldots, S_n^M$ of $S_n$ and appealing to the law of large numbers:
$$ \mathbb E_0 \max\{ S_n - K, 0 \}
\approx
\frac{1}{M} \sum_{m=1}^M \max \{S_n^m - K, 0 \}
$$
Use the following parameters:
```
β = 0.96
μ = 0.005
S0 = 10
h0 = 0
K = 100
n = 10
ρ = 0.5
ν = 0.01
M = 5_000_000
```
**Suggestion**: Start without jitting your functions, as jitted functions are harder to debug. Chose a smaller value for `M` and try to get your code to run. Then think about jitting.
The distribution of prices is heavy tailed, so the result has high variance even for large `M`. My best estimate is around $1,530.
### Solution
```
import numpy as np
from numpy.random import randn
from numba import jit, prange
from quantecon import tic, toc
```
Here's a solution that's jitted but not parallelized. A parallelized solution is below.
```
@jit(nopython=True)
def compute_call_price(β=0.96,
μ=0.005,
S0=10,
h0=0,
K=100,
n=10,
ρ=0.5,
ν=0.01,
M=5_000_000):
current_sum = 0.0
for m in range(M):
s = np.log(S0)
h = h0
for t in range(n):
s = s + μ + np.exp(h) * randn()
h = ρ * h + ν * randn()
current_sum += np.maximum(np.exp(s) - K, 0)
return β**n + current_sum / M
tic()
price = compute_call_price()
toc()
tic()
price = compute_call_price()
toc()
price
```
Let's try to parallelize this task.
```
@jit(nopython=True, parallel=True)
def compute_call_price_parallel(β=0.96,
μ=0.005,
S0=10,
h0=0,
K=100,
n=10,
ρ=0.5,
ν=0.01,
M=50_000_000):
current_sum = 0.0
for m in prange(M):
s = np.log(S0)
h = h0
for t in range(n):
s = s + μ + np.exp(h) * randn()
h = ρ * h + ν * randn()
current_sum += np.maximum(np.exp(s) - K, 0)
return β**n + current_sum / M
tic()
price = compute_call_price_parallel()
toc()
tic()
price = compute_call_price_parallel()
toc()
price
```
| github_jupyter |
# Weight Sampling Tutorial
If you want to fine-tune one of the trained original SSD models on your own dataset, chances are that your dataset doesn't have the same number of classes as the trained model you're trying to fine-tune.
This notebook explains a few options for how to deal with this situation. In particular, one solution is to sub-sample (or up-sample) the weight tensors of all the classification layers so that their shapes correspond to the number of classes in your dataset.
This notebook explains how this is done.
## 0. Our example
I'll use a concrete example to make the process clear, but of course the process explained here is the same for any dataset.
Consider the following example. You have a dataset on road traffic objects. Let this dataset contain annotations for the following object classes of interest:
`['car', 'truck', 'pedestrian', 'bicyclist', 'traffic_light', 'motorcycle', 'bus', 'stop_sign']`
That is, your dataset contains annotations for 8 object classes.
You would now like to train an SSD300 on this dataset. However, instead of going through all the trouble of training a new model from scratch, you would instead like to use the fully trained original SSD300 model that was trained on MS COCO and fine-tune it on your dataset.
The problem is: The SSD300 that was trained on MS COCO predicts 80 different classes, but your dataset has only 8 classes. The weight tensors of the classification layers of the MS COCO model don't have the right shape for your model that is supposed to learn only 8 classes. Bummer.
So what options do we have?
### Option 1: Just ignore the fact that we need only 8 classes
The maybe not so obvious but totally obvious option is: We could just ignore the fact that the trained MS COCO model predicts 80 different classes, but we only want to fine-tune it on 8 classes. We could simply map the 8 classes in our annotated dataset to any 8 indices out of the 80 that the MS COCO model predicts. The class IDs in our dataset could be indices 1-8, they could be the indices `[0, 3, 8, 1, 2, 10, 4, 6, 12]`, or any other 8 out of the 80. Whatever we would choose them to be. The point is that we would be training only 8 out of every 80 neurons that predict the class for a given box and the other 72 would simply not be trained. Nothing would happen to them, because the gradient for them would always be zero, because these indices don't appear in our dataset.
This would work, and it wouldn't even be a terrible option. Since only 8 out of the 80 classes would get trained, the model might get gradually worse at predicting the other 72 clases, but we don't care about them anyway, at least not right now. And if we ever realize that we now want to predict more than 8 different classes, our model would be expandable in that sense. Any new class we want to add could just get any one of the remaining free indices as its ID. We wouldn't need to change anything about the model, it would just be a matter of having the dataset annotated accordingly.
Still, in this example we don't want to take this route. We don't want to carry around the computational overhead of having overly complex classifier layers, 90 percent of which we don't use anyway, but still their whole output needs to be computed in every forward pass.
So what else could we do instead?
### Option 2: Just ignore those weights that are causing problems
We could build a new SSD300 with 8 classes and load into it the weights of the MS COCO SSD300 for all layers except the classification layers. Would that work? Yes, that would work. The only conflict is with the weights of the classification layers, and we can avoid this conflict by simply ignoring them. While this solution would be easy, it has a significant downside: If we're not loading trained weights for the classification layers of our new SSD300 model, then they will be initialized randomly. We'd still benefit from the trained weights for all the other layers, but the classifier layers would need to be trained from scratch.
Not the end of the world, but we like pre-trained stuff, because it saves us a lot of training time. So what else could we do?
### Option 3: Sub-sample the weights that are causing problems
Instead of throwing the problematic weights away like in option 2, we could also sub-sample them. If the weight tensors of the classification layers of the MS COCO model don't have the right shape for our new model, we'll just **make** them have the right shape. This way we can still benefit from the pre-trained weights in those classification layers. Seems much better than option 2.
The great thing in this example is: MS COCO happens to contain all of the eight classes that we care about. So when we sub-sample the weight tensors of the classification layers, we won't just do so randomly. Instead, we'll pick exactly those elements from the tensor that are responsible for the classification of the 8 classes that we care about.
However, even if the classes in your dataset were entirely different from the classes in any of the fully trained models, it would still make a lot of sense to use the weights of the fully trained model. Any trained weights are always a better starting point for the training than random initialization, even if your model will be trained on entirely different object classes.
And of course, in case you happen to have the opposite problem, where your dataset has **more** classes than the trained model you would like to fine-tune, then you can simply do the same thing in the opposite direction: Instead of sub-sampling the classification layer weights, you would then **up-sample** them. Works just the same way as what we'll be doing below.
Let's get to it.
```
import h5py
import numpy as np
import shutil
from misc_utils.tensor_sampling_utils import sample_tensors
```
## 1. Load the trained weights file and make a copy
First, we'll load the HDF5 file that contains the trained weights that we need (the source file). In our case this is "`VGG_coco_SSD_300x300_iter_400000.h5`" (download link available in the README of this repo), which are the weights of the original SSD300 model that was trained on MS COCO.
Then, we'll make a copy of that weights file. That copy will be our output file (the destination file).
```
# TODO: Set the path for the source weights file you want to load.
weights_source_path = 'models/VGG_coco_SSD_512x512_iter_360000.h5'
# TODO: Set the path and name for the destination weights file
# that you want to create.
weights_destination_path = 'models/VGG_coco_SSD_512x512_iter_400000_subsampled_6_classes.h5'
# Make a copy of the weights file.
shutil.copy(weights_source_path, weights_destination_path)
# Load both the source weights file and the copy we made.
# We will load the original weights file in read-only mode so that we can't mess up anything.
weights_source_file = h5py.File(weights_source_path, 'r')
weights_destination_file = h5py.File(weights_destination_path)
```
## 2. Figure out which weight tensors we need to sub-sample
Next, we need to figure out exactly which weight tensors we need to sub-sample. As mentioned above, the weights for all layers except the classification layers are fine, we don't need to change anything about those.
So which are the classification layers in SSD300? Their names are:
```
classifier_names = ['conv4_3_norm_mbox_conf',
'fc7_mbox_conf',
'conv6_2_mbox_conf',
'conv7_2_mbox_conf',
'conv8_2_mbox_conf',
'conv9_2_mbox_conf',
'conv10_2_mbox_conf']
```
## 3. Figure out which slices to pick
The following section is optional. I'll look at one classification layer and explain what we want to do, just for your understanding. If you don't care about that, just skip ahead to the next section.
We know which weight tensors we want to sub-sample, but we still need to decide which (or at least how many) elements of those tensors we want to keep. Let's take a look at the first of the classifier layers, "`conv4_3_norm_mbox_conf`". Its two weight tensors, the kernel and the bias, have the following shapes:
```
conv4_3_norm_mbox_conf_kernel = weights_source_file[classifier_names[0]][classifier_names[0]]['kernel:0']
conv4_3_norm_mbox_conf_bias = weights_source_file[classifier_names[0]][classifier_names[0]]['bias:0']
print("Shape of the '{}' weights:".format(classifier_names[0]))
print()
print("kernel:\t", conv4_3_norm_mbox_conf_kernel.shape)
print("bias:\t", conv4_3_norm_mbox_conf_bias.shape)
```
So the last axis has 324 elements. Why is that?
- MS COCO has 80 classes, but the model also has one 'backgroud' class, so that makes 81 classes effectively.
- The 'conv4_3_norm_mbox_loc' layer predicts 4 boxes for each spatial position, so the 'conv4_3_norm_mbox_conf' layer has to predict one of the 81 classes for each of those 4 boxes.
That's why the last axis has 4 * 81 = 324 elements.
So how many elements do we want in the last axis for this layer?
Let's do the same calculation as above:
- Our dataset has 8 classes, but our model will also have a 'background' class, so that makes 9 classes effectively.
- We need to predict one of those 9 classes for each of the four boxes at each spatial position.
That makes 4 * 9 = 36 elements.
Now we know that we want to keep 36 elements in the last axis and leave all other axes unchanged. But which 36 elements out of the original 324 elements do we want?
Should we just pick them randomly? If the object classes in our dataset had absolutely nothing to do with the classes in MS COCO, then choosing those 36 elements randomly would be fine (and the next section covers this case, too). But in our particular example case, choosing these elements randomly would be a waste. Since MS COCO happens to contain exactly the 8 classes that we need, instead of sub-sampling randomly, we'll just take exactly those elements that were trained to predict our 8 classes.
Here are the indices of the 9 classes in MS COCO that we are interested in:
`[0, 1, 2, 3, 4, 6, 8, 10, 12]`
The indices above represent the following classes in the MS COCO datasets:
`['background', 'person', 'bicycle', 'car', 'motorcycle', 'bus', 'truck', 'traffic_light', 'stop_sign']`
How did I find out those indices? I just looked them up in the annotations of the MS COCO dataset.
While these are the classes we want, we don't want them in this order. In our dataset, the classes happen to be in the following order as stated at the top of this notebook:
`['background', 'car', 'truck', 'pedestrian', 'bicyclist', 'traffic_light', 'motorcycle', 'bus', 'stop_sign']`
For example, '`traffic_light`' is class ID 5 in our dataset but class ID 10 in the SSD300 MS COCO model. So the order in which I actually want to pick the 9 indices above is this:
`[0, 3, 8, 1, 2, 10, 4, 6, 12]`
So out of every 81 in the 324 elements, I want to pick the 9 elements above. This gives us the following 36 indices:
```
n_classes_source = 81
#classes_of_interest = [0, 3, 8, 1, 2, 10, 4, 6, 12]
classes_of_interest = [0, 74,68,80,65,40,47]
subsampling_indices = []
for i in range(int(324/n_classes_source)):
indices = np.array(classes_of_interest) + i * n_classes_source
subsampling_indices.append(indices)
subsampling_indices = list(np.concatenate(subsampling_indices))
print(subsampling_indices)
```
These are the indices of the 36 elements that we want to pick from both the bias vector and from the last axis of the kernel tensor.
This was the detailed example for the '`conv4_3_norm_mbox_conf`' layer. And of course we haven't actually sub-sampled the weights for this layer yet, we have only figured out which elements we want to keep. The piece of code in the next section will perform the sub-sampling for all the classifier layers.
## 4. Sub-sample the classifier weights
The code in this section iterates over all the classifier layers of the source weights file and performs the following steps for each classifier layer:
1. Get the kernel and bias tensors from the source weights file.
2. Compute the sub-sampling indices for the last axis. The first three axes of the kernel remain unchanged.
3. Overwrite the corresponding kernel and bias tensors in the destination weights file with our newly created sub-sampled kernel and bias tensors.
The second step does what was explained in the previous section.
In case you want to **up-sample** the last axis rather than sub-sample it, simply set the `classes_of_interest` variable below to the length you want it to have. The added elements will be initialized either randomly or optionally with zeros. Check out the documentation of `sample_tensors()` for details.
```
# TODO: Set the number of classes in the source weights file. Note that this number must include
# the background class, so for MS COCO's 80 classes, this must be 80 + 1 = 81.
n_classes_source = 81
# TODO: Set the indices of the classes that you want to pick for the sub-sampled weight tensors.
# In case you would like to just randomly sample a certain number of classes, you can just set
# `classes_of_interest` to an integer instead of the list below. Either way, don't forget to
# include the background class. That is, if you set an integer, and you want `n` positive classes,
# then you must set `classes_of_interest = n + 1`.
#classes_of_interest = [0, 3, 8, 1, 2, 10, 4, 6, 12]
classes_of_interest = [0, 74,68,80,65,40,47]
# classes_of_interest = 9 # Uncomment this in case you want to just randomly sub-sample the last axis instead of providing a list of indices.
for name in classifier_names:
# Get the trained weights for this layer from the source HDF5 weights file.
kernel = weights_source_file[name][name]['kernel:0'].value
bias = weights_source_file[name][name]['bias:0'].value
# Get the shape of the kernel. We're interested in sub-sampling
# the last dimension, 'o'.
height, width, in_channels, out_channels = kernel.shape
# Compute the indices of the elements we want to sub-sample.
# Keep in mind that each classification predictor layer predicts multiple
# bounding boxes for every spatial location, so we want to sub-sample
# the relevant classes for each of these boxes.
if isinstance(classes_of_interest, (list, tuple)):
subsampling_indices = []
for i in range(int(out_channels/n_classes_source)):
indices = np.array(classes_of_interest) + i * n_classes_source
subsampling_indices.append(indices)
subsampling_indices = list(np.concatenate(subsampling_indices))
elif isinstance(classes_of_interest, int):
subsampling_indices = int(classes_of_interest * (out_channels/n_classes_source))
else:
raise ValueError("`classes_of_interest` must be either an integer or a list/tuple.")
# Sub-sample the kernel and bias.
# The `sample_tensors()` function used below provides extensive
# documentation, so don't hesitate to read it if you want to know
# what exactly is going on here.
new_kernel, new_bias = sample_tensors(weights_list=[kernel, bias],
sampling_instructions=[height, width, in_channels, subsampling_indices],
axes=[[3]], # The one bias dimension corresponds to the last kernel dimension.
init=['gaussian', 'zeros'],
mean=0.0,
stddev=0.005)
# Delete the old weights from the destination file.
del weights_destination_file[name][name]['kernel:0']
del weights_destination_file[name][name]['bias:0']
# Create new datasets for the sub-sampled weights.
weights_destination_file[name][name].create_dataset(name='kernel:0', data=new_kernel)
weights_destination_file[name][name].create_dataset(name='bias:0', data=new_bias)
# Make sure all data is written to our output file before this sub-routine exits.
weights_destination_file.flush()
```
That's it, we're done.
Let's just quickly inspect the shapes of the weights of the '`conv4_3_norm_mbox_conf`' layer in the destination weights file:
```
conv4_3_norm_mbox_conf_kernel = weights_destination_file[classifier_names[0]][classifier_names[0]]['kernel:0']
conv4_3_norm_mbox_conf_bias = weights_destination_file[classifier_names[0]][classifier_names[0]]['bias:0']
print("Shape of the '{}' weights:".format(classifier_names[0]))
print()
print("kernel:\t", conv4_3_norm_mbox_conf_kernel.shape)
print("bias:\t", conv4_3_norm_mbox_conf_bias.shape)
```
Nice! Exactly what we wanted, 36 elements in the last axis. Now the weights are compatible with our new SSD300 model that predicts 8 positive classes.
This is the end of the relevant part of this tutorial, but we can do one more thing and verify that the sub-sampled weights actually work. Let's do that in the next section.
## 5. Verify that our sub-sampled weights actually work
In our example case above we sub-sampled the fully trained weights of the SSD300 model trained on MS COCO from 80 classes to just the 8 classes that we needed.
We can now create a new SSD300 with 8 classes, load our sub-sampled weights into it, and see how the model performs on a few test images that contain objects for some of those 8 classes. Let's do it.
```
from keras.optimizers import Adam
from keras import backend as K
from keras.models import load_model
from models.keras_ssd300 import ssd_300
from models.keras_ssd512 import ssd_512
from keras_loss_function.keras_ssd_loss import SSDLoss
from keras_layers.keras_layer_AnchorBoxes import AnchorBoxes
from keras_layers.keras_layer_DecodeDetections import DecodeDetections
from keras_layers.keras_layer_DecodeDetectionsFast import DecodeDetectionsFast
from keras_layers.keras_layer_L2Normalization import L2Normalization
from data_generator.object_detection_2d_data_generator import DataGenerator
from data_generator.object_detection_2d_photometric_ops import ConvertTo3Channels
from data_generator.object_detection_2d_patch_sampling_ops import RandomMaxCropFixedAR
from data_generator.object_detection_2d_geometric_ops import Resize
```
### 5.1. Set the parameters for the model.
As always, set the parameters for the model. We're going to set the configuration for the SSD300 MS COCO model.
```
img_height = 480 # Height of the input images
img_width = 640 # Width of the input images
img_channels = 3 # Number of color channels of the input images
subtract_mean = [123, 117, 104] # The per-channel mean of the images in the dataset
swap_channels = [2, 1, 0] # The color channel order in the original SSD is BGR, so we should set this to `True`, but weirdly the results are better without swapping.
# TODO: Set the number of classes.
n_classes = 6 # Number of positive classes, e.g. 20 for Pascal VOC, 80 for MS COCO
scales = [0.04, 0.1, 0.26, 0.42, 0.58, 0.74, 0.9, 1.06] # The anchor box scaling factors used in the original SSD300 for the MS COCO datasets.
# scales = [0.1, 0.2, 0.37, 0.54, 0.71, 0.88, 1.05] # The anchor box scaling factors used in the original SSD300 for the Pascal VOC datasets.
aspect_ratios = [[1.0, 2.0, 0.5],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5],
[1.0, 2.0, 0.5]] # The anchor box aspect ratios used in the original SSD300; the order matters
two_boxes_for_ar1 = True
steps = [8, 16, 32, 64, 128, 256, 512] # The space between two adjacent anchor box center points for each predictor layer.
offsets = [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5] # The offsets of the first anchor box center points from the top and left borders of the image as a fraction of the step size for each predictor layer.
clip_boxes = False # Whether or not you want to limit the anchor boxes to lie entirely within the image boundaries
variances = [0.1, 0.1, 0.2, 0.2] # The variances by which the encoded target coordinates are scaled as in the original implementation
normalize_coords = True
```
### 5.2. Build the model
Build the model and load our newly created, sub-sampled weights into it.
```
weights_destination_path = 'models/VGG_coco_SSD_512x512_iter_400000_subsampled_6_classes.h5'
# 1: Build the Keras model
K.clear_session() # Clear previous models from memory.
model = ssd_512(image_size=(img_height, img_width, img_channels),
n_classes=n_classes,
mode='inference',
l2_regularization=0.0005,
scales=scales,
aspect_ratios_per_layer=aspect_ratios,
two_boxes_for_ar1=two_boxes_for_ar1,
steps=steps,
offsets=offsets,
clip_boxes=clip_boxes,
variances=variances,
normalize_coords=normalize_coords,
subtract_mean=subtract_mean,
divide_by_stddev=None,
swap_channels=swap_channels,
confidence_thresh=0.5,
iou_threshold=0.45,
top_k=200,
nms_max_output_size=400,
return_predictor_sizes=False)
print("Model built.")
# 2: Load the sub-sampled weights into the model.
# Load the weights that we've just created via sub-sampling.
weights_path = weights_destination_path
model.load_weights(weights_path, by_name=True)
print("Weights file loaded:", weights_path)
# 3: Instantiate an Adam optimizer and the SSD loss function and compile the model.
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
ssd_loss = SSDLoss(neg_pos_ratio=3, alpha=1.0)
model.compile(optimizer=adam, loss=ssd_loss.compute_loss)
```
### 5.3. Load some images to test our model on
We sub-sampled some of the road traffic categories from the trained SSD300 MS COCO weights, so let's try out our model on a few road traffic images. The Udacity road traffic dataset linked to in the `ssd7_training.ipynb` notebook lends itself to this task. Let's instantiate a `DataGenerator` and load the Udacity dataset. Everything here is preset already, but if you'd like to learn more about the data generator and its capabilities, take a look at the detailed tutorial in [this](https://github.com/pierluigiferrari/data_generator_object_detection_2d) repository.
```
dataset = DataGenerator()
# TODO: Set the paths to your dataset here.
images_path = '../../datasets/Udacity_Driving/driving_dataset_consolidated_small/'
labels_path = '../../datasets/Udacity_Driving/driving_dataset_consolidated_small/labels.csv'
dataset.parse_csv(images_dir=images_path,
labels_filename=labels_path,
input_format=['image_name', 'xmin', 'xmax', 'ymin', 'ymax', 'class_id'], # This is the order of the first six columns in the CSV file that contains the labels for your dataset. If your labels are in XML format, maybe the XML parser will be helpful, check the documentation.
include_classes='all',
random_sample=False)
print("Number of images in the dataset:", dataset.get_dataset_size())
```
Make sure the batch generator generates images of size `(300, 300)`. We'll first randomly crop the largest possible patch with aspect ratio 1.0 and then resize to `(300, 300)`.
```
convert_to_3_channels = ConvertTo3Channels()
random_max_crop = RandomMaxCropFixedAR(patch_aspect_ratio=img_width/img_height)
resize = Resize(height=img_height, width=img_width)
generator = dataset.generate(batch_size=1,
shuffle=True,
transformations=[convert_to_3_channels,
random_max_crop,
resize],
returns={'processed_images',
'processed_labels',
'filenames'},
keep_images_without_gt=False)
test = DataGenerator()
# TODO: Set the paths to the dataset here.
Pascal_VOC_dataset_images_dir = '../datasets/ICUB_6/testsameimg'
Pascal_VOC_dataset_annotations_dir = '../datasets/ICUB_6/testsameans'
Pascal_VOC_dataset_image_set_filename = '../datasets/ICUB_6/testsame.txt'
# The XML parser needs to now what object class names to look for and in which order to map them to integers.
classes = ['background','book','cellphone','hairbrush','mouse','perfume','sunglasses']
test.parse_xml(images_dirs=[Pascal_VOC_dataset_images_dir],
image_set_filenames=[Pascal_VOC_dataset_image_set_filename],
annotations_dirs=[Pascal_VOC_dataset_annotations_dir],
classes=classes,
include_classes='all',
exclude_truncated=False,
exclude_difficult=False,
ret=False)
generator = test.generate(batch_size=4,
shuffle=True,
transformations=[],
label_encoder=None,
returns={'processed_images',
'processed_labels',
'filenames'},
keep_images_without_gt=False)
# Generate samples
batch_images, batch_labels, batch_filenames = next(generator)
i = 0 # Which batch item to look at
print("Image:", batch_filenames[i])
print()
print("Ground truth boxes:\n")
print(batch_labels[i])
```
### 5.4. Make predictions and visualize them
```
# Make a prediction
y_pred = model.predict(batch_images)
import numpy as np
# Decode the raw prediction.
i = 0
confidence_threshold = 0.5
y_pred_thresh = [y_pred[k][y_pred[k,:,1] > confidence_threshold] for k in range(y_pred.shape[0])]
np.set_printoptions(precision=2, suppress=True, linewidth=90)
print("Predicted boxes:\n")
print(' class conf xmin ymin xmax ymax')
print(y_pred_thresh[0])
# Visualize the predictions.
from matplotlib import pyplot as plt
%matplotlib inline
plt.figure(figsize=(20,12))
plt.imshow(batch_images[i])
current_axis = plt.gca()
classes = ['background', 'car', 'truck', 'pedestrian', 'bicyclist',
'traffic_light', 'motorcycle', 'bus', 'stop_sign'] # Just so we can print class names onto the image instead of IDs
# Draw the predicted boxes in blue
for box in y_pred_thresh[i]:
class_id = box[0]
confidence = box[1]
xmin = box[2]
ymin = box[3]
xmax = box[4]
ymax = box[5]
label = '{}: {:.2f}'.format(classes[int(class_id)], confidence)
current_axis.add_patch(plt.Rectangle((xmin, ymin), xmax-xmin, ymax-ymin, color='blue', fill=False, linewidth=2))
current_axis.text(xmin, ymin, label, size='x-large', color='white', bbox={'facecolor':'blue', 'alpha':1.0})
# Draw the ground truth boxes in green (omit the label for more clarity)
for box in batch_labels[i]:
class_id = box[0]
xmin = box[1]
ymin = box[2]
xmax = box[3]
ymax = box[4]
label = '{}'.format(classes[int(class_id)])
current_axis.add_patch(plt.Rectangle((xmin, ymin), xmax-xmin, ymax-ymin, color='green', fill=False, linewidth=2))
#current_axis.text(box[1], box[3], label, size='x-large', color='white', bbox={'facecolor':'green', 'alpha':1.0})
```
Seems as if our sub-sampled weights were doing a good job, sweet. Now we can fine-tune this model on our dataset with 8 classes.
| github_jupyter |
## Build an MTH5 and Operate the Aurora Pipeline
Outlines the process of making an MTH5 file, generating a processing config, and running the aurora processor
```
# Required imports for theh program.
from pathlib import Path
import sys
import pandas as pd
from mth5.clients.make_mth5 import MakeMTH5
from mth5 import mth5, timeseries
from mt_metadata.utils.mttime import get_now_utc, MTime
from aurora.config.config_creator import ConfigCreator
from aurora.pipelines.process_mth5 import process_mth5_run
```
Build an MTH5 file from information extracted by IRIS
```
# Set path so MTH5 file builds to current working directory.
default_path = Path().cwd()
# Initialize the Make MTH5 code.
m = MakeMTH5(mth5_version='0.1.0')
m.client = "IRIS"
# Generate data frame of FDSN Network, Station, Location, Channel, Startime, Endtime codes of interest
ZUCAS04LQ1 = ['ZU', 'CAS04', '', 'LQE', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
ZUCAS04LQ2 = ['ZU', 'CAS04', '', 'LQN', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
ZUCAS04BF1 = ['ZU', 'CAS04', '', 'LFE', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
ZUCAS04BF2 = ['ZU', 'CAS04', '', 'LFN', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
ZUCAS04BF3 = ['ZU', 'CAS04', '', 'LFZ', '2020-06-02T19:00:00', '2020-07-13T19:00:00']
request_list = [ZUCAS04LQ1, ZUCAS04LQ2, ZUCAS04BF1, ZUCAS04BF2, ZUCAS04BF3]
# Turn list into dataframe
request_df = pd.DataFrame(request_list, columns=m.column_names)\
# Inspect the dataframe
print(request_df)
# Request the inventory information from IRIS
inventory = m.get_inventory_from_df(request_df, data=False)
# Inspect the inventory
inventory
```
Builds an MTH5 file from the user defined database.
Note: Intact keeps the MTH5 open after it is done building
```
mth5_object = m.make_mth5_from_fdsnclient(request_df, interact=True)
# mth5_object.open_mth5(h5_path, 'w')
# h5_path = str(default_path)+'/ZU_CAS04.h5'
#mth5_object.close_mth5()
```
Extract information from the open MTH5 Object
```
mth5_object
# Collect information from the MTh5 Object and use it in the config files.
mth5_filename = mth5_object.filename
version = mth5_object.file_version
# Edit and update the MTH5 metadata
s = mth5_object.get_station("CAS04")
s.metadata.location.declination.model = 'IGRF'
s.write_metadata()
# Get the available stations and runs from the MTH5 object
ch_summary = mth5_object.channel_summary
ch_summary
available_runs = ch_summary.run.unique()
sr = ch_summary.sample_rate.unique()
if len(sr) != 1:
print('Only one sample rate per run is available')
available_stations = ch_summary.station.unique()
sr[0]
available_stations[0]
mth5_object
```
Generate an Aurora Configuration file using MTH5 as an input
```
station_id = available_stations[0]
run_id = available_runs[0]
sample_rate = sr[0]
config_maker = ConfigCreator()
config_path = config_maker.create_run_config(station_id, run_id, mth5_filename, sample_rate)
config_path
```
Run the Aurora Pipeline using the input MTh5 and Confiugration File
```
show_plot='True'
tf_cls = process_mth5_run(
config_path,
run_id,
mth5_path=mth5_filename,
units="MT",
show_plot=False,
z_file_path=None,
return_collection=False,
)
type(tf_cls)
```
Write the transfer functions generated by the Aurora pipeline
```
tf_cls.write_tf_file(fn="emtfxml_test.xml", file_type="emtfxml")
tf_cls.write_tf_file(fn="emtfxml_test.xml", file_type="edi")
tf_cls.write_tf_file(fn="emtfxml_test.xml", file_type="zmm")
```
| github_jupyter |
```
import wandb
wandb.init(project="test")
from wandb.integration.sb3 import WandbCallback
'''
A large part of the code in this file was sourced from the rl-baselines-zoo library on GitHub.
In particular, the library provides a great parameter optimization set for the PPO2 algorithm,
as well as a great example implementation using optuna.
Source: https://github.com/araffin/rl-baselines-zoo/blob/master/utils/hyperparams_opt.py
'''
import optuna
import pandas as pd
import numpy as np
from pathlib import Path
import time
import numpy as np
import os
import datetime
import csv
import argparse
from functools import partial
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.vec_env import DummyVecEnv, VecVideoRecorder, SubprocVecEnv
#from wandb.integration.sb3 import WandbCallback
#import wandb
#env = Template_Gym()
#from stable_baselines.gail import generate_expert_traj
#from stable_baselines.gail import ExpertDataset
timestamp = datetime.datetime.now().strftime('%y%m%d%H%M%S')
config = {"policy_type": "MlpPolicy", "total_timesteps": 25000}
experiment_name = f"PPO_{int(time.time())}"
class Optimization():
def __init__(self):
self.reward_strategy = 'sortino2'
#self.input_data_file = 'data/coinbase_hourly.csv'
self.params_db_file = 'sqlite:///params.db'
# number of parallel jobs
self.n_jobs = 1
# maximum number of trials for finding the best hyperparams
self.n_trials = 100
#number of test episodes per trial
self.n_test_episodes = 10
# number of evaluations for pruning per trial
self.n_evaluations = 10
#self.df = pd.read_csv(input_data_file)
#self.df = df.drop(['Symbol'], axis=1)
#self.df = df.sort_values(['Date'])
#self.df = add_indicators(df.reset_index())
#self.train_len = int(len(df) * 0.8)
#self.df = df[:train_len]
#self.validation_len = int(train_len * 0.8)
#self.train_df = df[:validation_len]
#self.test_df = df[validation_len:]
def make_env(self, env_id, rank, seed=0, eval=False):
"""
Utility function for multiprocessed env.
:param env_id: (str) the environment ID
:param num_env: (int) the number of environment you wish to have in subprocesses
:param seed: (int) the inital seed for RNG
:param rank: (int) index of the subprocess
"""
def _init():
self.eval= eval
env = gym.make("CartPole-v1")
env.seed(seed + rank)
return env
#set_global_seeds(seed)
return _init
#def make_env():
#env = gym.make("CartPole-v1")
#env = Monitor(env) # record stats such as returns
#return env
def optimize_envs(self, trial):
return {
'reward_func': self.reward_strategy,
'forecast_len': int(trial.suggest_loguniform('forecast_len', 1, 200)),
'confidence_interval': trial.suggest_uniform('confidence_interval', 0.7, 0.99),
}
def optimize_ppo2(self,trial):
return {
'n_steps': int(trial.suggest_loguniform('n_steps', 16, 2048)),
'gamma': trial.suggest_loguniform('gamma', 0.9, 0.9999),
'learning_rate': trial.suggest_loguniform('learning_rate', 1e-5, 1.),
'ent_coef': trial.suggest_loguniform('ent_coef', 1e-8, 1e-1),
'clip_range': trial.suggest_uniform('clip_range', 0.1, 0.4),
'n_epochs': int(trial.suggest_loguniform('n_epochs', 1, 48)),
#'lam': trial.suggest_uniform('lam', 0.8, 1.)
