
code stringlengths 2.5k 150k | kind stringclasses 1 value |
|---|---|
<a href="https://colab.research.google.com/github/FaisalAhmed0/machine_learning_from_scratch/blob/main/Faisal_Mohamed_K_means_and_PCA.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
This notebook implements K means clustering algorithm and principal components analysis (PCA), using numpy.
# Imports and Data generation.
```
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import datasets
from sklearn.datasets import make_classification
seed = 42
def generate_data(size):
'''
generate_data(size)
This function generates synthetic data.
size: number of examples in the dataset.
return the dataset as a NumPy array.
'''
X, Y = datasets.make_classification(400, 3, 3, 0, n_classes=4, random_state=seed, n_clusters_per_class=1, class_sep=3)
# plt.scatter(X[:, 0], X[:, 1])
return X
# Generate data
data = pd.DataFrame(generate_data(1000))
```
# K Means
```
# print first five rows in the data
data.head()
# repeat
# 1. Initilize centroids
# 2. compute distances
# 3. Assign to each cluster its data point
# 4. update the centrioid
# 1. Initilize centroids
def initlialize_centroids(data, k):
'''
initlialize_centroids(data, k)
This function initializes random centroids by choosing them randomly from the data.
data: dataset as a pandas DataFrame.
k: number of centroids.
return the centroids as DataFrame.
'''
# np.random.seed(seed)
# data size
n = data.shape[0]
# Pick random indices
inds = np.random.choice(n, size=k, replace=False)
# pick the centriods
centriods = data.iloc[inds, :]
return centriods
# pick three random centriods
k = 4
centriods = initlialize_centroids(data, k)
centriods
# plt.scatter(centriods.to_numpy()[:, 0], centriods.to_numpy()[:, 1])
# 2. compute distances
from collections import defaultdict
def compute_distnce(data, centroids):
'''
compute_distnce(data, centriods)
This function computes the distance between each point and the centroids.
data: dataset as a pandas DataFrame.
centroids: cluster centroids.
it returns a data frame that contains the point distance from each cluster at each point.
'''
K = centroids.shape[0]
dis_df = pd.DataFrame(columns= [f"c{i}" for i in range(1, K+1)])
for k in range(K):
dis_df[f"c{k+1}"] = ((data - centroids.iloc[k, :])**2).sum(axis=1)
return dis_df
dis_df = compute_distnce(data, centriods)
dis_df
def assign_clusters(data, dis_df, centroids):
'''
assign_clusters(data, dis_df, centroids)
This function assigns a point to each cluster based on the smallest distance to the cluster centroid.
data: dataset as a pandas DataFrame.
dis_df: data frame that contains the point distance from each cluster at each point.
centroids: cluster centroids.
returns a dictionary that contains the points in each cluster.
'''
K = centriods.shape[0]
columns= [f"c{i}" for i in range(1, K+1)]
d = {i: v for i, v in zip(range(K), columns)}
argmin = dis_df.to_numpy().argmin(axis=1)
clusters = {k:[] for k in columns}
for i, dis in enumerate(dis_df.to_numpy()):
min_ind = dis.argmin()
# print(min_ind)
point = data.iloc[i]
cluster = d[min_ind]
clusters[cluster].append(point.to_numpy())
# print(clusters)
return clusters
clu = assign_clusters(data, dis_df, centriods)
# 4. update the centrioid
def update_cnetriod(clusters, k, n):
'''
update_cnetriod(clusters, k, n).
This function updates the values of the centroids after assigning each point to its corresponding cluster
clusters: a dictionary that contains the points in each cluster.
k: number of centroids.
n: the shape of the data return the updated centroids as DataFrame.
'''
d = {}
for i, cluster in enumerate(clusters):
d[f"c{i+1}"] = np.mean(clusters[cluster], axis=0)
# print(clusters[cluster])
# print(d[f"c{i+1}"], len(clusters[cluster]))
df = pd.DataFrame(d, columns=None).T
df.columns = [i for i in range(n)]
df.index = [i for i in range(k)]
# print(df)
return df
def K_means(data, iterations=1000, k=3, show_progress=False):
'''
K_means(data, iterations=1000, k=3, show_progress=False)
This function implements K-means clustring algoithm.
data: dataset as a pandas DataFrame.
iterations: number of training iterations.
k: number of clusters/centriods.
show_progress: print the values of centriods after each iteration.
'''
centriods = initlialize_centroids(data, k)
# print(centriods)
n = data.shape[1]
for i in range(iterations):
dis_df = compute_distnce(data.copy(), centriods)
# print(dis_df)
# print(f"dis: {dis_df}")
clusters = assign_clusters(data, dis_df, centriods)
centriods = update_cnetriod(clusters, k, n)
if show_progress:
print(f"Iteration: {i+1}")
print(centriods.to_numpy())
return centriods, clusters
# run K-means algorithm
final_centriods, _ = K_means(data, 10, 4, False)
# plot the results for the first two dimensions
plt.scatter(data.iloc[:, 0], data.iloc[:, 1])
plt.scatter(final_centriods.iloc[:, 0], final_centriods.iloc[:, 1])
# plot the results for the second two dimensions
plt.scatter(data.iloc[:, 1], data.iloc[:, 2])
plt.scatter(final_centriods.iloc[:, 1], final_centriods.iloc[:, 2])
```
# PCA
```
# PCA
# 1. Standarize your data
# 2. Compute the covariance matrix
# 3. Perform eigen decemposition to extract the k principle components
data = data.copy()
# 1. Standarize your data
def standardize_data(data):
return (data - data.mean()) / data.std()
# 2. Compute the covariance matrix
def cov_matrix(data):
return data.to_numpy().T @ data.to_numpy()
# 3. Perform eigen decemposition to extract the k principle components
def eig_decomp(m):
e, v = np.linalg.eig(m)
return e, v
def PCA(data, rank):
'''
PCA(data, rank)
This function implements PCA using Eigendecomposition.
return the prjection matrix and the eigenvalues
'''
# data_stand = standardize_data(data)
cov = cov_matrix(data)
e, v = eig_decomp(cov)
P = v[:, :rank]
return P, e
def PCA_SVD(data, rank):
'''
PCA(data, rank)
This function implements PCA using Singular Value Decomposition (SVD).
return the prjection matrix.
'''
U, D, V = np.linalg.svd(data)
P = V[:,:rank]
return P
P = PCA_SVD(data, 2)
# Using the first two principal components, we will plot the projected data and the centriods from the previous section
data_proj = data.to_numpy() @ P
centriods_proj = final_centriods.to_numpy() @ P
plt.scatter(data_proj[:, 0], data_proj[:, 1])
plt.scatter(centriods_proj[:, 0], centriods_proj[:, 1])
P = PCA(data, 2)
print(P[0])
data.shape
plt.scatter(data_proj[:, 0], data_proj[:, 1])
plt.scatter(centriods_proj[:, 0], centriods_proj[:, 1])
P, _ = PCA(data, 4)
# Now we will take the first three principal components, and plot the projected data and the centriods from the previous section
data_proj_3d = data.to_numpy() @ P
centriods_proj_3d = final_centriods.to_numpy() @ P
centriods_proj_3d
fig = plt.figure(figsize = (8, 7))
ax = plt.axes(projection ="3d")
ax.scatter3D(data_proj_3d[:, 0], data_proj_3d[:, 1], data_proj_3d[:, 2])
ax.scatter3D(centriods_proj_3d[:, 0], centriods_proj_3d[:, 1], centriods_proj_3d[:, 2])
```
| github_jupyter |
```
CLR = {
'blue': ['#e0f3ff', '#aadeff', '#2bb1ff', '#15587f', '#0b2c40'],
'gold': ['#fff3dc', '#ffebc7', '#ffddab', '#b59d79', '#5C4938'],
'red': ['#ffd8e8', '#ff9db6', '#ff3e72', '#6B404C', '#521424'],
'gray': ['#eeeeee', '#bbbbbb', '#999999', '#666666', '#333333'],
}
import pathlib
import matplotlib.pyplot as plt
import matplotlib.patches as ppt
d_loop = [(10, 0.9326189901912585), (20, 3.431747987633571), (30, 7.900712997070514), (40, 23.176472008344717), (50, 30.817242004559375), (60, 37.93227899586782), (70, 47.18338800012134), (80, 61.70217400358524), (90, 78.50472899735905), (100, 97.76843499275856), (110, 118.02218899538275), (120, 141.43822199548595), (200, 439.25697400118224), (250, 717.5912509992486)]
d_vectorized = [(10, 1.4458689984166995), (20, 5.35220600431785), (30, 10.920982997049578), (40, 17.124196005170234), (50, 24.84369200828951), (60, 35.458537997328676), (70, 48.63317900162656), (80, 62.86764900141861), (90, 79.89497699600179), (100, 98.36747299414128), (110, 119.616230003885), (120, 141.98320099967532), (200, 388.0320140015101), (250, 581.6465469979448)]
d_lookup = [(10, 0.06900400330778211), (20, 0.11245900532230735), (30, 0.15335599891841412), (40, 0.4065209941472858), (50, 0.37285100552253425), (60, 0.6236290064407513), (70, 0.8157380070770159), (80, 1.0058790066977963), (90, 1.3296270044520497), (100, 1.5350780013250187), (110, 1.9105770043097436), (120, 2.305513000464998), (200, 6.753337002010085), (250, 9.713487001135945), (400, 30.437451001489535), (500, 47.650370994233526), (1000, 191.76472099206876), (2000, 738.4437500004424)]
def fig_before(title: str, xlabel, ylabel):
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title(title)
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
return fig, ax
out_dir = pathlib.Path('opt/')
def fig_after(fig, ax, patches=None, fname=None):
if patches:
ax.legend(handles=patches)
if display:
plt.show(fig)
if fname:
for out_file in [str(out_dir/fname) + s for s in ('.png', '.svg')]:
print('saving to', out_file)
fig.savefig(out_file)
fig.clear()
plt.close(fig)
fig, ax = fig_before('Performance Comparison', 'Token Count', 'Miliseconds')
ax.set_xscale('log')
data = (d_loop, d_vectorized, d_lookup)
colors = (CLR['red'][2], CLR['blue'][2], CLR['gray'][4])
names = ('loop', 'vectorized', 'lookup')
patches = []
for d, color, name in zip(data, colors, names):
x, y = zip(*d)
ax.plot([q**2 for q in x], y, color=color)
patches.append(ppt.Patch(color=color, label=name))
ax.axvline(x=200**2, color='black', ls='dashed', lw=1)
fig_after(fig, ax, patches=patches, fname='benchmark')
for ds in data:
print()
for k, v in ds:
print(k, v)
```
| github_jupyter |
---
layout: post
mathjax: true
comments: true
title: Binary Search Algorithm
tags: [Algorithm]
---
Binary search is one of the simplest algorithms. It is designed to find a value within a sorted list by cutting the list in half at every iteration until the value has been found. It has a Big O runtime of $O(\log_2{N})$. This means that the worst case number of operations needed to find a value grows at a logarithmic rate. This is compared to a simple search that checks every item in the list until it finds the desired value. It has a Big O runtime of $O(N)$. The simple search operations grow linearly with the amount of items being searched.
Let's start off by building each algorithm, and then we'll compare search times and plot their runtimes.
## Imports
```
from math import floor
from typing import List, Tuple
import matplotlib.pyplot as plt
import numpy as np
%load_ext blackcellmagic
```
## Function Creation
Below I've annotated the binary search function quite a bit to keep track of what's going on. The sorted list is cut in half, and the halfway point is guessed. If the guess is higher than the actual value, the new high value is changed to one less than the mid-point. If the guess is lower, the new low is set to one greater than the mid. This continues until the value is found. Each iteration halves the list.
The simple search algorithms iterates through the list until it finds the value. While this is efficient in small lists, as we'll see in the next section, it slows down considerably as the list grows. This is where the binary search algorithm shines.
```
# Binary Search
def binary_search(sorted_list: List[int], item: int) -> Tuple[int, int]:
low: int = 0
high: int = len(sorted_list) - 1
steps: int = 0
while low <= high:
# Cut the list in half
mid: int = floor((low + high) / 2)
# Guess the midway point
guess: int = sorted_list[mid]
if guess == item:
steps += 1
return mid, steps
# If midway point is higher, make
# new high one less than mid-point
elif guess > item:
steps += 1
high = mid - 1
# If midway point lower, make
# new high one higher than mid-point
else:
steps += 1
low = mid + 1
return None, None
# Simple Search
def simple_search(sorted_list: List[int], item: int) -> Tuple[int, int]:
start = 0
steps = 0
while sorted_list[start] <= item:
guess = sorted_list[start]
if guess == item:
steps += 1
return start, steps
else:
steps += 1
start += 1
return None, None
```
## Testing the Function
Let's create a list of 100,000 integers in ascending order (remember binary search requires the values be sorted already). When we run our binary search on the list and set the value to 70,000, we can see that it only takes 16 operations to guess the right value! A comparable simple search would take 70,000 operations as it would have to check all values before! That's a huge time savings!
Let's quantify the time savings a bit with the `%%timeit` magic function.
```
# Create list
sl_100k = list(range(1, 100001))
# Run binary search
item_index, steps = binary_search(sl_100k, 70000)
# Output
print("List length = {}".format(len(sl_100k)))
print("Item index = {}".format(item_index))
print("Total steps = {}".format(steps))
%%timeit
binary_search(sl_100k, 70000)
%%timeit
simple_search(sl_100k, 70000)
```
The `%%timeit` function shows us that the binary search only took on average $4.43\mu s$ as compared to $10.1ms$ for the simple search! Let's do some quick math to quantify that speed up!
```
print(
"Simple search is roughly {:.2f} times slower than binary search in this scenario!".format(
10000 / 4.43
)
)
```
## Big O Evaluation
If we plot the Big O runtime of each function we can see the smooth logarithmic curve of the binary search growing to roughly 16 operations over our 100k item list. The simple search on the other hand has a linear runtime and our 100k item list has a worst case scenario of 100k operations (assuming the item was the last in the list). The difference doesn't look as drastic because the graphs have different scaled axis. Let's see what this looks like on the same scale.
```
bs = np.log2(np.array(sl_100k))
ss = np.array(sl_100k)
fig, ax = plt.subplots(figsize=(10, 10), nrows=2, ncols=1)
ax[0].plot(bs, color="darkgreen")
ax[0].set_ylim(0, 20)
ax[0].set_title("O(log2 N) - Binary Search")
ax[0].set_ylabel("Number of Operations")
ax[0].set_xlabel("Search Value")
ax[1].plot(ss, color="red")
ax[1].set_title("O(N) - Simple Search")
ax[1].set_ylabel("Number of Operations")
ax[1].set_xlabel("Search Value")
plt.show()
```
On the same scale, the binary search runtime looks like it's flat along the x-axis. Almost immediately the binary search outperforms the simple search!
```
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(bs, color="darkgreen")
ax.plot(ss, color="red")
ax.set_title("Binary Search vs Simple Search")
ax.set_ylabel("Number of Operations")
ax.set_xlabel("Search Value")
ax.legend(["Binary Search O(log2 N)", "Simple Search O(N)"])
plt.show()
```
## Recap
* Binary search is a lot faster than simple search.
* $O(\log_2 N)$ is faster than $O(N)$, but it gets a lot faster once the list of items you're searching through grows.
* Algorithm speed isn't measured in seonds.
* Algorithm times are measured in terms of growth of an algorithm.
* Algorithm times are written in Big O notation.
### Reference
[1] Bhargava, A. Y. (2016). Grokking algorithms: An illustrated guide for programmers and other curious people.
| github_jupyter |
```
from powersimdata.scenario.scenario import Scenario
Scenario().get_scenario_table().loc[824]#.tail()
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 12 02:15:00 2021
@author: YifanLi
"""
from powersimdata.scenario.scenario import Scenario
scenario_base = Scenario(824)
ct_base = scenario_base.state.get_ct()
grid_base = scenario_base.state.get_grid()
scenario = Scenario('')
scenario.state.set_builder(grid_model="usa_tamu", interconnect="Eastern")
scenario.state.builder.set_name("MISO South Renewable and Transmission Expansion Study", "August")
scenario.state.builder.set_time("2016-08-01 00:00:00","2016-08-31 23:00:00","24H")
scenario.state.builder.set_base_profile("demand", "vJan2021")
scenario.state.builder.set_base_profile("hydro", "vJan2021")
scenario.state.builder.set_base_profile("solar", "vJan2021")
scenario.state.builder.set_base_profile("wind", "vJan2021")
# MISO Retirement and Expansion: Future 1 on zonal level.
scenario.state.builder.change_table.scale_plant_capacity(
"coal", zone_name={"Arkansas": 0.396,
"Illinois Downstate": 0.714,
"Indiana": 0.292,
"Iowa": 0.875,
"Louisiana": 0.196,
"Michigan Northern": 0.152,
"Michigan Southern": 0.152,
"Minnesota Northern": 0.000,
"Minnesota Southern": 0.000,
"Missouri East": 0.215,
"Montana Eastern": 0.000,
"North Dakota": 0.782,
"Wisconsin": 0.384})
scenario.state.builder.change_table.scale_plant_capacity(
"dfo", zone_name={"Illinois Downstate": 0.649,
"Indiana": 0.000,
"Iowa": 0.747,
"Louisiana": 0.873,
"Michigan Northern": 0.768,
"Michigan Southern": 0.768,
"Minnesota Northern": 0.157,
"Minnesota Southern": 0.157,
"Missouri East": 0.374,
"Wisconsin": 0.612})
scenario.state.builder.change_table.scale_plant_capacity(
"hydro", zone_name={"Michigan Northern": 1.031,
"Michigan Southern": 1.031})
scenario.state.builder.change_table.scale_plant_capacity(
"ng", zone_name={"Arkansas": 1.035,
"East Texas": 1.200,
"Illinois Downstate": 1.600,
"Indiana": 1.926,
"Iowa": 1.248,
"Louisiana": 1.073,
"Michigan Northern": 1.149,
"Michigan Southern": 1.149,
"Minnesota Northern": 1.754,
"Minnesota Southern": 1.754,
"Mississippi": 1.110,
"Missouri East": 1.863,
"Montana Eastern": 0.684,
"North Dakota": 3.842,
"Wisconsin": 1.451})
scenario.state.builder.change_table.scale_plant_capacity(
"nuclear", zone_name={"Iowa": 0.000,
"Michigan Southern": 0.772,
"Minnesota Southern": 0.309})
scenario.state.builder.change_table.scale_plant_capacity(
"other", zone_name={"Minnesota Northern": 0.800,
"Minnesota Southern": 0.800})
scenario.state.builder.change_table.scale_plant_capacity(
"solar", zone_name={"Arkansas": 49.121,
"East Texas": 1744.620,
"Illinois Downstate": 1893.734,
"Indiana": 30.234,
"Iowa": 465.011,
"Louisiana": 6174.610,
"Michigan Southern": 101.703,
"Minnesota Northern": 13.290,
"Minnesota Southern": 13.290,
"Mississippi": 19.743,
"Missouri East": 642.325,
"North Dakota": 2372.070,
"Wisconsin": 203.416})
scenario.state.builder.change_table.scale_plant_capacity(
"wind", zone_name={"Illinois Downstate": 1.590,
"Indiana": 1.642,
"Iowa": 1.298,
"Michigan Northern": 1.625,
"Michigan Southern": 1.625,
"Minnesota Northern": 1.661,
"Minnesota Southern": 1.661,
"Mississippi": 201.000,
"Missouri East": 301.278,
"Montana Eastern": 0.000,
"North Dakota": 2.554,
"Wisconsin": 1.261})
scenario.state.builder.change_table.add_plant(
[{"type": "hydro", "bus_id": 45429, "Pmax": 10.3}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 13675, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 13625, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 46288, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 45496, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 46748, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 46363, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 42760, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 42905, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 42626, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 42627, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 42628, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 55161, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 52169, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 54914, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 60845, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 60486, "capacity": 5, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 38745, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39610, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39250, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39630, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39413, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39316, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39206, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39548, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39637, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39256, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39358, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39546, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39417, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39528, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39296, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39326, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39327, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39439, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39613, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39254, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39376, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39252, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39538, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 39375, "capacity": 6, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 40507, "capacity": 35, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 40104, "capacity": 35, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 40481, "capacity": 35, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 40818, "capacity": 35, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 40625, "capacity": 35, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 40036, "capacity": 35, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 40767, "capacity": 26, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 49264, "capacity": 13, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 52161, "capacity": 13, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 30532, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 56810, "capacity": 10, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
scenario.state.builder.change_table.add_storage_capacity(
[{"bus_id": 48723, "capacity": 20, "duration": 4, "InEff": 0.95, "OutEff": 0.95}])
# create scenario
scenario.create_scenario()
print('[*] Current secnario state:', scenario.state.name)
scenario.print_scenario_status()
# prep simulation inputs
from powersimdata.scenario.scenario import Scenario
scenario.prepare_simulation_input()
print('\n[*] PREPARED \n')
# launch simulation
process_run = scenario.launch_simulation(solver='gurobi')
print('\n[*] SIMULATION LAUNCHED \n')
scenario.print_scenario_status()
scenario.check_progress()
from powersimdata.scenario.scenario import Scenario
Scenario().get_scenario_table().tail(10)
from powersimdata import Scenario
scen_n = 3881
scenario = Scenario(scen_n)
# print name of Scenario object state
print(scenario.state.name)
# print scenario information
scenario.print_scenario_info()
# get change table
ct = scenario.get_ct()
# get grid
grid = scenario.get_grid()
# get demand profile
demand = scenario.get_demand()
# get hydro profile
hydro = scenario.get_hydro()
# get solar profile
solar = scenario.get_solar()
# get wind profile
wind = scenario.get_wind()
# get generation profile for generators
pg = scenario.get_pg()
# get generation profile for storage units (if present in scenario)
#pg_storage = scenario.get_storage_pg()
# get energy state of charge of storage units (if present in scenario)
#e_storage = scenario.get_storage_e()
# get power flow profile for AC lines
pf_ac = scenario.get_pf()
# get power flow profile for DC lines
pf_dc = scenario.get_dcline_pf()
# get locational marginal price profile for each bus
lmp = scenario.get_lmp()
# get congestion (upper power flow limit) profile for AC lines
congu = scenario.get_congu()
# get congestion (lower power flow limit) profile for AC lines
congl = scenario.get_congl()
# get time averaged congestion (lower and power flow limits) for AC lines
avg_cong = scenario.get_averaged_cong()
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4), dpi=100)
plt.plot(pg.sum(axis=1))
plt.xticks(rotation = 45)
plt.title(str(scen_n))
plt.tight_layout()
```
| github_jupyter |
## Data Visualization
- Pie Chart: Compare Percentages
- Bar Chart: Compare Scores across groups
- Histogram: Show frequency of values/value range
- Line Chart: Show trend of Scores
- Scatter Plot: Show Relationship between a pair of Scores
- Map: Show Geo Distribution of data
|Type|Variable Y|Variable X|
|:--:|:--:|:--:|
|Pie Chart|Fractions|None|
|Bar Chart|Numbers|Categories|
|Histogram|Integer|Categories/Value Range|
|Line Chart|Numbers|Time/Date/Period|
|Scatter Plot|Numbers|Numbers|
|Map|Latitude|Longtitude|
### Sign up for Plot.ly
1. Sign up for Plot.ly: https://plot.ly/Auth/login/?action=signup#
2. Get your API token: Settings -> API Keys -> Regenerate Key -> Copy your newly created key
3. Save your API key somewhere
<div class="alert alert-block alert-warning">
**<b>Reminder</b>** Free account can only call Plot.ly API 100 times per day and generate up to 25 graphs.</div>
```
import plotly.plotly as py #Import library and give it an abbreviated name
import plotly.graph_objs as go #go: graph object
from plotly import tools
py.sign_in('USER NAME', 'API TOKEN') #fill in your user name and API token
import package (as py)
! pip3 install plotly
```
***
## Pie Chart
```
labels = ['Female','Male']
values = [40,20]
trace = go.Pie(labels=labels, values=values)
py.iplot([trace])
a=[1,2,3]
type(a)
a={'name':'junior'}
type(a)
a[0]
#change data labels by re-defining parameter "textinfo"
labels = ['Female','Male']
values = [40,20]
trace = go.Pie(labels=labels, values=values, textinfo='label+value')
py.iplot([trace], filename='pie_chart')
#change color setting by re-defining "marker" parameter
labels = ['Female','Male']
values = [40,20]
trace = go.Pie(labels=labels, values=values, marker={'colors':['red','blue']})
py.iplot([trace], filename='pie_chart')
#turn the pie chart into a donut by re-defining "hole" parameter
labels = ['Female','Male']
values = [40,20]
trace = go.Pie(labels=labels, values=values, hole=0.2, marker={'colors':['red','blue']})
py.iplot([trace], filename='pie_chart')
#change the graph size to 400*300 and add a title by re-defining "width" and "height" in "layout"
labels = ['Female','Male']
values = [40,20]
trace = go.Pie(labels=labels, values=values)
layout=go.Layout(width=500,height=500,title='Gender Distribution')
fig=go.Figure([trace],layout)
py.iplot(fig, filename='pie_chart')
```
#### <font style="color: blue">Practice:</font>
---
<font style="color: blue"> Please download the Hong Kong census data about educational attainment from <a href='https://juniorworld.github.io/python-workshop-2018/doc/Hong Kong Census Educational Attainment.csv'>this link</a>.
<p>Create a pie chart to visualize the percentages of different education levels in 2016. The pie chart should meet following requirements:</p>
1. Donut style
2. Change slice colors
</font>
```
#Write down your code here
#---------------------------------------------------------
import pandas as pd
edu_table=pd.read_csv('doc\Hong Kong Census Educational Attainment.csv')
labels=edu_table['Level']
values=edu_table['2016']
trace=go.Pie(labels=labels,values=values,hole=0.2,marker={'colors':['red','blue','pink','orange','green','grey','yellow']})
py.iplot([trace],filename='pie chart')
edu_table
edu_table['2016']
edu_table.loc[0]
```
***
## Bar Chart
<br>For more details: https://plot.ly/python/reference/#bar
```
x = ['Female','Male']
y = [1.6,1.8]
trace = go.Bar(x=x,y=y)
py.iplot([trace], filename='bar_chart')
#Widen the gap between bars by increasing "bargap" parameters in layout
x = ['Female','Male']
y = [40,20]
trace = go.Bar(x=x,y=y)
layout = go.Layout(bargap=0.5)
fig = go.Figure([trace],layout)
py.iplot(fig, filename='bar_chart')
#Grouped bar chart
x = ['Female','Male']
y1 = [40,20]
y2 = [30,50]
trace1 = go.Bar(x=x,y=y1,name='class1')
trace2 = go.Bar(x=x,y=y2,name='class2')
py.iplot([trace1,trace2], filename='bar_chart')
#Stacked/Relative bar chart by re-defining "barmode" in layout
x = ['Female','Male']
y1 = [40,20]
y2 = [30,50]
trace1 = go.Bar(x=x,y=y1,name='class1')
trace2 = go.Bar(x=x,y=y2,name='class2')
layout = go.Layout(barmode='stack')
fig = go.Figure([trace1,trace2],layout)
py.iplot(fig, filename='bar_chart')
#100% Stacked bar chart by re-defining "barnorm" as "percent" in layout
x = ['Female','Male']
y1 = [40,20]
y2 = [30,50]
trace1 = go.Bar(x=x,y=y1)
trace2 = go.Bar(x=x,y=y2)
layout = go.Layout(barmode='stack',barnorm='percent')
fig = go.Figure([trace1,trace2],layout)
py.iplot(fig, filename='bar_chart')
x = ['Female','Male']
y1 = [40,20]
y2 = [30,50]
trace1 = go.Bar(x=x,y=y1)
trace2 = go.Bar(x=x,y=y2)
layout = go.Layout(barmode='stack',barnorm='fraction',yaxis={'tickformat':'%'})
fig = go.Figure([trace1,trace2],layout)
py.iplot(fig, filename='bar_chart')
```
#### <font style="color: blue">Practice:</font>
---
<font style="color: blue"> Please refer to "Hong Kong Census Educational Attainment.csv".
<p>Create a bar chart to visualize the percentages of different education levels in different years, i.e. 2006, 2011 and 2016. The bar chart should meet following requirements:</p>
1. A bar represents a year
2. 100% Stacked bar chart: higher education levels stacked on top of lower ones and the bar's full length is 100%
2. The gap between bar groups = 0.2
</font>
```
#Write down your code here
#---------------------------------------------------------
x=['year 2016','year 2011','year 2006']
y1 = edu_table.loc[0][1:]
y2 = edu_table.loc[1][1:]
y3 = edu_table.loc[2][1:]
y4 = edu_table.loc[3][1:]
y5 = edu_table.loc[4][1:]
y6 = edu_table.loc[5][1:]
y7 = edu_table.loc[6][1:]
label=edu_table['Level']
trace1 = go.Bar(x=x,y=y1,name=label[0])
trace2 = go.Bar(x=x,y=y2,name=label[1])
trace3 = go.Bar(x=x,y=y3,name=label[2])
trace4 = go.Bar(x=x,y=y4,name=label[3])
trace5 = go.Bar(x=x,y=y5,name=label[4])
trace6 = go.Bar(x=x,y=y6,name=label[5])
trace7 = go.Bar(x=x,y=y7,name=label[6])
layout = go.Layout(barnorm='percent',barmode='stack')
fig=go.Figure(data=[trace1,trace2,trace3,trace4,trace5,trace6,trace7],layout=layout)
py.iplot(fig,filename='barchart')
x=['year 2016','year 2011','year 2006']
label=edu_table['Level']
data=[]
for i in range(7):
trace=go.Bar(x=x,y=edu_table.loc[i][1:],name=label[i])
data.append(trace)
layout = go.Layout(barnorm='percent',barmode='stack')
fig=go.Figure(data,layout)
py.iplot(fig,filename='barchart')
edu_table2=edu_table[['2006','2011','2016']]
edu_table2
```
***
## Break
***
## Histogram
Histogram is a special type of bar chart where one's y value is its count. It is used to show data distribution: viusalize the skewness and central tendency.
<br>For more details: https://plot.ly/python/reference/#histogram
```
a=[1,2,3,3,4,4,4,5,5,6,7,3,3,2]
trace=go.Histogram(x=a)
py.iplot([trace],filename='Histogram')
#Change the bins by re-defining "size" parameter in xbins
a=[1,2,3,3,4,4,4,5,5,6,7,3,3,2]
trace=go.Histogram(x=a,xbins={'size':1})
py.iplot([trace],filename='Histogram')
#Convert into a 100% Histogram whose y value is percentage of getting a value
#Re-define the "histnorm" to a "percent" mode
a=[1,2,3,3,4,4,4,5,5,6,7,3,3,2]
trace=go.Histogram(x=a,xbins={'size':1},histnorm='probability')
layout=go.Layout(yaxis={'tickformat':'%'})
fig=go.Figure([trace],layout)
py.iplot(fig,filename='Histogram')
#Decrease every element in "a" by one unit to create a new list "b"
#Grouped Histogram
a=[1,2,3,3,4,4,4,5,5,6,7,3,3,2]
b=[i-1 for i in a] #Write your code here
trace1=go.Histogram(x=a,xbins={'size':1})
trace2=go.Histogram(x=b,xbins={'size':1})
py.iplot([trace1,trace2],filename='Histogram')
#Overlay Histogram of a and b
#Increase the transparency by re-defining "opacity" parameter
#Change color by re-defining "color" parameter in "marker"
#Change the value of "barmode" parameter in layout to "overlay"
trace1=go.Histogram(x=a,xbins={'size':1},opacity=0.5,marker={'color':'blue'})
trace2=go.Histogram(x=b,xbins={'size':1},opacity=0.5,marker={'color':'red'})
layout=go.Layout(barmode='overlay')
fig=go.Figure([trace1,trace2],layout)
py.iplot(fig,filename='Histogram')
```
#### <font style="color: blue">Practice:</font>
---
<font style="color: blue"> <font style="color: blue"> Please download YouTube Popularity data from <a href='https://juniorworld.github.io/python-workshop-2018/doc/Youtube.csv'>this link</a>.
<p>Create three Histograms to visualize the distribution of views, likes, dislikes and comments. The histograms should meet following requirements:</p>
1. One basic histogram to show distribution of "views"
2. One basic histogram to show distribution of "log(views)"
3. One 100% overlay histogram to show distributions of log(likes), log(dislikes) and log(comments)
Hint: to apply logarithmic transformation, you can use numpy's log10 function. For example: to calcualte the logrithm of a variable "a".
</font>
>```python
import numpy as np
a=np.log10(a)```
```
#Write your code here
pop_table=pd.read_csv('doc/Youtube.csv')
pop_table.head()
a=pop_table['views']
trace=go.Histogram(x=a)
py.iplot([trace],file='histogram')
import numpy as np
a=np.log10(pop_table['views'])
trace=go.Histogram(x=a)
py.iplot([trace],file='histogram')
a=np.log10(pop_table['likes'])
b=np.log10(pop_table['dislikes'])
c=np.log10(pop_table['comments'])
trace1=go.Histogram(x=a,opacity=0.5,name='likes')
trace2=go.Histogram(x=b,opacity=0.5,name='dislikes')
trace3=go.Histogram(x=c,opacity=0.5,name='comments')
layout=go.Layout(barmode='overlay')
fig=go.Figure([trace1,trace2,trace3],layout)
py.iplot(fig,filename='Histogram')
```
## Line Chart
In Plot.ly, line chart is defined as a special scatter plot whose scatters are connected by lines.
<br>For more details: https://plot.ly/python/reference/#scatter
```
#create your first line chart
x=[1,2,3]
y=[10,22,34]
trace1=go.Scatter(x=x,y=y,mode='lines') #mode='lines','markers','lines+markers'
py.iplot([trace1],filename='line chart')
#add markers to it by changing mode to "lines+markers"
x=[1,2,3]
y=[10,22,34]
trace1=go.Scatter(x=x,y=y,mode='lines+markers')
py.iplot([trace1],filename='line chart')
#make it a dashed line by re-defining the "dash" parameters in "line"
#try other alternative shapes: "solid", "dot", "dash", "longdash", "dashdot", or "longdashdot"
x=[1,2,3]
y=[10,22,34]
trace1=go.Scatter(x=x,y=y,mode='lines+markers',line={'dash':'dash'})
py.iplot([trace1],filename='line chart')
#fill the area below
x=[1,2,3]
y=[-10,22,34]
trace1=go.Scatter(x=x,y=y,mode='lines',fill='tozeroy') #mode='lines'
py.iplot([trace1],filename='line chart')
#add another trace to it
x=[1,2,3]
y1=[10,22,34]
y2=[34,22,10]
trace1=go.Scatter(x=x,y=y1,mode='lines')
trace2=go.Scatter(x=x,y=y2,mode='lines')
py.iplot([trace1,trace2],filename='line chart')
#change the range of axis
x=[1,2,3]
y1=[10,22,34]
y2=[34,22,10]
trace1=go.Scatter(x=x,y=y1,mode='lines')
trace2=go.Scatter(x=x,y=y2,mode='lines')
layout=go.Layout(yaxis={'range':[0,35]},xaxis={'range':[0,3]})
fig=go.Figure([trace1,trace2],layout)
py.iplot(fig,filename='line chart')
#stacked line chart by re-defining "stackgroup" parameter
x=[1,2,3]
y1=[10,22,34]
y2=[34,22,10]
trace1=go.Scatter(x=x,y=y1,mode='lines',stackgroup='1')
trace2=go.Scatter(x=x,y=y2,mode='lines',stackgroup='1')
py.iplot([trace1,trace2],filename='line chart')
```
#### <font style="color: blue">Practice:</font>
---
<font style="color: blue"> <font style="color: blue"> Please download stock price data from <a href='https://juniorworld.github.io/python-workshop-2018/doc/stock.csv'>this link</a>.
<p>Create a line chart to visualize the trend of these five listed companies. The line chart should meet following requirements:</p>
1. Name lines after companies
</font>
```
#Write your code here
```
## Scatter Plot
<br>For more details: https://plot.ly/python/reference/#scatter
```
#create your first scatter plot
x=[1,2,3,4,5]
y=[10,22,34,40,50]
trace1=go.Scatter(x=x,y=y,mode='markers')
py.iplot([trace1],filename='scatter')
#style the markers
x=[1,2,3,4,5]
y=[10,22,34,40,50]
trace1=go.Scatter(x=x,y=y,mode='markers',marker={'size':10,'color':'red'})
py.iplot([trace1],filename='scatter')
#assign different sizes and colors to markers
x=[1,2,3,4,5]
y=[10,22,34,40,50]
trace1=go.Scatter(x=x,y=y,mode='markers',marker={'size':y,'color':x})
py.iplot([trace1],filename='scatter')
#assign color according to values in colorscale
#"Colorscale" options: Greys,YlGnBu,Greens,YlOrRd,Bluered,RdBu,Reds,Blues,Picnic,Rainbow,Portland,Jet,Hot,Blackbody,Earth,Electric,Viridis,Cividis
x=[1,2,3,4,5]
y=[10,22,34,40,50]
trace1=go.Scatter(x=x,y=y,mode='markers',marker={'size':y,'color':x,'colorscale':'Rainbow'})
py.iplot([trace1],filename='scatter')
#give names to them
x=[1,2,3,4,5]
y=[10,22,34,40,50]
trace1=go.Scatter(x=x,y=y,mode='markers',marker={'size':y,'color':x,'colorscale':'Rainbow'},text=['a','b','c','d','e'])
py.iplot([trace1],filename='scatter')
#try plotting scatters in a 3D space
x=[1,2,3,4,5]
y=[10,22,34,40,50]
z=[2,3,4,5,6]
trace1=go.Scatter3d(x=x,y=y,z=z,mode='markers')
py.iplot([trace1],filename='scatter')
#Change axis titles
x=[1,2,3,4,5]
y=[10,22,34,40,50]
z=[2,3,4,5,6]
trace1=go.Scatter3d(x=x,y=y,z=z,mode='markers')
layout=go.Layout(scene={'xaxis':{'title':'length'},'yaxis':{'title':'width'},'zaxis':{'title':'height'}})
fig=go.Figure([trace1],layout)
py.iplot(fig,filename='scatter')
```
#### <font style="color: blue">Practice:</font>
---
<font style="color: blue"> <font style="color: blue"> Please download box office data from <a href='https://juniorworld.github.io/python-workshop-2018/doc/movies.csv'>this link</a>.
<p>Create a 3D scatter plot to visualize these movies. The scatter plot should meet following requirements:</p>
1. X axis represents "Production Budget"
2. Y axis represents "Box Office"
3. Z axis represents "ROI" (Return on Investment)
4. Size scatters according to their "IMDB Ratings"
5. Color scatters according to their "Genre"
6. Name scatters after movies
</font>
```
import pandas as pd
movies=pd.read_csv('doc\movies.csv')
colors=[]
for genre in movies['Genre']:
if genre =='Comedy':
colors.extend([1])
else:
colors.extend([len(genre)])
np.unique(movies['Genre'])
#Write your code here
x=movies['Production Budget (millions)']
y=movies['Box Office (millions)']
z=movies['ROI']
trace1=go.Scatter3d(x=x,y=y,z=z,mode='markers',marker={'size':movies['Rating IMDB']*2,'color':colors,'colorscale':'Rainbow'})
layout=go.Layout(title='movies',scene={'xaxis':{'title':'Production Budget (millions)'},'yaxis':{'title':'Box Office (millions)'},'zaxis':{'title':'ROI'}})
fig=go.Figure([trace1],layout)
py.iplot(fig,filename='scatter')
```
<div class="alert alert-block alert-info">
**<b>Tips</b>** Two tools to better work with colors in Python:
<br>1. W3S color palette: https://www.w3schools.com/colors/colors_palettes.asp
<br>2. colorlover: https://github.com/jackparmer/colorlover</div>
| github_jupyter |
# Name
Data preparation using Apache Pig on YARN with Cloud Dataproc
# Label
Cloud Dataproc, GCP, Cloud Storage, YARN, Pig, Apache, Kubeflow, pipelines, components
# Summary
A Kubeflow Pipeline component to prepare data by submitting an Apache Pig job on YARN to Cloud Dataproc.
# Details
## Intended use
Use the component to run an Apache Pig job as one preprocessing step in a Kubeflow Pipeline.
## Runtime arguments
| Argument | Description | Optional | Data type | Accepted values | Default |
|----------|-------------|----------|-----------|-----------------|---------|
| project_id | The ID of the Google Cloud Platform (GCP) project that the cluster belongs to. | No | GCPProjectID | | |
| region | The Cloud Dataproc region to handle the request. | No | GCPRegion | | |
| cluster_name | The name of the cluster to run the job. | No | String | | |
| queries | The queries to execute the Pig job. Specify multiple queries in one string by separating them with semicolons. You do not need to terminate queries with semicolons. | Yes | List | | None |
| query_file_uri | The HCFS URI of the script that contains the Pig queries. | Yes | GCSPath | | None |
| script_variables | Mapping of the query’s variable names to their values (equivalent to the Pig command: SET name="value";). | Yes | Dict | | None |
| pig_job | The payload of a [PigJob](https://cloud.google.com/dataproc/docs/reference/rest/v1/PigJob). | Yes | Dict | | None |
| job | The payload of a [Dataproc job](https://cloud.google.com/dataproc/docs/reference/rest/v1/projects.regions.jobs). | Yes | Dict | | None |
| wait_interval | The number of seconds to pause between polling the operation. | Yes | Integer | | 30 |
## Output
Name | Description | Type
:--- | :---------- | :---
job_id | The ID of the created job. | String
## Cautions & requirements
To use the component, you must:
* Set up a GCP project by following this [guide](https://cloud.google.com/dataproc/docs/guides/setup-project).
* [Create a new cluster](https://cloud.google.com/dataproc/docs/guides/create-cluster).
* Run the component under a secret [Kubeflow user service account](https://www.kubeflow.org/docs/started/getting-started-gke/#gcp-service-accounts) in a Kubeflow cluster. For example:
```
component_op(...).apply(gcp.use_gcp_secret('user-gcp-sa'))
```
* Grant the Kubeflow user service account the role `roles/dataproc.editor` on the project.
## Detailed description
This component creates a Pig job from [Dataproc submit job REST API](https://cloud.google.com/dataproc/docs/reference/rest/v1/projects.regions.jobs/submit).
Follow these steps to use the component in a pipeline:
1. Install the Kubeflow Pipeline SDK:
```
%%capture --no-stderr
KFP_PACKAGE = 'https://storage.googleapis.com/ml-pipeline/release/0.1.14/kfp.tar.gz'
!pip3 install $KFP_PACKAGE --upgrade
```
2. Load the component using KFP SDK
```
import kfp.components as comp
dataproc_submit_pig_job_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/pipelines/e8524eefb138725fc06600d1956da0f4dd477178/components/gcp/dataproc/submit_pig_job/component.yaml')
help(dataproc_submit_pig_job_op)
```
### Sample
Note: The following sample code works in an IPython notebook or directly in Python code. See the sample code below to learn how to execute the template.
#### Setup a Dataproc cluster
[Create a new Dataproc cluster](https://cloud.google.com/dataproc/docs/guides/create-cluster) (or reuse an existing one) before running the sample code.
#### Prepare a Pig query
Either put your Pig queries in the `queries` list, or upload your Pig queries into a file to a Cloud Storage bucket and then enter the Cloud Storage bucket’s path in `query_file_uri`. In this sample, we will use a hard coded query in the `queries` list to select data from a local `passwd` file.
For more details on Apache Pig, see the [Pig documentation.](http://pig.apache.org/docs/latest/)
#### Set sample parameters
```
PROJECT_ID = '<Please put your project ID here>'
CLUSTER_NAME = '<Please put your existing cluster name here>'
REGION = 'us-central1'
QUERY = '''
natality_csv = load 'gs://public-datasets/natality/csv' using PigStorage(':');
top_natality_csv = LIMIT natality_csv 10;
dump natality_csv;'''
EXPERIMENT_NAME = 'Dataproc - Submit Pig Job'
```
#### Example pipeline that uses the component
```
import kfp.dsl as dsl
import kfp.gcp as gcp
import json
@dsl.pipeline(
name='Dataproc submit Pig job pipeline',
description='Dataproc submit Pig job pipeline'
)
def dataproc_submit_pig_job_pipeline(
project_id = PROJECT_ID,
region = REGION,
cluster_name = CLUSTER_NAME,
queries = json.dumps([QUERY]),
query_file_uri = '',
script_variables = '',
pig_job='',
job='',
wait_interval='30'
):
dataproc_submit_pig_job_op(
project_id=project_id,
region=region,
cluster_name=cluster_name,
queries=queries,
query_file_uri=query_file_uri,
script_variables=script_variables,
pig_job=pig_job,
job=job,
wait_interval=wait_interval).apply(gcp.use_gcp_secret('user-gcp-sa'))
```
#### Compile the pipeline
```
pipeline_func = dataproc_submit_pig_job_pipeline
pipeline_filename = pipeline_func.__name__ + '.zip'
import kfp.compiler as compiler
compiler.Compiler().compile(pipeline_func, pipeline_filename)
```
#### Submit the pipeline for execution
```
#Specify pipeline argument values
arguments = {}
#Get or create an experiment and submit a pipeline run
import kfp
client = kfp.Client()
experiment = client.create_experiment(EXPERIMENT_NAME)
#Submit a pipeline run
run_name = pipeline_func.__name__ + ' run'
run_result = client.run_pipeline(experiment.id, run_name, pipeline_filename, arguments)
```
## References
* [Create a new Dataproc cluster](https://cloud.google.com/dataproc/docs/guides/create-cluster)
* [Pig documentation](http://pig.apache.org/docs/latest/)
* [Dataproc job](https://cloud.google.com/dataproc/docs/reference/rest/v1/projects.regions.jobs)
* [PigJob](https://cloud.google.com/dataproc/docs/reference/rest/v1/PigJob)
## License
By deploying or using this software you agree to comply with the [AI Hub Terms of Service](https://aihub.cloud.google.com/u/0/aihub-tos) and the [Google APIs Terms of Service](https://developers.google.com/terms/). To the extent of a direct conflict of terms, the AI Hub Terms of Service will control.
| github_jupyter |
# Quantum Kernel Alignment with Qiskit Runtime
<br>
**Classification with Support Vector Machines**<br>
Classification problems are widespread in machine learning applications. Examples include credit card risk, handwriting recognition, and medical diagnosis. One approach to tackling classification problems is the support vector machine (SVM) [1,2]. This supervised learning algorithm uses labeled data samples to train a model that can predict to which class a test sample belongs. It does this by finding a separating hyperplane maximizing the margin between data classes. Often, data is not linearly separable in the original space. In these cases, the kernel trick is used to implicitly encode a transformation of the data into a higher-dimensional feature space, through the inner product between pairs of data points, where the data may become separable.
**Quantum Kernels**<br>
Quantum computers can be used to encode classical data in a quantum-enhanced feature space. In 2019, IBM introduced an algorithm called the quantum kernel estimator (QKE) for computing quantum kernels [3]. This algorithm uses quantum circuits with data provided classically and offers an efficient way to evaluate inner products between data in a quantum feature space. For two data samples $\theta$ and $\theta'$, the kernel matrix is given as
$$
K(\theta, \theta') = \lvert\langle 0^n \rvert U^\dagger(\theta) U(\theta') \lvert 0^n \rangle \rvert^2,
$$
where $U(\theta)$ prepares the quantum feature state. Quantum kernels used in a classification framework inherit the convex optimization program of the SVM and avoid common limitations of variational quantum classifiers. A key observation of this paper was that a necessary condition for a computational advantage requires quantum circuits for the kernel that are hard to simulate classically. More recently, IBM proved that quantum kernels can offer superpolynomial speedups over any classical learner on a learning problem based on the hardness of the discrete logarithm problem [4]. This means that quantum kernels can someday offer quantum advantage on suitable problems.
**Quantum Kernels that Exploit Structure in Data**<br>
An important approach in the search for practical quantum advantage in machine learning is to identify quantum kernels for learning problems that have underlying structure in the data. We've taken a step in this direction in our recent paper [5], where we introduced a broad class of quantum kernels that exploit group structure in data. Examples of learning problems for data with group structure could include learning permutations or classifying translations. We call this new class of kernels _covariant quantum kernels_ as they are related to covariant quantum measurements. The quantum feature map is defined by a unitary representation $D(\theta)$ of a group $G$ for some element $\theta \in G$, and a fiducial reference state $\lvert\psi\rangle = V\lvert0^n\rangle$ prepared by a unitary circuit $V$. The kernel matrix is given as
$$
K(\theta, \theta') = \vert\langle 0^n \rvert V^\dagger D^\dagger(\theta) D(\theta') V \lvert 0^n \rangle \rvert^2. \qquad (1)
$$
In general, the choice of the fiducial state is not known _a priori_ and can significantly impact the performance of the classifier. Here, we use a method called quantum kernel alignment (QKA) to find a good fiducial state for a given group.
**Aligning Quantum Kernels on a Dataset**<br>
In practice, SVMs require a choice of the kernel function. Sometimes, symmetries in the data can inform this selection, other times it is chosen in an ad hoc manner. Kernel alignment is one approach to learning a kernel on a given dataset by iteratively adapting it to have high similarity to a target kernel informed from the underlying data distribution [6]. As a result, the SVM with an aligned kernel will likely generalize better to new data than with an unaligned kernel. Using this concept, we introduced in [5] an algorithm for quantum kernel alignment, which provides a way to learn a quantum kernel from a family of kernels. Specifically, the algorithm optimizes the parameters in a quantum circuit to maximize the alignment of a kernel while converging to the maximum SVM margin. In the context of covariant quantum kernels, we extend Eq. $(1)$ to
$$
K_\lambda(\theta,\theta') = \lvert\langle 0^n \rvert V^\dagger_\lambda D^\dagger(\theta) D(\theta') V_\lambda \lvert 0^n \rangle \rvert^2, \qquad (2)
$$
and use QKA to learn a good fiducial state parametrized by $\lambda$ for a given group.
**Covariant Quantum Kernels on a Specific Learning Problem**<br>
Let's try out QKA on a learning problem. In the following, we'll consider a binary classification problem we call _labeling cosets with error_ [5]. In this problem, we will use a group and a subgroup to form two cosets, which will represent our data classes. We take the group $G = SU(2)^{\otimes n}$ for $n$ qubits, which is the special unitary group of $2\times2$ matrices and has wide applicability in nature, for example, the Standard Model of particle physics and in many condensed matter systems. We take the graph-stabilizer subgroup $S_{\mathrm{graph}} \in G$ with $S_{\mathrm{graph}} = \langle \{ X_i \otimes_{k:(k,i) \in \mathcal{E}} Z_k \}_{i \in \mathcal{V}} \rangle$ for a graph $(\mathcal{E},\mathcal{V})$ with edges $\mathcal{E}$ and vertices $\mathcal{V}$. Note that the stabilizers fix a stabilizer state such that $D_s \lvert \psi\rangle = \lvert \psi\rangle$. This observation will be useful a bit later.
To generate the dataset, we write the rotations of the group as $D(\theta_1, \theta_2, 0)=\exp(i \theta_1 X) \exp(i \theta_2 Z) \in SU(2)$, so that each qubit is parametrized by the first two Euler angles (the third we set to zero). Then, we draw randomly two sets of angles $\mathbf{\theta}_\pm \in [-\pi/4, \pi/4]^{2n}$ for the $n$-qubit problem. From these two sets, we construct a binary classification problem by forming two left-cosets (representing the two classes) with those angles, $C_\pm = D(\mathbf{\theta}_\pm) S_{\mathrm{graph}}$ where $D(\mathbf{\theta}_\pm) = \otimes_{k=1}^n D(\theta_\pm^{2k-1}, \theta_\pm^{2k}, 0)$. Note that the elements of the cosets can again be written in terms of Euler angles. We build training and testing sets by randomly drawing elements from $C_\pm$ such that the dataset has samples $i=1,...,m$ containing the first two Euler angles for each qubit $\mathbf{\theta}_{y_i} = (\theta_{y_i}^{1}, \theta_{y_i}^{2}, \theta_{y_i}^{3}, \theta_{y_i}^{4}, ..., \theta_{y_i}^{2n-1}, \theta_{y_i}^{2n})$ and labels $y_i \in \{-1,1\}$ that indicate to which coset a sample belongs.
Next, we select a fiducial state. A natural candidate is the stabilizer state we encountered above. Why? Because this is a subgroup invariant state, $D_s\lvert\psi\rangle = \lvert\psi\rangle$, which causes the data for a given coset to be mapped to a unique state: $D(\mathbf{\theta}_\pm)D_s \lvert\psi\rangle = D(\mathbf{\theta}_\pm) \lvert\psi\rangle$. This means the classifier only needs to distinguish the _two_ states $D(\mathbf{\theta}_\pm) \lvert\psi\rangle \langle \psi\rvert D^\dagger(\mathbf{\theta}_\pm)$ for every element of the coset. In this tutorial, we will add a small Gaussian error with variance $0.01$ to the Euler angles of the dataset. This noise will perturb these two states, but if the variance is sufficiently small, we expect the states will still be classified correctly. Let's consider a parametrized version of the stabilizer state, associated with the coupling graph $(\mathcal{E},\mathcal{V})$ given by the device connectivity, as our fiducial state and then use kernel alignment to find its optimal parameters. Specifically, we'll replace the initial layers of Hadamards in the graph state with $y$-rotations by an angle $\lambda$,
$$
\lvert \psi_\lambda\rangle = V_\lambda \lvert 0^n\rangle = \prod_{(k,t) \in \mathcal{E}} CZ_{k,t} \prod_{k \in \mathcal{V}} \exp\left(i \frac{\lambda}{2} Y_k\right)\lvert 0^n\rangle,
$$
where $CZ=\mathrm{diag}(1,1,1,-1)$. Then, given two samples from our dataset, $\mathbf{\theta}$ and $\mathbf{\theta}'$, the kernel matrix is evaluated as in Eq. $(2)$. If we initialize the kernel with $\lambda \approx 0$, we expect the quantum kernel alignment algorithm to converge towards the optimal $\lambda = \pi/2$ and the classifier to yield 100\% test accuracy.
Let's define two specific problem instances to test these ideas out. We'll be using the quantum device `ibmq_montreal`, with coupling map shown below:
<br>
<img src="images/chip.png" width="500">
<br>
We'll pick two different subgraphs, one for 7 qubits and one for 10, to define our problem instances. Using these subgraphs, we'll generate the corresponding datasets as described above, and then align the quantum kernel with QKA to learn a good fiducial state.
<br>
<img src="images/subgraphs.png" width="550">
<br>
**Speeding up Algorithms with Qiskit Runtime**<br>
QKA is an iterative quantum-classical algorithm, in which quantum hardware is used to execute parametrized quantum circuits for evaluating the quantum kernel matrices with QKE, while a classical optimizer tunes the parameters of those circuits to maximize the alignment. Iterative algorithms of this type can be slow due to latency between the quantum and classical calculations. Qiskit Runtime is a new architecture that can speed up iterative algorithms like QKA by co-locating classical computations with the quantum hardware executions. In this tutorial, we'll use QKA with Qiskit Runtime to learn a good quantum kernel for the _labeling cosets with error_ problem defined above.
<br>
**References**<br>
[1] B. E. Boser, I. M. Guyon, and V. N. Vapnik, Proceedings of the Fifth Annual Workshop on Computational Learning Theory, COLT ’92 (Association for Computing Machinery, New York, NY, USA, 1992) pp. 144-152 [link](https://doi.org/10.1145/130385.130401) <br>
[2] V. Vapnik, The Nature of Statistical Learning Theory, Information Science and Statistics (Springer New York, 2013) [link](https://books.google.com/books?id=EqgACAAAQBAJ) <br>
[3] V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Nature 567, 209-212 (2019) [link](https://doi.org/10.1038/s41586-019-0980-2) <br>
[4] Y. Liu, S. Arunachalam, and K. Temme, arXiv:2010.02174 (2020) [link](https://arxiv.org/abs/2010.02174) <br>
[5] J. R. Glick, T. P. Gujarati, A. D. Córcoles, Y. Kim, A. Kandala, J. M. Gambetta, K. Temme, arXiv:2105.03406 (2021) [link](https://arxiv.org/abs/2105.03406)<br>
[6] N. Cristianini, J. Shawe-taylor, A. Elisseeff, and J. Kandola, Advances in Neural Information Processing Systems 14 (2001) [link](https://proceedings.neurips.cc/paper/2001/file/1f71e393b3809197ed66df836fe833e5-Paper.pdf) <br>
# Load your IBM Quantum account and get the quantum backend
We'll be using the 27-qubit device `ibmq_montreal` for this tutorial.
```
import sys
sys.path.insert(0, '..') # Add qiskit_runtime directory to the path
from qiskit import IBMQ
IBMQ.load_account()
provider = IBMQ.get_provider(project='qiskit-runtime') # Change this to your provider.
backend = provider.get_backend('ibmq_montreal')
```
# Invoke the Quantum Kernel Alignment program
Before executing the runtime program for QKA, we need to prepare the dataset and configure the input parameters for the algorithm.
### 1. Prepare the dataset
First, we load the dataset from the `csv` file and then extract the labeled training and test samples. Here, we'll look at the 7-qubit problem, shown above in subfigure a). A second dataset is also available for the 10-qubit problem in b).
```
import pandas as pd
df = pd.read_csv('../qiskit_runtime/qka/aux_file/dataset_graph7.csv',sep=',', header=None) # alterative problem: dataset_graph10.csv
data = df.values
```
Let's take a look at the data to see how it's formatted. Each row of the dataset contains a list of Euler angles, followed by the class label $\pm1$ in the last column. For an $n$-qubit problem, there are $2n$ features corresponding to the first two Euler angles for each qubit (recall discussion above). The rows alternate between class labels.
```
print(df.head(4))
```
Now, let's explicitly construct the training and test samples (denoted `x`) and their labels (denoted `y`).
```
import numpy as np
# choose number of training and test samples per class:
num_train = 10
num_test = 10
# extract training and test sets and sort them by class label
train = data[:2*num_train, :]
test = data[2*num_train:2*(num_train+num_test), :]
ind=np.argsort(train[:,-1])
x_train = train[ind][:,:-1]
y_train = train[ind][:,-1]
ind=np.argsort(test[:,-1])
x_test = test[ind][:,:-1]
y_test = test[ind][:,-1]
```
### 2. Configure the QKA algorithm
The first task is to set up the feature map and its entangler map, which specifies the arrangement of $CZ$ gates in the fiducial state. We will choose this to match the connectivity of the problem subgraph, pictured above. We also initialize the fiducial state parameter $\lambda$ with `initial_point`.
```
from qiskit_runtime.qka import FeatureMap
d = np.shape(data)[1]-1 # feature dimension is twice the qubit number
em = [[0,2],[3,4],[2,5],[1,4],[2,3],[4,6]] # we'll match this to the 7-qubit graph
# em = [[0,1],[2,3],[4,5],[6,7],[8,9],[1,2],[3,4],[5,6],[7,8]] # we'll match this to the 10-qubit graph
fm = FeatureMap(feature_dimension=d, entangler_map=em) # define the feature map
initial_point = [0.1] # set the initial parameter for the feature map
```
Let's print out the circuit for the feature map (the circuit for the kernel will be a feature map for one data sample composed with an inverse feature map for a second sample). The first part of the feature map is the fiducial state, which is prepared with a layer of $y$ rotations followed by $CZ$s. Then, the last two layers of $z$ and $x$ rotations in the circuit denote the group representation $D(\theta)$ for a data sample $\theta$. Note that a single-qubit rotation is defined as $RP(\phi) = \exp(- i [\phi/2] P)$ for $P \in {X, Y, Z}$.
```
from qiskit.tools.visualization import circuit_drawer
circuit_drawer(fm.construct_circuit(x=x_train[0], parameters=initial_point),
output='text', fold=200)
```
Next, we set the values for the SVM soft-margin penalty `C` and the number of SPSA iterations `maxiters` we use to align the quantum kernel.
```
C = 1 # SVM soft-margin penalty
maxiters = 10 # number of SPSA iterations
```
Finally, we decide how to map the virtual qubits of our problem graph to the physical qubits of the hardware. For example, in the 7-qubit problem, we can directly map the virtual qubits `[0, 1, 2, 3, 4, 5, 6]` to the physical qubits `[10, 11, 12, 13, 14, 15, 16]` of the device. This allows us to avoid introducing SWAP gates for qubits that are not connected, which can increase the circuit depth.
```
initial_layout = [10, 11, 12, 13, 14, 15, 16] # see figure above for the 7-qubit graph
# initial_layout = [9, 8, 11, 14, 16, 19, 22, 25, 24, 23] # see figure above for the 10-qubit graph
```
### 3. Set up and run the program
We're almost ready to run the program. First, let's take a look at the program metadata, which includes a description of the input parameters and their default values.
```
print(provider.runtime.program('quantum-kernel-alignment'))
```
We see that this program has several input parameters, which we'll configure below. To run the program, we'll set up its two main components: `inputs` (the input parameters from the program metadata) and `options` (the quantum backend). We'll also define a callback function so that the intermediate results of the algorithm will be printed as the program runs. Note that each step of the algorithm for the settings we've selected here takes approximately 11 minutes.
```
def interim_result_callback(job_id, interim_result):
print(f"interim result: {interim_result}\n")
program_inputs = {
'feature_map': fm,
'data': x_train,
'labels': y_train,
'initial_kernel_parameters': initial_point,
'maxiters': maxiters,
'C': C,
'initial_layout': initial_layout
}
options = {'backend_name': backend.name()}
job = provider.runtime.run(program_id="quantum-kernel-alignment",
options=options,
inputs=program_inputs,
callback=interim_result_callback,
)
print(job.job_id())
result = job.result()
```
### 4. Retrieve the results of the program
Now that we've run the program, we can retrieve the output, which is the aligned kernel parameter and the aligned kernel matrix. Let's also plot this kernel matrix (we'll subtract off the diagonal to show the contrast between the remaining entries). The kernel matrix is expected to have a block-diagonal structure. This reflects the fact that the kernel maps the input data effectively to just two states (modulo the small noise we added to the data; recall the discussion above). That is, data in the same coset (same class label) have a larger overlap than do data from different cosets.
```
print(f"aligned_kernel_parameters: {result['aligned_kernel_parameters']}")
from matplotlib import pyplot as plt
from pylab import cm
plt.rcParams['font.size'] = 20
plt.imshow(result['aligned_kernel_matrix']-np.identity(2*num_train), cmap=cm.get_cmap('bwr', 20))
plt.show()
```
# Use the results of the program to test an SVM on new data
Equipped with the aligned kernel and its optimized parameter, we can use the `sklearn` package to train an SVM and then evaluate its classification accuracy on new test points. Note that a second kernel matrix built from the test points is needed for the SVM decision function.
```
from qiskit_runtime.qka import KernelMatrix
from sklearn.svm import SVC
from sklearn import metrics
# train the SVM with the aligned kernel matrix:
kernel_aligned = result['aligned_kernel_matrix']
model = SVC(C=C, kernel='precomputed')
model.fit(X=kernel_aligned, y=y_train)
# test the SVM on new data:
km = KernelMatrix(feature_map=fm, backend=backend, initial_layout=initial_layout)
kernel_test = km.construct_kernel_matrix(x1_vec=x_test, x2_vec=x_train, parameters=result['aligned_kernel_parameters'])
labels_test = model.predict(X=kernel_test)
accuracy_test = metrics.balanced_accuracy_score(y_true=y_test, y_pred=labels_test)
print(f"accuracy test: {accuracy_test}")
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
```
| github_jupyter |
## High Order Functions and Lambdas by Guy Tsitsiashvili
## What is a high order function?
A high order function is a function that takes another function and manages some value's state.
for example if I want to have a function that loops over an array and another function that prints each value
```
def printNumber(n):
print(n)
def loopAnArray(function, arr):
for n in arr:
function(n)
```
What I did here is declaring two functions. First is to print a given number, the other takes a function and executes it on each array iteration
but you might ask why not build a function that runs on a loop AND prints each number like this:
```
def loopAndPrint(arr):
for n in arr:
print(n)
```
First let's test both implementations:
```
array = [1,2,3,4,5]
#simple implementation
print('test 1:')
loopAndPrint(array)
print() #empty line
#advanced implementation
print('test 2:')
loopAnArray(printNumber,array)
```
So why complicate things? Well as it is now, it really seems redundent but let's say I want to print each number squared.<br>
To do this I can create a function that loops and prints each number squared
```
def loopAndPrintSquared(arr):
for n in arr:
print(n**2)
loopAndPrintSquared(array)
```
Well it seems to work, but there is already an issue. Both ```loopAndPrint``` and ```LoopAndPrintSquared``` have common logic, which is iterating on a loop, the only difference is the print function. so why not create an independent ```printSquared``` function and pass it to the original ```loopAnArray``` function
```
def printSquared(n):
print(n**2)
loopAnArray(printSquare,array)
```
Nice! it works and there is not really a redundent step, now I can call both functions without having to write redundent for loops
```
print("Looping and printing a number from array:")
loopAnArray(printNumber,array)
print() #empty line
print("Looping and printing a squared number from array:")
loopAnArray(printSquare,array)
```
Now, let's say I want to print the array but with 10 added to each value or each value halved. To do this I need to declare a new function for each of these operatrion like so:
```
def printAdd10(n):
print(n+10)
def printHalved(n):
print(n/2)
print("Looping and adding 10 to each value:")
loopAnArray(printAdd10,array)
print()#empty line
print("Looping and halving each value:")
loopAnArray(printHalved,array)
```
What if I want to decide on spot what to do with the array? Let's say I want to handle huge data and each time try out something new.<br/> Well there is a solution for this.
## Let me introduce Lambdas!
A lambda is a function that takes arguments and returns a value that can be assigned to a variable.
```
printAdd5 = lambda n: print(n+5)
loopAnArray(printAdd5,array)
```
As you can see, the variable ```printAdd5``` holds a real function that takes an argument ```n``` and prints ```n+5```.<br/>
The whole beauty of lambdas is that they can be declarative, meaning they can be written just like any primitve expression.<br/>
So instead of declaring a function and then passing it to an high order function, we can pass a lambda directly.
```
print("Loop and add 3:")
loopAnArray(lambda n:print(n+3),array)
print()
print("Loop and raise to power of 5 ")
loopAnArray(lambda n:print(n**5),array)
print()
print("Loop a remainder of 2:")
loopAnArray(lambda n:print(n%2),array)
```
In the examples above, I passed 3 different functions without declaring any of them.<br/>
This is the power of lambda!
## Mutation (not of genes or viruses)
A mutation is basically taking a value and mutating it meaning changing it with a given logic.<br/>
All we did here was print values which is nice, but what if we want to modify the given array and return it.<br/><br/>
To do so I'll first create a new High order function that again, iterates over an array but in each iteration it pushes the result of the given function to a new array and returns it.
```
def modifyAnArray(function,arr):
newArr=[]
for n in arr:
newArr.append(function(n))
return newArr
```
What the above function does is taking a function and array, then pushing the **result** of the function to the array, then returning the array.<br/>
Now, remember that I said that lambda functions **return** a value? We didn't see it in action but when we printed from withing the lambda, the print function was itself returned.<br/>
So not to confuse what that means, let's now focus on returning values. Let's beging with a simple example of declaring a function traditonally and with lambda to return a value
```
def substract2(n):
return n-2
substract2Lambda = lambda n:n-2
print(substract2(5))
print(substract2Lambda(5))
```
As you can see, the lambda function returns a value without the ```return``` keyword.
Now let's use our knowledge to make some new arrays. To do so I'll use the ```modifyAnArray``` and pass some lambda functions to generate each new array
```
arrayOfRoots = modifyAnArray(lambda n:n**0.5,array)
arryOfTimes10 = modifyAnArray(lambda n:n*10,array)
arryOfRemainder3 = modifyAnArray(lambda n:n%3,array)
print(arrayOfRoots)
print(arryOfTimes10)
print(arryOfRemainder3)
```
## Transformations
Now let's make some interseting modifications, let's say we have an array of pairs, meaning each value of the array contains two numbers<br/>
for example ```pairs = [(1,2),(3,4),(5,6)]``` the pairs are 1,2 and 3,4 and 5,6<br/><br/>
Let's create a function that iterates those pairs and returns a new array with modified value.
```
def modifyPairsArray(function, arrOfPairs):
newArr=[]
for a,b in arrOfPairs:
newArr.append(function(a,b))
return newArr
```
A quick explanation of what happend here. ```modifyPairsArray``` takes a function and an array of pairs, then iterates each pairs with the variables ```a,b``` that represent each value of the pair, meaning ```a``` is the first value and ```b``` is the second value. The ```function``` argument should be a function that takes **two** parameters and return a value, the value can be anything from a number, a pair or a whole array.<br/>
Each of the returned value from ```function``` then is pushed to ```newArr``` and it is returned.
Let's start with an example that takes the pairs and switches each value's position. from now on I'll declare ```array``` to be the reference as an array of pairs
```
array = [(1,2),(3,4),(5,6)]
arrayOfSwapped = modifyPairsArray(lambda a,b:(b,a),array)
print(arrayOfSwapped)
```
As you can see that values were swapped.<br/>
Now let's say I want to make a new array that contains the maximum of each pair, that is called a transformation. meaning going from one data type to another.<br/>
In our case we're going from a pair to a number.
```
arrayOfMaximums = modifyPairsArray(lambda a,b: a if(a>b) else b,array)
print(arrayOfMaximums)
```
I'll explain the technicallity of the expression ```lambda a,b: a if(a>b) else b```. It might seem complicated but to say it in words what happened is: return a if a>b and if not return b. It is simply a syntactic thing to learn.<br/><br/>
Let's move on to creating an array of sums, multiples and powers of each other.
```
arrOfSums = modifyPairsArray(lambda a,b:a+b,array)
arrOfMultiples = modifyPairsArray(lambda a,b:a*b,array)
arrOfPowers = modifyPairsArray(lambda a,b:a**b,array)
print(arrOfSums)
print(arrOfMultiples)
print(arrOfPowers)
```
## Conclusion
There are basically endless of possibilities to use both high order functions and lambdas, this notebook touches only the tip of the iceberg. There are also dictionary manipulations and multiple argument of functions. In the future I'll maybe publish an advanced guide but for now I really hope this made sense.<br/>
If anything is wrong/misleading/ambigiuos please open an issue and I'll make sure to fix it.
Created with ♥ by Guy Tsitsiashvili.
| github_jupyter |
```
import networkx
import collections
%load_ext autoreload
%autoreload 2
from pymedphys._experimental import tree, graphviz
module_dependencies = tree.get_module_dependencies()
internal_modules = set(module_dependencies.keys())
root = 'pymedphys'
top_level_api = [item for item in module_dependencies[root] if not item[2].startswith('_')]
module_apis = [item[0] for item in top_level_api if item[0] == item[1]]
second_level_apis = {}
for module in module_apis:
second_level_apis[module] = [item for item in module_dependencies[module] if not item[2].startswith('_')]
exposure_module_maps = {
f"{root}.{item[2]}": item[1] for item in top_level_api if item[0] != item[1]
}
for module, second_level_api in second_level_apis.items():
exposure_module_maps = {
**exposure_module_maps,
**{f"{module}.{item[2]}": item[1] for item in second_level_api}
}
exposure_module_maps
def create_svg(api_names, module_name, href, module_dependencies, internal_modules):
di_graph = networkx.DiGraph()
di_graph.add_node(module_name)
traversal_nodes = {module_name}
while traversal_nodes:
node = traversal_nodes.pop()
raw_dependencies = module_dependencies[node]
for dependency in raw_dependencies:
if (
not dependency[2].startswith('_') and
not dependency[1] in di_graph and
dependency[1] in internal_modules
):
traversal_nodes.add(dependency[1])
di_graph.add_node(dependency[1])
di_graph.add_edge(node, dependency[1])
for api_name in api_names:
di_graph.add_node(api_name)
di_graph.add_edge(api_name, module_name)
edges = ""
for edge in di_graph.edges:
edges = edges + f'"{edge[0]}" -> "{edge[1]}";\n'
graphviz.dot_string_to_svg(
f"""
digraph sample {{
{{
node [shape=rectangle];
}}
rankdir = LR;
{edges}
}}
""",
f'{module_name}.svg'
)
api_name, module_name = list(exposure_module_maps.items())[0]
api_name, module_name
exposure_module_maps
module_api_map = collections.defaultdict(lambda: [])
for key, item in exposure_module_maps.items():
module_api_map[item].append(key)
module_api_map
href="https://github.com/pymedphys/pymedphys/tree/main/lib/pymedphys"
# create_svg(api_name, module_name, href, module_dependencies, internal_modules)
module_api_map
for module_name, api_names in module_api_map.items():
create_svg(api_names, module_name, module_dependencies, internal_modules)
# internal_modules
```
| github_jupyter |
# Evaluation metrics for classification models
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
pd.options.mode.chained_assignment = None
%matplotlib inline
```
### Back with the credit card default dataset
```
# Loading the dataset
DATA_DIR = '../data'
FILE_NAME = 'credit_card_default.csv'
data_path = os.path.join(DATA_DIR, FILE_NAME)
ccd = pd.read_csv(data_path, index_col="ID")
ccd.rename(columns=lambda x: x.lower(), inplace=True)
ccd.rename(columns={'default payment next month':'default'}, inplace=True)
# getting the groups of features
bill_amt_features = ['bill_amt'+ str(i) for i in range(1,7)]
pay_amt_features = ['pay_amt'+ str(i) for i in range(1,7)]
numerical_features = ['limit_bal','age'] + bill_amt_features + pay_amt_features
# Creating creating binary features
ccd['male'] = (ccd['sex'] == 1).astype('int')
ccd['grad_school'] = (ccd['education'] == 1).astype('int')
ccd['university'] = (ccd['education'] == 2).astype('int')
ccd['married'] = (ccd['marriage'] == 1).astype('int')
# simplifying pay features
pay_features= ['pay_' + str(i) for i in range(1,7)]
for x in pay_features:
ccd.loc[ccd[x] <= 0, x] = 0
# simplifying delayed features
delayed_features = ['delayed_' + str(i) for i in range(1,7)]
for pay, delayed in zip(pay_features, delayed_features):
ccd[delayed] = (ccd[pay] > 0).astype(int)
# creating a new feature: months delayed
ccd['months_delayed'] = ccd[delayed_features].sum(axis=1)
```
## Splitting and standarizing the dataset
```
numerical_features = numerical_features + ['months_delayed']
binary_features = ['male','married','grad_school','university']
X = ccd[numerical_features + binary_features]
y = ccd['default'].astype(int)
## Split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=5/30, random_state=25)
## Standarize
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train[numerical_features])
X_train.loc[:, numerical_features] = scaler.transform(X_train[numerical_features])
# Standarize also the testing set
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])
```
## Performance metrics
```
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=25,
max_features=6,
max_depth=4,
random_state=61)
rf.fit(X_train, y_train)
from sklearn.metrics import confusion_matrix
def CM(y_true, y_pred):
M = confusion_matrix(y_true, y_pred)
out = pd.DataFrame(M, index=["Obs Paid", "Obs Default"], columns=["Pred Paid", "Pred Default"])
return out
threshold = 0.5
y_pred_prob = rf.predict_proba(X_test)[:,1]
y_pred = (y_pred_prob > threshold).astype(int)
CM(y_test, y_pred)
from sklearn.metrics import precision_score, recall_score, accuracy_score
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
print("Precision: {:0.1f}%, Recall: {:.1f}%, Accuracy: {:0.1f}%".format(100*precision, 100*recall, 100*accuracy))
```
## Visualization methods for evaluating classification models
### Visualizing probabilities
```
plt.hist(y_pred_prob, bins=25, ec='k');
fig, ax = plt.subplots(figsize=(8,5))
sns.kdeplot(y_pred_prob[y_test==1], shade=True, color='red', label="Defaults", ax=ax)
sns.kdeplot(y_pred_prob[y_test==0], shade=True, color='green', label="Paid", ax=ax)
ax.set_title("Distribution of predicted probabilies", fontsize=16)
ax.legend()
plt.grid();
```
### ROC and precision-recall curves
```
threshold = 0.4
y_pred_prob = rf.predict_proba(X_test)[:,1]
y_pred = (y_pred_prob > threshold).astype(int)
CM(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
print("Precision: {:0.1f}%, Recall: {:.1f}%, Accuracy: {:0.1f}%".format(100*precision, 100*recall, 100*accuracy))
from sklearn.metrics import precision_recall_curve
precs, recs, ths = precision_recall_curve(y_test, y_pred_prob)
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(ths, precs[1:], label='Precision')
ax.plot(ths, recs[1:], label='Recall')
ax.set_title('Precision and recall for different thresholds', fontsize=16)
ax.set_xlabel('Theshold', fontsize=14)
ax.set_ylabel('Precision, Recall', fontsize=14)
ax.set_xlim(0.1,0.7)
ax.legend(); ax.grid();
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(precs, recs)
ax.set_title('Precision-recall curve', fontsize=16)
ax.set_xlabel('Precision', fontsize=14)
ax.set_ylabel('Recall', fontsize=14)
ax.set_xlim(0.3,0.7)
ax.grid();
from sklearn.metrics import roc_curve
fpr, tpr, ths = roc_curve(y_test, y_pred_prob)
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(fpr, tpr)
ax.set_title('ROC curve', fontsize=16)
ax.set_xlabel('False positive rate', fontsize=14)
ax.set_ylabel('Recall, true negative rate', fontsize=14)
ax.grid();
```
### Defining a custom metric for classification
```
def class_cost(y_true, y_pred, cost_fn=1, cost_fp=1):
M = confusion_matrix(y_true, y_pred)
N = len(y_true)
FN = M[1,0]
FP = M[0,1]
return (cost_fn*FN + cost_fp*FP)/N
class_cost(y_test, y_pred)
thresholds = np.arange(0.05, 0.95, 0.01)
costs = []
for th in thresholds:
y_pred = (y_pred_prob > th).astype(int)
costs.append(class_cost(y_test, y_pred, cost_fn=3, cost_fp=1))
costs = np.array(costs)
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(thresholds, costs)
ax.set_title('Cost vs threshold', fontsize=16)
ax.set_xlabel('Threshold', fontsize=14)
ax.set_ylabel('Cost', fontsize=14)
ax.grid();
min_cost_th = thresholds[costs.argmin()]
min_cost_th
y_pred = (y_pred_prob > min_cost_th).astype(int)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Precision: {:0.1f}%, Recall: {:.1f}%".format(100*precision, 100*recall))
CM(y_test, y_pred)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/NeuromatchAcademy/course-content/blob/master/tutorials/W3D2_HiddenDynamics/W3D2_Intro.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> <a href="https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W3D2_HiddenDynamics/W3D2_Intro.ipynb" target="_parent"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open in Kaggle"/></a>
# Intro
**Our 2021 Sponsors, including Presenting Sponsor Facebook Reality Labs**
<p align='center'><img src='https://github.com/NeuromatchAcademy/widgets/blob/master/sponsors.png?raw=True'/></p>
## Overview
Today you will learn about Hidden Markov Models (HMMs), which allow us to infer things in the world from a stream of data. Tutorials will continue our two running examples that help provide intuition: fishing (for a binary latent state) and tracking astrocat (for a gaussian latent state). In both examples, we've set up interactive visualizations to provide intuition, and then you will recreate the key inferences step by step. For the binary case, we start with a simple version where the latent state doesn't change, then we'll allow the latent state to change over time. There's plenty of bonus material, but your core learning objective is to understand and implement an algorithm to infer a changing hidden state from observations.
The HMM combines ideas from the linear dynamics lessons (which used Markov models) with inferences described in the Bayes day (which used Hidden variables). It also connects directly to later lessons in Optimal Control and Reinforcement Learning, which often use the HMM to guide actions.
The HMM is a pervasive model in neuroscience. It is used for data analysis, like inferring neural activity from fluorescence images. It is also a foundational model for what the brain should compute, as it interprets the physical world that is observed only through its senses.
## Prerequisites
In the content today, you will be using concepts from probability and statistics such as:
- Gaussian distributions (see [here](https://compneuro.neuromatch.io/tutorials/W0D5_Statistics/student/W0D5_Tutorial1.html#section-3-1-gaussian-distribution))
- likelihood functions (see [here](https://compneuro.neuromatch.io/tutorials/W0D5_Statistics/student/W0D5_Tutorial2.html#section-2-1-likelihoods))
- Markov processes (see [here](https://compneuro.neuromatch.io/tutorials/W0D5_Statistics/student/W0D5_Tutorial2.html#section-1-2-markov-chains) and [here](https://compneuro.neuromatch.io/tutorials/W2D2_LinearSystems/student/W2D2_Tutorial2.html))
## Video
```
# @markdown
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1bt4y1X7UX", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"bJIAWgycuVU", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
display(out)
```
## Slides
```
# @markdown
from IPython.display import IFrame
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/8u92f/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)
```
| github_jupyter |
<center>
<img src="https://gitlab.com/ibm/skills-network/courses/placeholder101/-/raw/master/labs/module%201/images/IDSNlogo.png" width="300" alt="cognitiveclass.ai logo" />
</center>
# **SpaceX Falcon 9 first stage Landing Prediction**
# Lab 1: Collecting the data
Estimated time needed: **45** minutes
In this capstone, we will predict if the Falcon 9 first stage will land successfully. SpaceX advertises Falcon 9 rocket launches on its website with a cost of 62 million dollars; other providers cost upward of 165 million dollars each, much of the savings is because SpaceX can reuse the first stage. Therefore if we can determine if the first stage will land, we can determine the cost of a launch. This information can be used if an alternate company wants to bid against SpaceX for a rocket launch. In this lab, you will collect and make sure the data is in the correct format from an API. The following is an example of a successful and launch.

Several examples of an unsuccessful landing are shown here:

