
_id stringlengths 1 6 | text stringlengths 0 7.5k | title stringlengths 0 167 |
|---|---|---|
95777 | من در درک تحلیل میانجی که اخیراً انجام دادم مشکل دارم. من از ماکرو Sobel Preacher & Hayes (2004) برای SPSS استفاده کردم. نتایج به این صورت است: ضریب تأثیرات مستقیم و کلی s.e. t Sig(دو) b(YX) ,1626 ,0526 3,0908 ,0035 b(MX) ,2954 ,0897 3,2948 ,0020 b(YM.X) ,2116 ,0959 2,2064,Y م)، 1263 ,0538 2,3462,0236 TOTAL EFEC... | اهمیت میانجیگری |
83646 | > یک فروشنده کازینو مشکوک است که مرگ او یک مرگ منصفانه نیست. او فکر می کند که دای شانس بیشتری به اعداد زوج می دهد (احتمال یک عدد زوج > بزرگتر از $0.5 است). او برای آزمایش مظنونان خود تصمیم به انجام یک آزمایش > می گیرد، او نتیجه ی رول های قالب مستقل 60 دلاری را یادداشت می کند. فروشنده میگوید که اگر تعداد اعداد زوج در آ... | یافتن ناحیه رد یک مورد معین |
72636 | فرض کنید که $X$، $Y$ و $Z$ $\text{i.i.d.} \sim \text{Uniform}(0,1)$ هستند. اجازه دهید $t > 0$ یک ثابت ثابت باشد. (i) محاسبه $P(X/Y \leq t)$ (ii) محاسبه $ P(XY \leq t)$ (iii) محاسبه $ P(XY/Z \leq t)$ من راه حل (i) را پیدا کردم ) بخشی که مقادیر مختلف $t$ را تضعیف می کند. $ P(X/Y \leq t) = \int_0^1\int_0^{yt}dx dy = t/2... | محاسبه احتمال |
66346 | من یک مدل مارکوف مخلوط (شامل خوشههای K یا مؤلفهها) دارم که سعی میکنم آن را آموزش دهم، به عنوان مثال، خوشهبندی را روی مجموعهای از توالیهای طول متفاوت انجام دهم. هر جزء از مدل یک زنجیره مارکوف مرتبه اول است. مدل با موارد زیر تعریف می شود:  که در آن ... | اجرای خوشهبندی EM برای مدل مارکوف مخلوط |
114863 | طبق آنچه من دیده ام، فرمول هموارسازی Kneser-Ny (مرتبه دوم) به نوعی به صورت $ \begin{align} P^2_{KN}(w_n|w_{n-1}) و= \ frac{\max \left\\{ C\left(w_{n-1}, w_n\right) - D, 0\right\\}}{\sum_{w'} C\left(w_{n-1}, w'\right)} + \lambda(w_{n-1}) \times P_{cont}(w_n) \end{تراز} $ با ضریب عادیسازی $\lambda (w_{n-1})$ به صورت $ \... | در هموارسازی کنسر-نی، کلمات غیبی چگونه مدیریت می شوند؟ |
50254 | نمیدانم این انجمن درستی برای این کار است یا نه، اما اینجا میگویم: من سعی میکنم یک مدل مارکوف پنهان را پیادهسازی کنم تا بتوانم بهترین دنباله/مسیر را برای یک فایل آموزشی پیشبینی و پیدا کنم. تا کنون، من ضرایب (MFCC) یک سیگنال را دارم و به دنبال آموزش آن هستم تا بتوانم (دو مجموعه داده) را با استفاده از الگوریتم Viterb... | مدل مارکوف پنهان با ضرایب MFCC |
79629 | من در حال توسعه یک HMM (یا DBN) برای تشخیص هوشیاری از مشاهدات سری زمانی بسته شدن چشم هستم. هوشیاری به عنوان یک متغیر باینری (هوشیار یا غیر هوشیار) تعریف می شود. در حالی که من چارچوب کلی و مفروضات HMM ها را درک می کنم، در مورد مفهوم مشاهدات یا انتشارات کمی سردرگم هستم. به طور خاص چه چیزی می تواند به عنوان یک مشاهده استف... | محدودیت در نوع مشاهدات HMM |
68915 | من سعی می کنم از خوشه بندی k-means برای پروفایل رفتار استفاده از دستگاه تلفن همراه برای کاربران فناوری اطلاعات استفاده کنم. دادههای من شامل متغیرها/خوانشهای سطح کاربر و سیستم مختلف مانند تعداد تماسها/اس ام اس، استفاده از پردازنده/حافظه، تعداد کاربران و برنامهها/سرویسهای سیستم و غیره است. قرائتها هر 5 دقیقه انجام ... | K-به معنی خوشه بندی برای پروفایل استفاده است |
50256 | چگونه می توانم یک تخمین هیستوگرام از این توزیع حاشیه ای را رسم کنم: p(x1): وارد کردن numpy به عنوان np import matplotlib.pyplot به عنوان plt از scipy.stats norm import linalg = np.linalg N = 100 mean = [1,1] cov = [ [0.3، 0.2]، [0.2، 0.2]] داده = np.random.multivariate_normal(mean, cov, N) L = linalg.cholesky(cov) # pr... | ترسیم تخمین هیستوگرام همراه با حل تحلیلی پارامترهای میانگین و کوواریانس |
64779 | من یک طبقهبندیکننده دارم و برای ارزیابی عملکرد آن از اعتبارسنجی متقاطع استفاده میکنم. در هر تکرار، مجموعه داده را به مجموعه های آموزشی و آزمایشی تقسیم می کنم. مجموعه تست فقط موضوعی است که قرار است آن را ارزیابی کنم (یکی را کنار بگذارید). اکنون، مجموعه آموزشی را **تقسیم میکنم** و انتخاب ویژگی را به این صورت انجام می... | انتخاب ویژگی در مجموعه آموزشی |
66342 | در یک مدل کاکس، مدل خطر متناسب را می توان به عنوان مثال: stset end، شکست (x==1) enter(start) مبدا (شروع) مقیاس (365.25) stcox a b c d estat phtest stphtest، detail /*test برای خطرات متناسب آزمایش کرد. */ stphplot، توسط (a) * ترسیم خطرات مختلف بر اساس زمان stphplot، توسط (b) stphplot، by(c) stphplot، by(d) stphplot، by(... | آزمون خطر متناسب وایبول و پواسون - داده های بقای آمار |
109532 | من مجموعه داده ای از 300 مشاهده دارم که 200 مشاهده طبیعی است و بقیه بیماری را دارند. من نمرات ارزیابی شناختی این 300 شرکتکننده را دارم، و ارزیابی به بخشهای مختلفی تقسیم میشود: هذیان، افسردگی، اضطراب، و غیره. و اینکه آیا امتیاز بخش خاصی می تواند پیش بینی خوبی برای ابتلای شرکت کننده به این بیماری باشد یا خیر. من از رگ... | چند تکنیک داده کاوی برای تجزیه و تحلیل علت بیماری چیست؟ |