}
def optimize_agent(self,trial):
#self.env_params = self.optimize_envs(trial)
env_id = "default"
num_e = 1 # Number of processes to use
env = gym.make("CartPole-v1")
#self.train_env = DummyVecEnv([lambda: env()])
self.train_env = gym.make('CartPole-v1')
#self.train_env = VecNormalize(self.train_env, norm_obs=True, norm_reward=True)
#self.test_env = DummyVecEnv([lambda: env()])
self.test_env = env = gym.make('CartPole-v1')
#self.test_env = VecNormalize(self.train_env, norm_obs=True, norm_reward=True)
self.model_params = self.optimize_ppo2(trial)
self.model = PPO(config["policy_type"], self.train_env, verbose=0, tensorboard_log=Path("./tensorboard2").name, **self.model_params)
#self.model = PPO2(CustomPolicy_2, self.env, verbose=0, learning_rate=1e-4, nminibatches=1, tensorboard_log="./min1" )
last_reward = -np.finfo(np.float16).max
#evaluation_interval = int(len(train_df) / self.n_evaluations)
evaluation_interval = 3000
for eval_idx in range(self.n_evaluations):
try:
self.model.learn(evaluation_interval)
except AssertionError:
raise
rewards = []
n_episodes, reward_sum = 0, 0.0
obs = self.test_env.reset()
while n_episodes < self.n_test_episodes:
action, _ = self.model.predict(obs)
obs, reward, done, _ = self.test_env.step(action)
reward_sum += reward
if done:
rewards.append(reward_sum)
reward_sum = 0.0
n_episodes += 1
obs = self.test_env.reset()
last_reward = np.mean(rewards)
trial.report(-1 * last_reward, eval_idx)
#if trial.should_prune(eval_idx):
#raise optuna.structs.TrialPruned()
return -1 * last_reward
def optimize(self):
study_name = 'ppo299_' + self.reward_strategy
#study = optuna.create_study(
#study_name=study_name, storage=self.params_db_file, load_if_exists=True)
study = optuna.create_study(
study_name=study_name, storage=self.params_db_file, load_if_exists=True)
try:
study.optimize(self.optimize_agent, n_trials=self.n_trials, n_jobs=self.n_jobs)
except KeyboardInterrupt:
pass
print('Number of finished trials: ', len(study.trials))
print('Best trial:')
trial = study.best_trial
print('Value: ', trial.value)
print('Params: ')
for key, value in trial.params.items():
print(' {}: {}'.format(key, value))
return study.trials_dataframe()
#if __name__ == '__main__':
run = Optimization()
run.optimize()
import time
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.vec_env import DummyVecEnv, VecVideoRecorder
from wandb.integration.sb3 import WandbCallback
import wandb
config = {"policy_type": "MlpPolicy", "total_timesteps": 25000}
experiment_name = f"PPO_{int(time.time())}"
# Initialise a W&B run
wandb.init(
name=experiment_name,
project="test",
config=config,
sync_tensorboard=True, # auto-upload sb3's tensorboard metrics
monitor_gym=True, # auto-upload the videos of agents playing the game
save_code=True, # optional
)
def make_env():
env = gym.make("CartPole-v1")
env = Monitor(env) # record stats such as returns
return env
env = DummyVecEnv([make_env])
env = VecVideoRecorder(env, "videos",
record_video_trigger=lambda x: x % 2000 == 0, video_length=200)
model = PPO(config["policy_type"], env, verbose=1,
tensorboard_log=f"runs/{experiment_name}")
# Add the WandbCallback
model.learn(
total_timesteps=config["total_timesteps"],
callback=WandbCallback(
gradient_save_freq=100,
model_save_freq=1000,
model_save_path=f"models/{experiment_name}",
),
)
import gym
from stable_baselines3 import PPO
env = gym.make("CartPole-v1")
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10000)
obs = env.reset()
for i in range(1000):
action, _states = model.predict(obs, deterministic=True)
obs, reward, done, info = env.step(action)
env.render()
if done:
obs = env.reset()
env.close()
"""
Sampler for PPO hyperparams.
:param trial:
:return:
"""
batch_size = trial.suggest_categorical("batch_size", [8, 16, 32, 64, 128, 256, 512])
n_steps = trial.suggest_categorical("n_steps", [8, 16, 32, 64, 128, 256, 512, 1024, 2048])
gamma = trial.suggest_categorical("gamma", [0.9, 0.95, 0.98, 0.99, 0.995, 0.999, 0.9999])
learning_rate = trial.suggest_loguniform("learning_rate", 1e-5, 1)
lr_schedule = "constant"
# Uncomment to enable learning rate schedule
# lr_schedule = trial.suggest_categorical('lr_schedule', ['linear', 'constant'])
ent_coef = trial.suggest_loguniform("ent_coef", 0.00000001, 0.1)
clip_range = trial.suggest_categorical("clip_range", [0.1, 0.2, 0.3, 0.4])
n_epochs = trial.suggest_categorical("n_epochs", [1, 5, 10, 20])
gae_lambda = trial.suggest_categorical("gae_lambda", [0.8, 0.9, 0.92, 0.95, 0.98, 0.99, 1.0])
max_grad_norm = trial.suggest_categorical("max_grad_norm", [0.3, 0.5, 0.6, 0.7, 0.8, 0.9, 1, 2, 5])
vf_coef = trial.suggest_uniform("vf_coef", 0, 1)
net_arch = trial.suggest_categorical("net_arch", ["small", "medium"])
# Uncomment for gSDE (continuous actions)
# log_std_init = trial.suggest_uniform("log_std_init", -4, 1)
# Uncomment for gSDE (continuous action)
# sde_sample_freq = trial.suggest_categorical("sde_sample_freq", [-1, 8, 16, 32, 64, 128, 256])
# Orthogonal initialization
ortho_init = False
# ortho_init = trial.suggest_categorical('ortho_init', [False, True])
# activation_fn = trial.suggest_categorical('activation_fn', ['tanh', 'relu', 'elu', 'leaky_relu'])
activation_fn = trial.suggest_categorical("activation_fn", ["tanh", "relu"])
'''
A large part of the code in this file was sourced from the rl-baselines-zoo library on GitHub.
In particular, the library provides a great parameter optimization set for the PPO2 algorithm,
as well as a great example implementation using optuna.
Source: https://github.com/araffin/rl-baselines-zoo/blob/master/utils/hyperparams_opt.py
'''
import optuna
import pandas as pd
import numpy as np
from pathlib import Path
import time
import gym
import numpy as np
import os
import datetime
import csv
import argparse
from functools import partial
import time
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.vec_env import DummyVecEnv, VecVideoRecorder, SubprocVecEnv, VecNormalize
#from stable_baselines3 import PPO
#from stable_baselines3.common.vec_env import DummyVecEnv, SubprocVecEnv
from stable_baselines3.common.env_util import make_vec_env
from stable_baselines3.common.utils import set_random_seed
#from wandb.integration.sb3 import WandbCallback
#import wandb
#from stable_baselines.common.policies import MlpLnLstmPolicy, LstmPolicy, CnnPolicy, MlpPolicy
#from stable_baselines.common.vec_env import DummyVecEnv, SubprocVecEnv,VecNormalize
#from stable_baselines3.common import set_global_seeds
#from stable_baselines import ACKTR, PPO2, SAC
#from stable_baselines.deepq import DQN
#from stable_baselines.deepq.policies import FeedForwardPolicy
#from ..env import Template_Gym
#from ..common import CustomPolicy, CustomPolicy_2, CustomLSTMPolicy, CustomPolicy_4, CustomPolicy_3, CustomPolicy_5
#from ..common import PairList, PairConfig, PairsConfigured
#env = Template_Gym()
#from stable_baselines.gail import generate_expert_traj
#from stable_baselines.gail import ExpertDataset
timestamp = datetime.datetime.now().strftime('%y%m%d%H%M%S')
#pc = PairsConfigured()
config = {"policy_type": "MlpPolicy", "total_timesteps": 25000}
experiment_name = f"PPO_{int(time.time())}"
class Optimization():
def __init__(self, config):
self.reward_strategy = 'Name it'
#self.input_data_file = 'data/coinbase_hourly.csv'
self.params_db_file = 'sqlite:///params.db'
# number of parallel jobs
self.n_jobs = 1
# maximum number of trials for finding the best hyperparams
self.n_trials = 100
#number of test episodes per trial
self.n_test_episodes = 10
# number of evaluations for pruning per trial
self.n_evaluations = 10
self.config = config
#self.df = pd.read_csv(input_data_file)
#self.df = df.drop(['Symbol'], axis=1)
#self.df = df.sort_values(['Date'])
#self.df = add_indicators(df.reset_index())
#self.train_len = int(len(df) * 0.8)
#self.df = df[:train_len]
#self.validation_len = int(train_len * 0.8)
#self.train_df = df[:validation_len]
#self.test_df = df[validation_len:]
#def make_env(self, env_id, rank, seed=0, eval=False):
"""
Utility function for multiprocessed env.
:param env_id: (str) the environment ID
:param num_env: (int) the number of environment you wish to have in subprocesses
:param seed: (int) the inital seed for RNG
:param rank: (int) index of the subprocess
"""
#def _init():
#self.config = config
#self.eval= eval
#env = gym.make(config["env_name"])
#env = Monitor(env)
#env = Template_Gym(config=self.config, eval=self.eval)
#env.seed(seed + rank)
#return env
#set_global_seeds(seed)
#return _init
#def make_env(env_id, rank, seed=0):
"""
Utility function for multiprocessed env.
:param env_id: (str) the environment ID
:param num_env: (int) the number of environments you wish to have in subprocesses
:param seed: (int) the inital seed for RNG
:param rank: (int) index of the subprocess
"""
#def _init():
#env = gym.make(env_id)
#env.seed(seed + rank)
#return env
#set_random_seed(seed)
#return _init
def make_env():
env = gym.make(config["env_name"])
env = Monitor(env) # record stats such as returns
return env
# Categorical parameter
#optimizer = trial.suggest_categorical('optimizer', ['MomentumSGD', 'Adam'])
# Int parameter
#num_layers = trial.suggest_int('num_layers', 1, 3)
# Uniform parameter
#dropout_rate = trial.suggest_uniform('dropout_rate', 0.0, 1.0)
# Loguniform parameter
#learning_rate = trial.suggest_loguniform('learning_rate', 1e-5, 1e-2)
# Discrete-uniform parameter
#drop_path_rate = trial.suggest_discrete_uniform('drop_path_rate', 0.0, 1.0, 0.1)
def optimize_envs(self, trial):
return {
'reward_func': self.reward_strategy,
'forecast_len': int(trial.suggest_loguniform('forecast_len', 1, 200)),
'confidence_interval': trial.suggest_uniform('confidence_interval', 0.7, 0.99),
}
def optimize_config(self, trial):
return {
'sl': trial.suggest_loguniform('sl', 1.0, 10.0),
'tp': trial.suggest_loguniform('tp', 1.0 ,10.0)
}
def optimize_ppo2(self,trial):
return {
#'n_steps': int(trial.suggest_int('n_steps', 16, 2048)),
#'gamma': trial.suggest_loguniform('gamma', 0.9, 0.9999),
#'learning_rate': trial.suggest_loguniform('learning_rate', 1e-5, 1.),
#'ent_coef': trial.suggest_loguniform('ent_coef', 1e-8, 1e-1),
#'cliprange': trial.suggest_uniform('cliprange', 0.1, 0.4),
#'noptepochs': int(trial.suggest_int('noptepochs', 1, 48)),
#'lam': trial.suggest_uniform('lam', 0.8, 1.)
'batch_size': trial.suggest_categorical("batch_size", [8, 16, 32, 64, 128, 256, 512]),
'n_steps': int(trial.suggest_categorical("n_steps", [8, 16, 32, 64, 128, 256, 512, 1024, 2048])),
'gamma': trial.suggest_categorical("gamma", [0.9, 0.95, 0.98, 0.99, 0.995, 0.999, 0.9999]),
'learning_rate': trial.suggest_loguniform("learning_rate", 1e-5, 1),
#'lr_schedule' = "constant"
# Uncomment to enable learning rate schedule
# lr_schedule = trial.suggest_categorical('lr_schedule', ['linear', 'constant'])
'ent_coef': trial.suggest_loguniform("ent_coef", 0.00000001, 0.1),
'clip_range': trial.suggest_categorical("clip_range", [0.1, 0.2, 0.3, 0.4]),
'n_epochs': trial.suggest_categorical("n_epochs", [1, 5, 10, 20]),
'gae_lambda': trial.suggest_categorical("gae_lambda", [0.8, 0.9, 0.92, 0.95, 0.98, 0.99, 1.0]),
'max_grad_norm': trial.suggest_categorical("max_grad_norm", [0.3, 0.5, 0.6, 0.7, 0.8, 0.9, 1, 2, 5]),
'vf_coef': trial.suggest_uniform("vf_coef", 0, 1)
#'net_arch' = trial.suggest_categorical("net_arch", ["small", "medium"])
# Uncomment for gSDE (continuous actions)
# log_std_init = trial.suggest_uniform("log_std_init", -4, 1)
# Uncomment for gSDE (continuous action)
# sde_sample_freq = trial.suggest_categorical("sde_sample_freq", [-1, 8, 16, 32, 64, 128, 256])
# Orthogonal initialization
#ortho_init = False
# ortho_init = trial.suggest_categorical('ortho_init', [False, True])
# activation_fn = trial.suggest_categorical('activation_fn', ['tanh', 'relu', 'elu', 'leaky_relu'])
#'activation_fn': trial.suggest_categorical("activation_fn", ["tanh", "relu"])
}
def optimize_lstm(self, trial):
return {
'lstm': trial.suggest_categorical('optimizer', ['lstm', 'mlp'])
}
def ob_types(self, trial):
return {
'lstm': trial.suggest_categorical('optimizer', ['lstm', 'mlp'])
}
def optimize_agent(self,trial):
run = wandb.init(
project="sb3",
config=config,
sync_tensorboard=True, # auto-upload sb3's tensorboard metrics
monitor_gym=True, # auto-upload the videos of agents playing the game
save_code=True, # optional
)
#self.env_params = self.optimize_envs(trial)
env_id = "default"+str()
num_e = self.n_jobs # Number of processes to use
#self.config_param = self.optimize_config(trial)
#self.config.sl = self.config_param['sl']
#self.config.sl = self.config_param['tp']
#self.model_type = self.optimize_lstm(trial)
#self.model_type = self.model_type['lstm']
#self.model_type = "mlp"
#if self.model_type == 'mlp':
#self.policy = CustomPolicy_5
#else:
#self.policy = MlpPolicy
#self.train_env = SubprocVecEnv([self.make_env(env_id+str('train'), i) for i in range(num_e)])
#SubprocVecEnv([make_env(env_id, i) for i in range(num_cpu)])
#self.train_env = SubprocVecEnv([self.make_env(env_id, i, eval=False) for i in range(num_e)])
#self.train_env = VecNormalize(self.train_env, norm_obs=True, norm_reward=True)
#self.test_env = SubprocVecEnv([self.make_env(env_id+str("test"), i) for i in range(num_e)])
#self.test_env = SubprocVecEnv([self.make_env(env_id, i, eval=True) for i in range(num_e)])
#self.test_env = VecNormalize(self.test_env, norm_obs=True, norm_reward=True)
env = gym.make("CartPole-v1")
self.train_env = DummyVecEnv([lambda: env])
self.train_env = VecVideoRecorder(self.train_env, "videos", record_video_trigger=lambda x: x % 2000 == 0, video_length=200)
#self.train_env = DummyVecEnv([env])
#self.train_env = VecNormalize(self.train_env, norm_obs=True, norm_reward=True)
self.test_env = DummyVecEnv([lambda: env])
self.test_env = VecVideoRecorder(self.test_env, "videos", record_video_trigger=lambda x: x % 2000 == 0, video_length=200)
#self.test_env = DummyVecEnv([env])
try:
self.test_env.load_running_average("saves")
self.train_env.load_running_average("saves")
except:
print('cant load')
self.model_params = self.optimize_ppo2(trial)
self.model = PPO(config["policy_type"], self.train_env, verbose=1, tensorboard_log=f"runs", **self.model_params )
#self.model = PPO2(CustomPolicy_2, self.env, verbose=0, learning_rate=1e-4, nminibatches=1, tensorboard_log="./min1" )
last_reward = -np.finfo(np.float16).max
#evaluation_interval = int(len(train_df) / self.n_evaluations)
evaluation_interval = 3500
for eval_idx in range(self.n_evaluations):
try:
#self.model.learn(evaluation_interval)
self.model.learn(
total_timesteps=evaluation_interval,
callback=WandbCallback(gradient_save_freq=100,
model_save_path=f"models/{run.id}",
verbose=2,
),
)
#self.test_env.save_running_average("saves")
#self.train_env.save_running_average("saves")
except:
print('did not work')
rewards = []
n_episodes, reward_sum = 0, 0.0
print('Eval')
obs = self.test_env.reset()
#state = None
#done = [False for _ in range(self.env.num_envs)]
while n_episodes < self.n_test_episodes:
action, _ = self.model.predict(obs, deterministic=True)
obs, reward, done, _ = self.test_env.step(action)
reward_sum += reward
if done:
rewards.append(reward_sum)
reward_sum = 0.0
n_episodes += 1
obs = self.test_env.reset()
last_reward = np.mean(rewards)
trial.report(-1 * last_reward, eval_idx)
if trial.should_prune():
raise optuna.structs.TrialPruned()
run.finish()
return -1 * last_reward
def optimize(self, config):
self.config = config
study_name = 'ppo2_single_ready'
study_name = 'ppo2_single_ready_nosltp'
study_name = 'ppo2_single_ready_nosltp_all_yeah'
study_name = 'ppo2_eur_gbp_op'
study_name = 'ppo2_gbp_chf_op'
study_name = 'ppo2_gbp_chf_h1_new1'
study_name = 'ppo2_gbp_chf_h4_r_new11'
study_name = 'ppo2_gbp_chf_h4_r_withvolfixed'
study_name = 'ppo2_gbp_chf_h4_r_withvolclosefix212'
study_name = 'ppo2_gbp_chf_h4_loged_sortinonew'
study_name = 'AUD_CHF_4H_SELL_C5_NEW'
study_name = 'wandb'
study = optuna.create_study(
study_name=study_name, storage=self.params_db_file, load_if_exists=True)
try:
study.optimize(self.optimize_agent, n_trials=self.n_trials, n_jobs=self.n_jobs)
except KeyboardInterrupt:
pass
print('Number of finished trials: ', len(study.trials))
print('Best trial:')
trial = study.best_trial
print(trial.number)
print('Value: ', trial.value)
print('Params: ')
for key, value in trial.params.items():
print(' {}: {}'.format(key, value))
return study.trials_dataframe()
#if __name__ == '__main__':
#optimize()
run = Optimization(config)
run.optimize(config)
```
| github_jupyter |
```
# HIDDEN
from datascience import *
from prob140 import *
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
%matplotlib inline
import math
from scipy import stats
from scipy import misc
```
## Expectations of Functions ##
Once we start using random variables as estimators, we will want to see how far the estimate is from a desired value. For example, we might want to see how far a random variable $X$ is from the number 10. That's a function of $X$. Let's call it $Y$. Then
$$
Y = |X - 10|
$$
which is not a linear function. To find $E(Y)$, we need a bit more technique. Throughout, we will assume that all the expectations that we are discussing are well defined.
This section is about finding the expectation of a function of a random variable whose distribution you know.
In what follows, let $X$ be a random variable whose distribution (and hence also expectation) are known.
### Linear Function Rule ###
Let $Y = aX + b$ for some constants $a$ and $b$. In an earlier section we showed that
$$
E(Y) = aE(X) + b
$$
This includes the case where $a=0$ and thus $Y$ is just the constant $b$ and thus has expectation $b$.
### Non-linear Function Rule ###
Now let $Y = g(X)$ where $g$ is any numerical function. Remember that $X$ is a function on $\Omega$. So the function that defines the random variable $Y$ is a *composition*:
$$
Y(\omega) = (g \circ X) (\omega) ~~~~~~~~~ \text{for } \omega \in \Omega
$$
This allows us to write $E(Y)$ in three equivalent ways:
#### On the range of $Y$ ####
$$
E(Y) = \sum_{\text{all }y} yP(Y=y)
$$
#### On the domain $\Omega$ ####
$$
E(Y) = E(g(X)) = \sum_{\omega \in \Omega} (g \circ X) (\omega) P(\omega)
$$
#### On the range of $X$ ####
$$
E(Y) = E(g(X)) = \sum_{\text{all }x} g(x)P(X=x)
$$
As before, it is a straightforward matter of grouping to show that all the forms are equivalent.
The first form looks the simplest, but there's a catch: you need to first find $P(Y=y)$. The second form involves an unnecessarily high level of detail.
The third form is the one to use. It uses the known distribution of $X$. It says that to find $E(Y)$ where $Y = g(X)$ for some function $g$:
- Take a generic value $x$ of $X$.
- Apply $g$ to $x$; this $g(x)$ is a generic value of $Y$.
- Weight $g(x)$ by $P(X=x)$, which is known.
- Do this for all $x$ and add. The sum is $E(Y)$.
The crucial thing to note about this method is that **we didn't have to first find the distribution of $Y$**. That saves us a lot of work. Let's see how our method works in some examples.
### Example 1: $Y = |X-3|$ ###
Let $X$ have a distribution we worked with earlier:
```
x = np.arange(1, 6)
probs = make_array(0.15, 0.25, 0.3, 0.2, 0.1)
dist = Table().values(x).probability(probs)
dist = dist.relabel('Value', 'x').relabel('Probability', 'P(X=x)')
dist
```
Let $g$ be the function defined by $g(x) = |x-3|$, and let $Y = g(X)$. In other words, $Y = |X - 3|$.
To calculate $E(Y)$, we first have to create a column that transforms the values of $X$ into values of $Y$:
```
dist_with_Y = dist.with_column('g(x)', np.abs(dist.column('x')-3)).move_to_end('P(X=x)')
dist_with_Y
```
To get $E(Y)$, find the appropriate weighed average: multiply the `g(x)` and `P(X=x)` columns, and add. The calculation shows that $E(Y) = 0.95$.
```
ev_Y = sum(dist_with_Y.column('g(x)') * dist_with_Y.column('P(X=x)'))
ev_Y
```
### Example 2: $Y = \min(X, 3)$ ###
Let $X$ be as above, but now let $Y = \min(X, 3)$. We want $E(Y)$. What we know is the distribution of $X$:
```
dist
```
To find $E(Y)$ we can just go row by row and replace the value of $x$ by the value of $\min(x, 3)$, and then find the weighted average:
```
ev_Y = 1*0.15 + 2*0.25 + 3*0.3 + 3*0.2 + 3*0.1
ev_Y
```
### Example 3: $E(X^2)$ for a Poisson Variable $X$ ###
Let $X$ have the Poisson $(\mu)$ distribution. You will see in the next chapter that it will be useful to know the value of $E(X^2)$. By our non-linear function rule,
$$
E(X^2) = \sum_{k=0}^\infty k^2 e^{-\mu} \frac{\mu^k}{k!}
$$
This sum turns out to be hard to simplify. The term for $k=0$ is 0. In each term for $k \ge 1$, one of the $k$'s in the numerator cancels a $k$ in the denominator but the other factor of $k$ in the numerator remains. It would be so nice if that factor $k$ were $k-1$ instead, so it could cancel $k-1$ in the denominator.
This motivates the following calculation. No matter what $X$ is, if we know $E(X)$ and can find $E(X(X-1))$, then we can use additivity to find $E(X^2)$ as follows:
$$
E(X(X-1)) = E(X^2 - X) = E(X^2) - E(X)
$$
so
$$
E(X^2) = E(X(X-1)) + E(X)
$$
Let's see if we can find $E(X(X-1))$ by applying the non-linear function rule.
\begin{align*}
E(X(X-1)) &= \sum_{k=0}^\infty k(k-1) e^{-\mu} \frac{\mu^k}{k!} \\ \\
&= e^{-\mu} \mu^2 \sum_{k=2}^\infty \frac{\mu^{k-2}}{(k-2)!} \\ \\
&= e^{-\mu}\mu^2 e^\mu \\ \\
&= \mu^2
\end{align*}
We know that $E(X) = \mu$, so
$$
E(X^2) = \mu^2 + \mu
$$
Notice that $E(X^2) > (E(X))^2$. This is an instance of a general fact. Later in the course we will see why it matters.
For now, as an exercise, see if you can find $E(X(X-1)(X-2))$ and hence $E(X^3)$.
| github_jupyter |
Objective
------------------------
Try out different hypothesis to investigate the effect of lockdown measures on mobility
- Assume that mobility is affected by weather, lockdown and miscellanous
- Consider misc. info to be one such as week info (if it is a holisday week etc...)
- Assume mobility follows a weekly pattern (people tend to spend less time in parks Mo-Fr for example). Exploit assumptions about human routines here
- Consider every day independent of one another
Methodology
----------------------------------
Consider
- Derive features for weather (initially consider simply the medan temperature)
- Lockdown index (some number)
- Mobility value
- is_weekend
# Data Sources
In order to run the cells the data has to be downloaded manually from these sources. Special thanks to the following sources for providing an open source license to access the data.
* Apple mobility data: https://covid19.apple.com/mobility
* Oxford stringency: https://github.com/OxCGRT/covid-policy-tracker
* Weather forecast from Yr, delivered by the Norwegian Meteorological Institute and NRK: https://api.met.no/weatherapi/locationforecast/2.0/
* Historical weather data from https://mesonet.agron.iastate.edu/ASOS/
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime
from ipywidgets import Dropdown,IntSlider
from IPython.display import display
import os
%matplotlib inline
from functools import reduce
try:
import graphviz
except:
!pip install graphviz
import graphviz
try:
import pydotplus
except:
!pip install pydotplus
from IPython.display import display
import networkx as nx
try:
import pydot
except:
!pip install pydot
try:
from dowhy import CausalModel
except:
#!pip install sympy
!pip install -I dowhy
from dowhy import CausalModel
```
Hypothesis I
------------------
Consider daily data for Berlin
Weather: historical air temperature
Mobility: Apple (Transit)
Stringency: OXCGRT
```
from project_lib import Project
project = Project.access()
Oxford_Stringency_Index_credentials = project.get_connected_data(name="Oxford Stringency Index")
import dsx_core_utils, os, io
import pandas as pd
from sqlalchemy import create_engine
import sqlalchemy
sqla_url= "db2+ibm_db://" + Oxford_Stringency_Index_credentials['username']+ ':' + Oxford_Stringency_Index_credentials['password'] + "@"+ Oxford_Stringency_Index_credentials['host'] + ":50001/BLUDB;Security=ssl;"
#sqlalchemy
engine = create_engine(sqla_url, pool_size=10, max_overflow=20)
conn = engine.connect()
# @hidden_cell
# The following code contains the credentials for a connection in your Project.
# You might want to remove those credentials before you share your notebook.
from project_lib import Project
project = Project.access()
Apple_transit_mobility_credentials = project.get_connected_data(name="Apple Transit Mobility")
apple_sqla_url= "db2+ibm_db://" + Apple_transit_mobility_credentials['username']+ ':' + Apple_transit_mobility_credentials['password'] + "@"+ Apple_transit_mobility_credentials['host'] + ":50001/BLUDB;Security=ssl;"
#sqlalchemy
apple_engine = create_engine(apple_sqla_url, pool_size=10, max_overflow=20)
apple_conn = apple_engine.connect()
app_mob_df = pd.read_sql_table(Apple_transit_mobility_credentials['datapath'].split("/")[-1].lower(), apple_conn,index_col=['Timestamp'])
be_app_trans_df = app_mob_df[app_mob_df.region=='Berlin']
be_app_trans_df.drop(columns=['region'],inplace=True)
ox_df = pd.read_sql_table("oxford_stringency_index", conn)
#ox_df.rename({'datetime_date':'date'},axis=1,inplace=True)
# Stringency Germany
#ox_df = pd.read_csv("/project_data/data_asset/sun/oxcgrt/OxCGRT_latest.csv")
ox_df["date"] = pd.to_datetime(ox_df["date"],format="%Y%m%d")
be_ox_df = ox_df[ox_df.countrycode=="DEU"]
be_ox_df.index= be_ox_df['date']
be_ox_df = be_ox_df[['stringencyindex']]
be_ox_df.rename({'stringencyindex':'lockdown'},axis=1,inplace=True)
# Max temperature
be_weather_df = pd.read_csv("/project_data/data_asset/mercury/weather/berlin_historical_weather.csv",index_col=[0])
be_weather_df.index = pd.to_datetime(be_weather_df.index)
dfs = [be_ox_df,be_app_trans_df,be_weather_df]
df_final = reduce(lambda left,right: pd.merge(left,right,left_index=True,right_index=True,how='inner'), dfs)
df_final['is_weekend'] = np.where((df_final.index.weekday == 5)|(df_final.index.weekday == 6),1,0)
#df_final.rename({'stringencyindex':'lockdown'},axis=1,inplace=True)
#df_final.to_csv('/project_data/data_asset/mercury/germany_daily_asset_with_other_weather_params.csv')
df_final.head()
fig,axs = plt.subplots(nrows=3,ncols=1,figsize=(12,8))
axs[0].plot(df_final['mobility'])
axs[1].plot(df_final['lockdown'])
axs[2].plot(df_final['air_temperature'])
```
Why do I think day information is good? Looking at the graph above, it suggests that there is a strong periodic component in the mobility info.
Let me plot the Power Spectral Density and check if there is any kind of periodicity in the data.
```
plt.figure(figsize=(16,8))
plt.stem(np.abs(np.fft.fft(df_final[df_final.index<=pd.to_datetime('2020-03-15')]['mobility'].values-np.mean(df_final[df_final.index<=pd.to_datetime('2020-03-15')]['mobility'].values))))
```
Let me consider week of the day as a feature for Causal Inference. Add it as a column in the datasource.