Most unsuccessful landings are planned. Space X performs a controlled landing in the oceans.
## Objectives
In this lab, you will make a get request to the SpaceX API. You will also do some basic data wrangling and formating.
* Request to the SpaceX API
* Clean the requested data
***
## Import Libraries and Define Auxiliary Functions
We will import the following libraries into the lab
```
# Requests allows us to make HTTP requests which we will use to get data from an API
import requests
# Pandas is a software library written for the Python programming language for data manipulation and analysis.
import pandas as pd
# NumPy is a library for the Python programming language, adding support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays
import numpy as np
# Datetime is a library that allows us to represent dates
import datetime
# Setting this option will print all collumns of a dataframe
pd.set_option('display.max_columns', None)
# Setting this option will print all of the data in a feature
pd.set_option('display.max_colwidth', None)
```
Below we will define a series of helper functions that will help us use the API to extract information using identification numbers in the launch data.
From the <code>rocket</code> column we would like to learn the booster name.
```
# Takes the dataset and uses the rocket column to call the API and append the data to the list
def getBoosterVersion(data):
for x in data['rocket']:
response = requests.get("https://api.spacexdata.com/v4/rockets/"+str(x)).json()
BoosterVersion.append(response['name'])
```
From the <code>launchpad</code> we would like to know the name of the launch site being used, the logitude, and the latitude.
```
# Takes the dataset and uses the launchpad column to call the API and append the data to the list
def getLaunchSite(data):
for x in data['launchpad']:
response = requests.get("https://api.spacexdata.com/v4/launchpads/"+str(x)).json()
Longitude.append(response['longitude'])
Latitude.append(response['latitude'])
LaunchSite.append(response['name'])
```
From the <code>payload</code> we would like to learn the mass of the payload and the orbit that it is going to.
```
# Takes the dataset and uses the payloads column to call the API and append the data to the lists
def getPayloadData(data):
for load in data['payloads']:
response = requests.get("https://api.spacexdata.com/v4/payloads/"+load).json()
PayloadMass.append(response['mass_kg'])
Orbit.append(response['orbit'])
```
From <code>cores</code> we would like to learn the outcome of the landing, the type of the landing, number of flights with that core, whether gridfins were used, wheter the core is reused, wheter legs were used, the landing pad used, the block of the core which is a number used to seperate version of cores, the number of times this specific core has been reused, and the serial of the core.
```
# Takes the dataset and uses the cores column to call the API and append the data to the lists
def getCoreData(data):
for core in data['cores']:
if core['core'] != None:
response = requests.get("https://api.spacexdata.com/v4/cores/"+core['core']).json()
Block.append(response['block'])
ReusedCount.append(response['reuse_count'])
Serial.append(response['serial'])
else:
Block.append(None)
ReusedCount.append(None)
Serial.append(None)
Outcome.append(str(core['landing_success'])+' '+str(core['landing_type']))
Flights.append(core['flight'])
GridFins.append(core['gridfins'])
Reused.append(core['reused'])
Legs.append(core['legs'])
LandingPad.append(core['landpad'])
```
Now let's start requesting rocket launch data from SpaceX API with the following URL:
```
spacex_url="https://api.spacexdata.com/v4/launches/past"
response = requests.get(spacex_url)
```
Check the content of the response
```
print(response.content)
```
You should see the response contains massive information about SpaceX launches. Next, let's try to discover some more relevant information for this project.
### Task 1: Request and parse the SpaceX launch data using the GET request
To make the requested JSON results more consistent, we will use the following static response object for this project:
```
static_json_url='https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/datasets/API_call_spacex_api.json'
```
We should see that the request was successfull with the 200 status response code
```
response.status_code
```
Now we decode the response content as a Json using <code>.json()</code> and turn it into a Pandas dataframe using <code>.json_normalize()</code>
```
# Use json_normalize meethod to convert the json result into a dataframe
data=pd.json_normalize(response.json())
```
Using the dataframe <code>data</code> print the first 5 rows
```
# Get the head of the dataframe
data.head()
```
You will notice that a lot of the data are IDs. For example the rocket column has no information about the rocket just an identification number.
We will now use the API again to get information about the launches using the IDs given for each launch. Specifically we will be using columns <code>rocket</code>, <code>payloads</code>, <code>launchpad</code>, and <code>cores</code>.
```
# Lets take a subset of our dataframe keeping only the features we want and the flight number, and date_utc.
data = data[['rocket', 'payloads', 'launchpad', 'cores', 'flight_number', 'date_utc']]
# We will remove rows with multiple cores because those are falcon rockets with 2 extra rocket boosters and rows that have multiple payloads in a single rocket.
data = data[data['cores'].map(len)==1]
data = data[data['payloads'].map(len)==1]
# Since payloads and cores are lists of size 1 we will also extract the single value in the list and replace the feature.
data['cores'] = data['cores'].map(lambda x : x[0])
data['payloads'] = data['payloads'].map(lambda x : x[0])
# We also want to convert the date_utc to a datetime datatype and then extracting the date leaving the time
data['date'] = pd.to_datetime(data['date_utc']).dt.date
# Using the date we will restrict the dates of the launches
data = data[data['date'] <= datetime.date(2020, 11, 13)]
```
* From the <code>rocket</code> we would like to learn the booster name
* From the <code>payload</code> we would like to learn the mass of the payload and the orbit that it is going to
* From the <code>launchpad</code> we would like to know the name of the launch site being used, the longitude, and the latitude.
* From <code>cores</code> we would like to learn the outcome of the landing, the type of the landing, number of flights with that core, whether gridfins were used, whether the core is reused, whether legs were used, the landing pad used, the block of the core which is a number used to seperate version of cores, the number of times this specific core has been reused, and the serial of the core.
The data from these requests will be stored in lists and will be used to create a new dataframe.
```
#Global variables
BoosterVersion = []
PayloadMass = []
Orbit = []
LaunchSite = []
Outcome = []
Flights = []
GridFins = []
Reused = []
Legs = []
LandingPad = []
Block = []
ReusedCount = []
Serial = []
Longitude = []
Latitude = []
```
These functions will apply the outputs globally to the above variables. Let's take a looks at <code>BoosterVersion</code> variable. Before we apply <code>getBoosterVersion</code> the list is empty:
```
BoosterVersion
```
Now, let's apply <code> getBoosterVersion</code> function method to get the booster version
```
# Call getBoosterVersion
getBoosterVersion(data)
```
the list has now been update
```
BoosterVersion[0:5]
```
we can apply the rest of the functions here:
```
# Call getLaunchSite
getLaunchSite(data)
# Call getPayloadData
getPayloadData(data)
# Call getCoreData
getCoreData(data)
```
Finally lets construct our dataset using the data we have obtained. We we combine the columns into a dictionary.
```
launch_dict = {'FlightNumber': list(data['flight_number']),
'Date': list(data['date']),
'BoosterVersion':BoosterVersion,
'PayloadMass':PayloadMass,
'Orbit':Orbit,
'LaunchSite':LaunchSite,
'Outcome':Outcome,
'Flights':Flights,
'GridFins':GridFins,
'Reused':Reused,
'Legs':Legs,
'LandingPad':LandingPad,
'Block':Block,
'ReusedCount':ReusedCount,
'Serial':Serial,
'Longitude': Longitude,
'Latitude': Latitude}
```
Then, we need to create a Pandas data frame from the dictionary launch_dict.
```
# Create a data from launch_dict
data=pd.DataFrame(launch_dict)
```
Show the summary of the dataframe
```
# Show the head of the dataframe
data.head()
```
### Task 2: Filter the dataframe to only include `Falcon 9` launches
Finally we will remove the Falcon 1 launches keeping only the Falcon 9 launches. Filter the data dataframe using the <code>BoosterVersion</code> column to only keep the Falcon 9 launches. Save the filtered data to a new dataframe called <code>data_falcon9</code>.
```
# Hint data['BoosterVersion']!='Falcon 1'
data_falcon9=data[data['BoosterVersion']!='Falcon 1']
```
Now that we have removed some values we should reset the FlgihtNumber column
```
data_falcon9.loc[:,'FlightNumber'] = list(range(1, data_falcon9.shape[0]+1))
data_falcon9
```
## Data Wrangling
We can see below that some of the rows are missing values in our dataset.
```
data_falcon9.isnull().sum()
```
Before we can continue we must deal with these missing values. The <code>LandingPad</code> column will retain None values to represent when landing pads were not used.
### Task 3: Dealing with Missing Values
Calculate below the mean for the <code>PayloadMass</code> using the <code>.mean()</code>. Then use the mean and the <code>.replace()</code> function to replace `np.nan` values in the data with the mean you calculated.
```
# Calculate the mean value of PayloadMass column
data_falcon9.PayloadMass.mean()
# Replace the np.nan values with its mean value
data_falcon9.PayloadMass.replace(np.nan,data_falcon9.PayloadMass.mean(),inplace=True)
```
You should see the number of missing values of the <code>PayLoadMass</code> change to zero.
Now we should have no missing values in our dataset except for in <code>LandingPad</code>.
We can now export it to a <b>CSV</b> for the next section,but to make the answers consistent, in the next lab we will provide data in a pre-selected date range.
<code>data_falcon9.to_csv('dataset_part\_1.csv', index=False)</code>
## Authors
<a href="https://www.linkedin.com/in/joseph-s-50398b136/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01">Joseph Santarcangelo</a> has a PhD in Electrical Engineering, his research focused on using machine learning, signal processing, and computer vision to determine how videos impact human cognition. Joseph has been working for IBM since he completed his PhD.
## Change Log
| Date (YYYY-MM-DD) | Version | Changed By | Change Description |
| ----------------- | ------- | ---------- | ----------------------------------- |
| 2020-09-20 | 1.1 | Joseph | get result each time you run |
| 2020-09-20 | 1.1 | Azim | Created Part 1 Lab using SpaceX API |
| 2020-09-20 | 1.0 | Joseph | Modified Multiple Areas |
Copyright © 2021 IBM Corporation. All rights reserved.
| github_jupyter |
```
from __future__ import print_function
from textwrap import dedent
import pytablewriter
table_name = "example_table"
headers = ["int", "float", "str", "bool", "mix", "time"]
data = [
[0, 0.1, "hoge", True, 0, "2017-01-01 03:04:05+0900"],
[2, "-2.23", "foo", False, None, "2017-12-23 12:34:51+0900"],
[3, 0, "bar", "true", "inf", "2017-03-03 22:44:55+0900"],
[-10, -9.9, "", "FALSE", "nan", "2017-01-01 00:00:00+0900"],
]
for name in pytablewriter.TableWriterFactory.get_format_names():
print(name)
for name in pytablewriter.TableWriterFactory.get_extensions():
print(name)
from pytablewriter import MarkdownTableWriter
writer = MarkdownTableWriter()
writer.table_name = "zone"
writer.headers = ["zone_id", "country_code", "zone_name"]
writer.value_matrix = [
["1", "AD", "Europe/Andorra"],
["2", "AE", "Asia/Dubai"],
["3", "AF", "Asia/Kabul"],
["4", "AG", "America/Antigua"],
["5", "AI", "America/Anguilla"],
]
writer.write_table()
writer = pytablewriter.CsvTableWriter()
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.SpaceAlignedTableWriter()
writer.headers = ["PID", "USER", "PR", "NI", "VIRT", "RES", "SHR", "S", "%CPU", "%MEM", "TIME+", "COMMAND"]
writer.value_matrix = csv1 = [
[32866, "root", 20, 0, 48344, 3924, 3448, "R", 5.6, 0.2, "0:00.03", "top"],
[1, "root", 20, 0, 212080, 7676, 5876, "S", 0, 0.4, "1:06.56", "systemd"],
[2, "root", 20, 0, 0, 0, 0, "S", 0, 0, "0:01.92", "kthreadd"],
[4, "root", 0, -20, 0, 0, 0, "S", 0, 0, "0:00.00", "kworker/0:0H"],
]
writer.write_table()
writer = pytablewriter.TsvTableWriter()
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.HtmlTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.JavaScriptTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.JsonTableWriter()
#writer.table_name = "Timezone"
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.JsonLinesTableWriter()
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.JsonTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.LatexMatrixWriter()
writer.table_name = "A"
writer.value_matrix = [
[0.01, 0.00125, 0.0],
[1.0, 99.9, 0.01],
[1.2, 999999.123, 0.001],
]
writer.write_table()
```
\begin{equation}
A = \left( \begin{array}{rrr}
0.01 & 0.0012 & 0.000 \\
1.00 & 99.9000 & 0.010 \\
1.20 & 999999.1230 & 0.001 \\
\end{array} \right)
\end{equation}
```
writer = pytablewriter.LatexMatrixWriter()
writer.table_name = "B"
writer.value_matrix = [
["a_{11}", "a_{12}", "\\ldots", "a_{1n}"],
["a_{21}", "a_{22}", "\\ldots", "a_{2n}"],
[r"\vdots", "\\vdots", "\\ddots", "\\vdots"],
["a_{n1}", "a_{n2}", "\\ldots", "a_{nn}"],
]
writer.write_table()
```
\begin{equation}
B = \left( \begin{array}{llll}
a_{11} & a_{12} & \ldots & a_{1n} \\
a_{21} & a_{22} & \ldots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \ldots & a_{nn} \\
\end{array} \right)
\end{equation}
```
writer = pytablewriter.LatexTableWriter()
writer.headers = headers
writer.value_matrix = data
writer.write_table()
```
\begin{array}{r | r | l | l | l | l} \hline
\verb|int| & \verb|float| & \verb|str| & \verb|bool| & \verb|mix| & \verb|time| \\ \hline
\hline
0 & 0.10 & hoge & True & 0 & \verb|2017-01-01 03:04:05+0900| \\ \hline
2 & -2.23 & foo & False & & \verb|2017-12-23 12:34:51+0900| \\ \hline
3 & 0.00 & bar & True & \infty & \verb|2017-03-03 22:44:55+0900| \\ \hline
-10 & -9.90 & & False & NaN & \verb|2017-01-01 00:00:00+0900| \\ \hline
\end{array}
```
from pytablewriter import MarkdownTableWriter
writer = MarkdownTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
from pytablewriter import MarkdownTableWriter
writer = MarkdownTableWriter()
writer.table_name = "write example with a margin"
writer.headers = headers
writer.value_matrix = data
writer.margin = 1 # add a whitespace for both sides of each cell
writer.write_table()
writer = pytablewriter.MediaWikiTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.NumpyTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.PandasDataFrameWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.PandasDataFrameWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.is_datetime_instance_formatting = False
writer.write_table()
writer = pytablewriter.PythonCodeTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.PythonCodeTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.is_datetime_instance_formatting = False
writer.write_table()
writer = pytablewriter.RstGridTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.RstSimpleTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.RstCsvTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.LtsvTableWriter()
writer.headers = headers
writer.value_matrix = data
writer.write_table()
writer = pytablewriter.TomlTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
from datetime import datetime
import pytablewriter as ptw
writer = ptw.JavaScriptTableWriter()
writer.headers = ["header_a", "header_b", "header_c"]
writer.value_matrix = [
[-1.1, "2017-01-02 03:04:05", datetime(2017, 1, 2, 3, 4, 5)],
[0.12, "2017-02-03 04:05:06", datetime(2017, 2, 3, 4, 5, 6)],
]
print("// without type hints: column data types detected automatically by default")
writer.table_name = "without type hint"
writer.write_table()
print("// with type hints: Integer, DateTime, String")
writer.table_name = "with type hint"
writer.type_hints = [ptw.Integer, ptw.DateTime, ptw.String]
writer.write_table()
from datetime import datetime
import pytablewriter as ptw
writer = ptw.PythonCodeTableWriter()
writer.value_matrix = [
[-1.1, float("inf"), "2017-01-02 03:04:05", datetime(2017, 1, 2, 3, 4, 5)],
[0.12, float("nan"), "2017-02-03 04:05:06", datetime(2017, 2, 3, 4, 5, 6)],
]
# column data types detected automatically by default
writer.table_name = "python variable without type hints"
writer.headers = ["float", "infnan", "string", "datetime"]
writer.write_table()
# set type hints
writer.table_name = "python variable with type hints"
writer.headers = ["hint_int", "hint_str", "hint_datetime", "hint_str"]
writer.type_hints = [ptw.Integer, ptw.String, ptw.DateTime, ptw.String]
writer.write_table()
writer = pytablewriter.MarkdownTableWriter()
writer.from_csv(dedent("""\
"i","f","c","if","ifc","bool","inf","nan","mix_num","time"
1,1.10,"aa",1.0,"1",True,Infinity,NaN,1,"2017-01-01 00:00:00+09:00"
2,2.20,"bbb",2.2,"2.2",False,Infinity,NaN,Infinity,"2017-01-02 03:04:05+09:00"
3,3.33,"cccc",-3.0,"ccc",True,Infinity,NaN,NaN,"2017-01-01 00:00:00+09:00"
"""))
writer.write_table()
writer = pytablewriter.MarkdownTableWriter()
writer.table_name = "ps"
writer.from_csv(
dedent("""\
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.4 77664 8784 ? Ss May11 0:02 /sbin/init
root 2 0.0 0.0 0 0 ? S May11 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? I< May11 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? I< May11 0:00 [mm_percpu_wq]
root 7 0.0 0.0 0 0 ? S May11 0:01 [ksoftirqd/0]
"""),
delimiter=" ")
writer.write_table()
from pytablewriter import MarkdownTableWriter
from pytablewriter.style import Align, Style
writer = MarkdownTableWriter()
writer.table_name = "specify alignment for each column manually"
writer.headers = ["left", "right", "center", "auto (int)", "auto (str)", "None (same as AUTO)"]
writer.value_matrix = [
[0, "r", "center align", 0, "a", "n"],
[11, "right align", "c", 11, "auto", "none"],
]
# set alignments for each column
writer.styles = [
Style(align=Align.LEFT),
Style(align=Align.RIGHT),
Style(align=Align.CENTER),
Style(align=Align.AUTO),
Style(align=Align.AUTO),
None,
]
writer.write_table()
from pytablewriter import MarkdownTableWriter
from pytablewriter.style import Style
writer = MarkdownTableWriter()
writer.table_name = "set style by styles"
writer.headers = [
"auto align",
"left align",
"center align",
"bold",
"italic",
"bold italic ts",
]
writer.value_matrix = [
[11, 11, 11, 11, 11, 11],
[1234, 1234, 1234, 1234, 1234, 1234],
]
# specify styles for each column
writer.styles = [
Style(),
Style(align="left"),
Style(align="center"),
Style(font_weight="bold"),
Style(font_style="italic"),
Style(font_weight="bold", font_style="italic", thousand_separator=","),
]
writer.write_table()
from pytablewriter import MarkdownTableWriter
from pytablewriter.style import Style
writer = MarkdownTableWriter()
writer.headers = ["A", "B", "C",]
writer.value_matrix = [[11, 11, 11], [1234, 1234, 1234]]
writer.table_name = "set style by index"
writer.set_style(1, Style(align="center", font_weight="bold"))
writer.set_style(2, Style(thousand_separator=" "))
writer.write_table()
writer.write_null_line()
writer.table_name = "set style by header"
writer.set_style("B", Style(font_style="italic"))
writer.write_table()
import pytablewriter
writer = pytablewriter.MarkdownTableWriter()
writer.headers = ["int", "float", "str", "bool", "mix", "time"]
writer.value_matrix = [
[0, 0.1, "hoge", True, 0, "2017-01-01 03:04:05+0900"],
[2, "-2.23", "foo", False, None, "2017-12-23 45:01:23+0900"],
[3, 0, "bar", "true", "inf", "2017-03-03 33:44:55+0900"],
[-10, -9.9, "", "FALSE", "nan", "2017-01-01 00:00:00+0900"],
]
print(writer.dumps())
from pytablewriter import MarkdownTableWriter
from pytablewriter.style import ThousandSeparator
writer = MarkdownTableWriter()
writer.headers = ["wo_format", "comma_i", "space_f"]
writer.value_matrix = [
[1000, 1234567, 1234567.8],
[1000, 1234567, 1234567.8],
[1000, 1234567, 1234567.8],
]
writer.styles = [
Style(thousand_separator=ThousandSeparator.NONE),
Style(thousand_separator=ThousandSeparator.COMMA),
Style(thousand_separator=ThousandSeparator.SPACE),
]
writer.write_table()
from pytablewriter import LatexTableWriter
from pytablewriter.style import Style, FontSize
writer = LatexTableWriter()
writer.table_name = "style test: font size"
writer.headers = ["none", "empty_style", "tiny", "small", "medium", "large"]
writer.value_matrix = [[111, 111, 111, 111, 111, 111], [1234, 1234, 1234, 1234, 1234, 1234]]
writer.styles = [
None,
Style(),
Style(font_size=FontSize.TINY),
Style(font_size=FontSize.SMALL),
Style(font_size=FontSize.MEDIUM),
Style(font_size=FontSize.LARGE),
]
writer.write_table()
```
\begin{array}{r | r | r | r | r | r} \hline
\verb|none| & \verb|empty_style| & \verb|tiny| & \verb|small| & \verb|medium| & \verb|large| \\ \hline
\hline
111 & 111 & \tiny 111 & \small 111 & \normalsize 111 & \large 111 \\ \hline
1234 & 1234 & \tiny 1234 & \small 1234 & \normalsize 1234 & \large 1234 \\ \hline
\end{array}
```
from pytablewriter import UnicodeTableWriter
writer = UnicodeTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = data
writer.write_table()
```
| github_jupyter |
```
import pickle
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
with open('cdrk_lastepisode_heat.pickle', 'rb') as f:
last_heat = pickle.load(f)
with open('cdrk_heat_unique0.pickle', 'rb') as f:
heat_uniq0 = pickle.load(f)
with open('cdrk_heat_freq0.pickle', 'rb') as f:
heat_freq0 = pickle.load(f)
with open('cdrk_heat_unique1.pickle', 'rb') as f:
heat_uniq1 = pickle.load(f)
with open('cdrk_heat_freq1.pickle', 'rb') as f:
heat_freq1 = pickle.load(f)
# with open('cdrk_random_corr0.pickle', 'rb') as f:
# rand_corr0 = pickle.load(f)
# with open('cdrk_recent_corr0.pickle', 'rb') as f:
# recen_corr0 = pickle.load(f)
with open('cdrk_classic_Q.pickle', 'rb') as f:
Q = pickle.load(f)
num_episodes = len(heat_freq0)
num_actions = 15
num_sub = 500
np.unique(last_heat[:, 0, :, :], return_counts=True)[1]/num_sub/num_actions**2
np.unique(last_heat[:, 0, :, :], return_counts=True)
full_freq0 = np.zeros((num_episodes, num_actions))
for i in range(num_episodes):
full_freq0[i, heat_uniq0[i].astype(int)] = heat_freq0[i]
np.argmax(np.sum(full_freq0, axis=0))
max_price = np.zeros(num_episodes)
max_freq = np.zeros(num_episodes)
bottom8_freq = np.zeros(num_episodes)
bottom3_freq = np.zeros(num_episodes)
for i in range(num_episodes):
max_price[i] = np.max(heat_uniq0[i])
max_freq[i] = np.argmax(full_freq0[i, :])
bottom8_freq[i] = np.sum(full_freq0[i, :10])
bottom3_freq[i] = np.sum(full_freq0[i, :3])
plt.figure(figsize=(8, 6))
ax = sns.heatmap(last_heat[-1, 1, :, :], cbar=False, annot=True)
plt.xlabel('Classic player')
plt.ylabel('Deep player')
cbar = ax.figure.colorbar(ax.collections[0])
cbar.set_ticks([0, 2, 4, 6, 8, 10, 12, 14])
# cbar.set_ticks([1.43, 1.51, 1.59, 1.67, 1.75, 1.83, 1.91, 1.99])
fig = ax.get_figure()
# fig.savefig('.eps', format='eps', dpi=200, bbox_inches='tight', pad_inches=0.1)
fig, ax = plt.subplots(figsize=(8, 6), dpi=120)
ax.plot(bottom8_freq/112500, color='tab:blue', label=r'Price $\leq$ 1.79')
ax.plot(full_freq0[:, 10]/112500, color='tab:orange', label =r'Price = 1.83')
ax.set_ylabel('Percent')
ax.set_xlabel('Episodes')
ax.legend(loc='best')
ax.grid(True)
# plt.savefig('.eps', format='eps', dpi=1000, bbox_inches='tight', pad_inches=0.1)
plt.show()
np.unique(max_price, return_counts=True)
fig, ax = plt.subplots(figsize=(8, 6), dpi=120)
ax.plot(1.43 + 0.04*max_price, color='tab:blue', label='Highest')
ax.plot(1.43 + 0.04*max_freq, color='tab:orange', label ='Most frequent')
ax.set_ylabel('Price')
ax.yaxis.set_ticks(np.arange(1.43, 2.0, 0.04))
ax.set_xlabel('Episodes')
ax.legend(loc='best')
ax.grid(True)
# plt.savefig('.eps', format='eps', dpi=1000, bbox_inches='tight', pad_inches=0.1)
plt.show()
full_freq1 = np.zeros((num_episodes, num_actions))
for i in range(num_episodes):
full_freq1[i, heat_uniq1[i].astype(int)] = heat_freq1[i]
max_price1 = np.zeros(num_episodes)
max_freq1 = np.zeros(num_episodes)
bottom8_freq1 = np.zeros(num_episodes)
bottom3_freq1 = np.zeros(num_episodes)
for i in range(num_episodes):
max_price1[i] = np.max(heat_uniq1[i])
max_freq1[i] = np.argmax(full_freq1[i, :])
bottom8_freq1[i] = np.sum(full_freq1[i, :8])
bottom3_freq1[i] = np.sum(full_freq1[i, :3])
fig, ax = plt.subplots(figsize=(18, 6), dpi=120)
ax.plot(bottom8_freq1/112500, color='tab:blue', label=r'Price $\leq$ 1.71')
ax.plot(bottom3_freq1/112500, color='tab:orange', label =r'Price $\leq$ 1.51')
ax.set_ylabel('Percent')
ax.set_xlabel('Episodes')
ax.legend(loc='best')
ax.grid(True)
# plt.savefig('.eps', format='eps', dpi=500, bbox_inches='tight', pad_inches=0.1)
plt.show()
fig, ax = plt.subplots(figsize=(18, 6), dpi=120)
ax.plot(1.43 + 0.04*max_price1, color='tab:blue', label='Highest price')
ax.plot(1.43 + 0.04*max_freq1, color='tab:orange', label ='Most frequent price')
ax.set_ylabel('Price')
ax.yaxis.set_ticks(np.arange(1.43, 2.0, 0.04))
ax.set_xlabel('Episodes')
ax.legend(loc='best')
ax.grid(True)
# plt.savefig('.eps', format='eps', dpi=500, bbox_inches='tight', pad_inches=0.1)
plt.show()
ind
N = 2000 - 30
ind = np.arange(N+1, N+31)
width = 0.5
# plt.style.use('default')
cm = plt.get_cmap('tab20')
plt.rcParams["axes.prop_cycle"] = plt.cycler('color', [cm(1.*i/num_actions) for i in range(num_actions)])
p = []
fig, ax = plt.subplots(figsize=(8,6), dpi=120)
for k in range(num_actions):
p.append(plt.bar(ind, full_freq1[N:N+30, k]/112500, width, bottom = np.sum(full_freq1[N:N+30, :k], axis=1)/112500))
plt.legend((p[0][0], p[1][0], p[2][0], p[3][0], p[4][0], p[5][0], p[6][0], p[7][0],
p[8][0], p[9][0], p[10][0], p[11][0], p[12][0], p[13][0], p[14][0]),
('1.43', '1.47', '1.51', '1.55', '1.59', '1.63', '1.67', '1.71',
'1.75', '1.79', '1.83', '1.87', '1.91', '1.95', '1.99'), bbox_to_anchor=(1.0, 1.0))
plt.xticks(ind)
plt.xticks(rotation=70)
ax.set_xlabel('Episodes')
ax.set_ylabel('Percent')
# plt.savefig('.eps', format='eps', dpi=1000, bbox_inches='tight', pad_inches=0.1)
plt.show()
```
| github_jupyter |
# Deterministic Inputs, Noisy “And” gate model (DINA)
This notebook will show you how to train and use the DINA.
First, we will show how to get the data (here we use Math1 from math2015 as the dataset).
Then we will show how to train a DINA and perform the parameters persistence.
At last, we will show how to load the parameters from the file and evaluate on the test dataset.
The script version could be found in [DINA.py](DINA.ipynb)
## Data Preparation
Before we process the data, we need to first acquire the dataset which is shown in [prepare_dataset.ipynb](prepare_dataset.ipynb)
```
# Data preprocessing, split train/valid/test data
import numpy as np
import random
import json
train_ratio = 0.8
valid_ratio = 0
# Q matrix
np.savetxt("../../data/math2015/Math1/q_m.csv", np.loadtxt("../../data/math2015/Math1/q.txt", dtype=int), delimiter=',', fmt='%d')
# response matrix, split dataset
R = (np.loadtxt("../../data/math2015/Math1/data.txt") == 1).astype(float)
stu_num, prob_num = R.shape[0], R.shape[1]
train_logs, valid_logs, test_logs = [], [], []
for stu in range(stu_num):
stu_logs = []
for prob in range(prob_num):
log = {'user_id': int(stu), 'item_id': int(prob), 'score': R[stu][prob]}
stu_logs.append(log)
random.shuffle(stu_logs)
train_logs += stu_logs[: int(train_ratio * prob_num)]
valid_logs += stu_logs[int(train_ratio * prob_num): int(train_ratio * prob_num) + int(valid_ratio * prob_num)]
test_logs += stu_logs[int(train_ratio * prob_num) + int(valid_ratio * prob_num):]
with open("../../data/math2015/Math1/train_data.json", 'w', encoding='utf8') as file:
json.dump(train_logs, file, indent=4, ensure_ascii=False)
with open("../../data/math2015/Math1/valid_data.json", 'w', encoding='utf8') as file:
json.dump(valid_logs, file, indent=4, ensure_ascii=False)
with open("../../data/math2015/Math1/test_data.json", 'w', encoding='utf8') as file:
json.dump(test_logs, file, indent=4, ensure_ascii=False)
print(train_logs[0], test_logs[0])
# Load the data from files
q_m = np.loadtxt("../../data/math2015/Math1/q_m.csv", dtype=int, delimiter=',')
prob_num, know_num = q_m.shape[0], q_m.shape[1]
# training data
with open("../../data/math2015/Math1/train_data.json", encoding='utf-8') as file:
train_set = json.load(file)
stu_num = max([x['user_id'] for x in train_set]) + 1
R = -1 * np.ones(shape=(stu_num, prob_num))
for log in train_set:
R[log['user_id'], log['item_id']] = log['score']
# testing data
with open("../../data/math2015/Math1/test_data.json", encoding='utf-8') as file:
test_set = json.load(file)
len(train_set), len(test_set)
```
## Training and Persistence
```
import logging
logging.getLogger().setLevel(logging.INFO)
from EduCDM import DINA
cdm = DINA(R, q_m, stu_num, prob_num, know_num, skip_value=-1)
cdm.train(epoch=2, epsilon=1e-3)
cdm.save("dina.params")
```
## Loading and Testing
```
cdm.load("dina.params")
rmse, mae = cdm.eval(test_set)
print("RMSE: %.6f, MAE: %.6f" % (rmse, mae))
```
## Incremental Training
```
new_data = [{'user_id': 0, 'item_id': 0, 'score': 1.0}, {'user_id': 1, 'item_id': 2, 'score': 0.0}]
cdm.inc_train(new_data, epoch=2, epsilon=1e-3)
```
## Evaluate User's State
```
stu_rec = np.array([0, 1, -1, 0, -1, 0, 1, 1, 0, 1, 0, 1, 0, -1, -1, -1, -1, 0, 1, -1])
dia_id, dia_state = cdm.transform(stu_rec)
print("id of user's state is %d, state is " % dia_id + str(dia_state))
# To see the relation between dia_id and dia_state
dia_state == cdm.all_states[dia_id]
```
| github_jupyter |
## Ejercicio 1
Dada la siguiente lista:
> ```ejer_1 = [1,2,3,4,5]```
Inviertela par que quede de la siguiente manera
> ```ejer_1 = [5,4,3,2,1]```
## Ejercicio 2
Eleva todos los elementos de la lista al cuadrado
> ```ejer_2 = [1,2,3,4,5]```
## Ejercicio 3
Crea una lista nueva con todas las combinaciones de las siguientes os listas:
> ```ejer_3_1 = ["Hola", "amigo"]```
>
> ```ejer_3_2 = ["Que", "tal"]```
Obten el siguiente output:
['Hola Que', 'Hola tal', 'amigo Que', 'amigo tal']
## Ejercicio 4
Dada la siguiente lista, encuentra el valor 45, sustituyelo por el 0
> ```ejer_4 = [20, 47, 19, 29, 45, 67, 78, 90]```
## Ejercicio 5
Dada la siguiente lista, elimina todos los valores iguales a 3
> ```ejer_5 = [3, 20, 3, 47, 19, 3, 29, 45, 67, 78, 90, 3, 3]```
```
ejer_5 = [3, 20, 3, 47, 19, 3, 29, 45, 67, 78, 90, 3, 3]
lista_nueva = []
for i in ejer_5:
if i != 3:
lista_nueva.append(i)
print(lista_nueva)
lista_nueva2 = []
for k in range(len(ejer_5)):
if ejer_5[k] != 3:
lista_nueva2.append(ejer_5[k])
print(lista_nueva2)
ejer_5 = [3, 20, 3, 47, 19, 3, 29, 45, 67, 78, 90, 3, 3]
for i in range(len(ejer_5)):
if ejer_5[i] == 3:
ejer_5.remove(3)
print(ejer_5)
print(ejer_5)
```
## Ejercicio 6
1. Crea una tupla con 3 elementos
2. Crea otra tupla con un elemento y comprueba su tipo
3. Crea una tupla con elementos de diferentes tipos
4. Imprime por pantalla el primer y ultimo elemento de la tupla del apartado 3. Usa `len` para el ultimo
5. Añade un elemento a la tupla del apartado 3.
6. Eliminar un elemento de la tupla del apartado 5, que se encuentre más o menos en la mitad.
7. Convierte la tupla del apartado 5 en una lista
## Ejercicio 7
Concatena todos los elementos de la tupla en un unico string. Para ello utiliza el metodo `.join()` de los Strings
> ```ejer_7 = ("cien", "cañones", "por", "banda")```
Resultado: `cien cañones por banda`
## Ejercicio 8
Obten el tercer elemento de la siguiente tupla, y el tercero empezando por la cola
> ```ejer_8 = (3, 20, 3, 47, 19, 3, 29, 45, 67, 78, 90, 3, 3)```
## Ejercicio 9
1. ¿Cuántas veces se repite el 3 en la siguiente tupla?
2. Crea una tupla nueva con los elementos desde la posicion 5 a la 10.
3. ¿Cuántos elementos tiene la tupla `ejer_9`?
> ```ejer_9 = (3, 20, 3, 47, 19, 3, 29, 45, 67, 78, 90, 3, 3, 5, 2, 4, 7, 9, 4, 2, 4, 3, 3, 4, 6, 7)```
## Ejercicio 10
Comprueba si el numero 60 esta en la tupla del ejercicio 9
## Ejercicio 11
1. Convierte la tupla del apartado 10 en una lista
2. Convierte la tupla del apartado 10 en un set
3. Convierte la tupla del apartado 10 en un diccionario. Usa también los indices
## Ejercicio 12
Convierte la siguiente tupla en un diccionario
> ```ejer_12 = [("x", 1), ("x", 2), ("x", 3), ("y", 1), ("y", 2), ("z", 1)]```
```
ejer_12 = [("x", 1), ("x", 2), ("x", 3), ("y", 1), ("y", 2), ("z", 1)]
dict(ejer_12)
dic = {}
dic['x'] = 1
dic['x'] = 2
dic['x'] = 3
dic['y'] = 1
dic['y'] = 2
dic['z'] = 1
dic
```
## Ejercicio 13
1. Crea una lista ordenada ascendente con las claves del diccionario
2. Crea otra lista ordenada descendente con los valores
3. Añade una nueva clave/valor
4. Busca la clave 2 dentro del diccionario
5. Itera la clave y el valor del diccionario con un unico for
> ```ejer_13 = {4:78, 2:98, 8:234, 5:29}```
## Ejercicio 14
Junta ambos diccionarios. Para ello, utiliza `update
> ```ejer_14_1 = {1: 11, 2: 22}```
>
> ```ejer_14_2 = {3: 33, 4: 44}```
## Ejercicio 15
Suma todos los valores del dicionario
> ```ejer_15 = {1: 11, 2: 22, 3: 33, 4: 44, 5: 55}```
## Ejercicio 16
Multiplica todos los valores del diccionario
> ```ejer_16 = {1: 11, 2: 22, 3: 33, 4: 44, 5: 55}```
## Ejercicio 17
1. Crea un set de tres elementos
2. Añade un cuarto
3. Elimina el utlimo elemento añadido
4. Elimina el elemento 10, si está presenta. Usa `discard()`
| github_jupyter |
# Notebook to find scraped charity names in the Panama Papers using Spark
```
# Imports
import re
import nltk
import json
import folium
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#stop words
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
#spark
import findspark
findspark.init(r'C:\Users\Ruijia\Spark')
from pyspark.sql import *
from pyspark.sql.functions import *
from pyspark.sql.functions import min
from pyspark.sql.functions import udf
from pyspark.sql.functions import split
from pyspark.sql.functions import explode
from pyspark.sql.types import StringType
from pyspark.sql.types import TimestampType
from pyspark.sql import SparkSession
from pyspark import SparkContext
spark = SparkSession.builder.getOrCreate()
# Addition of english stop words
def init_stopwords():
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
stop_words.add('&')
stop_words.add('co')
stop_words.add('co.')
stop_words.add('co.,')
stop_words.add('co.,ltd.')
stop_words.add('corp')
stop_words.add('corp.')
stop_words.add('corp.,')
stop_words.add('de')
stop_words.add('foundation')
stop_words.add('inc')
stop_words.add('inc.')
stop_words.add('limited')
stop_words.add('international')
stop_words.add('ltd')
stop_words.add('ltd.')
stop_words.add('s.a.')
stop_words.add('world')
stop_words.add('global')
stop_words = list(stop_words)
return stop_words
stop_words = init_stopwords()
def check_for_words(charity, shell, stop_words, tuning):
percentage = 0.6
if charity is None or shell is None:
return False
charity_words = [x.lower() for x in charity.split()]
shell_words = [x.lower() for x in shell.split()]
len_charity = len(charity_words)
len_shell = len(shell_words)
count_random_matches = 0
stop_word_random_matches = 0
for i in range(len_charity):
word = charity_words[i]
if word in shell_words:
count_random_matches += 1
if word in stop_words:
stop_word_random_matches += 1
if tuning:
#if only stopwords match, not valid
if count_random_matches - stop_word_random_matches < 1:
return False
#"Family foundations are tricky -> make sure they are not the only matching parts"
if ('family' in shell_words
and 'foundation' in shell_words
and 'family' in charity_words
and 'foundation' in charity_words
and count_random_matches < 3
and len_shell > 2
and len_charity > 2):
return False
if len_charity == 1 or len_shell == 1:
return (np.abs(len_charity - len_shell) < 2 and count_random_matches == 1)
return ((count_random_matches/len_charity >= percentage)
and (count_random_matches/len_shell >= percentage))
def extract_matches_between(leak, charity, sharp):
stop_words = init_stopwords()
charity_location = '../generated/' + charity + '/' + charity + '_charity_info.csv'
leak_location = '../data/' + leak + '/' + leak + '*.nodes.entity.csv'
leak_data = spark.read.csv(leak_location, header=True)
charity_data = spark.read.csv(charity_location, header=True)
charity_names = charity_data.select('name').selectExpr('name as CharityName')
shell_names = leak_data.select('node_id','name').withColumnRenamed('name', 'ShellName')
shells_vs_charities = shell_names.crossJoin(charity_names)
filtered_names = shells_vs_charities.rdd.filter(lambda r: check_for_words(r[1], r[2], stop_words, sharp) == True)
matches = filtered_names.toDF().toPandas()
matches.to_csv('../generated/matches/' + leak +'_'+ charity +'_matches.csv')
extract_matches_between('panama', 'forbes', False)
extract_matches_between('panama', 'wikipedia', True)
extract_matches_between('panama', 'INGO', False)
```
| github_jupyter |
[link text](https://)#Make your own Rick Sanchez (bot) with Transformers and DialoGPT fine-tuning
by [Rostyslav Neskorozhenyi](https://www.linkedin.com/in/slanj)
I am a big fan of 'Rick and Morty' and NLP (Natural Language Processing). After watching the last episode of a mad scientist's and his grandson's adventures I realized that it's not a coincidence and I have to apply my knowledge in NLP and Machine Learning to create my own Rick (in a form of chat-bot, at least for now).
Image from [Giphy](https://giphy.com/)
The path to creating virtual Rick was not easy. I tried many models and approaches but virtual Rick did not want to find a common language with me for a long time. Rick's first response to my greeting was "I am not your buddy" (to tell you the truth, in the beginning he knew only this phrase). But I did not give up and with the help of excellent Transformers library and Microsoft's Large-scale Pretrained Response Generation Model (DialoGPT) I managed to talk heart-to-heart with Rick. Here is one of our conversations:
**User**:Hey, Rick, make me a time machine <br>
**RickBot**: You're a monster! <br>
**User**:No, I just want to travel in time <br>
**RickBot**: To the past. <br>
**User**:yes <br>
**RickBot**: No time machine, please. <br>
**User**:But I need it <br>
**RickBot**: You don't need it, Morty. Just do it. <br>
**User**:I want to see antient Greece <br>
**RickBot**: Oh, geez. <br>
Image from [Giphy](https://giphy.com/)
```
from google.colab import drive
drive.mount('/content/drive')
```
## A bit of theory
In this article I will tell you how to create a virtual character whose statements will be based on a transcript of my favorite animated science fiction sitcom. You can use characters and sitcoms of your choice. I added code to convert a regular text file with dialogs into a format that the model understands.
As I already mentioned, [Transformers](https://huggingface.co/transformers/) library, which contains the latest NLP models (such as [BERT](https://huggingface.co/transformers/model_doc/bert.html), [XLNet](https://huggingface.co/transformers/model_doc/xlnet.html), [GPT-2](https://huggingface.co/transformers/model_doc/gpt2.html)) will help us in our task. You can read more about transformers in a beautifully illustrated [article](http://jalammar.github.io/illustrated-transformer/) by Jay Alammar.
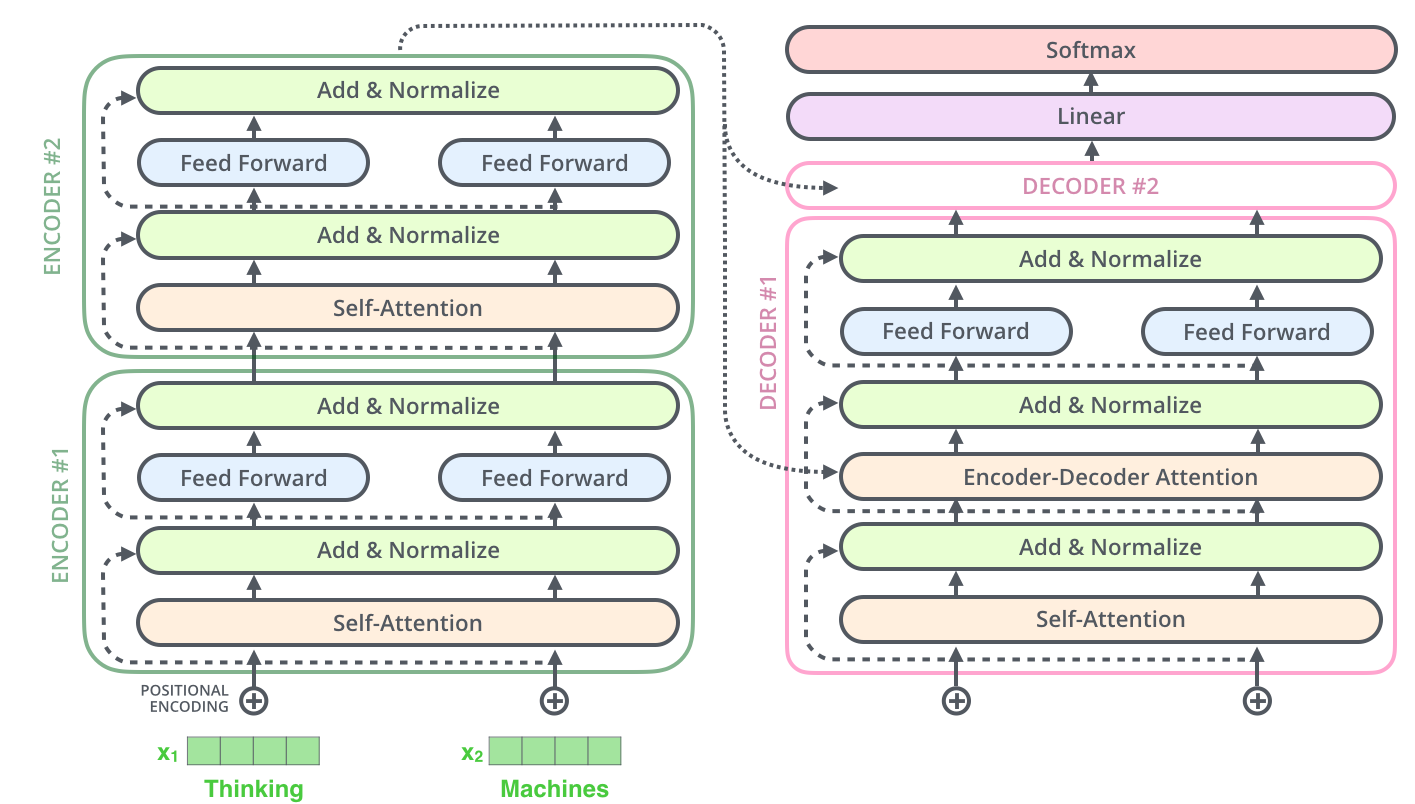 Image from[ http://jalammar.github.io](http://jalammar.github.io/illustrated-transformer/)
Not so long ago, Microsoft’s [DialoGPT](https://huggingface.co/transformers/model_doc/dialogpt.html) was added to the Transformers model collection. DialoGPT is a GPT-2 model, trained on 147M multi-turn dialogue from Reddit discussion thread (you can learn more about GPT-2 [here](http://jalammar.github.io/illustrated-gpt2/)). This model is ideally suited for creating a virtual character for a fascinating conversation and even in the small implementation option it can maintain a coherent dialogue, which we will see now.
## First dialogue with DialoGPT
We will conduct all our experiments in Google Colab, its resources are enough to train the small DialoGPT model. Firstly, we will connect to Google Drive and install the necessary modules.
```
from google.colab import drive
drive.mount('/content/drive/')
! pip -q install transformers
```
Let's move to the desired folder in which we will store all our data.
```
import os
os.chdir("/content/drive/My Drive/Colab Notebooks")
```
Try to chat with DialoGPT without fine-tuning.
```
from transformers import AutoModelWithLMHead, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-small")
model = AutoModelWithLMHead.from_pretrained("microsoft/DialoGPT-small")
for step in range(11):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = new_user_input_ids
#bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limibbting the total chat history to 1000 tokens
chat_history_ids = model.generate(
bot_input_ids, max_length=1000,
pad_token_id=tokenizer.eos_token_id
)
# pretty print last ouput tokens from bot
print("DialoGPT: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
**User:**Hi Rick <br>
**DialoGPT:** Hi Rick <br>
**User:**How are you? <br>
**DialoGPT:** I'm good, how are you? <br>
**User:**I am fine. Where is Morty? <br>
**DialoGPT:** He's in the basement. <br>
**User:**Who is Morty? <br>
**DialoGPT:** He's a Morty. <br>
**User:**Who are you? <br>
**DialoGPT:** I am a Morty. <br>
Image from [Giphy](https://giphy.com/)
Not bad but not too impressive. We will fix it with fine-tuning.
## Model initial configuration
Let's train our own Rick chatbot. For start, we will need basic configuration and a dataset.
Configuration and training scripts are mostly based on this [script](https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_language_modeling.py) from Huggingface and great [tutorial](https://nathancooper.io/i-am-a-nerd/chatbot/deep-learning/gpt2/2020/05/12/chatbot-part-1.html) from Nathan Cooper.
```
"""
Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, BERT, RoBERTa).
GPT and GPT-2 are fine-tuned using a causal language modeling (CLM) loss while BERT and RoBERTa are fine-tuned
using a masked language modeling (MLM) loss.
"""
import glob
import logging
import os
import pickle
import random
import re
import shutil
from typing import Dict, List, Tuple
import pandas as pd
import numpy as np
import torch
from sklearn.model_selection import train_test_split
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader, Dataset, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
from tqdm.notebook import tqdm, trange
from pathlib import Path
from transformers import (
MODEL_WITH_LM_HEAD_MAPPING,
WEIGHTS_NAME,
AdamW,
AutoConfig,
AutoModelWithLMHead,
AutoTokenizer,
PreTrainedModel,
PreTrainedTokenizer,
get_linear_schedule_with_warmup,
)
try:
from torch.utils.tensorboard import SummaryWriter
except ImportError:
from tensorboardX import SummaryWriter
# Configs
logger = logging.getLogger(__name__)
MODEL_CONFIG_CLASSES = list(MODEL_WITH_LM_HEAD_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
# Args to allow for easy convertion of python script to notebook
class Args():
def __init__(self):
self.output_dir = 'output-small'
self.model_type = 'gpt2'
self.model_name_or_path = 'microsoft/DialoGPT-small'
self.config_name = 'microsoft/DialoGPT-small'
self.tokenizer_name = 'microsoft/DialoGPT-small'
self.cache_dir = 'cached'
self.block_size = 512
self.do_train = True
self.do_eval = True
self.evaluate_during_training = False
self.per_gpu_train_batch_size = 4
self.per_gpu_eval_batch_size = 4
self.gradient_accumulation_steps = 1
self.learning_rate = 5e-5
self.weight_decay = 0.0
self.adam_epsilon = 1e-8
self.max_grad_norm = 1.0
self.num_train_epochs = 3
self.max_steps = -1
self.warmup_steps = 0
self.logging_steps = 1000
self.save_steps = 3500
self.save_total_limit = None
self.eval_all_checkpoints = False
self.no_cuda = False
self.overwrite_output_dir = True
self.overwrite_cache = True
self.should_continue = False
self.seed = 42
self.local_rank = -1
self.fp16 = False
self.fp16_opt_level = 'O1'
args = Args()
```
## Prepare Dataset
Our dialogues dataset will be based on a dataset used in Andrada Olteanu's [article](https://www.kaggle.com/andradaolteanu/sentiment-analysis-rick-and-morty-scripts/) about Rick and Morty sentiment analysis. Big thanks to her work and also to Gabriel Hernandes, author of original [text dataset](https://github.com/ghhernandes/rickmorty-gan/tree/master/data)!
Image from [Giphy](https://giphy.com/)
First of all we will use kaggle module to download needed dataset. You can read in more detail about module and how to get Kaggle API Token by this [link](https://github.com/Kaggle/kaggle-api). Or you can just download RickAndMortyScripts.csv file from [article](https://www.kaggle.com/andradaolteanu/sentiment-analysis-rick-and-morty-scripts/) and place this file in your working directory.
```
#!pip install kaggle
#!mkdir ~/.kaggle
#!cp kaggle.json ~/.kaggle/kaggle.json
#!kaggle datasets download andradaolteanu/rickmorty-scripts -f RickAndMortyScripts.csv
#!mv datasets%2F506221%2F935855%2FRickAndMortyScripts.csv RickAndMortyScripts.csv
os.chdir("/content/drive/My Drive/2022")
# Let's look at original dataset
#all_rick = pd.read_csv('/content/drive/My Drive/2022/RickAndMortyScripts.csv')
#all_rick = pd.read_csv('RickAndMortyScripts.csv')
all_rick = pd.read_csv('duplicate_row2.csv')
all_rick.head(10)
all_rick.columns = ['ignore', 'line']
```
We will convert this dataset in a way that every responce row will contain **n** previous responces as a context. For our purposes seven previous responces will be enough.
```
contexted = []
n = 1
for i in range(n, len(all_rick['line'])):
row = []
prev = i - 1 - n # we additionally substract 1, so row will contain current responce and 7 previous responces
for j in range(i, prev, -1):
row.append(all_rick['line'][j])
contexted.append(row)
len(contexted)
columns = ['response', 'context']
columns = columns + ['context/'+str(i) for i in range(n-1)]
columns
df = pd.DataFrame.from_records(contexted, columns=columns)
df.head(5)
# --------------------------------------
print('*' * 80)
df = pd.read_csv('response_context.csv')
df.drop('Unnamed: 0', axis=1, inplace=True)
df
```
Split our dataset into a training and test parts.
```
trn_df, val_df = train_test_split(df, test_size = 0.1)
trn_df.head()
```
```
# This is formatted as code
```
Now will convert our dataset in a format suitable for our model. Basically we will concatenate responses in one string for each row (additionally we will add special 'end of string' token between responses, so the model will understand end of each response in a string).
```
def construct_conv(row, tokenizer, eos = True):
flatten = lambda l: [item for sublist in l for item in sublist]
conv = list(reversed([tokenizer.encode(x) + [tokenizer.eos_token_id] for x in row]))
conv = flatten(conv)
return conv
class ConversationDataset(Dataset):
def __init__(self, tokenizer: PreTrainedTokenizer, args, df, block_size=512):
block_size = block_size - (tokenizer.model_max_length - tokenizer.max_len_single_sentence)
directory = args.cache_dir
cached_features_file = os.path.join(
directory, args.model_type + "_cached_lm_" + str(block_size)
)
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
with open(cached_features_file, "rb") as handle:
self.examples = pickle.load(handle)
else:
logger.info("Creating features from dataset file at %s", directory)
self.examples = []
for _, row in df.iterrows():
conv = construct_conv(row, tokenizer)
self.examples.append(conv)
logger.info("Saving features into cached file %s", cached_features_file)
with open(cached_features_file, "wb") as handle:
pickle.dump(self.examples, handle, protocol=pickle.HIGHEST_PROTOCOL)
def __len__(self):
return len(self.examples)
def __getitem__(self, item):
return torch.tensor(self.examples[item], dtype=torch.long)
# Cacheing and storing of data/checkpoints
def load_and_cache_examples(args, tokenizer, df_trn, df_val, evaluate=False):
return ConversationDataset(tokenizer, args, df_val if evaluate else df_trn)
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
def _sorted_checkpoints(args, checkpoint_prefix="checkpoint", use_mtime=False) -> List[str]:
ordering_and_checkpoint_path = []
glob_checkpoints = glob.glob(os.path.join(args.output_dir, "{}-*".format(checkpoint_prefix)))
for path in glob_checkpoints:
if use_mtime:
ordering_and_checkpoint_path.append((os.path.getmtime(path), path))
else:
regex_match = re.match(".*{}-([0-9]+)".format(checkpoint_prefix), path)
if regex_match and regex_match.groups():
ordering_and_checkpoint_path.append((int(regex_match.groups()[0]), path))
checkpoints_sorted = sorted(ordering_and_checkpoint_path)
checkpoints_sorted = [checkpoint[1] for checkpoint in checkpoints_sorted]
return checkpoints_sorted
def _rotate_checkpoints(args, checkpoint_prefix="checkpoint", use_mtime=False) -> None:
if not args.save_total_limit:
return
if args.save_total_limit <= 0:
return
# Check if we should delete older checkpoint(s)
checkpoints_sorted = _sorted_checkpoints(args, checkpoint_prefix, use_mtime)
if len(checkpoints_sorted) <= args.save_total_limit:
return
number_of_checkpoints_to_delete = max(0, len(checkpoints_sorted) - args.save_total_limit)
checkpoints_to_be_deleted = checkpoints_sorted[:number_of_checkpoints_to_delete]
for checkpoint in checkpoints_to_be_deleted:
logger.info("Deleting older checkpoint [{}] due to args.save_total_limit".format(checkpoint))
shutil.rmtree(checkpoint)
```
## Training and Evaluating
There will be quite a lot of code needed for training our model but don’t worry, everything should work as is, the main thing is to give the model the dataset in the right format.
Image from [Giphy](https://giphy.com/)
```
train_dataset = ConversationDataset(tokenizer, args, trn_df)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
train_dataset
def train(args, train_dataset, model: PreTrainedModel, tokenizer: PreTrainedTokenizer) -> Tuple[int, float]:
""" Train the model """
if args.local_rank in [-1, 0]:
tb_writer = SummaryWriter()
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
def collate(examples: List[torch.Tensor]):
if tokenizer._pad_token is None:
return pad_sequence(examples, batch_first=True)
return pad_sequence(examples, batch_first=True, padding_value=tokenizer.pad_token_id)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
train_dataloader = DataLoader(
train_dataset, sampler=train_sampler, batch_size=args.train_batch_size, collate_fn=collate, drop_last = True
)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
model = model.module if hasattr(model, "module") else model # Take care of distributed/parallel training
model.resize_token_embeddings(len(tokenizer))
# add_special_tokens_(model, tokenizer)
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
# Check if saved optimizer or scheduler states exist
if (
args.model_name_or_path
and os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt"))
and os.path.isfile(os.path.join(args.model_name_or_path, "scheduler.pt"))
):
# Load in optimizer and scheduler states
optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
logger.info(
" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size
* args.gradient_accumulation_steps
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
)
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 0
epochs_trained = 0
steps_trained_in_current_epoch = 0
# Check if continuing training from a checkpoint
if args.model_name_or_path and os.path.exists(args.model_name_or_path):
try:
# set global_step to gobal_step of last saved checkpoint from model path
checkpoint_suffix = args.model_name_or_path.split("-")[-1].split("/")[0]
global_step = int(checkpoint_suffix)
epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
logger.info(" Continuing training from checkpoint, will skip to saved global_step")
logger.info(" Continuing training from epoch %d", epochs_trained)
logger.info(" Continuing training from global step %d", global_step)
logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
except ValueError:
logger.info(" Starting fine-tuning.")
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(
epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
)
set_seed(args) # Added here for reproducibility
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
# Skip past any already trained steps if resuming training
if steps_trained_in_current_epoch > 0:
steps_trained_in_current_epoch -= 1
continue
inputs, labels = (batch, batch)
if inputs.shape[1] > 1024: continue
inputs = inputs.to(args.device)
labels = labels.to(args.device)
model.train()
outputs = model(inputs, labels=labels)
loss = outputs[0] # model outputs are always tuple in transformers (see doc)
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
# Log metrics
if (
args.local_rank == -1 and args.evaluate_during_training
): # Only evaluate when single GPU otherwise metrics may not average well
results = evaluate(args, model, tokenizer)
for key, value in results.items():
tb_writer.add_scalar("eval_{}".format(key), value, global_step)
tb_writer.add_scalar("lr", scheduler.get_lr()[0], global_step)
tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
logging_loss = tr_loss
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
checkpoint_prefix = "checkpoint"
# Save model checkpoint
output_dir = os.path.join(args.output_dir, "{}-{}".format(checkpoint_prefix, global_step))
os.makedirs(output_dir, exist_ok=True)
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
torch.save(args, os.path.join(output_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", output_dir)
_rotate_checkpoints(args, checkpoint_prefix)
torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
logger.info("Saving optimizer and scheduler states to %s", output_dir)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank in [-1, 0]:
tb_writer.close()
return global_step, tr_loss / global_step
# Evaluation of some model
def evaluate(args, model: PreTrainedModel, tokenizer: PreTrainedTokenizer, df_trn, df_val, prefix="") -> Dict:
# Loop to handle MNLI double evaluation (matched, mis-matched)
eval_output_dir = args.output_dir
eval_dataset = load_and_cache_examples(args, tokenizer, df_trn, df_val, evaluate=True)
os.makedirs(eval_output_dir, exist_ok=True)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
def collate(examples: List[torch.Tensor]):
if tokenizer._pad_token is None:
return pad_sequence(examples, batch_first=True)
return pad_sequence(examples, batch_first=True, padding_value=tokenizer.pad_token_id)
eval_sampler = SequentialSampler(eval_dataset)
eval_dataloader = DataLoader(
eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size, collate_fn=collate, drop_last = True
)
# multi-gpu evaluate
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(eval_dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
model.eval()
for batch in tqdm(eval_dataloader, desc="Evaluating"):
inputs, labels = (batch, batch)
inputs = inputs.to(args.device)
labels = labels.to(args.device)
with torch.no_grad():
outputs = model(inputs, labels=labels)
lm_loss = outputs[0]
eval_loss += lm_loss.mean().item()
nb_eval_steps += 1
eval_loss = eval_loss / nb_eval_steps
perplexity = torch.exp(torch.tensor(eval_loss))
result = {"perplexity": perplexity}
output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results {} *****".format(prefix))
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
return result
# Main runner
def main(df_trn, df_val):
args = Args()
if args.should_continue:
sorted_checkpoints = _sorted_checkpoints(args)
if len(sorted_checkpoints) == 0:
raise ValueError("Used --should_continue but no checkpoint was found in --output_dir.")
else:
args.model_name_or_path = sorted_checkpoints[-1]
if (
os.path.exists(args.output_dir)
and os.listdir(args.output_dir)
and args.do_train
and not args.overwrite_output_dir
and not args.should_continue
):
raise ValueError(
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
args.output_dir
)
)
# Setup CUDA, GPU & distributed training
device = torch.device("cuda")
args.n_gpu = torch.cuda.device_count()
args.device = device
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
args.local_rank,
device,
args.n_gpu,
bool(args.local_rank != -1),
args.fp16,
)
# Set seed
set_seed(args)
config = AutoConfig.from_pretrained(args.config_name, cache_dir=args.cache_dir)
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, cache_dir=args.cache_dir)
model = AutoModelWithLMHead.from_pretrained(
args.model_name_or_path,
from_tf=False,
config=config,
cache_dir=args.cache_dir,
)
model.to(args.device)
logger.info("Training/evaluation parameters %s", args)
# Training
if args.do_train:
train_dataset = load_and_cache_examples(args, tokenizer, df_trn, df_val, evaluate=False)
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
# Saving best-practices: if you use save_pretrained for the model and tokenizer, you can reload them using from_pretrained()
if args.do_train:
# Create output directory if needed
os.makedirs(args.output_dir, exist_ok=True)
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
# Load a trained model and vocabulary that you have fine-tuned
model = AutoModelWithLMHead.from_pretrained(args.output_dir)
tokenizer = AutoTokenizer.from_pretrained(args.output_dir)
model.to(args.device)
# Evaluation
results = {}
if args.do_eval and args.local_rank in [-1, 0]:
checkpoints = [args.output_dir]
if args.eval_all_checkpoints:
checkpoints = list(
os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
)
logging.getLogger("transformers.modeling_utils").setLevel(logging.WARN) # Reduce logging
logger.info("Evaluate the following checkpoints: %s", checkpoints)
for checkpoint in checkpoints:
global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
prefix = checkpoint.split("/")[-1] if checkpoint.find("checkpoint") != -1 else ""
model = AutoModelWithLMHead.from_pretrained(checkpoint)
model.to(args.device)
result = evaluate(args, model, tokenizer, df_trn, df_val, prefix=prefix)
result = dict((k + "_{}".format(global_step), v) for k, v in result.items())
results.update(result)
return results
```
It is time to train our model!
Image from [Giphy](https://giphy.com/)
```
main(trn_df, val_df)
```
## Chatting with Rick
```
print('-' * 100)
```
The model is ready, so it's time to chat with Rick. But don't forget that Rick can be rude, I warned you.
A variety of methods can be used in responces generation. You can find more details about these methods by this [link](https://huggingface.co/blog/how-to-generate).
Image from [Giphy](https://giphy.com/)
```
tokenizer = AutoTokenizer.from_pretrained('microsoft/DialoGPT-small')
model = AutoModelWithLMHead.from_pretrained('output-small')
# Let's chat for 5 lines
for step in range(12):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> ") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
#bot_input_ids = new_user_input_ids
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
#prev_ids = new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature = 0.8
)
# pretty print last ouput tokens from bot
print("AdviceBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
**User**:How are you, Rick? <br>
**RickBot**: I'm fine. <br>
**User**:Where is Morty? <br>
**RickBot**: He's in a hospital. <br>
**User**:Why? <br>
**RickBot**: Well, that depends on who breaks first -- me or the hospital. I mean, you know, the one that keeps giving me pills. <br>
**User**:I don't understand <br>
**RickBot**: Whoa! Whoa! <br>
**User**:I see, you took your pills <br>
**RickBot**: Hey, I-I'm not proud of this. <br>
I will give an example of a few more dialogues to show how Ricky is our Rick now.
Image from [Giphy](https://giphy.com/)
**User**:Who are you? <br>
**RickBot**: A musician, I'm not a musician, but I'm pretty close to you. <br>
**User**:What kind of musician are you? <br>
**RickBot**: Who cares? I'm a musician. <br>
**User**:Ok, play a song for me <br>
**RickBot**: Shut up and listen to me, Morty. Listen to me. Listen! I'm the leader of a bunch of different death worlds, and I'm just trying to assemble a band. I'm gonna make this one-piece, and you're gonna be part of it. <br>
**User**:ok <br>
**RickBot**: Whoa, whoa, hey, who's this? <br>
**User**:This is Morty <br>
**RickBot**: Geez!!! <br>
Image from [news.knowyourmeme.com](https://news.knowyourmeme.com/news/elon-musks-rick-and-morty-cameo-is-a-meme-reference)
**User**:What do you think about Elon Musk? <br>
**RickBot**: I think about him a lot. <br>
**User**:But what exactly do you think? <br>
**RickBot**: He's not a bad guy. He's just... not a very charismatic one. <br>
**User**:I think he is charismatic <br>
**RickBot**: He is. <br>
**User**:What else you can say about him? <br>
**RickBot**: You don't have to say anything. He is the leader of your class. <br>
**User**:ok, thank you <br>
**RickBot**: !!!
Image from [Giphy](https://giphy.com/)
**User**:hey, go get me a burger <br>
RickBot: Whoa, whoa, hold on a second, let's not get crazy. This is gonna be good. <br>
**User**:I'm hungry! c'mon, buy me a burger or better two <br>
**RickBot**: Holy crap. <br>
**User**:no crappy burger, a good one! <br>
**RickBot**: What the hell? <br>
**User**:don't be so bad, feed me <br>
**RickBot**: I'll be back as fast as I can, Morty. <br>
**User**:good boy, and don't forget ketchup and fries <br>
**RickBot**: !!!!!! <br>
**User**:what a hell? can you reply with words? <br>
**RickBot**: Yes!! I will!! We will go out on a date. <br>
## Conclusion
Image from [Giphy](https://giphy.com/)
Congratulations! Our virtual Rick is alive (almost)! With the help of fine-tuning our model on a small dataset, we were able to create a virtual character with whom we can conduct interesting dialogs.
Using the proposed approach you can create many interesting virtual characters based on an arbitrary dialogs dataset (just a csv file with replicas, one replica per line).
```
```
| github_jupyter |
```
import os, json
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
import numpy as np
```
## Hyperparameter analysis on loss and accuracy for various batch sizes and learning rates
```
#The following folder structure is required in the project directory:
#--saved_models
# +
# +
# --sgd_lr_bs
# +
# +
# --sgd_lr0001_bs10
# --sgd_lr0001_bs100
# --sgd_lr0001_bs1000
# --sgd_lr001_bs10
# .
# . ... for the foldernames: [ 'sgd_lr0001_bs10', 'sgd_lr0001_bs100', 'sgd_lr0001_bs1000', 'sgd_lr001_bs10', 'sgd_lr001_bs100', 'sgd_lr001_bs1000', 'sgd_lr01_bs10', 'sgd_lr01_bs100', 'sgd_lr01_bs1000' ]
# .
# --sgd_lr01_bs100
# --sgd_lr01_bs1000
```
## Generalization
Run on testdata and see how the models generalize
```
path_to_model = 'saved_models/sgd_lr_bs/sgd_lr0001_bs100'
model = keras.models.load_model(path_to_model)
print('done')
#load x_test, y_test
foldernames = [ 'sgd_lr0001_bs10', 'sgd_lr0001_bs100', 'sgd_lr0001_bs1000', 'sgd_lr001_bs10', 'sgd_lr001_bs100', 'sgd_lr001_bs1000',
'sgd_lr01_bs10', 'sgd_lr01_bs100', 'sgd_lr01_bs1000' ]
x_test = np.load('x_test.npy')
y_test = np.load('y_test.npy')
#run on test dataset
for foldername in foldernames:
model.load_weights('saved_models/sgd_lr_bs/'+foldername+'/deneme.h5')
print('got model')
metrics = model.evaluate(
x=x_test, y=y_test, batch_size=1, return_dict=True
)
path_to_metrics = 'saved_models/sgd_lr_bs/'+foldername+'/test_metrics'
with open(path_to_metrics, 'w') as json_data_file:
json.dump(metrics, json_data_file)
# create plot bs x lr and plot loss and acc on test data
import pandas as pd
losses = np.empty(shape=(0))
accuracies = np.empty(shape=(0))
batch_sizes = np.empty(shape=(0))
learn_rates = np.empty(shape=(0))
for foldername in foldernames:
path_to_metrics = 'saved_models/sgd_lr_bs/'+foldername+'/test_metrics'
with open(path_to_metrics) as json_data_file:
data = json.load(json_data_file)
lr = float(('0.')+(foldername.split('r')[1]).split('_')[0])
bs = foldername.split('s')[2]
losses = np.append(losses, data['loss'])
accuracies = np.append(accuracies, data['accuracy'])
batch_sizes = np.append(batch_sizes, bs)
learn_rates = np.append(learn_rates, lr)
metrics = np.empty([2, 9])
metrics_dict = {'losses': {}, 'accuracies': {}}
metrics_dict['losses'] = losses
metrics_dict['accuracies'] = accuracies
metrics_serializable = metrics.tolist()
with open('saved_models/metrics_summary.json','w') as f:
json.dump(metrics_serializable, f)
import math
import pandas as pd
import seaborn as sns
print('\n')
print('')
acc_color = 'tab:orange'
loss_color = 'tab:blue'
ymin_loss = 0.0
ymax_loss = 5.0
ymin_acc = 0.0
ymax_acc = 1.0
def truncate(number, digits) -> float:
stepper = 10.0 ** digits
return math.trunc(stepper * number) / stepper
def label_point(df, x, y, val, ax):
a = pd.concat({'x': df[x]}, axis=1)
for i, point in df.iterrows():
ax.text(point[x], point[y], str(truncate(point[val], 3)), fontsize=14)
loss = pd.DataFrame(losses, columns={'loss'})
accuracy = pd.DataFrame(accuracies, columns={'accuracy'})
bs = pd.DataFrame(batch_sizes, columns={'batch_size'})
lr = pd.DataFrame(learn_rates, columns={'learning_rate'})
df = pd.concat([loss, accuracy, bs, lr], axis=1)
print(df)
fig = plt.figure()
fig.subplots_adjust(top=3.0, bottom=0.5, left=0.5, right=3.0, hspace=0.3, wspace=1)
keys = ['loss', 'accuracy']
for i in (0, 1):
sb = fig.add_subplot(2, 2, i+1)
sb = sns.scatterplot(x='batch_size',
y='learning_rate',
size=keys[i],
data=df,
sizes=(200, 2000))
plt.legend(bbox_to_anchor=(1.1, 1.1),borderaxespad=1.7)
sb.set(yscale="log", ylim=(0.00001, 1.0))
sb.set_title(keys[i])
label_point(df, 'batch_size', 'learning_rate', keys[i], plt.gca())
for foldername in foldernames:
path_to_metrics = 'saved_models/sgd_lr_bs/'+foldername+'/test_metrics'
with open(path_to_metrics) as json_data_file:
data = json.load(json_data_file)
lr = ('0.')+(foldername.split('r')[1]).split('_')[0]
bs = foldername.split('s')[2]
data1 = data['loss']
data2 = data['accuracy']
figure = plt.figure(figsize=(15, 15))
i = 0
for foldername in foldernames:
path_to_json = 'saved_models/sgd_lr_bs/'+foldername+'/deneme.json'
with open(path_to_json) as json_data_file:
data = json.load(json_data_file)
if i < 3:
xmax = 24
elif i < 6:
xmax = 17
elif i < 9:
xmax = 10
else:
xmax = 2
ax = figure.add_subplot(4, 3, i+1)
figure.subplots_adjust(top=2.5, bottom=0.5, left=0.5, right=3.0, hspace=0.3, wspace=0.4)
ax.set_title(foldername, fontsize=50)
data1 = data['loss']
data2 = data['accuracy']
data3 = data['val_loss']
data4 = data['val_accuracy']
ax.set_xlabel('epoch', color=loss_color, fontsize = 30)
ax.set_ylabel('train_loss', color=loss_color, fontsize = 30)
ax.set_xlim([0, xmax])
ax.set_ylim([ymin_loss,ymax_loss])
ax.plot(data1, color=loss_color)
ax.plot(data3, '--', color=loss_color)
ax2 = ax.twinx()
ax2.set_ylabel('train_acc', color=acc_color, fontsize = 30)
ax2.set_ylim([ymin_acc,ymax_acc])
ax2.set_xlim([0, xmax])
ax2.plot(data2, color=acc_color)
ax2.plot(data4, '--', color=acc_color)
text = (truncate(df['accuracy'][i], 3))
text = 'test accuracy: ' + str(text)
ax.text(0.65, -0.05, text, transform=ax.transAxes, fontsize=24,
verticalalignment='top')
i+=1
figure.savefig('saved_models/train_val_graphs.pdf', bbox_inches='tight')
fig.savefig('saved_models/generalization.pdf', bbox_inches='tight')
```
| github_jupyter |
# Building ERDDAP Datasets
This notebook documents the process of creating XML fragments
for nowcast system run results files
for inclusion in `/results/erddap-datasets/datasets.xml`
which is symlinked to `/opt/tomcat/content/erddap/datasets.xml`
on the `skookum` ERDDAP server instance.
The contents are a combination of:
* instructions for using the
`GenerateDatasetsXml.sh` and `DasDds.sh` tools found in the
`/opt/tomcat/webapps/erddap/WEB-INF/` directory
* instructions for forcing the server to update the datasets collection
via the `/results/erddap/flags/` directory
* code and metadata to transform the output of `GenerateDatasetsXml.sh`
into XML fragments that are ready for inclusion in `/results/erddap-datasets/datasets.xml`
This is a snapshot of the `erddap-datasets/ERDDAP_datasets.ipynb` notebook that is used
to maintain the `datasets.xml` file.
Please see https://bitbucket.org/salishsea/erddap-datasets for the active,
version controlled version of this notebook,
and the production ``datasets.xml` file.
```
from collections import OrderedDict
from lxml import etree
```
**NOTE**
The next cell mounts the `/results` filesystem on `skookum` locally.
It is intended for use if when this notebook is run on a laptop
or other non-Waterhole machine that has `sshfs` installed
and a mount point for `/results` available in its root filesystem.
Don't execute the cell if that doesn't describe your situation.
```
!sshfs skookum:/results /results
```
The `metadata` dictionary below contains information for dataset
attribute tags whose values need to be changed,
or that need to be added for all datasets.
The keys are the dataset attribute names.
The values are dicts containing a required `text` item
and perhaps an optional `after` item.
The value associated with the `text` key is the text content
for the attribute tag.
When present,
the value associated with the `after` key is the name
of the dataset attribute after which a new attribute tag
containing the `text` value is to be inserted.
```
metadata = OrderedDict([
('coverage_content_type', {
'text': 'modelResult',
'after': 'cdm_data_type',
}),
('infoUrl', {
'text':
'https://salishsea-meopar-docs.readthedocs.io/en/latest/results_server/index.html#salish-sea-model-results',
}),
('institution', {'text': 'UBC EOAS'}),
('institution_fullname', {
'text': 'Earth, Ocean & Atmospheric Sciences, University of British Columbia',
'after': 'institution',
}),
('license', {
'text': '''The Salish Sea MEOPAR NEMO model results are copyright 2013-2021
by the Salish Sea MEOPAR Project Contributors and The University of British Columbia.
They are licensed under the Apache License, Version 2.0. http://www.apache.org/licenses/LICENSE-2.0''',
}),
('project', {
'text':'Salish Sea MEOPAR NEMO Model',
'after': 'title',
}),
('creator_name', {
'text': 'Salish Sea MEOPAR Project Contributors',
'after': 'project',
}),
('creator_email', {
'text': 'sallen@eos.ubc.ca',
'after': 'creator_name',
}),
('creator_url', {
'text': 'https://salishsea-meopar-docs.readthedocs.io/',
'after': 'creator_email',
}),
('acknowledgement', {
'text': 'MEOPAR, ONC, Compute Canada',
'after': 'creator_url',
}),
('drawLandMask', {
'text': 'over',
'after': 'acknowledgement',
}),
])
```
The `datasets` dictionary below provides the content
for the dataset `title` and `summary` attributes.
The `title` attribute content appears in the the datasets list table
(among other places).
It should be `<`80 characters long,
and note that only the 1st 40 characters will appear in the table.
The `summary` attribute content appears
(among other places)
when a user hovers the cursor over the `?` icon beside the `title`
content in the datasets list table.
The text that is inserted into the `summary` attribute tag
by code later in this notebook is the
`title` content followed by the `summary` content,
separated by a blank line.
The keys of the `datasets` dict are the `datasetID` strings that
are used in many places by the ERDDAP server.
They are structured as follows:
* `ubc` to indicate that the dataset was produced at UBC
* `SS` to indicate that the dataset is a product of the Salish Sea NEMO model
* a few letters to indicate the model runs that produce the dataset:
* `n` to indicate that the dataset is from a nowcast run,
* `f` for forecast,
* `f2` for forecast2 (aka preliminary forecast),
* `hg` for hindcast-green
* `ng` for nowcast-green,
* `a` for atmospheric forcing,
* a description of the dataset variables; e.g. `PointAtkinsonSSH` or `3DuVelocity`
* the time interval of values in the dataset; e.g. `15m`, `1h`, `1d`
* the dataset version; e.g. `V16-10`, or `V1`
Versioning was changed to a [CalVer](http://calver.org/) type scheme in Oct-2016.
Thereafter versions are of the form `Vyymm` and indicate the year and month when the dataset entered production.
So:
* `ubcSSnPointAtkinsonSSH15mV1` is the version 1 dataset of 15 minute averaged sea surface height values at Point Atkinson from `PointAtkinson.nc` output files
* `ubcSSn3DwVelocity1hV2` is the version 2 dataset of 1 hr averaged vertical (w) velocity values over the entire domain from `SalishSea_1h_*_grid_W.nc` output files
* `ubcSSnSurfaceTracers1dV1` is the version 1 dataset of daily averaged surface tracer values over the entire domain from `SalishSea_1d_*_grid_T.nc` output files
* `ubcSSnBathymetry2V16-07` is the version 16-07 dataset of longitude, latitude, and bathymetry of the Salish Sea NEMO model grid that came into use in Jul-2016.
The corresponding NEMO-generated mesh mask variables are in the `ubcSSn2DMeshMaskDbo2V16-07` (y, x variables),
and the `ubcSSn3DMeshMaskDbo2V16-07` (z, y, x variables) datasets.
The dataset version part of the `datasetID` is used to indicate changes in the variables
contained in the dataset.
For example,
the transition from the `ubcSSn3DwVelocity1hV1` to the `ubcSSn3DwVelocity1hV2` dataset
occurred on 24-Jan-2016 when we started to output vertical eddy viscosity and diffusivity
values at the `w` grid points.
All dataset ids end with their version identifier and their `summary` ends with a notation about the variables
that they contain; e.g.
```
v1: wVelocity variable
```
When the a dataset version is incremented a line describing the change is added
to the end of its `summary`; e.g.
```
v1: wVelocity variable
v2: Added eddy viscosity & diffusivity variables ve_eddy_visc & ve_eddy_diff
```
```
datasets = {
'ubcSSnBathymetry2V1' :{
'type': 'geolocation bathymetry',
'title': 'Salish Sea NEMO Model Grid, Geo-location and Bathymetry, v1',
'summary':'''Longitude, latitude, and bathymetry of the Salish Sea NEMO model grid.
The bathymetry values are those calculated by NEMO from the input bathymetry file.
NEMO modifies the input bathymetry to remove isolated holes, and too-small partial steps.
The model grid includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
v1: longitude, latitude and bathymetry variables
''',
'fileNameRegex': '.*SalishSea2_NEMO_bathy\.nc$'
},
'ubcSSnBathymetry2V16-07' :{
'type': 'geolocation bathymetry',
'title': 'Salish Sea NEMO Model Grid, Geo-location and Bathymetry, v16-07',
'summary':'''Longitude, latitude, and bathymetry of the Salish Sea NEMO model grid.
The bathymetry values are those calculated by NEMO from the input bathymetry file.
NEMO modifies the input bathymetry to remove isolated holes, and too-small partial steps.
The model grid includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
v1: longitude, latitude and bathymetry variables
v16-07: same variables,
bathymetry uniformly deepened by 1 grid level,
smoothed at Juan de Fuca & Johnstone Strait open boundaries,
Fraser River lengthened,
bathymetry deepened near mouth of Fraser River
''',
'fileNameRegex': '.*downbyone2_NEMO_bathy\.nc$'
},
'ubcSSn2DMeshMask2V1': {
'type': 'geolocation bathymetry',
'title': 'Salish Sea NEMO Model Grid, 2D Mesh Mask, v1',
'summary':'''NEMO grid variable value for the u-v plane of the
Salish Sea NEMO model Arakawa-C grid.
The values are those calculated by NEMO from the input coordinates and bathymetry files.
The variable names are those used by NEMO-3.4,
see the NEMO-3.4 book (http://www.nemo-ocean.eu/Media/Files/NEMO_book_V3_4.pdf) for details,
or the long_name attributes of the variables for succinct descriptions of the variables.
The model grid includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
v1: e1t, e2t, e1u, e2u, e1v, e2v, e1f, e2f, glamt, gphit, glamu, gphiu, glamv, gphiv,
tmaskutil, umaskutil, vmaskutil, fmaskutil, ff, mbathy variables
''',
'fileNameRegex': '.*mesh_mask_SalishSea2\.nc$',
},
'ubcSSn2DMeshMask2V16-07': {
'type': 'geolocation bathymetry',
'title': 'Salish Sea NEMO Model Grid, 2D Mesh Mask, v16-07',
'summary':'''NEMO grid variable value for the u-v plane of the
Salish Sea NEMO model Arakawa-C grid.
The values are those calculated by NEMO from the input coordinates and bathymetry files.
The variable names are those used by NEMO-3.6,
see the NEMO-3.6 book (http://www.nemo-ocean.eu/Media/Files/NEMO_book_V3_6.pdf) for details,
or the long_name attributes of the variables for succinct descriptions of the variables.
The model grid includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
v1: e1t, e2t, e1u, e2u, e1v, e2v, e1f, e2f, glamt, gphit, glamu, gphiu, glamv, gphiv,
tmaskutil, umaskutil, vmaskutil, fmaskutil, ff, mbathy variables
v16-07: e1t, e2t, e1u, e2u, e1v, e2v, e1f, e2f, glamt, gphit, glamu, gphiu, glamv, gphiv,
glamf, gphif, tmaskutil, umaskutil, vmaskutil, fmaskutil, ff, mbathy variables
''',
'fileNameRegex': '.*mesh_mask_downbyone2\.nc$',
},
'ubcSSn3DMeshMask2V1': {
'type': 'geolocation bathymetry',
'title': 'Salish Sea NEMO Model Grid, 3D Mesh Mask, v1',
'summary':'''NEMO grid variable value for the Salish Sea NEMO model Arakawa-C grid.
The values are those calculated by NEMO from the input coordinates and bathymetry files.
The variable names are those used by NEMO-3.4,
see the NEMO-3.4 book (http://www.nemo-ocean.eu/Media/Files/NEMO_book_V3_4.pdf) for details,
or the long_name attributes of the variables for succinct descriptions of the variables.
The model grid includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
v1: e3t, e3u, e3v, e3w, gdept, gdepu, gdepv, gdepw, tmask, umask, vmask, fmask variables
''',
'fileNameRegex': '.*mesh_mask_SalishSea2\.nc$'
},
'ubcSSn3DMeshMask2V16-07': {
'type': 'geolocation bathymetry',
'title': 'Salish Sea NEMO Model Grid, 3D Mesh Mask, v16-07',
'summary':'''NEMO grid variable value for the Salish Sea NEMO model Arakawa-C grid.
The values are those calculated by NEMO from the input coordinates and bathymetry files.
The variable names are those used by NEMO-3.6,
see the NEMO-3.6 book (http://www.nemo-ocean.eu/Media/Files/NEMO_book_V3_6.pdf) for details,
or the long_name attributes of the variables for succinct descriptions of the variables.
The model grid includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
v1: e3t_0, e3u_0, e3v_0, e3w_0, gdept_0, gdepu, gdepv, gdepw_0, tmask, umask, vmask, fmask variables
v16-07: e3t, e3u, e3v, e3w, gdept, gdepu, gdepv, gdepw, tmask, umask, vmask, fmask variables
''',
'fileNameRegex': '.*mesh_mask_downbyone2\.nc$'
},
'ubcSSnPointAtkinsonSSH15mV1': {
'type': 'tide gauge',
'title': 'Nowcast, Point Atkinson, Sea Surface Height, 15min, v1',
'summary': '''Sea surface height values averaged over 15 minute intervals from
Salish Sea NEMO model nowcast runs. The values are calculated at the model grid point
closest to the Point Atkinson tide gauge station on the north side of English Bay,
near Vancouver, British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: ssh variable
''',
'fileNameRegex': '.*PointAtkinson\.nc$',
},
'ubcSSnCampbellRiverSSH15mV1': {
'type': 'tide gauge',
'title': 'Nowcast, Campbell River, Sea Surface Height, 15min, v1',
'summary': '''Sea surface height values averaged over 15 minutes intervals from
Salish Sea NEMO model nowcast runs. The values are calculated at the model grid point
closest to the Campbell River tide gauge station at the north end of the Strait of Georgia,
near Campbell River, British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: ssh variable
''',
'fileNameRegex': '.*CampbellRiver\.nc$',
},
'ubcSSnCherryPointSSH15mV1': {
'type': 'tide gauge',
'title': 'Nowcast, Cherry Point, Sea Surface Height, 15min, v1',
'summary': '''Sea surface height values averaged over 15 minutes intervals from
Salish Sea NEMO model nowcast runs. The values are calculated at the model grid point
closest to the Cherry Point tide gauge station in the southern Strait of Georgia,
near Birch Bay, Washington.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: ssh variable
''',
'fileNameRegex': '.*CherryPoint\.nc$',
},
'ubcSSnFridayHarborSSH15mV1': {
'type': 'tide gauge',
'title': 'Nowcast, Friday Harbor, Sea Surface Height, 15min, v1',
'summary': '''Sea surface height values averaged over 15 minutes intervals from
Salish Sea NEMO model nowcast runs. The values are calculated at the model grid point
closest to the Friday Harbor tide gauge station at San Juan Island in Haro Strait,
near Friday Harbor, Washington.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: ssh variable
''',
'fileNameRegex': '.*FridayHarbor\.nc$',
},
'ubcSSnNanaimoSSH15mV1': {
'type': 'tide gauge',
'title': 'Nowcast, Nanaimo, Sea Surface Height, 15min, v1',
'summary': '''Sea surface height values averaged over 15 minutes intervals from
Salish Sea NEMO model nowcast runs. The values are calculated at the model grid point
closest to the Nanaimo tide gauge station on the west side of the central Strait of Georgia,
near Nanaimo, British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: ssh variable
''',
'fileNameRegex': '.*Nanaimo\.nc$',
},
'ubcSSnNeahBaySSH15mV1': {
'type': 'tide gauge',
'title': 'Nowcast, Neah Bay, Sea Surface Height, 15min, v1',
'summary': '''Sea surface height values averaged over 15 minutes intervals from
Salish Sea NEMO model nowcast runs. The values are calculated at the model grid point
closest to the Neah Bay tide gauge station on the south side of the west end of the Juan de Fuca Strait,
near Neah Bay, Washington.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: ssh variable
''',
'fileNameRegex': '.*NeahBay\.nc$',
},
'ubcSSnVictoriaSSH15mV1': {
'type': 'tide gauge',
'title': 'Nowcast, Victoria, Sea Surface Height, 15min, v1',
'summary': '''Sea surface height values averaged over 15 minutes intervals from
Salish Sea NEMO model nowcast runs. The values are calculated at the model grid point
closest to the Victoria tide gauge station on the north side of the east end of the Juan de Fuca Strait,
in the Victoria Inner Harbour, near Victoria, British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: ssh variable
''',
'fileNameRegex': '.*Victoria\.nc$',
},
'ubcSSnSandHeadsSSH15mV1': {
'type': 'tide gauge',
'title': 'Nowcast, Sand Heads, Sea Surface Height, 15min, v1',
'summary': '''Sea surface height values averaged over 15 minutes intervals from
Salish Sea NEMO model nowcast runs. The values are calculated at the model grid point
closest to the Sand Heads light station on the east side of the central Strait of Georgia,
near Steveston, British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: ssh variable
''',
'fileNameRegex': '.*Sandheads\.nc$',
},
'ubcSSn3DTracerFields1hV1': {
'type': '3d fields',
'title': 'Nowcast, Salish Sea, 3d Tracer Fields, Hourly, v1',
'summary': '''3d salinity and water temperature field values averaged over 1 hour intervals
from Salish Sea NEMO model nowcast runs. The values are calculated for the entire model grid
that includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: salinity (practical) and temperature variables
''',
'fileNameRegex': '.*SalishSea_1h_\d{8}_\d{8}_grid_T\.nc$',
},
'ubcSSnSurfaceTracerFields1hV1': {
'type': 'surface fields',
'title': 'Nowcast, Salish Sea, Surface Tracer Fields, Hourly, v1',
'summary': '''2d sea surface height and rainfall rate field values averaged over 1 hour intervals
from Salish Sea NEMO model nowcast runs. The values are calculated for the surface of the model grid
that includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: sea surface height and rainfall rate variables
''',
'fileNameRegex': '.*SalishSea_1h_\d{8}_\d{8}_grid_T\.nc$',
},
'ubcSSn3DuVelocity1hV1': {
'type': '3d fields',
'title': 'Nowcast, Salish Sea, 3d u Velocity Field, Hourly, v1',
'summary': '''3d zonal (u) component velocity field values averaged over 1 hour intervals
from Salish Sea NEMO model nowcast runs. The values are calculated for the entire model grid
that includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: uVelocity variable
''',
'fileNameRegex': '.*SalishSea_1h_\d{8}_\d{8}_grid_U\.nc$',
},
'ubcSSn3DvVelocity1hV1': {
'type': '3d fields',
'title': 'Nowcast, Salish Sea, 3d v Velocity Field, Hourly, v1',
'summary': '''3d meridional (v) component velocity field values averaged over 1 hour intervals
from Salish Sea NEMO model nowcast runs. The values are calculated for the entire model grid
that includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: vVelocity variable
''',
'fileNameRegex': '.*SalishSea_1h_\d{8}_\d{8}_grid_V\.nc$',
},
'ubcSSn3DwVelocity1hV1': {
'type': '3d fields',
'title': 'Nowcast, Salish Sea, 3d w Velocity Field, Hourly, v1',
'summary': '''3d vertical (w) component velocity field values averaged over 1 hour intervals
from Salish Sea NEMO model nowcast runs. The values are calculated for the entire model grid
that includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
Geo-location and depth data for the Salish Sea NEMO model grid are available in the ubcSSnBathymetry2V1 dataset.
v1: wVelocity variable
''',
'fileNameRegex': '.*SalishSea_1h_\d{8}_\d{8}_grid_W\.nc$',
},
'ubcSSaSurfaceAtmosphereFieldsV1': {
'type': 'surface fields',
'title': 'HRDPS, Salish Sea, Atmospheric Forcing Fields, Hourly, v1',
'summary': '''2d hourly atmospheric field values from the
Environment Canada HRDPS atmospheric forcing model that are used to force the Salish Sea NEMO model.
The model grid includes the Juan de Fuca Strait, the Strait of Georgia, Puget Sound,
and Johnstone Strait on the coasts of Washington State and British Columbia.
Geo-location data for the atmospheric forcing grid are available in the ubcSSaAtmosphereGridV1 dataset.
Atmospheric field values are interpolated on to the Salish Sea NEMO model grid (ubcSSnBathymetry2V1 dataset)
on-the-fly by NEMO.
v1: atmospheric pressure, precipitation rate, 2m specific humidity, 2m air temperature,
short-wave radiation flux, long-wave radiation flux, 10m u wind component, 10m v wind component variables
''',
'fileNameRegex': '.*ops_y\d{4}m\d{2}d\d{2}\.nc$',
},
}
datasets['ubcSSn3DwVelocity1hV2'] = datasets['ubcSSn3DwVelocity1hV1']
datasets['ubcSSn3DwVelocity1hV2'].update({
'title': datasets['ubcSSn3DwVelocity1hV1']['title'].replace(', v1', ', v2'),
'summary': datasets['ubcSSn3DwVelocity1hV1']['summary'] + '''
v2: Added eddy viscosity & diffusivity variables ve_eddy_visc & ve_eddy_diff''',
})
datasets['ubcSSn3DTracerFields1hV16-10'] = datasets['ubcSSn3DTracerFields1hV1']
datasets['ubcSSn3DTracerFields1hV16-10'].update({
'title': datasets['ubcSSn3DTracerFields1hV1']['title'].replace(', v1', ', v16-10'),
'summary': datasets['ubcSSn3DTracerFields1hV1']['summary'] + '''
v16-10: NEMO-3.6; ubcSSnBathymetry2V16-07 bathymetry; see infoUrl link for full details.
Changed salinity variable to reference salinity.
Made temperature variable explicitly potential temperature.
Added squared buoyancy frequency variable.''',
})
datasets['ubcSSnSurfaceTracerFields1hV16-10'] = datasets['ubcSSnSurfaceTracerFields1hV1']
datasets['ubcSSnSurfaceTracerFields1hV16-10'].update({
'title': datasets['ubcSSnSurfaceTracerFields1hV1']['title'].replace(', v1', ', v16-10'),
'summary': datasets['ubcSSnSurfaceTracerFields1hV1']['summary'] + '''
v16-10: NEMO-3.6; ubcSSnBathymetry2V16-07 bathymetry; see infoUrl link for full details.
Added mixed layer thickness defined by sigma theta variable.
Deleted rainfall rate variable.''',
})
datasets['ubcSSn3DuVelocity1hV16-10'] = datasets['ubcSSn3DuVelocity1hV1']
datasets['ubcSSn3DuVelocity1hV16-10'].update({
'title': datasets['ubcSSn3DuVelocity1hV1']['title'].replace(', v1', ', v16-10'),
'summary': datasets['ubcSSn3DuVelocity1hV1']['summary'] + '''
v16-10: NEMO-3.6; ubcSSnBathymetry2V16-07 bathymetry; see infoUrl link for full details.'''
})
datasets['ubcSSn3DvVelocity1hV16-10'] = datasets['ubcSSn3DvVelocity1hV1']
datasets['ubcSSn3DvVelocity1hV16-10'].update({
'title': datasets['ubcSSn3DvVelocity1hV1']['title'].replace(', v1', ', v16-10'),
'summary': datasets['ubcSSn3DvVelocity1hV1']['summary'] + '''
v16-10: NEMO-3.6; ubcSSnBathymetry2V16-07 bathymetry; see infoUrl link for full details.'''
})
```
The `dataset_vars` dictionary below is used to rename
variables from the often cryptic NEMO names to the names
that appear in the ERDDAP generated files and web content.
The keys are the NEMO variable names to replace.
The values are dicts that map the variable names to use in ERDDAP
to the `destinationName` attribute name.
```
dataset_vars = {
'sossheig': {'destinationName': 'ssh'},
'vosaline': {'destinationName': 'salinity'},
'votemper': {'destinationName': 'temperature'},
'vozocrtx': {'destinationName': 'uVelocity'},
'vomecrty': {'destinationName': 'vVelocity'},
'vovecrtz': {'destinationName': 'wVelocity'},
}
```
A few convenient functions to reduce code repetition:
```
def print_tree(root):
"""Display an XML tree fragment with indentation.
"""
print(etree.tostring(root, pretty_print=True).decode('ascii'))
def find_att(root, att):
"""Return the dataset attribute element named att
or raise a ValueError exception if it cannot be found.
"""
e = root.find('.//att[@name="{}"]'.format(att))
if e is None:
raise ValueError('{} attribute element not found'.format(att))
return e
def replace_yx_with_lonlat(root):
new_axes = {
'y': {'sourceName': 'nav_lon', 'destinationName': 'longitude'},
'x': {'sourceName': 'nav_lat', 'destinationName': 'latitude'},
}
for axis in root.findall('.//axisVariable'):
if axis.find('.//sourceName').text in new_axes:
key = axis.find('.//sourceName').text
new_axis = etree.Element('axisVariable')
etree.SubElement(new_axis, 'sourceName').text = new_axes[key]['sourceName']
etree.SubElement(new_axis, 'destinationName').text = new_axes[key]['destinationName']
axis.getparent().replace(axis, new_axis)
```
Now we're ready to produce a dataset!!!
Use the `/opt/tomcat/webapps/erddap/WEB-INF/GenerateDatasetsXml.sh` script
generate the initial version of an XML fragment for a dataset:
```
$ cd /opt/tomcat/webapps/erddap/WEB-INF/
$ bash GenerateDatasetsXml.sh EDDGridFromNcFiles /results/SalishSea/nowcast/
```
The `EDDGridFromNcFiles` and `/results/SalishSea/nowcast/` arguments
tell the script which `EDDType` and what parent directory to use,
avoiding having to type those in answer to prompts.
Answer the remaining prompts,
for example:
```
File name regex (e.g., ".*\.nc") (default="")
? .*SalishSea_1h_\d{8}_\d{8}_grid_W\.nc$
Full file name of one file (default="")
? /results/SalishSea/nowcast/28jan16/SalishSea_1h_20160128_20160128_grid_W.nc
ReloadEveryNMinutes (e.g., 10080) (default="")
? 10080
```
Other examples of file name regex are:
* `.*PointAtkinson.nc$`
* `.*SalishSea_1d_\d{8}_\d{8}_grid_W\.nc$`
The output is written to `/results/erddap/logs/GenerateDatasetsXml.out`
Now, we:
* set the `datasetID` we want to use
* parse the output of `GenerateDatasetsXml.sh` into an XML tree data structure
* set the `datasetID` dataset attribute value
* re-set the `fileNameRegex` dataset attribute value because it looses its `\` characters during parsing(?)
* edit and add dataset attributes from the `metadata` dict
* set the `title` and `summary` dataset attributes from the `datasets` dict
* set the names of the grid `x` and `y` axis variables
* rename data variables as specified in the `dataset_vars` dict
```
def update_xml(root, datasetID, metadata, datasets, dataset_vars):
root.attrib['datasetID'] = datasetID
root.find('.//fileNameRegex').text = datasets[datasetID]['fileNameRegex']
title = datasets[datasetID]['title']
summary = find_att(root, 'summary')
summary.text = '{0}\n\n{1}'.format(title, datasets[datasetID]['summary'])
e = etree.Element('att', name='title')
e.text = title
summary.addnext(e)
for att, info in metadata.items():
e = etree.Element('att', name=att)
e.text = info['text']
try:
root.find('.//att[@name="{}"]'.format(info['after'])).addnext(e)
except KeyError:
find_att(root, att).text = info['text']
for axis_name in root.findall('.//axisVariable/destinationName'):
if axis_name.text in ('x', 'y'):
axis_name.text = 'grid{}'.format(axis_name.text.upper())
if datasets[datasetID]['type'] == 'tide gauge':
replace_yx_with_lonlat(root)
for var_name in root.findall('.//dataVariable/destinationName'):
if var_name.text in dataset_vars:
var_name.text = dataset_vars[var_name.text]['destinationName']
parser = etree.XMLParser(remove_blank_text=True)
tree = etree.parse('/results/erddap/logs/GenerateDatasetsXml.out', parser)
root = tree.getroot()
datasetID = 'ubcSSn3DvVelocity1hV16-10'
update_xml(root, datasetID, metadata, datasets, dataset_vars)
```
Inspect the resulting dataset XML fragment below and edit the dicts and
code cell above until it is what is required for the dataset:
```
print_tree(root)
```
Extra processing step are required for some types of datasets.
See:
* [Surface Field Datasets](#Surface-Field-Datasets)
* [Model Grid Geo-location and Bathymetry Datasets](#Model-Grid-Geo-location-and-Bathymetry-Datasets)
* [EC HDRPS Atmospheric Forcing Datasets](#EC-HDRPS-Atmospheric-Forcing-Datasets)
Store the XML fragment for the dataset:
```
with open('/results/erddap-datasets/fragments/{}.xml'.format(datasetID), 'wb') as f:
f.write(etree.tostring(root, pretty_print=True))
```
Edit `/results/erddap-datasets/datasets.xml` to include the
XML fragment for the dataset that was stored by the above cell.
That file is symlinked to `/opt/tomcat/content/erddap/datasets.xml`.
Create a flag file to signal the ERDDAP server process to load the dataset:
```
$ cd /results/erddap/flag/
$ touch <datasetID>
```
If the dataset does not appear on https://salishsea.eos.ubc.ca/erddap/info/,
check `/results/erddap/logs/log.txt` for error messages from the dataset load process
(they may not be at the end of the file because ERDDAP is pretty chatty).
Once the dataset has been successfully loaded and you are happy with the metadata
that ERDDAP is providing for it,
commit the changes in `/results/erddap-datasets/` and push them to GitHub.
## Surface Field Datasets
The `/opt/tomcat/webapps/erddap/WEB-INF/GenerateDatasetsXml.sh` script produces and XML
fragment that uses all of the dimensions that it finds in the sample file it parses,
and includes only the variables that have all of those dimensions.
To produce an XML fragment for surface fields we need to do some additional work:
* Delete the depth axis
* Delete all of the `dataVariable` elements
* Add `dataVariable` elements for the surface variables
```
for axis in root.findall('.//axisVariable'):
if axis.find('.//destinationName').text == 'depth':
axis.getparent().remove(axis)
break
for var in root.findall('.//dataVariable'):
var.getparent().remove(var)
var = etree.SubElement(root, 'dataVariable')
etree.SubElement(var, 'sourceName').text = 'sossheig'
etree.SubElement(var, 'destinationName').text = 'ssh'
etree.SubElement(var, 'dataType').text = 'float'
attrs = etree.SubElement(var, 'addAttributes')
etree.SubElement(attrs, 'att', name='_ChunkSize').text = 'null'
etree.SubElement(attrs, 'att', name='coordinates').text = 'null'
var = etree.SubElement(root, 'dataVariable')
etree.SubElement(var, 'sourceName').text = 'rain_rate'
etree.SubElement(var, 'destinationName').text = 'rain_rate'
etree.SubElement(var, 'dataType').text = 'float'
attrs = etree.SubElement(var, 'addAttributes')
etree.SubElement(attrs, 'att', name='_ChunkSize').text = 'null'
etree.SubElement(attrs, 'att', name='coordinates').text = 'null'
find_att(root, 'keywords').text = (
'model results, height, local, sea, sea surface height, sossheig, source, surface, time_counter')
print_tree(root)
with open('/results/erddap-datasets/fragments/{}.xml'.format(datasetID), 'wb') as f:
f.write(etree.tostring(root, pretty_print=True))
```
## Model Grid Geo-location and Bathymetry Datasets
Model grid geo-location and bathymetry datasets require a lot of hand editing
because they are not model generated.
Here is an example of a finished one:
```
parser = etree.XMLParser(remove_blank_text=True)
tree = etree.parse('/results/erddap-datasets/fragments/ubcSSnBathymetry2V1.xml', parser)
root = tree.getroot()
print_tree(root)
```
## EC HDRPS Atmospheric Forcing Datasets
### Atmospheric Forcing Grid Geo-location Dataset
Use the `/opt/tomcat/webapps/erddap/WEB-INF/GenerateDatasetsXml.sh` script
generate the initial version of an XML fragment for the dataset:
```
$ cd /opt/tomcat/webapps/erddap/WEB-INF/
$ bash GenerateDatasetsXml.sh EDDGridFromNcFiles /results/forcing/atmospheric/GEM2.5/operational/ ops_y\d{4}m\d{2}d\d{2}.nc$ /results/forcing/atmospheric/GEM2.5/operational/ops_y2016m03d07.nc 10080
```
Like the model grid geo-location and bathymetry dataset,
the atmospheric forcing grid dataset requires a lot of hand editing.
Here is the finished dataset:
```
parser = etree.XMLParser(remove_blank_text=True)
tree = etree.parse('/results/erddap-datasets/fragments/ubcSSaAtmosphereGridV1.xml', parser)
root = tree.getroot()
print_tree(root)
```
### Atmospheric Forcing Model Fields
* Change the value of the `recursive` element to `false` so that the `/results/forcing/atmospheric/GEM2.5/operational/fcst/` directory is excluded
* Add Environment Canada acknowledgement and terms & conditions of use to `license` element
* Add Environment Canada to `acknowledgement` element
```
root.find('.//recursive').text = 'false'
find_att(root, 'license').text += '''
This dataset is derived from a product of the Environment Canada HRDPS (High Resolution Deterministic Prediction System)
model. The Terms and conditions of use of Meteorological Data from Environment Canada are available at
http://dd.weather.gc.ca/doc/LICENCE_GENERAL.txt.</att>'''
find_att(root, 'acknowledgement').text += ', Environment Canada'
for axis in root.findall('.//axisVariable'):
axis_name = axis.find('.//sourceName').text
if 'time' not in axis_name:
attrs = axis.find('.//addAttributes')
etree.SubElement(attrs, 'att', name='grid_spacing').text = 'null'
etree.SubElement(attrs, 'att', name='units').text = 'null'
etree.SubElement(attrs, 'att', name='long_name').text = axis_name.upper()
etree.SubElement(attrs, 'att', name='standard_name').text = axis_name
print_tree(root)
with open('/results/erddap-datasets/fragments/{}.xml'.format(datasetID), 'wb') as f:
f.write(etree.tostring(root, pretty_print=True))
```
| github_jupyter |
# Graphes : pathfinding avec A*
L'algorithme $A^*$ (A étoile) permet de trouver **le plus court chemin entre 2 noeuds d'un graphe**. C'est un algorithme classique très utilisé dans de nombreux domaines tels que par exemple les jeux vidéo ou le calcul d'itinéraires. Il en existe d'autres comme Greedy Search ou Dijkstra.
Les schémas ci-dessous sont tirés du livre de Peter Norvig, Stuart Russell, "Intelligence artificielle, une approche moderne".


Le principe de $A^*$ est le suivant : chaque noeud est caractérisé par ses coordonnées $(x, y)$, un coût pour atteindre ce noeud depuis le noeud initial, et une *valeur heuristique* c'est-à-dire une estimation du coût nécessaire pour atteindre le noeud final. Noter que $A^*$ peut être utilisé chaque fois qu'il est possible de décrire un problème dans ces termes et pas seulement dans le cas de la recherche d'un itinéraire. Mais dans notre exemple, le coût est la distance parcourue depuis le noeud de départ, et la valeur heuristique est la distance "à vol d'oiseau" pour atteindre la destination. La distance à vol d'oiseau est une estimation *minorante* de la distance qu'il faudra réellement parcourir. C'est une caractéristique important de l'heuristique pour garantir que le chemin trouvé sera *optimal* c'est-à-dire le plus court.
A partir d'un noeud donné, on regarde quels sont les noeuds immédiatement atteignables dans le graphe et on calcul leur valeur = coût + heuristique. On ajoute tous ces noeuds à une liste de noeuds à explorer, et on se rend sur le noeud ayant la valeur la plus basse. Puis l'on recommence cette procédure jusqu'au noeud final.
Prenons un exemple. On cherche le plus court chemin entre la ville de Arad et Bucarest. Voici l'exploration faite par $A^*$ :

Voici l'algorithme $A^*$ (dans le cas où l'heuristique est minorante) en pseudo-code :
**Fonction astart(g : Graphe, objectif : Noeud, depart : Noeud):**
{Liste des noeuds déjà rencontrés}
closedList = []
{Liste des noeuds à explorer}
openList = []
openList.ajouter(depart)
tant que openList n'est pas vide:
u = openList.retirer_meilleur_noeud()
closedList.ajouter(u)
si u == objectif:
chemin = reconstituer_chemin(u , depart)
retourner chemin
pour chaque voisin v de u dans g:
v.cout = u.cout + distance(u, v)
v.valeur = v.cout + estimation_distance(v, objectif)
si non(v existe dans closedList):
openList.ajouter(v)
retourner échec
## Exercice :
- Implémenter $A^*$ en python
- Tester $A^*$ avec le graphe de l'exemple
```
class Node():
def __init__(self, name, cost = 0, heuristic = 0, parent = None):
self.name = name
self.cost = cost
self.heuristic = heuristic
self.parent = parent
def __eq__(self, n):
return self.name == n.name
def __str__(self):
return self.name
def get_path(self):
if self.parent is None:
return [self.name]
else:
return self.parent.get_path() + [self.name]
heuristic = {
'Arad' : 366,
'Bucharest' : 0,
'Craiova' : 160,
'Dobreta' : 242,
'Eforie' : 161,
'Fagaras' : 176,
'Giurgiu' : 77,
'Hirsova' : 151,
'Iasi' : 226,
'Lugoj' : 244,
'Mehadia' : 241,
'Neamt' : 234,
'Oradea' : 380,
'Pitesti' : 100,
'Rimnicu Vilcea' : 193,
'Sibiu' : 253,
'Timisoara' : 329,
'Urziceni' : 80,
'Vaslui' : 199,
'Zerind' : 374}
graphe = {
'children' : {
'Arad' : ['Zerind', 'Sibiu', 'Timisoara'],
'Bucharest' : ['Pitesti', 'Giurgiu', 'Urziceni', 'Fagaras'],
'Craiova' : ['Dobreta', 'Rimnicu Vilcea', 'Pitesti'],
'Dobreta' : ['Mehadia', 'Craiova'],
'Eforie' : ['Hirsova'],
'Fagaras' : ['Sibiu', 'Bucharest'],
'Giurgiu' : ['Bucharest'],
'Hirsova' : ['Eforie', 'Urziceni'],
'Iasi' : ['Neamt', 'Vaslui'],
'Lugoj' : ['Timisoara', 'Mehadia'],
'Mehadia' : ['Lugoj', 'Dobreta'],
'Neamt' : ['Iasi'],
'Oradea' : ['Zerind', 'Sibiu'],
'Pitesti' : ['Rimnicu Vilcea', 'Craiova', 'Bucharest'],
'Rimnicu Vilcea' : ['Sibiu', 'Craiova', 'Pitesti'],
'Sibiu' : ['Arad', 'Oradea', 'Rimnicu Vilcea', 'Fagaras'],
'Timisoara' : ['Arad', 'Lugoj'],
'Urziceni' : ['Bucharest', 'Urziceni'],
'Vaslui' : ['Urziceni', 'Iasi'],
'Zerind' : ['Arad', 'Oradea']
},
'cost' : {
('Arad', 'Zerind') : 75,
('Arad', 'Sibiu') : 140,
('Arad', 'Timisoara') : 118,
('Zerind', 'Oradea') : 71,
('Oradea', 'Sibiu') : 151,
('Sibiu', 'Fagaras') : 99,
('Sibiu', 'Rimnicu Vilcea') : 80,
('Timisoara', 'Lugoj') : 111,
('Lugoj', 'Mehadia') : 70,
('Mehadia', 'Dobreta') : 75,
('Dobreta', 'Craiova') : 120,
('Craiova', 'Rimnicu Vilcea') : 146,
('Rimnicu Vilcea', 'Pitesti') : 97,
('Pitesti', 'Craiova') : 138,
('Pitesti', 'Bucharest') : 101,
('Fagaras', 'Bucharest') : 211,
('Bucharest', 'Giurgiu') : 90,
('Bucharest', 'Urziceni') : 85,
('Urziceni', 'Hirsova') : 98,
('Hirsova', 'Eforie') : 86,
('Urziceni', 'Vaslui') : 142,
('Vaslui', 'Iasi') : 92,
('Iasi', 'Neamt') : 87
}
}
def cost(u, v, graphe):
if (u, v) in graphe['cost']:
return graphe['cost'][(u, v)]
else:
return graphe['cost'][(v, u)]
def astart(graphe, depart, destination):
closeList = []
openList = [depart]
while openList:
best = openList.pop(0)
closeList.append(best)
if best == destination:
return best.get_path()
for voisin in graphe['children'][best.name]:
voisin_cost = best.cost + cost(best.name, voisin, graphe)
voisin_heuristic = heuristic[voisin]
node_voisin = Node(voisin, cost = voisin_cost, heuristic = voisin_heuristic, parent = best)
if (not node_voisin in closeList):
openList.append(node_voisin)
openList.sort(key = lambda x : x.cost + x.heuristic)
return []
depart = Node('Bucharest')
destination = Node('Bucharest')
astart(graphe, depart, destination)
depart = Node('Timisoara')
astart(graphe, depart, destination)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/iotanalytics/IoTTutorial/blob/main/code/detection_and_segmentation/Anomaly_Detection_with_Autoencoder_.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# **Anomaly Detection with Autoencoder**
Autoencoders are neural networks designed to learn a low dimensional representation given some input data. They consist of two components: an encoder (which learns to map input data to a low dimensional representation, termed the bottleneck), and a decoder (which learns to map this low dimensional representation back to the original input data). By structuring the learning problem in this manner, the encoder network learns an efficient “compression” function which maps input data to a salient lower dimension representation, such that the decoder network is able to successfully reconstruct the original input data. The model is trained by minimizing the reconstruction error: the difference (mean squared error) between the original input and the reconstructed output produced by the decoder.

# Use autoencoder to get the threshold for anomaly detection
It is important to note that the mapping function learned by an autoencoder is specific to the training data distribution, i.e., an autoencoder will typically not succeed at reconstructing data which is significantly different from data it has seen during training. This property of learning a distribution specific mapping (as opposed to a generic linear mapping) is particularly useful for the task of anomaly detection.
Applying an autoencoder for anomaly detection follows the general principle of first modeling normal behaviour and subsequently generating an anomaly score for a new data sample. To model normal behaviour we train the autoencoder on a normal data sample. This way, the model learns a mapping function that successfully reconstructs normal data samples with a very small reconstruction error (the difference between the actual sample and the version reconstructed by the model). This behavior is replicated at test time, where the reconstruction error is small for normal data samples, and large for abnormal data samples. To identify anomalies, we use the reconstruction error score as an anomaly score and flag samples with reconstruction errors above a given threshold.
```
import numpy as np
import pandas as pd
from tensorflow import keras
from tensorflow.keras import layers
from matplotlib import pyplot as plt
```
load the data, here we used benchmark data in kaggle
```
master_url_root = "https://raw.githubusercontent.com/numenta/NAB/master/data/"
df_small_noise_url_suffix = "artificialNoAnomaly/art_daily_small_noise.csv"
df_small_noise_url = master_url_root + df_small_noise_url_suffix
df_small_noise = pd.read_csv(
df_small_noise_url, parse_dates=True, index_col="timestamp"
)
df_daily_jumpsup_url_suffix = "artificialWithAnomaly/art_daily_jumpsup.csv"
df_daily_jumpsup_url = master_url_root + df_daily_jumpsup_url_suffix
df_daily_jumpsup = pd.read_csv(
df_daily_jumpsup_url, parse_dates=True, index_col="timestamp"
)
print(df_small_noise.head())
print(df_daily_jumpsup.head())
```
Visualize the data: time series with anomalies and without anomalies
```
fig, ax = plt.subplots()
df_small_noise.plot(legend=False, ax=ax)
plt.show()
fig, ax = plt.subplots()
df_daily_jumpsup.plot(legend=False, ax=ax)
plt.show()
```
Wrap up the function to preprocess the time series data, create sequences using raw data through time_steps set in advance.
```
# Normalize and save the mean and std we get,
# for normalizing test data.
TIME_STEPS = 288
# Generated training sequences for use in the model.
def create_sequences(values, time_steps=TIME_STEPS):
output = []
for i in range(len(values) - time_steps + 1):
output.append(values[i : (i + time_steps)])
return np.stack(output)
def AE_anomaly_detection(x_train, x_test, time_steps=TIME_STEPS):
training_mean = x_train.mean()
training_std = x_train.std()
df_training_value = (x_train - training_mean) / training_std
print("Number of training samples:", len(df_training_value))
x_train = create_sequences(df_training_value.values)
print("Training input shape: ", x_train.shape)
model = keras.Sequential(
[
layers.Input(shape=(x_train.shape[1], x_train.shape[2])),
layers.Conv1D(
filters=32, kernel_size=7, padding="same", strides=2, activation="relu"
),
layers.Dropout(rate=0.2),
layers.Conv1D(
filters=16, kernel_size=7, padding="same", strides=2, activation="relu"
),
layers.Conv1DTranspose(
filters=16, kernel_size=7, padding="same", strides=2, activation="relu"
),
layers.Dropout(rate=0.2),
layers.Conv1DTranspose(
filters=32, kernel_size=7, padding="same", strides=2, activation="relu"
),
layers.Conv1DTranspose(filters=1, kernel_size=7, padding="same"),
]
)
model.compile(optimizer=keras.optimizers.Adam(learning_rate=0.001), loss="mse")
history = model.fit(
x_train,
x_train,
epochs=50,
batch_size=128,
validation_split=0.1,
callbacks=[
keras.callbacks.EarlyStopping(monitor="val_loss", patience=5, mode="min")
],
)
# Get train MAE loss.
x_train_pred = model.predict(x_train)
train_mae_loss = np.mean(np.abs(x_train_pred - x_train), axis=1)
plt.hist(train_mae_loss, bins=50)
plt.xlabel("Train MAE loss")
plt.ylabel("No of samples")
plt.show()
# Get reconstruction loss threshold.
threshold = np.max(train_mae_loss)
print("Reconstruction error threshold: ", threshold)
##### test ...
test_mean = x_test.mean()
test_std = x_test.std()
####### prepare the test data
df_test_value = (x_test - test_mean) / test_std
#fig, ax = plt.subplots()
#df_test_value.plot(legend=False, ax=ax)
#plt.show()
# Create sequences from test values.
x_test = create_sequences(df_test_value.values)
print("Test input shape: ", x_test.shape)
# Get test MAE loss.
x_test_pred = model.predict(x_test)
test_mae_loss = np.mean(np.abs(x_test_pred - x_test), axis=1)
test_mae_loss = test_mae_loss.reshape((-1))
plt.hist(test_mae_loss, bins=50)
plt.xlabel("test MAE loss")
plt.ylabel("No of samples")
plt.show()
# Detect all the samples which are anomalies.
anomalies = test_mae_loss > threshold
print("Number of anomaly samples: ", np.sum(anomalies))
#print("Indices of anomaly samples: ", np.where(anomalies))
return anomalies
##### plot anomalies
anomalies = AE_anomaly_detection(df_small_noise, df_daily_jumpsup, time_steps=TIME_STEPS)
# data i is an anomaly if samples [(i - timesteps + 1) to (i)] are anomalies
test_mean = df_daily_jumpsup.mean()
test_std = df_daily_jumpsup.std()
df_test_value = (df_daily_jumpsup - test_mean) / test_std
anomalous_data_indices = []
for data_idx in range(TIME_STEPS - 1, len(df_test_value) - TIME_STEPS + 1):
if np.all(anomalies[data_idx - TIME_STEPS + 1 : data_idx]):
anomalous_data_indices.append(data_idx)
df_subset = df_daily_jumpsup.iloc[anomalous_data_indices]
fig, ax = plt.subplots()
df_daily_jumpsup.plot(legend=False, ax=ax)
df_subset.plot(legend=False, ax=ax, color="r")
plt.show()
```
## Pros and Cons of Autoencoder Algorithm for Anomaly Detection
**Pros**:
- An autoencoeder can perform tasks that a linear program cannot.
When an element of the neural network fails, it can continue without any problem with their parallel nature.
- An autoencoder constructed by neural network learns and does not need to be reprogrammed.
- It can be implemented in any application.
**Cons**:
- The neural network needs training to operate.
- The architecture of a neural network is different from the architecture of microprocessors therefore needs to be emulated.
- Requires high processing time for large neural network
| github_jupyter |
# Robot Class
In this project, we'll be localizing a robot in a 2D grid world. The basis for simultaneous localization and mapping (SLAM) is to gather information from a robot's sensors and motions over time, and then use information about measurements and motion to re-construct a map of the world.
### Uncertainty
As you've learned, robot motion and sensors have some uncertainty associated with them. For example, imagine a car driving up hill and down hill; the speedometer reading will likely overestimate the speed of the car going up hill and underestimate the speed of the car going down hill because it cannot perfectly account for gravity. Similarly, we cannot perfectly predict the *motion* of a robot. A robot is likely to slightly overshoot or undershoot a target location.
In this notebook, we'll look at the `robot` class that is *partially* given to you for the upcoming SLAM notebook. First, we'll create a robot and move it around a 2D grid world. Then, **you'll be tasked with defining a `sense` function for this robot that allows it to sense landmarks in a given world**! It's important that you understand how this robot moves, senses, and how it keeps track of different landmarks that it sees in a 2D grid world, so that you can work with it's movement and sensor data.
---
Before we start analyzing robot motion, let's load in our resources and define the `robot` class. You can see that this class initializes the robot's position and adds measures of uncertainty for motion. You'll also see a `sense()` function which is not yet implemented, and you will learn more about that later in this notebook.
```
# import some resources
import numpy as np
import matplotlib.pyplot as plt
import random
%matplotlib inline
# the robot class
class robot:
# --------
# init:
# creates a robot with the specified parameters and initializes
# the location (self.x, self.y) to the center of the world
#
def __init__(self, world_size = 100.0, measurement_range = 30.0,
motion_noise = 1.0, measurement_noise = 1.0):
self.measurement_noise = 0.0
self.world_size = world_size
self.measurement_range = measurement_range
self.x = world_size / 2.0
self.y = world_size / 2.0
self.motion_noise = motion_noise
self.measurement_noise = measurement_noise
self.landmarks = []
self.num_landmarks = 0
# returns a positive, random float
def rand(self):
return random.random() * 2.0 - 1.0
# --------
# move: attempts to move robot by dx, dy. If outside world
# boundary, then the move does nothing and instead returns failure
#
def move(self, dx, dy):
x = self.x + dx + self.rand() * self.motion_noise
y = self.y + dy + self.rand() * self.motion_noise
if x < 0.0 or x > self.world_size or y < 0.0 or y > self.world_size:
return False
else:
self.x = x
self.y = y
return True
# --------
# sense: returns x- and y- distances to landmarks within visibility range
# because not all landmarks may be in this range, the list of measurements
# is of variable length. Set measurement_range to -1 if you want all
# landmarks to be visible at all times
#
## TODO: complete the sense function
def sense(self):
''' This function does not take in any parameters, instead it references internal variables
(such as self.landamrks) to measure the distance between the robot and any landmarks
that the robot can see (that are within its measurement range).
This function returns a list of landmark indices, and the measured distances (dx, dy)
between the robot's position and said landmarks.
This function should account for measurement_noise and measurement_range.
One item in the returned list should be in the form: [landmark_index, dx, dy].
'''
measurements = []
## TODO: iterate through all of the landmarks in a world
## TODO: For each landmark
## 1. compute dx and dy, the distances between the robot and the landmark
## 2. account for measurement noise by *adding* a noise component to dx and dy
## - The noise component should be a random value between [-1.0, 1.0)*measurement_noise
## - Feel free to use the function self.rand() to help calculate this noise component
## - It may help to reference the `move` function for noise calculation
## 3. If either of the distances, dx or dy, fall outside of the internal var, measurement_range
## then we cannot record them; if they do fall in the range, then add them to the measurements list
## as list.append([index, dx, dy]), this format is important for data creation done later
## TODO: return the final, complete list of measurements
dx, dy = 0, 0
for index in range(num_landmarks):
# Compute dx and dy
dx = self.landmarks[index][0] - self.x
dy = self.landmarks[index][1] - self.y
# Add noise component to dx and dy
noise = self.rand() * self.measurement_noise
dx, dy = dx + noise, dy + noise
# Check dx and dy values
if (dx < self.measurement_range) or (dy < self.measurement_range):
measurements.append([index, dx, dy])
return measurements
# --------
# make_landmarks:
# make random landmarks located in the world
#
def make_landmarks(self, num_landmarks):
self.landmarks = []
for i in range(num_landmarks):
self.landmarks.append([round(random.random() * self.world_size),
round(random.random() * self.world_size)])
self.num_landmarks = num_landmarks
# called when print(robot) is called; prints the robot's location
def __repr__(self):
return 'Robot: [x=%.5f y=%.5f]' % (self.x, self.y)
```
## Define a world and a robot
Next, let's instantiate a robot object. As you can see in `__init__` above, the robot class takes in a number of parameters including a world size and some values that indicate the sensing and movement capabilities of the robot.
In the next example, we define a small 10x10 square world, a measurement range that is half that of the world and small values for motion and measurement noise. These values will typically be about 10 times larger, but we ust want to demonstrate this behavior on a small scale. You are also free to change these values and note what happens as your robot moves!
```
world_size = 10.0 # size of world (square)
measurement_range = 5.0 # range at which we can sense landmarks
motion_noise = 0.2 # noise in robot motion
measurement_noise = 0.2 # noise in the measurements
# instantiate a robot, r
r = robot(world_size, measurement_range, motion_noise, measurement_noise)
# print out the location of r
print(r)
```
## Visualizing the World
In the given example, we can see/print out that the robot is in the middle of the 10x10 world at (x, y) = (5.0, 5.0), which is exactly what we expect!
However, it's kind of hard to imagine this robot in the center of a world, without visualizing the grid itself, and so in the next cell we provide a helper visualization function, `display_world`, that will display a grid world in a plot and draw a red `o` at the location of our robot, `r`. The details of how this function wors can be found in the `helpers.py` file in the home directory; you do not have to change anything in this `helpers.py` file.
```
# import helper function
from helpers import display_world
# define figure size
plt.rcParams["figure.figsize"] = (5,5)
# call display_world and display the robot in it's grid world
print(r)
display_world(int(world_size), [r.x, r.y])
```
## Movement
Now you can really picture where the robot is in the world! Next, let's call the robot's `move` function. We'll ask it to move some distance `(dx, dy)` and we'll see that this motion is not perfect by the placement of our robot `o` and by the printed out position of `r`.
Try changing the values of `dx` and `dy` and/or running this cell multiple times; see how the robot moves and how the uncertainty in robot motion accumulates over multiple movements.
#### For a `dx` = 1, does the robot move *exactly* one spot to the right? What about `dx` = -1? What happens if you try to move the robot past the boundaries of the world?
```
# choose values of dx and dy (negative works, too)
dx = 1
dy = 2
r.move(dx, dy)
# print out the exact location
print(r)
# display the world after movement, not that this is the same call as before
# the robot tracks its own movement
display_world(int(world_size), [r.x, r.y])
```
## Landmarks
Next, let's create landmarks, which are measurable features in the map. You can think of landmarks as things like notable buildings, or something smaller such as a tree, rock, or other feature.
The robot class has a function `make_landmarks` which randomly generates locations for the number of specified landmarks. Try changing `num_landmarks` or running this cell multiple times to see where these landmarks appear. We have to pass these locations as a third argument to the `display_world` function and the list of landmark locations is accessed similar to how we find the robot position `r.landmarks`.
Each landmark is displayed as a purple `x` in the grid world, and we also print out the exact `[x, y]` locations of these landmarks at the end of this cell.
```
# create any number of landmarks
num_landmarks = 3
r.make_landmarks(num_landmarks)
# print out our robot's exact location
print(r)
# display the world including these landmarks
display_world(int(world_size), [r.x, r.y], r.landmarks)
# print the locations of the landmarks
print('Landmark locations [x,y]: ', r.landmarks)
```
## Sense
Once we have some landmarks to sense, we need to be able to tell our robot to *try* to sense how far they are away from it. It will be up t you to code the `sense` function in our robot class.
The `sense` function uses only internal class parameters and returns a list of the the measured/sensed x and y distances to the landmarks it senses within the specified `measurement_range`.
### TODO: Implement the `sense` function
Follow the `##TODO's` in the class code above to complete the `sense` function for the robot class. Once you have tested out your code, please **copy your complete `sense` code to the `robot_class.py` file in the home directory**. By placing this complete code in the `robot_class` Python file, we will be able to refernce this class in a later notebook.
The measurements have the format, `[i, dx, dy]` where `i` is the landmark index (0, 1, 2, ...) and `dx` and `dy` are the measured distance between the robot's location (x, y) and the landmark's location (x, y). This distance will not be perfect since our sense function has some associated `measurement noise`.
---
In the example in the following cell, we have a given our robot a range of `5.0` so any landmarks that are within that range of our robot's location, should appear in a list of measurements. Not all landmarks are guaranteed to be in our visibility range, so this list will be variable in length.
*Note: the robot's location is often called the **pose** or `[Pxi, Pyi]` and the landmark locations are often written as `[Lxi, Lyi]`. You'll see this notation in the next notebook.*
```
# try to sense any surrounding landmarks
measurements = r.sense()
# this will print out an empty list if `sense` has not been implemented
print(measurements)
```
**Refer back to the grid map above. Do these measurements make sense to you? Are all the landmarks captured in this list (why/why not)?**
---
## Data
#### Putting it all together
To perform SLAM, we'll collect a series of robot sensor measurements and motions, in that order, over a defined period of time. Then we'll use only this data to re-construct the map of the world with the robot and landmar locations. You can think of SLAM as peforming what we've done in this notebook, only backwards. Instead of defining a world and robot and creating movement and sensor data, it will be up to you to use movement and sensor measurements to reconstruct the world!
In the next notebook, you'll see this list of movements and measurements (which you'll use to re-construct the world) listed in a structure called `data`. This is an array that holds sensor measurements and movements in a specific order, which will be useful to call upon when you have to extract this data and form constraint matrices and vectors.
`data` is constructed over a series of time steps as follows:
```
data = []
# after a robot first senses, then moves (one time step)
# that data is appended like so:
data.append([measurements, [dx, dy]])
# for our example movement and measurement
print(data)
# in this example, we have only created one time step (0)
time_step = 0
# so you can access robot measurements:
print('Measurements: ', data[time_step][0])
# and its motion for a given time step:
print('Motion: ', data[time_step][1])
```
### Final robot class
Before moving on to the last notebook in this series, please make sure that you have copied your final, completed `sense` function into the `robot_class.py` file in the home directory. We will be using this file in the final implementation of slam!
| github_jupyter |
## *Data Science Unit 4 Sprint 3 Assignment 1*
# Recurrent Neural Networks and Long Short Term Memory (LSTM)

It is said that [**infinite monkeys typing for an infinite amount of time**](https://en.wikipedia.org/wiki/Infinite_monkey_theorem) will eventually type, among other things, the complete works of William Shakespeare. Let's see if we can get there a bit faster, with the power of Recurrent Neural Networks and LSTM.
We will focus specifically on Shakespeare's Sonnets in order to improve our model's ability to learn from the data.
```
import random
import sys
import os
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import LambdaCallback
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, Bidirectional
from tensorflow.keras.layers import LSTM
%matplotlib inline
# a custom data prep class that we'll be using
from data_cleaning_toolkit_class import data_cleaning_toolkit
```
### Use request to pull data from a URL
[**Read through the request documentation**](https://requests.readthedocs.io/en/master/user/quickstart/#make-a-request) in order to learn how to download the Shakespeare Sonnets from the Gutenberg website.
**Protip:** Do not over think it.
```
# download all of Shakespears Sonnets from the Project Gutenberg website
# here's the link for the sonnets
url_shakespeare_sonnets = "https://www.gutenberg.org/cache/epub/1041/pg1041.txt"
# use request and the url to download all of the sonnets - save the result to `r`
# YOUR CODE HERE
r = requests.get(url_shakespeare_sonnets)
# move the downloaded text out of the request object - save the result to `raw_text_data`
# hint: take at look at the attributes of `r`
# YOUR CODE HERE
raw_text_data = r.text
# check the data type of `raw_text_data`
type(raw_text_data)
```
### Data Cleaning
```
# as usual, we are tasked with cleaning up messy data
# Question: Do you see any characters that we could use to split up the text?
raw_text_data[:3000]
# split the text into lines and save the result to `split_data`
# YOUR CODE HERE
split_data = raw_text_data.splitlines()
# we need to drop all the boilder plate text (i.e. titles and descriptions) as well as white spaces
# so that we are left with only the sonnets themselves
split_data[:20]
```
**Use list index slicing in order to remove the titles and descriptions so we are only left with the sonnets.**
```
# sonnets exists between these indicies
# titles and descriptions exist outside of these indicies
# use index slicing to isolate the sonnet lines - save the result to `sonnets`
# YOUR CODE HERE
sonnets = split_data[45:-369]
# notice how all non-sonnet lines have far less characters than the actual sonnet lines?
# well, let's use that observation to filter out all the non-sonnet lines
sonnets[200:240]
# any string with less than n_chars characters will be filtered out - save results to `filtered_sonnets`
# YOUR CODE HERE
n_char = 10
filtered_sonnets = [line.lstrip() for line in sonnets if len(line) > n_char]
# ok - much better!
# but we still need to remove all the punctuation and case normalize the text
filtered_sonnets
```
### Use custom data cleaning tool
Use one of the methods in `data_cleaning_toolkit` to clean your data.
There is an example of this in the guided project.
```
# instantiate the data_cleaning_toolkit class - save result to `dctk`
# YOUR CODE HERE
dctk = data_cleaning_toolkit()
# use data_cleaning_toolkit to remove punctuation and to case normalize - save results to `clean_sonnets`
# YOUR CODE HERE
clean_sonnets = [dctk.clean_data(line) for line in filtered_sonnets]
# much better!
clean_sonnets
```
### Use your data tool to create character sequences
We'll need the `create_char_sequenes` method for this task. However this method requires a parameter call `maxlen` which is responsible for setting the maximum sequence length.
So what would be a good sequence length, exactly?
In order to answer that question, let's do some statistics!
```
def calc_stats(corpus):
"""
Calculates statisics on the length of every line in the sonnets
"""
# write a list comprehension that calculates each sonnets line length - save the results to `doc_lens`
# use numpy to calcualte and return the mean, median, std, max, min of the doc lens - all in one line of code
# YOUR CODE HERE
doc_lens = [len(line) for line in clean_sonnets]
return np.mean(doc_lens), np.median(doc_lens), np.std(doc_lens), np.max(doc_lens), np.min(doc_lens)
# sonnet line length statistics
mean ,med, std, max_, min_ = calc_stats(clean_sonnets)
mean, med, std, max_, min_
# using the results of the sonnet line length statistics, use your judgement and select a value for maxlen
# use .create_char_sequences() to create sequences
# YOUR CODE HERE
maxlen = 42
dctk.create_char_sequences(clean_sonnets, maxlen)
```
Take a look at the `data_cleaning_toolkit_class.py` file.
In the first 4 lines of code in the `create_char_sequences` method, class attributes `n_features` and `unique_chars` are created. Let's call them in the cells below.
```
# number of input features for our LSTM model
dctk.n_features
# unique charactes that appear in our sonnets
dctk.unique_chars
len(dctk.unique_chars)
```
## Time for Questions
----
**Question 1:**
Why are the `number of unique characters` (i.e. **dctk.unique_chars**) and the `number of model input features` (i.e. **dctk.n_features**) the same?
**Hint:** The model that we will shortly be building here is very similar to the text generation model that we built in the guided project.
**Answer 1:**
`number of unique characters` and the `number of model input features` are the same because the text generation model will treat every unique character as a possible feature/category to predict
**Question 2:**
Take a look at the print out of `dctk.unique_chars` one more time. Notice that there is a white space.
Why is it desirable to have a white space as a possible character to predict?
**Answer 2:**
It is desirable to have a white space as a possible character to predict to allow the model to learn from the training data that there are sometimes spaces between characters (separating the words) and thus make it more likely that the model will be able to form human-readable and -sensible words from the predicted characters.
----
### Use our data tool to create X and Y splits
You'll need the `create_X_and_Y` method for this task.
```
# TODO: provide a walk through of data_cleaning_toolkit with unit tests that check for understanding
X, y = dctk.create_X_and_Y()
```
```
# notice that our input matrix isn't actually a matrix - it's a rank 3 tensor
X.shape
```
In $X$.shape we see three numbers (*n1*, *n2*, *n3*). What do these numbers mean?
Well, *n1* tells us the number of samples that we have. But what about the other two?
```
# first index returns a single sample, which we can see is a sequence
first_sample_index = 0
X[first_sample_index]
```
Notice that each sequence (i.e. $X[i]$ where $i$ is some index value) is `maxlen` long and has `dctk.n_features` number of features. Let's try to better understand this shape.
```
# each sequence is maxlen long and has dctk.n_features number of features
X[first_sample_index].shape
```
**Each row corresponds to a character vector** and there are `maxlen` number of character vectors.
**Each column corresponds to a unique character** and there are `dctk.n_features` number of features.
```
# let's index for a single character vector
first_char_vect_index = 0
X[first_sample_index][first_char_vect_index]
```
Notice that there is a single `TRUE` value and all the rest of the values are `FALSE`.
This is a one-hot encoding for which character appears at each index within a sequence. Specifically, the cell above is looking at the first character in the sequence.
Only a single character can appear as the first character in a sequence, so there will necessarily be a single `TRUE` value and the rest will be `FALSE`.
Let's say that `TRUE` appears in the $ith$ index; by $ith$ index we simply mean some index in the general case. How can we find out which character that actually corresponds to?
To answer this question, we need to use the character-to-integer look up dictionaries.
```
# take a look at the index to character dictionary
# if a TRUE appears in the 0th index of a character vector,
# then we know that whatever char you see below next to the 0th key
# is the character that that character vector is endcoding for
dctk.int_char
# let's look at an example to tie it all together
seq_len_counter = 0
# index for a single sample
for seq_of_char_vects in X[first_sample_index]:
# get index with max value, which will be the one TRUE value
index_with_TRUE_val = np.argmax(seq_of_char_vects)
print (dctk.int_char[index_with_TRUE_val])
seq_len_counter+=1
print ("Sequence length: {}".format(seq_len_counter))
```
## Time for Questions
----
**Question 1:**
In your own words, how would you describe the numbers from the shape print out of `X.shape` to a fellow classmate?
**Answer 1:**
The first number in X.shape is the number of sequences created.
The second number in X.shape is the number of characters in each sequence (== maxlen == 42).
The third number in X.shape is the number of features/unique characters in each sequence (== 28).
### Build a Text Generation model
Now that we have prepped our data (and understood that process) let's finally build out our character generation model, similar to what we did in the guided project.
```
def sample(preds, temperature=1.0):
"""
Helper function to sample an index from a probability array
"""
# convert preds to array
preds = np.asarray(preds).astype('float64')
# scale values
preds = np.log(preds) / temperature
# exponentiate values
exp_preds = np.exp(preds)
# this equation should look familar to you (hint: it's an activation function)
preds = exp_preds / np.sum(exp_preds)
# Draw samples from a multinomial distribution
probas = np.random.multinomial(1, preds, 1)
# return the index that corresponds to the max probability
return np.argmax(probas)
def on_epoch_end(epoch, _):
""""
Function invoked at end of each epoch. Prints the text generated by our model.
"""
print()
print('----- Generating text after Epoch: %d' % epoch)
# randomly pick a starting index
# will be used to take a random sequence of chars from `text`
start_index = random.randint(0, len(text) - dctk.maxlen - 1)
# this is our seed string (i.e. input sequence into the model)
generated = ''
# start the sentence at index `start_index` and include the next` dctk.maxlen` number of chars
sentence = text[start_index: start_index + dctk.maxlen]
# add to generated
generated += sentence
print('----- Generating with seed: "' + sentence + '"')
sys.stdout.write(generated)
# use model to predict what the next 40 chars should be that follow the seed string
for i in range(40):
# shape of a single sample in a rank 3 tensor
x_dims = (1, dctk.maxlen, dctk.n_features)
# create an array of zeros with shape x_dims
# recall that python considers zeros and boolean FALSE as the same
x_pred = np.zeros(x_dims)
# create a seq vector for our randomly select sequence
# i.e. create a numerical encoding for each char in the sequence
for t, char in enumerate(sentence):
# for sample 0 in seq index t and character `char` encode a 1 (which is the same as a TRUE)
x_pred[0, t, dctk.char_int[char]] = 1
# next, take the seq vector and pass into model to get a prediction of what the next char should be
preds = model.predict(x_pred, verbose=0)[0]
# use the sample helper function to get index for next char
next_index = sample(preds)
# use look up dict to get next char
next_char = dctk.int_char[next_index]
# append next char to sequence
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
print()
# need this for on_epoch_end()
text = " ".join(clean_sonnets)
# create callback object that will print out text generation at the end of each epoch
# use for real-time monitoring of model performance
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
```
----
### Train Model
Build a text generation model using LSTMs. Feel free to reference the model used in the guided project.
It is recommended that you train this model to at least 50 epochs (but more if you're computer can handle it).
You are free to change up the architecture as you wish.
Just in case you have difficultly training a model, there is a pre-trained model saved to a file called `trained_text_gen_model.h5` that you can load in (the same way that you learned how to load in Keras models in Sprint 2 Module 4).
```
# build text generation model layer by layer
# fit model
# YOUR CODE HERE
model = Sequential()
# first LSTM layer
model.add(LSTM(256,
input_shape= (dctk.maxlen, dctk.n_features),
activation = 'tanh',
return_sequences=True))
# second LSTM layer
model.add(LSTM(128, activation = 'tanh'))
# Output layer
model.add(Dense(dctk.n_features, activation = 'softmax'))
# Compile
model.compile(loss = 'categorical_crossentropy',
optimizer = 'adam')
model.fit(X, y,
batch_size = 256,
epochs = 50,
workers = 8,
callbacks = [print_callback])
```
### Model Appears to be overfitting based on at least last 10 epochs
```
# save trained model to file
model.save("trained_text_gen_model.h5")
```
### Let's play with our trained model
Now that we have a trained model that, though far from perfect, is able to generate actual English words, we can take a look at the predictions to continue to learn more about how a text generation model works.
We can also take this as an opportunity to unpack the `def on_epoch_end` function to better understand how it works.
```
# this is our joined clean sonnet data
text
# randomly pick a starting index
# will be used to take a random sequence of chars from `text`
# run this cell a few times and you'll see `start_index` is random
start_index = random.randint(0, len(text) - dctk.maxlen - 1)
start_index
# next use the randomly selected starting index to sample a sequence from the `text`
# this is our seed string (i.e. input sequence into the model)
generated = ''
# start the sentence at index `start_index` and include the next` dctk.maxlen` number of chars
sentence = text[start_index: start_index + dctk.maxlen]
# add to generated
generated += sentence
generated
# this block of code let's us know what the seed string is
# i.e. the input sequence into the model
print('----- Generating with seed: "' + sentence + '"')
sys.stdout.write(generated)
# use model to predict what the next 40 chars should be that follow the seed string
for i in range(40):
# shape of a single sample in a rank 3 tensor
x_dims = (1, dctk.maxlen, dctk.n_features)
# create an array of zeros with shape x_dims
# recall that python considers zeros and boolean FALSE as the same
x_pred = np.zeros(x_dims)
# create a seq vector for our randomly select sequence
# i.e. create a numerical encoding for each char in the sequence
for t, char in enumerate(sentence):
# for sample 0 in seq index t and character `char` encode a 1 (which is the same as a TRUE)
x_pred[0, t, dctk.char_int[char]] = 1
# next, take the seq vector and pass into model to get a prediction of what the next char should be
preds = model.predict(x_pred, verbose=0)[0]
# use the sample helper function to get index for next char
next_index = sample(preds)
# use look up dict to get next char
next_char = dctk.int_char[next_index]
# append next char to sequence
sentence = sentence[1:] + next_char
# this is the seed string
generated
# these are the 40 chars that the model thinks should come after the seed stirng
sentence
# now put it all together
generated + sentence
```
# Resources and Stretch Goals
## Stretch goals:
- Refine the training and generation of text to be able to ask for different genres/styles of Shakespearean text (e.g. plays versus sonnets)
- Train a classification model that takes text and returns which work of Shakespeare it is most likely to be from
- Make it more performant! Many possible routes here - lean on Keras, optimize the code, and/or use more resources (AWS, etc.)
- Revisit the news example from class, and improve it - use categories or tags to refine the model/generation, or train a news classifier
- Run on bigger, better data
## Resources:
- [The Unreasonable Effectiveness of Recurrent Neural Networks](https://karpathy.github.io/2015/05/21/rnn-effectiveness/) - a seminal writeup demonstrating a simple but effective character-level NLP RNN
- [Simple NumPy implementation of RNN](https://github.com/JY-Yoon/RNN-Implementation-using-NumPy/blob/master/RNN%20Implementation%20using%20NumPy.ipynb) - Python 3 version of the code from "Unreasonable Effectiveness"
- [TensorFlow RNN Tutorial](https://github.com/tensorflow/models/tree/master/tutorials/rnn) - code for training a RNN on the Penn Tree Bank language dataset
- [4 part tutorial on RNN](http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/) - relates RNN to the vanishing gradient problem, and provides example implementation
- [RNN training tips and tricks](https://github.com/karpathy/char-rnn#tips-and-tricks) - some rules of thumb for parameterizing and training your RNN
| github_jupyter |
# Portfolio Optimization
Modern portfolio theory is also known as mean-variance optimization.
One fundamental assumption is that returns are **normally distributed**.
We will focus on:
* Normality test: Mean Variance Portfolio Theory (MPT) and Capital Asset Pricing Model (CAPM)
* Portfolio optimization
* Bayesian statistics
* Machine learning
***Portfolio theory***
Stock returns are assumed to be normally distributed. Investment decissions are then based on expected mean return as well as variance of returns.
***CAPM***
Again, when stock returns are normally distributed, prices of single stockscan be elegantly expressed in linear relationship to a broad market index;the relationship is generally expressed by a measure for the co-movement of a single stock with the market called beta or $\beta$.
***Efficient Markets Hypothesis***
An efficient market is a market where prices reflect all available information, where 'all' can be defined more narrowly or more widely (e.g. as in 'all publicly available information vs including also only privately available information'). If this hypothesis holds true, then stock prices fluctuate randomly and returns are normally distributed.
***Option Pricing Theory**
Brownian motion is the benchmark model for the modeling of random pricemovements of financial instruments; the famous Black-Scholes-Mertonoption pricing formula uses a geometric Brownian motion as the model fora stock’s random price fluctuations over time, leading to log-normallydistributed prices and normally distributed returns.
The Geometric Brownian Motion is a stochastic process used in financial modelling.
Log returns are normally distributed:
$\log \frac{S_t}{S_s} = -\log S_t - \log S_s$ where $0 < s < t$
## Simulated data
```
import math
import numpy as np
import scipy.stats as scs
import statsmodels.api as sm
from pylab import mpl, plt
import pandas as pd
import os
import warnings
np.random.seed(100)
plt.style.use('seaborn')
mpl.rcParams['font.family'] = 'serif'
%matplotlib inline
import sys, os
scr_dir = os.path.join(os.getcwd(), os.pardir, 'src')
sys.path.append(scr_dir)
from loader.load import YFinanceDataset
# Lets create a function to generate
## a Monte Carlo simulated geometric Brownian Motion
def gen_paths(s0, r, sigma, T, M, I):
"""
Parameters
----------
s0: (float) initial stock/index value
r: (float) constant short rate
sigma: (float) constant volatility
T: (float) final time horizon
M: (int) number of time steps/intervals
I: (int) number of paths to be simulated
Returns
-------
paths: ndarray, shape (M + 1, I) simulated paths
"""
dt = T/M
paths = np.zeros((M + 1, I))
paths[0] = s0
for t in range(1, M + 1):
result = np.random.standard_normal(I)
result = (result - result.mean())/result.std()
paths[t] = paths[t - 1] * np.exp((r - 0.5 * sigma ** 2) * dt + sigma * math.sqrt(dt) * result)
return paths
s0 = 100.
r = 0.05
sigma = 0.2
T = 1.0
M = 50
I = 250000
np.random.seed(1000)
paths = gen_paths(s0, r, sigma, T, M, I)
init_s = s0 * math.exp(r * T)
last_s = paths[-1].mean()
print(init_s)
print(last_s)
plt.figure(figsize=(10, 6))
plt.plot(paths[:, :10])
plt.xlabel('time steps')
plt.ylabel('index level');
paths[:, 0].round(4)
log_returns = np.log(paths[1:]/paths[:-1])
log_returns[:, 0].round(4)
def print_statistics(array):
sta = scs.describe(array)
print('{:14s} {:15s}'.format('statistic', 'value'))
print(30 * '-')
print('{:14s} {:15.5f}'.format('size', sta[0]))
print('{:14s} {:15.5f}'.format('min', np.min(sta[1][0])))
print('{:14s} {:15.5f}'.format('max', np.max(sta[1][1])))
print('{:14s} {:15.5f}'.format('mean', np.mean(sta[2])))
print('{:14s} {:15.5f}'.format('std', np.sqrt(sta[3])))
print('{:14s} {:15.5f}'.format('skew', sta[4]))
print('{:14s} {:15.5f}'.format('kurtosis', sta[5]))
#print_statistics(log_returns)
```
# Visual test of normality
```
plt.figure(figsize=(10, 6))
plt.hist(log_returns.flatten(), bins=70,
# normed=True,
label='frequency', color='b')
plt.xlabel('log return')
plt.ylabel('frequency')
x = np.linspace(plt.axis()[0], plt.axis()[1])
plt.plot(x, scs.norm.pdf(x, loc=r/M,
scale=sigma/np.sqrt(M)), 'r',
lw=2.0, label='pdf')
plt.legend();
```
# Test by quantile quantile graph
```
plt.figure(figsize=(10, 6))
sm.qqplot(log_returns.flatten()[::500], line='s')
plt.xlabel('theoretical quantiles')
plt.ylabel('sample quantiles');
```
## Other tests
* skewness: value near 0
* kurtosis test: value near 0
```
def normality_tests(arr):
''' Tests for normality distribution of given data set.
Parameters
==========
array: ndarray
object to generate statistics on
'''
print('Skew of data set %14.3f' % scs.skew(arr))
print('Skew test p-value %14.3f' % scs.skewtest(arr)[1])
print('Kurtosis of data set %14.3f' % scs.kurtosis(arr))
print('Kurtosis test p-value %14.3f' % scs.kurtosistest(arr)[1])
print('Norm test p-value %14.3f' % scs.normaltest(arr)[1])
# if p-value > 0.5 then normal distributed
normality_tests(log_returns.flatten())
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 6))
ax1.hist(paths[-1],bins=30)
ax1.set_xlabel('index level')
ax1.set_ylabel('frequency')
ax1.set_title('regular data')
ax2.hist(np.log(paths[-1]),bins=30)
ax2.set_xlabel('log index level')
ax2.set_title('log-data');
normality_tests(np.log(paths[-1]))
plt.figure(figsize=(10,6))
log_data=np.log(paths[-1])
plt.hist(log_data, bins=70, label='observed', color='b')
plt.xlabel('index levels')
plt.ylabel('frequency')
x=np.linspace(plt.axis()[0],plt.axis()[1])
plt.plot(x,scs.norm.pdf(
x,log_data.mean(),log_data.std()),'r',lw=2.0, label='pdf')
plt.legend();
def qqplot(log_data):
sm.qqplot(log_data, line='s')
plt.xlabel('theoretical quantiles')
plt.ylabel('sample quantiles');
qqplot(log_data)
```
## Real Data
```
data = YFinanceDataset().get_multiple_tickers(
ticker_names=[
'MSFT',
'IBM',
'KO',
'AAPL',
'AMZN',
'GOOG',
'NVDA'
])
data.info()
data.describe().T
data.head()
data.iloc[0:2]
(data/data.iloc[0] * 100).plot(figsize=(10, 6));
log_returns = np.log(data/data.shift(1))
log_returns.head()
log_returns.hist(bins=50, figsize=(10, 8));
for sym in data.columns:
print('\nResults for symbol {}'.format(sym))
print(30*'-')
log_data=np.array(log_returns[sym].dropna())
normality_tests(log_data)
qqplot(log_returns['AAPL_Close'].dropna())
qqplot(log_returns['GOOG_Close'].dropna())
```
# Portfolio Optimization
The portfolio weights sum to one:
$\sum_{i = 1}^{n}w_i = 1$
```
noa = data.shape[1] # (1000, 10)
rets = np.log(data/data.shift(1))
rets.hist(bins=40, figsize=(10, 8));
rets.mean() * 252 # annualized returns
rets.cov() * 252 # annualized covariance matrix
```
## weights
```
weights = np.random.random(noa)
weights /= np.sum(weights)
print('weights:', weights)
print()
print('weights sum:', weights.sum())
```
Formula for expected return of a portfolio:
$\mu_p = E\big(\sum_I w_i r_i \big) = \sum_I w_i \mu_i$
use linearity of expectation operator.
Expected portfolio variance is given by:
the covariance is
$\sigma_{ij} = E(r_i - \mu_i)(r_j - \mu_j)$
from this we get the variance
$\sigma ^2 = E((r_i - \mu_i)^2) = \sum_{i\in{I}}\sum_{j\in{I}}w_iw_j\sigma_{ij} = w^T\Sigma w$
```
np.sum(rets.mean() * weights) * 252
```
## variance
```
np.dot(weights.T, np.dot(rets.cov() * 252, weights)) # variance
math.sqrt(np.dot(weights.T,np.dot(rets.cov() * 252,weights))) # volatility
def port_ret(weights, rets):
return np.sum(rets.mean() * weights) * 252
def port_vol(weights):
return np.sqrt(np.dot(weights.T, np.dot(rets.cov() * 252, weights)))
prets=[]
pvols=[]
for p in range(2500):
weights = np.random.random(noa)
weights/=np.sum(weights)
prets.append(port_ret(weights))
pvols.append(port_vol(weights))
prets = np.array(prets)
pvols = np.array(pvols)
```
Sharpe Ratio:
$SR = \frac{\mu_p - r_f}{\sigma_p}$
```
plt.figure(figsize=(15,6))
plt.scatter(pvols,prets,c=prets/pvols,marker='o',cmap='coolwarm')
plt.xlabel('expected volatility')
plt.ylabel('expected return')
plt.colorbar(label='Sharpe ratio')
```
## Optimal portfolios
The optimal portfolio is found by minimizing with respect to the negative of the Sharpe Ratio. The weights are constrained to be between 0 and 1 and add up to 1.
### Minimize
The minimize is part of the optimize module in scipy: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html#scipy.optimize.minimize
```
import scipy.optimize as sco
def min_func_sharpe(weights):
return -port_ret(weights)/port_vol(weights)
cons = ({'type':'eq','fun': lambda x: np.sum(x) - 1})
bnds = tuple((0, 1) for x in range(noa))
eweights = np.array(noa * [1./noa])
eweights
min_func_sharpe(eweights)
%%time
opts=sco.minimize(min_func_sharpe,
eweights,method='SLSQP',
bounds=bnds,
constraints=cons)
opts
opts['x'].round(3)
port_ret(opts['x']).round(3)
port_vol(opts['x']).round(3)
port_ret(opts['x'])/port_vol(opts['x']) # sharpe ratio
```
## minimization of volatility
```
optv = sco.minimize(port_vol,eweights,
method='SLSQP',
bounds=bnds,
constraints=cons)
optv
np.mean(np.array([0.18576914, 0.18558958, 0.18524021, 0.18638385, 0.18620184])).round(3)
optv['x'].round(3)
port_vol(optv['x']).round(3)
port_ret(optv['x']).round(4)
(port_ret(optv['x'])/port_vol(optv['x'])).round(3)
port_ret(optv['x'])/port_vol(optv['x'])
```
## Efficient frontier
Fix a target return level and derive for each such level those portfolio weights that lead to the minimum volatility value. Because when iterating over different target return levels one condition for the minimization changes. That is why we update the dictionary of constraints.
```
cons = ({'type': 'eq', 'fun': lambda x: port_ret(x) - tret},
{'type': 'eq', 'fun': lambda x: np.sum(x) - 1})
bnds = tuple((0, 1) for x in weights)
%%time
trets = np.linspace(0.175, 0.3, 50)
tvols = []
for tret in trets:
res = sco.minimize(
port_vol,
eweights,
method='SLSQP',
bounds=bnds,
constraints=cons
)
tvols.append(res['fun'])
tvols = np.array(tvols)
plt.figure(figsize=(10,6))
plt.scatter(pvols,
prets, c=prets/pvols, marker='.',
alpha=0.8, cmap='coolwarm')
plt.plot(tvols, trets, 'b', lw=4.0)
plt.plot(port_vol(opts['x']), port_ret(opts['x']),'y*', markersize=15.0)
plt.plot(port_vol(optv['x']), port_ret(optv['x']),'r*', markersize=15.0)
plt.xlabel('expected volatility')
plt.ylabel('expected return')
plt.colorbar(label='Sharpe ratio');
```
| github_jupyter |

# _*Qiskit Finance: Portfolio Optimization*_
The latest version of this notebook is available on https://github.com/Qiskit/qiskit-iqx-tutorials.
***
### Contributors
Stefan Woerner<sup>[1]</sup>, Daniel Egger<sup>[1]</sup>, Shaohan Hu<sup>[1]</sup>, Stephen Wood<sup>[1]</sup>, Marco Pistoia<sup>[1]</sup>
### Affiliation
- <sup>[1]</sup>IBMQ
### Introduction
This tutorial shows how to solve the following mean-variance portfolio optimization problem for $n$ assets:
$\begin{aligned}
\min_{x \in \{0, 1\}^n} q x^T \Sigma x - \mu^T x\\
\text{subject to: } 1^T x = B
\end{aligned}$
where we use the following notation:
- $x \in \{0, 1\}^n$ denotes the vector of binary decision variables, which indicate which assets to pick ($x[i] = 1$) and which not to pick ($x[i] = 0$),
- $\mu \in \mathbb{R}^n$ defines the expected returns for the assets,
- $\Sigma \in \mathbb{R}^{n \times n}$ specifies the covariances between the assets,
- $q > 0$ controls the risk appetite of the decision maker,
- and $B$ denotes the budget, i.e. the number of assets to be selected out of $n$.
We assume the following simplifications:
- all assets have the same price (normalized to 1),
- the full budget $B$ has to be spent, i.e. one has to select exactly $B$ assets.
The equality constraint $1^T x = B$ is mapped to a penalty term $(1^T x - B)^2$ which is scaled by a parameter and subtracted from the objective function.
The resulting problem can be mapped to a Hamiltonian whose ground state corresponds to the optimal solution.
This notebook shows how to use the Variational Quantum Eigensolver (VQE) or the Quantum Approximate Optimization Algorithm (QAOA) to find the optimal solution for a given set of parameters.
Experiments on real quantum hardware for this problem are reported for instance in the following paper:
<br>
<a href="https://arxiv.org/abs/1907.04769">Improving Variational Quantum Optimization using CVaR. Barkoutsos et al. 2019.</a>
```
from qiskit import BasicAer
from qiskit.aqua import QuantumInstance
from qiskit.finance.ising import portfolio
from qiskit.optimization.ising.common import sample_most_likely
from qiskit.finance.data_providers import RandomDataProvider
from qiskit.aqua.algorithms import VQE, QAOA, ExactEigensolver
from qiskit.aqua.components.optimizers import COBYLA
from qiskit.aqua.components.variational_forms import RY
import numpy as np
import datetime
```
### [Optional] Setup token to run the experiment on a real device
If you would like to run the experiment on a real device, you need to setup your account first.
Note: If you do not store your token yet, use `IBMQ.save_account('MY_API_TOKEN')` to store it first.
```
from qiskit import IBMQ
provider = IBMQ.load_account()
```
### Define problem instance
Here an Operator instance is created for our Hamiltonian. In this case the paulis are from an Ising Hamiltonian translated from the portfolio problem. We use a random portfolio problem for this notebook. It is straight-forward to extend this to using real financial data as illustrated here:<br>
[Loading and Processing Stock-Market Time-Series Data](../data_providers/time_series.ipynb)
```
# set number of assets (= number of qubits)
num_assets = 4
# Generate expected return and covariance matrix from (random) time-series
stocks = [("TICKER%s" % i) for i in range(num_assets)]
data = RandomDataProvider(tickers=stocks,
start=datetime.datetime(2016,1,1),
end=datetime.datetime(2016,1,30))
data.run()
mu = data.get_period_return_mean_vector()
sigma = data.get_period_return_covariance_matrix()
q = 0.5 # set risk factor
budget = int(num_assets / 2) # set budget
penalty = num_assets # set parameter to scale the budget penalty term
qubitOp, offset = portfolio.get_operator(mu, sigma, q, budget, penalty)
```
We define some utility methods to print the results in a nice format.
```
def index_to_selection(i, num_assets):
s = "{0:b}".format(i).rjust(num_assets)
x = np.array([1 if s[i]=='1' else 0 for i in reversed(range(num_assets))])
return x
def print_result(result):
selection = sample_most_likely(result['eigvecs'][0])
value = portfolio.portfolio_value(selection, mu, sigma, q, budget, penalty)
print('Optimal: selection {}, value {:.4f}'.format(selection, value))
probabilities = np.abs(result['eigvecs'][0])**2
i_sorted = reversed(np.argsort(probabilities))
print('\n----------------- Full result ---------------------')
print('selection\tvalue\t\tprobability')
print('---------------------------------------------------')
for i in i_sorted:
x = index_to_selection(i, num_assets)
value = portfolio.portfolio_value(x, mu, sigma, q, budget, penalty)
probability = probabilities[i]
print('%10s\t%.4f\t\t%.4f' %(x, value, probability))
```
### ExactEigensolver (as a classical reference)
Lets solve the problem. First classically...
We can now use the Operator we built above without regard to the specifics of how it was created. We set the algorithm for the ExactEigensolver so we can have a classical reference. The problem is set for 'ising'. Backend is not required since this is computed classically not using quantum computation. The result is returned as a dictionary.
```
exact_eigensolver = ExactEigensolver(qubitOp, k=1)
result = exact_eigensolver.run()
print_result(result)
```
### Solution using VQE
We can now use the Variational Quantum Eigensolver (VQE) to solve the problem. We will specify the optimizer and variational form to be used.
Note: You can switch to different backends by providing the name of backend.
```
backend = BasicAer.get_backend('statevector_simulator')
seed = 50
cobyla = COBYLA()
cobyla.set_options(maxiter=500)
ry = RY(qubitOp.num_qubits, depth=3, entanglement='full')
vqe = VQE(qubitOp, ry, cobyla)
vqe.random_seed = seed
quantum_instance = QuantumInstance(backend=backend, seed_simulator=seed, seed_transpiler=seed)
result = vqe.run(quantum_instance)
print_result(result)
```
### Solution using QAOA
We also show here a result using the Quantum Approximate Optimization Algorithm (QAOA). This is another variational algorithm and it uses an internal variational form that is created based on the problem.
```
backend = BasicAer.get_backend('statevector_simulator')
seed = 50
cobyla = COBYLA()
cobyla.set_options(maxiter=250)
qaoa = QAOA(qubitOp, cobyla, 3)
qaoa.random_seed = seed
quantum_instance = QuantumInstance(backend=backend, seed_simulator=seed, seed_transpiler=seed)
result = qaoa.run(quantum_instance)
print_result(result)
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
```
| github_jupyter |
# Changes In The Daily Growth Rate
> Changes in the daily growth rate for select countries.
- comments: true
- author: Thomas Wiecki
- categories: [growth]
- image: images/covid-growth.png
- permalink: /growth-analysis/
```
from pathlib import Path
loadpy = Path('load_covid_data.py')
if not loadpy.exists():
! wget https://raw.githubusercontent.com/github/covid19-dashboard/master/_notebooks/load_covid_data.py
#hide
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import pandas as pd
import seaborn as sns
import load_covid_data
sns.set_context('talk')
plt.style.use('seaborn-whitegrid')
#hide
df = load_covid_data.load_data(drop_states=True)
annotate_kwargs = dict(
s='Based on COVID Data Repository by Johns Hopkins CSSE ({})\nBy Thomas Wiecki'.format(df.index.max().strftime('%B %d, %Y')),
xy=(0.05, 0.01), xycoords='figure fraction', fontsize=10)
#hide
# Country names seem to change quite a bit
df.country.unique()
#hide
european_countries = ['Italy', 'Germany', 'France (total)', 'Spain', 'United Kingdom (total)',
'Iran']
large_engl_countries = ['US (total)', 'Canada (total)', 'Australia (total)']
asian_countries = ['Singapore', 'Japan', 'Korea, South', 'Hong Kong']
south_american_countries = ['Argentina', 'Brazil', 'Colombia', 'Chile']
country_groups = [european_countries, large_engl_countries, asian_countries, south_american_countries]
line_styles = ['-', ':', '--', '-.']
df
#hide
def plot_countries(df, countries, min_confirmed=100, ls='-', col='confirmed'):
for country in countries:
df_country = df.loc[(df.country == country) & (df.confirmed >= min_confirmed)]
if len(df_country) == 0:
continue
df_country.reset_index()[col].plot(label=country, ls=ls)
sns.set_palette(sns.hls_palette(8, l=.45, s=.8)) # 8 countries max
fig, ax = plt.subplots(figsize=(12, 8))
for countries, ls in zip(country_groups, line_styles):
plot_countries(df, countries, ls=ls)
x = np.linspace(0, plt.xlim()[1] - 1)
ax.plot(x, 100 * (1.33) ** x, ls='--', color='k', label='33% daily growth')
ax.set(yscale='log',
title='Exponential growth of COVID-19 across countries',
xlabel='Days from first 100 confirmed cases',
ylabel='Confirmed cases (log scale)')
ax.get_yaxis().set_major_formatter(matplotlib.ticker.ScalarFormatter())
ax.legend(bbox_to_anchor=(1.0, 1.0))
ax.annotate(**annotate_kwargs)
sns.despine();
#hide
fig, ax = plt.subplots(figsize=(12, 8))
for countries, ls in zip(country_groups, line_styles):
plot_countries(df, countries, ls=ls)
x = np.linspace(0, plt.xlim()[1] - 1)
ax.plot(x, 100 * (1.33) ** x, ls='--', color='k', label='33% daily growth')
ax.set(title='Exponential growth of COVID-19 across countries',
xlabel='Days from first 100 confirmed cases',
ylabel='Confirmed cases', ylim=(0, 30000))
ax.legend(bbox_to_anchor=(1.0, 1.0))
ax.annotate(**annotate_kwargs)
sns.despine();
#hide_input
smooth_days = 4
fig, ax = plt.subplots(figsize=(14, 8))
df['pct_change'] = (df
.groupby('country')
.confirmed
.pct_change()
.rolling(smooth_days)
.mean()
)
for countries, ls in zip(country_groups, line_styles):
(df.set_index('country')
.loc[countries]
.loc[lambda x: x.confirmed > 100]
.reset_index()
.set_index('days_since_100')
.groupby('country', sort=False)['pct_change']
.plot(ls=ls)
)
ax.set(ylim=(0, 1),
xlim=(0, 20),
title='Are we seeing changes in daily growth rate?',
xlabel='Days from first 100 confirmed cases',
ylabel='Daily percent change (smoothed over {} days)'.format(smooth_days),
)
ax.axhline(.33, ls='--', color='k')
ax.get_yaxis().set_major_formatter(matplotlib.ticker.ScalarFormatter())
ax.legend(bbox_to_anchor=(1.0, .1))
sns.despine()
ax.annotate(**annotate_kwargs);
# This creates a preview image for the blog post and home page
fig.savefig('../images/covid-growth.png')
```
## Appendix: German ICU Capacity
```
#collapse-hide
sns.set_palette(sns.hls_palette(8, l=.45, s=.8)) # 8 countries max
fig, ax = plt.subplots(figsize=(12, 8))
p_crit = .05
# 28000 ICU beds total, 80% occupied
icu_germany = 28000
icu_germany_free = .2
df_tmp = df.loc[lambda x: (x.country == 'Germany') & (x.confirmed > 100)].critical_estimate
df_tmp.plot(ax=ax)
x = np.linspace(0, 30, 30)
pd.Series(index=pd.date_range(df_tmp.index[0], periods=30),
data=100*p_crit * (1.33) ** x).plot(ax=ax,ls='--', color='k', label='33% daily growth')
ax.axhline(icu_germany, color='.3', ls='-.', label='Total ICU beds')
ax.axhline(icu_germany * icu_germany_free, color='.5', ls=':', label='Free ICU beds')
ax.set(yscale='log',
title='When will Germany run out of ICU beds?',
ylabel='Expected critical cases (assuming {:.0f}% critical)'.format(100 * p_crit),
)
ax.get_yaxis().set_major_formatter(matplotlib.ticker.ScalarFormatter())
ax.legend(bbox_to_anchor=(1.0, 1.0))
sns.despine()
ax.annotate(**annotate_kwargs);
```
Updated daily by [GitHub Actions](https://github.com/features/actions).
This visualization was made by [Thomas Wiecki](https://twitter.com/twiecki)[^1].
[^1]: Data sourced from ["2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE"](https://systems.jhu.edu/research/public-health/ncov/) [GitHub repository](https://github.com/CSSEGISandData/COVID-19) and recreates the (pay-walled) plot in the [Financial Times]( https://www.ft.com/content/a26fbf7e-48f8-11ea-aeb3-955839e06441). This code is provided under the [BSD-3 License](https://github.com/twiecki/covid19/blob/master/LICENSE). Link to [original notebook](https://github.com/twiecki/covid19/blob/master/covid19_growth.ipynb).
| github_jupyter |
### Model features
- augmentation (6 image generated)
- 2 dropout layer
- adam optimizer with learning rate decay
```
NAME = '2dropout-augmentation'
LOAD = True
import sys
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import cv2
import random
from tqdm import tqdm
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
import keras
from keras import optimizers
from keras.applications.vgg16 import VGG16
from keras.models import Model
from keras.layers import Dense, Dropout, Flatten, BatchNormalization
# import third-party library
sys.path.append('./my_lib/')
from data_augmentation import DataAugmentation
# import data
csv_train = pd.read_csv('../input/labels.csv')
csv_test = pd.read_csv('../input/sample_submission.csv')
# read training CSV
csv_train.head(10)
# read test csv
csv_test.head(10)
# reduce dataset for test
# csv_train = csv_train.head(200)
# csv_test = csv_test.head(200)
# Generate Labels
targets_series = pd.Series(csv_train['breed'])
# print(targets_series)
one_hot = pd.get_dummies(targets_series, sparse = True)
labels = np.asarray(one_hot)
n_check = random.randint(0, len(labels)-1)
print(csv_train['breed'][n_check], 'is encoded as', ''.join((str(i) for i in labels[n_check])))
im_size = 90
x_train = []
y_train = []
x_test = []
for i, (f, breed) in enumerate(tqdm(csv_train.values)):
img = cv2.imread('../input/train/{}.jpg'.format(f))
x_train.append(cv2.resize(img, (im_size, im_size)))
y_train.append(labels[i])
```
Use external module to execute data augmentation.
The module execute:
- [ ] Inversion
- [ ] Sobel derivative
- [ ] Scharr derivative
- [ ] Laplacian <!--**(error not used for now)**-->
- [ ] Blur
- [ ] Gaussian blur [disable]
- [ ] Median blur
- [ ] Bilateral blur
- [x] Horizontal flips
- [x] Rotation
```
for i, images in enumerate(tqdm(DataAugmentation(x_train,
options={'inverse': False,
'sobel_derivative': False,
'scharr_derivative': False,
'laplacian': False,
'blur': False,
'gaussian_blur': False,
'median_blur': False,
'bilateral_blur': False,
'horizontal_flips': True,
'rotation': True,
# 'rotation_config': [(10,1.2)],
'shuffle_result': False}))):
for image in images:
if i == 4:
plt.imshow(image, cmap = 'gray', interpolation = 'bicubic')
plt.show()
x_train.append(image)
y_train.append(y_train[i])
print('dataset became:', len(x_train))
# check train
n_check = random.randint(0, len(y_train)-1)
print('label:', ''.join((str(i) for i in y_train[n_check])))
plt.imshow(x_train[n_check], cmap = 'gray', interpolation = 'bicubic')
plt.show()
for f in tqdm(csv_test['id'].values):
img = cv2.imread('../input/test/{}.jpg'.format(f))
x_test.append(cv2.resize(img, (im_size, im_size)))
# build np array and normalise them
x_train_raw = np.array(x_train, np.float32) / 255.
y_train_raw = np.array(y_train, np.uint8)
x_test_raw = np.array(x_test, np.float32) / 255.
print("x_train shape:", x_train_raw.shape)
print("y_train shape:", y_train_raw.shape)
print("x_test shape:", x_test_raw.shape)
num_classes = y_train_raw.shape[1]
classes = csv_test.columns.values[1:]
```
Using the __stratify__ parameter on __treain_test_split__ the split should be equally distributed per classes.
**TODO:** Add cross validation
```
X_train, X_valid, Y_train, Y_valid = train_test_split(x_train_raw, y_train_raw,
test_size=0.20, random_state=42,
stratify=y_train_raw)
```
**TODO:** try the optimizer _rmsprop_ instead of _adam_.
```
# Create the base pre-trained model
base_model = VGG16(weights="imagenet", include_top=False, input_shape=(im_size, im_size, 3))
# Add a new top layers
x = base_model.output
x = Flatten()(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
x = BatchNormalization()(x)
predictions = Dense(num_classes, activation='softmax')(x)
# This is the model we will train
model = Model(inputs=base_model.input, outputs=predictions)
# First: train only the top layers (which were randomly initialized)
for layer in base_model.layers:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
callbacks_list = [
keras.callbacks.ModelCheckpoint('../output/weights.' + NAME + '.{epoch:02d}-{val_loss:.2f}.hdf5',
monitor='val_loss', verbose=0, save_best_only=True, save_weights_only=True,
mode='auto', period=1),
keras.callbacks.EarlyStopping(monitor='val_loss', patience=5, verbose=1)]
model.summary()
# load previous backuped weigths
if LOAD:
model.load_weights('../output/weights.2dropout-augmentation.40-1.75.hdf5')
history = model.fit(X_train, Y_train, epochs=40, batch_size=48,
validation_data=(X_valid, Y_valid),
callbacks=callbacks_list, verbose=1)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
preds = model.predict(x_test_raw, verbose=1)
# save prediction to csv
frame = pd.DataFrame(preds, index=csv_test['id'].tolist(), columns=classes)
frame.to_csv("../output/predicted-{}.csv".format(NAME), index_label='id')
frame.head(10)
# check predict
n_check = random.randint(0, len(x_test_raw)-1)
plt.imshow(x_test_raw[n_check], cmap = 'gray_r', interpolation = 'bicubic')
plt.show()
pre = model.predict(np.array([x_test_raw[n_check]]))
arg_max = np.argmax(pre)
print(np.max(pre), arg_max, classes[arg_max])
```
| github_jupyter |
# 函数
- 函数可以用来定义可重复代码,组织和简化
- 一般来说一个函数在实际开发中为一个小功能
- 一个类为一个大功能
- 同样函数的长度不要超过一屏
## 定义一个函数
def function_name(list of parameters):
do something

- 以前使用的random 或者range 或者print.. 其实都是函数或者类
```
def fun_name():
print('函数')
fun_name()#()表示函数调用
```
## 调用一个函数
- functionName()
- "()" 就代表调用
```
def jiou_name():
'''
这是注释,加以说明,例:这是czg写的判断奇数偶数的函数。
'''
num = int(input('请输入一个数字:'))
if num%2==0:
print('这个数是偶数')
else:
print('这个数是奇数')
jiou_name()
```

## 带返回值和不带返回值的函数
- return 返回的内容
- return 返回多个值
- 一般情况下,在多个函数协同完成一个功能的时候,那么将会有返回值

- 当然也可以自定义返回None
```
def sushu_name():
'''
这是判断一数是不是素数的函数
'''
num = eval(input('请输入一个数字:' ))
for i in range(2,num):
if num % i == 0:
print('不是素数')
break
else:
print('素数')
return num
a=sushu_name()
print(a)
```
## EP:

## 类型和关键字参数
- 普通参数
- 多个参数
- 默认值参数
- 不定长参数
```
import os
def kuajiang(name):
os.system('say {}天才'.format(name))
kuajiang('星期五')
kuajiang(name = '常志国')
def y(x):
return x**2
y_ = y(100)
print(y_)
def san(num):
return num**3
def liang(num):
return num**2
def input_():
num = eval(input('>>'))
res3 = san(num)
res2 = liang(num)
print(res3-res2)
input_()
```
## 普通参数
## 多个参数
```
import os
def kuajiang1(name1,name2,name3 ):
os.system('say {}{}{}天才'.format(name1,name2,name3))
kuajiang1(name1 = '常志国',name2 = '国志常',name3 = '志国常')
import os
#如果参数有信心,都放在最后面。
def kuajiang2(name1,name2,name3= '志国常'):
os.system('say {}{}{}天才'.format(name1,name2,name3))
kuajiang2(name1 = '常志国',name2 = '国志常')
import
user = '123456@qq.com'
passward = 'czg'
is_ok_and_y = False
def login(user_login,passward_login):
if user_login ==user and passward_login==passward:
print('成功')
else:
print('失败')
def qitian():
global is_ok_and_y
if is_ok_and_y == False:
print('是否7天免登陆?y/n')
res = input('>>')
a=input('请输入账号:')
b=input('请输入密码:')
if res=='y':
login(user_login=a,passward_login=b)
is_ok_and_y = True
else:
login(user_login=a,passward_login=b)
else:
print('成功')
qitian()
```
## 默认值参数
## 强制命名
```
import os
#如果参数有信心,都放在最后面。
def kuajiang2(*,name1,name2,name3= '志国常'):# *强制命名
os.system('say {}{}{}天才'.format(name1,name2,name3))
kuajiang2(name1 = '常志国',name2 = '国志常')
```
## 不定长参数
- \*args
> - 不定长,来多少装多少,不装也是可以的
- 返回的数据类型是元组
- args 名字是可以修改的,只是我们约定俗成的是args
- \**kwargs
> - 返回的字典
- 输入的一定要是表达式(键值对)
- name,\*args,name2,\**kwargs 使用参数名
## 变量的作用域
- 局部变量 local
- 全局变量 global
- globals 函数返回一个全局变量的字典,包括所有导入的变量
- locals() 函数会以字典类型返回当前位置的全部局部变量。
```
def test(*args):
print(args)
test(1,2,3,3,4)
```
## 注意:
- global :在进行赋值操作的时候需要声明
- 官方解释:This is because when you make an assignment to a variable in a scope, that variable becomes local to that scope and shadows any similarly named variable in the outer scope.
- 
# Homework
- 1

```
def getPentagonalNumber():
i=1
while i<=100:
num=(i*(3*i-1))/2
print(num,end='\t')
i+=1
if (i-1)%10==0:
print()
getPentagonalNumber()
```
- 2

```
def sumDigits(num):
# num = eval(input('请输入一个数字:'))
sum_=0
while True:
number=num%10
sum_+=number
num=num//10
if num==0:
print(sum_)
break
sumDigits(num=1245)
```
- 3

```
def displaySortedNumbers(num1,num2,num3):
num = [num1,num2,num3]
num.sort()
print(num)
displaySortedNumbers(num1=3,num2=4,num3=1)
```
- 4

```
def future():
in_ = eval (input("输入本金"))
ratr = eval (input("输入年利率"))
for i in range(1,31):
years = i
future = in_ * (1 + ratr / 100/12) ** (years * 12)
print(str(years)+' '+str(future))
future()
```
- 5

```
def printChars(ch1, ch2, numberPerLine):
count = 1
for i in range(ord(ch1), ord(ch2) + 1):
if count % numberPerLine == 0:
print(chr(i))
else:
print(chr(i), end = "")
count += 1
printChars(ch1='1', ch2='Z', numberPerLine=10)
```
- 6

```
def numberOfDaysInAYear(year):
if year % 400 == 0 or (year % 4 == 0 and year % 100 != 0):
return 366
else:
return 365
for year in range(2010, 2021):
numberOfDaysInAYear(year)
print(str(year) + '年有'+ str(numberOfDaysInAYear(year))+'天')
```
- 7

```
def distance(x1,y1,x2,y2):
s=((x2-x1)**2+(y2-y1)**2)**0.5
print('两点的距离是:'+str(s))
distance(x1=eval(input('请输入x1 :')),y1=eval(input('请输入y1 :')),x2=eval(input('请输入x2 :')),y2=eval(input('请输入y2 :')))
```
- 8

```
def meisushu():
for p in range(2,32):
num=2**(p)-1
p+=1
for i in range(2,num):
if num % i == 0:
break
else:
print(num)
meisushu()
```
- 9


```
import time
print('当前时间是:'+time.strftime("%a %b %d %Y %H:%M:%S", time.localtime()))
```
- 10