95779 | سوال من در مورد تعداد مورد نیاز شبیه سازی برای روش تحلیل مونت کارلو است. تا آنجا که من می بینم تعداد مورد نیاز شبیه سازی برای هر درصد خطای مجاز $E$ (به عنوان مثال، 5) $$ n = \left\\{\frac{100 \cdot z_c \cdot \text{std}(x) است. }{E \cdot \text{mean}(x)} \right\\}^2 , $$ که $\text{std}(x)$ استاندارد است انحراف نمونهگیری... | تعداد شبیه سازی مورد نیاز برای تحلیل مونت کارلو |
72635 | وقتی دو نمونه به هم مرتبط یا وابسته هستند، اما مشاهدات مطابقت ندارند، آیا آزمایشی وجود دارد که تعیین کند که آیا نمونه ها (میانگین یا غیر آن) متفاوت هستند؟ من به طور گسترده جستجو کرده ام و فقط آزمایش هایی را برای نمونه های همسان پیدا کرده ام، که چیزی نیست که نیاز دارم. | تفاوت بین (میان) نمونه های مرتبط، اما مطابقت ندارند را آزمایش کنید |
111301 | من روی پروژهای کار میکنم که به ویژگیهای تمایز 6 و 5 درجهای لیکرت در یک مقیاس نگاه میکند. من از بسته ltm در R استفاده می کنم تا این را در یک پارادایم نظریه پاسخ آیتم (irt) با استفاده از یک مدل پاسخ درجه بندی شده (grm) بررسی کنم. برای هر مورد، یک مقدار تبعیض به من داده می شود که با شیب ICC در هر سطح با توجه به سطح ت... | تفسیر مقادیر تبعیض در مدلهای چندتومی IRT (grm). آیا برش یا لنگر وجود دارد؟ |
72631 | من یک سوال نظری در مورد یادگیری ماشین از نظر خوشه بندی می پرسم. آیا ممکن است با توجه به مجموعه ای از داده های کلاس هایی که دانش آموزان در یک ترم گذرانده اند، کلاس های اضافی را توصیه کنیم که دانش آموزان در صورت انتخاب کلاس ها باید در آنها شرکت کنند؟ من در امتداد خط تشکیل خوشههای کلاسها فکر میکنم و متوجه میشوم که آیا... | الگوریتمها/رویکردهای یادگیری ماشین برای توصیههای کلاس؟ |
79625 | من تازه وارد بیزی هستم و هنوز در تلاش برای کشف جزئیات این فرآیند هستم. در جایی خواندم که یکی از مزایای تخمین بیزی این است که به صرفه جویی در درجات آزادی کمک می کند و زمانی که تعداد نقاط داده کمتر و تعداد پارامترهای بیشتری وجود دارد می توان از آن استفاده کرد. آیا کسی می تواند به این موضوع بپردازد؟ من میدانم که ربطی به ... | بیزی در مقابل OLS درجات آزادی آیا برای تخمین بیزی باید در مورد d.o.f زحمت بکشیم؟ |
66347 | برای خواندن نتایج تحلیل رگرسیون برای پایان نامه کارشناسی ارشدم که باید هفته آینده تحویل بدهم، به کمک شما فوری نیاز دارم. DV من لگاریتم طبیعی مخارج تحقیق و توسعه است، IV یک متغیر ساختگی است با برچسب **نزول**، که در آن 1 = شرکت در حال کاهش است و 0 = شرکت در حال کاهش نیست. ناظر مالکیت مدیریتی است که بر حسب درصد (0-100٪ یا... | تفسیر تعامل بین ساختگی IV و تعدیل کننده پیوسته با log DV |
114865 | من در حال تجزیه و تحلیل دادههایی هستم که در مورد آنها ظن قوی دارم که مشابه خود هستند (پارامتر هرست بسته به روش تخمین و توالی نمونه از 0.60 تا 0.78 متغیر است). من همچنین مقادیر بالای تحقق را بسیار بیشتر مشاهده میکنم (در مقایسه با آزمایشهایی که هیچ شباهتی به خود مشکوک نیست) که نشان میدهد توزیع مولد میتواند دم بلند (... | تئوری ارزش افراطی و توزیعهای دنباله دار سنگین (طولانی). |
79622 | از اینکه برای خواندن این وقت گذاشتید متشکریم. من با یادگیری ماشینی تازه کار هستم و به همین دلیل در رقابت Kaggle شرکت می کنم تا به من کمک کند پیشرفت کنم، اما یک سوال دارم. چگونه می توانم طبقه بندی های مختلف را مقایسه کنم؟ پایتون من آنقدرها که میخواهم مرتب نیست، اما فکر میکنم درست است. لطفاً اگر کار عجیبی انجام می دهم ... | مقایسه طبقهبندیکنندههای مختلف (با استفاده از مقادیر اعتبارسنجی متقاطع کیت اسکی) |
111305 | می توان نشان داد که برای یک نمونه iid از توزیع یکنواخت(0، 1)، \begin{equation} n(1-U_{(n)}) \rightarrow exp(1) \\\ n(U_{(1) )}) \rightarrow exp(1) \end{equation} برای مشاهده این، کافی است تابع توزیع سمت چپ را پیدا کنید و سپس حد را به بی نهایت ببرید. اکنون، معلوم می شود که می توانیم نشان دهیم که آنها در واقع مجانبی مستق... | توزیع مجانبی آمار سفارش یکنواخت |
114868 | من مطالعه ای دارم که در آن یک پیش بینی کننده جدید (دودویی) برای یک بیماری (همچنین یک متغیر باینری) ایجاد کرده ام. مطالعه دارای دو بخش است. در قسمت اول، می خواهم آزمایش کنم که آیا پیش بینی کننده من به شدت با بیماری مرتبط است یا خیر. من در حال برنامه ریزی برای استفاده از آزمون کای اسکوئر در جدول پیش بینی کننده در مقابل ب... | رگرسیون لجستیک، مجذور کای و طراحی مطالعه |
61692 | به روز رسانی: من اطلاعات مهمی را در توضیحات قبلی خود حذف کردم... من در واقع با مشکل خاصی روبرو هستم که بهتر است به شرح زیر توضیح داده شود: با توجه به پارامترهای مشخص شده توسط کاربر $\alpha$ و $\beta$ (که در آن $0 <\ آلفا < \frac{1}{n+1}$, $\beta > 0$)، حداقل یک $n$-بردار $A=[a_1,a_2,....,a_N]$ ایجاد کنید به طوری که: $[... | تولید بردارها تحت محدودیت های 1 و 2 هنجار |
61693 | من در حال حاضر در حال گذراندن دوره PGM توسط Daphne Koller در Coursera هستم. در آن، ما به طور کلی یک شبکه بیزی را به عنوان گراف علت و معلولی متغیرهایی که بخشی از داده های مشاهده شده هستند، مدل می کنیم. اما در آموزشها و مثالهای PyMC، من به طور کلی میبینم که کاملاً شبیه به PGM مدلسازی نشده است یا حداقل گیج شدهام. در ... | استنتاج شبکه بیزی با استفاده از pymc (گیج شدن مبتدیان) |