```
df_final.dropna()
h1_causal_graph = nx.DiGraph()
h1_causal_graph.add_edge('is_weekend','mobility')
h1_causal_graph.add_edge('lockdown','mobility')
h1_causal_graph.add_edge('air_temperature','lockdown')
h1_causal_graph.add_edge('air_temperature','mobility')
graph_filename_h1='causal_mobility_weather_h1.dot'
nx.drawing.nx_pydot.write_dot(h1_causal_graph,graph_filename_h1)
with open(graph_filename_h1) as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
h1_model = CausalModel(data=df_final.dropna(),treatment=['lockdown'],outcome='mobility',instruments=[],graph=graph_filename_h1,proceed_when_unidentifiable=True)
print(h1_model)
h1_estimand = h1_model.identify_effect()
print(h1_estimand)
h1_estimate = h1_model.estimate_effect(h1_estimand,method_name='backdoor.linear_regression',test_significance=True)
print(h1_estimate)
```
Validate the causal effect estimate
```
h1_ref1 = h1_model.refute_estimate(estimand=h1_estimand, estimate=h1_estimate,method_name='placebo_treatment_refuter')
print(h1_ref1)
h1_ref2 = h1_model.refute_estimate(estimand=h1_estimand, estimate=h1_estimate,method_name='random_common_cause')
print(h1_ref2)
```
Hypothesis II
------------------
Using google mobility instead of Apple transit mobility
Consider daily data for Berlin
Weather: historical air temperature
Mobility: Google mobility data - transit station
Stringency: OXCGRT data
```
# @hidden_cell
# The following code contains the credentials for a connection in your Project.
# You might want to remove those credentials before you share your notebook.
Google_mobility_credentials = project.get_connected_data(name="Google mobility")
Google_mobility_df = pd.read_sql_table(Google_mobility_credentials['datapath'].split("/")[-1].lower(),conn)
be_google_mobility_df = Google_mobility_df[Google_mobility_df.sub_region_1=="Berlin"][['transit_stations_percent_change_from_baseline']]
be_google_mobility_df.index = pd.to_datetime(Google_mobility_df[Google_mobility_df.sub_region_1=="Berlin"]['date'])
dfs2 = [be_ox_df,be_google_mobility_df,be_weather_df]
df_final2 = reduce(lambda left,right: pd.merge(left,right,left_index=True,right_index=True,how='inner'), dfs2)
df_final2.rename({'transit_stations_percent_change_from_baseline':'mobility','StringencyIndex':'lockdown'},axis=1,inplace=True)
df_final2['is_weekend'] = np.where((df_final2.index.weekday == 5)|(df_final2.index.weekday == 6),1,0)
fig,axs = plt.subplots(nrows=3,ncols=1,figsize=(12,8))
axs[0].plot(df_final2['mobility'])
axs[1].plot(df_final2['lockdown'])
axs[2].plot(df_final2['air_temperature'])
h2_causal_graph = nx.DiGraph()
h2_causal_graph.add_edge('is_weekend','mobility')
h2_causal_graph.add_edge('lockdown','mobility')
h2_causal_graph.add_edge('air_temperature','lockdown')
h2_causal_graph.add_edge('air_temperature','mobility')
graph_filename_h2='causal_mobility_weather_h2.dot'
nx.drawing.nx_pydot.write_dot(h2_causal_graph,graph_filename_h2)
with open(graph_filename_h2) as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
h2_model = CausalModel(data=df_final2.dropna(),treatment=['lockdown'],outcome='mobility',instruments=[],graph=graph_filename_h2,proceed_when_unidentifiable=True)
print(h2_model)
h2_estimand = h2_model.identify_effect()
print(h2_estimand)
h2_estimate = h2_model.estimate_effect(h2_estimand,method_name='backdoor.linear_regression',test_significance=True)
print(h2_estimate)
h2_ref1 = h2_model.refute_estimate(estimand=h2_estimand, estimate=h2_estimate,method_name='placebo_treatment_refuter')
print(h2_ref1)
h2_ref2 = h2_model.refute_estimate(estimand=h2_estimand, estimate=h2_estimate,method_name='random_common_cause')
print(h2_ref2)
```
**Remark**
As Google data is available only from mid Feb whereas Apple mobility data is available since mid Jan. So, we use Apple mobility data
Hypothesis III
------------------
Consider daily data for Berlin
Weather: historical air temperature
Mobility: Apple (Transit)
Stringency: OXCGRT Clustering data
```
# @hidden_cell
# The following code contains the credentials for a connection in your Project.
# You might want to remove those credentials before you share your notebook.
from project_lib import Project
project = Project.access()
Emergent_DB2_Warehouse_credentials = project.get_connection(name="db2 Warehouse ealuser")
import dsx_core_utils, os, io
import pandas as pd
from sqlalchemy import create_engine
import sqlalchemy
sqla_url= "db2+ibm_db://" + Emergent_DB2_Warehouse_credentials['username']+ ':' + Emergent_DB2_Warehouse_credentials['password'] + "@"+ Emergent_DB2_Warehouse_credentials['host'] + ":50001/BLUDB;Security=ssl;"
#sqlalchemy
engine = create_engine(sqla_url, pool_size=10, max_overflow=20)
stringency_clustering_df = pd.read_sql_query('SELECT * FROM "EALUSER"."STRINGENCY_INDEX_CLUSTERING"',engine)
be_stringency_clustering_df = stringency_clustering_df[stringency_clustering_df.country=="Germany"]
be_stringency_clustering_df.index = pd.to_datetime(be_stringency_clustering_df['state_date'])
be_stringency_clustering_df = be_stringency_clustering_df.rename({'state_value':'lockdown'},axis=1)[['lockdown']]
dfs3 = [be_stringency_clustering_df,be_app_trans_df,be_weather_df]
df_final3 = reduce(lambda left,right: pd.merge(left,right,left_index=True,right_index=True,how='inner'), dfs3)
df_final3.rename({'change':'mobility'},axis=1,inplace=True)
df_final3['is_weekend'] = np.where((df_final3.index.weekday == 5)|(df_final3.index.weekday == 6),1,0)
#df_final.to_csv('/project_data/data_asset/mercury/germany_daily_asset_with_other_weather_params.csv')
fig,axs = plt.subplots(nrows=3,ncols=1,figsize=(12,8))
axs[0].plot(df_final3['mobility'])
axs[1].plot(df_final3['lockdown'])
axs[2].plot(df_final3['air_temperature'])
h3_causal_graph = nx.DiGraph()
h3_causal_graph.add_edge('is_weekend','mobility')
h3_causal_graph.add_edge('lockdown','mobility')
h3_causal_graph.add_edge('air_temperature','lockdown')
h3_causal_graph.add_edge('air_temperature','mobility')
graph_filename_h3='causal_mobility_weather_h3.dot'
nx.drawing.nx_pydot.write_dot(h3_causal_graph,graph_filename_h3)
with open(graph_filename_h3) as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
h3_model = CausalModel(data=df_final3.dropna(),treatment=['lockdown'],outcome='mobility',instruments=[],graph=graph_filename_h3,proceed_when_unidentifiable=True)
print(h3_model)
h3_estimand = h3_model.identify_effect()
print(h3_estimand)
h3_estimate = h3_model.estimate_effect(h3_estimand,method_name='backdoor.linear_regression',test_significance=True)
print(h3_estimate)
h3_ref1 = h3_model.refute_estimate(estimand=h3_estimand, estimate=h3_estimate,method_name='placebo_treatment_refuter')
print(h3_ref1)
h3_ref2 = h3_model.refute_estimate(estimand=h3_estimand, estimate=h3_estimate,method_name='random_common_cause')
print(h3_ref2)
```
**Remark**
The Causal estimate has a really low p value when we use the stringency clustering data. So, we can also replace the raw Oxford stringency data with the stringency clustering data
Hypothesis IV
------------------
Consider daily data for Berlin
Weather: historical air temperature
Mobility: Waze mobility data - Source: https://raw.githubusercontent.com/ActiveConclusion/COVID19_mobility/master/waze_reports/Waze_City-Level_Data.csv
Stringency: OXCGRT data
```
waze_df = pd.read_csv("https://raw.githubusercontent.com/ActiveConclusion/COVID19_mobility/master/waze_reports/Waze_City-Level_Data.csv")
waze_df['Date'] = pd.to_datetime(waze_df['Date'])
be_waze_df = waze_df[waze_df.City=="Berlin"]
be_waze_df.index = be_waze_df['Date']
be_waze_df = be_waze_df[['% Change In Waze Driven Miles/KMs']]
be_waze_df.columns = ['mobility']
dfs4 = [be_ox_df,be_waze_df,be_weather_df]
df_final4 = reduce(lambda left,right: pd.merge(left,right,left_index=True,right_index=True,how='inner'), dfs4)
df_final4['is_weekend'] = np.where((df_final4.index.weekday == 5)|(df_final4.index.weekday == 6),1,0)
#df_final4.rename({'StringencyIndex':'lockdown'},axis=1,inplace=True)
df_final4
fig,axs = plt.subplots(nrows=3,ncols=1,figsize=(12,8))
axs[0].plot(df_final4['mobility'])
axs[1].plot(df_final4['lockdown'])
axs[2].plot(df_final4['air_temperature'])
h4_causal_graph = nx.DiGraph()
h4_causal_graph.add_edge('is_weekend','mobility')
h4_causal_graph.add_edge('lockdown','mobility')
h4_causal_graph.add_edge('air_temperature','lockdown')
h4_causal_graph.add_edge('air_temperature','mobility')
graph_filename_h4='causal_mobility_weather_h4.dot'
nx.drawing.nx_pydot.write_dot(h4_causal_graph,graph_filename_h4)
with open(graph_filename_h4) as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
h4_model = CausalModel(data=df_final4.dropna(),treatment=['lockdown'],outcome='mobility',instruments=[],graph=graph_filename_h4,proceed_when_unidentifiable=True)
print(h4_model)
h4_estimand = h4_model.identify_effect()
print(h4_estimand)
h4_estimate = h4_model.estimate_effect(h4_estimand,method_name='backdoor.linear_regression',test_significance=True)
print(h4_estimate)
h4_ref1 = h4_model.refute_estimate(estimand=h4_estimand, estimate=h4_estimate,method_name='placebo_treatment_refuter')
print(h4_ref1)
h4_ref2 = h4_model.refute_estimate(estimand=h4_estimand, estimate=h4_estimate,method_name='random_common_cause')
print(h4_ref2)
```
**Comments**
As the data corresponds to only driving data, the plot shows that it is not really affected by the lockdown measures. Moreover, the driving mobility data is available only from 01.03.2020
Hypothesis V
------------------
Consider daily data for other cities/country such as London, New york and Singapore
Weather: historical air temperature
Mobility: Apple mobility (transit)
Stringency: OXCGRT data
1. London - EGLL, GBR
2. New York - NYC, USA
3. Singapore - WSAP, SGP
```
app_df = pd.read_csv("/project_data/data_asset/sun/apple_mobility/applemobilitytrends-2020-10-14.csv")
def region_specific_data(mobility_region,weather_station,stringency_country_code):
cs_app_trans_df = app_df[(app_df.region==mobility_region)&
(app_df.transportation_type=="transit")].drop(['geo_type','region','transportation_type',
'alternative_name','sub-region','country'],axis=1).transpose()
cs_app_trans_df.columns= ['mobility']
# Stringency Germany
if stringency_country_code == "GBR":
# Consider only England
cs_ox_df = ox_df[ox_df.regionname=="England"]
cs_ox_df.index= cs_ox_df['date']
cs_ox_df = cs_ox_df[['stringencyindex']]
elif stringency_country_code == "USA":
# Consider only New York
cs_ox_df = ox_df[ox_df.regionname=="New York"]
cs_ox_df.index= cs_ox_df['date']
cs_ox_df = cs_ox_df[['stringencyindex']]
else:
cs_ox_df = ox_df[ox_df.countrycode==stringency_country_code]
cs_ox_df.index= cs_ox_df['date']
cs_ox_df = cs_ox_df[['stringencyindex']]
# Max temperature
historical_url = "https://mesonet.agron.iastate.edu/cgi-bin/request/asos.py?station={}&data=tmpc&year1=2020&month1=1&day1=1&year2=2020&month2=10&day2=28&tz=Etc%2FUTC&format=onlycomma&latlon=no&missing=M&trace=T&direct=no&report_type=1&report_type=2".format(weather_station)
hist_weather_df = pd.read_csv(historical_url)
# Replace missing and trace as na
hist_weather_df.replace("M",np.nan,inplace=True)
hist_weather_df.replace("M",np.nan,inplace=True)
#Convert to float
hist_weather_df['tmpc'] = hist_weather_df['tmpc'].astype(np.float64)
hist_weather_df['valid'] = pd.to_datetime(hist_weather_df['valid'])
hist_weather_df.rename({'valid':'time','tmpc':'air_temperature'},axis=1, inplace=True)
hist_weather_df.index = hist_weather_df['time']
hist_weather_df = hist_weather_df.resample("1D").median()
dfs = [cs_ox_df,cs_app_trans_df,hist_weather_df]
df_final = reduce(lambda left,right: pd.merge(left,right,left_index=True,right_index=True,how='inner'), dfs)
df_final.rename({'stringencyindex':'lockdown'},axis=1,inplace=True)
df_final['is_weekend'] = np.where((df_final.index.weekday == 5)|(df_final.index.weekday == 6),1,0)
#return df_final
fig,axs = plt.subplots(nrows=3,ncols=1,figsize=(12,8))
axs[0].plot(df_final['mobility'])
axs[1].plot(df_final['lockdown'])
axs[2].plot(df_final['air_temperature'])
fig.suptitle(mobility_region)
plt.show()
causal_graph = nx.DiGraph()
causal_graph.add_edge('is_weekend','mobility')
causal_graph.add_edge('lockdown','mobility')
causal_graph.add_edge('air_temperature','lockdown')
causal_graph.add_edge('air_temperature','mobility')
graph_filename_='causal_mobility_weather_.dot'
nx.drawing.nx_pydot.write_dot(causal_graph,graph_filename_)
with open(graph_filename_) as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
_model = CausalModel(data=df_final.dropna(),treatment=['lockdown'],outcome='mobility',instruments=[],graph=graph_filename_,proceed_when_unidentifiable=True)
print(_model)
_estimand = _model.identify_effect()
print(_estimand)
_estimate = _model.estimate_effect(_estimand,method_name='backdoor.linear_regression',test_significance=True)
print(_estimate)
_ref1 = _model.refute_estimate(estimand=_estimand, estimate=_estimate,method_name='placebo_treatment_refuter')
print(_ref1)
_ref2 = _model.refute_estimate(estimand=_estimand, estimate=_estimate,method_name='random_common_cause')
print(_ref2)
return 1
region_specific_data('London','EGLL', 'GBR')
region_specific_data('New York','NYC', 'USA')
region_specific_data('Singapore','WSAP', 'SGP')
```
**Comments**
* For all three cities the estimator parameters given by the dowhy model are the same: "mobility ~ lockdown+is_weekend+air_temperature+lockdown*is_weekend"
**Author**
* Shri Nishanth Rajendran - AI Development Specialist, R² Data Labs, Rolls Royce
Special thanks to Deepak Srinivasan and Alvaro Corrales Cano
| github_jupyter |
# Setting up Jupyter Python Environment
There are several ways to setup your jupyter python environmnet. We will go from easiest to most advanced and from a local copy to a web based copy to a shared github binder hosted version. The goal is to avoid this: https://xkcd.com/1987/
Below the %% is a "magic" command and will be covered shortly. The image could be done via drag and drop and the image is in the same directory as the jupyter notebook for simplicity. Normally this would be in an "\images" directory. See https://stackoverflow.com/questions/32370281/how-to-embed-image-or-picture-in-jupyter-notebook-either-from-a-local-machine-o
Full list of magic commands... ... https://ipython.readthedocs.io/en/stable/interactive/magics.html#line-magics
Nice list of jupyter tips and tricks ... https://towardsdatascience.com/optimizing-jupyter-notebook-tips-tricks-and-nbextensions-26d75d502663
```
%%html
<img src="xkcd.png" , width="600" , height="400">
```
## Using a Local Jupyter Notebook - Anaconda
This is a local copy on your machine and will give you an Integrated Development Environment called Spyder as well, which is very helpful for programming.
1. Go to https://www.anaconda.com/
2. Select Anaconda Distribution - press Download Now button
3. Select your platform Windows - Mac or Linux
4. Select Python 3.7 (version 2.7 is for legacy code)
5. The relevant install will download
6. Run the steps for you platform to install the software
## Exercise 1 Setup up Anaconda
Setup Ananconda. This is on your local laptop. This will give you a full jupyter environment and is handy to have for running and testing notebooks
Create a new environment
1. Top left of the anaconda panel Select Environments (looks like a cube, or a container)
2. Bottom select Create with plus sign icon
3. In the dialog name the environment pd - this is short of pandas. Note that it wont let you have duplicate names!
4. Keep the 3.5 python package default
5. Press the create button - Note you need a connection to the internet for this to retrieve and setup packages
6. You will see the a progress bar and will have a small set of packages - this will take a minute or two
## Exercise 2 In Anaconda Install Pandas
1. Be sure exercise 1 is completed - you should have a fresh environment setup called "pd"
2. Change the packages to "Not Installed" - this will give the a large list of modules
3. Search for "pandas"
4. Select the pandas line and press apply
5. It will check requirements select apply again
6. You will see the requierements press ok
7. The package will install
## Exercise 3 In Anaconda Install Jupyter Notebook
Install jupyter notebook
1. Complete the exercises above
2. Select Home icon - top right of the environments screen
3. You wil see the new environment has been setup in the right corner
4. Select Install Jupyter Notebook - this will take several minutes as modules are pulled down from the web
5. Once completed the button will ready "Launch"
6. Press launch and a notebook server will run on your laptop in browser window
## Exercise 4 In Anaconda Test Jupyter Notebook
Create a notebook and test your setup
1. Complete the exercises above
2. In the jupyter notebook top right corner select New Notebook -> Python 3
3. You will have a new notebook called "Untitle"
4. Click to change the title to "Mybook" - note that you cannot have spaces in the title
5. At the first cell enter 2*3 and shift-Enter (or the triangle run icon) to run the cell
6. This is your first notebook!
We will cover notebook commands in detail in another notebook(!)
Also worth doing at some point is adding extensions to Jupyter Notebook. See https://towardsdatascience.com/optimizing-jupyter-notebook-tips-tricks-and-nbextensions-26d75d502663 specifically adding a variable viewer and code completion
- conda install -c conda-forge jupyter_contrib_nbextensions
- conda install -c conda-forge jupyter_nbextensions_configurator
- youtube https://www.youtube.com/watch?v=J6jphEdKO08
... although he uses pip install rather than conda ..
## Exercise 5 Optional Jupypterlab as Part of Anaconda
You can use jupyterlab as part of the local anaconda install or a pure stand alone environment to work with jupyter notebooks.
For this to work you need to switch to the location where your files reside.
1. Complete exercises above where anaconda is installed, an environment is setup and jupyberlab is installed and ready to launch
2. In the anaconda navigator select Environments
3. Select your environment
4. Select open Terminal
5. Change to the directory your code resides
6. At the prompt type jupyter lab
7. A connection to Jupyter lab should be started and you will see your file system
## Using a Simple Web Based Jupyter Notebook - Jupyterlab
This is a web based version. You can create notebooks here and download to your local environment
1. Go to https://jupyter.org/try
2. Select JupytperLabs
3. This will run a Binder server that will have your Jupyter environment in it
4. Once the environment is setup select File -> New -> Notebook
5. Select 3.7 notebook
6. You can now create, download, upload notebooks
This is running on the web so if your web connection goes down you will need to restart the kernal. You will see an indicator on the top far right of the jupyter notebook screen if there is a connection issue.
You can create a shareable link to this notebook select the file - right click and select Shareable link and this will allow you to revisit the work you've done from a prior session. As a backup I would recommend saving to you local disk when done.
## Exercise Optional Simple Web based Jupyter Lab Notebook
Follow the steps above to create a notebook and download to your local system
1. Select file in JupyterLab
2. Right click
3. Select download - note where it goes!
4. Move to local directory for Anaconda
5. Start jupyter notebook in that directory
6. Load file into local version of jupyter notebooks
## Using a Web Based Jupyter Notebook - Github and Binder
This is a web based way of sharing notebooks that uses the same technology as Jupyterlab but now you control and share the Jupyter environment. Basically this is taking an existing github repository of jupyter notebook code and creating a container using docker to run on a server. If you want more details see resource below
1. Youtube over of Binder 2018 Scipy 28 min https://www.youtube.com/watch?v=KcC0W5LP9GM&t=36s
2. Youtube how-to use and setup Binder Sarah Bonaretti 7 min https://www.youtube.com/watch?v=owSGVOov9pQ
3. Youtube using Github 20 min https://www.youtube.com/watch?v=nhNq2kIvi9s
It's actually fairly simple to do this if the github part is simplified and used as dropbox rather than version control
1. Setup up Github account
2. Create a public repo
3. Add a requirements.txt file for dependencies - more on this later
3. Upload jupyter notebook
4. Go to binder and point it at github repo
5. Copy the binder link
This binder link can be redistributed and used by multiple users.
## Exercise Github and Binder
We're going to use the simplest way possible to use github which involves no version control
Part 1 Github setup and File upload
1. Setup Github account - user name, email - this will receive a verification email, password - will need to be fairly strong
2. Verify that you're not a computer - usually a puzzle
3. Select plan - Free
4. Optional answer questions about experience and purpose of account
5. Verify the email account that you used
6. Create new repository (repo) call it test make it public
7. Add MIT license
8. Press Create repository
9. For now we can skip workflows because steps for loading files will be done manually
10. Select Code tab in github and Create file
11. File name is "requirements.txt"
12. File content is pandas
13. Press Commit new file to master branch
14. While we're here create a data directory as well - in file name add /data/info.txt and add a file (see https://github.com/KirstieJane/STEMMRoleModels/wiki/Creating-new-folders-in-GitHub-repository-via-the-browser)
14. Add the python notebook file - Select Upload
15. Find the file on your computer and upload
Part 2 Binder setup
1. Enter https://mybinder.org/
2. Enter repo name
3. Enter master
4. Press launch
5. Server should create jupyter notebook environment - be sure you have the right URL for your repo
6. Use the URL to test
this URL can be freely distributed to create and share this notebook
| github_jupyter |
# Studying avoided crossing for a 1 cavity-2 qubit system, <mark>with and without thermal losses</mark>
1. **Introduction**
2. **Problem parameters**
3. **Setting up operators, Hamiltonian's, and the initial state**
4. **Demonstrating avoided crossing**
* Plotting the ramp pulse generated
* Solving the Master equation and plotting the results (without thermal losses)
5. **Studying the effect of various ramp times on avoided crossing**
* { Case I } <u>No thermal losses</u>
* { Case II } <u>Thermal losses</u>
* Plotting the results
6. Calculating the Fidelity and Concurrence
**Author** : Soumya Shreeram (shreeramsoumya@gmail.com)<br>
**Supervisor** : Yu-Chin Chao (ychao@fnal.gov) <br>
**Date**: 9th August 2019<br>
This script was coded as part of the Helen Edwards Summer Internship program at Fermilab. The code studies the effect of avoided crossing for loading a photon from a qubit into the cavity. This is done by generating pulses with varying ramp times, and raising one of the qubit's frequecy above the cavity.
## 1. Introduction
The Jaynes-Cumming model is used to explain light-matter interaction in a system with a qubit and a single cavity mode. The Hamiltonian $H$ can be extended to describe a 2-qubit and cavity system as,
$$ H = \hbar \omega_c a^{\dagger}a+ \sum_{i=1}^2\frac{1}{2}\hbar \omega_{qi}\ \sigma_i^z + \sum_{i=1}^2\frac{1}{2} \hbar g(a^{\dagger} + a)(\sigma_i^-+\sigma_i^+)$$
which simplifies under the rotating-wave approximation as
$$ H_{\rm RWA} = \hbar \omega_c a^{\dagger}a+ \sum_{i=1}^2\frac{1}{2}\hbar \omega_a \sigma_i^z + \sum_{i=1}^2\frac{1}{2} \ \hbar g\ (a^{\dagger}\sigma_i^- + a\ \sigma_i^+)$$
where $\omega_c$ and $\omega_{qi}$ are the cavity and qubit frequencies, while $a$ and $\sigma_i^-$ are the annihalation operators for the cavity and qubit respectively. Note that $i=1,2$ represents the 2 qubits.
```
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d.axes3d import Axes3D
from matplotlib.ticker import LinearLocator, FormatStrFormatter
from matplotlib import cm
plt.rcParams.update({'font.size': 16})
import numpy as np
from numpy import ones,vstack
from numpy.linalg import lstsq
from math import pi
from scipy.signal import find_peaks
from time import sleep
import sys
from qutip import *
```
## 2. Problem parameters
Here we use $\hbar=1$; the coupling terms are redefined with a multiple of $2\pi$ before them for convinience.
```
def generateTimePulse(tr, th):
"""
Function that generates the pulse based on the input parameters
@param tr :: ramp up/down time for the pulse
@param th :: hold time for the pulse
@return t_pulse :: np array with 4 times that define the pulse
"""
t_pulse = [0, 0, 0, 0]
t_pulse[0] = 0
t_pulse[1] = tr + t_pulse[0]
t_pulse[2] = t_pulse[1] + th
t_pulse[3] = t_pulse[2] + tr
print("The time pulse is: ", t_pulse)
return t_pulse
"""------------- FREQUENCIES -----------------"""
w_q1 = 2*pi*6.5; # Qubit 1 frequency
w_q2 = 2*pi*6.8; # Qubit 2 frequency: range from 1-9 GHz
w_f = 2*pi*7.1; # Resonator/ Filter frequency
"""------------- COUPLING --------------------"""
g_q1f = 2*pi*0.135 # qubit 1-fitler coupling
#g_q2f = 2*pi*0.415 # qubit 2-fitler coupling
numF = 1 # number of filters
N = 2 # number of fock states
times = np.linspace(0,200,1500)
"""------------- DISSIPATION PARAMETERS -----"""
kappa = 5*10**-3 # cavity dissipation rate
n_th_a = 3*10**-3 # avg. no. of thermal bath excitation
r1 = 5*10**-6 # qubit relaxation rate
r2 = 1*10**-5 # qubit dephasing rate
"""------------- PULSE CONTROL PARAMETERS -----"""
tr = 0 # ramp up and ramp down times
th = 110 # hold time
t_pulse = generateTimePulse(tr, th)
# amplitude to raise pulse above cavity frequency (optional)
d = 0.25
w_top = w_f + 2*pi*d
no_ramps = 800 # number of ramps pulses sent into the Hamiltonian
```
## 3. Setting up the operators, Hamiltonian's, and Initial state
For every qubit: <br> <br>
**sm** $\ \rightarrow \ \hat{\sigma}^{+(-)}$ is the raising and lowering operator of the *qubit* <br>
**sz** $\ \ \rightarrow \ \sigma_z $ is the Pauli-z matrix of the *qubit* <br>
**n** $\ \ \ \rightarrow \ n$ is the number operator
```
def numOp(m):
"""
Computes the number operator
@param loweringMat :: lowering matrix operator for a system
"""
return m.dag()*m
def rwaCoupling(m1, m2):
return m1.dag()*m2 + m2.dag()*m1
def setXYlabel(ax, x, y, req_title, title_):
"""
Generic function to set labels for plots
"""
ax.set_xlabel(x)
ax.set_ylabel(y)
if req_title == True:
ax.set_title(title_)
return
```
### 3.1 Operators
```
# cavity
a = tensor(destroy(N), qeye(2), qeye(2))
nc = numOp(a)
# qubit 1
sm1 = tensor(qeye(N), sigmam(), qeye(2))
sz1 = tensor(qeye(N), sigmaz(), qeye(2))
n1 = numOp(sm1)
# qubit 2
sm2 = tensor(qeye(N), qeye(2), sigmam())
sz2 = tensor(qeye(N), qeye(2), sigmaz())
n2 = numOp(sm2)
# collapse operators
c_ops = []
# cavity relaxation
rate = kappa * (1 + n_th_a)
c_ops.append(np.sqrt(rate) * a)
# cavity excitation
# qubit 1 relaxation
c_ops.append(np.sqrt(r1 * (1+n_th_a)) * sm1)
c_ops.append(np.sqrt(r1 * n_th_a) * sm1.dag())
c_ops.append(np.sqrt(r2) * sz1)
# qubit 2 relaxation
c_ops.append(np.sqrt(r1 * (1+n_th_a)) * sm2)
c_ops.append(np.sqrt(r1 * n_th_a) * sm2.dag())
c_ops.append(np.sqrt(r2) * sz2)
```
### 3.2 Hamiltonian's and initial state
```
# Qubit Hamiltonians (Hq1+Hq2)
Hq1 = 0.5*sz1
Hq2 = 0.5*sz2
# Filter Hamiltonians (refer formula in the Introduction)
Hf = numOp(a)
# Qubit-Filter Hamiltonian
Hqf = g_q1f*(rwaCoupling(a, sm1) + rwaCoupling(a, sm2))
# time-independent Hamiltonian (see later)
H0 = w_f*Hf + w_q2*Hq2 + Hqf
H = H0 + w_q1*Hq1 # Resultant Hamiltonian
```
### 3.3 Initial State
```
# initial state of the system. Qubit 1: excited, Qubit 2: ground st.
psi0 = tensor(basis(N,0), basis(2,0), basis(2,1))
```
## 4. Demonstrating avoided crossing
In this section the qubit frequency is raised above the cavity frequency by applying a linearly varying ramp time $t$ (ns). The signal is held for a time $T-2t$ before it is ramped down again.
Tranformations on closed quantum states can be modelled by unitary operators. The combined time-dependent Hamiltonian for a system undergoing a tranformation that can be representated as,
$$ H(t) = H_0 + \sum_{i=0}^n c_i(t)H_i$$
where $H_0$ is called the time-independent drift Hamiltonian and $H_i$ are the control Hamiltonians with a time varying amplitude $c_i(t)$.
Here we write the Hamiltonian in a function-based time dependent way. See other ways [here](http://qutip.org/docs/latest/guide/dynamics/dynamics-time.html). Here the time-dependent coefficients, $f_n(t)$ of the Hamiltonian (e.g. `wf_t, w1_t,w2_t`) are expressed using Python functions
### 4.1 Functions
```
"""----------------------------------------
PULSE FUNCTIONS
------------------------------------------"""
def fitLine(t_pulse, i, j, w1, w2, t):
"""
Function generates a best fit line between [x1, y1] ->[x2, y2]
Input:
@param t_pulse :: np array containing the 4 points parameterizing the pulse
@param i,j :: indicies of t_pulse determining the start-stop times
@param w1, w2 :: lower and higher frequencies of the ramp pulse
@param t :: interable time variable
Returns:
@polynomial(t) :: best-fit y value at t
"""
# compute coefficients
coefficients = np.polyfit([t_pulse[i], t_pulse[j]], [w1, w2], 1)
# generate best-fit polynmial
polynomial = np.poly1d(coefficients)
return polynomial(t)
def rampUp(t_pulse, w1, w2, t):
"""
Generating a ramp up pulse
Input:
@param t_pulse :: np array containing the 4 points parameterizing the pulse
@param w1, w2 :: lower and higher frequencies of the ramp pulse
@param t :: interable time variable
Returns:
@param w :: int giving the y-value based on t
"""
t0 = t_pulse[0]
t1 = t_pulse[1]
if t0 != t1:
if t < t1:
return w1 + fitLine(t_pulse, 0, 1, 0, (w2-w1), t)*(t>t0)
if t > t1:
return w1 + (w2-w1)*(t>t1)
else:
return w1 + (w2 - w1)*(t > t1)
def rampDown(t_pulse, w1, w2, t):
"""
Generating a ramp Down pulse
Same as the ramp Up pulse given above only with the
"""
t2 = t_pulse[2]
t3 = t_pulse[3]
if t2 != t3:
if t > t2:
return w1 + fitLine(t_pulse, 2, 3, (w2-w1), 0, t)*(t>t2 and t<t3)
if t < t2:
return w1 + (w2-w1)*(t<t2)
else:
return w1 + (w2-w1)*(t<t2)
def wq1_t(t, args=None):
"""
Function defines the time depended co-efficent of the qubit 1
w_q1(t) is a pulse wave going from 0 to height (w_f-w_q1) at T0_1
"""
return (rampUp(t_pulse, w_q1, w_top, t) + rampDown(t_pulse, w_q1, w_top, t)-w_top)
def wq1_tdown(t, args=None):
"""
Function defines the time depended co-efficent of the qubit 1
w_q1(t) is a pulse wave going from 0 to height (w_f-w_q1) at T0_1
"""
return rampDown(t_pulse, w_q1, w_top, t)
def wf_t(t, args=None):
"""
Function defines the time depended co-efficent of the filters
(Although, there is no frequency change of the filters with time)
so w_f(t) = constant
"""
return w_f
def wq2_t(t, args=None):
"""
Function defines the time depended co-efficent of qubit 2
(Although, there is no frequency change of the quibit 2 with time)
so w_q2(t) = constant
"""
return w_q2
"""---------------------------------------------
HAMILTONIAN FUNCTIONS
---------------------------------------------"""
def plotPulse(ax, times, t_pulse, w_q1, w_top, colorCode, label_, ramp):
"""
Plots the required pulse
"""
if ramp == True:
plotting = ax.plot(times, [rampUp(t_pulse, w_q1, w_top, t)/(2*pi) for t in times], colorCode, label=label_)
elif ramp == False:
plotting = ax.plot(times, [rampDown(t_pulse, w_q1, w_top, t)/(2*pi) for t in times], colorCode, label=label_)
if ramp == 'Custom':
plotting = ax.plot(times, [(rampUp(t_pulse, w_q1, w_top, t) + rampDown(t_pulse, w_q1, w_top, t)-w_top)/(2*pi) for t in times], colorCode, label=r"$\Delta$t = %.1f ns"%(t_pulse[1]-t_pulse[0]))
return plotting
def labelTimes(t_r, t_H):
return r"$\Delta t = %.2f {\ \rm ns}, t_{\rm H} = %.2f {\ \rm ns}$"%(t_r, t_H)
def plotFrequencies(ax, times, wf_t, Colour, labels_, linestyle_):
"""
Function plots the frequencies as a function of times
"""
ax.plot(times, np.array(list(map(wf_t, times)))/(2*pi), Colour, linewidth=2, label=labels_, linestyle=linestyle_)
ax.legend(loc = 'center left', bbox_to_anchor = (1.0, 0.5))
return
def setLabels(ax, tr, th, plot_no):
"""
Function sets the labels of the x-y axis in the plot below
"""
if plot_no == 0:
ax.set_ylabel("Frequency (GHz)", fontsize=16)
ax.set_title(labelTimes(tr, th))
else:
ax.set_xlabel("Time (ns)")
ax.set_ylabel("Occupation \n probability")
return
def plotProb(ax, times, component, res, Colour, labels_, linestyle_):
"""
Function plots the occupation probabilities of the components after running mesolve
"""
ax.plot(times, np.real(expect(component, res.states)), Colour, linewidth=1.5, label=labels_, linestyle=linestyle_)
ax.legend(loc = 'center left', bbox_to_anchor = (1.0, 0.5))
return
```
### 4.1 Plotting the ramp pulse generated
The figure below demonstrated how the combination of ramping up and down forms the required pulse.