```
import random
import sys
def getDice():
i1 = random.randint(1, 6)
i2 = random.randint(1, 6)
print("和值为", i1, "+", i2, "=", i1 + i2)
dice=i1 + i2
if dice == 7 or dice == 11:
print("你赢了")
sys.exit()
elif dice == 2 or dice == 3 or dice == 12:
print("你输了")
sys.exit()
point = dice
print("无效数字:", point)
while dice != 7 and dice != point:
i1 = random.randint(1, 6)
i2 = random.randint(1, 6)
print("和值为", i1, "+", i2, "=", i1 + i2)
dice=i1 + i2
if dice == 7:
print("你输了")
else:
print("你赢了")
getDice()
```
- 11
### 去网上寻找如何用Python代码发送邮件
| github_jupyter |
# 09 - Decision Trees
by [Alejandro Correa Bahnsen](albahnsen.com/)
version 0.2, May 2016
## Part of the class [Machine Learning for Risk Management](https://github.com/albahnsen/ML_RiskManagement)
This notebook is licensed under a [Creative Commons Attribution-ShareAlike 3.0 Unported License](http://creativecommons.org/licenses/by-sa/3.0/deed.en_US). Special thanks goes to [Kevin Markham](https://github.com/justmarkham)
*Adapted from Chapter 8 of [An Introduction to Statistical Learning](http://www-bcf.usc.edu/~gareth/ISL/)*
Why are we learning about decision trees?
- Can be applied to both regression and classification problems
- Many useful properties
- Very popular
- Basis for more sophisticated models
- Have a different way of "thinking" than the other models we have studied
## Lesson objectives
Students will be able to:
- Explain how a decision tree is created
- Build a decision tree model in scikit-learn
- Tune a decision tree model and explain how tuning impacts the model
- Interpret a tree diagram
- Describe the key differences between regression and classification trees
- Decide whether a decision tree is an appropriate model for a given problem
# Part 1: Regression trees
Major League Baseball player data from 1986-87:
- **Years** (x-axis): number of years playing in the major leagues
- **Hits** (y-axis): number of hits in the previous year
- **Salary** (color): low salary is blue/green, high salary is red/yellow

Group exercise:
- The data above is our **training data**.
- We want to build a model that predicts the Salary of **future players** based on Years and Hits.
- We are going to "segment" the feature space into regions, and then use the **mean Salary in each region** as the predicted Salary for future players.
- Intuitively, you want to **maximize** the similarity (or "homogeneity") within a given region, and **minimize** the similarity between different regions.
Rules for segmenting:
- You can only use **straight lines**, drawn one at a time.
- Your line must either be **vertical or horizontal**.
- Your line **stops** when it hits an existing line.

Above are the regions created by a computer:
- $R_1$: players with **less than 5 years** of experience, mean Salary of **\$166,000 **
- $R_2$: players with **5 or more years** of experience and **less than 118 hits**, mean Salary of **\$403,000 **
- $R_3$: players with **5 or more years** of experience and **118 hits or more**, mean Salary of **\$846,000 **
**Note:** Years and Hits are both integers, but the convention is to use the **midpoint** between adjacent values to label a split.
These regions are used to make predictions on **out-of-sample data**. Thus, there are only three possible predictions! (Is this different from how **linear regression** makes predictions?)
Below is the equivalent regression tree:

The first split is **Years < 4.5**, thus that split goes at the top of the tree. When a splitting rule is **True**, you follow the left branch. When a splitting rule is **False**, you follow the right branch.
For players in the **left branch**, the mean Salary is \$166,000, thus you label it with that value. (Salary has been divided by 1000 and log-transformed to 5.11.)
For players in the **right branch**, there is a further split on **Hits < 117.5**, dividing players into two more Salary regions: \$403,000 (transformed to 6.00), and \$846,000 (transformed to 6.74).

**What does this tree tell you about your data?**
- Years is the most important factor determining Salary, with a lower number of Years corresponding to a lower Salary.
- For a player with a lower number of Years, Hits is not an important factor determining Salary.
- For a player with a higher number of Years, Hits is an important factor determining Salary, with a greater number of Hits corresponding to a higher Salary.
**Question:** What do you like and dislike about decision trees so far?
## Building a regression tree by hand
Your **training data** is a tiny dataset of [used vehicle sale prices](https://raw.githubusercontent.com/justmarkham/DAT8/master/data/vehicles_train.csv). Your goal is to **predict price** for testing data.
1. Read the data into a Pandas DataFrame.
2. Explore the data by sorting, plotting, or split-apply-combine (aka `group_by`).
3. Decide which feature is the most important predictor, and use that to create your first splitting rule.
- Only binary splits are allowed.
4. After making your first split, split your DataFrame into two parts, and then explore each part to figure out what other splits to make.
5. Stop making splits once you are convinced that it strikes a good balance between underfitting and overfitting.
- Your goal is to build a model that generalizes well.
- You are allowed to split on the same variable multiple times!
6. Draw your tree, labeling the leaves with the mean price for the observations in that region.
- Make sure nothing is backwards: You follow the **left branch** if the rule is true, and the **right branch** if the rule is false.
## How does a computer build a regression tree?
**Ideal approach:** Consider every possible partition of the feature space (computationally infeasible)
**"Good enough" approach:** recursive binary splitting
1. Begin at the top of the tree.
2. For **every feature**, examine **every possible cutpoint**, and choose the feature and cutpoint such that the resulting tree has the lowest possible mean squared error (MSE). Make that split.
3. Examine the two resulting regions, and again make a **single split** (in one of the regions) to minimize the MSE.
4. Keep repeating step 3 until a **stopping criterion** is met:
- maximum tree depth (maximum number of splits required to arrive at a leaf)
- minimum number of observations in a leaf
### Demo: Choosing the ideal cutpoint for a given feature
```
# vehicle data
import pandas as pd
import zipfile
with zipfile.ZipFile('../datasets/vehicles_train.csv.zip', 'r') as z:
f = z.open('vehicles_train.csv')
train = pd.io.parsers.read_table(f, index_col=False, sep=',')
# before splitting anything, just predict the mean of the entire dataset
train['prediction'] = train.price.mean()
train
year = 0
train['pred'] = train.loc[train.year<year, 'price'].mean()
train.loc[train.year>=year, 'pred'] = train.loc[train.year>=year, 'price'].mean()
(((train['price'] - train['pred'])**2).mean()) ** 0.5
train_izq = train.loc[train.year<0].copy()
train_izq.year.unique()
def error_año(train, year):
train['pred'] = train.loc[train.year<year, 'price'].mean()
train.loc[train.year>=year, 'pred'] = train.loc[train.year>=year, 'price'].mean()
return round(((((train['price'] - train['pred'])**2).mean()) ** 0.5), 2)
def error_miles(train, miles):
train['pred'] = train.loc[train.miles<miles, 'price'].mean()
train.loc[train.miles>=miles, 'pred'] = train.loc[train.miles>=miles, 'price'].mean()
return round(((((train['price'] - train['pred'])**2).mean()) ** 0.5), 2)
```
**Recap:** Before every split, this process is repeated for every feature, and the feature and cutpoint that produces the lowest MSE is chosen.
## Building a regression tree in scikit-learn
```
# encode car as 0 and truck as 1
train['vtype'] = train.vtype.map({'car':0, 'truck':1})
# define X and y
feature_cols = ['year', 'miles', 'doors', 'vtype']
X = train[feature_cols]
y = train.price
# instantiate a DecisionTreeRegressor (with random_state=1)
from sklearn.tree import DecisionTreeRegressor
treereg = DecisionTreeRegressor(random_state=1)
treereg
# use leave-one-out cross-validation (LOOCV) to estimate the RMSE for this model
import numpy as np
from sklearn.cross_validation import cross_val_score
scores = cross_val_score(treereg, X, y, cv=14, scoring='mean_squared_error')
np.mean(np.sqrt(-scores))
```
## What happens when we grow a tree too deep?
- Left: Regression tree for Salary **grown deeper**
- Right: Comparison of the **training, testing, and cross-validation errors** for trees with different numbers of leaves

The **training error** continues to go down as the tree size increases (due to overfitting), but the lowest **cross-validation error** occurs for a tree with 3 leaves.
## Tuning a regression tree
Let's try to reduce the RMSE by tuning the **max_depth** parameter:
```
# try different values one-by-one
treereg = DecisionTreeRegressor(max_depth=1, random_state=1)
scores = cross_val_score(treereg, X, y, cv=14, scoring='mean_squared_error')
np.mean(np.sqrt(-scores))
```
Or, we could write a loop to try a range of values:
```
# list of values to try
max_depth_range = range(1, 8)
# list to store the average RMSE for each value of max_depth
RMSE_scores = []
# use LOOCV with each value of max_depth
for depth in max_depth_range:
treereg = DecisionTreeRegressor(max_depth=depth, random_state=1)
MSE_scores = cross_val_score(treereg, X, y, cv=14, scoring='mean_squared_error')
RMSE_scores.append(np.mean(np.sqrt(-MSE_scores)))
%matplotlib inline
import matplotlib.pyplot as plt
# plot max_depth (x-axis) versus RMSE (y-axis)
plt.plot(max_depth_range, RMSE_scores)
plt.xlabel('max_depth')
plt.ylabel('RMSE (lower is better)')
# max_depth=3 was best, so fit a tree using that parameter
treereg = DecisionTreeRegressor(max_depth=3, random_state=1)
treereg.fit(X, y)
# "Gini importance" of each feature: the (normalized) total reduction of error brought by that feature
pd.DataFrame({'feature':feature_cols, 'importance':treereg.feature_importances_})
```
## Creating a tree diagram
```
# create a Graphviz file
from sklearn.tree import export_graphviz
export_graphviz(treereg, out_file='tree_vehicles.dot', feature_names=feature_cols)
# At the command line, run this to convert to PNG:
# dot -Tpng tree_vehicles.dot -o tree_vehicles.png
```

Reading the internal nodes:
- **samples:** number of observations in that node before splitting
- **mse:** MSE calculated by comparing the actual response values in that node against the mean response value in that node
- **rule:** rule used to split that node (go left if true, go right if false)
Reading the leaves:
- **samples:** number of observations in that node
- **value:** mean response value in that node
- **mse:** MSE calculated by comparing the actual response values in that node against "value"
## Making predictions for the testing data
```
# read the testing data
with zipfile.ZipFile('../datasets/vehicles_test.csv.zip', 'r') as z:
f = z.open('vehicles_test.csv')
test = pd.io.parsers.read_table(f, index_col=False, sep=',')
test['vtype'] = test.vtype.map({'car':0, 'truck':1})
test
```
**Question:** Using the tree diagram above, what predictions will the model make for each observation?
```
# use fitted model to make predictions on testing data
X_test = test[feature_cols]
y_test = test.price
y_pred = treereg.predict(X_test)
y_pred
# calculate RMSE
from sklearn.metrics import mean_squared_error
np.sqrt(mean_squared_error(y_test, y_pred))
```
# Part 2: Classification trees
**Example:** Predict whether Barack Obama or Hillary Clinton will win the Democratic primary in a particular county in 2008:

**Questions:**
- What are the observations? How many observations are there?
- What is the response variable?
- What are the features?
- What is the most predictive feature?
- Why does the tree split on high school graduation rate twice in a row?
- What is the class prediction for the following county: 15% African-American, 90% high school graduation rate, located in the South, high poverty, high population density?
- What is the predicted probability for that same county?
## Comparing regression trees and classification trees
|regression trees|classification trees|
|---|---|
|predict a continuous response|predict a categorical response|
|predict using mean response of each leaf|predict using most commonly occuring class of each leaf|
|splits are chosen to minimize MSE|splits are chosen to minimize Gini index (discussed below)|
## Splitting criteria for classification trees
Common options for the splitting criteria:
- **classification error rate:** fraction of training observations in a region that don't belong to the most common class
- **Gini index:** measure of total variance across classes in a region
### Example of classification error rate
Pretend we are predicting whether someone buys an iPhone or an Android:
- At a particular node, there are **25 observations** (phone buyers), of whom **10 bought iPhones and 15 bought Androids**.
- Since the majority class is **Android**, that's our prediction for all 25 observations, and thus the classification error rate is **10/25 = 40%**.
Our goal in making splits is to **reduce the classification error rate**. Let's try splitting on gender:
- **Males:** 2 iPhones and 12 Androids, thus the predicted class is Android
- **Females:** 8 iPhones and 3 Androids, thus the predicted class is iPhone
- Classification error rate after this split would be **5/25 = 20%**
Compare that with a split on age:
- **30 or younger:** 4 iPhones and 8 Androids, thus the predicted class is Android
- **31 or older:** 6 iPhones and 7 Androids, thus the predicted class is Android
- Classification error rate after this split would be **10/25 = 40%**
The decision tree algorithm will try **every possible split across all features**, and choose the split that **reduces the error rate the most.**
### Example of Gini index
Calculate the Gini index before making a split:
$$1 - \left(\frac {iPhone} {Total}\right)^2 - \left(\frac {Android} {Total}\right)^2 = 1 - \left(\frac {10} {25}\right)^2 - \left(\frac {15} {25}\right)^2 = 0.48$$
- The **maximum value** of the Gini index is 0.5, and occurs when the classes are perfectly balanced in a node.
- The **minimum value** of the Gini index is 0, and occurs when there is only one class represented in a node.
- A node with a lower Gini index is said to be more "pure".
Evaluating the split on **gender** using Gini index:
$$\text{Males: } 1 - \left(\frac {2} {14}\right)^2 - \left(\frac {12} {14}\right)^2 = 0.24$$
$$\text{Females: } 1 - \left(\frac {8} {11}\right)^2 - \left(\frac {3} {11}\right)^2 = 0.40$$
$$\text{Weighted Average: } 0.24 \left(\frac {14} {25}\right) + 0.40 \left(\frac {11} {25}\right) = 0.31$$
Evaluating the split on **age** using Gini index:
$$\text{30 or younger: } 1 - \left(\frac {4} {12}\right)^2 - \left(\frac {8} {12}\right)^2 = 0.44$$
$$\text{31 or older: } 1 - \left(\frac {6} {13}\right)^2 - \left(\frac {7} {13}\right)^2 = 0.50$$
$$\text{Weighted Average: } 0.44 \left(\frac {12} {25}\right) + 0.50 \left(\frac {13} {25}\right) = 0.47$$
Again, the decision tree algorithm will try **every possible split**, and will choose the split that **reduces the Gini index (and thus increases the "node purity") the most.**
### Comparing classification error rate and Gini index
- Gini index is generally preferred because it will make splits that **increase node purity**, even if that split does not change the classification error rate.
- Node purity is important because we're interested in the **class proportions** in each region, since that's how we calculate the **predicted probability** of each class.
- scikit-learn's default splitting criteria for classification trees is Gini index.
Note: There is another common splitting criteria called **cross-entropy**. It's numerically similar to Gini index, but slower to compute, thus it's not as popular as Gini index.
## Building a classification tree in scikit-learn
We'll build a classification tree using the Titanic data:
```
# read in the data
with zipfile.ZipFile('../datasets/titanic.csv.zip', 'r') as z:
f = z.open('titanic.csv')
titanic = pd.read_csv(f, sep=',', index_col=0)
# encode female as 0 and male as 1
titanic['Sex'] = titanic.Sex.map({'female':0, 'male':1})
# fill in the missing values for age with the median age
titanic.Age.fillna(titanic.Age.median(), inplace=True)
# create a DataFrame of dummy variables for Embarked
embarked_dummies = pd.get_dummies(titanic.Embarked, prefix='Embarked')
embarked_dummies.drop(embarked_dummies.columns[0], axis=1, inplace=True)
# concatenate the original DataFrame and the dummy DataFrame
titanic = pd.concat([titanic, embarked_dummies], axis=1)
# print the updated DataFrame
titanic.head()
```
- **Survived:** 0=died, 1=survived (response variable)
- **Pclass:** 1=first class, 2=second class, 3=third class
- What will happen if the tree splits on this feature?
- **Sex:** 0=female, 1=male
- **Age:** numeric value
- **Embarked:** C or Q or S
```
# define X and y
feature_cols = ['Pclass', 'Sex', 'Age', 'Embarked_Q', 'Embarked_S']
X = titanic[feature_cols]
y = titanic.Survived
# fit a classification tree with max_depth=3 on all data
from sklearn.tree import DecisionTreeClassifier
treeclf = DecisionTreeClassifier(max_depth=3, random_state=1)
treeclf.fit(X, y)
# create a Graphviz file
export_graphviz(treeclf, out_file='tree_titanic.dot', feature_names=feature_cols)
# At the command line, run this to convert to PNG:
# dot -Tpng tree_titanic.dot -o tree_titanic.png
```

Notice the split in the bottom right: the **same class** is predicted in both of its leaves. That split didn't affect the **classification error rate**, though it did increase the **node purity**, which is important because it increases the accuracy of our predicted probabilities.
```
# compute the feature importances
pd.DataFrame({'feature':feature_cols, 'importance':treeclf.feature_importances_})
```
# Part 3: Comparing decision trees with other models
**Advantages of decision trees:**
- Can be used for regression or classification
- Can be displayed graphically
- Highly interpretable
- Can be specified as a series of rules, and more closely approximate human decision-making than other models
- Prediction is fast
- Features don't need scaling
- Automatically learns feature interactions
- Tends to ignore irrelevant features
- Non-parametric (will outperform linear models if relationship between features and response is highly non-linear)

**Disadvantages of decision trees:**
- Performance is (generally) not competitive with the best supervised learning methods
- Can easily overfit the training data (tuning is required)
- Small variations in the data can result in a completely different tree (high variance)
- Recursive binary splitting makes "locally optimal" decisions that may not result in a globally optimal tree
- Doesn't tend to work well if the classes are highly unbalanced
- Doesn't tend to work well with very small datasets
| github_jupyter |
# Location Set Covering Problem (LSCP)
*Authors:* [Germano Barcelos](https://github.com/gegen07), [James Gaboardi](https://github.com/jGaboardi), [Levi J. Wolf](https://github.com/ljwolf), [Qunshan Zhao](https://github.com/qszhao)
Location Set Covering is a problem realized by Toregas, et al. (1971). He figured out that emergency services must have placed according to a response time, since, there is a allowable maximum service time when it's discussed how handle an emergency activity. Therefore he proprosed a model named LSCP that:
_Minimize the number of facilities needed and locate them so that every demand area is covered within a predefined maximal service distance or time._ Church L., Murray, A. (2018)
**LSCP can be written as:**
$\begin{array} \displaystyle \textbf{Minimize} & \sum_{j=1}^{n}{x_j} && (1) \\
\displaystyle \textbf{Subject to:} & \sum_{j\in N_i}{x_j} \geq 1 & \forall i & (2) \\
& x_j \in {0,1} & \forall j & (3) \\ \end{array}$
$\begin{array} \displaystyle \textbf{Where:}\\ & & \displaystyle i & \small = & \textrm{index referencing nodes of the network as demand} \\
& & j & \small = & \textrm{index referencing nodes of the network as potential facility sites} \\
& & S & \small = & \textrm{maximal acceptable service distance or time standard} \\
& & d_{ij} & \small = & \textrm{shortest distance or travel time between nodes} i \textrm{and} j \\
& & N_i & \small = & \{j | d_{ij} < S\} \\
& & x_j & \small = & \begin{cases}
1, \text{if a facility is located at node} j\\
0, \text{otherwise} \\
\end{cases} \end{array}$
_This excerpt above was quoted from Church L., Murray, A. (2018)_
This tutorial solves LSCP using `spopt.locate.coverage.LSCP` instance that depends on a array 2D representing the costs between facilities candidate sites and demand points. For that it uses a lattice 10x10 with simulated points to calculate the costs.
```
from spopt.locate.coverage import LSCP
from spopt.locate.util import simulated_geo_points
import numpy
import geopandas
import pulp
import spaghetti
from shapely.geometry import Point
import matplotlib.pyplot as plt
```
Since the model needs a distance cost matrix we should define some variables. In the comments, it's defined what these variables are for but solver. The solver, assigned below as `pulp.PULP_CBC_CMD`, is an interface to optimization solver developed by [COIN-OR](https://github.com/coin-or/Cbc). If you want to use another optimization interface as Gurobi or CPLEX see this [guide](https://coin-or.github.io/pulp/guides/how_to_configure_solvers.html) that explains how to achieve this.
```
CLIENT_COUNT = 100 # quantity demand points
FACILITY_COUNT = 5 # quantity supply points
MAX_COVERAGE = 8 # maximum service radius in meters
# Random seeds for reproducibility
CLIENT_SEED = 5
FACILITY_SEED = 6
solver = pulp.PULP_CBC_CMD(msg=False)
```
## Lattice 10x10
Create lattice 10x10 with 9 vertical lines in interior.
```
lattice = spaghetti.regular_lattice((0, 0, 10, 10), 9, exterior=True)
ntw = spaghetti.Network(in_data=lattice)
```
Transform spaghetti instance into geodataframe.
```
street = spaghetti.element_as_gdf(ntw, arcs=True)
street_buffered = geopandas.GeoDataFrame(
geopandas.GeoSeries(street["geometry"].buffer(0.2).unary_union),
crs=street.crs,
columns=["geometry"],
)
```
Plotting the network created by spaghetti we can verify that it seems a district with quarters and streets.
```
street.plot()
```
## Simulate points in a network
The function `simulated_geo_points` simulates points inside a network. In this case, it uses a lattice network 10x10 created by using spaghetti package.
Below we use the function defined above and simulate the points inside lattice bounds.
```
client_points = simulated_geo_points(street_buffered, needed=CLIENT_COUNT, seed=CLIENT_SEED)
facility_points = simulated_geo_points(
street_buffered, needed=FACILITY_COUNT, seed=FACILITY_SEED
)
```
Plotting the 100 client and 5 facility points we can see that the function generates dummy points to an area of 10x10 which is the area created by our lattice created on previous cells.
```
fig, ax = plt.subplots(figsize=(6, 6))
street.plot(ax=ax, alpha=0.8, zorder=1, label='streets')
facility_points.plot(ax=ax, color='red', zorder=2, label='facility candidate sites ($n$=5)')
client_points.plot(ax=ax, color='black', label='clients points ($n$=100)')
plt.legend(loc='upper left', bbox_to_anchor=(1.05, 1))
```
## Transform simulated points to real points
To use cost matrix or geodataframes we have to pay attention in some details. The client and facility points simulated don't belong to network, so if we calculate the distances now we are supposed to receive a wrong result. Before calculating distances we snap points to the networok and then calculate the distances.
Below we snap points that is not spatially belong to network and create new real points geodataframes
```
ntw.snapobservations(client_points, "clients", attribute=True)
clients_snapped = spaghetti.element_as_gdf(
ntw, pp_name="clients", snapped=True
)
ntw.snapobservations(facility_points, "facilities", attribute=True)
facilities_snapped = spaghetti.element_as_gdf(
ntw, pp_name="facilities", snapped=True
)
```
Now the plot seems more organized as the points belong to network.
The network created is plotted below with facility points and clients points:
```
fig, ax = plt.subplots(figsize=(6, 6))
street.plot(ax=ax, alpha=0.8, zorder=1, label='streets')
facilities_snapped.plot(ax=ax, color='red', zorder=2, label='facility candidate sites ($n$=5)')
clients_snapped.plot(ax=ax, color='black', label='clients points ($n$=100)')
plt.legend(loc='upper left', bbox_to_anchor=(1.05, 1))
```
## Calculating the cost matrix
Calculate distance between clients and facilities.
```
cost_matrix = ntw.allneighbordistances(
sourcepattern=ntw.pointpatterns["clients"],
destpattern=ntw.pointpatterns["facilities"],
)
```
The expected result here is a Dijkstra distance between clients and facilities points, so we our case an array 2D 100x5.
```
cost_matrix
```
With ``LSCP.from_cost_matrix`` we model LSC problem to cover all demand points with $p$ facility points within `max_coverage` meters as service radius using cost matrix calculated previously.
```
lscp_from_cost_matrix = LSCP.from_cost_matrix(cost_matrix, MAX_COVERAGE)
lscp_from_cost_matrix = lscp_from_cost_matrix.solve(solver)
```
Expected result is an instance of LSCP.
```
lscp_from_cost_matrix
```
## Using GeoDataFrame
With ``LSCP.from_geodataframe`` we model the LSC problem to cover all demand points with $p$ facility points within `max_coverage` meters as service radius using geodataframes without calculating the cost matrix previously.
```
lscp_from_geodataframe = LSCP.from_geodataframe(
clients_snapped, facilities_snapped, "geometry", "geometry", MAX_COVERAGE, distance_metric="euclidean"
)
lscp_from_geodataframe = lscp_from_geodataframe.solve(solver)
```
Expected result is an instance of LSCP.
```
lscp_from_geodataframe
```
## Plotting the results
The cell below describe the plotting of the results. For each method from LSCP class (from_cost_matrix, from_geodataframe) there is a plot displaying the facility site that was selected with a star colored and the points covered with the same color. Sometimes the demand points will be colored with not expected colors, it represents the coverage overlapping.
```
from matplotlib.patches import Patch
import matplotlib.lines as mlines
dv_colors = [
"darkcyan",
"mediumseagreen",
"cyan",
"darkslategray",
"lightskyblue",
"limegreen",
"darkgoldenrod",
"peachpuff",
"coral",
"mediumvioletred",
"blueviolet",
"fuchsia",
"thistle",
"lavender",
"saddlebrown",
]
def plot_results(lscp, facility_points):
arr_points = []
fac_sites = []
for i in range(FACILITY_COUNT):
if lscp.fac2cli[i]:
geom = client_points.iloc[lscp.fac2cli[i]]['geometry']
arr_points.append(geom)
fac_sites.append(i)
fig, ax = plt.subplots(figsize=(6, 6))
legend_elements = []
street.plot(ax=ax, alpha=1, color='black', zorder=1)
legend_elements.append(mlines.Line2D(
[],
[],
color='black',
label='streets',
))
facility_points.plot(ax=ax, color='brown', marker="*", markersize=80, zorder=2)
legend_elements.append(mlines.Line2D(
[],
[],
color='brown',
marker="*",
linewidth=0,
label=f'facility sites ($n$={FACILITY_COUNT})'
))
for i in range(len(arr_points)):
gdf = geopandas.GeoDataFrame(arr_points[i])
label = f"coverage_points by y{fac_sites[i]}"
legend_elements.append(Patch(facecolor=dv_colors[i], edgecolor="k", label=label))
gdf.plot(ax=ax, zorder=3, alpha=0.7, edgecolor="k", color=dv_colors[i], label=label)
facility_points.iloc[[fac_sites[i]]].plot(ax=ax,
marker="*",
markersize=200 * 3.0,
alpha=0.8,
zorder=4,
edgecolor="k",
facecolor=dv_colors[i])
legend_elements.append(mlines.Line2D(
[],
[],
color=dv_colors[i],
marker="*",
ms=20 / 2,
markeredgecolor="k",
linewidth=0,
alpha=0.8,
label=f"y{fac_sites[i]} facility selected",
))
plt.title("LSCP", fontweight="bold")
plt.legend(handles = legend_elements, loc='upper left', bbox_to_anchor=(1.05, 1))
```
### LSCP built from cost matrix
```
lscp_from_cost_matrix.facility_client_array()
plot_results(lscp_from_cost_matrix, facility_points)
```
### LSCP built from geodataframe
```
lscp_from_geodataframe.facility_client_array()
plot_results(lscp_from_geodataframe, facility_points)
```
You may notice that the models are different. This result is expected as the distance between facility and demand points is calculated with different metrics. The cost matrix is calculated with dijkstra distance while the distance using geodataframe is calculated with euclidean distance.
But why it needs just one facility point to cover all of those demand points? It can be explained by the nature of the problem. The problem was configured in a synthetic manner, the street is created with 10x10 lattice and the max_coverage parameter is 8 meters, so this result is not weird at all. You can change the max_coverage parameter to 2 meters and you will obtain a different result but be aware with how many points will be covered.
## References
- [Church, R. L., & Murray, A. T. (2018). Location covering models: History, applications and advancements (1st edition 2018). Springer](https://www.springer.com/gb/book/9783319998459)
- [Toregas, C., Swain, R., ReVelle, C., & Bergman, L. (1971). The location of emergency service facilities. Operations Research, 19(6), 1363–1373.](https://pubsonline.informs.org/doi/abs/10.1287/opre.19.6.1363)
| github_jupyter |
```
!pip3 install tqdm
from post_processing import *
from const import ROOT
from const import *
```
vert_path = os.path.join(".", 'vertical_hamming')
vert_path1 = os.path.join(".", 'vertical_hamming_res')
vert_file_list = glob.glob(os.path.join(vert_path, '*.png'))+ glob.glob(os.path.join(vert_path1, '*.png'))
df = pd.read_csv("0861_34.csv")
df = df.sort_values(by=['id'])
df3 = pd.read_csv("0861_50.csv")
df3 = df3.sort_values(by=['id'])
df4 = pd.read_csv("0863.csv")
df4 = df4.sort_values(by=['id'])
df2 = pd.read_csv("10folds_ne.csv")
len(vert_file_list)
```
df58 = pd.read_csv("final/optimized_stable_all_sigmoids.csv")
df256 = pd.read_csv("256_arith_mean.csv")
df2 = df256.copy()
for i in tqdm(range(len(df2))):
df2.loc[df2['id'] == df256.iloc[i]['id'],'rle_mask']=df58['rle_mask'][i]
df2.to_csv("final/ocnet256_resnet256_0450350101.csv",index=False)
vert_path = os.path.join(".", 'vertical_hamming')
vert_path1 = os.path.join(".", 'vertical_hamming_res')
vert_file_list = glob.glob(os.path.join(vert_path, '*.png'))+ glob.glob(os.path.join(vert_path1, '*.png'))
df = pd.read_csv("pb_0865.csv")
df = df.sort_values(by=['id'])
#df2 = pd.read_csv("256_arith_mean.csv")
ct=0
for i in tqdm(range(len(df))):
#print(row[1]["rle_mask"] is float)
try:
s=0
if not(type(df.iloc[i]["rle_mask"]) is float):
#print("s")
s=s+1
#print(s)
if s>0:
ct=ct+1
df2.loc[df2['id'] == df.iloc[i]['id'],'rle_mask']=' '.join(map(str, ""))
except ValueError:
a=1
print("setting {} masks to empty".format(ct))
ct=0
for i in tqdm(range(len(df2))):
#print(row[1]["rle_mask"] is float)
try:
s=0
if type(df2.iloc[i]["rle_mask"]) is float or df2.iloc[i]["rle_mask"] == '' :
#print("s")
s=s+1
#print(s)
if s>0:
ct=ct+1
#df2.loc[df2['id'] == df.iloc[i]['id'],'rle_mask']=' '.join(map(str, ""))
except ValueError:
a=1
print("{} empty masks in total".format(ct))
"""
100%|██████████| 18000/18000 [00:43<00:00, 410.06it/s]
7%|▋ | 1255/18000 [00:00<00:02, 6269.62it/s]
setting 7614 masks to empty
100%|██████████| 18000/18000 [00:02<00:00, 6322.42it/s]
7619 empty masks in total
"""
vert_path = os.path.join(".", 'vertical_hamming')
vert_path1 = os.path.join(".", 'vertical_hamming_res')
vert_file_list = glob.glob(os.path.join(vert_path, '*.png'))+ glob.glob(os.path.join(vert_path1, '*.png'))
df = pd.read_csv("0871.csv")
df = df.sort_values(by=['id'])
#df2 = pd.read_csv("256_arith_mean.csv")
ct=0
for i in tqdm(range(len(df))):
#print(row[1]["rle_mask"] is float)
try:
s=0
if type(df.iloc[i]["rle_mask"]) is float:
#print("s")
s=s+1
#print(s)
if s>0:
ct=ct+1
df2.loc[df2['id'] == df.iloc[i]['id'],'rle_mask']=' '.join(map(str, ""))
except ValueError:
a=1
print("setting {} masks to empty".format(ct))
ct=0
for i in tqdm(range(len(df2))):
#print(row[1]["rle_mask"] is float)
try:
s=0
if type(df2.iloc[i]["rle_mask"]) is float or df2.iloc[i]["rle_mask"] == '' :
#print("s")
s=s+1
#print(s)
if s>0:
ct=ct+1
#df2.loc[df2['id'] == df.iloc[i]['id'],'rle_mask']=' '.join(map(str, ""))
except ValueError:
a=1
print("{} empty masks in total".format(ct))
"""
100%|██████████| 18000/18000 [00:43<00:00, 410.06it/s]
7%|▋ | 1255/18000 [00:00<00:02, 6269.62it/s]
setting 7614 masks to empty
100%|██████████| 18000/18000 [00:02<00:00, 6322.42it/s]
7619 empty masks in total
"""
df2=df2.sort_values(by='id')
#df2.to_csv("final/test.csv",index=False)
df2.to_csv("final/ocnet256_resnet256_0450350101_0865empty.csv",index=False)
ct=0
#df2.to_csv("test.csv",index=False)
df=pd.read_csv("final/probe.csv")
#df=pd.read_csv("final/optimized_ocnet256_resnet256_0450350101_0871empty_leak4++_stage2+++_stage3++.csv")
for i in tqdm(range(len(df))):
#print(row[1]["rle_mask"] is float)
try:
s=0
if type(df.iloc[i]["rle_mask"]) is float :
#print("s")
s=s+1
#print(s)
if s>0:
ct=ct+1
#df2.loc[df2['id'] == df.iloc[i]['id'],'rle_mask']=' '.join(map(str, ""))
except ValueError:
a=1
print("{} empty masks in total".format(ct))
#df.to_csv("128_256_bc34_leak4.csv",index=False)
ct=0
for i in range(len(df)):
#print(row[1]["rle_mask"] is float)
try:
s=0
if type(df.iloc[i]["rle_mask"]) is float:
#print("s")
s=s+1
if type(df3.iloc[i]["rle_mask"]) is float:
s=s+1
if type(df4.iloc[i]["rle_mask"]) is float:
s=s+1
#print(s)
if s>1:
ct=ct+1
df2.loc[df2['id'] == df4.iloc[i]['id'],'rle_mask']=' '.join(map(str, ""))
except ValueError:
a=1
ct
type(df.loc[3]["rle_mask"]) is float
df = pd.read_csv("0871.csv")
df = df.sort_values(by=['id'])
i=0
for row in df.iterrows():
#print(row[1]["rle_mask"] is float)
try:
if type(row[1]["rle_mask"]) is float:
#print(1)
i=i+1
df.loc[df['id'] == row[1]['id'],'rle_mask']=' '.join(map(str, "1 2"))
else:
df.loc[df['id'] == row[1]['id'],'rle_mask']=' '.join(map(str, ""))
except ValueError:
a=1
i
#df.to_csv("binary_prediction_0871.csv",index=False)
df2.to_csv("80_stable_models_0871.csv",index=False)
ROOT='/Users/alexanderliao/data'
df=df2
for cand in vert_file_list:
mask=cand[cand.find("/",2)+1:cand.find(".png_",2)]
needs_treatment=cand[cand.find(".png_",2)+5:len(cand)-4]
img = Image.open(ROOT+'/train/masks/'+mask+'.png').convert('LA')
arr= np.array(img)[:,:,0]/255
new_code=rle_encoding(arr)
#img.show()
df.loc[df['id'] == needs_treatment,'rle_mask']=' '.join(map(str, new_code))
df.to_csv("ohem_ne_majvote_vert_corrected.csv",index=False)
cand[cand.find("/",2)+1:cand.find(".png_",2)]
cand[cand.find(".png_",2)+5:len(cand)-4]
cand.find(".png_",2)
a=rle_encoding(arr)
arr.shape
df.loc[df['id'] == 'b3680c53d9','rle_mask']=' '.join(map(str, a))
df.to_csv("submission_0861_vert_corrected.csv",index=False)
' '.join(map(str, a))
masks=[]
for cand in vert_file_list:
masks.append(cand[cand.find("/",2)+1:cand.find(".png_",2)]+".png")
bad_masks =[
'1eaf42beee.png'
,'33887a0ae7.png'
,'33dfce3a76.png'
,'3975043a11.png'
,'39cd06da7d.png'
,'483b35d589.png'
,'49336bb17b.png'
,'4ef0559016.png'
,'4fbda008c7.png'
,'4fdc882e4b.png'
,'50d3073821.png'
,'53e17edd83.png'
,'5b217529e7.png'
,'5f98029612.png'
,'608567ed23.png'
,'62aad7556c.png'
,'62d30854d7.png'
,'6460ce2df7.png'
,'6bc4c91c27.png'
,'7845115d01.png'
,'7deaf30c4a.png'
,'80a458a2b6.png'
,'81fa3d59b8.png'
,'8367b54eac.png'
,'849881c690.png'
,'876e6423e6.png'
,'90720e8172.png'
,'916aff36ae.png'
,'919bc0e2ba.png'
,'a266a2a9df.png'
,'a6625b8937.png'
,'a9ee40cf0d.png'
,'aeba5383e4.png'
,'b63b23fdc9.png'
,'baac3469ae.png'
,'be7014887d.png'
,'be90ab3e56.png'
,'bfa7ee102e.png'
,'bfbb9b9149.png'
,'c387a012fc.png'
,'c98dfd50ba.png'
,'caccd6708f.png'
,'cb4f7abe67.png'
,'d0bbe4fd97.png'
,'d4d2ed6bd2.png'
,'de7202d286.png'
,'f0c401b64b.png'
,'f19b7d20bb.png'
,'f641699848.png'
,'f75842e215.png'
,'00950d1627.png'
,'0280deb8ae.png'
,'06d21d76c4.png'
,'09152018c4.png'
,'09b9330300.png'
,'0b45bde756.png'
,'130229ec15.png'
,'15d76f1672.png'
,'182bfc6862.png'
,'23afbccfb5.png'
,'24522ec665.png'
,'285f4b2e82.png'
,'2bc179b78c.png'
,'2f746f8726.png'
,'3cb59a4fdc.png'
,'403cb8f4b3.png'
,'4f5df40ab2.png'
,'50b3aef4c4.png'
,'52667992f8.png'
,'52ac7bb4c1.png'
,'56f4bcc716.png'
,'58de316918.png'
,'640ceb328a.png'
,'71f7425387.png'
,'7c0b76979f.png'
,'7f0825a2f0.png'
,'834861f1b6.png'
,'87afd4b1ca.png'
,'88a5c49514.png'
,'9067effd34.png'
,'93a1541218.png'
,'95f6e2b2d1.png'
,'96216dae3b.png'
,'96523f824a.png'
,'99ee31b5bc.png'
,'9a4b15919d.png'
,'9b29ca561d.png'
,'9eb4a10b98.png'
,'ad2fa649f7.png'
,'b1be1fa682.png'
,'b24d3673e1.png'
,'b35b1b412b.png'
,'b525824dfc.png'
,'b7b83447c4.png'
,'b8a9602e21.png'
,'ba1287cb48.png'
,'be18a24c49.png'
,'c27409a765.png'
,'c2973c16f1.png'
,'c83d9529bd.png'
,'cef03959d8.png'
,'d4d34af4f7.png'
,'d9a52dc263.png'
,'dd6a04d456.png'
,'ddcb457a07.png'
,'e12cd094a6.png'
,'e6e3e58c43.png'
,'e73ed6e7f2.png'
,'f6e87c1458.png'
,'f7380099f6.png'
,'fb3392fee0.png'
,'fb47e8e74e.png'
,'febd1d2a67.png'
]
def diff(first, second):
second = set(second)
return [item for item in first if item not in second]
rest=diff(bad_masks,masks)
len(rest)
rest
import numpy as np
np.gradient([1,-1,-2,-3])
dicts = pickle.load( open( "linked_list.p", "rb" ) )
list1=dicts[58]
list1[1][4]
```
| github_jupyter |
```
import pdb
import os
import json
import time
from datetime import date, datetime, timedelta
import numpy as np
import pandas as pd
import plotly.graph_objects as go
import pandas as pd
from libsstock import (
loadStocks, computeIchimoku, checkVar, graphEvolutionTitre,
graphIchimoku, graphBestGain, graphWorseGain, graphCashLock, graphRendement,
graphEvolutionIntraday
)
from plotly_tools import genIMGfromFile
import telepot
from updateDB import updateDB, getStockData
def displayGraphValues(mybot, chat_id, msg):
df = loadStocks('mystocks.json')
genIMGfromFile(graphRendement(df), 'img.png', scale=1.3, width=800, height=500)
mybot.sendPhoto(chat_id, open('img.png', 'rb'))
def sendVarIf(mybot, chat_id, msg):
sendVarIfJson(mybot, chat_id, 'mystocks.json')
def sendVarIfALL(mybot, chat_id, msg):
sendVarIfJsonALL(mybot, chat_id, 'mystocks.json')
def sendVarIfprospects(mybot, chat_id, msg):
sendVarIfJson(mybot, chat_id, 'stockprospects.json')
def sendVarIfprospectsALL(mybot, chat_id, msg):
sendVarIfJsonALL(mybot, chat_id, 'stockprospects.json')
def sendVarIfJson(mybot, chat_id, fileJson):
(strOut, dfData) = checkVar(loadStocks(fileJson), 1, which='pos')
(strOut2, dfData) = checkVar(loadStocks(fileJson), 1, which='neg')
if len(strOut + strOut2) > 0:
mybot.sendMessage(
chat_id, strOut + strOut2
)
def sendVarIfJsonALL(mybot, chat_id, fileJson):
(strOut, dfData) = checkVar(loadStocks(fileJson), 1, which='all')
if len(strOut) > 0:
mybot.sendMessage(
chat_id, strOut
)
def genIntraday(mybot, chat_id, msg):
# recall for generate graph over a year
#pdb.set_trace()
stockName = msg["text"].replace('/stockintraday','').replace('_', '.')
print('Generate data for ' + stockName)
mybot.sendMessage(
chat_id, 'Generate data for ' + stockName
)
data=genIMGfromFile(graphEvolutionIntraday(stockName), 'img.png', scale=1.3, width=800, height=500)
mybot.sendPhoto(chat_id, open('img.png', 'rb'))
def genDataFromStock(mybot, chat_id, msg):
# recall for generate graph over a year
#pdb.set_trace()
stockName = msg["text"].replace('/stockinfo','').replace('_', '.')
print('Generate data for ' + stockName)
mybot.sendMessage(
chat_id, 'Generate data for ' + stockName
)
dfData = loadStocks('stockprospects.json')
dfData = dfData.loc[dfData['stockname'] == stockName]
histoData = getStockData(stockName)
data=genIMGfromFile(graphEvolutionTitre(histoData, dfData.iloc[0]), 'img.png', scale=1.3, width=800, height=500)
mybot.sendPhoto(chat_id, open('img.png', 'rb'))
histo = computeIchimoku(histoData)
startDate=date.today() - timedelta(days=60)
data=genIMGfromFile(graphIchimoku(
dfData, histo[histo.index > startDate]
), 'img.png', scale=1.3, width=800, height=500)
mybot.sendPhoto(chat_id, open('img.png', 'rb'))
startDate=date.today() - timedelta(days=360)
data=genIMGfromFile(graphIchimoku(
dfData, histo[histo.index > startDate]
), 'img.png', scale=1.3, width=800, height=500)
mybot.sendPhoto(chat_id, open('img.png', 'rb'))
startDate=date.today() - timedelta(days=360)
data=genIMGfromFile(graphEvolutionIntraday(stockName), 'img.png', scale=1.3, width=800, height=500)
mybot.sendPhoto(chat_id, open('img.png', 'rb'))
def listMenuItems(mybot, chat_id, msg):
mybot.sendMessage(
chat_id, '''
Commandes possibles :\n
''' + '\n'.join(['- /' + key + ' : ' + value['details'] for key, value in availableCommands.items()])
)
availableCommands = {
'menu': {'fct': listMenuItems, 'details': 'Affiche les commandes disponibles.'},
'gainetpertes': {'fct': displayGraphValues, 'details': 'Répartition des pertes et gain par actions.'},
'varportefeuille': {'fct': sendVarIfALL, 'details': 'Visualiser les variations sur les valeurs.'},
'varprospects': {'fct': sendVarIfprospectsALL, 'details': 'Visualiser les variations sur les valeurs en prospects.'},
'stockinfo': {'fct': genDataFromStock, 'details': 'Visualiser les variations sur les valeurs en prospects.'},
'stockintraday': {'fct': genIntraday, 'details': 'Visualiser les variations sur les valeurs en prospects.'},
}
def handle(msg):
#try:
global mybot
content_type, chat_type, chat_id = telepot.glance(msg)
msgDecoded = False
if content_type == 'text':
for cmd, value in availableCommands.items():
if '/' + cmd in msg["text"]:
msgDecoded = True
value['fct'](mybot, chat_id, msg)
if not msgDecoded:
mybot.sendMessage(chat_id, "Message '{}' non géré, essayez /menu.".format(msg["text"]))
#except Exception as e:
# print(e)
# mybot.sendMessage(chat_id, "Error : \n" + str(e))
def main():
global mybot
with open('credential.secret', 'r') as infile:
creds = json.load(infile)
bot_token = creds['bot_token']
bot_chatID = creds['bot_chatID']
alphaVantage= creds['av_token']
mybot = telepot.Bot(bot_token)
mybot.message_loop(handle)
mybot.sendMessage(
bot_chatID, '''
Bonjour, bienvenue sur le bot financier, essayer /menu pour les fonctions.
'''
)
while(1):
updateDB()
try:
thisHourSend = datetime.today().hour
if (datetime.today().weekday() in [0, 1, 2, 3, 4] and datetime.today().hour + 2 >= 9 and datetime.today().hour + 2 <= 18):
sendVarIf(mybot, bot_chatID, None)
#sendVarIfprospects(mybot, bot_chatID, None)
except:
pass
print('Sleeping 5 minutes')
time.sleep(60 * 5)
if __name__ == '__main__':
main()
dfData = loadStocks('stockprospects.json')
dfData = dfData.loc[dfData['stockname'] == stockName]
histoData = getStockData(stockName)
histoData = getStockData('SO.PA')
stockname = 'SO.PA'
from libs.datamodel import StockDay, StockIntraDay
from sqlalchemy import create_engine, desc, asc
from updateDB import HandleDB
handleDB = HandleDB()
value = handleDB.session.query(StockDay).filter(StockDay.stockname==stockname).order_by(desc(StockDay.datestamp)).first().priceClose
handleDB.close()
value
```
| github_jupyter |
# Theory documentation for `pneumoinfer`
```
# Add pneumoinfer to the system path
import sys
path = '/Users/Rob/work/pneumoinfer'
sys.path.append(path + '/source/')
from pneumoinfer import pneumoinfer
import numpy as np
import pandas as pd
import scipy.special as spec
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
```
---
## Motivating background
Multi-state models - stochastic processes occupying one of a finite set of states at each moment in time - appear to describe many natural phenomena, but are probably most frequently used in the mathematical modelling of population health. The statistical inference (or selection) of these models for real-world applications frequently involves data in the form of a sequence of individual state observations, which are often coupled with some diagnostic uncertainty.
There are over 90 known capsular serotypes of _Streptococcus pneumoniae_, which persist despite their mutual competition for the same ecological niche (the nasopharynx) and a known fitness gradient. Motivated by the global pneumococcal disease burden, a specific class of multi-state models has been developed to describe the carriage dynamics which offers a neat explanation of this persistence through immunity-driven stabilisation effects (see [Cobey & Lipsitch (2012)](https://pubmed.ncbi.nlm.nih.gov/22383809/)). This class of model typically uses a counting memory of past state (or serotype) occupations (or colonisations) as a model for human immunity (see, e.g., [Flasche et al. (2013)](https://royalsocietypublishing.org/doi/10.1098/rspb.2013.1939) for an alternative formulation and [Løchen & Anderson (2020)](https://pubmed.ncbi.nlm.nih.gov/31055164/) for a general review of the carriage transmission models). Building from these mathematical models, a range of statistical approaches have also been used to infer the pneumococcal carriage through a given population from nasopharyngeal swab sample data (e.g., [Lipsitch et al. (2012)](https://pubmed.ncbi.nlm.nih.gov/22441543/) and [Numminen et al. (2013)](https://pubmed.ncbi.nlm.nih.gov/23822205/)). All of this is obviously really important, e.g., to understanding more precisely how a vaccine covering a restricted range of serotypes can impact colonisation in a given community or region.
The design of policies for gathering data will always have a direct impact on the quality and utility of information that can be learned about a model via statistical inference. Therefore, it's typically useful to know _a priori_ the fundamental constraints a given policy might impose on this procedure. The purpose of the `pneumoinfer` class is to provide researchers with a rigorous framework to investigate these limitations for the inference of multi-state models with a counting memory - which are structurally inspired by the pneumococcus carriage models of [Cobey & Lipsitch (2012)](https://pubmed.ncbi.nlm.nih.gov/22383809/) and [Lipsitch et al. (2012)](https://pubmed.ncbi.nlm.nih.gov/22441543/). The framework should also useful in model inference with real data.
In this documentation, we're going to analyse the master equation of a stochastic model which includes memory effects from individual immunity and investigate a novel (to our knowledge) approximate ODE description for the dynamics, while assessing its validity. By then exploiting the new efficient ODE description, we will be able to develop a new method of inference that is very rapid in comparison to simulated likelihoods (or even ABC/likelihood-free inference methods). This is the main inference method that is implemented in the `pneumoinfer` class.
---
## The fixed $\Lambda_i$ model
Let's now construct a multi-state model which incorporates a counting memory of past state occupations. This will include: an event rate of state clearance $\tilde{\mu}_i$ - the rate at which an individual occupying the $i$-th indexed state returns to the null state; an event rate of susceptibility $\tilde{\Lambda}_i$ for an individual moving to the $i$-th state from the null state; and a state-specific factor matrix $f_{ii'}$ which rescales $\tilde{\Lambda}_{i'}$ to create an event rate for an individual moving directly between the $i$-th and $i'$-th states.
Now consider $\tilde{\mu}_i=\tilde{\mu}_i( \dots, n_{i}, \dots )$, i.e., a function of all previous state occupations by the individual, where $n_i$ are the state-specific counts of past occupations. The rate $\tilde{\mu}_i$ hence maintains a 'record' of past state occupations and updates accordingly through this memory. Additionally, we will make each rate $\tilde{\Lambda}_i=\tilde{\Lambda}_i(n_{i})$, i.e., a function _only_ of the state-specific count associated to each rate, respectively. The choice in the latter case comes from interpreting the counting memory as a model for capsular immunity - this will also turn out to be quite important for our approximation further on.
Note that in [Cobey & Lipsitch (2012)](https://pubmed.ncbi.nlm.nih.gov/22383809/), the models of nonspecific and specific immunity suggest choosing the following functions
$$
\begin{align}
\tilde{\mu}_i( \dots, n_{i}, \dots ) &= \mu_{\rm max} + (\mu_i - \mu_{\rm max})\exp \bigg( -\epsilon \sum_{\forall i'}n_{i'} \bigg) \\
\tilde{\Lambda}_i(n_i) &= \Lambda_{i}{\bf 1}_{n_i=0} + \sigma \Lambda_{i}{\bf 1}_{n_i>0} \,.
\end{align}
$$
In the expressions above: $\epsilon$ governs the level of (immune system maturation) with respect to the number of past state occupations; ${\bf 1}_A$ denotes an indicator function whose argument is unity when $A$ is satisfied, else $0$; and the susceptibility of an individual is assumed to be reduced by a constant factor of $\sigma$ after having occupied that state once or more.
The multi-state process that we're going to consider would be normally be described as a non-Markovian phenomenon. However, the modelling approach we will take is instead a bit more similar to the formal concept of a Markov embedding (as studied, e.g., recently in [Kanazawa & Sornette (2021)](https://arxiv.org/abs/2102.00242)). By creating a binary state occupation variable $x_i$ for the $i$-th serotype, and the probability of occupying state $(\dots , x_i , \dots , n_i , \dots )$ at time $t$ as $P(\dots , x_i , \dots , n_i , \dots , t)$, we may write a Markovian master equation for the process. Let's now define
$$
\begin{align}
p_i(\dots ,n_i,\dots ,t) &\equiv P(\dots, x_{i}=1, x_{i'}=0, \dots ,n_{i},\dots ,t)\quad \forall i'\neq i \\
q(\dots ,n_i,\dots ,t) &\equiv P(\dots, x_{i}=0, \dots ,n_{i},\dots ,t) \quad \forall i\,.
\end{align}
$$
Using these definitions, it is straightforward to show that the master equation satisfies
$$
\begin{align}
\frac{{\rm d}}{{\rm d}t}p_i(\dots ,n_i,\dots ,t) &= \tilde{\Lambda}_i(n_i-1)q(\dots ,n_{i}-1,\dots ,t) + \sum_{\forall i' \neq i}f_{i'i}\tilde{\Lambda}_i (n_i-1)p_{i'}(\dots ,n_{i'}, n_i-1,\dots ,t) \\
&\quad - \tilde{\mu}_i( \dots, n_{i}, \dots ) p_i(\dots ,n_i,\dots ,t) - \sum_{\forall i'\neq i}f_{ii'}\tilde{\Lambda}_{i'} (n_{i'}) p_i(\dots ,n_i,\dots ,t) \\
\frac{{\rm d}}{{\rm d}t}q(\dots ,n_i,\dots ,t) &= \sum_{\forall i}\tilde{\mu}_i( \dots, n_{i}, \dots )p_i(\dots ,n_i,\dots ,t) - \sum_{\forall i}\tilde{\Lambda}_i(n_i) q(\dots ,n_i,\dots ,t) \,.
\end{align}
$$
By defining the state space to encode the memory of past state occupations using the $n_i$ values themselves, the process is Markovian over the full $(\dots , x_i,\dots ,n_i,\dots)$ space. Note also that one may obtain the time-dependent joint distribution over the $(\dots ,n_i,\dots)$ space, i.e., $P(\dots, n_i, \dots, t)$, through marginalisation at any time
$$
\begin{equation}
P(\dots, n_i, \dots, t) = q(\dots, n_i, \dots, t) + \sum_{\forall i} p_i(\dots, n_i, \dots, t) \,.
\end{equation}
$$
Though we intend our analysis of this class of multi-state models to apply more generally beyond immediate applications to pneumococcus, it also is worth noting that restricting individuals to occupy a single state at a time only approximates the full pneumococcal carriage dynamics. The true process actually allows for some individuals to carry more than one serotype at at time. However, due to the relatively low and variable reported prevalence of simultaneous serotype carriers (or 'co-colonised' individuals) across different studies (see, e.g., [Gratten et al. (1989)](https://pubmed.ncbi.nlm.nih.gov/2639508/), [Huebner et al. (2000)](https://journals.lww.com/pidj/fulltext/2000/10000/lack_of_utility_of_serotyping_multiple_colonies.19.aspx) and many others...), the single-state occupation model should still a good tracer model of the underlying dynamical behaviour of the system. Note also that this additional complexity in the dynamics should be straightforward to incorporate into our framework for future analyses.
Let's now try an approximation for the joint distributions of $p_i(\dots, n_i, \dots, t)$ and $q(\dots, n_i, \dots, t)$ which assumes separability, such that
$$
\begin{align}
\ p_i(\dots, n_i, \dots, t) &\simeq p_i(t)P(\dots, n_i, \dots, t) \\
\ q(\dots, n_i, \dots, t) &\simeq q(t)P(\dots, n_i, \dots, t) \,.
\end{align}
$$
We shall evaluate the quality of this approximation later on (so don't worry) under different parametric conditions, but for now, let's just treat it as an ansatz.
By marginalising over states in the master equation, then substituting in the approximations above, and finally marginalising (each a summation from $n_{i'}=0$ to $\infty$) over the resulting relation $\forall n_{i'} \,\, i'\neq i$, one finds that the following time evolution equation is separately satisfied by each marginal $P(n_i,t)$ distribution
$$
\begin{align}
\frac{{\rm d}}{{\rm d}t}P(n_i,t) &= \bigg[ \tilde{\Lambda}_i(n_i-1)q(t) + \sum_{\forall i'\neq i} f_{i'i}\tilde{\Lambda}_{i} (n_{i}-1) p_{i'}(t) \bigg] P(n_{i}-1,t) \\
&\quad - \bigg[ \tilde{\Lambda}_i(n_i)q(t) + \sum_{\forall i'\neq i} f_{ii'}\tilde{\Lambda}_{i'} (n_{i'}) p_i(t)\bigg] P(n_i,t) \,.
\end{align}
$$
In addition to the separability assumption, the key point which allowed us to derive this one-step marginal master equation was the dependence of $\tilde{\Lambda}_i$ on _only_ $n_i$; in contrast to all of the past recorded states $(\dots, n_i, \dots)$ like $\tilde{\mu}_i$.
From this point on we'll focus on the specific pneumococcus model by inserting the rate function definitions from [Cobey & Lipsitch (2012)](https://pubmed.ncbi.nlm.nih.gov/22383809/) that we introduced at the start into the marginal master equation for $P(n_i,t)$. The `pneumoinfer` class is currently written for only these models (i.e., with just these choices of function), but it's useful to see how the steps above could be performed for more general models too. The solution to the marginal master equation with these function substitutions is simply a Poisson distribution $P(n_i,t) = {\rm Poisson}[n_i;{\rm E}_t(n_i)]$, where
$$
\begin{equation}
{\rm E}_t (n_i) = {\rm E}_{t_{\rm init}}(n_i) + \int^t_{t_{\rm init}}{\rm d}t'\bigg[ \sigma \Lambda_iq(t') +\sum_{\forall i'\neq i} f_{i'i}\sigma \Lambda_{i} p_{i'}(t')\bigg] \,.
\end{equation}
$$
Exploiting the properties of this Poisson distribution, if we now return to the full master equation and marginalise them over all $n_i$, while noting that
$$
\begin{align}
\ p_i(t) &= \sum_{\forall n_i}\sum_{n_{i}=0}^\infty p_i(\dots, n_i, \dots, t) \\
\ q(t) &= \sum_{\forall n_i}\sum_{n_{i}=0}^\infty q(\dots, n_i, \dots, t) \,,
\end{align}
$$
one arrives at the following finite (implicitly integro-differential) system
$$
\begin{align}
\frac{{\rm d}}{{\rm d}t}p_i(t) &= \Lambda_iF_{it} q(t) + \sum_{\forall i'\neq i} f_{i'i} \Lambda_iF_{it} p_{i'}(t) - \mu_iG_{it} p_i(t)-\sum_{\forall i'\neq i}f_{ii'}\Lambda_{i'}F_{i't} p_i(t) \\
\frac{{\rm d}}{{\rm d}t}q(t) &= \sum_{\forall i}\mu_iG_{it}p_i(t) - \sum_{\forall i}\Lambda_iF_{it}q(t)\,,
\end{align}
$$
where, to avoid repetition, we have defined
$$
\begin{align}
\ F_{it} &= P(n_i=0,t)+\sigma P(n_i>0,t) = e^{-{\rm E}_t(n_i)}+\sigma \big[ 1-e^{-{\rm E}_t(n_i)}\big] \\
\ G_{it} &= \frac{\mu_{\rm max}}{\mu_i} + \bigg( 1-\frac{\mu_{\rm max}}{\mu_i}\bigg) e^{\sum_{\forall i}{\rm E}_t(n_i)(e^{-\epsilon}-1)}\,,
\end{align}
$$
where to derive $G_{it}$ we have had to assume conditional independence between $n_i$ and $n_{i'}\,\,\forall i'\neq i$. The equation for ${\rm E}_t (n_i)$ can be differentiated to provide an equation for the time derivative of ${\rm E}_t(n_i)$ - evolving this equation alongside the system defined above yields an explicit finite ODE system. Note also that this approximation technique should apply to other forms of memory functions used for $\tilde{\mu}_i(\dots, n_i, \dots)$ and $\tilde{\Lambda}_i(n_i)$ by simply marginalising over their $n_i$ values, and so this approximate approach appears to be quite generalisable to other simlar systems.
In order to analyse the system properties and check the validity of the approach above, we're now going to make some decisions about the parameter space to explore. Let's independently draw the $(\mu_i,\Lambda_i)$ values from Gamma distributions with shapes $(\mu_\alpha,\Lambda_\alpha)$ and rates $(\mu_\beta,\Lambda_\beta)$. Let's also constrain the matrix values $f_{ii'}=f_{i}{\bf I}_{i'}$ (where ${\bf I}_{i'}$ denotes the elements of a simple vector of ones) which also happens to be consistent with pneumococcus data anyway (see, e.g., [Lipsitch et al. (2012)](https://pubmed.ncbi.nlm.nih.gov/22441543/)). We'll also need a metric of comparison between the marginalised distribution outputs from the fully simulated master equation and our approximation. To this end, it probably makes sense to look at the [Kullback-Leibler divergence](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence) between the marginal distributions for $x_i$ and $n_i$ in a full stochastic simulation and our approximation. In other words
$$
\begin{align}
\ D^{(x)}_{{}_{\rm KL}} &= \sum_{\forall i} p_{i, {\rm sim}}(t) \ln \Bigg[ \frac{p_{i, {\rm sim}}(t)}{p_i(t)} \Bigg] \\
&\simeq - \sum_{\forall i} \frac{\ln Z_{\rm sim}(x_i, t)}{Z_{\rm sim}(x_i, t)} -\sum_{\forall i} \frac{\ln p_i(t)}{Z_{\rm sim}(x_i, t)} \\
\ D^{(n_i)}_{{}_{\rm KL}} &= \sum_{n_i=0}^{\infty} P_{\rm sim}(n_i, t) \ln \Bigg[ \frac{P_{\rm sim}(n_i, t)}{P(n_i,t)} \Bigg] \\
&\simeq - \sum_{n_i=0}^{\infty}\frac{\ln Z_{\rm sim}(n_i, t)}{Z_{\rm sim}(n_i, t)} - \sum_{n_i=0}^{\infty} \frac{\ln {\rm Poisson}[n_i;{\rm E}_t(n_i)]}{Z_{\rm sim}(n_i, t)} \\
&\simeq - \sum_{n_i=0}^{\infty}\frac{\ln Z_{\rm sim}(n_i, t)}{Z_{\rm sim}(n_i, t)} - \sum_{n_i=0}^{\infty} \bigg[ \frac{n_i\ln {\rm E}_t(n_i) - {\rm E}_t(n_i) - \ln \Gamma (n_i+1)}{Z_{\rm sim}(n_i, t)} \bigg] \,,
\end{align}
$$
where $Z_{\rm sim}(x_i, t)$ and $Z_{\rm sim}(n_i, t)$ denote the marginal frequency counts in each state space derived from a stochastic simulation of the master equation. Note that for the whole $(\dots, n_i, \dots)$ space, a better comparison would involve Monte Carlo integration of the joint counts $Z_{\rm sim}(\dots, n_i, \dots, t)$. However, this is quite a lot more challenging with many dimensions (usually necessitating nested sampling) and so we'll consider it to be beyond the present scope.
Using the `run_sim` method of the `pneumoinfer` class, and the equations above, we can generate numerically-approximate plots of the Kullback-Leibler divergence on the marginal distributions over a range of numbers of states, parameters and points in time.
```
# Choose the number of states
nstat = 10
# Initialise pneumoinfer
pn = pneumoinfer(nstat)
# Create population members with gamma-distributed
# rate parameters
numpeople = 1
kmu = 1.0
param_dic = {
'Curr' : 0,
'npast' : np.zeros(nstat),
'Lam' : np.random.gamma(kmu,1.0/kmu,size=nstat),
'mu' : np.random.gamma(kmu,1.0/kmu,size=nstat),
'f' : np.random.gamma(kmu,1.0/kmu,size=nstat),
'eps' : 1.0/5.0,
'sig' : 1.0,
'mumax' : 1.0
}
pn.create_members(numpeople,param_dic)
# Run the ODE and full simulation (the latter for a
# given number of realisations
nreals = 10000
ode_tstepsize = 0.001
sim_trejectionstepsize = 0.01
total_time = 10.0
times = [0.2*float(i) + 0.1 for i in range(0,40)]
pn.run_ode(total_time,ode_tstepsize)
pn.run_sim(nreals,total_time,sim_trejectionstepsize,time_snaps=times)
# Setup plots for the DKL values using the outputs
DKLx, DKLn = [], []
for t in times:
counts = pd.Series(pn.sim_output['Curr'][t].flatten()).value_counts()
co = np.zeros(nstat + 1)
co[counts.index.values.astype(int)] = counts.values
co = co[1:]
it = np.argmin((pn.ode_output['time']-t)**2)
DKLx.append(
- np.sum(np.log(co[co>0])/co[co>0])
- np.sum(np.log(pn.ode_output['probCurr'][it][co>0])/co[co>0])
)
DKLnsum = 0.0
for i in range(0,nstat):
ncounts = pd.Series(pn.sim_output['npastsum'][t][i].flatten()).value_counts()
nco = np.zeros(1000)
ns = np.arange(0, 1000, 1)
nco[ncounts.index.values.astype(int)] = ncounts.values
DKLnsum += (
- np.sum(np.log(nco[nco>0])/nco[nco>0])
- np.sum(ns[nco>0] * np.log(pn.ode_output['Expnpast'][it][i])/nco[nco>0])
+ np.sum(pn.ode_output['Expnpast'][it][i]/nco[nco>0])
+ np.sum(spec.loggamma(ns[nco>0]+1)/nco[nco>0])
)
DKLn.append(DKLnsum)
fig, ax = plt.subplots(1, 2, figsize=(15,5))
ax[0].plot(times,DKLx)
ax[1].plot(times,np.asarray(DKLn)/np.asarray(times))
ax[0].set_xlabel('Time')
ax[0].set_ylabel(r'$D^{(x)}_{\rm KL}$')
ax[1].set_xlabel('Time')
ax[1].set_ylabel(r'$\sum_{\forall i}D^{(n_i)}_{\rm KL}\,/\,$Time')
plt.show()
```
The value of $D_{{}_{\rm KL}}^{(x)}$ generally stays small (and stable) throughout for most parameter choices. Interestingly, the same cannot be said for the $D_{{}_{\rm KL}}^{(n_i)}$ values, which appear to tend towards a deviation which is linearly proportional in time. If we now plot the time evolution of each set of quantities explicitly in time, we can see this is consistent with the observed deviations between the simulation and the ODE approximation.
```
fig, ax = plt.subplots(1,2,figsize=(15,5))
colours = sns.color_palette()
probs, ncounts = [], []
for t in times:
counts = pd.Series(pn.sim_output['Curr'][t].flatten()).value_counts()
nco = np.sum(pn.sim_output['npastsum'][t],axis=1)
ncounts.append(nco/nreals)
pr = np.zeros(nstat + 1)
pr[counts.index.values.astype(int)] = counts.values/float(nreals)
probs.append(list(pr))
for i in range(0,nstat):
ax[0].plot(times,np.asarray(probs)[:,i+1],label='State '+str(i+1),color=colours[i])
ax[0].plot(pn.ode_output['time'],pn.ode_output['probCurr'][:,i],color=colours[i])
ax[1].plot(times,np.asarray(ncounts)[:,i],label='State ' + str(i+1),color=colours[i])
ax[1].plot(pn.ode_output['time'],pn.ode_output['Expnpast'][:,i],'--',color=colours[i])
ax[0].set_xlabel('Time')
ax[0].set_ylabel(r'$p_i$')
ax[1].set_xlabel('Time')
ax[1].set_ylabel(r'$n_i$')
ax[1].legend(bbox_to_anchor=(1.3,1.0))
plt.show()
```
---
## A varying $\Lambda_{iu}$ model
We're now ready to introduce an alternative model which accounts for a stochastically-varying susceptibility $\Lambda_{iu}$ (a possible model for community exposure to infectious individuals), which is now additionally indexed by '$u$' which corresponds to each individual. In this model, we have
$$
\begin{equation}
\Lambda_{iu} = \Lambda_{\rm min} + \lambda\sum_{\forall u'\neq u}\beta_{uu'} \frac{x_{iu'}}{N_{\rm p}}\,,
\end{equation}
$$
where: the total population number is $N_{\rm p}$; $\beta_{uu'}$ are elements of a 'contact matrix' which rescales the event rate according to the spreading behaviour between the $u$-th and $u'$-th individuals; $\lambda$ is a constant normalisation for $\beta_{uu'}$; and $x_{iu'}$ records the state of the $u'$-th individual.
Extending the master equation we introduced in the previous section to include the susceptibility above and the states of $N_{\rm p}$ individuals, one can easily adapt the argument of the previous section to arrive at the following generalisation of the ODE system we found earlier
$$
\begin{align}
\frac{{\rm d}}{{\rm d}t}p_{iu}(t) &= {\rm E}_t(\Lambda_{iu})F_{it} q_u(t) + \sum_{\forall i'\neq i} f_{i'i} {\rm E}_t(\Lambda_{iu})F_{it} p_{i'u}(t) - \mu_iG_{it} p_{iu}(t)-\sum_{\forall i'\neq i}f_{ii'}{\rm E}_t(\Lambda_{i'u})F_{i't} p_{iu}(t) \\
\frac{{\rm d}}{{\rm d}t}q_u(t) &= \sum_{\forall i}\mu_iG_{it}p_{iu}(t) - \sum_{\forall i}{\rm E}_t(\Lambda_{iu})F_{it}q_u(t)\,.
\end{align}
$$
In the equations above, the state occupation probabilities of separate $u$-indexed individuals (or $u$-indexed categories of individual) are $p_{iu}(t)$ and $q_u(t)$, and we've also computed the expectation
$$
\begin{equation}
{\rm E}_t(\Lambda_{iu}) = \Lambda_{\rm min} + \lambda\sum_{\forall u'\neq u}\beta_{uu'} \frac{p_{iu'}(t)}{N_{\rm p}}\,.
\end{equation}
$$
The `pneumoinfer` class also implements ODE and full simulations for the varying $\Lambda_{iu}$ model, and we plot an example run of this method below.
```
# Once again, setup things as before
nstat = 10
pn = pneumoinfer(nstat)
# Now we add a contact matrix as well as its referenced
# index to each population member
pn._cont_mat = np.ones((3,3))
kmu = 1.0
param_dic = {
'npast' : np.zeros(nstat),
'Lam' : np.zeros(nstat),
'mu' : np.random.gamma(kmu,1.0/kmu,size=nstat),
'f' : np.random.gamma(kmu,1.0/kmu,size=nstat),
'eps' : 1.0/5.0,
'sig' : 1.0,
'mumax' : 1.0,
}
nind = 1000
for i in range(0,nind):
group_param_dic = param_dic.copy()
group_param_dic['Curr'] = np.random.randint(0,nstat+1)
group_param_dic['cind'] = np.random.randint(0,3)
pn.create_members(1,group_param_dic)
# Running the ODE and full sim in much the same way
# but only 1 realisation will be used for speed
nreals = 1
ode_tstepsize = 0.001
sim_trejectionstepsize = 0.01
total_time = 20.0
times = [0.2*float(i) + 0.1 for i in range(0,80)]
pn.run_ode(total_time,ode_tstepsize)
pn.run_sim(nreals,total_time,sim_trejectionstepsize,time_snaps=times)
colours = sns.color_palette()
probs = []
for t in times:
counts = pd.Series(pn.sim_output['Curr'][t].flatten()).value_counts()
pr = np.zeros(nstat + 1)
pr[counts.index.values.astype(int)] = counts.values/float(nreals)
probs.append(list(pr))
for i in range(0,nstat):
plt.plot(times,np.asarray(probs)[:,i+1]/float(nind),label='State '+str(i+1),color=colours[i])
plt.plot(pn.ode_output['time'],pn.ode_output['probCurr'][:,i],color=colours[i])
plt.legend(bbox_to_anchor=(1.3,1.0))
ax = plt.gca()
ax.set_xlabel('Time')
ax.set_ylabel(r'$p_i$')
plt.show()
```
---
## Computing the log-likelihood for inference
We're now ready to apply our ODE approximation to the statistical inference of the full simulation. We're going to assume that all data sets considered come in the form of a sequence of state observations (or longitudinally-monitored swab samples if you're talking about pneumococcus) for each sampled individual from the population which takes the form of counts, times and associated sample sizes ${\cal D}\equiv \{d_c,d_t,d_s\}$ (where $d_c=\{c_{ij}\}$, $d_t=\{t_j \, : \, t_{\rm init}<t_j\leq t_{\rm end}\}$ and $d_s=\{s_j\}$). Note that this sequence of state observations may also be regarded as a form of _filtration_ of the underlying stochastic process. Given a likelihood ${\cal L}$ of ${\cal D}$, these time intervals are independent of each other and so one may decompose ${\cal L}$ for the whole population as follows
$$
\begin{equation}
\ {\cal L}({\cal D} \vert \Theta ) = \prod_{\forall j \, : \, t_j\,\in \,d_t}{\cal L}( t_j \vert \Theta ) \,.
\end{equation}
$$
Assuming here the fixed $\Lambda_i$ model, the ODE solution then allows us to easily compute the multinomial likelihoods for the initial condition and into the future
$$
\begin{equation}
{\cal L}( t_j \vert \Theta ) = \frac{\Gamma (s_j+1)}{\prod_{\forall i}\Gamma (c_{ij}+1)}q(t_j)^{s_j-\sum_{\forall i}c_{ij}} \prod_{\forall i}p_i(t_j)^{c_{ij}} \,.
\end{equation}
$$
Note that the independence of the expression above with respect to previous timepoints is not trivial and relies on the Markovian embedding of the system that we have already discussed. Note also that the above relations can be easily adapted to accomodate the varying $\Lambda_{iu}$ model (and these are also implemented in the `pneumoinfer` log-likelihood code).
Let's now run a full simulation using the fixed $\Lambda_i$ model and use its output at different timepoints to construct a mock data set of state observations.
```
# Rerun a standard sim for the fixed Lamda model
# from which we will generate a mock data set
nstat = 10
pn = pneumoinfer(nstat)
numpeople = 1
kmu = 1.0
param_dic = {
'Curr' : 0,
'npast' : np.zeros(nstat),
'Lam' : np.random.gamma(kmu,1.0/kmu,size=nstat),
'mu' : np.random.gamma(kmu,1.0/kmu,size=nstat),
'f' : np.random.gamma(kmu,1.0/kmu,size=nstat),
'eps' : 1.0/5.0,
'sig' : 1.0,
'mumax' : 1.0
}
pn.create_members(numpeople,param_dic)
nreals = 1000
ode_tstepsize = 0.001
sim_trejectionstepsize = 0.01
total_time = 10.0
times = [0.2*float(i) + 0.1 for i in range(0,40)]
pn.run_ode(total_time,ode_tstepsize)
pn.run_sim(nreals,total_time,sim_trejectionstepsize,time_snaps=times)
# Create some mock state observation data
# out of the simulation runs above
data_times = np.random.choice(times,nstat,replace=False)
df = pd.Series(pn.sim_output['Curr'][data_times[0]].flatten()).value_counts().reset_index()
df['Time'] = data_times[0]
for t in data_times[1:]:
new_df = pd.Series(pn.sim_output['Curr'][t].flatten()).value_counts().reset_index()
new_df['Time'] = t
df = pd.concat([df, new_df], ignore_index=True)
df = df.rename(columns={'index' : 'Curr', 0 : 'Count'})
df.Curr = df.Curr.astype(int)
df
```
Note the form of the `pandas` dataframe given above: the `'Curr'` column denotes the state label (or serotype index) and the `'Count'` and `'Time'` columns describe the population number and time of the observation, respectively. Using this mock data, we can now compute the log-likelihood using the method provided in `pneumoinfer` to show that the sampler correctly identifies the maximum likelihood (up to some observation noise which explains the infrequent samples with a sightly higher log-likelihood).
```
# Usual setup again, but this time we
# add in the data via the keyword
nstat = 10
pn = pneumoinfer(nstat)
pn.create_members(1,param_dic,data=df)
# Generate some random samples away
# from the known log-likelihood maximum
maxLL = pn.lnlike(ode_tstepsize)
LLs = []
maxLams = pn.params['ode']['Lams']
maxmus = pn.params['ode']['mus']
maxfs = pn.params['ode']['fs']
for i in range(0,100):
tempLams = maxLams + np.random.normal(0.0,0.01,size=nstat).reshape(nstat,1)
tempmus = maxmus + np.random.normal(0.0,0.01,size=nstat).reshape(nstat,1)
tempfs = maxfs + np.random.normal(0.0,0.01,size=nstat).reshape(nstat,1)
pn.params['ode']['Lams'] = tempLams*(tempLams>0.0)
pn.params['ode']['mus'] = tempmus*(tempmus>0.0)
pn.params['ode']['fs'] = tempfs*(tempfs>0.0)
LLs.append(pn.lnlike(ode_tstepsize))
plt.plot(np.asarray(LLs)-maxLL)
ax = plt.gca()
ax.set_ylabel('LL-max(LL)')
plt.show()
```
---
## Additional notes: a method to compute the gradient of the log-likelihood
The current version of `pneumoinfer` does not support a gradient calculation for the log-likelihood (mainly because I was eager to move onto some other stuff!). However, to assist anyone wanting to implement this themselves, I thought it would be helpful to go through the calculation which computes the gradient (in principle) without resorting to numerical derivatives. This makes use of the 'multiple-adjoint' method as implemented in [Zhuang et al. (2021)](https://arxiv.org/abs/2006.02493). Consider the following 'data Lagrangian'
$$
\begin{align}
L &= \sum_{\forall j \, : \, t_j\,\in \,d_t} L_j\\
L_j &= \ln{\cal L}( t_j \vert \Theta ) + \int^{t_{j}}_{t_{j-1}}{\rm d}t \,{\sf h}(t)^{\rm T}\bigg[ \frac{{\rm d}}{{\rm d}t}{\sf V}(t) - {\sf M}_\Theta (t)\bigg] \\
&= \ln{\cal L}( t_j \vert \Theta) + {\sf h}(t_j)^{\rm T}{\sf V}(t_j)-{\sf h}(t_{j-1})^{\rm T}{\sf V}(t_{j-1}) - \int^{t_{j}}_{t_{j-1}}{\rm d}t \bigg[\frac{{\rm d}}{{\rm d}t}{\sf h}(t)^{\rm T} {\sf V}(t) + {\sf h}(t)^{\rm T}{\sf M}_\Theta (t)\bigg] \,,
\end{align}
$$
where ${\sf V}(t)=[\dots, {\rm E}_t(n_i),\dots, p_i(t), \dots , q(t)]^{\rm T}$, ${\sf h}(t)$ is a dynamical vector of Lagrange multipliers and ${\sf M}_\Theta (t)$ is just compact notation for the vector of ODE terms on the RHS. Varying $L_j$ with respect to the boundary condition ${\sf V}(t_j)$ and ${\sf V}(t)$, we obtain the constraints
$$
\begin{align}
\frac{\partial L_j}{\partial {\sf V}(t_j)} &= 0 \quad \Longleftrightarrow \quad \frac{\partial}{\partial {\sf V}(t_j)}\ln{\cal L}( t_j \vert \Theta ) + {\sf h}(t_j ) = 0 \\
\frac{\delta L_j}{\delta {\sf V}(t)} &= 0 \quad \Longleftrightarrow \quad \frac{{\rm d}}{{\rm d}t}{\sf h}(t) + \bigg[\frac{\partial}{\partial {\sf V}(t)}{\sf M}_\Theta (t)\bigg]^{\rm T}{\sf h}(t) = 0\,,
\end{align}
$$
Let us also note that if we vary $L_j$ with respect to $\Theta$ and optimise the likelihood, one obtains
$$
\begin{align}
\frac{\partial L_j}{\partial \Theta} &= \frac{\partial}{\partial \Theta}\ln{\cal L}( t_j \vert \Theta ) - \int^{t_{j}}_{t_{j-1}}{\rm d}t \,{\sf h}(t)^{\rm T}\frac{\partial}{\partial \Theta}{\sf M}_\Theta (t) \\
&\underset{{\rm opt}}{\longrightarrow} \int_{t_{j}}^{t_{j-1}}{\rm d}t \,{\sf h}(t)^{\rm T}\frac{\partial}{\partial \Theta}{\sf M}_\Theta (t)\,.
\end{align}
$$
The method proposed from here would be something like:
- Treat initial values of ${\rm E}_{t_0}(n_i)$ as a prior that should be varied to test the robustness of the inference.
- From the initialised states of the set of individuals run the forward ODE in time to obtain the value of $\frac{\partial}{\partial \Theta}{\sf M}_\Theta (t)$ at every observed timestep.
- For each interval edge determine ${\sf h}(t_j)$ using the first constraint equation and the ${\sf V}(t_j)$-gradient of the forward-time likelihood.
- For each interval solve the second equation to get its backward-time trajectory ${\sf h}(t)$.
- Integrate over ${\sf h}(t)$ and $\frac{\partial}{\partial \Theta}{\sf M}_\Theta (t)$ to determine the gradient in the last expression.
Seems like overkill, but could be interesting to implement in future if a large number of states/parameters are varied, e.g., for HMC sampling of the model posterior from a decent data set.
| github_jupyter |
# Young Audiences Data
```
#!pip3 install fuzzywuzzy
#!pip3 install 'fuzzywuzzy[speedup]'
#!pip3 install matplotlib
import pandas as pd
import glob
from collections import defaultdict
from fuzzywuzzy import process, fuzz
#import matplotlib.pyplot as plt
path = "/Users/jjgong/Desktop/ya-pay-equity/data/raw/"
# Use Glob to retrieve all of the file names
file_list = glob.glob(path+'*.xlsx')
# Sort files
file_list.sort()
```
## Data Upload
```
file_list
d = defaultdict(lambda: defaultdict())
for i,f in enumerate(file_list):
d[i]['name'] = file_list[i][45:-5]
d[i]['file'] = pd.read_excel(f)
# Get title and file
def get_name(d):
print(d['name'])
return d['file']
pd.set_option("max_columns", 500)
```
## Pricing Data
```
# Is null
#get_name(d[8])['company'].isna().sum()
get_name(d[0]).head(3) #columns - demographics data - Teaching Artist Demographics Collection 2021
get_name(d[1]).head()
get_name(d[2]).head() # Single Performance – one assembly in a school
get_name(d[5]).head() # Three Year Sales Report
#get_name(d[3]).columns
d.keys()
#get_name(d[3])
#df = get_name(d[2])
#df[['First Name', 'Last Name']] = df['Account Name'].str.split(' ', 1, expand=True)
#df
#get_name(d[4]).head() #- demographics data part 2 - Teaching Artist Demographics Collection Short 04 06 21
```
## Artist Info:
1. Number of teachers / performers-- Yes we know this- Working on getting the report. Will provide shortly.
2. Number of years of experience –We know # of years most artists have worked for us. Their start date is on the pricing reports. We do not collect data on how long they have been practicing the art form.
3. Professional certifications – We do not collect this data.
## Purchasing Entity:
1. Number of attendees / class size -- We collect that information from the school. Working on updating the sales report to include this information.
2. Age group of attendees / class -- We collect that information from the school. Working on updating the sales report to include this information
3. Number of sessions – depends on the number of students, the size of the performance or workshop space, size of the sound system, and the needs of the artist. Most assembly artists will do 250-300 students as a single performance and if more want us to schedule a second performance. Some artists will do as many students as the space will fit as one performance as they have a large sound system and like performing for large groups. It’s best to keep performances within a three grade span but often schools can’t afford the time or money for multiple shows. Workshops are always 25 students or less per workshop. No more than four in a day unless negotiated with the artist and they are paid more.
4. Length of each session – most sessions are 45 minutes
5. Genre/instrument of art form general_discipline: This is tracked on our yearly Chapter Report by our National Office into these 5 categories: Music, Theatre, Dance, Visual Art, Literary, and Media. ( Literary Art and Literary Arts is one in the same.
```
# Professional Learning Pricing - Artist is teaching Teachers how to use their art in the classroom
professional_learning = get_name(d[1])
professional_learning.head(5)
d[3]['name']
single_assembly = get_name(d[2]).head() # Single Performance – one assembly in a school
single_assembly
workshop_pricing = get_name(d[6]) # Workshop Pricing
workshop_pricing.head() # These are workshops
```
## Three Year Sales Data
```
three_year = get_name(d[5])
three_year.columns = [col.strip() for col in list(three_year.columns)]
# Mapping for IDs
id_map = defaultdict()
for aid, an in zip(three_year['Artist Payroll ID'], three_year['Artist: Account Name']):
if pd.isnull(aid)==False:
id_map[an] = aid
# Map the unmapped artist IDs
three_year.loc[three_year[pd.isnull(three_year['Artist Payroll ID'])].index, ['Artist Payroll ID']] = three_year[pd.isnull(three_year['Artist Payroll ID'])]['Artist: Account Name'].apply(lambda x: d.get(x, float('NaN')))
# Literary Art to Literary Arts
three_year.loc[three_year[three_year['Art Form (General Discipline)']=='Literary Arts'].index, ['Art Form (General Discipline)']] = 'Literary Art'
three_year.head()
# Map missing names
three_year['Artist Payroll ID'] = three_year.apply(lambda x: id_map.get(x['Artist: Account Name']) if pd.isnull(x['Artist Payroll ID']) else x, axis=1)['Artist: Account Name']
three_year[pd.isnull(three_year['Artist Payroll ID'])]
# Artist Payroll ID. Map some unmapped one
three_year['Artist Payroll ID'] = three_year.apply(lambda x: id_map.get(x['Artist: Account Name']) if pd.isnull(x['Artist Payroll ID']) else x, axis=1)['Artist Payroll ID']
three_year[pd.isnull(three_year['Artist Payroll ID'])]
id_map['123 Andrés']
three_year[pd.isnull(three_year['Artist Payroll ID'])]
three_year.head()
demographic = get_name(d[9])
dd = demographic.copy()
# Remove Unamed column
demographic = demographic.drop(labels=['Unnamed: 0'], axis=1)
# Drop duplicates
demographic = demographic.drop_duplicates(subset=['artist_id'], keep='last').reset_index(drop=True)
dd[dd['artist_id']==133]
demographic
len(three_year)
three_year['Component Type'].value_counts()
# Retrieve top 10 components
top_components = list(three_year['Component Type'].value_counts()[:9].index)
top_components.remove('Travel')
top_components.remove('Materials')
top_components.append('Virtual Planning Meeting')
top_components
# Group by
three_yr_grp = three_year.groupby(['Artist Payroll ID', 'Artist: Account Name', 'Art Form (General Discipline)', 'Contract Classification', 'Date', 'Contract #', 'Client Zip Code', 'Client', 'Billing Code', 'Component Type', 'Artist Business name']).sum()['Artist Fee'].reset_index().reset_index(drop=True)
# Retrieve only top performances. Remove other components
three_year_cnt = three_year[three_year['Component Type'].isin(top_components)].copy()
len(three_year_cnt)
# Retrieve only top performances. Remove other components
three_yr_grp = three_yr_grp[three_yr_grp['Component Type'].isin(top_components)].copy()
len(three_yr_grp)
```
### Review unique artists
```
# Retrieve unique artists
unique_artists = three_yr_grp.drop_duplicates(subset=['Artist Payroll ID', 'Artist: Account Name'])[['Artist Payroll ID', 'Artist: Account Name']].reset_index(drop=True)
unique_artists['Artist Payroll ID'].value_counts().iloc[:4]
unique_artists[unique_artists['Artist Payroll ID']==95.0]
demographic[demographic['artist_id']==95]
len(three_yr_grp[three_yr_grp['Artist: Account Name']=='Josh Robinson'])
len(three_yr_grp[three_yr_grp['Artist: Account Name']=='Poetry Meets Percussion'])
len(three_yr_grp[three_yr_grp['Artist: Account Name']=='Samba to Salsa'])
unique_artists[unique_artists['Artist Payroll ID']==0]
demographic[demographic['artist_id']==0]
three_yr_grp[three_yr_grp['Artist: Account Name']=='10HL'].head()
len(three_yr_grp[three_yr_grp['Artist: Account Name']=='10HL'])
len(three_yr_grp[three_yr_grp['Artist: Account Name']=='Oyin Hardy'])
unique_artists[unique_artists['Artist Payroll ID']==20]
demographic[demographic['artist_id']==20]
len(three_yr_grp[three_yr_grp['Artist: Account Name']=='Dave Fry'])
len(three_yr_grp[three_yr_grp['Artist: Account Name']=='RockRoots'])
unique_artists[unique_artists['Artist Payroll ID']==56]
demographic[demographic['artist_id']==56]
len(three_yr_grp[three_yr_grp['Artist: Account Name']=='The Junk Jam Band'])
three_yr_grp[three_yr_grp['Artist: Account Name']=='Zachary Green'].head()
#unique_artists['Artist: Account Name'].value_counts()
joined = three_yr_grp.merge(demographic, how='outer', left_on='Artist Payroll ID', right_on='artist_id')
len(joined)
num_include = list(set(joined['Artist Payroll ID'])-set([95, 0, 20, 56]))
included_df = joined[joined['Artist Payroll ID'].isin(num_include)]
null_demo = included_df[pd.isnull(included_df['artist_id'])].copy().reset_index(drop=True)
demo = included_df[~pd.isnull(included_df['artist_id'])].copy().reset_index(drop=True)
len(null_demo)
len(demo)
len(demo)/(len(null_demo)+len(demo))
demo['Artist Payroll ID'].nunique()
len(demo)/(len(null_demo)+len(demo))
null_demo['Artist Payroll ID'].nunique()
p = three_year[pd.isnull(three_year['Artist Payroll ID'])]
p = three_year.drop_duplicates(['Artist Payroll ID', 'Artist: Account Name'])
demo.head()
demo[demo['age']=='75 or older']
demo.to_excel('demographics.xlsx')
```
## Null Demo
```
len(joined)
null_demo
```
## Demo
```
null_demo
demo['Artist Payroll ID'].nunique()
demo['Artist Payroll ID'].nunique()
demographic[demographic['artist_id']==133]
three_yr_grp
three_year.info()
three_year.to_excel('sales_data.xlsx')
#three_year[pd.isnull(three_year['Artist Payroll ID'])]
three_year['Artist Business name'].value_counts().head()
len(three_year[three_year['Sale Price']>three_year['Artist Fee']])
len(three_year[three_year['Sale Price']==three_year['Artist Fee']])
len(three_year[three_year['Sale Price']<three_year['Artist Fee']])
three_year[three_year['Sale Price']<three_year['Artist Fee']]['Component Type'].value_counts()
three_year_cnt['Artist Fee'].mean()
three_yr_grp['Artist Fee'].mean()
three_year[three_year['Component Type']=='Workshop']['Sale Price'].mean()
three_year[three_year['Component Type']=='Travel']['Artist Fee'].mean()
three_year[three_year['Component Type']=='Workshop']['Artist Fee'].mean()
three_year['Sale Price']-three_year['Artist Fee']
three_year['Sale Price'].value_counts().head()
three_year['Artist Fee'].value_counts().head()
round(three_year['Component Type'].value_counts()/sum(three_year['Component Type'].value_counts()),4)*100
three_year['Component Type'].value_counts()
three_year['Component Type'].isin(['Workshop', 'Performance/Demo', 'Virtual Performance', ''])
three_year['Billing Code'].value_counts().head()
three_year['Artist Payroll ID'].nunique()
three_year['Artist: Account Name'].nunique()
three_year['Art Form (General Discipline)'].value_counts()
round(three_year['Art Form (General Discipline)'].value_counts()/sum(three_year['Art Form (General Discipline)'].value_counts()), 4)*100
three_year['Contract Classification'].value_counts()
three_year['Date'].min(), three_year['Date'].max()
three_year['Date'].dt.to_period('M').value_counts().head()
three_year.info()
three_year.groupby(pd.Grouper(key='Date', freq='M'))
three_year.describe()
three_year.info()
demo_1 = get_name(d[7])
demo_1.head()
demo_2 = get_name(d[8])
demo_2.head()
# from fuzzbuzz import fuzz
# from fuzzbuzz import process
#Iterate through indicationsa to see if there's a match with dosages
for ind in indications:
eo = process.extractOne(ind, d_keys, scorer=fuzz.partial_token_sort_ratio)
dosage_ind = eo[0]
score = eo[1]
dosage = dosages[dosage_ind]
if score<=50: #If low fuzzy match score then don't add
dosage_ind, dosage, score = None, None, None
df = df.append({'indication': ind, 'dosage_ind': dosage_ind, 'dosage': dosage, 'score': score}, ignore_index=True)
return df
demo_1.merge(demo_2, on=['first_name', 'last_name', 'state'])
get_name(d[6])
get_name(d[6])['Multiple Artists'].value_counts()
get_name(d[7]).info()
get_name(d[7]).head()
demo_2
demo_1
joined = demo_1.join(demo_2, on='respondent_id', how='outer', lsuffix='_demo1', rsuffix='_demo2')
joined
demo_1 = get_name(d[7])
demo_2 = get_name(d[8])
cols = list(joined.columns[joined.columns.str.contains('demo1|demo2')])
cols.sort()
remove_cols = ['age', 'city', 'collector_id', 'comapny', 'disabled', 'ethnicity', 'first_name', 'gender', 'last_name']
joined[cols]
demo_1.head()
demo_2.head()
get_name(d[8]).head()
df = pd.read_excel(file_list[0])
three_year = get_name(d[6]) # Workshop Pricing
df.info()
d = defaultdict()
for artist_id, name in zip(three_year['Artist Payroll ID'], three_year['Artist: Account Name']):
d[artist_id] = name
three_year['Artist: Account Name']
three_year[three_year['Artist: Account Name'].str.contains('Zachary')]
three_year
```
| github_jupyter |
# Character Sequence to Sequence
In this notebook, we'll build a model that takes in a sequence of letters, and outputs a sorted version of that sequence. We'll do that using what we've learned so far about Sequence to Sequence models. This notebook was updated to work with TensorFlow 1.1 and builds on the work of Dave Currie. Check out Dave's post [Text Summarization with Amazon Reviews](https://medium.com/towards-data-science/text-summarization-with-amazon-reviews-41801c2210b).
<img src="images/sequence-to-sequence.jpg"/>
## Dataset
The dataset lives in the /data/ folder. At the moment, it is made up of the following files:
* **letters_source.txt**: The list of input letter sequences. Each sequence is its own line.
* **letters_target.txt**: The list of target sequences we'll use in the training process. Each sequence here is a response to the input sequence in letters_source.txt with the same line number.
```
import numpy as np
import time
import helper
source_path = 'data/letters_source.txt'
target_path = 'data/letters_target.txt'
source_sentences = helper.load_data(source_path)
target_sentences = helper.load_data(target_path)
```
Let's start by examining the current state of the dataset. `source_sentences` contains the entire input sequence file as text delimited by newline symbols.
```
source_sentences[:50].split('\n')
```
`target_sentences` contains the entire output sequence file as text delimited by newline symbols. Each line corresponds to the line from `source_sentences`. `target_sentences` contains a sorted characters of the line.
```
target_sentences[:50].split('\n')
```
## Preprocess
To do anything useful with it, we'll need to turn the each string into a list of characters:
<img src="images/source_and_target_arrays.png"/>
Then convert the characters to their int values as declared in our vocabulary:
```
def extract_character_vocab(data):
special_words = ['<PAD>', '<UNK>', '<GO>', '<EOS>']
set_words = set([character for line in data.split('\n') for character in line])
int_to_vocab = {word_i: word for word_i, word in enumerate(special_words + list(set_words))}
vocab_to_int = {word: word_i for word_i, word in int_to_vocab.items()}
return int_to_vocab, vocab_to_int
# Build int2letter and letter2int dicts
source_int_to_letter, source_letter_to_int = extract_character_vocab(source_sentences)
target_int_to_letter, target_letter_to_int = extract_character_vocab(target_sentences)
# Convert characters to ids
source_letter_ids = [[source_letter_to_int.get(letter, source_letter_to_int['<UNK>']) for letter in line] for line in source_sentences.split('\n')]
target_letter_ids = [[target_letter_to_int.get(letter, target_letter_to_int['<UNK>']) for letter in line] + [target_letter_to_int['<EOS>']] for line in target_sentences.split('\n')]
print("Example source sequence")
print(source_letter_ids[:3])
print("\n")
print("Example target sequence")
print(target_letter_ids[:3])
```
This is the final shape we need them to be in. We can now proceed to building the model.
## Model
#### Check the Version of TensorFlow
This will check to make sure you have the correct version of TensorFlow
```
from distutils.version import LooseVersion
import tensorflow as tf
from tensorflow.python.layers.core import Dense
# Check TensorFlow Version
assert LooseVersion(tf.__version__) >= LooseVersion('1.1'), 'Please use TensorFlow version 1.1 or newer'
print('TensorFlow Version: {}'.format(tf.__version__))
```
### Hyperparameters
```
# Number of Epochs
epochs = 60
# Batch Size
batch_size = 128
# RNN Size
rnn_size = 50
# Number of Layers
num_layers = 2
# Embedding Size
encoding_embedding_size = 15
decoding_embedding_size = 15
# Learning Rate
learning_rate = 0.001
```
### Input
```
def get_model_inputs():
input_data = tf.placeholder(tf.int32, [None, None], name='input')
targets = tf.placeholder(tf.int32, [None, None], name='targets')
lr = tf.placeholder(tf.float32, name='learning_rate')
target_sequence_length = tf.placeholder(tf.int32, (None,), name='target_sequence_length')
max_target_sequence_length = tf.reduce_max(target_sequence_length, name='max_target_len')
source_sequence_length = tf.placeholder(tf.int32, (None,), name='source_sequence_length')
return input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length
```
### Sequence to Sequence Model
We can now start defining the functions that will build the seq2seq model. We are building it from the bottom up with the following components:
2.1 Encoder
- Embedding
- Encoder cell
2.2 Decoder
1- Process decoder inputs
2- Set up the decoder
- Embedding
- Decoder cell
- Dense output layer
- Training decoder
- Inference decoder
2.3 Seq2seq model connecting the encoder and decoder
2.4 Build the training graph hooking up the model with the
optimizer
### 2.1 Encoder
The first bit of the model we'll build is the encoder. Here, we'll embed the input data, construct our encoder, then pass the embedded data to the encoder.
- Embed the input data using [`tf.contrib.layers.embed_sequence`](https://www.tensorflow.org/api_docs/python/tf/contrib/layers/embed_sequence)
<img src="images/embed_sequence.png" />
- Pass the embedded input into a stack of RNNs. Save the RNN state and ignore the output.
<img src="images/encoder.png" />
```
def encoding_layer(input_data, rnn_size, num_layers,
source_sequence_length, source_vocab_size,
encoding_embedding_size):
# Encoder embedding
enc_embed_input = tf.contrib.layers.embed_sequence(input_data, source_vocab_size, encoding_embedding_size)
# RNN cell
def make_cell(rnn_size):
enc_cell = tf.contrib.rnn.LSTMCell(rnn_size,
initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return enc_cell
enc_cell = tf.contrib.rnn.MultiRNNCell([make_cell(rnn_size) for _ in range(num_layers)])
enc_output, enc_state = tf.nn.dynamic_rnn(enc_cell, enc_embed_input, sequence_length=source_sequence_length, dtype=tf.float32)
return enc_output, enc_state
```
## 2.2 Decoder
The decoder is probably the most involved part of this model. The following steps are needed to create it:
1- Process decoder inputs
2- Set up the decoder components
- Embedding
- Decoder cell
- Dense output layer
- Training decoder
- Inference decoder
### Process Decoder Input
In the training process, the target sequences will be used in two different places:
1. Using them to calculate the loss
2. Feeding them to the decoder during training to make the model more robust.
Now we need to address the second point. Let's assume our targets look like this in their letter/word form (we're doing this for readibility. At this point in the code, these sequences would be in int form):
<img src="images/targets_1.png"/>
We need to do a simple transformation on the tensor before feeding it to the decoder:
1- We will feed an item of the sequence to the decoder at each time step. Think about the last timestep -- where the decoder outputs the final word in its output. The input to that step is the item before last from the target sequence. The decoder has no use for the last item in the target sequence in this scenario. So we'll need to remove the last item.
We do that using tensorflow's tf.strided_slice() method. We hand it the tensor, and the index of where to start and where to end the cutting.
<img src="images/strided_slice_1.png"/>
2- The first item in each sequence we feed to the decoder has to be GO symbol. So We'll add that to the beginning.
<img src="images/targets_add_go.png"/>
Now the tensor is ready to be fed to the decoder. It looks like this (if we convert from ints to letters/symbols):
<img src="images/targets_after_processing_1.png"/>
```
# Process the input we'll feed to the decoder
def process_decoder_input(target_data, vocab_to_int, batch_size):
'''Remove the last word id from each batch and concat the <GO> to the begining of each batch'''
ending = tf.strided_slice(target_data, [0, 0], [batch_size, -1], [1, 1])
dec_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int['<GO>']), ending], 1)
return dec_input
```
### Set up the decoder components
- Embedding
- Decoder cell
- Dense output layer
- Training decoder
- Inference decoder
#### 1- Embedding
Now that we have prepared the inputs to the training decoder, we need to embed them so they can be ready to be passed to the decoder.
We'll create an embedding matrix like the following then have tf.nn.embedding_lookup convert our input to its embedded equivalent:
<img src="images/embeddings.png" />
#### 2- Decoder Cell
Then we declare our decoder cell. Just like the encoder, we'll use an tf.contrib.rnn.LSTMCell here as well.
We need to declare a decoder for the training process, and a decoder for the inference/prediction process. These two decoders will share their parameters (so that all the weights and biases that are set during the training phase can be used when we deploy the model).
First, we'll need to define the type of cell we'll be using for our decoder RNNs. We opted for LSTM.
#### 3- Dense output layer
Before we move to declaring our decoders, we'll need to create the output layer, which will be a tensorflow.python.layers.core.Dense layer that translates the outputs of the decoder to logits that tell us which element of the decoder vocabulary the decoder is choosing to output at each time step.
#### 4- Training decoder
Essentially, we'll be creating two decoders which share their parameters. One for training and one for inference. The two are similar in that both created using tf.contrib.seq2seq.**BasicDecoder** and tf.contrib.seq2seq.**dynamic_decode**. They differ, however, in that we feed the the target sequences as inputs to the training decoder at each time step to make it more robust.
We can think of the training decoder as looking like this (except that it works with sequences in batches):
<img src="images/sequence-to-sequence-training-decoder.png"/>
The training decoder **does not** feed the output of each time step to the next. Rather, the inputs to the decoder time steps are the target sequence from the training dataset (the orange letters).
#### 5- Inference decoder
The inference decoder is the one we'll use when we deploy our model to the wild.
<img src="images/sequence-to-sequence-inference-decoder.png"/>
We'll hand our encoder hidden state to both the training and inference decoders and have it process its output. TensorFlow handles most of the logic for us. We just have to use the appropriate methods from tf.contrib.seq2seq and supply them with the appropriate inputs.
```
def decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers, rnn_size,
target_sequence_length, max_target_sequence_length, enc_state, dec_input):
# 1. Decoder Embedding
target_vocab_size = len(target_letter_to_int)
dec_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
dec_embed_input = tf.nn.embedding_lookup(dec_embeddings, dec_input)
# 2. Construct the decoder cell
def make_cell(rnn_size):
dec_cell = tf.contrib.rnn.LSTMCell(rnn_size,
initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return dec_cell
dec_cell = tf.contrib.rnn.MultiRNNCell([make_cell(rnn_size) for _ in range(num_layers)])
# 3. Dense layer to translate the decoder's output at each time
# step into a choice from the target vocabulary
output_layer = Dense(target_vocab_size,
kernel_initializer = tf.truncated_normal_initializer(mean = 0.0, stddev=0.1))
# 4. Set up a training decoder and an inference decoder
# Training Decoder
with tf.variable_scope("decode"):
# Helper for the training process. Used by BasicDecoder to read inputs.
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=dec_embed_input,
sequence_length=target_sequence_length,
time_major=False)
# Basic decoder
training_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
training_helper,
enc_state,
output_layer)
# Perform dynamic decoding using the decoder
training_decoder_output = tf.contrib.seq2seq.dynamic_decode(training_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)[0]
# 5. Inference Decoder
# Reuses the same parameters trained by the training process
with tf.variable_scope("decode", reuse=True):
start_tokens = tf.tile(tf.constant([target_letter_to_int['<GO>']], dtype=tf.int32), [batch_size], name='start_tokens')
# Helper for the inference process.
inference_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(dec_embeddings,
start_tokens,
target_letter_to_int['<EOS>'])
# Basic decoder
inference_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
inference_helper,
enc_state,
output_layer)
# Perform dynamic decoding using the decoder
inference_decoder_output = tf.contrib.seq2seq.dynamic_decode(inference_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)[0]
return training_decoder_output, inference_decoder_output
```
## 2.3 Seq2seq model
Let's now go a step above, and hook up the encoder and decoder using the methods we just declared
```
def seq2seq_model(input_data, targets, lr, target_sequence_length,
max_target_sequence_length, source_sequence_length,
source_vocab_size, target_vocab_size,
enc_embedding_size, dec_embedding_size,
rnn_size, num_layers):
# Pass the input data through the encoder. We'll ignore the encoder output, but use the state
_, enc_state = encoding_layer(input_data,
rnn_size,
num_layers,
source_sequence_length,
source_vocab_size,
encoding_embedding_size)
# Prepare the target sequences we'll feed to the decoder in training mode
dec_input = process_decoder_input(targets, target_letter_to_int, batch_size)
# Pass encoder state and decoder inputs to the decoders
training_decoder_output, inference_decoder_output = decoding_layer(target_letter_to_int,
decoding_embedding_size,
num_layers,
rnn_size,
target_sequence_length,
max_target_sequence_length,
enc_state,
dec_input)
return training_decoder_output, inference_decoder_output
```
Model outputs *training_decoder_output* and *inference_decoder_output* both contain a 'rnn_output' logits tensor that looks like this:
<img src="images/logits.png"/>
The logits we get from the training tensor we'll pass to tf.contrib.seq2seq.**sequence_loss()** to calculate the loss and ultimately the gradient.
```
# Build the graph
train_graph = tf.Graph()
# Set the graph to default to ensure that it is ready for training
with train_graph.as_default():
# Load the model inputs
input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length = get_model_inputs()
# Create the training and inference logits
training_decoder_output, inference_decoder_output = seq2seq_model(input_data,
targets,
lr,
target_sequence_length,
max_target_sequence_length,
source_sequence_length,
len(source_letter_to_int),
len(target_letter_to_int),
encoding_embedding_size,
decoding_embedding_size,
rnn_size,
num_layers)
# Create tensors for the training logits and inference logits
training_logits = tf.identity(training_decoder_output.rnn_output, 'logits')
inference_logits = tf.identity(inference_decoder_output.sample_id, name='predictions')
# Create the weights for sequence_loss
masks = tf.sequence_mask(target_sequence_length, max_target_sequence_length, dtype=tf.float32, name='masks')
with tf.name_scope("optimization"):
# Loss function
cost = tf.contrib.seq2seq.sequence_loss(
training_logits,
targets,
masks)
# Optimizer
optimizer = tf.train.AdamOptimizer(lr)
# Gradient Clipping
gradients = optimizer.compute_gradients(cost)
capped_gradients = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gradients if grad is not None]
train_op = optimizer.apply_gradients(capped_gradients)
```
## Get Batches
There's little processing involved when we retreive the batches. This is a simple example assuming batch_size = 2
Source sequences (it's actually in int form, we're showing the characters for clarity):
<img src="images/source_batch.png" />
Target sequences (also in int, but showing letters for clarity):
<img src="images/target_batch.png" />
```
def pad_sentence_batch(sentence_batch, pad_int):
"""Pad sentences with <PAD> so that each sentence of a batch has the same length"""
max_sentence = max([len(sentence) for sentence in sentence_batch])
return [sentence + [pad_int] * (max_sentence - len(sentence)) for sentence in sentence_batch]
def get_batches(targets, sources, batch_size, source_pad_int, target_pad_int):
"""Batch targets, sources, and the lengths of their sentences together"""
for batch_i in range(0, len(sources)//batch_size):
start_i = batch_i * batch_size
sources_batch = sources[start_i:start_i + batch_size]
targets_batch = targets[start_i:start_i + batch_size]
pad_sources_batch = np.array(pad_sentence_batch(sources_batch, source_pad_int))
pad_targets_batch = np.array(pad_sentence_batch(targets_batch, target_pad_int))
# Need the lengths for the _lengths parameters
pad_targets_lengths = []
for target in pad_targets_batch:
pad_targets_lengths.append(len(target))
pad_source_lengths = []
for source in pad_sources_batch:
pad_source_lengths.append(len(source))
yield pad_targets_batch, pad_sources_batch, pad_targets_lengths, pad_source_lengths
```
## Train
We're now ready to train our model. If you run into OOM (out of memory) issues during training, try to decrease the batch_size.
```
# Split data to training and validation sets
train_source = source_letter_ids[batch_size:]
train_target = target_letter_ids[batch_size:]
valid_source = source_letter_ids[:batch_size]
valid_target = target_letter_ids[:batch_size]
(valid_targets_batch, valid_sources_batch, valid_targets_lengths, valid_sources_lengths) = next(get_batches(valid_target, valid_source, batch_size,
source_letter_to_int['<PAD>'],
target_letter_to_int['<PAD>']))
display_step = 20 # Check training loss after every 20 batches
checkpoint = "best_model.ckpt"
with tf.Session(graph=train_graph) as sess:
sess.run(tf.global_variables_initializer())
for epoch_i in range(1, epochs+1):
for batch_i, (targets_batch, sources_batch, targets_lengths, sources_lengths) in enumerate(
get_batches(train_target, train_source, batch_size,
source_letter_to_int['<PAD>'],
target_letter_to_int['<PAD>'])):
# Training step
_, loss = sess.run(
[train_op, cost],
{input_data: sources_batch,
targets: targets_batch,
lr: learning_rate,
target_sequence_length: targets_lengths,
source_sequence_length: sources_lengths})
# Debug message updating us on the status of the training
if batch_i % display_step == 0 and batch_i > 0:
# Calculate validation cost
validation_loss = sess.run(
[cost],
{input_data: valid_sources_batch,
targets: valid_targets_batch,
lr: learning_rate,
target_sequence_length: valid_targets_lengths,
source_sequence_length: valid_sources_lengths})
print('Epoch {:>3}/{} Batch {:>4}/{} - Loss: {:>6.3f} - Validation loss: {:>6.3f}'
.format(epoch_i,
epochs,
batch_i,
len(train_source) // batch_size,
loss,
validation_loss[0]))
# Save Model
saver = tf.train.Saver()
saver.save(sess, checkpoint)
print('Model Trained and Saved')
```
## Prediction
```
def source_to_seq(text):
'''Prepare the text for the model'''
sequence_length = 7
return [source_letter_to_int.get(word, source_letter_to_int['<UNK>']) for word in text]+ [source_letter_to_int['<PAD>']]*(sequence_length-len(text))
input_sentence = 'hello'
text = source_to_seq(input_sentence)
checkpoint = "./best_model.ckpt"
loaded_graph = tf.Graph()
with tf.Session(graph=loaded_graph) as sess:
# Load saved model
loader = tf.train.import_meta_graph(checkpoint + '.meta')
loader.restore(sess, checkpoint)
input_data = loaded_graph.get_tensor_by_name('input:0')
logits = loaded_graph.get_tensor_by_name('predictions:0')
source_sequence_length = loaded_graph.get_tensor_by_name('source_sequence_length:0')
target_sequence_length = loaded_graph.get_tensor_by_name('target_sequence_length:0')
#Multiply by batch_size to match the model's input parameters
answer_logits = sess.run(logits, {input_data: [text]*batch_size,
target_sequence_length: [len(text)]*batch_size,
source_sequence_length: [len(text)]*batch_size})[0]
pad = source_letter_to_int["<PAD>"]
print('Original Text:', input_sentence)
print('\nSource')
print(' Word Ids: {}'.format([i for i in text]))
print(' Input Words: {}'.format(" ".join([source_int_to_letter[i] for i in text])))
print('\nTarget')
print(' Word Ids: {}'.format([i for i in answer_logits if i != pad]))
print(' Response Words: {}'.format(" ".join([target_int_to_letter[i] for i in answer_logits if i != pad])))
```
| github_jupyter |
# RNN from scratch
```
%matplotlib inline
import math
import tensorflow as tf
from d2l import tensorflow as d2l
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
train_random_iter, vocab_random_iter = d2l.load_data_time_machine(
batch_size, num_steps, use_random_iter=True)
```
## [**独热编码**]
回想一下,在`train_iter`中,每个词元都表示为一个数字索引,
将这些索引直接输入神经网络可能会使学习变得困难。
我们通常将每个词元表示为更具表现力的特征向量。
最简单的表示称为*独热编码*(one-hot encoding),
它在 :numref:`subsec_classification-problem`中介绍过。
简言之,将每个索引映射为相互不同的单位向量:
假设词表中不同词元的数目为$N$(即`len(vocab)`),
词元索引的范围为$0$到$N-1$。
如果词元的索引是整数$i$,
那么我们将创建一个长度为$N$的全$0$向量,
并将第$i$处的元素设置为$1$。
此向量是原始词元的一个独热向量。
索引为$0$和$2$的独热向量如下所示:
```
tf.one_hot(tf.constant([0, 2]), len(vocab))
```
我们每次采样的(**小批量数据形状是二维张量:
(批量大小,时间步数)。**)
`one_hot`函数将这样一个小批量数据转换成三维张量,
张量的最后一个维度等于词表大小(`len(vocab)`)。
我们经常转换输入的维度,以便获得形状为
(时间步数,批量大小,词表大小)的输出。
这将使我们能够更方便地通过最外层的维度,
一步一步地更新小批量数据的隐状态。
```
X = tf.reshape(tf.range(10), (2, 5))
tf.one_hot(tf.transpose(X), 28).shape
```
## 初始化模型参数
接下来,我们[**初始化循环神经网络模型的模型参数**]。
隐藏单元数`num_hiddens`是一个可调的超参数。
当训练语言模型时,输入和输出来自相同的词表。
因此,它们具有相同的维度,即词表的大小。
```
def get_params(vocab_size, num_hiddens):
num_inputs = num_outputs = vocab_size
def normal(shape):
return tf.random.normal(shape=shape,stddev=0.01,mean=0,dtype=tf.float32)
# 隐藏层参数
W_xh = tf.Variable(normal((num_inputs, num_hiddens)), dtype=tf.float32)
W_hh = tf.Variable(normal((num_hiddens, num_hiddens)), dtype=tf.float32)
b_h = tf.Variable(tf.zeros(num_hiddens), dtype=tf.float32)
# 输出层参数
W_hq = tf.Variable(normal((num_hiddens, num_outputs)), dtype=tf.float32)
b_q = tf.Variable(tf.zeros(num_outputs), dtype=tf.float32)
params = [W_xh, W_hh, b_h, W_hq, b_q]
return params
```
## 循环神经网络模型
为了定义循环神经网络模型,
我们首先需要[**一个`init_rnn_state`函数在初始化时返回隐状态**]。
这个函数的返回是一个张量,张量全用0填充,
形状为(批量大小,隐藏单元数)。
在后面的章节中我们将会遇到隐状态包含多个变量的情况,
而使用元组可以更容易地处理些。
```
def init_rnn_state(batch_size, num_hiddens):
return (tf.zeros((batch_size, num_hiddens)), )
```
[**下面的`rnn`函数定义了如何在一个时间步内计算隐状态和输出。**]
循环神经网络模型通过`inputs`最外层的维度实现循环,
以便逐时间步更新小批量数据的隐状态`H`。
此外,这里使用$\tanh$函数作为激活函数。
如 :numref:`sec_mlp`所述,
当元素在实数上满足均匀分布时,$\tanh$函数的平均值为0。
$$\mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{b}_h).$$
$$\mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_q.$$
```
def rnn(inputs, state, params):
# `inputs`的形状:(`时间步数量`,`批量大小`,`词表大小`)
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
# `X`的形状:(`批量大小`,`词表大小`)
for X in inputs:
X = tf.reshape(X,[-1,W_xh.shape[0]])
H = tf.tanh(tf.matmul(X, W_xh) + tf.matmul(H, W_hh) + b_h)
Y = tf.matmul(H, W_hq) + b_q
outputs.append(Y)
return tf.concat(outputs, axis=0), (H,)
```
定义了所有需要的函数之后,接下来我们[**创建一个类来包装这些函数**],
并存储从零开始实现的循环神经网络模型的参数。
```
class RNNModelScratch: #@save
"""从零开始实现的循环神经网络模型"""
def __init__(self, vocab_size, num_hiddens,
init_state, forward_fn, get_params):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
self.init_state, self.forward_fn = init_state, forward_fn
self.trainable_variables = get_params(vocab_size, num_hiddens) #init_state forward_fn are functions
def __call__(self, X, state):
X = tf.one_hot(tf.transpose(X), self.vocab_size) # X is one_hot vector !!!
X = tf.cast(X, tf.float32)
return self.forward_fn(X, state, self.trainable_variables)
def begin_state(self, batch_size, *args, **kwargs):
return self.init_state(batch_size, self.num_hiddens)
```
让我们[**检查输出是否具有正确的形状**]。
例如,隐状态的维数是否保持不变。
```
# 定义tensorflow训练策略
device_name = d2l.try_gpu()._device_name
strategy = tf.distribute.OneDeviceStrategy(device_name)
num_hiddens = 512
with strategy.scope():
net = RNNModelScratch(len(vocab), num_hiddens, init_rnn_state, rnn,
get_params)
state = net.begin_state(X.shape[0]) # the initial state is all zeros
Y, new_state = net(X, state)
Y.shape, len(new_state), new_state[0].shape
```
我们可以看到输出形状是(时间步数$\times$批量大小,词表大小),
而隐状态形状保持不变,即(批量大小,隐藏单元数)。
## 预测
让我们[**首先定义预测函数来生成`prefix`之后的新字符**],
其中的`prefix`是一个用户提供的包含多个字符的字符串。
在循环遍历`prefix`中的开始字符时,
我们不断地将隐状态传递到下一个时间步,但是不生成任何输出。
这被称为*预热*(warm-up)期,
因为在此期间模型会自我更新(例如,更新隐状态),
但不会进行预测。
预热期结束后,隐状态的值通常比刚开始的初始值更适合预测,
从而预测字符并输出它们。
```
def predict_ch8(prefix, num_preds, net, vocab): #@save