34796 | من از بسته svydesign در R برای اجرای رگرسیون های لاجیت وزن دار نظرسنجی به صورت زیر استفاده می کنم: sdobj <- svydesign(id = ~ 0, weights = ~chweight, strata = ~strata, data = svdat) model1 <- svyglm(formula=formula1 ,design=sdobj,family = quasibinomial) با این حال، مستندات یک هشدار در مورد رگرسیون بدون تعیین اصلاحات جمع... | بررسی رگرسیون وزنی بدون FPC در R |
34791 | من می خواهم از معیار اطلاعات Akaike (AIC) برای انتخاب تعداد مناسبی از عوامل برای استخراج در PCA استفاده کنم. تنها مسئله این است که من مطمئن نیستم چگونه تعداد پارامترها را تعیین کنم. یک ماتریس $T\times N$ $X$ را در نظر بگیرید، که در آن $N$ نشان دهنده تعداد متغیرها و $T$ تعداد مشاهدات است، به طوری که $X\sim N\left(0,\Sig... | انتخاب مدل PCA با استفاده از AIC |
26715 | من در یک موضوع از تحلیل مدلسازی موضوع سردرگم هستم. وقتی تحلیل مدلسازی موضوع را بر روی مجموعهای از اسناد انجام میدهیم، آیا باید مجموعهای از فهرست نامزدهای موضوع را به عنوان ورودی تجزیه و تحلیل ارائه کنیم؟ یا موضوعات به دست آمده فقط از خود اسناد ورودی استخراج می شوند؟ | با توجه به لیست نامزدهای موضوع برای تحلیل مدلسازی موضوع (LDA) |
79628 | من در حال گذراندن دوره تحلیل داده های کوچک با استفاده از نرم افزار SAS هستم. تقریباً به من گفته شد که نتایج را با استفاده از دادهها و توضیحات ارائه شده در یک صفحه StatSci خاص تولید کنم که میخواهم آن را در اینجا کپی کنم: > **موسسه ورزش استرالیا** > > کلمات کلیدی: رگرسیون چندگانه، یک یا تجزیه و تحلیل واریانس دو طرفه، ع... | چگونه می توان نتایج موسسه ورزش استرالیا را تکرار کرد؟ |
77375 | من خوانده ام (به عنوان مثال در اینجا) که یک رگرسیون لجستیک (چند جمله ای) با یک طبقه بندی کننده آنتروپی حداکثر مطابقت دارد. سوال من این است که چگونه می توان به فرمول رگرسیون لجستیک که با اصل آنتروپی حداکثر شروع می شود، خاتمه داد؟ | رگرسیون لجستیک و حداکثر آنتروپی |
18215 | به خوبی شناخته شده است که فواصل اطمینان و آزمون فرضیه های آماری به شدت مرتبط هستند. سوالات من بر مقایسه میانگین ها برای دو گروه بر اساس یک متغیر عددی متمرکز است. بیایید فرض کنیم که چنین فرضیه ای با استفاده از آزمون t تست شده است. از طرف دیگر، می توان فواصل اطمینان را برای میانگین هر دو گروه محاسبه کرد. آیا رابطه ای بین... | رابطه بین فاصله اطمینان و آزمون فرضیه آماری برای آزمون t |
50250 | من سعی می کنم توزیع Weibull را به یک مجموعه داده در R برازم. من یک مجموعه داده loss به عنوان یک فایل csv. دارم و از fitdistr(loss,invexp) استفاده می کنم. من این پیام را دریافت کردم: > شکست infitdistr(از دست دادن، invweibull): توزیع پشتیبانی نشده چگونه می توانم توزیع معکوس Weibull را به یک مجموعه داده در R تطبیق دهم؟ * ... | برازش معکوس توزیع Weibull به داده ها در R |
37951 | مدتی است که برای سمینار خود به دنبال یک مطالعه مقدماتی خوب در مورد Copulas هستم. من در حال یافتن مطالب زیادی هستم که در مورد جنبه های نظری صحبت می کند، که خوب است، اما قبل از اینکه به آنها بپردازم، به دنبال ایجاد یک درک شهودی خوب در مورد موضوع هستم. آیا کسی می تواند مقاله خوبی را پیشنهاد کند که پایه و اساس خوبی برای یک... | خواندن مقدماتی در Copulas |
24636 | > **تکراری احتمالی:** > چگونه یک نمودار پراکنده زیبا در R انجام دهیم؟ چگونه از ggplot برای انجام نمودارهای چندک binned (یک نوع نمودار پراکندگی) استفاده کنیم؟ سلام به همه، من طرح پراکندگی را انجام دادم: plot(x, y). حالا میخواستم پلات های کوانتیل binned انجام بدم... ggplot2 میتونه کمکم کنه؟ به عنوان مثال، داده های x را د... | چگونه از ggplot برای انجام نمودارهای چندک binned (یک نوع نمودار پراکندگی) استفاده کنیم؟ |
28744 | این یک سوال بسیار ساده است اما من نمی توانم آن را در هیچ کجای اینترنت یا کتاب پیدا کنم. من می خواهم ببینم که چگونه یک بیزی توزیع نرمال چند متغیره را به روز می کند. برای مثال: تصور کنید که $$ P({\bf x}|{\bf μ},{\bf Σ}) = N({\bf \mu}, {\bf \Sigma}) \\\ P({ \bf \mu}) = N({\bf \mu_0}, {\bf \Sigma_0}) $$ پس از مشاهده مجموعه... | خلفی نرمال چند متغیره |
67968 | من یک مجموعه داده در هر دقیقه ضبط می کنم. با استفاده از تست توکی برای تشخیص پرت (به عنوان مثال، اگر تعداد نقاط بالاتر از Q2 + 2.3IQR بالای 10٪ از توزیع کل باشد) سپس پنجره یک دقیقهای را بهعنوان غیرعادی علامتگذاری میکنم. در دقیقه اول خوب کار می کند. در واقع، سیستم رفتار را برای چند دقیقه آینده ادامه میدهد و الگوریتم... | تشخیص بیرونی با استفاده از قانون میانی |
92465 | من یک مدل لاجیت مختلط را با glmer اجرا کردهام و شی glmer حاصل را به عنوان یک فایل Rdata در دیسک ذخیره کردهام. اما وقتی آن را بارگذاری میکنم و با استفاده از print (myglmerobject,corr=0) آن را چاپ میکنم، لیستی از متغیرها، همبستگیها، و غیره را میبینم تا نتایج خوبی که این دستور ایجاد میکند. آیا ایده ای دارید که چگون... | شی glmer ذخیره شده در R به درستی در R نشان داده نمی شود |