```
fig, ax = plt.subplots(1, 1, figsize=(7,5))
t_pulse1 = [t_pulse[0], t_pulse[1]+2.5, t_pulse[2]-2.5, t_pulse[3]]
t_pulse2 = [t_pulse[0], (t_pulse[3]-t_pulse[0])/2+t_pulse[0], (t_pulse[3]-t_pulse[0])/2+t_pulse[0], t_pulse[3]]
# plotting the pulses
plotPulse(ax, times, t_pulse, w_q1, w_top, 'g--', r"$\Delta$t = Ramp up", True)
plotPulse(ax, times, t_pulse, w_q1, w_top, 'b--', r"$\Delta$t = Ramp down", False)
plotPulse(ax, times, t_pulse, w_q1, w_top, 'r', ' ', 'Custom')
plotPulse(ax, times, t_pulse1, w_q1, w_top, '#03fcba', ' ', 'Custom')
plotPulse(ax, times, t_pulse2, w_q1, w_top, '#c4f2f1', ' ', 'Custom')
# guide lines
ax.axvline(x=t_pulse[0], color='#f2d4c4', linestyle='--')
ax.axvline(x=t_pulse[3], color='#f2d4c4', linestyle='--')
ax.axvline(x=t_pulse2[2], color='#f2d4c4', linestyle='--')
setXYlabel(ax, 'Time (ns)', 'Frequency (Hz)', False, '')
ax.legend(loc="upper right")
fig.tight_layout()
```
### 4.2 Solving the Master equation and plotting the results (without thermal losses)
```
opts = Options(nsteps = 50000, atol = 1e-30)
# time dependent Hamiltonian
H_t = [H0, [Hq1, wq1_t]]
# Evolving the system
res1 = mesolve(H_t, psi0, times, [], [])
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(12,7))
labels_ = ["cavity", "qubit 1", "qubit 2"]
w_list = [wf_t, wq1_t, wq2_t]
colors_ = ['#b4bfbc', 'b', '#b0ed3e']
linestyle_ = ['--', '-', '-']
components_ = [nc, n1, n2]
for i in [0, 1, 2]:
plotFrequencies(axes[0], times, w_list[i], colors_[i], labels_[i], linestyle_[i])
setLabels(axes[0], tr, th, 0)
for i in [0, 1, 2]:
plotProb(axes[1], times, components_[i], res1, colors_[i], labels_[i], linestyle_[i])
setLabels(axes[1], tr, th, 1)
fig.tight_layout()
```
## 5. Studying the effect of various ramp times on avoided crossing
```
def showProgress(idx, n):
"""
Function prints the progress bar for a running function
@param idx :: iterating index
@param n :: total number of iterating variables/ total length
"""
j = (idx+1)/n
sys.stdout.write('\r')
sys.stdout.write("[%-20s] %d%%" % ('='*int(20*j), 100*j))
sys.stdout.flush()
sleep(0.25)
return
def findIndex(times, t4):
"""
Function finds the index in the times array at required point t4
@param times :: np array contains the times at which H is evaluated
@param t4 :: the point at which the pulse ends
@returns param idx_array[0] :: the index of t4 in the times array
"""
idx_array = []
for i, t in enumerate(times):
if t >= t4 and t < t4+1:
idx_array.append(i)
return idx_array[0]
def genTimePulses(rampList):
"""
Generates pulses with variable ramp times
@param rampList :: List with
"""
ramp_vals = np.empty((0, 4))
for dt in rampList:
t_new = [t_pulse[0], t_pulse[1]+dt, t_pulse[2]-dt, t_pulse[3]]
ramp_vals = np.append(ramp_vals, [t_new], axis=0)
return ramp_vals
def printShape(ramp_dt_array):
print("\nDimensions of the resultant 2D array:", np.shape(ramp_dt_array))
return
# get the point after the ramp down excitation
t_idx = findIndex(times, t_pulse[3])
# generating a range of pulse with varying ramp times
rampList = np.linspace(t_pulse[1], (t_pulse[3]-t_pulse[0])/2+t_pulse[0], no_ramps)-t_pulse[1]
# generates the pulses
ramp_vals = genTimePulses(rampList)
```
### { Case I } No thermal losses: Evaluating the excited state population at <mark>all times</mark> of the pulse. The excited state population is studied for a range of different ramp pulses.
```
#ramp_dt_array2D = evaluateHam2D(ramp_vals, True, no_ramps, H0, Hq1, wq1_t)
no_loss = True
exp_vals = []
ramp_exp_arr = []
ramp_dt_array2D = np.empty((0, len(times)))
for i in range(no_ramps):
t_pulse = ramp_vals[i][:]
# time dependent Hamiltonian
H_t = [H0, [Hq1, wq1_t]]
# Evolving the system with/without thermal losses
if no_loss == True:
output = mesolve(H_t, psi0, times, [], [])
else:
output = mesolve(H_t, psi0, times, c_ops, [])
exp_vals = np.real(expect(n1, output.states))
exp_val = np.mean(exp_vals[t_idx:-1])
ramp_dt_array2D = np.append(ramp_dt_array2D, [exp_vals], axis=0)
ramp_exp_arr.append(exp_val)
# progress bar
showProgress(i, no_ramps)
printShape(ramp_dt_array2D)
```
### { Case II } <u>Thermal losses</u>: Evaluating the excited state population at the <mark>end of ramp down</mark> of the pulse. The excited state population is studied for a range of different ramp pulses.
```
no_loss = False
exp_valsi = []
ramp_exp_arri = []
ramp_dt_array2Di = np.empty((0, len(times)))
for i in range(no_ramps):
t_pulse = ramp_vals[i][:]
# time dependent Hamiltonian
H_t = [H0, [Hq1, wq1_t]]
# Evolving the system with/without thermal losses
if no_loss == True:
output = mesolve(H_t, psi0, times, [], [])
else:
output = mesolve(H_t, psi0, times, c_ops, [])
exp_valsi = np.real(expect(n1, output.states))
exp_vali = np.mean(exp_valsi[t_idx:-1])
ramp_dt_array2Di = np.append(ramp_dt_array2Di, [exp_valsi], axis=0)
ramp_exp_arri.append(exp_vali)
# progress bar
showProgress(i, no_ramps)
printShape(ramp_dt_array2Di)
```
### 5.1 Plotting the result obtained for different ramp times <mark>without thermal losses</mark>
```
def plotForVariousRamps(rampList, times, ramp_exp_arr, t_eval):
"""
Plots the variation in the excitation probability as a function of times and ramp up/down times
@param rampList :: array of times by which the ramp time is increased
@param times :: array of times at which H is evaluated
@praem ramp_dt_array2D :: 2D array of occupation probabilities resulting for evaluating at various ramp times
"""
fig, ax = plt.subplots(1, 2, figsize=(11,4))
ax[0].plot(rampList, ramp_exp_arr, 'k.-', markerfacecolor='r', markeredgecolor='r', markersize=8)
setXYlabel(ax[0], r'Ramp times $t$ (ns)', 'Excited population', True, '%d cavity'%(numF) )
Colors_ = ['r', 'b', 'g', '#ffd500']
for i,j in enumerate([0, findIndex(rampList, 18.3), findIndex(rampList, 36.7), findIndex(rampList, 55)]):
ax[1].hlines(ramp_exp_arr[j], times[t_eval], times[-1], color=Colors_[i], linewidth=2.5, label=r'$\Delta t =$ %.2f'%rampList[j])
ax[1].legend()
setXYlabel(ax[1], 'Times (ns)', 'Final occupation probabilty', False, 'Occupation probabilty vs times for various ramps\n' )
fig.tight_layout()
return
def plot3Dramps(rampList, times, ramp_dt_array2D):
"""
3D plot of the variation in the excitation probability as a function of times and ramp up/down times
@param rampList :: array of times by which the ramp time is increased
@param times :: array of times at which H is evaluated
@praem ramp_dt_array2D :: 2D array of occupation probabilities resulting for evaluating at various ramp times
"""
fig = plt.figure(figsize=(12,7))
ax = fig.gca(projection='3d')
X, Y = np.meshgrid(rampList, times)
surf = ax.plot_surface(X, Y, np.transpose(ramp_dt_array2D), rstride=1, cstride=1, cmap=cm.gist_heat, linewidth=1, antialiased=False)
#surf2 = ax.plot_wireframe(X, Y, np.transpose(ramp_dt_array2D), rstride=40, cstride=40, color='k', linewidth=0.5)
# Add a color bar, axis properties
fig.colorbar(surf, shrink=0.5, aspect=10)
ax.set_xlabel('\nRamp times' + r'$\ \Delta t$ (ns)')
ax.set_ylabel('\nTime (ns)')
ax.set_zlabel('\nOccupation Probabilities');
ax.set_title(labelTimes(tr, th))
ax.view_init(16, 25)
plt.show()
return
def FourierTransformOf(rampList, ramp_exp_arr):
"""
Function calculates the Fourier Transform of the input x-y data
@param rampLish :: x-values e.g. array of times
@param ramp_exp_arr :: real valued array whose FFT is calculated
@returns freq_arr :: x-vales in the freqeuncy domain
power :: Fourier transformed values of input ramp_exp_arr
"""
# fft of ram_exp_arr
ramp_FFT = np.fft.rfft(ramp_exp_arr)
power = np.real(ramp_FFT)*np.real(ramp_FFT)+np.imag(ramp_FFT)*np.imag(ramp_FFT)
# generating the FFT frequency array
start_pt = 1/rampList[-1]
freq_arr = np.linspace(start_pt, start_pt*len(power), len(power))
return freq_arr, power
def plotFFT(ax, rampList, ramp_exp_arr):
"""
Function finds the peaks in the FFT spectrum and plots the results
@param rampList :: x-vales e.g. array of times
@param ramp_exp_arr :: real valued array whose FFT is calculated
"""
rampList_FFT, ramp_exp_arr_FFT = FourierTransformOf(rampList, ramp_exp_arr)
# find peaks
peak, _ = find_peaks(ramp_exp_arr_FFT, distance=100)
# plot
ax.plot(rampList_FFT[1:], ramp_exp_arr_FFT[1:], color='#d97829', linestyle=':', marker= '.', markersize=8)
ax.plot(rampList_FFT[peak], ramp_exp_arr_FFT[peak], 'ro')
setXYlabel(ax, 'Frequency (GHz)', r'$\mathcal{F}\ [n_1]:$ 1 cavity', True, '(x, y) = (%.1f, %.2f)'%(ramp_exp_arr_FFT[peak], rampList_FFT[peak]))
fig.tight_layout()
return ramp_exp_arr_FFT[peak], rampList_FFT[peak]
def printResults(y, x):
print(' Power value: ', y)
print(' Frequency value: ', x)
return
plotForVariousRamps(rampList, times, ramp_exp_arr, t_idx)
```
Plotting the Fourier Transform of the above plot showing Excited population as a function of Ramp times (ns). The plot below helps to summarize the shift between slow and fast modes.
```
fig, ax = plt.subplots(1, 2, figsize=(8,4))
br_pt = 20
yf_peak, xf_peak = plotFFT(ax[0], rampList[:findIndex(rampList, br_pt)], ramp_exp_arr[:findIndex(rampList, br_pt)])
ax[0].set_xlim(0.01, 1.5)
yf_peak1, xf_peak1 = plotFFT(ax[1], rampList[findIndex(rampList, br_pt+5):], ramp_exp_arr[findIndex(rampList, br_pt+5):])
ax[1].set_xlim(0, 0.5)
print('Small ramp times (t<%.2f):'%br_pt)
printResults(yf_peak, xf_peak)
print('\nLarge ramp tines (t>%.2f):'%(br_pt+5))
printResults(yf_peak1, xf_peak1)
```
3D plot summing up the above two plots.
```
plot3Dramps(rampList, times, ramp_dt_array2D)
```
### 5.2 Plotting the result obtained for different ramp times <mark>with thermal losses</mark>
```
plotForVariousRamps(rampList, times, ramp_exp_arri, t_idx)
plot3Dramps(rampList, times, ramp_dt_array2Di)
```
## 6. Calculating the Fidelity and Concurrence
```
# extract the final state from the result of the simulation
rho_final = res1.states[-1]
# trace out the resonator mode and print the two-qubit density matrix
rho_qubits = ptrace(rho_final, [1, 2])
rho_qubits
# compare to the ideal result of the sqrtiswap gate (plus phase correction) for the current initial state
rho_qubits_ideal = ket2dm(tensor(phasegate(0), phasegate(-pi/2)) * sqrtiswap() * tensor(basis(2,0), basis(2,1)))
rho_qubits_ideal
print('Fidelity = ', fidelity(rho_qubits, rho_qubits_ideal))
print('Concurrence = ', concurrence(rho_qubits))
```
| github_jupyter |
# seaborn.jointplot
---
Seaborn's `jointplot` displays a relationship between 2 variables (bivariate) as well as 1D profiles (univariate) in the margins. This plot is a convenience class that wraps [JointGrid](http://seaborn.pydata.org/generated/seaborn.JointGrid.html#seaborn.JointGrid).
```
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
plt.rcParams['figure.figsize'] = (20.0, 10.0)
plt.rcParams['font.family'] = "serif"
```
The multivariate normal distribution is a nice tool to demonstrate this type of plot as it is sampling from a multidimensional Gaussian and there is natural clustering. I'll set the covariance matrix equal to the identity so that the X and Y variables are uncorrelated -- meaning we will just get a blob
```
# Generate some random multivariate data
x, y = np.random.RandomState(8).multivariate_normal([0, 0], [(1, 0), (0, 1)], 1000).T
df = pd.DataFrame({"x":x,"y":y})
```
Default plot
```
p = sns.jointplot(data=df,x='x', y='y')
```
Currently, `jointplot` wraps `JointGrid` with the following options for `kind`:
- scatter
- reg
- resid
- kde
- hex
Scatter is the default parameters
```
p = sns.jointplot(data=df,x='x', y='y',kind='scatter')
```
'reg' plots a linear regression line. Here the line is close to flat because we chose our variables to be uncorrelated
```
p = sns.jointplot(data=df,x='x', y='y',kind='reg')
```
'resid' plots the residual of the data to the regression line -- which is not very useful for this specific example because our regression line is almost flat and thus the residual is almost the same as the data.
```
x2, y2 = np.random.RandomState(9).multivariate_normal([0, 0], [(1, 0), (0, 1)], len(x)).T
df2 = pd.DataFrame({"x":x,"y":y2})
p = sns.jointplot(data=df,x='x', y='y',kind='resid')
```
`kde` plots a kernel density estimate in the margins and converts the interior into a shaded countour plot
```
p = sns.jointplot(data=df,x='x', y='y',kind='kde')
```
'hex' bins the data into hexagons with histograms in the margins. At this point you probably see the "pre-cooked" nature of `jointplot`. It provides nice defaults, but if you wanted, for example, a KDE on the margin of this hexplot you will need to use `JointGrid`.
```
p = sns.jointplot(data=df,x='x', y='y',kind='hex')
```
`stat_func` can be used to provide a function for computing a summary statistic from the data. The full x, y data vectors are passed in, so the function must provide one value or a tuple from many. As an example, I'll provide `tmin`, which when used in this way will return the smallest value of x that was greater than its corresponding value of y.
```
from scipy.stats import tmin
p = sns.jointplot(data=df, x='x', y='y',kind='kde',stat_func=tmin)
# tmin is computing roughly the equivalent of the following
print(df.loc[df.x>df.y,'x'].min())
```
Change the color
```
p = sns.jointplot(data=df,
x='x',
y='y',
kind='kde',
color="#99ffff")
```
```
p = sns.jointplot(data=df,
x='x',
y='y',
kind='kde',
ratio=1)
```
Create separation between 2D plot and marginal plots with `space`
```
p = sns.jointplot(data=df,
x='x',
y='y',
kind='kde',
space=2)
```
`xlim` and `ylim` can be used to adjust the field of view
```
p = sns.jointplot(data=df,
x='x',
y='y',
kind='kde',
xlim=(-15,15),
ylim=(-15,15))
```
Pass additional parameters to the marginal plots with `marginal_kws`. You can pass similar options to `joint_kws` and `annot_kws`
```
p = sns.jointplot(data=df,
x='x',
y='y',
kind='kde',
marginal_kws={'lw':5,
'color':'red'})
```
Finalize
```
sns.set(rc={'axes.labelsize':30,
'figure.figsize':(20.0, 10.0),
'xtick.labelsize':25,
'ytick.labelsize':20})
from itertools import chain
p = sns.jointplot(data=df,
x='x',
y='y',
kind='kde',
xlim=(-3,3),
ylim=(-3,3),
space=0,
stat_func=None,
marginal_kws={'lw':3,
'bw':0.2}).set_axis_labels('X','Y')
p.ax_marg_x.set_facecolor('#ccffccaa')
p.ax_marg_y.set_facecolor('#ccffccaa')
for l in chain(p.ax_marg_x.axes.lines,p.ax_marg_y.axes.lines):
l.set_linestyle('--')
l.set_color('black')
plt.text(-1.7,-2.7, "Joint Plot", fontsize = 55, color='Black', fontstyle='italic')
fig, ax = plt.subplots(1,1)
sns.set(rc={'axes.labelsize':30,
'figure.figsize':(20.0, 10.0),
'xtick.labelsize':25,
'ytick.labelsize':20})
from itertools import chain
p = sns.jointplot(data=df,
x='x',
y='y',
kind='kde',
xlim=(-3,3),
ylim=(-3,3),
space=0,
stat_func=None,
ax=ax,
marginal_kws={'lw':3,
'bw':0.2}).set_axis_labels('X','Y')
p.ax_marg_x.set_facecolor('#ccffccaa')
p.ax_marg_y.set_facecolor('#ccffccaa')
for l in chain(p.ax_marg_x.axes.lines,p.ax_marg_y.axes.lines):
l.set_linestyle('--')
l.set_color('black')
plt.text(-1.7,-2.7, "Joint Plot", fontsize = 55, color='Black', fontstyle='italic')
# p = sns.jointplot(data=df,
# x='x',
# y='y',
# kind='kde',
# xlim=(-3,3),
# ylim=(-3,3),
# space=0,
# stat_func=None,
# ax=ax[1],
# marginal_kws={'lw':3,
# 'bw':0.2}).set_axis_labels('X','Y')
# p.ax_marg_x.set_facecolor('#ccffccaa')
# p.ax_marg_y.set_facecolor('#ccffccaa')
# for l in chain(p.ax_marg_x.axes.lines,p.ax_marg_y.axes.lines):
# l.set_linestyle('--')
# l.set_color('black')
p.savefig('../../figures/jointplot.png')
```
| github_jupyter |
```
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn import metrics
import matplotlib.pylab as plt
%matplotlib inline
retail = pd.read_csv('/Users/feilynch/Desktop/COMP257/Portfolio3/files/online-retail.csv')
#retail.head()
#retail.shape
#retail.tail()
# explor data
retail.isnull().sum()
# drop no value rows
retail.dropna(subset = ['CustomerID', 'Description'], how = 'any', inplace = True)
retail.shape
# converted time series
retail['InvoiceDate'] = pd.to_datetime(retail.InvoiceDate)
#retail.head()
#retail.tail()
#retail['InvoiceDate'].min()
retail['InvoiceDate'].max()
ts = pd.to_datetime('2010-12-09')
sample = retail.loc[(retail.InvoiceDate >= ts) & (retail.Country == 'United Kingdom'), :]
#print(sample)
```
## now the sample dataframe only contains one year's invoice data dating from (2010-12-09 to 2011-12-10), There’s some research indicating that customer clusters vary geographically, so here I’ll restrict the data to one geographic unit, and one country the 'United Kingdom'.
sample.shape sample.head()
sample['Country'].nunique()
sample.describe() sample.info()
```
# first outliers detection, boxplot
sample.boxplot(return_type = 'dict')
plt.plot
#dected the sample_outliers and removed
sample_outliers = sample[(sample.Quantity > 10000) | (sample.Quantity < -20000) | (sample.UnitPrice > 5000)]
print(sample_outliers)
# removed outliers
sample.drop([61619,61624,173277,173382,173391,222681,502122,540421,540422], axis=0, inplace = True)
sample.boxplot(return_type = 'dict')
plt.plot
# add a column 'value' for the value of each transaction
sample = sample.assign(value=sample.Quantity * sample.UnitPrice)
sample.shape
# split into returns and sales, returns have a quantity less than zero
returns = sample.loc[sample.Quantity<=0]
sales = sample.loc[sample.Quantity>0]
print("Sales", sales.shape)
print("Returns", returns.shape)
## Adding Columns
sales_grouped = sales[['CustomerID', 'Quantity', 'UnitPrice', 'value']].groupby('CustomerID').aggregate(np.mean)
counts = sales.groupby('CustomerID').size().to_frame(name='count')
sales_grouped = sales_grouped.join(counts)
sales_grouped.describe()
```
## This next step computes the time from each invoice date to the most recent invoice date and converts it to days. The following step then aggregates this per customer using max amount of days to get the most recent invoice per customer. This is then added to the sales_grouped dataframe. "
```
# add recency of purchases
recency = pd.to_datetime(sales.InvoiceDate)-pd.to_datetime("2011-12-10")
# get just the number of days so that we can use this value in clustering
recency = recency.apply(lambda x: x.days)
# turn recency into a dataframe with the customerID column from sales
recency_df = sales[['CustomerID']].assign(recency=recency)
# aggregate recency using max to get the most recent sale per customer
grp = recency_df[['CustomerID', 'recency']].groupby('CustomerID').aggregate(np.max)
# customers is our final dataframe of customer data
customers = sales_grouped.join(grp)
#customers.head()
customers.shape
#customers.head()
# step 1: Select parameters for clustering, By RFM therom, choosed: value ,count ,recency 3 features as parameters,group by customers ID
features_list = ['value','count','recency']
customers_data = customers.dropna(axis=0)[features_list]
CustomerID_groups = customers_data.groupby('CustomerID').mean().reset_index().dropna(axis=0)
#CustomerID_groups.shape
#CustomerID_groups.head()
#CustomerID_groups.describe()
# scatter plot the original data set
CustomerID_groups.plot('count', 'value', kind='scatter')
```
## This first graph uses the variables’ original metrics and is almost completely uninterpretable. There’s a clump of data points in the lower left-hand corner of the plot, and then a few outliers. This is why we log-transformed the input variables.
```
# Log-transform positively-skewed variables
CustomerID_groups['value_log'] = np.log(CustomerID_groups['value'])
CustomerID_groups['count_log'] = np.log(CustomerID_groups['count'])
CustomerID_groups['recency_log'] = np.log(CustomerID_groups['recency'])
#CustomerID_groups.shape
#CustomerID_groups.head()
#CustomerID_groups.describe()
plt.title('Log-transform positively-skewed variables')
plt.scatter(CustomerID_groups['count_log'],CustomerID_groups['value_log'], s=50)
plt.show()
#CustomerID_groups.plot('count_log', 'value_log', kind='scatter')
#standardize variables as z-scores.
from scipy import stats
CustomerID_groups['value_log_z']= np.array(CustomerID_groups['value_log'])
stats.zscore(CustomerID_groups['value_log_z'])
CustomerID_groups['count_log_z']= np.array(CustomerID_groups['count_log'])
stats.zscore(CustomerID_groups['count_log_z'])
#CustomerID_groups.head()
#CustomerID_groups.describe()
#CustomerID_groups.shape
#standardize as z-scores.
plt.title('standardize as z-scores')
plt.scatter(CustomerID_groups['count_log_z'],CustomerID_groups['value_log_z'], s=50)
plt.show()
#CustomerID_groups.plot('count_log_z', 'value_log_z', kind='scatter')
```
## We can see that the data points are fairly continuously-distributed. 75% of the data can be counted between(2-6),and values between(2-5), There really aren’t clear clusters. This means that any cluster groupings we create won’t exactly reflect the truth.
## This third scatterplot is basically identical to the second – it illustrates that even though we’ve changed the scaling for the analysis, the shape of the distributions and the relationships among the variables remain the same. Therefore we chose Log-transformed data sets for our K-Means analysis.
## And then we choose the 'elbow method' to determine the optimal K-values.
```
# stept 2 select K-Means clustering algorithm for our analysis
# using 'Elbow Method' to determine best number K for clustering
def elbow_plot(data, maxK=10, seed_centroids=None):
"""
parameters:
- data: pandas DataFrame (data to be fitted)
- maxK (default = 10): integer (maximum number of clusters with which to run k-means)
- seed_centroids (default = None ): float (initial value of centroids for k-means)
"""
sse = {}
for k in range(1, maxK):
if seed_centroids is not None:
seeds = seed_centroids.head(k)
kmeans = KMeans(n_clusters=k, max_iter=500, n_init=100, random_state=0, init=np.reshape(seeds, (k,1))).fit(CustomerID_groups[features_list])
data["clusters"] = kmeans.labels_
else:
kmeans = KMeans(n_clusters=k, max_iter=300, n_init=100, random_state=0).fit(CustomerID_groups[features_list])
data["clusters"] = kmeans.labels_
# Inertia: Sum of distances of samples to their closest cluster center
sse[k] = kmeans.inertia_
plt.figure()
plt.title('Elbow Curve')
plt.plot(list(sse.keys()), list(sse.values()),'ko-')
plt.show()
return
elbow_plot(CustomerID_groups[features_list])
```
## Following the clustering analysis for K = 9, 7 and 5
```
# First we set K=9
km = KMeans(n_clusters=9)
CustomerID_groups['cluster'] = km.fit_predict(CustomerID_groups[features_list])
CustomerID_groups['cluster'].describe()
#CustomerID_groups.head()
CustomerID_groups.merge(CustomerID_groups[['CustomerID','cluster']]).groupby('cluster').mean()
# principal Component Analysis: we choose Log Transformed and PCA decomposition to plot the clusting graph
from sklearn import decomposition
pca = decomposition.PCA(n_components=2, whiten=True)
pca.fit(CustomerID_groups[features_list])
CustomerID_groups['x'] = pca.fit_transform(CustomerID_groups[features_list])[:,0]
CustomerID_groups['y'] = pca.fit_transform(CustomerID_groups[features_list])[:,1]
plt.title('PCA decomposition K-means Solution with 9 Clusters')
plt.scatter(CustomerID_groups['x'],CustomerID_groups['y'], c=CustomerID_groups['cluster'], s=50 )
plt.show()
plt.title('Log Transformed K-means Solution with 9 Clusters')
plt.scatter(CustomerID_groups['count_log'],CustomerID_groups['value_log'], c=CustomerID_groups['cluster'] )
plt.show()
```
# graphs become very hard to interpret visually, and the cluster centers overlap each other starting to make distinctions that may not be that helpful .
```
# second set K=7
km = KMeans(n_clusters=7)
CustomerID_groups['cluster'] = km.fit_predict(CustomerID_groups[features_list])
CustomerID_groups['cluster'].describe()
#CustomerID_groups.head()
CustomerID_groups.merge(CustomerID_groups[['CustomerID','cluster']]).groupby('cluster').mean()
from sklearn import decomposition
pca = decomposition.PCA(n_components=2, whiten=True)
pca.fit(CustomerID_groups[features_list])
CustomerID_groups['x'] = pca.fit_transform(CustomerID_groups[features_list])[:,0]
CustomerID_groups['y'] = pca.fit_transform(CustomerID_groups[features_list])[:,1]
plt.title('PCA decomposition K-means Solution with 7 Clusters')
plt.scatter(CustomerID_groups['x'],CustomerID_groups['y'], c=CustomerID_groups['cluster'], s=50 )
plt.show()
plt.title('Log Transformed K-means Solution with 7 Clusters')
plt.scatter(CustomerID_groups['count_log'],CustomerID_groups['value_log'], c=CustomerID_groups['cluster'] )
plt.show()
```
# the graph is a bit clearer than cluster 9, but still has a lot of overlapping present, but clearly we can see yellow dot group customers have some value, they also have high frequency with a reasonable purchase value.
```
# Third set K=5
km = KMeans(n_clusters=5)
CustomerID_groups['cluster'] = km.fit_predict(CustomerID_groups[features_list])
CustomerID_groups['cluster'].describe()
#CustomerID_groups.head()
CustomerID_groups.merge(CustomerID_groups[['CustomerID','cluster']]).groupby('cluster').mean()
#CustomerID_groups['cluster'].describe()
from sklearn import decomposition
pca = decomposition.PCA(n_components=2, whiten=True)
pca.fit(CustomerID_groups[features_list])
CustomerID_groups['x'] = pca.fit_transform(CustomerID_groups[features_list])[:,0]
CustomerID_groups['y'] = pca.fit_transform(CustomerID_groups[features_list])[:,1]
plt.title('PCA decomposition K-means Solution with 5 Clusters')
plt.scatter(CustomerID_groups['x'],CustomerID_groups['y'], c=CustomerID_groups['cluster'], s=50 )
plt.show()
plt.title('Log Transformed K-means Solution with 5 Clusters')
plt.scatter(CustomerID_groups['count_log'],CustomerID_groups['value_log'], c=CustomerID_groups['cluster'] )
plt.show()
```
# Characteristics for each cluster base on Log Transformed K-means Solution with 5 Clusters.
## Note: in all graphs above X = count, Y = value
### I really like the number 5-cluster solution, it is abundantly clear for each cluster.
### blue group (cluster 1) has a high-value, relatively-recent purchases and a low count (frequency), they are the the most valuable customer repesenting nearly 40% of total sales, is there any room to improve frenquency? (e.g. eliminating competition).
### green group (cluster2) has a low-value, high-count (frequency), and very recent purchase (5 days), it may be an indicator of promotional sales.
### yellow group (cluster4) looks like they have similar characteristics as cluster 1, with low recent purchases.
### brown group (cluster3) has a medium-value, high frequency and most recent purchase (25 days), they are potentially representative of regular customers.
CustomerID value count #Total_purchase recency count_log value_log
cluster
0 15547.952034 30.46 55 1675.30 -102 3.468813 2.898674
1 15098.000000 13305.50 3 39915 -65 1.098612 9.495933
2 14895.000000 8.45 5608 47387.60 -5 8.596671 2.065466
3 15651.663004 20.55 456 9370.80 -25 6.008713 2.464378
4 16090.666667 2859.76 3 8579 -130 0.730338 7.893476
### As we move beyond 5 clusters, the graphs become increasingly hard to interpret visually, and the cluster centers start to make distinctions that may not be that helpful.
# END
| github_jupyter |
# Advanced Regular Expressions Lab
Complete the following set of exercises to solidify your knowledge of regular expressions.
```
import re
```
### 1. Use a regular expression to find and extract all vowels in the following text.
```
text = "This is going to be a sentence with a good number of vowels in it."
pattern = '[aeiouAEIOU]'
re.findall(pattern, text)
```
### 2. Use a regular expression to find and extract all occurrences and tenses (singular and plural) of the word "puppy" in the text below.