"""在`prefix`后面生成新字符"""
state = net.begin_state(batch_size=1, dtype=tf.float32)
outputs = [vocab[prefix[0]]] # vocab['t'] 返回的是一个数 正常的是一个word vector
get_input = lambda: tf.reshape(tf.constant([outputs[-1]]),(1, 1)).numpy() # input都是output的最后一个元素
for y in prefix[1:]: # 预热期
_, state = net(get_input(), state)
outputs.append(vocab[y])
for _ in range(num_preds): # 预测`num_preds`步
y, state = net(get_input(), state)
outputs.append(int(y.numpy().argmax(axis=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
```
现在我们可以测试`predict_ch8`函数。
我们将前缀指定为`time traveller `,
并基于这个前缀生成10个后续字符。
鉴于我们还没有训练网络,它会生成荒谬的预测结果。
```
predict_ch8('time traveller ', 10, net, vocab)
```
## [**梯度裁剪**]
对于长度为$T$的序列,我们在迭代中计算这$T$个时间步上的梯度,
将会在反向传播过程中产生长度为$\mathcal{O}(T)$的矩阵乘法链。
如 :numref:`sec_numerical_stability`所述,
当$T$较大时,它可能导致数值不稳定,
例如可能导致梯度爆炸或梯度消失。
因此,循环神经网络模型往往需要额外的方式来支持稳定训练。
一般来说,当解决优化问题时,我们对模型参数采用更新步骤。
假定在向量形式的$\mathbf{x}$中,
或者在小批量数据的负梯度$\mathbf{g}$方向上。
例如,使用$\eta > 0$作为学习率时,在一次迭代中,
我们将$\mathbf{x}$更新为$\mathbf{x} - \eta \mathbf{g}$。
如果我们进一步假设目标函数$f$表现良好,
即函数$f$在常数$L$下是*利普希茨连续的*(Lipschitz continuous)。
也就是说,对于任意$\mathbf{x}$和$\mathbf{y}$我们有:
$$|f(\mathbf{x}) - f(\mathbf{y})| \leq L \|\mathbf{x} - \mathbf{y}\|.$$
在这种情况下,我们可以安全地假设:
如果我们通过$\eta \mathbf{g}$更新参数向量,则
$$|f(\mathbf{x}) - f(\mathbf{x} - \eta\mathbf{g})| \leq L \eta\|\mathbf{g}\|,$$
这意味着我们不会观察到超过$L \eta \|\mathbf{g}\|$的变化。
这既是坏事也是好事。
坏的方面,它限制了取得进展的速度;
好的方面,它限制了事情变糟的程度,尤其当我们朝着错误的方向前进时。
有时梯度可能很大,从而优化算法可能无法收敛。
我们可以通过降低$\eta$的学习率来解决这个问题。
但是如果我们很少得到大的梯度呢?
在这种情况下,这种做法似乎毫无道理。
一个流行的替代方案是通过将梯度$\mathbf{g}$投影回给定半径
(例如$\theta$)的球来裁剪梯度$\mathbf{g}$。
如下式:
(**$$\mathbf{g} \leftarrow \min\left(1, \frac{\theta}{\|\mathbf{g}\|}\right) \mathbf{g}.$$**)
通过这样做,我们知道梯度范数永远不会超过$\theta$,
并且更新后的梯度完全与$\mathbf{g}$的原始方向对齐。
它还有一个值得拥有的副作用,
即限制任何给定的小批量数据(以及其中任何给定的样本)对参数向量的影响,
这赋予了模型一定程度的稳定性。
梯度裁剪提供了一个快速修复梯度爆炸的方法,
虽然它并不能完全解决问题,但它是众多有效的技术之一。
下面我们定义一个函数来裁剪模型的梯度,
模型是从零开始实现的模型或由高级API构建的模型。
我们在此计算了所有模型参数的梯度的范数。
```
def grad_clipping(grads, theta): #@save
"""裁剪梯度"""
theta = tf.constant(theta, dtype=tf.float32)
new_grad = []
for grad in grads:
if isinstance(grad, tf.IndexedSlices):
new_grad.append(tf.convert_to_tensor(grad))
else:
new_grad.append(grad)
norm = tf.math.sqrt(sum((tf.reduce_sum(grad ** 2)).numpy()
for grad in new_grad))
norm = tf.cast(norm, tf.float32)
if tf.greater(norm, theta):
for i, grad in enumerate(new_grad):
new_grad[i] = grad * theta / norm
else:
new_grad = new_grad
return new_grad
```
## 训练
在训练模型之前,让我们[**定义一个函数在一个迭代周期内训练模型**]。
它与我们训练 :numref:`sec_softmax_scratch`模型的方式有三个不同之处:
1. 序列数据的不同采样方法(随机采样和顺序分区)将导致隐状态初始化的差异。
1. 我们在更新模型参数之前裁剪梯度。
这样的操作的目的是:即使训练过程中某个点上发生了梯度爆炸,也能保证模型不会发散。
1. 我们用困惑度来评价模型。如 :numref:`subsec_perplexity`所述,
这样的度量确保了不同长度的序列具有可比性。
具体来说,当使用顺序分区时,
我们只在每个迭代周期的开始位置初始化隐状态。
由于下一个小批量数据中的第$i$个子序列样本
与当前第$i$个子序列样本相邻,
因此当前小批量数据最后一个样本的隐状态,
将用于初始化下一个小批量数据第一个样本的隐状态。
这样,存储在隐状态中的序列的历史信息
可以在一个迭代周期内流经相邻的子序列。
然而,在任何一点隐状态的计算,
都依赖于同一迭代周期中前面所有的小批量数据,
这使得梯度计算变得复杂。
为了降低计算量,在处理任何一个小批量数据之前,
我们先分离梯度,使得隐状态的梯度计算总是限制在一个小批量数据的时间步内。
当使用随机抽样时,因为每个样本都是在一个随机位置抽样的,
因此需要为每个迭代周期重新初始化隐状态。
与 :numref:`sec_softmax_scratch`中的
`train_epoch_ch3`函数相同,
`updater`是更新模型参数的常用函数。
它既可以是从头开始实现的`d2l.sgd`函数,
也可以是深度学习框架中内置的优化函数。
```
#@save
def train_epoch_ch8(net, train_iter, loss, updater, use_random_iter):
"""训练模型一个迭代周期(定义见第8章)"""
state, timer = None, d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失之和, 词元数量
for X, Y in train_iter:
if state is None or use_random_iter:
# 在第一次迭代或使用随机抽样时初始化`state`
state = net.begin_state(batch_size=X.shape[0], dtype=tf.float32)
with tf.GradientTape(persistent=True) as g:
y_hat, state = net(X, state)
y = tf.reshape(tf.transpose(Y), (-1))
l = loss(y, y_hat)
params = net.trainable_variables
grads = g.gradient(l, params)
grads = grad_clipping(grads, 1)
updater.apply_gradients(zip(grads, params))
# Keras默认返回一个批量中的平均损失
metric.add(l * d2l.size(y), d2l.size(y))
return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
```
[**循环神经网络模型的训练函数既支持从零开始实现,
也可以使用高级API来实现。**]
```
#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, strategy,
use_random_iter=False):
"""训练模型(定义见第8章)"""
with strategy.scope():
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True)
updater = tf.keras.optimizers.SGD(lr)
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
predict = lambda prefix: predict_ch8(prefix, 50, net, vocab)
# 训练和预测
for epoch in range(num_epochs):
ppl, speed = train_epoch_ch8(net, train_iter, loss, updater,
use_random_iter)
if (epoch + 1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch + 1, [ppl])
device = d2l.try_gpu()._device_name
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict('time traveller'))
print(predict('traveller'))
```
[**现在,我们训练循环神经网络模型。**]
因为我们在数据集中只使用了10000个词元,
所以模型需要更多的迭代周期来更好地收敛。
```
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, strategy)
```
[**最后,让我们检查一下使用随机抽样方法的结果。**]
```
with strategy.scope():
net = RNNModelScratch(len(vocab), num_hiddens, init_rnn_state, rnn,
get_params)
train_ch8(net, train_iter, vocab_random_iter, lr, num_epochs, strategy,
use_random_iter=True)
```
| github_jupyter |
# Exercise 2 - Many-layered Earth
*Don't forget to hit * **Shift+Enter** * to run the code in any Cell.*
**PLEASE ENTER YOUR NAME HERE***
```
# First, import some additional libraries
import numpy as np
import matplotlib.pylab as plt
%matplotlib notebook
from eq_tools import *
```
In the cell below, we define two variables: *radii* and *velocities*.
These variables are *lists* and can hold multiple numbers.
The values in *radii* represent the outer radius of each layer of this hypothetical planet (think crust, mantle, core, etc.). They are given in kilometers (km).
The values in *velocities* represent the velocity that P-waves travel through that layer. They are given in kilometers per second (km/s).
Right now, these values are all set to 0. Edit this so that the values are reflective of your answers for the 2-layer Earth.
*Note that the radius is determined by the distance from the center of the Earth.*
## <font color='red'>Activity!</font>
Add more layers to *radii* and *velocities* to try to build a more realistic model of the Earth. See how close you can get it to match the model that is shown for comparison.
Try to keep your velocities between 4 and 20 km/s.
We've started you off by adding an additional layer...though it might not be the correct one!
```
# Simple planet
radii = [6400.0, 4800.0, 2400.0]
velocities = [14.0, 12.0, 15.0]
```
You can see a plot of radius versus velocity if you run the following cell.
```
plot_velocities(radii,velocities)
```
Run the cell below to produce an image of where the earthquake waves (drawn as rays) go.
You will also see a plot of arrival time versus angular distance from the spot of the earthquake.
You can edit the code below to change the number of earthquake rays drawn (*nrays*).
```
make_earthquake(radii,velocities,nrays=50,real_earth=True)
```
Once you've found a model of the Earth that you are satisfied with, answer the following questions.
## Question 1
How well does your model agree with the real Earth data? What could be done to improve your model?
***Your answer here***
## Question 2
How many layers does your Earth have?
***Your answer here***
## Question 3
Compare your depth versus velocity plot with that from the real Earth?
***Your answer here***
## Question 4
What is the depth of your core-mantle boundary? What is the velocity in your mantle? In your core?
***Your answer here***
## Question 5
Do you think there are other models that can produce the same travel-time curve? If so, could you determine which model is the correct one and how would you do it?
***Your answer here***
## Question 6
Imagine that you are asked to visit an 8th-grade science class to discuss what you have learned these two weeks about earthquakes and the Earth's interior. Write at least one paragraph explaining to those 8th-graders how we know what the interior of the Earth is like and what it is made of.
***Your answer here***
| github_jupyter |
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.
# Create Image
In this notebook, we show the following steps for deploying a web service using AzureML:
- Create an image
- Test image locally
```
import pandas as pd
from utilities import text_to_json, get_auth
from azureml.core.model import Model
from azureml.core.workspace import Workspace
from azureml.core.conda_dependencies import CondaDependencies
from dotenv import set_key, get_key, find_dotenv
env_path = find_dotenv(raise_error_if_not_found=True)
```
AML will use the following information to create an image, provision a cluster and deploy a service. Replace the values in the following cell with your information.
```
image_name = get_key(env_path, 'image_name')
```
## Get workspace
Load existing workspace from the config file.
```
ws = Workspace.from_config(auth=get_auth(env_path))
print(ws.name, ws.resource_group, ws.location, sep="\n")
```
## Load model
```
model_name = 'question_match_model'
model_version = int(get_key(env_path, 'model_version'))
model = Model(ws, name=model_name, version=model_version)
print(model.name, model.version)
```
## Create an image
We will now modify the `score.py` created in the previous notebook for the `init()` function to use the model we registered to the workspace earlier.
```
%%writefile score.py
import sys
import pandas as pd
import json
from duplicate_model import DuplicateModel
import logging
import timeit as t
from azureml.core.model import Model
sys.path.append('./scripts/')
def init():
logger = logging.getLogger("scoring_script")
global model
model_name = 'question_match_model'
model_path = Model.get_model_path(model_name)
questions_path = './data_folder/questions.tsv'
start = t.default_timer()
model = DuplicateModel(model_path, questions_path)
end = t.default_timer()
loadTimeMsg = "Model loading time: {0} ms".format(round((end-start)*1000, 2))
logger.info(loadTimeMsg)
def run(body):
logger = logging.getLogger("scoring_script")
json_load_text = json.loads(body)
text_to_score = json_load_text['input']
start = t.default_timer()
resp = model.score(text_to_score)
end = t.default_timer()
logger.info("Prediction took {0} ms".format(round((end-start)*1000, 2)))
return(json.dumps(resp))
```
Let's specifiy the conda and pip dependencies for the image.
```
conda_pack = ["scikit-learn==0.19.1", "pandas==0.23.3"]
requirements = ["lightgbm==2.1.2", "azureml-defaults==1.0.10"]
lgbmenv = CondaDependencies.create(conda_packages=conda_pack, pip_packages=requirements)
with open("lgbmenv.yml", "w") as f:
f.write(lgbmenv.serialize_to_string())
from azureml.core.image import ContainerImage
image_config = ContainerImage.image_configuration(
execution_script="score.py",
runtime="python",
conda_file="lgbmenv.yml",
description="Image with lightgbm model",
tags={"area": "text", "type": "lightgbm"},
dependencies=[
"./data_folder/questions.tsv",
"./duplicate_model.py",
"./scripts/item_selector.py",
],
)
image = ContainerImage.create(
name=image_name,
# this is the model object
models=[model],
image_config=image_config,
workspace=ws,
)
%%time
image.wait_for_creation(show_output = True)
print(image.name, image.version)
image_version = str(image.version)
set_key(env_path, "image_version", image_version)
```
You can find the logs of image creation in the following location.
```
image.image_build_log_uri
```
## Test image locally
Now, let's use one of the duplicate questions to test our image.
```
dupes_test_path = './data_folder/dupes_test.tsv'
dupes_test = pd.read_csv(dupes_test_path, sep='\t', encoding='latin1')
text_to_score = dupes_test.iloc[0,4]
text_to_score
jsontext = text_to_json(text_to_score)
%%time
image.run(input_data=jsontext)
```
## Conclusion
We have created a docker Image using AzureML and registred this image on Azure Container Registry (ACR). This docker image encapsulates a trained machine learning model and scoring scripts. In the next step, we can take this image and deploy it on the compute target of your choice: Azure Kubernetes Service (AKS) Cluster or Azure IoT Edge.
| github_jupyter |
# Moleculenet
The `MoleculeNetDataset` class is intended for datasets that consist of a table of smiles and corresponding targets and convert them into a tensors representation for graph networks. The class provides properties and methods for making graph features from smiles.
The typical input is a `csv` or `excel` file with smiles and corresponding graph labels.
The graph structure matches the molecular graph, i.e. the chemical structure. And features for atoms and bonds are generated with `RDkit` chemical informatics software.
The atomic coordinates
are generated by a conformer guess. Since this require some computation time, it is only done once and the
molecular coordinate or mol-blocks stored in a single SDF file with the base-name of the csv file.
For demonstration, we make an artifical table of smiles and some values and store them to file.
```
import os
os.makedirs("ExampleMol", exist_ok=True)
csv_data = "".join([
"smiles,Values1,Values2\n", # Need header!
"CCC, 1, 0.1\n",
"CCCO, 2, 0.3\nCCCN, 3, 0.2\n",
"CCCC=O, 4, 0.4\n"
"NOCF, 4, 1.4\n"
])
with open("ExampleMol/data.csv", "w") as f:
f.write(csv_data)
```
The file structure is:
```bash
├── ExampleMol
├── data.csv
└── data.sdf # After prepare_data
```
```
from kgcnn.data.moleculenet import MoleculeNetDataset
from kgcnn.mol.molgraph import OneHotEncoder
```
## 1. Initialization
To load the dataset from memeory the ``MoleculeNetDataset`` class requires the information of the directory the data is in and the name of the csv-file. Also recommended is to provide a name of the dataset.
```
dts = MoleculeNetDataset(file_name="data.csv",
data_directory="ExampleMol/",
dataset_name="ExampleMol")
```
## 2. Data Preparation
Precompute the molecular structure and possibly also coordinates and cache the information to file as SDF mol table format in the same folder as provided in the class initialization. The structure generation can be run in parallel but the SDF file generated may be large and must still fit in memory.
```
dts.prepare_data(
overwrite=True,
smiles_column_name="smiles",
add_hydrogen=True,
make_conformers=True,
optimize_conformer=True,
num_workers=None # Default is #cpus
)
```
## 3. Read Data
After ``prepare_data()`` is called, the cached mol-file can be read directly from the data-directory.
The reading step can also define the labels or targets to assigning property `graph_labels` from the column of the csv table. By default a simple graph is generated without attributes.
```
dts.read_in_memory(
label_column_name=["Values1", "Values2"],
add_hydrogen=False, # We remove H's
has_conformers=True # We keep strucutre
)
print("Number of graphs:", len(dts))
```
## 4. Setting Attributes
For molecular graphs nodes, edges or atoms and bonds should have attributes that are for `MoleculeNetDataset` generated from `RDkit` that includes chirality, stereo information (etc). Note that if a smile can not be processed by `RDkit` the graph will not have attributes.
This can be achieved by setting a list of identifiers of predefined attributes or supply custom functions.
Additionally an encoder can be provided to cast or transform the `RDkit` data formats into a list or value that eventually be cast into numpy `dtype="float"` array. Also one-hot-encoding or mapping on to distributions can be handled by encoders. Attributes
```
# Class to make attributes used by MoleculeNetDataset
import rdkit.Chem as Chem
from kgcnn.mol.graphRD import MolecularGraphRDKit
mol = MolecularGraphRDKit()
# Identifiers:
print("Atoms:", list(mol.atom_fun_dict.keys()))
print("Bonds:", list(mol.bond_fun_dict.keys()))
print("Molecule:", list(mol.mol_fun_dict.keys()))
```
Custom functions must take a `RDkit` Mol, Atom or Bond instance as input for node edge or graph respectively.
```
# Or make custom function
def mol_feature(m):
return m.GetNumAtoms()
dts.set_attributes(
# Nodes
nodes=["Symbol", "TotalNumHs"],
encoder_nodes={
"Symbol": OneHotEncoder(["C", "N", "O"], dtype="str", add_unknown=False)
},
# Edges
edges=["BondType", "Stereo"],
encoder_edges = {
"BondType": int
},
# Graph-level
graph=["ExactMolWt", mol_feature]
)
```
## 4. Checking graphs in dataset
```
import networkx as nx
dts.node_number, dts.node_symbol
print(dts[3])
G = nx.Graph()
G.add_nodes_from([(i, {"atom": x}) for i, x in enumerate(dts.node_symbol[3])])
G.add_edges_from(dts.edge_indices[3])
labels = nx.get_node_attributes(G, 'atom')
nx.draw(G,labels=labels)
Chem.MolFromSmiles("CCCC=O")
```
Checking the output of ``set_attributes`` method
```
dts.node_attributes
dts.edge_attributes
dts.graph_attributes
dts.graph_labels
```
| github_jupyter |
# Weight Initialization
In this lesson, you'll learn how to find good initial weights for a neural network. Having good initial weights can place the neural network close to the optimal solution. This allows the neural network to come to the best solution quicker.
## Testing Weights
### Dataset
To see how different weights perform, we'll test on the same dataset and neural network. Let's go over the dataset and neural network.
We'll be using the [MNIST dataset](https://en.wikipedia.org/wiki/MNIST_database) to demonstrate the different initial weights. As a reminder, the MNIST dataset contains images of handwritten numbers, 0-9, with normalized input (0.0 - 1.0). Run the cell below to download and load the MNIST dataset.
```
%matplotlib inline
import tensorflow as tf
import helper
from tensorflow.examples.tutorials.mnist import input_data
print('Getting MNIST Dataset...')
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
print('Data Extracted.')
```
### Neural Network
<img style="float: left" src="images/neural_network.png"/>
For the neural network, we'll test on a 3 layer neural network with ReLU activations and an Adam optimizer. The lessons you learn apply to other neural networks, including different activations and optimizers.
```
# Save the shapes of weights for each layer
layer_1_weight_shape = (mnist.train.images.shape[1], 256)
layer_2_weight_shape = (256, 128)
layer_3_weight_shape = (128, mnist.train.labels.shape[1])
```
## Initialize Weights
Let's start looking at some initial weights.
### All Zeros or Ones
If you follow the principle of [Occam's razor](https://en.wikipedia.org/wiki/Occam's_razor), you might think setting all the weights to 0 or 1 would be the best solution. This is not the case.
With every weight the same, all the neurons at each layer are producing the same output. This makes it hard to decide which weights to adjust.
Let's compare the loss with all ones and all zero weights using `helper.compare_init_weights`. This function will run two different initial weights on the neural network above for 2 epochs. It will plot the loss for the first 100 batches and print out stats after the 2 epochs (~860 batches). We plot the first 100 batches to better judge which weights performed better at the start.
Run the cell below to see the difference between weights of all zeros against all ones.
```
all_zero_weights = [
tf.Variable(tf.zeros(layer_1_weight_shape)),
tf.Variable(tf.zeros(layer_2_weight_shape)),
tf.Variable(tf.zeros(layer_3_weight_shape))
]
all_one_weights = [
tf.Variable(tf.ones(layer_1_weight_shape)),
tf.Variable(tf.ones(layer_2_weight_shape)),
tf.Variable(tf.ones(layer_3_weight_shape))
]
helper.compare_init_weights(
mnist,
'All Zeros vs All Ones',
[
(all_zero_weights, 'All Zeros'),
(all_one_weights, 'All Ones')])
```
As you can see the accuracy is close to guessing for both zeros and ones, around 10%.
The neural network is having a hard time determining which weights need to be changed, since the neurons have the same output for each layer. To avoid neurons with the same output, let's use unique weights. We can also randomly select these weights to avoid being stuck in a local minimum for each run.
A good solution for getting these random weights is to sample from a uniform distribution.
### Uniform Distribution
A [uniform distribution](https://en.wikipedia.org/wiki/Uniform_distribution_(continuous%29) has the equal probability of picking any number from a set of numbers. We'll be picking from a continous distribution, so the chance of picking the same number is low. We'll use TensorFlow's `tf.random_uniform` function to pick random numbers from a uniform distribution.
>#### [`tf.random_uniform(shape, minval=0, maxval=None, dtype=tf.float32, seed=None, name=None)`](https://www.tensorflow.org/api_docs/python/tf/random_uniform)
>Outputs random values from a uniform distribution.
>The generated values follow a uniform distribution in the range [minval, maxval). The lower bound minval is included in the range, while the upper bound maxval is excluded.
>- **shape:** A 1-D integer Tensor or Python array. The shape of the output tensor.
- **minval:** A 0-D Tensor or Python value of type dtype. The lower bound on the range of random values to generate. Defaults to 0.
- **maxval:** A 0-D Tensor or Python value of type dtype. The upper bound on the range of random values to generate. Defaults to 1 if dtype is floating point.
- **dtype:** The type of the output: float32, float64, int32, or int64.
- **seed:** A Python integer. Used to create a random seed for the distribution. See tf.set_random_seed for behavior.
- **name:** A name for the operation (optional).
We can visualize the uniform distribution by using a histogram. Let's map the values from `tf.random_uniform([1000], -3, 3)` to a histogram using the `helper.hist_dist` function. This will be `1000` random float values from `-3` to `3`, excluding the value `3`.
```
helper.hist_dist('Random Uniform (minval=-3, maxval=3)', tf.random_uniform([1000], -3, 3))
```
The histogram used 500 buckets for the 1000 values. Since the chance for any single bucket is the same, there should be around 2 values for each bucket. That's exactly what we see with the histogram. Some buckets have more and some have less, but they trend around 2.
Now that you understand the `tf.random_uniform` function, let's apply it to some initial weights.
### Baseline
Let's see how well the neural network trains using the default values for `tf.random_uniform`, where `minval=0.0` and `maxval=1.0`.
```
# Default for tf.random_uniform is minval=0 and maxval=1
basline_weights = [
tf.Variable(tf.random_uniform(layer_1_weight_shape)),
tf.Variable(tf.random_uniform(layer_2_weight_shape)),
tf.Variable(tf.random_uniform(layer_3_weight_shape))
]
helper.compare_init_weights(
mnist,
'Baseline',
[(basline_weights, 'tf.random_uniform [0, 1)')])
```
The loss graph is showing the neural network is learning, which it didn't with all zeros or all ones. We're headed in the right direction.
### General rule for setting weights
The general rule for setting the weights in a neural network is to be close to zero without being too small. A good pracitce is to start your weights in the range of $[-y, y]$ where
$y=1/\sqrt{n}$ ($n$ is the number of inputs to a given neuron).
Let's see if this holds true, let's first center our range over zero. This will give us the range [-1, 1).
```
uniform_neg1to1_weights = [
tf.Variable(tf.random_uniform(layer_1_weight_shape, -1, 1)),
tf.Variable(tf.random_uniform(layer_2_weight_shape, -1, 1)),
tf.Variable(tf.random_uniform(layer_3_weight_shape, -1, 1))
]
helper.compare_init_weights(
mnist,
'[0, 1) vs [-1, 1)',
[
(basline_weights, 'tf.random_uniform [0, 1)'),
(uniform_neg1to1_weights, 'tf.random_uniform [-1, 1)')])
```
We're going in the right direction, the accuracy and loss is better with [-1, 1). We still want smaller weights. How far can we go before it's too small?
### Too small
Let's compare [-0.1, 0.1), [-0.01, 0.01), and [-0.001, 0.001) to see how small is too small. We'll also set `plot_n_batches=None` to show all the batches in the plot.
```
uniform_neg01to01_weights = [
tf.Variable(tf.random_uniform(layer_1_weight_shape, -0.1, 0.1)),
tf.Variable(tf.random_uniform(layer_2_weight_shape, -0.1, 0.1)),
tf.Variable(tf.random_uniform(layer_3_weight_shape, -0.1, 0.1))
]
uniform_neg001to001_weights = [
tf.Variable(tf.random_uniform(layer_1_weight_shape, -0.01, 0.01)),
tf.Variable(tf.random_uniform(layer_2_weight_shape, -0.01, 0.01)),
tf.Variable(tf.random_uniform(layer_3_weight_shape, -0.01, 0.01))
]
uniform_neg0001to0001_weights = [
tf.Variable(tf.random_uniform(layer_1_weight_shape, -0.001, 0.001)),
tf.Variable(tf.random_uniform(layer_2_weight_shape, -0.001, 0.001)),
tf.Variable(tf.random_uniform(layer_3_weight_shape, -0.001, 0.001))
]
helper.compare_init_weights(
mnist,
'[-1, 1) vs [-0.1, 0.1) vs [-0.01, 0.01) vs [-0.001, 0.001)',
[
(uniform_neg1to1_weights, '[-1, 1)'),
(uniform_neg01to01_weights, '[-0.1, 0.1)'),
(uniform_neg001to001_weights, '[-0.01, 0.01)'),
(uniform_neg0001to0001_weights, '[-0.001, 0.001)')],
plot_n_batches=None)
```
Looks like anything [-0.01, 0.01) or smaller is too small. Let's compare this to our typical rule of using the range $y=1/\sqrt{n}$.
```
import numpy as np
general_rule_weights = [
tf.Variable(tf.random_uniform(layer_1_weight_shape, -1/np.sqrt(layer_1_weight_shape[0]), 1/np.sqrt(layer_1_weight_shape[0]))),
tf.Variable(tf.random_uniform(layer_2_weight_shape, -1/np.sqrt(layer_2_weight_shape[0]), 1/np.sqrt(layer_2_weight_shape[0]))),
tf.Variable(tf.random_uniform(layer_3_weight_shape, -1/np.sqrt(layer_3_weight_shape[0]), 1/np.sqrt(layer_3_weight_shape[0])))
]
helper.compare_init_weights(
mnist,
'[-0.1, 0.1) vs General Rule',
[
(uniform_neg01to01_weights, '[-0.1, 0.1)'),
(general_rule_weights, 'General Rule')],
plot_n_batches=None)
```
The range we found and $y=1/\sqrt{n}$ are really close.
Since the uniform distribution has the same chance to pick anything in the range, what if we used a distribution that had a higher chance of picking numbers closer to 0. Let's look at the normal distribution.
### Normal Distribution
Unlike the uniform distribution, the [normal distribution](https://en.wikipedia.org/wiki/Normal_distribution) has a higher likelihood of picking number close to it's mean. To visualize it, let's plot values from TensorFlow's `tf.random_normal` function to a histogram.
>[tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)](https://www.tensorflow.org/api_docs/python/tf/random_normal)
>Outputs random values from a normal distribution.
>- **shape:** A 1-D integer Tensor or Python array. The shape of the output tensor.
- **mean:** A 0-D Tensor or Python value of type dtype. The mean of the normal distribution.
- **stddev:** A 0-D Tensor or Python value of type dtype. The standard deviation of the normal distribution.
- **dtype:** The type of the output.
- **seed:** A Python integer. Used to create a random seed for the distribution. See tf.set_random_seed for behavior.
- **name:** A name for the operation (optional).
```
helper.hist_dist('Random Normal (mean=0.0, stddev=1.0)', tf.random_normal([1000]))
```
Let's compare the normal distribution against the previous uniform distribution.
```
normal_01_weights = [
tf.Variable(tf.random_normal(layer_1_weight_shape, stddev=0.1)),
tf.Variable(tf.random_normal(layer_2_weight_shape, stddev=0.1)),
tf.Variable(tf.random_normal(layer_3_weight_shape, stddev=0.1))
]
helper.compare_init_weights(
mnist,
'Uniform [-0.1, 0.1) vs Normal stddev 0.1',
[
(uniform_neg01to01_weights, 'Uniform [-0.1, 0.1)'),
(normal_01_weights, 'Normal stddev 0.1')])
```
The normal distribution gave a slight increasse in accuracy and loss. Let's move closer to 0 and drop picked numbers that are `x` number of standard deviations away. This distribution is called [Truncated Normal Distribution](https://en.wikipedia.org/wiki/Truncated_normal_distribution%29).
### Truncated Normal Distribution
>[tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)](https://www.tensorflow.org/api_docs/python/tf/truncated_normal)
>Outputs random values from a truncated normal distribution.
>The generated values follow a normal distribution with specified mean and standard deviation, except that values whose magnitude is more than 2 standard deviations from the mean are dropped and re-picked.
>- **shape:** A 1-D integer Tensor or Python array. The shape of the output tensor.
- **mean:** A 0-D Tensor or Python value of type dtype. The mean of the truncated normal distribution.
- **stddev:** A 0-D Tensor or Python value of type dtype. The standard deviation of the truncated normal distribution.
- **dtype:** The type of the output.
- **seed:** A Python integer. Used to create a random seed for the distribution. See tf.set_random_seed for behavior.
- **name:** A name for the operation (optional).
```
helper.hist_dist('Truncated Normal (mean=0.0, stddev=1.0)', tf.truncated_normal([1000]))
```
Again, let's compare the previous results with the previous distribution.
```
trunc_normal_01_weights = [
tf.Variable(tf.truncated_normal(layer_1_weight_shape, stddev=0.1)),
tf.Variable(tf.truncated_normal(layer_2_weight_shape, stddev=0.1)),
tf.Variable(tf.truncated_normal(layer_3_weight_shape, stddev=0.1))
]
helper.compare_init_weights(
mnist,
'Normal vs Truncated Normal',
[
(normal_01_weights, 'Normal'),
(trunc_normal_01_weights, 'Truncated Normal')])
```
There's no difference between the two, but that's because the neural network we're using is too small. A larger neural network will pick more points on the normal distribution, increasing the likelihood it's choices are larger than 2 standard deviations.
We've come a long way from the first set of weights we tested. Let's see the difference between the weights we used then and now.
```
helper.compare_init_weights(
mnist,
'Baseline vs Truncated Normal',
[
(basline_weights, 'Baseline'),
(trunc_normal_01_weights, 'Truncated Normal')])
```
That's a huge difference. You can barely see the truncated normal line. However, this is not the end your learning path. We've provided more resources for initializing weights in the classroom!
| github_jupyter |
```
#import urllib, urllib3
#from bs4 import BeautifulSoup
#import requests
#import time
#import io
#import numpy as np
##import nltk
##from nltk.corpus import wordnet as wn
#import pandas as pd
#from sklearn.feature_extraction.text import CountVectorizer
#import gensim
#from gensim.models.ldamodel import LdaModel
```
Downloading abstracts and from computer science papers using [arXiv.org](https://arxiv.org) API and group them by years:
```
import pandas as pd
df = pd.read_pickle("arxiv_data_cs_all.pickle.bz2")
print(len(df))
df[:2]
df.id[:2][0]
import re
def clean_id(s):
if s:
s = re.sub('.*(abs\/)', '', s)
s = re.sub('.*(cs\/)', '', s)
s = re.sub('.*(astro-ph\/)', '', s)
s = re.sub('.*(math\/)', '', s)
s = re.sub('.*(org\/)', '', s)
s = re.sub('.*(dyn\/)', '', s)
s = re.sub('.*(lg\/)', '', s)
s = re.sub('.*(mat\/)', '', s)
s = re.sub('.*(qc\/)', '', s)
s = re.sub('.*(ph\/)', '', s)
s = re.sub('.*(qc\/)', '', s)
s = re.sub('.*(nlin\/)', '', s)
s = re.sub('.*(th\/)', '', s)
s = re.sub('.*(bio\/)', '', s)
s = re.sub('.*(lat\/)', '', s)
s = re.sub('\..*$', '', s)
return s.strip()
return s
df_ids_y_m = df.id.map(clean_id)
s_y_m = list(map(lambda x: x[0:4], df_ids_y_m))
papers_y_m = pd.DataFrame(columns=['Year', 'Month', 'Papers'])
for i, item in enumerate(set(s_y_m)):
if s_y_m.count(item) > 1:
papers_y_m.loc[i, 'Year'] = item[0:2]
papers_y_m.loc[i, 'Month'] = item[2:4]
papers_y_m.loc[i, 'Papers'] = s_y_m.count(item)
papers_y_m.sort_values('Year', inplace=True)
papers_y_m.sort_values('Month', inplace=True, ascending=False)
papers_y_m.reset_index(inplace=True, drop=True)
papers_y_m['Year'] = (papers_y_m['Year'].astype(int).where(papers_y_m['Year'].astype(int) < 50,
papers_y_m['Year'].astype(int)-100)
+ 2000)
papers_y_m
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(20,10))
plt.bar(papers_y_m['Year'], papers_y_m['Papers'], width=0.9)
#plt.axis('off')
ax = plt.gca()
ax.set_title("Number of papers on Machine Learning \n (arXiv:cs) until Jun 09, 2019", size=25)
ax.set_xlim(1990.1, 2019.6)
rects = ax.patches
labels = [papers_y_m.loc[i, 'Papers'] for i in range(len(rects))]
for rect, label in zip(rects, labels):
height = rect.get_height()
rect.set_y = rect.get_y() + 10
ax.text(rect.get_x() + rect.get_width(), height + 15, label, ha='center', va='bottom', color='black')
ax.tick_params(axis ='x', which='minor', length=0)
ax.tick_params(axis ='both', which='major', length=0)
ax.set_yticklabels = ['']
ax.axes.get_yaxis().set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
plt.savefig("arxiv_data_cs_all_y_m.png", format="png", transparent=True,rasterized=True,dpi=300)
plt.show()
s_y = list(map(lambda x: x[0:2], df_ids_y_m.str.slice(stop=2)))
papers_y = pd.DataFrame(columns=['Year', 'Papers'])
for i, item in enumerate(set(s_y)):
if s_y.count(item) > 1:
papers_y.loc[i, 'Year'] = item
papers_y.loc[i, 'Papers'] = s_y.count(item)
papers_y['Year'] = (papers_y['Year'].astype(int).where(papers_y['Year'].astype(int) < 50,
papers_y['Year'].astype(int)-100)
+ 2000)
papers_y.sort_values('Year', inplace=True)
papers_y.reset_index(inplace=True, drop=True)
papers_y
piece_to_find = "he"
df[s_y.index(piece_to_find):s_y.index(piece_to_find)+1]
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(20,10))
plt.bar(papers_y['Year'], papers_y['Papers'], width=0.9)
#plt.axis('off')
ax = plt.gca()
ax.set_title("Number of papers per Year on Machine Learning \n (arXiv:cs) until Jun 09, 2019", size=25)
max_value = papers_y['Year'].max()
min_value = papers_y['Year'].min()
number_of_steps = 1
l = np.arange(min_value, max_value+1, number_of_steps)
ax.set(xticks=l, xticklabels=l)
rects = ax.patches
labels = [papers_y.loc[i, 'Papers'] for i in range(len(rects))]
for rect, label in zip(rects, labels):
height = rect.get_height()
rect.set_y(rect.get_y()+10)
ax.text(rect.get_x() + rect.get_width()/2, height + 15, str(label), ha='center', va='bottom', color='black')
ax.tick_params(axis ='x', which='minor', length=0)
ax.tick_params(axis ='both', which='major', length=0)
ax.set_yticklabels = ['']
ax.axes.get_yaxis().set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
plt.savefig("arxiv_data_cs_all_y.png", format="png", transparent=True,rasterized=True,dpi=300)
plt.show()
filename = "arxiv_data_cs_all_stats_years.json"
papers_y.to_json(filename)
filename = "arxiv_data_cs_all_stats_years_months.json"
papers_y_m.to_json(filename)
s_y_m = list(map(lambda x: x[0:4], df_ids_y_m))
papers_ym = pd.DataFrame(columns=['Year', 'Month', 'Papers'])
for i, item in enumerate(set(s_y_m)):
if s_y_m.count(item) > 1:
papers_ym.loc[i, 'Year'] = item[0:2]
papers_ym.loc[i, 'Month'] = item[2:4]
papers_ym.loc[i, 'Papers'] = s_y_m.count(item)
papers_y_m.sort_values('Year', inplace=True)
papers_y_m.sort_values('Month', inplace=True, ascending=False)
papers_y_m.reset_index(inplace=True, drop=True)
papers_ym['Year'] = (papers_ym['Year'].astype(int).where(papers_ym['Year'].astype(int) < 50,
papers_ym['Year'].astype(int)-100)
+ 2000)
papers_ym
def build_bf_cat_y_m(cat, df_cat_id):
s_cat = list(map(lambda x: x[0:4], df_cat_id.map(clean_id)))
papers_cat = pd.DataFrame(columns=['Year', 'Month', cat])
for i, item in enumerate(set(s_cat)):
if s_cat.count(item) > 1:
papers_cat.loc[i, 'Year'] = item[0:2]
papers_cat.loc[i, 'Month'] = item[2:4]
papers_cat.loc[i, cat] = s_cat.count(item)
papers_cat.sort_values('Year', inplace=True)
papers_cat.sort_values('Month', inplace=True, ascending=False)
papers_cat.reset_index(inplace=True, drop=True)
papers_cat['Year'] = (papers_cat['Year'].astype(int).where(papers_cat['Year'].astype(int) < 50,
papers_cat['Year'].astype(int)-100)
+ 2000)
return papers_cat
for cat in set(list(df.primary_category)):
df_cat_id = df["id"].where(df['primary_category'] == cat).dropna()
papers_df = build_bf_cat_y_m(cat, df_cat_id)
papers_ym = pd.merge(papers_ym, papers_df, on=['Year','Month'], how="outer")
papers_ym.fillna(0, inplace=True)
papers_ym
filename = "arxiv_data_cs_all_stats_primary_cats_years_months.json"
papers_ym.to_json(filename)
s_y = list(map(lambda x: x[0:2], df_ids_y_m.str.slice(stop=2)))
papers_y = pd.DataFrame(columns=['Year', 'Papers'])
for i, item in enumerate(set(s_y)):
if s_y.count(item) > 1:
papers_y.loc[i, 'Year'] = item
papers_y.loc[i, 'Papers'] = s_y.count(item)
papers_y['Year'] = (papers_y['Year'].astype(int).where(papers_y['Year'].astype(int) < 50,
papers_y['Year'].astype(int)-100)
+ 2000)
papers_y.sort_values('Year', inplace=True)
papers_y.reset_index(inplace=True, drop=True)
papers_y
def build_bf_cat_y(cat, df_cat_id):
s_cat = list(map(lambda x: x[0:2], df_cat_id.map(clean_id)))
papers_cat = pd.DataFrame(columns=['Year', cat])
for i, item in enumerate(set(s_cat)):
if s_cat.count(item) > 1:
papers_cat.loc[i, 'Year'] = item
papers_cat.loc[i, cat] = s_cat.count(item)
papers_cat['Year'] = (papers_cat['Year'].astype(int).where(papers_cat['Year'].astype(int) < 50,
papers_cat['Year'].astype(int)-100)
+ 2000)
papers_cat.sort_values('Year', inplace=True)
papers_cat.reset_index(inplace=True, drop=True)
return papers_cat
for cat in set(list(df.primary_category)):
df_cat_id = df["id"].where(df['primary_category'] == cat).dropna()
papers_df = build_bf_cat_y(cat, df_cat_id)
papers_y = pd.merge(papers_y, papers_df, on='Year', how="outer")
papers_y.fillna(0, inplace=True)
papers_y
filename = "arxiv_data_cs_all_stats_primary_cats_years.json"
papers_y.to_json(filename)
```
| github_jupyter |
# Interpretable forecasting with N-Beats
```
import os
import warnings
warnings.filterwarnings("ignore")
os.chdir("../../..")
import pandas as pd
import torch
import pytorch_lightning as pl
from pytorch_lightning.callbacks import EarlyStopping
from pytorch_forecasting import TimeSeriesDataSet, NBeats, Baseline
from pytorch_forecasting.data import NaNLabelEncoder
from pytorch_forecasting.data.examples import generate_ar_data
from pytorch_forecasting.metrics import SMAPE
```
## Load data
```
data = generate_ar_data(seasonality=10.0, timesteps=400, n_series=100)
data["static"] = 2
data["date"] = pd.Timestamp("2020-01-01") + pd.to_timedelta(data.time_idx, "D")
data.head()
# create dataset and dataloaders
max_encoder_length = 60
max_prediction_length = 20
training_cutoff = data["time_idx"].max() - max_prediction_length
context_length = max_encoder_length
prediction_length = max_prediction_length
training = TimeSeriesDataSet(
data[lambda x: x.time_idx <= training_cutoff],
time_idx="time_idx",
target="value",
categorical_encoders={"series": NaNLabelEncoder().fit(data.series)},
group_ids=["series"],
# only unknown variable is "value" - and N-Beats can also not take any additional variables
time_varying_unknown_reals=["value"],
max_encoder_length=context_length,
max_prediction_length=prediction_length,
)
validation = TimeSeriesDataSet.from_dataset(training, data, min_prediction_idx=training_cutoff+1)
batch_size = 128
train_dataloader = training.to_dataloader(train=True, batch_size=batch_size, num_workers=0)
val_dataloader = validation.to_dataloader(train=False, batch_size=batch_size, num_workers=0)
```
## Calculate baseline error
```
# calculate baseline absolute error
actuals = torch.cat([y for x, y in iter(val_dataloader)])
baseline_predictions = Baseline().predict(val_dataloader)
SMAPE()(baseline_predictions, actuals)
```
## Train network
Find optimal learning rate
```
trainer = pl.Trainer(gpus=0, gradient_clip_val=0.1)
net = NBeats.from_dataset(training, learning_rate=3e-2, weight_decay=1e-2)
# find optimal learning rate
res = trainer.lr_find(net, train_dataloader=train_dataloader, val_dataloaders=val_dataloader, min_lr=1e-5, max_lr=1e2)
print(f"suggested learning rate: {res.suggestion()}")
fig = res.plot(show=True, suggest=True)
fig.show()
net.hparams.learning_rate = res.suggestion()
```
Fit model
```
early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=10, verbose=False, mode="min")
trainer = pl.Trainer(
max_epochs=100,
gpus=0,
weights_summary="top",
gradient_clip_val=0.1,
early_stop_callback=early_stop_callback,
limit_train_batches=30,
)
net = NBeats.from_dataset(training, learning_rate=1.2e-2, log_interval=10, log_val_interval=1, weight_decay=1e-2)
trainer.fit(
net, train_dataloader=train_dataloader, val_dataloaders=val_dataloader,
)
```
### Evaluate Results
```
# best_model_path = trainer.checkpoint_callback.best_model_path
best_model_path = "/Users/beitnerjan/Documents/Github/temporal_fusion_transformer_pytorch/lightning_logs/version_212/checkpoints/epoch=19.ckpt"
best_model = NBeats.load_from_checkpoint(best_model_path)
print(best_model_path)
```
We calculate the error which is approximately half of the baseline error
```
actuals = torch.cat([y for x, y in iter(val_dataloader)])
predictions = best_model.predict(val_dataloader)
(actuals - predictions).abs().mean()
raw_predictions, x = best_model.predict(val_dataloader, mode="raw", return_x=True)
for idx in range(10):
best_model.plot_prediction(x, raw_predictions, idx=idx, add_loss_to_title=True);
```
## Interpret model
```
for idx in range(10):
best_model.plot_interpretation(x, raw_predictions, idx=idx)
;
```
| github_jupyter |
# Create a QComponent - Advanced
```
from qiskit_metal import draw, Dict
from qiskit_metal.toolbox_metal import math_and_overrides
from qiskit_metal.qlibrary.core import QComponent
import qiskit_metal as metal
design = metal.designs.DesignPlanar()
```
## Qubits and Junctions
The vast majority of junction management is actually under the QRenderers. The only information that a component designer needs to provide, is a linestring and width which indicates the location and orientation of a given junction. We can see this from a couple extracted lines of code from `TransmonPocket`
`...`
`rect_jj = draw.LineString([(0, -pad_gap / 2), (0, +pad_gap / 2)])`
`...`
`self.add_qgeometry('junction', dict(rect_jj=rect_jj), width=p.inductor_width)`
In this case, the linestring is drawn between the two charge islands of the `TransmonPocket`. Much more of the junctions options are from renderer options added when the QRenderers are initiated. These are covered more in the renderer tutorials and sessions.
It should be noted, currently multiple junctions in a component will receive the same renderer options. This is fine if, say, making a symmetric SQUID, though if trying to have asymmetry, (or, say fluxonium), a manner to handled multiple junction renderer options in a component is required.
```
from qiskit_metal.qlibrary.qubits.transmon_pocket import TransmonPocket
?TransmonPocket
```
## Exteriors, Interiors, and MultiPolygons
As was shown in 3.1, there is a great amount of flexibility already present in Metal for what a component can be, though as it is still in development, there are some limitations with respect to if renderers can accurately render a given shape, say, a multi-faceted polygon where some facets are composed of splines. What capabilities are currently missing and would be beneficial to be added are all part of the development process.
Currently, a poly can be generated with interior cut outs, such as the smiley face previously,
```
face = draw.shapely.geometry.Point(0, 0).buffer(1)
eye = draw.shapely.geometry.Point(0, 0).buffer(0.2)
eye_l = draw.translate(eye, -0.4, 0.4)
eye_r = draw.translate(eye, 0.4, 0.4)
smile = draw.shapely.geometry.Point(0, 0).buffer(0.8)
cut_sq = draw.shapely.geometry.box(-1, -0.3, 1, 1)
smile = draw.subtract(smile, cut_sq)
face = draw.subtract(face, smile)
face = draw.subtract(face, eye_r)
face = draw.subtract(face, eye_l)
face
```
This differs from qgeometries which have `subtract=True`, as that specifically sets that geometry to be "etched" from the ground plane. The polygon face is composed of an exterior;
```
face.exterior
```
and interiors, such as;
```
face.interiors[0]
```
A renderer must recognize the difference between these shapes, as the current QRenderers do. This allows for the component designer to generate complex shapes, without having to worry about how to add the qgeometries in any particular manner. This is also true with MultiPolygons.
```
big_square = draw.rectangle(10,10,0,0)
cut_rectangle = draw.rectangle(12,1,0,0)
multi_poly = draw.subtract(big_square, cut_rectangle)
multi_poly
type(multi_poly)
```
The MultiPolygon can still just be passed to add_qgeometry as one would with a regular polygon. It is broken up behind the scenes so two separate rectangles (with the appropriate coordinates) are added to the poly qgeometry table. This is handled by the add_qgeometry method of QGeometryTables.
```
?metal.qgeometries.QGeometryTables.add_qgeometry
```
This method also handles rounding of coordinates to try and avoid any numerical errors. It is called by `metal.qlibrary.core.QComponent.add_qgeometry` and should not be called directly.
## QComponent Inheritance
As is the case with python classes, one can extend a given component by creating a qcomponent which inherits said class, making it a parent/child relationship. While python does support multiple inheritances, Metal may run into some bugs, so it is best to keep inheritances as single paths of heritage.
A good example is `TransmonPocketCL`, which adds a "charge line" the a "standard" `TransmonPocket`. As can be seen in the below code, none of the charge islands or other connection pads are present, but will still be generated via the `super().make()` line in the `make()` method.
```
import numpy as np
from qiskit_metal import draw, Dict
from qiskit_metal.qlibrary.qubits.transmon_pocket import TransmonPocket
class TransmonPocketCL(TransmonPocket): # pylint: disable=invalid-name
"""
The base `TransmonPocketCL` class
Inherits `TransmonPocket` class
Description:
Create a standard pocket transmon qubit for a ground plane,
with two pads connected by a junction (see drawing below).
Connector lines can be added using the `connection_pads`
dictionary. Each connector line has a name and a list of default
properties.
This is a child of TransmonPocket, see TransmonPocket for the variables and
description of that class.
::
_________________
| |
|_______________| ^
________x________ | N
| | |
|_______________|
.. image::
Component_Qubit_Transmon_Pocket_CL.png
Charge Line:
* make_CL (bool): If a chargeline should be included.
* cl_gap (string): The cpw dielectric gap of the charge line.
* cl_width (string): The cpw width of the charge line.
* cl_length (string): The length of the charge line 'arm' coupling the the qubit pocket.
Measured from the base of the 90 degree bend.
* cl_ground_gap (string): How much ground is present between the charge line and the
qubit pocket.
* cl_pocket_edge (string): What side of the pocket the charge line is.
-180 to +180 from the 'west edge', will round to the nearest 90.
* cl_off_center (string): Distance from the center axis the qubit pocket is referenced to
"""
component_metadata = Dict(short_name='Q', _qgeometry_table_poly='True')
"""Component metadata"""
default_options = Dict(
make_CL=True,
cl_gap='6um', # the cpw dielectric gap of the charge line
cl_width='10um', # the cpw trace width of the charge line
# the length of the charge line 'arm' coupling the the qubit pocket.
cl_length='20um',
# Measured from the base of the 90 degree bend
cl_ground_gap=
'6um', # how much ground between the charge line and the qubit pocket
# -180 to +180 from the 'left edge', will round to the nearest 90.
cl_pocket_edge='0',
cl_off_center=
'100um', # distance from the center axis the qubit pocket is built on
)
"""Default drawing options"""
def make(self):
"""Define the way the options are turned into QGeometry."""
super().make()
if self.options.make_CL == True:
self.make_charge_line()
#####################################################################
def make_charge_line(self):
"""Creates the charge line if the user has charge line option to TRUE
"""
# Grab option values
name = 'Charge_Line'
p = self.p
cl_arm = draw.box(0, 0, -p.cl_width, p.cl_length)
cl_cpw = draw.box(0, 0, -8 * p.cl_width, p.cl_width)
cl_metal = draw.cascaded_union([cl_arm, cl_cpw])
cl_etcher = draw.buffer(cl_metal, p.cl_gap)
port_line = draw.LineString([(-8 * p.cl_width, 0),
(-8 * p.cl_width, p.cl_width)])
polys = [cl_metal, cl_etcher, port_line]
# Move the charge line to the side user requested
cl_rotate = 0
if (abs(p.cl_pocket_edge) > 135) or (abs(p.cl_pocket_edge) < 45):
polys = draw.translate(
polys, -(p.pocket_width / 2 + p.cl_ground_gap + p.cl_gap),
-(p.pad_gap + p.pad_height) / 2)
if (abs(p.cl_pocket_edge) > 135):
p.cl_rotate = 180
else:
polys = draw.translate(
polys, -(p.pocket_height / 2 + p.cl_groundGap + p.cl_gap),
-(p.pad_width) / 2)
cl_rotate = 90
if (p.cl_pocket_edge < 0):
cl_rotate = -90
# Rotate it to the pockets orientation
polys = draw.rotate(polys, p.orientation + cl_rotate, origin=(0, 0))
# Move to the final position
polys = draw.translate(polys, p.pos_x, p.pos_y)
[cl_metal, cl_etcher, port_line] = polys
# Generating pins
points = list(draw.shapely.geometry.shape(port_line).coords)
self.add_pin(name, points, p.cl_width) # TODO: chip
# Adding to element table
self.add_qgeometry('poly', dict(cl_metal=cl_metal))
self.add_qgeometry('poly', dict(cl_etcher=cl_etcher), subtract=True)
```
We can see this is the case by generating a TransmonPocketCL in the GUI.
```
gui = metal.MetalGUI(design)
my_transmon_cl = TransmonPocketCL(design,'my_transmon_cl',options=dict(connection_pads=dict(a=dict(),b=dict(loc_W=-1))))
gui.rebuild()
gui.autoscale()
gui.screenshot()
my_transmon_cl.options
```
We can see that `my_transmon_cl` inherited the appropriate options from `TransmonPocket`, and even got the junction renderer options since its parent class does declare `_qgeometry_table_junction='True'`
```
gui.main_window.close()
```
| github_jupyter |
# Basics of text processing
### Natural Language Processing and Information Extraction, 2021 WS
10/15/2021
Gábor Recski
## In this lecture
- Regular Expressions
- Text segmentation and normalization:
- sentence splitting and tokenization
- lemmatization, stemming, decompounding, morphology
## Import dependencies
```
# !pip install stanza
# !pip install nltk
# !pip install bash-kernel
# !python -m bash_kernel.install
import re
from collections import Counter
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize, sent_tokenize
import stanza
stanza.download('en')
```
## Regular expressions
### Basics
([SLP Ch.2](https://web.stanford.edu/~jurafsky/slp3/2.pdf))
```
re.findall('a', "Mary Ann stopped by Mona's")
text = open('data/alice_de.txt').read()
print(text[:100])
re.search('Alice', text)
text[52:57]
```
([SLP Ch.2](https://web.stanford.edu/~jurafsky/slp3/2.pdf))
```
re.search('[Kk]aninchen', text)
re.findall('[Kk]aninchen', text[:5000])
for match in re.finditer('[Kk]aninchen', text[:5000]):
print(match.group(), match.span())
```
([SLP Ch.2](https://web.stanford.edu/~jurafsky/slp3/2.pdf))
```
re.findall(' [A-Za-z][a-z][a-z] ', text[:5000])
Counter(re.findall(' [A-Za-z][a-z][a-z] ', text)).most_common(10)
```
([SLP Ch.2](https://web.stanford.edu/~jurafsky/slp3/2.pdf))
([SLP Ch.2](https://web.stanford.edu/~jurafsky/slp3/2.pdf))
([SLP Ch.2](https://web.stanford.edu/~jurafsky/slp3/2.pdf))
```
re.findall('...', text[:100])
```
([SLP Ch.2](https://web.stanford.edu/~jurafsky/slp3/2.pdf))
```
re.findall('\w', text[:50])
re.split('\s', text[:100])
```
([SLP Ch.2](https://web.stanford.edu/~jurafsky/slp3/2.pdf))
```
re.findall('(\w+)', text[:100])
Counter(re.findall('\w+', text)).most_common(20)
Counter(re.findall('[^\w\s]', text)).most_common(20)
```
### Substitution and groups
```
re.sub('\s+', ' ', text[:100])
print(re.sub('\s+', '\n', text[:100]))
re.findall('[^\s]+ [^\s]+ Kapitel.', text)
print(re.sub('\[([0-9]+)\] ([^\s]+) Kapitel.', '\\2 Kapitel (\\1):', text[:100]))
print(re.sub('CHAPTER ([^\s.]+).\n([^\n]*)', 'Chapter \\1: \\2', text[:100]))
re.findall('\[([0-9]+)\] ([^\s]+) Kapitel.', text)
```
Regular expressions are surprisingly powerful. Also, with the right implementation, they are literally as fast as you can get. That's because they are equivalent to [finite state automata (FSAs)](https://en.wikipedia.org/wiki/Finite-state_machine). Actually, every regular expression is a [regular grammar](https://en.wikipedia.org/wiki/Regular_grammar) defining a [regular language](https://en.wikipedia.org/wiki/Regular_language).
([XKCD #208](https://xkcd.com/208/))
## Text segmentation
### Sentence splitting
#### How to split a text into sentences?
```
text2 = "'Of course it's only because Tom isn't home,' said Mrs. Parsons vaguely."
```
Naive: split on `.`, `!`, `?`, etc.
```
re.split('[.!?]', text2)
```
Better: use language-specific list of abbreviation words, collocations, etc.
```
nltk.sent_tokenize(text2)
```
Custom lists of patterns are often necessary for special domains.
```
text3 = "An die Stelle der Landesgesetze vom 17. Jänner 1883, n.ö.L.G. u. V.Bl. Nr. 35, vom 26. Dezember 1890, n.ö.L.G. u. V.Bl. Nr. 48, vom 17. Juni 1920 n.ö.L.G. u. V.Bl. Nr. 547, vom 4. November 1920 n.ö.L.G. u. V.Bl. Nr. 808, und vom 9. Dezember 1927, L.G.Bl. für Wien Nr. 1 ex 1928, die, soweit dieses Gesetz nichts anderes bestimmt, zugleich ihre Wirksamkeit verlieren, hat die nachfolgende Bauordnung zu treten."
print(text3)
nltk.sent_tokenize(text3, language='german')
```
### Tokenization
#### How to split text into words?
#### Naive approach: split on whitespace
```
text2.split()
```
#### Better: separate punctuation marks
```
re.findall('(\w+|[^\w\s]+)', text2)[:30]
```
#### Best: add some language-specific conventions:
```
nltk.word_tokenize(text2)
```
## Text normalization
```
words = nltk.word_tokenize(text)
words[:10]
Counter(words).most_common(10)
```
Let's get rid of punctuation
```
words = [word for word in words if re.match('\w', word)]
Counter(words).most_common(10)
```
Filtering common function words is called __stopword removal__
```
from nltk.corpus import stopwords
nltk.download('stopwords')
stopwords = set(stopwords.words('german'))
print(stopwords)
words = [word for word in words if word.lower() not in stopwords]
Counter(words).most_common(20)
```
### Lemmatization and stemming
Words like _say_, _says_, and _said_ are all different **word forms** of the same **lemma**. Grouping them together can be useful in many applications.
**Stemming** is the reduction of words to a common prefix, using simple rules that only work some of the time:
```
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer('german')
for word in ('sagen', 'sag', 'gesagt'):
print(stemmer.stem(word, ))
for word in ('er', 'sein', 'ihm'):
print(stemmer.stem(word))
```
**Lemmatization** is the mapping of word forms to their lemma, using either a dictionary of word forms, a grammar of how words are formed (a **morphology**), or both.
```
stanza.download('de')
nlp_de = stanza.Pipeline('de', processors='tokenize,lemma,pos')
doc_de = nlp_de(text)
for sentence in doc_de.sentences[:5]:
for word in sentence.words:
print(word.text + '\t' + word.lemma)
print()
```
Now we can count lemmas
```
Counter(
word.lemma for sentence in doc_de.sentences for word in sentence.words
if word.lemma not in stopwords and re.match('\w', word.lemma)).most_common(20)
```
The full analysis of how a word form is built from its lemma is known as **morphological analysis**
```
for sentence in doc_de.sentences[:5]:
for word in sentence.words:
print('\t'.join([word.text, word.lemma, word.upos, word.feats if word.feats else '']))
print()
```
A special case of lemmatization is **decompounding**, recognizing multiple lemmas in a word
```
nlp_de('Achterbahn')
nlp_de('Mülleimer')
```
For English you might say that this is good enough... but _some languages_ allow forming compounds on the fly...
```
stanza.download('de')
nlp_de = stanza.Pipeline('de', processors='tokenize,lemma,pos')
nlp_de('Kassenidentifikationsnummer')
```
There is no good generic solution and no standard tool. There are some unsupervised approaches like [SECOS](https://github.com/riedlma/SECOS) and [CharSplit](https://github.com/dtuggener/CharSplit), and there are also full-fledged morphological analyzers that might work, like [SMOR](https://www.cis.lmu.de/~schmid/tools/SMOR/) and its extensions [zmorge](https://pub.cl.uzh.ch/users/sennrich/zmorge/) and [SMORLemma](https://github.com/rsennrich/SMORLemma).
## Examples
### Text processing with regular expressions
Load a sample text
```
text = open('data/alice_de.txt').read()
print(text[:1000])
def clean_text(text):
cleaned_text = re.sub('_','',text)
cleaned_text = re.sub('\n', ' ', cleaned_text)
return cleaned_text
text = clean_text(text)
print(text[:1000])
```
Let's split this into sentences, then words.
```
sens = sent_tokenize(text)
print('\n\n'.join(sens[:5]))
toks = [word_tokenize(sen) for sen in sens]
print('\n\n'.join('\n'.join(sen) for sen in toks[:5]))
```
Let's also write this to a file
```
with open('data/alice_tok_de.txt', 'w') as f:
f.write('\n\n'.join('\n'.join(sen) for sen in toks) + '\n')
```
Let's try to find all names using regexes
```
def find_names(toks):
curr_name = []
for sen in toks:
for tok in sen[1:]:
if re.match('[A-Z][a-z]+', tok):
curr_name.append(tok)
elif curr_name:
yield ' '.join(curr_name)
curr_name = []
if curr_name:
yield curr_name
def count_names(toks):
name_counter = Counter()
for name in find_names(toks):
name_counter[name] += 1
for name, count in name_counter.most_common():
print(name, count)
count_names(toks)
```
We can filter our tokens for stopwords:
```
toks_without_stopwords = [[tok for tok in sen if tok.lower() not in stopwords] for sen in toks]
print('\n\n'.join('\n'.join(sen) for sen in toks_without_stopwords[:5]))
count_names(toks_without_stopwords)
```
Let's also write the stopwords into a file
```
with open('data/stopwords_de.txt', 'w') as f:
f.write('\n'.join(sorted(stopwords)) + '\n')
```
Continue to [Text processing on the Linux command line](https://github.com/tuw-nlp-ie/tuw-nlp-ie-2021WS/blob/main/lectures/01_Text_processing/01b_Text_processing_Linux_command_line.ipynb)
| github_jupyter |
<a href="https://colab.research.google.com/github/kyle-gao/GRSS_TrackMSD2021/blob/main/MakeTilesDeepGlobe.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
"""
Copyright 2021 Yi Lin(Kyle) Gao
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License."""
```
#DeepGlobe Dataset
https://www.kaggle.com/balraj98/deepglobe-land-cover-classification-dataset#__sid=js0
```
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_datasets as tfds
import shutil
from PIL import Image
import os
from google.colab import drive
import PIL
drive.mount('/content/drive')
shutil.unpack_archive("/content/drive/MyDrive/DeepGlobeLandCover.zip.zip",'/content/DeepGlobe')
test_x = tf.keras.preprocessing.image.load_img(
"/content/DeepGlobe/train/100694_sat.jpg", grayscale=False, color_mode='rgb', target_size=None,
interpolation='nearest')
test_x
data_dir = "/content/DeepGlobe/train"
list_ds = tf.data.Dataset.list_files(str(data_dir+"/*.png"),shuffle=False) #DO NOT SHUFFLE
#dataset is made up of strings
def to_categorical(tensor,class_dict):
"""
converts last dimension to categorical according to keys
"""
for k,v in class_dict.items():
tensor[tensor==k]=v
return tensor
```
##Label
Each satellite image is paired with a mask image for land cover annotation. The mask is a RGB image with 7 classes of labels, using color-coding (R, G, B) as follows.
Urban land: 0,255,255 - Man-made, built up areas with human artifacts (can ignore roads for now which is hard to label)
Agriculture land: 255,255,0 - Farms, any planned (i.e. regular) plantation, cropland, orchards, vineyards, nurseries, and ornamental horticultural areas; confined feeding operations.
Rangeland: 255,0,255 - Any non-forest, non-farm, green land, grass
Forest land: 0,255,0 - Any land with x% tree crown density plus clearcuts.
Water: 0,0,255 - Rivers, oceans, lakes, wetland, ponds.
Barren land: 255,255,255 - Mountain, land, rock, dessert, beach, no vegetation
Unknown: 0,0,0 - Clouds and others
File names for satellite images and the corresponding mask image are id _sat.jpg and id _mask.png. id is a randomized integer.
Please note:
The values of the mask image may not be pure 0 and 255. When converting to labels, please binarize them at threshold 128.|
```
size = (512,512)
filenames = list(list_ds)
padding = 'VALID'
def deepglobe_write_tiles(filenames,size=(512,512),padding='VALID',save_dir = "/content/DeepGlobe224/"):
"""
Args-
filenames: tensorflow list_files dataset object
size: tuple of ints
padding=one of "VALID" "SAME"
save_dir-save directory
"""
(h,w) = size
for f in filenames:
fn=tf.strings.split(f,"_")
image_fn = (fn[0]+"_sat.jpg").numpy()
label_fn = (fn[0]+"_mask.png").numpy()
image = tf.keras.preprocessing.image.load_img(image_fn)
image = tf.keras.preprocessing.image.img_to_array(image)
label = tf.keras.preprocessing.image.load_img(label_fn)
label = tf.keras.preprocessing.image.img_to_array(label)
#(H,W,3)
""" - do this step in preprocessing instead since the encoding rescales everything to 255
#binarization
label [label >= 128] = 255
label[label < 128] = 0
labelnew = label[:,:,0]+0.1*label[:,:,1]+0.01*label[:,:,2] #contracts the last dimension without losing class information
class_dict = {(25.5+2.55):0, (255+25.5):1, (255+2.55):2,(25.5):3,2.55:4,(255+25.5+2.55):5,0:6}
labelnew = to_categorical(labelnew,class_dict) #(H,W) """
image = tf.expand_dims(image,axis=0)
image_tiles = tf.image.extract_patches(images=image,
sizes=[1,h, w, 1],
strides=[1,h, w, 1],
rates=[1, 1, 1, 1],
padding=padding)
image_tiles = tf.reshape(image_tiles, [-1,h,w,3])
#label = tf.expand_dims(labelnew,axis=-1)
label = tf.expand_dims(label,axis=0)
label_tiles = tf.image.extract_patches(images=label,
sizes=[1,h, w, 1],
strides=[1,h, w, 1],
rates=[1, 1, 1, 1],
padding=padding)
label_tiles = tf.reshape(label_tiles, [-1,h,w,3])
if not(os.path.isdir(save_dir)):
os.mkdir(save_dir)
for i in range(label_tiles.shape[0]):
imgtile_fn = (save_dir+fn[0].numpy().decode("utf-8").split("/")[-1]+"_"+str(i)+"_sat.jpg")
labeltile_fn = (save_dir+fn[0].numpy().decode("utf-8").split("/")[-1]+"_"+str(i)+"_mask.png")
tf.keras.preprocessing.image.save_img(imgtile_fn,image_tiles[i,:,:,:])
tf.keras.preprocessing.image.save_img(labeltile_fn,label_tiles[i,:,:,:])
print(image_fn)
deepglobe_write_tiles(filenames)
shutil.make_archive("/content/DeepGlobe_512",'zip',"/content/DeepGlobe224")
shutil.copy2("/content/DeepGlobe_512.zip","/content/drive/MyDrive")
```
| github_jupyter |
```
from matplotlib import pyplot as plt
from matplotlib import cm
import pandas as pd
from pprint import pprint
from random import randint, uniform, gauss
import numpy as np
#import matplotlib as mpl
#mpl.rcParams['text.usetex'] = True
#mpl.rcParams['text.latex.unicode'] = True
blues = cm.get_cmap(plt.get_cmap('Blues'))
greens = cm.get_cmap(plt.get_cmap('Greens'))
reds = cm.get_cmap(plt.get_cmap('Reds'))
oranges = cm.get_cmap(plt.get_cmap('Oranges'))
purples = cm.get_cmap(plt.get_cmap('Purples'))
greys = cm.get_cmap(plt.get_cmap('Greys'))
set1 = cm.get_cmap(plt.get_cmap('Set1'))
def tableau20(color):
# Use coordinated colors. These are the "Tableau 20" colors as
# RGB. Each pair is strong/light. For a theory of color
tableau20 = [(31 , 119, 180), (174, 199, 232), # blue [ 0,1 ]
(255, 127, 14 ), (255, 187, 120), # orange [ 2,3 ]
(44 , 160, 44 ), (152, 223, 138), # green [ 4,5 ]
(214, 39 , 40 ), (255, 152, 150), # red [ 6,7 ]
(148, 103, 189), (197, 176, 213), # purple [ 8,9 ]
(140, 86 , 75 ), (196, 156, 148), # brown [10,11]
(227, 119, 194), (247, 182, 210), # pink [12,13]
(188, 189, 34 ), (219, 219, 141), # yellow [14,15]
(23 , 190, 207), (158, 218, 229), # cyan [16,17]
(65 , 68 , 81 ), (96 , 99 , 106), # gray [18,19]
(127, 127, 127), (143, 135, 130), # gray [20,21]
(165, 172, 175), (199, 199, 199), # gray [22,23]
(207, 207, 207)] # gray [24]
# Scale the RGB values to the [0, 1] range, which is the format
# matplotlib accepts.
r, g, b = tableau20[color]
return (round(r/255.,1), round(g/255.,1), round(b/255.,1))
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))
import warnings
warnings.filterwarnings('ignore')
workflows = pd.read_csv('../Data/heterogeneous_campaign.csv')
workflows
print(workflows['num_oper'].mean(), workflows['num_oper'].std())
for i in range(1024,2048):
workflows.loc[len(workflows)] = [None, i + 1, gauss(75000, 6000)]
workflows.to_csv('../Data/heterogeneous_campaign.csv', index=False)
fig, axis = plt.subplots(nrows=1,ncols=1)
fig.set_size_inches(15,7.5)
_ = axis.scatter(range(1,1025), workflows['num_oper'],color=tableau20(0))
_ = axis.set_xticklabels(axis.get_xticks().astype('int').tolist(),fontsize=16)
_ = axis.set_yticklabels((axis.get_yticks()).astype('int').tolist(),fontsize=16)
_ = axis.set_xlabel('Workflow ID', fontsize=16)
_ = axis.set_ylabel('Thousand seconds', fontsize=16)
_ = axis.grid('on')
_ = axis.set_title('Heterogeneous workflow execution time distribution on 1 PetaFlop resource', fontsize=18)
StHeteroCampaigns_4DynHeteroResourcesHEFT_inaccur_90perc = pd.read_csv('../Data/heft/StHeteroCampaigns_4DynHeteroResourcesHEFT_inaccur_90perc2.csv')
StHeteroCampaigns_4DynHeteroResourcesHEFT_inaccur_90perc
test = StHeteroCampaigns_4DynHeteroResourcesHEFT_inaccur_90perc.loc[899]['AccuracyList']
accur = eval(test)
fig, axis = plt.subplots(nrows=1,ncols=1)
fig.set_size_inches(15,7.5)
_ = axis.scatter(range(1,1025), accur,color=tableau20(0))
_ = axis.set_xticklabels(axis.get_xticks().astype('int').tolist(),fontsize=16)
_ = axis.set_yticklabels(np.around(axis.get_yticks().astype('float'),decimals=2).tolist(),fontsize=16)
_ = axis.set_xlabel('Workflow ID', fontsize=16)
_ = axis.set_ylabel('Accuracy level', fontsize=16)
_ = axis.grid('on')
_ = axis.set_title('Heterogeneous workflow accuracy level distribution', fontsize=18)
final_workflows = [x*(1+y) for x,y in zip(workflows['num_oper'], accur)]
fig, axis = plt.subplots(nrows=1,ncols=1)
fig.set_size_inches(15,7.5)
_ = axis.scatter(range(1,1025),final_workflows,color=tableau20(0))
_ = axis.set_xticklabels(axis.get_xticks().astype('int').tolist(),fontsize=16)
_ = axis.set_yticklabels((axis.get_yticks()).astype('int').tolist(),fontsize=16)
_ = axis.set_xlabel('Workflow ID', fontsize=16)
_ = axis.set_ylabel('Thousand seconds', fontsize=16)
_ = axis.grid('on')
_ = axis.set_title('Heterogeneous workflow execution time distribution on 1 PetaFlop resource', fontsize=18)
def get_makespan(curr_plan, dyn_resources, used_resources, workflow_inaccur):
'''
Calculate makespan
'''
inaccur_list = []
resource_usage = [0] * len(dyn_resources)
tmp_idx = [0] * len(dyn_resources)
for placement in curr_plan:
workflow = placement[0]
resource_id = placement[1]['id']
perf = used_resources[resource_id - 1]['performance']
resource_usage[resource_id - 1] += workflow['num_oper'] / perf
#resource_usage[resource_id - 1] += workflow['num_oper'] / \
# dyn_resources[resource_id - 1,
# tmp_idx[resource_id - 1]]
tmp_idx[resource_id - 1] += 1
return max(resource_usage)
resources = [{'id': 1, 'performance': 1.3},
{'id': 2, 'performance': 2.76},
{'id': 3, 'performance': 10.68},
{'id': 4, 'performance': 23.516}]
expected_makespan = get_makespan(eval(StHeteroCampaigns_4DynHeteroResourcesHEFT_inaccur_90perc.loc[899]['plan']),[1,1,1,1],resources,None)
print (expected_makespan, StHeteroCampaigns_4DynHeteroResourcesHEFT_inaccur_90perc.loc[899]['makespan'])
work1=workflows.loc[0]['num_oper']
work2=workflows.loc[1]['num_oper']
work3=workflows.loc[2]['num_oper']
work4=workflows.loc[3]['num_oper']
work5=workflows.loc[4]['num_oper']
dist1=[]
dist2=[]
dist3=[]
dist4=[]
dist5=[]
dist6=[]
for _ in range(100000):
dist1.append(uniform(work1 * .6, work1 * 1.4))
dist2.append(uniform(work2 * .6, work2 * 1.4))
dist3.append(uniform(work3 * .6, work3 * 1.4))
dist4.append(uniform(work4 * .6, work4 * 1.4))
dist5.append(uniform(work4 * .6, work4 * 1.4))
dist6.append(dist1[-1] + dist2[-1] + dist3[-1] + dist4[-1]+dist5[-1])
fig, axis = plt.subplots(nrows=5,ncols=1,figsize=(15,25))
_ = axis[0].hist(dist1, bins=100)
_ = axis[1].hist(dist2, bins=100)
_ = axis[2].hist(dist3, bins=100)
_ = axis[3].hist(dist4, bins=100)
_ = axis[4].hist(dist6, bins=100)
print(np.mean(dist1),np.mean(dist2),np.mean(dist3),np.mean(dist4),np.mean(dist5))
print(work1,work2,work3,work4,work1+work2+work3+work4)
import scipy
size = len(dist6)
chi_square_statistics = list()
dist_names = ['weibull_min','norm','weibull_max','beta',
'invgauss','uniform','gamma','expon',
'lognorm','pearson3','triang']
percentile_bins = np.linspace(0,100,11)
percentile_cutoffs = np.percentile(dist6, percentile_bins)
observed_frequency, bins = (np.histogram(dist6, bins=percentile_cutoffs))
cum_observed_frequency = np.cumsum(observed_frequency)
for distribution in dist_names:
# Set up distribution and get fitted distribution parameters
dist = getattr(scipy.stats, distribution)
param = dist.fit(dist6)
print("{}\n{}\n".format(dist, param))
# Get expected counts in percentile bins
# cdf of fitted sistrinution across bins
cdf_fitted = dist.cdf(percentile_cutoffs, *param)
expected_frequency = []
for bin in range(len(percentile_bins)-1):
expected_cdf_area = cdf_fitted[bin+1] - cdf_fitted[bin]
expected_frequency.append(expected_cdf_area)
# Chi-square Statistics
expected_frequency = np.array(expected_frequency) * size
cum_expected_frequency = np.cumsum(expected_frequency)
ss = sum (((cum_expected_frequency - cum_observed_frequency) ** 2) / cum_observed_frequency)
chi_square_statistics.append(ss)
#Sort by minimum ch-square statistics
results = pd.DataFrame()
results['Distribution'] = dist_names
results['chi_square'] = chi_square_statistics
results.sort_values(['chi_square'], inplace=True)
print ('\nDistributions listed by Betterment of fit:')
print ('............................................')
print (results)
```
| github_jupyter |
Problem 1 - Static Map
For problem 1, I will create a static map of the travel times by car to the Forum shopping center. First of all, I will analyse the data to add georeference and obtain a classification of the travel times.
Data:
1- Travel time data: TravelTimes_to_5975373_Forum.txt.txt (Travel times and distances in the Helsinki Region to Forum shopping centers as text files)
2- Reference grid: MetropAccess_YKR_grid_EurefFIN.shp.
```
# Import modules needed
import numpy as np
import pandas as pd
import geopandas as gpd
from pyproj import CRS
import matplotlib.pyplot as plt
# Read text file into a variable called grid
grid = gpd.read_file('data/MetropAccess_YKR_grid_EurefFIN.shp')
# Check the data
grid
# Read the travel time data file for Forum
data = pd.read_csv('data/TravelTimes_to_5975373_Forum.txt', sep=';')
# Select only needed columns
data = data[['car_r_t', 'from_id', 'to_id']]
# Check the data
data
```
To continue, I first need to georeference. I do so merging the travel-time data to the reference grid.
```
# Join attributes from data to grid
data_geo = grid.merge(data, on=[grid['YKR_ID'], data['from_id']], how="left")
```
It is important to "clean" the dataset and remove all no data values.
```
# Remove no data values
data_geo[data_geo==-1]=np.nan
data_geo.dropna(inplace=True)
```
Now, I classify the travel times into five-minute intervals
1- Create a UserDefined classifier using the pysal/mapclassify library using these class breaks: 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60;
2 - Apply the classifier to car_r_t columns and store the results car_r_t_cl column.
```
import mapclassify
# Create a UserDefines Classifier
bins = [5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60]
classifier = mapclassify.UserDefined.make(bins)
# Classify the data
data_geo['car_r_t_cl'] = data_geo[['car_r_t']].apply(classifier)
# Check the data
data_geo
```
To add a new layer to the map, I read the dataset that holds the shopping centers' locations and I select only the one I need (Forum).
```
# Determine the file path and read the file
fp = 'data/shopping_centers.txt'
data_forum = pd.read_csv(fp, sep=';')
# Import the module
from geopandas.tools import geocode
# Select the specific row
data_forum = data_forum.iloc[1]
# Geocode the address using Nominatim
geo = geocode(data_forum['addr'], provider='nominatim', user_agent='autogis_CM', timeout=10)
# Check the data
geo
```
I now want to add a third layer holding the roads network.
```
# Determine the fie path and read the file
roads_fp = "data/roads.shp"
roads = gpd.read_file(roads_fp)
```
It is important that all layers have the same CRS system, so I check each layer and then reproject all of them to the same CRS
```
# Check the crs of each layer
print(roads.crs)
print(grid.crs)
print(geo.crs)
# Reproject geometries to ETRS89 / TM35FIN based on the grid crs:
roads = roads.to_crs(crs=grid.crs)
geo = geo.to_crs(crs=grid.crs)
```
I can finally plot the data I classified and all other layers:
```
# Control figure size
fig, ax = plt.subplots(figsize=(16,10))
# Visualize the travel times
data_geo.plot(ax=ax, column='car_r_t_cl', linewidth=0.03, cmap="Spectral", scheme='quantiles', k=6, alpha=0.9, legend=True)
# Set a title for the map
plt.title("Forum - Travel time by car")
# Set a title for the legend
ax.get_legend().set_title("Travel times (min)")
# Add roads and shopping center's location on top of the grid
# (use ax parameter to define the map on top of which the second items are plotted)
roads.plot(ax=ax, color="grey", linewidth=1.5)
geo.plot(ax=ax, color="black", linewidth=1.5)
# Remove the empty white-space around the axes
plt.tight_layout()
# Remove the axis labels
plt.axis('off')
# Save the figure in png
outfp = "docs/forum_accessibility.png"
plt.savefig(outfp, dpi=300)
```
[Link to test map](https://autogis-2020.github.io/exercise-5-mulaclel/forum_accessibility.png)
| github_jupyter |
```
# Importing the needed libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# In order to to read the Ciffar data set, we must define the unpickle function: https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz).
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
from google.colab import drive
drive.mount('/content/drive')
# Reading the data
data_1 = unpickle("/content/drive/My Drive/Colab Notebooks/cifar-10-batches-py/data_batch_1")
data_2 = unpickle("/content/drive/My Drive/Colab Notebooks/cifar-10-batches-py/data_batch_2")
data_3 = unpickle("/content/drive/My Drive/Colab Notebooks/cifar-10-batches-py/data_batch_3")
data_4 = unpickle("/content/drive/My Drive/Colab Notebooks/cifar-10-batches-py/data_batch_4")
data_5 = unpickle("/content/drive/My Drive/Colab Notebooks/cifar-10-batches-py/data_batch_5")
test_batch = unpickle("/content/drive/My Drive/Colab Notebooks/cifar-10-batches-py/test_batch")
# For the sake of computational cost, we will work on gray scale images - without feature normalization
data_1[b"data"] = data_1[b"data"].astype(float)[:,0:1024]
data_2[b"data"] = data_2[b"data"].astype(float)[:,0:1024]
data_3[b"data"] = data_3[b"data"].astype(float)[:,0:1024]
data_4[b"data"] = data_4[b"data"].astype(float)[:,0:1024]
data_5[b"data"] = data_5[b"data"].astype(float)[:,0:1024]
test_batch[b"data"] = test_batch[b"data"].astype(float)[:,0:1024]
#Preparing our data set for 5 fold validation. a list of 4 fold training set (training_data_n , training_labels_n)
#and a fold for validation (validation_data_n, validation_labels_n)
training_data_1 = []
training_data_1.append(data_1[b"data"])
training_data_1.append(data_2[b"data"])
training_data_1.append(data_3[b"data"])
training_data_1.append(data_4[b"data"])
training_labels_1 = data_1[b"labels"] + data_2[b"labels"] + data_3[b"labels"] + data_4[b"labels"]
validation_data_1 = data_5[b"data"]
validation_labels_1 = data_5[b"labels"]
training_data_2 = []
training_data_2.append(data_1[b"data"])
training_data_2.append(data_2[b"data"])
training_data_2.append(data_3[b"data"])
training_data_2.append(data_5[b"data"])
training_labels_2 = data_1[b"labels"] + data_2[b"labels"] + data_3[b"labels"] + data_5[b"labels"]
validation_data_2 = data_4[b"data"]
validation_labels_2 = data_4[b"labels"]
training_data_3 = []
training_data_3.append(data_1[b"data"])
training_data_3.append(data_2[b"data"])
training_data_3.append(data_4[b"data"])
training_data_3.append(data_5[b"data"])
training_labels_3 = data_1[b"labels"] + data_2[b"labels"] + data_4[b"labels"] + data_5[b"labels"]
validation_data_3 = data_3[b"data"]
validation_labels_3 = data_3[b"labels"]
training_data_4 = []
training_data_4.append(data_1[b"data"])
training_data_4.append(data_3[b"data"])
training_data_4.append(data_4[b"data"])
training_data_4.append(data_5[b"data"])
training_labels_4 = data_1[b"labels"] + data_3[b"labels"] + data_4[b"labels"] + data_5[b"labels"]
validation_data_4 = data_2[b"data"]
validation_labels_4 = data_2[b"labels"]
training_data_5 = []
training_data_5.append(data_2[b"data"])
training_data_5.append(data_3[b"data"])
training_data_5.append(data_4[b"data"])
training_data_5.append(data_5[b"data"])
training_labels_5 = data_2[b"labels"] + data_3[b"labels"] + data_4[b"labels"] + data_5[b"labels"]
validation_data_5 = data_1[b"data"]
validation_labels_5 = data_1[b"labels"]
#preparing our data set with feature normalization
normalized_data_1 = (data_1[b"data"].astype(float)[:,0:1024] - np.mean(data_1[b"data"].astype(float)[:,0:1024],axis=1)[:,np.newaxis])/(np.std(data_1[b"data"].astype(float)[:,0:1024], axis=1)[:, np.newaxis])
normalized_data_2 = (data_2[b"data"].astype(float)[:,0:1024] - np.mean(data_2[b"data"].astype(float)[:,0:1024],axis=1)[:,np.newaxis])/(np.std(data_2[b"data"].astype(float)[:,0:1024], axis=1)[:, np.newaxis])
normalized_data_3 = (data_3[b"data"].astype(float)[:,0:1024] - np.mean(data_3[b"data"].astype(float)[:,0:1024],axis=1)[:,np.newaxis])/(np.std(data_3[b"data"].astype(float)[:,0:1024], axis=1)[:, np.newaxis])
normalized_data_4 = (data_4[b"data"].astype(float)[:,0:1024] - np.mean(data_4[b"data"].astype(float)[:,0:1024],axis=1)[:,np.newaxis])/(np.std(data_4[b"data"].astype(float)[:,0:1024], axis=1)[:, np.newaxis])
normalized_data_5 = (data_5[b"data"].astype(float)[:,0:1024] - np.mean(data_5[b"data"].astype(float)[:,0:1024],axis=1)[:,np.newaxis])/(np.std(data_5[b"data"].astype(float)[:,0:1024], axis=1)[:, np.newaxis])
normalized_test_batch = (test_batch[b"data"].astype(float)[:,0:1024] - np.mean(test_batch[b"data"].astype(float)[:,0:1024],axis=1)[:,np.newaxis])/(np.std(test_batch[b"data"].astype(float)[:,0:1024], axis=1)[:, np.newaxis])
#Preparing our normalized data set for 5 fold validation. a list of 4 fold training set (normalized_training_data_n , normalized_training_labels_n)
#and a fold for validation (normalized_validation_data_n, normalized_validation_labels_n)
normalized_training_data_1 = []
normalized_training_data_1.append(normalized_data_1)
normalized_training_data_1.append(normalized_data_2)
normalized_training_data_1.append(normalized_data_3)
normalized_training_data_1.append(normalized_data_4)
training_labels_1 = data_1[b"labels"] + data_2[b"labels"] + data_3[b"labels"] + data_4[b"labels"]
normalized_validation_data_1 = normalized_data_5
validation_labels_1 = data_5[b"labels"]
normalized_training_data_2 = []
normalized_training_data_2.append(normalized_data_1)
normalized_training_data_2.append(normalized_data_2)
normalized_training_data_2.append(normalized_data_3)
normalized_training_data_2.append(normalized_data_5)
training_labels_2 = data_1[b"labels"] + data_2[b"labels"] + data_3[b"labels"] + data_5[b"labels"]
normalized_validation_data_2 = normalized_data_4
validation_labels_2 = data_4[b"labels"]
normalized_training_data_3 = []
normalized_training_data_3.append(normalized_data_1)
normalized_training_data_3.append(normalized_data_2)
normalized_training_data_3.append(normalized_data_4)
normalized_training_data_3.append(normalized_data_5)
training_labels_3 = data_1[b"labels"] + data_2[b"labels"] + data_4[b"labels"] + data_5[b"labels"]
normalized_validation_data_3 = normalized_data_3
validation_labels_3 = data_3[b"labels"]
normalized_training_data_4 = []
normalized_training_data_4.append(normalized_data_1)
normalized_training_data_4.append(normalized_data_3)
normalized_training_data_4.append(normalized_data_4)
normalized_training_data_4.append(normalized_data_5)
training_labels_4 = data_1[b"labels"] + data_3[b"labels"] + data_4[b"labels"] + data_5[b"labels"]
normalized_validation_data_4 = normalized_data_2
validation_labels_4 = data_2[b"labels"]
normalized_training_data_5 = []
normalized_training_data_5.append(normalized_data_2)
normalized_training_data_5.append(normalized_data_3)
normalized_training_data_5.append(normalized_data_4)
normalized_training_data_5.append(normalized_data_5)
training_labels_5 = data_2[b"labels"] + data_3[b"labels"] + data_4[b"labels"] + data_5[b"labels"]
normalized_validation_data_5 = normalized_data_1
validation_labels_5 = data_1[b"labels"]
#DistanceCalculation function --> inputs: training data as a list of 4 training_data or 4 normalized_training data, and validation_data or normalized_validation_data
#Output: a matrix that includes the distance of every validation image from each of the training image
# as a distance formula, i have used the formula which is described in the "No-loop implementation" part of the https://ljvmiranda921.github.io/notebook/2017/02/09/k-nearest-neighbors/
def DistanceCalculation(training_data, validation_data):
matrices = []
sumsquared_validation = np.diagonal(np.dot(validation_data, validation_data.T)) #b^2
for i in training_data:
sumsquared_training = np.diagonal(np.dot(i, i.T))[:, np.newaxis] #a^2
matrices.append(np.sqrt(sumsquared_training + sumsquared_validation - 2 * i.dot(validation_data.T))) # a^2 + b^2 -2*a*b
distances = np.concatenate((matrices[0],matrices[1],matrices[2],matrices[3]),axis=0)
return distances
#KNN function --> input: a distances matrix (a number of images in the training data * a number of images in the validation or test data set)
#output: the accuracy
def KNN(distances,training_lables, validation_labels,k):
#finding the indices of k smallest distances
sorted_distances_indices = np.argsort(distances, axis=0)
Ksmallest_distances_indices = sorted_distances_indices[0:k, ]
#Finding the labels of K smallest distances using their indices
Ksmallest_labels = np.zeros((k,10000))
for i in range(0,10000):
for j in range(0,k):
Ksmallest_labels[j,i] = Ksmallest_labels[j,i] + training_lables[Ksmallest_distances_indices[j,i]]
#predicted label: most frequent label in k smallest distances'label
#argmax(array, axis = None, out = None) : Returns indices of the max element of the array in a particular axis
#bincount: Count number of occurrences of each value in array of non-negative ints.
predicted_labels = []
for i in range(0,10000):
a = Ksmallest_labels[:,i].astype(int)
predicted_labels.append(np.bincount(a).argmax())
#comparing our result and calculating accuracy
a = 0
for i in range(0,10000):
if predicted_labels[i] == validation_labels[i]:
a = a + 1
accuracy = a/10000
return (accuracy)
distance_1 = DistanceCalculation(training_data_1, validation_data_1)
#finding the accuracy for k between 1 and 20 - data set: first set of folds wihtout feature normalization
Acc_1 = []
for i in range(1,21):
print(i)
Acc_1.append(KNN(distances = distance_1,training_lables = training_labels_1, validation_labels = validation_labels_1,k=i))
print(Acc_1)
#finding the accuracy for k between 1 and 20 - data set: first set of folds wiht feature normalization
normdistances_1 = DistanceCalculation(normalized_training_data_1, normalized_validation_data_1)
normalized_Acc_1 = []
for i in range(1,21):
print(i)
normalized_Acc_1.append(KNN(distances = normdistances_1,training_lables = training_labels_1, validation_labels = validation_labels_1,k=i))
print(normalized_Acc_1)
#finding the accuracy for k between 1 and 20 - data set: second set of folds wihtout feature normalization
distances_2 = DistanceCalculation(training_data_2,validation_data_2)
Acc_2 = []
for i in range(1,21):
print(i)
Acc_2.append(KNN(distances_2, training_labels_2, validation_labels_2, i))
print(Acc_2)
#finding the accuracy for k between 1 and 20 - data set: second set of folds wiht feature normalization
normdistances_2 = DistanceCalculation(normalized_training_data_2,normalized_validation_data_2)
normalized_Acc_2 = []
for i in range(1,21):
print(i)
normalized_Acc_2.append(KNN(normdistances_2, training_labels_2, validation_labels_2, i))
print(normalized_Acc_2)
#finding the accuracy for k between 1 and 20 - data set: third set of folds wihtout feature normalization
distances_3 = DistanceCalculation(training_data_3,validation_data_3)
Acc_3 = []
for i in range(1,21):
print(i)
Acc_3.append(KNN(distances_3, training_labels_3, validation_labels_3, i))
print(Acc_3)
#finding the accuracy for k between 1 and 20 - data set: third set of folds with feature normalization
normdistances_3 = DistanceCalculation(normalized_training_data_3,normalized_validation_data_3)
normalized_Acc_3 = []
for i in range(1,21):
print(i)
normalized_Acc_3.append(KNN(normdistances_3, training_labels_3, validation_labels_3, i))
print(normalized_Acc_3)
#finding the accuracy for k between 1 and 20 - data set: fourth set of folds without feature normalization
distances_4 = DistanceCalculation(training_data_4,validation_data_4)
Acc_4 = []
for i in range(1,21):
print(i)
Acc_4.append(KNN(distances_4, training_labels_4, validation_labels_4, i))
print(Acc_4)
#finding the accuracy for k between 1 and 20 - data set: fourth set of folds with feature normalization
normdistances_4 = DistanceCalculation(normalized_training_data_4,normalized_validation_data_4)
normalized_Acc_4 = []
for i in range(1,21):
print(i)
normalized_Acc_4.append(KNN(normdistances_4, training_labels_4, validation_labels_4, i))
print(normalized_Acc_4)
#finding the accuracy for k between 1 and 20 - data set: fifth set of folds without feature normalization
distances_5 = DistanceCalculation(training_data_5,validation_data_5)
Acc_5 = []
for i in range(1,21):
print(i)
Acc_5.append(KNN(distances_5, training_labels_5, validation_labels_5, i))
print(Acc_5)
#finding the accuracy for k between 1 and 20 - data set: fifth set of folds with feature normalization
normdistances_5 = DistanceCalculation(normalized_training_data_5,normalized_validation_data_5)
normalized_Acc_5 = []
for i in range(1,21):
print(i)
normalized_Acc_5.append(KNN(normdistances_5, training_labels_5, validation_labels_5, i))
print(normalized_Acc_5)
#now the proper k has been selected: proper K without feature normalization = 1, proper K with feature normalization = 14
#preparing our data for the test phase without feature normalization
training_data_final = []
training_data_final.append(data_1[b"data"])
training_data_final.append(data_2[b"data"])
training_data_final.append(data_3[b"data"])
training_data_final.append(data_4[b"data"])
training_data_final.append(data_5[b"data"])
training_labels_final = data_1[b"labels"] + data_2[b"labels"] + data_3[b"labels"] + data_4[b"labels"] + data_5[b"labels"]
test_data = test_batch[b"data"]
test_labels = test_batch[b"data"]
#preparing our data for the test phase with feature normalization
normalized_training_data_final = []
normalized_training_data_final.append(normalized_data_1)
normalized_training_data_final.append(normalized_data_2)
normalized_training_data_final.append(normalized_data_3)
normalized_training_data_final.append(normalized_data_4)
normalized_training_data_final.append(normalized_data_5)
training_labels_final = data_1[b"labels"] + data_2[b"labels"] + data_3[b"labels"] + data_4[b"labels"] + data_5[b"labels"]
normalized_test_data = normalized_test_batch
test_labels = test_batch[b"labels"]
distances_test = DistanceCalculation(training_data_final,test_data)
#Calculating the accuracy, the training and test data set have not been normalized
Acc_test = KNN(distances_test, training_labels_final, test_labels, 1)
print(Acc_test)
normalized_distance_test = DistanceCalculation(normalized_training_data_final,normalized_test_data)
#Calculating the accuracy, both of the training and test data set have been normalized
Acc_test_normalized = KNN(normalized_distance_test, training_labels_final, test_labels, 13)
print(Acc_test_normalized)
normalized_distance_test_noramal_test_data = DistanceCalculation(normalized_training_data_final,test_data)
#Calculating the accuracy, just the training set has been normalized
Acc_test_normalized_regular_test_data = KNN(normalized_distance_test_noramal_test_data, training_labels_final, test_labels, 13)
print(Acc_test_normalized_regular_test_data)
##we can see that we have reached the same accuracy for Acc_test_normalized_regular_test_data and Acc_test_normalized which make sense,
print("Hello world")
```
| github_jupyter |
# Autoencoder
---
# Tutorial Objectives
## Architecture

```
# @title Video 1: Extensions
from IPython.display import YouTubeVideo
video = YouTubeVideo(id="pgkrU9UqXiU", width=854, height=480, fs=1)
print("Video available at https://youtube.com/watch?v=" + video.id)
video
```
---
# Setup
Please execute the cell(s) below to initialize the notebook environment.
```
# Imports
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch import nn, optim
# @title Figure settings
#!pip install plotly --quiet
import plotly.graph_objects as go
from plotly.colors import qualitative
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/nma.mplstyle")
# @title Helper functions
def downloadMNIST():
"""
Download MNIST dataset and transform it to torch.Tensor
Args:
None
Returns:
x_train : training images (torch.Tensor) (60000, 28, 28)
x_test : test images (torch.Tensor) (10000, 28, 28)
y_train : training labels (torch.Tensor) (60000, )
y_train : test labels (torch.Tensor) (10000, )
"""
X, y = fetch_openml('mnist_784', version=1, return_X_y=True)
# Trunk the data
n_train = 60000
n_test = 10000
train_idx = np.arange(0, n_train)
test_idx = np.arange(n_train, n_train + n_test)
x_train, y_train = X[train_idx], y[train_idx]
x_test, y_test = X[test_idx], y[test_idx]
# Transform np.ndarrays to torch.Tensor
x_train = torch.from_numpy(np.reshape(x_train,
(len(x_train),
28, 28)).astype(np.float32))
x_test = torch.from_numpy(np.reshape(x_test,
(len(x_test),
28, 28)).astype(np.float32))
y_train = torch.from_numpy(y_train.astype(int))
y_test = torch.from_numpy(y_test.astype(int))
return (x_train, y_train, x_test, y_test)
def init_weights_kaiming_uniform(layer):
"""
Initializes weights from linear PyTorch layer
with kaiming uniform distribution.
Args:
layer (torch.Module)
Pytorch layer
Returns:
Nothing.
"""
# check for linear PyTorch layer
if isinstance(layer, nn.Linear):
# initialize weights with kaiming uniform distribution
nn.init.kaiming_uniform_(layer.weight.data)
def init_weights_kaiming_normal(layer):
"""
Initializes weights from linear PyTorch layer
with kaiming normal distribution.
Args:
layer (torch.Module)
Pytorch layer
Returns:nossa
Nothing.
"""
# check for linear PyTorch layer
if isinstance(layer, nn.Linear):
# initialize weights with kaiming normal distribution
nn.init.kaiming_normal_(layer.weight.data)
def get_layer_weights(layer):
"""
Retrieves learnable parameters from PyTorch layer.
Args:
layer (torch.Module)
Pytorch layer
Returns:
list with learnable parameters
"""
# initialize ounossatput list
weights = []
# check whether layer has learnable parameters
if layer.parameters():
# copy numpy array representation of each set of learnable parameters
for item in layer.parameters():
weights.append(item.detach().numpy())
return weights
def print_parameter_count(net):
"""
Prints count of learnable parameters per layer from PyTorch network.
Args:
net (torch.Sequential)
Pytorch network
Returns:
Nothing.
"""
params_n = 0
# loop all layers in network
for layer_idx, layer in enumerate(net):
# retrieve learnable parameters
weights = get_layer_weights(layer)
params_layer_n = 0
# loop list of learnable parameters and count them
for params in weights:
params_layer_n += params.size
params_n += params_layer_n
print(f'{layer_idx}\t {params_layer_n}\t {layer}')
print(f'\nTotal:\t {params_n}')
def eval_mse(y_pred, y_true):
"""
Evaluates mean square error (MSE) between y_pred and y_true
Args:
y_pred (torch.Tensor)
prediction samples
v (numpy array of floats)
ground truth samples
Returns:
MSE(y_pred, y_true)
"""
with torch.no_grad():
criterion = nn.MSELoss()
loss = criterion(y_pred, y_true)
return float(loss)
def eval_bce(y_pred, y_true):
"""
Evaluates binary cross-entropy (BCE) between y_pred and y_true
Args:
y_pred (torch.Tensor)
prediction samples
v (numpy array of floats)
ground truth samples
Returns:
BCE(y_pred, y_true)
"""
with torch.no_grad():
criterion = nn.BCELoss()
loss = criterion(y_pred, y_true)
return float(loss)
def plot_row(images, show_n=10, image_shape=None):
"""
Plots rows of images from list of iterables (iterables: list, numpy array
or torch.Tensor). Also accepts single iterable.
Randomly selects images in each list element if item count > show_n.
Args:
images (iterable or list of iterables)
single iterable with images, or list of iterables
show_n (integer)
maximum number of images per row
image_shape (tuple or list)
original shape of image if vectorized form
Returns:
Nothing.
"""
if not isinstance(images, (list, tuple)):
images = [images]
for items_idx, items in enumerate(images):
items = np.array(items)
if items.ndim == 1:
items = np.expand_dims(items, axis=0)
if len(items) > show_n:
selected = np.random.choice(len(items), show_n, replace=False)
items = items[selected]
if image_shape is not None:
items = items.reshape([-1]+list(image_shape))
plt.figure(figsize=(len(items) * 1.5, 2))
for image_idx, image in enumerate(items):
plt.subplot(1, len(items), image_idx + 1)
plt.imshow(image, cmap='gray', vmin=image.min(), vmax=image.max())
plt.axis('off')
plt.tight_layout()
def to_s2(u):
"""
Projects 3D coordinates to spherical coordinates (theta, phi) surface of
unit sphere S2.
theta: [0, pi]
phi: [-pi, pi]
Args:
u (list, numpy array or torch.Tensor of floats)
3D coordinates
Returns:
Sperical coordinates (theta, phi) on surface of unit sphere S2.
"""
x, y, z = (u[:, 0], u[:, 1], u[:, 2])
r = np.sqrt(x**2 + y**2 + z**2)
theta = np.arccos(z / r)
phi = np.arctan2(x, y)
return np.array([theta, phi]).T
def to_u3(s):
"""
Converts from 2D coordinates on surface of unit sphere S2 to 3D coordinates
(on surface of S2), i.e. (theta, phi) ---> (1, theta, phi).
Args:
s (list, numpy array or torch.Tensor of floats)
2D coordinates on unit sphere S_2
Returns:
3D coordinates on surface of unit sphere S_2
"""
theta, phi = (s[:, 0], s[:, 1])
x = np.sin(theta) * np.sin(phi)
y = np.sin(theta) * np.cos(phi)
z = np.cos(theta)
return np.array([x, y, z]).T
def xy_lim(x):
"""
Return arguments for plt.xlim and plt.ylim calculated from minimum
and maximum of x.
Args:
x (list, numpy array or torch.Tensor of floats)
data to be plotted
Returns:
Nothing.
"""
x_min = np.min(x, axis=0)
x_max = np.max(x, axis=0)
x_min = x_min - np.abs(x_max - x_min) * 0.05 - np.finfo(float).eps
x_max = x_max + np.abs(x_max - x_min) * 0.05 + np.finfo(float).eps
return [x_min[0], x_max[0]], [x_min[1], x_max[1]]
def plot_generative(x, decoder_fn, image_shape, n_row=16, s2=False):
"""
Plots images reconstructed by decoder_fn from a 2D grid in
latent space that is determined by minimum and maximum values in x.
Args:
x (list, numpy array or torch.Tensor of floats)
2D or 3D coordinates in latent space
decoder_fn (integer)
function returning vectorized images from 2D latent space coordinates
image_shape (tuple or list)
original shape of image
n_row (integer)
number of rows in grid
s2 (boolean)
convert 3D coordinates (x, y, z) to spherical coordinates (theta, phi)
Returns:
Nothing.
"""
if s2:
x = to_s2(np.array(x))
xlim, ylim = xy_lim(np.array(x))
dx = (xlim[1] - xlim[0]) / n_row
grid = [np.linspace(ylim[0] + dx / 2, ylim[1] - dx / 2, n_row),
np.linspace(xlim[0] + dx / 2, xlim[1] - dx / 2, n_row)]
canvas = np.zeros((image_shape[0] * n_row, image_shape[1] * n_row))
cmap = plt.get_cmap('gray')
for j, latent_y in enumerate(grid[0][::-1]):
for i, latent_x in enumerate(grid[1]):
latent = np.array([[latent_x, latent_y]], dtype=np.float32)
if s2:
latent = to_u3(latent)
with torch.no_grad():
x_decoded = decoder_fn(torch.from_numpy(latent))
x_decoded = x_decoded.reshape(image_shape)
canvas[j * image_shape[0]: (j + 1) * image_shape[0],
i * image_shape[1]: (i + 1) * image_shape[1]] = x_decoded
plt.imshow(canvas, cmap=cmap, vmin=canvas.min(), vmax=canvas.max())
plt.axis('off')
def plot_latent(x, y, show_n=500, s2=False, fontdict=None, xy_labels=None):
"""
Plots digit class of each sample in 2D latent space coordinates.
Args:
x (list, numpy array or torch.Tensor of floats)
2D coordinates in latent space
y (list, numpy array or torch.Tensor of floats)
digit class of each sample
n_row (integer)
number of samples
s2 (boolean)
convert 3D coordinates (x, y, z) to spherical coordinates (theta, phi)
fontdict (dictionary)
style option for plt.text
xy_labels (list)
optional list with [xlabel, ylabel]
Returns:
Nothing.
"""
if fontdict is None:
fontdict = {'weight': 'bold', 'size': 12}
if s2:
x = to_s2(np.array(x))
cmap = plt.get_cmap('tab10')
if len(x) > show_n:
selected = np.random.choice(len(x), show_n, replace=False)
x = x[selected]
y = y[selected]
for my_x, my_y in zip(x, y):
plt.text(my_x[0], my_x[1], str(int(my_y)),
color=cmap(int(my_y) / 10.),
fontdict=fontdict,
horizontalalignment='center',
verticalalignment='center',
alpha=0.8)
xlim, ylim = xy_lim(np.array(x))
plt.xlim(xlim)
plt.ylim(ylim)
if s2:
if xy_labels is None:
xy_labels = [r'$\varphi$', r'$\theta$']
plt.xticks(np.arange(0, np.pi + np.pi / 6, np.pi / 6),
['0', '$\pi/6$', '$\pi/3$', '$\pi/2$',
'$2\pi/3$', '$5\pi/6$', '$\pi$'])
plt.yticks(np.arange(-np.pi, np.pi + np.pi / 3, np.pi / 3),
['$-\pi$', '$-2\pi/3$', '$-\pi/3$', '0',
'$\pi/3$', '$2\pi/3$', '$\pi$'])
if xy_labels is None:
xy_labels = ['$Z_1$', '$Z_2$']
plt.xlabel(xy_labels[0])
plt.ylabel(xy_labels[1])
def plot_latent_generative(x, y, decoder_fn, image_shape, s2=False,
title=None, xy_labels=None):
"""
Two horizontal subplots generated with encoder map and decoder grid.
Args:
x (list, numpy array or torch.Tensor of floats)
2D coordinates in latent space
y (list, numpy array or torch.Tensor of floats)
digit class of each sample
decoder_fn (integer)
function returning vectorized images from 2D latent space coordinates
image_shape (tuple or list)
original shape of image
s2 (boolean)
convert 3D coordinates (x, y, z) to spherical coordinates (theta, phi)
title (string)
plot title
xy_labels (list)
optional list with [xlabel, ylabel]
Returns:
Nothing.
"""
fig = plt.figure(figsize=(12, 6))
if title is not None:
fig.suptitle(title, y=1.05)
ax = fig.add_subplot(121)
ax.set_title('Encoder map', y=1.05)
plot_latent(x, y, s2=s2, xy_labels=xy_labels)
ax = fig.add_subplot(122)
ax.set_title('Decoder grid', y=1.05)
plot_generative(x, decoder_fn, image_shape, s2=s2)
plt.tight_layout()
plt.show()
def plot_latent_3d(my_x, my_y, show_text=True, show_n=500):
"""
Plot digit class or marker in 3D latent space coordinates.
Args:
my_x (list, numpy array or torch.Tensor of floats)
2D coordinates in latent space
my_y (list, numpy array or torch.Tensor of floats)
digit class of each sample
show_text (boolean)
whether to show text
image_shape (tuple or list)
original shape of image
s2 (boolean)
convert 3D coordinates (x, y, z) to spherical coordinates (theta, phi)
title (string)
plot title
Returns:
Nothing.
"""
layout = {'margin': {'l': 0, 'r': 0, 'b': 0, 't': 0},
'scene': {'xaxis': {'showspikes': False,
'title': 'z1'},
'yaxis': {'showspikes': False,
'title': 'z2'},
'zaxis': {'showspikes': False,
'title': 'z3'}}
}
selected_idx = np.random.choice(len(my_x), show_n, replace=False)
colors = [qualitative.T10[idx] for idx in my_y[selected_idx]]
x = my_x[selected_idx, 0]
y = my_x[selected_idx, 1]
z = my_x[selected_idx, 2]
text = my_y[selected_idx]
if show_text:
trace = go.Scatter3d(x=x, y=y, z=z, text=text,
mode='text',
textfont={'color': colors, 'size': 12}
)
layout['hovermode'] = False
else:
trace = go.Scatter3d(x=x, y=y, z=z, text=text,
hoverinfo='text', mode='markers',
marker={'size': 5, 'color': colors, 'opacity': 0.8}
)
fig = go.Figure(data=trace, layout=layout)
fig.show()
def runSGD(net, input_train, input_test, criterion='bce',
n_epochs=10, batch_size=32, verbose=False):
"""
Trains autoencoder network with stochastic gradient descent with Adam
optimizer and loss criterion. Train samples are shuffled, and loss is
displayed at the end of each opoch for both MSE and BCE. Plots training loss
at each minibatch (maximum of 500 randomly selected values).
Args:
net (torch network)
ANN object (nn.Module)
input_train (torch.Tensor)
vectorized input images from train set
input_test (torch.Tensor)
vectorized input images from test set
criterion (string)
train loss: 'bce' or 'mse'
n_epochs (boolean)
number of full iterations of training data
batch_size (integer)
number of element in mini-batches
verbose (boolean)
print final loss
Returns:
Nothing.
"""
# Initialize loss function
if criterion == 'mse':
loss_fn = nn.MSELoss()
elif criterion == 'bce':
loss_fn = nn.BCELoss()
else:
print('Please specify either "mse" or "bce" for loss criterion')
# Initialize SGD optimizer
optimizer = optim.Adam(net.parameters())
# Placeholder for loss
track_loss = []
print('Epoch', '\t', 'Loss train', '\t', 'Loss test')
for i in range(n_epochs):
shuffle_idx = np.random.permutation(len(input_train))
batches = torch.split(input_train[shuffle_idx], batch_size)
for batch in batches:
output_train = net(batch)
loss = loss_fn(output_train, batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Keep track of loss at each epoch
track_loss += [float(loss)]
loss_epoch = f'{i+1}/{n_epochs}'
with torch.no_grad():
output_train = net(input_train)
loss_train = loss_fn(output_train, input_train)
loss_epoch += f'\t {loss_train:.4f}'
output_test = net(input_test)
loss_test = loss_fn(output_test, input_test)
loss_epoch += f'\t\t {loss_test:.4f}'
print(loss_epoch)
if verbose:
# Print loss
loss_mse = f'\nMSE\t {eval_mse(output_train, input_train):0.4f}'
loss_mse += f'\t\t {eval_mse(output_test, input_test):0.4f}'
print(loss_mse)
loss_bce = f'BCE\t {eval_bce(output_train, input_train):0.4f}'
loss_bce += f'\t\t {eval_bce(output_test, input_test):0.4f}'
print(loss_bce)
# Plot loss
step = int(np.ceil(len(track_loss) / 500))
x_range = np.arange(0, len(track_loss), step)
plt.figure()
plt.plot(x_range, track_loss[::step], 'C0')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.xlim([0, None])
plt.ylim([0, None])
plt.show()
class NormalizeLayer(nn.Module):
"""
pyTorch layer (nn.Module) that normalizes activations by their L2 norm.
Args:
None.
Returns:
Object inherited from nn.Module class.
"""
def __init__(self):
super().__init__()
def forward(self, x):
return nn.functional.normalize(x, p=2, dim=1)
```
---
# Section 1: Download and prepare MNIST dataset
We use the helper function `downloadMNIST` to download the dataset and transform it into `torch.Tensor` and assign train and test sets to (`x_train`, `y_train`) and (`x_test`, `y_test`).
The variable `input_size` stores the length of *vectorized* versions of the images `input_train` and `input_test` for training and test images.
**Instructions:**
* Please execute the cell below
```
# Download MNIST
x_train, y_train, x_test, y_test = downloadMNIST()
x_train = x_train / 255
x_test = x_test / 255
image_shape = x_train.shape[1:]
input_size = np.prod(image_shape)
input_train = x_train.reshape([-1, input_size])
input_test = x_test.reshape([-1, input_size])
test_selected_idx = np.random.choice(len(x_test), 10, replace=False)
train_selected_idx = np.random.choice(len(x_train), 10, replace=False)
print(f'shape image \t \t {image_shape}')
print(f'shape input_train \t {input_train.shape}')
print(f'shape input_test \t {input_test.shape}')
import sys
sys.path.append("../src/data/")
from file import read_file
import more_itertools as mit
PATH_AUD = '../data/raw/aud'
PATH_VIS = '../data/raw/vis'
PATH_INFO = '../data/raw/info_'
data_aud, data_vis, CHANNEL_NAMES = read_file(PATH_AUD, PATH_VIS)
aud = np.concatenate(data_aud.transpose([1,3,0,2]),0)
np.concatenate(data_aud.transpose([1,3,0,2]),0).shape
aud_32 = np.array(list(mit.windowed(aud, n=32)))
#.astype(np.float64)
por_canal = [torch.from_numpy(aud_.astype(np.float32)) for aud_ in aud_32.T]
240*539*20, 64 -> (240*539*20)-31, 32, 64
[(240*539*20)-31, 32], 64
(240*539*20)-31
```
---
# Section 2: Deeper autoencoder (2D)
The internal representation of shallow autoencoder with 2D latent space is similar to PCA, which shows that the autoencoder is not fully leveraging non-linear capabilities to model data. Adding capacity in terms of learnable parameters takes advantage of non-linear operations in encoding/decoding to capture non-linear patterns in data.
Adding hidden layers enables us to introduce additional parameters, either layerwise or depthwise. The same amount $N$ of additional parameters can be added in a single layer or distributed among several layers. Adding several hidden layers reduces the compression/decompression ratio of each layer.
## Exercise 1: Build deeper autoencoder (2D)
Implement this deeper version of the ANN autoencoder by adding four hidden layers. The number of units per layer in the encoder is the following:
```
784 -> 392 -> 64 -> 2
```
The shallow autoencoder has a compression ratio of **784:2 = 392:1**. The first additional hidden layer has a compression ratio of **2:1**, followed by a hidden layer that sets the bottleneck compression ratio of **32:1**.
The choice of hidden layer size aims to reduce the compression rate in the bottleneck layer while increasing the count of trainable parameters. For example, if the compression rate of the first hidden layer doubles from **2:1** to **4:1**, the count of trainable parameters halves from 667K to 333K.
This deep autoencoder's performance may be further improved by adding additional hidden layers and by increasing the count of trainable parameters in each layer. These improvements have a diminishing return due to challenges associated with training under high parameter count and depth. One option explored in the *Bonus* section is to add a first hidden layer with 2x - 3x the input size. This size increase results in millions of parameters at the cost of longer training time.
Weight initialization is particularly important in deep networks. The availability of large datasets and weight initialization likely drove the deep learning revolution of 2010. We'll implement Kaiming normal as follows:
```
model[:-2].apply(init_weights_kaiming_normal)
```
**Instructions:**
* Add four additional layers and activation functions to the network
* Adjust the definitions of `encoder` and `decoder`
* Check learnable parameter count for this autoencoder by executing the last cell
```
encoding_size = 2#[2,4,8,16]
input_size = 32
model_32 = nn.Sequential(
nn.Linear(input_size, int(input_size / 2)), #32
# Add activation function
nn.PReLU(),
# Add another layer
nn.Linear(int(input_size / 2), int(input_size / 4)),#16
# Add activation function
nn.PReLU(),
# Add another layer
nn.Linear(int(input_size / 4), int(input_size / 8)),#8
# Add activation function
nn.PReLU(),
# Add another layer
nn.Linear(int(input_size / 8), encoding_size), #4
# Add activation function
nn.PReLU(),
# Add another layer
nn.Linear(encoding_size, int(input_size / 8)), #2
# Add activation function
nn.PReLU(),
# Add another layer
nn.Linear(int(input_size / 8), int(input_size / 4)),#8
# Add activation function
nn.PReLU(),
# Add another layer
nn.Linear(int(input_size / 4), int(input_size / 2)),#16
# Add activation function
nn.PReLU(),
# Add another layeré´
nn.Linear(int(input_size / 2), input_size),#32
# Add another layer
nn.Sigmoid()
)
model_32[:-2].apply(init_weights_kaiming_normal)
print(f'Autoencoder \n\n {model_32}\n')
```
**Helper function:** `print_parameter_count`
Please uncomment the line below to inspect this function.
```
print_parameter_count(model_32)
```
## Train the autoencoder
Train the network for `n_epochs=10` epochs with `batch_size=128`, and observe how the internal representation successfully captures additional digit classes.
The encoder map shows well-separated clusters that correspond to the associated digits in the decoder grid. The decoder grid also shows that the network is robust to digit skewness, i.e., digits leaning to the left or the right are recognized in the same digit class.
**Instructions:**
* Please execute the cells below
```
n_epochs = 10
batch_size = 128
runSGD(model_32, por_canal[0], por_canal[0], n_epochs=n_epochs,
batch_size=batch_size)
with torch.no_grad():
output_test = model(input_test)
latent_test = encoder(input_test)
plot_row([input_test[test_selected_idx], output_test[test_selected_idx]],
image_shape=image_shape)
plot_latent_generative(latent_test, y_test, decoder, image_shape=image_shape)
```
---
# Section 3: Spherical latent space
The previous architecture generates representations that typically spread in different directions from coordinate $(z_1, z_2)=(0,0)$. This effect is due to the initialization of weights distributed randomly around `0`.
Adding a third unit to the bottleneck layer defines a coordinate $(z_1, z_2, z_3)$ in 3D space. The latent space from such a network will still spread out from $(z_1, z_2, z_3)=(0, 0, 0)$.
Collapsing the latent space on the surface of a sphere removes the possibility of spreading indefinitely from the origin $(0, 0, 0)$ in any direction since this will eventually lead back to the origin. This constraint generates a representation that fills the surface of the sphere.