111302 | دنباله ای برای این سوال من یک مجموعه داده دارم که در آن: * $\frac{4}{5}$ از نقاط از: $(x, y) \sim \mathcal{U}_{2}(0,30)$, $( z) \sim \mathcal{U}_{1}(14.5، 15.5)$. * $\frac{1}{5}$ از نقاط از: $(x, y, z) \sim \mathcal{U}_{3}(0,30)$ از کجا $\mathcal{U} گرفته شده است _{d}(x,y)$ باید به عنوان یک مجموعه بعدی $d$ از نقاط تف... | چگونه می توانم چگالی این مجموعه داده را که از دو توزیع سه بعدی مختلف تشکیل شده است محاسبه کنم؟ |
67964 | بگذارید دو نقطه در مختصات قطبی $(r_i، \theta_i)$ و $(r_j, \theta_j)$ نقاط هذلولی در $\mathbb{H}^2_\zeta$ با انحنای $K=-\zeta^2$ باشند. مختصات شعاعی این نقاط به صورت نمایی با توان $\alpha$ توزیع شده است: $p(r) = \alpha e^{\alpha(r - R)}$ با $R \approx \ln(N)$ (شعاع) از دیسک پوانکاره)، $N$ تعداد نقاط این دیسک است، توان $... | توزیع فاصله هذلولی بین نقاط تصادفی در دیسک پوانکاره |
111303 | من برخی از داده ها را دارم که تعداد دفعاتی است که یک فرد طی یک دوره 5 دلاری سال به مطب پزشک مراجعه کرده است. من میخواهم مدلی ایجاد کنم که بتواند محتملترین تعداد شمارشهایی را که یک فرد ممکن است به مطب پزشکان مراجعه کند، پیشبینی کند. وقتی به هیستوگرام توزیع شمارش نگاه کردم متوجه شدم که به درستی انحراف دارد، بنابراین ... | مدل پیش بینی از داده های شمارش |
23293 | من یک شی دارم: noise.lm این فقط یک مدل خطی ساده با X و Y است. وقتی resid(noise.lm) را تایپ میکنم، باقیماندهها را مانند این تولید میکند: 1 2 3 4 5 6 -0.40501681 -1.16960373 -0.66636219 - 0.41798296 1.37942381 0.84336242 من می خواهم به مقادیر باقیمانده بدون اعداد مشاهده دسترسی داشته باشم، شاید با ایجاد یک قاب داده ما... | چگونه می توانم خروجی باقیمانده را در یک متغیر دریافت کنم یا مانند یک قاب داده در R عمل کنم؟ |
77378 | آیا روشهای پیشبینی ناپارامتریک آماری خوبی در کنار روشهای یادگیری ماشینی مانند شبکههای عصبی/درختهای تصمیمگیری و غیره برای تحلیل سریهای زمانی وجود دارد؟ اگر چنین است، آیا بسته های R وجود دارد که آنها را پیاده سازی کند؟ با تشکر | آیا روش های پیش بینی ناپارامتریک وجود دارد؟ |
77376 | ما در اجرای مدل های خطی تعمیم یافته با داده های متناسب مشکل داریم. به عنوان مثال، ما دادههایی مانند این داریم: گونهها (رژیم غذایی) افراد در جنگل کل افراد نسبت جنگل X حشرهخوار 300.5 500.7 0.60 Y Frugivore 32.3 47.6 0.67 و میخواهیم تعیین کنیم که آیا این صفت بر نسبت افراد در جنگل تأثیر میگذارد یا خیر. توجه داشته باشی... | مدل های خطی تعمیم یافته با نسبت های پیوسته |
114860 | من انتخاب متغیر را با استفاده از کمند انجام می دهم. برای توضیح متغیر پاسخم، چندین پیشبین، هم مقولهای و هم عددی دارم، اما برای توضیح فرآیندی که زیربنای آن زمانی است که Lasso فقط یک دسته را از یک متغیر با چندین دسته انتخاب میکند، مشکل دارم. برای مثال، یکی از پیشبینیکنندههای من یک متغیر دستهبندی با چهار سطح است و L... | انتخاب متغیر: چرا دسته بندی های خاصی انتخاب می شوند اما دسته های دیگر انتخاب نمی شوند؟ |
92791 | من میدانم که آزمون بارتلت به این موضوع مربوط میشود که آیا نمونههای شما از جمعیتهایی با واریانسهای مساوی هستند یا خیر. اگر نمونهها از جمعیتهایی با واریانسهای مساوی باشند، در رد فرضیه صفر آزمون شکست میخوریم و بنابراین تحلیل مؤلفههای اصلی نامناسب است. من مطمئن نیستم که مشکل این وضعیت (داشتن یک مجموعه داده homosk... | چرا کرویت تشخیص داده شده توسط تست بارتلت به معنای نامناسب بودن PCA است؟ |
61697 | چگونه میتوان تابع تولید لحظه توزیع چندجملهای، $\underline{X} \sim \mathrm{multinomial}(n, \underline{p})$ را پیدا کرد؟ من می دانم که طبق تعریف ما $$M_X (\underline{\theta}) = \mathbb{E} \exp{(\underline{\theta}^T X)} = \mathbb{E} \exp{\sum_{ داریم i=1}^k \theta_i X_i }$$ اما نمیتوانم ببینم چگونه میتوانیم از اینجا ب... | تابع مولد لحظه توزیع چندجمله ای |
23292 | تا آنجایی که من می دانم، LARS مشکل زیر را حل می کند (با استفاده از علامت گذاری مشابه افرون و همکاران. رگرسیون کمترین زاویه): > با توجه به یک بردار y و یک ماتریس X. چند بردار ستونی را از X انتخاب کنید، و > y را به صورت یک بیان کنید. ترکیب خطی این بردارهای ستونی. در مشکل من، من مجموعه ای از بردارها دارم که می توانند یک م... | حداقل رگرسیون زاویه برای مجموعه ای از بردارها؟ |
24419 | من مجموعهای از اسناد دارم و میدانم که ممکن است یک موضوع واحد را به اشتراک بگذارند. آیا راهی برای شناسایی این موضوع وجود دارد؟ من می دانم که LDA (تخصیص دیریکله نهفته) یک رویکرد است. اما نتیجه LDA این است که هر سند را با مجموعه ای از موضوعات مرتبط می کند. با این حال، من بیشتر علاقه مند به یافتن یک موضوع مشترک هستم که ب... | رویکرد برچسب گذاری مجموعه ای از اسناد با استفاده از یک موضوع مشترک |
24414 | فقط در مورد دو گزینه در کلاس scikits SVM کنجکاو هستم. کسی میدونه مقیاس C و کوچک کردن چیکار میکنه؟ متاسفانه در مستندات زیاد نیست. با تشکر | گزینه های SVM در scikit-learn |
114861 | من در محاسبه خطر تجمعی در یک بازه زمانی کمی سردرگم هستم. ما می دانیم که $H(t)=\int^{t}_{0}h(u)du$، اگر $\Delta t=t_1-t_0$ (1) $H(\Delta t)=\ داشته باشم int^{\Delta t}_{0}h(u)du$ (2) $H(\Delta t)=\int^{t_1}_{0}h(u)du-\int^{t_0}_{0}h(u)du$. کدام یک صحیح است؟ (1) یا (2)؟ احساس کردم (1) ممکن است درست باشد. | خطر تجمعی یک بازه زمانی را محاسبه کنید |