```
text = "The puppy saw all the rest of the puppies playing and wanted to join them. I saw this and wanted a puppy of my own!"
pattern = 'pupp[yies]*'
re.findall(pattern, text)
```
### 3. Use a regular expression to find and extract all tenses (present and past) of the word "run" in the text below.
```
text = "I ran the relay race the only way I knew how to run it."
pattern = 'r[au]n'
re.findall(pattern, text)
```
### 4. Use a regular expression to find and extract all words that begin with the letter "r" from the previous text.
```
text = "I ran the relay race the only way I knew how to run it."
pattern = '[r*]\w+'
re.findall(pattern, text)
```
### 5. Use a regular expression to find and substitute the letter "i" for the exclamation marks in the text below.
```
text = "Th!s !s a sentence w!th spec!al characters !n !t."
re.sub("!", "i", text)
# OR
text.replace("!", "i")
```
### 6. Use a regular expression to find and extract words longer than 4 characters in the text below.
```
text = "This sentence has words of varying lengths."
pattern = '\w{4,}'
print(re.findall(pattern, text))
```
### 7. Use a regular expression to find and extract all occurrences of the letter "b", some letter(s), and then the letter "t" in the sentence below.
```
text = "I bet the robot couldn't beat the other bot with a bat, but instead it bit me."
pattern = 'b[a-z]*t'
print(re.findall(pattern, text))
```
### 8. Use a regular expression to find and extract all words that contain either "ea" or "eo" in them.
```
text = "During many of the peaks and troughs of history, the people living it didn't fully realize what was unfolding. But we all know we're navigating breathtaking history: Nearly every day could be — maybe will be — a book."
pattern = '\w*ea\w{2,}|\w*eo\w{2,}'
print(re.findall(pattern, text))
```
### 9. Use a regular expression to find and extract all the capitalized words in the text below individually.
```
text = "Teddy Roosevelt and Abraham Lincoln walk into a bar."
pattern = '[A-Z][a-z]*'
print(re.findall(pattern, text))
```
### 10. Use a regular expression to find and extract all the sets of consecutive capitalized words in the text above.
```
pattern = '[A-Z][a-z]* ?[A-Z][a-z]*'
pattern = '[A-Z][a-z]* [A-Z][a-z]*'
print(re.findall(pattern, text))
```
### 11. Use a regular expression to find and extract all the quotes from the text below.
*Hint: This one is a little more complex than the single quote example in the lesson because there are multiple quotes in the text.*
```
text = 'Roosevelt says to Lincoln, "I will bet you $50 I can get the bartender to give me a free drink." Lincoln says, "I am in!"'
pattern = '\"(.*?)\"'
print(re.findall(pattern, text))
```
### 12. Use a regular expression to find and extract all the numbers from the text below.
```
text = "There were 30 students in the class. Of the 30 students, 14 were male and 16 were female. Only 10 students got A's on the exam."
pattern = '\d{1,}'
re.findall(pattern, text)
```
### 13. Use a regular expression to find and extract all the social security numbers from the text below.
```
text = """
Henry's social security number is 876-93-2289 and his phone number is (847)789-0984.
Darlene's social security number is 098-32-5295 and her phone number is (987)222-0901.
"""
pattern = '\d+-\d+-\d+'
re.findall(pattern, text)
```
### 14. Use a regular expression to find and extract all the phone numbers from the text below.
```
pattern = '\(\d+\)\d+ ?-\d+'
re.findall(pattern, text)
```
### 15. Use a regular expression to find and extract all the formatted numbers (both social security and phone) from the text below.
```
pattern = '\S\d+\D ?\d+- ?\d+'
re.findall(pattern, text)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/tiffanysn/general_learning/blob/dev/Quantium_task_2_tiff.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
from google.colab import drive
drive.mount('/content/drive')
```
## Load required libraries and datasets
```
! cp drive/My\ Drive/QVI_data.csv .
import pandas as pd
import plotly.express as px
import numpy as np
df=pd.read_csv('QVI_data.csv')
df.shape
df.info()
df.describe(include= 'all')
df.info()
```
# Trial store 77
## Select control store
#### Add Month column
```
import datetime
df['year'] = pd.DatetimeIndex(df['DATE']).year
df['month']=pd.DatetimeIndex(df['DATE']).month
df['year_month']=pd.to_datetime(df['DATE']).dt.floor('d') - pd.offsets.MonthBegin(1)
df
```
#### Monthly calculation for each store
```
totSales= df.groupby(['STORE_NBR','year_month'])['TOT_SALES'].sum().reset_index()
totSales
measureOverTime2 = pd.DataFrame(data=totSales)
nTxn= df.groupby(['STORE_NBR','year_month'])['TXN_ID'].count().reset_index(drop=True)
nTxn
sorted(df['year_month'].unique())
measureOverTime2['nCustomers'] = df.groupby(['STORE_NBR','year_month','LYLTY_CARD_NBR'])['DATE'].count().groupby(['STORE_NBR','year_month']).count().reset_index(drop=True)
measureOverTime2.head()
measureOverTime2['nTxnPerCust'] = nTxn/measureOverTime2['nCustomers']
measureOverTime2.head()
totQty = df.groupby(['STORE_NBR','year_month'])['PROD_QTY'].sum().reset_index(drop=True)
totQty
measureOverTime2['nChipsPerTxn'] = totQty/nTxn
measureOverTime2
measureOverTime2['avgPricePerUnit'] = totSales['TOT_SALES']/totQty
measureOverTime2
```
#### Filter pre-trial & stores with full obs
```
measureOverTime2.set_index('year_month', inplace=True)
preTrialMeasures = measureOverTime2.loc['2018-06-01':'2019-01-01'].reset_index()
preTrialMeasures
```
#### Owen's *Solution*
```
measureOverTime = df.groupby(['STORE_NBR','year_month','LYLTY_CARD_NBR']).\
agg(
totSalesPerCust=('TOT_SALES', sum),
nTxn=('TXN_ID', "count"),
nChips=('PROD_QTY', sum)
).\
groupby(['STORE_NBR','year_month']).\
agg(
totSales=("totSalesPerCust", sum),
nCustomers=("nTxn", "count"),
nTxnPerCust=("nTxn", lambda x: x.sum()/x.count()),
totChips=("nChips", sum),
totTxn=("nTxn", sum)).\
reset_index()
measureOverTime['nChipsPerTxn'] = measureOverTime['totChips']/measureOverTime['totTxn']
measureOverTime['avgPricePerUnit'] = measureOverTime['totSales']/measureOverTime['totChips']
measureOverTime.drop(['totChips', 'totTxn'], axis=1, inplace=True)
```
#### Calculate correlation
```
preTrialMeasures
# Input
inputTable = preTrialMeasures
metricCol = 'TOT_SALES'
storeComparison = 77
x = 1
corr = preTrialMeasures.\
loc[preTrialMeasures['STORE_NBR'].\
isin([x,storeComparison])].\
loc[:, ['year_month', 'STORE_NBR', metricCol]].\
pivot(index='year_month', columns='STORE_NBR', values=metricCol).\
corr().\
iloc[0, 1]
preTrialMeasures.loc[preTrialMeasures['STORE_NBR'].isin([x,storeComparison])].loc[:, ['year_month', 'STORE_NBR', metricCol]].\
pivot(index='year_month', columns='STORE_NBR', values=metricCol).corr()
df = pd.DataFrame(columns=['Store1', 'Store2', 'corr_measure'])
df.append({'Store1':x, 'Store2':storeComparison, 'corr_measure':corr}, ignore_index=True)
def calculateCorrelation(inputTable, metricCol, storeComparison):
df = pd.DataFrame(columns=['Store1', 'Store2', 'corr_measure'])
for x in inputTable.STORE_NBR.unique():
if x in [77, 86, 88]:
pass
else:
corr = inputTable.\
loc[inputTable['STORE_NBR'].\
isin([x,storeComparison])].\
loc[:, ['year_month', 'STORE_NBR', metricCol]].\
pivot(index='year_month', columns='STORE_NBR', values=metricCol).\
corr().\
iloc[0, 1]
df = df.append({'Store1':storeComparison, 'Store2':x, 'corr_measure':corr}, ignore_index=True)
return(df)
calcCorrTable = calculateCorrelation(inputTable=preTrialMeasures, metricCol='nCustomers', storeComparison=77)
calcCorrTable
```
#### Calculate magnitude distance
```
inputTable = preTrialMeasures
metricCol = 'TOT_SALES'
storeComparison = '77'
x='2'
mag = preTrialMeasures.\
loc[preTrialMeasures['STORE_NBR'].isin([x, storeComparison])].\
loc[:, ['year_month', 'STORE_NBR', metricCol]].\
pivot(index='year_month', columns='STORE_NBR', values=metricCol).\
reset_index().rename_axis(None, axis=1)
mag
mag.columns = mag.columns.map(str)
mag
mag['measures'] = mag.apply(lambda row: row[x]-row[storeComparison], axis=1).abs()
mag
mag['Store1'] = x
mag['Store2'] = storeComparison
df_temp = mag.loc[:, ['Store1', 'Store2', 'year_month','measures']]
df_temp
df = pd.DataFrame(columns=['Store1', 'Store2', 'year_month','measures'])
df
inputTable = preTrialMeasures
metricCol = 'TOT_SALES'
storeComparison = '77'
df = pd.DataFrame(columns=['Store1', 'Store2', 'year_month','measures'])
for x in inputTable.STORE_NBR.unique():
if x in [77, 86, 88]:
pass
else:
mag = preTrialMeasures.\
loc[preTrialMeasures['STORE_NBR'].\
isin([x, storeComparison])].\
loc[:, ['year_month', 'STORE_NBR', metricCol]].\
pivot(index='year_month', columns='STORE_NBR', values=metricCol).\
reset_index().rename_axis(None, axis=1)
mag.columns = ['year_month', 'Store1', 'Store2']
mag['measures'] = mag.apply(lambda row: row['Store1']-row['Store2'], axis=1).abs()
mag['Store1'] = x
mag['Store2'] = storeComparison
df_temp = mag.loc[:, ['Store1', 'Store2', 'year_month','measures']]
df = pd.concat([df, df_temp])
df
def calculateMagnitudeDistance(inputTable, metricCol, storeComparison):
df = pd.DataFrame(columns=['Store1', 'Store2', 'year_month','measures'])
for x in inputTable.STORE_NBR.unique():
if x in [77, 86, 88]:
pass
else:
mag = preTrialMeasures.\
loc[preTrialMeasures['STORE_NBR'].\
isin([x, storeComparison])].\
loc[:, ['year_month', 'STORE_NBR', metricCol]].\
pivot(index='year_month', columns='STORE_NBR', values=metricCol).\
reset_index().rename_axis(None, axis=1)
mag.columns = ['year_month', 'Store1', 'Store2']
mag['measures'] = mag.apply(lambda row: row['Store1']-row['Store2'], axis=1).abs()
mag['Store1'] = storeComparison
mag['Store2'] = x
df_temp = mag.loc[:, ['Store1', 'Store2', 'year_month','measures']]
df = pd.concat([df, df_temp])
return df
def finalDistTable(inputTable, metricCol, storeComparison):
calcDistTable = calculateMagnitudeDistance(inputTable, metricCol, storeComparison)
minMaxDist = calcDistTable.groupby(['Store1','year_month'])['measures'].agg(['max','min']).reset_index()
distTable = calcDistTable.merge(minMaxDist, on=['year_month', 'Store1'])
distTable['magnitudeMeasure']= distTable.apply(lambda row: 1- (row['measures']-row['min'])/(row['max']-row['min']),axis=1)
finalDistTable = distTable.groupby(['Store1','Store2'])['magnitudeMeasure'].mean().reset_index()
finalDistTable.columns = ['Store1','Store2','mag_measure']
return finalDistTable
calcDistTable = calculateMagnitudeDistance(inputTable=preTrialMeasures, metricCol='nCustomers', storeComparison='77')
calcDistTable
```
#### Standardise the magnitude distance
```
#calcDistTable.groupby(['Store1','year_month'])['measures'].apply(lambda g: g.max() - g.min()).reset_index()
minMaxDist = calcDistTable.groupby(['Store1','year_month'])['measures'].agg(['max','min']).reset_index()
minMaxDist
calcDistTable.merge(minMaxDist, on=['year_month', 'Store1'])
distTable = calcDistTable.merge(minMaxDist, on=['year_month', 'Store1'])
distTable
distTable['magnitudeMeasure']= distTable.apply(lambda row: 1- (row['measures']-row['min'])/(row['max']-row['min']),axis=1)
distTable
```
#### Merge nTotSals & nCustomers
```
corr_nSales = calculateCorrelation(inputTable=preTrialMeasures, metricCol='TOT_SALES',storeComparison='77')
corr_nSales
corr_nCustomers = calculateCorrelation(inputTable=preTrialMeasures, metricCol='nCustomers',storeComparison='77')
corr_nCustomers
magnitude_nSales = finalDistTable(inputTable=preTrialMeasures, metricCol='TOT_SALES',storeComparison='77')
magnitude_nSales
magnitude_nCustomers = finalDistTable(inputTable=preTrialMeasures, metricCol='nCustomers',storeComparison='77')
magnitude_nCustomers
```
#### Get control store
```
score_nSales = corr_nSales.merge(magnitude_nSales, on=['Store1','Store2'])
score_nSales['scoreNSales'] = score_nSales.apply(lambda row: row['corr_measure']*0.5 + row['mag_measure']*0.5, axis=1)
score_nSales = score_nSales.loc[:,['Store1','Store2', 'scoreNSales']]
score_nSales
score_nCustomers = corr_nCustomers.merge(magnitude_nCustomers, on=['Store1','Store2'])
score_nCustomers['scoreNCust'] = score_nCustomers.apply(lambda row: row['corr_measure']*0.5 + row['mag_measure']*0.5, axis=1)
score_nCustomers = score_nCustomers.loc[:,['Store1','Store2','scoreNCust']]
score_nCustomers
score_Control = score_nSales.merge(score_nCustomers, on=['Store1','Store2'])
score_Control
score_Control['finalControlScore'] = score_Control.apply(lambda row: row['scoreNSales']*0.5 + row['scoreNCust']*0.5, axis=1)
score_Control
final_control_store = score_Control['finalControlScore'].max()
score_Control[score_Control['finalControlScore']==final_control_store]
```
#### Visualization the control store
```
measureOverTime['Store_type'] = measureOverTime.apply(lambda row: 'Trail' if row['STORE_NBR']==77 else ('Control' if row['STORE_NBR']==233 else 'Other stores'), axis=1)
measureOverTime
measureOverTime['Store_type'].unique()
measureOverTimeSales = measureOverTime.groupby(['year_month','Store_type'])['totSales'].mean().reset_index()
measureOverTimeSales
measureOverTimeSales.set_index('year_month',inplace=True)
pastSales = measureOverTimeSales.loc['2018-06-01':'2019-01-01'].reset_index()
pastSales
px.line(data_frame=pastSales, x='year_month', y='totSales', color='Store_type', title='Total sales by month',labels={'year_month':'Month of operation','totSales':'Total sales'})
measureOverTimeCusts = measureOverTime.groupby(['year_month','Store_type'])['nCustomers'].mean().reset_index()
measureOverTimeCusts
measureOverTimeCusts.set_index('year_month',inplace=True)
pastCustomers = measureOverTimeCusts.loc['2018-06-01':'2019-01-01'].reset_index()
pastCustomers
px.line(data_frame=pastCustomers, x='year_month', y='nCustomers', color='Store_type', title='Total customers by month',labels={'year_month':'Month of operation','nCustomers':'Total customers'})
```
## Assessment of trial period
### Calculate for totSales
#### Scale sales
```
preTrialMeasures
preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==77, 'TOT_SALES'].sum()
preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==233, 'TOT_SALES'].sum()
scalingFactorForControlSales = preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==77, 'TOT_SALES'].sum() / preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==233, 'TOT_SALES'].sum()
scalingFactorForControlSales
```
#### Apply the scaling factor
```
scaledControlSales = measureOverTimeSales.loc[measureOverTimeSales['Store_type']=='Control','totSales'].reset_index()
scaledControlSales
scaledControlSales['scaledControlSales'] = scaledControlSales.apply(lambda row: row['totSales']*scalingFactorForControlSales,axis=1)
scaledControlSales
TrailStoreSales = measureOverTimeSales.loc[measureOverTimeSales['Store_type']=='Trail',['totSales']]
TrailStoreSales
TrailStoreSales.columns = ['trailSales']
TrailStoreSales
```
#### %Diff between scaled control and trial for sales
```
percentageDiff = scaledControlSales.merge(TrailStoreSales, on='year_month',)
percentageDiff
percentageDiff['percentDiff'] = percentageDiff.apply(lambda row: (row['scaledControlSales']-row['trailSales'])/row['scaledControlSales'], axis=1)
percentageDiff
```
#### Get standard deviation
```
stdDev = percentageDiff.loc[percentageDiff['year_month']< '2019-02-01', 'percentDiff'].std(ddof=8-1)
stdDev
```
#### Calculate the t-values for the trial months
```
from scipy.stats import ttest_ind
control = percentageDiff.loc[percentageDiff['year_month']>'2019-01-01',['scaledControlSales']]
control
trail = percentageDiff.loc[percentageDiff['year_month']>'2019-01-01',['trailSales']]
trail
ttest_ind(control,trail)
```
The null hypothesis here is "the sales between control and trial stores has **NO** significantly difference in trial period." The pvalue is 0.32, which is 32% that they are same in sales,which is much greater than 5%. Fail to reject the null hypothesis. Therefore, we are not confident to say "the trial period impact trial store sales."
```
percentageDiff['t-value'] = percentageDiff.apply(lambda row: (row['percentDiff']- 0) / stdDev,axis=1)
percentageDiff
```
We can observe that the t-value is much larger than the 95th percentile value of the t-distribution for March and April.
i.e. the increase in sales in the trial store in March and April is statistically greater than in the control store.
#### 95th & 5th percentile of control store
```
measureOverTimeSales
pastSales_Controls95 = measureOverTimeSales.loc[measureOverTimeSales['Store_type']=='Control']
pastSales_Controls95['totSales'] = pastSales_Controls95.apply(lambda row: row['totSales']*(1+stdDev*2),axis=1)
pastSales_Controls95.iloc[0:13,0] = 'Control 95th % confidence interval'
pastSales_Controls95.reset_index()
pastSales_Controls5 = measureOverTimeSales.loc[measureOverTimeSales['Store_type']=='Control']
pastSales_Controls5['totSales'] = pastSales_Controls95.apply(lambda row: row['totSales']*(1-stdDev*2),axis=1)
pastSales_Controls5.iloc[0:13,0] = 'Control 5th % confidence interval'
pastSales_Controls5.reset_index()
trialAssessment = pd.concat([measureOverTimeSales,pastSales_Controls5,pastSales_Controls95])
trialAssessment = trialAssessment.sort_values(by=['year_month'])
trialAssessment = trialAssessment.reset_index()
trialAssessment
```
#### Visualization Trial
```
px.line(data_frame=trialAssessment, x='year_month', y='totSales', color='Store_type', title='Total sales by month',labels={'year_month':'Month of operation','totSales':'Total sales'})
```
### Calculate for nCustomers
#### Scales nCustomers
```
preTrialMeasures
preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==77,'nCustomers'].sum()
preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==233,'nCustomers'].sum()
scalingFactorForControlnCustomers = preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==77,'nCustomers'].sum() / preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==233,'nCustomers'].sum()
scalingFactorForControlnCustomers
```
#### Apply the scaling factor
```
measureOverTime
scaledControlNcustomers = measureOverTime.loc[measureOverTime['Store_type']=='Control',['year_month','nCustomers']]
scaledControlNcustomers
scaledControlNcustomers['scaledControlNcus'] = scaledControlNcustomers.apply(lambda row: row['nCustomers']*scalingFactorForControlnCustomers, axis=1)
scaledControlNcustomers
```
#### %Diff between scaled control & trail for nCustomers
```
measureOverTime.loc[measureOverTime['Store_type']=='Trail',['year_month','nCustomers']]
percentageDiff = scaledControlNcustomers.merge(measureOverTime.loc[measureOverTime['Store_type']=='Trail',['year_month','nCustomers']],on='year_month')
percentageDiff
percentageDiff.columns=['year_month','controlCustomers','scaledControlNcus','trialCustomers']
percentageDiff
percentageDiff['%Diff'] = percentageDiff.apply(lambda row: (row['scaledControlNcus']-row['trialCustomers'])/row['scaledControlNcus'],axis=1)
percentageDiff
```
#### Get standard deviation
```
stdDev = percentageDiff.loc[percentageDiff['year_month']< '2019-02-01', '%Diff'].std(ddof=8-1)
stdDev
```
#### Calculate the t-values for the trial months
```
percentageDiff['t-value'] = percentageDiff.apply(lambda row: (row['%Diff']- 0) / stdDev,axis=1)
percentageDiff
```
#### 95th & 5th percentile of control store
```
measureOverTimeCusts
pastNcus_Controls95 = measureOverTimeCusts.loc[measureOverTimeCusts['Store_type']=='Control']
pastNcus_Controls95['nCustomers'] = pastNcus_Controls95.apply(lambda row: row['nCustomers']*(1+stdDev*2),axis=1)
pastNcus_Controls95.iloc[0:13,0] = 'Control 95th % confidence interval'
pastNcus_Controls95.reset_index()
pastNcus_Controls5 = measureOverTimeCusts.loc[measureOverTimeCusts['Store_type']=='Control']
pastNcus_Controls5['nCustomers'] = pastNcus_Controls5.apply(lambda row: row['nCustomers']*(1-stdDev*2),axis=1)
pastNcus_Controls5.iloc[0:13,0] = 'Control 5th % confidence interval'
pastNcus_Controls5.reset_index()
trialAssessment = pd.concat([measureOverTimeCusts,pastNcus_Controls5,pastNcus_Controls95])
trialAssessment = trialAssessment.sort_values(by=['year_month'])
trialAssessment = trialAssessment.reset_index()
trialAssessment
```
#### Visualization Trial
```
px.line(data_frame=trialAssessment, x='year_month', y='nCustomers', color='Store_type', title='Total nCustomers by month',labels={'year_month':'Month of operation','nCustomers':'Total nCustomers'})
```
# Trial store 86
## Select control store
#### corr_nSales
```
measureOverTime
```
| github_jupyter |
# Think Bayes: Chapter 9
This notebook presents code and exercises from Think Bayes, second edition.
Copyright 2016 Allen B. Downey
MIT License: https://opensource.org/licenses/MIT
```
from __future__ import print_function, division
% matplotlib inline
import warnings
warnings.filterwarnings('ignore')
import math
import numpy as np
from thinkbayes2 import Pmf, Cdf, Suite, Joint
import thinkplot
```
## Improving Reading Ability
From DASL(http://lib.stat.cmu.edu/DASL/Stories/ImprovingReadingAbility.html)
> An educator conducted an experiment to test whether new directed reading activities in the classroom will help elementary school pupils improve some aspects of their reading ability. She arranged for a third grade class of 21 students to follow these activities for an 8-week period. A control classroom of 23 third graders followed the same curriculum without the activities. At the end of the 8 weeks, all students took a Degree of Reading Power (DRP) test, which measures the aspects of reading ability that the treatment is designed to improve.
> Summary statistics on the two groups of children show that the average score of the treatment class was almost ten points higher than the average of the control class. A two-sample t-test is appropriate for testing whether this difference is statistically significant. The t-statistic is 2.31, which is significant at the .05 level.
I'll use Pandas to load the data into a DataFrame.
```
import pandas as pd
df = pd.read_csv('drp_scores.csv', skiprows=21, delimiter='\t')
df.head()
```
And use `groupby` to compute the means for the two groups.
```
grouped = df.groupby('Treatment')
for name, group in grouped:
print(name, group.Response.mean())
```
The `Normal` class provides a `Likelihood` function that computes the likelihood of a sample from a normal distribution.
```
from scipy.stats import norm
class Normal(Suite, Joint):
def Likelihood(self, data, hypo):
"""
data: sequence of test scores
hypo: mu, sigma
"""
mu, sigma = hypo
likes = norm.pdf(data, mu, sigma)
return np.prod(likes)
```
The prior distributions for `mu` and `sigma` are uniform.
```
mus = np.linspace(20, 80, 101)
sigmas = np.linspace(5, 30, 101)
```
I use `itertools.product` to enumerate all pairs of `mu` and `sigma`.
```
from itertools import product
control = Normal(product(mus, sigmas))
data = df[df.Treatment=='Control'].Response
control.Update(data)
```
After the update, we can plot the probability of each `mu`-`sigma` pair as a contour plot.
```
thinkplot.Contour(control, pcolor=True)
thinkplot.Config(xlabel='mu', ylabel='sigma')
```
And then we can extract the marginal distribution of `mu`
```
pmf_mu0 = control.Marginal(0)
thinkplot.Pdf(pmf_mu0)
thinkplot.Config(xlabel='mu', ylabel='Pmf')
```
And the marginal distribution of `sigma`
```
pmf_sigma0 = control.Marginal(1)
thinkplot.Pdf(pmf_sigma0)
thinkplot.Config(xlabel='sigma', ylabel='Pmf')
```
**Exercise:** Run this analysis again for the control group. What is the distribution of the difference between the groups? What is the probability that the average "reading power" for the treatment group is higher? What is the probability that the variance of the treatment group is higher?
```
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# It looks like there is a high probability that the mean of
# the treatment group is higher, and the most likely size of
# the effect is 9-10 points.
# It looks like the variance of the treated group is substantially
# smaller, which suggests that the treatment might be helping
# low scorers more than high scorers.
```
## Paintball
Suppose you are playing paintball in an indoor arena 30 feet
wide and 50 feet long. You are standing near one of the 30 foot
walls, and you suspect that one of your opponents has taken cover
nearby. Along the wall, you see several paint spatters, all the same
color, that you think your opponent fired recently.
The spatters are at 15, 16, 18, and 21 feet, measured from the
lower-left corner of the room. Based on these data, where do you
think your opponent is hiding?
Here's the Suite that does the update. It uses `MakeLocationPmf`,
defined below.
```
class Paintball(Suite, Joint):
"""Represents hypotheses about the location of an opponent."""
def __init__(self, alphas, betas, locations):
"""Makes a joint suite of parameters alpha and beta.
Enumerates all pairs of alpha and beta.
Stores locations for use in Likelihood.
alphas: possible values for alpha
betas: possible values for beta
locations: possible locations along the wall
"""
self.locations = locations
pairs = [(alpha, beta)
for alpha in alphas
for beta in betas]
Suite.__init__(self, pairs)
def Likelihood(self, data, hypo):
"""Computes the likelihood of the data under the hypothesis.
hypo: pair of alpha, beta
data: location of a hit
Returns: float likelihood
"""
alpha, beta = hypo
x = data
pmf = MakeLocationPmf(alpha, beta, self.locations)
like = pmf.Prob(x)
return like
def MakeLocationPmf(alpha, beta, locations):
"""Computes the Pmf of the locations, given alpha and beta.
Given that the shooter is at coordinates (alpha, beta),
the probability of hitting any spot is inversely proportionate
to the strafe speed.
alpha: x position
beta: y position
locations: x locations where the pmf is evaluated
Returns: Pmf object
"""
pmf = Pmf()
for x in locations:
prob = 1.0 / StrafingSpeed(alpha, beta, x)
pmf.Set(x, prob)
pmf.Normalize()
return pmf
def StrafingSpeed(alpha, beta, x):
"""Computes strafing speed, given location of shooter and impact.
alpha: x location of shooter
beta: y location of shooter
x: location of impact
Returns: derivative of x with respect to theta
"""
theta = math.atan2(x - alpha, beta)
speed = beta / math.cos(theta)**2
return speed
```
The prior probabilities for `alpha` and `beta` are uniform.
```
alphas = range(0, 31)
betas = range(1, 51)
locations = range(0, 31)
suite = Paintball(alphas, betas, locations)
suite.UpdateSet([15, 16, 18, 21])
```
To visualize the joint posterior, I take slices for a few values of `beta` and plot the conditional distributions of `alpha`. If the shooter is close to the wall, we can be somewhat confident of his position. The farther away he is, the less certain we are.
```
locations = range(0, 31)
alpha = 10
betas = [10, 20, 40]
thinkplot.PrePlot(num=len(betas))
for beta in betas:
pmf = MakeLocationPmf(alpha, beta, locations)
pmf.label = 'beta = %d' % beta
thinkplot.Pdf(pmf)
thinkplot.Config(xlabel='Distance',
ylabel='Prob')
```
Here are the marginal posterior distributions for `alpha` and `beta`.
```
marginal_alpha = suite.Marginal(0, label='alpha')
marginal_beta = suite.Marginal(1, label='beta')
print('alpha CI', marginal_alpha.CredibleInterval(50))
print('beta CI', marginal_beta.CredibleInterval(50))
thinkplot.PrePlot(num=2)
thinkplot.Cdf(Cdf(marginal_alpha))
thinkplot.Cdf(Cdf(marginal_beta))
thinkplot.Config(xlabel='Distance',
ylabel='Prob')
```
To visualize the joint posterior, I take slices for a few values of `beta` and plot the conditional distributions of `alpha`. If the shooter is close to the wall, we can be somewhat confident of his position. The farther away he is, the less certain we are.
```
betas = [10, 20, 40]
thinkplot.PrePlot(num=len(betas))
for beta in betas:
cond = suite.Conditional(0, 1, beta)
cond.label = 'beta = %d' % beta
thinkplot.Pdf(cond)
thinkplot.Config(xlabel='Distance',
ylabel='Prob')
```
Another way to visualize the posterio distribution: a pseudocolor plot of probability as a function of `alpha` and `beta`.
```
thinkplot.Contour(suite.GetDict(), contour=False, pcolor=True)
thinkplot.Config(xlabel='alpha',
ylabel='beta',
axis=[0, 30, 0, 20])
```
Here's another visualization that shows posterior credible regions.
```
d = dict((pair, 0) for pair in suite.Values())
percentages = [75, 50, 25]
for p in percentages:
interval = suite.MaxLikeInterval(p)
for pair in interval:
d[pair] += 1
thinkplot.Contour(d, contour=False, pcolor=True)
thinkplot.Text(17, 4, '25', color='white')
thinkplot.Text(17, 15, '50', color='white')
thinkplot.Text(17, 30, '75')
thinkplot.Config(xlabel='alpha',
ylabel='beta',
legend=False)
```
**Exercise:** From [John D. Cook](http://www.johndcook.com/blog/2010/07/13/lincoln-index/)
"Suppose you have a tester who finds 20 bugs in your program. You want to estimate how many bugs are really in the program. You know there are at least 20 bugs, and if you have supreme confidence in your tester, you may suppose there are around 20 bugs. But maybe your tester isn't very good. Maybe there are hundreds of bugs. How can you have any idea how many bugs there are? There’s no way to know with one tester. But if you have two testers, you can get a good idea, even if you don’t know how skilled the testers are.
Suppose two testers independently search for bugs. Let k1 be the number of errors the first tester finds and k2 the number of errors the second tester finds. Let c be the number of errors both testers find. The Lincoln Index estimates the total number of errors as k1 k2 / c [I changed his notation to be consistent with mine]."
So if the first tester finds 20 bugs, the second finds 15, and they find 3 in common, we estimate that there are about 100 bugs. What is the Bayesian estimate of the number of errors based on this data?
```
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
```
**Exercise:** The GPS problem. According to [Wikipedia]()

> GPS included a (currently disabled) feature called Selective Availability (SA) that adds intentional, time varying errors of up to 100 meters (328 ft) to the publicly available navigation signals. This was intended to deny an enemy the use of civilian GPS receivers for precision weapon guidance.
> [...]
> Before it was turned off on May 2, 2000, typical SA errors were about 50 m (164 ft) horizontally and about 100 m (328 ft) vertically.[10] Because SA affects every GPS receiver in a given area almost equally, a fixed station with an accurately known position can measure the SA error values and transmit them to the local GPS receivers so they may correct their position fixes. This is called Differential GPS or DGPS. DGPS also corrects for several other important sources of GPS errors, particularly ionospheric delay, so it continues to be widely used even though SA has been turned off. The ineffectiveness of SA in the face of widely available DGPS was a common argument for turning off SA, and this was finally done by order of President Clinton in 2000.