Projecting to the surface of the sphere is implemented by dividing the coordinates $(z_1, z_2, z_3)$ by their $L_2$ norm.
$(z_1, z_2, z_3)\longmapsto (s_1, s_2, s_3)=(z_1, z_2, z_3)/\|(z_1, z_2, z_3)\|_2=(z_1, z_2, z_3)/ \sqrt{z_1^2+z_2^2+z_3^2}$
This mapping projects to the surface of the [$S_2$ sphere](https://en.wikipedia.org/wiki/N-sphere) with unit radius. (Why?)
## Section 3.1: Build and train autoencoder (3D)
We start by adding one unit to the bottleneck layer and visualize the latent space in 3D.
Please execute the cell below.
```
encoding_size = 3
model = nn.Sequential(
nn.Linear(input_size, int(input_size / 2)),
nn.PReLU(),
nn.Linear(int(input_size / 2), encoding_size * 32),
nn.PReLU(),
nn.Linear(encoding_size * 32, encoding_size),
nn.PReLU(),
nn.Linear(encoding_size, encoding_size * 32),
nn.PReLU(),
nn.Linear(encoding_size * 32, int(input_size / 2)),
nn.PReLU(),
nn.Linear(int(input_size / 2), input_size),
nn.Sigmoid()
)
model[:-2].apply(init_weights_kaiming_normal)
encoder = model[:6]
decoder = model[6:]
print(f'Autoencoder \n\n {model}')
```
## Section 3.2: Train the autoencoder
Train the network for `n_epochs=10` epochs with `batch_size=128`. Observe how the internal representation spreads from the origin and reaches much lower loss due to the additional degree of freedom in the bottleneck layer.
**Instructions:**
* Please execute the cell below
```
n_epochs = 10
batch_size = 128
runSGD(model, input_train, input_test, n_epochs=n_epochs,
batch_size=batch_size)
```
## Section 3.3: Visualize the latent space in 3D
**Helper function**: `plot_latent_3d`
Please uncomment the line below to inspect this function.
```
# help(plot_latent_3d)
with torch.no_grad():
latent_test = encoder(input_test)
plot_latent_3d(latent_test, y_test)
```
### Exercise 2: Build deep autoencoder (2D) with latent spherical space
We now constrain the latent space to the surface of a sphere $S_2$.
**Instructions:**
* Add the custom layer `NormalizeLayer` after the bottleneck layer
* Adjust the definitions of `encoder` and `decoder`
* Experiment with keyword `show_text=False` for `plot_latent_3d`
**Helper function**: `NormalizeLayer`
Please uncomment the line below to inspect this function.
```
# help(NormalizeLayer)
encoding_size = 3
model = nn.Sequential(
nn.Linear(input_size, int(input_size / 2)),
nn.PReLU(),
nn.Linear(int(input_size / 2), encoding_size * 32),
nn.PReLU(),
nn.Linear(encoding_size * 32, encoding_size),
nn.PReLU(),
#################################################
## TODO for students: add custom normalize layer
#################################################
# add the normalization layer
# ...,
nn.Linear(encoding_size, encoding_size * 32),
nn.PReLU(),
nn.Linear(encoding_size * 32, int(input_size / 2)),
nn.PReLU(),
nn.Linear(int(input_size / 2), input_size),
nn.Sigmoid()
)
model[:-2].apply(init_weights_kaiming_normal)
print(f'Autoencoder \n\n {model}\n')
# Adjust the value n_l to split your model correctly
# n_l = ...
# uncomment when you fill the code
# encoder = model[:n_l]
# decoder = model[n_l:]
# print(f'Encoder \n\n {encoder}\n')
# print(f'Decoder \n\n {decoder}')
# to_remove solution
encoding_size = 3
model = nn.Sequential(
nn.Linear(input_size, int(input_size / 2)),
nn.PReLU(),
nn.Linear(int(input_size / 2), encoding_size * 32),
nn.PReLU(),
nn.Linear(encoding_size * 32, encoding_size),
nn.PReLU(),
# add the normalization layer
NormalizeLayer(),
nn.Linear(encoding_size, encoding_size * 32),
nn.PReLU(),
nn.Linear(encoding_size * 32, int(input_size / 2)),
nn.PReLU(),
nn.Linear(int(input_size / 2), input_size),
nn.Sigmoid()
)
model[:-2].apply(init_weights_kaiming_normal)
print(f'Autoencoder \n\n {model}\n')
# Adjust the value n_l to split your model correctly
n_l = 7
# uncomment when you fill the code
encoder = model[:n_l]
decoder = model[n_l:]
print(f'Encoder \n\n {encoder}\n')
print(f'Decoder \n\n {decoder}')
```
## Section 3.4: Train the autoencoder
Train the network for `n_epochs=10` epochs with `batch_size=128` and observe how loss raises again and is comparable to the model with 2D latent space.
**Instructions:**
* Please execute the cell below
```
n_epochs = 10
batch_size = 128
runSGD(model, input_train, input_test, n_epochs=n_epochs,
batch_size=batch_size)
with torch.no_grad():
latent_test = encoder(input_test)
plot_latent_3d(latent_test, y_test)
```
## Section 3.5: Visualize latent space on surface of $S_2$
The 3D coordinates $(s_1, s_2, s_3)$ on the surface of the unit sphere $S_2$ can be mapped to [spherical coordinates](https://en.wikipedia.org/wiki/Spherical_coordinate_system) $(r, \theta, \phi)$, as follows:
$$
\begin{aligned}
r &= \sqrt{s_1^2 + s_2^2 + s_3^2} \\
\phi &= \arctan \frac{s_2}{s_1} \\
\theta &= \arccos\frac{s_3}{r}
\end{aligned}
$$