26717 | من اطلاعاتی در مورد حضور بیماران در یک سری جلسات مشاوره دارم. در هر جلسه، یک بیمار می تواند A، S یا D باشد. هر بیمار برای 12 جلسه داده دارد و 100 بیمار وجود دارد. من به چگونگی همبستگی خودکار متغیرها علاقه مند هستم. من فقط میتوانم جدولهای 3×3 (مثلاً) زمان 1 در مقابل زمان 2، زمان 1 در مقابل 3، زمان 2 در مقابل 3، و غیره... | همبستگی خودکار متغیر اسمی |
28748 | در اینجا یک مشکل احتمال وجود دارد: شما مشاهده می کنید که به طور متوسط هر 5 دقیقه در یک جاده 5/0 اتومبیل از جلوی شما عبور می کنند. احتمال دیدن حداقل 1 ماشین در 10 دقیقه چقدر است؟ من سعی می کنم این را از 2 راه حل کنم. راه اول این است که بگوییم: P (بدون ماشین در 5 دقیقه) = 1 - 0.5 = 0.5. P (بدون ماشین در 5 دقیقه اول و ب... | احتمال حوادث |
77374 | مفروضات مدل سازی ARIMA / Box-Jenkins برای پیش بینی سری های زمانی چیست؟ | مفروضات مدل سازی ARIMA برای پیش بینی سری های زمانی چیست؟ |
73272 | من این مشکل را هنگام استفاده از شیب صعود دارم. من مقداری داده مصنوعی دارم و پس از اولین تکرار، تابع هدف کاهش می یابد و از تکرار دوم همچنان افزایش می یابد. آیا برای تابع محدب امکان پذیر است؟ من همچنین نرخ یادگیری بسیار پایین 0.001 دارم. هر گونه پیشنهاد | مسائل مربوط به محاسبه عملیات نزول گرادیان |
113097 | از آنچه که من متوجه شدم، آرگومان cp به تابع rpart به همان روشی که آرگومان های minsplit یا minbucket پیش از هرس درخت کمک می کند. چیزی که من نمی فهمم این است که مقادیر CP چگونه محاسبه می شوند. به عنوان مثال df<-data.frame(x=c(1،2،3،3،3،4)، y=as.factor(c(TRUE، TRUE، FALSE، TRUE، FALSE، FALSE))، روش= class) mytree<-rpart(y... | چگونه مقادیر CP (پیچیدگی هزینه) در RPART (یا درخت های تصمیم به طور کلی) محاسبه می شوند. |
112700 | من یک داده طولی دارم که شبیه این است. تعداد نقاط زمانی برای هر شناسه متفاوت است. Y متغیر پاسخ باینری است (مقادیر 0 و 1 را بگیرید) و X1-X20 یا ویژگی های پیوسته یا طبقه ای هستند. شناسه نقطه زمانی X1 X2 ...X20 Y 1 09/19/2009 1 09/27/2010 2 02/05/2009 2 02/27/2010 2 03/01/2011 مقادیر گمشده ای برای X1-X20 نشان داده شده توسط... | انتخاب ویژگی برای داده های طولی |
55020 | رکوردهای داده شده برای یک تیم در 2 ترم پاییز و بهار. می خواهیم بررسی کنیم که آیا بین ترم پاییز یا بهار و نتیجه برد یا باخت رابطه وجود دارد یا خیر. آیا می توان از آزمون کای دو استفاده کرد؟ نمونه ای از داده های پاییز، برد بهار، برد باخت، برد باخت، برد باخت، برد برد، برد باخت، باخت باخت، برد باخت، باخت با تشکر فراوان | تست مجذور کای برای بررسی رابطه بین فصل و برد/باخت |
91846 | من در تلاش برای بیان یک عملیات 2 مرحلهای در نماد ماتریسی، خودم را گیج کردهام - دادهها شامل 2 تکه اطلاعات است - مقدار اقلام مشابه فروخته شده در فروشگاههای مختلف و قیمت آنها در هر فروشگاه. فرض کنید من دادهها را در قالب زیر دارم-- * * * فرض کنید ا... | سوال در مورد علامت گذاری عملیات ماتریس |
66343 | من برخی از مقالات و مطالب دیگر را در مورد ارزیابی سیستم های توصیه گر (RS) خوانده ام. اکثر آنها در مورد ویژگی های مختلف RS (مانند دقت، تنوع و غیره) و معیارهای مربوط به وظایف مختلف (مانند RMSE، دقت، فراخوانی و غیره) و برخی از پروتکل ها بحث می کنند. اما من هنوز در مورد پارتیشن بندی داده ها و روش دقیق اعتبار سنجی خیلی واضح... | روش استاندارد برای ارزیابی الگوریتم CF مبتنی بر کاربر با مجموعه داده آفلاین چیست؟ |
23295 | من قبلاً در معرض R قرار گرفته بودم، اما پس از 10 سال دوری از زبان، متوجه شدم که باید از ابتدا شروع کنم. من یک مجموعه داده بزرگ با بیش از 1 میلیون ردیف و 20 متغیر دارم. میدانم که راههای سریعتر و سریعتری برای استخراج آن دادهها وجود دارد، اما مشتری من اصرار دارد که از آزمایش فرضیه برای شناسایی بخشها/خوشههای مهم است... | تست متوالی |
32826 | برای یک مسابقه اخیر Kaggle، من (به صورت دستی) 10 ویژگی اضافی را برای مجموعه تمرینی خود تعریف کردم، که سپس برای آموزش یک طبقهبندی تصادفی جنگلها استفاده میشود. من تصمیم گرفتم PCA را روی مجموعه داده با ویژگی های جدید اجرا کنم تا ببینم چگونه آنها با یکدیگر مقایسه می شوند. من دریافتم که 98% از واریانس توسط مؤلفه اول (اول... | PCA و جنگل های تصادفی |
55023 | رگرسیون stata من در حال حاضر دارای متغیر زن است، اما میخواهم آزمایش کنم که آیا جنسیت روی متغیر دیگری اهمیت دارد یا خیر. چگونه می توانم متغیر مرد را ایجاد کنم؟ یا اصلا بهش نیاز دارم؟ آیا حذف متغیر زن نیز کارساز خواهد بود؟ | نحوه ایجاد متغیر male در stata |
32822 | موقعیتی را در نظر بگیرید که در آن ما یک طبقهبندی کننده را اجرا میکنیم (الگوریتم طبقهبندی واقعی در اینجا مهم نیست)، و برچسبهای کلاس بر اساس یک امتیاز داده میشوند. اگر نمره > 0، نقطه داده برچسب A، اگر امتیاز < 0، نقطه داده برچسب B می شود. تمام داده های آموزشی حاوی نقاط داده با نمرات مثبت یا منفی هستند. با این حال، د... | نحوه محاسبه دقت و یادآوری زمانی که برخی از داده های تست طبقه بندی نشده باقی می مانند |