Suppose it is 1 May 2000, and you are standing in a field that is 200m square. You are holding a GPS unit that indicates that your location is 51m north and 15m west of a known reference point in the middle of the field.
However, you know that each of these coordinates has been perturbed by a "feature" that adds random errors with mean 0 and standard deviation 30m.
1) After taking one measurement, what should you believe about your position?
Note: Since the intentional errors are independent, you could solve this problem independently for X and Y. But we'll treat it as a two-dimensional problem, partly for practice and partly to see how we could extend the solution to handle dependent errors.
You can start with the code in gps.py.
2) Suppose that after one second the GPS updates your position and reports coordinates (48, 90). What should you believe now?
3) Suppose you take 8 more measurements and get:
(11.903060613102866, 19.79168669735705)
(77.10743601503178, 39.87062906535289)
(80.16596823095534, -12.797927542984425)
(67.38157493119053, 83.52841028148538)
(89.43965206875271, 20.52141889230797)
(58.794021026248245, 30.23054016065644)
(2.5844401241265302, 51.012041625783766)
(45.58108994142448, 3.5718287379754585)
At this point, how certain are you about your location?
```
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
```
**Exercise:** [The Flea Beetle problem from DASL](http://lib.stat.cmu.edu/DASL/Datafiles/FleaBeetles.html)
Datafile Name: Flea Beetles
Datafile Subjects: Biology
Story Names: Flea Beetles
Reference: Lubischew, A.A. (1962) On the use of discriminant functions in taxonomy. Biometrics, 18, 455-477. Also found in: Hand, D.J., et al. (1994) A Handbook of Small Data Sets, London: Chapman & Hall, 254-255.
Authorization: Contact Authors
Description: Data were collected on the genus of flea beetle Chaetocnema, which contains three species: concinna (Con), heikertingeri (Hei), and heptapotamica (Hep). Measurements were made on the width and angle of the aedeagus of each beetle. The goal of the original study was to form a classification rule to distinguish the three species.
Number of cases: 74
Variable Names:
Width: The maximal width of aedeagus in the forpart (in microns)
Angle: The front angle of the aedeagus (1 unit = 7.5 degrees)
Species: Species of flea beetle from the genus Chaetocnema
Suggestions:
1. Plot CDFs for the width and angle data, broken down by species, to get a visual sense of whether the normal distribution is a good model.
2. Use the data to estimate the mean and standard deviation for each variable, broken down by species.
3. Given a joint posterior distribution for `mu` and `sigma`, what is the likelihood of a given datum?
4. Write a function that takes a measured width and angle and returns a posterior PMF of species.
5. Use the function to classify each of the specimens in the table and see how many you get right.
```
import pandas as pd
df = pd.read_csv('flea_beetles.csv', delimiter='\t')
df.head()
# Solution goes here
```
| github_jupyter |
**Documentation for getting started with ipyleaflet:**
https://ipyleaflet.readthedocs.io
**Video tutorial for this:**
https://www.youtube.com/watch?v=VW1gYD5eB6E
## Create default interactive map
```
# import the package
import ipyleaflet
# define m as a default map
m = ipyleaflet.Map()
# display map
m
```
## Customize default map settings
```
# import some classes from the package, so "ipyleaflet." no longer needs to be typed just before them
from ipyleaflet import Map, FullScreenControl, LayersControl, DrawControl, MeasureControl, ScaleControl
# define a map with new center and zoom settings
m = Map(center=[30, -85], zoom=3, scroll_wheel_zoom=True)
# set display height at 500 pixels
m.layout.height="500px"
# display map
m
```
## Add widget controls to interactive map interface
```
# add full screen control, default position is top left
m.add_control(FullScreenControl())
# add layers control
m.add_control(LayersControl(position="topright"))
# add draw control
m.add_control(DrawControl(position="topleft"))
# add measure control
m.add_control(MeasureControl())
# add scale control
m.add_control(ScaleControl(position="bottomleft"))
```
## Add basemaps
```
# import some classes from the package, so "ipyleaflet." no longer needs to be typed just before them
from ipyleaflet import basemaps, TileLayer
# add OpenTopoMap basemap layer
m.add_layer(basemaps.OpenTopoMap)
# add Esri.WorldImagery basemap layer
m.add_layer(basemaps.Esri.WorldImagery)
# display map
m
# define a tile layer for Google Maps
google_map = TileLayer(
url="https://mt1.google.com/vt/lyrs=m&x={x}&y={y}&z={z}",
attribution="Google",
name="Google Maps",
)
# add layer to map
m.add_layer(google_map)
# define a tile layer for Google Satellite Imagery
google_satellite = TileLayer(
url="https://mt1.google.com/vt/lyrs=y&x={x}&y={y}&z={z}",
attribution="Google",
name="Google Satellite"
)
# add layer to map
m.add_layer(google_satellite)
# display map
m
# disable the map attribution label
m.attribution_control = False
```
## Add markers
```
# import marker class from package
from ipyleaflet import Marker
# define three markers
marker1 = Marker(name='marker1', location=(40, -100))
marker2 = Marker(name='marker2', location=(30, -90))
marker3 = Marker(name='marker3', location=(20, -80))
# add them as layers
m.add_layer(marker1)
m.add_layer(marker2)
m.add_layer(marker3)
# display map
m
```
## Add marker cluster
```
# import classes from package
from ipyleaflet import Map, Marker, MarkerCluster
# define three markers
marker1 = Marker(name='marker1', location=(50, -100))
marker2 = Marker(name='marker2', location=(30, -110))
marker3 = Marker(name='marker3', location=(40, -90))
# define marker cluster
marker_cluster = MarkerCluster(
markers=(marker1, marker2, marker3), name="marker cluster"
)
# add marker cluster as map layer
m.add_layer(marker_cluster)
# display map
m
```
| github_jupyter |
```
import os
os.environ['CUDA_VISIBLE_DEVICES']='0,1,2,3,4,5,6,7'
# %run -p ../latent_ode_tinfocnf.py --sup True --cond True --noise_std 0.3 --a 0. --b 0.3 --noise_std_test 0.3 --a_test 0. --b_test 0.3 --adjoint False --visualize True --niters 2000 --lr 0.01 --save vis_sup --savedir ./results_sup_cond_nstd_0_3_a_0_b_0_3_nstdt_0_3_at_0_bt_0_3_published --gpu 0
# #
%run -p ../latent_ode_tinfocnf.py --sup True --cond True --noise_std 0.3 --a 0. --b 0.3 --noise_std_test 0.3 --a_test 0. --b_test 0.4 --adjoint False --visualize True --niters 2000 --lr 0.01 --save vis_sup --savedir ./results_sup_cond_nstd_0_3_a_0_b_0_3_nstdt_0_3_at_0_bt_0_4_published --gpu 1
#
# %run -p ../latent_ode_tinfocnf.py --sup True --cond True --noise_std 0.3 --a 0. --b 0.3 --noise_std_test 0.3 --a_test 0. --b_test 0.5 --adjoint False --visualize True --niters 2000_published --lr 0.01 --save vis_sup --savedir ./results_sup_cond_nstd_0_3_a_0_b_0_3_nstdt_0_3_at_0_bt_0_5 --gpu 4
# #
# %run -p ../latent_ode_tinfocnf.py --sup True --cond True --noise_std 0.3 --a 0. --b 0.3 --noise_std_test 0.3 --a_test 1. --b_test 0.3 --adjoint False --visualize True --niters 2000 --lr 0.01 --save vis_sup --savedir ./results_sup_cond_nstd_0_3_a_0_b_0_3_nstdt_0_3_at_1_bt_0_3 --gpu 4
# #
# %run -p ../latent_ode_tinfocnf.py --sup True --cond True --noise_std 0.3 --a 0. --b 0.3 --noise_std_test 0.3 --a_test 1. --b_test 0.4 --adjoint False --visualize True --niters 2000 --lr 0.01 --save vis_sup --savedir ./results_sup_cond_nstd_0_3_a_0_b_0_3_nstdt_0_3_at_1_bt_0_4 --gpu 4
# #
# %run -p ../latent_ode_tinfocnf.py --sup True --cond True --noise_std 0.3 --a 0. --b 0.3 --noise_std_test 0.3 --a_test 1. --b_test 0.5 --adjoint False --visualize True --niters 2000 --lr 0.01 --save vis_sup --savedir ./results_sup_cond_nstd_0_3_a_0_b_0_3_nstdt_0_3_at_1_bt_0_5 --gpu 4
# #
# %run -p ../latent_ode_tinfocnf.py --sup True --cond True --noise_std 0.3 --a 0. --b 0.3 --noise_std_test 0.3 --a_test 2. --b_test 0.3 --adjoint False --visualize True --niters 2000 --lr 0.01 --save vis_sup --savedir ./results_sup_cond_nstd_0_3_a_0_b_0_3_nstdt_0_3_at_2_bt_0_3 --gpu 4
# #
# %run -p ../latent_ode_tinfocnf.py --sup True --cond True --noise_std 0.3 --a 0. --b 0.3 --noise_std_test 0.3 --a_test 2. --b_test 0.4 --adjoint False --visualize True --niters 2000 --lr 0.01 --save vis_sup --savedir ./results_sup_cond_nstd_0_3_a_0_b_0_3_nstdt_0_3_at_2_bt_0_4 --gpu 4
# #
# %run -p ../latent_ode_tinfocnf.py --sup True --cond True --noise_std 0.3 --a 0. --b 0.3 --noise_std_test 0.3 --a_test 2. --b_test 0.5 --adjoint False --visualize True --niters 2000 --lr 0.01 --save vis_sup --savedir ./results_sup_cond_nstd_0_3_a_0_b_0_3_nstdt_0_3_at_2_bt_0_5 --gpu 4
# #
```
| github_jupyter |
```
import seaborn as sns
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
#load dataset into the notebook
data = pd.read_csv('titanic.csv')
data.head()
#get all coumns in small caps
data.columns.str.lower()
#lets look the mean of survival using gender
data.groupby('Sex')[['Survived']].mean()
#here we see that the survival rate for females was hire than that of men
#this shows that about 20% of men survived and 75% of females survived
#lets group them further by class
data.groupby(['Sex','Pclass'])[['Survived']].mean().unstack()
# this shows tha most females that survived outcomes survival of mens from both
# first , second and third classses
# It also show that most of people in the first class
# survival rate was hire than the restt
# the survival reduces as you move from first class to third class
#the above can also be written using pivot_table function as shown below
data.pivot_table('Survived', index='Sex', columns='Pclass')
#let then check the survival using
#we will group into different ages i.e 0 to 18 , 18 to 35 and 35 to 80
age = pd.cut(data['Age'], [0, 18,35, 80])
data.pivot_table('Survived', ['Sex', age], 'Pclass').unstack()
#The results also shows similar results to girl child in the first class
#as the survival as also in over 90% unlike boychild
#but for boychild in the ages between 0-18 their survival was abit high
#it also shows people of age 35 to 80 in both genders in the third class
#did not survived many like for mens its alsmost everyone died
#lets now compute the total for each class survival using margin keyword in the pivod table function
data.pivot_table('Survived', index='Sex', columns='Pclass', margins=True)
#the females were the ost survived unlike males
#First class people survived more than the others members
#the rate of survival generally was abit low about 40%
```
## Analysis of The Dataset
```
import copy
import warnings
warnings.filterwarnings('ignore')
```
## Description for Columns in the dataset
- survival - Survival (0 = No; 1 = Yes)
- class - Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd)
- name - Name
- sex - Sex
- age - Age
- sibsp - Number of Siblings/Spouses Aboard
- parch - Number of Parents/Children Aboard
- ticket - Ticket Number
- fare - Passenger Fare
- cabin - Cabin
- embarked - Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)
- boat - Lifeboat (if survived)
- body - Body number (if did not survive and body was recovered)
### This May also help : https://data.world/nrippner/titanic-disaster-dataset
```
# create new df
df = copy.copy(data)
df.shape
#check sample data
df.head()
#checking information from the df
df.info()
```
## Findings..
- Age , Cabin has nulls data
- It has 891 entries
- has fields with object data type ...Need to be cleaned to correct types
- 12 columns are in the df
```
#checking stats information about the numericals
df.describe().T
```
## Findings ..
- Looking on real Data ..we have columns like Survived , Age , sibsp , parch , fare
- The Age , sibsp , parch , fare seems to be unevenly distributed by checking on quartiles
## Checking THe Data Quality
```
#We gonna check the percentage of nulls in each column field.
nulls_sums = df.isna().sum()
percent_nulls = nulls_sums /(len(df))
percent_nulls
```
## Findings ..
- Cabin has 77.1% , Age has 19.7% and Embarked has 0.225% nulss
- Since Cabin Has very high amount of nulls , i will drop the column n from the df
- For Age , I will use median to replace the nulls since it is not a good idea to remove this either row_wise or column as it will affect the data greatly
- For embarked i will drop the rows with nulls as they are small
```
#remove the cabin col
df.drop('Cabin' , axis = 1 , inplace = True)
#fill nulls with median or mean for age
age_median = df['Age'].median(skipna = True)
df['Age'].fillna(age_median, inplace = True)
#drop the rows with nulls for embarked
#will use boolean to filter out nulls
df = df[df['Embarked'].isna() != True]
df.shape
# create a copy of df
df1 = df.copy()
df1.shape , df.shape
```
## Detecting Outliers
- Will Use boxplot
```
plt.figure(figsize = (14, 7))
# create a one row with for cols for four plots
plt.subplot(1,4,1)
# Draw for age
sns.boxplot(y= df['Age'])
plt.title("CHeck age outliers")
# for fare
plt.subplot(1,4,2)
sns.boxplot(y= df['Fare'])
plt.title("CHeck Fare outliers")
# siblings
plt.subplot(1,4,3)
sns.boxplot(y= df['SibSp'])
plt.title("CHeck sibsp outliers")
# for childres
plt.subplot(1,4,4)
sns.boxplot(y= df['Parch'])
plt.title("CHeck Parch outliers")
```
## Findings
- From the above 4 attributes we get all has outliers ...as there are many whiskers outside range
- Fare is the one with most outliers
```
#Lets now check survival rate with regard to siblings
sns.catplot(x = 'SibSp' , col = "Survived" , data = df , kind = 'count')
```
## Findings ...
- Mostof who survived were those that were single siblings aboard
- The rest many of then never survived
```
#Lets now check survival rate with regard to parents abord
sns.catplot(x = 'Parch' , col = "Survived" , data = df , kind = 'count')
```
## Findings ...
- Single parents also Survived most
- From The above two plots.
**WE can conclude that parch and sibsp shows whether a sibling is accompanied by parent or not**
- I will Merge the two cols labels(1 or 0) to see if a single person is with another one else
```
#if you add sibsp and parch and is over 0 , return 1 else zero
def checkAccopany(x):
if (x['Parch'] + x['SibSp'] > 0):
return 1
else:
return 0
# create the new merged col
df['is_Accompanied'] = df.apply(checkAccopany , axis = 1)
df.head()
#use survival and new is_accompanied col to check
sns.catplot(x = 'is_Accompanied' , col = "Survived" , data = df , kind = 'count')
```
## Findings
- Those who were not accompanied mostly perished more than those accompanied
- Those who were accompanied survived more than the other ones.
```
#now checking about fare..
#i will use distplot...shows distribution and histgrams combined
plt.figure(figsize = (12 , 7))
sns.distplot(df['Fare'])
plt.title("Fare Distributiron")
```
## Findings ...
- The fare is more skewed to the right. (more data is on the right)
- The skewness need to be removed... can use logs to standard it.
```
#using log function to try balance skewness
plt.figure(figsize = (12 , 7))
sns.distplot(df['Fare'].map(lambda x: np.log(x) if x >0 else 0))
plt.title(" Logarithmic Fare Distributiron")
```
## We have made the data be less skewed for uniformity..
- The fare column can now be replaced with log values since is more uniform
```
#perform logs to fare col
df['Fare'] = df['Fare'].map(lambda x: np.log(x) if x >0 else 0)
## LEts now check sex and class distribution using survival
sns.catplot(x = 'Sex' ,y = "Survived" , data = df , col = 'Pclass', kind = 'bar')
```
## Findings...
- Females were likely to have survived most.
- Those in the first class also survived more
```
#using embarked
sns.catplot(x = 'Sex' ,y = "Survived" , data = df , col = 'Embarked', kind = 'bar')
```
## Findings ..
- Those who boarded from Port Label **C** are likely to have Survived more than others
```
##Cecking Age survival rates
plt.figure(figsize = (12 , 6))
sns.distplot(df['Age'])
```
## Most of the people aboarded were likely to be most of agegroup 20 --- 40
```
#Checking survival based on ages
# 1. Those who survived
plt.figure(figsize = (12 , 6))
sns.distplot(df[df['Survived'] == 1]['Age'])
plt.title("Distribution Of Survived")
```
## Those wilth less than 60 years were most likely to survive.
- greater chances of survival was on btween 30 and 35 years
```
#Checking survival based on ages
# 1. Those who didn't survived
plt.figure(figsize = (12 , 6))
sns.distplot(df[df['Survived'] == 0]['Age'])
plt.title("Distribution Of who did not Survived")
```
## AGed were likely not to survive.
- Its skewed to left.. more of aged did not survive
```
##Survival based on fare..
sns.boxplot(x = 'Survived' , y = 'Fare' , data = df)
```
## __Most Survived are likely to have paid more fare.
- Those who survived have a mean fare greater than non survived
| github_jupyter |
```
import numpy as np
import pandas as pd
import scipy as sp
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
sns.set()
from IPython.core.pylabtools import figsize
import statsmodels.api as sm
from patsy import dmatrix
df = pd.read_csv('~/src/properties_2016.csv')
df.tail()
train_2016_df = pd.read_csv('~/src/train_2016.csv')
train_2016_df.tail()
df.tail()
cat = ['parcelid', 'airconditioningtypeid', 'architecturalstyletypeid', 'buildingqualitytypeid', \
'buildingclasstypeid', 'decktypeid', 'fips', 'hashottuborspa', 'heatingorsystemtypeid', \
'propertycountylandusecode', 'propertylandusetypeid', 'propertyzoningdesc', \
'pooltypeid10', 'pooltypeid2', 'pooltypeid7', \
'rawcensustractandblock', 'censustractandblock', 'regionidcounty', 'regionidcity', \
'regionidzip', 'regionidneighborhood', 'typeconstructiontypeid', 'yearbuilt', \
'assessmentyear', 'taxdelinquencyyear', 'fireplaceflag', 'storytypeid', 'taxdelinquencyflag']
cat
cat_df = df[cat]
cat_df.tail()
result_df = pd.merge(cat_df, train_2016_df)
result_df.tail()
# fillna를 위한 values 만들기, fillna 적용하기(Nan >> nulls_)
values = {}
for i in cat:
values[i] = "nulls_" + i[:10]
result_df.fillna(values, inplace=True)
result_df.tail()
def find_others(pvalue, a, b):
others = []
length = len(pvalue)
for i in range(length):
if pvalue.values[i] > 0.01:
others.append(pvalue.index[i][a:b])
del others[0]
del others[-1]
return others
# # transatctiondate 제거
# del result_df['transactiondate']
# result_df.tail()
# 수식 만들기
formula = "logerror ~ "
for i in cat[1:2]:
formula += "C(" + i + ") + "
formula = formula[:-3]
y = result_df.iloc[:, -1:]
X = result_df.iloc[:, :-1]
model = sm.OLS.from_formula(formula, data=result_df)
print(model.fit().summary())
sm.stats.anova_lm(model.fit())
result_df.head()
# 빈도 확인
for i in cat[1:]:
print(result_df[i].value_counts())
# others = [3, 9]
# for i in others:
# result_df.loc[result_df['airconditioningtypeid'] == i] = "nulls_airconditi"
# print(result_df.groupby(['airconditioningtypeid']).size().reset_index)
formula = "logerror ~ "
for i in cat[:]:
formula += "C(" + i + ") + "
formula = formula[:-3]
formula
# # formula for all(박제)
# formula = 'logerror ~ C(parcelid) + C(airconditioningtypeid) + C(architecturalstyletypeid) \
# + C(buildingqualitytypeid) + C(buildingclasstypeid) + C(decktypeid) + C(fips) \
# + C(hashottuborspa) + C(heatingorsystemtypeid) + C(propertycountylandusecode) \
# + C(propertylandusetypeid) + C(propertyzoningdesc) + C(pooltypeid10) + C(pooltypeid2) \
# + C(pooltypeid7) + C(rawcensustractandblock) + C(censustractandblock) + C(regionidcounty) \
# + C(regionidcity) + C(regionidzip) + C(regionidneighborhood) + C(typeconstructiontypeid) \
# + C(yearbuilt) + C(assessmentyear) + C(taxdelinquencyyear) + C(fireplaceflag) \
# + C(storytypeid) + C(taxdelinquencyflag)'
# formula
formula = 'logerror ~ C(parcelid) + C(airconditioningtypeid) + C(architecturalstyletypeid) \
+ C(buildingqualitytypeid) + C(buildingclasstypeid) + C(decktypeid) + C(fips) \
+ C(hashottuborspa) + C(heatingorsystemtypeid) + C(propertycountylandusecode) \
+ C(propertylandusetypeid) + C(pooltypeid10) + C(pooltypeid2) \
+ C(pooltypeid7) + C(regionidcounty) \
+ C(regionidcity) + C(regionidzip) + C(regionidneighborhood) + C(typeconstructiontypeid) \
+ C(yearbuilt) + C(assessmentyear) + C(taxdelinquencyyear) + C(fireplaceflag) \
+ C(storytypeid) + C(taxdelinquencyflag)'
formula
# VIF(C)
result_df.iloc[:, 15:].tail()
## pvalues가 큰 값 제거하는 프로그램
# 1.yearbuilt : .. > 3
# 2.regionidneighborhood :
# 수식 만들기
formula = "logerror ~ C(regionidneighborhood)"
model = sm.OLS.from_formula(formula, data=result_df)
result = model.fit()
print(result.summary())
# sm.stats.anova_lm(model.fit())
a = model.fit().pvalues
a[a < 0.01]
a.index[1][-7:-3]
# pvalues 만들기
pvalue = result.pvalues
pvalue.tail()
pvalue = pvalue.reset_index()
pvalue.tail()
pvalue.index.values
pvalue.tail()
others = []
length = len(pvalue)
for i in range(length):
if pvalue.iloc[:,-1:].values[i] > 0.01:
idx = pvalue.index.values[i] + 1
others.append(idx)
others
len(others), len(pvalue), type(others)
result_copy = result_df.copy()
result_copy.tail()
result_copy["regionidneighborhood"].replace(others, 1, inplace=True)
result_copy["regionidneighborhood"].tail()
result_copy[15:].tail()
result_copy['regionidneighborhood'].value_counts()
pvalue.index.values[0] + 1
others = []
length = len(pvalue)
for i in range(length):
if pvalue.values[i] > 0.01:
others.append(pvalue.index[i][a:b])
xxx_df['A'].index.values.tolist()
def find_others(pvalue, a, b):
others = []
length = len(pvalue)
for i in range(length):
if pvalue.values[i] > 0.01:
others.append(pvalue.index[i][a:b])
del others[0]
del others[-1]
list(np.array(others).astype(float))
return others
others = find_others(pvalue, -7, -3)
others
result_df["yearbuilt"].replace(to_replace=others, "others", inplace=True)
result_df["yearbuilt"].tail()
# 수식 만들기
formula = "logerror ~ C(yearbuilt)"
model = sm.OLS.from_formula(formula, data=result_df)
result = model.fit()
print(result.summary())
# sm.stats.anova_lm(model.fit())
result_df['yearbuilt'].tail()
xxx_df = pd.DataFrame()
xxx_df['A'] = [1, 2, 3, 4]
xxx_df['B'] = [1, 2, 3, 4]
xxx_df
xxx_df['A'].index.values.tolist()
result_copy["regionidneighborhood"].replace(others, value="others", inplace=True)
result_copy["regionidneighborhood"].tail()
type(others)
xxx_df.replace([1, 2, 3], 9, inplace=True)
xxx_df
xxx_df
# 수식 만들기
formula = "logerror ~ C(yearbuilt)"
model = sm.OLS.from_formula(formula, data=result_df)
print(model.fit().summary2())
# sm.stats.anova_lm(model.fit())
```
## _poolfamily_
```
pool = ['parcelid', 'hashottuborspa', 'poolcnt', 'pooltypeid10', 'pooltypeid2', 'pooltypeid7']
pool_df = df[pool]
pool_df.tail()
pool_df.isna().sum()
result = pd.merge(pool_df, train_2016_df)
result.tail()
result.isna().sum()
result.fillna(0, inplace=True)
result.tail()
X = result.iloc[:, 1:6]
y = result.iloc[:, 6:7]
model = sm.OLS.from_formula("logerror ~ C(hashottuborspa) + C(poolcnt) + C(pooltypeid10) + \
C(pooltypeid2) + C(pooltypeid7) + 0", data = result)
print(model.fit().summary())
```
## _architecturalstyletypeid_
```
arch_df = df[["parcelid", "architecturalstyletypeid"]]
arch_df.tail()
arch_count = df.groupby(["architecturalstyletypeid"]).size().reset_index(name="counts")
arch_count
arch_df = pd.merge(arch_df, train_2016_df)
arch_df.tail()
arch_dummy = pd.get_dummies(arch_df['architecturalstyletypeid'], columns=['two', 'three', 'seven', 'eight', 'ten', 'twentyone'])
arch_dummy.tail()
result_df = pd.concat([arch_dummy, train_2016_df], axis=1)
result_df.tail()
result_df.columns = ['Bungalow', 'CapeCod', 'Contemporary', 'Conventional', \
'FrenchProvincial', 'RanchRambler', 'parcelid', 'logerror', 'transactiondate']
result_df.tail()
model_architect = sm.OLS.from_formula("logerror ~ C(Bungalow) + C(CapeCod) + C(Contemporary) +\
C(Conventional) + C(FrenchProvincial) + C(RanchRambler)", data=result_df)
sm.stats.anova_lm(model_architect.fit())
# 전체
print(model_architect.fit().summary())
model_architect = sm.OLS.from_formula("logerror ~ C(Bungalow) + C(Contemporary) +\
C(Conventional) + C(FrenchProvincial) + C(RanchRambler)", data=result_df)
sm.stats.anova_lm(model_architect.fit())
# CapeCod 제거
print(model_architect.fit().summary())
arch_df.tail()
model_arch = sm.OLS.from_formula("logerror ~ C(architecturalstyletypeid) + 0", data=arch_df)
sm.stats.anova_lm(model_arch.fit())
arch_count = df.groupby(["architecturalstyletypeid"]).size().reset_index(name="counts")
arch_count
```
## _construction_
```
construction = ['architecturalstyletypeid', 'typeconstructiontypeid', \
'buildingclasstypeid', 'buildingqualitytypeid']
construction
construction_df = df[construction]
construction_df.tail()
construction_df.isna().sum()
df1 = pd.get_dummies(construction_df['architecturalstyletypeid'])
df1
train_2016_df.tail()
result_df = pd.merge(construction_df, train_2016_df)
result_df.tail()
result_df
construction_df1 = construction_df.groupby(["architecturalstyletypeid"]).size().reset_index(name="counts")
construction_df1
construction_df2 = construction_df.groupby(["typeconstructiontypeid"]).size().reset_index(name="counts")
construction_df2
construction_df3 = construction_df.groupby(["buildingclasstypeid"]).size().reset_index(name="counts")
construction_df3
construction_df4 = construction_df.groupby(["buildingqualitytypeid"]).size().reset_index(name="counts")
construction_df4
construction
result_df1 = result_df.dropna()
result_df1.tail()
result_df2 = result_df.fillna(0)
result_df2.tail()
result_df.tail()
construction_df1 = result_df.groupby(["architecturalstyletypeid"]).size().reset_index(name="counts")
construction_df1
sample = ["secon", "three", "seven", "eight", "ten", "twentyone"]
df1 = pd.get_dummies(result_df['architecturalstyletypeid'])
df1.head()
len(df1)
architect_df = pd.DataFrame(columns=sample)
architect_df.head()
architect_df
result2 = pd.concat([df1, train_2016_df])
result2.tail()
pd
df1.iloc[:, :1].tail()
model0 = sm.OLS.from_formula("logerror ~ C(architecturalstyletypeid) + C(typeconstructiontypeid) \
+ C(buildingclasstypeid) + C(buildingqualitytypeid) + 0", data=result_df2)
print(model0.fit().summary())
dmatrix("architecturalstyletypeid", construction_df)
model1 = sm.OLS.from_formula("logerror ~ C(architecturalstyletypeid) + 0", data=result_df)
print(model1.fit().summary())
sns.stripplot(x="architecturalstyletypeid", y="logerror", data=result_df, jitter=True, alpha=.3)
sns.pointplot(x="architecturalstyletypeid", y="logerror", data=result_df, dodge=True, color='r')
plt.show()
model_architect = sm.OLS.from_formula("logerror ~ C(architecturalstyletypeid) + 0", data=result_df)
sm.stats.anova_lm(model_architect.fit())
result_df.tail()
pd.get_dummies()
```
## _카테고리 데이터 모델링_
```
df.tail()
cat = ['parcelid', 'airconditioningtypeid', 'architecturalstyletypeid', 'buildingqualitytypeid', \
'buildingclasstypeid', 'decktypeid', 'fips', 'heatingorsystemtypeid', \
'propertycountylandusecode', 'propertylandusetypeid', 'propertyzoningdesc', \
'rawcensustractandblock', 'censustractandblock', 'regionidcounty', 'regionidcity', \
'regionidzip', 'regionidneighborhood', 'typeconstructiontypeid', 'yearbuilt', \
'assessmentyear', 'taxdelinquencyyear']
cat
cat_df = df[cat]
cat_df.tail()
result_df = pd.merge(cat_df, train_2016_df)
result_df.tail()
values = {}
for i in cat:
values[i] = "nulls_" + i[:10]
values
result_df.fillna(values, inplace=True)
del result_df['transactiondate']
result_df.tail()
formula = "logerror ~ "
for i in cat[1:]:
formula += "C(" + i + ") + "
formula = formula[:-3]
formula
y = result_df.iloc[:, -1:]
X = result_df.iloc[:, :-1]
model = sm.OLS.from_formula(formula, data=result_df)
print(model.fit().summary())
result_df
```
| github_jupyter |
# Publications markdown generator for academicpages
Takes a TSV of publications with metadata and converts them for use with [academicpages.github.io](academicpages.github.io). This is an interactive Jupyter notebook ([see more info here](http://jupyter-notebook-beginner-guide.readthedocs.io/en/latest/what_is_jupyter.html)). The core python code is also in `publications.py`. Run either from the `markdown_generator` folder after replacing `publications.tsv` with one containing your data.
TODO: Make this work with BibTex and other databases of citations, rather than Stuart's non-standard TSV format and citation style.
## Data format
The TSV needs to have the following columns: pub_date, title, venue, excerpt, citation, site_url, and paper_url, with a header at the top.
- `excerpt` and `paper_url` can be blank, but the others must have values.
- `pub_date` must be formatted as YYYY-MM-DD.
- `url_slug` will be the descriptive part of the .md file and the permalink URL for the page about the paper. The .md file will be `YYYY-MM-DD-[url_slug].md` and the permalink will be `https://[yourdomain]/publications/YYYY-MM-DD-[url_slug]`
This is how the raw file looks (it doesn't look pretty, use a spreadsheet or other program to edit and create).
```
import os, collections
import pandas as pd
```
## Import TSV
Pandas makes this easy with the read_csv function. We are using a TSV, so we specify the separator as a tab, or `\t`.
I found it important to put this data in a tab-separated values format, because there are a lot of commas in this kind of data and comma-separated values can get messed up. However, you can modify the import statement, as pandas also has read_excel(), read_json(), and others.
```
oldContents = os.listdir("../_publications/")
publications = pd.read_csv("publications.tsv", sep="\t", header=0)
print("Imported generator `publications.tsv` file:")
publications
```
## Escape special characters
YAML is very picky about how it takes a valid string, so we are replacing single and double quotes (and ampersands) with their HTML encoded equivilents. This makes them look not so readable in raw format, but they are parsed and rendered nicely.