What is the domain (numerical range) spanned by ($\theta, \phi)$?
We return to a 2D representation since the angles $(\theta, \phi)$ are the only degrees of freedom on the surface of the sphere. Add the keyword `s2=True` to `plot_latent_generative` to un-wrap the sphere's surface similar to a world map.
Task: Check the numerical range of the plot axis to help identify $\theta$ and $\phi$, and visualize the unfolding of the 3D plot from the previous exercise.
**Instructions:**
* Please execute the cells below
```
with torch.no_grad():
output_test = model(input_test)
plot_row([input_test[test_selected_idx], output_test[test_selected_idx]],
image_shape=image_shape)
plot_latent_generative(latent_test, y_test, decoder,
image_shape=image_shape, s2=True)
```
---
# Summary
We learned two techniques to improve representation capacity: adding a few hidden layers and projecting latent space on the sphere $S_2$.
The expressive power of autoencoder improves with additional hidden layers. Projecting latent space on the surface of $S_2$ spreads out digits classes in a more visually pleasing way but may not always produce a lower loss.
**Deep autoencoder architectures have rich internal representations to deal with sophisticated tasks such as the MNIST cognitive task.**
We now have powerful tools to explore how simple algorithms build robust models of the world by capturing relevant data patterns.
```
# @title Video 2: Wrap-up
from IPython.display import YouTubeVideo
video = YouTubeVideo(id="GnkmzCqEK3E", width=854, height=480, fs=1)
print("Video available at https://youtube.com/watch?v=" + video.id)
video
```
---
# Bonus
## Deep and thick autoencoder
In this exercise, we first expand the first hidden layer to double the input size, followed by compression to half the input size leading to 3.8M parameters. Please **do not train this network during tutorial** due to long training time.
**Instructions:**
* Please uncomment and execute the cells below
```
# encoding_size = 3
# model = nn.Sequential(
# nn.Linear(input_size, int(input_size * 2)),
# nn.PReLU(),
# nn.Linear(int(input_size * 2), int(input_size / 2)),
# nn.PReLU(),
# nn.Linear(int(input_size / 2), encoding_size * 32),
# nn.PReLU(),
# nn.Linear(encoding_size * 32, encoding_size),
# nn.PReLU(),
# NormalizeLayer(),
# nn.Linear(encoding_size, encoding_size * 32),
# nn.PReLU(),
# nn.Linear(encoding_size * 32, int(input_size / 2)),
# nn.PReLU(),
# nn.Linear(int(input_size / 2), int(input_size * 2)),
# nn.PReLU(),
# nn.Linear(int(input_size * 2), input_size),
# nn.Sigmoid()
# )
# model[:-2].apply(init_weights_kaiming_normal)
# encoder = model[:9]
# decoder = model[9:]
# print_parameter_count(model)
# n_epochs = 5
# batch_size = 128
# runSGD(model, input_train, input_test, n_epochs=n_epochs,
# batch_size=batch_size)
# Visualization
# with torch.no_grad():
# output_test = model(input_test)
# plot_row([input_test[test_selected_idx], output_test[test_selected_idx]],
# image_shape=image_shape)
# plot_latent_generative(latent_test, y_test, decoder,
# image_shape=image_shape, s2=True)
```
| github_jupyter |
# <b> 423_liulim_Final Project_Fall 2019</b>
#### <i>-- Handwritten Text Recognition</i>
```
## Mount Google Drive to use the file in Google Drive
from google.colab import drive
drive.mount('/content/drive')
## Imports Modules
from __future__ import division
import numpy as np
import os
import glob
from PIL import Image
from random import *
from keras.utils import to_categorical
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
%matplotlib inline
## Import keras to create nerual network
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Lambda, ELU, Activation, BatchNormalization
from keras.layers.convolutional import Convolution2D, Cropping2D, ZeroPadding2D, MaxPooling2D
from keras.optimizers import SGD, Adam, RMSprop
## Create a mapping for all writers
## Create a dictionary with image form and writer mapping
d = {}
with open('/content/drive/My Drive/forms_for_parsing.txt') as f:
content = f.readlines()
for line in content:
key = line.split(' ')[0]
writer = line.split(' ')[1]
d[key] = writer
content[0]
# Create array of image names and corresponding target writer names
tmp = []
target_list = []
path_to_files = os.path.join('/content/drive/My Drive/data_subset', '*')
for filename in sorted(glob.glob(path_to_files)):
tmp.append(filename)
image_name = filename.split('/')[-1]
file, ext = os.path.splitext(image_name)
parts = file.split('-')
form = parts[0] + '-' + parts[1]
for key in d:
if key == form:
target_list.append(str(d[form]))
img_files = np.asarray(tmp)
img_targets = np.asarray(target_list)
# Test to show visualization of the first 10 image in gray color map
for filename in img_files[:10]:
img=mpimg.imread(filename)
plt.figure(figsize=(10,10))
plt.imshow(img, cmap ='gray')
# Encode
encoder = LabelEncoder()
encoder.fit(img_targets)
encoded_Y = encoder.transform(img_targets)
print(img_files[:10], img_targets[:10], encoded_Y[:10])
## Import the sklearn module
from sklearn.model_selection import train_test_split
## Split the original dataset to train, test and validation by 4:1:1
train_files, rem_files, train_targets, rem_targets = train_test_split(
img_files, encoded_Y, train_size=0.66, random_state=52, shuffle= True)
validation_files, test_files, validation_targets, test_targets = train_test_split(
rem_files, rem_targets, train_size=0.5, random_state=22, shuffle=True)
print(train_files.shape, validation_files.shape, test_files.shape)
print(train_targets.shape, validation_targets.shape, test_targets.shape)
batch_size = 16
num_classes = 50
## Create a funtion for generate data
def generate_data(samples, target_files, batch_size=batch_size, factor = 0.1 ):
num_samples = len(samples)
from sklearn.utils import shuffle
while 1: # While loop so the look will never end
for offset in range(0, num_samples, batch_size):
batch_samples = samples[offset:offset+batch_size]
batch_targets = target_files[offset:offset+batch_size]
images = []
targets = []
## Resize
for i in range(len(batch_samples)):
batch_sample = batch_samples[i]
batch_target = batch_targets[i]
im = Image.open(batch_sample)
cur_width = im.size[0]
cur_height = im.size[1]
# print(cur_width, cur_height)
height_fac = 113 / cur_height
new_width = int(cur_width * height_fac)
size = new_width, 113
imresize = im.resize((size), Image.ANTIALIAS) # Resize so height = 113 while keeping aspect ratio
now_width = imresize.size[0]
now_height = imresize.size[1]
# Generate crops of size 113x113 from this resized image and keep random 10% of crops
avail_x_points = list(range(0, now_width - 113 )) # total x start points are from 0 to width -113
# Pick random x%
pick_num = int(len(avail_x_points)*factor)
random_startx = sample(avail_x_points, pick_num)
for start in random_startx:
imcrop = imresize.crop((start, 0, start+113, 113))
images.append(np.asarray(imcrop))
targets.append(batch_target)
X_train = np.array(images)
y_train = np.array(targets)
## Reshape X_train for feeding in later
X_train = X_train.reshape(X_train.shape[0], 113, 113, 1)
## Convert to float and normalize
X_train = X_train.astype('float32')
X_train /= 255
## Convert y to one hot vector
y_train = to_categorical(y_train, num_classes)
yield shuffle(X_train, y_train)
# Generate data for training, testing and validation
train_generator = generate_data(train_files, train_targets, batch_size=batch_size, factor = 0.3)
validation_generator = generate_data(validation_files, validation_targets, batch_size=batch_size, factor = 0.3)
test_generator = generate_data(test_files, test_targets, batch_size=batch_size, factor = 0.1)
## Build a neural network in Keras
## Resize image to 56x56
def resize_image(image):
import tensorflow as tf
return tf.image.resize_images(image,[56,56])
row, col, ch = 113, 113, 1
## Create the model by Sequential and add input shape
model = Sequential()
model.add(ZeroPadding2D((1, 1), input_shape=(row, col, ch)))
## Resise data within the neural network for easy interpretation
model.add(Lambda(resize_image))
## CNN model
model.add(Convolution2D(filters= 32, kernel_size =(5,5), strides= (2,2), padding='same', name='conv1')) #96
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2), name='pool1'))
model.add(Convolution2D(filters= 64, kernel_size =(3,3), strides= (1,1), padding='same', name='conv2')) #256
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2), name='pool2'))
model.add(Convolution2D(filters= 128, kernel_size =(3,3), strides= (1,1), padding='same', name='conv3')) #256
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2), name='pool3'))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(512, name='dense1')) #1024
# model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256, name='dense2')) #1024
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes,name='output'))
model.add(Activation('softmax')) #softmax since output is within 50 classes
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
#model.save_weights('low_loss.hdf5')
print(model.summary())
## Train the model
nb_epoch = 5
samples_per_epoch = 3268
nb_val_samples = 842
## save every checkpoint
from keras.callbacks import ModelCheckpoint
filepath="/content/drive/My Drive/checkpoint2/check-{epoch:02d}-{val_loss:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath= filepath, verbose=1, save_best_only=False)
callbacks_list = [checkpoint]
## Fitting Model
history_object = model.fit_generator(train_generator, samples_per_epoch= samples_per_epoch,
validation_data=validation_generator,
nb_val_samples=nb_val_samples, nb_epoch=nb_epoch, verbose=1, callbacks=callbacks_list)
## Prediction on test set
# model.load_weights('low_loss.hdf5')
train_scores = model.evaluate_generator(train_generator, 842)
test_scores = model.evaluate_generator(test_generator, 842)
val_scores = model.evaluate_generator(validation_generator, 842)
print("Accuracy = ", test_scores[1])
images = []
for filename in test_files[:50]:
im = Image.open(filename)
cur_width = im.size[0]
cur_height = im.size[1]
# print(cur_width, cur_height)
height_fac = 113 / cur_height
new_width = int(cur_width * height_fac)
size = new_width, 113
imresize = im.resize((size), Image.ANTIALIAS) # Resize so height = 113 while keeping aspect ratio
now_width = imresize.size[0]
now_height = imresize.size[1]
# Generate crops of size 113x113 from this resized image and keep random 10% of crops
avail_x_points = list(range(0, now_width - 113 ))# total x start points are from 0 to width -113
# Pick random x%
factor = 0.1
pick_num = int(len(avail_x_points)*factor)
random_startx = sample(avail_x_points, pick_num)
for start in random_startx:
imcrop = imresize.crop((start, 0, start+113, 113))
images.append(np.asarray(imcrop))
X_test = np.array(images)
X_test = X_test.reshape(X_test.shape[0], 113, 113, 1)
#convert to float and normalize
X_test = X_test.astype('float32')
X_test /= 255
shuffle(X_test)
print(X_test.shape)
predictions = model.predict(X_test, verbose =1)
print(predictions.shape)
predicted_writer = []
for pred in predictions:
predicted_writer.append(np.argmax(pred))
print(len(predicted_writer))
writer_number = 10
total_images =10
counter = 0
for i in range(len(predicted_writer)//10):
if predicted_writer[i] == writer_number:
image = X_test[i].squeeze()
plt.figure(figsize=(2,2))
plt.imshow(image, cmap ='gray')
## too many images, runtime result collaposed
```
## Other Models
```
def resize_image(image):
import tensorflow as tf
return tf.image.resize_images(image,[56,56])
row, col, ch = 113, 113, 1
model1 = Sequential()
model1.add(ZeroPadding2D((1, 1), input_shape=(row, col, ch)))
model1.add(Lambda(resize_image))
# CNN model
model1.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model1.add(BatchNormalization())
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Dropout(0.3))
model1.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model1.add(BatchNormalization())
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Dropout(0.3))
model1.add(Convolution2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model1.add(BatchNormalization())
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Dropout(0.3))
model1.add(Convolution2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model1.add(BatchNormalization())
model1.add(MaxPooling2D(pool_size=(2, 2) , dim_ordering="th"))
model1.add(Flatten())
model1.add(Dropout(0.3))
model1.add(Dense(36, name='digit1', activation='softmax'))
model1.add(Dense(36, name='digit2', activation='softmax'))
model1.add(Dense(36, name='digit3', activation='softmax'))
model1.add(Dense(36, name='digit4', activation='softmax'))
model1.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
print(model1.summary())
def resize_image(image):
import tensorflow as tf
return tf.image.resize_images(image,[56,56])
row, col, ch = 113, 113, 1
model3 = Sequential()
model3.add(ZeroPadding2D((1, 1), input_shape=(row, col, ch)))
model3.add(Lambda(resize_image))
# CNN model
model3.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model3.add(BatchNormalization())
model3.add(MaxPooling2D(pool_size=(2, 2)))
model3.add(Dropout(0.3))
model3.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model3.add(BatchNormalization())
model3.add(MaxPooling2D(pool_size=(2, 2)))
model3.add(Dropout(0.3))
model3.add(BatchNormalization())
model3.add(MaxPooling2D(pool_size=(2, 2)))
model3.add(Dropout(0.3))
model3.add(Convolution2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model3.add(BatchNormalization())
model3.add(MaxPooling2D(pool_size=(2, 2) , dim_ordering="th"))
model3.add(Flatten())
model3.add(Dropout(0.3))
model3.add(Dense(1024, activation='relu'))
model3.add(Dropout(0.3))
model3.add(Dense(512, activation='relu'))
model3.add(Dropout(0.3))
model3.add(Dense(36, name='digit1', activation='softmax'))
model3.add(Dense(36, name='digit2', activation='softmax'))
model3.add(Dense(36, name='digit3', activation='softmax'))
model3.add(Dense(36, name='digit4', activation='softmax'))
model3.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model3.summary()
```
| github_jupyter |
```
# -*- coding: utf-8 -*-
"""
EVCのためのEV-GMMを構築します. そして, 適応学習する.
詳細 : https://pdfs.semanticscholar.org/cbfe/71798ded05fb8bf8674580aabf534c4dbb8bc.pdf
This program make EV-GMM for EVC. Then, it make adaptation learning.
Check detail : https://pdfs.semanticscholar.org/cbfe/71798ded05fb8bf8674580abf534c4dbb8bc.pdf
"""
from __future__ import division, print_function
import os
from shutil import rmtree
import argparse
import glob
import pickle
import time
import numpy as np
from numpy.linalg import norm
from sklearn.decomposition import PCA
from sklearn.mixture import GMM # sklearn 0.20.0から使えない
from sklearn.preprocessing import StandardScaler
import scipy.signal
import scipy.sparse
%matplotlib inline
import matplotlib.pyplot as plt
import IPython
from IPython.display import Audio
import soundfile as sf
import wave
import pyworld as pw
import librosa.display
from dtw import dtw
import warnings
warnings.filterwarnings('ignore')
"""
Parameters
__Mixtured : GMM混合数
__versions : 実験セット
__convert_source : 変換元話者のパス
__convert_target : 変換先話者のパス
"""
# parameters
__Mixtured = 40
__versions = 'pre-stored0.1.3'
__convert_source = 'input/EJM10/V01/T01/TIMIT/000/*.wav'
__convert_target = 'adaptation/EJM05/V01/T01/ATR503/A/*.wav'
# settings
__same_path = './utterance/' + __versions + '/'
__output_path = __same_path + 'output/EJM05/' # EJF01, EJF07, EJM04, EJM05
Mixtured = __Mixtured
pre_stored_pickle = __same_path + __versions + '.pickle'
pre_stored_source_list = __same_path + 'pre-source/**/V01/T01/**/*.wav'
pre_stored_list = __same_path + "pre/**/V01/T01/**/*.wav"
#pre_stored_target_list = "" (not yet)
pre_stored_gmm_init_pickle = __same_path + __versions + '_init-gmm.pickle'
pre_stored_sv_npy = __same_path + __versions + '_sv.npy'
save_for_evgmm_covarXX = __output_path + __versions + '_covarXX.npy'
save_for_evgmm_covarYX = __output_path + __versions + '_covarYX.npy'
save_for_evgmm_fitted_source = __output_path + __versions + '_fitted_source.npy'
save_for_evgmm_fitted_target = __output_path + __versions + '_fitted_target.npy'
save_for_evgmm_weights = __output_path + __versions + '_weights.npy'
save_for_evgmm_source_means = __output_path + __versions + '_source_means.npy'
for_convert_source = __same_path + __convert_source
for_convert_target = __same_path + __convert_target
converted_voice_npy = __output_path + 'sp_converted_' + __versions
converted_voice_wav = __output_path + 'sp_converted_' + __versions
mfcc_save_fig_png = __output_path + 'mfcc3dim_' + __versions
f0_save_fig_png = __output_path + 'f0_converted' + __versions
converted_voice_with_f0_wav = __output_path + 'sp_f0_converted' + __versions
EPSILON = 1e-8
class MFCC:
"""
MFCC() : メル周波数ケプストラム係数(MFCC)を求めたり、MFCCからスペクトルに変換したりするクラス.
動的特徴量(delta)が実装途中.
ref : http://aidiary.hatenablog.com/entry/20120225/1330179868
"""
def __init__(self, frequency, nfft=1026, dimension=24, channels=24):
"""
各種パラメータのセット
nfft : FFTのサンプル点数
frequency : サンプリング周波数
dimension : MFCC次元数
channles : メルフィルタバンクのチャンネル数(dimensionに依存)
fscale : 周波数スケール軸
filterbankl, fcenters : フィルタバンク行列, フィルタバンクの頂点(?)
"""
self.nfft = nfft
self.frequency = frequency
self.dimension = dimension
self.channels = channels
self.fscale = np.fft.fftfreq(self.nfft, d = 1.0 / self.frequency)[: int(self.nfft / 2)]
self.filterbank, self.fcenters = self.melFilterBank()
def hz2mel(self, f):
"""
周波数からメル周波数に変換
"""
return 1127.01048 * np.log(f / 700.0 + 1.0)
def mel2hz(self, m):
"""
メル周波数から周波数に変換
"""
return 700.0 * (np.exp(m / 1127.01048) - 1.0)
def melFilterBank(self):
"""
メルフィルタバンクを生成する
"""
fmax = self.frequency / 2
melmax = self.hz2mel(fmax)
nmax = int(self.nfft / 2)
df = self.frequency / self.nfft
dmel = melmax / (self.channels + 1)
melcenters = np.arange(1, self.channels + 1) * dmel
fcenters = self.mel2hz(melcenters)
indexcenter = np.round(fcenters / df)
indexstart = np.hstack(([0], indexcenter[0:self.channels - 1]))
indexstop = np.hstack((indexcenter[1:self.channels], [nmax]))
filterbank = np.zeros((self.channels, nmax))
for c in np.arange(0, self.channels):
increment = 1.0 / (indexcenter[c] - indexstart[c])
# np,int_ は np.arangeが[0. 1. 2. ..]となるのをintにする
for i in np.int_(np.arange(indexstart[c], indexcenter[c])):
filterbank[c, i] = (i - indexstart[c]) * increment
decrement = 1.0 / (indexstop[c] - indexcenter[c])
# np,int_ は np.arangeが[0. 1. 2. ..]となるのをintにする
for i in np.int_(np.arange(indexcenter[c], indexstop[c])):
filterbank[c, i] = 1.0 - ((i - indexcenter[c]) * decrement)
return filterbank, fcenters
def mfcc(self, spectrum):
"""
スペクトルからMFCCを求める.
"""
mspec = []
mspec = np.log10(np.dot(spectrum, self.filterbank.T))
mspec = np.array(mspec)
return scipy.fftpack.realtransforms.dct(mspec, type=2, norm="ortho", axis=-1)
def delta(self, mfcc):
"""
MFCCから動的特徴量を求める.
現在は,求める特徴量フレームtをt-1とt+1の平均としている.
"""
mfcc = np.concatenate([
[mfcc[0]],
mfcc,
[mfcc[-1]]
]) # 最初のフレームを最初に、最後のフレームを最後に付け足す
delta = None
for i in range(1, mfcc.shape[0] - 1):
slope = (mfcc[i+1] - mfcc[i-1]) / 2
if delta is None:
delta = slope
else:
delta = np.vstack([delta, slope])
return delta
def imfcc(self, mfcc, spectrogram):
"""
MFCCからスペクトルを求める.
"""
im_sp = np.array([])
for i in range(mfcc.shape[0]):
mfcc_s = np.hstack([mfcc[i], [0] * (self.channels - self.dimension)])
mspectrum = scipy.fftpack.idct(mfcc_s, norm='ortho')
# splrep はスプライン補間のための補間関数を求める
tck = scipy.interpolate.splrep(self.fcenters, np.power(10, mspectrum))
# splev は指定座標での補間値を求める
im_spectrogram = scipy.interpolate.splev(self.fscale, tck)
im_sp = np.concatenate((im_sp, im_spectrogram), axis=0)
return im_sp.reshape(spectrogram.shape)
def trim_zeros_frames(x, eps=1e-7):
"""
無音区間を取り除く.
"""
T, D = x.shape
s = np.sum(np.abs(x), axis=1)
s[s < 1e-7] = 0.
return x[s > eps]
def analyse_by_world_with_harverst(x, fs):
"""
WORLD音声分析合成器で基本周波数F0,スペクトル包絡,非周期成分を求める.
基本周波数F0についてはharvest法により,より精度良く求める.
"""
# 4 Harvest with F0 refinement (using Stonemask)
frame_period = 5
_f0_h, t_h = pw.harvest(x, fs, frame_period=frame_period)
f0_h = pw.stonemask(x, _f0_h, t_h, fs)
sp_h = pw.cheaptrick(x, f0_h, t_h, fs)
ap_h = pw.d4c(x, f0_h, t_h, fs)
return f0_h, sp_h, ap_h
def wavread(file):
"""
wavファイルから音声トラックとサンプリング周波数を抽出する.
"""
wf = wave.open(file, "r")
fs = wf.getframerate()
x = wf.readframes(wf.getnframes())
x = np.frombuffer(x, dtype= "int16") / 32768.0
wf.close()
return x, float(fs)
def preEmphasis(signal, p=0.97):
"""
MFCC抽出のための高域強調フィルタ.
波形を通すことで,高域成分が強調される.
"""
return scipy.signal.lfilter([1.0, -p], 1, signal)
def alignment(source, target, path):
"""
タイムアライメントを取る.
target音声をsource音声の長さに合うように調整する.
"""
# ここでは814に合わせよう(targetに合わせる)
# p_p = 0 if source.shape[0] > target.shape[0] else 1
#shapes = source.shape if source.shape[0] > target.shape[0] else target.shape
shapes = source.shape
align = np.array([])
for (i, p) in enumerate(path[0]):
if i != 0:
if j != p:
temp = np.array(target[path[1][i]])
align = np.concatenate((align, temp), axis=0)
else:
temp = np.array(target[path[1][i]])
align = np.concatenate((align, temp), axis=0)
j = p
return align.reshape(shapes)
"""
pre-stored学習のためのパラレル学習データを作る。
時間がかかるため、利用できるlearn-data.pickleがある場合はそれを利用する。
それがない場合は一から作り直す。
"""
timer_start = time.time()
if os.path.exists(pre_stored_pickle):
print("exist, ", pre_stored_pickle)
with open(pre_stored_pickle, mode='rb') as f:
total_data = pickle.load(f)
print("open, ", pre_stored_pickle)
print("Load pre-stored time = ", time.time() - timer_start , "[sec]")
else:
source_mfcc = []
#source_data_sets = []
for name in sorted(glob.iglob(pre_stored_source_list, recursive=True)):
print(name)
x, fs = sf.read(name)
f0, sp, ap = analyse_by_world_with_harverst(x, fs)
mfcc = MFCC(fs)
source_mfcc_temp = mfcc.mfcc(sp)
#source_data = np.hstack([source_mfcc_temp, mfcc.delta(source_mfcc_temp)]) # static & dynamic featuers
source_mfcc.append(source_mfcc_temp)
#source_data_sets.append(source_data)
total_data = []
i = 0
_s_len = len(source_mfcc)
for name in sorted(glob.iglob(pre_stored_list, recursive=True)):
print(name, len(total_data))
x, fs = sf.read(name)
f0, sp, ap = analyse_by_world_with_harverst(x, fs)
mfcc = MFCC(fs)
target_mfcc = mfcc.mfcc(sp)
dist, cost, acc, path = dtw(source_mfcc[i%_s_len], target_mfcc, dist=lambda x, y: norm(x - y, ord=1))
#print('Normalized distance between the two sounds:' + str(dist))
#print("target_mfcc = {0}".format(target_mfcc.shape))
aligned = alignment(source_mfcc[i%_s_len], target_mfcc, path)
#target_data_sets = np.hstack([aligned, mfcc.delta(aligned)]) # static & dynamic features
#learn_data = np.hstack((source_data_sets[i], target_data_sets))
learn_data = np.hstack([source_mfcc[i%_s_len], aligned])
total_data.append(learn_data)
i += 1
with open(pre_stored_pickle, 'wb') as output:
pickle.dump(total_data, output)
print("Make, ", pre_stored_pickle)
print("Make pre-stored time = ", time.time() - timer_start , "[sec]")
"""
全事前学習出力話者からラムダを推定する.
ラムダは適応学習で変容する.
"""
S = len(total_data)
D = int(total_data[0].shape[1] / 2)
print("total_data[0].shape = ", total_data[0].shape)
print("S = ", S)
print("D = ", D)
timer_start = time.time()
if os.path.exists(pre_stored_gmm_init_pickle):
print("exist, ", pre_stored_gmm_init_pickle)
with open(pre_stored_gmm_init_pickle, mode='rb') as f:
initial_gmm = pickle.load(f)
print("open, ", pre_stored_gmm_init_pickle)
print("Load initial_gmm time = ", time.time() - timer_start , "[sec]")
else:
initial_gmm = GMM(n_components = Mixtured, covariance_type = 'full')
initial_gmm.fit(np.vstack(total_data))
with open(pre_stored_gmm_init_pickle, 'wb') as output:
pickle.dump(initial_gmm, output)
print("Make, ", initial_gmm)
print("Make initial_gmm time = ", time.time() - timer_start , "[sec]")
weights = initial_gmm.weights_
source_means = initial_gmm.means_[:, :D]
target_means = initial_gmm.means_[:, D:]
covarXX = initial_gmm.covars_[:, :D, :D]
covarXY = initial_gmm.covars_[:, :D, D:]
covarYX = initial_gmm.covars_[:, D:, :D]
covarYY = initial_gmm.covars_[:, D:, D:]
fitted_source = source_means
fitted_target = target_means
"""
SVはGMMスーパーベクトルで、各pre-stored学習における出力話者について平均ベクトルを推定する。
GMMの学習を見てみる必要があるか?
"""
timer_start = time.time()
if os.path.exists(pre_stored_sv_npy):
print("exist, ", pre_stored_sv_npy)
sv = np.load(pre_stored_sv_npy)
print("open, ", pre_stored_sv_npy)
print("Load pre_stored_sv time = ", time.time() - timer_start , "[sec]")
else:
sv = []
for i in range(S):
gmm = GMM(n_components = Mixtured, params = 'm', init_params = '', covariance_type = 'full')
gmm.weights_ = initial_gmm.weights_
gmm.means_ = initial_gmm.means_
gmm.covars_ = initial_gmm.covars_
gmm.fit(total_data[i])
sv.append(gmm.means_)
sv = np.array(sv)
np.save(pre_stored_sv_npy, sv)
print("Make pre_stored_sv time = ", time.time() - timer_start , "[sec]")
"""
各事前学習出力話者のGMM平均ベクトルに対して主成分分析(PCA)を行う.
PCAで求めた固有値と固有ベクトルからeigenvectorsとbiasvectorsを作る.
"""
timer_start = time.time()
#source_pca
source_n_component, source_n_features = sv[:, :, :D].reshape(S, Mixtured*D).shape
# 標準化(分散を1、平均を0にする)
source_stdsc = StandardScaler()
# 共分散行列を求める
source_X_std = source_stdsc.fit_transform(sv[:, :, :D].reshape(S, Mixtured*D))
# PCAを行う
source_cov = source_X_std.T @ source_X_std / (source_n_component - 1)
source_W, source_V_pca = np.linalg.eig(source_cov)
print(source_W.shape)
print(source_V_pca.shape)
# データを主成分の空間に変換する
source_X_pca = source_X_std @ source_V_pca
print(source_X_pca.shape)
#target_pca
target_n_component, target_n_features = sv[:, :, D:].reshape(S, Mixtured*D).shape
# 標準化(分散を1、平均を0にする)
target_stdsc = StandardScaler()
#共分散行列を求める
target_X_std = target_stdsc.fit_transform(sv[:, :, D:].reshape(S, Mixtured*D))
#PCAを行う
target_cov = target_X_std.T @ target_X_std / (target_n_component - 1)
target_W, target_V_pca = np.linalg.eig(target_cov)
print(target_W.shape)
print(target_V_pca.shape)
# データを主成分の空間に変換する
target_X_pca = target_X_std @ target_V_pca
print(target_X_pca.shape)
eigenvectors = source_X_pca.reshape((Mixtured, D, S)), target_X_pca.reshape((Mixtured, D, S))
source_bias = np.mean(sv[:, :, :D], axis=0)
target_bias = np.mean(sv[:, :, D:], axis=0)
biasvectors = source_bias.reshape((Mixtured, D)), target_bias.reshape((Mixtured, D))
print("Do PCA time = ", time.time() - timer_start , "[sec]")
"""
声質変換に用いる変換元音声と目標音声を読み込む.
"""
timer_start = time.time()
source_mfcc_for_convert = []
source_sp_for_convert = []
source_f0_for_convert = []
source_ap_for_convert = []
fs_source = None
for name in sorted(glob.iglob(for_convert_source, recursive=True)):
print("source = ", name)
x_source, fs_source = sf.read(name)
f0_source, sp_source, ap_source = analyse_by_world_with_harverst(x_source, fs_source)
mfcc_source = MFCC(fs_source)
#mfcc_s_tmp = mfcc_s.mfcc(sp)
#source_mfcc_for_convert = np.hstack([mfcc_s_tmp, mfcc_s.delta(mfcc_s_tmp)])
source_mfcc_for_convert.append(mfcc_source.mfcc(sp_source))
source_sp_for_convert.append(sp_source)
source_f0_for_convert.append(f0_source)
source_ap_for_convert.append(ap_source)
target_mfcc_for_fit = []
target_f0_for_fit = []
target_ap_for_fit = []
for name in sorted(glob.iglob(for_convert_target, recursive=True)):
print("target = ", name)
x_target, fs_target = sf.read(name)
f0_target, sp_target, ap_target = analyse_by_world_with_harverst(x_target, fs_target)
mfcc_target = MFCC(fs_target)
#mfcc_target_tmp = mfcc_target.mfcc(sp_target)
#target_mfcc_for_fit = np.hstack([mfcc_t_tmp, mfcc_t.delta(mfcc_t_tmp)])
target_mfcc_for_fit.append(mfcc_target.mfcc(sp_target))
target_f0_for_fit.append(f0_target)
target_ap_for_fit.append(ap_target)
# 全部numpy.arrrayにしておく
source_data_mfcc = np.array(source_mfcc_for_convert)
source_data_sp = np.array(source_sp_for_convert)
source_data_f0 = np.array(source_f0_for_convert)
source_data_ap = np.array(source_ap_for_convert)
target_mfcc = np.array(target_mfcc_for_fit)
target_f0 = np.array(target_f0_for_fit)
target_ap = np.array(target_ap_for_fit)
print("Load Input and Target Voice time = ", time.time() - timer_start , "[sec]")
"""
適応話者学習を行う.
つまり,事前学習出力話者から目標話者の空間を作りだす.
適応話者文数ごとにfitted_targetを集めるのは未実装.
"""
timer_start = time.time()
epoch=1000
py = GMM(n_components = Mixtured, covariance_type = 'full')
py.weights_ = weights
py.means_ = target_means
py.covars_ = covarYY
fitted_target = None
for i in range(len(target_mfcc)):
print("adaptation = ", i+1, "/", len(target_mfcc))
target = target_mfcc[i]
for x in range(epoch):
print("epoch = ", x)
predict = py.predict_proba(np.atleast_2d(target))
y = np.sum([predict[:, i: i + 1] * (target - biasvectors[1][i])
for i in range(Mixtured)], axis = 1)
gamma = np.sum(predict, axis = 0)
left = np.sum([gamma[i] * np.dot(eigenvectors[1][i].T,
np.linalg.solve(py.covars_, eigenvectors[1])[i])
for i in range(Mixtured)], axis=0)
right = np.sum([np.dot(eigenvectors[1][i].T,
np.linalg.solve(py.covars_, y)[i])
for i in range(Mixtured)], axis = 0)
weight = np.linalg.solve(left, right)
fitted_target = np.dot(eigenvectors[1], weight) + biasvectors[1]
py.means_ = fitted_target
print("Load Input and Target Voice time = ", time.time() - timer_start , "[sec]")
"""
変換に必要なものを残しておく.
"""
np.save(save_for_evgmm_covarXX, covarXX)
np.save(save_for_evgmm_covarYX, covarYX)
np.save(save_for_evgmm_fitted_source, fitted_source)
np.save(save_for_evgmm_fitted_target, fitted_target)
np.save(save_for_evgmm_weights, weights)
np.save(save_for_evgmm_source_means, source_means)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_08_5_kaggle_project.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# T81-558: Applications of Deep Neural Networks
**Module 8: Kaggle Data Sets**
* Instructor: [Jeff Heaton](https://sites.wustl.edu/jeffheaton/), McKelvey School of Engineering, [Washington University in St. Louis](https://engineering.wustl.edu/Programs/Pages/default.aspx)
* For more information visit the [class website](https://sites.wustl.edu/jeffheaton/t81-558/).
# Module 8 Material
* Part 8.1: Introduction to Kaggle [[Video]](https://www.youtube.com/watch?v=v4lJBhdCuCU&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_08_1_kaggle_intro.ipynb)
* Part 8.2: Building Ensembles with Scikit-Learn and Keras [[Video]](https://www.youtube.com/watch?v=LQ-9ZRBLasw&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_08_2_keras_ensembles.ipynb)
* Part 8.3: How Should you Architect Your Keras Neural Network: Hyperparameters [[Video]](https://www.youtube.com/watch?v=1q9klwSoUQw&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_08_3_keras_hyperparameters.ipynb)
* Part 8.4: Bayesian Hyperparameter Optimization for Keras [[Video]](https://www.youtube.com/watch?v=sXdxyUCCm8s&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_08_4_bayesian_hyperparameter_opt.ipynb)
* **Part 8.5: Current Semester's Kaggle** [[Video]](https://www.youtube.com/watch?v=PHQt0aUasRg&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_08_5_kaggle_project.ipynb)
# Google CoLab Instructions
The following code ensures that Google CoLab is running the correct version of TensorFlow.
```
# Start CoLab
try:
%tensorflow_version 2.x
COLAB = True
print("Note: using Google CoLab")
except:
print("Note: not using Google CoLab")
COLAB = False
# Nicely formatted time string
def hms_string(sec_elapsed):
h = int(sec_elapsed / (60 * 60))
m = int((sec_elapsed % (60 * 60)) / 60)
s = sec_elapsed % 60
return "{}:{:>02}:{:>05.2f}".format(h, m, s)
```
# Part 8.5: Current Semester's Kaggle
Kaggke competition site for current semester (Fall 2020):
* [Spring 2021 Kaggle Assignment](https://www.kaggle.com/c/applications-of-deep-learning-wustl-spring-2021b)
Previous Kaggle competition sites for this class (NOT this semester's assignment, feel free to use code):
* [Fall 2020 Kaggle Assignment](https://www.kaggle.com/c/applications-of-deep-learning-wustl-fall-2020)
* [Spring 2020 Kaggle Assignment](https://www.kaggle.com/c/applications-of-deep-learningwustl-spring-2020)
* [Fall 2019 Kaggle Assignment](https://kaggle.com/c/applications-of-deep-learningwustl-fall-2019)
* [Spring 2019 Kaggle Assignment](https://www.kaggle.com/c/applications-of-deep-learningwustl-spring-2019)
* [Fall 2018 Kaggle Assignment](https://www.kaggle.com/c/wustl-t81-558-washu-deep-learning-fall-2018)
* [Spring 2018 Kaggle Assignment](https://www.kaggle.com/c/wustl-t81-558-washu-deep-learning-spring-2018)
* [Fall 2017 Kaggle Assignment](https://www.kaggle.com/c/wustl-t81-558-washu-deep-learning-fall-2017)
* [Spring 2017 Kaggle Assignment](https://inclass.kaggle.com/c/applications-of-deep-learning-wustl-spring-2017)
* [Fall 2016 Kaggle Assignment](https://inclass.kaggle.com/c/wustl-t81-558-washu-deep-learning-fall-2016)
# Iris as a Kaggle Competition
If the Iris data were used as a Kaggle, you would be given the following three files:
* [kaggle_iris_test.csv](https://data.heatonresearch.com/data/t81-558/datasets/kaggle_iris_test.csv) - The data that Kaggle will evaluate you on. Contains only input, you must provide answers. (contains x)
* [kaggle_iris_train.csv](https://data.heatonresearch.com/data/t81-558/datasets/kaggle_iris_train.csv) - The data that you will use to train. (contains x and y)
* [kaggle_iris_sample.csv](https://data.heatonresearch.com/data/t81-558/datasets/kaggle_iris_sample.csv) - A sample submission for Kaggle. (contains x and y)
Important features of the Kaggle iris files (that differ from how we've previously seen files):
* The iris species is already index encoded.
* Your training data is in a separate file.
* You will load the test data to generate a submission file.
The following program generates a submission file for "Iris Kaggle". You can use it as a starting point for assignment 3.
```
import os
import pandas as pd
from sklearn.model_selection import train_test_split
import tensorflow as tf
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.callbacks import EarlyStopping
df_train = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/datasets/"+\
"kaggle_iris_train.csv", na_values=['NA','?'])
# Encode feature vector
df_train.drop('id', axis=1, inplace=True)
num_classes = len(df_train.groupby('species').species.nunique())
print("Number of classes: {}".format(num_classes))
# Convert to numpy - Classification
x = df_train[['sepal_l', 'sepal_w', 'petal_l', 'petal_w']].values
dummies = pd.get_dummies(df_train['species']) # Classification
species = dummies.columns
y = dummies.values
# Split into train/test
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.25, random_state=45)
# Train, with early stopping
model = Sequential()
model.add(Dense(50, input_dim=x.shape[1], activation='relu'))
model.add(Dense(25))
model.add(Dense(y.shape[1],activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
monitor = EarlyStopping(monitor='val_loss', min_delta=1e-3,
patience=5, verbose=1, mode='auto',
restore_best_weights=True)
model.fit(x_train,y_train,validation_data=(x_test,y_test),
callbacks=[monitor],verbose=0,epochs=1000)
```
Now that we've trained the neural network, we can check its log loss.
```
from sklearn import metrics
# Calculate multi log loss error
pred = model.predict(x_test)
score = metrics.log_loss(y_test, pred)
print("Log loss score: {}".format(score))
```
Now we are ready to generate the Kaggle submission file. We will use the iris test data that does not contain a $y$ target value. It is our job to predict this value and submit to Kaggle.
```
# Generate Kaggle submit file
# Encode feature vector
df_test = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/datasets/"+\
"kaggle_iris_test.csv", na_values=['NA','?'])
# Convert to numpy - Classification
ids = df_test['id']
df_test.drop('id', axis=1, inplace=True)
x = df_test[['sepal_l', 'sepal_w', 'petal_l', 'petal_w']].values
y = dummies.values
# Generate predictions
pred = model.predict(x)
#pred
# Create submission data set
df_submit = pd.DataFrame(pred)
df_submit.insert(0,'id',ids)
df_submit.columns = ['id','species-0','species-1','species-2']
# Write submit file locally
df_submit.to_csv("iris_submit.csv", index=False)
print(df_submit)
```
### MPG as a Kaggle Competition (Regression)
If the Auto MPG data were used as a Kaggle, you would be given the following three files:
* [kaggle_mpg_test.csv](https://data.heatonresearch.com/data/t81-558/datasets/kaggle_auto_test.csv) - The data that Kaggle will evaluate you on. Contains only input, you must provide answers. (contains x)
* [kaggle_mpg_train.csv](https://data.heatonresearch.com/data/t81-558/datasets/kaggle_auto_test.csv) - The data that you will use to train. (contains x and y)
* [kaggle_mpg_sample.csv](https://data.heatonresearch.com/data/t81-558/datasets/kaggle_auto_sample.csv) - A sample submission for Kaggle. (contains x and y)
Important features of the Kaggle iris files (that differ from how we've previously seen files):
The following program generates a submission file for "MPG Kaggle".
```
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import EarlyStopping
import pandas as pd
import io
import os
import requests
import numpy as np
from sklearn import metrics
save_path = "."
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/datasets/"+\
"kaggle_auto_train.csv",
na_values=['NA', '?'])
cars = df['name']
# Handle missing value
df['horsepower'] = df['horsepower'].fillna(df['horsepower'].median())
# Pandas to Numpy
x = df[['cylinders', 'displacement', 'horsepower', 'weight',
'acceleration', 'year', 'origin']].values
y = df['mpg'].values # regression
# Split into train/test
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.25, random_state=42)
# Build the neural network
model = Sequential()
model.add(Dense(25, input_dim=x.shape[1], activation='relu')) # Hidden 1
model.add(Dense(10, activation='relu')) # Hidden 2
model.add(Dense(1)) # Output
model.compile(loss='mean_squared_error', optimizer='adam')
monitor = EarlyStopping(monitor='val_loss', min_delta=1e-3, patience=5,
verbose=1, mode='auto', restore_best_weights=True)
model.fit(x_train,y_train,validation_data=(x_test,y_test),
verbose=2,callbacks=[monitor],epochs=1000)
# Predict
pred = model.predict(x_test)
```
Now that we've trained the neural network, we can check its RMSE error.
```
import numpy as np
# Measure RMSE error. RMSE is common for regression.
score = np.sqrt(metrics.mean_squared_error(pred,y_test))
print("Final score (RMSE): {}".format(score))
```
Now we are ready to generate the Kaggle submission file. We will use the MPG test data that does not contain a $y$ target value. It is our job to predict this value and submit to Kaggle.
```
import pandas as pd
# Generate Kaggle submit file
# Encode feature vector
df_test = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/datasets/"+\
"kaggle_auto_test.csv", na_values=['NA','?'])
# Convert to numpy - regression
ids = df_test['id']
df_test.drop('id', axis=1, inplace=True)
# Handle missing value
df_test['horsepower'] = df_test['horsepower'].\
fillna(df['horsepower'].median())
x = df_test[['cylinders', 'displacement', 'horsepower', 'weight',
'acceleration', 'year', 'origin']].values
# Generate predictions
pred = model.predict(x)
#pred
# Create submission data set
df_submit = pd.DataFrame(pred)
df_submit.insert(0,'id',ids)
df_submit.columns = ['id','mpg']
# Write submit file locally
df_submit.to_csv("auto_submit.csv", index=False)
print(df_submit)
```
# Module 8 Assignment
You can find the first assignment here: [assignment 8](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/assignments/assignment_yourname_class8.ipynb)
| github_jupyter |
```
# import packages
%matplotlib inline
import os
import sys
from multiprocessing import Process, Queue
import pandas as pd
import optuna
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
sys.path.append('/opt/conda/GSASII/')
# Configurations
### Change here ###
STUDY_NAME = 'YOUR_MATERIAL'
RANDOM_SEED = 1024
DATA_DIR = '/bbo_rietveld/data/' + STUDY_NAME
# all output files include GSAS project file (*.gpx) will be saved in WORK_DIR
WORK_DIR = '/bbo_rietveld/work/' + STUDY_NAME
# make directories
! rm -f $WORK_DIR/$STUDY_NAME*
! mkdir -p $WORK_DIR
class ProjectBBO:
def __init__(self, trial_number):
import GSASIIscriptable as G2sc
import shutil
# Create a project with a default project name
### Change here ###
shutil.copyfile(DATA_DIR+'/'+'YOUR_PROJECT_FILE.gpx',
WORK_DIR+'/'+'BBO_seed{0}_trial_{1}.gpx'.format(RANDOM_SEED, trial_number))
self.gpx = G2sc.G2Project(gpxfile=os.path.join(WORK_DIR, 'BBO_seed{0}_trial_{1}.gpx'.format(RANDOM_SEED, trial_number)))
# Add two histograms to the project
self.hist1 = self.gpx.histograms()[0]
self.phase0 = self.gpx.phases()[0]
self.hist1.data['Instrument Parameters'][0]['I(L2)/I(L1)'] = [0.5, 0.5, 0]
# Set to use iso
for val in self.phase0.data['Atoms']:
val[9] = 'I'
def refine_and_calc_Rwp(self, param_dict):
self.gpx.do_refinements([param_dict])
for hist in self.gpx.histograms():
_, Rwp = hist.name, hist.get_wR()
return Rwp
def objective(trial):
"""
Parameters
----------
trial : optuna.trial object
Returns
-------
Rwp : float
"""
# Here, you should define search space and perform the refinement.
# Please see other notebook.
# Copy and paste from other notebook and some modifications would be enough.
return Rwp
# Create Optuna study
study = optuna.create_study(study_name=STUDY_NAME + '_seed%s' % (RANDOM_SEED),
sampler=optuna.samplers.TPESampler(n_startup_trials=20, seed=RANDOM_SEED))
```
Run 200 refinements to find the best configuration. It may take abount an hour to complete.
```
# Optimize
study.optimize(objective, n_trials=200, n_jobs=1)
# Results
df = study.trials_dataframe()
df.columns = [' '.join(col).replace('params', '').strip() for col in df.columns.values]
df.rename(columns={'value':'Rwp', 'number':'trial'}, inplace=True)
df.drop(columns=['state', 'system_attrs _number'], inplace=True)
df.sort_values('Rwp')
# Best configuration
study.best_params
# Best Rwp
study.best_value
# Rwp plot
def rwp_plot():
minvalues = [df.iloc[0]['Rwp']]
for i in range(1, df.shape[0]):
minvalues.append(min(minvalues[-1], df.iloc[i]['Rwp']))
minvalues = pd.DataFrame(minvalues)
minvalues.plot(legend=None)
# plt.ylim([6, 16])
plt.grid(color='#cccccc')
plt.ylabel('$R_{wp}$')
plt.xlabel('Number of trials')
plt.show()
rwp_plot()
# Rietveld plot
def rietveld_plot():
import GSASIIscriptable as G2sc
gpx = G2sc.G2Project(
'%s/%s_seed%s_trial_%s.gpx' % (WORK_DIR, STUDY_NAME, RANDOM_SEED, study.best_trial.number))
hist1 = gpx.histograms()[0]
phase0 = gpx.phases()[0]
hist = hist1
i = 5
two_theta = hist.getdata("X")[::i]
Yobs = hist.getdata("Yobs")[::i]
Ycalc = hist.getdata("Ycalc")[::i]
bg = hist.getdata("Background")[::i]
residual = hist.getdata("Residual")[::i]
fig = plt.figure()
gs = GridSpec(5, 1, figure=fig)
ax1 = fig.add_subplot(gs[:4, :])
ax2 = fig.add_subplot(gs[4, :])
fig.subplots_adjust(hspace=0)
ax1.grid(color='#cccccc')
ax1.scatter(two_theta, Yobs, marker='P', lw=0.0001, c='Black', label='XRD (Obs)')
ax1.plot(two_theta, Ycalc, label='XRD (Calc)')
ax1.plot(two_theta, bg, color='red', label='Background (Calc)')
ax1.set_ylabel('Intensity')
ax1.legend()
ax2.plot(two_theta, residual, color='blue')
plt.setp(ax1.get_xticklabels(), visible=False);
# ax2.set_ylim(-6600, 6600)
plt.xlabel(r'$2\theta$ (deg.)')
ax2.set_ylabel('Residual')
# change 2theta range according to your data
ax1.set_xlim(15, 150)
ax2.set_xlim(15, 150)
plt.show()
rietveld_plot()
```
| github_jupyter |
set [SDC](https://commons.wikimedia.org/wiki/Commons:Structured_data#:~:text=Structured%20data%20on%20Commons%20is,from%20Wikidata%2C%20Wikimedia's%20knowledge%20base.) depicts from files uploaded in [spa2Commons](https://commons.wikimedia.org/wiki/Category:Uploaded_with_spa2Commons)
### Theory depicts
* all pictures from [SPA](https://portrattarkiv.se/about) depicts one person
* one category in WIkicommons is connected to the person that the picture depicts
#### How to
##### Using Minefield and a pile
see below _1. get WD object the Picture depict_
* a csv file is created from a pile using
* petscan creates the pile ex. [set output pagepile](https://petscan.wmflabs.org/?psid=20485153)--> [pagepile 39223](https://pagepile.toolforge.org/api.php?action=get_data&id=39223)
* example [petscan files modified after 20211103](https://petscan.wmflabs.org/?psid=20577669)
* [minefield](https://hay.toolforge.org/minefield/) creates the csv file
* see [gist](https://gist.github.com/salgo60/b5d05fae5c865b678edb338b09e4b302)
* [video](https://www.youtube.com/watch?v=FUoG0veIeMY&feature=youtu.be)
### Theory SPA identifier
* a picture uploaded to Wikicommons using [SPA2common javascript](https://github.com/salgo60/spa2Commons) will have the link to the SPA picture in the template Information and param **Source** ex. [File:Axel_Sammuli_SPA3.jpg](https://commons.wikimedia.org/wiki/File:Axel_Sammuli_SPA3.jpg) --> SPA id = [SPA idYB0QHyfj0hAAAAAAAAAf8g](https://portrattarkiv.se/details/YB0QHyfj0hAAAAAAAAAf8g)
#### How to
* read all pictures in category [spa2Commons](https://commons.wikimedia.org/wiki/Category:Uploaded_with_spa2Commons) and check param **Source**
* this is done in a [PAWS notebook](https://hub.paws.wmcloud.org/user/Salgo60/notebooks/Traverse%20category%20to%20find%20SPA%20id%20.ipynb)
### Misc
* [SPARQL mwapi](https://en.wikibooks.org/wiki/SPARQL/SERVICE_-_mwapi)
* [API:Categories](https://www.mediawiki.org/wiki/API:Categories)
* Test SPARQL
* [get files in Categories](https://wcqs-beta.wmflabs.org/#%23Wikidata%20items%20of%20files%20in%20Category%3AArtworks%20with%20structured%20data%20with%20redirected%20P6243%20property%0ASELECT%20%3Ffile%20%3Ftitle%20%20%3Fspa%20%0AWITH%0A%7B%0A%20%20SELECT%20%3Ffile%20%3Ftitle%0A%20%20WHERE%0A%20%20%7B%0A%20%20%20%20SERVICE%20wikibase%3Amwapi%0A%20%20%20%20%7B%0A%20%20%20%20%20%20bd%3AserviceParam%20wikibase%3Aapi%20%22Generator%22%20.%0A%20%20%20%20%20%20bd%3AserviceParam%20wikibase%3Aendpoint%20%22commons.wikimedia.org%22%20.%0A%20%20%20%20%20%20bd%3AserviceParam%20mwapi%3Agcmtitle%20%22Category%3AUploaded_with_spa2Commons%22%20.%0A%20%20%20%20%20%20bd%3AserviceParam%20mwapi%3Agenerator%20%22categorymembers%22%20.%0A%20%20%20%20%20%20bd%3AserviceParam%20mwapi%3Agcmtype%20%22file%22%20.%0A%20%20%20%20%20%20bd%3AserviceParam%20mwapi%3Agcmlimit%20%22max%22%20.%0A%20%20%20%20%20%20%3Ftitle%20wikibase%3AapiOutput%20mwapi%3Atitle%20.%0A%20%20%20%20%20%20%3Fpageid%20wikibase%3AapiOutput%20%22%40pageid%22%20.%0A%20%20%20%20%7D%0A%20%20%20%20BIND%20%28URI%28CONCAT%28%27https%3A%2F%2Fcommons.wikimedia.org%2Fentity%2FM%27%2C%20%3Fpageid%29%29%20AS%20%3Ffile%29%0A%20%20%7D%0A%7D%20AS%20%25get_files%0AWHERE%0A%7B%0A%20%20INCLUDE%20%25get_files%0A%20%20OPTIONAL%20%7B%3Ffile%20wdt%3AP4819%20%3Fspa%7D%0A%7D)
* [PAWS Example Notebooks](https://wikitech.wikimedia.org/wiki/PAWS/PAWS_examples_and_recipes)
* [hub.toolforge.org](https://hub.toolforge.org)
* [writeSDoCfromExcel](https://github.com/KBNLwikimedia/SDoC/blob/main/writeSDoCfromExcel/WriteSDoCfromExcel_nopasswd.py)
```
from datetime import datetime
start_time = datetime.now()
print("Last run: ", start_time)
import requests
S = requests.Session()
URL = "https://commons.wikipedia.org/w/api.php"
def get_Category(pageName):
PARAMS = {
"action": "query",
"format": "json",
"prop": "categories",
"titles": pageName
}
#print (PARAMS)
r = S.get(url=URL, params=PARAMS)
data = r.json()
# TODO dont get hidden categories
filtercat = {
"Category:CC-BY-4.0",
"Category:Swedish Portrait Archive",
"Category:Uploaded with spa2Commons",
"Category:Template Unknown (author)",
"Category:Images with extracted images",
"Category:Extracted images",
"Category:Scanned with HP Deskjet F4200",
"Category:Pages using duplicate arguments in template calls",
"Category:Creative Commons Attribution-Share Alike missing SDC copyright status",
"Category:Creative Commons Attribution-Share Alike 4.0 missing SDC copyright license",
"Category:Creative Commons Attribution missing SDC copyright status",
"Category:Creative Commons Attribution 4.0 missing SDC copyright license",
"Category:Media requiring renaming - rationale 3",
"Media requiring renaming - target already exists"
}
target_category = ""
PAGES = data["query"]["pages"]
for k, v in PAGES.items():
# print(k,v)
for cat in v['categories']:
if cat["title"] not in filtercat:
target_category = cat["title"]
#print("\tTarget cat" ,target_category)
return target_category
common_name = "File:A_G_Ahlqvist_SPA10.jpg"
get_Category(common_name)
def getWD(commonsCategory):
urlHub = "https://hub.toolforge.org/commons:" + commonsCategory + "?format=json&site=wd"
#print(urlHub)
hub = S.get(url=urlHub)
data = hub.json()
try:
wd = data["destination"]["url"].replace("https://www.wikidata.org/wiki/","")
except:
print("Error", data)
wd =""
return wd
test_category ="Category:Axel_Rappe_(1838%E2%80%931918)"
getWD(test_category)
```
### 1. get WD object the Picture depict
```
# used tool xxxx to get csv files with pictures
import csv
mid_wd_list = []
cat2commonsfiles = "Cat_2commons.csv"
cat2commonsfiles = "Cat_2commons_20211101.csv"
cat2commonsfiles = "Cat_2commons_20211103.csv"
cat2commonsfiles = "Cat_2commons_20211106.csv"
cat2commonsfiles = "Cat_2commons_20211114.csv"
cat2commonsfiles = "Cat_2commons_20211126.csv"
with open(cat2commonsfiles) as csvfile:
cat_reader = csv.DictReader(csvfile, delimiter=',', quotechar='"')
# cat_reader = csv.DictReader(csvfile, delimiter=';', quotechar='"')
# cat_reader = csv.DictReader(csvfile, delimiter=',', quotechar='"')
for row in cat_reader:
# print(row)
# print(row["mid"],get_Category(row["title"]),row["url"])
# print(row["mid"],getWD(get_Category(row["title"])))
mid_wd_list.append([row["mid"],getWD(get_Category(row["title"]))])
#print(mid_wd_list)
import pandas as pd
df = pd.DataFrame(mid_wd_list)
df.head(10)
df.to_csv("SPACategories_Mid_WD.txt")
df.shape
end = datetime.now()
print("Ended: ", end)
print('Time elapsed (hh:mm:ss.ms) {}'.format(datetime.now() - start_time))
```
| github_jupyter |
# Image Classification
In this project, you'll classify images from the [CIFAR-10 dataset](https://www.cs.toronto.edu/~kriz/cifar.html). The dataset consists of airplanes, dogs, cats, and other objects. You'll preprocess the images, then train a convolutional neural network on all the samples. The images need to be normalized and the labels need to be one-hot encoded. You'll get to apply what you learned and build a convolutional, max pooling, dropout, and fully connected layers. At the end, you'll get to see your neural network's predictions on the sample images.
## Get the Data
Run the following cell to download the [CIFAR-10 dataset for python](https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz).
```
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
from urllib.request import urlretrieve
from os.path import isfile, isdir
from tqdm import tqdm
import problem_unittests as tests
import tarfile
cifar10_dataset_folder_path = 'cifar-10-batches-py'
# Use Floyd's cifar-10 dataset if present
floyd_cifar10_location = '/cifar/cifar-10-python.tar.gz'
if isfile(floyd_cifar10_location):
tar_gz_path = floyd_cifar10_location
else:
tar_gz_path = 'cifar-10-python.tar.gz'
class DLProgress(tqdm):
last_block = 0
def hook(self, block_num=1, block_size=1, total_size=None):
self.total = total_size
self.update((block_num - self.last_block) * block_size)
self.last_block = block_num
if not isfile(tar_gz_path):
with DLProgress(unit='B', unit_scale=True, miniters=1, desc='CIFAR-10 Dataset') as pbar:
urlretrieve(
'https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz',
tar_gz_path,
pbar.hook)
if not isdir(cifar10_dataset_folder_path):
with tarfile.open(tar_gz_path) as tar:
tar.extractall()
tar.close()
tests.test_folder_path(cifar10_dataset_folder_path)
```
## Explore the Data
The dataset is broken into batches to prevent your machine from running out of memory. The CIFAR-10 dataset consists of 5 batches, named `data_batch_1`, `data_batch_2`, etc.. Each batch contains the labels and images that are one of the following:
* airplane
* automobile
* bird
* cat
* deer
* dog
* frog
* horse
* ship
* truck
Understanding a dataset is part of making predictions on the data. Play around with the code cell below by changing the `batch_id` and `sample_id`. The `batch_id` is the id for a batch (1-5). The `sample_id` is the id for a image and label pair in the batch.
Ask yourself "What are all possible labels?", "What is the range of values for the image data?", "Are the labels in order or random?". Answers to questions like these will help you preprocess the data and end up with better predictions.
```
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import helper
import numpy as np
# Explore the dataset
batch_id = 2
sample_id = 8
helper.display_stats(cifar10_dataset_folder_path, batch_id, sample_id)
```
## Implement Preprocess Functions
### Normalize
In the cell below, implement the `normalize` function to take in image data, `x`, and return it as a normalized Numpy array. The values should be in the range of 0 to 1, inclusive. The return object should be the same shape as `x`.
```
def normalize(x):
"""
Normalize a list of sample image data in the range of 0 to 1
: x: List of image data. The image shape is (32, 32, 3)
: return: Numpy array of normalize data
"""
# TODO: Implement Function
image_array = np.reshape(x, (-1, 32,32,3))
min_value = np.amin(image_array)
max_value = np.amax(image_array)
normalized_image_array = np.vectorize(lambda x, min, max: (x-min)/(max-min))(image_array, min_value, max_value)
return normalized_image_array
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
tests.test_normalize(normalize)
```
### One-hot encode
Just like the previous code cell, you'll be implementing a function for preprocessing. This time, you'll implement the `one_hot_encode` function. The input, `x`, are a list of labels. Implement the function to return the list of labels as One-Hot encoded Numpy array. The possible values for labels are 0 to 9. The one-hot encoding function should return the same encoding for each value between each call to `one_hot_encode`. Make sure to save the map of encodings outside the function.
Hint: Don't reinvent the wheel.
```
def one_hot_encode(x):
"""
One hot encode a list of sample labels. Return a one-hot encoded vector for each label.
: x: List of sample Labels
: return: Numpy array of one-hot encoded labels
"""
# TODO: Implement Function
from sklearn import preprocessing
lb = preprocessing.LabelBinarizer()
lb.fit(list(range(0,10)))
hot_encoding = lb.transform(x)
return hot_encoding
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
tests.test_one_hot_encode(one_hot_encode)
```
### Randomize Data
As you saw from exploring the data above, the order of the samples are randomized. It doesn't hurt to randomize it again, but you don't need to for this dataset.
## Preprocess all the data and save it
Running the code cell below will preprocess all the CIFAR-10 data and save it to file. The code below also uses 10% of the training data for validation.
```
"""
DON'T MODIFY ANYTHING IN THIS CELL
"""
# Preprocess Training, Validation, and Testing Data
helper.preprocess_and_save_data(cifar10_dataset_folder_path, normalize, one_hot_encode)
```
# Check Point
This is your first checkpoint. If you ever decide to come back to this notebook or have to restart the notebook, you can start from here. The preprocessed data has been saved to disk.
```
"""
DON'T MODIFY ANYTHING IN THIS CELL
"""
import pickle
import problem_unittests as tests
import helper
# Load the Preprocessed Validation data
valid_features, valid_labels = pickle.load(open('preprocess_validation.p', mode='rb'))
```
## Build the network
For the neural network, you'll build each layer into a function. Most of the code you've seen has been outside of functions. To test your code more thoroughly, we require that you put each layer in a function. This allows us to give you better feedback and test for simple mistakes using our unittests before you submit your project.
>**Note:** If you're finding it hard to dedicate enough time for this course each week, we've provided a small shortcut to this part of the project. In the next couple of problems, you'll have the option to use classes from the [TensorFlow Layers](https://www.tensorflow.org/api_docs/python/tf/layers) or [TensorFlow Layers (contrib)](https://www.tensorflow.org/api_guides/python/contrib.layers) packages to build each layer, except the layers you build in the "Convolutional and Max Pooling Layer" section. TF Layers is similar to Keras's and TFLearn's abstraction to layers, so it's easy to pickup.
>However, if you would like to get the most out of this course, try to solve all the problems _without_ using anything from the TF Layers packages. You **can** still use classes from other packages that happen to have the same name as ones you find in TF Layers! For example, instead of using the TF Layers version of the `conv2d` class, [tf.layers.conv2d](https://www.tensorflow.org/api_docs/python/tf/layers/conv2d), you would want to use the TF Neural Network version of `conv2d`, [tf.nn.conv2d](https://www.tensorflow.org/api_docs/python/tf/nn/conv2d).
Let's begin!
### Input
The neural network needs to read the image data, one-hot encoded labels, and dropout keep probability. Implement the following functions
* Implement `neural_net_image_input`
* Return a [TF Placeholder](https://www.tensorflow.org/api_docs/python/tf/placeholder)
* Set the shape using `image_shape` with batch size set to `None`.
* Name the TensorFlow placeholder "x" using the TensorFlow `name` parameter in the [TF Placeholder](https://www.tensorflow.org/api_docs/python/tf/placeholder).
* Implement `neural_net_label_input`
* Return a [TF Placeholder](https://www.tensorflow.org/api_docs/python/tf/placeholder)
* Set the shape using `n_classes` with batch size set to `None`.
* Name the TensorFlow placeholder "y" using the TensorFlow `name` parameter in the [TF Placeholder](https://www.tensorflow.org/api_docs/python/tf/placeholder).
* Implement `neural_net_keep_prob_input`
* Return a [TF Placeholder](https://www.tensorflow.org/api_docs/python/tf/placeholder) for dropout keep probability.
* Name the TensorFlow placeholder "keep_prob" using the TensorFlow `name` parameter in the [TF Placeholder](https://www.tensorflow.org/api_docs/python/tf/placeholder).
These names will be used at the end of the project to load your saved model.
Note: `None` for shapes in TensorFlow allow for a dynamic size.
```
import tensorflow as tf
def neural_net_image_input(image_shape):
"""
Return a Tensor for a batch of image input
: image_shape: Shape of the images
: return: Tensor for image input.
"""
# TODO: Implement Function
return tf.placeholder(tf.float32, [None, image_shape[0], image_shape[1], image_shape[2]], name="x")
def neural_net_label_input(n_classes):
"""
Return a Tensor for a batch of label input
: n_classes: Number of classes
: return: Tensor for label input.
"""
# TODO: Implement Function
return tf.placeholder(tf.float32, [None, n_classes], name="y")
def neural_net_keep_prob_input():
"""
Return a Tensor for keep probability
: return: Tensor for keep probability.
"""
# TODO: Implement Function
return tf.placeholder(tf.float32, name="keep_prob")
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
tf.reset_default_graph()
tests.test_nn_image_inputs(neural_net_image_input)
tests.test_nn_label_inputs(neural_net_label_input)
tests.test_nn_keep_prob_inputs(neural_net_keep_prob_input)
```
### Convolution and Max Pooling Layer
Convolution layers have a lot of success with images. For this code cell, you should implement the function `conv2d_maxpool` to apply convolution then max pooling:
* Create the weight and bias using `conv_ksize`, `conv_num_outputs` and the shape of `x_tensor`.
* Apply a convolution to `x_tensor` using weight and `conv_strides`.
* We recommend you use same padding, but you're welcome to use any padding.
* Add bias
* Add a nonlinear activation to the convolution.
* Apply Max Pooling using `pool_ksize` and `pool_strides`.
* We recommend you use same padding, but you're welcome to use any padding.
**Note:** You **can't** use [TensorFlow Layers](https://www.tensorflow.org/api_docs/python/tf/layers) or [TensorFlow Layers (contrib)](https://www.tensorflow.org/api_guides/python/contrib.layers) for **this** layer, but you can still use TensorFlow's [Neural Network](https://www.tensorflow.org/api_docs/python/tf/nn) package. You may still use the shortcut option for all the **other** layers.
```
def conv2d_maxpool(x_tensor, conv_num_outputs, conv_ksize, conv_strides, pool_ksize, pool_strides):
"""
Apply convolution then max pooling to x_tensor
:param x_tensor: TensorFlow Tensor
:param conv_num_outputs: Number of outputs for the convolutional layer
:param conv_ksize: kernal size 2-D Tuple for the convolutional layer
:param conv_strides: Stride 2-D Tuple for convolution
:param pool_ksize: kernal size 2-D Tuple for pool
:param pool_strides: Stride 2-D Tuple for pool
: return: A tensor that represents convolution and max pooling of x_tensor
"""
# TODO: Implement Function
return None
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
tests.test_con_pool(conv2d_maxpool)
```
### Flatten Layer
Implement the `flatten` function to change the dimension of `x_tensor` from a 4-D tensor to a 2-D tensor. The output should be the shape (*Batch Size*, *Flattened Image Size*). Shortcut option: you can use classes from the [TensorFlow Layers](https://www.tensorflow.org/api_docs/python/tf/layers) or [TensorFlow Layers (contrib)](https://www.tensorflow.org/api_guides/python/contrib.layers) packages for this layer. For more of a challenge, only use other TensorFlow packages.
```
def flatten(x_tensor):
"""
Flatten x_tensor to (Batch Size, Flattened Image Size)
: x_tensor: A tensor of size (Batch Size, ...), where ... are the image dimensions.
: return: A tensor of size (Batch Size, Flattened Image Size).
"""
# TODO: Implement Function
return None
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
tests.test_flatten(flatten)
```
### Fully-Connected Layer
Implement the `fully_conn` function to apply a fully connected layer to `x_tensor` with the shape (*Batch Size*, *num_outputs*). Shortcut option: you can use classes from the [TensorFlow Layers](https://www.tensorflow.org/api_docs/python/tf/layers) or [TensorFlow Layers (contrib)](https://www.tensorflow.org/api_guides/python/contrib.layers) packages for this layer. For more of a challenge, only use other TensorFlow packages.
```
def fully_conn(x_tensor, num_outputs):
"""
Apply a fully connected layer to x_tensor using weight and bias
: x_tensor: A 2-D tensor where the first dimension is batch size.
: num_outputs: The number of output that the new tensor should be.
: return: A 2-D tensor where the second dimension is num_outputs.
"""
# TODO: Implement Function
return None
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
tests.test_fully_conn(fully_conn)
```
### Output Layer
Implement the `output` function to apply a fully connected layer to `x_tensor` with the shape (*Batch Size*, *num_outputs*). Shortcut option: you can use classes from the [TensorFlow Layers](https://www.tensorflow.org/api_docs/python/tf/layers) or [TensorFlow Layers (contrib)](https://www.tensorflow.org/api_guides/python/contrib.layers) packages for this layer. For more of a challenge, only use other TensorFlow packages.
**Note:** Activation, softmax, or cross entropy should **not** be applied to this.
```
def output(x_tensor, num_outputs):
"""
Apply a output layer to x_tensor using weight and bias
: x_tensor: A 2-D tensor where the first dimension is batch size.
: num_outputs: The number of output that the new tensor should be.
: return: A 2-D tensor where the second dimension is num_outputs.
"""
# TODO: Implement Function
return None
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
tests.test_output(output)
```
### Create Convolutional Model
Implement the function `conv_net` to create a convolutional neural network model. The function takes in a batch of images, `x`, and outputs logits. Use the layers you created above to create this model:
* Apply 1, 2, or 3 Convolution and Max Pool layers
* Apply a Flatten Layer
* Apply 1, 2, or 3 Fully Connected Layers
* Apply an Output Layer
* Return the output
* Apply [TensorFlow's Dropout](https://www.tensorflow.org/api_docs/python/tf/nn/dropout) to one or more layers in the model using `keep_prob`.
```
def conv_net(x, keep_prob):
"""
Create a convolutional neural network model
: x: Placeholder tensor that holds image data.
: keep_prob: Placeholder tensor that hold dropout keep probability.
: return: Tensor that represents logits
"""
# TODO: Apply 1, 2, or 3 Convolution and Max Pool layers
# Play around with different number of outputs, kernel size and stride
# Function Definition from Above:
# conv2d_maxpool(x_tensor, conv_num_outputs, conv_ksize, conv_strides, pool_ksize, pool_strides)
# TODO: Apply a Flatten Layer
# Function Definition from Above:
# flatten(x_tensor)
# TODO: Apply 1, 2, or 3 Fully Connected Layers
# Play around with different number of outputs
# Function Definition from Above:
# fully_conn(x_tensor, num_outputs)
# TODO: Apply an Output Layer
# Set this to the number of classes
# Function Definition from Above:
# output(x_tensor, num_outputs)
# TODO: return output
return None
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
##############################
## Build the Neural Network ##
##############################
# Remove previous weights, bias, inputs, etc..
tf.reset_default_graph()
# Inputs
x = neural_net_image_input((32, 32, 3))
y = neural_net_label_input(10)
keep_prob = neural_net_keep_prob_input()
# Model
logits = conv_net(x, keep_prob)
# Name logits Tensor, so that is can be loaded from disk after training
logits = tf.identity(logits, name='logits')
# Loss and Optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
optimizer = tf.train.AdamOptimizer().minimize(cost)
# Accuracy
correct_pred = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32), name='accuracy')
tests.test_conv_net(conv_net)
```
## Train the Neural Network
### Single Optimization
Implement the function `train_neural_network` to do a single optimization. The optimization should use `optimizer` to optimize in `session` with a `feed_dict` of the following:
* `x` for image input
* `y` for labels
* `keep_prob` for keep probability for dropout
This function will be called for each batch, so `tf.global_variables_initializer()` has already been called.
Note: Nothing needs to be returned. This function is only optimizing the neural network.
```
def train_neural_network(session, optimizer, keep_probability, feature_batch, label_batch):
"""
Optimize the session on a batch of images and labels
: session: Current TensorFlow session
: optimizer: TensorFlow optimizer function
: keep_probability: keep probability
: feature_batch: Batch of Numpy image data
: label_batch: Batch of Numpy label data
"""
# TODO: Implement Function
pass
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
tests.test_train_nn(train_neural_network)
```
### Show Stats
Implement the function `print_stats` to print loss and validation accuracy. Use the global variables `valid_features` and `valid_labels` to calculate validation accuracy. Use a keep probability of `1.0` to calculate the loss and validation accuracy.
```
def print_stats(session, feature_batch, label_batch, cost, accuracy):
"""
Print information about loss and validation accuracy
: session: Current TensorFlow session
: feature_batch: Batch of Numpy image data
: label_batch: Batch of Numpy label data
: cost: TensorFlow cost function
: accuracy: TensorFlow accuracy function
"""
# TODO: Implement Function
pass
```
### Hyperparameters
Tune the following parameters:
* Set `epochs` to the number of iterations until the network stops learning or start overfitting
* Set `batch_size` to the highest number that your machine has memory for. Most people set them to common sizes of memory:
* 64
* 128
* 256
* ...
* Set `keep_probability` to the probability of keeping a node using dropout
```
# TODO: Tune Parameters
epochs = None
batch_size = None
keep_probability = None
```
### Train on a Single CIFAR-10 Batch
Instead of training the neural network on all the CIFAR-10 batches of data, let's use a single batch. This should save time while you iterate on the model to get a better accuracy. Once the final validation accuracy is 50% or greater, run the model on all the data in the next section.
```
"""
DON'T MODIFY ANYTHING IN THIS CELL
"""
print('Checking the Training on a Single Batch...')
with tf.Session() as sess:
# Initializing the variables
sess.run(tf.global_variables_initializer())
# Training cycle
for epoch in range(epochs):
batch_i = 1
for batch_features, batch_labels in helper.load_preprocess_training_batch(batch_i, batch_size):
train_neural_network(sess, optimizer, keep_probability, batch_features, batch_labels)
print('Epoch {:>2}, CIFAR-10 Batch {}: '.format(epoch + 1, batch_i), end='')
print_stats(sess, batch_features, batch_labels, cost, accuracy)
```
### Fully Train the Model
Now that you got a good accuracy with a single CIFAR-10 batch, try it with all five batches.
```
"""
DON'T MODIFY ANYTHING IN THIS CELL
"""
save_model_path = './image_classification'
print('Training...')
with tf.Session() as sess:
# Initializing the variables
sess.run(tf.global_variables_initializer())
# Training cycle
for epoch in range(epochs):
# Loop over all batches
n_batches = 5
for batch_i in range(1, n_batches + 1):
for batch_features, batch_labels in helper.load_preprocess_training_batch(batch_i, batch_size):
train_neural_network(sess, optimizer, keep_probability, batch_features, batch_labels)
print('Epoch {:>2}, CIFAR-10 Batch {}: '.format(epoch + 1, batch_i), end='')
print_stats(sess, batch_features, batch_labels, cost, accuracy)
# Save Model
saver = tf.train.Saver()
save_path = saver.save(sess, save_model_path)
```
# Checkpoint
The model has been saved to disk.
## Test Model
Test your model against the test dataset. This will be your final accuracy. You should have an accuracy greater than 50%. If you don't, keep tweaking the model architecture and parameters.
```
"""
DON'T MODIFY ANYTHING IN THIS CELL
"""
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import tensorflow as tf
import pickle
import helper
import random
# Set batch size if not already set
try:
if batch_size:
pass
except NameError:
batch_size = 64
save_model_path = './image_classification'
n_samples = 4
top_n_predictions = 3
def test_model():
"""
Test the saved model against the test dataset
"""
test_features, test_labels = pickle.load(open('preprocess_test.p', mode='rb'))
loaded_graph = tf.Graph()
with tf.Session(graph=loaded_graph) as sess:
# Load model
loader = tf.train.import_meta_graph(save_model_path + '.meta')
loader.restore(sess, save_model_path)
# Get Tensors from loaded model
loaded_x = loaded_graph.get_tensor_by_name('x:0')
loaded_y = loaded_graph.get_tensor_by_name('y:0')
loaded_keep_prob = loaded_graph.get_tensor_by_name('keep_prob:0')
loaded_logits = loaded_graph.get_tensor_by_name('logits:0')
loaded_acc = loaded_graph.get_tensor_by_name('accuracy:0')
# Get accuracy in batches for memory limitations
test_batch_acc_total = 0
test_batch_count = 0
for test_feature_batch, test_label_batch in helper.batch_features_labels(test_features, test_labels, batch_size):
test_batch_acc_total += sess.run(
loaded_acc,
feed_dict={loaded_x: test_feature_batch, loaded_y: test_label_batch, loaded_keep_prob: 1.0})
test_batch_count += 1
print('Testing Accuracy: {}\n'.format(test_batch_acc_total/test_batch_count))
# Print Random Samples
random_test_features, random_test_labels = tuple(zip(*random.sample(list(zip(test_features, test_labels)), n_samples)))
random_test_predictions = sess.run(
tf.nn.top_k(tf.nn.softmax(loaded_logits), top_n_predictions),
feed_dict={loaded_x: random_test_features, loaded_y: random_test_labels, loaded_keep_prob: 1.0})
helper.display_image_predictions(random_test_features, random_test_labels, random_test_predictions)
test_model()
```
## Why 50-80% Accuracy?
You might be wondering why you can't get an accuracy any higher. First things first, 50% isn't bad for a simple CNN. Pure guessing would get you 10% accuracy. However, you might notice people are getting scores [well above 80%](http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html#43494641522d3130). That's because we haven't taught you all there is to know about neural networks. We still need to cover a few more techniques.
## Submitting This Project
When submitting this project, make sure to run all the cells before saving the notebook. Save the notebook file as "dlnd_image_classification.ipynb" and save it as a HTML file under "File" -> "Download as". Include the "helper.py" and "problem_unittests.py" files in your submission.
| github_jupyter |
[[source]](../api/alibi.explainers.counterfactual.rst)
# Counterfactual Instances
## Overview
A counterfactual explanation of an outcome or a situation $Y$ takes the form "If $X$ had not occured, $Y$ would not have occured" ([Interpretable Machine Learning](https://christophm.github.io/interpretable-ml-book/counterfactual.html)). In the context of a machine learning classifier $X$ would be an instance of interest and $Y$ would be the label predicted by the model. The task of finding a counterfactual explanation is then to find some $X^\prime$ that is in some way related to the original instance $X$ but leading to a different prediction $Y^\prime$. Reasoning in counterfactual terms is very natural for humans, e.g. asking what should have been done differently to achieve a different result. As a consequence counterfactual instances for machine learning predictions is a promising method for human-interpretable explanations.
The counterfactual method described here is the most basic way of defining the problem of finding such $X^\prime$. Our algorithm loosely follows Wachter et al. (2017): [Counterfactual Explanations without Opening the Black Box: Automated Decisions and the GDPR](https://arxiv.org/abs/1711.00399). For an extension to the basic method which provides ways of finding higher quality counterfactual instances $X^\prime$ in a quicker time, please refer to [Counterfactuals Guided by Prototypes](CFProto.ipynb).
We can reason that the most basic requirements for a counterfactual $X^\prime$ are as follows:
- The predicted class of $X^\prime$ is different from the predicted class of $X$
- The difference between $X$ and $X^\prime$ should be human-interpretable.
While the first condition is straight-forward, the second condition does not immediately lend itself to a condition as we need to first define "interpretability" in a mathematical sense. For this method we restrict ourselves to a particular definition by asserting that $X^\prime$ should be as close as possible to $X$ without violating the first condition. The main issue with this definition of "interpretability" is that the difference between $X^\prime$ and $X$ required to change the model prediciton might be so small as to be un-interpretable to the human eye in which case [we need a more sophisticated approach](CFProto.ipynb).
That being said, we can now cast the search for $X^\prime$ as a simple optimization problem with the following loss:
$$L = L_{\text{pred}} + \lambda L_{\text{dist}},$$
where the first loss term $L_{\text{pred}}$ guides the search towards points $X^\prime$ which would change the model prediction and the second term $\lambda L_{\text{dist}}$ ensures that $X^\prime$ is close to $X$. This form of loss has a single hyperparameter $\lambda$ weighing the contributions of the two competing terms.
The specific loss in our implementation is as follows:
$$L(X^\prime\vert X) = (f_t(X^\prime) - p_t)^2 + \lambda L_1(X^\prime, X).$$
Here $t$ is the desired target class for $X^\prime$ which can either be specified in advance or left up to the optimization algorithm to find, $p_t$ is the target probability of this class (typically $p_t=1$), $f_t$ is the model prediction on class $t$ and $L_1$ is the distance between the proposed counterfactual instance $X^\prime$ and the instance to be explained $X$. The use of the $L_1$ distance should ensure that the $X^\prime$ is a sparse counterfactual - minimizing the number of features to be changed in order to change the prediction.
The optimal value of the hyperparameter $\lambda$ will vary from dataset to dataset and even within a dataset for each instance to be explained and the desired target class. As such it is difficult to set and we learn it as part of the optimization algorithm, i.e. we want to optimize
$$\min_{X^{\prime}}\max_{\lambda}L(X^\prime\vert X)$$
subject to
$$\vert f_t(X^\prime)-p_t\vert\leq\epsilon \text{ (counterfactual constraint)},$$
where $\epsilon$ is a tolerance parameter. In practice this is done in two steps, on the first pass we sweep a broad range of $\lambda$, e.g. $\lambda\in(10^{-1},\dots,10^{-10}$) to find lower and upper bounds $\lambda_{\text{lb}}, \lambda_{\text{ub}}$ where counterfactuals exist. Then we use bisection to find the maximum $\lambda\in[\lambda_{\text{lb}}, \lambda_{\text{ub}}]$ such that the counterfactual constraint still holds. The result is a set of counterfactual instances $X^\prime$ with varying distance from the test instance $X$.
## Usage
### Initialization
The counterfactual (CF) explainer method works on fully black-box models, meaning they can work with arbitrary functions that take arrays and return arrays. However, if the user has access to a full TensorFlow (TF) or Keras model, this can be passed in as well to take advantage of the automatic differentiation in TF to speed up the search. This section describes the initialization for a TF/Keras model, for fully black-box models refer to [numerical gradients](#Numerical-Gradients).
First we load the TF/Keras model:
```python
model = load_model('my_model.h5')
```
Then we can initialize the counterfactual object:
```python
shape = (1,) + x_train.shape[1:]
cf = Counterfactual(model, shape, distance_fn='l1', target_proba=1.0,
target_class='other', max_iter=1000, early_stop=50, lam_init=1e-1,
max_lam_steps=10, tol=0.05, learning_rate_init=0.1,
feature_range=(-1e10, 1e10), eps=0.01, init='identity',
decay=True, write_dir=None, debug=False)
```
Besides passing the model, we set a number of **hyperparameters** ...
... **general**:
* `shape`: shape of the instance to be explained, starting with batch dimension. Currently only single explanations are supported, so the batch dimension should be equal to 1.
* `feature_range`: global or feature-wise min and max values for the perturbed instance.
* `write_dir`: write directory for Tensorboard logging of the loss terms. It can be helpful when tuning the hyperparameters for your use case. It makes it easy to verify that e.g. not 1 loss term dominates the optimization, that the number of iterations is OK etc. You can access Tensorboard by running `tensorboard --logdir {write_dir}` in the terminal.
* `debug`: flag to enable/disable writing to Tensorboard.
... related to the **optimizer**:
* `max_iterations`: number of loss optimization steps for each value of $\lambda$; the multiplier of the distance loss term.
* `learning_rate_init`: initial learning rate, follows linear decay.
* `decay`: flag to disable learning rate decay if desired
* `early_stop`: early stopping criterion for the search. If no counterfactuals are found for this many steps or if this many counterfactuals are found in a row we change $\lambda$ accordingly and continue the search.
* `init`: how to initialize the search, currently only `"identity"` is supported meaning the search starts from the original instance.
... related to the **objective function**:
* `distance_fn`: distance function between the test instance $X$ and the proposed counterfactual $X^\prime$, currently only `"l1"` is supported.
* `target_proba`: desired target probability for the returned counterfactual instance. Defaults to `1.0`, but it could be useful to reduce it to allow a looser definition of a counterfactual instance.
* `tol`: the tolerance within the `target_proba`, this works in tandem with `target_proba` to specify a range of acceptable predicted probability values for the counterfactual.
* `target_class`: desired target class for the returned counterfactual instance. Can be either an integer denoting the specific class membership or the string `other` which will find a counterfactual instance whose predicted class is anything other than the class of the test instance.
* `lam_init`: initial value of the hyperparameter $\lambda$. This is set to a high value $\lambda=1e^{-1}$ and annealed during the search to find good bounds for $\lambda$ and for most applications should be fine to leave as default.
* `max_lam_steps`: the number of steps (outer loops) to search for with a different value of $\lambda$.
While the default values for the loss term coefficients worked well for the simple examples provided in the notebooks, it is recommended to test their robustness for your own applications.
<div class="alert alert-warning">
Warning
Once a `Counterfactual` instance is initialized, the parameters of it are frozen even if creating a new instance. This is due to TensorFlow behaviour which holds on to some global state. In order to change parameters of the explainer in the same session (e.g. for explaining different models), you will need to reset the TensorFlow graph manually:
```python
import tensorflow as tf
tf.keras.backend.clear_session()
```
You may need to reload your model after this. Then you can create a new `Counterfactual` instance with new parameters.
</div>
### Fit
The method is purely unsupervised so no fit method is necessary.
### Explanation
We can now explain the instance $X$:
```python
explanation = cf.explain(X)
```
The ```explain``` method returns an `Explanation` object with the following attributes:
* *cf*: dictionary containing the counterfactual instance found with the smallest distance to the test instance, it has the following keys:
* *X*: the counterfactual instance
* *distance*: distance to the original instance
* *lambda*: value of $\lambda$ corresponding to the counterfactual
* *index*: the step in the search procedure when the counterfactual was found
* *class*: predicted class of the counterfactual
* *proba*: predicted class probabilities of the counterfactual
* *loss*: counterfactual loss
* *orig_class*: predicted class of original instance
* *orig_proba*: predicted class probabilites of the original instance
* *all*: dictionary of all instances encountered during the search that satisfy the counterfactual constraint but have higher distance to the original instance than the returned counterfactual. This is organized by levels of $\lambda$, i.e. ```explanation['all'][0]``` will be a list of dictionaries corresponding to instances satisfying the counterfactual condition found in the first iteration over $\lambda$ during bisection.
### Numerical Gradients
So far, the whole optimization problem could be defined within the TF graph, making automatic differentiation possible. It is however possible that we do not have access to the model architecture and weights, and are only provided with a ```predict``` function returning probabilities for each class. The counterfactual can then be initialized in the same way as before, but using a prediction function:
```python
# define model
model = load_model('mnist_cnn.h5')
predict_fn = lambda x: cnn.predict(x)
# initialize explainer
shape = (1,) + x_train.shape[1:]
cf = Counterfactual(predict_fn, shape, distance_fn='l1', target_proba=1.0,
target_class='other', max_iter=1000, early_stop=50, lam_init=1e-1,
max_lam_steps=10, tol=0.05, learning_rate_init=0.1,
feature_range=(-1e10, 1e10), eps=0.01, init
```
In this case, we need to evaluate the gradients of the loss function with respect to the input features $X$ numerically:
$$\frac{\partial L_{\text{pred}}}{\partial X} = \frac{\partial L_\text{pred}}{\partial p} \frac{\partial p}{\partial X}
$$
where $L_\text{pred}$ is the predict function loss term, $p$ the predict function and $x$ the input features to optimize. There is now an additional hyperparameter to consider:
* `eps`: a float or an array of floats to define the perturbation size used to compute the numerical gradients of $^{\delta p}/_{\delta X}$. If a single float, the same perturbation size is used for all features, if the array dimension is *(1 x nb of features)*, then a separate perturbation value can be used for each feature. For the Iris dataset, `eps` could look as follows:
```python
eps = np.array([[1e-2, 1e-2, 1e-2, 1e-2]]) # 4 features, also equivalent to eps=1e-2
```
## Examples
[Counterfactual instances on MNIST](../examples/cf_mnist.ipynb)
| github_jupyter |
# Introduction
In this document I'll show a python implementation of *stacked generalization* (or *stacking*), an ensemble technique introduced in [Wolpert, David H., 1992. Stacked generalization, Neural Networks, Volume 5, Issue 2, Pages 241-259].
Stacking uses cross validation to combine the results of several predictive models to improve their accuracy.
A particular case of stacked generalization (*blending*) was used by the winners of the Netflix Prize (http://www.netflixprize.com/assets/GrandPrize2009_BPC_BigChaos.pdf). Ensemble techniques are also extremely popular in several other competitions like the ones hosted on Kaggle. More important, these methods usually perform very well also on "real world" predictive modeling tasks. Stacked generalization is particularly effective when we have datasets describing different aspects of the "thing" we are trying to predict (eg. a dataset of patients' signals). [Olivetti et. at. 2014. MEG Decoding Across Subjects](http://arxiv.org/abs/1404.4175) - [and a related Kaggle competition](https://www.kaggle.com/c/decoding-the-human-brain) - is an example of using stacking to build a robust predictor across subjects.
# Stacked Generalization
In its original formulation, the method works as follows:
1. Split a dataset set into two disjoint sets (train/test).
2. Train and test $k$ models, with *cross validation*, on the first part. These are called **level-0 models**
3. Build train and test **level-1 datasets**, using the predictions from 2) as inputs
4. Train a higher level model (**level-1 model**) on the **level 1 data** from 3) and use it to predict unseen instances from the test set in 1.
A complement to Wolpert's work is [Ting, Witten 1998. Issues in Stacked Generalization http://arxiv.org/pdf/1105.5466.pdf]; this paper presents empirical results that fill in on what Wolpert described as "black art". These can be considered a sort of "best practices" for stacking. In particular:
1. Logistic Regression performs well as the level-1 model
2. For classification tasks, build level-1 data using class probabilities rather than the predicted class labels.
3. Like any ensemble method, stacking is ideal for parallel computation
4. Stacking can work well with just two or three level-0 models
In terms of potential pitfalls, the common issue with loss of interpretability in model ensembles comes to mind. [Perlich, Swirszcz 2010](http://www.sigkdd.org/sites/default/files/issues/12-2-2010-12/v12-02-4-UR-Perlich.pdf) suggest tha cross validation and stacking should be handled with care (eg. use stratified k-fold to improve robustness) when the dataset is skewed (eg. very small number of positive examples).
## Data
I'm not really interested in the method performance, so I'll create an artificial dataset to experiment with a classification task.
```
from sklearn.cross_validation import train_test_split, StratifiedKFold
from sklearn.metrics import accuracy_score
from sklearn.datasets import make_classification
import numpy as np
n_features = 20
n_samples = 10000
X, y = make_classification(n_features=n_features, n_samples=n_samples)
```
Divide the dataset into a 75% - 25% training/test split to satisfy Step 1.
```
X_train, X_test, y_train, y_test = train_test_split(X, y)
```
Cross validation will be carried out by means of stratified k-fold.
```
skf = StratifiedKFold(y_test, n_folds=3)
```
## Models
I'm using decision trees (cart) as level-0 classifiers
```
from sklearn.tree import DecisionTreeClassifier
n_models = 3
clfs = [DecisionTreeClassifier()] * n_models
```
and logistic regression as the level 1 model
```
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
```
# Iterative version
We start the process by training and testing a classification tree $M_k^{-j}$ on a training set $L^{-j}$, for each fold $j$. We use the predictions of these models to build the level-1 dataset $L_{cv}$ that is the train set for the level-1 classifier $\tilde{M}$. In this loop we also take care of building a level-1 test set for $\tilde{M}$, by collecting the predictions of each models $M_k^{-j}$ on unseen instances (X_test).
The code comments follow [Ting, Witten 1998] naming conventions.
```
level_1_train = np.zeros((X_train.shape[0], len(clfs)))
level_1_test = np.zeros((X_test.shape[0], len(clfs), len(skf)))
for k, clf in enumerate(clfs):
for j, (train_index, test_index) in enumerate(skf):
# L^(-j), L_j
X_train_cv, X_test_cv = X_train[train_index], X_test[test_index]
y_train_cv, y_test_cv = y_train[train_index], y_test[test_index]
# M_k^(-j) - level 0 model (M_k) on the training set L^{-j}
clf.fit(X_train_cv, y_train_cv)
# L_cv = z_kj
# we use this dataset to train the level-1 model
# this is a 2-class problems, so we consider only the probability
# p of class 0.
level_1_train[test_index, k] = clf.predict_proba(X_test_cv)[:, 0]
# We build a level-1 test set to be used with the level 1 classifier.
# This is the output of model M_k^(-j) on the held out test set
level_1_test[:, k, j] = clf.predict_proba(X_test)[:, 0]
```
We conclude the training process by fitting a logistic regression on level-1 data.
```
lr.fit(level_1_train, y_train)
```
Finally we predict labels on the level-1 test set. The per-fold classifiers predictions of each model $M_k^{-j}$ are blended using their mean as a combiner. This leads to what [Ting, Witten 1998] refer to as *final level-0 models* $M_k$.
```
pred = lr.predict(level_1_test.mean(2))
```
## Parallel version
Cross validation does not require any form of comunication between the models being trained. This makes stacked generalization a good candidate for parallelization.
In this section I'll be using [joblib](https://pythonhosted.org/joblib/parallel.html#working-with-numerical-data-in-shared-memory-memmaping), a frontend to the [multiprocessing](https://docs.python.org/2/library/multiprocessing.html) framework, to paralleize the training/testing of level-0 models as well as the generation of level 1 data. The results of parallel computations are written to shared, mem-mapped, *ndarray*s. In general this is **not** a good idea; numpy does not provide atomic operations and writes to shared segments can lead to data corruption. However, in this specific case we can rely on the fact that each classifier $k$ and fold $j$ are allocated exclusive segments of the shared *ndarray*s.
```
from joblib import Parallel, delayed
from joblib import load, dump, cpu_count
import tempfile
import shutil
import os
import numpy as np
mmap_dir = tempfile.mkdtemp()
```
X_train, X_test, y_train, y_test have been defined above.
For each input dataset, I'm releaseing the reference on the original in memory array (dump) and replacing it with a reference to the mem mapped ndarray. gc.collect() is called in Parallel just before forking. joblib.dump crashes Ipython Notebook, so for the sake of this example I **will not** mmap input dataset. I leave to code here as a template for future reuse.
```{python}
X_train = np.memmap(os.path.join(mmap_dir, "X_train"),
shape=X_train.shape,
mode='w+')
dump(X_train, os.path.join(mmap_dir, "X_train"))
X_train = load(os.path.join(mmap_dir, "X_train"), mmap_mode='r')
X_test = np.memmap(os.path.join(mmap_dir, "X_test"),
shape=X_test.shape,
mode='w+')
dump(X_test, os.path.join(mmap_dir, "X_test"))
X_test = load(os.path.join(mmap_dir, "X_test"), mmap_mode='r')
y_train = np.memmap(os.path.join(mmap_dir, "y_train"),
shape=y_train.shape,
mode='w+')
dump(y_train, os.path.join(mmap_dir, "y_train"))
y_train = load(os.path.join(mmap_dir, "y_train"), mmap_mode='r')
y_test = np.memmap(os.path.join(mmap_dir, "y_test"),
shape=y_train.shape,
mode='w+')
dump(y_test, os.path.join(mmap_dir, "y_test"))
y_test = load(os.path.join(mmap_dir, "y_test"), mmap_mode='r')
```
Output data.
```
level_1_train = np.memmap(os.path.join(mmap_dir, "level_1_train"),
shape=(X_train.shape[0], len(clfs)),
mode='w+')
level_1_test = np.memmap(os.path.join(mmap_dir, "level_1_test"),
shape=(X_test.shape[0], len(clfs), len(skf)),
mode='w+')
```
cross_validate implements the training of level-0 models and generation of mem-mapped level-1 data.
```
def cross_validate(params):
(level_1_train,
level_1_test,
X_train,
X_test,
y_train,
y_test,
train_index,
test_index,
k,
j,
clf
) = params
X_train_cv, X_test_cv = X_train[train_index], X_test[test_index]
y_train_cv, y_test_cv = y_train[train_index], y_test[test_index]
clf.fit(X_train_cv, y_train_cv)
level_1_train[test_index, k] = clf.predict_proba(X_test_cv)[:, 0]
level_1_test[:,k,j] = clf.predict_proba(X_test)[:, 0]
```
We can use list comprehension to generate a list of parameters to pass to cross_validate() via delayed(). Each element of the list, is itself a list containing the $k$ model and $j$ fold data.
Note that we could be passing the $j$-th fold as eg. X_train[train_index] rather that the whole X_train. However, the function is supposed to use a mem-mapped version of the input data, hence we would pass a reference rather than a copy of the object.
```
params = [[level_1_train,
level_1_test,
X_train,
X_test,
y_train,
y_test,
train_index,
test_index,
k,
j,
clf]
for k, clf in enumerate(clfs)
for j, (train_index, test_index) in enumerate(skf)]
#n_jobs = max(1, min(cpu_count()-1, len(clfs)*len(skf)))
n_jobs = 4
results = Parallel(n_jobs=n_jobs)(delayed(cross_validate)(param) for param in params)
```
Like in the iterative case, we use logistic regression as the level-1 model and predict unseen instances on the blended level-1 test set.
```
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(level_1_train, y_train)
pred = lr.predict(level_1_test.mean(2))
```
At last we clean up mmap data
```
shutil.rmtree(mmap_dir)
```
# Conclusion
Is stacking a silver bullet that improves classification accuracy in every possible task? No, as it is the case with predictive modeling, performance depends on a number of factors. YMMV.
| github_jupyter |
```
from rasa_nlu.training_data import TrainingData, Message
import io
import logging
import numpy as np
import os
import pickle
import typing
from tqdm import tqdm
from typing import Any, Dict, List, Optional, Text, Tuple
from rasa_nlu.classifiers import INTENT_RANKING_LENGTH
from rasa_nlu.components import Component
logger = logging.getLogger(__name__)
import spacy
LANGUAGE = 'en'
spacy_nlp = spacy.load(LANGUAGE)
examples = [Message("anywhere in the west", {
"intent": "restaurant_search",
"entities": [{"start": 16, "end": 20,
"value": "west", "entity": "location"}],
"spacy_doc": spacy_nlp("anywhere in the west")
}),
Message("central indian restaurant", {
"intent": "restaurant_search",
"entities": [
{"start": 0, "end": 7, "value": "central",
"entity": "location",
"extractor": "random_extractor"},
{"start": 8, "end": 14, "value": "indian",
"entity": "cuisine",
"extractor": "CRFEntityExtractor"}
],
"spacy_doc": spacy_nlp("central indian restaurant")
}),
Message("hi there!", {"intent": "greet", "entities": [],
"spacy_doc": spacy_nlp("hi there!")}),
Message("good morning", {"intent": "greet", "entities": [],
"spacy_doc": spacy_nlp("good morning")}),
Message("thank you", {"intent": "thanks", "entities": [],
"spacy_doc": spacy_nlp("thank you")}),
Message("good bye", {"intent": "thanks", "entities": [],
"spacy_doc": spacy_nlp("good bye")})
]
examples
training_data = TrainingData(training_examples=examples)
distinct_intents = set([example.get("intent") for example in training_data.intent_examples])
distinct_intents
intent_dict = {intent: idx for idx, intent in enumerate(sorted(distinct_intents))}
intent_dict
def _create_intent_token_dict(intents,
intent_split_symbol):
"""Create intent token dictionary"""
distinct_tokens = set([token
for intent in intents
for token in intent.split(intent_split_symbol)])
return {token: idx
for idx, token in enumerate(sorted(distinct_tokens))}
inv_intent_dict = {v: k for k, v in intent_dict.items()}
inv_intent_dict
defaults = {'hidden_layers_sizes_a': [256, 128],
'hidden_layers_sizes_b': [],
'batch_size': [64, 256],
'epochs': 300,
'embed_dim': 20,
'mu_pos': 0.8,
'mu_neg': -0.4,
'similarity_type': 'cosine',
'num_neg': 20,
'use_max_sim_neg': True,
'random_seed': None,
'C2': 0.002,
'C_emb': 0.8,
'droprate': 0.2,
'intent_tokenization_flag': False,
'intent_split_symbol': '_',
'evaluate_every_num_epochs': 10,
'evaluate_on_num_examples': 1000}
import numpy as np
def _create_encoded_intents(intent_dict):
"""Create matrix with intents encoded in rows as bag of words.
If intent_tokenization_flag is off, returns identity matrix.
"""
return np.eye(len(intent_dict))
encoded_all_intents = _create_encoded_intents(intent_dict)
encoded_all_intents
size = len(training_data.training_examples)
def _create_all_Y(size):
"""Stack encoded_all_intents on top of each other
to create candidates for training examples and
to calculate training accuracy
"""
return np.stack([encoded_all_intents] * size)
all_Y = _create_all_Y(size)
all_Y
def _prepare_data_for_training(training_data, intent_dict):
"""Prepare data for training"""
X = np.stack([e.get("text_features")
for e in training_data.intent_examples])
intents_for_X = np.array([intent_dict[e.get("intent")]
for e in training_data.intent_examples])
Y = np.stack([encoded_all_intents[intent_idx]
for intent_idx in intents_for_X])
return X, Y, intents_for_X
from rasa_nlu.featurizers.count_vectors_featurizer import CountVectorsFeaturizer
ftr = CountVectorsFeaturizer({"token_pattern": r'(?u)\b\w+\b'})
ftr.train(training_data)
training_data.intent_examples[0].get('text_features')
X, Y, intents_for_X = _prepare_data_for_training(training_data,
intent_dict)
X
Y
intents_for_X
num_neg = min(defaults['num_neg'], encoded_all_intents.shape[0]-1)
def _create_tf_embed_nn(x_in, is_training, layer_sizes, name):
"""Create nn with hidden layers and name"""
reg = tf.contrib.layers.l2_regularizer(defaults['C2'])
x = x_in
for i, layer_size in enumerate(layer_sizes):
x = tf.layers.dense(inputs=x, units=layer_size,
activation=tf.nn.relu, kernel_regularizer=reg,
name='hidden_layer_{}_{}'.format(name, i))
x = tf.layers.dropout(x, rate=defaults['droprate'],
training=is_training)
x = tf.layers.dense(inputs=x, units=defaults['embed_dim'],
kernel_regularizer=reg,
name='embed_layer_{}'.format(name))
return x
def _create_tf_embed(a_in, b_in, is_training):
"""Create tf graph for training"""
emb_a = _create_tf_embed_nn(a_in, is_training,
defaults['hidden_layers_sizes_a'],
name='a')
emb_b = _create_tf_embed_nn(b_in, is_training,
defaults['hidden_layers_sizes_b'],
name='b')
return emb_a, emb_b
def _tf_sim(a, b):
"""Define similarity
in two cases:
sim: between embedded words and embedded intent labels
sim_emb: between individual embedded intent labels only
"""
if defaults['similarity_type'] == 'cosine':
a = tf.nn.l2_normalize(a, -1)
b = tf.nn.l2_normalize(b, -1)
if defaults['similarity_type'] in {'cosine', 'inner'}:
sim = tf.reduce_sum(tf.expand_dims(a, 1) * b, -1)
sim_emb = tf.reduce_sum(b[:, 0:1, :] * b[:, 1:, :], -1)
return sim, sim_emb
else:
raise ValueError("Wrong similarity type {}, "
"should be 'cosine' or 'inner'"
"".format(defaults['similarity_type']))
def _tf_loss(sim, sim_emb):
"""Define loss"""
loss = tf.maximum(0., defaults['mu_pos'] - sim[:, 0])
if defaults['use_max_sim_neg']:
max_sim_neg = tf.reduce_max(sim[:, 1:], -1)
loss += tf.maximum(0., defaults['mu_neg'] + max_sim_neg)
else:
max_margin = tf.maximum(0., defaults['mu_neg'] + sim[:, 1:])
loss += tf.reduce_sum(max_margin, -1)
max_sim_emb = tf.maximum(0., tf.reduce_max(sim_emb, -1))
loss += max_sim_emb * defaults['C_emb']
loss = (tf.reduce_mean(loss) + tf.losses.get_regularization_loss())
return loss
def _create_batch_b(batch_pos_b, intent_ids):
"""Create batch of intents.
Where the first is correct intent
and the rest are wrong intents sampled randomly
"""
batch_pos_b = batch_pos_b[:, np.newaxis, :]
# sample negatives
batch_neg_b = np.zeros((batch_pos_b.shape[0], num_neg,
batch_pos_b.shape[-1]))
for b in range(batch_pos_b.shape[0]):
# create negative indexes out of possible ones
# except for correct index of b
negative_indexes = [i for i in
range(encoded_all_intents.shape[0])
if i != intent_ids[b]]
negs = np.random.choice(negative_indexes, size=num_neg)
batch_neg_b[b] = encoded_all_intents[negs]
return np.concatenate([batch_pos_b, batch_neg_b], 1)
def _linearly_increasing_batch_size(epoch):
"""Linearly increase batch size with every epoch.
The idea comes from https://arxiv.org/abs/1711.00489
"""
if not isinstance(defaults['batch_size'], list):
return int(defaults['batch_size'])
if defaults['epochs'] > 1:
return int(defaults['batch_size'][0] +
epoch * (defaults['batch_size'][1] -
defaults['batch_size'][0]) / (defaults['epochs'] - 1))
else:
return int(defaults['batch_size'][0])
def _output_training_stat(a_in, b_in, X, intents_for_X, is_training,
session, sim_op):
"""Output training statistics"""
n = defaults['evaluate_on_num_examples']
ids = np.random.permutation(len(X))[:n]
all_Y = _create_all_Y(X[ids].shape[0])
train_sim = session.run(sim_op,
feed_dict={a_in: X[ids],
b_in: all_Y,
is_training: False})
train_acc = np.mean(np.argmax(train_sim, -1) == intents_for_X[ids])
return train_acc
def _train_tf(a_in, b_in, X, Y, intents_for_X, loss, is_training,
train_op, session, sim_op):
"""Train tf graph"""
session.run(tf.global_variables_initializer())
if defaults['evaluate_on_num_examples']:
logger.info("Accuracy is updated every {} epochs"
"".format(defaults['evaluate_every_num_epochs']))
pbar = tqdm(range(defaults['epochs']), desc="Epochs")
train_acc = 0
last_loss = 0
for ep in pbar:
indices = np.random.permutation(len(X))
batch_size = _linearly_increasing_batch_size(ep)
batches_per_epoch = (len(X) // batch_size +
int(len(X) % batch_size > 0))
ep_loss = 0
for i in range(batches_per_epoch):
end_idx = (i + 1) * batch_size
start_idx = i * batch_size
batch_a = X[indices[start_idx:end_idx]]
batch_pos_b = Y[indices[start_idx:end_idx]]
intents_for_b = intents_for_X[indices[start_idx:end_idx]]
# add negatives
batch_b = _create_batch_b(batch_pos_b, intents_for_b)
sess_out = session.run(
{'loss': loss, 'train_op': train_op},
feed_dict={a_in: batch_a,
b_in: batch_b,
is_training: True}
)
ep_loss += sess_out.get('loss') / batches_per_epoch
if defaults['evaluate_on_num_examples']:
if (ep == 0 or
(ep + 1) % defaults['evaluate_every_num_epochs'] == 0 or
(ep + 1) == defaults['epochs']):
train_acc = _output_training_stat(a_in, b_in, X,
intents_for_X,
is_training,
session, sim_op)
last_loss = ep_loss
pbar.set_postfix({
"loss": "{:.3f}".format(ep_loss),
"acc": "{:.3f}".format(train_acc)
})
else:
pbar.set_postfix({
"loss": "{:.3f}".format(ep_loss)
})
if defaults['evaluate_on_num_examples']:
logger.info("Finished training embedding classifier, "
"loss={:.3f}, train accuracy={:.3f}"
"".format(last_loss, train_acc))
graph = tf.Graph()
with graph.as_default():
random_seed = None
np.random.seed(random_seed)
print('placeholders')
a_in = tf.placeholder(tf.float32, (None, X.shape[-1]), name='a')
b_in = tf.placeholder(tf.float32, (None, None, Y.shape[-1]), name='b')
is_training = tf.placeholder_with_default(False, shape=())
print('Embeddings for features and intent')
word_embed, intent_embed = _create_tf_embed(a_in, b_in, is_training)
print('Similarity estimation')
sim_op, sim_emb = _tf_sim(word_embed, intent_embed)
print('loss estimation')
loss = _tf_loss(sim_op, sim_emb)
print('optimizer')
train_op = tf.train.AdamOptimizer().minimize(loss)
session = tf.Session()
print('training begins')
_train_tf(a_in, b_in, X, Y, intents_for_X,
loss, is_training, train_op, session, sim_op)
def _calculate_message_sim(X, all_Y):
"""Load tf graph and calculate message similarities"""
message_sim = session.run(sim_op, feed_dict={a_in: X,
b_in: all_Y})
message_sim = message_sim.flatten() # sim is a matrix
intent_ids = message_sim.argsort()[::-1]
message_sim[::-1].sort()
if defaults['similarity_type'] == 'cosine':
# clip negative values to zero
message_sim[message_sim < 0] = 0
elif defaults['similarity_type'] == 'inner':
# normalize result to [0, 1] with softmax
message_sim = np.exp(message_sim)
message_sim /= np.sum(message_sim)
# transform sim to python list for JSON serializing
return intent_ids, message_sim.tolist()
def process(message, **kwargs):
"""Return the most likely intent and its similarity to the input."""
intent = {"name": None, "confidence": 0.0}
intent_ranking = []
if session is None:
logger.error("There is no trained tf.session: "
"component is either not trained or "
"didn't receive enough training data")
else:
# get features (bag of words) for a message
# noinspection PyPep8Naming
X = message.get("text_features").reshape(1, -1)
# stack encoded_all_intents on top of each other
# to create candidates for test examples
# noinspection PyPep8Naming
all_Y = _create_all_Y(X.shape[0])
# load tf graph and session
intent_ids, message_sim = _calculate_message_sim(X, all_Y)
# if X contains all zeros do not predict some label
if X.any() and intent_ids.size > 0:
intent = {"name": inv_intent_dict[intent_ids[0]],
"confidence": message_sim[0]}
ranking = list(zip(list(intent_ids), message_sim))
ranking = ranking[:INTENT_RANKING_LENGTH]
intent_ranking = [{"name": inv_intent_dict[intent_idx],
"confidence": score}
for intent_idx, score in ranking]
return intent, intent_ranking
message.set("intent", intent, add_to_output=True)
message.set("intent_ranking", intent_ranking, add_to_output=True)
def persist(file_name, model_dir):
"""Persist this model into the passed directory.
Return the metadata necessary to load the model again.
"""
if session is None:
return {"file": None}
checkpoint = os.path.join(model_dir, file_name + ".ckpt")
try:
os.makedirs(os.path.dirname(checkpoint))
except OSError as e:
# be happy if someone already created the path
import errno
if e.errno != errno.EEXIST:
raise
with graph.as_default():
graph.clear_collection('message_placeholder')
graph.add_to_collection('message_placeholder',
a_in)
graph.clear_collection('intent_placeholder')
graph.add_to_collection('intent_placeholder',
b_in)
graph.clear_collection('similarity_op')
graph.add_to_collection('similarity_op',
sim_op)
graph.clear_collection('word_embed')
graph.add_to_collection('word_embed',
word_embed)
graph.clear_collection('intent_embed')
graph.add_to_collection('intent_embed',
intent_embed)
saver = tf.train.Saver()
saver.save(session, checkpoint)
with io.open(os.path.join(
model_dir,
file_name + "_inv_intent_dict.pkl"), 'wb') as f:
pickle.dump(inv_intent_dict, f)
with io.open(os.path.join(
model_dir,
file_name + "_encoded_all_intents.pkl"), 'wb') as f:
pickle.dump(encoded_all_intents, f)
return {"file": file_name}
def load(meta, model_dir, model_metadata, cached_component, **kwargs):
if model_dir and meta.get("file"):
file_name = meta.get("file")
checkpoint = os.path.join(model_dir, file_name + ".ckpt")
graph = tf.Graph()
with graph.as_default():
sess = tf.Session()
saver = tf.train.import_meta_graph(checkpoint + '.meta')
saver.restore(sess, checkpoint)
a_in = tf.get_collection('message_placeholder')[0]
b_in = tf.get_collection('intent_placeholder')[0]
sim_op = tf.get_collection('similarity_op')[0]
word_embed = tf.get_collection('word_embed')[0]
intent_embed = tf.get_collection('intent_embed')[0]
with io.open(os.path.join(
model_dir,
file_name + "_inv_intent_dict.pkl"), 'rb') as f:
inv_intent_dict = pickle.load(f)
with io.open(os.path.join(
model_dir,
file_name + "_encoded_all_intents.pkl"), 'rb') as f:
encoded_all_intents = pickle.load(f)
return cls(
component_config=meta,
inv_intent_dict=inv_intent_dict,
encoded_all_intents=encoded_all_intents,
session=sess,
graph=graph,
message_placeholder=a_in,
intent_placeholder=b_in,
similarity_op=sim_op,
word_embed=word_embed,
intent_embed=intent_embed
)
else:
logger.warning("Failed to load nlu model. Maybe path {} "
"doesn't exist"
"".format(os.path.abspath(model_dir)))
return cls(component_config=meta)
# save output
model_dir = '/Users/varunn/Documents/NLP-data/'
file_name = 'embedding_intent_classifier_exampledataset'
persist(file_name=file_name, model_dir=model_dir)
test_inp = Message("show me some indian restuarants")
test_inp.as_dict()
ftr.process(test_inp)
test_inp.as_dict()
process(test_inp)
```
| github_jupyter |
# Combining Data With Joins
## Overview
Teaching: 15
Exercises: 10
### Questions
- "How do I bring data together from separate tables?"
### Objectives
- "Employ joins to combine data from two tables."
- "Apply functions to manipulate individual values."
- "Employ aliases to assign new names to tables and columns in a query."
### Key points
- "Use the `JOIN` command to combine data from two tables---the `ON` or `USING` keywords specify which columns link the tables."
- "Regular `JOIN` returns only matching rows. Other join commands provide different behavior, e.g., `LEFT JOIN` retains all rows of the table on the left side of the command."
- "`COALESCE` allows you to specify a value to use in place of `NULL`, which can help in joins"
- "`NULLIF` can be used to replace certain values with `NULL` in results"
- "Many other functions like `COALESCE` and `NULLIF` can operate on individual values."
## Setup
### Copy the original dataset to a folder `notebooks/data`
```
! mkdir -p data; cp -R ../files/original-data/* ./data
```
### Configure SQL Magic extension and connect to the database
First enable the SQL magic extension, configure extension to return Pandas data frames (in order for the notebook to handle large result sets better), and then connect to our database again.
```
%load_ext sql
%config SqlMagic.autopandas=True
%sql sqlite:///data/portal_mammals.sqlite
```
## Joins
To combine data from two tables we use the SQL `JOIN` command, which comes after
the `FROM` command.
Database tables are used to organize and group data by common characteristics or principles.
Often, we need to combine elements from separate tables into a single tables or queries for analysis and visualization.
A JOIN is a means for combining columns from multiple tables by using values common to each.
The JOIN command combined with ON is used to combine fields from separate tables.
The `JOIN` command on its own will result in a cross product, where each row in
the first table is paired with each row in the second table. Usually this is not
what is desired when combining two tables with data that is related in some way.
For that, we need to tell the computer which columns provide the link between the two
tables using the word `ON`. What we want is to join the data with the same
species id.
```
%%sql
SELECT *
FROM surveys
JOIN species
ON surveys.species_id = species.species_id;
```
`ON` is like `WHERE`. It filters things out according to a test condition. We use
the `table.colname` format to tell the manager what column in which table we are
referring to.
The output of the `JOIN` command will have columns from the first table plus the
columns from the second table. For the above command, the output will be a table
that has the following column names:
| record_id | month | day | year | plot_id | species_id | sex | hindfoot_length | weight | species_id | genus | species | taxa |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ... |||||||||||||
| 96 | 8 | 20 | 1997 | 12 | **DM** | M | 36 | 41 | **DM** | Dipodomys | merriami | Rodent |
| ... ||||||||||||||
Alternatively, we can use the word `USING`, as a short-hand. `USING` only
works on columns which share the same name. In this case we are
telling the manager that we want to combine `surveys` with `species` and that
the common column is `species_id`.
```
%%sql
SELECT *
FROM surveys
JOIN species
USING (species_id);
```
The output will only have one **species_id** column
| record_id | month | day | year | plot_id | species_id | sex | hindfoot_length | weight | genus | species | taxa |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ... ||||||||||||
| 96 | 8 | 20 | 1997 | 12 | DM | M | 36 | 41 | Dipodomys | merriami | Rodent |
| ... |||||||||||||
We often won't want all of the fields from both tables, so anywhere we would
have used a field name in a non-join query, we can use `table.colname`.
For example, what if we wanted information on when individuals of each
species were captured, but instead of their species ID we wanted their
actual species names.
```
%%sql
SELECT surveys.year, surveys.month, surveys.day, species.genus, species.species
FROM surveys
JOIN species
ON surveys.species_id = species.species_id;
```
| year | month | day | genus | species |
|---|---|---|---|---|
| ... |||||
| 1977 | 7 | 16 | Neotoma | albigula|
| 1977 | 7 | 16 | Dipodomys | merriami|
|...||||||
Many databases, including SQLite, also support a join through the `WHERE` clause of a query.
For example, you may see the query above written without an explicit JOIN.
```
%%sql
SELECT surveys.year, surveys.month, surveys.day, species.genus, species.species
FROM surveys, species
WHERE surveys.species_id = species.species_id;
```
For the remainder of this lesson, we'll stick with the explicit use of the `JOIN` keyword for
joining tables in SQL.
### Challenge
> - Write a query that returns the genus, the species name, and the weight
> of every individual captured at the site
#### Solution
```
%%sql
SELECT species.genus, species.species, surveys.weight
FROM surveys
JOIN species
ON surveys.species_id = species.species_id;
```
## Different join types
We can count the number of records returned by our original join query.
```
%%sql
SELECT COUNT(*)
FROM surveys
JOIN species
USING (species_id);
```
Notice that this number is smaller than the number of records present in the
survey data.
```
%%sql
SELECT COUNT(*) FROM surveys;
```
This is because, by default, SQL only returns records where the joining value
is present in the joined columns of both tables (i.e. it takes the _intersection_
of the two join columns). This joining behaviour is known as an `INNER JOIN`.
In fact the `JOIN` command is simply shorthand for `INNER JOIN` and the two
terms can be used interchangably as they will produce the same result.
We can also tell the computer that we wish to keep all the records in the first
table by using the command `LEFT OUTER JOIN`, or `LEFT JOIN` for short.
### Challenge
> - Re-write the original query to keep all the entries present in the `surveys`
> table. How many records are returned by this query?
#### Solution
```
%%sql
SELECT * FROM surveys
LEFT JOIN species
USING (species_id);
```
### Challenge
> - Count the number of records in the `surveys` table that have a `NULL` value
> in the `species_id` column.
Remember: In SQL a `NULL` value in one table can never be joined to a `NULL` value in a
second table because `NULL` is not equal to anything, not even itself.
#### Solution
```
%%sql
SELECT COUNT(*)
FROM surveys
WHERE species_id IS NULL;
```
### Combining joins with sorting and aggregation
Joins can be combined with sorting, filtering, and aggregation. So, if we
wanted average mass of the individuals on each different type of treatment, we
could do something like
```
%%sql
SELECT plots.plot_type, AVG(surveys.weight)
FROM surveys
JOIN plots
ON surveys.plot_id = plots.plot_id
GROUP BY plots.plot_type;
```
### Challenge
> - Write a query that returns the number of animals caught of each genus in each plot.
> Order the results by plot number (ascending) and by descending number of individuals in each plot.
#### Solution
```
%%sql
SELECT surveys.plot_id, species.genus, COUNT(*) AS number_indiv
FROM surveys
JOIN species
ON surveys.species_id = species.species_id
GROUP BY species.genus, surveys.plot_id
ORDER BY surveys.plot_id ASC, number_indiv DESC;
```
### Challenge
> - Write a query that finds the average weight of each rodent species (i.e., only include species with Rodent in the taxa field).
#### Solution
```
%%sql
SELECT surveys.species_id, AVG(surveys.weight)
FROM surveys
JOIN species
ON surveys.species_id = species.species_id
WHERE species.taxa = 'Rodent'
GROUP BY surveys.species_id;
```
## Functions `COALESCE` and `NULLIF` and more
SQL includes numerous functions for manipulating data. You've already seen some
of these being used for aggregation (`SUM` and `COUNT`) but there are functions
that operate on individual values as well. Probably the most important of these
are `COALESCE` and `NULLIF`. `COALESCE` allows us to specify a value to use in
place of `NULL`.
We can represent unknown sexes with `'U'` instead of `NULL`:
```
%%sql
SELECT species_id, sex, COALESCE(sex, 'U')
FROM surveys;
```
The lone "sex" column is only included in the query above to illustrate where
`COALESCE` has changed values; this isn't a usage requirement.
### Challenge
> - Write a query that returns 30 instead of `NULL` for values in the
> `hindfoot_length` column.
#### Solution
```
%%sql
SELECT hindfoot_length, COALESCE(hindfoot_length, 30)
FROM surveys;
```
### Challenge
> - Write a query that calculates the average hind-foot length of each species,
> assuming that unknown lengths are 30 (as above).
#### Solution
```
%%sql
SELECT species_id, AVG(COALESCE(hindfoot_length, 30))
FROM surveys
GROUP BY species_id;
```
### COALESCE combined with JOIN
`COALESCE` can be particularly useful in `JOIN`. When joining the `species` and
`surveys` tables earlier, some results were excluded because the `species_id`
was `NULL` in the surveys table. We can use `COALESCE` to include them again, re-writing the `NULL` to
a valid joining value:
```
%%sql
SELECT surveys.year, surveys.month, surveys.day, species.genus, species.species
FROM surveys
JOIN species
ON COALESCE(surveys.species_id, 'AB') = species.species_id;
```
### Challenge
> - Write a query that returns the number of animals caught of each genus in each
> plot, assuming that unknown species are all of the genus "Rodent".
#### Solution
```
%%sql
SELECT plot_id, COALESCE(genus, 'Rodent') AS genus2, COUNT(*)
FROM surveys
LEFT JOIN species
ON surveys.species_id=species.species_id
GROUP BY plot_id, genus2;
```
### NULLIF
The inverse of `COALESCE` is `NULLIF`. This returns `NULL` if the first argument
is equal to the second argument. If the two are not equal, the first argument
is returned. This is useful for "nulling out" specific values.
We can "null out" plot 7:
```
%%sql
SELECT species_id, plot_id, NULLIF(plot_id, 7)
FROM surveys;
```
### Other functions
Some more functions which are common to SQL databases are listed in the table
below:
| Function | Description |
|------------------------------|-------------------------------------------------------------------------------------------------|
| `ABS(n)` | Returns the absolute (positive) value of the numeric expression *n* |
| `COALESCE(x1, ..., xN)` | Returns the first of its parameters that is not NULL |
| `LENGTH(s)` | Returns the length of the string expression *s* |
| `LOWER(s)` | Returns the string expression *s* converted to lowercase |
| `NULLIF(x, y)` | Returns NULL if *x* is equal to *y*, otherwise returns *x* |
| `ROUND(n)` or `ROUND(n, x)` | Returns the numeric expression *n* rounded to *x* digits after the decimal point (0 by default) |
| `TRIM(s)` | Returns the string expression *s* without leading and trailing whitespace characters |
| `UPPER(s)` | Returns the string expression *s* converted to uppercase |
Finally, some useful functions which are particular to SQLite are listed in the
table below:
| Function | Description |
|-------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `RANDOM()` | Returns a random integer between -9223372036854775808 and +9223372036854775807. |
| `REPLACE(s, f, r)` | Returns the string expression *s* in which every occurrence of *f* has been replaced with *r* |
| `SUBSTR(s, x, y)` or `SUBSTR(s, x)` | Returns the portion of the string expression *s* starting at the character position *x* (leftmost position is 1), *y* characters long (or to the end of *s* if *y* is omitted) |
### Challenge
> Write a query that returns genus names (no repeats), sorted from longest genus name down
> to shortest.
#### Solution
```
%%sql
SELECT DISTINCT genus
FROM species
ORDER BY LENGTH(genus) DESC;
```
## Aliases when joining
As we saw before, aliases make things clearer, and are especially useful when joining tables.
```
%%sql
SELECT surv.year AS yr, surv.month AS mo, surv.day AS day, sp.genus AS gen, sp.species AS sp
FROM surveys AS surv
JOIN species AS sp
ON surv.species_id = sp.species_id;
```
To practice we have some optional challenges for you.
### Challenge (optional)
> SQL queries help us *ask* specific *questions* which we want to answer about our data. The real skill with SQL is to know how to translate our scientific questions into a sensible SQL query (and subsequently visualize and interpret our results).
>
> Have a look at the following questions; these questions are written in plain English. Can you translate them to *SQL queries* and give a suitable answer?
>
> 1. How many plots from each type are there?
>
> 2. How many specimens are of each sex are there for each year, including those whose sex is unknown?
>
> 3. How many specimens of each species were captured in each type of plot, excluding specimens of unknown species?
>
> 4. What is the average weight of each taxa?
>
> 5. What are the minimum, maximum and average weight for each species of Rodent?
>
> 6. What is the average hindfoot length for male and female rodent of each species? Is there a Male / Female difference?
>
> 7. What is the average weight of each rodent species over the course of the years? Is there any noticeable trend for any of the species?
#### Proposed solutions
##### 1. Solution:
```
%%sql
SELECT plot_type, COUNT(*) AS num_plots
FROM plots
GROUP BY plot_type;
```
##### 2. Solution:
```
%%sql
SELECT year, sex, COUNT(*) AS num_animal
FROM surveys
GROUP BY sex, year;
```
##### 3. Solution:
```
%%sql
SELECT species_id, plot_type, COUNT(*)
FROM surveys
JOIN plots USING(plot_id)
WHERE species_id IS NOT NULL
GROUP BY species_id, plot_type;
```
##### 4. Solution:
```
%%sql
SELECT taxa, AVG(weight)
FROM surveys
JOIN species ON species.species_id = surveys.species_id
GROUP BY taxa;
```
##### 5. Solution:
```
%%sql
SELECT surveys.species_id, MIN(weight), MAX(weight), AVG(weight) FROM surveys
JOIN species ON surveys.species_id = species.species_id
WHERE taxa = 'Rodent'
GROUP BY surveys.species_id;
```
##### 6. Solution:
```
%%sql
SELECT surveys.species_id, sex, AVG(hindfoot_length)
FROM surveys JOIN species ON surveys.species_id = species.species_id
WHERE (taxa = 'Rodent') AND (sex IS NOT NULL)
GROUP BY surveys.species_id, sex;
```
##### 7. Solution:
```
%%sql
SELECT surveys.species_id, year, AVG(weight) as mean_weight
FROM surveys
JOIN species ON surveys.species_id = species.species_id
WHERE taxa = 'Rodent' GROUP BY surveys.species_id, year;
```
## End of episode
| github_jupyter |
```
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, StandardScaler, MinMaxScaler
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn import svm
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from imblearn.over_sampling import SMOTE
from helper import get_performance
EPOCHS = 700
BATCH_SIZE = 2048
ACTIVATION = 'swish'
LEARNING_RATE = 0.0007
FOLDS = 5
# Reading the dataset
data = pd.read_csv("dataset/Job_Change/aug_train.csv")
aug_train = data.sample(frac=1, replace=True, random_state=1).reset_index(drop=True)
# Seperate aug_train into target and features
y = aug_train['target']
X_aug_train = aug_train.drop('target',axis = 'columns')
# save the index for X_aug_train
X_aug_train_index = X_aug_train.index.to_list()
class MultiColumnLabelEncoder:
def __init__(self,columns = None):
self.columns = columns # array of column names to encode
def fit(self,X,y=None):
return self # not relevant here
def transform(self,X):
'''
Transforms columns of X specified in self.columns using
LabelEncoder(). If no columns specified, transforms all
columns in X.
'''
output = X.copy()
if self.columns is not None:
for col in self.columns:
# convert float NaN --> string NaN
output[col] = output[col].fillna('NaN')
output[col] = LabelEncoder().fit_transform(output[col])
else:
for colname,col in output.iteritems():
output[colname] = LabelEncoder().fit_transform(col)
return output
def fit_transform(self,X,y=None):
return self.fit(X,y).transform(X)
# store the catagorical features names as a list
cat_features = X_aug_train.select_dtypes(['object']).columns.to_list()
# use MultiColumnLabelEncoder to apply LabelEncoding on cat_features
# uses NaN as a value , no imputation will be used for missing data
X = MultiColumnLabelEncoder(columns = cat_features).fit_transform(X_aug_train)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.30, random_state = 42)
print("Train data: ", X_train.shape)
print("Test data: ", X_test.shape)
y_train.value_counts()
y_test.value_counts()
```
# Default Model
```
model_default = DecisionTreeClassifier()
scores_default = cross_val_score(model_default, X=X_train, y=y_train, cv = FOLDS)
model_default.fit(X_train, y_train)
y_pred_default = model_default.predict(X_test)
get_performance(X_test, y_test, y_pred_default)
pd.DataFrame(y_pred_default).value_counts()
```
# SMOTE Oversampling
```
# SMOTE Oversampling
# Transform data
oversample = SMOTE()
X_train_sm, y_train_sm = oversample.fit_resample(X_train, y_train)
model_SMOTE = DecisionTreeClassifier()
scores_SMOTE = cross_val_score(model_SMOTE, X=X_train_sm, y=y_train_sm, cv = FOLDS)
model_SMOTE.fit(X_train_sm, y_train_sm)
y_pred_SMOTE = model_SMOTE.predict(X_test)
get_performance(X_test, y_test, y_pred_SMOTE)
print(X_train_sm.shape,y_train_sm.shape)
```
# MAPS
```
import time
import sys
sys.path.insert(1, './mmd')
from mmd import diagnoser
from scipy import stats as st
import numpy
#notebook's library
%matplotlib inline
from helper import get_top_f1_rules, get_relevent_attributs_target, get_MMD_results, get_biased_features, get_BGMD_results
from helper import generateTrain_data_Weights
default_result = pd.concat([X_test, y_test], axis=1, join='inner')
default_result.loc[:,"pred"] = y_pred_default
def mispredict_label(row):
if row['target'] == row['pred']:
return False
return True
default_result_copy = default_result.copy()
X_test_copy = X_test.copy()
X_test_copy['mispredict'] = default_result_copy.apply(lambda row: mispredict_label(row), axis=1)
# Get relevent attributes and target
relevant_attributes, Target = get_relevent_attributs_target(X_test_copy)
# Generate MMD rules and correspodning information
MMD_rules, MMD_time, MMD_Features = get_MMD_results(X_test_copy, relevant_attributes, Target)
#Get biased attributes this time
biased_attributes = get_biased_features(X_test_copy, relevant_attributes)
BGMD_rules, BGMD_time, BGMD_Features = get_BGMD_results(X_test_copy, biased_attributes, Target)
print('MMD Spent:', MMD_time, 'BGMD Spent:', BGMD_time)
MMD_rules, BGMD_rules
from helper import get_test_data_in_misprediction_areas
final_result = pd.concat([X_test, y_test], axis=1, join='inner')
indexes_in_misprediction_area = get_test_data_in_misprediction_areas(BGMD_rules, X_test)
y_actual_MD = []
for index in indexes_in_misprediction_area:
y_actual_MD.append(final_result.loc[index]['target'])
from collections import Counter
from sklearn.metrics import precision_recall_fscore_support
grid_upweights = range(1, 101)
best_weight_all = 1
best_f1_all = 0
best_weight_mis = 1
best_f1_mis = 0
f1_all = []
f1_mispredicted = []
acc_all = []
acc_mispredicted = []
recall_all = []
recall_mispredicted = []
for upweight in grid_upweights:
# give extra weights to training samples in mispredited areas
print('Upweight_value: ', upweight)
weights = generateTrain_data_Weights(BGMD_rules, X_train, upweight_value=upweight)
c = Counter(weights)
print(c.items())
MAPS_model = DecisionTreeClassifier()
scores_MAPS = cross_val_score(MAPS_model, X=X_train, y=y_train, cv = FOLDS)
MAPS_model.fit(X_train, y_train, sample_weight = weights)
y_pred_MAPS = MAPS_model.predict(X_test)
total_result = get_performance(X_test, y_test, y_pred_MAPS)
acc_all.append(total_result[0])
recall_all.append(total_result[1])
f1_all.append(total_result[2])
final_result['y_pred_MAPS'] = y_pred_MAPS
y_pred_MAPS_MD = []
for index in indexes_in_misprediction_area:
y_pred_MAPS_MD.append(final_result.loc[index]['y_pred_MAPS'])
MAPS_MD_metric = precision_recall_fscore_support(y_actual_MD, y_pred_MAPS_MD, average='weighted')
acc_mispredicted.append(MAPS_MD_metric[0])
recall_mispredicted.append(MAPS_MD_metric[1])
f1_mispredicted.append(MAPS_MD_metric[2])
if total_result[2] > best_f1_all:
best_f1_all = total_result[2]
best_weight_all = upweight;
if MAPS_MD_metric[2] > best_f1_mis:
best_f1_mis = MAPS_MD_metric[2]
best_weight_mis = upweight
print("Best weight on all is: ", best_weight_all)
print("Best weight on misprediction area is: ", best_weight_mis)
plt.plot(grid_upweights, f1_mispredicted, label = "f1 on mispredicted area")
plt.legend()
plt.show()
plt.plot(grid_upweights, f1_all, label = "f1 on all data")
plt.show()
from helper import get_mispredicted_region_test
weights = generateTrain_data_Weights(BGMD_rules, X_train, upweight_value=best_weight_mis)
c = Counter(weights)
MAPS_model = DecisionTreeClassifier()
scores_MAPS = cross_val_score(MAPS_model, X=X_train, y=y_train, cv = FOLDS)
MAPS_model.fit(X_train, y_train, sample_weight = weights)
y_pred_MAPS = MAPS_model.predict(X_test)
get_performance(X_test, y_test, y_pred_MAPS)
default_MD_metric, SMOTE_MD_metric, MAPS_MD_metric = get_mispredicted_region_test(X_test, y_test, y_pred_default, y_pred_SMOTE, y_pred_MAPS, BGMD_rules, ylabel='target')
dict = {'acc_all': acc_all, 'recall_all': recall_all, 'f1_all': f1_all, 'acc_mispredicted': acc_mispredicted, 'recall_mispredicted': recall_mispredicted, 'f1_mispredicted': f1_mispredicted}
out = pd.DataFrame(dict)
out.to_csv('MAPS_Job_Change_DT.csv')
```
# Just Train Twice
```
from helper import generate_JTT_Weights
X_train_1st, X_val, y_train_1st, y_val = train_test_split(X_train, y_train, test_size = 0.33, random_state = 29)
model_JTT = DecisionTreeClassifier()
scores_JTT_1st = cross_val_score(model_JTT, X_train_1st, y=y_train_1st, cv = FOLDS)
model_JTT.fit(X_train_1st, y_train_1st)
y_pred_JTT_val = model_JTT.predict(X_val)
get_performance(X_val, y_val, y_pred_JTT_val)
grid_upweights_JTT = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200]
best_weight_all_JTT = 1
best_f1_all_JTT = 0
f1_all_JTT = [];
for upweight in grid_upweights_JTT:
weights = generate_JTT_Weights(y_val.to_list(), y_pred_JTT_val, weight = upweight)
#combine train and validate data
weights = np.concatenate((np.ones(len(X_train_1st)), weights))
y_train_2nd = np.concatenate((y_train_1st, y_val))
X_train_2nd = pd.concat([X_train_1st, X_val])
X_train_2nd['val_weight'] = weights
X_train_2nd['target'] = y_train_2nd
X_train_2nd = X_train_2nd.sample(frac=1, random_state=1).reset_index(drop=True)
weights = X_train_2nd['val_weight'].to_list()
y_train_2nd = X_train_2nd['target']
X_train_2nd = X_train_2nd.drop(['val_weight', 'target'], axis=1)
model_JTT = DecisionTreeClassifier()
scores_JTT_2nd = cross_val_score(model_JTT, X_train_2nd, y=y_train_2nd, cv = FOLDS)
model_JTT.fit(X_train_2nd, y_train_2nd, sample_weight = weights)
y_pred_JTT = model_JTT.predict(X_test)
total_result_JTT = get_performance(X_test, y_test, y_pred_JTT)
f1_all_JTT.append(total_result_JTT[2])
if total_result_JTT[2] > best_f1_all_JTT:
best_f1_all_JTT = total_result_JTT[2]
best_weight_all_JTT = upweight;
print("JTT Best weight on all is: ", best_weight_all_JTT)
print("JTT Best f1 score on all: ", best_f1_all_JTT)
plt.plot(grid_upweights_JTT, f1_all_JTT, label = "f1 on all data")
plt.legend()
plt.show()
weights = generate_JTT_Weights(y_val.to_list(), y_pred_JTT_val, weight = best_weight_all_JTT)
#combine train and validate data
weights = np.concatenate((np.ones(len(X_train_1st)), weights))
y_train_2nd = np.concatenate((y_train_1st, y_val))
X_train_2nd = pd.concat([X_train_1st, X_val])
X_train_2nd['val_weight'] = weights
X_train_2nd['target'] = y_train_2nd
X_train_2nd = X_train_2nd.sample(frac=1, random_state=1).reset_index(drop=True)
weights = X_train_2nd['val_weight'].to_list()
y_train_2nd = X_train_2nd['target']
X_train_2nd = X_train_2nd.drop(['val_weight', 'target'], axis=1)
model_JTT = DecisionTreeClassifier()
scores_JTT_2nd = cross_val_score(model_JTT, X_train_2nd, y=y_train_2nd, cv = FOLDS)
model_JTT.fit(X_train_2nd, y_train_2nd, sample_weight = weights)
y_pred_JTT = model_JTT.predict(X_test)
total_result_JTT = get_performance(X_test, y_test, y_pred_JTT)
default_MD_metric, SMOTE_MD_metric, MAPS_MD_metric = get_mispredicted_region_test(X_test, y_test, y_pred_JTT, y_pred_SMOTE, y_pred_MAPS, BGMD_rules, ylabel='target')
```
| github_jupyter |
# Your first neural network
In this project, you'll build your first neural network and use it to predict daily bike rental ridership. We've provided some of the code, but left the implementation of the neural network up to you (for the most part). After you've submitted this project, feel free to explore the data and the model more.
```
%matplotlib inline
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = 'retina'
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
```
## Load and prepare the data
A critical step in working with neural networks is preparing the data correctly. Variables on different scales make it difficult for the network to efficiently learn the correct weights. Below, we've written the code to load and prepare the data. You'll learn more about this soon!
```
data_path = 'Bike-Sharing-Dataset/hour.csv'
rides = pd.read_csv(data_path)
rides.head()
```
## Checking out the data
This dataset has the number of riders for each hour of each day from January 1 2011 to December 31 2012. The number of riders is split between casual and registered, summed up in the `cnt` column. You can see the first few rows of the data above.
Below is a plot showing the number of bike riders over the first 10 days or so in the data set. (Some days don't have exactly 24 entries in the data set, so it's not exactly 10 days.) You can see the hourly rentals here. This data is pretty complicated! The weekends have lower over all ridership and there are spikes when people are biking to and from work during the week. Looking at the data above, we also have information about temperature, humidity, and windspeed, all of these likely affecting the number of riders. You'll be trying to capture all this with your model.
```
rides[:24*10].plot(x='dteday', y='cnt')
```
### Dummy variables
Here we have some categorical variables like season, weather, month. To include these in our model, we'll need to make binary dummy variables. This is simple to do with Pandas thanks to `get_dummies()`.
```
dummy_fields = ['season', 'weathersit', 'mnth', 'hr', 'weekday']
for each in dummy_fields:
dummies = pd.get_dummies(rides[each], prefix=each, drop_first=False)
rides = pd.concat([rides, dummies], axis=1)
fields_to_drop = ['instant', 'dteday', 'season', 'weathersit',
'weekday', 'atemp', 'mnth', 'workingday', 'hr']
data = rides.drop(fields_to_drop, axis=1)
data.head()
```
### Scaling target variables
To make training the network easier, we'll standardize each of the continuous variables. That is, we'll shift and scale the variables such that they have zero mean and a standard deviation of 1.
The scaling factors are saved so we can go backwards when we use the network for predictions.
```
quant_features = ['casual', 'registered', 'cnt', 'temp', 'hum', 'windspeed']
# Store scalings in a dictionary so we can convert back later
scaled_features = {}
for each in quant_features:
mean, std = data[each].mean(), data[each].std()
scaled_features[each] = [mean, std]
data.loc[:, each] = (data[each] - mean)/std
```
### Splitting the data into training, testing, and validation sets
We'll save the data for the last approximately 21 days to use as a test set after we've trained the network. We'll use this set to make predictions and compare them with the actual number of riders.
```
# Save data for approximately the last 21 days
test_data = data[-21*24:]
# Now remove the test data from the data set
data = data[:-21*24]
# Separate the data into features and targets
target_fields = ['cnt', 'casual', 'registered']
features, targets = data.drop(target_fields, axis=1), data[target_fields]
test_features, test_targets = test_data.drop(target_fields, axis=1), test_data[target_fields]
features.head()
```
We'll split the data into two sets, one for training and one for validating as the network is being trained. Since this is time series data, we'll train on historical data, then try to predict on future data (the validation set).
```
# Hold out the last 60 days or so of the remaining data as a validation set
train_features, train_targets = features[:-60*24], targets[:-60*24]
val_features, val_targets = features[-60*24:], targets[-60*24:]
```
## Time to build the network
Below you'll build your network. We've built out the structure. You'll implement both the forward pass and backwards pass through the network. You'll also set the hyperparameters: the learning rate, the number of hidden units, and the number of training passes.
<img src="assets/neural_network.png" width=300px>
The network has two layers, a hidden layer and an output layer. The hidden layer will use the sigmoid function for activations. The output layer has only one node and is used for the regression, the output of the node is the same as the input of the node. That is, the activation function is $f(x)=x$. A function that takes the input signal and generates an output signal, but takes into account the threshold, is called an activation function. We work through each layer of our network calculating the outputs for each neuron. All of the outputs from one layer become inputs to the neurons on the next layer. This process is called *forward propagation*.
We use the weights to propagate signals forward from the input to the output layers in a neural network. We use the weights to also propagate error backwards from the output back into the network to update our weights. This is called *backpropagation*.
> **Hint:** You'll need the derivative of the output activation function ($f(x) = x$) for the backpropagation implementation. If you aren't familiar with calculus, this function is equivalent to the equation $y = x$. What is the slope of that equation? That is the derivative of $f(x)$.
Below, you have these tasks:
1. Implement the sigmoid function to use as the activation function. Set `self.activation_function` in `__init__` to your sigmoid function.
2. Implement the forward pass in the `train` method.
3. Implement the backpropagation algorithm in the `train` method, including calculating the output error.
4. Implement the forward pass in the `run` method.
```
#############
# In the my_answers.py file, fill out the TODO sections as specified
#############
from my_answers import NeuralNetwork
def MSE(y, Y):
mse = np.mean((y-Y)**2)
return mse
```
## Unit tests
Run these unit tests to check the correctness of your network implementation. This will help you be sure your network was implemented correctly befor you starting trying to train it. These tests must all be successful to pass the project.
```
import unittest
inputs = np.array([[0.5, -0.2, 0.1]])
targets = np.array([[0.4]])
test_w_i_h = np.array([[0.1, -0.2],
[0.4, 0.5],
[-0.3, 0.2]])
test_w_h_o = np.array([[0.3],
[-0.1]])
class TestMethods(unittest.TestCase):
##########
# Unit tests for data loading
##########
def test_data_path(self):
# Test that file path to dataset has been unaltered
self.assertTrue(data_path.lower() == 'bike-sharing-dataset/hour.csv')
def test_data_loaded(self):
# Test that data frame loaded
self.assertTrue(isinstance(rides, pd.DataFrame))
##########
# Unit tests for network functionality
##########
def test_activation(self):
network = NeuralNetwork(3, 2, 1, 0.5)
# Test that the activation function is a sigmoid
self.assertTrue(np.all(network.activation_function(0.5) == 1/(1+np.exp(-0.5))))
def test_train(self):
# Test that weights are updated correctly on training
network = NeuralNetwork(3, 2, 1, 0.5)
network.weights_input_to_hidden = test_w_i_h.copy()
network.weights_hidden_to_output = test_w_h_o.copy()
network.train(inputs, targets)
self.assertTrue(np.allclose(network.weights_hidden_to_output,
np.array([[ 0.37275328],
[-0.03172939]])))
self.assertTrue(np.allclose(network.weights_input_to_hidden,
np.array([[ 0.10562014, -0.20185996],
[0.39775194, 0.50074398],
[-0.29887597, 0.19962801]])))
def test_run(self):
# Test correctness of run method
network = NeuralNetwork(3, 2, 1, 0.5)
network.weights_input_to_hidden = test_w_i_h.copy()
network.weights_hidden_to_output = test_w_h_o.copy()
self.assertTrue(np.allclose(network.run(inputs), 0.09998924))
suite = unittest.TestLoader().loadTestsFromModule(TestMethods())
unittest.TextTestRunner().run(suite)
```
## Training the network
Here you'll set the hyperparameters for the network. The strategy here is to find hyperparameters such that the error on the training set is low, but you're not overfitting to the data. If you train the network too long or have too many hidden nodes, it can become overly specific to the training set and will fail to generalize to the validation set. That is, the loss on the validation set will start increasing as the training set loss drops.
You'll also be using a method know as Stochastic Gradient Descent (SGD) to train the network. The idea is that for each training pass, you grab a random sample of the data instead of using the whole data set. You use many more training passes than with normal gradient descent, but each pass is much faster. This ends up training the network more efficiently. You'll learn more about SGD later.
### Choose the number of iterations
This is the number of batches of samples from the training data we'll use to train the network. The more iterations you use, the better the model will fit the data. However, this process can have sharply diminishing returns and can waste computational resources if you use too many iterations. You want to find a number here where the network has a low training loss, and the validation loss is at a minimum. The ideal number of iterations would be a level that stops shortly after the validation loss is no longer decreasing.
### Choose the learning rate
This scales the size of weight updates. If this is too big, the weights tend to explode and the network fails to fit the data. Normally a good choice to start at is 0.1; however, if you effectively divide the learning rate by n_records, try starting out with a learning rate of 1. In either case, if the network has problems fitting the data, try reducing the learning rate. Note that the lower the learning rate, the smaller the steps are in the weight updates and the longer it takes for the neural network to converge.
### Choose the number of hidden nodes
In a model where all the weights are optimized, the more hidden nodes you have, the more accurate the predictions of the model will be. (A fully optimized model could have weights of zero, after all.) However, the more hidden nodes you have, the harder it will be to optimize the weights of the model, and the more likely it will be that suboptimal weights will lead to overfitting. With overfitting, the model will memorize the training data instead of learning the true pattern, and won't generalize well to unseen data.
Try a few different numbers and see how it affects the performance. You can look at the losses dictionary for a metric of the network performance. If the number of hidden units is too low, then the model won't have enough space to learn and if it is too high there are too many options for the direction that the learning can take. The trick here is to find the right balance in number of hidden units you choose. You'll generally find that the best number of hidden nodes to use ends up being between the number of input and output nodes.
```
import sys
####################
### Set the hyperparameters in you myanswers.py file ###
####################
from my_answers import iterations, learning_rate, hidden_nodes, output_nodes
learning_rates = [1.83]
hidden_nodes = [6]
for lr in learning_rates:
for hn in hidden_nodes:
print("\nLR: " + str(lr) + " --- Hidden Nodes: " + str(hn))
N_i = train_features.shape[1]
network = NeuralNetwork(N_i, hn, output_nodes, lr)
losses = {'train':[], 'validation':[]}
for ii in range(iterations):
# Go through a random batch of 128 records from the training data set
batch = np.random.choice(train_features.index, size=128)
X, y = train_features.iloc[batch].values, train_targets.iloc[batch]['cnt']
network.train(X, y)
# Printing out the training progress
train_loss = MSE(network.run(train_features).T, train_targets['cnt'].values)
val_loss = MSE(network.run(val_features).T, val_targets['cnt'].values)
sys.stdout.write("\rProgress: {:2.1f}".format(100 * ii/float(iterations)) \
+ "% ... Training loss: " + str(train_loss)[:5] \
+ " ... Validation loss: " + str(val_loss)[:5] \
+ " ... Diff Train - Validation " + str(train_loss-val_loss)[:5])
sys.stdout.flush()
losses['train'].append(train_loss)
losses['validation'].append(val_loss)
plt.plot(losses['train'], label='Training loss')
plt.plot(losses['validation'], label='Validation loss')
plt.legend()
_ = plt.ylim()
```
## Check out your predictions
Here, use the test data to view how well your network is modeling the data. If something is completely wrong here, make sure each step in your network is implemented correctly.
```
fig, ax = plt.subplots(figsize=(8,4))
mean, std = scaled_features['cnt']
predictions = network.run(test_features).T*std + mean
ax.plot(predictions[0], label='Prediction')
ax.plot((test_targets['cnt']*std + mean).values, label='Data')
ax.set_xlim(right=len(predictions))
ax.legend()
dates = pd.to_datetime(rides.iloc[test_data.index]['dteday'])
dates = dates.apply(lambda d: d.strftime('%b %d'))
ax.set_xticks(np.arange(len(dates))[12::24])
_ = ax.set_xticklabels(dates[12::24], rotation=45)
```
## OPTIONAL: Thinking about your results(this question will not be evaluated in the rubric).
Answer these questions about your results. How well does the model predict the data? Where does it fail? Why does it fail where it does?
> **Note:** You can edit the text in this cell by double clicking on it. When you want to render the text, press control + enter
#### Your answer below
The model precits quite well the data in general. There is however a specific period where it fails. This is during the Christmas perdio: 24-25-26 December. One explanation is the following: the model cannot anticipate that during this period the activity drops, because people stays at home in family. It's normal during this holiday time the model over predict the number of rides. I don't know if it is possible to improve this period predictions.
Not correlated to previous questions, here are one comment:
I had difficulties with the backpropagation. I mean I could do it quickly, but I feel I don't get the intuition to understand the shape matrices. I try to make it work by swiping, or adding a .T or [:, None], but it is not easy to have a precise understanding of this.
| github_jupyter |
```
import pandas as pd
races = pd.read_csv("datasets/races.csv", sep=",")
races = races.set_index("raceId")
print(races)
races.to_csv("staging warehouse/races.csv")
pitstops = pd.read_csv("datasets/pit_stops.csv", sep=",")
pitstops.drop(columns = 'milliseconds', axis = 1, inplace= True)
pitstops = pitstops.set_index("raceId")
print(pitstops)
pitstops.to_csv("staging warehouse/pitstops.csv")
drivers = pd.read_csv("datasets/drivers.csv", sep=",")
drivers = drivers.set_index("driverId")
drivers.drop(coumns = 'url', axis = 1, inplace= True)
print(drivers)
drivers.to_csv("staging warehouse/drivers.csv")
circuits = pd.read_csv("datasets/circuits.csv", sep=",")
circuits = circuits.set_index("circuitId")
circuits.drop(columns = 'url', axis = 1, inplace= True)
print(circuits)
circuits.to_csv("staging warehouse/circuits.csv")
laps = pd.read_csv("datasets/lap_times.csv", sep=",")
laps.drop(columns = 'milliseconds', axis = 1, inplace= True)
laps = laps.set_index("raceId")
print(laps)
laps.to_csv("staging warehouse/laps.csv")
status = pd.read_csv("datasets/status.csv", sep=",")
status = status.set_index("statusId")
print(status)
status.to_csv("staging warehouse/status.csv")
seasons = pd.read_csv("datasets/seasons.csv", sep=",")
seasons = seasons.set_index("year")
print(seasons)
seasons.to_csv("staging warehouse/seasons.csv")
constructor_results = pd.read_csv("datasets/constructor_results.csv", sep=",")
constructor_results.drop(columns = 'status', axis = 1, inplace= True)
constructor_results = constructor_results.set_index("constructorResultsId")
print(constructor_results)
constructor_results.to_csv("staging warehouse/constructor_results.csv")
constructors = pd.read_csv("datasets/constructors.csv", sep=",")
constructors.drop(columns = 'constructorRef', axis = 1, inplace= True)
constructors = constructors.set_index("constructorId")
print(constructors)
constructors.to_csv("staging warehouse/constructors.csv")
driver_results = pd.read_csv("datasets/results.csv", sep=",")
driver_results.drop(columns = ['position', 'positionOrder', 'milliseconds', 'rank', 'time', 'fastestLapSpeed'], axis = 1, inplace= True)
# driver_results['positionText'] = list(map(lambda pos: pos if pos.isdigit() else None, driver_results['positionText']))
# driver_results['fastestLap'] = list(map(lambda pos: pos if pos.isdigit() else None, driver_results['fastestLap']))
driver_results = driver_results.set_index("resultId")
print(driver_results)
driver_results.to_csv("staging warehouse/driver_results.csv")
```
| github_jupyter |
```
import joblib
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.tree
import sklearn.metrics
import sklearn.ensemble
import sklearn.preprocessing
import sklearn.model_selection # For cross_val_score, GridSearchCV, RandomizedSearchCV
import pandas as pd
plt.rcParams.update({'figure.max_open_warning': 0})
#training as y target values of y = tomororrow_is_buy
data = pd.read_csv('out.csv')
data.drop(data.columns[data.columns.str.contains('unnamed',case = False)],axis = 1, inplace = True)
data = data.dropna(axis=1)
X = data.drop(["date","ticker","tomorrw_is_buy","tomorrow_is_strong_buy","week_is_buy","week_is_strong_buy","4week_is_buy","4week_is_strong_buy"],axis=1)
y = data.tomorrw_is_buy
X = X.values
y = y.values
data.head()
%%time
for i in range(1000000): # Burn some CPU cycles in a
pass # loop that does nothing
#split data into 60-20-20
#test set
x_remaining, Xtest, y_remaining, ytest = sklearn.model_selection.train_test_split(X, y, test_size=0.20,
random_state=0)
#validation and training set
Xtrn, Xval, ytrn, yval = sklearn.model_selection.train_test_split(x_remaining, y_remaining, test_size=0.25,
random_state=0)
print(Xtrn.shape,Xval.shape,ytrn.shape,yval.shape)
#scaling values
scaler = sklearn.preprocessing.StandardScaler()
X_trn = scaler.fit_transform(Xtrn.reshape(Xtrn.shape[0],-1))
X_test = scaler.transform(Xtest.reshape(Xtest.shape[0],-1))
X_val = scaler.transform(Xval.reshape(Xval.shape[0],-1))
import importlib
def train_estimators(X, y, estimator_type, param_name, param_vals, **kwargs):
train_estimator = []
s = "%s" %kwargs #converts kwargs to string
s = str(estimator_type).split("'")[1] #gets import_module which is sklearn.tree
position1 = (s.find("."))
position2 = (s.find(".",position1+1))
for i in range(len(param_vals)):
model_class = getattr(importlib.import_module(s[:position2]),(str(estimator_type).split(".")[-1][:-2]))
kwargs[param_name] = param_vals[i] #adds param_name into the kwargs dictionnary
model = model_class(**kwargs) # instantiates the model
train_estimator.append(model.fit(X,y))
print(f' Training {train_estimator[i]}...')
return train_estimator
def score_estimators(X, y, estimators):
score = []
for i in range(np.array(estimators).shape[0]):
score.append(estimators[i].score(X,y))
return score
def plot_estimator_scores(estimators, param_name, param_vals):
train_score,val_score,test_score = [],[],[]
train_score = score_estimators(X_trn,ytrn,estimators)
val_score = score_estimators(X_val, yval, estimators)
test_score = score_estimators(X_test, ytest, estimators)
#finding best scores
best_train = max(np.array(train_score))
best_val = max(np.array(val_score))
best_test = max(np.array(test_score))
min_score = np.concatenate((train_score,val_score,test_score))
best_score = np.concatenate((train_score,val_score,test_score))
#plotting code
#makes sure the x axis points are evenly spaced
locs, labels = plt.xticks()
plt.plot(locs,np.array(train_score).ravel(),'-ok',color='green',label='train = %.3f' %(best_train))
plt.plot(locs,val_score,'-ok',color='red',label='validate = %.3f' %(best_val))
plt.plot(locs,test_score,linestyle='dotted',color='black',label='test = %.3f' %(best_test))
plt.scatter(locs[val_score.index(best_val)],best_val, s=150, marker='x',color="red")
plt.xticks(locs,param_vals)
plt.ylim(0,1.02)
# plt.ylim(min(min_score)-0.02,max(best_score)+0.01)
plt.legend(loc="lower left")
plt.xlabel(param_name)
plt.ylabel("score")
plt.title(f'{estimators[0].__class__.__name__} score vs {param_name}')
%%time
tree_estimators = train_estimators(X_trn, ytrn, sklearn.tree.DecisionTreeClassifier,
'max_depth', [1, 5, 10, 20, 50, 100], splitter='random', random_state=0)
plot_estimator_scores(tree_estimators,'max_depth',[1, 5, 10, 20, 50, 100])
joblib.dump(tree_estimators, "tree_estimators.joblib")
%%time
forest = train_estimators(X_trn, ytrn, sklearn.ensemble.RandomForestClassifier,
'max_depth', [1, 5, 10, 20, 50, 100], random_state=0)
%%time
joblib.dump(forest, "forest.joblib")
plot_estimator_scores(forest,'max_depth',[1, 5, 10, 20, 50, 100])
%%time
logistic = train_estimators(X_trn, ytrn, sklearn.linear_model.LogisticRegression,
'C', [1e-05, 0.0001, 0.001, 0.01, 0.1,1.0], max_iter=10000,random_state=0)
plot_estimator_scores(logistic,'C',[1e-05, 0.0001, 0.001, 0.01, 0.1, 1.0])
joblib.dump(logistic, "logistic.joblib")
%%time
import warnings
warnings.filterwarnings('ignore', 'Solver terminated early.*')
svm = train_estimators(X_trn, ytrn, sklearn.svm.SVC,
'C', [0.01, 0.1,1.0, 10.0, 100.0,1000.0], gamma=0.001,max_iter=100,random_state=0)
%%time
joblib.dump(svm, "svm.joblib")
plot_estimator_scores(svm,'C',[0.01, 0.1,1.0, 10.0, 100.0,1000.0])
X = data.drop(["date","ticker","tomorrw_is_buy","tomorrow_is_strong_buy","week_is_buy","week_is_strong_buy","4week_is_buy","4week_is_strong_buy"],axis=1)
y = data.week_is_buy
X = X.values
y = y.values
#split data into 60-20-20
#test set
x_remaining, Xtest, y_remaining, ytest = sklearn.model_selection.train_test_split(X, y, test_size=0.20,
random_state=0)
#validation and training set
Xtrn, Xval, ytrn, yval = sklearn.model_selection.train_test_split(x_remaining, y_remaining, test_size=0.25,
random_state=0)
#scaling values
scaler = sklearn.preprocessing.StandardScaler()
X_trn = scaler.fit_transform(Xtrn.reshape(Xtrn.shape[0],-1))
X_test = scaler.transform(Xtest.reshape(Xtest.shape[0],-1))
X_val = scaler.transform(Xval.reshape(Xval.shape[0],-1))
%%time
tree_estimators = train_estimators(X_trn, ytrn, sklearn.tree.DecisionTreeClassifier,
'max_depth', [1, 5, 10, 20, 50, 100], splitter='random', random_state=0)
plot_estimator_scores(tree_estimators,'max_depth',[1, 5, 10, 20, 50, 100])
joblib.dump(tree_estimators, "tree_estimators2.joblib")
%%time
forest = train_estimators(X_trn, ytrn, sklearn.ensemble.RandomForestClassifier,
'max_depth', [1, 5, 10, 20, 50, 100], random_state=0)
%%time
joblib.dump(forest, "forest2.joblib")
plot_estimator_scores(forest,'max_depth',[1, 5, 10, 20, 50, 100])
%%time
logistic = train_estimators(X_trn, ytrn, sklearn.linear_model.LogisticRegression,
'C', [1e-05, 0.0001, 0.001, 0.01, 0.1,1.0], max_iter=10000,random_state=0)
plot_estimator_scores(logistic,'C',[1e-05, 0.0001, 0.001, 0.01, 0.1, 1.0])
joblib.dump(logistic, "logistic2.joblib")
%%time
import warnings
warnings.filterwarnings('ignore', 'Solver terminated early.*')
svm = train_estimators(X_trn, ytrn, sklearn.svm.SVC,
'C', [0.01, 0.1,1.0, 10.0, 100.0,1000.0], gamma=0.001,max_iter=100,random_state=0)
%%time
joblib.dump(svm, "svm2.joblib")
plot_estimator_scores(svm,'C',[0.01, 0.1,1.0, 10.0, 100.0,1000.0])
X = data.drop(["date","ticker","tomorrw_is_buy","tomorrow_is_strong_buy","week_is_buy","week_is_strong_buy","4week_is_buy","4week_is_strong_buy"],axis=1)
y = data["4week_is_buy"]
X = X.values
y = y.values
#split data into 60-20-20
#test set
x_remaining, Xtest, y_remaining, ytest = sklearn.model_selection.train_test_split(X, y, test_size=0.20,
random_state=0)
#validation and training set
Xtrn, Xval, ytrn, yval = sklearn.model_selection.train_test_split(x_remaining, y_remaining, test_size=0.25,
random_state=0)
#scaling values
scaler = sklearn.preprocessing.StandardScaler()
X_trn = scaler.fit_transform(Xtrn.reshape(Xtrn.shape[0],-1))
X_test = scaler.transform(Xtest.reshape(Xtest.shape[0],-1))
X_val = scaler.transform(Xval.reshape(Xval.shape[0],-1))
%%time
tree_estimators = train_estimators(X_trn, ytrn, sklearn.tree.DecisionTreeClassifier,
'max_depth', [1, 5, 10, 20, 50, 100], splitter='random', random_state=0)
plot_estimator_scores(tree_estimators,'max_depth',[1, 5, 10, 20, 50, 100])
joblib.dump(tree_estimators, "tree_estimators3.joblib")
%%time
forest = train_estimators(X_trn, ytrn, sklearn.ensemble.RandomForestClassifier,
'max_depth', [1, 5, 10, 20, 50, 100], random_state=0)
%%time
joblib.dump(forest, "forest3.joblib")
plot_estimator_scores(forest,'max_depth',[1, 5, 10, 20, 50, 100])
%%time
logistic = train_estimators(X_trn, ytrn, sklearn.linear_model.LogisticRegression,
'C', [1e-05, 0.0001, 0.001, 0.01, 0.1,1.0], max_iter=10000,random_state=0)
plot_estimator_scores(logistic,'C',[1e-05, 0.0001, 0.001, 0.01, 0.1, 1.0])
joblib.dump(logistic, "logistic3.joblib")
%%time
import warnings
warnings.filterwarnings('ignore', 'Solver terminated early.*')
svm = train_estimators(X_trn, ytrn, sklearn.svm.SVC,
'C', [0.01, 0.1,1.0, 10.0, 100.0,1000.0], gamma=0.001,max_iter=100,random_state=0)
%%time
joblib.dump(svm, "svm3.joblib")
plot_estimator_scores(svm,'C',[0.01, 0.1,1.0, 10.0, 100.0,1000.0])
```
| github_jupyter |
```
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory('./dataset/train',
target_size=(48,48),
batch_size=64,
color_mode='grayscale',
class_mode='categorical')
validation_generator = val_datagen.flow_from_directory('./dataset/test',
target_size=(48,48),
batch_size=64,
color_mode='grayscale',
class_mode='categorical')
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3,3), activation='relu', input_shape=(48,48,1)))
model.add(tf.keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Conv2D(128, kernel_size=(3,3), activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
model.add(tf.keras.layers.Conv2D(128, kernel_size=(3,3), activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units=1024, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(units=7, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit_generator(train_generator,
steps_per_epoch=28709//64,
epochs=30,
validation_data = validation_generator,
validation_steps=7178//64)
model.save('model.h5')
train_generator.class_indices
from tensorflow.keras.models import load_model
from keras.preprocessing import image
import numpy as np
model = load_model('model.h5')
result = {0:'angry',
1:'disgust',
2:'fear',
3:'happy',
4:'neutral',
5:'sad',
6:'surprise'}
test_image = './dataset/test_data/happy.jpg'
img = image.load_img(test_image, target_size=(48,48))
img = img.convert('L')
x = image.img_to_array(img)
x /= 255
x = x.reshape(1, 48, 48, 1)
predict = model.predict(x)
print(predict)
final_prediction = result[np.argmax(predict[0])]
print(final_prediction)
```
| github_jupyter |
# Scikit Learn and the K-nearest Neighbor Algorithm
In this notebook we'll introduce the `sklearn` package and a few important concepts in machine learning:
* Splitting data into test, train, and validation sets.
* Fitting models to a dataset.
* And using "Hyperparameters" to tune models.
Lets revisit the example we saw in the first class:
```
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# Load the data
heart_dataset = pd.read_csv('../../datasets/uci-heart-disease/heart.csv')
# Split the data into input and labels
labels = heart_dataset['target']
input_data = heart_dataset.drop(columns=['target'])
# Split the data into training and test
training_data, test_data, training_labels, test_labels = train_test_split(
input_data,
labels,
test_size=0.20
)
# Build the model
model = KNeighborsClassifier()
model.fit(training_data, training_labels)
# See how it did.
print("Test accuracy: ", model.score(test_data, test_labels))
```
# Test/Train/Validation Splits:
In machine learning, it's important to avoid something called "overfitting" our models. This happens when a model more or less "memorizes" the training data, but performs poorly on data that is "held out" of the training process. A model that is "overfit" won't "generalize" to unseen data — making it useless in the real world!
To avoid and detect overfitting we will commonly split our data into 3 buckets:
* Training data: the data that the model actually learns from.
* Validation data: data that the model doesn't learn from, but that we use to validate the results throughout the process of building our models.
* Test data: data that is held out entierly during the model building process in order to give an unbiased measure of the final models performance.
* If we use the test data, and then change our model, the test data is no longer "unbiased" as we will have incorporated information from the test data (i.e. our models poor "test performance") into the next version of the model. In this case we have turned the test data into validation data, and we should get new test data.
In the above example we've only made two buckets of data, which we called training and test... In theory we COULD do this:
```
# Split the data into training+validation and test
training_and_validation_data, test_data, training_and_validation_labels, test_labels = train_test_split(
input_data,
labels,
test_size=0.20
)
# Split the training+validation data into training and validation
training_data, validation_data, training_labels, validation_labels = train_test_split(
training_and_validation_data,
training_and_validation_labels,
test_size=0.20
)
# Then use only training and validation to evaluate our model and make changes to the model's performance...
```
While the above CAN be done, it's much more common to make the test/train split much earlier in the data pipeline. Many datasets for ML tasks come with a test set already prepared and separate from the training set. ML practitioners then perform a training/validation split with all of the training data. The training and test data will be saved separately, in their own folders or CSV files or labeled differently in the database/data warehouse software.
If you've collected your own data and want to do ML with it, I strongly suggest you split out 10%-20% of that data, set it aside, and don't look at it until the very end of your ML pipeline to get an unbiased evaluation once you've built a model you like.
# SKLearn's API
Scikit learn has a wonderfully unified API that always follows this pattern:
* Create a model from a class.
* This is where you set the "hyperparameters" of the model.
* Call that model's `.fit` method using the training data to train the model.
* Call that model's `.score` method to evaluate the model against the validation/test data.
For example:
```
# Lets build multiple models using a few different "hyperparameters"
model_one = KNeighborsClassifier()
model_two = KNeighborsClassifier(weights='distance')
model_three = KNeighborsClassifier(n_neighbors=10, weights='distance')
for i, model in enumerate([model_one, model_two, model_three]):
model.fit(training_data, training_labels)
print(f' {i+1} validation accuracy: ', model.score(validation_data, validation_labels))
```
# The K-Nearest Neighbor's Model
So what is the actual difference between these three models? How does KNN actually work?
KNN is a relatively straightforward model. When you want to make a prediction with KNN you simply compare the item you're making a prediction about to the training dataset using a distance function and based on the class of the "nearest" neighbors the model makes a prediction.
K is how many neighbors to look at, if k is 5 the model looks at the 5 nearest neighbors and whichever class is most common among those 5 neighbors is the one selected. Lets look at some pictures from the pre-reading (https://towardsdatascience.com/laymans-introduction-to-knn-c793ed392bc2):




These examples are all in 2-dimensional space, but the algorithm generalizes to n-dimensions (based on the number of features in our training data).
K is controlled in `sklearn` by the `n_neighbors` parameter.
Another hyperparameter in KNN is the `weights` parameter, which has 3 possible values, from the docs (https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html):
* ‘uniform’ : uniform weights. All points in each neighborhood are weighted equally.
* ‘distance’ : weight points by the inverse of their distance. in this case, closer neighbors of a query point will have a greater influence than neighbors which are further away.
* [callable] : a user-defined function which accepts an array of distances, and returns an array of the same shape containing the weights.
Similarly, the distance metric can be provided:
> metric: str or callable, default=’minkowski’
> the distance metric to use for the tree. The default metric is minkowski, and with p=2 is equivalent to the standard Euclidean metric. See the documentation of DistanceMetric for a list of available metrics. If metric is “precomputed”, X is assumed to be a distance matrix and must be square during fit. X may be a sparse graph, in which case only “nonzero” elements may be considered neighbors.
| github_jupyter |
# Clean Data
### Imports
```
import numpy as np
import pandas as pd
# visualization
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
# personal module scripts
import clean_data
```
## Clean NFL Combine Data
```
combine_file = r'data\nfl_combine_1987_2020.csv'
df_raw_combine = pd.read_csv(combine_file)
df_raw_combine.head()
# Keep raw data import for reference - build copy to modify
df_combine = df_raw_combine
# Drop dummy '0' column and Wonderlic scores data
combine_cols_to_drop = ['Unnamed: 0', 'Wonderlic']
df_combine.drop(columns=combine_cols_to_drop, inplace=True)
# Clean column headers
df_combine.columns = df_combine.columns.str.lower()
df_combine.rename(columns={'college':'school'}, inplace=True)
# Clean school names
df_combine['school'] = df_combine['school'].str.strip()
# Drop years prior to 2000 (no draft data)
print(df_combine.shape)
df_combine.drop(df_combine[df_combine['year']<2000].index, inplace=True)
print('Cleaned combine size: ', df_combine.shape)
df_combine.head()
```
## Import position mapping data
The "combine" dataset maps players to very specific positions (ie, "Free Safety" or "Outside Linebacker").
Map these granular positions to more standard positions. Also classify each position as "Offense" or "Defense", and indicate if the position is a "Skill" position or on the line of scrimmage.
```
df_positions = pd.read_csv('data/position_mapping.csv')
df_positions.head()
```
### Merge the draft and position mapping datasets
```
print('Granular position counts in combine dataset:')
print(df_combine['pos'].value_counts())
df_combine = df_combine.merge(df_positions,
how='left',
on='pos')
print('\nPosition Group counts after merging with position map:')
print(df_combine['pos_group'].value_counts())
df_combine.head()
```
#### Visualize combine performance distributions by position
```
positions = df_combine['pos_group'].unique()
positions_to_drop = ['SN', 'K'] # Long snappers and kickers/punters
positions = [pos for pos in positions if pos not in positions_to_drop]
print(positions)
print('Unique Positions: ', len(positions))
print(df_combine.columns)
stat_columns = ['height (in)', 'weight (lbs)',
'hand size (in)', 'arm length (in)', '40 yard', 'bench press',
'vert leap (in)', 'broad jump (in)', 'shuttle', '3cone', '60yd shuttle']
num_stats = len(stat_columns)
fig, axes = plt.subplots(len(positions), num_stats,
sharex=False,
sharey=True,
figsize=(25,25))
fig.suptitle('NFL Combine Statistics - Distribution by Position (2000-2020)', fontsize=30)
fig.supxlabel('Measurement', fontsize=30)
fig.supylabel('Position', fontsize=30)
fig.tight_layout(rect=[0.03, 0.03, 1, .95])
# Loop over axes and data
for row, pos in enumerate(positions):
x_positions = df_combine[df_combine['pos_group']==pos]
for col, stat in enumerate(stat_columns):
# Get axis
ax = axes[row,col]
x = x_positions[stat]
ax.hist(x,
range=[df_combine[stat].min(),df_combine[stat].max()],
alpha=.5, bins=10)
# Set Y label once per row
if col==0:
ax.set_ylabel(pos, fontsize='xx-large')
# Set X label above first row and below last row
if row == 0:
ax.set_title(stat, fontsize='xx-large')
if row == len(positions) - 1:
ax.set_xlabel(stat, fontsize='xx-large')
fig.show()
fig.savefig('images/stats_by_position.png', format='png')
```
## Import and clean NFL Draft Data
```
draft_file = r'data\espn_draft_history_2000_2021_cleaned.csv'
df_raw_draft = pd.read_csv(draft_file)
# Keep raw data import for reference - build copy to modify
df_draft = df_raw_draft
# Clean column headers
df_draft.columns = df_draft.columns.str.lower()
# Clean school names
df_draft['school'] = df_draft['school'].str.strip()
```
### Are there duplicated names?
```
df_combine['name'].value_counts(sort='descending').head(10)
```
### Answer: Yes
So we cannot simply join the 2 datasets on player 'name' columns. Need to also join on
college and year.
## Do college names match in both datasets?
```
draft_school = pd.DataFrame(df_draft['school'].unique()).rename(columns={0:'school'})
draft_school['source'] = 'draft'
combine_school = pd.DataFrame(df_combine['school'].unique()).rename(columns={0:'school'})
combine_school['source'] = 'combine'
print(type(combine_school))
print(combine_school.head())
schools = draft_school.merge(combine_school, on='school', how='outer',
suffixes=['_draft', '_combine']).sort_values(by='school')
# List all cases with mismatches
na_mask = schools.isna().any(axis=1)
schools[na_mask].head(10)
```
### So we see that the 'combine' dataset frequently has the state appended to the school name;
Ex: "Abilene Christian (TX)". Remove these from school names, with the exception of "Miami (OH).
```
df_combine['school'] = df_combine['school'].str.replace('Miami (OH)', 'Miami - OH')
print(df_combine['school'].head())
regex_replace_parens = r'\([^)]*[a-zA-Z][^)]*\)'
df_combine['school'] = df_combine['school'].str.replace(regex_replace_parens,
'', regex=True)
df_combine['school'].head()
```
## Standardize player names between datasets
Player names in the "Draft" dataset include suffixes including "Jr., II, III, IV", but these are NOT included in the "combine" dataset.
Standardize player names between datasets by removing these values from the "Draft" dataset.
```
regex_suffixes_to_remove = r'Jr\.$|III$|IIII$|IV$|, Jr.$'
df_draft['name'] = df_draft['name'].str.replace(regex_suffixes_to_remove,
'', regex=True)
```
### Merge the Draft and NFL Combine datasets
```
df_merged = df_combine.merge(df_draft, how='left',
on=['name', 'school', 'year'])
df_merged.head()
# df_merged.to_clipboard()
```
## Investigate merged data
```
df_merged.info()
```
## Data Cleaning:
* Very few 60-yard shuttle records; drop column
* Overwrite blank "Round" column values with '8' (will indicate undrafted)
* Drop kickers, long snappers, QBs and Fullbacks (too few, draft status not driven by stats)
```
# Drop 60yd shuttle (too few data points), duplicative columns related to
# player position, and things like year and team name
merged_cols_to_drop = ['year', 'name', 'school', 'pos',
'60yd shuttle',
'pk(ovr)', 'team', 'position']
try:
df_merged.drop(columns=merged_cols_to_drop, inplace=True)
except:
print('Issue dropping columns')
# overwite blank 'round' values with '8' (will indicate undrafted)
df_merged['round'].fillna(8, inplace=True)
#df_merged.dropna(inplace=True)
print('\n Remaining Columns')
print(df_merged.columns)
positions_to_drop = ['SN', 'K', 'QB', 'FB']
positions_mask = \
df_merged[df_merged['pos_group'].isin(positions_to_drop)].index
print(positions_mask)
print(df_merged.shape)
df_merged.drop(positions_mask, inplace=True)
print(df_merged.head())
```
## Drop all but Cornerbacks
```
df_merged.drop(df_merged[df_merged['pos_group']!='CB'].index, inplace=True)
df_merged['pos_group'].value_counts()
```
### How many players don't have much combine data? Drop them
```
metrics_cols = ['height (in)', 'weight (lbs)', 'hand size (in)', 'arm length (in)',
'40 yard', 'bench press', 'vert leap (in)', 'broad jump (in)',
'shuttle', '3cone']
# See count of records by number of missing metrics values
# 10 total metrics values, drop if they don't have at least 8
print('\n Missing metrics per row')
print(df_merged[metrics_cols].isna().sum(axis=1).value_counts())
df_merged.dropna(axis=0, thresh=7,
subset=metrics_cols, inplace=True)
print('\nRemaining missing metrics by row')
print(df_merged[metrics_cols].isna().sum(axis=1).value_counts())
df_merged.head(10)
df_merged.columns
```
## Impute missing values based on average of players with same position
```
print(df_merged.head(10))
df_merged = clean_data.group_imputer(
df=df_merged,
grouping_col='pos_group',
cols_to_impute=metrics_cols)
print('\n')
print(df_merged.head(10))
```
## Begin Modeling
### Imports for modeling
```
from sklearn.model_selection import train_test_split
# encoders
from category_encoders import OneHotEncoder, OrdinalEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
#metrics
from sklearn.metrics import accuracy_score, precision_score
from sklearn.metrics import classification_report, roc_auc_score, confusion_matrix, plot_confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
#pipeline
from sklearn.pipeline import make_pipeline
# machine learning
from sklearn.linear_model import LogisticRegression, RidgeClassifierCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import RandomizedSearchCV
# Boosted Models
# Use this one if you have an M1 chip.
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
# Permutation Importance
from sklearn.inspection import permutation_importance
# for displaying images and html
from IPython.display import Image
from IPython.core.display import HTML
```
### Split data
```
target = 'round'
X = df_merged.drop(columns=target)
y = df_merged[target]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=.2,
random_state=42)
print(f'X_train shape: {X_train.shape} X_test shape: {X_test.shape}')
```
## Baseline Accuracy
```
baseline = y.value_counts(normalize=True).max()
baseline
```
## Build Random Forest Model/Pipeline
```
# Base Model
model_rf = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(random_state=42)
)
# Parameter distributions for hyperparameter tuning
# Note double underscores __ in keys below
param_distributions = {
'simpleimputer__strategy': ['mean', 'most_frequent'],
'randomforestclassifier__max_depth': range(3,50,5),
'randomforestclassifier__n_estimators': range(10,2000, 10),
'randomforestclassifier__bootstrap': [True, False],
'randomforestclassifier__warm_start': [True, False]
}
tuned_rf = RandomizedSearchCV(
model_rf,
param_distributions=param_distributions,
n_iter=25,
cv=5,
verbose=1,
n_jobs=8
)
model_rf.fit(X_train, y_train)
tuned_rf.fit(X_train, y_train)
```
### Evaluate Random Forest Model/Pipeline
```
print('Tuned RF training best score: ', tuned_rf.best_score_)
print('Tuned RF best parameters: ', tuned_rf.best_params_)
print('Random Forest Training Accuracy', model_rf.score(X_train, y_train))
print('Random Forest Validation Accuracy', model_rf.score(X_test, y_test))
X_train
#y_pred = tuned_rf.predict()
conf_matrix = confusion_matrix(y_true=y_test, y_pred=tuned_rf.predict(X_test))
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix)
display.plot()
```
### Get Permutation importances for model
```
importances = model_rf.named_steps['randomforestclassifier'].feature_importances_
gini_imp = pd.DataFrame(data=importances, index=X_test.columns, columns=['gini_impurity']).sort_values(by='gini_impurity')
gini_imp.tail(10).plot(kind='barh');
```
## Build XGBoost Model/Pipeline
```
model_xgb = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
GradientBoostingClassifier(
loss='deviance',
# learning_rate=0.1,
n_estimators=500,
subsample=1,
max_depth=4,
random_state=42
)
)
model_xgb.fit(X_train, y_train)
```
### Evaluate XGBoost Model/Pipeline
```
print('XGBoost Forest Training Accuracy', model_xgb.score(X_train, y_train))
print('XGBoost Forest Validation Accuracy', model_xgb.score(X_test, y_test))
conf_matrix = confusion_matrix(y_true=y_test, y_pred=model_xgb.predict(X_test))
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix,
display_labels=model_xgb.classes_)
display.plot()
```
## Build Ridge Regression Model/Pipeline
```
# very similar to RandomForest
model_ridge = make_pipeline(
OneHotEncoder(),
SimpleImputer(),
RidgeClassifierCV(cv=5)
)
model_ridge.fit(X_train, y_train)
```
### Evaluate Ridge Regression Model/Pipeline
```
print('Ridge Regression Training Accuracy', model_ridge.score(X_train, y_train))
print('Ridge Regression Validation Accuracy', model_ridge.score(X_test, y_test))
# model_ridge.named_steps.ridgeclassifiercv.coef_
```
# Module 4 Work
(10/14/2021)
* Make at least 1 partial dependence plot to explain your model.
* Make at least 1 Shapley force plot to explain an individual prediction.
* Share at least 1 visualization (of any type) on Slack!
### imports
| github_jupyter |
## Importing files
```
import keras
from keras.datasets import cifar10
import numpy as np
from keras.applications.vgg16 import VGG16, preprocess_input
import scipy
from scipy import misc
import os
```
## Load data
```
(x_train,y_train),(x_test,y_test) = cifar10.load_data()
y_train = np.squeeze(y_train)
```
## Load the model
```
model = VGG16(weights='imagenet',include_top = False, input_shape = (64,64,3))
model.summary()
```
## Obtain bottleneck features for train dataset
```
if os.path.exists('vgg16_features_train.npz'):
print('bottleneck features detected train')
features = np.load('vgg16_features_train.npz')['features']
else:
print('bottleneck features are calculated now')
big_x_train = np.array([scipy.misc.imresize(x_train[i], (64, 64, 3))
for i in range(0, len(x_train))]).astype('float32')
vgg16_input_train = preprocess_input(big_x_train)
print('train data preprocessed')
features = model.predict(vgg16_input_train)
np.savez('vgg16_features_train',features = features)
print('bottleneck features saved for train')
```
## Obtain bottleneck features for test dataset
```
if os.path.exists('vgg16_features_test.npz'):
print('bottleneck features detected test')
features_test = np.load('vgg16_features_test.npz')['features_test']
else:
print('bottleneck features are calculated now')
big_x_test = np.array([scipy.misc.imresize(x_test[i], (64, 64, 3))
for i in range(0, len(x_test))]).astype('float32')
vgg16_input_test = preprocess_input(big_x_test)
print('test data preprocessed')
features_test = model.predict(vgg16_input_test)
np.savez('vgg16_features_test',features_test = features_test)
print('bottleneck features saved for test')
```
## One hot encoding the labels
```
for i in range(5):
print(y_train[i])
from keras.utils import to_categorical
number_of_labels = len(np.unique(y_train))
y_train = to_categorical(y_train,num_classes=number_of_labels)
y_test = to_categorical(y_test,num_classes=number_of_labels)
for i in range(5):
print(y_train[i])
```
## Model Architecture
```
from keras.layers import Dense, Flatten, Dropout
from keras.models import Sequential
model = Sequential()
model.add(Flatten(input_shape=(2,2,512)))
model.add(Dense(500, activation= 'relu'))
model.add(Dropout(0.5))
model.add(Dense(500, activation= 'relu'))
model.add(Dropout(0.15))
model.add(Dense(10, activation='softmax'))
model.summary()
```
## Compile the model
```
model.compile(loss='categorical_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
```
## Train the model
```
from keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint(filepath = 'weights_Transfer_learning.best.hdf5', verbose = 1, save_best_only = True)
model.fit(features,y_train, epochs=10, batch_size=100, verbose=1,callbacks=[checkpoint], validation_split=0.15, shuffle=True)
```
## Load the model weights that yielded best validation accuracy
```
model.load_weights('weights_Transfer_learning.best.hdf5')
```
## Evaluate model classification accuracy on test set
```
score= model.evaluate(features_test,y_test,verbose=0)
print(model.metrics_names)
print(score)
accuracy=100*score[1]
print('Test accuracy:',accuracy)
```
| github_jupyter |
# 11.3 Date Ranges, Frequencies, and Shifting(日期范围,频度,和位移)
普通的时间序列通常是不规律的,但我们希望能有一个固定的频度,比如每天,每月,或没15分钟,即使有一些缺失值也没关系。幸运的是,pandas中有一套方法和工具来进行重采样,推断频度,并生成固定频度的日期范围。例如,我们可以把样本时间序列变为固定按日的频度,需要调用resample:
```
import pandas as pd
import numpy as np
from datetime import datetime
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
datetime(2011, 1, 7), datetime(2011, 1, 8),
datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts = pd.Series(np.random.randn(6), index=dates)
ts
resampler = ts.resample('D')
```
这里的'D'表示按日的频度(daily frequency)。
关于频度(frequency)和重采样(resampling)的转换,会在11.6进行具体介绍,这里我们展示一些基本的用法。
# 1 Generating Date Ranges(生成日期范围)
之前虽然用过,但没有做解释,其实pandas.date_range是用来生成DatetimeIndex的,使用时要根据频度来指明长度:
```
index = pd.date_range('2012-04-01', '2012-06-01')
index
```
默认,date_range会生成按日频度的时间戳。如果我们只传入一个开始或一个结束时间,还必须传入一个数字来表示时期:
```
pd.date_range(start='2012-04-01', periods=20)
pd.date_range(end='2012-06-01', periods=20)
```
开始和结束的日期,严格指定了用于生成日期索引(date index)的边界。例如,如果我们希望日期索引包含每个月的最后一个工作日,我们要设定频度为'BM'(business end of month,每个月的最后一个工作日,更多频度可以看下面的表格),而且只有在这个日期范围内的日期会被包含进去:
```
pd.date_range('2000-01-01', '2000-12-01', freq='BM')
```
时间序列频度:

date_range会默认保留开始或结束的时间戳:
```
pd.date_range('2012-05-02 12:56:31', periods=5)
```
有些时候我们的时间序列数据带有小时,分,秒这样的信息,但我们想要让这些时间戳全部归一化到午夜(normalized to midnight, 即晚上0点),这个时候要用到normalize选项:
```
nor_date = pd.date_range('2012-05-02 12:56:31', periods=5, normalize=True)
nor_date
nor_date[0]
```
可以看到小时,分,秒全部变为0
# 2 Frequencies and Date Offsets(频度和日期偏移)
pandas中的频度由一个基本频度(base frequency)和一个乘法器(multiplier)组成。基本频度通常用一个字符串别名(string alias)来代表,比如'M'表示月,'H'表示小时。对每一个基本频度,还有一个被称之为日期偏移(date offset)的对象。例如,小时频度能用Hour类来表示:
```
from pandas.tseries.offsets import Hour, Minute
hour = Hour()
hour
```
通过传入一个整数,我们可以定义一个乘以偏移的乘法(a multiple of an offset):
```
four_hours = Hour(4)
four_hours
```
在很多情况下,我们不需要创建这些对象,而是使用字符串别名,比如'H'或'4H'。在频度前加一个整数,就能作为一个乘法器:
```
pd.date_range('2000-01-01', '2000-01-03 23:59', freq='4H')
```
很多偏移(offset)还能和加法结合:
```
Hour(2) + Minute(30)
```
同样的,我们可以传入频度字符串,比如'1h30min',这种表达也能被解析:
```
pd.date_range('2000-01-01', periods=10, freq='1h30min')
```
### Week of month dates(月中的第几周日期)
一个有用的类(class)是月中的第几周(Week of month),用WOM表示。丽日我们想得到每个月的第三个星期五:
```
rng = pd.date_range('2012-01-01', '2012-09-01', freq='WOM-3FRI')
rng
list(rng)
```
# 3 Shifting (Leading and Lagging) Data (偏移(提前与推后)数据)
偏移(shifting)表示按照时间把数据向前或向后推移。Series和DataFrame都有一个shift方法实现偏移,索引(index)不会被更改:
```
ts = pd.Series(np.random.randn(4),
index=pd.date_range('1/1/2000', periods=4, freq='M'))
ts
ts.shift(2)
ts.shift(-2)
```
当我们进行位移的时候,就像上面这样会引入缺失值。
shift的一个普通的用法是计算时间序列的百分比变化,可以表示为:
```
ts / ts.shift(1) - 1
```
因为普通的shift不会对index进行修改,一些数据会被丢弃。因此如果频度是已知的,可以把频度传递给shift,这样的话时间戳会自动变化:
```
ts
ts.shift(2)
ts.shift(2, freq='M')
```
其他一些频度也可以导入,能让我们前后移动数据:
```
ts.shift(3, freq='D')
ts.shift(1, freq='90T')
```
T表示分钟。
### Shifting dates with offsets(用偏移量来移动日期)
pandas的日期偏移(date offset)能被用于datetime或Timestamp对象:
```
from pandas.tseries.offsets import Day, MonthEnd
now = datetime(2011, 11, 17)
now + 3 * Day()
```
如果我们添加一个像MonthEnd这样的anchored offset(依附偏移;锚点位置),日期会根据频度规则进行递增:
```
now + MonthEnd()
now + MonthEnd(2)
```
依附偏移可以让日期向前或向后滚动,利用rollforward和rollback方法:
```
offset = MonthEnd()
offset.rollforward(now)
offset.rollback(now)
```
一个比较创造性的日期偏移(date offset)用法是配合groupby一起用:
```
ts = pd.Series(np.random.randn(20),
index=pd.date_range('1/15/2000', periods=20, freq='4d'))
ts
ts.groupby(offset.rollforward).mean()
```
一个简单且快捷的方式是用resample(11.6会进行更详细的介绍):
```
ts.resample('M').mean()
```
| github_jupyter |
# Look at hyperoptimization results for BioWTA on vowel data, when optimizing `n_features`
```
import h5py
import gc
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from typing import Sequence, Union, Tuple, Optional
from tqdm.notebook import tqdm
from bioslds.hdf import read_namespace_hierarchy
from bioslds.plotting import FigureManager, colorbar
paper_style = [
"seaborn-paper",
{"font.size": 8, "axes.labelsize": 8, "xtick.labelsize": 6, "ytick.labelsize": 6},
]
```
## Useful definitions
```
def make_two_param_plot(
ax: plt.Axes,
values: dict,
key1: str,
key2: str,
log1: bool = False,
log2: bool = False,
mask: Union[None, slice, Sequence] = None,
fct_key: str = "fct",
vmin: float = 0.5,
vmax: float = 1.0,
):
# make the scatter plot
if mask is None:
mask = slice(None, None)
h = ax.scatter(
values[key1][mask],
values[key2][mask],
c=values[fct_key][mask],
cmap="Reds",
vmin=vmin,
vmax=vmax,
alpha=0.3,
ec=None,
)
ax.set_xlabel(key1)
ax.set_ylabel(key2)
if log1:
ax.set_xscale("log")
if log2:
ax.set_yscale("log")
ax.set_xlim(np.min(all_values[key1]), np.max(all_values[key1]))
ax.set_ylim(np.min(all_values[key2]), np.max(all_values[key2]))
colorbar(h)
def make_summary_figure(
values: dict,
fct_key: str = "fct",
top_fraction: float = 0.01,
log_scale: Optional[Sequence] = None,
vmin: float = 0.5,
vmax: float = 1.0,
) -> Tuple[plt.Figure, Sequence]:
if log_scale is None:
log_scale = []
# keep only the keys that have some variation and are not scores
keys = [
key
for key in values.keys()
if not key.startswith("fct") and np.std(values[key]) > 0
]
# identify the top 5% highest scores
scores = values[fct_key]
n = len(scores)
n_highscore = max(1, int(np.round(top_fraction * n)))
highscore_idxs = np.argsort(scores)[-n_highscore:]
highscores = scores[highscore_idxs]
# make the figure
n_keys = len(keys)
with plt.style.context(paper_style):
with FigureManager(
n_keys,
n_keys,
squeeze=False,
figsize=(9, 3 * 9 / 4),
despine_kws={"offset": 5},
) as (fig, axs):
# draw histograms on the diagonal
for i in range(n_keys):
ax = axs[i, i]
crt_values = values[keys[i]]
sns.histplot(
crt_values,
element="step",
stat="density",
alpha=0.2,
color="gray",
log_scale=keys[i] in log_scale,
label="all",
ax=ax,
)
# now draw the high-scoring values
crt_highscore_values = crt_values[highscore_idxs]
sns.kdeplot(
crt_highscore_values,
color="C1",
log_scale=keys[i] in log_scale,
shade=True,
label=f"best {int(top_fraction * 100)}%",
ax=ax,
)
sns.rugplot(
crt_highscore_values, height=0.05, c="C1", lw=0.5, ax=ax,
)
ax.legend(frameon=False, fontsize=6, loc="upper left")
ax.set_xlabel(keys[i])
ax.set_ylabel("pdf")
ax.set_xlim(np.min(crt_values), np.max(crt_values))
# now the off-diagonals
for i in range(n_keys):
crt_values1 = values[keys[i]]
crt_highscore_values1 = crt_values1[highscore_idxs]
for j in range(n_keys):
if j == i:
continue
crt_values2 = values[keys[j]]
crt_highscore_values2 = crt_values2[highscore_idxs]
ax = axs[j, i]
h = ax.scatter(
crt_values1,
crt_values2,
c=scores,
cmap="Greys",
vmin=vmin,
vmax=vmax,
alpha=0.2,
ec=None,
)
# now the high-scoring set
h = ax.scatter(
crt_highscore_values1,
crt_highscore_values2,
c=highscores,
cmap="Reds",
vmin=vmin,
# vmax=np.max(highscores),
alpha=0.7,
ec=None,
)
ax.set_xlabel(keys[i])
ax.set_ylabel(keys[j])
if keys[i] in log_scale:
ax.set_xscale("log")
if keys[j] in log_scale:
ax.set_yscale("log")
ax.set_xlim(np.min(crt_values1), np.max(crt_values1))
ax.set_ylim(np.min(crt_values2), np.max(crt_values2))
return fig, axs
def make_optimal_parameter_figure(
values: dict,
fct_key: Union[str, Sequence] = "fct",
top_fraction: float = 0.01,
log_scale: Optional[Sequence] = None,
) -> Tuple[plt.Figure, Sequence]:
if log_scale is None:
log_scale = []
if isinstance(fct_key, str):
fct_key = [fct_key]
# keep only the keys that have some variation and are not scores
keys = [
key
for key in values.keys()
if not key.startswith("fct") and np.std(values[key]) > 0
]
# make the figure
n_keys = len(keys)
with FigureManager(n_keys, len(fct_key), squeeze=False) as (fig, axs):
for k, crt_key in enumerate(fct_key):
ax_col = axs[:, k]
scores = values[crt_key]
n = len(scores)
n_highscore = max(1, int(np.round(top_fraction * n)))
score_order = np.argsort(scores)[::-1]
ordered_scores = scores[score_order]
score_estimate = np.cumsum(ordered_scores) / np.arange(1, n + 1)
for i in range(n_keys):
ax = ax_col[i]
crt_values = values[keys[i]]
if keys[i] not in log_scale:
crt_cum_estimate = np.cumsum(crt_values[score_order]) / np.arange(
1, n + 1
)
else:
crt_cum_estimate = np.exp(
np.cumsum(np.log(crt_values[score_order])) / np.arange(1, n + 1)
)
ax.plot(score_estimate, crt_cum_estimate)
ax.set_xlabel(f"average score ({crt_key})")
ax.set_ylabel(keys[i])
if keys[i] in log_scale:
ax.set_yscale("log")
# annotate the `top_fraction` estimate
crt_len = 0.25 * np.diff(ax.get_xlim())[0]
crt_top_estimate = crt_cum_estimate[n_highscore]
ax.plot(
np.asarray([-crt_len, 0]) + 2 * [ax.get_xlim()[1]],
2 * [crt_top_estimate],
"--",
c="C1",
label=f"best {keys[i]} = {crt_top_estimate:.3g}",
)
ax.legend(frameon=False)
ax_col[0].set_title(crt_key)
ax.set_ylim(np.min(crt_values), np.max(crt_values))
return fig, axs
```
## Data loading
```
quantile_choice = 0.05
# good_threshold = 0.85
good_threshold = 0.70
start_seed = 800
n_seeds = 40
batch_path = os.path.join("..", "..", "batch", "biowta_vowels_ao_long_n_feat")
results = {"fct": [], "fct_quantile": [], "fct_good": []}
for crt_seed in tqdm(range(start_seed, start_seed + n_seeds)):
# load the data
fname = os.path.join(batch_path, f"test_{crt_seed}.hdf5")
with h5py.File(fname, "r") as f:
crt_res = read_namespace_hierarchy(f)
# initialize parameter lists
if crt_seed == start_seed:
results.update({key: [] for key in crt_res["params"][0].keys()})
# process and keep the relevant parts of the data
for key in results:
if key not in ["fct", "fct_quantile", "fct_good"]:
crt_values = [_[key] for _ in crt_res["params"]]
results[key].extend(crt_values)
# now update some special values:
# median scrore
results["fct"].extend(crt_res["fct_scalar"])
# quantile score
for crt_eval in crt_res["fct_full"]:
crt_quant = np.quantile(crt_eval[1].trial_scores, quantile_choice)
results["fct_quantile"].append(crt_quant)
# fraction of "good" runs
for crt_eval in crt_res["fct_full"]:
crt_good = np.mean(crt_eval[1].trial_scores >= good_threshold)
results["fct_good"].append(crt_good)
# ensure everything is a Numpy array
for key in results:
results[key] = np.asarray(results[key])
# don't keep too much useless stuff in memory
del f
del crt_res
del crt_eval
_ = gc.collect()
fig, _ = make_summary_figure(
results,
log_scale=["rate", "exp_streak", "temperature", "timescale", "n_features"],
fct_key="fct_good",
vmin=0.0,
vmax=1.0,
top_fraction=0.02,
)
summary = pd.DataFrame()
# summary["mod_key"] = configurations_human.keys()
summary["mod_name"] = ["biowta"]
for fct_type in ["fct", "fct_quantile", "fct_good"]:
summary[f"best_{fct_type}"] = [np.max(results[fct_type])]
keys = [
key
for key in results.keys()
if not key.startswith("fct") and np.std(results[key]) > 0
]
chosen_fct = "fct_good"
for key in keys:
if not key.startswith("fct"):
key_values = []
crt_idx = np.argmax(results[chosen_fct])
key_values.append(results[key][crt_idx])
summary[f"{key}_at_best_{chosen_fct}"] = key_values
summary
```
| github_jupyter |
___
<a href='http://www.pieriandata.com'> <img src='../../Pierian_Data_Logo.png' /></a>
___
# SF Salaries Exercise - Solutions
Welcome to a quick exercise for you to practice your pandas skills! We will be using the [SF Salaries Dataset](https://www.kaggle.com/kaggle/sf-salaries) from Kaggle! Just follow along and complete the tasks outlined in bold below. The tasks will get harder and harder as you go along.
** Import pandas as pd.**
```
import pandas as pd
```
** Read Salaries.csv as a dataframe called sal.**
```
sal = pd.read_csv('Salaries.csv')
```
** Check the head of the DataFrame. **
```
sal.head()
```
** Use the .info() method to find out how many entries there are.**
```
sal.info() # 148654 Entries
```
**What is the average BasePay ?**
```
sal['BasePay'].mean()
```
** What is the highest amount of OvertimePay in the dataset ? **
```
sal['OvertimePay'].max()
```
** What is the job title of JOSEPH DRISCOLL ? Note: Use all caps, otherwise you may get an answer that doesn't match up (there is also a lowercase Joseph Driscoll). **
```
sal[sal['EmployeeName']=='JOSEPH DRISCOLL']['JobTitle']
```
** How much does JOSEPH DRISCOLL make (including benefits)? **
```
sal[sal['EmployeeName']=='JOSEPH DRISCOLL']['TotalPayBenefits']
```
** What is the name of highest paid person (including benefits)?**
```
sal[sal['TotalPayBenefits']== sal['TotalPayBenefits'].max()] #['EmployeeName']
# or
# sal.loc[sal['TotalPayBenefits'].idxmax()]
```
** What is the name of lowest paid person (including benefits)? Do you notice something strange about how much he or she is paid?**
```
sal[sal['TotalPayBenefits']== sal['TotalPayBenefits'].min()] #['EmployeeName']
# or
# sal.loc[sal['TotalPayBenefits'].idxmax()]['EmployeeName']
## ITS NEGATIVE!! VERY STRANGE
```
** What was the average (mean) BasePay of all employees per year? (2011-2014) ? **
```
sal.groupby('Year').mean()['BasePay']
```
** How many unique job titles are there? **
```
sal['JobTitle'].nunique()
```
** What are the top 5 most common jobs? **
```
sal['JobTitle'].value_counts().head(5)
```
** How many Job Titles were represented by only one person in 2013? (e.g. Job Titles with only one occurence in 2013?) **
```
sum(sal[sal['Year']==2013]['JobTitle'].value_counts() == 1) # pretty tricky way to do this...
```
** How many people have the word Chief in their job title? (This is pretty tricky) **
```
def chief_string(title):
if 'chief' in title.lower():
return True
else:
return False
sum(sal['JobTitle'].apply(lambda x: chief_string(x)))
```
** Bonus: Is there a correlation between length of the Job Title string and Salary? **
```
sal['title_len'] = sal['JobTitle'].apply(len)
sal[['title_len','TotalPayBenefits']].corr() # No correlation.
```
# Great Job!
| github_jupyter |
```
import matplotlib
from matplotlib.pylab import *
%matplotlib inline
matplotlib.rcParams['font.size'] = 16
import json
repos = []
with open('data/repos_with_annotation_infos.json') as input_file:
for line in input_file:
repos.append(json.loads(line))
repos = repos[1:]
import math
N = math.ceil(sqrt(len(repos)))
import numpy as np
all_annotations = np.zeros((N, N)) + 1
inline_annotations = np.zeros((N, N)) + 1
comment_annotations = np.zeros((N, N)) + 1
pyi_annotations = np.zeros((N, N)) + 1
for i, repo in enumerate(repos):
all_annotations[i%N,i//N] = 1 + sum([file['annotation_hints']+file['return_hints']+file['type_comments']+file['typing_imports']+(1 if file['pyi_file'] else 0) for file in repo['files']])
inline_annotations[i%N,i//N] = 1 + sum([file['annotation_hints']+file['return_hints'] for file in repo['files']])
comment_annotations[i%N,i//N] = 1 + sum([file['type_comments'] for file in repo['files']])
pyi_annotations[i%N,i//N] = 1 + sum([(1 if file['pyi_file'] else 0) for file in repo['files']])
print("All annotations:",np.sum(all_annotations > 1))
print("Inline annotations:",np.sum(inline_annotations > 1))
print("Comment annotations:",np.sum(comment_annotations > 1))
print("Pyi annotations:",np.sum(pyi_annotations > 1))
print("All annotations:",np.sum(all_annotations > 11))
print("Inline annotations:",np.sum(inline_annotations > 11))
print("Comment annotations:",np.sum(comment_annotations > 11))
print("Pyi annotations:",np.sum(pyi_annotations > 11))
print("All annotations:",np.sum(all_annotations > 101))
print("Inline annotations:",np.sum(inline_annotations > 101))
print("Comment annotations:",np.sum(comment_annotations > 101))
print("Pyi annotations:",np.sum(pyi_annotations > 101))
from matplotlib.colors import LogNorm
from matplotlib.ticker import LogFormatterMathtext
figure(figsize=(14,14))
ax = gca()
imshow(pyi_annotations, interpolation=None, aspect='equal', norm=LogNorm())
# Major ticks
ax.set_xticks(np.arange(0, N, 1));
ax.set_yticks(np.arange(0, N, 1));
# Labels for major ticks
ax.set_xticklabels([]);
ax.set_yticklabels([]);
# Minor ticks
ax.set_xticks(np.arange(-.5, N, 1), minor=True);
ax.set_yticks(np.arange(-.5, N, 1), minor=True);
ax.grid(which='minor', color='black', linestyle='-', linewidth=2)
colorbar(orientation='horizontal',format=LogFormatterMathtext(), fraction=0.0465, pad=0.03)
title("Pyi files")
repos_by_count = {}
for repo in repos:
repos_by_count[repo['repo']['full_name']] = sum([file['annotation_hints']+file['return_hints']+file['type_comments']+file['typing_imports']+(1 if file['pyi_file'] else 0) for file in repo['files']])
sorted_repos = sorted(repos_by_count.items(), key = lambda x:-x[1])
print("\n".join(["{}: {}".format(x[0],x[1]) for x in sorted_repos[:20]]))
figure(figsize=(18,4))
N = 20
x = list(range(N))
bar(x, [repo[1] for repo in sorted_repos[:N]])
ax = gca()
ax.set_xticks(x)
ax.set_xticklabels([repo[0] for repo in sorted_repos[:N]], rotation=90);
xlim(left=-0.5, right=N-0.5);
title("Python projects with the most type hints")
sorted_repos[:20]
```
| github_jupyter |
# Deep Neural Network for Image Classification: Application
When you finish this, you will have finished the last programming assignment of Week 4, and also the last programming assignment of this course!
You will use the functions you'd implemented in the previous assignment to build a deep network, and apply it to cat vs non-cat classification. Hopefully, you will see an improvement in accuracy relative to your previous logistic regression implementation.
**After this assignment you will be able to:**
- Build and apply a deep neural network to supervised learning.
Let's get started!
## 1 - Packages
Let's first import all the packages that you will need during this assignment.
- [numpy](https://www.numpy.org/) is the fundamental package for scientific computing with Python.
- [matplotlib](http://matplotlib.org) is a library to plot graphs in Python.
- [h5py](http://www.h5py.org) is a common package to interact with a dataset that is stored on an H5 file.
- [PIL](http://www.pythonware.com/products/pil/) and [scipy](https://www.scipy.org/) are used here to test your model with your own picture at the end.
- dnn_app_utils provides the functions implemented in the "Building your Deep Neural Network: Step by Step" assignment to this notebook.
- np.random.seed(1) is used to keep all the random function calls consistent. It will help us grade your work.
```
import time
import numpy as np
import h5py
import matplotlib.pyplot as plt
import scipy
from PIL import Image
from scipy import ndimage
from dnn_app_utils_v3 import *
%matplotlib inline
plt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
%load_ext autoreload
%autoreload 2
np.random.seed(1)
```
## 2 - Dataset
You will use the same "Cat vs non-Cat" dataset as in "Logistic Regression as a Neural Network" (Assignment 2). The model you had built had 70% test accuracy on classifying cats vs non-cats images. Hopefully, your new model will perform a better!
**Problem Statement**: You are given a dataset ("data.h5") containing:
- a training set of m_train images labelled as cat (1) or non-cat (0)
- a test set of m_test images labelled as cat and non-cat
- each image is of shape (num_px, num_px, 3) where 3 is for the 3 channels (RGB).
Let's get more familiar with the dataset. Load the data by running the cell below.
```
train_x_orig, train_y, test_x_orig, test_y, classes = load_data()
```
The following code will show you an image in the dataset. Feel free to change the index and re-run the cell multiple times to see other images.
```
# Example of a picture
index = 10
plt.imshow(train_x_orig[index])
print ("y = " + str(train_y[0,index]) + ". It's a " + classes[train_y[0,index]].decode("utf-8") + " picture.")
# Explore your dataset
m_train = train_x_orig.shape[0]
num_px = train_x_orig.shape[1]
m_test = test_x_orig.shape[0]
print ("Number of training examples: " + str(m_train))
print ("Number of testing examples: " + str(m_test))
print ("Each image is of size: (" + str(num_px) + ", " + str(num_px) + ", 3)")
print ("train_x_orig shape: " + str(train_x_orig.shape))
print ("train_y shape: " + str(train_y.shape))
print ("test_x_orig shape: " + str(test_x_orig.shape))
print ("test_y shape: " + str(test_y.shape))
```
As usual, you reshape and standardize the images before feeding them to the network. The code is given in the cell below.
<img src="images/imvectorkiank.png" style="width:450px;height:300px;">
<caption><center> <u>Figure 1</u>: Image to vector conversion. <br> </center></caption>
```
# Reshape the training and test examples
train_x_flatten = train_x_orig.reshape(train_x_orig.shape[0], -1).T # The "-1" makes reshape flatten the remaining dimensions
test_x_flatten = test_x_orig.reshape(test_x_orig.shape[0], -1).T
# Standardize data to have feature values between 0 and 1.
train_x = train_x_flatten/255.
test_x = test_x_flatten/255.
print ("train_x's shape: " + str(train_x.shape))
print ("test_x's shape: " + str(test_x.shape))
```
$12,288$ equals $64 \times 64 \times 3$ which is the size of one reshaped image vector.
## 3 - Architecture of your model
Now that you are familiar with the dataset, it is time to build a deep neural network to distinguish cat images from non-cat images.
You will build two different models:
- A 2-layer neural network
- An L-layer deep neural network
You will then compare the performance of these models, and also try out different values for $L$.
Let's look at the two architectures.
### 3.1 - 2-layer neural network
<img src="images/2layerNN_kiank.png" style="width:650px;height:400px;">
<caption><center> <u>Figure 2</u>: 2-layer neural network. <br> The model can be summarized as: ***INPUT -> LINEAR -> RELU -> LINEAR -> SIGMOID -> OUTPUT***. </center></caption>
<u>Detailed Architecture of figure 2</u>:
- The input is a (64,64,3) image which is flattened to a vector of size $(12288,1)$.
- The corresponding vector: $[x_0,x_1,...,x_{12287}]^T$ is then multiplied by the weight matrix $W^{[1]}$ of size $(n^{[1]}, 12288)$.
- You then add a bias term and take its relu to get the following vector: $[a_0^{[1]}, a_1^{[1]},..., a_{n^{[1]}-1}^{[1]}]^T$.
- You then repeat the same process.
- You multiply the resulting vector by $W^{[2]}$ and add your intercept (bias).
- Finally, you take the sigmoid of the result. If it is greater than 0.5, you classify it to be a cat.
### 3.2 - L-layer deep neural network
It is hard to represent an L-layer deep neural network with the above representation. However, here is a simplified network representation:
<img src="images/LlayerNN_kiank.png" style="width:650px;height:400px;">
<caption><center> <u>Figure 3</u>: L-layer neural network. <br> The model can be summarized as: ***[LINEAR -> RELU] $\times$ (L-1) -> LINEAR -> SIGMOID***</center></caption>
<u>Detailed Architecture of figure 3</u>:
- The input is a (64,64,3) image which is flattened to a vector of size (12288,1).
- The corresponding vector: $[x_0,x_1,...,x_{12287}]^T$ is then multiplied by the weight matrix $W^{[1]}$ and then you add the intercept $b^{[1]}$. The result is called the linear unit.
- Next, you take the relu of the linear unit. This process could be repeated several times for each $(W^{[l]}, b^{[l]})$ depending on the model architecture.
- Finally, you take the sigmoid of the final linear unit. If it is greater than 0.5, you classify it to be a cat.
### 3.3 - General methodology
As usual you will follow the Deep Learning methodology to build the model:
1. Initialize parameters / Define hyperparameters
2. Loop for num_iterations:
a. Forward propagation
b. Compute cost function
c. Backward propagation
d. Update parameters (using parameters, and grads from backprop)
4. Use trained parameters to predict labels
Let's now implement those two models!
## 4 - Two-layer neural network
**Question**: Use the helper functions you have implemented in the previous assignment to build a 2-layer neural network with the following structure: *LINEAR -> RELU -> LINEAR -> SIGMOID*. The functions you may need and their inputs are:
```python
def initialize_parameters(n_x, n_h, n_y):
...
return parameters
def linear_activation_forward(A_prev, W, b, activation):
...
return A, cache
def compute_cost(AL, Y):
...
return cost
def linear_activation_backward(dA, cache, activation):
...
return dA_prev, dW, db
def update_parameters(parameters, grads, learning_rate):
...
return parameters
```
```
### CONSTANTS DEFINING THE MODEL ####
n_x = 12288 # num_px * num_px * 3
n_h = 7
n_y = 1
layers_dims = (n_x, n_h, n_y)
# GRADED FUNCTION: two_layer_model
def two_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):
"""
Implements a two-layer neural network: LINEAR->RELU->LINEAR->SIGMOID.
Arguments:
X -- input data, of shape (n_x, number of examples)
Y -- true "label" vector (containing 1 if cat, 0 if non-cat), of shape (1, number of examples)
layers_dims -- dimensions of the layers (n_x, n_h, n_y)
num_iterations -- number of iterations of the optimization loop
learning_rate -- learning rate of the gradient descent update rule
print_cost -- If set to True, this will print the cost every 100 iterations
Returns:
parameters -- a dictionary containing W1, W2, b1, and b2
"""
np.random.seed(1)
grads = {}
costs = [] # to keep track of the cost
m = X.shape[1] # number of examples
(n_x, n_h, n_y) = layers_dims
# Initialize parameters dictionary, by calling one of the functions you'd previously implemented
### START CODE HERE ### (≈ 1 line of code)
parameters = initialize_parameters(n_x, n_h, n_y)
### END CODE HERE ###
# Get W1, b1, W2 and b2 from the dictionary parameters.
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> SIGMOID. Inputs: "X, W1, b1, W2, b2". Output: "A1, cache1, A2, cache2".
### START CODE HERE ### (≈ 2 lines of code)
A1, cache1 = linear_activation_forward(X, W1, b1, 'relu')
A2, cache2 = linear_activation_forward(A1, W2, b2, 'sigmoid')
### END CODE HERE ###
# Compute cost
### START CODE HERE ### (≈ 1 line of code)
cost = compute_cost(A2, Y)
### END CODE HERE ###
# Initializing backward propagation
dA2 = - (np.divide(Y, A2) - np.divide(1 - Y, 1 - A2))
# Backward propagation. Inputs: "dA2, cache2, cache1". Outputs: "dA1, dW2, db2; also dA0 (not used), dW1, db1".
### START CODE HERE ### (≈ 2 lines of code)
dA1, dW2, db2 = linear_activation_backward(dA2, cache2, 'sigmoid')
dA0, dW1, db1 = linear_activation_backward(dA1, cache1, 'relu')
### END CODE HERE ###
# Set grads['dWl'] to dW1, grads['db1'] to db1, grads['dW2'] to dW2, grads['db2'] to db2
grads['dW1'] = dW1
grads['db1'] = db1
grads['dW2'] = dW2
grads['db2'] = db2
# Update parameters.
### START CODE HERE ### (approx. 1 line of code)
parameters = update_parameters(parameters, grads, learning_rate)
### END CODE HERE ###
# Retrieve W1, b1, W2, b2 from parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Print the cost every 100 training example
if print_cost and i % 100 == 0:
print("Cost after iteration {}: {}".format(i, np.squeeze(cost)))
if print_cost and i % 100 == 0:
costs.append(cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
```
Run the cell below to train your parameters. See if your model runs. The cost should be decreasing. It may take up to 5 minutes to run 2500 iterations. Check if the "Cost after iteration 0" matches the expected output below, if not click on the square (⬛) on the upper bar of the notebook to stop the cell and try to find your error.
```
parameters = two_layer_model(train_x, train_y, layers_dims = (n_x, n_h, n_y), num_iterations = 2500, print_cost=True)
```
**Expected Output**:
<table>
<tr>
<td> **Cost after iteration 0**</td>
<td> 0.6930497356599888 </td>
</tr>
<tr>
<td> **Cost after iteration 100**</td>
<td> 0.6464320953428849 </td>
</tr>
<tr>
<td> **...**</td>
<td> ... </td>
</tr>
<tr>
<td> **Cost after iteration 2400**</td>
<td> 0.048554785628770226 </td>
</tr>
</table>
Good thing you built a vectorized implementation! Otherwise it might have taken 10 times longer to train this.
Now, you can use the trained parameters to classify images from the dataset. To see your predictions on the training and test sets, run the cell below.
```
predictions_train = predict(train_x, train_y, parameters)
```
**Expected Output**:
<table>
<tr>
<td> **Accuracy**</td>
<td> 1.0 </td>
</tr>
</table>
```
predictions_test = predict(test_x, test_y, parameters)
```
**Expected Output**:
<table>
<tr>
<td> **Accuracy**</td>
<td> 0.72 </td>
</tr>
</table>
**Note**: You may notice that running the model on fewer iterations (say 1500) gives better accuracy on the test set. This is called "early stopping" and we will talk about it in the next course. Early stopping is a way to prevent overfitting.
Congratulations! It seems that your 2-layer neural network has better performance (72%) than the logistic regression implementation (70%, assignment week 2). Let's see if you can do even better with an $L$-layer model.
## 5 - L-layer Neural Network
**Question**: Use the helper functions you have implemented previously to build an $L$-layer neural network with the following structure: *[LINEAR -> RELU]$\times$(L-1) -> LINEAR -> SIGMOID*. The functions you may need and their inputs are:
```python
def initialize_parameters_deep(layers_dims):
...
return parameters
def L_model_forward(X, parameters):
...
return AL, caches
def compute_cost(AL, Y):
...
return cost
def L_model_backward(AL, Y, caches):
...
return grads
def update_parameters(parameters, grads, learning_rate):
...
return parameters
```
```
### CONSTANTS ###
layers_dims = [12288, 20, 7, 5, 1] # 4-layer model
# GRADED FUNCTION: L_layer_model
def L_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):#lr was 0.009
"""
Implements a L-layer neural network: [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID.
Arguments:
X -- data, numpy array of shape (num_px * num_px * 3, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
layers_dims -- list containing the input size and each layer size, of length (number of layers + 1).
learning_rate -- learning rate of the gradient descent update rule
num_iterations -- number of iterations of the optimization loop
print_cost -- if True, it prints the cost every 100 steps
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(1)
costs = [] # keep track of cost
# Parameters initialization. (≈ 1 line of code)
### START CODE HERE ###
parameters = initialize_parameters_deep(layers_dims)
### END CODE HERE ###
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: [LINEAR -> RELU]*(L-1) -> LINEAR -> SIGMOID.
### START CODE HERE ### (≈ 1 line of code)
AL, caches = L_model_forward(X, parameters)
### END CODE HERE ###
# Compute cost.
### START CODE HERE ### (≈ 1 line of code)
cost = compute_cost(AL, Y)
### END CODE HERE ###
# Backward propagation.
### START CODE HERE ### (≈ 1 line of code)
grads = L_model_backward(AL, Y, caches)
### END CODE HERE ###
# Update parameters.
### START CODE HERE ### (≈ 1 line of code)
parameters = update_parameters(parameters, grads, learning_rate)
### END CODE HERE ###
# Print the cost every 100 training example
if print_cost and i % 100 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
if print_cost and i % 100 == 0:
costs.append(cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
```
You will now train the model as a 4-layer neural network.
Run the cell below to train your model. The cost should decrease on every iteration. It may take up to 5 minutes to run 2500 iterations. Check if the "Cost after iteration 0" matches the expected output below, if not click on the square (⬛) on the upper bar of the notebook to stop the cell and try to find your error.
```
parameters = L_layer_model(train_x, train_y, layers_dims, num_iterations = 2500, print_cost = True)
```
**Expected Output**:
<table>
<tr>
<td> **Cost after iteration 0**</td>
<td> 0.771749 </td>
</tr>
<tr>
<td> **Cost after iteration 100**</td>
<td> 0.672053 </td>
</tr>
<tr>
<td> **...**</td>
<td> ... </td>
</tr>
<tr>
<td> **Cost after iteration 2400**</td>
<td> 0.092878 </td>
</tr>
</table>
```
pred_train = predict(train_x, train_y, parameters)
```
<table>
<tr>
<td>
**Train Accuracy**
</td>
<td>
0.985645933014
</td>
</tr>
</table>
```
pred_test = predict(test_x, test_y, parameters)
```
**Expected Output**:
<table>
<tr>
<td> **Test Accuracy**</td>
<td> 0.8 </td>
</tr>
</table>
Congrats! It seems that your 4-layer neural network has better performance (80%) than your 2-layer neural network (72%) on the same test set.
This is good performance for this task. Nice job!
Though in the next course on "Improving deep neural networks" you will learn how to obtain even higher accuracy by systematically searching for better hyperparameters (learning_rate, layers_dims, num_iterations, and others you'll also learn in the next course).
## 6) Results Analysis
First, let's take a look at some images the L-layer model labeled incorrectly. This will show a few mislabeled images.
```
print_mislabeled_images(classes, test_x, test_y, pred_test)
```
**A few types of images the model tends to do poorly on include:**
- Cat body in an unusual position
- Cat appears against a background of a similar color
- Unusual cat color and species
- Camera Angle
- Brightness of the picture
- Scale variation (cat is very large or small in image)
## 7) Test with your own image (optional/ungraded exercise) ##
Congratulations on finishing this assignment. You can use your own image and see the output of your model. To do that:
1. Click on "File" in the upper bar of this notebook, then click "Open" to go on your Coursera Hub.
2. Add your image to this Jupyter Notebook's directory, in the "images" folder
3. Change your image's name in the following code
4. Run the code and check if the algorithm is right (1 = cat, 0 = non-cat)!
```
## START CODE HERE ##
my_image = "my_image.jpg" # change this to the name of your image file
my_label_y = [1] # the true class of your image (1 -> cat, 0 -> non-cat)
## END CODE HERE ##
fname = "images/" + my_image
image = np.array(ndimage.imread(fname, flatten=False))
my_image = scipy.misc.imresize(image, size=(num_px,num_px)).reshape((num_px*num_px*3,1))
my_image = my_image/255.
my_predicted_image = predict(my_image, my_label_y, parameters)
plt.imshow(image)
print ("y = " + str(np.squeeze(my_predicted_image)) + ", your L-layer model predicts a \"" + classes[int(np.squeeze(my_predicted_image)),].decode("utf-8") + "\" picture.")
```
**References**:
- for auto-reloading external module: http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
| github_jupyter |
```
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/My\ Drive/Insight/Project/Reddit\ images
!pip install psaw
!pip install praw
from google.colab import files
src = list(files.upload().values())[0]
open('redcreds.py','wb').write(src)
import redcreds
from psaw import PushshiftAPI
api = PushshiftAPI()
import pandas as pd
import praw
reddit = praw.Reddit(client_id = redcreds.my_client_id,client_secret=redcreds.my_client_secret, password=redcreds.password, user_agent=redcreds.user_agent, username=redcreds.username)
import requests, re, urllib
import bs4 as bs
import urllib.request
import requests
gen = list(api.search_submissions(subreddit='Malefashion',
filter=['url','id', 'title', 'subreddit'],
limit=100000))
pd.DataFrame(gen)
pd.DataFrame(gen).to_csv('malefashion_ids_links.csv')
mf_links=pd.read_csv('malefashion_ids_links.csv')
print(mf_links.shape)
mf_links.head(20)
counter = 0
list_score=[]
list_ratio=[]
for index, row in mf_links.iterrows():
if mf_links.loc[index,'title'].startswith('[WIWT]'):
print(mf_links.loc[index, 'title'])
counter+=1
print(counter)
upvote=praw.models.Submission(reddit, id = str(mf_links.loc[index,'id'])).upvote_ratio
score=praw.models.Submission(reddit, id = str(mf_links.loc[index,'id'])).score
list_ratio.append(upvote)
list_score.append(score)
#urllib.request.urlretrieve(mf_links.loc[index,'url'], str(upvote)+'-'+str(score)+'-'+str(mf_links.loc[index,'title'])+'.jpg')
#
else:
mf_links.drop(index,inplace = True)
print(mf_links.shape)
mf_links.head(10)
pd.DataFrame(mf_links).to_csv('malefashion_ids_links.csv')
mf_links=pd.read_csv('malefashion_ids_links.csv')
print(mf_links.shape)
mf_links.head(20)
mf_links.drop('Unnamed: 0.1', axis = 1, inplace = True)
mf_links['upvote_ratio']=list_ratio
mf_links['score']=list_score
mf_links
mf_links.sort_values('score', ascending=False, inplace = True)
pd.DataFrame(mf_links).to_csv('malefashion_ids_links.csv')
mf_links=pd.read_csv('malefashion_ids_links.csv')
print(mf_links.shape)
mf_links.head(20)
gen2 = list(api.search_submissions(subreddit='Streetwear',
filter=['url','id', 'title', 'subreddit'],
limit=100000))
pd.DataFrame(gen2)
pd.DataFrame(gen2).to_csv('streetwear_ids_links.csv')
counter = 0
list_score=[]
list_ratio=[]
for index, row in sw_links.iterrows():
if sw_links.loc[index,'title'].startswith('[WDYWT]'):
print(sw_links.loc[index, 'title'])
counter+=1
print(counter)
upvote=praw.models.Submission(reddit, id = str(mf_links.loc[index,'id'])).upvote_ratio
score=praw.models.Submission(reddit, id = str(mf_links.loc[index,'id'])).score
list_ratio.append(upvote)
list_score.append(score)
#urllib.request.urlretrieve(mf_links.loc[index,'url'], str(upvote)+'-'+str(score)+'-'+str(mf_links.loc[index,'title'])+'.jpg')
else:
sw_links.drop(index, inplace=True)
mf_links=pd.read_csv('malefashion_ids_links.csv')
print(mf_links.shape)
mf_links.head(20)
counter=0
for index, row in mf_links.iterrows():
try:
counter+=1
if mf_links.loc[index,'url'].endswith('jpg') or mf_links.loc[index,'url'].endswith('png'):
print(counter)
print(mf_links.loc[index,'url'])
urllib.request.urlretrieve(mf_links.loc[index,'url'], str(mf_links.loc[index,'upvote_ratio'])+'-'+str(mf_links.loc[index,'score'])+'-'+str(counter)+'.jpg')
except:
pass
pwd
```
| github_jupyter |
# CNN 变体网络
```
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
```
## 载入数据
```
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape((-1,28,28,1))
x_test = x_test.reshape((-1,28,28,1))
print(x_train.shape, ' ', y_train.shape)
print(x_test.shape, ' ', y_test.shape)
```
## 简单的深度网络