32821 | امیدوارم کسی بتواند به من کمک کند که از کدام مدل (شکستگی، لایه یا خوشه) برای داده های خود استفاده کنم. من دادههای جفت شدهای دارم، بنابراین باید هنگام مدلسازی Cox PH آن را در نظر بگیرم و مطمئن نیستم کدام مدل نتیجه دقیقتری به من میدهد. مطالعه من به بررسی مدت زمانی بود که یک فرد پس از قرار گرفتن در معرض یک محرک خاص آ... | از کدام مدل برای خطرات متناسب کاکس با داده های جفت شده استفاده کنم؟ |
73279 | آیا کسی می تواند نتیجه کمی گیج کننده از یک مدل lmer4 در R را روشن کند؟ من یک اثر تصادفی تو در تو دارم، اما واریانس توضیح داده شده توسط هر سطح یکسان به نظر می رسد، و نمی توانم دلیل آن را ببینم. من مجموعه داده ای از مشاهدات زنبور عسل در آرایه های کنترل شده اسنپدراگون ها، با فرکانس های نسبی متفاوت از دو شکل رنگی دارم. پنج... | چرا واریانس اثرات تصادفی تو در تو یکسان به نظر می رسد؟ |
109599 | اگر می خواهید دو الگوریتم یادگیری را با هم مقایسه کنید، به طور کلی از کدام متریک استفاده کنید: ROC یا دقت؟ من می دانم که در ROC، شما هم حساسیت و هم ویژگی را دریافت می کنید؟ | ROC در مقابل دقت |
107876 | من می خواهم اقتصاد یک بازی آنلاین را مطالعه کنم. به طور خاص می خواهم بررسی کنم که آیا امکان ایجاد یک مدل پیش بینی وجود دارد یا خیر. من سعی میکنم کل مفهوم را توصیف کنم و از کاغذ یا مدلهایی درخواست میکنم که مناسب موقعیت من باشد. من برای مقالات تحقیق کردم اما چیزی پیدا نکردم. کاربران راه های مختلفی برای کسب درآمد دارند... | مدل پیشبینی اقتصاد بازی آنلاین |
24418 | من در یک کلاس روانسنجی در حال بررسی ماتریس چند ویژگی-چند روشی هستم. ما فقط باید بتوانیم آنها را تجزیه و تحلیل کنیم، اما من واقعاً دوست دارم بتوانم آنها را بسازیم. فکر میکنم که بتوانم این کار را انجام دهم (در اصل این بازآرایی ماتریس همبستگی با ضریب آلفا برای قطرها است). من کاملا مطمئن هستم که آن را دریافت کردم، اما یک ... | یک ماتریس و مجموعه داده چند صفتی-چند روشی |
92798 | در ادامه این سوال $p(h|D) = \frac{p(D|h)p(h)}{p(D)}$p(h) = $احتمال قبلی فرضیه $h$$p (D)$ = احتمال قبلی داده های آموزشی $D$ $p(h|D)$ = احتمال $h$ داده شده $D$ $p(D|h)$ = احتمال $D$ با توجه به $h$ I هستم وارد کردن داده های آموزشی $D$ به یک ماشین به شکل جدولی با $n$ نمونه های آموزشی. ماشین فقط نمونه های آموزشی $m$ را در ب... | فرمول های احتمالات در قضیه بیز |
56590 | من در حال خواندن کتابچه راهنمای فنی برای یک مطالعه مرتبط بین دو ارزیابی هستم. کاملاً واضح است که جدول خروجی مدل از یک معادله رگرسیون لجستیک برازش است. شانس قبولی در آزمون 2 به عنوان تابعی از نمره در آزمون 1 (نمره RIT):  احمقانه به نظر می رسد زمانی که ... | معادله رگرسیون لجستیک را از جدول داده های شانس دوباره ایجاد کنید |
107870 | من در جایی چنین جمله ای پیدا کردم، اما از طرف دیگر در برخی منابع یافتم که مشکلی ندارد. در مورد خطر بیش از حد برازش هنگام استفاده از 1-NN در مسئله طبقه بندی باینری که متغیرهای توضیحی مقادیر TF-IDF هستند (اندازه گیری کسینوس) چطور؟ | آیا k-NN با k=1 همیشه به برازش بیش از حد دلالت دارد؟ |
91842 | من یک سوال بسیار اساسی در مورد تنظیم پارامتر با استفاده از جستجوی شبکه دارم. به طور معمول برخی از روش های یادگیری ماشین دارای پارامترهایی هستند که باید با استفاده از جستجوی شبکه تنظیم شوند. برای مثال، در فرمول استاندارد زیر SVMها: $$ \min_w\frac{1}{2}\|w\|^2 + C\sum_{i=0}^{N}{\rm{hinge\ loss }}(x_i,y_i,w) $$ باید پارام... | چگونه تنظیم پارامترها را برای یادگیری ماشین انجام دهیم؟ |
28743 | آخرین فناوری در محاسبه کارآمد هموارسازی اسپلاین ها چیست؟ الگوریتمی که من اغلب از آن یاد میکنم الگوریتم Reinsch است که به سال 1967 بازمیگردد. همانطور که میدانم، گرانترین بخش انجام تجزیه Cholesky است. از آن زمان تاکنون چه الگوریتم های دیگری برای هموارسازی اسپلاین ها وجود داشته است؟ | پیشرفته ترین در صاف کردن اسپلاین ها |
409 | در حال حاضر من از انحراف معیار میانگین برای تخمین عدم قطعیت استفاده میکنم: 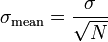 که در آن _N_ به صدها و میانگین یک میانگین سری زمانی (ماهانه) است. سپس آن را به این شکل ارائه میدهم: ![میانگین stdev بعلاوه منهای ... | چگونه عدم قطعیت اندازه گیری را تقریبی کنیم؟ |
92796 | اخیراً چند کتاب آمار را دوباره خواندم و به نکته عجیبی اشاره کردم: همه آنها مفروضات رگرسیون خطی را مورد بحث قرار می دهند و نیاز به یک متغیر وابسته توزیع شده نرمال را ذکر می کنند. در مرحله بعد، همیشه در مورد متغیرهایی که غیرعادی هستند و درمان بالقوه هستند مانند sqrt، log، معکوس و غیره بحث می شود. اما کتاب ها هرگز در مورد... | تبدیل متغیر وابسته: چگونه آن را تفسیر کنیم؟ |
20386 | در مدلهای خطی، در کتاب من، شاخص شرط به صورت $\sqrt{\lambda_{max} \over \lambda_{min}}$ تعریف میشود که $\lambda_{max}$ حداکثر مقدار ویژه $ZZ^*$ است. ، یعنی ماتریس همبستگی متغیرهای مستقل و $\lambda_{min}$ حداقل مقدار ویژه است. من نتوانستم بفهمم چرا شاخص وضعیت به من کمک می کند تا چند خطی بودن را پیدا کنم. بنابراین، من ب... | درک شاخص شرایط مورد استفاده برای یافتن چند خطی |