```
html_escape_table = {
"&": "&",
'"': """,
"'": "'"
}
def html_escape(text):
"""Produce entities within text."""
return "".join(html_escape_table.get(c,c) for c in text)
```
## Creating the markdown files
This is where the heavy lifting is done. This loops through all the rows in the TSV dataframe, then starts to concatentate a big string (```md```) that contains the markdown for each type. It does the YAML metadata first, then does the description for the individual page.
```
for row, item in publications.iterrows():
md_filename = str(item.pub_date) + "-" + item.url_slug + ".md"
html_filename = str(item.pub_date) + "-" + item.url_slug
year = item.pub_date[:4]
tags = item.tags.split(",")
## YAML variables
md = "---\ntitle: \"" + item.title + '"\n'
md += 'collection: publications\n'
md += 'category: publications\n'
md += 'type: publications\n'
md += 'layout: manuscript\n'
md += 'permalink: /publications/' + html_filename + '/\n'
md += "redirect_from:\n"
md += ' - "/publications/' + html_filename + '.html"\n'
md += ' - "/publications/' + html_filename + '"\n'
if len(str(item.excerpt)) > 5:
md += "excerpt: '" + html_escape(item.excerpt) + "'\n"
md += "date: " + str(item.pub_date) + "\n"
md += "venue: '" + html_escape(item.venue) + "'\n"
if len(str(item.paper_url)) > 5:
md += "paperurl: '" + item.paper_url + "'\n"
md += "citation: '" + html_escape(item.citation) + "'\n"
md += "assesses: " + item.assesses + "\n"
md += "educationalLevel: " + item.educationalLevel + "\n"
md += "author_profile: true\n"
## Add tags in lowercase (they are delimited using "," in the tsv file)
md += "tags:\n"
for tag in tags:
md += " - " + html_escape(tag.lower()) + "\n"
md += "keywords:\n"
for tag in tags:
md += " - " + html_escape(tag.lower()) + "\n"
md += "---\n"
## Markdown description for individual page
md += "\n" + html_escape(item.abstract) + "\n"
if len(str(item.paper_url)) > 5:
md += "\n[Download paper here](" + item.paper_url + ")\n"
# md += "\nRecommended citation: " + item.citation
md_filename = os.path.basename(md_filename)
with open("../_publications/" + md_filename, 'w') as f:
f.write(md)
```
These files are in the publications directory, one directory below where we're working from.
We can print the contents using the python os `listdir` method to see what has been exported.
```
newContents = os.listdir("../_publications/")
if collections.Counter(oldContents) == collections.Counter(newContents):
print("No new files added.")
print("Existing files:")
for f in oldContents:
print("\t" + f)
else:
print("Generated new files:")
for f in newContents:
print("\t" + f)
```
| github_jupyter |
# Read datasets
```
import pandas as pd
countries_of_the_world = pd.read_csv('../datasets/countries-of-the-world.csv')
countries_of_the_world.head()
mpg = pd.read_csv('../datasets/mpg.csv')
mpg.head()
student_data = pd.read_csv('../datasets/student-alcohol-consumption.csv')
student_data.head()
young_people_survey_data = pd.read_csv('../datasets/young-people-survey-responses.csv')
young_people_survey_data.head()
import matplotlib.pyplot as plt
import seaborn as sns
```
# Count plots
In this exercise, we'll return to exploring our dataset that contains the responses to a survey sent out to young people. We might suspect that young people spend a lot of time on the internet, but how much do they report using the internet each day? Let's use a count plot to break down the number of survey responses in each category and then explore whether it changes based on age.
As a reminder, to create a count plot, we'll use the catplot() function and specify the name of the categorical variable to count (x=____), the Pandas DataFrame to use (data=____), and the type of plot (kind="count").
Seaborn has been imported as sns and matplotlib.pyplot has been imported as plt.
```
survey_data = young_people_survey_data
# Create count plot of internet usage
sns.catplot(x="Internet usage", data=survey_data, kind="count")
# Show plot
plt.show()
# Change the orientation of the plot
sns.catplot(y="Internet usage", data=survey_data,
kind="count")
# Show plot
plt.show()
survey_data["Age Category"] = ['Less than 21' if x < 21 else '21+' for x in survey_data['Age']]
# Create column subplots based on age category
sns.catplot(y="Internet usage",
data=survey_data,
kind="count",
col="Age Category")
# Show plot
plt.show()
```
# Bar plots with percentages
Let's continue exploring the responses to a survey sent out to young people. The variable "Interested in Math" is True if the person reported being interested or very interested in mathematics, and False otherwise. What percentage of young people report being interested in math, and does this vary based on gender? Let's use a bar plot to find out.
As a reminder, we'll create a bar plot using the catplot() function, providing the name of categorical variable to put on the x-axis (x=____), the name of the quantitative variable to summarize on the y-axis (y=____), the Pandas DataFrame to use (data=____), and the type of categorical plot (kind="bar").
Seaborn has been imported as sns and matplotlib.pyplot has been imported as plt.
```
survey_data["Interested in Math"] = [True if x > 3 else False for x in survey_data['Mathematics']]
# Create a bar plot of interest in math, separated by gender
sns.catplot(x="Gender",
y="Interested in Math",
data=survey_data,
kind="bar")
# Show plot
plt.show()
```
# Customizing bar plots
In this exercise, we'll explore data from students in secondary school. The "study_time" variable records each student's reported weekly study time as one of the following categories: "<2 hours", "2 to 5 hours", "5 to 10 hours", or ">10 hours". Do students who report higher amounts of studying tend to get better final grades? Let's compare the average final grade among students in each category using a bar plot.
Seaborn has been imported as sns and matplotlib.pyplot has been imported as plt.
```
# Create bar plot of average final grade in each study category
sns.catplot(x="study_time",
y="G3",
data=student_data,
kind="bar")
# Show plot
plt.show()
# Rearrange the categories
sns.catplot(x="study_time", y="G3",
data=student_data,
kind="bar",
order=["<2 hours",
"2 to 5 hours",
"5 to 10 hours",
">10 hours"])
# Show plot
plt.show()
# Turn off the confidence intervals
sns.catplot(x="study_time", y="G3",
data=student_data,
kind="bar",
order=["<2 hours",
"2 to 5 hours",
"5 to 10 hours",
">10 hours"],
ci=None)
# Show plot
plt.show()
```
# Create and interpret a box plot
Let's continue using the student_data dataset. In an earlier exercise, we explored the relationship between studying and final grade by using a bar plot to compare the average final grade ("G3") among students in different categories of "study_time".
In this exercise, we'll try using a box plot look at this relationship instead. As a reminder, to create a box plot you'll need to use the catplot() function and specify the name of the categorical variable to put on the x-axis (x=____), the name of the quantitative variable to summarize on the y-axis (y=____), the Pandas DataFrame to use (data=____), and the type of plot (kind="box").
We have already imported matplotlib.pyplot as plt and seaborn as sns.
```
# Specify the category ordering
study_time_order = ["<2 hours", "2 to 5 hours",
"5 to 10 hours", ">10 hours"]
# Create a box plot and set the order of the categories
sns.catplot(x="study_time",
y="G3",
data=student_data,
kind='box',
order=study_time_order)
# Show plot
plt.show()
```
## Question
Which of the following is a correct interpretation of this box plot?
Possible Answers: The median grade among students studying less than 2 hours is 10.0.
# Omitting outliers
Now let's use the student_data dataset to compare the distribution of final grades ("G3") between students who have internet access at home and those who don't. To do this, we'll use the "internet" variable, which is a binary (yes/no) indicator of whether the student has internet access at home.
Since internet may be less accessible in rural areas, we'll add subgroups based on where the student lives. For this, we can use the "location" variable, which is an indicator of whether a student lives in an urban ("Urban") or rural ("Rural") location.
Seaborn has already been imported as sns and matplotlib.pyplot has been imported as plt. As a reminder, you can omit outliers in box plots by setting the sym parameter equal to an empty string ("").
```
# Create a box plot with subgroups and omit the outliers
sns.catplot(x="internet",
y="G3",
data=student_data,
kind='box',
hue="location",
sym="")
# Show plot
plt.show()
```
# Adjusting the whiskers
In the lesson we saw that there are multiple ways to define the whiskers in a box plot. In this set of exercises, we'll continue to use the student_data dataset to compare the distribution of final grades ("G3") between students who are in a romantic relationship and those that are not. We'll use the "romantic" variable, which is a yes/no indicator of whether the student is in a romantic relationship.
Let's create a box plot to look at this relationship and try different ways to define the whiskers.
We've already imported Seaborn as sns and matplotlib.pyplot as plt.
```
# Extend the whiskers to the 5th and 95th percentile
sns.catplot(x="romantic", y="G3",
data=student_data,
kind="box",
whis=0.5)
# Show plot
plt.show()
# Extend the whiskers to the 5th and 95th percentile
sns.catplot(x="romantic", y="G3",
data=student_data,
kind="box",
whis=[5, 95])
# Show plot
plt.show()
# Set the whiskers at the min and max values
sns.catplot(x="romantic", y="G3",
data=student_data,
kind="box",
whis=[0, 100])
# Show plot
plt.show()
```
# Customizing point plots
Let's continue to look at data from students in secondary school, this time using a point plot to answer the question: does the quality of the student's family relationship influence the number of absences the student has in school? Here, we'll use the "famrel" variable, which describes the quality of a student's family relationship from 1 (very bad) to 5 (very good).
As a reminder, to create a point plot, use the catplot() function and specify the name of the categorical variable to put on the x-axis (x=____), the name of the quantitative variable to summarize on the y-axis (y=____), the Pandas DataFrame to use (data=____), and the type of categorical plot (kind="point").
We've already imported Seaborn as sns and matplotlib.pyplot as plt.
```
# Create a point plot of family relationship vs. absences
sns.catplot(x="famrel", y="absences",
data=student_data,
kind="point")
# Show plot
plt.show()
# Add caps to the confidence interval
sns.catplot(x="famrel", y="absences",
data=student_data,
kind="point",
capsize=0.2)
# Show plot
plt.show()
# Remove the lines joining the points
sns.catplot(x="famrel", y="absences",
data=student_data,
kind="point",
capsize=0.2,
join=False)
# Show plot
plt.show()
```
# Point plots with subgroups
Let's continue exploring the dataset of students in secondary school. This time, we'll ask the question: is being in a romantic relationship associated with higher or lower school attendance? And does this association differ by which school the students attend? Let's find out using a point plot.
We've already imported Seaborn as sns and matplotlib.pyplot as plt.
Use sns.catplot() and the student_data DataFrame to create a point plot with relationship status ("romantic") on the x-axis and number of absences ("absences") on the y-axis. Create subgroups based on the school that they attend ("school")
```
# Create a point plot with subgroups
sns.catplot(x="romantic",
y="absences",
data=student_data,
kind="point",
hue="school")
# Show plot
plt.show()
# Turn off the confidence intervals for this plot
sns.catplot(x="romantic", y="absences",
data=student_data,
kind="point",
hue="school",
ci=None)
# Show plot
plt.show()
# Import median function from numpy
from numpy import median
# Plot the median number of absences instead of the mean
sns.catplot(x="romantic", y="absences",
data=student_data,
kind="point",
hue="school",
ci=None, estimator=median)
# Show plot
plt.show()
```
| github_jupyter |
# Preprocessing
To begin the training process, the raw images first had to be preprocessed. For the most part, this meant removing the banners that contained image metadata while retaining as much useful image data as possible. To remove the banners, I used a technique called "reflective padding" which meant I remove the banner region, then pad the edges with its own reflection. An example of this is shown here:
In order to remove the banners, however, they must first be detected. This was done using kernels in OpenCV to detect vertical and horizontal lines within the image. For instance, let's say you start with this image:
```
from pathlib import Path
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
file = '../data/Raw_Data/Particles/L2_000b4469b73e3fb3558d20b33b91fcb0.jpg'
img = mpimg.imread(file)
fig, ax = plt.subplots(1, 1, figsize=(10,10))
ax.set_axis_off()
ax.imshow(img)
```
The first step would be to create a binary mask of the image where all pixels above a threshold becomes 255 and all pixels below the threshold becomes 0. Since the banners in our images are mostly white, the threshold value chosen was 250. This is to ensure it is mostly only the banner that is left in the mask.
```
import cv2
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # binarization only works if the image is first converted to greyscale
ret, thresh = cv2.threshold(gray, 250, 255, cv2.THRESH_BINARY) # binarize the image using 250 as the threshold value
fig, ax = plt.subplots(1, 1, figsize=(10,10))
ax.set_axis_off()
ax.imshow(thresh)
```
Next, use [erosion and dilation](https://docs.opencv.org/2.4/doc/tutorials/imgproc/erosion_dilatation/erosion_dilatation.html) to find where the vertical and horizontal lines are within the image. By successively replacing pixels with the minimum (erosion) then maximum value (dilation) over the area of a kernel, largely vertical regions of the image are maintained using a tall thin kernel while a short long kernel mantains the largely horizontal regions of the image.
```
# Find the verticle and horizontal lines in the image
verticle_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 13))
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 1))
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
img_v = cv2.erode(thresh, verticle_kernel, iterations = 3)
vert_lines_img = cv2.dilate(img_v, verticle_kernel, iterations = 3)
img_h = cv2.erode(thresh, horizontal_kernel, iterations = 3)
hori_lines_img = cv2.dilate(img_h, horizontal_kernel, iterations = 3)
fig, ax = plt.subplots(1, 2, figsize=(20,20))
ax[0].set_axis_off()
ax[0].imshow(vert_lines_img)
ax[1].set_axis_off()
ax[1].imshow(hori_lines_img)
```
The two masks are then added together and a final erosion + binarization is performed on the inverted array to ensure we are left with a binary mask where pixel values of 0 indicate the banner region and pixel values of 255 indicate everywhere else.
```
img_add = cv2.addWeighted(vert_lines_img, 0.5, hori_lines_img, 0.5, 0.0)
img_final = cv2.erode(~img_add, kernel, iterations = 3)
ret, thresh2 = cv2.threshold(img_final, 128, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
fig, ax = plt.subplots(1, 2, figsize=(20,20))
ax[0].set_axis_off()
ax[0].imshow(img_add)
ax[1].set_axis_off()
ax[1].imshow(thresh2)
img_final
```
| github_jupyter |
<a href="https://colab.research.google.com/github/GavinHacker/recsys_model/blob/master/7_recbaserecall.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# 使用基于电影相似度进行推荐的方法进行召回
### install library
```
!pip install pymysql
from google.colab import drive
drive.mount('/content/drive')
```
## Functional code
```
import pandas as pd
import pymysql
import pymysql.cursors
from functools import reduce
import numpy as np
import pandas as pd
import uuid
import datetime
#from pyfm import pylibfm
from sklearn.feature_extraction import DictVectorizer
from sklearn.metrics.pairwise import pairwise_distances
np.set_printoptions(precision=3)
np.set_printoptions(suppress=True)
from sklearn.datasets import dump_svmlight_file
from sklearn.preprocessing import OneHotEncoder
import pickle as pkl
from sklearn.metrics import roc_auc_score, mean_squared_error
from sklearn.datasets import load_svmlight_file
from sklearn.linear_model import LogisticRegression
def get_connection():
return pymysql.connect(host='rm-2zeqqm6994abi7b6dqo.mysql.rds.aliyuncs.com',
user='noone',
password='Huawei12#$',
db='recsys',
port=3306,
charset ='utf8',
use_unicode=True)
```
## 获取最新的comment,实际recsys_core实现的时候使用mqlog消息
```
def get_comment_data():
df_comment_new_data = pd.read_sql_query("select * from comment_new where newdata = 1 ", get_connection())
df_comment_new_data_ldim = df_comment_new_data.loc[:,['ID','MOVIEID','USERID']]
return df_comment_new_data_ldim
```
## 获取基于相似度推荐的电影集合
```
def get_ibmovie_by_movieid(movieid, connection):
sql = 'select DISTINCT recmovieid from ibmovie where movieid = \'%s\'' % movieid
try:
with connection.cursor() as cursor:
cout=cursor.execute(sql)
return cursor.fetchall()
except Exception as e:
print(e)
connection.close()
return None
```
## 对recmovie表插入数据,保留原始movieid,即根据哪个电影推荐而来
```
def insert_or_update_recmovie(movieid, userid, srcmovieid, connection):
_id = uuid.uuid4()
time_now = datetime.datetime.now()
q_sql = 'select id from recmovie where userid=\'%s\' and movieid=\'%s\'' % (userid, movieid)
i_sql = 'insert into recmovie (id, userid, movieid, rectime, srcmovieid) values (\'%s\', \'%s\', \'%s\', \'%s\', \'%s\')' % (_id, userid, movieid, time_now, srcmovieid)
exist_list = None
try:
with connection.cursor() as cursor:
#print(q_sql)
cout=cursor.execute(q_sql)
exist_list = cursor.fetchall()
if len(exist_list) > 0:
with connection.cursor() as cursor:
for item in exist_list:
u_sql = 'update recmovie set rectime=\'%s\' where id=\'%s\'' % (time_now, item[0])
cursor.execute(u_sql)
else:
with connection.cursor() as cursor:
cursor.execute(i_sql)
except Exception as e:
print(e)
connection.close()
return None
```
* test code
insert_or_update_recmovie('10430817','cf2349f9c01f9a5cd4050aebd30ab74f',conn)
```
def update_comment_new_data_flag(rid, connection):
sql = 'update comment_new set newdata = 0 where id = \'%s\'' % rid
try:
with connection.cursor() as cursor:
cout=cursor.execute(sql)
except Exception as e:
print(e)
connection.close()
```
## 根据用户的打分进行相似电影召回,暂不限数量,具体召回数量取决于用户看过的电影的相似电影集合交集
```
def func_main():
df_comment_new_data_ldim = get_comment_data()
conn = get_connection()
for i in df_comment_new_data_ldim.index:
print(df_comment_new_data_ldim.iloc[i]['MOVIEID'], df_comment_new_data_ldim.iloc[i]['USERID'])
ibmovie_list = get_ibmovie_by_movieid(df_comment_new_data_ldim.iloc[i]['MOVIEID'], get_connection())
for j in ibmovie_list:
insert_or_update_recmovie(j[0],'cf2349f9c01f9a5cd4050aebd30ab74f', df_comment_new_data_ldim.iloc[i]['MOVIEID'], conn)
update_comment_new_data_flag(df_comment_new_data_ldim.iloc[i]['ID'], conn)
conn.commit()
#func_main()
```
| github_jupyter |
# Linear Regression with One Variable
The code in this notebook is an implementation of the linear regression algorithm from scratch. The goal is to predict housing prices in a specific area of a city given data based on house-size vs price.
```
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
```
## Tasks to Complete:
1. Implement linear regression, gradient descent functions
2. Test on set of points that fit a straight line of the form y = mx + c perfectly as a test case
3. Animate graph changes after each simultaneous update
4. Test with housing prices
## Order of implementation
1. Pick random value for theta0 and theta1
2. Set h(x) as theta0 + theta1 * x
3. perform gradient descent until temp0 and temp1 are equal to theta0 and theta1
4. set h(x) with new parameters
5. plot the line
```
def sumDiff(hList, yList, m):
sums = 0
div = 0
for i in range(m):
sums += hList[i] - yList[i]
return sums/m
def gradDesc(x,y,alpha,iterations):
m = x.shape[0]
theta0 = np.random.randint(low=2, high=5);
theta1 = np.random.randint(low=2, high=5);
temp0 = 1
temp1 = 5
for j in range(iterations):
h = theta0 + theta1 * x
a = sumDiff(h,y,m)
b = sumDiff(h*x,y*x, m)
temp0 = theta0 - alpha*a
temp1 = theta1 - alpha*b
theta0 = temp0
theta1 = temp1
return round(theta0,2), round(theta1,2)
g = [0,1,2]
h = [0,2,4]
g=np.array(g)
h=np.array(h)
print(gradDesc(g,h,0.5,500))
```
## Points to note:
1. When using a while loop and exiting only after a=b=0 won't work as for a specific set of values a and b might never be exactly equal to zero. Therefore, we either have to loop a set number of times or use the while loop but keep a range of values, say less than± 0.001 about 0.
2. Made use of numpy arrays instead of python lists. This lets us multiply two arrays with ease. This makes the partial derivative with respect to theta1 much easier to calculate.
## The Path ahead:
1. Plotting points on a graph and showing a visual on how the line changes.
2. Use real world data to predict an outcome using the algorithm.
3. Might creat a webpage and host the above as a mini-project.
```
a = np.random.randint(0,50,200)
b = np.random.randint(10,30,200)
a = np.array(a)
b= np.array(b)
c = a
d = b
c,m = gradDesc(a,b,0.0008, 10000)
x = np.linspace(0,50,100)
y = m*x + c
plt.scatter(a,b, marker='x')
plt.xlim(0,50)
plt.ylim(0,50)
plt.plot(x,y, 'r')
plt.show()
import pandas as pd
df = pd.read_csv("data1.csv") #house prices in delhi
domainX = np.array(df["Area"].tolist())
rangeY = np.array(df["Price"].tolist())
yScale = 100000
xScale = 100
domainX = domainX/xScale
rangeY = rangeY/yScale
plt.scatter(domainX,rangeY, marker='x')
c,m = gradDesc(domainX,rangeY,0.000006, 20000)
x = np.linspace(0,250,100)
y = m*x + c
plt.plot(x,y, 'r')
plt.show()
print((m*13+c)*yScale)
```
| github_jupyter |
```
import atoti as tt
session = tt.create_session()
import pandas as pd
#housing_df = pd.read_csv('njhousingdata.csv', index_col='city')
housing_df_nc = pd.read_csv('njhousingdata_nc.csv', index_col='city')
aveprice_df = pd.read_csv('AvgSalesPrice2020unclean.csv', index_col='city')
schooldf = pd.read_csv('njschoolrankings.csv', index_col='city')
#list_frames = [housing_df, aveprice_df, schooldf]
list_frames_nc = [housing_df_nc, aveprice_df, schooldf]
#for item in list_frames:
# for item in list_frames_nc:
# print(item.dtypes)
#for item in list_frames:
for item in list_frames_nc:
for col in list(item):
if (item[col].dtype != 'object' and item[col].dtype == 'int64'):
item[col] = item[col].astype(float)
#for item in list_frames:
# for item in list_frames_nc:
# print(item.dtypes)
#joined_housing_df = pd.concat(list_frames, axis = 1)
# joined_housing_df = pd.concat(list_frames_nc, axis = 1)
# joined_housing_df.to_csv("nj_data.csv",index=True)
DUMMY = session.create_cube(session.read_pandas(pd.concat(list_frames_nc, axis = 1), keys=["city"]))
nj_data = session.read_csv("nj_data.csv", keys=["city"])
# nj_data.head()
cube = session.create_cube(nj_data)
# cube.schema
m=cube.measures
# m
h=cube.hierarchies
# h
session.visualize()
m['% vacant'] = m['vacant housing units.MEAN'] / m['total housing units.MEAN'] * 100
```
```
# m['aa f householderno husband.MEAN'] = m['In family households - f householderno husband.MEAN'] / m['total housing units.MEAN']
#
for measures in m:
if 'In family households - ' in measures:
name = 'percent ' + measures[23:]
m[name] = m[measures] / m['Total household population.MEAN']
# del m[measures]
for measures in m:
if "family households - " in measures:
name = "percent " + measures[20:]
m[name] = m[measures] / m['Total household population.MEAN']
# del m[measures]
# m
session.visualize()
### Levels:
# From the tutorial:
# Hierarchies are also made of levels.
# Levels of the same hierarchy are attributes with a parent-child relationship.
# For instance, a city belongs to a country so Country and City could be the two levels of a Geography hierarchy.
# I think this may be a useful way to group types of meaures that have similar categories.
# practically, I'm not sure what the intention is, but maybe doing things like :
# "derived family household" measures makes sense as aa level.
lvls = cube.levels
lvls
# It also seems like they use levels as separators wh
# for measures in m:
# if "family households - " in measures:
# name = "percent " + measures[20:]
# m[name] = m[measures] / m['Total household population.MEAN']
import sklearn
```
| github_jupyter |
# 03 - Registering a Model in your Workspace
Now that we have trained a set of models and identified the run containing the best model, we want to deploy the model for inferencing.
```
import environs
e_vars = environs.Env()
e_vars.read_env('../workshop.env')
USER_NAME = e_vars.str("USER_NAME")
EXPERIMENT_NAME = e_vars.str('EXPERIMENT_NAME')
ENVIRONMENT_NAME = e_vars.str("ENVIRONMENT_NAME")
DATASET_NAME = e_vars.str("DATASET_NAME")
SERVICE_NAME = e_vars.str("SERVICE_NAME")
MODEL_NAME = e_vars.str("MODEL_NAME")
if not USER_NAME:
raise NotImplementedError("Please enter your username in the `.env` file and run this cell again.")
from azureml.core import Workspace, Experiment
ws = Workspace.from_config()
experiment = Experiment(ws, EXPERIMENT_NAME)
```
### Find the Best Run
We can use the SDK to search through our runs to determine which was the best run. In our case, we'll use RMSE to determine the best metric.
```
from tqdm import tqdm
def find_best_run(experiment, metric, goal='minimize'):
runs = {}
run_metrics = {}
# Create dictionaries containing the runs and the metrics for all runs containing the metric
for r in tqdm(experiment.get_runs(include_children=True)):
metrics = r.get_metrics()
if metric in metrics.keys():
runs[r.id] = r
run_metrics[r.id] = metrics
if goal == 'minimize':
min_run = min(run_metrics, key=lambda k: run_metrics[k][metric])
return runs[min_run]
else:
max_run = max(run_metrics, key=lambda k: run_metrics[k][metric])
return runs[max_run]
best_run = find_best_run(experiment, 'rmse', 'minimize')
# Display the metrics
best_run.get_metrics()
```
### Register a model from best run
We have already identified which run contains the "best model" by our evaluation criteria. Each run has a file structure associated with it that contains various files collected during the run. Since a run can have many outputs we need to tell AML which file from those outputs represents the model that we want to use for our deployment. We can use the `run.get_file_names()` method to list the files associated with the run, and then use the `run.register_model()` method to place the model in the workspace's model registry.
When using `run.register_model()` we supply a `model_name` that is meaningful for our scenario and the `model_path` of the model relative to the run. In this case, the model path is what is returned from `run.get_file_names()`
```
# View the files in the run
for f in best_run.get_file_names():
if 'logs' not in f:
print(f)
# Register the model with the workspace
model = best_run.register_model(model_name=MODEL_NAME, model_path='outputs/model.pkl')
```
Once a model is registered, it is accessible from the list of models on the AML workspace. If you register models with the same name multiple times, AML keeps a version history of those models for you. The `Model.list()` lists all models in a workspace, and can be filtered by name, tags, or model properties.
```
# Find all models called "diabetes_regression_model" and display their version numbers
from azureml.core.model import Model
models = Model.list(ws, name=MODEL_NAME)
for m in models:
print(m.name, m.version)
```
<br><br><br><br><br>
###### Copyright (c) Microsoft Corporation. All rights reserved.
###### Licensed under the MIT License.
| github_jupyter |
# Learning new associations
Being able to learn an input-output mapping
(or a _heteroassociative memory_)
is useful for storing and recalling associations.
This is also a task required by more complicated models
that require some notion of long-term memory.
In a perfect world, the PES rule could be applied
to learn this mapping from examples.
However, when two distinct inputs cause the same neurons to fire,
their decoded values will depend on one another.
This leads to difficulty when trying to store
multiple independent associations in the same memory.
To solve this problem,
a vector-space analog of Oja's rule,
dubbed Vector-Oja's rule (or simply _Voja's rule_) was proposed.
In essence, this unsupervised learning rule
makes neurons fire selectively in response to their input.
When used in conjunction with properly-chosen intercepts
(corresponding to the largest dot-product between pairs of inputs),
this approach makes it possible to scalably
learn new associations in a spiking network.
Voja's rule works by moving the encoders
of the active neurons toward the current input.
This can be stated succinctly as,
$$
\Delta e_i = \kappa a_i (x - e_i)
$$
where $e_i$ is the encoder of the $i^{th}$ neuron,
$\kappa$ is a modulatory learning rate
(positive to move towards, and negative to move away),
$a_i$ is the filtered activity of the $i^{th}$ neuron,
and $x$ is the input vector encoded by each neuron.
To see how this is related to Oja's rule,
substituting $e_i$ with the row of weights $W_i$,
$x$ for the pre-synaptic activity vector $b$,
and letting $s = 1 / a_i$ be a dynamic normalizing factor, gives
$$
\Delta W_i = \kappa a_i (b - s a_i W_i)
$$
which is the update rule for a single row using Oja.
For more details,
see [Learning large-scale heteroassociative memories in spiking neurons](
http://compneuro.uwaterloo.ca/publications/voelker2014a.html).
This notebook will lead the reader through
a basic example of building a network
that can store and recall new associations.
## Step 1: Configure some example data
First, we will setup some keys (inputs) and values (outputs)
for our network to store and recall.
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import nengo
num_items = 5
d_key = 2
d_value = 4
rng = np.random.RandomState(seed=7)
keys = nengo.dists.UniformHypersphere(surface=True).sample(
num_items, d_key, rng=rng)
values = nengo.dists.UniformHypersphere(surface=False).sample(
num_items, d_value, rng=rng)
```
An important quantity is the largest dot-product
between all pairs of keys,
since a neuron's intercept should not go below this value
if it's positioned between these two keys.
Otherwise, the neuron will move back and forth
between encoding those two inputs.
```
intercept = (np.dot(keys, keys.T) - np.eye(num_items)).flatten().max()
print("Intercept: %s" % intercept)
```
## Step 2: Build the model
We define a helper function that is useful
for creating nodes that cycle through keys/values.
```
def cycle_array(x, period, dt=0.001):
"""Cycles through the elements"""
i_every = int(round(period / dt))
if i_every != period / dt:
raise ValueError("dt (%s) does not divide period (%s)" % (dt, period))
def f(t):
i = int(round((t - dt) / dt)) # t starts at dt
return x[int(i / i_every) % len(x)]
return f
```
We create three inputs:
the keys, the values, and a modulatory learning signal.
The model is run continuously in two phases:
the first half learns the set of associations,
and the second tests recall.
The learning signal will be set to 0
o allow learning during the first phase,
and -1 to inhibit learning during the second phase.
The memory is confined to a single ensemble.
Roughly speaking, its encoders will hold the keys,
and its decoders will hold the values.
```
# Model constants
n_neurons = 200
dt = 0.001
period = 0.3
T = period * num_items * 2
# Model network
model = nengo.Network()
with model:
# Create the inputs/outputs
stim_keys = nengo.Node(output=cycle_array(keys, period, dt))
stim_values = nengo.Node(output=cycle_array(values, period, dt))
learning = nengo.Node(output=lambda t: -int(t >= T / 2))
recall = nengo.Node(size_in=d_value)
# Create the memory
memory = nengo.Ensemble(
n_neurons, d_key, intercepts=[intercept] * n_neurons)
# Learn the encoders/keys
voja = nengo.Voja(learning_rate=5e-2, post_synapse=None)
conn_in = nengo.Connection(
stim_keys, memory, synapse=None, learning_rule_type=voja)
nengo.Connection(learning, conn_in.learning_rule, synapse=None)
# Learn the decoders/values, initialized to a null function
conn_out = nengo.Connection(
memory,
recall,
learning_rule_type=nengo.PES(1e-3),
function=lambda x: np.zeros(d_value))
# Create the error population
error = nengo.Ensemble(n_neurons, d_value)
nengo.Connection(
learning, error.neurons, transform=[[10.0]] * n_neurons, synapse=None)
# Calculate the error and use it to drive the PES rule
nengo.Connection(stim_values, error, transform=-1, synapse=None)
nengo.Connection(recall, error, synapse=None)
nengo.Connection(error, conn_out.learning_rule)
# Setup probes
p_keys = nengo.Probe(stim_keys, synapse=None)
p_values = nengo.Probe(stim_values, synapse=None)
p_learning = nengo.Probe(learning, synapse=None)
p_error = nengo.Probe(error, synapse=0.005)
p_recall = nengo.Probe(recall, synapse=None)
p_encoders = nengo.Probe(conn_in.learning_rule, 'scaled_encoders')
```
## Step 3: Running the model
```
with nengo.Simulator(model, dt=dt) as sim:
sim.run(T)
t = sim.trange()
```
## Step 4: Plotting simulation output
We first start by checking the keys, values, and learning signals.