```
x_shape = x_train.shape
deep_model = keras.Sequential(
[
layers.Conv2D(input_shape=((x_shape[1], x_shape[2], x_shape[3])),
filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.MaxPool2D(pool_size=(2,2)),
layers.Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.MaxPool2D(pool_size=(2,2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(10, activation='softmax')
])
deep_model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
deep_model.summary()
history = deep_model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.1)
deep_model.evaluate(x_test, y_test)
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'valivation'], loc='upper left')
plt.show()
```
## 添加了其它功能层的深度卷积
```
x_shape = x_train.shape
deep_model = keras.Sequential(
[
layers.Conv2D(input_shape=((x_shape[1], x_shape[2], x_shape[3])),
filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.BatchNormalization(),
layers.Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.BatchNormalization(),
layers.MaxPool2D(pool_size=(2,2)),
layers.Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.BatchNormalization(),
layers.BatchNormalization(),
layers.Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.MaxPool2D(pool_size=(2,2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dropout(0.2),
layers.Dense(10, activation='softmax')
])
deep_model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
deep_model.summary()
history = deep_model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.1)
%matplotlib inline
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'valivation'], loc='upper left')
plt.show()
deep_model.evaluate(x_test, y_test)
```
## NIN 网络
Min等人在 2013年 [Network In Network](https://arxiv.org/abs/1312.4400) 提出了减少模型中参数数量的方法之一 即“网络中的网络(NIN)”或“1X1卷积” 方法很简单 - 在其他卷积层之后添加卷积层 具有降低图像空间的维度(深度)的效果,有效地减少了参数的数量

GoogleNet 中就用到了 NIN 结构
```
x_shape = x_train.shape
deep_model = keras.Sequential(
[
layers.Conv2D(input_shape=((x_shape[1], x_shape[2], x_shape[3])),
filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.BatchNormalization(),
layers.Conv2D(filters=16, kernel_size=(1,1), strides=(1,1), padding='valid', activation='relu'),
layers.BatchNormalization(),
layers.MaxPool2D(pool_size=(2,2)),
layers.Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'),
layers.BatchNormalization(),
layers.Conv2D(filters=16, kernel_size=(1,1), strides=(1,1), padding='valid', activation='relu'),
layers.BatchNormalization(),
layers.MaxPool2D(pool_size=(2,2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dropout(0.2),
layers.Dense(10, activation='softmax')
])
deep_model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
deep_model.summary()
history = deep_model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.1)
%matplotlib inline
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'valivation'], loc='upper left')
plt.show()
deep_model.evaluate(x_test, y_test)
```
| github_jupyter |
# DSE Course 1, Session 4: Visualization
**Instructor**: Wesley Beckner
**Contact**: wesleybeckner@gmail.com
<br>
---
<br>
In this session we'll be discussing visualization strategies. And, more specifically, how we can manipulate our `pandas dataframes` to give us the visualizations we desire. Before we get there, however, we're going to start by introducing a python module called Matplotlib.
<br>
---
## 4.1 Visualization with Matplotlib
Lets start by importing our `matplotlib` module.
Pyplot is a module of Matplotlib that provides functions to add plot elements like text, lines, and images. typically we import this module like so
```
import matplotlib.pyplot as plt
```
where `plt` is shorthand for the `matplotlib.pyplot` library
```
import matplotlib.pyplot as plt
```
### 4.1.1 The Basics
Matplotlib is strongly object oriented and its principal objects are the **_figure_** and the **_axes_**. But before we get into that I want us to explore the _most basic_ use case. In this basic use case, we don't declare the `figure` and `axes` objects explicitly, but rather work directly in the `pyplot` namespace.
I'm going to create a list of x and y values and plot them with `pyplot`
```
x = [1,2,3,4,5,6,7]
y = [1,1,2,3,5,8,13]
plt.plot(x,y)
```
```
x = [1,2,3,4,5,6,7]
y = [1,1,2,3,5,8,13]
plt.plot(x, y)
```
We can label the axes of our figure using the `xlabel` and `ylabel` attributes, and label our title using the `title` attribute.
```
plt.plot([1,2,3,4,5,6,7],[1,1,2,3,5,8,13])
plt.title('The Fibonacci Sequence')
plt.xlabel('Order in Sequence')
plt.ylabel('Value')
```
```
plt.plot([1,2,3,4,5,6,7],[1,1,2,3,5,8,13])
plt.title('The Fibonacci Sequence')
plt.xlabel('Order in Sequence')
plt.ylabel('Value')
```
> What do we think about the out-of-the-box formatting of `pyplot`? What are some things we can do to make it better? Could we make it bigger? Perhaps different dimensions? Does anyone recognize that default line color?
Before we make any changes, let's become acquianted with the more appropriate way to work in `matplotlib.pyplot`. In this formality, we explicitly create our `figure` and `axes` objects.
```
# This is one way to do it...
# plt.plot([1,2,3,4,5,6,7],[1,1,2,3,5,8,13])
# but we can also do it this way, concretely declaring the figure, axes
# objects directly
# We declare the figure
fig = plt.figure()
# and then add axes
ax = fig.add_subplot(111)
```
You can think of the `figure` as a canvas, where you specify dimensions and possibly unifying attributes of its contents, like, background color, border, etc. You use the canvas, the `figure`, to containerize your other objects, primarily your `axes`, and to save its contents with `savefig`.
You can think of an `axes` as the actual graphs or plots themselves. And when we declare these objects, we have access to all the methods of `matplotlib.pyplot` (e.g. `.plot`, `.scatter`, `.hist` etc.) You can place many of these `axes` into the `figure` container in a variety of ways.
The last component of a `pyplot` figure are the `axis`, the graphical axis we typically think of.
```
# This is one way to do it...
# plt.plot([1,2,3,4,5,6,7],[1,1,2,3,5,8,13])
# but we can also do it this way, concretely declaring the figure, axes
# objects directly
# We declare the figure
fig = plt.figure()
# and then add axes
ax = fig.add_subplot(111)
```
`plt.subplots` returns a `figure` and `axes` object(s) together:
```
### We can also do it in 1 line
fig, ax = plt.subplots(1, 1, figsize=(8,8))
```
and we'll go ahead and adjust the figure size with the parameter `figsize` and set it equal to a tuple containing the `x` and `y` dimensions of the figure in inches.
```
### We can also do it in 1 line
fig, ax = plt.subplots(1, 1, figsize=(10,5))
```
To recap, by convention we typically separate our plots into three components: a Figure, its Axes, and their Axis:
* **_Figure_**: It is a whole `figure` which may contain one or more than one `axes` (plots). You can think of a `figure` as a canvas which contains plots.
* **_Axes_**: It is what we generally think of as a plot. A `figure` can contain many `axes`. It contains two or three (in the case of 3D) `axis` objects. Each `axes` has a title, an x-label and a y-label.
* **_Axis_**: They are the traditional `axis` we think of in a graph and take care of generating the graph limits.
<br>
**Example:**
> `fig, ax = plt.subplots(1, 1, figsize=(8,8))` is creating the figure (`fig`) and axes (`ax`) explicitly, and depending on whether we create 2D or 3D plots, the axes will contain 2-3 `axis`.
#### Exercise 1: Adjust Figure Size
<ol type="a">
<li>create a <code>figure</code> and <code>axes</code> using <code>plt.subplots()</code>. adjust the figure size to be 6 inches (width) by 3 inches (height). Plot the values of the fibonacci sequence we defined earlier</li>
<li>(Bonus) Repeat, this time inverting the y-values using list splicing</li>
<li>(Bonus) Explore other <code>plt.plot()</code> attributes using the built in Colab tooltip</li>
</ol>
Plotting building blocks for Exercise 1:
* `plt.subplots()`
* `ax.plot()`
* slicing `[::]`
```
x = [1,2,3,4,5,6,7]
y = [1,1,2,3,5,8,13]
```
```
# Cell for Exercise 1
x = [1,2,3,4,5,6,7]
y = [1,1,2,3,5,8,13]
```
### 4.1.2 Manipulating Plot Attributes
We can manipulate many parameters of a `figure`'s `axes`: `marker`, `linestyle`, and `color`, to name a few. Each of these parameters takes string values.
```
fig, ax = plt.subplots(1,1, figsize=(5,5))
ax.plot([1,2,3,4,5,6,7],[1,1,2,3,5,8,13], marker='^', linestyle='--',
color='tab:blue')
ax.plot([1,2,3,4,5,6,7],[0,3,8,6,5,4,1], marker='.', linestyle='-.',
color='#59A41F')
ax.set_title('My Random Values')
ax.set_xlabel('Order in Sequence')
ax.set_ylabel('Value')
```
List of marker styles
```
{'': 'nothing',
' ': 'nothing',
'*': 'star',
'+': 'plus',
',': 'pixel',
'.': 'point',
0: 'tickleft',
'1': 'tri_down',
1: 'tickright',
10: 'caretupbase',
11: 'caretdownbase',
'2': 'tri_up',
2: 'tickup',
'3': 'tri_left',
3: 'tickdown',
'4': 'tri_right',
4: 'caretleft',
5: 'caretright',
6: 'caretup',
7: 'caretdown',
'8': 'octagon',
8: 'caretleftbase',
9: 'caretrightbase',
'<': 'triangle_left',
'>': 'triangle_right',
'D': 'diamond',
'H': 'hexagon2',
'None': 'nothing',
None: 'nothing',
'P': 'plus_filled',
'X': 'x_filled',
'^': 'triangle_up',
'_': 'hline',
'd': 'thin_diamond',
'h': 'hexagon1',
'o': 'circle',
'p': 'pentagon',
's': 'square',
'v': 'triangle_down',
'x': 'x',
'|': 'vline'}
```
List of line styles
```
{'': '_draw_nothing',
' ': '_draw_nothing',
'-': '_draw_solid',
'--': '_draw_dashed',
'-.': '_draw_dash_dot',
':': '_draw_dotted',
'None': '_draw_nothing'}
```
List of base colors
```
{'b': (0, 0, 1),
'c': (0, 0.75, 0.75),
'g': (0, 0.5, 0),
'k': (0, 0, 0),
'm': (0.75, 0, 0.75),
'r': (1, 0, 0),
'w': (1, 1, 1),
'y': (0.75, 0.75, 0)}
```
list access
```
import matplotlib as mp
mp.markers.MarkerStyle.markers
mp.lines.lineStyles
mp.colors.BASE_COLORS
```
Taking these long lists of available parameters, I'm going to play around with a few and see how they appear in our plot.
```
import matplotlib as mp
mp.markers.MarkerStyle.markers
# mp.lines.lineStyles
# mp.colors.BASE_COLORS
plt.plot([1,2,3], [4,5,6])
plt.title('title')
ax.title
fig, ax = plt.subplots(1,1, figsize=(5,5))
ax.plot([1,2,3,4,5,6,7],[1,1,2,3,5,8,13],
marker='s',
linestyle=':',
color='tab:blue')
ax.plot([1,2,3,4,5,6,7],[0,3,8,6,5,4,1], marker='.',
linestyle='-.', color='#3E1515')
ax.set_title('My Random Values')
ax.set_xlabel('Order in Sequence')
ax.set_ylabel('Value')
```
If we want to make a *scatter plot* without any lines at all, we set the `linestyle` to an empty string
```
fig, ax = plt.subplots(1,1, figsize=(5,5))
plt.plot([1,2,3,4,5,6,7],[1,1,2,3,5,8,13], marker='*', linestyle='', color='tab:green')
ax.set_title('The Fibonacci Sequence')
ax.set_xlabel('Order in Sequence')
ax.set_ylabel('Value')
```
```
fig, ax = plt.subplots(1,1, figsize=(5,5))
plt.plot([1,2,3,4,5,6,7],[1,1,2,3,5,8,13], marker='h', linestyle='', ms=10,
color='tab:green')
ax.set_title('The Fibonacci Sequence')
ax.set_xlabel('Order in Sequence')
ax.set_ylabel('Value')
```
#### Exercise 2: Choose Lines, Colors, and Markers
<ol type="a">
<li>Recreate the "My Random Values" plot with a variety of markers, linestyles, and colors.</li>
<li>(Bonus) Can you set the markers and lines to colors belonging to the Tableau 20? Try it with and without the hex values!</li>
</ol>
Plotting building blocks for Exercise 2:
* `marker=''`
* `linestyle=''`
* `color=''`
<img src="https://jrnold.github.io/ggthemes/reference/tableau_color_pal-2.png" width=800>
```
# Cell for Exercise 2
### DO NOT CHANGE BELOW ###
x = [1,2,3,4,5,6,7]
y1 = [1,1,2,3,5,8,13]
y2 = [0,3,8,6,5,4,1]
y3 = [10,15,12,9,3,2,1]
y4 = [2,4,2,1,2,4,5]
fig, ax = plt.subplots(1,1, figsize=(5,5))
ax.set_title('My Random Values')
ax.set_xlabel('Order in Sequence')
ax.set_ylabel('Value')
### END OF DO NOT CHANGE ###
### change these lines w/ marker, linestyle, color attributes
ax.plot(x,y1)
ax.plot(x,y2)
ax.plot(x,y3)
ax.plot(x,y4)
```
```
# Cell for Exercise 2
### DO NOT CHANGE BELOW ###
x = [1,2,3,4,5,6,7]
y1 = [1,1,2,3,5,8,13]
y2 = [0,3,8,6,5,4,1]
y3 = [10,15,12,9,3,2,1]
y4 = [2,4,2,1,2,4,5]
fig, ax = plt.subplots(1,1, figsize=(5,5))
ax.set_title('My Random Values')
ax.set_xlabel('Order in Sequence')
ax.set_ylabel('Value')
### END OF DO NOT CHANGE ###
### change these lines w/ marker, linestyle, color attributes
ax.plot(x,y1)
ax.plot(x,y2)
ax.plot(x,y3)
ax.plot(x,y4)
```
### 4.1.3 Subplots
Remember that `fig, ax = plt.subplots()` satement we used earlier? We're now going to use that same approach but this time, the second variable that is returned (what we call `ax` in the cell bellow) is no longer an `axes` object! Instead, it is an `array` of `axes` objects.
I'm also going to introduce another module, **_random_**, to generate some random values
```
import random
fig, ax = plt.subplots(2, 2, figsize=(10,10))
ax[0,1].plot(range(10), [random.random() for i in range(10)],
c='tab:orange')
ax[1,0].plot(range(10), [random.random() for i in range(10)],
c='tab:green')
ax[1,1].plot(range(10), [random.random() for i in range(10)],
c='tab:red')
ax[0,0].plot(range(10), [random.random() for i in range(10)],
c='tab:blue')
```
**_quick note:_** In the above cell we use something called **_list comprehension_** to quickly populate a list of objects (in this case those objects are floats). We won't dive too deeply into that now, but you can think of list comprehension as a more concise way of writing a `for()` loop. In future cases where list comprehension appears in this notebook I will include code snipets of the corresponding for loop.
```
import random
# this list comprehension
print([random.random() for i in range(10)])
# produces the same output as this for loop
ls = []
for i in range(10):
ls.append(random.random())
print(ls)
```
```
import random
random.seed(42)
# this list comprehension
print([random.random() for i in range(10)])
random.seed(42)
# produces the same output as this for loop
ls = []
for i in range(10):
ls.append(random.random())
print(ls)
```
The second thing we'll need to talk about is the grid of the ax object
```
fig, ax = plt.subplots(2,2)
ax.shape
ax
```
This is exactly like accessing a matrix:
`matrix[row,column] = element`
we have the pandas equivalent:
`df.iloc[0,1] = element`
```
import random
fig, ax = plt.subplots(2, 2, figsize=(10,10))
ax[0,0].plot(range(10), [random.random() for i in range(10)],
c='tab:blue')
ax[0,1].plot(range(10), [random.random() for i in range(10)],
c='tab:orange')
ax[1,0].plot(range(10), [random.random() for i in range(10)],
c='tab:green')
ax[1,1].plot(range(10), [random.random() for i in range(10)],
c='tab:red')
```
#### Exercise 3: Subplots
<ol type="a">
<li>Create a 2x1 <code>figure</code> where the first <code>axes</code> is a plot of the fibonacci sequence up to the 10th sequence value and the second <code>axes</code> is a plot of 10 random integers with values between 10 and 20 (exclusive). Use different markers, colors, and lines for each plot.</li>
<li>Since the focus of this tutorial is on visualization, I'll go ahead and provide my own code for generating random integers between 10 and 20 (exclusive). If you have extra time, prove to yourself that this code works!</li>
<li>(remember docstrings are your friend!)</li>
</ol>
```
import random
[round(random.random() * 8) + 11 for i in range(10)]
```
---
```
# Cell for Exercise 3
### DO NOT CHANGE ###
import random
# create the fig, ax objects
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
# generate x, y1, and y2
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y1 = [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
y2 = [round(random.random() * 8) + 11 for i in range(10)]
### END OF DO NOT CHANGE ###
# Note: no skeleton code here is given for the figure, I want you to write this
# code out yourself. Here is pseudo-code to get you started:
# plot the left axes, set the title and axes labels
# title: Fibonacci Sequence; xlabel: x values; ylabel: y values
### YOUR CODE HERE ###
# plot the right axes, set the title and axes labels
# title: My Random Values; xlabel: x values; ylabel: y values
### YOUR CODE HERE ###
```
```
# Cell for Exercise 3
### DO NOT CHANGE ###
import random
# create the fig, ax objects
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
# generate x, y1, and y2
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y1 = [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
y2 = [round(random.random() * 8) + 11 for i in range(10)]
### END OF DO NOT CHANGE ###
# Note: no skeleton code here is given for the figure, I want you to write this
# code out yourself. Here is pseudo-code to get you started:
# plot the left axes, set the title and axes labels
# title: Fibonacci Sequence; xlabel: x values; ylabel: y values
### YOUR CODE HERE ###
# plot the right axes, set the title and axes labels
# title: My Random Values; xlabel: x values; ylabel: y values
### YOUR CODE HERE ###
```
## 4.2 Visualization with Pandas
Now lets discover the power of `pandas` plots! While the objectives of the exercizes may be to make certain visualizations, throughout our experience we'll be using `pandas` tricks to create the data splices we need, so in the following is a mix of new plotting stuff, with pandas data selection/splicing stuff.
We're also going to import a new module called `seaborn`. It is another plotting library based off `matplotlib`. We're going to use it to pull some stylistic features.
```
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston
```
```
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from ipywidgets import interact
```
The following few cells should look familiar from last tutorial session, we're going to use some essential `pandas` methods to get a general sense of what our dataset looks like
> There are many ways to construct a dataframe, as an exercise, you might think of otherways to perform that task here.
```
df = pd.read_csv("https://raw.githubusercontent.com/wesleybeckner/ds_for_engineers/main/data/wine_quality/winequalityN.csv")
df.describe()
```
```
# In your subsequent time with pandas you'll discover that there are a host of
# ways to populate a dataframe. In the following, I can create a dataframe
# simply by using read_csv because the data is formated in a way that
# pandas can easily intuit.
df = pd.read_csv("https://raw.githubusercontent.com/wesleybeckner/"\
"ds_for_engineers/main/data/wine_quality/winequalityN.csv")
# we check the shape of our data to see if its as we expect
df.shape
# we check the column names
df.columns
```
Lets start by looking at basic description of our data. This gives us a sense of what visualizations we can employ to begin understanding our dataset.
```
df.describe()
```
The first thing we notice is that all the data is numerical that we can pull standard statistical information from (mean, std, max, etc.)
What kind of visualizations do you think of with data like this?
I tend to think of scatter, box, and histogram plots for numerical data and bar or pie charts for categorical data.
### 4.2.1 Scatter Plots
The way to generate a plot in the fewest keystrokes is to simply call the `plot()` method within the `dataframe` object
```
df.plot()
```
```
# the simplest plot we can make is the following so let's start here.
# We can generate a figure simply by using the plot() method of our dataframe
# object.
df.plot()
```
This gives us a raw view of the data, but here I'd like to introduce some standard plotting steps: recall the `fig`, `ax` format we used previously.
```
fig, ax = plt.subplots(1, 1, figsize = (10, 5))
df.plot(ax=ax)
```
```
fig, ax = plt.subplots(1, 1, figsize = (10, 5))
df.plot(ax=ax)
```
To make this into a scatter plot, we set the linestyle (or ls) to an empty string, and select a marker type.
```
fig, ax = plt.subplots(1, 1, figsize = (10, 5))
df.plot(ax=ax, linestyle='', marker='.')
```
```
fig, ax = plt.subplots(1, 1, figsize = (10, 5))
df.plot(ax=ax, ls='', marker='.', ms=2)
```
#### Exercise 4: Scatter Plots with Pandas
We have some values that range in the single digits and some that are 10+. Make two separate scatter plots within the same figure, stacked on top of each other:
* Top plot: scatter of all feature data that ranges from 0-10
* Bottom plot: scatter of all feature data 10+ range
Logic building blocks for Exercise 4:
* `df.columns`
* `all()`
* `any()`
* `for`
* `if`
* `in`
* `>`, `>=`
In the following code block, use these two sets of column names to create your figure:
```
low_features = [col for col in df.columns if all(df[col] < 10)]
high_features = [col for col in df.columns if any(df[col] >= 10)]
```
```
# Cell for Exercise 4
low_features = [col for col in df.select_dtypes('number').columns if all(df[col] < 10)]
high_features = [col for col in df.select_dtypes('number').columns if any(df[col] >= 10)]
### YOUR CODE HERE ###
```
### 4.2.2 Bar Plots
One of the more common methods of depicting aggregate data is bar plots. We almost always see these kinds of plots used to display and compare between averages, but sometimes between singular data values as well.
```
fig, ax = plt.subplots(1, 1, figsize=(5,5))
df.apply(pd.Series.mean).plot(kind='barh', ax=ax)
```
```
fig, ax = plt.subplots(1, 1, figsize=(5,5))
df.select_dtypes('number').apply(pd.Series.mean).plot(kind='barh', ax=ax)
fig, ax = plt.subplots(1, 1, figsize=(5,5))
df.groupby('type').apply(pd.Series.mean).T.plot(kind='barh', ax=ax)
```
### 4.2.3 Box Plots
Maybe we thought it was usefull to see the feature data in the scatter plots ( we can visually scan for correlations between feature sets, check outliers, etc.) but perhaps more instructive, is a boxplot. A box plot or boxplot is a statistical method for graphically depicting aggregate data through their quartiles. It will be useful to inspect the [boxplot API](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.boxplot.html) to see the default behavior for representing the quartiles and outliers.
```
fig, ax = plt.subplots(1, 1, figsize = (10, 5))
df.plot(kind='box', ax=ax)
```
```
# we call the boxplot method by setting the kind parameter to 'box' within
# dataframe.plot()
fig, ax = plt.subplots(1, 1, figsize = (10, 5))
df.plot(kind='box', ax=ax, rot=90)
```
### 4.2.4 Histograms
What are some other kinds of plots we can make? A good one to be aware of is the histogram.
```
plt.title('Demo Hist')
plt.xlabel('Random Data')
plt.ylabel('Frequency')
plt.hist(df['RAD'])
```
```
plt.title('Demo Hist')
plt.xlabel('Quality')
plt.ylabel('Frequency')
plt.hist(df['density'])
df['quality'].plot(kind='hist')
```
### 4.2.5 Kernel Density Estimates
Another useful plot type for data analysis is the kernel density estimate. You can think of this plot as exactly like a histogram, except instead of creating bins in which to accrue datapoints, you deposit a gaussian distribution around every datapoint in your dataset. By this mechanism, you avoid creating bias in your data summary as you otherwise would be when predifining bin sizes and locations in a histogram.
```
fig, ax = plt.subplots(1, 1, figsize = (10, 5))
df['quality'].plot(kind='kde', ax=ax)
```
#### 4.2.5.1 Skew and Tailedness
While we're on the topic of KDEs/histograms and other statistical plots, this is a convenient time to talk about skew and tailedness or, otherwise known as kurtosis
* `df.skew()` indicates the skewdness of the data
* `df.kurtosis()` indicates the tailedness of the data
```
# from scipy.stats import skewnorm
from ipywidgets import FloatSlider
slider = FloatSlider(
value=0.5,
min=0.5,
max=5,
step=0.5,
description='Shape:',
disabled=False,
continuous_update=False,
orientation='horizontal',
readout=True,
readout_format='.1f'
)
import numpy as np
def inspect_kurt_skew(a=slider):
# theres another hyperparameter, lambda for the center
# of weibull. the shape parameter is sometimes called
# a, or k
fig, ax = plt.subplots(1, 1, figsize=(5,5))
s = np.random.weibull(a, 1000)
statdf = pd.DataFrame(s)
statdf[0].plot(kind='kde', ax=ax)
print("skew: {:.2f}".format(statdf[0].skew()))
print("kurtosis: {:.2f}".format(statdf[0].kurt()))
interact(inspect_kurt_skew)
```
### 4.2.6 Correlation Plots
Often, we'll want to quantify the strength of a relationship between input variables. We can do this by calculating correlations.
We won't go into great detail here about how Pearson's correlation is calculated, but the StatQuest videos on this subject are here for reference (and are really good... if you can stomach Starmer's
humor)
* [StatQuest: Correlation](https://youtu.be/xZ_z8KWkhXE?t=822)
* [StatQuest: Covariance](https://www.youtube.com/watch?v=qtaqvPAeEJY&ab_channel=StatQuestwithJoshStarmer)
The main takeaway is that pearson's correlation ranges from -1 to 1 and indicates how positively or negatively correlated the variables in question are. For our purposes, this can give insight into what variables will be important in our machine learning model.
We can get the [pearson's correlation](https://en.wikipedia.org/wiki/Pearson_correlation_coefficient) between all the input features using the `dataframe.corr()` method.

Fig: pearson's correlation value and corresponding scatter plot of feature-x and feature-y
```
df.corr()
```
So we have this raw table of pearsons correlations between each of our input features, how do we and how should we turn this into a plot?
Typically we'd use a heat map on an feature vs feature grid to view this kind of data. In the following I'm going to use some `numpy` methods you may not have seen before. Links to the documentation for these methods are at the end of the notebook.
```
import numpy as np
fig, ax = plt.subplots(1, 1, figsize = (10,10))
# create a mask to white-out the upper triangle
mask = np.triu(np.ones_like(df.corr(), dtype=bool))
# we'll want a divergent colormap for this so our eye
# is not attracted to the values close to 0
cmap = sns.diverging_palette(230, 20, as_cmap=True)
sns.heatmap(df.corr(), mask=mask, cmap=cmap, ax=ax)
```
```
sns.heatmap(df.corr())
import numpy as np
fig, ax = plt.subplots(1, 1, figsize = (10,10))
# create a mask to white-out the upper triangle
mask = np.triu(np.ones_like(df.corr(), dtype=bool))
# we'll want a divergent colormap for this so our eye
# is not attracted to the values close to 0
cmap = sns.diverging_palette(230, 20, as_cmap=True)
sns.heatmap(df.corr(), mask=mask, cmap=cmap, ax=ax)
```
What do we notice?
density and alcohol content are negatively correlated, no surprise there. What about the quality field? If we were to try to predict quality, what other chemical features would we pay close attention to?
Alcohol content has a strong positive correlation with quality; chlorides and volatile acidity a somewhat positive correlation. Let's take a look at alcohol vs quality
```
# what can we conclude about this data view? Outliers?
fig, ax = plt.subplots(1,1,figsize=(7,7))
ax.plot(df['alcohol'], df['quality'], ls='', marker='.')
ax.set_title('alcohol vs quality')
ax.set_xlabel('% Alcohol')
ax.set_ylabel('quality')
```
What do we notice about this? The quality is binned, so it's really hard to see any trend here! A boxplot would be better!
```
fig, ax = plt.subplots(1,1,figsize=(10,5))
df.boxplot(column='alcohol', by='quality', ax=ax)
```
We can continue to change our code by hand to iterate through whatever pairwise combinations of input variables we are interested in... but there is a better way to do this! Introducing... IpyWidgets!
## 4.3 Visualization with IpyWidgets
### 4.3.1 Interact
Here we're going to introduce a very basic use case of IPython's widgets using `interact`. The `interact` method (`ipywidgets.interact`) automatically creates user interface (UI) controls for exploring code and data interactively. It is the easiest way to get started using IPython’s widgets.
```
from ipywidgets import interact
def my_plot(col=df.select_dtypes('number').columns):
fig, ax = plt.subplots(1,1,figsize=(10,5))
df.boxplot(column=col, by='quality', ax=ax)
```
```
def my_plot(col=df.select_dtypes('number').columns):
fig, ax = plt.subplots(1,1,figsize=(10,5))
df.boxplot(column=col, by='quality', ax=ax)
```
After defining our function that returns our plot, and defining input parameters for the fields we would like to interact with, we call our function with `interact`
```
interact(my_plot)
```
```
interact(my_plot)
```
Let's break this down. Normally, I would just set my y-variable to a value, so that when I call my function, my figure is generated with the corresponding data field:
```
def my_plot(col='alcohol'):
fig, ax = plt.subplots(1,1,figsize=(10,5))
df.boxplot(column=col, by='quality', ax=ax)
my_plot()
```
Instead, we want to give `interact()` a list of values for the user to select from, this is the difference between a regular function, and one we might feed into interact.
```
y = ['fixed acidity',
'volatile acidity',
'citric acid',
'residual sugar',
'chlorides',
'free sulfur dioxide',
'total sulfur dioxide',
'density',
'pH',
'sulphates',
'alcohol',
'quality']
```
```
list(df.select_dtypes('number').columns)
```
#### Exercise 5: IpyWidgets and Figures in Functions
In the previous section we created a single dropdown menu to select our y variable for our plot. Here, we would like to expand this functionality to the x variable.
* Return a figure from your function and update the xlabel, ylabel, and title of your plot based on the input fields (x and y)
* add a docstring to your function
* checkout sklearn for inspiration on [docstrings](https://github.com/scikit-learn/scikit-learn/blob/main/sklearn/linear_model/_logistic.py)
* Bonus: what are some other input parameters than we can provide our figure function?
Building blocks for Exercise 5:
* `ax.set_title()`
* `ax.set_xlabel()`
* `ax.set_ylabel()`
```
# Code block for Exercise 5
from ipywidgets import interact
def my_plot(col=df.select_dtypes('number').columns,
by=df.select_dtypes('number').columns[::-1]):
'''
An awesome plot. Long description. a general description.
Parameters
----------
x: dtype
description of x
y: dtype
description of y
Returns
-------
fig: dtype
a description of it
'''
### DO NOT CHANGE BELOW ###
fig, ax = plt.subplots(1,1,figsize=(10,5))
if by == 'quality':
df.boxplot(column=col, by=by, ax=ax)
else:
df.plot(x=col, y=by, ls='', marker='.', ax=ax)
### END OF DO NOT CHANGE ###
### YOUR CODE HERE ###
```
```
# Code block for Exercise 5
from ipywidgets import interact
def my_plot(col=df.select_dtypes('number').columns,
by=df.select_dtypes('number').columns[::-1]):
'''
An awesome plot. Long description. a general description.
Parameters
----------
x: list
default value is the first item in the list. some stuff
y: list
description of y
Returns
-------
fig: matplotlib figure
a description of it
'''
### DO NOT CHANGE BELOW ###
fig, ax = plt.subplots(1,1,figsize=(10,5))
if by == 'quality':
df.boxplot(column=col, by=by, ax=ax)
else:
df.plot(x=col, y=by, ls='', marker='.', ax=ax)
### END OF DO NOT CHANGE ###
### YOUR CODE HERE ###
interact(my_plot)
```
## 4.4 Lab for Visualization
> **_If you would like a more difficult breakout activity, skip forward to the advanced users cell_**
We're going to continue on this idea of interactive ploting with IpyWidgets. The objective is to provide our users with a little more intuitive interface than what we've covered so far. Rather than selecting ad hoc through x, y values, the user will select from a list of x, y pairs that are sorted by the absolute value of their pearson's correlation. For example, the first five selection options will be:
* free sulfur dioxide, total sulfur dioxide, 0.721
* density, alcohol, -0.687
* residual sugar, density, 0.552
* residual sugar, total sulfur dioxide, 0.496
* fixed acidity, density, 0.459
When the dropdown is selected, it should update the plotted data, along with the x and y axes labels and plot title.
Example output:
<img src="https://raw.githubusercontent.com/wesleybeckner/ds_for_engineers/main/assets/C1_S4_breakout_solution.JPG" width=500>
**Bonus**
If you finish the lab, format your output so that on the left side of your image contains the raw feature 1 vs feature 2 plot and the right side contains two sublots of the KDEs of the data.
To get you started, I've created the DataFrame needed to make the dropdown menu.
```
# create a list of lists. The sublist contains feature 1 v feature 2 and their
# pearsons correlation. Think of this: you would like to loop through df.corr()
# and store those values in a [[feature 1, feature 2, corr],...[...]] list
corrs = []
for i in range(df.corr().shape[0]):
for j in range(i+1,df.corr().shape[0]):
corrs.append([df.corr().index[i],df.corr().columns[j],df.corr().iloc[i,j]])
# Now create a new dataframe from this list of lists
# sort this dataframe by the absolute value of the pearsons correlation.
# you will need to reset the index by these sorted values.
dff = pd.DataFrame(corrs, columns=['Feature 1', 'Feature 2', 'Pearsons'])
dff = dff.reindex(dff.Pearsons.abs().sort_values(ascending=False).index)
dff = dff.reset_index(drop=True)
# turn the rows of the new dataframe into list items for the drop down menu
# i.e. create a nicely formatted list of labels
ls = []
for index in dff.index:
txt = ''
for item in dff.iloc[index].values:
if type(item) != str:
txt += '{:.3f}'.format(item)
else:
txt += str(item) + ', '
ls.append(txt)
# set this list as the index of the dataframe to appear in the dropdown menu
dff.index = ls
```
Use this DataFrame to create the dropdown menu for your figure. Good luck!
```
dff.head()
# Code block for breakout
### YOUR CODE ###
def my_plot():
# instead of x and y fields (like exercise 5), parameterize with a x vs y
# field, sorted by abs(pearsons) from the provided DataFrame, dff.
# set the values x, and y based on the dropdown selection
# x =
# y =
corr = df.corr()
pearson = corr[x][y]
fig, ax = plt.subplots(1,1,figsize=(7,7))
ax.plot(df[x], df[y], ls='', marker='.')
ax.set_title('{} vs {} ({:.2f} corr)'.format(x, y, pearson))
ax.set_xlabel('{}'.format(x))
ax.set_ylabel('{}'.format(y))
from ipywidgets import SelectMultiple
wine_types = SelectMultiple(
options=['red', 'white'],
value=['red', 'white']
)
def my_plot(row=dff.index, types=wine_types):
# instead of x and y fields, parameterize with a x vs y field.
# fill the field with the top 10 highest magniuted pearson correlations
# and sort them
x = dff.loc[row]['Feature 1']
y = dff.loc[row]['Feature 2']
corr = df.corr()
pearson = corr[x][y]
fig, ax = plt.subplots(1,1,figsize=(7,7))
ax.set_title('{} vs {} ({:.2f} corr)'.format(x, y, pearson))
ax.set_xlabel('{}'.format(x))
ax.set_ylabel('{}'.format(y))
ax.set_xlim(min(df[x]), max(df[x]))
ax.set_ylim(min(df[y]), max(df[y]))
wht = df.loc[df['type'] == 'white']
red = df.loc[df['type'] == 'red']
if 'red' in types:
ax.plot(red[x], red[y], ls='', marker='.', c='tab:red', alpha=.5)
if 'white' in types:
ax.plot(wht[x], wht[y], ls='', marker='.', c='tab:green', alpha=.5)
interact(my_plot)
```
## Advanced Users
Starting with the visualization we created using IpyWidgets, improve the visualization by listing x vs y pairs in the dropdown menu (instead of separate dropdowns for x and y). Sort these fields programatically by the highest to lowest **absolute** pearson's correlation. For example, the first 5 dropdown selections should be the following:
* RAD TAX 0.910
* NOX DIS -0.769
* INDUS NOX 0.764
* AGE DIS -0.748
* LSTAT TARGET -0.738
When the dropdown is selected, it should update the plotted data, along with the x and y axes labels and plot title.
Example output:
<img src="https://raw.githubusercontent.com/wesleybeckner/ds_for_engineers/main/assets/C1_S4_breakout_solution.JPG" width=500>
**Bonus**
If you finish the breakout room, format your output so that on the left side of your image contains the raw feature 1 vs feature 2 plot and the right side contains two sublots of the KDEs of the data.
```
# create a list of lists. The sublist contains feature 1 v feature 2 and their
# pearsons correlation. Think of this: you would like to loop through df.corr()
# and store those values in a [[feature 1, feature 2, corr],...[...]] list
### YOUR CODE ###
# Now create a new dataframe from this list of lists
# sort this dataframe by the absolute value of the pearsons correlation.
# you will need to reset the index by these sorted values.
# hint:
# 1) <mydf>.reindex(<mydf>.<mycolumn>.abs().sort_values(ascending=False).index)
# 2) <mydf>.reset_index(drop=True)
### YOUR CODE ###
# turn the rows of the new dataframe into list items for the drop down menu
# i.e. create a nicely formatted list of labels
### YOUR CODE ###
# set this list as the index of the dataframe to appear in the dropdown menu
### YOUR CODE ###
def my_plot():
# instead of x and y fields (like exercise 5), parameterize with a x vs y
# field, sorted by abs(pearsons).
# set the values x, and y based on the dropdown selection
corr = df.corr()
pearson = corr[x][y]
fig, ax = plt.subplots(1,1,figsize=(7,7))
ax.plot(df[x], df[y], ls='', marker='.')
ax.set_title('{} vs {} ({:.2f} corr)'.format(x, y, pearson))
ax.set_xlabel('{}'.format(x))
ax.set_ylabel('{}'.format(y))
```
# References
* [`numpy.triu`](https://numpy.org/doc/stable/reference/generated/numpy.triu.html)
* [`numpy.ones_like`](https://numpy.org/doc/stable/reference/generated/numpy.ones_like.html)
* [`ipywidgets`](https://ipywidgets.readthedocs.io/en/latest/)
* [StatQuest: Correlation](https://youtu.be/xZ_z8KWkhXE?t=822)
* [StatQuest: Covariance](https://www.youtube.com/watch?v=qtaqvPAeEJY&ab_channel=StatQuestwithJoshStarmer)
# Enrichment Topics
## 4.4 Other Plot Types
### 4.4.1 Bar Plots (Advanced)
Similar to how we created bar plots with pandas, we can use matplotlib to make barplots
```
pokemon = ['Charmander', 'Pikachu', 'Squirtle', 'Bulbasaur']
hp = [10, 12, 8, 16]
plt.bar(pokemon, hp, color='tab:blue')
plt.title('Pokemon HP')
plt.xlabel('Pokemon')
plt.ylabel('HP')
```
```
pokemon = ['Charmander', 'Pikachu', 'Squirtle', 'Bulbasaur']
hp = [10, 12, 8, 16]
plt.bar(pokemon, hp, color='tab:blue')
plt.title('Pokemon HP')
plt.xlabel('Pokemon')
plt.ylabel('HP')
```
Doing the same but with horizontally oriented bars
```
pokemon = ['Charmander', 'Pikachu', 'Squirtle', 'Bulbasaur']
hp = [10, 12, 8, 16]
plt.barh(pokemon, hp, color='tab:blue')
plt.title('Pokemon HP')
plt.ylabel('Pokemon')
plt.xlabel('HP')
```
```
pokemon = ['Charmander', 'Pikachu', 'Squirtle', 'Bulbasaur']
hp = [10, 12, 8, 16]
plt.barh(pokemon, hp, color='tab:blue')
plt.title('Pokemon HP')
plt.ylabel('Pokemon')
plt.xlabel('HP')
```
We can also add error bars
```
pokemon = ['Charmander', 'Pikachu', 'Squirtle', 'Bulbasaur']
hp = [10, 12, 8, 16]
variance = [i * random.random()*.25 for i in hp]
plt.barh(pokemon, hp, xerr=variance, color='tab:blue')
plt.title('Pokemon HP')
plt.ylabel('Pokemon')
plt.xlabel('HP')
```
for loop version of list comprehension
```
hp = [10, 12, 8, 16]
variance = []
for i in hp:
variance.append(i * random.random()*.25)
print(variance)
```
```
pokemon = ['Charmander', 'Pikachu', 'Squirtle', 'Bulbasaur']
hp = [10, 12, 8, 16]
variance = [i * random.random()*.25 for i in hp]
plt.barh(pokemon, hp, xerr=variance, color='tab:blue')
plt.title('Pokemon HP')
plt.ylabel('Pokemon')
plt.xlabel('HP')
```
### 4.4.2 3D Plots
You can also create 3D plots in matplotlib using `ax.scatter3D`
```
ax = plt.axes(projection='3d')
ax.scatter3D(range(10),[i*random.random()*.25 for i in range(10)])
```
for loop version of list comprehension:
```
ls = []
for i in range(10):
ls.append(i*random.random()*.25)
print(ls)
```
```
ax = plt.axes(projection='3d')
ax.scatter3D(range(10),[i*random.random()*.25 for i in range(10)])
```
## 4.5 Visualization with Plotly
Another great plotting library, that is gaining in popularity (especially in enterprise settings) is plotly. As an added exercise, if you have additional time, explore some of the [plotly examples](https://plotly.com/python/) then recreate the breakout room assignment using plotly instead of matplotlib.
### 4.5.1 Scatter Plot with Size and Color
```
import plotly.express as px
x = 'quality'
y = 'alcohol'
color = 'quality'
size = 'alcohol'
corr = df.corr()
pearson = corr[x][y]
fig = px.scatter(df, x=x, y=y, color=color, size=size,
title='{} vs {} ({:.2f} corr)'.format(x, y, pearson),
width=800, height=800)
fig.show()
```
### 4.5.2 Plotly with IpyWidgets
```
def my_plot(x=df.columns, y=df.columns, color=df.columns, size=df.columns):
corr = df.corr()
pearson = corr[x][y]
fig = px.scatter(df, x=x, y=y, color=color, size=size,
title='{} vs {} ({:.2f} corr)'.format(x, y, pearson),
width=800, height=800)
fig.show()
interact(my_plot)
```
| github_jupyter |
<div style = "font-family:Georgia;
font-size:2.5vw;
color:lightblue;
font-style:bold;
text-align:center;
background:url('./Animations/Title Background.gif') no-repeat center;
background-size:cover)">
<br><br>
Histograms of Oriented Gradients (HOG)
<br><br><br>
</div>
<h1 style = "text-align:left">Introduction</h1>
As we saw with the ORB algorithm, we can use keypoints in images to do keypoint-based matching to detect objects in images. These type of algorithms work great when you want to detect objects that have a lot of consistent internal features that are not affected by the background. For example, these algorithms work well for facial detection because faces have a lot of consistent internal features that don’t get affected by the image background, such as the eyes, nose, and mouth. However, these type of algorithms don’t work so well when attempting to do more general object recognition, say for example, pedestrian detection in images. The reason is that people don’t have consistent internal features, like faces do, because the body shape and style of every person is different (see Fig. 1). This means that every person is going to have a different set of internal features, and so we need something that can more generally describe a person.
<br>
<figure>
<img src = "./Animations/pedestrians.jpeg" width = "100%" style = "border: thin silver solid; padding: 10px">
<figcaption style = "text-align:left; font-style:italic">Fig. 1. - Pedestrians.</figcaption>
</figure>
<br>
One option is to try to detect pedestrians by their contours instead. Detecting objects in images by their contours (boundaries) is very challenging because we have to deal with the difficulties brought about by the contrast between the background and the foreground. For example, suppose you wanted to detect a pedestrian in an image that is walking in front of a white building and she is wearing a white coat and black pants (see Fig. 2). We can see in Fig. 2, that since the background of the image is mostly white, the black pants are going to have a very high contrast, but the coat, since it is white as well, is going to have very low contrast. In this case, detecting the edges of pants is going to be easy but detecting the edges of the coat is going to be very difficult. This is where **HOG** comes in. HOG stands for **Histograms of Oriented Gradients** and it was first introduced by Navneet Dalal and Bill Triggs in 2005.
<br>
<figure>
<img src = "./Animations/woman.jpg" width = "100%" style = "border: thin silver solid; padding: 10px">
<figcaption style = "text-align:left; font-style:italic">Fig. 2. - High and Low Contrast.</figcaption>
</figure>
<br>
The HOG algorithm works by creating histograms of the distribution of gradient orientations in an image and then normalizing them in a very special way. This special normalization is what makes HOG so effective at detecting the edges of objects even in cases where the contrast is very low. These normalized histograms are put together into a feature vector, known as the HOG descriptor, that can be used to train a machine learning algorithm, such as a Support Vector Machine (SVM), to detect objects in images based on their boundaries (edges). Due to its great success and reliability, HOG has become one of the most widely used algorithms in computer vison for object detection.
In this notebook, you will learn:
* How the HOG algorithm works
* How to use OpenCV to create a HOG descriptor
* How to visualize the HOG descriptor.
# The HOG Algorithm
As its name suggests, the HOG algorithm, is based on creating histograms from the orientation of image gradients. The HOG algorithm is implemented in a series of steps:
1. Given the image of particular object, set a detection window (region of interest) that covers the entire object in the image (see Fig. 3).
2. Calculate the magnitude and direction of the gradient for each individual pixel in the detection window.
3. Divide the detection window into connected *cells* of pixels, with all cells being of the same size (see Fig. 3). The size of the cells is a free parameter and it is usually chosen so as to match the scale of the features that want to be detected. For example, in a 64 x 128 pixel detection window, square cells 6 to 8 pixels wide are suitable for detecting human limbs.
4. Create a Histogram for each cell, by first grouping the gradient directions of all pixels in each cell into a particular number of orientation (angular) bins; and then adding up the gradient magnitudes of the gradients in each angular bin (see Fig. 3). The number of bins in the histogram is a free parameter and it is usually set to 9 angular bins.
5. Group adjacent cells into *blocks* (see Fig. 3). The number of cells in each block is a free parameter and all blocks must be of the same size. The distance between each block (known as the stride) is a free parameter but it is usually set to half the block size, in which case you will get overlapping blocks (*see video below*). The HOG algorithm has been shown empirically to work better with overlapping blocks.
6. Use the cells contained within each block to normalize the cell histograms in that block (see Fig. 3). If you have overlapping blocks this means that most cells will be normalized with respect to different blocks (*see video below*). Therefore, the same cell may have several different normalizations.
7. Collect all the normalized histograms from all the blocks into a single feature vector called the HOG descriptor.
8. Use the resulting HOG descriptors from many images of the same type of object to train a machine learning algorithm, such as an SVM, to detect those type of objects in images. For example, you could use the HOG descriptors from many images of pedestrians to train an SVM to detect pedestrians in images. The training is done with both positive a negative examples of the object you want detect in the image.
9. Once the SVM has been trained, a sliding window approach is used to try to detect and locate objects in images. Detecting an object in the image entails finding the part of the image that looks similar to the HOG pattern learned by the SVM.
<br>
<figure>
<img src = "./Animations/HOG Diagram2.png" width = "100%" style = "border: thin silver solid; padding: 1px">
<figcaption style = "text-align:left; font-style:italic">Fig. 3. - HOG Diagram.</figcaption>
</figure>
<br>
<figure>
<video src = "./Animations/HOG Animation - Medium.mp4" width="100%" controls autoplay loop> </video>
<figcaption style = "text-align:left; font-style:italic">Vid. 1. - HOG Animation.</figcaption>
</figure>
# Why The HOG Algorithm Works
As we learned above, HOG creates histograms by adding the magnitude of the gradients in particular orientations in localized portions of the image called *cells*. By doing this we guarantee that stronger gradients will contribute more to the magnitude of their respective angular bin, while the effects of weak and randomly oriented gradients resulting from noise are minimized. In this manner the histograms tell us the dominant gradient orientation of each cell.
### Dealing with contrast
Now, the magnitude of the dominant orientation can vary widely due to variations in local illumination and the contrast between the background and the foreground.
To account for the background-foreground contrast differences, the HOG algorithm tries to detect edges locally. In order to do this, it defines groups of cells, called **blocks**, and normalizes the histograms using this local group of cells. By normalizing locally, the HOG algorithm can detect the edges in each block very reliably; this is called **block normalization**.
In addition to using block normalization, the HOG algorithm also uses overlapping blocks to increase its performance. By using overlapping blocks, each cell contributes several independent components to the final HOG descriptor, where each component corresponds to a cell being normalized with respect to a different block. This may seem redundant but, it has been shown empirically that by normalizing each cell several times with respect to different local blocks, the performance of the HOG algorithm increases dramatically.
### Loading Images and Importing Resources
The first step in building our HOG descriptor is to load the required packages into Python and to load our image.
We start by using OpenCV to load an image of a triangle tile. Since, the `cv2.imread()` function loads images as BGR we will convert our image to RGB so we can display it with the correct colors. As usual we will convert our BGR image to Gray Scale for analysis.
```
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Set the default figure size
plt.rcParams['figure.figsize'] = [17.0, 7.0]
# Load the image
image = cv2.imread('./images/triangle_tile.jpeg')
# Convert the original image to RGB
original_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Convert the original image to gray scale
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Print the shape of the original and gray scale images
print('The original image has shape: ', original_image.shape)
print('The gray scale image has shape: ', gray_image.shape)
# Display the images
plt.subplot(121)
plt.imshow(original_image)
plt.title('Original Image')
plt.subplot(122)
plt.imshow(gray_image, cmap='gray')
plt.title('Gray Scale Image')
plt.show()
```
# Creating The HOG Descriptor
We will be using OpenCV’s `HOGDescriptor` class to create the HOG descriptor. The parameters of the HOG descriptor are setup using the `HOGDescriptor()` function. The parameters of the `HOGDescriptor()` function and their default values are given below:
`cv2.HOGDescriptor(win_size = (64, 128),
block_size = (16, 16),
block_stride = (8, 8),
cell_size = (8, 8),
nbins = 9,
win_sigma = DEFAULT_WIN_SIGMA,
threshold_L2hys = 0.2,
gamma_correction = true,
nlevels = DEFAULT_NLEVELS)`
Parameters:
* **win_size** – *Size*
Size of detection window in pixels (*width, height*). Defines the region of interest. Must be an integer multiple of cell size.
* **block_size** – *Size*
Block size in pixels (*width, height*). Defines how many cells are in each block. Must be an integer multiple of cell size and it must be smaller than the detection window. The smaller the block the finer detail you will get.
* **block_stride** – *Size*
Block stride in pixels (*horizontal, vertical*). It must be an integer multiple of cell size. The `block_stride` defines the distance between adjecent blocks, for example, 8 pixels horizontally and 8 pixels vertically. Longer `block_strides` makes the algorithm run faster (because less blocks are evaluated) but the algorithm may not perform as well.
* **cell_size** – *Size*
Cell size in pixels (*width, height*). Determines the size fo your cell. The smaller the cell the finer detail you will get.
* **nbins** – *int*
Number of bins for the histograms. Determines the number of angular bins used to make the histograms. With more bins you capture more gradient directions. HOG uses unsigned gradients, so the angular bins will have values between 0 and 180 degrees.
* **win_sigma** – *double*
Gaussian smoothing window parameter. The performance of the HOG algorithm can be improved by smoothing the pixels near the edges of the blocks by applying a Gaussian spatial window to each pixel before computing the histograms.
* **threshold_L2hys** – *double*
L2-Hys (Lowe-style clipped L2 norm) normalization method shrinkage. The L2-Hys method is used to normalize the blocks and it consists of an L2-norm followed by clipping and a renormalization. The clipping limits the maximum value of the descriptor vector for each block to have the value of the given threshold (0.2 by default). After the clipping the descriptor vector is renormalized as described in *IJCV*, 60(2):91-110, 2004.
* **gamma_correction** – *bool*
Flag to specify whether the gamma correction preprocessing is required or not. Performing gamma correction slightly increases the performance of the HOG algorithm.
* **nlevels** – *int*
Maximum number of detection window increases.
As we can see, the `cv2.HOGDescriptor()`function supports a wide range of parameters. The first few arguments (`block_size, block_stride, cell_size`, and `nbins`) are probably the ones you are most likely to change. The other parameters can be safely left at their default values and you will get good results.
In the code below, we will use the `cv2.HOGDescriptor()`function to set the cell size, block size, block stride, and the number of bins for the histograms of the HOG descriptor. We will then use `.compute(image)`method to compute the HOG descriptor (feature vector) for the given `image`.
```
# Specify the parameters for our HOG descriptor
# Cell Size in pixels (width, height). Must be smaller than the size of the detection window
# and must be chosen so that the resulting Block Size is smaller than the detection window.
cell_size = (6, 6)
# Number of cells per block in each direction (x, y). Must be chosen so that the resulting
# Block Size is smaller than the detection window
num_cells_per_block = (2, 2)
# Block Size in pixels (width, height). Must be an integer multiple of Cell Size.
# The Block Size must be smaller than the detection window
block_size = (num_cells_per_block[0] * cell_size[0],
num_cells_per_block[1] * cell_size[1])
# Calculate the number of cells that fit in our image in the x and y directions
x_cells = gray_image.shape[1] // cell_size[0]
y_cells = gray_image.shape[0] // cell_size[1]
# Horizontal distance between blocks in units of Cell Size. Must be an integer and it must
# be set such that (x_cells - num_cells_per_block[0]) / h_stride = integer.
h_stride = 1
# Vertical distance between blocks in units of Cell Size. Must be an integer and it must
# be set such that (y_cells - num_cells_per_block[1]) / v_stride = integer.
v_stride = 1
# Block Stride in pixels (horizantal, vertical). Must be an integer multiple of Cell Size
block_stride = (cell_size[0] * h_stride, cell_size[1] * v_stride)
# Number of gradient orientation bins
num_bins = 9
# Specify the size of the detection window (Region of Interest) in pixels (width, height).
# It must be an integer multiple of Cell Size and it must cover the entire image. Because
# the detection window must be an integer multiple of cell size, depending on the size of
# your cells, the resulting detection window might be slightly smaller than the image.
# This is perfectly ok.
win_size = (x_cells * cell_size[0] , y_cells * cell_size[1])
# Print the shape of the gray scale image for reference
print('\nThe gray scale image has shape: ', gray_image.shape)
print()
# Print the parameters of our HOG descriptor
print('HOG Descriptor Parameters:\n')
print('Window Size:', win_size)
print('Cell Size:', cell_size)
print('Block Size:', block_size)
print('Block Stride:', block_stride)
print('Number of Bins:', num_bins)
print()
# Set the parameters of the HOG descriptor using the variables defined above
hog = cv2.HOGDescriptor(win_size, block_size, block_stride, cell_size, num_bins)
# Compute the HOG Descriptor for the gray scale image
hog_descriptor = hog.compute(gray_image)
```
# Number of Elements In The HOG Descriptor
The resulting HOG Descriptor (feature vector), contains the normalized histograms from all cells from all blocks in the detection window concatenated in one long vector. Therefore, the size of the HOG feature vector will be given by the total number of blocks in the detection window, multiplied by the number of cells per block, times the number of orientation bins:
<span class="mathquill">
\begin{equation}
\mbox{total_elements} = (\mbox{total_number_of_blocks})\mbox{ } \times \mbox{ } (\mbox{number_cells_per_block})\mbox{ } \times \mbox{ } (\mbox{number_of_bins})
\end{equation}
</span>
If we don’t have overlapping blocks (*i.e.* the `block_stride`equals the `block_size`), the total number of blocks can be easily calculated by dividing the size of the detection window by the block size. However, in the general case we have to take into account the fact that we have overlapping blocks. To find the total number of blocks in the general case (*i.e.* for any `block_stride` and `block_size`), we can use the formula given below:
<span class="mathquill">
\begin{equation}
\mbox{Total}_i = \left( \frac{\mbox{block_size}_i}{\mbox{block_stride}_i} \right)\left( \frac{\mbox{window_size}_i}{\mbox{block_size}_i} \right) - \left [\left( \frac{\mbox{block_size}_i}{\mbox{block_stride}_i} \right) - 1 \right]; \mbox{ for } i = x,y
\end{equation}
</span>
Where <span class="mathquill">Total$_x$</span>, is the total number of blocks along the width of the detection window, and <span class="mathquill">Total$_y$</span>, is the total number of blocks along the height of the detection window. This formula for <span class="mathquill">Total$_x$</span> and <span class="mathquill">Total$_y$</span>, takes into account the extra blocks that result from overlapping. After calculating <span class="mathquill">Total$_x$</span> and <span class="mathquill">Total$_y$</span>, we can get the total number of blocks in the detection window by multiplying <span class="mathquill">Total$_x$ $\times$ Total$_y$</span>. The above formula can be simplified considerably because the `block_size`, `block_stride`, and `window_size`are all defined in terms of the `cell_size`. By making all the appropriate substitutions and cancelations the above formula reduces to:
<span class="mathquill">
\begin{equation}
\mbox{Total}_i = \left(\frac{\mbox{cells}_i - \mbox{num_cells_per_block}_i}{N_i}\right) + 1\mbox{ }; \mbox{ for } i = x,y
\end{equation}
</span>
Where <span class="mathquill">cells$_x$</span> is the total number of cells along the width of the detection window, and <span class="mathquill">cells$_y$</span>, is the total number of cells along the height of the detection window. And <span class="mathquill">$N_x$</span> is the horizontal block stride in units of `cell_size` and <span class="mathquill">$N_y$</span> is the vertical block stride in units of `cell_size`.
Let's calculate what the number of elements for the HOG feature vector should be and check that it matches the shape of the HOG Descriptor calculated above.
```
# Calculate the total number of blocks along the width of the detection window
tot_bx = np.uint32(((x_cells - num_cells_per_block[0]) / h_stride) + 1)
# Calculate the total number of blocks along the height of the detection window
tot_by = np.uint32(((y_cells - num_cells_per_block[1]) / v_stride) + 1)
# Calculate the total number of elements in the feature vector
tot_els = (tot_bx) * (tot_by) * num_cells_per_block[0] * num_cells_per_block[1] * num_bins
# Print the total number of elements the HOG feature vector should have
print('\nThe total number of elements in the HOG Feature Vector should be: ',
tot_bx, 'x',
tot_by, 'x',
num_cells_per_block[0], 'x',
num_cells_per_block[1], 'x',
num_bins, '=',
tot_els)
# Print the shape of the HOG Descriptor to see that it matches the above
print('\nThe HOG Descriptor has shape:', hog_descriptor.shape)
print()
```
# Visualizing The HOG Descriptor
We can visualize the HOG Descriptor by plotting the histogram associated with each cell as a collection of vectors. To do this, we will plot each bin in the histogram as a single vector whose magnitude is given by the height of the bin and its orientation is given by the angular bin that its associated with. Since any given cell might have multiple histograms associated with it, due to the overlapping blocks, we will choose to average all the histograms for each cell to produce a single histogram for each cell.
OpenCV has no easy way to visualize the HOG Descriptor, so we have to do some manipulation first in order to visualize it. We will start by reshaping the HOG Descriptor in order to make our calculations easier. We will then compute the average histogram of each cell and finally we will convert the histogram bins into vectors. Once we have the vectors, we plot the corresponding vectors for each cell in an image.
The code below produces an interactive plot so that you can interact with the figure. The figure contains:
* the grayscale image,
* the HOG Descriptor (feature vector),
* a zoomed-in portion of the HOG Descriptor, and
* the histogram of the selected cell.
**You can click anywhere on the gray scale image or the HOG Descriptor image to select a particular cell**. Once you click on either image a *magenta* rectangle will appear showing the cell you selected. The Zoom Window will show you a zoomed in version of the HOG descriptor around the selected cell; and the histogram plot will show you the corresponding histogram for the selected cell. The interactive window also has buttons at the bottom that allow for other functionality, such as panning, and giving you the option to save the figure if desired. The home button returns the figure to its default value.
**NOTE**: If you are running this notebook in the Udacity workspace, there is around a 2 second lag in the interactive plot. This means that if you click in the image to zoom in, it will take about 2 seconds for the plot to refresh.
```
%matplotlib notebook
import copy
import matplotlib.patches as patches
# Set the default figure size
plt.rcParams['figure.figsize'] = [9.8, 9]
# Reshape the feature vector to [blocks_y, blocks_x, num_cells_per_block_x, num_cells_per_block_y, num_bins].
# The blocks_x and blocks_y will be transposed so that the first index (blocks_y) referes to the row number
# and the second index to the column number. This will be useful later when we plot the feature vector, so
# that the feature vector indexing matches the image indexing.
hog_descriptor_reshaped = hog_descriptor.reshape(tot_bx,
tot_by,
num_cells_per_block[0],
num_cells_per_block[1],
num_bins).transpose((1, 0, 2, 3, 4))
# Print the shape of the feature vector for reference
print('The feature vector has shape:', hog_descriptor.shape)
# Print the reshaped feature vector
print('The reshaped feature vector has shape:', hog_descriptor_reshaped.shape)
# Create an array that will hold the average gradients for each cell
ave_grad = np.zeros((y_cells, x_cells, num_bins))
# Print the shape of the ave_grad array for reference
print('The average gradient array has shape: ', ave_grad.shape)
# Create an array that will count the number of histograms per cell
hist_counter = np.zeros((y_cells, x_cells, 1))
# Add up all the histograms for each cell and count the number of histograms per cell
for i in range (num_cells_per_block[0]):
for j in range(num_cells_per_block[1]):
ave_grad[i:tot_by + i,
j:tot_bx + j] += hog_descriptor_reshaped[:, :, i, j, :]
hist_counter[i:tot_by + i,
j:tot_bx + j] += 1
# Calculate the average gradient for each cell
ave_grad /= hist_counter
# Calculate the total number of vectors we have in all the cells.
len_vecs = ave_grad.shape[0] * ave_grad.shape[1] * ave_grad.shape[2]
# Create an array that has num_bins equally spaced between 0 and 180 degress in radians.
deg = np.linspace(0, np.pi, num_bins, endpoint = False)
# Each cell will have a histogram with num_bins. For each cell, plot each bin as a vector (with its magnitude
# equal to the height of the bin in the histogram, and its angle corresponding to the bin in the histogram).
# To do this, create rank 1 arrays that will hold the (x,y)-coordinate of all the vectors in all the cells in the
# image. Also, create the rank 1 arrays that will hold all the (U,V)-components of all the vectors in all the
# cells in the image. Create the arrays that will hold all the vector positons and components.
U = np.zeros((len_vecs))
V = np.zeros((len_vecs))
X = np.zeros((len_vecs))
Y = np.zeros((len_vecs))
# Set the counter to zero
counter = 0
# Use the cosine and sine functions to calculate the vector components (U,V) from their maginitudes. Remember the
# cosine and sine functions take angles in radians. Calculate the vector positions and magnitudes from the
# average gradient array
for i in range(ave_grad.shape[0]):
for j in range(ave_grad.shape[1]):
for k in range(ave_grad.shape[2]):
U[counter] = ave_grad[i,j,k] * np.cos(deg[k])
V[counter] = ave_grad[i,j,k] * np.sin(deg[k])
X[counter] = (cell_size[0] / 2) + (cell_size[0] * i)
Y[counter] = (cell_size[1] / 2) + (cell_size[1] * j)
counter = counter + 1
# Create the bins in degress to plot our histogram.
angle_axis = np.linspace(0, 180, num_bins, endpoint = False)
angle_axis += ((angle_axis[1] - angle_axis[0]) / 2)
# Create a figure with 4 subplots arranged in 2 x 2
fig, ((a,b),(c,d)) = plt.subplots(2,2)
# Set the title of each subplot
a.set(title = 'Gray Scale Image\n(Click to Zoom)')
b.set(title = 'HOG Descriptor\n(Click to Zoom)')
c.set(title = 'Zoom Window', xlim = (0, 18), ylim = (0, 18), autoscale_on = False)
d.set(title = 'Histogram of Gradients')
# Plot the gray scale image
a.imshow(gray_image, cmap = 'gray')
a.set_aspect(aspect = 1)
# Plot the feature vector (HOG Descriptor)
b.quiver(Y, X, U, V, color = 'white', headwidth = 0, headlength = 0, scale_units = 'inches', scale = 5)
b.invert_yaxis()
b.set_aspect(aspect = 1)
b.set_facecolor('black')
# Define function for interactive zoom
def onpress(event):
#Unless the left mouse button is pressed do nothing
if event.button != 1:
return
# Only accept clicks for subplots a and b
if event.inaxes in [a, b]:
# Get mouse click coordinates
x, y = event.xdata, event.ydata
# Select the cell closest to the mouse click coordinates
cell_num_x = np.uint32(x / cell_size[0])
cell_num_y = np.uint32(y / cell_size[1])
# Set the edge coordinates of the rectangle patch
edgex = x - (x % cell_size[0])
edgey = y - (y % cell_size[1])
# Create a rectangle patch that matches the the cell selected above
rect = patches.Rectangle((edgex, edgey),
cell_size[0], cell_size[1],
linewidth = 1,
edgecolor = 'magenta',
facecolor='none')
# A single patch can only be used in a single plot. Create copies
# of the patch to use in the other subplots
rect2 = copy.copy(rect)
rect3 = copy.copy(rect)
# Update all subplots
a.clear()
a.set(title = 'Gray Scale Image\n(Click to Zoom)')
a.imshow(gray_image, cmap = 'gray')
a.set_aspect(aspect = 1)
a.add_patch(rect)
b.clear()
b.set(title = 'HOG Descriptor\n(Click to Zoom)')
b.quiver(Y, X, U, V, color = 'white', headwidth = 0, headlength = 0, scale_units = 'inches', scale = 5)
b.invert_yaxis()
b.set_aspect(aspect = 1)
b.set_facecolor('black')
b.add_patch(rect2)
c.clear()
c.set(title = 'Zoom Window')
c.quiver(Y, X, U, V, color = 'white', headwidth = 0, headlength = 0, scale_units = 'inches', scale = 1)
c.set_xlim(edgex - cell_size[0], edgex + (2 * cell_size[0]))
c.set_ylim(edgey - cell_size[1], edgey + (2 * cell_size[1]))
c.invert_yaxis()
c.set_aspect(aspect = 1)
c.set_facecolor('black')
c.add_patch(rect3)
d.clear()
d.set(title = 'Histogram of Gradients')
d.grid()
d.set_xlim(0, 180)
d.set_xticks(angle_axis)
d.set_xlabel('Angle')
d.bar(angle_axis,
ave_grad[cell_num_y, cell_num_x, :],
180 // num_bins,
align = 'center',
alpha = 0.5,
linewidth = 1.2,
edgecolor = 'k')
fig.canvas.draw()
# Create a connection between the figure and the mouse click
fig.canvas.mpl_connect('button_press_event', onpress)
plt.show()
```
# Understanding The Histograms
Let's take a look at a couple of snapshots of the above figure to see if the histograms for the selected cell make sense. Let's start looking at a cell that is inside a triangle and not near an edge:
<br>
<figure>
<img src = "./Animations/snapshot1.png" width = "70%" style = "border: thin silver solid; padding: 1px">
<figcaption style = "text-align:center; font-style:italic">Fig. 4. - Histograms Inside a Triangle.</figcaption>
</figure>
<br>
In this case, since the triangle is nearly all of the same color there shouldn't be any dominant gradient in the selected cell. As we can clearly see in the Zoom Window and the histogram, this is indeed the case. We have many gradients but none of them clearly dominates over the other.
Now let’s take a look at a cell that is near a horizontal edge:
<br>
<figure>
<img src = "./Animations/snapshot2.png" width = "70%" style = "border: thin silver solid; padding: 1px">
<figcaption style = "text-align:center; font-style:italic">Fig. 5. - Histograms Near a Horizontal Edge.</figcaption>
</figure>
<br>
Remember that edges are areas of an image where the intensity changes abruptly. In these cases, we will have a high intensity gradient in some particular direction. This is exactly what we see in the corresponding histogram and Zoom Window for the selected cell. In the Zoom Window, we can see that the dominant gradient is pointing up, almost at 90 degrees, since that’s the direction in which there is a sharp change in intensity. Therefore, we should expect to see the 90-degree bin in the histogram to dominate strongly over the others. This is in fact what we see.
Now let’s take a look at a cell that is near a vertical edge:
<br>
<figure>
<img src = "./Animations/snapshot3.png" width = "70%" style = "border: thin silver solid; padding: 1px">
<figcaption style = "text-align:center; font-style:italic">Fig. 6. - Histograms Near a Vertical Edge.</figcaption>
</figure>
<br>
In this case we expect the dominant gradient in the cell to be horizontal, close to 180 degrees, since that’s the direction in which there is a sharp change in intensity. Therefore, we should expect to see the 170-degree bin in the histogram to dominate strongly over the others. This is what we see in the histogram but we also see that there is another dominant gradient in the cell, namely the one in the 10-degree bin. The reason for this, is because the HOG algorithm is using unsigned gradients, which means 0 degrees and 180 degrees are considered the same. Therefore, when the histograms are being created, angles between 160 and 180 degrees, contribute proportionally to both the 10-degree bin and the 170-degree bin. This results in there being two dominant gradients in the cell near the vertical edge instead of just one.
To conclude let’s take a look at a cell that is near a diagonal edge.
<br>
<figure>
<img src = "./Animations/snapshot4.png" width = "70%" style = "border: thin silver solid; padding: 1px">
<figcaption style = "text-align:center; font-style:italic">Fig. 7. - Histograms Near a Diagonal Edge.</figcaption>
</figure>
<br>
To understand what we are seeing, let’s first remember that gradients have an *x*-component, and a *y*-component, just like vectors. Therefore, the resulting orientation of a gradient is going to be given by the vector sum of its components. For this reason, on vertical edges the gradients are horizontal, because they only have an x-component, as we saw in Figure 4. While on horizontal edges the gradients are vertical, because they only have a y-component, as we saw in Figure 3. Consequently, on diagonal edges, the gradients are also going to be diagonal because both the *x* and *y* components are non-zero. Since the diagonal edges in the image are close to 45 degrees, we should expect to see a dominant gradient orientation in the 50-degree bin. This is in fact what we see in the histogram but, just like in Figure 4., we see there are two dominant gradients instead of just one. The reason for this is that when the histograms are being created, angles that are near the boundaries of bins, contribute proportionally to the adjacent bins. For example, a gradient with an angle of 40 degrees, is right in the middle of the 30-degree and 50-degree bin. Therefore, the magnitude of the gradient is split evenly into the 30-degree and 50-degree bin. This results in there being two dominant gradients in the cell near the diagonal edge instead of just one.
Now that you know how HOG is implemented, in the workspace you will find a notebook named *Examples*. In there, you will be able set your own paramters for the HOG descriptor for various images. Have fun!
| github_jupyter |
# Submitting and Managing Jobs
Launch this tutorial in a Jupyter Notebook on Binder:
[](https://mybinder.org/v2/gh/htcondor/htcondor-python-bindings-tutorials/master?urlpath=lab/tree/Submitting-and-Managing-Jobs.ipynb)
## What is HTCondor?
An HTCondor pool provides a way for you (as a user) to submit units of work, called **jobs**, to be executed on a distributed network of computing resources.
HTCondor provides tools to monitor your jobs as they run, and make certain kinds of changes to them after submission, which we call "managing" jobs.
In this tutorial, we will learn how to submit and manage jobs *from Python*.
We will see how to submit jobs with various toy executables, how to ask HTCondor for information about them, and how to tell HTCondor to do things with them.
All of these things are possible from the command line as well, using tools like `condor_submit`, `condor_qedit`, and `condor_hold`.
However, working from Python instead of the command line gives us access to the full power of Python to do things like generate jobs programmatically based on user input, pass information consistently from submission to management, or even expose an HTCondor pool to a web application.
We start by importing the HTCondor Python bindings modules, which provide the functions we will need to talk to HTCondor.
```
import htcondor # for submitting jobs, querying HTCondor daemons, etc.
import classad # for interacting with ClassAds, HTCondor's internal data format
```
## Submitting a Simple Job
To submit a job, we must first describe it.
A submit description is held in a `Submit` object.
`Submit` objects consist of key-value pairs, and generally behave like Python dictionaries.
If you're familiar with HTCondor's submit file syntax, you should think of each line in the submit file as a single key-value pair in the `Submit` object.
Let's start by writing a `Submit` object that describes a job that executes the `hostname` command on an execute node, which prints out the "name" of the node.
Since `hostname` prints its results to standard output (stdout), we will capture stdout and bring it back to the submit machine so we can see the name.
```
hostname_job = htcondor.Submit({
"executable": "/bin/hostname", # the program to run on the execute node
"output": "hostname.out", # anything the job prints to standard output will end up in this file
"error": "hostname.err", # anything the job prints to standard error will end up in this file
"log": "hostname.log", # this file will contain a record of what happened to the job
"request_cpus": "1", # how many CPU cores we want
"request_memory": "128MB", # how much memory we want
"request_disk": "128MB", # how much disk space we want
})
print(hostname_job)
```
The available descriptors are documented in the [`condor_submit` manual page](https://htcondor.readthedocs.io/en/latest/man-pages/condor_submit.html).
The keys of the Python dictionary you pass to `htcondor.Submit` should be the same as for the submit descriptors, and the values should be **strings containing exactly what would go on the right-hand side**.
Note that we gave the `Submit` object several relative filepaths.
These paths are relative to the directory containing this Jupyter notebook (or, more generally, the current working directory).
When we run the job, you should see those files appear in the file browser on the left as HTCondor creates them.
Now that we have a job description, let's submit a job.
The `htcondor.Schedd.submit` method returns a `SubmitResult` object that contains information about the job, such as its `ClusterId`.
```
schedd = htcondor.Schedd() # get the Python representation of the scheduler
submit_result = schedd.submit(hostname_job) # submit the job
print(submit_result.cluster()) # print the job's ClusterId
```
The job's `ClusterId` uniquely identifies this submission.
Later in this module, we will use it to ask the HTCondor scheduler for information about our jobs.
For now, our job will hopefully have finished running.
You should be able to see the files in the file browser on the left.
Try opening one of them and seeing what's inside.
We can also look at the output from inside Python:
```
import os
import time
output_path = "hostname.out"
# this is a crude way to wait for the job to finish
# see the Advanced tutorial "Scalable Job Tracking" for better methods!
while not os.path.exists(output_path):
print("Output file doesn't exist yet; sleeping for one second")
time.sleep(1)
with open(output_path, mode = "r") as f:
print(f.read())
```
If you got some text, it worked!
If the file never shows up, it means your job didn't run.
You might try looking at the `log` or `error` files specified in the submit description to see if there is any useful information in them about why the job failed.
## Submitting Multiple Jobs
By default, each `submit` will submit a single job.
A more common use case is to submit many jobs at once, often sharing some base submit description.
Let's write a new submit description which runs `sleep`.
When we have multiple **jobs** in a single **cluster**, each job will be identified not just by its **ClusterId** but also by a **ProcID**.
We can use the ProcID to separate the output and error files for each individual job.
Anything that looks like `$(...)` in a submit description is a **macro**, a placeholder which will be "expanded" later by HTCondor into a real value for that particular job.
The ProcID expands to a series of incrementing integers, starting at 0.
So the first job in a cluster will have ProcID 0, the next will have ProcID 1, etc.
```
sleep_job = htcondor.Submit({
"executable": "/bin/sleep",
"arguments": "10s", # sleep for 10 seconds
"output": "sleep-$(ProcId).out", # output and error for each job, using the $(ProcId) macro
"error": "sleep-$(ProcId).err",
"log": "sleep.log", # we still send all of the HTCondor logs for every job to the same file (not split up!)
"request_cpus": "1",
"request_memory": "128MB",
"request_disk": "128MB",
})
print(sleep_job)
```
We will submit 10 of these jobs.
All we need to change from our previous `submit` call is to add the `count` keyword argument.
```
schedd = htcondor.Schedd()
submit_result = schedd.submit(sleep_job, count=10) # submit 10 jobs
print(submit_result.cluster())
```
Now that we have a bunch of jobs in flight, we might want to check how they're doing.
We can ask the HTCondor scheduler about jobs by using its `query` method.
We give it a **constraint**, which tells it which jobs to look for, and a **projection**, which tells it what information to return.
```
schedd.query(
constraint=f"ClusterId == {submit_result.cluster()}",
projection=["ClusterId", "ProcId", "Out"],
)
```
There are a few things to notice here:
- Depending on how long it took you to run the cell, you may only get a few of your 10 jobs in the query. Jobs that have finished **leave the queue**, and will no longer show up in queries. To see those jobs, you must use the `history` method instead, which behaves like `query`, but **only** looks at jobs that have left the queue.
- The results may not have come back in ProcID-sorted order. If you want to guarantee the order of the results, you must do so yourself.
- Attributes are often renamed between the submit description and the actual job description in the queue. See [the manual](https://htcondor.readthedocs.io/en/latest/classad-attributes/job-classad-attributes.html) for a description of the job attribute names.
- The objects returned by the query are instances of `ClassAd`. ClassAds are the common data exchange format used by HTCondor. In Python, they mostly behave like dictionaries.
## Using Itemdata to Vary Over Parameters
By varying some part of the submit description using the ProcID, we can change how each individual job behaves.
Perhaps it will use a different input file, or a different argument.
However, we often want more flexibility than that.
Perhaps our input files are named after different cities, or by timestamp, or some other naming scheme that already exists.
To use such information in the submit description, we need to use **itemdata**.
Itemdata lets us pass arbitrary extra information when we queue, which we can reference with macros inside the submit description.
This lets use the full power of Python to generate the submit descriptions for our jobs.
Let's mock this situation out by generating some files with randomly-chosen names.
We'll also switch to using `pathlib.Path`, Python's more modern file path manipulation library.
```
from pathlib import Path
import random
import string
import shutil
def random_string(length):
"""Produce a random lowercase ASCII string with the given length."""
return "".join(random.choices(string.ascii_lowercase, k = length))
# make a directory to hold the input files, clearing away any existing directory
input_dir = Path.cwd() / "inputs"
shutil.rmtree(input_dir, ignore_errors = True)
input_dir.mkdir()
# make 5 input files
for idx in range(5):
rs = random_string(5)
input_file = input_dir / "{}.txt".format(rs)
input_file.write_text("Hello from job {}".format(rs))
```
Now we'll get a list of all the files we just created in the input directory.
This is precisely the kind of situation where Python affords us a great deal of flexibility over a submit file: we can use Python instead of the HTCondor submit language to generate and inspect the information we're going to put into the submit description.
```
input_files = list(input_dir.glob("*.txt"))
for path in input_files:
print(path)
```
Now we'll make our submit description.
Our goal is just to print out the text held in each file, which we can do using `cat`.
We will tell HTCondor to transfer the input file to the execute location by including it in `transfer_input_files`.
We also need to call `cat` on the right file via `arguments`.
Keep in mind that HTCondor will move the files in `transfer_input_files` directly to the scratch directory on the execute machine, so instead of the full path, we just need the file's "name", the last component of its path.
`pathlib` will make it easy to extract this information.
```
cat_job = htcondor.Submit({
"executable": "/bin/cat",
"arguments": "$(input_file_name)", # we will pass in the value for this macro via itemdata
"transfer_input_files": "$(input_file)", # we also need HTCondor to move the file to the execute node
"should_transfer_files": "yes", # force HTCondor to transfer files even though we're running entirely inside a container (and it normally wouldn't need to)
"output": "cat-$(ProcId).out",
"error": "cat-$(ProcId).err",
"log": "cat.log",
"request_cpus": "1",
"request_memory": "128MB",
"request_disk": "128MB",
})
print(cat_job)
```
The itemdata should be passed as a list of dictionaries, where the keys are the macro names to replace in the submit description.
In our case, the keys are `input_file` and `input_file_name`, so should have a list of 10 dictionaries, each with two entries.
HTCondor expects the input file list to be a comma-separated list of POSIX-style paths, so we explicitly convert our `Path` to a POSIX string.
```
itemdata = [{"input_file": path.as_posix(), "input_file_name": path.name} for path in input_files]
for item in itemdata:
print(item)
```
Now we'll submit the jobs, adding the `itemdata` parameter to the `submit` call:
```
schedd = htcondor.Schedd()
submit_result = schedd.submit(cat_job, itemdata = iter(itemdata)) # submit one job for each item in the itemdata
print(submit_result.cluster())
```
Let's do a query to make sure we got the itemdata right (these jobs run fast, so you might need to re-run the jobs if your first run has already left the queue):
```
schedd.query(
constraint=f"ClusterId == {submit_result.cluster()}",
projection=["ClusterId", "ProcId", "Out", "Args", "TransferInput"],
)
```
And let's take a look at all the output:
```
# again, this is very crude - see the advanced tutorials!
while not len(list(Path.cwd().glob("cat-*.out"))) == len(itemdata):
print("Not all output files exist yet; sleeping for one second")
time.sleep(1)
for output_file in Path.cwd().glob("cat-*.out"):
print(output_file, "->", output_file.read_text())
```
## Managing Jobs
Once a job is in queue, the scheduler will try its best to execute it to completion.
There are several cases where you may want to interrupt the normal flow of jobs.
Perhaps the results are no longer needed; perhaps the job needs to be edited to correct a submission error.
These actions fall under the purview of **job management**.
There are two `Schedd` methods dedicated to job management:
* `edit()`: Change an attribute for a set of jobs.
* `act()`: Change the state of a job (remove it from the queue, hold it, suspend it, etc.).
The `act` method takes an argument from the `JobAction` enum.
Commonly-used values include:
* `Hold`: put a job on hold, vacating a running job if necessary. A job will stay in the hold
state until told otherwise.
* `Release`: Release a job from the hold state, returning it to Idle.
* `Remove`: Remove a job from the queue. If it is running, it will stop running.
This requires the execute node to acknowledge it has successfully vacated the job, so ``Remove`` may
not be instantaneous.
* `Vacate`: Cause a running job to be killed on the remote resource and return to the Idle state. With
`Vacate`, jobs may be given significant time to cleanly shut down.
To play with this, let's bring back our sleep submit description, but increase the sleep time significantly so that we have time to interact with the jobs.
```
long_sleep_job = htcondor.Submit({
"executable": "/bin/sleep",
"arguments": "10m", # sleep for 10 minutes
"output": "sleep-$(ProcId).out",
"error": "sleep-$(ProcId).err",
"log": "sleep.log",
"request_cpus": "1",
"request_memory": "128MB",
"request_disk": "128MB",
})
print(long_sleep_job)
schedd = htcondor.Schedd()
submit_result = schedd.submit(long_sleep_job, count=5)
```
As an experiment, let's set an arbitrary attribute on the jobs and check that it worked.
When we're really working, we could do things like change the amount of memory a job has requested by editing its `RequestMemory` attribute.
The job attributes that are built-in to HTCondor are described [here](https://htcondor.readthedocs.io/en/latest/classad-attributes/job-classad-attributes.html), but your site may specify additional, custom attributes as well.
```
# sets attribute foo to the string "bar" for all of our jobs
# note the nested quotes around bar! The outer "" make it a Python string; the inner "" make it a ClassAd string.
schedd.edit(f"ClusterId == {submit_result.cluster()}", "foo", "\"bar\"")
# do a query to check the value of attribute foo
schedd.query(
constraint=f"ClusterId == {submit_result.cluster()}",
projection=["ClusterId", "ProcId", "JobStatus", "foo"],
)
```
Although the job status appears to be an attribute, we cannot `edit` it directly.
As mentioned above, we must instead `act` on the job.
Let's hold the first two jobs so that they stop running, but leave the others going.
```
# hold the first two jobs
schedd.act(htcondor.JobAction.Hold, f"ClusterId == {submit_result.cluster()} && ProcID <= 1")
# check the status of the jobs
ads = schedd.query(
constraint=f"ClusterId == {submit_result.cluster()}",
projection=["ClusterId", "ProcId", "JobStatus"],
)
for ad in ads:
# the ClassAd objects returned by the query act like dictionaries, so we can extract individual values out of them using []
print(f"ProcID = {ad['ProcID']} has JobStatus = {ad['JobStatus']}")
```
The various job statuses are represented by numbers. `1` means `Idle`, `2` means `Running`, and `5` means `Held`. If you see `JobStatus = 5` above for `ProcID = 0` and `ProcID = 1`, then we succeeded!
The opposite of `JobAction.Hold` is `JobAction.Release`.
Let's release those jobs and let them go back to `Idle`.
```
schedd.act(htcondor.JobAction.Release, f"ClusterId == {submit_result.cluster()}")
ads = schedd.query(
constraint=f"ClusterId == {submit_result.cluster()}",
projection=["ClusterId", "ProcId", "JobStatus"],
)
for ad in ads:
# the ClassAd objects returned by the query act like dictionaries, so we can extract individual values out of them using []
print(f"ProcID = {ad['ProcID']} has JobStatus = {ad['JobStatus']}")
```
Note that we simply released all the jobs in the cluster.
Releasing a job that is not held doesn't do anything, so we don't have to be extremely careful.
Finally, let's clean up after ourselves:
```
schedd.act(htcondor.JobAction.Remove, f"ClusterId == {submit_result.cluster()}")
```
## Exercises
Now let's practice what we've learned.
- In each exercise, you will be given a piece of code and a test that does not yet pass.
- The exercises are vaguely in order of increasing difficulty.
- Modify the code, or add new code to it, to pass the test. Do whatever it takes!
- You can run the test by running the block it is in.
- Feel free to look at the test for clues as to how to modify the code.
- Many of the exercises can be solved either by using Python to generate inputs, or by using advanced features of the [ClassAd language](https://htcondor.readthedocs.io/en/latest/misc-concepts/classad-mechanism.html#htcondor-s-classad-mechanism). Either way is valid!
- Don't modify the test. That's cheating!
### Exercise 1: Incrementing Sleeps
Submit five jobs which sleep for `5`, `6`, `7`, `8`, and `9` seconds, respectively.
```
# MODIFY OR ADD TO THIS BLOCK...
incrementing_sleep = htcondor.Submit({
"executable": "/bin/sleep",
"arguments": "1",
"output": "ex1-$(ProcId).out",
"error": "ex1-$(ProcId).err",
"log": "ex1.log",
"request_cpus": "1",
"request_memory": "128MB",
"request_disk": "128MB",
})
schedd = htcondor.Schedd()
submit_result = schedd.submit(incrementing_sleep)
# ... TO MAKE THIS TEST PASS
expected = [str(i) for i in range(5, 10)]
print("Expected ", expected)
ads = schedd.query(f"ClusterId == {submit_result.cluster()}", projection = ["Args"])
arguments = sorted(ad["Args"] for ad in ads)
print("Got ", arguments)
assert arguments == expected, "Arguments were not what we expected!"
print("The test passed. Good job!")
```
### Exercise 2: Echo to Target
Run a job that makes the text `Echo to Target` appear in a file named `ex3.txt`.
```
# MODIFY OR ADD TO THIS BLOCK...
echo = htcondor.Submit({
"request_cpus": "1",
"request_memory": "128MB",
"request_disk": "128MB",
})
schedd = htcondor.Schedd()
submit_result = schedd.submit(echo)
# ... TO MAKE THIS TEST PASS
does_file_exist = os.path.exists("ex3.txt")
assert does_file_exist, "ex3.txt does not exist!"
expected = "Echo to Target"
print("Expected ", expected)
contents = open("ex3.txt", mode = "r").read().strip()
print("Got ", contents)
assert expected in contents, "Contents were not what we expected!"
print("The test passed. Good job!")
```
### Exercise 3: Holding Odds
Hold all of the odd-numbered jobs in this large cluster.
- Note that the test block **removes all of the jobs you own** when it runs, to prevent these long-running jobs from corrupting other tests!
```
# MODIFY OR ADD TO THIS BLOCK...
long_sleep = htcondor.Submit({
"executable": "/bin/sleep",
"arguments": "10m",
"output": "ex2-$(ProcId).out",
"error": "ex2-$(ProcId).err",
"log": "ex2.log",
"request_cpus": "1",
"request_memory": "128MB",
"request_disk": "128MB",
})
schedd = htcondor.Schedd()
submit_result = schedd.submit(long_sleep, count=100)
# ... TO MAKE THIS TEST PASS
import getpass
try:
ads = schedd.query(f"ClusterId == {submit_result.cluster()}", projection = ["ProcID", "JobStatus"])
proc_to_status = {int(ad["ProcID"]): ad["JobStatus"] for ad in sorted(ads, key = lambda ad: ad["ProcID"])}
for proc, status in proc_to_status.items():
print("Proc {} has status {}".format(proc, status))
assert len(proc_to_status) == 100, "Wrong number of jobs (perhaps you need to resubmit them?)."
assert all(status == 5 for proc, status in proc_to_status.items() if proc % 2 != 0), "Not all odd jobs were held."
assert all(status != 5 for proc, status in proc_to_status.items() if proc % 2 == 0), "An even job was held."
print("The test passed. Good job!")
finally:
schedd.act(htcondor.JobAction.Remove, f'Owner=="{getpass.getuser()}"')
```
| github_jupyter |
```
import numpy as np
import pandas as pd
dataset=pd.read_csv("data/spam_ham_dataset.csv", usecols=["label","text","label_num"])
df = dataset.copy()
df.head()
df.info()
df.dtypes
print("shape :",df.shape)
print("columns: ", df.columns)
df.nunique()
df.label.unique()
df["label"].value_counts()
df.label.value_counts().plot.barh();
import nltk
import re
import string
nltk.download('stopwords')
from nltk.corpus import stopwords
def preprocessing_text(text):
#remove punctuation
text = [char for char in text if char not in string.punctuation]
text = ''.join(text)
#remove stopwords
text = [word for word in text.split() if word.lower() not in stopwords.words('english')]
return text
df_f = df
df_f["text"].apply(preprocessing_text)
#convert the data from categorical to numerical values
from sklearn.feature_extraction.text import CountVectorizer
cove = CountVectorizer(analyzer=preprocessing_text)
covec = cove.fit_transform(df_f["text"])
#to compare the classification algorithms
from pandas.plotting import scatter_matrix
from sklearn import model_selection
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(covec, df_f['label_num'], test_size=0.20, random_state=1)
X_train= X_train.todense()
models = [
("LR", LogisticRegression(solver='lbfgs',max_iter=1000)),
("LDA", LinearDiscriminantAnalysis()),
("KNN", KNeighborsClassifier()),
("DT", DecisionTreeClassifier()),
("NB", GaussianNB()),
("SVM", SVC())
]
results = []
names = []
for name, model in models:
kfold = model_selection.KFold(n_splits=10, random_state=124, shuffle = True)
cross_v_results = model_selection.cross_val_score(model, X_train, y_train, cv=kfold, scoring="accuracy")
results.append(cross_v_results)
names.append(name)
print(f"{name} |mean {cross_v_results.mean()} |standard deviation {cross_v_results.std()}")
# Algorithm that gives the best results is logistic regression
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
X_train, X_test, y_train, y_test = train_test_split(covec, df_f['label_num'], test_size=0.20, random_state=1)
lr = LogisticRegression(solver='lbfgs', max_iter=1000)
lr.fit(X_train, y_train)
pred = lr.predict(X_test)
print('accuracy degeri :', accuracy_score(y_test, pred))
#------------
print(confusion_matrix(y_test, pred))
#------------
print(classification_report(y_test, pred))
#------------
print("Micro average f1 score: {:.3f}".format(
f1_score(y_test, pred, average="micro")))
print("Macro average f1 score: {:.3f}".format(
f1_score(y_test, pred, average="macro")))
```
## The classification of new data
```
new_data_1 = pd.read_csv("data/spam_ham_dataset3.csv")
target_names = ["ham","spam"]
vector = cove.transform(new_data_1["text"])
y_pred_=lr.predict_proba(vector)*100
pred_df_test=pd.DataFrame(y_pred_,columns=target_names)
print(pred_df_test)
#new observation
counter =0
max=0
first=0
labelofthefirst=''
col=''
total=0
new_da=pd.DataFrame(new_data_1["text"])
pred_df_test=pd.DataFrame(y_pred_,columns=target_names)
mail=[]
def test_mail(i,j,deger):
mail.append((new_da.iloc[i,0],j,deger))
for i in range(len(new_da)):
for j in pred_df_test.columns:
if pred_df_test.loc(axis=0)[i,j]>40: #threshold
counter =counter +1
if counter ==1:
first=pred_df_test.loc[i,j]
labelofthefirst=j
total=total+1
test_mail(i,labelofthefirst,first)
if counter >=2:
total=total+1
test_mail(i,j,pred_df_test.loc[i,j])
counter =0
```
| github_jupyter |
# What is the Requests Resource?
Requests is an Apache2 Licensed HTTP library, written in Python. It is designed to be used by humans to interact with the language. This means you don’t have to manually add query strings to URLs, or form-encode your POST data. Don’t worry if that made no sense to you. It will in due time.
### What can Requests do?
Requests will allow you to send HTTP/1.1 requests using Python. With it, you can add content like headers, form data, multipart files, and parameters via simple Python libraries. It also allows you to access the response data of Python in the same way.
In programming, a library is a collection or pre-configured selection of routines, functions, and operations that a program can use. These elements are often referred to as modules, and stored in object format.
Libraries are important, because you load a module and take advantage of everything it offers without explicitly linking to every program that relies on them. They are truly standalone, so you can build your own programs with them and yet they remain separate from other programs.
Think of modules as a sort of code template.
To reiterate, Requests is a Python library.
<h3>Step 1: Import the requests library</h3>
```
import requests
```
<h3>Step 2: Send an HTTP request, get the response, and save in a variable</h3>
```
response = requests.get("http://www.epicurious.com/search/Tofu+Chili")
type(response)
```
<h3>Step 3: Check the response status code to see if everything went as planned</h3>
<li>status code 200: the request response cycle was successful
<li>any other status code: it didn't work (e.g., 404 = page not found)
```
print(response.status_code)
```
<h3>Step 4: Get the content of the response</h3>
<li>Convert to utf-8 if necessary
```
response.content.decode('utf-8')
```
<h4>Problem: Get the contents of Wikipedia's main page and look for the string "Did you know" in it</h4>
```
url = "https://en.wikipedia.org/wiki/main_page"
#The rest of your code should go below this line
response1 = requests.get(url)
response1.status_code
response1.content
```
Here we can see letter **b** at the first position. It means that this is the representation called **byte string**. Let's transform it to Unicode. And to decode it into Unicode, we use the function **decode**, and we give it the coding scheme.
The **coding scheme** can vary.
There are lots of coding schemes.
But **UTF8** or **UTF16** are the most common.
So generally, if you're going to an English language web page,
you can expect that the result is going
to come back in UTF8 format.
It's going to come back.
It needs to be decoded using UTF8 as your decoder.
```
response1.content.decode('utf-8')
```
Let's found the subtitle "Did you know..." from the main page and get number of byte where ir is situated.
```
response1.content.decode('utf-8').find("Did_you_know...")
```
<h2>JSON</h2>
<li>The python library - json - deals with converting text to and from JSON
```
import json
data_string = '[{"b": [2, 4], "c": 3.0, "a": "A"}]'
python_data = json.loads(data_string)
print(python_data)
```
<h3>json.loads recursively decodes a string in JSON format into equivalent python objects</h3>
<li>data_string's outermost element is converted into a python list
<li>the first element of that list is converted into a dictionary
<li>the key of that dictionary is converted into a string
<li>the value of that dictionary is converted into a list of two integer elements
```
print(type(data_string),type(python_data))
print(type(python_data[0]),python_data[0])
print(type(python_data[0]['b']),python_data[0]['b'])
```
<h3>json.loads will throw an exception if the format is incorrect</h3>
```
#Correct
json.loads('"Hello"')
```
The next code is wrong. And the reason I get that exception
is because here I have a string, but it
doesn't contain a JSON object.
**To contain a JSON object, it should have a string inside it.**
```
#Wrong
json.loads("Hello")
import json
data_string = json.dumps(python_data)
print(type(data_string))
print(data_string)
```
<h2>requests library and JSON</h2>
Luckily for us, we don't even have to do this.
The **Request Library** has a function
that automatically loads a JSON string into Python.
So for example, if we go to the API
that we saw earlier for Google APIs to get geocoding
and we send our request, instead of having to do response.content.decode and all that kind of stuff,
when we get the request back we can just call the JSON function
on it and it'll automatically load it,
assuming of course that it is a proper JSON string.
```
address="Columbia University, New York, NY"
url="https://maps.googleapis.com/maps/api/geocode/json?address=%s" % (address)
response = requests.get(url).json()
print(type(response))
```
<h3>Exception checking!</h3>
So you should always be ready to face the fact
that your code may not work.
You may be expecting a JSON object back,
but the server instead sends you a malformed JSON object.
Be ready for that, too.
So always check for exceptions.
And that's what we're going to do now.
We're going to make sure that we have everything properly
checked over here.
```
address="Columbia University, New York, NY"
url="https://maps.googleapis.com/maps/api/geocode/json?address=%s" % (address)
try:
response = requests.get(url)
if not response.status_code == 200:
print("HTTP error",response.status_code)
else:
try:
response_data = response.json()
except:
print("Response not in valid JSON format")
except:
print("Something went wrong with requests.get")
print(type(response_data))
```
So let's see what the URL looks like.
```
url
```
We get the response data.
And we notice that it's of type Dictionary.
So let's take a look at what this dictionary looks like.
```
response_data
```
We've got a JSON but it doesn't mean that Google actually
gave us the data we wanted.
Because if Google, if the Google part doesn't work,
they're going to send back a JSON object with the result
of an error inside it.
So the status here will be **'Bad'** instead of **"OK"**.
<h2>Problem 1: Write a function that takes an address as an argument and returns a (latitude, longitude) tuple</h2>
```
response_data['results']
response_data['results'][0]
for thing in response_data['results'][0]:
print(thing)
response_data['results'][0]['geometry']
response_data['results'][0]['geometry']['location']
def get_lat_lng(address):
#python code goes here
import requests, time
url="https://maps.googleapis.com/maps/api/geocode/json?address=%s" % (address)
try:
response = requests.get(url)
if not response.status_code == 200:
print("HTTP error",response.status_code)
else:
try:
response_data = response.json()
except:
print("Response not in valid JSON format")
except:
print("Something went wrong with requests.get")
try:
time.sleep(1)
lat = response_data['results'][0]['geometry']['location']['lat']
lng = response_data['results'][0]['geometry']['location']['lng']
except:
print("Try another one.")
return (lat,lng)
get_lat_lng("Columbia University, New York, NY")
get_lat_lng("Maidan Nezalezhnosti, Kyiv, Ukraine")
```
<h2>Problem 2: Extend the function so that it takes a possibly incomplete address as an argument and returns a list of tuples of the form (complete address, latitude, longitude)</h2>
```
get_lat_lng("London")
address="Lon"
url="https://maps.googleapis.com/maps/api/geocode/json?address=%s" % (address)
try:
response = requests.get(url)
if not response.status_code == 200:
print("HTTP error",response.status_code)
else:
try:
response_data = response.json()
except:
print("Response not in valid JSON format")
except:
print("Something went wrong with requests.get")
print(type(response_data))
response_data['results'][1]['address_components'][0]['long_name']
propos_adr = []
for i in range(len(response_data['results'])):
adr = response_data['results'][i]['address_components'][0]['long_name']
lat = response_data['results'][i]['geometry']['location']['lat']
lng = response_data['results'][i]['geometry']['location']['lng']
propos_adr.append((adr,lat,lng))
propos_adr
def get_lat_lng_incompl(address):
#python code goes here
import requests, time
url="https://maps.googleapis.com/maps/api/geocode/json?address=%s" % (address)
try:
response = requests.get(url)
if not response.status_code == 200:
print("HTTP error",response.status_code)
else:
try:
response_data = response.json()
except:
print("Response not in valid JSON format")
except:
print("Something went wrong with requests.get")
try:
time.sleep(1)
propos_adr = []
for i in range(len(response_data['results'])):
adr = response_data['results'][i]['address_components'][0]['long_name']
lat = response_data['results'][i]['geometry']['location']['lat']
lng = response_data['results'][i]['geometry']['location']['lng']
propos_adr.append((adr,lat,lng))
except:
print("Try another one.")
return propos_adr
get_lat_lng_incompl("Chi")
```
<h1>XML</h1>
<li>The python library - lxml - deals with converting an xml string to python objects and vice versa</li>
```
data_string = """
<Bookstore>
<Book ISBN="ISBN-13:978-1599620787" Price="15.23" Weight="1.5">
<Title>New York Deco</Title>
<Authors>
<Author Residence="New York City">
<First_Name>Richard</First_Name>
<Last_Name>Berenholtz</Last_Name>
</Author>
</Authors>
</Book>
<Book ISBN="ISBN-13:978-1579128562" Price="15.80">
<Remark>
Five Hundred Buildings of New York and over one million other books are available for Amazon Kindle.
</Remark>
<Title>Five Hundred Buildings of New York</Title>
<Authors>
<Author Residence="Beijing">
<First_Name>Bill</First_Name>
<Last_Name>Harris</Last_Name>
</Author>
<Author Residence="New York City">
<First_Name>Jorg</First_Name>
<Last_Name>Brockmann</Last_Name>
</Author>
</Authors>
</Book>
</Bookstore>
"""
from lxml import etree
root = etree.XML(data_string)
print(root.tag,type(root.tag))
print(etree.tostring(root, pretty_print=True).decode("utf-8"))
```
<h3>Iterating over an XML tree</h3>
<li>Use an iterator.
<li>The iterator will generate every tree element for a given subtree
```
for element in root.iter():
print(element)
```
<h4>Or just use the child in subtree construction
```
for child in root:
print(child)
```
<h4>Accessing the tag</h4>
```
for child in root:
print(child.tag)
```
<h4>Using the iterator to get specific tags<h4>
<li>In the below example, only the author tags are accessed
<li>For each author tag, the .find function accesses the First_Name and Last_Name tags
<li>The .find function only looks at the children, not other descendants, so be careful!
<li>The .text attribute prints the text in a leaf node
```
for element in root.iter("Author"):
print(element.find('First_Name').text,element.find('Last_Name').text)
```
<h4>Problem: Find the last names of all authors in the tree “root” using xpath</h4>
```
for element in root.findall("Book/Title"):
print(element.text)
for element in root.findall("Book/Authors/Author/Last_Name"):
print(element.text)
```
<h4>Using values of attributes as filters</h4>
<li>Example: Find the first name of the author of a book that weighs 1.5 oz
```
root.find('Book[@Weight="1.5"]/Authors/Author/First_Name').text
```
<h4>Problem: Print first and last names of all authors who live in New York City</h4>
```
books = root.findall("Book")
for i in range(len(books)):
print(root.findall('Book/Authors/Author[@Residence="New York City"]/First_Name')[i].text,
root.findall('Book/Authors/Author[@Residence="New York City"]/Last_Name')[i].text)
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
device_info = pd.read_csv('device_info.csv')
email_info = pd.read_csv('email_info.csv')
employee_info = pd.read_csv('employee_info.csv')
http_info = pd.read_csv('http_info.csv')
logon_info = pd.read_csv('logon_info.csv')
employee_info.head()
# Filter Emails Sent Within the Company
fil_dtaa = email_info['to'].apply(lambda t: t.split('@')[1] != 'dtaa.com')
df_fil_dtaa = email_info[fil_dtaa]
# Filter Group Emails
fil_group = df_fil_dtaa['to'].apply(lambda t: ';' not in t)
df_fil_group = df_fil_dtaa[fil_group]
# Filter Non-Defense Contract Company Emails
email_to_rm = ['comcast.net','aol.com','gmail.com','yahoo.com','cox.net','hotmail.com','verizon.net',
'juno.com','netzero.com','msn.com','charter.net','earthlink.net','sbcglobal.net','bellsouth.net',
'optonline.net','hp.com']
fil_common_email = df_fil_group['to'].apply(lambda t: t.split('@')[1] not in email_to_rm)
df_fil_common_email = df_fil_group[fil_common_email]
# Filter All Emails with No Attachments
fil_no_attach = df_fil_common_email['attachments'].apply(lambda t: t != 0)
df_pure = df_fil_common_email[fil_no_attach]
# Suspect Company Emails
print(df_pure['to'].apply(lambda t: t.split('@')[1]).unique())
# Create DataFrames With Only Raytheon, Boeing, Harris, Northropgrumman, and Lockheed Emails
df_ray = df_pure[df_pure['to'].apply(lambda t: t.split('@')[1] == 'raytheon.com')]
df_boeing = df_pure[df_pure['to'].apply(lambda t: t.split('@')[1] == 'boeing.com')]
df_harris = df_pure[df_pure['to'].apply(lambda t: t.split('@')[1] == 'harris.com')]
df_north = df_pure[df_pure['to'].apply(lambda t: t.split('@')[1] == 'northropgrumman.com')]
df_lock = df_pure[df_pure['to'].apply(lambda t: t.split('@')[1] == 'lockheed.com')]
df_ray_cnts = pd.DataFrame(columns=['email','counts_from'])
df_ray_cnts['email'] = list(df_ray.groupby('from').size().index)
df_ray_cnts['counts_from'] = list(df_ray.groupby('from').size())
df_ray_cnts.sort_values('counts_from',ascending=False).head(10)
x_ray = list(df_ray_cnts.email.unique())
y_ray = list(df_ray_cnts.counts_from)
#plot_ray = plt.figure(figsize=(20,5))
ax = plt.subplots(1,1,figsize=(20,5))
plt.plot(x_ray,y_ray)
plt.xticks(rotation=90,size=10)
#plt.xticks(range(len), list(df_ray_cnts.email), color='red')
plt.margins(0.005)
plt.show()
df_boeing_cnts = pd.DataFrame(columns=['email','counts_from'])
df_boeing_cnts['email'] = list(df_boeing.groupby('from').size().index)
df_boeing_cnts['counts_from'] = list(df_boeing.groupby('from').size())
df_boeing_cnts.sort_values('counts_from',ascending=False).head(10)
df_harris_cnts = pd.DataFrame(columns=['email','counts_from'])
df_harris_cnts['email'] = list(df_harris.groupby('from').size().index)
df_harris_cnts['counts_from'] = list(df_harris.groupby('from').size())
df_harris_cnts.sort_values('counts_from',ascending=False).head(10)
df_north_cnts = pd.DataFrame(columns=['email','counts_from'])
df_north_cnts['email'] = list(df_north.groupby('from').size().index)
df_north_cnts['counts_from'] = list(df_north.groupby('from').size())
df_north_cnts.sort_values('counts_from',ascending=False).head(10)
x_boe = list(df_boeing_cnts.email.unique())
y_boe = list(df_boeing_cnts.counts_from)
#plot_ray = plt.figure(figsize=(20,5))
ax = plt.subplots(1,1,figsize=(35,10))
plt.plot(x_boe,y_boe)
plt.xticks(rotation=90,size=15)
#plt.xticks(range(len), list(df_ray_cnts.email), color='red')
plt.margins(0.005)
plt.show()
x_har = list(df_harris_cnts.email.unique())
y_har = list(df_harris_cnts.counts_from)
#plot_ray = plt.figure(figsize=(20,5))
ax = plt.subplots(1,1,figsize=(35,10))
plt.plot(x_har,y_har)
plt.xticks(rotation=90,size=15)
#plt.xticks(range(len), list(df_ray_cnts.email), color='red')
plt.margins(0.005)
plt.show()
x_nor = list(df_north_cnts.email.unique())
y_nor = list(df_north_cnts.counts_from)
#plot_ray = plt.figure(figsize=(20,5))
ax = plt.subplots(1,1,figsize=(35,10))
plt.plot(x_nor,y_nor)
plt.xticks(rotation=90,size=15)
#plt.xticks(range(len), list(df_ray_cnts.email), color='red')
plt.margins(0.005)
plt.show()
```
| github_jupyter |
# Ganesh Bhandarkar 1806554 Python Assignment 6
### Graph Theory
```
from collections import defaultdict
g = defaultdict(list)
edges = []
def addEdge(g,u,v):
g[u].append(v)
g[v].append(u)
def createGraph(g):
for node in g:
for neighbour in g[node]:
edges.append((node,neighbour))
def printGraph():
for j in g:
print(j," -> ",end = "")
for i in g[j]:
print(i,", ",end = '')
print()
addEdge(g,'a','c')
addEdge(g,'b','d')
addEdge(g,'b','e')
addEdge(g,'a','d')
printGraph()
from collections import defaultdict
g = defaultdict(list)
edges = []
def addEdge(g,u,v,w):
g[u].append(tuple({v,w}))
def createGraph(g):
for node in g:
for neighbour in g[node]:
edges.append((node,neighbour))
return g
def printGraph():
for j in g:
print(j," -> ",end = "")
for i in g[j]:
print(i,", ",end = '')
print()
addEdge(g,'a','c',4)
addEdge(g,'b','c',3)
addEdge(g,'b','e',2)
addEdge(g,'c','d',7)
addEdge(g,'c','e',1)
addEdge(g,'c','a',11)
printGraph()
#createGraph(g)
```
### Class and Data Structure
```
class Student:
def __init__(self, name, rollno, cgpa):
self.name = name
self.rollno = rollno
self.cgpa = cgpa
def readdata(self, Name, Rollno, cgpa ):
ob = Student(Name, Rollno, cgpa )
ls.append(ob)
def printdata(self, ob):
print("Name : ", ob.name)
print("RollNo : ", ob.rollno)
print("CGPA : ", ob.cgpa)
print("\n")
ls =[]
stud = Student('', 0, 0)
n = int(input())
for i in range(0,n):
name = input("enter name")
roll = int(input("enter roll"))
cgpa = int(input("enter cgpa"))
stud.readdata(name, roll, cgpa)
print("\n")
print("\nList of Students\n")
for i in range(ls.__len__()):
stud.printdata(ls[i])
class Person():
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# def readdata(self, name, age, gender ):
# ob = Person( name, age, gender )
# person.append(ob)
def tell(self):
print('Name : ', self.name,"\nAge : ",self.age, '\nGender : ',self.gender)
print('Empid :',self.empid,"\nDesignation :",self.desi,"\nSalary :",self.salary)
# def printdata(self, ob):
# print(ob.name)
# print(ob.age)
# print(ob.gender)
# print("\n")
class Employee(Person):
def __init__(self,name,age,gender, empid, desi, salary):
Person.__init__(self, name, age, gender)
self.empid = empid
self.desi = desi
self.salary = salary
Person.tell(self)
# def readdata(self, name, age, gender ):
# ob = Employee(name, age, gender , empid, desi, salary)
# employ.append(ob)
Employee('Rahul', 20, 'male',345,"intern", 200000)
class Stack():
def __init__(self):
self.stack = []
def isEmpty(self):
return self.stack == []
def PUSH(self,x):
self.stack.append(x)
def POP(self):
return self.stack.pop()
def printStack(self):
return self.stack
s = Stack()
while True:
print('push ')
print('pop')
print('quit')
do = input('What would you like to do? ').split()
operation = do[0].strip().lower()
if operation == 'push':
s.PUSH(int(do[1]))
elif operation == 'pop':
if s.isEmpty():
print('Stack is empty.')
else:
print('Popped value: ', s.POP())
elif operation == 'quit':
break
print(s.printStack(),end = "")
print()
class Queue():
def __init__(self):
self.queue = []
def isEmpty(self):
return self.queue == []
def INSERT(self,x):
self.queue.append(x)
def REMOVE(self):
return self.queue.pop(0)
def printQueue(self):
return self.queue
s = Queue()
while True:
print('push enter value')
print('pop')
print('quit')
do = input('What would you like to do? ').split()
operation = do[0].strip().lower()
if operation == 'push':
s.INSERT(int(do[1]))
elif operation == 'pop':
if s.isEmpty():
print('Stack is empty.')
else:
print('Popped value: ', s.REMOVE())
elif operation == 'quit':
break
print(s.printQueue(),end = "")
print()
```
| github_jupyter |
# Document AI Form Parser Visualizer
This notebook shows you how to analyze a pdf using the Google Cloud DocumentAI API
```
# Install necessary Python libraries and restart your kernel after.
!pip install -r ../requirements.txt
from google.cloud import documentai_v1beta3 as documentai
from PIL import Image, ImageDraw
import os
import pandas as pd
```
## Download our sample pdf from GCS
```
PDF_URI = "gs://cesummit_workshop_data/form.pdf" #@param {type: "string"}
# Download the doc
!gsutil cp $PDF_URI ./form.pdf
```
## Set your Processor Variables
```
PROJECT_ID = "YOUR_PROJECT_ID_HERE"
LOCATION = "us" # Format is 'us' or 'eu'
PROCESSOR_ID = "PROCESSOR_ID" # Create processor in Cloud Console
```
The following code calls the synchronous API and parses the form fields and values.
```
def process_document_sample():
# Instantiates a client
client_options = {"api_endpoint": "{}-documentai.googleapis.com".format(LOCATION)}
client = documentai.DocumentProcessorServiceClient(client_options=client_options)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
name = f"projects/{PROJECT_ID}/locations/{LOCATION}/processors/{PROCESSOR_ID}"
with open('form.pdf', "rb") as image:
image_content = image.read()
# Read the file into memory
document = {"content": image_content, "mime_type": "application/pdf"}
# Configure the process request
request = {"name": name, "document": document}
# Recognizes text entities in the PDF document
result = client.process_document(request=request)
document = result.document
print("Document processing complete.\n\n")
# For a full list of Document object attributes, please reference this page: https://googleapis.dev/python/documentai/latest/_modules/google/cloud/documentai_v1beta3/types/document.html#Document
document_pages = document.pages
keys = []
keysConf = []
values = []
valuesConf = []
# Grab each key/value pair and their corresponding confidence scores.
for page in document_pages:
for form_field in page.form_fields:
fieldName=get_text(form_field.field_name,document)
keys.append(fieldName.replace(':', ''))
nameConfidence = round(form_field.field_name.confidence,4)
keysConf.append(nameConfidence)
fieldValue = get_text(form_field.field_value,document)
values.append(fieldValue.replace(':', ''))
valueConfidence = round(form_field.field_value.confidence,4)
valuesConf.append(valueConfidence)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame({'Key': keys, 'Key Conf': keysConf, 'Value': values, 'Value Conf': valuesConf})
display(df)
return document
def get_text(doc_element: dict, document: dict):
"""
Document AI identifies form fields by their offsets
in document text. This function converts offsets
to text snippets.
"""
response = ""
# If a text segment spans several lines, it will
# be stored in different text segments.
for segment in doc_element.text_anchor.text_segments:
start_index = (
int(segment.start_index)
if segment in doc_element.text_anchor.text_segments
else 0
)
end_index = int(segment.end_index)
response += document.text[start_index:end_index]
return response
doc = process_document_sample()
```
## Draw the bounding boxes
We will now download the pdf above a jpg and use the spatial data to mark our values.
```
JPG_URI = "gs://cesummit_workshop_data/form.jpg" #@param {type: "string"}
# Download the doc
!gsutil cp $JPG_URI ./form.jpg
document_image = Image.open('form.jpg')
draw = ImageDraw.Draw(document_image)
for form_field in doc.pages[0].form_fields:
# Draw the bounding box around the form_fields
# First get the co-ords of the field name
vertices = []
for vertex in form_field.field_name.bounding_poly.normalized_vertices:
vertices.append({'x': vertex.x * document_image.size[0], 'y': vertex.y * document_image.size[1]})
draw.polygon([
vertices[0]['x'], vertices[0]['y'],
vertices[1]['x'], vertices[1]['y'],
vertices[2]['x'], vertices[2]['y'],
vertices[3]['x'], vertices[3]['y']], outline='red')
vertices = []
for vertex in form_field.field_value.bounding_poly.normalized_vertices:
vertices.append({'x': vertex.x * document_image.size[0], 'y': vertex.y * document_image.size[1]})
draw.polygon([
vertices[0]['x'], vertices[0]['y'],
vertices[1]['x'], vertices[1]['y'],
vertices[2]['x'], vertices[2]['y'],
vertices[3]['x'], vertices[3]['y']], outline='blue')
document_image
```
| github_jupyter |
```
pip install ta==0.4.7
import glob
import os
import pickle
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
import datetime as dt
from ta import add_all_ta_features
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
%matplotlib inline
```
## Get CSVs Filename Into a Variable
```
csv_paths = glob.glob('arb_data/*.csv') # modify to your filepath for data
model_paths = glob.glob('arb_pickles/*.pkl')
len(csv_paths), len(model_paths)
csv_paths[:]
def resample_ohlcv(df, period='5T'):
""" Changes the time period on cryptocurrency ohlcv data.
Period is a string denoted by 'time_in_minutesT'(ex: '1T', '5T', '60T')."""
# Set date as the index. This is needed for the function to run
df = df.set_index(['date'])
# Aggregation function
ohlc_dict = {'open':'first',
'high':'max',
'low':'min',
'close': 'last',
'base_volume': 'sum'}
# Apply resampling.
df = df.resample(period, how=ohlc_dict, closed='left', label='left')
return df
# function to handle nans in the data introduced by resampling
def fill_nan(df):
# forward filling the closing price where there were gaps in ohlcv csv
df['close'] = df['close'].ffill()
# backfilling the rest of the nans
df = df.bfill(axis=1)
# returning the revised dataframe
return df
# function to engineer features that can be engineered pre-merge...
def engineer_features(df, period='5T'):
# convert unix closing_time to datetime
df['date'] = pd.to_datetime(df['closing_time'], unit='s')
# time resampling to fill gaps in data
df = resample_ohlcv(df, period)
# move date off the index
df = df.reset_index()
# create closing_time
closing_time = df.date.values
df.drop(columns='date', inplace=True)
# create feature to indicate where rows were gaps in data
df['nan_ohlcv'] = df['close'].apply(lambda x: 1 if pd.isnull(x) else 0)
# fill gaps in data
df = fill_nan(df)
# adding all the technical analysis features...
df = add_all_ta_features(df, 'open', 'high', 'low', 'close','base_volume', fillna=True)
# add closing time column
df['closing_time'] = closing_time
return df
# the following functions are used in engineering features post-merge...
# function to create column showing which exchange has a higher closing price
def get_higher_closing_price(df):
# i.e., if exchange 1 has the higher closing price...
if (df['close_exchange_1'] - df['close_exchange_2']) > 0:
# return exchange 1
return 1
# otherwise, if exchange 2 has the higher closing price...
elif (df['close_exchange_1'] - df['close_exchange_2']) < 0:
# return exchange 2
return 2
# otherwise, i.e., if neither has a higher closing price...
else:
# return equivalent
return 0
# function to create column showing percentage by which higher price is higher
def get_pct_higher(df):
# i.e., if exchange 1 has a higher closing price than exchange 2...
if df['higher_closing_price'] == 1:
# return the percentage by which the exchange 1 closing price is
# greater than the exchange 2 closing price
return ((df['close_exchange_1'] /
df['close_exchange_2'])-1)*100
# otherwise, if exchange 2 has a higher closing price than exchange 1...
elif df['higher_closing_price'] == 2:
# return the percentage by which the exchange 2 closing price is
# greater than the exchange 1 closing price
return ((df['close_exchange_2'] /
df['close_exchange_1'])-1)*100
# otherwise, i.e., if the closing prices are equivalent...
else:
# return zero
return 0
# function to create column showing available arbitrage opportunities
def get_arbitrage_opportunity(df):
# assuming the total fees are 0.55%, if the higher closing price is less
# than 0.55% higher than the lower closing price...
if df['pct_higher'] < .55:
# return 0, for no arbitrage
return 0
# otherwise, if the exchange 1 closing price is more than 0.55% higher
# than the exchange 2 closing price...
elif df['higher_closing_price'] == 1:
# return -1, for arbitrage from exchange 2 to exchange 1
return -1
# otherwise, if the exchange 2 closing price is more than 0.55% higher
# than the exchange 1 closing price...
elif df['higher_closing_price'] == 2:
# return 1, for arbitrage from exchange 1 to exchange 2
return 1
# function to create column showing how long arbitrage opportunity has lasted
def get_window_length(df):
# converting arbitrage_opportunity column to a list...
target_list = df['arbitrage_opportunity'].to_list()
# setting initial window length to 5, for 5 minutes; will be updated...
window_length = 5
# creating empty list to fill with values and ultimately convert to column
window_lengths = []
# for i in the range of the length of the arbitrage_opportunity column...
for i in range(len(target_list)):
# if a value in the arbitrage_opportunity column is equal to the
# previous value in the arbitrage_opportunity column...
if target_list[i] == target_list[i-1]:
# increase the window length by five minutes...
window_length += 5
# and append that window length to the list.
window_lengths.append(window_length)
# otherwise, i.e., if a value in the arbitrage_opportunity column is
# not equal to the previous value in the arbitrage_opportunity column
else:
# reset the window length to five minutes...
window_length = 5
# and append that window length to the list
window_lengths.append(window_length)
# convert the window lengths list to a column, showing how long arbitrage
# window / no_arbitrage window has lasted.
df['window_length'] = window_lengths
# return the dataframe with the new window length column
return df
def merge_dfs(df1, df2):
print('from merge func:', df1.shape, df2.shape)
# merging two modified ohlcv dfs on closing time to create arbitrage df
df = pd.merge(df1, df2, on='closing_time',
suffixes=('_exchange_1', '_exchange_2'))
print('from merge func:', df.shape)
df['closing_time'] = pd.to_datetime(df['closing_time'])
print(type(df.closing_time[0]))
# Create additional date features.
df['year'] = df['closing_time'].dt.year
df['month'] = df['closing_time'].dt.month
df['day'] = df['closing_time'].dt.day
# getting higher_closing_price feature to create pct_higher feature
df['higher_closing_price'] = df.apply(get_higher_closing_price, axis=1)
# getting pct_higher feature to create arbitrage_opportunity feature
df['pct_higher'] = df.apply(get_pct_higher, axis=1)
# getting arbitrage_opportunity feature
df['arbitrage_opportunity'] = df.apply(get_arbitrage_opportunity, axis=1)
# getting window_length feature
df = get_window_length(df)
return df
# creating target column...
# 1 = ex1 -> ex2, -1 = ex2 -> ex1, 0 = no arb
# function to get target values; takes df and window length to target
def get_target_value(df, interval=30):
# i.e., if the coming arbitrage window is as long as the targeted interval
if df['window_length_shift'] >= interval:
# then if the coming arbitrage window is for exchange 1 to 2...
if df['arbitrage_opportunity_shift'] == 1:
# return 1, which means arbitrage from exchange 1 to 2
return 1
# otherwise, if the coming arbitrage window is for exchange 2 to 1...
elif df['arbitrage_opportunity_shift'] == -1:
# return -1, which means arbitrage from exchange 2 to 1...
return -1
# otherwise, if we are coming up on no arbitrage opportunity...
elif df['arbitrage_opportunity_shift'] == 0:
# return 0, which means no arbitrage opportunity
return 0
# otherwise, i.e., if the coming window is less than our targeted interval
else:
# return 0, which means no arbitrage opportunity
return 0
# function to create target column
def get_target(df, interval=30):
# used to shift rows; assumes candle length is five minutes, interval is
# in minutes
rows_to_shift = int(-1*(interval/5))
# arbitrage_opportunity feature, shifted by length of targeted interval,
# minus one to predict ten minutes in advance rather than five
df['arbitrage_opportunity_shift'] = df['arbitrage_opportunity'].shift(
rows_to_shift - 1)
# window_length feature, shifted by length of targeted interval, minus one
# to predict ten minutes in advance rather than five
df['window_length_shift'] = df['window_length'].shift(rows_to_shift - 1)
# creating target column; this will indicate if an arbitrage opportunity
# that lasts as long as the targeted interval is forthcoming
df['target'] = df.apply(get_target_value, axis=1)
# dropping rows where target could not be calculated due to shift
df = df[:rows_to_shift - 1]
# returning resulting dataframe
return df
def get_close_shift(df, interval=30):
rows_to_shift = int(-1*(interval/5))
df['close_exchange_1_shift'] = df['close_exchange_1'].shift(
rows_to_shift - 2)
df['close_exchange_2_shift'] = df['close_exchange_2'].shift(
rows_to_shift - 2)
return df
# function to create profit feature
def get_profit(df):
# if exchange 1 has the higher closing price...
if df['higher_closing_price'] == 1:
# see how much money you would make if you bought on exchange 2, sold
# on exchange 1, and took account of 0.55% fees
return (((df['close_exchange_1_shift'] /
df['close_exchange_2'])-1)*100)-.55
# otherwise, if exchange 2 has the higher closing price...
elif df['higher_closing_price'] == 2:
# see how much money you would make if you bought on exchange 1, sold
# on exchange 2, and took account of 0.55% fees
return (((df['close_exchange_2_shift'] /
df['close_exchange_1'])-1)*100)-.55
# otherwise, i.e., if the closing prices are the same...
else:
# return zero, because in that case you shouldn't make a trade
return 0
def get_exchange_trading_pair(ex_tp):
if len(ex_tp.split('_')) == 5:
exchange = ex_tp.split('_')[0] + '_' + ex_tp.split('_')[1]
trading_pair = ex_tp.split('_')[2] + '_' + ex_tp.split('_')[3]
else:
exchange = ex_tp.split('_')[0]
trading_pair = ex_tp.split('_')[1] + '_' + ex_tp.split('_')[2]
return exchange, trading_pair
csv_paths = glob.glob('new_arb_csv/*.csv') # modify to your filepath for data
model_paths = glob.glob('arb_pickles/*.pkl')
len(csv_paths), len(model_paths)
def arb(csv_paths, model_paths):
df_dict = {}
for csv_path in csv_paths:
csv_name = csv_path.split('/')[1][:-4]
for model_path in model_paths:
model_name = model_path.split('/')[1][:-4]
if csv_name == model_name:
print("\n \n",csv_name,"==", model_name)
# read csv
df = pd.read_csv("new_arb_csv/"+csv_name+".csv", index_col=0)
# convert str closing_time to datetime
df['closing_time'] = pd.to_datetime(df['closing_time'])
# 70/30 train/test split
test_train_split_row = round(len(df)*.7)
# get closing_time for t/t split
test_train_split_time = df['closing_time'][test_train_split_row]
# remove 1 week from each end of the t/t datasets to create a
# two week gap between the data - prevents data leakage
train_cutoff_time = test_train_split_time - dt.timedelta(days=7)
test_cutoff_time = test_train_split_time + dt.timedelta(days=7)
print('cutoff time:', train_cutoff_time, test_cutoff_time)
# train and test subsets
train = df[df['closing_time'] < train_cutoff_time]
test = df[df['closing_time'] > test_cutoff_time]
# printing shapes to track progress
print('train and test shape: ', train.shape, test.shape)
# specifying features for model to use; not using open, high, or
# low, which are highly correlated with close and do not improve
# model performance
features = ['close_exchange_1','base_volume_exchange_1',
'nan_ohlcv_exchange_1','volume_adi_exchange_1', 'volume_obv_exchange_1',
'volume_cmf_exchange_1', 'volume_fi_exchange_1','volume_em_exchange_1',
'volume_vpt_exchange_1','volume_nvi_exchange_1', 'volatility_atr_exchange_1',
'volatility_bbhi_exchange_1','volatility_bbli_exchange_1',
'volatility_kchi_exchange_1', 'volatility_kcli_exchange_1',
'volatility_dchi_exchange_1','volatility_dcli_exchange_1',
'trend_macd_signal_exchange_1', 'trend_macd_diff_exchange_1', 'trend_adx_exchange_1',
'trend_adx_pos_exchange_1', 'trend_adx_neg_exchange_1',
'trend_vortex_ind_pos_exchange_1', 'trend_vortex_ind_neg_exchange_1',
'trend_vortex_diff_exchange_1', 'trend_trix_exchange_1',
'trend_mass_index_exchange_1', 'trend_cci_exchange_1',
'trend_dpo_exchange_1', 'trend_kst_sig_exchange_1',
'trend_kst_diff_exchange_1', 'trend_aroon_up_exchange_1',
'trend_aroon_down_exchange_1',
'trend_aroon_ind_exchange_1',
'momentum_rsi_exchange_1', 'momentum_mfi_exchange_1',
'momentum_tsi_exchange_1', 'momentum_uo_exchange_1',
'momentum_stoch_signal_exchange_1',
'momentum_wr_exchange_1', 'momentum_ao_exchange_1',
'others_dr_exchange_1', 'close_exchange_2',
'base_volume_exchange_2', 'nan_ohlcv_exchange_2',
'volume_adi_exchange_2', 'volume_obv_exchange_2',
'volume_cmf_exchange_2', 'volume_fi_exchange_2',
'volume_em_exchange_2', 'volume_vpt_exchange_2',
'volume_nvi_exchange_2', 'volatility_atr_exchange_2',
'volatility_bbhi_exchange_2',
'volatility_bbli_exchange_2',
'volatility_kchi_exchange_2',
'volatility_kcli_exchange_2',
'volatility_dchi_exchange_2',
'volatility_dcli_exchange_2',
'trend_macd_signal_exchange_2',
'trend_macd_diff_exchange_2', 'trend_adx_exchange_2',
'trend_adx_pos_exchange_2', 'trend_adx_neg_exchange_2',
'trend_vortex_ind_pos_exchange_2',
'trend_vortex_ind_neg_exchange_2',
'trend_vortex_diff_exchange_2', 'trend_trix_exchange_2',
'trend_mass_index_exchange_2', 'trend_cci_exchange_2',
'trend_dpo_exchange_2', 'trend_kst_sig_exchange_2',
'trend_kst_diff_exchange_2', 'trend_aroon_up_exchange_2',
'trend_aroon_down_exchange_2',
'trend_aroon_ind_exchange_2',
'momentum_rsi_exchange_2', 'momentum_mfi_exchange_2',
'momentum_tsi_exchange_2', 'momentum_uo_exchange_2',
'momentum_stoch_signal_exchange_2',
'momentum_wr_exchange_2', 'momentum_ao_exchange_2',
'others_dr_exchange_2', 'year', 'month', 'day',
'higher_closing_price', 'pct_higher',
'arbitrage_opportunity', 'window_length']
# specifying name of target column
target = 'target'
# separating features from target
ct = test['closing_time']
X_test = test[features]
y_test = test[target]
print('train test shapes:', X_test.shape, y_test.shape)
model = pickle.load(open(model_path, 'rb'))
print('model loaded')
# make predictions
y_preds = model.predict(X_test)
print('predictions made!')
X_test['pred'] = y_preds
df = X_test
df = pd.concat([ct,df], axis=1)
df['pct_diff'] = (df['close_exchange_1'] - df['close_exchange_2']) / df['close_exchange_1']
df['zero'] = 0
# 'arb_ex1_ex2' # 1 = ex1 -> ex2, -1 = ex2 -> ex1, 0 = no arb
df['arb_ex1_ex2'] = df['pred'].apply(lambda x: 1 if x == 1 else np.NaN)
df['arb_ex2_ex1'] = df['pred'].apply(lambda x: 1 if x == -1 else np.NaN)
df['arb_ex1_ex2'] = (df['arb_ex1_ex2'] * df['pct_diff'])
df['arb_ex2_ex1'] = (df['arb_ex2_ex1'] * df['pct_diff'])
df_dict[model_name] = df
return df_dict
df_dict = arb(csv_paths, model_paths)
import numpy as np
from scipy.signal import savgol_filter
# df_dict['bitfinex_coinbase_pro_ltc_usd'][['closing_time', 'close_exchange_1', 'close_exchange_2', 'pred', 'pct_diff']]
fig, ax = plt.subplots(figsize=(40, 8))
sns.set(style="ticks", context="talk")
plt.style.use("dark_background")
flatui = ['#63e4a7', '#4eb9ff', '#4bc1f6', '#4fc9e5', '#57d5c7', '#5dddb9', '#63e4a7']
myFmt = mdates.DateFormatter("%b %d '%y ")
sns.set_palette(flatui)
# Y2 = savgol_filter(df['2_minus_1'], 101, 3)
flatui1 = ['#63e4a7']
sns.set_palette(flatui)
ax1 = sns.lineplot(x='closing_time', y='2_minus_1', data=df[6000:20000], linewidth=.5, label='Price Difference %');
ax3 = sns.regplot(x='closing_time', y='markers', data=df[6000:20000], marker="o", fit_reg=False, scatter_kws={"zorder":10, "color":"red","alpha":.5,"s":10}, label='Arb Ex.1 to Ex.2');
sns.despine(left=True)
ax.tick_params(axis=u'both', which=u'both',length=0)
ax.set_ylabel('');
ax.set_xlabel('');
plt.setp(ax.get_xticklabels(), rotation=45)
ax.xaxis.set_major_formatter(myFmt)
ax.tick_params(axis='x', colors='grey')
ax.tick_params(axis='y', colors='grey')
ax.spines['bottom'].set_color('grey')
ax.spines['bottom'].set_linewidth(0.5)
for tick in ax.get_xticklabels():
tick.set_fontname("avenir")
for tick in ax.get_yticklabels():
tick.set_fontname("avenir")
lines, labels = ax1.get_legend_handles_labels()
leg = plt.legend(lines , labels , loc='upper left')
leg.get_frame().set_linewidth(0.0)
sns.set_context("poster", font_scale = 1, rc={"grid.linewidth": 8})
ax.set_title("bitfinex_coinbase_pro_ltc_usd", fontsize=12);
```
# Arbitrage Visualization Function
csv has 3 columns ['closing_time', '2_minus_1', 'pred']
```
import os
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# looks thru dir for csv
for filename in os.listdir('simple_csvs'):
if filename.endswith('.csv'):
print(filename)
# create df from csv
df = pd.read_csv('simple_csvs/' + filename, index_col=0)
# cutting df for smaller df (more recent time)
df = df[df['closing_time'] >= 1571356800]
# change closetime to datetime format
df['closing_time'] = pd.to_datetime(df['closing_time'], unit='s')
print("plotting...")
# creating figure and setting size
fig, ax = plt.subplots(figsize=(18, 10))
fig.clf()
sns.set(style="ticks", context="talk")
# setting dark background
plt.style.use("dark_background")
# using these color palette
flatui = ['#4eb9ff', '#4bc1f6', '#4fc9e5',
'#57d5c7', '#5dddb9', '#63e4a7']
# seperate df into 6
sixth_of_length = (len(df)//6)
# create 6 lineplots to create a gradient look
sns.set_palette(flatui)
ax = sns.lineplot(x='closing_time', y='2_minus_1_over_1',
data=df[:sixth_of_length])
for i in range(1, 6):
sns.set_palette(flatui)
if i != 3:
ax = sns.lineplot(x='closing_time', y='2_minus_1_over_1',
data=df[(sixth_of_length*i):
(sixth_of_length*(i+1))])
else:
ax = sns.lineplot(x='closing_time', y='2_minus_1_over_1',
data=df[(sixth_of_length*i):
(sixth_of_length*(i+1))],
label='Percentage Price Difference')
# creating 2 df seperated by prediction
df_1_to_2 = df[df['pred'] == 1]
df_2_to_1 = df[df['pred'] == -1]
# creating 2 scatter plot with new df
# arbitrage indicator
dots_1_to_2 = sns.scatterplot(x='closing_time', y='2_minus_1_over_1',
data=df_1_to_2, color='indigo',
zorder=10, label='Arbitrage from '
'Exchange 1 to 2')
dots_2_to_1 = sns.scatterplot(x='closing_time', y='2_minus_1_over_1',
data=df_2_to_1, color='violet',
zorder=10, label='Arbitrage from '
'Exchange 2 to 1')
sns.despine(left=True, right=True, top=True)
ax.set_xlabel('')
ax.set_ylabel('')
# setting y tick labels
vals = ax.get_yticks()
ax.set_yticklabels(['{:,.2%}'.format(x) for x in vals])
# get rid of '-' on tick label
ax.tick_params(axis=u'both', which=u'both',length=0)
# change x and y tick color grey
ax.tick_params(axis='x', colors='grey')
ax.tick_params(axis='y', colors='grey')
# set bottom spine grey and change linewidth
ax.spines['bottom'].set_color('grey')
ax.spines['bottom'].set_linewidth(0.5)
# change font style
for tick in ax.get_xticklabels():
tick.set_fontname("avenir")
for tick in ax.get_yticklabels():
tick.set_fontname("avenir")
# format datetime for x-axis tick label
myFmt = mdates.DateFormatter("%b. %d ")
ax.xaxis.set_major_formatter(myFmt)
# rotate x-tick labels at a 45 degree angle
plt.setp(ax.get_xticklabels(), rotation=45)
# creates Legend
lines, labels = ax.get_legend_handles_labels()
leg = plt.legend(lines, labels, loc='upper left')
leg.get_frame().set_linewidth(0.0)
currency_pairs = {'bch_btc': 'bch/btc'.upper(),
'bch_usd': 'bch/usd'.upper(),
'bch_usdt': 'bch/usdt'.upper(),
'eos_usdt': 'eos/usdt'.upper(),
'etc_usd': 'etc/usd'.upper(),
'eth_btc': 'eth/btc'.upper(),
'eth_usdc': 'eth/usdc'.upper(),
'ltc_btc': 'ltc/btc'.upper(),
'ltc_usd': 'ltc/usd'.upper(),
'ltc_usdt': 'ltc/usdt'.upper()}
exchange_pairs = {'bitfinex_coinbase_pro_': 'Bitfinex/Coinbase Pro ',
'bitfinex_gemini_': 'Bitfinex/Gemini ',
'bitfinex_hitbtc_': 'Bitfinex/Hitbtc ',
'coinbase_pro_gemini_': 'Coinbase Pro/Gemini ',
'coinbase_pro_hitbtc_': 'Coinbase Pro/Hitbtc ',
'gemini_hitbtc_': 'Gemini/Hitbtc ',
'kraken_gemini_': 'Kraken/Gemini '}
name = filename
for currency_pair in currency_pairs:
if currency_pair in name:
name = name.replace(currency_pair,
currency_pairs[currency_pair])
for exchange_pair in exchange_pairs:
if exchange_pair in name:
name = name.replace(exchange_pair,
exchange_pairs[exchange_pair])
# set titles
ax.set_title(name.replace('.csv', ''), fontsize=12);
# save figures into png folder
fig = ax.get_figure()
fig.savefig('pngs/' + filename.replace('.csv', '.png'))
print("done!")
```
| github_jupyter |
```
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
import os.path as osp
import sys
import cv2
import numpy as np
import matplotlib.pyplot as plt
ids = list()
for line in open('train.txt'):
ids.append(line.strip())
ids
VOC_CLASSES = ( # always index 0
'specularity','saturation','artifact',
'blur','contrast','bubbles','instrument','blood')
def class_to_ind(a):
class_to_ind = dict(zip(VOC_CLASSES, range(len(VOC_CLASSES))))
b=class_to_ind[a]
return b
lber = class_to_ind('blur')
lber
for line in open('00001.txt'):
name=line.split(' ')
class_to_ind(name[0])
print(line.split(' ')[1])
#class_to_ind(name[0])
ids[4]
def __class_to_ind__(class_name):
class_to_ind = dict(zip(VOC_CLASSES, range(len(VOC_CLASSES))))
ind = class_to_ind[class_name]
return ind
def __txt2list__(path):
res = []
for line in open(path):
name_laber = line.split(' ')[0]
label_ind = __class_to_ind__(name_laber)
xmin = int(line.split(' ')[1])
ymin = int(line.split(' ')[2])
xmax = int(line.split(' ')[3])
ymax = int(line.split(' ')[4])
bndbox = [xmin, ymin, xmax, ymax, label_ind]
res += [bndbox]
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
_txtpath = osp.join('./data/EAD2020_dataType_framesOnly/yolo2voc', '%s.txt')
_imgpath = osp.join('./data/EAD2020_dataType_framesOnly/frames', '%s.jpg')
img_id='00002'
target = __txt2list__(_txtpath % img_id)
img = cv2.imread(_imgpath % img_id)
img.shape
target=np.array(target)
target[:, :4]
ids = list()
root ='train.txt'
for line in open(root):
ids.append(line.strip())
len(ids)
def load_image(path):
image = cv2.imread(path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image
class EADDetection(Dataset):
def __init__(self, root,transform=None):
self.root = root
self.transform = transform
self._txtpath = osp.join('./data/EAD2020_dataType_framesOnly/yolo2voc', '%s.txt')
self._imgpath = osp.join('./data/EAD2020_dataType_framesOnly/frames', '%s.jpg')
self.ids = list()
for line in open(self.root):
self.ids.append(line.strip())
def __getitem__(self, index):
img_id = self.ids[index]
img = load_image(self._imgpath % img_id)
height, width, channels = img.shape
target = __txt2list__(self._txtpath % img_id)
target = np.array(target)
bbox = target[:, :4]
labels = target[:, 4]
# annotation = {'image': img, 'bboxes': bbox, 'category_id': labels}
# augmentation = self.transform(**annotation)
# img = augmentation['image']
# bbox = augmentation['bboxes']
# labels = augmentation['category_id']
return {'image': img, 'bboxes': bbox, 'category_id': labels}
def __len__(self):
return len(self.ids)
def __num_class__(self):
return len(VOC_CLASSES)
def label_to_name(self, label):
return VOC_CLASSES[label]
mydata = EADDetection(root)
len(mydata)
img=next(iter(mydata))['image']
mydata.__getitem__(967)
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
import os.path as osp
import sys
import cv2
import matplotlib.pyplot as plt
EAD_CLASSES = ( # always index 0
'specularity','saturation','artifact',
'blur','contrast','bubbles','instrument','blood')
def __class_to_ind__(class_name):
class_to_ind = dict(zip(EAD_CLASSES, range(len(EAD_CLASSES))))
ind = class_to_ind[class_name]
return ind
def __txt2list__(path):
res = []
for line in open(path):
name_laber = line.split(' ')[0]
label_ind = __class_to_ind__(name_laber)
xmin = int(line.split(' ')[1])
ymin = int(line.split(' ')[2])
xmax = int(line.split(' ')[3])
ymax = int(line.split(' ')[4])
bndbox = [xmin, ymin, xmax, ymax, label_ind]
res += [bndbox]
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
def load_image(path):
image = cv2.imread(path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image
class EADDetection(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
self._txtpath = osp.join('./data/EAD2020_dataType_framesOnly/yolo2voc', '%s.txt')
self._imgpath = osp.join('./data/EAD2020_dataType_framesOnly/frames', '%s.jpg')
self.ids = list()
for line in open(self.root):
self.ids.append(line.strip())
def __getitem__(self, index):
img_id = self.ids[index]
img = load_image(self._imgpath % img_id)
height, width, channels = img.shape
target = __txt2list__(self._txtpath % img_id)
target = np.array(target)
bbox = target[:, :4]
labels = target[:, 4]
if self.transform is not None:
annotation = {'image': img, 'bboxes': bbox, 'category_id': labels}
augmentation = self.transform(**annotation)
img = augmentation['image']
bbox = augmentation['bboxes']
labels = augmentation['category_id']
return {'image': img, 'bboxes': bbox, 'category_id': labels}
def __len__(self):
return len(self.ids)
def __num_class__(self):
return len(EAD_CLASSES)
def label_to_name(self, label):
return EAD_CLASSES[label]
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
import os.path as osp
import sys
import cv2
import matplotlib.pyplot as plt
EAD_CLASSES = ( # always index 0
'specularity','saturation','artifact',
'blur','contrast','bubbles','instrument','blood')
def __class_to_ind__(class_name):
class_to_ind = dict(zip(EAD_CLASSES, range(len(EAD_CLASSES))))
ind = class_to_ind[class_name]
return ind
def __txt2list__(path):
res = []
for line in open(path):
name_laber = line.split(' ')[0]
label_ind = __class_to_ind__(name_laber)
xmin = int(line.split(' ')[1])
ymin = int(line.split(' ')[2])
xmax = int(line.split(' ')[3])
ymax = int(line.split(' ')[4])
bndbox = [xmin, ymin, xmax, ymax, label_ind]
res += [bndbox]
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
def load_image(path):
image = cv2.imread(path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image
class EADDetection(Dataset):
def __init__(self, root, transform=None, dataset_name='EAD20'):
self.root = root
self.transform = transform
self.name = dataset_name
self._txtpath = osp.join('./data/EAD2020_dataType_framesOnly/yolo2voc', '%s.txt')
self._imgpath = osp.join('./data/EAD2020_dataType_framesOnly/frames', '%s.jpg')
self.ids = list()
for line in open(self.root):
self.ids.append(line.strip())
def __getitem__(self, index):
im, gt, h, w = self.pull_item(index)
return im, gt
def pull_item(self, index):
img_id = self.ids[index]
img = cv2.imread(self._imgpath % img_id)
#img = load_image(self._imgpath % img_id)
height, width, channels = img.shape
print(img)
target = __txt2list__(self._txtpath % img_id)
if self.transform is not None:
target = np.array(target)
img, boxes, labels = self.transform(img, target[:, :4], target[:, 4])
# to rgb
img = img[:, :, (2, 1, 0)]
# img = img.transpose(2, 0, 1)
target = np.hstack((boxes, np.expand_dims(labels, axis=1)))
return torch.from_numpy(img).permute(2, 0, 1), target, height, width
# return torch.from_numpy(img), target, height, width
# def __getitem__(self, index):
# img_id = self.ids[index]
#
# img = load_image(self._imgpath % img_id)
# height, width, channels = img.shape
#
# target = __txt2list__(self._txtpath % img_id)
# target = np.array(target)
# bbox = target[:, :4]
# labels = target[:, 4]
#
# if self.transform is not None:
# annotation = {'image': img, 'bboxes': bbox, 'category_id': labels}
# augmentation = self.transform(**annotation)
# img = augmentation['image']
# img = np.transpose(img, (2, 0, 1)).astype(np.float32)
# bbox = augmentation['bboxes']
# labels = augmentation['category_id']
# return {'image': img, 'bboxes': bbox, 'category_id': labels}
def __len__(self):
return len(self.ids)
def __num_class__(self):
return len(EAD_CLASSES)
def label_to_name(self, label):
return EAD_CLASSES[label]
mydata= EADDetection(root)
mydata.__getitem__(967)
```
| github_jupyter |
### Coupling GIPL and ECSimpleSnow models
Before you begin, install:
```conda install -c conda-forge pymt pymt_gipl pymt_ecsimplesnow seaborn```
```
import pymt.models
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import matplotlib.colors as mcolors
from matplotlib.colors import LinearSegmentedColormap
sns.set(style='whitegrid', font_scale= 1.2)
```
#### Load ECSimpleSnow module from PyMT
```
ec = pymt.models.ECSimpleSnow()
print(ec.name)
# List input and output variable names.
print(ec.output_var_names)
print(ec.input_var_names)
```
#### Load GIPL module from PyMT
```
gipl = pymt.models.GIPL()
print(gipl.name)
# List input and output variable names.
print(gipl.output_var_names)
print(gipl.input_var_names)
```
Call the setup method on both ECSimpleSnow and GIPL to get default configuration files and data.
```
ec_defaults = ec.setup('.')
print(ec_defaults)
gipl_defaults = gipl.setup('.')
print(gipl_defaults)
ec.initialize('snow_model.cfg')
gipl.initialize('gipl_config.cfg')
# Get soil depth: [unit: m]
depth = gipl.get_grid_z(2)
n_depth = int(len(depth))
# Get the length of forcing data:
ntime = int(gipl.end_time)
# Define a variable to store soil temperature through the time period
tsoil = np.zeros((n_depth, ntime)) * np.nan
print('Final soil temperatures will be ', tsoil.shape)
fig = plt.figure(figsize=[12,6])
ax2 = fig.add_subplot(2,3,1)
ax2.set_title('Air Temperature (Input)')
ax3 = fig.add_subplot(2,3,2)
ax3.set_title('Precipition (Input)')
ax4 = fig.add_subplot(2,3,4)
ax4.set_title('Snow Depth (EC Output)')
ax5 = fig.add_subplot(2,3,5)
ax5.set_title('Snow Density (EC Output)')
ax1 = fig.add_subplot(2,3,(3,6))
ax1.set_ylim([15,0])
ax1.set_xlim([-20,20])
ax1.set_xlabel('Soil Temperature ($^oC$)')
ax1.set_ylabel('Depth (m)')
ax1.plot([0,0],[15,0],'k--')
for i in np.arange(365):
ec.update() # Update Snow Model Once
# Get output from snow model
tair = ec.get_value('land_surface_air__temperature')
prec = ec.get_value('precipitation_mass_flux')
snd = ec.get_value('snowpack__depth', units='m')
rsn = ec.get_value('snowpack__mass-per-volume_density', units = 'g cm-3')
# Pass value to GIPL model
gipl.set_value('land_surface_air__temperature', tair)
gipl.set_value('snowpack__depth', snd)
gipl.set_value('snow__thermal_conductivity', rsn * rsn * 2.846)
gipl.update() # Update GIPL model Once
tsoil[:,i] = gipl.get_value('soil__temperature') # Save results to a matrix
ax1.plot(tsoil[depth>=0,i], depth[depth>=0],color = [0.7,0.7,0.7], alpha = 0.1)
ax2.scatter(i, tair, c = 'k')
ax3.scatter(i, prec, c = 'k')
ax4.scatter(i, snd , c = 'k')
ax5.scatter(i, rsn , c = 'k')
ax1.plot(tsoil[depth>=0,:].max(axis=1), depth[depth>=0], 'r', linewidth = 2, label = 'Max')
ax1.plot(tsoil[depth>=0,:].min(axis=1), depth[depth>=0], 'b', linewidth = 2, label = 'Min')
ax1.plot(tsoil[depth>=0,:].mean(axis=1), depth[depth>=0], 'k', linewidth = 2, label = 'Mean')
ax1.legend()
ax1.set_title('Ground Temperatures (GIPL output)')
ax2.set_xticks([])
ax3.set_xticks([])
fig = plt.figure(figsize=[9,4])
divnorm = mcolors.DivergingNorm(vmin=-25., vcenter=0., vmax=10)
plt.contourf(np.arange(ntime), depth, tsoil, np.linspace(-25,10,15),
norm = divnorm,
cmap="RdBu_r", extend = 'both')
plt.ylim([5,0])
cb = plt.colorbar()
plt.xlabel('Day')
plt.ylabel('Depth (m)')
cb.ax.set_ylabel('Soil Temperature ($^oC$)')
plt.contour(np.arange(ntime), depth, tsoil, [0]) # ZERO
```
| github_jupyter |
## Questionário 22 (Q22)
**Orientações para submissão:**
- Registre suas respostas no questionário de mesmo nome no SIGAA.
- O tempo de registro das respostas no questionário será de 10 minutos. Portanto, resolva primeiro as questões e depois registre-as.
- Haverá apenas 1 (uma) tentativa de resposta.
- Submeta seu arquivo-fonte (utilizado para resolver as questões) em formato _.ipynb_ pelo SIGAA anexando-o à Tarefa denominada "Envio de arquivo" correspondente ao questionário.
*Nota:* o arquivo-fonte será utilizado apenas como prova de execução da tarefa. Nenhuma avaliação será feita quanto ao estilo de programação.
<hr>
**Questão 1**. O texto abaixo é uma mensagem encriptada. Cada grupo de 4 caracteres corresponde a um número hexadecimal.
```
0x45 0x6d 0x20 0x61 0x6c 0x67 0x75 0x6d 0x20 0x6c 0x75 0x67 0x61 0x72 0x2c 0x20 0x61 0x6c 0x67 0x6f 0x20 0x69 0x6e 0x63 0x72 0xed 0x76 0x65 0x6c 0x20 0x65 0x73 0x74 0xe1 0x20 0x65 0x73 0x70 0x65 0x72 0x61 0x6e 0x64 0x6f 0x20 0x70 0x61 0x72 0x61 0x20 0x73 0x65 0x72 0x20 0x64 0x65 0x73 0x63 0x6f 0x62 0x65 0x72 0x74 0x6f 0x2e
```
Use seus conhecimentos de funções _built_in_ para decodificar a mensagem, que é inteligível na Língua Portuguesa. Em seguida, determine quais são os caracteres da mensagem que correspondem, respectivamente, ao maior e menor valor binário entre os elementos da sequência. Assinale a alternativa que melhor descreve a mensagem decodificada, o caracter associado ao maior valor binário e o caracter associado ao menor valor binário, nesta sequência.
A. `'Em nenhum lugar, todo possível está aguardando para ser manifesto'`, `'ê'` e `' '`.
B. `'Em algum lugar, tudo incrível está esperando para ser incompleto.'`, `'s` e `'a'`.
C. `'Em nenhum lugar, algo possível deve aguardar para ser descoberto'`, `'ê'` e `'í'`.
D. `'Em algum lugar, algo incrível está esperando para ser descoberto.'`, `'í` e `' '`.
_Obs.:_ Considere que os espaços na mensagem original não devem ser considerados como caracteres na mensagem decodificada e que ali servem apenas para separar os quartetos hexadecimais.
**Questão 2**. Rindalve é um jovem promissor que conquistou um excelente emprego, mas sofre com a indisciplina financeira. Ele paga o aluguel da casa onde mora sempre com atraso de alguns dias e, extrapola o limite do cartão de crédito com frequência. Neste mês, Jonas pagou seu aluguel de <span> R$</span> 6.500,00 com 12 dias de atraso e hoje faz 6 dias que a fatura de seu cartão, fechada em <span> R$</span> 7.234,77, venceu.
A imobiliária que administra a casa de Jonas usa a seguinte regra para calcular o valor adicional devido em caso de atraso no pagamento do aluguel:
- mora de 6,25% sobre o valor do aluguel + juro simples de 0,025% ao dia
A administradora de seu cartão de crédito, por outro lado, usa a seguinte regra para calcular o valor adicional devido em caso de atraso no pagamento da fatura do cartão:
- juro composto de 1,44% ao dia.
Crie uma função para calcular o valor total atualizado $V_T$ que Jonas deverá desembolsar, em reais, para quitar as despesas citadas. Então, marque a alternativa correta.
A. <span> R$</span> 19.048,09
B. <span> R$</span> 19.396,08
C. <span> R$</span> 14.808,54
D. <span> R$</span> 16.396,77
**Questão 3**. O Ministério da Saúde disponibiliza uma lista de remédios através do programa _Farmácia Popular_. Clicando [aqui](https://antigo.saude.gov.br/images/pdf/2019/janeiro/07/Lista-Medicamentos.pdf), você será redirecionado a uma dessas listas. Crie um _dict_ em Python com as informações relevantes contidas na tabela do arquivo PDF. Em seguida, crie uma função regular que recebe o seu _dict_ como argumento e retorne 3 objetos: um _str_, um _tuple_ e um _int_, os quais nesta, ordem, responderão às seguintes perguntas:
- Para que doença a maior quantidade de remédios na gratuidade é indicada?
- Qual é a quantidade de remédios nas classes _gratuidade_ e _copagamento_?
- Quantos remédios têm a letra C como inicial de seu nome?
Assinale a alternativa correta:
A. `'HIPERTENSÃO', (20, 15), 3`
B. `'ASMA', (20, 15), 7`
C. `'DIABETES', (10, 20), 8`
D. `'ASMA', (18, 17), 6`
_Obs.:_ tente usar funções anônimas sempre que possível.
| github_jupyter |
## Individual Variable Data Exploration Notebook
```
import numpy as np
import pandas as pd
import missingno as msno
import matplotlib.pyplot as plt
import seaborn as sns
data_train = pd.read_csv('claim_data_v2_train.csv')
data_train.sample(3)
def visualize_cat(attr, df=data_train):
df_i = df[['Fraudulent_Claim', attr]].groupby([attr])['Fraudulent_Claim'].agg(['count','sum', 'mean'])
m = 'Pct Fraud'
df_i = df_i.rename({'count': 'frequency', 'sum': 'Survivers', 'mean': m}, axis='columns')
print(df_i)
fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
df_i['frequency'].plot.bar(ax=ax1, alpha=.8)
df_i[m].plot.line(ax=ax2, color='k')
ax1.set_ylabel('frequency')
ax2.set_ylabel('Pct Fraud')
ax2.set_ylim(bottom=0, top=1, auto=False)
ax2.legend()
data_train["Fraudulent_Claim"].describe()
#Convert Fraud Claim data from Y/N to 1/0
data_train.Fraudulent_Claim.replace(('Y', 'N'), (1, 0), inplace=True)
#Test to see if fraud claim data converted correctly
data_train.head()
data_train.columns
data_train.describe(include='all')
# missing data
msno.matrix(data_train)
corrmat= data_train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);
```
# Describe Each Variable - Find Outliers
#### Claim Amount
```
data_train['Claim_Amount'].hist()
```
Log tranformation
```
data_train['Claim_Amount'].apply(np.log).hist()
```
#### Income
Income has a major outlier of $10M
```
data_train['Income'].describe()
```
Top 10 Earners
```
data_train['Income'].sort_values(ascending=False).head(10)
data_train['Income'].plot.box()
```
Drop values above the boxplot (greater than Q3+1.5*IQR)
```
cutoff = data_train['Income'].quantile(.75) + (data_train['Income'].quantile(.75) - data_train['Income'].quantile(.25))
print("Cutoff value:", cutoff)
data_train['Income'][data_train['Income']<cutoff].plot.box()
```
Graph histogram without 0 income and without outliers
```
data_train['Income'][(data_train['Income']<cutoff) & (data_train['Income']>0)].hist()
```
#### Premium
Validate that Annual Premium is 12 times Monthly Premium
```
data_train[data_train['Monthly_Premium'] * 12 != data_train['Annual_Premium']]
data_train['Monthly_Premium'].describe()
```
Premium is approximately uniformly distributed between 50 and 140
```
data_train['Monthly_Premium'].hist()
data_train['Months_Since_Last_Claim'].describe()
data_train['Months_Since_Last_Claim'].plot.box()
data_train['Months_Since_Last_Claim'].hist(bins=range(0, 72, 6))
data_train['Months_Since_Policy_Inception'].hist()
data_train['Outstanding_Balance'].hist()
def get_categorical_dist(attr):
return data_train.groupby(attr).size().sort_values(ascending=False)
get_categorical_dist('State_Code')
get_categorical_dist('Education')
get_categorical_dist('Employment_Status')
get_categorical_dist('Gender')
get_categorical_dist('Marital_Status')
get_categorical_dist('Location')
get_categorical_dist('Claim_Cause')
get_categorical_dist('Claim_Report_Type')
get_categorical_dist('Vehicle_Class')
get_categorical_dist('Vehicle_Model')
get_categorical_dist('Fraudulent_Claim')
get_categorical_dist('Claim_Date')
#missing data
data_train.isna().sum()
sns.catplot(x="Fraudulent_Claim", y="Claim_Amount", kind="violin",data=data_train);
sns.catplot(x="Fraudulent_Claim", y="Income", kind="violin",data=data_train);
```
| github_jupyter |
```
import gust
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from numpy import matrix
import scipy
import scipy.sparse as sp
import torch.distributions as dist
from time import time
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.spatial.distance import squareform
# Load the dataset using `gust` library
# graph.standardize() makes the graph unweighted, undirected and selects
# the largest connected component
# graph.unpack() returns the necessary vectors / matrices
A, X, _, y = gust.load_dataset('cora').standardize().unpack()
sss = StratifiedShuffleSplit(n_splits=5, test_size=0.8, random_state=0)
train_index, test_index = sss.split(self, emb, Y, groups=None)
train_X = A[train_index]
test_X = A[test_index]
train_y = y[train_index]
test_y = y[test_index]
torch.set_default_tensor_type('torch.cuda.FloatTensor')
A, X, _, z = gust.load_dataset('cora_ml').standardize().unpack()
sss = StratifiedShuffleSplit(n_splits=5, test_size=0.8, random_state=0)
#adj = torch.FloatTensor(A.toarray()).cuda()
#A = A[0:4,0:4]
def laplacian(A):
#Transition Matrix P=D-A
num_nodes = A.shape[0]
D = np.ravel(A.sum(1))
L = sp.diags(D) - A
return L
def sym_normalized_laplacian(A):
#Symmetric, Normalized Laplacian P=D^(−1/2)AD^(−1/2)
num_nodes = A.shape[0]
D = np.ravel(A.sum(1))
#D[D == 0] = 1 # avoid division by 0 error
D_sqrt = np.sqrt(D)