32794 | در اینجا «قطع» به معنای کاهش دقت اعداد تصادفی و کوتاه نکردن سری اعداد تصادفی است. به عنوان مثال، اگر من $n$ اعداد واقعا تصادفی داشته باشم (از هر توزیعی، به عنوان مثال، نرمال، یکنواخت و غیره) با دقت دلخواه داشته باشم و همه اعداد را کوتاه کنم تا در نهایت به مجموعه ای از اعداد $n$ برسید. ، هر کدام دقیقاً 2 رقم بعد از اعشا... | آیا اعداد کوتاه شده از یک مولد اعداد تصادفی هنوز تصادفی هستند؟ |
74794 | همچنین، آیا هیچ آموزش/وبلاگ در دسترس است که از آن آگاه هستید؟ | چگونه با استفاده از پایتون اعتبار متقابل سری های زمانی را انجام می دهید؟ |
24412 | این یک سوال اطلاعاتی کمی طولانی است. ما در حال جمعآوری دادهها از یک آزمایش کیفیت آب برای اندازهگیری آلودگی مدفوع هستیم. این آزمایش فلورسانس را در 11 محفظه مجزا اندازه گیری می کند. به دلیل فلورسانس بیشتر محفظه ها، آب آلوده تر است و روشی غیر خطی برای تعیین کمیت آلودگی آب بر اساس تعداد محفظه وجود دارد. یعنی یک محفظه مر... | تجزیه و تحلیل داده های طبقه بندی شده در جایی که آخرین دسته نامحدود است |
73276 | یک متغیر تصادفی X را در نظر بگیرید که میخواهیم مقدار آن را با استفاده از تخمینگر MMSE بیزی تخمین بزنیم. اجازه دهید $O_1(X)$ مجموعهای از مشاهدات باشد که به نحوی پیچیده به $X$ بستگی دارد (گرفته شده توسط $P(O_1|X)$) سپس تخمینگر MMSE میانگین شرطی $\hat{X}_1= است. \mathbb{E}[X|O_1]$. اکنون مجموعه دیگری از مشاهدات را در ... | برآوردگرهای بیزی MMSE از تبدیل مشاهدات |
23875 | من باید همبستگی بین دو مجموعه داده را پیدا کنم که غیرخطی هستند و فقط مقادیری بین 0 و 10 دارند. هر دو مجموعه دارای تعداد یکسانی از مقادیر هستند. من سعی کردم از R پیرسون استفاده کنم و با اضافه کردن n+10 به هر نقطه داده، مقداری خطی بودن را معرفی کنم. با این حال، این همبستگی قوی را در جایی که واقعاً نباید وجود داشته باشد، ... | ضریب همبستگی برای استفاده با مجموعه های محدود غیرخطی |
35444 | مجموعه داده های من کوچک است، تقریباً 12 در هر گروه (دو گروه). علاوه بر این، توزیع داده ها عادی نیست. در نتیجه، من یک آزمون Mann-Whitney U را اجرا کردم. با این حال، من یک ANOVA یک طرفه را نیز اجرا کردم و دقیقاً همان نتایج را گرفتم. کدام آزمایش را باید گزارش کنم و اشکالی ندارد که بگوییم هر دو را با نتایج مساوی اجرا کردم ... | کدام آزمایش را باید گزارش دهم، ANOVA یا Mann-Whitney؟ |
77372 | من به دنبال راههای خوبی برای تخمین وضعیت واقعی سیستم از روی مجموعهای از مشاهدات هستم که چندین مقدار صحیح را میگیرند. به عنوان مثال من دنباله ای از مشاهدات X_i از متغیر مجهول Y را دارم. هم مشاهدات و هم مقدار واقعی Y متعلق به مجموعه {1،2،3،4،5} هستند. آیا تکنیک خاصی برای این موقعیت ها فراتر از میانگین متحرک وجود دارد؟... | فیلتر کردن داده های گسسته |
107871 | من می خواهم آزمایش کنم که آیا بیماری آلزایمر باعث تغییر در پیری مغز در مقایسه با بیماران سالم می شود یا خیر. بنابراین من یک مدل رگرسیون خطی از پارامترهای طیفی ضبط مغز (ویژگی ها یا متغیرهای وابسته) در مقابل سن (سن متغیر مستقل است) ساخته ام. اکنون میخواهم مدل را بر روی بیماران سالم برازش دهم و سپس از ضرایب برای محاسبه س... | چگونه می توان آزمایش کرد که آیا تفاوت معنی داری در میانگین مربعات خطا بین دو مجموعه داده وجود دارد؟ |
32825 | من مطالعه ای را انجام دادم که در آن یک متغیر واحد به طور مکرر برای هر شرکت کننده، تحت شرایط مختلف اندازه گیری شد. تجزیه و تحلیل این داده ها با SPSS، با استفاده از مدل خطی عمومی -> ANOVA اندازه گیری های مکرر، و مشخص کردن هر معیار در فاکتورهای درون موضوعی، نسبتاً ساده بوده است. مشکل من زمانی پیش میآید که سعی میکنم برخی... | چگونه باید داده ها را با متغیرهای اندازه گیری مکرر و فاکتورهای عدد صحیح بین موضوع تجزیه و تحلیل کنم؟ |
91847 | فرض کنید من یک مدل رگرسیون لجستیک مانند این دارم: set.seed(123) df<-data.frame(y=rbinom(100,1,0.5), x1=rnorm(100,10,2), x2=rbinom( 100،20،0.6)) fit<-glm(y~x1*x2,data=df,family=binomial) coef(summary(fit)) Estimate Std. خطای z مقدار Pr(>|z|) (برق) 5.08314564 6.43692399 0.7896855 0.4297115 x1 -0.66691041 0.64071095 -1.04... | چگونه می توان ماتریس پیش بینی را با توجه به فرمول یک مدل رگرسیون در R بازیابی کرد؟ |
107874 | من در حوزه هدف گذاری تبلیغات موبایلی تحلیل داده انجام می دهم. من تقریباً **18 ویژگی** دارم و برای ترکیبی از این ویژگی ها، بسته به اینکه روی قالب کلیک شده باشد یا خیر، نتیجه درست یا نادرست است **(1/0)**. مشکل اینجاست که **کلاس خروجی بسیار کج است**. نرخ کلیک در حدود **0.4%** است. (یعنی مقدار 1 فقط 4 از 1000 بار است). من ... | چگونه می توان با یک کلاس کج در طبقه بندی باینری که دارای ویژگی های زیادی است برخورد کرد؟ |
23874 | این پست ادامه پست قبلی من است (که به 'lme' علاقه مند بود) و از همان مجموعه داده استفاده می کند. اکنون می خواهم بدانم چگونه با استفاده از `lme4` آن را تجزیه و تحلیل کنم. ## داده ها داده ها از یک آزمایش رفتاری است که در آن شرکت کنندگان در 6 گروه (بر اساس دو عامل متقاطع) روی 16 کارآزمایی (دو عامل 4 سطحی متقاطع) کار کردند.... | چگونه با استفاده از lme4 این مجموعه داده را با 2 فاکتور بین، دو فاکتور درونی تجزیه و تحلیل کنیم؟ |