```
plt.figure()
plt.title("Keys")
plt.plot(t, sim.data[p_keys])
plt.ylim(-1, 1)
plt.figure()
plt.title("Values")
plt.plot(t, sim.data[p_values])
plt.ylim(-1, 1)
plt.figure()
plt.title("Learning")
plt.plot(t, sim.data[p_learning])
plt.ylim(-1.2, 0.2);
```
Next, we look at the error during training and testing.
In the top figure, the error being minimized by PES
goes to zero for each association during the training phase.
In the bottom figure, the recall error is close to zero,
with momentary spikes each time a new key is presented.
```
train = t <= T / 2
test = ~train
plt.figure()
plt.title("Value Error During Training")
plt.plot(t[train], sim.data[p_error][train])
plt.figure()
plt.title("Value Error During Recall")
plt.plot(t[test], sim.data[p_recall][test] - sim.data[p_values][test]);
```
## Step 5: Examining encoder changes
We can also plot the two-dimensional encoders before and after training.
Initially, they are uniformly distributed around the unit circle.
Afterward, we see that each key has attracted all of its nearby neurons.
Notably, almost all neurons are participating
in the representation of a unique association.
```
scale = (sim.data[memory].gain / memory.radius)[:, np.newaxis]
def plot_2d(text, xy):
plt.figure()
plt.title(text)
plt.scatter(xy[:, 0], xy[:, 1], label="Encoders")
plt.scatter(
keys[:, 0], keys[:, 1], c='red', s=150, alpha=0.6, label="Keys")
plt.xlim(-1.5, 1.5)
plt.ylim(-1.5, 2)
plt.legend()
plt.gca().set_aspect('equal')
plot_2d("Before", sim.data[p_encoders][0].copy() / scale)
plot_2d("After", sim.data[p_encoders][-1].copy() / scale)
```
| github_jupyter |
```
from datascience import *
import seaborn as sns
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
from matplotlib.lines import Line2D
plt.style.use('seaborn')
#Data clarification
#Rank - Current World ranking based on 4 last competitions
#Name - Name of the participant
#Country - Country of origin of participant
#Age - Age of participant
#Average Arrow - Average lifetime competitive arrow score, reference: http://texasarchery.info/wp-content/uploads/2015/08/NASP-JOAD-How-to-score.jpg
base = pd.read_csv('Cleaned Data Men age and avg arrow.csv')
base2 = pd.read_csv('Cleaned Data Men age and avg arrow.csv')
base = base.drop(columns=['Country'])
base
#quick mean age calculation for paper
base['Age'].mean()
BaseByAge = base.sort_values(by=['Age'],ascending= False)
#Calculate how many arhers of each age there are
#Would like to show if there is a strong preference for certain ages
AgeAmount = base.groupby('Age',as_index = False).count()
#list(AgeAmount)
AgeAmount
#Time to clean the data after some unexpected results
CleanedAgeA = AgeAmount.drop(columns=['Name','Score','Average Arrow'])
CleanedAgeA = CleanedAgeA.rename(columns={'World Rank': '# of Archers'})
#Goal here was to keep the original cleaned data set,unfortunately this did not work, but is fixed later
CleanedAgeAB = CleanedAgeA
CleanedAgeAB['cum_sum'] = CleanedAgeA['# of Archers'].cumsum()
CleanedAgeAB['Cumulative %'] = 100*CleanedAgeA.cum_sum/CleanedAgeA['# of Archers'].sum()
CleanedAgeAB
#I Realize now that calculating the percentage was entirely pointless
# as our data has 100 points, therefore the cumulative sum is the same as the
#percentage
df1 = CleanedAgeAB.drop(columns=['cum_sum',"# of Archers"])
df2 = CleanedAgeAB.drop(columns=['cum_sum',"Cumulative %"])
#Goal: Make a chart showcasing most archers are very young
CleanedAgeAB.plot.area(x = 'Age', y = ["# of Archers",'Cumulative %'],alpha = 0.5)
#Goal: make a graph representing the presence of each age in the dataset
#CleanedAgeA = CleanedAgeA.drop(columns = ['cum_sum','Cumulative %'])
ax = CleanedAgeA.plot.bar(x = 'Age',y = '# of Archers',legend = False,colormap = 'Accent')
ax.set_ylabel("# of Archers")
#The following data could probably be grouped into age brackets to produce a cleaner graph, but this one is more accurate
#Question 2 Graphs begin here
#Goal: Produce a graph showing performance for archers aged under 25 and 25 and over
#1st, seperate the data by age groups
ElderData = BaseByAge.iloc[0:44]
YoungData = BaseByAge.iloc[44:100]
#Find the means of desired variables
df1 = ElderData.mean()
df2 = YoungData.mean()
CombinedMeans = pd.concat([df1,df2], axis = 1)
CombinedMeans.columns = ['Older','Younger']
CombinedMeans
#Creating a small multiple figure in order to show difference in performance
#of younger and older archers
fig, axs = plt.subplots(1,4)
row1 = CombinedMeans.iloc[0]
row2 = CombinedMeans.iloc[1]
row3 = CombinedMeans.iloc[2]
row4 = CombinedMeans.iloc[3]
fig.subplots_adjust(wspace = 1)
axs[1].set_ylim(50,51)
axs[1].set_ylabel('Average World Placement')
axs[2].set_ylim(80,90)
axs[2].set_ylabel('Average Score')
axs[0].set_ylim(20,30)
axs[0].set_ylabel('Average Age')
axs[3].set_ylim(9,9.1)
axs[3].set_ylabel('Average Arrow Points')
row1.plot.bar(ax = axs[1])
row2.plot.bar(ax = axs[2])
row3.plot.bar(ax = axs[0])
row4.plot.bar(ax = axs[3])
#Question 3: Since Recurrent shoulder pains are more prevalent in
#archers aged 20 and up, can this be observed in their performance or sport retirement age?
#Question 4: Since there seem to be many factors such as stress, anxiety, probability of injury, and heart rate control that can influence the performance of an archer, is there a formula for the "perfect" archer?
#Question 5: If the above question is true, can these trends be noticed in the world of professional archery today?
#Goal: Compile a data set comparing the performance of archers younger than 20, and archers older than 20,but younger than 23 in order to minimize the effect of longer training by older archers
#We should end up with data about archers ages 17-19 and 20-23
#print(BaseByAge.iloc[51:88])
injuryYoung = BaseByAge.iloc[88:100]
injuryOld = BaseByAge.iloc[51:88]
#Since we are evaluating performance based on age again, we can do the same calculations as we did before
df1 = injuryYoung.mean()
df2 = injuryOld.mean()
CombinedMeans = pd.concat([df1,df2], axis = 1)
CombinedMeans.columns = ['Younger','Older']
CombinedMeans
#This data does not support the conclusion of the research paper
#plausible causes: more training could mean easily overcoming any disadvantages the pain could cause
#Archers who feel chronic pain do not perform as well and do not compete at the highest levels,
#meaning they are not represented in our dataset
#without access to medical records, we cannot establish if some archers stop due to shoulder pain, making us unable
#to associate pain with retirement age
fig, axs = plt.subplots(1,4)
row1 = CombinedMeans.iloc[0]
row2 = CombinedMeans.iloc[1]
row3 = CombinedMeans.iloc[2]
row4 = CombinedMeans.iloc[3]
fig.subplots_adjust(wspace = 1)
axs[1].set_ylim(45,60)
axs[1].set_ylabel('Average World Placement')
axs[2].set_ylim(70,90)
axs[2].set_ylabel('Average Score')
axs[0].set_ylim(15,25)
axs[0].set_ylabel('Average Age')
axs[3].set_ylim(9,9.1)
axs[3].set_ylabel('Average Arrow Points')
row1.plot.bar(ax = axs[1])
row2.plot.bar(ax = axs[2])
row3.plot.bar(ax = axs[0])
row4.plot.bar(ax = axs[3])
#Based on the articles,Let us summarize what each found to be the best age for an archer
#Article 1: an archer of age under 35
#Article 2: an archer of age over 25
#Article 3: an archer of age under 20 - although this data does not agree with our research so far
#Article 4: an archer of around the age of late 20's/early 30's but younger than 50
#Article 5: an archer of around the age of late 20's/early 30's but younger than 50
#This leaves us with the optimal age of around 27-35
#Time to test if this trend stands true for the current world of archery
#Goal: Compare and contrast different "generations" of archers in order to see which performs the best
#print(BaseByAge.iloc[0:4])
ageGroup1 = BaseByAge.iloc[73:100]
ageGroup2 = BaseByAge.iloc[30:73]
ageGroup3 = BaseByAge.iloc[11:30]
ageGroup4 = BaseByAge.iloc[5:11]
ageGroup5 = BaseByAge.iloc[0:4]
df1 = ageGroup1.mean()
df2 = ageGroup2.mean()
df3 = ageGroup3.mean()
df4 = ageGroup4.mean()
df5 = ageGroup5.mean()
CombinedMeans = pd.concat([df1,df2,df3,df4,df5], axis = 1)
CombinedMeans.columns = ['17-21','22-26','27-31','32-34','35-37']
CombinedMeans
#Would like to space x labels out so they are more readable
fig, axs = plt.subplots(1,4)
fig.set_tight_layout
row1 = CombinedMeans.iloc[0]
row2 = CombinedMeans.iloc[1]
row3 = CombinedMeans.iloc[2]
row4 = CombinedMeans.iloc[3]
fig.subplots_adjust(wspace = 1.3)
axs[1].set_ylim(30,65)
axs[1].set_ylabel('Average World Placement')
axs[2].set_ylim(70,115)
axs[2].set_ylabel('Average Score')
axs[0].set_ylim(17,37)
axs[0].set_ylabel('Average Age')
axs[3].set_ylim(9.04,9.12)
axs[3].set_ylabel('Average Arrow Points')
row1.plot.bar(ax = axs[1])
row2.plot.bar(ax = axs[2])
row3.plot.bar(ax = axs[0])
row4.plot.bar(ax = axs[3])
df = pd.read_csv("Cleaned Data Men age and avg arrow.csv", index_col = 0)
df = df.drop(columns=['Country'])
df.columns = ["Name", "Score", "Age", "Average_Arrow"]
model = 'Score ~ %s'%(" + ".join(df.columns.values[1:]))
linear_regression = smf.ols(model, data = df).fit()
linear_regression.summary()
linear_regression.params
std_err = linear_regression.params - linear_regression.conf_int()[0]
std_err
bd_df = pd.DataFrame({'coef' : linear_regression.params.values[1:], 'err' : std_err.values[1:], 'name' : std_err.index.values [1:]})
bd_df
#START OF PROJECT 2
#Initialization of new data
df2 = pd.read_csv("New Archery Data.csv", index_col = 0)
df3 = pd.read_csv("Younger.csv", index_col = 0)
df4 = pd.read_csv("Older.csv", index_col = 0)
df2.columns = ["Name", "Score","Age", "Average_Arrow"]
sns.lmplot(x = "Age", y = "Score", data = df3
, x_estimator = np.mean, x_ci = .95)
#Adding some statistics that may be necessary for the calculations
df2.sort_values(by=['Age'],ascending= True)
AgeAmount = df2.groupby('Age',as_index = False).count()
CleanedAgeA = AgeAmount.drop(columns=['Score','Average_Arrow'])
CleanedAgeA = CleanedAgeA.rename(columns={'Name': '# of Archers'})
CleanedAgeAB = CleanedAgeA
CleanedAgeAB['Cumulative Amount'] = CleanedAgeA['# of Archers'].cumsum()
CleanedAgeAB['% of total'] = (CleanedAgeAB['# of Archers'] /199 * 100)
CleanedAgeAB['Cumulative %'] = CleanedAgeAB['% of total'].cumsum()
CleanedAgeAB = CleanedAgeAB.round(2)
df = CleanedAgeAB
df
#Now that we have a base new dataset, it's time to do some analysis
#TO DO LIST:
#1 Present the data at hand in an appealing way
#2 Find out if there is a visible decline at the age of around 35 - How fast do we age?
#3 Find out if people older than 28 tend to perform better than those 17-28 - Psych skills of elite archers
#4 Find out if people of around 20-30 perform better than those who are around 40-50 - Lars and Bo - heart rate and focus
#1 shows us Most of the archers are between 20 and 30
#Most archers quit before they reach their best age
df.plot.area(x = 'Age', y = ["# of Archers",'Cumulative %'],alpha = 0.5)
#df.plot.(x = 'Age', y = ["# of Archers","Cumulative %"])
#2 Here we can see that archers steadily increase their performance until 33
#and performance decreases after
sns.lmplot(x = "Age", y = "Score", data = df3
, x_estimator = np.mean, x_ci = .95)
sns.lmplot(x = "Age", y = "Score", data = df4
, x_estimator = np.mean, x_ci = .95)
#3
n3y = pd.read_csv("17-28.csv", index_col = 0)
n3o = pd.read_csv("28+.csv",index_col = 0)
n3b = pd.read_csv("29-33.csv",index_col=0)
n3y.mean().plot(kind = 'bar')
fig, axs = plt.subplots(1,3,sharey = True)
row1 = n3y.mean()
row2 = n3o.mean()
row3 = n3b.mean()
#axs[0].set_ylabel()
axs[0].set_xlabel("Ages 17-28")
axs[1].set_xlabel("Ages 28-50")
axs[2].set_xlabel("Ages 28-33")
row1.plot.bar(ax = axs[0])
row2.plot.bar(ax = axs[1])
row3.plot.bar(ax = axs[2])
axs[0].axhline(54, color = 'r')
axs[1].axhline(54, color = 'r')
axs[1].axhline(58, color = 'orange')
axs[2].axhline(54, color = 'r')
axs[2].axhline(58, color = 'orange')
#This shows us there is a difference in performance of archers aged
# 17-28 and 28+, but also if we take into account the results of goal#2
#We get an even better score for this age group of archers
#4
n4y = pd.read_csv("20-30.csv", index_col = 0)
n4o = pd.read_csv("40-50.csv", index_col = 0)
fig, axs = plt.subplots(1,2,sharey = True)
row1 = n4y.mean()
row2 = n4o.mean()
#axs[0].set_ylabel()
axs[0].set_xlabel("Ages 20-30")
axs[1].set_xlabel("Ages 40-50")
row1.plot.bar(ax = axs[0])
row2.plot.bar(ax = axs[1])
#axs[0].axhline(54, color = 'r')
```
| github_jupyter |
### Tensor manipulation
Slicing
```
import tensorflow as tf
import numpy as np
t = np.array([0., 1., 2., 3., 4., 5., 6.,])
print(t)
print(t.ndim, t.shape)
print(t[-1], t[4:-1], t[:2], t[4:])
t2 = np.array([[0., 1., 2.], [3., 4., 5.], [6., 7., 8.], [9., 10., 11.]])
print(t2)
print(t2.ndim, t2.shape)
print(t2[-1])
print(t2[2:-1])
print(t2[:2])
print(t2[2:])
print(t2[-1, -1])
print(t2[1:-1, 0:1])
print(t2[2:,:2])
```
Shape, Rank, Axis
```
sess = tf.Session()
t3 = tf.constant([1, 2, 3, 4])
_t3 = t3.eval(session=sess)
print(_t3, _t3.shape, t3)
t4 = tf.constant([[1,2],[3,4]])
_t4 = sess.run(t4)
print(_t4, _t4.shape, t4)
```
Matmul vs multiply
```
m1 = tf.constant([[1., 2.], [3., 4.]])
m2 = tf.constant([[1.], [2.]])
_m1, _m2 = sess.run([m1, m2])
print(_m1, "matrix 1 shape: ", _m1.shape)
print(_m2, "matrix 2 shape: ", _m2.shape)
mm = tf.matmul(m1, m2)
mm2 = m1 * m2
_mm, _mm2 = sess.run([mm, mm2])
print(_mm)
print(_mm2)
```
Broadcasting
```
# Operations between same shapes
m3 = tf.constant([[3., 1.]])
m4 = tf.constant([[2., 2.]])
mm3 = m3 + m4
_mm3 = sess.run(mm3)
print(_mm3)
# Operations between different shapes
m5 = tf.constant(3.)
mm5 = m3 + m5
_mm5 = sess.run(mm5)
print(_mm5)
m6 = tf.constant([[3.], [4.]])
mm6 = m3 + m6
_mm6 = sess.run(mm6)
print(_mm6)
```
Reduce mean
```
r1 = tf.reduce_mean([1, 2], axis=0)
print(sess.run(r1)) # 1, not 1.5 because of int32
_r2 = [[ 1., 2.],
[ 3., 4.]]
print("_r2[0][1] = ", _r2[0][1])
# [0] is index of axis = 0, [1] is index of axis = 1
r2 = tf.reduce_mean(_r2)
print(sess.run(r2))
r3 = tf.reduce_mean(_r2, axis=0)
print(sess.run(r3))
r4 = tf.reduce_mean(_r2, axis=1)
print(sess.run(r4))
r5 = tf.reduce_mean(_r2, axis=-1)
print(sess.run(r5))
_r6 = np.array([[[1., 2.],[3., 4.]],
[[5., 6.],[7., 8.]]])
print("-- 2x2x2 ------")
print(_r6.shape)
r6 = tf.reduce_mean(_r6, axis=0)
print("---------------")
print(_r6[0,:,:])
print(_r6[1,:,:])
print(sess.run(r6))
r7 = tf.reduce_mean(_r6, axis=1)
print("---------------")
print(_r6[:,0,:])
print(_r6[:,1,:])
print(sess.run(r7))
r8 = tf.reduce_mean(_r6, axis=2)
print("---------------")
print(_r6[:,:,0])
print(_r6[:,:,1])
print(sess.run(r8))
```
reduce_sum
```
_s2 = np.array(_r2)
s1 = tf.reduce_sum(_s2, axis=0)
print("---------------")
print(_s2[0,:])
print(_s2[1,:])
print(sess.run(s1))
s2 = tf.reduce_sum(_s2, axis=1)
print("---------------")
print(_s2[:,0])
print(_s2[:,1])
print(sess.run(s2))
s3 = tf.reduce_mean(tf.reduce_sum(_s2, axis=-1))
print("---------------")
print(sess.run(s3))
```
argmax
```
_m2 = np.array([[0, 1, 2],
[2, 1, 0]])
m1 = tf.argmax(_m2, axis=0)
print("---------------")
print(_m2[0,:])
print(_m2[1,:])
print(sess.run(m1)) # return value is index of series
m2 = tf.argmax(_m2, axis=1)
print("---------------")
print(_m2[:,0])
print(_m2[:,1])
print(_m2[:,2])
print(sess.run(m2))
```
reshape, squeeze, expand
```
print(_m2.shape)
h1 = tf.reshape(_m2, shape=[-1, 2])
print(sess.run(h1))
h2 = tf.reshape(_m2, shape=[-1, 1, 1, 2])
h3 = sess.run(h2)
print(h3)
h4 = tf.squeeze([[0], [1], [2]])
print(sess.run(h4))
h5 = tf.squeeze(h3)
h6 = sess.run(h5)
print(h6)
h7 = tf.expand_dims(h6, 1)
h8 = sess.run(h7)
print(h6.shape, h8.shape, h8)
```
onehot
```
_o0 = np.array([[0], [1], [2], [0]])
_o1 = tf.one_hot(_o0, depth=4)
o1 = sess.run(_o1)
print(o1)
_o2 = tf.reshape(o1, shape=[-1, 4])
o2 = sess.run(_o2)
print(o2)
_o3 = tf.argmax(o2, axis=-1)
o3 = sess.run(_o3)
print(o3)
```
casting
```
c1 = tf.cast([1.8, 2.2, 3.3, 4.4], tf.int32).eval(session=sess)
print(c1)
c2 = tf.cast([True, False, 1 == 1, 1 == 0], tf.int32).eval(session=sess)
print(c2)
```
stack
```
_c3 = [1, 2]
_c4 = [3, 4]
_c5 = [5, 6]
c6 = tf.stack([_c3, _c4, _c5]).eval(session=sess)
print(c6)
c7 = tf.stack([_c3, _c4, _c5], axis=1).eval(session=sess)
print(c7)
```
ones and zeros like
```
print(_m2)
z1 = tf.ones_like(_m2).eval(session=sess)
print(z1)
z2 = tf.zeros_like(_m2).eval(session=sess)
print(z2)
```
zip
```
_z3 = [1, 2, 3]
_z4 = [4, 5, 6]
_z5 = [7, 8, 9]
for x, y in zip(_z3, _z4):
print(x, y)
for x, y, z in zip(_z3, _z4, _z5):
print(x, y, z)
```
| github_jupyter |
# Tutorial: optimal binning with binary target
## Basic
To get us started, let's load a well-known dataset from the UCI repository and transform the data into a ``pandas.DataFrame``.
```
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
df = pd.DataFrame(data.data, columns=data.feature_names)
```
We choose a variable to discretize and the binary target.
```
variable = "mean radius"
x = df[variable].values
y = data.target
```
Import and instantiate an ``OptimalBinning`` object class. We pass the variable name, its data type, and a solver, in this case, we choose the constraint programming solver.
```
from optbinning import OptimalBinning
optb = OptimalBinning(name=variable, dtype="numerical", solver="cp")
```
We fit the optimal binning object with arrays ``x`` and ``y``.
```
optb.fit(x, y)
```
You can check if an optimal solution has been found via the ``status`` attribute:
```
optb.status
```
You can also retrieve the optimal split points via the ``splits`` attribute:
```
optb.splits
```
#### The binning table
The optimal binning algorithms return a binning table; a binning table displays the binned data and several metrics for each bin. Class ``OptimalBinning`` returns an object ``BinningTable`` via the ``binning_table`` attribute.
```
binning_table = optb.binning_table
type(binning_table)
```
The `binning_table` is instantiated, but not built. Therefore, the first step is to call the method `build`, which returns a ``pandas.DataFrame``.
```
binning_table.build()
```
Let's describe the columns of this binning table:
- Bin: the intervals delimited by the optimal split points.
- Count: the number of records for each bin.
- Count (%): the percentage of records for each bin.
- Non-event: the number of non-event records $(y = 0)$ for each bin.
- Event: the number of event records $(y = 1)$ for each bin.
- Event rate: the percentage of event records for each bin.
- WoE: the Weight-of-Evidence for each bin.
- IV: the Information Value (also known as Jeffrey's divergence) for each bin.
- JS: the Jensen-Shannon divergence for each bin.
The last row shows the total number of records, non-event records, event records, and IV and JS.
You can use the method ``plot`` to visualize the histogram and WoE or event rate curve. Note that the Bin ID corresponds to the binning table index.
```
binning_table.plot(metric="woe")
binning_table.plot(metric="event_rate")
```
Note that WoE is inversely related to the event rate, i.e., a monotonically ascending event rate ensures a monotonically descending WoE and vice-versa. We will see more monotonic trend options in the advanced tutorial.
##### Event rate / WoE transformation
Now that we have checked the binned data, we can transform our original data into WoE or event rate values. You can check the correctness of the transformation using pandas ``value_counts`` method, for instance.
```
x_transform_woe = optb.transform(x, metric="woe")
pd.Series(x_transform_woe).value_counts()
x_transform_event_rate = optb.transform(x, metric="event_rate")
pd.Series(x_transform_event_rate).value_counts()
x_transform_indices = optb.transform(x, metric="indices")
pd.Series(x_transform_indices).value_counts()
x_transform_bins = optb.transform(x, metric="bins")
pd.Series(x_transform_bins).value_counts()
```
#### Categorical variable
Let's load the application_train.csv file from the Kaggle's competition https://www.kaggle.com/c/home-credit-default-risk/data.
```
df_cat = pd.read_csv("data/kaggle/HomeCreditDefaultRisk/application_train.csv",
engine='c')
variable_cat = "NAME_INCOME_TYPE"
x_cat = df_cat[variable_cat].values
y_cat = df_cat.TARGET.values
df_cat[variable_cat].value_counts()
```
We instantiate an ``OptimalBinning`` object class with the variable name, its data type (**categorical**) and a solver, in this case, we choose the mixed-integer programming solver. Also, for this particular example, we set a ``cat_cutoff=0.1`` to create bin others with categories in which the percentage of occurrences is below 10%. This will merge categories State servant, Unemployed, Student, Businessman and Maternity leave.
```
optb = OptimalBinning(name=variable_cat, dtype="categorical", solver="mip",
cat_cutoff=0.1)
optb.fit(x_cat, y_cat)
optb.status
```
The optimal split points are the list of classes belonging to each bin.
```
optb.splits
binning_table = optb.binning_table
binning_table.build()
```
You can use the method ``plot`` to visualize the histogram and WoE or event rate curve. Note that for categorical variables the optimal bins are **always** monotonically ascending with respect to the event rate. Finally, note that bin 3 corresponds to bin others and is represented by using a lighter color.
```
binning_table.plot(metric="event_rate")
```
Same as for the numerical dtype, we can transform our original data into WoE or event rate values. Transformation of data including categories not present during training return zero WoE or event rate.
```
x_new = ["Businessman", "Working", "Unknown"]
x_transform_woe = optb.transform(x_new, metric="woe")
pd.DataFrame({variable_cat: x_new, "WoE": x_transform_woe})
```
## Advanced
#### Optimal binning Information
The ``OptimalBinning`` can print overview information about the options settings, problem statistics, and the solution of the computation. By default, ``print_level=1``.
```
optb = OptimalBinning(name=variable, dtype="numerical", solver="mip")
optb.fit(x, y)
```
If ``print_level=0``, a minimal output including the header, variable name, status, and total time are printed.
```
optb.information(print_level=0)
```
If ``print_level>=1``, statistics on the pre-binning phase and the solver are printed. More detailed timing statistics are also included.
```
optb.information(print_level=1)
```
If ``print_level=2``, the list of all options of the ``OptimalBinning`` are displayed. The output contains the option name, its current value and an indicator for how it was set. The unchanged options from the default settings are noted by "d", and the options set by the user changed from the default settings are noted by "U". This is inspired by the NAG solver e04mtc printed output, see https://www.nag.co.uk/numeric/cl/nagdoc_cl26/html/e04/e04mtc.html#fcomments.
```
optb.information(print_level=2)
```
#### Binning table statistical analysis
The ``analysis`` method performs a statistical analysis of the binning table, computing the statistics Gini index, Information Value (IV), Jensen-Shannon divergence, and the quality score. Additionally, several statistical significance tests between consecutive bins of the contingency table are performed: a frequentist test using the Chi-square test or the Fisher's exact test, and a Bayesian A/B test using the beta distribution as a conjugate prior of the Bernoulli distribution.
```
binning_table.analysis(pvalue_test="chi2")
binning_table.analysis(pvalue_test="fisher")
```
#### Event rate / WoE monotonicity
The ``monotonic_trend`` option permits forcing a monotonic trend to the event rate curve. The default setting "auto" should be the preferred option, however, some business constraints might require to impose different trends. The default setting "auto" chooses the monotonic trend most likely to maximize the information value from the options "ascending", "descending", "peak" and "valley" using a machine-learning-based classifier.
```
variable = "mean texture"
x = df[variable].values
y = data.target
optb = OptimalBinning(name=variable, dtype="numerical", solver="cp")
optb.fit(x, y)
binning_table = optb.binning_table
binning_table.build()
binning_table.plot(metric="event_rate")
```
For example, we can force the variable mean texture to be monotonically descending with respect to the probability of having breast cancer.
```
optb = OptimalBinning(name=variable, dtype="numerical", solver="cp",
monotonic_trend="descending")
optb.fit(x, y)
binning_table = optb.binning_table
binning_table.build()
binning_table.plot(metric="event_rate")
```
#### Reduction of dominating bins
Version 0.3.0 introduced a new constraint to produce more homogeneous solutions by reducing a concentration metric such as the difference between the largest and smallest bin. The added regularization parameter ``gamma`` controls the importance of the reduction term. Larger values specify stronger regularization. Continuing with the previous example
```
optb = OptimalBinning(name=variable, dtype="numerical", solver="cp",
monotonic_trend="descending", gamma=0.5)
optb.fit(x, y)
binning_table = optb.binning_table
binning_table.build()
binning_table.plot(metric="event_rate")
```
Note that the new solution produces more homogeneous bins, removing the dominance of bin 7 previously observed.
#### User-defined split points
In some situations, we have defined split points or bins required to satisfy a priori belief, knowledge or business constraint. The ``OptimalBinning`` permits to pass user-defined split points for numerical variables and user-defined bins for categorical variables. The supplied information is used as a pre-binning, disallowing any pre-binning method set by the user. Furthermore, version 0.5.0 introduces ``user_splits_fixed`` parameter, to allow the user to fix some user-defined splits, so these must appear in the solution.
Example numerical variable:
```
user_splits = [ 14, 15, 16, 17, 20, 21, 22, 27]
user_splits_fixed = [False, True, True, False, False, False, False, False]
optb = OptimalBinning(name=variable, dtype="numerical", solver="mip",
user_splits=user_splits, user_splits_fixed=user_splits_fixed)
optb.fit(x, y)
binning_table = optb.binning_table
binning_table.build()
optb.information()
```
Example categorical variable:
```
user_splits = np.array([
['Businessman'],
['Working'],
['Commercial associate'],
['Pensioner', 'Maternity leave'],
['State servant'],
['Unemployed', 'Student']], dtype=object)
optb = OptimalBinning(name=variable_cat, dtype="categorical", solver="cp",
user_splits=user_splits,
user_splits_fixed=[False, True, True, True, True, True])
optb.fit(x_cat, y_cat)
binning_table = optb.binning_table
binning_table.build()
optb.binning_table.plot(metric="event_rate")
optb.information()
```
#### Performance: choosing a solver
For small problems, say less than ``max_n_prebins<=20``, the ``solver="mip"`` tends to be faster than ``solver="cp"``. However, for medium and large problems, experiments show the contrary. For very large problems, we recommend the use of the commercial solver LocalSolver via ``solver="ls"``. See the specific LocalSolver tutorial.
#### Missing data and special codes
For this example, let's load data from the FICO Explainable Machine Learning Challenge: https://community.fico.com/s/explainable-machine-learning-challenge
```
df = pd.read_csv("data/FICO_challenge/heloc_dataset_v1.csv", sep=",")
```
The data dictionary of this challenge includes three special values/codes:
* -9 No Bureau Record or No Investigation
* -8 No Usable/Valid Trades or Inquiries
* -7 Condition not Met (e.g. No Inquiries, No Delinquencies)
```
special_codes = [-9, -8, -7]
variable = "AverageMInFile"
x = df[variable].values
y = df.RiskPerformance.values
df.RiskPerformance.unique()
```
Target is a categorical dichotomic variable, which can be easily transform into numerical.
```
mask = y == "Bad"
y[mask] = 1
y[~mask] = 0
y = y.astype(int)
```
For the sake of completeness, we include a few missing values
```
idx = np.random.randint(0, len(x), 500)
x = x.astype(float)
x[idx] = np.nan
optb = OptimalBinning(name=variable, dtype="numerical", solver="mip",
special_codes=special_codes)
optb.fit(x, y)
optb.information(print_level=1)
binning_table = optb.binning_table
binning_table.build()
```
Note the dashed bins 10 and 11, corresponding to the special codes bin and the missing bin, respectively.
```
binning_table.plot(metric="event_rate")
```
#### Treat special codes separately
Version 0.13.0 introduced the option to pass a dictionary of special codes to treat them separately. This feature provides more flexibility to the modeller. Note that a special code can be a single value or a list of values, for example, a combination of several special values.
```
special_codes = {'special_1': -9, "special_2": -8, "special_3": -7}
x[10:20] = -8
x[100:105] = -7
optb = OptimalBinning(name=variable, dtype="numerical", solver="mip",
special_codes=special_codes)
optb.fit(x, y)
optb.binning_table.build()
optb.binning_table.plot(metric="event_rate")
special_codes = {'special_1': -9, "special_comb": [-7, -8]}
optb = OptimalBinning(name=variable, dtype="numerical", solver="mip",
special_codes=special_codes)
optb.fit(x, y)
optb.binning_table.build()
```
#### Verbosity option
For debugging purposes, we can print information on each step of the computation by triggering the ``verbose`` option.
```
optb = OptimalBinning(name=variable, dtype="numerical", solver="mip", verbose=True)
optb.fit(x, y)
```
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.