a=np.ones(D_sqrt.shape[0])
D_sqrt_inv = np.divide(a, D_sqrt, out=np.zeros_like(a), where=D!=0)
L = sp.diags(D_sqrt_inv) * A * sp.diags(D_sqrt_inv)
#L = A / D_sqrt[:, None] / D_sqrt[None, :]
return L
def Transition(A):
#Laplacian P=D^−1A
num_nodes = A.shape[0]
D = np.ravel(A.sum(1))
#D[D == 0] = 1 # avoid division by 0 error
a=np.ones(D.shape[0])
D_inv = np.divide(a, D, out=np.zeros_like(a), where=D!=0)
L = sp.diags(D_inv) * A
return L
def PPR(A):
#Personalized PageRank Matrix as described in https://openreview.net/pdf?id=H1gL-2A9Ym with the there used hyperparameter alpha=0.1
#P=alpha(I-(1-alpha)*D^-1/2(A+I)D^-1/2)^-1
print(A.toarray())
alpha = 0.1
num_nodes = A.shape[0]
D = np.ravel(A.sum(1))
#D[D == 0] = 1 # avoid division by 0 error
D_sqrt = np.sqrt(D)
a=np.ones(D_sqrt.shape[0])
D_sqrt_inv = np.divide(a, D_sqrt, out=np.zeros_like(a), where=D!=0)
A_tilde = sp.diags(D_sqrt_inv) * (A + sp.identity(A.shape[0])) * sp.diags(D_sqrt_inv)
print('A_tilde: ', A_tilde.toarray())
L_inv = (sp.identity(A.shape[0]) - (1-alpha) * A_tilde)
print('L_inv: ', L_inv.toarray())
L = alpha * np.linalg.pinv(L_inv.toarray())
print(L)
return L
def NetMF(A):
eps=1e-5
#volume of the graph, usually for weighted graphs, here weight 1
vol = A.sum()
#b is the number of negative samples, hyperparameter
b = 3
#T is the window size, as a small window size algorithm is used, set T=10, which showed the best results in the paper
T=10
#Transition Matrix P=D^-1A
num_nodes = A.shape[0]
D = np.ravel(A.sum(1))
#D[D == 0] = 1 # avoid division by 0 error
a=np.ones(D.shape[0])
D_inv = np.divide(a, D, out=np.zeros_like(a), where=D!=0)
P = np.diag(D_inv) * A.todense()
#Compute M = vol(G)/bT (sum_r=1^T P^r)D^-1
sum_np=0
for r in range(1,T+1):
sum_np+=np.linalg.matrix_power(P,r)
M = sum_np * np.diag(D_inv) * vol / (b*T)
M_max = np.maximum(M,np.ones(M.shape[0]))
#Compute SVD of M
u, s, vh = np.linalg.svd(np.log(M_max), full_matrices=True)
#Compute L
L = u*np.diag(np.sqrt(s+eps))
print(L.sum(axis=1))
return L
def simrank_quick(A, C = 0.8, acc = 0.1):
#https://link.springer.com/chapter/10.1007/978-3-642-14246-8_29
#Algorithm 2: PAUG-SimRank: Parallel Accelerative SimRank for Undirected Graphs
#Step 1: Spectral Predecomposition
A = A.todense()
print(torch.tensor(A))
eigvalues, eigvectors = torch.eig(torch.tensor(A), eigenvectors=True)
eigvalues = eigvalues[:,0]
#Step 2: Iterative Elementwise Matrix Multiplication
#for i in range(eigvalues.shape[0]):
return
def simrank(A, C = 0.8, acc = 1e-10):
#https://link.springer.com/chapter/10.1007/978-3-642-14246-8_29
#Algorithm 1: AUG-SimRank: Accelerative SimRank for Undirected Graphs
A_torch = torch.tensor(A.todense())
#Calculate Transition Probability Q
Q_torch = A_torch / A_torch.sum(1, keepdims=True)
Q = np.squeeze(np.asarray((A / np.sum(A,axis = 1))))
#Decompose Q
eigvalues_t, eigvectors_t = torch.eig(Q_torch, eigenvectors=True)
eigvalues_np, eigvectors_np = np.linalg.eig(Q)
#for undirected graphs all eigenvalues are real
eigvectors_np=np.real(eigvectors_np)
eigvalues_np=np.real(eigvalues_np)
eigvalues_t_real = eigvalues_t[:,0]
#Initialize
#S_old = torch.eye(Q.shape[0])
S_old_np = np.identity(Q.shape[0])
S_old_t = torch.eye(Q_torch.shape[0])
M_np = C * np.diag(eigvalues_np) @ np.transpose(np.diag(eigvalues_np))
M_t = C * torch.diag(eigvalues_t_real) @ torch.diag(eigvalues_t_real).T
#Converge
while True:
S_new_np = np.maximum(np.multiply(M_np, S_old_np), np.identity(M_np.shape[0]))
if (np.absolute(S_new_np-S_old_np)).max()<acc:
break
S_old_np = S_new_np
#L = eigvectors @ S_new @ np.linalg.inv(eigvectors)
print('S_new_np: ', S_new_np)
L_np = np.dot(eigvectors_np, np.dot(S_new_np, np.linalg.inv(eigvectors_np)))
#Converge
while True:
S_new_t = torch.max(M_t*S_old_t,torch.eye(M_t.shape[0]))
if torch.max(torch.abs(S_new_t-S_old_t))<acc:
break
S_old_t = S_new_t
print('S_new_t: ', S_new_t)
L_t = eigvectors_t @ S_new_t @ torch.inverse(eigvectors_t)
return L_np, L_t
L = laplacian(A)
N = A.shape[0]
D = 32
Z = nn.Parameter(torch.empty(N, D).normal_(std=0.1))
x = nn.Parameter(torch.empty(N, D).normal_(std=0.1))
opt = torch.optim.Adam([Z], lr=1e-2)
e1, e2 = A.nonzero()
def sig(Z, b=0.1, eps=1e-8):
dist = torch.matmul(Z,Z.T) +b
sigdist = 1/(1+torch.exp(dist+eps)+eps)
logsigdist = torch.log(sigdist+eps)
pos_term = logsigdist[e1,e2]
neg_term = torch.log(1-sigdist)
neg_term[np.diag_indices(N)] = 0.0
return -(pos_term.sum() + neg_term.sum()) / Z.shape[0]**2
def dist(Z, eps=1e-5):
gamma = 0.1
dist = ((Z[:, None] - Z[None, :]).pow(2.0).sum(-1) + eps).sqrt()
neg_term = torch.log(-torch.expm1(-dist)*gamma + eps)
neg_term[np.diag_indices(N)] = 0.0
pos_term = -dist[e1, e2]
neg_term[e1, e2] = 0.0
return -(pos_term.sum() + neg_term.sum()) / Z.shape[0]**2
def exp(Z, eps=1e-8):
#e1, e2 = similarity_measure.nonzero()
emb_abs = torch.FloatTensor.abs(Z)
dist = -torch.matmul(emb_abs, emb_abs.T)
neg_term = dist
neg_term[np.diag_indices(Z.shape[0])] = 0.0
expdist = torch.exp(dist)
embedding = 1 - expdist
logdist = torch.log(embedding + eps)
pos_term = logdist[e1, e2]
size=Z.shape[0]
return -(pos_term.sum() + neg_term.sum()) / Z.shape[0]**2
def kl(L, Z, eps=1e-8):
#P=softmax(ZZ^T)
dist=torch.matmul(Z,Z.T)
sigdist = 1/(1+torch.exp(dist+eps)+eps)
logsigdist = torch.log(sigdist+eps)
losses = T*logsigdist
return losses.sum()
for epoch in range(500):
opt.zero_grad()
loss = dist(Z)
loss.backward()
opt.step()
print(loss.item())
for train_index, test_index in sss.split(X, y):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
```
| github_jupyter |
# Nooksack Groundwater-Surface Water Model Coupling
### Install packages and libraries
```
#Packages not on HydroShare R kernal
install.packages('hydroGOF')
install.packages('writexl')
#May be needed for PC use of code
#install.packages('data.table')
#install.packages('dplyr')
library(data.table)
library(dplyr)
library(hydroGOF)
library(writexl)
library(reshape2)
```
### File management and decompression
```
getwd()
list.files()
```
### Only need to run the cell below the first time the data is downloaded from HydroShare to this HPC workspace. See working directory above.
```
unzip('modelruns_1952WRIA1_081418.zip')
```
### Open a new terminal, change directory, and unzip all model files
cd
'/home/jovyan/work/notebooks/data/fb5e45f7bfea4765a445a190b809cbdb/fb5e45f7bfea4765a445a190b809cbdb/data/contents'
Run
> gunzip modelruns_1952WRIA1_081418/*/*
```
# assign Project 2018 as the current directory
Project2018 <- getwd()
WMoff2018_Models <- file.path(Project2018, 'modelruns_1952WRIA1_081418/modelruns_1952WRIA1_110912_WMoff')
WMon2012_Models <- file.path(Project2018, 'modelruns_1952WRIA1_081418/modelruns_1952WRIA1_110912_WMon')
# set working directory
setwd(WMon2012_Models)
```
### Read in files and data
```
list.files()
```
# 1.0 Recharge Calculations
```
# read topsbd (mod: changed to fread for spead and added data.table=T)
topsbd <- fread('topsbd_v8.txt', skip = 1, header = T, data.table=T)
colnames(topsbd)
head(topsbd,10)
# generate TimeStep by subbasin matrices (mod: added 'mean' as the aggregation function)
Zbar <- topsbd %>% select(TimeStep, Basin, Afrac, WTDepth_mm) %>% mutate(afrac_test = Afrac*WTDepth_mm) %>% dcast(TimeStep~Basin, value.var='afrac_test', fun.aggregate=sum)
PET <- topsbd %>% select(TimeStep, Basin, Afrac, Pet_mm) %>% mutate(afrac_test = Afrac*Pet_mm) %>% dcast(TimeStep~Basin, value.var='afrac_test', fun.aggregate=sum)
AET <- topsbd %>% select(TimeStep, Basin, Afrac, Aet_mm) %>% mutate(afrac_test = Afrac*Aet_mm) %>% dcast(TimeStep~Basin, value.var='afrac_test', fun.aggregate=sum)
Rain <- topsbd %>% select(TimeStep, Basin, Afrac, Prec_mm) %>% mutate(afrac_test = Afrac*Prec_mm) %>% dcast(TimeStep~Basin, value.var='afrac_test', fun.aggregate=sum)
SatEx <- topsbd %>% select(TimeStep, Basin, Afrac, SatEx_mm) %>% mutate(afrac_test = Afrac*SatEx_mm) %>% dcast(TimeStep~Basin, value.var='afrac_test', fun.aggregate=sum)
InfEx <- topsbd %>% select(TimeStep, Basin, Afrac, InfEx_mm) %>% mutate(afrac_test = Afrac*InfEx_mm) %>% dcast(TimeStep~Basin, value.var='afrac_test', fun.aggregate=sum)
SurfRO <- topsbd %>% select(TimeStep, Basin, Afrac, SurfRo_mm) %>% mutate(afrac_test = Afrac*SurfRo_mm) %>% dcast(TimeStep~Basin, value.var='afrac_test', fun.aggregate=sum)
SoilStore <- topsbd %>% select(TimeStep, Basin, Afrac, SoilStore_mm) %>% mutate(afrac_test = Afrac*SoilStore_mm) %>% dcast(TimeStep~Basin, value.var='afrac_test', fun.aggregate=sum)
# load Recharge inputs
#Basins <- read.table("basin.txt", header=T, row.names=1) # mod: added row.names=1
Precipitation_mm <- Rain
Depth_to_Water_mm <- Zbar
Evaporation_mm = fread("Evaporation_mm.txt", header=T)
Soil_storage_mm <- SoilStore
# Make if statement here
Surface_runoff_cms = fread("TotalRunoff_noWithdrawal_cms.txt", header=T)
#dim(Basins)
dim(Precipitation_mm)
dim(Evaporation_mm)
dim(Depth_to_Water_mm) # matrices sourced from Basin are selected subset of basins
dim(Surface_runoff_cms)
```
## Print individual text files of water budget variables
See variable names for text file naming
```
# print these outputs from topsbd_v8.txt
for (mat in c('InfEx', 'PET', 'AET', 'SatEx', 'Rain', 'Zbar', 'SoilStore', 'Surface_runoff_cms')){
write.table(mat %>% get() %>% data.frame(), file = paste0(mat, '.txt'), col.names = T, row.names = F, append = F)
print(paste(mat, 'printed to', paste0(mat, '.txt')))
}
```
### Functions for aggregation
```
# function to calculate the water year
wtr_yr <- function(dates, start_month=10) {
# Convert dates into POSIXlt
dates.posix = as.POSIXlt(as.character(dates), format = '%Y%m%d')
# Calculate offset based on the month of the year
offset = ifelse(dates.posix$mon >= start_month, 1, 0)
# adjust the current year to the appropriate Water year
adj.year = dates.posix$year + 1900 + offset # year + adjustment for date origin + offset
return(adj.year)
}
# function to read in the time series files
findmeta <- function(file){
# index last row of metadata, depends on use of "Ver#" start to header line
meta_end <- grep('^Ver', readLines(file))
# metadata
meta <- readLines(file)[1:meta_end] %>%
gsub("^\\t+|\\t+$|^\\s+|\\s+$|^ ","",.) %>% # removing leading and trailing spaces and tabs
gsub("\\t+"," ",.) # separate tab-separated metadata
print(paste("metadata headers for", file))
return(meta)
}
# function to read in .dat format output files
read_dat <- function(file, meta){
# column names based on tab separation
col.Names <- meta %>% gsub("\\t+$","",.) %>%
strsplit(' |\t') %>%
tail(1) %>%
unlist() %>%
.[-c(1,2)] %>%
.[.!=""]
# arrange the data
dat <- read.csv(file, sep='', skip = length(meta), header = F)
nonNA <- colnames(dat)[which(colSums(is.na(dat)) != nrow(dat))]
dat <- dat[colnames(dat) %in% nonNA] %>% data.table()
setnames(dat, colnames(dat), col.Names)
return(dat)
}
```
### Algorithm to Calculate Recharge
```
# functionalize the timesteploop
timesteploop <- function(TimeStep, basin_subset, totalRecharge_depot, Precipitation_mm, Evaporation_mm,
Surface_runoff_cms, Soil_storage_mm, totalRecharge=0){
# for every TimeStep
for(ts in TimeStep){
# for each catchment
for (CatchID in basin_subset[['Basins']]){
Drainage = as.character(basin_subset[Basins==CatchID,'Drainages'])
### Look up P, E, and SR values for this daily timestep and convert to inches
P <- Precipitation_mm[ts, CatchID]*0.0393701 #Precipitation (in)
E <- as.numeric(Evaporation_mm[ts, Drainage, with=F])*0.0393701 #Evaporation (in)
SR <- as.numeric(Surface_runoff_cms[ts, Drainage, with=F])*61024*60*60*24/Basinpars[CatchID, "BasinArea_in2"] #Surface runoff/Basin area (in)
if(ts==1){
CDW <- as.numeric(0) ### Calculate change in depth to water (in)
CSS <- as.numeric(0) ### Calculate change in soil storage term (in)
} else {
# take the difference between the current water depth and the previous water depth at this Drainage
CDW <- (Depth_to_Water_mm[ts, CatchID] - Depth_to_Water_mm[ts-1, CatchID])*0.0393701
CSS <- (Soil_storage_mm[ts, CatchID] - Soil_storage_mm[ts-1, CatchID])*0.0393701
}
### Calculate daily recharge
dailyRecharge = P-E-SR+CSS
### Calculate running total of daily recharge
totalRecharge = totalRecharge + dailyRecharge
# store the data
totalRecharge_depot <- rbindlist(list(totalRecharge_depot,
data.table(CatchID,ts,P,E,SR,CDW,CSS,dailyRecharge)),
use.names = T, fill = T)
}
}
fwrite(totalRecharge_depot, file='dailyRecharge_depot.txt', sep='\t', col.names=T, row.names=F, append=F)
return(totalRecharge_depot)
}
```
### Load input files and list basins selected for analysis
```
Project2018
WMon2012_Models
### Load input files (if they have not already been read in above) ###
if(!"Basinpars" %in% ls()){
Basinpars = read.table("basinpars.txt", sep=',', header=T)
}
if(!"TimeSteps" %in% ls()){
TimeSteps <- read.table('DateTime_yyyymmdd_hhmmss.txt', header = T)
}
if(!"Precipitation_mm" %in% ls()){
Precipitation_mm = read.table("Precipitation_mm.txt", header=T)
}
if(!"Evaporation_mm" %in% ls()){
Evaporation_mm = read.table("Evaporation_mm.txt", header=T)
}
if(!"Surface_runoff_cms" %in% ls()){
Surface_runoff_cms = read.table("Surface_runoff_cms.txt", header=T)
}
if(!"Soil_storage_mm" %in% ls()){
Soil_storage_mm = read.table("SoilStore.txt", header=T)
}
if(!"Depth_to_Water_mm" %in% ls()){
Depth_to_Water_mm = read.table("Zbar.txt", header=T)
}
# compute basin area
Basinpars['BasinArea_in2'] <- Basinpars[,'direct_area']*(0.0393701^2)
# compute basin_subset
basin_subset <- data.table(Basins=colnames(Precipitation_mm)[!colnames(Precipitation_mm) %in% c('TimeStep')])
basin_subset[,Drainages:=paste0('Drainage',Basins)]
# daily iteration deposition
totalRecharge_depot <- data.table()
```
### Run the Recharge Calculation for Subbasins
unzip(paste0(getwd(),'totalRecharge_depot.txt.gz'))
```
(length(TimeSteps$TimeStep)/365) * as.numeric(tdiff) / 60 # to hours
length(basin_subset$Basin)
length(TimeSteps$TimeStep)
### Calculate average annual recharge (inches) for the basin ###
ptm <- Sys.time()
#totalRecharge_depot <- timesteploop(TimeSteps$TimeStep[1:365], ## Test a short output
totalRecharge_depot <- timesteploop(TimeSteps$TimeStep,
basin_subset,
totalRecharge_depot=data.table(),
Precipitation_mm,
Evaporation_mm,
Surface_runoff_cms,
Soil_storage_mm,
totalRecharge=0)
(tdiff = ptm - Sys.time())
totalRecharge_depot[(CatchID==6),]
fwrite(totalRecharge_depot, paste0(getwd(),'totalRecharge_summary.txt'), sep = '\t', row.names = F, col.names = T, append = F)
print(paste("Finished printing the RechargeCalculator within", getwd()))
```
### Calculate Aggregated Recharge
```
totalRecharge_depot <- fread(paste0(getwd(),'/totalRecharge_depot.txt'), sep = '\t', header = T)
# additional calculations
totalRecharge_depot <- totalRecharge_depot %>%
merge(., DateTime_water_year.txt, by.x='ts', by.y = 'TimeStep') %>%
# MonthlyRecharge total
group_by(month, water_year, CatchID) %>%
mutate(monthlyRecharge = sum(dailyRecharge)) %>%
# AnnualRecharge total
group_by(water_year, CatchID) %>%
mutate(annualRecharge = sum(dailyRecharge)) %>%
# WaterYear average AnnualRecharge
#group_by(water_year, CatchID) %>%
#mutate(averageMonthlyRechargeByWateryear = mean(monthlyRecharge)) %>%
#data.table() %>%
group_by(CatchID) %>%
mutate(averageAnnualRecharge = mean(annualRecharge)) %>%
data.table()
# print
fwrite(totalRecharge_depot, paste0(getwd(),'/totalRecharge_summary.txt'), sep = '\t', row.names = F, col.names = T, append = F)
print(paste("Finished printing the RechargeCalculator within", getwd()))
```
# 2.0 Water Budget Calculations
### Set up to read model inputs
```
ModelSet_folder <- getwd()
print(paste('start', ModelSet_folder))
# set start date and end date of rain year
Rain_start <- as.numeric(19000101) #as.numeric(20061001)
Rain_end <- as.numeric(20150930)
calib_start <- as.numeric(20030613)
calib_end <- as.numeric(20051231)
valid_start <- as.numeric(20060101)
valid_end <- as.numeric(20160930)
# set target files
#WM on #used with WMon
readus_WMon <-c('FlowAtStreamNodes_cms.txt',
'UserDemand_cms.txt',
'UserWithdrawal_cms.txt',
'TotalRunoff_noWithdrawal_cms.txt',
'UserDeficit_cms.txt',
'Precipitation_mm.txt',
'Evaporation_mm.txt',
'DateTime_yyyymmdd_hhmmss.txt',
'Artificial_Drainage.txt',
'basinpars.txt',
'StreamFlowLinks.txt',
'DrainageID.txt',
'DrainageInfo.txt',
'MonthlyDemandFraction.txt',
'user.txt')
#WMoff
readus_WMoff<-c('FlowAtStreamNodes_cms.txt',
'TotalRunoff_noWithdrawal_cms.txt',
'Precipitation_mm.txt',
'Evaporation_mm.txt',
'DateTime_yyyymmdd_hhmmss.txt',
'Artificial_Drainage.txt',
'basinpars.txt',
'StreamFlowLinks.txt',
'DrainageID.txt',
'DrainageInfo.txt')
```
### Select list of files based on the working directory (WM on/off)
```
readus<-readus_WMon
if('WMon' %in% getwd()){
readus<-readus_WMon
} else {
readus<-readus_WMoff
}
# readus files - data tables named after the names of the files
for (i in readus){
assign(i, i %>% fread(header=T, data.table=T))
print(paste('reading', i))
}
```
### Set up time and unit dimensions
```
# Abstract the Year, Month, and range for the Water Year period
DateTime_water_year.txt <- DateTime_yyyymmdd_hhmmss.txt %>%
mutate(year = substring(yyyymmdd, 1,4) %>% as.numeric(),
month = substring(yyyymmdd, 5, 6) %>% as.numeric(),
day = substring(yyyymmdd, 7, 8) %>% as.numeric(),
water_year = wtr_yr(yyyymmdd, start_month = 9)) %>%
filter(yyyymmdd >= Rain_start,
yyyymmdd <= Rain_end) %>%
arrange(TimeStep) %>%
data.table()
# calib
DateTime_calib.txt <- DateTime_yyyymmdd_hhmmss.txt %>%
mutate(year = substring(yyyymmdd, 1,4) %>% as.numeric(),
month = substring(yyyymmdd, 5, 6) %>% as.numeric(),
day = substring(yyyymmdd, 7, 8) %>% as.numeric(),
water_year = wtr_yr(yyyymmdd, start_month = 9)) %>%
filter(yyyymmdd >= calib_start,
yyyymmdd <= calib_end) %>%
arrange(TimeStep) %>%
data.table()
# validation
DateTime_valid.txt <- DateTime_yyyymmdd_hhmmss.txt %>%
mutate(year = substring(yyyymmdd, 1,4) %>% as.numeric(),
month = substring(yyyymmdd, 5, 6) %>% as.numeric(),
day = substring(yyyymmdd, 7, 8) %>% as.numeric(),
water_year = wtr_yr(yyyymmdd, start_month = 9)) %>%
filter(yyyymmdd >= valid_start,
yyyymmdd <= valid_end) %>%
arrange(TimeStep) %>%
data.table()
# convert mm to inches
Precipitation_in.txt <- Precipitation_mm.txt %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(./25.4)) %>%
merge(., DateTime_water_year.txt, by = 'TimeStep') %>%
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('Drainage')) %>%
data.table()
Evaporation_in.txt <- Evaporation_mm.txt %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(./25.4)) %>%
merge(., DateTime_water_year.txt, by = 'TimeStep') %>%
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('Drainage')) %>%
data.table()
# convert cms to cfs: 1cms = 35.3147 cfs
FlowAtStreamNodes_cfs.txt <- FlowAtStreamNodes_cms.txt %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*35.3147)) %>%
merge(., DateTime_water_year.txt, by = 'TimeStep') %>%
mutate(FlowAtOutlet = Node1) %>% #
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('Node')) %>%
data.table()
Artificial_Drainage_cfs.txt <- Artificial_Drainage.txt %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*35.3147)) %>%
merge(., DateTime_water_year.txt, by = 'TimeStep') %>%
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('Drainage')) %>%
data.table()
# convert cms to gal/day: 1cms * 264.172 gal/m^3 * 86400 s/day = 23688461 gal/day
UserDemand_gpd.txt <- UserDemand_cms.txt %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*264.172*86400)) %>%
merge(., DateTime_water_year.txt, by = 'TimeStep') %>%
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('User')) %>%
data.table()
UserWithdrawal_gpd.txt <- UserWithdrawal_cms.txt %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*264.172*86400)) %>%
merge(., DateTime_water_year.txt, by = 'TimeStep') %>%
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('User')) %>%
data.table()
# find meta lines for rain.dat
rain.dat_meta <- findmeta('rain.dat')
# read in rain.dat
rain.dat <- read_dat('rain.dat', rain.dat_meta)
# apply conversion from mm to inches. Code-base taken from Precipitation.
# convert mm to inches
rain_in_obs.dat <- rain.dat %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(./25.4)) %>%
merge(., DateTime_water_year.txt, by.x = 'Date', by.y = 'yyyymmdd') %>%
arrange(TimeStep) %>%
select(-c(Date, year, day, Hour, hhmmss))
```
### Calculate Monthly Summaries
```
# monthly average for the 9 water years
monthlySummary_Precipitation_in.txt <- Precipitation_in.txt %>%
# group by TimeStep and Month
select(-c(TimeStep, yyyymmdd, year, day)) %>%
melt(., id.vars = c('month', 'water_year'), variable.name = 'Drainages', value.name = 'Precipitation') %>%
# calculate total by month, year, and drainage
group_by(month, water_year, Drainages) %>%
summarise(sumByMonthyByWateryearByDrainage = sum(Precipitation)) %>%
# calculate mean by month, year, and drainage
group_by(month, Drainages) %>%
summarise(meanByMonthByDrainage = mean(sumByMonthyByWateryearByDrainage)) %>%
# calculate mean and sd by month
group_by(month) %>%
mutate(meanByMonth = mean(meanByMonthByDrainage),
sdByMonth = sd(meanByMonthByDrainage)) %>%
# reformat the table to wide for each DrainageID
dcast(., month + meanByMonth + sdByMonth ~ Drainages, value.var = 'meanByMonthByDrainage') %>%
data.table()
# monthly average for the 9 water years
monthlySummary_Evaporation_in.txt <- Evaporation_in.txt %>%
# group by TimeStep and Month
select(-c(TimeStep, yyyymmdd, year, day)) %>%
melt(., id.vars = c('month', 'water_year'), variable.name = 'Drainages', value.name = 'Evaporation') %>%
# calculate total by month, year, and drainage
group_by(month, water_year, Drainages) %>%
summarise(sumByMonthyByWateryearByDrainage = sum(Evaporation)) %>%
# calculate mean by month, year, and drainage
group_by(month, Drainages) %>%
summarise(meanByMonthByDrainage = mean(sumByMonthyByWateryearByDrainage)) %>%
# calculate mean and sd by month
group_by(month) %>%
mutate(meanByMonth = mean(meanByMonthByDrainage),
sdByMonth = sd(meanByMonthByDrainage)) %>%
# reformat the table to wide for each DrainageID
dcast(., month + meanByMonth + sdByMonth ~ Drainages, value.var = 'meanByMonthByDrainage') %>%
data.table()
# the average and sd of the average Drainages
monthlySummary_Artificial_Drainage_cfs.txt <- Artificial_Drainage_cfs.txt %>%
# group by TimeStep and Month
select(-c(TimeStep, yyyymmdd, year, day)) %>%
melt(., id.vars = c('month','water_year'), variable.name = 'Drainages', value.name = 'Artificial_Drainages') %>%
# calculate the sum of artificial drainage for each month and wateryear
group_by(month, water_year) %>%
mutate(sumByMonthByWateryear = sum(Artificial_Drainages)) %>%
# calculate mean by month and drainage
group_by(month, Drainages) %>%
mutate(meanByMonthByDrainage = mean(Artificial_Drainages)) %>%
# calculate mean and sd by month
group_by(month) %>%
mutate(meanByMonth = mean(meanByMonthByDrainage),
sdByMonth = sd(meanByMonthByDrainage),
meanOfSumByMonth = mean(sumByMonthByWateryear)) %>%
# reformat the table to wide for each DrainageID
select(month, meanOfSumByMonth, meanByMonth, sdByMonth, Drainages, meanByMonthByDrainage) %>%
unique() %>% # meanByMonthByDrainage should be the most stringent - get rid of duplicate rows
dcast(., month + meanOfSumByMonth + meanByMonth + sdByMonth ~ Drainages, value.var = 'meanByMonthByDrainage') %>%
data.table()
# the average and sd of the average Node
monthlySummary_FlowAtStreamNodes_cfs.txt <- FlowAtStreamNodes_cfs.txt %>%
# group by TimeStep and Month
select(-c(TimeStep, yyyymmdd, year, day, water_year)) %>%
melt(., id.vars = c('month'), variable.name = 'Node', value.name = 'FlowAtStreamNodes') %>%
# calculate mean by month and node
group_by(month, Node) %>%
summarise(meanByMonthByNode = mean(FlowAtStreamNodes)) %>%
# calculate mean and sd by month
group_by(month) %>%
mutate(meanByMonth = mean(meanByMonthByNode),
sdByMonth = sd(meanByMonthByNode)) %>%
# reformat the table to wide for each NodeID
dcast(., month+meanByMonth+sdByMonth~Node, value.var = 'meanByMonthByNode') %>%
select(month, meanByMonth, sdByMonth, Node1, Node4, Node28) %>%
data.table()
# the average and sd of the average User
monthlySummary_UserDemand_gpd.txt <- UserDemand_gpd.txt %>%
# group by TimeStep and Month
select(-c(TimeStep, yyyymmdd, year, day, water_year)) %>%
melt(., id.vars = c('month'), variable.name = 'User', value.name = 'UserDemand_gpd') %>%
mutate(UserType = UserType_table[match(User, user),UserType]) %>%
# calculate mean by month, and UserType
group_by(month, UserType) %>%
mutate(meanByMonthByUserType = mean(UserDemand_gpd)) %>%
# calculate mean and sd by month
group_by(month) %>%
mutate(meanByMonth = mean(UserDemand_gpd),
sdByMonth = sd(UserDemand_gpd)) %>%
# reformat the table to wide for each UserType
select(-c(User, UserDemand_gpd)) %>%
dcast(., month + meanByMonth + sdByMonth ~ UserType, fun = mean, value.var = c('meanByMonthByUserType')) %>%
data.table()
# the average monthly sum for each UserType
monthlySums_UserDemand_gpd.txt <- UserDemand_gpd.txt %>%
# group by month and water_year
select(-c(TimeStep, yyyymmdd, year, day)) %>%
melt(., id.vars = c('month','water_year'), variable.name = 'User', value.name = 'UserDemand_gpd') %>%
mutate(UserType = UserType_table[match(User, user),UserType]) %>%
# calculate sum by month, water_year, and UserType
group_by(month, water_year, UserType) %>%
mutate(UserDemand_gpm = sum(UserDemand_gpd)) %>%
# calculate mean of the sums by month, and UserType
group_by(month, UserType) %>%
mutate(mean_UserDemand_gpm = mean(UserDemand_gpm)) %>%
# calculate
group_by(month) %>%
mutate(sumByMonth = sum(UserDemand_gpd),
meanByMonth = mean(UserDemand_gpd),
sdByMonth = sd(UserDemand_gpd),
varByMonth = var(UserDemand_gpd)) %>%
# reformat the table to wide for each UserType
select(-c(User, water_year, UserDemand_gpd)) %>%
dcast(., month + sumByMonth + meanByMonth + sdByMonth + varByMonth ~ UserType, fun = mean, value.var = c('mean_UserDemand_gpm')) %>%
data.table()
# the average and sd of the average User
monthlySummary_UserWithdrawal_gpd.txt <- UserWithdrawal_gpd.txt %>%
# group by TimeStep and Month
select(-c(TimeStep, yyyymmdd, year, day, water_year)) %>%
melt(., id.vars = c('month'), variable.name = 'User', value.name = 'UserWithdrawal_gpd') %>%
mutate(UserType = UserType_table[match(User, user),UserType]) %>%
# calculate mean by month, and UserType
group_by(month, UserType) %>%
mutate(meanByMonthByUserType = mean(UserWithdrawal_gpd)) %>%
# calculate mean and sd by month
group_by(month) %>%
mutate(meanByMonth = mean(UserWithdrawal_gpd),
sdByMonth = sd(UserWithdrawal_gpd)) %>%
# reformat the table to wide for each UserType
select(-c(User, UserWithdrawal_gpd)) %>%
dcast(., month + meanByMonth + sdByMonth ~ UserType, fun = mean, value.var = c('meanByMonthByUserType')) %>%
data.table()
# the average monthly sum for each UserType
monthlySums_UserWithdrawal_gpd.txt <- UserWithdrawal_gpd.txt %>%
# group by TimeStep and Month
select(-c(TimeStep, yyyymmdd, year, day)) %>%
melt(., id.vars = c('month','water_year'), variable.name = 'User', value.name = 'UserWithdrawal_gpd') %>%
mutate(UserType = UserType_table[match(User, user),UserType]) %>%
# calculate mean by month, water_year, and UserType
group_by(month, water_year, UserType) %>%
mutate(UserWithdrawal_gpm = sum(UserWithdrawal_gpd)) %>%
# calculate mean of the sums by month, and UserType
group_by(month, UserType) %>%
mutate(mean_UserWithdrawal_gpm = mean(UserWithdrawal_gpm)) %>%
# calculate
group_by(month) %>%
mutate(sumByMonth = sum(UserWithdrawal_gpd),
meanByMonth = mean(UserWithdrawal_gpd),
sdByMonth = sd(UserWithdrawal_gpd),
varByMonth = var(UserWithdrawal_gpd)) %>%
# reformat the table to wide for each UserType
select(-c(User, water_year, UserWithdrawal_gpd)) %>%
dcast(., month + sumByMonth + meanByMonth + sdByMonth + varByMonth ~ UserType, fun = mean, value.var = c('mean_UserWithdrawal_gpm')) %>%
data.table()
# monthly average for the 9 water years
# monthlySummary_rain_in.dat <- rain_in_obs.dat %>%
# # group by TimeStep and Month
# melt(., id.vars = c('TimeStep', 'water_year', 'month'), variable.name = 'zone_code', value.name = 'rain_in_obs') %>%
# mutate(zone_code = paste0('zone_',zone_code)) %>%
# # calculate total by month, water_year, and zone_code
# group_by(month, water_year, zone_code) %>%
# mutate(sumByMonthByWateryearByZonecode = sum(rain_in_obs)) %>%
# # calculate mean by month, and drainage
# group_by(month, zone_code) %>%
# mutate(mean_rain_in_obs = mean(sumByMonthByWateryearByZonecode)) %>%
# # calculate mean and sd by month
# group_by(month) %>%
# mutate(meanSumByMonth = mean(sumByMonthByWateryearByZonecode),
# meanByMonth = mean(rain_in_obs),
# sdByMonth = sd(rain_in_obs)) %>%
# # reformat the table to wide for each DrainageID
# select(-c(TimeStep, water_year, rain_in_obs, sumByMonthByWateryearByZonecode)) %>%
# dcast(., month+meanSumByMonth+meanByMonth+sdByMonth~zone_code, fun=mean, value.var = c('mean_rain_in_obs')) %>%
# data.table()
```
### Calculate Annual Summaries
```
# annual average for the 9 water years
yearlySummary_Precipitation_in.txt <- Precipitation_in.txt %>%
# group by TimeStep and Month
select(-c(TimeStep, yyyymmdd, year, day)) %>%
melt(., id.vars = c('month', 'water_year'), variable.name = 'Drainages', value.name = 'Precipitation') %>%
# calculate total by month, wateryear, and drainage
group_by(month, water_year, Drainages) %>%
summarise(sumByMonthByWateryearByDrainage = sum(Precipitation)) %>%
# calculate mean by wateryear, and drainage
group_by(water_year, Drainages) %>%
summarise(meanByWateryearByDrainage = sum(sumByMonthByWateryearByDrainage)) %>%
# calculate mean and sd by month
group_by(water_year) %>%
mutate(meanByWateryear = mean(meanByWateryearByDrainage),
sdByWateryear = sd(meanByWateryearByDrainage)) %>%
# reformat the table to wide for each DrainageID
dcast(., water_year + meanByWateryear + sdByWateryear ~ Drainages, value.var = 'meanByWateryearByDrainage') %>%
data.table()
# annual average for the 9 water years
yearlySummary_Evaporation_in.txt <- Evaporation_in.txt %>%
# group by TimeStep and Month
select(-c(TimeStep, yyyymmdd, year, day)) %>%
melt(., id.vars = c('month', 'water_year'), variable.name = 'Drainages', value.name = 'Evaporation') %>%
# calculate total by month, wateryear, and drainage
group_by(month, water_year, Drainages) %>%
summarise(sumByMonthByWateryearByDrainage = sum(Evaporation)) %>%
# calculate mean by wateryear, and drainage
group_by(water_year, Drainages) %>%
summarise(meanByWateryearByDrainage = sum(sumByMonthByWateryearByDrainage)) %>%
# calculate mean and sd by month
group_by(water_year) %>%
mutate(meanByWateryear = mean(meanByWateryearByDrainage),
sdByWateryear = sd(meanByWateryearByDrainage)) %>%
# reformat the table to wide for each DrainageID
dcast(., water_year + meanByWateryear + sdByWateryear ~ Drainages, value.var = 'meanByWateryearByDrainage') %>%
data.table()
# the average annual sum for each UserType
yearlySums_UserDemand_gpd.txt <- UserDemand_gpd.txt %>%
# group by month and water_year
select(-c(TimeStep, yyyymmdd, year, month, day)) %>%
melt(., id.vars = c('water_year'), variable.name = 'User', value.name = 'UserDemand_gpd') %>%
mutate(UserType = UserType_table[match(User, user),UserType]) %>%
# calculate sum by water_year, and UserType
group_by(water_year, UserType) %>%
mutate(UserDemand_gpy = sum(UserDemand_gpd)) %>%
# calculate sum by water_year
group_by(water_year) %>%
mutate(sumByWateryear = sum(UserDemand_gpd)) %>%
# reformat the table to wide for each UserType
select(-c(UserDemand_gpd, User)) %>%
dcast(., water_year + sumByWateryear ~ UserType, fun = mean, value.var = c('UserDemand_gpy')) %>%
data.table()
# the average annual sum for each UserType
yearlySums_UserWithdrawal_gpd.txt <- UserWithdrawal_gpd.txt %>%
# group by month and water_year
select(-c(TimeStep, yyyymmdd, year, month, day)) %>%
melt(., id.vars = c('water_year'), variable.name = 'User', value.name = 'UserWithdrawal_gpd') %>%
mutate(UserType = UserType_table[match(User, user),UserType]) %>%
# calculate sum by water_year, and UserType
group_by(water_year, UserType) %>%
mutate(UserWithdrawal_gpy = sum(UserWithdrawal_gpd)) %>%
# calculate sum by water_year
group_by(water_year) %>%
mutate(sumByWateryear = sum(UserWithdrawal_gpd)) %>%
# reformat the table to wide for each UserType
select(-c(UserWithdrawal_gpd, User)) %>%
dcast(., water_year + sumByWateryear ~ UserType, fun = mean, value.var = c('UserWithdrawal_gpy')) %>%
data.table()
# # annual average for the 9 water years
# yearlySummary_rain_in_obs.dat <- rain_in_obs.dat %>%
# # group by TimeStep and Month
# select(-c(TimeStep)) %>%
# melt(., id.vars = c('month', 'water_year'), variable.name = 'zone_code', value.name = 'rain_in_obs') %>%
# mutate(zone_code = paste0('zone_',zone_code)) %>%
# # calculate total by month, wateryear, and drainage
# group_by(month, water_year, zone_code) %>%
# mutate(sumByMonthByWateryearByZonecode = sum(rain_in_obs)) %>%
# # calculate mean by wateryear, and drainage
# group_by(water_year, zone_code) %>%
# mutate(meanByWateryearByZonecode = mean(sumByMonthByWateryearByZonecode)) %>%
# # calculate mean and sd by month
# group_by(water_year) %>%
# mutate(sumByWateryear = sum(rain_in_obs),
# meanByWateryear = mean(sumByMonthByWateryearByZonecode),
# sdByWateryear = sd(sumByMonthByWateryearByZonecode)) %>%
# # reformat the table to wide for each DrainageID
# select(-c(month, rain_in_obs, sumByMonthByWateryearByZonecode)) %>%
# dcast(., water_year + sumByWateryear + meanByWateryear + sdByWateryear ~ zone_code, fun = mean, value.var = c('meanByWateryearByZonecode')) %>%
# data.table()
```
### Calculate Artificial Drainage Flows and User Demand
```
# Calculate the Ratios
AD_FASN_Summary <- Artificial_Drainage_cfs.txt %>%
# group by TimeStep and Month
select(-c(yyyymmdd, year, month, day, water_year)) %>%
melt(., id.vars = c('TimeStep'), variable.name = 'Drainages', value.name = 'Artificial_Drainages') %>%
# calculate the sum of artificial drainage for each month and wateryear
group_by(TimeStep) %>%
summarise(sumArtDrainByTimeStep = sum(Artificial_Drainages)) %>%
# merge with FlowAtStreamNodes
merge(., FlowAtStreamNodes_cfs.txt %>%
select(TimeStep, water_year, month, Node1) %>%
group_by(water_year, month) %>%
mutate(monthlyMeanNode1 = mean(Node1)),
all=F, fill=T) %>%
mutate(ratio_ArtDrain_Node1 = sumArtDrainByTimeStep/Node1,
ratio_ArtDrain_monthlyMeanNode1 = sumArtDrainByTimeStep/monthlyMeanNode1) %>%
data.table()
# UserTypes (Currently numbered like this as of 9/14/2016)
UserType_table <- rbindlist(list(
data.table(user = paste0('User', 1:19), UserType = 'SelfSupply_US'),
data.table(user = paste0('User', 20:31), UserType = 'SelfSupply_CAN'),
data.table(user = paste0('User', 32:80), UserType = 'PWS_US'),
data.table(user = paste0('User', 81:89), UserType = 'Commercial_US'),
data.table(user = paste0('User', 90:100), UserType = 'Commercial_CAN'),
data.table(user = paste0('User', 101:115), UserType = 'Dairy_US'),
data.table(user = paste0('User', c(116:126,130:140,142,145:161)), UserType = 'Irrigation_US'),
data.table(user = paste0('User', c(127, 128, 129, 141, 143, 144)), UserType = 'Irrigation_CAN'),
data.table(user = paste0('User', 162:163), UserType = 'Reservoir_US')), use.names = T, fill = T)
```
### Calculate Flow Model Ouputs and Streamflow Observations
```
# find meta lines for streamflow_calibration.dat
streamflow_calibration.dat_meta <- findmeta('streamflow_calibration.dat')
col.Names <- streamflow_calibration.dat_meta %>% gsub("\\t+$","",.) %>% strsplit(' |\t') %>% tail(1) %>% unlist() %>% .[-c(1,2)] %>% .[.!=""]
# read in streamflow_calibration.dat using readlines approach. read_dat was not working due to extra space characters.
# streamflow_calibration.dat <- read_dat('streamflow_calibration.dat', streamflow_calibration.dat_meta)
dat <- readLines('streamflow_calibration.dat', skip = length(streamflow_calibration.dat_meta)) %>%
.[-c(1:4)] %>%
gsub('^[[:space:]]+|[[:space:]]+$','', .) %>%
gsub('[[:space:]]+','\t', .) %>%
strsplit(., '\t') %>%
do.call(rbind, .) %>%
data.table()
nonNA <- colnames(dat)[which(colSums(is.na(dat)) != nrow(dat))]
dat <- dat %>% select(nonNA)
setnames(dat, colnames(dat), paste0('SF',col.Names))
streamflow_calibration.dat <- dat %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(as.numeric(.))) %>% data.table()
# convert cms to cfs: 1cms = 35.3147 cfs
FlowAtStreamNodes_calib_cfs.txt <- FlowAtStreamNodes_cms.txt %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*35.3147)) %>%
merge(., DateTime_calib.txt, by = 'TimeStep') %>%
mutate(FlowAtOutlet = Node1) %>% #
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('Node')) %>%
data.table()
# convert cms to cfs: 1cms = 35.3147 cfs
FlowAtStreamNodes_valid_cfs.txt <- FlowAtStreamNodes_cms.txt %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*35.3147)) %>%
merge(., DateTime_valid.txt, by = 'TimeStep', all.y = T) %>%
mutate(FlowAtOutlet = Node1) %>% #
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('Node')) %>%
data.table()
# multiple flowatstreamnodes
# FlowAtStreamNodes_calib_cfs.txt
# FlowAtStreamNodes_valid_cfs.txt
# FlowAtStreamNodes_cfs.txt
# compare node4 (streamflow_calibration1) and node28 (streamflow_calibration2)
# the comparison between FlowAtStreamNodes (model output) and streamflow_calibration (obs)
# rename the metadata file
streamflow_calibration_calib_cfs.dat_meta <- streamflow_calibration.dat_meta
# adjust streamflow_calibration to cfs and filter for the calibration date range
streamflow_calibration_calib_cfs.dat <- streamflow_calibration.dat %>%
# convert cms to cfs
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*35.3147)) %>%
#mutate(SF152 = ifelse(SF152 == -999*35.3147, NA, SF152),
# SF236 = ifelse(SF236 == -999*35.3147, NA, SF236)) %>%
# add date sequence and convert to the %Y%m%d format
mutate(date = seq(from = as.Date('20030613', format = '%Y%m%d'), by = 'day', length.out = nrow(streamflow_calibration.dat)),
date = format(date, '%Y%m%d')) %>%
# filter for the respective model run dates
filter(date %in% FlowAtStreamNodes_calib_cfs.txt[,yyyymmdd])
# # PATCH NEEDED: location observation files to use for imputation
# # obs data update for column 1
# BertrandStreamflow <- read.table(paste(ObsStreamflowData,'BertrandStreamflow.txt', sep='/'), sep = '\t', header = T) %>%
# mutate(Date = format(as.Date(Date, format = '%M/%d/%Y'), '%Y%m%d')) %>%
# setnames(., colnames(.), c('Date', 'Flow_cfs')) %>%
# data.table()
# CanadaStreamflow <- read.table(paste(ObsStreamflowData,'Daily__Sep-15-2016_10_14_39PM__ddf.txt', sep='/'), sep = '\t', header = T) %>%
# mutate(Date = format(as.Date(Date, format = '%M/%d/%Y'), '%Y%m%d')) %>%
# data.table()
# # PATCH NEEDED: impute missing values using reference nodes
# # add the missing values
# streamflow_calibration_valid_cfs.dat <- streamflow_calibration_valid_cfs.dat %>%
# mutate(SF152 = ifelse(is.na(SF152), BertrandStreamflow[match(date, Date), Flow_cfs], SF152),
# SF236 = ifelse(is.na(SF236), CanadaStreamflow[match(date, Date), Value]*35.3147, SF236)) %>%
# mutate(date = as.integer(date)) %>%
# data.table()
# FlowAtStreamNodes_valid_cfs.txt <- FlowAtStreamNodes_valid_cfs.txt[yyyymmdd %in% streamflow_calibration_valid_cfs.dat[,date],]
# # PATCH NEEDED: compute nash-suttcliffe coefficient using reference nodes
# # operations linked to a reference node have been removed (e.g., SF152 and SF 236)
# NSEc1 <- NSE(sim = FlowAtStreamNodes_calib_cfs.txt[,Node4], obs = streamflow_calibration_calib_cfs.dat[,SF152], na.rm=T)
# NSEc2 <- NSE(sim = FlowAtStreamNodes_calib_cfs.txt[,Node28], obs = streamflow_calibration_calib_cfs.dat[,SF236], na.rm=T)
```
### Compile Table of Contents and Print Spreadsheet
```
# compile TableofContents
TableofContents.txt <- rbindlist(list(
data.table(fileName='TableofContents.txt', desc='table of contents'),
data.table(fileName='DateTime_water_year.txt', desc='Time steps and datetime reference with water year'),
data.table(fileName='UserType_table', desc='list of simulated users'),
data.table(fileName='Precipitation_in.txt', desc='Precipitation in inches'),
data.table(fileName='Evaporation_in.txt', desc='Evapotranspiration in inches'),
data.table(fileName='FlowAtStreamNodes_cfs.txt', desc='Streamflow at Node in cubic feet per second'),
data.table(fileName='Artificial_Drainage_cfs.txt', desc='Artificial drainage in cubic feet per second'),
data.table(fileName='UserDemand_gpd.txt', desc='User type water demand fraction in gallons per day'),
data.table(fileName='UserWithdrawal_gpd.txt', desc='User type water withdrawal in gallons per day'),
data.table(fileName='rain_in_obs.dat', desc='Observed rainfall in inches'),
data.table(fileName='monthlySummary_Artificial_Drainage_cfs.txt', desc='Monthly Artificial drainage', jname='MonAve_ArtDrain_cfs'),
data.table(fileName='monthlySummary_Evaporation_in.txt', desc='Monthly Evapotranspiration', jname='MonSum__Evap_in'),
data.table(fileName='monthlySummary_Precipitation_in.txt', desc='Monthly Precipitation',jname='MonAve_Precip_in'),
data.table(fileName='monthlySummary_FlowAtStreamNodes_cfs.txt', desc='Monthly Streamflow at node',jname='MonAve_FlowAtStreamNodes_cfs'),
#data.table(fileName='monthlySummary_rain_in.dat', desc='Monthly summary of rainfall in inches',jname='ObsMonAve_Precip_in'),
data.table(fileName='monthlySummary_UserDemand_gpd.txt', desc='Monthly User Demand',jname='AveDaily_UserDemand_gpd'),
data.table(fileName='monthlySummary_UserWithdrawal_gpd.txt', desc='Monthly User Withdrawal'),
data.table(fileName='monthlySums_UserDemand_gpd.txt', desc='Monthly sum of User water demand',jname='MonSum_UserDemand_Gallons'),
data.table(fileName='monthlySums_UserWithdrawal_gpd.txt', desc='Monthly sum of User water withdrawal'),
data.table(fileName='yearlySummary_Evaporation_in.txt', desc='Yearly Evapotranspiration',jname='AnnSumSubbasin_Evap_in'),
data.table(fileName='yearlySummary_Precipitation_in.txt', desc='Yearly Precipitation',jname='AnnSumSubbasin_Precip_in'),
#data.table(fileName='yearlySummary_rain_in_obs.dat', desc='Yearly summary of rainfall in inches'),
data.table(fileName='yearlySums_UserDemand_gpd.txt', desc='Yearly summary of user water demand in gallons per day'),
data.table(fileName='yearlySums_UserWithdrawal_gpd.txt', desc='Yearly summary of user water withdrawal in gallons per day'),
data.table(fileName='AD_FASN_Summary', desc='Artificial draining and flow-at-Stream node summary'),
data.table(fileName='streamflow_calibration_calib_cfs.dat', desc='Streamflow calibration data in cubic feet per second')),
use.names=T, fill=T)
# append Sheet id
TableofContents.txt[,SheetName:=paste0('Sheet', row.names(TableofContents.txt))]
# print to txt files
for (j in as.vector(TableofContents.txt[['fileName']])){
# "streamflow_calibration_valid_cfs.dat" excluded until additional patch work
# start
print(paste('start', j))
# separate protocol for .dat files
if(grepl('.dat',j)){
write.table(j %>% gsub('_in_obs','',.) %>% paste0(., '_meta') %>% get(), file = j, append = F, sep = '\t', row.names = F, col.names = F, quote = F)
write.table(j, file = j, append = T, sep = '\t', row.names = F, col.names = F)
} else if (grepl('.txt', j)){
write.table(j %>% get(), file = j, col.names = T, row.names = F, append = F)
} else {
write.table(j %>% get(), file = paste0(j,'.txt'), col.names = T, row.names = F, append = F)
}
# finished
print(paste('finished', j))
}
tabs <- list(TableofContents.txt,
DateTime_water_year.txt,
UserType_table,
Precipitation_in.txt,
Evaporation_in.txt,
FlowAtStreamNodes_cfs.txt,
Artificial_Drainage_cfs.txt,
UserDemand_gpd.txt,
UserWithdrawal_gpd.txt,
rain_in_obs.dat,
monthlySummary_Artificial_Drainage_cfs.txt,
monthlySummary_Evaporation_in.txt,
monthlySummary_Precipitation_in.txt,
monthlySummary_FlowAtStreamNodes_cfs.txt,
#monthlySummary_rain_in.dat,
monthlySummary_UserDemand_gpd.txt,
monthlySummary_UserWithdrawal_gpd.txt,
monthlySums_UserDemand_gpd.txt,
monthlySums_UserWithdrawal_gpd.txt,
yearlySummary_Evaporation_in.txt,
yearlySummary_Precipitation_in.txt,
#yearlySummary_rain_in_obs.dat,
yearlySums_UserDemand_gpd.txt,
yearlySums_UserWithdrawal_gpd.txt,
AD_FASN_Summary,
streamflow_calibration_calib_cfs.dat)
# print these outputs to xlsx using these names
write_xlsx(tabs, path = paste(ModelSet_folder,'modelruns_summary.xlsx',sep='/'), col_names = TRUE)
```
# END of Usable code (as far as I can tell)
```
### The code chunk above is too long. Also needs a loop if there is no user data.
# find meta lines for rain.dat
rain.dat_meta <- findmeta('rain.dat')
# read in rain.dat
rain.dat <- read_dat('rain.dat', rain.dat_meta)
# apply conversion from mm to inches. Code-base taken from Precipitation.
# convert mm to inches
rain_in_obs.dat <- rain.dat %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(./25.4)) %>%
merge(., DateTime_water_year.txt, by.x = 'Date', by.y = 'yyyymmdd') %>%
arrange(TimeStep) %>%
select(-c(Date, year, day, Hour, hhmmss))
# monthly average for the 9 water years
monthlySummary_rain_in.dat <- rain_in_obs.dat %>%
# group by TimeStep and Month
melt(., id.vars = c('TimeStep', 'water_year', 'month'), variable.name = 'zone_code', value.name = 'rain_in_obs') %>%
mutate(zone_code = paste0('zone_',zone_code)) %>%
# calculate total by month, water_year, and zone_code
group_by(month, water_year, zone_code) %>%
mutate(sumByMonthByWateryearByZonecode = sum(rain_in_obs)) %>%
# calculate mean by month, and drainage
group_by(month, zone_code) %>%
mutate(mean_rain_in_obs = mean(sumByMonthByWateryearByZonecode)) %>%
# calculate mean and sd by month
group_by(month) %>%
mutate(meanSumByMonth = mean(sumByMonthByWateryearByZonecode),
meanByMonth = mean(rain_in_obs),
sdByMonth = sd(rain_in_obs)) %>%
# reformat the table to wide for each DrainageID
select(-c(TimeStep, water_year, rain_in_obs, sumByMonthByWateryearByZonecode)) %>%
dcast(., month+meanSumByMonth+meanByMonth+sdByMonth~zone_code, fun=mean, value.var = c('mean_rain_in_obs')) %>%
data.table()
# annual average for the 9 water years
yearlySummary_rain_in_obs.dat <- rain_in_obs.dat %>%
# group by TimeStep and Month
select(-c(TimeStep)) %>%
melt(., id.vars = c('month', 'water_year'), variable.name = 'zone_code', value.name = 'rain_in_obs') %>%
mutate(zone_code = paste0('zone_',zone_code)) %>%
# calculate total by month, wateryear, and drainage
group_by(month, water_year, zone_code) %>%
mutate(sumByMonthByWateryearByZonecode = sum(rain_in_obs)) %>%
# calculate mean by wateryear, and drainage
group_by(water_year, zone_code) %>%
mutate(meanByWateryearByZonecode = mean(sumByMonthByWateryearByZonecode)) %>%
# calculate mean and sd by month
group_by(water_year) %>%
mutate(sumByWateryear = sum(rain_in_obs),
meanByWateryear = mean(sumByMonthByWateryearByZonecode),
sdByWateryear = sd(sumByMonthByWateryearByZonecode)) %>%
# reformat the table to wide for each DrainageID
select(-c(month, rain_in_obs, sumByMonthByWateryearByZonecode)) %>%
dcast(., water_year + sumByWateryear + meanByWateryear + sdByWateryear ~ zone_code, fun = mean, value.var = c('meanByWateryearByZonecode')) %>%
data.table()
# find meta lines for streamflow_calibration.dat
streamflow_calibration.dat_meta <- findmeta('streamflow_calibration.dat')
col.Names <- streamflow_calibration.dat_meta %>% gsub("\\t+$","",.) %>% strsplit(' |\t') %>% tail(1) %>% unlist() %>% .[-c(1,2)] %>% .[.!=""]
# read in streamflow_calibration.dat using readlines approach. read_dat was not working due to extra space characters.
# streamflow_calibration.dat <- read_dat('streamflow_calibration.dat', streamflow_calibration.dat_meta)
dat <- readLines('streamflow_calibration.dat', skip = length(streamflow_calibration.dat_meta)) %>%
.[-c(1:4)] %>%
gsub('^[[:space:]]+|[[:space:]]+$','', .) %>%
gsub('[[:space:]]+','\t', .) %>%
strsplit(., '\t') %>%
do.call(rbind, .) %>%
data.table()
nonNA <- colnames(dat)[which(colSums(is.na(dat)) != nrow(dat))]
dat <- dat %>% select(nonNA)
setnames(dat, colnames(dat), paste0('SF',col.Names))
streamflow_calibration.dat <- dat %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(as.numeric(.))) %>% data.table()
# convert cms to cfs: 1cms = 35.3147 cfs
FlowAtStreamNodes_calib_cfs.txt <- FlowAtStreamNodes_cms.txt %>%
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*35.3147)) %>%
merge(., DateTime_calib.txt, by = 'TimeStep') %>%
mutate(FlowAtOutlet = Node1) %>% #
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('Node')) %>%
data.table()
# convert cms to cfs: 1cms = 35.3147 cfs
FlowAtStreamNodes_valid_cfs.txt <- FlowAtStreamNodes_cms.txt %>%
mutate_at(colnames(FlowAtStreamNodes_cms.txt)[!colnames(FlowAtStreamNodes_cms.txt) %in% c('Date','Hour', 'TimeStep')], funs(.*35.3147)) %>%
merge(., DateTime_valid.txt, by = 'TimeStep', all.y = T) %>%
mutate(FlowAtOutlet = Node1) %>% #
arrange(TimeStep) %>%
select(TimeStep, yyyymmdd, year, month, day, water_year, contains('Node')) %>%
data.table()
# multiple flowatstreamnodes
# FlowAtStreamNodes_calib_cfs.txt
# FlowAtStreamNodes_valid_cfs.txt
# FlowAtStreamNodes_cfs.txt
# compare node4 (streamflow_calibration1) and node28 (streamflow_calibration2)
# the comparison between FlowAtStreamNodes (model output) and streamflow_calibration (obs)
# rename the metadata file
streamflow_calibration_calib_cfs.dat_meta <- streamflow_calibration.dat_meta
# adjust streamflow_calibration to cfs and filter for the calibration date range
streamflow_calibration_calib_cfs.dat <- streamflow_calibration.dat %>%
# convert cms to cfs
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*35.3147)) %>%
#mutate(SF152 = ifelse(SF152 == -999*35.3147, NA, SF152),
# SF236 = ifelse(SF236 == -999*35.3147, NA, SF236)) %>%
# add date sequence and convert to the %Y%m%d format
mutate(date = seq(from = as.Date('20030613', format = '%Y%m%d'), by = 'day', length.out = nrow(streamflow_calibration.dat)),
date = format(date, '%Y%m%d')) %>%
# filter for the respective model run dates
filter(date %in% FlowAtStreamNodes_calib_cfs.txt[,yyyymmdd])
# # PATCH NEEDED: location observation files to use for imputation
# # obs data update for column 1
# BertrandStreamflow <- read.table(paste(ObsStreamflowData,'BertrandStreamflow.txt', sep='/'), sep = '\t', header = T) %>%
# mutate(Date = format(as.Date(Date, format = '%M/%d/%Y'), '%Y%m%d')) %>%
# setnames(., colnames(.), c('Date', 'Flow_cfs')) %>%
# data.table()
# CanadaStreamflow <- read.table(paste(ObsStreamflowData,'Daily__Sep-15-2016_10_14_39PM__ddf.txt', sep='/'), sep = '\t', header = T) %>%
# mutate(Date = format(as.Date(Date, format = '%M/%d/%Y'), '%Y%m%d')) %>%
# data.table()
# # PATCH NEEDED: impute missing values using reference nodes
# # add the missing values
# streamflow_calibration_valid_cfs.dat <- streamflow_calibration_valid_cfs.dat %>%
# mutate(SF152 = ifelse(is.na(SF152), BertrandStreamflow[match(date, Date), Flow_cfs], SF152),
# SF236 = ifelse(is.na(SF236), CanadaStreamflow[match(date, Date), Value]*35.3147, SF236)) %>%
# mutate(date = as.integer(date)) %>%
# data.table()
# FlowAtStreamNodes_valid_cfs.txt <- FlowAtStreamNodes_valid_cfs.txt[yyyymmdd %in% streamflow_calibration_valid_cfs.dat[,date],]
# # PATCH NEEDED: compute nash-suttcliffe coefficient using reference nodes
# # operations linked to a reference node have been removed (e.g., SF152 and SF 236)
# NSEc1 <- NSE(sim = FlowAtStreamNodes_calib_cfs.txt[,Node4], obs = streamflow_calibration_calib_cfs.dat[,SF152], na.rm=T)
# NSEc2 <- NSE(sim = FlowAtStreamNodes_calib_cfs.txt[,Node28], obs = streamflow_calibration_calib_cfs.dat[,SF236], na.rm=T)
tab_names <- rbindlist(list(
data.table(iname = 'monthlySummary_Artificial_Drainage_cfs.txt', jname = 'MonAve_ArtDrain_cfs'),
data.table(iname = 'monthlySummary_Evaporation_in.txt', jname = 'MonSum__Evap_in'),
data.table(iname = 'monthlySummary_FlowAtStreamNodes_cfs.txt', jname = 'MonAve_FlowAtStreamNodes_cfs'),
data.table(iname = 'monthlySummary_Precipitation_in.txt', jname = 'MonAve_Precip_in'),
data.table(iname = 'monthlySummary_rain_in.dat', jname = 'ObsMonAve_Precip_in'),
data.table(iname = 'monthlySummary_UserDemand_gpd.txt', jname = 'AveDaily_UserDemand_gpd'),
data.table(iname = 'monthlySums_UserDemand_gpd.txt', jname = 'MonSum_UserDemand_Gallons'),
data.table(iname = 'yearlySummary_Evaporation_in.txt', jname = 'AnnSumSubbasin_Evap_in'),
data.table(iname = 'yearlySummary_Precipitation_in.txt', jname = 'AnnSumSubbasin_Precip_in')), use.names = T, fill = T)
tab_names
# multiple flowatstreamnodes
# FlowAtStreamNodes_calib_cfs.txt
# FlowAtStreamNodes_valid_cfs.txt
# FlowAtStreamNodes_cfs.txt
# compare node4 (streamflow_calibration1) and node28 (streamflow_calibration2)
# the comparison between FlowAtStreamNodes (model output) and streamflow_calibration (obs)
# rename the metadata file
streamflow_calibration_calib_cfs.dat_meta <- streamflow_calibration.dat_meta
# adjust streamflow_calibration to cfs and filter for the calibration date range
streamflow_calibration_calib_cfs.dat <- streamflow_calibration.dat %>%
# convert cms to cfs
mutate_at(colnames(.)[!colnames(.) %in% c('Date','Hour','TimeStep')], funs(.*35.3147)) %>%
#mutate(SF152 = ifelse(SF152 == -999*35.3147, NA, SF152),
# SF236 = ifelse(SF236 == -999*35.3147, NA, SF236)) %>%
# add date sequence and convert to the %Y%m%d format
mutate(date = seq(from = as.Date('20030613', format = '%Y%m%d'), by = 'day', length.out = nrow(streamflow_calibration.dat)),
date = format(date, '%Y%m%d')) %>%
# filter for the respective model run dates
filter(date %in% FlowAtStreamNodes_calib_cfs.txt[,yyyymmdd])
# # PATCH NEEDED: generate calibration and validation summary tables
# # generate the NSE summary table
# NSE_Summary.txt <- rbind(
# c('calibration', paste0(calib_start, '-', calib_end), NSEc1, NSEc2),
# c('validation', paste0(valid_start, '-', valid_end), NSEv1, NSEv2)) %>%
# data.frame() %>%
# setnames(., colnames(.), c('NSE_mode','DateRange','Node4_SF152', 'Node28_SF236')) %>%
# data.table()
# # PATCH NEEDED: location observation files to use for imputation
# # obs data update for column 1
# BertrandStreamflow <- read.table(paste(ObsStreamflowData,'BertrandStreamflow.txt', sep='/'), sep = '\t', header = T) %>%
# mutate(Date = format(as.Date(Date, format = '%M/%d/%Y'), '%Y%m%d')) %>%
# setnames(., colnames(.), c('Date', 'Flow_cfs')) %>%
# data.table()
# CanadaStreamflow <- read.table(paste(ObsStreamflowData,'Daily__Sep-15-2016_10_14_39PM__ddf.txt', sep='/'), sep = '\t', header = T) %>%
# mutate(Date = format(as.Date(Date, format = '%M/%d/%Y'), '%Y%m%d')) %>%
# data.table()
# # PATCH NEEDED: impute missing values using reference nodes
# # add the missing values
# streamflow_calibration_valid_cfs.dat <- streamflow_calibration_valid_cfs.dat %>%
# mutate(SF152 = ifelse(is.na(SF152), BertrandStreamflow[match(date, Date), Flow_cfs], SF152),
# SF236 = ifelse(is.na(SF236), CanadaStreamflow[match(date, Date), Value]*35.3147, SF236)) %>%
# mutate(date = as.integer(date)) %>%
# data.table()
# FlowAtStreamNodes_valid_cfs.txt <- FlowAtStreamNodes_valid_cfs.txt[yyyymmdd %in% streamflow_calibration_valid_cfs.dat[,date],]
# # PATCH NEEDED: compute nash-suttcliffe coefficient using reference nodes
# # operations linked to a reference node have been removed (e.g., SF152 and SF 236)
# NSEc1 <- NSE(sim = FlowAtStreamNodes_calib_cfs.txt[,Node4], obs = streamflow_calibration_calib_cfs.dat[,SF152], na.rm=T)
# NSEc2 <- NSE(sim = FlowAtStreamNodes_calib_cfs.txt[,Node28], obs = streamflow_calibration_calib_cfs.dat[,SF236], na.rm=T)
# # PATCH NEEDED: generate calibration and validation summary tables
# # generate the NSE summary table
# NSE_Summary.txt <- rbind(
# c('calibration', paste0(calib_start, '-', calib_end), NSEc1, NSEc2),
# c('validation', paste0(valid_start, '-', valid_end), NSEv1, NSEv2)) %>%
# data.frame() %>%
# setnames(., colnames(.), c('NSE_mode','DateRange','Node4_SF152', 'Node28_SF236')) %>%
# data.table()
# print to txt files
for (j in c('Precipitation_in.txt',
'Evaporation_in.txt',
'FlowAtStreamNodes_cfs.txt',
'Artificial_Drainage_cfs.txt',
'UserDemand_gpd.txt',
'UserWithdrawal_gpd.txt',
'DateTime_water_year.txt',
'rain_in_obs.dat',
"monthlySummary_Artificial_Drainage_cfs.txt",
"monthlySummary_Evaporation_in.txt",
"monthlySummary_Precipitation_in.txt",
"monthlySummary_FlowAtStreamNodes_cfs.txt",
"monthlySummary_UserDemand_gpd.txt",
"monthlySummary_UserWithdrawal_gpd.txt",
"yearlySummary_Evaporation_in.txt",
"yearlySummary_Precipitation_in.txt",
"AD_FASN_Summary",
"monthlySums_UserDemand_gpd.txt",
"monthlySums_UserWithdrawal_gpd.txt",
"streamflow_calibration_calib_cfs.dat")){
# "streamflow_calibration_valid_cfs.dat" excluded until additional patch work
# start
print(paste('start', j))
# separate protocol for .dat files
if(grepl('.dat',j)){
write.table(j %>% gsub('_in_obs','',.) %>% paste0(., '_meta') %>% get(), file = j, append = F, sep = '\t', row.names = F, col.names = F, quote = F)
write.table(j, file = j, append = T, sep = '\t', row.names = F, col.names = F)
} else {
write.table(j %>% get(), file = j, col.names = T, row.names = F, append = F)
}
# finished
print(paste('finished', j))
}
# Create the monthly and yearly summaries as a new xlsx workbook
# print to xlsx workbook
tabs <- list(AD_FASN_Summary,
monthlySummary_Artificial_Drainage_cfs.txt,
monthlySummary_Evaporation_in.txt,
monthlySummary_FlowAtStreamNodes_cfs.txt,
monthlySummary_Precipitation_in.txt,
monthlySummary_rain_in.dat,
monthlySummary_UserDemand_gpd.txt,
monthlySummary_UserWithdrawal_gpd.txt,
monthlySums_UserDemand_gpd.txt,
monthlySums_UserWithdrawal_gpd.txt,
UserType_table,
yearlySummary_Evaporation_in.txt,
yearlySummary_Precipitation_in.txt,
yearlySummary_rain_in_obs.dat,
yearlySums_UserDemand_gpd.txt,
yearlySums_UserWithdrawal_gpd.txt)
# print these outputs to xlsx using these names
write_xlsx(tabs, path = paste0(ModelSet_folder,'modelruns_summary.xlsx'), col_names = TRUE)
# compute the totalRecharge object
#source(file.path(WMon2018_Models, "RechargeCalculator_kbcb_jp.R"))
# concerns:
# CatchID does not exist within Basins
# where is BasinArea_in2 created?
# where is Test1 initialized?
# functionalize the timesteploop
timesteploop <- function(TimeStep, totalRecharge_depot){
for(TimeStep in TimeSteps$TimeStep){
# CatchID + 1 will be used to adjust for TimeStep as the new column 1
### Look up P, E, and SR values for this daily timestep and convert to inches
P <- Precipitation_mm[TimeStep, CatchID + 1]*0.0393701 #Precipitation (in)
E <- Evaporation_mm[TimeStep, CatchID + 1]*0.0393701 #Evaporation (in)
SR <- Surface_runoff_cms[TimeStep, CatchID + 1]*61024*60*60*24/Basins[CatchID, "BasinArea_in2"] #Surface runoff/Basin area (in)
if(TimeStep==1){
CDW <- as.numeric(0) ### Calculate change in depth to water (in)
CSS <- as.numeric(0) ### Calculate change in soil storage term (in)
} else {
# take the difference between the current water depth and the previous water depth at this Drainage
CDW <- (Depth_to_Water_mm[TimeStep, CatchID + 1] - Depth_to_Water_mm[TimeStep-1, CatchID + 1])*0.0393701
CSS <- (Soil_storage_mm[TimeStep, CatchID + 1] - Soil_storage_mm[TimeStep-1, CatchID + 1])*0.0393701
}
### Calculate daily recharge
dailyRecharge = P-E-SR+CSS
### Calculate running total of daily recharge
totalRecharge = totalRecharge + dailyRecharge
# store the data
totalRecharge_depot <- rbindlist(list(totalRecharge_depot, data.table(CatchID, TimeStep, dailyRecharge, totalRecharge)), use.names = T, fill = T)
}
return(totalRecharge_depot)
}
# daily iteration deposition
totalRecharge_depot <- data.table()
ptm <- Sys.time()
# for each subbasin
for (CatchID in Basins$CatchID) {
### Calculate average annual recharge (inches) for the basin ###
totalRecharge=0
# for each timestep
totalRecharge_depot <- timesteploop(TimeStep, totalRecharge_depot)
print(CatchID)
ptm - Sys.time()
}
totalRecharge_depot <- read.table(file.path(Test1,'/totalRecharge_depot.txt'), sep = '\t', header = T)
# additional calculations
totalRecharge_depot <- totalRecharge_depot %>%
# merge(., DateTime_water_year.txt, by = 'TimeStep') %>%
# MonthlyRecharge total
group_by(month, water_year, CatchID) %>%
mutate(monthlyRecharge = sum(dailyRecharge)) %>%
# WaterYear average AnnualRecharge
group_by(water_year, CatchID) %>%
mutate(averageAnnualRecharge = mean(monthlyRecharge)) %>%
data.table() %>%
group_by(CatchID) %>%
mutate(averageAnnualRechargeByCatchID = mean(averageAnnualRecharge)) %>%
data.table()
# print
write.table(totalRecharge_depot, 'totalRecharge_depot.txt', sep = '\t', row.names = F, col.names = T, append = F)
print(paste("Finished printing the RechargeCalculator within", getwd()))
```
| github_jupyter |
# Cryptographie - principes de base
## 0- Principes
Le but de la cryptographie est de cacher un texte donné de tel manière que seul son destinataire légitime puisse le lire.
Les manières de cacher ce textes sont multiples. On s'intéresse ici à une transformation du texte pour le rendre illisible.
En pratique pour nous, le texte à cacher est une chaîne de caractères s. On cherche donc à calculer une chaîne de caractère tirée de s de telle manière que notre destinataire (avec qui on peut éventuellement partager un secret, la <b>clé</b>), et avec un peu de chance seul lui, puisse déchiffrer ce texte.
### Cadre
On se limite à des textes contenant uniquement des caractères en minuscule et des espaces, pour simplifier les raisonnements. Dans le texte de référence utilisé, tous les autres caractères seront remplacés par des espaces.
### Texte à cacher
On fixe pour tout le cours un texte à crypter : les histoires extraordinaires d'Edgar Poe, traduites par Charles Baudelaire et disponible librement sur le site du projet Gutenberg ici : http://www.gutenberg.org/ebooks/20761
Le fichier texte, légèrement nettoyé (majuscules enlevé, préface enlevée) est dans le dossier contenant ce notebook et peut donc être ouvert directement par Python :
```
with open('HistoiresExtraordinaires.txt') as f:
texte = f.read()
texte = texte.replace('\r', '')
print(texte[:2500]) #on regarde si le texte a bien été importé
```
## 1- Chiffrement de César
### 1.1 - Description
Le principe est assez simple :
<ul>
<li>on donne un numéro à chaque lettre de l'alphabet</li>
<li>la clé de chiffrage est un nombre entre 1 et le nombre de lettre - 1</li>
<li>la chaîne cryptée est obtenue en décalant tous les caractères de clé dans l'alphabet, étant entendu que l'on revient au début à la fin de la liste...</li>
</ul>
```
LETTRES = 'abcdefghijklmnopqrstuvwxyz '
def indice(lettre):
"""
Retourne l'indice de la lettre donnée dans la chaîne LETTRES
indice('a') retourne 0, indice('z') retourne 25
indice(' ') retourne 26, indice(n'importe quoi d'autre) retourne 26
"""
if 97<=ord(lettre)<=122:
return ord(lettre)-ord("a")
else:
return 26
def cesar(chaine, cle):
#s est notre chaine codée qu'on construit au fur et à mesure
s = ''
n = len(LETTRES)
for i in range(len(chaine)):
#on décale la lettre chaine[i] de clé. On fait % n pour revenir à 0 si on dépasse 26
s = s + LETTRES[(indice(chaine[i]) + cle) % n]
return s
cesar(texte, 14)[:500]
```
### 1.2 - Retrouver le texte d'origine
Le principe pour notre correspondant est assez simple, il suffit de décaler dans l'autre sens.
```
#on crypte
messageCode=cesar('hello world',3)
print(messageCode)
#on décrypte
messageDecode=cesar(messageCode,-3)
print(messageDecode)
#modulo 27, faire +14 ou -13 revient au même
cesar(cesar('hello world', 13), 14)
#bien sûr, avec notre texte qui contient des caractères autres que des minuscules
#on perd un peu d'information qui se transforme en espace
cesar(cesar(texte, 4), -4)[:500]
```
### 1.3 - Cryptanalyse
Il est très facile de retrouver la clé secrète du chiffrement de césar si on connait l'alphabet utilisé.
Ainsi un espion, le gouvernement, ou toute autre personne satisfaisant votre sens de la théorie du complot, peut retrouver le message en clair.
La méthode est simple : force brute. On essaie toutes les clés possible et on regarde à la main les messages obtenus. il y a tellement peu de clés possible que la cryptanalyse est quasiment immédiate.
```
import random
#on choisit une clé aléatoire qu'on n'affiche pas pour la démonstration
cle_choisie = random.randint(1, len(LETTRES) - 1)
message = 'ceci est un message un tout petit peu plus long'
crypte = cesar(message, cle_choisie)
for i in range(1, len(LETTRES)):
print('clé : ', i, ' message décodé : ' + cesar(crypte, -i))
```
Pas trop difficile de deviner ce qu'avait choisi python comme clé...
## 2 - Chiffrement par permutation
### 2.1 - Principe
Au lieu de bêtement décaler chaque lettre, on choisit une bijection de l'alphabet dans lui même, c'est à dire que chaque lettre est transformée en une autre.
En pratique une bijection est représentée par une chaîne de caractère ou une liste possédant les même lettres que LETTRES mais dans le désordre
```
def permute(chaine, bijection):
s = ''
n = len(LETTRES)
for c in chaine:
s = s + bijection[indice(c)]
return s
#ou on peut faire une permutation très simple en inversant simplement les "o" et les "e"
bij1='abcdofghijklmnepqrstuvwxyz '
print(permute('hello world', bij1))
#ou une permutation plus complexe car complètement aléatoire
bij = list(LETTRES)
random.shuffle(bij)
print(permute('hello world', bij))
```
### 2.2 - Déchiffrement
Comment retrouver le message d'origine connaissant le message chiffré et la permutation ? Facile, il suffit de calculer la réciproque, c'est à dire trouver la position du caractère courant dans bijection.
```
def decode_permute(chiffre, bijection):
s = ''
n = len(LETTRES)
for c in chiffre:
s = s + LETTRES[bijection.index(c)]
return s
#on crypte
messageCode=permute('hello world', bij)
print(messageCode)
#on décrypte
messageDecode=decode_permute(messageCode,bij)
print(messageDecode)
```
Cette fois le nombre de clé est plutôt vaste : le "a" peut se transformer en 26 lettres différentes, le "b" en 25 (puisque ça ne peut pas être la même que "a"), le "c" en 24, etc. Cela fait donc $26 \times 25 \times 24 \times ... \times 2 \times 1 = 26! \approx 3 \times 10^{29}$ possibilités de clés. Si on pouvait lire 1 000 000 de textes à la seconde (pour vérifier si c'est le bon), il faudrait quand même un million de milliard d'année pour arriver au bout...
On ne peut donc pas attaquer ce genre de code par de la force brute.
### 2.3 - Cryptanalyse
Idée : la probabilité d'apparition des lettres dans un texte en français n'est pas du tout uniforme. On doit pouvoir identifier les voyelles et les consones courantes assez rapidement. On peut aussi utiliser le fait que certaines lettres sont souvent doublées en français, comme le l ou le t ou le p ou encore que de nombreux mots se terminent par s.
```
def frequence(chaine):
"""
Calcule le nombre d'occurences de chaque lettre dans la chaine donnée.
"""
#on crée un liste de compteurs initialisés à 0
occ = [ 0 for c in LETTRES]
#on incrémente le compteur de la lettre rencontrée dans la chaine
for c in chaine:
i = indice(c)
occ[i] = occ[i] + 1
#on modifie les compteurs en transformant les effectifs en fréquences
total = max(len(chaine), 1)
for i in range(len(LETTRES)):
occ[i] = 100 * occ[i] / total
#on affiche les résultats triés par ordre de fréquence en affichant la fréquence et la lettre
resultat = [(occ[i], LETTRES[i]) for i in range(len(LETTRES))]
resultat.sort()
return resultat
#on suppose que le texte est codée par une bijection secrète IL FAUT FAIRE COMME SI ON NE CONNAISSAIT PAS CETTE BIJECTION!!!
bij=['u', 'm', 'k', 'i', 'q', 'y', 'l', 'c', 'p', 'a', 'j', ' ', 't', 'n', 'x', 'f', 'r', 'g', 'v', 'o', 'e', 's', 'h', 'w', 'z', 'd', 'b']
messageCode = permute(texte, bij)
frequence(messageCode)
```
Il suffit maintenant d'aller sur [wikipedia](https://fr.wikipedia.org/wiki/Fr%C3%A9quence_d%27apparition_des_lettres_en_fran%C3%A7ais#Fr%C3%A9quence_des_caract%C3%A8res_dans_le_corpus_de_Wikip%C3%A9dia_en_fran%C3%A7ais) ou tout autre site pour trouver une table référence des fréquence de lettres dans les textes en français.
On peut deviner plusieurs choses :
<ul>
<li>l'espace correspond au 23,56%</li>
<li>le e doit correspondre à la lettre la plus fréquente</li>
</ul>
Pour trouver des chiffres plus proches des tables données, il faut considérer des textes sans espaces. Allons-y
```
messageCode2 = messageCode.replace('b', '')
frequence(messageCode2)
```
Les chiffres obtenus sont proches de ceux de la table de référence. Essayons de décrypter.
On va créer une fonction qui permute deux lettres données :
```
def echange(chaine, c1, c2):
s = ''
for c in chaine:
#si on rencontre c1, on remplace par c2
if c == c1:
s += c2
#si on rencontre c2, on remplace par c2
elif c == c2:
s += c1
#sinon on garde le même caractère
else:
s += c
return s
c2 = echange(messageCode, 'b', ' ');
c2 = echange(c2, 'q', 'e')
c2 = echange(c2, 'v', 'a')
c2 = echange(c2, 'u', 'i')
c2 = echange(c2, 'o', 's')
c2 = echange(c2, 'n', 'n')
c2 = echange(c2, 'p', 'r')
c2 = echange(c2, 'g', 't')
c2[:5000]
```
Beaucoup de mots se terminent par a, ce sont sûrement des s. On voit aussi le 2eme mot avec un double b, on parie sur un double l à la place :
```
c2 = echange(c2, 'a', 's')
c2 = echange(c2, 'b', 'l')
c2[0:5000]
```
Prochaine étape, utiliser les espaces de manière plus systématiques, pour réutiliser l'idée précédente. Par exemple, trouver les mots de longueur 1 et 2.
```
mots = c2.split()
long_1 = [m for m in mots if len(m)== 1]
mots_1 = set() #ensemble : ne peut pas contenir deux fois le même élément
for m in long_1:
mots_1.add((m, long_1.count(m)))
print(mots_1)
long_2 = [m for m in mots if len(m) == 2]
mots_2 = set() #ensemble : ne peut pas contenir deux fois le même élément
for m in long_2:
mots_2.add((m, long_2.count(m)))
print(mots_2)
```
Le but est de trouver a, l, d qui sont très commun en mots d'une lettre comme en mots de deux ("l'", "d'", "la", "le"...)
On observe que le mot "ue" apparait 5249 fois, comme on est assez sûr du e et sans doute du l, on peut parier que le u se transforme en d.
De même, on on observe que "le" et "li" apparaissent environ 3000 fois, donc on parie que ce sont les mots le et la. On va donc inverser le i et le a.
```
c3 = echange(c2, 'u', 'd')
c3 = echange(c2, 'i', 'a')
c3[0:5000]
```
On voit "elles sxni" qui ressemblent à "elles sont".
On va tenter les permutations x<->o et i<->t.
```
c3 = echange(c3, 'x', 'o')
c3 = echange(c3, "i", "t")
c3[:5000]
c3 = echange(c3, 'z', 'y')
c3 = echange(c3, "i", "r")
c3[:5000]
c3 = echange(c3, 'c', 'h')
c3 = echange(c3, "x", "w")
c3 = echange(c3, "u", "d")
c3[:5000]
```
et ainsi de suite...
La décodage allant, on commence à comprendre le sens et pouvoir déchiffrer plus facilement.
Pour faciliter la lecture, il faudrait afficher différemment les lettres déjà trouvées. On y est presque. Le reste est à finir en exercice.
## 3- Vigénère
### 3.1 - Principe
La principale faiblesse du codage par substitution est que tous les "e" deviennnent une seule et même lettre dans le message codé et qu'une analyse statistique permet d'identifier par quoi elle a été substituée.
Le code de Vigénère apporte une soution à cette faiblesse car il introduit l'idée d'une substitution polyalphabétique, c'est à dire qu'une lettre donnée ne sera pas toujours transformée en la même lettre.
Au lieu d'utiliser un décalage uniforme sur tout le texte comme dans le code de César, on choisit un mot clé qui sert à indiquer de combien on se décale.
<ul>
<li>On transforme le mot clé en liste de chiffres, qui seront nos décalages (a->+0, b->+1, c->+2,...), par exemple, si la clé est bac, alors la liste des décalages est de (1,0,2) (a->+0, b->+1, c->+2,...)</li>
<li>la première lettre du texte est décalée grâce au premier chiffre de la clé</li>
<li>la deuxième lettre du texte est décalée grâce au deuxième chiffre de la clé</li>
<li>on poursuit ainsi, en reprennant la clé depuis le début quand on l'a épuisée</li>
</ul>
La vidéo suivante, à regarder, explique le cryptage par substitution et de Vigénère : https://youtu.be/PIw_nuWsOFU
```
def vigenere(texte, mot_cle):
liste_cle = [indice(c) for c in mot_cle]
s = ''
long_cle = len(liste_cle)
long_alph = len(LETTRES)
for i in range(len(texte)):
s = s + LETTRES[(indice(texte[i]) + liste_cle[i % long_cle]) % long_alph]
return s
vigenere('ceci est un test', 'motcle')
def dechiffre_vigenere(texte, mot_cle):
liste_cle = [-indice(c) for c in mot_cle]
s = ''
long_cle = len(liste_cle)
long_alph = len(LETTRES)
for i in range(len(texte)):
s = s + LETTRES[(indice(texte[i]) + liste_cle[i % long_cle]) % long_alph]
return s
dechiffre_vigenere('osvkkidgswydeskv', 'motcle')
```
### 3.2 - Cryptanalyse
Elle est beaucoup plus délicate que la précédente. L'idée est de trouver d'abord la longueur de la clé en procédant à des mesures d'incidences. Ensuite, on peut procéder à une analyse de fréquence pour déterminer chaque décalage.
La page Bibmath consacrée à la cryptanalyse de Vigénère détaille assez clairement ce procédé : http://www.bibmath.net/crypto/index.php?action=affiche&quoi=poly/viganalyse
On va regarder un exemple pour montrer le procédé :
```
#on code notre texte avec une clé de 5 caractères. ON SUPPOSE QU'ON NE CONNAIT PAS CETTE CLÉ
cle= "alien"
messageCode=vigenere(texte, cle)
messageCode=messageCode[:5000] #on se restreint à 5000 caractères pour ne pas surcharger le processeur
print(messageCode)
```
On commence par lister tous les trigrammes existant dans ce texte et on les met dans un dicionnaire. La valeur associée dans le dictionnaire correspond à l'index de sa position dans le texte.
```
#on crée le dictionnaire vide
dictTrigrammes={}
#on parcourt le message codé au complet jusqu'à l'avant dernier caractère
for i in range(len(messageCode)-2):
if messageCode[i:i+3] not in dictTrigrammes: #si le trigramme n'a jamais été rencontré
dictTrigrammes[messageCode[i:i+3]]=[i] #on crée une liste des positions de ce trigramme initialisée à [i]
else:
dictTrigrammes[messageCode[i:i+3]].append(i) #si le trigramme a déjà été rencontré, on ajoute sa nouvelle position
print(dictTrigrammes)
```
On veut connaitre l'écart qu'il y a entre les trigrammes identiques. On crée donc le dictionnaire dictTrigrammesEcart qui recense l'écart entre chacun des trigrammes.
```
dictTrigrammesEcart=dict()
for (key,value) in dictTrigrammes.items():
dictTrigrammesEcart[key]=[value[i+1]-value[i] for i in range(len(value)-1)]
print(dictTrigrammesEcart)
```
L'idée en regardant ce dictionnaire est de dire qu'un trigramme réapparait quand ce sont les trois même lettres qui ont été codées par les mêmes lettres de la clé. Cela veut donc dire que les écarts trouvés entre les trigrammes sont des multiples de la longueur de la clé.
Ici par exemple, presque tous les écarts semblent être des multiples de 5, ce qui nous amène à poser l'hypothèse que la clé est de longueur 5.
Tous les 5 caractères, le décalage est donc le même. Il faut donc trouver quel décalage a été fait sur les caractères en position 0,5,10,15... puis de trouver quel décalage a été fait sur les caractères en position 1,6,11,16..., puis ceux en position 2,7,12,17 et ainsi de suite.
Pour cela on va créer une fonction <code>sousTexte(texte,longueur,pos)</code> (à faire en exercice)
```
def sousTexte(texte,longueur,pos):
#renvoit les caractères de texte situés aux positions pos, pos+longueur, pos+longueur*2, pos+longueur*3...
#par exemple sousTexte("abcdefghijkl",2,0) renvoit "acegik" (on commence à 0 et on saute de 2 en 2)
#par exemple sousTexte("abcdefghijkl",2,1) renvoit "bdfhjl" (on commence à 1 et on saute de 2 en 2)
#par exemple sousTexte("abcdefghijkl",3,1) renvoit "behk" (on commence à 1 et on saute de 3 en 3)
```
On peut désormais analyser les fréquences des sous-textes. L'analyse des fréquences permettra de deviner le décalage.
Par exemple, si mon sous-texte contient une très grande fréquence de "g", alors je peux supposer que la lettre "e" a été décalée en "g" et que le décalage est donc de +2. Le caractère de la clé à cette position est donc c (a->+0, b->+1, c->+2,...)
```
sousTexte0=sousTexte(messageCode,5,0) #on récupère le sous-texte composé des caractères 0,5,10,15...
print(frequence(sousTexte)) #on observe quelle lettre est la plus fréquente, c'était sûrement un "e" dans le message en clair
```
Le reste de la cryptanalyse de Vigénère est à terminer en exercice. Vous allez donc implémenter la fonction <code>sousTexte()</code> et utiliser les analyses de fréquences pour en déduire la clé utilisée.
| github_jupyter |
# Backtesting: EW vs CW
```
import numpy as np
import pandas as pd
import edhec_risk_kit_204 as erk
%load_ext autoreload
%autoreload 2
ind49_rets = erk.get_ind_returns(weighting="vw", n_inds=49)["1974":]
ind49_mcap = erk.get_ind_market_caps(49, weights=True)["1974":]
```
In this section we'll develop a basic infrastructure to backtest various portfolio construction techniques and compare them. Here we'll start with something quite simple and straightforward - we'll write trivially simple weight-optimizers for Equally Weighted and Cap Weighted portfolios and compare them. Obviously, there are no Covariance estimates required for either one of these weighting schemes. In following sessions we'll enhance these optimizers to use more complex weighting schemes that will rely on covariance estimates.
```
def weight_ew(r):
"""
Returns the weights of the EW portfolio based on the asset returns "r" as a DataFrame
"""
n = len(r.columns)
return pd.Series(1/n, index=r.columns)
def backtest_ws(r, estimation_window=60, weighting=weight_ew):
"""
Backtests a given weighting scheme, given some parameters:
r : asset returns to use to build the portfolio
estimation_window: the window to use to estimate parameters
weighting: the weighting scheme to use, must be a function that takes "r", and a variable number of keyword-value arguments
"""
n_periods = r.shape[0]
windows = [(start, start+estimation_window) for start in range(n_periods-estimation_window+1)]
# windows is a list of tuples which gives us the (integer) location of the start and stop (non inclusive)
# for each estimation window
weights = [weighting(r.iloc[win[0]:win[1]]) for win in windows]
# List -> DataFrame
weights = pd.DataFrame(weights, index=r.iloc[estimation_window-1:].index, columns=r.columns)
# return weights
returns = (weights * r).sum(axis="columns", min_count=1) #mincount is to generate NAs if all inputs are NAs
return returns
ewr = backtest_ws(ind49_rets, weighting=weight_ew)
ewi = (1+ewr).cumprod()
ewi.plot(figsize=(12,6), title="49 Industries - Equally Weighted");
```
Now, let's add capweighting. We'll need to compute capweights, which we've already been provided through the marketcap file. We can refactor the code we've developed in the past to add a convenience function to our toolkit. Note the use of `**kwargs` to be able to take a variable number of keyword arguments to the function so that we can call any weighting function and let that weighting function take care of whatever arguments it needs. We'll have to refactor `weight_ew` with this new signature, but thats the only change (for now) for `weight_ew`.
```
def weight_ew(r, **kwargs):
"""
Returns the weights of the EW portfolio based on the asset returns "r" as a DataFrame
"""
n = len(r.columns)
return pd.Series(1/n, index=r.columns)
def weight_cw(r, cap_weights, **kwargs):
"""
Returns the weights of the CW portfolio based on the time series of capweights
"""
return cap_weights.loc[r.index[0]]
def backtest_ws(r, estimation_window=60, weighting=weight_ew, **kwargs):
"""
Backtests a given weighting scheme, given some parameters:
r : asset returns to use to build the portfolio
estimation_window: the window to use to estimate parameters
weighting: the weighting scheme to use, must be a function that takes "r", and a variable number of keyword-value arguments
"""
n_periods = r.shape[0]
# return windows
windows = [(start, start+estimation_window) for start in range(n_periods-estimation_window+1)]
weights = [weighting(r.iloc[win[0]:win[1]], **kwargs) for win in windows]
# convert list of weights to DataFrame
weights = pd.DataFrame(weights, index=r.iloc[estimation_window-1:].index, columns=r.columns)
# return weights
returns = (weights * r).sum(axis="columns", min_count=1) #mincount is to generate NAs if all inputs are NAs
return returns
ewr = backtest_ws(ind49_rets)
cwr = backtest_ws(ind49_rets, weighting=weight_cw, cap_weights=ind49_mcap)
btr = pd.DataFrame({"EW": ewr, "CW": cwr})
(1+btr).cumprod().plot(figsize=(12,5), title="49 Industries - CapWeighted vs Equally Weighted")
erk.summary_stats(btr.dropna())
```
# Improving EW with CapWeight Tethering
Often in practice, we'll want to implement some sort of a modification of a pure strategy. For instance, although Equal Weight portfolios are popular, they'll be constrained in some way - for instance to match the sector weights of the cap-weighted benchmark or to make sure that microcap stocks are not overweighted. The motivation for doing so could be to make a portfolio more tradeable (e.g. some microcaps may not have the liquidity) or to improve the tracking error to the Cap-Weighted index.
As an illustration of how that can be achieved, we enhance our simple `weight_ew` allocator to (i) drop microcap stocks beyond a particular threshold, and (ii) impose a constraint that ensures that the maximum weight assigned to any stock is no more than some multiple of the weight it would be in a cap-weighted portfolio.
```
def weight_ew(r, cap_weights=None, max_cw_mult=None, microcap_threshold=None, **kwargs):
"""
Returns the weights of the EW portfolio based on the asset returns "r" as a DataFrame
If supplied a set of capweights and a capweight tether, it is applied and reweighted
"""
n = len(r.columns)
ew = pd.Series(1/n, index=r.columns)
if cap_weights is not None:
cw = cap_weights.loc[r.index[0]] # starting cap weight
## exclude microcaps
if microcap_threshold is not None and microcap_threshold > 0:
microcap = cw < microcap_threshold
ew[microcap] = 0
ew = ew/ew.sum()
#limit weight to a multiple of capweight
if max_cw_mult is not None and max_cw_mult > 0:
ew = np.minimum(ew, cw*max_cw_mult)
ew = ew/ew.sum() #reweight
return ew
def weight_cw(r, cap_weights, **kwargs):
"""
Returns the weights of the CW portfolio based on the time series of capweights
"""
w = cap_weights.loc[r.index[0]]
return w/w.sum()
def backtest_ws(r, estimation_window=60, weighting=weight_ew, **kwargs):
"""
Backtests a given weighting scheme, given some parameters:
r : asset returns to use to build the portfolio
estimation_window: the window to use to estimate parameters
weighting: the weighting scheme to use, must be a function that takes "r", and a variable number of keyword-value arguments
"""
n_periods = r.shape[0]
# return windows
windows = [(start, start+estimation_window) for start in range(n_periods-estimation_window+1)]
weights = [weighting(r.iloc[win[0]:win[1]], **kwargs) for win in windows]
# convert to DataFrame
weights = pd.DataFrame(weights, index=r.iloc[estimation_window-1:].index, columns=r.columns)
returns = (weights * r).sum(axis="columns", min_count=1) #mincount is to generate NAs if all inputs are NAs
return returns
ewr = backtest_ws(ind49_rets)
ewtr = backtest_ws(ind49_rets, cap_weights=ind49_mcap, max_cw_mult=5, microcap_threshold=.005)
cwr = backtest_ws(ind49_rets, weighting=weight_cw, cap_weights=ind49_mcap)
btr = pd.DataFrame({"EW": ewr, "EW-Tethered": ewtr, "CW": cwr})
(1+btr).cumprod().plot(figsize=(12,5))
erk.summary_stats(btr.dropna())
```
Don't forget to add the code we've just developed to the toolkit, we're going to use it in future sessions!
## A Final Note ...
One of the motivations of adding the tethering constraint is to improve tracking error to the cap-weighted portfolio. Let's see if we did manage to achieve that:
```
erk.tracking_error(ewr, cwr),erk.tracking_error(ewtr, cwr)
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import plotly.graph_objects as go
import plotly.offline as po
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
import matplotlib.pyplot as plt
import dash
import plotly.express as px
import random
import plotly.figure_factory as ff
```
# Loading Datasets
```
pokemon = pd.read_csv("C:/Users/DELL/Documents/GitHub/Public/Data-Visualization/Plotly/Datasets/pokemon_updated.csv")
pokemon.head(10)
stdperf = pd.read_csv("C:/Users/DELL/Documents/GitHub/Public/Data-Visualization/Plotly/Datasets/studentp.csv")
stdperf.head(10)
corona = pd.read_csv('C:/Users/DELL/Documents/GitHub/Public/COVID-19/covid/data/countries-aggregated.csv' ,
index_col='Date' , parse_dates=True)
corona.head(10)
spotify = pd.read_csv("C:/Users/DELL/Documents/GitHub/Public/Data-Visualization/Plotly/Datasets/spotify.csv" , index_col="Date")
spotify.head(10)
housing = pd.read_csv('C:/Users/DELL/Documents/GitHub/Data-Visualization/housing.csv')
housing.tail()
insurance = pd.read_csv('C:/Users/DELL/Documents/GitHub/Data-Visualization/insurance.csv')
insurance.head(10)
employment = pd.read_excel("C:/Users/DELL/Documents/GitHub/Public/Data-Visualization/Plotly/Datasets/unemployment.xlsx")
employment.head(10)
helpdesk = pd.read_csv("C:/Users/DELL/Documents/GitHub/Public/Data-Visualization/Plotly/Datasets/helpdesk.csv")
helpdesk.head(10)
fish= pd.read_csv("C:/Users/DELL/Documents/GitHub/Public/Data-Visualization/Plotly/Datasets/Fish.csv")
fish.head(10)
exercise = pd.read_csv("C:/Users/DELL/Documents/GitHub/Public/Data-Visualization/Plotly/Datasets/exercise.csv")
exercise.head(10)
suicide = pd.read_csv("C:/Users/DELL/Documents/GitHub/Public/Data-Visualization/Plotly/Datasets/suicide.csv")
suicide.head(10)
canada = pd.read_csv("C:/Users/DELL/Documents/GitHub/Public/Data-Visualization/Plotly/Datasets/canada.csv")
canada.head()
canada.columns
canada.drop(columns=['AREA' , 'DEV', 'DevName' , 'REG', 'Type', 'Coverage' , 'AreaName', 'RegName' ], inplace=True)
canada.head()
canada.rename(columns={'OdName':'Country'} , inplace=True)
canada.set_index(canada.Country,inplace=True)
canada.head()
canada2 = canada.copy()
canada2.head()
canada.index.name=None
canada.head()
del canada['Country']
canada.head()
canada = canada.transpose()
canada.head()
```
# Sankey Diagram
```
#Simple Sankey Diagram
fig = go.Figure(
go.Sankey(
node = {
"label": ["India", "USA", "China", "Pakistan", "Bangladesh", "Mexico"],
},
link = {
"source": [0, 1, 2, 3, 4, 0, 2, 5],
"target": [1, 2, 3, 4, 5, 3, 5, 3],
"value": [300, 400, 200, 450, 700, 200,150, 200]
}
)
)
fig.show()
#Simple Sankey Diagram
fig = go.Figure(
go.Sankey(
node = dict(
thickness = 40, # Changing thickness of nodes
color = "lightgreen", # Changing color of the node
line = dict(color = "red", width = 0.5), # Changing line color
label = ["India", "USA", "China", "Pakistan", "Bangladesh", "Mexico"],
),
link = {
"source": [0, 1, 2, 3, 4, 0, 2, 5],
"target": [1, 2, 3, 4, 5, 3, 5, 3],
"value": [300, 400, 200, 450, 550, 200,150, 200]
}
)
)
fig.show()
#Simple Sankey Diagram
fig = go.Figure(
go.Sankey(
node = {
"label": ["Married: NO", "Married: Yes",
"Pet: No", "Pet: Yes",
"Happy: Yes", "Happy: No"],
"color" : px.colors.qualitative.Set3 # Node color
},
link = dict(
source = [0, 0, 1, 1, 2, 2, 3, 5],
target = [2, 3, 2, 3, 5, 4, 4, 3],
value = [200, 300, 400, 600, 150, 350,700],
color = px.colors.qualitative.Set2 # Color of links
)
)
)
fig.show()
```
# END
| github_jupyter |
# NumPy - Indexing & Slicing
Contents of ndarray object can be accessed and modified by indexing or slicing, just like Python's in-built container objects.
As mentioned earlier, items in ndarray object follows zero-based index. Three types of indexing methods are available − field access, basic slicing and advanced indexing.
Basic slicing is an extension of Python's basic concept of slicing to n dimensions. A Python slice object is constructed by giving start, stop, and step parameters to the built-in slice function. This slice object is passed to the array to extract a part of array.
```
import numpy as np
a = np.arange(10)
s = slice(2,7,2)
a[s]
```
In the above example, an ndarray object is prepared by arange() function. Then a slice object is defined with start, stop, and step values 2, 7, and 2 respectively. When this slice object is passed to the ndarray, a part of it starting with index 2 up to 7 with a step of 2 is sliced.
The same result can also be obtained by giving the slicing parameters separated by a colon : (start:stop:step) directly to the ndarray object
```
a = np.arange(10)
b = a[2:7:2]
b
```
If only one parameter is put, a single item corresponding to the index will be returned. If a : is inserted in front of it, all items from that index onwards will be extracted. If two parameters (with : between them) is used, items between the two indexes (not including the stop index) with default step one are sliced.
```
import numpy as np
a = np.arange(10)
b = a[5]
b
# slice items starting from index
a[2:]
# slice items between indexes
a[2:5]
# For Multi -Dimensional Array
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print (a)
# slice items starting from index
print ('Now we will slice the array from the index a[1:]' )
print (a[1:])
```
Slicing can also include ellipsis (…) to make a selection tuple of the same length as the dimension of an array. If ellipsis is used at the row position, it will return an ndarray comprising of items in rows.
```
# array to begin with
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print ('Our array is:')
print (a)
# this returns array of items in the second column
print ('The items in the second column are:' )
print (a[...,1] )
# Now we will slice all items from the second row
print ('The items in the second row are:')
print (a[1,...] )
# Now we will slice all items from column 1 onwards
print ('The items column 1 onwards are:' )
print (a[...,1:])
```
# NumPy - Advanced Indexing
It is possible to make a selection from ndarray that is a non-tuple sequence, ndarray object of integer or Boolean data type, or a tuple with at least one item being a sequence object. Advanced indexing always returns a copy of the data. As against this, the slicing only presents a view.
There are two types of advanced indexing − Integer and Boolean.
### Integer Indexing
This mechanism helps in selecting any arbitrary item in an array based on its Ndimensional index. Each integer array represents the number of indexes into that dimension. When the index consists of as many integer arrays as the dimensions of the target ndarray, it becomes straightforward.
In the following example, one element of specified column from each row of ndarray object is selected. Hence, the row index contains all row numbers, and the column index specifies the element to be selected.
```
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
y
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('Our array is:' )
print (x)
print ('\n')
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
print ('The corner elements of this array are:' )
y
```
### Boolean Array Indexing
This type of advanced indexing is used when the resultant object is meant to be the result of Boolean operations, such as comparison operators.
```
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('Our array is:' )
print (x)
print ('\n')
# Now we will print the items greater than 5
print ('The items greater than 5 are:' )
x[x > 5]
```
# NumPy - Broadcasting
The term broadcasting refers to the ability of NumPy to treat arrays of different shapes during arithmetic operations. Arithmetic operations on arrays are usually done on corresponding elements. If two arrays are of exactly the same shape, then these operations are smoothly performed.
```
a = np.array([1,2,3,4])
b = np.array([10,20,30,40])
c = a * b
c
```
If the dimensions of two arrays are dissimilar, element-to-element operations are not possible. However, operations on arrays of non-similar shapes is still possible in NumPy, because of the broadcasting capability. The smaller array is broadcast to the size of the larger array so that they have compatible shapes.
### Broadcasting is possible if the following rules are satisfied −
<ul>
<li> Array with smaller ndim than the other is prepended with '1' in its shape.</li>
<li> Size in each dimension of the output shape is maximum of the input sizes in that dimension.</li>
<li> An input can be used in calculation, if its size in a particular dimension matches the output size or its value is exactly 1.</li>
<li> If an input has a dimension size of 1, the first data entry in that dimension is used for all calculations along that dimension.</li>
</ul>
### A set of arrays is said to be broadcastable if the above rules produce a valid result and one of the following is true
<ul>
<li> Arrays have exactly the same shape.</li>
<li>Arrays have the same number of dimensions and the length of each dimension is either a common length or 1.</li>
<li>Array having too few dimensions can have its shape prepended with a dimension of length 1, so that the above stated property is true.</li>
</ul>
```
a = np.array([[0.0,0.0,0.0],[10.0,10.0,10.0],[20.0,20.0,20.0],[30.0,30.0,30.0]])
b = np.array([1.0,2.0,3.0])
print ('First array:')
print (a)
print ('\n')
print ('Second array:')
print (b)
print ('\n')
print ('First Array + Second Array' )
print (a + b)
```
# NumPy - Iterating Over Array
NumPy package contains an iterator object numpy.nditer. It is an efficient multidimensional iterator object using which it is possible to iterate over an array. Each element of an array is visited using Python’s standard Iterator interface.
Let us create a 3X4 array using arange() function and iterate over it using nditer.
```
a = np.arange(0,60,5)
a = a.reshape(3,4)
print ('Original array is:')
print (a)
print ('\n')
print ('Modified array is:')
for x in np.nditer(a):
print (x)
```
The order of iteration is chosen to match the memory layout of an array, without considering a particular ordering. This can be seen by iterating over the transpose of the above array.
```
print ('Original array is:')
print (a)
print ('\n')
print ('Transpose of the original array is:' )
b = a.T
print (b)
print ('\n')
print ('Modified array is:')
for x in np.nditer(a):
print (x)
```
| github_jupyter |
# Step 1:
- uncheck `Snippets menus are often ... right as normal.`
# Step 2:
```json
{
"name": "J.COp Snippets (v1.0)",
"menu-direction": "right",
"sub-menu-direction": "right",
"sub-menu": [
{
"name": "Scikit-learn",
"sub-menu": [
{
"name": "Import common packages",
"snippet": [
"import numpy as np",
"import pandas as pd",
"",
"from sklearn.model_selection import train_test_split",
"from sklearn.pipeline import Pipeline",
"from sklearn.compose import ColumnTransformer",
"",
"from jcopml.pipeline import num_pipe, cat_pipe",
"from jcopml.utils import save_model, load_model",
"from jcopml.plot import plot_missing_value",
"from jcopml.feature_importance import mean_score_decrease"
]
},
{
"name": "Import csv data",
"snippet": [
"df = pd.read_csv(\"____________\", index_col=\"___________\", parse_dates=[\"____________\"])",
"df.head()"
]
},
{
"name": "Dataset Splitting",
"sub-menu": [
{
"name": "Shuffle Split",
"snippet": [
"X = df.drop(columns=\"___________\")",
"y = \"_____________\"",
"",
"X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)",
"X_train.shape, X_test.shape, y_train.shape, y_test.shape"
]
},
{
"name": "Stratified Shuffle Split",
"snippet": [
"X = df.drop(columns=\"___________\")",
"y = \"_____________\"",
"",
"X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)",
"X_train.shape, X_test.shape, y_train.shape, y_test.shape"
]
}
]
},
{
"name": "Preprocessor",
"sub-menu": [
{
"name": "Common",
"snippet": [
"preprocessor = ColumnTransformer([",
" ('numeric', num_pipe(), [\"______________\"]),",
" ('categoric', cat_pipe(encoder='onehot'), [\"_____________\"]),",
"])"
]
},
{
"name": "Advance example",
"snippet": [
"# Note: You could not use gsp, rsp, and bsp recommendation in advance mode",
"# You should specify your own parameter grid / interval when tuning",
"preprocessor = ColumnTransformer([",
" ('numeric1', num_pipe(impute='mean', poly=2, scaling='standard', transform='yeo-johnson'), [\"______________\"]),",
" ('numeric2', num_pipe(impute='median', poly=2, scaling='robust'), [\"______________\"]),",
" ('categoric1', cat_pipe(encoder='ordinal'), [\"_____________\"]),",
" ('categoric2', cat_pipe(encoder='onehot'), [\"_____________\"]) ",
"])"
]
}
]
},
{
"name": "Supervised Learning Pipeline",
"sub-menu": [
{
"name": "Regression",
"sub-menu": [
{
"name": "K-Nearest Neighbor (KNN)",
"snippet": [
"from sklearn.neighbors import KNeighborsRegressor",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', KNeighborsRegressor())",
"])"
]
},
{
"name": "Support Vector Machine (SVM)",
"snippet": [
"from sklearn.svm import SVR",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', SVR(max_iter=500))",
"])"
]
},
{
"name": "Random Forest (RF)",
"snippet": [
"from sklearn.ensemble import RandomForestRegressor",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', RandomForestRegressor(n_jobs=-1, random_state=42))",
"])"
]
},
{
"name": "Extreme Gradient Boosting (XGBoost)",
"snippet": [
"from xgboost import XGBRegressor",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', XGBRegressor(n_jobs=-1, random_state=42))",
"])"
]
},
{
"name": "Linear Regression",
"snippet": [
"from sklearn.linear_model import LinearRegression",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', LinearRegression())",
"])"
]
},
{
"name": "ElasticNet Regression",
"snippet": [
"from sklearn.linear_model import ElasticNet",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', ElasticNet())",
"])"
]
}
]
},
{
"name": "Classification",
"sub-menu": [
{
"name": "K-Nearest Neighbor (KNN)",
"snippet": [
"from sklearn.neighbors import KNeighborsClassifier",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', KNeighborsClassifier())",
"])"
]
},
{
"name": "Support Vector Machine (SVM)",
"snippet": [
"from sklearn.svm import SVC",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', SVC(max_iter=500))",
"])"
]
},
{
"name": "Random Forest (RF)",
"snippet": [
"from sklearn.ensemble import RandomForestClassifier",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', RandomForestClassifier(n_jobs=-1, random_state=42))",
"])"
]
},
{
"name": "Extreme Gradient Boosting (XGBoost)",
"snippet": [
"from xgboost import XGBClassifier",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', XGBClassifier(n_jobs=-1, random_state=42))",
"])"
]
},
{
"name": "Logistic Regression",
"snippet": [
"from sklearn.linear_model import LogisticRegression",
"pipeline = Pipeline([",
" ('prep', preprocessor),",
" ('algo', LogisticRegression(solver='lbfgs', n_jobs=-1, random_state=42))",
"])"
]
}
]
}
]
},
{
"name": "Hyperparameter Tuning",
"sub-menu": [
{
"name": "Grid Search",
"snippet": [
"from sklearn.model_selection import GridSearchCV",
"from jcopml.tuning import grid_search_params as gsp",
"",
"model = GridSearchCV(pipeline, gsp.\"_______________\", cv=\"___\", scoring='___', n_jobs=-1, verbose=1)",
"model.fit(X_train, y_train)",
"",
"print(model.best_params_)",
"print(model.score(X_train, y_train), model.best_score_, model.score(X_test, y_test))"
]
},
{
"name": "Randomized Search",
"snippet": [
"from sklearn.model_selection import RandomizedSearchCV",
"from jcopml.tuning import random_search_params as rsp",
"",
"model = RandomizedSearchCV(pipeline, rsp.\"_______________\", cv=\"___\", scoring='___', n_iter=\"___\", n_jobs=-1, verbose=1, random_state=42)",
"model.fit(X_train, y_train)",
"",
"print(model.best_params_)",
"print(model.score(X_train, y_train), model.best_score_, model.score(X_test, y_test))"
]
},
{
"name": "Bayesian Search",
"snippet": [
"from jcopml.tuning.skopt import BayesSearchCV",
"from jcopml.tuning import bayes_search_params as bsp",
"",
"model = BayesSearchCV(pipeline, bsp.\"_______________\", cv=\"___\", scoring=\"__\", n_iter=\"___\", n_jobs=-1, verbose=1, random_state=42)",
"model.fit(X_train, y_train)",
"",
"print(model.best_params_)",
"print(model.score(X_train, y_train), model.best_score_, model.score(X_test, y_test))"
]
}
]
},
{
"name": "Save model",
"sub-menu": [
{
"name": "Save the whole search object",
"snippet": ["save_model(model, \"__________.pkl\")"]
},
{
"name": "Save best estimator only",
"snippet": ["save_model(model.best_estimator_, \"__________.pkl\")"]
}
]
}
]
},
{
"name": "PyTorch",
"sub-menu": [
{
"name": "Import common packages",
"snippet": [
"import torch",
"from torch import nn, optim",
"from jcopdl.callback import Callback, set_config",
"",
"device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")",
"device"
]
},
{
"name": "Dataset & Dataloader",
"sub-menu": [
{
"name": "Tensor Dataset",
"snippet": [
"from torch.utils.data import TensorDataset, DataLoader",
"",
"bs = \"______\"",
"",
"train_set = TensorDataset(\"________\")",
"trainloader = DataLoader(train_set, batch_size=bs, shuffle=True, num_workers=\"__\")",
"",
"test_set = TensorDataset(\"_________\")",
"testloader = DataLoader(test_set, batch_size=bs, shuffle=\"____\")"
]
},
{
"name": "Torchvision Image Folder",
"snippet": [
"from torchvision import datasets, transforms",
"from torch.utils.data import DataLoader",
"",
"bs = \"______\"",
"crop_size = \"____\"",
"",
"train_transform = transforms.Compose([",
" \"____________\",",
" transforms.ToTensor()",
"])",
"",
"test_transform = transforms.Compose([",
" \"____________\",",
" transforms.ToTensor()",
"])",
"",
"train_set = datasets.ImageFolder(\"________\", transform=train_transform)",
"trainloader = DataLoader(train_set, batch_size=bs, shuffle=True, num_workers=4)",
"",
"test_set = datasets.ImageFolder(\"________\", transform=test_transform)",
"testloader = DataLoader(test_set, batch_size=bs, shuffle=\"____\")"
]
}
]
},
{
"name": "Arsitektur & Config",
"sub-menu": [
{
"name": "Template",
"snippet": [
"class MyCustomModule(nn.Module):",
" def __init__(self):",
" super().__init__()",
" ",
" ",
" def forward(self, x):",
" "
]
},
{
"name": "ANN Example",
"snippet": [
"from jcopdl.layers import linear_block",
"",
"class NN(nn.Module):",
" def __init__(self):",
" super().__init__()",
" self.fc = nn.Sequential(",
" linear_block(input_size, n1, dropout=dropout),",
" linear_block(n1, n2, dropout=dropout),",
" linear_block(n2, output_size, activation='_________')",
" ),",
" ",
" def forward(self, x):",
" return self.fc(x)"
]
},
{
"name": "CNN Example",
"snippet": [
"from jcopdl.layers import linear_block, conv_block",
"",
"class CNN(nn.Module):",
" def __init__(self):",
" super().__init__()",
" self.conv = nn.Sequential(",
" conv_block(\"___\", \"___\"),",
" conv_block(\"___\", \"___\"), ",
" nn.Flatten()",
" )",
" ",
" self.fc = nn.Sequential(",
" linear_block(\"_____\", \"_____\", dropout=\"_____\"),",
" linear_block(\"_____\", \"_____\", activation=\"______\")",
" )",
" ",
" def forward(self, x):",
" return self.fc(self.conv(x))"
]
}
]
},
{
"name": "Training Preparation (MCOC)",
"snippet": [
"model = \"_______\"",
"criterion = \"_______\"",
"optimizer = optim.AdamW(model.parameters(), lr=0.001)",
"callback = Callback(model, config, outdir=\"model\")"
]
},
{
"name": "Training Loop",
"sub-menu": [
{
"name": "Standard",
"snippet": [
"from tqdm.auto import tqdm",
"",
"def loop_fn(mode, dataset, dataloader, model, criterion, optimizer, device):",
" if mode == \"train\":",
" model.train()",
" elif mode == \"test\":",
" model.eval()",
" cost = 0",
" for feature, target in tqdm(dataloader, desc=mode.title()):",
" feature, target = feature.to(device), target.to(device)",
" output = model(feature)",
" loss = criterion(output, target)",
" ",
" if mode == \"train\":",
" loss.backward()",
" optimizer.step()",
" optimizer.zero_grad()",
" ",
" cost += loss.item() * feature.shape[0]",
" cost = cost / len(dataset)",
" return cost"
]
},
{
"name": "Include accuracy",
"snippet": [
"from tqdm.auto import tqdm",
"",
"def loop_fn(mode, dataset, dataloader, model, criterion, optimizer, device):",
" if mode == \"train\":",
" model.train()",
" elif mode == \"test\":",
" model.eval()",
" cost = correct = 0",
" for feature, target in tqdm(dataloader, desc=mode.title()):",
" feature, target = feature.to(device), target.to(device)",
" output = model(feature)",
" loss = criterion(output, target)",
" ",
" if mode == \"train\":",
" loss.backward()",
" optimizer.step()",
" optimizer.zero_grad()",
" ",
" cost += loss.item() * feature.shape[0]",
" correct += (output.argmax(1) == target).sum().item()",
" cost = cost / len(dataset)",
" acc = correct / len(dataset)",
" return cost, acc"
]
},
{
"name": "RNN with BPTT",
"snippet": [
"from tqdm.auto import tqdm",
"",
"def loop_fn(mode, dataset, dataloader, model, criterion, optimizer, device):",
" if mode == \"train\":",
" model.train()",
" elif mode == \"test\":",
" model.eval()",
" cost = 0",
" for feature, target in tqdm(dataloader, desc=mode.title()):",
" feature, target = feature.to(device), target.to(device)",
" output, hidden = model(feature, None)",
" loss = criterion(output, target)",
" ",
" if mode == \"train\":",
" loss.backward()",
" optimizer.step()",
" optimizer.zero_grad()",
" ",
" cost += loss.item() * feature.shape[0]",
" cost = cost / len(dataset)",
" return cost"
]
},
{
"name": "RNN with Truncated BPTT",
"snippet": [
"from tqdm.auto import tqdm",
"",
"def loop_fn(mode, dataset, dataloader, model, criterion, optimizer, device):",
" if mode == \"train\":",
" model.train()",
" elif mode == \"test\":",
" model.eval()",
" cost = 0",
" for feature, target in tqdm(dataloader, desc=mode.title()):",
" hidden = None",
" for step in range(feature.shape[1]):",
" feature_step, target_step = feature[:, step, :, :].to(device), target[:, step, :, :].to(device)",
" output, hidden = model(feature_step, hidden)",
" loss = criterion(output, target_step)",
" ",
" if mode == \"train\":",
" loss.backward()",
" optimizer.step()",
" optimizer.zero_grad()",
"",
" hidden.detach_()",
" ",
" cost += loss.item() * feature.shape[0]",
" cost = cost / len(dataset)",
" return cost"
]
}
]
},
{
"name": "Training",
"sub-menu": [
{
"name": "Standard",
"snippet": [
"while True:",
" train_cost = loop_fn(\"train\", train_set, trainloader, model, criterion, optimizer, device)",
" with torch.no_grad():",
" test_cost = loop_fn(\"test\", test_set, testloader, model, criterion, optimizer, device)",
" ",
" # Logging",
" callback.log(train_cost, test_cost)",
"",
" # Checkpoint",
" callback.save_checkpoint()",
" ",
" # Runtime Plotting",
" callback.cost_runtime_plotting()",
" ",
" # Early Stopping",
" if callback.early_stopping(model, monitor=\"test_cost\"):",
" callback.plot_cost()",
" break"
]
},
{
"name": "Include accuracy",
"snippet": [
"while True:",
" train_cost, train_score = loop_fn(\"train\", train_set, trainloader, model, criterion, optimizer, device)",
" with torch.no_grad():",
" test_cost, test_score = loop_fn(\"test\", test_set, testloader, model, criterion, optimizer, device)",
" ",
" # Logging",
" callback.log(train_cost, test_cost, train_score, test_score)",
"",
" # Checkpoint",
" callback.save_checkpoint()",
" ",
" # Runtime Plotting",
" callback.cost_runtime_plotting()",
" callback.score_runtime_plotting()",
" ",
" # Early Stopping",
" if callback.early_stopping(model, monitor=\"test_score\"):",
" callback.plot_cost()",
" callback.plot_score()",
" break"
]
}
]
},
{
"name": "Load Best Model",
"snippet": [
"weights = torch.load(\"________________\", map_location=\"cpu\")",
"model.load_state_dict(weights)",
"model = model.to(device);"
]
}
]
}
]
}
```
| github_jupyter |
# Introduction to Deep Learning with PyTorch
In this notebook, you'll get introduced to [PyTorch](http://pytorch.org/), a framework for building and training neural networks. PyTorch in a lot of ways behaves like the arrays you love from Numpy. These Numpy arrays, after all, are just tensors. PyTorch takes these tensors and makes it simple to move them to GPUs for the faster processing needed when training neural networks. It also provides a module that automatically calculates gradients (for backpropagation!) and another module specifically for building neural networks. All together, PyTorch ends up being more coherent with Python and the Numpy/Scipy stack compared to TensorFlow and other frameworks.
## Neural Networks
Deep Learning is based on artificial neural networks which have been around in some form since the late 1950s. The networks are built from individual parts approximating neurons, typically called units or simply "neurons." Each unit has some number of weighted inputs. These weighted inputs are summed together (a linear combination) then passed through an activation function to get the unit's output.
<img src="assets/simple_neuron.png" width=400px>
Mathematically this looks like:
$$
\begin{align}
y &= f(w_1 x_1 + w_2 x_2 + b) \\
y &= f\left(\sum_i w_i x_i +b \right)
\end{align}
$$
With vectors this is the dot/inner product of two vectors:
$$
h = \begin{bmatrix}
x_1 \, x_2 \cdots x_n
\end{bmatrix}
\cdot
\begin{bmatrix}
w_1 \\
w_2 \\
\vdots \\
w_n
\end{bmatrix}
$$
## Tensors
It turns out neural network computations are just a bunch of linear algebra operations on *tensors*, a generalization of matrices. A vector is a 1-dimensional tensor, a matrix is a 2-dimensional tensor, an array with three indices is a 3-dimensional tensor (RGB color images for example). The fundamental data structure for neural networks are tensors and PyTorch (as well as pretty much every other deep learning framework) is built around tensors.
<img src="assets/tensor_examples.svg" width=600px>
With the basics covered, it's time to explore how we can use PyTorch to build a simple neural network.
```
# First, import PyTorch
import torch
def activation(x):
""" Sigmoid activation function
Arguments
---------
x: torch.Tensor
"""
return 1/(1+torch.exp(-x))
### Generate some data
torch.manual_seed(7) # Set the random seed so things are predictable
# Features are 5 random normal variables
features = torch.randn((1, 5))
# True weights for our data, random normal variables again
weights = torch.randn_like(features)
# and a true bias term
bias = torch.randn((1, 1))
print(bias)
```
Above I generated data we can use to get the output of our simple network. This is all just random for now, going forward we'll start using normal data. Going through each relevant line:
`features = torch.randn((1, 5))` creates a tensor with shape `(1, 5)`, one row and five columns, that contains values randomly distributed according to the normal distribution with a mean of zero and standard deviation of one.
`weights = torch.randn_like(features)` creates another tensor with the same shape as `features`, again containing values from a normal distribution.
Finally, `bias = torch.randn((1, 1))` creates a single value from a normal distribution.
PyTorch tensors can be added, multiplied, subtracted, etc, just like Numpy arrays. In general, you'll use PyTorch tensors pretty much the same way you'd use Numpy arrays. They come with some nice benefits though such as GPU acceleration which we'll get to later. For now, use the generated data to calculate the output of this simple single layer network.
> **Exercise**: Calculate the output of the network with input features `features`, weights `weights`, and bias `bias`. Similar to Numpy, PyTorch has a [`torch.sum()`](https://pytorch.org/docs/stable/torch.html#torch.sum) function, as well as a `.sum()` method on tensors, for taking sums. Use the function `activation` defined above as the activation function.
```
## Calculate the output of this network using the weights and bias tensors
torch.mm(features, weights.reshape(5,1)) + bias
```
You can do the multiplication and sum in the same operation using a matrix multiplication. In general, you'll want to use matrix multiplications since they are more efficient and accelerated using modern libraries and high-performance computing on GPUs.
Here, we want to do a matrix multiplication of the features and the weights. For this we can use [`torch.mm()`](https://pytorch.org/docs/stable/torch.html#torch.mm) or [`torch.matmul()`](https://pytorch.org/docs/stable/torch.html#torch.matmul) which is somewhat more complicated and supports broadcasting. If we try to do it with `features` and `weights` as they are, we'll get an error
```python
>> torch.mm(features, weights)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-13-15d592eb5279> in <module>()
----> 1 torch.mm(features, weights)
RuntimeError: size mismatch, m1: [1 x 5], m2: [1 x 5] at /Users/soumith/minicondabuild3/conda-bld/pytorch_1524590658547/work/aten/src/TH/generic/THTensorMath.c:2033
```
As you're building neural networks in any framework, you'll see this often. Really often. What's happening here is our tensors aren't the correct shapes to perform a matrix multiplication. Remember that for matrix multiplications, the number of columns in the first tensor must equal to the number of rows in the second column. Both `features` and `weights` have the same shape, `(1, 5)`. This means we need to change the shape of `weights` to get the matrix multiplication to work.
**Note:** To see the shape of a tensor called `tensor`, use `tensor.shape`. If you're building neural networks, you'll be using this method often.
There are a few options here: [`weights.reshape()`](https://pytorch.org/docs/stable/tensors.html#torch.Tensor.reshape), [`weights.resize_()`](https://pytorch.org/docs/stable/tensors.html#torch.Tensor.resize_), and [`weights.view()`](https://pytorch.org/docs/stable/tensors.html#torch.Tensor.view).
* `weights.reshape(a, b)` will return a new tensor with the same data as `weights` with size `(a, b)` sometimes, and sometimes a clone, as in it copies the data to another part of memory.
* `weights.resize_(a, b)` returns the same tensor with a different shape. However, if the new shape results in fewer elements than the original tensor, some elements will be removed from the tensor (but not from memory). If the new shape results in more elements than the original tensor, new elements will be uninitialized in memory. Here I should note that the underscore at the end of the method denotes that this method is performed **in-place**. Here is a great forum thread to [read more about in-place operations](https://discuss.pytorch.org/t/what-is-in-place-operation/16244) in PyTorch.
* `weights.view(a, b)` will return a new tensor with the same data as `weights` with size `(a, b)`.
I usually use `.view()`, but any of the three methods will work for this. So, now we can reshape `weights` to have five rows and one column with something like `weights.view(5, 1)`.
> **Exercise**: Calculate the output of our little network using matrix multiplication.
```
## Calculate the output of this network using matrix multiplication
torch.mm(features, weights.reshape(5,1)) + bias
```
### Stack them up!
That's how you can calculate the output for a single neuron. The real power of this algorithm happens when you start stacking these individual units into layers and stacks of layers, into a network of neurons. The output of one layer of neurons becomes the input for the next layer. With multiple input units and output units, we now need to express the weights as a matrix.
<img src='assets/multilayer_diagram_weights.png' width=450px>
The first layer shown on the bottom here are the inputs, understandably called the **input layer**. The middle layer is called the **hidden layer**, and the final layer (on the right) is the **output layer**. We can express this network mathematically with matrices again and use matrix multiplication to get linear combinations for each unit in one operation. For example, the hidden layer ($h_1$ and $h_2$ here) can be calculated
$$
\vec{h} = [h_1 \, h_2] =
\begin{bmatrix}
x_1 \, x_2 \cdots \, x_n
\end{bmatrix}
\cdot
\begin{bmatrix}
w_{11} & w_{12} \\
w_{21} &w_{22} \\
\vdots &\vdots \\
w_{n1} &w_{n2}
\end{bmatrix}
$$
The output for this small network is found by treating the hidden layer as inputs for the output unit. The network output is expressed simply
$$
y = f_2 \! \left(\, f_1 \! \left(\vec{x} \, \mathbf{W_1}\right) \mathbf{W_2} \right)
$$
```
### Generate some data
torch.manual_seed(7) # Set the random seed so things are predictable
# Features are 3 random normal variables
features = torch.randn((1, 3))
# Define the size of each layer in our network
n_input = features.shape[1] # Number of input units, must match number of input features
n_hidden = 2 # Number of hidden units
n_output = 1 # Number of output units
# Weights for inputs to hidden layer
W1 = torch.randn(n_input, n_hidden) ## (3,2)
# Weights for hidden layer to output layer
W2 = torch.randn(n_hidden, n_output) ## (2,1)
print (W1, W2)
# and bias terms for hidden and output layers
B1 = torch.randn((1, n_hidden))
B2 = torch.randn((1, n_output))
print (B1, B2)
```
> **Exercise:** Calculate the output for this multi-layer network using the weights `W1` & `W2`, and the biases, `B1` & `B2`.
```
## Your solution here
h1 = activation(torch.mm(features, W1.reshape(n_input,n_hidden)) + B1)
output = activation(torch.mm(h1, W2.reshape( n_hidden,n_output)) + B2)
print(output)
```
If you did this correctly, you should see the output `tensor([[ 0.3171]])`.
The number of hidden units a parameter of the network, often called a **hyperparameter** to differentiate it from the weights and biases parameters. As you'll see later when we discuss training a neural network, the more hidden units a network has, and the more layers, the better able it is to learn from data and make accurate predictions.
## Numpy to Torch and back
Special bonus section! PyTorch has a great feature for converting between Numpy arrays and Torch tensors. To create a tensor from a Numpy array, use `torch.from_numpy()`. To convert a tensor to a Numpy array, use the `.numpy()` method.
```
import numpy as np
a = np.random.rand(4,3)
a
b = torch.from_numpy(a)
b
b.numpy()
```
The memory is shared between the Numpy array and Torch tensor, so if you change the values in-place of one object, the other will change as well.
```
# Multiply PyTorch Tensor by 2, in place
b.mul_(2)
# Numpy array matches new values from Tensor
a
```
| github_jupyter |
<table align="left">
<td>
<a href="https://colab.research.google.com/github/nyandwi/machine_learning_complete/blob/main/6_classical_machine_learning_with_scikit-learn/10_intro_to_unsupervised_learning_with_kmeans_clustering.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
</td>
</table>
*This notebook was created by [Jean de Dieu Nyandwi](https://twitter.com/jeande_d) for the love of machine learning community. For any feedback, errors or suggestion, he can be reached on email (johnjw7084 at gmail dot com), [Twitter](https://twitter.com/jeande_d), or [LinkedIn](https://linkedin.com/in/nyandwi).*
<a name='0'></a>
# Intro to Unsupervised Learning - K-Means Clustering
K-Means clustering is a type of unsupervised learning algorithms. In unsupervised learning, the machine learning model do not get the labels during training. It instead has to figure out the labels itself. It's like learning without instructions. It's like a teacher telling you, "hey, here are 1000 exercises to use while preparing for a test, the test will be only 5 questions from all of those exercises." That can feel like a struggle, you will do all you can to narrow down these 100 exercises to 5. Some questions may be similar, or may be solved by one method, etc..the goal will merely be to narrow down the exercises, while maximizing the chance of passing the test.
That type of example can be compared to clustering. The model is given bunch of data (lacking labels) and the job of the model is to find the labels that can be present according to the supplied data.
K-Means Clustering require the number of clusters to be specified before training. The way this type of algorithm works is beyond the scope of this notebook but here are 3 main steps of how such algorithm work:
* K-Means will randomly assigns samples of data to initial centroids of all clusters. This step is called initialization. A centroid is also referred to as a cluster center and it is the mean of all the sample of data in a cluster.
* It then reassigns the samples to the nearest centroids.
* It also find the new centroids of all clusters by taking the mean value of all of the samples assigned to each previous centroids.
The last two steps are repeated until the stopping criterion is fulfilled or when difference between the old and new centroids is constant.
Unspervised learning has got its applications in areas such as grouping web search results, customer segmentation, news aggregation and more.
## KMeans Clustering
### Contents
* [1 - Imports](#1)
* [2 - Loading the data](#2)
* [3 - Exploratory Analysis](#3)
* [4 - Preprocessing the data](#4)
* [5 - Trainin K-Means Clustering to Find Clusters](#5)
* [6 - Evaluating K-Means Clustering](#6)
* [7 - Final Notes](#7)
<a name='1'></a>
## 1 - Imports
```
import numpy as np
import pandas as pd
import seaborn as sns
import sklearn
import matplotlib.pyplot as plt
%matplotlib inline
```
<a name='2'></a>
## 2 - Loading the data
In this notebook, we will use a different dataset. Up to this point creating these notebooks, my goal has been to look on the other side, to try something new, to try new a dataset. If you have went through some notebooks about other algorithms, no doubt that you have learned something new or perhaps nothing new but you experienced a new dataset.
In this notebook, we will use a mushroom dataset. The dataset describes mushrooms in terms of their physical characteristics and they are classified into: poisonous or edible.
The dataset also includes descriptions of hypothetical samples corresponding to 23 species of gilled mushrooms in the Agaricus and Lepiota Family. Each species is identified as definitely edible, definitely poisonous, or of unknown edibility and not recommended. This latter class was combined with the poisonous one. The Guide clearly states that there is no simple rule for determining the edibility of a mushroom; no rule like `leaflets three, let it be for Poisonous Oak and Ivy.`
The dataset contains the labels (edibility) but for the purpose of doing clustering, we will remove the labels.
```
# Let's firs hide warnings just in case
import warnings
warnings.filterwarnings('ignore')
from sklearn.datasets import fetch_openml
mushroom_data = fetch_openml(name='mushroom', version=1)
mushroom_data.data.shape
```
As you can see above, there are 8124 examples and 22 features.
```
# Description of the data
print(mushroom_data.DESCR)
# Displaying feature names
mushroom_data.feature_names
# Displaying target name
mushroom_data.target_names
# Getting the whole dataframe
mushroom_data = mushroom_data.frame
```
<a name='3'></a>
## 3 - Exploratory Data Analysis
### Taking a quick look into the dataset
```
mushroom_data.head()
# Displaying the last rows
mushroom_data.tail()
mushroom_data.info()
```
All features are categorical. So we will make sure to handle them.
### Checking Summary Statistics
```
# Summary stats
mushroom_data.describe()
```
### Checking Missing Values
```
# Checking missing values
mushroom_data.isnull().sum()
```
It seems that we have missing values in the feature `stalk-root`.
Usually there are three things to do with if them if they are present:
* We can remove all missing values completely
* We can leave them as they are or
* We can fill them with a given strategy such as mean, media or most frequent value. Either `Sklearn` or Pandas provides a quick ways to fill these kind of values.
We will handle that during the data preprocessing.
### More Data Exploration
Before preprocessing the data, let's take a look into specific features.
I want to also make note that I do not know alot about mushrooms. I thought that it would be interesting to use this real world datasets, and perhaps some people who will come across this may some of mushroom samples and their characteristics.
```
plt.figure(figsize=(12,7))
sns.countplot(data=mushroom_data, x='cap-shape', hue='class')
```
In cap_shape, the letters stands for: `ell=b,conical=c,convex=x,flat=f, knobbed=k,sunken=s`. It seems that the convex type is dominant and most of it are edible.
```
plt.figure(figsize=(12,7))
sns.countplot(data=mushroom_data, x='cap-color', hue='class')
```
The above is the cap color. The alphabets stands for `brown=n,buff=b,cinnamon=c,gray=g,green=r,pink=p,purple=u,red=e,white=w,yellow=y `.
Also it seems that most caps are brown(n), either edible or brown.
```
plt.figure(figsize=(12,7))
sns.countplot(data=mushroom_data, x='population')
```
The most populations are most several. Here are what the letters stand for: `abundant=a,clustered=c,numerous=n, scattered=s,several=v,solitary=y`.
```
plt.figure(figsize=(12,7))
sns.countplot(data=mushroom_data, x='habitat')
plt.figure(figsize=(12,7))
sns.countplot(data=mushroom_data, x='stalk-root')
```
Above is the feature that is missing values. We will remove all missing values. Since the missing values are of one category, we will drop it to avoid adding noise in the dataset.
And finally, we can look in the class feature. There are two categories, `e(edible)` and `p(poisonous)`.
```
plt.figure(figsize=(12,7))
sns.countplot(data=mushroom_data, x='class')
```
<a name='4'></a>
## 4 - Data Preprocessing
Let's remove the missing values first.
```
mushroom_df = mushroom_data.dropna()
```
For the purpose of performing clustering, we will remove the labels.
```
mushroom = mushroom_df.drop('class', axis=1)
mushroom_labels = mushroom_df['class']
```
Let's now convert all categorical features into the numerics.
```
from sklearn.preprocessing import OrdinalEncoder
encoder = OrdinalEncoder()
mushroom_prepared = encoder.fit_transform(mushroom)
mushroom_prepared
```
As you can see above, `mushroom_prepared` is a NumPy array. We can convert it back to the Pandas Dataframe although KMeans algorithm can accept both as input.
```
mushroom_prep_df = pd.DataFrame(mushroom_prepared, columns=mushroom.columns)
mushroom_prep_df.head()
```
No alphabets anymore. They were perfectly encoded or converted to numerics representation.
We are now ready to find the labels with KMeans Clustering. Again, this is for the assumption that we do not have labels, or to make it simple, we have a data about the characteristics of different plants, but we do not know if they are edible or not. We want to use unsupervised learning to figure that out.
<a name='5'></a>
## 5 - Training K-Means Clustering to Find Clusters
We are going to create a KMeans model from `sklearn.cluster`. We will remember to provide the number of the clusters, which is 2 in our case.
```
from sklearn.cluster import KMeans
k_clust = KMeans(n_clusters=2, random_state=42)
k_clust.fit(mushroom_prep_df)
```
We can access the cluster centers by `model.cluster_centers_`.
```
k_clust.cluster_centers_
```
Also, we can get the labels that the KMeans provided for each data point.
```
k_labels = k_clust.labels_
k_labels
```
<a name='6'></a>
### 6 -Evaluating K-Means Clustering
In real world, evaluating the performance of KMeans is not an easy thing, because there are not true labels to compare with the clustered labels. In our case since we have them, we can find things like accuracy score, or even find the confusion matrix to display the actual and predicted classes. Not to mention classification report to find things like Recall, Precision, or F1 Score.
But again since we are merely comparing the labels(true and clustered), we do not need that extra metrics.
Before finding the accuracy score, I will first convert the true labels into the numbers or encode them. For simplicity, I will use a map function.
```
map_dict = {
'p':0,
'e':1
}
mushroom_labels_prep = mushroom_labels.map(map_dict)
mushroom_labels_prep
from sklearn.metrics import accuracy_score
accuracy_score(mushroom_labels_prep, k_labels)
```
This is not excellent, but it's so impressive. Why? Well, KMeans never saw the labels, it was only feed the data of different characteristics of poisonous and edible mushrooms and its job was to try to find patterns in the data so as to learn if a given mushroom specy is a poisonous or edible.
KMeans algorithm is very useful in areas where you have a bunch of unlabeled data. Take an example in customer segmentation. You may want to provide different promotions to some groups of your customers but you have no clue of who would benefit from that particular promotion. So, you can try to find the group of customers using this algorithm. It will try to group similar customers according to their interests, and will likely appreciate the promotion.
The same concept can be applied to grouping the equipments that has similar defects in an industry. That was just mentioning few, there are more applications of KMeans clustering.
<a name='7'></a>
### 7 - Final Notes
In this notebook, we learned the idea behind unsupervised learning and KMeans clustering. We also practiced that on mushroom dataset where we were interested in grouping the species that can be poisonous or edible.
If you like mushrooms and you know some of their characteristics, no doubt that you enjoyed this notebook. Maybe pick one edible sample and make it your next meal :)
## [BACK TO TOP](#0)
| github_jupyter |
# Overnight returns
[Overnight Returns and Firm-Specific Investor Sentiment](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2554010)
> **Abtract**: We explore the possibility that overnight returns can serve as a measure of firm-specific investor sentiment by analyzing whether they exhibit characteristics expected of a sentiment measure. First, we document short-term persistence in overnight returns, consistent with existing evidence of short-term persistence in share demand of sentiment-influenced retail investors. Second, we find that short-term persistence is stronger for harder-to-value firms, consistent with evidence that sentiment plays a larger role when there is less objective data available for valuation. Third, we show that stocks with high (low) overnight returns underperform (outperform) over the longer-term, consistent with evidence of temporary sentiment-driven mispricing.
> **p 2, I**: The recent work of Berkman, Koch, Tuttle, and Zhang (2012) suggests that a stock’s
overnight (close-to-open) return can serve as a measure of firm-level sentiment.
> **p 3, I**: Specifically, Berkman et al. (2012) find that attention-generating events (high absolute returns or
strong net buying by retail investors) on one day lead to higher demand by individual investors,
concentrated near the open of the next trading day...This creates temporary price pressure at the
open, resulting in elevated overnight returns that are reversed during the trading day.
> **p 3, I**: We conduct three sets of analyses. **In the first
we test for short-run persistence in overnight returns.** The basis for expecting this from a
measure of sentiment is the evidence in Barber et al. (2009) that the order imbalances of retail
investors, who are the investors most likely to exhibit sentiment, persist for periods extending
over several weeks...In the third analysis we
examine whether stocks with high overnight returns underperform those with low overnight
returns over the long term.
## Install packages
```
import sys
!{sys.executable} -m pip install -r requirements.txt
import cvxpy as cvx
import numpy as np
import pandas as pd
import time
import os
import quiz_helper
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = (14, 8)
```
### data bundle
```
import os
import quiz_helper
from zipline.data import bundles
os.environ['ZIPLINE_ROOT'] = os.path.join(os.getcwd(), '..', '..','data','module_4_quizzes_eod')
ingest_func = bundles.csvdir.csvdir_equities(['daily'], quiz_helper.EOD_BUNDLE_NAME)
bundles.register(quiz_helper.EOD_BUNDLE_NAME, ingest_func)
print('Data Registered')
```
### Build pipeline engine
```
from zipline.pipeline import Pipeline
from zipline.pipeline.factors import AverageDollarVolume
from zipline.utils.calendars import get_calendar
universe = AverageDollarVolume(window_length=120).top(500)
trading_calendar = get_calendar('NYSE')
bundle_data = bundles.load(quiz_helper.EOD_BUNDLE_NAME)
engine = quiz_helper.build_pipeline_engine(bundle_data, trading_calendar)
```
### View Data¶
With the pipeline engine built, let's get the stocks at the end of the period in the universe we're using. We'll use these tickers to generate the returns data for the our risk model.
```
universe_end_date = pd.Timestamp('2016-01-05', tz='UTC')
universe_tickers = engine\
.run_pipeline(
Pipeline(screen=universe),
universe_end_date,
universe_end_date)\
.index.get_level_values(1)\
.values.tolist()
universe_tickers
```
# Get Returns data
```
from zipline.data.data_portal import DataPortal
data_portal = DataPortal(
bundle_data.asset_finder,
trading_calendar=trading_calendar,
first_trading_day=bundle_data.equity_daily_bar_reader.first_trading_day,
equity_minute_reader=None,
equity_daily_reader=bundle_data.equity_daily_bar_reader,
adjustment_reader=bundle_data.adjustment_reader)
```
## Get pricing data helper function
```
from quiz_helper import get_pricing
```
## get pricing data into a dataframe
```
returns_df = \
get_pricing(
data_portal,
trading_calendar,
universe_tickers,
universe_end_date - pd.DateOffset(years=5),
universe_end_date)\
.pct_change()[1:].fillna(0) #convert prices into returns
returns_df
```
## Sector data helper function
We'll create an object for you, which defines a sector for each stock. The sectors are represented by integers. We inherit from the Classifier class. [Documentation for Classifier](https://www.quantopian.com/posts/pipeline-classifiers-are-here), and the [source code for Classifier](https://github.com/quantopian/zipline/blob/master/zipline/pipeline/classifiers/classifier.py)
```
from zipline.pipeline.classifiers import Classifier
from zipline.utils.numpy_utils import int64_dtype
class Sector(Classifier):
dtype = int64_dtype
window_length = 0
inputs = ()
missing_value = -1
def __init__(self):
self.data = np.load('../../data/project_4_sector/data.npy')
def _compute(self, arrays, dates, assets, mask):
return np.where(
mask,
self.data[assets],
self.missing_value,
)
sector = Sector()
```
## We'll use 2 years of data to calculate the factor
**Note:** Going back 2 years falls on a day when the market is closed. Pipeline package doesn't handle start or end dates that don't fall on days when the market is open. To fix this, we went back 2 extra days to fall on the next day when the market is open.
```
factor_start_date = universe_end_date - pd.DateOffset(years=2, days=2)
factor_start_date
```
## Walk through "Returns" class
We'll walk through how the `Returns` class works, because we'll create a new class that inherits from `Returns` in order to calculate a customized return.
### Returns inherits from CustomFactor
The zipline package has a class [zipline.pipeline.factors.Returns](https://www.zipline.io/appendix.html?highlight=returns#zipline.pipeline.factors.Returns) which inherits from class [zipline.pipeline.CustomFactor](https://www.zipline.io/appendix.html?highlight=custom%20factor#zipline.pipeline.CustomFactor). The [source code for Returns is here](https://www.zipline.io/_modules/zipline/pipeline/factors/basic.html#Returns), and the [source code for CustomFactor is here.](https://www.zipline.io/_modules/zipline/pipeline/factors/factor.html#CustomFactor)
**Please open the links to the documentation and source code and follow along with our notes about the code**
### Inputs variable
The CustomFactor class takes the `inputs` as a parameter of the constructor for the class, otherwise it looks for a class-level variable named `inputs`. `inputs` takes a list of BoundColumn instances. These help us choose what kind of price-volume data to use as input. The `Returns` class sets this to
```
inputs = [USEquityPricing.close]
```
### USEquityPricing class
The class [USEquityPricing](https://www.zipline.io/appendix.html?highlight=usequitypricing#zipline.pipeline.data.USEquityPricing) has a couple BoundColumn instances that we can choose from.
close = USEquityPricing.close
high = USEquityPricing.high
low = USEquityPricing.low
open = USEquityPricing.open
volume = USEquityPricing.volume
## Quiz 1
If we wish to calculate close to open returns, which columns from USEquityPricing do you think we'll want to put into the list and set as `inputs`?
## Quiz 1 Answer
`USEquityPricing.open` and `USEquityPricing.close`
### window_length variable
The CustomFactor class takes `window_length` (an integer) as a constructor parameter, otherwise it looks for a class-level variable named `window_length`. If we chose a `window_length = 2` then this means that we'll be passing two days' worth of data (two rows) into the `compute` function.
## Quiz 2
What window length would you choose if you were calculating daily close to open returns? Assume we have daily data.
## Answer 2
window length of 2 to have 2 days of data.
### Compute function
The function definition of the `Returns` class includes the `compute` function
```
def compute(self, today, assets, out, close):
out[:] = (close[-1] - close[0]) / close[0]
```
* `today`: this is handled by parent classes; it has the datetime for the "today" row for the given subset of data. We won't use it for this function implementation.
* `assets`: this is handled by parent classes: it has the column header names for the "out" and "close". We won't use it for this function implementation.
* `out`: this points to a numpy array that will store the result of our compute. It stores our "return" value of the `compute` function instead of explicitly returning a variable.
* `*input`: a tuple of numpy arrays that contain input data that we'll use to compute a signal. In the `Returns` definition of `compute`, the input is a single value `close`, but we can list more if we need additional columns of data to compute a return.
If we set the `window_length=2`, then the `compute` function gets two rows worth of data from `close`. The index 1 value is the most recent value, and the index 0 value is the earliest in time. Recall that in Python, the -1 index is the same as getting the highest indexed value, so with a numpy array of just length two, -1 gives us the value at index 1.
So the line of code is calculating the one-day return using the close price, and storing that into the `out` variable.
$ Return = \frac{close_1 - close_0}{close_0} $
## Quiz 3
Given a numpy array for open prices called `open` and a numpy array for close prices called `close`, what code would you write to get the most recent open price? Assume that you have 2 days of data.
## Answer 3
open[1] or open[-1] (because python lets us do reverse indexing) are valid answers. Use the -1 index allows us to get the most recent price (the very last index of the numpy array) regardless of the window length, so you may prefer to use -1 to make your code easier to maintain or modify.
## Close To Open Returns (Overnight Returns)
The close-to-open return is the change in price between when the market closed on one day and when it opened on the next. So it's
$ CloseToOpen = \frac{open_1 - close_0}{close_0}$
We'll now create a class `CTO` that inherits from `Return`, and override the `compute` function.
## Quiz 4
Create a customized class `CloseToOpenReturns` that inherit from the Returns class. Define the compute function to calculate overnight returns.
```
from zipline.pipeline.data import USEquityPricing
from zipline.pipeline.factors import Returns
class CloseToOpenReturns(Returns):
"""
"""
# TODO: Set window_length (we're calculating daily returns)
window_length = 2
# TODO: set inputs
inputs = [USEquityPricing.open, USEquityPricing.close]
# The compute method is passed the current day, the assets list, a pre-allocated out vector, and the
# factor's items in the list `inputs`
def compute(self, today, assets, out, opens, closes):
#TODO: calculate close-to-open return and save into out[:]
out[:] = (opens[-1] - closes[0]) / closes[0]
```
## Trailing overnight returns
The cumulative overnight returns over a week may be predictive of future returns; hence it's a kind of momentum signal.
$ TrailingOvernightReturns = \sum_{1}^{Days}CloseToOpen_t$
Where $Days$ could be 5 if we are looking at a weekly window.
So we want to take the `CloseToOpenReturns` as our input into another class, `TrailingOvernightReturns`, which also inherits from `Returns`.
### mask
Note that we're going to create another class that inherits from `Returns`. Recall that `Returns` inherits from [CustomFactor](https://www.zipline.io/appendix.html?highlight=factor#zipline.pipeline.CustomFactor), which has a `mask` parameter for its constructor. The `mask` parameter takes in a `Filter` object, which determines which stock series get passed to the `compute` function. Note that when we used `AverageDollarVolume` and stored its output in the variable `universe`, this `universe` variable is of type `Filter`.
## Quiz 5
If you wanted to create an object of type CloseToOpen, and also define the object so that it only computes returns on the set of stocks in universe that we selected earlier in this notebook, what code would you write?
## Answer 5
We could instantiate a CloseToOpen object with `CloseToOpenReturns(mask=universe)`, and this would only calculate close to open returns for the stocks defined in our `universe` variable.
## numpy.nansum
Numpy has a `nansum` function that treat NaN (not a number) as zeros. Note that by default, if we give numpy.nansum a 2D numpy array, it will calculate a single sum across all rows and columns. For our purposes, we want to compute a sum over 5 days (5 rows), and each column has daily close to open returns for a single stock. It helps to think of the a matrix (2D numpy array) as a nested list of lists. This makes it easier to decide whether to set `axis=0` or `axis=1`.
```
tmp =
[
[stock1day1, stock2day1 ]
[stock1day2, stock2day2 ]
...
]
```
If we look at the outermost list, each element is a list that represents one day's worth of data. If we used `np.nansum(tmp,axis=0)`, this would sum across the days for each stock. If we think of this as a 2D matrix, setting `axis=0` is like calculating a sum for each column.
If we set `axis=0`, this applies `nansum` to the outermost list (axis 0), so that we end up with:
```
[
sum_of_stock_1, sum_of_stock_2
]
```
Alternatively, if we set `axis=1`, this applies `nansum` to the lists nested inside the outermost list. Each of these nested lists represent data for a single day, for all stocks, so that we get:
```
[
sum_of_day_1,
sum_of_day_2,
]
```
## Example using numpy.nansum
```
tmp = np.array([
[1, 2, 3],
[np.nan, np.nan, np.nan],
[1, 1, 1]
])
print(f"Sum across rows and columns: numpy.nansum(tmp) \n{np.nansum(tmp)}")
print(f"Sum for each column: numpy.nansum(tmp,axis=0) \n{np.nansum(tmp,axis=0)}")
print(f"Sum for each row: numpy.nansum(tmp,axis=1) \n{np.nansum(tmp,axis=1)}")
```
## Quiz 6
For our purposes, we want want a sum for each stock series. Which axis do you think we should choose?
## Answer 6
We want to set axis = 0 so that we have a sum for each stock (each column).
## Quiz 7
Create a class TrailingOvernightReturns that inherits from Returns and takes the cumulative weekly sum of overnight returns.
```
class TrailingOvernightReturns(Returns):
"""
Sum of trailing close-to-open returns; we expect sentiment persistence at short horizons, so we
look at the 5-day (ie., 1 week) window
"""
# TODO: choose a window_length to calculate a weekly return
window_length = 5
# TODO: set inputs to a list containing the daily close to open returns
# Filter the close to open returns by our stock universe
inputs = [CloseToOpenReturns(mask=universe)]
def compute(self, today, assets, out, close_to_open):
#TODO: calculate the sum of close_to_open
#choose the axis so that there is a sum for each stock (each column)
#treat NaN as zeros
out[:] = np.nansum(close_to_open, axis=0)
```
## Quiz 8
Create a factor by instantiating the TrailingOvernightReturns class that you just defined. Demean by sector, rank and covnert to a zscore.
```
# TODO: create an overnight_returns_factor variable
overnight_returns_factor = (
TrailingOvernightReturns().
demean(groupby=Sector()).
rank().
zscore()
)
# create a pipeline called p
p = Pipeline(screen=universe)
p.add(overnight_returns_factor, 'Overnight_Sentiment')
```
## Visualize pipeline
```
p.show_graph(format='png')
```
## run pipeline and view the factor data
```
df = engine.run_pipeline(p, factor_start_date, universe_end_date)
df.head()
```
## Visualize factor returns
These are returns that a theoretical portfolio would have if its stock weights were determined by a single alpha factor's values.
```
from quiz_helper import make_factor_plot
make_factor_plot(df, data_portal, trading_calendar, factor_start_date, universe_end_date);
```
## Solutions
Check out the [solution notebook here.](./overnight_returns_solution.ipynb)
| github_jupyter |
## Lab 5.3 - CNN for cats and dogs
Now that we have imported our custom image data, formatted them as proper feature and target numpy arrays, and split them between individual training and test data sets, we can use Keras to create another Convolutional Neural Network (CNN) and train it to classify images of cats and dogs (the holy grail of Arificial Intelligence!)
First, let's use the pickle library to bring in the data sets we generated in the previous part of the lab:
```
import pickle
pickle_file = '-catsdogs.pickle'
with open(pickle_file, 'rb') as f:
save = pickle.load(f)
X_train = save['X_train']
y_train = save['y_train']
X_test = save['X_test']
y_test = save['y_test']
del save # hint to help gc free up memory
print('Training set', X_train.shape, y_train.shape)
print('Test set', X_test.shape, y_test.shape)
```
Now that the data is imported, go through and implement the CNN from scratch based on the one developed in Lab 5.1.
Experiment with different hyper-parameters as well as different architectures for your network. If you're not getting the results you want try a deeper network by adding more convolutional or fully connected layers. Remember that with CNN's, all convolutional layers should go in the beginning, and the fully connected layers should go at the end. You can also try to make the network 'wider' by adding more depth to each convolutional layer or more neurons to the fully connected layers. If you are noticing problems with over-fitting you can experiment with larger dropout rates or other regularlization strategies.
You can also experiment with filters of a larger size in the convolutional layers. Larger filters will capture more information in the image at the expense of longer training times. For more information about the tradeoffs between depth and width in a CNN, you can read this paper:
https://arxiv.org/pdf/1409.1556.pdf
Known as the 'VGG paper', this research is currently one of the state-of-the-art benchmarks for image recognition using CNN's. The authors' hypothesis for the paper was that depth in a CNN (total number of layers) is much more important than the size of the filters or the depth within each convolutional layer. Thus they used very small filter sizes (only 3x3) but focused on making the networks as deep as possible. If you are still getting poor results and want to develop a deeper network, a good place to start would be to try to implement one of the networks from the 'VGG paper'. The deepest ones will probably take too long to train without having a dedicated graphics card, but you should be able to train one of the medium ones (for example network 'B') using just the virtual machine developed in the first lab.
Just like when we initially loaded the data, with large networks you again run the risk of overloading your RAM memory, which will either throw an error during model compilation or training, or cause your Python kernel to crash. If you run into these issues, try reducing the complexity of your network (either using less layers, or reducing the depth of each layer) or using a smaller mini-batch size. If you are using the virtual machine, your RAM will be quite limited so you will not be able to train very deep or complex networks. This is ok for the demonstration purposes of the class, but for your own work you may want to use a native installation of Python and the related libraries so that you can use the full potential of your computer.
Ofcourse classifying dogs and cats is a much more difficult problem than digit classification, so you should not expect to reach the same level of performance we did before. With an average sized network training over night on the virtual machine, you should be able to get at least 80% accuracy on the test dataset. Once you get a result you like, submit your work on this file as a pull request back to the main project.
```
## implement your CNN starting here.
import numpy as np
np.random.seed(1337) # for reproducibility
#from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
from keras import backend as K
#from keras.datasets import mnist
import pickle
K.set_image_dim_ordering('tf')
num_classes = 2
img_rows, img_cols = X_train.shape[1], X_train.shape[2]
print X_train.shape
print img_rows, img_cols
if K.image_dim_ordering() == 'th':
X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols)
X_test = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
Y_train = np_utils.to_categorical(y_train, num_classes)
Y_test = np_utils.to_categorical(y_test, num_classes)
print X_train.shape
print y_train.shape
%matplotlib inline
from matplotlib.pyplot import imshow
import matplotlib.pyplot as plt
img_num = 0
img = X_train[img_num][:,:,0]
print img.shape
print y_train.shape
imshow(img, cmap = plt.get_cmap('gray'), vmin = 0, vmax = 1, interpolation='nearest')
# model hyperparameters
batch_size = 128
nb_epoch = 30
# network architecture
patch_size_1 = 3
patch_size_2 = 3
patch_size_3 = 3
depth_1 = 20
depth_2 = 40
depth_3 = 60
pool_size = 2
num_hidden_1 = 1000
num_hidden_2 = 1000
num_hidden_3 = 1000
dropout = 0.5
# create new Keras Sequential model
model = Sequential()
# add first convolutional layer to model and specify it's depth and filter size
# for the first layer we also have to specify the size of each input image
# which we calculated above
model.add(Convolution2D(depth_1, patch_size_1, patch_size_1,
border_mode='valid',
input_shape=input_shape))
# apply 'relu' activation function for first layer
model.add(Activation('relu'))
# apply max pooling to reduce the size of the image by a factor of 2
model.add(MaxPooling2D(pool_size=(pool_size, pool_size)))
# repeat these operations for the second convolutional layer
# this time Keras can figure out the input size
# from the previous layer on it's own
model.add(Convolution2D(depth_2, patch_size_2, patch_size_2,
border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(pool_size, pool_size)))
#extra below:
model.add(Convolution2D(depth_3, patch_size_3, patch_size_3,
border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(pool_size, pool_size)))
# flatten the three-dimensional convolutional layer to a single layer of neurons
model.add(Flatten())
# add the first fully connected layer, applying 'relu' activation and dropout
model.add(Dense(num_hidden_1))
model.add(Activation('relu'))
model.add(Dropout(dropout))
# add the second fully connected layer
model.add(Dense(num_hidden_2))
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(num_hidden_3))
model.add(Activation('relu'))
model.add(Dropout(dropout))
# add the final classification layer with the number of neurons
# matching the number of classes we are trying to learn
model.add(Dense(num_classes))
# apply the 'softmax' activation to the final layer to convert the output to
# a probability distribution
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch,
verbose=1, validation_data=(X_test, Y_test))
score = model.evaluate(X_test, Y_test, verbose=0)
print 'Test score:', score[0]
print 'Test accuracy: {:.2%}'.format(score[1])
```
| github_jupyter |
<a href="https://colab.research.google.com/github/rajdeepd/tensorflow_2.0_book_code/blob/master/ch04/inception_v3_all_images_25_epochs_colab_modelfit.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
import sys
IN_COLAB = 'google.colab' in sys.modules
print('Google Colab? ' + str(IN_COLAB))
if not IN_COLAB:
#!python -m pip show tensorflow
!which python
!python -m pip show tensorflow
!pwd
from google.colab import drive
drive.mount("/content/gdrive")
!ls "/content/gdrive/My Drive/cancer_detection/metastatic_cancer"
%matplotlib inline
import sys
sys.executable
```
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/applications/vgg19
```
# Imports
import numpy as np
import pandas as pd
from glob import glob
from skimage.io import imread
import os
import shutil
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, roc_auc_score
from sklearn.model_selection import train_test_split
import tensorflow
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras.utils import plot_model
from tensorflow.keras.layers import Dropout, Flatten, Dense, GlobalAveragePooling2D, Average, Input, Concatenate, GlobalMaxPooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import CSVLogger, ModelCheckpoint
from tensorflow.keras.optimizers import Adam
#!pip show tensorflow
TF_VERSION = tensorflow.__version__
TF_VERSION
if IN_COLAB:
BASE = '/content/gdrive/My Drive/cancer_detection/metastatic_cancer'
else:
BASE = '.'
# Output files
model_type='inceptionv3'
no_of_images = 'all'
EPOCHS = 25
if IN_COLAB:
PLOTS = 'plots_'+ TF_VERSION + '_google_collab'
VERSION = TF_VERSION
else:
PLOTS = 'plots_' + TF_VERSION
VERSION = TF_VERSION
_APPEND = '_' + model_type + '_' + str(no_of_images) + '_' + str(EPOCHS)
APPEND = _APPEND + ".png"
if IN_COLAB:
if not os.path.exists(BASE + "/training_logs_" + VERSION):
os.mkdir(BASE + "/training_logs_" + VERSION)
if not os.path.exists(BASE + "/model_summary/"):
os.mkdir(BASE + "/model_summary/")
if not os.path.exists(BASE + "/model_summary/" + "model_summary_" + VERSION):
os.mkdir(BASE + "/model_summary/" + "model_summary_" + VERSION)
if not os.path.exists(BASE + '/' + PLOTS):
os.mkdir(BASE + '/' + PLOTS)
if IN_COLAB:
TRAINING_LOGS_FILE = BASE + "/training_logs_" + VERSION + '/training_logs' + _APPEND + '.csv'
MODEL_SUMMARY_FILE = BASE + "/model_summary/" "model_summary_" + VERSION + "/model_summary" + _APPEND + ".txt"
MODEL_PLOT_FILE = BASE + '/' + PLOTS + "/model_plot_" + APPEND
MODEL_FILE = "model_" + VERSION + "/model_" + model_type + "_all_collab.h5"
TRAINING_PLOT_FILE = BASE + '/'+ PLOTS + "/training" + APPEND
VALIDATION_PLOT_FILE = BASE + '/'+ PLOTS + "/validation" + APPEND
ROC_PLOT_FILE = BASE + '/'+ PLOTS + "/roc" + APPEND
else:
TRAINING_LOGS_FILE = "training_logs_" + VERSION + '/training_logs' + _APPEND + '.csv'
MODEL_SUMMARY_FILE = "model_summary_" + VERSION + "/model_summary" + _APPEND + ".txt"
MODEL_PLOT_FILE = PLOTS + "/model_plot_" + APPEND
MODEL_FILE = "model_" + VERSION + "/model_" + model_type + "_all_collab.h5"
TRAINING_PLOT_FILE = PLOTS + "/training" + APPEND
VALIDATION_PLOT_FILE = PLOTS + "/validation" + APPEND
ROC_PLOT_FILE = PLOTS + "/roc" + APPEND
# Hyperparams
SAMPLE_COUNT = 85000
#TRAINING_RATIO = 0.9
IMAGE_SIZE = 96
IMAGE_SIZE2 = 224
BATCH_SIZE = 192
VERBOSITY = 1
TESTING_BATCH_SIZE = 5000
import pathlib
data_dir = pathlib.Path(BASE)
data_dir
data_dir_training = pathlib.Path(BASE + '/training')
image_count = len(list(data_dir_training.glob('*/*.tif')))
print(image_count)
import PIL
import PIL.Image
zeros = list(data_dir_training.glob('0/*'))
PIL.Image.open(str(zeros[0]))
import PIL
import PIL.Image
zeros = list(data_dir_training.glob('1/*'))
PIL.Image.open(str(zeros[0]))
training_path= BASE + '/training'
validation_path = BASE + '/validation'
# Data augmentation
training_data_generator = ImageDataGenerator(rescale=1./255,
horizontal_flip=True,
vertical_flip=True,
rotation_range=180,
zoom_range=0.4,
width_shift_range=0.3,
height_shift_range=0.3,
shear_range=0.3,
channel_shift_range=0.3)
# Data generation
training_generator = training_data_generator.flow_from_directory(training_path,
target_size=(IMAGE_SIZE2,IMAGE_SIZE2),
batch_size=BATCH_SIZE,
class_mode='binary')
validation_generator = ImageDataGenerator(rescale=1./255).flow_from_directory(validation_path,
target_size=(IMAGE_SIZE2,
IMAGE_SIZE2),
batch_size=BATCH_SIZE,
class_mode='binary')
testing_generator = ImageDataGenerator(rescale=1./255).flow_from_directory(validation_path,
target_size=(IMAGE_SIZE2,IMAGE_SIZE2),
batch_size=BATCH_SIZE,
class_mode='binary',
shuffle=False)
# Model
input_shape = (IMAGE_SIZE2, IMAGE_SIZE2, 3)
inputs = Input(input_shape)
inceptionv3 = InceptionV3(include_top=False, input_shape=(224, 224, 3))(inputs)
outputs = GlobalAveragePooling2D()(inceptionv3)
outputs = Dropout(0.5)(outputs)
outputs = Dense(1, activation='sigmoid')(outputs)
model = Model(inputs, outputs)
model.compile(optimizer=Adam(lr=0.0001, decay=0.00001),
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
plot_model(model,
to_file=MODEL_PLOT_FILE,
show_shapes=True,
show_layer_names=True)
import os
if not os.path.exists("training_logs_" + VERSION):
os.makedirs("training_logs_" + VERSION)
file = open(TRAINING_LOGS_FILE, 'w+')
history = model.fit(training_generator,
steps_per_epoch=len(training_generator),
validation_data=validation_generator,
validation_steps=len(validation_generator),
epochs=EPOCHS,
verbose=VERBOSITY,
callbacks=[#PlotLossesKeras(),
ModelCheckpoint(MODEL_FILE,
monitor='val_accuracy',
verbose=VERBOSITY,
save_best_only=True,
mode='max'),
CSVLogger(TRAINING_LOGS_FILE,
append=True,
separator=';')
])
history.history
# Training plots
common_title = model_type + ' with ' + str(no_of_images) + ' samples'
epochs = [i for i in range(1, len(history.history['loss'])+1)]
plt.plot(epochs, history.history['loss'], color='blue', label="training_loss")
plt.plot(epochs, history.history['val_loss'], color='red', label="validation_loss")
plt.legend(loc='best')
#plt.title('training: ' + common_title)
plt.xlabel('epoch')
plt.savefig(TRAINING_PLOT_FILE, bbox_inches='tight')
plt.close()
plt.plot(epochs, history.history['accuracy'], color='blue', label="training_accuracy")
plt.plot(epochs, history.history['val_accuracy'], color='red',label="validation_accuracy")
plt.legend(loc='best')
plt.title('Validation (TF '+ VERSION + '): ' + common_title )
plt.xlabel('epoch')
plt.savefig(VALIDATION_PLOT_FILE, bbox_inches='tight')
plt.show()
plt.close()
# ROC testing plot
#model.load_weights(MODEL_FILE)
predictions = model.predict_generator(testing_generator, steps=len(testing_generator), verbose=VERBOSITY)
false_positive_rate, true_positive_rate, threshold = roc_curve(testing_generator.classes, predictions)
area_under_curve = auc(false_positive_rate, true_positive_rate)
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(false_positive_rate, true_positive_rate, label='AUC = {:.3f}'.format(area_under_curve))
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve: ' + common_title + ' TF ' + VERSION)
plt.legend(loc='best')
plt.savefig(ROC_PLOT_FILE, bbox_inches='tight')
plt.show()
plt.close()
```
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.