32795 | مربع کای مدل من می گوید که مدل «پر» من به طور قابل توجهی بهتر از مدل تهی نیست. اما -2LL من 80 است (آیا این _کم_زیبا نیست؟) و Nagelkerke $R^2$ من 0.20 است. از طرف دیگر، یک IV قابل توجه در مدل من وجود ندارد... پس چگونه باید -2LL پایین تر و 0.20 Nagelkerke $R^2$ نه چندان کوچک را تفسیر کنم؟ | چگونه می توان مقدار نسبتاً خوب -2LL و Nagelkerke $R ^2$ را بدون هیچ IV قابل توجهی تفسیر کرد |
71282 | من سعی می کنم تراکم هسته را برای تعداد روزهایی که یک کودک بیمار است تخمین بزنم. حدود 73 درصد از کودکان گزارش می دهند که بیمار نیستند، یعنی صفر. چگونه می توانم چگالی هسته را برای این متغیر سانسور شده با استفاده از Stata تخمین بزنم؟ | تخمین چگالی هسته برای یک متغیر با تعداد زیادی صفر |
67967 | من یک ماتریس $x=N\times M$ از نقاط داده $N$ دارم که هر کدام دارای ویژگیهای $M$ هستند. همچنین $y$ بردار برچسب های باینری است. در مورد من، $N$ بسیار کوچکتر از $M$ است، بنابراین قبل از اجرای یک طبقهبندی کننده مانند SVM از PCA برای کاهش ابعاد استفاده کردم. من 100 مؤلفه اول را انتخاب کردم که 85 درصد واریانس را توضیح داد. ... | تمایز و کاهش ابعاد |
20385 | من در حال حاضر در جستجوی الگوریتمی هستم که با توجه به تاریخچه قیمت ها (30، 50، 100، ...) تعیین کند که آیا زمان خرید چیزی (یک کالا، یک سهام، یک سرویس و غیره) فرا رسیده است یا خیر. ایده من چیزی شبیه به این است: > با توجه به تاریخچه قیمت ها، شما باید همین الان خرید کنید زیرا احتمال دارد قیمت > افزایش یابد. یا، > با توجه ب... | الگوریتمی برای ارزیابی اینکه آیا باید اکنون بخرید یا صبر کنید |
35442 | من سعی می کنم راهی برای انجام رگرسیون لجستیک تودرتو در R پیدا کنم که متناسب با نیازهای من باشد. من یک مجموعه داده بسیار بزرگ با تقریبا 200 متغیر در دسترس دارم. من بهترین مدل خود را پیدا کرده ام و شامل 12 مورد از این متغیرها است. من از مشکلات استفاده از 12 متغیر در رگرسیون لجستیک آگاه هستم و نمی خواهم آنها را در اینجا پ... | رگرسیون لجستیک تو در تو در R |
61526 | تست متوالی برای سری های زمانی رایج است. به یک نوع تست SupF یا یک آزمون چو برای شکست ساختاری در پارامترها در شبکه ای از نقاط داده فکر کنید. بنابراین، ما آمارهای زیادی (به تعداد نقاط داده و مدول چند نقطه از ابتدا و پایان) و مقادیر P مربوط به آنها داریم. FDR برای مورد مستقل خوب است، آنچه که من توضیح دادم آمار تست بسیار هم... | پسوند FDR به دامنه سری زمانی؟ |
56596 | من یک مجموعه داده از مقادیر x و y دارم که میخواهم یک تناسب خطی روی آن ایجاد کنم. با استفاده از «polyfit(x,y,1)» ضرایب «a» و «b» را برای برازش خطی «ax = b» برای این داده به دست میآورم، اما همچنین میخواهم عدم قطعیت یا انحراف استاندارد را برای این ضرایب پیدا کنم. . کسی راه آسانی برای انجام این کار می شناسد؟ Google-fu م... | یافتن عدم قطعیت در ضرایب از polyfit در Matlab |
61529 | من مطمئن نیستم که کدام تحلیل برای تحلیل مسیر یا SEM (مدل سازی معادلات ساختاری) مناسب تر است. من به روابط بین تعدادی از متغیرها نگاه می کنم که توسط مقیاس ها اندازه گیری شده اند (یعنی خرده مقیاس های برون گرایی و روان رنجوری BFI، خرده مقیاس خودپسندی SLSC-R، و غیره) فکر می کنم دو انتخاب دارم: 1. رفتار یک SEM با استفاده از ... | SEM یا تحلیل مسیر: متغیرهای پنهان با آیتم های جداگانه به عنوان شاخص، یا امتیازات ترکیبی به عنوان متغیرهای مشاهده شده؟ |
56042 | توزیع $\bar{X}^{-1}$ با X یک متغیر تصادفی پیوسته iid است که به طور یکنواخت توزیع شده است؟ آیا می توانم از CLT در اینجا استفاده کنم؟ | توزیع $\bar{X}^{-1}$ چگونه است؟ |
61521 | من میخواهم بر اساس یک اندازهگیری انسانشناختی، نقطه برش جنسیت را پیدا کنم. من میتوانم منحنیها را ترسیم کنم و میدانم که در صورتی که حساسیت و ویژگی هر دو به یک اندازه مهم هستند، باید نزدیکترین نقطه به گوشه سمت چپ بالای کادر (یا اگر منحنی منفی است، نزدیکترین نقطه به گوشه پایین سمت راست) تعیین شود. به عنوان برش. با ... | نقطه برش در منحنی ROC. آیا یک تابع ساده وجود دارد؟ |
56593 | همانطور که از عنوان پیداست، چگونه باید K را در K-Nearest Neighbours تنظیم کنید؟ آیا این فقط یک مورد است که مقادیر کمتر K بیشتر مستعد برازش شدن هستند و مقادیر بزرگتر K احتمالاً انعکاس دقیق تری ارائه می دهند (کمتر مستعد نویز هستند). همچنین مقدار بهینه K تا حد زیادی به مجموعه آموزشی بستگی دارد، اما من نمیدانستم که آیا یک... | به طور کلی چگونه K را در K-NN تنظیم می کنید؟ |
23879 | فرض کنید من یک کد ساده مانند آنچه در زیر آمده است دارم. مرتب سازی proc; توسط var1 var2; اجرا؛ proc gplot; نمودار y*x ; توسط var1 var2; اجرا؛ در خروجی، یک دسته نمودار وجود دارد. علاوه بر تمام ترکیبهای مقادیر var1 و var2، نمودارهایی را نیز دریافت میکنم که در آن «var1=.»... | SAS: هنگام استفاده از دستور by، var1 = . میانگین در خروجی؟ |
27140 | من یک بازی رولت را شبیه سازی می کنم (در R)، که در آن قماربازی را شبیه سازی می کنم که با 100 پوند شروع می شود، طبق استراتژی 10 بار چرخ را می چرخاند (مثلاً 5 پوند برای هر چرخش روی قرمز شرط می بندم). در پایان این شبیه سازی موجودی بانک یا بیشتر یا کمتر از 100 پوند خواهد بود. اگر بالاتر باشد، چرخش یک برد و در غیر این صورت ی... | محاسبه انحراف معیار خروجی یک آزمایش عددی |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.